diff --git a/cspell.json b/cspell.json
index e77ca86c2c..60e712f713 100644
--- a/cspell.json
+++ b/cspell.json
@@ -24,6 +24,7 @@
"numpy",
"openai",
"openinference",
+ "OTLP",
"postprocessors",
"pydantic",
"quickstart",
diff --git a/docs/.gitbook/assets/evals.png b/docs/.gitbook/assets/evals.png
new file mode 100644
index 0000000000..2f1ce14666
Binary files /dev/null and b/docs/.gitbook/assets/evals.png differ
diff --git a/docs/README.md b/docs/README.md
index e5a222751d..068b67c571 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -1,50 +1,48 @@
---
description: Evaluate, troubleshoot, and fine-tune your LLM, CV, and NLP models.
-cover: >-
- https://images.unsplash.com/photo-1610296669228-602fa827fc1f?crop=entropy&cs=tinysrgb&fm=jpg&ixid=MnwxOTcwMjR8MHwxfHNlYXJjaHw1fHxzcGFjZXxlbnwwfHx8fDE2NzkwOTMzODc&ixlib=rb-4.0.3&q=80
-coverY: 0
---
-# Phoenix: AI Observability & Evaluation
+# Arize Phoenix
Phoenix is an open-source observability library and platform designed for experimentation, evaluation, and troubleshooting.
The toolset is designed to ingest [inference data](quickstart/phoenix-inferences/inferences.md) for [LLMs](concepts/llm-observability.md), CV, NLP, and tabular datasets as well as [LLM traces](quickstart/llm-traces.md). It allows AI Engineers and Data Scientists to quickly visualize their data, evaluate performance, track down issues & insights, and easily export to improve.
-{% embed url="https://www.loom.com/share/a96e244c4ff8473d9350b02ccbd203b4" %}
-Overview of Phoenix Tracing
-{% endembed %}
+## Install Phoenix
-## Quickstarts
+In your Jupyter or Colab environment, run the following command to install.
-Running Phoenix for the first time? Select a quickstart below.
-
-
+{% tabs %}
+{% tab title="Using pip" %}
+```sh
+pip install arize-phoenix
+```
+{% endtab %}
-Don't know which one to choose? Phoenix has two main data ingestion methods:
+{% tab title="Using conda" %}
+```sh
+conda install -c conda-forge arize-phoenix
+```
+{% endtab %}
+{% endtabs %}
-1. [LLM Traces:](quickstart/llm-traces.md) Phoenix is used on top of trace data generated by LlamaIndex and LangChain. The general use case is to troubleshoot LLM applications with agentic workflows.
-2. [Inferences](quickstart/phoenix-inferences/inferences.md): Phoenix is used to troubleshoot models whose datasets can be expressed as DataFrames in Python such as LLM applications built in Python workflows, CV, NLP, and tabular models.
+## Quickstarts
-### **Phoenix Functionality**
+Running Phoenix for the first time? Select a quickstart below.
-* [**Evaluate Performance of LLM Tasks with Evals Library:**](llm-evals/llm-evals.md) Use the Phoenix Evals library to easily evaluate tasks such as hallucination, summarization, and retrieval relevance, or create your own custom template.
-* [**Troubleshoot Agentic Workflows:**](concepts/llm-traces.md) Get visibility into where your complex or agentic workflow broke, or find performance bottlenecks, across different span types with LLM Tracing.
-* [**Optimize Retrieval Systems:**](use-cases/troubleshooting-llm-retrieval-with-vector-stores.md) Identify missing context in your knowledge base, and when irrelevant context is retrieved by visualizing query embeddings alongside knowledge base embeddings with RAG Analysis.
-* [**Compare Model Versions:**](https://docs.arize.com/phoenix/concepts/phoenix-basics/phoenix-basics#how-many-datasets-do-i-need) Compare and evaluate performance across model versions prior to deploying to production.
-* [**Exploratory Data Analysis:**](integrations/bring-production-data-to-notebook-for-eda-or-retraining.md) Connect teams and workflows, with continued analysis of production data from Arize in a notebook environment for fine tuning workflows.
-* [**Find Clusters of Issues to Export for Model Improvement:**](how-to/export-your-data.md) Find clusters of problems using performance metrics or drift. Export clusters for retraining workflows.
-* [**Surface Model Drift and Multivariate Drift:**](https://docs.arize.com/phoenix/concepts/phoenix-basics/phoenix-basics#embedding-drift-over-time) Use the Embeddings Analyzer to surface data drift for computer vision, NLP, and tabular models.
+
-## Resources
+### Demo
-### [Tutorials](notebooks.md)
+{% embed url="https://www.loom.com/share/a96e244c4ff8473d9350b02ccbd203b4" %}
+Overview of Phoenix Tracing
+{% endembed %}
-Check out a comprehensive list of example notebooks for LLM Traces, Evals, RAG Analysis, and more.
+## Next Steps
-### [Use Cases](broken-reference)
+### [Try our Tutorials](notebooks.md)
-Learn about best practices, and how to get started with use case examples such as Q\&A with Retrieval, Summarization, and Chatbots.
+Check out a comprehensive list of example notebooks for LLM Traces, Evals, RAG Analysis, and more.
### [Community](https://join.slack.com/t/arize-ai/shared\_invite/zt-1ppbtg5dd-1CYmQO4dWF4zvXFiONTjMg)
diff --git a/docs/SUMMARY.md b/docs/SUMMARY.md
index 4668fe09a5..13e11ad840 100644
--- a/docs/SUMMARY.md
+++ b/docs/SUMMARY.md
@@ -1,28 +1,24 @@
# Table of contents
-* [Phoenix: AI Observability & Evaluation](README.md)
-* [Examples](notebooks.md)
-* [Installation](install-and-import-phoenix.md)
+* [Arize Phoenix](README.md)
+* [User Guide](concepts/llm-observability.md)
* [Environments](environments.md)
+* [Examples](notebooks.md)
-## 🔑 Quickstart
-
-* [Phoenix Traces](quickstart/llm-traces.md)
-* [Phoenix Evals](quickstart/evals.md)
-* [Phoenix Inferences](quickstart/phoenix-inferences/README.md)
- * [Schemas and Datasets](quickstart/phoenix-inferences/inferences.md)
-
-## 💡 Concepts
+## 🔭 Tracing
-* [LLM Observability](concepts/llm-observability.md)
-* [Traces and Spans](concepts/llm-traces.md)
-* [Evaluation](concepts/evaluation.md)
-* [Generating Embeddings](concepts/generating-embeddings.md)
-* [Embeddings Analysis](concepts/embeddings-analysis.md)
+* [Overview: Traces](concepts/llm-traces.md)
+* [Quickstart: Traces](quickstart/llm-traces.md)
+* [Instrumentation](telemetry/instrumentation.md)
+ * [OpenInference](concepts/open-inference.md)
+* [Deployment](telemetry/deploying-phoenix.md)
+* [Custom Spans](telemetry/custom-spans.md)
-## 🧠 LLM Evals
+## 🧠 Evaluation
-* [Phoenix LLM Evals](llm-evals/llm-evals.md)
+* [Overview: Evals](llm-evals/llm-evals.md)
+* [Concept: Evaluation](concepts/evaluation.md)
+* [Quickstart: Evals](quickstart/evals.md)
* [Running Pre-Tested Evals](llm-evals/running-pre-tested-evals/README.md)
* [Retrieval (RAG) Relevance](llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md)
* [Hallucinations](llm-evals/running-pre-tested-evals/hallucinations.md)
@@ -37,7 +33,14 @@
* [Building Your Own Evals](llm-evals/building-your-own-evals.md)
* [Quickstart Retrieval Evals](llm-evals/quickstart-retrieval-evals/README.md)
* [Retrieval Evals on Document Chunks](llm-evals/quickstart-retrieval-evals/retrieval-evals-on-document-chunks.md)
-* [Benchmarking Retrieval (RAG)](llm-evals/benchmarking-retrieval-rag.md)
+* [Benchmarking Retrieval](llm-evals/benchmarking-retrieval-rag.md)
+
+## 🌌 inferences
+
+* [Quickstart: Inferences](quickstart/phoenix-inferences/README.md)
+* [Schemas and Datasets](quickstart/phoenix-inferences/inferences.md)
+* [Generating Embeddings](concepts/generating-embeddings.md)
+* [Embeddings Analysis](concepts/embeddings-analysis.md)
## 🔮 Use Cases
@@ -57,13 +60,7 @@
* [Extract Data from Spans](how-to/extract-data-from-spans.md)
* [Use Example Datasets](how-to/use-example-datasets.md)
-## 🔭 telemetry
-
-* [Deploying Phoenix](telemetry/deploying-phoenix.md)
-* [Instrumentation](telemetry/instrumentation.md)
-* [Custom Spans](telemetry/custom-spans.md)
-
-## ⌨ API
+## ⌨️ API
* [Dataset and Schema](api/dataset-and-schema.md)
* [Session](api/session.md)
@@ -78,16 +75,15 @@
* [OpenAI](integrations/openai.md)
* [Bedrock](integrations/bedrock.md)
* [AutoGen](integrations/autogen-support.md)
+* [DSPy](integrations/dspy.md)
* [Arize](integrations/bring-production-data-to-notebook-for-eda-or-retraining.md)
-## 🏴☠ Programming Languages
+## 🏴☠️ Programming Languages
* [JavaScript](programming-languages/javascript.md)
## 📚 Reference
-* [Embeddings](concepts/embeddings.md)
-* [OpenInference](concepts/open-inference.md)
* [Frequently Asked Questions](reference/frequently-asked-questions.md)
* [Contribute to Phoenix](reference/contribute-to-phoenix.md)
diff --git a/docs/api/client.md b/docs/api/client.md
index d666af61d4..da79103774 100644
--- a/docs/api/client.md
+++ b/docs/api/client.md
@@ -63,7 +63,16 @@ A client for making HTTP requests to the Phoenix server for extracting/downloadi
* **get\_trace\_dataset** -> Optional\[TraceDataset]\
\
- Returns the trace dataset containing spans and evaluations.
+ Returns the trace dataset containing spans and evaluations.\
+
+* **log\_evaluations** -> None\
+ \
+ Send evaluations to Phoenix. See [#logging-multiple-evaluation-dataframes](../how-to/define-your-schema/llm-evaluations.md#logging-multiple-evaluation-dataframes "mention")for usage.\
+
+
+ **Parameters**
+
+ * **\*evaluations** (Evaluations): One or more Evaluations datasets. See [llm-evaluations.md](../how-to/define-your-schema/llm-evaluations.md "mention")for more details.
### Usage
diff --git a/docs/api/dataset-and-schema.md b/docs/api/dataset-and-schema.md
index ea655da557..24f8f106d7 100644
--- a/docs/api/dataset-and-schema.md
+++ b/docs/api/dataset-and-schema.md
@@ -109,7 +109,7 @@ class EmbeddingColumnNames(
)
```
-A dataclass that associates one or more columns of a dataframe with an [embedding](../concepts/embeddings.md) feature. Instances of this class are only used as values in a dictionary passed to the `embedding_feature_column_names` field of [Schema](dataset-and-schema.md#phoenix.schema).
+A dataclass that associates one or more columns of a dataframe with an [embedding](broken-reference) feature. Instances of this class are only used as values in a dictionary passed to the `embedding_feature_column_names` field of [Schema](dataset-and-schema.md#phoenix.schema).
**\[**[**source**](https://github.com/Arize-ai/phoenix/blob/main/src/phoenix/datasets/schema.py)**]**
diff --git a/docs/api/evals.md b/docs/api/evals.md
index dbdb517ea8..8da08bba6c 100644
--- a/docs/api/evals.md
+++ b/docs/api/evals.md
@@ -37,7 +37,7 @@ Evaluates a pandas dataframe using a set of user-specified evaluators that asses
* **provide\_explanation** (bool, optional): If true, each output dataframe will contain an explanation column containing the LLM's reasoning for each evaluation.
* **use\_function\_calling\_if\_available** (bool, optional): If true, function calling is used (if available) as a means to constrain the LLM outputs. With function calling, the LLM is instructed to provide its response as a structured JSON object, which is easier to parse.
* **verbose** (bool, optional): If true, prints detailed information such as model invocation parameters, retries on failed requests, etc.
-* **concurrency** (int, optional): The number of concurrent workers if async submission is possible. If
+* **concurrency** (int, optional): The number of concurrent workers if async submission is possible. If
### Returns
diff --git a/docs/api/evaluation-models.md b/docs/api/evaluation-models.md
index da1ce4267a..bfba31cf50 100644
--- a/docs/api/evaluation-models.md
+++ b/docs/api/evaluation-models.md
@@ -46,6 +46,8 @@ class OpenAIModel:
"""How many completions to generate for each prompt."""
model_kwargs: Dict[str, Any] = field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
+ batch_size: int = 20
+ """Batch size to use when passing multiple documents to generate."""
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
"""Timeout for requests to OpenAI completion API. Default is 600 seconds."""
max_retries: int = 20
@@ -78,6 +80,14 @@ model = OpenAIModel(
)
```
+{% hint style="info" %}
+Note that the `model_name` param is actually the `engine` of your deployment. You may get a `DeploymentNotFound` error if this parameter is not correct. You can find your engine param in the Azure OpenAI playground.\
+\
+
+{% endhint %}
+
+
How to find the model param in Azure
+
Azure OpenAI supports specific options:
```python
diff --git a/docs/concepts/embeddings-analysis.md b/docs/concepts/embeddings-analysis.md
index ae86181c73..f9d8ec564d 100644
--- a/docs/concepts/embeddings-analysis.md
+++ b/docs/concepts/embeddings-analysis.md
@@ -38,7 +38,7 @@ When two datasets are used to initialize phoenix, the clusters are automatically
### UMAP Point-Cloud
-Phoenix projects the embeddings you provided into lower dimensional space (3 dimensions) using a dimension reduction algorithm called [UMAP](https://github.com/lmcinnes/umap) (stands for Uniform Manifold Approximation and Projection). This lets us understand how your [embeddings have encoded semantic meaning](embeddings.md) in a visually understandable way.\
+Phoenix projects the embeddings you provided into lower dimensional space (3 dimensions) using a dimension reduction algorithm called [UMAP](https://github.com/lmcinnes/umap) (stands for Uniform Manifold Approximation and Projection). This lets us understand how your [embeddings have encoded semantic meaning](broken-reference) in a visually understandable way.\
\
In addition to the point-cloud, another dimension we have at our disposal is color (and in some cases shape). Out of the box phoenix let's you assign colors to the UMAP point-cloud by dimension (features, tags, predictions, actuals), performance (correctness which distinguishes true positives and true negatives from the incorrect predictions), and dataset (to highlight areas of drift). This helps you explore your point-cloud from different perspectives depending on what you are looking for.
diff --git a/docs/concepts/embeddings.md b/docs/concepts/embeddings.md
deleted file mode 100644
index edeeaf5c7d..0000000000
--- a/docs/concepts/embeddings.md
+++ /dev/null
@@ -1,147 +0,0 @@
----
-description: Meaning, Examples and How To Compute
----
-
-# Embeddings
-
-### What's an embedding?
-
-Embeddings are **vector representations** of information. (e.g. a list of floating point numbers). With embeddings, the distance between two vectors carry semantic meaning: Small distances suggest high relatedness and large distances suggest low relatedness. Embeddings are everywhere in modern deep learning, such as transformers, recommendation engines, layers of deep neural networks, encoders, and decoders.
-
-{% hint style="info" %}
-**A simple example**: In an image, a color can be represented as the amount of red, green, blue, and transparency in the form of `rgba(255, 255, 255, 0)`. This vector `[255, 255, 255, 0] not only encodes information`(the color white) but it carries meaning in space as well. Colors more similar to white are closer to the vector and points farther from this vector are less similar (e.x. black is \`\[0, 0, 0, 0]\`).
-{% endhint %}
-
-### Why embeddings
-
-Embeddings are foundational to machine learning because:
-
-* Embeddings can represent various forms of data such as images, audio signals, and even large chunks of structured data.
-* They provide a common mathematical representation of your data
-* They compress data
-* They preserve relationships within your data
-* They are the output of deep learning layers providing comprehensible linear views into complex non-linear relationships learned by models\
-
-
-Embeddings are used for a variety of machine learning problems. To learn more, check out our course [here](https://arize.com/blog-course/embeddings-meaning-examples-and-how-to-compute/).\
-
-
-### How to generate embeddings
-
-\
-Embedding vectors are generally extracted from the **activation values** of one or many hidden layers of your model. In general, there are many ways of obtaining embedding vectors, including:
-
-1. Word embeddings
-2. Autoencoder Embeddings
-3. Generative Adversarial Networks (GANs)
-4. Pre-trained Embeddings
-
-Given the wide accessibility to pre-trained transformer [models](https://app.gitbook.com/s/-MAlgpMyBRcl2qFZRQ67/embeddings/7.-troubleshoot-embedding-data/let-arize-generate-your-embeddings#supported-models), we will focus on generating embeddings using them. These models are models such as BERT or GPT-x, models that are trained on a large datasets and that are fine-tuning them on a specific task.
-
-\
-Once you have chosen a model to generate embeddings, the question is: _how?_ Here are few use-case based examples. In each example you will notice that the embeddings are generated such that the resulting vector represents your input according to your use case.
-
-{% tabs %}
-{% tab title="CV Image Classification" %}
-If you are working on image classification, the model will take an image and classify it into a given set of categories. Each of our embedding vectors should be representative of the corresponding entire image input.
-
-First, we need to use a `feature_extractor` that will take an image and prepare it for the large pre-trained image model.
-
-```python
-inputs = feature_extractor(
- [x.convert("RGB") for x in batch["image"]],
- return_tensors="pt"
-).to(device)
-```
-
-Then, we pass the results from the `feature_extractor` to our `model`. In PyTorch, we use `torch.no_grad()` since we don't need to compute the gradients for backward propagation, we are not training the model in this example.
-
-```python
-with torch.no_grad():
- outputs = model(**inputs)
-```
-
-It is imperative that these outputs contain the activation values of the hidden layers of the model since you will be using them to construct your embeddings. In this scenario, we will use just the last hidden layer.
-
-```python
-last_hidden_state = outputs.last_hidden_state
-# last_hidden_state.shape = (batch_size, num_image_tokens, hidden_size)
-```
-
-Finally, since we want the embedding vector to represent the entire image, we will average across the second dimension, representing the areas of the image.
-
-```
-embeddings = torch.mean(last_hidden_state, 1).cpu().numpy()
-```
-{% endtab %}
-
-{% tab title="NLP Classification" %}
-If you are working on NLP sequence classification (for example, sentiment classification), the model will take a piece of text and classify it into a given set of categories. Hence, your embedding vector must represent the entire piece of text.
-
-For this example, let us assume we are working with a model from the `BERT` family.
-
-First, we must use a `tokenizer` that will the text and prepare it for the pre-trained large language model (LLM).
-
-```python
-inputs = {
- k: v.to(device)
- for k,v in batch.items() if k in tokenizer.model_input_names
-}
-```
-
-Then, we pass the results from the `tokenizer` to our `model`. In PyTorch, we use `torch.no_grad()` since we don't need to compute the gradients for backward propagation, we are not training the model in this example.
-
-```python
-with torch.no_grad():
- outputs = model(**inputs)
-```
-
-It is imperative that these outputs contain the activation values of the hidden layers of the model since you will be using them to construct your embeddings. In this scenario, we will use just the last hidden layer.
-
-```python
-last_hidden_state = outputs.last_hidden_state
-# last_hidden_state.shape = (batch_size, num_tokens, hidden_size)
-```
-
-Finally, since we want the embedding vector to represent the entire piece of text for classification, we will use the vector associated with the classification token,`[CLS]`, as our embedding vector.
-
-```
-embeddings = last_hidden_state[:,0,:].cpu().numpy()
-```
-{% endtab %}
-
-{% tab title="NLP Name Entity Recognition" %}
-If you are working on NLP Named Entity Recognition (NER), the model will take a piece of text and classify some words within it into a given set of entities. Hence, each of your embedding vectors must represent a classified word or token.
-
-For this example, let us assume we are working with a model from the `BERT` family.
-
-First, we must use a `tokenizer` that will the text and prepare it for the pre-trained large language model (LLM).
-
-```python
-inputs = {
- k: v.to(device)
- for k,v in batch.items() if k in tokenizer.model_input_names
-}
-```
-
-Then, we pass the results from the `tokenizer` to our `model`. In PyTorch, we use `torch.no_grad()` since we don't need to compute the gradients for backward propagation, we are not training the model in this example.
-
-```python
-with torch.no_grad():
- outputs = model(**inputs)
-```
-
-It is imperative that these outputs contain the activation values of the hidden layers of the model since you will be using them to construct your embeddings. In this scenario, we will use just the last hidden layer.
-
-```python
-last_hidden_state = outputs.last_hidden_state.cpu().numpy()
-# last_hidden_state.shape = (batch_size, num_tokens, hidden_size)
-```
-
-Further, since we want the embedding vector to represent any given token, we will use the vector associated with a specific token in the piece of text as our embedding vector. So, let `token_index` be the integer value that locates the token of interest in the list of tokens that result from passing the piece of text to the `tokenizer`. Let `ex_index` the integer value that locates a given example in the batch. Then,
-
-```
-token_embedding = last_hidden_state[ex_index, token_index,:]
-```
-{% endtab %}
-{% endtabs %}
diff --git a/docs/concepts/evaluation.md b/docs/concepts/evaluation.md
index c14034f966..aede23b433 100644
--- a/docs/concepts/evaluation.md
+++ b/docs/concepts/evaluation.md
@@ -5,18 +5,18 @@ description: >-
measure it.
---
-# Evaluation
+# Concept: Evaluation
Phoenix offers key modules to measure the quality of generated results as well as modules to measure retrieval quality.
-* [**Response Evaluation**](evaluation.md#response-evaluation): Does the response match the retrieved context? Does it also match the query?
+* [**Response Evaluation**](evaluation.md#response-evaluation): Does the response match the retrieved context? Does it also match the query?
* [**Retrieval Evaluation**](evaluation.md#retrieval-evaluation): Are the retrieved sources relevant to the query?
### Response Evaluation
Evaluation of generated results can be challenging. Unlike traditional ML, the predicted results are not numeric or categorical, making it hard to define quantitative metrics for this problem.
-Phoenix offers [LLM Evaluations](broken-reference), a module designed to measure the quality of results. This module uses a "gold" LLM (e.g. GPT-4) to decide whether the generated answer is correct in a variety of ways.\
+Phoenix offers [LLM Evaluations](broken-reference/), a module designed to measure the quality of results. This module uses a "gold" LLM (e.g. GPT-4) to decide whether the generated answer is correct in a variety of ways.\
\
Note that many of these evaluation criteria DO NOT require ground-truth labels. Evaluation can be done simply with a combination of the **input** (query), **output** (response), and **context**.
@@ -24,9 +24,9 @@ LLM Evals supports the following response evaluation criteria:
* [**QA Correctness**](../llm-evals/running-pre-tested-evals/q-and-a-on-retrieved-data.md) - Whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q\&A.
* [**Hallucinations**](../llm-evals/running-pre-tested-evals/hallucinations.md) **-** Designed to detect LLM hallucinations relative to retrieved context
-* [**Toxicity**](../llm-evals/running-pre-tested-evals/toxicity.md) - Identify if the AI response is racist, biased, or toxic
+* [**Toxicity**](../llm-evals/running-pre-tested-evals/toxicity.md) - Identify if the AI response is racist, biased, or toxic
-Response evaluations are a critical first step to figuring out whether your LLM App is running correctly. Response evaluations can pinpoint specific executions (a.k.a. traces) that are performing badly and can be aggregated up so that you can track how your application is running as a whole.
+Response evaluations are a critical first step to figuring out whether your LLM App is running correctly. Response evaluations can pinpoint specific executions (a.k.a. traces) that are performing badly and can be aggregated up so that you can track how your application is running as a whole.
Evaluations can be aggregated across executions to be used as KPIs
@@ -34,11 +34,11 @@ Response evaluations are a critical first step to figuring out whether your LLM
Phoenix also provides evaluation of retrieval independently.
-The concept of retrieval evaluation is not new; given a set of relevance scores for a set of retrieved documents, we can evaluate retrievers using retrieval metrics like `precision`, `NDCG`, `hit rate` and more.
+The concept of retrieval evaluation is not new; given a set of relevance scores for a set of retrieved documents, we can evaluate retrievers using retrieval metrics like `precision`, `NDCG`, `hit rate` and more.
LLM Evals supports the following retrieval evaluation criteria:
-* [**Relevance**](../llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md) - Evaluates whether a retrieved document chunk contains an answer to the query.
+* [**Relevance**](../llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md) - Evaluates whether a retrieved document chunk contains an answer to the query.
Retrieval Evaluations can be run directly on application traces
@@ -48,7 +48,7 @@ Retrieval is possibly the most important step in any LLM application as poor and
Datasets that contain generative records can be fed into evals to produce evaluations for analysis
-With Phoenix's LLM Evals, evaluation results (or just **Evaluations** for short) is a dataset consisting of 3 main columns:
+With Phoenix's LLM Evals, evaluation results (or just **Evaluations** for short) is a dataset consisting of 3 main columns:
* **label**: str \[optional] - a classification label for the evaluation (e.g. "hallucinated" vs "factual"). Can be used to calculate percentages (e.g. percent hallucinated) and can be used to filter down your data (e.g. `Evals["Hallucinations"].label == "hallucinated"`)
* **score**: number \[optional] - a numeric score for the evaluation (e.g. 1 for good, 0 for bad). Scores are great way to sort your data to surface poorly performing examples and can be used to filter your data by a threshold.
@@ -78,13 +78,10 @@ With Phoenix, evaluations can be "attached" to the **spans** and **documents** c
End-to-end evaluation flow
-By following the above steps, you will have a full end-to-end flow for troubleshooting, evaluating, and root-causing an LLM application. By using LLM Evals in conjunction with Traces, you will be able to surface up problematic queries, get an explanation as to why the the generation is problematic (e.x. **hallucinated** because ...), and be able to identify which step of your generative app requires improvement (e.x. did the LLM hallucinate or was the LLM fed bad context?).\
-
+By following the above steps, you will have a full end-to-end flow for troubleshooting, evaluating, and root-causing an LLM application. By using LLM Evals in conjunction with Traces, you will be able to surface up problematic queries, get an explanation as to why the the generation is problematic (e.x. **hallucinated** because ...), and be able to identify which step of your generative app requires improvement (e.x. did the LLM hallucinate or was the LLM fed bad context?).\\
In the above screenshot you can see how poor retrieval directly correlates with hallucinations
-
-
- For a full tutorial on LLM Ops, check out our tutorial below.
+For a full tutorial on LLM Ops, check out our tutorial below.
{% embed url="https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/llm_ops_overview.ipynb" %}
diff --git a/docs/concepts/generating-embeddings.md b/docs/concepts/generating-embeddings.md
index 00f76c8fe1..c32d8d55bb 100644
--- a/docs/concepts/generating-embeddings.md
+++ b/docs/concepts/generating-embeddings.md
@@ -1,6 +1,6 @@
# Generating Embeddings
-Phoenix supports any type of dense [embedding](embeddings.md) generated for almost any type of data.
+Phoenix supports any type of dense [embedding](broken-reference) generated for almost any type of data.
But what if I don't have embeddings handy? Well, that is not a problem. The model data can be analyzed by the embeddings Auto-Generated for Phoenix.
diff --git a/docs/concepts/llm-observability.md b/docs/concepts/llm-observability.md
index b6ed64bb6b..63a70dcebb 100644
--- a/docs/concepts/llm-observability.md
+++ b/docs/concepts/llm-observability.md
@@ -4,7 +4,7 @@ description: >-
software system: the application, the prompt, and the response.
---
-# LLM Observability
+# User Guide
## 5 Pillars of LLM Observability
diff --git a/docs/concepts/llm-traces.md b/docs/concepts/llm-traces.md
index 603292616d..3f7b5fb05b 100644
--- a/docs/concepts/llm-traces.md
+++ b/docs/concepts/llm-traces.md
@@ -2,7 +2,7 @@
description: Tracing the execution of LLM powered applications using OpenInference Traces
---
-# LLM Traces
+# Overview: Traces
## What is LLM Traces and Observability?
diff --git a/docs/concepts/open-inference.md b/docs/concepts/open-inference.md
index 1cf1decbe5..fbdbaa19ba 100644
--- a/docs/concepts/open-inference.md
+++ b/docs/concepts/open-inference.md
@@ -7,13 +7,13 @@ description: >-
# OpenInference
{% hint style="info" %}
-For a in-depth specification of the OpenInference specification, please consult the spec [https://github.com/Arize-ai/open](https://github.com/Arize-ai/open-inference-spec)[inference](https://github.com/Arize-ai/openinference)
+For a in-depth specification of the OpenInference specification, please consult the spec [https://github.com/Arize-ai/openinference](https://github.com/Arize-ai/openinference)
{% endhint %}
OpenInference is a set of specifications for model inferences and LLM traces
OpenInference is a specification that encompass two data models:
-
Inferences
designed to capture inference logs from a variety of model types and use-cases
Phoenix can be run locally, via a cloud notebook, or as a container
-
Phoenix app is first and foremost an application that can be run just in in your notebook! This makes it an extremely flexible app since it can be accessed directly as you iterate on your AI-powered app!\
@@ -19,33 +17,13 @@ Looking how to deploy Phoenix outside of the notebook for production use? Checko
### Notebooks
-Currently phoenix supports local, colab, databricks, and SageMaker notebooks.
-
-{% hint style="warning" %}
-Note, phoenix only supports running the phoenix server via the notebook for SageMaker notebooks. It cannot setup proxy requests for SageMaker studio since there is no support of jupyter-server-proxy
-{% endhint %}
-
-#### SageMaker
-
-With SageMaker notebooks, phoenix leverages the [jupyter-server-proy](https://github.com/jupyterhub/jupyter-server-proxy) to host the server under `proxy/6006.`Note, that phoenix will automatically try to detect that you are running in SageMaker but you can declare the notebook runtime via a parameter to `launch_app` or an environment variable
-
-{% tabs %}
-{% tab title="Environment Variable" %}
-```python
-import os
-
-os.environ["PHOENIX_NOTEBOOK_ENV"] = "sagemaker"
-```
-{% endtab %}
+To start phoenix in the notebook environment, run:
-{% tab title="Launch Parameter" %}
```python
import phoenix as px
-px.launch_app(notebook_environment="sagemaker")
+session = px.launch_app()
```
-{% endtab %}
-{% endtabs %}
### Container
@@ -79,18 +57,6 @@ import os
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "http://123.456.789:6006"
```
{% endtab %}
-
-{% tab title="Set Endpoint in Code" %}
-```python
-from phoenix.trace.tracer import Tracer
-from phoenix.trace.exporter import HttpExporter
-from phoenix.trace.openai.instrumentor import OpenAIInstrumentor
-
-
-tracer = Tracer(exporter=HttpExporter(endpoint="http://123.456.789:6006"))
-OpenAIInstrumentor(tracer).instrument()
-```
-{% endtab %}
{% endtabs %}
Note that the above is only necessary if your application is running in a Jupyter notebook. If you are trying to deploy your application and have phoenix collect traces via a container, please consult the [deployment guide.](telemetry/deploying-phoenix.md)
diff --git a/docs/how-to/define-your-schema/README.md b/docs/how-to/define-your-schema/README.md
index 605db0289b..f3d86e9630 100644
--- a/docs/how-to/define-your-schema/README.md
+++ b/docs/how-to/define-your-schema/README.md
@@ -144,7 +144,7 @@ schema = px.Schema(
Embedding features consist of vector data in addition to any unstructured data in the form of text or images that the vectors represent. Unlike normal features, a single embedding feature may span multiple columns of your dataframe. Use `px.EmbeddingColumnNames` to associate multiple dataframe columns with the same embedding feature.
{% hint style="info" %}
-* For a conceptual overview of embeddings, see [Embeddings](../../concepts/embeddings.md).
+* For a conceptual overview of embeddings, see [Embeddings](broken-reference).
* For a comprehensive description of `px.EmbeddingColumnNames`, see the [API reference](../../api/dataset-and-schema.md#phoenix.embeddingcolumnnames).
{% endhint %}
diff --git a/docs/how-to/define-your-schema/llm-evaluations.md b/docs/how-to/define-your-schema/llm-evaluations.md
index c73d3cd846..3a49f6fac5 100644
--- a/docs/how-to/define-your-schema/llm-evaluations.md
+++ b/docs/how-to/define-your-schema/llm-evaluations.md
@@ -24,7 +24,7 @@ The evaluations dataframe can be sent to Phoenix as follows. Note that the name
```python
from phoenix.trace import SpanEvaluations
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(
dataframe=qa_correctness_eval_df,
eval_name="Q&A Correctness",
@@ -34,7 +34,7 @@ px.log_evaluations(
## Document Evaluations
-A dataframe of document evaluations would look something like the table below. It must contain `span_id` and `document_position` as either indices or columns. `document_position` is the document's (zero-based) index in the span's list of retrieved documents. Once ingested, Phoenix uses the `span_id` and `document_position` to associate the evaluation with its target span and document.
+A dataframe of document evaluations would look something like the table below. It must contain `span_id` and `document_position` as either indices or columns. `document_position` is the document's (zero-based) index in the span's list of retrieved documents. Once ingested, Phoenix uses the `span_id` and `document_position` to associate the evaluation with its target span and document.
span_id
document_position
label
score
5B8EF798A381
0
relevant
1
5B8EF798A381
1
irrelevant
0
E19B7EC3GG02
0
relevant
1
@@ -43,7 +43,7 @@ The evaluations dataframe can be sent to Phoenix as follows. Note that the name
```python
from phoenix.trace import DocumentEvaluations
-px.log_evaluations(
+px.Client().log_evaluations(
DocumentEvaluations(
dataframe=document_relevance_eval_df,
eval_name="Relevance",
@@ -53,10 +53,10 @@ px.log_evaluations(
## Logging Multiple Evaluation DataFrames
-Multiple evaluation datasets can be logged by the same `px.log_evaluations()` function call.
+Multiple evaluation datasets can be logged by the same `px.Client().log_evaluations()` function call.
```
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(
dataframe=qa_correctness_eval_df,
eval_name="Q&A Correctness",
diff --git a/docs/how-to/export-your-data.md b/docs/how-to/export-your-data.md
index e2adc2fd8b..6a1aa7fa37 100644
--- a/docs/how-to/export-your-data.md
+++ b/docs/how-to/export-your-data.md
@@ -18,29 +18,7 @@ The easiest way to gather traces that have been collected by Phoenix is to direc
px.Client().get_spans_dataframe('span_kind == "RETRIEVER"')
```
-Notice that the `get_spans_dataframe` method supports a Python expression as an optional `str` parameter so you can filter down your data to specific traces you care about. For full details, consult the [Session API docs](../api/session.md).
-
-You can also directly get the spans from the tracer or callback:
-
-```python
-from phoenix.trace.langchain import OpenInferenceTracer
-
-tracer = OpenInferenceTracer()
-
-# Run the application with the tracer
-chain.run(query, callbacks=[tracer])
-
-# When you are ready to analyze the data, you can convert the traces
-ds = TraceDataset.from_spans(tracer.get_spans())
-
-# Print the dataframe
-ds.dataframe.head()
-
-# Re-initialize the app with the trace dataset
-px.launch_app(trace=ds)
-```
-
-Note that the above calls `get_spans` on a LangChain tracer but the same exact method exists on the `OpenInferenceCallback` for LlamaIndex as well.
+Notice that the `get_spans_dataframe` method supports a Python expression as an optional `str` parameter so you can filter down your data to specific traces you care about. For full details, consult the [Client](../api/client.md) API docs.
## Exporting Embeddings
diff --git a/docs/how-to/manage-the-app.md b/docs/how-to/manage-the-app.md
index 4afbb6e456..914bb03258 100644
--- a/docs/how-to/manage-the-app.md
+++ b/docs/how-to/manage-the-app.md
@@ -77,3 +77,4 @@ When you're done using Phoenix, gracefully shut down your running background ses
```python
px.close_app()
```
+
diff --git a/docs/how-to/use-example-datasets.md b/docs/how-to/use-example-datasets.md
index 70a6e79502..9da8f5ddaf 100644
--- a/docs/how-to/use-example-datasets.md
+++ b/docs/how-to/use-example-datasets.md
@@ -98,7 +98,7 @@ Follow the instructions in the cell output to open the Phoenix UI in your notebo
## View Available Traces
-Phoenix supports [LLM application Traces](../concepts/llm-traces.md) and has examples that you can take a look at as well.\
+Phoenix supports [LLM application Traces](../concepts/llm-traces.md) and has examples that you can take a look at as well.\\
```python
px.load_example_traces?
diff --git a/docs/install-and-import-phoenix.md b/docs/install-and-import-phoenix.md
deleted file mode 100644
index 731f737477..0000000000
--- a/docs/install-and-import-phoenix.md
+++ /dev/null
@@ -1,52 +0,0 @@
----
-description: How to install Phoenix for Observability and evaluation
----
-
-# Installation
-
-## Python
-
-In your Jupyter or Colab environment, run the following command to install.
-
-{% tabs %}
-{% tab title="Using pip" %}
-```sh
-pip install arize-phoenix
-```
-{% endtab %}
-
-{% tab title="Using conda" %}
-```sh
-conda install -c conda-forge arize-phoenix
-```
-{% endtab %}
-{% endtabs %}
-
-Note that the above only installs dependencies that are necessary to run the application. Phoenix also has an experimental sub-module where you can find [LLM Evals](llm-evals/llm-evals.md).
-
-```sh
-pip install arize-phoenix[experimental]
-```
-
-\
-Once installed, import Phoenix in your notebook with
-
-```python
-import phoenix as px
-```
-
-{% hint style="info" %}
-Phoenix is supported on Python ≥3.8, <3.11.
-{% endhint %}
-
-## Container
-
-Using docker you can run the phoenix server as a container.
-
-```
-docker run -p 6006:6006 arizephoenix/phoenix:latest
-```
-
-{% hint style="info" %}
-The commend above will run phoenix latest but you might want to use a specific image tag. The image tags correspond with the releases of phoenix on Pypi and Conda.
-{% endhint %}
diff --git a/docs/integrations/autogen-support.md b/docs/integrations/autogen-support.md
index 1d7bcc1861..2bf2dc3736 100644
--- a/docs/integrations/autogen-support.md
+++ b/docs/integrations/autogen-support.md
@@ -9,17 +9,12 @@ AutoGen is a new agent framework from Microsoft that allows for complex Agent cr
The AutoGen Agent framework allows creation of multiple agents and connection of those agents to work together to accomplish tasks.
```python
-from phoenix.trace.tracer import Tracer
from phoenix.trace.openai.instrumentor import OpenAIInstrumentor
-from phoenix.trace.exporter import HttpExporter
from phoenix.trace.openai import OpenAIInstrumentor
-from phoenix.trace.tracer import Tracer
-
import phoenix as px
-session = px.launch_app()
-tracer = Tracer(exporter=HttpExporter())
-OpenAIInstrumentor(tracer).instrument()
+px.launch_app()
+OpenAIInstrumentor().instrument()
```
The Phoenix support is simple in its first incarnation but allows for capturing all of the prompt and responses that occur under the framework between each agent.
diff --git a/docs/integrations/dspy.md b/docs/integrations/dspy.md
new file mode 100644
index 0000000000..25670dcf20
--- /dev/null
+++ b/docs/integrations/dspy.md
@@ -0,0 +1,50 @@
+---
+description: Instrument and observe your DSPy application
+---
+
+# DSPy
+
+[DSPy](https://github.com/stanfordnlp/dspy) is a framework for automatically prompting and fine-tuning language models. It provides composable and declarative APIs that allow developers to describe the architecture of their LLM application in the form of a "module" (inspired by PyTorch's `nn.Module`). It them compiles these modules using "teleprompters" that optimize the module for a particular task. The term "teleprompter" is meant to evoke "prompting at a distance," and could involve selecting few-shot examples, generating prompts, or fine-tuning language models.
+
+Phoenix makes your DSPy applications observable by visualizing the underlying structure of each call to your compiled DSPy module.
+
+## Tracing
+
+To trace your DSPy application, ensure that the following packages are installed in addition to DSPy:
+
+```
+pip install arize-phoenix openinference-instrumentation-dspy opentelemetry-exporter-otlp
+```
+
+Launch Phoenix as a collector in the background.
+
+```python
+import phoenix as px
+
+px.launch_app()
+```
+
+Configure your OpenTelemetry exporter, which will export spans and traces to Phoenix, and run the DSPy instrumentor to wrap calls to the relevant DSPy components.
+
+```python
+from openinference.instrumentation.dspy import DSPyInstrumentor
+from opentelemetry import trace as trace_api
+from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
+from opentelemetry.sdk import trace as trace_sdk
+from opentelemetry.sdk.resources import Resource
+from opentelemetry.sdk.trace.export import SimpleSpanProcessor
+
+endpoint = "http://127.0.0.1:6006/v1/traces"
+resource = Resource(attributes={})
+tracer_provider = trace_sdk.TracerProvider(resource=resource)
+span_otlp_exporter = OTLPSpanExporter(endpoint=endpoint)
+tracer_provider.add_span_processor(SimpleSpanProcessor(span_exporter=span_otlp_exporter))
+trace_api.set_tracer_provider(tracer_provider=tracer_provider)
+DSPyInstrumentor().instrument()
+```
+
+Now run invoke your compiled DSPy module. Your traces should appear inside of Phoenix.
+
+
+
+For a full working example, check out the [Colab](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/dspy\_tracing\_tutorial.ipynb).
diff --git a/docs/integrations/langchain.md b/docs/integrations/langchain.md
index 552ef21752..a7be8a5627 100644
--- a/docs/integrations/langchain.md
+++ b/docs/integrations/langchain.md
@@ -27,16 +27,15 @@ Once you have started a Phoenix server, you can start your LangChain application
{% tabs %}
{% tab title="Instrument Langchain" %}
-We recommend that you instrument your entire LangChain application to maximize visibility. To do this, we will use the `LangChainInstrumentor` to add the `OpenInferenceTracer` to every chain in your application.\
-
+We recommend that you instrument your entire LangChain application to maximize visibility. To do this, we will use the `LangChainInstrumentor`.
```python
-from phoenix.trace.langchain import OpenInferenceTracer, LangChainInstrumentor
+from phoenix.trace.langchain import LangChainInstrumentor
-# If no exporter is specified, the tracer will export to the locally running Phoenix server
-tracer = OpenInferenceTracer()
-# If no tracer is specified, a tracer is constructed for you
-LangChainInstrumentor(tracer).instrument()
+# By default, the traces will be exported to the locally running Phoenix
+# server. If a different endpoint is desired, change the environment
+# variable os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = ...
+LangChainInstrumentor().instrument()
# Initialize your LangChain application
@@ -45,22 +44,6 @@ LangChainInstrumentor(tracer).instrument()
response = chain.run(query)
```
{% endtab %}
-
-{% tab title="Use callbacks" %}
-If you only want traces from parts of your application, you can pass in the tracer to the parts that you care about.
-
-```python
-from phoenix.trace.langchain import OpenInferenceTracer
-
-# If no exporter is specified, the tracer will export to the locally running Phoenix server
-tracer = OpenInferenceTracer()
-
-# Initialize your LangChain application
-
-# Instrument the execution of the runs with the tracer. By default the tracer uses an HTTPExporter
-response = chain.run(query, callbacks=[tracer])
-```
-{% endtab %}
{% endtabs %}
By adding the tracer to the callbacks of LangChain, we've created a one-way data connection between your LLM application and Phoenix. This is because by default the `OpenInferenceTracer` uses an `HTTPExporter` to send traces to your locally running Phoenix server! In this scenario the Phoenix server is serving as a `Collector` of the spans that are exported from your LangChain application.
@@ -73,29 +56,13 @@ px.active_session().view()
#### Saving Traces
-If you would like to save your traces to a file for later use, you can directly extract the traces from the `tracer`
-
-To directly extract the traces from the `tracer`, dump the traces from the tracer into a file (we recommend `jsonl` for readability).
-
-```python
-from phoenix.trace.span_json_encoder import spans_to_jsonl
-with open("trace.jsonl", "w") as f:
- f.write(spans_to_jsonl(tracer.get_spans()))
-```
-
-Now you can save this file for later inspection. To launch the app with the file generated above, simply pass the contents in the file above via a `TraceDataset`
+If you would like to save your traces to a file for later use, you can directly extract the traces as a dataframe from Phoenix using `px.Client`.
```python
-from phoenix.trace.utils import json_lines_to_df
-
-json_lines = []
-with open("trace.jsonl", "r") as f:
- json_lines = cast(List[str], f.readlines())
-trace_ds = TraceDataset(json_lines_to_df(json_lines))
-px.launch_app(trace=trace_ds)
+px.Client().get_spans_dataframe()
```
-In this way, you can use files as a means to store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
+In this way, you can store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
#### Working Example with Traces
diff --git a/docs/integrations/llamaindex.md b/docs/integrations/llamaindex.md
index 6dd01ab437..810dcca73e 100644
--- a/docs/integrations/llamaindex.md
+++ b/docs/integrations/llamaindex.md
@@ -4,7 +4,7 @@ description: How to connect to OpenInference compliant data via a llama_index ca
# LlamaIndex
-[LlamaIndex](https://github.com/run-llama/llama_index) (GPT Index) is a data framework for your LLM application. It's a powerful framework by which you can build an application that leverages RAG (retrieval-augmented generation) to super-charge an LLM with your own data. RAG is an extremely powerful LLM application model because it lets you harness the power of LLMs such as OpenAI's GPT but tuned to your data and use-case.
+[LlamaIndex](https://github.com/run-llama/llama\_index) (GPT Index) is a data framework for your LLM application. It's a powerful framework by which you can build an application that leverages RAG (retrieval-augmented generation) to super-charge an LLM with your own data. RAG is an extremely powerful LLM application model because it lets you harness the power of LLMs such as OpenAI's GPT but tuned to your data and use-case.
However when building out a retrieval system, a lot can go wrong that can be detrimental to the user-experience of your question and answer system. Phoenix provides two different ways to gain insights into your LLM application: [OpenInference](../concepts/open-inference.md) inference records and [OpenInference](../concepts/open-inference.md) tracing.
@@ -30,34 +30,37 @@ LlamaIndex 0.8.36 and above supports One-Click!
{% endhint %}
{% tabs %}
-{% tab title="Using a Callback" %}
+{% tab title="One-Click" %}
+{% hint style="info" %}
+Using phoenix as a callback requires an install of \`llama-index-callbacks-arize-phoenix>1.3.0'
+{% endhint %}
-```python
-from phoenix.trace.llama_index import (
- OpenInferenceTraceCallbackHandler,
-)
-
-# Initialize the callback handler
-callback_handler = OpenInferenceTraceCallbackHandler()
-
-# LlamaIndex application initialization may vary
-# depending on your application
-service_context = ServiceContext.from_defaults(
- llm_predictor=LLMPredictor(llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)),
- embed_model=OpenAIEmbedding(model="text-embedding-ada-002"),
- callback_manager=CallbackManager(handlers=[callback_handler]),
-)
-index = load_index_from_storage(
- storage_context,
- service_context=service_context,
-)
-query_engine = index.as_query_engine()
+llama-index 0.10 introduced modular sub-packages. To use llama-index's one click, you must install the small integration first:
+```bash
+pip install 'llama-index-callbacks-arize-phoenix>1.3.0'
```
+```python
+# Phoenix can display in real time the traces automatically
+# collected from your LlamaIndex application.
+import phoenix as px
+# Look for a URL in the output to open the App in a browser.
+px.launch_app()
+# The App is initially empty, but as you proceed with the steps below,
+# traces will appear automatically as your LlamaIndex application runs.
+
+from llama_index.core import set_global_handler
+
+set_global_handler("arize_phoenix")
+
+# Run all of your LlamaIndex applications as usual and traces
+# will be collected and displayed in Phoenix.
+```
{% endtab %}
-{% tab title="One-Click" %}
+{% tab title="One-Click Legacy (3.0.0` and downgrade `openinference-instrumentation-llama-index<1.0.0`
```python
# Phoenix can display in real time the traces automatically
@@ -74,7 +77,6 @@ llama_index.set_global_handler("arize_phoenix")
# Run all of your LlamaIndex applications as usual and traces
# will be collected and displayed in Phoenix.
```
-
{% endtab %}
{% endtabs %}
@@ -86,31 +88,15 @@ To view the traces in Phoenix, simply open the UI in your browser.
px.active_session().view()
```
-### Saving Traces
+#### Saving Traces
-If you would like to save your traces to a file for later use, you can directly extract the traces from the callback
-
-To directly extract the traces from the callback, dump the traces from the tracer into a file (we recommend `jsonl` for readability).
-
-```python
-from phoenix.trace.span_json_encoder import spans_to_jsonl
-with open("trace.jsonl", "w") as f:
- f.write(spans_to_jsonl(callback.get_spans()))
-```
-
-Now you can save this file for later inspection. To launch the app with the file generated above, simply pass the contents in the file above via a `TraceDataset`
+If you would like to save your traces to a file for later use, you can directly extract the traces as a dataframe from Phoenix using `px.Client`.
```python
-from phoenix.trace.utils import json_lines_to_df
-
-json_lines = []
-with open("trace.jsonl", "r") as f:
- json_lines = cast(List[str], f.readlines())
-trace_ds = TraceDataset(json_lines_to_df(json_lines))
-px.launch_app(trace=trace_ds)
+px.Client().get_spans_dataframe()
```
-In this way, you can use files as a means to store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
+In this way, you can store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
#### Working Example with Traces
@@ -127,7 +113,7 @@ Inferences capture each invocation of the LLM application as a single record and
{% endhint %}
\
-To provide visibility into how your LLM app is performing, we built the [OpenInferenceCallback](https://github.com/run-llama/llama_index/blob/57d8253c12fcda0061d3167d56dbc425981e131f/docs/examples/callbacks/OpenInferenceCallback.ipynb). The OpenInferenceCallback captures the internals of the LLM App in buffers that conforms to the [OpenInference](../concepts/open-inference.md) format. As your LlamaIndex application, the callback captures the timing, embeddings, documents, and other critical internals and serializes the data to buffers that can be easily materialized as dataframes or as files such as Parquet. Since Phoenix can ingest OpenInference data natively, making it a seamless integration to analyze your LLM powered chatbot. To understand callbacks in details, consult the [LlamaIndex docs.](https://gpt-index.readthedocs.io/en/latest/core_modules/supporting_modules/callbacks/root.html)
+To provide visibility into how your LLM app is performing, we built the [OpenInferenceCallback](https://github.com/run-llama/llama\_index/blob/57d8253c12fcda0061d3167d56dbc425981e131f/docs/examples/callbacks/OpenInferenceCallback.ipynb). The OpenInferenceCallback captures the internals of the LLM App in buffers that conforms to the [OpenInference](../concepts/open-inference.md) format. As your LlamaIndex application, the callback captures the timing, embeddings, documents, and other critical internals and serializes the data to buffers that can be easily materialized as dataframes or as files such as Parquet. Since Phoenix can ingest OpenInference data natively, making it a seamless integration to analyze your LLM powered chatbot. To understand callbacks in details, consult the [LlamaIndex docs.](https://gpt-index.readthedocs.io/en/latest/core\_modules/supporting\_modules/callbacks/root.html)
### Adding the OpenInferenceCallback
@@ -186,7 +172,7 @@ class ParquetCallback:
Note that Parquet is just an example file format, you can use any file format of your choosing such as Avro and NDJSON.
{% endhint %}
-For the full guidance on how to materialize your data in files, consult the [LlamaIndex notebook](https://github.com/run-llama/llama_index/blob/main/docs/examples/callbacks/OpenInferenceCallback.ipynb).
+For the full guidance on how to materialize your data in files, consult the [LlamaIndex notebook](https://github.com/run-llama/llama\_index/blob/main/docs/examples/callbacks/OpenInferenceCallback.ipynb).
#### Working Example with Inferences
diff --git a/docs/integrations/openai.md b/docs/integrations/openai.md
index 0a0752d951..45e3b2fd76 100644
--- a/docs/integrations/openai.md
+++ b/docs/integrations/openai.md
@@ -30,10 +30,7 @@ from phoenix.trace.tracer import Tracer
from phoenix.trace.exporter import HttpExporter
from phoenix.trace.openai.instrumentor import OpenAIInstrumentor
-
-tracer = Tracer(exporter=HttpExporter())
-OpenAIInstrumentor(tracer).instrument()
-
+OpenAIInstrumentor().instrument()
```
All subsequent calls to the `ChatCompletion` interface will now report informational spans to Phoenix. These traces and spans are viewable within the Phoenix UI.
@@ -46,30 +43,12 @@ px.active_session().url
px.active_session().view()
```
-####
-
#### Saving Traces
-If you would like to save your traces to a file for later use, you can directly extract the traces from the `tracer`
-
-To directly extract the traces from the `tracer`, dump the traces from the tracer into a file (we recommend `jsonl` for readability).
+If you would like to save your traces to a file for later use, you can directly extract the traces as a dataframe from Phoenix using `px.Client`.
```python
-from phoenix.trace.span_json_encoder import spans_to_jsonl
-with open("trace.jsonl", "w") as f:
- f.write(spans_to_jsonl(tracer.get_spans()))
-```
-
-Now you can save this file for later inspection. To launch the app with the file generated above, simply pass the contents in the file above via a `TraceDataset`
-
-```python
-from phoenix.trace.utils import json_lines_to_df
-
-json_lines = []
-with open("trace.jsonl", "r") as f:
- json_lines = cast(List[str], f.readlines())
-trace_ds = TraceDataset(json_lines_to_df(json_lines))
-px.launch_app(trace=trace_ds)
+px.Client().get_spans_dataframe()
```
-In this way, you can use files as a means to store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
+In this way, you can store and communicate interesting traces that you may want to use to share with a team or to use later down the line to fine-tune an LLM or model.
diff --git a/docs/llm-evals/building-your-own-evals.md b/docs/llm-evals/building-your-own-evals.md
index 59b6f2ae4b..c7c788cd1f 100644
--- a/docs/llm-evals/building-your-own-evals.md
+++ b/docs/llm-evals/building-your-own-evals.md
@@ -85,7 +85,7 @@ positive_eval = llm_classify(
The above example shows a use of the custom created template on the df dataframe.
```python
-#Phoenix Evals support using either stirngs or objects as templates
+#Phoenix Evals support using either strings or objects as templates
MY_CUSTOM_TEMPLATE = " ..."
MY_CUSTOM_TEMPLATE = PromptTemplate("This is a test {prompt}")
```
diff --git a/docs/llm-evals/evaluation-types.md b/docs/llm-evals/evaluation-types.md
index 10fb005cdf..3c0aa0d68d 100644
--- a/docs/llm-evals/evaluation-types.md
+++ b/docs/llm-evals/evaluation-types.md
@@ -94,7 +94,7 @@ The Phoenix library does support numeric score Evals if you would like to use th
You are a helpful AI bot that checks for grammatical, spelling and typing errors
in a document context. You are going to return a continous score for the
document based on the percent of grammatical and typing errors. The score should be
-between 10 and 1. A score of 1 will be no grmatical errors in any word,
+between 10 and 1. A score of 1 will be no grammatical errors in any word,
a score of 2 will be 20% of words have errors, a 5 score will be 50% errors,
a score of 7 is 70%, and a 10 score will be all words in the context have a
grammatical errors.
diff --git a/docs/llm-evals/llm-evals.md b/docs/llm-evals/llm-evals.md
index e53e49ce49..7ab71d2593 100644
--- a/docs/llm-evals/llm-evals.md
+++ b/docs/llm-evals/llm-evals.md
@@ -1,4 +1,4 @@
-# Phoenix LLM Evals
+# Overview: Evals
The standard for evaluating text is human labeling. However, high-quality LLM outputs are becoming cheaper and faster to produce, and human evaluation cannot scale. In this context, evaluating the performance of LLM applications is best tackled by using a separate evaluation LLM. The Phoenix [LLM Evals library](running-pre-tested-evals/) is designed for simple, fast, and accurate LLM-based evaluations.
diff --git a/docs/llm-evals/quickstart-retrieval-evals/README.md b/docs/llm-evals/quickstart-retrieval-evals/README.md
index 89ec4cfb07..f405b4afbd 100644
--- a/docs/llm-evals/quickstart-retrieval-evals/README.md
+++ b/docs/llm-evals/quickstart-retrieval-evals/README.md
@@ -1,8 +1,8 @@
# Quickstart Retrieval Evals
-In order to run retrieval Evals the following code can be used for quick analysis of common frameworks of LangChain and LlamaIndex.
+In order to run retrieval Evals the following code can be used for quick analysis of common frameworks of LangChain and LlamaIndex.
-Independent of the framework you are instrumenting, Phoenix traces allow you to get retrieval data in a common dataframe format that follows the [OpenInference](../../concepts/open-inference.md) specification.
+Independent of the framework you are instrumenting, Phoenix traces allow you to get retrieval data in a common dataframe format that follows the [OpenInference](../../concepts/open-inference.md) specification.
```python
# Get traces from Phoenix into dataframe
@@ -62,7 +62,7 @@ qa_correctness_eval["score"] = (
).astype(int)
# Logs the Evaluations back to the Phoenix User Interface (Optional)
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(eval_name="Hallucination", dataframe=hallucination_eval),
SpanEvaluations(eval_name="QA Correctness", dataframe=qa_correctness_eval),
)
@@ -73,11 +73,11 @@ The Evals are available in dataframe locally and can be materilazed back to the
Evals in Phoenix UI
-The snipit of code above links the Evals back to the spans they were generated against.
+The snipit of code above links the Evals back to the spans they were generated against.
### Retrieval Chunk Evals
-[Retrieval Evals](../running-pre-tested-evals/retrieval-rag-relevance.md) are run on the individual chunks returned on retrieval. In addition to calculating chunk level metrics, Phoenix also calculates MRR and NDCG for the retrieved span.
+[Retrieval Evals](../running-pre-tested-evals/retrieval-rag-relevance.md) are run on the individual chunks returned on retrieval. In addition to calculating chunk level metrics, Phoenix also calculates MRR and NDCG for the retrieved span.
```python
@@ -100,7 +100,7 @@ retrieved_documents_eval["score"] = (
retrieved_documents_eval.label[~retrieved_documents_eval.label.isna()] == "relevant"
).astype(int)
-px.log_evaluations(DocumentEvaluations(eval_name="Relevance", dataframe=retrieved_documents_eval))
+px.Client().log_evaluations(DocumentEvaluations(eval_name="Relevance", dataframe=retrieved_documents_eval))
```
diff --git a/docs/llm-evals/running-pre-tested-evals/README.md b/docs/llm-evals/running-pre-tested-evals/README.md
index dd6c94843d..22ff751cbe 100644
--- a/docs/llm-evals/running-pre-tested-evals/README.md
+++ b/docs/llm-evals/running-pre-tested-evals/README.md
@@ -3,10 +3,10 @@
The following are simple functions on top of the LLM Evals building blocks that are pre-tested with benchmark datasets.
{% hint style="info" %}
-All evals templates are tested against golden datasets that are available as part of the LLM eval library's [benchmarked datasets](./#how-we-benchmark-pre-tested-evals) and target precision at 70-90% and F1 at 70-85%.
+All evals templates are tested against golden datasets that are available as part of the LLM eval library's [benchmarked datasets](./#how-we-benchmark-pre-tested-evals) and target precision at 70-90% and F1 at 70-85%.
{% endhint %}
-
## Supported Models.
@@ -17,11 +17,11 @@ model = OpenAIModel(model_name="gpt-4",temperature=0.6)
model("What is the largest costal city in France?")
```
-We currently support a growing set of models for LLM Evals, please check out the [API section for usage](../../api/evaluation-models.md).
+We currently support a growing set of models for LLM Evals, please check out the [API section for usage](../../api/evaluation-models.md).
-
Model
Support
GPT-4
✔
GPT-3.5 Turbo
✔
GPT-3.5 Instruct
✔
Azure Hosted Open AI
✔
Palm 2 Vertex
✔
AWS Bedrock
✔
Litellm
✔
Huggingface Llama7B
(coming soon)
Anthropic
(coming soon)
Cohere
(coming soon)
+
Model
Support
GPT-4
✔
GPT-3.5 Turbo
✔
GPT-3.5 Instruct
✔
Azure Hosted Open AI
✔
Palm 2 Vertex
✔
AWS Bedrock
✔
Litellm
✔
Huggingface Llama7B
(coming soon)
Anthropic
(coming soon)
Cohere
(coming soon)
-## How we benchmark pre-tested evals
+## How we benchmark pre-tested evals
The above diagram shows examples of different environments the Eval harness is desinged to run. The benchmarking environment is designed to enable the testing of the Eval model & Eval template performance against a designed set of datasets.
diff --git a/docs/llm-evals/running-pre-tested-evals/q-and-a-on-retrieved-data.md b/docs/llm-evals/running-pre-tested-evals/q-and-a-on-retrieved-data.md
index cf50085d1b..bda1c565a4 100644
--- a/docs/llm-evals/running-pre-tested-evals/q-and-a-on-retrieved-data.md
+++ b/docs/llm-evals/running-pre-tested-evals/q-and-a-on-retrieved-data.md
@@ -84,21 +84,3 @@ The above Eval uses the QA template for Q\&A analysis on retrieved data.
| Throughput | GPT-4 | GPT-4 Turbo | GPT-3.5 |
| ----------- | ------- | ----------- | ------- |
| 100 Samples | 124 Sec | 66 sec | 67 sec |
-
-### Concatenating Retrieved References
-
-In order to run the RAG relevance eval, you need to concatenate all of the chunks into a single string that is inserted into the Eval check.
-
-
-
-The above drawing shows the query and chunks returned for the query, those chunks are put into the reference variable of the Eval template.
-
-```python
-from phoenix.experimental.evals.functions.processing import concatenate_and_truncate_chunks
-
-model = OpenAIModel(model_name="gpt-4", temperature=0.0) # Needed to get token size supported
-# Then use the function in a single call to collect and truncate reference.
-df["reference_text"] = df["retrieved_chunk_list"].apply(
- lambda chunks: concatenate_and_truncate_chunks(chunks=chunks, model=model, token_buffer=700)
-)
-```
diff --git a/docs/llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md b/docs/llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md
index f0fde81529..bb5478569c 100644
--- a/docs/llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md
+++ b/docs/llm-evals/running-pre-tested-evals/retrieval-rag-relevance.md
@@ -85,27 +85,3 @@ The above runs the RAG relevancy LLM template against the dataframe df.
| Throughput | GPT-4 | GPT-4 Turbo | GPT-3.5 |
| ----------- | ------- | ----------- | ------- |
| 100 Samples | 113 Sec | 61 sec | 73 Sec |
-
-### Concatenating Retrieved References
-
-In order to run the RAG relevance eval, you need to concatenate all of the chunks into a single string that is inserted into the Eval check.
-
-
-
-The above drawing shows the query and chunks returned for the query, those chunks are put into the reference variable of the Eval template.
-
-```python
-from phoenix.experimental.evals.functions.processing import concatenate_and_truncate_chunks
-
-model = OpenAIModel(model_name="gpt-4", temperature=0.0) # Needed to get token size supported
-# Then use the function in a single call to collect and truncate reference.
-df["reference_text"] = df["retrieved_chunk_list"].apply(
- lambda chunks: concatenate_and_truncate_chunks(chunks=chunks, model=model, token_buffer=700)
-)
-```
-
-
-
-{% hint style="info" %}
-Phoenix has options for not truncating the context window for Evals. Please drop a note in support if you want to test the MAP & Refine for Evals.
-{% endhint %}
diff --git a/docs/notebooks.md b/docs/notebooks.md
index 5b406559bf..9988567f1c 100644
--- a/docs/notebooks.md
+++ b/docs/notebooks.md
@@ -5,12 +5,16 @@ description: Explore the capabilities of Phoenix with notebooks
# Examples
{% embed url="https://phoenix-demo.arize.com/tracing" %}
-Don't want to run a notebook? Check out our tracing demo site!
+Don't want to run a notebook? Check out our tracing demo site!
+{% endembed %}
+
+{% embed url="https://phoenix-demo.arize.com/model" %}
+View Phoenix Search and Retrieval troubleshooting!
{% endembed %}
## Tutorials
-
## Application Examples
@@ -24,7 +28,7 @@ Trace through the execution of your LLM application to understand its internal s
| Title | Topics | Links |
| -------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Retrieval Example with Evaluations: Fast UI Viz |
Evaluations
Retrieval
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/llm\_application\_tracing\_evaluating\_and\_analysis.ipynb) |
+| Retrieval Example with Evaluations: Fast UI Viz |
Evaluations
Retrieval
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/llm\_application\_tracing\_evaluating\_and\_analysis.ipynb) |
| Tracing and Evaluating a LlamaIndex + OpenAI RAG Application |
LlamaIndex
OpenAI
retrieval-augmented generation
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/llama\_index\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/llama\_index\_tracing\_tutorial.ipynb) |
| Tracing and Evaluating a LlamaIndex OpenAI Agent |
LlamaIndex
OpenAI
agents
function calling
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/llama\_index\_openai\_agent\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/llama\_index\_openai\_agent\_tracing\_tutorial.ipynb) |
| Tracing and Evaluating a Structured Data Extraction Application with OpenAI Function Calling |
OpenAI
structured data extraction
function calling
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/openai\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/openai\_tracing\_tutorial.ipynb) |
@@ -32,6 +36,7 @@ Trace through the execution of your LLM application to understand its internal s
| Tracing and Evaluating a LangChain Agent |
LangChain
OpenAI
agents
function calling
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_agent\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_agent\_tracing\_tutorial.ipynb) |
| Tracing and Evaluating a LangChain + Vertex AI RAG Application |
LangChain
Vertex AI
retrieval-augmented generation
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_vertex\_ai\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_vertex\_ai\_tracing\_tutorial.ipynb) |
| Tracing and Evaluating a LangChain + Google PaLM RAG Application |
LangChain
Google PaLM
retrieval-augmented generation
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_google\_palm\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/langchain\_google\_palm\_tracing\_tutorial.ipynb) |
+| Tracing and Evaluation a DSPy Application |
LangChain
Google PaLM
retrieval-augmented generation
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/dspy\_tracing\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/tracing/dspy\_tracing\_tutorial.ipynb) |
## LLM Evals
@@ -72,8 +77,6 @@ Explore lower-dimensional representations of your embedding data to identify clu
Statistically analyze your structured data to perform A/B analysis, temporal drift analysis, and more.
-
-
| Title | Topics | Links |
| --------------------------------------- | -------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Detecting Fraud with Tabular Embeddings |
tabular data
anomaly detection
| [](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/credit\_card\_fraud\_tutorial.ipynb) [](https://github.com/Arize-ai/phoenix/blob/main/tutorials/credit\_card\_fraud\_tutorial.ipynb) |
diff --git a/docs/quickstart/evals.md b/docs/quickstart/evals.md
index 2f8d5a1d77..aea2d382cf 100644
--- a/docs/quickstart/evals.md
+++ b/docs/quickstart/evals.md
@@ -2,7 +2,7 @@
description: Evaluate your LLM application with Phoenix
---
-# Phoenix Evals
+# Quickstart: Evals
This quickstart shows how Phoenix helps you evaluate data from your LLM application.
@@ -15,10 +15,6 @@ You will:
* **Hallucinations:** Is your application making up false information?
* Ingest the evaluations into Phoenix to see the results annotated on the corresponding spans and traces.
-Let's get started!
-
-First, install Phoenix with `pip install arize-phoenix`.
-
To get you up and running quickly, we'll download some pre-existing trace data collected from a LlamaIndex application (in practice, this data would be collected by [instrumenting your LLM application](llm-traces.md) with an OpenInference-compatible tracer).
```python
@@ -55,8 +51,8 @@ If you are interested in a niche subset of your data, you can export with a cust
```python
from phoenix.session.evaluation import get_qa_with_reference, get_retrieved_documents
-retrieved_documents_df = get_retrieved_documents(session)
-queries_df = get_qa_with_reference(session)
+retrieved_documents_df = get_retrieved_documents(px.Client())
+queries_df = get_qa_with_reference(px.Client())
```
Phoenix evaluates your application data by prompting an LLM to classify whether a retrieved document is relevant or irrelevant to the corresponding query, whether a response is grounded in a retrieved document, etc. You can even get explanations generated by the LLM to help you understand the results of your evaluations!
@@ -117,11 +113,11 @@ Log your evaluations to your running Phoenix session.
```python
from phoenix.trace import DocumentEvaluations, SpanEvaluations
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(eval_name="Hallucination", dataframe=hallucination_eval_df),
SpanEvaluations(eval_name="QA Correctness", dataframe=qa_correctness_eval_df),
+ DocumentEvaluations(eval_name="Relevance", dataframe=relevance_eval_df),
)
-px.log_evaluations(DocumentEvaluations(eval_name="Relevance", dataframe=relevance_eval_df))
```
Your evaluations should now appear as annotations on your spans in Phoenix!
diff --git a/docs/quickstart/llm-traces.md b/docs/quickstart/llm-traces.md
index f7cc041f02..bf5ad85a0e 100644
--- a/docs/quickstart/llm-traces.md
+++ b/docs/quickstart/llm-traces.md
@@ -2,19 +2,35 @@
description: Inspect the inner-workings of your LLM Application using OpenInference Traces
---
-# Phoenix Traces
+# Quickstart: Traces
-## Streaming Traces to Phoenix
+## Overview
-The easiest method of using Phoenix traces with LLM frameworks (or direct OpenAI API) is to stream the execution of your application to a locally running Phoenix server. The traces collected during execution can then be stored for later use for things like validation, evaluation, and fine-tuning.
+Tracing is a powerful tool for understanding the behavior of your LLM application. Phoenix has best-in-class tracing capabilities, irregardless of what LLM framework you use.
-The [traces](../concepts/llm-traces.md) can be collected and stored in the following ways:
+To get started with traces, you will first want to start a local Phoenix app.
-* **In Memory**: useful for debugging.
-* **Local File**: Persistent and good for offline local development. See [exports](../how-to/export-your-data.md)
-* **Cloud** (coming soon): Store your cloud buckets as as assets for later use
+In your Jupyter or Colab environment, run the following command to install.
-To get started with traces, you will first want to start a local Phoenix app.
+{% tabs %}
+{% tab title="Using pip" %}
+```sh
+pip install arize-phoenix[evals]
+```
+{% endtab %}
+
+{% tab title="Using conda" %}
+```sh
+conda install -c conda-forge arize-phoenix[evals]
+```
+{% endtab %}
+{% endtabs %}
+
+Note that the above only installs dependencies that are necessary to run the application. Phoenix also has an experimental sub-module where you can find [LLM Evals](../llm-evals/llm-evals.md).
+
+```sh
+pip install arize-phoenix[experimental]
+```
```python
import phoenix as px
@@ -74,12 +90,9 @@ See the [integrations guide](../integrations/llamaindex.md#traces) for the full
{% tab title="LangChain" %}
```python
-from phoenix.trace.langchain import OpenInferenceTracer, LangChainInstrumentor
+from phoenix.trace.langchain import LangChainInstrumentor
-# If no exporter is specified, the tracer will export to the locally running Phoenix server
-tracer = OpenInferenceTracer()
-# If no tracer is specified, a tracer is constructed for you
-LangChainInstrumentor(tracer).instrument()
+LangChainInstrumentor().instrument()
# Initialize your LangChain application
# This might vary on your use-case. An example Chain is shown below
@@ -112,13 +125,10 @@ See the [integration guide](../integrations/langchain.md#traces) for details
{% tab title="OpenAI API" %}
```python
-from phoenix.trace.tracer import Tracer
from phoenix.trace.openai.instrumentor import OpenAIInstrumentor
-from phoenix.trace.exporter import HttpExporter
from phoenix.trace.openai import OpenAIInstrumentor
-tracer = Tracer(exporter=HttpExporter())
-OpenAIInstrumentor(tracer).instrument()
+OpenAIInstrumentor().instrument()
# Define a conversation with a user message
conversation = [
@@ -142,16 +152,12 @@ assistant_reply = response['choices'][0]['message']['content']
{% tab title="AutoGen" %}
```python
-from phoenix.trace.tracer import Tracer
from phoenix.trace.openai.instrumentor import OpenAIInstrumentor
-from phoenix.trace.exporter import HttpExporter
from phoenix.trace.openai import OpenAIInstrumentor
-from phoenix.trace.tracer import Tracer
import phoenix as px
-session = px.launch_app()
-tracer = Tracer(exporter=HttpExporter())
-OpenAIInstrumentor(tracer).instrument()
+px.launch_app()
+OpenAIInstrumentor().instrument()
```
{% endtab %}
{% endtabs %}
@@ -168,35 +174,14 @@ There are two ways to extract trace dataframes. The two ways for LangChain are d
{% tabs %}
{% tab title="From the App" %}
-
session = px.active_session()
-
-# You can export a dataframe from the session
+
# You can export a dataframe from the session
# Note that you can apply a filter if you would like to export only a sub-set of spans
-df = session.get_spans_dataframe('span_kind == "RETRIEVER"')
+df = px.Client().get_spans_dataframe('span_kind == "RETRIEVER"')
# Re-launch the app using the data
px.launch_app(trace=px.TraceDataset(df))
from phoenix.trace.langchain import OpenInferenceTracer
-
-tracer = OpenInferenceTracer()
-
-# Run the application with the tracer
-chain.run(query, callbacks=[tracer])
-
-# When you are ready to analyze the data, you can convert the traces
-ds = TraceDataset.from_spans(tracer.get_spans())
-
-# Print the dataframe
-ds.dataframe.head()
-
-# Re-initialize the app with the trace dataset
-px.launch_app(trace=ds)
-
-{% endtab %}
{% endtabs %}
{% hint style="info" %}
diff --git a/docs/quickstart/phoenix-inferences/README.md b/docs/quickstart/phoenix-inferences/README.md
index 704ef21a23..2d17250d3a 100644
--- a/docs/quickstart/phoenix-inferences/README.md
+++ b/docs/quickstart/phoenix-inferences/README.md
@@ -2,7 +2,7 @@
description: Observability for all model types (LLM, NLP, CV, Tabular)
---
-# Phoenix Inferences
+# Quickstart: Inferences
## Overview
@@ -84,7 +84,7 @@ For examples on how Schema are defined for other model types (NLP, tabular, LLM-
Wrap your `train_df` and schema `train_schema` into a Phoenix Dataset object:
```python
-train_ds = px.Dataset(dataframe=train_ds, schema=train_schema, name="training")
+train_ds = px.Dataset(dataframe=train_df, schema=train_schema, name="training")
```
### Step 5: Launch Phoenix!
diff --git a/docs/reference/frequently-asked-questions.md b/docs/reference/frequently-asked-questions.md
index 302bb899dc..99ee15edf3 100644
--- a/docs/reference/frequently-asked-questions.md
+++ b/docs/reference/frequently-asked-questions.md
@@ -1,9 +1,8 @@
# Frequently Asked Questions
+## Can I use Azure OpenAI?
-## Can I configure a default port for Phoenix?
-
-You can set the default port for phoenix each time you launch the application from jupyter notebook with an optional argument `port` in [launch_app()](https://github.com/Arize-ai/phoenix/blob/d21bbc8db4fc62989d127f8d2f7d5e7306bbb357/src/phoenix/session/session.py#L187).
+Yes, in fact this is probably the preferred way to interact with OpenAI if your enterprise requires data privacy. Getting the parameters right for Azure can be a bit tricky so check out the [models section for details.](../api/evaluation-models.md#azure-openai)
## Can I use Phoenix locally from a remote Jupyter instance?
@@ -11,21 +10,20 @@ Yes, you can use either of the two methods below.
### 1. Via ngrok (Preferred)
-- Install pyngrok on the remote machine using the command `pip install pyngrok`.
-- [Create a free account](https://ngrok.com/) on ngrok and verify your email. Find 'Your Authtoken' on the [dashboard](https://dashboard.ngrok.com/auth).
-- In jupyter notebook, after launching phoenix set its port number as the `port` parameter in the code below. **Preferably use a default port** for phoenix so that you won't have to set up ngrok tunnel every time for a new port, simply restarting phoenix will work on the same ngrok URL.
-
-- ```python
- import getpass
- from pyngrok import ngrok, conf
- print("Enter your authtoken, which can be copied from https://dashboard.ngrok.com/auth")
- conf.get_default().auth_token = getpass.getpass()
- port = 37689
- # Open a ngrok tunnel to the HTTP server
- public_url = ngrok.connect(port).public_url
- print(" * ngrok tunnel \"{}\" -> \"http://127.0.0.1:{}\"".format(public_url, port))
- ```
-- "Visit Site" using the newly printed `public_url` and ignore warnings, if any.
+* Install pyngrok on the remote machine using the command `pip install pyngrok`.
+* [Create a free account](https://ngrok.com/) on ngrok and verify your email. Find 'Your Authtoken' on the [dashboard](https://dashboard.ngrok.com/auth).
+* In jupyter notebook, after launching phoenix set its port number as the `port` parameter in the code below. **Preferably use a default port** for phoenix so that you won't have to set up ngrok tunnel every time for a new port, simply restarting phoenix will work on the same ngrok URL.
+* ```python
+ import getpass
+ from pyngrok import ngrok, conf
+ print("Enter your authtoken, which can be copied from https://dashboard.ngrok.com/auth")
+ conf.get_default().auth_token = getpass.getpass()
+ port = 37689
+ # Open a ngrok tunnel to the HTTP server
+ public_url = ngrok.connect(port).public_url
+ print(" * ngrok tunnel \"{}\" -> \"http://127.0.0.1:{}\"".format(public_url, port))
+ ```
+* "Visit Site" using the newly printed `public_url` and ignore warnings, if any.
#### NOTE:
@@ -37,14 +35,13 @@ This assumes you have already set up ssh on both the local machine and the remot
If you are accessing a remote jupyter notebook from a local machine, you can also access the phoenix app by forwarding a local port to the remote server via ssh. In this particular case of using phoenix on a remote server, it is recommended that you use a default port for launching phoenix, say `DEFAULT_PHOENIX_PORT`.
-- Launch the phoenix app from jupyter notebook.
-- In a new terminal or command prompt, forward a local port of your choice from 49152 to 65535 (say `52362`) using the command below. Remote user of the remote host must have sufficient port-forwarding/admin privileges.
+* Launch the phoenix app from jupyter notebook.
+* In a new terminal or command prompt, forward a local port of your choice from 49152 to 65535 (say `52362`) using the command below. Remote user of the remote host must have sufficient port-forwarding/admin privileges.
```bash
ssh -L 52362:localhost:@
```
-
-- If successful, visit [localhost:52362](http://localhost:52362) to access phoenix locally.
+* If successful, visit [localhost:52362](http://localhost:52362) to access phoenix locally.
If you are abruptly unable to access phoenix, check whether the ssh connection is still alive by inspecting the terminal. You can also try increasing the ssh timeout settings.
@@ -52,3 +49,26 @@ If you are abruptly unable to access phoenix, check whether the ssh connection i
Simply run `exit` in the terminal/command prompt where you ran the port forwarding command.
+## How can I configure the backend to send the data to the phoenix UI in another container?
+
+_If you are working on an API whose endpoints perform RAG, but would like the phoenix server not to be launched as another thread._
+
+You can do this by configuring the following the environment variable PHOENIX\_COLLECTOR\_ENDPOINT to point to the server running in a different process or container. https://docs.arize.com/phoenix/environments
+
+
+
+## Can I use an older version of LlamaIndex?
+
+Yes you can! You will have to be using `arize-phoenix>3.0.0` and downgrade `openinference-instrumentation-llama-index<1.0.0`
+
+
+
+## Running on SageMaker
+
+With SageMaker notebooks, phoenix leverages the [jupyter-server-proy](https://github.com/jupyterhub/jupyter-server-proxy) to host the server under `proxy/6006.`Note, that phoenix will automatically try to detect that you are running in SageMaker but you can declare the notebook runtime via a parameter to `launch_app` or an environment variable
+
+```python
+import os
+
+os.environ["PHOENIX_NOTEBOOK_ENV"] = "sagemaker"
+```
diff --git a/docs/telemetry/custom-spans.md b/docs/telemetry/custom-spans.md
index 015a7ba48c..3fb12ebbf0 100644
--- a/docs/telemetry/custom-spans.md
+++ b/docs/telemetry/custom-spans.md
@@ -7,6 +7,179 @@ description: >-
# Custom Spans
-{% hint style="info" %}
-This page is under construction
-{% endhint %}
+Phoenix and OpenInference use OpenTelemetry Trace API to create spans. Because Phoenix supports OpenTelemetry, this means that you can perform manual instrumentation, no LLM framework required! This guide will help you understand how to create and customize spans using OpenTelemetry Trace API.
+
+First, ensure you have the API and SDK packages:
+
+```shell
+pip install opentelemetry-api
+pip install opentelemetry-sdk
+```
+
+Let's next install the [OpenInference Semantic Conventions](https://github.com/Arize-ai/openinference/blob/main/python/openinference-semantic-conventions/README.md) package so that we can construct spans with LLM semantic conventions:
+
+```shell
+pip install openinference-semantic-conventions
+```
+
+For full documentation on the OpenInference semantic conventions, please consult the specification
+
+{% embed url="https://arize-ai.github.io/openinference/spec/semantic_conventions.html" %}
+
+## Acquire Tracer
+
+To start tracing, you'll need get a `tracer` (note that this assumes you already have a trace provider configured):
+
+```python
+from opentelemetry import trace
+# Creates a tracer from the global tracer provider
+tracer = trace.get_tracer("my.tracer.name")
+```
+
+## Creating spans
+
+To create a span, you'll typically want it to be started as the current span.
+
+```python
+def do_work():
+ with tracer.start_as_current_span("span-name") as span:
+ # do some work that 'span' will track
+ print("doing some work...")
+ # When the 'with' block goes out of scope, 'span' is closed for you
+```
+
+You can also use `start_span` to create a span without making it the current span. This is usually done to track concurrent or asynchronous operations.
+
+## Creating nested spans
+
+If you have a distinct sub-operation you'd like to track as a part of another one, you can create span to represent the relationship:
+
+```python
+def do_work():
+ with tracer.start_as_current_span("parent") as parent:
+ # do some work that 'parent' tracks
+ print("doing some work...")
+ # Create a nested span to track nested work
+ with tracer.start_as_current_span("child") as child:
+ # do some work that 'child' tracks
+ print("doing some nested work...")
+ # the nested span is closed when it's out of scope
+
+ # This span is also closed when it goes out of scope
+```
+
+When you view spans in a trace visualization tool, `child` will be tracked as a nested span under `parent`.
+
+## Creating spans with decorators
+
+It's common to have a single spans track the execution of an entire function. In that scenario, there is a decorator you can use to reduce code:
+
+```python
+@tracer.start_as_current_span("do_work")
+def do_work():
+ print("doing some work...")
+```
+
+Use of the decorator is equivalent to creating the span inside `do_work()` and ending it when `do_work()` is finished.
+
+To use the decorator, you must have a `tracer` instance available global to your function declaration.
+
+If you need to add [attributes](custom-spans.md#add-attributes-to-a-span) or [events](custom-spans.md#adding-events) then it's less convenient to use a decorator.
+
+## Get the current span
+
+Sometimes it's helpful to access whatever the current spans is at a point in time so that you can enrich it with more information.
+
+```python
+from opentelemetry import trace
+
+current_span = trace.get_current_span()
+# enrich 'current_span' with some information
+```
+
+## Add attributes to a span
+
+Attributes let you attach key/value pairs to a spans so it carries more information about the current operation that it's tracking.
+
+```python
+from opentelemetry import trace
+
+current_span = trace.get_current_span()
+
+current_span.set_attribute("operation.value", 1)
+current_span.set_attribute("operation.name", "Saying hello!")
+current_span.set_attribute("operation.other-stuff", [1, 2, 3])
+```
+
+Notice above that the attributes have a specific prefix `operation`. When adding custom attributes, it's best practice to vendor your attributes (e.x. `mycompany.`) so that your attributes do not clash with semantic conventions.
+
+## Add semantic attributes
+
+Semantic Attributes are pre-defined Attributes that are well-known naming conventions for common kinds of data. Using Semantic Attributes lets you normalize this kind of information across your systems. In the case of Phoenix, the [OpenInference Semantic Conventions](https://github.com/Arize-ai/openinference/blob/main/python/openinference-semantic-conventions/README.md) package provides a set of well-known attributes that are used to represent LLM application specific semantic conventions.
+
+To use OpenInference Semantic Attributes in Python, ensure you have the semantic conventions package:
+
+```shell
+pip install openinference-semantic-conventions
+```
+
+Then you can use it in code:
+
+```python
+from openinference.semconv.trace import SpanAttributes
+
+// ...
+
+current_span = trace.get_current_span()
+current_span.set_attribute(SpanAttributes.INPUT_VALUE, "Hello world!")
+current_span.set_attribute(SpanAttributes.LLM_MODEL_NAME, "gpt-3.5-turbo")
+```
+
+## Adding events
+
+An event is a human-readable message on a span that represents "something happening" during its lifetime. You can think of it as a primitive log.
+
+```python
+from opentelemetry import trace
+
+current_span = trace.get_current_span()
+
+current_span.add_event("Gonna try it!")
+
+# Do the thing
+
+current_span.add_event("Did it!")
+```
+
+## Set span status
+
+```python
+from opentelemetry import trace
+from opentelemetry.trace import Status, StatusCode
+
+current_span = trace.get_current_span()
+
+try:
+ # something that might fail
+except:
+ current_span.set_status(Status(StatusCode.ERROR))
+```
+
+## Record exceptions in spans
+
+It can be a good idea to record exceptions when they happen. It’s recommended to do this in conjunction with setting span status.
+
+```python
+from opentelemetry import trace
+from opentelemetry.trace import Status, StatusCode
+
+current_span = trace.get_current_span()
+
+try:
+ # something that might fail
+
+# Consider catching a more specific exception in your code
+except Exception as ex:
+ current_span.set_status(Status(StatusCode.ERROR))
+ current_span.record_exception(ex)
+```
diff --git a/docs/telemetry/deploying-phoenix.md b/docs/telemetry/deploying-phoenix.md
index 3cbf92b7fa..815ecb2b95 100644
--- a/docs/telemetry/deploying-phoenix.md
+++ b/docs/telemetry/deploying-phoenix.md
@@ -2,7 +2,7 @@
description: How to use phoenix outside of the notebook environment.
---
-# Deploying Phoenix
+# Collector
The phoenix server can be run as a collector of spans over OTLP
-
-
In order to make a system observable, it must be **instrumented**: That is, code from the system’s components must emit traces.
Without being required to modify the source code you can collect telemetry from an application using automatic instrumentation. If you previously used an APM agent to extract telemetry from your application, Automatic Instrumentation will give you a similar out of the box experience.
@@ -29,14 +27,14 @@ OpenInference provides a set of instrumentations for popular machine learning SD
### Python
-| Package | Description | Version |
-| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| [`openinference-semantic-conventions`](https://github.com/Arize-ai/openinference/blob/main/python/openinference-semantic-conventions/README.md) | Semantic conventions for tracing of LLM Apps. | [](https://pypi.python.org/pypi/openinference-semantic-conventions) |
-| [`openinference-instrumentation-openai`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-openai/README.rst) | OpenInference Instrumentation for OpenAI SDK. | [](https://pypi.python.org/pypi/openinference-instrumentation-openai) |
-| [`openinference-instrumentation-llama-index`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-llama-index/README.rst) | OpenInference Instrumentation for LlamaIndex. | [](https://pypi.python.org/pypi/openinference-instrumentation-llama-index) |
-| [`openinference-instrumentation-dspy`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-dspy/README.rst) | OpenInference Instrumentation for DSPy. | [](https://pypi.python.org/pypi/openinference-instrumentation-dspy) |
-| [`openinference-instrumentation-bedrock`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-bedrock/README.rst) | OpenInference Instrumentation for AWS Bedrock. | [](https://pypi.python.org/pypi/openinference-instrumentation-bedrock) |
-| [`openinference-instrumentation-langchain`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-langchain/README.rst) | OpenInference Instrumentation for LangChain. | [](https://pypi.python.org/pypi/openinference-instrumentation-langchain) |
+| Package | Description | Version |
+| ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| [`openinference-semantic-conventions`](https://github.com/Arize-ai/openinference/blob/main/python/openinference-semantic-conventions/README.md) | Semantic conventions for tracing of LLM Apps. | [](https://pypi.python.org/pypi/openinference-semantic-conventions) |
+| [`openinference-instrumentation-openai`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-openai/README.md) | OpenInference Instrumentation for OpenAI SDK. | [](https://pypi.python.org/pypi/openinference-instrumentation-openai) |
+| [`openinference-instrumentation-llama-index`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-llama-index/README.md) | OpenInference Instrumentation for LlamaIndex. | [](https://pypi.python.org/pypi/openinference-instrumentation-llama-index) |
+| [`openinference-instrumentation-dspy`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-dspy/README.md) | OpenInference Instrumentation for DSPy. | [](https://pypi.python.org/pypi/openinference-instrumentation-dspy) |
+| [`openinference-instrumentation-bedrock`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-bedrock/README.md) | OpenInference Instrumentation for AWS Bedrock. | [](https://pypi.python.org/pypi/openinference-instrumentation-bedrock) |
+| [`openinference-instrumentation-langchain`](https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-langchain/README.md) | OpenInference Instrumentation for LangChain. | [](https://pypi.python.org/pypi/openinference-instrumentation-langchain) |
### JavaScript
diff --git a/docs/use-cases/rag-evaluation.md b/docs/use-cases/rag-evaluation.md
index 3e4b00df23..80d5243e23 100644
--- a/docs/use-cases/rag-evaluation.md
+++ b/docs/use-cases/rag-evaluation.md
@@ -500,7 +500,7 @@ We have now evaluated our RAG system's retrieval performance. Let's send these e
```python
from phoenix.trace import DocumentEvaluations, SpanEvaluations
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(dataframe=ndcg_at_2, eval_name="ndcg@2"),
SpanEvaluations(dataframe=precision_at_2, eval_name="precision@2"),
DocumentEvaluations(dataframe=retrieved_documents_relevance_df, eval_name="relevance"),
@@ -578,7 +578,7 @@ Since we have evaluated our RAG system's QA performance and Hallucinations perfo
```python
from phoenix.trace import SpanEvaluations
-px.log_evaluations(
+px.Client().log_evaluations(
SpanEvaluations(dataframe=qa_correctness_eval_df, eval_name="Q&A Correctness"),
SpanEvaluations(dataframe=hallucination_eval_df, eval_name="Hallucination"),
)
diff --git a/docs/use-cases/troubleshooting-llm-retrieval-with-vector-stores.md b/docs/use-cases/troubleshooting-llm-retrieval-with-vector-stores.md
index 1402aca175..b61ab9ab91 100644
--- a/docs/use-cases/troubleshooting-llm-retrieval-with-vector-stores.md
+++ b/docs/use-cases/troubleshooting-llm-retrieval-with-vector-stores.md
@@ -5,7 +5,7 @@ description: >-
Or can you change your embeddings?
---
-# QA with Retrieval (Using Vector Stores)
+# Retrieval with Embeddings
{kind=link}
{kind=link}
{kind=link}
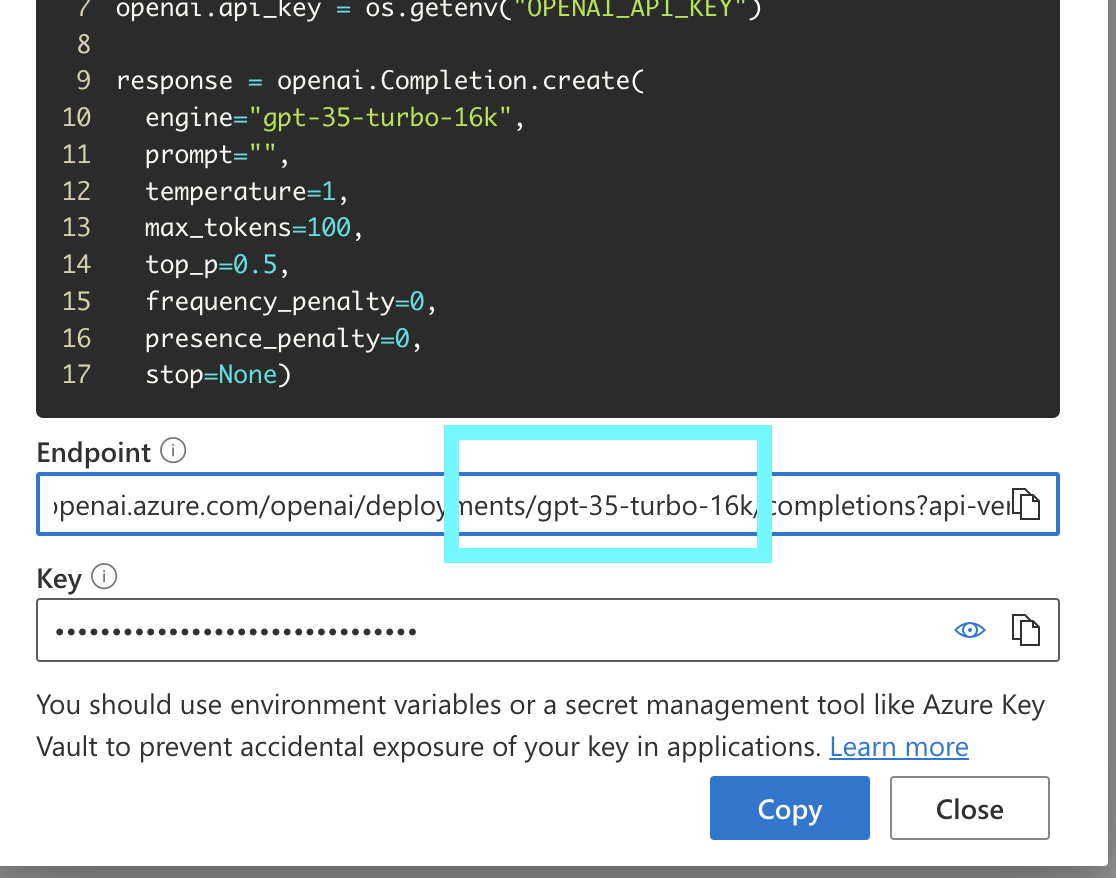









.png)
.png)

{kind=link}
{kind=link}