diff --git a/README.md b/README.md
index 74b0ce0b56..8ed4acac1f 100644
--- a/README.md
+++ b/README.md
@@ -85,6 +85,7 @@ Supported backbones:
- [x] [Swin Transformer (ICCV'2021)](configs/swin)
- [x] [Twins (NeurIPS'2021)](configs/twins)
- [x] [ConvNeXt (CVPR'2022)](configs/convnext)
+- [x] [BEiT (ICLR'2022)](configs/beit)
Supported methods:
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 6adea211ff..acaa12e489 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -84,6 +84,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [Swin Transformer (ICCV'2021)](configs/swin)
- [x] [Twins (NeurIPS'2021)](configs/twins)
- [x] [ConvNeXt (CVPR'2022)](configs/convnext)
+- [x] [BEiT (ICLR'2022)](configs/beit)
已支持的算法:
diff --git a/configs/_base_/models/upernet_beit.py b/configs/_base_/models/upernet_beit.py
new file mode 100644
index 0000000000..9c5bfa3310
--- /dev/null
+++ b/configs/_base_/models/upernet_beit.py
@@ -0,0 +1,50 @@
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='BEiT',
+ img_size=(640, 640),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ mlp_ratio=4,
+ out_indices=(3, 5, 7, 11),
+ qv_bias=True,
+ attn_drop_rate=0.0,
+ drop_path_rate=0.1,
+ norm_cfg=dict(type='LN', eps=1e-6),
+ act_cfg=dict(type='GELU'),
+ norm_eval=False,
+ init_values=0.1),
+ neck=dict(type='Feature2Pyramid', embed_dim=768, rescales=[4, 2, 1, 0.5]),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[768, 768, 768, 768],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=768,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=768,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/beit/README.md b/configs/beit/README.md
new file mode 100644
index 0000000000..31bf285356
--- /dev/null
+++ b/configs/beit/README.md
@@ -0,0 +1,84 @@
+# BEiT
+
+[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
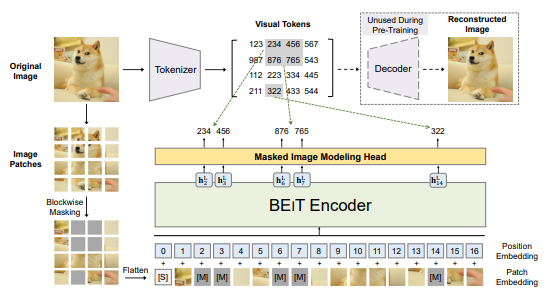
+We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%). The code and pretrained models are available at [this https URL](https://github.com/microsoft/unilm/tree/master/beit).
+
+
+
+
+