An autonomous pipeline to create covers with any RVC v2 trained AI voice from YouTube videos or a local audio file. For developers who may want to add a singing functionality into their AI assistant/chatbot/vtuber, or for people who want to hear their favourite characters sing their favourite song.
Showcase: https://www.youtube.com/watch?v=2qZuE4WM7CM
Setup Guide: https://www.youtube.com/watch?v=pdlhk4vVHQk

WebUI is under constant development and testing, but you can try it out right now on both local and colab!
- WebUI for easier conversions and downloading of voice models
- Support for cover generations from a local audio file
- Option to keep intermediate files generated. e.g. Isolated vocals/instrumentals
- Download suggested public voice models from table with search/tag filters
- Support for Pixeldrain download links for voice models
- Implement new rmvpe pitch extraction technique for faster and higher quality vocal conversions
- Volume control for AI main vocals, backup vocals and instrumentals
- Index Rate for Voice conversion
- Reverb Control for AI main vocals
- Local network sharing option for webui
- Extra RVC options - filter_radius, rms_mix_rate, protect
- Local file upload via file browser option
- Upload of locally trained RVC v2 models via WebUI
- Pitch detection method control, e.g. rmvpe/mangio-crepe
- Pitch change for vocals and instrumentals together. Same effect as changing key of song in Karaoke.
- Audio output format option: wav or mp3.
Install and pull any new requirements and changes by opening a command line window in the AICoverGen directory and running the following commands.
pip install -r requirements.txt
git pull
For colab users, simply click Runtime in the top navigation bar of the colab notebook and Disconnect and delete runtime in the dropdown menu.
Then follow the instructions in the notebook to run the webui.
For those without a powerful enough NVIDIA GPU, you may try AICoverGen out using Google Colab.
For those who face issues with Google Colab notebook disconnecting after a few minutes, here's an alternative that doesn't use the WebUI.
For those who want to run this locally, follow the setup guide below.
Follow the instructions here to install Git on your computer. Also follow this guide to install Python VERSION 3.9 if you haven't already. Using other versions of Python may result in dependency conflicts.
Follow the instructions here to install ffmpeg on your computer.
Follow the instructions here to install sox and add it to your Windows path environment.
Open a command line window and run these commands to clone this entire repository and install the additional dependencies required.
git clone https://github.com/SociallyIneptWeeb/AICoverGen
cd AICoverGen
pip install -r requirements.txt
Run the following command to download the required MDXNET vocal separation models and hubert base model.
python src/download_models.py
To run the AICoverGen WebUI, run the following command.
python src/webui.py
| Flag | Description |
|---|---|
-h, --help |
Show this help message and exit. |
--share |
Create a public URL. This is useful for running the web UI on Google Colab. |
--listen |
Make the web UI reachable from your local network. |
--listen-host LISTEN_HOST |
The hostname that the server will use. |
--listen-port LISTEN_PORT |
The listening port that the server will use. |
Once the following output message Running on local URL: http://127.0.0.1:7860 appears, you can click on the link to open a tab with the WebUI.

Navigate to the Download model tab, and paste the download link to the RVC model and give it a unique name.
You may search the AI Hub Discord where already trained voice models are available for download. You may refer to the examples for how the download link should look like.
The downloaded zip file should contain the .pth model file and an optional .index file.
Once the 2 input fields are filled in, simply click Download! Once the output message says [NAME] Model successfully downloaded!, you should be able to use it in the Generate tab after clicking the refresh models button!
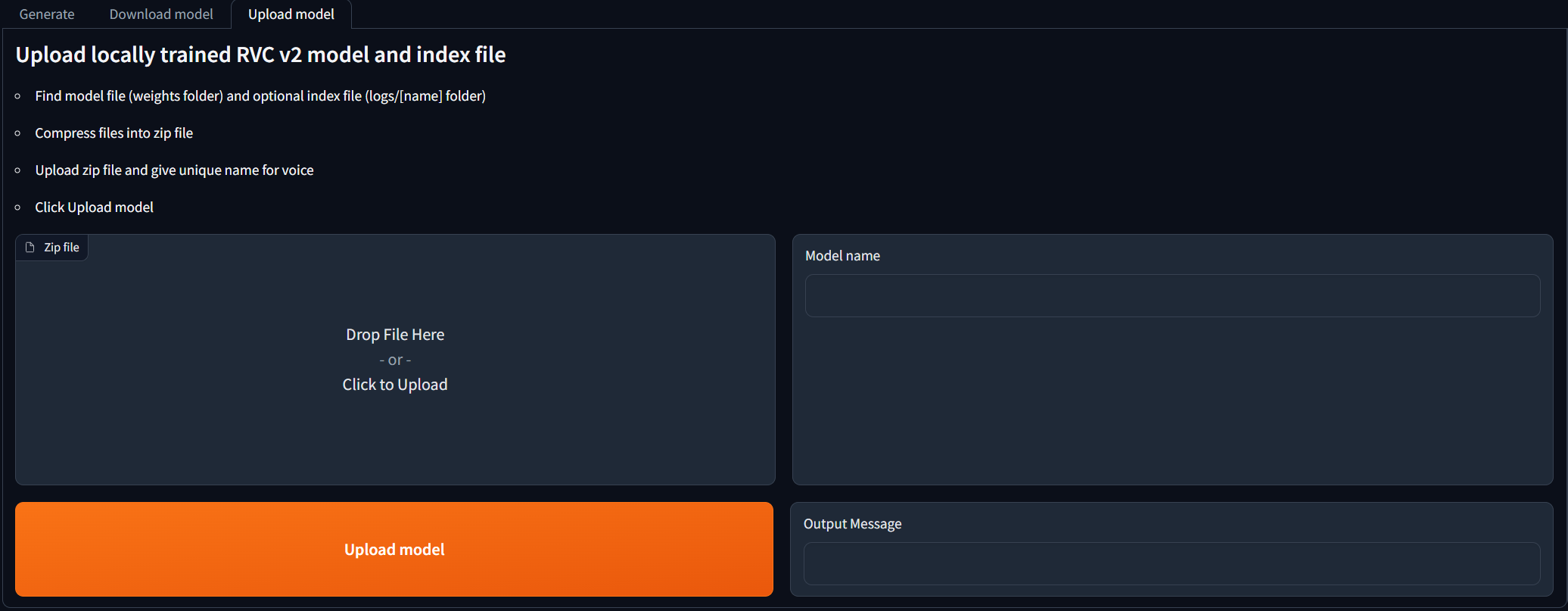
For people who have trained RVC v2 models locally and would like to use them for AI Cover generations.
Navigate to the Upload model tab, and follow the instructions.
Once the output message says [NAME] Model successfully uploaded!, you should be able to use it in the Generate tab after clicking the refresh models button!
- From the Voice Models dropdown menu, select the voice model to use. Click
Updateif you added the files manually to the rvc_models directory to refresh the list. - In the song input field, copy and paste the link to any song on YouTube or the full path to a local audio file.
- Pitch should be set to either -12, 0, or 12 depending on the original vocals and the RVC AI modal. This ensures the voice is not out of tune.
- Other advanced options for Voice conversion and audio mixing can be viewed by clicking the accordion arrow to expand.
Once all Main Options are filled in, click Generate and the AI generated cover should appear in a less than a few minutes depending on your GPU.
Unzip (if needed) and transfer the .pth and .index files to a new folder in the rvc_models directory. Each folder should only contain one .pth and one .index file.
The directory structure should look something like this:
├── rvc_models
│ ├── John
│ │ ├── JohnV2.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── May
│ │ ├── May.pth
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
│ ├── MODELS.txt
│ └── hubert_base.pt
├── mdxnet_models
├── song_output
└── src
To run the AI cover generation pipeline using the command line, run the following command.
python src/main.py [-h] -i SONG_INPUT -dir RVC_DIRNAME -p PITCH_CHANGE [-k | --keep-files | --no-keep-files] [-ir INDEX_RATE] [-fr FILTER_RADIUS] [-rms RMS_MIX_RATE] [-palgo PITCH_DETECTION_ALGO] [-hop CREPE_HOP_LENGTH] [-pro PROTECT] [-mv MAIN_VOL] [-bv BACKUP_VOL] [-iv INST_VOL] [-pall PITCH_CHANGE_ALL] [-rsize REVERB_SIZE] [-rwet REVERB_WETNESS] [-rdry REVERB_DRYNESS] [-rdamp REVERB_DAMPING] [-oformat OUTPUT_FORMAT]
| Flag | Description |
|---|---|
-h, --help |
Show this help message and exit. |
-i SONG_INPUT |
Link to a song on YouTube or path to a local audio file. Should be enclosed in double quotes for Windows and single quotes for Unix-like systems. |
-dir MODEL_DIR_NAME |
Name of folder in rvc_models directory containing your .pth and .index files for a specific voice. |
-p PITCH_CHANGE |
Change pitch of AI vocals in octaves. Set to 0 for no change. Generally, use 1 for male to female conversions and -1 for vice-versa. |
-k |
Optional. Can be added to keep all intermediate audio files generated. e.g. Isolated AI vocals/instrumentals. Leave out to save space. |
-ir INDEX_RATE |
Optional. Default 0.5. Control how much of the AI's accent to leave in the vocals. 0 <= INDEX_RATE <= 1. |
-fr FILTER_RADIUS |
Optional. Default 3. If >=3: apply median filtering median filtering to the harvested pitch results. 0 <= FILTER_RADIUS <= 7. |
-rms RMS_MIX_RATE |
Optional. Default 0.25. Control how much to use the original vocal's loudness (0) or a fixed loudness (1). 0 <= RMS_MIX_RATE <= 1. |
-palgo PITCH_DETECTION_ALGO |
Optional. Default rmvpe. Best option is rmvpe (clarity in vocals), then mangio-crepe (smoother vocals). |
-hop CREPE_HOP_LENGTH |
Optional. Default 128. Controls how often it checks for pitch changes in milliseconds when using mangio-crepe algo specifically. Lower values leads to longer conversions and higher risk of voice cracks, but better pitch accuracy. |
-pro PROTECT |
Optional. Default 0.33. Control how much of the original vocals' breath and voiceless consonants to leave in the AI vocals. Set 0.5 to disable. 0 <= PROTECT <= 0.5. |
-mv MAIN_VOCALS_VOLUME_CHANGE |
Optional. Default 0. Control volume of main AI vocals. Use -3 to decrease the volume by 3 decibels, or 3 to increase the volume by 3 decibels. |
-bv BACKUP_VOCALS_VOLUME_CHANGE |
Optional. Default 0. Control volume of backup AI vocals. |
-iv INSTRUMENTAL_VOLUME_CHANGE |
Optional. Default 0. Control volume of the background music/instrumentals. |
-pall PITCH_CHANGE_ALL |
Optional. Default 0. Change pitch/key of background music, backup vocals and AI vocals in semitones. Reduces sound quality slightly. |
-rsize REVERB_SIZE |
Optional. Default 0.15. The larger the room, the longer the reverb time. 0 <= REVERB_SIZE <= 1. |
-rwet REVERB_WETNESS |
Optional. Default 0.2. Level of AI vocals with reverb. 0 <= REVERB_WETNESS <= 1. |
-rdry REVERB_DRYNESS |
Optional. Default 0.8. Level of AI vocals without reverb. 0 <= REVERB_DRYNESS <= 1. |
-rdamp REVERB_DAMPING |
Optional. Default 0.7. Absorption of high frequencies in the reverb. 0 <= REVERB_DAMPING <= 1. |
-oformat OUTPUT_FORMAT |
Optional. Default mp3. wav for best quality and large file size, mp3 for decent quality and small file size. |
The use of the converted voice for the following purposes is prohibited.
-
Criticizing or attacking individuals.
-
Advocating for or opposing specific political positions, religions, or ideologies.
-
Publicly displaying strongly stimulating expressions without proper zoning.
-
Selling of voice models and generated voice clips.
-
Impersonation of the original owner of the voice with malicious intentions to harm/hurt others.
-
Fraudulent purposes that lead to identity theft or fraudulent phone calls.
I am not liable for any direct, indirect, consequential, incidental, or special damages arising out of or in any way connected with the use/misuse or inability to use this software.