diff --git a/.github/ISSUE_TEMPLATE/daily-problem.md b/.github/ISSUE_TEMPLATE/daily-problem.md
new file mode 100644
index 000000000..f5155c2a2
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/daily-problem.md
@@ -0,0 +1,12 @@
+---
+name: Daily Problem
+about: Contribute Daily Problem
+title: "【每日一题】- 2020-xx-xx - xxx "
+labels: Daily Question
+assignees: ''
+
+---
+
+[anything]
+
+题目地址:xxxxxx
diff --git a/.github/ISSUE_TEMPLATE/translation.md b/.github/ISSUE_TEMPLATE/translation.md
new file mode 100644
index 000000000..effb306f2
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/translation.md
@@ -0,0 +1,10 @@
+---
+name: Translation
+about: translation
+title: 'feat(translation): xxxxxxx'
+labels: 国际化
+assignees: ''
+
+---
+
+
diff --git a/CONTRIBUTING.en.md b/CONTRIBUTING.en.md
new file mode 100644
index 000000000..244950a7b
--- /dev/null
+++ b/CONTRIBUTING.en.md
@@ -0,0 +1,23 @@
+# Contributing
+
+## Translation
+
+Please pick any work without translation by `submit new issue`. English version and Chinese version are distinguished by file name, e.g. Chinese version file name abc.md, the corresponding English version should be abc.en.md.
+
+Manual translation instead of machine translation, there is no need to translate the technical jargon.
+
+## Contributing to problems
+
+Please follow the template of "problems", what you need to submit are:
+
+- Problem and solution markdown file
+- Add the link of the solution in README.md
+- Add the link of the solution in README.en.md (optional)
+- draw.io file(xml) or pictures (optional)
+
+> Template for reference: [1014.best-sightseeing-pair](./templates/problems/1014.best-sightseeing-pair.md)
+> Online painting tools like https://excalidraw.com/, draw.io, processon or iPad apps
+
+## Contributing to daily problem
+
+- Please follow the template of "daily problem" and submit the issue with correct tags (can refer to official tags on LeetCode).
\ No newline at end of file
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8198a762b..bde3efd14 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -2,7 +2,7 @@
## 翻译
-只需要看哪个没有被翻译即可认领,认领方式为`提交新的issue`形式。英文版本和中文版通过文件名区分。比如中文的文件名是abc.md,那么英文的应该是abc.en.md。
+只需要看哪个没有被翻译即可认领,认领方式为`提交新的issue`形式。英文版本和中文版通过文件名区分。比如中文的文件名是 abc.md,那么英文的应该是 abc.en.md。
尽可能使用意译,避免机械性的英文翻译,专有名词无需翻译。
@@ -15,6 +15,9 @@
- README.en.md (如果你是英文题解的话)
- drawio 文件 或者图片(如果你画图的话)
+> 模板可参考 [1014.best-sightseeing-pair](./templates/problems/1014.best-sightseeing-pair.md)
+> 也可以使用其他画图工具,比如 https://excalidraw.com/ 或者 draw.io 或者 processon 或者 ipad 画图
+
## 贡献每日一题
-- 直接按照“每日一题”格式要求提交issue即可,需要注意的是,要打上正确的tag,如果LeetCode题目,可以参考官方给的tag。
+- 直接按照“每日一题”格式要求提交 issue 即可,需要注意的是,要打上正确的 tag,如果 LeetCode 题目,可以参考官方给的 tag。
diff --git a/Kapture 2020-08-19 at 11.37.36.gif b/Kapture 2020-08-19 at 11.37.36.gif
new file mode 100644
index 000000000..612471535
Binary files /dev/null and b/Kapture 2020-08-19 at 11.37.36.gif differ
diff --git a/LICENSE.txt b/LICENSE.txt
index de40f2de2..362f1cbd3 100644
--- a/LICENSE.txt
+++ b/LICENSE.txt
@@ -1,201 +1,100 @@
- Apache License
- Version 2.0, January 2004
- http://www.apache.org/licenses/
-
- TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
-
- 1. Definitions.
-
- "License" shall mean the terms and conditions for use, reproduction,
- and distribution as defined by Sections 1 through 9 of this document.
-
- "Licensor" shall mean the copyright owner or entity authorized by
- the copyright owner that is granting the License.
-
- "Legal Entity" shall mean the union of the acting entity and all
- other entities that control, are controlled by, or are under common
- control with that entity. For the purposes of this definition,
- "control" means (i) the power, direct or indirect, to cause the
- direction or management of such entity, whether by contract or
- otherwise, or (ii) ownership of fifty percent (50%) or more of the
- outstanding shares, or (iii) beneficial ownership of such entity.
-
- "You" (or "Your") shall mean an individual or Legal Entity
- exercising permissions granted by this License.
-
- "Source" form shall mean the preferred form for making modifications,
- including but not limited to software source code, documentation
- source, and configuration files.
-
- "Object" form shall mean any form resulting from mechanical
- transformation or translation of a Source form, including but
- not limited to compiled object code, generated documentation,
- and conversions to other media types.
-
- "Work" shall mean the work of authorship, whether in Source or
- Object form, made available under the License, as indicated by a
- copyright notice that is included in or attached to the work
- (an example is provided in the Appendix below).
-
- "Derivative Works" shall mean any work, whether in Source or Object
- form, that is based on (or derived from) the Work and for which the
- editorial revisions, annotations, elaborations, or other modifications
- represent, as a whole, an original work of authorship. For the purposes
- of this License, Derivative Works shall not include works that remain
- separable from, or merely link (or bind by name) to the interfaces of,
- the Work and Derivative Works thereof.
-
- "Contribution" shall mean any work of authorship, including
- the original version of the Work and any modifications or additions
- to that Work or Derivative Works thereof, that is intentionally
- submitted to Licensor for inclusion in the Work by the copyright owner
- or by an individual or Legal Entity authorized to submit on behalf of
- the copyright owner. For the purposes of this definition, "submitted"
- means any form of electronic, verbal, or written communication sent
- to the Licensor or its representatives, including but not limited to
- communication on electronic mailing lists, source code control systems,
- and issue tracking systems that are managed by, or on behalf of, the
- Licensor for the purpose of discussing and improving the Work, but
- excluding communication that is conspicuously marked or otherwise
- designated in writing by the copyright owner as "Not a Contribution."
-
- "Contributor" shall mean Licensor and any individual or Legal Entity
- on behalf of whom a Contribution has been received by Licensor and
- subsequently incorporated within the Work.
-
- 2. Grant of Copyright License. Subject to the terms and conditions of
- this License, each Contributor hereby grants to You a perpetual,
- worldwide, non-exclusive, no-charge, royalty-free, irrevocable
- copyright license to reproduce, prepare Derivative Works of,
- publicly display, publicly perform, sublicense, and distribute the
- Work and such Derivative Works in Source or Object form.
-
- 3. Grant of Patent License. Subject to the terms and conditions of
- this License, each Contributor hereby grants to You a perpetual,
- worldwide, non-exclusive, no-charge, royalty-free, irrevocable
- (except as stated in this section) patent license to make, have made,
- use, offer to sell, sell, import, and otherwise transfer the Work,
- where such license applies only to those patent claims licensable
- by such Contributor that are necessarily infringed by their
- Contribution(s) alone or by combination of their Contribution(s)
- with the Work to which such Contribution(s) was submitted. If You
- institute patent litigation against any entity (including a
- cross-claim or counterclaim in a lawsuit) alleging that the Work
- or a Contribution incorporated within the Work constitutes direct
- or contributory patent infringement, then any patent licenses
- granted to You under this License for that Work shall terminate
- as of the date such litigation is filed.
-
- 4. Redistribution. You may reproduce and distribute copies of the
- Work or Derivative Works thereof in any medium, with or without
- modifications, and in Source or Object form, provided that You
- meet the following conditions:
-
- (a) You must give any other recipients of the Work or
- Derivative Works a copy of this License; and
-
- (b) You must cause any modified files to carry prominent notices
- stating that You changed the files; and
-
- (c) You must retain, in the Source form of any Derivative Works
- that You distribute, all copyright, patent, trademark, and
- attribution notices from the Source form of the Work,
- excluding those notices that do not pertain to any part of
- the Derivative Works; and
-
- (d) If the Work includes a "NOTICE" text file as part of its
- distribution, then any Derivative Works that You distribute must
- include a readable copy of the attribution notices contained
- within such NOTICE file, excluding those notices that do not
- pertain to any part of the Derivative Works, in at least one
- of the following places: within a NOTICE text file distributed
- as part of the Derivative Works; within the Source form or
- documentation, if provided along with the Derivative Works; or,
- within a display generated by the Derivative Works, if and
- wherever such third-party notices normally appear. The contents
- of the NOTICE file are for informational purposes only and
- do not modify the License. You may add Your own attribution
- notices within Derivative Works that You distribute, alongside
- or as an addendum to the NOTICE text from the Work, provided
- that such additional attribution notices cannot be construed
- as modifying the License.
-
- You may add Your own copyright statement to Your modifications and
- may provide additional or different license terms and conditions
- for use, reproduction, or distribution of Your modifications, or
- for any such Derivative Works as a whole, provided Your use,
- reproduction, and distribution of the Work otherwise complies with
- the conditions stated in this License.
-
- 5. Submission of Contributions. Unless You explicitly state otherwise,
- any Contribution intentionally submitted for inclusion in the Work
- by You to the Licensor shall be under the terms and conditions of
- this License, without any additional terms or conditions.
- Notwithstanding the above, nothing herein shall supersede or modify
- the terms of any separate license agreement you may have executed
- with Licensor regarding such Contributions.
-
- 6. Trademarks. This License does not grant permission to use the trade
- names, trademarks, service marks, or product names of the Licensor,
- except as required for reasonable and customary use in describing the
- origin of the Work and reproducing the content of the NOTICE file.
-
- 7. Disclaimer of Warranty. Unless required by applicable law or
- agreed to in writing, Licensor provides the Work (and each
- Contributor provides its Contributions) on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
- implied, including, without limitation, any warranties or conditions
- of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
- PARTICULAR PURPOSE. You are solely responsible for determining the
- appropriateness of using or redistributing the Work and assume any
- risks associated with Your exercise of permissions under this License.
-
- 8. Limitation of Liability. In no event and under no legal theory,
- whether in tort (including negligence), contract, or otherwise,
- unless required by applicable law (such as deliberate and grossly
- negligent acts) or agreed to in writing, shall any Contributor be
- liable to You for damages, including any direct, indirect, special,
- incidental, or consequential damages of any character arising as a
- result of this License or out of the use or inability to use the
- Work (including but not limited to damages for loss of goodwill,
- work stoppage, computer failure or malfunction, or any and all
- other commercial damages or losses), even if such Contributor
- has been advised of the possibility of such damages.
-
- 9. Accepting Warranty or Additional Liability. While redistributing
- the Work or Derivative Works thereof, You may choose to offer,
- and charge a fee for, acceptance of support, warranty, indemnity,
- or other liability obligations and/or rights consistent with this
- License. However, in accepting such obligations, You may act only
- on Your own behalf and on Your sole responsibility, not on behalf
- of any other Contributor, and only if You agree to indemnify,
- defend, and hold each Contributor harmless for any liability
- incurred by, or claims asserted against, such Contributor by reason
- of your accepting any such warranty or additional liability.
-
- END OF TERMS AND CONDITIONS
-
- APPENDIX: How to apply the Apache License to your work.
-
- To apply the Apache License to your work, attach the following
- boilerplate notice, with the fields enclosed by brackets "[]"
- replaced with your own identifying information. (Don't include
- the brackets!) The text should be enclosed in the appropriate
- comment syntax for the file format. We also recommend that a
- file or class name and description of purpose be included on the
- same "printed page" as the copyright notice for easier
- identification within third-party archives.
-
- Copyright 2015-2016 Netflix, Inc., Microsoft Corp. and contributors
-
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License.
\ No newline at end of file
+
+Creative Commons Corporation (“Creative Commons”) is not a law firm and does not provide legal services or legal advice. Distribution of Creative Commons public licenses does not create a lawyer-client or other relationship. Creative Commons makes its licenses and related information available on an “as-is” basis. Creative Commons gives no warranties regarding its licenses, any material licensed under their terms and conditions, or any related information. Creative Commons disclaims all liability for damages resulting from their use to the fullest extent possible.
+
+Using Creative Commons Public Licenses
+
+Creative Commons public licenses provide a standard set of terms and conditions that creators and other rights holders may use to share original works of authorship and other material subject to copyright and certain other rights specified in the public license below. The following considerations are for informational purposes only, are not exhaustive, and do not form part of our licenses.
+
+Considerations for licensors: Our public licenses are intended for use by those authorized to give the public permission to use material in ways otherwise restricted by copyright and certain other rights. Our licenses are irrevocable. Licensors should read and understand the terms and conditions of the license they choose before applying it. Licensors should also secure all rights necessary before applying our licenses so that the public can reuse the material as expected. Licensors should clearly mark any material not subject to the license. This includes other CC-licensed material, or material used under an exception or limitation to copyright. More considerations for licensors.
+
+Considerations for the public: By using one of our public licenses, a licensor grants the public permission to use the licensed material under specified terms and conditions. If the licensor’s permission is not necessary for any reason–for example, because of any applicable exception or limitation to copyright–then that use is not regulated by the license. Our licenses grant only permissions under copyright and certain other rights that a licensor has authority to grant. Use of the licensed material may still be restricted for other reasons, including because others have copyright or other rights in the material. A licensor may make special requests, such as asking that all changes be marked or described. Although not required by our licenses, you are encouraged to respect those requests where reasonable. More considerations for the public.
+
+Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License
+By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
+
+Section 1 – Definitions.
+
+Adapted Material means material subject to Copyright and Similar Rights that is derived from or based upon the Licensed Material and in which the Licensed Material is translated, altered, arranged, transformed, or otherwise modified in a manner requiring permission under the Copyright and Similar Rights held by the Licensor. For purposes of this Public License, where the Licensed Material is a musical work, performance, or sound recording, Adapted Material is always produced where the Licensed Material is synched in timed relation with a moving image.
+Copyright and Similar Rights means copyright and/or similar rights closely related to copyright including, without limitation, performance, broadcast, sound recording, and Sui Generis Database Rights, without regard to how the rights are labeled or categorized. For purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright and Similar Rights.
+Effective Technological Measures means those measures that, in the absence of proper authority, may not be circumvented under laws fulfilling obligations under Article 11 of the WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international agreements.
+Exceptions and Limitations means fair use, fair dealing, and/or any other exception or limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
+Licensed Material means the artistic or literary work, database, or other material to which the Licensor applied this Public License.
+Licensed Rights means the rights granted to You subject to the terms and conditions of this Public License, which are limited to all Copyright and Similar Rights that apply to Your use of the Licensed Material and that the Licensor has authority to license.
+Licensor means the individual(s) or entity(ies) granting rights under this Public License.
+NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
+Share means to provide material to the public by any means or process that requires permission under the Licensed Rights, such as reproduction, public display, public performance, distribution, dissemination, communication, or importation, and to make material available to the public including in ways that members of the public may access the material from a place and at a time individually chosen by them.
+Sui Generis Database Rights means rights other than copyright resulting from Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, as amended and/or succeeded, as well as other essentially equivalent rights anywhere in the world.
+You means the individual or entity exercising the Licensed Rights under this Public License. Your has a corresponding meaning.
+Section 2 – Scope.
+
+License grant.
+Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
+reproduce and Share the Licensed Material, in whole or in part, for NonCommercial purposes only; and
+produce and reproduce, but not Share, Adapted Material for NonCommercial purposes only.
+Exceptions and Limitations. For the avoidance of doubt, where Exceptions and Limitations apply to Your use, this Public License does not apply, and You do not need to comply with its terms and conditions.
+Term. The term of this Public License is specified in Section 6(a).
+Media and formats; technical modifications allowed. The Licensor authorizes You to exercise the Licensed Rights in all media and formats whether now known or hereafter created, and to make technical modifications necessary to do so. The Licensor waives and/or agrees not to assert any right or authority to forbid You from making technical modifications necessary to exercise the Licensed Rights, including technical modifications necessary to circumvent Effective Technological Measures. For purposes of this Public License, simply making modifications authorized by this Section 2(a)(4) never produces Adapted Material.
+Downstream recipients.
+Offer from the Licensor – Licensed Material. Every recipient of the Licensed Material automatically receives an offer from the Licensor to exercise the Licensed Rights under the terms and conditions of this Public License.
+No downstream restrictions. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, the Licensed Material if doing so restricts exercise of the Licensed Rights by any recipient of the Licensed Material.
+No endorsement. Nothing in this Public License constitutes or may be construed as permission to assert or imply that You are, or that Your use of the Licensed Material is, connected with, or sponsored, endorsed, or granted official status by, the Licensor or others designated to receive attribution as provided in Section 3(a)(1)(A)(i).
+Other rights.
+
+Moral rights, such as the right of integrity, are not licensed under this Public License, nor are publicity, privacy, and/or other similar personality rights; however, to the extent possible, the Licensor waives and/or agrees not to assert any such rights held by the Licensor to the limited extent necessary to allow You to exercise the Licensed Rights, but not otherwise.
+Patent and trademark rights are not licensed under this Public License.
+To the extent possible, the Licensor waives any right to collect royalties from You for the exercise of the Licensed Rights, whether directly or through a collecting society under any voluntary or waivable statutory or compulsory licensing scheme. In all other cases the Licensor expressly reserves any right to collect such royalties, including when the Licensed Material is used other than for NonCommercial purposes.
+Section 3 – License Conditions.
+
+Your exercise of the Licensed Rights is expressly made subject to the following conditions.
+
+Attribution.
+
+If You Share the Licensed Material, You must:
+
+retain the following if it is supplied by the Licensor with the Licensed Material:
+identification of the creator(s) of the Licensed Material and any others designated to receive attribution, in any reasonable manner requested by the Licensor (including by pseudonym if designated);
+a copyright notice;
+a notice that refers to this Public License;
+a notice that refers to the disclaimer of warranties;
+a URI or hyperlink to the Licensed Material to the extent reasonably practicable;
+indicate if You modified the Licensed Material and retain an indication of any previous modifications; and
+indicate the Licensed Material is licensed under this Public License, and include the text of, or the URI or hyperlink to, this Public License.
+For the avoidance of doubt, You do not have permission under this Public License to Share Adapted Material.
+You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on the medium, means, and context in which You Share the Licensed Material. For example, it may be reasonable to satisfy the conditions by providing a URI or hyperlink to a resource that includes the required information.
+If requested by the Licensor, You must remove any of the information required by Section 3(a)(1)(A) to the extent reasonably practicable.
+Section 4 – Sui Generis Database Rights.
+
+Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the Licensed Material:
+
+for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce, and Share all or a substantial portion of the contents of the database for NonCommercial purposes only and provided You do not Share Adapted Material;
+if You include all or a substantial portion of the database contents in a database in which You have Sui Generis Database Rights, then the database in which You have Sui Generis Database Rights (but not its individual contents) is Adapted Material; and
+You must comply with the conditions in Section 3(a) if You Share all or a substantial portion of the contents of the database.
+For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under this Public License where the Licensed Rights include other Copyright and Similar Rights.
+Section 5 – Disclaimer of Warranties and Limitation of Liability.
+
+Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
+To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
+The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
+Section 6 – Term and Termination.
+
+This Public License applies for the term of the Copyright and Similar Rights licensed here. However, if You fail to comply with this Public License, then Your rights under this Public License terminate automatically.
+Where Your right to use the Licensed Material has terminated under Section 6(a), it reinstates:
+
+automatically as of the date the violation is cured, provided it is cured within 30 days of Your discovery of the violation; or
+upon express reinstatement by the Licensor.
+For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have to seek remedies for Your violations of this Public License.
+For the avoidance of doubt, the Licensor may also offer the Licensed Material under separate terms or conditions or stop distributing the Licensed Material at any time; however, doing so will not terminate this Public License.
+Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
+Section 7 – Other Terms and Conditions.
+
+The Licensor shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
+Any arrangements, understandings, or agreements regarding the Licensed Material not stated herein are separate from and independent of the terms and conditions of this Public License.
+Section 8 – Interpretation.
+
+For the avoidance of doubt, this Public License does not, and shall not be interpreted to, reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could lawfully be made without permission under this Public License.
+To the extent possible, if any provision of this Public License is deemed unenforceable, it shall be automatically reformed to the minimum extent necessary to make it enforceable. If the provision cannot be reformed, it shall be severed from this Public License without affecting the enforceability of the remaining terms and conditions.
+No term or condition of this Public License will be waived and no failure to comply consented to unless expressly agreed to by the Licensor.
+Nothing in this Public License constitutes or may be interpreted as a limitation upon, or waiver of, any privileges and immunities that apply to the Licensor or You, including from the legal processes of any jurisdiction or authority.
+Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the “Licensor.” The text of the Creative Commons public licenses is dedicated to the public domain under the CC0 Public Domain Dedication. Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at creativecommons.org/policies, Creative Commons does not authorize the use of the trademark “Creative Commons” or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
+
+Creative Commons may be contacted at creativecommons.org.
diff --git a/README.en.md b/README.en.md
index 06467a36c..8133190ee 100644
--- a/README.en.md
+++ b/README.en.md
@@ -4,8 +4,8 @@
[]()
[]()
[]()
-
-
+
+
> since 2019-09-03 19:40
@@ -13,16 +13,16 @@
---
-
+
-This essay records the course of and my emotion to this project from initialisation to 10,000 stars.
+This essay records the course of and my emotion to this project from initialization to 10,000 stars.
[Milestone for 10,000+ stars](./thanksGiving.md)
-If you are interested in this project, **do not mean your star**. This project will be **supported for a long enough time** by the comminity. Thanks for every audience and contributor.
+If you are interested in this project, **do not mean your star**. This project will be **supported for a long enough time** by the community. Thanks for every audience and contributor.
## Introduction
-
+
LeetCode Solutions: A Journey of Problem Solving.
@@ -36,7 +36,7 @@ This repository is divided into five parts for now:
- The fourth part is daily challenges which were held at group chat. We usually solve one problem altogether to get more feedback. Moreover, the problems can be drafted to add to the problem solving module.
-- The fifth part is a future plannning on content that will be introduced into the above parts.
+- The fifth part is a future planning on content that will be introduced into the above parts.
> Only when having mastered the basic data structures and algorithms can you solve complex problems easily.
@@ -44,7 +44,7 @@ This repository is divided into five parts for now:
I, a programmer, am all passionate about technology.
-Used to write `.net` and `Java`, I am a frontend engineer and focused on the engineering, optimization and standardlization for frontend.
+Used to write `.net` and `Java`, I am a frontend engineer and focused on the engineering, optimization and standardization for frontend.
If you want to do some contributions or collaborations, just feel free to contact me via [azl397985856@gmail.com].
@@ -55,11 +55,11 @@ If you want to do some contributions or collaborations, just feel free to contac
- Here will be the place to update Anki Flashcards in the future as well.
- Here is a mind mapping graph showing the summary of categorizations of problems that are questioned frequently in interviews. We could analyze according to the information in the graph.
-
+
(Picture credited by [LeetCode-cn](https://www.zhihu.com/question/24964987/answer/586425979).)
-The algorithms mainly includes:
+The algorithms mainly include:
- Basic skills: Divide-and-Conquer; Binary; Greedy
- Sorting algorithms: Quicksort; Merge Sort; Counting Sort
@@ -67,7 +67,7 @@ The algorithms mainly includes:
- Graph theory: Shortest Path Problem; Minimal Spanning Tree
- Dynamic Programming: Knapsack Problem; Longest Common Subsequence (LCS) Problem
-The data structures mainly includes:
+The data structures mainly include:
- Array and linked list: Singly/Doubly-Linked List
- Stack and queue
@@ -76,181 +76,68 @@ The data structures mainly includes:
- Tree and Graph: Lowest Common Ancestor (LCA); Disjoint-Set
- String: Prefix Tree (Trie); Suffix Tree
-## Previews
+## Previews (Translation in Progress)
-[0042.trapping-rain-water](./problems/42.trapping-rain-water.md):
+[0547.friend-circles](./problems/547.friend-circles-en.md) :
-
+
-[0547.friend-circles](./problems/547.friend-circles-en.md):
+[backtrack problems](./problems/90.subsets-ii-en.md):
-
+
-[backtrack problems](./problems/90.subsets-ii.md):
+[0454.4-sum-ii](./problems/454.4-sum-ii.en.md) :
-
+
-[0198.house-robber](./problems/198.house-robber.md):
+## Portals
-
+### Solutions to LeetCode Classic Problems
-[0454.4-sum-ii](./problems/454.4-sum-ii.md):
+> Here only lists some **representative problems** but not all.
-
+#### Easy (Translation in Progress)
-## Top Problems Progress
+- [0001.TwoSum](./problems/1.two-sum.en.md)🆕
+- [0053.maximum-sum-subarray](./problems/53.maximum-sum-subarray-en.md) 🆕
+- [0198.house-robber](./problems/198.house-robber.en.md)🆕
+- [0501.find-mode-in-binary-search-tree](./problems/501.Find-Mode-in-Binary-Search-Tree-en.md)🆕
-- [Top 100 Liked Questions](https://leetcode.com/problemset/top-100-liked-questions/) (84 / 100)
+#### Medium (Translation in Progress)
-- [Top Interview Questions](https://leetcode.com/problemset/top-interview-questions/) (115 / 145)
+- [0002. Add Two Numbers](./problems/2.add-two-numbers.en.md)
+- [0078.subsets](./problems/78.subsets-en.md)
+- [0079.word-search](./problems/79.word-search-en.md)
+- [0086.partition-list](./problems/86.partition-list.md)
+- [0090.subsets-ii](./problems/90.subsets-ii-en.md)
-## Portals
+* [0474.ones-and-zeros](./problems/474.ones-and-zeros-en.md)
-### Solutions to LeetCode Classic Problems
+* [0547.friend-circles](./problems/547.friend-circles-en.md) 🆕
+* [0560.subarray-sum-equals-k](./problems/560.subarray-sum-equals-k.en.md)
-> Here only lists some **representative problems** but not all.
+* [1011.capacity-to-ship-packages-within-d-days](./problems/1011.capacity-to-ship-packages-within-d-days-en.md) 🆕
-#### Easy
+* [1371.find-the-longest-substring-containing-vowels-in-even-counts](./problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.en.md) 🆕
+
+#### Hard (Translation in Progress)
-- [0001.TwoSum](./problems/1.TwoSum.md)🆕
-- [0020.Valid Parentheses](./problems/20.validParentheses.md)
-- [0021.MergeTwoSortedLists](./problems/21.MergeTwoSortedLists.md) 🆕
-- [0026.remove-duplicates-from-sorted-array](./problems/26.remove-duplicates-from-sorted-array.md)
-- [0053.maximum-sum-subarray](./problems/53.maximum-sum-subarray-en.md) 🆕
-- [0088.merge-sorted-array](./problems/88.merge-sorted-array.md)
-- [0104.maximum-depth-of-binary-tree](./problems/104.maximum-depth-of-binary-tree.md)
-- [0121.best-time-to-buy-and-sell-stock](./problems/121.best-time-to-buy-and-sell-stock.md)
-- [0122.best-time-to-buy-and-sell-stock-ii](./problems/122.best-time-to-buy-and-sell-stock-ii.md)
-- [0125.valid-palindrome](./problems/125.valid-palindrome.md) 🆕
-- [0136.single-number](./problems/136.single-number.md)
-- [0155.min-stack](./problems/155.min-stack.md) 🆕
-- [0167.two-sum-ii-input-array-is-sorted](./problems/167.two-sum-ii-input-array-is-sorted.md)
-- [0172.factorial-trailing-zeroes](./problems/172.factorial-trailing-zeroes.md)
-- [0169.majority-element](./problems/169.majority-element.md)
-- [0190.reverse-bits](./problems/190.reverse-bits.md)
-- [0191.number-of-1-bits](./problems/191.number-of-1-bits.md)
-- [0198.house-robber](./problems/198.house-robber.md)
-- [0203.remove-linked-list-elements](./problems/203.remove-linked-list-elements.md)
-- [0206.reverse-linked-list](./problems/206.reverse-linked-list.md)
-- [0219.contains-duplicate-ii](./problems/219.contains-duplicate-ii.md)
-- [0226.invert-binary-tree](./problems/226.invert-binary-tree.md)
-- [0232.implement-queue-using-stacks](./problems/232.implement-queue-using-stacks.md) 🆕
-- [0263.ugly-number](./problems/263.ugly-number.md)
-- [0283.move-zeroes](./problems/283.move-zeroes.md)
-- [0342.power-of-four](./problems/342.power-of-four.md)
-- [0371.sum-of-two-integers](./problems/371.sum-of-two-integers.md)
-- [0349.intersection-of-two-arrays](./problems/349.intersection-of-two-arrays.md)
-- [0437.path-sum-iii](./problems/437.path-sum-iii.md) 🆕
-- [0455.AssignCookies](./problems/455.AssignCookies.md) 🆕
-- [0501.find-mode-in-binary-search-tree](./problems/501.Find-Mode-in-Binary-Search-Tree.md) 🆕
-- [0575.distribute-candies](./problems/575.distribute-candies.md)
-
-#### Medium
-
-- [0002. Add Two Numbers](./problems/2.addTwoNumbers.md)
-- [0003. Longest Substring Without Repeating Characters](./problems/3.longestSubstringWithoutRepeatingCharacters.md)
-- [0005.longest-palindromic-substring](./problems/5.longest-palindromic-substring.md)
-- [0011.container-with-most-water](./problems/11.container-with-most-water.md)
-- [0015.3-sum](./problems/15.3-sum.md)
-- [0017.Letter-Combinations-of-a-Phone-Number](./problems/17.Letter-Combinations-of-a-Phone-Number.md) 🆕
-- [0019. Remove Nth Node From End of List](./problems/19.removeNthNodeFromEndofList.md)
-- [0022.GenerateParentheses](./problems/22.GenerateParentheses.md) 🆕
-- [0024. Swap Nodes In Pairs](./problems/24.swapNodesInPairs.md)
-- [0029.divide-two-integers](./problems/29.divide-two-integers.md)
-- [0031.next-permutation](./problems/31.next-permutation.md)
-- [0033.search-in-rotated-sorted-array](./problems/33.search-in-rotated-sorted-array.md)
-- [0039.combination-sum](./problems/39.combination-sum.md)
-- [0040.combination-sum-ii](./problems/40.combination-sum-ii.md)
-- [0046.permutations](./problems/46.permutations.md)
-- [0047.permutations-ii](./problems/47.permutations-ii.md)
-- [0048.rotate-image](./problems/48.rotate-image.md)
-- [0049.group-anagrams](./problems/49.group-anagrams.md)
-- [0055.jump-game](./problems/55.jump-game.md)
-- [0056.merge-intervals](./problems/56.merge-intervals.md)
-- [0062.unique-paths](./problems/62.unique-paths.md)
-- [0073.set-matrix-zeroes](./problems/73.set-matrix-zeroes.md)
-- [0075.sort-colors](./problems/75.sort-colors.md)
-- [0078.subsets](./problems/78.subsets.md)
-- [0079.word-search](./problems/79.word-search-en.md)
-- [0086.partition-list](./problems/86.partition-list.md)
-- [0090.subsets-ii](./problems/90.subsets-ii.md)
-- [0091.decode-ways](./problems/91.decode-ways.md)
-- [0092.reverse-linked-list-ii](./problems/92.reverse-linked-list-ii.md)
-- [0094.binary-tree-inorder-traversal](./problems/94.binary-tree-inorder-traversal.md)
-- [0098.validate-binary-search-tree](./problems/98.validate-binary-search-tree.md)
-- [0102.binary-tree-level-order-traversal](./problems/102.binary-tree-level-order-traversal.md)
-- [0103.binary-tree-zigzag-level-order-traversal](./problems/103.binary-tree-zigzag-level-order-traversal.md)
-- [105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md](./problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md)
-- [0113.path-sum-ii](./problems/113.path-sum-ii.md)
-- [0129.sum-root-to-leaf-numbers](./problems/129.sum-root-to-leaf-numbers.md)
-- [0130.surrounded-regions](./problems/130.surrounded-regions.md)
-- [0131.palindrome-partitioning](./problems/131.palindrome-partitioning.md)
-- [0139.word-break](./problems/139.word-break.md)
-- [0144.binary-tree-preorder-traversal](./problems/144.binary-tree-preorder-traversal.md)
-- [0150.evaluate-reverse-polish-notation](./problems/150.evaluate-reverse-polish-notation.md)
-- [0152.maximum-product-subarray](./problems/152.maximum-product-subarray.md)
-- [0199.binary-tree-right-side-view](./problems/199.binary-tree-right-side-view.md)
-- [0200.number-of-islands](./problems/200.number-of-islands.md) 🆕
-- [0201.bitwise-and-of-numbers-range](./problems/201.bitwise-and-of-numbers-range.md)
-- [0208.implement-trie-prefix-tree](./problems/208.implement-trie-prefix-tree.md)
-- [0209.minimum-size-subarray-sum](./problems/209.minimum-size-subarray-sum.md)
-- [0215.kth-largest-element-in-an-array](./problems/215.kth-largest-element-in-an-array.md) 🆕
-- [0221.maximal-square](./problems/221.maximal-square.md)
-- [0229.majority-element-ii](./problems/229.majority-element-ii.md) 🆕
-- [0230.kth-smallest-element-in-a-bst](./problems/230.kth-smallest-element-in-a-bst.md)
-- [0236.lowest-common-ancestor-of-a-binary-tree](./problems/236.lowest-common-ancestor-of-a-binary-tree.md)
-- [0238.product-of-array-except-self](./problems/238.product-of-array-except-self.md)
-- [0240.search-a-2-d-matrix-ii](./problems/240.search-a-2-d-matrix-ii.md)
-- [0279.perfect-squares](./problems/279.perfect-squares.md)
-- [0309.best-time-to-buy-and-sell-stock-with-cooldown](./problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
-- [0322.coin-change](./problems/322.coin-change.md)
-- [0328.odd-even-linked-list](./problems/328.odd-even-linked-list.md)
-- [0334.increasing-triplet-subsequence](./problems/334.increasing-triplet-subsequence.md)
-- [0365.water-and-jug-problem](./problems/365.water-and-jug-problem.md)
-- [0378.kth-smallest-element-in-a-sorted-matrix](./problems/378.kth-smallest-element-in-a-sorted-matrix.md)
-- [0416.partition-equal-subset-sum](./problems/416.partition-equal-subset-sum.md)
-- [0445.add-two-numbers-ii](./problems/445.add-two-numbers-ii.md)
-- [0454.4-sum-ii](./problems/454.4-sum-ii.md)
-- [0474.ones-and-zeros](./problems/474.ones-and-zeros-en.md)
-- [0494.target-sum](./problems/494.target-sum.md)
-- [0516.longest-palindromic-subsequence](./problems/516.longest-palindromic-subsequence.md)
-- [0518.coin-change-2](./problems/518.coin-change-2.md)
-- [0547.friend-circles](./problems/547.friend-circles-en.md) 🆕
-- [0609.find-duplicate-file-in-system](./problems/609.find-duplicate-file-in-system.md)
-- [0875.koko-eating-bananas](./problems/875.koko-eating-bananas.md)
-- [0877.stone-game](./problems/877.stone-game.md)
-- [0887.super-egg-drop](./problems/887.super-egg-drop.md)
-- [0900.rle-iterator](./problems/900.rle-iterator.md)
-- [0912.sort-an-array](./problems/912.sort-an-array.md) 🆕
-- [1031.maximum-sum-of-two-non-overlapping-subarrays](./problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md)
-- [1218.longest-arithmetic-subsequence-of-given-difference.md](./problems/1218.longest-arithmetic-subsequence-of-given-difference.md) 🆕
-
-#### Hard
-
-- [0004.median-of-two-sorted-array](./problems/4.median-of-two-sorted-array.md) 🆕
-- [0023.merge-k-sorted-lists](./problems/23.merge-k-sorted-lists.md)
- [0025.reverse-nodes-in-k-group](./problems/25.reverse-nodes-in-k-groups-en.md) 🆕
-- [0032.longest-valid-parentheses](./problems/32.longest-valid-parentheses.md) 🆕
-- [0042.trapping-rain-water](./problems/42.trapping-rain-water.md)
-- [0052.N-Queens-II](./problems/52.N-Queens-II.md) 🆕
-- [0124.binary-tree-maximum-path-sum](./problems/124.binary-tree-maximum-path-sum.md)
-- [0128.longest-consecutive-sequence](./problems/128.longest-consecutive-sequence.md)
-- [0145.binary-tree-postorder-traversal](./problems/145.binary-tree-postorder-traversal.md)
-- [0239.sliding-window-maximum](./problems/239.sliding-window-maximum.md)
-- [0295.find-median-from-data-stream](./problems/295.find-median-from-data-stream.md) 🆕
-- [0301.remove-invalid-parentheses](./problems/301.remove-invalid-parentheses.md)
-- [0460.lfu-cache](./problems/460.lfu-cache.md) 🆕
+- [0042.trapping-rain-water](./problems/42.trapping-rain-water.en.md)🆕
- [1168.optimize-water-distribution-in-a-village](./problems/1168.optimize-water-distribution-in-a-village-en.md) 🆕
-### Summary of Data Structures and Algorithms
+### Summary of Data Structures and Algorithm
-- [Data Structure](./thinkings/basic-data-structure-en.md) (Drafts)
-- [Basic Algorithm](./thinkings/basic-algorithm-en.md)Drafts
-- [Binary Tree Traversal](./thinkings/binary-tree-traversal-en.md)
+- [Data Structure](./thinkings/basic-data-structure-en.md)
+- [Basic Algorithm](./thinkings/basic-algorithm-en.md)
+- [Binary Tree Traversal](./thinkings/binary-tree-traversal.en.md)
- [Dynamic Programming](./thinkings/dynamic-programming-en.md)
- [Huffman Encode and Run Length Encode](./thinkings/run-length-encode-and-huffman-encode-en.md)
- [Bloom Filter](./thinkings/bloom-filter-en.md)
- [String Problems](./thinkings/string-problems-en.md)
+- [Sliding Window Technique](./thinkings/slide-window.en.md)
+- [Union Find](./thinkings/union-find.en.md) 🆕
+- [Trie](./thinkings/trie.en.md) 🆕
### Anki Flashcards
@@ -274,18 +161,6 @@ Latest updated flashcards (only lists the front page):
> problems added:#2 #3 #11
-### Daily Problems
-
-- [summary](./daily/)
-
-- [project](https://github.com/azl397985856/leetcode/projects/1)
-
-### Future Plans
-
-- [Complete Anki Flashcards](./assets/anki/)
-
-- [Collection of String Problem](./todo/str/)
-
## Community Chat Groups
We're still on the early stage, so feedback from community is very welcome. For sake of reducing the costs of communication, I created some chat groups.
@@ -296,18 +171,18 @@ We're still on the early stage, so feedback from community is very welcome. For
### QQ (For China Region)
-
+
### WeChat (For China Region)
-
+
(Add this bot and reply "leetcode" to join the group.)
## Contribution
- If you have any ideas, [Issues](https://github.com/azl397985856/leetcode/issues) or chat in groups.
-- If you want to commit to the repository, Pull Request is welcome.
+- If you want to commit to the repository, Pull Request is welcome. Here is the [CONTRIBUTION GUIDE](./CONTRIBUTING.en.md)
- If you want to edit images resources in this project, [here](./assets/drawio/) lists the files that can be edited on [draw.io](https://www.draw.io/).
## Thank you
diff --git a/README.md b/README.md
index 713d07c52..7aff5c721 100644
--- a/README.md
+++ b/README.md
@@ -6,21 +6,16 @@
[]()
[](#关注我)
-[](#关注我)
+[](#关注我)
[](https://juejin.im/user/58af98305c497d0067780b3b)
[](https://www.zhihu.com/people/lu-xiao-13-70)
[](https://space.bilibili.com/519510412/)
-
-
-
-> 统计数据的时间是从 2019-09-03 19:40 起至今
-
简体中文 | [English](./README.en.md)
---
-
+
- 2019-07-10 :[纪念项目 Star 突破 1W 的一个短文](./thanksGiving.md), 记录了项目的"兴起"之路,大家有兴趣可以看一下,如果对这个项目感兴趣,请**点击一下 Star**, 项目会**持续更新**,感谢大家的支持。
@@ -29,7 +24,15 @@
- 2020-04-12: [项目突破三万 Star](./thanksGiving3.md)。
- 2020-04-14: 官网`力扣加加`上线啦 💐💐💐💐💐,有专题讲解,每日一题,下载区和视频题解,后续会增加更多内容,还不赶紧收藏起来?地址:http://leetcode-solution.cn/
-
+
+
+## 项目预览
+
+
+
+可以清晰地看出仓库组织关系。
+
+(你可以下载本仓库 和 obsidian 软件,然后用 obsidian 打开获得更好的阅读效果)
## 介绍
@@ -49,26 +52,33 @@ leetcode 题解,记录自己的 leetcode 解题之路。
> 只有熟练掌握基础的数据结构与算法,才能对复杂问题迎刃有余。
-## 关于我
+## 非科学人士看过来
-擅长前端工程化,前端性能优化,前端标准化等,做过。net, 搞过 Java,现在是一名前端工程师,我的个人博客:https://lucifer.ren/blog/
+如果是国内的非科学用户,可以使用 https://lucifer.ren/leetcode ,整站做了静态化,速度贼快!但是阅读体验可能一般,大家也可以访问[力扣加加](http://leetcode-solution.cn/)(暂时没有静态化)获得更好的阅读体验。
-我经常会在开源社区进行一些输出和分享,比较受欢迎的有 [宇宙最强的前端面试指南](https://github.com/azl397985856/fe-interview)
-和 [我的第一本小书](https://github.com/azl397985856/automate-everything)。目前本人正在写一本关于《leetcode 题解》的实体书,感兴趣的可以通过邮箱或者微信联系我,我会在出版的第一时间通知你,并给出首发优惠价。有需要可以直接群里联系我,或者发送到我的个人邮箱 [azl397985856@gmail.com]。 新书详情戳这里:[《或许是一本可以彻底改变你刷 LeetCode 效率的题解书》](https://lucifer.ren/blog/2020/04/07/leetcode-book.intro/)
+另外需要科学的,我推荐一个工具, 用户体验真的是好,用起来超简单, 提供一站式工具,包括网络检测工具,浏览器插件等,支持多种客户端(还有我最喜欢的 Switch 加速器),价格也不贵,基础套餐折算到月大约 11.2 块/月。它还支持签到送天数,也就是说你可以每天签到无限续期。地址:https://glados.space/landing/M9OHH-Q88JQ-DX72D-R04RN
+
+## 怎么刷 LeetCode?
+
+- [我是如何刷 LeetCode 的](https://www.zhihu.com/question/280279208/answer/824585814)
+- [算法小白如何高效、快速刷 leetcode?](https://www.zhihu.com/question/321738058/answer/1279464192)
+
+## 刷题插件
+
+- [刷题效率低?或许你就差这么一个插件](https://lucifer.ren/blog/2020/06/06/algo-chrome-extension/)
+- [力扣刷题插件](https://lucifer.ren/blog/2020/08/16/leetcode-cheat/)
+
+## 91 天学算法
+
+- [91 天,遇见不一样的自己](https://lucifer.ren/blog/2020/05/30/91algo-05-30/)
## 食用指南
- 对于最近添加的部分, 后面会有 🆕 标注
- 对于最近更新的部分, 后面会有 🖊 标注
-- 将来会在这里更新 anki 卡片
-- 这里有一份 leetcode 官方账号在知乎上给出的一个《互联网公司最常见的面试算法题有哪些?》的答案,我这里尽量去覆盖回答中的题目和知识点
- 原文地址: https://www.zhihu.com/question/24964987/answer/586425979
-
-- 这里有一份我在知乎上的回答 [《大家都是如何刷 LeetCode 的?》](https://www.zhihu.com/question/280279208/answer/824585814)
-
- 这里有一张互联网公司面试中经常考察的问题类型总结的思维导图,我们可以结合图片中的信息分析一下。
-
+
(图片来自 leetcode)
@@ -93,7 +103,7 @@ leetcode 题解,记录自己的 leetcode 解题之路。
[0042.trapping-rain-water](./problems/42.trapping-rain-water.md):
-
+ [0547.friend-circles](./problems/547.friend-circles-en.md):
@@ -111,184 +121,15 @@ leetcode 题解,记录自己的 leetcode 解题之路。
[0547.friend-circles](./problems/547.friend-circles-en.md):
@@ -111,184 +121,15 @@ leetcode 题解,记录自己的 leetcode 解题之路。
 -## Top 题目进度
-
-- [Top 100 Liked Questions](https://leetcode.com/problemset/top-100-liked-questions/) (84 / 100)
-
-- [Top Interview Questions](https://leetcode.com/problemset/top-interview-questions/) (115 / 145)
-
## 传送门
### leetcode 经典题目的解析
> 这里仅列举具有**代表性题目**,并不是全部题目
-#### 简单难度
-
-- [0001.TwoSum](./problems/1.TwoSum.md) 🆕
-- [0020.Valid Parentheses](./problems/20.validParentheses.md)
-- [0021.MergeTwoSortedLists](./problems/21.MergeTwoSortedLists.md) 🆕
-- [0026.remove-duplicates-from-sorted-array](./problems/26.remove-duplicates-from-sorted-array.md)
-- [0053.maximum-sum-subarray](./problems/53.maximum-sum-subarray-cn.md) 🆕
-- [0088.merge-sorted-array](./problems/88.merge-sorted-array.md)
-- [0104.maximum-depth-of-binary-tree](./problems/104.maximum-depth-of-binary-tree.md)
-- [0121.best-time-to-buy-and-sell-stock](./problems/121.best-time-to-buy-and-sell-stock.md)
-- [0122.best-time-to-buy-and-sell-stock-ii](./problems/122.best-time-to-buy-and-sell-stock-ii.md)
-- [0125.valid-palindrome](./problems/125.valid-palindrome.md) 🆕
-- [0136.single-number](./problems/136.single-number.md)
-- [0155.min-stack](./problems/155.min-stack.md) 🆕
-- [0167.two-sum-ii-input-array-is-sorted](./problems/167.two-sum-ii-input-array-is-sorted.md)
-- [0169.majority-element](./problems/169.majority-element.md)
-- [0172.factorial-trailing-zeroes](./problems/172.factorial-trailing-zeroes.md)
-- [0190.reverse-bits](./problems/190.reverse-bits.md)
-- [0191.number-of-1-bits](./problems/191.number-of-1-bits.md)
-- [0198.house-robber](./problems/198.house-robber.md)
-- [0203.remove-linked-list-elements](./problems/203.remove-linked-list-elements.md)
-- [0206.reverse-linked-list](./problems/206.reverse-linked-list.md)
-- [0219.contains-duplicate-ii](./problems/219.contains-duplicate-ii.md)
-- [0226.invert-binary-tree](./problems/226.invert-binary-tree.md)
-- [0232.implement-queue-using-stacks](./problems/232.implement-queue-using-stacks.md) 🆕
-- [0263.ugly-number](./problems/263.ugly-number.md)
-- [0283.move-zeroes](./problems/283.move-zeroes.md)
-- [0342.power-of-four](./problems/342.power-of-four.md)
-- [0349.intersection-of-two-arrays](./problems/349.intersection-of-two-arrays.md)
-- [0371.sum-of-two-integers](./problems/371.sum-of-two-integers.md)
-- [0437.path-sum-iii](./problems/437.path-sum-iii.md) 🆕
-- [0455.AssignCookies](./problems/455.AssignCookies.md) 🆕
-- [0501.find-mode-in-binary-search-tree](./problems/501.Find-Mode-in-Binary-Search-Tree.md)🆕
-- [0575.distribute-candies](./problems/575.distribute-candies.md)
-- [0874.walking-robot-simulation](./problems/874.walking-robot-simulation.md) 🆕
-- [1260.shift-2d-grid](./problems/1260.shift-2d-grid.md) 🆕
-- [1332.remove-palindromic-subsequences](./problems/1332.remove-palindromic-subsequences.md) 🆕
-
-#### 中等难度
-
-- [0002. Add Two Numbers](./problems/2.addTwoNumbers.md)
-- [0003. Longest Substring Without Repeating Characters](./problems/3.longestSubstringWithoutRepeatingCharacters.md)
-- [0005.longest-palindromic-substring](./problems/5.longest-palindromic-substring.md)
-- [0011.container-with-most-water](./problems/11.container-with-most-water.md)
-- [0015.3-sum](./problems/15.3-sum.md)
-- [0017.Letter-Combinations-of-a-Phone-Number](./problems/17.Letter-Combinations-of-a-Phone-Number.md) 🆕
-- [0019. Remove Nth Node From End of List](./problems/19.removeNthNodeFromEndofList.md)
-- [0022.GenerateParentheses](./problems/22.GenerateParentheses.md) 🆕
-- [0024. Swap Nodes In Pairs](./problems/24.swapNodesInPairs.md)
-- [0029.divide-two-integers](./problems/29.divide-two-integers.md)
-- [0031.next-permutation](./problems/31.next-permutation.md)
-- [0033.search-in-rotated-sorted-array](./problems/33.search-in-rotated-sorted-array.md)
-- [0039.combination-sum](./problems/39.combination-sum.md)
-- [0040.combination-sum-ii](./problems/40.combination-sum-ii.md)
-- [0046.permutations](./problems/46.permutations.md)
-- [0047.permutations-ii](./problems/47.permutations-ii.md)
-- [0048.rotate-image](./problems/48.rotate-image.md)
-- [0049.group-anagrams](./problems/49.group-anagrams.md)
-- [0050.pow-x-n](./problems/50.pow-x-n.md) 🆕
-- [0055.jump-game](./problems/55.jump-game.md)
-- [0056.merge-intervals](./problems/56.merge-intervals.md)
-- [0060.permutation-sequence](./problems/60.permutation-sequence.md) 🆕
-- [0062.unique-paths](./problems/62.unique-paths.md) 🖊
-- [0073.set-matrix-zeroes](./problems/73.set-matrix-zeroes.md)
-- [0075.sort-colors](./problems/75.sort-colors.md)
-- [0078.subsets](./problems/78.subsets.md)
-- [0079.word-search](./problems/79.word-search-en.md)
-- [0080.remove-duplicates-from-sorted-array-ii](./problems/80.remove-duplicates-from-sorted-array-ii.md) 🆕
-- [0086.partition-list](./problems/86.partition-list.md)
-- [0090.subsets-ii](./problems/90.subsets-ii.md)
-- [0091.decode-ways](./problems/91.decode-ways.md)
-- [0092.reverse-linked-list-ii](./problems/92.reverse-linked-list-ii.md) 🖊
-- [0094.binary-tree-inorder-traversal](./problems/94.binary-tree-inorder-traversal.md)
-- [0095.unique-binary-search-trees-ii](./problems/95.unique-binary-search-trees-ii.md) 🆕
-- [0096.unique-binary-search-trees](./problems/96.unique-binary-search-trees.md) 🆕
-- [0098.validate-binary-search-tree](./problems/98.validate-binary-search-tree.md)
-- [0102.binary-tree-level-order-traversal](./problems/102.binary-tree-level-order-traversal.md)
-- [0103.binary-tree-zigzag-level-order-traversal](./problems/103.binary-tree-zigzag-level-order-traversal.md)
-- [105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md](./problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md)
-- [0113.path-sum-ii](./problems/113.path-sum-ii.md)
-- [0129.sum-root-to-leaf-numbers](./problems/129.sum-root-to-leaf-numbers.md)
-- [0130.surrounded-regions](./problems/130.surrounded-regions.md)
-- [0131.palindrome-partitioning](./problems/131.palindrome-partitioning.md)
-- [0139.word-break](./problems/139.word-break.md)
-- [0144.binary-tree-preorder-traversal](./problems/144.binary-tree-preorder-traversal.md)
-- [0150.evaluate-reverse-polish-notation](./problems/150.evaluate-reverse-polish-notation.md)
-- [0152.maximum-product-subarray](./problems/152.maximum-product-subarray.md) 🖊
-- [0199.binary-tree-right-side-view](./problems/199.binary-tree-right-side-view.md)
-- [0200.number-of-islands](./problems/200.number-of-islands.md) 🆕
-- [0201.bitwise-and-of-numbers-range](./problems/201.bitwise-and-of-numbers-range.md) 🖊
-- [0208.implement-trie-prefix-tree](./problems/208.implement-trie-prefix-tree.md)
-- [0209.minimum-size-subarray-sum](./problems/209.minimum-size-subarray-sum.md)
-- [0211.add-and-search-word-data-structure-design](./problems/211.add-and-search-word-data-structure-design.md) 🆕
-- [0215.kth-largest-element-in-an-array](./problems/215.kth-largest-element-in-an-array.md) 🆕
-- [0221.maximal-square](./problems/221.maximal-square.md)
-- [0229.majority-element-ii](./problems/229.majority-element-ii.md) 🆕
-- [0230.kth-smallest-element-in-a-bst](./problems/230.kth-smallest-element-in-a-bst.md)
-- [0236.lowest-common-ancestor-of-a-binary-tree](./problems/236.lowest-common-ancestor-of-a-binary-tree.md)
-- [0238.product-of-array-except-self](./problems/238.product-of-array-except-self.md)
-- [0240.search-a-2-d-matrix-ii](./problems/240.search-a-2-d-matrix-ii.md)
-- [0279.perfect-squares](./problems/279.perfect-squares.md)
-- [0309.best-time-to-buy-and-sell-stock-with-cooldown](./problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
-- [0322.coin-change](./problems/322.coin-change.md)
-- [0328.odd-even-linked-list](./problems/328.odd-even-linked-list.md)
-- [0334.increasing-triplet-subsequence](./problems/334.increasing-triplet-subsequence.md)
-- [0365.water-and-jug-problem](./problems/365.water-and-jug-problem.md)
-- [0378.kth-smallest-element-in-a-sorted-matrix](./problems/378.kth-smallest-element-in-a-sorted-matrix.md)
-- [0380.insert-delete-getrandom-o1](./problems/380.insert-delete-getrandom-o1.md)🆕
-- [0416.partition-equal-subset-sum](./problems/416.partition-equal-subset-sum.md)
-- [0445.add-two-numbers-ii](./problems/445.add-two-numbers-ii.md)
-- [0454.4-sum-ii](./problems/454.4-sum-ii.md)
-- [0474.ones-and-zeros](./problems/474.ones-and-zeros-en.md)
-- [0494.target-sum](./problems/494.target-sum.md)
-- [0516.longest-palindromic-subsequence](./problems/516.longest-palindromic-subsequence.md)
-- [0518.coin-change-2](./problems/518.coin-change-2.md)
-- [0547.friend-circles](./problems/547.friend-circles-en.md) 🆕
-- [0609.find-duplicate-file-in-system](./problems/609.find-duplicate-file-in-system.md)
-- [0820.short-encoding-of-words](./problems/820.short-encoding-of-words.md) 🆕
-- [0875.koko-eating-bananas](./problems/875.koko-eating-bananas.md)
-- [0877.stone-game](./problems/877.stone-game.md)
-- [0887.super-egg-drop](./problems/887.super-egg-drop.md)
-- [0900.rle-iterator](./problems/900.rle-iterator.md)
-- [0912.sort-an-array](./problems/912.sort-an-array.md) 🆕
-- [0935.knight-dialer](./problems/935.knight-dialer.md) 🆕
-- [1011.capacity-to-ship-packages-within-d-days](./problems/1011.capacity-to-ship-packages-within-d-days.md) 🆕
-- [1014.best-sightseeing-pair](./problems/1014.best-sightseeing-pair.md) 🆕
-- [1015.smallest-integer-divisible-by-k](./problems/1015.smallest-integer-divisible-by-k.md) 🆕
-- [1019.next-greater-node-in-linked-list](./problems/1019.next-greater-node-in-linked-list.md) 🆕
-- [1020.number-of-enclaves](./problems/1020.number-of-enclaves.md) 🆕
-- [1023.camelcase-matching](./problems/1023.camelcase-matching.md) 🆕
-- [1031.maximum-sum-of-two-non-overlapping-subarrays](./problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md)
-- [1104.path-in-zigzag-labelled-binary-tree](./problems/1104.path-in-zigzag-labelled-binary-tree.md) 🆕
-- [1131.maximum-of-absolute-value-expression](./problems/1131.maximum-of-absolute-value-expression.md) 🆕
-- [1186.maximum-subarray-sum-with-one-deletion](./problems/1186.maximum-subarray-sum-with-one-deletion.md) 🆕
-- [1218.longest-arithmetic-subsequence-of-given-difference](./problems/1218.longest-arithmetic-subsequence-of-given-difference.md) 🆕
-- [1227.airplane-seat-assignment-probability](./problems/1227.airplane-seat-assignment-probability.md) 🆕
-- [1261.find-elements-in-a-contaminated-binary-tree](./problems/1261.find-elements-in-a-contaminated-binary-tree.md) 🆕
-- [1262.greatest-sum-divisible-by-three](./problems/1262.greatest-sum-divisible-by-three.md) 🆕
-- [1297.maximum-number-of-occurrences-of-a-substring](./problems/1297.maximum-number-of-occurrences-of-a-substring.md) 🆕
-- [1310.xor-queries-of-a-subarray](./problems/1310.xor-queries-of-a-subarray.md) 🆕
-- [1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance](./problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md) 🆕
-
-#### 困难难度
-
-- [0004.median-of-two-sorted-array](./problems/4.median-of-two-sorted-array.md)
-- [0023.merge-k-sorted-lists](./problems/23.merge-k-sorted-lists.md)
-- [0025.reverse-nodes-in-k-group](./problems/25.reverse-nodes-in-k-groups-cn.md)
-- [0030.substring-with-concatenation-of-all-words](./problems/30.substring-with-concatenation-of-all-words.md)
-- [0032.longest-valid-parentheses](./problems/32.longest-valid-parentheses.md)
-- [0042.trapping-rain-water](./problems/42.trapping-rain-water.md)
-- [0052.N-Queens-II](./problems/52.N-Queens-II.md) 🆕
-- [0084.largest-rectangle-in-histogram](./problems/84.largest-rectangle-in-histogram.md) 🆕
-- [0085.maximal-rectangle](./problems/85.maximal-rectangle.md)
-- [0124.binary-tree-maximum-path-sum](./problems/124.binary-tree-maximum-path-sum.md)
-- [0128.longest-consecutive-sequence](./problems/128.longest-consecutive-sequence.md)
-- [0145.binary-tree-postorder-traversal](./problems/145.binary-tree-postorder-traversal.md)
-- [0212.word-search-ii](./problems/212.word-search-ii.md) 🆕
-- [0239.sliding-window-maximum](./problems/239.sliding-window-maximum.md)
-- [0295.find-median-from-data-stream](./problems/295.find-median-from-data-stream.md) 🆕
-- [0301.remove-invalid-parentheses](./problems/301.remove-invalid-parentheses.md)
-- [0335.self-crossPing](./problems/335.self-crossing.md) 🆕
-- [0460.lfu-cache](./problems/460.lfu-cache.md)
-- [0472.concatenated-words](./problems/472.concatenated-words.md) 🆕
-- [0493.reverse-pairs](./problems/493.reverse-pairs.md) 🆕
-- [0895.maximum-frequency-stack](./problems/895.maximum-frequency-stack.md) 🆕
-- [1168.optimize-water-distribution-in-a-village](./problems/1168.optimize-water-distribution-in-a-village-cn.md) 🆕
+- [简单难度](./collections/easy.md)
+- [中等难度](./collections/medium.md)
+- [困难难度](./collections/hard.md)
### 数据结构与算法的总结
@@ -299,17 +140,20 @@ leetcode 题解,记录自己的 leetcode 解题之路。
- [哈夫曼编码和游程编码](./thinkings/run-length-encode-and-huffman-encode.md)
- [布隆过滤器](./thinkings/bloom-filter.md)
- [字符串问题](./thinkings/string-problems.md)
-- [前缀树专题](./thinkings/trie.md)
+- [前缀树专题](./thinkings/trie.md) 🖊
- [《日程安排》专题](https://lucifer.ren/blog/2020/02/03/leetcode-%E6%88%91%E7%9A%84%E6%97%A5%E7%A8%8B%E5%AE%89%E6%8E%92%E8%A1%A8%E7%B3%BB%E5%88%97/)
- [《构造二叉树》专题](https://lucifer.ren/blog/2020/02/08/%E6%9E%84%E9%80%A0%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%93%E9%A2%98/)
- [《贪婪策略》专题](./thinkings/greedy.md)
- [《深度优先遍历》专题](./thinkings/DFS.md)
-- [滑动窗口(思路 + 模板)](./thinkings/slide-window.md) 🆕
-- [位运算](./thinkings/bit.md) 🆕
-- [设计题](./thinkings/design.md) 🆕
-- [小岛问题](./thinkings/island.md) 🆕
-- [最大公约数](./thinkings/GCD.md) 🆕
+- [滑动窗口(思路 + 模板)](./thinkings/slide-window.md)
+- [位运算](./thinkings/bit.md)
+- [设计题](./thinkings/design.md)
+- [小岛问题](./thinkings/island.md)
+- [最大公约数](./thinkings/GCD.md)
- [并查集](./thinkings/union-find.md) 🆕
+- [前缀和](./thinkings/prefix.md) 🆕
+- [字典序列删除](https://lucifer.ren/blog/2020/06/13/%E5%88%A0%E9%99%A4%E9%97%AE%E9%A2%98/)🆕
+- [平衡二叉树专题](./thinkings/balanced-tree.md)
### anki 卡片
@@ -341,11 +185,7 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
- [每日一题汇总](./daily/)
-
-
-- [每日一题认领区](https://github.com/azl397985856/leetcode/projects/1)
-
-
+* [每日一题认领区](https://github.com/azl397985856/leetcode/projects/1)
### 计划
@@ -361,21 +201,22 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
- 单调栈
-## 关注我
+- BFS & DFS
-我重新整理了下自己的公众号,并且我还给它换了一个名字`脑洞前端`,它是一个帮助你打开大前端新世界大门的钥匙 🔑,在这里你可以听到新奇的观点,看到一些技术尝新,还会收到系统性总结和思考。
+## 哪里能找到我?
-在这里我会尽量通过图的形式来阐述一些概念和逻辑,帮助大家快速理解,图解是我的目标。
+点关注,不迷路。如果再给 ➕ 个星标就更棒啦!
-之后我的文章会同步到微信公众号 `脑洞前端` ,你可以关注获取最新的文章,并和我进行交流。
+> 关注加加,星标加加~
-另外你可以回复大前端进大前端微信交流群, 回复 leetcode 拉你进 leetcode 微信群,如果想加入 qq 群,请回复 qq。
+
-## Top 题目进度
-
-- [Top 100 Liked Questions](https://leetcode.com/problemset/top-100-liked-questions/) (84 / 100)
-
-- [Top Interview Questions](https://leetcode.com/problemset/top-interview-questions/) (115 / 145)
-
## 传送门
### leetcode 经典题目的解析
> 这里仅列举具有**代表性题目**,并不是全部题目
-#### 简单难度
-
-- [0001.TwoSum](./problems/1.TwoSum.md) 🆕
-- [0020.Valid Parentheses](./problems/20.validParentheses.md)
-- [0021.MergeTwoSortedLists](./problems/21.MergeTwoSortedLists.md) 🆕
-- [0026.remove-duplicates-from-sorted-array](./problems/26.remove-duplicates-from-sorted-array.md)
-- [0053.maximum-sum-subarray](./problems/53.maximum-sum-subarray-cn.md) 🆕
-- [0088.merge-sorted-array](./problems/88.merge-sorted-array.md)
-- [0104.maximum-depth-of-binary-tree](./problems/104.maximum-depth-of-binary-tree.md)
-- [0121.best-time-to-buy-and-sell-stock](./problems/121.best-time-to-buy-and-sell-stock.md)
-- [0122.best-time-to-buy-and-sell-stock-ii](./problems/122.best-time-to-buy-and-sell-stock-ii.md)
-- [0125.valid-palindrome](./problems/125.valid-palindrome.md) 🆕
-- [0136.single-number](./problems/136.single-number.md)
-- [0155.min-stack](./problems/155.min-stack.md) 🆕
-- [0167.two-sum-ii-input-array-is-sorted](./problems/167.two-sum-ii-input-array-is-sorted.md)
-- [0169.majority-element](./problems/169.majority-element.md)
-- [0172.factorial-trailing-zeroes](./problems/172.factorial-trailing-zeroes.md)
-- [0190.reverse-bits](./problems/190.reverse-bits.md)
-- [0191.number-of-1-bits](./problems/191.number-of-1-bits.md)
-- [0198.house-robber](./problems/198.house-robber.md)
-- [0203.remove-linked-list-elements](./problems/203.remove-linked-list-elements.md)
-- [0206.reverse-linked-list](./problems/206.reverse-linked-list.md)
-- [0219.contains-duplicate-ii](./problems/219.contains-duplicate-ii.md)
-- [0226.invert-binary-tree](./problems/226.invert-binary-tree.md)
-- [0232.implement-queue-using-stacks](./problems/232.implement-queue-using-stacks.md) 🆕
-- [0263.ugly-number](./problems/263.ugly-number.md)
-- [0283.move-zeroes](./problems/283.move-zeroes.md)
-- [0342.power-of-four](./problems/342.power-of-four.md)
-- [0349.intersection-of-two-arrays](./problems/349.intersection-of-two-arrays.md)
-- [0371.sum-of-two-integers](./problems/371.sum-of-two-integers.md)
-- [0437.path-sum-iii](./problems/437.path-sum-iii.md) 🆕
-- [0455.AssignCookies](./problems/455.AssignCookies.md) 🆕
-- [0501.find-mode-in-binary-search-tree](./problems/501.Find-Mode-in-Binary-Search-Tree.md)🆕
-- [0575.distribute-candies](./problems/575.distribute-candies.md)
-- [0874.walking-robot-simulation](./problems/874.walking-robot-simulation.md) 🆕
-- [1260.shift-2d-grid](./problems/1260.shift-2d-grid.md) 🆕
-- [1332.remove-palindromic-subsequences](./problems/1332.remove-palindromic-subsequences.md) 🆕
-
-#### 中等难度
-
-- [0002. Add Two Numbers](./problems/2.addTwoNumbers.md)
-- [0003. Longest Substring Without Repeating Characters](./problems/3.longestSubstringWithoutRepeatingCharacters.md)
-- [0005.longest-palindromic-substring](./problems/5.longest-palindromic-substring.md)
-- [0011.container-with-most-water](./problems/11.container-with-most-water.md)
-- [0015.3-sum](./problems/15.3-sum.md)
-- [0017.Letter-Combinations-of-a-Phone-Number](./problems/17.Letter-Combinations-of-a-Phone-Number.md) 🆕
-- [0019. Remove Nth Node From End of List](./problems/19.removeNthNodeFromEndofList.md)
-- [0022.GenerateParentheses](./problems/22.GenerateParentheses.md) 🆕
-- [0024. Swap Nodes In Pairs](./problems/24.swapNodesInPairs.md)
-- [0029.divide-two-integers](./problems/29.divide-two-integers.md)
-- [0031.next-permutation](./problems/31.next-permutation.md)
-- [0033.search-in-rotated-sorted-array](./problems/33.search-in-rotated-sorted-array.md)
-- [0039.combination-sum](./problems/39.combination-sum.md)
-- [0040.combination-sum-ii](./problems/40.combination-sum-ii.md)
-- [0046.permutations](./problems/46.permutations.md)
-- [0047.permutations-ii](./problems/47.permutations-ii.md)
-- [0048.rotate-image](./problems/48.rotate-image.md)
-- [0049.group-anagrams](./problems/49.group-anagrams.md)
-- [0050.pow-x-n](./problems/50.pow-x-n.md) 🆕
-- [0055.jump-game](./problems/55.jump-game.md)
-- [0056.merge-intervals](./problems/56.merge-intervals.md)
-- [0060.permutation-sequence](./problems/60.permutation-sequence.md) 🆕
-- [0062.unique-paths](./problems/62.unique-paths.md) 🖊
-- [0073.set-matrix-zeroes](./problems/73.set-matrix-zeroes.md)
-- [0075.sort-colors](./problems/75.sort-colors.md)
-- [0078.subsets](./problems/78.subsets.md)
-- [0079.word-search](./problems/79.word-search-en.md)
-- [0080.remove-duplicates-from-sorted-array-ii](./problems/80.remove-duplicates-from-sorted-array-ii.md) 🆕
-- [0086.partition-list](./problems/86.partition-list.md)
-- [0090.subsets-ii](./problems/90.subsets-ii.md)
-- [0091.decode-ways](./problems/91.decode-ways.md)
-- [0092.reverse-linked-list-ii](./problems/92.reverse-linked-list-ii.md) 🖊
-- [0094.binary-tree-inorder-traversal](./problems/94.binary-tree-inorder-traversal.md)
-- [0095.unique-binary-search-trees-ii](./problems/95.unique-binary-search-trees-ii.md) 🆕
-- [0096.unique-binary-search-trees](./problems/96.unique-binary-search-trees.md) 🆕
-- [0098.validate-binary-search-tree](./problems/98.validate-binary-search-tree.md)
-- [0102.binary-tree-level-order-traversal](./problems/102.binary-tree-level-order-traversal.md)
-- [0103.binary-tree-zigzag-level-order-traversal](./problems/103.binary-tree-zigzag-level-order-traversal.md)
-- [105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md](./problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md)
-- [0113.path-sum-ii](./problems/113.path-sum-ii.md)
-- [0129.sum-root-to-leaf-numbers](./problems/129.sum-root-to-leaf-numbers.md)
-- [0130.surrounded-regions](./problems/130.surrounded-regions.md)
-- [0131.palindrome-partitioning](./problems/131.palindrome-partitioning.md)
-- [0139.word-break](./problems/139.word-break.md)
-- [0144.binary-tree-preorder-traversal](./problems/144.binary-tree-preorder-traversal.md)
-- [0150.evaluate-reverse-polish-notation](./problems/150.evaluate-reverse-polish-notation.md)
-- [0152.maximum-product-subarray](./problems/152.maximum-product-subarray.md) 🖊
-- [0199.binary-tree-right-side-view](./problems/199.binary-tree-right-side-view.md)
-- [0200.number-of-islands](./problems/200.number-of-islands.md) 🆕
-- [0201.bitwise-and-of-numbers-range](./problems/201.bitwise-and-of-numbers-range.md) 🖊
-- [0208.implement-trie-prefix-tree](./problems/208.implement-trie-prefix-tree.md)
-- [0209.minimum-size-subarray-sum](./problems/209.minimum-size-subarray-sum.md)
-- [0211.add-and-search-word-data-structure-design](./problems/211.add-and-search-word-data-structure-design.md) 🆕
-- [0215.kth-largest-element-in-an-array](./problems/215.kth-largest-element-in-an-array.md) 🆕
-- [0221.maximal-square](./problems/221.maximal-square.md)
-- [0229.majority-element-ii](./problems/229.majority-element-ii.md) 🆕
-- [0230.kth-smallest-element-in-a-bst](./problems/230.kth-smallest-element-in-a-bst.md)
-- [0236.lowest-common-ancestor-of-a-binary-tree](./problems/236.lowest-common-ancestor-of-a-binary-tree.md)
-- [0238.product-of-array-except-self](./problems/238.product-of-array-except-self.md)
-- [0240.search-a-2-d-matrix-ii](./problems/240.search-a-2-d-matrix-ii.md)
-- [0279.perfect-squares](./problems/279.perfect-squares.md)
-- [0309.best-time-to-buy-and-sell-stock-with-cooldown](./problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
-- [0322.coin-change](./problems/322.coin-change.md)
-- [0328.odd-even-linked-list](./problems/328.odd-even-linked-list.md)
-- [0334.increasing-triplet-subsequence](./problems/334.increasing-triplet-subsequence.md)
-- [0365.water-and-jug-problem](./problems/365.water-and-jug-problem.md)
-- [0378.kth-smallest-element-in-a-sorted-matrix](./problems/378.kth-smallest-element-in-a-sorted-matrix.md)
-- [0380.insert-delete-getrandom-o1](./problems/380.insert-delete-getrandom-o1.md)🆕
-- [0416.partition-equal-subset-sum](./problems/416.partition-equal-subset-sum.md)
-- [0445.add-two-numbers-ii](./problems/445.add-two-numbers-ii.md)
-- [0454.4-sum-ii](./problems/454.4-sum-ii.md)
-- [0474.ones-and-zeros](./problems/474.ones-and-zeros-en.md)
-- [0494.target-sum](./problems/494.target-sum.md)
-- [0516.longest-palindromic-subsequence](./problems/516.longest-palindromic-subsequence.md)
-- [0518.coin-change-2](./problems/518.coin-change-2.md)
-- [0547.friend-circles](./problems/547.friend-circles-en.md) 🆕
-- [0609.find-duplicate-file-in-system](./problems/609.find-duplicate-file-in-system.md)
-- [0820.short-encoding-of-words](./problems/820.short-encoding-of-words.md) 🆕
-- [0875.koko-eating-bananas](./problems/875.koko-eating-bananas.md)
-- [0877.stone-game](./problems/877.stone-game.md)
-- [0887.super-egg-drop](./problems/887.super-egg-drop.md)
-- [0900.rle-iterator](./problems/900.rle-iterator.md)
-- [0912.sort-an-array](./problems/912.sort-an-array.md) 🆕
-- [0935.knight-dialer](./problems/935.knight-dialer.md) 🆕
-- [1011.capacity-to-ship-packages-within-d-days](./problems/1011.capacity-to-ship-packages-within-d-days.md) 🆕
-- [1014.best-sightseeing-pair](./problems/1014.best-sightseeing-pair.md) 🆕
-- [1015.smallest-integer-divisible-by-k](./problems/1015.smallest-integer-divisible-by-k.md) 🆕
-- [1019.next-greater-node-in-linked-list](./problems/1019.next-greater-node-in-linked-list.md) 🆕
-- [1020.number-of-enclaves](./problems/1020.number-of-enclaves.md) 🆕
-- [1023.camelcase-matching](./problems/1023.camelcase-matching.md) 🆕
-- [1031.maximum-sum-of-two-non-overlapping-subarrays](./problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md)
-- [1104.path-in-zigzag-labelled-binary-tree](./problems/1104.path-in-zigzag-labelled-binary-tree.md) 🆕
-- [1131.maximum-of-absolute-value-expression](./problems/1131.maximum-of-absolute-value-expression.md) 🆕
-- [1186.maximum-subarray-sum-with-one-deletion](./problems/1186.maximum-subarray-sum-with-one-deletion.md) 🆕
-- [1218.longest-arithmetic-subsequence-of-given-difference](./problems/1218.longest-arithmetic-subsequence-of-given-difference.md) 🆕
-- [1227.airplane-seat-assignment-probability](./problems/1227.airplane-seat-assignment-probability.md) 🆕
-- [1261.find-elements-in-a-contaminated-binary-tree](./problems/1261.find-elements-in-a-contaminated-binary-tree.md) 🆕
-- [1262.greatest-sum-divisible-by-three](./problems/1262.greatest-sum-divisible-by-three.md) 🆕
-- [1297.maximum-number-of-occurrences-of-a-substring](./problems/1297.maximum-number-of-occurrences-of-a-substring.md) 🆕
-- [1310.xor-queries-of-a-subarray](./problems/1310.xor-queries-of-a-subarray.md) 🆕
-- [1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance](./problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md) 🆕
-
-#### 困难难度
-
-- [0004.median-of-two-sorted-array](./problems/4.median-of-two-sorted-array.md)
-- [0023.merge-k-sorted-lists](./problems/23.merge-k-sorted-lists.md)
-- [0025.reverse-nodes-in-k-group](./problems/25.reverse-nodes-in-k-groups-cn.md)
-- [0030.substring-with-concatenation-of-all-words](./problems/30.substring-with-concatenation-of-all-words.md)
-- [0032.longest-valid-parentheses](./problems/32.longest-valid-parentheses.md)
-- [0042.trapping-rain-water](./problems/42.trapping-rain-water.md)
-- [0052.N-Queens-II](./problems/52.N-Queens-II.md) 🆕
-- [0084.largest-rectangle-in-histogram](./problems/84.largest-rectangle-in-histogram.md) 🆕
-- [0085.maximal-rectangle](./problems/85.maximal-rectangle.md)
-- [0124.binary-tree-maximum-path-sum](./problems/124.binary-tree-maximum-path-sum.md)
-- [0128.longest-consecutive-sequence](./problems/128.longest-consecutive-sequence.md)
-- [0145.binary-tree-postorder-traversal](./problems/145.binary-tree-postorder-traversal.md)
-- [0212.word-search-ii](./problems/212.word-search-ii.md) 🆕
-- [0239.sliding-window-maximum](./problems/239.sliding-window-maximum.md)
-- [0295.find-median-from-data-stream](./problems/295.find-median-from-data-stream.md) 🆕
-- [0301.remove-invalid-parentheses](./problems/301.remove-invalid-parentheses.md)
-- [0335.self-crossPing](./problems/335.self-crossing.md) 🆕
-- [0460.lfu-cache](./problems/460.lfu-cache.md)
-- [0472.concatenated-words](./problems/472.concatenated-words.md) 🆕
-- [0493.reverse-pairs](./problems/493.reverse-pairs.md) 🆕
-- [0895.maximum-frequency-stack](./problems/895.maximum-frequency-stack.md) 🆕
-- [1168.optimize-water-distribution-in-a-village](./problems/1168.optimize-water-distribution-in-a-village-cn.md) 🆕
+- [简单难度](./collections/easy.md)
+- [中等难度](./collections/medium.md)
+- [困难难度](./collections/hard.md)
### 数据结构与算法的总结
@@ -299,17 +140,20 @@ leetcode 题解,记录自己的 leetcode 解题之路。
- [哈夫曼编码和游程编码](./thinkings/run-length-encode-and-huffman-encode.md)
- [布隆过滤器](./thinkings/bloom-filter.md)
- [字符串问题](./thinkings/string-problems.md)
-- [前缀树专题](./thinkings/trie.md)
+- [前缀树专题](./thinkings/trie.md) 🖊
- [《日程安排》专题](https://lucifer.ren/blog/2020/02/03/leetcode-%E6%88%91%E7%9A%84%E6%97%A5%E7%A8%8B%E5%AE%89%E6%8E%92%E8%A1%A8%E7%B3%BB%E5%88%97/)
- [《构造二叉树》专题](https://lucifer.ren/blog/2020/02/08/%E6%9E%84%E9%80%A0%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%93%E9%A2%98/)
- [《贪婪策略》专题](./thinkings/greedy.md)
- [《深度优先遍历》专题](./thinkings/DFS.md)
-- [滑动窗口(思路 + 模板)](./thinkings/slide-window.md) 🆕
-- [位运算](./thinkings/bit.md) 🆕
-- [设计题](./thinkings/design.md) 🆕
-- [小岛问题](./thinkings/island.md) 🆕
-- [最大公约数](./thinkings/GCD.md) 🆕
+- [滑动窗口(思路 + 模板)](./thinkings/slide-window.md)
+- [位运算](./thinkings/bit.md)
+- [设计题](./thinkings/design.md)
+- [小岛问题](./thinkings/island.md)
+- [最大公约数](./thinkings/GCD.md)
- [并查集](./thinkings/union-find.md) 🆕
+- [前缀和](./thinkings/prefix.md) 🆕
+- [字典序列删除](https://lucifer.ren/blog/2020/06/13/%E5%88%A0%E9%99%A4%E9%97%AE%E9%A2%98/)🆕
+- [平衡二叉树专题](./thinkings/balanced-tree.md)
### anki 卡片
@@ -341,11 +185,7 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
- [每日一题汇总](./daily/)
-
-
-- [每日一题认领区](https://github.com/azl397985856/leetcode/projects/1)
-
-
+* [每日一题认领区](https://github.com/azl397985856/leetcode/projects/1)
### 计划
@@ -361,21 +201,22 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
- 单调栈
-## 关注我
+- BFS & DFS
-我重新整理了下自己的公众号,并且我还给它换了一个名字`脑洞前端`,它是一个帮助你打开大前端新世界大门的钥匙 🔑,在这里你可以听到新奇的观点,看到一些技术尝新,还会收到系统性总结和思考。
+## 哪里能找到我?
-在这里我会尽量通过图的形式来阐述一些概念和逻辑,帮助大家快速理解,图解是我的目标。
+点关注,不迷路。如果再给 ➕ 个星标就更棒啦!
-之后我的文章会同步到微信公众号 `脑洞前端` ,你可以关注获取最新的文章,并和我进行交流。
+> 关注加加,星标加加~
-另外你可以回复大前端进大前端微信交流群, 回复 leetcode 拉你进 leetcode 微信群,如果想加入 qq 群,请回复 qq。
+ -
- +## 关于我
-## 捐赠
+擅长前端工程化,前端性能优化,前端标准化等,做过。net, 搞过 Java,现在是一名前端工程师,我的个人博客:https://lucifer.ren/blog/
-[点击查看完整的捐赠列表](./donation.md)
+我经常会在开源社区进行一些输出和分享,比较受欢迎的有 [宇宙最强的前端面试指南](https://github.com/azl397985856/fe-interview)
+和 [我的第一本小书](https://github.com/azl397985856/automate-everything)。目前本人正在写一本关于《leetcode 题解》的实体书,感兴趣的可以通过邮箱或者微信联系我,我会在出版的第一时间通知你,并给出首发优惠价。有需要可以直接群里联系我,或者发送到我的个人邮箱 [azl397985856@gmail.com]。 新书详情戳这里:[《或许是一本可以彻底改变你刷 LeetCode 效率的题解书》](https://lucifer.ren/blog/2020/04/07/leetcode-book.intro/)
### 微信
@@ -385,10 +226,14 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
+## 关于我
-## 捐赠
+擅长前端工程化,前端性能优化,前端标准化等,做过。net, 搞过 Java,现在是一名前端工程师,我的个人博客:https://lucifer.ren/blog/
-[点击查看完整的捐赠列表](./donation.md)
+我经常会在开源社区进行一些输出和分享,比较受欢迎的有 [宇宙最强的前端面试指南](https://github.com/azl397985856/fe-interview)
+和 [我的第一本小书](https://github.com/azl397985856/automate-everything)。目前本人正在写一本关于《leetcode 题解》的实体书,感兴趣的可以通过邮箱或者微信联系我,我会在出版的第一时间通知你,并给出首发优惠价。有需要可以直接群里联系我,或者发送到我的个人邮箱 [azl397985856@gmail.com]。 新书详情戳这里:[《或许是一本可以彻底改变你刷 LeetCode 效率的题解书》](https://lucifer.ren/blog/2020/04/07/leetcode-book.intro/)
### 微信
@@ -385,10 +226,14 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
 +## 捐赠
+
+[点击查看完整的捐赠列表](./donation.md)
+
## 贡献
- 如果有想法和创意,请提 [issue](https://github.com/azl397985856/leetcode/issues) 或者进群提
-- 如果想贡献代码,请提 [PR](https://github.com/azl397985856/leetcode/pulls)
+- 如果想贡献增加题解或者翻译, 可以参考[贡献指南](./CONTRIBUTING.md)
> 关于如何提交题解,我写了一份 [指南](./templates/problems/1014.best-sightseeing-pair.md)
- 如果需要修改项目中图片,[这里](./assets/drawio/) 存放了项目中绘制图的源代码, 大家可以用 [draw.io](https://www.draw.io/) 打开进行编辑。
@@ -398,4 +243,4 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
## License
-[Apache-2.0](./LICENSE.txt)
+[CC BY-NC-ND 4.0](./LICENSE.txt)
diff --git a/assets/drawio/208.implement-trie-prefix-tree.en.drawio b/assets/drawio/208.implement-trie-prefix-tree.en.drawio
new file mode 100644
index 000000000..d0543b9e5
--- /dev/null
+++ b/assets/drawio/208.implement-trie-prefix-tree.en.drawio
@@ -0,0 +1 @@
+7Ztdj6M2FIZ/TS4bgc1HcjlJN7sXXXWrqTSXKy92AlqDqe1sMv31tYMhgMkOVQlEHRJpEr824HkfsA/HZAG36fkjR3n8mWFCF8DB5wX8dQHA2nfVXy28FoIXrgvhwBNcSO5VeE7+JkZ0jHpMMBGNhpIxKpO8KUYsy0gkGxrinJ2azfaMNo+aowOxhOcIUVt9SbCMC3XlO1f9E0kOcXlk1zE1KSobG0HECLNTTYIfFnDLGZPFt/S8JVR7V/pSbLe7UVt1jJNM9tngS/r8SYT+6Y/Njx14kfj3z3j1Cyj28gPRo/mHTWfla+mA2osyWxU2pziR5DlHka45KdxKi2VKVclVX5HICwL75EzUQTdm34RLcr7ZabeyQp1ChKVE8lfVxGzgrY175vRxA1M+XWGUUlzjUGrI4D9Ue746pL4Yk/6FYdAyDD2YY6DpGPAmdsyzHMsfyzEYNB2D7sSO+Q/vmNtybDWxY4HlGH0wx8KmY97U41hoOUYezLHWOObDiR1bvT1VVlO8ozzASMTajEuhZpaQnH0nW0YZV0rGMm0wRd8I/cJEIhOWKTlSLhFVv9EeJioc+a3V4BuTkqW1Bk80OegKyTQcZErVflTXct3L9HzQcdoyFREiS0xyTiIkCV7mTKiWXy8xk2q/Tygt+7gA0HE2252iteFMItMFCAaasVrXBugYf0EHaf9epNcz6TuRbs0boGPeGJV02Z8Z9dCood8KEfypUbsz6hbqwVi3AmjP9Sdm3eO29p2xvhNq35katX1DnogXxrHSFvBJp4v40Q5tlQOyFcO2KbRhpQnG9FYwzNkxw9UZtGeZrAHZ7bwnEBjdpLjccBggALZvxWwgVU5qHCL2Df+7JuLDyYnYCYUWkT2i4n+MxGuNWqAjGHHhqEjsjMX7QlKNU1XSreMqGReJnRJ5X0g8pxXGBZMj6ZFzeTPoqoHpjr+KIK9c3QEdARglKPuaojxPssMyP4r4Gnq1MNzChRMVu5menYiQwxALVk1ibthzqoF3I9YjdzITq89EUxMDPVIgM7HaRAUmJ9YjkzETq81jTke0Ny6xHvmImViN2OTzGLDTCjOxnxDzvcmJ2WkH10Jmx+rNDJ8yLri87Kza3tfvAaN7922IxWsYYqvWeqrbsfbidQADdwNmZyXsa2wGdg0VOx4ZGBeYnbOAM7DbwGDHEwvjArMzGt4M7DYwr2MxY1xgdr7Dn4H9BNjkc5id7ghmYLeBdYWJowIrh+Q5ru/3hE7Q8fTwuHE97Mp2BFQaaxb60f/SneCvIyuMgOsQO2FYl4KD/vwzJgvzywD1yfWaulDeCFWQl6qcs4gIXWZ7LXKkDBUKU9UiOvKLncDJGNbCXh2+qmSqUuQsw8UmUYw4itQ1uyx7rVwoOl50qMdwMfR6wsDrBj7w3zxnYHlH/x+vclW8/mLiUlf72Qn88A8=
\ No newline at end of file
diff --git a/assets/problems/208.implement-trie-prefix-tree-1.en.png b/assets/problems/208.implement-trie-prefix-tree-1.en.png
new file mode 100644
index 000000000..3a5a98673
Binary files /dev/null and b/assets/problems/208.implement-trie-prefix-tree-1.en.png differ
diff --git a/collections/easy.md b/collections/easy.md
new file mode 100644
index 000000000..074a4a8d7
--- /dev/null
+++ b/collections/easy.md
@@ -0,0 +1,36 @@
+- [0001.two-sum](../problems/1.two-sum.md)
+- [0020.Valid Parentheses](../problems/20.valid-parentheses.md)
+- [0021.MergeTwoSortedLists](../problems/21.merge-two-sorted-lists.md)
+- [0026.remove-duplicates-from-sorted-array](../problems/26.remove-duplicates-from-sorted-array.md)
+- [0053.maximum-sum-subarray](../problems/53.maximum-sum-subarray-cn.md)
+- [0088.merge-sorted-array](../problems/88.merge-sorted-array.md)
+- [0101.symmetric-tree](../problems/101.symmetric-tree.md)🆕
+- [0104.maximum-depth-of-binary-tree](../problems/104.maximum-depth-of-binary-tree.md)
+- [0108.convert-sorted-array-to-binary-search-tree](../problems/108.convert-sorted-array-to-binary-search-tree.md)
+- [0121.best-time-to-buy-and-sell-stock](../problems/121.best-time-to-buy-and-sell-stock.md)
+- [0122.best-time-to-buy-and-sell-stock-ii](../problems/122.best-time-to-buy-and-sell-stock-ii.md)
+- [0125.valid-palindrome](../problems/125.valid-palindrome.md)
+- [0136.single-number](../problems/136.single-number.md)
+- [0155.min-stack](../problems/155.min-stack.md) 🆕
+- [0167.two-sum-ii-input-array-is-sorted](../problems/167.two-sum-ii-input-array-is-sorted.md)
+- [0169.majority-element](../problems/169.majority-element.md)
+- [0172.factorial-trailing-zeroes](../problems/172.factorial-trailing-zeroes.md)
+- [0190.reverse-bits](../problems/190.reverse-bits.md)
+- [0191.number-of-1-bits](../problems/191.number-of-1-bits.md)
+- [0198.house-robber](../problems/198.house-robber.md)
+- [0203.remove-linked-list-elements](../problems/203.remove-linked-list-elements.md)
+- [0206.reverse-linked-list](../problems/206.reverse-linked-list.md)
+- [0219.contains-duplicate-ii](../problems/219.contains-duplicate-ii.md)
+- [0226.invert-binary-tree](../problems/226.invert-binary-tree.md)
+- [0232.implement-queue-using-stacks](../problems/232.implement-queue-using-stacks.md) 🆕
+- [0263.ugly-number](../problems/263.ugly-number.md)
+- [0283.move-zeroes](../problems/283.move-zeroes.md)
+- [0342.power-of-four](../problems/342.power-of-four.md)
+- [0349.intersection-of-two-arrays](../problems/349.intersection-of-two-arrays.md)
+- [0371.sum-of-two-integers](../problems/371.sum-of-two-integers.md)
+- [0437.path-sum-iii](../problems/437.path-sum-iii.md) 🆕
+- [0455.AssignCookies](../problems/455.AssignCookies.md) 🆕
+- [0575.distribute-candies](../problems/575.distribute-candies.md)
+- [0874.walking-robot-simulation](../problems/874.walking-robot-simulation.md) 🆕
+- [1260.shift-2d-grid](../problems/1260.shift-2d-grid.md) 🆕
+- [1332.remove-palindromic-subsequences](../problems/1332.remove-palindromic-subsequences.md) 🆕
diff --git a/collections/hard.md b/collections/hard.md
new file mode 100644
index 000000000..ffc8ef8fc
--- /dev/null
+++ b/collections/hard.md
@@ -0,0 +1,27 @@
+- [0004.median-of-two-sorted-array](../problems/4.median-of-two-sorted-arrays.md)
+- [0023.merge-k-sorted-lists](../problems/23.merge-k-sorted-lists.md)
+- [0025.reverse-nodes-in-k-group](../problems/25.reverse-nodes-in-k-groups-cn.md)
+- [0030.substring-with-concatenation-of-all-words](../problems/30.substring-with-concatenation-of-all-words.md)
+- [0032.longest-valid-parentheses](../problems/32.longest-valid-parentheses.md)
+- [0042.trapping-rain-water](../problems/42.trapping-rain-water.md)🖊
+- [0052.N-Queens-II](../problems/52.N-Queens-II.md)
+- [0084.largest-rectangle-in-histogram](../problems/84.largest-rectangle-in-histogram.md)
+- [0085.maximal-rectangle](../problems/85.maximal-rectangle.md)
+- [0124.binary-tree-maximum-path-sum](../problems/124.binary-tree-maximum-path-sum.md)
+- [0128.longest-consecutive-sequence](../problems/128.longest-consecutive-sequence.md)
+- [0145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
+- [0212.word-search-ii](../problems/212.word-search-ii.md)
+- [0239.sliding-window-maximum](../problems/239.sliding-window-maximum.md)
+- [0295.find-median-from-data-stream](../problems/295.find-median-from-data-stream.md)
+- [0301.remove-invalid-parentheses](../problems/301.remove-invalid-parentheses.md)
+- [0312.burst-balloons](../problems/312.burst-balloons.md) 🆕
+- [0335.self-crossPing](../problems/335.self-crossing.md)
+- [0460.lfu-cache](../problems/460.lfu-cache.md)
+- [0472.concatenated-words](../problems/472.concatenated-words.md) 🆕
+- [0493.reverse-pairs](../problems/493.reverse-pairs.md) 🆕
+- [0887.super-egg-drop](../problems/887.super-egg-drop.md)
+- [0895.maximum-frequency-stack](../problems/895.maximum-frequency-stack.md) 🆕
+
+- [1032.stream-of-characters](../problems/1032.stream-of-characters.md) 🆕
+- [1168.optimize-water-distribution-in-a-village](../problems/1168.optimize-water-distribution-in-a-village-cn.md) 🆕
+- [1449.form-largest-integer-with-digits-that-add-up-to-target](../problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md) 🆕
diff --git a/collections/medium.md b/collections/medium.md
new file mode 100644
index 000000000..1f4bb8739
--- /dev/null
+++ b/collections/medium.md
@@ -0,0 +1,108 @@
+- [0002.add-two-numbers](../problems/2.add-two-numbers.md)
+- [0003.longest-substring-without-repeating-characters](../problems/3.longest-substring-without-repeating-characters.md)
+- [0005.longest-palindromic-substring](../problems/5.longest-palindromic-substring.md)
+- [0011.container-with-most-water](../problems/11.container-with-most-water.md)
+- [0015.3-sum](../problems/15.3sum.md)
+- [0017.Letter-Combinations-of-a-Phone-Number](../problems/17.Letter-Combinations-of-a-Phone-Number.md) 🆕
+- [0019. Remove Nth Node From End of List](../problems/19.removeNthNodeFromEndofList.md)
+- [0022.generate-parentheses.md](../problems/22.generate-parentheses.md) 🆕
+- [0024. Swap Nodes In Pairs](../problems/24.swapNodesInPairs.md)
+- [0029.divide-two-integers](../problems/29.divide-two-integers.md)
+- [0031.next-permutation](../problems/31.next-permutation.md)
+- [0033.search-in-rotated-sorted-array](../problems/33.search-in-rotated-sorted-array.md)
+- [0039.combination-sum](../problems/39.combination-sum.md)
+- [0040.combination-sum-ii](../problems/40.combination-sum-ii.md)
+- [0046.permutations](../problems/46.permutations.md)
+- [0047.permutations-ii](../problems/47.permutations-ii.md)
+- [0048.rotate-image](../problems/48.rotate-image.md)
+- [0049.group-anagrams](../problems/49.group-anagrams.md)
+- [0050.pow-x-n](../problems/50.pow-x-n.md) 🆕
+- [0055.jump-game](../problems/55.jump-game.md)
+- [0056.merge-intervals](../problems/56.merge-intervals.md)
+- [0060.permutation-sequence](../problems/60.permutation-sequence.md) 🆕
+- [0062.unique-paths](../problems/62.unique-paths.md) 🖊
+- [0073.set-matrix-zeroes](../problems/73.set-matrix-zeroes.md)
+- [0075.sort-colors](../problems/75.sort-colors.md)
+- [0078.subsets](../problems/78.subsets.md)
+- [0079.word-search](../problems/79.word-search-en.md)
+- [0080.remove-duplicates-from-sorted-array-ii](../problems/80.remove-duplicates-from-sorted-array-ii.md) 🆕
+- [0086.partition-list](../problems/86.partition-list.md)
+- [0090.subsets-ii](../problems/90.subsets-ii.md)
+- [0091.decode-ways](../problems/91.decode-ways.md)
+- [0092.reverse-linked-list-ii](../problems/92.reverse-linked-list-ii.md) 🖊
+- [0094.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
+- [0095.unique-binary-search-trees-ii](../problems/95.unique-binary-search-trees-ii.md) 🆕
+- [0096.unique-binary-search-trees](../problems/96.unique-binary-search-trees.md) 🆕
+- [0098.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
+- [0102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
+- [0103.binary-tree-zigzag-level-order-traversal](../problems/103.binary-tree-zigzag-level-order-traversal.md)
+- [105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md](../problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md)
+- [0113.path-sum-ii](../problems/113.path-sum-ii.md)
+- [0129.sum-root-to-leaf-numbers](../problems/129.sum-root-to-leaf-numbers.md)
+- [0130.surrounded-regions](../problems/130.surrounded-regions.md)
+- [0131.palindrome-partitioning](../problems/131.palindrome-partitioning.md)
+- [0139.word-break](../problems/139.word-break.md)
+- [0144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
+- [0150.evaluate-reverse-polish-notation](../problems/150.evaluate-reverse-polish-notation.md)
+- [0152.maximum-product-subarray](../problems/152.maximum-product-subarray.md) 🖊
+- [0199.binary-tree-right-side-view](../problems/199.binary-tree-right-side-view.md)
+- [0200.number-of-islands](../problems/200.number-of-islands.md) 🆕
+- [0201.bitwise-and-of-numbers-range](../problems/201.bitwise-and-of-numbers-range.md) 🖊
+- [0208.implement-trie-prefix-tree](../problems/208.implement-trie-prefix-tree.md)
+- [0209.minimum-size-subarray-sum](../problems/209.minimum-size-subarray-sum.md)
+- [0211.add-and-search-word-data-structure-design](../problems/211.add-and-search-word-data-structure-design.md) 🆕
+- [0215.kth-largest-element-in-an-array](../problems/215.kth-largest-element-in-an-array.md) 🆕
+- [0221.maximal-square](../problems/221.maximal-square.md)
+- [0229.majority-element-ii](../problems/229.majority-element-ii.md) 🆕
+- [0230.kth-smallest-element-in-a-bst](../problems/230.kth-smallest-element-in-a-bst.md)
+- [0236.lowest-common-ancestor-of-a-binary-tree](../problems/236.lowest-common-ancestor-of-a-binary-tree.md)
+- [0238.product-of-array-except-self](../problems/238.product-of-array-except-self.md)
+- [0240.search-a-2-d-matrix-ii](../problems/240.search-a-2-d-matrix-ii.md)
+- [0279.perfect-squares](../problems/279.perfect-squares.md)
+- [0309.best-time-to-buy-and-sell-stock-with-cooldown](../problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+- [0322.coin-change](../problems/322.coin-change.md)
+- [0328.odd-even-linked-list](../problems/328.odd-even-linked-list.md)
+- [0334.increasing-triplet-subsequence](../problems/334.increasing-triplet-subsequence.md)
+- [0337.house-robber-iii.md](../problems/337.house-robber-iii.md)
+- [0343.integer-break](../problems/343.integer-break.md)🆕
+- [0365.water-and-jug-problem](../problems/365.water-and-jug-problem.md)
+- [0378.kth-smallest-element-in-a-sorted-matrix](../problems/378.kth-smallest-element-in-a-sorted-matrix.md)
+- [0380.insert-delete-getrandom-o1](../problems/380.insert-delete-getrandom-o1.md)
+- [0416.partition-equal-subset-sum](../problems/416.partition-equal-subset-sum.md)🖊
+- [0445.add-two-numbers-ii](../problems/445.add-two-numbers-ii.md)
+- [0454.4-sum-ii](../problems/454.4-sum-ii.md)
+- [0474.ones-and-zeros](../problems/474.ones-and-zeros-en.md)
+- [0494.target-sum](../problems/494.target-sum.md)
+- [0516.longest-palindromic-subsequence](../problems/516.longest-palindromic-subsequence.md)
+- [0518.coin-change-2](../problems/518.coin-change-2.md)
+- [0547.friend-circles](../problems/547.friend-circles-en.md)
+- [0560.subarray-sum-equals-k](../problems/560.subarray-sum-equals-k.md)
+- [0609.find-duplicate-file-in-system](../problems/609.find-duplicate-file-in-system.md)
+- [0611.valid-triangle-number](../problems/611.valid-triangle-number.md)
+- [0718.maximum-length-of-repeated-subarray](../problems/718.maximum-length-of-repeated-subarray.md)
+- [0785.is-graph-bipartite](../problems/785.is-graph-bipartite.md) 🆕
+- [0820.short-encoding-of-words](../problems/820.short-encoding-of-words.md) 🖊
+- [0875.koko-eating-bananas](../problems/875.koko-eating-bananas.md)
+- [0877.stone-game](../problems/877.stone-game.md)
+- [0886.possible-bipartition](../problems/886.possible-bipartition.md) 🆕
+- [0900.rle-iterator](../problems/900.rle-iterator.md)
+- [0912.sort-an-array](../problems/912.sort-an-array.md)
+- [0935.knight-dialer](../problems/935.knight-dialer.md) 🆕
+- [1011.capacity-to-ship-packages-within-d-days](../problems/1011.capacity-to-ship-packages-within-d-days.md)
+- [1014.best-sightseeing-pair](../problems/1014.best-sightseeing-pair.md) 🆕
+- [1015.smallest-integer-divisible-by-k](../problems/1015.smallest-integer-divisible-by-k.md)
+- [1019.next-greater-node-in-linked-list](../problems/1019.next-greater-node-in-linked-list.md) 🆕
+- [1020.number-of-enclaves](../problems/1020.number-of-enclaves.md)
+- [1023.camelcase-matching](../problems/1023.camelcase-matching.md)
+- [1031.maximum-sum-of-two-non-overlapping-subarrays](../problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md)
+- [1104.path-in-zigzag-labelled-binary-tree](../problems/1104.path-in-zigzag-labelled-binary-tree.md)
+- [1131.maximum-of-absolute-value-expression](../problems/1131.maximum-of-absolute-value-expression.md)
+- [1186.maximum-subarray-sum-with-one-deletion](../problems/1186.maximum-subarray-sum-with-one-deletion.md) 🆕
+- [1218.longest-arithmetic-subsequence-of-given-difference](../problems/1218.longest-arithmetic-subsequence-of-given-difference.md)
+- [1227.airplane-seat-assignment-probability](../problems/1227.airplane-seat-assignment-probability.md)
+- [1261.find-elements-in-a-contaminated-binary-tree](../problems/1261.find-elements-in-a-contaminated-binary-tree.md)
+- [1262.greatest-sum-divisible-by-three](../problems/1262.greatest-sum-divisible-by-three.md)
+- [1297.maximum-number-of-occurrences-of-a-substring](../problems/1297.maximum-number-of-occurrences-of-a-substring.md)
+- [1310.xor-queries-of-a-subarray](../problems/1310.xor-queries-of-a-subarray.md) 🆕
+- [1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance](../problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md) 🆕
+- [1371.find-the-longest-substring-containing-vowels-in-even-counts](../problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md) 🆕
diff --git a/daily/2019-06-27.md b/daily/2019-06-27.md
index 9ad5b2a19..3c7c90854 100644
--- a/daily/2019-06-27.md
+++ b/daily/2019-06-27.md
@@ -52,7 +52,7 @@ function sqrt(num) {
也就是说,函数上任一点(x,f(x))处的切线斜率是2x。
那么,x-f(x)/(2x)就是一个比x更接近的近似值。代入 f(x)=x^2-a得到x-(x^2-a)/(2x),也就是(x+a/x)/2。
-
+
(图片来自Wikipedia)
diff --git a/daily/2019-07-10.md b/daily/2019-07-10.md
index 013bfdb5f..37a5078a9 100644
--- a/daily/2019-07-10.md
+++ b/daily/2019-07-10.md
@@ -28,7 +28,7 @@
这个题目解释起来比较费劲,我在网上找了一个现成的图来解释一下:
-
+
图中“1+”是指“1号小球为重”这一可能性。“1-”是指“1号小球为轻”这一可能性。
一开始一共有24种可能性。
diff --git a/daily/2019-07-23.md b/daily/2019-07-23.md
index e8efd3730..9f4507227 100644
--- a/daily/2019-07-23.md
+++ b/daily/2019-07-23.md
@@ -14,7 +14,7 @@
```
-
+
## 参考答案
diff --git a/daily/2019-07-26.md b/daily/2019-07-26.md
index e3cf1b33f..0ce407f2b 100644
--- a/daily/2019-07-26.md
+++ b/daily/2019-07-26.md
@@ -8,7 +8,7 @@
## 题目描述
-
+
## 参考答案
diff --git a/daily/2019-07-29.md b/daily/2019-07-29.md
index a0899caac..b8790fcc4 100644
--- a/daily/2019-07-29.md
+++ b/daily/2019-07-29.md
@@ -37,7 +37,7 @@ Example 2:
2. row->col、col->row 的切换都伴随读取的初始位置的变化;
3. 结束条件是row头>row尾或者col顶>col底
-
+
时间复杂度O(m*n), 空间复杂度O(1)
diff --git a/daily/2019-07-30.md b/daily/2019-07-30.md
index c06fd3224..529eb8a15 100644
--- a/daily/2019-07-30.md
+++ b/daily/2019-07-30.md
@@ -22,7 +22,7 @@
那么沿着这条纬线(记为E纬线)上任意一点向东走一英里,始终会回到原点,只是走的圈数不同而已。
根据题目倒推,在这条纬线以北一英里存在一条纬线(记为N纬线),从N纬线的任意一点向南一英里到达E纬线W点,沿着E纬线向东一英里,必会回到W点,再向北走一英里恰好可以回到起点。北极点可能包含在这个集合中,也可能不在。
如下图示供参考:
-
+
所以答案是无数个点
diff --git a/daily/2019-08-13.md b/daily/2019-08-13.md
index 6ca9f33a0..ef9504fa8 100644
--- a/daily/2019-08-13.md
+++ b/daily/2019-08-13.md
@@ -61,7 +61,7 @@ m 和 n =150,肯定超时。
最后将探测结果进行合并即可。合并的条件就是当前单元既能流入太平洋又能流入大西洋。
-
+
扩展:
如果题目改为能够流入大西洋或者太平洋,我们只需要最后合并的时候,条件改为求或即可
diff --git a/problems/1.two-sum.en.md b/problems/1.two-sum.en.md
new file mode 100644
index 000000000..09b882a15
--- /dev/null
+++ b/problems/1.two-sum.en.md
@@ -0,0 +1,55 @@
+## Problem
+
+https://leetcode-cn.com/problems/two-sum
+
+## Problem Description
+
+```
+Given an array of integers, return indices of the two numbers such that they add up to a specific target.
+
+You may assume that each input would have exactly one solution, and you may not use the same element twice.
+
+Example:
+
+Given nums = [2, 7, 11, 15], target = 9,
+
+Because nums[0] + nums[1] = 2 + 7 = 9,
+return [0, 1].
+```
+
+## Solution
+
+The easiest solution to come up with is Brute Force. We could write two for-loops to traverse every element, and find the target numbers that meet the requirement. However, the time complexity of this solution is O(N^2), while the space complexity is O(1). Apparently, we need to find a way to optimize this solution since the time complexity is too high. What we could do is to record the numbers we have traversed and the relevant index with a Map. Whenever we meet a new number during traversal, we go back to the Map and check whether the `diff` between this number and the target number appeared before. If it did, the problem has been solved and there's no need to continue.
+
+## Key Points
+
+- Find the difference instead of the sum
+- Connect every number with its index through the help of Map
+- Less time by more space. Reduce the time complexity from O(N) to O(1)
+
+## Code
+
+- Support Language: JS
+
+```js
+/**
+ * @param {number[]} nums
+ * @param {number} target
+ * @return {number[]}
+ */
+const twoSum = function (nums, target) {
+ const map = new Map();
+ for (let i = 0; i < nums.length; i++) {
+ const diff = target - nums[i];
+ if (map.has(diff)) {
+ return [map.get(diff), i];
+ }
+ map.set(nums[i], i);
+ }
+};
+```
+
+**_Complexity Anlysis_**
+
+- _Time Complexity_: O(N)
+- _Space Complexity_:O(N)
diff --git a/problems/1.TwoSum.md b/problems/1.two-sum.md
similarity index 62%
rename from problems/1.TwoSum.md
rename to problems/1.two-sum.md
index 2f8299473..0f8a965a9 100644
--- a/problems/1.TwoSum.md
+++ b/problems/1.two-sum.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/two-sum
## 题目描述
+
```
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
@@ -14,7 +16,31 @@ https://leetcode-cn.com/problems/two-sum
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
```
+
+## 前置知识
+
+- 哈希表
+
+## 公司
+
+- 字节
+- 百度
+- 腾讯
+- adobe
+- airbnb
+- amazon
+- apple
+- bloomberg
+- dropbox
+- facebook
+- linkedin
+- microsoft
+- uber
+- yahoo
+- yelp
+
## 思路
+
最容易想到的就是暴力枚举,我们可以利用两层 for 循环来遍历每个元素,并查找满足条件的目标元素。不过这样时间复杂度为 O(N^2),空间复杂度为 O(1),时间复杂度较高,我们要想办法进行优化。我们可以增加一个 Map 记录已经遍历过的数字及其对应的索引值。这样当遍历一个新数字的时候去 Map 里查询,target 与该数的差值是否已经在前面的数字中出现过。如果出现过,那么已经得出答案,就不必再往下执行了。
## 关键点
@@ -24,7 +50,8 @@ https://leetcode-cn.com/problems/two-sum
- 以空间换时间,将查找时间从 O(N) 降低到 O(1)
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -33,18 +60,25 @@ https://leetcode-cn.com/problems/two-sum
* @return {number[]}
*/
const twoSum = function (nums, target) {
- const map = new Map();
- for (let i = 0; i < nums.length; i++) {
- const diff = target - nums[i];
- if (map.has(diff)) {
- return [map.get(diff), i];
- }
- map.set(nums[i], i);
+ const map = new Map();
+ for (let i = 0; i < nums.length; i++) {
+ const diff = target - nums[i];
+ if (map.has(diff)) {
+ return [map.get(diff), i];
}
-}
+ map.set(nums[i], i);
+ }
+};
```
-***复杂度分析***
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
-- 时间复杂度:O(N)
-- 空间复杂度:O(N)
+
diff --git a/problems/101.symmetric-tree.md b/problems/101.symmetric-tree.md
new file mode 100644
index 000000000..2e58602c9
--- /dev/null
+++ b/problems/101.symmetric-tree.md
@@ -0,0 +1,126 @@
+## 题目地址(101. 对称二叉树)
+
+https://leetcode-cn.com/problems/symmetric-tree/
+
+## 题目描述
+
+```
+给定一个二叉树,检查它是否是镜像对称的。
+
+
+
+例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
+
+ 1
+ / \
+ 2 2
+ / \ / \
+3 4 4 3
+
+
+但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
+
+ 1
+ / \
+ 2 2
+ \ \
+ 3 3
+
+
+进阶:
+
+你可以运用递归和迭代两种方法解决这个问题吗?
+
+
+```
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- linkedin
+- microsoft
+
+## 前置知识
+
+- [二叉树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 思路
+
+看到这题的时候,我的第一直觉是 DFS。然后我就想:`如果左子树是镜像,并且右子树也是镜像,是不是就说明整体是镜像?`。经过几秒的思考, 这显然是不对的,不符合题意。
+
+
+
+很明显其中左子树中的节点会和右子树中的节点进行比较,我把比较的元素进行了颜色区分,方便大家看。
+
+这里我的想法是:`遍历每一个节点的时候,我都可以通过某种方法知道它对应的对称节点是谁。这样的话我直接比较两者是否一致就行了。`
+
+最初我的想法是两次遍历,第一次遍历的同时将遍历结果存储到哈希表中,然后第二次遍历去哈希表取。
+
+这种方法可行,但是需要 N 的空间(N 为节点总数)。我想到如果两者可以同时进行遍历,是不是就省去了哈希表的开销。
+
+
+
+如果不明白的话,我举个简单例子:
+
+```
+给定一个数组,检查它是否是镜像对称的。例如,数组 [1,2,2,3,2,2,1] 是对称的。
+```
+
+如果用哈希表的话大概是:
+
+```py
+seen = dict()
+for i, num in enumerate(nums):
+ seen[i] = num
+for i, num in enumerate(nums):
+ if seen[len(nums) - 1 - i] != num:
+ return False
+return True
+```
+
+而同时遍历的话大概是这样的:
+
+```py
+l = 0
+r = len(nums) - 1
+
+while l < r:
+ if nums[l] != nums[r]: return False
+ l += 1
+ r -= 1
+return True
+
+```
+
+> 其实更像本题一点的话应该是从中间分别向两边扩展 😂
+
+## 代码
+
+```py
+
+class Solution:
+ def isSymmetric(self, root: TreeNode) -> bool:
+ def dfs(root1, root2):
+ if root1 == root2: return True
+ if not root1 or not root2: return False
+ if root1.val != root2.val: return False
+ return dfs(root1.left, root2.right) and dfs(root1.right, root2.left)
+ if not root: return True
+ return dfs(root.left, root.right)
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$,其中 N 为节点数。
+- 空间复杂度:递归的深度最高为节点数,因此空间复杂度是 $O(N)$,其中 N 为节点数。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/1011.capacity-to-ship-packages-within-d-days.md b/problems/1011.capacity-to-ship-packages-within-d-days-cn.md
similarity index 98%
rename from problems/1011.capacity-to-ship-packages-within-d-days.md
rename to problems/1011.capacity-to-ship-packages-within-d-days-cn.md
index 5e257be42..82e9a75fc 100644
--- a/problems/1011.capacity-to-ship-packages-within-d-days.md
+++ b/problems/1011.capacity-to-ship-packages-within-d-days-cn.md
@@ -47,6 +47,14 @@ https://leetcode-cn.com/problems/capacity-to-ship-packages-within-d-days
1 <= D <= weights.length <= 50000
1 <= weights[i] <= 500
+## 前置知识
+
+- 二分法
+
+## 公司
+
+- 阿里
+
## 思路
这道题和[猴子吃香蕉](https://github.com/azl397985856/leetcode/blob/master/problems/875.koko-eating-bananas.md) 简直一摸一样,没有看过的建议看一下那道题。
diff --git a/problems/1011.capacity-to-ship-packages-within-d-days-en.md b/problems/1011.capacity-to-ship-packages-within-d-days-en.md
new file mode 100644
index 000000000..a313d6ef5
--- /dev/null
+++ b/problems/1011.capacity-to-ship-packages-within-d-days-en.md
@@ -0,0 +1,187 @@
+## Problem
+
+https://leetcode-cn.com/problems/capacity-to-ship-packages-within-d-days
+
+## Problem Description
+
+A conveyor belt has packages that must be shipped from one port to another within D days.
+
+The i-th package on the conveyor belt has a weight of weights[i]. Each day, we load the ship with packages on the conveyor belt (in the order given by weights). We may not load more weight than the maximum weight capacity of the ship.
+
+Return the least weight capacity of the ship that will result in all the packages on the conveyor belt being shipped within D days.
+
+**Example 1:**
+
+```
+Input: weights = [1,2,3,4,5,6,7,8,9,10], D = 5
+Output: 15
+Explanation:
+A ship capacity of 15 is the minimum to ship all the packages in 5 days like this:
+1st day: 1, 2, 3, 4, 5
+2nd day: 6, 7
+3rd day: 8
+4th day: 9
+5th day: 10
+
+Note that the cargo must be shipped in the order given, so using a ship of capacity 14 and splitting the packages into parts like (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) is not allowed.
+```
+
+**Example 2:**
+
+```
+Input: weights = [3,2,2,4,1,4], D = 3
+Output: 6
+Explanation:
+A ship capacity of 6 is the minimum to ship all the packages in 3 days like this:
+1st day: 3, 2
+2nd day: 2, 4
+3rd day: 1, 4
+```
+
+**Example 3:**
+
+```
+Input: weights = [1,2,3,1,1], D = 4
+Output: 3
+Explanation:
+1st day: 1
+2nd day: 2
+3rd day: 3
+4th day: 1, 1
+```
+
+
+
+ **Note:**
+
+1. `1 <= D <= weights.length <= 50000`
+2. `1 <= weights[i] <= 500`
+
+
+
+## Solution
+
+The problem is same as [**LeetCode 875 koko-eating-bananas**] (https://github.com/azl397985856/leetcode/blob/master/problems/875.koko-eating-bananas-en.md) practically.
+
+It is easy to solve this kind of problems if you take a closer look into it.
+
+
+The essence is to search a given number in finite discrete data like [ 1,2,3,4, ... , total ].
+
+However, We should find the cargo that can be shipped in D days rather than look for the target directly.
+
+
+Consider the following questions:
+
+- Can it be shipped if the capacity is 1?
+- Can it be shipped if the capacity is 2?
+- Can it be shipped if the capacity is 3?
+- ...
+- Can it be shipped if the capacity is total ? ( Yeap we can, D is greater than or equal to 1)
+
+During the process, we directly `return` if the answer is *yes*.
+
+If the answer is *no*, just keep asking.
+
+This is a typical binary search problem, the only difference is the judgement condition:
+
+
+```python
+def canShip(opacity):
+ # Whether the capacity of the specified ship can be shipped in D days
+ lo = 0
+ hi = total
+ while lo < hi:
+ mid = (lo + hi) // 2
+ if canShip(mid):
+ hi = mid
+ else:
+ lo = mid + 1
+ return lo
+```
+
+## Key Points
+
+- if you are so familiar with binary search as well its transformation, you can easily find out that using binary search to find one number in a given number sequence of a certain length.
+
+## Code (`JS/Python`)
+
+- `Python`
+
+```python
+class Solution:
+ def shipWithinDays(self, weights: List[int], D: int) -> int:
+ lo = 0
+ hi = 0
+
+ def canShip(opacity):
+ days = 1
+ remain = opacity
+ for weight in weights:
+ if weight > opacity:
+ return False
+ remain -= weight
+ if remain < 0:
+ days += 1
+ remain = opacity - weight
+ return days <= D
+
+ for weight in weights:
+ hi += weight
+ while lo < hi:
+ mid = (lo + hi) // 2
+ if canShip(mid):
+ hi = mid
+ else:
+ lo = mid + 1
+
+ return lo
+```
+
+- `JavaScript`
+
+```js
+/**
+ * @param {number[]} weights
+ * @param {number} D
+ * @return {number}
+ */
+var shipWithinDays = function(weights, D) {
+ let high = weights.reduce((acc, cur) => acc + cur)
+ let low = 0
+
+ while(low < high) {
+ let mid = Math.floor((high + low) / 2)
+ if (canShip(mid)) {
+ high = mid
+ } else {
+ low = mid + 1
+ }
+ }
+
+ return low
+
+ function canShip(opacity) {
+ let remain = opacity
+ let count = 1
+ for (let weight of weights) {
+ if (weight > opacity) {
+ return false
+ }
+ remain -= weight
+ if (remain < 0) {
+ count++
+ remain = opacity - weight
+ }
+ if (count > D) {
+ return false
+ }
+ }
+ return count <= D
+ }
+};
+```
+
+## References
+
+## Extension
diff --git a/problems/1014.best-sightseeing-pair.md b/problems/1014.best-sightseeing-pair.md
index 45caa61a3..6f6404c14 100644
--- a/problems/1014.best-sightseeing-pair.md
+++ b/problems/1014.best-sightseeing-pair.md
@@ -21,6 +21,15 @@ https://leetcode-cn.com/problems/best-sightseeing-pair/description/
2 <= A.length <= 50000
1 <= A[i] <= 1000
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
最简单的思路就是两两组合,找出最大的,妥妥超时,我们来看下代码:
diff --git a/problems/1015.smallest-integer-divisible-by-k.md b/problems/1015.smallest-integer-divisible-by-k.md
index bbfca68a4..3d7ee887d 100644
--- a/problems/1015.smallest-integer-divisible-by-k.md
+++ b/problems/1015.smallest-integer-divisible-by-k.md
@@ -34,6 +34,14 @@ https://leetcode-cn.com/problems/smallest-integer-divisible-by-k/description/
```
+## 前置知识
+
+- 循环节
+
+## 公司
+
+- 暂无
+
## 思路
这道题是说给定一个 K 值,能否找到一个形如 1,11,111,1111 。。。 这样的数字 n 使得 n % K == 0。
diff --git a/problems/1019.next-greater-node-in-linked-list.md b/problems/1019.next-greater-node-in-linked-list.md
index 964a37842..57854a3c1 100644
--- a/problems/1019.next-greater-node-in-linked-list.md
+++ b/problems/1019.next-greater-node-in-linked-list.md
@@ -35,6 +35,16 @@ https://leetcode-cn.com/problems/next-greater-node-in-linked-list/submissions/
给定列表的长度在 [0, 10000] 范围内
```
+## 前置知识
+
+- 链表
+- 栈
+
+## 公司
+
+- 腾讯
+- 字节
+
## 思路
看完题目就应该想到单调栈才行,LeetCode 上关于单调栈的题目还不少,难度都不小。但是一旦你掌握了这个算法,那么这些题目对你来说都不是问题了。
diff --git a/problems/102.binary-tree-level-order-traversal.md b/problems/102.binary-tree-level-order-traversal.md
index 43d476069..8822c35e0 100644
--- a/problems/102.binary-tree-level-order-traversal.md
+++ b/problems/102.binary-tree-level-order-traversal.md
@@ -4,16 +4,20 @@ https://leetcode.com/problems/binary-tree-level-order-traversal/description/
## 题目描述
```
-Given a binary tree, return the level order traversal of its nodes' values. (ie, from left to right, level by level).
+给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+
+
+
+示例:
+二叉树:[3,9,20,null,null,15,7],
-For example:
-Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
-return its level order traversal as:
+返回其层次遍历结果:
+
[
[3],
[9,20],
@@ -21,8 +25,21 @@ return its level order traversal as:
]
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+这是一个典型的二叉树遍历问题, 关于二叉树遍历,我总结了一个[专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md),大家可以先去看下那个,然后再来刷这道题。
+
这道题可以借助`队列`实现,首先把root入队,然后入队一个特殊元素Null(来表示每层的结束)。
@@ -51,52 +68,6 @@ return its level order traversal as:
Javascript Code:
```js
-/*
- * @lc app=leetcode id=102 lang=javascript
- *
- * [102] Binary Tree Level Order Traversal
- *
- * https://leetcode.com/problems/binary-tree-level-order-traversal/description/
- *
- * algorithms
- * Medium (47.18%)
- * Total Accepted: 346.4K
- * Total Submissions: 731.3K
- * Testcase Example: '[3,9,20,null,null,15,7]'
- *
- * Given a binary tree, return the level order traversal of its nodes' values.
- * (ie, from left to right, level by level).
- *
- *
- * For example:
- * Given binary tree [3,9,20,null,null,15,7],
- *
- *
- * 3
- * / \
- * 9 20
- * / \
- * 15 7
- *
- *
- *
- * return its level order traversal as:
- *
- * [
- * [3],
- * [9,20],
- * [15,7]
- * ]
- *
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[][]}
@@ -223,6 +194,22 @@ class Solution:
return result
```
+***复杂度分析***
+- 时间复杂度:$O(N)$,其中N为树中节点总数。
+- 空间复杂度:$O(N)$,其中N为树中节点总数。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+## 扩展
+
+实际上这道题方法很多, 比如经典的三色标记法。
+
## 相关题目
- [103.binary-tree-zigzag-level-order-traversal](./103.binary-tree-zigzag-level-order-traversal.md)
- [104.maximum-depth-of-binary-tree](./104.maximum-depth-of-binary-tree.md)
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/1020.number-of-enclaves.md b/problems/1020.number-of-enclaves.md
index bd77a2542..467acdd12 100644
--- a/problems/1020.number-of-enclaves.md
+++ b/problems/1020.number-of-enclaves.md
@@ -36,6 +36,11 @@ https://leetcode-cn.com/problems/number-of-enclaves/
```
+## 前置知识
+
+- DFS
+- hashset
+
## 解法一 (暴力法)
### 思路
@@ -99,6 +104,10 @@ class Solution:
## 解法二 (消除法)
+## 公司
+
+- 暂无
+
### 思路
上面的解法时间复杂度和空间复杂度都很差,我们考虑进行优化, 这里我们使用消除法。
diff --git a/problems/1023.camelcase-matching.md b/problems/1023.camelcase-matching.md
index cfeb79694..35ff75939 100644
--- a/problems/1023.camelcase-matching.md
+++ b/problems/1023.camelcase-matching.md
@@ -43,6 +43,14 @@ https://leetcode-cn.com/problems/camelcase-matching/
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 暂无
+
## 思路
这道题是一道典型的双指针题目。不过这里的双指针并不是指向同一个数组或者字符串,而是指向多个,这道题是指向两个,分别是 query 和 pattern,这种题目非常常见,能够识别和掌握这种题目的解题模板非常重要。对 queries 的每一项我们的逻辑是一样的,这里就以其中一项为例进行讲解。
diff --git a/problems/103.binary-tree-zigzag-level-order-traversal.md b/problems/103.binary-tree-zigzag-level-order-traversal.md
index 7cf53ec5b..e72934cd6 100644
--- a/problems/103.binary-tree-zigzag-level-order-traversal.md
+++ b/problems/103.binary-tree-zigzag-level-order-traversal.md
@@ -23,6 +23,17 @@ return its zigzag level order traversal as:
]
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题可以借助`队列`实现,首先把root入队,然后入队一个特殊元素Null(来表示每层的结束)。
diff --git a/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md b/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
index f37648075..c37453837 100644
--- a/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
+++ b/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
@@ -37,11 +37,19 @@ L + M <= A.length <= 1000
0 <= A[i] <= 1000
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 字节
+
## 思路(动态规划)
题目中要求在前N(数组长度)个数中找出长度分别为L和M的非重叠子数组之和的最大值, 因此, 我们可以定义数组A中前i个数可构成的非重叠子数组L和M的最大值为SUMM[i], 并找到SUMM[i]和SUMM[i-1]的关系, 那么最终解就是SUMM[N]. 以下为图解:
-
+
## 关键点解析
diff --git a/problems/1032.stream-of-characters.md b/problems/1032.stream-of-characters.md
new file mode 100644
index 000000000..81930f1a8
--- /dev/null
+++ b/problems/1032.stream-of-characters.md
@@ -0,0 +1,166 @@
+## 题目地址(1032. 字符流)
+
+https://leetcode-cn.com/problems/stream-of-characters/
+
+## 题目描述
+
+```
+按下述要求实现 StreamChecker 类:
+
+StreamChecker(words):构造函数,用给定的字词初始化数据结构。
+query(letter):如果存在某些 k >= 1,可以用查询的最后 k个字符(按从旧到新顺序,包括刚刚查询的字母)拼写出给定字词表中的某一字词时,返回 true。否则,返回 false。
+
+
+示例:
+
+StreamChecker streamChecker = new StreamChecker(["cd","f","kl"]); // 初始化字典
+streamChecker.query('a'); // 返回 false
+streamChecker.query('b'); // 返回 false
+streamChecker.query('c'); // 返回 false
+streamChecker.query('d'); // 返回 true,因为 'cd' 在字词表中
+streamChecker.query('e'); // 返回 false
+streamChecker.query('f'); // 返回 true,因为 'f' 在字词表中
+streamChecker.query('g'); // 返回 false
+streamChecker.query('h'); // 返回 false
+streamChecker.query('i'); // 返回 false
+streamChecker.query('j'); // 返回 false
+streamChecker.query('k'); // 返回 false
+streamChecker.query('l'); // 返回 true,因为 'kl' 在字词表中。
+
+
+提示:
+
+1 <= words.length <= 2000
+1 <= words[i].length <= 2000
+字词只包含小写英文字母。
+待查项只包含小写英文字母。
+待查项最多 40000 个。
+
+```
+
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 字节
+
+## 思路
+
+题目要求`按从旧到新顺序`查询,因此可以将从旧到新的 query 存起来形成一个单词 stream。
+
+比如:
+
+```js
+streamChecker.query("a"); // stream: a
+streamChecker.query("b"); // stream:ba
+streamChecker.query("c"); // stream:cba
+```
+
+这里有两个小的点需要注意:
+
+1. 如果用数组来存储, 由于每次都往数组头部插入一个元素,因此每次 query 操作的时间复杂度为 $O(N)$,其中 $N$ 为截止当前执行 query 的次数,我们可以使用双端队列进行优化。
+2. 由于不必 query 形成的查询全部命中。比如 stream 为 cba 的时候,找到单词 c, bc, abc 都是可以的。如果是找到 c,cb,cba 比较好吧,现在是反的。其实我们可以反序插入是,类似的技巧在[211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/211.add-and-search-word-data-structure-design.md) 也有用到。
+
+之后我们用拼接的单词在 words 中查询即可, 最简单的方式当然是每次 query 都去扫描一次,这种方式毫无疑问会超时。
+
+我们可以采用构建 Trie 的形式,即已空间环时间, 其代码和常规的 Trie 类似,只需要将 search(word) 函数做一个简单修改即可,我们不需要检查整个 word 是否存在, 而已 word 的前缀存在即可。
+
+> 提示:可以通过对 words 去重,来用空间换区时间。
+
+具体算法:
+
+- init 中 构建 Trie 和 双端队列 stream
+- query 时,往 stream 的左边 append 即可。
+- 调用 Trie 的 search(和常规的 search 稍有不同, 我上面已经讲了)
+
+核心代码(Python):
+
+```py
+class StreamChecker:
+
+ def __init__(self, words: List[str]):
+ self.trie = Trie()
+ self.stream = deque([])
+
+ for word in set(words):
+ self.trie.insert(word[::-1])
+
+ def query(self, letter: str) -> bool:
+ self.stream.appendleft(letter)
+ return self.trie.search(self.stream)
+```
+
+## 关键点解析
+
+- 前缀树模板
+- 倒序插入
+
+## 代码
+
+- 语言支持: Python
+
+Python Code:
+
+```python
+class Trie:
+
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.Trie = {}
+
+ def insert(self, word):
+ """
+ Inserts a word into the trie.
+ :type word: str
+ :rtype: void
+ """
+ curr = self.Trie
+ for w in word:
+ if w not in curr:
+ curr[w] = {}
+ curr = curr[w]
+ curr['#'] = 1
+
+ def search(self, word):
+ """
+ Returns if the word is in the trie.
+ :type word: str
+ :rtype: bool
+ """
+ curr = self.Trie
+ for w in word:
+ if w not in curr:
+ return False
+ if "#" in curr[w]:
+ return True
+ curr = curr[w]
+ return False
+
+
+class StreamChecker:
+
+ def __init__(self, words: List[str]):
+ self.trie = Trie()
+ self.stream = deque([])
+
+ for word in set(words):
+ self.trie.insert(word[::-1])
+
+ def query(self, letter: str) -> bool:
+ self.stream.appendleft(letter)
+ return self.trie.search(self.stream)
+
+
+```
+
+## 相关题目
+
+- [0208.implement-trie-prefix-tree](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
+- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
diff --git a/problems/104.maximum-depth-of-binary-tree.md b/problems/104.maximum-depth-of-binary-tree.md
index a52654195..02449d83e 100644
--- a/problems/104.maximum-depth-of-binary-tree.md
+++ b/problems/104.maximum-depth-of-binary-tree.md
@@ -24,6 +24,21 @@ return its depth = 3.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- apple
+- linkedin
+- uber
+- yahoo
+
## 思路
由于树是一种递归的数据结构,因此用递归去解决的时候往往非常容易,这道题恰巧也是如此,
@@ -147,6 +162,18 @@ class Solution:
depth += 1
return depth
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
## 相关题目
- [102.binary-tree-level-order-traversal](./102.binary-tree-level-order-traversal.md)
- [103.binary-tree-zigzag-level-order-traversal](./103.binary-tree-zigzag-level-order-traversal.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md b/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
index 24c809165..d24903dae 100644
--- a/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
+++ b/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
@@ -26,6 +26,17 @@ Return the following binary tree:
15 7
```
+## 前置知识
+
+- 二叉树
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路/Thinking Path
目标是构造二叉树。
@@ -68,7 +79,7 @@ If you can't figure out how to get the index of the left and right child, please
- according to the properties of preoder traversal, all right sub-tree nodes are behine all left sub-tree nodes. The length of left sub-tree can help us to divide left and right sub-trees.
- the length of left sub-tree can be find in the inorder traversal. The location of current node is `inRoot`(or whatever your call it). The start index of current inorder array is `inStart`(or whatever your call it). So, the lenght of the left sub-tree is `leftChldLen = inRoot - inStart`.
-
+
## 代码/Code
diff --git a/problems/108.convert-sorted-array-to-binary-search-tree.md b/problems/108.convert-sorted-array-to-binary-search-tree.md
new file mode 100644
index 000000000..5c1128a06
--- /dev/null
+++ b/problems/108.convert-sorted-array-to-binary-search-tree.md
@@ -0,0 +1,182 @@
+## 题目地址(108. 将有序数组转换为二叉搜索树)
+
+https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/
+
+## 题目描述
+
+```
+将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定有序数组: [-10,-3,0,5,9],
+
+一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+## 前置知识
+
+- [二叉搜索树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [平衡二叉树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- airbnb
+
+## 思路
+
+由于输入是一个**升序排列的有序数组**。因此任意选择一点,将其作为根节点,其左部分左节点,其右部分右节点即可。 因此我们很容易写出递归代码。
+
+而题目要求是**高度平衡**的二叉搜索树,因此我们必须要取中点。 不难证明:`由于是中点,因此左右两部分差不会大于 1,也就是说其形成的左右子树节点数最多相差 1,因此左右子树高度差的绝对值不超过 1`。
+
+形象一点来看就像你提起一根绳子,从中点提的话才能使得两边绳子长度相差最小。
+
+
+
+## 关键点
+
+- 找中点
+
+## 代码
+
+代码支持:JS,C++,Java,Python
+
+JS Code:
+
+```js
+var sortedArrayToBST = function (nums) {
+ // 由于数组是排序好的,因此一个思路就是将数组分成两半,一半是左子树,另一半是右子树
+ // 然后运用“树的递归性质”递归完成操作即可。
+ if (nums.length === 0) return null;
+ const mid = nums.length >> 1;
+ const root = new TreeNode(nums[mid]);
+
+ root.left = sortedArrayToBST(nums.slice(0, mid));
+ root.right = sortedArrayToBST(nums.slice(mid + 1));
+ return root;
+};
+```
+
+Python Code:
+
+```py
+class Solution:
+ def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
+ if not nums: return None
+ mid = (len(nums) - 1) // 2
+ root = TreeNode(nums[mid])
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
+```
+
+
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:每次递归都 copy 了 N 的 空间,因此空间复杂度为 $O(N ^ 2)$
+
+然而,实际上没必要开辟新的空间:
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ TreeNode* sortedArrayToBST(vector& nums) {
+ return reBuild(nums, 0, nums.size()-1);
+ }
+
+ TreeNode* reBuild(vector& nums, int left, int right)
+ {
+ // 终止条件:中序遍历为空
+ if(left > right)
+ {
+ return NULL;
+ }
+ // 建立当前子树的根节点
+ int mid = (left+right)/2;
+ TreeNode * root = new TreeNode(nums[mid]);
+
+ // 左子树的下层递归
+ root->left = reBuild(nums, left, mid-1);
+ // 右子树的下层递归
+ root->right = reBuild(nums, mid+1, right);
+ // 返回根节点
+ return root;
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public TreeNode sortedArrayToBST(int[] nums) {
+ return dfs(nums, 0, nums.length - 1);
+ }
+
+ private TreeNode dfs(int[] nums, int lo, int hi) {
+ if (lo > hi) {
+ return null;
+ }
+ int mid = lo + (hi - lo) / 2;
+ TreeNode root = new TreeNode(nums[mid]);
+ root.left = dfs(nums, lo, mid - 1);
+ root.right = dfs(nums, mid + 1, hi);
+ return root;
+ }
+}
+
+```
+
+Python Code:
+```python
+class Solution(object):
+ def sortedArrayToBST(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: TreeNode
+ """
+ return self.reBuild(nums, 0, len(nums)-1)
+
+ def reBuild(self, nums, left, right):
+ # 终止条件:
+ if left > right:
+ return
+ # 建立当前子树的根节点
+ mid = (left + right)//2
+ root = TreeNode(nums[mid])
+ # 左右子树的下层递归
+ root.left = self.reBuild(nums, left, mid-1)
+ root.right = self.reBuild(nums, mid+1, right)
+
+ return root
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:隐式调用栈的开销为 $O(N)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+公众号【 [力扣加加](https://tva1.sinaimg.cn/large/007S8ZIlly1gfcuzagjalj30p00dwabs.jpg)】
+知乎专栏【 [Lucifer - 知乎](https://www.zhihu.com/people/lu-xiao-13-70)】
+
+点关注,不迷路!
diff --git a/problems/11.container-with-most-water.md b/problems/11.container-with-most-water.md
index b6b5de395..db21738ff 100644
--- a/problems/11.container-with-most-water.md
+++ b/problems/11.container-with-most-water.md
@@ -1,72 +1,84 @@
## 题目地址
-https://leetcode.com/problems/container-with-most-water/description/
+
+https://leetcode-cn.com/problems/container-with-most-water/description/
## 题目描述
-```
-Given n non-negative integers a1, a2, ..., an , where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
-Note: You may not slant the container and n is at least 2.
-```
-
-
-```
+给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
-The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
+说明:你不能倾斜容器,且 n 的值至少为 2。
-
+
+
-Example:
-Input: [1,8,6,2,5,4,8,3,7]
-Output: 49
-```
+图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
+
+
+
+示例:
+
+输入:[1,8,6,2,5,4,8,3,7]
+输出:49
+
+
+
+
+
+
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 字节
+- 腾讯
+- 百度
+- 阿里
## 思路
-符合直觉的解法是,我们可以对两两进行求解,计算可以承载的水量。 然后不断更新最大值,最后返回最大值即可。
-这种解法,需要两层循环,时间复杂度是O(n^2)
-eg:
+题目中说`找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。` ,因此符合直觉的解法就是固定两个端点,计算可以承载的水量, 然后不断更新最大值,最后返回最大值即可。这种算法,需要两层循环,时间复杂度是 $O(n^2)$。
+
+
+代码(JS):
```js
- // 这个解法比较暴力,效率比较低
- // 时间复杂度是O(n^2)
- let max = 0;
- for(let i = 0; i < height.length; i++) {
- for(let j = i + 1; j < height.length; j++) {
- const currentArea = Math.abs(i - j) * Math.min(height[i], height[j]);
- if (currentArea > max) {
- max = currentArea;
- }
- }
+let max = 0;
+for (let i = 0; i < height.length; i++) {
+ for (let j = i + 1; j < height.length; j++) {
+ const currentArea = Math.abs(i - j) * Math.min(height[i], height[j]);
+ if (currentArea > max) {
+ max = currentArea;
}
- return max;
-
+ }
+}
+return max;
```
-> 这种符合直觉的解法有点像冒泡排序, 大家可以稍微类比一下
+虽然解法效率不高,但是可以通过(JS可以通过,Python 不可以,其他语言没有尝试)。那么有没有更优的解法呢?
-那么有没有更加优的解法呢?我们来换个角度来思考这个问题,上述的解法是通过两两组合,这无疑是完备的,
-那我门是否可以先计算长度为n的面积,然后计算长度为n-1的面积,... 计算长度为1的面积。 这样去不断更新最大值呢?
-很显然这种解法也是完备的,但是似乎时间复杂度还是O(n ^ 2), 不要着急。
+我们来换个角度来思考这个问题,上述的解法是通过两两组合,这无疑是完备的。我们换个角度思考,是否可以先计算长度为 n 的面积,然后计算长度为 n-1 的面积,... 计算长度为 1 的面积。 这样去不断更新最大值呢?很显然这种解法也是完备的,但是似乎时间复杂度还是 $O(n ^ 2)$, 不要着急。
-考虑一下,如果我们计算n-1长度的面积的时候,是直接直接排除一半的结果的。
+考虑一下,如果我们计算 n-1 长度的面积的时候,是可以直接排除一半的结果的。
如图:
-
+
+比如我们计算 n 面积的时候,假如左侧的线段高度比右侧的高度低,那么我们通过左移右指针来将长度缩短为 n-1 的做法是没有意义的,
+因为`新的形成的面积变成了(n-1) * heightOfLeft 这个面积一定比刚才的长度为 n 的面积 (n * heightOfLeft) 小`。
-比如我们计算n面积的时候,假如左侧的线段高度比右侧的高度低,那么我们通过左移右指针来将长度缩短为n-1的做法是没有意义的,
-因为`新的形成的面积变成了(n-1) * heightOfLeft 这个面积一定比刚才的长度为n的面积nn * heightOfLeft 小`
+也就是说**最大面积一定是当前的面积或者通过移动短的端点得到。**
-也就是说最大面积`一定是当前的面积或者通过移动短的线段得到`。
## 关键点解析
- 双指针优化时间复杂度
-
## 代码
-* 语言支持:JS,C++
+
+- 语言支持:JS,C++,Python
JavaScript Code:
@@ -75,30 +87,34 @@ JavaScript Code:
* @param {number[]} height
* @return {number}
*/
-var maxArea = function(height) {
- if (!height || height.length <= 1) return 0;
-
- let leftPos = 0;
- let rightPos = height.length - 1;
- let max = 0;
- while(leftPos < rightPos) {
-
- const currentArea = Math.abs(leftPos - rightPos) * Math.min(height[leftPos] , height[rightPos]);
- if (currentArea > max) {
- max = currentArea;
- }
- // 更新小的
- if (height[leftPos] < height[rightPos]) {
- leftPos++;
- } else { // 如果相等就随便了
- rightPos--;
- }
+var maxArea = function (height) {
+ if (!height || height.length <= 1) return 0;
+
+ let leftPos = 0;
+ let rightPos = height.length - 1;
+ let max = 0;
+ while (leftPos < rightPos) {
+ const currentArea =
+ Math.abs(leftPos - rightPos) *
+ Math.min(height[leftPos], height[rightPos]);
+ if (currentArea > max) {
+ max = currentArea;
+ }
+ // 更新小的
+ if (height[leftPos] < height[rightPos]) {
+ leftPos++;
+ } else {
+ // 如果相等就随便了
+ rightPos--;
}
+ }
- return max;
+ return max;
};
```
+
C++ Code:
+
```C++
class Solution {
public:
@@ -115,11 +131,30 @@ public:
};
```
-***复杂度分析***
-- 时间复杂度:$O(N)$
-- 空间复杂度:$O(1)$
+Python Code:
+
+```py
+class Solution:
+ def maxArea(self, heights):
+ l, r = 0, len(heights) - 1
+ ans = 0
+ while l < r:
+ ans = max(ans, (r - l) * min(heights[l], heights[r]))
+ if heights[r] > heights[l]:
+ l += 1
+ else:
+ r -= 1
+ return ans
+```
+
+**_复杂度分析_**
+
+- 时间复杂度:由于左右指针移动的次数加起来正好是 n, 因此时间复杂度为 $O(N)$。
+- 空间复杂度:$O(1)$。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/1104.path-in-zigzag-labelled-binary-tree.md b/problems/1104.path-in-zigzag-labelled-binary-tree.md
index 235577570..2a0dc76d8 100644
--- a/problems/1104.path-in-zigzag-labelled-binary-tree.md
+++ b/problems/1104.path-in-zigzag-labelled-binary-tree.md
@@ -10,7 +10,7 @@ https://leetcode-cn.com/problems/path-in-zigzag-labelled-binary-tree/description
而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
-
+
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label 节点的路径,该路径是由途经的节点标号所组成的。
@@ -27,23 +27,31 @@ https://leetcode-cn.com/problems/path-in-zigzag-labelled-binary-tree/description
1 <= label <= 10^6
+## 前置知识
+
+- 二叉树
+
+## 公司
+
+- 暂无
+
## 思路
假如这道题不是之字形,那么就会非常简单。 我们可以根据子节点的 label 轻松地求出父节点的 label,公示是 label // 2(其中 label 为子节点的 label)。
如果是这样的话,这道题应该是 easy 难度,代码也不难写出。我们继续考虑之字形。我们不妨先观察一下,找下规律。
-
+
以上图最后一行为例,对于 15 节点,之字变换之前对应的应该是 8 节点。14 节点对应的是 9 节点。。。
全部列举出来是这样的:
-
+
我们发现之字变换前后的 label 相加是一个定值。
-
+
因此我们只需要求解出每一层的这个定值,然后减去当前值就好了。(注意我们不需要区分偶数行和奇数行)
问题的关键转化为求解这个定值,这个定值其实很好求,因为每一层的最大值和最小值我们很容易求,而最大值和最小值的和正是我们要求的这个数字。
diff --git a/problems/113.path-sum-ii.md b/problems/113.path-sum-ii.md
index e0e3d09b1..014395153 100644
--- a/problems/113.path-sum-ii.md
+++ b/problems/113.path-sum-ii.md
@@ -26,6 +26,17 @@ Return:
]
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求值`,而是枚举所有可能,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -37,7 +48,9 @@ Return:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
diff --git a/problems/1131.maximum-of-absolute-value-expression.md b/problems/1131.maximum-of-absolute-value-expression.md
index 763af2464..13bb775be 100644
--- a/problems/1131.maximum-of-absolute-value-expression.md
+++ b/problems/1131.maximum-of-absolute-value-expression.md
@@ -24,15 +24,25 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
2 <= arr1.length == arr2.length <= 40000
-10^6 <= arr1[i], arr2[i] <= 10^6
+## 前置知识
+
+- 数组
+
## 解法一(数学分析)
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
### 思路
如图我们要求的是这样一个表达式的最大值。arr1 和 arr2 为两个不同的数组,且二者长度相同。i 和 j 是两个合法的索引。
> 红色竖线表示的是绝对值的符号
-
+
我们对其进行分类讨论,有如下八种情况:
@@ -41,7 +51,7 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
> |i - j| 两种情况
> 因此一共是 2 \* 2 \* 2 = 8 种
-
+
由于 i 和 j 之前没有大小关系,也就说二者可以相互替代。因此:
@@ -54,11 +64,11 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
为了方便,我们将 i 和 j 都提取到一起:
-
+
容易看出等式的最大值就是前面的最大值,和后面最小值的差值。如图:
-
+
再仔细观察,会发现前面部分和后面部分是一样的,原因还是上面所说的 i 和 j 可以互换。因此我们要做的就是:
@@ -93,17 +103,17 @@ class Solution:
### 思路
-
+
(图来自: https://zh.wikipedia.org/wiki/%E6%9B%BC%E5%93%88%E9%A0%93%E8%B7%9D%E9%9B%A2)
一维曼哈顿距离可以理解为一条线上两点之间的距离: |x1 - x2|,其值为 max(x1 - x2, x2 - x1)
-
+
在平面上,坐标(x1, y1)的点 P1 与坐标(x2, y2)的点 P2 的曼哈顿距离为:|x1-x2| + |y1 - y2|,其值为 max(x1 - x2 + y1 - y2, x2 - x1 + y1 - y2, x1 - x2 + y2 - y1, x2 -x1 + y2 - y1)
-
+
然后这道题目是更复杂的三维曼哈顿距离,其中(i, arr[i], arr[j])可以看作三位空间中的一个点,问题转化为曼哈顿距离最远的两个点的距离。
延续上面的思路,|x1-x2| + |y1 - y2| + |z1 - z2|,其值为 :
@@ -182,6 +192,6 @@ class Solution:
- [1030. 距离顺序排列矩阵单元格](https://leetcode-cn.com/problems/matrix-cells-in-distance-order/)
-
+
- [1162. 地图分析](https://leetcode-cn.com/problems/as-far-from-land-as-possible/)
diff --git a/problems/1168.optimize-water-distribution-in-a-village-cn.md b/problems/1168.optimize-water-distribution-in-a-village-cn.md
index f0398a673..213ff2bba 100644
--- a/problems/1168.optimize-water-distribution-in-a-village-cn.md
+++ b/problems/1168.optimize-water-distribution-in-a-village-cn.md
@@ -27,11 +27,21 @@ wells.length == n
0 <= pipes[i][2] <= 10^5
pipes[i][0] != pipes[i][1]
```
-example 1 pic:
-
+## 前置知识
+
+- 图
+- 最小生成树
+
+## 公司
+
+- 暂无
## 思路
+
+
+
+
题意,在每个城市打井需要一定的花费,也可以用其他城市的井水,城市之间建立连接管道需要一定的花费,怎么样安排可以花费最少的前灌溉所有城市。
这是一道连通所有点的最短路径/最小生成树问题,把城市看成图中的点,管道连接城市看成是连接两个点之间的边。这里打井的花费是直接在点上,而且并不是所有
@@ -58,7 +68,7 @@ example 1 pic:
如图:
-
+
从图中可以看到,最后所有的节点都是连通的。
@@ -184,4 +194,4 @@ class Solution:
4. [Bellman-Ford算法](https://www.wikiwand.com/zh-hans/%E8%B4%9D%E5%B0%94%E6%9B%BC-%E7%A6%8F%E7%89%B9%E7%AE%97%E6%B3%95)
5. [Kruskal算法](https://www.wikiwand.com/zh-hans/%E5%85%8B%E9%B2%81%E6%96%AF%E5%85%8B%E5%B0%94%E6%BC%94%E7%AE%97%E6%B3%95)
6. [Prim's 算法](https://www.wikiwand.com/zh-hans/%E6%99%AE%E6%9E%97%E5%A7%86%E7%AE%97%E6%B3%95)
-7. [最小生成树](https://www.wikiwand.com/zh/%E6%9C%80%E5%B0%8F%E7%94%9F%E6%88%90%E6%A0%91)
\ No newline at end of file
+7. [最小生成树](https://www.wikiwand.com/zh/%E6%9C%80%E5%B0%8F%E7%94%9F%E6%88%90%E6%A0%91)
diff --git a/problems/1168.optimize-water-distribution-in-a-village-en.md b/problems/1168.optimize-water-distribution-in-a-village-en.md
index 3eac1ad67..0e4ebd752 100644
--- a/problems/1168.optimize-water-distribution-in-a-village-en.md
+++ b/problems/1168.optimize-water-distribution-in-a-village-en.md
@@ -34,7 +34,7 @@ pipes[i][0] != pipes[i][1]
```
example 1 pic:
-
+
## Solution
@@ -61,7 +61,7 @@ For example:`n = 5, wells=[1,2,2,3,2], pipes=[[1,2,1],[2,3,1],[4,5,7]]`
As below pic:
-
+
From pictures, we can see that all nodes already connected with minimum costs.
diff --git a/problems/1186.maximum-subarray-sum-with-one-deletion.md b/problems/1186.maximum-subarray-sum-with-one-deletion.md
index 40e15d392..e8b0cfbb2 100644
--- a/problems/1186.maximum-subarray-sum-with-one-deletion.md
+++ b/problems/1186.maximum-subarray-sum-with-one-deletion.md
@@ -39,6 +39,15 @@ https://leetcode.com/problems/maximum-subarray-sum-with-one-deletion/
```
+## 前置知识
+
+- 数组
+- 动态规划
+
+## 公司
+
+- 字节
+
## 思路
### 暴力法
diff --git a/problems/121.best-time-to-buy-and-sell-stock.md b/problems/121.best-time-to-buy-and-sell-stock.md
index d30c088e3..8d07a4158 100644
--- a/problems/121.best-time-to-buy-and-sell-stock.md
+++ b/problems/121.best-time-to-buy-and-sell-stock.md
@@ -24,6 +24,22 @@ Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- amazon
+- bloomberg
+- facebook
+- microsoft
+- uber
+
## 思路
由于我们是想获取到最大的利润,我们的策略应该是低点买入,高点卖出。
@@ -32,7 +48,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
用图表示的话就是这样:
-
+
## 关键点解析
@@ -40,7 +56,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
## 代码
-语言支持:JS,Python,C++
+语言支持:JS,C++,Java,Python
JS Code:
@@ -65,26 +81,6 @@ var maxProfit = function(prices) {
};
```
-
-
-Python Code:
-
-```python
-class Solution:
- def maxProfit(self, prices: 'List[int]') -> int:
- if not prices: return 0
-
- min_price = float('inf')
- max_profit = 0
-
- for price in prices:
- if price < min_price:
- min_price = price
- elif max_profit < price - min_price:
- max_profit = price - min_price
- return max_profit
-```
-
C++ Code:
```c++
/**
@@ -107,10 +103,53 @@ public:
}
};
```
+Java Code:
+```java
+class Solution {
+ public int maxProfit(int[] prices) {
+ int minprice = Integer.MAX_VALUE;
+ int maxprofit = 0;
+ for (int price: prices) {
+ maxprofit = Math.max(maxprofit, price - minprice);
+ minprice = Math.min(price, minprice);
+ }
+ return maxprofit;
+ }
+}
+```
+Python Code:
+
+```python
+class Solution:
+ def maxProfit(self, prices: 'List[int]') -> int:
+ if not prices: return 0
+
+ min_price = float('inf')
+ max_profit = 0
+
+ for price in prices:
+ if price < min_price:
+ min_price = price
+ elif max_profit < price - min_price:
+ max_profit = price - min_price
+ return max_profit
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
## 相关题目
- [122.best-time-to-buy-and-sell-stock-ii](./122.best-time-to-buy-and-sell-stock-ii.md)
- [309.best-time-to-buy-and-sell-stock-with-cooldown](./309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/1218.longest-arithmetic-subsequence-of-given-difference.md b/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
index 06440d4ae..06f269acd 100644
--- a/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
+++ b/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
@@ -34,6 +34,15 @@ https://leetcode-cn.com/problems/longest-arithmetic-subsequence-of-given-differe
```
+## 前置知识
+
+- 数组
+- 动态规划
+
+## 公司
+
+- 腾讯
+
## 思路
最直观的思路是双层循环,我们暴力的枚举出以每一个元素为开始元素,以最后元素结尾的的所有情况。很明显这是所有的情况,这就是暴力法的精髓, 很明显这种解法会TLE(超时),不过我们先来看一下代码,顺着这个思维继续思考。
diff --git a/problems/122.best-time-to-buy-and-sell-stock-ii.md b/problems/122.best-time-to-buy-and-sell-stock-ii.md
index 142b29928..a7b7d85bf 100644
--- a/problems/122.best-time-to-buy-and-sell-stock-ii.md
+++ b/problems/122.best-time-to-buy-and-sell-stock-ii.md
@@ -31,6 +31,18 @@ Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+
## 思路
由于我们是想获取到最大的利润,我们的策略应该是低点买入,高点卖出。
@@ -41,7 +53,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
用图表示的话就是这样:
-
+
## 关键点解析
@@ -49,7 +61,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
## 代码
-语言支持:JS,Python
+语言支持:JS,C++,Java
JS Code:
@@ -70,26 +82,57 @@ var maxProfit = function(prices) {
return profit;
};
```
-
-
-
-Python Code:
-
-```python
-class Solution:
- def maxProfit(self, prices: 'List[int]') -> int:
- gains = [prices[i] - prices[i-1] for i in range(1, len(prices))
- if prices[i] - prices[i-1] > 0]
- return sum(gains)
-#评论区里都讲这是一道开玩笑的送分题.
+C++ Code:
+
+```c++
+class Solution {
+public:
+ int maxProfit(vector& prices) {
+ int res = 0;
+ for(int i=1;i prices[i-1])
+ {
+ res += prices[i] - prices[i-1];
+ }
+ }
+ return res;
+ }
+};
```
+Java Code:
+
+```java
+class Solution {
+ public int maxProfit(int[] prices) {
+ int res = 0;
+ for(int i=1;i prices[i-1])
+ {
+ res += prices[i] - prices[i-1];
+ }
+ }
+ return res;
+ }
+}
+```
-
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
## 相关题目
- [121.best-time-to-buy-and-sell-stock](./121.best-time-to-buy-and-sell-stock.md)
- [309.best-time-to-buy-and-sell-stock-with-cooldown](./309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/1227.airplane-seat-assignment-probability.md b/problems/1227.airplane-seat-assignment-probability.md
index bf9b2ecb2..2141acd9b 100644
--- a/problems/1227.airplane-seat-assignment-probability.md
+++ b/problems/1227.airplane-seat-assignment-probability.md
@@ -36,10 +36,19 @@ https://leetcode-cn.com/problems/airplane-seat-assignment-probability/descriptio
```
+## 前置知识
+
+- 记忆化搜索
+- 动态规划
+
## 暴力递归
这是一道 LeetCode 为数不多的概率题,我们来看下。
+## 公司
+
+- 字节
+
### 思路
我们定义原问题为 f(n)。对于第一个人来说,他有 n 中选择,就是分别选择 n 个座位中的一个。由于选择每个位置的概率是相同的,那么选择每个位置的概率应该都是 1 / n。
@@ -52,12 +61,12 @@ https://leetcode-cn.com/problems/airplane-seat-assignment-probability/descriptio
此时的问题转化关系如图:
-
+
(红色表示票丢的人)
整个过程分析:
-
+
### 代码
diff --git a/problems/124.binary-tree-maximum-path-sum.md b/problems/124.binary-tree-maximum-path-sum.md
index 1c4c6606e..d0ccf8c88 100644
--- a/problems/124.binary-tree-maximum-path-sum.md
+++ b/problems/124.binary-tree-maximum-path-sum.md
@@ -31,6 +31,17 @@ Input: [-10,9,20,null,null,15,7]
Output: 42
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目的path让我误解了,然后浪费了很多时间来解这道题
@@ -39,33 +50,29 @@ Output: 42
首先是官网给的两个例子:
- 
+ 
接着是我自己画的一个例子:
- 
+ 
-大家可以结合上面的demo来继续理解一下path, 除非你理解了path,否则不要往下看。
+如图红色的部分是最大路径上的节点。大家可以结合上面的demo来继续理解一下path, 除非你理解了path,否则不要往下看。
- 树的题目,基本都是考察递归思想的。因此我们需要思考如何去定义我们的递归函数,
- 在这里我定义了一个递归函数,它的功能是,`返回以当前节点为根节点的MathPath`
- 但是有两个条件:
+ 树的题目,基本都是考察递归思想的。因此我们需要思考如何去定义我们的递归函数,在这里我定义了一个递归函数,它的功能是,`返回以当前节点为根节点的MaxPath`
- 1. 第一是跟节点必须选择
- 2. 第二是左右子树只能选择一个
+但是有两个条件:
- 为什么要有这两个条件?
+1. 根节点必须选择
+2. 左右子树只能选择一个
- 我的想法是原问题可以转化为:
+为什么要有这两个条件?
- 以每一个节点为根节点,我们分别求出max path,最后计算最大值,因此第一个条件需要满足.
+我的想法是原问题可以转化为:以每一个节点为根节点,分别求出 MaxPath,最后计算最大值,因此第一个条件需要满足.
- 对于第二个,由于递归函数子节点的返回值会被父节点使用,因此我们如果两个孩子都选择了
- 就不符合max path的定义了,这也是我没有理解题意,绕了很大弯子的原因。
+对于第二个条件,由于递归函数子节点的返回值会被父节点使用,因此我们如果两个孩子都选择了就不符合 MaxPath 的定义了。实际上这道题,当遍历到某一个节点的时候,我们需要子节点的信息,然后同时结合自身的 val 来决定要不要选取左右子树以及选取的话要选哪一个, 因此这个过程本质上就是`后序遍历`
-
- 因此我的做法就是不断调用递归函数,然后在调用过程中不断计算和更新max,最后在主函数中将max返回即可。
+基本算法就是不断调用递归函数,然后在调用过程中不断计算和更新 MaxPath,最后在主函数中将 MaxPath 返回即可。
## 关键点解析
@@ -74,7 +81,7 @@ Output: 42
## 代码
-代码支持:JavaScript,Java
+代码支持:JavaScript,Java,Python
- JavaScript
@@ -150,5 +157,23 @@ class Solution {
}
```
+- Python
+
+```py
+
+class Solution:
+ ans = float('-inf')
+ def maxPathSum(self, root: TreeNode) -> int:
+ def helper(node):
+ if not node: return 0
+ l = helper(node.left)
+ r = helper(node.right)
+ self.ans = max(self.ans, max(l,0) + max(r, 0) + node.val)
+ return max(l, r, 0) + node.val
+ helper(root)
+ return self.ans
+ ```
+
## 相关题目
- [113.path-sum-ii](./113.path-sum-ii.md)
+
diff --git a/problems/125.valid-palindrome.md b/problems/125.valid-palindrome.md
index b7578be26..5f0bf2a7e 100644
--- a/problems/125.valid-palindrome.md
+++ b/problems/125.valid-palindrome.md
@@ -21,6 +21,22 @@ Output: false
```
+## 前置知识
+
+- 回文
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- facebook
+- microsoft
+- uber
+- zenefits
+
## 思路
这是一道考察回文的题目,而且是最简单的形式,即判断一个字符串是否是回文。
@@ -34,11 +50,11 @@ Output: false
拿“noon”这样一个回文串来说,我们的判断过程是这样的:
-
+
拿“abaa”这样一个不是回文的字符串来说,我们的判断过程是这样的:
-
+
@@ -145,3 +161,15 @@ class Solution:
s = ''.join(i for i in s if i.isalnum()).lower()
return s == s[::-1]
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/1260.shift-2d-grid.md b/problems/1260.shift-2d-grid.md
index 1729456b2..9c5af2f5b 100644
--- a/problems/1260.shift-2d-grid.md
+++ b/problems/1260.shift-2d-grid.md
@@ -45,8 +45,19 @@ https://leetcode-cn.com/problems/shift-2d-grid/description/
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 数学
+
## 暴力法
+## 公司
+
+- 字节
+
+### 思路
+
我们直接翻译题目,没有任何 hack 的做法。
### 代码
@@ -78,7 +89,7 @@ class Solution:
### 思路
我们仔细观察矩阵会发现,其实这样的矩阵迁移是有规律的。 如图:
-
+
因此这个问题就转化为我们一直的一维矩阵转移问题,LeetCode 也有原题[189. 旋转数组](https://leetcode-cn.com/problems/rotate-array/),同时我也写了一篇文章[文科生都能看懂的循环移位算法](https://lucifer.ren/blog/2019/12/11/rotate-list/)专门讨论这个,最终我们使用的是三次旋转法,相关数学证明也有写,很详细,这里不再赘述。
@@ -135,6 +146,10 @@ class Solution:
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
## 相关题目
- [189. 旋转数组](https://leetcode-cn.com/problems/rotate-array/)
@@ -142,3 +157,11 @@ class Solution:
## 参考
- [文科生都能看懂的循环移位算法](https://lucifer.ren/blog/2019/12/11/rotate-list/)
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/1261.find-elements-in-a-contaminated-binary-tree.md b/problems/1261.find-elements-in-a-contaminated-binary-tree.md
index a5d5c5e8e..a0e3ac01d 100644
--- a/problems/1261.find-elements-in-a-contaminated-binary-tree.md
+++ b/problems/1261.find-elements-in-a-contaminated-binary-tree.md
@@ -20,7 +20,7 @@ bool find(int target) 判断目标值 target 是否存在于还原后的二
示例 1:
-
+
输入:
["FindElements","find","find"]
@@ -33,7 +33,7 @@ findElements.find(1); // return False
findElements.find(2); // return True
示例 2:
-
+
输入:
["FindElements","find","find","find"]
@@ -47,7 +47,7 @@ findElements.find(3); // return True
findElements.find(5); // return False
示例 3:
-
+
输入:
["FindElements","find","find","find","find"]
@@ -72,8 +72,16 @@ TreeNode.val == -1
```
+## 前置知识
+
+- 二进制
+
## 暴力法
+## 公司
+
+- 暂无
+
### 思路
最简单想法就是递归建立树,然后 find 的时候递归查找即可,代码也很简单。
@@ -184,12 +192,12 @@ class FindElements:
如果我们把树中的数全部加 1 会怎么样?
-
+
(图参考 https://leetcode.com/problems/find-elements-in-a-contaminated-binary-tree/discuss/431229/Python-Special-Way-for-find()-without-HashSet-O(1)-Space-O(logn)-Time)
仔细观察发现,每一行的左右子树分别有不同的前缀:
-
+
Ok,那么算法就来了。为了便于理解,我们来举个具体的例子,比如 target 是 9,我们首先将其加 1,二进制表示就是 1010。不考虑第一位,就是 010,我们只要:
diff --git a/problems/1262.greatest-sum-divisible-by-three.md b/problems/1262.greatest-sum-divisible-by-three.md
index a6d3802c5..fc8f517ed 100644
--- a/problems/1262.greatest-sum-divisible-by-three.md
+++ b/problems/1262.greatest-sum-divisible-by-three.md
@@ -33,15 +33,26 @@ https://leetcode-cn.com/problems/greatest-sum-divisible-by-three/description/
```
+## 前置知识
+
+- 数组
+- 回溯法
+- 排序
+
## 暴力法
+## 公司
+
+- 字节
+- 网易有道
+
### 思路
一种方式是找出所有的能够被 3 整除的子集,然后挑选出和最大的。由于我们选出了所有的子集,那么时间复杂度就是 $O(2^N)$ , 毫无疑问会超时。这里我们使用回溯法找子集,如果不清楚回溯法,可以参考我之前的题解,很多题目都用到了,比如[78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md)。
更多回溯题目,可以访问上方链接查看(可以使用一套模板搞定):
-
+
### 代码
@@ -83,11 +94,11 @@ class Solution:
以题目中的例 1 为例:
-
+
以题目中的例 2 为例:
-
+
### 代码
@@ -169,7 +180,7 @@ class Solution:
我在[数据结构与算法在前端领域的应用 - 第二篇](https://lucifer.ren/blog/2019/09/19/algorthimn-fe-2/) 中讲到了有限状态机。
-
+
状态机表示若干个状态以及在这些状态之间的转移和动作等行为的数学模型。通俗的描述状态机就是定义了一套状态変更的流程:状态机包含一个状态集合,定义当状态机处于某一个状态的时候它所能接收的事件以及可执行的行为,执行完成后,状态机所处的状态。
@@ -239,3 +250,7 @@ class Solution:
## 扩展
实际上,我们可以采取加法(贪婪策略),感兴趣的可以试一下。
+
+另外如果题目改成了`请你找出并返回能被x整除的元素最大和`,你只需要将我的解法中的 3 改成 x 即可。
+
+
diff --git a/problems/128.longest-consecutive-sequence.md b/problems/128.longest-consecutive-sequence.md
index f7d4bce96..1c2ac9327 100644
--- a/problems/128.longest-consecutive-sequence.md
+++ b/problems/128.longest-consecutive-sequence.md
@@ -21,6 +21,17 @@ Submissions
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道最最长连续数字序列长度的题目, 官网给出的难度是`hard`.
@@ -53,7 +64,7 @@ return Math.max(count, maxCount);
思路就是将之前”排序之后,通过比较前后元素是否相差 1 来判断是否连续“的思路改为
不排序而是`直接遍历,然后在内部循环里面查找是否存在当前值的邻居元素`,但是马上有一个
-问题,内部我们`查找是否存在当前值的邻居元素`的过程如果使用数组时间复杂度是 O(n),
+问题,内部我们`查找是否存在当前值的邻居元素`的过程如果使用数组,时间复杂度是 O(n),
那么总体的复杂度就是 O(n^2),完全不可以接受。怎么办呢?
我们换个思路,用空间来换时间。比如用类似于 hashmap 这样的数据结构优化查询部分,将时间复杂度降低到 O(1), 代码见后面`代码部分`
@@ -65,48 +76,20 @@ return Math.max(count, maxCount);
## 代码
```js
-/*
- * @lc app=leetcode id=128 lang=javascript
- *
- * [128] Longest Consecutive Sequence
- *
- * https://leetcode.com/problems/longest-consecutive-sequence/description/
- *
- * algorithms
- * Hard (40.98%)
- * Total Accepted: 200.3K
- * Total Submissions: 484.5K
- * Testcase Example: '[100,4,200,1,3,2]'
- *
- * Given an unsorted array of integers, find the length of the longest
- * consecutive elements sequence.
- *
- * Your algorithm should run in O(n) complexity.
- *
- * Example:
- *
- *
- * Input: [100, 4, 200, 1, 3, 2]
- * Output: 4
- * Explanation: The longest consecutive elements sequence is [1, 2, 3, 4].
- * Therefore its length is 4.
- *
- *
- */
/**
* @param {number[]} nums
* @return {number}
*/
var longestConsecutive = function(nums) {
- nums = new Set(nums);
+ set = new Set(nums);
let max = 0;
- let y = 0;
- nums.forEach(x => {
+ let temp = 0;
+ set.forEach(x => {
// 说明x是连续序列的开头元素
- if (!nums.has(x - 1)) {
- y = x + 1;
- while (nums.has(y)) {
- y = y + 1;
+ if (!set.has(x - 1)) {
+ temp = x + 1;
+ while (set.has(y)) {
+ temp = temp + 1;
}
max = Math.max(max, y - x); // y - x 就是从x开始到最后有多少连续的数字
}
diff --git a/problems/129.sum-root-to-leaf-numbers.md b/problems/129.sum-root-to-leaf-numbers.md
index 551629cde..c3d9de9f3 100644
--- a/problems/129.sum-root-to-leaf-numbers.md
+++ b/problems/129.sum-root-to-leaf-numbers.md
@@ -41,6 +41,16 @@ Therefore, sum = 495 + 491 + 40 = 1026.
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这是一道非常适合训练递归的题目。虽然题目不难,但是要想一次写正确,并且代码要足够优雅却不是很容易。
@@ -51,12 +61,12 @@ Therefore, sum = 495 + 491 + 40 = 1026.
整个过程如图所示:
-
+
那么数字具体的计算逻辑,如图所示,相信大家通过这个不难发现规律:
-
+
## 关键点解析
diff --git a/problems/1297.maximum-number-of-occurrences-of-a-substring.md b/problems/1297.maximum-number-of-occurrences-of-a-substring.md
index 194fea2d8..2b8d09d33 100644
--- a/problems/1297.maximum-number-of-occurrences-of-a-substring.md
+++ b/problems/1297.maximum-number-of-occurrences-of-a-substring.md
@@ -40,10 +40,19 @@ https://leetcode-cn.com/problems/maximum-number-of-occurrences-of-a-substring
s 只包含小写英文字母。
```
+## 前置知识
+
+- 字符串
+- 滑动窗口
+
## 暴力法
题目给的数据量不是很大,为 1 <= maxLetters <= 26,我们试一下暴力法。
+## 公司
+
+- 字节
+
### 思路
暴力法如下:
diff --git a/problems/130.surrounded-regions.md b/problems/130.surrounded-regions.md
index 060ec587d..c35d76e44 100644
--- a/problems/130.surrounded-regions.md
+++ b/problems/130.surrounded-regions.md
@@ -27,11 +27,22 @@ Surrounded regions shouldn’t be on the border, which means that any 'O' on the
```
+## 前置知识
+
+- DFS
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我们需要将所有被X包围的O变成X,并且题目明确说了边缘的所有O都是不可以变成X的。
-
+
其实我们观察会发现,我们除了边缘的O以及和边缘O连通的O是不需要变成X的,其他都要变成X。
@@ -42,7 +53,7 @@ Surrounded regions shouldn’t be on the border, which means that any 'O' on the
> 我将`边缘的O以及和边缘O连通的O` 标记为了 "A"
-
+
@@ -156,4 +167,16 @@ class Solution:
> 解题模板是一样的
+**复杂度分析**
+- 时间复杂度:$O(row * col)$
+- 空间复杂度:$O(row * col)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
+
diff --git a/problems/131.palindrome-partitioning.md b/problems/131.palindrome-partitioning.md
index e241a9d40..f47b15fbd 100644
--- a/problems/131.palindrome-partitioning.md
+++ b/problems/131.palindrome-partitioning.md
@@ -21,12 +21,30 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道求解所有可能性的题目, 这时候可以考虑使用回溯法。 回溯法解题的模板我们已经在很多题目中用过了,
这里就不多说了。大家可以结合其他几道题目加深一下理解。
+这里我画了一个图:
+
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
+
+
## 关键点解析
- 回溯法
diff --git a/problems/1310.xor-queries-of-a-subarray.md b/problems/1310.xor-queries-of-a-subarray.md
index cf9292f0c..73704bb18 100644
--- a/problems/1310.xor-queries-of-a-subarray.md
+++ b/problems/1310.xor-queries-of-a-subarray.md
@@ -43,6 +43,10 @@ queries[i].length == 2
0 <= queries[i][0] <= queries[i][1] < arr.length
```
+## 前置知识
+
+- 前缀和
+
## 暴力法
### 思路
@@ -68,6 +72,10 @@ class Solution:
## 前缀表达式
+## 公司
+
+- 暂无
+
### 思路
比较常见的是前缀和,这个概念其实很容易理解,即一个数组中,第 n 位存储的是数组前 n 个数字的和。
@@ -76,7 +84,7 @@ class Solution:
这道题是前缀对前缀异或,我们利用了异或的性质 `x ^ y ^ x = y`。
-
+
### 代码
@@ -163,6 +171,6 @@ public:
- [303. 区域和检索 - 数组不可变](https://leetcode-cn.com/problems/range-sum-query-immutable/description/)
-
+
- [1186.删除一次得到子数组最大和](https://lucifer.ren/blog/2019/12/11/leetcode-1186/)
diff --git a/problems/1332.remove-palindromic-subsequences.md b/problems/1332.remove-palindromic-subsequences.md
index fe4b081e7..3e2870b9c 100644
--- a/problems/1332.remove-palindromic-subsequences.md
+++ b/problems/1332.remove-palindromic-subsequences.md
@@ -45,6 +45,14 @@ s 仅包含字母 'a' 和 'b'
在真实的面试中遇到过这道题?
```
+## 前置知识
+
+- 回文
+
+## 公司
+
+- 暂无
+
## 思路
这又是一道“抖机灵”的题目,类似的题目有[1297.maximum-number-of-occurrences-of-a-substring](https://github.com/azl397985856/leetcode/blob/77db8fa47c7ee0a14b320f7c2d22f7c61ae53c35/problems/1297.maximum-number-of-occurrences-of-a-substring.md)
@@ -55,6 +63,11 @@ s 仅包含字母 'a' 和 'b'
- 否则需要两次
- 一定要注意特殊情况, 对于空字符串,我们需要 0 次
+
+## 关键点解析
+
+- 注意审题目,一定要利用题目条件“只含有 a 和 b 两个字符”否则容易做的很麻烦
+
## 代码
代码支持:Python3
@@ -92,6 +105,15 @@ class Solution:
```
-## 关键点解析
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
-- 注意审题目,一定要利用题目条件“只含有 a 和 b 两个字符”否则容易做的很麻烦
diff --git a/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md b/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
index cb0de611e..173a78f86 100644
--- a/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
+++ b/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
@@ -17,7 +17,7 @@ https://leetcode-cn.com/problems/find-the-city-with-the-smallest-number-of-neigh
```
-
+
```
@@ -36,7 +36,7 @@ https://leetcode-cn.com/problems/find-the-city-with-the-smallest-number-of-neigh
```
-
+
```
@@ -64,6 +64,15 @@ edges[i].length == 3
```
+## 前置知识
+
+- 动态规划
+- Floyd-Warshall
+
+## 公司
+
+- 暂无
+
## 思路
这道题的本质就是:
diff --git a/problems/136.single-number.md b/problems/136.single-number.md
index b3099686a..25535eef5 100644
--- a/problems/136.single-number.md
+++ b/problems/136.single-number.md
@@ -12,6 +12,17 @@ Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
根据题目描述,由于加上了时间复杂度必须是 O(n),并且空间复杂度为 O(1)的条件,因此不能用排序方法,也不能使用 map 数据结构。
@@ -36,7 +47,7 @@ Your algorithm should have a linear runtime complexity. Could you implement it w
## 代码
-* 语言支持:JS,C++,Python
+* 语言支持:JS,C,C++,Java,Python
JavaScrip Code:
```js
@@ -89,7 +100,20 @@ var singleNumber = function(nums) {
return ret;
};
```
-C++:
+C Code:
+```C
+int singleNumber(int* nums, int numsSize){
+ int res=0;
+ for(int i=0;i int:
+ for i in range(len(s), 0, -1):
+ for j in range(len(s) - i + 1):
+ sub = s[j:j + i]
+ has_odd_vowel = False
+ for vowel in ['a', 'e', 'i', 'o', 'u']:
+ if sub.count(vowel) % 2 != 0:
+ has_odd_vowel = True
+ break
+ if not has_odd_vowel: return i
+ return 0
+```
+
+JavaScript Code:
+```js
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const vowels = ['a', 'e', 'i', 'o', 'u']
+ const hasEvenVowels = s => !vowels.some(v => (s.match(new RegExp(v, 'g'))||[]).length % 2 !== 0)
+
+ for (let subStrLen = s.length; subStrLen >= 0; subStrLen--) {
+ let remove = s.length - subStrLen + 1
+
+ for (let start = 0; start < remove; start++) {
+ let subStr = s.slice(start, start + subStrLen)
+ if (hasEvenVowels(subStr)) {
+ return subStrLen
+ }
+ }
+ }
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n^3)$. Considering every substring takes $O(n^2)$ time. For each of the subarray we calculate the numbers of vowels taking $O(n^2)$ time in the worst case, taking a total of $O(n^3)$ time.
+- Space complexity: $O(1)$.
+
+## Approach2: Prefix Sum + Pruning
+
+### Algorithm
+
+Notice that in the last approach there is a step for `counting the numbers of vowels for each substring`. If we look closely, we will discover a lot of duplicate computations. Optimization at this part will get us better efficiency.
+
+For problems involving consecutive numbers, we can consider using prefix sum to get to a better solution.
+
+By using this strategy we trade space complexity for time complexity, reducing the time complexity to $O(n ^ 2)$, while increasing the space complexity to $O(n)$, which is a worthwhile trade-off in many situations.
+
+### Code(`Python3/Java/JavaScript`)
+
+Python3 Code:
+```py
+class Solution:
+ i_mapper = {
+ "a": 0,
+ "e": 1,
+ "i": 2,
+ "o": 3,
+ "u": 4
+ }
+ def check(self, s, pre, l, r):
+ for i in range(5):
+ if s[l] in self.i_mapper and i == self.i_mapper[s[l]]: cnt = 1
+ else: cnt = 0
+ if (pre[r][i] - pre[l][i] + cnt) % 2 != 0: return False
+ return True
+ def findTheLongestSubstring(self, s: str) -> int:
+ n = len(s)
+
+ pre = [[0] * 5 for _ in range(n)]
+
+ # pre
+ for i in range(n):
+ for j in range(5):
+ if s[i] in self.i_mapper and self.i_mapper[s[i]] == j:
+ pre[i][j] = pre[i - 1][j] + 1
+ else:
+ pre[i][j] = pre[i - 1][j]
+ for i in range(n - 1, -1, -1):
+ for j in range(n - i):
+ if self.check(s, pre, j, i + j):
+ return i + 1
+ return 0
+```
+
+Java Code:
+```java
+class Solution {
+ public int findTheLongestSubstring(String s) {
+
+ int len = s.length();
+
+ if (len == 0)
+ return 0;
+
+ int[][] preSum = new int[len][5];
+ int start = getIndex(s.charAt(0));
+ if (start != -1)
+ preSum[0][start]++;
+
+ // preSum
+ for (int i = 1; i < len; i++) {
+
+ int idx = getIndex(s.charAt(i));
+
+ for (int j = 0; j < 5; j++) {
+
+ if (idx == j)
+ preSum[i][j] = preSum[i - 1][j] + 1;
+ else
+ preSum[i][j] = preSum[i - 1][j];
+ }
+ }
+
+ for (int i = len - 1; i >= 0; i--) {
+
+ for (int j = 0; j < len - i; j++) {
+ if (checkValid(preSum, s, i, i + j))
+ return i + 1
+ }
+ }
+ return 0
+ }
+
+
+ public boolean checkValid(int[][] preSum, String s, int left, int right) {
+
+ int idx = getIndex(s.charAt(left));
+
+ for (int i = 0; i < 5; i++)
+ if (((preSum[right][i] - preSum[left][i] + (idx == i ? 1 : 0)) & 1) == 1)
+ return false;
+
+ return true;
+ }
+ public int getIndex(char ch) {
+
+ if (ch == 'a')
+ return 0;
+ else if (ch == 'e')
+ return 1;
+ else if (ch == 'i')
+ return 2;
+ else if (ch == 'o')
+ return 3;
+ else if (ch == 'u')
+ return 4;
+ else
+ return -1;
+ }
+}
+```
+
+JavaScript Code:
+```js
+/**
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const prefixes = Array(s.length + 1).fill(0).map(el => Array(5).fill(0))
+ const vowels = {
+ a: 0,
+ e: 1,
+ i: 2,
+ o: 3,
+ u: 4
+ }
+
+ for (let i = 1; i < s.length + 1; i++) {
+ const letter = s[i - 1]
+ for (let j = 0; j < 5; j++) {
+ prefixes[i][j] = prefixes[i - 1][j]
+ }
+ if (letter in vowels) {
+ prefixes[i][vowels[letter]] = prefixes[i - 1][vowels[letter]] + 1
+ }
+ }
+
+ const check = (s, prefixes, l, r) => {
+ for (let i = 0; i < 5; i++) {
+ const count = s[l] in vowels && vowels[s[l]] === i
+ if ((prefixes[r + 1][i] - prefixes[l + 1][i] + count) % 2 !== 0) {
+ return false
+ }
+ }
+ return true
+ }
+
+ for (let r = s.length - 1; r >= 0; r--) {
+ for (let l = 0; l < s.length - r; l++) {
+ if (check(s, prefixes, l, l + r)) {
+ return r + 1
+ }
+ }
+ }
+
+ return 0
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n^2)$.
+- Space complexity: $O(n)$.
+
+## Approach 3: Prefix Sum + State Compression
+
+### Algorithm
+
+In approach 2 we reduce the time complexity by trading space (prefix) for time. However, the time complexity of $O(n^2)$ is still a lot. Is there still room for optimization?
+
+All we care about is parity. We don't need to count the specific number of occurrences of each vowel. Instead, we can use two states `odd or even`. Since we only need to deal with two states, we can consider using bit operation.
+
+- Use a 5-bit binary to represent the parity of the number of occurrences of each vowel with 0 for even and 1 for odd.
+- The 5 bits of the binary represent 'uoiea' respectively. For example, `10110` means the current substring includes even numbers of 'a' and 'o' and odd numbers of 'e', 'i', and 'u'.
+- This binary is assigned to `cur` in the code below.
+
+Why are we using 0 for even numbers and 1 for odd numbers? Keep reading.
+
+This algorithm involves elementary mathematics knowledge.
+
+- If two numbers are of the same parity, then the subtraction must be even.
+- If two numbers are of different parity, then the subtraction must be odd.
+
+Now let's look at the question again. `Why are we using 0 for even numbers and 1 for odd numbers?` Because we want to use the XOR bitwise operation, which works as follows.
+
+- If XOR is performed on the two binaries, each bit will be bit-operated.
+-If two bits are the same, we get 0, otherwise, we get 1.
+
+This is very similar to the above mathematics knowledge. If the parity of two numbers is the same, we get an even number, otherwise, we get an odd number. So it is natural to use 0 for even numbers and 1 for odd numbers.
+
+### Code(`Python3/JavaScript`)
+
+Python3 Code:
+```py
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+ seen = {0: -1}
+ res = cur = 0
+
+ for i in range(len(s)):
+ if s[i] in mapper:
+ cur ^= mapper.get(s[i])
+ # If all numbers are of the same parity, then the subtraction must be even.
+ if cur in seen:
+ res = max(res, i - seen.get(cur))
+ else:
+ seen[cur] = i
+ return res
+```
+
+JavaScript Code:
+```js
+/**
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+
+ let max = 0, cur = 0
+ const seen = { 0: -1 }
+ for (let i = 0; i < s.length; i++) {
+ if (s[i] in mapper) {
+ cur ^= mapper[s[i]]
+ }
+ if (cur in seen) {
+ max = Math.max(max, i - seen[cur])
+ }
+ else {
+ seen[cur] = i
+ }
+ }
+
+ return max
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n)$.
+- Space complexity: $O(n)$.
+
+## Keypoints
+
+- Prefix Sum
+- State Compression
+
+## Extension
+
+- [You can do whatever you want while mastering prefix sum](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)(Chinese)
diff --git a/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md b/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md
new file mode 100644
index 000000000..b38fe1d32
--- /dev/null
+++ b/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md
@@ -0,0 +1,274 @@
+# 题目地址(1371. 每个元音包含偶数次的最长子字符串)
+
+https://leetcode-cn.com/problems/find-the-longest-substring-containing-vowels-in-even-counts/
+
+## 题目描述
+
+```
+给你一个字符串 s ,请你返回满足以下条件的最长子字符串的长度:每个元音字母,即 'a','e','i','o','u' ,在子字符串中都恰好出现了偶数次。
+
+
+
+示例 1:
+
+输入:s = "eleetminicoworoep"
+输出:13
+解释:最长子字符串是 "leetminicowor" ,它包含 e,i,o 各 2 个,以及 0 个 a,u 。
+示例 2:
+
+输入:s = "leetcodeisgreat"
+输出:5
+解释:最长子字符串是 "leetc" ,其中包含 2 个 e 。
+示例 3:
+
+输入:s = "bcbcbc"
+输出:6
+解释:这个示例中,字符串 "bcbcbc" 本身就是最长的,因为所有的元音 a,e,i,o,u 都出现了 0 次。
+
+
+提示:
+
+1 <= s.length <= 5 x 10^5
+s 只包含小写英文字母。
+
+```
+
+## 前置知识
+
+- 前缀和
+- 状态压缩
+
+## 暴力法 + 剪枝
+
+## 公司
+
+- 暂无
+
+### 思路
+
+首先拿到这道题的时候,我想到第一反应是滑动窗口行不行。 但是很快这个想法就被我否定了,因为滑动窗口(这里是可变滑动窗口)我们需要扩张和收缩窗口大小,而这里不那么容易。因为题目要求的是奇偶性,而不是类似“元音出现最多的子串”等。
+
+突然一下子没了思路。那就试试暴力法吧。暴力法的思路比较朴素和直观。 那就是`双层循环找到所有子串,然后对于每一个子串,统计元音个数,如果子串的元音个数都是偶数,则更新答案,最后返回最大的满足条件的子串长度即可`。
+
+这里我用了一个小的 trick。枚举所有子串的时候,我是从最长的子串开始枚举的,这样我找到一个满足条件的直接返回就行了(early return),不必维护最大值。`这样不仅减少了代码量,还提高了效率。`
+
+### 代码
+
+代码支持:Python3
+
+Python3 Code:
+
+```python
+
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ for i in range(len(s), 0, -1):
+ for j in range(len(s) - i + 1):
+ sub = s[j:j + i]
+ has_odd_vowel = False
+ for vowel in ['a', 'e', 'i', 'o', 'u']:
+ if sub.count(vowel) % 2 != 0:
+ has_odd_vowel = True
+ break
+ if not has_odd_vowel: return i
+ return 0
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:双层循环找出所有子串的复杂度是$O(n^2)$,统计元音个数复杂度也是$O(n)$,因此这种算法的时间复杂度为$O(n^3)$。
+- 空间复杂度:$O(1)$
+
+## 前缀和 + 剪枝
+
+### 思路
+
+上面思路中`对于每一个子串,统计元音个数`,我们仔细观察的话,会发现有很多重复的统计。那么优化这部分的内容就可以获得更好的效率。
+
+对于这种连续的数字问题,这里我们考虑使用[前缀和](https://oi-wiki.org/basic/prefix-sum/)来优化。
+
+经过这种空间换时间的策略之后,我们的时间复杂度会降低到$O(n ^ 2)$,但是相应空间复杂度会上升到$O(n)$,这种取舍在很多情况下是值得的。
+
+### 代码
+
+代码支持:Python3,Java
+
+Python3 Code:
+
+```python
+class Solution:
+ i_mapper = {
+ "a": 0,
+ "e": 1,
+ "i": 2,
+ "o": 3,
+ "u": 4
+ }
+ def check(self, s, pre, l, r):
+ for i in range(5):
+ if s[l] in self.i_mapper and i == self.i_mapper[s[l]]: cnt = 1
+ else: cnt = 0
+ if (pre[r][i] - pre[l][i] + cnt) % 2 != 0: return False
+ return True
+ def findTheLongestSubstring(self, s: str) -> int:
+ n = len(s)
+
+ pre = [[0] * 5 for _ in range(n)]
+
+ # pre
+ for i in range(n):
+ for j in range(5):
+ if s[i] in self.i_mapper and self.i_mapper[s[i]] == j:
+ pre[i][j] = pre[i - 1][j] + 1
+ else:
+ pre[i][j] = pre[i - 1][j]
+ for i in range(n - 1, -1, -1):
+ for j in range(n - i):
+ if self.check(s, pre, j, i + j):
+ return i + 1
+ return 0
+```
+
+Java Code:
+
+```java
+class Solution {
+ public int findTheLongestSubstring(String s) {
+
+ int len = s.length();
+
+ if (len == 0)
+ return 0;
+
+ int[][] preSum = new int[len][5];
+ int start = getIndex(s.charAt(0));
+ if (start != -1)
+ preSum[0][start]++;
+
+ // preSum
+ for (int i = 1; i < len; i++) {
+
+ int idx = getIndex(s.charAt(i));
+
+ for (int j = 0; j < 5; j++) {
+
+ if (idx == j)
+ preSum[i][j] = preSum[i - 1][j] + 1;
+ else
+ preSum[i][j] = preSum[i - 1][j];
+ }
+ }
+
+ for (int i = len - 1; i >= 0; i--) {
+
+ for (int j = 0; j < len - i; j++) {
+ if (checkValid(preSum, s, j, i + j))
+ return i + 1;
+ }
+ }
+ return 0;
+ }
+
+
+ public boolean checkValid(int[][] preSum, String s, int left, int right) {
+
+ int idx = getIndex(s.charAt(left));
+
+ for (int i = 0; i < 5; i++)
+ if (((preSum[right][i] - preSum[left][i] + (idx == i ? 1 : 0)) & 1) == 1)
+ return false;
+
+ return true;
+ }
+ public int getIndex(char ch) {
+
+ if (ch == 'a')
+ return 0;
+ else if (ch == 'e')
+ return 1;
+ else if (ch == 'i')
+ return 2;
+ else if (ch == 'o')
+ return 3;
+ else if (ch == 'u')
+ return 4;
+ else
+ return -1;
+ }
+}
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(n^2)$。
+- 空间复杂度:$O(n)$
+
+## 前缀和 + 状态压缩
+
+### 思路
+
+前面的前缀和思路,我们通过空间(prefix)换取时间的方式降低了时间复杂度。但是时间复杂度仍然是平方,我们是否可以继续优化呢?
+
+实际上由于我们只关心奇偶性,并不关心每一个元音字母具体出现的次数。因此我们可以使用`是奇数,是偶数`两个状态来表示,由于只有两个状态,我们考虑使用位运算。
+
+我们使用 5 位的二进制来表示以 i 结尾的字符串中包含各个元音的奇偶性,其中 0 表示偶数,1 表示奇数,并且最低位表示 a,然后依次是 e,i,o,u。比如 `10110` 则表示的是包含偶数个 a 和 o,奇数个 e,i,u,我们用变量 `cur` 来表示。
+
+为什么用 0 表示偶数?1 表示奇数?
+
+回答这个问题,你需要继续往下看。
+
+其实这个解法还用到了一个性质,这个性质是小学数学知识:
+
+- 如果两个数字奇偶性相同,那么其相减一定是偶数。
+- 如果两个数字奇偶性不同,那么其相减一定是奇数。
+
+看到这里,我们再来看上面抛出的问题`为什么用 0 表示偶数?1 表示奇数?`。因为这里我们打算用异或运算,而异或的性质是:
+
+如果对两个二进制做异或,会对其每一位进行位运算,如果相同则位 0,否则位 1。这和上面的性质非常相似。上面说`奇偶性相同则位偶数,否则为奇数`。因此很自然地`用 0 表示偶数?1 表示奇数`会更加方便。
+
+### 代码
+
+代码支持:Python3
+
+Python3 Code:
+
+```python
+
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+ seen = {0: -1}
+ res = cur = 0
+
+ for i in range(len(s)):
+ if s[i] in mapper:
+ cur ^= mapper.get(s[i])
+ # 全部奇偶性都相同,相减一定都是偶数
+ if cur in seen:
+ res = max(res, i - seen.get(cur))
+ else:
+ seen[cur] = i
+ return res
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(n)$。
+- 空间复杂度:$O(n)$
+
+## 关键点解析
+
+- 前缀和
+- 状态压缩
+
+## 相关题目
+
+- [掌握前缀表达式真的可以为所欲为!](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)
diff --git a/problems/139.word-break.md b/problems/139.word-break.md
index 142b3bab5..c8e28798b 100644
--- a/problems/139.word-break.md
+++ b/problems/139.word-break.md
@@ -1,4 +1,3 @@
-
## 题目地址
https://leetcode.com/problems/word-break/description/
@@ -30,40 +29,49 @@ Output: false
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题是给定一个字典和一个句子,判断该句子是否可以由字典里面的单词组出来,一个单词可以用多次。
暴力的方法是无解的,复杂度极其高。 我们考虑其是否可以拆分为小问题来解决。
-对于问题`(s, wordDict)` 我们是否可以用(s', wordDict) 来解决。 其中s' 是s 的子序列,
-当s'变成寻常(长度为0)的时候问题就解决了。 我们状态转移方程变成了这道题的难点。
+对于问题`(s, wordDict)` 我们是否可以用(s', wordDict) 来解决。 其中 s' 是 s 的子序列,
+当 s'变成寻常(长度为 0)的时候问题就解决了。 我们状态转移方程变成了这道题的难点。
-我们可以建立一个数组dp, dp[i]代表 字符串 s.substring(0, i) 能否由字典里面的单词组成,
-值得注意的是,这里我们无法建立dp[i] 和 dp[i - 1] 的关系,
-我们可以建立的是dp[i - word.length] 和 dp[i] 的关系。
+我们可以建立一个数组 dp, dp[i]代表 字符串 s.substring(0, i) 能否由字典里面的单词组成,
+值得注意的是,这里我们无法建立 dp[i] 和 dp[i - 1] 的关系,
+我们可以建立的是 dp[i - word.length] 和 dp[i] 的关系。
我们用图来感受一下:
-
-
+
没有明白也没有关系,我们分步骤解读一下:
-(以下的图左边都代表s,右边都是dict,灰色代表没有处理的字符,绿色代表匹配成功,红色代表匹配失败)
-
-
+(以下的图左边都代表 s,右边都是 dict,灰色代表没有处理的字符,绿色代表匹配成功,红色代表匹配失败)
-
+
-
+
-
+
+
上面分步解释了算法的基本过程,下面我们感性认识下这道题,我把它比喻为
你正在`往一个老式手电筒🔦中装电池`
-
+
## 代码
@@ -125,15 +133,15 @@ Output: false
* @param {string[]} wordDict
* @return {boolean}
*/
-var wordBreak = function(s, wordDict) {
+var wordBreak = function (s, wordDict) {
const dp = Array(s.length + 1);
dp[0] = true;
for (let i = 0; i < s.length + 1; i++) {
for (let word of wordDict) {
- if (dp[i - word.length] && word.length <= i) {
- if (s.substring(i - word.length, i) === word) {
- dp[i] = true;
- }
+ if (word.length <= i && dp[i - word.length]) {
+ if (s.substring(i - word.length, i) === word) {
+ dp[i] = true;
+ }
}
}
}
diff --git a/problems/144.binary-tree-preorder-traversal.md b/problems/144.binary-tree-preorder-traversal.md
index 12e92fb1b..fe8e07a52 100644
--- a/problems/144.binary-tree-preorder-traversal.md
+++ b/problems/144.binary-tree-preorder-traversal.md
@@ -21,6 +21,18 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
```
+## 前置知识
+
+- 递归
+- 栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是前序遍历,这个和之前的`leetcode 94 号问题 - 中序遍历`完全不一回事。
@@ -28,7 +40,11 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
前序遍历是`根左右`的顺序,注意是`根`开始,那么就很简单。直接先将根节点入栈,然后
看有没有右节点,有则入栈,再看有没有左节点,有则入栈。 然后出栈一个元素,重复即可。
-> 其他树的非递归遍历课没这么简单
+> 其他树的非递归遍历可没这么简单
+
+
+
+(迭代 VS 递归)
## 关键点解析
@@ -53,44 +69,6 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
JavaScript Code:
```js
-/*
- * @lc app=leetcode id=144 lang=javascript
- *
- * [144] Binary Tree Preorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-preorder-traversal/description/
- *
- * algorithms
- * Medium (50.36%)
- * Total Accepted: 314K
- * Total Submissions: 621.2K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the preorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [1,2,3]
- *
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[]}
@@ -110,13 +88,13 @@ var preorderTraversal = function(root) {
let t = stack.pop();
while (t) {
- ret.push(t.val);
if (t.right) {
stack.push(t.right);
}
if (t.left) {
stack.push(t.left);
}
+ ret.push(t.val);
t = stack.pop();
}
@@ -154,3 +132,7 @@ public:
}
};
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md b/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md
new file mode 100644
index 000000000..920be35fe
--- /dev/null
+++ b/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md
@@ -0,0 +1,224 @@
+# 题目地址(1449. 数位成本和为目标值的最大数字)
+
+https://leetcode-cn.com/problems/form-largest-integer-with-digits-that-add-up-to-target/
+
+## 题目描述
+
+```
+给你一个整数数组 cost 和一个整数 target 。请你返回满足如下规则可以得到的 最大 整数:
+
+给当前结果添加一个数位(i + 1)的成本为 cost[i] (cost 数组下标从 0 开始)。
+总成本必须恰好等于 target 。
+添加的数位中没有数字 0 。
+由于答案可能会很大,请你以字符串形式返回。
+
+如果按照上述要求无法得到任何整数,请你返回 "0" 。
+
+
+
+示例 1:
+
+输入:cost = [4,3,2,5,6,7,2,5,5], target = 9
+输出:"7772"
+解释:添加数位 '7' 的成本为 2 ,添加数位 '2' 的成本为 3 。所以 "7772" 的代价为 2*3+ 3*1 = 9 。 "997" 也是满足要求的数字,但 "7772" 是较大的数字。
+ 数字 成本
+ 1 -> 4
+ 2 -> 3
+ 3 -> 2
+ 4 -> 5
+ 5 -> 6
+ 6 -> 7
+ 7 -> 2
+ 8 -> 5
+ 9 -> 5
+示例 2:
+
+输入:cost = [7,6,5,5,5,6,8,7,8], target = 12
+输出:"85"
+解释:添加数位 '8' 的成本是 7 ,添加数位 '5' 的成本是 5 。"85" 的成本为 7 + 5 = 12 。
+示例 3:
+
+输入:cost = [2,4,6,2,4,6,4,4,4], target = 5
+输出:"0"
+解释:总成本是 target 的条件下,无法生成任何整数。
+示例 4:
+
+输入:cost = [6,10,15,40,40,40,40,40,40], target = 47
+输出:"32211"
+
+
+提示:
+
+cost.length == 9
+1 <= cost[i] <= 5000
+1 <= target <= 5000
+
+```
+
+## 前置知识
+
+- 数组
+- 动态规划
+- 背包问题
+
+## 公司
+
+- 暂无
+
+## 思路
+
+由于数组可以重复选择,因此这是一个完全背包问题。
+
+### 01 背包
+
+对于 01 背包问题,我们的套路是:
+
+```py
+for i in 0 to N:
+ for j in 1 to V + 1:
+ dp[j] = max(dp[j], dp[j - cost[i])
+```
+
+而一般我们为了处理边界问题,我们一般会这么写代码:
+
+```py
+for i in 1 to N + 1:
+ # 这里是倒序的,原因在于这里是01背包。
+ for j in V to 0:
+ dp[j] = max(dp[j], dp[j - cost[i - 1])
+```
+
+其中 dp[j] 表示只能选择前 i 个物品,背包容量为 j 的情况下,能够获得的最大价值。
+
+> dp[j] 不是没 i 么? 其实我这里 i 指的是 dp[j]当前所处的循环中的 i 值
+
+### 完全背包问题
+
+回到问题,我们这是完全背包问题:
+
+```py
+for i in 1 to N + 1:
+ # 这里不是倒序,原因是我们这里是完全背包问题
+ for j in 1 to V + 1:
+ dp[j] = max(dp[j], dp[j - cost[i - 1])
+
+```
+
+### 为什么 01 背包需要倒序,而完全背包则不可以
+
+实际上,这是一个骚操作,我来详细给你讲一下。
+
+其实要回答这个问题,我要先将 01 背包和完全背包退化二维的情况。
+
+对于 01 背包:
+
+```py
+for i in 1 to N + 1:
+ for j in V to 0:
+ dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - cost[i - 1])
+```
+
+注意等号左边是 i,右边是 i - 1,这很好理解,因为 i 只能取一次嘛。
+
+那么如果我们不降序遍历会怎么样呢?
+
+
+
+如图橙色部分表示已经遍历的部分,而让我们去用[j - cost[i - 1]] 往前面回溯的时候,实际上回溯的是 dp[i]j - cost[i - 1]],而不是 dp[i - 1]j - cost[i - 1]]。
+
+如果是降序就可以了,如图:
+
+
+
+这个明白的话,我们继续思考为什么完全背包就要不降序了呢?
+
+我们还是像上面一样写出二维的代码:
+
+```py
+for i in 1 to N + 1:
+ for j in 1 to V + 1:
+ dp[i][j] = max(dp[i - 1][j], dp[i][j - cost[i - 1])
+
+```
+
+由于 i 可以取无数次,那么正序遍历正好可以满足,如上图。
+
+### 恰好装满 VS 可以不装满
+
+题目有两种可能,一种是要求背包恰好装满,一种是可以不装满(只要不超过容量就行)。而本题是要求`恰好装满`的。而这两种情况仅仅影响我们`dp数组初始化`。
+
+- 恰好装满。只需要初始化 dp[0] 为 0, 其他初始化为负数即可。
+- 可以不装满。 只需要全部初始化为 0,即可,
+
+原因很简单,我多次强调过 dp 数组本质上是记录了一个个自问题。 dp[0]是一个子问题,dp[1]是一个子问题。。。
+
+有了上面的知识就不难理解了。 初始化的时候,我们还没有进行任何选择,那么也就是说 dp[0] = 0,因为我们可以通过什么都不选达到最大值 0。而 dp[1],dp[2]...则在当前什么都不选的情况下无法达成,也就是无解,因为为了区分,我们可以用负数来表示,当然你可以用任何可以区分的东西表示,比如 None。
+
+### 回到本题
+
+而这道题和普通的完全背包不一样,这个是选择一个组成的最大数。由小学数学知识`一个数字的全排列中,按照数字降序排列是最大的`,我这里用了一个骚操作,那就是 cost 从后往前遍历,因为后面表示的数字大。
+
+## 代码
+
+```py
+class Solution:
+ def largestNumber(self, cost: List[int], target: int) -> str:
+ dp = [0] + [float('-inf')] * target
+ for i in range(9, 0, -1):
+ for j in range(1, target+1):
+ if j >= cost[i - 1]:
+ dp[j] = max(dp[j], (dp[j-cost[i - 1]] * 10) + i)
+ return str(dp[target]) if dp[target] > 0 else '0'
+
+```
+
+**_复杂度分析_**
+
+- 时间复杂度:$O(target))$
+- 空间复杂度:$O(target)$
+
+## 扩展
+
+最后贴几个我写过的背包问题,让大家看看历史是多么的相似。
+
+
+([322. 硬币找零(完全背包问题)](https://github.com/azl397985856/leetcode/blob/master/problems/322.coin-change.md))
+
+> 这里内外循环和本题正好是反的,我只是为了"秀技"(好玩),实际上在这里对答案并不影响。
+
+
+([518. 零钱兑换 II](https://github.com/azl397985856/leetcode/blob/master/problems/518.coin-change-2.md))
+
+> 这里内外循环和本题正好是反的,但是这里必须这么做,否则结果是不对的,具体可以点进去链接看我那个题解
+
+所以这两层循环的位置起的实际作用是什么? 代表的含义有什么不同?
+
+本质上:
+
+```py
+for i in 1 to N + 1:
+ for j in V to 0:
+ ...
+
+```
+
+这种情况选择物品 1 和物品 3(随便举的例子),是一种方式。选择物品 3 个物品 1(注意是有顺序的)是同一种方式。 **原因在于你是固定物品,去扫描容量**。
+
+而:
+
+```py
+for j in V to 0:
+ for i in 1 to N + 1:
+ ...
+
+```
+
+这种情况选择物品 1 和物品 3(随便举的例子),是一种方式。选择物品 3 个物品 1(注意是有顺序的)也是一种方式。**原因在于你是固定容量,去扫描物品**。
+
+**因此总的来说,如果你认为[1,3]和[3,1]是一种,那么就用方法 1 的遍历,否则用方法 2。**
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/145.binary-tree-postorder-traversal.md b/problems/145.binary-tree-postorder-traversal.md
index 0b20ea243..6f7832b88 100644
--- a/problems/145.binary-tree-postorder-traversal.md
+++ b/problems/145.binary-tree-postorder-traversal.md
@@ -22,6 +22,18 @@ Note: Recursive solution is trivial, could you do it iteratively?
```
+## 前置知识
+
+- 栈
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
相比于前序遍历,后续遍历思维上难度要大些,前序遍历是通过一个stack,首先压入父亲结点,然后弹出父亲结点,并输出它的value,之后压人其右儿子,左儿子即可。
@@ -54,37 +66,6 @@ mid是一个具体的节点,left和right`递归求出即可`
## 代码
```js
-/*
- * @lc app=leetcode id=145 lang=javascript
- *
- * [145] Binary Tree Postorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-postorder-traversal/description/
- *
- * algorithms
- * Hard (47.06%)
- * Total Accepted: 242.6K
- * Total Submissions: 512.8K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the postorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [3,2,1]
- *
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
/**
* Definition for a binary tree node.
* function TreeNode(val) {
@@ -133,3 +114,9 @@ var postorderTraversal = function(root) {
};
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
+
+
diff --git a/problems/146.lru-cache.md b/problems/146.lru-cache.md
index 0abd27250..bc6dd3436 100644
--- a/problems/146.lru-cache.md
+++ b/problems/146.lru-cache.md
@@ -28,6 +28,17 @@ cache.get(4); // returns 4
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
`本题已被收录到我的新书中,敬请期待~`
diff --git a/problems/15.3-sum.md b/problems/15.3sum.md
similarity index 73%
rename from problems/15.3-sum.md
rename to problems/15.3sum.md
index 85ae152f6..3170eec8d 100644
--- a/problems/15.3-sum.md
+++ b/problems/15.3sum.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/3sum/description/
## 题目描述
+
```
Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Find all unique triplets in the array which gives the sum of zero.
@@ -20,32 +22,44 @@ A solution set is:
]
```
+
+## 前置知识
+
+- 排序
+- 双指针
+- 分治
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
-我们采用`分治`的思想. 想要找出三个数相加等于0,我们可以数组依次遍历,
-每一项a[i]我们都认为它是最终能够用组成0中的一个数字,那么我们的目标就是找到
-剩下的元素(除a[i])`两个`相加等于-a[i].
+我们采用`分治`的思想. 想要找出三个数相加等于 0,我们可以数组依次遍历,
+每一项 a[i]我们都认为它是最终能够用组成 0 中的一个数字,那么我们的目标就是找到
+剩下的元素(除 a[i])`两个`相加等于-a[i].
通过上面的思路,我们的问题转化为了`给定一个数组,找出其中两个相加等于给定值`,
-这个问题是比较简单的, 我们只需要对数组进行排序,然后双指针解决即可。 加上我们需要外层遍历依次数组,因此总的时间复杂度应该是O(N^2)。
+这个问题是比较简单的, 我们只需要对数组进行排序,然后双指针解决即可。 加上我们需要外层遍历依次数组,因此总的时间复杂度应该是 O(N^2)。
思路如图所示:
-
-
-> 在这里之所以要排序解决是因为, 我们算法的瓶颈在这里不在于排序,而在于O(N^2),如果我们瓶颈是排序,就可以考虑别的方式了
+
+> 在这里之所以要排序解决是因为, 我们算法的瓶颈在这里不在于排序,而在于 O(N^2),如果我们瓶颈是排序,就可以考虑别的方式了
> 如果找某一个特定元素,一个指针就够了。如果是找两个元素满足一定关系(比如求和等于特定值),需要双指针,
-当然前提是数组有序。
+> 当然前提是数组有序。
+
## 关键点解析
- 排序之后,用双指针
- 分治
## 代码
-```js
+```js
/*
* @lc app=leetcode id=15 lang=javascript
*
@@ -84,7 +98,7 @@ A solution set is:
* @param {number[]} nums
* @return {number[][]}
*/
-var threeSum = function(nums) {
+var threeSum = function (nums) {
if (nums.length < 3) return [];
const list = [];
nums.sort((a, b) => a - b);
@@ -93,27 +107,23 @@ var threeSum = function(nums) {
if (nums[i] > 0) break;
// skip duplicated result without set
if (i > 0 && nums[i] === nums[i - 1]) continue;
- let left = i;
+ let left = i + 1;
let right = nums.length - 1;
-
+
// for each index i
// we want to find the triplet [i, left, right] which sum to 0
while (left < right) {
- // skip i === left or i === right, in that case, the index i will be used twice
- if (left === i) {
- left++;
- } else if (right === i) {
- right--;
- } else if (nums[left] + nums[right] + nums[i] === 0) {
+ // since left < right, and left > i, no need to compare i === left and i === right.
+ if (nums[left] + nums[right] + nums[i] === 0) {
list.push([nums[left], nums[right], nums[i]]);
// skip duplicated result without set
- while(nums[left] === nums[left + 1]) {
- left++;
+ while (nums[left] === nums[left + 1]) {
+ left++;
}
left++;
// skip duplicated result without set
- while(nums[right] === nums[right - 1]) {
- right--;
+ while (nums[right] === nums[right - 1]) {
+ right--;
}
right--;
continue;
diff --git a/problems/150.evaluate-reverse-polish-notation.md b/problems/150.evaluate-reverse-polish-notation.md
index 8b56c0d5a..c2a8617ef 100644
--- a/problems/150.evaluate-reverse-polish-notation.md
+++ b/problems/150.evaluate-reverse-polish-notation.md
@@ -15,6 +15,16 @@ Note:
Division between two integers should truncate toward zero.
The given RPN expression is always valid. That means the expression would always evaluate to a result and there won't be any divide by zero operation.
```
+
+## 前置知识
+
+- 栈
+
+## 公司
+
+- 阿里
+- 腾讯
+
## 思路
逆波兰表达式又叫做后缀表达式。在通常的表达式中,二元运算符总是置于与之相关的两个运算对象之间,这种表示法也称为`中缀表示`。
diff --git a/problems/152.maximum-product-subarray.md b/problems/152.maximum-product-subarray.md
index f784d48f7..ce944c52a 100644
--- a/problems/152.maximum-product-subarray.md
+++ b/problems/152.maximum-product-subarray.md
@@ -3,29 +3,37 @@
https://leetcode.com/problems/maximum-product-subarray/description/
## 题目描述
-
```
-Given an integer array nums, find the contiguous subarray within an array (containing at least one number) which has the largest product.
+给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
-Example 1:
+
-Input: [2,3,-2,4]
-Output: 6
-Explanation: [2,3] has the largest product 6.
-Example 2:
+示例 1:
-Input: [-2,0,-1]
-Output: 0
-Explanation: The result cannot be 2, because [-2,-1] is not a subarray.
+输入: [2,3,-2,4]
+输出: 6
+解释: 子数组 [2,3] 有最大乘积 6。
+示例 2:
+输入: [-2,0,-1]
+输出: 0
+解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
```
-## 思路
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
-> 这道题目的通过率非常低
+## 思路
-这道题目要我们求解连续的 n 个数中乘积最大的积是多少。这里提到了连续,笔者首先
-想到的就是滑动窗口,但是这里比较特殊,我们不能仅仅维护一个最大值,因此最小值(比如-20)乘以一个比较小的数(比如-10)
+这道题目要我们求解连续的 n 个数中乘积最大的积是多少。这里提到了连续,笔者首先想到的就是滑动窗口,但是这里比较特殊,我们不能仅仅维护一个最大值,因此最小值(比如-20)乘以一个比较小的数(比如-10)
可能就会很大。 因此这种思路并不方便。
首先来暴力求解,我们使用两层循环来枚举所有可能项,这种解法的时间复杂度是O(n^2), 代码如下:
@@ -36,7 +44,6 @@ var maxProduct = function(nums) {
let temp = null;
for (let i = 0; i < nums.length; i++) {
temp = nums[i];
- max = Math.max(temp, max);
for (let j = i + 1; j < nums.length; j++) {
temp *= nums[j];
max = Math.max(temp, max);
@@ -47,9 +54,11 @@ var maxProduct = function(nums) {
};
```
-因此我们需要同时记录乘积最大值和乘积最小值,然后比较元素和这两个的乘积,去不断更新最大值。
-
+
+前面说了`最小值(比如-20)乘以一个比较小的数(比如-10)可能就会很大` 。因此我们需要同时记录乘积最大值和乘积最小值,然后比较元素和这两个的乘积,去不断更新最大值。当然,我们也可以选择只取当前元素。因此实际上我们的选择有三种,而如何选择就取决于哪个选择带来的价值最大(乘积最大或者最小)。
+
+
这种思路的解法由于只需要遍历一次,其时间复杂度是O(n),代码见下方代码区。
@@ -137,3 +146,7 @@ var maxProduct = function(nums) {
**复杂度分析**
- 时间复杂度:$O(N)$
- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
diff --git a/problems/155.min-stack.md b/problems/155.min-stack.md
index ab07da5f8..ce78a6c29 100644
--- a/problems/155.min-stack.md
+++ b/problems/155.min-stack.md
@@ -23,111 +23,90 @@ minStack.getMin(); --> Returns -2.
```
-# 差值法
+## 前置知识
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+## 公司
+- amazon
+- bloomberg
+- google
+- snapchat
+- uber
+- zenefits
-## 思路
-符合直觉的方法是,每次对栈进行修改操作(push和pop)的时候更新最小值。 然后getMin只需要返回我们计算的最小值即可,
-top也是直接返回栈顶元素即可。 这种做法每次修改栈都需要更新最小值,因此时间复杂度是O(n).
-
-
-
-是否有更高效的算法呢?答案是有的。
-
-我们每次入栈的时候,保存的不再是真正的数字,而是它与当前最小值的差(当前元素没有入栈的时候的最小值)。
-这样我们pop和top的时候拿到栈顶元素再加上**上一个**最小值即可。
-另外我们在push和pop的时候去更新min,这样getMin的时候就简单了,直接返回min。
-
-> 注意上面加粗的“上一个”,不是“当前的最小值”
+## 两个栈
-经过上面的分析,问题的关键转化为“如何求得上一个最小值”,解决这个的关键点在于利用min。
+## 公司
-pop或者top的时候:
+- 阿里
+- 腾讯
+- 百度
+- 字节
-- 如果栈顶元素小于0,说明栈顶是当前最小的元素,它出栈会对min造成影响,我们需要去更新min。
-上一个最小的是“min - 栈顶元素”,我们需要将上一个最小值更新为当前的最小值
+### 思路
- > 因为栈顶元素入栈的时候的通过 `栈顶元素 = 真实值 - 上一个最小的元素` 得到的,
- 而真实值 = min, 因此可以得出`上一个最小的元素 = 真实值 -栈顶元素`
+我们使用两个栈:
-- 如果栈顶元素大于0,说明它对最小值`没有影响`,上一个最小值就是上上个最小值。
+- 一个栈存放全部的元素,push,pop都是正常操作这个正常栈。
+- 另一个存放最小栈。 每次push,如果比最小栈的栈顶还小,我们就push进最小栈,否则不操作
+- 每次pop的时候,我们都判断其是否和最小栈栈顶元素相同,如果相同,那么我们pop掉最小栈的栈顶元素即可
-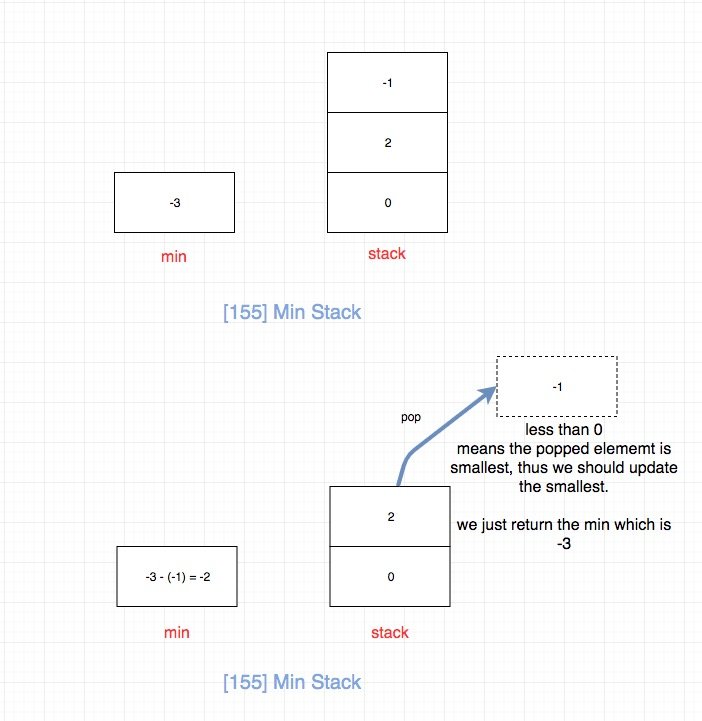
-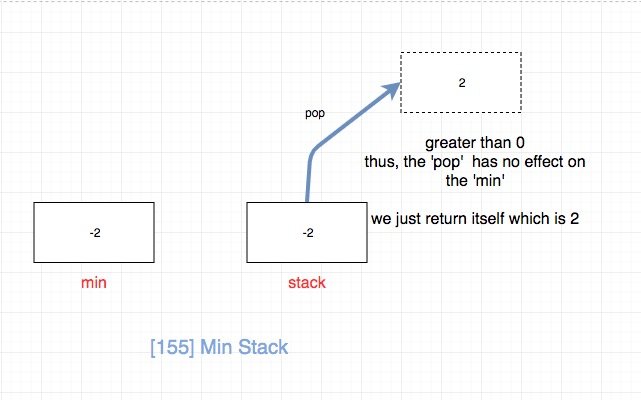
+### 关键点
-## 关键点
+- 往minstack中 push的判断条件。 应该是stack为空或者x小于等于minstack栈顶元素
-- 最小栈存储的不应该是真实值,而是真实值和min的差值
-- top的时候涉及到对数据的还原,这里千万注意是**上一个**最小值
-## 代码
+### 代码
-* 语言支持:JS,Python
+* 语言支持:JS,C++,Java,Python
-Javascript Code:
+JavaScript Code:
```js
-/*
- * @lc app=leetcode id=155 lang=javascript
- *
- * [155] Min Stack
- */
/**
* initialize your data structure here.
*/
var MinStack = function() {
- this.stack = [];
- this.minV = Number.MAX_VALUE;
+ this.stack = []
+ this.minStack = []
};
-/**
+/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
- // update 'min'
- const minV = this.minV;
- if (x < this.minV) {
- this.minV = x;
- }
- return this.stack.push(x - minV);
+ this.stack.push(x)
+ if (this.minStack.length == 0 || x <= this.minStack[this.minStack.length - 1]) {
+ this.minStack.push(x)
+ }
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
- const item = this.stack.pop();
- const minV = this.minV;
-
- if (item < 0) {
- this.minV = minV - item;
- return minV;
- }
- return item + minV;
+ const x = this.stack.pop()
+ if (x !== void 0 && x === this.minStack[this.minStack.length - 1]) {
+ this.minStack.pop()
+ }
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
- const item = this.stack[this.stack.length - 1];
- const minV = this.minV;
-
- if (item < 0) {
- return minV;
- }
- return item + minV;
+ return this.stack[this.stack.length - 1]
};
/**
* @return {number}
*/
MinStack.prototype.min = function() {
- return this.minV;
+ return this.minStack[this.minStack.length - 1]
};
-/**
+/**
* Your MinStack object will be instantiated and called as such:
* var obj = new MinStack()
* obj.push(x)
@@ -137,7 +116,107 @@ MinStack.prototype.min = function() {
*/
```
-Python Code:
+C++ Code:
+```c++
+class MinStack {
+ stack data;
+ stack helper;
+public:
+ /** initialize your data structure here. */
+ MinStack() {
+
+ }
+
+ void push(int x) {
+ data.push(x);
+ if(helper.empty() || helper.top() >= x)
+ {
+ helper.push(x);
+ }
+
+ }
+
+ void pop() {
+ int top = data.top();
+ data.pop();
+ if(top == helper.top())
+ {
+ helper.pop();
+ }
+
+ }
+
+ int top() {
+ return data.top();
+ }
+
+ int getMin() {
+ return helper.top();
+ }
+};
+
+/**
+ * Your MinStack object will be instantiated and called as such:
+ * MinStack* obj = new MinStack();
+ * obj->push(x);
+ * obj->pop();
+ * int param_3 = obj->top();
+ * int param_4 = obj->getMin();
+ */
+```
+
+Java Code:
+```java
+public class MinStack {
+
+ // 数据栈
+ private Stack data;
+ // 辅助栈
+ private Stack helper;
+
+ /**
+ * initialize your data structure here.
+ */
+ public MinStack() {
+ data = new Stack<>();
+ helper = new Stack<>();
+ }
+
+ public void push(int x) {
+ // 辅助栈在必要的时候才增加
+ data.add(x);
+ if (helper.isEmpty() || helper.peek() >= x) {
+ helper.add(x);
+ }
+ }
+
+ public void pop() {
+ // 关键 3:data 一定得 pop()
+ if (!data.isEmpty()) {
+ // 注意:声明成 int 类型,这里完成了自动拆箱,从 Integer 转成了 int,
+ // 因此下面的比较可以使用 "==" 运算符
+ int top = data.pop();
+ if(top == helper.peek()){
+ helper.pop();
+ }
+ }
+ }
+
+ public int top() {
+ if(!data.isEmpty()){
+ return data.peek();
+ }
+ }
+
+ public int getMin() {
+ if(!helper.isEmpty()){
+ return helper.peek();
+ }
+ }
+}
+```
+
+Python3 Code:
```python
class MinStack:
@@ -146,33 +225,24 @@ class MinStack:
"""
initialize your data structure here.
"""
- self.minV = float('inf')
self.stack = []
+ self.minstack = []
def push(self, x: int) -> None:
- self.stack.append(x - self.minV)
- if x < self.minV:
- self.minV = x
+ self.stack.append(x)
+ if not self.minstack or x <= self.minstack[-1]:
+ self.minstack.append(x)
def pop(self) -> None:
- if not self.stack:
- return
tmp = self.stack.pop()
- if tmp < 0:
- self.minV -= tmp
+ if tmp == self.minstack[-1]:
+ self.minstack.pop()
def top(self) -> int:
- if not self.stack:
- return
- tmp = self.stack[-1]
- if tmp < 0:
- return self.minV
- else:
- return self.minV + tmp
+ return self.stack[-1]
def min(self) -> int:
- return self.minV
-
+ return self.minstack[-1]
# Your MinStack object will be instantiated and called as such:
@@ -188,70 +258,111 @@ class MinStack:
- 空间复杂度:O(1)
-# 两个栈
+## 一个栈
-## 思路
+### 思路
-我们使用两个栈:
+符合直觉的方法是,每次对栈进行修改操作(push和pop)的时候更新最小值。 然后getMin只需要返回我们计算的最小值即可,
+top也是直接返回栈顶元素即可。 这种做法每次修改栈都需要更新最小值,因此时间复杂度是O(n).
-- 一个栈存放全部的元素,push,pop都是正常操作这个正常栈。
-- 另一个存放最小栈。 每次push,如果比最小栈的栈顶还小,我们就push进最小栈,否则不操作
-- 每次pop的时候,我们都判断其是否和最小栈栈顶元素相同,如果相同,那么我们pop掉最小栈的栈顶元素即可
+
-## 关键点
+是否有更高效的算法呢?答案是有的。
-- 往minstack中 push的判断条件。 应该是stack为空或者x小于等于minstack栈顶元素
+我们每次入栈的时候,保存的不再是真正的数字,而是它与当前最小值的差(当前元素没有入栈的时候的最小值)。
+这样我们pop和top的时候拿到栈顶元素再加上**上一个**最小值即可。
+另外我们在push和pop的时候去更新min,这样getMin的时候就简单了,直接返回min。
+
+> 注意上面加粗的“上一个”,不是“当前的最小值”
+经过上面的分析,问题的关键转化为“如何求得上一个最小值”,解决这个的关键点在于利用min。
+
+pop或者top的时候:
-## 代码
+- 如果栈顶元素小于0,说明栈顶是当前最小的元素,它出栈会对min造成影响,我们需要去更新min。
+上一个最小的是“min - 栈顶元素”,我们需要将上一个最小值更新为当前的最小值
-JavaScript:
+ > 因为栈顶元素入栈的时候的通过 `栈顶元素 = 真实值 - 上一个最小的元素` 得到的,
+ 而真实值 = min, 因此可以得出`上一个最小的元素 = 真实值 -栈顶元素`
+
+- 如果栈顶元素大于0,说明它对最小值`没有影响`,上一个最小值就是上上个最小值。
+
+
+
+
+### 关键点
+
+- 最小栈存储的不应该是真实值,而是真实值和min的差值
+- top的时候涉及到对数据的还原,这里千万注意是**上一个**最小值
+
+### 代码
+
+* 语言支持:JS,C++,Java,Python
+
+Javascript Code:
```js
+/*
+ * @lc app=leetcode id=155 lang=javascript
+ *
+ * [155] Min Stack
+ */
/**
* initialize your data structure here.
*/
var MinStack = function() {
- this.stack = []
- this.minStack = []
+ this.stack = [];
+ this.minV = Number.MAX_VALUE;
};
-/**
+/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
- this.stack.push(x)
- if (this.minStack.length == 0 || x <= this.minStack[this.minStack.length - 1]) {
- this.minStack.push(x)
- }
+ // update 'min'
+ const minV = this.minV;
+ if (x < this.minV) {
+ this.minV = x;
+ }
+ return this.stack.push(x - minV);
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
- const x = this.stack.pop()
- if (x !== void 0 && x === this.minStack[this.minStack.length - 1]) {
- this.minStack.pop()
- }
+ const item = this.stack.pop();
+ const minV = this.minV;
+
+ if (item < 0) {
+ this.minV = minV - item;
+ return minV;
+ }
+ return item + minV;
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
- return this.stack[this.stack.length - 1]
+ const item = this.stack[this.stack.length - 1];
+ const minV = this.minV;
+
+ if (item < 0) {
+ return minV;
+ }
+ return item + minV;
};
/**
* @return {number}
*/
MinStack.prototype.min = function() {
- return this.minStack[this.minStack.length - 1]
+ return this.minV;
};
-/**
+/**
* Your MinStack object will be instantiated and called as such:
* var obj = new MinStack()
* obj.push(x)
@@ -261,8 +372,124 @@ MinStack.prototype.min = function() {
*/
```
+C++ Code:
+
+```c++
+class MinStack {
+ stack data;
+ long min = INT_MAX;
+public:
+ /** initialize your data structure here. */
+ MinStack() {
+
+ }
+
+ void push(int x) {
+ data.push(x - min);
+ if(x < min)
+ {
+ min = x;
+ }
+
+ }
+
+ void pop() {
+ long top = data.top();
+ data.pop();
+ // 更新最小值
+ if(top < 0)
+ {
+ min -= top;
+ }
+
+ }
+
+ int top() {
+ long top = data.top();
+ // 最小值为 min
+ if (top < 0)
+ {
+ return min;
+ }
+ else{
+ return min+top;
+ }
+ }
+
+ int getMin() {
+ return min;
+ }
+};
-Python3:
+/**
+ * Your MinStack object will be instantiated and called as such:
+ * MinStack* obj = new MinStack();
+ * obj->push(x);
+ * obj->pop();
+ * int param_3 = obj->top();
+ * int param_4 = obj->getMin();
+ */
+```
+
+
+Java Code:
+
+```java
+class MinStack {
+ long min;
+ Stack stack;
+
+ /** initialize your data structure here. */
+ public MinStack() {
+ stack = new Stack<>();
+ }
+
+ public void push(int x) {
+ if (stack.isEmpty()) {
+ stack.push(0L);
+ min = x;
+ }
+ else {
+ stack.push(x - min);
+ if (x < min)
+ min = x;
+ }
+ }
+
+ public void pop() {
+ long p = stack.pop();
+
+ if (p < 0) {
+ // if (p < 0), the popped value is the min
+ // Recall p is added by this statement: stack.push(x - min);
+ // So, p = x - old_min
+ // old_min = x - p
+ // again, if (p < 0), x is the min so:
+ // old_min = min - p
+ min = min - p;
+ }
+ }
+
+ public int top() {
+ long p = stack.peek();
+
+ if (p < 0) {
+ return (int) min;
+ }
+ else {
+ // p = x - min
+ // x = p + min
+ return (int) (p + min);
+ }
+ }
+
+ public int getMin() {
+ return (int) min;
+ }
+}
+```
+
+Python Code:
```python
class MinStack:
@@ -271,24 +498,33 @@ class MinStack:
"""
initialize your data structure here.
"""
+ self.minV = float('inf')
self.stack = []
- self.minstack = []
def push(self, x: int) -> None:
- self.stack.append(x)
- if not self.minstack or x <= self.minstack[-1]:
- self.minstack.append(x)
+ self.stack.append(x - self.minV)
+ if x < self.minV:
+ self.minV = x
def pop(self) -> None:
+ if not self.stack:
+ return
tmp = self.stack.pop()
- if tmp == self.minstack[-1]:
- self.minstack.pop()
+ if tmp < 0:
+ self.minV -= tmp
def top(self) -> int:
- return self.stack[-1]
+ if not self.stack:
+ return
+ tmp = self.stack[-1]
+ if tmp < 0:
+ return self.minV
+ else:
+ return self.minV + tmp
def min(self) -> int:
- return self.minstack[-1]
+ return self.minV
+
# Your MinStack object will be instantiated and called as such:
@@ -301,4 +537,11 @@ class MinStack:
**复杂度分析**
- 时间复杂度:O(1)
-- 空间复杂度:O(N)
+- 空间复杂度:O(1)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/167.two-sum-ii-input-array-is-sorted.md b/problems/167.two-sum-ii-input-array-is-sorted.md
index 945365519..42b40c6aa 100644
--- a/problems/167.two-sum-ii-input-array-is-sorted.md
+++ b/problems/167.two-sum-ii-input-array-is-sorted.md
@@ -23,6 +23,18 @@ Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- amazon
+
## 思路
由于题目没有对空间复杂度有求,用一个hashmap 存储已经访问过的数字即可。
@@ -35,51 +47,16 @@ Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
## 关键点解析
-无
+- 由于是有序的,因此双指针更好
## 代码
-* 语言支持:JS,Python
+* 语言支持:JS,C++,Java,Python
Javascript Code:
```js
-/*
- * @lc app=leetcode id=167 lang=javascript
- *
- * [167] Two Sum II - Input array is sorted
- *
- * https://leetcode.com/problems/two-sum-ii-input-array-is-sorted/description/
- *
- * algorithms
- * Easy (49.46%)
- * Total Accepted: 221.8K
- * Total Submissions: 447K
- * Testcase Example: '[2,7,11,15]\n9'
- *
- * Given an array of integers that is already sorted in ascending order, find
- * two numbers such that they add up to a specific target number.
- *
- * The function twoSum should return indices of the two numbers such that they
- * add up to the target, where index1 must be less than index2.
- *
- * Note:
- *
- *
- * Your returned answers (both index1 and index2) are not zero-based.
- * You may assume that each input would have exactly one solution and you may
- * not use the same element twice.
- *
- *
- * Example:
- *
- *
- * Input: numbers = [2,7,11,15], target = 9
- * Output: [1,2]
- * Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
- *
- */
/**
* @param {number[]} numbers
* @param {number} target
@@ -99,6 +76,64 @@ var twoSum = function(numbers, target) {
};
```
+C++ Code:
+
+```c++
+class Solution {
+public:
+ vector twoSum(vector& numbers, int target) {
+ int n = numbers.size();
+ int left = 0;
+ int right = n-1;
+ while(left <= right)
+ {
+ if(numbers[left] + numbers[right] == target)
+ {
+ return {left + 1, right + 1};
+ }
+ else if (numbers[left] + numbers[right] > target)
+ {
+ right--;
+ }
+ else
+ {
+ left++;
+ }
+ }
+ return {-1, -1};
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public int[] twoSum(int[] numbers, int target) {
+ int n = numbers.length;
+ int left = 0;
+ int right = n-1;
+ while(left <= right)
+ {
+ if(numbers[left] + numbers[right] == target)
+ {
+ return new int[]{left + 1, right + 1};
+ }
+ else if (numbers[left] + numbers[right] > target)
+ {
+ right--;
+ }
+ else
+ {
+ left++;
+ }
+ }
+
+ return new int[]{-1, -1};
+ }
+}
+```
+
Python Code:
```python
@@ -123,3 +158,14 @@ class Solution:
if numbers[left] + numbers[right] == target:
return [left+1, right+1]
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/169.majority-element.md b/problems/169.majority-element.md
index e96aa912e..0d1b77f7e 100644
--- a/problems/169.majority-element.md
+++ b/problems/169.majority-element.md
@@ -20,6 +20,19 @@ Output: 2
```
+## 前置知识
+
+- 投票算法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- adobe
+- zenefits
+
## 思路
符合直觉的做法是利用额外的空间去记录每个元素出现的次数,并用一个单独的变量记录当前出现次数最多的元素。
@@ -28,13 +41,12 @@ Output: 2
投票算法的原理是通过不断消除不同元素直到没有不同元素,剩下的元素就是我们要找的元素。
-
+
## 关键点解析
- 投票算法
-
## 代码
* 语言支持:JS,Python
@@ -79,6 +91,9 @@ class Solution:
- 时间复杂度:$O(N)$,其中N为数组长度
- 空间复杂度:$O(1)$
-欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
-
+
diff --git a/problems/17.Letter-Combinations-of-a-Phone-Number.md b/problems/17.Letter-Combinations-of-a-Phone-Number.md
index 3845eb7e5..959db150b 100644
--- a/problems/17.Letter-Combinations-of-a-Phone-Number.md
+++ b/problems/17.Letter-Combinations-of-a-Phone-Number.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
## 题目描述
+
```
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
@@ -17,20 +19,36 @@ https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+- 腾讯
+
## 思路
+
使用回溯法进行求解,回溯是一种通过穷举所有可能情况来找到所有解的算法。如果一个候选解最后被发现并不是可行解,回溯算法会舍弃它,并在前面的一些步骤做出一些修改,并重新尝试找到可行解。究其本质,其实就是枚举。
如果没有更多的数字需要被输入,说明当前的组合已经产生。
如果还有数字需要被输入:
+
- 遍历下一个数字所对应的所有映射的字母
-- 将当前的字母添加到组合最后,也就是 str + tmp[r]
+- 将当前的字母添加到组合最后,也就是 str + tmp[r]
## 关键点
-利用回溯思想解题,在for循环中调用递归。
+
+- 回溯
+- 回溯模板
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -38,40 +56,39 @@ https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
* @return {string[]}
*/
const letterCombinations = function (digits) {
- if (!digits) {
- return [];
+ if (!digits) {
+ return [];
+ }
+ const len = digits.length;
+ const map = new Map();
+ map.set("2", "abc");
+ map.set("3", "def");
+ map.set("4", "ghi");
+ map.set("5", "jkl");
+ map.set("6", "mno");
+ map.set("7", "pqrs");
+ map.set("8", "tuv");
+ map.set("9", "wxyz");
+ const result = [];
+
+ function generate(i, str) {
+ if (i == len) {
+ result.push(str);
+ return;
}
- const len = digits.length;
- const map = new Map();
- map.set('2', 'abc');
- map.set('3', 'def');
- map.set('4', 'ghi');
- map.set('5', 'jkl');
- map.set('6', 'mno');
- map.set('7', 'pqrs');
- map.set('8', 'tuv');
- map.set('9', 'wxyz');
- const result = [];
-
- function generate(i, str) {
- if (i == len) {
- result.push(str);
- return;
- }
- const tmp = map.get(digits[i]);
- for (let r = 0; r < tmp.length; r++) {
- generate(i + 1, str + tmp[r]);
- }
+ const tmp = map.get(digits[i]);
+ for (let r = 0; r < tmp.length; r++) {
+ generate(i + 1, str + tmp[r]);
}
- generate(0, '');
- return result;
+ }
+ generate(0, "");
+ return result;
};
```
-***复杂度分析***
+**_复杂度分析_**
N + M 是输入数字的总数
-- 时间复杂度:O(3^N * 4^M)
-- 空间复杂度:O(3^N * 4^M)
-
+- 时间复杂度:O(3^N \* 4^M)
+- 空间复杂度:O(3^N \* 4^M)
diff --git a/problems/172.factorial-trailing-zeroes.md b/problems/172.factorial-trailing-zeroes.md
index 59b25d862..666facb4c 100644
--- a/problems/172.factorial-trailing-zeroes.md
+++ b/problems/172.factorial-trailing-zeroes.md
@@ -21,6 +21,17 @@ Note: Your solution should be in logarithmic time complexity.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- bloomberg
+
## 思路
我们需要求解这n个数字相乘的结果末尾有多少个0,由于题目要求log的复杂度,因此暴力求解是不行的。
@@ -28,16 +39,16 @@ Note: Your solution should be in logarithmic time complexity.
通过观察,我们发现如果想要结果末尾是0,必须是分解质因数之后,2 和 5 相乘才行,同时因数分解之后发现5的个数远小于2,
因此我们只需要求解这n数字分解质因数之后一共有多少个5即可.
-
+
如图如果n为30,那么结果应该是图中红色5的个数,即7。
-
+
我们的结果并不是直接f(n) = n / 5, 比如n为30, 25中是有两个5的。
类似,n为150,会有7个这样的数字,通过观察我们发现规律`f(n) = n/5 + n/5^2 + n/5^3 + n/5^4 + n/5^5+..`
-
+
如果可以发现上面的规律,用递归还是循环实现这个算式就看你的了。
## 关键点解析
@@ -94,3 +105,14 @@ class Solution:
if n == 0: return 0
return n // 5 + self.trailingZeroes(n // 5)
```
+
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/19.removeNthNodeFromEndofList.md b/problems/19.removeNthNodeFromEndofList.md
index 26d7aa0ff..33e3fe864 100644
--- a/problems/19.removeNthNodeFromEndofList.md
+++ b/problems/19.removeNthNodeFromEndofList.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/remove-nth-node-from-end-of-list/description
## 题目描述
+
Given a linked list, remove the n-th node from the end of list and return its head.
Example:
@@ -17,25 +19,35 @@ Follow up:
Could you do this in one pass?
-## 思路
+## 前置知识
+
+- 链表
+- 双指针
+
+## 公司
-双指针,指针A先移动n次, 指针B再开始移动。当A到达null的时候, 指针b的位置正好是倒数n
+- 阿里
+- 百度
+- 腾讯
+- 字节
-我们可以设想假设设定了双指针p和q的话,当q指向末尾的NULL,p与q之间相隔的元素个数为n时,那么删除掉p的下一个指针就完成了要求。
+## 思路
-设置虚拟节点dummyHead指向head
+双指针,指针 A 先移动 n 次, 指针 B 再开始移动。当 A 到达 null 的时候, 指针 b 的位置正好是倒数 n
-设定双指针p和q,初始都指向虚拟节点dummyHead
+我们可以设想假设设定了双指针 p 和 q 的话,当 q 指向末尾的 NULL,p 与 q 之间相隔的元素个数为 n 时,那么删除掉 p 的下一个指针就完成了要求。
-移动q,直到p与q之间相隔的元素个数为n
+设置虚拟节点 dummyHead 指向 head
-同时移动p与q,直到q指向的为NULL
+设定双指针 p 和 q,初始都指向虚拟节点 dummyHead
-将p的下一个节点指向下下个节点
+移动 q,直到 p 与 q 之间相隔的元素个数为 n
+同时移动 p 与 q,直到 q 指向的为 NULL
+将 p 的下一个节点指向下下个节点
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -45,7 +57,7 @@ Could you do this in one pass?
2. 使用双指针
-3. 使用一个dummyHead简化操作
+3. 使用一个 dummyHead 简化操作
## 代码
@@ -69,24 +81,24 @@ Support: JS, Java
*
* Given a linked list, remove the n-th node from the end of list and return
* its head.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Given linked list: 1->2->3->4->5, and n = 2.
- *
+ *
* After removing the second node from the end, the linked list becomes
* 1->2->3->5.
- *
- *
+ *
+ *
* Note:
- *
+ *
* Given n will always be valid.
- *
+ *
* Follow up:
- *
+ *
* Could you do this in one pass?
- *
+ *
*/
/**
* Definition for singly-linked list.
@@ -100,10 +112,10 @@ Support: JS, Java
* @param {number} n
* @return {ListNode}
*/
-var removeNthFromEnd = function(head, n) {
+var removeNthFromEnd = function (head, n) {
let i = -1;
const noop = {
- next: null
+ next: null,
};
const dummyHead = new ListNode(); // 增加一个dummyHead 简化操作
@@ -112,17 +124,15 @@ var removeNthFromEnd = function(head, n) {
let currentP1 = dummyHead;
let currentP2 = dummyHead;
-
while (currentP1) {
-
if (i === n) {
currentP2 = currentP2.next;
}
if (i !== n) {
- i++;
+ i++;
}
-
+
currentP1 = currentP1.next;
}
@@ -130,7 +140,6 @@ var removeNthFromEnd = function(head, n) {
return dummyHead.next;
};
-
```
- Java Code
@@ -165,4 +174,4 @@ class Solution {
return dummy.next;
}
}
-```
\ No newline at end of file
+```
diff --git a/problems/190.reverse-bits.md b/problems/190.reverse-bits.md
index 768ff8c56..f102e01ab 100644
--- a/problems/190.reverse-bits.md
+++ b/problems/190.reverse-bits.md
@@ -27,6 +27,18 @@ In Java, the compiler represents the signed integers using 2's complement notati
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- airbnb
+- apple
+
## 思路
这道题是给定一个32位的无符号整型,让你按位翻转, 第一位变成最后一位, 第二位变成倒数第二位。。。
@@ -165,6 +177,10 @@ class Solution:
return result
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
## 拓展
不使用迭代也可以完成相同的操作:
1. 两两相邻的1位对调
@@ -186,3 +202,10 @@ public:
}
};
```
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/191.number-of-1-bits.md b/problems/191.number-of-1-bits.md
index b4f8bc37e..8a88589c6 100644
--- a/problems/191.number-of-1-bits.md
+++ b/problems/191.number-of-1-bits.md
@@ -32,6 +32,19 @@ In Java, the compiler represents the signed integers using 2's complement notati
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- apple
+- microsoft
+
## 思路
这个题目的大意是: 给定一个无符号的整数, 返回其用二进制表式的时候的1的个数。
@@ -109,10 +122,14 @@ class Solution(object):
return count
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(N)$
+
## 扩展
可以使用位操作来达到目的。例如8位的整数21:
-
+
C++ Code:
```c++
@@ -139,3 +156,10 @@ public:
}
};
```
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/198.house-robber.en.md b/problems/198.house-robber.en.md
new file mode 100755
index 000000000..54d6420a3
--- /dev/null
+++ b/problems/198.house-robber.en.md
@@ -0,0 +1,180 @@
+## House Robber
+
+https://leetcode.com/problems/house-robber/description/
+
+## Problem Description
+
+```
+You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
+
+Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
+
+Example 1:
+
+Input: [1,2,3,1]
+Output: 4
+Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
+ Total amount you can rob = 1 + 3 = 4.
+Example 2:
+
+Input: [2,7,9,3,1]
+Output: 12
+Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
+ Total amount you can rob = 2 + 9 + 1 = 12.
+
+```
+
+## Prerequisites
+
+- Dynamic Programming
+
+## Solution
+
+This is a simple and classical dynamic programming problem, but it's helpful for understanding dynamic programming.
+
+Frequent questions when it comes to DP problems involve:
+1. Why the solution works like that? Why it works without any DP array?
+2. Why we can apply the idea of Fibonacci Numbers to the Climbing Stairs problem?
+
+We will take a look at these problems here. Similar to other DP problems, we are essentially deciding whether rob the ith house or not.
+
+If we rob the ith house, the gain would be `nums[i] + dp[i - 2]`.
+> We cannot rob i-1th house, otherwise the alarm will be triggered.
+
+If we do not rob the ith house, the gain would be `dp[i - 1]`.
+> The dp here is our subproblem.
+
+Since we always want a larger gain, it's easy to obtain the transition formula: `dp[i] = Math.max(dp[i - 2] + nums[i - 2], dp[i - 1]);`
+> Note: For the convenience of calculation, we set both dp[0] and dp[1] to be 0. This way, dp[i] is actually for the i-1th house.
+
+We can use the following graph to illustrate the above process:
+
+
+If we optimize it further, we only need dp[i - 1] and dp[i - 2] when determining each dp[i]. For example, to calculate dp[6], we would only need dp[5] and dp[4], and there's no need to keep dp[3], dp[2], and so on, in memory.
+
+Then, the code will be:
+
+```js
+let a = 0;
+let b = 0;
+
+for (let i = 0; i < nums.length; i++) {
+ const temp = b;
+ b = Math.max(a + nums[i], b);
+ a = temp;
+}
+
+return b;
+```
+
+The above code optimized the space complexity from O(n) to O(1). The same optimization applies to a lot of DP problems.
+
+## Key Points
+
+## Code (JS/C++/Python)
+
+JavaScript Code:
+
+```js
+/*
+ * @lc app=leetcode id=198 lang=javascript
+ *
+ * [198] House Robber
+ *
+ * https://leetcode.com/problems/house-robber/description/
+ *
+ * algorithms
+ * Easy (40.80%)
+ * Total Accepted: 312.1K
+ * Total Submissions: 762.4K
+ * Testcase Example: '[1,2,3,1]'
+ *
+ * You are a professional robber planning to rob houses along a street. Each
+ * house has a certain amount of money stashed, the only constraint stopping
+ * you from robbing each of them is that adjacent houses have security system
+ * connected and it will automatically contact the police if two adjacent
+ * houses were broken into on the same night.
+ *
+ * Given a list of non-negative integers representing the amount of money of
+ * each house, determine the maximum amount of money you can rob tonight
+ * without alerting the police.
+ *
+ * Example 1:
+ *
+ *
+ * Input: [1,2,3,1]
+ * Output: 4
+ * Explanation: Rob house 1 (money = 1) and then rob house 3 (money =
+ * 3).
+ * Total amount you can rob = 1 + 3 = 4.
+ *
+ * Example 2:
+ *
+ *
+ * Input: [2,7,9,3,1]
+ * Output: 12
+ * Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house
+ * 5 (money = 1).
+ * Total amount you can rob = 2 + 9 + 1 = 12.
+ *
+ *
+ */
+/**
+ * @param {number[]} nums
+ * @return {number}
+ */
+var rob = function(nums) {
+ // Tag: DP
+ const dp = [];
+ dp[0] = 0;
+ dp[1] = 0;
+
+ for (let i = 2; i < nums.length + 2; i++) {
+ dp[i] = Math.max(dp[i - 2] + nums[i - 2], dp[i - 1]);
+ }
+
+ return dp[nums.length + 1];
+};
+```
+
+C++ Code:
+
+> This is slightly different from the JavaScript solution, but it uses the same transition function.
+
+```C++
+class Solution {
+public:
+ int rob(vector& nums) {
+ if (nums.empty()) return 0;
+ auto sz = nums.size();
+ if (sz == 1) return nums[0];
+ auto prev = nums[0];
+ auto cur = max(prev, nums[1]);
+ for (auto i = 2; i < sz; ++i) {
+ auto tmp = cur;
+ cur = max(nums[i] + prev, cur);
+ prev = tmp;
+ }
+ return cur;
+ }
+};
+```
+
+Python Code:
+
+```python
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ if not nums:
+ return 0
+
+ length = len(nums)
+ if length == 1:
+ return nums[0]
+ else:
+ prev = nums[0]
+ cur = max(prev, nums[1])
+ for i in range(2, length):
+ cur, prev = max(prev + nums[i], cur), cur
+ return cur
+```
diff --git a/problems/198.house-robber.md b/problems/198.house-robber.md
index c294a2b2b..6918051ff 100644
--- a/problems/198.house-robber.md
+++ b/problems/198.house-robber.md
@@ -24,6 +24,19 @@ Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (m
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- airbnb
+- linkedin
+
## 思路
这是一道非常典型且简单的动态规划问题,但是在这里我希望通过这个例子,
@@ -46,7 +59,7 @@ Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (m
上述过程用图来表示的话,是这样的:
-
+
我们仔细观察的话,其实我们只需要保证前一个 dp[i - 1] 和 dp[i - 2] 两个变量就好了,
比如我们计算到 i = 6 的时候,即需要计算 dp[6]的时候, 我们需要 dp[5], dp[4],但是我们
@@ -77,7 +90,7 @@ return b;
## 代码
-* 语言支持:JS,C++,Python
+- 语言支持:JS,C++,Python
JavaScript Code:
@@ -129,7 +142,7 @@ JavaScript Code:
* @param {number[]} nums
* @return {number}
*/
-var rob = function(nums) {
+var rob = function (nums) {
// Tag: DP
const dp = [];
dp[0] = 0;
@@ -145,7 +158,7 @@ var rob = function(nums) {
C++ Code:
-> 与JavaScript代码略有差异,但状态迁移方程是一样的。
+> 与 JavaScript 代码略有差异,但状态迁移方程是一样的。
```C++
class Solution {
@@ -184,3 +197,18 @@ class Solution:
cur, prev = max(prev + nums[i], cur), cur
return cur
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [337.house-robber-iii](https://github.com/azl397985856/leetcode/blob/master/problems/337.house-robber-iii.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 35K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/199.binary-tree-right-side-view.md b/problems/199.binary-tree-right-side-view.md
index 40a844b26..c09838c27 100644
--- a/problems/199.binary-tree-right-side-view.md
+++ b/problems/199.binary-tree-right-side-view.md
@@ -20,6 +20,17 @@ Explanation:
5 4 <---
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
> 这道题和 leetcode 102 号问题《102.binary-tree-level-order-traversal》很像
diff --git a/problems/2.add-two-numbers.en.md b/problems/2.add-two-numbers.en.md
new file mode 100644
index 000000000..ecd31f1f7
--- /dev/null
+++ b/problems/2.add-two-numbers.en.md
@@ -0,0 +1,174 @@
+## Problem
+https://leetcode.com/problems/add-two-numbers/description/
+
+## Problem Description
+```
+You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
+
+You may assume the two numbers do not contain any leading zero, except the number 0 itself.
+
+Example
+
+Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)
+Output: 7 -> 0 -> 8
+Explanation: 342 + 465 = 807.
+
+```
+## Solution
+
+Define a new variable `carried` that represents the carry value during the calculation, and a new linked list
+Traverse the two linked lists from the start to the end simultaneously, and calculate the sum of node value from each linked list. The sum of the result and `carried` would be appended as a new node to the end of the new linked list.
+
+
+
+(Image Reference: https://github.com/MisterBooo/LeetCodeAnimation)
+
+## Key Point Analysis
+
+1. The characteristics and application of this data structure - linked list
+
+2. Define a variable named `carried` to replace the role of carry-over, calculate `carried` after each sum and apply it to the next round's calculation
+
+## Code
+* Language Support: JS, C++
+
+JavaScript:
+```js
+/**
+ * Definition for singly-linked list.
+ * function ListNode(val) {
+ * this.val = val;
+ * this.next = null;
+ * }
+ */
+/**
+ * @param {ListNode} l1
+ * @param {ListNode} l2
+ * @return {ListNode}
+ */
+var addTwoNumbers = function(l1, l2) {
+ if (l1 === null || l2 === null) return null
+
+ // using dummyHead can simplify linked list's calculation, dummyHead.next points to the new linked list
+ let dummyHead = new ListNode(0)
+ let cur1 = l1
+ let cur2 = l2
+ let cur = dummyHead // cur is for the calculation in new linked list
+ let carry = 0 // carry-over symbol
+
+ while (cur1 !== null || cur2 !== null) {
+ let val1 = cur1 !== null ? cur1.val : 0
+ let val2 = cur2 !== null ? cur2.val : 0
+ let sum = val1 + val2 + carry
+ let newNode = new ListNode(sum % 10) // the result of sum%10 ranges from 0 to 9, which is the value of the current digit
+ carry = sum >= 10 ? 1 : 0 // sum>=10, carry=1, so carry-over exists here
+ cur.next = newNode
+ cur = cur.next
+
+ if (cur1 !== null) {
+ cur1 = cur1.next
+ }
+
+ if (cur2 !== null) {
+ cur2 = cur2.next
+ }
+ }
+
+ if (carry > 0) {
+ // If there's still carry-over in the end, then add a new node
+ cur.next = new ListNode(carry)
+ }
+
+ return dummyHead.next
+};
+```
+C++
+> C++ code is slightly different from the JavaScript code above: the step that checks whether carry equals to 0 is put in the while-loop.
+```c++
+/**
+ * Definition for singly-linked list.
+ * struct ListNode {
+ * int val;
+ * ListNode *next;
+ * ListNode(int x) : val(x), next(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ ListNode* ret = nullptr;
+ ListNode* cur = nullptr;
+ int carry = 0;
+ while (l1 != nullptr || l2 != nullptr || carry != 0) {
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto temp = new ListNode(carry % 10);
+ carry /= 10;
+ if (ret == nullptr) {
+ ret = temp;
+ cur = ret;
+ }
+ else {
+ cur->next = temp;
+ cur = cur->next;
+ }
+ l1 = l1 == nullptr ? nullptr : l1->next;
+ l2 = l2 == nullptr ? nullptr : l2->next;
+ }
+ return ret;
+ }
+};
+```
+## Extension
+The singly-linked list also has a recursive structure based on its definition. Therefore, the recursive apporach works on reversing a linked list, as well.
+> Because a singly-linked list is a linear data structure, the recursive approach means that the use of stack would also be linear. When the linked list's length reaches a certain level, the recursion would result in a stack overflow. Therefore, using recursion to manipulate a linked list is not recommended in reality.
+
+### Description
+
+1. Add up the first node of two linked lists, and covert the result to a number between 0 and 10, record the carry-over as well.
+2. Proceed to add up the two linked lists after the first node with carry-over recursively
+3. Point the next of the head node from the first step to the linked list returned from the second step
+
+### C++ Implementation
+```C++
+// Normal recursion
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ return addTwoNumbers(l1, l2, 0);
+ }
+
+private:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2, int carry) {
+ if (l1 == nullptr && l2 == nullptr && carry == 0) return nullptr;
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto ret = new ListNode(carry % 10);
+ ret->next = addTwoNumbers(l1 == nullptr ? l1 : l1->next,
+ l2 == nullptr ? l2 : l2->next,
+ carry / 10);
+ return ret;
+ }
+};
+// (Similiar) Tail recursion
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ ListNode* head = nullptr;
+ addTwoNumbers(head, nullptr, l1, l2, 0);
+ return head;
+ }
+
+private:
+ void addTwoNumbers(ListNode*& head, ListNode* cur, ListNode* l1, ListNode* l2, int carry) {
+ if (l1 == nullptr && l2 == nullptr && carry == 0) return;
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto temp = new ListNode(carry % 10);
+ if (cur == nullptr) {
+ head = temp;
+ cur = head;
+ } else {
+ cur->next = temp;
+ cur = cur->next;
+ }
+ addTwoNumbers(head, cur, l1 == nullptr ? l1 : l1->next, l2 == nullptr ? l2 : l2->next, carry / 10);
+ }
+};
\ No newline at end of file
diff --git a/problems/2.addTwoNumbers.md b/problems/2.add-two-numbers.md
similarity index 72%
rename from problems/2.addTwoNumbers.md
rename to problems/2.add-two-numbers.md
index ecfac154a..659b11453 100644
--- a/problems/2.addTwoNumbers.md
+++ b/problems/2.add-two-numbers.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/add-two-numbers/description/
## 题目描述
+
```
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
@@ -14,12 +16,23 @@ Output: 7 -> 0 -> 8
Explanation: 342 + 465 = 807.
```
+
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
-设立一个表示进位的变量carried,建立一个新链表,
-把输入的两个链表从头往后同时处理,每两个相加,将结果加上carried后的值作为一个新节点到新链表后面。
+设立一个表示进位的变量 carried,建立一个新链表,
+把输入的两个链表从头往后同时处理,每两个相加,将结果加上 carried 后的值作为一个新节点到新链表后面。
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -27,12 +40,14 @@ Explanation: 342 + 465 = 807.
1. 链表这种数据结构的特点和使用
-2. 用一个carried变量来实现进位的功能,每次相加之后计算carried,并用于下一位的计算
+2. 用一个 carried 变量来实现进位的功能,每次相加之后计算 carried,并用于下一位的计算
## 代码
-* 语言支持:JS,C++
+
+- 语言支持:JS,C++
JavaScript:
+
```js
/**
* Definition for singly-linked list.
@@ -46,44 +61,47 @@ JavaScript:
* @param {ListNode} l2
* @return {ListNode}
*/
-var addTwoNumbers = function(l1, l2) {
- if (l1 === null || l2 === null) return null
+var addTwoNumbers = function (l1, l2) {
+ if (l1 === null || l2 === null) return null;
// 使用dummyHead可以简化对链表的处理,dummyHead.next指向新链表
- let dummyHead = new ListNode(0)
- let cur1 = l1
- let cur2 = l2
- let cur = dummyHead // cur用于计算新链表
- let carry = 0 // 进位标志
+ let dummyHead = new ListNode(0);
+ let cur1 = l1;
+ let cur2 = l2;
+ let cur = dummyHead; // cur用于计算新链表
+ let carry = 0; // 进位标志
while (cur1 !== null || cur2 !== null) {
- let val1 = cur1 !== null ? cur1.val : 0
- let val2 = cur2 !== null ? cur2.val : 0
- let sum = val1 + val2 + carry
- let newNode = new ListNode(sum % 10) // sum%10取模结果范围为0~9,即为当前节点的值
- carry = sum >= 10 ? 1 : 0 // sum>=10,carry=1,表示有进位
- cur.next = newNode
- cur = cur.next
+ let val1 = cur1 !== null ? cur1.val : 0;
+ let val2 = cur2 !== null ? cur2.val : 0;
+ let sum = val1 + val2 + carry;
+ let newNode = new ListNode(sum % 10); // sum%10取模结果范围为0~9,即为当前节点的值
+ carry = sum >= 10 ? 1 : 0; // sum>=10,carry=1,表示有进位
+ cur.next = newNode;
+ cur = cur.next;
if (cur1 !== null) {
- cur1 = cur1.next
+ cur1 = cur1.next;
}
if (cur2 !== null) {
- cur2 = cur2.next
+ cur2 = cur2.next;
}
}
if (carry > 0) {
// 如果最后还有进位,新加一个节点
- cur.next = new ListNode(carry)
+ cur.next = new ListNode(carry);
}
- return dummyHead.next
+ return dummyHead.next;
};
```
+
C++
-> C++代码与上面的JavaScript代码略有不同:将carry是否为0的判断放到了while循环中
+
+> C++代码与上面的 JavaScript 代码略有不同:将 carry 是否为 0 的判断放到了 while 循环中
+
```c++
/**
* Definition for singly-linked list.
@@ -118,18 +136,21 @@ public:
}
};
```
+
## 拓展
-通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行reverse操作。
+通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行 reverse 操作。
+
> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
### 描述
-1. 将两个链表的第一个节点值相加,结果转为0-10之间的个位数,并设置进位信息
+1. 将两个链表的第一个节点值相加,结果转为 0-10 之间的个位数,并设置进位信息
2. 将两个链表第一个节点以后的链表做带进位的递归相加
-3. 将第一步得到的头节点的next指向第二步返回的链表
+3. 将第一步得到的头节点的 next 指向第二步返回的链表
+
+### C++实现
-### C++实现
```C++
// 普通递归
class Solution {
@@ -137,7 +158,7 @@ public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
return addTwoNumbers(l1, l2, 0);
}
-
+
private:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2, int carry) {
if (l1 == nullptr && l2 == nullptr && carry == 0) return nullptr;
@@ -157,7 +178,7 @@ public:
addTwoNumbers(head, nullptr, l1, l2, 0);
return head;
}
-
+
private:
void addTwoNumbers(ListNode*& head, ListNode* cur, ListNode* l1, ListNode* l2, int carry) {
if (l1 == nullptr && l2 == nullptr && carry == 0) return;
diff --git a/problems/20.valid-parentheses.md b/problems/20.valid-parentheses.md
new file mode 100644
index 000000000..a7769d9e3
--- /dev/null
+++ b/problems/20.valid-parentheses.md
@@ -0,0 +1,255 @@
+## 题目地址
+
+https://leetcode.com/problems/valid-parentheses/description
+
+## 题目描述
+
+```
+Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
+
+An input string is valid if:
+
+Open brackets must be closed by the same type of brackets.
+Open brackets must be closed in the correct order.
+Note that an empty string is also considered valid.
+
+Example 1:
+
+Input: "()"
+Output: true
+Example 2:
+
+Input: "()[]{}"
+Output: true
+Example 3:
+
+Input: "(]"
+Output: false
+Example 4:
+
+Input: "([)]"
+Output: false
+Example 5:
+
+Input: "{[]}"
+Output: true
+```
+
+## 前置知识
+
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+- airbnb
+- amazon
+- bloomberg
+- facebook
+- google
+- microsoft
+- twitter
+- zenefits
+
+## 栈
+
+### 思路
+
+关于这道题的思路,邓俊辉讲的非常好,没有看过的同学可以看一下,[视频地址](http://www.xuetangx.com/courses/course-v1:TsinghuaX+30240184+sp/courseware/ad1a23c053df4501a3facd66ef6ccfa9/8d6f450e7f7a445098ae1d507fda80f6/)。
+
+使用栈,遍历输入字符串
+
+如果当前字符为左半边括号时,则将其压入栈中
+
+如果遇到右半边括号时,分类讨论:
+
+1)如栈不为空且为对应的左半边括号,则取出栈顶元素,继续循环
+
+2)若此时栈为空,则直接返回 false
+
+3)若不为对应的左半边括号,反之返回 false
+
+
+
+(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
+> 值得注意的是,如果题目要求只有一种括号,那么我们其实可以使用更简洁,更省内存的方式 - 计数器来进行求解,而
+> 不必要使用栈。
+
+> 事实上,这类问题还可以进一步扩展,我们可以去解析类似 HTML 等标记语法, 比如
+
+### 关键点解析
+
+1. 栈的基本特点和操作
+2. 如果你用的是 JS 没有现成的栈,可以用数组来模拟
+ 入: push 出:pop
+
+> 入: push 出 shift 就是队列
+
+### 代码
+
+代码支持:JS,Python
+
+Javascript Code:
+
+```js
+/**
+ * @param {string} s
+ * @return {boolean}
+ */
+var isValid = function (s) {
+ let valid = true;
+ const stack = [];
+ const mapper = {
+ "{": "}",
+ "[": "]",
+ "(": ")",
+ };
+
+ for (let i in s) {
+ const v = s[i];
+ if (["(", "[", "{"].indexOf(v) > -1) {
+ stack.push(v);
+ } else {
+ const peak = stack.pop();
+ if (v !== mapper[peak]) {
+ return false;
+ }
+ }
+ }
+
+ if (stack.length > 0) return false;
+
+ return valid;
+};
+```
+
+Python Code:
+
+```py
+ class Solution:
+ def isValid(self,s):
+ stack = []
+ map = {
+ "{":"}",
+ "[":"]",
+ "(":")"
+ }
+ for x in s:
+ if x in map:
+ stack.append(map[x])
+ else:
+ if len(stack)!=0:
+ top_element = stack.pop()
+ if x != top_element:
+ return False
+ else:
+ continue
+ else:
+ return False
+ return len(stack) == 0
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## O(1) 空间
+
+### 思路
+
+基本思路是修改参数,将参数作为我们的栈。 随着我们不断遍历, s 慢慢变成了一个栈。
+
+因此 Python,Java,JS 等**字符串不可变**的语言无法使用此方法达到 $O(1)$。
+
+具体参考: [No stack O(1) space complexity O(n) time complexity solution in C++]()
+
+### 代码
+
+代码支持:C++
+
+C++:
+
+```c++
+class Solution {
+public:
+ bool isValid(string s) {
+ int top = -1;
+ for(int i =0;i 值得注意的是,如果题目要求只有一种括号,那么我们其实可以使用更简洁,更省内存的方式 - 计数器来进行求解,而
-不必要使用栈。
-
-> 事实上,这类问题还可以进一步扩展,我们可以去解析类似 HTML 等标记语法, 比如
-
-## 关键点解析
-
-1. 栈的基本特点和操作
-2. 如果你用的是 JS 没有现成的栈,可以用数组来模拟
-入: push 出:pop
-
-> 入: push 出 shift 就是队列
-## 代码
-
-* 语言支持:JS,Python
-
-Javascript Code:
-```js
-/**
- * @param {string} s
- * @return {boolean}
- */
-var isValid = function(s) {
- let valid = true;
- const stack = [];
- const mapper = {
- '{': "}",
- "[": "]",
- "(": ")"
- }
-
- for(let i in s) {
- const v = s[i];
- if (['(', '[', '{'].indexOf(v) > -1) {
- stack.push(v);
- } else {
- const peak = stack.pop();
- if (v !== mapper[peak]) {
- return false;
- }
- }
- }
-
- if (stack.length > 0) return false;
-
- return valid;
-};
-```
-Python Code:
-```
- class Solution:
- def isValid(self,s):
- stack = []
- map = {
- "{":"}",
- "[":"]",
- "(":")"
- }
- for x in s:
- if x in map:
- stack.append(map[x])
- else:
- if len(stack)!=0:
- top_element = stack.pop()
- if x != top_element:
- return False
- else:
- continue
- else:
- return False
- return len(stack) == 0
-```
-
-## 扩展
-如果让你检查 XML 标签是否闭合如何检查, 更进一步如果要你实现一个简单的 XML 的解析器,应该怎么实现?
diff --git a/problems/200.number-of-islands.md b/problems/200.number-of-islands.md
index 4615308d9..f64648d22 100644
--- a/problems/200.number-of-islands.md
+++ b/problems/200.number-of-islands.md
@@ -28,11 +28,22 @@ Output: 3
```
+## 前置知识
+
+- DFS
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
如图,我们其实就是要求红色区域的个数,换句话说就是求连续区域的个数。
-
+
符合直觉的做法是用DFS来解:
@@ -157,7 +168,7 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
## 相关题目
diff --git a/problems/201.bitwise-and-of-numbers-range.md b/problems/201.bitwise-and-of-numbers-range.md
index 5d148cc8b..2d3d2cbe1 100644
--- a/problems/201.bitwise-and-of-numbers-range.md
+++ b/problems/201.bitwise-and-of-numbers-range.md
@@ -18,6 +18,17 @@ Output: 0
```
+## 前置知识
+
+- 位运算
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
一个显而易见的解法是, 从m到n依次进行`求与`的操作。
diff --git a/problems/203.remove-linked-list-elements.md b/problems/203.remove-linked-list-elements.md
index 7955c0052..d9390dbdb 100644
--- a/problems/203.remove-linked-list-elements.md
+++ b/problems/203.remove-linked-list-elements.md
@@ -12,6 +12,17 @@ Output: 1->2->3->4->5
```
+## 前置知识
+
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这个一个链表基本操作的题目,思路就不多说了。
## 关键点解析
@@ -88,3 +99,15 @@ class Solution:
cur = cur.next
return prev.next
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/206.reverse-linked-list.md b/problems/206.reverse-linked-list.md
index 2a29e7135..a86de6317 100644
--- a/problems/206.reverse-linked-list.md
+++ b/problems/206.reverse-linked-list.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-linked-list/description/
## 题目描述
+
Reverse a singly linked list.
Example:
@@ -12,10 +14,34 @@ Follow up:
A linked list can be reversed either iteratively or recursively. Could you implement both?
+## 前置知识
+
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- adobe
+- amazon
+- apple
+- bloomberg
+- facebook
+- microsoft
+- snapchat
+- twitter
+- uber
+- yahoo
+- yelp
+- zenefits
+
## 思路
+
这个就是常规操作了,使用一个变量记录前驱 pre,一个变量记录后继 next.
不断更新`current.next = pre` 就好了
+
## 关键点解析
- 链表的基本操作(交换)
@@ -40,22 +66,21 @@ JavaScript Code:
* @param {ListNode} head
* @return {ListNode}
*/
-var reverseList = function(head) {
- if (!head || !head.next) return head;
+var reverseList = function (head) {
+ if (!head || !head.next) return head;
- let cur = head;
- let pre = null;
+ let cur = head;
+ let pre = null;
- while(cur) {
- const next = cur.next;
- cur.next = pre;
- pre = cur;
- cur = next;
- }
+ while (cur) {
+ const next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
+ }
- return pre;
+ return pre;
};
-
```
C++ Code:
@@ -132,19 +157,23 @@ class Solution {
}
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
## 拓展
通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行 reverse 操作。
-> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
-### 描述
+> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
1. 除第一个节点外,递归将链表 reverse
2. 将第一个节点添加到已 reverse 的链表之后
> 这里需要注意的是,每次需要保存已经 reverse 的链表的头节点和尾节点
-### C++实现
+C++实现
+
```c++
// 普通递归
class Solution {
@@ -192,28 +221,30 @@ public:
};
```
-### JavaScript 实现
+JavaScript 实现
+
```javascript
-var reverseList = function(head) {
+var reverseList = function (head) {
// 递归结束条件
if (head === null || head.next === null) {
- return head
+ return head;
}
// 递归反转 子链表
- let newReverseList = reverseList(head.next)
+ let newReverseList = reverseList(head.next);
// 获取原来链表的第 2 个节点 newReverseListTail
- let newReverseListTail = head.next
+ let newReverseListTail = head.next;
// 调整原来头结点和第 2 个节点的指向
- newReverseListTail.next = head
- head.next = null
+ newReverseListTail.next = head;
+ head.next = null;
// 将调整后的链表返回
- return newReverseList
-}
+ return newReverseList;
+};
```
-### Python 实现
+Python 实现
+
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
@@ -223,3 +254,19 @@ class Solution:
head.next = None
return ans
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## 相关题目
+
+- [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md)
+- [25.reverse-nodes-in-k-groups](./25.reverse-nodes-in-k-groups-cn.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/208.implement-trie-prefix-tree.md b/problems/208.implement-trie-prefix-tree.md
index 959d3e964..6d413a1be 100644
--- a/problems/208.implement-trie-prefix-tree.md
+++ b/problems/208.implement-trie-prefix-tree.md
@@ -24,6 +24,17 @@ All inputs are guaranteed to be non-empty strings.
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道很直接的题目,上来就让你实现`前缀树(字典树)`。这算是基础数据结构中的
@@ -55,25 +66,12 @@ function computeIndex(c) {
其实不管 insert, search 和 startWith 的逻辑都是差不多的,都是从 root 出发,
找到我们需要操作的 child, 然后进行相应操作(添加,修改,返回)。
-
+
## 关键点解析
- 前缀树
-- 核心逻辑
-
-```js
- const c = word[i];
- const current = computeIndex(c)
-if (!ws.children[current]) {
- ws.children[current] = new TrieNode(c);
- }
- ws = ws.children[current]; // 深度递增
-}
-
-```
-
## 代码
```js
@@ -125,7 +123,7 @@ function computeIndex(c) {
/**
* Initialize your data structure here.
*/
-var Trie = function() {
+var Trie = function () {
this.root = new TrieNode(null);
};
@@ -134,7 +132,7 @@ var Trie = function() {
* @param {string} word
* @return {void}
*/
-Trie.prototype.insert = function(word) {
+Trie.prototype.insert = function (word) {
let ws = this.root;
for (let i = 0; i < word.length; i++) {
const c = word[i];
@@ -152,7 +150,7 @@ Trie.prototype.insert = function(word) {
* @param {string} word
* @return {boolean}
*/
-Trie.prototype.search = function(word) {
+Trie.prototype.search = function (word) {
let ws = this.root;
for (let i = 0; i < word.length; i++) {
const c = word[i];
@@ -168,7 +166,7 @@ Trie.prototype.search = function(word) {
* @param {string} prefix
* @return {boolean}
*/
-Trie.prototype.startsWith = function(prefix) {
+Trie.prototype.startsWith = function (prefix) {
let ws = this.root;
for (let i = 0; i < prefix.length; i++) {
const c = prefix[i];
@@ -194,3 +192,4 @@ Trie.prototype.startsWith = function(prefix) {
- [0212.word-search-ii](./212.word-search-ii.md)
- [0472.concatenated-words](./problems/472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/209.minimum-size-subarray-sum.md b/problems/209.minimum-size-subarray-sum.md
index df3c648e0..b154b52b0 100644
--- a/problems/209.minimum-size-subarray-sum.md
+++ b/problems/209.minimum-size-subarray-sum.md
@@ -17,11 +17,22 @@ If you have figured out the O(n) solution, try coding another solution of which
```
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
用滑动窗口来记录序列, 每当滑动窗口中的 sum 超过 s, 就去更新最小值,并根据先进先出的原则更新滑动窗口,直至 sum 刚好小于 s
-
+
> 这道题目和 leetcode 3 号题目有点像,都可以用滑动窗口的思路来解决
@@ -117,7 +128,7 @@ public:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
## 扩展
diff --git a/problems/21.MergeTwoSortedLists.md b/problems/21.MergeTwoSortedLists.md
deleted file mode 100644
index 86b5ce76d..000000000
--- a/problems/21.MergeTwoSortedLists.md
+++ /dev/null
@@ -1,63 +0,0 @@
-## 题目地址
-https://leetcode-cn.com/problems/merge-two-sorted-lists
-
-## 题目描述
-```
-将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
-
-示例:
-
-输入:1->2->4, 1->3->4
-输出:1->1->2->3->4->4
-
-```
-
-## 思路
-使用递归来解题,将两个链表头部较小的一个与剩下的元素合并,并返回排好序的链表头,当两条链表中的一条为空时终止递归。
-
-
-## 关键点
-
-- 掌握链表数据结构
-- 考虑边界情况
-
-## 代码
-* 语言支持:JS
-
-```js
-/**
- * Definition for singly-linked list.
- * function ListNode(val) {
- * this.val = val;
- * this.next = null;
- * }
- */
-/**
- * @param {ListNode} l1
- * @param {ListNode} l2
- * @return {ListNode}
- */
-const mergeTwoLists = function (l1, l2) {
- if (l1 === null) {
- return l2;
- }
- if (l2 === null) {
- return l1;
- }
- if (l1.val < l2.val) {
- l1.next = mergeTwoLists(l1.next, l2);
- return l1;
- } else {
- l2.next = mergeTwoLists(l1, l2.next);
- return l2;
- }
-};
-```
-
-***复杂度分析***
-
-M、N 是两条链表 l1、l2 的长度
-
-- 时间复杂度:O(M+N)
-- 空间复杂度:O(M+N)
-
diff --git a/problems/21.merge-two-sorted-lists.md b/problems/21.merge-two-sorted-lists.md
new file mode 100644
index 000000000..1e977dabc
--- /dev/null
+++ b/problems/21.merge-two-sorted-lists.md
@@ -0,0 +1,91 @@
+## 题目地址
+
+https://leetcode-cn.com/problems/merge-two-sorted-lists
+
+## 题目描述
+
+```
+将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
+
+示例:
+
+输入:1->2->4, 1->3->4
+输出:1->1->2->3->4->4
+
+```
+
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 字节
+- 腾讯
+- amazon
+- apple
+- linkedin
+- microsoft
+
+## 公司
+
+- 阿里、字节、腾讯
+
+## 思路
+
+使用递归来解题,将两个链表头部较小的一个与剩下的元素合并,并返回排好序的链表头,当两条链表中的一条为空时终止递归。
+
+## 关键点
+
+- 掌握链表数据结构
+- 考虑边界情况 2
+
+## 代码
+
+- 语言支持:JS
+
+```js
+/**
+ * Definition for singly-linked list.
+ * function ListNode(val) {
+ * this.val = val;
+ * this.next = null;
+ * }
+ */
+/**
+ * @param {ListNode} l1
+ * @param {ListNode} l2
+ * @return {ListNode}
+ */
+const mergeTwoLists = function (l1, l2) {
+ if (l1 === null) {
+ return l2;
+ }
+ if (l2 === null) {
+ return l1;
+ }
+ if (l1.val < l2.val) {
+ l1.next = mergeTwoLists(l1.next, l2);
+ return l1;
+ } else {
+ l2.next = mergeTwoLists(l1, l2.next);
+ return l2;
+ }
+};
+```
+
+**复杂度分析**
+
+M、N 是两条链表 l1、l2 的长度
+
+- 时间复杂度:$O(M+N)$
+- 空间复杂度:$O(M+N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/211.add-and-search-word-data-structure-design.md b/problems/211.add-and-search-word-data-structure-design.md
index a0b4037be..445312aab 100644
--- a/problems/211.add-and-search-word-data-structure-design.md
+++ b/problems/211.add-and-search-word-data-structure-design.md
@@ -26,6 +26,15 @@ search("b..") -> true
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 腾讯
+
## 思路
我们首先不考虑字符"."的情况。这种情况比较简单,我们 addWord 直接添加到数组尾部,search 则线性查找即可。
@@ -36,7 +45,7 @@ search("b..") -> true
关于前缀树,LeetCode 有很多题目。有的是直接考察,让你实现一个前缀树,有的是间接考察,比如本题。前缀树代码见下方,大家之后可以直接当成前缀树的解题模板使用。
-
+
由于我们这道题需要考虑特殊字符".",因此我们需要对标准前缀树做一点改造,insert 不做改变,我们只需要改变 search 即可,代码(Python 3):
diff --git a/problems/212.word-search-ii.md b/problems/212.word-search-ii.md
index fe978fa87..b3edcff12 100644
--- a/problems/212.word-search-ii.md
+++ b/problems/212.word-search-ii.md
@@ -31,6 +31,16 @@ words = ["oath","pea","eat","rain"] and board =
```
+## 前置知识
+
+- 前缀树
+- DFS
+
+## 公司
+
+- 百度
+- 字节
+
## 思路
我们需要对矩阵中每一项都进行深度优先遍历(DFS)。 递归的终点是
@@ -44,7 +54,7 @@ words = ["oath","pea","eat","rain"] and board =
刚才我提到了一个关键词“前缀”,我们考虑使用前缀树来优化。使得复杂度降低为$O(h)$, 其中 h 是前缀树深度,也就是最长的字符串长度。
-
+
## 关键点
@@ -138,5 +148,6 @@ class Solution:
- [0208.implement-trie-prefix-tree](./208.implement-trie-prefix-tree.md)
- [0211.add-and-search-word-data-structure-design](./211.add-and-search-word-data-structure-design.md)
-- [0472.concatenated-words](./problems/472.concatenated-words.md)
+- [0472.concatenated-words](./472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/215.kth-largest-element-in-an-array.md b/problems/215.kth-largest-element-in-an-array.md
index 47f741530..8fcdea381 100644
--- a/problems/215.kth-largest-element-in-an-array.md
+++ b/problems/215.kth-largest-element-in-an-array.md
@@ -18,6 +18,18 @@ Note:
You may assume k is always valid, 1 ≤ k ≤ array's length.
```
+## 前置知识
+
+- 堆
+- Quick Select
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题要求在一个无序的数组中,返回第K大的数。根据时间复杂度不同,这题有3种不同的解法。
@@ -40,7 +52,7 @@ You may assume k is always valid, 1 ≤ k ≤ array's length.
扫描一遍数组,最后堆顶就是第`K`大的元素。 直接返回。
例如:
-
+
*时间复杂度*:`O(n * logk) , n is array length`
*空间复杂度*:`O(k)`
@@ -65,7 +77,7 @@ Quick Select 类似快排,选取pivot,把小于pivot的元素都移到pivot
如下图:
```
-
+
*时间复杂度*:
- 平均是:`O(n)`
diff --git a/problems/219.contains-duplicate-ii.md b/problems/219.contains-duplicate-ii.md
index c2c85b964..8fc0aeab4 100644
--- a/problems/219.contains-duplicate-ii.md
+++ b/problems/219.contains-duplicate-ii.md
@@ -23,16 +23,29 @@ Output: false
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
由于题目没有对空间复杂度有求,用一个hashmap 存储已经访问过的数字即可,
每次访问都会看hashmap中是否有这个元素,有的话拿出索引进行比对,是否满足条件(相隔不大于k),如果满足返回true即可。
+## 公司
+- airbnb
+- palantir
## 关键点解析
-无
-
+- 空间换时间
## 代码
@@ -135,3 +148,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/22.GenerateParentheses.md b/problems/22.generate-parentheses.md
similarity index 59%
rename from problems/22.GenerateParentheses.md
rename to problems/22.generate-parentheses.md
index 352f265e5..b11565b75 100644
--- a/problems/22.GenerateParentheses.md
+++ b/problems/22.generate-parentheses.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/generate-parentheses
## 题目描述
+
```
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
@@ -18,18 +20,29 @@ https://leetcode-cn.com/problems/generate-parentheses
```
+## 前置知识
+
+- DFS
+- 回溯法
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+
## 思路
深度优先搜索(回溯思想),从空字符串开始构造,做加法。
-
## 关键点
- 当 l < r 时记得剪枝
-
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -41,32 +54,31 @@ https://leetcode-cn.com/problems/generate-parentheses
* @param res 结果集
*/
const generateParenthesis = function (n) {
- const res = [];
-
- function dfs(l, r, str) {
- if (l == n && r == n) {
- return res.push(str);
- }
- // l 小于 r 时不满足条件 剪枝
- if (l < r) {
- return;
- }
- // l 小于 n 时可以插入左括号,最多可以插入 n 个
- if (l < n) {
- dfs(l + 1, r, str + '(');
- }
- // r < l 时 可以插入右括号
- if (r < l) {
- dfs(l, r + 1, str + ')');
- }
+ const res = [];
+
+ function dfs(l, r, str) {
+ if (l == n && r == n) {
+ return res.push(str);
+ }
+ // l 小于 r 时不满足条件 剪枝
+ if (l < r) {
+ return;
}
- dfs(0, 0, '');
- return res;
+ // l 小于 n 时可以插入左括号,最多可以插入 n 个
+ if (l < n) {
+ dfs(l + 1, r, str + "(");
+ }
+ // r < l 时 可以插入右括号
+ if (r < l) {
+ dfs(l, r + 1, str + ")");
+ }
+ }
+ dfs(0, 0, "");
+ return res;
};
```
-
-***复杂度分析***
+**_复杂度分析_**
- 时间复杂度:O(2^N)
- 空间复杂度:O(2^N)
diff --git a/problems/221.maximal-square.md b/problems/221.maximal-square.md
index 3649d73ce..d7ccc44d3 100644
--- a/problems/221.maximal-square.md
+++ b/problems/221.maximal-square.md
@@ -21,9 +21,21 @@ Input:
Output: 4
```
+## 前置知识
+
+- 动态规划
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-
+
符合直觉的做法是暴力求解处所有的正方形,逐一计算面积,然后记录最大的。这种时间复杂度很高。
@@ -37,13 +49,13 @@ Output: 4
dp[2][2]等于1(之前已经计算好了),那么其实这里的瓶颈在于三者的最小值, 即`Min(1, 1, 3)`, 也就是`1`。 那么dp[3][3] 就等于
`Min(1, 1, 3) + 1`。
-
+
dp[i - 1][j - 1]我们直接拿到,关键是`往上和往左进行延伸`, 最直观的做法是我们内层加一个循环去做就好了。
但是我们仔细观察一下,其实我们根本不需要这样算。 我们可以直接用dp[i - 1][j]和dp[i][j -1]。
具体就是`Min(dp[i - 1][j - 1], dp[i][j - 1], dp[i - 1][j]) + 1`。
-
+
事实上,这道题还有空间复杂度O(N)的解法,其中N指的是列数。
大家可以去这个[leetcode讨论](https://leetcode.com/problems/maximal-square/discuss/61803/C%2B%2B-space-optimized-DP)看一下。
@@ -55,9 +67,31 @@ dp[i - 1][j - 1]我们直接拿到,关键是`往上和往左进行延伸`, 最
## 代码
-```js
+代码支持:Python,JavaScript:
+
+Python Code:
+
+```python
+class Solution:
+ def maximalSquare(self, matrix: List[List[str]]) -> int:
+ res = 0
+ m = len(matrix)
+ if m == 0:
+ return 0
+ n = len(matrix[0])
+ dp = [[0] * (n + 1) for _ in range(m + 1)]
+
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ dp[i][j] = min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) + 1 if matrix[i - 1][j - 1] == "1" else 0
+ res = max(res, dp[i][j])
+ return res ** 2
+```
+
+JavaScript Code:
+```js
/*
* @lc app=leetcode id=221 lang=javascript
@@ -99,3 +133,7 @@ var maximalSquare = function(matrix) {
```
+***复杂度分析***
+
+- 时间复杂度:$O(M * N)$,其中M为行数,N为列数。
+- 空间复杂度:$O(M * N)$,其中M为行数,N为列数。
diff --git a/problems/226.invert-binary-tree.md b/problems/226.invert-binary-tree.md
index 664bcf1f4..1812c2c39 100644
--- a/problems/226.invert-binary-tree.md
+++ b/problems/226.invert-binary-tree.md
@@ -29,6 +29,17 @@ This problem was inspired by this original tweet by Max Howell:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so f*** off.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
遍历树(随便怎么遍历),然后将左右子树交换位置。
## 关键点解析
@@ -44,48 +55,6 @@ Google: 90% of our engineers use the software you wrote (Homebrew), but you can
Javascript Code:
```js
-/*
- * @lc app=leetcode id=226 lang=javascript
- *
- * [226] Invert Binary Tree
- *
- * https://leetcode.com/problems/invert-binary-tree/description/
- *
- * algorithms
- * Easy (57.14%)
- * Total Accepted: 311K
- * Total Submissions: 540.6K
- * Testcase Example: '[4,2,7,1,3,6,9]'
- *
- * Invert a binary tree.
- *
- * Example:
- *
- * Input:
- *
- *
- * 4
- * / \
- * 2 7
- * / \ / \
- * 1 3 6 9
- *
- * Output:
- *
- *
- * 4
- * / \
- * 7 2
- * / \ / \
- * 9 6 3 1
- *
- * Trivia:
- * This problem was inspired by this original tweet by Max Howell:
- *
- * Google: 90% of our engineers use the software you wrote (Homebrew), but you
- * can’t invert a binary tree on a whiteboard so f*** off.
- *
- */
/**
* Definition for a binary tree node.
* function TreeNode(val) {
@@ -181,3 +150,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/229.majority-element-ii.md b/problems/229.majority-element-ii.md
index bbe4b64d8..aa684a25b 100644
--- a/problems/229.majority-element-ii.md
+++ b/problems/229.majority-element-ii.md
@@ -19,6 +19,17 @@ Input: [1,1,1,3,3,2,2,2]
Output: [1,2]
```
+## 前置知识
+
+- 摩尔投票法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目和[169.majority-element](./169.majority-element.md) 很像。
@@ -35,9 +46,9 @@ Output: [1,2]
这里画了一个图,大家可以感受一下:
-
+
-
+
diff --git a/problems/23.merge-k-sorted-lists.md b/problems/23.merge-k-sorted-lists.md
index 5efe60fe4..121fea4ab 100644
--- a/problems/23.merge-k-sorted-lists.md
+++ b/problems/23.merge-k-sorted-lists.md
@@ -16,6 +16,18 @@ https://leetcode-cn.com/problems/merge-k-sorted-lists/description/
]
输出: 1->1->2->3->4->4->5->6
+## 前置知识
+
+- 链表
+- 归并排序
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+
## 思路
这道题目是合并 k 个已排序的链表,号称 leetcode 目前`最难`的链表题。 和之前我们解决的[88.merge-sorted-array](./88.merge-sorted-array.md)很像。
@@ -30,14 +42,14 @@ https://leetcode-cn.com/problems/merge-k-sorted-lists/description/
具体我们可以来看一个动画
-
+
(动画来自 https://zhuanlan.zhihu.com/p/61796021 )
## 关键点解析
- 分治
-- 合并排序(merge sort)
+- 归并排序(merge sort)
## 代码
@@ -159,4 +171,4 @@ class Solution:
## 相关题目
--[88.merge-sorted-array](./88.merge-sorted-array.md)
+- [88.merge-sorted-array](./88.merge-sorted-array.md)
diff --git a/problems/230.kth-smallest-element-in-a-bst.md b/problems/230.kth-smallest-element-in-a-bst.md
index b11e07d78..85fc9d9fe 100644
--- a/problems/230.kth-smallest-element-in-a-bst.md
+++ b/problems/230.kth-smallest-element-in-a-bst.md
@@ -35,6 +35,17 @@ What if the BST is modified (insert/delete operations) often and you need to fin
```
+## 前置知识
+
+- 中序遍历
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
解法一:
diff --git a/problems/232.implement-queue-using-stacks.md b/problems/232.implement-queue-using-stacks.md
index d5f4b1eaf..39b3e2e85 100644
--- a/problems/232.implement-queue-using-stacks.md
+++ b/problems/232.implement-queue-using-stacks.md
@@ -27,6 +27,19 @@ Depending on your language, stack may not be supported natively. You may simulat
You may assume that all operations are valid (for example, no pop or peek operations will be called on an empty queue).
```
+## 前置知识
+
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- microsoft
+
## 思路
这道题目是让我们用栈来模拟实现队列。 我们知道栈和队列都是一种受限的数据结构。
@@ -44,20 +57,20 @@ You may assume that all operations are valid (for example, no pop or peek operat
push之前是这样的:
-
+
然后我们将栈中的元素转移到辅助栈:
-
+
最后将新的元素添加到栈顶。
-
+
整个过程是这样的:
-
+
## 关键点解析
- 在push的时候利用辅助栈(双栈)
@@ -235,6 +248,10 @@ class MyQueue {
*/
````
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
## 扩展
- 类似的题目有用队列实现栈,思路是完全一样的,大家有兴趣可以试一下。
- 栈混洗也是借助另外一个栈来完成的,从这点来看,两者有相似之处。
@@ -250,3 +267,12 @@ class MyQueue {
- [reference](https://leetcode.com/problems/implement-queue-using-stacks/discuss/64284/Do-you-know-when-we-should-use-two-stacks-to-implement-a-queue)
- [further reading](https://stackoverflow.com/questions/2050120/why-use-two-stacks-to-make-a-queue/2050402#2050402)
+
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/236.lowest-common-ancestor-of-a-binary-tree.md b/problems/236.lowest-common-ancestor-of-a-binary-tree.md
index f5a85d6e0..f10600ea4 100644
--- a/problems/236.lowest-common-ancestor-of-a-binary-tree.md
+++ b/problems/236.lowest-common-ancestor-of-a-binary-tree.md
@@ -12,7 +12,7 @@ According to the definition of LCA on Wikipedia: “The lowest common ancestor i
Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]
```
-
+
```
Example 1:
@@ -33,6 +33,17 @@ All of the nodes' values will be unique.
p and q are different and both values will exist in the binary tree.
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求解二叉树中,两个给定节点的最近的公共祖先。是一道非常经典的二叉树题目。
@@ -47,7 +58,7 @@ p and q are different and both values will exist in the binary tree.
对于具体的代码而言就是,我们假设这个树就一个结构,然后尝试去解决,然后在适当地方去递归自身即可。 如下图所示:
-
+
我们来看下核心代码:
diff --git a/problems/238.product-of-array-except-self.md b/problems/238.product-of-array-except-self.md
index 70f5a0119..b1a167703 100644
--- a/problems/238.product-of-array-except-self.md
+++ b/problems/238.product-of-array-except-self.md
@@ -1,24 +1,41 @@
-## 题目地址
+## 题目地址(238. 除自身以外数组的乘积)
https://leetcode.com/problems/product-of-array-except-self/description/
## 题目描述
```
-Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
+给你一个长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
-Example:
+
-Input: [1,2,3,4]
-Output: [24,12,8,6]
-Note: Please solve it without division and in O(n).
+示例:
-Follow up:
-Could you solve it with constant space complexity? (The output array does not count as extra space for the purpose of space complexity analysis.)
+输入: [1,2,3,4]
+输出: [24,12,8,6]
+
+
+提示:题目数据保证数组之中任意元素的全部前缀元素和后缀(甚至是整个数组)的乘积都在 32 位整数范围内。
+
+说明: 请不要使用除法,且在 O(n) 时间复杂度内完成此题。
+
+进阶:
+你可以在常数空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组不被视为额外空间。)
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题的意思是给定一个数组,返回一个新的数组,这个数组每一项都是其他项的乘积。
@@ -28,7 +45,7 @@ Could you solve it with constant space complexity? (The output array does not co
考虑我们先进行一次遍历, 然后维护一个数组,第i项代表前i个元素(不包括i)的乘积。
然后我们反向遍历一次,然后维护另一个数组,同样是第i项代表前i个元素(不包括i)的乘积。
-
+
有意思的是第一个数组和第二个数组的反转(reverse)做乘法(有点像向量运算)就是我们想要的运算。
@@ -42,38 +59,6 @@ Could you solve it with constant space complexity? (The output array does not co
## 代码
```js
-
-/*
- * @lc app=leetcode id=238 lang=javascript
- *
- * [238] Product of Array Except Self
- *
- * https://leetcode.com/problems/product-of-array-except-self/description/
- *
- * algorithms
- * Medium (53.97%)
- * Total Accepted: 246.5K
- * Total Submissions: 451.4K
- * Testcase Example: '[1,2,3,4]'
- *
- * Given an array nums of n integers where n > 1, return an array output such
- * that output[i] is equal to the product of all the elements of nums except
- * nums[i].
- *
- * Example:
- *
- *
- * Input: [1,2,3,4]
- * Output: [24,12,8,6]
- *
- *
- * Note: Please solve it without division and in O(n).
- *
- * Follow up:
- * Could you solve it with constant space complexity? (The output array does
- * not count as extra space for the purpose of space complexity analysis.)
- *
- */
/**
* @param {number[]} nums
* @return {number[]}
@@ -100,3 +85,11 @@ var productExceptSelf = function(nums) {
return ret;
};
```
+
+***复杂度分析***
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的LeetCode题解
diff --git a/problems/239.sliding-window-maximum.md b/problems/239.sliding-window-maximum.md
index f45f39c07..4e7ac9834 100644
--- a/problems/239.sliding-window-maximum.md
+++ b/problems/239.sliding-window-maximum.md
@@ -28,6 +28,18 @@ Follow up:
Could you solve it in linear time?
```
+## 前置知识
+
+- 队列
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的想法是直接遍历 nums, 然后然后用一个变量 slideWindow 去承载 k 个元素,
@@ -79,7 +91,7 @@ class Solution:
如果你仔细观察的话,发现双端队列其实是一个递减的一个队列。因此队首的元素一定是最大的。用图来表示就是:
-
+
## 关键点解析
diff --git a/problems/24.swapNodesInPairs.md b/problems/24.swapNodesInPairs.md
index 368a353f5..d7054b6ba 100644
--- a/problems/24.swapNodesInPairs.md
+++ b/problems/24.swapNodesInPairs.md
@@ -11,6 +11,18 @@ You may not modify the values in the list's nodes, only nodes itself may be chan
Example:
Given 1->2->3->4, you should return the list as 2->1->4->3.
+
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
设置一个 dummy 节点简化操作,dummy next 指向 head。
@@ -24,7 +36,7 @@ Given 1->2->3->4, you should return the list as 2->1->4->3.
7. current 移动两格
8. 重复
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
diff --git a/problems/240.search-a-2-d-matrix-ii.md b/problems/240.search-a-2-d-matrix-ii.md
index 8be96b8ef..95877fc64 100644
--- a/problems/240.search-a-2-d-matrix-ii.md
+++ b/problems/240.search-a-2-d-matrix-ii.md
@@ -26,13 +26,24 @@ Given target = 20, return false.
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的做法是两层循环遍历,时间复杂度是O(m * n),
有没有时间复杂度更好的做法呢? 答案是有,那就是充分运用矩阵的特性(横向纵向都递增),
我们可以从角落(左下或者右上)开始遍历,这样时间复杂度是O(m + n).
-
+
其中蓝色代表我们选择的起点元素, 红色代表目标元素。
@@ -65,7 +76,7 @@ JavaScript Code:
* @return {boolean}
*/
var searchMatrix = function(matrix, target) {
- if (!matrix || matrix.length === 0) return 0;
+ if (!matrix || matrix.length === 0) return false;
let colIndex = 0;
let rowIndex = matrix.length - 1;
diff --git a/problems/25.reverse-nodes-in-k-groups-cn.md b/problems/25.reverse-nodes-in-k-groups-cn.md
index 828681528..401233712 100644
--- a/problems/25.reverse-nodes-in-k-groups-cn.md
+++ b/problems/25.reverse-nodes-in-k-groups-cn.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-nodes-in-k-group/
## 题目描述
+
```
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list.
@@ -22,13 +24,26 @@ You may not alter the values in the list's nodes, only nodes itself may be chang
```
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-题意是以 `k` 个nodes为一组进行翻转,返回翻转后的`linked list`.
-从左往右扫描一遍`linked list`,扫描过程中,以k为单位把数组分成若干段,对每一段进行翻转。给定首尾nodes,如何对链表进行翻转。
+题意是以 `k` 个 nodes 为一组进行翻转,返回翻转后的`linked list`.
+
+从左往右扫描一遍`linked list`,扫描过程中,以 k 为单位把数组分成若干段,对每一段进行翻转。给定首尾 nodes,如何对链表进行翻转。
+
+链表的翻转过程,初始化一个为`null`的 `previous node(prev)`,然后遍历链表的同时,当前`node (curr)`的下一个(next)指向前一个`node(prev)`,
+在改变当前 node 的指向之前,用一个临时变量记录当前 node 的下一个`node(curr.next)`. 即
-链表的翻转过程,初始化一个为`null `的 `previous node(prev)`,然后遍历链表的同时,当前`node (curr)`的下一个(next)指向前一个`node(prev)`,
-在改变当前node的指向之前,用一个临时变量记录当前node的下一个`node(curr.next)`. 即
```
ListNode temp = curr.next;
curr.next = prev;
@@ -38,7 +53,7 @@ curr = temp;
举例如图:翻转整个链表 `1->2->3->4->null` -> `4->3->2->1->null`
-
+
这里是对每一组(`k个nodes`)进行翻转,
@@ -46,7 +61,7 @@ curr = temp;
2. 用一个`start` 变量记录当前分组的起始节点位置的前一个节点
-3. 用一个`end `变量记录要翻转的最后一个节点位置
+3. 用一个`end`变量记录要翻转的最后一个节点位置
4. 翻转一组(`k个nodes`)即`(start, end) - start and end exclusively`。
@@ -54,32 +69,33 @@ curr = temp;
6. 如果不需要翻转,`end` 就往后移动一个(`end=end.next`),每一次移动,都要`count+1`.
-如图所示 步骤4和5: 翻转区间链表区间`(start, end)`
-
-
+如图所示 步骤 4 和 5: 翻转区间链表区间`(start, end)`
+
举例如图,`head=[1,2,3,4,5,6,7,8], k = 3`
+
-
-
-
->**NOTE**: 一般情况下对链表的操作,都有可能会引入一个新的`dummy node`,因为`head`有可能会改变。这里`head 从1->3`,
-`dummy (List(0)) `保持不变。
+> **NOTE**: 一般情况下对链表的操作,都有可能会引入一个新的`dummy node`,因为`head`有可能会改变。这里`head 从1->3`,
+> `dummy (List(0))`保持不变。
#### 复杂度分析
-- *时间复杂度:* `O(n) - n is number of Linked List`
-- *空间复杂度:* `O(1)`
+
+- _时间复杂度:_ `O(n) - n is number of Linked List`
+- _空间复杂度:_ `O(1)`
## 关键点分析
-1. 创建一个dummy node
-2. 对链表以k为单位进行分组,记录每一组的起始和最后节点位置
+
+1. 创建一个 dummy node
+2. 对链表以 k 为单位进行分组,记录每一组的起始和最后节点位置
3. 对每一组进行翻转,更换起始和最后的位置
4. 返回`dummy.next`.
## 代码 (`Java/Python3/javascript`)
-*Java Code*
+
+_Java Code_
+
```java
class ReverseKGroupsLinkedList {
public ListNode reverseKGroup(ListNode head, int k) {
@@ -138,7 +154,8 @@ class ReverseKGroupsLinkedList {
}
```
-*Python3 Cose*
+_Python3 Cose_
+
```python
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
@@ -153,97 +170,155 @@ class Solution:
count += 1
if count % k == 0:
start = self.reverse(start, end.next)
+ # end 调到下一个
end = start.next
else:
end = end.next
return dummy.next
+ # (start, end) 左右都开放
def reverse(self, start, end):
prev, curr = start, start.next
first = curr
+ # 反转
while curr != end:
- temp = curr.next
+ next = curr.next
curr.next = prev
prev = curr
- curr = temp
+ curr = next
+ # 将反转后的链表添加到原链表中
start.next = prev
- first.next = curr
+ first.next = end
+ # 返回反转前的头, 也就是反转后的尾部
return first
+
```
-*javascript code*
+_javascript code_
+
```js
/**
* @param {ListNode} head
* @param {number} k
* @return {ListNode}
*/
-var reverseKGroup = function(head, k) {
+var reverseKGroup = function (head, k) {
// 标兵
- let dummy = new ListNode()
- dummy.next = head
- let [start, end] = [dummy, dummy.next]
- let count = 0
- while(end) {
- count++
+ let dummy = new ListNode();
+ dummy.next = head;
+ let [start, end] = [dummy, dummy.next];
+ let count = 0;
+ while (end) {
+ count++;
if (count % k === 0) {
- start = reverseList(start, end.next)
- end = start.next
+ start = reverseList(start, end.next);
+ end = start.next;
} else {
- end = end.next
+ end = end.next;
}
}
- return dummy.next
+ return dummy.next;
// 翻转stat -> end的链表
function reverseList(start, end) {
- let [pre, cur] = [start, start.next]
- const first = cur
- while(cur !== end) {
- let next = cur.next
- cur.next = pre
- pre = cur
- cur = next
+ let [pre, cur] = [start, start.next];
+ const first = cur;
+ while (cur !== end) {
+ let next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
}
- start.next = pre
- first.next = cur
- return first
+ start.next = pre;
+ first.next = cur;
+ return first;
}
};
-
```
## 参考(References)
+
- [Leetcode Discussion (yellowstone)](https://leetcode.com/problems/reverse-nodes-in-k-group/discuss/11440/Non-recursive-Java-solution-and-idea)
-## 扩展
+## 扩展 1
- 要求从后往前以`k`个为一组进行翻转。**(字节跳动(ByteDance)面试题)**
- 例子,`1->2->3->4->5->6->7->8, k = 3`,
+ 例子,`1->2->3->4->5->6->7->8, k = 3`,
- 从后往前以`k=3`为一组,
- - `6->7->8` 为一组翻转为`8->7->6`,
- - `3->4->5`为一组翻转为`5->4->3`.
- - `1->2`只有2个nodes少于`k=3`个,不翻转。
+ 从后往前以`k=3`为一组,
- 最后返回: `1->2->5->4->3->8->7->6`
+ - `6->7->8` 为一组翻转为`8->7->6`,
+ - `3->4->5`为一组翻转为`5->4->3`.
+ - `1->2`只有 2 个 nodes 少于`k=3`个,不翻转。
+
+ 最后返回: `1->2->5->4->3->8->7->6`
这里的思路跟从前往后以`k`个为一组进行翻转类似,可以进行预处理:
1. 翻转链表
-2. 对翻转后的链表进行从前往后以k为一组翻转。
+2. 对翻转后的链表进行从前往后以 k 为一组翻转。
-3. 翻转步骤2中得到的链表。
+3. 翻转步骤 2 中得到的链表。
例子:`1->2->3->4->5->6->7->8, k = 3`
1. 翻转链表得到:`8->7->6->5->4->3->2->1`
-2. 以k为一组翻转: `6->7->8->3->4->5->2->1`
+2. 以 k 为一组翻转: `6->7->8->3->4->5->2->1`
+
+3. 翻转步骤#2 链表: `1->2->5->4->3->8->7->6`
+
+## 扩展 2
+
+如果这道题你按照 [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md) 提到的 `p1, p2, p3, p4`(四点法) 的思路来思考的话会很清晰。
+
+代码如下(Python):
+
+```py
+
+class Solution:
+ def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
+ if head is None or k < 2:
+ return head
+ dummy = ListNode(0)
+ dummy.next = head
+ pre = dummy
+ cur = head
+ count = 0
+ while cur:
+ count += 1
+ if count % k == 0:
+ pre = self.reverse(pre, cur.next)
+ # end 调到下一个位置
+ cur = pre.next
+ else:
+ cur = cur.next
+ return dummy.next
+ # (p1, p4) 左右都开放
+
+ def reverse(self, p1, p4):
+ prev, curr = p1, p1.next
+ p2 = curr
+ # 反转
+ while curr != p4:
+ next = curr.next
+ curr.next = prev
+ prev = curr
+ curr = next
+ # 将反转后的链表添加到原链表中
+ # prev 相当于 p3
+ p1.next = prev
+ p2.next = p4
+ # 返回反转前的头, 也就是反转后的尾部
+ return p2
+
+# @lc code=end
+
+```
-3. 翻转步骤#2链表: `1->2->5->4->3->8->7->6`
+## 相关题目
-## 类似题目
-- [Swap Nodes in Pairs](https://leetcode.com/problems/swap-nodes-in-pairs/)
\ No newline at end of file
+- [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md)
+- [206.reverse-linked-list](./206.reverse-linked-list.md)
diff --git a/problems/25.reverse-nodes-in-k-groups-en.md b/problems/25.reverse-nodes-in-k-groups-en.md
index 9cf1d3115..fa717e331 100644
--- a/problems/25.reverse-nodes-in-k-groups-en.md
+++ b/problems/25.reverse-nodes-in-k-groups-en.md
@@ -45,7 +45,7 @@ curr = temp;
For example(as below pic): reverse the whole linked list `1->2->3->4->null` -> `4->3->2->1->null`
-
+
Here Reverse each group(`k nodes`):
@@ -63,13 +63,13 @@ Here Reverse each group(`k nodes`):
As below pic show steps 4 and 5, reverse linked list in range `(start, end)`:
-
+
For example(as below pic),`head=[1,2,3,4,5,6,7,8], k = 3`
-
+
>**NOTE**: Usually we create a `dummy node` to solve linked list problem, because head node may be changed during operation.
diff --git a/problems/26.remove-duplicates-from-sorted-array.md b/problems/26.remove-duplicates-from-sorted-array.md
index eedbdb1e4..af608022c 100644
--- a/problems/26.remove-duplicates-from-sorted-array.md
+++ b/problems/26.remove-duplicates-from-sorted-array.md
@@ -39,6 +39,21 @@ for (int i = 0; i < len; i++) {
}
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- facebook
+- microsoft
+
## 思路
使用快慢指针来记录遍历的坐标。
@@ -51,10 +66,12 @@ for (int i = 0; i < len; i++) {
- 当快指针走完整个数组后,慢指针当前的坐标加 1 就是数组中不同数字的个数
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+> 实际上这就是双指针中的快慢指针。在这里快指针是读指针, 慢指针是写指针。
+
## 关键点解析
- 双指针
@@ -125,3 +142,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/263.ugly-number.md b/problems/263.ugly-number.md
index d8e04d5b9..576354f03 100644
--- a/problems/263.ugly-number.md
+++ b/problems/263.ugly-number.md
@@ -31,11 +31,23 @@ Input is within the 32-bit signed integer range: [−231, 231 − 1].
```
+## 前置知识
+
+- 数学
+- 因数分解
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
题目要求给定一个数字,判断是否为“丑陋数”(ugly number), 丑陋数是指只包含质因子2, 3, 5的正整数。
-
+
根据定义,我们将给定数字除以2、3、5(顺序无所谓),直到无法整除。
如果得到1,说明是所有因子都是2或3或5,如果不是1,则不是丑陋数。
@@ -64,7 +76,7 @@ Input is within the 32-bit signed integer range: [−231, 231 − 1].
## 代码
-* 语言支持:JS, Python
+* 语言支持:JS, C++, Java, Python
Javascript Code:
@@ -94,6 +106,47 @@ var isUgly = function(num) {
};
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(logN)$
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ bool isUgly(int num) {
+ int ugly[] = {2,3,5};
+ for(int u : ugly)
+ {
+ while(num%u==0 && num%u < num)
+ {
+ num/=u;
+ }
+ }
+ return num == 1;
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public boolean isUgly(int num) {
+ int [] ugly = {2,3,5};
+ for(int u : ugly)
+ {
+ while(num%u==0 && num%u < num)
+ {
+ num/=u;
+ }
+ }
+ return num == 1;
+ }
+}
+```
+
Python Code:
```python
@@ -107,3 +160,13 @@ class Solution:
num /= i
return num == 1
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/279.perfect-squares.md b/problems/279.perfect-squares.md
index 174e364a8..ef7616d41 100644
--- a/problems/279.perfect-squares.md
+++ b/problems/279.perfect-squares.md
@@ -20,6 +20,17 @@ Explanation: 13 = 4 + 9.
```
+## 前置知识
+
+- 递归
+- 动态规划
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
直接递归处理即可,但是这种暴力的解法很容易超时。如果你把递归的过程化成一棵树的话(其实就是递归树),
diff --git a/problems/283.move-zeroes.md b/problems/283.move-zeroes.md
index f4eb15e1f..c9483b30d 100644
--- a/problems/283.move-zeroes.md
+++ b/problems/283.move-zeroes.md
@@ -16,6 +16,21 @@ You must do this in-place without making a copy of the array.
Minimize the total number of operations.
```
+
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- facebook
+
## 思路
如果题目没有要求 modify in-place 的话,我们可以先遍历一遍将包含 0 的和不包含 0 的存到两个数组,
@@ -28,11 +43,11 @@ Minimize the total number of operations.
## 关键点解析
-无
+- 双指针
## 代码
-* 语言支持:JS, C++, Python
+* 语言支持:JS, C++, Java,Python
JavaScript Code:
@@ -82,6 +97,28 @@ public:
};
```
+Java Code:
+
+```java
+class Solution {
+ public void moveZeroes(int[] nums) {
+ // 双指针
+ int i = 0;
+ for(int j=0; j> 1` 一定是父节点的下标。
-
+
> 这是因为我用满二叉树来存储的堆
diff --git a/problems/3.longestSubstringWithoutRepeatingCharacters.md b/problems/3.longest-substring-without-repeating-characters.md
similarity index 64%
rename from problems/3.longestSubstringWithoutRepeatingCharacters.md
rename to problems/3.longest-substring-without-repeating-characters.md
index fd5453357..2b2571094 100644
--- a/problems/3.longestSubstringWithoutRepeatingCharacters.md
+++ b/problems/3.longest-substring-without-repeating-characters.md
@@ -16,11 +16,20 @@ Given "bbbbb", the answer is "b", with the length of 1.
Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer must be a substring, "pwke" is a subsequence and not a substring.
```
-## 思路
+## 前置知识
+
+- 哈希表
+- [滑动窗口](https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md)
+
+## 公司
-用一个 hashmap 来建立字符和其出现位置之间的映射。
+- 阿里
+- 字节
+- 腾讯
-维护一个滑动窗口,窗口内的都是没有重复的字符,去尽可能的扩大窗口的大小,窗口不停的向右滑动。
+## 思路
+
+用一个 hashmap 来建立字符和其出现位置之间的映射。同时维护一个滑动窗口,窗口内的都是没有重复的字符,去尽可能的扩大窗口的大小,窗口不停的向右滑动。
(1)如果当前遍历到的字符从未出现过,那么直接扩大右边界;
@@ -30,7 +39,7 @@ Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer
(4)维护一个结果 res,每次用出现过的窗口大小来更新结果 res,最后返回 res 获取结果。
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -42,42 +51,7 @@ Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer
## 代码
-代码支持:JavaScript,Python3
-
-JavaScript Code:
-
-```js
-/**
- * @param {string} s
- * @return {number}
- */
-var lengthOfLongestSubstring = function(s) {
- const mapper = {}; // 记录已经出现过的charactor
- let res = 0;
- let slidingWindow = [];
-
- for (let c of s) {
- if (mapper[c]) {
- // 已经出现过了
- // 则删除
- const delIndex = slidingWindow.findIndex(_c => _c === c);
-
- for (let i = 0; i < delIndex; i++) {
- mapper[slidingWindow[i]] = false;
- }
-
- slidingWindow = slidingWindow.slice(delIndex + 1).concat(c);
- } else {
- // 新字符
- if (slidingWindow.push(c) > res) {
- res = slidingWindow.length;
- }
- }
- mapper[c] = true;
- }
- return res;
-};
-```
+代码支持:Python3
Python3 Code:
@@ -100,3 +74,14 @@ class Solution:
return ans
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/30.substring-with-concatenation-of-all-words.md b/problems/30.substring-with-concatenation-of-all-words.md
index ce9999e74..2b5512e9e 100644
--- a/problems/30.substring-with-concatenation-of-all-words.md
+++ b/problems/30.substring-with-concatenation-of-all-words.md
@@ -30,6 +30,19 @@ https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/descr
```
+## 前置知识
+
+- 字符串
+- 数组
+- 哈希表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
本题是要我们找出 words 中`所有单词按照任意顺序串联`形成的单词中恰好出现在 s 中的索引,因此顺序是不重要的。换句话说,我们只要统计每一个单词的出现情况即可。以题目中 s = "barfoothefoobarman", words = ["foo","bar"] 为例。 我们只需要统计 foo 出现了一次,bar 出现了一次即可。我们只需要在 s 中找到同样包含一次 foo 和一次 bar 的子串即可。由于 words 中的字符串都是等长的,因此编码上也会比较简单。
diff --git a/problems/301.remove-invalid-parentheses.md b/problems/301.remove-invalid-parentheses.md
index 9e308507e..43b69f624 100644
--- a/problems/301.remove-invalid-parentheses.md
+++ b/problems/301.remove-invalid-parentheses.md
@@ -23,6 +23,18 @@ Output: [""]
```
+## 前置知识
+
+- BFS
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我们的思路是先写一个函数用来判断给定字符串是否是有效的。 然后再写一个函数,这个函数
@@ -32,7 +44,7 @@ Output: [""]
而且由于题目要求是要删除最少的小括号,因此我们的思路是使用广度优先遍历,而不是深度有限的遍历。
-
+
> 没有动图,请脑补
diff --git a/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md b/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
index c2372d3f5..cd2e4df4b 100644
--- a/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
+++ b/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
@@ -18,6 +18,16 @@ Output: 3
Explanation: transactions = [buy, sell, cooldown, buy, sell]
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
这是一道典型的 DP 问题, DP 问题的核心是找到状态和状态转移方程。
@@ -73,7 +83,7 @@ sell[i]对应第 i 的 action 只能是 sell 或者 cooldown。
* @param {number[]} prices
* @return {number}
*/
-var maxProfit = function(prices) {
+var maxProfit = function (prices) {
if (prices == null || prices.length <= 1) return 0;
// 定义状态变量
diff --git a/problems/31.next-permutation.md b/problems/31.next-permutation.md
index 29c8f00b3..43ea07d37 100644
--- a/problems/31.next-permutation.md
+++ b/problems/31.next-permutation.md
@@ -19,6 +19,17 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的方法是我们按顺序求出所有的排列,如果当前排列等于 nums,那么我直接取下一个
@@ -26,7 +37,7 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
这种题目比较抽象,写几个例子通常会帮助理解问题的规律。我找了几个例子,其中蓝色背景表示的是当前数字找下一个更大排列的时候`需要改变的元素`.
-
+
我们不难发现,蓝色的数字都是从后往前第一个不递增的元素,并且我们的下一个更大的排列
只需要改变蓝色的以及之后部分即可,前面的不需要变。
@@ -37,18 +48,18 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
另外我们也可以以回溯的角度来思考这个问题,让我们先回溯一次:
-
+
这个时候可以选择的元素只有2,我们无法组成更大的排列,我们继续回溯,直到如图:
-
+
我们发现我们可以交换4或者2实现变大的效果,但是要保证变大的幅度最小(下一个更大),
我们需要选择最小的,由于之前我们发现后面是从左到右递减的,显然就是交换最右面大于1的。
之后就是不断交换使之幅度最小:
-
+
## 关键点解析
- 写几个例子通常会帮助理解问题的规律
diff --git a/problems/312.burst-balloons.md b/problems/312.burst-balloons.md
new file mode 100644
index 000000000..90a535273
--- /dev/null
+++ b/problems/312.burst-balloons.md
@@ -0,0 +1,177 @@
+### 题目地址(312. 戳气球)
+
+https://leetcode-cn.com/problems/burst-balloons/
+
+### 题目描述
+
+```
+有 n 个气球,编号为0 到 n-1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
+
+现在要求你戳破所有的气球。每当你戳破一个气球 i 时,你可以获得 nums[left] * nums[i] * nums[right] 个硬币。 这里的 left 和 right 代表和 i 相邻的两个气球的序号。注意当你戳破了气球 i 后,气球 left 和气球 right 就变成了相邻的气球。
+
+求所能获得硬币的最大数量。
+
+说明:
+
+你可以假设 nums[-1] = nums[n] = 1,但注意它们不是真实存在的所以并不能被戳破。
+0 ≤ n ≤ 500, 0 ≤ nums[i] ≤ 100
+示例:
+
+输入: [3,1,5,8]
+输出: 167
+解释: nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> []
+ coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167
+```
+
+## 前置知识
+
+- 回溯法
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+#### 回溯法
+
+分析一下这道题,就是要戳破所有的气球,获得硬币的最大数量,然后左右两边的气球相邻了。我的第一反应就是暴力,回溯法。
+
+但是肯定会超时,为什么呢?因为题目给的气球数量有点多,最多 500 个;500 的阶乘,会超时爆栈;但是我们依然写一下代码,找下突破口,小伙伴们千万不要看不起暴力,暴力是优化的突破口;
+
+如果小伙伴对回溯法不太熟悉,我建议你记住下面的模版,也可以看我之前写的文章,回溯法基本可以使用以下的模版写。回溯法省心省力,0 智商负担。
+
+#### 代码
+
+```js
+var maxCoins = function (nums) {
+ let res = Number.MIN_VALUE;
+ backtrack(nums, 0);
+ return res;
+ // 回溯法,状态树很大
+ function backtrack(nums, score) {
+ if (nums.length == 0) {
+ res = Math.max(res, score);
+ return;
+ }
+ for (let i = 0, n = nums.length; i < n; i++) {
+ let point =
+ (i - 1 < 0 ? 1 : nums[i - 1]) *
+ nums[i] *
+ (i + 1 >= n ? 1 : nums[i + 1]);
+ let tempNums = [].concat(nums);
+ // 做选择 在 nums 中删除元素 nums[i]
+ nums.splice(i, 1);
+ // 递归回溯
+ backtrack(nums, score + point);
+ // 撤销选择
+ nums = [...tempNums];
+ }
+ }
+};
+```
+
+#### 动态规划
+
+回溯法的缺点也很明显,复杂度很高,对应本题戳气球;小伙伴们可以脑补一下执行过程的状态树,这里我偷个懒就不画了;通过仔细观察这个状态树,我们会发现这个状态树的【选择】上,会有一些重复的选择分支;很明显存在了重复子问题;自然我就想到了能不能用动态规划来解决;
+
+判读能不能用动态规划解决,还有一个问题,就是必须存在最优子结构;什么意思呢?其实就是根据局部最优,推导出答案;假设我们戳破第 k 个气球是最优策略的最后一步,和上一步有没有联系呢?根据题目意思,戳破第 k 个,前一个和后一个就变成相邻的了,看似是会有联系,其实是没有的。因为戳破第 k 个和 k-1 个是没有联系的,脑补一下回溯法的状态树就更加明确了;
+
+既然用动态规划,那就老套路了,把动态规划的三个问题想清楚定义好;然后找出题目的【状态】和【选择】,然后根据【状态】枚举,枚举的过程中根据【选择】计算递推就能得到答案了。
+
+那本题的【选择】是什么呢?就是戳哪一个气球。那【状态】呢?就是题目给的气球数量。
+
+1. 定义状态
+
+- 这里有个细节,就是题目说明有两个虚拟气球,nums[-1] = nums[n] = 1;如果当前戳破的气球是最后一个或者第一个,前面/后面没有气球了,不能乘以 0,而是乘以 1。
+
+- 定义状态的最关键两个点,往子问题(问题规模变小)想,最后一步最优策略是什么;我们假设最后戳破的气球是 k,戳破 k 获得最大数量的银币就是 nums[i] * nums[k] * nums[j] 再加上前面戳破的最大数量和后面的最大数量,即:nums[i] * nums[k] * nums[j] + 前面最大数量 + 后面最大数量,就是答案。
+
+> 注意 i 不一定是 k - 1,同理 j 也不一定是 k + 1,因此可能 i - 1 和 i + 1 已经被戳破了。
+
+- 而如果我们不考虑两个虚拟气球而直接定义状态,戳到最后两个气球的时候又该怎么定义状态来避免和前面的产生联系呢?这两个虚拟气球就恰到好处了,这也是本题的一个难点之一。
+
+- 那我们可以这样来定义状态,dp[i][j] = x 表示戳破气球 i 和气球 j 之间(开区间,不包括 i 和 j)的所有气球,可以获得的最大硬币数为 x。为什么开区间?因为不能和已经计算过的产生联系,我们这样定义之后,利用两个虚拟气球,戳到最后两个气球的时候就完美的避开了所有状态的联系。
+
+2. 状态转移方程
+
+- 而对于 dp[i][j],i 和 j 之间会有很多气球,到底该戳哪个先呢?我们直接设为 k,枚举选择最优的 k 就可以了。
+ - 1。
+- 所以,最终的状态转移方程为:dp[i][j] = max(dp[i][j], dp[i][k] + dp[k][j] + nums[k] * nums[i] * nums[j])。由于是开区间,因此 k 为 i + 1, i + 2... j - 1。
+
+3. 初始值和边界
+
+- 由于我们利用了两个虚拟气球,边界就是气球数 n + 2
+- 初始值,当 i == j 时,很明显两个之间没有气球,所有为 0;
+
+4. 如何枚举状态
+
+- 因为我们最终要求的答案是 dp[0][n + 1],就是戳破虚拟气球之间的所有气球获得的最大值;
+- 当 i == j 时,i 和 j 之间是没有气球的,所以枚举的状态很明显是 dp table 的左上部分,也就是 j 大于 i,如下图所示,只给出一部分方便思考。
+
+
+(图有错误。图中 dp[k][i] 应该是 dp[i][k],dp[j][k] 应该是 dp[k][j])
+
+> 从上图可以看出,我们需要从下到上,从左到右进行遍历。
+
+#### 代码
+
+
+代码支持: JS, Python
+
+JS Code:
+
+```js
+var maxCoins = function (nums) {
+ let n = nums.length;
+ // 添加两侧的虚拟气球
+ let points = [1, ...nums, 1];
+ let dp = Array.from(Array(n + 2), () => Array(n + 2).fill(0));
+ // 最后一行开始遍历,从下往上
+ for (let i = n; i >= 0; i--) {
+ // 从左往右
+ for (let j = i + 1; j < n + 2; j++) {
+ for (let k = i + 1; k < j; k++) {
+ dp[i][j] = Math.max(
+ dp[i][j],
+ points[j] * points[k] * points[i] + dp[i][k] + dp[k][j]
+ );
+ }
+ }
+ }
+ return dp[0][n + 1];
+};
+```
+
+Python Code:
+
+```py
+class Solution:
+ def maxCoins(self, nums: List[int]) -> int:
+ n = len(nums)
+ points = [1] + nums + [1]
+ dp = [[0] * (n + 2) for _ in range(n + 2)]
+
+ for i in range(n, -1, -1):
+ for j in range(i + 1, n + 2):
+ for k in range(i + 1, j):
+ dp[i][j] = max(dp[i][j], dp[i][k] + dp[k][j] + points[i] * points[k] * points[j])
+ return dp[0][-1]
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N ^ 3)$
+- 空间复杂度:$O(N ^ 2)$
+
+### 总结
+
+简单的 dp 题目会直接告诉你怎么定义状态,告诉你怎么选择计算,你只需要根据套路判断一下能不能用 dp 解题即可,而判断能不能,往往暴力就是突破口。而困难点的 dp,我觉的都是细节问题了,要注意的细节太多了。感觉力扣加加,路西法大佬,把我领进了动态规划的大门,共勉。
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/32.longest-valid-parentheses.md b/problems/32.longest-valid-parentheses.md
index 370d89656..a549898b0 100644
--- a/problems/32.longest-valid-parentheses.md
+++ b/problems/32.longest-valid-parentheses.md
@@ -1,4 +1,5 @@
## 题目地址
+
https://leetcode.com/problems/longest-valid-parentheses/
## 题目描述
@@ -18,44 +19,234 @@ Output: 4
Explanation: The longest valid parentheses substring is "()()"
```
-## 思路(动态规划)
+## 前置知识
-所有的动态规划问题, 首先需要解决的就是如何寻找合适的子问题.
-该题需要我们找到最长的有效括号对, 我们首先想到的就是定义**dp[i]为前i个字符串的最长有效括号对长度**, 但是随后我们会发现, 这样的定义, 我们无法找到dp[i]和dp[i-1]的任何关系.
-所以, 我们需要重新找一个新的定义: 定义**dp[i]为以第i个字符结尾的最长有效括号对长度**. 然后, 我们通过下面这个例子找一下dp[i]和dp[i-1]之间的关系.
+- 动态规划
-```python
-s = '(())())'
+## 暴力(超时)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+符合直觉的做法是:分别计算以 i 开头的 最长有效括号(i 从 0 到 n - 1·),从中取出最大的即可。
+
+### 代码
+
+代码支持: Python
+
+```py
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ n = len(s)
+ ans = 0
+
+ def validCnt(start):
+ # cnt 为 ) 的数量减去 ( 的数量
+ cnt = 0
+ ans = 0
+ for i in range(start, n):
+ if s[i] == '(':
+ cnt += 1
+ if s[i] == ')':
+ cnt -= 1
+ if cnt < 0:
+ return i - start
+ if cnt == 0:
+ ans = max(ans, i - start + 1)
+ return ans
+ for i in range(n):
+ ans = max(ans, validCnt(i))
+
+ return ans
```
-从上面的例子我们可以观察出一下几点结论(**描述中i为图中的dp数组的下标, 对应s的下标应为i-1, 第i个字符的i从1开始**).
-1. base case: 空字符串的最长有效括号对长度肯定为0, 即: dp[0] = 0;
-2. s的第**1**个字符结尾的最长有效括号对长度为0, s的第**2**个字符结尾的最长有效括号对长度也为0, 这个时候我们可以得出结论: 最长有效括号对不可能以'('结尾, 即: dp[1] = d[2] = 0;
-3. 当i等于3时, 我们可以看出dp[2]=0, dp[3]=2, 因为第2个字符(**s[1]**)和第3个字符(**s[2]**)是配对的;
- 当i等于4时, 我们可以看出dp[3]=2, dp[4]=4, 因为我们配对的是第1个字符(**s[0]**)和第4个字符(**s[3]**);
- 因此, 我们可以得出结论: 如果第**i**个字符和第i-1-dp[i-1]个字符是配对的, 则dp[i] = dp[i-1] + 2, 其中: i-1-dp[i-1] >= 1, 因为第0个字符没有任何意义;
-4. 根据第3条规则来计算的话, 我们发现dp[5]=0, dp[6]=2, 但是显然, dp[6]应该为6才对, 但是我们发现可以将"(())"和"()"进行拼接, 即: dp[i] += dp[i-dp[i]], 即: dp[6] = 2 + dp[6-2] = 2 + dp[4] = 6
+**复杂度分析**
-根据以上规则, 我们求解dp数组的结果为: [0, 0, 0, 2, 4, 0, 6, 0], 其中最长有效括号对的长度为6. 以下为图解:
-
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(1)$
-## 关键点解析
+## 栈
-1. 第3点特征, 需要检查的字符是s[i-1]和s[i-2-dp[i-1]], 根据定义可知: i-1 >= dp[i-1], 但是i-2不一定大于dp[i-1], 因此, 需要检查越界;
-3. 第4点特征最容易遗漏, 还有就是不需要检查越界, 因为根据定义可知: i >= dp[i], 所以dp[i-dp[i]]的边界情况是dp[0];
+### 思路
-## 思路(栈)
主要思路和常规的括号解法一样,遇到'('入栈,遇到')'出栈,并计算两个括号之间的长度。
因为这个题存在非法括号对的情况且求是合法括号对的最大长度 所以有两个注意点是:
+
1. **栈中存的是符号的下标**
2. **当栈为空时且当前扫描到的符号是')'时,需要将这个符号入栈作为分割符**
+3. 栈中初始化一个 -1,作为**分割符**
+
+### 代码
-## 代码
+- 语言支持: Python, javascript
-* 语言支持: Python, javascript
+javascript code:
+
+```js
+// 用栈来解
+var longestValidParentheses = function (s) {
+ let stack = new Array();
+ let longest = 0;
+ stack.push(-1);
+ for (let i = 0; i < s.length; i++) {
+ if (s[i] === "(") {
+ stack.push(i);
+ } else {
+ stack.pop();
+ if (stack.length === 0) {
+ stack.push(i);
+ } else {
+ longest = Math.max(longest, i - stack[stack.length - 1]);
+ }
+ }
+ }
+ return longest;
+};
+```
Python Code:
+
+```py
+
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ if not s:
+ return 0
+ res = 0
+ stack = [-1]
+ for i in range(len(s)):
+ if s[i] == "(":
+ stack.append(i)
+ else:
+ stack.pop()
+ if not stack:
+ stack.append(i)
+ else:
+ res = max(res, i - stack[-1])
+ return res
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## O(1) 空间
+
+### 思路
+
+我们可以采用解法一中的计数方法。
+
+- 从左到右遍历一次,并分别记录左右括号的数量 left 和 right。
+- 如果 right > left ,说明截止上次可以匹配的点到当前点这一段无法匹配,重置 left 和 right 为 0
+- 如果 right == left, 此时可以匹配,此时有效括号长度为 left + right,我们获得一个局部最优解。如果其比全局最优解大,我们更新全局最优解
+
+值得注意的是,对形如 `(((()` 这样的,更新全局最优解的逻辑永远无法执行。一种方式是再从右往左遍历一次即可,具体看代码。
+
+> 类似的思想有哨兵元素,虚拟节点。只不过本题无法采用这种方法。
+
+### 代码
+
+代码支持:Java,Python
+
+```java
+public class Solution {
+ public int longestValidParentheses(String s) {
+ int left = 0, right = 0, maxlength = 0;
+ for (int i = 0; i < s.length(); i++) {
+ if (s.charAt(i) == '(') {
+ left++;
+ } else {
+ right++;
+ }
+ if (left == right) {
+ maxlength = Math.max(maxlength, left + right);
+ }
+ if (right > left) {
+ left = right = 0;
+ }
+ }
+ left = right = 0;
+ for (int i = s.length() - 1; i >= 0; i--) {
+ if (s.charAt(i) == '(') {
+ left++;
+ } else {
+ right++;
+ }
+ if (left == right) {
+ maxlength = Math.max(maxlength, left + right);
+ }
+ if (left > right) {
+ left = right = 0;
+ }
+ }
+ return maxlength;
+ }
+}
+```
+
+```py
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ ans = l = r = 0
+ for c in s:
+ if c == '(':
+ l += 1
+ else:
+ r += 1
+ if l == r:
+ ans = max(ans, l + r)
+ if r > l:
+ l = r = 0
+ l = r = 0
+ for c in s[::-1]:
+ if c == '(':
+ l += 1
+ else:
+ r += 1
+ if l == r:
+ ans = max(ans, l + r)
+ if r < l:
+ l = r = 0
+
+ return ans
+```
+
+## 动态规划
+
+### 思路
+
+所有的动态规划问题, 首先需要解决的就是如何寻找合适的子问题.
+该题需要我们找到最长的有效括号对, 我们首先想到的就是定义**dp[i]为前 i 个字符串的最长有效括号对长度**, 但是随后我们会发现, 这样的定义, 我们无法找到 dp[i]和 dp[i-1]的任何关系.
+所以, 我们需要重新找一个新的定义: 定义**dp[i]为以第 i 个字符结尾的最长有效括号对长度**. 然后, 我们通过下面这个例子找一下 dp[i]和 dp[i-1]之间的关系.
+
+```python
+s = '(())())'
```
+
+从上面的例子我们可以观察出一下几点结论(**描述中 i 为图中的 dp 数组的下标, 对应 s 的下标应为 i-1, 第 i 个字符的 i 从 1 开始**).
+
+1. base case: 空字符串的最长有效括号对长度肯定为 0, 即: dp[0] = 0;
+2. s 的第**1**个字符结尾的最长有效括号对长度为 0, s 的第**2**个字符结尾的最长有效括号对长度也为 0, 这个时候我们可以得出结论: 最长有效括号对不可能以'('结尾, 即: dp[1] = d[2] = 0;
+3. 当 i 等于 3 时, 我们可以看出 dp[2]=0, dp[3]=2, 因为第 2 个字符(**s[1]**)和第 3 个字符(**s[2]**)是配对的;
+ 当 i 等于 4 时, 我们可以看出 dp[3]=2, dp[4]=4, 因为我们配对的是第 1 个字符(**s[0]**)和第 4 个字符(**s[3]**);
+ 因此, 我们可以得出结论: 如果第**i**个字符和第i-1-dp[i-1]个字符是配对的, 则 dp[i] = dp[i-1] + 2, 其中: i-1-dp[i-1] >= 1, 因为第 0 个字符没有任何意义;
+4. 根据第 3 条规则来计算的话, 我们发现 dp[5]=0, dp[6]=2, 但是显然, dp[6]应该为 6 才对, 但是我们发现可以将"(())"和"()"进行拼接, 即: dp[i] += dp[i-dp[i]], 即: dp[6] = 2 + dp[6-2] = 2 + dp[4] = 6
+
+根据以上规则, 我们求解 dp 数组的结果为: [0, 0, 0, 2, 4, 0, 6, 0], 其中最长有效括号对的长度为 6. 以下为图解:
+
+
+### 代码
+
+Python Code:
+
+```py
class Solution:
def longestValidParentheses(self, s: str) -> int:
mlen = 0
@@ -81,28 +272,14 @@ class Solution:
return mlen
```
-javascript code:
-```js
-// 用栈来解
-var longestValidParentheses = function(s) {
- let stack = new Array()
- let longest = 0
- stack.push(-1)
- for(let i = 0; i < s.length; i++) {
- if (s[i] === '(') {
- stack.push(i)
- } else {
- stack.pop()
- if (stack.length === 0) {
- stack.push(i)
- } else {
- longest = Math.max(longest, i - stack[stack.length - 1])
- }
- }
- }
- return longest
-};
-```
+### 关键点解析
+
+1. 第 3 点特征, 需要检查的字符是 s[i-1]和 s[i-2-dp[i-1]], 根据定义可知: i-1 >= dp[i-1], 但是 i-2 不一定大于 dp[i-1], 因此, 需要检查越界;
+2. 第 4 点特征最容易遗漏, 还有就是不需要检查越界, 因为根据定义可知: i >= dp[i], 所以 dp[i-dp[i]]的边界情况是 dp[0];
+
+## 相关题目
+
+- [20.valid-parentheses](./20.valid-parentheses.md)
## 扩展
diff --git a/problems/322.coin-change.md b/problems/322.coin-change.md
index 3839254db..9a6f3c095 100644
--- a/problems/322.coin-change.md
+++ b/problems/322.coin-change.md
@@ -1,15 +1,16 @@
-
## 题目地址
+
https://leetcode.com/problems/coin-change/description/
## 题目描述
+
```
You are given coins of different denominations and a total amount of money amount. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
Example 1:
Input: coins = [1, 2, 5], amount = 11
-Output: 3
+Output: 3
Explanation: 11 = 5 + 5 + 1
Example 2:
@@ -19,10 +20,28 @@ Note:
You may assume that you have an infinite number of each kind of coin.
```
+
+## 前置知识
+
+- 贪心算法
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+- 阿里巴巴(盒马生鲜)
+
+## 岗位信息
+
+- 阿里巴巴(盒马生鲜):前端技术二面
+
## 思路
+## 思路
-假如我们把coin逆序排列,然后逐个取,取到刚好不大于amout,依次类推。
+假如我们把 coin 逆序排列,然后逐个取,取到刚好不大于 amout,依次类推。
```
eg: 对于 [1,2,5] 组成 11 块
@@ -46,7 +65,7 @@ eg: 对于 [1,2,5] 组成 11 块
因此结果是 3
```
-熟悉贪心算法的同学应该已经注意到了,这就是贪心算法,贪心算法更amount尽快地变得更小。
+熟悉贪心算法的同学应该已经注意到了,这就是贪心算法,贪心算法更 amount 尽快地变得更小。
`经验表明,贪心策略是正确的`。 注意,我说的是经验表明, 贪心算法也有可能出错。 就拿这道题目来说,
他也是不正确的! 比如 `coins = [1, 5, 11] amout = 15`, 因此这种做法有时候不靠谱,我们还是采用靠谱的做法.
@@ -79,24 +98,26 @@ class Solution:
dp[i][j] = dp[i][j - 1]
return -1 if dp[-1][-1] == amount + 1 else dp[-1][-1]
- ```
-
- **复杂度分析**
+```
+
+**复杂度分析**
+
- 时间复杂度:$O(amonut * len(coins))$
- 空间复杂度:$O(amount * len(coins))$
-dp[i][j] 依赖于` dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个优化的信号,我们可以将其优化到一维,具体见下方。
+dp[i][j] 依赖于`dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个优化的信号,我们可以将其优化到一维,具体见下方。
+
## 关键点解析
- 动态规划
- 子问题
-用dp[i] 来表示组成i块钱,需要最少的硬币数,那么
+用 dp[i] 来表示组成 i 块钱,需要最少的硬币数,那么
-1. 第j个硬币我可以选择不拿 这个时候, 硬币数 = dp[i]
+1. 第 j 个硬币我可以选择不拿 这个时候, 硬币数 = dp[i]
-2. 第j个硬币我可以选择拿 这个时候, 硬币数 = dp[i - coins[j]] + 1
+2. 第 j 个硬币我可以选择拿 这个时候, 硬币数 = dp[i - coins[j]] + 1
- 和背包问题不同, 硬币是可以拿任意个
@@ -104,33 +125,33 @@ dp[i][j] 依赖于` dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个
## 代码
-
-* 语言支持:JS,C++,Python3
+- 语言支持:JS,C++,Python3
JavaScript Code:
-```js
-var coinChange = function(coins, amount) {
- if (amount === 0) {
- return 0;
- }
- const dp = Array(amount + 1).fill(Number.MAX_VALUE)
- dp[0] = 0;
- for (let i = 1; i < dp.length; i++) {
- for (let j = 0; j < coins.length; j++) {
- if (i - coins[j] >= 0) {
- dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
- }
+```js
+var coinChange = function (coins, amount) {
+ if (amount === 0) {
+ return 0;
+ }
+ const dp = Array(amount + 1).fill(Number.MAX_VALUE);
+ dp[0] = 0;
+ for (let i = 1; i < dp.length; i++) {
+ for (let j = 0; j < coins.length; j++) {
+ if (i - coins[j] >= 0) {
+ dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
+ }
- return dp[dp.length - 1] === Number.MAX_VALUE ? -1 : dp[dp.length - 1];
-
-
+ return dp[dp.length - 1] === Number.MAX_VALUE ? -1 : dp[dp.length - 1];
};
```
+
C++ Code:
-> C++中采用INT_MAX,因此判断时需要加上`dp[a - coin] < INT_MAX`以防止溢出
+
+> C++中采用 INT_MAX,因此判断时需要加上`dp[a - coin] < INT_MAX`以防止溢出
+
```C++
class Solution {
public:
@@ -166,10 +187,10 @@ class Solution:
```
**复杂度分析**
+
- 时间复杂度:$O(amonut * len(coins))$
- 空间复杂度:$O(amount)$
-
## 扩展
这是一道很简单描述的题目, 因此很多时候会被用到大公司的电面中。
diff --git a/problems/328.odd-even-linked-list.md b/problems/328.odd-even-linked-list.md
index d91266feb..2a39a048f 100644
--- a/problems/328.odd-even-linked-list.md
+++ b/problems/328.odd-even-linked-list.md
@@ -23,6 +23,17 @@ The relative order inside both the even and odd groups should remain as it was i
The first node is considered odd, the second node even and so on ...
```
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的想法是,先遍历一遍找出奇数的节点。然后再遍历一遍找出偶数节点,最后串起来。
diff --git a/problems/33.search-in-rotated-sorted-array.md b/problems/33.search-in-rotated-sorted-array.md
index 96d81c67c..9aa1fc1bd 100644
--- a/problems/33.search-in-rotated-sorted-array.md
+++ b/problems/33.search-in-rotated-sorted-array.md
@@ -25,6 +25,18 @@ Output: -1
```
+## 前置知识
+
+- 数组
+- 二分法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个我在网上看到的前端头条技术终面的一个算法题。
@@ -50,10 +62,10 @@ Output: -1
我们以([6,7,8,1,2,3,4,5], 4)为例讲解一下:
-
+
-
+
## 关键点解析
diff --git a/problems/334.increasing-triplet-subsequence.md b/problems/334.increasing-triplet-subsequence.md
index 7c359e351..63622c93b 100644
--- a/problems/334.increasing-triplet-subsequence.md
+++ b/problems/334.increasing-triplet-subsequence.md
@@ -23,6 +23,15 @@ Input: [5,4,3,2,1]
Output: false
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 百度
+- 字节
+
## 思路
这道题是求解顺序数字是否有三个递增的排列, 注意这里没有要求连续的,因此诸如滑动窗口的思路是不可以的。
题目要求O(n)的时间复杂度和O(1)的空间复杂度,因此暴力的做法就不用考虑了。
@@ -30,7 +39,7 @@ Output: false
我们的目标就是`依次`找到三个数字,其顺序是递增的。因此我们的做法可以是依次遍历,
然后维护三个变量,分别记录最小值,第二小值,第三小值。只要我们能够填满这三个变量就返回true,否则返回false。
-
+
## 关键点解析
- 维护三个变量,分别记录最小值,第二小值,第三小值。只要我们能够填满这三个变量就返回true,否则返回false
diff --git a/problems/335.self-crossing.md b/problems/335.self-crossing.md
index 0ff94829f..290afba41 100644
--- a/problems/335.self-crossing.md
+++ b/problems/335.self-crossing.md
@@ -41,6 +41,14 @@ https://leetcode-cn.com/problems/self-crossing/
```
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 暂无
+
## 思路
符合直觉的做法是$O(N)$时间和空间复杂度的算法。这种算法非常简单,但是题目要求我们使用空间复杂度为$O(1)$的做法。
@@ -52,24 +60,24 @@ https://leetcode-cn.com/problems/self-crossing/
1. 我们画的圈不断增大。
2. 我们画的圈不断减少。
-
+
(有没有感觉像迷宫?)
这样我们会发现,其实我们画最新一笔的时候,并不是之前画的所有的都需要考虑,我们只需要最近的几个就可以了,实际上是最近的五个,不过不知道也没关系,我们稍后会讲解。
-
+
红色部分指的是我们需要考虑的,而剩余没有被红色标注的部分则无需考虑。不是因为我们无法与之相交,而是我们`一旦与之相交,则必然我们也一定会与红色标记部分相交`。
然而我们画的方向也是不用考虑的。比如我当前画的方向是从左到右,那和我画的方向是从上到下有区别么?在这里是没区别的,不信我帮你将上图顺时针旋转 90 度看一下:
-
+
方向对于我们考虑是否相交没有差别。
当我们仔细思考的时候,会发现其实相交的情况只有以下几种:
-
+
这个时候代码就呼之欲出了。
diff --git a/problems/337.house-robber-iii.md b/problems/337.house-robber-iii.md
new file mode 100644
index 000000000..1fc289ddf
--- /dev/null
+++ b/problems/337.house-robber-iii.md
@@ -0,0 +1,203 @@
+## 题目地址(337. 打家劫舍 III)
+
+https://leetcode-cn.com/problems/house-robber-iii/
+
+## 题目描述
+
+```
+在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
+
+计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
+
+示例 1:
+
+输入: [3,2,3,null,3,null,1]
+
+ 3
+ / \
+ 2 3
+ \ \
+ 3 1
+
+输出: 7
+解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.
+示例 2:
+
+输入: [3,4,5,1,3,null,1]
+
+ 3
+ / \
+ 4 5
+ / \ \
+ 1 3 1
+
+输出: 9
+解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9.
+
+
+```
+
+## 前置知识
+
+- 二叉树
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+和 198.house-robber 类似,这道题也是相同的思路。 只不过数据结构从数组换成了树。
+
+我们仍然是对每一项进行决策:**如果我抢的话,所得到的最大价值是多少。如果我不抢的话,所得到的最大价值是多少。**
+
+- 遍历二叉树,都每一个节点我们都需要判断抢还是不抢。
+
+ - 如果抢了的话, 那么我们不能继续抢其左右子节点
+ - 如果不抢的话,那么我们可以继续抢左右子节点,当然也可以不抢。抢不抢取决于哪个价值更大。
+
+- 抢不抢取决于哪个价值更大。
+
+这是一个明显的递归问题,我们使用递归来解决。由于没有重复子问题,因此没有必要 cache ,也没有必要动态规划。
+
+## 关键点
+
+- 对每一个节点都分析,是抢还是不抢
+
+## 代码
+
+语言支持:JS, C++,Java,Python
+
+JavaScript Code:
+
+```js
+function helper(root) {
+ if (root === null) return [0, 0];
+ // 0: rob 1: notRob
+ const l = helper(root.left);
+ const r = helper(root.right);
+
+ const robed = root.val + l[1] + r[1];
+ const notRobed = Math.max(l[0], l[1]) + Math.max(r[0], r[1]);
+
+ return [robed, notRobed];
+}
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var rob = function (root) {
+ const [robed, notRobed] = helper(root);
+ return Math.max(robed, notRobed);
+};
+```
+
+C++ Code:
+```c++
+/**
+ * Definition for a binary tree node.
+ * struct TreeNode {
+ * int val;
+ * TreeNode *left;
+ * TreeNode *right;
+ * TreeNode(int x) : val(x), left(NULL), right(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ int rob(TreeNode* root) {
+ pair res = dfs(root);
+ return max(res.first, res.second);
+ }
+
+ pair dfs(TreeNode* root)
+ {
+ pair res = {0, 0};
+ if(root == NULL)
+ {
+ return res;
+ }
+
+ pair left = dfs(root->left);
+ pair right = dfs(root->right);
+ // 0 代表不偷,1 代表偷
+ res.first = max(left.first, left.second) + max(right.first, right.second);
+ res.second = left.first + right.first + root->val;
+ return res;
+ }
+
+};
+```
+
+Java Code:
+```java
+/**
+ * Definition for a binary tree node.
+ * public class TreeNode {
+ * int val;
+ * TreeNode left;
+ * TreeNode right;
+ * TreeNode(int x) { val = x; }
+ * }
+ */
+class Solution {
+ public int rob(TreeNode root) {
+ int[] res = dfs(root);
+ return Math.max(res[0], res[1]);
+ }
+
+ public int[] dp(TreeNode root)
+ {
+ int[] res = new int[2];
+ if(root == null)
+ {
+ return res;
+ }
+
+ int[] left = dfs(root.left);
+ int[] right = dfs(root.right);
+ // 0 代表不偷,1 代表偷
+ res[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
+ res[1] = left[0] + right[0] + root.val;
+ return res;
+ }
+}
+```
+
+Python Code:
+
+```python
+
+class Solution:
+ def rob(self, root: TreeNode) -> int:
+ def dfs(node):
+ if not node:
+ return [0, 0]
+ [l_rob, l_not_rob] = dfs(node.left)
+ [r_rob, r_not_rob] = dfs(node.right)
+ return [node.val + l_not_rob + r_not_rob, max([l_rob, l_not_rob]) + max([r_rob, r_not_rob])]
+ return max(dfs(root))
+
+
+# @lc code=end
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$,其中 N 为树的节点个数。
+- 空间复杂度:$O(h)$,其中 h 为树的高度。
+
+## 相关题目
+
+- [198.house-robber](https://github.com/azl397985856/leetcode/blob/master/problems/198.house-robber.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 35K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/342.power-of-four.md b/problems/342.power-of-four.md
index b07b83f8d..36b05052b 100644
--- a/problems/342.power-of-four.md
+++ b/problems/342.power-of-four.md
@@ -19,6 +19,15 @@ Follow up: Could you solve it without loops/recursion?
```
+## 前置知识
+
+- 数论
+
+## 公司
+
+- 百度
+- twosigma
+
## 思路
符合直觉的做法是不停除以 4 直到不能整除,然后判断是否为 1 即可。 代码如下:
@@ -34,7 +43,7 @@ return num == 1;
我们先来看下,4 的幂次方用 2 进制表示是什么样的.
-
+
发现规律: 4 的幂次方的二进制表示 1 的位置都是在奇数位(且不在最低位),其他位置都为 0
@@ -53,13 +62,13 @@ return num == 1;
`求与`, 如果等于本身,那么毫无疑问,这个 1 不再偶数位置,一定在奇数位置,因为如果在偶数位置,`求与`的结果就是 0 了
题目要求 n 是 32 位有符号整形,那么我们的特殊数字就应该是`01010101010101010101010101010101`(不用数了,一共 32 位)。
-
+
如上图,64和这个特殊数字求与,得到的是本身。 8 是 2的次方,但是不是4的次方,我们求与结果就是0了。
为了体现自己的逼格,我们可以使用计算器,来找一个逼格比较高的数字,这里我选了十六进制,结果是`0x55555555`。
-
+
代码见下方代码区。
@@ -129,3 +138,15 @@ class Solution:
binary_num = bin(num)[2:]
return binary_num.strip('0') == '1' and len(binary_num) % 2 == 1
```
+
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/343.integer-break.md b/problems/343.integer-break.md
new file mode 100644
index 000000000..10a22bd24
--- /dev/null
+++ b/problems/343.integer-break.md
@@ -0,0 +1,203 @@
+## 题目地址(343. 整数拆分)
+
+https://leetcode-cn.com/problems/integer-break/
+
+## 题目描述
+
+给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
+
+示例 1:
+
+输入: 2
+输出: 1
+解释: 2 = 1 + 1, 1 × 1 = 1。
+示例 2:
+
+输入: 10
+输出: 36
+解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
+说明: 你可以假设 n 不小于 2 且不大于 58。
+
+## 前置知识
+
+- 递归
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+希望通过这篇题解让大家知道“题解区的水有多深”,让大家知道“什么才是好的题解”。
+
+我看了很多人的题解直接就是两句话,然后跟上代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+这种题解说实话,只针对那些”自己会, 然后去题解区看看有没有新的更好的解法的人“。但是大多数看题解的人是那种`自己没思路,不会做的人`。那么这种题解就没什么用了。
+
+我认为`好的题解应该是新手友好的,并且能够将解题人思路完整展现的题解`。比如看到这个题目,我首先想到了什么(对错没有关系),然后头脑中经过怎么样的筛选将算法筛选到具体某一个或某几个。我的最终算法是如何想到的,有没有一些先行知识。
+
+当然我也承认自己有很多题解也是直接给的答案,这对很多人来说用处不大,甚至有可能有反作用,给他们一种”我已经会了“的假象。实际上他们根本不懂解题人本身原本的想法, 也许是写题解的人觉得”这很自然“,也可能”只是为了秀技“。
+
+Ok,下面来讲下`我是如何解这道题的`。
+
+### 抽象
+
+首先看到这道题,自然而然地先对问题进行抽象,这种抽象能力是必须的。LeetCode 实际上有很多这种穿着华丽外表的题,当你把这个衣服扒开的时候,会发现都是差不多的,甚至两个是一样的,这样的例子实际上有很多。 就本题来说,就有一个剑指 Offer 的原题[《剪绳子》](https://leetcode-cn.com/problems/jian-sheng-zi-lcof/)和其本质一样,只是换了描述方式。类似的有力扣 137 和 645 等等,大家可以自己去归纳总结。
+
+> 137 和 645 我贴个之前写的题解 https://leetcode-cn.com/problems/single-number/solution/zhi-chu-xian-yi-ci-de-shu-xi-lie-wei-yun-suan-by-3/
+
+**培养自己抽象问题的能力,不管是在算法上还是工程上。** 务必记住这句话!
+
+数学是一门非常抽象的学科,同时也很方便我们抽象问题。为了显得我的题解比较高级,引入一些你们看不懂的数学符号也是很有必要的(开玩笑,没有什么高级数学符号啦)。
+
+> 实际上这道题可以用纯数学角度来解,但是我相信大多数人并不想看。即使你看了,大多人的感受也是“好 nb,然而并没有什么用”。
+
+这道题抽象一下就是:
+
+令:
+
+(图 1)
+求:
+
+(图 2)
+
+## 第一直觉
+
+经过上面的抽象,我的第一直觉这可能是一个数学题,我回想了下数学知识,然后用数学法 AC 了。 数学就是这么简单平凡且枯燥。
+
+然而如果没有数学的加持的情况下,我继续思考怎么做。我想是否可以枚举所有的情况(如图 1),然后对其求最大值(如图 2)。
+
+问题转化为如何枚举所有的情况。经过了几秒钟的思考,我发现这是一个很明显的递归问题。 具体思考过程如下:
+
+- 我们将原问题抽象为 f(n)
+- 那么 f(n) 等价于 max(1 \* fn(n - 1), 2 \* f(n - 2), ..., (n - 1) \* f(1))。
+
+用数学公式表示就是:
+
+
+(图 3)
+
+截止目前,是一点点数学 + 一点点递归,我们继续往下看。现在问题是不是就很简单啦?直接翻译图三为代码即可,我们来看下这个时候的代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ if n == 2: return 1
+ res = 0
+ for i in range(1, n):
+ res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+ return res
+```
+
+毫无疑问,超时了。原因很简单,就是算法中包含了太多的重复计算。如果经常看我的题解的话,这句话应该不陌生。我随便截一个我之前讲过这个知识点的图。
+
+
+(图 4)
+
+> 原文链接:https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md
+
+大家可以尝试自己画图理解一下。
+
+> 看到这里,有没有种殊途同归的感觉呢?
+
+## 考虑优化
+
+如上,我们可以考虑使用记忆化递归的方式来解决。只是用一个 hashtable 存储计算过的值即可。
+
+```python
+class Solution:
+ @lru_cache()
+ def integerBreak(self, n: int) -> int:
+ if n == 2: return 1
+ res = 0
+ for i in range(1, n):
+ res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+ return res
+```
+
+为了简单起见(偷懒起见),我直接用了 lru_cache 注解, 上面的代码是可以 AC 的。
+
+## 动态规划
+
+看到这里的同学应该发现了,这个套路是不是很熟悉?下一步就是将其改造成动态规划了。
+
+如图 4,我们的思考方式是从顶向下,这符合人们思考问题的方式。将其改造成如下图的自底向上方式就是动态规划。
+
+
+(图 5)
+
+现在再来看下文章开头的代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+dp table 存储的是图 3 中 f(n)的值。一个自然的想法是令 dp[i] 等价于 f(i)。而由于上面分析了原问题等价于 f(n),那么很自然的原问题也等价于 dp[n]。
+
+而 dp[i]等价于 f(i),那么上面针对 f(i) 写的递归公式对 dp[i] 也是适用的,我们拿来试试。
+
+```
+// 关键语句
+res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+```
+
+翻译过来就是:
+
+```
+dp[i] = max(dp[i], max(i * dp(n - i),i * (n - i)))
+```
+
+而这里的 n 是什么呢?我们说了`dp是自底向下的思考方式`,那么在达到 n 之前是看不到整体的`n` 的。因此这里的 n 实际上是 1,2,3,4... n。
+
+自然地,我们用一层循环来生成上面一系列的 n 值。接着我们还要生成一系列的 i 值,注意到 n - i 是要大于 0 的,因此 i 只需要循环到 n - 1 即可。
+
+思考到这里,我相信上面的代码真的是`不难得出`了。
+
+## 关键点
+
+- 数学抽象
+- 递归分析
+- 记忆化递归
+- 动态规划
+
+## 代码
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+## 总结
+
+培养自己的解题思维很重要, 不要直接看别人的答案。而是要将别人的东西变成自己的, 而要做到这一点,你就要知道“他们是怎么想到的”,“想到这点是不是有什么前置知识”,“类似题目有哪些”。
+
+最优解通常不是一下子就想到了,这需要你在不那么优的解上摔了很多次跟头之后才能记住的。因此在你没有掌握之前,不要直接去看最优解。 在你掌握了之后,我不仅鼓励你去写最优解,还鼓励去一题多解,从多个解决思考问题。 到了那个时候, 萌新也会惊讶地呼喊“哇塞, 这题还可以这么解啊?”。 你也会低调地发出“害,解题就是这么简单平凡且枯燥。”的声音。
+
+## 扩展
+
+正如我开头所说,这种套路实在是太常见了。希望大家能够识别这种问题的本质,彻底掌握这种套路。另外我对这个套路也在我的新书《LeetCode 题解》中做了介绍,本书目前刚完成草稿的编写,如果你想要第一时间获取到我们的题解新书,那么请发送邮件到 `azl397985856@gmail.com`,标题著明“书籍《LeetCode 题解》预定”字样。。
diff --git a/problems/349.intersection-of-two-arrays.md b/problems/349.intersection-of-two-arrays.md
index 17b255e4f..c5e13eac1 100644
--- a/problems/349.intersection-of-two-arrays.md
+++ b/problems/349.intersection-of-two-arrays.md
@@ -22,6 +22,17 @@ The result can be in any order.
```
+## 前置知识
+
+- hashtable
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
先遍历第一个数组,将其存到hashtable中,
@@ -29,7 +40,7 @@ The result can be in any order.
## 关键点解析
-无
+- 空间换时间
## 代码
@@ -38,46 +49,6 @@ The result can be in any order.
Javascript Code:
```js
-/*
- * @lc app=leetcode id=349 lang=javascript
- *
- * [349] Intersection of Two Arrays
- *
- * https://leetcode.com/problems/intersection-of-two-arrays/description/
- *
- * algorithms
- * Easy (53.11%)
- * Total Accepted: 203.6K
- * Total Submissions: 380.9K
- * Testcase Example: '[1,2,2,1]\n[2,2]'
- *
- * Given two arrays, write a function to compute their intersection.
- *
- * Example 1:
- *
- *
- * Input: nums1 = [1,2,2,1], nums2 = [2,2]
- * Output: [2]
- *
- *
- *
- * Example 2:
- *
- *
- * Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
- * Output: [9,4]
- *
- *
- * Note:
- *
- *
- * Each element in the result must be unique.
- * The result can be in any order.
- *
- *
- *
- *
- */
/**
* @param {number[]} nums1
* @param {number[]} nums2
@@ -124,3 +95,13 @@ class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return set(nums1) & set(nums2)
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/365.water-and-jug-problem.md b/problems/365.water-and-jug-problem.md
index 6db36849e..aef2a16f9 100644
--- a/problems/365.water-and-jug-problem.md
+++ b/problems/365.water-and-jug-problem.md
@@ -28,6 +28,17 @@ Output: False
## BFS(超时)
+## 前置知识
+
+- BFS
+- 最大公约数
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
### 思路
两个水壶的水我们考虑成状态,然后我们不断进行倒的操作,改变状态。那么初始状态就是(0 0) 目标状态就是 (any, z)或者 (z, any),其中any 指的是任意升水。
@@ -205,4 +216,4 @@ def GCD(a, b):
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/371.sum-of-two-integers.md b/problems/371.sum-of-two-integers.md
index a52df6a53..9948ac8c4 100644
--- a/problems/371.sum-of-two-integers.md
+++ b/problems/371.sum-of-two-integers.md
@@ -18,17 +18,28 @@ Output: 1
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
不能使用加减法来求加法。 我们只能朝着位元算的角度来思考了。
由于`异或`是`相同则位0,不同则位1`,因此我们可以把异或看成是一种不进位的加减法。
-
+
由于`与`是`全部位1则位1,否则位0`,因此我们可以求与之后左移一位来表示进位。
-
+
然后我们对上述两个元算结果递归求解即可。 递归的结束条件就是其中一个为0,我们直接返回另一个。
@@ -39,6 +50,8 @@ Output: 1
- 求与之后左移一位来可以表示进位
## 代码
+代码支持:JS,C++,Java,Python
+Javascript Code:
```js
/*
* @lc app=leetcode id=371 lang=javascript
@@ -58,4 +71,73 @@ var getSum = function(a, b) {
return getSum(a ^ b, (a & b) << 1);
};
```
+C++ Code:
+```c++
+class Solution {
+public:
+ int getSum(int a, int b) {
+ if(a==0) return b;
+ if(b==0) return a;
+
+ while(b!=0)
+ {
+ // 防止 AddressSanitizer 对有符号左移的溢出保护处理
+ auto carry = ((unsigned int ) (a & b))<<1;
+ // 计算无进位的结果
+ a = a^b;
+ //将存在进位的位置置1
+ b =carry;
+ }
+ return a;
+ }
+};
+```
+
+Java Code:
+```java
+class Solution {
+ public int getSum(int a, int b) {
+ if(a==0) return b;
+ if(b==0) return a;
+
+ while(b!=0)
+ {
+ int carry = a&b;
+ // 计算无进位的结果
+ a = a^b;
+ //将存在进位的位置置1
+ b =carry<<1;
+ }
+ return a;
+ }
+}
+```
+
+Python Code:
+```python
+# python整数类型为Unifying Long Integers, 即无限长整数类型.
+# 模拟 32bit 有符号整型加法
+class Solution:
+ def getSum(self, a: int, b: int) -> int:
+ a &= 0xFFFFFFFF
+ b &= 0xFFFFFFFF
+ while b:
+ carry = a & b
+ a ^= b
+ b = ((carry) << 1) & 0xFFFFFFFF
+ # print((a, b))
+ return a if a < 0x80000000 else ~(a^0xFFFFFFFF)
+```
+
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+> 由于题目数据规模不会变化,因此其实复杂度分析是没有意义的。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/378.kth-smallest-element-in-a-sorted-matrix.md b/problems/378.kth-smallest-element-in-a-sorted-matrix.md
index 8054da9c1..98c87feeb 100644
--- a/problems/378.kth-smallest-element-in-a-sorted-matrix.md
+++ b/problems/378.kth-smallest-element-in-a-sorted-matrix.md
@@ -23,6 +23,17 @@ Note:
You may assume k is always valid, 1 ≤ k ≤ n2.
```
+## 前置知识
+
+- 二分查找
+- 堆
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
显然用大顶堆可以解决,时间复杂度 Klogn n 为总的数字个数,
@@ -36,18 +47,18 @@ You may assume k is always valid, 1 ≤ k ≤ n2.
最普通的二分法是有序数组中查找指定值(或者说满足某个条件的值)。由于是有序的,我们可以根据索引关系来确定大小关系,
因此这种思路比较直接,但是对于这道题目索引大小和数字大小没有直接的关系,因此这种二分思想就行不通了。
-
+
(普通的基于索引判断的二分法)
- 我们能够找到矩阵中最大的元素(右下角)和最小的元素(左上角)。我们可以求出值的中间,而不是上面那种普通二分法的索引的中间。
-
+
- 找到中间值之后,我们可以拿这个值去计算有多少元素是小于等于它的。
具体方式就是比较行的最后一列,如果中间值比最后一列大,说明中间元素肯定大于这一行的所有元素。 否则我们从后往前遍历直到不大于。
-
+
- 上一步我们会计算一个count,我们拿这个count和k进行比较
@@ -61,7 +72,7 @@ You may assume k is always valid, 1 ≤ k ≤ n2.
整个计算过程是这样的:
-
+
这里有一个大家普遍都比较疑惑的点,也是我当初非常疑惑,困扰我很久的点, leetcode评论区也有很多人来问,就是“能够确保最终我们找到的元素一定在矩阵中么?”
diff --git a/problems/380.insert-delete-getrandom-o1.md b/problems/380.insert-delete-getrandom-o1.md
index 2688099c0..13f0bfccb 100644
--- a/problems/380.insert-delete-getrandom-o1.md
+++ b/problems/380.insert-delete-getrandom-o1.md
@@ -38,6 +38,18 @@ randomSet.getRandom();
```
+## 前置知识
+
+- 数组
+- 哈希表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个设计题。这道题的核心就是考察基本数据结构和算法的操作以及复杂度。
@@ -46,13 +58,15 @@ randomSet.getRandom();
- 数组支持随机访问,其按照索引查询的时间复杂度为$O(1)$,按值查询的时间复杂度为$O(N)$, 而插入和删除的时间复杂度为$O(N)$。
- 链表不支持随机访问,其查询的时间复杂度为$O(N)$,但是对于插入和删除的复杂度为$O(1)$(不考虑找到选要处理的节点花费的时间)。
-- 对于哈希表,正常情况下其查询复杂度平均为$O(1)$,插入和删除的复杂度为$O(1)$。
+- 对于哈希表,正常情况下其查询复杂度平均为$O(N)$,插入和删除的复杂度为$O(1)$。
-由于题目要求 getRandom 返回要随机,那么如果单纯使用链表以及哈希表肯定是不行的。而又由于对于插入和删除我们也需要平均复杂度为$O(1)$,因此单纯使用数组也是不行的。我们考虑多种使用数据结构来实现。
+由于题目要求 getRandom 返回要随机并且要在$O(1)$复杂度内,那么如果单纯使用链表或者哈希表肯定是不行的。
+
+而又由于对于插入和删除也需要复杂度为$O(1)$,因此单纯使用数组也是不行的,因此考虑多种使用数据结构来实现。
> 实际上 LeetCode 设计题,几乎没有单纯一个数据结构搞定的,基本都需要多种数据结构结合,这个时候需要你对各种数据结构以及其基本算法的复杂度有着清晰的认知。
-对于 getRandom 用数组很简单。对于判断是否已经有了存在的元素,我们使用哈希表也很容易做到。因此我们将数组随机访问,以及哈希表$O(1)$按值检索的特性结合起来,即同时使用这两种数据结构。
+对于 getRandom 用数组很简单。对于判断是否已经有了存在的元素,我们使用哈希表也很容易做到。因此我们可以将数组随机访问,以及哈希表$O(1)$按检索值的特性结合起来,即同时使用这两种数据结构。
对于删除和插入,我们需要一些技巧。
@@ -68,9 +82,25 @@ randomSet.getRandom();
对于 1,我们可以通过哈希表来实现。 key 是插入的数字,value 是数组对应的索引。删除的时候我们根据 key 反查出索引就可以快速找到。
+> 题目说明了不会存在重复元素,所以我们可以这么做。思考一下,如果没有这个限制会怎么样?
+
对于 2,我们可以通过和数组最后一项进行交换的方式来实现,这样就避免了数据移动。同时数组其他项的索引仍然保持不变,非常好!
-> 相应的我们插入的时候,需要维护哈希表
+> 相应地,我们插入的时候,需要维护哈希表
+
+图解:
+
+以依次【1,2,3,4】之后为初始状态,那么此时状态是这样的:
+
+
+
+而当要插入一个新的5的时候, 我们只需要分别向数组末尾和哈希表中插入这条记录即可。
+
+
+
+而删除的时候稍微有一点复杂:
+
+
## 关键点解析
@@ -139,3 +169,13 @@ class RandomizedSet:
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
```
+
+***复杂度分析***
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的LeetCode题解
+
+
diff --git a/problems/39.combination-sum.md b/problems/39.combination-sum.md
index be782f4ae..c88fb052e 100644
--- a/problems/39.combination-sum.md
+++ b/problems/39.combination-sum.md
@@ -31,6 +31,17 @@ A solution set is:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -42,7 +53,9 @@ A solution set is:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
diff --git a/problems/4.median-of-two-sorted-array.md b/problems/4.median-of-two-sorted-arrays.md
similarity index 53%
rename from problems/4.median-of-two-sorted-array.md
rename to problems/4.median-of-two-sorted-arrays.md
index 6f8a27eba..2629be528 100644
--- a/problems/4.median-of-two-sorted-array.md
+++ b/problems/4.median-of-two-sorted-arrays.md
@@ -1,86 +1,109 @@
-## 题目地址
+## 题目地址(4. 寻找两个正序数组的中位数)
+
https://leetcode.com/problems/median-of-two-sorted-arrays/
## 题目描述
+
```
-There are two sorted arrays nums1 and nums2 of size m and n respectively.
+给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。
+
+请你找出这两个正序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
-Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
+你可以假设 nums1 和 nums2 不会同时为空。
-You may assume nums1 and nums2 cannot be both empty.
+
-Example 1:
+示例 1:
nums1 = [1, 3]
nums2 = [2]
-The median is 2.0
-Example 2:
+则中位数是 2.0
+示例 2:
nums1 = [1, 2]
nums2 = [3, 4]
-The median is (2 + 3)/2 = 2.5
+则中位数是 (2 + 3)/2 = 2.5
+
```
+## 前置知识
+
+- 中位数
+- 分治法
+- 二分查找
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
-首先了解一下Median的概念,一个数组中median就是把数组分成左右等分的中位数。
+
+首先了解一下 Median 的概念,一个数组中 median 就是把数组分成左右等分的中位数。
如下图:
-
+
这道题,很容易想到暴力解法,时间复杂度和空间复杂度都是`O(m+n)`, 不符合题中给出`O(log(m+n))`时间复杂度的要求。
-我们可以从简单的解法入手,试了一下,暴力解法也是可以被Leetcode Accept的. 分析中会给出两种解法,暴力求解和二分解法。
+我们可以从简单的解法入手,试了一下,暴力解法也是可以被 Leetcode Accept 的. 分析中会给出两种解法,暴力求解和二分解法。
#### 解法一 - 暴力 (Brute Force)
-暴力解主要是要merge两个排序的数组`(A,B)`成一个排序的数组。
+
+暴力解主要是要 merge 两个排序的数组`(A,B)`成一个排序的数组。
用两个`pointer(i,j)`,`i` 从数组`A`起始位置开始,即`i=0`开始,`j` 从数组`B`起始位置, 即`j=0`开始.
一一比较 `A[i] 和 B[j]`,
-1. 如果`A[i] <= B[j]`, 则把`A[i]` 放入新的数组中,i往后移一位,即 `i+1`.
-2. 如果`A[i] > B[j]`, 则把`B[j]` 放入新的数组中,j往后移一位,即 `j+1`.
+
+1. 如果`A[i] <= B[j]`, 则把`A[i]` 放入新的数组中,i 往后移一位,即 `i+1`.
+2. 如果`A[i] > B[j]`, 则把`B[j]` 放入新的数组中,j 往后移一位,即 `j+1`.
3. 重复步骤#1 和 #2,直到`i`移到`A`最后,或者`j`移到`B`最后。
4. 如果`j`移动到`B`数组最后,那么直接把剩下的所有`A`依次放入新的数组中.
5. 如果`i`移动到`A`数组最后,那么直接把剩下的所有`B`依次放入新的数组中.
-Merge的过程如下图。
-
-
+Merge 的过程如下图。
+
-*时间复杂度: `O(m+n) - m is length of A, n is length of B`*
+_时间复杂度: `O(m+n) - m is length of A, n is length of B`_
-*空间复杂度: `O(m+n)`*
+_空间复杂度: `O(m+n)`_
#### 解法二 - 二分查找 (Binary Search)
+
由于题中给出的数组都是排好序的,在排好序的数组中查找很容易想到可以用二分查找(Binary Search), 这里对数组长度小的做二分,
-保证数组A 和 数组B 做partition 之后
+保证数组 A 和 数组 B 做 partition 之后
`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
-对数组A的做partition的位置是区间`[0,m]`
+对数组 A 的做 partition 的位置是区间`[0,m]`
如图:
-
+
下图给出几种不同情况的例子(注意但左边或者右边没有元素的时候,左边用`INF_MIN`,右边用`INF_MAX`表示左右的元素:
-
+
-下图给出具体做的partition 解题的例子步骤,
-
+下图给出具体做的 partition 解题的例子步骤,
+
-*时间复杂度: `O(log(min(m, n)) - m is length of A, n is length of B`*
+_时间复杂度: `O(log(min(m, n)) - m is length of A, n is length of B`_
-*空间复杂度: `O(1)` - 这里没有用额外的空间*
+_空间复杂度: `O(1)` - 这里没有用额外的空间_
## 关键点分析
-1. 暴力求解,在线性时间内merge两个排好序的数组成一个数组。
+
+1. 暴力求解,在线性时间内 merge 两个排好序的数组成一个数组。
2. 二分查找,关键点在于
- - 要partition两个排好序的数组成左右两等份,partition需要满足`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
- - 并且partition后 A左边最大(`maxLeftA`), A右边最小(`minRightA`), B左边最大(`maxLeftB`), B右边最小(`minRightB`) 满足
-`(maxLeftA <= minRightB && maxLeftB <= minRightA)`
+- 要 partition 两个排好序的数组成左右两等份,partition 需要满足`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
+
+- 并且 partition 后 A 左边最大(`maxLeftA`), A 右边最小(`minRightA`), B 左边最大(`maxLeftB`), B 右边最小(`minRightB`) 满足
+ `(maxLeftA <= minRightB && maxLeftB <= minRightA)`
+
+有了这两个条件,那么 median 就在这四个数中,根据奇数或者是偶数,
-有了这两个条件,那么median就在这四个数中,根据奇数或者是偶数,
```
奇数:
median = max(maxLeftA, maxLeftB)
@@ -88,9 +111,15 @@ median = max(maxLeftA, maxLeftB)
median = (max(maxLeftA, maxLeftB) + min(minRightA, minRightB)) / 2
```
-## 代码(Java code)
-*解法一 - 暴力解法(Brute force)*
-```java
+## 代码
+
+代码支持: Java,JS:
+
+Java Code:
+
+_解法一 - 暴力解法(Brute force)_
+
+```java []
class MedianTwoSortedArrayBruteForce {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int[] newArr = mergeTwoSortedArray(nums1, nums2);
@@ -127,8 +156,85 @@ class MedianTwoSortedArrayBruteForce {
}
}
```
-*解法二 - 二分查找(Binary Search)*
-```java
+
+```javascript []
+/**
+ * @param {number[]} nums1
+ * @param {number[]} nums2
+ * @return {number}
+ */
+var findMedianSortedArrays = function (nums1, nums2) {
+ // 归并排序
+ const merged = [];
+ let i = 0;
+ let j = 0;
+ while (i < nums1.length && j < nums2.length) {
+ if (nums1[i] < nums2[j]) {
+ merged.push(nums1[i++]);
+ } else {
+ merged.push(nums2[j++]);
+ }
+ }
+ while (i < nums1.length) {
+ merged.push(nums1[i++]);
+ }
+ while (j < nums2.length) {
+ merged.push(nums2[j++]);
+ }
+
+ const { length } = merged;
+ return length % 2 === 1
+ ? merged[Math.floor(length / 2)]
+ : (merged[length / 2] + merged[length / 2 - 1]) / 2;
+};
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(max(m, n))$
+- 空间复杂度:$O(m + n)$
+
+_解法二 - 二分查找(Binary Search)_
+
+```js []
+/**
+ * 二分解法
+ * @param {number[]} nums1
+ * @param {number[]} nums2
+ * @return {number}
+ */
+var findMedianSortedArrays = function (nums1, nums2) {
+ // make sure to do binary search for shorten array
+ if (nums1.length > nums2.length) {
+ [nums1, nums2] = [nums2, nums1];
+ }
+ const m = nums1.length;
+ const n = nums2.length;
+ let low = 0;
+ let high = m;
+ while (low <= high) {
+ const i = low + Math.floor((high - low) / 2);
+ const j = Math.floor((m + n + 1) / 2) - i;
+
+ const maxLeftA = i === 0 ? -Infinity : nums1[i - 1];
+ const minRightA = i === m ? Infinity : nums1[i];
+ const maxLeftB = j === 0 ? -Infinity : nums2[j - 1];
+ const minRightB = j === n ? Infinity : nums2[j];
+
+ if (maxLeftA <= minRightB && minRightA >= maxLeftB) {
+ return (m + n) % 2 === 1
+ ? Math.max(maxLeftA, maxLeftB)
+ : (Math.max(maxLeftA, maxLeftB) + Math.min(minRightA, minRightB)) / 2;
+ } else if (maxLeftA > minRightB) {
+ high = i - 1;
+ } else {
+ low = low + 1;
+ }
+ }
+};
+```
+
+```java []
class MedianSortedTwoArrayBinarySearch {
public static double findMedianSortedArraysBinarySearch(int[] nums1, int[] nums2) {
// do binary search for shorter length array, make sure time complexity log(min(m,n)).
@@ -172,75 +278,13 @@ class MedianSortedTwoArrayBinarySearch {
}
```
-## 代码 (javascript code)
-*解法一 - 暴力解法(Brute force)*
-```js
-/**
- * @param {number[]} nums1
- * @param {number[]} nums2
- * @return {number}
- */
-var findMedianSortedArrays = function(nums1, nums2) {
- // 归并排序
- const merged = []
- let i = 0
- let j = 0
- while(i < nums1.length && j < nums2.length) {
- if (nums1[i] < nums2[j]) {
- merged.push(nums1[i++])
- } else {
- merged.push(nums2[j++])
- }
- }
- while(i < nums1.length) {
- merged.push(nums1[i++])
- }
- while(j < nums2.length) {
- merged.push(nums2[j++])
- }
+**复杂度分析**
- const { length } = merged
- return length % 2 === 1
- ? merged[Math.floor(length / 2)]
- : (merged[length / 2] + merged[length / 2 - 1]) / 2
-};
-```
+- 时间复杂度:$O(log(min(m, n)))$
+- 空间复杂度:$O(log(min(m, n)))$
-*解法二 - 二分查找(Binary Search)*
-```js
-/**
- * 二分解法
- * @param {number[]} nums1
- * @param {number[]} nums2
- * @return {number}
- */
-var findMedianSortedArrays = function(nums1, nums2) {
- // make sure to do binary search for shorten array
- if (nums1.length > nums2.length) {
- [nums1, nums2] = [nums2, nums1]
- }
- const m = nums1.length
- const n = nums2.length
- let low = 0
- let high = m
- while(low <= high) {
- const i = low + Math.floor((high - low) / 2)
- const j = Math.floor((m + n + 1) / 2) - i
-
- const maxLeftA = i === 0 ? -Infinity : nums1[i-1]
- const minRightA = i === m ? Infinity : nums1[i]
- const maxLeftB = j === 0 ? -Infinity : nums2[j-1]
- const minRightB = j === n ? Infinity : nums2[j]
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
- if (maxLeftA <= minRightB && minRightA >= maxLeftB) {
- return (m + n) % 2 === 1
- ? Math.max(maxLeftA, maxLeftB)
- : (Math.max(maxLeftA, maxLeftB) + Math.min(minRightA, minRightB)) / 2
- } else if (maxLeftA > minRightB) {
- high = i - 1
- } else {
- low = low + 1
- }
- }
-};
-```
\ No newline at end of file
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/40.combination-sum-ii.md b/problems/40.combination-sum-ii.md
index 9a2d3e16f..231f21874 100644
--- a/problems/40.combination-sum-ii.md
+++ b/problems/40.combination-sum-ii.md
@@ -32,6 +32,17 @@ A solution set is:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -43,7 +54,9 @@ A solution set is:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -58,57 +71,6 @@ A solution set is:
* 语言支持: Javascript,Python3
```js
-/*
- * @lc app=leetcode id=40 lang=javascript
- *
- * [40] Combination Sum II
- *
- * https://leetcode.com/problems/combination-sum-ii/description/
- *
- * algorithms
- * Medium (40.31%)
- * Total Accepted: 212.8K
- * Total Submissions: 519K
- * Testcase Example: '[10,1,2,7,6,1,5]\n8'
- *
- * Given a collection of candidate numbers (candidates) and a target number
- * (target), find all unique combinations in candidates where the candidate
- * numbers sums to target.
- *
- * Each number in candidates may only be used once in the combination.
- *
- * Note:
- *
- *
- * All numbers (including target) will be positive integers.
- * The solution set must not contain duplicate combinations.
- *
- *
- * Example 1:
- *
- *
- * Input: candidates = [10,1,2,7,6,1,5], target = 8,
- * A solution set is:
- * [
- * [1, 7],
- * [1, 2, 5],
- * [2, 6],
- * [1, 1, 6]
- * ]
- *
- *
- * Example 2:
- *
- *
- * Input: candidates = [2,5,2,1,2], target = 5,
- * A solution set is:
- * [
- * [1,2,2],
- * [5]
- * ]
- *
- *
- */
function backtrack(list, tempList, nums, remain, start) {
if (remain < 0) return;
else if (remain === 0) return list.push([...tempList]);
diff --git a/problems/416.partition-equal-subset-sum.md b/problems/416.partition-equal-subset-sum.md
index 2e7082574..24cf41c91 100644
--- a/problems/416.partition-equal-subset-sum.md
+++ b/problems/416.partition-equal-subset-sum.md
@@ -1,137 +1,298 @@
-## 题目地址
+### 题目地址
-https://leetcode.com/problems/partition-equal-subset-sum/description/
+#### [416. 分割等和子集](https://leetcode-cn.com/problems/partition-equal-subset-sum/)
-## 题目描述
+### 题目描述
+
+> 给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
+>
+> 注意:
+>
+> 每个数组中的元素不会超过 100
+> 数组的大小不会超过 200
+>
+> 示例 1:
+>
+> 输入: [1, 5, 11, 5]
+>
+> 输出: true
+>
+> 解释: 数组可以分割成 [1, 5, 5] 和 [11].
+>
+> 示例 2:
+>
+> 输入: [1, 2, 3, 5]
+>
+> 输出: false
+>
+> 解释: 数组不能分割成两个元素和相等的子集.
+
+## 前置知识
+
+- DFS
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+抽象能力不管是在工程还是算法中都占据着绝对重要的位置。比如上题我们可以抽象为:
+
+**给定一个非空数组,和是 sum,能否找到这样的一个子序列,使其和为 2/sum**
+
+我们做过二数和,三数和, 四数和,看到这种类似的题会不会舒适一点,思路更开阔一点。
+
+老司机们看到转化后的题,会立马想到背包问题,这里会提供**深度优先搜索**和**背包**两种解法。
+
+### 深度优先遍历
+
+我们再来看下题目描述,sum 有两种情况,
+
+1. 如果 sum % 2 === 1, 则肯定无解,因为 sum/2 为小数,而数组全由整数构成,子数组和不可能为小数。
+2. 如果 sum % 2 === 0, 需要找到和为 2/sum 的子序列
+ 针对 2,我们要在 nums 里找到满足条件的子序列 subNums。 这个过程可以类比为在一个大篮子里面有 N 个球,每个球代表不同的数字,我们用一小篮子去抓取球,使得拿到的球数字和为 2/sum。那么很自然的一个想法就是,对大篮子里面的每一个球,我们考虑取它或者不取它,如果我们足够耐心,最后肯定能穷举所有的情况,判断是否有解。上述思维表述为伪代码如下:
```
-Given a non-empty array containing only positive integers, find if the array can be partitioned into two subsets such that the sum of elements in both subsets is equal.
+令 target = sum / 2, nums 为输入数组, cur 为当前当前要选择的数字的索引
+nums 为输入数组,target为当前求和目标,cur为当前判断的数
+function dfs(nums, target, cur)
+ 如果target < 0 或者 cur > nums.length
+ return false
+ 否则
+ 如果 target = 0, 说明找到答案了,返回true
+ 否则
+ 取当前数或者不取,进入递归 dfs(nums, target - nums[cur], cur + 1) || dfs(nums, target, cur + 1)
+```
-Note:
+因为对每个数都考虑取不取,所以这里时间复杂度是 O(2 ^ n), 其中 n 是 nums 数组长度,
-Each of the array element will not exceed 100.
-The array size will not exceed 200.
-
+#### javascript 实现
-Example 1:
+```javascript
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ return dfs(nums, sum, 0);
+};
-Input: [1, 5, 11, 5]
+function dfs(nums, target, cur) {
+ if (target < 0 || cur > nums.length) {
+ return false;
+ }
+ return (
+ target === 0 ||
+ dfs(nums, target - nums[cur], cur + 1) ||
+ dfs(nums, target, cur + 1)
+ );
+}
+```
-Output: true
+不出所料,这里是超时了,我们看看有没优化空间
-Explanation: The array can be partitioned as [1, 5, 5] and [11].
-
+1. 如果 nums 中最大值 > 2/sum, 那么肯定无解
+2. 在搜索过程中,我们对每个数都是取或者不取,并且数组中所有项都为正数。我们设取的数和为 `pickedSum`,不难得 pickedSum <= 2/sum, 同时要求丢弃的数为 `discardSum`,不难得 pickedSum <= 2 / sum。
-Example 2:
+我们同时引入这两个约束条件加强剪枝:
-Input: [1, 2, 3, 5]
+优化后的代码如下
-Output: false
+```javascript
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ nums = nums.sort((a, b) => b - a);
+ if (sum < nums[0]) {
+ return false;
+ }
+ return dfs(nums, sum, sum, 0);
+};
-Explanation: The array cannot be partitioned into equal sum subsets.
+function dfs(nums, pickRemain, discardRemain, cur) {
+ if (pickRemain === 0 || discardRemain === 0) {
+ return true;
+ }
+ if (pickRemain < 0 || discardRemain < 0 || cur > nums.length) {
+ return false;
+ }
+ return (
+ dfs(nums, pickRemain - nums[cur], discardRemain, cur + 1) ||
+ dfs(nums, pickRemain, discardRemain - nums[cur], cur + 1)
+ );
+}
```
-## 思路
+leetcode 是 AC 了,但是时间复杂度 O(2 ^ n), 算法时间复杂度很差,我们看看有没更好的。
+
+### DP 解法
+
+在用 DFS 是时候,我们是不关心取数的规律的,只要保证接下来要取的数在之前没有被取过即可。那如果我们有规律去安排取数策略的时候会怎么样呢,比如第一次取数安排在第一位,第二位取数安排在第二位,在判断第 i 位是取数的时候,我们是已经知道前 i-1 个数每次是否取的所有子序列组合,记集合 S 为这个子序列的和。再看第 i 位取数的情况, 有两种情况取或者不取
+
+1. 取的情况,如果 target-nums[i]在集合 S 内,则返回 true,说明前 i 个数能找到和为 target 的序列
+2. 不取的情况,如果 target 在集合 S 内,则返回 true,否则返回 false
-题目要求给定一个数组, 问是否能划分为和相等的两个数组。
+也就是说,前 i 个数能否构成和为 target 的子序列取决为前 i-1 数的情况。
-这是一个典型的背包问题,我们可以遍历数组,对于每一个,我们都分两种情况考虑,拿或者不拿。
+记 F[i, target] 为 nums 数组内前 i 个数能否构成和为 target 的子序列的可能,则状态转移方程为
-背包问题处理这种离散的可以划分子问题解决的问题很有用。
+`F[i, target] = F[i - 1, target] || F[i - 1, target - nums[i]]`
-
+状态转移方程出来了,代码就很好写了,DFS + DP 都可以解,有不清晰的可以参考下 [递归和动态规划](../thinkings/dynamic-programming.md),
+这里只提供 DP 解法
-如果能够识别出这是一道背包问题,那么就相对容易了。
+#### 伪代码表示
-
-## 关键点解析
+```
+n = nums.length
+target 为 nums 各数之和
+如果target不能被2整除,
+ 返回false
+
+令dp为n * target 的二维矩阵, 并初始为false
+遍历0:n, dp[i][0] = true 表示前i个数组成和为0的可能
+
+遍历 0 到 n
+ 遍历 0 到 target
+ if 当前值j大于nums[i]
+ dp[i + 1][j] = dp[i][j-nums[i]] || dp[i][j]
+ else
+ dp[i+1][j] = dp[i][j]
+```
-- 背包问题
+算法时间复杂度 O(n\*m), 空间复杂度 O(n\*m), m 为 sum(nums) / 2
-## 代码
+#### javascript 实现
```js
-/*
- * @lc app=leetcode id=416 lang=javascript
- *
- * [416] Partition Equal Subset Sum
- *
- * https://leetcode.com/problems/partition-equal-subset-sum/description/
- *
- * algorithms
- * Medium (39.97%)
- * Total Accepted: 79.7K
- * Total Submissions: 198.5K
- * Testcase Example: '[1,5,11,5]'
- *
- * Given a non-empty array containing only positive integers, find if the array
- * can be partitioned into two subsets such that the sum of elements in both
- * subsets is equal.
- *
- * Note:
- *
- *
- * Each of the array element will not exceed 100.
- * The array size will not exceed 200.
- *
- *
- *
- *
- * Example 1:
- *
- *
- * Input: [1, 5, 11, 5]
- *
- * Output: true
- *
- * Explanation: The array can be partitioned as [1, 5, 5] and [11].
- *
- *
- *
- *
- * Example 2:
- *
- *
- * Input: [1, 2, 3, 5]
- *
- * Output: false
- *
- * Explanation: The array cannot be partitioned into equal sum subsets.
- *
- *
- *
- *
- */
-/**
- * @param {number[]} nums
- * @return {boolean}
- */
-var canPartition = function(nums) {
- let sum = 0;
- for(let num of nums) {
- sum += num;
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ } else {
+ sum = sum / 2;
+ }
+
+ const dp = Array.from(nums).map(() =>
+ Array.from({ length: sum + 1 }).fill(false)
+ );
+
+ for (let i = 0; i < nums.length; i++) {
+ dp[i][0] = true;
+ }
+
+ for (let i = 0; i < dp.length - 1; i++) {
+ for (let j = 0; j < dp[0].length; j++) {
+ dp[i + 1][j] =
+ j - nums[i] >= 0 ? dp[i][j] || dp[i][j - nums[i]] : dp[i][j];
}
+ }
+
+ return dp[nums.length - 1][sum];
+};
+```
+
+再看看有没有优化空间,看状态转移方程
+`F[i, target] = F[i - 1, target] || F[i - 1, target - nums[i]]`
+第 n 行的状态只依赖于第 n-1 行的状态,也就是说我们可以把二维空间压缩成一维
- if (sum & 1 === 1) return false;
+伪代码
- const half = sum >> 1;
+```
+遍历 0 到 n
+ 遍历 j 从 target 到 0
+ if 当前值j大于nums[i]
+ dp[j] = dp[j-nums[i]] || dp[j]
+ else
+ dp[j] = dp[j]
+```
- let dp = Array(half);
- dp[0] = [true, ...Array(nums.length).fill(false)];
+时间复杂度 O(n\*m), 空间复杂度 O(n)
+javascript 实现
- for(let i = 1; i < nums.length + 1; i++) {
- dp[i] = [true, ...Array(half).fill(false)];
- for(let j = 1; j < half + 1; j++) {
- if (j >= nums[i - 1]) {
- dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
- }
- }
+```js
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ const dp = Array.from({ length: sum + 1 }).fill(false);
+ dp[0] = true;
+
+ for (let i = 0; i < nums.length; i++) {
+ for (let j = sum; j > 0; j--) {
+ dp[j] = dp[j] || (j - nums[i] >= 0 && dp[j - nums[i]]);
}
+ }
- return dp[nums.length][half]
+ return dp[sum];
};
+```
+
+其实这道题和 [leetcode 518](https://leetcode-cn.com/problems/coin-change-2/) 是换皮题,它们都可以归属于背包问题
+
+## 背包问题
+
+### 背包问题描述
+
+有 N 件物品和一个容量为 V 的背包。放入第 i 件物品耗费的费用是 Ci,得到的
+价值是 Wi。求解将哪些物品装入背包可使价值总和最大。
+
+背包问题的特性是,每种物品,我们都可以选择放或者不放。令 F[i, v]表示前 i 件物品放入到容量为 v 的背包的状态。
+
+针对上述背包,F[i, v]表示能得到最大价值,那么状态转移方程为
+
+```
+F[i, v] = max{F[i-1, v], F[i-1, v-Ci] + Wi}
+```
+
+针对 416. 分割等和子集这题,F[i, v]的状态含义就表示前 i 个数能组成和为 v 的可能,状态转移方程为
+
+```
+F[i, v] = F[i-1, v] || F[i-1, v-Ci]
+```
+
+再回过头来看下[leetcode 518](https://leetcode-cn.com/problems/coin-change-2/), 原题如下
+
+> 给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
+带入背包思想,F[i,v] 表示用前 i 种硬币能兑换金额数为 v 的组合数,状态转移方程为
+`F[i, v] = F[i-1, v] + F[i-1, v-Ci]`
+
+#### javascript 实现
+
+```javascript
+/**
+ * @param {number} amount
+ * @param {number[]} coins
+ * @return {number}
+ */
+var change = function (amount, coins) {
+ const dp = Array.from({ length: amount + 1 }).fill(0);
+ dp[0] = 1;
+ for (let i = 0; i < coins.length; i++) {
+ for (let j = 1; j <= amount; j++) {
+ dp[j] = dp[j] + (j - coins[i] >= 0 ? dp[j - coins[i]] : 0);
+ }
+ }
+ return dp[amount];
+};
```
+### 参考
+
+[背包九讲](https://raw.githubusercontent.com/tianyicui/pack/master/V2.pdf)
diff --git a/problems/42.trapping-rain-water.en.md b/problems/42.trapping-rain-water.en.md
new file mode 100755
index 000000000..38f346912
--- /dev/null
+++ b/problems/42.trapping-rain-water.en.md
@@ -0,0 +1,229 @@
+## Trapping Rain Water
+
+https://leetcode.com/problems/trapping-rain-water/description/
+
+## Problem Description
+
+> Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
+
+
+
+> The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. Thanks Marcos for contributing this image!
+
+```
+Input: [0,1,0,2,1,0,1,3,2,1,2,1]
+Output: 6
+```
+
+## Prerequisites
+
+- Space-time tradeoff
+- Two Pointers
+- Monotonic Stack
+
+## Two Arrays
+
+### Solution
+
+The difficulty of this problem is `hard`.
+We'd like to compute how much water a given elevation map can trap.
+
+A brute force solution would be adding up the maximum level of water that each element of the map can trap.
+
+Pseudo Code:
+
+```js
+for (let i = 0; i < height.length; i++) {
+ area += h[i] - height[i]; // the maximum level of water that the element i can trap
+}
+```
+
+Now the problem becomes how to calculating h[i], which is in fact the minimum of maximum height of bars on both sides minus height[i]:
+`h[i] = Math.min(leftMax, rightMax)` where `leftMax = Math.max(leftMax[i-1], height[i])` and `rightMax = Math.max(rightMax[i+1], height[i])`.
+
+For the given example, h would be [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1].
+
+The key is to calculate `leftMax` and `rightMax`.
+
+### Key Points
+
+- Figure out the modeling of `h[i] = Math.min(leftMax, rightMax)`
+
+### Code (JavaScript/Python3/C++)
+
+JavaScript Code:
+
+```js
+/*
+ * @lc app=leetcode id=42 lang=javascript
+ *
+ * [42] Trapping Rain Water
+ *
+ */
+/**
+ * @param {number[]} height
+ * @return {number}
+ */
+var trap = function (height) {
+ let max = 0;
+ let volume = 0;
+ const leftMax = [];
+ const rightMax = [];
+
+ for (let i = 0; i < height.length; i++) {
+ leftMax[i] = max = Math.max(height[i], max);
+ }
+
+ max = 0;
+
+ for (let i = height.length - 1; i >= 0; i--) {
+ rightMax[i] = max = Math.max(height[i], max);
+ }
+
+ for (let i = 0; i < height.length; i++) {
+ volume = volume + Math.min(leftMax[i], rightMax[i]) - height[i];
+ }
+
+ return volume;
+};
+```
+
+Python Code:
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l, r = [0] * (n + 1), [0] * (n + 1)
+ ans = 0
+ for i in range(1, len(heights) + 1):
+ l[i] = max(l[i - 1], heights[i - 1])
+ for i in range(len(heights) - 1, 0, -1):
+ r[i] = max(r[i + 1], heights[i])
+ for i in range(len(heights)):
+ ans += max(0, min(l[i + 1], r[i]) - heights[i])
+ return ans
+```
+
+C++ code:
+
+```c++
+int trap(vector& heights)
+{
+ if(heights == null)
+ return 0;
+ int ans = 0;
+ int size = heights.size();
+ vector left_max(size), right_max(size);
+ left_max[0] = heights[0];
+ for (int i = 1; i < size; i++) {
+ left_max[i] = max(heights[i], left_max[i - 1]);
+ }
+ right_max[size - 1] = heights[size - 1];
+ for (int i = size - 2; i >= 0; i--) {
+ right_max[i] = max(heights[i], right_max[i + 1]);
+ }
+ for (int i = 1; i < size - 1; i++) {
+ ans += min(left_max[i], right_max[i]) - heights[i];
+ }
+ return ans;
+}
+
+```
+
+**Complexity Analysis**
+
+- Time Complexity: $O(N)$
+- Space Complexity: $O(N)$
+
+## Two Pointers
+
+### Solution
+
+The above code is easy to understand, but it needs the extra space of N. We can tell from it that we in fact only cares about the minimum of (left[i], right[i]). Specifically:
+
+- If l[i + 1] < r[i], the maximum in the left side of i will determine the height of trapping water.
+- If l[i + 1] >= r[i], the maximum in the right side of i will determine the height of trapping water.
+
+Thus, we don't need to keep two complete arrays. We can rather keep only a left max and a right max, using constant variable. This problem is a typical two pointers problem.
+
+Algorithm:
+
+1. Initialize two pointers `left` and `right`, pointing to the begin and the end of our height array respectively.
+2. Initialize the left maximum height and the right maximum height to be 0.
+3. Compare height[left] and height[right]
+
+ - If height[left] < height[right]
+ - 3.1.1 If height[left] >= left_max, the current trapping volume is (left_max - height[left])
+ - 3.1.2 Otherwise, no water is trapped and the volume is 0
+ - 3.2 Iterate the left pointer to the right
+ - 3.3 If height[left] >= height[right]
+ - 3.3.1 If height[right] >= right_max, the current trapping volume is (right_max - height[right])
+ - 3.3.2 Otherwise, no water is trapped and the volume is 0
+ - 3.4 Iterate the right pointer to the left
+
+### Code (Python3/C++)
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l_max = r_max = 0
+ l, r = 0, n - 1
+ ans = 0
+ while l < r:
+ if heights[l] < heights[r]:
+ if heights[l] < l_max:
+ ans += l_max - heights[l]
+ else:
+ l_max = heights[l]
+ l += 1
+ else:
+ if heights[r] < r_max:
+ ans += r_max - heights[r]
+ else:
+ r_max = heights[r]
+ r -= 1
+ return ans
+```
+
+```c++
+
+class Solution {
+public:
+ int trap(vector& heights)
+{
+ int left = 0, right = heights.size() - 1;
+ int ans = 0;
+ int left_max = 0, right_max = 0;
+ while (left < right) {
+ if (heights[left] < heights[right]) {
+ heights[left] >= left_max ? (left_max = heights[left]) : ans += (left_max - heights[left]);
+ ++left;
+ }
+ else {
+ heights[right] >= right_max ? (right_max = heights[right]) : ans += (right_max - heights[right]);
+ --right;
+ }
+ }
+ return ans;
+}
+
+};
+```
+
+**Complexity Analysis**
+
+- Time Complexity: $O(N)$
+- Space Complexity: $O(1)$
+
+## Similar Problems
+
+- [84.largest-rectangle-in-histogram](https://github.com/azl397985856/leetcode/blob/master/problems/84.largest-rectangle-in-histogram.md)
+
+For more solutions, visit my [LeetCode Solution Repo](https://github.com/azl397985856/leetcode) (which has 30K stars).
+
+Follow my WeChat official account 力扣加加, which has lots of graphic solutions and teaches you how to recognize problem patterns to solve problems with efficiency.
+
+
+
diff --git a/problems/42.trapping-rain-water.md b/problems/42.trapping-rain-water.md
old mode 100644
new mode 100755
index baaedce0e..627b71248
--- a/problems/42.trapping-rain-water.md
+++ b/problems/42.trapping-rain-water.md
@@ -1,9 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/trapping-rain-water/description/
## 题目描述
-
```
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
@@ -13,7 +13,7 @@ The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In th
```
-
+
```
Example:
@@ -23,41 +23,55 @@ Output: 6
```
-## 思路
+## 前置知识
+
+- 空间换时间
+- 双指针
+- 单调栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 双数组
+
+### 思路
这是一道雨水收集的问题, 难度为`hard`. 如图所示,让我们求下过雨之后最多可以积攒多少的水。
-如果采用暴力求解的话,思路应该是height数组依次求和,然后相加。
+如果采用暴力求解的话,思路应该是 height 数组依次求和,然后相加。
伪代码:
```js
-
-for(let i = 0; i < height.length; i++) {
- area += (h[i] - height[i]) * 1; // h为下雨之后的水位
+for (let i = 0; i < height.length; i++) {
+ area += (h[i] - height[i]) * 1; // h为下雨之后的水位
}
-
```
-问题转化为求h,那么h[i]又等于`左右两侧柱子的最大值中的较小值`,即
+
+问题转化为求 h,那么 h[i]又等于`左右两侧柱子的最大值中的较小值`,即
`h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`
-如上图那么h为 [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1]
+如上图那么 h 为 [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1]
问题的关键在于求解`左边柱子最大值`和`右边柱子最大值`,
我们其实可以用两个数组来表示`leftMax`, `rightMax`,
-以leftMax为例,leftMax[i]代表i的左侧柱子的最大值,因此我们维护两个数组即可。
-## 关键点解析
+以 leftMax 为例,leftMax[i]代表 i 的左侧柱子的最大值,因此我们维护两个数组即可。
-- 建模 `h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`(h为下雨之后的水位)
+### 关键点解析
-## 代码
+- 建模 `h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`(h 为下雨之后的水位)
-代码支持 JavaScript,Python3:
+### 代码
+
+代码支持 JavaScript,Python3,C++:
JavaScript Code:
```js
-
/*
* @lc app=leetcode id=42 lang=javascript
*
@@ -68,29 +82,28 @@ JavaScript Code:
* @param {number[]} height
* @return {number}
*/
-var trap = function(height) {
- let max = 0;
- let volumn = 0;
- const leftMax = [];
- const rightMax = [];
-
- for(let i = 0; i < height.length; i++) {
- leftMax[i] = max = Math.max(height[i], max);
- }
+var trap = function (height) {
+ let max = 0;
+ let volume = 0;
+ const leftMax = [];
+ const rightMax = [];
- max = 0;
+ for (let i = 0; i < height.length; i++) {
+ leftMax[i] = max = Math.max(height[i], max);
+ }
- for(let i = height.length - 1; i >= 0; i--) {
- rightMax[i] = max = Math.max(height[i], max);
- }
+ max = 0;
- for(let i = 0; i < height.length; i++) {
- volumn = volumn + Math.min(leftMax[i], rightMax[i]) - height[i]
- }
+ for (let i = height.length - 1; i >= 0; i--) {
+ rightMax[i] = max = Math.max(height[i], max);
+ }
- return volumn;
-};
+ for (let i = 0; i < height.length; i++) {
+ volume = volume + Math.min(leftMax[i], rightMax[i]) - height[i];
+ }
+ return volume;
+};
```
Python Code:
@@ -107,5 +120,130 @@ class Solution:
r[i] = max(r[i + 1], heights[i])
for i in range(len(heights)):
ans += max(0, min(l[i + 1], r[i]) - heights[i])
- return ans
+ return ans
+```
+
+C++ Code:
+
+```c++
+int trap(vector& heights)
+{
+ if(heights == null)
+ return 0;
+ int ans = 0;
+ int size = heights.size();
+ vector left_max(size), right_max(size);
+ left_max[0] = heights[0];
+ for (int i = 1; i < size; i++) {
+ left_max[i] = max(heights[i], left_max[i - 1]);
+ }
+ right_max[size - 1] = heights[size - 1];
+ for (int i = size - 2; i >= 0; i--) {
+ right_max[i] = max(heights[i], right_max[i + 1]);
+ }
+ for (int i = 1; i < size - 1; i++) {
+ ans += min(left_max[i], right_max[i]) - heights[i];
+ }
+ return ans;
+}
+
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## 双指针
+
+### 思路
+
+上面代码比较好理解,但是需要额外的 \${N} 的空间。从上面解法可以看出,我们实际上只关心左右两侧较小的那一个,并不需要两者都计算出来。具体来说:
+
+- 如果 l[i + 1] < r[i] 那么 最终积水的高度由 i 的左侧最大值决定。
+- 如果 l[i + 1] >= r[i] 那么 最终积水的高度由 i 的右侧最大值决定。
+
+因此我们不必维护完整的两个数组,而是可以只进行一次遍历,同时维护左侧最大值和右侧最大值,使用常数变量完成即可。这是一个典型的双指针问题,
+
+具体算法:
+
+1. 维护两个指针 left 和 right,分别指向头尾。
+2. 初始化左侧和右侧最高的高度都为 0。
+3. 比较 height[left] 和 height[right]
+
+ - 3.1 如果 height[left] < height[right]
+ - 3.1.1 如果 height[left] >= left_max, 则当前格子积水面积为(left_max - height[left])
+ - 3.1.2 否则无法积水,即积水面积为 0
+ - 3.2 左指针右移一位
+
+ - 3.3 如果 height[left] >= height[right]
+ - 3.3.1 如果 height[right] >= right_max, 则当前格子积水面积为(right_max - height[right])
+ - 3.3.2 否则无法积水,即积水面积为 0
+ - 3.4 右指针左移一位
+
+### 代码
+
+代码支持 Python3,C++:
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l_max = r_max = 0
+ l, r = 0, n - 1
+ ans = 0
+ while l < r:
+ if heights[l] < heights[r]:
+ if heights[l] < l_max:
+ ans += l_max - heights[l]
+ else:
+ l_max = heights[l]
+ l += 1
+ else:
+ if heights[r] < r_max:
+ ans += r_max - heights[r]
+ else:
+ r_max = heights[r]
+ r -= 1
+ return ans
+```
+
+```c++
+
+class Solution {
+public:
+ int trap(vector& heights)
+{
+ int left = 0, right = heights.size() - 1;
+ int ans = 0;
+ int left_max = 0, right_max = 0;
+ while (left < right) {
+ if (heights[left] < heights[right]) {
+ heights[left] >= left_max ? (left_max = heights[left]) : ans += (left_max - heights[left]);
+ ++left;
+ }
+ else {
+ heights[right] >= right_max ? (right_max = heights[right]) : ans += (right_max - heights[right]);
+ --right;
+ }
+ }
+ return ans;
+}
+
+};
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [84.largest-rectangle-in-histogram](https://github.com/azl397985856/leetcode/blob/master/problems/84.largest-rectangle-in-histogram.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/437.path-sum-iii.md b/problems/437.path-sum-iii.md
index 869ccf0d5..79243299b 100644
--- a/problems/437.path-sum-iii.md
+++ b/problems/437.path-sum-iii.md
@@ -32,6 +32,17 @@ Return 3. The paths that sum to 8 are:
3. -3 -> 11
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是要我们求解出任何一个节点出发到子孙节点的路径中和为指定值。
注意这里,不一定是从根节点出发,也不一定在叶子节点结束。
@@ -90,11 +101,11 @@ var pathSum = function(root, sum) {
当我们执行到底部的时候:
-
+
接着往上回溯:
-
+
很容易看出,我们的hashmap不应该有第一张图的那个记录了,因此需要减去。
@@ -152,8 +163,18 @@ function helper(root, acc, target, hashmap) {
}
var pathSum = function(root, sum) {
- // 时间复杂度和空间复杂度都是O(n)
const hashmap = {};
return helper(root, 0, sum, hashmap);
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/445.add-two-numbers-ii.md b/problems/445.add-two-numbers-ii.md
index 3f8e2e730..13c1786f6 100644
--- a/problems/445.add-two-numbers-ii.md
+++ b/problems/445.add-two-numbers-ii.md
@@ -19,6 +19,17 @@ Output: 7 -> 8 -> 0 -> 7
```
+## 前置知识
+
+- 链表
+- 栈
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+
## 思路
由于需要从低位开始加,然后进位。 因此可以采用栈来简化操作。
diff --git a/problems/454.4-Sum-ii.en.md b/problems/454.4-Sum-ii.en.md
new file mode 100644
index 000000000..4d5144ac2
--- /dev/null
+++ b/problems/454.4-Sum-ii.en.md
@@ -0,0 +1,100 @@
+
+
+## Problem Address
+https://leetcode.com/problems/4sum-ii/description/
+
+## Problem Description
+
+```
+Given four lists A, B, C, D of integer values, compute how many tuples (i, j, k, l) there are such that A[i] + B[j] + C[k] + D[l] is zero.
+
+To make problem a bit easier, all A, B, C, D have same length of N where 0 ≤ N ≤ 500. All integers are in the range of -228 to 228 - 1 and the result is guaranteed to be at most 231 - 1.
+
+Example:
+
+Input:
+A = [ 1, 2]
+B = [-2,-1]
+C = [-1, 2]
+D = [ 0, 2]
+
+Output:
+2
+
+Explanation:
+The two tuples are:
+1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
+2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
+```
+## Solution
+
+The normal solution to complete the search would require four rounds of traversal, and that would make the time complexity reaches O(n^4), which doesn't work obviously. We have to figure out a more effective algorithm.
+
+My idea is to separate these four lists into two groups and combine them two by two. We then calculate separately `all the sums from these two groups, and the relevant counts`
+
+As the picture shows:
+
+
+
+
+Now that we got two `hashTable`, and the result would appear with some basic calculations.
+
+## Key Point Analysis
+- Less time by more space.
+- Divide the lists by 2, and calculate all the possible sums from two groups, then combine the result.
+
+## Code
+
+Language Support: `JavaScript`,`Python3`
+
+`JavaScript`:
+```js
+
+/*
+ * @lc app=leetcode id=454 lang=javascript
+ *
+ * [454] 4Sum II
+ *
+ * https://leetcode.com/problems/4sum-ii/description/
+/**
+ * @param {number[]} A
+ * @param {number[]} B
+ * @param {number[]} C
+ * @param {number[]} D
+ * @return {number}
+ */
+var fourSumCount = function(A, B, C, D) {
+ const sumMapper = {};
+ let res = 0;
+ for (let i = 0; i < A.length; i++) {
+ for (let j = 0; j < B.length; j++) {
+ sumMapper[A[i] + B[j]] = (sumMapper[A[i] + B[j]] || 0) + 1;
+ }
+ }
+
+ for (let i = 0; i < C.length; i++) {
+ for (let j = 0; j < D.length; j++) {
+ res += sumMapper[- (C[i] + D[j])] || 0;
+ }
+ }
+
+ return res;
+};
+```
+
+`Python3`:
+
+```python
+class Solution:
+ def fourSumCount(self, A: List[int], B: List[int], C: List[int], D: List[int]) -> int:
+ mapper = {}
+ res = 0
+ for i in A:
+ for j in B:
+ mapper[i + j] = mapper.get(i + j, 0) + 1
+
+ for i in C:
+ for j in D:
+ res += mapper.get(-1 * (i + j), 0)
+ return res
+ ```
\ No newline at end of file
diff --git a/problems/454.4-sum-ii.md b/problems/454.4-sum-ii.md
index 6cadc5aa4..dd3b750de 100644
--- a/problems/454.4-sum-ii.md
+++ b/problems/454.4-sum-ii.md
@@ -26,6 +26,16 @@ The two tuples are:
1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
```
+
+## 前置知识
+
+- hashTable
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
如果按照常规思路去完成查找需要四层遍历,时间复杂是O(n^4), 显然是行不通的。
@@ -36,7 +46,7 @@ The two tuples are:
如图:
-
+
这个时候我们得到了两个`hashTable`, 我们只需要进行简单的数学运算就可以得到结果。
diff --git a/problems/455.AssignCookies.md b/problems/455.AssignCookies.md
index a0e38ca49..569b8a4a9 100644
--- a/problems/455.AssignCookies.md
+++ b/problems/455.AssignCookies.md
@@ -35,7 +35,19 @@ https://leetcode-cn.com/problems/assign-cookies
所以你应该输出2.
```
+## 前置知识
+
+- [贪心算法](https://github.com/azl397985856/leetcode/blob/master/thinkings/greedy.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
+
贪心算法+双指针求解
给一个孩子的饼干应当尽量小并且能满足孩子,大的留来满足胃口大的孩子。因为胃口小的孩子最容易得到满足,所以优先满足胃口小的孩子需求。按照从小到大的顺序使用饼干尝试是否可满足某个孩子。
@@ -47,6 +59,7 @@ https://leetcode-cn.com/problems/assign-cookies
## 代码
+
* 语言支持:JS
```js
@@ -78,5 +91,13 @@ const findContentChildren = function (g, s) {
***复杂度分析***
-- 时间复杂度:O(NlogN)
+- 时间复杂度:由于使用了排序,因此时间复杂度为 O(NlogN)
- 空间复杂度:O(1)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/46.permutations.md b/problems/46.permutations.md
index e4d9df106..47f333955 100644
--- a/problems/46.permutations.md
+++ b/problems/46.permutations.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/permutations/description/
## 题目描述
+
```
Given a collection of distinct integers, return all possible permutations.
@@ -20,18 +22,31 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -42,7 +57,7 @@ Output:
## 代码
-* 语言支持: Javascript, Python3
+- 语言支持: Javascript, Python3
Javascript Code:
@@ -79,31 +94,33 @@ Javascript Code:
*
*/
function backtrack(list, tempList, nums) {
- if (tempList.length === nums.length) return list.push([...tempList]);
- for(let i = 0; i < nums.length; i++) {
- if (tempList.includes(nums[i])) continue;
- tempList.push(nums[i]);
- backtrack(list, tempList, nums);
- tempList.pop();
- }
+ if (tempList.length === nums.length) return list.push([...tempList]);
+ for (let i = 0; i < nums.length; i++) {
+ if (tempList.includes(nums[i])) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var permute = function(nums) {
- const list = [];
- backtrack(list, [], nums)
- return list
+var permute = function (nums) {
+ const list = [];
+ backtrack(list, [], nums);
+ return list;
};
```
+
Python3 Code:
+
```Python
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
"""itertools库内置了这个函数"""
return itertools.permutations(nums)
-
+
def permute2(self, nums: List[int]) -> List[List[int]]:
"""自己写回溯法"""
res = []
@@ -170,7 +187,7 @@ class Solution:
- [39.combination-sum](./39.combination-sum.md)
- [40.combination-sum-ii](./40.combination-sum-ii.md)
- [47.permutations-ii](./47.permutations-ii.md)
-- [60.permutation-sequence](./60.permutation-sequence.md)(TODO)
+- [60.permutation-sequence](./60.permutation-sequence.md)
- [78.subsets](./78.subsets.md)
- [90.subsets-ii](./90.subsets-ii.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
diff --git a/problems/460.lfu-cache.md b/problems/460.lfu-cache.md
index d9e9f30a3..43cf54be7 100644
--- a/problems/460.lfu-cache.md
+++ b/problems/460.lfu-cache.md
@@ -28,6 +28,18 @@ cache.get(3); // returns 3
cache.get(4); // returns 4
```
+## 前置知识
+
+- 链表
+- HashMap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
`本题已被收录到我的新书中,敬请期待~`
@@ -51,7 +63,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node1 插入 doublylinkedlist head->next = node1.
如下图,
```
-
+
```
2. put(2, 2),
- 首先查找 nodeMap 中有没有 key=2 对应的 value,
@@ -60,7 +72,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node2 插入 doublylinkedlist head->next = node2.
如下图,
```
-
+
```
3. get(1),
- 首先查找 nodeMap 中有没有 key=1 对应的 value,nodeMap:{[1, node1], [2, node2]},
@@ -69,7 +81,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node1
如下图,
```
-
+
```
4. put(3, 3),
- 判断 cache 的 capacity,已满,需要淘汰使用次数最少的元素,找到最小的 freq=1,删除双链表 tail node.prev
@@ -80,7 +92,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node3 插入 doublylinkedlist head->next = node3.
如下图,
```
-
+
```
5. get(2)
- 查找 nodeMap,如果没有对应的 key 的 value,返回 -1。
@@ -92,7 +104,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node3
如下图,
```
-
+
```
7. put(4, 4),
- 判断 cache 的 capacity,已满,需要淘汰使用次数最少的元素,找到最小的 freq=1,删除双链表 tail node.prev
@@ -103,7 +115,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node4 插入 doublylinkedlist head->next = node4.
如下图,
```
-
+
```
8. get(1)
- 查找 nodeMap,如果没有对应的 key 的 value,返回 -1。
@@ -115,7 +127,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=3,node3
如下图,
```
-
+
```
10. get(4)
- 首先查找 nodeMap 中有没有 key=4 对应的 value,nodeMap:{[4, node4], [3, node3]},
@@ -124,7 +136,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node4
如下图,
```
-
+
## 关键点分析
用两个`Map`分别保存 `nodeMap {key, node}` 和 `freqMap{frequent, DoublyLinkedList}`。
diff --git a/problems/47.permutations-ii.md b/problems/47.permutations-ii.md
index 0ab000f58..3c4aeb950 100644
--- a/problems/47.permutations-ii.md
+++ b/problems/47.permutations-ii.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/permutations-ii/description/
## 题目描述
+
```
Given a collection of numbers that might contain duplicates, return all possible unique permutations.
@@ -17,18 +19,31 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -37,10 +52,9 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -92,19 +106,26 @@ function backtrack(list, nums, tempList, visited) {
* @param {number[]} nums
* @return {number[][]}
*/
-var permuteUnique = function(nums) {
+var permuteUnique = function (nums) {
const list = [];
- backtrack(list, nums.sort((a, b) => a - b), [], []);
+ backtrack(
+ list,
+ nums.sort((a, b) => a - b),
+ [],
+ []
+ );
return list;
};
```
+
Python3 code:
+
```Python
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
"""与46题一样,当然也可以直接调用itertools的函数,然后去重"""
return list(set(itertools.permutations(nums)))
-
+
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
"""自己写回溯法,与46题相比,需要去重"""
# 排序是为了去重
diff --git a/problems/472.concatenated-words.md b/problems/472.concatenated-words.md
index 409948d64..5082446b6 100644
--- a/problems/472.concatenated-words.md
+++ b/problems/472.concatenated-words.md
@@ -26,6 +26,15 @@ https://leetcode-cn.com/problems/concatenated-words/
不需要考虑答案输出的顺序。
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
本题我的思路是直接使用前缀树来解决。**标准的前缀树模板**我在之前的题解中提到了,感兴趣的可以到下方的相关题目中查看。
@@ -39,7 +48,7 @@ https://leetcode-cn.com/problems/concatenated-words/
我们构造的前缀树大概是这样的:
-
+
问题的关键在于第二步中的**查找每一个单词有几个单词表中的单词组成**。 其实如果你了解前缀树的话应该不难写出来。 比如查找 catsdogcats:
@@ -119,3 +128,4 @@ class Solution:
- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/474.ones-and-zeros-en.md b/problems/474.ones-and-zeros-en.md
index f6e1da7bb..43036fa35 100644
--- a/problems/474.ones-and-zeros-en.md
+++ b/problems/474.ones-and-zeros-en.md
@@ -112,7 +112,7 @@ DP formula:
For example:
-
+
####
- *Time Complexity:* `O(l * m * n) - l is strs length,m is number of 0,n number of 1`
diff --git a/problems/48.rotate-image.md b/problems/48.rotate-image.md
index 9cf8f5909..2b0757f76 100644
--- a/problems/48.rotate-image.md
+++ b/problems/48.rotate-image.md
@@ -48,18 +48,30 @@ rotate the input matrix in-place such that it becomes:
```
+## 前置知识
+
+- 原地算法
+- 矩阵
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目让我们 in-place,也就说空间复杂度要求 O(1),如果没有这个限制的话,很简单。
通过观察发现,我们只需要将第 i 行变成第 n - i - 1 列, 因此我们只需要保存一个原有矩阵,然后按照这个规律一个个更新即可。
-
+
代码:
```js
-var rotate = function(matrix) {
+var rotate = function (matrix) {
// 时间复杂度O(n^2) 空间复杂度O(n)
const oMatrix = JSON.parse(JSON.stringify(matrix)); // clone
const n = oMatrix.length;
@@ -71,16 +83,16 @@ var rotate = function(matrix) {
};
```
-如果要求空间复杂度是O(1)的话,我们可以用一个temp记录即可,这个时候就不能逐个遍历了。
-比如遍历到1的时候,我们把1存到temp,然后更新1的值为7。 1被换到了3的位置,我们再将3存到temp,依次类推。
+如果要求空间复杂度是 O(1)的话,我们可以用一个 temp 记录即可,这个时候就不能逐个遍历了。
+比如遍历到 1 的时候,我们把 1 存到 temp,然后更新 1 的值为 7。 1 被换到了 3 的位置,我们再将 3 存到 temp,依次类推。
但是这种解法写起来比较麻烦,这里我就不写了。
事实上有一个更加巧妙的做法,我们可以巧妙地利用对称轴旋转达到我们的目的,如图,我们先进行一次以对角线为轴的翻转,然后
再进行一次以水平轴心线为轴的翻转即可。
-
+
-这种做法的时间复杂度是O(n^2) ,空间复杂度是O(1)
+这种做法的时间复杂度是 O(n^2) ,空间复杂度是 O(1)
## 关键点解析
@@ -88,7 +100,7 @@ var rotate = function(matrix) {
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -100,7 +112,7 @@ var rotate = function(matrix) {
* @param {number[][]} matrix
* @return {void} Do not return anything, modify matrix in-place instead.
*/
-var rotate = function(matrix) {
+var rotate = function (matrix) {
// 时间复杂度O(n^2) 空间复杂度O(1)
// 做法: 先沿着对角线翻转,然后沿着水平线翻转
@@ -123,7 +135,9 @@ var rotate = function(matrix) {
}
};
```
+
Python3 Code:
+
```Python
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
@@ -137,7 +151,7 @@ class Solution:
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
for m in matrix:
m.reverse()
-
+
def rotate2(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
diff --git a/problems/49.group-anagrams.md b/problems/49.group-anagrams.md
index e8c7c6964..af9c0b399 100644
--- a/problems/49.group-anagrams.md
+++ b/problems/49.group-anagrams.md
@@ -22,6 +22,18 @@ All inputs will be in lowercase.
The order of your output does not matter.
```
+## 前置知识
+
+- 哈希表
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
一个简单的解法就是遍历数组,然后对每一项都进行排序,然后将其添加到 hashTable 中,最后输出 hashTable 中保存的值即可。
@@ -31,14 +43,11 @@ The order of your output does not matter.
代码:
```js
-var groupAnagrams = function(strs) {
+var groupAnagrams = function (strs) {
const hashTable = {};
function sort(str) {
- return str
- .split("")
- .sort()
- .join("");
+ return str.split("").sort().join("");
}
// 这个方法需要排序,因此不是很优,但是很直观,容易想到
@@ -60,7 +69,7 @@ var groupAnagrams = function(strs) {
然后我们给每一个字符一个固定的数组下标,然后我们只需要更新每个字符出现的次数。 最后形成的 counts 数组如果一致,则说明他们可以通过
交换顺序得到。这种算法空间复杂度 O(n), 时间复杂度 O(n \* k), n 为数组长度,k 为字符串的平均长度.
-
+
## 关键点解析
@@ -68,7 +77,7 @@ var groupAnagrams = function(strs) {
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -80,7 +89,7 @@ var groupAnagrams = function(strs) {
* @param {string[]} strs
* @return {string[][]}
*/
-var groupAnagrams = function(strs) {
+var groupAnagrams = function (strs) {
// 类似桶排序
let counts = [];
@@ -102,7 +111,9 @@ var groupAnagrams = function(strs) {
return Object.values(hashTable);
};
```
+
Python3 Code:
+
```Python
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
diff --git a/problems/493.reverse-pairs.md b/problems/493.reverse-pairs.md
index 0470c9720..4bd2c23c8 100644
--- a/problems/493.reverse-pairs.md
+++ b/problems/493.reverse-pairs.md
@@ -24,8 +24,20 @@ https://leetcode-cn.com/problems/reverse-pairs/description/
```
+## 前置知识
+
+- 归并排序
+- 逆序数
+- 分治
+
## 暴力法
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
### 思路
读完这道题你应该就能联想到逆序数才行。求解逆序数最简单的做法是使用双层循环暴力求解。我们仿照求解决逆序数的解法来解这道题(其实唯一的区别就是系数从 1 变成了 2)。
diff --git a/problems/494.target-sum.md b/problems/494.target-sum.md
index 6611e253f..b2079534b 100644
--- a/problems/494.target-sum.md
+++ b/problems/494.target-sum.md
@@ -28,17 +28,28 @@ Your output answer is guaranteed to be fitted in a 32-bit integer.
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
题目是给定一个数组,让你在数字前面添加 `+`或者`-`,使其和等于 target.
-
+
暴力法的时间复杂度是指数级别的,因此我们不予考虑。我们需要换种思路.
我们将最终的结果分成两组,一组是我们添加了`+`的,一组是我们添加了`-`的。
-
+
如上图,问题转化为如何求其中一组,我们不妨求前面标`+`的一组
@@ -46,7 +57,7 @@ Your output answer is guaranteed to be fitted in a 32-bit integer.
通过进一步分析,我们得到了这样的关系:
-
+
因此问题转化为,求解`sumCount(nums, target)`,即 nums 数组中能够组成
target 的总数一共有多少种,这是一道我们之前做过的题目,使用动态规划可以解决。
diff --git a/problems/5.longest-palindromic-substring.md b/problems/5.longest-palindromic-substring.md
index 9bb366ed6..f8f8ec028 100644
--- a/problems/5.longest-palindromic-substring.md
+++ b/problems/5.longest-palindromic-substring.md
@@ -4,7 +4,7 @@ https://leetcode-cn.com/problems/longest-palindromic-substring/
## 题目描述
-给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
+给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
@@ -16,15 +16,25 @@ https://leetcode-cn.com/problems/longest-palindromic-substring/
输入: "cbbd"
输出: "bb"
+## 前置知识
+
+- 回文
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
这是一道最长回文的题目,要我们求出给定字符串的最大回文子串。
-
+
解决这类问题的核心思想就是两个字“延伸”,具体来说
-- 如果一个字符串是回文串,那么在它左右分别加上一个相同的字符,那么它一定还是一个回文串
+- 如果在一个不是回文字符串的字符串两端添加任何字符,或者在回文串左右分别加不同的字符,得到的一定不是回文串
- 如果一个字符串不是回文串,或者在回文串左右分别加不同的字符,得到的一定不是回文串
事实上,上面的分析已经建立了大问题和小问题之间的关联,
@@ -38,11 +48,13 @@ if (s[i] === s[j] && dp[i + 1][j - 1]) {
dp[i][j] = true;
}
```
-
-base case就是一个字符(轴对称点是本身),或者两个字符(轴对称点是介于两者之间的虚拟点)。
+
+
+base case 就是一个字符(轴对称点是本身),或者两个字符(轴对称点是介于两者之间的虚拟点)。
+
+
-
## 关键点
- ”延伸“(extend)
@@ -68,7 +80,7 @@ class Solution:
for i in range(n - 1):
e1 = extend(i, i, s)
- e2 = extend(i, i + 1, s)
+ e2 = extend(i, i + 1, s)
if max(len(e1), len(e2)) > len(res):
res = e1 if len(e1) > len(e2) else e2
return res
@@ -86,7 +98,7 @@ JavaScript Code:
* @param {string} s
* @return {string}
*/
-var longestPalindrome = function(s) {
+var longestPalindrome = function (s) {
// babad
// tag : dp
if (!s || s.length === 0) return "";
@@ -118,6 +130,17 @@ var longestPalindrome = function(s) {
};
```
+**_复杂度分析_**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N^2)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
+
## 相关题目
- [516.longest-palindromic-subsequence](./516.longest-palindromic-subsequence.md)
diff --git a/problems/50.pow-x-n.md b/problems/50.pow-x-n.md
index 42291b1a7..e791c8e78 100644
--- a/problems/50.pow-x-n.md
+++ b/problems/50.pow-x-n.md
@@ -27,8 +27,20 @@ n 是 32 位有符号整数,其数值范围是 [−231, 231 − 1] 。
```
+## 前置知识
+
+- 递归
+- 位运算
+
## 解法零 - 遍历法
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
### 思路
这道题是让我们实现数学函数`幂`,因此直接调用系统内置函数是不被允许的。
@@ -135,9 +147,9 @@ class Solution:
以 x 的 10 次方举例。10 的 2 进制是 1010,然后用 2 进制转 10 进制的方法把它展成 2 的幂次的和。
-
+
-
+
因此我们的算法就是:
@@ -146,7 +158,7 @@ class Solution:
- 将 n 的二进制表示中`1的位置`pick 出来。比如 n 的第 i 位为 1,那么就将 x^i pick 出来。
- 将 pick 出来的结果相乘
-
+
这里有两个问题:
@@ -186,4 +198,4 @@ class Solution:
- [458.可怜的小猪](https://leetcode-cn.com/problems/poor-pigs/description/)
-
+
diff --git a/problems/501.Find-Mode-in-Binary-Search-Tree.md b/problems/501.Find-Mode-in-Binary-Search-Tree-en.md
similarity index 99%
rename from problems/501.Find-Mode-in-Binary-Search-Tree.md
rename to problems/501.Find-Mode-in-Binary-Search-Tree-en.md
index ab93db037..00dd184bb 100644
--- a/problems/501.Find-Mode-in-Binary-Search-Tree.md
+++ b/problems/501.Find-Mode-in-Binary-Search-Tree-en.md
@@ -86,4 +86,4 @@ class Solution {
helper(root.right);
}
}
-```
\ No newline at end of file
+```
diff --git a/problems/516.longest-palindromic-subsequence.md b/problems/516.longest-palindromic-subsequence.md
index 17a0b20f6..1099920a4 100644
--- a/problems/516.longest-palindromic-subsequence.md
+++ b/problems/516.longest-palindromic-subsequence.md
@@ -23,18 +23,29 @@ Output:
One possible longest palindromic subsequence is "bb".
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道最长回文的题目,要我们求出给定字符串的最大回文子序列。
-
+
解决这类问题的核心思想就是两个字“延伸”,具体来说
- 如果一个字符串是回文串,那么在它左右分别加上一个相同的字符,那么它一定还是一个回文串,因此`回文长度增加2`
- 如果一个字符串不是回文串,或者在回文串左右分别加不同的字符,得到的一定不是回文串,因此`回文长度不变,我们取[i][j-1]和[i+1][j]的较大值`
-
+
事实上,上面的分析已经建立了大问题和小问题之间的关联,
基于此,我们可以建立动态规划模型。
@@ -52,7 +63,7 @@ if (s[i] === s[j]) {
base case 就是一个字符(轴对称点是本身)
-
+
## 关键点
diff --git a/problems/518.coin-change-2.md b/problems/518.coin-change-2.md
index 2057a1704..e5518110e 100644
--- a/problems/518.coin-change-2.md
+++ b/problems/518.coin-change-2.md
@@ -34,17 +34,28 @@ https://leetcode-cn.com/problems/coin-change-2/description/
硬币种类不超过 500 种
结果符合 32 位符号整数
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+- 背包问题
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这个题目和 coin-change 的思路比较类似。
我们还是按照 coin-change 的思路来, 如果将问题画出来大概是这样:
-
+
进一步我们可以对问题进行空间复杂度上的优化(这种写法比较难以理解,但是相对更省空间)
-
+
> 这里用动图会更好理解, 有时间的话我会做一个动图出来, 现在大家脑补一下吧
@@ -60,7 +71,7 @@ https://leetcode-cn.com/problems/coin-change-2/description/
2. 第 j 个硬币我可以选择拿 这个时候, 组成数 = dp[i - coins[j]] + dp[i]
-- 和背包问题不同, 硬币是可以拿任意个
+- 和 01 背包问题不同, 硬币是可以拿任意个,属于完全背包问题
- 对于每一个 dp[i] 我们都选择遍历一遍 coin, 不断更新 dp[i]
@@ -89,7 +100,7 @@ return dp[dp.length - 1][coins.length];
- 当我们选择一维数组去解的时候,内外循环将会对结果造成影响
-
+
eg:
@@ -117,10 +128,8 @@ return dp[dp.length - 1];
## 代码
-
代码支持:Python3,JavaScript:
-
JavaSCript Code:
```js
@@ -135,7 +144,7 @@ JavaSCript Code:
* @param {number[]} coins
* @return {number}
*/
-var change = function(amount, coins) {
+var change = function (amount, coins) {
if (amount === 0) return 1;
const dp = [1].concat(Array(amount).fill(0));
@@ -154,7 +163,7 @@ var change = function(amount, coins) {
Python Code:
-```
+```python
class Solution:
def change(self, amount: int, coins: List[int]) -> int:
dp = [0] * (amount + 1)
diff --git a/problems/52.N-Queens-II.md b/problems/52.N-Queens-II.md
index e3175ea80..343a210d1 100644
--- a/problems/52.N-Queens-II.md
+++ b/problems/52.N-Queens-II.md
@@ -26,6 +26,17 @@ n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并
]
```
+## 前置知识
+
+- 回溯
+- 深度优先遍历
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
使用深度优先搜索配合位运算,二进制为 1 代表不可放置,0 相反
diff --git a/problems/53.maximum-sum-subarray-cn.md b/problems/53.maximum-sum-subarray-cn.md
index 7f09c6cd7..7d4ab98be 100644
--- a/problems/53.maximum-sum-subarray-cn.md
+++ b/problems/53.maximum-sum-subarray-cn.md
@@ -14,6 +14,22 @@ Follow up:
If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
```
+## 前置知识
+- [滑动窗口](https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md)
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+## 公司
+
+- 阿里
+- 百度
+- 字节
+- 腾讯
+- bloomberg
+- linkedin
+- microsoft
+
+## 公司
+
+- 阿里、百度、字节、腾讯
## 思路
@@ -27,9 +43,10 @@ If you have figured out the O(n) solution, try coding another solution using the
求子序列和,那么我们要知道子序列的首尾位置,然后计算首尾之间的序列和。用2个for循环可以枚举所有子序列的首尾位置。
然后用一个for循环求解序列和。这里时间复杂度太高,`O(n^3)`.
-#### 复杂度分析
-- *时间复杂度:* `O(n^3) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N ^ 3)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
+
#### 解法二 - 前缀和 + 暴力解
**优化暴力解:** (震惊,居然AC了)
@@ -41,9 +58,9 @@ If you have figured out the O(n) solution, try coding another solution using the
那么序列和 `subarraySum=prefixSum[r] - prefixSum[l - 1];`
用一个全局变量`maxSum`, 比较每次求解的子序列和,`maxSum = max(maxSum, subarraySum)`.
-#### 复杂度分析
-- *时间复杂度:* `O(n^2) - n 是数组长度`
-- *空间复杂度:* `O(n) - prefixSum 数组空间为n`
+**复杂度分析**
+- 时间复杂度:$O(N ^ 2)$, 其中 N 是数组长度
+- 空间复杂度:$O(N)$
>如果用更改原数组表示前缀和数组,空间复杂度降为`O(1)`
@@ -59,9 +76,9 @@ If you have figured out the O(n) solution, try coding another solution using the
然后我们再减去之前的` S(k)`,其中 `k = 0,1,i - 1`,中的最小值即可。 因此我们需要
用一个变量来维护这个最小值,还需要一个变量维护最大值。
-#### 复杂度分析
-- *时间复杂度:* `O(n) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
#### 解法四 - [分治法](https://www.wikiwand.com/zh-hans/%E5%88%86%E6%B2%BB%E6%B3%95)
@@ -76,11 +93,11 @@ If you have figured out the O(n) solution, try coding another solution using the
分别求出三种情况下最大子序列和,三者中最大值即为最大子序列和。
举例说明,如下图:
-
+
-#### 复杂度分析
-- *时间复杂度:* `O(nlogn) - n 是数组长度`
-- *空间复杂度:* `O(logn)` - 因为调用栈的深度最多是logn。
+**复杂度分析**
+- 时间复杂度:$O(NlogN)$, 其中 N 是数组长度
+- 空间复杂度:$O(logN)$
#### 解法五 - [动态规划](https://www.wikiwand.com/zh-hans/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92)
动态规划的难点在于找到状态转移方程,
@@ -102,11 +119,11 @@ If you have figured out the O(n) solution, try coding another solution using the
- `maxSum = max(currMaxSum, maxSum)`
如图:
-
+
-#### 复杂度分析
-- *时间复杂度:* `O(n) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
## 关键点分析
1. 暴力解,列举所有组合子序列首尾位置的组合,求解最大的子序列和, 优化可以预先处理,得到前缀和
@@ -367,3 +384,11 @@ function LSS(list) {
## 相似题
- [Maximum Product Subarray](https://leetcode.com/problems/maximum-product-subarray/)
- [Longest Turbulent Subarray](https://leetcode.com/problems/longest-turbulent-subarray/)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/53.maximum-sum-subarray-en.md b/problems/53.maximum-sum-subarray-en.md
index 965f140b3..029d7ff4e 100644
--- a/problems/53.maximum-sum-subarray-en.md
+++ b/problems/53.maximum-sum-subarray-en.md
@@ -91,7 +91,7 @@ The maximum sum is `max(left, right, crossMaxSum)`
For example, `nums=[-2,1,-3,4,-1,2,1,-5,4]`
-
+
#### Complexity Analysis
@@ -118,7 +118,7 @@ From above DP formula, notice only need to access its previous element at each s
- `maxSum = max(currMaxSum, maxSum)`
As below pic:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n) - n array length`
diff --git a/problems/547.friend-circles-en.md b/problems/547.friend-circles-en.md
index 47e6377af..dfe634bc2 100644
--- a/problems/547.friend-circles-en.md
+++ b/problems/547.friend-circles-en.md
@@ -43,7 +43,7 @@ this problem become to find number of connected components in a undirected graph
For example, how to transfer Adjacency Matrix into a graph problem. As below pic:
-
+
Connected components in a graph problem usually can be solved using *DFS*, *BFS*, *Union-Find*.
@@ -56,7 +56,7 @@ Below we will explain details on each approach.
as below pic show *DFS* traverse process:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n*n) - n is the number of students, traverse n*n matrix`
@@ -70,7 +70,7 @@ as below pic show *DFS* traverse process:
as below pic show *BFS* (Level traverse) traverse process:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n*n) - n is the number of students, traverse n*n matrix`
@@ -93,7 +93,7 @@ To know more details and implementations, see further reading lists.
as below Union-Find approach process:
-
+
> **Note:** here using weighted-union-find to avoid Union and Find take `O(n)` in the worst case.
diff --git a/problems/547.friend-circles.md b/problems/547.friend-circles.md
index a334ee5f0..b372ebd11 100644
--- a/problems/547.friend-circles.md
+++ b/problems/547.friend-circles.md
@@ -31,6 +31,17 @@ N 在[1,200]的范围内。
对于所有学生,有 M[i][i] = 1。
如果有 M[i][j] = 1,则有 M[j][i] = 1。
+## 前置知识
+
+- 并查集
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
并查集有一个功能是可以轻松计算出连通分量,然而本题的朋友圈的个数,本质上就是连通分量的个数,因此用并查集可以完美解决。
@@ -83,4 +94,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/55.jump-game.md b/problems/55.jump-game.md
index db822c348..863733321 100644
--- a/problems/55.jump-game.md
+++ b/problems/55.jump-game.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/jump-game/description/
## 题目描述
+
```
Given an array of non-negative integers, you are initially positioned at the first index of the array.
@@ -24,35 +25,97 @@ Explanation: You will always arrive at index 3 no matter what. Its maximum
```
+## 前置知识
+
+- 贪心
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是一道典型的`贪心`类型题目。思路就是用一个变量记录当前能够到达的最大的索引,我们逐个遍历数组中的元素去更新这个索引。变量完成判断这个索引是否大于数组下表即可。
+
## 关键点解析
- 建模 (记录和更新当前位置能够到达的最大的索引即可)
## 代码
-* 语言支持: Javascript,Python3
-
+- 语言支持: Javascript,C++,Java,Python3
+Javascript Code:
```js
/**
* @param {number[]} nums
* @return {boolean}
*/
-var canJump = function(nums) {
+var canJump = function (nums) {
let max = 0; // 能够走到的数组下标
- for(let i = 0; i < nums.length; i++) {
- if (max < i) return false; // 当前这一步都走不到,后面更走不到了
- max = Math.max(nums[i] + i, max);
+ for (let i = 0; i < nums.length; i++) {
+ if (max < i) return false; // 当前这一步都走不到,后面更走不到了
+ max = Math.max(nums[i] + i, max);
}
- return max >= nums.length - 1
+ return max >= nums.length - 1;
+};
+```
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ bool canJump(vector& nums) {
+ int n=nums.size();
+ int k=0;
+ for(int i=0;ik){
+ return false;
+ }
+ // 能跳到最后一个位置
+ if(k>=n-1){
+ return true;
+ }
+ // 从当前位置能跳的最远的位置
+ k = max(k, i+nums[i]);
+ }
+ return k >= n-1;
+ }
};
+```
+Java Code:
+
+```java
+class Solution {
+ public boolean canJump(int[] nums) {
+ int n=nums.length;
+ int k=0;
+ for(int i=0;ik){
+ return false;
+ }
+ // 能跳到最后一个位置
+ if(k>=n-1){
+ return true;
+ }
+ // 从当前位置能跳的最远的位置
+ k = Math.max(k, i+nums[i]);
+ }
+ return k >= n-1;
+ }
+}
```
+
Python3 Code:
+
```Python
class Solution:
def canJump(self, nums: List[int]) -> bool:
@@ -69,10 +132,11 @@ class Solution:
return _max >= _len - 1
```
-***复杂度分析***
+**_复杂度分析_**
+
- 时间复杂度:$O(N)$
- 空间复杂度:$O(1)$
-更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
diff --git a/problems/56.merge-intervals.md b/problems/56.merge-intervals.md
index 9acfdab8b..d9f324e99 100644
--- a/problems/56.merge-intervals.md
+++ b/problems/56.merge-intervals.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/merge-intervals/description/
## 题目描述
+
```
Given a collection of intervals, merge all overlapping intervals.
@@ -20,24 +21,34 @@ NOTE: input types have been changed on April 15, 2019. Please reset to default c
```
+## 前置知识
+
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
- 先对数组进行排序,排序的依据就是每一项的第一个元素的大小。
- 然后我们对数组进行遍历,遍历的时候两两运算(具体运算逻辑见下)
- 判断是否相交,如果不相交,则跳过
- 如果相交,则合并两项
+
## 关键点解析
- 对数组进行排序简化操作
-- 如果不排序,需要借助一些hack,这里不介绍了
+- 如果不排序,需要借助一些 hack,这里不介绍了
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
-
-
/*
* @lc app=leetcode id=56 lang=javascript
*
@@ -56,7 +67,7 @@ function intersected(a, b) {
function mergeTwo(a, b) {
return [Math.min(a[0], b[0]), Math.max(a[1], b[1])];
}
-var merge = function(intervals) {
+var merge = function (intervals) {
// 这种算法需要先排序
intervals.sort((a, b) => a[0] - b[0]);
for (let i = 0; i < intervals.length - 1; i++) {
@@ -68,22 +79,24 @@ var merge = function(intervals) {
intervals[i + 1] = mergeTwo(cur, next);
}
}
- return intervals.filter(q => q);
+ return intervals.filter((q) => q);
};
```
+
Python3 Code:
+
```Python
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
"""先排序,后合并"""
if len(intervals) <= 1:
return intervals
-
+
# 排序
def get_first(a_list):
return a_list[0]
intervals.sort(key=get_first)
-
+
# 合并
res = [intervals[0]]
for i in range(1, len(intervals)):
@@ -91,10 +104,11 @@ class Solution:
res[-1] = [res[-1][0], max(res[-1][1], intervals[i][1])]
else:
res.append(intervals[i])
-
+
return res
```
-***复杂度分析***
+**_复杂度分析_**
+
- 时间复杂度:由于采用了排序,因此复杂度大概为 $O(NlogN)$
- 空间复杂度:$O(N)$
diff --git a/problems/560.subarray-sum-equals-k.en.md b/problems/560.subarray-sum-equals-k.en.md
new file mode 100644
index 000000000..31141e4e9
--- /dev/null
+++ b/problems/560.subarray-sum-equals-k.en.md
@@ -0,0 +1,146 @@
+## Problem
+
+https://leetcode.com/problems/subarray-sum-equals-k/description/
+
+## Problem Description
+
+```
+Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
+
+Example 1:
+Input:nums = [1,1,1], k = 2
+Output: 2
+Note:
+The length of the array is in range [1, 20,000].
+The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
+```
+
+## Solution
+
+The simplest method is `Brute-force`. Consider every possible subarray, find the sum of the elements of each of those subarrays and check for the equality of the sum with `k`. Whenever the sum equals `k`, we increment the `count`. Time Complexity is O(n^2). Implementation is as followed.
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ for j in range(i, n):
+ if (sum(nums[i:j + 1]) == k): cnt += 1
+ return cnt
+```
+
+If we implement the `sum()` method on our own, we get the time of complexity O(n^3).
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ for j in range(i, n):
+ sum = 0
+ for x in range(i, j + 1):
+ sum += nums[x]
+ if (sum == k): cnt += 1
+ return cnt
+```
+
+At first glance I think "maybe it can be solved by using the sliding window technique". However, I give that thought up when I find out that the given array may contain negative numbers, which makes it more complicated to expand or narrow the range of the sliding window. Then I think about using a prefix sum array, with which we can obtain the sum of the elements between every two indices by subtracting the prefix sum corresponding to the two indices. It sounds feasible, so I implement it as followed.
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ pre = [0] * (n + 1)
+ for i in range(1, n + 1):
+ pre[i] = pre[i - 1] + nums[i - 1]
+ for i in range(1, n + 1):
+ for j in range(i, n + 1):
+ if (pre[j] - pre[i - 1] == k): cnt += 1
+ return cnt
+```
+
+Actually, there is a more clever way to do this. Instead of using a prefix sum array, we use a hashmap to reduce the time complexity to O(n).
+
+Algorithm:
+
+- We make use of a hashmap to store the cumulative sum `acc` and the number of times the same sum occurs. We use `acc` as the `key` of the hashmap and the number of times the same `acc` occurs as the `value`.
+
+- We traverse over the given array and keep on finding the cumulative sum `acc`. Every time we encounter a new `acc` we add a new entry to the hashmap. If the same `acc` occurs, we increment the count corresponding to that `acc` in the hashmap. If `acc` equals `k`, obviously `count` should be incremented. If `acc - k` got, we should increment `account` by `hashmap[acc - k]`.
+
+- The idea behind this is that if the cumulative sum upto two indices is the same, the sum of the elements between those two indices is zero. So if the cumulative sum upto two indices is at a different of `k`, the sum of the elements between those indices is `k`. As `hashmap[acc - k]` keeps track of the number of times a subarray with sum `acc - k` has occured upto the current index, by doing a simple substraction `acc - (acc - k)` we can see that `hashmap[acc - k]` actually also determines the number of times a subarray with sum `k` has occured upto the current index. So we increment the `count` by `hashmap[acc - k]`.
+
+Here is a graph demonstrating this algorithm in the case of `nums = [1,2,3,3,0,3,4,2], k = 6`.
+
+
+
+When we are at `nums[3]`, the hashmap is as the picture shows, and `count` is 2 by this time. `[1, 2, 3]` accounts for one of the count, and `[3, 3]` accounts for another.
+
+The subarray `[3, 3]` is obtained from `hashmap[acc - k]`, which is `hashmap[9 - 6]`.
+
+## Key Points
+
+- Prefix sum array
+- Make use of a hashmap to track cumulative sum and avoid repetitive calculation.
+
+## Code (`JavaScript/Python`)
+
+*JavaScript Code*
+```js
+/*
+ * @lc app=leetcode id=560 lang=javascript
+ *
+ * [560] Subarray Sum Equals K
+ */
+/**
+ * @param {number[]} nums
+ * @param {number} k
+ * @return {number}
+ */
+var subarraySum = function (nums, k) {
+ const hashmap = {};
+ let acc = 0;
+ let count = 0;
+
+ for (let i = 0; i < nums.length; i++) {
+ acc += nums[i];
+
+ if (acc === k) count++;
+
+ if (hashmap[acc - k] !== void 0) {
+ count += hashmap[acc - k];
+ }
+
+ if (hashmap[acc] === void 0) {
+ hashmap[acc] = 1;
+ } else {
+ hashmap[acc] += 1;
+ }
+ }
+
+ return count;
+};
+```
+
+*Python Cose*
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ d = {}
+ acc = count = 0
+ for num in nums:
+ acc += num
+ if acc == k:
+ count += 1
+ if acc - k in d:
+ count += d[acc-k]
+ if acc in d:
+ d[acc] += 1
+ else:
+ d[acc] = 1
+ return count
+```
+
+## Extension
+
+There is a similar but a bit more complicated problem. Link to the problem: [437.path-sum-iii](https://github.com/azl397985856/leetcode/blob/master/problems/437.path-sum-iii.md)(Chinese).
diff --git a/problems/560.subarray-sum-equals-k.md b/problems/560.subarray-sum-equals-k.md
index 3728ba25e..a8aabe182 100644
--- a/problems/560.subarray-sum-equals-k.md
+++ b/problems/560.subarray-sum-equals-k.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/subarray-sum-equals-k/description/
## 题目描述
+
```
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
@@ -13,31 +15,73 @@ The length of the array is in range [1, 20,000].
The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
```
+
+## 前置知识
+
+- 哈希表
+- 前缀和
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
-符合直觉的做法是暴力求解所有的子数组,然后分别计算和,如果等于k,count就+1.这种做法的时间复杂度为O(n^2).
-这里有一种更加巧妙的方法,我们可以借助额外的空间,使用hashmap来简化时间复杂度,这种算法的时间复杂度可以达到O(n).
+符合直觉的做法是暴力求解所有的子数组,然后分别计算和,如果等于 k,count 就+1.这种做法的时间复杂度为 O(n^2),代码如下:
+
+```python
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ sum = 0
+ for j in range(i, n):
+ sum += nums[j]
+ if (sum == k): cnt += 1
+ return cnt
+```
+
+实际上刚开始看到这题目的时候,我想“是否可以用滑动窗口解决?”。但是很快我就放弃了,因为看了下数组中项的取值范围有负数,这样我们扩张或者收缩窗口就比较复杂。第二个想法是前缀和,保存一个数组的前缀和,然后利用差分法得出任意区间段的和,这种想法是可行的,代码如下:
+
+```python
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ pre = [0] * (n + 1)
+ for i in range(1, n + 1):
+ pre[i] = pre[i - 1] + nums[i - 1]
+ for i in range(1, n + 1):
+ for j in range(i, n + 1):
+ if (pre[j] - pre[i - 1] == k): cnt += 1
+ return cnt
+```
+
+这里有一种更加巧妙的方法,可以不使用前缀和数组,而是使用 hashmap 来简化时间复杂度,这种算法的时间复杂度可以达到 O(n).
+
+具体算法:
-我们维护一个hashmap,hashmap的key为累加值acc,value为累加值acc出现的次数。
-我们迭代数组,然后不断更新acc和hashmap,如果acc 等于k,那么很明显应该+1. 如果hashmap[acc - k] 存在,
-我们就把它加到结果中去即可。
+- 维护一个 hashmap,hashmap 的 key 为累加值 acc,value 为累加值 acc 出现的次数。
+- 迭代数组,然后不断更新 acc 和 hashmap,如果 acc 等于 k,那么很明显应该+1. 如果 hashmap[acc - k] 存在,我们就把它加到结果中去即可。
-语言比较难以解释,我画了一个图来演示nums = [1,2,3,3,0,3,4,2], k = 6的情况。
+语言比较难以解释,我画了一个图来演示 nums = [1,2,3,3,0,3,4,2], k = 6 的情况。
-
+
-如图,当访问到nums[3]的时候,hashmap如图所示,这个时候count为2.
+如图,当访问到 nums[3]的时候,hashmap 如图所示,这个时候 count 为 2.
其中之一是[1,2,3],这个好理解。还有一个是[3,3].
-这个[3,3]正是我们通过hashmap[acc - k]即hashmap[9 - 6]得到的。
+这个[3,3]正是我们通过 hashmap[acc - k]即 hashmap[9 - 6]得到的。
## 关键点解析
-- 可以利用hashmap记录和的累加值来避免重复计算
+- 前缀和
+- 可以利用 hashmap 记录和的累加值来避免重复计算
## 代码
-* 语言支持:JS, Python
+- 语言支持:JS, Python
Javascript Code:
@@ -52,7 +96,7 @@ Javascript Code:
* @param {number} k
* @return {number}
*/
-var subarraySum = function(nums, k) {
+var subarraySum = function (nums, k) {
const hashmap = {};
let acc = 0;
let count = 0;
diff --git a/problems/575.distribute-candies.md b/problems/575.distribute-candies.md
index 79202751c..4f321fae5 100644
--- a/problems/575.distribute-candies.md
+++ b/problems/575.distribute-candies.md
@@ -23,12 +23,21 @@ The length of the given array is in range [2, 10,000], and will be even.
The number in given array is in range [-100,000, 100,000].
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
由于糖果是偶数,并且我们只需要做到两个人糖果数量一样即可。
考虑两种情况:
-
+
- 如果糖果种类大于n / 2(糖果种类数为n),妹妹最多可以获得的糖果种类应该是`n / 2`(因为妹妹只有n / 2个糖).
- 糖果种类数小于n / 2, 妹妹能够得到的糖果种类可以是糖果的种类数(糖果种类本身就这么多).
@@ -69,3 +78,14 @@ class Solution:
def distributeCandies(self, candies: List[int]) -> int:
return min(len(set(candies)), len(candies) >> 1)
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/60.permutation-sequence.md b/problems/60.permutation-sequence.md
index c6706f076..3de364a8d 100644
--- a/problems/60.permutation-sequence.md
+++ b/problems/60.permutation-sequence.md
@@ -2,16 +2,18 @@
https://leetcode-cn.com/problems/permutation-sequence/description/
-## 标签
+## 前置知识
- 数学
- 回溯
-- 找规律
- factorial
## 公司
-Twitter
+- 阿里
+- 百度
+- 字节
+- Twitter
## 题目描述
diff --git a/problems/609.find-duplicate-file-in-system.md b/problems/609.find-duplicate-file-in-system.md
index 8b3ab5090..2ad737810 100644
--- a/problems/609.find-duplicate-file-in-system.md
+++ b/problems/609.find-duplicate-file-in-system.md
@@ -50,6 +50,10 @@ Follow-up beyond contest:
```
+## 前置知识
+
+- 哈希表
+
## 思路
思路就是hashtable去存储,key为文件内容,value为fullfilename,
遍历一遍去填充hashtable, 最后将hashtable中的值打印出来即可。
diff --git a/problems/611.valid-triangle-number.md b/problems/611.valid-triangle-number.md
new file mode 100644
index 000000000..9c30437ab
--- /dev/null
+++ b/problems/611.valid-triangle-number.md
@@ -0,0 +1,160 @@
+## 题目地址(611. 有效三角形的个数)
+
+https://leetcode-cn.com/problems/valid-triangle-number/
+
+## 题目描述
+
+```
+给定一个包含非负整数的数组,你的任务是统计其中可以组成三角形三条边的三元组个数。
+
+示例 1:
+
+输入: [2,2,3,4]
+输出: 3
+解释:
+有效的组合是:
+2,3,4 (使用第一个 2)
+2,3,4 (使用第二个 2)
+2,2,3
+注意:
+
+数组长度不超过1000。
+数组里整数的范围为 [0, 1000]。
+
+```
+
+## 前置知识
+
+- 排序
+- 双指针
+- 二分法
+- 三角形边的关系
+
+## 暴力法(超时)
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+首先要有一个数学前提: `如果三条线段中任意两条的和都大于第三边,那么这三条线段可以组成一个三角形`。即给定三个线段 a,b,c,如果满足 a + b > c and a + c > b and b + c > a,则线段 a,b,c 可以构成三角形,否则不可以。
+
+力扣中有一些题目是需要一些数学前提的,不过这些数学前提都比较简单,一般不会超过高中数学知识,并且也不会特别复杂。一般都是小学初中知识即可。
+
+> 如果你在面试中碰到不知道的数学前提,可以寻求面试官提示试试。
+
+### 关键点解析
+
+- 三角形边的关系
+- 三层循环确定三个线段
+
+### 代码
+
+代码支持: Python
+
+```py
+class Solution:
+ def is_triangle(self, a, b, c):
+ if a == 0 or b == 0 or c == 0: return False
+ if a + b > c and a + c > b and b + c > a: return True
+ return False
+ def triangleNumber(self, nums: List[int]) -> int:
+ n = len(nums)
+ ans = 0
+ for i in range(n - 2):
+ for j in range(i + 1, n - 1):
+ for k in range(j + 1, n):
+ if self.is_triangle(nums[i], nums[j], nums[k]): ans += 1
+
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N ^ 3)$,其中 N 为 数组长度。
+- 空间复杂度:$O(1)$
+
+## 优化的暴力法
+
+### 思路
+
+暴力法的时间复杂度为 $O(N ^ 3)$, 其中 $N$ 最大为 1000。一般来说, $O(N ^ 3)$ 的算法在数据量 <= 500 是可以 AC 的。1000 的数量级则需要考虑 $O(N ^ 2)$ 或者更好的解法。
+
+OK,到这里了。我给大家一个干货。 应该是其他博主不太会提的。原因可能是他们不知道, 也可能是他们觉得太小儿科不需要说。
+
+1. 由于前面我根据数据规模推测到到了解法的复杂度区间是 $N ^ 2$, $N ^ 2 * logN$,不可能是 $N$ (WHY?)。
+2. 降低时间复杂度的方法主要有: `空间换时间` 和 `排序换时间`(我们一般都是使用基于比较的排序方法)。而`排序换时间`仅仅在总体复杂度大于 $O(NlogN)$ 才适用(原因不用多说了吧?)。
+
+这里由于总体的时间复杂度是 $O(N ^ 3)$,因此我自然想到了`排序换时间`。当我们对 nums 进行一次排序之后,我发现:
+
+- is_triangle 函数有一些判断是无效的
+
+```py
+ def is_triangle(self, a, b, c):
+ if a == 0 or b == 0 or c == 0: return False
+ # a + c > b 和 b + c > a 是无效的判断,因为恒成立
+ if a + b > c and a + c > b and b + c > a: return True
+ return False
+```
+
+- 因此我们的目标变为找到`a + b > c`即可,因此第三层循环是可以提前退出的。
+
+```py
+for i in range(n - 2):
+ for j in range(i + 1, n - 1):
+ k = j + 1
+ while k < n and num[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+```
+
+- 这也仅仅是减枝而已,复杂度没有变化。通过进一步观察,发现 k 没有必要每次都从 j + 1 开始。而是从上次找到的 k 值开始就行。原因很简单, 当 nums[i] + nums[j] > nums[k] 时,我们想要找到下一个满足 nums[i] + nums[j] > nums[k] 的 新的 k 值,由于进行了排序,因此这个 k 肯定比之前的大(单调递增性),因此上一个 k 值之前的数都是无效的,可以跳过。
+
+```py
+for i in range(n - 2):
+ k = i + 2
+ for j in range(i + 1, n - 1):
+ while k < n and nums[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+```
+
+由于 K 不会后退,因此最内层循环总共最多执行 N 次,因此总的时间复杂度为 $O(N ^ 2)$。
+
+> 这个复杂度分析有点像单调栈,大家可以结合起来理解。
+
+### 关键点分析
+
+- 排序
+
+### 代码
+
+```py
+class Solution:
+ def triangleNumber(self, nums: List[int]) -> int:
+ n = len(nums)
+ ans = 0
+ nums.sort()
+ for i in range(n - 2):
+ if nums[i] == 0: continue
+ k = i + 2
+ for j in range(i + 1, n - 1):
+ while k < n and nums[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N ^ 2)$
+- 空间复杂度:取决于排序算法
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/62.unique-paths.md b/problems/62.unique-paths.md
index 8076e82de..4e6ce882b 100644
--- a/problems/62.unique-paths.md
+++ b/problems/62.unique-paths.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/unique-paths/description/
## 题目描述
+
```
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
@@ -11,7 +12,8 @@ The robot can only move either down or right at any point in time. The robot is
How many possible unique paths are there?
```
-
+
+
```
Above is a 7 x 3 grid. How many possible unique paths are there?
@@ -33,38 +35,35 @@ Input: m = 7, n = 3
Output: 28
```
+## 前置知识
+
+- 动态规划
+- 排列组合
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+首先这道题可以用排列组合的解法来解,需要一点高中的知识。
+
+
+
+而这道题我们用动态规划来解。
+
这是一道典型的适合使用动态规划解决的题目,它和爬楼梯等都属于动态规划中最简单的题目,因此也经常会被用于面试之中。
读完题目你就能想到动态规划的话,建立模型并解决恐怕不是难事。其实我们很容易看出,由于机器人只能右移动和下移动,
因此第[i, j]个格子的总数应该等于[i - 1, j] + [i, j -1], 因为第[i,j]个格子一定是从左边或者上面移动过来的。
-
+
代码大概是:
-JS Code:
-
-```js
- const dp = [];
- for (let i = 0; i < m + 1; i++) {
- dp[i] = [];
- dp[i][0] = 0;
- }
- for (let i = 0; i < n + 1; i++) {
- dp[0][i] = 0;
- }
- for (let i = 1; i < m + 1; i++) {
- for(let j = 1; j < n + 1; j++) {
- dp[i][j] = j === 1 ? 1 : dp[i - 1][j] + dp[i][j - 1]; // 转移方程
- }
- }
-
- return dp[m][n];
-
-```
-
Python Code:
```python
@@ -77,47 +76,47 @@ class Solution:
d[col][row] = d[col - 1][row] + d[col][row - 1]
return d[m - 1][n - 1]
- ```
-
- **复杂度分析**
-
- - 时间复杂度:$O(M * N)$
- - 空间复杂度:$O(M * N)$
+```
-由于dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到O(n).
+**复杂度分析**
-
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(M * N)$
-具体代码请查看代码区。
+由于 dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到 O(n).
+
+
+具体代码请查看代码区。
当然你也可以使用记忆化递归的方式来进行,由于递归深度的原因,性能比上面的方法差不少:
-> 直接暴力递归的话会超时。
+> 直接暴力递归的话可能会超时。
Python3 Code:
+
```python
class Solution:
- visited = dict()
-
+
+ @lru_cache
def uniquePaths(self, m: int, n: int) -> int:
- if (m, n) in self.visited:
- return self.visited[(m, n)]
if m == 1 or n == 1:
return 1
cnt = self.uniquePaths(m - 1, n) + self.uniquePaths(m, n - 1)
- self.visited[(m, n)] = cnt
return cnt
- ```
+```
+
## 关键点
+- 排列组合原理
- 记忆化递归
- 基本动态规划问题
-- 空间复杂度可以进一步优化到O(n), 这会是一个考点
+- 空间复杂度可以进一步优化到 O(n), 这会是一个考点
+
## 代码
-代码支持JavaScript,Python3
+代码支持 JavaScript,Python3
JavaScript Code:
@@ -134,13 +133,13 @@ JavaScript Code:
* @param {number} n
* @return {number}
*/
-var uniquePaths = function(m, n) {
+var uniquePaths = function (m, n) {
const dp = Array(n).fill(1);
-
- for(let i = 1; i < m; i++) {
- for(let j = 1; j < n; j++) {
+
+ for (let i = 1; i < m; i++) {
+ for (let j = 1; j < n; j++) {
dp[j] = dp[j] + dp[j - 1];
- }
+ }
}
return dp[n - 1];
@@ -160,12 +159,18 @@ class Solution:
return dp[n - 1]
```
- **复杂度分析**
-
- - 时间复杂度:$O(M * N)$
- - 空间复杂度:$O(N)$
-
- ## 扩展
-
- 你可以做到比$O(M * N)$更快,比$O(N)$更省内存的算法么?这里有一份[资料](https://leetcode.com/articles/unique-paths/)可供参考。
- > 提示: 考虑数学
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(N)$
+
+## 扩展
+
+你可以做到比$O(M * N)$更快,比$O(N)$更省内存的算法么?这里有一份[资料](https://leetcode.com/articles/unique-paths/)可供参考。
+
+> 提示: 考虑数学
+
+## 相关题目
+
+- [70. 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs/)
+- [63. 不同路径 II](./63.unique-paths-ii.md)
diff --git a/problems/63.unique-paths-ii.md b/problems/63.unique-paths-ii.md
new file mode 100644
index 000000000..4a04b939f
--- /dev/null
+++ b/problems/63.unique-paths-ii.md
@@ -0,0 +1,144 @@
+## 题目地址
+
+https://leetcode-cn.com/problems/unique-paths-ii/
+
+## 题目描述
+
+```
+
+一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
+
+机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
+
+现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
+```
+
+
+
+```
+网格中的障碍物和空位置分别用 1 和 0 来表示。
+
+说明:m 和 n 的值均不超过 100。
+
+示例 1:
+
+输入:
+[
+ [0,0,0],
+ [0,1,0],
+ [0,0,0]
+]
+输出: 2
+解释:
+3x3 网格的正中间有一个障碍物。
+从左上角到右下角一共有 2 条不同的路径:
+1. 向右 -> 向右 -> 向下 -> 向下
+2. 向下 -> 向下 -> 向右 -> 向右
+
+```
+
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+这是一道典型的适合使用动态规划解决的题目,它和爬楼梯等都属于动态规划中最简单的题目,因此也经常会被用于面试之中。
+
+读完题目你就能想到动态规划的话,建立模型并解决恐怕不是难事。其实我们很容易看出,由于机器人只能右移动和下移动,
+因此第[i, j]个格子的总数应该等于[i - 1, j] + [i, j -1], 因为第[i,j]个格子一定是从左边或者上面移动过来的。
+
+
+
+dp[i][j] 表示 到格子 obstacleGrid[i - 1][j - 1] 的所有路径数。
+
+由于有障碍物的存在, 因此我们的路径有了限制,具体来说就是:`如果当前各自是障碍物, 那么 dp[i][j] = 0`。否则 dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+
+代码大概是:
+
+Python Code:
+
+```python
+class Solution:
+ def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
+ m = len(obstacleGrid)
+ n = len(obstacleGrid[0])
+ if obstacleGrid[0][0]:
+ return 0
+
+ dp = [[0] * (n + 1) for _ in range(m + 1)]
+ dp[1][1] = 1
+
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if i == 1 and j == 1:
+ continue
+ if obstacleGrid[i - 1][j - 1] == 0:
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+ else:
+ dp[i][j] = 0
+ return dp[m][n]
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(M * N)$
+
+由于 dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到 O(n).
+
+
+
+具体代码请查看代码区。
+
+当然你也可以使用记忆化递归的方式来进行,由于递归深度的原因,性能比上面的方法差不少。
+
+> 直接暴力递归的话会超时。
+
+## 关键点
+
+- 记忆化递归
+- 基本动态规划问题
+- 空间复杂度可以进一步优化到 O(n), 这会是一个考点
+
+## 代码
+
+代码支持 Python3
+
+Python3 Code:
+
+```python
+class Solution:
+ def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
+ m = len(obstacleGrid)
+ n = len(obstacleGrid[0])
+ if obstacleGrid[0][0]:
+ return 0
+
+ dp = [0] * (n + 1)
+ dp[1] = 1
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if obstacleGrid[i - 1][j - 1] == 0:
+ dp[j] += dp[j - 1]
+ else:
+ dp[j] = 0
+ return dp[-1]
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(N)$
+
+## 相关题目
+
+- [70. 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs/)
+- [62. 不同路径](./62.unique-paths.md)
diff --git a/problems/718.maximum-length-of-repeated-subarray.md b/problems/718.maximum-length-of-repeated-subarray.md
new file mode 100644
index 000000000..dfe06b8c5
--- /dev/null
+++ b/problems/718.maximum-length-of-repeated-subarray.md
@@ -0,0 +1,88 @@
+## 题目地址(718. 最长重复子数组)
+
+https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray/
+
+## 题目描述
+
+```
+给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
+
+示例 1:
+
+输入:
+A: [1,2,3,2,1]
+B: [3,2,1,4,7]
+输出: 3
+解释:
+长度最长的公共子数组是 [3, 2, 1]。
+说明:
+
+1 <= len(A), len(B) <= 1000
+0 <= A[i], B[i] < 100
+```
+
+## 前置知识
+
+- 哈希表
+- 数组
+- 二分查找
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+这就是最经典的最长公共子序列问题。一般这种求解**两个数组或者字符串求最大或者最小**的题目都可以考虑动态规划,并且通常都定义 dp[i][j] 为 `以 A[i], B[j] 结尾的 xxx`。这道题就是:`以 A[i], B[j] 结尾的两个数组中公共的、长度最长的子数组的长度`。 算法很简单:
+
+- 双层循环找出所有的 i, j 组合,时间复杂度 $O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+ - 如果 A[i] == B[j],dp[i][j] = dp[i - 1][j - 1] + 1
+ - 否则,dp[i][j] = 0
+- 循环过程记录最大值即可。
+
+## 关键点解析
+
+- dp 建模套路
+
+## 代码
+
+代码支持:Python
+
+Python Code:
+
+```py
+class Solution:
+ def findLength(self, A, B):
+ m, n = len(A), len(B)
+ ans = 0
+ dp = [[0 for _ in range(n + 1)] for _ in range(m + 1)]
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if A[i - 1] == B[j - 1]:
+ dp[i][j] = dp[i - 1][j - 1] + 1
+ ans = max(ans, dp[i][j])
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+- 空间复杂度:$O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+
+## 更多
+
+- [你的衣服我扒了 - 《最长公共子序列》](https://lucifer.ren/blog/2020/07/01/LCS/)
+
+## 扩展
+
+二分查找也是可以的,不过并不容易想到,大家可以试试。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/721.accounts-merge.md b/problems/721.accounts-merge.md
index cb9ac8929..e4bde5c2d 100644
--- a/problems/721.accounts-merge.md
+++ b/problems/721.accounts-merge.md
@@ -27,6 +27,14 @@ accounts 的长度将在[1,1000]的范围内。
accounts[i]的长度将在[1,10]的范围内。
accounts[i][j]的长度将在[1,30]的范围内。
+## 前置知识
+
+- 并查集
+
+## 公司
+
+- 字节
+
## 思路
我们抛开 name 不管。 我们只根据 email 建立并查集即可。这样一个连通分量中的 email 就是一个人,我们在用一个 hashtable 记录 email 和 name 的映射,将其输出即可。
@@ -75,4 +83,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/73.set-matrix-zeroes.md b/problems/73.set-matrix-zeroes.md
index 6509cec85..51ea285f4 100644
--- a/problems/73.set-matrix-zeroes.md
+++ b/problems/73.set-matrix-zeroes.md
@@ -43,19 +43,29 @@ Follow up:
```
+## 前置知识
+
+- 状态压缩
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
符合直觉的想法是,使用一个 m + n 的数组来表示每一行每一列是否”全部是 0“,
先遍历一遍去构建这样的 m + n 数组,然后根据这个 m + n 数组去修改 matrix 即可。
-
+
这样的时间复杂度 O(m \* n), 空间复杂度 O(m + n).
代码如下:
```js
-var setZeroes = function(matrix) {
+var setZeroes = function (matrix) {
if (matrix.length === 0) return matrix;
const m = matrix.length;
const n = matrix[0].length;
@@ -90,32 +100,33 @@ var setZeroes = function(matrix) {
};
```
-但是这道题目还有一个follow up, 要求使用O(1)的时间复杂度。因此上述的方法就不行了。
-但是我们要怎么去存取这些信息(哪一行哪一列应该全部为0)呢?
+但是这道题目还有一个 follow up, 要求使用 O(1)的时间复杂度。因此上述的方法就不行了。
+但是我们要怎么去存取这些信息(哪一行哪一列应该全部为 0)呢?
-一种思路是使用第一行第一列的数据来代替上述的zeros数组。 这样我们就不必借助额外的存储空间,空间复杂度自然就是O(1)了。
+一种思路是使用第一行第一列的数据来代替上述的 zeros 数组。 这样我们就不必借助额外的存储空间,空间复杂度自然就是 O(1)了。
-由于我们不能先操作第一行和第一列, 因此我们需要记录下”第一行和第一列是否全是0“这样的一个数据,最后根据这个信息去
+由于我们不能先操作第一行和第一列, 因此我们需要记录下”第一行和第一列是否全是 0“这样的一个数据,最后根据这个信息去
修改第一行和第一列。
具体步骤如下:
-- 记录下”第一行和第一列是否全是0“这样的一个数据
-- 遍历除了第一行和第一列之外的所有的数据,如果是0,那就更新第一行第一列中对应的元素为0
-> 你可以把第一行第一列看成我们上面那种解法使用的m + n 数组。
-- 根据第一行第一列的数据,更新matrix
-- 最后根据我们最开始记录的”第一行和第一列是否全是0“去更新第一行和第一列即可
-
-
+- 记录下”第一行和第一列是否全是 0“这样的一个数据
+- 遍历除了第一行和第一列之外的所有的数据,如果是 0,那就更新第一行第一列中对应的元素为 0
+ > 你可以把第一行第一列看成我们上面那种解法使用的 m + n 数组。
+- 根据第一行第一列的数据,更新 matrix
+- 最后根据我们最开始记录的”第一行和第一列是否全是 0“去更新第一行和第一列即可
+
## 关键点
-- 使用第一行和第一列来替代我们m + n 数组
-- 先记录下”第一行和第一列是否全是0“这样的一个数据,否则会因为后续对第一行第一列的更新造成数据丢失
+
+- 使用第一行和第一列来替代我们 m + n 数组
+- 先记录下”第一行和第一列是否全是 0“这样的一个数据,否则会因为后续对第一行第一列的更新造成数据丢失
- 最后更新第一行第一列
+
## 代码
-* 语言支持:JS,Python3
+- 语言支持:JS,Python3
```js
/*
@@ -127,7 +138,7 @@ var setZeroes = function(matrix) {
* @param {number[][]} matrix
* @return {void} Do not return anything, modify matrix in-place instead.
*/
-var setZeroes = function(matrix) {
+var setZeroes = function (matrix) {
if (matrix.length === 0) return matrix;
const m = matrix.length;
const n = matrix[0].length;
@@ -178,9 +189,11 @@ var setZeroes = function(matrix) {
return matrix;
};
```
+
Python3 Code:
-直接修改第一行和第一列为0的解法:
+直接修改第一行和第一列为 0 的解法:
+
```python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
@@ -190,16 +203,16 @@ class Solution:
def setRowZeros(matrix: List[List[int]], i:int) -> None:
C = len(matrix[0])
matrix[i] = [0] * C
-
+
def setColZeros(matrix: List[List[int]], j:int) -> None:
R = len(matrix)
for i in range(R):
matrix[i][j] = 0
-
+
isCol = False
R = len(matrix)
C = len(matrix[0])
-
+
for i in range(R):
if matrix[i][0] == 0:
isCol = True
@@ -210,17 +223,18 @@ class Solution:
for j in range(1, C):
if matrix[0][j] == 0:
setColZeros(matrix, j)
-
+
for i in range(R):
if matrix[i][0] == 0:
setRowZeros(matrix, i)
-
+
if isCol:
setColZeros(matrix, 0)
```
-另一种方法是用一个特殊符合标记需要改变的结果,只要这个特殊标记不在我们的题目数据范围(0和1)即可,这里用None。
+另一种方法是用一个特殊符合标记需要改变的结果,只要这个特殊标记不在我们的题目数据范围(0 和 1)即可,这里用 None。
+
```python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
diff --git a/problems/75.sort-colors.md b/problems/75.sort-colors.md
index 1282b9ec1..8fc9f9541 100644
--- a/problems/75.sort-colors.md
+++ b/problems/75.sort-colors.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/sort-colors/description/
## 题目描述
+
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the same color are adjacent, with the colors in the order red, white and blue.
Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively.
@@ -18,12 +20,26 @@ A rather straight forward solution is a two-pass algorithm using counting sort.
First, iterate the array counting number of 0's, 1's, and 2's, then overwrite array with total number of 0's, then 1's and followed by 2's.
Could you come up with a one-pass algorithm using only constant space?
+## 前置知识
+
+- [荷兰国旗问题](https://en.wikipedia.org/wiki/Dutch_national_flag_problem)
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+
这个问题是典型的荷兰国旗问题 (https://en.wikipedia.org/wiki/Dutch_national_flag_problem)。 因为我们可以将红白蓝三色小球想象成条状物,有序排列后正好组成荷兰国旗。
有两种解决思路。
## 解法一
+
- 遍历数组,统计红白蓝三色球(0,1,2)的个数
- 根据红白蓝三色球(0,1,2)的个数重排数组
@@ -31,15 +47,14 @@ Could you come up with a one-pass algorithm using only constant space?
## 解法二
-我们可以把数组分成三部分,前部(全部是0),中部(全部是1)和后部(全部是2)三个部分。每一个元素(红白蓝分别对应0、1、2)必属于其中之一。将前部和后部各排在数组的前边和后边,中部自然就排好了。
+我们可以把数组分成三部分,前部(全部是 0),中部(全部是 1)和后部(全部是 2)三个部分。每一个元素(红白蓝分别对应 0、1、2)必属于其中之一。将前部和后部各排在数组的前边和后边,中部自然就排好了。
-我们用三个指针,设置两个指针begin指向前部的末尾的下一个元素(刚开始默认前部无0,所以指向第一个位置),end指向后部开头的前一个位置(刚开始默认后部无2,所以指向最后一个位置),然后设置一个遍历指针current,从头开始进行遍历。
+我们用三个指针,设置两个指针 begin 指向前部的末尾的下一个元素(刚开始默认前部无 0,所以指向第一个位置),end 指向后部开头的前一个位置(刚开始默认后部无 2,所以指向最后一个位置),然后设置一个遍历指针 current,从头开始进行遍历。
这种思路的时间复杂度也是$O(n)$, 只需要遍历数组一次。
### 关键点解析
-
- 荷兰国旗问题
- counting sort
@@ -49,7 +64,7 @@ Could you come up with a one-pass algorithm using only constant space?
Python3 Code:
-``` python
+```python
class Solution:
def sortColors(self, nums: List[int]) -> None:
"""
@@ -57,7 +72,7 @@ class Solution:
"""
p0 = cur = 0
p2 = len(nums) - 1
-
+
while cur <= p2:
if nums[cur] == 0:
nums[cur], nums[p0] = nums[p0], nums[cur]
@@ -69,5 +84,3 @@ class Solution:
else:
cur += 1
```
-
-
diff --git a/problems/78.subsets-en.md b/problems/78.subsets-en.md
new file mode 100644
index 000000000..dcafa79fc
--- /dev/null
+++ b/problems/78.subsets-en.md
@@ -0,0 +1,136 @@
+## Problem Link
+https://leetcode.com/problems/subsets/description/
+
+## Description
+```
+Given a set of distinct integers, nums, return all possible subsets (the power set).
+
+Note: The solution set must not contain duplicate subsets.
+
+Example:
+
+Input: nums = [1,2,3]
+Output:
+[
+ [3],
+ [1],
+ [2],
+ [1,2,3],
+ [1,3],
+ [2,3],
+ [1,2],
+ []
+]
+
+
+```
+
+## Solution
+
+Since this problem is seeking `Subset` not `Extreme Value`, dynamic programming is not an ideal solution. Other approaches should be taken into our consideration.
+
+Actually, there is a general approach to solve problems similar to this one -- backtracking. Given a [Code Template](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)) here, it demonstrates how backtracking works with varieties of problems. Apart from current one, many problems can be solved by such a general approach. For more details, please check the `Related Problems` section below.
+
+Given a picture as followed, let's start with problem-solving ideas of this general solution.
+
+
+
+See Code Template details below.
+
+## Key Points
+
+- Backtrack Approach
+- Backtrack Code Template/ Formula
+
+
+## Code
+
+* Supported Language:JS,C++
+
+JavaScript Code:
+```js
+
+/*
+ * @lc app=leetcode id=78 lang=javascript
+ *
+ * [78] Subsets
+ *
+ * https://leetcode.com/problems/subsets/description/
+ *
+ * algorithms
+ * Medium (51.19%)
+ * Total Accepted: 351.6K
+ * Total Submissions: 674.8K
+ * Testcase Example: '[1,2,3]'
+ *
+ * Given a set of distinct integers, nums, return all possible subsets (the
+ * power set).
+ *
+ * Note: The solution set must not contain duplicate subsets.
+ *
+ * Example:
+ *
+ *
+ * Input: nums = [1,2,3]
+ * Output:
+ * [
+ * [3],
+ * [1],
+ * [2],
+ * [1,2,3],
+ * [1,3],
+ * [2,3],
+ * [1,2],
+ * []
+ * ]
+ *
+ */
+function backtrack(list, tempList, nums, start) {
+ list.push([...tempList]);
+ for(let i = start; i < nums.length; i++) {
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
+}
+/**
+ * @param {number[]} nums
+ * @return {number[][]}
+ */
+var subsets = function(nums) {
+ const list = [];
+ backtrack(list, [], nums, 0);
+ return list;
+};
+```
+C++ Code:
+```C++
+class Solution {
+public:
+ vector> subsets(vector& nums) {
+ auto ret = vector>();
+ auto tmp = vector();
+ backtrack(ret, tmp, nums, 0);
+ return ret;
+ }
+
+ void backtrack(vector>& list, vector& tempList, vector& nums, int start) {
+ list.push_back(tempList);
+ for (auto i = start; i < nums.size(); ++i) {
+ tempList.push_back(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop_back();
+ }
+ }
+};
+```
+
+## Related Problems
+
+- [39.combination-sum](./39.combination-sum.md)(chinese)
+- [40.combination-sum-ii](./40.combination-sum-ii.md)(chinese)
+- [46.permutations](./46.permutations.md)(chinese)
+- [47.permutations-ii](./47.permutations-ii.md)(chinese)
+- [90.subsets-ii](./90.subsets-ii-en.md)
+- [113.path-sum-ii](./113.path-sum-ii.md)(chinese)
+- [131.palindrome-partitioning](./131.palindrome-partitioning.md)(chinese)
diff --git a/problems/78.subsets.md b/problems/78.subsets.md
index 00a8864fb..72176ebf8 100644
--- a/problems/78.subsets.md
+++ b/problems/78.subsets.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/subsets/description/
## 题目描述
+
```
Given a set of distinct integers, nums, return all possible subsets (the power set).
@@ -26,18 +27,31 @@ Output:
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 每一层灰色的部分,表示当前有哪些节点是可以选择的, 红色部分则是选择路径。1,2,3,4,5,6 则分别表示我们的 6 个子集。
通用写法的具体代码见下方代码区。
@@ -46,14 +60,13 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持:JS,C++
+- 语言支持:JS,C++
JavaScript Code:
-```js
+```js
/*
* @lc app=leetcode id=78 lang=javascript
*
@@ -69,12 +82,12 @@ JavaScript Code:
*
* Given a set of distinct integers, nums, return all possible subsets (the
* power set).
- *
+ *
* Note: The solution set must not contain duplicate subsets.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Input: nums = [1,2,3]
* Output:
* [
@@ -87,27 +100,29 @@ JavaScript Code:
* [1,2],
* []
* ]
- *
+ *
*/
function backtrack(list, tempList, nums, start) {
- list.push([...tempList]);
- for(let i = start; i < nums.length; i++) {
- tempList.push(nums[i]);
- backtrack(list, tempList, nums, i + 1);
- tempList.pop();
- }
+ list.push([...tempList]);
+ for (let i = start; i < nums.length; i++) {
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var subsets = function(nums) {
- const list = [];
- backtrack(list, [], nums, 0);
- return list;
+var subsets = function (nums) {
+ const list = [];
+ backtrack(list, [], nums, 0);
+ return list;
};
```
+
C++ Code:
+
```C++
class Solution {
public:
@@ -117,7 +132,7 @@ public:
backtrack(ret, tmp, nums, 0);
return ret;
}
-
+
void backtrack(vector>& list, vector& tempList, vector& nums, int start) {
list.push_back(tempList);
for (auto i = start; i < nums.size(); ++i) {
@@ -138,5 +153,3 @@ public:
- [90.subsets-ii](./90.subsets-ii.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
- [131.palindrome-partitioning](./131.palindrome-partitioning.md)
-
-
diff --git a/problems/785.is-graph-bipartite.md b/problems/785.is-graph-bipartite.md
new file mode 100644
index 000000000..d2086dc99
--- /dev/null
+++ b/problems/785.is-graph-bipartite.md
@@ -0,0 +1,114 @@
+## 题目地址(785. 判断二分图)
+
+https://leetcode-cn.com/problems/is-graph-bipartite/
+
+## 题目描述
+
+```
+给定一个无向图 graph,当这个图为二分图时返回 true。
+
+如果我们能将一个图的节点集合分割成两个独立的子集 A 和 B,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B 集合,我们就将这个图称为二分图。
+
+graph 将会以邻接表方式给出,graph[i]表示图中与节点 i 相连的所有节点。每个节点都是一个在 0 到 graph.length-1 之间的整数。这图中没有自环和平行边: graph[i] 中不存在 i,并且 graph[i]中没有重复的值。
+
+示例 1:
+输入: [[1,3], [0,2], [1,3], [0,2]]
+输出: true
+解释:
+无向图如下:
+0----1
+| |
+| |
+3----2
+我们可以将节点分成两组: {0, 2} 和 {1, 3}。
+
+示例 2:
+输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
+输出: false
+解释:
+无向图如下:
+0----1
+| \ |
+| \ |
+3----2
+我们不能将节点分割成两个独立的子集。
+注意:
+
+graph 的长度范围为 [1, 100]。
+graph[i] 中的元素的范围为 [0, graph.length - 1]。
+graph[i] 不会包含 i 或者有重复的值。
+图是无向的: 如果 j 在 graph[i]里边, 那么 i 也会在 graph[j]里边。
+```
+
+## 前置知识
+
+- 图的遍历
+- DFS
+
+## 公司
+
+- 暂无
+
+## 思路
+
+和 886 思路一样。 我甚至**直接拿过来 dfs 函数一行代码没改就 AC 了**。
+
+唯一需要调整的地方是 graph 。 我将其转换了一下,具体可以看代码,非常简单易懂。
+
+具体算法:
+
+- 设置一个长度为 N 的数组 colors,colors[i] 表示 节点 i 的颜色,0 表示无颜色, 1 表示一种颜色, - 1 表示另一种颜色。
+- 初始化 colors 全部为 0
+- 构图(这里有邻接矩阵) 使得 grid[i][j] 表示 i 和 j 是否有连接(这里用 0 表示无, 1 表示有)
+- 遍历图。
+ - 如果当前节点未染色,则染色,不妨染为颜色 1
+ - 递归遍历其邻居
+ - 如果邻居没有染色, 则染为另一种颜色。即 color \* - 1,其中 color 为当前节点的颜色
+ - 否则,判断当前节点和邻居的颜色是否一致,不一致则返回 False,否则返回 True
+
+强烈建议两道题一起练习一下。
+
+## 关键点
+
+- 图的建立和遍历
+- colors 数组
+
+## 代码
+
+```py
+class Solution:
+ def dfs(self, grid, colors, i, color, N):
+ colors[i] = color
+ for j in range(N):
+ if grid[i][j] == 1:
+ if colors[j] == color:
+ return False
+ if colors[j] == 0 and not self.dfs(grid, colors, j, -1 * color, N):
+ return False
+ return True
+
+ def isBipartite(self, graph: List[List[int]]) -> bool:
+ N = len(graph)
+ grid = [[0] * N for _ in range(N)]
+ colors = [0] * N
+ for i in range(N):
+ for j in graph[i]:
+ grid[i][j] = 1
+ for i in range(N):
+ if colors[i] == 0 and not self.dfs(grid, colors, i, 1, N):
+ return False
+ return True
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N)$
+
+## 相关问题
+
+- [886. 可能的二分法](./886.possible-bipartition.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/79.word-search-en.md b/problems/79.word-search-en.md
index ed3e745fe..b1910c371 100644
--- a/problems/79.word-search-en.md
+++ b/problems/79.word-search-en.md
@@ -40,7 +40,7 @@ board, word:`SEE` as below pic:
as below pic:
```
-
+
Staring position(1,0), check whether adjacent cells match word next letter `E`.
```
@@ -52,7 +52,7 @@ Staring position(1,0), check whether adjacent cells match word next letter `
as below pic:
```
-
+
Didn't find matching from starting position, so
```
@@ -61,7 +61,7 @@ Didn't find matching from starting position, so
as below pic:
```
-
+
New starting position(1,3),check whether adjacent cells match word next letter `E`.
```
@@ -73,7 +73,7 @@ New starting position(1,3),check whether adjacent cells match word next
as below pic:
```
-
+
Start position(0,3), DFS,check whether adjacent cells match word next letter `E`
```
@@ -85,7 +85,7 @@ Start position(0,3), DFS,check whether adjacent cells match word next lett
as below pic:
```
-
+
Start from position(0,3)not matching word, start position (2, 3) DFS search:
```
@@ -98,10 +98,10 @@ Start from position(0,3)not matching word, start position (2, 3) DFS searc
as below pic:
```
-
+
Found match with word, return `True`.
-
+
#### Complexity Analysis
- *Time Complexity:* `O(m*n) - m is number of board rows, n is number of board columns `
@@ -120,8 +120,9 @@ Found match with word, return `True`.
```java
public class LC79WordSearch {
public boolean exist(char[][] board, String word) {
- if (board == null || board.length == 0 || board[0].length == 0
- || word == null || word.length() == 0) return true;
+ if (board == null || word == null) return false;
+ if (word.length() == 0) return true;
+ if (board.length == 0) return false;
int rows = board.length;
int cols = board[0].length;
for (int r = 0; r < rows; r++) {
@@ -239,4 +240,4 @@ var exist = function(board, word) {
```
## References
-1. [Backtracking Wiki](https://www.wikiwand.com/en/Backtracking)
\ No newline at end of file
+1. [Backtracking Wiki](https://www.wikiwand.com/en/Backtracking)
diff --git a/problems/79.word-search.md b/problems/79.word-search.md
index 99adc5d7b..8cc7630d7 100644
--- a/problems/79.word-search.md
+++ b/problems/79.word-search.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/word-search/
## 题目描述
+
```
Given a 2D board and a word, find if the word exists in the grid.
@@ -21,44 +23,62 @@ Given word = "SEE", return true.
Given word = "ABCB", return false.
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-在2D表中搜索是否有满足给定单词的字符组合,要求所有字符都是相邻的(方向不限). 题中也没有要求字符的起始和结束位置。
+在 2D 表中搜索是否有满足给定单词的字符组合,要求所有字符都是相邻的(方向不限). 题中也没有要求字符的起始和结束位置。
-在起始位置不确定的情况下,扫描二维数组,找到字符跟给定单词的第一个字符相同的,四个方向(上,下,左,右)分别DFS搜索,
+在起始位置不确定的情况下,扫描二维数组,找到字符跟给定单词的第一个字符相同的,四个方向(上,下,左,右)分别 DFS 搜索,
如果任意方向满足条件,则返回结果。不满足,回溯,重新搜索。
举例说明:如图二维数组,单词:"SEE"
+
```
1. 扫描二维数组,找到board[1,0] = word[0],匹配单词首字母。
2. 做DFS(上,下,左,右 四个方向)
如下图:
```
-
+
+
起始位置(1,0),判断相邻的字符是否匹配单词下一个字符 `E`.
+
```
1. 标记当前字符(1,0)为已经访问过,board[1][0] = '*'
-2. 上(0,0)字符为 'A' 不匹配,
+2. 上(0,0)字符为 'A' 不匹配,
3. 下(2,0)字符为 'A',不匹配,
4. 左(-1,0)超越边界,不匹配,
5. 右(1,1)字符 'F',不匹配
如下图:
```
-
-由于从起始位置DFS都不满足条件,所以
+
+
+由于从起始位置 DFS 都不满足条件,所以
+
```
-1. 回溯,标记起始位置(1,0)为未访问。board[1][0] = 'S'.
+1. 回溯,标记起始位置(1,0)为未访问。board[1][0] = 'S'.
2. 然后继续扫描二维数组,找到下一个起始位置(1,3)
如下图:
```
-
+
+
起始位置(1,3),判断相邻的字符是否匹配单词下一个字符 `E`.
+
```
1. 标记当前字符(1, 3)为已经访问过,board[1][3] = '*'
2. 上(0,3)字符为 'E', 匹配, 继续DFS搜索(参考位置为(0,3)位置DFS搜索步骤描述)
@@ -68,9 +88,11 @@ Given word = "ABCB", return false.
如下图:
```
-
-位置(0,3)满足条件,继续DFS,判断相邻的字符是否匹配单词下一个字符 `E`
+
+
+位置(0,3)满足条件,继续 DFS,判断相邻的字符是否匹配单词下一个字符 `E`
+
```
1. 标记当前字符(0,3)为已经访问过,board[0][3] = '*'
2. 上 (-1,3)超越边界,不匹配
@@ -80,11 +102,13 @@ Given word = "ABCB", return false.
如下图
```
-
-从位置(0,3)DFS不满足条件,继续位置(2,3)DFS搜索
+
+
+从位置(0,3)DFS 不满足条件,继续位置(2,3)DFS 搜索
+
```
-1. 回溯,标记起始位置(0,3)为未访问。board[0][3] = 'E'.
+1. 回溯,标记起始位置(0,3)为未访问。board[0][3] = 'E'.
2. 回到满足条件的位置(2,3),继续DFS搜索,判断相邻的字符是否匹配单词下一个字符 'E'
3. 上 (1,3)已访问过
4. 下(3,3)超越边界,不匹配
@@ -93,34 +117,40 @@ Given word = "ABCB", return false.
如下图:
```
-
+
+
单词匹配完成,满足条件,返回 `True`.
-
+
#### 复杂度分析
-- *时间复杂度:* `O(m*n) - m 是二维数组行数, n 是二维数组列数`
-- *空间复杂度:* `O(1) - 这里在原数组中标记当前访问过,没有用到额外空间`
->**注意**:如果用 Set 或者是 boolean[][]来标记字符位置是否已经访问过,需要额外的空间 `O(m*n)`.
+- _时间复杂度:_ `O(m*n) - m 是二维数组行数, n 是二维数组列数`
+- _空间复杂度:_ `O(1) - 这里在原数组中标记当前访问过,没有用到额外空间`
+
+> **注意**:如果用 Set 或者是 boolean[][]来标记字符位置是否已经访问过,需要额外的空间 `O(m*n)`.
## 关键点分析
-- 遍历二维数组的每一个点,找到起始点相同的字符,做DFS
-- DFS过程中,要记录已经访问过的节点,防止重复遍历,这里(Java Code中)用 `*` 表示当前已经访问过,也可以用Set或者是boolean[][]数组记录访问过的节点位置。
-- 是否匹配当前单词中的字符,不符合回溯,这里记得把当前 `*` 重新设为当前字符。如果用Set或者是boolean[][]数组,记得把当前位置重设为没有访问过。
+
+- 遍历二维数组的每一个点,找到起始点相同的字符,做 DFS
+- DFS 过程中,要记录已经访问过的节点,防止重复遍历,这里(Java Code 中)用 `*` 表示当前已经访问过,也可以用 Set 或者是 boolean[][]数组记录访问过的节点位置。
+- 是否匹配当前单词中的字符,不符合回溯,这里记得把当前 `*` 重新设为当前字符。如果用 Set 或者是 boolean[][]数组,记得把当前位置重设为没有访问过。
## 代码 (`Java/Javascript/Python3`)
-*Java Code*
+
+_Java Code_
+
```java
public class LC79WordSearch {
public boolean exist(char[][] board, String word) {
- if (board == null || board.length == 0 || board[0].length == 0
- || word == null || word.length() == 0) return true;
+ if (board == null || word == null) return false;
+ if (word.length() == 0) return true;
+ if (board.length == 0) return false;
int rows = board.length;
int cols = board[0].length;
for (int r = 0; r < rows; r++) {
for (int c = 0; c < cols; c++) {
- // scan board, start with word first character
+ // scan board, start with word first character
if (board[r][c] == word.charAt(0)) {
if (helper(board, word, r, c, 0)) {
return true;
@@ -130,7 +160,7 @@ public class LC79WordSearch {
}
return false;
}
-
+
private boolean helper(char[][] board, String word, int r, int c, int start) {
// already match word all characters, return true
if (start == word.length()) return true;
@@ -146,20 +176,21 @@ public class LC79WordSearch {
board[r][c] = word.charAt(start);
return res;
}
-
+
private boolean isValid(char[][] board, int r, int c) {
return r >= 0 && r < board.length && c >= 0 && c < board[0].length;
}
}
```
-*Python3 Code*
+_Python3 Code_
+
```python
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
n = len(board[0])
-
+
def dfs(board, r, c, word, index):
if index == len(word):
return True
@@ -169,7 +200,7 @@ class Solution:
res = dfs(board, r - 1, c, word, index + 1) or dfs(board, r + 1, c, word, index + 1) or dfs(board, r, c - 1, word, index + 1) or dfs(board, r, c + 1, word, index + 1)
board[r][c] = word[index]
return res
-
+
for r in range(m):
for c in range(n):
if board[r][c] == word[0]:
@@ -177,7 +208,8 @@ class Solution:
return True
```
-*Javascript Code* from [**@lucifer**](https://github.com/azl397985856)
+_Javascript Code_ from [**@lucifer**](https://github.com/azl397985856)
+
```javascript
/*
* @lc app=leetcode id=79 lang=javascript
@@ -197,7 +229,7 @@ function DFS(board, row, col, rows, cols, word, cur) {
// 如果你用hashmap记录访问的字母, 那么你需要每次backtrack的时候手动清除hashmap,并且需要额外的空间
// 这里我们使用一个little trick
-
+
board[row][col] = null;
// 上下左右
@@ -216,7 +248,7 @@ function DFS(board, row, col, rows, cols, word, cur) {
* @param {string} word
* @return {boolean}
*/
-var exist = function(board, word) {
+var exist = function (board, word) {
if (word.length === 0) return true;
if (board.length === 0) return false;
@@ -234,4 +266,5 @@ var exist = function(board, word) {
```
## 参考(References)
-1. [回溯法 Wiki](https://www.wikiwand.com/zh/%E5%9B%9E%E6%BA%AF%E6%B3%95)
\ No newline at end of file
+
+1. [回溯法 Wiki](https://www.wikiwand.com/zh/%E5%9B%9E%E6%BA%AF%E6%B3%95)
diff --git a/problems/80.remove-duplicates-from-sorted-array-ii.md b/problems/80.remove-duplicates-from-sorted-array-ii.md
index 1d2efee91..455f7943a 100644
--- a/problems/80.remove-duplicates-from-sorted-array-ii.md
+++ b/problems/80.remove-duplicates-from-sorted-array-ii.md
@@ -42,11 +42,21 @@ for (int i = 0; i < len; i++) {
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
”删除排序“类题目截止到现在(2020-1-15)一共有四道题:
-
+
这道题是[26.remove-duplicates-from-sorted-array](./26.remove-duplicates-from-sorted-array.md) 的进阶版本,唯一的不同是不再是全部元素唯一,而是全部元素不超过 2 次。实际上这种问题可以更抽象一步,即“删除排序数组中的重复项,使得相同数字最多出现 k 次”
。 那么这道题 k 就是 2, 26.remove-duplicates-from-sorted-array 的 k 就是 1。
@@ -62,9 +72,9 @@ for (int i = 0; i < len; i++) {
图解(红色的两个数字,表示我们需要比较的两个数字):
-
+
-
+
## 关键点分析
@@ -99,8 +109,8 @@ class Solution:
- 82. 删除排序链表中的重复元素 II
-
+
- 83. 删除排序链表中的重复元素
-
+
diff --git a/problems/820.short-encoding-of-words.md b/problems/820.short-encoding-of-words.md
index 037765ec2..594070833 100644
--- a/problems/820.short-encoding-of-words.md
+++ b/problems/820.short-encoding-of-words.md
@@ -1,6 +1,6 @@
## 题目地址(820. 单词的压缩编码)
-https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
+https://leetcode-cn.com/problems/short-encoding-of-words/
## 题目描述
@@ -30,15 +30,24 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 字节
## 思路
-读完题目之后就发现这题是一个后缀树。 因此符合直觉的想法是使用前缀树 + 倒序插入的形式来模拟后缀树。
+读完题目之后就发现如果将列表中每一个单词分别倒序就是一个后缀树问题。比如 `["time", "me", "bell"]` 倒序之后就是 ["emit", "em", "lleb"],我们要求的结果无非就是 "emit" 的长度 + "llem"的长度 + "##"的长度(em 和 emit 有公共前缀,计算一个就好了)。
+因此符合直觉的想法是使用前缀树 + 倒序插入的形式来模拟后缀树。
-下面的代码看起来复杂,但是很多题目我都是用这个模板,稍微调整下细节就能AC。我这里总结了一套[前缀树专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)
+下面的代码看起来复杂,但是很多题目我都是用这个模板,稍微调整下细节就能 AC。我这里总结了一套[前缀树专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)
-
+
前缀树的 api 主要有以下几个:
@@ -50,13 +59,11 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
一个前缀树大概是这个样子:
-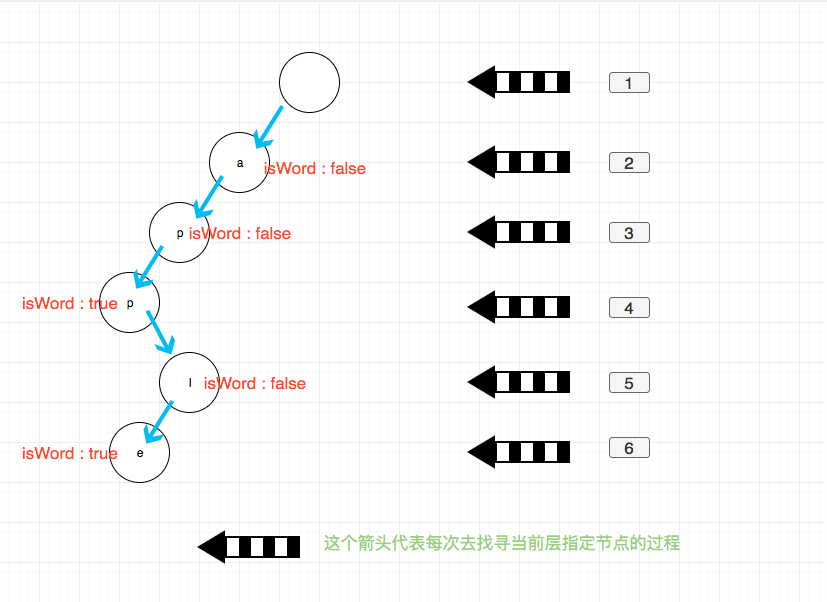
-
+
如图每一个节点存储一个字符,然后外加一个控制信息表示是否是单词结尾,实际使用过程可能会有细微差别,不过变化不大。
-
-这道题需要考虑edge case, 比如这个列表是 ["time", "time", "me", "bell"] 这种包含重复元素的情况,这里我使用hashset来去重。
+这道题需要考虑 edge case, 比如这个列表是 ["time", "time", "me", "bell"] 这种包含重复元素的情况,这里我使用 hashset 来去重。
## 关键点
@@ -87,7 +94,7 @@ class Trie:
curr = curr[w]
curr['#'] = 1
- def isTail(self, word):
+ def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
@@ -96,6 +103,10 @@ class Trie:
curr = self.Trie
for w in word:
curr = curr[w]
+ # len(curr) == 1 means we meet '#'
+ # when we search 'em'(which reversed from 'me')
+ # the result is len(curr) > 1
+ # cause the curr look like { '#': 1, i: {...}}
return len(curr) == 1
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
@@ -105,17 +116,26 @@ class Solution:
for word in words:
trie.insert(word[::-1])
for word in words:
- if trie.isTail(word[::-1]):
+ if trie.search(word[::-1]):
cnt += len(word) + 1
return cnt
```
-***复杂度分析***
-- 时间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
-- 空间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+**_复杂度分析_**
+
+- 时间复杂度:$O(N)$,其中 N 为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+- 空间复杂度:$O(N)$,其中 N 为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+
-
+## 相关题目
+- [0208.implement-trie-prefix-tree](./208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](./211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](./212.word-search-ii.md)
+- [0472.concatenated-words](./472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/84.largest-rectangle-in-histogram.md b/problems/84.largest-rectangle-in-histogram.md
index 8b618f837..d4e38f5a6 100644
--- a/problems/84.largest-rectangle-in-histogram.md
+++ b/problems/84.largest-rectangle-in-histogram.md
@@ -9,11 +9,11 @@ https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
求在该柱状图中,能够勾勒出来的矩形的最大面积。
-
+
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
-
+
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
@@ -22,8 +22,19 @@ https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
输入:[2,1,5,6,2,3]
输出:10
+## 前置知识
+
+- 单调栈
+
## 暴力枚举 - 左右端点法(TLE)
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
### 思路
我们暴力尝试`所有可能的矩形`。由于矩阵是二维图形, 我我们可以使用`左右两个端点来唯一确认一个矩阵`。因此我们使用双层循环枚举所有的可能性即可。 而矩形的面积等于`(右端点坐标 - 左端点坐标 + 1) * 最小的高度`,最小的高度我们可以在遍历的时候顺便求出。
@@ -130,7 +141,11 @@ class Solution:
实际上,读完第二种方法的时候,你应该注意到了。我们的核心是求左边第一个比 i 小的和右边第一个比 i 小的。 如果你熟悉单调栈的话,那么应该会想到这是非常适合使用单调栈来处理的场景。
-为了简单起见,我在 heights 首尾添加了两个哨兵元素,这样可以减少边界处理的额外代码。
+从左到右遍历柱子,对于每一个柱子,我们想找到第一个高度小于它的柱子,那么我们就可以使用一个单调递增栈来实现。 如果柱子大于栈顶的柱子,那么说明不是我们要找的柱子,我们把它塞进去继续遍历,如果比栈顶小,那么我们就找到了第一个小于的柱子。 **对于栈顶元素,其右边第一个小于它的就是当前遍历到的柱子,左边第一个小于它的就是栈中下一个要被弹出的元素**,因此以当前栈顶为最小柱子的面积为**当前栈顶的柱子高度 \* (当前遍历到的柱子索引 - 1 - 栈中下一个要被弹出的元素索引 - 1 + 1)**
+
+这种方法只需要遍历一次,并用一个栈。由于每一个元素最多进栈出栈一次,因此时间和空间复杂度都是$O(N)$。
+
+为了统一算法逻辑,减少边界处理,我在 heights 首尾添加了两个哨兵元素,**这样我们可以保证所有的柱子都会出栈**。
### 代码
@@ -150,6 +165,30 @@ class Solution:
- 时间复杂度:$O(N)$
- 空间复杂度:$O(N)$
+2020-05-30 更新:
+
+有的观众反应看不懂为啥需要两个哨兵。 其实末尾的哨兵就是为了将栈清空,防止遍历完成栈中还有没参与运算的数据。
+
+而前面的哨兵有什么用呢? 我这里把上面代码进行了拆解:
+
+```py
+class Solution:
+ def largestRectangleArea(self, heights: List[int]) -> int:
+ n, heights, st, ans = len(heights),[0] + heights + [0], [], 0
+ for i in range(n + 2):
+ while st and heights[st[-1]] > heights[i]:
+ a = heights[st[-1]]
+ # 如果没有前面的哨兵,这里可能会越界。
+ st.pop()
+ ans = max(ans, a * (i - 1 - st[-1]))
+ st.append(i)
+ return ans
+```
+
+## 相关题目
+
+- [42.trapping-rain-water](https://github.com/azl397985856/leetcode/blob/master/problems/42.trapping-rain-water.md)
+
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/85.maximal-rectangle.md b/problems/85.maximal-rectangle.md
index 78e259399..e6d36059c 100644
--- a/problems/85.maximal-rectangle.md
+++ b/problems/85.maximal-rectangle.md
@@ -4,11 +4,12 @@ https://leetcode-cn.com/problems/maximal-rectangle/
## 题目描述
-给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
+给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例:
输入:
+
```
[
["1","0","1","0","0"],
@@ -17,8 +18,20 @@ https://leetcode-cn.com/problems/maximal-rectangle/
["1","0","0","1","0"]
]
```
+
输出:6
+## 前置知识
+
+- 单调栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我在 [【84. 柱状图中最大的矩形】多种方法(Python3)](https://leetcode-cn.com/problems/largest-rectangle-in-histogram/solution/84-zhu-zhuang-tu-zhong-zui-da-de-ju-xing-duo-chong/ "【84. 柱状图中最大的矩形】多种方法(Python3)") 使用了多种方法来解决。 然而在这道题,我们仍然可以使用完全一样的思路去完成。 不熟悉的可以看下我的题解。本题解是基于那道题的题解来进行的。
@@ -36,7 +49,7 @@ https://leetcode-cn.com/problems/maximal-rectangle/
我们逐行扫描得到 `84. 柱状图中最大的矩形` 中的 heights 数组:
-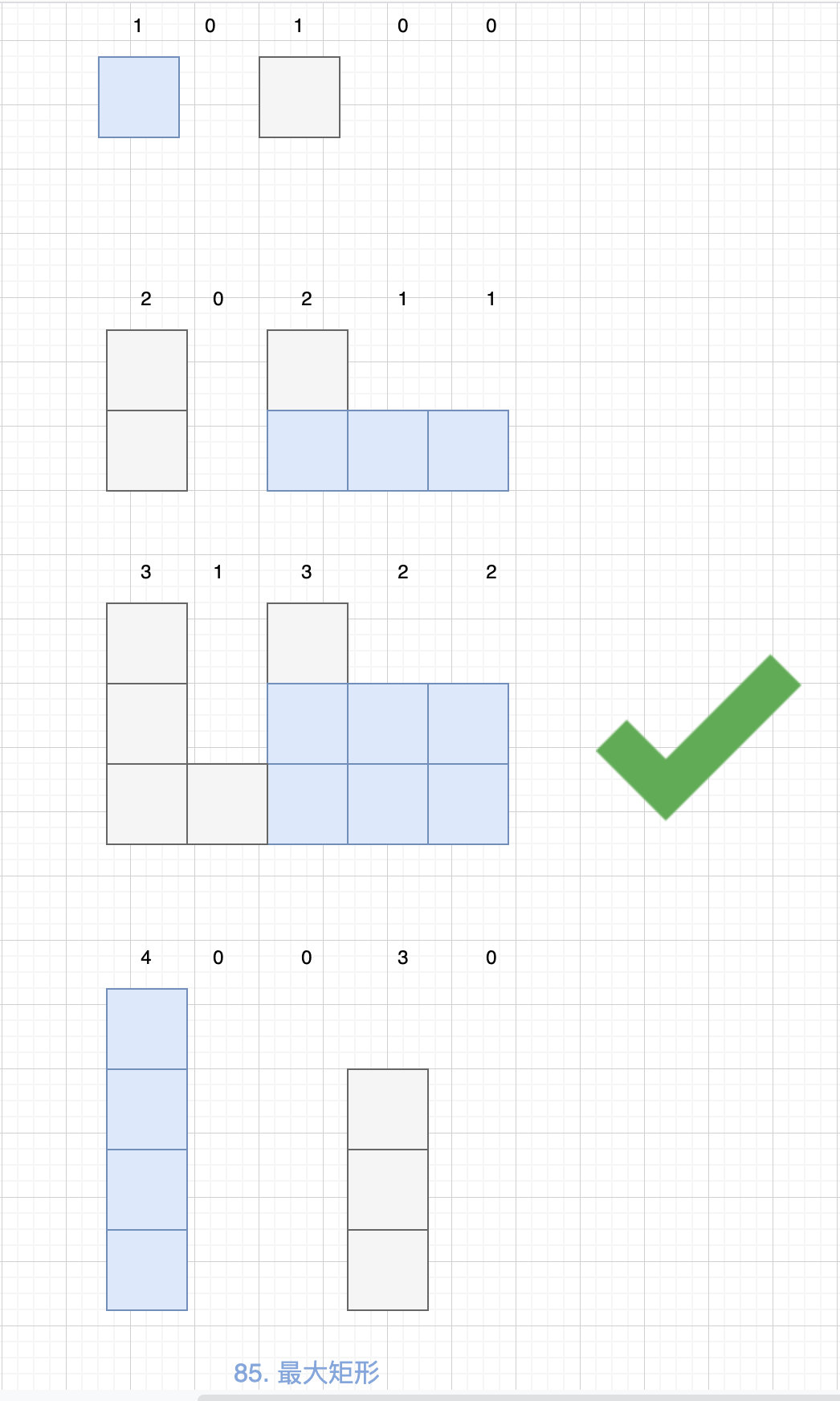
+
这样我们就可以使用`84. 柱状图中最大的矩形` 中的解法来进行了,这里我们使用单调栈来解。
@@ -70,9 +83,10 @@ class Solution:
```
**复杂度分析**
+
- 时间复杂度:$O(M * N)$
- 空间复杂度:$O(N)$
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
\ No newline at end of file
+
diff --git a/problems/86.partition-list.md b/problems/86.partition-list.md
index 12b07ed87..719e2523f 100644
--- a/problems/86.partition-list.md
+++ b/problems/86.partition-list.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/partition-list/description/
## 题目描述
+
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
You should preserve the original relative order of the nodes in each of the two partitions.
@@ -11,30 +13,41 @@ Example:
Input: head = 1->4->3->2->5->2, x = 3
Output: 1->2->2->4->3->5
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-- 设定两个虚拟节点,dummyHead1用来保存小于该值的链表,dummyHead2来保存大于等于该值的链表
+- 设定两个虚拟节点,dummyHead1 用来保存小于该值的链表,dummyHead2 来保存大于等于该值的链表
-- 遍历整个原始链表,将小于该值的放于dummyHead1中,其余的放置在dummyHead2中
+- 遍历整个原始链表,将小于该值的放于 dummyHead1 中,其余的放置在 dummyHead2 中
-遍历结束后,将dummyHead2插入到dummyHead1后面
+遍历结束后,将 dummyHead2 插入到 dummyHead1 后面
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
## 关键点解析
- 链表的基本操作(遍历)
-- 虚拟节点dummy 简化操作
+- 虚拟节点 dummy 简化操作
- 遍历完成之后记得`currentL1.next = null;`否则会内存溢出
-> 如果单纯的遍历是不需要上面操作的,但是我们的遍历会导致currentL1.next和currentL2.next
-中有且仅有一个不是null, 如果不这么操作的话会导致两个链表成环,造成溢出。
-
+> 如果单纯的遍历是不需要上面操作的,但是我们的遍历会导致 currentL1.next 和 currentL2.next
+> 中有且仅有一个不是 null, 如果不这么操作的话会导致两个链表成环,造成溢出。
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -52,17 +65,17 @@ Output: 1->2->2->4->3->5
*
* Given a linked list and a value x, partition it such that all nodes less
* than x come before nodes greater than or equal to x.
- *
+ *
* You should preserve the original relative order of the nodes in each of the
* two partitions.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Input: head = 1->4->3->2->5->2, x = 3
* Output: 1->2->2->4->3->5
- *
- *
+ *
+ *
*/
/**
* Definition for singly-linked list.
@@ -76,38 +89,40 @@ Output: 1->2->2->4->3->5
* @param {number} x
* @return {ListNode}
*/
-var partition = function(head, x) {
- const dummyHead1 = {
- next: null
+var partition = function (head, x) {
+ const dummyHead1 = {
+ next: null,
+ };
+ const dummyHead2 = {
+ next: null,
+ };
+
+ let current = {
+ next: head,
+ };
+ let currentL1 = dummyHead1;
+ let currentL2 = dummyHead2;
+ while (current.next) {
+ current = current.next;
+ if (current.val < x) {
+ currentL1.next = current;
+ currentL1 = current;
+ } else {
+ currentL2.next = current;
+ currentL2 = current;
}
- const dummyHead2 = {
- next: null
- }
-
- let current = {
- next: head
- };
- let currentL1 = dummyHead1;
- let currentL2 = dummyHead2;
- while(current.next) {
- current = current.next;
- if (current.val < x) {
- currentL1.next = current;
- currentL1 = current;
- } else {
- currentL2.next = current;
- currentL2 = current;
- }
- }
-
- currentL2.next = null;
-
- currentL1.next = dummyHead2.next;
+ }
+
+ currentL2.next = null;
- return dummyHead1.next;
+ currentL1.next = dummyHead2.next;
+
+ return dummyHead1.next;
};
```
+
Python3 Code:
+
```python
class Solution:
def partition(self, head: ListNode, x: int) -> ListNode:
@@ -121,7 +136,7 @@ class Solution:
sep_node = first_node
pre_node = first_node
current_node = head
-
+
while current_node is not None:
if current_node.val < x:
# 注意有可能出现前一个节点就是分离节点的情况
@@ -139,6 +154,6 @@ class Solution:
else:
pre_node = current_node
current_node = pre_node.next
-
+
return first_node.next
```
diff --git a/problems/874.walking-robot-simulation.md b/problems/874.walking-robot-simulation.md
index f2ed8b1d7..32d4514a8 100644
--- a/problems/874.walking-robot-simulation.md
+++ b/problems/874.walking-robot-simulation.md
@@ -43,6 +43,14 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
```
+## 前置知识
+
+- hashtable
+
+## 公司
+
+- 暂无
+
## 思路
这道题之所以是简单难度,是因为其没有什么技巧。你只需要看懂题目描述,然后把题目描述转化为代码即可。
@@ -65,13 +73,13 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
为了代码书写简单,我建立了一个直角坐标系。用`机器人的朝向和 x 轴正方向的夹角度数`来作为枚举值,并且这个度数是 `0 <= deg < 360`。我们不难知道,其实这个取值就是`0`, `90`,`180`,`270` 四个值。那么当 0 度的时候,我们只需要不断地 x+1,90 度的时候我们不断地 y + 1 等等。
-
+
## 关键点解析
- 理解题意,这道题容易理解错题意,求解为`最终位置距离原点的距离`
- 建立坐标系
-- 使用集合简化线形查找的时间复杂度。
+- 空间换时间
## 代码
@@ -116,3 +124,14 @@ class Solution:
ans = max(ans, pos[0] ** 2 + pos[1] ** 2)
return ans
```
+
+**复杂度分析**
+- 时间复杂度:$O(N * M)$, 其中 N 为 commands 的长度, M 为 commands 数组的平均值。
+- 空间复杂度:$O(obstacles)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/875.koko-eating-bananas.md b/problems/875.koko-eating-bananas.md
index 197effc57..68aa950d4 100644
--- a/problems/875.koko-eating-bananas.md
+++ b/problems/875.koko-eating-bananas.md
@@ -1,48 +1,57 @@
-## 题目地址
-https://leetcode.com/problems/koko-eating-bananas/description/
+## 题目地址(875. 爱吃香蕉的珂珂)
+https://leetcode-cn.com/problems/koko-eating-bananas/description/
## 题目描述
```
-Koko loves to eat bananas. There are N piles of bananas, the i-th pile has piles[i] bananas. The guards have gone and will come back in H hours.
+珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
-Koko can decide her bananas-per-hour eating speed of K. Each hour, she chooses some pile of bananas, and eats K bananas from that pile. If the pile has less than K bananas, she eats all of them instead, and won't eat any more bananas during this hour.
+珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
-Koko likes to eat slowly, but still wants to finish eating all the bananas before the guards come back.
+珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
-Return the minimum integer K such that she can eat all the bananas within H hours.
+返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
-
+
-Example 1:
+示例 1:
-Input: piles = [3,6,7,11], H = 8
-Output: 4
-Example 2:
+输入: piles = [3,6,7,11], H = 8
+输出: 4
+示例 2:
-Input: piles = [30,11,23,4,20], H = 5
-Output: 30
-Example 3:
+输入: piles = [30,11,23,4,20], H = 5
+输出: 30
+示例 3:
-Input: piles = [30,11,23,4,20], H = 6
-Output: 23
-
+输入: piles = [30,11,23,4,20], H = 6
+输出: 23
+
-Note:
+提示:
1 <= piles.length <= 10^4
piles.length <= H <= 10^9
1 <= piles[i] <= 10^9
+
```
+## 前置知识
+
+- 二分查找
+
+## 公司
+
+- 字节
+
## 思路
-符合直觉的做法是,选择最大的堆的香蕉数,然后试一下能不能行,如果不行则直接返回上次计算的结果,
-如果行,我们减少1个香蕉,试试行不行,依次类推。计算出刚好不行的即可。这种解法的时间复杂度是O(n)。
+符合直觉的做法是,选择最大的堆的香蕉数,然后试一下能不能行,如果不行则直接返回上次计算的结果,如果行,我们减少1个香蕉,试试行不行,依次类推。计算出刚好不行的即可。这种解法的时间复杂度比较高,为 $O(N * M)$,其中 N 为 piles 长度, M 为 Piles 中最大的数。。
-这道题如果能看出来是二分法解决,那么其实很简单。为什么它是二分问题呢?
-我这里画了个图,我相信你看了就明白了。
+这道题如果能看出来是二分法解决,那么其实很简单。为什么它是二分问题呢?我这里画了个图,我相信你看了就明白了。
-
+
+
+> 香蕉堆的香蕉个数上限是 10^9, 珂珂这也太能吃了吧?
## 关键点解析
@@ -51,79 +60,36 @@ piles.length <= H <= 10^9
## 代码
+ 代码支持:Python,JavaScript
+
+ Python Code:
+
+```py
+class Solution:
+ def canEatAllBananas(self, piles, H, K):
+ t = 0
+ for pile in piles:
+ t += math.ceil(pile / K)
+ return t <= H
+ def minEatingSpeed(self, piles: List[int], H: int) -> int:
+ l, r = 1, max(piles)
+ # [l, r) , 左闭右开的好处是如果能找到,那么返回 l 和 r 都是一样的,因为最终 l 等于 r。
+ while l < r:
+ mid = (l + r) >> 1
+ if self.canEatAllBananas(piles, H, mid):
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+```
+
+
+ JavaScript Code:
+
```js
-/*
- * @lc app=leetcode id=875 lang=javascript
- *
- * [875] Koko Eating Bananas
- *
- * https://leetcode.com/problems/koko-eating-bananas/description/
- *
- * algorithms
- * Medium (44.51%)
- * Total Accepted: 11.3K
- * Total Submissions: 24.8K
- * Testcase Example: '[3,6,7,11]\n8'
- *
- * Koko loves to eat bananas. There are N piles of bananas, the i-th pile has
- * piles[i] bananas. The guards have gone and will come back in H hours.
- *
- * Koko can decide her bananas-per-hour eating speed of K. Each hour, she
- * chooses some pile of bananas, and eats K bananas from that pile. If the
- * pile has less than K bananas, she eats all of them instead, and won't eat
- * any more bananas during this hour.
- *
- * Koko likes to eat slowly, but still wants to finish eating all the bananas
- * before the guards come back.
- *
- * Return the minimum integer K such that she can eat all the bananas within H
- * hours.
- *
- *
- *
- *
- *
- *
- *
- * Example 1:
- *
- *
- * Input: piles = [3,6,7,11], H = 8
- * Output: 4
- *
- *
- *
- * Example 2:
- *
- *
- * Input: piles = [30,11,23,4,20], H = 5
- * Output: 30
- *
- *
- *
- * Example 3:
- *
- *
- * Input: piles = [30,11,23,4,20], H = 6
- * Output: 23
- *
- *
- *
- *
- * Note:
- *
- *
- * 1 <= piles.length <= 10^4
- * piles.length <= H <= 10^9
- * 1 <= piles[i] <= 10^9
- *
- *
- *
- *
- *
- */
- function canEatAllBananas(piles, H, mid) {
+function canEatAllBananas(piles, H, mid) {
let h = 0;
for(let pile of piles) {
h += Math.ceil(pile / mid);
@@ -139,7 +105,7 @@ piles.length <= H <= 10^9
var minEatingSpeed = function(piles, H) {
let lo = 1,
hi = Math.max(...piles);
-
+ // [l, r) , 左闭右开的好处是如果能找到,那么返回 l 和 r 都是一样的,因为最终 l 等于 r。
while(lo <= hi) {
let mid = lo + ((hi - lo) >> 1);
if (canEatAllBananas(piles, H, mid)) {
@@ -153,3 +119,98 @@ var minEatingSpeed = function(piles, H) {
};
```
+**复杂度分析**
+- 时间复杂度:$O(max(N, N * logM))$,其中 N 为 piles 长度, M 为 Piles 中最大的数。
+- 空间复杂度:$O(1)$
+
+## 模板
+
+分享几个常用的的二分法模板。
+
+
+### 查找一个数
+
+```java
+public int binarySearch(int[] nums, int target) {
+ // 左右都闭合的区间 [l, r]
+ int left = 0;
+ int right = nums.length - 1;
+
+ while(left <= right) {
+ int mid = left + (right - left) / 2;
+ if(nums[mid] == target)
+ return mid;
+ else if (nums[mid] < target)
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ else if (nums[mid] > target)
+ // 搜索区间变为 [left, mid - 1]
+ right = mid - 1;
+ }
+ return -1;
+}
+```
+
+### 寻找最左边的满足条件的值
+
+```java
+public int binarySearchLeft(int[] nums, int target) {
+ // 搜索区间为 [left, right]
+ int left = 0;
+ int right = nums.length - 1;
+ while (left <= right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] < target) {
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ // 搜索区间变为 [left, mid-1]
+ right = mid - 1;
+ } else if (nums[mid] == target) {
+ // 收缩右边界
+ right = mid - 1;
+ }
+ }
+ // 检查是否越界
+ if (left >= nums.length || nums[left] != target)
+ return -1;
+ return left;
+}
+```
+
+### 寻找最右边的满足条件的值
+
+```java
+public int binarySearchRight(int[] nums, int target) {
+ // 搜索区间为 [left, right]
+ int left = 0
+ int right = nums.length - 1;
+ while (left <= right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] < target) {
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ // 搜索区间变为 [left, mid-1]
+ right = mid - 1;
+ } else if (nums[mid] == target) {
+ // 收缩左边界
+ left = mid + 1;
+ }
+ }
+ // 检查是否越界
+ if (right < 0 || nums[right] != target)
+ return -1;
+ return right;
+}
+```
+
+> 如果题目重点不是二分,也就是说二分只是众多步骤中的一步,大家也可以直接调用语言的 API,比如 Python 的 bisect 模块。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/877.stone-game.md b/problems/877.stone-game.md
index 44468a876..f7dbe630a 100644
--- a/problems/877.stone-game.md
+++ b/problems/877.stone-game.md
@@ -36,6 +36,15 @@ sum(piles) is odd.
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
由于 piles 是偶数的,并且 piles 的总和是奇数的。
diff --git a/problems/88.merge-sorted-array.md b/problems/88.merge-sorted-array.md
index 9d7be9641..68f53cef6 100644
--- a/problems/88.merge-sorted-array.md
+++ b/problems/88.merge-sorted-array.md
@@ -20,23 +20,35 @@ nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
```
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- loomberg
+- facebook
+- microsoft
+
+## 前置知识
+
+- 归并排序
+
## 思路
符合直觉的做法是`将nums2插到num1的末尾, 然后排序`
-
具体代码:
```js
- // 这种解法连m都用不到
- // 这显然不是出题人的意思
- if (n === 0) return;
- let current2 = 0;
- for(let i = nums1.length - 1; i >= nums1.length - n ; i--) {
- nums1[i] = nums2[current2++];
- }
- nums1.sort((a, b) => a - b); // 当然你可以自己写排序,这里懒得写了,因为已经偏离了题目本身
-
+// 这种解法连m都用不到
+// 这显然不是出题人的意思
+if (n === 0) return;
+let current2 = 0;
+for (let i = nums1.length - 1; i >= nums1.length - n; i--) {
+ nums1[i] = nums2[current2++];
+}
+nums1.sort((a, b) => a - b); // 当然你可以自己写排序,这里懒得写了,因为已经偏离了题目本身
```
这道题目其实和基本排序算法中的`merge sort`非常像,但是 merge sort 很多时候,合并的时候我们通常是
@@ -92,9 +104,9 @@ function merge(nums1, nums2) {
- 红色代表当前正在进行比较的元素
- 绿色代表已经就位的元素
-
-
-
+
+
+
## 关键点解析
@@ -104,11 +116,10 @@ function merge(nums1, nums2) {
代码支持:Python3, C++, JavaScript
-
JavaSCript Code:
```js
-var merge = function(nums1, m, nums2, n) {
+var merge = function (nums1, m, nums2, n) {
// 设置一个指针,指针初始化指向nums1的末尾(根据#62,应该是index为 m+n-1 的位置,因为nums1的长度有可能更长)
// 然后不断左移指针更新元素
let current = m + n - 1;
@@ -139,6 +150,7 @@ var merge = function(nums1, m, nums2, n) {
```
C++ code:
+
```
class Solution {
public:
@@ -162,6 +174,7 @@ public:
```
Python Code
+
```python
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
@@ -185,11 +198,11 @@ class Solution:
nums1[:n] = nums2[:n]
```
-
**复杂度分析**
+
- 时间复杂度:$O(M + N)$
- 空间复杂度:$O(1)$
-欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/886.possible-bipartition.md b/problems/886.possible-bipartition.md
new file mode 100644
index 000000000..c726e66c4
--- /dev/null
+++ b/problems/886.possible-bipartition.md
@@ -0,0 +1,151 @@
+## 题目地址(886. 可能的二分法)
+
+https://leetcode-cn.com/problems/is-graph-bipartite/
+
+## 题目描述
+
+```
+给定一组 N 人(编号为 1, 2, ..., N), 我们想把每个人分进任意大小的两组。
+
+每个人都可能不喜欢其他人,那么他们不应该属于同一组。
+
+形式上,如果 dislikes[i] = [a, b],表示不允许将编号为 a 和 b 的人归入同一组。
+
+当可以用这种方法将每个人分进两组时,返回 true;否则返回 false。
+
+
+
+示例 1:
+
+输入:N = 4, dislikes = [[1,2],[1,3],[2,4]]
+输出:true
+解释:group1 [1,4], group2 [2,3]
+示例 2:
+
+输入:N = 3, dislikes = [[1,2],[1,3],[2,3]]
+输出:false
+示例 3:
+
+输入:N = 5, dislikes = [[1,2],[2,3],[3,4],[4,5],[1,5]]
+输出:false
+
+
+提示:
+
+1 <= N <= 2000
+0 <= dislikes.length <= 10000
+dislikes[i].length == 2
+1 <= dislikes[i][j] <= N
+dislikes[i][0] < dislikes[i][1]
+对于dislikes[i] == dislikes[j] 不存在 i != j
+
+```
+
+## 前置知识
+
+- 图的遍历
+- DFS
+
+## 公司
+
+- 暂无
+
+## 思路
+
+这是一个图的问题。解决这种问题一般是要遍历图才行的,这也是图的套路。 那么遍历的话,你要有一个合适的数据结构。 比较常见的图存储方式是邻接矩阵和邻接表。
+
+而我们这里为了操作方便(代码量),直接使用邻接矩阵。由于是互相不喜欢,不存在一个喜欢另一个,另一个不喜欢一个的情况,因此这是无向图。而无向图邻接矩阵实际上是会浪费空间,具体看我下方画的图。
+
+而题目给我们的二维矩阵并不是现成的邻接矩阵形式,因此我们需要自己生成。
+
+我们用 1 表示互相不喜欢(dislike each other)。
+
+```py
+ graph = [[0] * N for i in range(N)]
+ for a, b in dislikes:
+ graph[a - 1][b - 1] = 1
+ graph[b - 1][a - 1] = 1
+```
+
+
+
+同时可以用 hashmap 或者数组存储 N 个人的分组情况, 业界关于这种算法一般叫染色法,因此我们命名为 colors,其实对应的本题叫 groups 更合适。
+
+
+
+我们用:
+
+- 0 表示没有分组
+- 1 表示分组 1
+- -1 表示分组 2
+
+之所以用 0,1,-1,而不是 0,1,2 是因为我们会在不能分配某一组的时候尝试分另外一组,这个时候有其中一组转变为另外一组就可以直接乘以-1,而 0,1,2 这种就稍微麻烦一点而已。
+
+具体算法:
+
+- 遍历每一个人,尝试给他们进行分组,比如默认分配组 1.
+
+
+
+- 然后遍历这个人讨厌的人,尝试给他们分另外一组,如果不可以分配另外一组,则返回 False
+
+那问题的关键在于如何判断“不可以分配另外一组”呢?
+
+
+
+实际上,我们已经用 colors 记录了分组信息,对于每一个人如果分组确定了,我们就更新 colors,那么对于一个人如果分配了一个组,并且他讨厌的人也被分组之后,**分配的组和它只能是一组**,那么“就是不可以分配另外一组”。
+
+代码表示就是:
+
+```py
+# 其中j 表示当前是第几个人,N表示总人数。 dfs的功能就是根据colors和graph分配组,true表示可以分,false表示不可以,具体代码见代码区。
+if colors[j] == 0 and not self.dfs(graph, colors, j, -1 * color, N)
+```
+
+## 关键点
+
+- 二分图
+- 染色法
+- 图的建立和遍历
+- colors 数组
+
+## 代码
+
+```py
+class Solution:
+ def dfs(self, graph, colors, i, color, N):
+ colors[i] = color
+ for j in range(N):
+ # dislike eachother
+ if graph[i][j] == 1:
+ if colors[j] == color:
+ return False
+ if colors[j] == 0 and not self.dfs(graph, colors, j, -1 * color, N):
+ return False
+ return True
+
+ def possibleBipartition(self, N: int, dislikes: List[List[int]]) -> bool:
+ graph = [[0] * N for i in range(N)]
+ colors = [0] * N
+ for a, b in dislikes:
+ graph[a - 1][b - 1] = 1
+ graph[b - 1][a - 1] = 1
+ for i in range(N):
+ if colors[i] == 0 and not self.dfs(graph, colors, i, 1, N):
+ return False
+ return True
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N)$
+
+## 相关问题
+
+- [785. 判断二分图](785.is-graph-bipartite.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/887.super-egg-drop.md b/problems/887.super-egg-drop.md
index 2d6d9b463..2241474eb 100644
--- a/problems/887.super-egg-drop.md
+++ b/problems/887.super-egg-drop.md
@@ -1,29 +1,29 @@
-
## 题目地址
+
https://leetcode.com/problems/super-egg-drop/description/
## 题目描述
```
-You are given K eggs, and you have access to a building with N floors from 1 to N.
+You are given K eggs, and you have access to a building with N floors from 1 to N.
Each egg is identical in function, and if an egg breaks, you cannot drop it again.
You know that there exists a floor F with 0 <= F <= N such that any egg dropped at a floor higher than F will break, and any egg dropped at or below floor F will not break.
-Each move, you may take an egg (if you have an unbroken one) and drop it from any floor X (with 1 <= X <= N).
+Each move, you may take an egg (if you have an unbroken one) and drop it from any floor X (with 1 <= X <= N).
Your goal is to know with certainty what the value of F is.
What is the minimum number of moves that you need to know with certainty what F is, regardless of the initial value of F?
-
+
Example 1:
Input: K = 1, N = 2
Output: 2
-Explanation:
+Explanation:
Drop the egg from floor 1. If it breaks, we know with certainty that F = 0.
Otherwise, drop the egg from floor 2. If it breaks, we know with certainty that F = 1.
If it didn't break, then we know with certainty F = 2.
@@ -36,7 +36,7 @@ Example 3:
Input: K = 3, N = 14
Output: 4
-
+
Note:
@@ -46,84 +46,90 @@ Note:
```
+## 前置知识
+
+- 动态规划
+
## 思路
+> 本题已经重制,重制版更清晰 [《丢鸡蛋问题》重制版来袭~](https://lucifer.ren/blog/2020/06/08/887.super-egg-drop/)
+
这是一道典型的动态规划题目,但是又和一般的动态规划不一样。
拿题目给的例子为例,两个鸡蛋,六层楼,我们最少扔几次?
-
+
-一个符合直觉的做法是,建立dp[i][j], 代表i个鸡蛋,j层楼最少扔几次,然后我们取dp[K][N]即可。
+一个符合直觉的做法是,建立 dp[i][j], 代表 i 个鸡蛋,j 层楼最少扔几次,然后我们取 dp[K][n]即可。
代码大概这样的:
```js
- const dp = Array(K + 1);
- dp[0] = Array(N + 1).fill(0);
- for (let i = 1; i < K + 1; i++) {
- dp[i] = [0];
- for (let j = 1; j < N + 1; j++) {
- // 只有一个鸡蛋
- if (i === 1) {
- dp[i][j] = j;
- continue;
- }
- // 只有一层楼
- if (j === 1) {
- dp[i][j] = 1;
- continue;
- }
-
- // 每一层我们都模拟一遍
- const all = [];
- for (let k = 1; k < j + 1; k++) {
- const brokenCount = dp[i - 1][k - 1]; // 如果碎了
- const notBrokenCount = dp[i][j - k]; // 如果没碎
- all.push(Math.max(brokenCount, notBrokenCount)); // 最坏的可能
- }
- dp[i][j] = Math.min(...all) + 1; // 最坏的集合中我们取最好的情况
- }
+const dp = Array(K + 1);
+dp[0] = Array(N + 1).fill(0);
+for (let i = 1; i < K + 1; i++) {
+ dp[i] = [0];
+ for (let j = 1; j < N + 1; j++) {
+ // 只有一个鸡蛋
+ if (i === 1) {
+ dp[i][j] = j;
+ continue;
+ }
+ // 只有一层楼
+ if (j === 1) {
+ dp[i][j] = 1;
+ continue;
}
- return dp[K][N];
+ // 每一层我们都模拟一遍
+ const all = [];
+ for (let k = 1; k < j + 1; k++) {
+ const brokenCount = dp[i - 1][k - 1]; // 如果碎了
+ const notBrokenCount = dp[i][j - k]; // 如果没碎
+ all.push(Math.max(brokenCount, notBrokenCount)); // 最坏的可能
+ }
+ dp[i][j] = Math.min(...all) + 1; // 最坏的集合中我们取最好的情况
+ }
+}
+
+return dp[K][N];
```
果不其然,当我提交的时候,超时了。 这个的时复杂度是很高的,可以看到,我们内层暴力的求解所有可能,然后
-取最好的,这个过程非常耗时,大概是O(N^2 * K).
+取最好的,这个过程非常耗时,大概是 O(N^2 \* K).
-然后我看了一位leetcode[网友](https://leetcode.com/lee215/)的回答,
+然后我看了一位 leetcode[网友](https://leetcode.com/lee215/)的回答,
他的想法是`dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
我们按照他的思路重新建模:
-
+
可以看到右下角的部分根本就不需要计算,从而节省很多时间
-## 关键点解析
-- dp建模思路要发生变化, 即
-`dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
+## 关键点解析
+- dp 建模思路要发生变化, 即
+ `dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
## 代码
-
```js
/**
* @param {number} K
* @param {number} N
* @return {number}
*/
-var superEggDrop = function(K, N) {
+var superEggDrop = function (K, N) {
// 不选择dp[K][M]的原因是dp[M][K]可以简化操作
- const dp = Array(N + 1).fill(0).map(_ => Array(K + 1).fill(0))
-
+ const dp = Array(N + 1)
+ .fill(0)
+ .map((_) => Array(K + 1).fill(0));
+
let m = 0;
while (dp[m][K] < N) {
- m++;
- for (let k = 1; k <= K; ++k)
- dp[m][k] = dp[m - 1][k - 1] + 1 + dp[m - 1][k];
+ m++;
+ for (let k = 1; k <= K; ++k) dp[m][k] = dp[m - 1][k - 1] + 1 + dp[m - 1][k];
}
return m;
};
diff --git a/problems/895.maximum-frequency-stack.md b/problems/895.maximum-frequency-stack.md
index b7d4eb859..67521e180 100644
--- a/problems/895.maximum-frequency-stack.md
+++ b/problems/895.maximum-frequency-stack.md
@@ -46,27 +46,36 @@ pop() -> 返回 4 。
```
+## 前置知识
+
+- 栈
+- 哈希表
+
+## 公司
+
+- 暂无
+
## 思路
我们以题目给的例子来讲解。
- 使用fraq 来存储对应的数字出现次数。key 是数字,value频率
-
+
- 由于题目限制“如果最频繁的元素不只一个,则移除并返回最接近栈顶的元素。”,我们考虑使用栈来维护一个频率表 fraq_stack。key是频率,value是数字组成的栈。
-
+
- 同时用max_fraq 记录当前的最大频率值。
- 第一次pop的时候,我们最大的频率是3。由fraq_stack 知道我们需要pop掉5。
-
+
- 之后pop依次是这样的(红色数字表示顺序)
-
+
## 关键点解析
@@ -109,6 +118,6 @@ class FreqStack:
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/90.subsets-ii-en.md b/problems/90.subsets-ii-en.md
new file mode 100644
index 000000000..e6b8c3b3c
--- /dev/null
+++ b/problems/90.subsets-ii-en.md
@@ -0,0 +1,166 @@
+## Problem Link
+
+https://leetcode.com/problems/subsets-ii/description/
+
+## Description
+```
+Given a collection of integers that might contain duplicates, nums, return all possible subsets (the power set).
+
+Note: The solution set must not contain duplicate subsets.
+
+Example:
+
+Input: [1,2,2]
+Output:
+[
+ [2],
+ [1],
+ [1,2,2],
+ [2,2],
+ [1,2],
+ []
+]
+
+```
+
+## Solution
+
+Since this problem is seeking `Subset` not `Extreme Value`, dynamic programming is not an ideal solution. Other approaches should be taken into our consideration.
+
+Actually, there is a general approach to solve problems similar to this one -- backtracking. Given a [Code Template](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)) here, it demonstrates how backtracking works with varieties of problems. Apart from current one, many problems can be solved by such a general approach. For more details, please check the `Related Problems` section below.
+
+Given a picture as followed, let's start with problem-solving ideas of this general solution.
+
+
+
+See Code Template details below.
+
+## Key Points
+
+- Backtrack Approach
+- Backtrack Code Template/ Formula
+
+## Code
+
+* Supported Language:JS,C++,Python3
+
+JavaScript Code:
+
+```js
+
+
+/*
+ * @lc app=leetcode id=90 lang=javascript
+ *
+ * [90] Subsets II
+ *
+ * https://leetcode.com/problems/subsets-ii/description/
+ *
+ * algorithms
+ * Medium (41.53%)
+ * Total Accepted: 197.1K
+ * Total Submissions: 469.1K
+ * Testcase Example: '[1,2,2]'
+ *
+ * Given a collection of integers that might contain duplicates, nums, return
+ * all possible subsets (the power set).
+ *
+ * Note: The solution set must not contain duplicate subsets.
+ *
+ * Example:
+ *
+ *
+ * Input: [1,2,2]
+ * Output:
+ * [
+ * [2],
+ * [1],
+ * [1,2,2],
+ * [2,2],
+ * [1,2],
+ * []
+ * ]
+ *
+ *
+ */
+function backtrack(list, tempList, nums, start) {
+ list.push([...tempList]);
+ for(let i = start; i < nums.length; i++) {
+ //nums can be duplicated, which is different from Problem 78 - subsets
+ //So the situation should be taken into consideration
+ if (i > start && nums[i] === nums[i - 1]) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1)
+ tempList.pop();
+ }
+}
+/**
+ * @param {number[]} nums
+ * @return {number[][]}
+ */
+var subsetsWithDup = function(nums) {
+ const list = [];
+ backtrack(list, [], nums.sort((a, b) => a - b), 0, [])
+ return list;
+};
+```
+C++ Code:
+
+```C++
+class Solution {
+private:
+ void subsetsWithDup(vector& nums, size_t start, vector& tmp, vector>& res) {
+ res.push_back(tmp);
+ for (auto i = start; i < nums.size(); ++i) {
+ if (i > start && nums[i] == nums[i - 1]) continue;
+ tmp.push_back(nums[i]);
+ subsetsWithDup(nums, i + 1, tmp, res);
+ tmp.pop_back();
+ }
+ }
+public:
+ vector> subsetsWithDup(vector& nums) {
+ auto tmp = vector();
+ auto res = vector>();
+ sort(nums.begin(), nums.end());
+ subsetsWithDup(nums, 0, tmp, res);
+ return res;
+ }
+};
+```
+Python Code:
+
+```Python
+class Solution:
+ def subsetsWithDup(self, nums: List[int], sorted: bool=False) -> List[List[int]]:
+ """Backtrack Approach: by sorting parameters first to avoid repeting sort later"""
+ if not nums:
+ return [[]]
+ elif len(nums) == 1:
+ return [[], nums]
+ else:
+ # Sorting first to filter duplicated numbers
+ # Note,this problem takes higher time complexity
+ # So, it could greatly improve time efficiency by adding one parameter to avoid repeting sort in following procedures
+ if not sorted:
+ nums.sort()
+ # Backtrack Approach
+ pre_lists = self.subsetsWithDup(nums[:-1], sorted=True)
+ all_lists = [i+[nums[-1]] for i in pre_lists] + pre_lists
+ # distinct elements
+ result = []
+ for i in all_lists:
+ if i not in result:
+ result.append(i)
+ return result
+```
+
+## Related Problems
+
+- [39.combination-sum](./39.combination-sum.md)(chinese)
+- [40.combination-sum-ii](./40.combination-sum-ii.md)(chinese)
+- [46.permutations](./46.permutations.md)(chinese)
+- [47.permutations-ii](./47.permutations-ii.md)(chinese)
+- [78.subsets](./78.subsets-en.md)
+- [113.path-sum-ii](./113.path-sum-ii.md)(chinese)
+- [131.palindrome-partitioning](./131.palindrome-partitioning.md)(chinese)
diff --git a/problems/90.subsets-ii.md b/problems/90.subsets-ii.md
index 36c2e845f..7ddd15724 100644
--- a/problems/90.subsets-ii.md
+++ b/problems/90.subsets-ii.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/subsets-ii/description/
## 题目描述
+
```
Given a collection of integers that might contain duplicates, nums, return all possible subsets (the power set).
@@ -23,18 +24,31 @@ Output:
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -43,71 +57,41 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持:JS,C++,Python3
+- 语言支持:JS,C++,Python3
JavaScript Code:
```js
-
-
-/*
- * @lc app=leetcode id=90 lang=javascript
- *
- * [90] Subsets II
- *
- * https://leetcode.com/problems/subsets-ii/description/
- *
- * algorithms
- * Medium (41.53%)
- * Total Accepted: 197.1K
- * Total Submissions: 469.1K
- * Testcase Example: '[1,2,2]'
- *
- * Given a collection of integers that might contain duplicates, nums, return
- * all possible subsets (the power set).
- *
- * Note: The solution set must not contain duplicate subsets.
- *
- * Example:
- *
- *
- * Input: [1,2,2]
- * Output:
- * [
- * [2],
- * [1],
- * [1,2,2],
- * [2,2],
- * [1,2],
- * []
- * ]
- *
- *
- */
function backtrack(list, tempList, nums, start) {
- list.push([...tempList]);
- for(let i = start; i < nums.length; i++) {
- // 和78.subsets的区别在于这道题nums可以有重复
- // 因此需要过滤这种情况
- if (i > start && nums[i] === nums[i - 1]) continue;
- tempList.push(nums[i]);
- backtrack(list, tempList, nums, i + 1)
- tempList.pop();
- }
+ list.push([...tempList]);
+ for (let i = start; i < nums.length; i++) {
+ // 和78.subsets的区别在于这道题nums可以有重复
+ // 因此需要过滤这种情况
+ if (i > start && nums[i] === nums[i - 1]) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var subsetsWithDup = function(nums) {
- const list = [];
- backtrack(list, [], nums.sort((a, b) => a - b), 0, [])
- return list;
+var subsetsWithDup = function (nums) {
+ const list = [];
+ backtrack(
+ list,
+ [],
+ nums.sort((a, b) => a - b),
+ 0,
+ []
+ );
+ return list;
};
```
+
C++ Code:
```C++
@@ -132,6 +116,7 @@ public:
}
};
```
+
Python Code:
```Python
@@ -168,7 +153,3 @@ class Solution:
- [78.subsets](./78.subsets.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
- [131.palindrome-partitioning](./131.palindrome-partitioning.md)
-
-
-
-
diff --git a/problems/900.rle-iterator.md b/problems/900.rle-iterator.md
index 0ad626740..35efc769a 100644
--- a/problems/900.rle-iterator.md
+++ b/problems/900.rle-iterator.md
@@ -43,6 +43,14 @@ Each call to RLEIterator.next(int n) will have 1 <= n <= 10^9.
```
+## 前置知识
+
+- 哈夫曼编码和游程编码
+
+## 公司
+
+- 暂无
+
## 思路
这是一个游程编码的典型题目。
diff --git a/problems/91.decode-ways.md b/problems/91.decode-ways.md
index c7bb38161..178cdd871 100644
--- a/problems/91.decode-ways.md
+++ b/problems/91.decode-ways.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/decode-ways/description/
## 题目描述
+
```
A message containing letters from A-Z is being encoded to numbers using the following mapping:
@@ -24,6 +25,18 @@ Output: 3
Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
```
+## 前置知识
+
+- 爬楼梯问题
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目和爬楼梯问题有异曲同工之妙。
@@ -33,8 +46,8 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
- 对于一个数字来说[1,9]这九个数字能够被识别为一种编码方式
- 对于两个数字来说[10, 26]这几个数字能被识别为一种编码方式
-我们考虑用dp[i]来切分子问题, 那么dp[i]表示的意思是当前字符串的以索引i结尾的子问题。
-这样的话,我们最后只需要取dp[s.length] 就可以解决问题了。
+我们考虑用 dp[i]来切分子问题, 那么 dp[i]表示的意思是当前字符串的以索引 i 结尾的子问题。
+这样的话,我们最后只需要取 dp[s.length] 就可以解决问题了。
关于递归公式,让我们`先局部后整体`。对于局部,我们遍历到一个元素的时候,
我们有两种方式来组成编码方式,第一种是这个元素本身(需要自身是[1,9]),
@@ -42,17 +55,13 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
`dp[i] = 以自身去编码(一位) + 以前面的元素和自身去编码(两位)` .这显然是完备的,
这样我们通过层层推导就可以得到结果。
-
## 关键点解析
- 爬楼梯问题(我把这种题目统称为爬楼梯问题)
-
## 代码
```js
-
-
/*
* @lc app=leetcode id=91 lang=javascript
*
@@ -100,7 +109,7 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
* @param {string} s
* @return {number}
*/
-var numDecodings = function(s) {
+var numDecodings = function (s) {
if (s == null || s.length == 0) {
return 0;
}
@@ -108,8 +117,8 @@ var numDecodings = function(s) {
dp[0] = 1;
dp[1] = s[0] !== "0" ? 1 : 0;
for (let i = 2; i < s.length + 1; i++) {
- const one = +s.slice(i - 1, i);
- const two = +s.slice(i - 2, i);
+ const one = +s.slice(i - 1, i);
+ const two = +s.slice(i - 2, i);
if (two >= 10 && two <= 26) {
dp[i] = dp[i - 2];
@@ -126,4 +135,4 @@ var numDecodings = function(s) {
## 扩展
-如果编码的范围不再是1-26,而是三位的话怎么办?
+如果编码的范围不再是 1-26,而是三位的话怎么办?
diff --git a/problems/912.sort-an-array.md b/problems/912.sort-an-array.md
index f98daf5cb..03d0d5dfc 100644
--- a/problems/912.sort-an-array.md
+++ b/problems/912.sort-an-array.md
@@ -24,6 +24,17 @@ Note:
-50000 <= A[i] <= 50000
```
+## 前置知识
+
+- 数组
+- 排序
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这是一个很少见的直接考察`排序`的题目。 其他题目一般都是暗含`排序`,这道题则简单粗暴,直接让你排序。
@@ -51,7 +62,7 @@ Note:
这样一次遍历,我们统计出了所有的数字出现的位置和次数。 我们再来一次遍历,将其输出到即可。
-
+
### 解法二 - 快速排序
@@ -69,7 +80,7 @@ Note:
- 数组随机一项元素
-
+
(图片来自: https://www.geeksforgeeks.org/quick-sort/)
diff --git a/problems/92.reverse-linked-list-ii.md b/problems/92.reverse-linked-list-ii.md
index 3278c21c1..e46f3199a 100644
--- a/problems/92.reverse-linked-list-ii.md
+++ b/problems/92.reverse-linked-list-ii.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-linked-list-ii/description/
## 题目描述
+
Reverse a linked list from position m to n. Do it in one-pass.
Note: 1 ≤ m ≤ n ≤ length of list.
@@ -11,26 +13,38 @@ Example:
Input: 1->2->3->4->5->NULL, m = 2, n = 4
Output: 1->4->3->2->5->NULL
-## 思路
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路(四点法)
-这道题和[206.reverse-linked-list](https://github.com/azl397985856/leetcode/blob/master/problems/206.reverse-linked-list.md) 有点类似,并且这道题是206的升级版。 让我们反转某一个区间,而不是整个链表,我们可以将206看作本题的特殊情况(special case)。
+这道题和[206.reverse-linked-list](https://github.com/azl397985856/leetcode/blob/master/problems/206.reverse-linked-list.md) 有点类似,并且这道题是 206 的升级版。 让我们反转某一个区间,而不是整个链表,我们可以将 206 看作本题的特殊情况(special case)。
核心在于**取出需要反转的这一小段链表,反转完后再插入到原先的链表中。**
以本题为例:
-反转的是2,3,4这三个点,那么我们可以先取出2,用cur指针指向2,然后当取出3的时候,我们将3指向2的,把cur指针前移到3,依次类推,到4后停止,这样我们得到一个新链表4->3->2, cur指针指向4。
+反转的是 2,3,4 这三个点,那么我们可以先取出 2,用 cur 指针指向 2,然后当取出 3 的时候,我们将 3 指向 2 的,把 cur 指针前移到 3,依次类推,到 4 后停止,这样我们得到一个新链表 4->3->2, cur 指针指向 4。
-对于原链表来说,有两个点的位置很重要,需要用指针记录下来,分别是1和5,把新链表插入的时候需要这两个点的位置。用pre指针记录1的位置当4结点被取走后,5的位置需要记下来
+对于原链表来说,有两个点的位置很重要,需要用指针记录下来,分别是 1 和 5,把新链表插入的时候需要这两个点的位置。用 pre 指针记录 1 的位置当 4 结点被取走后,5 的位置需要记下来
这样我们就可以把反转后的那一小段链表加入到原链表中
-
+
-(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+(图片来自网络)
+- 首先我们直接返回 head 是不行的。 当 m 不等于 1 的时候是没有问题的,但只要 m 为 1,就会有问题。
-首先我们直接返回head是不行的。 当 m 不等于1的时候是没有问题的,但只要 m 为1,就会有问题。
+- 其次如果链表商都小于 4 的时候,p1,p2,p3,p4 就有可能为空。为了防止 NPE,我们也要充分地判空。
```python
class Solution:
@@ -39,7 +53,7 @@ class Solution:
cur = head
i = 0
p1 = p2 = p3 = p4 = None
- # ...
+ # 一坨逻辑
if p1:
p1.next = p3
else:
@@ -48,72 +62,73 @@ class Solution:
p2.next = p4
return head
```
-
- 如上代码是不可以的,我们考虑使用dummy节点。
- ```python
- class Solution:
- def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
- pre = None
- cur = head
- i = 0
- p1 = p2 = p3 = p4 = None
- dummy = ListNode(0)
- dummy.next = head
- # ...
+如上代码是不可以的,我们考虑使用 dummy 节点。
- if p1:
- p1.next = p3
- else:
- dummy.next = p3
- if p2:
- p2.next = p4
-
- return dummy.next
- ```
-
- 关于链表反转部分, 顺序比较重要,我们需要:
-
- - 先 cur.next = pre
- - 再 更新p2和p2.next(其中要设置p2.next = None,否则会互相应用,造成无限循环)
- - 最后更新 pre 和 cur
-
- 上述的顺序不能错,不然会有问题。原因就在于`p2.next = None`,如果这个放在最后,那么我们的cur会提前断开。
-
- ```python
- while cur:
- i += 1
- if i == m - 1:
- p1 = cur
- next = cur.next
- if m < i <= n:
- cur.next = pre
+```python
+class Solution:
+ def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
+ pre = None
+ cur = head
+ i = 0
+ p1 = p2 = p3 = p4 = None
+ dummy = ListNode(0)
+ dummy.next = head
+ # 一坨逻辑
+ if p1:
+ p1.next = p3
+ else:
+ dummy.next = p3
+ if p2:
+ p2.next = p4
+
+ return dummy.next
+```
- if i == m:
- p2 = cur
- p2.next = None
+关于链表反转部分, 顺序比较重要,我们需要:
- if i == n:
- p3 = cur
+- 先 cur.next = pre
+- 再 更新 p2 和 p2.next(其中要设置 p2.next = None,否则会互相应用,造成无限循环)
+- 最后更新 pre 和 cur
- if i == n + 1:
- p4 = cur
+上述的顺序不能错,不然会有问题。原因就在于`p2.next = None`,如果这个放在最后,那么我们的 cur 会提前断开。
- pre = cur
- cur = next
- ```
+```python
+ while cur:
+ i += 1
+ if i == m - 1:
+ p1 = cur
+ next = cur.next
+ if m < i <= n:
+ cur.next = pre
+
+ if i == m:
+ p2 = cur
+ p2.next = None
+
+ if i == n:
+ p3 = cur
+
+ if i == n + 1:
+ p4 = cur
+
+ pre = cur
+ cur = next
+```
## 关键点解析
+- 四点法
- 链表的基本操作
-- 考虑特殊情况 m 是 1 或者 n是链表长度的情况,我们可以采用虚拟节点dummy 简化操作
+- 考虑特殊情况 m 是 1 或者 n 是链表长度的情况,我们可以采用虚拟节点 dummy 简化操作
- 用四个变量记录特殊节点, 然后操作这四个节点使之按照一定方式连接即可。
-- 注意更新current和pre的位置, 否则有可能出现溢出
-
+- 注意更新 current 和 pre 的位置, 否则有可能出现溢出
## 代码
-语言支持:JS, C++, Python3
+我把这个方法称为 `四点法`
+
+语言支持:JS, Python3
JavaScript Code:
@@ -138,152 +153,106 @@ JavaScript Code:
* @param {number} n
* @return {ListNode}
*/
-var reverseBetween = function(head, m, n) {
- // 虚拟节点,简化操作
- const dummyHead = {
- next: head
+var reverseBetween = function (head, m, n) {
+ // 虚拟节点,简化操作
+ const dummyHead = {
+ next: head,
+ };
+
+ let cur = dummyHead.next; // 当前遍历的节点
+ let pre = cur; // 因为要反转,因此我们需要记住前一个节点
+ let index = 0; // 链表索引,用来判断是否是特殊位置(头尾位置)
+
+ // 上面提到的四个特殊节点
+ let p1 = (p2 = p3 = p4 = null);
+
+ while (cur) {
+ const next = cur.next;
+ index++;
+
+ // 对 (m - n) 范围内的节点进行反转
+ if (index > m && index <= n) {
+ cur.next = pre;
}
- let cur = dummyHead.next; // 当前遍历的节点
- let pre = cur; // 因为要反转,因此我们需要记住前一个节点
- let index = 0; // 链表索引,用来判断是否是特殊位置(头尾位置)
-
- // 上面提到的四个特殊节点
- let p1 = p2 = p3 = p4 = null
-
- while(cur) {
- const next = cur.next;
- index++;
-
- // 对 (m - n) 范围内的节点进行反转
- if (index > m && index <= n) {
- cur.next = pre;
- }
-
- // 下面四个if都是边界, 用于更新四个特殊节点的值
- if (index === m - 1) {
- p1 = cur;
- }
- if (index === m) {
- p2 = cur;
- }
-
- if (index === n) {
- p3 = cur;
- }
-
- if (index === n + 1) {
- p4 = cur;;
- }
+ // 下面四个if都是边界, 用于更新四个特殊节点的值
+ if (index === m - 1) {
+ p1 = cur;
+ }
+ if (index === m) {
+ p2 = cur;
+ }
- pre = cur;
+ if (index === n) {
+ p3 = cur;
+ }
- cur = next;
+ if (index === n + 1) {
+ p4 = cur;
}
- // 两个链表合并起来
- (p1 || dummyHead).next = p3; // 特殊情况需要考虑
- p2.next = p4;
+ pre = cur;
- return dummyHead.next;
-};
+ cur = next;
+ }
-```
-C++ Code:
-```c++
-/**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * ListNode *next;
- * ListNode(int x) : val(x), next(NULL) {}
- * };
- */
-class Solution {
-public:
- ListNode* reverseBetween(ListNode* head, int s, int e) {
- if (s == e) return head;
- ListNode* prev = nullptr;
- auto cur = head;
- for (int i = 1; i < s; ++i) {
- prev = cur;
- cur = cur->next;
- }
- // 此时各指针指向:
- // x -> x -> x -> x -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> x -> x -> x ->
- // ^head ^prev ^cur
- ListNode* p = nullptr;
- auto c = cur;
- auto tail = c;
- ListNode* n = nullptr;
- for (int i = s; i <= e; ++i) {
- n = c->next;
- c->next = p;
- p = c;
- c = n;
- }
- // 此时各指针指向:
- // x -> x -> x -> x 8 -> 7 -> 6 -> 5 -> 4 -> 3 -> 2 -> 1 x -> x -> x ->
- // ^head ^prev ^p ^cur ^c
- // ^tail
- if (prev != nullptr) { // 若指向前一个节点的指针不为空,则说明s在链表中间(不是头节点)
- prev->next = p;
- cur->next = c;
- return head;
- } else {
- if (tail != nullptr) tail->next = c;
- return p;
- }
- }
+ // 两个链表合并起来
+ (p1 || dummyHead).next = p3; // 特殊情况需要考虑
+ p2.next = p4;
+
+ return dummyHead.next;
};
```
+
Python Code:
+
```Python
-# Definition for singly-linked list.
-# class ListNode:
-# def __init__(self, x):
-# self.val = x
-# self.next = None
class Solution:
def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
- """采用先翻转中间部分,之后与不变的前后部分拼接的思路"""
- # 处理特殊情况
- if m == n:
+ if not head.next or n == 1:
return head
-
- # 例行性的先放一个开始节点,方便操作
- first = ListNode(0)
- first.next = head
-
- # 通过以下两个节点记录拼接点
- before_m = first # 原链表m前的部分
- after_n = None # 原链表n后的部分
-
- # 通过以下两个节点记录翻转后的链表
- between_mn_head = None
- between_mn_end = None
-
- index = 0
- cur_node = first
- while index < n:
- index += 1
- cur_node = cur_node.next
- if index == m - 1:
- before_m = cur_node
- elif index == m:
- between_mn_end = ListNode(cur_node.val)
- between_mn_head = between_mn_end
- elif index > m:
- temp = between_mn_head
- between_mn_head = ListNode(cur_node.val)
- between_mn_head.next = temp
- if index == n:
- after_n = cur_node.next
-
- # 进行拼接
- between_mn_end.next = after_n
- before_m.next = between_mn_head
-
- return first.next
+ dummy = ListNode()
+ dummy.next = head
+ pre = None
+ cur = head
+ i = 0
+ p1 = p2 = p3 = p4 = None
+ while cur:
+ i += 1
+ next = cur.next
+ if m < i <= n:
+ cur.next = pre
+ if i == m - 1:
+ p1 = cur
+ if i == m:
+ p2 = cur
+ if i == n:
+ p3 = cur
+ if i == n + 1:
+ p4 = cur
+ pre = cur
+ cur = next
+ if not p1:
+ dummy.next = p3
+ else:
+ p1.next = p3
+ p2.next = p4
+ return dummy.next
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [25.reverse-nodes-in-k-groups](./25.reverse-nodes-in-k-groups-cn.md)
+- [206.reverse-linked-list](./206.reverse-linked-list.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/935.knight-dialer.md b/problems/935.knight-dialer.md
index 1e4aa392d..3150086e0 100644
--- a/problems/935.knight-dialer.md
+++ b/problems/935.knight-dialer.md
@@ -8,7 +8,7 @@ https://leetcode-cn.com/problems/knight-dialer/
```
-
+
```
@@ -42,8 +42,17 @@ https://leetcode-cn.com/problems/knight-dialer/
```
+## 前置知识
+
+- DFS
+- 记忆化搜索
+
## 深度优先遍历(DFS)
+## 公司
+
+- 暂无
+
### 思路
这道题要求解一个数字。并且每一个格子能够跳的状态是确定的。 因此我们的思路就是“状态机”(动态规划),暴力遍历(BFS or DFS),这里我们使用 DFS。(注意这几种思路并无本质不同)
@@ -112,4 +121,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/94.binary-tree-inorder-traversal.md b/problems/94.binary-tree-inorder-traversal.md
index 4c8c02ad9..bdad3ff9b 100644
--- a/problems/94.binary-tree-inorder-traversal.md
+++ b/problems/94.binary-tree-inorder-traversal.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/binary-tree-inorder-traversal/description/
## 题目描述
+
```
Given a binary tree, return the inorder traversal of its nodes' values.
@@ -17,6 +19,19 @@ Input: [1,null,2,3]
Output: [1,3,2]
Follow up: Recursive solution is trivial, could you do it iteratively?
```
+
+## 前置知识
+
+- 二叉树
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
递归的方式相对简单,非递归的方式借助栈这种数据结构实现起来会相对轻松。
@@ -31,109 +46,71 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
- 再将当前指针移到其右子节点上,若存在右子节点,则在下次循环时又可将其所有左子结点压入栈中, 重复上步骤
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
## 关键点解析
- 二叉树的基本操作(遍历)
-> 不同的遍历算法差异还是蛮大的
+ > 不同的遍历算法差异还是蛮大的
- 如果非递归的话利用栈来简化操作
- 如果数据规模不大的话,建议使用递归
- 递归的问题需要注意两点,一个是终止条件,一个如何缩小规模
-1. 终止条件,自然是当前这个元素是null(链表也是一样)
+1. 终止条件,自然是当前这个元素是 null(链表也是一样)
2. 由于二叉树本身就是一个递归结构, 每次处理一个子树其实就是缩小了规模,
-难点在于如何合并结果,这里的合并结果其实就是`left.concat(mid).concat(right)`,
-mid是一个具体的节点,left和right`递归求出即可`
-
+ 难点在于如何合并结果,这里的合并结果其实就是`left.concat(mid).concat(right)`,
+ mid 是一个具体的节点,left 和 right`递归求出即可`
## 代码
-* 语言支持:JS,C++,Python3, Java
+- 语言支持:JS,C++,Python3, Java
JavaScript Code:
```js
-/*
- * @lc app=leetcode id=94 lang=javascript
- *
- * [94] Binary Tree Inorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-inorder-traversal/description/
- *
- * algorithms
- * Medium (55.22%)
- * Total Accepted: 422.4K
- * Total Submissions: 762.1K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the inorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [1,3,2]
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[]}
*/
-var inorderTraversal = function(root) {
- // 1. Recursive solution
- // if (!root) return [];
- // const left = root.left ? inorderTraversal(root.left) : [];
- // const right = root.right ? inorderTraversal(root.right) : [];
- // return left.concat([root.val]).concat(right);
-
- // 2. iterative solutuon
- if (!root) return [];
- const stack = [root];
- const ret = [];
- let left = root.left;
-
- let item = null; // stack 中弹出的当前项
-
- while(left) {
- stack.push(left);
- left = left.left;
- }
-
- while(item = stack.pop()) {
- ret.push(item.val);
- let t = item.right;
-
- while(t) {
- stack.push(t);
- t = t.left;
- }
+var inorderTraversal = function (root) {
+ // 1. Recursive solution
+ // if (!root) return [];
+ // const left = root.left ? inorderTraversal(root.left) : [];
+ // const right = root.right ? inorderTraversal(root.right) : [];
+ // return left.concat([root.val]).concat(right);
+
+ // 2. iterative solutuon
+ if (!root) return [];
+ const stack = [root];
+ const ret = [];
+ let left = root.left;
+
+ let item = null; // stack 中弹出的当前项
+
+ while (left) {
+ stack.push(left);
+ left = left.left;
+ }
+
+ while ((item = stack.pop())) {
+ ret.push(item.val);
+ let t = item.right;
+
+ while (t) {
+ stack.push(t);
+ t = t.left;
}
+ }
- return ret;
-
+ return ret;
};
-
```
+
C++ Code:
```c++
@@ -162,7 +139,9 @@ public:
}
};
```
+
Python Code:
+
```Python
# Definition for a binary tree node.
# class TreeNode:
@@ -225,14 +204,14 @@ class Solution {
inorder(root);
return res;
}
-
+
public void inorder (TreeNode root) {
if (root == null) return;
-
+
inorder(root.left);
-
+
res.add(root.val);
-
+
inorder(root.right);
}
}
@@ -268,3 +247,7 @@ class Solution {
}
}
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/95.unique-binary-search-trees-ii.md b/problems/95.unique-binary-search-trees-ii.md
index 603c8e488..bb6571054 100644
--- a/problems/95.unique-binary-search-trees-ii.md
+++ b/problems/95.unique-binary-search-trees-ii.md
@@ -30,6 +30,18 @@ https://leetcode-cn.com/problems/unique-binary-search-trees-ii/description/
```
+## 前置知识
+
+- 二叉搜索树
+- 分治
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个经典的使用分治思路的题目。基本思路和[96.unique-binary-search-trees](./96.unique-binary-search-trees.md)一样。
diff --git a/problems/96.unique-binary-search-trees.md b/problems/96.unique-binary-search-trees.md
index effd3bb8e..e2b42f2fc 100644
--- a/problems/96.unique-binary-search-trees.md
+++ b/problems/96.unique-binary-search-trees.md
@@ -22,6 +22,18 @@ https://leetcode-cn.com/problems/unique-binary-search-trees-ii/description/
```
+## 前置知识
+
+- 二叉搜索树
+- 分治
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个经典的使用分治思路的题目。
@@ -82,7 +94,14 @@ class Solution:
self.visited[n] = res
return res
```
+**复杂度分析**
+- 时间复杂度:一层循环是 N,另外递归深度是 N,因此总的时间复杂度是 $O(N^2)$
+- 空间复杂度:递归的栈深度和visited 的大小都是 N,因此总的空间复杂度为 $O(N)$
## 相关题目
-- [95.unique-binary-search-trees-ii](./95.unique-binary-search-trees-ii.md)
+- [95.unique-binary-search-trees-ii](https://github.com/azl397985856/leetcode/blob/master/problems/95.unique-binary-search-trees-ii.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/98.validate-binary-search-tree.md b/problems/98.validate-binary-search-tree.md
index 2a08c2704..15faf7649 100644
--- a/problems/98.validate-binary-search-tree.md
+++ b/problems/98.validate-binary-search-tree.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/validate-binary-search-tree/description/
## 题目描述
+
```
Given a binary tree, determine if it is a valid binary search tree (BST).
@@ -10,7 +12,7 @@ Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the node's key.
The right subtree of a node contains only nodes with keys greater than the node's key.
Both the left and right subtrees must also be binary search trees.
-
+
Example 1:
@@ -35,13 +37,28 @@ Explanation: The root node's value is 5 but its right child's value is 4.
```
+## 前置知识
+
+- 中序遍历
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+
### 中序遍历
+
这道题是让你验证一棵树是否为二叉查找树(BST)。 由于中序遍历的性质`如果一个树遍历的结果是有序数组,那么他也是一个二叉查找树(BST)`,
-我们只需要中序遍历,然后两两判断是否有逆序的元素对即可,如果有,则不是BST,否则即为一个BST。
+我们只需要中序遍历,然后两两判断是否有逆序的元素对即可,如果有,则不是 BST,否则即为一个 BST。
### 定义法
+
根据定义,一个结点若是在根的左子树上,那它应该小于根结点的值而大于左子树最小值;若是在根的右子树上,那它应该大于根结点的值而小于右子树最大值。也就是说,每一个结点必须落在某个取值范围:
+
1. 根结点的取值范围为(考虑某个结点为最大或最小整数的情况):(long_min, long_max)
2. 左子树的取值范围为:(current_min, root.value)
3. 右子树的取值范围为:(root.value, current_max)
@@ -56,9 +73,10 @@ Explanation: The root node's value is 5 but its right child's value is 4.
### 中序遍历
-* 语言支持:JS,C++, Java
+- 语言支持:JS,C++, Java
JavaScript Code:
+
```js
/*
* @lc app=leetcode id=98 lang=javascript
@@ -76,36 +94,35 @@ JavaScript Code:
* @param {TreeNode} root
* @return {boolean}
*/
-var isValidBST = function(root) {
- if (root === null) return true;
- if (root.left === null && root.right === null) return true;
- const stack = [root];
- let cur = root;
- let pre = null;
-
- function insertAllLefts(cur) {
- while(cur && cur.left) {
- const l = cur.left;
- stack.push(l);
- cur = l;
- }
+var isValidBST = function (root) {
+ if (root === null) return true;
+ if (root.left === null && root.right === null) return true;
+ const stack = [root];
+ let cur = root;
+ let pre = null;
+
+ function insertAllLefts(cur) {
+ while (cur && cur.left) {
+ const l = cur.left;
+ stack.push(l);
+ cur = l;
}
- insertAllLefts(cur);
+ }
+ insertAllLefts(cur);
- while(cur = stack.pop()) {
- if (pre && cur.val <= pre.val) return false;
- const r = cur.right;
+ while ((cur = stack.pop())) {
+ if (pre && cur.val <= pre.val) return false;
+ const r = cur.right;
- if (r) {
- stack.push(r);
- insertAllLefts(r);
- }
- pre = cur;
+ if (r) {
+ stack.push(r);
+ insertAllLefts(r);
}
+ pre = cur;
+ }
- return true;
+ return true;
};
-
```
C++ Code:
@@ -118,7 +135,7 @@ public:
TreeNode* prev = nullptr;
return validateBstInorder(root, prev);
}
-
+
private:
bool validateBstInorder(TreeNode* root, TreeNode*& prev) {
if (root == nullptr) return true;
@@ -185,7 +202,7 @@ class Solution {
### 定义法
-* 语言支持:C++,Python3, Java, JS
+- 语言支持:C++,Python3, Java, JS
C++ Code:
@@ -265,15 +282,15 @@ class Solution:
"""
if root is None:
return True
-
+
is_valid_left = root.left is None or\
(root.left.val < root.val and area[0] < root.left.val < area[1])
is_valid_right = root.right is None or\
(root.right.val > root.val and area[0] < root.right.val < area[1])
-
+
# 左右节点都符合,说明本节点符合要求
is_valid = is_valid_left and is_valid_right
-
+
# 递归下去
return is_valid\
and self.isValidBST(root.left, (area[0], root.val))\
@@ -292,7 +309,7 @@ Java Code:
* TreeNode(int x) { val = x; }
* }
*/
-class Solution {
+class Solution {
public boolean isValidBST(TreeNode root) {
return helper(root, null, null);
}
@@ -326,16 +343,16 @@ JavaScript Code:
* @return {boolean}
*/
var isValidBST = function (root) {
- if (!root) return true;
- return valid(root);
+ if (!root) return true;
+ return valid(root);
};
function valid(root, min = -Infinity, max = Infinity) {
- if (!root) return true;
- const val = root.val;
- if (val <= min) return false;
- if (val >= max) return false;
- return valid(root.left, min, val) && valid(root.right, val, max)
+ if (!root) return true;
+ const val = root.val;
+ if (val <= min) return false;
+ if (val >= max) return false;
+ return valid(root.left, min, val) && valid(root.right, val, max);
}
```
diff --git a/templates/problems/1014.best-sightseeing-pair.md b/templates/problems/1014.best-sightseeing-pair.md
index 9303967f7..92d3ad556 100644
--- a/templates/problems/1014.best-sightseeing-pair.md
+++ b/templates/problems/1014.best-sightseeing-pair.md
@@ -17,9 +17,11 @@
> (518. 零钱兑换 II) 替换成你自己的题目序号和名称
2. 题目描述
-3. 思路
-4. 关键点
-5. 代码
+3. 前置知识
+4. 公司
+5. 思路
+6. 关键点
+7. 代码
可选项:
diff --git a/thanksGiving.md b/thanksGiving.md
index 0704ca65e..b1e4abfa1 100644
--- a/thanksGiving.md
+++ b/thanksGiving.md
@@ -2,23 +2,23 @@
就在今天,我的《leetcode题解》项目首次突破1wstar, 在这里我特地写下这篇文章来记录这个时刻,同时非常感谢大家的支持和陪伴。
-
+
(star增长曲线图)
前几天,去了一趟山城重庆,在那里遇到了最美的人和最漂亮的风景。
-
+
-
+
-
+
我是一个念旧的人,现在是节后的第一天,让我开启回忆模式:
- 2017-05-30 项目成立,那是的它只是用来占位而已,目的就是让自己知道之后要做这件事。
-
+
(第一次提交)
@@ -28,7 +28,7 @@
在朋友圈推广:
-
+
(在朋友圈宣传)
@@ -37,11 +37,11 @@
- 之后我组建了微信和qq群,来让大家活跃起来,促进交流,戒指目前(2019-06-10)微信群总人数已经超过700,
里面有非常多的学生,留学生以及全球各地各大公司的员工。
-
+
(qq群)
-
+
(微信群)
@@ -49,35 +49,35 @@
之后先后通过@每日时报, @阮一峰,@d2,@hello-github等的宣传,又迎来的一次高峰,
在那一段时间大概突破了1k。
-
+
(阮一峰的周报)
-
+
(hello-github也收录了我和我的仓库)
二次元的司徒正美老师虽然没有帮忙宣传,但是它的star也在某种程度上起到了宣传作用。
-
+
(司徒正美)
并且之后这个项目在github trending活跃了一个月左右,甚至有一次冲上了日榜的总榜第一,并被“开发者头条”收入《GitHub Trending - All - Daily》。
-
+
(日榜第一)
-
+
(开发者头条的微博号)
截止到2019-06-10,项目star首次破万,幸运的是我刚好捕捉到了第9999个小可爱.
-
+
(9999,一个很有意思的数字)
@@ -85,33 +85,33 @@
现在,项目除了JS,也在逐步加入C++,python,多编程语言正在筹备中。
-
+
(我们正在努力加入更多编程语言)
另外,在大家的帮助下,我们也逐步走上了国际化,不仅仅有人来主动做翻译,还组建了电报群。
-
+
(英文主页)
-
+
(英文翻译进展)
也不知道什么时候,《量子论》竟然悄悄地在知乎帮我宣传。
-
+
(知乎 - 量子论)
与此同时,我在知乎的最高赞竟然给了这条评论。
-
+
- 2019-06-04 首次在三个群里同步开通《每日一题》,大家也非常踊跃地帮忙整理题目,甚至出题给思路,非常感谢大家。
-
+
非常感谢大家一直以来的陪伴和支持,我们一起努力,加油💪。
diff --git a/thanksGiving2.md b/thanksGiving2.md
index 35d222ee8..d74bc0d09 100644
--- a/thanksGiving2.md
+++ b/thanksGiving2.md
@@ -1,17 +1,17 @@
假期这几天我买了《逆转裁判 123》合集,面对着这香喷喷的冷饭吃了半天。从 GBA 玩到 NDS,从 NDS 玩到 3DS, 现在 NS 虽然没有出新作有点遗憾。不过有了高清重制,也当是个回忆和收藏了 🎉🎉
目前打通了第一第二关,剩下的过一段时间再玩好啦 😁
-
+
回到正题,就在今天,我的《leetcode 题解》项目成功突破 2w star, 并且现在 Github 搜索关键字"LeetCode"我的项目已经排名第一啦,这是继 1W star 之后的第二个巨大突破,非常感谢大家一路以来的支持和陪伴。
-
+
最近在写一本关于 LeetCode 题解的书,有很多人表示想买,这无形之中给了我很大的压力,名字还没定,暂时给它取一个代号《攻克 LeetCode》。
## 新书《攻克 LeetCode》
-
+
这里是[《攻克 LeetCode》的草稿目录](https://lucifer.ren/blog/2019/10/03/draft/),目前有 20 章的内容,本书要讲的内容就是 LeetCode 上反复出现的算法,经过我进一步提炼,抽取数百道题目在这里进行讲解,帮助大家理清整体思绪,从而高效率地刷题,做到事半功倍。我这里总结了 7 个常见的数据结构和 7 个常见的算法以及 5 个常见的算法思想。
@@ -27,11 +27,11 @@
## 2W star 截图
-
+
## Star 曲线
-
+
(star 增长曲线图)
@@ -41,29 +41,29 @@
上回提到知乎上的“量子位”在帮我做宣传,引入了不小的流量。 我就想为什么不自己去拉流量呢?我自己以作者的角度去回答一些问题岂不是更好,更受欢迎么?于是我就开始在知乎上回答问题,很开心其中一个还获得了专业认可。
-
+
事实上并没有我想的那么好,我回答了两个 LeetCode 话题的内容,虽然也有几百的点赞和感谢,但是这离我的目标还差很远。
-
+
-
+
但是转念一想,我知乎刚起步,也没什么粉丝,并且写答案的时间也就一个月左右,这样想就好多了。 我相信将来会有更多的人看到我的答案,然后加入进来。
-
+
-
+
## 建立自己的博客
现在我发表的文章都是在各大平台。这有一个很大的问题就是各个平台很难满足你的需求,比如按照标签,按照日期进行归档。 甚至很多平台的阅读体验很差,比如没有导航功能,广告太多等。因此我觉得自己搭建一个博客还是很有必要的,这个渠道也为我吸引了少部分的流量,目前添加的主要内容大概有:
-
+
-
+
-
+
总体上来说效果还是不错的,之后的文章会在博客首发,各个平台也会陆续更新,感兴趣的可以来个 RSS 订阅,订阅方式已经在[《每日一荐 - 九月刊》](https://lucifer.ren/blog/2019/09/30/daily-featured-2019-09/)里面介绍了。
@@ -71,23 +71,23 @@
GithubDaily 转载了量子位的文章也为我的仓库涨了至少几百的 star,非常感谢。GithubDaily 是一个拥有 3W 多读者的公众号,大家有兴趣的可以关注一波。
-
+
-
+
## 其他自媒体的推荐
一些其他自媒体也会帮忙推广我的项目
-
+
## 口耳相传
我后来才知道竟然有海外华侨和一些华人社区都能看到我了。
-
+
-
+
(一亩三分地是一个集中讨论美国加拿大留学的论坛)
另外通过朋友之间口耳相传的介绍也变得越来越多。
diff --git a/thanksGiving3.md b/thanksGiving3.md
index a94ad5720..c9130370f 100644
--- a/thanksGiving3.md
+++ b/thanksGiving3.md
@@ -2,13 +2,13 @@
## 30k 截图
-
+
## Star 曲线
Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升趋势。
-
+
(star 增长曲线图)
@@ -18,15 +18,15 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
三月份是满勤奖,四月份有一次忘记了,缺卡一天。
-
+
-
+
## 新书即将上线
新书详情戳这里:[《或许是一本可以彻底改变你刷 LeetCode 效率的题解书》](https://lucifer.ren/blog/2020/04/07/leetcode-book.intro/),目前正在申请书号。
-
+
点名感谢各位作者,审阅,以及行政小姐姐。
@@ -34,7 +34,7 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
最近开始做视频题解了,目前更新了五个视频。和文字题解不同,视频题解可以承载的内容会更多。 https://space.bilibili.com/519510412
-
+
我计划更新一些文字题解很难表述的内容,当然还会提供 PPT,如果你喜欢文字,直接看 PPT 即可。
@@ -46,7 +46,7 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
我们的官网`力扣加加`上线啦 💐💐💐💐💐,有专题讲解,每日一题,下载区和视频题解,后续会增加更多内容,还不赶紧收藏起来?地址:http://leetcode-solution.cn/
-
+
点名感谢@三天 @CYL @Josephjinn
@@ -54,12 +54,12 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
很多朋友也在关注我的项目,非常开心。点名感谢 @被单-加加 @童欧巴。
-
+
## 交流群
交流群人数也有了很大的提升。 粉丝人数也扩充到了 7000+。交流群数目也增加到了 10 个。其中 QQ 群人数最多,有将近 1800 人。为了限制人数,我开启了收费模式,希望大家不要打我 😂。
-
+
非常感谢大家一直以来的陪伴和支持,Fighting 💪。
diff --git a/thinkings/GCD.md b/thinkings/GCD.md
index c99f97b29..cf2304288 100644
--- a/thinkings/GCD.md
+++ b/thinkings/GCD.md
@@ -46,19 +46,19 @@ def GCD(a: int, b: int) -> int:
实际上这正是一个最大公约数的应用场景,我们的目标就是求解 1680 和 640 的最大公约数。
-
+
将 1680 米 \* 640 米 的土地分割,相当于对将 400 米 \* 640 米 的土地进行分割。 为什么呢? 假如 400 米 \* 640 米分割的正方形边长为 x,那么有 640 % x == 0,那么肯定也满足剩下的两块 640 米 \* 640 米的。
-
+
我们不断进行上面的分割:
-
+
直到边长为 80,没有必要进行下去了。
-
+
辗转相除法如果 a 和 b 都很大的时候,a % b 性能会较低。在中国,《九章算术》中提到了一种类似辗转相减法的 [更相减损术](https://zh.wikisource.org/wiki/%E4%B9%9D%E7%AB%A0%E7%AE%97%E8%A1%93#-.7BA.7Czh-hans:.E5.8D.B7.3Bzh-hant:.E5.8D.B7.7D-.E7.AC.AC.E4.B8.80.E3.80.80.E6.96.B9.E7.94.B0.E4.BB.A5.E5.BE.A1.E7.94.B0.E7.96.87.E7.95.8C.E5.9F.9F "更相减损术")。它的原理是:`两个正整数 a 和 b(a>b),它们的最大公约数等于 a-b 的差值 c 和较小数 b 的最大公约数。`。
diff --git a/thinkings/balanced-tree.md b/thinkings/balanced-tree.md
new file mode 100644
index 000000000..f5ad38545
--- /dev/null
+++ b/thinkings/balanced-tree.md
@@ -0,0 +1,310 @@
+# 衡二叉树专题
+
+力扣关于平衡二叉树的题目还是有一些的,并且都非常经典,推荐大家练习。今天给大家精选了 4 道题,如果你彻底搞明白了这几道题,碰到其他的平衡二叉树的题目应该不至于没有思路。当你领会了我的思路之后, 建议再找几个题目练手,巩固一下学习成果。
+
+## 110. 平衡二叉树(简单)
+
+最简单的莫过于判断一个树是否为平衡二叉树了,我们来看下。
+
+### 题目描述
+
+```
+给定一个二叉树,判断它是否是高度平衡的二叉树。
+
+本题中,一棵高度平衡二叉树定义为:
+
+一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
+
+示例 1:
+
+给定二叉树 [3,9,20,null,null,15,7]
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+返回 true 。
+
+示例 2:
+
+给定二叉树 [1,2,2,3,3,null,null,4,4]
+
+ 1
+ / \
+ 2 2
+ / \
+ 3 3
+ / \
+ 4 4
+返回 false
+
+
+```
+
+### 思路
+
+由于平衡二叉树定义为就是**一个二叉树每个节点的左右两个子树的高度差的绝对值不超过 1。**用伪代码描述就是:
+
+```py
+if abs(高度(root.left) - 高度(root.right)) <= 1 and root.left 也是平衡二叉树 and root.right 也是平衡二叉树:
+ print('是平衡二叉树')
+else:
+ print('不是平衡二叉树')
+```
+
+而 root.left 和 root.right **如何判断是否是二叉平衡树就和 root 是一样的了**,可以看出这个问题有明显的递归性。
+
+因此我们首先需要知道如何计算一个子树的高度。这个可以通过递归的方式轻松地计算出来。计算子树高度的 Python 代码如下:
+
+```py
+def dfs(node, depth):
+ if not node: return 0
+ l = dfs(node.left, depth + 1)
+ r = dfs(node.right, depth + 1)
+ return max(l, r) + 1
+```
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def isBalanced(self, root: TreeNode) -> bool:
+ def dfs(node, depth):
+ if not node: return 0
+ l = dfs(node.left, depth + 1)
+ r = dfs(node.right, depth + 1)
+ return max(l, r) + 1
+ if not root: return True
+ if abs(dfs(root.left, 0) - dfs(root.right, 0)) > 1: return False
+ return self.isBalanced(root.left) and self.isBalanced(root.right)
+```
+
+**复杂度分析**
+
+- 时间复杂度:对于 isBalanced 来说,由于每个节点最多被访问一次,这部分的时间复杂度为 $O(N)$,而 dfs 函数 每次被调用的次数不超过 $log N$,因此总的时间复杂度为 $O(NlogN)$,其中 $N$ 为 树的节点总数。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。
+
+## 108. 将有序数组转换为二叉搜索树(简单)
+
+108 和 109 基本是一样的,只不过数据结构不一样,109 变成了链表了而已。由于链表操作比数组需要考虑更多的因素,因此 109 是 中等难度。
+
+### 题目描述
+
+```
+将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定有序数组: [-10,-3,0,5,9],
+
+一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+### 思路
+
+对于这个问题或者 `给定一个二叉搜索树,将其改为平衡(后面会讲)` 基本思路都是一样的。
+
+题目的要求是将有序数组转化为:
+
+1. 高度平衡的二叉树
+2. 二叉搜索树
+
+由于平衡二叉树是左右两个子树的高度差的绝对值不超过 1。因此一种简单的方法是**选择中点作为根节点,根节点左侧的作为左子树,右侧的作为右子树即可。**原因很简单,这样分配可以保证左右子树的节点数目差不超过 1。因此高度差自然也不会超过 1 了。
+
+上面的操作同时也满足了二叉搜索树,原因就是题目给的数组是有序的。
+
+> 你也可以选择别的数作为根节点,而不是中点,这也可以看出答案是不唯一的。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
+ if not nums: return None
+ mid = (len(nums) - 1) // 2
+ root = TreeNode(nums[mid])
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为数组长度。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。同时由于是平衡二叉树,因此 $h$ 就是 $log N$。
+
+## 109. 有序链表转换二叉搜索树(中等)
+
+### 题目描述
+
+```
+`给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定的有序链表: [-10, -3, 0, 5, 9],
+
+一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+### 思路
+
+和 108 思路一样。 不同的是数据结构的不同,因此我们需要关注的是链表和数组的操作差异。
+
+
+
+(数组的情况)
+
+我们再来看下链表:
+
+
+(链表的情况)
+
+找到中点,只需要使用经典的快慢指针即可。同时为了防止环的出现, 我们需要斩断指向 mid 的 next 指针,因此需要记录一下中点前的一个节点,这只需要用一个变量 pre 记录即可。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def sortedListToBST(self, head: ListNode) -> TreeNode:
+ if not head:
+ return head
+ pre, slow, fast = None, head, head
+
+ while fast and fast.next:
+ fast = fast.next.next
+ pre = slow
+ slow = slow.next
+ if pre:
+ pre.next = None
+ node = TreeNode(slow.val)
+ if slow == fast:
+ return node
+ node.left = self.sortedListToBST(head)
+ node.right = self.sortedListToBST(slow.next)
+ return node
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为链表长度。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。同时由于是平衡二叉树,因此 $h$ 就是 $log N$。
+
+## 1382. 将二叉搜索树变平衡(中等)
+
+### 题目描述
+
+```
+给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。
+
+如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。
+
+如果有多种构造方法,请你返回任意一种。
+
+
+
+示例:
+
+```
+
+
+
+```
+
+输入:root = [1,null,2,null,3,null,4,null,null]
+输出:[2,1,3,null,null,null,4]
+解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。
+
+
+提示:
+
+树节点的数目在 1 到 10^4 之间。
+树节点的值互不相同,且在 1 到 10^5 之间。
+
+```
+
+### 思路
+
+由于`二叉搜索树的中序遍历是一个有序数组`,因此问题很容易就转化为 `108. 将有序数组转换为二叉搜索树(简单)`。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def inorder(self, node):
+ if not node: return []
+ return self.inorder(node.left) + [node.val] + self.inorder(node.right)
+ def balanceBST(self, root: TreeNode) -> TreeNode:
+ nums = self.inorder(root)
+ def dfs(start, end):
+ if start == end: return TreeNode(nums[start])
+ if start > end: return None
+ mid = (start + end) // 2
+ root = TreeNode(nums[mid])
+ root.left = dfs(start, mid - 1)
+ root.right = dfs(mid + 1, end)
+ return root
+ return dfs(0, len(nums) - 1)
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为链表长度。
+- 空间复杂度:虽然使用了递归,但是瓶颈不在栈空间,而是开辟的长度为 $N$ 的 nums 数组,因此空间复杂度为 $O(N)$,其中 $N$ 为树的节点总数。
+
+## 总结
+
+本文通过四道关于二叉平衡树的题帮助大家识别此类型题目背后的思维逻辑,我们来总结一下学到的知识。
+
+平衡二叉树指的是:`一个二叉树每个节点的左右两个子树的高度差的绝对值不超过1。`
+
+如果需要让你判断一个树是否是平衡二叉树,只需要死扣定义,然后用递归即可轻松解决。
+
+如果需要你将一个数组或者链表(逻辑上都是线性的数据结构)转化为平衡二叉树,只需要随便选一个节点,并分配一半到左子树,另一半到右子树即可。
+
+同时,如果要求你转化为平衡二叉搜索树,则可以选择排序数组(或链表)的中点,左边的元素为左子树, 右边的元素为右子树即可。
+
+> 小提示 1: 如果不需要是二叉搜索树则不需要排序,否则需要排序。
+
+> 小提示 2: 你也可以不选择中点, 算法需要相应调整,感兴趣的同学可以试试。
+
+> 小提示 3: 链表的操作需要特别注意环的存在。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/thinkings/basic-data-structure-en.md b/thinkings/basic-data-structure-en.md
index 3ce5f2316..16e4f2ac3 100644
--- a/thinkings/basic-data-structure-en.md
+++ b/thinkings/basic-data-structure-en.md
@@ -30,7 +30,7 @@ Now, let's have a look at some interesting examples.
`hooks` is essentially an array.
-
+
So, why `hooks` uses array? Maybe we can find the answer from the other side. What if not array?
@@ -108,7 +108,7 @@ For the same TCP connection, all HTTP/1.0 requests will be add into a queue. Whi
Just like waiting the traffic lights, if you are on the left-turn or right-turning lane, you cannot move even if the straight lane is good to go when the left/right turning light is still red.
-
+
`HTTP/1.0` and `HTTP/1.1`:
Accoding to `HTTP/1.0` protocal, one TCP connect will be established for each request and be terminated immediately after receiving the corresponding response. And the next HTTP request cannot be sent until the response of previous request has been received.
@@ -117,7 +117,7 @@ However, according to `HTTP/1.1`, all the responses are reqired to be sent bac
The process can be represented as follow:
-
+
### Stack
@@ -138,7 +138,7 @@ Besides, there is usually an operation called `peek` which is used to retrieve t
Explaining of `push` and `pop` operations:
-
+
(Picture from: https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
@@ -165,7 +165,7 @@ foo();
It may look like this inside the program during executing:
-
+
> The figure above does not contains the other parts of the execution context, like `this` and `scope` which are the key to closure. Here is not going to talk about the closure but to explain the stack structure.
> Some statements in community like *the `scope` of execution context is the variables which declared by the super class in execution stack* which are completely wrong. JS uses Lexical Scoping. And `scope` is the parent object of function when it is defined. There is nothing to do with the execution.
@@ -190,7 +190,7 @@ Many people know that `fiber` is implemented on Linked List. But not many of the
The appearance of `fiber` solves the problem that `react` must
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。
-
+
图片来自 Lin Clark 在 ReactConf 2017 分享
diff --git a/thinkings/basic-data-structure.md b/thinkings/basic-data-structure.md
index 402774be9..61624aa1f 100644
--- a/thinkings/basic-data-structure.md
+++ b/thinkings/basic-data-structure.md
@@ -30,7 +30,7 @@
Hooks 的本质就是一个数组, 伪代码:
-
+
那么为什么 hooks 要用数组? 我们可以换个角度来解释,如果不用数组会怎么样?
@@ -108,7 +108,7 @@ React 将`如何确保组件内部hooks保存的状态之间的对应关系`这
这就好像我们在等红绿灯,即使旁边绿灯亮了,你的这个车道是红灯,你还是不能走,还是要等着。
-
+
`HTTP/1.0` 和 `HTTP/1.1`:
在`HTTP/1.0` 中每一次请求都需要建立一个 TCP 连接,请求结束后立即断开连接。
@@ -118,7 +118,7 @@ React 将`如何确保组件内部hooks保存的状态之间的对应关系`这
如果用图来表示的话,过程大概是:
-
+
`HTTP/2` 和 `HTTP/1.1`:
@@ -144,7 +144,7 @@ pop, 移除栈最顶端(末尾)的元素.
栈的 push 和 pop 操作的示意:
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
@@ -169,7 +169,7 @@ foo();
真正执行的时候,内部大概是这样的:
-
+
> 我画的图没有画出执行上下文中其他部分(this 和 scope 等), 这部分是闭包的关键,而我这里不是讲闭包的,是为了讲解栈的。
@@ -194,7 +194,7 @@ foo();
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。
-
+
图片来自 Lin Clark 在 ReactConf 2017 分享
@@ -273,7 +273,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
实际使用的树有可能会更复杂,比如使用在游戏中的碰撞检测可能会用到四叉树或者八叉树。以及 k 维的树结构 `k-d 树`等。
-
+
(图片来自 https://zh.wikipedia.org/wiki/K-d%E6%A0%91)
### 二叉树
@@ -318,7 +318,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
- 在一个 最小堆(min heap) 中, 如果 P 是 C 的一个父级节点, 那么 P 的 key(或 value)应小于或等于 C 的对应值.
正因为此,堆顶元素一定是最小的,我们会利用这个特点求最小值或者第 k 小的值。
-
+
- 在一个 最大堆(max heap) 中, P 的 key(或 value)大于 C 的对应值。
@@ -346,7 +346,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
二叉查找树,之所以叫查找树就是因为其非常适合查找,举个例子,
如下一颗二叉查找树,我们想找节点值小于且最接近 58 的节点,搜索的流程如图所示:
-
+
(图片来自 https://www.geeksforgeeks.org/floor-in-binary-search-tree-bst/)
另外我们二叉查找树有一个性质是: `其中序遍历的结果是一个有序数组`。
@@ -388,7 +388,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
又称 Trie 树,是一种树形结构。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
-
+
(图来自 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fr=aladdin)
它有 3 个基本性质:
@@ -436,13 +436,13 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
例如在无向无权图中:
-
+
(图片来自 https://zhuanlan.zhihu.com/p/25498681)
可以看出在无向图中,邻接矩阵关于对角线对称,而邻接链表总有两条对称的边
而在有向无权图中:
-
+
(图片来自 https://zhuanlan.zhihu.com/p/25498681)
diff --git a/thinkings/binary-tree-traversal-en.md b/thinkings/binary-tree-traversal-en.md
index 686235e2f..809371a47 100644
--- a/thinkings/binary-tree-traversal-en.md
+++ b/thinkings/binary-tree-traversal-en.md
@@ -22,7 +22,7 @@ DFS simplifies operations with stack. Meanwhile, a tree is a recursive data stru
Diagrammatic graph of DFS:
-
+
(source: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
@@ -55,7 +55,7 @@ If we think from this point of view, the algorithm can be different. All nodes i
The whole process is like this:
-
+
This idea is something like the `backtrack`. It is important, because this idea can help us to `unify the understanding of three traversal methods`.
@@ -98,7 +98,7 @@ For condition 2, variables are required for recording the traversal status for e
The key point of level-order is recording the traversal status of each level. An identifier bit can be used to represent the status of current level.
-
+
(source: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
diff --git a/thinkings/binary-tree-traversal.en.md b/thinkings/binary-tree-traversal.en.md
new file mode 100644
index 000000000..70f3e9409
--- /dev/null
+++ b/thinkings/binary-tree-traversal.en.md
@@ -0,0 +1,193 @@
+# Binary Tree Traversal
+
+## Overview
+
+Binary tree as a basic data structure and traversal as a fundamental algorithm, their combination leads to a lot of classic problems. This patern is often seen in many problems, either directly or indirectly.
+
+> If you have grasped the traversal of binary trees, other complicated trees will probably be easy for you.
+
+Following are the generally used ways for traversing trees.
+
+- Depth First Traversals (DFS): Inorder, Preorder, Postorder
+
+- Breadth First or Level Order Traversal (BFS)
+
+There are applications for both DFS and BFS. Check out leetcode problem No.301 and No.609.
+
+Stack can be used to simplify the process of DFS traversal. Besides, since tree is a recursive data structure, recursion and stack are two key points for DFS.
+
+Graph for DFS:
+
+
+
+(from https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
+
+The key point of BFS is how to decide whether the traversal of each level is done. The answer is using a variable as a flag to represent the end of the traversal of current level.
+
+Let's dive into details.
+
+## Preorder Traversal
+
+related problem[144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
+
+The traversal order of preorder traversal is `root-left-right`.
+
+Algorithm Preorder
+
+1. Visit the root node and push it into a stack.
+
+2. Pop a node from the stack, and push its right and left child node into the stack respectively.
+
+3. Repeat step 2.
+
+Conclusion: This problem involves the clasic recursive data structure (i.e. a binary tree), and the algorithm above demonstrates how a simplified solution can be reached by using a stack.
+
+If you look at the bigger picture, you'll find that the process of traversal is as followed. `Visit the left subtrees repectively from top to bottom, and visit the right subtrees repectively from bottom to top`. If we are to implement it from this perspective, things will be somewhat different. For the `top to bottom` part we can simply use recursion, and for the `bottom to top` part we can turn to stack.
+
+The traversal will look something like this.
+
+
+
+This way of problem solving is a bit similar to `backtrack`, on which I have written a post. You can benefit a lot from it because it can be used to `solve all three DFS traversal problems` mentioned aboved. If you don't know this yet, make a memo on it.
+
+## Inorder Traversal
+
+related problem[94.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
+
+The traversal order of inorder traversal is `left-root-right`.
+
+So the root node is not printed first. Things are getting a bit complicated here.
+
+Algorithm Inorder
+
+1. Visit the root and push it into a stack.
+
+2. If there is a left child node, push it into the stack. Repeat this process until a leaf node reached.
+
+> At this point the root node and all the left nodes are in the stack.
+
+3. Start popping nodes from the stack. If a node has a right child node, push the child node into the stack. Repeat step 2.
+
+It's worth pointing out that the inorder traversal of a binary search tree (BST) is a sorted array, which is helpful for coming up simplified solutions for some problems. e.g. [230.kth-smallest-element-in-a-bst](../problems/230.kth-smallest-element-in-a-bst.md) and [98.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
+
+## Postorder Traversal
+
+related problem[145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
+
+The traversal order of postorder traversal is `left-right-root`.
+
+This one is a bit of a challange. It deserves the `hard` tag of leetcode.
+
+In this case, the root node is printed not as the first but the last one. A cunning way to do it is to:
+
+Record whether the current node has been visited. If 1) it's a leaf node or 2) both its left and right subtrees have been traversed, then it can be popped from the stack.
+
+As for `1) it's a leaf node`, you can easily tell whether a node is a leaf if both its left and right are `null`.
+
+As for `2) both its left and right subtrees have been traversed`, we only need a variable to record whether a node has been visited or not. In the worst case, we need to record the status for every single node and the space complexity is O(n). But if you come to think about it, as we are using a stack and start printing the result from the leaf nodes, it makes sense that we only record the status for the current node popping from the stack, reducing the space complexity to O(1). Please click the link above for more details.
+
+## Level Order Traversal
+
+The key point of level order traversal is how do we know whether the traversal of each level is done. The answer is that we use a variable as a flag representing the end of the traversal of the current level.
+
+
+
+(from https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
+
+Algorithm Level Order
+
+1. Visit the root node, put it in a FIFO queue, put in the queue a special flag (we are using `null` here).
+
+2. Dequeue a node.
+
+3. If the node equals `null`, it means that all nodes of the current level have been visited. If the queue is empty, we do nothing. Or else we put in another `null`.
+
+4. If the node is not `null`, meaning the traversal of current level has not finished yet, we enqueue its left subtree and right subtree repectively.
+
+related problem[102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
+
+## Bi-color marking
+
+We know that there is a tri-color marking in garbage collection algorithm, which works as described below.
+
+- The white color represents "not visited".
+
+- The gray color represents "not all child nodes visited".
+
+- The black color represents "all child nodes visited".
+
+Enlightened by tri-color marking, a bi-color marking method can be invented to solve all three traversal problems with one solution.
+
+The core idea is as followed.
+
+- Use a color to mark whether a node has been visited or not. Nodes yet to be visited are marked as white and visited nodes are marked as gray.
+
+- If we are visiting a white node, turn it into gray, and push it's right child node, itself, and it's left child node into the stack respectively.
+
+- If we are visiting a gray node, print it.
+
+Implementing inorder traversal with tri-color marking:
+
+```python
+class Solution:
+ def inorderTraversal(self, root: TreeNode) -> List[int]:
+ WHITE, GRAY = 0, 1
+ res = []
+ stack = [(WHITE, root)]
+ while stack:
+ color, node = stack.pop()
+ if node is None: continue
+ if color == WHITE:
+ stack.append((WHITE, node.right))
+ stack.append((GRAY, node))
+ stack.append((WHITE, node.left))
+ else:
+ res.append(node.val)
+ return res
+```
+
+Implementation of preorder and postorder traversal algorithms can be easily done by changing the order of pushing the child nodes into the stack.
+
+## Morris Traversal
+
+We can also use a method called Morris traversal, which involves no recursion or stack, and the time complexity is O(1).
+
+```python
+def MorrisTraversal(root):
+ curr = root
+
+ while curr:
+ # If left child is null, print the
+ # current node data. And, update
+ # the current pointer to right child.
+ if curr.left is None:
+ print(curr.data, end= " ")
+ curr = curr.right
+
+ else:
+ # Find the inorder predecessor
+ prev = curr.left
+
+ while prev.right is not None and prev.right is not curr:
+ prev = prev.right
+
+ # If the right child of inorder
+ # predecessor already points to
+ # the current node, update the
+ # current with it's right child
+ if prev.right is curr:
+ prev.right = None
+ curr = curr.right
+
+ # else If right child doesn't point
+ # to the current node, then print this
+ # node's data and update the right child
+ # pointer with the current node and update
+ # the current with it's left child
+ else:
+ print (curr.data, end=" ")
+ prev.right = curr
+ curr = curr.left
+```
+
+Reference: [what-is-morris-traversal](https://www.educative.io/edpresso/what-is-morris-traversal)
diff --git a/thinkings/binary-tree-traversal.md b/thinkings/binary-tree-traversal.md
index 0d54b8111..382b01755 100644
--- a/thinkings/binary-tree-traversal.md
+++ b/thinkings/binary-tree-traversal.md
@@ -2,8 +2,7 @@
## 概述
-二叉树作为一个基础的数据结构,遍历算法作为一个基础的算法,两者结合当然是经典的组合了。
-很多题目都会有 ta 的身影,有直接问二叉树的遍历的,有间接问的。
+二叉树作为一个基础的数据结构,遍历算法作为一个基础的算法,两者结合当然是经典的组合了。很多题目都会有 ta 的身影,有直接问二叉树的遍历的,有间接问的。比如要你找到树中满足条件的节点,就是间接考察树的遍历,因为你要找到树中满足条件的点,就需要进行遍历。
> 你如果掌握了二叉树的遍历,那么也许其他复杂的树对于你来说也并不遥远了
@@ -14,12 +13,14 @@ DFS 都可以使用栈来简化操作,并且其实树本身是一种递归的
DFS 图解:
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以用一个标识位来表式当前层的结束。
+首先不管是前中还是后序遍历,变的只是根节点的位置, 左右节点的顺序永远是先左后右。 比如前序遍历就是根在前面,即根左右。中序就是根在中间,即左根右。后序就是根在后面,即左右根。
+
下面我们依次讲解:
## 前序遍历
@@ -42,7 +43,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
如果从这个角度出发去写的话,算法就不一样了。从上向下我们可以直接递归访问即可,从下向上我们只需要借助栈也可以轻易做到。
整个过程大概是这样:
-
+
这种思路解题有点像我总结过的一个解题思路`backtrack` - 回溯法。这种思路有一个好处就是
可以`统一三种遍历的思路`. 这个很重要,如果不了解的朋友,希望能够记住这一点。
@@ -85,7 +86,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
层次遍历的关键点在于如何记录每一层次是否遍历完成, 我们可以用一个标识位来表式当前层的结束。
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
@@ -103,7 +104,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
## 双色标记法
-我们直到垃圾回收算法中,有一种算法叫三色标记法。 即:
+我们知道垃圾回收算法中,有一种算法叫三色标记法。 即:
- 用白色表示尚未访问
- 灰色表示尚未完全访问子节点
@@ -137,11 +138,15 @@ class Solution:
return res
```
-如要实现前序、后序遍历,只需要调整左右子节点的入栈顺序即可。
+可以看出,实现上 WHITE 就表示的是递归中的第一次进入过程,Gray 则表示递归中的从叶子节点返回的过程。 因此这种迭代的写法更接近递归写法的本质。
+
+如要实现前序、后序遍历,只需要调整左右子节点的入栈顺序即可。可以看出使用三色标记法, 其写法类似递归的形式,因此便于记忆和书写,缺点是使用了额外的内存空间。不过这个额外的空间是线性的,影响倒是不大。
+
+> 虽然递归也是额外的线性时间,但是递归的栈开销还是比一个 0,1 变量开销大的。
## Morris 遍历
-我们可以使用一种叫做 Morris 遍历的方法,既不使用递归也不借助于栈。从而在$O(1)$时间完成这个过程。
+我们可以使用一种叫做 Morris 遍历的方法,既不使用递归也不借助于栈。从而在 $O(1)$ 空间完成这个过程。
```python
def MorrisTraversal(root):
@@ -182,3 +187,15 @@ def MorrisTraversal(root):
```
参考: [what-is-morris-traversal](https://www.educative.io/edpresso/what-is-morris-traversal)
+
+## 相关题目
+
+- [lowest-common-ancestor-of-a-binary-tree](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
+- [binary-tree-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/)
+- [binary-tree-zigzag-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/)
+- [validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
+- [maximum-depth-of-binary-tree](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
+- [balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
+- [binary-tree-level-order-traversal-ii](https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/)
+- [binary-tree-maximum-path-sum](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/)
+- [insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
diff --git a/thinkings/bit.md b/thinkings/bit.md
index 14db86ac1..00d6fe705 100644
--- a/thinkings/bit.md
+++ b/thinkings/bit.md
@@ -190,8 +190,13 @@ class Solution:
- 空间复杂度:$O(1)$
-更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经接近30K star啦。
+## 相关题目
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+- [number-of-1-bits](https://leetcode-cn.com/problems/number-of-1-bits/)
+- [counting-bits](https://leetcode-cn.com/problems/counting-bits/)
+- [reverse-bits](https://leetcode-cn.com/problems/reverse-bits/)
-
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/thinkings/bloom-filter-en.md b/thinkings/bloom-filter-en.md
index 5d5ce202f..4b14f2948 100644
--- a/thinkings/bloom-filter-en.md
+++ b/thinkings/bloom-filter-en.md
@@ -42,7 +42,7 @@ Here are four interesting properties of Bloom filter:
- Deleting elements from filter is not possible because, if we delete a single element by clearing bits at indices generated by k hash functions, it might cause deletion of few other elements.
-
+
### Application of Bloom Filter
diff --git a/thinkings/bloom-filter.md b/thinkings/bloom-filter.md
index ea18f295b..39f6eb0a5 100644
--- a/thinkings/bloom-filter.md
+++ b/thinkings/bloom-filter.md
@@ -1,24 +1,29 @@
## 场景
+
假设你现在要处理这样一个问题,你有一个网站并且拥有`很多`访客,每当有用户访问时,你想知道这个ip是不是第一次访问你的网站。
### hashtable 可以么
-一个显而易见的答案是将所有的ip用hashtable存起来,每次访问都去hashtable中取,然后判断即可。但是题目说了网站有`很多`访客,
-假如有10亿个用户访问过,每个ip的长度是4 byte,那么你一共需要4 * 1000000000 = 4000000000Bytes = 4G , 如果是判断URL黑名单,
-由于每个URL会更长,那么需要的空间可能会远远大于你的期望。
+
+一个显而易见的答案是将所有的 IP 用 hashtable 存起来,每次访问都去 hashtable 中取,然后判断即可。但是题目说了网站有`很多`访客,
+假如有10亿个用户访问过,假设 IP 是 IPV4, 那么每个 IP 的长度是 4 byte,那么你一共需要4 * 1000000000 = 4000000000Bytes = 4G 。
+
+如果是判断 URL 黑名单,由于每个 URL 会更长(可能远大于上面 IPV4 地址的 4 byte),那么需要的空间可能会远远大于你的期望。
### bit
-另一个稍微难想到的解法是bit, 我们知道bit有0和1两种状态,那么用来表示存在,不存在再合适不过了。
-加入有10亿个ip,我们就可以用10亿个bit来存储,那么你一共需要 1 * 1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32,
-如果是存储URL这种更长的字符串,效率会更高。
+另一个稍微难想到的解法是bit, 我们知道bit有 0 和 1 两种状态,那么用来表示**存在**与**不存在**再合适不过了。
+
+假如有 10 亿个 IP,就可以用 10 亿个 bit 来存储,那么你一共需要 1 * 1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32, 如果是存储URL这种更长的字符串,效率会更高。 问题是,我们怎么把 IPV4 和 bit 的位置关联上呢?
-基于这种想法,我们只需要两个操作,set(ip) 和 has(ip)
+比如`192.168.1.1` 应该是用第几位表示,`10.18.1.1` 应该是用第几位表示呢? 答案是使用哈希函数。
+
+基于这种想法,我们只需要两个操作,set(ip) 和 has(ip),以及一个内置函数 hash(ip) 用于将 IP 映射到 bit 表。
这样做有两个非常致命的缺点:
1. 当样本分布极度不均匀的时候,会造成很大空间上的浪费
-> 我们可以通过散列函数来解决
+> 我们可以通过优化散列函数来解决
2. 当元素不是整型(比如URL)的时候,BitSet就不适用了
@@ -26,19 +31,23 @@
### 布隆过滤器
-布隆过滤器其实就是`bit + 多个散列函数`, 如果经过多次散列的值再bit上都为1,那么可能存在(可能有冲突)。 如果
-有一个不为1,那么一定不存在(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。
+布隆过滤器其实就是`bit + 多个散列函数`。k 次 hash(ip) 会生成多个索引,并将其 k 个索引位置的二进制置为 1。 如果经过 k 个索引位置的值都为 1,那么认为其**可能存在**(因为有冲突的可能)。 如果有一个不为1,那么**一定不存在**(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。也就是说布隆过滤器回答了:**可能存在** 和 **一定不存在** 的问题。
+
+
-
+从上图可以看出, 布隆过滤器本质上是由**一个很长的二进制向量**和**多个哈希函数**组成。
+
+由于没有 hashtable 的100% 可靠性,因此这本质上是一种**可靠性换取空间的做法**。除了可靠性,布隆过滤器删除起来也比较麻烦。
### 布隆过滤器的应用
1. 网络爬虫
+
判断某个URL是否已经被爬取过
2. K-V数据库 判断某个key是否存在
-比如Hbase的每个Region中都包含一个BloomFilter,用于在查询时快速判断某个key在该region中是否存在。
+比如 Hbase 的每个 Region 中都包含一个 BloomFilter,用于在查询时快速判断某个 key 在该 region 中是否存在。
3. 钓鱼网站识别
diff --git a/thinkings/dynamic-programming-en.md b/thinkings/dynamic-programming-en.md
index a81e19c26..514d7dbfb 100644
--- a/thinkings/dynamic-programming-en.md
+++ b/thinkings/dynamic-programming-en.md
@@ -48,7 +48,7 @@ function sum(nums) {
Let's review this problem intuitively with a recursion tree.
-
+
This method works, but not quit good. Because there are certain costs in executing functions. Let's take JS as example.
For each time a function executed, it requires stack push operations, pre-processing and executing processes. So, recurse a function is easy to cause stack overflow.
@@ -72,7 +72,7 @@ function climbStairs(n) {
This question is just like the `fibnacci` series. Let's have a look at the recursion tree of `fibnacci` question again.
-
+
Some results are calculated repeatedly. Just like the red nodes showing. If a structure like `hashtable` is used to store the intermedia results, the reduplicative calculations can be avoided.
Similarly, DP also uses "table look-up" to solve the problem of reduplicative calculation.
@@ -104,7 +104,7 @@ function climbStairs(n) {
Here is the process of "table look-up" in DP:
-
+
> dotted box is the "table look-up"
diff --git a/thinkings/dynamic-programming.md b/thinkings/dynamic-programming.md
index aa88db8b3..a36caf93a 100644
--- a/thinkings/dynamic-programming.md
+++ b/thinkings/dynamic-programming.md
@@ -1,58 +1,69 @@
# 递归和动态规划
-动态规划可以理解为是查表的递归。那么什么是递归?
+动态规划可以理解为是**查表的递归(记忆化)**。那么什么是递归?什么是查表(记忆化)?
## 递归
-定义: 递归算法是一种直接或者间接调用自身函数或者方法的算法。
+递归是指在函数的定义中使用函数自身的方法。
-算法中使用递归可以很简单地完成一些用循环实现的功能,比如二叉树的左中右序遍历。递归在算法中有非常广泛的使用,
-包括现在日趋流行的函数式编程。
+算法中使用递归可以很简单地完成一些用循环实现的功能,比如二叉树的左中右序遍历。递归在算法中有非常广泛的使用,包括现在日趋流行的函数式编程。
-> 纯粹的函数式编程中没有循环,只有递归。
+有意义的递归算法会把问题分解成规模缩小的同类子问题,当子问题缩减到寻常的时候,就可以知道它的解。然后建立递归函数之间的联系即可解决原问题,这也是我们使用递归的意义。准确来说, 递归并不是算法,它是和迭代对应的一种编程方法。只不过,由于隐式地借助了函数调用栈,因此递归写起来更简单。
-接下来我们来讲解一下递归。通俗来说,递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解
+一个问题要使用递归来解决必须有递归终止条件(算法的有穷性)。虽然以下代码也是递归,但由于其无法结束,因此不是一个有效的算法:
-### 递归的三个要素
+```py
+def f(n):
+ return n + f(n - 1)
+```
-1. 一个问题的解可以分解为几个子问题的解
-2. 子问题的求解思路除了规模之外,没有任何区别
-3. 有递归终止条件
+更多的情况应该是:
-我这里列举了几道算法题目,这几道算法题目都可以用递归轻松写出来:
+```py
+def f(n):
+ if n == 1: return 1
+ return n + f(n - 1)
+```
-- 递归实现 sum
+### 练习递归
-- 二叉树的遍历
+一个简单练习递归的方式是将你写的迭代全部改成递归形式。比如你写了一个程序,功能是“将一个字符串逆序输出”,那么使用迭代将其写出来会非常容易,那么你是否可以使用递归写出来呢?通过这样的练习,可以让你逐步适应使用递归来写程序。
-- 走楼梯问题
+如果你已经对递归比较熟悉了,那么我们继续往下看。
-- 汉诺塔问题
+### 递归中的重复计算
-- 杨辉三角
+递归中可能存在这么多的重复计算,为了消除这种重复计算,一种简单的方式就是记忆化递归。即一边递归一边使用“记录表”(比如哈希表或者数组)记录我们已经计算过的情况,当下次再次碰到的时候,如果之前已经计算了,那么直接返回即可,这样就避免了重复计算。而**动态规划中 DP 数组其实和这里“记录表”的作用是一样的**。
-### 练习递归
+### 递归的时间复杂度分析
-一个简单练习递归的方式是将你写的迭代全部改成递归形式。比如你写了一个程序,功能是“将一个字符串逆序输出”,那么使用迭代将其写出来会非常容易,那么你是否可以使用递归写出来呢?通过这样的练习,可以让你逐步适应使用递归来写程序。
+敬请期待我的新书。
-### 递归中的重复计算
+### 小结
-递归中存在这么多的重复计算,一种简单的方式就是记忆化递归。即一边递归一边使用“记录表”记录我们已经计算过的情况,这样就避免了重复计算。而动态规划中 DP 数组其实和“记录表”一样。
+使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。这里我列举了几道算法题目,这几道算法题目都可以用递归轻松写出来:
-你可以尝试使记忆化更加通用和非侵入性,即应用记忆化技术而不改变原来的功能。 (提示:可以参考一种被称作 decorator 的设计模式)。
+- 递归实现 sum
-### 递归的时间复杂度分析
+- 二叉树的遍历
-敬请期待我的新书。
+- 走楼梯问题
+
+- 汉诺塔问题
+
+- 杨辉三角
+
+当你已经适应了递归的时候,那就让我们继续学习动态规划吧!
## 动态规划
-`如果说递归是从问题的结果倒推,直到问题的规模缩小到寻常。 那么动态规划就是从寻常入手, 逐步扩大规模到最优子结构。` 这句话需要一定的时间来消化,
-如果不理解,可以过一段时间再来看。
+如果你已经熟悉了递归的技巧,那么使用递归解决问题非常符合人的直觉,代码写起来也比较简单。这个时候我们来关注另一个问题 - **重复计算** 。我们可以通过分析(可以尝试画一个递归树),可以看出递归在缩小问题规模的同时**是否可能会重复计算**。 [279.perfect-squares](../problems/279.perfect-squares.md) 中 我通过递归的方式来解决这个问题,同时内部维护了一个缓存来存储计算过的运算,这么做可以减少很多运算。 这其实和动态规划有着异曲同工的地方。
+
+> 小提示:如果你发现并没有重复计算,那么就没有必要用记忆化递归或者动态规划了。
+
+因此动态规划就是枚举所以可能。不过相比暴力枚举,动态规划不会有重复计算。因此如何保证枚举时不重不漏是关键点之一。 递归由于使用了函数调用栈来存储数据,因此如果栈变得很大,那么会容易爆栈。
-递归的解决问题非常符合人的直觉,代码写起来比较简单。但是我们通过分析(可以尝试画一个递归树),可以看出递归在缩小问题规模的同时可能会
-重复计算。 [279.perfect-squares](../problems/279.perfect-squares.md) 中 我通过递归的方式来解决这个问题,同时内部维护了一个缓存
-来存储计算过的运算,那么我们可以减少很多运算。 这其实和动态规划有着异曲同工的地方。
+### 爆栈
我们结合求和问题来讲解一下,题目是给定一个数组,求出数组中所有项的和,要求使用递归实现。
@@ -69,19 +80,21 @@ function sum(nums) {
我们用递归树来直观地看一下。
-
+
-这种做法本身没有问题,但是每次执行一个函数都有一定的开销,拿 JS 引擎执行 JS 来说,
-每次函数执行都会进行入栈操作,并进行预处理和执行过程,所以对于内存来说是一个挑战。
-很容易造成爆栈。
+这种做法本身没有问题,但是每次执行一个函数都有一定的开销,拿 JS 引擎执行 JS 来说,每次函数执行都会进行入栈操作,并进行预处理和执行过程,所以内存会有额外的开销,数据量大的时候很容易造成爆栈。
> 浏览器中的 JS 引擎对于代码执行栈的长度是有限制的,超过会爆栈,抛出异常。
-我们再举一个更加明显的例子,问题描述:
+### 重复计算
+
+我们再举一个重复计算的例子,问题描述:
一个人爬楼梯,每次只能爬 1 个或 2 个台阶,假设有 n 个台阶,那么这个人有多少种不同的爬楼梯方法?
-代码:
+由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 `上 n - 1 级台阶的数目加上 n - 1 级台阶的数目`。
+
+递归代码:
```js
function climbStairs(n) {
@@ -91,18 +104,55 @@ function climbStairs(n) {
}
```
-这道题和 fibnacci 数列一摸一样,我们继续用一个递归树来直观感受以下:
+我们继续用一个递归树来直观感受以下:
+
+
-
+> 红色表示重复的计算
可以看出这里面有很多重复计算,我们可以使用一个 hashtable 去缓存中间计算结果,从而省去不必要的计算。
-那么动态规划是怎么解决这个问题呢? 答案就是“查表”。
-刚才我们说了`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
+那么动态规划是怎么解决这个问题呢? 答案也是“查表”,不过区别于递归使用函数调用栈,动态规划通常使用的是 dp 数组,数组的索引通常是问题规模,值通常是递归函数的返回值。`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
+
+如果上面的爬楼梯问题,使用动态规划,代码是这样的:
+
+```js
+function climbStairs(n) {
+ if (n == 1) return 1;
+ const dp = new Array(n);
+ dp[0] = 1;
+ dp[1] = 2;
+
+ for (let i = 2; i < n; i++) {
+ dp[i] = dp[i - 1] + dp[i - 2];
+ }
+ return dp[dp.length - 1];
+}
+```
+
+不会也没关系,我们将递归的代码稍微改造一下。其实就是将函数的名字改一下:
+
+```js
+function dp(n) {
+ if (n === 1) return 1;
+ if (n === 2) return 2;
+ return dp(n - 1) + dp(n - 2);
+}
+```
+
+> dp[n] 和 dp(n) 对比看,这样是不是有点理解了呢? 只不过递归用调用栈枚举状态, 而动态规划使用迭代枚举状态。
+
+动态规划的查表过程如果画成图,就是这样的:
+
+
+
+> 虚线代表的是查表过程
+
+这道题目是动态规划中最简单的问题了,因为设计到单个因素的变化,如果涉及到多个因素,就比较复杂了,比如著名的背包问题,挖金矿问题等。
-从刚才的两个例子,我想大家可能对前半句话有了一定的理解,我们接下来讲解下后半句。
+对于单个因素的,我们最多只需要一个一维数组即可,对于如背包问题我们需要二维数组等更高纬度。
-如果爬楼梯的问题,使用动态规划,代码是这样的:
+爬楼梯我们并没有必要使用一维数组,而是借助两个变量来实现的,空间复杂度是 O(1)。代码:
```js
function climbStairs(n) {
@@ -123,26 +173,25 @@ function climbStairs(n) {
}
```
-动态规划的查表过程如果画成图,就是这样的:
-
-
-
-> 虚线代表的是查表过程
-
-这道题目是动态规划中最简单的问题了,因为设计到单个因素的变化,如果涉及到多个因素,就比较复杂了,比如著名的背包问题,挖金矿问题等。
+之所以能这么做,是因为爬楼梯问题的状态转移方程中**当前状态只和前两个状态有关**,因此只需要存储这两个即可。 动态规划问题有很多这种讨巧的方式,这个技巧叫做滚动数组。
-对于单个因素的,我们最多只需要一个一维数组即可,对于如背包问题我们需要二维数组等更高纬度。
+再次强调一下:
-> 爬楼梯我们并没有使用一维数组,而是借助两个变量来实现的,空间复杂度是 O(1).
-> 之所以能这么做,是因为爬楼梯问题的状态转移方程只和前两个有关,因此只需要存储这两个即可。 动态规划问题有时候有很多这种讨巧的方式,但并不是所有的
+- 如果说递归是从问题的结果倒推,直到问题的规模缩小到寻常。 那么动态规划就是从寻常入手, 逐步扩大规模到最优子结构。
+- 记忆化递归和动态规划没有本质不同。都是枚举状态,并根据状态直接的联系逐步推导求解。
+- 动态规划性能通常更好。 一方面是递归的栈开销,一方面是滚动数组的技巧。
-### 动态规划的两个要素
+### 动态规划的三个要素
1. 状态转移方程
2. 临界条件
-在上面讲解的爬楼梯问题中
+3. 枚举状态
+
+> 可以看出,用递归解决也是一样的思路
+
+在上面讲解的爬楼梯问题中,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么:
```
f(1) 与 f(2) 就是【边界】
@@ -150,41 +199,130 @@ f(n) = f(n-1) + f(n-2) 就是【状态转移公式】
```
+我用动态规划的形式表示一下:
+
+```
+dp[0] 与 dp[1] 就是【边界】
+dp[n] = dp[n - 1] + dp[n - 2] 就是【状态转移方程】
+```
+
+可以看出两者是多么的相似。
+
+实际上临界条件相对简单,大家只有多刷几道题,里面就有感觉。困难的是找到状态转移方程和枚举状态。这两个核心点的都建立在**已经抽象好了状态**的基础上。比如爬楼梯的问题,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么 f(1), f(2), ... 就是各个**独立的状态**。
+
+不过状态的定义都有特点的套路。 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ....。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ....。
+
+当然状态转移方程可能不止一个, 不同的转移方程对应的效率也可能大相径庭,这个就是比较玄学的话题了,需要大家在做题的过程中领悟。
+
+搞定了状态的定义,那么我们来看下状态转移方程。
+
+#### 状态转移方程
+
+爬楼梯问题由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 `上 n - 1 级台阶的数目加上 n - 1 级台阶的数目`。
+
+上面的这个理解是核心, 它就是我们的状态转移方程,用代码表示就是 `f(n) = f(n - 1) + f(n - 2)`。
+
+实际操作的过程,有可能题目和爬楼梯一样直观,我们不难想到。也可能隐藏很深或者维度过高。 如果你实在想不到,可以尝试画图打开思路,这也是我刚学习动态规划时候的方法。当你做题量上去了,你的题感就会来,那个时候就可以不用画图了。
+
+状态转移方程实在是没有什么灵丹妙药,不同的题目有不同的解法。状态转移方程同时也是解决动态规划问题中最最困难和关键的点,大家一定要多多练习,提高题感。接下来,我们来看下不那么困难,但是新手疑问比较多的问题 - **如何枚举状态**。
+
+#### 如何枚举状态
+
+前面说了如何枚举状态,才能不重不漏是枚举状态的关键所在。
+
+- 如果是一维状态,那么我们使用一层循环可以搞定。
+- 如果是两维状态,那么我们使用两层循环可以搞定。
+- 。。。
+
+这样可以保证不重不漏。
+
+但是实际操作的过程有很多细节比如:
+
+- 一维状态我是先枚举左边的还是右边的?(从左到右遍历还是从右到左遍历)
+- 二维状态我是先枚举左上边的还是右上的,还是左下的还是右下的?
+- 里层循环和外层循环的位置关系(可以互换么)
+- 。。。
+
+其实这个东西和很多因素有关,很难总结出一个规律,而且我认为也完全没有必要去总结规律。不过这里我还是总结了一个关键点,那就是:
+
+- **如果你没有使用滚动数组的技巧**,那么遍历顺序取决于状态转移方程。比如:
+
+```py
+for i in range(1, n + 1):
+ dp[i] = dp[i - 1] + 1;
+```
+
+那么我们就需要从左到右遍历,原因很简单,因为 dp[i] 依赖于 dp[i - 1],因此计算 dp[i] 的时候, dp[i - 1] 需要已经计算好了。
+
+> 二维的也是一样的,大家可以试试。
+
+- **如果你使用了滚动数组的技巧**,则怎么遍历都可以,但是不同的遍历意义通常不不同的。比如我将二维的压缩到了一维:
+
+```py
+for i in range(1, n + 1):
+ for j in range(1, n + 1):
+ dp[j] = dp[j - 1] + 1;
+```
+
+这样是可以的。 dp[j - 1] 实际上指的是压缩前的 dp[i][j - 1]
+
+而:
+
+```py
+for i in range(1, n + 1):
+ # 倒着遍历
+ for j in range(n, 0, -1):
+ dp[j] = dp[j - 1] + 1;
+```
+
+这样也是可以的。 但是 dp[j - 1] 实际上指的是压缩前的 dp[i - 1][j - 1]。因此实际中采用怎么样的遍历手段取决于题目。我特意写了一个 [【完全背包问题】套路题(1449. 数位成本和为目标值的最大数字](https://leetcode-cn.com/problems/form-largest-integer-with-digits-that-add-up-to-target/solution/wan-quan-bei-bao-wen-ti-tao-lu-ti-1449-shu-wei-che/) 文章,通过一个具体的例子告诉大家不同的遍历有什么实际不同,强烈建议大家看看,并顺手给个三连。
+
+- 关于里外循环的问题,其实和上面原理类似。
+
+这个比较微妙,大家可以参考这篇文章理解一下 [0518.coin-change-2](../problems/518.coin-change-2.md)。
+
+#### 小结
+
+关于如何确定临界条件通常是比较简单的,多做几个题就可以快速掌握。
+
+关于如何确定状态转移方程,这个其实比较困难。 不过所幸的是,这些套路性比较强, 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ....。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ....。 这样遇到新的题目可以往上套, 实在套不出那就先老实画图,不断观察,提高题感。
+
+关于如何枚举状态,如果没有滚动数组, 那么根据转移方程决定如何枚举即可。 如果用了滚动数组,那么要注意压缩后和压缩前的 dp 对应关系即可。
+
### 动态规划为什么要画表格
动态规划问题要画表格,但是有的人不知道为什么要画,就觉得这个是必然的,必要要画表格才是动态规划。
-其实动态规划本质上是将大问题转化为小问题,然后大问题的解是和小问题有关联的,换句话说大问题可以由小问题进行计算得到。
-
-这一点是和递归一样的, 但是动态规划是一种类似查表的方法来缩短时间复杂度和空间复杂度。
+其实动态规划本质上是将大问题转化为小问题,然后大问题的解是和小问题有关联的,换句话说大问题可以由小问题进行计算得到。这一点是和用递归解决一样的, 但是动态规划是一种类似查表的方法来缩短时间复杂度和空间复杂度。
画表格的目的就是去不断推导,完成状态转移, 表格中的每一个 cell 都是一个`小问题`, 我们填表的过程其实就是在解决问题的过程,
+
我们先解决规模为寻常的情况,然后根据这个结果逐步推导,通常情况下,表格的右下角是问题的最大的规模,也就是我们想要求解的规模。
比如我们用动态规划解决背包问题, 其实就是在不断根据之前的小问题`A[i - 1][j] A[i -1][w - wj]`来询问:
-1. 我是应该选择它
-2. 还是不选择它
+- 应该选择它
+- 还是不选择它
至于判断的标准很简单,就是价值最大,因此我们要做的就是对于选择和不选择两种情况分别求价值,然后取最大,最后更新 cell 即可。
-其实大部分的动态规划问题套路都是“选择”或者“不选择”,也就是说是一种“选择题”。 并且大多数动态规划题目还伴随着空间的优化,这是动态规划相对于传统的记忆化递归优势的地方。除了这点优势,就是上文提到的使用动态规划可以减少递归产生的函数调用栈,因此性能上更好。
+其实大部分的动态规划问题套路都是“选择”或者“不选择”,也就是说是一种“选择题”。 并且大多数动态规划题目还伴随着空间的优化(滚动数组),这是动态规划相对于传统的记忆化递归优势的地方。除了这点优势,就是上文提到的使用动态规划可以减少递归产生的函数调用栈,因此性能上更好。
### 相关问题
- [0091.decode-ways](../problems/91.decode-ways.md)
- [0139.word-break](../problems/139.word-break.md)
-- [0198.house-robber](../problems/0198.house-robber.md)
+- [0198.house-robber](../problems/198.house-robber.md)
- [0309.best-time-to-buy-and-sell-stock-with-cooldown](../problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
- [0322.coin-change](../problems/322.coin-change.md)
- [0416.partition-equal-subset-sum](../problems/416.partition-equal-subset-sum.md)
- [0518.coin-change-2](../problems/518.coin-change-2.md)
-> 太多了,没有逐一列举
-
## 总结
-本篇文章总结了算法中比较常用的两个方法 - 递归和动态规划。
+本篇文章总结了算法中比较常用的两个方法 - 递归和动态规划。递归的话可以拿树的题目练手,动态规划的话则将我上面推荐的刷完,再考虑去刷力扣的动态规划标签即可。
+
+大家前期学习动态规划的时候,可以先尝试使用记忆化递归解决。然后将其改造为动态规划,这样多练习几次就会有感觉。之后大家可以练习一下滚动数组,这个技巧很有用,并且相对来说比较简单。 比较动态规划的难点在于**枚举所以状态(无重复)** 和 **寻找状态转移方程**。
如果你只能记住一句话,那么请记住:`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
diff --git a/thinkings/greedy.md b/thinkings/greedy.md
index 179ac3190..3576b6292 100644
--- a/thinkings/greedy.md
+++ b/thinkings/greedy.md
@@ -42,11 +42,11 @@ LeetCode 上对于贪婪策略有 73 道题目。我们将其分成几个类型
如下图,开始的位置是 2,可跳的范围是橙色的。然后因为 3 可以跳的更远,所以跳到 3 的位置。
-
+
如下图,然后现在的位置就是 3 了,能跳的范围是橙色的,然后因为 4 可以跳的更远,所以下次跳到 4 的位置。
-
+
写代码的话,我们用 end 表示当前能跳的边界,对于上边第一个图的橙色 1,第二个图中就是橙色的 4,遍历数组的时候,到了边界,我们就重新更新新的边界。
@@ -125,7 +125,7 @@ class Solution:
贪婪策略,我们选择满足条件的最大值。和上面的不同,这次我们需要手动进行一次排序,实际上贪婪策略经常伴随着排序,我们按照 clip[0]从小到大进行排序。
-
+
如图:
@@ -137,11 +137,11 @@ class Solution:
那么这种情况下 t1 实际上是不需要的,因为 t2 完全可以覆盖它:
-
+
那什么样 t1 才是需要的呢?如图:
-
+
用代码来说的话就是`s > t2 and t2 <= t1`
@@ -191,7 +191,7 @@ class Solution:
示例 1:
-
+
输入:n = 5, ranges = [3,4,1,1,0,0]
输出:1
diff --git a/thinkings/prefix.md b/thinkings/prefix.md
new file mode 100644
index 000000000..6adb11fbc
--- /dev/null
+++ b/thinkings/prefix.md
@@ -0,0 +1,4 @@
+## 题目列表
+
+- [掌握前缀表达式真的可以为所欲为!](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)
+- [1371.find-the-longest-substring-containing-vowels-in-even-counts](../problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md) 🆕
diff --git a/thinkings/run-length-encode-and-huffman-encode.md b/thinkings/run-length-encode-and-huffman-encode.md
index c1a11e4c4..92d1e754e 100644
--- a/thinkings/run-length-encode-and-huffman-encode.md
+++ b/thinkings/run-length-encode-and-huffman-encode.md
@@ -38,7 +38,7 @@ eg:
结果是这样的:
-
+
|character|frequency|encoding|
|:-:|:-:|:-:|
diff --git a/thinkings/slide-window.en.md b/thinkings/slide-window.en.md
new file mode 100644
index 000000000..4f4729d3c
--- /dev/null
+++ b/thinkings/slide-window.en.md
@@ -0,0 +1,87 @@
+# Sliding Window Technique
+
+I first encountered the term "sliding window" when learning about the sliding window protocols, which is used in Transmission Control Protocol (TCP) for packet-based data transimission. It is used to improved transmission efficiency in order to avoid congestions. The sender and the receiver each has a window size, w1 and w2, respectively. The window size may vary based on the network traffic flow. However, in a simpler implementation, the sizes are fixed, and they must be greater than 0 to perform any task.
+
+The sliding window technique in algorithms is very similar, but it applies to more scenarios. Now, let's go over this technique.
+
+## Introduction
+
+Sliding window technique, also known as two pointers technique, can help reduce time complexity in problems that ask for "consecutive" or "contiguous" items. For example, [209. Minimum Size Subarray Sum](https://leetcode-cn.com/problems/minimum-size-subarray-sum/solution/209-chang-du-zui-xiao-de-zi-shu-zu-hua-dong-chua-2/). For more related problems, go to the `List of Problems` below.
+
+## Common Types
+
+This technique is mainly for solving problems ask about "consecutive substring" or "contiguous subarray". It would be helpful if you can relate these terms with this technique in your mind. Whether the technique solve the exact problem or not, it would come in handy.
+
+There are mainly three types of application:
+
+- Fixed window size
+- Variable window size and looking for the maximum window size that meet the requirement
+- Variable window size and looking for the minimum window size that meet the requirement (e.g. Problem#209 mentioned above)
+
+The last two are catogorized as "variable window". Of course, they are all of the same essentially. It's all about the implementation details.
+
+### Fixed Window Size
+
+For fixed window size problem, we only need to keep track of the left pointer l and the right pointer r, which indicate the boundaries of a fixed window, and make sure that:
+
+1. l is initialized to be 0
+2. r is initialied such that the window's size = r - l + 1
+3. Always move l and r simultaneously
+4. Decide if the consecutive elements contained within the window satisfy the required conditions.
+ - 4.1 If they satisfy, based on whether we need an optimal solution or not, we either return the solution or keep updating until we find the optimal one.
+ - 4.2 Otherwise, we continue to find an appropriate window
+
+
+
+### Variable Window Size
+
+For variable window, we initialize the left and right pointers the same way. Then we need to make sure that:
+
+1. Both l and r are initialized to 0
+2. Move r to the right by one step
+3. Decide if the consecutive elements contained within the window satisfy the required conditions
+ - 3.1 If they satisfy
+ - 3.1.1 and we need an optimal solution, we try moving the pointer l to minimize our window's size and repeat step 3.1
+ - 3.1.2 else we return the current solution
+ - 3.2 If they don't satisfy, we continue to find an appropriate window
+
+If we view it another way, it's simply moving the pointer r to find an appropriate window and we only move the pointer l once we find an appropriate window to minimize the window and find an optimal solution.
+
+
+
+## Code Template
+
+The following code snippet is a solution for problem #209 written in Python.
+
+```python
+class Solution:
+ def minSubArrayLen(self, s: int, nums: List[int]) -> int:
+ l = total = 0
+ ans = len(nums) + 1
+ for r in range(len(nums)):
+ total += nums[r]
+ while total >= s:
+ ans = min(ans, r - l + 1)
+ total -= nums[l]
+ l += 1
+ return 0 if ans == len(nums) + 1 else ans
+```
+
+## List of problems (Not Translated Yet)
+
+Some problems here are intuitive that you know the sliding window technique would be useful while others need a second thought to realize that.
+
+- [【Python,JavaScript】滑动窗口(3. 无重复字符的最长子串)](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/solution/pythonjavascript-hua-dong-chuang-kou-3-wu-zhong-fu/)
+- [76. 最小覆盖子串](https://leetcode-cn.com/problems/minimum-window-substring/solution/python-hua-dong-chuang-kou-76-zui-xiao-fu-gai-zi-c/)
+- [209. 长度最小的子数组](https://leetcode-cn.com/problems/minimum-size-subarray-sum/solution/209-chang-du-zui-xiao-de-zi-shu-zu-hua-dong-chua-2/)
+- [【Python】滑动窗口(438. 找到字符串中所有字母异位词)](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/solution/python-hua-dong-chuang-kou-438-zhao-dao-zi-fu-chua/)
+- [【904. 水果成篮】(Python3)](https://leetcode-cn.com/problems/fruit-into-baskets/solution/904-shui-guo-cheng-lan-python3-by-fe-lucifer/)
+- [【930. 和相同的二元子数组】(Java,Python)](https://leetcode-cn.com/problems/binary-subarrays-with-sum/solution/930-he-xiang-tong-de-er-yuan-zi-shu-zu-javapython-/)
+- [【992. K 个不同整数的子数组】滑动窗口(Python)](https://leetcode-cn.com/problems/subarrays-with-k-different-integers/solution/992-k-ge-bu-tong-zheng-shu-de-zi-shu-zu-hua-dong-c/)
+- [【1004. 最大连续 1 的个数 III】滑动窗口(Python3)](https://leetcode-cn.com/problems/max-consecutive-ones-iii/solution/1004-zui-da-lian-xu-1de-ge-shu-iii-hua-dong-chuang/)
+- [【1234. 替换子串得到平衡字符串】[Java/C++/Python] Sliding Window](https://leetcode.com/problems/replace-the-substring-for-balanced-string/discuss/408978/javacpython-sliding-window/367697)
+- [【1248. 统计「优美子数组」】滑动窗口(Python)](https://leetcode-cn.com/problems/count-number-of-nice-subarrays/solution/1248-tong-ji-you-mei-zi-shu-zu-hua-dong-chuang-kou/)
+
+## Further Readings
+
+- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)(English)
diff --git a/thinkings/slide-window.md b/thinkings/slide-window.md
index 5f3f1766a..429bbf6d5 100644
--- a/thinkings/slide-window.md
+++ b/thinkings/slide-window.md
@@ -31,7 +31,7 @@
- 4.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解
- 4.2 如果不满足,则继续。
-
+
### 可变窗口大小
@@ -39,16 +39,30 @@
1. l 和 r 都初始化为 0
2. r 指针移动一步
-4. 判断窗口内的连续元素是否满足题目限定的条件
- - 4.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解。并尝试通过移动 l 指针缩小窗口大小。循环执行 4.1
- - 4.2 如果不满足,则继续。
+3. 判断窗口内的连续元素是否满足题目限定的条件
+ - 3.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解。并尝试通过移动 l 指针缩小窗口大小。循环执行 3.1
+ - 3.2 如果不满足,则继续。
形象地来看的话,就是 r 指针不停向右移动,l 指针仅仅在窗口满足条件之后才会移动,起到窗口收缩的效果。
-
+
## 模板代码
+### 伪代码
+```
+初始化慢指针 = 0
+初始化 ans
+
+for 快指针 in 可迭代集合
+ 更新窗口内信息
+ while 窗口内不符合题意
+ 扩展或者收缩窗口
+ 慢指针移动
+返回 ans
+```
+### 代码
+
以下是 209 题目的代码,使用 Python 编写,大家意会即可。
```python
@@ -65,7 +79,7 @@ class Solution:
return 0 if ans == len(nums) + 1 else ans
```
-## 题目列表
+## 题目列表(有题解)
以下题目有的信息比较直接,有的题目信息比较隐蔽,需要自己发掘
@@ -80,6 +94,7 @@ class Solution:
- [【1234. 替换子串得到平衡字符串】[Java/C++/Python] Sliding Window](https://leetcode.com/problems/replace-the-substring-for-balanced-string/discuss/408978/javacpython-sliding-window/367697)
- [【1248. 统计「优美子数组」】滑动窗口(Python)](https://leetcode-cn.com/problems/count-number-of-nice-subarrays/solution/1248-tong-ji-you-mei-zi-shu-zu-hua-dong-chuang-kou/)
+
## 扩展阅读
-- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)
\ No newline at end of file
+- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)
diff --git a/thinkings/trie.en.md b/thinkings/trie.en.md
new file mode 100644
index 000000000..64593b643
--- /dev/null
+++ b/thinkings/trie.en.md
@@ -0,0 +1,25 @@
+## Trie
+
+When this article is done (2020-07-13), there are 17 LeetCode problems about [Trie (Prefix Tree)](https://leetcode.com/tag/trie/). Among them, 2 problems are easy, 8 are medium, and 7 are hard.
+
+Here we summarize four of them. Once you figure them out, `Trie` should not be a challenge to you anymore. Hope this article is helpful to you.
+
+The main interface of a trie should include the following:
+
+- `insert(word)`: Insert a word
+- `search(word)`: Search for a word
+- `startWith(prefix)`: Search for a word with the given prefix
+
+Among all of the above, `startWith` is one of the most essential methods, which leads to the naming for 'Prefix Tree'. You can start with [208.implement-trie-prefix-tree](https://leetcode.com/problems/implement-trie-prefix-tree) to get yourself familiar with this data structure, and then try to solve other problems.
+
+Here's the graph illustration of a trie:
+
+
+As the graph shows, each node of the trie would store a character and a boolean `isWord`, which suggests whether the node is the end of a word. There might be some slight differences in the actual implementation, but they are essentially the same.
+
+### Related Problems' Solutions in this Repo (To Be Updated)
+- [0208.implement-trie-prefix-tree](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
+- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
diff --git a/thinkings/trie.md b/thinkings/trie.md
index c9ff2feaf..e2f1696dc 100644
--- a/thinkings/trie.md
+++ b/thinkings/trie.md
@@ -14,7 +14,7 @@
一个前缀树大概是这个样子:
-
+
如图每一个节点存储一个字符,然后外加一个控制信息表示是否是单词结尾,实际使用过程可能会有细微差别,不过变化不大。
@@ -25,3 +25,4 @@
- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](../problems/1032.stream-of-characters.md)
diff --git a/thinkings/union-find.en.md b/thinkings/union-find.en.md
new file mode 100644
index 000000000..d8effbf2a
--- /dev/null
+++ b/thinkings/union-find.en.md
@@ -0,0 +1,146 @@
+# Union Find Data Structure
+
+Leetcode has many problems concerning the union-find data structure. To be specific, the official number is 30(until 2020-02-20). And some problems, though not labeled with `Union Find`, can be solved more easily by applying this data structure. A problem-solving pattern can be found among this kind of problem. Once you have grasped the pattern, you can solve these problems with higher speed and fewer mistakes, which is the benefit of using patterns.
+
+Related problems:
+
+- [547. Friend Circles](../problems/547.friend-circles.md) Chinese
+- [721. Accounts Merge](https://leetcode-cn.com/problems/accounts-merge/solution/mo-ban-ti-bing-cha-ji-python3-by-fe-lucifer-3/) Chinese
+- [990. Satisfiability of Equality Equations](https://github.com/azl397985856/leetcode/issues/304) Chinese
+
+It's recommended that you practice with these problems after reading this blog, to see if you understand the idea of a union-find data structure.
+
+## Overview
+
+A disjoint-set data structure (also called a union-find data structure or merge–find set) is a tree-like data structure that supports union & find operations on disjoint sets. A union-find algorithm is an algorithm that performs two operations on such a data structure.
+
+- Find: Determine which subset a particular element is in. This can be used for determining if two elements are in the same subset.
+- Union: Join two subsets into a single subset.
+
+To define how these operations work more precisely, we need to first define how subsets are represented. A common strategy is to choose one member from each subset to represent it, called the representative. Find(x) operation will return the representative of the subset in which x exists and Union operation accepts two representatives as parameters.
+
+## Lively Explanation
+
+Let's say there are two Marshals, each holds a group of Generals, which holds a group of sergeants, and so on.
+
+How do we determine whether two Generals belong two the same Marshal (connectivity)?
+
+
+
+The question is easy enough. All we have to do is to find the Marshals of these two Generals respectively. If the results are the same Marshal, then the two Generals belong to the same Marshal. Use `parent[x] = y` to represent `x's parent is y`. By looking for `parent` recursively, a `root` can be reached finally. Then a conclusion can be drawn by comparing the roots obtained.
+
+The process described above involves two basic operations: `find` and `connected`. Besides these two, `union` operation can be used to merge two subsets into one.
+
+There are two Marshals in the picture.
+
+
+
+How do we merge them? The simplest way is pointing one of the Marshals to the other one.
+
+
+
+Done with the lively explanation of the three core APIs `find`, `connected`, and `union`. Now let's see how to implement these APIs.
+
+## Core API
+
+### find
+
+```python
+def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ return x
+```
+
+### connected
+
+```python
+def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+### union
+
+```python
+def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+```
+
+## Complete Code
+
+```python
+class UF:
+ parent = {}
+ cnt = 0
+ def __init__(self, M):
+ # Initiate parent and cnt
+
+ def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ return x
+ def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+ self.cnt -= 1
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+## Code with path compression
+
+```python
+class UF:
+ parent = {}
+ size = {}
+ cnt = 0
+ def __init__(self, M):
+ # Initiate parent, size and cnt
+
+ def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ # path compression
+ self.parent[x] = self.parent[self.parent[x]];
+ return x
+ def union(self, p, q):
+ if self.connected(p, q): return
+ # Attach the tree with fewer elements to the root of the tree with more elements in order to balance the tree.
+ leader_p = self.find(p)
+ leader_q = self.find(q)
+ if self.size[leader_p] < self.size[leader_q]:
+ self.parent[leader_p] = leader_q
+ else:
+ self.parent[leader_q] = leader_p
+ self.cnt -= 1
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+The code above implements path compression with recursion, which, though is easier to write, contains the risk of stack overflow. The following is how we can do it with iteration.
+
+```python
+class UF:
+ parent = {}
+ def __init__(self, equations):
+ # Initiation
+
+ def find(self, x):
+ # root
+ r = x
+ while r != parent[r]:
+ r = parent[r]
+ k = x
+ while k != r:
+ # Store the parent node of parent[k] temporarily.
+ j = parent[k]
+ parent[k] = r
+ k = j
+ return r
+ def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
diff --git a/thinkings/union-find.md b/thinkings/union-find.md
index 972975f20..02d330db1 100644
--- a/thinkings/union-find.md
+++ b/thinkings/union-find.md
@@ -25,7 +25,7 @@
我们如何判断某两个师长是否属于同一个司令呢(连通性)?
-
+
很简单,我们顺着师长,往上找,找到司令。 如果两个师长找到的是同一个司令,那么就属于同一个司令。我们用 parent[x] = y 表示 x 的 parent 是 y,通过不断沿着搜索 parent 搜索找到 root,然后比较 root 是否相同即可得出结论。
@@ -33,11 +33,11 @@
如图有两个司令:
-
+
我们将其合并为一个联通域,最简单的方式就是直接将其中一个司令指向另外一个即可:
-
+
以上就是三个核心 API `find`,`connnected` 和 `union`, 的形象化解释,下面我们来看下代码实现。
@@ -111,8 +111,10 @@ class UF:
leader_q = self.find(q)
if self.size[leader_p] < self.size[leader_q]:
self.parent[leader_p] = leader_q
+ self.size[leader_p] += self.size[leader_q]
else:
self.parent[leader_q] = leader_p
+ self.size[leader_q] += self.size[leader_p]
self.cnt -= 1
def connected(self, p, q):
return self.find(p) == self.find(q)
+## 捐赠
+
+[点击查看完整的捐赠列表](./donation.md)
+
## 贡献
- 如果有想法和创意,请提 [issue](https://github.com/azl397985856/leetcode/issues) 或者进群提
-- 如果想贡献代码,请提 [PR](https://github.com/azl397985856/leetcode/pulls)
+- 如果想贡献增加题解或者翻译, 可以参考[贡献指南](./CONTRIBUTING.md)
> 关于如何提交题解,我写了一份 [指南](./templates/problems/1014.best-sightseeing-pair.md)
- 如果需要修改项目中图片,[这里](./assets/drawio/) 存放了项目中绘制图的源代码, 大家可以用 [draw.io](https://www.draw.io/) 打开进行编辑。
@@ -398,4 +243,4 @@ anki - 文件 - 导入 - 下拉格式选择“打包的 anki 集合”,然后
## License
-[Apache-2.0](./LICENSE.txt)
+[CC BY-NC-ND 4.0](./LICENSE.txt)
diff --git a/assets/drawio/208.implement-trie-prefix-tree.en.drawio b/assets/drawio/208.implement-trie-prefix-tree.en.drawio
new file mode 100644
index 000000000..d0543b9e5
--- /dev/null
+++ b/assets/drawio/208.implement-trie-prefix-tree.en.drawio
@@ -0,0 +1 @@
+7Ztdj6M2FIZ/TS4bgc1HcjlJN7sXXXWrqTSXKy92AlqDqe1sMv31tYMhgMkOVQlEHRJpEr824HkfsA/HZAG36fkjR3n8mWFCF8DB5wX8dQHA2nfVXy28FoIXrgvhwBNcSO5VeE7+JkZ0jHpMMBGNhpIxKpO8KUYsy0gkGxrinJ2azfaMNo+aowOxhOcIUVt9SbCMC3XlO1f9E0kOcXlk1zE1KSobG0HECLNTTYIfFnDLGZPFt/S8JVR7V/pSbLe7UVt1jJNM9tngS/r8SYT+6Y/Njx14kfj3z3j1Cyj28gPRo/mHTWfla+mA2osyWxU2pziR5DlHka45KdxKi2VKVclVX5HICwL75EzUQTdm34RLcr7ZabeyQp1ChKVE8lfVxGzgrY175vRxA1M+XWGUUlzjUGrI4D9Ue746pL4Yk/6FYdAyDD2YY6DpGPAmdsyzHMsfyzEYNB2D7sSO+Q/vmNtybDWxY4HlGH0wx8KmY97U41hoOUYezLHWOObDiR1bvT1VVlO8ozzASMTajEuhZpaQnH0nW0YZV0rGMm0wRd8I/cJEIhOWKTlSLhFVv9EeJioc+a3V4BuTkqW1Bk80OegKyTQcZErVflTXct3L9HzQcdoyFREiS0xyTiIkCV7mTKiWXy8xk2q/Tygt+7gA0HE2252iteFMItMFCAaasVrXBugYf0EHaf9epNcz6TuRbs0boGPeGJV02Z8Z9dCood8KEfypUbsz6hbqwVi3AmjP9Sdm3eO29p2xvhNq35katX1DnogXxrHSFvBJp4v40Q5tlQOyFcO2KbRhpQnG9FYwzNkxw9UZtGeZrAHZ7bwnEBjdpLjccBggALZvxWwgVU5qHCL2Df+7JuLDyYnYCYUWkT2i4n+MxGuNWqAjGHHhqEjsjMX7QlKNU1XSreMqGReJnRJ5X0g8pxXGBZMj6ZFzeTPoqoHpjr+KIK9c3QEdARglKPuaojxPssMyP4r4Gnq1MNzChRMVu5menYiQwxALVk1ibthzqoF3I9YjdzITq89EUxMDPVIgM7HaRAUmJ9YjkzETq81jTke0Ny6xHvmImViN2OTzGLDTCjOxnxDzvcmJ2WkH10Jmx+rNDJ8yLri87Kza3tfvAaN7922IxWsYYqvWeqrbsfbidQADdwNmZyXsa2wGdg0VOx4ZGBeYnbOAM7DbwGDHEwvjArMzGt4M7DYwr2MxY1xgdr7Dn4H9BNjkc5id7ghmYLeBdYWJowIrh+Q5ru/3hE7Q8fTwuHE97Mp2BFQaaxb60f/SneCvIyuMgOsQO2FYl4KD/vwzJgvzywD1yfWaulDeCFWQl6qcs4gIXWZ7LXKkDBUKU9UiOvKLncDJGNbCXh2+qmSqUuQsw8UmUYw4itQ1uyx7rVwoOl50qMdwMfR6wsDrBj7w3zxnYHlH/x+vclW8/mLiUlf72Qn88A8=
\ No newline at end of file
diff --git a/assets/problems/208.implement-trie-prefix-tree-1.en.png b/assets/problems/208.implement-trie-prefix-tree-1.en.png
new file mode 100644
index 000000000..3a5a98673
Binary files /dev/null and b/assets/problems/208.implement-trie-prefix-tree-1.en.png differ
diff --git a/collections/easy.md b/collections/easy.md
new file mode 100644
index 000000000..074a4a8d7
--- /dev/null
+++ b/collections/easy.md
@@ -0,0 +1,36 @@
+- [0001.two-sum](../problems/1.two-sum.md)
+- [0020.Valid Parentheses](../problems/20.valid-parentheses.md)
+- [0021.MergeTwoSortedLists](../problems/21.merge-two-sorted-lists.md)
+- [0026.remove-duplicates-from-sorted-array](../problems/26.remove-duplicates-from-sorted-array.md)
+- [0053.maximum-sum-subarray](../problems/53.maximum-sum-subarray-cn.md)
+- [0088.merge-sorted-array](../problems/88.merge-sorted-array.md)
+- [0101.symmetric-tree](../problems/101.symmetric-tree.md)🆕
+- [0104.maximum-depth-of-binary-tree](../problems/104.maximum-depth-of-binary-tree.md)
+- [0108.convert-sorted-array-to-binary-search-tree](../problems/108.convert-sorted-array-to-binary-search-tree.md)
+- [0121.best-time-to-buy-and-sell-stock](../problems/121.best-time-to-buy-and-sell-stock.md)
+- [0122.best-time-to-buy-and-sell-stock-ii](../problems/122.best-time-to-buy-and-sell-stock-ii.md)
+- [0125.valid-palindrome](../problems/125.valid-palindrome.md)
+- [0136.single-number](../problems/136.single-number.md)
+- [0155.min-stack](../problems/155.min-stack.md) 🆕
+- [0167.two-sum-ii-input-array-is-sorted](../problems/167.two-sum-ii-input-array-is-sorted.md)
+- [0169.majority-element](../problems/169.majority-element.md)
+- [0172.factorial-trailing-zeroes](../problems/172.factorial-trailing-zeroes.md)
+- [0190.reverse-bits](../problems/190.reverse-bits.md)
+- [0191.number-of-1-bits](../problems/191.number-of-1-bits.md)
+- [0198.house-robber](../problems/198.house-robber.md)
+- [0203.remove-linked-list-elements](../problems/203.remove-linked-list-elements.md)
+- [0206.reverse-linked-list](../problems/206.reverse-linked-list.md)
+- [0219.contains-duplicate-ii](../problems/219.contains-duplicate-ii.md)
+- [0226.invert-binary-tree](../problems/226.invert-binary-tree.md)
+- [0232.implement-queue-using-stacks](../problems/232.implement-queue-using-stacks.md) 🆕
+- [0263.ugly-number](../problems/263.ugly-number.md)
+- [0283.move-zeroes](../problems/283.move-zeroes.md)
+- [0342.power-of-four](../problems/342.power-of-four.md)
+- [0349.intersection-of-two-arrays](../problems/349.intersection-of-two-arrays.md)
+- [0371.sum-of-two-integers](../problems/371.sum-of-two-integers.md)
+- [0437.path-sum-iii](../problems/437.path-sum-iii.md) 🆕
+- [0455.AssignCookies](../problems/455.AssignCookies.md) 🆕
+- [0575.distribute-candies](../problems/575.distribute-candies.md)
+- [0874.walking-robot-simulation](../problems/874.walking-robot-simulation.md) 🆕
+- [1260.shift-2d-grid](../problems/1260.shift-2d-grid.md) 🆕
+- [1332.remove-palindromic-subsequences](../problems/1332.remove-palindromic-subsequences.md) 🆕
diff --git a/collections/hard.md b/collections/hard.md
new file mode 100644
index 000000000..ffc8ef8fc
--- /dev/null
+++ b/collections/hard.md
@@ -0,0 +1,27 @@
+- [0004.median-of-two-sorted-array](../problems/4.median-of-two-sorted-arrays.md)
+- [0023.merge-k-sorted-lists](../problems/23.merge-k-sorted-lists.md)
+- [0025.reverse-nodes-in-k-group](../problems/25.reverse-nodes-in-k-groups-cn.md)
+- [0030.substring-with-concatenation-of-all-words](../problems/30.substring-with-concatenation-of-all-words.md)
+- [0032.longest-valid-parentheses](../problems/32.longest-valid-parentheses.md)
+- [0042.trapping-rain-water](../problems/42.trapping-rain-water.md)🖊
+- [0052.N-Queens-II](../problems/52.N-Queens-II.md)
+- [0084.largest-rectangle-in-histogram](../problems/84.largest-rectangle-in-histogram.md)
+- [0085.maximal-rectangle](../problems/85.maximal-rectangle.md)
+- [0124.binary-tree-maximum-path-sum](../problems/124.binary-tree-maximum-path-sum.md)
+- [0128.longest-consecutive-sequence](../problems/128.longest-consecutive-sequence.md)
+- [0145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
+- [0212.word-search-ii](../problems/212.word-search-ii.md)
+- [0239.sliding-window-maximum](../problems/239.sliding-window-maximum.md)
+- [0295.find-median-from-data-stream](../problems/295.find-median-from-data-stream.md)
+- [0301.remove-invalid-parentheses](../problems/301.remove-invalid-parentheses.md)
+- [0312.burst-balloons](../problems/312.burst-balloons.md) 🆕
+- [0335.self-crossPing](../problems/335.self-crossing.md)
+- [0460.lfu-cache](../problems/460.lfu-cache.md)
+- [0472.concatenated-words](../problems/472.concatenated-words.md) 🆕
+- [0493.reverse-pairs](../problems/493.reverse-pairs.md) 🆕
+- [0887.super-egg-drop](../problems/887.super-egg-drop.md)
+- [0895.maximum-frequency-stack](../problems/895.maximum-frequency-stack.md) 🆕
+
+- [1032.stream-of-characters](../problems/1032.stream-of-characters.md) 🆕
+- [1168.optimize-water-distribution-in-a-village](../problems/1168.optimize-water-distribution-in-a-village-cn.md) 🆕
+- [1449.form-largest-integer-with-digits-that-add-up-to-target](../problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md) 🆕
diff --git a/collections/medium.md b/collections/medium.md
new file mode 100644
index 000000000..1f4bb8739
--- /dev/null
+++ b/collections/medium.md
@@ -0,0 +1,108 @@
+- [0002.add-two-numbers](../problems/2.add-two-numbers.md)
+- [0003.longest-substring-without-repeating-characters](../problems/3.longest-substring-without-repeating-characters.md)
+- [0005.longest-palindromic-substring](../problems/5.longest-palindromic-substring.md)
+- [0011.container-with-most-water](../problems/11.container-with-most-water.md)
+- [0015.3-sum](../problems/15.3sum.md)
+- [0017.Letter-Combinations-of-a-Phone-Number](../problems/17.Letter-Combinations-of-a-Phone-Number.md) 🆕
+- [0019. Remove Nth Node From End of List](../problems/19.removeNthNodeFromEndofList.md)
+- [0022.generate-parentheses.md](../problems/22.generate-parentheses.md) 🆕
+- [0024. Swap Nodes In Pairs](../problems/24.swapNodesInPairs.md)
+- [0029.divide-two-integers](../problems/29.divide-two-integers.md)
+- [0031.next-permutation](../problems/31.next-permutation.md)
+- [0033.search-in-rotated-sorted-array](../problems/33.search-in-rotated-sorted-array.md)
+- [0039.combination-sum](../problems/39.combination-sum.md)
+- [0040.combination-sum-ii](../problems/40.combination-sum-ii.md)
+- [0046.permutations](../problems/46.permutations.md)
+- [0047.permutations-ii](../problems/47.permutations-ii.md)
+- [0048.rotate-image](../problems/48.rotate-image.md)
+- [0049.group-anagrams](../problems/49.group-anagrams.md)
+- [0050.pow-x-n](../problems/50.pow-x-n.md) 🆕
+- [0055.jump-game](../problems/55.jump-game.md)
+- [0056.merge-intervals](../problems/56.merge-intervals.md)
+- [0060.permutation-sequence](../problems/60.permutation-sequence.md) 🆕
+- [0062.unique-paths](../problems/62.unique-paths.md) 🖊
+- [0073.set-matrix-zeroes](../problems/73.set-matrix-zeroes.md)
+- [0075.sort-colors](../problems/75.sort-colors.md)
+- [0078.subsets](../problems/78.subsets.md)
+- [0079.word-search](../problems/79.word-search-en.md)
+- [0080.remove-duplicates-from-sorted-array-ii](../problems/80.remove-duplicates-from-sorted-array-ii.md) 🆕
+- [0086.partition-list](../problems/86.partition-list.md)
+- [0090.subsets-ii](../problems/90.subsets-ii.md)
+- [0091.decode-ways](../problems/91.decode-ways.md)
+- [0092.reverse-linked-list-ii](../problems/92.reverse-linked-list-ii.md) 🖊
+- [0094.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
+- [0095.unique-binary-search-trees-ii](../problems/95.unique-binary-search-trees-ii.md) 🆕
+- [0096.unique-binary-search-trees](../problems/96.unique-binary-search-trees.md) 🆕
+- [0098.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
+- [0102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
+- [0103.binary-tree-zigzag-level-order-traversal](../problems/103.binary-tree-zigzag-level-order-traversal.md)
+- [105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md](../problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md)
+- [0113.path-sum-ii](../problems/113.path-sum-ii.md)
+- [0129.sum-root-to-leaf-numbers](../problems/129.sum-root-to-leaf-numbers.md)
+- [0130.surrounded-regions](../problems/130.surrounded-regions.md)
+- [0131.palindrome-partitioning](../problems/131.palindrome-partitioning.md)
+- [0139.word-break](../problems/139.word-break.md)
+- [0144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
+- [0150.evaluate-reverse-polish-notation](../problems/150.evaluate-reverse-polish-notation.md)
+- [0152.maximum-product-subarray](../problems/152.maximum-product-subarray.md) 🖊
+- [0199.binary-tree-right-side-view](../problems/199.binary-tree-right-side-view.md)
+- [0200.number-of-islands](../problems/200.number-of-islands.md) 🆕
+- [0201.bitwise-and-of-numbers-range](../problems/201.bitwise-and-of-numbers-range.md) 🖊
+- [0208.implement-trie-prefix-tree](../problems/208.implement-trie-prefix-tree.md)
+- [0209.minimum-size-subarray-sum](../problems/209.minimum-size-subarray-sum.md)
+- [0211.add-and-search-word-data-structure-design](../problems/211.add-and-search-word-data-structure-design.md) 🆕
+- [0215.kth-largest-element-in-an-array](../problems/215.kth-largest-element-in-an-array.md) 🆕
+- [0221.maximal-square](../problems/221.maximal-square.md)
+- [0229.majority-element-ii](../problems/229.majority-element-ii.md) 🆕
+- [0230.kth-smallest-element-in-a-bst](../problems/230.kth-smallest-element-in-a-bst.md)
+- [0236.lowest-common-ancestor-of-a-binary-tree](../problems/236.lowest-common-ancestor-of-a-binary-tree.md)
+- [0238.product-of-array-except-self](../problems/238.product-of-array-except-self.md)
+- [0240.search-a-2-d-matrix-ii](../problems/240.search-a-2-d-matrix-ii.md)
+- [0279.perfect-squares](../problems/279.perfect-squares.md)
+- [0309.best-time-to-buy-and-sell-stock-with-cooldown](../problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+- [0322.coin-change](../problems/322.coin-change.md)
+- [0328.odd-even-linked-list](../problems/328.odd-even-linked-list.md)
+- [0334.increasing-triplet-subsequence](../problems/334.increasing-triplet-subsequence.md)
+- [0337.house-robber-iii.md](../problems/337.house-robber-iii.md)
+- [0343.integer-break](../problems/343.integer-break.md)🆕
+- [0365.water-and-jug-problem](../problems/365.water-and-jug-problem.md)
+- [0378.kth-smallest-element-in-a-sorted-matrix](../problems/378.kth-smallest-element-in-a-sorted-matrix.md)
+- [0380.insert-delete-getrandom-o1](../problems/380.insert-delete-getrandom-o1.md)
+- [0416.partition-equal-subset-sum](../problems/416.partition-equal-subset-sum.md)🖊
+- [0445.add-two-numbers-ii](../problems/445.add-two-numbers-ii.md)
+- [0454.4-sum-ii](../problems/454.4-sum-ii.md)
+- [0474.ones-and-zeros](../problems/474.ones-and-zeros-en.md)
+- [0494.target-sum](../problems/494.target-sum.md)
+- [0516.longest-palindromic-subsequence](../problems/516.longest-palindromic-subsequence.md)
+- [0518.coin-change-2](../problems/518.coin-change-2.md)
+- [0547.friend-circles](../problems/547.friend-circles-en.md)
+- [0560.subarray-sum-equals-k](../problems/560.subarray-sum-equals-k.md)
+- [0609.find-duplicate-file-in-system](../problems/609.find-duplicate-file-in-system.md)
+- [0611.valid-triangle-number](../problems/611.valid-triangle-number.md)
+- [0718.maximum-length-of-repeated-subarray](../problems/718.maximum-length-of-repeated-subarray.md)
+- [0785.is-graph-bipartite](../problems/785.is-graph-bipartite.md) 🆕
+- [0820.short-encoding-of-words](../problems/820.short-encoding-of-words.md) 🖊
+- [0875.koko-eating-bananas](../problems/875.koko-eating-bananas.md)
+- [0877.stone-game](../problems/877.stone-game.md)
+- [0886.possible-bipartition](../problems/886.possible-bipartition.md) 🆕
+- [0900.rle-iterator](../problems/900.rle-iterator.md)
+- [0912.sort-an-array](../problems/912.sort-an-array.md)
+- [0935.knight-dialer](../problems/935.knight-dialer.md) 🆕
+- [1011.capacity-to-ship-packages-within-d-days](../problems/1011.capacity-to-ship-packages-within-d-days.md)
+- [1014.best-sightseeing-pair](../problems/1014.best-sightseeing-pair.md) 🆕
+- [1015.smallest-integer-divisible-by-k](../problems/1015.smallest-integer-divisible-by-k.md)
+- [1019.next-greater-node-in-linked-list](../problems/1019.next-greater-node-in-linked-list.md) 🆕
+- [1020.number-of-enclaves](../problems/1020.number-of-enclaves.md)
+- [1023.camelcase-matching](../problems/1023.camelcase-matching.md)
+- [1031.maximum-sum-of-two-non-overlapping-subarrays](../problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md)
+- [1104.path-in-zigzag-labelled-binary-tree](../problems/1104.path-in-zigzag-labelled-binary-tree.md)
+- [1131.maximum-of-absolute-value-expression](../problems/1131.maximum-of-absolute-value-expression.md)
+- [1186.maximum-subarray-sum-with-one-deletion](../problems/1186.maximum-subarray-sum-with-one-deletion.md) 🆕
+- [1218.longest-arithmetic-subsequence-of-given-difference](../problems/1218.longest-arithmetic-subsequence-of-given-difference.md)
+- [1227.airplane-seat-assignment-probability](../problems/1227.airplane-seat-assignment-probability.md)
+- [1261.find-elements-in-a-contaminated-binary-tree](../problems/1261.find-elements-in-a-contaminated-binary-tree.md)
+- [1262.greatest-sum-divisible-by-three](../problems/1262.greatest-sum-divisible-by-three.md)
+- [1297.maximum-number-of-occurrences-of-a-substring](../problems/1297.maximum-number-of-occurrences-of-a-substring.md)
+- [1310.xor-queries-of-a-subarray](../problems/1310.xor-queries-of-a-subarray.md) 🆕
+- [1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance](../problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md) 🆕
+- [1371.find-the-longest-substring-containing-vowels-in-even-counts](../problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md) 🆕
diff --git a/daily/2019-06-27.md b/daily/2019-06-27.md
index 9ad5b2a19..3c7c90854 100644
--- a/daily/2019-06-27.md
+++ b/daily/2019-06-27.md
@@ -52,7 +52,7 @@ function sqrt(num) {
也就是说,函数上任一点(x,f(x))处的切线斜率是2x。
那么,x-f(x)/(2x)就是一个比x更接近的近似值。代入 f(x)=x^2-a得到x-(x^2-a)/(2x),也就是(x+a/x)/2。
-
+
(图片来自Wikipedia)
diff --git a/daily/2019-07-10.md b/daily/2019-07-10.md
index 013bfdb5f..37a5078a9 100644
--- a/daily/2019-07-10.md
+++ b/daily/2019-07-10.md
@@ -28,7 +28,7 @@
这个题目解释起来比较费劲,我在网上找了一个现成的图来解释一下:
-
+
图中“1+”是指“1号小球为重”这一可能性。“1-”是指“1号小球为轻”这一可能性。
一开始一共有24种可能性。
diff --git a/daily/2019-07-23.md b/daily/2019-07-23.md
index e8efd3730..9f4507227 100644
--- a/daily/2019-07-23.md
+++ b/daily/2019-07-23.md
@@ -14,7 +14,7 @@
```
-
+
## 参考答案
diff --git a/daily/2019-07-26.md b/daily/2019-07-26.md
index e3cf1b33f..0ce407f2b 100644
--- a/daily/2019-07-26.md
+++ b/daily/2019-07-26.md
@@ -8,7 +8,7 @@
## 题目描述
-
+
## 参考答案
diff --git a/daily/2019-07-29.md b/daily/2019-07-29.md
index a0899caac..b8790fcc4 100644
--- a/daily/2019-07-29.md
+++ b/daily/2019-07-29.md
@@ -37,7 +37,7 @@ Example 2:
2. row->col、col->row 的切换都伴随读取的初始位置的变化;
3. 结束条件是row头>row尾或者col顶>col底
-
+
时间复杂度O(m*n), 空间复杂度O(1)
diff --git a/daily/2019-07-30.md b/daily/2019-07-30.md
index c06fd3224..529eb8a15 100644
--- a/daily/2019-07-30.md
+++ b/daily/2019-07-30.md
@@ -22,7 +22,7 @@
那么沿着这条纬线(记为E纬线)上任意一点向东走一英里,始终会回到原点,只是走的圈数不同而已。
根据题目倒推,在这条纬线以北一英里存在一条纬线(记为N纬线),从N纬线的任意一点向南一英里到达E纬线W点,沿着E纬线向东一英里,必会回到W点,再向北走一英里恰好可以回到起点。北极点可能包含在这个集合中,也可能不在。
如下图示供参考:
-
+
所以答案是无数个点
diff --git a/daily/2019-08-13.md b/daily/2019-08-13.md
index 6ca9f33a0..ef9504fa8 100644
--- a/daily/2019-08-13.md
+++ b/daily/2019-08-13.md
@@ -61,7 +61,7 @@ m 和 n =150,肯定超时。
最后将探测结果进行合并即可。合并的条件就是当前单元既能流入太平洋又能流入大西洋。
-
+
扩展:
如果题目改为能够流入大西洋或者太平洋,我们只需要最后合并的时候,条件改为求或即可
diff --git a/problems/1.two-sum.en.md b/problems/1.two-sum.en.md
new file mode 100644
index 000000000..09b882a15
--- /dev/null
+++ b/problems/1.two-sum.en.md
@@ -0,0 +1,55 @@
+## Problem
+
+https://leetcode-cn.com/problems/two-sum
+
+## Problem Description
+
+```
+Given an array of integers, return indices of the two numbers such that they add up to a specific target.
+
+You may assume that each input would have exactly one solution, and you may not use the same element twice.
+
+Example:
+
+Given nums = [2, 7, 11, 15], target = 9,
+
+Because nums[0] + nums[1] = 2 + 7 = 9,
+return [0, 1].
+```
+
+## Solution
+
+The easiest solution to come up with is Brute Force. We could write two for-loops to traverse every element, and find the target numbers that meet the requirement. However, the time complexity of this solution is O(N^2), while the space complexity is O(1). Apparently, we need to find a way to optimize this solution since the time complexity is too high. What we could do is to record the numbers we have traversed and the relevant index with a Map. Whenever we meet a new number during traversal, we go back to the Map and check whether the `diff` between this number and the target number appeared before. If it did, the problem has been solved and there's no need to continue.
+
+## Key Points
+
+- Find the difference instead of the sum
+- Connect every number with its index through the help of Map
+- Less time by more space. Reduce the time complexity from O(N) to O(1)
+
+## Code
+
+- Support Language: JS
+
+```js
+/**
+ * @param {number[]} nums
+ * @param {number} target
+ * @return {number[]}
+ */
+const twoSum = function (nums, target) {
+ const map = new Map();
+ for (let i = 0; i < nums.length; i++) {
+ const diff = target - nums[i];
+ if (map.has(diff)) {
+ return [map.get(diff), i];
+ }
+ map.set(nums[i], i);
+ }
+};
+```
+
+**_Complexity Anlysis_**
+
+- _Time Complexity_: O(N)
+- _Space Complexity_:O(N)
diff --git a/problems/1.TwoSum.md b/problems/1.two-sum.md
similarity index 62%
rename from problems/1.TwoSum.md
rename to problems/1.two-sum.md
index 2f8299473..0f8a965a9 100644
--- a/problems/1.TwoSum.md
+++ b/problems/1.two-sum.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/two-sum
## 题目描述
+
```
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
@@ -14,7 +16,31 @@ https://leetcode-cn.com/problems/two-sum
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
```
+
+## 前置知识
+
+- 哈希表
+
+## 公司
+
+- 字节
+- 百度
+- 腾讯
+- adobe
+- airbnb
+- amazon
+- apple
+- bloomberg
+- dropbox
+- facebook
+- linkedin
+- microsoft
+- uber
+- yahoo
+- yelp
+
## 思路
+
最容易想到的就是暴力枚举,我们可以利用两层 for 循环来遍历每个元素,并查找满足条件的目标元素。不过这样时间复杂度为 O(N^2),空间复杂度为 O(1),时间复杂度较高,我们要想办法进行优化。我们可以增加一个 Map 记录已经遍历过的数字及其对应的索引值。这样当遍历一个新数字的时候去 Map 里查询,target 与该数的差值是否已经在前面的数字中出现过。如果出现过,那么已经得出答案,就不必再往下执行了。
## 关键点
@@ -24,7 +50,8 @@ https://leetcode-cn.com/problems/two-sum
- 以空间换时间,将查找时间从 O(N) 降低到 O(1)
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -33,18 +60,25 @@ https://leetcode-cn.com/problems/two-sum
* @return {number[]}
*/
const twoSum = function (nums, target) {
- const map = new Map();
- for (let i = 0; i < nums.length; i++) {
- const diff = target - nums[i];
- if (map.has(diff)) {
- return [map.get(diff), i];
- }
- map.set(nums[i], i);
+ const map = new Map();
+ for (let i = 0; i < nums.length; i++) {
+ const diff = target - nums[i];
+ if (map.has(diff)) {
+ return [map.get(diff), i];
}
-}
+ map.set(nums[i], i);
+ }
+};
```
-***复杂度分析***
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
-- 时间复杂度:O(N)
-- 空间复杂度:O(N)
+
diff --git a/problems/101.symmetric-tree.md b/problems/101.symmetric-tree.md
new file mode 100644
index 000000000..2e58602c9
--- /dev/null
+++ b/problems/101.symmetric-tree.md
@@ -0,0 +1,126 @@
+## 题目地址(101. 对称二叉树)
+
+https://leetcode-cn.com/problems/symmetric-tree/
+
+## 题目描述
+
+```
+给定一个二叉树,检查它是否是镜像对称的。
+
+
+
+例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
+
+ 1
+ / \
+ 2 2
+ / \ / \
+3 4 4 3
+
+
+但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
+
+ 1
+ / \
+ 2 2
+ \ \
+ 3 3
+
+
+进阶:
+
+你可以运用递归和迭代两种方法解决这个问题吗?
+
+
+```
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- linkedin
+- microsoft
+
+## 前置知识
+
+- [二叉树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 思路
+
+看到这题的时候,我的第一直觉是 DFS。然后我就想:`如果左子树是镜像,并且右子树也是镜像,是不是就说明整体是镜像?`。经过几秒的思考, 这显然是不对的,不符合题意。
+
+
+
+很明显其中左子树中的节点会和右子树中的节点进行比较,我把比较的元素进行了颜色区分,方便大家看。
+
+这里我的想法是:`遍历每一个节点的时候,我都可以通过某种方法知道它对应的对称节点是谁。这样的话我直接比较两者是否一致就行了。`
+
+最初我的想法是两次遍历,第一次遍历的同时将遍历结果存储到哈希表中,然后第二次遍历去哈希表取。
+
+这种方法可行,但是需要 N 的空间(N 为节点总数)。我想到如果两者可以同时进行遍历,是不是就省去了哈希表的开销。
+
+
+
+如果不明白的话,我举个简单例子:
+
+```
+给定一个数组,检查它是否是镜像对称的。例如,数组 [1,2,2,3,2,2,1] 是对称的。
+```
+
+如果用哈希表的话大概是:
+
+```py
+seen = dict()
+for i, num in enumerate(nums):
+ seen[i] = num
+for i, num in enumerate(nums):
+ if seen[len(nums) - 1 - i] != num:
+ return False
+return True
+```
+
+而同时遍历的话大概是这样的:
+
+```py
+l = 0
+r = len(nums) - 1
+
+while l < r:
+ if nums[l] != nums[r]: return False
+ l += 1
+ r -= 1
+return True
+
+```
+
+> 其实更像本题一点的话应该是从中间分别向两边扩展 😂
+
+## 代码
+
+```py
+
+class Solution:
+ def isSymmetric(self, root: TreeNode) -> bool:
+ def dfs(root1, root2):
+ if root1 == root2: return True
+ if not root1 or not root2: return False
+ if root1.val != root2.val: return False
+ return dfs(root1.left, root2.right) and dfs(root1.right, root2.left)
+ if not root: return True
+ return dfs(root.left, root.right)
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$,其中 N 为节点数。
+- 空间复杂度:递归的深度最高为节点数,因此空间复杂度是 $O(N)$,其中 N 为节点数。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/1011.capacity-to-ship-packages-within-d-days.md b/problems/1011.capacity-to-ship-packages-within-d-days-cn.md
similarity index 98%
rename from problems/1011.capacity-to-ship-packages-within-d-days.md
rename to problems/1011.capacity-to-ship-packages-within-d-days-cn.md
index 5e257be42..82e9a75fc 100644
--- a/problems/1011.capacity-to-ship-packages-within-d-days.md
+++ b/problems/1011.capacity-to-ship-packages-within-d-days-cn.md
@@ -47,6 +47,14 @@ https://leetcode-cn.com/problems/capacity-to-ship-packages-within-d-days
1 <= D <= weights.length <= 50000
1 <= weights[i] <= 500
+## 前置知识
+
+- 二分法
+
+## 公司
+
+- 阿里
+
## 思路
这道题和[猴子吃香蕉](https://github.com/azl397985856/leetcode/blob/master/problems/875.koko-eating-bananas.md) 简直一摸一样,没有看过的建议看一下那道题。
diff --git a/problems/1011.capacity-to-ship-packages-within-d-days-en.md b/problems/1011.capacity-to-ship-packages-within-d-days-en.md
new file mode 100644
index 000000000..a313d6ef5
--- /dev/null
+++ b/problems/1011.capacity-to-ship-packages-within-d-days-en.md
@@ -0,0 +1,187 @@
+## Problem
+
+https://leetcode-cn.com/problems/capacity-to-ship-packages-within-d-days
+
+## Problem Description
+
+A conveyor belt has packages that must be shipped from one port to another within D days.
+
+The i-th package on the conveyor belt has a weight of weights[i]. Each day, we load the ship with packages on the conveyor belt (in the order given by weights). We may not load more weight than the maximum weight capacity of the ship.
+
+Return the least weight capacity of the ship that will result in all the packages on the conveyor belt being shipped within D days.
+
+**Example 1:**
+
+```
+Input: weights = [1,2,3,4,5,6,7,8,9,10], D = 5
+Output: 15
+Explanation:
+A ship capacity of 15 is the minimum to ship all the packages in 5 days like this:
+1st day: 1, 2, 3, 4, 5
+2nd day: 6, 7
+3rd day: 8
+4th day: 9
+5th day: 10
+
+Note that the cargo must be shipped in the order given, so using a ship of capacity 14 and splitting the packages into parts like (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) is not allowed.
+```
+
+**Example 2:**
+
+```
+Input: weights = [3,2,2,4,1,4], D = 3
+Output: 6
+Explanation:
+A ship capacity of 6 is the minimum to ship all the packages in 3 days like this:
+1st day: 3, 2
+2nd day: 2, 4
+3rd day: 1, 4
+```
+
+**Example 3:**
+
+```
+Input: weights = [1,2,3,1,1], D = 4
+Output: 3
+Explanation:
+1st day: 1
+2nd day: 2
+3rd day: 3
+4th day: 1, 1
+```
+
+
+
+ **Note:**
+
+1. `1 <= D <= weights.length <= 50000`
+2. `1 <= weights[i] <= 500`
+
+
+
+## Solution
+
+The problem is same as [**LeetCode 875 koko-eating-bananas**] (https://github.com/azl397985856/leetcode/blob/master/problems/875.koko-eating-bananas-en.md) practically.
+
+It is easy to solve this kind of problems if you take a closer look into it.
+
+
+The essence is to search a given number in finite discrete data like [ 1,2,3,4, ... , total ].
+
+However, We should find the cargo that can be shipped in D days rather than look for the target directly.
+
+
+Consider the following questions:
+
+- Can it be shipped if the capacity is 1?
+- Can it be shipped if the capacity is 2?
+- Can it be shipped if the capacity is 3?
+- ...
+- Can it be shipped if the capacity is total ? ( Yeap we can, D is greater than or equal to 1)
+
+During the process, we directly `return` if the answer is *yes*.
+
+If the answer is *no*, just keep asking.
+
+This is a typical binary search problem, the only difference is the judgement condition:
+
+
+```python
+def canShip(opacity):
+ # Whether the capacity of the specified ship can be shipped in D days
+ lo = 0
+ hi = total
+ while lo < hi:
+ mid = (lo + hi) // 2
+ if canShip(mid):
+ hi = mid
+ else:
+ lo = mid + 1
+ return lo
+```
+
+## Key Points
+
+- if you are so familiar with binary search as well its transformation, you can easily find out that using binary search to find one number in a given number sequence of a certain length.
+
+## Code (`JS/Python`)
+
+- `Python`
+
+```python
+class Solution:
+ def shipWithinDays(self, weights: List[int], D: int) -> int:
+ lo = 0
+ hi = 0
+
+ def canShip(opacity):
+ days = 1
+ remain = opacity
+ for weight in weights:
+ if weight > opacity:
+ return False
+ remain -= weight
+ if remain < 0:
+ days += 1
+ remain = opacity - weight
+ return days <= D
+
+ for weight in weights:
+ hi += weight
+ while lo < hi:
+ mid = (lo + hi) // 2
+ if canShip(mid):
+ hi = mid
+ else:
+ lo = mid + 1
+
+ return lo
+```
+
+- `JavaScript`
+
+```js
+/**
+ * @param {number[]} weights
+ * @param {number} D
+ * @return {number}
+ */
+var shipWithinDays = function(weights, D) {
+ let high = weights.reduce((acc, cur) => acc + cur)
+ let low = 0
+
+ while(low < high) {
+ let mid = Math.floor((high + low) / 2)
+ if (canShip(mid)) {
+ high = mid
+ } else {
+ low = mid + 1
+ }
+ }
+
+ return low
+
+ function canShip(opacity) {
+ let remain = opacity
+ let count = 1
+ for (let weight of weights) {
+ if (weight > opacity) {
+ return false
+ }
+ remain -= weight
+ if (remain < 0) {
+ count++
+ remain = opacity - weight
+ }
+ if (count > D) {
+ return false
+ }
+ }
+ return count <= D
+ }
+};
+```
+
+## References
+
+## Extension
diff --git a/problems/1014.best-sightseeing-pair.md b/problems/1014.best-sightseeing-pair.md
index 45caa61a3..6f6404c14 100644
--- a/problems/1014.best-sightseeing-pair.md
+++ b/problems/1014.best-sightseeing-pair.md
@@ -21,6 +21,15 @@ https://leetcode-cn.com/problems/best-sightseeing-pair/description/
2 <= A.length <= 50000
1 <= A[i] <= 1000
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
最简单的思路就是两两组合,找出最大的,妥妥超时,我们来看下代码:
diff --git a/problems/1015.smallest-integer-divisible-by-k.md b/problems/1015.smallest-integer-divisible-by-k.md
index bbfca68a4..3d7ee887d 100644
--- a/problems/1015.smallest-integer-divisible-by-k.md
+++ b/problems/1015.smallest-integer-divisible-by-k.md
@@ -34,6 +34,14 @@ https://leetcode-cn.com/problems/smallest-integer-divisible-by-k/description/
```
+## 前置知识
+
+- 循环节
+
+## 公司
+
+- 暂无
+
## 思路
这道题是说给定一个 K 值,能否找到一个形如 1,11,111,1111 。。。 这样的数字 n 使得 n % K == 0。
diff --git a/problems/1019.next-greater-node-in-linked-list.md b/problems/1019.next-greater-node-in-linked-list.md
index 964a37842..57854a3c1 100644
--- a/problems/1019.next-greater-node-in-linked-list.md
+++ b/problems/1019.next-greater-node-in-linked-list.md
@@ -35,6 +35,16 @@ https://leetcode-cn.com/problems/next-greater-node-in-linked-list/submissions/
给定列表的长度在 [0, 10000] 范围内
```
+## 前置知识
+
+- 链表
+- 栈
+
+## 公司
+
+- 腾讯
+- 字节
+
## 思路
看完题目就应该想到单调栈才行,LeetCode 上关于单调栈的题目还不少,难度都不小。但是一旦你掌握了这个算法,那么这些题目对你来说都不是问题了。
diff --git a/problems/102.binary-tree-level-order-traversal.md b/problems/102.binary-tree-level-order-traversal.md
index 43d476069..8822c35e0 100644
--- a/problems/102.binary-tree-level-order-traversal.md
+++ b/problems/102.binary-tree-level-order-traversal.md
@@ -4,16 +4,20 @@ https://leetcode.com/problems/binary-tree-level-order-traversal/description/
## 题目描述
```
-Given a binary tree, return the level order traversal of its nodes' values. (ie, from left to right, level by level).
+给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+
+
+
+示例:
+二叉树:[3,9,20,null,null,15,7],
-For example:
-Given binary tree [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
-return its level order traversal as:
+返回其层次遍历结果:
+
[
[3],
[9,20],
@@ -21,8 +25,21 @@ return its level order traversal as:
]
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+这是一个典型的二叉树遍历问题, 关于二叉树遍历,我总结了一个[专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md),大家可以先去看下那个,然后再来刷这道题。
+
这道题可以借助`队列`实现,首先把root入队,然后入队一个特殊元素Null(来表示每层的结束)。
@@ -51,52 +68,6 @@ return its level order traversal as:
Javascript Code:
```js
-/*
- * @lc app=leetcode id=102 lang=javascript
- *
- * [102] Binary Tree Level Order Traversal
- *
- * https://leetcode.com/problems/binary-tree-level-order-traversal/description/
- *
- * algorithms
- * Medium (47.18%)
- * Total Accepted: 346.4K
- * Total Submissions: 731.3K
- * Testcase Example: '[3,9,20,null,null,15,7]'
- *
- * Given a binary tree, return the level order traversal of its nodes' values.
- * (ie, from left to right, level by level).
- *
- *
- * For example:
- * Given binary tree [3,9,20,null,null,15,7],
- *
- *
- * 3
- * / \
- * 9 20
- * / \
- * 15 7
- *
- *
- *
- * return its level order traversal as:
- *
- * [
- * [3],
- * [9,20],
- * [15,7]
- * ]
- *
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[][]}
@@ -223,6 +194,22 @@ class Solution:
return result
```
+***复杂度分析***
+- 时间复杂度:$O(N)$,其中N为树中节点总数。
+- 空间复杂度:$O(N)$,其中N为树中节点总数。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+## 扩展
+
+实际上这道题方法很多, 比如经典的三色标记法。
+
## 相关题目
- [103.binary-tree-zigzag-level-order-traversal](./103.binary-tree-zigzag-level-order-traversal.md)
- [104.maximum-depth-of-binary-tree](./104.maximum-depth-of-binary-tree.md)
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/1020.number-of-enclaves.md b/problems/1020.number-of-enclaves.md
index bd77a2542..467acdd12 100644
--- a/problems/1020.number-of-enclaves.md
+++ b/problems/1020.number-of-enclaves.md
@@ -36,6 +36,11 @@ https://leetcode-cn.com/problems/number-of-enclaves/
```
+## 前置知识
+
+- DFS
+- hashset
+
## 解法一 (暴力法)
### 思路
@@ -99,6 +104,10 @@ class Solution:
## 解法二 (消除法)
+## 公司
+
+- 暂无
+
### 思路
上面的解法时间复杂度和空间复杂度都很差,我们考虑进行优化, 这里我们使用消除法。
diff --git a/problems/1023.camelcase-matching.md b/problems/1023.camelcase-matching.md
index cfeb79694..35ff75939 100644
--- a/problems/1023.camelcase-matching.md
+++ b/problems/1023.camelcase-matching.md
@@ -43,6 +43,14 @@ https://leetcode-cn.com/problems/camelcase-matching/
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 暂无
+
## 思路
这道题是一道典型的双指针题目。不过这里的双指针并不是指向同一个数组或者字符串,而是指向多个,这道题是指向两个,分别是 query 和 pattern,这种题目非常常见,能够识别和掌握这种题目的解题模板非常重要。对 queries 的每一项我们的逻辑是一样的,这里就以其中一项为例进行讲解。
diff --git a/problems/103.binary-tree-zigzag-level-order-traversal.md b/problems/103.binary-tree-zigzag-level-order-traversal.md
index 7cf53ec5b..e72934cd6 100644
--- a/problems/103.binary-tree-zigzag-level-order-traversal.md
+++ b/problems/103.binary-tree-zigzag-level-order-traversal.md
@@ -23,6 +23,17 @@ return its zigzag level order traversal as:
]
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题可以借助`队列`实现,首先把root入队,然后入队一个特殊元素Null(来表示每层的结束)。
diff --git a/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md b/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
index f37648075..c37453837 100644
--- a/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
+++ b/problems/1031.maximum-sum-of-two-non-overlapping-subarrays.md
@@ -37,11 +37,19 @@ L + M <= A.length <= 1000
0 <= A[i] <= 1000
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 字节
+
## 思路(动态规划)
题目中要求在前N(数组长度)个数中找出长度分别为L和M的非重叠子数组之和的最大值, 因此, 我们可以定义数组A中前i个数可构成的非重叠子数组L和M的最大值为SUMM[i], 并找到SUMM[i]和SUMM[i-1]的关系, 那么最终解就是SUMM[N]. 以下为图解:
-
+
## 关键点解析
diff --git a/problems/1032.stream-of-characters.md b/problems/1032.stream-of-characters.md
new file mode 100644
index 000000000..81930f1a8
--- /dev/null
+++ b/problems/1032.stream-of-characters.md
@@ -0,0 +1,166 @@
+## 题目地址(1032. 字符流)
+
+https://leetcode-cn.com/problems/stream-of-characters/
+
+## 题目描述
+
+```
+按下述要求实现 StreamChecker 类:
+
+StreamChecker(words):构造函数,用给定的字词初始化数据结构。
+query(letter):如果存在某些 k >= 1,可以用查询的最后 k个字符(按从旧到新顺序,包括刚刚查询的字母)拼写出给定字词表中的某一字词时,返回 true。否则,返回 false。
+
+
+示例:
+
+StreamChecker streamChecker = new StreamChecker(["cd","f","kl"]); // 初始化字典
+streamChecker.query('a'); // 返回 false
+streamChecker.query('b'); // 返回 false
+streamChecker.query('c'); // 返回 false
+streamChecker.query('d'); // 返回 true,因为 'cd' 在字词表中
+streamChecker.query('e'); // 返回 false
+streamChecker.query('f'); // 返回 true,因为 'f' 在字词表中
+streamChecker.query('g'); // 返回 false
+streamChecker.query('h'); // 返回 false
+streamChecker.query('i'); // 返回 false
+streamChecker.query('j'); // 返回 false
+streamChecker.query('k'); // 返回 false
+streamChecker.query('l'); // 返回 true,因为 'kl' 在字词表中。
+
+
+提示:
+
+1 <= words.length <= 2000
+1 <= words[i].length <= 2000
+字词只包含小写英文字母。
+待查项只包含小写英文字母。
+待查项最多 40000 个。
+
+```
+
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 字节
+
+## 思路
+
+题目要求`按从旧到新顺序`查询,因此可以将从旧到新的 query 存起来形成一个单词 stream。
+
+比如:
+
+```js
+streamChecker.query("a"); // stream: a
+streamChecker.query("b"); // stream:ba
+streamChecker.query("c"); // stream:cba
+```
+
+这里有两个小的点需要注意:
+
+1. 如果用数组来存储, 由于每次都往数组头部插入一个元素,因此每次 query 操作的时间复杂度为 $O(N)$,其中 $N$ 为截止当前执行 query 的次数,我们可以使用双端队列进行优化。
+2. 由于不必 query 形成的查询全部命中。比如 stream 为 cba 的时候,找到单词 c, bc, abc 都是可以的。如果是找到 c,cb,cba 比较好吧,现在是反的。其实我们可以反序插入是,类似的技巧在[211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/211.add-and-search-word-data-structure-design.md) 也有用到。
+
+之后我们用拼接的单词在 words 中查询即可, 最简单的方式当然是每次 query 都去扫描一次,这种方式毫无疑问会超时。
+
+我们可以采用构建 Trie 的形式,即已空间环时间, 其代码和常规的 Trie 类似,只需要将 search(word) 函数做一个简单修改即可,我们不需要检查整个 word 是否存在, 而已 word 的前缀存在即可。
+
+> 提示:可以通过对 words 去重,来用空间换区时间。
+
+具体算法:
+
+- init 中 构建 Trie 和 双端队列 stream
+- query 时,往 stream 的左边 append 即可。
+- 调用 Trie 的 search(和常规的 search 稍有不同, 我上面已经讲了)
+
+核心代码(Python):
+
+```py
+class StreamChecker:
+
+ def __init__(self, words: List[str]):
+ self.trie = Trie()
+ self.stream = deque([])
+
+ for word in set(words):
+ self.trie.insert(word[::-1])
+
+ def query(self, letter: str) -> bool:
+ self.stream.appendleft(letter)
+ return self.trie.search(self.stream)
+```
+
+## 关键点解析
+
+- 前缀树模板
+- 倒序插入
+
+## 代码
+
+- 语言支持: Python
+
+Python Code:
+
+```python
+class Trie:
+
+ def __init__(self):
+ """
+ Initialize your data structure here.
+ """
+ self.Trie = {}
+
+ def insert(self, word):
+ """
+ Inserts a word into the trie.
+ :type word: str
+ :rtype: void
+ """
+ curr = self.Trie
+ for w in word:
+ if w not in curr:
+ curr[w] = {}
+ curr = curr[w]
+ curr['#'] = 1
+
+ def search(self, word):
+ """
+ Returns if the word is in the trie.
+ :type word: str
+ :rtype: bool
+ """
+ curr = self.Trie
+ for w in word:
+ if w not in curr:
+ return False
+ if "#" in curr[w]:
+ return True
+ curr = curr[w]
+ return False
+
+
+class StreamChecker:
+
+ def __init__(self, words: List[str]):
+ self.trie = Trie()
+ self.stream = deque([])
+
+ for word in set(words):
+ self.trie.insert(word[::-1])
+
+ def query(self, letter: str) -> bool:
+ self.stream.appendleft(letter)
+ return self.trie.search(self.stream)
+
+
+```
+
+## 相关题目
+
+- [0208.implement-trie-prefix-tree](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
+- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
diff --git a/problems/104.maximum-depth-of-binary-tree.md b/problems/104.maximum-depth-of-binary-tree.md
index a52654195..02449d83e 100644
--- a/problems/104.maximum-depth-of-binary-tree.md
+++ b/problems/104.maximum-depth-of-binary-tree.md
@@ -24,6 +24,21 @@ return its depth = 3.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- apple
+- linkedin
+- uber
+- yahoo
+
## 思路
由于树是一种递归的数据结构,因此用递归去解决的时候往往非常容易,这道题恰巧也是如此,
@@ -147,6 +162,18 @@ class Solution:
depth += 1
return depth
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
## 相关题目
- [102.binary-tree-level-order-traversal](./102.binary-tree-level-order-traversal.md)
- [103.binary-tree-zigzag-level-order-traversal](./103.binary-tree-zigzag-level-order-traversal.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md b/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
index 24c809165..d24903dae 100644
--- a/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
+++ b/problems/105.Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.md
@@ -26,6 +26,17 @@ Return the following binary tree:
15 7
```
+## 前置知识
+
+- 二叉树
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路/Thinking Path
目标是构造二叉树。
@@ -68,7 +79,7 @@ If you can't figure out how to get the index of the left and right child, please
- according to the properties of preoder traversal, all right sub-tree nodes are behine all left sub-tree nodes. The length of left sub-tree can help us to divide left and right sub-trees.
- the length of left sub-tree can be find in the inorder traversal. The location of current node is `inRoot`(or whatever your call it). The start index of current inorder array is `inStart`(or whatever your call it). So, the lenght of the left sub-tree is `leftChldLen = inRoot - inStart`.
-
+
## 代码/Code
diff --git a/problems/108.convert-sorted-array-to-binary-search-tree.md b/problems/108.convert-sorted-array-to-binary-search-tree.md
new file mode 100644
index 000000000..5c1128a06
--- /dev/null
+++ b/problems/108.convert-sorted-array-to-binary-search-tree.md
@@ -0,0 +1,182 @@
+## 题目地址(108. 将有序数组转换为二叉搜索树)
+
+https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/
+
+## 题目描述
+
+```
+将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定有序数组: [-10,-3,0,5,9],
+
+一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+## 前置知识
+
+- [二叉搜索树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [平衡二叉树](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- airbnb
+
+## 思路
+
+由于输入是一个**升序排列的有序数组**。因此任意选择一点,将其作为根节点,其左部分左节点,其右部分右节点即可。 因此我们很容易写出递归代码。
+
+而题目要求是**高度平衡**的二叉搜索树,因此我们必须要取中点。 不难证明:`由于是中点,因此左右两部分差不会大于 1,也就是说其形成的左右子树节点数最多相差 1,因此左右子树高度差的绝对值不超过 1`。
+
+形象一点来看就像你提起一根绳子,从中点提的话才能使得两边绳子长度相差最小。
+
+
+
+## 关键点
+
+- 找中点
+
+## 代码
+
+代码支持:JS,C++,Java,Python
+
+JS Code:
+
+```js
+var sortedArrayToBST = function (nums) {
+ // 由于数组是排序好的,因此一个思路就是将数组分成两半,一半是左子树,另一半是右子树
+ // 然后运用“树的递归性质”递归完成操作即可。
+ if (nums.length === 0) return null;
+ const mid = nums.length >> 1;
+ const root = new TreeNode(nums[mid]);
+
+ root.left = sortedArrayToBST(nums.slice(0, mid));
+ root.right = sortedArrayToBST(nums.slice(mid + 1));
+ return root;
+};
+```
+
+Python Code:
+
+```py
+class Solution:
+ def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
+ if not nums: return None
+ mid = (len(nums) - 1) // 2
+ root = TreeNode(nums[mid])
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
+```
+
+
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:每次递归都 copy 了 N 的 空间,因此空间复杂度为 $O(N ^ 2)$
+
+然而,实际上没必要开辟新的空间:
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ TreeNode* sortedArrayToBST(vector& nums) {
+ return reBuild(nums, 0, nums.size()-1);
+ }
+
+ TreeNode* reBuild(vector& nums, int left, int right)
+ {
+ // 终止条件:中序遍历为空
+ if(left > right)
+ {
+ return NULL;
+ }
+ // 建立当前子树的根节点
+ int mid = (left+right)/2;
+ TreeNode * root = new TreeNode(nums[mid]);
+
+ // 左子树的下层递归
+ root->left = reBuild(nums, left, mid-1);
+ // 右子树的下层递归
+ root->right = reBuild(nums, mid+1, right);
+ // 返回根节点
+ return root;
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public TreeNode sortedArrayToBST(int[] nums) {
+ return dfs(nums, 0, nums.length - 1);
+ }
+
+ private TreeNode dfs(int[] nums, int lo, int hi) {
+ if (lo > hi) {
+ return null;
+ }
+ int mid = lo + (hi - lo) / 2;
+ TreeNode root = new TreeNode(nums[mid]);
+ root.left = dfs(nums, lo, mid - 1);
+ root.right = dfs(nums, mid + 1, hi);
+ return root;
+ }
+}
+
+```
+
+Python Code:
+```python
+class Solution(object):
+ def sortedArrayToBST(self, nums):
+ """
+ :type nums: List[int]
+ :rtype: TreeNode
+ """
+ return self.reBuild(nums, 0, len(nums)-1)
+
+ def reBuild(self, nums, left, right):
+ # 终止条件:
+ if left > right:
+ return
+ # 建立当前子树的根节点
+ mid = (left + right)//2
+ root = TreeNode(nums[mid])
+ # 左右子树的下层递归
+ root.left = self.reBuild(nums, left, mid-1)
+ root.right = self.reBuild(nums, mid+1, right)
+
+ return root
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:隐式调用栈的开销为 $O(N)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+公众号【 [力扣加加](https://tva1.sinaimg.cn/large/007S8ZIlly1gfcuzagjalj30p00dwabs.jpg)】
+知乎专栏【 [Lucifer - 知乎](https://www.zhihu.com/people/lu-xiao-13-70)】
+
+点关注,不迷路!
diff --git a/problems/11.container-with-most-water.md b/problems/11.container-with-most-water.md
index b6b5de395..db21738ff 100644
--- a/problems/11.container-with-most-water.md
+++ b/problems/11.container-with-most-water.md
@@ -1,72 +1,84 @@
## 题目地址
-https://leetcode.com/problems/container-with-most-water/description/
+
+https://leetcode-cn.com/problems/container-with-most-water/description/
## 题目描述
-```
-Given n non-negative integers a1, a2, ..., an , where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
-Note: You may not slant the container and n is at least 2.
-```
-
-
-```
+给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
-The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
+说明:你不能倾斜容器,且 n 的值至少为 2。
-
+
+
-Example:
-Input: [1,8,6,2,5,4,8,3,7]
-Output: 49
-```
+图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
+
+
+
+示例:
+
+输入:[1,8,6,2,5,4,8,3,7]
+输出:49
+
+
+
+
+
+
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 字节
+- 腾讯
+- 百度
+- 阿里
## 思路
-符合直觉的解法是,我们可以对两两进行求解,计算可以承载的水量。 然后不断更新最大值,最后返回最大值即可。
-这种解法,需要两层循环,时间复杂度是O(n^2)
-eg:
+题目中说`找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。` ,因此符合直觉的解法就是固定两个端点,计算可以承载的水量, 然后不断更新最大值,最后返回最大值即可。这种算法,需要两层循环,时间复杂度是 $O(n^2)$。
+
+
+代码(JS):
```js
- // 这个解法比较暴力,效率比较低
- // 时间复杂度是O(n^2)
- let max = 0;
- for(let i = 0; i < height.length; i++) {
- for(let j = i + 1; j < height.length; j++) {
- const currentArea = Math.abs(i - j) * Math.min(height[i], height[j]);
- if (currentArea > max) {
- max = currentArea;
- }
- }
+let max = 0;
+for (let i = 0; i < height.length; i++) {
+ for (let j = i + 1; j < height.length; j++) {
+ const currentArea = Math.abs(i - j) * Math.min(height[i], height[j]);
+ if (currentArea > max) {
+ max = currentArea;
}
- return max;
-
+ }
+}
+return max;
```
-> 这种符合直觉的解法有点像冒泡排序, 大家可以稍微类比一下
+虽然解法效率不高,但是可以通过(JS可以通过,Python 不可以,其他语言没有尝试)。那么有没有更优的解法呢?
-那么有没有更加优的解法呢?我们来换个角度来思考这个问题,上述的解法是通过两两组合,这无疑是完备的,
-那我门是否可以先计算长度为n的面积,然后计算长度为n-1的面积,... 计算长度为1的面积。 这样去不断更新最大值呢?
-很显然这种解法也是完备的,但是似乎时间复杂度还是O(n ^ 2), 不要着急。
+我们来换个角度来思考这个问题,上述的解法是通过两两组合,这无疑是完备的。我们换个角度思考,是否可以先计算长度为 n 的面积,然后计算长度为 n-1 的面积,... 计算长度为 1 的面积。 这样去不断更新最大值呢?很显然这种解法也是完备的,但是似乎时间复杂度还是 $O(n ^ 2)$, 不要着急。
-考虑一下,如果我们计算n-1长度的面积的时候,是直接直接排除一半的结果的。
+考虑一下,如果我们计算 n-1 长度的面积的时候,是可以直接排除一半的结果的。
如图:
-
+
+比如我们计算 n 面积的时候,假如左侧的线段高度比右侧的高度低,那么我们通过左移右指针来将长度缩短为 n-1 的做法是没有意义的,
+因为`新的形成的面积变成了(n-1) * heightOfLeft 这个面积一定比刚才的长度为 n 的面积 (n * heightOfLeft) 小`。
-比如我们计算n面积的时候,假如左侧的线段高度比右侧的高度低,那么我们通过左移右指针来将长度缩短为n-1的做法是没有意义的,
-因为`新的形成的面积变成了(n-1) * heightOfLeft 这个面积一定比刚才的长度为n的面积nn * heightOfLeft 小`
+也就是说**最大面积一定是当前的面积或者通过移动短的端点得到。**
-也就是说最大面积`一定是当前的面积或者通过移动短的线段得到`。
## 关键点解析
- 双指针优化时间复杂度
-
## 代码
-* 语言支持:JS,C++
+
+- 语言支持:JS,C++,Python
JavaScript Code:
@@ -75,30 +87,34 @@ JavaScript Code:
* @param {number[]} height
* @return {number}
*/
-var maxArea = function(height) {
- if (!height || height.length <= 1) return 0;
-
- let leftPos = 0;
- let rightPos = height.length - 1;
- let max = 0;
- while(leftPos < rightPos) {
-
- const currentArea = Math.abs(leftPos - rightPos) * Math.min(height[leftPos] , height[rightPos]);
- if (currentArea > max) {
- max = currentArea;
- }
- // 更新小的
- if (height[leftPos] < height[rightPos]) {
- leftPos++;
- } else { // 如果相等就随便了
- rightPos--;
- }
+var maxArea = function (height) {
+ if (!height || height.length <= 1) return 0;
+
+ let leftPos = 0;
+ let rightPos = height.length - 1;
+ let max = 0;
+ while (leftPos < rightPos) {
+ const currentArea =
+ Math.abs(leftPos - rightPos) *
+ Math.min(height[leftPos], height[rightPos]);
+ if (currentArea > max) {
+ max = currentArea;
+ }
+ // 更新小的
+ if (height[leftPos] < height[rightPos]) {
+ leftPos++;
+ } else {
+ // 如果相等就随便了
+ rightPos--;
}
+ }
- return max;
+ return max;
};
```
+
C++ Code:
+
```C++
class Solution {
public:
@@ -115,11 +131,30 @@ public:
};
```
-***复杂度分析***
-- 时间复杂度:$O(N)$
-- 空间复杂度:$O(1)$
+Python Code:
+
+```py
+class Solution:
+ def maxArea(self, heights):
+ l, r = 0, len(heights) - 1
+ ans = 0
+ while l < r:
+ ans = max(ans, (r - l) * min(heights[l], heights[r]))
+ if heights[r] > heights[l]:
+ l += 1
+ else:
+ r -= 1
+ return ans
+```
+
+**_复杂度分析_**
+
+- 时间复杂度:由于左右指针移动的次数加起来正好是 n, 因此时间复杂度为 $O(N)$。
+- 空间复杂度:$O(1)$。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/1104.path-in-zigzag-labelled-binary-tree.md b/problems/1104.path-in-zigzag-labelled-binary-tree.md
index 235577570..2a0dc76d8 100644
--- a/problems/1104.path-in-zigzag-labelled-binary-tree.md
+++ b/problems/1104.path-in-zigzag-labelled-binary-tree.md
@@ -10,7 +10,7 @@ https://leetcode-cn.com/problems/path-in-zigzag-labelled-binary-tree/description
而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
-
+
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label 节点的路径,该路径是由途经的节点标号所组成的。
@@ -27,23 +27,31 @@ https://leetcode-cn.com/problems/path-in-zigzag-labelled-binary-tree/description
1 <= label <= 10^6
+## 前置知识
+
+- 二叉树
+
+## 公司
+
+- 暂无
+
## 思路
假如这道题不是之字形,那么就会非常简单。 我们可以根据子节点的 label 轻松地求出父节点的 label,公示是 label // 2(其中 label 为子节点的 label)。
如果是这样的话,这道题应该是 easy 难度,代码也不难写出。我们继续考虑之字形。我们不妨先观察一下,找下规律。
-
+
以上图最后一行为例,对于 15 节点,之字变换之前对应的应该是 8 节点。14 节点对应的是 9 节点。。。
全部列举出来是这样的:
-
+
我们发现之字变换前后的 label 相加是一个定值。
-
+
因此我们只需要求解出每一层的这个定值,然后减去当前值就好了。(注意我们不需要区分偶数行和奇数行)
问题的关键转化为求解这个定值,这个定值其实很好求,因为每一层的最大值和最小值我们很容易求,而最大值和最小值的和正是我们要求的这个数字。
diff --git a/problems/113.path-sum-ii.md b/problems/113.path-sum-ii.md
index e0e3d09b1..014395153 100644
--- a/problems/113.path-sum-ii.md
+++ b/problems/113.path-sum-ii.md
@@ -26,6 +26,17 @@ Return:
]
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求值`,而是枚举所有可能,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -37,7 +48,9 @@ Return:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
diff --git a/problems/1131.maximum-of-absolute-value-expression.md b/problems/1131.maximum-of-absolute-value-expression.md
index 763af2464..13bb775be 100644
--- a/problems/1131.maximum-of-absolute-value-expression.md
+++ b/problems/1131.maximum-of-absolute-value-expression.md
@@ -24,15 +24,25 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
2 <= arr1.length == arr2.length <= 40000
-10^6 <= arr1[i], arr2[i] <= 10^6
+## 前置知识
+
+- 数组
+
## 解法一(数学分析)
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
### 思路
如图我们要求的是这样一个表达式的最大值。arr1 和 arr2 为两个不同的数组,且二者长度相同。i 和 j 是两个合法的索引。
> 红色竖线表示的是绝对值的符号
-
+
我们对其进行分类讨论,有如下八种情况:
@@ -41,7 +51,7 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
> |i - j| 两种情况
> 因此一共是 2 \* 2 \* 2 = 8 种
-
+
由于 i 和 j 之前没有大小关系,也就说二者可以相互替代。因此:
@@ -54,11 +64,11 @@ https://leetcode-cn.com/problems/maximum-of-absolute-value-expression/descriptio
为了方便,我们将 i 和 j 都提取到一起:
-
+
容易看出等式的最大值就是前面的最大值,和后面最小值的差值。如图:
-
+
再仔细观察,会发现前面部分和后面部分是一样的,原因还是上面所说的 i 和 j 可以互换。因此我们要做的就是:
@@ -93,17 +103,17 @@ class Solution:
### 思路
-
+
(图来自: https://zh.wikipedia.org/wiki/%E6%9B%BC%E5%93%88%E9%A0%93%E8%B7%9D%E9%9B%A2)
一维曼哈顿距离可以理解为一条线上两点之间的距离: |x1 - x2|,其值为 max(x1 - x2, x2 - x1)
-
+
在平面上,坐标(x1, y1)的点 P1 与坐标(x2, y2)的点 P2 的曼哈顿距离为:|x1-x2| + |y1 - y2|,其值为 max(x1 - x2 + y1 - y2, x2 - x1 + y1 - y2, x1 - x2 + y2 - y1, x2 -x1 + y2 - y1)
-
+
然后这道题目是更复杂的三维曼哈顿距离,其中(i, arr[i], arr[j])可以看作三位空间中的一个点,问题转化为曼哈顿距离最远的两个点的距离。
延续上面的思路,|x1-x2| + |y1 - y2| + |z1 - z2|,其值为 :
@@ -182,6 +192,6 @@ class Solution:
- [1030. 距离顺序排列矩阵单元格](https://leetcode-cn.com/problems/matrix-cells-in-distance-order/)
-
+
- [1162. 地图分析](https://leetcode-cn.com/problems/as-far-from-land-as-possible/)
diff --git a/problems/1168.optimize-water-distribution-in-a-village-cn.md b/problems/1168.optimize-water-distribution-in-a-village-cn.md
index f0398a673..213ff2bba 100644
--- a/problems/1168.optimize-water-distribution-in-a-village-cn.md
+++ b/problems/1168.optimize-water-distribution-in-a-village-cn.md
@@ -27,11 +27,21 @@ wells.length == n
0 <= pipes[i][2] <= 10^5
pipes[i][0] != pipes[i][1]
```
-example 1 pic:
-
+## 前置知识
+
+- 图
+- 最小生成树
+
+## 公司
+
+- 暂无
## 思路
+
+
+
+
题意,在每个城市打井需要一定的花费,也可以用其他城市的井水,城市之间建立连接管道需要一定的花费,怎么样安排可以花费最少的前灌溉所有城市。
这是一道连通所有点的最短路径/最小生成树问题,把城市看成图中的点,管道连接城市看成是连接两个点之间的边。这里打井的花费是直接在点上,而且并不是所有
@@ -58,7 +68,7 @@ example 1 pic:
如图:
-
+
从图中可以看到,最后所有的节点都是连通的。
@@ -184,4 +194,4 @@ class Solution:
4. [Bellman-Ford算法](https://www.wikiwand.com/zh-hans/%E8%B4%9D%E5%B0%94%E6%9B%BC-%E7%A6%8F%E7%89%B9%E7%AE%97%E6%B3%95)
5. [Kruskal算法](https://www.wikiwand.com/zh-hans/%E5%85%8B%E9%B2%81%E6%96%AF%E5%85%8B%E5%B0%94%E6%BC%94%E7%AE%97%E6%B3%95)
6. [Prim's 算法](https://www.wikiwand.com/zh-hans/%E6%99%AE%E6%9E%97%E5%A7%86%E7%AE%97%E6%B3%95)
-7. [最小生成树](https://www.wikiwand.com/zh/%E6%9C%80%E5%B0%8F%E7%94%9F%E6%88%90%E6%A0%91)
\ No newline at end of file
+7. [最小生成树](https://www.wikiwand.com/zh/%E6%9C%80%E5%B0%8F%E7%94%9F%E6%88%90%E6%A0%91)
diff --git a/problems/1168.optimize-water-distribution-in-a-village-en.md b/problems/1168.optimize-water-distribution-in-a-village-en.md
index 3eac1ad67..0e4ebd752 100644
--- a/problems/1168.optimize-water-distribution-in-a-village-en.md
+++ b/problems/1168.optimize-water-distribution-in-a-village-en.md
@@ -34,7 +34,7 @@ pipes[i][0] != pipes[i][1]
```
example 1 pic:
-
+
## Solution
@@ -61,7 +61,7 @@ For example:`n = 5, wells=[1,2,2,3,2], pipes=[[1,2,1],[2,3,1],[4,5,7]]`
As below pic:
-
+
From pictures, we can see that all nodes already connected with minimum costs.
diff --git a/problems/1186.maximum-subarray-sum-with-one-deletion.md b/problems/1186.maximum-subarray-sum-with-one-deletion.md
index 40e15d392..e8b0cfbb2 100644
--- a/problems/1186.maximum-subarray-sum-with-one-deletion.md
+++ b/problems/1186.maximum-subarray-sum-with-one-deletion.md
@@ -39,6 +39,15 @@ https://leetcode.com/problems/maximum-subarray-sum-with-one-deletion/
```
+## 前置知识
+
+- 数组
+- 动态规划
+
+## 公司
+
+- 字节
+
## 思路
### 暴力法
diff --git a/problems/121.best-time-to-buy-and-sell-stock.md b/problems/121.best-time-to-buy-and-sell-stock.md
index d30c088e3..8d07a4158 100644
--- a/problems/121.best-time-to-buy-and-sell-stock.md
+++ b/problems/121.best-time-to-buy-and-sell-stock.md
@@ -24,6 +24,22 @@ Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- amazon
+- bloomberg
+- facebook
+- microsoft
+- uber
+
## 思路
由于我们是想获取到最大的利润,我们的策略应该是低点买入,高点卖出。
@@ -32,7 +48,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
用图表示的话就是这样:
-
+
## 关键点解析
@@ -40,7 +56,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
## 代码
-语言支持:JS,Python,C++
+语言支持:JS,C++,Java,Python
JS Code:
@@ -65,26 +81,6 @@ var maxProfit = function(prices) {
};
```
-
-
-Python Code:
-
-```python
-class Solution:
- def maxProfit(self, prices: 'List[int]') -> int:
- if not prices: return 0
-
- min_price = float('inf')
- max_profit = 0
-
- for price in prices:
- if price < min_price:
- min_price = price
- elif max_profit < price - min_price:
- max_profit = price - min_price
- return max_profit
-```
-
C++ Code:
```c++
/**
@@ -107,10 +103,53 @@ public:
}
};
```
+Java Code:
+```java
+class Solution {
+ public int maxProfit(int[] prices) {
+ int minprice = Integer.MAX_VALUE;
+ int maxprofit = 0;
+ for (int price: prices) {
+ maxprofit = Math.max(maxprofit, price - minprice);
+ minprice = Math.min(price, minprice);
+ }
+ return maxprofit;
+ }
+}
+```
+Python Code:
+
+```python
+class Solution:
+ def maxProfit(self, prices: 'List[int]') -> int:
+ if not prices: return 0
+
+ min_price = float('inf')
+ max_profit = 0
+
+ for price in prices:
+ if price < min_price:
+ min_price = price
+ elif max_profit < price - min_price:
+ max_profit = price - min_price
+ return max_profit
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
## 相关题目
- [122.best-time-to-buy-and-sell-stock-ii](./122.best-time-to-buy-and-sell-stock-ii.md)
- [309.best-time-to-buy-and-sell-stock-with-cooldown](./309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/1218.longest-arithmetic-subsequence-of-given-difference.md b/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
index 06440d4ae..06f269acd 100644
--- a/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
+++ b/problems/1218.longest-arithmetic-subsequence-of-given-difference.md
@@ -34,6 +34,15 @@ https://leetcode-cn.com/problems/longest-arithmetic-subsequence-of-given-differe
```
+## 前置知识
+
+- 数组
+- 动态规划
+
+## 公司
+
+- 腾讯
+
## 思路
最直观的思路是双层循环,我们暴力的枚举出以每一个元素为开始元素,以最后元素结尾的的所有情况。很明显这是所有的情况,这就是暴力法的精髓, 很明显这种解法会TLE(超时),不过我们先来看一下代码,顺着这个思维继续思考。
diff --git a/problems/122.best-time-to-buy-and-sell-stock-ii.md b/problems/122.best-time-to-buy-and-sell-stock-ii.md
index 142b29928..a7b7d85bf 100644
--- a/problems/122.best-time-to-buy-and-sell-stock-ii.md
+++ b/problems/122.best-time-to-buy-and-sell-stock-ii.md
@@ -31,6 +31,18 @@ Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+
## 思路
由于我们是想获取到最大的利润,我们的策略应该是低点买入,高点卖出。
@@ -41,7 +53,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
用图表示的话就是这样:
-
+
## 关键点解析
@@ -49,7 +61,7 @@ Explanation: In this case, no transaction is done, i.e. max profit = 0.
## 代码
-语言支持:JS,Python
+语言支持:JS,C++,Java
JS Code:
@@ -70,26 +82,57 @@ var maxProfit = function(prices) {
return profit;
};
```
-
-
-
-Python Code:
-
-```python
-class Solution:
- def maxProfit(self, prices: 'List[int]') -> int:
- gains = [prices[i] - prices[i-1] for i in range(1, len(prices))
- if prices[i] - prices[i-1] > 0]
- return sum(gains)
-#评论区里都讲这是一道开玩笑的送分题.
+C++ Code:
+
+```c++
+class Solution {
+public:
+ int maxProfit(vector& prices) {
+ int res = 0;
+ for(int i=1;i prices[i-1])
+ {
+ res += prices[i] - prices[i-1];
+ }
+ }
+ return res;
+ }
+};
```
+Java Code:
+
+```java
+class Solution {
+ public int maxProfit(int[] prices) {
+ int res = 0;
+ for(int i=1;i prices[i-1])
+ {
+ res += prices[i] - prices[i-1];
+ }
+ }
+ return res;
+ }
+}
+```
-
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
## 相关题目
- [121.best-time-to-buy-and-sell-stock](./121.best-time-to-buy-and-sell-stock.md)
- [309.best-time-to-buy-and-sell-stock-with-cooldown](./309.best-time-to-buy-and-sell-stock-with-cooldown.md)
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/1227.airplane-seat-assignment-probability.md b/problems/1227.airplane-seat-assignment-probability.md
index bf9b2ecb2..2141acd9b 100644
--- a/problems/1227.airplane-seat-assignment-probability.md
+++ b/problems/1227.airplane-seat-assignment-probability.md
@@ -36,10 +36,19 @@ https://leetcode-cn.com/problems/airplane-seat-assignment-probability/descriptio
```
+## 前置知识
+
+- 记忆化搜索
+- 动态规划
+
## 暴力递归
这是一道 LeetCode 为数不多的概率题,我们来看下。
+## 公司
+
+- 字节
+
### 思路
我们定义原问题为 f(n)。对于第一个人来说,他有 n 中选择,就是分别选择 n 个座位中的一个。由于选择每个位置的概率是相同的,那么选择每个位置的概率应该都是 1 / n。
@@ -52,12 +61,12 @@ https://leetcode-cn.com/problems/airplane-seat-assignment-probability/descriptio
此时的问题转化关系如图:
-
+
(红色表示票丢的人)
整个过程分析:
-
+
### 代码
diff --git a/problems/124.binary-tree-maximum-path-sum.md b/problems/124.binary-tree-maximum-path-sum.md
index 1c4c6606e..d0ccf8c88 100644
--- a/problems/124.binary-tree-maximum-path-sum.md
+++ b/problems/124.binary-tree-maximum-path-sum.md
@@ -31,6 +31,17 @@ Input: [-10,9,20,null,null,15,7]
Output: 42
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目的path让我误解了,然后浪费了很多时间来解这道题
@@ -39,33 +50,29 @@ Output: 42
首先是官网给的两个例子:
- 
+ 
接着是我自己画的一个例子:
- 
+ 
-大家可以结合上面的demo来继续理解一下path, 除非你理解了path,否则不要往下看。
+如图红色的部分是最大路径上的节点。大家可以结合上面的demo来继续理解一下path, 除非你理解了path,否则不要往下看。
- 树的题目,基本都是考察递归思想的。因此我们需要思考如何去定义我们的递归函数,
- 在这里我定义了一个递归函数,它的功能是,`返回以当前节点为根节点的MathPath`
- 但是有两个条件:
+ 树的题目,基本都是考察递归思想的。因此我们需要思考如何去定义我们的递归函数,在这里我定义了一个递归函数,它的功能是,`返回以当前节点为根节点的MaxPath`
- 1. 第一是跟节点必须选择
- 2. 第二是左右子树只能选择一个
+但是有两个条件:
- 为什么要有这两个条件?
+1. 根节点必须选择
+2. 左右子树只能选择一个
- 我的想法是原问题可以转化为:
+为什么要有这两个条件?
- 以每一个节点为根节点,我们分别求出max path,最后计算最大值,因此第一个条件需要满足.
+我的想法是原问题可以转化为:以每一个节点为根节点,分别求出 MaxPath,最后计算最大值,因此第一个条件需要满足.
- 对于第二个,由于递归函数子节点的返回值会被父节点使用,因此我们如果两个孩子都选择了
- 就不符合max path的定义了,这也是我没有理解题意,绕了很大弯子的原因。
+对于第二个条件,由于递归函数子节点的返回值会被父节点使用,因此我们如果两个孩子都选择了就不符合 MaxPath 的定义了。实际上这道题,当遍历到某一个节点的时候,我们需要子节点的信息,然后同时结合自身的 val 来决定要不要选取左右子树以及选取的话要选哪一个, 因此这个过程本质上就是`后序遍历`
-
- 因此我的做法就是不断调用递归函数,然后在调用过程中不断计算和更新max,最后在主函数中将max返回即可。
+基本算法就是不断调用递归函数,然后在调用过程中不断计算和更新 MaxPath,最后在主函数中将 MaxPath 返回即可。
## 关键点解析
@@ -74,7 +81,7 @@ Output: 42
## 代码
-代码支持:JavaScript,Java
+代码支持:JavaScript,Java,Python
- JavaScript
@@ -150,5 +157,23 @@ class Solution {
}
```
+- Python
+
+```py
+
+class Solution:
+ ans = float('-inf')
+ def maxPathSum(self, root: TreeNode) -> int:
+ def helper(node):
+ if not node: return 0
+ l = helper(node.left)
+ r = helper(node.right)
+ self.ans = max(self.ans, max(l,0) + max(r, 0) + node.val)
+ return max(l, r, 0) + node.val
+ helper(root)
+ return self.ans
+ ```
+
## 相关题目
- [113.path-sum-ii](./113.path-sum-ii.md)
+
diff --git a/problems/125.valid-palindrome.md b/problems/125.valid-palindrome.md
index b7578be26..5f0bf2a7e 100644
--- a/problems/125.valid-palindrome.md
+++ b/problems/125.valid-palindrome.md
@@ -21,6 +21,22 @@ Output: false
```
+## 前置知识
+
+- 回文
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- facebook
+- microsoft
+- uber
+- zenefits
+
## 思路
这是一道考察回文的题目,而且是最简单的形式,即判断一个字符串是否是回文。
@@ -34,11 +50,11 @@ Output: false
拿“noon”这样一个回文串来说,我们的判断过程是这样的:
-
+
拿“abaa”这样一个不是回文的字符串来说,我们的判断过程是这样的:
-
+
@@ -145,3 +161,15 @@ class Solution:
s = ''.join(i for i in s if i.isalnum()).lower()
return s == s[::-1]
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/1260.shift-2d-grid.md b/problems/1260.shift-2d-grid.md
index 1729456b2..9c5af2f5b 100644
--- a/problems/1260.shift-2d-grid.md
+++ b/problems/1260.shift-2d-grid.md
@@ -45,8 +45,19 @@ https://leetcode-cn.com/problems/shift-2d-grid/description/
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 数学
+
## 暴力法
+## 公司
+
+- 字节
+
+### 思路
+
我们直接翻译题目,没有任何 hack 的做法。
### 代码
@@ -78,7 +89,7 @@ class Solution:
### 思路
我们仔细观察矩阵会发现,其实这样的矩阵迁移是有规律的。 如图:
-
+
因此这个问题就转化为我们一直的一维矩阵转移问题,LeetCode 也有原题[189. 旋转数组](https://leetcode-cn.com/problems/rotate-array/),同时我也写了一篇文章[文科生都能看懂的循环移位算法](https://lucifer.ren/blog/2019/12/11/rotate-list/)专门讨论这个,最终我们使用的是三次旋转法,相关数学证明也有写,很详细,这里不再赘述。
@@ -135,6 +146,10 @@ class Solution:
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
## 相关题目
- [189. 旋转数组](https://leetcode-cn.com/problems/rotate-array/)
@@ -142,3 +157,11 @@ class Solution:
## 参考
- [文科生都能看懂的循环移位算法](https://lucifer.ren/blog/2019/12/11/rotate-list/)
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/1261.find-elements-in-a-contaminated-binary-tree.md b/problems/1261.find-elements-in-a-contaminated-binary-tree.md
index a5d5c5e8e..a0e3ac01d 100644
--- a/problems/1261.find-elements-in-a-contaminated-binary-tree.md
+++ b/problems/1261.find-elements-in-a-contaminated-binary-tree.md
@@ -20,7 +20,7 @@ bool find(int target) 判断目标值 target 是否存在于还原后的二
示例 1:
-
+
输入:
["FindElements","find","find"]
@@ -33,7 +33,7 @@ findElements.find(1); // return False
findElements.find(2); // return True
示例 2:
-
+
输入:
["FindElements","find","find","find"]
@@ -47,7 +47,7 @@ findElements.find(3); // return True
findElements.find(5); // return False
示例 3:
-
+
输入:
["FindElements","find","find","find","find"]
@@ -72,8 +72,16 @@ TreeNode.val == -1
```
+## 前置知识
+
+- 二进制
+
## 暴力法
+## 公司
+
+- 暂无
+
### 思路
最简单想法就是递归建立树,然后 find 的时候递归查找即可,代码也很简单。
@@ -184,12 +192,12 @@ class FindElements:
如果我们把树中的数全部加 1 会怎么样?
-
+
(图参考 https://leetcode.com/problems/find-elements-in-a-contaminated-binary-tree/discuss/431229/Python-Special-Way-for-find()-without-HashSet-O(1)-Space-O(logn)-Time)
仔细观察发现,每一行的左右子树分别有不同的前缀:
-
+
Ok,那么算法就来了。为了便于理解,我们来举个具体的例子,比如 target 是 9,我们首先将其加 1,二进制表示就是 1010。不考虑第一位,就是 010,我们只要:
diff --git a/problems/1262.greatest-sum-divisible-by-three.md b/problems/1262.greatest-sum-divisible-by-three.md
index a6d3802c5..fc8f517ed 100644
--- a/problems/1262.greatest-sum-divisible-by-three.md
+++ b/problems/1262.greatest-sum-divisible-by-three.md
@@ -33,15 +33,26 @@ https://leetcode-cn.com/problems/greatest-sum-divisible-by-three/description/
```
+## 前置知识
+
+- 数组
+- 回溯法
+- 排序
+
## 暴力法
+## 公司
+
+- 字节
+- 网易有道
+
### 思路
一种方式是找出所有的能够被 3 整除的子集,然后挑选出和最大的。由于我们选出了所有的子集,那么时间复杂度就是 $O(2^N)$ , 毫无疑问会超时。这里我们使用回溯法找子集,如果不清楚回溯法,可以参考我之前的题解,很多题目都用到了,比如[78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md)。
更多回溯题目,可以访问上方链接查看(可以使用一套模板搞定):
-
+
### 代码
@@ -83,11 +94,11 @@ class Solution:
以题目中的例 1 为例:
-
+
以题目中的例 2 为例:
-
+
### 代码
@@ -169,7 +180,7 @@ class Solution:
我在[数据结构与算法在前端领域的应用 - 第二篇](https://lucifer.ren/blog/2019/09/19/algorthimn-fe-2/) 中讲到了有限状态机。
-
+
状态机表示若干个状态以及在这些状态之间的转移和动作等行为的数学模型。通俗的描述状态机就是定义了一套状态変更的流程:状态机包含一个状态集合,定义当状态机处于某一个状态的时候它所能接收的事件以及可执行的行为,执行完成后,状态机所处的状态。
@@ -239,3 +250,7 @@ class Solution:
## 扩展
实际上,我们可以采取加法(贪婪策略),感兴趣的可以试一下。
+
+另外如果题目改成了`请你找出并返回能被x整除的元素最大和`,你只需要将我的解法中的 3 改成 x 即可。
+
+
diff --git a/problems/128.longest-consecutive-sequence.md b/problems/128.longest-consecutive-sequence.md
index f7d4bce96..1c2ac9327 100644
--- a/problems/128.longest-consecutive-sequence.md
+++ b/problems/128.longest-consecutive-sequence.md
@@ -21,6 +21,17 @@ Submissions
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道最最长连续数字序列长度的题目, 官网给出的难度是`hard`.
@@ -53,7 +64,7 @@ return Math.max(count, maxCount);
思路就是将之前”排序之后,通过比较前后元素是否相差 1 来判断是否连续“的思路改为
不排序而是`直接遍历,然后在内部循环里面查找是否存在当前值的邻居元素`,但是马上有一个
-问题,内部我们`查找是否存在当前值的邻居元素`的过程如果使用数组时间复杂度是 O(n),
+问题,内部我们`查找是否存在当前值的邻居元素`的过程如果使用数组,时间复杂度是 O(n),
那么总体的复杂度就是 O(n^2),完全不可以接受。怎么办呢?
我们换个思路,用空间来换时间。比如用类似于 hashmap 这样的数据结构优化查询部分,将时间复杂度降低到 O(1), 代码见后面`代码部分`
@@ -65,48 +76,20 @@ return Math.max(count, maxCount);
## 代码
```js
-/*
- * @lc app=leetcode id=128 lang=javascript
- *
- * [128] Longest Consecutive Sequence
- *
- * https://leetcode.com/problems/longest-consecutive-sequence/description/
- *
- * algorithms
- * Hard (40.98%)
- * Total Accepted: 200.3K
- * Total Submissions: 484.5K
- * Testcase Example: '[100,4,200,1,3,2]'
- *
- * Given an unsorted array of integers, find the length of the longest
- * consecutive elements sequence.
- *
- * Your algorithm should run in O(n) complexity.
- *
- * Example:
- *
- *
- * Input: [100, 4, 200, 1, 3, 2]
- * Output: 4
- * Explanation: The longest consecutive elements sequence is [1, 2, 3, 4].
- * Therefore its length is 4.
- *
- *
- */
/**
* @param {number[]} nums
* @return {number}
*/
var longestConsecutive = function(nums) {
- nums = new Set(nums);
+ set = new Set(nums);
let max = 0;
- let y = 0;
- nums.forEach(x => {
+ let temp = 0;
+ set.forEach(x => {
// 说明x是连续序列的开头元素
- if (!nums.has(x - 1)) {
- y = x + 1;
- while (nums.has(y)) {
- y = y + 1;
+ if (!set.has(x - 1)) {
+ temp = x + 1;
+ while (set.has(y)) {
+ temp = temp + 1;
}
max = Math.max(max, y - x); // y - x 就是从x开始到最后有多少连续的数字
}
diff --git a/problems/129.sum-root-to-leaf-numbers.md b/problems/129.sum-root-to-leaf-numbers.md
index 551629cde..c3d9de9f3 100644
--- a/problems/129.sum-root-to-leaf-numbers.md
+++ b/problems/129.sum-root-to-leaf-numbers.md
@@ -41,6 +41,16 @@ Therefore, sum = 495 + 491 + 40 = 1026.
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这是一道非常适合训练递归的题目。虽然题目不难,但是要想一次写正确,并且代码要足够优雅却不是很容易。
@@ -51,12 +61,12 @@ Therefore, sum = 495 + 491 + 40 = 1026.
整个过程如图所示:
-
+
那么数字具体的计算逻辑,如图所示,相信大家通过这个不难发现规律:
-
+
## 关键点解析
diff --git a/problems/1297.maximum-number-of-occurrences-of-a-substring.md b/problems/1297.maximum-number-of-occurrences-of-a-substring.md
index 194fea2d8..2b8d09d33 100644
--- a/problems/1297.maximum-number-of-occurrences-of-a-substring.md
+++ b/problems/1297.maximum-number-of-occurrences-of-a-substring.md
@@ -40,10 +40,19 @@ https://leetcode-cn.com/problems/maximum-number-of-occurrences-of-a-substring
s 只包含小写英文字母。
```
+## 前置知识
+
+- 字符串
+- 滑动窗口
+
## 暴力法
题目给的数据量不是很大,为 1 <= maxLetters <= 26,我们试一下暴力法。
+## 公司
+
+- 字节
+
### 思路
暴力法如下:
diff --git a/problems/130.surrounded-regions.md b/problems/130.surrounded-regions.md
index 060ec587d..c35d76e44 100644
--- a/problems/130.surrounded-regions.md
+++ b/problems/130.surrounded-regions.md
@@ -27,11 +27,22 @@ Surrounded regions shouldn’t be on the border, which means that any 'O' on the
```
+## 前置知识
+
+- DFS
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我们需要将所有被X包围的O变成X,并且题目明确说了边缘的所有O都是不可以变成X的。
-
+
其实我们观察会发现,我们除了边缘的O以及和边缘O连通的O是不需要变成X的,其他都要变成X。
@@ -42,7 +53,7 @@ Surrounded regions shouldn’t be on the border, which means that any 'O' on the
> 我将`边缘的O以及和边缘O连通的O` 标记为了 "A"
-
+
@@ -156,4 +167,16 @@ class Solution:
> 解题模板是一样的
+**复杂度分析**
+- 时间复杂度:$O(row * col)$
+- 空间复杂度:$O(row * col)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
+
diff --git a/problems/131.palindrome-partitioning.md b/problems/131.palindrome-partitioning.md
index e241a9d40..f47b15fbd 100644
--- a/problems/131.palindrome-partitioning.md
+++ b/problems/131.palindrome-partitioning.md
@@ -21,12 +21,30 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道求解所有可能性的题目, 这时候可以考虑使用回溯法。 回溯法解题的模板我们已经在很多题目中用过了,
这里就不多说了。大家可以结合其他几道题目加深一下理解。
+这里我画了一个图:
+
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
+
+
## 关键点解析
- 回溯法
diff --git a/problems/1310.xor-queries-of-a-subarray.md b/problems/1310.xor-queries-of-a-subarray.md
index cf9292f0c..73704bb18 100644
--- a/problems/1310.xor-queries-of-a-subarray.md
+++ b/problems/1310.xor-queries-of-a-subarray.md
@@ -43,6 +43,10 @@ queries[i].length == 2
0 <= queries[i][0] <= queries[i][1] < arr.length
```
+## 前置知识
+
+- 前缀和
+
## 暴力法
### 思路
@@ -68,6 +72,10 @@ class Solution:
## 前缀表达式
+## 公司
+
+- 暂无
+
### 思路
比较常见的是前缀和,这个概念其实很容易理解,即一个数组中,第 n 位存储的是数组前 n 个数字的和。
@@ -76,7 +84,7 @@ class Solution:
这道题是前缀对前缀异或,我们利用了异或的性质 `x ^ y ^ x = y`。
-
+
### 代码
@@ -163,6 +171,6 @@ public:
- [303. 区域和检索 - 数组不可变](https://leetcode-cn.com/problems/range-sum-query-immutable/description/)
-
+
- [1186.删除一次得到子数组最大和](https://lucifer.ren/blog/2019/12/11/leetcode-1186/)
diff --git a/problems/1332.remove-palindromic-subsequences.md b/problems/1332.remove-palindromic-subsequences.md
index fe4b081e7..3e2870b9c 100644
--- a/problems/1332.remove-palindromic-subsequences.md
+++ b/problems/1332.remove-palindromic-subsequences.md
@@ -45,6 +45,14 @@ s 仅包含字母 'a' 和 'b'
在真实的面试中遇到过这道题?
```
+## 前置知识
+
+- 回文
+
+## 公司
+
+- 暂无
+
## 思路
这又是一道“抖机灵”的题目,类似的题目有[1297.maximum-number-of-occurrences-of-a-substring](https://github.com/azl397985856/leetcode/blob/77db8fa47c7ee0a14b320f7c2d22f7c61ae53c35/problems/1297.maximum-number-of-occurrences-of-a-substring.md)
@@ -55,6 +63,11 @@ s 仅包含字母 'a' 和 'b'
- 否则需要两次
- 一定要注意特殊情况, 对于空字符串,我们需要 0 次
+
+## 关键点解析
+
+- 注意审题目,一定要利用题目条件“只含有 a 和 b 两个字符”否则容易做的很麻烦
+
## 代码
代码支持:Python3
@@ -92,6 +105,15 @@ class Solution:
```
-## 关键点解析
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
-- 注意审题目,一定要利用题目条件“只含有 a 和 b 两个字符”否则容易做的很麻烦
diff --git a/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md b/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
index cb0de611e..173a78f86 100644
--- a/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
+++ b/problems/1334.find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance.md
@@ -17,7 +17,7 @@ https://leetcode-cn.com/problems/find-the-city-with-the-smallest-number-of-neigh
```
-
+
```
@@ -36,7 +36,7 @@ https://leetcode-cn.com/problems/find-the-city-with-the-smallest-number-of-neigh
```
-
+
```
@@ -64,6 +64,15 @@ edges[i].length == 3
```
+## 前置知识
+
+- 动态规划
+- Floyd-Warshall
+
+## 公司
+
+- 暂无
+
## 思路
这道题的本质就是:
diff --git a/problems/136.single-number.md b/problems/136.single-number.md
index b3099686a..25535eef5 100644
--- a/problems/136.single-number.md
+++ b/problems/136.single-number.md
@@ -12,6 +12,17 @@ Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
根据题目描述,由于加上了时间复杂度必须是 O(n),并且空间复杂度为 O(1)的条件,因此不能用排序方法,也不能使用 map 数据结构。
@@ -36,7 +47,7 @@ Your algorithm should have a linear runtime complexity. Could you implement it w
## 代码
-* 语言支持:JS,C++,Python
+* 语言支持:JS,C,C++,Java,Python
JavaScrip Code:
```js
@@ -89,7 +100,20 @@ var singleNumber = function(nums) {
return ret;
};
```
-C++:
+C Code:
+```C
+int singleNumber(int* nums, int numsSize){
+ int res=0;
+ for(int i=0;i int:
+ for i in range(len(s), 0, -1):
+ for j in range(len(s) - i + 1):
+ sub = s[j:j + i]
+ has_odd_vowel = False
+ for vowel in ['a', 'e', 'i', 'o', 'u']:
+ if sub.count(vowel) % 2 != 0:
+ has_odd_vowel = True
+ break
+ if not has_odd_vowel: return i
+ return 0
+```
+
+JavaScript Code:
+```js
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const vowels = ['a', 'e', 'i', 'o', 'u']
+ const hasEvenVowels = s => !vowels.some(v => (s.match(new RegExp(v, 'g'))||[]).length % 2 !== 0)
+
+ for (let subStrLen = s.length; subStrLen >= 0; subStrLen--) {
+ let remove = s.length - subStrLen + 1
+
+ for (let start = 0; start < remove; start++) {
+ let subStr = s.slice(start, start + subStrLen)
+ if (hasEvenVowels(subStr)) {
+ return subStrLen
+ }
+ }
+ }
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n^3)$. Considering every substring takes $O(n^2)$ time. For each of the subarray we calculate the numbers of vowels taking $O(n^2)$ time in the worst case, taking a total of $O(n^3)$ time.
+- Space complexity: $O(1)$.
+
+## Approach2: Prefix Sum + Pruning
+
+### Algorithm
+
+Notice that in the last approach there is a step for `counting the numbers of vowels for each substring`. If we look closely, we will discover a lot of duplicate computations. Optimization at this part will get us better efficiency.
+
+For problems involving consecutive numbers, we can consider using prefix sum to get to a better solution.
+
+By using this strategy we trade space complexity for time complexity, reducing the time complexity to $O(n ^ 2)$, while increasing the space complexity to $O(n)$, which is a worthwhile trade-off in many situations.
+
+### Code(`Python3/Java/JavaScript`)
+
+Python3 Code:
+```py
+class Solution:
+ i_mapper = {
+ "a": 0,
+ "e": 1,
+ "i": 2,
+ "o": 3,
+ "u": 4
+ }
+ def check(self, s, pre, l, r):
+ for i in range(5):
+ if s[l] in self.i_mapper and i == self.i_mapper[s[l]]: cnt = 1
+ else: cnt = 0
+ if (pre[r][i] - pre[l][i] + cnt) % 2 != 0: return False
+ return True
+ def findTheLongestSubstring(self, s: str) -> int:
+ n = len(s)
+
+ pre = [[0] * 5 for _ in range(n)]
+
+ # pre
+ for i in range(n):
+ for j in range(5):
+ if s[i] in self.i_mapper and self.i_mapper[s[i]] == j:
+ pre[i][j] = pre[i - 1][j] + 1
+ else:
+ pre[i][j] = pre[i - 1][j]
+ for i in range(n - 1, -1, -1):
+ for j in range(n - i):
+ if self.check(s, pre, j, i + j):
+ return i + 1
+ return 0
+```
+
+Java Code:
+```java
+class Solution {
+ public int findTheLongestSubstring(String s) {
+
+ int len = s.length();
+
+ if (len == 0)
+ return 0;
+
+ int[][] preSum = new int[len][5];
+ int start = getIndex(s.charAt(0));
+ if (start != -1)
+ preSum[0][start]++;
+
+ // preSum
+ for (int i = 1; i < len; i++) {
+
+ int idx = getIndex(s.charAt(i));
+
+ for (int j = 0; j < 5; j++) {
+
+ if (idx == j)
+ preSum[i][j] = preSum[i - 1][j] + 1;
+ else
+ preSum[i][j] = preSum[i - 1][j];
+ }
+ }
+
+ for (int i = len - 1; i >= 0; i--) {
+
+ for (int j = 0; j < len - i; j++) {
+ if (checkValid(preSum, s, i, i + j))
+ return i + 1
+ }
+ }
+ return 0
+ }
+
+
+ public boolean checkValid(int[][] preSum, String s, int left, int right) {
+
+ int idx = getIndex(s.charAt(left));
+
+ for (int i = 0; i < 5; i++)
+ if (((preSum[right][i] - preSum[left][i] + (idx == i ? 1 : 0)) & 1) == 1)
+ return false;
+
+ return true;
+ }
+ public int getIndex(char ch) {
+
+ if (ch == 'a')
+ return 0;
+ else if (ch == 'e')
+ return 1;
+ else if (ch == 'i')
+ return 2;
+ else if (ch == 'o')
+ return 3;
+ else if (ch == 'u')
+ return 4;
+ else
+ return -1;
+ }
+}
+```
+
+JavaScript Code:
+```js
+/**
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const prefixes = Array(s.length + 1).fill(0).map(el => Array(5).fill(0))
+ const vowels = {
+ a: 0,
+ e: 1,
+ i: 2,
+ o: 3,
+ u: 4
+ }
+
+ for (let i = 1; i < s.length + 1; i++) {
+ const letter = s[i - 1]
+ for (let j = 0; j < 5; j++) {
+ prefixes[i][j] = prefixes[i - 1][j]
+ }
+ if (letter in vowels) {
+ prefixes[i][vowels[letter]] = prefixes[i - 1][vowels[letter]] + 1
+ }
+ }
+
+ const check = (s, prefixes, l, r) => {
+ for (let i = 0; i < 5; i++) {
+ const count = s[l] in vowels && vowels[s[l]] === i
+ if ((prefixes[r + 1][i] - prefixes[l + 1][i] + count) % 2 !== 0) {
+ return false
+ }
+ }
+ return true
+ }
+
+ for (let r = s.length - 1; r >= 0; r--) {
+ for (let l = 0; l < s.length - r; l++) {
+ if (check(s, prefixes, l, l + r)) {
+ return r + 1
+ }
+ }
+ }
+
+ return 0
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n^2)$.
+- Space complexity: $O(n)$.
+
+## Approach 3: Prefix Sum + State Compression
+
+### Algorithm
+
+In approach 2 we reduce the time complexity by trading space (prefix) for time. However, the time complexity of $O(n^2)$ is still a lot. Is there still room for optimization?
+
+All we care about is parity. We don't need to count the specific number of occurrences of each vowel. Instead, we can use two states `odd or even`. Since we only need to deal with two states, we can consider using bit operation.
+
+- Use a 5-bit binary to represent the parity of the number of occurrences of each vowel with 0 for even and 1 for odd.
+- The 5 bits of the binary represent 'uoiea' respectively. For example, `10110` means the current substring includes even numbers of 'a' and 'o' and odd numbers of 'e', 'i', and 'u'.
+- This binary is assigned to `cur` in the code below.
+
+Why are we using 0 for even numbers and 1 for odd numbers? Keep reading.
+
+This algorithm involves elementary mathematics knowledge.
+
+- If two numbers are of the same parity, then the subtraction must be even.
+- If two numbers are of different parity, then the subtraction must be odd.
+
+Now let's look at the question again. `Why are we using 0 for even numbers and 1 for odd numbers?` Because we want to use the XOR bitwise operation, which works as follows.
+
+- If XOR is performed on the two binaries, each bit will be bit-operated.
+-If two bits are the same, we get 0, otherwise, we get 1.
+
+This is very similar to the above mathematics knowledge. If the parity of two numbers is the same, we get an even number, otherwise, we get an odd number. So it is natural to use 0 for even numbers and 1 for odd numbers.
+
+### Code(`Python3/JavaScript`)
+
+Python3 Code:
+```py
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+ seen = {0: -1}
+ res = cur = 0
+
+ for i in range(len(s)):
+ if s[i] in mapper:
+ cur ^= mapper.get(s[i])
+ # If all numbers are of the same parity, then the subtraction must be even.
+ if cur in seen:
+ res = max(res, i - seen.get(cur))
+ else:
+ seen[cur] = i
+ return res
+```
+
+JavaScript Code:
+```js
+/**
+ * @param {string} s
+ * @return {number}
+ */
+var findTheLongestSubstring = function (s) {
+ const mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+
+ let max = 0, cur = 0
+ const seen = { 0: -1 }
+ for (let i = 0; i < s.length; i++) {
+ if (s[i] in mapper) {
+ cur ^= mapper[s[i]]
+ }
+ if (cur in seen) {
+ max = Math.max(max, i - seen[cur])
+ }
+ else {
+ seen[cur] = i
+ }
+ }
+
+ return max
+};
+```
+
+### Complexity Analysis
+
+- Time complexity: $O(n)$.
+- Space complexity: $O(n)$.
+
+## Keypoints
+
+- Prefix Sum
+- State Compression
+
+## Extension
+
+- [You can do whatever you want while mastering prefix sum](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)(Chinese)
diff --git a/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md b/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md
new file mode 100644
index 000000000..b38fe1d32
--- /dev/null
+++ b/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md
@@ -0,0 +1,274 @@
+# 题目地址(1371. 每个元音包含偶数次的最长子字符串)
+
+https://leetcode-cn.com/problems/find-the-longest-substring-containing-vowels-in-even-counts/
+
+## 题目描述
+
+```
+给你一个字符串 s ,请你返回满足以下条件的最长子字符串的长度:每个元音字母,即 'a','e','i','o','u' ,在子字符串中都恰好出现了偶数次。
+
+
+
+示例 1:
+
+输入:s = "eleetminicoworoep"
+输出:13
+解释:最长子字符串是 "leetminicowor" ,它包含 e,i,o 各 2 个,以及 0 个 a,u 。
+示例 2:
+
+输入:s = "leetcodeisgreat"
+输出:5
+解释:最长子字符串是 "leetc" ,其中包含 2 个 e 。
+示例 3:
+
+输入:s = "bcbcbc"
+输出:6
+解释:这个示例中,字符串 "bcbcbc" 本身就是最长的,因为所有的元音 a,e,i,o,u 都出现了 0 次。
+
+
+提示:
+
+1 <= s.length <= 5 x 10^5
+s 只包含小写英文字母。
+
+```
+
+## 前置知识
+
+- 前缀和
+- 状态压缩
+
+## 暴力法 + 剪枝
+
+## 公司
+
+- 暂无
+
+### 思路
+
+首先拿到这道题的时候,我想到第一反应是滑动窗口行不行。 但是很快这个想法就被我否定了,因为滑动窗口(这里是可变滑动窗口)我们需要扩张和收缩窗口大小,而这里不那么容易。因为题目要求的是奇偶性,而不是类似“元音出现最多的子串”等。
+
+突然一下子没了思路。那就试试暴力法吧。暴力法的思路比较朴素和直观。 那就是`双层循环找到所有子串,然后对于每一个子串,统计元音个数,如果子串的元音个数都是偶数,则更新答案,最后返回最大的满足条件的子串长度即可`。
+
+这里我用了一个小的 trick。枚举所有子串的时候,我是从最长的子串开始枚举的,这样我找到一个满足条件的直接返回就行了(early return),不必维护最大值。`这样不仅减少了代码量,还提高了效率。`
+
+### 代码
+
+代码支持:Python3
+
+Python3 Code:
+
+```python
+
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ for i in range(len(s), 0, -1):
+ for j in range(len(s) - i + 1):
+ sub = s[j:j + i]
+ has_odd_vowel = False
+ for vowel in ['a', 'e', 'i', 'o', 'u']:
+ if sub.count(vowel) % 2 != 0:
+ has_odd_vowel = True
+ break
+ if not has_odd_vowel: return i
+ return 0
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:双层循环找出所有子串的复杂度是$O(n^2)$,统计元音个数复杂度也是$O(n)$,因此这种算法的时间复杂度为$O(n^3)$。
+- 空间复杂度:$O(1)$
+
+## 前缀和 + 剪枝
+
+### 思路
+
+上面思路中`对于每一个子串,统计元音个数`,我们仔细观察的话,会发现有很多重复的统计。那么优化这部分的内容就可以获得更好的效率。
+
+对于这种连续的数字问题,这里我们考虑使用[前缀和](https://oi-wiki.org/basic/prefix-sum/)来优化。
+
+经过这种空间换时间的策略之后,我们的时间复杂度会降低到$O(n ^ 2)$,但是相应空间复杂度会上升到$O(n)$,这种取舍在很多情况下是值得的。
+
+### 代码
+
+代码支持:Python3,Java
+
+Python3 Code:
+
+```python
+class Solution:
+ i_mapper = {
+ "a": 0,
+ "e": 1,
+ "i": 2,
+ "o": 3,
+ "u": 4
+ }
+ def check(self, s, pre, l, r):
+ for i in range(5):
+ if s[l] in self.i_mapper and i == self.i_mapper[s[l]]: cnt = 1
+ else: cnt = 0
+ if (pre[r][i] - pre[l][i] + cnt) % 2 != 0: return False
+ return True
+ def findTheLongestSubstring(self, s: str) -> int:
+ n = len(s)
+
+ pre = [[0] * 5 for _ in range(n)]
+
+ # pre
+ for i in range(n):
+ for j in range(5):
+ if s[i] in self.i_mapper and self.i_mapper[s[i]] == j:
+ pre[i][j] = pre[i - 1][j] + 1
+ else:
+ pre[i][j] = pre[i - 1][j]
+ for i in range(n - 1, -1, -1):
+ for j in range(n - i):
+ if self.check(s, pre, j, i + j):
+ return i + 1
+ return 0
+```
+
+Java Code:
+
+```java
+class Solution {
+ public int findTheLongestSubstring(String s) {
+
+ int len = s.length();
+
+ if (len == 0)
+ return 0;
+
+ int[][] preSum = new int[len][5];
+ int start = getIndex(s.charAt(0));
+ if (start != -1)
+ preSum[0][start]++;
+
+ // preSum
+ for (int i = 1; i < len; i++) {
+
+ int idx = getIndex(s.charAt(i));
+
+ for (int j = 0; j < 5; j++) {
+
+ if (idx == j)
+ preSum[i][j] = preSum[i - 1][j] + 1;
+ else
+ preSum[i][j] = preSum[i - 1][j];
+ }
+ }
+
+ for (int i = len - 1; i >= 0; i--) {
+
+ for (int j = 0; j < len - i; j++) {
+ if (checkValid(preSum, s, j, i + j))
+ return i + 1;
+ }
+ }
+ return 0;
+ }
+
+
+ public boolean checkValid(int[][] preSum, String s, int left, int right) {
+
+ int idx = getIndex(s.charAt(left));
+
+ for (int i = 0; i < 5; i++)
+ if (((preSum[right][i] - preSum[left][i] + (idx == i ? 1 : 0)) & 1) == 1)
+ return false;
+
+ return true;
+ }
+ public int getIndex(char ch) {
+
+ if (ch == 'a')
+ return 0;
+ else if (ch == 'e')
+ return 1;
+ else if (ch == 'i')
+ return 2;
+ else if (ch == 'o')
+ return 3;
+ else if (ch == 'u')
+ return 4;
+ else
+ return -1;
+ }
+}
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(n^2)$。
+- 空间复杂度:$O(n)$
+
+## 前缀和 + 状态压缩
+
+### 思路
+
+前面的前缀和思路,我们通过空间(prefix)换取时间的方式降低了时间复杂度。但是时间复杂度仍然是平方,我们是否可以继续优化呢?
+
+实际上由于我们只关心奇偶性,并不关心每一个元音字母具体出现的次数。因此我们可以使用`是奇数,是偶数`两个状态来表示,由于只有两个状态,我们考虑使用位运算。
+
+我们使用 5 位的二进制来表示以 i 结尾的字符串中包含各个元音的奇偶性,其中 0 表示偶数,1 表示奇数,并且最低位表示 a,然后依次是 e,i,o,u。比如 `10110` 则表示的是包含偶数个 a 和 o,奇数个 e,i,u,我们用变量 `cur` 来表示。
+
+为什么用 0 表示偶数?1 表示奇数?
+
+回答这个问题,你需要继续往下看。
+
+其实这个解法还用到了一个性质,这个性质是小学数学知识:
+
+- 如果两个数字奇偶性相同,那么其相减一定是偶数。
+- 如果两个数字奇偶性不同,那么其相减一定是奇数。
+
+看到这里,我们再来看上面抛出的问题`为什么用 0 表示偶数?1 表示奇数?`。因为这里我们打算用异或运算,而异或的性质是:
+
+如果对两个二进制做异或,会对其每一位进行位运算,如果相同则位 0,否则位 1。这和上面的性质非常相似。上面说`奇偶性相同则位偶数,否则为奇数`。因此很自然地`用 0 表示偶数?1 表示奇数`会更加方便。
+
+### 代码
+
+代码支持:Python3
+
+Python3 Code:
+
+```python
+
+class Solution:
+ def findTheLongestSubstring(self, s: str) -> int:
+ mapper = {
+ "a": 1,
+ "e": 2,
+ "i": 4,
+ "o": 8,
+ "u": 16
+ }
+ seen = {0: -1}
+ res = cur = 0
+
+ for i in range(len(s)):
+ if s[i] in mapper:
+ cur ^= mapper.get(s[i])
+ # 全部奇偶性都相同,相减一定都是偶数
+ if cur in seen:
+ res = max(res, i - seen.get(cur))
+ else:
+ seen[cur] = i
+ return res
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(n)$。
+- 空间复杂度:$O(n)$
+
+## 关键点解析
+
+- 前缀和
+- 状态压缩
+
+## 相关题目
+
+- [掌握前缀表达式真的可以为所欲为!](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)
diff --git a/problems/139.word-break.md b/problems/139.word-break.md
index 142b3bab5..c8e28798b 100644
--- a/problems/139.word-break.md
+++ b/problems/139.word-break.md
@@ -1,4 +1,3 @@
-
## 题目地址
https://leetcode.com/problems/word-break/description/
@@ -30,40 +29,49 @@ Output: false
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题是给定一个字典和一个句子,判断该句子是否可以由字典里面的单词组出来,一个单词可以用多次。
暴力的方法是无解的,复杂度极其高。 我们考虑其是否可以拆分为小问题来解决。
-对于问题`(s, wordDict)` 我们是否可以用(s', wordDict) 来解决。 其中s' 是s 的子序列,
-当s'变成寻常(长度为0)的时候问题就解决了。 我们状态转移方程变成了这道题的难点。
+对于问题`(s, wordDict)` 我们是否可以用(s', wordDict) 来解决。 其中 s' 是 s 的子序列,
+当 s'变成寻常(长度为 0)的时候问题就解决了。 我们状态转移方程变成了这道题的难点。
-我们可以建立一个数组dp, dp[i]代表 字符串 s.substring(0, i) 能否由字典里面的单词组成,
-值得注意的是,这里我们无法建立dp[i] 和 dp[i - 1] 的关系,
-我们可以建立的是dp[i - word.length] 和 dp[i] 的关系。
+我们可以建立一个数组 dp, dp[i]代表 字符串 s.substring(0, i) 能否由字典里面的单词组成,
+值得注意的是,这里我们无法建立 dp[i] 和 dp[i - 1] 的关系,
+我们可以建立的是 dp[i - word.length] 和 dp[i] 的关系。
我们用图来感受一下:
-
-
+
没有明白也没有关系,我们分步骤解读一下:
-(以下的图左边都代表s,右边都是dict,灰色代表没有处理的字符,绿色代表匹配成功,红色代表匹配失败)
-
-
+(以下的图左边都代表 s,右边都是 dict,灰色代表没有处理的字符,绿色代表匹配成功,红色代表匹配失败)
-
+
-
+
-
+
+
上面分步解释了算法的基本过程,下面我们感性认识下这道题,我把它比喻为
你正在`往一个老式手电筒🔦中装电池`
-
+
## 代码
@@ -125,15 +133,15 @@ Output: false
* @param {string[]} wordDict
* @return {boolean}
*/
-var wordBreak = function(s, wordDict) {
+var wordBreak = function (s, wordDict) {
const dp = Array(s.length + 1);
dp[0] = true;
for (let i = 0; i < s.length + 1; i++) {
for (let word of wordDict) {
- if (dp[i - word.length] && word.length <= i) {
- if (s.substring(i - word.length, i) === word) {
- dp[i] = true;
- }
+ if (word.length <= i && dp[i - word.length]) {
+ if (s.substring(i - word.length, i) === word) {
+ dp[i] = true;
+ }
}
}
}
diff --git a/problems/144.binary-tree-preorder-traversal.md b/problems/144.binary-tree-preorder-traversal.md
index 12e92fb1b..fe8e07a52 100644
--- a/problems/144.binary-tree-preorder-traversal.md
+++ b/problems/144.binary-tree-preorder-traversal.md
@@ -21,6 +21,18 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
```
+## 前置知识
+
+- 递归
+- 栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是前序遍历,这个和之前的`leetcode 94 号问题 - 中序遍历`完全不一回事。
@@ -28,7 +40,11 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
前序遍历是`根左右`的顺序,注意是`根`开始,那么就很简单。直接先将根节点入栈,然后
看有没有右节点,有则入栈,再看有没有左节点,有则入栈。 然后出栈一个元素,重复即可。
-> 其他树的非递归遍历课没这么简单
+> 其他树的非递归遍历可没这么简单
+
+
+
+(迭代 VS 递归)
## 关键点解析
@@ -53,44 +69,6 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
JavaScript Code:
```js
-/*
- * @lc app=leetcode id=144 lang=javascript
- *
- * [144] Binary Tree Preorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-preorder-traversal/description/
- *
- * algorithms
- * Medium (50.36%)
- * Total Accepted: 314K
- * Total Submissions: 621.2K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the preorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [1,2,3]
- *
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[]}
@@ -110,13 +88,13 @@ var preorderTraversal = function(root) {
let t = stack.pop();
while (t) {
- ret.push(t.val);
if (t.right) {
stack.push(t.right);
}
if (t.left) {
stack.push(t.left);
}
+ ret.push(t.val);
t = stack.pop();
}
@@ -154,3 +132,7 @@ public:
}
};
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md b/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md
new file mode 100644
index 000000000..920be35fe
--- /dev/null
+++ b/problems/1449.form-largest-integer-with-digits-that-add-up-to-target.md
@@ -0,0 +1,224 @@
+# 题目地址(1449. 数位成本和为目标值的最大数字)
+
+https://leetcode-cn.com/problems/form-largest-integer-with-digits-that-add-up-to-target/
+
+## 题目描述
+
+```
+给你一个整数数组 cost 和一个整数 target 。请你返回满足如下规则可以得到的 最大 整数:
+
+给当前结果添加一个数位(i + 1)的成本为 cost[i] (cost 数组下标从 0 开始)。
+总成本必须恰好等于 target 。
+添加的数位中没有数字 0 。
+由于答案可能会很大,请你以字符串形式返回。
+
+如果按照上述要求无法得到任何整数,请你返回 "0" 。
+
+
+
+示例 1:
+
+输入:cost = [4,3,2,5,6,7,2,5,5], target = 9
+输出:"7772"
+解释:添加数位 '7' 的成本为 2 ,添加数位 '2' 的成本为 3 。所以 "7772" 的代价为 2*3+ 3*1 = 9 。 "997" 也是满足要求的数字,但 "7772" 是较大的数字。
+ 数字 成本
+ 1 -> 4
+ 2 -> 3
+ 3 -> 2
+ 4 -> 5
+ 5 -> 6
+ 6 -> 7
+ 7 -> 2
+ 8 -> 5
+ 9 -> 5
+示例 2:
+
+输入:cost = [7,6,5,5,5,6,8,7,8], target = 12
+输出:"85"
+解释:添加数位 '8' 的成本是 7 ,添加数位 '5' 的成本是 5 。"85" 的成本为 7 + 5 = 12 。
+示例 3:
+
+输入:cost = [2,4,6,2,4,6,4,4,4], target = 5
+输出:"0"
+解释:总成本是 target 的条件下,无法生成任何整数。
+示例 4:
+
+输入:cost = [6,10,15,40,40,40,40,40,40], target = 47
+输出:"32211"
+
+
+提示:
+
+cost.length == 9
+1 <= cost[i] <= 5000
+1 <= target <= 5000
+
+```
+
+## 前置知识
+
+- 数组
+- 动态规划
+- 背包问题
+
+## 公司
+
+- 暂无
+
+## 思路
+
+由于数组可以重复选择,因此这是一个完全背包问题。
+
+### 01 背包
+
+对于 01 背包问题,我们的套路是:
+
+```py
+for i in 0 to N:
+ for j in 1 to V + 1:
+ dp[j] = max(dp[j], dp[j - cost[i])
+```
+
+而一般我们为了处理边界问题,我们一般会这么写代码:
+
+```py
+for i in 1 to N + 1:
+ # 这里是倒序的,原因在于这里是01背包。
+ for j in V to 0:
+ dp[j] = max(dp[j], dp[j - cost[i - 1])
+```
+
+其中 dp[j] 表示只能选择前 i 个物品,背包容量为 j 的情况下,能够获得的最大价值。
+
+> dp[j] 不是没 i 么? 其实我这里 i 指的是 dp[j]当前所处的循环中的 i 值
+
+### 完全背包问题
+
+回到问题,我们这是完全背包问题:
+
+```py
+for i in 1 to N + 1:
+ # 这里不是倒序,原因是我们这里是完全背包问题
+ for j in 1 to V + 1:
+ dp[j] = max(dp[j], dp[j - cost[i - 1])
+
+```
+
+### 为什么 01 背包需要倒序,而完全背包则不可以
+
+实际上,这是一个骚操作,我来详细给你讲一下。
+
+其实要回答这个问题,我要先将 01 背包和完全背包退化二维的情况。
+
+对于 01 背包:
+
+```py
+for i in 1 to N + 1:
+ for j in V to 0:
+ dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - cost[i - 1])
+```
+
+注意等号左边是 i,右边是 i - 1,这很好理解,因为 i 只能取一次嘛。
+
+那么如果我们不降序遍历会怎么样呢?
+
+
+
+如图橙色部分表示已经遍历的部分,而让我们去用[j - cost[i - 1]] 往前面回溯的时候,实际上回溯的是 dp[i]j - cost[i - 1]],而不是 dp[i - 1]j - cost[i - 1]]。
+
+如果是降序就可以了,如图:
+
+
+
+这个明白的话,我们继续思考为什么完全背包就要不降序了呢?
+
+我们还是像上面一样写出二维的代码:
+
+```py
+for i in 1 to N + 1:
+ for j in 1 to V + 1:
+ dp[i][j] = max(dp[i - 1][j], dp[i][j - cost[i - 1])
+
+```
+
+由于 i 可以取无数次,那么正序遍历正好可以满足,如上图。
+
+### 恰好装满 VS 可以不装满
+
+题目有两种可能,一种是要求背包恰好装满,一种是可以不装满(只要不超过容量就行)。而本题是要求`恰好装满`的。而这两种情况仅仅影响我们`dp数组初始化`。
+
+- 恰好装满。只需要初始化 dp[0] 为 0, 其他初始化为负数即可。
+- 可以不装满。 只需要全部初始化为 0,即可,
+
+原因很简单,我多次强调过 dp 数组本质上是记录了一个个自问题。 dp[0]是一个子问题,dp[1]是一个子问题。。。
+
+有了上面的知识就不难理解了。 初始化的时候,我们还没有进行任何选择,那么也就是说 dp[0] = 0,因为我们可以通过什么都不选达到最大值 0。而 dp[1],dp[2]...则在当前什么都不选的情况下无法达成,也就是无解,因为为了区分,我们可以用负数来表示,当然你可以用任何可以区分的东西表示,比如 None。
+
+### 回到本题
+
+而这道题和普通的完全背包不一样,这个是选择一个组成的最大数。由小学数学知识`一个数字的全排列中,按照数字降序排列是最大的`,我这里用了一个骚操作,那就是 cost 从后往前遍历,因为后面表示的数字大。
+
+## 代码
+
+```py
+class Solution:
+ def largestNumber(self, cost: List[int], target: int) -> str:
+ dp = [0] + [float('-inf')] * target
+ for i in range(9, 0, -1):
+ for j in range(1, target+1):
+ if j >= cost[i - 1]:
+ dp[j] = max(dp[j], (dp[j-cost[i - 1]] * 10) + i)
+ return str(dp[target]) if dp[target] > 0 else '0'
+
+```
+
+**_复杂度分析_**
+
+- 时间复杂度:$O(target))$
+- 空间复杂度:$O(target)$
+
+## 扩展
+
+最后贴几个我写过的背包问题,让大家看看历史是多么的相似。
+
+
+([322. 硬币找零(完全背包问题)](https://github.com/azl397985856/leetcode/blob/master/problems/322.coin-change.md))
+
+> 这里内外循环和本题正好是反的,我只是为了"秀技"(好玩),实际上在这里对答案并不影响。
+
+
+([518. 零钱兑换 II](https://github.com/azl397985856/leetcode/blob/master/problems/518.coin-change-2.md))
+
+> 这里内外循环和本题正好是反的,但是这里必须这么做,否则结果是不对的,具体可以点进去链接看我那个题解
+
+所以这两层循环的位置起的实际作用是什么? 代表的含义有什么不同?
+
+本质上:
+
+```py
+for i in 1 to N + 1:
+ for j in V to 0:
+ ...
+
+```
+
+这种情况选择物品 1 和物品 3(随便举的例子),是一种方式。选择物品 3 个物品 1(注意是有顺序的)是同一种方式。 **原因在于你是固定物品,去扫描容量**。
+
+而:
+
+```py
+for j in V to 0:
+ for i in 1 to N + 1:
+ ...
+
+```
+
+这种情况选择物品 1 和物品 3(随便举的例子),是一种方式。选择物品 3 个物品 1(注意是有顺序的)也是一种方式。**原因在于你是固定容量,去扫描物品**。
+
+**因此总的来说,如果你认为[1,3]和[3,1]是一种,那么就用方法 1 的遍历,否则用方法 2。**
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/145.binary-tree-postorder-traversal.md b/problems/145.binary-tree-postorder-traversal.md
index 0b20ea243..6f7832b88 100644
--- a/problems/145.binary-tree-postorder-traversal.md
+++ b/problems/145.binary-tree-postorder-traversal.md
@@ -22,6 +22,18 @@ Note: Recursive solution is trivial, could you do it iteratively?
```
+## 前置知识
+
+- 栈
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
相比于前序遍历,后续遍历思维上难度要大些,前序遍历是通过一个stack,首先压入父亲结点,然后弹出父亲结点,并输出它的value,之后压人其右儿子,左儿子即可。
@@ -54,37 +66,6 @@ mid是一个具体的节点,left和right`递归求出即可`
## 代码
```js
-/*
- * @lc app=leetcode id=145 lang=javascript
- *
- * [145] Binary Tree Postorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-postorder-traversal/description/
- *
- * algorithms
- * Hard (47.06%)
- * Total Accepted: 242.6K
- * Total Submissions: 512.8K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the postorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [3,2,1]
- *
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
/**
* Definition for a binary tree node.
* function TreeNode(val) {
@@ -133,3 +114,9 @@ var postorderTraversal = function(root) {
};
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
+
+
diff --git a/problems/146.lru-cache.md b/problems/146.lru-cache.md
index 0abd27250..bc6dd3436 100644
--- a/problems/146.lru-cache.md
+++ b/problems/146.lru-cache.md
@@ -28,6 +28,17 @@ cache.get(4); // returns 4
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
`本题已被收录到我的新书中,敬请期待~`
diff --git a/problems/15.3-sum.md b/problems/15.3sum.md
similarity index 73%
rename from problems/15.3-sum.md
rename to problems/15.3sum.md
index 85ae152f6..3170eec8d 100644
--- a/problems/15.3-sum.md
+++ b/problems/15.3sum.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/3sum/description/
## 题目描述
+
```
Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Find all unique triplets in the array which gives the sum of zero.
@@ -20,32 +22,44 @@ A solution set is:
]
```
+
+## 前置知识
+
+- 排序
+- 双指针
+- 分治
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
-我们采用`分治`的思想. 想要找出三个数相加等于0,我们可以数组依次遍历,
-每一项a[i]我们都认为它是最终能够用组成0中的一个数字,那么我们的目标就是找到
-剩下的元素(除a[i])`两个`相加等于-a[i].
+我们采用`分治`的思想. 想要找出三个数相加等于 0,我们可以数组依次遍历,
+每一项 a[i]我们都认为它是最终能够用组成 0 中的一个数字,那么我们的目标就是找到
+剩下的元素(除 a[i])`两个`相加等于-a[i].
通过上面的思路,我们的问题转化为了`给定一个数组,找出其中两个相加等于给定值`,
-这个问题是比较简单的, 我们只需要对数组进行排序,然后双指针解决即可。 加上我们需要外层遍历依次数组,因此总的时间复杂度应该是O(N^2)。
+这个问题是比较简单的, 我们只需要对数组进行排序,然后双指针解决即可。 加上我们需要外层遍历依次数组,因此总的时间复杂度应该是 O(N^2)。
思路如图所示:
-
-
-> 在这里之所以要排序解决是因为, 我们算法的瓶颈在这里不在于排序,而在于O(N^2),如果我们瓶颈是排序,就可以考虑别的方式了
+
+> 在这里之所以要排序解决是因为, 我们算法的瓶颈在这里不在于排序,而在于 O(N^2),如果我们瓶颈是排序,就可以考虑别的方式了
> 如果找某一个特定元素,一个指针就够了。如果是找两个元素满足一定关系(比如求和等于特定值),需要双指针,
-当然前提是数组有序。
+> 当然前提是数组有序。
+
## 关键点解析
- 排序之后,用双指针
- 分治
## 代码
-```js
+```js
/*
* @lc app=leetcode id=15 lang=javascript
*
@@ -84,7 +98,7 @@ A solution set is:
* @param {number[]} nums
* @return {number[][]}
*/
-var threeSum = function(nums) {
+var threeSum = function (nums) {
if (nums.length < 3) return [];
const list = [];
nums.sort((a, b) => a - b);
@@ -93,27 +107,23 @@ var threeSum = function(nums) {
if (nums[i] > 0) break;
// skip duplicated result without set
if (i > 0 && nums[i] === nums[i - 1]) continue;
- let left = i;
+ let left = i + 1;
let right = nums.length - 1;
-
+
// for each index i
// we want to find the triplet [i, left, right] which sum to 0
while (left < right) {
- // skip i === left or i === right, in that case, the index i will be used twice
- if (left === i) {
- left++;
- } else if (right === i) {
- right--;
- } else if (nums[left] + nums[right] + nums[i] === 0) {
+ // since left < right, and left > i, no need to compare i === left and i === right.
+ if (nums[left] + nums[right] + nums[i] === 0) {
list.push([nums[left], nums[right], nums[i]]);
// skip duplicated result without set
- while(nums[left] === nums[left + 1]) {
- left++;
+ while (nums[left] === nums[left + 1]) {
+ left++;
}
left++;
// skip duplicated result without set
- while(nums[right] === nums[right - 1]) {
- right--;
+ while (nums[right] === nums[right - 1]) {
+ right--;
}
right--;
continue;
diff --git a/problems/150.evaluate-reverse-polish-notation.md b/problems/150.evaluate-reverse-polish-notation.md
index 8b56c0d5a..c2a8617ef 100644
--- a/problems/150.evaluate-reverse-polish-notation.md
+++ b/problems/150.evaluate-reverse-polish-notation.md
@@ -15,6 +15,16 @@ Note:
Division between two integers should truncate toward zero.
The given RPN expression is always valid. That means the expression would always evaluate to a result and there won't be any divide by zero operation.
```
+
+## 前置知识
+
+- 栈
+
+## 公司
+
+- 阿里
+- 腾讯
+
## 思路
逆波兰表达式又叫做后缀表达式。在通常的表达式中,二元运算符总是置于与之相关的两个运算对象之间,这种表示法也称为`中缀表示`。
diff --git a/problems/152.maximum-product-subarray.md b/problems/152.maximum-product-subarray.md
index f784d48f7..ce944c52a 100644
--- a/problems/152.maximum-product-subarray.md
+++ b/problems/152.maximum-product-subarray.md
@@ -3,29 +3,37 @@
https://leetcode.com/problems/maximum-product-subarray/description/
## 题目描述
-
```
-Given an integer array nums, find the contiguous subarray within an array (containing at least one number) which has the largest product.
+给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
-Example 1:
+
-Input: [2,3,-2,4]
-Output: 6
-Explanation: [2,3] has the largest product 6.
-Example 2:
+示例 1:
-Input: [-2,0,-1]
-Output: 0
-Explanation: The result cannot be 2, because [-2,-1] is not a subarray.
+输入: [2,3,-2,4]
+输出: 6
+解释: 子数组 [2,3] 有最大乘积 6。
+示例 2:
+输入: [-2,0,-1]
+输出: 0
+解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
```
-## 思路
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
-> 这道题目的通过率非常低
+## 思路
-这道题目要我们求解连续的 n 个数中乘积最大的积是多少。这里提到了连续,笔者首先
-想到的就是滑动窗口,但是这里比较特殊,我们不能仅仅维护一个最大值,因此最小值(比如-20)乘以一个比较小的数(比如-10)
+这道题目要我们求解连续的 n 个数中乘积最大的积是多少。这里提到了连续,笔者首先想到的就是滑动窗口,但是这里比较特殊,我们不能仅仅维护一个最大值,因此最小值(比如-20)乘以一个比较小的数(比如-10)
可能就会很大。 因此这种思路并不方便。
首先来暴力求解,我们使用两层循环来枚举所有可能项,这种解法的时间复杂度是O(n^2), 代码如下:
@@ -36,7 +44,6 @@ var maxProduct = function(nums) {
let temp = null;
for (let i = 0; i < nums.length; i++) {
temp = nums[i];
- max = Math.max(temp, max);
for (let j = i + 1; j < nums.length; j++) {
temp *= nums[j];
max = Math.max(temp, max);
@@ -47,9 +54,11 @@ var maxProduct = function(nums) {
};
```
-因此我们需要同时记录乘积最大值和乘积最小值,然后比较元素和这两个的乘积,去不断更新最大值。
-
+
+前面说了`最小值(比如-20)乘以一个比较小的数(比如-10)可能就会很大` 。因此我们需要同时记录乘积最大值和乘积最小值,然后比较元素和这两个的乘积,去不断更新最大值。当然,我们也可以选择只取当前元素。因此实际上我们的选择有三种,而如何选择就取决于哪个选择带来的价值最大(乘积最大或者最小)。
+
+
这种思路的解法由于只需要遍历一次,其时间复杂度是O(n),代码见下方代码区。
@@ -137,3 +146,7 @@ var maxProduct = function(nums) {
**复杂度分析**
- 时间复杂度:$O(N)$
- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
diff --git a/problems/155.min-stack.md b/problems/155.min-stack.md
index ab07da5f8..ce78a6c29 100644
--- a/problems/155.min-stack.md
+++ b/problems/155.min-stack.md
@@ -23,111 +23,90 @@ minStack.getMin(); --> Returns -2.
```
-# 差值法
+## 前置知识
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+## 公司
+- amazon
+- bloomberg
+- google
+- snapchat
+- uber
+- zenefits
-## 思路
-符合直觉的方法是,每次对栈进行修改操作(push和pop)的时候更新最小值。 然后getMin只需要返回我们计算的最小值即可,
-top也是直接返回栈顶元素即可。 这种做法每次修改栈都需要更新最小值,因此时间复杂度是O(n).
-
-
-
-是否有更高效的算法呢?答案是有的。
-
-我们每次入栈的时候,保存的不再是真正的数字,而是它与当前最小值的差(当前元素没有入栈的时候的最小值)。
-这样我们pop和top的时候拿到栈顶元素再加上**上一个**最小值即可。
-另外我们在push和pop的时候去更新min,这样getMin的时候就简单了,直接返回min。
-
-> 注意上面加粗的“上一个”,不是“当前的最小值”
+## 两个栈
-经过上面的分析,问题的关键转化为“如何求得上一个最小值”,解决这个的关键点在于利用min。
+## 公司
-pop或者top的时候:
+- 阿里
+- 腾讯
+- 百度
+- 字节
-- 如果栈顶元素小于0,说明栈顶是当前最小的元素,它出栈会对min造成影响,我们需要去更新min。
-上一个最小的是“min - 栈顶元素”,我们需要将上一个最小值更新为当前的最小值
+### 思路
- > 因为栈顶元素入栈的时候的通过 `栈顶元素 = 真实值 - 上一个最小的元素` 得到的,
- 而真实值 = min, 因此可以得出`上一个最小的元素 = 真实值 -栈顶元素`
+我们使用两个栈:
-- 如果栈顶元素大于0,说明它对最小值`没有影响`,上一个最小值就是上上个最小值。
+- 一个栈存放全部的元素,push,pop都是正常操作这个正常栈。
+- 另一个存放最小栈。 每次push,如果比最小栈的栈顶还小,我们就push进最小栈,否则不操作
+- 每次pop的时候,我们都判断其是否和最小栈栈顶元素相同,如果相同,那么我们pop掉最小栈的栈顶元素即可
-
-
+### 关键点
-## 关键点
+- 往minstack中 push的判断条件。 应该是stack为空或者x小于等于minstack栈顶元素
-- 最小栈存储的不应该是真实值,而是真实值和min的差值
-- top的时候涉及到对数据的还原,这里千万注意是**上一个**最小值
-## 代码
+### 代码
-* 语言支持:JS,Python
+* 语言支持:JS,C++,Java,Python
-Javascript Code:
+JavaScript Code:
```js
-/*
- * @lc app=leetcode id=155 lang=javascript
- *
- * [155] Min Stack
- */
/**
* initialize your data structure here.
*/
var MinStack = function() {
- this.stack = [];
- this.minV = Number.MAX_VALUE;
+ this.stack = []
+ this.minStack = []
};
-/**
+/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
- // update 'min'
- const minV = this.minV;
- if (x < this.minV) {
- this.minV = x;
- }
- return this.stack.push(x - minV);
+ this.stack.push(x)
+ if (this.minStack.length == 0 || x <= this.minStack[this.minStack.length - 1]) {
+ this.minStack.push(x)
+ }
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
- const item = this.stack.pop();
- const minV = this.minV;
-
- if (item < 0) {
- this.minV = minV - item;
- return minV;
- }
- return item + minV;
+ const x = this.stack.pop()
+ if (x !== void 0 && x === this.minStack[this.minStack.length - 1]) {
+ this.minStack.pop()
+ }
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
- const item = this.stack[this.stack.length - 1];
- const minV = this.minV;
-
- if (item < 0) {
- return minV;
- }
- return item + minV;
+ return this.stack[this.stack.length - 1]
};
/**
* @return {number}
*/
MinStack.prototype.min = function() {
- return this.minV;
+ return this.minStack[this.minStack.length - 1]
};
-/**
+/**
* Your MinStack object will be instantiated and called as such:
* var obj = new MinStack()
* obj.push(x)
@@ -137,7 +116,107 @@ MinStack.prototype.min = function() {
*/
```
-Python Code:
+C++ Code:
+```c++
+class MinStack {
+ stack data;
+ stack helper;
+public:
+ /** initialize your data structure here. */
+ MinStack() {
+
+ }
+
+ void push(int x) {
+ data.push(x);
+ if(helper.empty() || helper.top() >= x)
+ {
+ helper.push(x);
+ }
+
+ }
+
+ void pop() {
+ int top = data.top();
+ data.pop();
+ if(top == helper.top())
+ {
+ helper.pop();
+ }
+
+ }
+
+ int top() {
+ return data.top();
+ }
+
+ int getMin() {
+ return helper.top();
+ }
+};
+
+/**
+ * Your MinStack object will be instantiated and called as such:
+ * MinStack* obj = new MinStack();
+ * obj->push(x);
+ * obj->pop();
+ * int param_3 = obj->top();
+ * int param_4 = obj->getMin();
+ */
+```
+
+Java Code:
+```java
+public class MinStack {
+
+ // 数据栈
+ private Stack data;
+ // 辅助栈
+ private Stack helper;
+
+ /**
+ * initialize your data structure here.
+ */
+ public MinStack() {
+ data = new Stack<>();
+ helper = new Stack<>();
+ }
+
+ public void push(int x) {
+ // 辅助栈在必要的时候才增加
+ data.add(x);
+ if (helper.isEmpty() || helper.peek() >= x) {
+ helper.add(x);
+ }
+ }
+
+ public void pop() {
+ // 关键 3:data 一定得 pop()
+ if (!data.isEmpty()) {
+ // 注意:声明成 int 类型,这里完成了自动拆箱,从 Integer 转成了 int,
+ // 因此下面的比较可以使用 "==" 运算符
+ int top = data.pop();
+ if(top == helper.peek()){
+ helper.pop();
+ }
+ }
+ }
+
+ public int top() {
+ if(!data.isEmpty()){
+ return data.peek();
+ }
+ }
+
+ public int getMin() {
+ if(!helper.isEmpty()){
+ return helper.peek();
+ }
+ }
+}
+```
+
+Python3 Code:
```python
class MinStack:
@@ -146,33 +225,24 @@ class MinStack:
"""
initialize your data structure here.
"""
- self.minV = float('inf')
self.stack = []
+ self.minstack = []
def push(self, x: int) -> None:
- self.stack.append(x - self.minV)
- if x < self.minV:
- self.minV = x
+ self.stack.append(x)
+ if not self.minstack or x <= self.minstack[-1]:
+ self.minstack.append(x)
def pop(self) -> None:
- if not self.stack:
- return
tmp = self.stack.pop()
- if tmp < 0:
- self.minV -= tmp
+ if tmp == self.minstack[-1]:
+ self.minstack.pop()
def top(self) -> int:
- if not self.stack:
- return
- tmp = self.stack[-1]
- if tmp < 0:
- return self.minV
- else:
- return self.minV + tmp
+ return self.stack[-1]
def min(self) -> int:
- return self.minV
-
+ return self.minstack[-1]
# Your MinStack object will be instantiated and called as such:
@@ -188,70 +258,111 @@ class MinStack:
- 空间复杂度:O(1)
-# 两个栈
+## 一个栈
-## 思路
+### 思路
-我们使用两个栈:
+符合直觉的方法是,每次对栈进行修改操作(push和pop)的时候更新最小值。 然后getMin只需要返回我们计算的最小值即可,
+top也是直接返回栈顶元素即可。 这种做法每次修改栈都需要更新最小值,因此时间复杂度是O(n).
-- 一个栈存放全部的元素,push,pop都是正常操作这个正常栈。
-- 另一个存放最小栈。 每次push,如果比最小栈的栈顶还小,我们就push进最小栈,否则不操作
-- 每次pop的时候,我们都判断其是否和最小栈栈顶元素相同,如果相同,那么我们pop掉最小栈的栈顶元素即可
+
-## 关键点
+是否有更高效的算法呢?答案是有的。
-- 往minstack中 push的判断条件。 应该是stack为空或者x小于等于minstack栈顶元素
+我们每次入栈的时候,保存的不再是真正的数字,而是它与当前最小值的差(当前元素没有入栈的时候的最小值)。
+这样我们pop和top的时候拿到栈顶元素再加上**上一个**最小值即可。
+另外我们在push和pop的时候去更新min,这样getMin的时候就简单了,直接返回min。
+
+> 注意上面加粗的“上一个”,不是“当前的最小值”
+经过上面的分析,问题的关键转化为“如何求得上一个最小值”,解决这个的关键点在于利用min。
+
+pop或者top的时候:
-## 代码
+- 如果栈顶元素小于0,说明栈顶是当前最小的元素,它出栈会对min造成影响,我们需要去更新min。
+上一个最小的是“min - 栈顶元素”,我们需要将上一个最小值更新为当前的最小值
-JavaScript:
+ > 因为栈顶元素入栈的时候的通过 `栈顶元素 = 真实值 - 上一个最小的元素` 得到的,
+ 而真实值 = min, 因此可以得出`上一个最小的元素 = 真实值 -栈顶元素`
+
+- 如果栈顶元素大于0,说明它对最小值`没有影响`,上一个最小值就是上上个最小值。
+
+
+
+
+### 关键点
+
+- 最小栈存储的不应该是真实值,而是真实值和min的差值
+- top的时候涉及到对数据的还原,这里千万注意是**上一个**最小值
+
+### 代码
+
+* 语言支持:JS,C++,Java,Python
+
+Javascript Code:
```js
+/*
+ * @lc app=leetcode id=155 lang=javascript
+ *
+ * [155] Min Stack
+ */
/**
* initialize your data structure here.
*/
var MinStack = function() {
- this.stack = []
- this.minStack = []
+ this.stack = [];
+ this.minV = Number.MAX_VALUE;
};
-/**
+/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
- this.stack.push(x)
- if (this.minStack.length == 0 || x <= this.minStack[this.minStack.length - 1]) {
- this.minStack.push(x)
- }
+ // update 'min'
+ const minV = this.minV;
+ if (x < this.minV) {
+ this.minV = x;
+ }
+ return this.stack.push(x - minV);
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
- const x = this.stack.pop()
- if (x !== void 0 && x === this.minStack[this.minStack.length - 1]) {
- this.minStack.pop()
- }
+ const item = this.stack.pop();
+ const minV = this.minV;
+
+ if (item < 0) {
+ this.minV = minV - item;
+ return minV;
+ }
+ return item + minV;
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
- return this.stack[this.stack.length - 1]
+ const item = this.stack[this.stack.length - 1];
+ const minV = this.minV;
+
+ if (item < 0) {
+ return minV;
+ }
+ return item + minV;
};
/**
* @return {number}
*/
MinStack.prototype.min = function() {
- return this.minStack[this.minStack.length - 1]
+ return this.minV;
};
-/**
+/**
* Your MinStack object will be instantiated and called as such:
* var obj = new MinStack()
* obj.push(x)
@@ -261,8 +372,124 @@ MinStack.prototype.min = function() {
*/
```
+C++ Code:
+
+```c++
+class MinStack {
+ stack data;
+ long min = INT_MAX;
+public:
+ /** initialize your data structure here. */
+ MinStack() {
+
+ }
+
+ void push(int x) {
+ data.push(x - min);
+ if(x < min)
+ {
+ min = x;
+ }
+
+ }
+
+ void pop() {
+ long top = data.top();
+ data.pop();
+ // 更新最小值
+ if(top < 0)
+ {
+ min -= top;
+ }
+
+ }
+
+ int top() {
+ long top = data.top();
+ // 最小值为 min
+ if (top < 0)
+ {
+ return min;
+ }
+ else{
+ return min+top;
+ }
+ }
+
+ int getMin() {
+ return min;
+ }
+};
-Python3:
+/**
+ * Your MinStack object will be instantiated and called as such:
+ * MinStack* obj = new MinStack();
+ * obj->push(x);
+ * obj->pop();
+ * int param_3 = obj->top();
+ * int param_4 = obj->getMin();
+ */
+```
+
+
+Java Code:
+
+```java
+class MinStack {
+ long min;
+ Stack stack;
+
+ /** initialize your data structure here. */
+ public MinStack() {
+ stack = new Stack<>();
+ }
+
+ public void push(int x) {
+ if (stack.isEmpty()) {
+ stack.push(0L);
+ min = x;
+ }
+ else {
+ stack.push(x - min);
+ if (x < min)
+ min = x;
+ }
+ }
+
+ public void pop() {
+ long p = stack.pop();
+
+ if (p < 0) {
+ // if (p < 0), the popped value is the min
+ // Recall p is added by this statement: stack.push(x - min);
+ // So, p = x - old_min
+ // old_min = x - p
+ // again, if (p < 0), x is the min so:
+ // old_min = min - p
+ min = min - p;
+ }
+ }
+
+ public int top() {
+ long p = stack.peek();
+
+ if (p < 0) {
+ return (int) min;
+ }
+ else {
+ // p = x - min
+ // x = p + min
+ return (int) (p + min);
+ }
+ }
+
+ public int getMin() {
+ return (int) min;
+ }
+}
+```
+
+Python Code:
```python
class MinStack:
@@ -271,24 +498,33 @@ class MinStack:
"""
initialize your data structure here.
"""
+ self.minV = float('inf')
self.stack = []
- self.minstack = []
def push(self, x: int) -> None:
- self.stack.append(x)
- if not self.minstack or x <= self.minstack[-1]:
- self.minstack.append(x)
+ self.stack.append(x - self.minV)
+ if x < self.minV:
+ self.minV = x
def pop(self) -> None:
+ if not self.stack:
+ return
tmp = self.stack.pop()
- if tmp == self.minstack[-1]:
- self.minstack.pop()
+ if tmp < 0:
+ self.minV -= tmp
def top(self) -> int:
- return self.stack[-1]
+ if not self.stack:
+ return
+ tmp = self.stack[-1]
+ if tmp < 0:
+ return self.minV
+ else:
+ return self.minV + tmp
def min(self) -> int:
- return self.minstack[-1]
+ return self.minV
+
# Your MinStack object will be instantiated and called as such:
@@ -301,4 +537,11 @@ class MinStack:
**复杂度分析**
- 时间复杂度:O(1)
-- 空间复杂度:O(N)
+- 空间复杂度:O(1)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/167.two-sum-ii-input-array-is-sorted.md b/problems/167.two-sum-ii-input-array-is-sorted.md
index 945365519..42b40c6aa 100644
--- a/problems/167.two-sum-ii-input-array-is-sorted.md
+++ b/problems/167.two-sum-ii-input-array-is-sorted.md
@@ -23,6 +23,18 @@ Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- amazon
+
## 思路
由于题目没有对空间复杂度有求,用一个hashmap 存储已经访问过的数字即可。
@@ -35,51 +47,16 @@ Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
## 关键点解析
-无
+- 由于是有序的,因此双指针更好
## 代码
-* 语言支持:JS,Python
+* 语言支持:JS,C++,Java,Python
Javascript Code:
```js
-/*
- * @lc app=leetcode id=167 lang=javascript
- *
- * [167] Two Sum II - Input array is sorted
- *
- * https://leetcode.com/problems/two-sum-ii-input-array-is-sorted/description/
- *
- * algorithms
- * Easy (49.46%)
- * Total Accepted: 221.8K
- * Total Submissions: 447K
- * Testcase Example: '[2,7,11,15]\n9'
- *
- * Given an array of integers that is already sorted in ascending order, find
- * two numbers such that they add up to a specific target number.
- *
- * The function twoSum should return indices of the two numbers such that they
- * add up to the target, where index1 must be less than index2.
- *
- * Note:
- *
- *
- * Your returned answers (both index1 and index2) are not zero-based.
- * You may assume that each input would have exactly one solution and you may
- * not use the same element twice.
- *
- *
- * Example:
- *
- *
- * Input: numbers = [2,7,11,15], target = 9
- * Output: [1,2]
- * Explanation: The sum of 2 and 7 is 9. Therefore index1 = 1, index2 = 2.
- *
- */
/**
* @param {number[]} numbers
* @param {number} target
@@ -99,6 +76,64 @@ var twoSum = function(numbers, target) {
};
```
+C++ Code:
+
+```c++
+class Solution {
+public:
+ vector twoSum(vector& numbers, int target) {
+ int n = numbers.size();
+ int left = 0;
+ int right = n-1;
+ while(left <= right)
+ {
+ if(numbers[left] + numbers[right] == target)
+ {
+ return {left + 1, right + 1};
+ }
+ else if (numbers[left] + numbers[right] > target)
+ {
+ right--;
+ }
+ else
+ {
+ left++;
+ }
+ }
+ return {-1, -1};
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public int[] twoSum(int[] numbers, int target) {
+ int n = numbers.length;
+ int left = 0;
+ int right = n-1;
+ while(left <= right)
+ {
+ if(numbers[left] + numbers[right] == target)
+ {
+ return new int[]{left + 1, right + 1};
+ }
+ else if (numbers[left] + numbers[right] > target)
+ {
+ right--;
+ }
+ else
+ {
+ left++;
+ }
+ }
+
+ return new int[]{-1, -1};
+ }
+}
+```
+
Python Code:
```python
@@ -123,3 +158,14 @@ class Solution:
if numbers[left] + numbers[right] == target:
return [left+1, right+1]
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/169.majority-element.md b/problems/169.majority-element.md
index e96aa912e..0d1b77f7e 100644
--- a/problems/169.majority-element.md
+++ b/problems/169.majority-element.md
@@ -20,6 +20,19 @@ Output: 2
```
+## 前置知识
+
+- 投票算法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- adobe
+- zenefits
+
## 思路
符合直觉的做法是利用额外的空间去记录每个元素出现的次数,并用一个单独的变量记录当前出现次数最多的元素。
@@ -28,13 +41,12 @@ Output: 2
投票算法的原理是通过不断消除不同元素直到没有不同元素,剩下的元素就是我们要找的元素。
-
+
## 关键点解析
- 投票算法
-
## 代码
* 语言支持:JS,Python
@@ -79,6 +91,9 @@ class Solution:
- 时间复杂度:$O(N)$,其中N为数组长度
- 空间复杂度:$O(1)$
-欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
-
+
diff --git a/problems/17.Letter-Combinations-of-a-Phone-Number.md b/problems/17.Letter-Combinations-of-a-Phone-Number.md
index 3845eb7e5..959db150b 100644
--- a/problems/17.Letter-Combinations-of-a-Phone-Number.md
+++ b/problems/17.Letter-Combinations-of-a-Phone-Number.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
## 题目描述
+
```
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
@@ -17,20 +19,36 @@ https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+- 腾讯
+
## 思路
+
使用回溯法进行求解,回溯是一种通过穷举所有可能情况来找到所有解的算法。如果一个候选解最后被发现并不是可行解,回溯算法会舍弃它,并在前面的一些步骤做出一些修改,并重新尝试找到可行解。究其本质,其实就是枚举。
如果没有更多的数字需要被输入,说明当前的组合已经产生。
如果还有数字需要被输入:
+
- 遍历下一个数字所对应的所有映射的字母
-- 将当前的字母添加到组合最后,也就是 str + tmp[r]
+- 将当前的字母添加到组合最后,也就是 str + tmp[r]
## 关键点
-利用回溯思想解题,在for循环中调用递归。
+
+- 回溯
+- 回溯模板
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -38,40 +56,39 @@ https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number
* @return {string[]}
*/
const letterCombinations = function (digits) {
- if (!digits) {
- return [];
+ if (!digits) {
+ return [];
+ }
+ const len = digits.length;
+ const map = new Map();
+ map.set("2", "abc");
+ map.set("3", "def");
+ map.set("4", "ghi");
+ map.set("5", "jkl");
+ map.set("6", "mno");
+ map.set("7", "pqrs");
+ map.set("8", "tuv");
+ map.set("9", "wxyz");
+ const result = [];
+
+ function generate(i, str) {
+ if (i == len) {
+ result.push(str);
+ return;
}
- const len = digits.length;
- const map = new Map();
- map.set('2', 'abc');
- map.set('3', 'def');
- map.set('4', 'ghi');
- map.set('5', 'jkl');
- map.set('6', 'mno');
- map.set('7', 'pqrs');
- map.set('8', 'tuv');
- map.set('9', 'wxyz');
- const result = [];
-
- function generate(i, str) {
- if (i == len) {
- result.push(str);
- return;
- }
- const tmp = map.get(digits[i]);
- for (let r = 0; r < tmp.length; r++) {
- generate(i + 1, str + tmp[r]);
- }
+ const tmp = map.get(digits[i]);
+ for (let r = 0; r < tmp.length; r++) {
+ generate(i + 1, str + tmp[r]);
}
- generate(0, '');
- return result;
+ }
+ generate(0, "");
+ return result;
};
```
-***复杂度分析***
+**_复杂度分析_**
N + M 是输入数字的总数
-- 时间复杂度:O(3^N * 4^M)
-- 空间复杂度:O(3^N * 4^M)
-
+- 时间复杂度:O(3^N \* 4^M)
+- 空间复杂度:O(3^N \* 4^M)
diff --git a/problems/172.factorial-trailing-zeroes.md b/problems/172.factorial-trailing-zeroes.md
index 59b25d862..666facb4c 100644
--- a/problems/172.factorial-trailing-zeroes.md
+++ b/problems/172.factorial-trailing-zeroes.md
@@ -21,6 +21,17 @@ Note: Your solution should be in logarithmic time complexity.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- bloomberg
+
## 思路
我们需要求解这n个数字相乘的结果末尾有多少个0,由于题目要求log的复杂度,因此暴力求解是不行的。
@@ -28,16 +39,16 @@ Note: Your solution should be in logarithmic time complexity.
通过观察,我们发现如果想要结果末尾是0,必须是分解质因数之后,2 和 5 相乘才行,同时因数分解之后发现5的个数远小于2,
因此我们只需要求解这n数字分解质因数之后一共有多少个5即可.
-
+
如图如果n为30,那么结果应该是图中红色5的个数,即7。
-
+
我们的结果并不是直接f(n) = n / 5, 比如n为30, 25中是有两个5的。
类似,n为150,会有7个这样的数字,通过观察我们发现规律`f(n) = n/5 + n/5^2 + n/5^3 + n/5^4 + n/5^5+..`
-
+
如果可以发现上面的规律,用递归还是循环实现这个算式就看你的了。
## 关键点解析
@@ -94,3 +105,14 @@ class Solution:
if n == 0: return 0
return n // 5 + self.trailingZeroes(n // 5)
```
+
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/19.removeNthNodeFromEndofList.md b/problems/19.removeNthNodeFromEndofList.md
index 26d7aa0ff..33e3fe864 100644
--- a/problems/19.removeNthNodeFromEndofList.md
+++ b/problems/19.removeNthNodeFromEndofList.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/remove-nth-node-from-end-of-list/description
## 题目描述
+
Given a linked list, remove the n-th node from the end of list and return its head.
Example:
@@ -17,25 +19,35 @@ Follow up:
Could you do this in one pass?
-## 思路
+## 前置知识
+
+- 链表
+- 双指针
+
+## 公司
-双指针,指针A先移动n次, 指针B再开始移动。当A到达null的时候, 指针b的位置正好是倒数n
+- 阿里
+- 百度
+- 腾讯
+- 字节
-我们可以设想假设设定了双指针p和q的话,当q指向末尾的NULL,p与q之间相隔的元素个数为n时,那么删除掉p的下一个指针就完成了要求。
+## 思路
-设置虚拟节点dummyHead指向head
+双指针,指针 A 先移动 n 次, 指针 B 再开始移动。当 A 到达 null 的时候, 指针 b 的位置正好是倒数 n
-设定双指针p和q,初始都指向虚拟节点dummyHead
+我们可以设想假设设定了双指针 p 和 q 的话,当 q 指向末尾的 NULL,p 与 q 之间相隔的元素个数为 n 时,那么删除掉 p 的下一个指针就完成了要求。
-移动q,直到p与q之间相隔的元素个数为n
+设置虚拟节点 dummyHead 指向 head
-同时移动p与q,直到q指向的为NULL
+设定双指针 p 和 q,初始都指向虚拟节点 dummyHead
-将p的下一个节点指向下下个节点
+移动 q,直到 p 与 q 之间相隔的元素个数为 n
+同时移动 p 与 q,直到 q 指向的为 NULL
+将 p 的下一个节点指向下下个节点
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -45,7 +57,7 @@ Could you do this in one pass?
2. 使用双指针
-3. 使用一个dummyHead简化操作
+3. 使用一个 dummyHead 简化操作
## 代码
@@ -69,24 +81,24 @@ Support: JS, Java
*
* Given a linked list, remove the n-th node from the end of list and return
* its head.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Given linked list: 1->2->3->4->5, and n = 2.
- *
+ *
* After removing the second node from the end, the linked list becomes
* 1->2->3->5.
- *
- *
+ *
+ *
* Note:
- *
+ *
* Given n will always be valid.
- *
+ *
* Follow up:
- *
+ *
* Could you do this in one pass?
- *
+ *
*/
/**
* Definition for singly-linked list.
@@ -100,10 +112,10 @@ Support: JS, Java
* @param {number} n
* @return {ListNode}
*/
-var removeNthFromEnd = function(head, n) {
+var removeNthFromEnd = function (head, n) {
let i = -1;
const noop = {
- next: null
+ next: null,
};
const dummyHead = new ListNode(); // 增加一个dummyHead 简化操作
@@ -112,17 +124,15 @@ var removeNthFromEnd = function(head, n) {
let currentP1 = dummyHead;
let currentP2 = dummyHead;
-
while (currentP1) {
-
if (i === n) {
currentP2 = currentP2.next;
}
if (i !== n) {
- i++;
+ i++;
}
-
+
currentP1 = currentP1.next;
}
@@ -130,7 +140,6 @@ var removeNthFromEnd = function(head, n) {
return dummyHead.next;
};
-
```
- Java Code
@@ -165,4 +174,4 @@ class Solution {
return dummy.next;
}
}
-```
\ No newline at end of file
+```
diff --git a/problems/190.reverse-bits.md b/problems/190.reverse-bits.md
index 768ff8c56..f102e01ab 100644
--- a/problems/190.reverse-bits.md
+++ b/problems/190.reverse-bits.md
@@ -27,6 +27,18 @@ In Java, the compiler represents the signed integers using 2's complement notati
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- airbnb
+- apple
+
## 思路
这道题是给定一个32位的无符号整型,让你按位翻转, 第一位变成最后一位, 第二位变成倒数第二位。。。
@@ -165,6 +177,10 @@ class Solution:
return result
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
## 拓展
不使用迭代也可以完成相同的操作:
1. 两两相邻的1位对调
@@ -186,3 +202,10 @@ public:
}
};
```
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/191.number-of-1-bits.md b/problems/191.number-of-1-bits.md
index b4f8bc37e..8a88589c6 100644
--- a/problems/191.number-of-1-bits.md
+++ b/problems/191.number-of-1-bits.md
@@ -32,6 +32,19 @@ In Java, the compiler represents the signed integers using 2's complement notati
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- apple
+- microsoft
+
## 思路
这个题目的大意是: 给定一个无符号的整数, 返回其用二进制表式的时候的1的个数。
@@ -109,10 +122,14 @@ class Solution(object):
return count
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(N)$
+
## 扩展
可以使用位操作来达到目的。例如8位的整数21:
-
+
C++ Code:
```c++
@@ -139,3 +156,10 @@ public:
}
};
```
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/198.house-robber.en.md b/problems/198.house-robber.en.md
new file mode 100755
index 000000000..54d6420a3
--- /dev/null
+++ b/problems/198.house-robber.en.md
@@ -0,0 +1,180 @@
+## House Robber
+
+https://leetcode.com/problems/house-robber/description/
+
+## Problem Description
+
+```
+You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
+
+Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
+
+Example 1:
+
+Input: [1,2,3,1]
+Output: 4
+Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
+ Total amount you can rob = 1 + 3 = 4.
+Example 2:
+
+Input: [2,7,9,3,1]
+Output: 12
+Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
+ Total amount you can rob = 2 + 9 + 1 = 12.
+
+```
+
+## Prerequisites
+
+- Dynamic Programming
+
+## Solution
+
+This is a simple and classical dynamic programming problem, but it's helpful for understanding dynamic programming.
+
+Frequent questions when it comes to DP problems involve:
+1. Why the solution works like that? Why it works without any DP array?
+2. Why we can apply the idea of Fibonacci Numbers to the Climbing Stairs problem?
+
+We will take a look at these problems here. Similar to other DP problems, we are essentially deciding whether rob the ith house or not.
+
+If we rob the ith house, the gain would be `nums[i] + dp[i - 2]`.
+> We cannot rob i-1th house, otherwise the alarm will be triggered.
+
+If we do not rob the ith house, the gain would be `dp[i - 1]`.
+> The dp here is our subproblem.
+
+Since we always want a larger gain, it's easy to obtain the transition formula: `dp[i] = Math.max(dp[i - 2] + nums[i - 2], dp[i - 1]);`
+> Note: For the convenience of calculation, we set both dp[0] and dp[1] to be 0. This way, dp[i] is actually for the i-1th house.
+
+We can use the following graph to illustrate the above process:
+
+
+If we optimize it further, we only need dp[i - 1] and dp[i - 2] when determining each dp[i]. For example, to calculate dp[6], we would only need dp[5] and dp[4], and there's no need to keep dp[3], dp[2], and so on, in memory.
+
+Then, the code will be:
+
+```js
+let a = 0;
+let b = 0;
+
+for (let i = 0; i < nums.length; i++) {
+ const temp = b;
+ b = Math.max(a + nums[i], b);
+ a = temp;
+}
+
+return b;
+```
+
+The above code optimized the space complexity from O(n) to O(1). The same optimization applies to a lot of DP problems.
+
+## Key Points
+
+## Code (JS/C++/Python)
+
+JavaScript Code:
+
+```js
+/*
+ * @lc app=leetcode id=198 lang=javascript
+ *
+ * [198] House Robber
+ *
+ * https://leetcode.com/problems/house-robber/description/
+ *
+ * algorithms
+ * Easy (40.80%)
+ * Total Accepted: 312.1K
+ * Total Submissions: 762.4K
+ * Testcase Example: '[1,2,3,1]'
+ *
+ * You are a professional robber planning to rob houses along a street. Each
+ * house has a certain amount of money stashed, the only constraint stopping
+ * you from robbing each of them is that adjacent houses have security system
+ * connected and it will automatically contact the police if two adjacent
+ * houses were broken into on the same night.
+ *
+ * Given a list of non-negative integers representing the amount of money of
+ * each house, determine the maximum amount of money you can rob tonight
+ * without alerting the police.
+ *
+ * Example 1:
+ *
+ *
+ * Input: [1,2,3,1]
+ * Output: 4
+ * Explanation: Rob house 1 (money = 1) and then rob house 3 (money =
+ * 3).
+ * Total amount you can rob = 1 + 3 = 4.
+ *
+ * Example 2:
+ *
+ *
+ * Input: [2,7,9,3,1]
+ * Output: 12
+ * Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house
+ * 5 (money = 1).
+ * Total amount you can rob = 2 + 9 + 1 = 12.
+ *
+ *
+ */
+/**
+ * @param {number[]} nums
+ * @return {number}
+ */
+var rob = function(nums) {
+ // Tag: DP
+ const dp = [];
+ dp[0] = 0;
+ dp[1] = 0;
+
+ for (let i = 2; i < nums.length + 2; i++) {
+ dp[i] = Math.max(dp[i - 2] + nums[i - 2], dp[i - 1]);
+ }
+
+ return dp[nums.length + 1];
+};
+```
+
+C++ Code:
+
+> This is slightly different from the JavaScript solution, but it uses the same transition function.
+
+```C++
+class Solution {
+public:
+ int rob(vector& nums) {
+ if (nums.empty()) return 0;
+ auto sz = nums.size();
+ if (sz == 1) return nums[0];
+ auto prev = nums[0];
+ auto cur = max(prev, nums[1]);
+ for (auto i = 2; i < sz; ++i) {
+ auto tmp = cur;
+ cur = max(nums[i] + prev, cur);
+ prev = tmp;
+ }
+ return cur;
+ }
+};
+```
+
+Python Code:
+
+```python
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ if not nums:
+ return 0
+
+ length = len(nums)
+ if length == 1:
+ return nums[0]
+ else:
+ prev = nums[0]
+ cur = max(prev, nums[1])
+ for i in range(2, length):
+ cur, prev = max(prev + nums[i], cur), cur
+ return cur
+```
diff --git a/problems/198.house-robber.md b/problems/198.house-robber.md
index c294a2b2b..6918051ff 100644
--- a/problems/198.house-robber.md
+++ b/problems/198.house-robber.md
@@ -24,6 +24,19 @@ Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (m
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- airbnb
+- linkedin
+
## 思路
这是一道非常典型且简单的动态规划问题,但是在这里我希望通过这个例子,
@@ -46,7 +59,7 @@ Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (m
上述过程用图来表示的话,是这样的:
-
+
我们仔细观察的话,其实我们只需要保证前一个 dp[i - 1] 和 dp[i - 2] 两个变量就好了,
比如我们计算到 i = 6 的时候,即需要计算 dp[6]的时候, 我们需要 dp[5], dp[4],但是我们
@@ -77,7 +90,7 @@ return b;
## 代码
-* 语言支持:JS,C++,Python
+- 语言支持:JS,C++,Python
JavaScript Code:
@@ -129,7 +142,7 @@ JavaScript Code:
* @param {number[]} nums
* @return {number}
*/
-var rob = function(nums) {
+var rob = function (nums) {
// Tag: DP
const dp = [];
dp[0] = 0;
@@ -145,7 +158,7 @@ var rob = function(nums) {
C++ Code:
-> 与JavaScript代码略有差异,但状态迁移方程是一样的。
+> 与 JavaScript 代码略有差异,但状态迁移方程是一样的。
```C++
class Solution {
@@ -184,3 +197,18 @@ class Solution:
cur, prev = max(prev + nums[i], cur), cur
return cur
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [337.house-robber-iii](https://github.com/azl397985856/leetcode/blob/master/problems/337.house-robber-iii.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 35K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/199.binary-tree-right-side-view.md b/problems/199.binary-tree-right-side-view.md
index 40a844b26..c09838c27 100644
--- a/problems/199.binary-tree-right-side-view.md
+++ b/problems/199.binary-tree-right-side-view.md
@@ -20,6 +20,17 @@ Explanation:
5 4 <---
```
+## 前置知识
+
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
> 这道题和 leetcode 102 号问题《102.binary-tree-level-order-traversal》很像
diff --git a/problems/2.add-two-numbers.en.md b/problems/2.add-two-numbers.en.md
new file mode 100644
index 000000000..ecd31f1f7
--- /dev/null
+++ b/problems/2.add-two-numbers.en.md
@@ -0,0 +1,174 @@
+## Problem
+https://leetcode.com/problems/add-two-numbers/description/
+
+## Problem Description
+```
+You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
+
+You may assume the two numbers do not contain any leading zero, except the number 0 itself.
+
+Example
+
+Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)
+Output: 7 -> 0 -> 8
+Explanation: 342 + 465 = 807.
+
+```
+## Solution
+
+Define a new variable `carried` that represents the carry value during the calculation, and a new linked list
+Traverse the two linked lists from the start to the end simultaneously, and calculate the sum of node value from each linked list. The sum of the result and `carried` would be appended as a new node to the end of the new linked list.
+
+
+
+(Image Reference: https://github.com/MisterBooo/LeetCodeAnimation)
+
+## Key Point Analysis
+
+1. The characteristics and application of this data structure - linked list
+
+2. Define a variable named `carried` to replace the role of carry-over, calculate `carried` after each sum and apply it to the next round's calculation
+
+## Code
+* Language Support: JS, C++
+
+JavaScript:
+```js
+/**
+ * Definition for singly-linked list.
+ * function ListNode(val) {
+ * this.val = val;
+ * this.next = null;
+ * }
+ */
+/**
+ * @param {ListNode} l1
+ * @param {ListNode} l2
+ * @return {ListNode}
+ */
+var addTwoNumbers = function(l1, l2) {
+ if (l1 === null || l2 === null) return null
+
+ // using dummyHead can simplify linked list's calculation, dummyHead.next points to the new linked list
+ let dummyHead = new ListNode(0)
+ let cur1 = l1
+ let cur2 = l2
+ let cur = dummyHead // cur is for the calculation in new linked list
+ let carry = 0 // carry-over symbol
+
+ while (cur1 !== null || cur2 !== null) {
+ let val1 = cur1 !== null ? cur1.val : 0
+ let val2 = cur2 !== null ? cur2.val : 0
+ let sum = val1 + val2 + carry
+ let newNode = new ListNode(sum % 10) // the result of sum%10 ranges from 0 to 9, which is the value of the current digit
+ carry = sum >= 10 ? 1 : 0 // sum>=10, carry=1, so carry-over exists here
+ cur.next = newNode
+ cur = cur.next
+
+ if (cur1 !== null) {
+ cur1 = cur1.next
+ }
+
+ if (cur2 !== null) {
+ cur2 = cur2.next
+ }
+ }
+
+ if (carry > 0) {
+ // If there's still carry-over in the end, then add a new node
+ cur.next = new ListNode(carry)
+ }
+
+ return dummyHead.next
+};
+```
+C++
+> C++ code is slightly different from the JavaScript code above: the step that checks whether carry equals to 0 is put in the while-loop.
+```c++
+/**
+ * Definition for singly-linked list.
+ * struct ListNode {
+ * int val;
+ * ListNode *next;
+ * ListNode(int x) : val(x), next(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ ListNode* ret = nullptr;
+ ListNode* cur = nullptr;
+ int carry = 0;
+ while (l1 != nullptr || l2 != nullptr || carry != 0) {
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto temp = new ListNode(carry % 10);
+ carry /= 10;
+ if (ret == nullptr) {
+ ret = temp;
+ cur = ret;
+ }
+ else {
+ cur->next = temp;
+ cur = cur->next;
+ }
+ l1 = l1 == nullptr ? nullptr : l1->next;
+ l2 = l2 == nullptr ? nullptr : l2->next;
+ }
+ return ret;
+ }
+};
+```
+## Extension
+The singly-linked list also has a recursive structure based on its definition. Therefore, the recursive apporach works on reversing a linked list, as well.
+> Because a singly-linked list is a linear data structure, the recursive approach means that the use of stack would also be linear. When the linked list's length reaches a certain level, the recursion would result in a stack overflow. Therefore, using recursion to manipulate a linked list is not recommended in reality.
+
+### Description
+
+1. Add up the first node of two linked lists, and covert the result to a number between 0 and 10, record the carry-over as well.
+2. Proceed to add up the two linked lists after the first node with carry-over recursively
+3. Point the next of the head node from the first step to the linked list returned from the second step
+
+### C++ Implementation
+```C++
+// Normal recursion
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ return addTwoNumbers(l1, l2, 0);
+ }
+
+private:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2, int carry) {
+ if (l1 == nullptr && l2 == nullptr && carry == 0) return nullptr;
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto ret = new ListNode(carry % 10);
+ ret->next = addTwoNumbers(l1 == nullptr ? l1 : l1->next,
+ l2 == nullptr ? l2 : l2->next,
+ carry / 10);
+ return ret;
+ }
+};
+// (Similiar) Tail recursion
+class Solution {
+public:
+ ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
+ ListNode* head = nullptr;
+ addTwoNumbers(head, nullptr, l1, l2, 0);
+ return head;
+ }
+
+private:
+ void addTwoNumbers(ListNode*& head, ListNode* cur, ListNode* l1, ListNode* l2, int carry) {
+ if (l1 == nullptr && l2 == nullptr && carry == 0) return;
+ carry += (l1 == nullptr ? 0 : l1->val) + (l2 == nullptr ? 0 : l2->val);
+ auto temp = new ListNode(carry % 10);
+ if (cur == nullptr) {
+ head = temp;
+ cur = head;
+ } else {
+ cur->next = temp;
+ cur = cur->next;
+ }
+ addTwoNumbers(head, cur, l1 == nullptr ? l1 : l1->next, l2 == nullptr ? l2 : l2->next, carry / 10);
+ }
+};
\ No newline at end of file
diff --git a/problems/2.addTwoNumbers.md b/problems/2.add-two-numbers.md
similarity index 72%
rename from problems/2.addTwoNumbers.md
rename to problems/2.add-two-numbers.md
index ecfac154a..659b11453 100644
--- a/problems/2.addTwoNumbers.md
+++ b/problems/2.add-two-numbers.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/add-two-numbers/description/
## 题目描述
+
```
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
@@ -14,12 +16,23 @@ Output: 7 -> 0 -> 8
Explanation: 342 + 465 = 807.
```
+
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
-设立一个表示进位的变量carried,建立一个新链表,
-把输入的两个链表从头往后同时处理,每两个相加,将结果加上carried后的值作为一个新节点到新链表后面。
+设立一个表示进位的变量 carried,建立一个新链表,
+把输入的两个链表从头往后同时处理,每两个相加,将结果加上 carried 后的值作为一个新节点到新链表后面。
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -27,12 +40,14 @@ Explanation: 342 + 465 = 807.
1. 链表这种数据结构的特点和使用
-2. 用一个carried变量来实现进位的功能,每次相加之后计算carried,并用于下一位的计算
+2. 用一个 carried 变量来实现进位的功能,每次相加之后计算 carried,并用于下一位的计算
## 代码
-* 语言支持:JS,C++
+
+- 语言支持:JS,C++
JavaScript:
+
```js
/**
* Definition for singly-linked list.
@@ -46,44 +61,47 @@ JavaScript:
* @param {ListNode} l2
* @return {ListNode}
*/
-var addTwoNumbers = function(l1, l2) {
- if (l1 === null || l2 === null) return null
+var addTwoNumbers = function (l1, l2) {
+ if (l1 === null || l2 === null) return null;
// 使用dummyHead可以简化对链表的处理,dummyHead.next指向新链表
- let dummyHead = new ListNode(0)
- let cur1 = l1
- let cur2 = l2
- let cur = dummyHead // cur用于计算新链表
- let carry = 0 // 进位标志
+ let dummyHead = new ListNode(0);
+ let cur1 = l1;
+ let cur2 = l2;
+ let cur = dummyHead; // cur用于计算新链表
+ let carry = 0; // 进位标志
while (cur1 !== null || cur2 !== null) {
- let val1 = cur1 !== null ? cur1.val : 0
- let val2 = cur2 !== null ? cur2.val : 0
- let sum = val1 + val2 + carry
- let newNode = new ListNode(sum % 10) // sum%10取模结果范围为0~9,即为当前节点的值
- carry = sum >= 10 ? 1 : 0 // sum>=10,carry=1,表示有进位
- cur.next = newNode
- cur = cur.next
+ let val1 = cur1 !== null ? cur1.val : 0;
+ let val2 = cur2 !== null ? cur2.val : 0;
+ let sum = val1 + val2 + carry;
+ let newNode = new ListNode(sum % 10); // sum%10取模结果范围为0~9,即为当前节点的值
+ carry = sum >= 10 ? 1 : 0; // sum>=10,carry=1,表示有进位
+ cur.next = newNode;
+ cur = cur.next;
if (cur1 !== null) {
- cur1 = cur1.next
+ cur1 = cur1.next;
}
if (cur2 !== null) {
- cur2 = cur2.next
+ cur2 = cur2.next;
}
}
if (carry > 0) {
// 如果最后还有进位,新加一个节点
- cur.next = new ListNode(carry)
+ cur.next = new ListNode(carry);
}
- return dummyHead.next
+ return dummyHead.next;
};
```
+
C++
-> C++代码与上面的JavaScript代码略有不同:将carry是否为0的判断放到了while循环中
+
+> C++代码与上面的 JavaScript 代码略有不同:将 carry 是否为 0 的判断放到了 while 循环中
+
```c++
/**
* Definition for singly-linked list.
@@ -118,18 +136,21 @@ public:
}
};
```
+
## 拓展
-通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行reverse操作。
+通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行 reverse 操作。
+
> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
### 描述
-1. 将两个链表的第一个节点值相加,结果转为0-10之间的个位数,并设置进位信息
+1. 将两个链表的第一个节点值相加,结果转为 0-10 之间的个位数,并设置进位信息
2. 将两个链表第一个节点以后的链表做带进位的递归相加
-3. 将第一步得到的头节点的next指向第二步返回的链表
+3. 将第一步得到的头节点的 next 指向第二步返回的链表
+
+### C++实现
-### C++实现
```C++
// 普通递归
class Solution {
@@ -137,7 +158,7 @@ public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
return addTwoNumbers(l1, l2, 0);
}
-
+
private:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2, int carry) {
if (l1 == nullptr && l2 == nullptr && carry == 0) return nullptr;
@@ -157,7 +178,7 @@ public:
addTwoNumbers(head, nullptr, l1, l2, 0);
return head;
}
-
+
private:
void addTwoNumbers(ListNode*& head, ListNode* cur, ListNode* l1, ListNode* l2, int carry) {
if (l1 == nullptr && l2 == nullptr && carry == 0) return;
diff --git a/problems/20.valid-parentheses.md b/problems/20.valid-parentheses.md
new file mode 100644
index 000000000..a7769d9e3
--- /dev/null
+++ b/problems/20.valid-parentheses.md
@@ -0,0 +1,255 @@
+## 题目地址
+
+https://leetcode.com/problems/valid-parentheses/description
+
+## 题目描述
+
+```
+Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
+
+An input string is valid if:
+
+Open brackets must be closed by the same type of brackets.
+Open brackets must be closed in the correct order.
+Note that an empty string is also considered valid.
+
+Example 1:
+
+Input: "()"
+Output: true
+Example 2:
+
+Input: "()[]{}"
+Output: true
+Example 3:
+
+Input: "(]"
+Output: false
+Example 4:
+
+Input: "([)]"
+Output: false
+Example 5:
+
+Input: "{[]}"
+Output: true
+```
+
+## 前置知识
+
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+- airbnb
+- amazon
+- bloomberg
+- facebook
+- google
+- microsoft
+- twitter
+- zenefits
+
+## 栈
+
+### 思路
+
+关于这道题的思路,邓俊辉讲的非常好,没有看过的同学可以看一下,[视频地址](http://www.xuetangx.com/courses/course-v1:TsinghuaX+30240184+sp/courseware/ad1a23c053df4501a3facd66ef6ccfa9/8d6f450e7f7a445098ae1d507fda80f6/)。
+
+使用栈,遍历输入字符串
+
+如果当前字符为左半边括号时,则将其压入栈中
+
+如果遇到右半边括号时,分类讨论:
+
+1)如栈不为空且为对应的左半边括号,则取出栈顶元素,继续循环
+
+2)若此时栈为空,则直接返回 false
+
+3)若不为对应的左半边括号,反之返回 false
+
+
+
+(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
+> 值得注意的是,如果题目要求只有一种括号,那么我们其实可以使用更简洁,更省内存的方式 - 计数器来进行求解,而
+> 不必要使用栈。
+
+> 事实上,这类问题还可以进一步扩展,我们可以去解析类似 HTML 等标记语法, 比如
+
+### 关键点解析
+
+1. 栈的基本特点和操作
+2. 如果你用的是 JS 没有现成的栈,可以用数组来模拟
+ 入: push 出:pop
+
+> 入: push 出 shift 就是队列
+
+### 代码
+
+代码支持:JS,Python
+
+Javascript Code:
+
+```js
+/**
+ * @param {string} s
+ * @return {boolean}
+ */
+var isValid = function (s) {
+ let valid = true;
+ const stack = [];
+ const mapper = {
+ "{": "}",
+ "[": "]",
+ "(": ")",
+ };
+
+ for (let i in s) {
+ const v = s[i];
+ if (["(", "[", "{"].indexOf(v) > -1) {
+ stack.push(v);
+ } else {
+ const peak = stack.pop();
+ if (v !== mapper[peak]) {
+ return false;
+ }
+ }
+ }
+
+ if (stack.length > 0) return false;
+
+ return valid;
+};
+```
+
+Python Code:
+
+```py
+ class Solution:
+ def isValid(self,s):
+ stack = []
+ map = {
+ "{":"}",
+ "[":"]",
+ "(":")"
+ }
+ for x in s:
+ if x in map:
+ stack.append(map[x])
+ else:
+ if len(stack)!=0:
+ top_element = stack.pop()
+ if x != top_element:
+ return False
+ else:
+ continue
+ else:
+ return False
+ return len(stack) == 0
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## O(1) 空间
+
+### 思路
+
+基本思路是修改参数,将参数作为我们的栈。 随着我们不断遍历, s 慢慢变成了一个栈。
+
+因此 Python,Java,JS 等**字符串不可变**的语言无法使用此方法达到 $O(1)$。
+
+具体参考: [No stack O(1) space complexity O(n) time complexity solution in C++]()
+
+### 代码
+
+代码支持:C++
+
+C++:
+
+```c++
+class Solution {
+public:
+ bool isValid(string s) {
+ int top = -1;
+ for(int i =0;i 值得注意的是,如果题目要求只有一种括号,那么我们其实可以使用更简洁,更省内存的方式 - 计数器来进行求解,而
-不必要使用栈。
-
-> 事实上,这类问题还可以进一步扩展,我们可以去解析类似 HTML 等标记语法, 比如
-
-## 关键点解析
-
-1. 栈的基本特点和操作
-2. 如果你用的是 JS 没有现成的栈,可以用数组来模拟
-入: push 出:pop
-
-> 入: push 出 shift 就是队列
-## 代码
-
-* 语言支持:JS,Python
-
-Javascript Code:
-```js
-/**
- * @param {string} s
- * @return {boolean}
- */
-var isValid = function(s) {
- let valid = true;
- const stack = [];
- const mapper = {
- '{': "}",
- "[": "]",
- "(": ")"
- }
-
- for(let i in s) {
- const v = s[i];
- if (['(', '[', '{'].indexOf(v) > -1) {
- stack.push(v);
- } else {
- const peak = stack.pop();
- if (v !== mapper[peak]) {
- return false;
- }
- }
- }
-
- if (stack.length > 0) return false;
-
- return valid;
-};
-```
-Python Code:
-```
- class Solution:
- def isValid(self,s):
- stack = []
- map = {
- "{":"}",
- "[":"]",
- "(":")"
- }
- for x in s:
- if x in map:
- stack.append(map[x])
- else:
- if len(stack)!=0:
- top_element = stack.pop()
- if x != top_element:
- return False
- else:
- continue
- else:
- return False
- return len(stack) == 0
-```
-
-## 扩展
-如果让你检查 XML 标签是否闭合如何检查, 更进一步如果要你实现一个简单的 XML 的解析器,应该怎么实现?
diff --git a/problems/200.number-of-islands.md b/problems/200.number-of-islands.md
index 4615308d9..f64648d22 100644
--- a/problems/200.number-of-islands.md
+++ b/problems/200.number-of-islands.md
@@ -28,11 +28,22 @@ Output: 3
```
+## 前置知识
+
+- DFS
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
如图,我们其实就是要求红色区域的个数,换句话说就是求连续区域的个数。
-
+
符合直觉的做法是用DFS来解:
@@ -157,7 +168,7 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
## 相关题目
diff --git a/problems/201.bitwise-and-of-numbers-range.md b/problems/201.bitwise-and-of-numbers-range.md
index 5d148cc8b..2d3d2cbe1 100644
--- a/problems/201.bitwise-and-of-numbers-range.md
+++ b/problems/201.bitwise-and-of-numbers-range.md
@@ -18,6 +18,17 @@ Output: 0
```
+## 前置知识
+
+- 位运算
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
一个显而易见的解法是, 从m到n依次进行`求与`的操作。
diff --git a/problems/203.remove-linked-list-elements.md b/problems/203.remove-linked-list-elements.md
index 7955c0052..d9390dbdb 100644
--- a/problems/203.remove-linked-list-elements.md
+++ b/problems/203.remove-linked-list-elements.md
@@ -12,6 +12,17 @@ Output: 1->2->3->4->5
```
+## 前置知识
+
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这个一个链表基本操作的题目,思路就不多说了。
## 关键点解析
@@ -88,3 +99,15 @@ class Solution:
cur = cur.next
return prev.next
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/206.reverse-linked-list.md b/problems/206.reverse-linked-list.md
index 2a29e7135..a86de6317 100644
--- a/problems/206.reverse-linked-list.md
+++ b/problems/206.reverse-linked-list.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-linked-list/description/
## 题目描述
+
Reverse a singly linked list.
Example:
@@ -12,10 +14,34 @@ Follow up:
A linked list can be reversed either iteratively or recursively. Could you implement both?
+## 前置知识
+
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- adobe
+- amazon
+- apple
+- bloomberg
+- facebook
+- microsoft
+- snapchat
+- twitter
+- uber
+- yahoo
+- yelp
+- zenefits
+
## 思路
+
这个就是常规操作了,使用一个变量记录前驱 pre,一个变量记录后继 next.
不断更新`current.next = pre` 就好了
+
## 关键点解析
- 链表的基本操作(交换)
@@ -40,22 +66,21 @@ JavaScript Code:
* @param {ListNode} head
* @return {ListNode}
*/
-var reverseList = function(head) {
- if (!head || !head.next) return head;
+var reverseList = function (head) {
+ if (!head || !head.next) return head;
- let cur = head;
- let pre = null;
+ let cur = head;
+ let pre = null;
- while(cur) {
- const next = cur.next;
- cur.next = pre;
- pre = cur;
- cur = next;
- }
+ while (cur) {
+ const next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
+ }
- return pre;
+ return pre;
};
-
```
C++ Code:
@@ -132,19 +157,23 @@ class Solution {
}
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
## 拓展
通过单链表的定义可以得知,单链表也是递归结构,因此,也可以使用递归的方式来进行 reverse 操作。
-> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
-### 描述
+> 由于单链表是线性的,使用递归方式将导致栈的使用也是线性的,当链表长度达到一定程度时,递归会导致爆栈,因此,现实中并不推荐使用递归方式来操作链表。
1. 除第一个节点外,递归将链表 reverse
2. 将第一个节点添加到已 reverse 的链表之后
> 这里需要注意的是,每次需要保存已经 reverse 的链表的头节点和尾节点
-### C++实现
+C++实现
+
```c++
// 普通递归
class Solution {
@@ -192,28 +221,30 @@ public:
};
```
-### JavaScript 实现
+JavaScript 实现
+
```javascript
-var reverseList = function(head) {
+var reverseList = function (head) {
// 递归结束条件
if (head === null || head.next === null) {
- return head
+ return head;
}
// 递归反转 子链表
- let newReverseList = reverseList(head.next)
+ let newReverseList = reverseList(head.next);
// 获取原来链表的第 2 个节点 newReverseListTail
- let newReverseListTail = head.next
+ let newReverseListTail = head.next;
// 调整原来头结点和第 2 个节点的指向
- newReverseListTail.next = head
- head.next = null
+ newReverseListTail.next = head;
+ head.next = null;
// 将调整后的链表返回
- return newReverseList
-}
+ return newReverseList;
+};
```
-### Python 实现
+Python 实现
+
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
@@ -223,3 +254,19 @@ class Solution:
head.next = None
return ans
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## 相关题目
+
+- [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md)
+- [25.reverse-nodes-in-k-groups](./25.reverse-nodes-in-k-groups-cn.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/208.implement-trie-prefix-tree.md b/problems/208.implement-trie-prefix-tree.md
index 959d3e964..6d413a1be 100644
--- a/problems/208.implement-trie-prefix-tree.md
+++ b/problems/208.implement-trie-prefix-tree.md
@@ -24,6 +24,17 @@ All inputs are guaranteed to be non-empty strings.
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道很直接的题目,上来就让你实现`前缀树(字典树)`。这算是基础数据结构中的
@@ -55,25 +66,12 @@ function computeIndex(c) {
其实不管 insert, search 和 startWith 的逻辑都是差不多的,都是从 root 出发,
找到我们需要操作的 child, 然后进行相应操作(添加,修改,返回)。
-
+
## 关键点解析
- 前缀树
-- 核心逻辑
-
-```js
- const c = word[i];
- const current = computeIndex(c)
-if (!ws.children[current]) {
- ws.children[current] = new TrieNode(c);
- }
- ws = ws.children[current]; // 深度递增
-}
-
-```
-
## 代码
```js
@@ -125,7 +123,7 @@ function computeIndex(c) {
/**
* Initialize your data structure here.
*/
-var Trie = function() {
+var Trie = function () {
this.root = new TrieNode(null);
};
@@ -134,7 +132,7 @@ var Trie = function() {
* @param {string} word
* @return {void}
*/
-Trie.prototype.insert = function(word) {
+Trie.prototype.insert = function (word) {
let ws = this.root;
for (let i = 0; i < word.length; i++) {
const c = word[i];
@@ -152,7 +150,7 @@ Trie.prototype.insert = function(word) {
* @param {string} word
* @return {boolean}
*/
-Trie.prototype.search = function(word) {
+Trie.prototype.search = function (word) {
let ws = this.root;
for (let i = 0; i < word.length; i++) {
const c = word[i];
@@ -168,7 +166,7 @@ Trie.prototype.search = function(word) {
* @param {string} prefix
* @return {boolean}
*/
-Trie.prototype.startsWith = function(prefix) {
+Trie.prototype.startsWith = function (prefix) {
let ws = this.root;
for (let i = 0; i < prefix.length; i++) {
const c = prefix[i];
@@ -194,3 +192,4 @@ Trie.prototype.startsWith = function(prefix) {
- [0212.word-search-ii](./212.word-search-ii.md)
- [0472.concatenated-words](./problems/472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/209.minimum-size-subarray-sum.md b/problems/209.minimum-size-subarray-sum.md
index df3c648e0..b154b52b0 100644
--- a/problems/209.minimum-size-subarray-sum.md
+++ b/problems/209.minimum-size-subarray-sum.md
@@ -17,11 +17,22 @@ If you have figured out the O(n) solution, try coding another solution of which
```
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
用滑动窗口来记录序列, 每当滑动窗口中的 sum 超过 s, 就去更新最小值,并根据先进先出的原则更新滑动窗口,直至 sum 刚好小于 s
-
+
> 这道题目和 leetcode 3 号题目有点像,都可以用滑动窗口的思路来解决
@@ -117,7 +128,7 @@ public:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
## 扩展
diff --git a/problems/21.MergeTwoSortedLists.md b/problems/21.MergeTwoSortedLists.md
deleted file mode 100644
index 86b5ce76d..000000000
--- a/problems/21.MergeTwoSortedLists.md
+++ /dev/null
@@ -1,63 +0,0 @@
-## 题目地址
-https://leetcode-cn.com/problems/merge-two-sorted-lists
-
-## 题目描述
-```
-将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
-
-示例:
-
-输入:1->2->4, 1->3->4
-输出:1->1->2->3->4->4
-
-```
-
-## 思路
-使用递归来解题,将两个链表头部较小的一个与剩下的元素合并,并返回排好序的链表头,当两条链表中的一条为空时终止递归。
-
-
-## 关键点
-
-- 掌握链表数据结构
-- 考虑边界情况
-
-## 代码
-* 语言支持:JS
-
-```js
-/**
- * Definition for singly-linked list.
- * function ListNode(val) {
- * this.val = val;
- * this.next = null;
- * }
- */
-/**
- * @param {ListNode} l1
- * @param {ListNode} l2
- * @return {ListNode}
- */
-const mergeTwoLists = function (l1, l2) {
- if (l1 === null) {
- return l2;
- }
- if (l2 === null) {
- return l1;
- }
- if (l1.val < l2.val) {
- l1.next = mergeTwoLists(l1.next, l2);
- return l1;
- } else {
- l2.next = mergeTwoLists(l1, l2.next);
- return l2;
- }
-};
-```
-
-***复杂度分析***
-
-M、N 是两条链表 l1、l2 的长度
-
-- 时间复杂度:O(M+N)
-- 空间复杂度:O(M+N)
-
diff --git a/problems/21.merge-two-sorted-lists.md b/problems/21.merge-two-sorted-lists.md
new file mode 100644
index 000000000..1e977dabc
--- /dev/null
+++ b/problems/21.merge-two-sorted-lists.md
@@ -0,0 +1,91 @@
+## 题目地址
+
+https://leetcode-cn.com/problems/merge-two-sorted-lists
+
+## 题目描述
+
+```
+将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
+
+示例:
+
+输入:1->2->4, 1->3->4
+输出:1->1->2->3->4->4
+
+```
+
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+- [链表](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 字节
+- 腾讯
+- amazon
+- apple
+- linkedin
+- microsoft
+
+## 公司
+
+- 阿里、字节、腾讯
+
+## 思路
+
+使用递归来解题,将两个链表头部较小的一个与剩下的元素合并,并返回排好序的链表头,当两条链表中的一条为空时终止递归。
+
+## 关键点
+
+- 掌握链表数据结构
+- 考虑边界情况 2
+
+## 代码
+
+- 语言支持:JS
+
+```js
+/**
+ * Definition for singly-linked list.
+ * function ListNode(val) {
+ * this.val = val;
+ * this.next = null;
+ * }
+ */
+/**
+ * @param {ListNode} l1
+ * @param {ListNode} l2
+ * @return {ListNode}
+ */
+const mergeTwoLists = function (l1, l2) {
+ if (l1 === null) {
+ return l2;
+ }
+ if (l2 === null) {
+ return l1;
+ }
+ if (l1.val < l2.val) {
+ l1.next = mergeTwoLists(l1.next, l2);
+ return l1;
+ } else {
+ l2.next = mergeTwoLists(l1, l2.next);
+ return l2;
+ }
+};
+```
+
+**复杂度分析**
+
+M、N 是两条链表 l1、l2 的长度
+
+- 时间复杂度:$O(M+N)$
+- 空间复杂度:$O(M+N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/211.add-and-search-word-data-structure-design.md b/problems/211.add-and-search-word-data-structure-design.md
index a0b4037be..445312aab 100644
--- a/problems/211.add-and-search-word-data-structure-design.md
+++ b/problems/211.add-and-search-word-data-structure-design.md
@@ -26,6 +26,15 @@ search("b..") -> true
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 腾讯
+
## 思路
我们首先不考虑字符"."的情况。这种情况比较简单,我们 addWord 直接添加到数组尾部,search 则线性查找即可。
@@ -36,7 +45,7 @@ search("b..") -> true
关于前缀树,LeetCode 有很多题目。有的是直接考察,让你实现一个前缀树,有的是间接考察,比如本题。前缀树代码见下方,大家之后可以直接当成前缀树的解题模板使用。
-
+
由于我们这道题需要考虑特殊字符".",因此我们需要对标准前缀树做一点改造,insert 不做改变,我们只需要改变 search 即可,代码(Python 3):
diff --git a/problems/212.word-search-ii.md b/problems/212.word-search-ii.md
index fe978fa87..b3edcff12 100644
--- a/problems/212.word-search-ii.md
+++ b/problems/212.word-search-ii.md
@@ -31,6 +31,16 @@ words = ["oath","pea","eat","rain"] and board =
```
+## 前置知识
+
+- 前缀树
+- DFS
+
+## 公司
+
+- 百度
+- 字节
+
## 思路
我们需要对矩阵中每一项都进行深度优先遍历(DFS)。 递归的终点是
@@ -44,7 +54,7 @@ words = ["oath","pea","eat","rain"] and board =
刚才我提到了一个关键词“前缀”,我们考虑使用前缀树来优化。使得复杂度降低为$O(h)$, 其中 h 是前缀树深度,也就是最长的字符串长度。
-
+
## 关键点
@@ -138,5 +148,6 @@ class Solution:
- [0208.implement-trie-prefix-tree](./208.implement-trie-prefix-tree.md)
- [0211.add-and-search-word-data-structure-design](./211.add-and-search-word-data-structure-design.md)
-- [0472.concatenated-words](./problems/472.concatenated-words.md)
+- [0472.concatenated-words](./472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/215.kth-largest-element-in-an-array.md b/problems/215.kth-largest-element-in-an-array.md
index 47f741530..8fcdea381 100644
--- a/problems/215.kth-largest-element-in-an-array.md
+++ b/problems/215.kth-largest-element-in-an-array.md
@@ -18,6 +18,18 @@ Note:
You may assume k is always valid, 1 ≤ k ≤ array's length.
```
+## 前置知识
+
+- 堆
+- Quick Select
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题要求在一个无序的数组中,返回第K大的数。根据时间复杂度不同,这题有3种不同的解法。
@@ -40,7 +52,7 @@ You may assume k is always valid, 1 ≤ k ≤ array's length.
扫描一遍数组,最后堆顶就是第`K`大的元素。 直接返回。
例如:
-
+
*时间复杂度*:`O(n * logk) , n is array length`
*空间复杂度*:`O(k)`
@@ -65,7 +77,7 @@ Quick Select 类似快排,选取pivot,把小于pivot的元素都移到pivot
如下图:
```
-
+
*时间复杂度*:
- 平均是:`O(n)`
diff --git a/problems/219.contains-duplicate-ii.md b/problems/219.contains-duplicate-ii.md
index c2c85b964..8fc0aeab4 100644
--- a/problems/219.contains-duplicate-ii.md
+++ b/problems/219.contains-duplicate-ii.md
@@ -23,16 +23,29 @@ Output: false
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
由于题目没有对空间复杂度有求,用一个hashmap 存储已经访问过的数字即可,
每次访问都会看hashmap中是否有这个元素,有的话拿出索引进行比对,是否满足条件(相隔不大于k),如果满足返回true即可。
+## 公司
+- airbnb
+- palantir
## 关键点解析
-无
-
+- 空间换时间
## 代码
@@ -135,3 +148,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/22.GenerateParentheses.md b/problems/22.generate-parentheses.md
similarity index 59%
rename from problems/22.GenerateParentheses.md
rename to problems/22.generate-parentheses.md
index 352f265e5..b11565b75 100644
--- a/problems/22.GenerateParentheses.md
+++ b/problems/22.generate-parentheses.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode-cn.com/problems/generate-parentheses
## 题目描述
+
```
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
@@ -18,18 +20,29 @@ https://leetcode-cn.com/problems/generate-parentheses
```
+## 前置知识
+
+- DFS
+- 回溯法
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+
## 思路
深度优先搜索(回溯思想),从空字符串开始构造,做加法。
-
## 关键点
- 当 l < r 时记得剪枝
-
## 代码
-* 语言支持:JS
+
+- 语言支持:JS
```js
/**
@@ -41,32 +54,31 @@ https://leetcode-cn.com/problems/generate-parentheses
* @param res 结果集
*/
const generateParenthesis = function (n) {
- const res = [];
-
- function dfs(l, r, str) {
- if (l == n && r == n) {
- return res.push(str);
- }
- // l 小于 r 时不满足条件 剪枝
- if (l < r) {
- return;
- }
- // l 小于 n 时可以插入左括号,最多可以插入 n 个
- if (l < n) {
- dfs(l + 1, r, str + '(');
- }
- // r < l 时 可以插入右括号
- if (r < l) {
- dfs(l, r + 1, str + ')');
- }
+ const res = [];
+
+ function dfs(l, r, str) {
+ if (l == n && r == n) {
+ return res.push(str);
+ }
+ // l 小于 r 时不满足条件 剪枝
+ if (l < r) {
+ return;
}
- dfs(0, 0, '');
- return res;
+ // l 小于 n 时可以插入左括号,最多可以插入 n 个
+ if (l < n) {
+ dfs(l + 1, r, str + "(");
+ }
+ // r < l 时 可以插入右括号
+ if (r < l) {
+ dfs(l, r + 1, str + ")");
+ }
+ }
+ dfs(0, 0, "");
+ return res;
};
```
-
-***复杂度分析***
+**_复杂度分析_**
- 时间复杂度:O(2^N)
- 空间复杂度:O(2^N)
diff --git a/problems/221.maximal-square.md b/problems/221.maximal-square.md
index 3649d73ce..d7ccc44d3 100644
--- a/problems/221.maximal-square.md
+++ b/problems/221.maximal-square.md
@@ -21,9 +21,21 @@ Input:
Output: 4
```
+## 前置知识
+
+- 动态规划
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-
+
符合直觉的做法是暴力求解处所有的正方形,逐一计算面积,然后记录最大的。这种时间复杂度很高。
@@ -37,13 +49,13 @@ Output: 4
dp[2][2]等于1(之前已经计算好了),那么其实这里的瓶颈在于三者的最小值, 即`Min(1, 1, 3)`, 也就是`1`。 那么dp[3][3] 就等于
`Min(1, 1, 3) + 1`。
-
+
dp[i - 1][j - 1]我们直接拿到,关键是`往上和往左进行延伸`, 最直观的做法是我们内层加一个循环去做就好了。
但是我们仔细观察一下,其实我们根本不需要这样算。 我们可以直接用dp[i - 1][j]和dp[i][j -1]。
具体就是`Min(dp[i - 1][j - 1], dp[i][j - 1], dp[i - 1][j]) + 1`。
-
+
事实上,这道题还有空间复杂度O(N)的解法,其中N指的是列数。
大家可以去这个[leetcode讨论](https://leetcode.com/problems/maximal-square/discuss/61803/C%2B%2B-space-optimized-DP)看一下。
@@ -55,9 +67,31 @@ dp[i - 1][j - 1]我们直接拿到,关键是`往上和往左进行延伸`, 最
## 代码
-```js
+代码支持:Python,JavaScript:
+
+Python Code:
+
+```python
+class Solution:
+ def maximalSquare(self, matrix: List[List[str]]) -> int:
+ res = 0
+ m = len(matrix)
+ if m == 0:
+ return 0
+ n = len(matrix[0])
+ dp = [[0] * (n + 1) for _ in range(m + 1)]
+
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ dp[i][j] = min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) + 1 if matrix[i - 1][j - 1] == "1" else 0
+ res = max(res, dp[i][j])
+ return res ** 2
+```
+
+JavaScript Code:
+```js
/*
* @lc app=leetcode id=221 lang=javascript
@@ -99,3 +133,7 @@ var maximalSquare = function(matrix) {
```
+***复杂度分析***
+
+- 时间复杂度:$O(M * N)$,其中M为行数,N为列数。
+- 空间复杂度:$O(M * N)$,其中M为行数,N为列数。
diff --git a/problems/226.invert-binary-tree.md b/problems/226.invert-binary-tree.md
index 664bcf1f4..1812c2c39 100644
--- a/problems/226.invert-binary-tree.md
+++ b/problems/226.invert-binary-tree.md
@@ -29,6 +29,17 @@ This problem was inspired by this original tweet by Max Howell:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so f*** off.
```
+## 前置知识
+
+- [递归](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
遍历树(随便怎么遍历),然后将左右子树交换位置。
## 关键点解析
@@ -44,48 +55,6 @@ Google: 90% of our engineers use the software you wrote (Homebrew), but you can
Javascript Code:
```js
-/*
- * @lc app=leetcode id=226 lang=javascript
- *
- * [226] Invert Binary Tree
- *
- * https://leetcode.com/problems/invert-binary-tree/description/
- *
- * algorithms
- * Easy (57.14%)
- * Total Accepted: 311K
- * Total Submissions: 540.6K
- * Testcase Example: '[4,2,7,1,3,6,9]'
- *
- * Invert a binary tree.
- *
- * Example:
- *
- * Input:
- *
- *
- * 4
- * / \
- * 2 7
- * / \ / \
- * 1 3 6 9
- *
- * Output:
- *
- *
- * 4
- * / \
- * 7 2
- * / \ / \
- * 9 6 3 1
- *
- * Trivia:
- * This problem was inspired by this original tweet by Max Howell:
- *
- * Google: 90% of our engineers use the software you wrote (Homebrew), but you
- * can’t invert a binary tree on a whiteboard so f*** off.
- *
- */
/**
* Definition for a binary tree node.
* function TreeNode(val) {
@@ -181,3 +150,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/229.majority-element-ii.md b/problems/229.majority-element-ii.md
index bbe4b64d8..aa684a25b 100644
--- a/problems/229.majority-element-ii.md
+++ b/problems/229.majority-element-ii.md
@@ -19,6 +19,17 @@ Input: [1,1,1,3,3,2,2,2]
Output: [1,2]
```
+## 前置知识
+
+- 摩尔投票法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目和[169.majority-element](./169.majority-element.md) 很像。
@@ -35,9 +46,9 @@ Output: [1,2]
这里画了一个图,大家可以感受一下:
-
+
-
+
diff --git a/problems/23.merge-k-sorted-lists.md b/problems/23.merge-k-sorted-lists.md
index 5efe60fe4..121fea4ab 100644
--- a/problems/23.merge-k-sorted-lists.md
+++ b/problems/23.merge-k-sorted-lists.md
@@ -16,6 +16,18 @@ https://leetcode-cn.com/problems/merge-k-sorted-lists/description/
]
输出: 1->1->2->3->4->4->5->6
+## 前置知识
+
+- 链表
+- 归并排序
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+- 字节
+
## 思路
这道题目是合并 k 个已排序的链表,号称 leetcode 目前`最难`的链表题。 和之前我们解决的[88.merge-sorted-array](./88.merge-sorted-array.md)很像。
@@ -30,14 +42,14 @@ https://leetcode-cn.com/problems/merge-k-sorted-lists/description/
具体我们可以来看一个动画
-
+
(动画来自 https://zhuanlan.zhihu.com/p/61796021 )
## 关键点解析
- 分治
-- 合并排序(merge sort)
+- 归并排序(merge sort)
## 代码
@@ -159,4 +171,4 @@ class Solution:
## 相关题目
--[88.merge-sorted-array](./88.merge-sorted-array.md)
+- [88.merge-sorted-array](./88.merge-sorted-array.md)
diff --git a/problems/230.kth-smallest-element-in-a-bst.md b/problems/230.kth-smallest-element-in-a-bst.md
index b11e07d78..85fc9d9fe 100644
--- a/problems/230.kth-smallest-element-in-a-bst.md
+++ b/problems/230.kth-smallest-element-in-a-bst.md
@@ -35,6 +35,17 @@ What if the BST is modified (insert/delete operations) often and you need to fin
```
+## 前置知识
+
+- 中序遍历
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
解法一:
diff --git a/problems/232.implement-queue-using-stacks.md b/problems/232.implement-queue-using-stacks.md
index d5f4b1eaf..39b3e2e85 100644
--- a/problems/232.implement-queue-using-stacks.md
+++ b/problems/232.implement-queue-using-stacks.md
@@ -27,6 +27,19 @@ Depending on your language, stack may not be supported natively. You may simulat
You may assume that all operations are valid (for example, no pop or peek operations will be called on an empty queue).
```
+## 前置知识
+
+- [栈](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- microsoft
+
## 思路
这道题目是让我们用栈来模拟实现队列。 我们知道栈和队列都是一种受限的数据结构。
@@ -44,20 +57,20 @@ You may assume that all operations are valid (for example, no pop or peek operat
push之前是这样的:
-
+
然后我们将栈中的元素转移到辅助栈:
-
+
最后将新的元素添加到栈顶。
-
+
整个过程是这样的:
-
+
## 关键点解析
- 在push的时候利用辅助栈(双栈)
@@ -235,6 +248,10 @@ class MyQueue {
*/
````
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
## 扩展
- 类似的题目有用队列实现栈,思路是完全一样的,大家有兴趣可以试一下。
- 栈混洗也是借助另外一个栈来完成的,从这点来看,两者有相似之处。
@@ -250,3 +267,12 @@ class MyQueue {
- [reference](https://leetcode.com/problems/implement-queue-using-stacks/discuss/64284/Do-you-know-when-we-should-use-two-stacks-to-implement-a-queue)
- [further reading](https://stackoverflow.com/questions/2050120/why-use-two-stacks-to-make-a-queue/2050402#2050402)
+
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/236.lowest-common-ancestor-of-a-binary-tree.md b/problems/236.lowest-common-ancestor-of-a-binary-tree.md
index f5a85d6e0..f10600ea4 100644
--- a/problems/236.lowest-common-ancestor-of-a-binary-tree.md
+++ b/problems/236.lowest-common-ancestor-of-a-binary-tree.md
@@ -12,7 +12,7 @@ According to the definition of LCA on Wikipedia: “The lowest common ancestor i
Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]
```
-
+
```
Example 1:
@@ -33,6 +33,17 @@ All of the nodes' values will be unique.
p and q are different and both values will exist in the binary tree.
```
+## 前置知识
+
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求解二叉树中,两个给定节点的最近的公共祖先。是一道非常经典的二叉树题目。
@@ -47,7 +58,7 @@ p and q are different and both values will exist in the binary tree.
对于具体的代码而言就是,我们假设这个树就一个结构,然后尝试去解决,然后在适当地方去递归自身即可。 如下图所示:
-
+
我们来看下核心代码:
diff --git a/problems/238.product-of-array-except-self.md b/problems/238.product-of-array-except-self.md
index 70f5a0119..b1a167703 100644
--- a/problems/238.product-of-array-except-self.md
+++ b/problems/238.product-of-array-except-self.md
@@ -1,24 +1,41 @@
-## 题目地址
+## 题目地址(238. 除自身以外数组的乘积)
https://leetcode.com/problems/product-of-array-except-self/description/
## 题目描述
```
-Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
+给你一个长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
-Example:
+
-Input: [1,2,3,4]
-Output: [24,12,8,6]
-Note: Please solve it without division and in O(n).
+示例:
-Follow up:
-Could you solve it with constant space complexity? (The output array does not count as extra space for the purpose of space complexity analysis.)
+输入: [1,2,3,4]
+输出: [24,12,8,6]
+
+
+提示:题目数据保证数组之中任意元素的全部前缀元素和后缀(甚至是整个数组)的乘积都在 32 位整数范围内。
+
+说明: 请不要使用除法,且在 O(n) 时间复杂度内完成此题。
+
+进阶:
+你可以在常数空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组不被视为额外空间。)
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题的意思是给定一个数组,返回一个新的数组,这个数组每一项都是其他项的乘积。
@@ -28,7 +45,7 @@ Could you solve it with constant space complexity? (The output array does not co
考虑我们先进行一次遍历, 然后维护一个数组,第i项代表前i个元素(不包括i)的乘积。
然后我们反向遍历一次,然后维护另一个数组,同样是第i项代表前i个元素(不包括i)的乘积。
-
+
有意思的是第一个数组和第二个数组的反转(reverse)做乘法(有点像向量运算)就是我们想要的运算。
@@ -42,38 +59,6 @@ Could you solve it with constant space complexity? (The output array does not co
## 代码
```js
-
-/*
- * @lc app=leetcode id=238 lang=javascript
- *
- * [238] Product of Array Except Self
- *
- * https://leetcode.com/problems/product-of-array-except-self/description/
- *
- * algorithms
- * Medium (53.97%)
- * Total Accepted: 246.5K
- * Total Submissions: 451.4K
- * Testcase Example: '[1,2,3,4]'
- *
- * Given an array nums of n integers where n > 1, return an array output such
- * that output[i] is equal to the product of all the elements of nums except
- * nums[i].
- *
- * Example:
- *
- *
- * Input: [1,2,3,4]
- * Output: [24,12,8,6]
- *
- *
- * Note: Please solve it without division and in O(n).
- *
- * Follow up:
- * Could you solve it with constant space complexity? (The output array does
- * not count as extra space for the purpose of space complexity analysis.)
- *
- */
/**
* @param {number[]} nums
* @return {number[]}
@@ -100,3 +85,11 @@ var productExceptSelf = function(nums) {
return ret;
};
```
+
+***复杂度分析***
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的LeetCode题解
diff --git a/problems/239.sliding-window-maximum.md b/problems/239.sliding-window-maximum.md
index f45f39c07..4e7ac9834 100644
--- a/problems/239.sliding-window-maximum.md
+++ b/problems/239.sliding-window-maximum.md
@@ -28,6 +28,18 @@ Follow up:
Could you solve it in linear time?
```
+## 前置知识
+
+- 队列
+- 滑动窗口
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的想法是直接遍历 nums, 然后然后用一个变量 slideWindow 去承载 k 个元素,
@@ -79,7 +91,7 @@ class Solution:
如果你仔细观察的话,发现双端队列其实是一个递减的一个队列。因此队首的元素一定是最大的。用图来表示就是:
-
+
## 关键点解析
diff --git a/problems/24.swapNodesInPairs.md b/problems/24.swapNodesInPairs.md
index 368a353f5..d7054b6ba 100644
--- a/problems/24.swapNodesInPairs.md
+++ b/problems/24.swapNodesInPairs.md
@@ -11,6 +11,18 @@ You may not modify the values in the list's nodes, only nodes itself may be chan
Example:
Given 1->2->3->4, you should return the list as 2->1->4->3.
+
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
设置一个 dummy 节点简化操作,dummy next 指向 head。
@@ -24,7 +36,7 @@ Given 1->2->3->4, you should return the list as 2->1->4->3.
7. current 移动两格
8. 重复
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
diff --git a/problems/240.search-a-2-d-matrix-ii.md b/problems/240.search-a-2-d-matrix-ii.md
index 8be96b8ef..95877fc64 100644
--- a/problems/240.search-a-2-d-matrix-ii.md
+++ b/problems/240.search-a-2-d-matrix-ii.md
@@ -26,13 +26,24 @@ Given target = 20, return false.
```
+## 前置知识
+
+- 数组
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的做法是两层循环遍历,时间复杂度是O(m * n),
有没有时间复杂度更好的做法呢? 答案是有,那就是充分运用矩阵的特性(横向纵向都递增),
我们可以从角落(左下或者右上)开始遍历,这样时间复杂度是O(m + n).
-
+
其中蓝色代表我们选择的起点元素, 红色代表目标元素。
@@ -65,7 +76,7 @@ JavaScript Code:
* @return {boolean}
*/
var searchMatrix = function(matrix, target) {
- if (!matrix || matrix.length === 0) return 0;
+ if (!matrix || matrix.length === 0) return false;
let colIndex = 0;
let rowIndex = matrix.length - 1;
diff --git a/problems/25.reverse-nodes-in-k-groups-cn.md b/problems/25.reverse-nodes-in-k-groups-cn.md
index 828681528..401233712 100644
--- a/problems/25.reverse-nodes-in-k-groups-cn.md
+++ b/problems/25.reverse-nodes-in-k-groups-cn.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-nodes-in-k-group/
## 题目描述
+
```
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list.
@@ -22,13 +24,26 @@ You may not alter the values in the list's nodes, only nodes itself may be chang
```
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-题意是以 `k` 个nodes为一组进行翻转,返回翻转后的`linked list`.
-从左往右扫描一遍`linked list`,扫描过程中,以k为单位把数组分成若干段,对每一段进行翻转。给定首尾nodes,如何对链表进行翻转。
+题意是以 `k` 个 nodes 为一组进行翻转,返回翻转后的`linked list`.
+
+从左往右扫描一遍`linked list`,扫描过程中,以 k 为单位把数组分成若干段,对每一段进行翻转。给定首尾 nodes,如何对链表进行翻转。
+
+链表的翻转过程,初始化一个为`null`的 `previous node(prev)`,然后遍历链表的同时,当前`node (curr)`的下一个(next)指向前一个`node(prev)`,
+在改变当前 node 的指向之前,用一个临时变量记录当前 node 的下一个`node(curr.next)`. 即
-链表的翻转过程,初始化一个为`null `的 `previous node(prev)`,然后遍历链表的同时,当前`node (curr)`的下一个(next)指向前一个`node(prev)`,
-在改变当前node的指向之前,用一个临时变量记录当前node的下一个`node(curr.next)`. 即
```
ListNode temp = curr.next;
curr.next = prev;
@@ -38,7 +53,7 @@ curr = temp;
举例如图:翻转整个链表 `1->2->3->4->null` -> `4->3->2->1->null`
-
+
这里是对每一组(`k个nodes`)进行翻转,
@@ -46,7 +61,7 @@ curr = temp;
2. 用一个`start` 变量记录当前分组的起始节点位置的前一个节点
-3. 用一个`end `变量记录要翻转的最后一个节点位置
+3. 用一个`end`变量记录要翻转的最后一个节点位置
4. 翻转一组(`k个nodes`)即`(start, end) - start and end exclusively`。
@@ -54,32 +69,33 @@ curr = temp;
6. 如果不需要翻转,`end` 就往后移动一个(`end=end.next`),每一次移动,都要`count+1`.
-如图所示 步骤4和5: 翻转区间链表区间`(start, end)`
-
-
+如图所示 步骤 4 和 5: 翻转区间链表区间`(start, end)`
+
举例如图,`head=[1,2,3,4,5,6,7,8], k = 3`
+
-
-
-
->**NOTE**: 一般情况下对链表的操作,都有可能会引入一个新的`dummy node`,因为`head`有可能会改变。这里`head 从1->3`,
-`dummy (List(0)) `保持不变。
+> **NOTE**: 一般情况下对链表的操作,都有可能会引入一个新的`dummy node`,因为`head`有可能会改变。这里`head 从1->3`,
+> `dummy (List(0))`保持不变。
#### 复杂度分析
-- *时间复杂度:* `O(n) - n is number of Linked List`
-- *空间复杂度:* `O(1)`
+
+- _时间复杂度:_ `O(n) - n is number of Linked List`
+- _空间复杂度:_ `O(1)`
## 关键点分析
-1. 创建一个dummy node
-2. 对链表以k为单位进行分组,记录每一组的起始和最后节点位置
+
+1. 创建一个 dummy node
+2. 对链表以 k 为单位进行分组,记录每一组的起始和最后节点位置
3. 对每一组进行翻转,更换起始和最后的位置
4. 返回`dummy.next`.
## 代码 (`Java/Python3/javascript`)
-*Java Code*
+
+_Java Code_
+
```java
class ReverseKGroupsLinkedList {
public ListNode reverseKGroup(ListNode head, int k) {
@@ -138,7 +154,8 @@ class ReverseKGroupsLinkedList {
}
```
-*Python3 Cose*
+_Python3 Cose_
+
```python
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
@@ -153,97 +170,155 @@ class Solution:
count += 1
if count % k == 0:
start = self.reverse(start, end.next)
+ # end 调到下一个
end = start.next
else:
end = end.next
return dummy.next
+ # (start, end) 左右都开放
def reverse(self, start, end):
prev, curr = start, start.next
first = curr
+ # 反转
while curr != end:
- temp = curr.next
+ next = curr.next
curr.next = prev
prev = curr
- curr = temp
+ curr = next
+ # 将反转后的链表添加到原链表中
start.next = prev
- first.next = curr
+ first.next = end
+ # 返回反转前的头, 也就是反转后的尾部
return first
+
```
-*javascript code*
+_javascript code_
+
```js
/**
* @param {ListNode} head
* @param {number} k
* @return {ListNode}
*/
-var reverseKGroup = function(head, k) {
+var reverseKGroup = function (head, k) {
// 标兵
- let dummy = new ListNode()
- dummy.next = head
- let [start, end] = [dummy, dummy.next]
- let count = 0
- while(end) {
- count++
+ let dummy = new ListNode();
+ dummy.next = head;
+ let [start, end] = [dummy, dummy.next];
+ let count = 0;
+ while (end) {
+ count++;
if (count % k === 0) {
- start = reverseList(start, end.next)
- end = start.next
+ start = reverseList(start, end.next);
+ end = start.next;
} else {
- end = end.next
+ end = end.next;
}
}
- return dummy.next
+ return dummy.next;
// 翻转stat -> end的链表
function reverseList(start, end) {
- let [pre, cur] = [start, start.next]
- const first = cur
- while(cur !== end) {
- let next = cur.next
- cur.next = pre
- pre = cur
- cur = next
+ let [pre, cur] = [start, start.next];
+ const first = cur;
+ while (cur !== end) {
+ let next = cur.next;
+ cur.next = pre;
+ pre = cur;
+ cur = next;
}
- start.next = pre
- first.next = cur
- return first
+ start.next = pre;
+ first.next = cur;
+ return first;
}
};
-
```
## 参考(References)
+
- [Leetcode Discussion (yellowstone)](https://leetcode.com/problems/reverse-nodes-in-k-group/discuss/11440/Non-recursive-Java-solution-and-idea)
-## 扩展
+## 扩展 1
- 要求从后往前以`k`个为一组进行翻转。**(字节跳动(ByteDance)面试题)**
- 例子,`1->2->3->4->5->6->7->8, k = 3`,
+ 例子,`1->2->3->4->5->6->7->8, k = 3`,
- 从后往前以`k=3`为一组,
- - `6->7->8` 为一组翻转为`8->7->6`,
- - `3->4->5`为一组翻转为`5->4->3`.
- - `1->2`只有2个nodes少于`k=3`个,不翻转。
+ 从后往前以`k=3`为一组,
- 最后返回: `1->2->5->4->3->8->7->6`
+ - `6->7->8` 为一组翻转为`8->7->6`,
+ - `3->4->5`为一组翻转为`5->4->3`.
+ - `1->2`只有 2 个 nodes 少于`k=3`个,不翻转。
+
+ 最后返回: `1->2->5->4->3->8->7->6`
这里的思路跟从前往后以`k`个为一组进行翻转类似,可以进行预处理:
1. 翻转链表
-2. 对翻转后的链表进行从前往后以k为一组翻转。
+2. 对翻转后的链表进行从前往后以 k 为一组翻转。
-3. 翻转步骤2中得到的链表。
+3. 翻转步骤 2 中得到的链表。
例子:`1->2->3->4->5->6->7->8, k = 3`
1. 翻转链表得到:`8->7->6->5->4->3->2->1`
-2. 以k为一组翻转: `6->7->8->3->4->5->2->1`
+2. 以 k 为一组翻转: `6->7->8->3->4->5->2->1`
+
+3. 翻转步骤#2 链表: `1->2->5->4->3->8->7->6`
+
+## 扩展 2
+
+如果这道题你按照 [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md) 提到的 `p1, p2, p3, p4`(四点法) 的思路来思考的话会很清晰。
+
+代码如下(Python):
+
+```py
+
+class Solution:
+ def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
+ if head is None or k < 2:
+ return head
+ dummy = ListNode(0)
+ dummy.next = head
+ pre = dummy
+ cur = head
+ count = 0
+ while cur:
+ count += 1
+ if count % k == 0:
+ pre = self.reverse(pre, cur.next)
+ # end 调到下一个位置
+ cur = pre.next
+ else:
+ cur = cur.next
+ return dummy.next
+ # (p1, p4) 左右都开放
+
+ def reverse(self, p1, p4):
+ prev, curr = p1, p1.next
+ p2 = curr
+ # 反转
+ while curr != p4:
+ next = curr.next
+ curr.next = prev
+ prev = curr
+ curr = next
+ # 将反转后的链表添加到原链表中
+ # prev 相当于 p3
+ p1.next = prev
+ p2.next = p4
+ # 返回反转前的头, 也就是反转后的尾部
+ return p2
+
+# @lc code=end
+
+```
-3. 翻转步骤#2链表: `1->2->5->4->3->8->7->6`
+## 相关题目
-## 类似题目
-- [Swap Nodes in Pairs](https://leetcode.com/problems/swap-nodes-in-pairs/)
\ No newline at end of file
+- [92.reverse-linked-list-ii](./92.reverse-linked-list-ii.md)
+- [206.reverse-linked-list](./206.reverse-linked-list.md)
diff --git a/problems/25.reverse-nodes-in-k-groups-en.md b/problems/25.reverse-nodes-in-k-groups-en.md
index 9cf1d3115..fa717e331 100644
--- a/problems/25.reverse-nodes-in-k-groups-en.md
+++ b/problems/25.reverse-nodes-in-k-groups-en.md
@@ -45,7 +45,7 @@ curr = temp;
For example(as below pic): reverse the whole linked list `1->2->3->4->null` -> `4->3->2->1->null`
-
+
Here Reverse each group(`k nodes`):
@@ -63,13 +63,13 @@ Here Reverse each group(`k nodes`):
As below pic show steps 4 and 5, reverse linked list in range `(start, end)`:
-
+
For example(as below pic),`head=[1,2,3,4,5,6,7,8], k = 3`
-
+
>**NOTE**: Usually we create a `dummy node` to solve linked list problem, because head node may be changed during operation.
diff --git a/problems/26.remove-duplicates-from-sorted-array.md b/problems/26.remove-duplicates-from-sorted-array.md
index eedbdb1e4..af608022c 100644
--- a/problems/26.remove-duplicates-from-sorted-array.md
+++ b/problems/26.remove-duplicates-from-sorted-array.md
@@ -39,6 +39,21 @@ for (int i = 0; i < len; i++) {
}
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- facebook
+- microsoft
+
## 思路
使用快慢指针来记录遍历的坐标。
@@ -51,10 +66,12 @@ for (int i = 0; i < len; i++) {
- 当快指针走完整个数组后,慢指针当前的坐标加 1 就是数组中不同数字的个数
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+> 实际上这就是双指针中的快慢指针。在这里快指针是读指针, 慢指针是写指针。
+
## 关键点解析
- 双指针
@@ -125,3 +142,14 @@ public:
}
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/263.ugly-number.md b/problems/263.ugly-number.md
index d8e04d5b9..576354f03 100644
--- a/problems/263.ugly-number.md
+++ b/problems/263.ugly-number.md
@@ -31,11 +31,23 @@ Input is within the 32-bit signed integer range: [−231, 231 − 1].
```
+## 前置知识
+
+- 数学
+- 因数分解
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
题目要求给定一个数字,判断是否为“丑陋数”(ugly number), 丑陋数是指只包含质因子2, 3, 5的正整数。
-
+
根据定义,我们将给定数字除以2、3、5(顺序无所谓),直到无法整除。
如果得到1,说明是所有因子都是2或3或5,如果不是1,则不是丑陋数。
@@ -64,7 +76,7 @@ Input is within the 32-bit signed integer range: [−231, 231 − 1].
## 代码
-* 语言支持:JS, Python
+* 语言支持:JS, C++, Java, Python
Javascript Code:
@@ -94,6 +106,47 @@ var isUgly = function(num) {
};
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(logN)$
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ bool isUgly(int num) {
+ int ugly[] = {2,3,5};
+ for(int u : ugly)
+ {
+ while(num%u==0 && num%u < num)
+ {
+ num/=u;
+ }
+ }
+ return num == 1;
+ }
+};
+```
+
+Java Code:
+
+```java
+class Solution {
+ public boolean isUgly(int num) {
+ int [] ugly = {2,3,5};
+ for(int u : ugly)
+ {
+ while(num%u==0 && num%u < num)
+ {
+ num/=u;
+ }
+ }
+ return num == 1;
+ }
+}
+```
+
Python Code:
```python
@@ -107,3 +160,13 @@ class Solution:
num /= i
return num == 1
```
+**复杂度分析**
+- 时间复杂度:$O(logN)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/279.perfect-squares.md b/problems/279.perfect-squares.md
index 174e364a8..ef7616d41 100644
--- a/problems/279.perfect-squares.md
+++ b/problems/279.perfect-squares.md
@@ -20,6 +20,17 @@ Explanation: 13 = 4 + 9.
```
+## 前置知识
+
+- 递归
+- 动态规划
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
直接递归处理即可,但是这种暴力的解法很容易超时。如果你把递归的过程化成一棵树的话(其实就是递归树),
diff --git a/problems/283.move-zeroes.md b/problems/283.move-zeroes.md
index f4eb15e1f..c9483b30d 100644
--- a/problems/283.move-zeroes.md
+++ b/problems/283.move-zeroes.md
@@ -16,6 +16,21 @@ You must do this in-place without making a copy of the array.
Minimize the total number of operations.
```
+
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- bloomberg
+- facebook
+
## 思路
如果题目没有要求 modify in-place 的话,我们可以先遍历一遍将包含 0 的和不包含 0 的存到两个数组,
@@ -28,11 +43,11 @@ Minimize the total number of operations.
## 关键点解析
-无
+- 双指针
## 代码
-* 语言支持:JS, C++, Python
+* 语言支持:JS, C++, Java,Python
JavaScript Code:
@@ -82,6 +97,28 @@ public:
};
```
+Java Code:
+
+```java
+class Solution {
+ public void moveZeroes(int[] nums) {
+ // 双指针
+ int i = 0;
+ for(int j=0; j> 1` 一定是父节点的下标。
-
+
> 这是因为我用满二叉树来存储的堆
diff --git a/problems/3.longestSubstringWithoutRepeatingCharacters.md b/problems/3.longest-substring-without-repeating-characters.md
similarity index 64%
rename from problems/3.longestSubstringWithoutRepeatingCharacters.md
rename to problems/3.longest-substring-without-repeating-characters.md
index fd5453357..2b2571094 100644
--- a/problems/3.longestSubstringWithoutRepeatingCharacters.md
+++ b/problems/3.longest-substring-without-repeating-characters.md
@@ -16,11 +16,20 @@ Given "bbbbb", the answer is "b", with the length of 1.
Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer must be a substring, "pwke" is a subsequence and not a substring.
```
-## 思路
+## 前置知识
+
+- 哈希表
+- [滑动窗口](https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md)
+
+## 公司
-用一个 hashmap 来建立字符和其出现位置之间的映射。
+- 阿里
+- 字节
+- 腾讯
-维护一个滑动窗口,窗口内的都是没有重复的字符,去尽可能的扩大窗口的大小,窗口不停的向右滑动。
+## 思路
+
+用一个 hashmap 来建立字符和其出现位置之间的映射。同时维护一个滑动窗口,窗口内的都是没有重复的字符,去尽可能的扩大窗口的大小,窗口不停的向右滑动。
(1)如果当前遍历到的字符从未出现过,那么直接扩大右边界;
@@ -30,7 +39,7 @@ Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer
(4)维护一个结果 res,每次用出现过的窗口大小来更新结果 res,最后返回 res 获取结果。
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
@@ -42,42 +51,7 @@ Given "pwwkew", the answer is "wke", with the length of 3. Note that the answer
## 代码
-代码支持:JavaScript,Python3
-
-JavaScript Code:
-
-```js
-/**
- * @param {string} s
- * @return {number}
- */
-var lengthOfLongestSubstring = function(s) {
- const mapper = {}; // 记录已经出现过的charactor
- let res = 0;
- let slidingWindow = [];
-
- for (let c of s) {
- if (mapper[c]) {
- // 已经出现过了
- // 则删除
- const delIndex = slidingWindow.findIndex(_c => _c === c);
-
- for (let i = 0; i < delIndex; i++) {
- mapper[slidingWindow[i]] = false;
- }
-
- slidingWindow = slidingWindow.slice(delIndex + 1).concat(c);
- } else {
- // 新字符
- if (slidingWindow.push(c) > res) {
- res = slidingWindow.length;
- }
- }
- mapper[c] = true;
- }
- return res;
-};
-```
+代码支持:Python3
Python3 Code:
@@ -100,3 +74,14 @@ class Solution:
return ans
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/30.substring-with-concatenation-of-all-words.md b/problems/30.substring-with-concatenation-of-all-words.md
index ce9999e74..2b5512e9e 100644
--- a/problems/30.substring-with-concatenation-of-all-words.md
+++ b/problems/30.substring-with-concatenation-of-all-words.md
@@ -30,6 +30,19 @@ https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/descr
```
+## 前置知识
+
+- 字符串
+- 数组
+- 哈希表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
本题是要我们找出 words 中`所有单词按照任意顺序串联`形成的单词中恰好出现在 s 中的索引,因此顺序是不重要的。换句话说,我们只要统计每一个单词的出现情况即可。以题目中 s = "barfoothefoobarman", words = ["foo","bar"] 为例。 我们只需要统计 foo 出现了一次,bar 出现了一次即可。我们只需要在 s 中找到同样包含一次 foo 和一次 bar 的子串即可。由于 words 中的字符串都是等长的,因此编码上也会比较简单。
diff --git a/problems/301.remove-invalid-parentheses.md b/problems/301.remove-invalid-parentheses.md
index 9e308507e..43b69f624 100644
--- a/problems/301.remove-invalid-parentheses.md
+++ b/problems/301.remove-invalid-parentheses.md
@@ -23,6 +23,18 @@ Output: [""]
```
+## 前置知识
+
+- BFS
+- 队列
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我们的思路是先写一个函数用来判断给定字符串是否是有效的。 然后再写一个函数,这个函数
@@ -32,7 +44,7 @@ Output: [""]
而且由于题目要求是要删除最少的小括号,因此我们的思路是使用广度优先遍历,而不是深度有限的遍历。
-
+
> 没有动图,请脑补
diff --git a/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md b/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
index c2372d3f5..cd2e4df4b 100644
--- a/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
+++ b/problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md
@@ -18,6 +18,16 @@ Output: 3
Explanation: transactions = [buy, sell, cooldown, buy, sell]
```
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
这是一道典型的 DP 问题, DP 问题的核心是找到状态和状态转移方程。
@@ -73,7 +83,7 @@ sell[i]对应第 i 的 action 只能是 sell 或者 cooldown。
* @param {number[]} prices
* @return {number}
*/
-var maxProfit = function(prices) {
+var maxProfit = function (prices) {
if (prices == null || prices.length <= 1) return 0;
// 定义状态变量
diff --git a/problems/31.next-permutation.md b/problems/31.next-permutation.md
index 29c8f00b3..43ea07d37 100644
--- a/problems/31.next-permutation.md
+++ b/problems/31.next-permutation.md
@@ -19,6 +19,17 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的方法是我们按顺序求出所有的排列,如果当前排列等于 nums,那么我直接取下一个
@@ -26,7 +37,7 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
这种题目比较抽象,写几个例子通常会帮助理解问题的规律。我找了几个例子,其中蓝色背景表示的是当前数字找下一个更大排列的时候`需要改变的元素`.
-
+
我们不难发现,蓝色的数字都是从后往前第一个不递增的元素,并且我们的下一个更大的排列
只需要改变蓝色的以及之后部分即可,前面的不需要变。
@@ -37,18 +48,18 @@ Here are some examples. Inputs are in the left-hand column and its corresponding
另外我们也可以以回溯的角度来思考这个问题,让我们先回溯一次:
-
+
这个时候可以选择的元素只有2,我们无法组成更大的排列,我们继续回溯,直到如图:
-
+
我们发现我们可以交换4或者2实现变大的效果,但是要保证变大的幅度最小(下一个更大),
我们需要选择最小的,由于之前我们发现后面是从左到右递减的,显然就是交换最右面大于1的。
之后就是不断交换使之幅度最小:
-
+
## 关键点解析
- 写几个例子通常会帮助理解问题的规律
diff --git a/problems/312.burst-balloons.md b/problems/312.burst-balloons.md
new file mode 100644
index 000000000..90a535273
--- /dev/null
+++ b/problems/312.burst-balloons.md
@@ -0,0 +1,177 @@
+### 题目地址(312. 戳气球)
+
+https://leetcode-cn.com/problems/burst-balloons/
+
+### 题目描述
+
+```
+有 n 个气球,编号为0 到 n-1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
+
+现在要求你戳破所有的气球。每当你戳破一个气球 i 时,你可以获得 nums[left] * nums[i] * nums[right] 个硬币。 这里的 left 和 right 代表和 i 相邻的两个气球的序号。注意当你戳破了气球 i 后,气球 left 和气球 right 就变成了相邻的气球。
+
+求所能获得硬币的最大数量。
+
+说明:
+
+你可以假设 nums[-1] = nums[n] = 1,但注意它们不是真实存在的所以并不能被戳破。
+0 ≤ n ≤ 500, 0 ≤ nums[i] ≤ 100
+示例:
+
+输入: [3,1,5,8]
+输出: 167
+解释: nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> []
+ coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167
+```
+
+## 前置知识
+
+- 回溯法
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+#### 回溯法
+
+分析一下这道题,就是要戳破所有的气球,获得硬币的最大数量,然后左右两边的气球相邻了。我的第一反应就是暴力,回溯法。
+
+但是肯定会超时,为什么呢?因为题目给的气球数量有点多,最多 500 个;500 的阶乘,会超时爆栈;但是我们依然写一下代码,找下突破口,小伙伴们千万不要看不起暴力,暴力是优化的突破口;
+
+如果小伙伴对回溯法不太熟悉,我建议你记住下面的模版,也可以看我之前写的文章,回溯法基本可以使用以下的模版写。回溯法省心省力,0 智商负担。
+
+#### 代码
+
+```js
+var maxCoins = function (nums) {
+ let res = Number.MIN_VALUE;
+ backtrack(nums, 0);
+ return res;
+ // 回溯法,状态树很大
+ function backtrack(nums, score) {
+ if (nums.length == 0) {
+ res = Math.max(res, score);
+ return;
+ }
+ for (let i = 0, n = nums.length; i < n; i++) {
+ let point =
+ (i - 1 < 0 ? 1 : nums[i - 1]) *
+ nums[i] *
+ (i + 1 >= n ? 1 : nums[i + 1]);
+ let tempNums = [].concat(nums);
+ // 做选择 在 nums 中删除元素 nums[i]
+ nums.splice(i, 1);
+ // 递归回溯
+ backtrack(nums, score + point);
+ // 撤销选择
+ nums = [...tempNums];
+ }
+ }
+};
+```
+
+#### 动态规划
+
+回溯法的缺点也很明显,复杂度很高,对应本题戳气球;小伙伴们可以脑补一下执行过程的状态树,这里我偷个懒就不画了;通过仔细观察这个状态树,我们会发现这个状态树的【选择】上,会有一些重复的选择分支;很明显存在了重复子问题;自然我就想到了能不能用动态规划来解决;
+
+判读能不能用动态规划解决,还有一个问题,就是必须存在最优子结构;什么意思呢?其实就是根据局部最优,推导出答案;假设我们戳破第 k 个气球是最优策略的最后一步,和上一步有没有联系呢?根据题目意思,戳破第 k 个,前一个和后一个就变成相邻的了,看似是会有联系,其实是没有的。因为戳破第 k 个和 k-1 个是没有联系的,脑补一下回溯法的状态树就更加明确了;
+
+既然用动态规划,那就老套路了,把动态规划的三个问题想清楚定义好;然后找出题目的【状态】和【选择】,然后根据【状态】枚举,枚举的过程中根据【选择】计算递推就能得到答案了。
+
+那本题的【选择】是什么呢?就是戳哪一个气球。那【状态】呢?就是题目给的气球数量。
+
+1. 定义状态
+
+- 这里有个细节,就是题目说明有两个虚拟气球,nums[-1] = nums[n] = 1;如果当前戳破的气球是最后一个或者第一个,前面/后面没有气球了,不能乘以 0,而是乘以 1。
+
+- 定义状态的最关键两个点,往子问题(问题规模变小)想,最后一步最优策略是什么;我们假设最后戳破的气球是 k,戳破 k 获得最大数量的银币就是 nums[i] * nums[k] * nums[j] 再加上前面戳破的最大数量和后面的最大数量,即:nums[i] * nums[k] * nums[j] + 前面最大数量 + 后面最大数量,就是答案。
+
+> 注意 i 不一定是 k - 1,同理 j 也不一定是 k + 1,因此可能 i - 1 和 i + 1 已经被戳破了。
+
+- 而如果我们不考虑两个虚拟气球而直接定义状态,戳到最后两个气球的时候又该怎么定义状态来避免和前面的产生联系呢?这两个虚拟气球就恰到好处了,这也是本题的一个难点之一。
+
+- 那我们可以这样来定义状态,dp[i][j] = x 表示戳破气球 i 和气球 j 之间(开区间,不包括 i 和 j)的所有气球,可以获得的最大硬币数为 x。为什么开区间?因为不能和已经计算过的产生联系,我们这样定义之后,利用两个虚拟气球,戳到最后两个气球的时候就完美的避开了所有状态的联系。
+
+2. 状态转移方程
+
+- 而对于 dp[i][j],i 和 j 之间会有很多气球,到底该戳哪个先呢?我们直接设为 k,枚举选择最优的 k 就可以了。
+ - 1。
+- 所以,最终的状态转移方程为:dp[i][j] = max(dp[i][j], dp[i][k] + dp[k][j] + nums[k] * nums[i] * nums[j])。由于是开区间,因此 k 为 i + 1, i + 2... j - 1。
+
+3. 初始值和边界
+
+- 由于我们利用了两个虚拟气球,边界就是气球数 n + 2
+- 初始值,当 i == j 时,很明显两个之间没有气球,所有为 0;
+
+4. 如何枚举状态
+
+- 因为我们最终要求的答案是 dp[0][n + 1],就是戳破虚拟气球之间的所有气球获得的最大值;
+- 当 i == j 时,i 和 j 之间是没有气球的,所以枚举的状态很明显是 dp table 的左上部分,也就是 j 大于 i,如下图所示,只给出一部分方便思考。
+
+
+(图有错误。图中 dp[k][i] 应该是 dp[i][k],dp[j][k] 应该是 dp[k][j])
+
+> 从上图可以看出,我们需要从下到上,从左到右进行遍历。
+
+#### 代码
+
+
+代码支持: JS, Python
+
+JS Code:
+
+```js
+var maxCoins = function (nums) {
+ let n = nums.length;
+ // 添加两侧的虚拟气球
+ let points = [1, ...nums, 1];
+ let dp = Array.from(Array(n + 2), () => Array(n + 2).fill(0));
+ // 最后一行开始遍历,从下往上
+ for (let i = n; i >= 0; i--) {
+ // 从左往右
+ for (let j = i + 1; j < n + 2; j++) {
+ for (let k = i + 1; k < j; k++) {
+ dp[i][j] = Math.max(
+ dp[i][j],
+ points[j] * points[k] * points[i] + dp[i][k] + dp[k][j]
+ );
+ }
+ }
+ }
+ return dp[0][n + 1];
+};
+```
+
+Python Code:
+
+```py
+class Solution:
+ def maxCoins(self, nums: List[int]) -> int:
+ n = len(nums)
+ points = [1] + nums + [1]
+ dp = [[0] * (n + 2) for _ in range(n + 2)]
+
+ for i in range(n, -1, -1):
+ for j in range(i + 1, n + 2):
+ for k in range(i + 1, j):
+ dp[i][j] = max(dp[i][j], dp[i][k] + dp[k][j] + points[i] * points[k] * points[j])
+ return dp[0][-1]
+```
+
+**复杂度分析**
+- 时间复杂度:$O(N ^ 3)$
+- 空间复杂度:$O(N ^ 2)$
+
+### 总结
+
+简单的 dp 题目会直接告诉你怎么定义状态,告诉你怎么选择计算,你只需要根据套路判断一下能不能用 dp 解题即可,而判断能不能,往往暴力就是突破口。而困难点的 dp,我觉的都是细节问题了,要注意的细节太多了。感觉力扣加加,路西法大佬,把我领进了动态规划的大门,共勉。
+
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/32.longest-valid-parentheses.md b/problems/32.longest-valid-parentheses.md
index 370d89656..a549898b0 100644
--- a/problems/32.longest-valid-parentheses.md
+++ b/problems/32.longest-valid-parentheses.md
@@ -1,4 +1,5 @@
## 题目地址
+
https://leetcode.com/problems/longest-valid-parentheses/
## 题目描述
@@ -18,44 +19,234 @@ Output: 4
Explanation: The longest valid parentheses substring is "()()"
```
-## 思路(动态规划)
+## 前置知识
-所有的动态规划问题, 首先需要解决的就是如何寻找合适的子问题.
-该题需要我们找到最长的有效括号对, 我们首先想到的就是定义**dp[i]为前i个字符串的最长有效括号对长度**, 但是随后我们会发现, 这样的定义, 我们无法找到dp[i]和dp[i-1]的任何关系.
-所以, 我们需要重新找一个新的定义: 定义**dp[i]为以第i个字符结尾的最长有效括号对长度**. 然后, 我们通过下面这个例子找一下dp[i]和dp[i-1]之间的关系.
+- 动态规划
-```python
-s = '(())())'
+## 暴力(超时)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+符合直觉的做法是:分别计算以 i 开头的 最长有效括号(i 从 0 到 n - 1·),从中取出最大的即可。
+
+### 代码
+
+代码支持: Python
+
+```py
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ n = len(s)
+ ans = 0
+
+ def validCnt(start):
+ # cnt 为 ) 的数量减去 ( 的数量
+ cnt = 0
+ ans = 0
+ for i in range(start, n):
+ if s[i] == '(':
+ cnt += 1
+ if s[i] == ')':
+ cnt -= 1
+ if cnt < 0:
+ return i - start
+ if cnt == 0:
+ ans = max(ans, i - start + 1)
+ return ans
+ for i in range(n):
+ ans = max(ans, validCnt(i))
+
+ return ans
```
-从上面的例子我们可以观察出一下几点结论(**描述中i为图中的dp数组的下标, 对应s的下标应为i-1, 第i个字符的i从1开始**).
-1. base case: 空字符串的最长有效括号对长度肯定为0, 即: dp[0] = 0;
-2. s的第**1**个字符结尾的最长有效括号对长度为0, s的第**2**个字符结尾的最长有效括号对长度也为0, 这个时候我们可以得出结论: 最长有效括号对不可能以'('结尾, 即: dp[1] = d[2] = 0;
-3. 当i等于3时, 我们可以看出dp[2]=0, dp[3]=2, 因为第2个字符(**s[1]**)和第3个字符(**s[2]**)是配对的;
- 当i等于4时, 我们可以看出dp[3]=2, dp[4]=4, 因为我们配对的是第1个字符(**s[0]**)和第4个字符(**s[3]**);
- 因此, 我们可以得出结论: 如果第**i**个字符和第i-1-dp[i-1]个字符是配对的, 则dp[i] = dp[i-1] + 2, 其中: i-1-dp[i-1] >= 1, 因为第0个字符没有任何意义;
-4. 根据第3条规则来计算的话, 我们发现dp[5]=0, dp[6]=2, 但是显然, dp[6]应该为6才对, 但是我们发现可以将"(())"和"()"进行拼接, 即: dp[i] += dp[i-dp[i]], 即: dp[6] = 2 + dp[6-2] = 2 + dp[4] = 6
+**复杂度分析**
-根据以上规则, 我们求解dp数组的结果为: [0, 0, 0, 2, 4, 0, 6, 0], 其中最长有效括号对的长度为6. 以下为图解:
-
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(1)$
-## 关键点解析
+## 栈
-1. 第3点特征, 需要检查的字符是s[i-1]和s[i-2-dp[i-1]], 根据定义可知: i-1 >= dp[i-1], 但是i-2不一定大于dp[i-1], 因此, 需要检查越界;
-3. 第4点特征最容易遗漏, 还有就是不需要检查越界, 因为根据定义可知: i >= dp[i], 所以dp[i-dp[i]]的边界情况是dp[0];
+### 思路
-## 思路(栈)
主要思路和常规的括号解法一样,遇到'('入栈,遇到')'出栈,并计算两个括号之间的长度。
因为这个题存在非法括号对的情况且求是合法括号对的最大长度 所以有两个注意点是:
+
1. **栈中存的是符号的下标**
2. **当栈为空时且当前扫描到的符号是')'时,需要将这个符号入栈作为分割符**
+3. 栈中初始化一个 -1,作为**分割符**
+
+### 代码
-## 代码
+- 语言支持: Python, javascript
-* 语言支持: Python, javascript
+javascript code:
+
+```js
+// 用栈来解
+var longestValidParentheses = function (s) {
+ let stack = new Array();
+ let longest = 0;
+ stack.push(-1);
+ for (let i = 0; i < s.length; i++) {
+ if (s[i] === "(") {
+ stack.push(i);
+ } else {
+ stack.pop();
+ if (stack.length === 0) {
+ stack.push(i);
+ } else {
+ longest = Math.max(longest, i - stack[stack.length - 1]);
+ }
+ }
+ }
+ return longest;
+};
+```
Python Code:
+
+```py
+
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ if not s:
+ return 0
+ res = 0
+ stack = [-1]
+ for i in range(len(s)):
+ if s[i] == "(":
+ stack.append(i)
+ else:
+ stack.pop()
+ if not stack:
+ stack.append(i)
+ else:
+ res = max(res, i - stack[-1])
+ return res
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## O(1) 空间
+
+### 思路
+
+我们可以采用解法一中的计数方法。
+
+- 从左到右遍历一次,并分别记录左右括号的数量 left 和 right。
+- 如果 right > left ,说明截止上次可以匹配的点到当前点这一段无法匹配,重置 left 和 right 为 0
+- 如果 right == left, 此时可以匹配,此时有效括号长度为 left + right,我们获得一个局部最优解。如果其比全局最优解大,我们更新全局最优解
+
+值得注意的是,对形如 `(((()` 这样的,更新全局最优解的逻辑永远无法执行。一种方式是再从右往左遍历一次即可,具体看代码。
+
+> 类似的思想有哨兵元素,虚拟节点。只不过本题无法采用这种方法。
+
+### 代码
+
+代码支持:Java,Python
+
+```java
+public class Solution {
+ public int longestValidParentheses(String s) {
+ int left = 0, right = 0, maxlength = 0;
+ for (int i = 0; i < s.length(); i++) {
+ if (s.charAt(i) == '(') {
+ left++;
+ } else {
+ right++;
+ }
+ if (left == right) {
+ maxlength = Math.max(maxlength, left + right);
+ }
+ if (right > left) {
+ left = right = 0;
+ }
+ }
+ left = right = 0;
+ for (int i = s.length() - 1; i >= 0; i--) {
+ if (s.charAt(i) == '(') {
+ left++;
+ } else {
+ right++;
+ }
+ if (left == right) {
+ maxlength = Math.max(maxlength, left + right);
+ }
+ if (left > right) {
+ left = right = 0;
+ }
+ }
+ return maxlength;
+ }
+}
+```
+
+```py
+class Solution:
+ def longestValidParentheses(self, s: str) -> int:
+ ans = l = r = 0
+ for c in s:
+ if c == '(':
+ l += 1
+ else:
+ r += 1
+ if l == r:
+ ans = max(ans, l + r)
+ if r > l:
+ l = r = 0
+ l = r = 0
+ for c in s[::-1]:
+ if c == '(':
+ l += 1
+ else:
+ r += 1
+ if l == r:
+ ans = max(ans, l + r)
+ if r < l:
+ l = r = 0
+
+ return ans
+```
+
+## 动态规划
+
+### 思路
+
+所有的动态规划问题, 首先需要解决的就是如何寻找合适的子问题.
+该题需要我们找到最长的有效括号对, 我们首先想到的就是定义**dp[i]为前 i 个字符串的最长有效括号对长度**, 但是随后我们会发现, 这样的定义, 我们无法找到 dp[i]和 dp[i-1]的任何关系.
+所以, 我们需要重新找一个新的定义: 定义**dp[i]为以第 i 个字符结尾的最长有效括号对长度**. 然后, 我们通过下面这个例子找一下 dp[i]和 dp[i-1]之间的关系.
+
+```python
+s = '(())())'
```
+
+从上面的例子我们可以观察出一下几点结论(**描述中 i 为图中的 dp 数组的下标, 对应 s 的下标应为 i-1, 第 i 个字符的 i 从 1 开始**).
+
+1. base case: 空字符串的最长有效括号对长度肯定为 0, 即: dp[0] = 0;
+2. s 的第**1**个字符结尾的最长有效括号对长度为 0, s 的第**2**个字符结尾的最长有效括号对长度也为 0, 这个时候我们可以得出结论: 最长有效括号对不可能以'('结尾, 即: dp[1] = d[2] = 0;
+3. 当 i 等于 3 时, 我们可以看出 dp[2]=0, dp[3]=2, 因为第 2 个字符(**s[1]**)和第 3 个字符(**s[2]**)是配对的;
+ 当 i 等于 4 时, 我们可以看出 dp[3]=2, dp[4]=4, 因为我们配对的是第 1 个字符(**s[0]**)和第 4 个字符(**s[3]**);
+ 因此, 我们可以得出结论: 如果第**i**个字符和第i-1-dp[i-1]个字符是配对的, 则 dp[i] = dp[i-1] + 2, 其中: i-1-dp[i-1] >= 1, 因为第 0 个字符没有任何意义;
+4. 根据第 3 条规则来计算的话, 我们发现 dp[5]=0, dp[6]=2, 但是显然, dp[6]应该为 6 才对, 但是我们发现可以将"(())"和"()"进行拼接, 即: dp[i] += dp[i-dp[i]], 即: dp[6] = 2 + dp[6-2] = 2 + dp[4] = 6
+
+根据以上规则, 我们求解 dp 数组的结果为: [0, 0, 0, 2, 4, 0, 6, 0], 其中最长有效括号对的长度为 6. 以下为图解:
+
+
+### 代码
+
+Python Code:
+
+```py
class Solution:
def longestValidParentheses(self, s: str) -> int:
mlen = 0
@@ -81,28 +272,14 @@ class Solution:
return mlen
```
-javascript code:
-```js
-// 用栈来解
-var longestValidParentheses = function(s) {
- let stack = new Array()
- let longest = 0
- stack.push(-1)
- for(let i = 0; i < s.length; i++) {
- if (s[i] === '(') {
- stack.push(i)
- } else {
- stack.pop()
- if (stack.length === 0) {
- stack.push(i)
- } else {
- longest = Math.max(longest, i - stack[stack.length - 1])
- }
- }
- }
- return longest
-};
-```
+### 关键点解析
+
+1. 第 3 点特征, 需要检查的字符是 s[i-1]和 s[i-2-dp[i-1]], 根据定义可知: i-1 >= dp[i-1], 但是 i-2 不一定大于 dp[i-1], 因此, 需要检查越界;
+2. 第 4 点特征最容易遗漏, 还有就是不需要检查越界, 因为根据定义可知: i >= dp[i], 所以 dp[i-dp[i]]的边界情况是 dp[0];
+
+## 相关题目
+
+- [20.valid-parentheses](./20.valid-parentheses.md)
## 扩展
diff --git a/problems/322.coin-change.md b/problems/322.coin-change.md
index 3839254db..9a6f3c095 100644
--- a/problems/322.coin-change.md
+++ b/problems/322.coin-change.md
@@ -1,15 +1,16 @@
-
## 题目地址
+
https://leetcode.com/problems/coin-change/description/
## 题目描述
+
```
You are given coins of different denominations and a total amount of money amount. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
Example 1:
Input: coins = [1, 2, 5], amount = 11
-Output: 3
+Output: 3
Explanation: 11 = 5 + 5 + 1
Example 2:
@@ -19,10 +20,28 @@ Note:
You may assume that you have an infinite number of each kind of coin.
```
+
+## 前置知识
+
+- 贪心算法
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+- 阿里巴巴(盒马生鲜)
+
+## 岗位信息
+
+- 阿里巴巴(盒马生鲜):前端技术二面
+
## 思路
+## 思路
-假如我们把coin逆序排列,然后逐个取,取到刚好不大于amout,依次类推。
+假如我们把 coin 逆序排列,然后逐个取,取到刚好不大于 amout,依次类推。
```
eg: 对于 [1,2,5] 组成 11 块
@@ -46,7 +65,7 @@ eg: 对于 [1,2,5] 组成 11 块
因此结果是 3
```
-熟悉贪心算法的同学应该已经注意到了,这就是贪心算法,贪心算法更amount尽快地变得更小。
+熟悉贪心算法的同学应该已经注意到了,这就是贪心算法,贪心算法更 amount 尽快地变得更小。
`经验表明,贪心策略是正确的`。 注意,我说的是经验表明, 贪心算法也有可能出错。 就拿这道题目来说,
他也是不正确的! 比如 `coins = [1, 5, 11] amout = 15`, 因此这种做法有时候不靠谱,我们还是采用靠谱的做法.
@@ -79,24 +98,26 @@ class Solution:
dp[i][j] = dp[i][j - 1]
return -1 if dp[-1][-1] == amount + 1 else dp[-1][-1]
- ```
-
- **复杂度分析**
+```
+
+**复杂度分析**
+
- 时间复杂度:$O(amonut * len(coins))$
- 空间复杂度:$O(amount * len(coins))$
-dp[i][j] 依赖于` dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个优化的信号,我们可以将其优化到一维,具体见下方。
+dp[i][j] 依赖于`dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个优化的信号,我们可以将其优化到一维,具体见下方。
+
## 关键点解析
- 动态规划
- 子问题
-用dp[i] 来表示组成i块钱,需要最少的硬币数,那么
+用 dp[i] 来表示组成 i 块钱,需要最少的硬币数,那么
-1. 第j个硬币我可以选择不拿 这个时候, 硬币数 = dp[i]
+1. 第 j 个硬币我可以选择不拿 这个时候, 硬币数 = dp[i]
-2. 第j个硬币我可以选择拿 这个时候, 硬币数 = dp[i - coins[j]] + 1
+2. 第 j 个硬币我可以选择拿 这个时候, 硬币数 = dp[i - coins[j]] + 1
- 和背包问题不同, 硬币是可以拿任意个
@@ -104,33 +125,33 @@ dp[i][j] 依赖于` dp[i][j - 1]`和 `dp[i - coins[j - 1]][j] + 1)` 这是一个
## 代码
-
-* 语言支持:JS,C++,Python3
+- 语言支持:JS,C++,Python3
JavaScript Code:
-```js
-var coinChange = function(coins, amount) {
- if (amount === 0) {
- return 0;
- }
- const dp = Array(amount + 1).fill(Number.MAX_VALUE)
- dp[0] = 0;
- for (let i = 1; i < dp.length; i++) {
- for (let j = 0; j < coins.length; j++) {
- if (i - coins[j] >= 0) {
- dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
- }
+```js
+var coinChange = function (coins, amount) {
+ if (amount === 0) {
+ return 0;
+ }
+ const dp = Array(amount + 1).fill(Number.MAX_VALUE);
+ dp[0] = 0;
+ for (let i = 1; i < dp.length; i++) {
+ for (let j = 0; j < coins.length; j++) {
+ if (i - coins[j] >= 0) {
+ dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
+ }
- return dp[dp.length - 1] === Number.MAX_VALUE ? -1 : dp[dp.length - 1];
-
-
+ return dp[dp.length - 1] === Number.MAX_VALUE ? -1 : dp[dp.length - 1];
};
```
+
C++ Code:
-> C++中采用INT_MAX,因此判断时需要加上`dp[a - coin] < INT_MAX`以防止溢出
+
+> C++中采用 INT_MAX,因此判断时需要加上`dp[a - coin] < INT_MAX`以防止溢出
+
```C++
class Solution {
public:
@@ -166,10 +187,10 @@ class Solution:
```
**复杂度分析**
+
- 时间复杂度:$O(amonut * len(coins))$
- 空间复杂度:$O(amount)$
-
## 扩展
这是一道很简单描述的题目, 因此很多时候会被用到大公司的电面中。
diff --git a/problems/328.odd-even-linked-list.md b/problems/328.odd-even-linked-list.md
index d91266feb..2a39a048f 100644
--- a/problems/328.odd-even-linked-list.md
+++ b/problems/328.odd-even-linked-list.md
@@ -23,6 +23,17 @@ The relative order inside both the even and odd groups should remain as it was i
The first node is considered odd, the second node even and so on ...
```
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
符合直觉的想法是,先遍历一遍找出奇数的节点。然后再遍历一遍找出偶数节点,最后串起来。
diff --git a/problems/33.search-in-rotated-sorted-array.md b/problems/33.search-in-rotated-sorted-array.md
index 96d81c67c..9aa1fc1bd 100644
--- a/problems/33.search-in-rotated-sorted-array.md
+++ b/problems/33.search-in-rotated-sorted-array.md
@@ -25,6 +25,18 @@ Output: -1
```
+## 前置知识
+
+- 数组
+- 二分法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个我在网上看到的前端头条技术终面的一个算法题。
@@ -50,10 +62,10 @@ Output: -1
我们以([6,7,8,1,2,3,4,5], 4)为例讲解一下:
-
+
-
+
## 关键点解析
diff --git a/problems/334.increasing-triplet-subsequence.md b/problems/334.increasing-triplet-subsequence.md
index 7c359e351..63622c93b 100644
--- a/problems/334.increasing-triplet-subsequence.md
+++ b/problems/334.increasing-triplet-subsequence.md
@@ -23,6 +23,15 @@ Input: [5,4,3,2,1]
Output: false
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 百度
+- 字节
+
## 思路
这道题是求解顺序数字是否有三个递增的排列, 注意这里没有要求连续的,因此诸如滑动窗口的思路是不可以的。
题目要求O(n)的时间复杂度和O(1)的空间复杂度,因此暴力的做法就不用考虑了。
@@ -30,7 +39,7 @@ Output: false
我们的目标就是`依次`找到三个数字,其顺序是递增的。因此我们的做法可以是依次遍历,
然后维护三个变量,分别记录最小值,第二小值,第三小值。只要我们能够填满这三个变量就返回true,否则返回false。
-
+
## 关键点解析
- 维护三个变量,分别记录最小值,第二小值,第三小值。只要我们能够填满这三个变量就返回true,否则返回false
diff --git a/problems/335.self-crossing.md b/problems/335.self-crossing.md
index 0ff94829f..290afba41 100644
--- a/problems/335.self-crossing.md
+++ b/problems/335.self-crossing.md
@@ -41,6 +41,14 @@ https://leetcode-cn.com/problems/self-crossing/
```
+## 前置知识
+
+- 滑动窗口
+
+## 公司
+
+- 暂无
+
## 思路
符合直觉的做法是$O(N)$时间和空间复杂度的算法。这种算法非常简单,但是题目要求我们使用空间复杂度为$O(1)$的做法。
@@ -52,24 +60,24 @@ https://leetcode-cn.com/problems/self-crossing/
1. 我们画的圈不断增大。
2. 我们画的圈不断减少。
-
+
(有没有感觉像迷宫?)
这样我们会发现,其实我们画最新一笔的时候,并不是之前画的所有的都需要考虑,我们只需要最近的几个就可以了,实际上是最近的五个,不过不知道也没关系,我们稍后会讲解。
-
+
红色部分指的是我们需要考虑的,而剩余没有被红色标注的部分则无需考虑。不是因为我们无法与之相交,而是我们`一旦与之相交,则必然我们也一定会与红色标记部分相交`。
然而我们画的方向也是不用考虑的。比如我当前画的方向是从左到右,那和我画的方向是从上到下有区别么?在这里是没区别的,不信我帮你将上图顺时针旋转 90 度看一下:
-
+
方向对于我们考虑是否相交没有差别。
当我们仔细思考的时候,会发现其实相交的情况只有以下几种:
-
+
这个时候代码就呼之欲出了。
diff --git a/problems/337.house-robber-iii.md b/problems/337.house-robber-iii.md
new file mode 100644
index 000000000..1fc289ddf
--- /dev/null
+++ b/problems/337.house-robber-iii.md
@@ -0,0 +1,203 @@
+## 题目地址(337. 打家劫舍 III)
+
+https://leetcode-cn.com/problems/house-robber-iii/
+
+## 题目描述
+
+```
+在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
+
+计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
+
+示例 1:
+
+输入: [3,2,3,null,3,null,1]
+
+ 3
+ / \
+ 2 3
+ \ \
+ 3 1
+
+输出: 7
+解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.
+示例 2:
+
+输入: [3,4,5,1,3,null,1]
+
+ 3
+ / \
+ 4 5
+ / \ \
+ 1 3 1
+
+输出: 9
+解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9.
+
+
+```
+
+## 前置知识
+
+- 二叉树
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+和 198.house-robber 类似,这道题也是相同的思路。 只不过数据结构从数组换成了树。
+
+我们仍然是对每一项进行决策:**如果我抢的话,所得到的最大价值是多少。如果我不抢的话,所得到的最大价值是多少。**
+
+- 遍历二叉树,都每一个节点我们都需要判断抢还是不抢。
+
+ - 如果抢了的话, 那么我们不能继续抢其左右子节点
+ - 如果不抢的话,那么我们可以继续抢左右子节点,当然也可以不抢。抢不抢取决于哪个价值更大。
+
+- 抢不抢取决于哪个价值更大。
+
+这是一个明显的递归问题,我们使用递归来解决。由于没有重复子问题,因此没有必要 cache ,也没有必要动态规划。
+
+## 关键点
+
+- 对每一个节点都分析,是抢还是不抢
+
+## 代码
+
+语言支持:JS, C++,Java,Python
+
+JavaScript Code:
+
+```js
+function helper(root) {
+ if (root === null) return [0, 0];
+ // 0: rob 1: notRob
+ const l = helper(root.left);
+ const r = helper(root.right);
+
+ const robed = root.val + l[1] + r[1];
+ const notRobed = Math.max(l[0], l[1]) + Math.max(r[0], r[1]);
+
+ return [robed, notRobed];
+}
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var rob = function (root) {
+ const [robed, notRobed] = helper(root);
+ return Math.max(robed, notRobed);
+};
+```
+
+C++ Code:
+```c++
+/**
+ * Definition for a binary tree node.
+ * struct TreeNode {
+ * int val;
+ * TreeNode *left;
+ * TreeNode *right;
+ * TreeNode(int x) : val(x), left(NULL), right(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ int rob(TreeNode* root) {
+ pair res = dfs(root);
+ return max(res.first, res.second);
+ }
+
+ pair dfs(TreeNode* root)
+ {
+ pair res = {0, 0};
+ if(root == NULL)
+ {
+ return res;
+ }
+
+ pair left = dfs(root->left);
+ pair right = dfs(root->right);
+ // 0 代表不偷,1 代表偷
+ res.first = max(left.first, left.second) + max(right.first, right.second);
+ res.second = left.first + right.first + root->val;
+ return res;
+ }
+
+};
+```
+
+Java Code:
+```java
+/**
+ * Definition for a binary tree node.
+ * public class TreeNode {
+ * int val;
+ * TreeNode left;
+ * TreeNode right;
+ * TreeNode(int x) { val = x; }
+ * }
+ */
+class Solution {
+ public int rob(TreeNode root) {
+ int[] res = dfs(root);
+ return Math.max(res[0], res[1]);
+ }
+
+ public int[] dp(TreeNode root)
+ {
+ int[] res = new int[2];
+ if(root == null)
+ {
+ return res;
+ }
+
+ int[] left = dfs(root.left);
+ int[] right = dfs(root.right);
+ // 0 代表不偷,1 代表偷
+ res[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
+ res[1] = left[0] + right[0] + root.val;
+ return res;
+ }
+}
+```
+
+Python Code:
+
+```python
+
+class Solution:
+ def rob(self, root: TreeNode) -> int:
+ def dfs(node):
+ if not node:
+ return [0, 0]
+ [l_rob, l_not_rob] = dfs(node.left)
+ [r_rob, r_not_rob] = dfs(node.right)
+ return [node.val + l_not_rob + r_not_rob, max([l_rob, l_not_rob]) + max([r_rob, r_not_rob])]
+ return max(dfs(root))
+
+
+# @lc code=end
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$,其中 N 为树的节点个数。
+- 空间复杂度:$O(h)$,其中 h 为树的高度。
+
+## 相关题目
+
+- [198.house-robber](https://github.com/azl397985856/leetcode/blob/master/problems/198.house-robber.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 35K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/342.power-of-four.md b/problems/342.power-of-four.md
index b07b83f8d..36b05052b 100644
--- a/problems/342.power-of-four.md
+++ b/problems/342.power-of-four.md
@@ -19,6 +19,15 @@ Follow up: Could you solve it without loops/recursion?
```
+## 前置知识
+
+- 数论
+
+## 公司
+
+- 百度
+- twosigma
+
## 思路
符合直觉的做法是不停除以 4 直到不能整除,然后判断是否为 1 即可。 代码如下:
@@ -34,7 +43,7 @@ return num == 1;
我们先来看下,4 的幂次方用 2 进制表示是什么样的.
-
+
发现规律: 4 的幂次方的二进制表示 1 的位置都是在奇数位(且不在最低位),其他位置都为 0
@@ -53,13 +62,13 @@ return num == 1;
`求与`, 如果等于本身,那么毫无疑问,这个 1 不再偶数位置,一定在奇数位置,因为如果在偶数位置,`求与`的结果就是 0 了
题目要求 n 是 32 位有符号整形,那么我们的特殊数字就应该是`01010101010101010101010101010101`(不用数了,一共 32 位)。
-
+
如上图,64和这个特殊数字求与,得到的是本身。 8 是 2的次方,但是不是4的次方,我们求与结果就是0了。
为了体现自己的逼格,我们可以使用计算器,来找一个逼格比较高的数字,这里我选了十六进制,结果是`0x55555555`。
-
+
代码见下方代码区。
@@ -129,3 +138,15 @@ class Solution:
binary_num = bin(num)[2:]
return binary_num.strip('0') == '1' and len(binary_num) % 2 == 1
```
+
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/343.integer-break.md b/problems/343.integer-break.md
new file mode 100644
index 000000000..10a22bd24
--- /dev/null
+++ b/problems/343.integer-break.md
@@ -0,0 +1,203 @@
+## 题目地址(343. 整数拆分)
+
+https://leetcode-cn.com/problems/integer-break/
+
+## 题目描述
+
+给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
+
+示例 1:
+
+输入: 2
+输出: 1
+解释: 2 = 1 + 1, 1 × 1 = 1。
+示例 2:
+
+输入: 10
+输出: 36
+解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
+说明: 你可以假设 n 不小于 2 且不大于 58。
+
+## 前置知识
+
+- 递归
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+希望通过这篇题解让大家知道“题解区的水有多深”,让大家知道“什么才是好的题解”。
+
+我看了很多人的题解直接就是两句话,然后跟上代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+这种题解说实话,只针对那些”自己会, 然后去题解区看看有没有新的更好的解法的人“。但是大多数看题解的人是那种`自己没思路,不会做的人`。那么这种题解就没什么用了。
+
+我认为`好的题解应该是新手友好的,并且能够将解题人思路完整展现的题解`。比如看到这个题目,我首先想到了什么(对错没有关系),然后头脑中经过怎么样的筛选将算法筛选到具体某一个或某几个。我的最终算法是如何想到的,有没有一些先行知识。
+
+当然我也承认自己有很多题解也是直接给的答案,这对很多人来说用处不大,甚至有可能有反作用,给他们一种”我已经会了“的假象。实际上他们根本不懂解题人本身原本的想法, 也许是写题解的人觉得”这很自然“,也可能”只是为了秀技“。
+
+Ok,下面来讲下`我是如何解这道题的`。
+
+### 抽象
+
+首先看到这道题,自然而然地先对问题进行抽象,这种抽象能力是必须的。LeetCode 实际上有很多这种穿着华丽外表的题,当你把这个衣服扒开的时候,会发现都是差不多的,甚至两个是一样的,这样的例子实际上有很多。 就本题来说,就有一个剑指 Offer 的原题[《剪绳子》](https://leetcode-cn.com/problems/jian-sheng-zi-lcof/)和其本质一样,只是换了描述方式。类似的有力扣 137 和 645 等等,大家可以自己去归纳总结。
+
+> 137 和 645 我贴个之前写的题解 https://leetcode-cn.com/problems/single-number/solution/zhi-chu-xian-yi-ci-de-shu-xi-lie-wei-yun-suan-by-3/
+
+**培养自己抽象问题的能力,不管是在算法上还是工程上。** 务必记住这句话!
+
+数学是一门非常抽象的学科,同时也很方便我们抽象问题。为了显得我的题解比较高级,引入一些你们看不懂的数学符号也是很有必要的(开玩笑,没有什么高级数学符号啦)。
+
+> 实际上这道题可以用纯数学角度来解,但是我相信大多数人并不想看。即使你看了,大多人的感受也是“好 nb,然而并没有什么用”。
+
+这道题抽象一下就是:
+
+令:
+
+(图 1)
+求:
+
+(图 2)
+
+## 第一直觉
+
+经过上面的抽象,我的第一直觉这可能是一个数学题,我回想了下数学知识,然后用数学法 AC 了。 数学就是这么简单平凡且枯燥。
+
+然而如果没有数学的加持的情况下,我继续思考怎么做。我想是否可以枚举所有的情况(如图 1),然后对其求最大值(如图 2)。
+
+问题转化为如何枚举所有的情况。经过了几秒钟的思考,我发现这是一个很明显的递归问题。 具体思考过程如下:
+
+- 我们将原问题抽象为 f(n)
+- 那么 f(n) 等价于 max(1 \* fn(n - 1), 2 \* f(n - 2), ..., (n - 1) \* f(1))。
+
+用数学公式表示就是:
+
+
+(图 3)
+
+截止目前,是一点点数学 + 一点点递归,我们继续往下看。现在问题是不是就很简单啦?直接翻译图三为代码即可,我们来看下这个时候的代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ if n == 2: return 1
+ res = 0
+ for i in range(1, n):
+ res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+ return res
+```
+
+毫无疑问,超时了。原因很简单,就是算法中包含了太多的重复计算。如果经常看我的题解的话,这句话应该不陌生。我随便截一个我之前讲过这个知识点的图。
+
+
+(图 4)
+
+> 原文链接:https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md
+
+大家可以尝试自己画图理解一下。
+
+> 看到这里,有没有种殊途同归的感觉呢?
+
+## 考虑优化
+
+如上,我们可以考虑使用记忆化递归的方式来解决。只是用一个 hashtable 存储计算过的值即可。
+
+```python
+class Solution:
+ @lru_cache()
+ def integerBreak(self, n: int) -> int:
+ if n == 2: return 1
+ res = 0
+ for i in range(1, n):
+ res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+ return res
+```
+
+为了简单起见(偷懒起见),我直接用了 lru_cache 注解, 上面的代码是可以 AC 的。
+
+## 动态规划
+
+看到这里的同学应该发现了,这个套路是不是很熟悉?下一步就是将其改造成动态规划了。
+
+如图 4,我们的思考方式是从顶向下,这符合人们思考问题的方式。将其改造成如下图的自底向上方式就是动态规划。
+
+
+(图 5)
+
+现在再来看下文章开头的代码:
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+dp table 存储的是图 3 中 f(n)的值。一个自然的想法是令 dp[i] 等价于 f(i)。而由于上面分析了原问题等价于 f(n),那么很自然的原问题也等价于 dp[n]。
+
+而 dp[i]等价于 f(i),那么上面针对 f(i) 写的递归公式对 dp[i] 也是适用的,我们拿来试试。
+
+```
+// 关键语句
+res = max(res, max(i * self.integerBreak(n - i),i * (n - i)))
+```
+
+翻译过来就是:
+
+```
+dp[i] = max(dp[i], max(i * dp(n - i),i * (n - i)))
+```
+
+而这里的 n 是什么呢?我们说了`dp是自底向下的思考方式`,那么在达到 n 之前是看不到整体的`n` 的。因此这里的 n 实际上是 1,2,3,4... n。
+
+自然地,我们用一层循环来生成上面一系列的 n 值。接着我们还要生成一系列的 i 值,注意到 n - i 是要大于 0 的,因此 i 只需要循环到 n - 1 即可。
+
+思考到这里,我相信上面的代码真的是`不难得出`了。
+
+## 关键点
+
+- 数学抽象
+- 递归分析
+- 记忆化递归
+- 动态规划
+
+## 代码
+
+```python
+class Solution:
+ def integerBreak(self, n: int) -> int:
+ dp = [1] * (n + 1)
+ for i in range(3, n + 1):
+ for j in range(1, i):
+ dp[i] = max(j * dp[i - j], j * (i - j), dp[i])
+ return dp[n]
+```
+
+## 总结
+
+培养自己的解题思维很重要, 不要直接看别人的答案。而是要将别人的东西变成自己的, 而要做到这一点,你就要知道“他们是怎么想到的”,“想到这点是不是有什么前置知识”,“类似题目有哪些”。
+
+最优解通常不是一下子就想到了,这需要你在不那么优的解上摔了很多次跟头之后才能记住的。因此在你没有掌握之前,不要直接去看最优解。 在你掌握了之后,我不仅鼓励你去写最优解,还鼓励去一题多解,从多个解决思考问题。 到了那个时候, 萌新也会惊讶地呼喊“哇塞, 这题还可以这么解啊?”。 你也会低调地发出“害,解题就是这么简单平凡且枯燥。”的声音。
+
+## 扩展
+
+正如我开头所说,这种套路实在是太常见了。希望大家能够识别这种问题的本质,彻底掌握这种套路。另外我对这个套路也在我的新书《LeetCode 题解》中做了介绍,本书目前刚完成草稿的编写,如果你想要第一时间获取到我们的题解新书,那么请发送邮件到 `azl397985856@gmail.com`,标题著明“书籍《LeetCode 题解》预定”字样。。
diff --git a/problems/349.intersection-of-two-arrays.md b/problems/349.intersection-of-two-arrays.md
index 17b255e4f..c5e13eac1 100644
--- a/problems/349.intersection-of-two-arrays.md
+++ b/problems/349.intersection-of-two-arrays.md
@@ -22,6 +22,17 @@ The result can be in any order.
```
+## 前置知识
+
+- hashtable
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
先遍历第一个数组,将其存到hashtable中,
@@ -29,7 +40,7 @@ The result can be in any order.
## 关键点解析
-无
+- 空间换时间
## 代码
@@ -38,46 +49,6 @@ The result can be in any order.
Javascript Code:
```js
-/*
- * @lc app=leetcode id=349 lang=javascript
- *
- * [349] Intersection of Two Arrays
- *
- * https://leetcode.com/problems/intersection-of-two-arrays/description/
- *
- * algorithms
- * Easy (53.11%)
- * Total Accepted: 203.6K
- * Total Submissions: 380.9K
- * Testcase Example: '[1,2,2,1]\n[2,2]'
- *
- * Given two arrays, write a function to compute their intersection.
- *
- * Example 1:
- *
- *
- * Input: nums1 = [1,2,2,1], nums2 = [2,2]
- * Output: [2]
- *
- *
- *
- * Example 2:
- *
- *
- * Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
- * Output: [9,4]
- *
- *
- * Note:
- *
- *
- * Each element in the result must be unique.
- * The result can be in any order.
- *
- *
- *
- *
- */
/**
* @param {number[]} nums1
* @param {number[]} nums2
@@ -124,3 +95,13 @@ class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return set(nums1) & set(nums2)
```
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/365.water-and-jug-problem.md b/problems/365.water-and-jug-problem.md
index 6db36849e..aef2a16f9 100644
--- a/problems/365.water-and-jug-problem.md
+++ b/problems/365.water-and-jug-problem.md
@@ -28,6 +28,17 @@ Output: False
## BFS(超时)
+## 前置知识
+
+- BFS
+- 最大公约数
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
### 思路
两个水壶的水我们考虑成状态,然后我们不断进行倒的操作,改变状态。那么初始状态就是(0 0) 目标状态就是 (any, z)或者 (z, any),其中any 指的是任意升水。
@@ -205,4 +216,4 @@ def GCD(a, b):
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/371.sum-of-two-integers.md b/problems/371.sum-of-two-integers.md
index a52df6a53..9948ac8c4 100644
--- a/problems/371.sum-of-two-integers.md
+++ b/problems/371.sum-of-two-integers.md
@@ -18,17 +18,28 @@ Output: 1
```
+## 前置知识
+
+- [位运算](https://github.com/azl397985856/leetcode/blob/master/thinkings/bit.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
不能使用加减法来求加法。 我们只能朝着位元算的角度来思考了。
由于`异或`是`相同则位0,不同则位1`,因此我们可以把异或看成是一种不进位的加减法。
-
+
由于`与`是`全部位1则位1,否则位0`,因此我们可以求与之后左移一位来表示进位。
-
+
然后我们对上述两个元算结果递归求解即可。 递归的结束条件就是其中一个为0,我们直接返回另一个。
@@ -39,6 +50,8 @@ Output: 1
- 求与之后左移一位来可以表示进位
## 代码
+代码支持:JS,C++,Java,Python
+Javascript Code:
```js
/*
* @lc app=leetcode id=371 lang=javascript
@@ -58,4 +71,73 @@ var getSum = function(a, b) {
return getSum(a ^ b, (a & b) << 1);
};
```
+C++ Code:
+```c++
+class Solution {
+public:
+ int getSum(int a, int b) {
+ if(a==0) return b;
+ if(b==0) return a;
+
+ while(b!=0)
+ {
+ // 防止 AddressSanitizer 对有符号左移的溢出保护处理
+ auto carry = ((unsigned int ) (a & b))<<1;
+ // 计算无进位的结果
+ a = a^b;
+ //将存在进位的位置置1
+ b =carry;
+ }
+ return a;
+ }
+};
+```
+
+Java Code:
+```java
+class Solution {
+ public int getSum(int a, int b) {
+ if(a==0) return b;
+ if(b==0) return a;
+
+ while(b!=0)
+ {
+ int carry = a&b;
+ // 计算无进位的结果
+ a = a^b;
+ //将存在进位的位置置1
+ b =carry<<1;
+ }
+ return a;
+ }
+}
+```
+
+Python Code:
+```python
+# python整数类型为Unifying Long Integers, 即无限长整数类型.
+# 模拟 32bit 有符号整型加法
+class Solution:
+ def getSum(self, a: int, b: int) -> int:
+ a &= 0xFFFFFFFF
+ b &= 0xFFFFFFFF
+ while b:
+ carry = a & b
+ a ^= b
+ b = ((carry) << 1) & 0xFFFFFFFF
+ # print((a, b))
+ return a if a < 0x80000000 else ~(a^0xFFFFFFFF)
+```
+
+**复杂度分析**
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+> 由于题目数据规模不会变化,因此其实复杂度分析是没有意义的。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/378.kth-smallest-element-in-a-sorted-matrix.md b/problems/378.kth-smallest-element-in-a-sorted-matrix.md
index 8054da9c1..98c87feeb 100644
--- a/problems/378.kth-smallest-element-in-a-sorted-matrix.md
+++ b/problems/378.kth-smallest-element-in-a-sorted-matrix.md
@@ -23,6 +23,17 @@ Note:
You may assume k is always valid, 1 ≤ k ≤ n2.
```
+## 前置知识
+
+- 二分查找
+- 堆
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
显然用大顶堆可以解决,时间复杂度 Klogn n 为总的数字个数,
@@ -36,18 +47,18 @@ You may assume k is always valid, 1 ≤ k ≤ n2.
最普通的二分法是有序数组中查找指定值(或者说满足某个条件的值)。由于是有序的,我们可以根据索引关系来确定大小关系,
因此这种思路比较直接,但是对于这道题目索引大小和数字大小没有直接的关系,因此这种二分思想就行不通了。
-
+
(普通的基于索引判断的二分法)
- 我们能够找到矩阵中最大的元素(右下角)和最小的元素(左上角)。我们可以求出值的中间,而不是上面那种普通二分法的索引的中间。
-
+
- 找到中间值之后,我们可以拿这个值去计算有多少元素是小于等于它的。
具体方式就是比较行的最后一列,如果中间值比最后一列大,说明中间元素肯定大于这一行的所有元素。 否则我们从后往前遍历直到不大于。
-
+
- 上一步我们会计算一个count,我们拿这个count和k进行比较
@@ -61,7 +72,7 @@ You may assume k is always valid, 1 ≤ k ≤ n2.
整个计算过程是这样的:
-
+
这里有一个大家普遍都比较疑惑的点,也是我当初非常疑惑,困扰我很久的点, leetcode评论区也有很多人来问,就是“能够确保最终我们找到的元素一定在矩阵中么?”
diff --git a/problems/380.insert-delete-getrandom-o1.md b/problems/380.insert-delete-getrandom-o1.md
index 2688099c0..13f0bfccb 100644
--- a/problems/380.insert-delete-getrandom-o1.md
+++ b/problems/380.insert-delete-getrandom-o1.md
@@ -38,6 +38,18 @@ randomSet.getRandom();
```
+## 前置知识
+
+- 数组
+- 哈希表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个设计题。这道题的核心就是考察基本数据结构和算法的操作以及复杂度。
@@ -46,13 +58,15 @@ randomSet.getRandom();
- 数组支持随机访问,其按照索引查询的时间复杂度为$O(1)$,按值查询的时间复杂度为$O(N)$, 而插入和删除的时间复杂度为$O(N)$。
- 链表不支持随机访问,其查询的时间复杂度为$O(N)$,但是对于插入和删除的复杂度为$O(1)$(不考虑找到选要处理的节点花费的时间)。
-- 对于哈希表,正常情况下其查询复杂度平均为$O(1)$,插入和删除的复杂度为$O(1)$。
+- 对于哈希表,正常情况下其查询复杂度平均为$O(N)$,插入和删除的复杂度为$O(1)$。
-由于题目要求 getRandom 返回要随机,那么如果单纯使用链表以及哈希表肯定是不行的。而又由于对于插入和删除我们也需要平均复杂度为$O(1)$,因此单纯使用数组也是不行的。我们考虑多种使用数据结构来实现。
+由于题目要求 getRandom 返回要随机并且要在$O(1)$复杂度内,那么如果单纯使用链表或者哈希表肯定是不行的。
+
+而又由于对于插入和删除也需要复杂度为$O(1)$,因此单纯使用数组也是不行的,因此考虑多种使用数据结构来实现。
> 实际上 LeetCode 设计题,几乎没有单纯一个数据结构搞定的,基本都需要多种数据结构结合,这个时候需要你对各种数据结构以及其基本算法的复杂度有着清晰的认知。
-对于 getRandom 用数组很简单。对于判断是否已经有了存在的元素,我们使用哈希表也很容易做到。因此我们将数组随机访问,以及哈希表$O(1)$按值检索的特性结合起来,即同时使用这两种数据结构。
+对于 getRandom 用数组很简单。对于判断是否已经有了存在的元素,我们使用哈希表也很容易做到。因此我们可以将数组随机访问,以及哈希表$O(1)$按检索值的特性结合起来,即同时使用这两种数据结构。
对于删除和插入,我们需要一些技巧。
@@ -68,9 +82,25 @@ randomSet.getRandom();
对于 1,我们可以通过哈希表来实现。 key 是插入的数字,value 是数组对应的索引。删除的时候我们根据 key 反查出索引就可以快速找到。
+> 题目说明了不会存在重复元素,所以我们可以这么做。思考一下,如果没有这个限制会怎么样?
+
对于 2,我们可以通过和数组最后一项进行交换的方式来实现,这样就避免了数据移动。同时数组其他项的索引仍然保持不变,非常好!
-> 相应的我们插入的时候,需要维护哈希表
+> 相应地,我们插入的时候,需要维护哈希表
+
+图解:
+
+以依次【1,2,3,4】之后为初始状态,那么此时状态是这样的:
+
+
+
+而当要插入一个新的5的时候, 我们只需要分别向数组末尾和哈希表中插入这条记录即可。
+
+
+
+而删除的时候稍微有一点复杂:
+
+
## 关键点解析
@@ -139,3 +169,13 @@ class RandomizedSet:
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
```
+
+***复杂度分析***
+- 时间复杂度:$O(1)$
+- 空间复杂度:$O(1)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的LeetCode题解
+
+
diff --git a/problems/39.combination-sum.md b/problems/39.combination-sum.md
index be782f4ae..c88fb052e 100644
--- a/problems/39.combination-sum.md
+++ b/problems/39.combination-sum.md
@@ -31,6 +31,17 @@ A solution set is:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -42,7 +53,9 @@ A solution set is:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
diff --git a/problems/4.median-of-two-sorted-array.md b/problems/4.median-of-two-sorted-arrays.md
similarity index 53%
rename from problems/4.median-of-two-sorted-array.md
rename to problems/4.median-of-two-sorted-arrays.md
index 6f8a27eba..2629be528 100644
--- a/problems/4.median-of-two-sorted-array.md
+++ b/problems/4.median-of-two-sorted-arrays.md
@@ -1,86 +1,109 @@
-## 题目地址
+## 题目地址(4. 寻找两个正序数组的中位数)
+
https://leetcode.com/problems/median-of-two-sorted-arrays/
## 题目描述
+
```
-There are two sorted arrays nums1 and nums2 of size m and n respectively.
+给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。
+
+请你找出这两个正序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
-Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
+你可以假设 nums1 和 nums2 不会同时为空。
-You may assume nums1 and nums2 cannot be both empty.
+
-Example 1:
+示例 1:
nums1 = [1, 3]
nums2 = [2]
-The median is 2.0
-Example 2:
+则中位数是 2.0
+示例 2:
nums1 = [1, 2]
nums2 = [3, 4]
-The median is (2 + 3)/2 = 2.5
+则中位数是 (2 + 3)/2 = 2.5
+
```
+## 前置知识
+
+- 中位数
+- 分治法
+- 二分查找
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
-首先了解一下Median的概念,一个数组中median就是把数组分成左右等分的中位数。
+
+首先了解一下 Median 的概念,一个数组中 median 就是把数组分成左右等分的中位数。
如下图:
-
+
这道题,很容易想到暴力解法,时间复杂度和空间复杂度都是`O(m+n)`, 不符合题中给出`O(log(m+n))`时间复杂度的要求。
-我们可以从简单的解法入手,试了一下,暴力解法也是可以被Leetcode Accept的. 分析中会给出两种解法,暴力求解和二分解法。
+我们可以从简单的解法入手,试了一下,暴力解法也是可以被 Leetcode Accept 的. 分析中会给出两种解法,暴力求解和二分解法。
#### 解法一 - 暴力 (Brute Force)
-暴力解主要是要merge两个排序的数组`(A,B)`成一个排序的数组。
+
+暴力解主要是要 merge 两个排序的数组`(A,B)`成一个排序的数组。
用两个`pointer(i,j)`,`i` 从数组`A`起始位置开始,即`i=0`开始,`j` 从数组`B`起始位置, 即`j=0`开始.
一一比较 `A[i] 和 B[j]`,
-1. 如果`A[i] <= B[j]`, 则把`A[i]` 放入新的数组中,i往后移一位,即 `i+1`.
-2. 如果`A[i] > B[j]`, 则把`B[j]` 放入新的数组中,j往后移一位,即 `j+1`.
+
+1. 如果`A[i] <= B[j]`, 则把`A[i]` 放入新的数组中,i 往后移一位,即 `i+1`.
+2. 如果`A[i] > B[j]`, 则把`B[j]` 放入新的数组中,j 往后移一位,即 `j+1`.
3. 重复步骤#1 和 #2,直到`i`移到`A`最后,或者`j`移到`B`最后。
4. 如果`j`移动到`B`数组最后,那么直接把剩下的所有`A`依次放入新的数组中.
5. 如果`i`移动到`A`数组最后,那么直接把剩下的所有`B`依次放入新的数组中.
-Merge的过程如下图。
-
-
+Merge 的过程如下图。
+
-*时间复杂度: `O(m+n) - m is length of A, n is length of B`*
+_时间复杂度: `O(m+n) - m is length of A, n is length of B`_
-*空间复杂度: `O(m+n)`*
+_空间复杂度: `O(m+n)`_
#### 解法二 - 二分查找 (Binary Search)
+
由于题中给出的数组都是排好序的,在排好序的数组中查找很容易想到可以用二分查找(Binary Search), 这里对数组长度小的做二分,
-保证数组A 和 数组B 做partition 之后
+保证数组 A 和 数组 B 做 partition 之后
`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
-对数组A的做partition的位置是区间`[0,m]`
+对数组 A 的做 partition 的位置是区间`[0,m]`
如图:
-
+
下图给出几种不同情况的例子(注意但左边或者右边没有元素的时候,左边用`INF_MIN`,右边用`INF_MAX`表示左右的元素:
-
+
-下图给出具体做的partition 解题的例子步骤,
-
+下图给出具体做的 partition 解题的例子步骤,
+
-*时间复杂度: `O(log(min(m, n)) - m is length of A, n is length of B`*
+_时间复杂度: `O(log(min(m, n)) - m is length of A, n is length of B`_
-*空间复杂度: `O(1)` - 这里没有用额外的空间*
+_空间复杂度: `O(1)` - 这里没有用额外的空间_
## 关键点分析
-1. 暴力求解,在线性时间内merge两个排好序的数组成一个数组。
+
+1. 暴力求解,在线性时间内 merge 两个排好序的数组成一个数组。
2. 二分查找,关键点在于
- - 要partition两个排好序的数组成左右两等份,partition需要满足`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
- - 并且partition后 A左边最大(`maxLeftA`), A右边最小(`minRightA`), B左边最大(`maxLeftB`), B右边最小(`minRightB`) 满足
-`(maxLeftA <= minRightB && maxLeftB <= minRightA)`
+- 要 partition 两个排好序的数组成左右两等份,partition 需要满足`len(Aleft)+len(Bleft)=(m+n+1)/2 - m是数组A的长度, n是数组B的长度`
+
+- 并且 partition 后 A 左边最大(`maxLeftA`), A 右边最小(`minRightA`), B 左边最大(`maxLeftB`), B 右边最小(`minRightB`) 满足
+ `(maxLeftA <= minRightB && maxLeftB <= minRightA)`
+
+有了这两个条件,那么 median 就在这四个数中,根据奇数或者是偶数,
-有了这两个条件,那么median就在这四个数中,根据奇数或者是偶数,
```
奇数:
median = max(maxLeftA, maxLeftB)
@@ -88,9 +111,15 @@ median = max(maxLeftA, maxLeftB)
median = (max(maxLeftA, maxLeftB) + min(minRightA, minRightB)) / 2
```
-## 代码(Java code)
-*解法一 - 暴力解法(Brute force)*
-```java
+## 代码
+
+代码支持: Java,JS:
+
+Java Code:
+
+_解法一 - 暴力解法(Brute force)_
+
+```java []
class MedianTwoSortedArrayBruteForce {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int[] newArr = mergeTwoSortedArray(nums1, nums2);
@@ -127,8 +156,85 @@ class MedianTwoSortedArrayBruteForce {
}
}
```
-*解法二 - 二分查找(Binary Search)*
-```java
+
+```javascript []
+/**
+ * @param {number[]} nums1
+ * @param {number[]} nums2
+ * @return {number}
+ */
+var findMedianSortedArrays = function (nums1, nums2) {
+ // 归并排序
+ const merged = [];
+ let i = 0;
+ let j = 0;
+ while (i < nums1.length && j < nums2.length) {
+ if (nums1[i] < nums2[j]) {
+ merged.push(nums1[i++]);
+ } else {
+ merged.push(nums2[j++]);
+ }
+ }
+ while (i < nums1.length) {
+ merged.push(nums1[i++]);
+ }
+ while (j < nums2.length) {
+ merged.push(nums2[j++]);
+ }
+
+ const { length } = merged;
+ return length % 2 === 1
+ ? merged[Math.floor(length / 2)]
+ : (merged[length / 2] + merged[length / 2 - 1]) / 2;
+};
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(max(m, n))$
+- 空间复杂度:$O(m + n)$
+
+_解法二 - 二分查找(Binary Search)_
+
+```js []
+/**
+ * 二分解法
+ * @param {number[]} nums1
+ * @param {number[]} nums2
+ * @return {number}
+ */
+var findMedianSortedArrays = function (nums1, nums2) {
+ // make sure to do binary search for shorten array
+ if (nums1.length > nums2.length) {
+ [nums1, nums2] = [nums2, nums1];
+ }
+ const m = nums1.length;
+ const n = nums2.length;
+ let low = 0;
+ let high = m;
+ while (low <= high) {
+ const i = low + Math.floor((high - low) / 2);
+ const j = Math.floor((m + n + 1) / 2) - i;
+
+ const maxLeftA = i === 0 ? -Infinity : nums1[i - 1];
+ const minRightA = i === m ? Infinity : nums1[i];
+ const maxLeftB = j === 0 ? -Infinity : nums2[j - 1];
+ const minRightB = j === n ? Infinity : nums2[j];
+
+ if (maxLeftA <= minRightB && minRightA >= maxLeftB) {
+ return (m + n) % 2 === 1
+ ? Math.max(maxLeftA, maxLeftB)
+ : (Math.max(maxLeftA, maxLeftB) + Math.min(minRightA, minRightB)) / 2;
+ } else if (maxLeftA > minRightB) {
+ high = i - 1;
+ } else {
+ low = low + 1;
+ }
+ }
+};
+```
+
+```java []
class MedianSortedTwoArrayBinarySearch {
public static double findMedianSortedArraysBinarySearch(int[] nums1, int[] nums2) {
// do binary search for shorter length array, make sure time complexity log(min(m,n)).
@@ -172,75 +278,13 @@ class MedianSortedTwoArrayBinarySearch {
}
```
-## 代码 (javascript code)
-*解法一 - 暴力解法(Brute force)*
-```js
-/**
- * @param {number[]} nums1
- * @param {number[]} nums2
- * @return {number}
- */
-var findMedianSortedArrays = function(nums1, nums2) {
- // 归并排序
- const merged = []
- let i = 0
- let j = 0
- while(i < nums1.length && j < nums2.length) {
- if (nums1[i] < nums2[j]) {
- merged.push(nums1[i++])
- } else {
- merged.push(nums2[j++])
- }
- }
- while(i < nums1.length) {
- merged.push(nums1[i++])
- }
- while(j < nums2.length) {
- merged.push(nums2[j++])
- }
+**复杂度分析**
- const { length } = merged
- return length % 2 === 1
- ? merged[Math.floor(length / 2)]
- : (merged[length / 2] + merged[length / 2 - 1]) / 2
-};
-```
+- 时间复杂度:$O(log(min(m, n)))$
+- 空间复杂度:$O(log(min(m, n)))$
-*解法二 - 二分查找(Binary Search)*
-```js
-/**
- * 二分解法
- * @param {number[]} nums1
- * @param {number[]} nums2
- * @return {number}
- */
-var findMedianSortedArrays = function(nums1, nums2) {
- // make sure to do binary search for shorten array
- if (nums1.length > nums2.length) {
- [nums1, nums2] = [nums2, nums1]
- }
- const m = nums1.length
- const n = nums2.length
- let low = 0
- let high = m
- while(low <= high) {
- const i = low + Math.floor((high - low) / 2)
- const j = Math.floor((m + n + 1) / 2) - i
-
- const maxLeftA = i === 0 ? -Infinity : nums1[i-1]
- const minRightA = i === m ? Infinity : nums1[i]
- const maxLeftB = j === 0 ? -Infinity : nums2[j-1]
- const minRightB = j === n ? Infinity : nums2[j]
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
- if (maxLeftA <= minRightB && minRightA >= maxLeftB) {
- return (m + n) % 2 === 1
- ? Math.max(maxLeftA, maxLeftB)
- : (Math.max(maxLeftA, maxLeftB) + Math.min(minRightA, minRightB)) / 2
- } else if (maxLeftA > minRightB) {
- high = i - 1
- } else {
- low = low + 1
- }
- }
-};
-```
\ No newline at end of file
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
diff --git a/problems/40.combination-sum-ii.md b/problems/40.combination-sum-ii.md
index 9a2d3e16f..231f21874 100644
--- a/problems/40.combination-sum-ii.md
+++ b/problems/40.combination-sum-ii.md
@@ -32,6 +32,17 @@ A solution set is:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
@@ -43,7 +54,9 @@ A solution set is:
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -58,57 +71,6 @@ A solution set is:
* 语言支持: Javascript,Python3
```js
-/*
- * @lc app=leetcode id=40 lang=javascript
- *
- * [40] Combination Sum II
- *
- * https://leetcode.com/problems/combination-sum-ii/description/
- *
- * algorithms
- * Medium (40.31%)
- * Total Accepted: 212.8K
- * Total Submissions: 519K
- * Testcase Example: '[10,1,2,7,6,1,5]\n8'
- *
- * Given a collection of candidate numbers (candidates) and a target number
- * (target), find all unique combinations in candidates where the candidate
- * numbers sums to target.
- *
- * Each number in candidates may only be used once in the combination.
- *
- * Note:
- *
- *
- * All numbers (including target) will be positive integers.
- * The solution set must not contain duplicate combinations.
- *
- *
- * Example 1:
- *
- *
- * Input: candidates = [10,1,2,7,6,1,5], target = 8,
- * A solution set is:
- * [
- * [1, 7],
- * [1, 2, 5],
- * [2, 6],
- * [1, 1, 6]
- * ]
- *
- *
- * Example 2:
- *
- *
- * Input: candidates = [2,5,2,1,2], target = 5,
- * A solution set is:
- * [
- * [1,2,2],
- * [5]
- * ]
- *
- *
- */
function backtrack(list, tempList, nums, remain, start) {
if (remain < 0) return;
else if (remain === 0) return list.push([...tempList]);
diff --git a/problems/416.partition-equal-subset-sum.md b/problems/416.partition-equal-subset-sum.md
index 2e7082574..24cf41c91 100644
--- a/problems/416.partition-equal-subset-sum.md
+++ b/problems/416.partition-equal-subset-sum.md
@@ -1,137 +1,298 @@
-## 题目地址
+### 题目地址
-https://leetcode.com/problems/partition-equal-subset-sum/description/
+#### [416. 分割等和子集](https://leetcode-cn.com/problems/partition-equal-subset-sum/)
-## 题目描述
+### 题目描述
+
+> 给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
+>
+> 注意:
+>
+> 每个数组中的元素不会超过 100
+> 数组的大小不会超过 200
+>
+> 示例 1:
+>
+> 输入: [1, 5, 11, 5]
+>
+> 输出: true
+>
+> 解释: 数组可以分割成 [1, 5, 5] 和 [11].
+>
+> 示例 2:
+>
+> 输入: [1, 2, 3, 5]
+>
+> 输出: false
+>
+> 解释: 数组不能分割成两个元素和相等的子集.
+
+## 前置知识
+
+- DFS
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+抽象能力不管是在工程还是算法中都占据着绝对重要的位置。比如上题我们可以抽象为:
+
+**给定一个非空数组,和是 sum,能否找到这样的一个子序列,使其和为 2/sum**
+
+我们做过二数和,三数和, 四数和,看到这种类似的题会不会舒适一点,思路更开阔一点。
+
+老司机们看到转化后的题,会立马想到背包问题,这里会提供**深度优先搜索**和**背包**两种解法。
+
+### 深度优先遍历
+
+我们再来看下题目描述,sum 有两种情况,
+
+1. 如果 sum % 2 === 1, 则肯定无解,因为 sum/2 为小数,而数组全由整数构成,子数组和不可能为小数。
+2. 如果 sum % 2 === 0, 需要找到和为 2/sum 的子序列
+ 针对 2,我们要在 nums 里找到满足条件的子序列 subNums。 这个过程可以类比为在一个大篮子里面有 N 个球,每个球代表不同的数字,我们用一小篮子去抓取球,使得拿到的球数字和为 2/sum。那么很自然的一个想法就是,对大篮子里面的每一个球,我们考虑取它或者不取它,如果我们足够耐心,最后肯定能穷举所有的情况,判断是否有解。上述思维表述为伪代码如下:
```
-Given a non-empty array containing only positive integers, find if the array can be partitioned into two subsets such that the sum of elements in both subsets is equal.
+令 target = sum / 2, nums 为输入数组, cur 为当前当前要选择的数字的索引
+nums 为输入数组,target为当前求和目标,cur为当前判断的数
+function dfs(nums, target, cur)
+ 如果target < 0 或者 cur > nums.length
+ return false
+ 否则
+ 如果 target = 0, 说明找到答案了,返回true
+ 否则
+ 取当前数或者不取,进入递归 dfs(nums, target - nums[cur], cur + 1) || dfs(nums, target, cur + 1)
+```
-Note:
+因为对每个数都考虑取不取,所以这里时间复杂度是 O(2 ^ n), 其中 n 是 nums 数组长度,
-Each of the array element will not exceed 100.
-The array size will not exceed 200.
-
+#### javascript 实现
-Example 1:
+```javascript
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ return dfs(nums, sum, 0);
+};
-Input: [1, 5, 11, 5]
+function dfs(nums, target, cur) {
+ if (target < 0 || cur > nums.length) {
+ return false;
+ }
+ return (
+ target === 0 ||
+ dfs(nums, target - nums[cur], cur + 1) ||
+ dfs(nums, target, cur + 1)
+ );
+}
+```
-Output: true
+不出所料,这里是超时了,我们看看有没优化空间
-Explanation: The array can be partitioned as [1, 5, 5] and [11].
-
+1. 如果 nums 中最大值 > 2/sum, 那么肯定无解
+2. 在搜索过程中,我们对每个数都是取或者不取,并且数组中所有项都为正数。我们设取的数和为 `pickedSum`,不难得 pickedSum <= 2/sum, 同时要求丢弃的数为 `discardSum`,不难得 pickedSum <= 2 / sum。
-Example 2:
+我们同时引入这两个约束条件加强剪枝:
-Input: [1, 2, 3, 5]
+优化后的代码如下
-Output: false
+```javascript
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ nums = nums.sort((a, b) => b - a);
+ if (sum < nums[0]) {
+ return false;
+ }
+ return dfs(nums, sum, sum, 0);
+};
-Explanation: The array cannot be partitioned into equal sum subsets.
+function dfs(nums, pickRemain, discardRemain, cur) {
+ if (pickRemain === 0 || discardRemain === 0) {
+ return true;
+ }
+ if (pickRemain < 0 || discardRemain < 0 || cur > nums.length) {
+ return false;
+ }
+ return (
+ dfs(nums, pickRemain - nums[cur], discardRemain, cur + 1) ||
+ dfs(nums, pickRemain, discardRemain - nums[cur], cur + 1)
+ );
+}
```
-## 思路
+leetcode 是 AC 了,但是时间复杂度 O(2 ^ n), 算法时间复杂度很差,我们看看有没更好的。
+
+### DP 解法
+
+在用 DFS 是时候,我们是不关心取数的规律的,只要保证接下来要取的数在之前没有被取过即可。那如果我们有规律去安排取数策略的时候会怎么样呢,比如第一次取数安排在第一位,第二位取数安排在第二位,在判断第 i 位是取数的时候,我们是已经知道前 i-1 个数每次是否取的所有子序列组合,记集合 S 为这个子序列的和。再看第 i 位取数的情况, 有两种情况取或者不取
+
+1. 取的情况,如果 target-nums[i]在集合 S 内,则返回 true,说明前 i 个数能找到和为 target 的序列
+2. 不取的情况,如果 target 在集合 S 内,则返回 true,否则返回 false
-题目要求给定一个数组, 问是否能划分为和相等的两个数组。
+也就是说,前 i 个数能否构成和为 target 的子序列取决为前 i-1 数的情况。
-这是一个典型的背包问题,我们可以遍历数组,对于每一个,我们都分两种情况考虑,拿或者不拿。
+记 F[i, target] 为 nums 数组内前 i 个数能否构成和为 target 的子序列的可能,则状态转移方程为
-背包问题处理这种离散的可以划分子问题解决的问题很有用。
+`F[i, target] = F[i - 1, target] || F[i - 1, target - nums[i]]`
-
+状态转移方程出来了,代码就很好写了,DFS + DP 都可以解,有不清晰的可以参考下 [递归和动态规划](../thinkings/dynamic-programming.md),
+这里只提供 DP 解法
-如果能够识别出这是一道背包问题,那么就相对容易了。
+#### 伪代码表示
-
-## 关键点解析
+```
+n = nums.length
+target 为 nums 各数之和
+如果target不能被2整除,
+ 返回false
+
+令dp为n * target 的二维矩阵, 并初始为false
+遍历0:n, dp[i][0] = true 表示前i个数组成和为0的可能
+
+遍历 0 到 n
+ 遍历 0 到 target
+ if 当前值j大于nums[i]
+ dp[i + 1][j] = dp[i][j-nums[i]] || dp[i][j]
+ else
+ dp[i+1][j] = dp[i][j]
+```
-- 背包问题
+算法时间复杂度 O(n\*m), 空间复杂度 O(n\*m), m 为 sum(nums) / 2
-## 代码
+#### javascript 实现
```js
-/*
- * @lc app=leetcode id=416 lang=javascript
- *
- * [416] Partition Equal Subset Sum
- *
- * https://leetcode.com/problems/partition-equal-subset-sum/description/
- *
- * algorithms
- * Medium (39.97%)
- * Total Accepted: 79.7K
- * Total Submissions: 198.5K
- * Testcase Example: '[1,5,11,5]'
- *
- * Given a non-empty array containing only positive integers, find if the array
- * can be partitioned into two subsets such that the sum of elements in both
- * subsets is equal.
- *
- * Note:
- *
- *
- * Each of the array element will not exceed 100.
- * The array size will not exceed 200.
- *
- *
- *
- *
- * Example 1:
- *
- *
- * Input: [1, 5, 11, 5]
- *
- * Output: true
- *
- * Explanation: The array can be partitioned as [1, 5, 5] and [11].
- *
- *
- *
- *
- * Example 2:
- *
- *
- * Input: [1, 2, 3, 5]
- *
- * Output: false
- *
- * Explanation: The array cannot be partitioned into equal sum subsets.
- *
- *
- *
- *
- */
-/**
- * @param {number[]} nums
- * @return {boolean}
- */
-var canPartition = function(nums) {
- let sum = 0;
- for(let num of nums) {
- sum += num;
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ } else {
+ sum = sum / 2;
+ }
+
+ const dp = Array.from(nums).map(() =>
+ Array.from({ length: sum + 1 }).fill(false)
+ );
+
+ for (let i = 0; i < nums.length; i++) {
+ dp[i][0] = true;
+ }
+
+ for (let i = 0; i < dp.length - 1; i++) {
+ for (let j = 0; j < dp[0].length; j++) {
+ dp[i + 1][j] =
+ j - nums[i] >= 0 ? dp[i][j] || dp[i][j - nums[i]] : dp[i][j];
}
+ }
+
+ return dp[nums.length - 1][sum];
+};
+```
+
+再看看有没有优化空间,看状态转移方程
+`F[i, target] = F[i - 1, target] || F[i - 1, target - nums[i]]`
+第 n 行的状态只依赖于第 n-1 行的状态,也就是说我们可以把二维空间压缩成一维
- if (sum & 1 === 1) return false;
+伪代码
- const half = sum >> 1;
+```
+遍历 0 到 n
+ 遍历 j 从 target 到 0
+ if 当前值j大于nums[i]
+ dp[j] = dp[j-nums[i]] || dp[j]
+ else
+ dp[j] = dp[j]
+```
- let dp = Array(half);
- dp[0] = [true, ...Array(nums.length).fill(false)];
+时间复杂度 O(n\*m), 空间复杂度 O(n)
+javascript 实现
- for(let i = 1; i < nums.length + 1; i++) {
- dp[i] = [true, ...Array(half).fill(false)];
- for(let j = 1; j < half + 1; j++) {
- if (j >= nums[i - 1]) {
- dp[i][j] = dp[i - 1][j] || dp[i - 1][j - nums[i - 1]];
- }
- }
+```js
+var canPartition = function (nums) {
+ let sum = nums.reduce((acc, num) => acc + num, 0);
+ if (sum % 2) {
+ return false;
+ }
+ sum = sum / 2;
+ const dp = Array.from({ length: sum + 1 }).fill(false);
+ dp[0] = true;
+
+ for (let i = 0; i < nums.length; i++) {
+ for (let j = sum; j > 0; j--) {
+ dp[j] = dp[j] || (j - nums[i] >= 0 && dp[j - nums[i]]);
}
+ }
- return dp[nums.length][half]
+ return dp[sum];
};
+```
+
+其实这道题和 [leetcode 518](https://leetcode-cn.com/problems/coin-change-2/) 是换皮题,它们都可以归属于背包问题
+
+## 背包问题
+
+### 背包问题描述
+
+有 N 件物品和一个容量为 V 的背包。放入第 i 件物品耗费的费用是 Ci,得到的
+价值是 Wi。求解将哪些物品装入背包可使价值总和最大。
+
+背包问题的特性是,每种物品,我们都可以选择放或者不放。令 F[i, v]表示前 i 件物品放入到容量为 v 的背包的状态。
+
+针对上述背包,F[i, v]表示能得到最大价值,那么状态转移方程为
+
+```
+F[i, v] = max{F[i-1, v], F[i-1, v-Ci] + Wi}
+```
+
+针对 416. 分割等和子集这题,F[i, v]的状态含义就表示前 i 个数能组成和为 v 的可能,状态转移方程为
+
+```
+F[i, v] = F[i-1, v] || F[i-1, v-Ci]
+```
+
+再回过头来看下[leetcode 518](https://leetcode-cn.com/problems/coin-change-2/), 原题如下
+
+> 给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
+带入背包思想,F[i,v] 表示用前 i 种硬币能兑换金额数为 v 的组合数,状态转移方程为
+`F[i, v] = F[i-1, v] + F[i-1, v-Ci]`
+
+#### javascript 实现
+
+```javascript
+/**
+ * @param {number} amount
+ * @param {number[]} coins
+ * @return {number}
+ */
+var change = function (amount, coins) {
+ const dp = Array.from({ length: amount + 1 }).fill(0);
+ dp[0] = 1;
+ for (let i = 0; i < coins.length; i++) {
+ for (let j = 1; j <= amount; j++) {
+ dp[j] = dp[j] + (j - coins[i] >= 0 ? dp[j - coins[i]] : 0);
+ }
+ }
+ return dp[amount];
+};
```
+### 参考
+
+[背包九讲](https://raw.githubusercontent.com/tianyicui/pack/master/V2.pdf)
diff --git a/problems/42.trapping-rain-water.en.md b/problems/42.trapping-rain-water.en.md
new file mode 100755
index 000000000..38f346912
--- /dev/null
+++ b/problems/42.trapping-rain-water.en.md
@@ -0,0 +1,229 @@
+## Trapping Rain Water
+
+https://leetcode.com/problems/trapping-rain-water/description/
+
+## Problem Description
+
+> Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
+
+
+
+> The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. Thanks Marcos for contributing this image!
+
+```
+Input: [0,1,0,2,1,0,1,3,2,1,2,1]
+Output: 6
+```
+
+## Prerequisites
+
+- Space-time tradeoff
+- Two Pointers
+- Monotonic Stack
+
+## Two Arrays
+
+### Solution
+
+The difficulty of this problem is `hard`.
+We'd like to compute how much water a given elevation map can trap.
+
+A brute force solution would be adding up the maximum level of water that each element of the map can trap.
+
+Pseudo Code:
+
+```js
+for (let i = 0; i < height.length; i++) {
+ area += h[i] - height[i]; // the maximum level of water that the element i can trap
+}
+```
+
+Now the problem becomes how to calculating h[i], which is in fact the minimum of maximum height of bars on both sides minus height[i]:
+`h[i] = Math.min(leftMax, rightMax)` where `leftMax = Math.max(leftMax[i-1], height[i])` and `rightMax = Math.max(rightMax[i+1], height[i])`.
+
+For the given example, h would be [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1].
+
+The key is to calculate `leftMax` and `rightMax`.
+
+### Key Points
+
+- Figure out the modeling of `h[i] = Math.min(leftMax, rightMax)`
+
+### Code (JavaScript/Python3/C++)
+
+JavaScript Code:
+
+```js
+/*
+ * @lc app=leetcode id=42 lang=javascript
+ *
+ * [42] Trapping Rain Water
+ *
+ */
+/**
+ * @param {number[]} height
+ * @return {number}
+ */
+var trap = function (height) {
+ let max = 0;
+ let volume = 0;
+ const leftMax = [];
+ const rightMax = [];
+
+ for (let i = 0; i < height.length; i++) {
+ leftMax[i] = max = Math.max(height[i], max);
+ }
+
+ max = 0;
+
+ for (let i = height.length - 1; i >= 0; i--) {
+ rightMax[i] = max = Math.max(height[i], max);
+ }
+
+ for (let i = 0; i < height.length; i++) {
+ volume = volume + Math.min(leftMax[i], rightMax[i]) - height[i];
+ }
+
+ return volume;
+};
+```
+
+Python Code:
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l, r = [0] * (n + 1), [0] * (n + 1)
+ ans = 0
+ for i in range(1, len(heights) + 1):
+ l[i] = max(l[i - 1], heights[i - 1])
+ for i in range(len(heights) - 1, 0, -1):
+ r[i] = max(r[i + 1], heights[i])
+ for i in range(len(heights)):
+ ans += max(0, min(l[i + 1], r[i]) - heights[i])
+ return ans
+```
+
+C++ code:
+
+```c++
+int trap(vector& heights)
+{
+ if(heights == null)
+ return 0;
+ int ans = 0;
+ int size = heights.size();
+ vector left_max(size), right_max(size);
+ left_max[0] = heights[0];
+ for (int i = 1; i < size; i++) {
+ left_max[i] = max(heights[i], left_max[i - 1]);
+ }
+ right_max[size - 1] = heights[size - 1];
+ for (int i = size - 2; i >= 0; i--) {
+ right_max[i] = max(heights[i], right_max[i + 1]);
+ }
+ for (int i = 1; i < size - 1; i++) {
+ ans += min(left_max[i], right_max[i]) - heights[i];
+ }
+ return ans;
+}
+
+```
+
+**Complexity Analysis**
+
+- Time Complexity: $O(N)$
+- Space Complexity: $O(N)$
+
+## Two Pointers
+
+### Solution
+
+The above code is easy to understand, but it needs the extra space of N. We can tell from it that we in fact only cares about the minimum of (left[i], right[i]). Specifically:
+
+- If l[i + 1] < r[i], the maximum in the left side of i will determine the height of trapping water.
+- If l[i + 1] >= r[i], the maximum in the right side of i will determine the height of trapping water.
+
+Thus, we don't need to keep two complete arrays. We can rather keep only a left max and a right max, using constant variable. This problem is a typical two pointers problem.
+
+Algorithm:
+
+1. Initialize two pointers `left` and `right`, pointing to the begin and the end of our height array respectively.
+2. Initialize the left maximum height and the right maximum height to be 0.
+3. Compare height[left] and height[right]
+
+ - If height[left] < height[right]
+ - 3.1.1 If height[left] >= left_max, the current trapping volume is (left_max - height[left])
+ - 3.1.2 Otherwise, no water is trapped and the volume is 0
+ - 3.2 Iterate the left pointer to the right
+ - 3.3 If height[left] >= height[right]
+ - 3.3.1 If height[right] >= right_max, the current trapping volume is (right_max - height[right])
+ - 3.3.2 Otherwise, no water is trapped and the volume is 0
+ - 3.4 Iterate the right pointer to the left
+
+### Code (Python3/C++)
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l_max = r_max = 0
+ l, r = 0, n - 1
+ ans = 0
+ while l < r:
+ if heights[l] < heights[r]:
+ if heights[l] < l_max:
+ ans += l_max - heights[l]
+ else:
+ l_max = heights[l]
+ l += 1
+ else:
+ if heights[r] < r_max:
+ ans += r_max - heights[r]
+ else:
+ r_max = heights[r]
+ r -= 1
+ return ans
+```
+
+```c++
+
+class Solution {
+public:
+ int trap(vector& heights)
+{
+ int left = 0, right = heights.size() - 1;
+ int ans = 0;
+ int left_max = 0, right_max = 0;
+ while (left < right) {
+ if (heights[left] < heights[right]) {
+ heights[left] >= left_max ? (left_max = heights[left]) : ans += (left_max - heights[left]);
+ ++left;
+ }
+ else {
+ heights[right] >= right_max ? (right_max = heights[right]) : ans += (right_max - heights[right]);
+ --right;
+ }
+ }
+ return ans;
+}
+
+};
+```
+
+**Complexity Analysis**
+
+- Time Complexity: $O(N)$
+- Space Complexity: $O(1)$
+
+## Similar Problems
+
+- [84.largest-rectangle-in-histogram](https://github.com/azl397985856/leetcode/blob/master/problems/84.largest-rectangle-in-histogram.md)
+
+For more solutions, visit my [LeetCode Solution Repo](https://github.com/azl397985856/leetcode) (which has 30K stars).
+
+Follow my WeChat official account 力扣加加, which has lots of graphic solutions and teaches you how to recognize problem patterns to solve problems with efficiency.
+
+
+
diff --git a/problems/42.trapping-rain-water.md b/problems/42.trapping-rain-water.md
old mode 100644
new mode 100755
index baaedce0e..627b71248
--- a/problems/42.trapping-rain-water.md
+++ b/problems/42.trapping-rain-water.md
@@ -1,9 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/trapping-rain-water/description/
## 题目描述
-
```
Given n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.
@@ -13,7 +13,7 @@ The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In th
```
-
+
```
Example:
@@ -23,41 +23,55 @@ Output: 6
```
-## 思路
+## 前置知识
+
+- 空间换时间
+- 双指针
+- 单调栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 双数组
+
+### 思路
这是一道雨水收集的问题, 难度为`hard`. 如图所示,让我们求下过雨之后最多可以积攒多少的水。
-如果采用暴力求解的话,思路应该是height数组依次求和,然后相加。
+如果采用暴力求解的话,思路应该是 height 数组依次求和,然后相加。
伪代码:
```js
-
-for(let i = 0; i < height.length; i++) {
- area += (h[i] - height[i]) * 1; // h为下雨之后的水位
+for (let i = 0; i < height.length; i++) {
+ area += (h[i] - height[i]) * 1; // h为下雨之后的水位
}
-
```
-问题转化为求h,那么h[i]又等于`左右两侧柱子的最大值中的较小值`,即
+
+问题转化为求 h,那么 h[i]又等于`左右两侧柱子的最大值中的较小值`,即
`h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`
-如上图那么h为 [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1]
+如上图那么 h 为 [0, 1, 1, 2, 2, 2 ,2, 3, 2, 2, 2, 1]
问题的关键在于求解`左边柱子最大值`和`右边柱子最大值`,
我们其实可以用两个数组来表示`leftMax`, `rightMax`,
-以leftMax为例,leftMax[i]代表i的左侧柱子的最大值,因此我们维护两个数组即可。
-## 关键点解析
+以 leftMax 为例,leftMax[i]代表 i 的左侧柱子的最大值,因此我们维护两个数组即可。
-- 建模 `h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`(h为下雨之后的水位)
+### 关键点解析
-## 代码
+- 建模 `h[i] = Math.min(左边柱子最大值, 右边柱子最大值)`(h 为下雨之后的水位)
-代码支持 JavaScript,Python3:
+### 代码
+
+代码支持 JavaScript,Python3,C++:
JavaScript Code:
```js
-
/*
* @lc app=leetcode id=42 lang=javascript
*
@@ -68,29 +82,28 @@ JavaScript Code:
* @param {number[]} height
* @return {number}
*/
-var trap = function(height) {
- let max = 0;
- let volumn = 0;
- const leftMax = [];
- const rightMax = [];
-
- for(let i = 0; i < height.length; i++) {
- leftMax[i] = max = Math.max(height[i], max);
- }
+var trap = function (height) {
+ let max = 0;
+ let volume = 0;
+ const leftMax = [];
+ const rightMax = [];
- max = 0;
+ for (let i = 0; i < height.length; i++) {
+ leftMax[i] = max = Math.max(height[i], max);
+ }
- for(let i = height.length - 1; i >= 0; i--) {
- rightMax[i] = max = Math.max(height[i], max);
- }
+ max = 0;
- for(let i = 0; i < height.length; i++) {
- volumn = volumn + Math.min(leftMax[i], rightMax[i]) - height[i]
- }
+ for (let i = height.length - 1; i >= 0; i--) {
+ rightMax[i] = max = Math.max(height[i], max);
+ }
- return volumn;
-};
+ for (let i = 0; i < height.length; i++) {
+ volume = volume + Math.min(leftMax[i], rightMax[i]) - height[i];
+ }
+ return volume;
+};
```
Python Code:
@@ -107,5 +120,130 @@ class Solution:
r[i] = max(r[i + 1], heights[i])
for i in range(len(heights)):
ans += max(0, min(l[i + 1], r[i]) - heights[i])
- return ans
+ return ans
+```
+
+C++ Code:
+
+```c++
+int trap(vector& heights)
+{
+ if(heights == null)
+ return 0;
+ int ans = 0;
+ int size = heights.size();
+ vector left_max(size), right_max(size);
+ left_max[0] = heights[0];
+ for (int i = 1; i < size; i++) {
+ left_max[i] = max(heights[i], left_max[i - 1]);
+ }
+ right_max[size - 1] = heights[size - 1];
+ for (int i = size - 2; i >= 0; i--) {
+ right_max[i] = max(heights[i], right_max[i + 1]);
+ }
+ for (int i = 1; i < size - 1; i++) {
+ ans += min(left_max[i], right_max[i]) - heights[i];
+ }
+ return ans;
+}
+
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+## 双指针
+
+### 思路
+
+上面代码比较好理解,但是需要额外的 \${N} 的空间。从上面解法可以看出,我们实际上只关心左右两侧较小的那一个,并不需要两者都计算出来。具体来说:
+
+- 如果 l[i + 1] < r[i] 那么 最终积水的高度由 i 的左侧最大值决定。
+- 如果 l[i + 1] >= r[i] 那么 最终积水的高度由 i 的右侧最大值决定。
+
+因此我们不必维护完整的两个数组,而是可以只进行一次遍历,同时维护左侧最大值和右侧最大值,使用常数变量完成即可。这是一个典型的双指针问题,
+
+具体算法:
+
+1. 维护两个指针 left 和 right,分别指向头尾。
+2. 初始化左侧和右侧最高的高度都为 0。
+3. 比较 height[left] 和 height[right]
+
+ - 3.1 如果 height[left] < height[right]
+ - 3.1.1 如果 height[left] >= left_max, 则当前格子积水面积为(left_max - height[left])
+ - 3.1.2 否则无法积水,即积水面积为 0
+ - 3.2 左指针右移一位
+
+ - 3.3 如果 height[left] >= height[right]
+ - 3.3.1 如果 height[right] >= right_max, 则当前格子积水面积为(right_max - height[right])
+ - 3.3.2 否则无法积水,即积水面积为 0
+ - 3.4 右指针左移一位
+
+### 代码
+
+代码支持 Python3,C++:
+
+```python
+class Solution:
+ def trap(self, heights: List[int]) -> int:
+ n = len(heights)
+ l_max = r_max = 0
+ l, r = 0, n - 1
+ ans = 0
+ while l < r:
+ if heights[l] < heights[r]:
+ if heights[l] < l_max:
+ ans += l_max - heights[l]
+ else:
+ l_max = heights[l]
+ l += 1
+ else:
+ if heights[r] < r_max:
+ ans += r_max - heights[r]
+ else:
+ r_max = heights[r]
+ r -= 1
+ return ans
+```
+
+```c++
+
+class Solution {
+public:
+ int trap(vector& heights)
+{
+ int left = 0, right = heights.size() - 1;
+ int ans = 0;
+ int left_max = 0, right_max = 0;
+ while (left < right) {
+ if (heights[left] < heights[right]) {
+ heights[left] >= left_max ? (left_max = heights[left]) : ans += (left_max - heights[left]);
+ ++left;
+ }
+ else {
+ heights[right] >= right_max ? (right_max = heights[right]) : ans += (right_max - heights[right]);
+ --right;
+ }
+ }
+ return ans;
+}
+
+};
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [84.largest-rectangle-in-histogram](https://github.com/azl397985856/leetcode/blob/master/problems/84.largest-rectangle-in-histogram.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/437.path-sum-iii.md b/problems/437.path-sum-iii.md
index 869ccf0d5..79243299b 100644
--- a/problems/437.path-sum-iii.md
+++ b/problems/437.path-sum-iii.md
@@ -32,6 +32,17 @@ Return 3. The paths that sum to 8 are:
3. -3 -> 11
```
+## 前置知识
+
+- hashmap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是要我们求解出任何一个节点出发到子孙节点的路径中和为指定值。
注意这里,不一定是从根节点出发,也不一定在叶子节点结束。
@@ -90,11 +101,11 @@ var pathSum = function(root, sum) {
当我们执行到底部的时候:
-
+
接着往上回溯:
-
+
很容易看出,我们的hashmap不应该有第一张图的那个记录了,因此需要减去。
@@ -152,8 +163,18 @@ function helper(root, acc, target, hashmap) {
}
var pathSum = function(root, sum) {
- // 时间复杂度和空间复杂度都是O(n)
const hashmap = {};
return helper(root, 0, sum, hashmap);
};
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/445.add-two-numbers-ii.md b/problems/445.add-two-numbers-ii.md
index 3f8e2e730..13c1786f6 100644
--- a/problems/445.add-two-numbers-ii.md
+++ b/problems/445.add-two-numbers-ii.md
@@ -19,6 +19,17 @@ Output: 7 -> 8 -> 0 -> 7
```
+## 前置知识
+
+- 链表
+- 栈
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+
## 思路
由于需要从低位开始加,然后进位。 因此可以采用栈来简化操作。
diff --git a/problems/454.4-Sum-ii.en.md b/problems/454.4-Sum-ii.en.md
new file mode 100644
index 000000000..4d5144ac2
--- /dev/null
+++ b/problems/454.4-Sum-ii.en.md
@@ -0,0 +1,100 @@
+
+
+## Problem Address
+https://leetcode.com/problems/4sum-ii/description/
+
+## Problem Description
+
+```
+Given four lists A, B, C, D of integer values, compute how many tuples (i, j, k, l) there are such that A[i] + B[j] + C[k] + D[l] is zero.
+
+To make problem a bit easier, all A, B, C, D have same length of N where 0 ≤ N ≤ 500. All integers are in the range of -228 to 228 - 1 and the result is guaranteed to be at most 231 - 1.
+
+Example:
+
+Input:
+A = [ 1, 2]
+B = [-2,-1]
+C = [-1, 2]
+D = [ 0, 2]
+
+Output:
+2
+
+Explanation:
+The two tuples are:
+1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
+2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
+```
+## Solution
+
+The normal solution to complete the search would require four rounds of traversal, and that would make the time complexity reaches O(n^4), which doesn't work obviously. We have to figure out a more effective algorithm.
+
+My idea is to separate these four lists into two groups and combine them two by two. We then calculate separately `all the sums from these two groups, and the relevant counts`
+
+As the picture shows:
+
+
+
+
+Now that we got two `hashTable`, and the result would appear with some basic calculations.
+
+## Key Point Analysis
+- Less time by more space.
+- Divide the lists by 2, and calculate all the possible sums from two groups, then combine the result.
+
+## Code
+
+Language Support: `JavaScript`,`Python3`
+
+`JavaScript`:
+```js
+
+/*
+ * @lc app=leetcode id=454 lang=javascript
+ *
+ * [454] 4Sum II
+ *
+ * https://leetcode.com/problems/4sum-ii/description/
+/**
+ * @param {number[]} A
+ * @param {number[]} B
+ * @param {number[]} C
+ * @param {number[]} D
+ * @return {number}
+ */
+var fourSumCount = function(A, B, C, D) {
+ const sumMapper = {};
+ let res = 0;
+ for (let i = 0; i < A.length; i++) {
+ for (let j = 0; j < B.length; j++) {
+ sumMapper[A[i] + B[j]] = (sumMapper[A[i] + B[j]] || 0) + 1;
+ }
+ }
+
+ for (let i = 0; i < C.length; i++) {
+ for (let j = 0; j < D.length; j++) {
+ res += sumMapper[- (C[i] + D[j])] || 0;
+ }
+ }
+
+ return res;
+};
+```
+
+`Python3`:
+
+```python
+class Solution:
+ def fourSumCount(self, A: List[int], B: List[int], C: List[int], D: List[int]) -> int:
+ mapper = {}
+ res = 0
+ for i in A:
+ for j in B:
+ mapper[i + j] = mapper.get(i + j, 0) + 1
+
+ for i in C:
+ for j in D:
+ res += mapper.get(-1 * (i + j), 0)
+ return res
+ ```
\ No newline at end of file
diff --git a/problems/454.4-sum-ii.md b/problems/454.4-sum-ii.md
index 6cadc5aa4..dd3b750de 100644
--- a/problems/454.4-sum-ii.md
+++ b/problems/454.4-sum-ii.md
@@ -26,6 +26,16 @@ The two tuples are:
1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
```
+
+## 前置知识
+
+- hashTable
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
如果按照常规思路去完成查找需要四层遍历,时间复杂是O(n^4), 显然是行不通的。
@@ -36,7 +46,7 @@ The two tuples are:
如图:
-
+
这个时候我们得到了两个`hashTable`, 我们只需要进行简单的数学运算就可以得到结果。
diff --git a/problems/455.AssignCookies.md b/problems/455.AssignCookies.md
index a0e38ca49..569b8a4a9 100644
--- a/problems/455.AssignCookies.md
+++ b/problems/455.AssignCookies.md
@@ -35,7 +35,19 @@ https://leetcode-cn.com/problems/assign-cookies
所以你应该输出2.
```
+## 前置知识
+
+- [贪心算法](https://github.com/azl397985856/leetcode/blob/master/thinkings/greedy.md)
+- 双指针
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
+
贪心算法+双指针求解
给一个孩子的饼干应当尽量小并且能满足孩子,大的留来满足胃口大的孩子。因为胃口小的孩子最容易得到满足,所以优先满足胃口小的孩子需求。按照从小到大的顺序使用饼干尝试是否可满足某个孩子。
@@ -47,6 +59,7 @@ https://leetcode-cn.com/problems/assign-cookies
## 代码
+
* 语言支持:JS
```js
@@ -78,5 +91,13 @@ const findContentChildren = function (g, s) {
***复杂度分析***
-- 时间复杂度:O(NlogN)
+- 时间复杂度:由于使用了排序,因此时间复杂度为 O(NlogN)
- 空间复杂度:O(1)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/46.permutations.md b/problems/46.permutations.md
index e4d9df106..47f333955 100644
--- a/problems/46.permutations.md
+++ b/problems/46.permutations.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/permutations/description/
## 题目描述
+
```
Given a collection of distinct integers, return all possible permutations.
@@ -20,18 +22,31 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -42,7 +57,7 @@ Output:
## 代码
-* 语言支持: Javascript, Python3
+- 语言支持: Javascript, Python3
Javascript Code:
@@ -79,31 +94,33 @@ Javascript Code:
*
*/
function backtrack(list, tempList, nums) {
- if (tempList.length === nums.length) return list.push([...tempList]);
- for(let i = 0; i < nums.length; i++) {
- if (tempList.includes(nums[i])) continue;
- tempList.push(nums[i]);
- backtrack(list, tempList, nums);
- tempList.pop();
- }
+ if (tempList.length === nums.length) return list.push([...tempList]);
+ for (let i = 0; i < nums.length; i++) {
+ if (tempList.includes(nums[i])) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var permute = function(nums) {
- const list = [];
- backtrack(list, [], nums)
- return list
+var permute = function (nums) {
+ const list = [];
+ backtrack(list, [], nums);
+ return list;
};
```
+
Python3 Code:
+
```Python
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
"""itertools库内置了这个函数"""
return itertools.permutations(nums)
-
+
def permute2(self, nums: List[int]) -> List[List[int]]:
"""自己写回溯法"""
res = []
@@ -170,7 +187,7 @@ class Solution:
- [39.combination-sum](./39.combination-sum.md)
- [40.combination-sum-ii](./40.combination-sum-ii.md)
- [47.permutations-ii](./47.permutations-ii.md)
-- [60.permutation-sequence](./60.permutation-sequence.md)(TODO)
+- [60.permutation-sequence](./60.permutation-sequence.md)
- [78.subsets](./78.subsets.md)
- [90.subsets-ii](./90.subsets-ii.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
diff --git a/problems/460.lfu-cache.md b/problems/460.lfu-cache.md
index d9e9f30a3..43cf54be7 100644
--- a/problems/460.lfu-cache.md
+++ b/problems/460.lfu-cache.md
@@ -28,6 +28,18 @@ cache.get(3); // returns 3
cache.get(4); // returns 4
```
+## 前置知识
+
+- 链表
+- HashMap
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
`本题已被收录到我的新书中,敬请期待~`
@@ -51,7 +63,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node1 插入 doublylinkedlist head->next = node1.
如下图,
```
-
+
```
2. put(2, 2),
- 首先查找 nodeMap 中有没有 key=2 对应的 value,
@@ -60,7 +72,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node2 插入 doublylinkedlist head->next = node2.
如下图,
```
-
+
```
3. get(1),
- 首先查找 nodeMap 中有没有 key=1 对应的 value,nodeMap:{[1, node1], [2, node2]},
@@ -69,7 +81,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node1
如下图,
```
-
+
```
4. put(3, 3),
- 判断 cache 的 capacity,已满,需要淘汰使用次数最少的元素,找到最小的 freq=1,删除双链表 tail node.prev
@@ -80,7 +92,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node3 插入 doublylinkedlist head->next = node3.
如下图,
```
-
+
```
5. get(2)
- 查找 nodeMap,如果没有对应的 key 的 value,返回 -1。
@@ -92,7 +104,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node3
如下图,
```
-
+
```
7. put(4, 4),
- 判断 cache 的 capacity,已满,需要淘汰使用次数最少的元素,找到最小的 freq=1,删除双链表 tail node.prev
@@ -103,7 +115,7 @@ cache.get(4); // returns 4
没有就新建 doublylinkedlist(head, tail), 把 node4 插入 doublylinkedlist head->next = node4.
如下图,
```
-
+
```
8. get(1)
- 查找 nodeMap,如果没有对应的 key 的 value,返回 -1。
@@ -115,7 +127,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=3,node3
如下图,
```
-
+
```
10. get(4)
- 首先查找 nodeMap 中有没有 key=4 对应的 value,nodeMap:{[4, node4], [3, node3]},
@@ -124,7 +136,7 @@ cache.get(4); // returns 4
- 更新 freqMap,插入 freq=2,node4
如下图,
```
-
+
## 关键点分析
用两个`Map`分别保存 `nodeMap {key, node}` 和 `freqMap{frequent, DoublyLinkedList}`。
diff --git a/problems/47.permutations-ii.md b/problems/47.permutations-ii.md
index 0ab000f58..3c4aeb950 100644
--- a/problems/47.permutations-ii.md
+++ b/problems/47.permutations-ii.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/permutations-ii/description/
## 题目描述
+
```
Given a collection of numbers that might contain duplicates, return all possible unique permutations.
@@ -17,18 +19,31 @@ Output:
```
+## 前置知识
+
+- 回溯法
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -37,10 +52,9 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -92,19 +106,26 @@ function backtrack(list, nums, tempList, visited) {
* @param {number[]} nums
* @return {number[][]}
*/
-var permuteUnique = function(nums) {
+var permuteUnique = function (nums) {
const list = [];
- backtrack(list, nums.sort((a, b) => a - b), [], []);
+ backtrack(
+ list,
+ nums.sort((a, b) => a - b),
+ [],
+ []
+ );
return list;
};
```
+
Python3 code:
+
```Python
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
"""与46题一样,当然也可以直接调用itertools的函数,然后去重"""
return list(set(itertools.permutations(nums)))
-
+
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
"""自己写回溯法,与46题相比,需要去重"""
# 排序是为了去重
diff --git a/problems/472.concatenated-words.md b/problems/472.concatenated-words.md
index 409948d64..5082446b6 100644
--- a/problems/472.concatenated-words.md
+++ b/problems/472.concatenated-words.md
@@ -26,6 +26,15 @@ https://leetcode-cn.com/problems/concatenated-words/
不需要考虑答案输出的顺序。
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
本题我的思路是直接使用前缀树来解决。**标准的前缀树模板**我在之前的题解中提到了,感兴趣的可以到下方的相关题目中查看。
@@ -39,7 +48,7 @@ https://leetcode-cn.com/problems/concatenated-words/
我们构造的前缀树大概是这样的:
-
+
问题的关键在于第二步中的**查找每一个单词有几个单词表中的单词组成**。 其实如果你了解前缀树的话应该不难写出来。 比如查找 catsdogcats:
@@ -119,3 +128,4 @@ class Solution:
- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/474.ones-and-zeros-en.md b/problems/474.ones-and-zeros-en.md
index f6e1da7bb..43036fa35 100644
--- a/problems/474.ones-and-zeros-en.md
+++ b/problems/474.ones-and-zeros-en.md
@@ -112,7 +112,7 @@ DP formula:
For example:
-
+
####
- *Time Complexity:* `O(l * m * n) - l is strs length,m is number of 0,n number of 1`
diff --git a/problems/48.rotate-image.md b/problems/48.rotate-image.md
index 9cf8f5909..2b0757f76 100644
--- a/problems/48.rotate-image.md
+++ b/problems/48.rotate-image.md
@@ -48,18 +48,30 @@ rotate the input matrix in-place such that it becomes:
```
+## 前置知识
+
+- 原地算法
+- 矩阵
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目让我们 in-place,也就说空间复杂度要求 O(1),如果没有这个限制的话,很简单。
通过观察发现,我们只需要将第 i 行变成第 n - i - 1 列, 因此我们只需要保存一个原有矩阵,然后按照这个规律一个个更新即可。
-
+
代码:
```js
-var rotate = function(matrix) {
+var rotate = function (matrix) {
// 时间复杂度O(n^2) 空间复杂度O(n)
const oMatrix = JSON.parse(JSON.stringify(matrix)); // clone
const n = oMatrix.length;
@@ -71,16 +83,16 @@ var rotate = function(matrix) {
};
```
-如果要求空间复杂度是O(1)的话,我们可以用一个temp记录即可,这个时候就不能逐个遍历了。
-比如遍历到1的时候,我们把1存到temp,然后更新1的值为7。 1被换到了3的位置,我们再将3存到temp,依次类推。
+如果要求空间复杂度是 O(1)的话,我们可以用一个 temp 记录即可,这个时候就不能逐个遍历了。
+比如遍历到 1 的时候,我们把 1 存到 temp,然后更新 1 的值为 7。 1 被换到了 3 的位置,我们再将 3 存到 temp,依次类推。
但是这种解法写起来比较麻烦,这里我就不写了。
事实上有一个更加巧妙的做法,我们可以巧妙地利用对称轴旋转达到我们的目的,如图,我们先进行一次以对角线为轴的翻转,然后
再进行一次以水平轴心线为轴的翻转即可。
-
+
-这种做法的时间复杂度是O(n^2) ,空间复杂度是O(1)
+这种做法的时间复杂度是 O(n^2) ,空间复杂度是 O(1)
## 关键点解析
@@ -88,7 +100,7 @@ var rotate = function(matrix) {
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -100,7 +112,7 @@ var rotate = function(matrix) {
* @param {number[][]} matrix
* @return {void} Do not return anything, modify matrix in-place instead.
*/
-var rotate = function(matrix) {
+var rotate = function (matrix) {
// 时间复杂度O(n^2) 空间复杂度O(1)
// 做法: 先沿着对角线翻转,然后沿着水平线翻转
@@ -123,7 +135,9 @@ var rotate = function(matrix) {
}
};
```
+
Python3 Code:
+
```Python
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
@@ -137,7 +151,7 @@ class Solution:
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
for m in matrix:
m.reverse()
-
+
def rotate2(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
diff --git a/problems/49.group-anagrams.md b/problems/49.group-anagrams.md
index e8c7c6964..af9c0b399 100644
--- a/problems/49.group-anagrams.md
+++ b/problems/49.group-anagrams.md
@@ -22,6 +22,18 @@ All inputs will be in lowercase.
The order of your output does not matter.
```
+## 前置知识
+
+- 哈希表
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
一个简单的解法就是遍历数组,然后对每一项都进行排序,然后将其添加到 hashTable 中,最后输出 hashTable 中保存的值即可。
@@ -31,14 +43,11 @@ The order of your output does not matter.
代码:
```js
-var groupAnagrams = function(strs) {
+var groupAnagrams = function (strs) {
const hashTable = {};
function sort(str) {
- return str
- .split("")
- .sort()
- .join("");
+ return str.split("").sort().join("");
}
// 这个方法需要排序,因此不是很优,但是很直观,容易想到
@@ -60,7 +69,7 @@ var groupAnagrams = function(strs) {
然后我们给每一个字符一个固定的数组下标,然后我们只需要更新每个字符出现的次数。 最后形成的 counts 数组如果一致,则说明他们可以通过
交换顺序得到。这种算法空间复杂度 O(n), 时间复杂度 O(n \* k), n 为数组长度,k 为字符串的平均长度.
-
+
## 关键点解析
@@ -68,7 +77,7 @@ var groupAnagrams = function(strs) {
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -80,7 +89,7 @@ var groupAnagrams = function(strs) {
* @param {string[]} strs
* @return {string[][]}
*/
-var groupAnagrams = function(strs) {
+var groupAnagrams = function (strs) {
// 类似桶排序
let counts = [];
@@ -102,7 +111,9 @@ var groupAnagrams = function(strs) {
return Object.values(hashTable);
};
```
+
Python3 Code:
+
```Python
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
diff --git a/problems/493.reverse-pairs.md b/problems/493.reverse-pairs.md
index 0470c9720..4bd2c23c8 100644
--- a/problems/493.reverse-pairs.md
+++ b/problems/493.reverse-pairs.md
@@ -24,8 +24,20 @@ https://leetcode-cn.com/problems/reverse-pairs/description/
```
+## 前置知识
+
+- 归并排序
+- 逆序数
+- 分治
+
## 暴力法
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
### 思路
读完这道题你应该就能联想到逆序数才行。求解逆序数最简单的做法是使用双层循环暴力求解。我们仿照求解决逆序数的解法来解这道题(其实唯一的区别就是系数从 1 变成了 2)。
diff --git a/problems/494.target-sum.md b/problems/494.target-sum.md
index 6611e253f..b2079534b 100644
--- a/problems/494.target-sum.md
+++ b/problems/494.target-sum.md
@@ -28,17 +28,28 @@ Your output answer is guaranteed to be fitted in a 32-bit integer.
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
题目是给定一个数组,让你在数字前面添加 `+`或者`-`,使其和等于 target.
-
+
暴力法的时间复杂度是指数级别的,因此我们不予考虑。我们需要换种思路.
我们将最终的结果分成两组,一组是我们添加了`+`的,一组是我们添加了`-`的。
-
+
如上图,问题转化为如何求其中一组,我们不妨求前面标`+`的一组
@@ -46,7 +57,7 @@ Your output answer is guaranteed to be fitted in a 32-bit integer.
通过进一步分析,我们得到了这样的关系:
-
+
因此问题转化为,求解`sumCount(nums, target)`,即 nums 数组中能够组成
target 的总数一共有多少种,这是一道我们之前做过的题目,使用动态规划可以解决。
diff --git a/problems/5.longest-palindromic-substring.md b/problems/5.longest-palindromic-substring.md
index 9bb366ed6..f8f8ec028 100644
--- a/problems/5.longest-palindromic-substring.md
+++ b/problems/5.longest-palindromic-substring.md
@@ -4,7 +4,7 @@ https://leetcode-cn.com/problems/longest-palindromic-substring/
## 题目描述
-给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
+给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
@@ -16,15 +16,25 @@ https://leetcode-cn.com/problems/longest-palindromic-substring/
输入: "cbbd"
输出: "bb"
+## 前置知识
+
+- 回文
+
+## 公司
+
+- 阿里
+- 百度
+- 腾讯
+
## 思路
这是一道最长回文的题目,要我们求出给定字符串的最大回文子串。
-
+
解决这类问题的核心思想就是两个字“延伸”,具体来说
-- 如果一个字符串是回文串,那么在它左右分别加上一个相同的字符,那么它一定还是一个回文串
+- 如果在一个不是回文字符串的字符串两端添加任何字符,或者在回文串左右分别加不同的字符,得到的一定不是回文串
- 如果一个字符串不是回文串,或者在回文串左右分别加不同的字符,得到的一定不是回文串
事实上,上面的分析已经建立了大问题和小问题之间的关联,
@@ -38,11 +48,13 @@ if (s[i] === s[j] && dp[i + 1][j - 1]) {
dp[i][j] = true;
}
```
-
-base case就是一个字符(轴对称点是本身),或者两个字符(轴对称点是介于两者之间的虚拟点)。
+
+
+base case 就是一个字符(轴对称点是本身),或者两个字符(轴对称点是介于两者之间的虚拟点)。
+
+
-
## 关键点
- ”延伸“(extend)
@@ -68,7 +80,7 @@ class Solution:
for i in range(n - 1):
e1 = extend(i, i, s)
- e2 = extend(i, i + 1, s)
+ e2 = extend(i, i + 1, s)
if max(len(e1), len(e2)) > len(res):
res = e1 if len(e1) > len(e2) else e2
return res
@@ -86,7 +98,7 @@ JavaScript Code:
* @param {string} s
* @return {string}
*/
-var longestPalindrome = function(s) {
+var longestPalindrome = function (s) {
// babad
// tag : dp
if (!s || s.length === 0) return "";
@@ -118,6 +130,17 @@ var longestPalindrome = function(s) {
};
```
+**_复杂度分析_**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N^2)$
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
+
+
+
## 相关题目
- [516.longest-palindromic-subsequence](./516.longest-palindromic-subsequence.md)
diff --git a/problems/50.pow-x-n.md b/problems/50.pow-x-n.md
index 42291b1a7..e791c8e78 100644
--- a/problems/50.pow-x-n.md
+++ b/problems/50.pow-x-n.md
@@ -27,8 +27,20 @@ n 是 32 位有符号整数,其数值范围是 [−231, 231 − 1] 。
```
+## 前置知识
+
+- 递归
+- 位运算
+
## 解法零 - 遍历法
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
### 思路
这道题是让我们实现数学函数`幂`,因此直接调用系统内置函数是不被允许的。
@@ -135,9 +147,9 @@ class Solution:
以 x 的 10 次方举例。10 的 2 进制是 1010,然后用 2 进制转 10 进制的方法把它展成 2 的幂次的和。
-
+
-
+
因此我们的算法就是:
@@ -146,7 +158,7 @@ class Solution:
- 将 n 的二进制表示中`1的位置`pick 出来。比如 n 的第 i 位为 1,那么就将 x^i pick 出来。
- 将 pick 出来的结果相乘
-
+
这里有两个问题:
@@ -186,4 +198,4 @@ class Solution:
- [458.可怜的小猪](https://leetcode-cn.com/problems/poor-pigs/description/)
-
+
diff --git a/problems/501.Find-Mode-in-Binary-Search-Tree.md b/problems/501.Find-Mode-in-Binary-Search-Tree-en.md
similarity index 99%
rename from problems/501.Find-Mode-in-Binary-Search-Tree.md
rename to problems/501.Find-Mode-in-Binary-Search-Tree-en.md
index ab93db037..00dd184bb 100644
--- a/problems/501.Find-Mode-in-Binary-Search-Tree.md
+++ b/problems/501.Find-Mode-in-Binary-Search-Tree-en.md
@@ -86,4 +86,4 @@ class Solution {
helper(root.right);
}
}
-```
\ No newline at end of file
+```
diff --git a/problems/516.longest-palindromic-subsequence.md b/problems/516.longest-palindromic-subsequence.md
index 17a0b20f6..1099920a4 100644
--- a/problems/516.longest-palindromic-subsequence.md
+++ b/problems/516.longest-palindromic-subsequence.md
@@ -23,18 +23,29 @@ Output:
One possible longest palindromic subsequence is "bb".
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一道最长回文的题目,要我们求出给定字符串的最大回文子序列。
-
+
解决这类问题的核心思想就是两个字“延伸”,具体来说
- 如果一个字符串是回文串,那么在它左右分别加上一个相同的字符,那么它一定还是一个回文串,因此`回文长度增加2`
- 如果一个字符串不是回文串,或者在回文串左右分别加不同的字符,得到的一定不是回文串,因此`回文长度不变,我们取[i][j-1]和[i+1][j]的较大值`
-
+
事实上,上面的分析已经建立了大问题和小问题之间的关联,
基于此,我们可以建立动态规划模型。
@@ -52,7 +63,7 @@ if (s[i] === s[j]) {
base case 就是一个字符(轴对称点是本身)
-
+
## 关键点
diff --git a/problems/518.coin-change-2.md b/problems/518.coin-change-2.md
index 2057a1704..e5518110e 100644
--- a/problems/518.coin-change-2.md
+++ b/problems/518.coin-change-2.md
@@ -34,17 +34,28 @@ https://leetcode-cn.com/problems/coin-change-2/description/
硬币种类不超过 500 种
结果符合 32 位符号整数
+## 前置知识
+
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+- 背包问题
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这个题目和 coin-change 的思路比较类似。
我们还是按照 coin-change 的思路来, 如果将问题画出来大概是这样:
-
+
进一步我们可以对问题进行空间复杂度上的优化(这种写法比较难以理解,但是相对更省空间)
-
+
> 这里用动图会更好理解, 有时间的话我会做一个动图出来, 现在大家脑补一下吧
@@ -60,7 +71,7 @@ https://leetcode-cn.com/problems/coin-change-2/description/
2. 第 j 个硬币我可以选择拿 这个时候, 组成数 = dp[i - coins[j]] + dp[i]
-- 和背包问题不同, 硬币是可以拿任意个
+- 和 01 背包问题不同, 硬币是可以拿任意个,属于完全背包问题
- 对于每一个 dp[i] 我们都选择遍历一遍 coin, 不断更新 dp[i]
@@ -89,7 +100,7 @@ return dp[dp.length - 1][coins.length];
- 当我们选择一维数组去解的时候,内外循环将会对结果造成影响
-
+
eg:
@@ -117,10 +128,8 @@ return dp[dp.length - 1];
## 代码
-
代码支持:Python3,JavaScript:
-
JavaSCript Code:
```js
@@ -135,7 +144,7 @@ JavaSCript Code:
* @param {number[]} coins
* @return {number}
*/
-var change = function(amount, coins) {
+var change = function (amount, coins) {
if (amount === 0) return 1;
const dp = [1].concat(Array(amount).fill(0));
@@ -154,7 +163,7 @@ var change = function(amount, coins) {
Python Code:
-```
+```python
class Solution:
def change(self, amount: int, coins: List[int]) -> int:
dp = [0] * (amount + 1)
diff --git a/problems/52.N-Queens-II.md b/problems/52.N-Queens-II.md
index e3175ea80..343a210d1 100644
--- a/problems/52.N-Queens-II.md
+++ b/problems/52.N-Queens-II.md
@@ -26,6 +26,17 @@ n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并
]
```
+## 前置知识
+
+- 回溯
+- 深度优先遍历
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
使用深度优先搜索配合位运算,二进制为 1 代表不可放置,0 相反
diff --git a/problems/53.maximum-sum-subarray-cn.md b/problems/53.maximum-sum-subarray-cn.md
index 7f09c6cd7..7d4ab98be 100644
--- a/problems/53.maximum-sum-subarray-cn.md
+++ b/problems/53.maximum-sum-subarray-cn.md
@@ -14,6 +14,22 @@ Follow up:
If you have figured out the O(n) solution, try coding another solution using the divide and conquer approach, which is more subtle.
```
+## 前置知识
+- [滑动窗口](https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md)
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+## 公司
+
+- 阿里
+- 百度
+- 字节
+- 腾讯
+- bloomberg
+- linkedin
+- microsoft
+
+## 公司
+
+- 阿里、百度、字节、腾讯
## 思路
@@ -27,9 +43,10 @@ If you have figured out the O(n) solution, try coding another solution using the
求子序列和,那么我们要知道子序列的首尾位置,然后计算首尾之间的序列和。用2个for循环可以枚举所有子序列的首尾位置。
然后用一个for循环求解序列和。这里时间复杂度太高,`O(n^3)`.
-#### 复杂度分析
-- *时间复杂度:* `O(n^3) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N ^ 3)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
+
#### 解法二 - 前缀和 + 暴力解
**优化暴力解:** (震惊,居然AC了)
@@ -41,9 +58,9 @@ If you have figured out the O(n) solution, try coding another solution using the
那么序列和 `subarraySum=prefixSum[r] - prefixSum[l - 1];`
用一个全局变量`maxSum`, 比较每次求解的子序列和,`maxSum = max(maxSum, subarraySum)`.
-#### 复杂度分析
-- *时间复杂度:* `O(n^2) - n 是数组长度`
-- *空间复杂度:* `O(n) - prefixSum 数组空间为n`
+**复杂度分析**
+- 时间复杂度:$O(N ^ 2)$, 其中 N 是数组长度
+- 空间复杂度:$O(N)$
>如果用更改原数组表示前缀和数组,空间复杂度降为`O(1)`
@@ -59,9 +76,9 @@ If you have figured out the O(n) solution, try coding another solution using the
然后我们再减去之前的` S(k)`,其中 `k = 0,1,i - 1`,中的最小值即可。 因此我们需要
用一个变量来维护这个最小值,还需要一个变量维护最大值。
-#### 复杂度分析
-- *时间复杂度:* `O(n) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
#### 解法四 - [分治法](https://www.wikiwand.com/zh-hans/%E5%88%86%E6%B2%BB%E6%B3%95)
@@ -76,11 +93,11 @@ If you have figured out the O(n) solution, try coding another solution using the
分别求出三种情况下最大子序列和,三者中最大值即为最大子序列和。
举例说明,如下图:
-
+
-#### 复杂度分析
-- *时间复杂度:* `O(nlogn) - n 是数组长度`
-- *空间复杂度:* `O(logn)` - 因为调用栈的深度最多是logn。
+**复杂度分析**
+- 时间复杂度:$O(NlogN)$, 其中 N 是数组长度
+- 空间复杂度:$O(logN)$
#### 解法五 - [动态规划](https://www.wikiwand.com/zh-hans/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92)
动态规划的难点在于找到状态转移方程,
@@ -102,11 +119,11 @@ If you have figured out the O(n) solution, try coding another solution using the
- `maxSum = max(currMaxSum, maxSum)`
如图:
-
+
-#### 复杂度分析
-- *时间复杂度:* `O(n) - n 是数组长度`
-- *空间复杂度:* `O(1)`
+**复杂度分析**
+- 时间复杂度:$O(N)$, 其中 N 是数组长度
+- 空间复杂度:$O(1)$
## 关键点分析
1. 暴力解,列举所有组合子序列首尾位置的组合,求解最大的子序列和, 优化可以预先处理,得到前缀和
@@ -367,3 +384,11 @@ function LSS(list) {
## 相似题
- [Maximum Product Subarray](https://leetcode.com/problems/maximum-product-subarray/)
- [Longest Turbulent Subarray](https://leetcode.com/problems/longest-turbulent-subarray/)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/53.maximum-sum-subarray-en.md b/problems/53.maximum-sum-subarray-en.md
index 965f140b3..029d7ff4e 100644
--- a/problems/53.maximum-sum-subarray-en.md
+++ b/problems/53.maximum-sum-subarray-en.md
@@ -91,7 +91,7 @@ The maximum sum is `max(left, right, crossMaxSum)`
For example, `nums=[-2,1,-3,4,-1,2,1,-5,4]`
-
+
#### Complexity Analysis
@@ -118,7 +118,7 @@ From above DP formula, notice only need to access its previous element at each s
- `maxSum = max(currMaxSum, maxSum)`
As below pic:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n) - n array length`
diff --git a/problems/547.friend-circles-en.md b/problems/547.friend-circles-en.md
index 47e6377af..dfe634bc2 100644
--- a/problems/547.friend-circles-en.md
+++ b/problems/547.friend-circles-en.md
@@ -43,7 +43,7 @@ this problem become to find number of connected components in a undirected graph
For example, how to transfer Adjacency Matrix into a graph problem. As below pic:
-
+
Connected components in a graph problem usually can be solved using *DFS*, *BFS*, *Union-Find*.
@@ -56,7 +56,7 @@ Below we will explain details on each approach.
as below pic show *DFS* traverse process:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n*n) - n is the number of students, traverse n*n matrix`
@@ -70,7 +70,7 @@ as below pic show *DFS* traverse process:
as below pic show *BFS* (Level traverse) traverse process:
-
+
#### Complexity Analysis
- *Time Complexity:* `O(n*n) - n is the number of students, traverse n*n matrix`
@@ -93,7 +93,7 @@ To know more details and implementations, see further reading lists.
as below Union-Find approach process:
-
+
> **Note:** here using weighted-union-find to avoid Union and Find take `O(n)` in the worst case.
diff --git a/problems/547.friend-circles.md b/problems/547.friend-circles.md
index a334ee5f0..b372ebd11 100644
--- a/problems/547.friend-circles.md
+++ b/problems/547.friend-circles.md
@@ -31,6 +31,17 @@ N 在[1,200]的范围内。
对于所有学生,有 M[i][i] = 1。
如果有 M[i][j] = 1,则有 M[j][i] = 1。
+## 前置知识
+
+- 并查集
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
并查集有一个功能是可以轻松计算出连通分量,然而本题的朋友圈的个数,本质上就是连通分量的个数,因此用并查集可以完美解决。
@@ -83,4 +94,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/55.jump-game.md b/problems/55.jump-game.md
index db822c348..863733321 100644
--- a/problems/55.jump-game.md
+++ b/problems/55.jump-game.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/jump-game/description/
## 题目描述
+
```
Given an array of non-negative integers, you are initially positioned at the first index of the array.
@@ -24,35 +25,97 @@ Explanation: You will always arrive at index 3 no matter what. Its maximum
```
+## 前置知识
+
+- 贪心
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是一道典型的`贪心`类型题目。思路就是用一个变量记录当前能够到达的最大的索引,我们逐个遍历数组中的元素去更新这个索引。变量完成判断这个索引是否大于数组下表即可。
+
## 关键点解析
- 建模 (记录和更新当前位置能够到达的最大的索引即可)
## 代码
-* 语言支持: Javascript,Python3
-
+- 语言支持: Javascript,C++,Java,Python3
+Javascript Code:
```js
/**
* @param {number[]} nums
* @return {boolean}
*/
-var canJump = function(nums) {
+var canJump = function (nums) {
let max = 0; // 能够走到的数组下标
- for(let i = 0; i < nums.length; i++) {
- if (max < i) return false; // 当前这一步都走不到,后面更走不到了
- max = Math.max(nums[i] + i, max);
+ for (let i = 0; i < nums.length; i++) {
+ if (max < i) return false; // 当前这一步都走不到,后面更走不到了
+ max = Math.max(nums[i] + i, max);
}
- return max >= nums.length - 1
+ return max >= nums.length - 1;
+};
+```
+
+C++ Code:
+
+```c++
+class Solution {
+public:
+ bool canJump(vector& nums) {
+ int n=nums.size();
+ int k=0;
+ for(int i=0;ik){
+ return false;
+ }
+ // 能跳到最后一个位置
+ if(k>=n-1){
+ return true;
+ }
+ // 从当前位置能跳的最远的位置
+ k = max(k, i+nums[i]);
+ }
+ return k >= n-1;
+ }
};
+```
+Java Code:
+
+```java
+class Solution {
+ public boolean canJump(int[] nums) {
+ int n=nums.length;
+ int k=0;
+ for(int i=0;ik){
+ return false;
+ }
+ // 能跳到最后一个位置
+ if(k>=n-1){
+ return true;
+ }
+ // 从当前位置能跳的最远的位置
+ k = Math.max(k, i+nums[i]);
+ }
+ return k >= n-1;
+ }
+}
```
+
Python3 Code:
+
```Python
class Solution:
def canJump(self, nums: List[int]) -> bool:
@@ -69,10 +132,11 @@ class Solution:
return _max >= _len - 1
```
-***复杂度分析***
+**_复杂度分析_**
+
- 时间复杂度:$O(N)$
- 空间复杂度:$O(1)$
-更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
diff --git a/problems/56.merge-intervals.md b/problems/56.merge-intervals.md
index 9acfdab8b..d9f324e99 100644
--- a/problems/56.merge-intervals.md
+++ b/problems/56.merge-intervals.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/merge-intervals/description/
## 题目描述
+
```
Given a collection of intervals, merge all overlapping intervals.
@@ -20,24 +21,34 @@ NOTE: input types have been changed on April 15, 2019. Please reset to default c
```
+## 前置知识
+
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
- 先对数组进行排序,排序的依据就是每一项的第一个元素的大小。
- 然后我们对数组进行遍历,遍历的时候两两运算(具体运算逻辑见下)
- 判断是否相交,如果不相交,则跳过
- 如果相交,则合并两项
+
## 关键点解析
- 对数组进行排序简化操作
-- 如果不排序,需要借助一些hack,这里不介绍了
+- 如果不排序,需要借助一些 hack,这里不介绍了
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
-
-
/*
* @lc app=leetcode id=56 lang=javascript
*
@@ -56,7 +67,7 @@ function intersected(a, b) {
function mergeTwo(a, b) {
return [Math.min(a[0], b[0]), Math.max(a[1], b[1])];
}
-var merge = function(intervals) {
+var merge = function (intervals) {
// 这种算法需要先排序
intervals.sort((a, b) => a[0] - b[0]);
for (let i = 0; i < intervals.length - 1; i++) {
@@ -68,22 +79,24 @@ var merge = function(intervals) {
intervals[i + 1] = mergeTwo(cur, next);
}
}
- return intervals.filter(q => q);
+ return intervals.filter((q) => q);
};
```
+
Python3 Code:
+
```Python
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
"""先排序,后合并"""
if len(intervals) <= 1:
return intervals
-
+
# 排序
def get_first(a_list):
return a_list[0]
intervals.sort(key=get_first)
-
+
# 合并
res = [intervals[0]]
for i in range(1, len(intervals)):
@@ -91,10 +104,11 @@ class Solution:
res[-1] = [res[-1][0], max(res[-1][1], intervals[i][1])]
else:
res.append(intervals[i])
-
+
return res
```
-***复杂度分析***
+**_复杂度分析_**
+
- 时间复杂度:由于采用了排序,因此复杂度大概为 $O(NlogN)$
- 空间复杂度:$O(N)$
diff --git a/problems/560.subarray-sum-equals-k.en.md b/problems/560.subarray-sum-equals-k.en.md
new file mode 100644
index 000000000..31141e4e9
--- /dev/null
+++ b/problems/560.subarray-sum-equals-k.en.md
@@ -0,0 +1,146 @@
+## Problem
+
+https://leetcode.com/problems/subarray-sum-equals-k/description/
+
+## Problem Description
+
+```
+Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
+
+Example 1:
+Input:nums = [1,1,1], k = 2
+Output: 2
+Note:
+The length of the array is in range [1, 20,000].
+The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
+```
+
+## Solution
+
+The simplest method is `Brute-force`. Consider every possible subarray, find the sum of the elements of each of those subarrays and check for the equality of the sum with `k`. Whenever the sum equals `k`, we increment the `count`. Time Complexity is O(n^2). Implementation is as followed.
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ for j in range(i, n):
+ if (sum(nums[i:j + 1]) == k): cnt += 1
+ return cnt
+```
+
+If we implement the `sum()` method on our own, we get the time of complexity O(n^3).
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ for j in range(i, n):
+ sum = 0
+ for x in range(i, j + 1):
+ sum += nums[x]
+ if (sum == k): cnt += 1
+ return cnt
+```
+
+At first glance I think "maybe it can be solved by using the sliding window technique". However, I give that thought up when I find out that the given array may contain negative numbers, which makes it more complicated to expand or narrow the range of the sliding window. Then I think about using a prefix sum array, with which we can obtain the sum of the elements between every two indices by subtracting the prefix sum corresponding to the two indices. It sounds feasible, so I implement it as followed.
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ pre = [0] * (n + 1)
+ for i in range(1, n + 1):
+ pre[i] = pre[i - 1] + nums[i - 1]
+ for i in range(1, n + 1):
+ for j in range(i, n + 1):
+ if (pre[j] - pre[i - 1] == k): cnt += 1
+ return cnt
+```
+
+Actually, there is a more clever way to do this. Instead of using a prefix sum array, we use a hashmap to reduce the time complexity to O(n).
+
+Algorithm:
+
+- We make use of a hashmap to store the cumulative sum `acc` and the number of times the same sum occurs. We use `acc` as the `key` of the hashmap and the number of times the same `acc` occurs as the `value`.
+
+- We traverse over the given array and keep on finding the cumulative sum `acc`. Every time we encounter a new `acc` we add a new entry to the hashmap. If the same `acc` occurs, we increment the count corresponding to that `acc` in the hashmap. If `acc` equals `k`, obviously `count` should be incremented. If `acc - k` got, we should increment `account` by `hashmap[acc - k]`.
+
+- The idea behind this is that if the cumulative sum upto two indices is the same, the sum of the elements between those two indices is zero. So if the cumulative sum upto two indices is at a different of `k`, the sum of the elements between those indices is `k`. As `hashmap[acc - k]` keeps track of the number of times a subarray with sum `acc - k` has occured upto the current index, by doing a simple substraction `acc - (acc - k)` we can see that `hashmap[acc - k]` actually also determines the number of times a subarray with sum `k` has occured upto the current index. So we increment the `count` by `hashmap[acc - k]`.
+
+Here is a graph demonstrating this algorithm in the case of `nums = [1,2,3,3,0,3,4,2], k = 6`.
+
+
+
+When we are at `nums[3]`, the hashmap is as the picture shows, and `count` is 2 by this time. `[1, 2, 3]` accounts for one of the count, and `[3, 3]` accounts for another.
+
+The subarray `[3, 3]` is obtained from `hashmap[acc - k]`, which is `hashmap[9 - 6]`.
+
+## Key Points
+
+- Prefix sum array
+- Make use of a hashmap to track cumulative sum and avoid repetitive calculation.
+
+## Code (`JavaScript/Python`)
+
+*JavaScript Code*
+```js
+/*
+ * @lc app=leetcode id=560 lang=javascript
+ *
+ * [560] Subarray Sum Equals K
+ */
+/**
+ * @param {number[]} nums
+ * @param {number} k
+ * @return {number}
+ */
+var subarraySum = function (nums, k) {
+ const hashmap = {};
+ let acc = 0;
+ let count = 0;
+
+ for (let i = 0; i < nums.length; i++) {
+ acc += nums[i];
+
+ if (acc === k) count++;
+
+ if (hashmap[acc - k] !== void 0) {
+ count += hashmap[acc - k];
+ }
+
+ if (hashmap[acc] === void 0) {
+ hashmap[acc] = 1;
+ } else {
+ hashmap[acc] += 1;
+ }
+ }
+
+ return count;
+};
+```
+
+*Python Cose*
+
+```py
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ d = {}
+ acc = count = 0
+ for num in nums:
+ acc += num
+ if acc == k:
+ count += 1
+ if acc - k in d:
+ count += d[acc-k]
+ if acc in d:
+ d[acc] += 1
+ else:
+ d[acc] = 1
+ return count
+```
+
+## Extension
+
+There is a similar but a bit more complicated problem. Link to the problem: [437.path-sum-iii](https://github.com/azl397985856/leetcode/blob/master/problems/437.path-sum-iii.md)(Chinese).
diff --git a/problems/560.subarray-sum-equals-k.md b/problems/560.subarray-sum-equals-k.md
index 3728ba25e..a8aabe182 100644
--- a/problems/560.subarray-sum-equals-k.md
+++ b/problems/560.subarray-sum-equals-k.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/subarray-sum-equals-k/description/
## 题目描述
+
```
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
@@ -13,31 +15,73 @@ The length of the array is in range [1, 20,000].
The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
```
+
+## 前置知识
+
+- 哈希表
+- 前缀和
+
+## 公司
+
+- 阿里
+- 腾讯
+- 字节
+
## 思路
-符合直觉的做法是暴力求解所有的子数组,然后分别计算和,如果等于k,count就+1.这种做法的时间复杂度为O(n^2).
-这里有一种更加巧妙的方法,我们可以借助额外的空间,使用hashmap来简化时间复杂度,这种算法的时间复杂度可以达到O(n).
+符合直觉的做法是暴力求解所有的子数组,然后分别计算和,如果等于 k,count 就+1.这种做法的时间复杂度为 O(n^2),代码如下:
+
+```python
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ for i in range(n):
+ sum = 0
+ for j in range(i, n):
+ sum += nums[j]
+ if (sum == k): cnt += 1
+ return cnt
+```
+
+实际上刚开始看到这题目的时候,我想“是否可以用滑动窗口解决?”。但是很快我就放弃了,因为看了下数组中项的取值范围有负数,这样我们扩张或者收缩窗口就比较复杂。第二个想法是前缀和,保存一个数组的前缀和,然后利用差分法得出任意区间段的和,这种想法是可行的,代码如下:
+
+```python
+class Solution:
+ def subarraySum(self, nums: List[int], k: int) -> int:
+ cnt, n = 0, len(nums)
+ pre = [0] * (n + 1)
+ for i in range(1, n + 1):
+ pre[i] = pre[i - 1] + nums[i - 1]
+ for i in range(1, n + 1):
+ for j in range(i, n + 1):
+ if (pre[j] - pre[i - 1] == k): cnt += 1
+ return cnt
+```
+
+这里有一种更加巧妙的方法,可以不使用前缀和数组,而是使用 hashmap 来简化时间复杂度,这种算法的时间复杂度可以达到 O(n).
+
+具体算法:
-我们维护一个hashmap,hashmap的key为累加值acc,value为累加值acc出现的次数。
-我们迭代数组,然后不断更新acc和hashmap,如果acc 等于k,那么很明显应该+1. 如果hashmap[acc - k] 存在,
-我们就把它加到结果中去即可。
+- 维护一个 hashmap,hashmap 的 key 为累加值 acc,value 为累加值 acc 出现的次数。
+- 迭代数组,然后不断更新 acc 和 hashmap,如果 acc 等于 k,那么很明显应该+1. 如果 hashmap[acc - k] 存在,我们就把它加到结果中去即可。
-语言比较难以解释,我画了一个图来演示nums = [1,2,3,3,0,3,4,2], k = 6的情况。
+语言比较难以解释,我画了一个图来演示 nums = [1,2,3,3,0,3,4,2], k = 6 的情况。
-
+
-如图,当访问到nums[3]的时候,hashmap如图所示,这个时候count为2.
+如图,当访问到 nums[3]的时候,hashmap 如图所示,这个时候 count 为 2.
其中之一是[1,2,3],这个好理解。还有一个是[3,3].
-这个[3,3]正是我们通过hashmap[acc - k]即hashmap[9 - 6]得到的。
+这个[3,3]正是我们通过 hashmap[acc - k]即 hashmap[9 - 6]得到的。
## 关键点解析
-- 可以利用hashmap记录和的累加值来避免重复计算
+- 前缀和
+- 可以利用 hashmap 记录和的累加值来避免重复计算
## 代码
-* 语言支持:JS, Python
+- 语言支持:JS, Python
Javascript Code:
@@ -52,7 +96,7 @@ Javascript Code:
* @param {number} k
* @return {number}
*/
-var subarraySum = function(nums, k) {
+var subarraySum = function (nums, k) {
const hashmap = {};
let acc = 0;
let count = 0;
diff --git a/problems/575.distribute-candies.md b/problems/575.distribute-candies.md
index 79202751c..4f321fae5 100644
--- a/problems/575.distribute-candies.md
+++ b/problems/575.distribute-candies.md
@@ -23,12 +23,21 @@ The length of the given array is in range [2, 10,000], and will be even.
The number in given array is in range [-100,000, 100,000].
```
+## 前置知识
+
+- [数组](https://github.com/azl397985856/leetcode/blob/master/thinkings/basic-data-structure.md)
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
由于糖果是偶数,并且我们只需要做到两个人糖果数量一样即可。
考虑两种情况:
-
+
- 如果糖果种类大于n / 2(糖果种类数为n),妹妹最多可以获得的糖果种类应该是`n / 2`(因为妹妹只有n / 2个糖).
- 糖果种类数小于n / 2, 妹妹能够得到的糖果种类可以是糖果的种类数(糖果种类本身就这么多).
@@ -69,3 +78,14 @@ class Solution:
def distributeCandies(self, candies: List[int]) -> int:
return min(len(set(candies)), len(candies) >> 1)
```
+
+**复杂度分析**
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(N)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/60.permutation-sequence.md b/problems/60.permutation-sequence.md
index c6706f076..3de364a8d 100644
--- a/problems/60.permutation-sequence.md
+++ b/problems/60.permutation-sequence.md
@@ -2,16 +2,18 @@
https://leetcode-cn.com/problems/permutation-sequence/description/
-## 标签
+## 前置知识
- 数学
- 回溯
-- 找规律
- factorial
## 公司
-Twitter
+- 阿里
+- 百度
+- 字节
+- Twitter
## 题目描述
diff --git a/problems/609.find-duplicate-file-in-system.md b/problems/609.find-duplicate-file-in-system.md
index 8b3ab5090..2ad737810 100644
--- a/problems/609.find-duplicate-file-in-system.md
+++ b/problems/609.find-duplicate-file-in-system.md
@@ -50,6 +50,10 @@ Follow-up beyond contest:
```
+## 前置知识
+
+- 哈希表
+
## 思路
思路就是hashtable去存储,key为文件内容,value为fullfilename,
遍历一遍去填充hashtable, 最后将hashtable中的值打印出来即可。
diff --git a/problems/611.valid-triangle-number.md b/problems/611.valid-triangle-number.md
new file mode 100644
index 000000000..9c30437ab
--- /dev/null
+++ b/problems/611.valid-triangle-number.md
@@ -0,0 +1,160 @@
+## 题目地址(611. 有效三角形的个数)
+
+https://leetcode-cn.com/problems/valid-triangle-number/
+
+## 题目描述
+
+```
+给定一个包含非负整数的数组,你的任务是统计其中可以组成三角形三条边的三元组个数。
+
+示例 1:
+
+输入: [2,2,3,4]
+输出: 3
+解释:
+有效的组合是:
+2,3,4 (使用第一个 2)
+2,3,4 (使用第二个 2)
+2,2,3
+注意:
+
+数组长度不超过1000。
+数组里整数的范围为 [0, 1000]。
+
+```
+
+## 前置知识
+
+- 排序
+- 双指针
+- 二分法
+- 三角形边的关系
+
+## 暴力法(超时)
+
+## 公司
+
+- 腾讯
+- 百度
+- 字节
+
+### 思路
+
+首先要有一个数学前提: `如果三条线段中任意两条的和都大于第三边,那么这三条线段可以组成一个三角形`。即给定三个线段 a,b,c,如果满足 a + b > c and a + c > b and b + c > a,则线段 a,b,c 可以构成三角形,否则不可以。
+
+力扣中有一些题目是需要一些数学前提的,不过这些数学前提都比较简单,一般不会超过高中数学知识,并且也不会特别复杂。一般都是小学初中知识即可。
+
+> 如果你在面试中碰到不知道的数学前提,可以寻求面试官提示试试。
+
+### 关键点解析
+
+- 三角形边的关系
+- 三层循环确定三个线段
+
+### 代码
+
+代码支持: Python
+
+```py
+class Solution:
+ def is_triangle(self, a, b, c):
+ if a == 0 or b == 0 or c == 0: return False
+ if a + b > c and a + c > b and b + c > a: return True
+ return False
+ def triangleNumber(self, nums: List[int]) -> int:
+ n = len(nums)
+ ans = 0
+ for i in range(n - 2):
+ for j in range(i + 1, n - 1):
+ for k in range(j + 1, n):
+ if self.is_triangle(nums[i], nums[j], nums[k]): ans += 1
+
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N ^ 3)$,其中 N 为 数组长度。
+- 空间复杂度:$O(1)$
+
+## 优化的暴力法
+
+### 思路
+
+暴力法的时间复杂度为 $O(N ^ 3)$, 其中 $N$ 最大为 1000。一般来说, $O(N ^ 3)$ 的算法在数据量 <= 500 是可以 AC 的。1000 的数量级则需要考虑 $O(N ^ 2)$ 或者更好的解法。
+
+OK,到这里了。我给大家一个干货。 应该是其他博主不太会提的。原因可能是他们不知道, 也可能是他们觉得太小儿科不需要说。
+
+1. 由于前面我根据数据规模推测到到了解法的复杂度区间是 $N ^ 2$, $N ^ 2 * logN$,不可能是 $N$ (WHY?)。
+2. 降低时间复杂度的方法主要有: `空间换时间` 和 `排序换时间`(我们一般都是使用基于比较的排序方法)。而`排序换时间`仅仅在总体复杂度大于 $O(NlogN)$ 才适用(原因不用多说了吧?)。
+
+这里由于总体的时间复杂度是 $O(N ^ 3)$,因此我自然想到了`排序换时间`。当我们对 nums 进行一次排序之后,我发现:
+
+- is_triangle 函数有一些判断是无效的
+
+```py
+ def is_triangle(self, a, b, c):
+ if a == 0 or b == 0 or c == 0: return False
+ # a + c > b 和 b + c > a 是无效的判断,因为恒成立
+ if a + b > c and a + c > b and b + c > a: return True
+ return False
+```
+
+- 因此我们的目标变为找到`a + b > c`即可,因此第三层循环是可以提前退出的。
+
+```py
+for i in range(n - 2):
+ for j in range(i + 1, n - 1):
+ k = j + 1
+ while k < n and num[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+```
+
+- 这也仅仅是减枝而已,复杂度没有变化。通过进一步观察,发现 k 没有必要每次都从 j + 1 开始。而是从上次找到的 k 值开始就行。原因很简单, 当 nums[i] + nums[j] > nums[k] 时,我们想要找到下一个满足 nums[i] + nums[j] > nums[k] 的 新的 k 值,由于进行了排序,因此这个 k 肯定比之前的大(单调递增性),因此上一个 k 值之前的数都是无效的,可以跳过。
+
+```py
+for i in range(n - 2):
+ k = i + 2
+ for j in range(i + 1, n - 1):
+ while k < n and nums[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+```
+
+由于 K 不会后退,因此最内层循环总共最多执行 N 次,因此总的时间复杂度为 $O(N ^ 2)$。
+
+> 这个复杂度分析有点像单调栈,大家可以结合起来理解。
+
+### 关键点分析
+
+- 排序
+
+### 代码
+
+```py
+class Solution:
+ def triangleNumber(self, nums: List[int]) -> int:
+ n = len(nums)
+ ans = 0
+ nums.sort()
+ for i in range(n - 2):
+ if nums[i] == 0: continue
+ k = i + 2
+ for j in range(i + 1, n - 1):
+ while k < n and nums[i] + nums[j] > nums[k]:
+ k += 1
+ ans += k - j - 1
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N ^ 2)$
+- 空间复杂度:取决于排序算法
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/62.unique-paths.md b/problems/62.unique-paths.md
index 8076e82de..4e6ce882b 100644
--- a/problems/62.unique-paths.md
+++ b/problems/62.unique-paths.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/unique-paths/description/
## 题目描述
+
```
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
@@ -11,7 +12,8 @@ The robot can only move either down or right at any point in time. The robot is
How many possible unique paths are there?
```
-
+
+
```
Above is a 7 x 3 grid. How many possible unique paths are there?
@@ -33,38 +35,35 @@ Input: m = 7, n = 3
Output: 28
```
+## 前置知识
+
+- 动态规划
+- 排列组合
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+首先这道题可以用排列组合的解法来解,需要一点高中的知识。
+
+
+
+而这道题我们用动态规划来解。
+
这是一道典型的适合使用动态规划解决的题目,它和爬楼梯等都属于动态规划中最简单的题目,因此也经常会被用于面试之中。
读完题目你就能想到动态规划的话,建立模型并解决恐怕不是难事。其实我们很容易看出,由于机器人只能右移动和下移动,
因此第[i, j]个格子的总数应该等于[i - 1, j] + [i, j -1], 因为第[i,j]个格子一定是从左边或者上面移动过来的。
-
+
代码大概是:
-JS Code:
-
-```js
- const dp = [];
- for (let i = 0; i < m + 1; i++) {
- dp[i] = [];
- dp[i][0] = 0;
- }
- for (let i = 0; i < n + 1; i++) {
- dp[0][i] = 0;
- }
- for (let i = 1; i < m + 1; i++) {
- for(let j = 1; j < n + 1; j++) {
- dp[i][j] = j === 1 ? 1 : dp[i - 1][j] + dp[i][j - 1]; // 转移方程
- }
- }
-
- return dp[m][n];
-
-```
-
Python Code:
```python
@@ -77,47 +76,47 @@ class Solution:
d[col][row] = d[col - 1][row] + d[col][row - 1]
return d[m - 1][n - 1]
- ```
-
- **复杂度分析**
-
- - 时间复杂度:$O(M * N)$
- - 空间复杂度:$O(M * N)$
+```
-由于dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到O(n).
+**复杂度分析**
-
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(M * N)$
-具体代码请查看代码区。
+由于 dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到 O(n).
+
+
+具体代码请查看代码区。
当然你也可以使用记忆化递归的方式来进行,由于递归深度的原因,性能比上面的方法差不少:
-> 直接暴力递归的话会超时。
+> 直接暴力递归的话可能会超时。
Python3 Code:
+
```python
class Solution:
- visited = dict()
-
+
+ @lru_cache
def uniquePaths(self, m: int, n: int) -> int:
- if (m, n) in self.visited:
- return self.visited[(m, n)]
if m == 1 or n == 1:
return 1
cnt = self.uniquePaths(m - 1, n) + self.uniquePaths(m, n - 1)
- self.visited[(m, n)] = cnt
return cnt
- ```
+```
+
## 关键点
+- 排列组合原理
- 记忆化递归
- 基本动态规划问题
-- 空间复杂度可以进一步优化到O(n), 这会是一个考点
+- 空间复杂度可以进一步优化到 O(n), 这会是一个考点
+
## 代码
-代码支持JavaScript,Python3
+代码支持 JavaScript,Python3
JavaScript Code:
@@ -134,13 +133,13 @@ JavaScript Code:
* @param {number} n
* @return {number}
*/
-var uniquePaths = function(m, n) {
+var uniquePaths = function (m, n) {
const dp = Array(n).fill(1);
-
- for(let i = 1; i < m; i++) {
- for(let j = 1; j < n; j++) {
+
+ for (let i = 1; i < m; i++) {
+ for (let j = 1; j < n; j++) {
dp[j] = dp[j] + dp[j - 1];
- }
+ }
}
return dp[n - 1];
@@ -160,12 +159,18 @@ class Solution:
return dp[n - 1]
```
- **复杂度分析**
-
- - 时间复杂度:$O(M * N)$
- - 空间复杂度:$O(N)$
-
- ## 扩展
-
- 你可以做到比$O(M * N)$更快,比$O(N)$更省内存的算法么?这里有一份[资料](https://leetcode.com/articles/unique-paths/)可供参考。
- > 提示: 考虑数学
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(N)$
+
+## 扩展
+
+你可以做到比$O(M * N)$更快,比$O(N)$更省内存的算法么?这里有一份[资料](https://leetcode.com/articles/unique-paths/)可供参考。
+
+> 提示: 考虑数学
+
+## 相关题目
+
+- [70. 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs/)
+- [63. 不同路径 II](./63.unique-paths-ii.md)
diff --git a/problems/63.unique-paths-ii.md b/problems/63.unique-paths-ii.md
new file mode 100644
index 000000000..4a04b939f
--- /dev/null
+++ b/problems/63.unique-paths-ii.md
@@ -0,0 +1,144 @@
+## 题目地址
+
+https://leetcode-cn.com/problems/unique-paths-ii/
+
+## 题目描述
+
+```
+
+一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
+
+机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
+
+现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
+```
+
+
+
+```
+网格中的障碍物和空位置分别用 1 和 0 来表示。
+
+说明:m 和 n 的值均不超过 100。
+
+示例 1:
+
+输入:
+[
+ [0,0,0],
+ [0,1,0],
+ [0,0,0]
+]
+输出: 2
+解释:
+3x3 网格的正中间有一个障碍物。
+从左上角到右下角一共有 2 条不同的路径:
+1. 向右 -> 向右 -> 向下 -> 向下
+2. 向下 -> 向下 -> 向右 -> 向右
+
+```
+
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+这是一道典型的适合使用动态规划解决的题目,它和爬楼梯等都属于动态规划中最简单的题目,因此也经常会被用于面试之中。
+
+读完题目你就能想到动态规划的话,建立模型并解决恐怕不是难事。其实我们很容易看出,由于机器人只能右移动和下移动,
+因此第[i, j]个格子的总数应该等于[i - 1, j] + [i, j -1], 因为第[i,j]个格子一定是从左边或者上面移动过来的。
+
+
+
+dp[i][j] 表示 到格子 obstacleGrid[i - 1][j - 1] 的所有路径数。
+
+由于有障碍物的存在, 因此我们的路径有了限制,具体来说就是:`如果当前各自是障碍物, 那么 dp[i][j] = 0`。否则 dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+
+代码大概是:
+
+Python Code:
+
+```python
+class Solution:
+ def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
+ m = len(obstacleGrid)
+ n = len(obstacleGrid[0])
+ if obstacleGrid[0][0]:
+ return 0
+
+ dp = [[0] * (n + 1) for _ in range(m + 1)]
+ dp[1][1] = 1
+
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if i == 1 and j == 1:
+ continue
+ if obstacleGrid[i - 1][j - 1] == 0:
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+ else:
+ dp[i][j] = 0
+ return dp[m][n]
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(M * N)$
+
+由于 dp[i][j] 只依赖于左边的元素和上面的元素,因此空间复杂度可以进一步优化, 优化到 O(n).
+
+
+
+具体代码请查看代码区。
+
+当然你也可以使用记忆化递归的方式来进行,由于递归深度的原因,性能比上面的方法差不少。
+
+> 直接暴力递归的话会超时。
+
+## 关键点
+
+- 记忆化递归
+- 基本动态规划问题
+- 空间复杂度可以进一步优化到 O(n), 这会是一个考点
+
+## 代码
+
+代码支持 Python3
+
+Python3 Code:
+
+```python
+class Solution:
+ def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
+ m = len(obstacleGrid)
+ n = len(obstacleGrid[0])
+ if obstacleGrid[0][0]:
+ return 0
+
+ dp = [0] * (n + 1)
+ dp[1] = 1
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if obstacleGrid[i - 1][j - 1] == 0:
+ dp[j] += dp[j - 1]
+ else:
+ dp[j] = 0
+ return dp[-1]
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(M * N)$
+- 空间复杂度:$O(N)$
+
+## 相关题目
+
+- [70. 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs/)
+- [62. 不同路径](./62.unique-paths.md)
diff --git a/problems/718.maximum-length-of-repeated-subarray.md b/problems/718.maximum-length-of-repeated-subarray.md
new file mode 100644
index 000000000..dfe06b8c5
--- /dev/null
+++ b/problems/718.maximum-length-of-repeated-subarray.md
@@ -0,0 +1,88 @@
+## 题目地址(718. 最长重复子数组)
+
+https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray/
+
+## 题目描述
+
+```
+给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
+
+示例 1:
+
+输入:
+A: [1,2,3,2,1]
+B: [3,2,1,4,7]
+输出: 3
+解释:
+长度最长的公共子数组是 [3, 2, 1]。
+说明:
+
+1 <= len(A), len(B) <= 1000
+0 <= A[i], B[i] < 100
+```
+
+## 前置知识
+
+- 哈希表
+- 数组
+- 二分查找
+- 动态规划
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路
+
+这就是最经典的最长公共子序列问题。一般这种求解**两个数组或者字符串求最大或者最小**的题目都可以考虑动态规划,并且通常都定义 dp[i][j] 为 `以 A[i], B[j] 结尾的 xxx`。这道题就是:`以 A[i], B[j] 结尾的两个数组中公共的、长度最长的子数组的长度`。 算法很简单:
+
+- 双层循环找出所有的 i, j 组合,时间复杂度 $O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+ - 如果 A[i] == B[j],dp[i][j] = dp[i - 1][j - 1] + 1
+ - 否则,dp[i][j] = 0
+- 循环过程记录最大值即可。
+
+## 关键点解析
+
+- dp 建模套路
+
+## 代码
+
+代码支持:Python
+
+Python Code:
+
+```py
+class Solution:
+ def findLength(self, A, B):
+ m, n = len(A), len(B)
+ ans = 0
+ dp = [[0 for _ in range(n + 1)] for _ in range(m + 1)]
+ for i in range(1, m + 1):
+ for j in range(1, n + 1):
+ if A[i - 1] == B[j - 1]:
+ dp[i][j] = dp[i - 1][j - 1] + 1
+ ans = max(ans, dp[i][j])
+ return ans
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+- 空间复杂度:$O(m * n)$,其中 m 和 n 分别为 A 和 B 的 长度。
+
+## 更多
+
+- [你的衣服我扒了 - 《最长公共子序列》](https://lucifer.ren/blog/2020/07/01/LCS/)
+
+## 扩展
+
+二分查找也是可以的,不过并不容易想到,大家可以试试。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/721.accounts-merge.md b/problems/721.accounts-merge.md
index cb9ac8929..e4bde5c2d 100644
--- a/problems/721.accounts-merge.md
+++ b/problems/721.accounts-merge.md
@@ -27,6 +27,14 @@ accounts 的长度将在[1,1000]的范围内。
accounts[i]的长度将在[1,10]的范围内。
accounts[i][j]的长度将在[1,30]的范围内。
+## 前置知识
+
+- 并查集
+
+## 公司
+
+- 字节
+
## 思路
我们抛开 name 不管。 我们只根据 email 建立并查集即可。这样一个连通分量中的 email 就是一个人,我们在用一个 hashtable 记录 email 和 name 的映射,将其输出即可。
@@ -75,4 +83,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/73.set-matrix-zeroes.md b/problems/73.set-matrix-zeroes.md
index 6509cec85..51ea285f4 100644
--- a/problems/73.set-matrix-zeroes.md
+++ b/problems/73.set-matrix-zeroes.md
@@ -43,19 +43,29 @@ Follow up:
```
+## 前置知识
+
+- 状态压缩
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
符合直觉的想法是,使用一个 m + n 的数组来表示每一行每一列是否”全部是 0“,
先遍历一遍去构建这样的 m + n 数组,然后根据这个 m + n 数组去修改 matrix 即可。
-
+
这样的时间复杂度 O(m \* n), 空间复杂度 O(m + n).
代码如下:
```js
-var setZeroes = function(matrix) {
+var setZeroes = function (matrix) {
if (matrix.length === 0) return matrix;
const m = matrix.length;
const n = matrix[0].length;
@@ -90,32 +100,33 @@ var setZeroes = function(matrix) {
};
```
-但是这道题目还有一个follow up, 要求使用O(1)的时间复杂度。因此上述的方法就不行了。
-但是我们要怎么去存取这些信息(哪一行哪一列应该全部为0)呢?
+但是这道题目还有一个 follow up, 要求使用 O(1)的时间复杂度。因此上述的方法就不行了。
+但是我们要怎么去存取这些信息(哪一行哪一列应该全部为 0)呢?
-一种思路是使用第一行第一列的数据来代替上述的zeros数组。 这样我们就不必借助额外的存储空间,空间复杂度自然就是O(1)了。
+一种思路是使用第一行第一列的数据来代替上述的 zeros 数组。 这样我们就不必借助额外的存储空间,空间复杂度自然就是 O(1)了。
-由于我们不能先操作第一行和第一列, 因此我们需要记录下”第一行和第一列是否全是0“这样的一个数据,最后根据这个信息去
+由于我们不能先操作第一行和第一列, 因此我们需要记录下”第一行和第一列是否全是 0“这样的一个数据,最后根据这个信息去
修改第一行和第一列。
具体步骤如下:
-- 记录下”第一行和第一列是否全是0“这样的一个数据
-- 遍历除了第一行和第一列之外的所有的数据,如果是0,那就更新第一行第一列中对应的元素为0
-> 你可以把第一行第一列看成我们上面那种解法使用的m + n 数组。
-- 根据第一行第一列的数据,更新matrix
-- 最后根据我们最开始记录的”第一行和第一列是否全是0“去更新第一行和第一列即可
-
-
+- 记录下”第一行和第一列是否全是 0“这样的一个数据
+- 遍历除了第一行和第一列之外的所有的数据,如果是 0,那就更新第一行第一列中对应的元素为 0
+ > 你可以把第一行第一列看成我们上面那种解法使用的 m + n 数组。
+- 根据第一行第一列的数据,更新 matrix
+- 最后根据我们最开始记录的”第一行和第一列是否全是 0“去更新第一行和第一列即可
+
## 关键点
-- 使用第一行和第一列来替代我们m + n 数组
-- 先记录下”第一行和第一列是否全是0“这样的一个数据,否则会因为后续对第一行第一列的更新造成数据丢失
+
+- 使用第一行和第一列来替代我们 m + n 数组
+- 先记录下”第一行和第一列是否全是 0“这样的一个数据,否则会因为后续对第一行第一列的更新造成数据丢失
- 最后更新第一行第一列
+
## 代码
-* 语言支持:JS,Python3
+- 语言支持:JS,Python3
```js
/*
@@ -127,7 +138,7 @@ var setZeroes = function(matrix) {
* @param {number[][]} matrix
* @return {void} Do not return anything, modify matrix in-place instead.
*/
-var setZeroes = function(matrix) {
+var setZeroes = function (matrix) {
if (matrix.length === 0) return matrix;
const m = matrix.length;
const n = matrix[0].length;
@@ -178,9 +189,11 @@ var setZeroes = function(matrix) {
return matrix;
};
```
+
Python3 Code:
-直接修改第一行和第一列为0的解法:
+直接修改第一行和第一列为 0 的解法:
+
```python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
@@ -190,16 +203,16 @@ class Solution:
def setRowZeros(matrix: List[List[int]], i:int) -> None:
C = len(matrix[0])
matrix[i] = [0] * C
-
+
def setColZeros(matrix: List[List[int]], j:int) -> None:
R = len(matrix)
for i in range(R):
matrix[i][j] = 0
-
+
isCol = False
R = len(matrix)
C = len(matrix[0])
-
+
for i in range(R):
if matrix[i][0] == 0:
isCol = True
@@ -210,17 +223,18 @@ class Solution:
for j in range(1, C):
if matrix[0][j] == 0:
setColZeros(matrix, j)
-
+
for i in range(R):
if matrix[i][0] == 0:
setRowZeros(matrix, i)
-
+
if isCol:
setColZeros(matrix, 0)
```
-另一种方法是用一个特殊符合标记需要改变的结果,只要这个特殊标记不在我们的题目数据范围(0和1)即可,这里用None。
+另一种方法是用一个特殊符合标记需要改变的结果,只要这个特殊标记不在我们的题目数据范围(0 和 1)即可,这里用 None。
+
```python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
diff --git a/problems/75.sort-colors.md b/problems/75.sort-colors.md
index 1282b9ec1..8fc9f9541 100644
--- a/problems/75.sort-colors.md
+++ b/problems/75.sort-colors.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/sort-colors/description/
## 题目描述
+
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the same color are adjacent, with the colors in the order red, white and blue.
Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively.
@@ -18,12 +20,26 @@ A rather straight forward solution is a two-pass algorithm using counting sort.
First, iterate the array counting number of 0's, 1's, and 2's, then overwrite array with total number of 0's, then 1's and followed by 2's.
Could you come up with a one-pass algorithm using only constant space?
+## 前置知识
+
+- [荷兰国旗问题](https://en.wikipedia.org/wiki/Dutch_national_flag_problem)
+- 排序
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+
这个问题是典型的荷兰国旗问题 (https://en.wikipedia.org/wiki/Dutch_national_flag_problem)。 因为我们可以将红白蓝三色小球想象成条状物,有序排列后正好组成荷兰国旗。
有两种解决思路。
## 解法一
+
- 遍历数组,统计红白蓝三色球(0,1,2)的个数
- 根据红白蓝三色球(0,1,2)的个数重排数组
@@ -31,15 +47,14 @@ Could you come up with a one-pass algorithm using only constant space?
## 解法二
-我们可以把数组分成三部分,前部(全部是0),中部(全部是1)和后部(全部是2)三个部分。每一个元素(红白蓝分别对应0、1、2)必属于其中之一。将前部和后部各排在数组的前边和后边,中部自然就排好了。
+我们可以把数组分成三部分,前部(全部是 0),中部(全部是 1)和后部(全部是 2)三个部分。每一个元素(红白蓝分别对应 0、1、2)必属于其中之一。将前部和后部各排在数组的前边和后边,中部自然就排好了。
-我们用三个指针,设置两个指针begin指向前部的末尾的下一个元素(刚开始默认前部无0,所以指向第一个位置),end指向后部开头的前一个位置(刚开始默认后部无2,所以指向最后一个位置),然后设置一个遍历指针current,从头开始进行遍历。
+我们用三个指针,设置两个指针 begin 指向前部的末尾的下一个元素(刚开始默认前部无 0,所以指向第一个位置),end 指向后部开头的前一个位置(刚开始默认后部无 2,所以指向最后一个位置),然后设置一个遍历指针 current,从头开始进行遍历。
这种思路的时间复杂度也是$O(n)$, 只需要遍历数组一次。
### 关键点解析
-
- 荷兰国旗问题
- counting sort
@@ -49,7 +64,7 @@ Could you come up with a one-pass algorithm using only constant space?
Python3 Code:
-``` python
+```python
class Solution:
def sortColors(self, nums: List[int]) -> None:
"""
@@ -57,7 +72,7 @@ class Solution:
"""
p0 = cur = 0
p2 = len(nums) - 1
-
+
while cur <= p2:
if nums[cur] == 0:
nums[cur], nums[p0] = nums[p0], nums[cur]
@@ -69,5 +84,3 @@ class Solution:
else:
cur += 1
```
-
-
diff --git a/problems/78.subsets-en.md b/problems/78.subsets-en.md
new file mode 100644
index 000000000..dcafa79fc
--- /dev/null
+++ b/problems/78.subsets-en.md
@@ -0,0 +1,136 @@
+## Problem Link
+https://leetcode.com/problems/subsets/description/
+
+## Description
+```
+Given a set of distinct integers, nums, return all possible subsets (the power set).
+
+Note: The solution set must not contain duplicate subsets.
+
+Example:
+
+Input: nums = [1,2,3]
+Output:
+[
+ [3],
+ [1],
+ [2],
+ [1,2,3],
+ [1,3],
+ [2,3],
+ [1,2],
+ []
+]
+
+
+```
+
+## Solution
+
+Since this problem is seeking `Subset` not `Extreme Value`, dynamic programming is not an ideal solution. Other approaches should be taken into our consideration.
+
+Actually, there is a general approach to solve problems similar to this one -- backtracking. Given a [Code Template](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)) here, it demonstrates how backtracking works with varieties of problems. Apart from current one, many problems can be solved by such a general approach. For more details, please check the `Related Problems` section below.
+
+Given a picture as followed, let's start with problem-solving ideas of this general solution.
+
+
+
+See Code Template details below.
+
+## Key Points
+
+- Backtrack Approach
+- Backtrack Code Template/ Formula
+
+
+## Code
+
+* Supported Language:JS,C++
+
+JavaScript Code:
+```js
+
+/*
+ * @lc app=leetcode id=78 lang=javascript
+ *
+ * [78] Subsets
+ *
+ * https://leetcode.com/problems/subsets/description/
+ *
+ * algorithms
+ * Medium (51.19%)
+ * Total Accepted: 351.6K
+ * Total Submissions: 674.8K
+ * Testcase Example: '[1,2,3]'
+ *
+ * Given a set of distinct integers, nums, return all possible subsets (the
+ * power set).
+ *
+ * Note: The solution set must not contain duplicate subsets.
+ *
+ * Example:
+ *
+ *
+ * Input: nums = [1,2,3]
+ * Output:
+ * [
+ * [3],
+ * [1],
+ * [2],
+ * [1,2,3],
+ * [1,3],
+ * [2,3],
+ * [1,2],
+ * []
+ * ]
+ *
+ */
+function backtrack(list, tempList, nums, start) {
+ list.push([...tempList]);
+ for(let i = start; i < nums.length; i++) {
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
+}
+/**
+ * @param {number[]} nums
+ * @return {number[][]}
+ */
+var subsets = function(nums) {
+ const list = [];
+ backtrack(list, [], nums, 0);
+ return list;
+};
+```
+C++ Code:
+```C++
+class Solution {
+public:
+ vector> subsets(vector& nums) {
+ auto ret = vector>();
+ auto tmp = vector();
+ backtrack(ret, tmp, nums, 0);
+ return ret;
+ }
+
+ void backtrack(vector>& list, vector& tempList, vector& nums, int start) {
+ list.push_back(tempList);
+ for (auto i = start; i < nums.size(); ++i) {
+ tempList.push_back(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop_back();
+ }
+ }
+};
+```
+
+## Related Problems
+
+- [39.combination-sum](./39.combination-sum.md)(chinese)
+- [40.combination-sum-ii](./40.combination-sum-ii.md)(chinese)
+- [46.permutations](./46.permutations.md)(chinese)
+- [47.permutations-ii](./47.permutations-ii.md)(chinese)
+- [90.subsets-ii](./90.subsets-ii-en.md)
+- [113.path-sum-ii](./113.path-sum-ii.md)(chinese)
+- [131.palindrome-partitioning](./131.palindrome-partitioning.md)(chinese)
diff --git a/problems/78.subsets.md b/problems/78.subsets.md
index 00a8864fb..72176ebf8 100644
--- a/problems/78.subsets.md
+++ b/problems/78.subsets.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/subsets/description/
## 题目描述
+
```
Given a set of distinct integers, nums, return all possible subsets (the power set).
@@ -26,18 +27,31 @@ Output:
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 每一层灰色的部分,表示当前有哪些节点是可以选择的, 红色部分则是选择路径。1,2,3,4,5,6 则分别表示我们的 6 个子集。
通用写法的具体代码见下方代码区。
@@ -46,14 +60,13 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持:JS,C++
+- 语言支持:JS,C++
JavaScript Code:
-```js
+```js
/*
* @lc app=leetcode id=78 lang=javascript
*
@@ -69,12 +82,12 @@ JavaScript Code:
*
* Given a set of distinct integers, nums, return all possible subsets (the
* power set).
- *
+ *
* Note: The solution set must not contain duplicate subsets.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Input: nums = [1,2,3]
* Output:
* [
@@ -87,27 +100,29 @@ JavaScript Code:
* [1,2],
* []
* ]
- *
+ *
*/
function backtrack(list, tempList, nums, start) {
- list.push([...tempList]);
- for(let i = start; i < nums.length; i++) {
- tempList.push(nums[i]);
- backtrack(list, tempList, nums, i + 1);
- tempList.pop();
- }
+ list.push([...tempList]);
+ for (let i = start; i < nums.length; i++) {
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var subsets = function(nums) {
- const list = [];
- backtrack(list, [], nums, 0);
- return list;
+var subsets = function (nums) {
+ const list = [];
+ backtrack(list, [], nums, 0);
+ return list;
};
```
+
C++ Code:
+
```C++
class Solution {
public:
@@ -117,7 +132,7 @@ public:
backtrack(ret, tmp, nums, 0);
return ret;
}
-
+
void backtrack(vector>& list, vector& tempList, vector& nums, int start) {
list.push_back(tempList);
for (auto i = start; i < nums.size(); ++i) {
@@ -138,5 +153,3 @@ public:
- [90.subsets-ii](./90.subsets-ii.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
- [131.palindrome-partitioning](./131.palindrome-partitioning.md)
-
-
diff --git a/problems/785.is-graph-bipartite.md b/problems/785.is-graph-bipartite.md
new file mode 100644
index 000000000..d2086dc99
--- /dev/null
+++ b/problems/785.is-graph-bipartite.md
@@ -0,0 +1,114 @@
+## 题目地址(785. 判断二分图)
+
+https://leetcode-cn.com/problems/is-graph-bipartite/
+
+## 题目描述
+
+```
+给定一个无向图 graph,当这个图为二分图时返回 true。
+
+如果我们能将一个图的节点集合分割成两个独立的子集 A 和 B,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B 集合,我们就将这个图称为二分图。
+
+graph 将会以邻接表方式给出,graph[i]表示图中与节点 i 相连的所有节点。每个节点都是一个在 0 到 graph.length-1 之间的整数。这图中没有自环和平行边: graph[i] 中不存在 i,并且 graph[i]中没有重复的值。
+
+示例 1:
+输入: [[1,3], [0,2], [1,3], [0,2]]
+输出: true
+解释:
+无向图如下:
+0----1
+| |
+| |
+3----2
+我们可以将节点分成两组: {0, 2} 和 {1, 3}。
+
+示例 2:
+输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
+输出: false
+解释:
+无向图如下:
+0----1
+| \ |
+| \ |
+3----2
+我们不能将节点分割成两个独立的子集。
+注意:
+
+graph 的长度范围为 [1, 100]。
+graph[i] 中的元素的范围为 [0, graph.length - 1]。
+graph[i] 不会包含 i 或者有重复的值。
+图是无向的: 如果 j 在 graph[i]里边, 那么 i 也会在 graph[j]里边。
+```
+
+## 前置知识
+
+- 图的遍历
+- DFS
+
+## 公司
+
+- 暂无
+
+## 思路
+
+和 886 思路一样。 我甚至**直接拿过来 dfs 函数一行代码没改就 AC 了**。
+
+唯一需要调整的地方是 graph 。 我将其转换了一下,具体可以看代码,非常简单易懂。
+
+具体算法:
+
+- 设置一个长度为 N 的数组 colors,colors[i] 表示 节点 i 的颜色,0 表示无颜色, 1 表示一种颜色, - 1 表示另一种颜色。
+- 初始化 colors 全部为 0
+- 构图(这里有邻接矩阵) 使得 grid[i][j] 表示 i 和 j 是否有连接(这里用 0 表示无, 1 表示有)
+- 遍历图。
+ - 如果当前节点未染色,则染色,不妨染为颜色 1
+ - 递归遍历其邻居
+ - 如果邻居没有染色, 则染为另一种颜色。即 color \* - 1,其中 color 为当前节点的颜色
+ - 否则,判断当前节点和邻居的颜色是否一致,不一致则返回 False,否则返回 True
+
+强烈建议两道题一起练习一下。
+
+## 关键点
+
+- 图的建立和遍历
+- colors 数组
+
+## 代码
+
+```py
+class Solution:
+ def dfs(self, grid, colors, i, color, N):
+ colors[i] = color
+ for j in range(N):
+ if grid[i][j] == 1:
+ if colors[j] == color:
+ return False
+ if colors[j] == 0 and not self.dfs(grid, colors, j, -1 * color, N):
+ return False
+ return True
+
+ def isBipartite(self, graph: List[List[int]]) -> bool:
+ N = len(graph)
+ grid = [[0] * N for _ in range(N)]
+ colors = [0] * N
+ for i in range(N):
+ for j in graph[i]:
+ grid[i][j] = 1
+ for i in range(N):
+ if colors[i] == 0 and not self.dfs(grid, colors, i, 1, N):
+ return False
+ return True
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N)$
+
+## 相关问题
+
+- [886. 可能的二分法](./886.possible-bipartition.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/79.word-search-en.md b/problems/79.word-search-en.md
index ed3e745fe..b1910c371 100644
--- a/problems/79.word-search-en.md
+++ b/problems/79.word-search-en.md
@@ -40,7 +40,7 @@ board, word:`SEE` as below pic:
as below pic:
```
-
+
Staring position(1,0), check whether adjacent cells match word next letter `E`.
```
@@ -52,7 +52,7 @@ Staring position(1,0), check whether adjacent cells match word next letter `
as below pic:
```
-
+
Didn't find matching from starting position, so
```
@@ -61,7 +61,7 @@ Didn't find matching from starting position, so
as below pic:
```
-
+
New starting position(1,3),check whether adjacent cells match word next letter `E`.
```
@@ -73,7 +73,7 @@ New starting position(1,3),check whether adjacent cells match word next
as below pic:
```
-
+
Start position(0,3), DFS,check whether adjacent cells match word next letter `E`
```
@@ -85,7 +85,7 @@ Start position(0,3), DFS,check whether adjacent cells match word next lett
as below pic:
```
-
+
Start from position(0,3)not matching word, start position (2, 3) DFS search:
```
@@ -98,10 +98,10 @@ Start from position(0,3)not matching word, start position (2, 3) DFS searc
as below pic:
```
-
+
Found match with word, return `True`.
-
+
#### Complexity Analysis
- *Time Complexity:* `O(m*n) - m is number of board rows, n is number of board columns `
@@ -120,8 +120,9 @@ Found match with word, return `True`.
```java
public class LC79WordSearch {
public boolean exist(char[][] board, String word) {
- if (board == null || board.length == 0 || board[0].length == 0
- || word == null || word.length() == 0) return true;
+ if (board == null || word == null) return false;
+ if (word.length() == 0) return true;
+ if (board.length == 0) return false;
int rows = board.length;
int cols = board[0].length;
for (int r = 0; r < rows; r++) {
@@ -239,4 +240,4 @@ var exist = function(board, word) {
```
## References
-1. [Backtracking Wiki](https://www.wikiwand.com/en/Backtracking)
\ No newline at end of file
+1. [Backtracking Wiki](https://www.wikiwand.com/en/Backtracking)
diff --git a/problems/79.word-search.md b/problems/79.word-search.md
index 99adc5d7b..8cc7630d7 100644
--- a/problems/79.word-search.md
+++ b/problems/79.word-search.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/word-search/
## 题目描述
+
```
Given a 2D board and a word, find if the word exists in the grid.
@@ -21,44 +23,62 @@ Given word = "SEE", return true.
Given word = "ABCB", return false.
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-在2D表中搜索是否有满足给定单词的字符组合,要求所有字符都是相邻的(方向不限). 题中也没有要求字符的起始和结束位置。
+在 2D 表中搜索是否有满足给定单词的字符组合,要求所有字符都是相邻的(方向不限). 题中也没有要求字符的起始和结束位置。
-在起始位置不确定的情况下,扫描二维数组,找到字符跟给定单词的第一个字符相同的,四个方向(上,下,左,右)分别DFS搜索,
+在起始位置不确定的情况下,扫描二维数组,找到字符跟给定单词的第一个字符相同的,四个方向(上,下,左,右)分别 DFS 搜索,
如果任意方向满足条件,则返回结果。不满足,回溯,重新搜索。
举例说明:如图二维数组,单词:"SEE"
+
```
1. 扫描二维数组,找到board[1,0] = word[0],匹配单词首字母。
2. 做DFS(上,下,左,右 四个方向)
如下图:
```
-
+
+
起始位置(1,0),判断相邻的字符是否匹配单词下一个字符 `E`.
+
```
1. 标记当前字符(1,0)为已经访问过,board[1][0] = '*'
-2. 上(0,0)字符为 'A' 不匹配,
+2. 上(0,0)字符为 'A' 不匹配,
3. 下(2,0)字符为 'A',不匹配,
4. 左(-1,0)超越边界,不匹配,
5. 右(1,1)字符 'F',不匹配
如下图:
```
-
-由于从起始位置DFS都不满足条件,所以
+
+
+由于从起始位置 DFS 都不满足条件,所以
+
```
-1. 回溯,标记起始位置(1,0)为未访问。board[1][0] = 'S'.
+1. 回溯,标记起始位置(1,0)为未访问。board[1][0] = 'S'.
2. 然后继续扫描二维数组,找到下一个起始位置(1,3)
如下图:
```
-
+
+
起始位置(1,3),判断相邻的字符是否匹配单词下一个字符 `E`.
+
```
1. 标记当前字符(1, 3)为已经访问过,board[1][3] = '*'
2. 上(0,3)字符为 'E', 匹配, 继续DFS搜索(参考位置为(0,3)位置DFS搜索步骤描述)
@@ -68,9 +88,11 @@ Given word = "ABCB", return false.
如下图:
```
-
-位置(0,3)满足条件,继续DFS,判断相邻的字符是否匹配单词下一个字符 `E`
+
+
+位置(0,3)满足条件,继续 DFS,判断相邻的字符是否匹配单词下一个字符 `E`
+
```
1. 标记当前字符(0,3)为已经访问过,board[0][3] = '*'
2. 上 (-1,3)超越边界,不匹配
@@ -80,11 +102,13 @@ Given word = "ABCB", return false.
如下图
```
-
-从位置(0,3)DFS不满足条件,继续位置(2,3)DFS搜索
+
+
+从位置(0,3)DFS 不满足条件,继续位置(2,3)DFS 搜索
+
```
-1. 回溯,标记起始位置(0,3)为未访问。board[0][3] = 'E'.
+1. 回溯,标记起始位置(0,3)为未访问。board[0][3] = 'E'.
2. 回到满足条件的位置(2,3),继续DFS搜索,判断相邻的字符是否匹配单词下一个字符 'E'
3. 上 (1,3)已访问过
4. 下(3,3)超越边界,不匹配
@@ -93,34 +117,40 @@ Given word = "ABCB", return false.
如下图:
```
-
+
+
单词匹配完成,满足条件,返回 `True`.
-
+
#### 复杂度分析
-- *时间复杂度:* `O(m*n) - m 是二维数组行数, n 是二维数组列数`
-- *空间复杂度:* `O(1) - 这里在原数组中标记当前访问过,没有用到额外空间`
->**注意**:如果用 Set 或者是 boolean[][]来标记字符位置是否已经访问过,需要额外的空间 `O(m*n)`.
+- _时间复杂度:_ `O(m*n) - m 是二维数组行数, n 是二维数组列数`
+- _空间复杂度:_ `O(1) - 这里在原数组中标记当前访问过,没有用到额外空间`
+
+> **注意**:如果用 Set 或者是 boolean[][]来标记字符位置是否已经访问过,需要额外的空间 `O(m*n)`.
## 关键点分析
-- 遍历二维数组的每一个点,找到起始点相同的字符,做DFS
-- DFS过程中,要记录已经访问过的节点,防止重复遍历,这里(Java Code中)用 `*` 表示当前已经访问过,也可以用Set或者是boolean[][]数组记录访问过的节点位置。
-- 是否匹配当前单词中的字符,不符合回溯,这里记得把当前 `*` 重新设为当前字符。如果用Set或者是boolean[][]数组,记得把当前位置重设为没有访问过。
+
+- 遍历二维数组的每一个点,找到起始点相同的字符,做 DFS
+- DFS 过程中,要记录已经访问过的节点,防止重复遍历,这里(Java Code 中)用 `*` 表示当前已经访问过,也可以用 Set 或者是 boolean[][]数组记录访问过的节点位置。
+- 是否匹配当前单词中的字符,不符合回溯,这里记得把当前 `*` 重新设为当前字符。如果用 Set 或者是 boolean[][]数组,记得把当前位置重设为没有访问过。
## 代码 (`Java/Javascript/Python3`)
-*Java Code*
+
+_Java Code_
+
```java
public class LC79WordSearch {
public boolean exist(char[][] board, String word) {
- if (board == null || board.length == 0 || board[0].length == 0
- || word == null || word.length() == 0) return true;
+ if (board == null || word == null) return false;
+ if (word.length() == 0) return true;
+ if (board.length == 0) return false;
int rows = board.length;
int cols = board[0].length;
for (int r = 0; r < rows; r++) {
for (int c = 0; c < cols; c++) {
- // scan board, start with word first character
+ // scan board, start with word first character
if (board[r][c] == word.charAt(0)) {
if (helper(board, word, r, c, 0)) {
return true;
@@ -130,7 +160,7 @@ public class LC79WordSearch {
}
return false;
}
-
+
private boolean helper(char[][] board, String word, int r, int c, int start) {
// already match word all characters, return true
if (start == word.length()) return true;
@@ -146,20 +176,21 @@ public class LC79WordSearch {
board[r][c] = word.charAt(start);
return res;
}
-
+
private boolean isValid(char[][] board, int r, int c) {
return r >= 0 && r < board.length && c >= 0 && c < board[0].length;
}
}
```
-*Python3 Code*
+_Python3 Code_
+
```python
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
n = len(board[0])
-
+
def dfs(board, r, c, word, index):
if index == len(word):
return True
@@ -169,7 +200,7 @@ class Solution:
res = dfs(board, r - 1, c, word, index + 1) or dfs(board, r + 1, c, word, index + 1) or dfs(board, r, c - 1, word, index + 1) or dfs(board, r, c + 1, word, index + 1)
board[r][c] = word[index]
return res
-
+
for r in range(m):
for c in range(n):
if board[r][c] == word[0]:
@@ -177,7 +208,8 @@ class Solution:
return True
```
-*Javascript Code* from [**@lucifer**](https://github.com/azl397985856)
+_Javascript Code_ from [**@lucifer**](https://github.com/azl397985856)
+
```javascript
/*
* @lc app=leetcode id=79 lang=javascript
@@ -197,7 +229,7 @@ function DFS(board, row, col, rows, cols, word, cur) {
// 如果你用hashmap记录访问的字母, 那么你需要每次backtrack的时候手动清除hashmap,并且需要额外的空间
// 这里我们使用一个little trick
-
+
board[row][col] = null;
// 上下左右
@@ -216,7 +248,7 @@ function DFS(board, row, col, rows, cols, word, cur) {
* @param {string} word
* @return {boolean}
*/
-var exist = function(board, word) {
+var exist = function (board, word) {
if (word.length === 0) return true;
if (board.length === 0) return false;
@@ -234,4 +266,5 @@ var exist = function(board, word) {
```
## 参考(References)
-1. [回溯法 Wiki](https://www.wikiwand.com/zh/%E5%9B%9E%E6%BA%AF%E6%B3%95)
\ No newline at end of file
+
+1. [回溯法 Wiki](https://www.wikiwand.com/zh/%E5%9B%9E%E6%BA%AF%E6%B3%95)
diff --git a/problems/80.remove-duplicates-from-sorted-array-ii.md b/problems/80.remove-duplicates-from-sorted-array-ii.md
index 1d2efee91..455f7943a 100644
--- a/problems/80.remove-duplicates-from-sorted-array-ii.md
+++ b/problems/80.remove-duplicates-from-sorted-array-ii.md
@@ -42,11 +42,21 @@ for (int i = 0; i < len; i++) {
```
+## 前置知识
+
+- 双指针
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
”删除排序“类题目截止到现在(2020-1-15)一共有四道题:
-
+
这道题是[26.remove-duplicates-from-sorted-array](./26.remove-duplicates-from-sorted-array.md) 的进阶版本,唯一的不同是不再是全部元素唯一,而是全部元素不超过 2 次。实际上这种问题可以更抽象一步,即“删除排序数组中的重复项,使得相同数字最多出现 k 次”
。 那么这道题 k 就是 2, 26.remove-duplicates-from-sorted-array 的 k 就是 1。
@@ -62,9 +72,9 @@ for (int i = 0; i < len; i++) {
图解(红色的两个数字,表示我们需要比较的两个数字):
-
+
-
+
## 关键点分析
@@ -99,8 +109,8 @@ class Solution:
- 82. 删除排序链表中的重复元素 II
-
+
- 83. 删除排序链表中的重复元素
-
+
diff --git a/problems/820.short-encoding-of-words.md b/problems/820.short-encoding-of-words.md
index 037765ec2..594070833 100644
--- a/problems/820.short-encoding-of-words.md
+++ b/problems/820.short-encoding-of-words.md
@@ -1,6 +1,6 @@
## 题目地址(820. 单词的压缩编码)
-https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
+https://leetcode-cn.com/problems/short-encoding-of-words/
## 题目描述
@@ -30,15 +30,24 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
```
+## 前置知识
+
+- 前缀树
+
+## 公司
+
+- 阿里
+- 字节
## 思路
-读完题目之后就发现这题是一个后缀树。 因此符合直觉的想法是使用前缀树 + 倒序插入的形式来模拟后缀树。
+读完题目之后就发现如果将列表中每一个单词分别倒序就是一个后缀树问题。比如 `["time", "me", "bell"]` 倒序之后就是 ["emit", "em", "lleb"],我们要求的结果无非就是 "emit" 的长度 + "llem"的长度 + "##"的长度(em 和 emit 有公共前缀,计算一个就好了)。
+因此符合直觉的想法是使用前缀树 + 倒序插入的形式来模拟后缀树。
-下面的代码看起来复杂,但是很多题目我都是用这个模板,稍微调整下细节就能AC。我这里总结了一套[前缀树专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)
+下面的代码看起来复杂,但是很多题目我都是用这个模板,稍微调整下细节就能 AC。我这里总结了一套[前缀树专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)
-
+
前缀树的 api 主要有以下几个:
@@ -50,13 +59,11 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
一个前缀树大概是这个样子:
-
-
+
如图每一个节点存储一个字符,然后外加一个控制信息表示是否是单词结尾,实际使用过程可能会有细微差别,不过变化不大。
-
-这道题需要考虑edge case, 比如这个列表是 ["time", "time", "me", "bell"] 这种包含重复元素的情况,这里我使用hashset来去重。
+这道题需要考虑 edge case, 比如这个列表是 ["time", "time", "me", "bell"] 这种包含重复元素的情况,这里我使用 hashset 来去重。
## 关键点
@@ -87,7 +94,7 @@ class Trie:
curr = curr[w]
curr['#'] = 1
- def isTail(self, word):
+ def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
@@ -96,6 +103,10 @@ class Trie:
curr = self.Trie
for w in word:
curr = curr[w]
+ # len(curr) == 1 means we meet '#'
+ # when we search 'em'(which reversed from 'me')
+ # the result is len(curr) > 1
+ # cause the curr look like { '#': 1, i: {...}}
return len(curr) == 1
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
@@ -105,17 +116,26 @@ class Solution:
for word in words:
trie.insert(word[::-1])
for word in words:
- if trie.isTail(word[::-1]):
+ if trie.search(word[::-1]):
cnt += len(word) + 1
return cnt
```
-***复杂度分析***
-- 时间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
-- 空间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+**_复杂度分析_**
+
+- 时间复杂度:$O(N)$,其中 N 为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+- 空间复杂度:$O(N)$,其中 N 为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
+
+大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+
-
+## 相关题目
+- [0208.implement-trie-prefix-tree](./208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](./211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](./212.word-search-ii.md)
+- [0472.concatenated-words](./472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
diff --git a/problems/84.largest-rectangle-in-histogram.md b/problems/84.largest-rectangle-in-histogram.md
index 8b618f837..d4e38f5a6 100644
--- a/problems/84.largest-rectangle-in-histogram.md
+++ b/problems/84.largest-rectangle-in-histogram.md
@@ -9,11 +9,11 @@ https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
求在该柱状图中,能够勾勒出来的矩形的最大面积。
-
+
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
-
+
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
@@ -22,8 +22,19 @@ https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
输入:[2,1,5,6,2,3]
输出:10
+## 前置知识
+
+- 单调栈
+
## 暴力枚举 - 左右端点法(TLE)
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
### 思路
我们暴力尝试`所有可能的矩形`。由于矩阵是二维图形, 我我们可以使用`左右两个端点来唯一确认一个矩阵`。因此我们使用双层循环枚举所有的可能性即可。 而矩形的面积等于`(右端点坐标 - 左端点坐标 + 1) * 最小的高度`,最小的高度我们可以在遍历的时候顺便求出。
@@ -130,7 +141,11 @@ class Solution:
实际上,读完第二种方法的时候,你应该注意到了。我们的核心是求左边第一个比 i 小的和右边第一个比 i 小的。 如果你熟悉单调栈的话,那么应该会想到这是非常适合使用单调栈来处理的场景。
-为了简单起见,我在 heights 首尾添加了两个哨兵元素,这样可以减少边界处理的额外代码。
+从左到右遍历柱子,对于每一个柱子,我们想找到第一个高度小于它的柱子,那么我们就可以使用一个单调递增栈来实现。 如果柱子大于栈顶的柱子,那么说明不是我们要找的柱子,我们把它塞进去继续遍历,如果比栈顶小,那么我们就找到了第一个小于的柱子。 **对于栈顶元素,其右边第一个小于它的就是当前遍历到的柱子,左边第一个小于它的就是栈中下一个要被弹出的元素**,因此以当前栈顶为最小柱子的面积为**当前栈顶的柱子高度 \* (当前遍历到的柱子索引 - 1 - 栈中下一个要被弹出的元素索引 - 1 + 1)**
+
+这种方法只需要遍历一次,并用一个栈。由于每一个元素最多进栈出栈一次,因此时间和空间复杂度都是$O(N)$。
+
+为了统一算法逻辑,减少边界处理,我在 heights 首尾添加了两个哨兵元素,**这样我们可以保证所有的柱子都会出栈**。
### 代码
@@ -150,6 +165,30 @@ class Solution:
- 时间复杂度:$O(N)$
- 空间复杂度:$O(N)$
+2020-05-30 更新:
+
+有的观众反应看不懂为啥需要两个哨兵。 其实末尾的哨兵就是为了将栈清空,防止遍历完成栈中还有没参与运算的数据。
+
+而前面的哨兵有什么用呢? 我这里把上面代码进行了拆解:
+
+```py
+class Solution:
+ def largestRectangleArea(self, heights: List[int]) -> int:
+ n, heights, st, ans = len(heights),[0] + heights + [0], [], 0
+ for i in range(n + 2):
+ while st and heights[st[-1]] > heights[i]:
+ a = heights[st[-1]]
+ # 如果没有前面的哨兵,这里可能会越界。
+ st.pop()
+ ans = max(ans, a * (i - 1 - st[-1]))
+ st.append(i)
+ return ans
+```
+
+## 相关题目
+
+- [42.trapping-rain-water](https://github.com/azl397985856/leetcode/blob/master/problems/42.trapping-rain-water.md)
+
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/85.maximal-rectangle.md b/problems/85.maximal-rectangle.md
index 78e259399..e6d36059c 100644
--- a/problems/85.maximal-rectangle.md
+++ b/problems/85.maximal-rectangle.md
@@ -4,11 +4,12 @@ https://leetcode-cn.com/problems/maximal-rectangle/
## 题目描述
-给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
+给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例:
输入:
+
```
[
["1","0","1","0","0"],
@@ -17,8 +18,20 @@ https://leetcode-cn.com/problems/maximal-rectangle/
["1","0","0","1","0"]
]
```
+
输出:6
+## 前置知识
+
+- 单调栈
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
我在 [【84. 柱状图中最大的矩形】多种方法(Python3)](https://leetcode-cn.com/problems/largest-rectangle-in-histogram/solution/84-zhu-zhuang-tu-zhong-zui-da-de-ju-xing-duo-chong/ "【84. 柱状图中最大的矩形】多种方法(Python3)") 使用了多种方法来解决。 然而在这道题,我们仍然可以使用完全一样的思路去完成。 不熟悉的可以看下我的题解。本题解是基于那道题的题解来进行的。
@@ -36,7 +49,7 @@ https://leetcode-cn.com/problems/maximal-rectangle/
我们逐行扫描得到 `84. 柱状图中最大的矩形` 中的 heights 数组:
-
+
这样我们就可以使用`84. 柱状图中最大的矩形` 中的解法来进行了,这里我们使用单调栈来解。
@@ -70,9 +83,10 @@ class Solution:
```
**复杂度分析**
+
- 时间复杂度:$O(M * N)$
- 空间复杂度:$O(N)$
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
\ No newline at end of file
+
diff --git a/problems/86.partition-list.md b/problems/86.partition-list.md
index 12b07ed87..719e2523f 100644
--- a/problems/86.partition-list.md
+++ b/problems/86.partition-list.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/partition-list/description/
## 题目描述
+
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
You should preserve the original relative order of the nodes in each of the two partitions.
@@ -11,30 +13,41 @@ Example:
Input: head = 1->4->3->2->5->2, x = 3
Output: 1->2->2->4->3->5
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
-- 设定两个虚拟节点,dummyHead1用来保存小于该值的链表,dummyHead2来保存大于等于该值的链表
+- 设定两个虚拟节点,dummyHead1 用来保存小于该值的链表,dummyHead2 来保存大于等于该值的链表
-- 遍历整个原始链表,将小于该值的放于dummyHead1中,其余的放置在dummyHead2中
+- 遍历整个原始链表,将小于该值的放于 dummyHead1 中,其余的放置在 dummyHead2 中
-遍历结束后,将dummyHead2插入到dummyHead1后面
+遍历结束后,将 dummyHead2 插入到 dummyHead1 后面
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
## 关键点解析
- 链表的基本操作(遍历)
-- 虚拟节点dummy 简化操作
+- 虚拟节点 dummy 简化操作
- 遍历完成之后记得`currentL1.next = null;`否则会内存溢出
-> 如果单纯的遍历是不需要上面操作的,但是我们的遍历会导致currentL1.next和currentL2.next
-中有且仅有一个不是null, 如果不这么操作的话会导致两个链表成环,造成溢出。
-
+> 如果单纯的遍历是不需要上面操作的,但是我们的遍历会导致 currentL1.next 和 currentL2.next
+> 中有且仅有一个不是 null, 如果不这么操作的话会导致两个链表成环,造成溢出。
## 代码
-* 语言支持: Javascript,Python3
+- 语言支持: Javascript,Python3
```js
/*
@@ -52,17 +65,17 @@ Output: 1->2->2->4->3->5
*
* Given a linked list and a value x, partition it such that all nodes less
* than x come before nodes greater than or equal to x.
- *
+ *
* You should preserve the original relative order of the nodes in each of the
* two partitions.
- *
+ *
* Example:
- *
- *
+ *
+ *
* Input: head = 1->4->3->2->5->2, x = 3
* Output: 1->2->2->4->3->5
- *
- *
+ *
+ *
*/
/**
* Definition for singly-linked list.
@@ -76,38 +89,40 @@ Output: 1->2->2->4->3->5
* @param {number} x
* @return {ListNode}
*/
-var partition = function(head, x) {
- const dummyHead1 = {
- next: null
+var partition = function (head, x) {
+ const dummyHead1 = {
+ next: null,
+ };
+ const dummyHead2 = {
+ next: null,
+ };
+
+ let current = {
+ next: head,
+ };
+ let currentL1 = dummyHead1;
+ let currentL2 = dummyHead2;
+ while (current.next) {
+ current = current.next;
+ if (current.val < x) {
+ currentL1.next = current;
+ currentL1 = current;
+ } else {
+ currentL2.next = current;
+ currentL2 = current;
}
- const dummyHead2 = {
- next: null
- }
-
- let current = {
- next: head
- };
- let currentL1 = dummyHead1;
- let currentL2 = dummyHead2;
- while(current.next) {
- current = current.next;
- if (current.val < x) {
- currentL1.next = current;
- currentL1 = current;
- } else {
- currentL2.next = current;
- currentL2 = current;
- }
- }
-
- currentL2.next = null;
-
- currentL1.next = dummyHead2.next;
+ }
+
+ currentL2.next = null;
- return dummyHead1.next;
+ currentL1.next = dummyHead2.next;
+
+ return dummyHead1.next;
};
```
+
Python3 Code:
+
```python
class Solution:
def partition(self, head: ListNode, x: int) -> ListNode:
@@ -121,7 +136,7 @@ class Solution:
sep_node = first_node
pre_node = first_node
current_node = head
-
+
while current_node is not None:
if current_node.val < x:
# 注意有可能出现前一个节点就是分离节点的情况
@@ -139,6 +154,6 @@ class Solution:
else:
pre_node = current_node
current_node = pre_node.next
-
+
return first_node.next
```
diff --git a/problems/874.walking-robot-simulation.md b/problems/874.walking-robot-simulation.md
index f2ed8b1d7..32d4514a8 100644
--- a/problems/874.walking-robot-simulation.md
+++ b/problems/874.walking-robot-simulation.md
@@ -43,6 +43,14 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
```
+## 前置知识
+
+- hashtable
+
+## 公司
+
+- 暂无
+
## 思路
这道题之所以是简单难度,是因为其没有什么技巧。你只需要看懂题目描述,然后把题目描述转化为代码即可。
@@ -65,13 +73,13 @@ https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
为了代码书写简单,我建立了一个直角坐标系。用`机器人的朝向和 x 轴正方向的夹角度数`来作为枚举值,并且这个度数是 `0 <= deg < 360`。我们不难知道,其实这个取值就是`0`, `90`,`180`,`270` 四个值。那么当 0 度的时候,我们只需要不断地 x+1,90 度的时候我们不断地 y + 1 等等。
-
+
## 关键点解析
- 理解题意,这道题容易理解错题意,求解为`最终位置距离原点的距离`
- 建立坐标系
-- 使用集合简化线形查找的时间复杂度。
+- 空间换时间
## 代码
@@ -116,3 +124,14 @@ class Solution:
ans = max(ans, pos[0] ** 2 + pos[1] ** 2)
return ans
```
+
+**复杂度分析**
+- 时间复杂度:$O(N * M)$, 其中 N 为 commands 的长度, M 为 commands 数组的平均值。
+- 空间复杂度:$O(obstacles)$
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经35K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
diff --git a/problems/875.koko-eating-bananas.md b/problems/875.koko-eating-bananas.md
index 197effc57..68aa950d4 100644
--- a/problems/875.koko-eating-bananas.md
+++ b/problems/875.koko-eating-bananas.md
@@ -1,48 +1,57 @@
-## 题目地址
-https://leetcode.com/problems/koko-eating-bananas/description/
+## 题目地址(875. 爱吃香蕉的珂珂)
+https://leetcode-cn.com/problems/koko-eating-bananas/description/
## 题目描述
```
-Koko loves to eat bananas. There are N piles of bananas, the i-th pile has piles[i] bananas. The guards have gone and will come back in H hours.
+珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
-Koko can decide her bananas-per-hour eating speed of K. Each hour, she chooses some pile of bananas, and eats K bananas from that pile. If the pile has less than K bananas, she eats all of them instead, and won't eat any more bananas during this hour.
+珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
-Koko likes to eat slowly, but still wants to finish eating all the bananas before the guards come back.
+珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
-Return the minimum integer K such that she can eat all the bananas within H hours.
+返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
-
+
-Example 1:
+示例 1:
-Input: piles = [3,6,7,11], H = 8
-Output: 4
-Example 2:
+输入: piles = [3,6,7,11], H = 8
+输出: 4
+示例 2:
-Input: piles = [30,11,23,4,20], H = 5
-Output: 30
-Example 3:
+输入: piles = [30,11,23,4,20], H = 5
+输出: 30
+示例 3:
-Input: piles = [30,11,23,4,20], H = 6
-Output: 23
-
+输入: piles = [30,11,23,4,20], H = 6
+输出: 23
+
-Note:
+提示:
1 <= piles.length <= 10^4
piles.length <= H <= 10^9
1 <= piles[i] <= 10^9
+
```
+## 前置知识
+
+- 二分查找
+
+## 公司
+
+- 字节
+
## 思路
-符合直觉的做法是,选择最大的堆的香蕉数,然后试一下能不能行,如果不行则直接返回上次计算的结果,
-如果行,我们减少1个香蕉,试试行不行,依次类推。计算出刚好不行的即可。这种解法的时间复杂度是O(n)。
+符合直觉的做法是,选择最大的堆的香蕉数,然后试一下能不能行,如果不行则直接返回上次计算的结果,如果行,我们减少1个香蕉,试试行不行,依次类推。计算出刚好不行的即可。这种解法的时间复杂度比较高,为 $O(N * M)$,其中 N 为 piles 长度, M 为 Piles 中最大的数。。
-这道题如果能看出来是二分法解决,那么其实很简单。为什么它是二分问题呢?
-我这里画了个图,我相信你看了就明白了。
+这道题如果能看出来是二分法解决,那么其实很简单。为什么它是二分问题呢?我这里画了个图,我相信你看了就明白了。
-
+
+
+> 香蕉堆的香蕉个数上限是 10^9, 珂珂这也太能吃了吧?
## 关键点解析
@@ -51,79 +60,36 @@ piles.length <= H <= 10^9
## 代码
+ 代码支持:Python,JavaScript
+
+ Python Code:
+
+```py
+class Solution:
+ def canEatAllBananas(self, piles, H, K):
+ t = 0
+ for pile in piles:
+ t += math.ceil(pile / K)
+ return t <= H
+ def minEatingSpeed(self, piles: List[int], H: int) -> int:
+ l, r = 1, max(piles)
+ # [l, r) , 左闭右开的好处是如果能找到,那么返回 l 和 r 都是一样的,因为最终 l 等于 r。
+ while l < r:
+ mid = (l + r) >> 1
+ if self.canEatAllBananas(piles, H, mid):
+ r = mid
+ else:
+ l = mid + 1
+ return l
+
+```
+
+
+ JavaScript Code:
+
```js
-/*
- * @lc app=leetcode id=875 lang=javascript
- *
- * [875] Koko Eating Bananas
- *
- * https://leetcode.com/problems/koko-eating-bananas/description/
- *
- * algorithms
- * Medium (44.51%)
- * Total Accepted: 11.3K
- * Total Submissions: 24.8K
- * Testcase Example: '[3,6,7,11]\n8'
- *
- * Koko loves to eat bananas. There are N piles of bananas, the i-th pile has
- * piles[i] bananas. The guards have gone and will come back in H hours.
- *
- * Koko can decide her bananas-per-hour eating speed of K. Each hour, she
- * chooses some pile of bananas, and eats K bananas from that pile. If the
- * pile has less than K bananas, she eats all of them instead, and won't eat
- * any more bananas during this hour.
- *
- * Koko likes to eat slowly, but still wants to finish eating all the bananas
- * before the guards come back.
- *
- * Return the minimum integer K such that she can eat all the bananas within H
- * hours.
- *
- *
- *
- *
- *
- *
- *
- * Example 1:
- *
- *
- * Input: piles = [3,6,7,11], H = 8
- * Output: 4
- *
- *
- *
- * Example 2:
- *
- *
- * Input: piles = [30,11,23,4,20], H = 5
- * Output: 30
- *
- *
- *
- * Example 3:
- *
- *
- * Input: piles = [30,11,23,4,20], H = 6
- * Output: 23
- *
- *
- *
- *
- * Note:
- *
- *
- * 1 <= piles.length <= 10^4
- * piles.length <= H <= 10^9
- * 1 <= piles[i] <= 10^9
- *
- *
- *
- *
- *
- */
- function canEatAllBananas(piles, H, mid) {
+function canEatAllBananas(piles, H, mid) {
let h = 0;
for(let pile of piles) {
h += Math.ceil(pile / mid);
@@ -139,7 +105,7 @@ piles.length <= H <= 10^9
var minEatingSpeed = function(piles, H) {
let lo = 1,
hi = Math.max(...piles);
-
+ // [l, r) , 左闭右开的好处是如果能找到,那么返回 l 和 r 都是一样的,因为最终 l 等于 r。
while(lo <= hi) {
let mid = lo + ((hi - lo) >> 1);
if (canEatAllBananas(piles, H, mid)) {
@@ -153,3 +119,98 @@ var minEatingSpeed = function(piles, H) {
};
```
+**复杂度分析**
+- 时间复杂度:$O(max(N, N * logM))$,其中 N 为 piles 长度, M 为 Piles 中最大的数。
+- 空间复杂度:$O(1)$
+
+## 模板
+
+分享几个常用的的二分法模板。
+
+
+### 查找一个数
+
+```java
+public int binarySearch(int[] nums, int target) {
+ // 左右都闭合的区间 [l, r]
+ int left = 0;
+ int right = nums.length - 1;
+
+ while(left <= right) {
+ int mid = left + (right - left) / 2;
+ if(nums[mid] == target)
+ return mid;
+ else if (nums[mid] < target)
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ else if (nums[mid] > target)
+ // 搜索区间变为 [left, mid - 1]
+ right = mid - 1;
+ }
+ return -1;
+}
+```
+
+### 寻找最左边的满足条件的值
+
+```java
+public int binarySearchLeft(int[] nums, int target) {
+ // 搜索区间为 [left, right]
+ int left = 0;
+ int right = nums.length - 1;
+ while (left <= right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] < target) {
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ // 搜索区间变为 [left, mid-1]
+ right = mid - 1;
+ } else if (nums[mid] == target) {
+ // 收缩右边界
+ right = mid - 1;
+ }
+ }
+ // 检查是否越界
+ if (left >= nums.length || nums[left] != target)
+ return -1;
+ return left;
+}
+```
+
+### 寻找最右边的满足条件的值
+
+```java
+public int binarySearchRight(int[] nums, int target) {
+ // 搜索区间为 [left, right]
+ int left = 0
+ int right = nums.length - 1;
+ while (left <= right) {
+ int mid = left + (right - left) / 2;
+ if (nums[mid] < target) {
+ // 搜索区间变为 [mid+1, right]
+ left = mid + 1;
+ } else if (nums[mid] > target) {
+ // 搜索区间变为 [left, mid-1]
+ right = mid - 1;
+ } else if (nums[mid] == target) {
+ // 收缩左边界
+ left = mid + 1;
+ }
+ }
+ // 检查是否越界
+ if (right < 0 || nums[right] != target)
+ return -1;
+ return right;
+}
+```
+
+> 如果题目重点不是二分,也就是说二分只是众多步骤中的一步,大家也可以直接调用语言的 API,比如 Python 的 bisect 模块。
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
+
+
diff --git a/problems/877.stone-game.md b/problems/877.stone-game.md
index 44468a876..f7dbe630a 100644
--- a/problems/877.stone-game.md
+++ b/problems/877.stone-game.md
@@ -36,6 +36,15 @@ sum(piles) is odd.
```
+## 前置知识
+
+- 动态规划
+
+## 公司
+
+- 阿里
+- 字节
+
## 思路
由于 piles 是偶数的,并且 piles 的总和是奇数的。
diff --git a/problems/88.merge-sorted-array.md b/problems/88.merge-sorted-array.md
index 9d7be9641..68f53cef6 100644
--- a/problems/88.merge-sorted-array.md
+++ b/problems/88.merge-sorted-array.md
@@ -20,23 +20,35 @@ nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
```
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+- loomberg
+- facebook
+- microsoft
+
+## 前置知识
+
+- 归并排序
+
## 思路
符合直觉的做法是`将nums2插到num1的末尾, 然后排序`
-
具体代码:
```js
- // 这种解法连m都用不到
- // 这显然不是出题人的意思
- if (n === 0) return;
- let current2 = 0;
- for(let i = nums1.length - 1; i >= nums1.length - n ; i--) {
- nums1[i] = nums2[current2++];
- }
- nums1.sort((a, b) => a - b); // 当然你可以自己写排序,这里懒得写了,因为已经偏离了题目本身
-
+// 这种解法连m都用不到
+// 这显然不是出题人的意思
+if (n === 0) return;
+let current2 = 0;
+for (let i = nums1.length - 1; i >= nums1.length - n; i--) {
+ nums1[i] = nums2[current2++];
+}
+nums1.sort((a, b) => a - b); // 当然你可以自己写排序,这里懒得写了,因为已经偏离了题目本身
```
这道题目其实和基本排序算法中的`merge sort`非常像,但是 merge sort 很多时候,合并的时候我们通常是
@@ -92,9 +104,9 @@ function merge(nums1, nums2) {
- 红色代表当前正在进行比较的元素
- 绿色代表已经就位的元素
-
-
-
+
+
+
## 关键点解析
@@ -104,11 +116,10 @@ function merge(nums1, nums2) {
代码支持:Python3, C++, JavaScript
-
JavaSCript Code:
```js
-var merge = function(nums1, m, nums2, n) {
+var merge = function (nums1, m, nums2, n) {
// 设置一个指针,指针初始化指向nums1的末尾(根据#62,应该是index为 m+n-1 的位置,因为nums1的长度有可能更长)
// 然后不断左移指针更新元素
let current = m + n - 1;
@@ -139,6 +150,7 @@ var merge = function(nums1, m, nums2, n) {
```
C++ code:
+
```
class Solution {
public:
@@ -162,6 +174,7 @@ public:
```
Python Code
+
```python
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
@@ -185,11 +198,11 @@ class Solution:
nums1[:n] = nums2[:n]
```
-
**复杂度分析**
+
- 时间复杂度:$O(M + N)$
- 空间复杂度:$O(1)$
-欢迎关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/886.possible-bipartition.md b/problems/886.possible-bipartition.md
new file mode 100644
index 000000000..c726e66c4
--- /dev/null
+++ b/problems/886.possible-bipartition.md
@@ -0,0 +1,151 @@
+## 题目地址(886. 可能的二分法)
+
+https://leetcode-cn.com/problems/is-graph-bipartite/
+
+## 题目描述
+
+```
+给定一组 N 人(编号为 1, 2, ..., N), 我们想把每个人分进任意大小的两组。
+
+每个人都可能不喜欢其他人,那么他们不应该属于同一组。
+
+形式上,如果 dislikes[i] = [a, b],表示不允许将编号为 a 和 b 的人归入同一组。
+
+当可以用这种方法将每个人分进两组时,返回 true;否则返回 false。
+
+
+
+示例 1:
+
+输入:N = 4, dislikes = [[1,2],[1,3],[2,4]]
+输出:true
+解释:group1 [1,4], group2 [2,3]
+示例 2:
+
+输入:N = 3, dislikes = [[1,2],[1,3],[2,3]]
+输出:false
+示例 3:
+
+输入:N = 5, dislikes = [[1,2],[2,3],[3,4],[4,5],[1,5]]
+输出:false
+
+
+提示:
+
+1 <= N <= 2000
+0 <= dislikes.length <= 10000
+dislikes[i].length == 2
+1 <= dislikes[i][j] <= N
+dislikes[i][0] < dislikes[i][1]
+对于dislikes[i] == dislikes[j] 不存在 i != j
+
+```
+
+## 前置知识
+
+- 图的遍历
+- DFS
+
+## 公司
+
+- 暂无
+
+## 思路
+
+这是一个图的问题。解决这种问题一般是要遍历图才行的,这也是图的套路。 那么遍历的话,你要有一个合适的数据结构。 比较常见的图存储方式是邻接矩阵和邻接表。
+
+而我们这里为了操作方便(代码量),直接使用邻接矩阵。由于是互相不喜欢,不存在一个喜欢另一个,另一个不喜欢一个的情况,因此这是无向图。而无向图邻接矩阵实际上是会浪费空间,具体看我下方画的图。
+
+而题目给我们的二维矩阵并不是现成的邻接矩阵形式,因此我们需要自己生成。
+
+我们用 1 表示互相不喜欢(dislike each other)。
+
+```py
+ graph = [[0] * N for i in range(N)]
+ for a, b in dislikes:
+ graph[a - 1][b - 1] = 1
+ graph[b - 1][a - 1] = 1
+```
+
+
+
+同时可以用 hashmap 或者数组存储 N 个人的分组情况, 业界关于这种算法一般叫染色法,因此我们命名为 colors,其实对应的本题叫 groups 更合适。
+
+
+
+我们用:
+
+- 0 表示没有分组
+- 1 表示分组 1
+- -1 表示分组 2
+
+之所以用 0,1,-1,而不是 0,1,2 是因为我们会在不能分配某一组的时候尝试分另外一组,这个时候有其中一组转变为另外一组就可以直接乘以-1,而 0,1,2 这种就稍微麻烦一点而已。
+
+具体算法:
+
+- 遍历每一个人,尝试给他们进行分组,比如默认分配组 1.
+
+
+
+- 然后遍历这个人讨厌的人,尝试给他们分另外一组,如果不可以分配另外一组,则返回 False
+
+那问题的关键在于如何判断“不可以分配另外一组”呢?
+
+
+
+实际上,我们已经用 colors 记录了分组信息,对于每一个人如果分组确定了,我们就更新 colors,那么对于一个人如果分配了一个组,并且他讨厌的人也被分组之后,**分配的组和它只能是一组**,那么“就是不可以分配另外一组”。
+
+代码表示就是:
+
+```py
+# 其中j 表示当前是第几个人,N表示总人数。 dfs的功能就是根据colors和graph分配组,true表示可以分,false表示不可以,具体代码见代码区。
+if colors[j] == 0 and not self.dfs(graph, colors, j, -1 * color, N)
+```
+
+## 关键点
+
+- 二分图
+- 染色法
+- 图的建立和遍历
+- colors 数组
+
+## 代码
+
+```py
+class Solution:
+ def dfs(self, graph, colors, i, color, N):
+ colors[i] = color
+ for j in range(N):
+ # dislike eachother
+ if graph[i][j] == 1:
+ if colors[j] == color:
+ return False
+ if colors[j] == 0 and not self.dfs(graph, colors, j, -1 * color, N):
+ return False
+ return True
+
+ def possibleBipartition(self, N: int, dislikes: List[List[int]]) -> bool:
+ graph = [[0] * N for i in range(N)]
+ colors = [0] * N
+ for a, b in dislikes:
+ graph[a - 1][b - 1] = 1
+ graph[b - 1][a - 1] = 1
+ for i in range(N):
+ if colors[i] == 0 and not self.dfs(graph, colors, i, 1, N):
+ return False
+ return True
+
+```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N^2)$
+- 空间复杂度:$O(N)$
+
+## 相关问题
+
+- [785. 判断二分图](785.is-graph-bipartite.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/887.super-egg-drop.md b/problems/887.super-egg-drop.md
index 2d6d9b463..2241474eb 100644
--- a/problems/887.super-egg-drop.md
+++ b/problems/887.super-egg-drop.md
@@ -1,29 +1,29 @@
-
## 题目地址
+
https://leetcode.com/problems/super-egg-drop/description/
## 题目描述
```
-You are given K eggs, and you have access to a building with N floors from 1 to N.
+You are given K eggs, and you have access to a building with N floors from 1 to N.
Each egg is identical in function, and if an egg breaks, you cannot drop it again.
You know that there exists a floor F with 0 <= F <= N such that any egg dropped at a floor higher than F will break, and any egg dropped at or below floor F will not break.
-Each move, you may take an egg (if you have an unbroken one) and drop it from any floor X (with 1 <= X <= N).
+Each move, you may take an egg (if you have an unbroken one) and drop it from any floor X (with 1 <= X <= N).
Your goal is to know with certainty what the value of F is.
What is the minimum number of moves that you need to know with certainty what F is, regardless of the initial value of F?
-
+
Example 1:
Input: K = 1, N = 2
Output: 2
-Explanation:
+Explanation:
Drop the egg from floor 1. If it breaks, we know with certainty that F = 0.
Otherwise, drop the egg from floor 2. If it breaks, we know with certainty that F = 1.
If it didn't break, then we know with certainty F = 2.
@@ -36,7 +36,7 @@ Example 3:
Input: K = 3, N = 14
Output: 4
-
+
Note:
@@ -46,84 +46,90 @@ Note:
```
+## 前置知识
+
+- 动态规划
+
## 思路
+> 本题已经重制,重制版更清晰 [《丢鸡蛋问题》重制版来袭~](https://lucifer.ren/blog/2020/06/08/887.super-egg-drop/)
+
这是一道典型的动态规划题目,但是又和一般的动态规划不一样。
拿题目给的例子为例,两个鸡蛋,六层楼,我们最少扔几次?
-
+
-一个符合直觉的做法是,建立dp[i][j], 代表i个鸡蛋,j层楼最少扔几次,然后我们取dp[K][N]即可。
+一个符合直觉的做法是,建立 dp[i][j], 代表 i 个鸡蛋,j 层楼最少扔几次,然后我们取 dp[K][n]即可。
代码大概这样的:
```js
- const dp = Array(K + 1);
- dp[0] = Array(N + 1).fill(0);
- for (let i = 1; i < K + 1; i++) {
- dp[i] = [0];
- for (let j = 1; j < N + 1; j++) {
- // 只有一个鸡蛋
- if (i === 1) {
- dp[i][j] = j;
- continue;
- }
- // 只有一层楼
- if (j === 1) {
- dp[i][j] = 1;
- continue;
- }
-
- // 每一层我们都模拟一遍
- const all = [];
- for (let k = 1; k < j + 1; k++) {
- const brokenCount = dp[i - 1][k - 1]; // 如果碎了
- const notBrokenCount = dp[i][j - k]; // 如果没碎
- all.push(Math.max(brokenCount, notBrokenCount)); // 最坏的可能
- }
- dp[i][j] = Math.min(...all) + 1; // 最坏的集合中我们取最好的情况
- }
+const dp = Array(K + 1);
+dp[0] = Array(N + 1).fill(0);
+for (let i = 1; i < K + 1; i++) {
+ dp[i] = [0];
+ for (let j = 1; j < N + 1; j++) {
+ // 只有一个鸡蛋
+ if (i === 1) {
+ dp[i][j] = j;
+ continue;
+ }
+ // 只有一层楼
+ if (j === 1) {
+ dp[i][j] = 1;
+ continue;
}
- return dp[K][N];
+ // 每一层我们都模拟一遍
+ const all = [];
+ for (let k = 1; k < j + 1; k++) {
+ const brokenCount = dp[i - 1][k - 1]; // 如果碎了
+ const notBrokenCount = dp[i][j - k]; // 如果没碎
+ all.push(Math.max(brokenCount, notBrokenCount)); // 最坏的可能
+ }
+ dp[i][j] = Math.min(...all) + 1; // 最坏的集合中我们取最好的情况
+ }
+}
+
+return dp[K][N];
```
果不其然,当我提交的时候,超时了。 这个的时复杂度是很高的,可以看到,我们内层暴力的求解所有可能,然后
-取最好的,这个过程非常耗时,大概是O(N^2 * K).
+取最好的,这个过程非常耗时,大概是 O(N^2 \* K).
-然后我看了一位leetcode[网友](https://leetcode.com/lee215/)的回答,
+然后我看了一位 leetcode[网友](https://leetcode.com/lee215/)的回答,
他的想法是`dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
我们按照他的思路重新建模:
-
+
可以看到右下角的部分根本就不需要计算,从而节省很多时间
-## 关键点解析
-- dp建模思路要发生变化, 即
-`dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
+## 关键点解析
+- dp 建模思路要发生变化, 即
+ `dp[M][K]means that, given K eggs and M moves,what is the maximum number of floor that we can check.`
## 代码
-
```js
/**
* @param {number} K
* @param {number} N
* @return {number}
*/
-var superEggDrop = function(K, N) {
+var superEggDrop = function (K, N) {
// 不选择dp[K][M]的原因是dp[M][K]可以简化操作
- const dp = Array(N + 1).fill(0).map(_ => Array(K + 1).fill(0))
-
+ const dp = Array(N + 1)
+ .fill(0)
+ .map((_) => Array(K + 1).fill(0));
+
let m = 0;
while (dp[m][K] < N) {
- m++;
- for (let k = 1; k <= K; ++k)
- dp[m][k] = dp[m - 1][k - 1] + 1 + dp[m - 1][k];
+ m++;
+ for (let k = 1; k <= K; ++k) dp[m][k] = dp[m - 1][k - 1] + 1 + dp[m - 1][k];
}
return m;
};
diff --git a/problems/895.maximum-frequency-stack.md b/problems/895.maximum-frequency-stack.md
index b7d4eb859..67521e180 100644
--- a/problems/895.maximum-frequency-stack.md
+++ b/problems/895.maximum-frequency-stack.md
@@ -46,27 +46,36 @@ pop() -> 返回 4 。
```
+## 前置知识
+
+- 栈
+- 哈希表
+
+## 公司
+
+- 暂无
+
## 思路
我们以题目给的例子来讲解。
- 使用fraq 来存储对应的数字出现次数。key 是数字,value频率
-
+
- 由于题目限制“如果最频繁的元素不只一个,则移除并返回最接近栈顶的元素。”,我们考虑使用栈来维护一个频率表 fraq_stack。key是频率,value是数字组成的栈。
-
+
- 同时用max_fraq 记录当前的最大频率值。
- 第一次pop的时候,我们最大的频率是3。由fraq_stack 知道我们需要pop掉5。
-
+
- 之后pop依次是这样的(红色数字表示顺序)
-
+
## 关键点解析
@@ -109,6 +118,6 @@ class FreqStack:
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
-
+
diff --git a/problems/90.subsets-ii-en.md b/problems/90.subsets-ii-en.md
new file mode 100644
index 000000000..e6b8c3b3c
--- /dev/null
+++ b/problems/90.subsets-ii-en.md
@@ -0,0 +1,166 @@
+## Problem Link
+
+https://leetcode.com/problems/subsets-ii/description/
+
+## Description
+```
+Given a collection of integers that might contain duplicates, nums, return all possible subsets (the power set).
+
+Note: The solution set must not contain duplicate subsets.
+
+Example:
+
+Input: [1,2,2]
+Output:
+[
+ [2],
+ [1],
+ [1,2,2],
+ [2,2],
+ [1,2],
+ []
+]
+
+```
+
+## Solution
+
+Since this problem is seeking `Subset` not `Extreme Value`, dynamic programming is not an ideal solution. Other approaches should be taken into our consideration.
+
+Actually, there is a general approach to solve problems similar to this one -- backtracking. Given a [Code Template](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)) here, it demonstrates how backtracking works with varieties of problems. Apart from current one, many problems can be solved by such a general approach. For more details, please check the `Related Problems` section below.
+
+Given a picture as followed, let's start with problem-solving ideas of this general solution.
+
+
+
+See Code Template details below.
+
+## Key Points
+
+- Backtrack Approach
+- Backtrack Code Template/ Formula
+
+## Code
+
+* Supported Language:JS,C++,Python3
+
+JavaScript Code:
+
+```js
+
+
+/*
+ * @lc app=leetcode id=90 lang=javascript
+ *
+ * [90] Subsets II
+ *
+ * https://leetcode.com/problems/subsets-ii/description/
+ *
+ * algorithms
+ * Medium (41.53%)
+ * Total Accepted: 197.1K
+ * Total Submissions: 469.1K
+ * Testcase Example: '[1,2,2]'
+ *
+ * Given a collection of integers that might contain duplicates, nums, return
+ * all possible subsets (the power set).
+ *
+ * Note: The solution set must not contain duplicate subsets.
+ *
+ * Example:
+ *
+ *
+ * Input: [1,2,2]
+ * Output:
+ * [
+ * [2],
+ * [1],
+ * [1,2,2],
+ * [2,2],
+ * [1,2],
+ * []
+ * ]
+ *
+ *
+ */
+function backtrack(list, tempList, nums, start) {
+ list.push([...tempList]);
+ for(let i = start; i < nums.length; i++) {
+ //nums can be duplicated, which is different from Problem 78 - subsets
+ //So the situation should be taken into consideration
+ if (i > start && nums[i] === nums[i - 1]) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1)
+ tempList.pop();
+ }
+}
+/**
+ * @param {number[]} nums
+ * @return {number[][]}
+ */
+var subsetsWithDup = function(nums) {
+ const list = [];
+ backtrack(list, [], nums.sort((a, b) => a - b), 0, [])
+ return list;
+};
+```
+C++ Code:
+
+```C++
+class Solution {
+private:
+ void subsetsWithDup(vector& nums, size_t start, vector& tmp, vector>& res) {
+ res.push_back(tmp);
+ for (auto i = start; i < nums.size(); ++i) {
+ if (i > start && nums[i] == nums[i - 1]) continue;
+ tmp.push_back(nums[i]);
+ subsetsWithDup(nums, i + 1, tmp, res);
+ tmp.pop_back();
+ }
+ }
+public:
+ vector> subsetsWithDup(vector& nums) {
+ auto tmp = vector();
+ auto res = vector>();
+ sort(nums.begin(), nums.end());
+ subsetsWithDup(nums, 0, tmp, res);
+ return res;
+ }
+};
+```
+Python Code:
+
+```Python
+class Solution:
+ def subsetsWithDup(self, nums: List[int], sorted: bool=False) -> List[List[int]]:
+ """Backtrack Approach: by sorting parameters first to avoid repeting sort later"""
+ if not nums:
+ return [[]]
+ elif len(nums) == 1:
+ return [[], nums]
+ else:
+ # Sorting first to filter duplicated numbers
+ # Note,this problem takes higher time complexity
+ # So, it could greatly improve time efficiency by adding one parameter to avoid repeting sort in following procedures
+ if not sorted:
+ nums.sort()
+ # Backtrack Approach
+ pre_lists = self.subsetsWithDup(nums[:-1], sorted=True)
+ all_lists = [i+[nums[-1]] for i in pre_lists] + pre_lists
+ # distinct elements
+ result = []
+ for i in all_lists:
+ if i not in result:
+ result.append(i)
+ return result
+```
+
+## Related Problems
+
+- [39.combination-sum](./39.combination-sum.md)(chinese)
+- [40.combination-sum-ii](./40.combination-sum-ii.md)(chinese)
+- [46.permutations](./46.permutations.md)(chinese)
+- [47.permutations-ii](./47.permutations-ii.md)(chinese)
+- [78.subsets](./78.subsets-en.md)
+- [113.path-sum-ii](./113.path-sum-ii.md)(chinese)
+- [131.palindrome-partitioning](./131.palindrome-partitioning.md)(chinese)
diff --git a/problems/90.subsets-ii.md b/problems/90.subsets-ii.md
index 36c2e845f..7ddd15724 100644
--- a/problems/90.subsets-ii.md
+++ b/problems/90.subsets-ii.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/subsets-ii/description/
## 题目描述
+
```
Given a collection of integers that might contain duplicates, nums, return all possible subsets (the power set).
@@ -23,18 +24,31 @@ Output:
```
+## 前置知识
+
+- 回溯
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目是求集合,并不是`求极值`,因此动态规划不是特别切合,因此我们需要考虑别的方法。
这种题目其实有一个通用的解法,就是回溯法。
网上也有大神给出了这种回溯法解题的
-[通用写法](https://leetcode.com/problems/combination-sum/discuss/16502/A-general-approach-to-backtracking-questions-in-Java-(Subsets-Permutations-Combination-Sum-Palindrome-Partitioning)),这里的所有的解法使用通用方法解答。
+[通用写法](),这里的所有的解法使用通用方法解答。
除了这道题目还有很多其他题目可以用这种通用解法,具体的题目见后方相关题目部分。
我们先来看下通用解法的解题思路,我画了一张图:
-
+
+
+> 图是 [78.subsets](https://github.com/azl397985856/leetcode/blob/master/problems/78.subsets.md),都差不多,仅做参考。
通用写法的具体代码见下方代码区。
@@ -43,71 +57,41 @@ Output:
- 回溯法
- backtrack 解题公式
-
## 代码
-* 语言支持:JS,C++,Python3
+- 语言支持:JS,C++,Python3
JavaScript Code:
```js
-
-
-/*
- * @lc app=leetcode id=90 lang=javascript
- *
- * [90] Subsets II
- *
- * https://leetcode.com/problems/subsets-ii/description/
- *
- * algorithms
- * Medium (41.53%)
- * Total Accepted: 197.1K
- * Total Submissions: 469.1K
- * Testcase Example: '[1,2,2]'
- *
- * Given a collection of integers that might contain duplicates, nums, return
- * all possible subsets (the power set).
- *
- * Note: The solution set must not contain duplicate subsets.
- *
- * Example:
- *
- *
- * Input: [1,2,2]
- * Output:
- * [
- * [2],
- * [1],
- * [1,2,2],
- * [2,2],
- * [1,2],
- * []
- * ]
- *
- *
- */
function backtrack(list, tempList, nums, start) {
- list.push([...tempList]);
- for(let i = start; i < nums.length; i++) {
- // 和78.subsets的区别在于这道题nums可以有重复
- // 因此需要过滤这种情况
- if (i > start && nums[i] === nums[i - 1]) continue;
- tempList.push(nums[i]);
- backtrack(list, tempList, nums, i + 1)
- tempList.pop();
- }
+ list.push([...tempList]);
+ for (let i = start; i < nums.length; i++) {
+ // 和78.subsets的区别在于这道题nums可以有重复
+ // 因此需要过滤这种情况
+ if (i > start && nums[i] === nums[i - 1]) continue;
+ tempList.push(nums[i]);
+ backtrack(list, tempList, nums, i + 1);
+ tempList.pop();
+ }
}
/**
* @param {number[]} nums
* @return {number[][]}
*/
-var subsetsWithDup = function(nums) {
- const list = [];
- backtrack(list, [], nums.sort((a, b) => a - b), 0, [])
- return list;
+var subsetsWithDup = function (nums) {
+ const list = [];
+ backtrack(
+ list,
+ [],
+ nums.sort((a, b) => a - b),
+ 0,
+ []
+ );
+ return list;
};
```
+
C++ Code:
```C++
@@ -132,6 +116,7 @@ public:
}
};
```
+
Python Code:
```Python
@@ -168,7 +153,3 @@ class Solution:
- [78.subsets](./78.subsets.md)
- [113.path-sum-ii](./113.path-sum-ii.md)
- [131.palindrome-partitioning](./131.palindrome-partitioning.md)
-
-
-
-
diff --git a/problems/900.rle-iterator.md b/problems/900.rle-iterator.md
index 0ad626740..35efc769a 100644
--- a/problems/900.rle-iterator.md
+++ b/problems/900.rle-iterator.md
@@ -43,6 +43,14 @@ Each call to RLEIterator.next(int n) will have 1 <= n <= 10^9.
```
+## 前置知识
+
+- 哈夫曼编码和游程编码
+
+## 公司
+
+- 暂无
+
## 思路
这是一个游程编码的典型题目。
diff --git a/problems/91.decode-ways.md b/problems/91.decode-ways.md
index c7bb38161..178cdd871 100644
--- a/problems/91.decode-ways.md
+++ b/problems/91.decode-ways.md
@@ -1,8 +1,9 @@
-
## 题目地址
+
https://leetcode.com/problems/decode-ways/description/
## 题目描述
+
```
A message containing letters from A-Z is being encoded to numbers using the following mapping:
@@ -24,6 +25,18 @@ Output: 3
Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
```
+## 前置知识
+
+- 爬楼梯问题
+- [动态规划](https://github.com/azl397985856/leetcode/blob/master/thinkings/dynamic-programming.md)
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这道题目和爬楼梯问题有异曲同工之妙。
@@ -33,8 +46,8 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
- 对于一个数字来说[1,9]这九个数字能够被识别为一种编码方式
- 对于两个数字来说[10, 26]这几个数字能被识别为一种编码方式
-我们考虑用dp[i]来切分子问题, 那么dp[i]表示的意思是当前字符串的以索引i结尾的子问题。
-这样的话,我们最后只需要取dp[s.length] 就可以解决问题了。
+我们考虑用 dp[i]来切分子问题, 那么 dp[i]表示的意思是当前字符串的以索引 i 结尾的子问题。
+这样的话,我们最后只需要取 dp[s.length] 就可以解决问题了。
关于递归公式,让我们`先局部后整体`。对于局部,我们遍历到一个元素的时候,
我们有两种方式来组成编码方式,第一种是这个元素本身(需要自身是[1,9]),
@@ -42,17 +55,13 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
`dp[i] = 以自身去编码(一位) + 以前面的元素和自身去编码(两位)` .这显然是完备的,
这样我们通过层层推导就可以得到结果。
-
## 关键点解析
- 爬楼梯问题(我把这种题目统称为爬楼梯问题)
-
## 代码
```js
-
-
/*
* @lc app=leetcode id=91 lang=javascript
*
@@ -100,7 +109,7 @@ Explanation: It could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
* @param {string} s
* @return {number}
*/
-var numDecodings = function(s) {
+var numDecodings = function (s) {
if (s == null || s.length == 0) {
return 0;
}
@@ -108,8 +117,8 @@ var numDecodings = function(s) {
dp[0] = 1;
dp[1] = s[0] !== "0" ? 1 : 0;
for (let i = 2; i < s.length + 1; i++) {
- const one = +s.slice(i - 1, i);
- const two = +s.slice(i - 2, i);
+ const one = +s.slice(i - 1, i);
+ const two = +s.slice(i - 2, i);
if (two >= 10 && two <= 26) {
dp[i] = dp[i - 2];
@@ -126,4 +135,4 @@ var numDecodings = function(s) {
## 扩展
-如果编码的范围不再是1-26,而是三位的话怎么办?
+如果编码的范围不再是 1-26,而是三位的话怎么办?
diff --git a/problems/912.sort-an-array.md b/problems/912.sort-an-array.md
index f98daf5cb..03d0d5dfc 100644
--- a/problems/912.sort-an-array.md
+++ b/problems/912.sort-an-array.md
@@ -24,6 +24,17 @@ Note:
-50000 <= A[i] <= 50000
```
+## 前置知识
+
+- 数组
+- 排序
+
+## 公司
+
+- 阿里
+- 百度
+- 字节
+
## 思路
这是一个很少见的直接考察`排序`的题目。 其他题目一般都是暗含`排序`,这道题则简单粗暴,直接让你排序。
@@ -51,7 +62,7 @@ Note:
这样一次遍历,我们统计出了所有的数字出现的位置和次数。 我们再来一次遍历,将其输出到即可。
-
+
### 解法二 - 快速排序
@@ -69,7 +80,7 @@ Note:
- 数组随机一项元素
-
+
(图片来自: https://www.geeksforgeeks.org/quick-sort/)
diff --git a/problems/92.reverse-linked-list-ii.md b/problems/92.reverse-linked-list-ii.md
index 3278c21c1..e46f3199a 100644
--- a/problems/92.reverse-linked-list-ii.md
+++ b/problems/92.reverse-linked-list-ii.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/reverse-linked-list-ii/description/
## 题目描述
+
Reverse a linked list from position m to n. Do it in one-pass.
Note: 1 ≤ m ≤ n ≤ length of list.
@@ -11,26 +13,38 @@ Example:
Input: 1->2->3->4->5->NULL, m = 2, n = 4
Output: 1->4->3->2->5->NULL
-## 思路
+## 前置知识
+
+- 链表
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
+## 思路(四点法)
-这道题和[206.reverse-linked-list](https://github.com/azl397985856/leetcode/blob/master/problems/206.reverse-linked-list.md) 有点类似,并且这道题是206的升级版。 让我们反转某一个区间,而不是整个链表,我们可以将206看作本题的特殊情况(special case)。
+这道题和[206.reverse-linked-list](https://github.com/azl397985856/leetcode/blob/master/problems/206.reverse-linked-list.md) 有点类似,并且这道题是 206 的升级版。 让我们反转某一个区间,而不是整个链表,我们可以将 206 看作本题的特殊情况(special case)。
核心在于**取出需要反转的这一小段链表,反转完后再插入到原先的链表中。**
以本题为例:
-反转的是2,3,4这三个点,那么我们可以先取出2,用cur指针指向2,然后当取出3的时候,我们将3指向2的,把cur指针前移到3,依次类推,到4后停止,这样我们得到一个新链表4->3->2, cur指针指向4。
+反转的是 2,3,4 这三个点,那么我们可以先取出 2,用 cur 指针指向 2,然后当取出 3 的时候,我们将 3 指向 2 的,把 cur 指针前移到 3,依次类推,到 4 后停止,这样我们得到一个新链表 4->3->2, cur 指针指向 4。
-对于原链表来说,有两个点的位置很重要,需要用指针记录下来,分别是1和5,把新链表插入的时候需要这两个点的位置。用pre指针记录1的位置当4结点被取走后,5的位置需要记下来
+对于原链表来说,有两个点的位置很重要,需要用指针记录下来,分别是 1 和 5,把新链表插入的时候需要这两个点的位置。用 pre 指针记录 1 的位置当 4 结点被取走后,5 的位置需要记下来
这样我们就可以把反转后的那一小段链表加入到原链表中
-
+
-(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+(图片来自网络)
+- 首先我们直接返回 head 是不行的。 当 m 不等于 1 的时候是没有问题的,但只要 m 为 1,就会有问题。
-首先我们直接返回head是不行的。 当 m 不等于1的时候是没有问题的,但只要 m 为1,就会有问题。
+- 其次如果链表商都小于 4 的时候,p1,p2,p3,p4 就有可能为空。为了防止 NPE,我们也要充分地判空。
```python
class Solution:
@@ -39,7 +53,7 @@ class Solution:
cur = head
i = 0
p1 = p2 = p3 = p4 = None
- # ...
+ # 一坨逻辑
if p1:
p1.next = p3
else:
@@ -48,72 +62,73 @@ class Solution:
p2.next = p4
return head
```
-
- 如上代码是不可以的,我们考虑使用dummy节点。
- ```python
- class Solution:
- def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
- pre = None
- cur = head
- i = 0
- p1 = p2 = p3 = p4 = None
- dummy = ListNode(0)
- dummy.next = head
- # ...
+如上代码是不可以的,我们考虑使用 dummy 节点。
- if p1:
- p1.next = p3
- else:
- dummy.next = p3
- if p2:
- p2.next = p4
-
- return dummy.next
- ```
-
- 关于链表反转部分, 顺序比较重要,我们需要:
-
- - 先 cur.next = pre
- - 再 更新p2和p2.next(其中要设置p2.next = None,否则会互相应用,造成无限循环)
- - 最后更新 pre 和 cur
-
- 上述的顺序不能错,不然会有问题。原因就在于`p2.next = None`,如果这个放在最后,那么我们的cur会提前断开。
-
- ```python
- while cur:
- i += 1
- if i == m - 1:
- p1 = cur
- next = cur.next
- if m < i <= n:
- cur.next = pre
+```python
+class Solution:
+ def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
+ pre = None
+ cur = head
+ i = 0
+ p1 = p2 = p3 = p4 = None
+ dummy = ListNode(0)
+ dummy.next = head
+ # 一坨逻辑
+ if p1:
+ p1.next = p3
+ else:
+ dummy.next = p3
+ if p2:
+ p2.next = p4
+
+ return dummy.next
+```
- if i == m:
- p2 = cur
- p2.next = None
+关于链表反转部分, 顺序比较重要,我们需要:
- if i == n:
- p3 = cur
+- 先 cur.next = pre
+- 再 更新 p2 和 p2.next(其中要设置 p2.next = None,否则会互相应用,造成无限循环)
+- 最后更新 pre 和 cur
- if i == n + 1:
- p4 = cur
+上述的顺序不能错,不然会有问题。原因就在于`p2.next = None`,如果这个放在最后,那么我们的 cur 会提前断开。
- pre = cur
- cur = next
- ```
+```python
+ while cur:
+ i += 1
+ if i == m - 1:
+ p1 = cur
+ next = cur.next
+ if m < i <= n:
+ cur.next = pre
+
+ if i == m:
+ p2 = cur
+ p2.next = None
+
+ if i == n:
+ p3 = cur
+
+ if i == n + 1:
+ p4 = cur
+
+ pre = cur
+ cur = next
+```
## 关键点解析
+- 四点法
- 链表的基本操作
-- 考虑特殊情况 m 是 1 或者 n是链表长度的情况,我们可以采用虚拟节点dummy 简化操作
+- 考虑特殊情况 m 是 1 或者 n 是链表长度的情况,我们可以采用虚拟节点 dummy 简化操作
- 用四个变量记录特殊节点, 然后操作这四个节点使之按照一定方式连接即可。
-- 注意更新current和pre的位置, 否则有可能出现溢出
-
+- 注意更新 current 和 pre 的位置, 否则有可能出现溢出
## 代码
-语言支持:JS, C++, Python3
+我把这个方法称为 `四点法`
+
+语言支持:JS, Python3
JavaScript Code:
@@ -138,152 +153,106 @@ JavaScript Code:
* @param {number} n
* @return {ListNode}
*/
-var reverseBetween = function(head, m, n) {
- // 虚拟节点,简化操作
- const dummyHead = {
- next: head
+var reverseBetween = function (head, m, n) {
+ // 虚拟节点,简化操作
+ const dummyHead = {
+ next: head,
+ };
+
+ let cur = dummyHead.next; // 当前遍历的节点
+ let pre = cur; // 因为要反转,因此我们需要记住前一个节点
+ let index = 0; // 链表索引,用来判断是否是特殊位置(头尾位置)
+
+ // 上面提到的四个特殊节点
+ let p1 = (p2 = p3 = p4 = null);
+
+ while (cur) {
+ const next = cur.next;
+ index++;
+
+ // 对 (m - n) 范围内的节点进行反转
+ if (index > m && index <= n) {
+ cur.next = pre;
}
- let cur = dummyHead.next; // 当前遍历的节点
- let pre = cur; // 因为要反转,因此我们需要记住前一个节点
- let index = 0; // 链表索引,用来判断是否是特殊位置(头尾位置)
-
- // 上面提到的四个特殊节点
- let p1 = p2 = p3 = p4 = null
-
- while(cur) {
- const next = cur.next;
- index++;
-
- // 对 (m - n) 范围内的节点进行反转
- if (index > m && index <= n) {
- cur.next = pre;
- }
-
- // 下面四个if都是边界, 用于更新四个特殊节点的值
- if (index === m - 1) {
- p1 = cur;
- }
- if (index === m) {
- p2 = cur;
- }
-
- if (index === n) {
- p3 = cur;
- }
-
- if (index === n + 1) {
- p4 = cur;;
- }
+ // 下面四个if都是边界, 用于更新四个特殊节点的值
+ if (index === m - 1) {
+ p1 = cur;
+ }
+ if (index === m) {
+ p2 = cur;
+ }
- pre = cur;
+ if (index === n) {
+ p3 = cur;
+ }
- cur = next;
+ if (index === n + 1) {
+ p4 = cur;
}
- // 两个链表合并起来
- (p1 || dummyHead).next = p3; // 特殊情况需要考虑
- p2.next = p4;
+ pre = cur;
- return dummyHead.next;
-};
+ cur = next;
+ }
-```
-C++ Code:
-```c++
-/**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * ListNode *next;
- * ListNode(int x) : val(x), next(NULL) {}
- * };
- */
-class Solution {
-public:
- ListNode* reverseBetween(ListNode* head, int s, int e) {
- if (s == e) return head;
- ListNode* prev = nullptr;
- auto cur = head;
- for (int i = 1; i < s; ++i) {
- prev = cur;
- cur = cur->next;
- }
- // 此时各指针指向:
- // x -> x -> x -> x -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> x -> x -> x ->
- // ^head ^prev ^cur
- ListNode* p = nullptr;
- auto c = cur;
- auto tail = c;
- ListNode* n = nullptr;
- for (int i = s; i <= e; ++i) {
- n = c->next;
- c->next = p;
- p = c;
- c = n;
- }
- // 此时各指针指向:
- // x -> x -> x -> x 8 -> 7 -> 6 -> 5 -> 4 -> 3 -> 2 -> 1 x -> x -> x ->
- // ^head ^prev ^p ^cur ^c
- // ^tail
- if (prev != nullptr) { // 若指向前一个节点的指针不为空,则说明s在链表中间(不是头节点)
- prev->next = p;
- cur->next = c;
- return head;
- } else {
- if (tail != nullptr) tail->next = c;
- return p;
- }
- }
+ // 两个链表合并起来
+ (p1 || dummyHead).next = p3; // 特殊情况需要考虑
+ p2.next = p4;
+
+ return dummyHead.next;
};
```
+
Python Code:
+
```Python
-# Definition for singly-linked list.
-# class ListNode:
-# def __init__(self, x):
-# self.val = x
-# self.next = None
class Solution:
def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
- """采用先翻转中间部分,之后与不变的前后部分拼接的思路"""
- # 处理特殊情况
- if m == n:
+ if not head.next or n == 1:
return head
-
- # 例行性的先放一个开始节点,方便操作
- first = ListNode(0)
- first.next = head
-
- # 通过以下两个节点记录拼接点
- before_m = first # 原链表m前的部分
- after_n = None # 原链表n后的部分
-
- # 通过以下两个节点记录翻转后的链表
- between_mn_head = None
- between_mn_end = None
-
- index = 0
- cur_node = first
- while index < n:
- index += 1
- cur_node = cur_node.next
- if index == m - 1:
- before_m = cur_node
- elif index == m:
- between_mn_end = ListNode(cur_node.val)
- between_mn_head = between_mn_end
- elif index > m:
- temp = between_mn_head
- between_mn_head = ListNode(cur_node.val)
- between_mn_head.next = temp
- if index == n:
- after_n = cur_node.next
-
- # 进行拼接
- between_mn_end.next = after_n
- before_m.next = between_mn_head
-
- return first.next
+ dummy = ListNode()
+ dummy.next = head
+ pre = None
+ cur = head
+ i = 0
+ p1 = p2 = p3 = p4 = None
+ while cur:
+ i += 1
+ next = cur.next
+ if m < i <= n:
+ cur.next = pre
+ if i == m - 1:
+ p1 = cur
+ if i == m:
+ p2 = cur
+ if i == n:
+ p3 = cur
+ if i == n + 1:
+ p4 = cur
+ pre = cur
+ cur = next
+ if not p1:
+ dummy.next = p3
+ else:
+ p1.next = p3
+ p2.next = p4
+ return dummy.next
```
+
+**复杂度分析**
+
+- 时间复杂度:$O(N)$
+- 空间复杂度:$O(1)$
+
+## 相关题目
+
+- [25.reverse-nodes-in-k-groups](./25.reverse-nodes-in-k-groups-cn.md)
+- [206.reverse-linked-list](./206.reverse-linked-list.md)
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
+
+
diff --git a/problems/935.knight-dialer.md b/problems/935.knight-dialer.md
index 1e4aa392d..3150086e0 100644
--- a/problems/935.knight-dialer.md
+++ b/problems/935.knight-dialer.md
@@ -8,7 +8,7 @@ https://leetcode-cn.com/problems/knight-dialer/
```
-
+
```
@@ -42,8 +42,17 @@ https://leetcode-cn.com/problems/knight-dialer/
```
+## 前置知识
+
+- DFS
+- 记忆化搜索
+
## 深度优先遍历(DFS)
+## 公司
+
+- 暂无
+
### 思路
这道题要求解一个数字。并且每一个格子能够跳的状态是确定的。 因此我们的思路就是“状态机”(动态规划),暴力遍历(BFS or DFS),这里我们使用 DFS。(注意这几种思路并无本质不同)
@@ -112,4 +121,4 @@ class Solution:
欢迎关注我的公众号《脑洞前端》获取更多更新鲜的 LeetCode 题解
-
+
diff --git a/problems/94.binary-tree-inorder-traversal.md b/problems/94.binary-tree-inorder-traversal.md
index 4c8c02ad9..bdad3ff9b 100644
--- a/problems/94.binary-tree-inorder-traversal.md
+++ b/problems/94.binary-tree-inorder-traversal.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/binary-tree-inorder-traversal/description/
## 题目描述
+
```
Given a binary tree, return the inorder traversal of its nodes' values.
@@ -17,6 +19,19 @@ Input: [1,null,2,3]
Output: [1,3,2]
Follow up: Recursive solution is trivial, could you do it iteratively?
```
+
+## 前置知识
+
+- 二叉树
+- 递归
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
递归的方式相对简单,非递归的方式借助栈这种数据结构实现起来会相对轻松。
@@ -31,109 +46,71 @@ Follow up: Recursive solution is trivial, could you do it iteratively?
- 再将当前指针移到其右子节点上,若存在右子节点,则在下次循环时又可将其所有左子结点压入栈中, 重复上步骤
-
+
(图片来自: https://github.com/MisterBooo/LeetCodeAnimation)
+
## 关键点解析
- 二叉树的基本操作(遍历)
-> 不同的遍历算法差异还是蛮大的
+ > 不同的遍历算法差异还是蛮大的
- 如果非递归的话利用栈来简化操作
- 如果数据规模不大的话,建议使用递归
- 递归的问题需要注意两点,一个是终止条件,一个如何缩小规模
-1. 终止条件,自然是当前这个元素是null(链表也是一样)
+1. 终止条件,自然是当前这个元素是 null(链表也是一样)
2. 由于二叉树本身就是一个递归结构, 每次处理一个子树其实就是缩小了规模,
-难点在于如何合并结果,这里的合并结果其实就是`left.concat(mid).concat(right)`,
-mid是一个具体的节点,left和right`递归求出即可`
-
+ 难点在于如何合并结果,这里的合并结果其实就是`left.concat(mid).concat(right)`,
+ mid 是一个具体的节点,left 和 right`递归求出即可`
## 代码
-* 语言支持:JS,C++,Python3, Java
+- 语言支持:JS,C++,Python3, Java
JavaScript Code:
```js
-/*
- * @lc app=leetcode id=94 lang=javascript
- *
- * [94] Binary Tree Inorder Traversal
- *
- * https://leetcode.com/problems/binary-tree-inorder-traversal/description/
- *
- * algorithms
- * Medium (55.22%)
- * Total Accepted: 422.4K
- * Total Submissions: 762.1K
- * Testcase Example: '[1,null,2,3]'
- *
- * Given a binary tree, return the inorder traversal of its nodes' values.
- *
- * Example:
- *
- *
- * Input: [1,null,2,3]
- * 1
- * \
- * 2
- * /
- * 3
- *
- * Output: [1,3,2]
- *
- * Follow up: Recursive solution is trivial, could you do it iteratively?
- *
- */
-/**
- * Definition for a binary tree node.
- * function TreeNode(val) {
- * this.val = val;
- * this.left = this.right = null;
- * }
- */
/**
* @param {TreeNode} root
* @return {number[]}
*/
-var inorderTraversal = function(root) {
- // 1. Recursive solution
- // if (!root) return [];
- // const left = root.left ? inorderTraversal(root.left) : [];
- // const right = root.right ? inorderTraversal(root.right) : [];
- // return left.concat([root.val]).concat(right);
-
- // 2. iterative solutuon
- if (!root) return [];
- const stack = [root];
- const ret = [];
- let left = root.left;
-
- let item = null; // stack 中弹出的当前项
-
- while(left) {
- stack.push(left);
- left = left.left;
- }
-
- while(item = stack.pop()) {
- ret.push(item.val);
- let t = item.right;
-
- while(t) {
- stack.push(t);
- t = t.left;
- }
+var inorderTraversal = function (root) {
+ // 1. Recursive solution
+ // if (!root) return [];
+ // const left = root.left ? inorderTraversal(root.left) : [];
+ // const right = root.right ? inorderTraversal(root.right) : [];
+ // return left.concat([root.val]).concat(right);
+
+ // 2. iterative solutuon
+ if (!root) return [];
+ const stack = [root];
+ const ret = [];
+ let left = root.left;
+
+ let item = null; // stack 中弹出的当前项
+
+ while (left) {
+ stack.push(left);
+ left = left.left;
+ }
+
+ while ((item = stack.pop())) {
+ ret.push(item.val);
+ let t = item.right;
+
+ while (t) {
+ stack.push(t);
+ t = t.left;
}
+ }
- return ret;
-
+ return ret;
};
-
```
+
C++ Code:
```c++
@@ -162,7 +139,9 @@ public:
}
};
```
+
Python Code:
+
```Python
# Definition for a binary tree node.
# class TreeNode:
@@ -225,14 +204,14 @@ class Solution {
inorder(root);
return res;
}
-
+
public void inorder (TreeNode root) {
if (root == null) return;
-
+
inorder(root.left);
-
+
res.add(root.val);
-
+
inorder(root.right);
}
}
@@ -268,3 +247,7 @@ class Solution {
}
}
```
+
+## 相关专题
+
+- [二叉树的遍历](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md)
diff --git a/problems/95.unique-binary-search-trees-ii.md b/problems/95.unique-binary-search-trees-ii.md
index 603c8e488..bb6571054 100644
--- a/problems/95.unique-binary-search-trees-ii.md
+++ b/problems/95.unique-binary-search-trees-ii.md
@@ -30,6 +30,18 @@ https://leetcode-cn.com/problems/unique-binary-search-trees-ii/description/
```
+## 前置知识
+
+- 二叉搜索树
+- 分治
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个经典的使用分治思路的题目。基本思路和[96.unique-binary-search-trees](./96.unique-binary-search-trees.md)一样。
diff --git a/problems/96.unique-binary-search-trees.md b/problems/96.unique-binary-search-trees.md
index effd3bb8e..e2b42f2fc 100644
--- a/problems/96.unique-binary-search-trees.md
+++ b/problems/96.unique-binary-search-trees.md
@@ -22,6 +22,18 @@ https://leetcode-cn.com/problems/unique-binary-search-trees-ii/description/
```
+## 前置知识
+
+- 二叉搜索树
+- 分治
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
这是一个经典的使用分治思路的题目。
@@ -82,7 +94,14 @@ class Solution:
self.visited[n] = res
return res
```
+**复杂度分析**
+- 时间复杂度:一层循环是 N,另外递归深度是 N,因此总的时间复杂度是 $O(N^2)$
+- 空间复杂度:递归的栈深度和visited 的大小都是 N,因此总的空间复杂度为 $O(N)$
## 相关题目
-- [95.unique-binary-search-trees-ii](./95.unique-binary-search-trees-ii.md)
+- [95.unique-binary-search-trees-ii](https://github.com/azl397985856/leetcode/blob/master/problems/95.unique-binary-search-trees-ii.md)
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/problems/98.validate-binary-search-tree.md b/problems/98.validate-binary-search-tree.md
index 2a08c2704..15faf7649 100644
--- a/problems/98.validate-binary-search-tree.md
+++ b/problems/98.validate-binary-search-tree.md
@@ -1,7 +1,9 @@
## 题目地址
+
https://leetcode.com/problems/validate-binary-search-tree/description/
## 题目描述
+
```
Given a binary tree, determine if it is a valid binary search tree (BST).
@@ -10,7 +12,7 @@ Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the node's key.
The right subtree of a node contains only nodes with keys greater than the node's key.
Both the left and right subtrees must also be binary search trees.
-
+
Example 1:
@@ -35,13 +37,28 @@ Explanation: The root node's value is 5 but its right child's value is 4.
```
+## 前置知识
+
+- 中序遍历
+
+## 公司
+
+- 阿里
+- 腾讯
+- 百度
+- 字节
+
## 思路
+
### 中序遍历
+
这道题是让你验证一棵树是否为二叉查找树(BST)。 由于中序遍历的性质`如果一个树遍历的结果是有序数组,那么他也是一个二叉查找树(BST)`,
-我们只需要中序遍历,然后两两判断是否有逆序的元素对即可,如果有,则不是BST,否则即为一个BST。
+我们只需要中序遍历,然后两两判断是否有逆序的元素对即可,如果有,则不是 BST,否则即为一个 BST。
### 定义法
+
根据定义,一个结点若是在根的左子树上,那它应该小于根结点的值而大于左子树最小值;若是在根的右子树上,那它应该大于根结点的值而小于右子树最大值。也就是说,每一个结点必须落在某个取值范围:
+
1. 根结点的取值范围为(考虑某个结点为最大或最小整数的情况):(long_min, long_max)
2. 左子树的取值范围为:(current_min, root.value)
3. 右子树的取值范围为:(root.value, current_max)
@@ -56,9 +73,10 @@ Explanation: The root node's value is 5 but its right child's value is 4.
### 中序遍历
-* 语言支持:JS,C++, Java
+- 语言支持:JS,C++, Java
JavaScript Code:
+
```js
/*
* @lc app=leetcode id=98 lang=javascript
@@ -76,36 +94,35 @@ JavaScript Code:
* @param {TreeNode} root
* @return {boolean}
*/
-var isValidBST = function(root) {
- if (root === null) return true;
- if (root.left === null && root.right === null) return true;
- const stack = [root];
- let cur = root;
- let pre = null;
-
- function insertAllLefts(cur) {
- while(cur && cur.left) {
- const l = cur.left;
- stack.push(l);
- cur = l;
- }
+var isValidBST = function (root) {
+ if (root === null) return true;
+ if (root.left === null && root.right === null) return true;
+ const stack = [root];
+ let cur = root;
+ let pre = null;
+
+ function insertAllLefts(cur) {
+ while (cur && cur.left) {
+ const l = cur.left;
+ stack.push(l);
+ cur = l;
}
- insertAllLefts(cur);
+ }
+ insertAllLefts(cur);
- while(cur = stack.pop()) {
- if (pre && cur.val <= pre.val) return false;
- const r = cur.right;
+ while ((cur = stack.pop())) {
+ if (pre && cur.val <= pre.val) return false;
+ const r = cur.right;
- if (r) {
- stack.push(r);
- insertAllLefts(r);
- }
- pre = cur;
+ if (r) {
+ stack.push(r);
+ insertAllLefts(r);
}
+ pre = cur;
+ }
- return true;
+ return true;
};
-
```
C++ Code:
@@ -118,7 +135,7 @@ public:
TreeNode* prev = nullptr;
return validateBstInorder(root, prev);
}
-
+
private:
bool validateBstInorder(TreeNode* root, TreeNode*& prev) {
if (root == nullptr) return true;
@@ -185,7 +202,7 @@ class Solution {
### 定义法
-* 语言支持:C++,Python3, Java, JS
+- 语言支持:C++,Python3, Java, JS
C++ Code:
@@ -265,15 +282,15 @@ class Solution:
"""
if root is None:
return True
-
+
is_valid_left = root.left is None or\
(root.left.val < root.val and area[0] < root.left.val < area[1])
is_valid_right = root.right is None or\
(root.right.val > root.val and area[0] < root.right.val < area[1])
-
+
# 左右节点都符合,说明本节点符合要求
is_valid = is_valid_left and is_valid_right
-
+
# 递归下去
return is_valid\
and self.isValidBST(root.left, (area[0], root.val))\
@@ -292,7 +309,7 @@ Java Code:
* TreeNode(int x) { val = x; }
* }
*/
-class Solution {
+class Solution {
public boolean isValidBST(TreeNode root) {
return helper(root, null, null);
}
@@ -326,16 +343,16 @@ JavaScript Code:
* @return {boolean}
*/
var isValidBST = function (root) {
- if (!root) return true;
- return valid(root);
+ if (!root) return true;
+ return valid(root);
};
function valid(root, min = -Infinity, max = Infinity) {
- if (!root) return true;
- const val = root.val;
- if (val <= min) return false;
- if (val >= max) return false;
- return valid(root.left, min, val) && valid(root.right, val, max)
+ if (!root) return true;
+ const val = root.val;
+ if (val <= min) return false;
+ if (val >= max) return false;
+ return valid(root.left, min, val) && valid(root.right, val, max);
}
```
diff --git a/templates/problems/1014.best-sightseeing-pair.md b/templates/problems/1014.best-sightseeing-pair.md
index 9303967f7..92d3ad556 100644
--- a/templates/problems/1014.best-sightseeing-pair.md
+++ b/templates/problems/1014.best-sightseeing-pair.md
@@ -17,9 +17,11 @@
> (518. 零钱兑换 II) 替换成你自己的题目序号和名称
2. 题目描述
-3. 思路
-4. 关键点
-5. 代码
+3. 前置知识
+4. 公司
+5. 思路
+6. 关键点
+7. 代码
可选项:
diff --git a/thanksGiving.md b/thanksGiving.md
index 0704ca65e..b1e4abfa1 100644
--- a/thanksGiving.md
+++ b/thanksGiving.md
@@ -2,23 +2,23 @@
就在今天,我的《leetcode题解》项目首次突破1wstar, 在这里我特地写下这篇文章来记录这个时刻,同时非常感谢大家的支持和陪伴。
-
+
(star增长曲线图)
前几天,去了一趟山城重庆,在那里遇到了最美的人和最漂亮的风景。
-
+
-
+
-
+
我是一个念旧的人,现在是节后的第一天,让我开启回忆模式:
- 2017-05-30 项目成立,那是的它只是用来占位而已,目的就是让自己知道之后要做这件事。
-
+
(第一次提交)
@@ -28,7 +28,7 @@
在朋友圈推广:
-
+
(在朋友圈宣传)
@@ -37,11 +37,11 @@
- 之后我组建了微信和qq群,来让大家活跃起来,促进交流,戒指目前(2019-06-10)微信群总人数已经超过700,
里面有非常多的学生,留学生以及全球各地各大公司的员工。
-
+
(qq群)
-
+
(微信群)
@@ -49,35 +49,35 @@
之后先后通过@每日时报, @阮一峰,@d2,@hello-github等的宣传,又迎来的一次高峰,
在那一段时间大概突破了1k。
-
+
(阮一峰的周报)
-
+
(hello-github也收录了我和我的仓库)
二次元的司徒正美老师虽然没有帮忙宣传,但是它的star也在某种程度上起到了宣传作用。
-
+
(司徒正美)
并且之后这个项目在github trending活跃了一个月左右,甚至有一次冲上了日榜的总榜第一,并被“开发者头条”收入《GitHub Trending - All - Daily》。
-
+
(日榜第一)
-
+
(开发者头条的微博号)
截止到2019-06-10,项目star首次破万,幸运的是我刚好捕捉到了第9999个小可爱.
-
+
(9999,一个很有意思的数字)
@@ -85,33 +85,33 @@
现在,项目除了JS,也在逐步加入C++,python,多编程语言正在筹备中。
-
+
(我们正在努力加入更多编程语言)
另外,在大家的帮助下,我们也逐步走上了国际化,不仅仅有人来主动做翻译,还组建了电报群。
-
+
(英文主页)
-
+
(英文翻译进展)
也不知道什么时候,《量子论》竟然悄悄地在知乎帮我宣传。
-
+
(知乎 - 量子论)
与此同时,我在知乎的最高赞竟然给了这条评论。
-
+
- 2019-06-04 首次在三个群里同步开通《每日一题》,大家也非常踊跃地帮忙整理题目,甚至出题给思路,非常感谢大家。
-
+
非常感谢大家一直以来的陪伴和支持,我们一起努力,加油💪。
diff --git a/thanksGiving2.md b/thanksGiving2.md
index 35d222ee8..d74bc0d09 100644
--- a/thanksGiving2.md
+++ b/thanksGiving2.md
@@ -1,17 +1,17 @@
假期这几天我买了《逆转裁判 123》合集,面对着这香喷喷的冷饭吃了半天。从 GBA 玩到 NDS,从 NDS 玩到 3DS, 现在 NS 虽然没有出新作有点遗憾。不过有了高清重制,也当是个回忆和收藏了 🎉🎉
目前打通了第一第二关,剩下的过一段时间再玩好啦 😁
-
+
回到正题,就在今天,我的《leetcode 题解》项目成功突破 2w star, 并且现在 Github 搜索关键字"LeetCode"我的项目已经排名第一啦,这是继 1W star 之后的第二个巨大突破,非常感谢大家一路以来的支持和陪伴。
-
+
最近在写一本关于 LeetCode 题解的书,有很多人表示想买,这无形之中给了我很大的压力,名字还没定,暂时给它取一个代号《攻克 LeetCode》。
## 新书《攻克 LeetCode》
-
+
这里是[《攻克 LeetCode》的草稿目录](https://lucifer.ren/blog/2019/10/03/draft/),目前有 20 章的内容,本书要讲的内容就是 LeetCode 上反复出现的算法,经过我进一步提炼,抽取数百道题目在这里进行讲解,帮助大家理清整体思绪,从而高效率地刷题,做到事半功倍。我这里总结了 7 个常见的数据结构和 7 个常见的算法以及 5 个常见的算法思想。
@@ -27,11 +27,11 @@
## 2W star 截图
-
+
## Star 曲线
-
+
(star 增长曲线图)
@@ -41,29 +41,29 @@
上回提到知乎上的“量子位”在帮我做宣传,引入了不小的流量。 我就想为什么不自己去拉流量呢?我自己以作者的角度去回答一些问题岂不是更好,更受欢迎么?于是我就开始在知乎上回答问题,很开心其中一个还获得了专业认可。
-
+
事实上并没有我想的那么好,我回答了两个 LeetCode 话题的内容,虽然也有几百的点赞和感谢,但是这离我的目标还差很远。
-
+
-
+
但是转念一想,我知乎刚起步,也没什么粉丝,并且写答案的时间也就一个月左右,这样想就好多了。 我相信将来会有更多的人看到我的答案,然后加入进来。
-
+
-
+
## 建立自己的博客
现在我发表的文章都是在各大平台。这有一个很大的问题就是各个平台很难满足你的需求,比如按照标签,按照日期进行归档。 甚至很多平台的阅读体验很差,比如没有导航功能,广告太多等。因此我觉得自己搭建一个博客还是很有必要的,这个渠道也为我吸引了少部分的流量,目前添加的主要内容大概有:
-
+
-
+
-
+
总体上来说效果还是不错的,之后的文章会在博客首发,各个平台也会陆续更新,感兴趣的可以来个 RSS 订阅,订阅方式已经在[《每日一荐 - 九月刊》](https://lucifer.ren/blog/2019/09/30/daily-featured-2019-09/)里面介绍了。
@@ -71,23 +71,23 @@
GithubDaily 转载了量子位的文章也为我的仓库涨了至少几百的 star,非常感谢。GithubDaily 是一个拥有 3W 多读者的公众号,大家有兴趣的可以关注一波。
-
+
-
+
## 其他自媒体的推荐
一些其他自媒体也会帮忙推广我的项目
-
+
## 口耳相传
我后来才知道竟然有海外华侨和一些华人社区都能看到我了。
-
+
-
+
(一亩三分地是一个集中讨论美国加拿大留学的论坛)
另外通过朋友之间口耳相传的介绍也变得越来越多。
diff --git a/thanksGiving3.md b/thanksGiving3.md
index a94ad5720..c9130370f 100644
--- a/thanksGiving3.md
+++ b/thanksGiving3.md
@@ -2,13 +2,13 @@
## 30k 截图
-
+
## Star 曲线
Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升趋势。
-
+
(star 增长曲线图)
@@ -18,15 +18,15 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
三月份是满勤奖,四月份有一次忘记了,缺卡一天。
-
+
-
+
## 新书即将上线
新书详情戳这里:[《或许是一本可以彻底改变你刷 LeetCode 效率的题解书》](https://lucifer.ren/blog/2020/04/07/leetcode-book.intro/),目前正在申请书号。
-
+
点名感谢各位作者,审阅,以及行政小姐姐。
@@ -34,7 +34,7 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
最近开始做视频题解了,目前更新了五个视频。和文字题解不同,视频题解可以承载的内容会更多。 https://space.bilibili.com/519510412
-
+
我计划更新一些文字题解很难表述的内容,当然还会提供 PPT,如果你喜欢文字,直接看 PPT 即可。
@@ -46,7 +46,7 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
我们的官网`力扣加加`上线啦 💐💐💐💐💐,有专题讲解,每日一题,下载区和视频题解,后续会增加更多内容,还不赶紧收藏起来?地址:http://leetcode-solution.cn/
-
+
点名感谢@三天 @CYL @Josephjinn
@@ -54,12 +54,12 @@ Start 曲线上来看,有一点放缓。但是整体仍然是明显的上升
很多朋友也在关注我的项目,非常开心。点名感谢 @被单-加加 @童欧巴。
-
+
## 交流群
交流群人数也有了很大的提升。 粉丝人数也扩充到了 7000+。交流群数目也增加到了 10 个。其中 QQ 群人数最多,有将近 1800 人。为了限制人数,我开启了收费模式,希望大家不要打我 😂。
-
+
非常感谢大家一直以来的陪伴和支持,Fighting 💪。
diff --git a/thinkings/GCD.md b/thinkings/GCD.md
index c99f97b29..cf2304288 100644
--- a/thinkings/GCD.md
+++ b/thinkings/GCD.md
@@ -46,19 +46,19 @@ def GCD(a: int, b: int) -> int:
实际上这正是一个最大公约数的应用场景,我们的目标就是求解 1680 和 640 的最大公约数。
-
+
将 1680 米 \* 640 米 的土地分割,相当于对将 400 米 \* 640 米 的土地进行分割。 为什么呢? 假如 400 米 \* 640 米分割的正方形边长为 x,那么有 640 % x == 0,那么肯定也满足剩下的两块 640 米 \* 640 米的。
-
+
我们不断进行上面的分割:
-
+
直到边长为 80,没有必要进行下去了。
-
+
辗转相除法如果 a 和 b 都很大的时候,a % b 性能会较低。在中国,《九章算术》中提到了一种类似辗转相减法的 [更相减损术](https://zh.wikisource.org/wiki/%E4%B9%9D%E7%AB%A0%E7%AE%97%E8%A1%93#-.7BA.7Czh-hans:.E5.8D.B7.3Bzh-hant:.E5.8D.B7.7D-.E7.AC.AC.E4.B8.80.E3.80.80.E6.96.B9.E7.94.B0.E4.BB.A5.E5.BE.A1.E7.94.B0.E7.96.87.E7.95.8C.E5.9F.9F "更相减损术")。它的原理是:`两个正整数 a 和 b(a>b),它们的最大公约数等于 a-b 的差值 c 和较小数 b 的最大公约数。`。
diff --git a/thinkings/balanced-tree.md b/thinkings/balanced-tree.md
new file mode 100644
index 000000000..f5ad38545
--- /dev/null
+++ b/thinkings/balanced-tree.md
@@ -0,0 +1,310 @@
+# 衡二叉树专题
+
+力扣关于平衡二叉树的题目还是有一些的,并且都非常经典,推荐大家练习。今天给大家精选了 4 道题,如果你彻底搞明白了这几道题,碰到其他的平衡二叉树的题目应该不至于没有思路。当你领会了我的思路之后, 建议再找几个题目练手,巩固一下学习成果。
+
+## 110. 平衡二叉树(简单)
+
+最简单的莫过于判断一个树是否为平衡二叉树了,我们来看下。
+
+### 题目描述
+
+```
+给定一个二叉树,判断它是否是高度平衡的二叉树。
+
+本题中,一棵高度平衡二叉树定义为:
+
+一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
+
+示例 1:
+
+给定二叉树 [3,9,20,null,null,15,7]
+
+ 3
+ / \
+ 9 20
+ / \
+ 15 7
+返回 true 。
+
+示例 2:
+
+给定二叉树 [1,2,2,3,3,null,null,4,4]
+
+ 1
+ / \
+ 2 2
+ / \
+ 3 3
+ / \
+ 4 4
+返回 false
+
+
+```
+
+### 思路
+
+由于平衡二叉树定义为就是**一个二叉树每个节点的左右两个子树的高度差的绝对值不超过 1。**用伪代码描述就是:
+
+```py
+if abs(高度(root.left) - 高度(root.right)) <= 1 and root.left 也是平衡二叉树 and root.right 也是平衡二叉树:
+ print('是平衡二叉树')
+else:
+ print('不是平衡二叉树')
+```
+
+而 root.left 和 root.right **如何判断是否是二叉平衡树就和 root 是一样的了**,可以看出这个问题有明显的递归性。
+
+因此我们首先需要知道如何计算一个子树的高度。这个可以通过递归的方式轻松地计算出来。计算子树高度的 Python 代码如下:
+
+```py
+def dfs(node, depth):
+ if not node: return 0
+ l = dfs(node.left, depth + 1)
+ r = dfs(node.right, depth + 1)
+ return max(l, r) + 1
+```
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def isBalanced(self, root: TreeNode) -> bool:
+ def dfs(node, depth):
+ if not node: return 0
+ l = dfs(node.left, depth + 1)
+ r = dfs(node.right, depth + 1)
+ return max(l, r) + 1
+ if not root: return True
+ if abs(dfs(root.left, 0) - dfs(root.right, 0)) > 1: return False
+ return self.isBalanced(root.left) and self.isBalanced(root.right)
+```
+
+**复杂度分析**
+
+- 时间复杂度:对于 isBalanced 来说,由于每个节点最多被访问一次,这部分的时间复杂度为 $O(N)$,而 dfs 函数 每次被调用的次数不超过 $log N$,因此总的时间复杂度为 $O(NlogN)$,其中 $N$ 为 树的节点总数。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。
+
+## 108. 将有序数组转换为二叉搜索树(简单)
+
+108 和 109 基本是一样的,只不过数据结构不一样,109 变成了链表了而已。由于链表操作比数组需要考虑更多的因素,因此 109 是 中等难度。
+
+### 题目描述
+
+```
+将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定有序数组: [-10,-3,0,5,9],
+
+一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+### 思路
+
+对于这个问题或者 `给定一个二叉搜索树,将其改为平衡(后面会讲)` 基本思路都是一样的。
+
+题目的要求是将有序数组转化为:
+
+1. 高度平衡的二叉树
+2. 二叉搜索树
+
+由于平衡二叉树是左右两个子树的高度差的绝对值不超过 1。因此一种简单的方法是**选择中点作为根节点,根节点左侧的作为左子树,右侧的作为右子树即可。**原因很简单,这样分配可以保证左右子树的节点数目差不超过 1。因此高度差自然也不会超过 1 了。
+
+上面的操作同时也满足了二叉搜索树,原因就是题目给的数组是有序的。
+
+> 你也可以选择别的数作为根节点,而不是中点,这也可以看出答案是不唯一的。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
+ if not nums: return None
+ mid = (len(nums) - 1) // 2
+ root = TreeNode(nums[mid])
+ root.left = self.sortedArrayToBST(nums[:mid])
+ root.right = self.sortedArrayToBST(nums[mid + 1:])
+ return root
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为数组长度。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。同时由于是平衡二叉树,因此 $h$ 就是 $log N$。
+
+## 109. 有序链表转换二叉搜索树(中等)
+
+### 题目描述
+
+```
+`给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
+
+本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+
+示例:
+
+给定的有序链表: [-10, -3, 0, 5, 9],
+
+一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
+
+ 0
+ / \
+ -3 9
+ / /
+ -10 5
+
+```
+
+### 思路
+
+和 108 思路一样。 不同的是数据结构的不同,因此我们需要关注的是链表和数组的操作差异。
+
+
+
+(数组的情况)
+
+我们再来看下链表:
+
+
+(链表的情况)
+
+找到中点,只需要使用经典的快慢指针即可。同时为了防止环的出现, 我们需要斩断指向 mid 的 next 指针,因此需要记录一下中点前的一个节点,这只需要用一个变量 pre 记录即可。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def sortedListToBST(self, head: ListNode) -> TreeNode:
+ if not head:
+ return head
+ pre, slow, fast = None, head, head
+
+ while fast and fast.next:
+ fast = fast.next.next
+ pre = slow
+ slow = slow.next
+ if pre:
+ pre.next = None
+ node = TreeNode(slow.val)
+ if slow == fast:
+ return node
+ node.left = self.sortedListToBST(head)
+ node.right = self.sortedListToBST(slow.next)
+ return node
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为链表长度。
+- 空间复杂度:由于使用了递归,这里的空间复杂度的瓶颈在栈空间,因此空间复杂度为 $O(h)$,其中 $h$ 为树的高度。同时由于是平衡二叉树,因此 $h$ 就是 $log N$。
+
+## 1382. 将二叉搜索树变平衡(中等)
+
+### 题目描述
+
+```
+给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。
+
+如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。
+
+如果有多种构造方法,请你返回任意一种。
+
+
+
+示例:
+
+```
+
+
+
+```
+
+输入:root = [1,null,2,null,3,null,4,null,null]
+输出:[2,1,3,null,null,null,4]
+解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。
+
+
+提示:
+
+树节点的数目在 1 到 10^4 之间。
+树节点的值互不相同,且在 1 到 10^5 之间。
+
+```
+
+### 思路
+
+由于`二叉搜索树的中序遍历是一个有序数组`,因此问题很容易就转化为 `108. 将有序数组转换为二叉搜索树(简单)`。
+
+### 代码
+
+代码支持: Python3
+
+Python3 Code:
+
+```py
+class Solution:
+ def inorder(self, node):
+ if not node: return []
+ return self.inorder(node.left) + [node.val] + self.inorder(node.right)
+ def balanceBST(self, root: TreeNode) -> TreeNode:
+ nums = self.inorder(root)
+ def dfs(start, end):
+ if start == end: return TreeNode(nums[start])
+ if start > end: return None
+ mid = (start + end) // 2
+ root = TreeNode(nums[mid])
+ root.left = dfs(start, mid - 1)
+ root.right = dfs(mid + 1, end)
+ return root
+ return dfs(0, len(nums) - 1)
+```
+
+**复杂度分析**
+
+- 时间复杂度:由于每个节点最多被访问一次,因此总的时间复杂度为 $O(N)$,其中 $N$ 为链表长度。
+- 空间复杂度:虽然使用了递归,但是瓶颈不在栈空间,而是开辟的长度为 $N$ 的 nums 数组,因此空间复杂度为 $O(N)$,其中 $N$ 为树的节点总数。
+
+## 总结
+
+本文通过四道关于二叉平衡树的题帮助大家识别此类型题目背后的思维逻辑,我们来总结一下学到的知识。
+
+平衡二叉树指的是:`一个二叉树每个节点的左右两个子树的高度差的绝对值不超过1。`
+
+如果需要让你判断一个树是否是平衡二叉树,只需要死扣定义,然后用递归即可轻松解决。
+
+如果需要你将一个数组或者链表(逻辑上都是线性的数据结构)转化为平衡二叉树,只需要随便选一个节点,并分配一半到左子树,另一半到右子树即可。
+
+同时,如果要求你转化为平衡二叉搜索树,则可以选择排序数组(或链表)的中点,左边的元素为左子树, 右边的元素为右子树即可。
+
+> 小提示 1: 如果不需要是二叉搜索树则不需要排序,否则需要排序。
+
+> 小提示 2: 你也可以不选择中点, 算法需要相应调整,感兴趣的同学可以试试。
+
+> 小提示 3: 链表的操作需要特别注意环的存在。
+
+更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 30K star 啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/thinkings/basic-data-structure-en.md b/thinkings/basic-data-structure-en.md
index 3ce5f2316..16e4f2ac3 100644
--- a/thinkings/basic-data-structure-en.md
+++ b/thinkings/basic-data-structure-en.md
@@ -30,7 +30,7 @@ Now, let's have a look at some interesting examples.
`hooks` is essentially an array.
-
+
So, why `hooks` uses array? Maybe we can find the answer from the other side. What if not array?
@@ -108,7 +108,7 @@ For the same TCP connection, all HTTP/1.0 requests will be add into a queue. Whi
Just like waiting the traffic lights, if you are on the left-turn or right-turning lane, you cannot move even if the straight lane is good to go when the left/right turning light is still red.
-
+
`HTTP/1.0` and `HTTP/1.1`:
Accoding to `HTTP/1.0` protocal, one TCP connect will be established for each request and be terminated immediately after receiving the corresponding response. And the next HTTP request cannot be sent until the response of previous request has been received.
@@ -117,7 +117,7 @@ However, according to `HTTP/1.1`, all the responses are reqired to be sent bac
The process can be represented as follow:
-
+
### Stack
@@ -138,7 +138,7 @@ Besides, there is usually an operation called `peek` which is used to retrieve t
Explaining of `push` and `pop` operations:
-
+
(Picture from: https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
@@ -165,7 +165,7 @@ foo();
It may look like this inside the program during executing:
-
+
> The figure above does not contains the other parts of the execution context, like `this` and `scope` which are the key to closure. Here is not going to talk about the closure but to explain the stack structure.
> Some statements in community like *the `scope` of execution context is the variables which declared by the super class in execution stack* which are completely wrong. JS uses Lexical Scoping. And `scope` is the parent object of function when it is defined. There is nothing to do with the execution.
@@ -190,7 +190,7 @@ Many people know that `fiber` is implemented on Linked List. But not many of the
The appearance of `fiber` solves the problem that `react` must
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。
-
+
图片来自 Lin Clark 在 ReactConf 2017 分享
diff --git a/thinkings/basic-data-structure.md b/thinkings/basic-data-structure.md
index 402774be9..61624aa1f 100644
--- a/thinkings/basic-data-structure.md
+++ b/thinkings/basic-data-structure.md
@@ -30,7 +30,7 @@
Hooks 的本质就是一个数组, 伪代码:
-
+
那么为什么 hooks 要用数组? 我们可以换个角度来解释,如果不用数组会怎么样?
@@ -108,7 +108,7 @@ React 将`如何确保组件内部hooks保存的状态之间的对应关系`这
这就好像我们在等红绿灯,即使旁边绿灯亮了,你的这个车道是红灯,你还是不能走,还是要等着。
-
+
`HTTP/1.0` 和 `HTTP/1.1`:
在`HTTP/1.0` 中每一次请求都需要建立一个 TCP 连接,请求结束后立即断开连接。
@@ -118,7 +118,7 @@ React 将`如何确保组件内部hooks保存的状态之间的对应关系`这
如果用图来表示的话,过程大概是:
-
+
`HTTP/2` 和 `HTTP/1.1`:
@@ -144,7 +144,7 @@ pop, 移除栈最顶端(末尾)的元素.
栈的 push 和 pop 操作的示意:
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
@@ -169,7 +169,7 @@ foo();
真正执行的时候,内部大概是这样的:
-
+
> 我画的图没有画出执行上下文中其他部分(this 和 scope 等), 这部分是闭包的关键,而我这里不是讲闭包的,是为了讲解栈的。
@@ -194,7 +194,7 @@ foo();
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。
-
+
图片来自 Lin Clark 在 ReactConf 2017 分享
@@ -273,7 +273,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
实际使用的树有可能会更复杂,比如使用在游戏中的碰撞检测可能会用到四叉树或者八叉树。以及 k 维的树结构 `k-d 树`等。
-
+
(图片来自 https://zh.wikipedia.org/wiki/K-d%E6%A0%91)
### 二叉树
@@ -318,7 +318,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
- 在一个 最小堆(min heap) 中, 如果 P 是 C 的一个父级节点, 那么 P 的 key(或 value)应小于或等于 C 的对应值.
正因为此,堆顶元素一定是最小的,我们会利用这个特点求最小值或者第 k 小的值。
-
+
- 在一个 最大堆(max heap) 中, P 的 key(或 value)大于 C 的对应值。
@@ -346,7 +346,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
二叉查找树,之所以叫查找树就是因为其非常适合查找,举个例子,
如下一颗二叉查找树,我们想找节点值小于且最接近 58 的节点,搜索的流程如图所示:
-
+
(图片来自 https://www.geeksforgeeks.org/floor-in-binary-search-tree-bst/)
另外我们二叉查找树有一个性质是: `其中序遍历的结果是一个有序数组`。
@@ -388,7 +388,7 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
又称 Trie 树,是一种树形结构。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
-
+
(图来自 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fr=aladdin)
它有 3 个基本性质:
@@ -436,13 +436,13 @@ return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是
例如在无向无权图中:
-
+
(图片来自 https://zhuanlan.zhihu.com/p/25498681)
可以看出在无向图中,邻接矩阵关于对角线对称,而邻接链表总有两条对称的边
而在有向无权图中:
-
+
(图片来自 https://zhuanlan.zhihu.com/p/25498681)
diff --git a/thinkings/binary-tree-traversal-en.md b/thinkings/binary-tree-traversal-en.md
index 686235e2f..809371a47 100644
--- a/thinkings/binary-tree-traversal-en.md
+++ b/thinkings/binary-tree-traversal-en.md
@@ -22,7 +22,7 @@ DFS simplifies operations with stack. Meanwhile, a tree is a recursive data stru
Diagrammatic graph of DFS:
-
+
(source: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
@@ -55,7 +55,7 @@ If we think from this point of view, the algorithm can be different. All nodes i
The whole process is like this:
-
+
This idea is something like the `backtrack`. It is important, because this idea can help us to `unify the understanding of three traversal methods`.
@@ -98,7 +98,7 @@ For condition 2, variables are required for recording the traversal status for e
The key point of level-order is recording the traversal status of each level. An identifier bit can be used to represent the status of current level.
-
+
(source: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
diff --git a/thinkings/binary-tree-traversal.en.md b/thinkings/binary-tree-traversal.en.md
new file mode 100644
index 000000000..70f3e9409
--- /dev/null
+++ b/thinkings/binary-tree-traversal.en.md
@@ -0,0 +1,193 @@
+# Binary Tree Traversal
+
+## Overview
+
+Binary tree as a basic data structure and traversal as a fundamental algorithm, their combination leads to a lot of classic problems. This patern is often seen in many problems, either directly or indirectly.
+
+> If you have grasped the traversal of binary trees, other complicated trees will probably be easy for you.
+
+Following are the generally used ways for traversing trees.
+
+- Depth First Traversals (DFS): Inorder, Preorder, Postorder
+
+- Breadth First or Level Order Traversal (BFS)
+
+There are applications for both DFS and BFS. Check out leetcode problem No.301 and No.609.
+
+Stack can be used to simplify the process of DFS traversal. Besides, since tree is a recursive data structure, recursion and stack are two key points for DFS.
+
+Graph for DFS:
+
+
+
+(from https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
+
+The key point of BFS is how to decide whether the traversal of each level is done. The answer is using a variable as a flag to represent the end of the traversal of current level.
+
+Let's dive into details.
+
+## Preorder Traversal
+
+related problem[144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
+
+The traversal order of preorder traversal is `root-left-right`.
+
+Algorithm Preorder
+
+1. Visit the root node and push it into a stack.
+
+2. Pop a node from the stack, and push its right and left child node into the stack respectively.
+
+3. Repeat step 2.
+
+Conclusion: This problem involves the clasic recursive data structure (i.e. a binary tree), and the algorithm above demonstrates how a simplified solution can be reached by using a stack.
+
+If you look at the bigger picture, you'll find that the process of traversal is as followed. `Visit the left subtrees repectively from top to bottom, and visit the right subtrees repectively from bottom to top`. If we are to implement it from this perspective, things will be somewhat different. For the `top to bottom` part we can simply use recursion, and for the `bottom to top` part we can turn to stack.
+
+The traversal will look something like this.
+
+
+
+This way of problem solving is a bit similar to `backtrack`, on which I have written a post. You can benefit a lot from it because it can be used to `solve all three DFS traversal problems` mentioned aboved. If you don't know this yet, make a memo on it.
+
+## Inorder Traversal
+
+related problem[94.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
+
+The traversal order of inorder traversal is `left-root-right`.
+
+So the root node is not printed first. Things are getting a bit complicated here.
+
+Algorithm Inorder
+
+1. Visit the root and push it into a stack.
+
+2. If there is a left child node, push it into the stack. Repeat this process until a leaf node reached.
+
+> At this point the root node and all the left nodes are in the stack.
+
+3. Start popping nodes from the stack. If a node has a right child node, push the child node into the stack. Repeat step 2.
+
+It's worth pointing out that the inorder traversal of a binary search tree (BST) is a sorted array, which is helpful for coming up simplified solutions for some problems. e.g. [230.kth-smallest-element-in-a-bst](../problems/230.kth-smallest-element-in-a-bst.md) and [98.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
+
+## Postorder Traversal
+
+related problem[145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
+
+The traversal order of postorder traversal is `left-right-root`.
+
+This one is a bit of a challange. It deserves the `hard` tag of leetcode.
+
+In this case, the root node is printed not as the first but the last one. A cunning way to do it is to:
+
+Record whether the current node has been visited. If 1) it's a leaf node or 2) both its left and right subtrees have been traversed, then it can be popped from the stack.
+
+As for `1) it's a leaf node`, you can easily tell whether a node is a leaf if both its left and right are `null`.
+
+As for `2) both its left and right subtrees have been traversed`, we only need a variable to record whether a node has been visited or not. In the worst case, we need to record the status for every single node and the space complexity is O(n). But if you come to think about it, as we are using a stack and start printing the result from the leaf nodes, it makes sense that we only record the status for the current node popping from the stack, reducing the space complexity to O(1). Please click the link above for more details.
+
+## Level Order Traversal
+
+The key point of level order traversal is how do we know whether the traversal of each level is done. The answer is that we use a variable as a flag representing the end of the traversal of the current level.
+
+
+
+(from https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
+
+Algorithm Level Order
+
+1. Visit the root node, put it in a FIFO queue, put in the queue a special flag (we are using `null` here).
+
+2. Dequeue a node.
+
+3. If the node equals `null`, it means that all nodes of the current level have been visited. If the queue is empty, we do nothing. Or else we put in another `null`.
+
+4. If the node is not `null`, meaning the traversal of current level has not finished yet, we enqueue its left subtree and right subtree repectively.
+
+related problem[102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
+
+## Bi-color marking
+
+We know that there is a tri-color marking in garbage collection algorithm, which works as described below.
+
+- The white color represents "not visited".
+
+- The gray color represents "not all child nodes visited".
+
+- The black color represents "all child nodes visited".
+
+Enlightened by tri-color marking, a bi-color marking method can be invented to solve all three traversal problems with one solution.
+
+The core idea is as followed.
+
+- Use a color to mark whether a node has been visited or not. Nodes yet to be visited are marked as white and visited nodes are marked as gray.
+
+- If we are visiting a white node, turn it into gray, and push it's right child node, itself, and it's left child node into the stack respectively.
+
+- If we are visiting a gray node, print it.
+
+Implementing inorder traversal with tri-color marking:
+
+```python
+class Solution:
+ def inorderTraversal(self, root: TreeNode) -> List[int]:
+ WHITE, GRAY = 0, 1
+ res = []
+ stack = [(WHITE, root)]
+ while stack:
+ color, node = stack.pop()
+ if node is None: continue
+ if color == WHITE:
+ stack.append((WHITE, node.right))
+ stack.append((GRAY, node))
+ stack.append((WHITE, node.left))
+ else:
+ res.append(node.val)
+ return res
+```
+
+Implementation of preorder and postorder traversal algorithms can be easily done by changing the order of pushing the child nodes into the stack.
+
+## Morris Traversal
+
+We can also use a method called Morris traversal, which involves no recursion or stack, and the time complexity is O(1).
+
+```python
+def MorrisTraversal(root):
+ curr = root
+
+ while curr:
+ # If left child is null, print the
+ # current node data. And, update
+ # the current pointer to right child.
+ if curr.left is None:
+ print(curr.data, end= " ")
+ curr = curr.right
+
+ else:
+ # Find the inorder predecessor
+ prev = curr.left
+
+ while prev.right is not None and prev.right is not curr:
+ prev = prev.right
+
+ # If the right child of inorder
+ # predecessor already points to
+ # the current node, update the
+ # current with it's right child
+ if prev.right is curr:
+ prev.right = None
+ curr = curr.right
+
+ # else If right child doesn't point
+ # to the current node, then print this
+ # node's data and update the right child
+ # pointer with the current node and update
+ # the current with it's left child
+ else:
+ print (curr.data, end=" ")
+ prev.right = curr
+ curr = curr.left
+```
+
+Reference: [what-is-morris-traversal](https://www.educative.io/edpresso/what-is-morris-traversal)
diff --git a/thinkings/binary-tree-traversal.md b/thinkings/binary-tree-traversal.md
index 0d54b8111..382b01755 100644
--- a/thinkings/binary-tree-traversal.md
+++ b/thinkings/binary-tree-traversal.md
@@ -2,8 +2,7 @@
## 概述
-二叉树作为一个基础的数据结构,遍历算法作为一个基础的算法,两者结合当然是经典的组合了。
-很多题目都会有 ta 的身影,有直接问二叉树的遍历的,有间接问的。
+二叉树作为一个基础的数据结构,遍历算法作为一个基础的算法,两者结合当然是经典的组合了。很多题目都会有 ta 的身影,有直接问二叉树的遍历的,有间接问的。比如要你找到树中满足条件的节点,就是间接考察树的遍历,因为你要找到树中满足条件的点,就需要进行遍历。
> 你如果掌握了二叉树的遍历,那么也许其他复杂的树对于你来说也并不遥远了
@@ -14,12 +13,14 @@ DFS 都可以使用栈来简化操作,并且其实树本身是一种递归的
DFS 图解:
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以用一个标识位来表式当前层的结束。
+首先不管是前中还是后序遍历,变的只是根节点的位置, 左右节点的顺序永远是先左后右。 比如前序遍历就是根在前面,即根左右。中序就是根在中间,即左根右。后序就是根在后面,即左右根。
+
下面我们依次讲解:
## 前序遍历
@@ -42,7 +43,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
如果从这个角度出发去写的话,算法就不一样了。从上向下我们可以直接递归访问即可,从下向上我们只需要借助栈也可以轻易做到。
整个过程大概是这样:
-
+
这种思路解题有点像我总结过的一个解题思路`backtrack` - 回溯法。这种思路有一个好处就是
可以`统一三种遍历的思路`. 这个很重要,如果不了解的朋友,希望能够记住这一点。
@@ -85,7 +86,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
层次遍历的关键点在于如何记录每一层次是否遍历完成, 我们可以用一个标识位来表式当前层的结束。
-
+
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
@@ -103,7 +104,7 @@ BFS 的关键点在于如何记录每一层次是否遍历完成, 我们可以
## 双色标记法
-我们直到垃圾回收算法中,有一种算法叫三色标记法。 即:
+我们知道垃圾回收算法中,有一种算法叫三色标记法。 即:
- 用白色表示尚未访问
- 灰色表示尚未完全访问子节点
@@ -137,11 +138,15 @@ class Solution:
return res
```
-如要实现前序、后序遍历,只需要调整左右子节点的入栈顺序即可。
+可以看出,实现上 WHITE 就表示的是递归中的第一次进入过程,Gray 则表示递归中的从叶子节点返回的过程。 因此这种迭代的写法更接近递归写法的本质。
+
+如要实现前序、后序遍历,只需要调整左右子节点的入栈顺序即可。可以看出使用三色标记法, 其写法类似递归的形式,因此便于记忆和书写,缺点是使用了额外的内存空间。不过这个额外的空间是线性的,影响倒是不大。
+
+> 虽然递归也是额外的线性时间,但是递归的栈开销还是比一个 0,1 变量开销大的。
## Morris 遍历
-我们可以使用一种叫做 Morris 遍历的方法,既不使用递归也不借助于栈。从而在$O(1)$时间完成这个过程。
+我们可以使用一种叫做 Morris 遍历的方法,既不使用递归也不借助于栈。从而在 $O(1)$ 空间完成这个过程。
```python
def MorrisTraversal(root):
@@ -182,3 +187,15 @@ def MorrisTraversal(root):
```
参考: [what-is-morris-traversal](https://www.educative.io/edpresso/what-is-morris-traversal)
+
+## 相关题目
+
+- [lowest-common-ancestor-of-a-binary-tree](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
+- [binary-tree-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/)
+- [binary-tree-zigzag-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/)
+- [validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
+- [maximum-depth-of-binary-tree](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
+- [balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
+- [binary-tree-level-order-traversal-ii](https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/)
+- [binary-tree-maximum-path-sum](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/)
+- [insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
diff --git a/thinkings/bit.md b/thinkings/bit.md
index 14db86ac1..00d6fe705 100644
--- a/thinkings/bit.md
+++ b/thinkings/bit.md
@@ -190,8 +190,13 @@ class Solution:
- 空间复杂度:$O(1)$
-更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经接近30K star啦。
+## 相关题目
-大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
+- [number-of-1-bits](https://leetcode-cn.com/problems/number-of-1-bits/)
+- [counting-bits](https://leetcode-cn.com/problems/counting-bits/)
+- [reverse-bits](https://leetcode-cn.com/problems/reverse-bits/)
-
+
+更多题解可以访问我的LeetCode题解仓库:https://github.com/azl397985856/leetcode 。 目前已经30K star啦。
+
+关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
diff --git a/thinkings/bloom-filter-en.md b/thinkings/bloom-filter-en.md
index 5d5ce202f..4b14f2948 100644
--- a/thinkings/bloom-filter-en.md
+++ b/thinkings/bloom-filter-en.md
@@ -42,7 +42,7 @@ Here are four interesting properties of Bloom filter:
- Deleting elements from filter is not possible because, if we delete a single element by clearing bits at indices generated by k hash functions, it might cause deletion of few other elements.
-
+
### Application of Bloom Filter
diff --git a/thinkings/bloom-filter.md b/thinkings/bloom-filter.md
index ea18f295b..39f6eb0a5 100644
--- a/thinkings/bloom-filter.md
+++ b/thinkings/bloom-filter.md
@@ -1,24 +1,29 @@
## 场景
+
假设你现在要处理这样一个问题,你有一个网站并且拥有`很多`访客,每当有用户访问时,你想知道这个ip是不是第一次访问你的网站。
### hashtable 可以么
-一个显而易见的答案是将所有的ip用hashtable存起来,每次访问都去hashtable中取,然后判断即可。但是题目说了网站有`很多`访客,
-假如有10亿个用户访问过,每个ip的长度是4 byte,那么你一共需要4 * 1000000000 = 4000000000Bytes = 4G , 如果是判断URL黑名单,
-由于每个URL会更长,那么需要的空间可能会远远大于你的期望。
+
+一个显而易见的答案是将所有的 IP 用 hashtable 存起来,每次访问都去 hashtable 中取,然后判断即可。但是题目说了网站有`很多`访客,
+假如有10亿个用户访问过,假设 IP 是 IPV4, 那么每个 IP 的长度是 4 byte,那么你一共需要4 * 1000000000 = 4000000000Bytes = 4G 。
+
+如果是判断 URL 黑名单,由于每个 URL 会更长(可能远大于上面 IPV4 地址的 4 byte),那么需要的空间可能会远远大于你的期望。
### bit
-另一个稍微难想到的解法是bit, 我们知道bit有0和1两种状态,那么用来表示存在,不存在再合适不过了。
-加入有10亿个ip,我们就可以用10亿个bit来存储,那么你一共需要 1 * 1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32,
-如果是存储URL这种更长的字符串,效率会更高。
+另一个稍微难想到的解法是bit, 我们知道bit有 0 和 1 两种状态,那么用来表示**存在**与**不存在**再合适不过了。
+
+假如有 10 亿个 IP,就可以用 10 亿个 bit 来存储,那么你一共需要 1 * 1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32, 如果是存储URL这种更长的字符串,效率会更高。 问题是,我们怎么把 IPV4 和 bit 的位置关联上呢?
-基于这种想法,我们只需要两个操作,set(ip) 和 has(ip)
+比如`192.168.1.1` 应该是用第几位表示,`10.18.1.1` 应该是用第几位表示呢? 答案是使用哈希函数。
+
+基于这种想法,我们只需要两个操作,set(ip) 和 has(ip),以及一个内置函数 hash(ip) 用于将 IP 映射到 bit 表。
这样做有两个非常致命的缺点:
1. 当样本分布极度不均匀的时候,会造成很大空间上的浪费
-> 我们可以通过散列函数来解决
+> 我们可以通过优化散列函数来解决
2. 当元素不是整型(比如URL)的时候,BitSet就不适用了
@@ -26,19 +31,23 @@
### 布隆过滤器
-布隆过滤器其实就是`bit + 多个散列函数`, 如果经过多次散列的值再bit上都为1,那么可能存在(可能有冲突)。 如果
-有一个不为1,那么一定不存在(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。
+布隆过滤器其实就是`bit + 多个散列函数`。k 次 hash(ip) 会生成多个索引,并将其 k 个索引位置的二进制置为 1。 如果经过 k 个索引位置的值都为 1,那么认为其**可能存在**(因为有冲突的可能)。 如果有一个不为1,那么**一定不存在**(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。也就是说布隆过滤器回答了:**可能存在** 和 **一定不存在** 的问题。
+
+
-
+从上图可以看出, 布隆过滤器本质上是由**一个很长的二进制向量**和**多个哈希函数**组成。
+
+由于没有 hashtable 的100% 可靠性,因此这本质上是一种**可靠性换取空间的做法**。除了可靠性,布隆过滤器删除起来也比较麻烦。
### 布隆过滤器的应用
1. 网络爬虫
+
判断某个URL是否已经被爬取过
2. K-V数据库 判断某个key是否存在
-比如Hbase的每个Region中都包含一个BloomFilter,用于在查询时快速判断某个key在该region中是否存在。
+比如 Hbase 的每个 Region 中都包含一个 BloomFilter,用于在查询时快速判断某个 key 在该 region 中是否存在。
3. 钓鱼网站识别
diff --git a/thinkings/dynamic-programming-en.md b/thinkings/dynamic-programming-en.md
index a81e19c26..514d7dbfb 100644
--- a/thinkings/dynamic-programming-en.md
+++ b/thinkings/dynamic-programming-en.md
@@ -48,7 +48,7 @@ function sum(nums) {
Let's review this problem intuitively with a recursion tree.
-
+
This method works, but not quit good. Because there are certain costs in executing functions. Let's take JS as example.
For each time a function executed, it requires stack push operations, pre-processing and executing processes. So, recurse a function is easy to cause stack overflow.
@@ -72,7 +72,7 @@ function climbStairs(n) {
This question is just like the `fibnacci` series. Let's have a look at the recursion tree of `fibnacci` question again.
-
+
Some results are calculated repeatedly. Just like the red nodes showing. If a structure like `hashtable` is used to store the intermedia results, the reduplicative calculations can be avoided.
Similarly, DP also uses "table look-up" to solve the problem of reduplicative calculation.
@@ -104,7 +104,7 @@ function climbStairs(n) {
Here is the process of "table look-up" in DP:
-
+
> dotted box is the "table look-up"
diff --git a/thinkings/dynamic-programming.md b/thinkings/dynamic-programming.md
index aa88db8b3..a36caf93a 100644
--- a/thinkings/dynamic-programming.md
+++ b/thinkings/dynamic-programming.md
@@ -1,58 +1,69 @@
# 递归和动态规划
-动态规划可以理解为是查表的递归。那么什么是递归?
+动态规划可以理解为是**查表的递归(记忆化)**。那么什么是递归?什么是查表(记忆化)?
## 递归
-定义: 递归算法是一种直接或者间接调用自身函数或者方法的算法。
+递归是指在函数的定义中使用函数自身的方法。
-算法中使用递归可以很简单地完成一些用循环实现的功能,比如二叉树的左中右序遍历。递归在算法中有非常广泛的使用,
-包括现在日趋流行的函数式编程。
+算法中使用递归可以很简单地完成一些用循环实现的功能,比如二叉树的左中右序遍历。递归在算法中有非常广泛的使用,包括现在日趋流行的函数式编程。
-> 纯粹的函数式编程中没有循环,只有递归。
+有意义的递归算法会把问题分解成规模缩小的同类子问题,当子问题缩减到寻常的时候,就可以知道它的解。然后建立递归函数之间的联系即可解决原问题,这也是我们使用递归的意义。准确来说, 递归并不是算法,它是和迭代对应的一种编程方法。只不过,由于隐式地借助了函数调用栈,因此递归写起来更简单。
-接下来我们来讲解一下递归。通俗来说,递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解
+一个问题要使用递归来解决必须有递归终止条件(算法的有穷性)。虽然以下代码也是递归,但由于其无法结束,因此不是一个有效的算法:
-### 递归的三个要素
+```py
+def f(n):
+ return n + f(n - 1)
+```
-1. 一个问题的解可以分解为几个子问题的解
-2. 子问题的求解思路除了规模之外,没有任何区别
-3. 有递归终止条件
+更多的情况应该是:
-我这里列举了几道算法题目,这几道算法题目都可以用递归轻松写出来:
+```py
+def f(n):
+ if n == 1: return 1
+ return n + f(n - 1)
+```
-- 递归实现 sum
+### 练习递归
-- 二叉树的遍历
+一个简单练习递归的方式是将你写的迭代全部改成递归形式。比如你写了一个程序,功能是“将一个字符串逆序输出”,那么使用迭代将其写出来会非常容易,那么你是否可以使用递归写出来呢?通过这样的练习,可以让你逐步适应使用递归来写程序。
-- 走楼梯问题
+如果你已经对递归比较熟悉了,那么我们继续往下看。
-- 汉诺塔问题
+### 递归中的重复计算
-- 杨辉三角
+递归中可能存在这么多的重复计算,为了消除这种重复计算,一种简单的方式就是记忆化递归。即一边递归一边使用“记录表”(比如哈希表或者数组)记录我们已经计算过的情况,当下次再次碰到的时候,如果之前已经计算了,那么直接返回即可,这样就避免了重复计算。而**动态规划中 DP 数组其实和这里“记录表”的作用是一样的**。
-### 练习递归
+### 递归的时间复杂度分析
-一个简单练习递归的方式是将你写的迭代全部改成递归形式。比如你写了一个程序,功能是“将一个字符串逆序输出”,那么使用迭代将其写出来会非常容易,那么你是否可以使用递归写出来呢?通过这样的练习,可以让你逐步适应使用递归来写程序。
+敬请期待我的新书。
-### 递归中的重复计算
+### 小结
-递归中存在这么多的重复计算,一种简单的方式就是记忆化递归。即一边递归一边使用“记录表”记录我们已经计算过的情况,这样就避免了重复计算。而动态规划中 DP 数组其实和“记录表”一样。
+使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。这里我列举了几道算法题目,这几道算法题目都可以用递归轻松写出来:
-你可以尝试使记忆化更加通用和非侵入性,即应用记忆化技术而不改变原来的功能。 (提示:可以参考一种被称作 decorator 的设计模式)。
+- 递归实现 sum
-### 递归的时间复杂度分析
+- 二叉树的遍历
-敬请期待我的新书。
+- 走楼梯问题
+
+- 汉诺塔问题
+
+- 杨辉三角
+
+当你已经适应了递归的时候,那就让我们继续学习动态规划吧!
## 动态规划
-`如果说递归是从问题的结果倒推,直到问题的规模缩小到寻常。 那么动态规划就是从寻常入手, 逐步扩大规模到最优子结构。` 这句话需要一定的时间来消化,
-如果不理解,可以过一段时间再来看。
+如果你已经熟悉了递归的技巧,那么使用递归解决问题非常符合人的直觉,代码写起来也比较简单。这个时候我们来关注另一个问题 - **重复计算** 。我们可以通过分析(可以尝试画一个递归树),可以看出递归在缩小问题规模的同时**是否可能会重复计算**。 [279.perfect-squares](../problems/279.perfect-squares.md) 中 我通过递归的方式来解决这个问题,同时内部维护了一个缓存来存储计算过的运算,这么做可以减少很多运算。 这其实和动态规划有着异曲同工的地方。
+
+> 小提示:如果你发现并没有重复计算,那么就没有必要用记忆化递归或者动态规划了。
+
+因此动态规划就是枚举所以可能。不过相比暴力枚举,动态规划不会有重复计算。因此如何保证枚举时不重不漏是关键点之一。 递归由于使用了函数调用栈来存储数据,因此如果栈变得很大,那么会容易爆栈。
-递归的解决问题非常符合人的直觉,代码写起来比较简单。但是我们通过分析(可以尝试画一个递归树),可以看出递归在缩小问题规模的同时可能会
-重复计算。 [279.perfect-squares](../problems/279.perfect-squares.md) 中 我通过递归的方式来解决这个问题,同时内部维护了一个缓存
-来存储计算过的运算,那么我们可以减少很多运算。 这其实和动态规划有着异曲同工的地方。
+### 爆栈
我们结合求和问题来讲解一下,题目是给定一个数组,求出数组中所有项的和,要求使用递归实现。
@@ -69,19 +80,21 @@ function sum(nums) {
我们用递归树来直观地看一下。
-
+
-这种做法本身没有问题,但是每次执行一个函数都有一定的开销,拿 JS 引擎执行 JS 来说,
-每次函数执行都会进行入栈操作,并进行预处理和执行过程,所以对于内存来说是一个挑战。
-很容易造成爆栈。
+这种做法本身没有问题,但是每次执行一个函数都有一定的开销,拿 JS 引擎执行 JS 来说,每次函数执行都会进行入栈操作,并进行预处理和执行过程,所以内存会有额外的开销,数据量大的时候很容易造成爆栈。
> 浏览器中的 JS 引擎对于代码执行栈的长度是有限制的,超过会爆栈,抛出异常。
-我们再举一个更加明显的例子,问题描述:
+### 重复计算
+
+我们再举一个重复计算的例子,问题描述:
一个人爬楼梯,每次只能爬 1 个或 2 个台阶,假设有 n 个台阶,那么这个人有多少种不同的爬楼梯方法?
-代码:
+由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 `上 n - 1 级台阶的数目加上 n - 1 级台阶的数目`。
+
+递归代码:
```js
function climbStairs(n) {
@@ -91,18 +104,55 @@ function climbStairs(n) {
}
```
-这道题和 fibnacci 数列一摸一样,我们继续用一个递归树来直观感受以下:
+我们继续用一个递归树来直观感受以下:
+
+
-
+> 红色表示重复的计算
可以看出这里面有很多重复计算,我们可以使用一个 hashtable 去缓存中间计算结果,从而省去不必要的计算。
-那么动态规划是怎么解决这个问题呢? 答案就是“查表”。
-刚才我们说了`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
+那么动态规划是怎么解决这个问题呢? 答案也是“查表”,不过区别于递归使用函数调用栈,动态规划通常使用的是 dp 数组,数组的索引通常是问题规模,值通常是递归函数的返回值。`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
+
+如果上面的爬楼梯问题,使用动态规划,代码是这样的:
+
+```js
+function climbStairs(n) {
+ if (n == 1) return 1;
+ const dp = new Array(n);
+ dp[0] = 1;
+ dp[1] = 2;
+
+ for (let i = 2; i < n; i++) {
+ dp[i] = dp[i - 1] + dp[i - 2];
+ }
+ return dp[dp.length - 1];
+}
+```
+
+不会也没关系,我们将递归的代码稍微改造一下。其实就是将函数的名字改一下:
+
+```js
+function dp(n) {
+ if (n === 1) return 1;
+ if (n === 2) return 2;
+ return dp(n - 1) + dp(n - 2);
+}
+```
+
+> dp[n] 和 dp(n) 对比看,这样是不是有点理解了呢? 只不过递归用调用栈枚举状态, 而动态规划使用迭代枚举状态。
+
+动态规划的查表过程如果画成图,就是这样的:
+
+
+
+> 虚线代表的是查表过程
+
+这道题目是动态规划中最简单的问题了,因为设计到单个因素的变化,如果涉及到多个因素,就比较复杂了,比如著名的背包问题,挖金矿问题等。
-从刚才的两个例子,我想大家可能对前半句话有了一定的理解,我们接下来讲解下后半句。
+对于单个因素的,我们最多只需要一个一维数组即可,对于如背包问题我们需要二维数组等更高纬度。
-如果爬楼梯的问题,使用动态规划,代码是这样的:
+爬楼梯我们并没有必要使用一维数组,而是借助两个变量来实现的,空间复杂度是 O(1)。代码:
```js
function climbStairs(n) {
@@ -123,26 +173,25 @@ function climbStairs(n) {
}
```
-动态规划的查表过程如果画成图,就是这样的:
-
-
-
-> 虚线代表的是查表过程
-
-这道题目是动态规划中最简单的问题了,因为设计到单个因素的变化,如果涉及到多个因素,就比较复杂了,比如著名的背包问题,挖金矿问题等。
+之所以能这么做,是因为爬楼梯问题的状态转移方程中**当前状态只和前两个状态有关**,因此只需要存储这两个即可。 动态规划问题有很多这种讨巧的方式,这个技巧叫做滚动数组。
-对于单个因素的,我们最多只需要一个一维数组即可,对于如背包问题我们需要二维数组等更高纬度。
+再次强调一下:
-> 爬楼梯我们并没有使用一维数组,而是借助两个变量来实现的,空间复杂度是 O(1).
-> 之所以能这么做,是因为爬楼梯问题的状态转移方程只和前两个有关,因此只需要存储这两个即可。 动态规划问题有时候有很多这种讨巧的方式,但并不是所有的
+- 如果说递归是从问题的结果倒推,直到问题的规模缩小到寻常。 那么动态规划就是从寻常入手, 逐步扩大规模到最优子结构。
+- 记忆化递归和动态规划没有本质不同。都是枚举状态,并根据状态直接的联系逐步推导求解。
+- 动态规划性能通常更好。 一方面是递归的栈开销,一方面是滚动数组的技巧。
-### 动态规划的两个要素
+### 动态规划的三个要素
1. 状态转移方程
2. 临界条件
-在上面讲解的爬楼梯问题中
+3. 枚举状态
+
+> 可以看出,用递归解决也是一样的思路
+
+在上面讲解的爬楼梯问题中,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么:
```
f(1) 与 f(2) 就是【边界】
@@ -150,41 +199,130 @@ f(n) = f(n-1) + f(n-2) 就是【状态转移公式】
```
+我用动态规划的形式表示一下:
+
+```
+dp[0] 与 dp[1] 就是【边界】
+dp[n] = dp[n - 1] + dp[n - 2] 就是【状态转移方程】
+```
+
+可以看出两者是多么的相似。
+
+实际上临界条件相对简单,大家只有多刷几道题,里面就有感觉。困难的是找到状态转移方程和枚举状态。这两个核心点的都建立在**已经抽象好了状态**的基础上。比如爬楼梯的问题,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么 f(1), f(2), ... 就是各个**独立的状态**。
+
+不过状态的定义都有特点的套路。 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ....。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ....。
+
+当然状态转移方程可能不止一个, 不同的转移方程对应的效率也可能大相径庭,这个就是比较玄学的话题了,需要大家在做题的过程中领悟。
+
+搞定了状态的定义,那么我们来看下状态转移方程。
+
+#### 状态转移方程
+
+爬楼梯问题由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 `上 n - 1 级台阶的数目加上 n - 1 级台阶的数目`。
+
+上面的这个理解是核心, 它就是我们的状态转移方程,用代码表示就是 `f(n) = f(n - 1) + f(n - 2)`。
+
+实际操作的过程,有可能题目和爬楼梯一样直观,我们不难想到。也可能隐藏很深或者维度过高。 如果你实在想不到,可以尝试画图打开思路,这也是我刚学习动态规划时候的方法。当你做题量上去了,你的题感就会来,那个时候就可以不用画图了。
+
+状态转移方程实在是没有什么灵丹妙药,不同的题目有不同的解法。状态转移方程同时也是解决动态规划问题中最最困难和关键的点,大家一定要多多练习,提高题感。接下来,我们来看下不那么困难,但是新手疑问比较多的问题 - **如何枚举状态**。
+
+#### 如何枚举状态
+
+前面说了如何枚举状态,才能不重不漏是枚举状态的关键所在。
+
+- 如果是一维状态,那么我们使用一层循环可以搞定。
+- 如果是两维状态,那么我们使用两层循环可以搞定。
+- 。。。
+
+这样可以保证不重不漏。
+
+但是实际操作的过程有很多细节比如:
+
+- 一维状态我是先枚举左边的还是右边的?(从左到右遍历还是从右到左遍历)
+- 二维状态我是先枚举左上边的还是右上的,还是左下的还是右下的?
+- 里层循环和外层循环的位置关系(可以互换么)
+- 。。。
+
+其实这个东西和很多因素有关,很难总结出一个规律,而且我认为也完全没有必要去总结规律。不过这里我还是总结了一个关键点,那就是:
+
+- **如果你没有使用滚动数组的技巧**,那么遍历顺序取决于状态转移方程。比如:
+
+```py
+for i in range(1, n + 1):
+ dp[i] = dp[i - 1] + 1;
+```
+
+那么我们就需要从左到右遍历,原因很简单,因为 dp[i] 依赖于 dp[i - 1],因此计算 dp[i] 的时候, dp[i - 1] 需要已经计算好了。
+
+> 二维的也是一样的,大家可以试试。
+
+- **如果你使用了滚动数组的技巧**,则怎么遍历都可以,但是不同的遍历意义通常不不同的。比如我将二维的压缩到了一维:
+
+```py
+for i in range(1, n + 1):
+ for j in range(1, n + 1):
+ dp[j] = dp[j - 1] + 1;
+```
+
+这样是可以的。 dp[j - 1] 实际上指的是压缩前的 dp[i][j - 1]
+
+而:
+
+```py
+for i in range(1, n + 1):
+ # 倒着遍历
+ for j in range(n, 0, -1):
+ dp[j] = dp[j - 1] + 1;
+```
+
+这样也是可以的。 但是 dp[j - 1] 实际上指的是压缩前的 dp[i - 1][j - 1]。因此实际中采用怎么样的遍历手段取决于题目。我特意写了一个 [【完全背包问题】套路题(1449. 数位成本和为目标值的最大数字](https://leetcode-cn.com/problems/form-largest-integer-with-digits-that-add-up-to-target/solution/wan-quan-bei-bao-wen-ti-tao-lu-ti-1449-shu-wei-che/) 文章,通过一个具体的例子告诉大家不同的遍历有什么实际不同,强烈建议大家看看,并顺手给个三连。
+
+- 关于里外循环的问题,其实和上面原理类似。
+
+这个比较微妙,大家可以参考这篇文章理解一下 [0518.coin-change-2](../problems/518.coin-change-2.md)。
+
+#### 小结
+
+关于如何确定临界条件通常是比较简单的,多做几个题就可以快速掌握。
+
+关于如何确定状态转移方程,这个其实比较困难。 不过所幸的是,这些套路性比较强, 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ....。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ....。 这样遇到新的题目可以往上套, 实在套不出那就先老实画图,不断观察,提高题感。
+
+关于如何枚举状态,如果没有滚动数组, 那么根据转移方程决定如何枚举即可。 如果用了滚动数组,那么要注意压缩后和压缩前的 dp 对应关系即可。
+
### 动态规划为什么要画表格
动态规划问题要画表格,但是有的人不知道为什么要画,就觉得这个是必然的,必要要画表格才是动态规划。
-其实动态规划本质上是将大问题转化为小问题,然后大问题的解是和小问题有关联的,换句话说大问题可以由小问题进行计算得到。
-
-这一点是和递归一样的, 但是动态规划是一种类似查表的方法来缩短时间复杂度和空间复杂度。
+其实动态规划本质上是将大问题转化为小问题,然后大问题的解是和小问题有关联的,换句话说大问题可以由小问题进行计算得到。这一点是和用递归解决一样的, 但是动态规划是一种类似查表的方法来缩短时间复杂度和空间复杂度。
画表格的目的就是去不断推导,完成状态转移, 表格中的每一个 cell 都是一个`小问题`, 我们填表的过程其实就是在解决问题的过程,
+
我们先解决规模为寻常的情况,然后根据这个结果逐步推导,通常情况下,表格的右下角是问题的最大的规模,也就是我们想要求解的规模。
比如我们用动态规划解决背包问题, 其实就是在不断根据之前的小问题`A[i - 1][j] A[i -1][w - wj]`来询问:
-1. 我是应该选择它
-2. 还是不选择它
+- 应该选择它
+- 还是不选择它
至于判断的标准很简单,就是价值最大,因此我们要做的就是对于选择和不选择两种情况分别求价值,然后取最大,最后更新 cell 即可。
-其实大部分的动态规划问题套路都是“选择”或者“不选择”,也就是说是一种“选择题”。 并且大多数动态规划题目还伴随着空间的优化,这是动态规划相对于传统的记忆化递归优势的地方。除了这点优势,就是上文提到的使用动态规划可以减少递归产生的函数调用栈,因此性能上更好。
+其实大部分的动态规划问题套路都是“选择”或者“不选择”,也就是说是一种“选择题”。 并且大多数动态规划题目还伴随着空间的优化(滚动数组),这是动态规划相对于传统的记忆化递归优势的地方。除了这点优势,就是上文提到的使用动态规划可以减少递归产生的函数调用栈,因此性能上更好。
### 相关问题
- [0091.decode-ways](../problems/91.decode-ways.md)
- [0139.word-break](../problems/139.word-break.md)
-- [0198.house-robber](../problems/0198.house-robber.md)
+- [0198.house-robber](../problems/198.house-robber.md)
- [0309.best-time-to-buy-and-sell-stock-with-cooldown](../problems/309.best-time-to-buy-and-sell-stock-with-cooldown.md)
- [0322.coin-change](../problems/322.coin-change.md)
- [0416.partition-equal-subset-sum](../problems/416.partition-equal-subset-sum.md)
- [0518.coin-change-2](../problems/518.coin-change-2.md)
-> 太多了,没有逐一列举
-
## 总结
-本篇文章总结了算法中比较常用的两个方法 - 递归和动态规划。
+本篇文章总结了算法中比较常用的两个方法 - 递归和动态规划。递归的话可以拿树的题目练手,动态规划的话则将我上面推荐的刷完,再考虑去刷力扣的动态规划标签即可。
+
+大家前期学习动态规划的时候,可以先尝试使用记忆化递归解决。然后将其改造为动态规划,这样多练习几次就会有感觉。之后大家可以练习一下滚动数组,这个技巧很有用,并且相对来说比较简单。 比较动态规划的难点在于**枚举所以状态(无重复)** 和 **寻找状态转移方程**。
如果你只能记住一句话,那么请记住:`递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。`
diff --git a/thinkings/greedy.md b/thinkings/greedy.md
index 179ac3190..3576b6292 100644
--- a/thinkings/greedy.md
+++ b/thinkings/greedy.md
@@ -42,11 +42,11 @@ LeetCode 上对于贪婪策略有 73 道题目。我们将其分成几个类型
如下图,开始的位置是 2,可跳的范围是橙色的。然后因为 3 可以跳的更远,所以跳到 3 的位置。
-
+
如下图,然后现在的位置就是 3 了,能跳的范围是橙色的,然后因为 4 可以跳的更远,所以下次跳到 4 的位置。
-
+
写代码的话,我们用 end 表示当前能跳的边界,对于上边第一个图的橙色 1,第二个图中就是橙色的 4,遍历数组的时候,到了边界,我们就重新更新新的边界。
@@ -125,7 +125,7 @@ class Solution:
贪婪策略,我们选择满足条件的最大值。和上面的不同,这次我们需要手动进行一次排序,实际上贪婪策略经常伴随着排序,我们按照 clip[0]从小到大进行排序。
-
+
如图:
@@ -137,11 +137,11 @@ class Solution:
那么这种情况下 t1 实际上是不需要的,因为 t2 完全可以覆盖它:
-
+
那什么样 t1 才是需要的呢?如图:
-
+
用代码来说的话就是`s > t2 and t2 <= t1`
@@ -191,7 +191,7 @@ class Solution:
示例 1:
-
+
输入:n = 5, ranges = [3,4,1,1,0,0]
输出:1
diff --git a/thinkings/prefix.md b/thinkings/prefix.md
new file mode 100644
index 000000000..6adb11fbc
--- /dev/null
+++ b/thinkings/prefix.md
@@ -0,0 +1,4 @@
+## 题目列表
+
+- [掌握前缀表达式真的可以为所欲为!](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/)
+- [1371.find-the-longest-substring-containing-vowels-in-even-counts](../problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md) 🆕
diff --git a/thinkings/run-length-encode-and-huffman-encode.md b/thinkings/run-length-encode-and-huffman-encode.md
index c1a11e4c4..92d1e754e 100644
--- a/thinkings/run-length-encode-and-huffman-encode.md
+++ b/thinkings/run-length-encode-and-huffman-encode.md
@@ -38,7 +38,7 @@ eg:
结果是这样的:
-
+
|character|frequency|encoding|
|:-:|:-:|:-:|
diff --git a/thinkings/slide-window.en.md b/thinkings/slide-window.en.md
new file mode 100644
index 000000000..4f4729d3c
--- /dev/null
+++ b/thinkings/slide-window.en.md
@@ -0,0 +1,87 @@
+# Sliding Window Technique
+
+I first encountered the term "sliding window" when learning about the sliding window protocols, which is used in Transmission Control Protocol (TCP) for packet-based data transimission. It is used to improved transmission efficiency in order to avoid congestions. The sender and the receiver each has a window size, w1 and w2, respectively. The window size may vary based on the network traffic flow. However, in a simpler implementation, the sizes are fixed, and they must be greater than 0 to perform any task.
+
+The sliding window technique in algorithms is very similar, but it applies to more scenarios. Now, let's go over this technique.
+
+## Introduction
+
+Sliding window technique, also known as two pointers technique, can help reduce time complexity in problems that ask for "consecutive" or "contiguous" items. For example, [209. Minimum Size Subarray Sum](https://leetcode-cn.com/problems/minimum-size-subarray-sum/solution/209-chang-du-zui-xiao-de-zi-shu-zu-hua-dong-chua-2/). For more related problems, go to the `List of Problems` below.
+
+## Common Types
+
+This technique is mainly for solving problems ask about "consecutive substring" or "contiguous subarray". It would be helpful if you can relate these terms with this technique in your mind. Whether the technique solve the exact problem or not, it would come in handy.
+
+There are mainly three types of application:
+
+- Fixed window size
+- Variable window size and looking for the maximum window size that meet the requirement
+- Variable window size and looking for the minimum window size that meet the requirement (e.g. Problem#209 mentioned above)
+
+The last two are catogorized as "variable window". Of course, they are all of the same essentially. It's all about the implementation details.
+
+### Fixed Window Size
+
+For fixed window size problem, we only need to keep track of the left pointer l and the right pointer r, which indicate the boundaries of a fixed window, and make sure that:
+
+1. l is initialized to be 0
+2. r is initialied such that the window's size = r - l + 1
+3. Always move l and r simultaneously
+4. Decide if the consecutive elements contained within the window satisfy the required conditions.
+ - 4.1 If they satisfy, based on whether we need an optimal solution or not, we either return the solution or keep updating until we find the optimal one.
+ - 4.2 Otherwise, we continue to find an appropriate window
+
+
+
+### Variable Window Size
+
+For variable window, we initialize the left and right pointers the same way. Then we need to make sure that:
+
+1. Both l and r are initialized to 0
+2. Move r to the right by one step
+3. Decide if the consecutive elements contained within the window satisfy the required conditions
+ - 3.1 If they satisfy
+ - 3.1.1 and we need an optimal solution, we try moving the pointer l to minimize our window's size and repeat step 3.1
+ - 3.1.2 else we return the current solution
+ - 3.2 If they don't satisfy, we continue to find an appropriate window
+
+If we view it another way, it's simply moving the pointer r to find an appropriate window and we only move the pointer l once we find an appropriate window to minimize the window and find an optimal solution.
+
+
+
+## Code Template
+
+The following code snippet is a solution for problem #209 written in Python.
+
+```python
+class Solution:
+ def minSubArrayLen(self, s: int, nums: List[int]) -> int:
+ l = total = 0
+ ans = len(nums) + 1
+ for r in range(len(nums)):
+ total += nums[r]
+ while total >= s:
+ ans = min(ans, r - l + 1)
+ total -= nums[l]
+ l += 1
+ return 0 if ans == len(nums) + 1 else ans
+```
+
+## List of problems (Not Translated Yet)
+
+Some problems here are intuitive that you know the sliding window technique would be useful while others need a second thought to realize that.
+
+- [【Python,JavaScript】滑动窗口(3. 无重复字符的最长子串)](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/solution/pythonjavascript-hua-dong-chuang-kou-3-wu-zhong-fu/)
+- [76. 最小覆盖子串](https://leetcode-cn.com/problems/minimum-window-substring/solution/python-hua-dong-chuang-kou-76-zui-xiao-fu-gai-zi-c/)
+- [209. 长度最小的子数组](https://leetcode-cn.com/problems/minimum-size-subarray-sum/solution/209-chang-du-zui-xiao-de-zi-shu-zu-hua-dong-chua-2/)
+- [【Python】滑动窗口(438. 找到字符串中所有字母异位词)](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/solution/python-hua-dong-chuang-kou-438-zhao-dao-zi-fu-chua/)
+- [【904. 水果成篮】(Python3)](https://leetcode-cn.com/problems/fruit-into-baskets/solution/904-shui-guo-cheng-lan-python3-by-fe-lucifer/)
+- [【930. 和相同的二元子数组】(Java,Python)](https://leetcode-cn.com/problems/binary-subarrays-with-sum/solution/930-he-xiang-tong-de-er-yuan-zi-shu-zu-javapython-/)
+- [【992. K 个不同整数的子数组】滑动窗口(Python)](https://leetcode-cn.com/problems/subarrays-with-k-different-integers/solution/992-k-ge-bu-tong-zheng-shu-de-zi-shu-zu-hua-dong-c/)
+- [【1004. 最大连续 1 的个数 III】滑动窗口(Python3)](https://leetcode-cn.com/problems/max-consecutive-ones-iii/solution/1004-zui-da-lian-xu-1de-ge-shu-iii-hua-dong-chuang/)
+- [【1234. 替换子串得到平衡字符串】[Java/C++/Python] Sliding Window](https://leetcode.com/problems/replace-the-substring-for-balanced-string/discuss/408978/javacpython-sliding-window/367697)
+- [【1248. 统计「优美子数组」】滑动窗口(Python)](https://leetcode-cn.com/problems/count-number-of-nice-subarrays/solution/1248-tong-ji-you-mei-zi-shu-zu-hua-dong-chuang-kou/)
+
+## Further Readings
+
+- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)(English)
diff --git a/thinkings/slide-window.md b/thinkings/slide-window.md
index 5f3f1766a..429bbf6d5 100644
--- a/thinkings/slide-window.md
+++ b/thinkings/slide-window.md
@@ -31,7 +31,7 @@
- 4.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解
- 4.2 如果不满足,则继续。
-
+
### 可变窗口大小
@@ -39,16 +39,30 @@
1. l 和 r 都初始化为 0
2. r 指针移动一步
-4. 判断窗口内的连续元素是否满足题目限定的条件
- - 4.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解。并尝试通过移动 l 指针缩小窗口大小。循环执行 4.1
- - 4.2 如果不满足,则继续。
+3. 判断窗口内的连续元素是否满足题目限定的条件
+ - 3.1 如果满足,再判断是否需要更新最优解,如果需要则更新最优解。并尝试通过移动 l 指针缩小窗口大小。循环执行 3.1
+ - 3.2 如果不满足,则继续。
形象地来看的话,就是 r 指针不停向右移动,l 指针仅仅在窗口满足条件之后才会移动,起到窗口收缩的效果。
-
+
## 模板代码
+### 伪代码
+```
+初始化慢指针 = 0
+初始化 ans
+
+for 快指针 in 可迭代集合
+ 更新窗口内信息
+ while 窗口内不符合题意
+ 扩展或者收缩窗口
+ 慢指针移动
+返回 ans
+```
+### 代码
+
以下是 209 题目的代码,使用 Python 编写,大家意会即可。
```python
@@ -65,7 +79,7 @@ class Solution:
return 0 if ans == len(nums) + 1 else ans
```
-## 题目列表
+## 题目列表(有题解)
以下题目有的信息比较直接,有的题目信息比较隐蔽,需要自己发掘
@@ -80,6 +94,7 @@ class Solution:
- [【1234. 替换子串得到平衡字符串】[Java/C++/Python] Sliding Window](https://leetcode.com/problems/replace-the-substring-for-balanced-string/discuss/408978/javacpython-sliding-window/367697)
- [【1248. 统计「优美子数组」】滑动窗口(Python)](https://leetcode-cn.com/problems/count-number-of-nice-subarrays/solution/1248-tong-ji-you-mei-zi-shu-zu-hua-dong-chuang-kou/)
+
## 扩展阅读
-- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)
\ No newline at end of file
+- [LeetCode Sliding Window Series Discussion](https://leetcode.com/problems/binary-subarrays-with-sum/discuss/186683/)
diff --git a/thinkings/trie.en.md b/thinkings/trie.en.md
new file mode 100644
index 000000000..64593b643
--- /dev/null
+++ b/thinkings/trie.en.md
@@ -0,0 +1,25 @@
+## Trie
+
+When this article is done (2020-07-13), there are 17 LeetCode problems about [Trie (Prefix Tree)](https://leetcode.com/tag/trie/). Among them, 2 problems are easy, 8 are medium, and 7 are hard.
+
+Here we summarize four of them. Once you figure them out, `Trie` should not be a challenge to you anymore. Hope this article is helpful to you.
+
+The main interface of a trie should include the following:
+
+- `insert(word)`: Insert a word
+- `search(word)`: Search for a word
+- `startWith(prefix)`: Search for a word with the given prefix
+
+Among all of the above, `startWith` is one of the most essential methods, which leads to the naming for 'Prefix Tree'. You can start with [208.implement-trie-prefix-tree](https://leetcode.com/problems/implement-trie-prefix-tree) to get yourself familiar with this data structure, and then try to solve other problems.
+
+Here's the graph illustration of a trie:
+
+
+As the graph shows, each node of the trie would store a character and a boolean `isWord`, which suggests whether the node is the end of a word. There might be some slight differences in the actual implementation, but they are essentially the same.
+
+### Related Problems' Solutions in this Repo (To Be Updated)
+- [0208.implement-trie-prefix-tree](https://github.com/azl397985856/leetcode/blob/b8e8fa5f0554926efa9039495b25ed7fc158372a/problems/208.implement-trie-prefix-tree.md)
+- [0211.add-and-search-word-data-structure-design](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/211.add-and-search-word-data-structure-design.md)
+- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
+- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
+- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
diff --git a/thinkings/trie.md b/thinkings/trie.md
index c9ff2feaf..e2f1696dc 100644
--- a/thinkings/trie.md
+++ b/thinkings/trie.md
@@ -14,7 +14,7 @@
一个前缀树大概是这个样子:
-
+
如图每一个节点存储一个字符,然后外加一个控制信息表示是否是单词结尾,实际使用过程可能会有细微差别,不过变化不大。
@@ -25,3 +25,4 @@
- [0212.word-search-ii](https://github.com/azl397985856/leetcode/blob/b0b69f8f11dace3a9040b54532105d42e88e6599/problems/212.word-search-ii.md)
- [0472.concatenated-words](https://github.com/azl397985856/leetcode/blob/master/problems/472.concatenated-words.md)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
+- [1032.stream-of-characters](../problems/1032.stream-of-characters.md)
diff --git a/thinkings/union-find.en.md b/thinkings/union-find.en.md
new file mode 100644
index 000000000..d8effbf2a
--- /dev/null
+++ b/thinkings/union-find.en.md
@@ -0,0 +1,146 @@
+# Union Find Data Structure
+
+Leetcode has many problems concerning the union-find data structure. To be specific, the official number is 30(until 2020-02-20). And some problems, though not labeled with `Union Find`, can be solved more easily by applying this data structure. A problem-solving pattern can be found among this kind of problem. Once you have grasped the pattern, you can solve these problems with higher speed and fewer mistakes, which is the benefit of using patterns.
+
+Related problems:
+
+- [547. Friend Circles](../problems/547.friend-circles.md) Chinese
+- [721. Accounts Merge](https://leetcode-cn.com/problems/accounts-merge/solution/mo-ban-ti-bing-cha-ji-python3-by-fe-lucifer-3/) Chinese
+- [990. Satisfiability of Equality Equations](https://github.com/azl397985856/leetcode/issues/304) Chinese
+
+It's recommended that you practice with these problems after reading this blog, to see if you understand the idea of a union-find data structure.
+
+## Overview
+
+A disjoint-set data structure (also called a union-find data structure or merge–find set) is a tree-like data structure that supports union & find operations on disjoint sets. A union-find algorithm is an algorithm that performs two operations on such a data structure.
+
+- Find: Determine which subset a particular element is in. This can be used for determining if two elements are in the same subset.
+- Union: Join two subsets into a single subset.
+
+To define how these operations work more precisely, we need to first define how subsets are represented. A common strategy is to choose one member from each subset to represent it, called the representative. Find(x) operation will return the representative of the subset in which x exists and Union operation accepts two representatives as parameters.
+
+## Lively Explanation
+
+Let's say there are two Marshals, each holds a group of Generals, which holds a group of sergeants, and so on.
+
+How do we determine whether two Generals belong two the same Marshal (connectivity)?
+
+
+
+The question is easy enough. All we have to do is to find the Marshals of these two Generals respectively. If the results are the same Marshal, then the two Generals belong to the same Marshal. Use `parent[x] = y` to represent `x's parent is y`. By looking for `parent` recursively, a `root` can be reached finally. Then a conclusion can be drawn by comparing the roots obtained.
+
+The process described above involves two basic operations: `find` and `connected`. Besides these two, `union` operation can be used to merge two subsets into one.
+
+There are two Marshals in the picture.
+
+
+
+How do we merge them? The simplest way is pointing one of the Marshals to the other one.
+
+
+
+Done with the lively explanation of the three core APIs `find`, `connected`, and `union`. Now let's see how to implement these APIs.
+
+## Core API
+
+### find
+
+```python
+def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ return x
+```
+
+### connected
+
+```python
+def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+### union
+
+```python
+def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+```
+
+## Complete Code
+
+```python
+class UF:
+ parent = {}
+ cnt = 0
+ def __init__(self, M):
+ # Initiate parent and cnt
+
+ def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ return x
+ def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+ self.cnt -= 1
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+## Code with path compression
+
+```python
+class UF:
+ parent = {}
+ size = {}
+ cnt = 0
+ def __init__(self, M):
+ # Initiate parent, size and cnt
+
+ def find(self, x):
+ while x != self.parent[x]:
+ x = self.parent[x]
+ # path compression
+ self.parent[x] = self.parent[self.parent[x]];
+ return x
+ def union(self, p, q):
+ if self.connected(p, q): return
+ # Attach the tree with fewer elements to the root of the tree with more elements in order to balance the tree.
+ leader_p = self.find(p)
+ leader_q = self.find(q)
+ if self.size[leader_p] < self.size[leader_q]:
+ self.parent[leader_p] = leader_q
+ else:
+ self.parent[leader_q] = leader_p
+ self.cnt -= 1
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
+
+The code above implements path compression with recursion, which, though is easier to write, contains the risk of stack overflow. The following is how we can do it with iteration.
+
+```python
+class UF:
+ parent = {}
+ def __init__(self, equations):
+ # Initiation
+
+ def find(self, x):
+ # root
+ r = x
+ while r != parent[r]:
+ r = parent[r]
+ k = x
+ while k != r:
+ # Store the parent node of parent[k] temporarily.
+ j = parent[k]
+ parent[k] = r
+ k = j
+ return r
+ def union(self, p, q):
+ if self.connected(p, q): return
+ self.parent[self.find(p)] = self.find(q)
+ def connected(self, p, q):
+ return self.find(p) == self.find(q)
+```
diff --git a/thinkings/union-find.md b/thinkings/union-find.md
index 972975f20..02d330db1 100644
--- a/thinkings/union-find.md
+++ b/thinkings/union-find.md
@@ -25,7 +25,7 @@
我们如何判断某两个师长是否属于同一个司令呢(连通性)?
-
+
很简单,我们顺着师长,往上找,找到司令。 如果两个师长找到的是同一个司令,那么就属于同一个司令。我们用 parent[x] = y 表示 x 的 parent 是 y,通过不断沿着搜索 parent 搜索找到 root,然后比较 root 是否相同即可得出结论。
@@ -33,11 +33,11 @@
如图有两个司令:
-
+
我们将其合并为一个联通域,最简单的方式就是直接将其中一个司令指向另外一个即可:
-
+
以上就是三个核心 API `find`,`connnected` 和 `union`, 的形象化解释,下面我们来看下代码实现。
@@ -111,8 +111,10 @@ class UF:
leader_q = self.find(q)
if self.size[leader_p] < self.size[leader_q]:
self.parent[leader_p] = leader_q
+ self.size[leader_p] += self.size[leader_q]
else:
self.parent[leader_q] = leader_p
+ self.size[leader_q] += self.size[leader_p]
self.cnt -= 1
def connected(self, p, q):
return self.find(p) == self.find(q)