diff --git a/.github/workflows/docker/docker-compose.yaml b/.github/workflows/docker/docker-compose.yaml
index c285cb6306..c854771eb6 100644
--- a/.github/workflows/docker/docker-compose.yaml
+++ b/.github/workflows/docker/docker-compose.yaml
@@ -1,6 +1,6 @@
services:
trinity-node-1:
- image: trinity-rft-unittest:20250918
+ image: trinity-rft-unittest:20250924
pull_policy: never
command: sh -c "pip install -e .[dev] && ray start --head --dashboard-host 0.0.0.0 --include-dashboard true --block"
environment:
@@ -28,7 +28,7 @@ services:
capabilities: [gpu]
trinity-node-2:
- image: trinity-rft-unittest:20250918
+ image: trinity-rft-unittest:20250924
pull_policy: never
command: sh -c "pip install -e .[dev] && ray start --address=trinity-node-1:6379 --block"
environment:
diff --git a/README.md b/README.md
index e5709161bc..83773a2977 100644
--- a/README.md
+++ b/README.md
@@ -18,47 +18,36 @@
-
-## 🚀 News
-
-* [2025-09] ✨ [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
-* [2025-08] 🎵 Introducing [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord): dynamic SFT + RL integration for advanced LLM fine-tuning ([paper](https://arxiv.org/pdf/2508.11408)).
-* [2025-08] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 released.
-* [2025-07] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 released.
-* [2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: [link](https://arxiv.org/abs/2505.17826).
-* [2025-06] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 released.
-* [2025-05] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 released, plus [technical report](https://arxiv.org/abs/2505.17826).
-* [2025-04] Trinity-RFT open sourced.
-
-
## 💡 What is Trinity-RFT?
-Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It supports a wide range of applications and provides a unified platform for RL research in the [era of experience](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf).
+Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It provides three independent modules for users with different needs:
-The RFT process is modularized into three core components:
+* 🤖 **Explorer**:For agent application developers. [[tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_workflow.html)
+ - Train an agent application to enhance its ability to complete tasks in a specified environment
+ - Examples: [Multi-Turn Interaction](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html), [ReAct Agent](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html)
-* **Explorer**: Handles agent-environment interaction
-* **Trainer**: Manages model training
-* **Buffer**: Manages data storage and processing
+* 🧠 **Trainer**: For RL algorithm researchers. [[tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_algorithm.html)
+ - Design and validate new RL algorithms in compact, plug-and-play classes
+ - Examples: [Mixture of RL Algorithms](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html)
+* 🗄️ **Buffer**: For data engineers. [[tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/develop_operator.html)
+ - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios
+ - Examples: [Data Functionalities](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html)
- -
-
-## ✨ Key Features
+Trinity-RFT unifies the above three modules and provides the following key features:
* **Flexible RFT Modes:**
- Supports synchronous/asynchronous, on-policy/off-policy, and online/offline training. Rollout and training can run separately and scale independently across devices.
-
-
-## ✨ Key Features
+Trinity-RFT unifies the above three modules and provides the following key features:
* **Flexible RFT Modes:**
- Supports synchronous/asynchronous, on-policy/off-policy, and online/offline training. Rollout and training can run separately and scale independently across devices.
 -* **Agent Framework Compatible Workflows:**
- - Supports both concatenated and general multi-turn agentic workflows. Automatically collects training data from model API clients (e.g., OpenAI) and is compatible with agent frameworks like AgentScope.
+* **General Agentic-RL Support:**
+ - Supports both concatenated and general multi-turn agentic workflows. Able to directly train agent applications developed using agent frameworks like AgentScope.
-* **Agent Framework Compatible Workflows:**
- - Supports both concatenated and general multi-turn agentic workflows. Automatically collects training data from model API clients (e.g., OpenAI) and is compatible with agent frameworks like AgentScope.
+* **General Agentic-RL Support:**
+ - Supports both concatenated and general multi-turn agentic workflows. Able to directly train agent applications developed using agent frameworks like AgentScope.
 -* **Powerful Data Pipelines:**
+* **Full Lifecycle Data Pipelines:**
- Enables pipeline processing of rollout and experience data, supporting active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
-* **Powerful Data Pipelines:**
+* **Full Lifecycle Data Pipelines:**
- Enables pipeline processing of rollout and experience data, supporting active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
 @@ -69,26 +58,24 @@ The RFT process is modularized into three core components:
@@ -69,26 +58,24 @@ The RFT process is modularized into three core components:
 +## 🚀 News
+* [2025-09] ✨ [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
+* [2025-08] 🎵 Introducing [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord): dynamic SFT + RL integration for advanced LLM fine-tuning ([paper](https://arxiv.org/pdf/2508.11408)).
+* [2025-08] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 released.
+* [2025-07] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 released.
+* [2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: [link](https://arxiv.org/abs/2505.17826).
+* [2025-06] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 released.
+* [2025-05] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 released, plus [technical report](https://arxiv.org/abs/2505.17826).
+* [2025-04] Trinity-RFT open sourced.
-## 🛠️ What can I use Trinity-RFT for?
-
-* **Train agent applications with RL and minimal migration cost** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#workflows-for-rl-environment-developers)
- - Implement agent-environment interaction logic in a single workflow class ([example1](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html), [example2](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)),
- - Or import workflows from agent frameworks like AgentScope ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html)).
-
-* **Rapid RL algorithm design and validation** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers)
- - Develop custom RL algorithms (loss design, sampling strategy, etc.) in compact, plug-and-play classes ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html)).
-
-* **Custom datasets and data pipelines for RFT** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#operators-for-data-developers)
- - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html)).
---
## Table of contents
-- [Getting started](#getting-started)
+- [Quick Start](#quick-start)
- [Step 1: installation](#step-1-installation)
- [Step 2: prepare dataset and model](#step-2-prepare-dataset-and-model)
- [Step 3: configurations](#step-3-configurations)
@@ -101,7 +88,7 @@ The RFT process is modularized into three core components:
-## Getting started
+## Quick Start
> [!NOTE]
@@ -110,8 +97,6 @@ The RFT process is modularized into three core components:
### Step 1: installation
-#### Prerequisites
-
Before installing, make sure your system meets the following requirements:
- **Python**: version 3.10 to 3.12 (inclusive)
@@ -119,9 +104,9 @@ Before installing, make sure your system meets the following requirements:
- **GPUs**: at least 2 GPUs
-#### Option A: Install from Source (Recommended)
+#### From Source (Recommended)
-This method gives you full control and is best if you plan to customize or contribute to the project.
+If you plan to customize or contribute to Trinity-RFT, this is the best option.
##### 1. Clone the Repository
@@ -132,69 +117,59 @@ cd Trinity-RFT
##### 2. Set Up a Virtual Environment
-Choose one of the following options to create an isolated environment:
+Choose one of the following options:
###### Using Conda
+
```bash
conda create -n trinity python=3.10
conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
###### Using venv
+
```bash
python3.10 -m venv .venv
source .venv/bin/activate
-```
-##### 3. Install the Package
-
-Install in editable mode so you can make changes without reinstalling:
-
-```bash
pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-##### 4. Install Flash Attention
-
-Flash Attention boosts training speed. It takes a few minutes to compile — please be patient!
-
-```bash
-pip install flash-attn==2.8.1
-```
+###### Using `uv`
-If you encounter issues during installation, try this alternative:
+[`uv`](https://github.com/astral-sh/uv) is a modern Python package installer.
```bash
-pip install flash-attn==2.8.1 --no-build-isolation
+uv sync --extra dev --extra flash_attn
```
-##### ⚡ Fast Alternative: Use `uv` (Optional)
+#### Via PyPI
-If you'd like a faster installation, try [`uv`](https://github.com/astral-sh/uv), a modern Python package installer:
+If you just want to use the package without modifying the code:
```bash
-uv venv
-source .venv/bin/activate
-
-uv pip install -e ".[dev]"
-uv pip install flash-attn==2.8.1 --no-build-isolation
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
```
-#### Option B: Install via pip (Quick Start)
-
-If you just want to use the package without modifying the code:
+Or with `uv`:
```bash
-pip install trinity-rft==0.3.0
-pip install flash-attn==2.8.1 # Install Flash Attention separately
-
-# Use uv to install trinity-rft
-# uv pip install trinity-rft==0.3.0
-# uv pip install flash-attn==2.8.1
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
```
-#### Option C: Use Docker
+
+#### Using Docker
We provide a Docker setup for hassle-free environment configuration.
@@ -202,11 +177,11 @@ We provide a Docker setup for hassle-free environment configuration.
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
-## Build the Docker image
+# Build the Docker image
## Tip: You can modify the Dockerfile to add mirrors or set API keys
docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-## Run the container
+# Run the container, replacing with your actual path
docker run -it \
--gpus all \
--shm-size="64g" \
@@ -216,9 +191,7 @@ docker run -it \
trinity-rft:latest
```
-💡 **Note**: Replace `` with the actual path on your machine where datasets and model checkpoints are stored.
-
-> If you'd like to integrate with **Megatron-LM**, check out our [example setup guide for Megatron](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_megatron.html).
+> For training with **Megatron-LM**, please refer to [Megatron-LM Backend](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_megatron.html).
### Step 2: prepare dataset and model
diff --git a/README_zh.md b/README_zh.md
index 312f80e76d..4db8563886 100644
--- a/README_zh.md
+++ b/README_zh.md
@@ -18,47 +18,35 @@
+## 💡 什么是 Trinity-RFT ?
-## 🚀 新闻
-
-* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
-* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
-* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
-* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
-* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
-* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
-* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
-* [2025-04] Trinity-RFT 开源。
-
-
-## 💡 什么是 Trinity-RFT?
-
-Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。它支持广泛的应用场景,并为 [Experience 时代](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf) 的 RL 研究提供统一平台。
-
-RFT 流程被模块化为三个核心组件:
+Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。其提供三个独立模块,满足不同用户的需求:
-* **Explorer**:负责智能体与环境的交互
-* **Trainer**:负责模型训练
-* **Buffer**:负责数据存储与处理
+* 🤖 **Explorer**:面向智能体应用开发者。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_workflow.html)
+ - 训练智能体应用,以增强其在指定环境中完成任务的能力
+ - 示例:[多轮交互](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_multi_turn.html),[ReAct 智能体](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html)
+* 🧠 **Trainer**:面向 RL 算法研究者。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_algorithm.html)
+ - 在简洁、可插拔的类中设计和验证新的 RL 算法
+ - 示例:[混合 RL 算法](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_mix_algo.html)
-
+* 🗄️ **Buffer**:面向数据工程师。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_operator.html)
+ - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景
+ - 示例:[数据功能](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html)
-
-
-## ✨ 核心特性
+Trinity-RFT 统一了上述三个模块,并提供以下核心特性:
* **灵活的 RFT 模式:**
- 支持同步/异步、on-policy/off-policy 以及在线/离线训练。采样与训练可分离运行,并可在多设备上独立扩展。
-* **兼容 Agent 框架的工作流:**
- - 支持拼接式和通用多轮智能体工作流。可自动收集来自模型 API 客户端(如 OpenAI)的训练数据,并兼容 AgentScope 等智能体框架。
+* **通用 Agentic-RL:**
+ - 支持拼接式和通用多轮交互,能够直接训练使用 AgentScope 等智能体框架开发的 Agent 应用。
-* **强大的数据流水线:**
+* **全流程的数据流水线:**
- 支持 rollout 和经验数据的流水线处理,贯穿 RFT 生命周期实现主动管理(优先级、清洗、增强等)。
@@ -69,36 +57,32 @@ RFT 流程被模块化为三个核心组件:
+## 🚀 新闻
-
-## 🛠️ Trinity-RFT 能做什么?
-
-* **用 RL 训练智能体应用** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#workflows-for-rl-environment-developers)
- - 在 Workflow 中实现智能体-环境交互逻辑 ([示例1](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_multi_turn.html),[示例2](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_step_wise.html)),
- - 或直接使用 Agent 框架(如 AgentScope)编写好的工作流 ([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html))。
-
-* **快速设计和验证 RL 算法** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers)
- - 在简洁、可插拔的类中开发自定义 RL 算法(损失、采样及其他技巧)([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html))。
-
-* **为 RFT 定制数据集和数据流水线** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#operators-for-data-developers)
- - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景 ([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html))。
-
+* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
+* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
+* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
+* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
+* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
+* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
+* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
+* [2025-04] Trinity-RFT 开源。
---
## 目录
-- [快速上手](#getting-started)
- - [第一步:安装](#step-1-installation)
- - [第二步:准备数据集和模型](#step-2-prepare-dataset-and-model)
- - [第三步:配置](#step-3-configurations)
- - [第四步:运行 RFT 流程](#step-4-run-the-rft-process)
-- [更多教程](#further-tutorials)
-- [未来功能](#upcoming-features)
-- [贡献指南](#contribution-guide)
-- [致谢](#acknowledgements)
-- [引用](#citation)
+- [快速上手](#快速上手)
+ - [第一步:安装](#第一步安装)
+ - [第二步:准备数据集和模型](#第二步准备数据集和模型)
+ - [第三步:准备配置文件](#第三步准备配置文件)
+ - [第四步:运行 RFT 流程](#第四步运行-rft-流程)
+- [更多教程](#更多教程)
+- [开发路线图](#开发路线图)
+- [贡献指南](#贡献指南)
+- [致谢](#致谢)
+- [引用](#引用)
@@ -111,103 +95,88 @@ RFT 流程被模块化为三个核心组件:
### 第一步:安装
-#### 环境要求
在安装之前,请确保您的系统满足以下要求:
- **Python**:版本 3.10 至 3.12(含)
- **CUDA**:版本 12.4 至 12.8(含)
- **GPU**:至少 2 块 GPU
+## 源码安装(推荐)
-#### 方式 A:从源码安装(推荐)
-
-这种方式可以让您完全控制项目代码,适合打算自定义功能或参与项目开发的用户。
+如需修改、扩展 Trinity-RFT,推荐使用此方法。
-##### 1. 克隆代码仓库
+### 1. 克隆仓库
```bash
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
```
-##### 2. 创建虚拟环境
+### 2. 创建虚拟环境
-选择以下任意一种方式,创建一个独立的 Python 环境:
+可选择以下任一方式:
+
+#### 使用 Conda
-###### 使用 Conda
```bash
conda create -n trinity python=3.10
conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-###### 使用 venv
+#### 使用 venv
+
```bash
python3.10 -m venv .venv
source .venv/bin/activate
-```
-
-##### 3. 安装软件包
-
-以“可编辑模式”安装,这样您可以修改代码而无需重新安装:
-```bash
pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-##### 4. 安装 Flash Attention
+#### 使用 `uv`
-Flash Attention 可以显著提升训练速度。编译需要几分钟时间,请耐心等待!
+[`uv`](https://github.com/astral-sh/uv) 是现代的 Python 包管理工具。
```bash
-pip install flash-attn==2.8.1
+uv sync --extra dev --extra flash_attn
```
-如果安装过程中出现问题,可以尝试以下命令:
+## 通过 PyPI 安装
-```bash
-pip install flash-attn==2.8.1 --no-build-isolation
-```
-
-
-##### ⚡ 快速替代方案:使用 `uv`(可选)
-
-如果您希望安装得更快,可以试试 [`uv`](https://github.com/astral-sh/uv),这是一个现代化的 Python 包安装工具:
+如果您只需使用 Trinity-RFT 而不打算修改代码:
```bash
-uv venv
-source .venv/bin/activate
-
-uv pip install -e ".[dev]"
-uv pip install flash-attn==2.8.1 --no-build-isolation
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
```
-#### 方式 B:通过 pip 安装(快速开始)
-
-如果您只是想使用这个工具,不需要修改代码,可以选择这种方式:
+或使用 `uv`:
```bash
-pip install trinity-rft==0.3.0
-pip install flash-attn==2.8.1 # 单独安装 Flash Attention
-
-# 也可以用 uv 来安装 trinity-rft
-# uv pip install trinity-rft==0.3.0
-# uv pip install flash-attn==2.8.1
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
```
-#### 方式 C:使用 Docker
+## 使用 Docker
-我们提供了 Docker 配置,可以免去复杂的环境设置。
+我们提供了 Docker 环境,方便快速配置。
```bash
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
# 构建 Docker 镜像
-# 注意:您可以编辑 Dockerfile 来定制环境
-# 例如,设置 pip 镜像源或设置 API 密钥
+## 提示:可根据需要修改 Dockerfile 添加镜像源或设置 API 密钥
docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-# 启动容器
+# 运行容器,请将 替换为实际需要挂载的路径
docker run -it \
--gpus all \
--shm-size="64g" \
@@ -217,9 +186,9 @@ docker run -it \
trinity-rft:latest
```
-💡 **注意**:请将 `` 替换为您电脑上实际存放数据集和模型文件的路径。
-
-> 如果您想集成 **Megatron-LM**,请参考我们的 [Megatron 示例配置指南](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_megatron.html)。
+```{note}
+如需使用 **Megatron-LM** 进行训练,请参考 {ref}`Megatron-LM Backend `。
+```
### 第二步:准备数据集和模型
@@ -256,7 +225,7 @@ modelscope download --dataset {dataset_name} --local_dir $DATASET_PATH/{dataset_
-### 第三步:配置
+### 第三步:准备配置文件
Trinity-RFT 提供了一个 Web 界面来配置您的 RFT 流程。
@@ -368,7 +337,7 @@ trinity run --config examples/grpo_gsm8k/gsm8k.yaml
-## 未来功能
+## 开发路线图
路线图:[#51](https://github.com/modelscope/Trinity-RFT/issues/51)
diff --git a/docs/sphinx_doc/source/index.rst b/docs/sphinx_doc/source/index.rst
index 84f2904160..5b89ea2147 100644
--- a/docs/sphinx_doc/source/index.rst
+++ b/docs/sphinx_doc/source/index.rst
@@ -9,6 +9,21 @@ Welcome to Trinity-RFT's documentation!
.. include:: main.md
:parser: myst_parser.sphinx_
+.. toctree::
+ :maxdepth: 2
+ :glob:
+ :hidden:
+ :caption: Guidelines
+
+ tutorial/trinity_installation.md
+ tutorial/develop_overview.md
+ tutorial/develop_workflow.md
+ tutorial/develop_algorithm.md
+ tutorial/example_mix_algo.md
+ tutorial/develop_operator.md
+ tutorial/trinity_configs.md
+ tutorial/synchronizer.md
+
.. toctree::
:maxdepth: 1
@@ -27,17 +42,6 @@ Welcome to Trinity-RFT's documentation!
tutorial/example_megatron.md
tutorial/example_data_functionalities.md
-.. toctree::
- :maxdepth: 2
- :glob:
- :hidden:
- :caption: Guidelines
-
- tutorial/trinity_programming_guide.md
- tutorial/trinity_configs.md
- tutorial/example_mix_algo.md
- tutorial/synchronizer.md
-
.. toctree::
:maxdepth: 2
:hidden:
diff --git a/docs/sphinx_doc/source/main.md b/docs/sphinx_doc/source/main.md
index 432c039145..b813b74d18 100644
--- a/docs/sphinx_doc/source/main.md
+++ b/docs/sphinx_doc/source/main.md
@@ -1,41 +1,32 @@
-## 🚀 News
-
-* [2025-09] ✨ [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
-* [2025-08] 🎵 Introducing [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord): dynamic SFT + RL integration for advanced LLM fine-tuning ([paper](https://arxiv.org/pdf/2508.11408)).
-* [2025-08] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 released.
-* [2025-07] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 released.
-* [2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: [link](https://arxiv.org/abs/2505.17826).
-* [2025-06] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 released.
-* [2025-05] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 released, plus [technical report](https://arxiv.org/abs/2505.17826).
-* [2025-04] Trinity-RFT open sourced.
-
-
## 💡 What is Trinity-RFT?
-Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It supports a wide range of applications and provides a unified platform for RL research in the [era of experience](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf).
+Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It provides three independent modules for users with different needs:
-The RFT process is modularized into three core components:
+* 🤖 **Explorer**:For agent application developers. [[tutorial]](/tutorial/develop_workflow.md)
+ - Train an agent application to enhance its ability to complete tasks in a specified environment
+ - Examples: [Multi-Turn Interaction](/tutorial/example_multi_turn.md), [ReAct Agent](/tutorial/example_react.md)
-* **Explorer**: Handles agent-environment interaction
-* **Trainer**: Manages model training
-* **Buffer**: Manages data storage and processing
+* 🧠 **Trainer**: For RL algorithm researchers. [[tutorial]](/tutorial/develop_algorithm.md)
+ - Design and validate new RL algorithms in compact, plug-and-play classes
+ - Examples: [Mixture of RL Algorithms](/tutorial/example_mix_algo.md)
-
+* 🗃️ **Buffer**: For data engineers. [[tutorial]](/tutorial/develop_operator.md)
+ - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios
+ - Examples: [Data Functionalities](/tutorial/example_data_functionalities.md)
-
-## ✨ Key Features
+Trinity-RFT unifies the above three modules and provides the following key features:
* **Flexible RFT Modes:**
- Supports synchronous/asynchronous, on-policy/off-policy, and online/offline training. Rollout and training can run separately and scale independently across devices.
-* **Agent Framework Compatible Workflows:**
- - Supports both concatenated and general multi-turn agentic workflows. Automatically collects training data from model API clients (e.g., OpenAI) and is compatible with agent frameworks like AgentScope.
+* **General Agentic-RL Support:**
+ - Supports both concatenated and general multi-turn agentic workflows. Able to directly train agent applications developed using agent frameworks like AgentScope.
-* **Powerful Data Pipelines:**
+* **Full Lifecycle Data Pipelines:**
- Enables pipeline processing of rollout and experience data, supporting active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
@@ -46,19 +37,6 @@ The RFT process is modularized into three core components:
-## 🛠️ What can I use Trinity-RFT for?
-
-* **Train agent applications with RL and minimal migration cost**
- - Implement agent-environment interaction logic in a single workflow class ([example 1](tutorial/example_multi_turn.md), [example 2](tutorial/example_step_wise.md)),
- - Or import workflows from agent frameworks like AgentScope ([example](/tutorial/example_react.md)).
-
-* **Rapid RL algorithm design and validation**
- - Develop custom RL algorithms (loss design, sampling strategy, etc.) in compact, plug-and-play classes ([tutorial](tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers), [example](tutorial/example_mix_algo.md)).
-
-* **Custom datasets and data pipelines for RFT**
- - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios ([tutorial](tutorial/trinity_programming_guide.md#operators-for-data-developers), [example](tutorial/example_data_functionalities.md)).
-
-
## Acknowledgements
This project is built upon many excellent open-source projects, including:
diff --git a/docs/sphinx_doc/source/tutorial/develop_algorithm.md b/docs/sphinx_doc/source/tutorial/develop_algorithm.md
new file mode 100644
index 0000000000..41b6a184b9
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_algorithm.md
@@ -0,0 +1,216 @@
+(Algorithms)=
+## Algorithms Development Guide
+
+In Trinity-RFT, the algorithm module is primarily responsible for extracting experience data from the Replay Buffer during the RL process and calculating the loss to update models based on this data.
+
+To avoid implementing a new Trainer class each time a new algorithm is added, we have decomposed the representative PPO algorithm process into multiple sub-modules to adapt to various algorithms.
+
+### Step 0: Basic Concepts of Algorithm Module
+
+Trinity-RFT breaks down the algorithm module into the following sub-modules:
+
+- **Sample Strategy** ({class}`trinity.algorithm.SampleStrategy`): Responsible for sampling experience data from the buffer module. By customizing this module, you can implement functionalities like filtering experience data or mixed sampling from multiple data sources.
+- **Advantage Fn**({class}`trinity.algorithm.AdvantageFn`): Responsible for calculating the Advantage and Returns of experience data.
+- **Policy Loss Fn**({class}`trinity.algorithm.PolicyLossFn`): Responsible for calculating the core training loss of the policy network.
+- **KL Fn**({class}`trinity.algorithm.KLFn`): Responsible for calculating KL Divergence, which is generally used in two places in existing RL algorithms: Reward Penalty and Actor Loss.
+- **Entropy Loss Fn**({class}`trinity.algorithm.EntropyLossFn`): Responsible for calculating the entropy loss of the policy network.
+
+We provide several implementations of above modules in `trinity/algorithm`.
+
+---
+
+### Step 1: Implement Algorithm Components
+
+
+Trinity-RFT allows developers to customize all the above modules. Developers only need to implement specific modules according to the requirements of their new algorithm. This section will provide a simple introduction using the {ref}`OPMD ` algorithm as an example.
+
+The main difference between OPMD and PPO algorithms lies in the calculation of Advantage and Policy Loss.
+OPMD relies on a group-based advantage calculation and does not use the Critic model.
+To implement OPMD, developers need to implement advantage calculation in `AdvantageFn` and policy loss calculation in `PolicyLossFn`.
+
+---
+
+#### Step 1.1: Implement `AdvantageFn`
+
+The {class}`trinity.algorithm.AdvantageFn` interface includes three methods:
+
+- `__call__`: The main entrance for advantage calculation. It receives a list of experiences ({class}`trinity.common.experience.Experience`) and returns a list of experiences with calculated advantages and returns, along with a metrics dictionary for logging.
+- `default_args`: A class method that returns the default initialization parameters in dictionary form. It will be used by default when users don't specify initialization parameters in the configuration file.
+- `compute_in_trainer`: This class method indicates whether to compute advantages in the Trainer. If it returns `False`, the `AdvantageFn` will be called in the experience data processing pipeline.
+
+For convenience, Trinity-RFT provides an abstract class {class}`trinity.algorithm.advantage_fn.GroupAdvantage` that implements the `__call__` method for group-based advantage calculation, you can focus on how to group the experiences and calculate advantages on grouped experiences with the following two methods:
+
+- `group_experiences`: This method groups a experiences generated in a step into multiple sub-groups.
+
+- `calculate_group_advantage`: This method calculates the advantage for each group of experiences.
+
+Here's an implementation example for the OPMD algorithm's advantage function:
+
+```python
+from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
+
+@ADVANTAGE_FN.register_module("opmd")
+class OPMDGroupAdvantage(GroupAdvantage):
+ """OPMD Group Advantage computation"""
+
+ def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.opmd_baseline = opmd_baseline
+ self.tau = tau
+
+ def group_experiences(self, exps):
+ return group_by(exps, id_type="task")
+
+ def calculate_group_advantage(
+ self, group_id: str, exps: List[Experience]
+ ) -> Tuple[List[Experience], Dict]:
+ with torch.no_grad():
+ if len(exps) == 1:
+ group_baseline = torch.tensor(0.0)
+ else:
+ group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
+ if self.opmd_baseline == "mean":
+ group_baseline = torch.mean(group_rewards)
+ else:
+ group_baseline = self.tau * (
+ torch.logsumexp(group_rewards / self.tau, dim=-1)
+ - torch.log(torch.tensor(len(exps)))
+ )
+ for exp in exps:
+ score = exp.reward - group_baseline
+ exp.advantages = score * exp.action_mask
+ exp.returns = exp.advantages.clone()
+ metrics = {
+ "group_baseline": group_baseline.item(),
+ }
+ return exps, metrics
+
+ @classmethod
+ def default_args(cls) -> dict:
+ return {"opmd_baseline": "mean", "tau": 1.0}
+```
+
+After implementation, you need to register this module through {class}`trinity.algorithm.ADVANTAGE_FN`. Once registered, the module can be configured in the configuration file using the registered name.
+
+
+#### Step 1.2: Implement `PolicyLossFn`
+
+Developers need to implement the {class}`trinity.algorithm.PolicyLossFn` interface, which is similar to `AdvantageFn` and includes two methods:
+
+- `__call__`: Calculates the loss based on input parameters. Unlike `AdvantageFn`, the input parameters here are all `torch.Tensor`. This interface automatically scans the parameter list of the `__call__` method and converts it to the corresponding fields in the experience data. Therefore, please write all tensor names needed for loss calculation directly in the parameter list, rather than selecting parameters from `kwargs`.
+- `default_args`: Returns default initialization parameters in dictionary form, which will be used by default when users don't specify initialization parameters in the configuration file.
+
+Similarly, after implementation, you need to register this module through {class}`trinity.algorithm.POLICY_LOSS_FN`.
+
+Here's an implementation example for the OPMD algorithm's Policy Loss Fn. Since OPMD's Policy Loss only requires logprob, action_mask, and advantages, only these three items are specified in the parameter list of the `__call__` method:
+
+
+```python
+@POLICY_LOSS_FN.register_module("opmd")
+class OPMDPolicyLossFn(PolicyLossFn):
+ def __init__(self, tau: float = 1.0) -> None:
+ self.tau = tau
+
+ def __call__( # type: ignore
+ self,
+ logprob: torch.Tensor,
+ action_mask: torch.Tensor,
+ advantages: torch.Tensor,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Dict]:
+ pg_losses = -advantages * logprob
+ opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
+ opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
+ return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
+
+ @classmethod
+ def default_args(cls) -> Dict:
+ return {"tau": 1.0, "loss_agg_mode": "token-mean"}
+```
+
+---
+
+### Step 2: Register Your Algorithm
+
+The above steps implement the components needed for the algorithm, but these components are scattered and need to be configured in multiple places to take effect.
+
+To simplify configuration, Trinity-RFT provides {class}`trinity.algorithm.AlgorithmType` to describe a complete algorithm and registers it in {class}`trinity.algorithm.ALGORITHM_TYPE`, enabling one-click configuration.
+
+The `AlgorithmType` class includes the following attributes and methods:
+
+- `use_critic`: Whether to use the Critic model
+- `use_reference`: Whether to use the Reference model
+- `compute_advantage_in_trainer`: Whether to calculate Advantages in Trainer; if False, the `AdvantageFn` call in trainer will be skipped
+- `can_balance_batch`: Whether the algorithm allows automatic balancing when splitting a batch into microbatches (which permute the order of samples)
+- `schema`: The format of experience data corresponding to the algorithm
+- `default_config`: Gets the default configuration of the algorithm, which will override attributes with the same name in `ALGORITHM_TYPE`
+
+Similarly, after implementation, you need to register this module through `ALGORITHM_TYPE`.
+
+Below is the implementation for the OPMD algorithm.
+Since the OPMD algorithm doesn't need to use the Critic model, `use_critic` is set to `False`.
+The dictionary returned by the `default_config` method indicates that OPMD will use the `opmd` type `AdvantageFn` and `PolicyLossFn` implemented in Step 1, will not apply KL Penalty on rewards, but will add a `k2` type KL loss when calculating the final loss.
+
+```python
+@ALGORITHM_TYPE.register_module("opmd")
+class OPMDAlgorithm(AlgorithmType):
+ """OPMD algorithm."""
+
+ use_critic: bool = False
+ use_reference: bool = True
+ compute_advantage_in_trainer: bool = False
+ can_balance_batch: bool = True
+ schema: str = "experience"
+
+ @classmethod
+ def default_config(cls) -> Dict:
+ return {
+ "repeat_times": 2,
+ "advantage_fn": "opmd",
+ "sample_strategy": "warmup",
+ "policy_loss_fn": "opmd",
+ "kl_penalty_fn": "none",
+ "kl_loss_fn": "k2",
+ "entropy_loss_fn": "default",
+ }
+```
+
+```{tip}
+To ensure the registration takes effect, please make sure to import the newly implemented modules in the corresponding `__init__.py` files, for example:
+
+- Import `OPMDGroupAdvantage` in `trinity/algorithm/advantage_fn/__init__.py`
+- Import `OPMDPolicyLossFn` in `trinity/algorithm/policy_loss_fn/__init__.py`
+- Import `OPMDAlgorithm` in `trinity/algorithm/__init__.py`
+
+You can also place these classes in the `trinity/plugins` directory, and Trinity-RFT will automatically load all modules in the `plugins` directory at startup, without needing to import them in `__init__.py`.
+```
+
+---
+
+### Step 3: Use Your Algorithm
+
+After completing all the above steps, you can use the newly registered algorithm through a YAML configuration file.
+
+For default configurations, you just need to add the following content to your `config.yaml` file:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+# some other configs
+```
+
+If you need to modify certain parameters, you can simply add the corresponding parameters within the `algorithm` section. For example, if you need to modify `repeat_times` and the initialization parameters of `AdvantageFn` and `PolicyLossFn`, the modified `config.yaml` file would be as follows:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+ repeat_times: 8
+ advantage_fn_args:
+ opmd_baseline: "logavgexp"
+ tau: 0.99
+ policy_loss_fn_args:
+ tau: 0.99
+# some other configs
+```
diff --git a/docs/sphinx_doc/source/tutorial/develop_operator.md b/docs/sphinx_doc/source/tutorial/develop_operator.md
new file mode 100644
index 0000000000..f658e5bff6
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_operator.md
@@ -0,0 +1,82 @@
+## Operator Development Guide
+
+### Step 0: Basic Concepts of Operator Module
+
+In Trinity-RFT, the operator module is responsible for processing experience data in the buffer module. It supports existing data processing capabilities from [Data-Juicer](https://github.com/modelscope/data-juicer) naturally, and allows developers to implement their own operators as well.
+By customizing operators, developers can implement various data processing functionalities, such as data augmentation, filtering, and transformation. You can even implement advantages/returns calculation as operators, as shown in {ref}`Algorithms ` section.
+
+- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`): The operator that wraps the data processing operators from Data-Juicer. It provides a simple interface for developers to list the Data-Juicer operators they want to use. The full list of Data-Juicer operators can be found [here](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html).
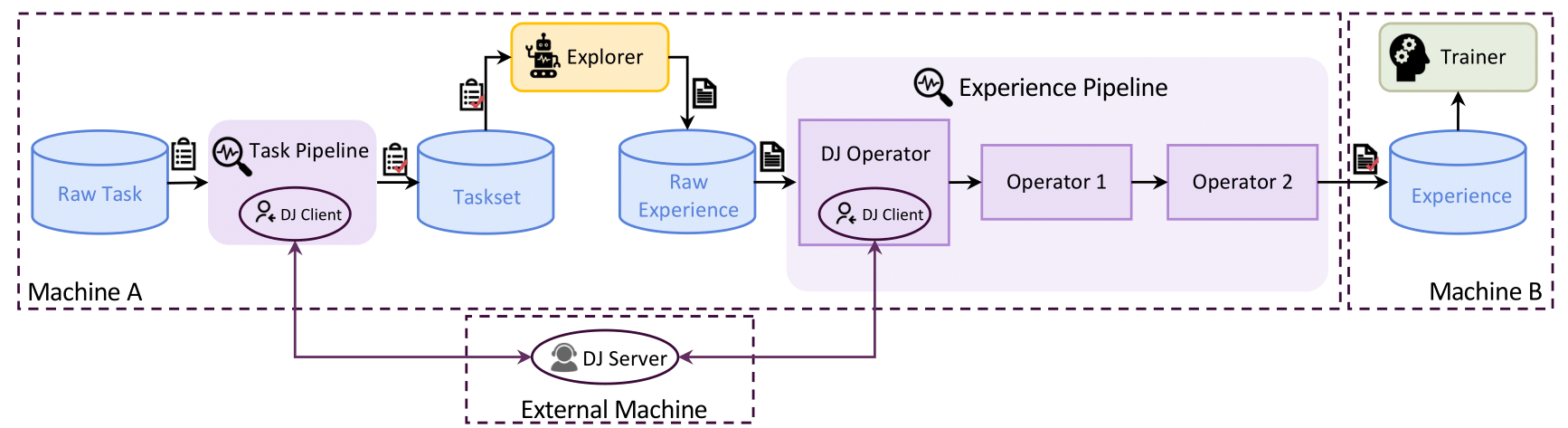
+- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`): The base class for all operators used in experience data processing. It defines the interface and common functionalities that all operators should have. Each operator processes a batch of experience data and returns the processed data with metrics for logging.
+- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`): The experience data processing pipeline that manages a sequence of operators. It takes raw experiences from the `Explorer`, passes them through each operator in the pipeline, and writes the final processed experiences into the input buffer of the `Trainer`.
+
+```{note}
+Except for `ExperiencePipeline`, Trinity-RFT also provides `TaskPipeline` for task data processing.
+In the current version, the `TaskPipeline` only supports using Data-Juicer operators. Please see this {ref}`section ` for details.
+```
+---
+
+Developers can implement and use their own operators by following the steps below.
+
+### Step 1: Implement Operator
+
+The `ExperienceOperator` interface includes only one `process` method. The `ExperiencePipeline` will call this method with a list of `Experience` generated by the `Explorer` in one explore step. The `process` method should return a tuple containing the processed list of `Experience` and a dictionary of metrics for logging.
+
+```python
+class ExperienceOperator(ABC):
+
+ @abstractmethod
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ """Process a list of experiences and return a transformed list.
+
+ Args:
+ exps (List[Experience]): List of experiences to process, which contains
+ all experiences generated by the Explorer in one explore step.
+ Returns:
+ Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
+ """
+```
+
+Here is an implementation of a simple operator that filters out experiences with rewards below a certain threshold:
+
+```python
+from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
+from trinity.common.experience import Experience
+
+
+@EXPERIENCE_OPERATORS.register_module("reward_filter")
+class RewardFilter(ExperienceOperator):
+
+ def __init__(self, threshold: float = 0.0) -> None:
+ self.threshold = threshold
+
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
+ metrics = {"filtered_count": len(exps) - len(filtered_exps)}
+ return filtered_exps, metrics
+```
+
+After implementation, you need to register this module through {class}`trinity.data.operators.EXPERIENCE_OPERATORS`. Once registered, the module can be configured in the configuration file using the registered name.
+
+### Step 2: Use Your Operator
+
+After completing the above steps, you can use the newly registered operator through a YAML configuration file.
+
+```yaml
+# some other configs
+data_processor:
+ experience_pipeline:
+ operators:
+ - name: "reward_filter"
+ args:
+ threshold: 0.1
+synchronizer:
+ sync_method: nccl
+ sync_style: dynamic_by_explorer
+ sync_interval: 2
+# some other configs
+```
+
+```{tip}
+The `RewardFilter` reduces the number of experiences, which may cause the trainer can't get enough experiences to start a training step. To avoid the issue, you can use the advanced {ref}`Dynamic Synchronization ` feature provided by Trinity-RFT as shown in the above configuration file.
+The above setting means that the `Explorer` will sync with the `Trainer` every 2 steps and will continue running regardless of how many steps the `Trainer` has completed. This ensures that the `Trainer` can always get enough experiences to start a training step as long as the `Explorer` is running.
+```
diff --git a/docs/sphinx_doc/source/tutorial/develop_overview.md b/docs/sphinx_doc/source/tutorial/develop_overview.md
new file mode 100644
index 0000000000..f47cb967ff
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_overview.md
@@ -0,0 +1,31 @@
+# Developer Guide
+
+Trinity-RFT divides the RL training process into three modules: **Explorer**, **Trainer**, and **Buffer**.
+
+Explorer provides the `Workflow` interface to customize agent-environment interaction, Trainer provides the `Algorithm` interface to customize RL algorithms, and Buffer provides the `Operator` interface to customize data processing operators.
+
+The table below lists the main functions of each extension interface, its target users, and the corresponding development tutorials. Developers can refer to the respective module development tutorials and extend Trinity-RFT based on their needs.
+
+| Extension Interface | Target Users | Main Functions | Tutorial Link |
+|---------------------|-------------------|------------------------------------------|----------------------------|
+| `Workflow` | Agent Application Developers | Enhance agent's ability to complete tasks in a specified environment | [🔗](./develop_workflow.md) |
+| `Algorithm` | RL Algorithm Researchers | Design new RL algorithms | [🔗](./develop_algorithm.md) |
+| `Operator` | Data Engineers | Design new data cleaning and augmentation strategies | [🔗](./develop_operator.md) |
+
+```{tip}
+Trinity-RFT provides a modular development approach, allowing you to flexibly add custom modules without modifying the framework code.
+You can place your module code in the `trinity/plugins` directory. Trinity-RFT will automatically load all Python files in that directory at runtime and register the custom modules within them.
+Trinity-RFT also supports specifying other directories at runtime by setting the `--plugin-dir` option, for example: `trinity run --config --plugin-dir `.
+```
+
+For modules you plan to contribute to Trinity-RFT, please follow these steps:
+
+1. Implement your code in the appropriate directory, such as `trinity/common/workflows` for `Workflow`, `trinity/algorithm` for `Algorithm`, and `trinity/buffer/operators` for `Operator`.
+
+2. Register your module in the corresponding `__init__.py` file of the directory.
+
+3. Add tests for your module in the `tests` directory, following the naming conventions and structure of existing tests.
+
+4. Before submitting your code, ensure it passes the code style check by running `pre-commit run --all-files`.
+
+5. Submit a Pull Request to the Trinity-RFT repository, providing a detailed description of your module's functionality and purpose.
diff --git a/docs/sphinx_doc/source/tutorial/develop_workflow.md b/docs/sphinx_doc/source/tutorial/develop_workflow.md
new file mode 100644
index 0000000000..0b3201b322
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_workflow.md
@@ -0,0 +1,291 @@
+(Workflows)=
+## Workflow Development Guide
+
+In Trinity-RFT, workflows are the core components that define the interaction between Agents and Environments.
+A qualified workflow needs to use the trained model to complete the specified task and obtain feedback information (reward) from the environment. Below are the steps to create a new workflow:
+
+---
+
+### Step 0: Basic Concepts
+
+Before starting development, it's important to understand several core concepts:
+
+- **Task** ({class}`trinity.common.workflows.Task`): Represents a data structure that can be converted into a `Workflow`. The content of the `Task` varies depending on the task type:
+ - **Math problems**: A `Task` contains the problem description and the golden answer.
+ - **Programming scenarios**: A `Task` includes the problem description, test cases, runtime environment, and other complex information.
+
+- **Workflow** ({class}`trinity.common.workflows.Workflow`): Describes how a `Task` is executed. It defines the interaction flow between Agents and Environments, including logic similar to *Rollout* and *Reward* calculations in other frameworks. After execution, it generates a list of `Experience`. Trinity-RFT includes several built-in workflows:
+ - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`): For math scenarios, submits problems to LLM, parses LLM responses, and calculates scores (rewards).
+ - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`): For webshop scenarios, it contains multi-turn interaction with environment.
+ - `AgentScopeReactMathWorkflow` ({class}`trinity.common.workflows.AgentScopeReactMathWorkflow`): For math scenarios, it directly uses a pre-implemented ReActAgent (based on AgentScope) to solve math problems.
+
+- **Experience** ({class}`trinity.common.experience.Experience`): The output of running a `Workflow`. The internal data format depends on the training algorithm used. For example, for common PPO/GRPO algorithms, `Experience` includes lists of token IDs, action masks (identifying which tokens were generated by the LLM), log probabilities, rewards, etc.
+
+---
+
+### Step 1: Prepare Task Dataset
+
+The task dataset is loaded via the `buffer.explorer_input.taskset` configuration entry in your YAML config file.
+To handle differences in `Task` contents, Trinity-RFT provides a unified `Task` interface containing the following fields.
+
+- **`workflow`** (`str`): The registered name of your workflow class. You can specify it in `buffer.explorer_input.taskset.default_workflow_type` of your YAML config file.
+- **`reward_fn`** (`Optional[str]`): The registered name of your reward function. You can specify it in `buffer.explorer_input.taskset.default_reward_fn_type`. Note that some workflows already include built-in reward calculation; in such cases, you can omit this field.
+- **`raw_task`** (`Dict`): A record of raw data in `Dict` format. For highly customized workflow, you can directly use `raw_task` to initialize your `Workflow` instance without relying on the following fields.
+- **`format_args`** ({class}`trinity.common.config.FormatConfig`): Parameters to facilitate the construction of `Workflow` instances. For example, the `prompt_key` and `response_key` can be used to get the prompt and response from `raw_task`. These settings come from the YAML configuration file and can be set in `buffer.explorer_input.task_set.format`.
+- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`): Parameters that control the rollout process, such as `temperature`. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.rollout_args`.
+- **`workflow_args`** (`Dict`): A dictionary of parameters to facilitate the construction of `Workflow` instances. Provides more flexibility than `format_args` and `rollout_args` by using a dictionary. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.workflow_args`. Normally, you do not need to set this field.
+
+```{tip}
+`workflow`, `workflow_args` and `raw_task` provide different levels of customization.
+
+- `workflow` provides the global settings for all tasks that uses the same workflow. (Global Level)
+- `workflow_args` can be set for each task dataset, allowing different task datasets using the same workflow to behave differently. (Dataset Level)
+- `raw_task` provides the ability to customize the behavior of each task, which is most flexible. (Data Sample Level)
+```
+
+In the math problem scenario, the `Task` dataset can be a `jsonl` file, where each line contains JSON with `question` and `answer` fields representing the problem description and standard answer, respectively. For example:
+
+```json
+{"question": "1+1=", "answer": "2"}
+{"question": "2+2=", "answer": "4"}
+...
+```
+
+Example configuration snippet:
+
+```yaml
+# some config
+buffer:
+ explorer_input:
+ taskset:
+ default_workflow: "math_workflow"
+ path: ${oc.env:TRINITY_TASKSET_PATH}
+ format:
+ prompt_key: "question"
+ response_key: "answer"
+ rollout_args:
+ temperature: 1.0
+ # some other configs
+```
+
+In this example, each task object's `raw_task` is a `Dict` with two keys (`question` and `answer`). The `MathWorkflow` uses the `prompt_key` and `response_key` to extract the question and answer from the `raw_task` and use the `rollout_args` to generate the response.
+
+---
+
+### Step 2: Implement a New Workflow
+
+The `Workflow` base class interface is as follows:
+
+```python
+class Workflow(ABC):
+
+ def __init__(
+ self,
+ *,
+ task: Task,
+ model: ModelWrapper,
+ auxiliary_models: Optional[List[openai.OpenAI]] = None,
+ ):
+ self.task = task
+ self.model = model
+ self.auxiliary_models = auxiliary_models
+
+ @abstractmethod
+ def run(self) -> List[Experience]:
+ """Run the workflow and return a list of Experiences."""
+```
+
+#### Initialize Your Workflow
+
+During initialization, `Workflow` receives the following parameters:
+
+- `task`({class}`trinity.common.workflows.Task`): A single data item from the task dataset.
+- `model`({class}`trinity.common.models.model.ModelWrapper`): The model being trained, which provides an interface similar to OpenAI, capable of receiving a list of conversation messages and returning content generated by the LLM (including reply text `response_text`, full sequence token ids `tokens`, prompt part token length `prompt_length`, and a list of output token logprobs `logprobs`).
+- `auxiliary_models`(`List[openai.OpenAI]`):A list of auxiliary models not involved in training. All are provided via OpenAI-compatible APIs.
+
+```{tip}
+You can switch to using the OpenAI API by setting `explorer.rollout_model.enable_openai_api` to `true` in your config file and calling `model.get_openai_client()` to get an `openai.OpenAI` instance in your workflow.
+And the `model` field when calling openai API can be obtained via `openai_client.models.list().data[0].id` or `openai_client.model_path`.
+```
+
+Here's an example of initializing a simple workflow using only `raw_task` and `rollout_args`. In more complex cases, you can use the `format_args` for further customization.
+
+```python
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+ # Optional: If you want to use OpenAI API in your workflow
+ # self.openai_client = self.model.get_openai_client()
+```
+
+#### Implementing the `run` method
+
+The `run` method is the core of your workflow. It returns a list of `Experience`.
+Below is a simple implementation for a math workflow.
+
+We first call the model to generate multiple response using the provided question and rollout arguments.
+Then we calculate the reward for each response using the `calculate_reward` function.
+Finally, we construct a list of `Experience` with the responses and rewards and return it.
+
+```python
+class ExampleWorkflow(Workflow):
+
+ # the __init__ function
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+```
+
+#### Registering Your Workflow
+
+Register your workflow using the `WORKFLOWS.register_module` decorator.
+Ensure the name does not conflict with existing workflows.
+
+```python
+# import some packages
+from trinity.common.workflows.workflow import WORKFLOWS
+
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ pass
+```
+
+For workflows that are prepared to be contributed to Trinity-RFT project, you need to place the above code in `trinity/common/workflows` folder, e.g., `trinity/common/workflows/example_workflow.py`. And add the following line to `trinity/common/workflows/__init__.py`:
+
+```python
+# existing import lines
+from trinity.common.workflows.example_workflow import ExampleWorkflow
+
+__all__ = [
+ # existing __all__ lines
+ "ExampleWorkflow",
+]
+```
+
+#### Avoid Re-initialization
+
+For heavy workflows, re-initializing every time can incurs extra computational costs.
+In this case, you can implement the `resettable` and `reset` methods to avoid re-initialization.
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ # some code
+ # ...
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+#### Full Code Example
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+---
+
+### Step 3: Use Your Workflow
+
+After implementing and registering your workflow, you need to update the configuration file to set the `default_workflow_type` in the `buffer.explorer_input.taskset` domain to the newly registered `Workflow` name.
+
+```yaml
+buffer:
+ # Other fields
+ explorer_input:
+ taskset:
+ path: /path/to/taskset
+ default_workflow_type: example_workflow
+ # Other fields
+```
+
+Now you can run your workflow in Trinity-RFT using the command:
+
+```
+trinity run --config
+```
diff --git a/docs/sphinx_doc/source/tutorial/example_megatron.md b/docs/sphinx_doc/source/tutorial/example_megatron.md
index b7ed7ba22e..fb5fd0a121 100644
--- a/docs/sphinx_doc/source/tutorial/example_megatron.md
+++ b/docs/sphinx_doc/source/tutorial/example_megatron.md
@@ -1,48 +1,17 @@
+(Megatron-LM)=
# Megatron-LM Backend
This guide walks you through how to train models using **Megatron-LM** in a clear way.
----
-
-## Step 1: Installation
-
-### Minimum Requirements
-
-Before you begin, make sure your system meets these requirements:
-
-- **GPUs**: At least 2 GPUs (for distributed training)
-- **CUDA**: Version 12.4 or higher
-- **Python**: Version 3.10 or higher
-
----
-
-### Install Dependencies
-
-Start by cloning the repository and setting up a virtual environment:
-
-```bash
-# Clone the repository
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
+```{note}
+This guide assumes you have already set up your environment following {ref}`Installation `. If you haven't done so, please refer to that guide first.
```
-#### Option A: Using Conda
-
-```bash
-# Create and activate a new environment
-conda create -n trinity python=3.10
-conda activate trinity
-```
+---
-#### Option B: Using venv
+## Step 1: Installation
-```bash
-# Create and activate a virtual environment
-python3.10 -m venv .venv
-source .venv/bin/activate
-```
-#### Install the Package
Install the project in editable mode with Megatron support:
@@ -54,19 +23,6 @@ pip install -e .[megatron]
pip install -e .\[megatron\]
```
-#### Install Flash Attention
-
-After installing the base dependencies, install `flash-attn`. This may take several minutes to compile — please be patient!
-
-```bash
-pip install flash-attn==2.8.1 -v
-```
-
-If you run into installation issues, try this alternative:
-
-```bash
-pip install flash-attn -v --no-build-isolation
-```
#### Install Apex (from NVIDIA)
diff --git a/docs/sphinx_doc/source/tutorial/example_mix_algo.md b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
index 4203cb8734..56312a7b98 100644
--- a/docs/sphinx_doc/source/tutorial/example_mix_algo.md
+++ b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
@@ -1,4 +1,4 @@
-# Algorithm Development
+# Advanced Algorithm Development
```{note}
This guide is an advanced version of the {ref}`Algorithms ` section in the Developer Guide.
diff --git a/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md b/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
index 4041c78761..0e85550e55 100644
--- a/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
+++ b/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
@@ -4,62 +4,7 @@ This tutorial shows a quick start guide for running RFT with Trinity-RFT.
## Step 0: Environment Preparation
-Minimal environment requirements:
-
-- GPUs: At least 2 GPUs
-- CUDA: Version >= 12.4
-- Python: Version >= 3.10
-
-```shell
-# Pull the source code from GitHub
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# Create a new environment using Conda or venv
-# Option 1: Conda
-conda create -n trinity python=3.10
-conda activate trinity
-
-# Option 2: venv
-python3.10 -m venv .venv
-source .venv/bin/activate
-
-# Install the package in editable mode
-# for bash
-pip install -e .[dev]
-# for zsh
-pip install -e .\[dev\]
-
-# Install flash-attn after all dependencies are installed
-# Note: flash-attn will take a long time to compile, please be patient.
-pip install flash-attn -v
-# Try the following command if you encounter errors during installation
-# pip install flash-attn -v --no-build-isolation
-```
-
-Installation using pip:
-
-```shell
-pip install trinity-rft
-```
-
-Installation from docker:
-
-We provided a dockerfile for Trinity-RFT.
-
-```shell
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# build the docker image
-# Note: you can edit the dockerfile to customize the environment
-# e.g., use pip mirrors or set api key
-docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-
-# run the docker image
-docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v :/data trinity-rft:latest
-```
-
+Please follow the instructions in [Installation](./trinity_installation.md) to set up the environment.
## Step 1: Model and Data Preparation
diff --git a/docs/sphinx_doc/source/tutorial/trinity_configs.md b/docs/sphinx_doc/source/tutorial/trinity_configs.md
index 88579f2fcc..731f5c2de4 100644
--- a/docs/sphinx_doc/source/tutorial/trinity_configs.md
+++ b/docs/sphinx_doc/source/tutorial/trinity_configs.md
@@ -658,3 +658,126 @@ trainer:
- `trainer.del_local_ckpt_after_load`: Whether to delete local checkpoints after loading.
- `trainer.max_actor_ckpt_to_keep`: Maximum number of actor checkpoints to keep.
- `trainer.max_critic_ckpt_to_keep`: Maximum number of critic checkpoints to keep.
+
+
+## Adding New Config Entries for the Config Generator (Advanced)
+
+This section introduces how to add new configuration parameters to the Config Generator page of Trinity-RFT.
+
+### Step 0: Understanding Streamlit
+
+Before adding new parameters to the Config Generator page, it is essential to familiarize yourself with the relevant API and mechanisms of [Streamlit](https://docs.streamlit.io/develop/api-reference). This project primarily utilizes various input components from Streamlit and employs `st.session_state` to store user-input parameters.
+
+### Step 1: Implement New Config Entries
+
+To illustrate the process of creating a new parameter setting for the Config Generator page, we will use `train_batch_size` as an example.
+
+1. Determine the appropriate scope for the parameter. Currently, parameters are categorized into four files:
+ - `trinity/manager/config_registry/buffer_config_manager.py`
+ - `trinity/manager/config_registry/explorer_config_manager.py`
+ - `trinity/manager/config_registry/model_config_manager.py`
+ - `trinity/manager/config_registry/trainer_config_manager.py`
+
+ In this case, `train_batch_size` should be placed in the `buffer_config_manager.py` file.
+
+2. Create a parameter setting function using Streamlit. The function name must follow the convention of starting with 'set_', and the remainder of the name becomes the config name.
+
+3. Decorate the parameter setting function with the `CONFIG_GENERATORS.register_config` decorator. This decorator requires the following information:
+ - Default value of the parameter
+ - Visibility condition (if applicable)
+ - Additional config parameters (if needed)
+
+```{note}
+The `CONFIG_GENERATORS.register_config` decorator automatically passes `key=config_name` as an argument to the registered configuration function. Ensure that your function accepts this keyword argument.
+```
+
+For `train_batch_size`, we will use the following settings:
+
+- Default value: 96
+- Visibility condition: `lambda: st.session_state["trainer_gpu_num"] > 0`
+- Additional config: `{"_train_batch_size_per_gpu": 16}`
+
+Here's the complete code for the `train_batch_size` parameter:
+
+```python
+@CONFIG_GENERATORS.register_config(
+ default_value=96,
+ visible=lambda: st.session_state["trainer_gpu_num"] > 0,
+ other_configs={"_train_batch_size_per_gpu": 16},
+)
+def set_train_batch_size(**kwargs):
+ key = kwargs.get("key")
+ trainer_gpu_num = st.session_state["trainer_gpu_num"]
+ st.session_state[key] = (
+ st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
+ )
+
+ def on_change():
+ st.session_state["_train_batch_size_per_gpu"] = max(
+ st.session_state[key] // st.session_state["trainer_gpu_num"], 1
+ )
+
+ st.number_input(
+ "Train Batch Size",
+ min_value=trainer_gpu_num,
+ step=trainer_gpu_num,
+ help=_str_for_train_batch_size(),
+ on_change=on_change,
+ **kwargs,
+ )
+```
+
+If the parameter requires validation, create a check function. For `train_batch_size`, we need to ensure it is divisible by `trainer_gpu_num`. If not, a warning should be displayed, and the parameter should be added to `unfinished_fields`.
+
+Decorate the check function with the `CONFIG_GENERATORS.register_check` decorator:
+
+```python
+@CONFIG_GENERATORS.register_check()
+def check_train_batch_size(unfinished_fields: set, key: str):
+ if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
+ unfinished_fields.add(key)
+ st.warning(_str_for_train_batch_size())
+```
+
+```{note}
+The `CONFIG_GENERATORS.register_check` decorator automatically receives `key=config_name` and `unfinished_fields=self.unfinished_fields` as arguments. Ensure your function accepts these keyword arguments.
+```
+
+### Step 2: Integrating New Parameters into `config_manager.py`
+
+To successfully integrate new parameters into the `config_manager.py` file, please adhere to the following procedure:
+
+1. Parameter Categorization:
+ Determine the appropriate section for the new parameter based on its functionality. The config generator page is structured into two primary modes:
+ - Beginner Mode: Comprises "Essential Configs" and "Important Configs" sections.
+ - Expert Mode: Includes "Model", "Buffer", "Explorer and Synchronizer", and "Trainer" sections.
+
+2. Parameter Addition:
+ Incorporate the new parameter into the relevant section using the `self.get_configs` method within the `ConfigManager` class.
+
+ Example:
+
+ ```python
+ class ConfigManager:
+ def _expert_buffer_part(self):
+ self.get_configs("total_epochs", "train_batch_size")
+ ```
+
+3. YAML File Integration:
+ Locate the appropriate position for the new parameter within the YAML file structure. This should be done in the `generate_config` function and its associated sub-functions.
+
+4. Parameter Value Assignment:
+ Utilize `st.session_state` to retrieve the parameter value from the config generator page and assign it to the corresponding field in the YAML.
+
+ Example:
+
+ ```python
+ class ConfigManager:
+ def _gen_buffer_config(self):
+ buffer_config = {
+ "batch_size": st.session_state["train_batch_size"],
+ # Additional configuration parameters
+ }
+ ```
+
+By following these steps, you can successfully add new parameters to the Config Generator page and ensure they are properly integrated into the configuration management system.
diff --git a/docs/sphinx_doc/source/tutorial/trinity_installation.md b/docs/sphinx_doc/source/tutorial/trinity_installation.md
new file mode 100644
index 0000000000..f4c13a2ce7
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/trinity_installation.md
@@ -0,0 +1,111 @@
+(Installation)=
+# Installation
+
+For installing Trinity-RFT, you have three options: from source (recommended), via PyPI, or using Docker.
+
+Before installing, ensure your system meets the following requirements:
+
+- **Python**: Version 3.10 to 3.12 (inclusive)
+- **CUDA**: Version 12.4 to 12.8 (inclusive)
+- **GPUs**: At least 2 GPUs
+
+---
+
+## From Source (Recommended)
+
+This method is best if you plan to customize or contribute to Trinity-RFT.
+
+### 1. Clone the Repository
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+```
+
+### 2. Set Up a Virtual Environment
+
+Choose one of the following options:
+
+#### Using Conda
+
+```bash
+conda create -n trinity python=3.10
+conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### Using venv
+
+```bash
+python3.10 -m venv .venv
+source .venv/bin/activate
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### Using `uv`
+
+[`uv`](https://github.com/astral-sh/uv) is a modern Python package installer.
+
+```bash
+uv sync --extra dev --extra flash_attn
+```
+
+---
+
+## Via PyPI
+
+If you just want to use the package without modifying the code:
+
+```bash
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
+```
+
+Or with `uv`:
+
+```bash
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
+```
+
+---
+
+## Using Docker
+
+We provide a Docker setup for hassle-free environment configuration.
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+
+# Build the Docker image
+## Tip: You can modify the Dockerfile to add mirrors or set API keys
+docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
+
+# Run the container, replacing with your actual path
+docker run -it \
+ --gpus all \
+ --shm-size="64g" \
+ --rm \
+ -v $PWD:/workspace \
+ -v :/data \
+ trinity-rft:latest
+```
+
+```{note}
+For training with **Megatron-LM**, please refer to {ref}`Megatron-LM Backend `.
+```
+
+---
+
+## Troubleshooting
+
+If you encounter installation issues, refer to the FAQ or [GitHub Issues](https://github.com/modelscope/Trinity-RFT/issues).
diff --git a/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md b/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md
deleted file mode 100644
index 2b1ffac957..0000000000
--- a/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md
+++ /dev/null
@@ -1,746 +0,0 @@
-# Developer Guide
-
-This guide introduces how to develop new modules in Trinity-RFT and provides relevant development guidelines.
-
-In Trinity-RFT, we decompose the RL pipeline into three main modules (**Explorer**, **Trainer** and **Buffer**) to facilitate customization and extension.
-Below is a table summarizing the modules and components that developers with different targets need to focus on.
-
-| Development Target | Core Module | Key Component |
-|--------------------|-------------|---------------|
-| Apply existing RL algorithms to new environments. | *Explorer* | `Workflow` |
-| Design new RL algorithms. | *Trainer* | `Algorithm` |
-| Enhance the RL process from the data perspective. | *Buffer* | `Operator` |
-
-```{note}
-Trinity-RFT is under active development, and the following interfaces may change. Please refer to the latest code when using this guide.
-```
-
-```{tip}
-For modules that only used for local testing or not intended for contribution, you can place them in the `trinity/plugins` directory. Trinity-RFT will automatically load all modules in this directory, and you can use those modules without adding them to the `__init__.py` file. You can specify another directory by setting the `--plugin-dir` option when running Trinity-RFT, e.g., `trinity run --config /path/to/your/config --plugin-dir /path/to/your/plugins`.
-```
-
----
-
-(Workflows)=
-## Workflows (For RL Environment Developers)
-
-In Trinity-RFT, workflows are the core components that define the interaction between Agents and Environments.
-A qualified workflow needs to use the trained model to complete the specified task and obtain feedback information (reward) from the environment. Below are the steps to create a new workflow:
-
----
-
-### Step 0: Basic Concepts
-
-Before starting development, it's important to understand several core concepts:
-
-- **Task** ({class}`trinity.common.workflows.Task`): Represents a data structure that can be converted into a `Workflow`. The content of the `Task` varies depending on the task type:
- - **Math problems**: A `Task` contains the problem description and the golden answer.
- - **Programming scenarios**: A `Task` includes the problem description, test cases, runtime environment, and other complex information.
-
-- **Workflow** ({class}`trinity.common.workflows.Workflow`): Describes how a `Task` is executed. It defines the interaction flow between Agents and Environments, including logic similar to *Rollout* and *Reward* calculations in other frameworks. After execution, it generates a list of `Experience`. Trinity-RFT includes several built-in workflows:
- - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`): For math scenarios, submits problems to LLM, parses LLM responses, and calculates scores (rewards).
- - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`): For webshop scenarios, it contains multi-turn interaction with environment.
- - `CodeWorkflow` (Coming soon): For coding scenarios, executes returned code, runs tests, and calculates rewards based on test results.
- - ...
-
-- **Experience** ({class}`trinity.common.experience.Experience`): The output of running a `Workflow`. The internal data format depends on the training algorithm used. For example, for common PPO/GRPO algorithms, `Experience` includes lists of token IDs, action masks (identifying which tokens were generated by the LLM), log probabilities, rewards, etc.
-
----
-
-### Step 1: Prepare Task Dataset
-
-The task dataset is loaded via the `buffer.explorer_input.taskset` configuration entry in your YAML config file.
-To handle differences in `Task` contents, Trinity-RFT provides a unified `Task` interface containing the following fields.
-
-- **`workflow`** (`str`): The registered name of your workflow class. You can specify it in `buffer.explorer_input.taskset.default_workflow_type` of your YAML config file.
-- **`reward_fn`** (`Optional[str]`): The registered name of your reward function. You can specify it in `buffer.explorer_input.taskset.default_reward_fn_type`. Note that some workflows already include built-in reward calculation; in such cases, you can omit this field.
-- **`raw_task`** (`Dict`): A record of raw data in `Dict` format. For highly customized workflow, you can directly use `raw_task` to initialize your `Workflow` instance without relying on the following fields.
-- **`format_args`** ({class}`trinity.common.config.FormatConfig`): Parameters to facilitate the construction of `Workflow` instances. For example, the `prompt_key` and `response_key` can be used to get the prompt and response from `raw_task`. These settings come from the YAML configuration file and can be set in `buffer.explorer_input.task_set.format`.
-- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`): Parameters that control the rollout process, such as `temperature`. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.rollout_args`.
-- **`workflow_args`** (`Dict`): A dictionary of parameters to facilitate the construction of `Workflow` instances. Provides more flexibility than `format_args` and `rollout_args` by using a dictionary. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.workflow_args`. Normally, you do not need to set this field.
-
-```{tip}
-`workflow`, `workflow_args` and `raw_task` provide different levels of customization.
-
-- `workflow` provides the global settings for all tasks that uses the same workflow. (Global Level)
-- `workflow_args` can be set for each task dataset, allowing different task datasets using the same workflow to behave differently. (Dataset Level)
-- `raw_task` provides the ability to customize the behavior of each task, which is most flexible. (Data Sample Level)
-```
-
-In the math problem scenario, the `Task` dataset can be a `jsonl` file, where each line contains JSON with `question` and `answer` fields representing the problem description and standard answer, respectively. For example:
-
-```json
-{"question": "1+1=", "answer": "2"}
-{"question": "2+2=", "answer": "4"}
-...
-```
-
-Example configuration snippet:
-
-```yaml
-# some config
-buffer:
- explorer_input:
- taskset:
- default_workflow: "math_workflow"
- path: ${oc.env:TRINITY_TASKSET_PATH}
- format:
- prompt_key: "question"
- response_key: "answer"
- rollout_args:
- temperature: 1.0
- # some other configs
-```
-
-In this example, each task object's `raw_task` is a `Dict` with two keys (`question` and `answer`). The `MathWorkflow` uses the `prompt_key` and `response_key` to extract the question and answer from the `raw_task` and use the `rollout_args` to generate the response.
-
----
-
-### Step 2: Implement a New Workflow
-
-The `Workflow` base class interface is as follows:
-
-```python
-class Workflow(ABC):
-
- def __init__(
- self,
- *,
- task: Task,
- model: ModelWrapper,
- auxiliary_models: Optional[List[openai.OpenAI]] = None,
- ):
- self.task = task
- self.model = model
- self.auxiliary_models = auxiliary_models
-
- @abstractmethod
- def run(self) -> List[Experience]:
- """Run the workflow and return a list of Experiences."""
-```
-
-#### Initialize Your Workflow
-
-During initialization, `Workflow` receives the following parameters:
-
-- `task`({class}`trinity.common.workflows.Task`): A single data item from the task dataset.
-- `model`({class}`trinity.common.models.model.ModelWrapper`): The model being trained, which provides an interface similar to OpenAI, capable of receiving a list of conversation messages and returning content generated by the LLM (including reply text `response_text`, full sequence token ids `tokens`, prompt part token length `prompt_length`, and a list of output token logprobs `logprobs`).
-- `auxiliary_models`(`List[openai.OpenAI]`):A list of auxiliary models not involved in training. All are provided via OpenAI-compatible APIs.
-
-```{tip}
-You can switch to using the OpenAI API by setting `explorer.rollout_model.enable_openai_api` to `true` in your config file and calling `model.get_openai_client()` to get an `openai.OpenAI` instance in your workflow.
-And the `model` field when calling openai API can be obtained via `openai_client.models.list().data[0].id` or `openai_client.model_path`.
-```
-
-Here's an example of initializing a simple workflow using only `raw_task` and `rollout_args`. In more complex cases, you can use the `format_args` for further customization.
-
-```python
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
- # Optional: If you want to use OpenAI API in your workflow
- # self.openai_client = self.model.get_openai_client()
-```
-
-#### Implementing the `run` method
-
-The `run` method is the core of your workflow. It returns a list of `Experience`.
-Below is a simple implementation for a math workflow.
-
-We first call the model to generate multiple response using the provided question and rollout arguments.
-Then we calculate the reward for each response using the `calculate_reward` function.
-Finally, we construct a list of `Experience` with the responses and rewards and return it.
-
-```python
-class ExampleWorkflow(Workflow):
-
- # the __init__ function
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-```
-
-#### Registering Your Workflow
-
-Register your workflow using the `WORKFLOWS.register_module` decorator.
-Ensure the name does not conflict with existing workflows.
-
-```python
-# import some packages
-from trinity.common.workflows.workflow import WORKFLOWS
-
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- pass
-```
-
-For workflows that are prepared to be contributed to Trinity-RFT project, you need to place the above code in `trinity/common/workflows` folder, e.g., `trinity/common/workflows/example_workflow.py`. And add the following line to `trinity/common/workflows/__init__.py`:
-
-```python
-# existing import lines
-from trinity.common.workflows.example_workflow import ExampleWorkflow
-
-__all__ = [
- # existing __all__ lines
- "ExampleWorkflow",
-]
-```
-
-#### Avoid Re-initialization
-
-For heavy workflows, re-initializing every time can incurs extra computational costs.
-In this case, you can implement the `resettable` and `reset` methods to avoid re-initialization.
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- # some code
- # ...
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
-#### Full Code Example
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
----
-
-### Step 3: Use Your Workflow
-
-After implementing and registering your workflow, you need to update the configuration file to set the `default_workflow_type` in the `buffer.explorer_input.taskset` domain to the newly registered `Workflow` name.
-
-```yaml
-buffer:
- # Other fields
- explorer_input:
- taskset:
- path: /path/to/taskset
- default_workflow_type: example_workflow
- # Other fields
-```
-
-Now you can run your workflow in Trinity-RFT using the command:
-
-```
-trinity run --config
-```
-
----
-
-(Algorithms)=
-## Algorithms (For RL Algorithm Developers)
-
-Trinity-RFT provides a standardized process for implementing new algorithms.
-
-### Step 0: Basic Concepts of Algorithm Module
-
-In Trinity-RFT, the algorithm module is primarily responsible for extracting experience data from the Replay Buffer during the RL process and calculating the loss to update models based on this data.
-To avoid implementing a new Trainer class each time a new algorithm is added, we have decomposed the representative PPO algorithm process into multiple sub-modules to adapt to various algorithms.
-
-- **Sample Strategy** ({class}`trinity.algorithm.SampleStrategy`): Responsible for sampling experience data from the buffer module. By customizing this module, you can implement functionalities like filtering experience data or mixed sampling from multiple data sources.
-- **Advantage Fn**({class}`trinity.algorithm.AdvantageFn`): Responsible for calculating the Advantage and Returns of experience data.
-- **Policy Loss Fn**({class}`trinity.algorithm.PolicyLossFn`): Responsible for calculating the core training loss of the policy network.
-- **KL Fn**({class}`trinity.algorithm.KLFn`): Responsible for calculating KL Divergence, which is generally used in two places in existing RL algorithms: Reward Penalty and Actor Loss.
-- **Entropy Loss Fn**({class}`trinity.algorithm.EntropyLossFn`): Responsible for calculating the entropy loss of the policy network.
-
-We provide several implementations of above modules in `trinity/algorithm`.
-
----
-
-### Step 1: Implement Algorithm Components
-
-
-Trinity-RFT allows developers to customize all the above modules. Developers only need to implement specific modules according to the requirements of their new algorithm. This section will provide a simple introduction using the {ref}`OPMD ` algorithm as an example.
-
-The main difference between OPMD and PPO algorithms lies in the calculation of Advantage and Policy Loss.
-OPMD relies on a group-based advantage calculation and does not use the Critic model.
-To implement OPMD, developers need to implement advantage calculation in `AdvantageFn` and policy loss calculation in `PolicyLossFn`.
-
----
-
-#### Step 1.1: Implement `AdvantageFn`
-
-The {class}`trinity.algorithm.AdvantageFn` interface includes three methods:
-
-- `__call__`: The main entrance for advantage calculation. It receives a list of experiences ({class}`trinity.common.experience.Experience`) and returns a list of experiences with calculated advantages and returns, along with a metrics dictionary for logging.
-- `default_args`: A class method that returns the default initialization parameters in dictionary form. It will be used by default when users don't specify initialization parameters in the configuration file.
-- `compute_in_trainer`: This class method indicates whether to compute advantages in the Trainer. If it returns `False`, the `AdvantageFn` will be called in the experience data processing pipeline.
-
-For convenience, Trinity-RFT provides an abstract class {class}`trinity.algorithm.advantage_fn.GroupAdvantage` that implements the `__call__` method for group-based advantage calculation, you can focus on how to group the experiences and calculate advantages on grouped experiences with the following two methods:
-
-- `group_experiences`: This method groups a experiences generated in a step into multiple sub-groups.
-
-- `calculate_group_advantage`: This method calculates the advantage for each group of experiences.
-
-Here's an implementation example for the OPMD algorithm's advantage function:
-
-```python
-from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
-
-@ADVANTAGE_FN.register_module("opmd")
-class OPMDGroupAdvantage(GroupAdvantage):
- """OPMD Group Advantage computation"""
-
- def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
- super().__init__(**kwargs)
- self.opmd_baseline = opmd_baseline
- self.tau = tau
-
- def group_experiences(self, exps):
- return group_by(exps, id_type="task")
-
- def calculate_group_advantage(
- self, group_id: str, exps: List[Experience]
- ) -> Tuple[List[Experience], Dict]:
- with torch.no_grad():
- if len(exps) == 1:
- group_baseline = torch.tensor(0.0)
- else:
- group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
- if self.opmd_baseline == "mean":
- group_baseline = torch.mean(group_rewards)
- else:
- group_baseline = self.tau * (
- torch.logsumexp(group_rewards / self.tau, dim=-1)
- - torch.log(torch.tensor(len(exps)))
- )
- for exp in exps:
- score = exp.reward - group_baseline
- exp.advantages = score * exp.action_mask
- exp.returns = exp.advantages.clone()
- metrics = {
- "group_baseline": group_baseline.item(),
- }
- return exps, metrics
-
- @classmethod
- def default_args(cls) -> dict:
- return {"opmd_baseline": "mean", "tau": 1.0}
-```
-
-After implementation, you need to register this module through {class}`trinity.algorithm.ADVANTAGE_FN`. Once registered, the module can be configured in the configuration file using the registered name.
-
-
-#### Step 1.3: Implement `PolicyLossFn`
-
-Developers need to implement the {class}`trinity.algorithm.PolicyLossFn` interface, which is similar to `AdvantageFn` and includes two methods:
-
-- `__call__`: Calculates the loss based on input parameters. Unlike `AdvantageFn`, the input parameters here are all `torch.Tensor`. This interface automatically scans the parameter list of the `__call__` method and converts it to the corresponding fields in the experience data. Therefore, please write all tensor names needed for loss calculation directly in the parameter list, rather than selecting parameters from `kwargs`.
-- `default_args`: Returns default initialization parameters in dictionary form, which will be used by default when users don't specify initialization parameters in the configuration file.
-
-Similarly, after implementation, you need to register this module through {class}`trinity.algorithm.POLICY_LOSS_FN`.
-
-Here's an implementation example for the OPMD algorithm's Policy Loss Fn. Since OPMD's Policy Loss only requires logprob, action_mask, and advantages, only these three items are specified in the parameter list of the `__call__` method:
-
-
-```python
-@POLICY_LOSS_FN.register_module("opmd")
-class OPMDPolicyLossFn(PolicyLossFn):
- def __init__(self, tau: float = 1.0) -> None:
- self.tau = tau
-
- def __call__( # type: ignore
- self,
- logprob: torch.Tensor,
- action_mask: torch.Tensor,
- advantages: torch.Tensor,
- **kwargs,
- ) -> Tuple[torch.Tensor, Dict]:
- pg_losses = -advantages * logprob
- opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
- opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
- return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
-
- @classmethod
- def default_args(cls) -> Dict:
- return {"tau": 1.0, "loss_agg_mode": "token-mean"}
-```
-
----
-
-### Step 2: Register Your Algorithm
-
-The above steps implement the components needed for the algorithm, but these components are scattered and need to be configured in multiple places to take effect.
-
-To simplify configuration, Trinity-RFT provides {class}`trinity.algorithm.AlgorithmType` to describe a complete algorithm and registers it in {class}`trinity.algorithm.ALGORITHM_TYPE`, enabling one-click configuration.
-
-The `AlgorithmType` class includes the following attributes and methods:
-
-- `use_critic`: Whether to use the Critic model
-- `use_reference`: Whether to use the Reference model
-- `compute_advantage_in_trainer`: Whether to calculate Advantages in Trainer; if False, the `AdvantageFn` call in trainer will be skipped
-- `can_balance_batch`: Whether the algorithm allows automatic balancing when splitting a batch into microbatches (which permute the order of samples)
-- `schema`: The format of experience data corresponding to the algorithm
-- `default_config`: Gets the default configuration of the algorithm, which will override attributes with the same name in `ALGORITHM_TYPE`
-
-Similarly, after implementation, you need to register this module through `ALGORITHM_TYPE`.
-
-Below is the implementation for the OPMD algorithm.
-Since the OPMD algorithm doesn't need to use the Critic model, `use_critic` is set to `False`.
-The dictionary returned by the `default_config` method indicates that OPMD will use the `opmd` type `AdvantageFn` and `PolicyLossFn` implemented in Step 1, will not apply KL Penalty on rewards, but will add a `k2` type KL loss when calculating the final loss.
-
-```python
-@ALGORITHM_TYPE.register_module("opmd")
-class OPMDAlgorithm(AlgorithmType):
- """OPMD algorithm."""
-
- use_critic: bool = False
- use_reference: bool = True
- compute_advantage_in_trainer: bool = False
- can_balance_batch: bool = True
- schema: str = "experience"
-
- @classmethod
- def default_config(cls) -> Dict:
- return {
- "repeat_times": 2,
- "advantage_fn": "opmd",
- "sample_strategy": "warmup",
- "policy_loss_fn": "opmd",
- "kl_penalty_fn": "none",
- "kl_loss_fn": "k2",
- "entropy_loss_fn": "default",
- }
-```
-
----
-
-### Step 3: Use Your Algorithm
-
-After completing all the above steps, you can use the newly registered algorithm through a YAML configuration file.
-
-For default configurations, you just need to add the following content to your `config.yaml` file:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
-# some other configs
-```
-
-If you need to modify certain parameters, you can simply add the corresponding parameters within the `algorithm` section. For example, if you need to modify `repeat_times` and the initialization parameters of `AdvantageFn` and `PolicyLossFn`, the modified `config.yaml` file would be as follows:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
- repeat_times: 8
- advantage_fn_args:
- opmd_baseline: "logavgexp"
- tau: 0.99
- policy_loss_fn_args:
- tau: 0.99
-# some other configs
-```
-
----
-
-## Operators (For Data Developers)
-
-### Step 0: Basic Concepts of Operator Module
-
-In Trinity-RFT, the operator module is responsible for processing experience data in the buffer module. It supports existing data processing capabilities from [Data-Juicer](https://github.com/modelscope/data-juicer) naturally, and allows developers to implement their own operators as well.
-By customizing operators, developers can implement various data processing functionalities, such as data augmentation, filtering, and transformation. You can even implement advantages/returns calculation as operators, as shown in {ref}`Algorithms ` section.
-
-- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`): The operator that wraps the data processing operators from Data-Juicer. It provides a simple interface for developers to list the Data-Juicer operators they want to use. The full list of Data-Juicer operators can be found [here](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html).
-- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`): The base class for all operators used in experience data processing. It defines the interface and common functionalities that all operators should have. Each operator processes a batch of experience data and returns the processed data with metrics for logging.
-- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`): The experience data processing pipeline that manages a sequence of operators. It takes raw experiences from the `Explorer`, passes them through each operator in the pipeline, and writes the final processed experiences into the input buffer of the `Trainer`.
-
-```{note}
-Except for `ExperiencePipeline`, Trinity-RFT also provides `TaskPipeline` for task data processing.
-In the current version, the `TaskPipeline` only supports using Data-Juicer operators. Please see this {ref}`section ` for details.
-```
----
-
-Developers can implement and use their own operators by following the steps below.
-
-### Step 1: Implement Operator
-
-The `ExperienceOperator` interface includes only one `process` method. The `ExperiencePipeline` will call this method with a list of `Experience` generated by the `Explorer` in one explore step. The `process` method should return a tuple containing the processed list of `Experience` and a dictionary of metrics for logging.
-
-```python
-class ExperienceOperator(ABC):
-
- @abstractmethod
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- """Process a list of experiences and return a transformed list.
-
- Args:
- exps (List[Experience]): List of experiences to process, which contains
- all experiences generated by the Explorer in one explore step.
- Returns:
- Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
- """
-```
-
-Here is an implementation of a simple operator that filters out experiences with rewards below a certain threshold:
-
-```python
-from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
-from trinity.common.experience import Experience
-
-
-@EXPERIENCE_OPERATORS.register_module("reward_filter")
-class RewardFilter(ExperienceOperator):
-
- def __init__(self, threshold: float = 0.0) -> None:
- self.threshold = threshold
-
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
- metrics = {"filtered_count": len(exps) - len(filtered_exps)}
- return filtered_exps, metrics
-```
-
-After implementation, you need to register this module through {class}`trinity.data.operators.EXPERIENCE_OPERATORS`. Once registered, the module can be configured in the configuration file using the registered name.
-
-### Step 2: Use Your Operator
-
-After completing the above steps, you can use the newly registered operator through a YAML configuration file.
-
-```yaml
-# some other configs
-data_processor:
- experience_pipeline:
- operators:
- - name: "reward_filter"
- args:
- threshold: 0.1
-synchronizer:
- sync_method: nccl
- sync_style: dynamic_by_explorer
- sync_interval: 2
-# some other configs
-```
-
-```{tip}
-The `RewardFilter` reduces the number of experiences, which may cause the trainer can't get enough experiences to start a training step. To avoid the issue, you can use the advanced {ref}`Dynamic Synchronization ` feature provided by Trinity-RFT as shown in the above configuration file.
-The above setting means that the `Explorer` will sync with the `Trainer` every 2 steps and will continue running regardless of how many steps the `Trainer` has completed. This ensures that the `Trainer` can always get enough experiences to start a training step as long as the `Explorer` is running.
-```
-
----
-
-## Adding New Config Entries for the Config Generator (Advanced)
-
-### Step 0: Understanding Streamlit
-
-Before adding new parameters to the Config Generator page, it is essential to familiarize yourself with the relevant API and mechanisms of [Streamlit](https://docs.streamlit.io/develop/api-reference). This project primarily utilizes various input components from Streamlit and employs `st.session_state` to store user-input parameters.
-
-### Step 1: Implement New Config Entries
-
-To illustrate the process of creating a new parameter setting for the Config Generator page, we will use `train_batch_size` as an example.
-
-1. Determine the appropriate scope for the parameter. Currently, parameters are categorized into four files:
- - `trinity/manager/config_registry/buffer_config_manager.py`
- - `trinity/manager/config_registry/explorer_config_manager.py`
- - `trinity/manager/config_registry/model_config_manager.py`
- - `trinity/manager/config_registry/trainer_config_manager.py`
-
- In this case, `train_batch_size` should be placed in the `buffer_config_manager.py` file.
-
-2. Create a parameter setting function using Streamlit. The function name must follow the convention of starting with 'set_', and the remainder of the name becomes the config name.
-
-3. Decorate the parameter setting function with the `CONFIG_GENERATORS.register_config` decorator. This decorator requires the following information:
- - Default value of the parameter
- - Visibility condition (if applicable)
- - Additional config parameters (if needed)
-
-```{note}
-The `CONFIG_GENERATORS.register_config` decorator automatically passes `key=config_name` as an argument to the registered configuration function. Ensure that your function accepts this keyword argument.
-```
-
-For `train_batch_size`, we will use the following settings:
-
-- Default value: 96
-- Visibility condition: `lambda: st.session_state["trainer_gpu_num"] > 0`
-- Additional config: `{"_train_batch_size_per_gpu": 16}`
-
-Here's the complete code for the `train_batch_size` parameter:
-
-```python
-@CONFIG_GENERATORS.register_config(
- default_value=96,
- visible=lambda: st.session_state["trainer_gpu_num"] > 0,
- other_configs={"_train_batch_size_per_gpu": 16},
-)
-def set_train_batch_size(**kwargs):
- key = kwargs.get("key")
- trainer_gpu_num = st.session_state["trainer_gpu_num"]
- st.session_state[key] = (
- st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
- )
-
- def on_change():
- st.session_state["_train_batch_size_per_gpu"] = max(
- st.session_state[key] // st.session_state["trainer_gpu_num"], 1
- )
-
- st.number_input(
- "Train Batch Size",
- min_value=trainer_gpu_num,
- step=trainer_gpu_num,
- help=_str_for_train_batch_size(),
- on_change=on_change,
- **kwargs,
- )
-```
-
-If the parameter requires validation, create a check function. For `train_batch_size`, we need to ensure it is divisible by `trainer_gpu_num`. If not, a warning should be displayed, and the parameter should be added to `unfinished_fields`.
-
-Decorate the check function with the `CONFIG_GENERATORS.register_check` decorator:
-
-```python
-@CONFIG_GENERATORS.register_check()
-def check_train_batch_size(unfinished_fields: set, key: str):
- if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
- unfinished_fields.add(key)
- st.warning(_str_for_train_batch_size())
-```
-
-```{note}
-The `CONFIG_GENERATORS.register_check` decorator automatically receives `key=config_name` and `unfinished_fields=self.unfinished_fields` as arguments. Ensure your function accepts these keyword arguments.
-```
-
-### Step 2: Integrating New Parameters into `config_manager.py`
-
-To successfully integrate new parameters into the `config_manager.py` file, please adhere to the following procedure:
-
-1. Parameter Categorization:
- Determine the appropriate section for the new parameter based on its functionality. The config generator page is structured into two primary modes:
- - Beginner Mode: Comprises "Essential Configs" and "Important Configs" sections.
- - Expert Mode: Includes "Model", "Buffer", "Explorer and Synchronizer", and "Trainer" sections.
-
-2. Parameter Addition:
- Incorporate the new parameter into the relevant section using the `self.get_configs` method within the `ConfigManager` class.
-
- Example:
-
- ```python
- class ConfigManager:
- def _expert_buffer_part(self):
- self.get_configs("total_epochs", "train_batch_size")
- ```
-
-3. YAML File Integration:
- Locate the appropriate position for the new parameter within the YAML file structure. This should be done in the `generate_config` function and its associated sub-functions.
-
-4. Parameter Value Assignment:
- Utilize `st.session_state` to retrieve the parameter value from the config generator page and assign it to the corresponding field in the YAML.
-
- Example:
-
- ```python
- class ConfigManager:
- def _gen_buffer_config(self):
- buffer_config = {
- "batch_size": st.session_state["train_batch_size"],
- # Additional configuration parameters
- }
- ```
-
-By meticulously following these steps, you can ensure that new parameters are successfully added to the Config Generator page and properly integrated into the configuration system. This process maintains the integrity and functionality of the configuration management framework.
-
----
-
-## Contributing your Code
-
-For modules that are prepared to be contributed to the Trinity-RFT project, please follow the steps below:
-
-1. Implement your code in the appropriate directory, such as `trinity/common/workflows` for workflows, `trinity/algorithm` for algorithms, `trinity/buffer/operators` for operators.
-
-2. Register your module in the corresponding `__init__.py` file of the directory.
-
-3. Add tests for your module in the `tests` directory, following the naming conventions and structure of existing tests.
-
-4. Before submitting the code, make sure it passes the code style check with `pre-commit run --all-files`.
-
-5. Submit a pull request to the Trinity-RFT repository, including a clear description of your changes.
diff --git a/docs/sphinx_doc/source_zh/index.rst b/docs/sphinx_doc/source_zh/index.rst
index a05d73ebf1..3e0a929e08 100644
--- a/docs/sphinx_doc/source_zh/index.rst
+++ b/docs/sphinx_doc/source_zh/index.rst
@@ -8,12 +8,26 @@
.. include:: main.md
:parser: myst_parser.sphinx_
+.. toctree::
+ :maxdepth: 2
+ :glob:
+ :hidden:
+ :caption: 教程
+
+ tutorial/trinity_installation.md
+ tutorial/develop_overview.md
+ tutorial/develop_workflow.md
+ tutorial/develop_algorithm.md
+ tutorial/example_mix_algo.md
+ tutorial/develop_operator.md
+ tutorial/trinity_configs.md
+ tutorial/synchronizer.md
.. toctree::
:maxdepth: 1
:glob:
:hidden:
- :caption: 教程
+ :caption: 样例
tutorial/example_reasoning_basic.md
tutorial/example_reasoning_advanced.md
@@ -26,17 +40,6 @@
tutorial/example_megatron.md
tutorial/example_data_functionalities.md
-.. toctree::
- :maxdepth: 2
- :glob:
- :hidden:
- :caption: 帮助文档
-
- tutorial/trinity_programming_guide.md
- tutorial/trinity_configs.md
- tutorial/example_mix_algo.md
- tutorial/synchronizer.md
-
.. toctree::
:maxdepth: 2
:hidden:
diff --git a/docs/sphinx_doc/source_zh/main.md b/docs/sphinx_doc/source_zh/main.md
index 2c39a5c75c..eb89d59d17 100644
--- a/docs/sphinx_doc/source_zh/main.md
+++ b/docs/sphinx_doc/source_zh/main.md
@@ -1,43 +1,32 @@
-## 🚀 新闻
-
-* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
-* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
-* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
-* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
-* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
-* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
-* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
-* [2025-04] Trinity-RFT 开源。
-
-
## 💡 什么是 Trinity-RFT?
-Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。它支持广泛的应用场景,并为 [Experience 时代](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf) 的 RL 研究提供统一平台。
-
-RFT 流程被模块化为三个核心组件:
+Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。其提供三个独立模块,满足不同用户的需求:
-* **Explorer**:负责智能体与环境的交互
-* **Trainer**:负责模型训练
-* **Buffer**:负责数据存储与处理
+* 🤖 **Explorer**:面向智能体应用开发者。[[教程]](/tutorial/develop_workflow.md)
+ - 训练智能体应用,以增强其在指定环境中完成任务的能力
+ - 示例:[多轮交互](/tutorial/example_multi_turn.md),[ReAct 智能体](/tutorial/example_react.md)
+* 🧠 **Trainer**:面向 RL 算法研究者。[[教程]](/tutorial/develop_algorithm.md)
+ - 在简洁、可插拔的类中设计和验证新的 RL 算法
+ - 示例:[混合 RL 算法](/tutorial/example_mix_algo.md)
-
+* 🗄️ **Buffer**:面向数据工程师。[[教程]](/tutorial/develop_operator.md)
+ - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景
+ - 示例:[数据功能](/tutorial/example_data_functionalities.md)
-
-
-## ✨ 核心特性
+Trinity-RFT 统一了上述三个模块,并提供以下核心特性:
* **灵活的 RFT 模式:**
- 支持同步/异步、on-policy/off-policy 以及在线/离线训练。采样与训练可分离运行,并可在多设备上独立扩展。
-* **兼容 Agent 框架的工作流:**
- - 支持拼接式和通用多轮智能体工作流。可自动收集来自模型 API 客户端(如 OpenAI)的训练数据,并兼容 AgentScope 等智能体框架。
+* **通用 Agentic-RL:**
+ - 支持拼接式和通用多轮交互,能够直接训练使用 AgentScope 等智能体框架开发的 Agent 应用。
-* **强大的数据流水线:**
+* **全流程的数据流水线:**
- 支持 rollout 和经验数据的流水线处理,贯穿 RFT 生命周期实现主动管理(优先级、清洗、增强等)。
@@ -47,22 +36,6 @@ RFT 流程被模块化为三个核心组件:
-
-
-
-## 🛠️ Trinity-RFT 能做什么?
-
-* **用 RL 训练智能体应用**
- - 在 Workflow 中实现智能体-环境交互逻辑 ([示例1](tutorial/example_multi_turn.md),[示例2](tutorial/example_step_wise.md)),
- - 或直接使用 Agent 框架(如 AgentScope)编写好的工作流 ([示例](tutorial/example_react.md))。
-
-* **快速设计和验证 RL 算法**
- - 在简洁、可插拔的类中开发自定义 RL 算法(损失、采样及其他技巧) ([教程](tutorial/trinity_programming_guide.md#algorithms-for-rl-algorithm-developers),[示例](tutorial/example_mix_algo.md))。
-
-* **为 RFT 定制数据集和数据流水线**
- - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景 ([教程](tutorial/trinity_programming_guide.md#operators-for-data-developers),[示例](tutorial/example_data_functionalities.md))。
-
-
## 致谢
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md b/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md
new file mode 100644
index 0000000000..d003d6e2fd
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md
@@ -0,0 +1,214 @@
+(Algorithms)=
+## Algorithm 开发指南
+
+在 Trinity-RFT 中,Algorithm 模块主要负责在 RL 过程中从 Buffer 提取 experience 数据,并基于这些数据计算损失以更新模型。为了避免每次添加新算法时都实现新的 Trainer 类,我们将典型的 PPO 算法流程分解为多个子模块,以适应各种 RL 算法。
+
+### 步骤 0:Algorithm 子模块概览
+
+Trinity-RFT 将 Algorithm 模块拆分为以下几个子模块:
+
+- **采样策略(Sample Strategy)** ({class}`trinity.algorithm.SampleStrategy`):负责从缓冲区模块中采样 experience 数据。通过自定义此模块,你可以实现过滤 experience 数据或从多个数据源混合采样的功能。
+- **优势函数(Advantage Fn)**({class}`trinity.algorithm.AdvantageFn`):负责计算 experience 数据的优势值(Advantage)和回报值(Returns)。
+- **策略损失函数(Policy Loss Fn)**({class}`trinity.algorithm.PolicyLossFn`):负责计算策略网络的核心训练损失。
+- **KL 函数(KL Fn)**({class}`trinity.algorithm.KLFn`):负责计算 KL 散度,通常在现有 RL 算法中用于两个地方:奖励惩罚和 Actor 损失。
+- **熵损失函数(Entropy Loss Fn)**({class}`trinity.algorithm.EntropyLossFn`):负责计算策略网络的熵损失。
+
+我们在 `trinity/algorithm` 中提供了上述模块的若干实现。
+
+---
+
+### 步骤 1:实现算法组件
+
+Trinity-RFT 允许开发者自定义所有上述模块。开发者只需根据新算法的需求实现特定模块。本节将以 {ref}`OPMD ` 算法为例进行简要介绍。
+
+OPMD 与 PPO 算法的主要区别在于优势值和策略损失的计算。OPMD 依赖于基于组的优势值计算,且不使用 Critic 模型。为此,开发者需要实现新的优势函数 (`AdvantageFn`) 以及策略损失函数 (`PolicyLossFn`)。
+
+---
+
+#### 步骤 1.1:实现 `AdvantageFn`
+
+{class}`trinity.algorithm.AdvantageFn` 接口包含三个方法:
+
+- `__call__`:优势值计算的主要入口。接收一个 experience 列表 ({class}`trinity.common.experience.Experience`),返回一个包含计算出的优势值和回报值的 experience 列表,以及一个用于日志记录的指标字典。
+- `default_args`:类方法,返回默认初始化参数(字典形式)。当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
+- `compute_in_trainer`:类方法,指示是否在 Trainer 中计算优势值。若返回 `False`,则 `AdvantageFn` 将在 experience 数据处理流水线中被调用。
+
+为方便起见,Trinity-RFT 提供了一个抽象类 {class}`trinity.algorithm.advantage_fn.GroupAdvantage`,它实现了基于组的优势值计算的 `__call__` 方法,你可以专注于如何对 experience 进行分组以及如何在分组后的 experience 上计算优势值,通过以下两个方法实现:
+
+- `group_experiences`:此方法将一步生成的 experience 划分为多个子组。
+
+- `calculate_group_advantage`:此方法计算每组 experience 的优势值。
+
+以下是 OPMD 算法优势函数的实现示例:
+
+```python
+from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
+
+@ADVANTAGE_FN.register_module("opmd")
+class OPMDGroupAdvantage(GroupAdvantage):
+ """OPMD Group Advantage computation"""
+
+ def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.opmd_baseline = opmd_baseline
+ self.tau = tau
+
+ def group_experiences(self, exps):
+ return group_by(exps, id_type="task")
+
+ def calculate_group_advantage(
+ self, group_id: str, exps: List[Experience]
+ ) -> Tuple[List[Experience], Dict]:
+ with torch.no_grad():
+ if len(exps) == 1:
+ group_baseline = torch.tensor(0.0)
+ else:
+ group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
+ if self.opmd_baseline == "mean":
+ group_baseline = torch.mean(group_rewards)
+ else:
+ group_baseline = self.tau * (
+ torch.logsumexp(group_rewards / self.tau, dim=-1)
+ - torch.log(torch.tensor(len(exps)))
+ )
+ for exp in exps:
+ score = exp.reward - group_baseline
+ exp.advantages = score * exp.action_mask
+ exp.returns = exp.advantages.clone()
+ metrics = {
+ "group_baseline": group_baseline.item(),
+ }
+ return exps, metrics
+
+ @classmethod
+ def default_args(cls) -> dict:
+ return {"opmd_baseline": "mean", "tau": 1.0}
+```
+
+实现后,你需要通过 {class}`trinity.algorithm.ADVANTAGE_FN` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
+
+#### 步骤 1.2:实现 `PolicyLossFn`
+
+开发者需要实现 {class}`trinity.algorithm.PolicyLossFn` 接口,其与 `AdvantageFn` 类似,包含两个方法:
+
+- `__call__`:根据输入参数计算损失。与 `AdvantageFn` 不同,这里的输入参数均为 `torch.Tensor`。该接口会自动扫描 `__call__` 方法的参数列表,并将其转换为 experience 数据中的对应字段。因此,请直接在参数列表中写出损失计算所需的所有张量名称,而不是从 `kwargs` 中选择参数。
+- `default_args`:返回默认初始化参数(字典形式),当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
+
+同样,实现后需要通过 {class}`trinity.algorithm.POLICY_LOSS_FN` 注册此模块。
+
+以下是 OPMD 算法策略损失函数的实现示例。由于 OPMD 的策略损失仅需 logprob、action_mask 和 advantages,因此 `__call__` 方法的参数列表中仅指定这三个项:
+
+```python
+@POLICY_LOSS_FN.register_module("opmd")
+class OPMDPolicyLossFn(PolicyLossFn):
+ def __init__(
+ self, backend: str = "verl", tau: float = 1.0, loss_agg_mode: str = "token-mean"
+ ) -> None:
+ super().__init__(backend=backend)
+ self.tau = tau
+ self.loss_agg_mode = loss_agg_mode
+
+ def __call__( # type: ignore
+ self,
+ logprob: torch.Tensor,
+ action_mask: torch.Tensor,
+ advantages: torch.Tensor,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Dict]:
+ pg_losses = -advantages * logprob
+ opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
+ opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
+ return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
+
+ @classmethod
+ def default_args(cls) -> Dict:
+ return {"tau": 1.0}
+```
+
+---
+
+### 步骤 2:注册新算法
+
+上述步骤实现了算法所需的组件,但这些组件是分散的,需要在多个地方配置才能生效。
+
+为简化配置,Trinity-RFT 提供了 {class}`trinity.algorithm.AlgorithmType` 来描述完整算法,并在 {class}`trinity.algorithm.ALGORITHM_TYPE` 中注册,实现一键配置。
+
+`AlgorithmType` 类包含以下属性和方法:
+
+- `use_critic`:是否使用 Critic 模型
+- `use_reference`:是否使用 Reference 模型
+- `compute_advantage_in_trainer`:是否在 Trainer 中计算优势值;若为 False,则跳过 Trainer 中的 `AdvantageFn` 调用
+- `can_balance_batch`:算法是否允许在将批次拆分为微批次时自动平衡(打乱样本顺序)
+- `schema`:算法对应的 experience 数据格式
+- `default_config`:获取算法的默认配置,将覆盖 `ALGORITHM_TYPE` 中同名属性
+
+同样,实现后需要通过 `ALGORITHM_TYPE` 注册此模块。
+
+以下是 OPMD 算法的实现。
+由于 OPMD 算法不需要使用 Critic 模型,`use_critic` 设置为 `False`。
+`default_config` 方法返回的字典表明 OPMD 将使用步骤 1 中实现的 `opmd` 类型的 `AdvantageFn` 和 `PolicyLossFn`,不会对奖励应用 KL 惩罚,但在计算最终损失时会添加 `k2` 类型的 KL 损失。
+
+```python
+@ALGORITHM_TYPE.register_module("opmd")
+class OPMDAlgorithm(AlgorithmType):
+ """OPMD algorithm."""
+
+ use_critic: bool = False
+ use_reference: bool = True
+ compute_advantage_in_trainer: bool = False
+ can_balance_batch: bool = True
+ schema: str = "experience"
+
+ @classmethod
+ def default_config(cls) -> Dict:
+ return {
+ "repeat_times": 2,
+ "advantage_fn": "opmd",
+ "sample_strategy": "warmup",
+ "policy_loss_fn": "opmd",
+ "kl_penalty_fn": "none",
+ "kl_loss_fn": "k2",
+ "entropy_loss_fn": "default",
+ }
+```
+
+
+```{tip}
+为了保证注册生效,请确保在对应的 __init__.py 文件中导入了新实现的模块,例如:
+
+- 在 `trinity/algorithm/advantage_fn/__init__.py` 中导入 `OPMDGroupAdvantage`
+- 在 `trinity/algorithm/policy_loss_fn/__init__.py` 中导入 `OPMDPolicyLossFn`
+- 在 `trinity/algorithm/__init__.py` 中导入 `OPMDAlgorithm`
+
+也可以将这些类放在 `trinity/plugins` 目录下,Trinity-RFT 会在启动时自动加载 `plugins` 目录中的所有模块,无需在 `__init__.py` 中导入。
+```
+
+---
+
+### 步骤 3:使用新算法
+
+完成上述所有步骤后,你可以通过 YAML 配置文件使用新注册的算法。
+
+对于默认配置,你只需在 `config.yaml` 文件中添加以下内容:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+# some other configs
+```
+
+如果需要修改某些参数,可以在 `algorithm` 部分直接添加对应参数。例如,若需要修改 `repeat_times` 以及 `AdvantageFn` 和 `PolicyLossFn` 的初始化参数,修改后的 `config.yaml` 文件如下:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+ repeat_times: 8
+ advantage_fn_args:
+ opmd_baseline: "logavgexp"
+ tau: 0.99
+ policy_loss_fn_args:
+ tau: 0.99
+# some other configs
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_operator.md b/docs/sphinx_doc/source_zh/tutorial/develop_operator.md
new file mode 100644
index 0000000000..692e6432f2
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_operator.md
@@ -0,0 +1,84 @@
+(Operators)=
+## Operator 开发指南
+
+
+### 步骤 0:Operator 模块基本概念
+
+Operator 模块负责处理由 Explorer 所生成的轨迹数据(我们称之为 `Experience`)。它原生支持来自 [Data-Juicer](https://github.com/modelscope/data-juicer) 的数据处理功能,也允许开发者实现自己的算子。
+通过自定义数据处理算子,开发者可以实现各种数据处理功能,如数据增强、过滤和转换。你甚至可以将优势值/回报值计算实现为 Operator,如 {ref}`算法 ` 部分所示。
+
+- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`):封装后的 Data-Juicer 算子,使用时只需在配置文件中标明想要使用的 Data-Juicer 算子列表即可。完整的 Data-Juicer 算子列表请见 [此处](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html)。
+- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`):用于 experience 数据处理的所有数据处理算子的基类。定义了所有数据处理算子应具备的接口和通用功能。每个算子处理一批 experience 数据,并返回处理后的数据及用于日志记录的指标。
+- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`):管理一系列数据处理算子的 experience 数据处理流水线。它从 `Explorer` 获取原始 experience,通过流水线中的每个算子处理,最后将最终处理过的 experience 写入 `Trainer` 的输入缓冲区。
+
+```{note}
+除了 `ExperiencePipeline`,Trinity-RFT 还提供 `TaskPipeline` 用于任务数据处理。
+当前版本中,`TaskPipeline` 仅支持使用 Data-Juicer 算子。详情请参见 {ref}`数据处理 ` 部分。
+```
+---
+
+开发者可通过以下步骤实现并使用自己的算子。
+
+### 步骤 1:实现数据处理算子
+
+`ExperienceOperator` 接口仅包含一个 `process` 方法。`ExperiencePipeline` 将调用此方法,传入 `Explorer` 在一次探索步骤中生成的一组 `Experience`。`process` 方法应返回一个元组,包含处理后的 `Experience` 列表和用于日志记录的指标字典。
+
+```python
+class ExperienceOperator(ABC):
+
+ @abstractmethod
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ """Process a list of experiences and return a transformed list.
+
+ Args:
+ exps (List[Experience]): List of experiences to process, which contains
+ all experiences generated by the Explorer in one explore step.
+ Returns:
+ Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
+ """
+```
+
+以下是一个简单数据处理算子的实现示例,该算子过滤掉奖励低于某一阈值的 experience:
+
+```python
+from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
+from trinity.common.experience import Experience
+
+
+@EXPERIENCE_OPERATORS.register_module("reward_filter")
+class RewardFilter(ExperienceOperator):
+
+ def __init__(self, threshold: float = 0.0) -> None:
+ self.threshold = threshold
+
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
+ metrics = {"filtered_count": len(exps) - len(filtered_exps)}
+ return filtered_exps, metrics
+```
+
+实现后,你需要通过 {class}`trinity.data.operators.EXPERIENCE_OPERATORS` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
+
+### 步骤 2:使用此算子
+
+完成上述步骤后,你可以通过 YAML 配置文件使用新注册的算子。
+
+```yaml
+# some other configs
+data_processor:
+ experience_pipeline:
+ operators:
+ - name: "reward_filter"
+ args:
+ threshold: 0.1
+synchronizer:
+ sync_method: nccl
+ sync_style: dynamic_by_explorer
+ sync_interval: 2
+# some other configs
+```
+
+```{tip}
+`RewardFilter` 会减少 experience 数量,可能导致 Trainer 无法获得足够的 experience 来启动训练流程。为避免此问题,你可以使用 Trinity-RFT 提供的 {ref}`动态同步 ` 功能 (`dynamic_by_explorer`)。
+上述设置意味着 `Explorer` 每运行 2 步就会与 `Trainer` 同步一次,且无论 `Trainer` 当前完成了多少步都会继续运行。这确保了只要 `Explorer` 在运行,`Trainer` 就总能获得足够的 experience 来启动训练步骤。
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_overview.md b/docs/sphinx_doc/source_zh/tutorial/develop_overview.md
new file mode 100644
index 0000000000..9e79780758
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_overview.md
@@ -0,0 +1,31 @@
+# 开发者指南
+
+Trinity-RFT 将 RL 训练过程拆分为了三个模块:**Explorer**、**Trainer** 和 **Buffer**。
+
+其中 Explorer 提供了能够自定义智能体与环境交互的 `Workflow` 接口,Trainer 提供了能够自定义 RL 算法的 `Algorithm` 接口,Buffer 提供了能够自定义数据处理算子的 `Operator` 接口。
+
+下表列出了各扩展接口的主要目标用户、功能以及对应的开发教程。开发者可以参考对应的模块开发教程,并根据自身需求对 Trinity-RFT 进行扩展。
+
+| 扩展接口 | 目标用户 | 主要功能 | 教程链接 |
+|--------------|----------------|-----------------------------------|------------------|
+| `Workflow` | 智能体应用开发者 | 提升 Agent 在指定环境中完成任务的能力 | [🔗](./develop_workflow.md) |
+| `Algorithm` | RL 算法研究者 | 设计新的 RL 算法 | [🔗](./develop_algorithm.md) |
+| `Operator` | 数据工程师 | 设计新的数据清洗、增强策略 | [🔗](./develop_operator.md) |
+
+```{tip}
+Trinity-RFT 提供了插件化的开发方式,可以在不修改框架代码的前提下,灵活地添加自定义模块。
+开发者可以将自己编写的模块代码放在 `trinity/plugins` 目录下。Trinity-RFT 会在运行时自动加载该目录下的所有 Python 文件,并注册其中的自定义模块。
+Trinity-RFT 也支持在运行时通过设置 `--plugin-dir` 选项来指定其他目录,例如:`trinity run --config --plugin-dir `。
+```
+
+对于准备向 Trinity-RFT 提交的模块,请遵循以下步骤:
+
+1. 在适当目录中实现你的代码,例如 `trinity/common/workflows` 用于 `Workflow`,`trinity/algorithm` 用于 `Algorithm`,`trinity/buffer/operators` 用于 `Operator`。
+
+2. 在目录对应的 `__init__.py` 文件中注册你的模块。
+
+3. 在 `tests` 目录中为你的模块添加测试,遵循现有测试的命名约定和结构。
+
+4. 提交代码前,确保通过 `pre-commit run --all-files` 完成代码风格检查。
+
+5. 向 Trinity-RFT 仓库提交 Pull Request,在描述中详细说明你的模块功能和用途。
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md b/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md
new file mode 100644
index 0000000000..9e45393a78
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md
@@ -0,0 +1,291 @@
+(Workflows)=
+## Workflow 开发指南
+
+在 Trinity-RFT 中,工作流(Workflow)是定义 Agent 与 Environment 之间交互的核心组件。
+一个合格的工作流需要使用训练好的模型完成指定任务,并从环境中获取反馈信息(奖励)。以下是创建新工作流的步骤:
+
+---
+
+### 步骤 0:基本概念
+
+在开始开发之前,理解以下几个核心概念非常重要:
+
+- **任务(Task)** ({class}`trinity.common.workflows.Task`):表示可转换为 `Workflow` 的数据结构。`Task` 的内容根据任务类型而异:
+ - **数学问题**:`Task` 包含问题描述和标准答案。
+ - **编程场景**:`Task` 包括问题描述、测试用例、运行环境等复杂信息。
+
+- **工作流(Workflow)** ({class}`trinity.common.workflows.Workflow`):描述 `Task` 如何执行。它定义了 Agent 与 Environment 的交互流程,包括类似其他框架中的 *Rollout* 和 *Reward* 计算逻辑。执行后生成一组 `Experience`。Trinity-RFT 包含多个内置工作流:
+ - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`):用于数学场景,将问题提交给 LLM,解析 LLM 响应,并计算分数(奖励)。
+ - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`):用于 webshop 场景,包含与环境的多轮交互。
+ - `AgentScopeReactMathWorkflow` ({class}`trinity.common.workflows.AgentScopeReactMathWorkflow`):用于数学场景,直接使用现有的 ReActAgent(基于 AgentScope)来解决数学问题。
+
+- **经验(Experience)** ({class}`trinity.common.experience.Experience`):运行 `Workflow` 的输出。内部数据格式取决于所使用的训练算法。例如,对于常见的 PPO/GRPO 算法,`Experience` 包含 token ID 列表、动作掩码(标识哪些 token 是由 LLM 生成的)、对数概率、奖励等。
+
+---
+
+### 步骤 1:准备任务数据集
+
+任务数据集通过 YAML 配置文件中的 `buffer.explorer_input.taskset` 配置项加载。
+为处理 `Task` 内容的差异,Trinity-RFT 提供了一个统一的 `Task` 接口,包含以下字段:
+
+- **`workflow`** (`str`):你的工作流类的注册名称。你可以在 YAML 配置文件的 `buffer.explorer_input.taskset.default_workflow_type` 中指定。
+- **`reward_fn`** (`Optional[str]`):你的奖励函数的注册名称。你可以在 `buffer.explorer_input.taskset.default_reward_fn_type` 中指定。注意某些工作流已内置奖励计算;此时可省略该字段。
+- **`raw_task`** (`Dict`):原始数据的记录,以 `Dict` 格式存储。对于高度定制化的工作流,你可以直接使用 `raw_task` 初始化 `Workflow` 实例,而不依赖以下字段。
+- **`format_args`** ({class}`trinity.common.config.FormatConfig`):便于构造 `Workflow` 实例的参数。例如,`prompt_key` 和 `response_key` 可用于从 `raw_task` 中提取 prompt 和 response。这些设置来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.format` 中设置。
+- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`):控制 rollout 过程的参数,如 `temperature`。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.rollout_args` 中设置。
+- **`workflow_args`** (`Dict`):用于构造 `Workflow` 实例的参数字典。相比 `format_args` 和 `rollout_args` 更灵活。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.workflow_args` 中设置。通常无需设置此字段。
+
+```{tip}
+`workflow`、`workflow_args` 和 `raw_task` 提供了不同级别的自定义能力。
+
+- `workflow` 为使用相同工作流的所有任务提供全局设置。(全局级别)
+- `workflow_args` 可为每个任务数据集设置,允许使用相同工作流的不同任务数据集表现出不同行为。(数据集级别)
+- `raw_task` 提供对每个任务行为的自定义能力,最为灵活。(数据样本级别)
+```
+
+在数学问题场景中,`Task` 数据集可以是一个 `jsonl` 文件,每行包含带有 `question` 和 `answer` 字段的 JSON,分别表示问题描述和标准答案。例如:
+
+```json
+{"question": "1+1=", "answer": "2"}
+{"question": "2+2=", "answer": "4"}
+...
+```
+
+配置示例片段:
+
+```yaml
+# some config
+buffer:
+ explorer_input:
+ taskset:
+ default_workflow: "math_workflow"
+ path: ${oc.env:TRINITY_TASKSET_PATH}
+ format:
+ prompt_key: "question"
+ response_key: "answer"
+ rollout_args:
+ temperature: 1.0
+ # some other configs
+```
+
+在此示例中,每个任务对象的 `raw_task` 是一个包含两个键(`question` 和 `answer`)的 `Dict`。`MathWorkflow` 使用 `prompt_key` 和 `response_key` 从 `raw_task` 中提取问题和答案,并使用 `rollout_args` 生成响应。
+
+---
+
+### 步骤 2:实现新的工作流
+
+`Workflow` 基类接口如下:
+
+```python
+class Workflow(ABC):
+
+ def __init__(
+ self,
+ *,
+ task: Task,
+ model: ModelWrapper,
+ auxiliary_models: Optional[List[openai.OpenAI]] = None,
+ ):
+ self.task = task
+ self.model = model
+ self.auxiliary_models = auxiliary_models
+
+ @abstractmethod
+ def run(self) -> List[Experience]:
+ """Run the workflow and return a list of Experiences."""
+```
+
+#### 初始化你的工作流
+
+`Workflow` 接受以下初始化参数:
+
+- `task`({class}`trinity.common.workflows.Task`):数据集中的单个任务。
+- `model`({class}`trinity.common.models.model.ModelWrapper`):正在训练的模型,提供类似于 OpenAI 的接口,能够接收对话消息列表并返回 LLM 生成的内容(包括回复文本 `response_text`、完整序列 token id `tokens`、prompt 部分 token 长度 `prompt_length`,以及输出 token 对数概率列表 `logprobs`)。
+- `auxiliary_models`(`List[openai.OpenAI]`):未参与训练的辅助模型列表。所有模型均通过兼容 OpenAI 的 API 提供。
+
+```{tip}
+你可以在配置文件中将 `explorer.rollout_model.enable_openai_api` 设置为 `true`,并在工作流中调用 `model.get_openai_client()` 获取 `openai.OpenAI` 实例,从而切换为使用 OpenAI API。
+调用 OpenAI API 时,`model` 字段可通过 `openai_client.models.list().data[0].id` 或 `openai_client.model_path` 获取。
+```
+
+以下是一个仅使用 `raw_task` 和 `rollout_args` 初始化简单工作流的示例。在更复杂的情况下,你可以使用 `format_args` 进行进一步自定义。
+
+```python
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+ # Optional: If you want to use OpenAI API in your workflow
+ # self.openai_client = self.model.get_openai_client()
+```
+
+#### 实现 `run` 方法
+
+`run` 方法是工作流的核心方法。它返回一个 `Experience` 列表。
+以下是一个数学工作流的简单实现。
+
+我们首先调用模型,使用给定的问题和 rollout 参数生成多个响应。
+然后使用 `calculate_reward` 函数计算每个响应的奖励。
+最后,我们构建一个包含响应和奖励的 `Experience` 列表并返回。
+
+```python
+class ExampleWorkflow(Workflow):
+
+ # the __init__ function
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+```
+
+#### 注册你的工作流
+
+使用 `WORKFLOWS.register_module` 装饰器注册你的工作流。
+确保名称不与现有工作流冲突。
+
+```python
+# import some packages
+from trinity.common.workflows.workflow import WORKFLOWS
+
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ pass
+```
+
+对于准备贡献给 Trinity-RFT 项目的模块,你需要将上述代码放入 `trinity/common/workflows` 文件夹中,例如 `trinity/common/workflows/example_workflow.py`。并在 `trinity/common/workflows/__init__.py` 中添加以下行:
+
+```python
+# existing import lines
+from .example_workflow import ExampleWorkflow
+
+__all__ = [
+ # existing __all__ lines
+ "ExampleWorkflow",
+]
+```
+
+#### 避免重复初始化
+
+对于重型工作流,每次重新初始化会带来额外计算开销。
+此时,你可以实现 `resettable` 和 `reset` 方法以避免重复初始化。
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ # some code
+ # ...
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+#### 完整代码示例
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+---
+
+### 步骤 3:使用你的工作流
+
+实现并注册工作流后,你需要更新配置文件,将 `buffer.explorer_input.taskset` 域中的 `default_workflow_type` 设置为新注册的 `Workflow` 名称。
+
+```yaml
+buffer:
+ # Other fields
+ explorer_input:
+ taskset:
+ path: /path/to/taskset
+ default_workflow_type: example_workflow
+ # Other fields
+```
+
+现在你可以使用以下命令在 Trinity-RFT 中运行你的工作流:
+
+```
+trinity run --config
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_megatron.md b/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
index befbb7f5d6..1c34b27cb4 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
@@ -1,7 +1,12 @@
+(Megatron-LM)=
# Megatron-LM 支持
本指南将清晰地引导你如何使用 **Megatron-LM** 来训练模型。
+```{note}
+本指南假设你已经按照 {ref}`安装指南 ` 设置好了环境。如果还没有,请先参考该指南。
+```
+
---
## 步骤 1:安装
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md b/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
index 66272d1559..4c0b575fd5 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
@@ -1,10 +1,6 @@
-# 集成新算法
+# Algorithm 进阶开发
-```{note}
-本指南是开发者指南中 {ref}`算法模块 ` 部分的进阶版本。
-```
-
-本指南介绍了如何将新算法集成到 Trinity-RFT 中。
+本指南将会介绍如何将相对复杂的 RL 算法集成到 Trinity-RFT 中。
作为示例,我们引入了由更高级别的 LLM 生成的一些“专家”数据,并提出了一种名为 MIX 的算法,该算法优化以下策略目标:
$$
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md b/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
index a98fff2b69..961c9c43c6 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
@@ -4,61 +4,7 @@
## 第 0 步:环境准备
-最低环境要求:
-
-- GPU:至少 2 块 GPU
-- CUDA:版本 >= 12.4
-- Python:版本 >= 3.10
-
-```shell
-# 从 GitHub 拉取源码
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# 使用 Conda 或 venv 创建新环境
-# 选项 1: Conda
-conda create -n trinity python=3.10
-conda activate trinity
-
-# 选项 2: venv
-python3.10 -m venv .venv
-source .venv/bin/activate
-
-# 以可编辑模式安装包
-# 对于 bash
-pip install -e .[dev]
-# 对于 zsh
-pip install -e .\[dev\]
-
-# 在所有依赖安装完成后安装 flash-attn
-# 注意:flash-attn 编译时间较长,请耐心等待。
-pip install flash-attn -v
-# 如果安装过程中遇到错误,可尝试以下命令
-# pip install flash-attn -v --no-build-isolation
-```
-
-使用 pip 安装:
-
-```shell
-pip install trinity-rft
-```
-
-通过 Docker 安装:
-
-我们为 Trinity-RFT 提供了 Dockerfile。
-
-```shell
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# 构建 Docker 镜像
-# 注意:你可以编辑 Dockerfile 来自定义环境
-# 例如,使用 pip 镜像或设置 API key
-docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-
-# 运行 Docker 镜像
-docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v :/data trinity-rft:latest
-```
+请按照[安装指南](./trinity_installation.md)中的说明进行环境设置。
## 第 1 步:模型和数据准备
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md b/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
index b7151020de..1f2ed9f114 100644
--- a/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
+++ b/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
@@ -418,7 +418,7 @@ trainer:
---
-## 服务配置
+## Service 配置
配置 Trinity-RFT 使用的服务。目前仅支持 Data Juicer 服务。
@@ -469,7 +469,7 @@ data_processor:
--
-## 日志配置
+## Log 配置
Ray actor 日志配置。
@@ -484,7 +484,7 @@ log:
---
-## 阶段配置
+## Stage 配置
对于多阶段训练,可以在 `stages` 字段中定义多个阶段。每个阶段可以有自己的 `algorithm`、`buffer` 和其他配置。如果某个参数未在阶段中指定,则继承自全局配置。多个阶段将按定义顺序依次执行。
@@ -657,3 +657,126 @@ trainer:
- `trainer.del_local_ckpt_after_load`: 加载后是否删除本地检查点。
- `trainer.max_actor_ckpt_to_keep`: 最多保留的 actor 检查点数量。
- `trainer.max_critic_ckpt_to_keep`: 最多保留的 critic 检查点数量。
+
+
+## 图形化配置生成器(高级)
+
+本节将介绍如何为配置生成器页面添加新的配置参数。
+
+### 步骤 0:了解 Streamlit
+
+在为配置生成器页面添加新参数之前,需要先了解 [Streamlit](https://docs.streamlit.io/develop/api-reference) 的相关 API 和机制。本项目主要使用 Streamlit 的各种输入组件,并利用 `st.session_state` 存储用户输入的参数。
+
+### 步骤 1:实现新配置项
+
+为了说明如何为配置生成器页面创建新参数设置,我们以 `train_batch_size` 为例。
+
+1. 确定参数的合适作用域。目前参数分为四个文件:
+ - `trinity/manager/config_registry/buffer_config_manager.py`
+ - `trinity/manager/config_registry/explorer_config_manager.py`
+ - `trinity/manager/config_registry/model_config_manager.py`
+ - `trinity/manager/config_registry/trainer_config_manager.py`
+
+ 本例中,`train_batch_size` 应放在 `buffer_config_manager.py` 文件中。
+
+2. 使用 Streamlit 创建参数设置函数。函数名必须以 'set_' 开头,其余部分成为配置名称。
+
+3. 使用 `CONFIG_GENERATORS.register_config` 装饰器装饰参数设置函数。该装饰器需要以下信息:
+ - 参数的默认值
+ - 可见性条件(如适用)
+ - 额外配置参数(如需要)
+
+```{note}
+`CONFIG_GENERATORS.register_config` 装饰器会自动将 `key=config_name` 作为参数传递给注册的配置函数。确保你的函数接受此关键字参数。
+```
+
+对于 `train_batch_size`,我们将使用以下设置:
+
+- 默认值:96
+- 可见性条件:`lambda: st.session_state["trainer_gpu_num"] > 0`
+- 额外配置:`{"_train_batch_size_per_gpu": 16}`
+
+以下是 `train_batch_size` 参数的完整代码:
+
+```python
+@CONFIG_GENERATORS.register_config(
+ default_value=96,
+ visible=lambda: st.session_state["trainer_gpu_num"] > 0,
+ other_configs={"_train_batch_size_per_gpu": 16},
+)
+def set_train_batch_size(**kwargs):
+ key = kwargs.get("key")
+ trainer_gpu_num = st.session_state["trainer_gpu_num"]
+ st.session_state[key] = (
+ st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
+ )
+
+ def on_change():
+ st.session_state["_train_batch_size_per_gpu"] = max(
+ st.session_state[key] // st.session_state["trainer_gpu_num"], 1
+ )
+
+ st.number_input(
+ "Train Batch Size",
+ min_value=trainer_gpu_num,
+ step=trainer_gpu_num,
+ help=_str_for_train_batch_size(),
+ on_change=on_change,
+ **kwargs,
+ )
+```
+
+如果参数需要验证,创建一个检查函数。对于 `train_batch_size`,我们需要确保它能被 `trainer_gpu_num` 整除。若不能,则显示警告,并将参数添加到 `unfinished_fields`。
+
+使用 `CONFIG_GENERATORS.register_check` 装饰器装饰检查函数:
+
+```python
+@CONFIG_GENERATORS.register_check()
+def check_train_batch_size(unfinished_fields: set, key: str):
+ if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
+ unfinished_fields.add(key)
+ st.warning(_str_for_train_batch_size())
+```
+
+```{note}
+`CONFIG_GENERATORS.register_check` 装饰器会自动接收 `key=config_name` 和 `unfinished_fields=self.unfinished_fields` 作为参数。确保你的函数接受这些关键字参数。
+```
+
+### 步骤 2:将新参数集成到 `config_manager.py`
+
+要成功将新参数集成到 `config_manager.py` 文件中,请遵循以下步骤:
+
+1. **参数分类**:
+ 根据其功能确定新参数的合适部分。配置生成器页面分为两种主要模式:
+ - 初学者模式:包含“基本配置”和“重要配置”部分。
+ - 专家模式:包含“模型”、“缓冲区”、“Explorer 和 Synchronizer”以及“Trainer”部分。
+
+2. **添加参数**:
+ 在 `ConfigManager` 类的 `self.get_configs` 方法中,将新参数添加到相应部分。
+
+ 示例:
+
+ ```python
+ class ConfigManager:
+ def _expert_buffer_part(self):
+ self.get_configs("total_epochs", "train_batch_size")
+ ```
+
+3. **集成到 YAML 文件**:
+ 在 YAML 文件结构中找到新参数的合适位置。应在 `generate_config` 函数及其关联子函数中完成。
+
+4. **赋值参数值**:
+ 使用 `st.session_state` 从配置生成器页面获取参数值,并将其赋给 YAML 中的对应字段。
+
+ 示例:
+
+ ```python
+ class ConfigManager:
+ def _gen_buffer_config(self):
+ buffer_config = {
+ "batch_size": st.session_state["train_batch_size"],
+ # Additional configuration parameters
+ }
+ ```
+
+严格遵循这些步骤,你可以确保新参数成功添加到配置生成器页面,并正确集成到配置系统中。
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md b/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md
new file mode 100644
index 0000000000..fd7130ecb3
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md
@@ -0,0 +1,111 @@
+(Installation)=
+# 安装指南
+
+安装 Trinity-RFT 有三种方式:源码安装(推荐)、通过 PyPI 安装,或使用 Docker。
+
+在安装前,请确保您的系统满足以下要求:
+
+- **Python**:3.10 至 3.12(包含)
+- **CUDA**:12.4 至 12.8(包含)
+- **GPU**:至少 2 块 GPU
+
+---
+
+## 源码安装(推荐)
+
+如需修改、扩展 Trinity-RFT,推荐使用此方法。
+
+### 1. 克隆仓库
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+```
+
+### 2. 创建虚拟环境
+
+可选择以下任一方式:
+
+#### 使用 Conda
+
+```bash
+conda create -n trinity python=3.10
+conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### 使用 venv
+
+```bash
+python3.10 -m venv .venv
+source .venv/bin/activate
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### 使用 `uv`
+
+[`uv`](https://github.com/astral-sh/uv) 是现代的 Python 包管理工具。
+
+```bash
+uv sync --extra dev --extra flash_attn
+```
+
+---
+
+## 通过 PyPI 安装
+
+如果您只需使用 Trinity-RFT 而不打算修改代码:
+
+```bash
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
+```
+
+或使用 `uv`:
+
+```bash
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
+```
+
+---
+
+## 使用 Docker
+
+我们提供了 Docker 环境,方便快速配置。
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+
+# 构建 Docker 镜像
+## 提示:可根据需要修改 Dockerfile 添加镜像源或设置 API 密钥
+docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
+
+# 运行容器,请将 替换为实际需要挂载的路径
+docker run -it \
+ --gpus all \
+ --shm-size="64g" \
+ --rm \
+ -v $PWD:/workspace \
+ -v :/data \
+ trinity-rft:latest
+```
+
+```{note}
+如需使用 **Megatron-LM** 进行训练,请参考 {ref}`Megatron-LM Backend `。
+```
+
+---
+
+## 常见问题
+
+如遇安装问题,请参考 FAQ 或 [GitHub Issues](https://github.com/modelscope/Trinity-RFT/issues)。
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md b/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md
deleted file mode 100644
index b9b88e65e0..0000000000
--- a/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md
+++ /dev/null
@@ -1,747 +0,0 @@
-# 开发者指南
-
-本指南介绍了如何在 Trinity-RFT 中开发新模块,并提供相关的开发规范。
-
-在 Trinity-RFT 中,我们将 RL 流程分解为三个主要模块(**Explorer**、**Trainer** 和 **Buffer**),以便于自定义和扩展。
-下表总结了不同开发目标的开发者需要关注的核心模块和关键组件。
-
-| 开发目标 | 核心模块 | 关键组件 |
-|--------------------|-------------|---------------|
-| 将现有 RL 算法应用于新环境 | *Explorer* | `Workflow` |
-| 设计新的 RL 算法 | *Trainer* | `Algorithm` |
-| 从数据角度增强 RL 流程 | *Buffer* | `Operator` |
-
-```{note}
-Trinity-RFT 正在积极开发中,以下接口可能会发生变化。使用本指南时请参考最新代码。
-```
-
-```{tip}
-对于仅用于本地测试或不打算贡献的模块,你可以将其放在 `trinity/plugins` 目录中。Trinity-RFT 会自动加载该目录下的所有模块,且无需将其添加到 `__init__.py` 文件中。你也可以通过运行 Trinity-RFT 时设置 `--plugin-dir` 选项来指定其他目录,例如:`trinity run --config /path/to/your/config --plugin-dir /path/to/your/plugins`。
-```
-
----
-
-(Workflows)=
-## 工作流(适用于 RL 环境开发者)
-
-在 Trinity-RFT 中,工作流(Workflow)是定义 Agent 与 Environment 之间交互的核心组件。
-一个合格的工作流需要使用训练好的模型完成指定任务,并从环境中获取反馈信息(奖励)。以下是创建新工作流的步骤:
-
----
-
-### 步骤 0:基本概念
-
-在开始开发之前,理解以下几个核心概念非常重要:
-
-- **任务(Task)** ({class}`trinity.common.workflows.Task`):表示可转换为 `Workflow` 的数据结构。`Task` 的内容根据任务类型而异:
- - **数学问题**:`Task` 包含问题描述和标准答案。
- - **编程场景**:`Task` 包括问题描述、测试用例、运行环境等复杂信息。
-
-- **工作流(Workflow)** ({class}`trinity.common.workflows.Workflow`):描述 `Task` 如何执行。它定义了 Agent 与 Environment 的交互流程,包括类似其他框架中的 *Rollout* 和 *Reward* 计算逻辑。执行后生成一组 `Experience`。Trinity-RFT 包含多个内置工作流:
- - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`):用于数学场景,将问题提交给 LLM,解析 LLM 响应,并计算分数(奖励)。
- - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`):用于 webshop 场景,包含与环境的多轮交互。
- - `CodeWorkflow`(即将推出):用于编码场景,执行返回的代码,运行测试,并根据测试结果计算奖励。
- - ...
-
-- **经验(Experience)** ({class}`trinity.common.experience.Experience`):运行 `Workflow` 的输出。内部数据格式取决于所使用的训练算法。例如,对于常见的 PPO/GRPO 算法,`Experience` 包含 token ID 列表、动作掩码(标识哪些 token 是由 LLM 生成的)、对数概率、奖励等。
-
----
-
-### 步骤 1:准备任务数据集
-
-任务数据集通过 YAML 配置文件中的 `buffer.explorer_input.taskset` 配置项加载。
-为处理 `Task` 内容的差异,Trinity-RFT 提供了一个统一的 `Task` 接口,包含以下字段:
-
-- **`workflow`** (`str`):你的工作流类的注册名称。你可以在 YAML 配置文件的 `buffer.explorer_input.taskset.default_workflow_type` 中指定。
-- **`reward_fn`** (`Optional[str]`):你的奖励函数的注册名称。你可以在 `buffer.explorer_input.taskset.default_reward_fn_type` 中指定。注意某些工作流已内置奖励计算;此时可省略该字段。
-- **`raw_task`** (`Dict`):原始数据的记录,以 `Dict` 格式存储。对于高度定制化的工作流,你可以直接使用 `raw_task` 初始化 `Workflow` 实例,而不依赖以下字段。
-- **`format_args`** ({class}`trinity.common.config.FormatConfig`):便于构造 `Workflow` 实例的参数。例如,`prompt_key` 和 `response_key` 可用于从 `raw_task` 中提取 prompt 和 response。这些设置来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.format` 中设置。
-- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`):控制 rollout 过程的参数,如 `temperature`。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.rollout_args` 中设置。
-- **`workflow_args`** (`Dict`):用于构造 `Workflow` 实例的参数字典。相比 `format_args` 和 `rollout_args` 更灵活。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.workflow_args` 中设置。通常无需设置此字段。
-
-```{tip}
-`workflow`、`workflow_args` 和 `raw_task` 提供了不同级别的自定义能力。
-
-- `workflow` 为使用相同工作流的所有任务提供全局设置。(全局级别)
-- `workflow_args` 可为每个任务数据集设置,允许使用相同工作流的不同任务数据集表现出不同行为。(数据集级别)
-- `raw_task` 提供对每个任务行为的自定义能力,最为灵活。(数据样本级别)
-```
-
-在数学问题场景中,`Task` 数据集可以是一个 `jsonl` 文件,每行包含带有 `question` 和 `answer` 字段的 JSON,分别表示问题描述和标准答案。例如:
-
-```json
-{"question": "1+1=", "answer": "2"}
-{"question": "2+2=", "answer": "4"}
-...
-```
-
-配置示例片段:
-
-```yaml
-# some config
-buffer:
- explorer_input:
- taskset:
- default_workflow: "math_workflow"
- path: ${oc.env:TRINITY_TASKSET_PATH}
- format:
- prompt_key: "question"
- response_key: "answer"
- rollout_args:
- temperature: 1.0
- # some other configs
-```
-
-在此示例中,每个任务对象的 `raw_task` 是一个包含两个键(`question` 和 `answer`)的 `Dict`。`MathWorkflow` 使用 `prompt_key` 和 `response_key` 从 `raw_task` 中提取问题和答案,并使用 `rollout_args` 生成响应。
-
----
-
-### 步骤 2:实现新的工作流
-
-`Workflow` 基类接口如下:
-
-```python
-class Workflow(ABC):
-
- def __init__(
- self,
- *,
- task: Task,
- model: ModelWrapper,
- auxiliary_models: Optional[List[openai.OpenAI]] = None,
- ):
- self.task = task
- self.model = model
- self.auxiliary_models = auxiliary_models
-
- @abstractmethod
- def run(self) -> List[Experience]:
- """Run the workflow and return a list of Experiences."""
-```
-
-#### 初始化你的工作流
-
-`Workflow` 接受以下初始化参数:
-
-- `task`({class}`trinity.common.workflows.Task`):数据集中的单个任务。
-- `model`({class}`trinity.common.models.model.ModelWrapper`):正在训练的模型,提供类似于 OpenAI 的接口,能够接收对话消息列表并返回 LLM 生成的内容(包括回复文本 `response_text`、完整序列 token id `tokens`、prompt 部分 token 长度 `prompt_length`,以及输出 token 对数概率列表 `logprobs`)。
-- `auxiliary_models`(`List[openai.OpenAI]`):未参与训练的辅助模型列表。所有模型均通过兼容 OpenAI 的 API 提供。
-
-```{tip}
-你可以在配置文件中将 `explorer.rollout_model.enable_openai_api` 设置为 `true`,并在工作流中调用 `model.get_openai_client()` 获取 `openai.OpenAI` 实例,从而切换为使用 OpenAI API。
-调用 OpenAI API 时,`model` 字段可通过 `openai_client.models.list().data[0].id` 或 `openai_client.model_path` 获取。
-```
-
-以下是一个仅使用 `raw_task` 和 `rollout_args` 初始化简单工作流的示例。在更复杂的情况下,你可以使用 `format_args` 进行进一步自定义。
-
-```python
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
- # Optional: If you want to use OpenAI API in your workflow
- # self.openai_client = self.model.get_openai_client()
-```
-
-#### 实现 `run` 方法
-
-`run` 方法是工作流的核心方法。它返回一个 `Experience` 列表。
-以下是一个数学工作流的简单实现。
-
-我们首先调用模型,使用给定的问题和 rollout 参数生成多个响应。
-然后使用 `calculate_reward` 函数计算每个响应的奖励。
-最后,我们构建一个包含响应和奖励的 `Experience` 列表并返回。
-
-```python
-class ExampleWorkflow(Workflow):
-
- # the __init__ function
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-```
-
-#### 注册你的工作流
-
-使用 `WORKFLOWS.register_module` 装饰器注册你的工作流。
-确保名称不与现有工作流冲突。
-
-```python
-# import some packages
-from trinity.common.workflows.workflow import WORKFLOWS
-
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- pass
-```
-
-对于准备贡献给 Trinity-RFT 项目的模块,你需要将上述代码放入 `trinity/common/workflows` 文件夹中,例如 `trinity/common/workflows/example_workflow.py`。并在 `trinity/common/workflows/__init__.py` 中添加以下行:
-
-```python
-# existing import lines
-from .example_workflow import ExampleWorkflow
-
-__all__ = [
- # existing __all__ lines
- "ExampleWorkflow",
-]
-```
-
-#### 避免重复初始化
-
-对于重型工作流,每次重新初始化会带来额外计算开销。
-此时,你可以实现 `resettable` 和 `reset` 方法以避免重复初始化。
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- # some code
- # ...
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
-#### 完整代码示例
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
----
-
-### 步骤 3:使用你的工作流
-
-实现并注册工作流后,你需要更新配置文件,将 `buffer.explorer_input.taskset` 域中的 `default_workflow_type` 设置为新注册的 `Workflow` 名称。
-
-```yaml
-buffer:
- # Other fields
- explorer_input:
- taskset:
- path: /path/to/taskset
- default_workflow_type: example_workflow
- # Other fields
-```
-
-现在你可以使用以下命令在 Trinity-RFT 中运行你的工作流:
-
-```
-trinity run --config
-```
-
----
-
-(Algorithms)=
-## 算法(适用于 RL 算法开发者)
-
-Trinity-RFT 提供了实现新算法的标准化流程。
-
-### 步骤 0:算法模块基本概念
-
-在 Trinity-RFT 中,算法模块主要负责在 RL 过程中从回放缓冲区提取 experience 数据,并基于这些数据计算损失以更新模型。
-为了避免每次添加新算法时都实现新的 Trainer 类,我们将典型的 PPO 算法流程分解为多个子模块,以适应各种算法。
-
-- **采样策略(Sample Strategy)** ({class}`trinity.algorithm.SampleStrategy`):负责从缓冲区模块中采样 experience 数据。通过自定义此模块,你可以实现过滤 experience 数据或从多个数据源混合采样的功能。
-- **优势函数(Advantage Fn)**({class}`trinity.algorithm.AdvantageFn`):负责计算 experience 数据的优势值(Advantage)和回报值(Returns)。
-- **策略损失函数(Policy Loss Fn)**({class}`trinity.algorithm.PolicyLossFn`):负责计算策略网络的核心训练损失。
-- **KL 函数(KL Fn)**({class}`trinity.algorithm.KLFn`):负责计算 KL 散度,通常在现有 RL 算法中用于两个地方:奖励惩罚和 Actor 损失。
-- **熵损失函数(Entropy Loss Fn)**({class}`trinity.algorithm.EntropyLossFn`):负责计算策略网络的熵损失。
-
-我们在 `trinity/algorithm` 中提供了上述模块的若干实现。
-
----
-
-### 步骤 1:实现算法组件
-
-Trinity-RFT 允许开发者自定义所有上述模块。开发者只需根据新算法的需求实现特定模块。本节将以 {ref}`OPMD ` 算法为例进行简要介绍。
-
-OPMD 与 PPO 算法的主要区别在于优势值和策略损失的计算。
-OPMD 依赖于基于组的优势值计算,且不使用 Critic 模型。
-要实现 OPMD,开发者需要在 `AdvantageFn` 中实现优势值计算,在 `PolicyLossFn` 中实现策略损失计算。
-
----
-
-#### 步骤 1.1:实现 `AdvantageFn`
-
-{class}`trinity.algorithm.AdvantageFn` 接口包含三个方法:
-
-- `__call__`:优势值计算的主要入口。接收一个 experience 列表 ({class}`trinity.common.experience.Experience`),返回一个包含计算出的优势值和回报值的 experience 列表,以及一个用于日志记录的指标字典。
-- `default_args`:类方法,返回默认初始化参数(字典形式)。当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
-- `compute_in_trainer`:类方法,指示是否在 Trainer 中计算优势值。若返回 `False`,则 `AdvantageFn` 将在 experience 数据处理流水线中被调用。
-
-为方便起见,Trinity-RFT 提供了一个抽象类 {class}`trinity.algorithm.advantage_fn.GroupAdvantage`,它实现了基于组的优势值计算的 `__call__` 方法,你可以专注于如何对 experience 进行分组以及如何在分组后的 experience 上计算优势值,通过以下两个方法实现:
-
-- `group_experiences`:此方法将一步生成的 experience 划分为多个子组。
-
-- `calculate_group_advantage`:此方法计算每组 experience 的优势值。
-
-以下是 OPMD 算法优势函数的实现示例:
-
-```python
-from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
-
-@ADVANTAGE_FN.register_module("opmd")
-class OPMDGroupAdvantage(GroupAdvantage):
- """OPMD Group Advantage computation"""
-
- def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
- super().__init__(**kwargs)
- self.opmd_baseline = opmd_baseline
- self.tau = tau
-
- def group_experiences(self, exps):
- return group_by(exps, id_type="task")
-
- def calculate_group_advantage(
- self, group_id: str, exps: List[Experience]
- ) -> Tuple[List[Experience], Dict]:
- with torch.no_grad():
- if len(exps) == 1:
- group_baseline = torch.tensor(0.0)
- else:
- group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
- if self.opmd_baseline == "mean":
- group_baseline = torch.mean(group_rewards)
- else:
- group_baseline = self.tau * (
- torch.logsumexp(group_rewards / self.tau, dim=-1)
- - torch.log(torch.tensor(len(exps)))
- )
- for exp in exps:
- score = exp.reward - group_baseline
- exp.advantages = score * exp.action_mask
- exp.returns = exp.advantages.clone()
- metrics = {
- "group_baseline": group_baseline.item(),
- }
- return exps, metrics
-
- @classmethod
- def default_args(cls) -> dict:
- return {"opmd_baseline": "mean", "tau": 1.0}
-```
-
-实现后,你需要通过 {class}`trinity.algorithm.ADVANTAGE_FN` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
-
-#### 步骤 1.3:实现 `PolicyLossFn`
-
-开发者需要实现 {class}`trinity.algorithm.PolicyLossFn` 接口,其与 `AdvantageFn` 类似,包含两个方法:
-
-- `__call__`:根据输入参数计算损失。与 `AdvantageFn` 不同,这里的输入参数均为 `torch.Tensor`。该接口会自动扫描 `__call__` 方法的参数列表,并将其转换为 experience 数据中的对应字段。因此,请直接在参数列表中写出损失计算所需的所有张量名称,而不是从 `kwargs` 中选择参数。
-- `default_args`:返回默认初始化参数(字典形式),当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
-
-同样,实现后需要通过 {class}`trinity.algorithm.POLICY_LOSS_FN` 注册此模块。
-
-以下是 OPMD 算法策略损失函数的实现示例。由于 OPMD 的策略损失仅需 logprob、action_mask 和 advantages,因此 `__call__` 方法的参数列表中仅指定这三个项:
-
-```python
-@POLICY_LOSS_FN.register_module("opmd")
-class OPMDPolicyLossFn(PolicyLossFn):
- def __init__(
- self, backend: str = "verl", tau: float = 1.0, loss_agg_mode: str = "token-mean"
- ) -> None:
- super().__init__(backend=backend)
- self.tau = tau
- self.loss_agg_mode = loss_agg_mode
-
- def __call__( # type: ignore
- self,
- logprob: torch.Tensor,
- action_mask: torch.Tensor,
- advantages: torch.Tensor,
- **kwargs,
- ) -> Tuple[torch.Tensor, Dict]:
- pg_losses = -advantages * logprob
- opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
- opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
- return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
-
- @classmethod
- def default_args(cls) -> Dict:
- return {"tau": 1.0}
-```
-
----
-
-### 步骤 2:注册你的算法
-
-上述步骤实现了算法所需的组件,但这些组件是分散的,需要在多个地方配置才能生效。
-
-为简化配置,Trinity-RFT 提供了 {class}`trinity.algorithm.AlgorithmType` 来描述完整算法,并在 {class}`trinity.algorithm.ALGORITHM_TYPE` 中注册,实现一键配置。
-
-`AlgorithmType` 类包含以下属性和方法:
-
-- `use_critic`:是否使用 Critic 模型
-- `use_reference`:是否使用 Reference 模型
-- `compute_advantage_in_trainer`:是否在 Trainer 中计算优势值;若为 False,则跳过 Trainer 中的 `AdvantageFn` 调用
-- `can_balance_batch`:算法是否允许在将批次拆分为微批次时自动平衡(打乱样本顺序)
-- `schema`:算法对应的 experience 数据格式
-- `default_config`:获取算法的默认配置,将覆盖 `ALGORITHM_TYPE` 中同名属性
-
-同样,实现后需要通过 `ALGORITHM_TYPE` 注册此模块。
-
-以下是 OPMD 算法的实现。
-由于 OPMD 算法不需要使用 Critic 模型,`use_critic` 设置为 `False`。
-`default_config` 方法返回的字典表明 OPMD 将使用步骤 1 中实现的 `opmd` 类型的 `AdvantageFn` 和 `PolicyLossFn`,不会对奖励应用 KL 惩罚,但在计算最终损失时会添加 `k2` 类型的 KL 损失。
-
-```python
-@ALGORITHM_TYPE.register_module("opmd")
-class OPMDAlgorithm(AlgorithmType):
- """OPMD algorithm."""
-
- use_critic: bool = False
- use_reference: bool = True
- compute_advantage_in_trainer: bool = False
- can_balance_batch: bool = True
- schema: str = "experience"
-
- @classmethod
- def default_config(cls) -> Dict:
- return {
- "repeat_times": 2,
- "advantage_fn": "opmd",
- "sample_strategy": "warmup",
- "policy_loss_fn": "opmd",
- "kl_penalty_fn": "none",
- "kl_loss_fn": "k2",
- "entropy_loss_fn": "default",
- }
-```
-
----
-
-### 步骤 3:使用你的算法
-
-完成上述所有步骤后,你可以通过 YAML 配置文件使用新注册的算法。
-
-对于默认配置,你只需在 `config.yaml` 文件中添加以下内容:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
-# some other configs
-```
-
-如果需要修改某些参数,可以在 `algorithm` 部分直接添加对应参数。例如,若需要修改 `repeat_times` 以及 `AdvantageFn` 和 `PolicyLossFn` 的初始化参数,修改后的 `config.yaml` 文件如下:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
- repeat_times: 8
- advantage_fn_args:
- opmd_baseline: "logavgexp"
- tau: 0.99
- policy_loss_fn_args:
- tau: 0.99
-# some other configs
-```
-
----
-
-## 数据处理算子(适用于数据开发者)
-
-### 步骤 0:Operator 模块基本概念
-
-在 Trinity-RFT 中,Operator 模块负责处理缓冲区模块中的 experience 数据。它天然支持来自 [Data-Juicer](https://github.com/modelscope/data-juicer) 的现有数据处理功能,也允许开发者实现自己的算子。
-通过自定义数据处理算子,开发者可以实现各种数据处理功能,如数据增强、过滤和转换。你甚至可以将优势值/回报值计算实现为 Operator,如 {ref}`算法 ` 部分所示。
-
-- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`):封装来自 Data-Juicer 的数据处理算子。为开发者提供简单接口,列出想要使用的 Data-Juicer 算子。完整的 Data-Juicer 算子列表请见 [此处](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html)。
-- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`):用于 experience 数据处理的所有数据处理算子的基类。定义了所有数据处理算子应具备的接口和通用功能。每个算子处理一批 experience 数据,并返回处理后的数据及用于日志记录的指标。
-- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`):管理一系列数据处理算子的 experience 数据处理流水线。它从 `Explorer` 获取原始 experience,通过流水线中的每个算子处理,最后将最终处理过的 experience 写入 `Trainer` 的输入缓冲区。
-
-```{note}
-除了 `ExperiencePipeline`,Trinity-RFT 还提供 `TaskPipeline` 用于任务数据处理。
-当前版本中,`TaskPipeline` 仅支持使用 Data-Juicer 算子。详情请参见 {ref}`数据处理 ` 部分。
-```
----
-
-开发者可通过以下步骤实现并使用自己的算子。
-
-### 步骤 1:实现数据处理算子
-
-`ExperienceOperator` 接口仅包含一个 `process` 方法。`ExperiencePipeline` 将调用此方法,传入 `Explorer` 在一次探索步骤中生成的一组 `Experience`。`process` 方法应返回一个元组,包含处理后的 `Experience` 列表和用于日志记录的指标字典。
-
-```python
-class ExperienceOperator(ABC):
-
- @abstractmethod
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- """Process a list of experiences and return a transformed list.
-
- Args:
- exps (List[Experience]): List of experiences to process, which contains
- all experiences generated by the Explorer in one explore step.
- Returns:
- Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
- """
-```
-
-以下是一个简单数据处理算子的实现示例,该算子过滤掉奖励低于某一阈值的 experience:
-
-```python
-from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
-from trinity.common.experience import Experience
-
-
-@EXPERIENCE_OPERATORS.register_module("reward_filter")
-class RewardFilter(ExperienceOperator):
-
- def __init__(self, threshold: float = 0.0) -> None:
- self.threshold = threshold
-
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
- metrics = {"filtered_count": len(exps) - len(filtered_exps)}
- return filtered_exps, metrics
-```
-
-实现后,你需要通过 {class}`trinity.data.operators.EXPERIENCE_OPERATORS` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
-
-### 步骤 2:使用此算子
-
-完成上述步骤后,你可以通过 YAML 配置文件使用新注册的算子。
-
-```yaml
-# some other configs
-data_processor:
- experience_pipeline:
- operators:
- - name: "reward_filter"
- args:
- threshold: 0.1
-synchronizer:
- sync_method: nccl
- sync_style: dynamic_by_explorer
- sync_interval: 2
-# some other configs
-```
-
-```{tip}
-`RewardFilter` 会减少 experience 数量,可能导致 Trainer 无法获得足够的 experience 启动训练步骤。为避免此问题,你可以使用 Trinity-RFT 提供的高级 {ref}`动态同步 ` 功能,如上配置所示。
-上述设置意味着 `Explorer` 每 2 步与 `Trainer` 同步一次,且无论 `Trainer` 完成了多少步都会继续运行。这确保了只要 `Explorer` 在运行,`Trainer` 就总能获得足够的 experience 来启动训练步骤。
-```
-
----
-
-## 为配置生成器添加新配置项(高级)
-
-### 步骤 0:了解 Streamlit
-
-在为配置生成器页面添加新参数之前,必须熟悉 [Streamlit](https://docs.streamlit.io/develop/api-reference) 的相关 API 和机制。本项目主要使用 Streamlit 的各种输入组件,并利用 `st.session_state` 存储用户输入的参数。
-
-### 步骤 1:实现新配置项
-
-为了说明如何为配置生成器页面创建新参数设置,我们以 `train_batch_size` 为例。
-
-1. 确定参数的合适作用域。目前参数分为四个文件:
- - `trinity/manager/config_registry/buffer_config_manager.py`
- - `trinity/manager/config_registry/explorer_config_manager.py`
- - `trinity/manager/config_registry/model_config_manager.py`
- - `trinity/manager/config_registry/trainer_config_manager.py`
-
- 本例中,`train_batch_size` 应放在 `buffer_config_manager.py` 文件中。
-
-2. 使用 Streamlit 创建参数设置函数。函数名必须以 'set_' 开头,其余部分成为配置名称。
-
-3. 使用 `CONFIG_GENERATORS.register_config` 装饰器装饰参数设置函数。该装饰器需要以下信息:
- - 参数的默认值
- - 可见性条件(如适用)
- - 额外配置参数(如需要)
-
-```{note}
-`CONFIG_GENERATORS.register_config` 装饰器会自动将 `key=config_name` 作为参数传递给注册的配置函数。确保你的函数接受此关键字参数。
-```
-
-对于 `train_batch_size`,我们将使用以下设置:
-
-- 默认值:96
-- 可见性条件:`lambda: st.session_state["trainer_gpu_num"] > 0`
-- 额外配置:`{"_train_batch_size_per_gpu": 16}`
-
-以下是 `train_batch_size` 参数的完整代码:
-
-```python
-@CONFIG_GENERATORS.register_config(
- default_value=96,
- visible=lambda: st.session_state["trainer_gpu_num"] > 0,
- other_configs={"_train_batch_size_per_gpu": 16},
-)
-def set_train_batch_size(**kwargs):
- key = kwargs.get("key")
- trainer_gpu_num = st.session_state["trainer_gpu_num"]
- st.session_state[key] = (
- st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
- )
-
- def on_change():
- st.session_state["_train_batch_size_per_gpu"] = max(
- st.session_state[key] // st.session_state["trainer_gpu_num"], 1
- )
-
- st.number_input(
- "Train Batch Size",
- min_value=trainer_gpu_num,
- step=trainer_gpu_num,
- help=_str_for_train_batch_size(),
- on_change=on_change,
- **kwargs,
- )
-```
-
-如果参数需要验证,创建一个检查函数。对于 `train_batch_size`,我们需要确保它能被 `trainer_gpu_num` 整除。若不能,则显示警告,并将参数添加到 `unfinished_fields`。
-
-使用 `CONFIG_GENERATORS.register_check` 装饰器装饰检查函数:
-
-```python
-@CONFIG_GENERATORS.register_check()
-def check_train_batch_size(unfinished_fields: set, key: str):
- if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
- unfinished_fields.add(key)
- st.warning(_str_for_train_batch_size())
-```
-
-```{note}
-`CONFIG_GENERATORS.register_check` 装饰器会自动接收 `key=config_name` 和 `unfinished_fields=self.unfinished_fields` 作为参数。确保你的函数接受这些关键字参数。
-```
-
-### 步骤 2:将新参数集成到 `config_manager.py`
-
-要成功将新参数集成到 `config_manager.py` 文件中,请遵循以下步骤:
-
-1. **参数分类**:
- 根据其功能确定新参数的合适部分。配置生成器页面分为两种主要模式:
- - 初学者模式:包含“基本配置”和“重要配置”部分。
- - 专家模式:包含“模型”、“缓冲区”、“Explorer 和 Synchronizer”以及“Trainer”部分。
-
-2. **添加参数**:
- 在 `ConfigManager` 类的 `self.get_configs` 方法中,将新参数添加到相应部分。
-
- 示例:
-
- ```python
- class ConfigManager:
- def _expert_buffer_part(self):
- self.get_configs("total_epochs", "train_batch_size")
- ```
-
-3. **集成到 YAML 文件**:
- 在 YAML 文件结构中找到新参数的合适位置。应在 `generate_config` 函数及其关联子函数中完成。
-
-4. **赋值参数值**:
- 使用 `st.session_state` 从配置生成器页面获取参数值,并将其赋给 YAML 中的对应字段。
-
- 示例:
-
- ```python
- class ConfigManager:
- def _gen_buffer_config(self):
- buffer_config = {
- "batch_size": st.session_state["train_batch_size"],
- # Additional configuration parameters
- }
- ```
-
-严格遵循这些步骤,你可以确保新参数成功添加到配置生成器页面,并正确集成到配置系统中。此过程保持了配置管理框架的完整性和功能性。
-
----
-
-## 贡献你的代码
-
-对于准备贡献给 Trinity-RFT 项目的模块,请遵循以下步骤:
-
-1. 在适当目录中实现你的代码,例如 `trinity/common/workflows` 用于工作流,`trinity/algorithm` 用于算法,`trinity/buffer/operators` 用于操作符。
-
-2. 在目录对应的 `__init__.py` 文件中注册你的模块。
-
-3. 在 `tests` 目录中为你的模块添加测试,遵循现有测试的命名约定和结构。
-
-4. 提交代码前,确保通过 `pre-commit run --all-files` 完成代码风格检查。
-
-5. 向 Trinity-RFT 仓库提交 Pull Request,包含对你更改的清晰描述。
diff --git a/pyproject.toml b/pyproject.toml
index 451be9db4f..5e78e3e8b4 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -120,6 +120,9 @@ exclude = '''
[tool.isort]
known_third_party = ["wandb"]
+[tool.uv.extra-build-dependencies]
+flash-attn = ["torch", "numpy"]
+
[project.urls]
"Homepage" = "https://github.com/modelscope/Trinity-RFT"
"Documentation" = "https://modelscope.github.io/Trinity-RFT/"
+## 🚀 News
+* [2025-09] ✨ [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
+* [2025-08] 🎵 Introducing [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord): dynamic SFT + RL integration for advanced LLM fine-tuning ([paper](https://arxiv.org/pdf/2508.11408)).
+* [2025-08] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 released.
+* [2025-07] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 released.
+* [2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: [link](https://arxiv.org/abs/2505.17826).
+* [2025-06] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 released.
+* [2025-05] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 released, plus [technical report](https://arxiv.org/abs/2505.17826).
+* [2025-04] Trinity-RFT open sourced.
-## 🛠️ What can I use Trinity-RFT for?
-
-* **Train agent applications with RL and minimal migration cost** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#workflows-for-rl-environment-developers)
- - Implement agent-environment interaction logic in a single workflow class ([example1](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_multi_turn.html), [example2](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_step_wise.html)),
- - Or import workflows from agent frameworks like AgentScope ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_react.html)).
-
-* **Rapid RL algorithm design and validation** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers)
- - Develop custom RL algorithms (loss design, sampling strategy, etc.) in compact, plug-and-play classes ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_mix_algo.html)).
-
-* **Custom datasets and data pipelines for RFT** [[Tutorial]](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/trinity_programming_guide.html#operators-for-data-developers)
- - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios ([example](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_data_functionalities.html)).
---
## Table of contents
-- [Getting started](#getting-started)
+- [Quick Start](#quick-start)
- [Step 1: installation](#step-1-installation)
- [Step 2: prepare dataset and model](#step-2-prepare-dataset-and-model)
- [Step 3: configurations](#step-3-configurations)
@@ -101,7 +88,7 @@ The RFT process is modularized into three core components:
-## Getting started
+## Quick Start
> [!NOTE]
@@ -110,8 +97,6 @@ The RFT process is modularized into three core components:
### Step 1: installation
-#### Prerequisites
-
Before installing, make sure your system meets the following requirements:
- **Python**: version 3.10 to 3.12 (inclusive)
@@ -119,9 +104,9 @@ Before installing, make sure your system meets the following requirements:
- **GPUs**: at least 2 GPUs
-#### Option A: Install from Source (Recommended)
+#### From Source (Recommended)
-This method gives you full control and is best if you plan to customize or contribute to the project.
+If you plan to customize or contribute to Trinity-RFT, this is the best option.
##### 1. Clone the Repository
@@ -132,69 +117,59 @@ cd Trinity-RFT
##### 2. Set Up a Virtual Environment
-Choose one of the following options to create an isolated environment:
+Choose one of the following options:
###### Using Conda
+
```bash
conda create -n trinity python=3.10
conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
###### Using venv
+
```bash
python3.10 -m venv .venv
source .venv/bin/activate
-```
-##### 3. Install the Package
-
-Install in editable mode so you can make changes without reinstalling:
-
-```bash
pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-##### 4. Install Flash Attention
-
-Flash Attention boosts training speed. It takes a few minutes to compile — please be patient!
-
-```bash
-pip install flash-attn==2.8.1
-```
+###### Using `uv`
-If you encounter issues during installation, try this alternative:
+[`uv`](https://github.com/astral-sh/uv) is a modern Python package installer.
```bash
-pip install flash-attn==2.8.1 --no-build-isolation
+uv sync --extra dev --extra flash_attn
```
-##### ⚡ Fast Alternative: Use `uv` (Optional)
+#### Via PyPI
-If you'd like a faster installation, try [`uv`](https://github.com/astral-sh/uv), a modern Python package installer:
+If you just want to use the package without modifying the code:
```bash
-uv venv
-source .venv/bin/activate
-
-uv pip install -e ".[dev]"
-uv pip install flash-attn==2.8.1 --no-build-isolation
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
```
-#### Option B: Install via pip (Quick Start)
-
-If you just want to use the package without modifying the code:
+Or with `uv`:
```bash
-pip install trinity-rft==0.3.0
-pip install flash-attn==2.8.1 # Install Flash Attention separately
-
-# Use uv to install trinity-rft
-# uv pip install trinity-rft==0.3.0
-# uv pip install flash-attn==2.8.1
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
```
-#### Option C: Use Docker
+
+#### Using Docker
We provide a Docker setup for hassle-free environment configuration.
@@ -202,11 +177,11 @@ We provide a Docker setup for hassle-free environment configuration.
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
-## Build the Docker image
+# Build the Docker image
## Tip: You can modify the Dockerfile to add mirrors or set API keys
docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-## Run the container
+# Run the container, replacing with your actual path
docker run -it \
--gpus all \
--shm-size="64g" \
@@ -216,9 +191,7 @@ docker run -it \
trinity-rft:latest
```
-💡 **Note**: Replace `` with the actual path on your machine where datasets and model checkpoints are stored.
-
-> If you'd like to integrate with **Megatron-LM**, check out our [example setup guide for Megatron](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_megatron.html).
+> For training with **Megatron-LM**, please refer to [Megatron-LM Backend](https://modelscope.github.io/Trinity-RFT/en/main/tutorial/example_megatron.html).
### Step 2: prepare dataset and model
diff --git a/README_zh.md b/README_zh.md
index 312f80e76d..4db8563886 100644
--- a/README_zh.md
+++ b/README_zh.md
@@ -18,47 +18,35 @@
+## 💡 什么是 Trinity-RFT ?
-## 🚀 新闻
-
-* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
-* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
-* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
-* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
-* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
-* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
-* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
-* [2025-04] Trinity-RFT 开源。
-
-
-## 💡 什么是 Trinity-RFT?
-
-Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。它支持广泛的应用场景,并为 [Experience 时代](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf) 的 RL 研究提供统一平台。
-
-RFT 流程被模块化为三个核心组件:
+Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。其提供三个独立模块,满足不同用户的需求:
-* **Explorer**:负责智能体与环境的交互
-* **Trainer**:负责模型训练
-* **Buffer**:负责数据存储与处理
+* 🤖 **Explorer**:面向智能体应用开发者。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_workflow.html)
+ - 训练智能体应用,以增强其在指定环境中完成任务的能力
+ - 示例:[多轮交互](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_multi_turn.html),[ReAct 智能体](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html)
+* 🧠 **Trainer**:面向 RL 算法研究者。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_algorithm.html)
+ - 在简洁、可插拔的类中设计和验证新的 RL 算法
+ - 示例:[混合 RL 算法](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_mix_algo.html)
-
+* 🗄️ **Buffer**:面向数据工程师。[[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/develop_operator.html)
+ - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景
+ - 示例:[数据功能](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html)
-
-
-## ✨ 核心特性
+Trinity-RFT 统一了上述三个模块,并提供以下核心特性:
* **灵活的 RFT 模式:**
- 支持同步/异步、on-policy/off-policy 以及在线/离线训练。采样与训练可分离运行,并可在多设备上独立扩展。
-* **兼容 Agent 框架的工作流:**
- - 支持拼接式和通用多轮智能体工作流。可自动收集来自模型 API 客户端(如 OpenAI)的训练数据,并兼容 AgentScope 等智能体框架。
+* **通用 Agentic-RL:**
+ - 支持拼接式和通用多轮交互,能够直接训练使用 AgentScope 等智能体框架开发的 Agent 应用。
-* **强大的数据流水线:**
+* **全流程的数据流水线:**
- 支持 rollout 和经验数据的流水线处理,贯穿 RFT 生命周期实现主动管理(优先级、清洗、增强等)。
@@ -69,36 +57,32 @@ RFT 流程被模块化为三个核心组件:
+## 🚀 新闻
-
-## 🛠️ Trinity-RFT 能做什么?
-
-* **用 RL 训练智能体应用** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#workflows-for-rl-environment-developers)
- - 在 Workflow 中实现智能体-环境交互逻辑 ([示例1](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_multi_turn.html),[示例2](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_step_wise.html)),
- - 或直接使用 Agent 框架(如 AgentScope)编写好的工作流 ([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html))。
-
-* **快速设计和验证 RL 算法** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers)
- - 在简洁、可插拔的类中开发自定义 RL 算法(损失、采样及其他技巧)([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_react.html))。
-
-* **为 RFT 定制数据集和数据流水线** [[教程]](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/trinity_programming_guide.html#operators-for-data-developers)
- - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景 ([示例](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_data_functionalities.html))。
-
+* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
+* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
+* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
+* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
+* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
+* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
+* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
+* [2025-04] Trinity-RFT 开源。
---
## 目录
-- [快速上手](#getting-started)
- - [第一步:安装](#step-1-installation)
- - [第二步:准备数据集和模型](#step-2-prepare-dataset-and-model)
- - [第三步:配置](#step-3-configurations)
- - [第四步:运行 RFT 流程](#step-4-run-the-rft-process)
-- [更多教程](#further-tutorials)
-- [未来功能](#upcoming-features)
-- [贡献指南](#contribution-guide)
-- [致谢](#acknowledgements)
-- [引用](#citation)
+- [快速上手](#快速上手)
+ - [第一步:安装](#第一步安装)
+ - [第二步:准备数据集和模型](#第二步准备数据集和模型)
+ - [第三步:准备配置文件](#第三步准备配置文件)
+ - [第四步:运行 RFT 流程](#第四步运行-rft-流程)
+- [更多教程](#更多教程)
+- [开发路线图](#开发路线图)
+- [贡献指南](#贡献指南)
+- [致谢](#致谢)
+- [引用](#引用)
@@ -111,103 +95,88 @@ RFT 流程被模块化为三个核心组件:
### 第一步:安装
-#### 环境要求
在安装之前,请确保您的系统满足以下要求:
- **Python**:版本 3.10 至 3.12(含)
- **CUDA**:版本 12.4 至 12.8(含)
- **GPU**:至少 2 块 GPU
+## 源码安装(推荐)
-#### 方式 A:从源码安装(推荐)
-
-这种方式可以让您完全控制项目代码,适合打算自定义功能或参与项目开发的用户。
+如需修改、扩展 Trinity-RFT,推荐使用此方法。
-##### 1. 克隆代码仓库
+### 1. 克隆仓库
```bash
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
```
-##### 2. 创建虚拟环境
+### 2. 创建虚拟环境
-选择以下任意一种方式,创建一个独立的 Python 环境:
+可选择以下任一方式:
+
+#### 使用 Conda
-###### 使用 Conda
```bash
conda create -n trinity python=3.10
conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-###### 使用 venv
+#### 使用 venv
+
```bash
python3.10 -m venv .venv
source .venv/bin/activate
-```
-
-##### 3. 安装软件包
-
-以“可编辑模式”安装,这样您可以修改代码而无需重新安装:
-```bash
pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
```
-##### 4. 安装 Flash Attention
+#### 使用 `uv`
-Flash Attention 可以显著提升训练速度。编译需要几分钟时间,请耐心等待!
+[`uv`](https://github.com/astral-sh/uv) 是现代的 Python 包管理工具。
```bash
-pip install flash-attn==2.8.1
+uv sync --extra dev --extra flash_attn
```
-如果安装过程中出现问题,可以尝试以下命令:
+## 通过 PyPI 安装
-```bash
-pip install flash-attn==2.8.1 --no-build-isolation
-```
-
-
-##### ⚡ 快速替代方案:使用 `uv`(可选)
-
-如果您希望安装得更快,可以试试 [`uv`](https://github.com/astral-sh/uv),这是一个现代化的 Python 包安装工具:
+如果您只需使用 Trinity-RFT 而不打算修改代码:
```bash
-uv venv
-source .venv/bin/activate
-
-uv pip install -e ".[dev]"
-uv pip install flash-attn==2.8.1 --no-build-isolation
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
```
-#### 方式 B:通过 pip 安装(快速开始)
-
-如果您只是想使用这个工具,不需要修改代码,可以选择这种方式:
+或使用 `uv`:
```bash
-pip install trinity-rft==0.3.0
-pip install flash-attn==2.8.1 # 单独安装 Flash Attention
-
-# 也可以用 uv 来安装 trinity-rft
-# uv pip install trinity-rft==0.3.0
-# uv pip install flash-attn==2.8.1
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
```
-#### 方式 C:使用 Docker
+## 使用 Docker
-我们提供了 Docker 配置,可以免去复杂的环境设置。
+我们提供了 Docker 环境,方便快速配置。
```bash
git clone https://github.com/modelscope/Trinity-RFT
cd Trinity-RFT
# 构建 Docker 镜像
-# 注意:您可以编辑 Dockerfile 来定制环境
-# 例如,设置 pip 镜像源或设置 API 密钥
+## 提示:可根据需要修改 Dockerfile 添加镜像源或设置 API 密钥
docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-# 启动容器
+# 运行容器,请将 替换为实际需要挂载的路径
docker run -it \
--gpus all \
--shm-size="64g" \
@@ -217,9 +186,9 @@ docker run -it \
trinity-rft:latest
```
-💡 **注意**:请将 `` 替换为您电脑上实际存放数据集和模型文件的路径。
-
-> 如果您想集成 **Megatron-LM**,请参考我们的 [Megatron 示例配置指南](https://modelscope.github.io/Trinity-RFT/zh/main/tutorial/example_megatron.html)。
+```{note}
+如需使用 **Megatron-LM** 进行训练,请参考 {ref}`Megatron-LM Backend `。
+```
### 第二步:准备数据集和模型
@@ -256,7 +225,7 @@ modelscope download --dataset {dataset_name} --local_dir $DATASET_PATH/{dataset_
-### 第三步:配置
+### 第三步:准备配置文件
Trinity-RFT 提供了一个 Web 界面来配置您的 RFT 流程。
@@ -368,7 +337,7 @@ trinity run --config examples/grpo_gsm8k/gsm8k.yaml
-## 未来功能
+## 开发路线图
路线图:[#51](https://github.com/modelscope/Trinity-RFT/issues/51)
diff --git a/docs/sphinx_doc/source/index.rst b/docs/sphinx_doc/source/index.rst
index 84f2904160..5b89ea2147 100644
--- a/docs/sphinx_doc/source/index.rst
+++ b/docs/sphinx_doc/source/index.rst
@@ -9,6 +9,21 @@ Welcome to Trinity-RFT's documentation!
.. include:: main.md
:parser: myst_parser.sphinx_
+.. toctree::
+ :maxdepth: 2
+ :glob:
+ :hidden:
+ :caption: Guidelines
+
+ tutorial/trinity_installation.md
+ tutorial/develop_overview.md
+ tutorial/develop_workflow.md
+ tutorial/develop_algorithm.md
+ tutorial/example_mix_algo.md
+ tutorial/develop_operator.md
+ tutorial/trinity_configs.md
+ tutorial/synchronizer.md
+
.. toctree::
:maxdepth: 1
@@ -27,17 +42,6 @@ Welcome to Trinity-RFT's documentation!
tutorial/example_megatron.md
tutorial/example_data_functionalities.md
-.. toctree::
- :maxdepth: 2
- :glob:
- :hidden:
- :caption: Guidelines
-
- tutorial/trinity_programming_guide.md
- tutorial/trinity_configs.md
- tutorial/example_mix_algo.md
- tutorial/synchronizer.md
-
.. toctree::
:maxdepth: 2
:hidden:
diff --git a/docs/sphinx_doc/source/main.md b/docs/sphinx_doc/source/main.md
index 432c039145..b813b74d18 100644
--- a/docs/sphinx_doc/source/main.md
+++ b/docs/sphinx_doc/source/main.md
@@ -1,41 +1,32 @@
-## 🚀 News
-
-* [2025-09] ✨ [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 released: enhanced Buffer, FSDP2 & Megatron support, multi-modal models, and new RL algorithms/examples.
-* [2025-08] 🎵 Introducing [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord): dynamic SFT + RL integration for advanced LLM fine-tuning ([paper](https://arxiv.org/pdf/2508.11408)).
-* [2025-08] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 released.
-* [2025-07] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 released.
-* [2025-07] Technical report (arXiv v2) updated with new features, examples, and experiments: [link](https://arxiv.org/abs/2505.17826).
-* [2025-06] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 released.
-* [2025-05] [[Release Notes](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 released, plus [technical report](https://arxiv.org/abs/2505.17826).
-* [2025-04] Trinity-RFT open sourced.
-
-
## 💡 What is Trinity-RFT?
-Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It supports a wide range of applications and provides a unified platform for RL research in the [era of experience](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf).
+Trinity-RFT is a flexible, general-purpose framework for reinforcement fine-tuning (RFT) of large language models (LLMs). It provides three independent modules for users with different needs:
-The RFT process is modularized into three core components:
+* 🤖 **Explorer**:For agent application developers. [[tutorial]](/tutorial/develop_workflow.md)
+ - Train an agent application to enhance its ability to complete tasks in a specified environment
+ - Examples: [Multi-Turn Interaction](/tutorial/example_multi_turn.md), [ReAct Agent](/tutorial/example_react.md)
-* **Explorer**: Handles agent-environment interaction
-* **Trainer**: Manages model training
-* **Buffer**: Manages data storage and processing
+* 🧠 **Trainer**: For RL algorithm researchers. [[tutorial]](/tutorial/develop_algorithm.md)
+ - Design and validate new RL algorithms in compact, plug-and-play classes
+ - Examples: [Mixture of RL Algorithms](/tutorial/example_mix_algo.md)
-
+* 🗃️ **Buffer**: For data engineers. [[tutorial]](/tutorial/develop_operator.md)
+ - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios
+ - Examples: [Data Functionalities](/tutorial/example_data_functionalities.md)
-
-## ✨ Key Features
+Trinity-RFT unifies the above three modules and provides the following key features:
* **Flexible RFT Modes:**
- Supports synchronous/asynchronous, on-policy/off-policy, and online/offline training. Rollout and training can run separately and scale independently across devices.
-* **Agent Framework Compatible Workflows:**
- - Supports both concatenated and general multi-turn agentic workflows. Automatically collects training data from model API clients (e.g., OpenAI) and is compatible with agent frameworks like AgentScope.
+* **General Agentic-RL Support:**
+ - Supports both concatenated and general multi-turn agentic workflows. Able to directly train agent applications developed using agent frameworks like AgentScope.
-* **Powerful Data Pipelines:**
+* **Full Lifecycle Data Pipelines:**
- Enables pipeline processing of rollout and experience data, supporting active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
@@ -46,19 +37,6 @@ The RFT process is modularized into three core components:
-## 🛠️ What can I use Trinity-RFT for?
-
-* **Train agent applications with RL and minimal migration cost**
- - Implement agent-environment interaction logic in a single workflow class ([example 1](tutorial/example_multi_turn.md), [example 2](tutorial/example_step_wise.md)),
- - Or import workflows from agent frameworks like AgentScope ([example](/tutorial/example_react.md)).
-
-* **Rapid RL algorithm design and validation**
- - Develop custom RL algorithms (loss design, sampling strategy, etc.) in compact, plug-and-play classes ([tutorial](tutorial/trinity_programming_guide.html#algorithms-for-rl-algorithm-developers), [example](tutorial/example_mix_algo.md)).
-
-* **Custom datasets and data pipelines for RFT**
- - Design task-specific datasets and build data pipelines for cleaning, augmentation, and human-in-the-loop scenarios ([tutorial](tutorial/trinity_programming_guide.md#operators-for-data-developers), [example](tutorial/example_data_functionalities.md)).
-
-
## Acknowledgements
This project is built upon many excellent open-source projects, including:
diff --git a/docs/sphinx_doc/source/tutorial/develop_algorithm.md b/docs/sphinx_doc/source/tutorial/develop_algorithm.md
new file mode 100644
index 0000000000..41b6a184b9
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_algorithm.md
@@ -0,0 +1,216 @@
+(Algorithms)=
+## Algorithms Development Guide
+
+In Trinity-RFT, the algorithm module is primarily responsible for extracting experience data from the Replay Buffer during the RL process and calculating the loss to update models based on this data.
+
+To avoid implementing a new Trainer class each time a new algorithm is added, we have decomposed the representative PPO algorithm process into multiple sub-modules to adapt to various algorithms.
+
+### Step 0: Basic Concepts of Algorithm Module
+
+Trinity-RFT breaks down the algorithm module into the following sub-modules:
+
+- **Sample Strategy** ({class}`trinity.algorithm.SampleStrategy`): Responsible for sampling experience data from the buffer module. By customizing this module, you can implement functionalities like filtering experience data or mixed sampling from multiple data sources.
+- **Advantage Fn**({class}`trinity.algorithm.AdvantageFn`): Responsible for calculating the Advantage and Returns of experience data.
+- **Policy Loss Fn**({class}`trinity.algorithm.PolicyLossFn`): Responsible for calculating the core training loss of the policy network.
+- **KL Fn**({class}`trinity.algorithm.KLFn`): Responsible for calculating KL Divergence, which is generally used in two places in existing RL algorithms: Reward Penalty and Actor Loss.
+- **Entropy Loss Fn**({class}`trinity.algorithm.EntropyLossFn`): Responsible for calculating the entropy loss of the policy network.
+
+We provide several implementations of above modules in `trinity/algorithm`.
+
+---
+
+### Step 1: Implement Algorithm Components
+
+
+Trinity-RFT allows developers to customize all the above modules. Developers only need to implement specific modules according to the requirements of their new algorithm. This section will provide a simple introduction using the {ref}`OPMD ` algorithm as an example.
+
+The main difference between OPMD and PPO algorithms lies in the calculation of Advantage and Policy Loss.
+OPMD relies on a group-based advantage calculation and does not use the Critic model.
+To implement OPMD, developers need to implement advantage calculation in `AdvantageFn` and policy loss calculation in `PolicyLossFn`.
+
+---
+
+#### Step 1.1: Implement `AdvantageFn`
+
+The {class}`trinity.algorithm.AdvantageFn` interface includes three methods:
+
+- `__call__`: The main entrance for advantage calculation. It receives a list of experiences ({class}`trinity.common.experience.Experience`) and returns a list of experiences with calculated advantages and returns, along with a metrics dictionary for logging.
+- `default_args`: A class method that returns the default initialization parameters in dictionary form. It will be used by default when users don't specify initialization parameters in the configuration file.
+- `compute_in_trainer`: This class method indicates whether to compute advantages in the Trainer. If it returns `False`, the `AdvantageFn` will be called in the experience data processing pipeline.
+
+For convenience, Trinity-RFT provides an abstract class {class}`trinity.algorithm.advantage_fn.GroupAdvantage` that implements the `__call__` method for group-based advantage calculation, you can focus on how to group the experiences and calculate advantages on grouped experiences with the following two methods:
+
+- `group_experiences`: This method groups a experiences generated in a step into multiple sub-groups.
+
+- `calculate_group_advantage`: This method calculates the advantage for each group of experiences.
+
+Here's an implementation example for the OPMD algorithm's advantage function:
+
+```python
+from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
+
+@ADVANTAGE_FN.register_module("opmd")
+class OPMDGroupAdvantage(GroupAdvantage):
+ """OPMD Group Advantage computation"""
+
+ def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.opmd_baseline = opmd_baseline
+ self.tau = tau
+
+ def group_experiences(self, exps):
+ return group_by(exps, id_type="task")
+
+ def calculate_group_advantage(
+ self, group_id: str, exps: List[Experience]
+ ) -> Tuple[List[Experience], Dict]:
+ with torch.no_grad():
+ if len(exps) == 1:
+ group_baseline = torch.tensor(0.0)
+ else:
+ group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
+ if self.opmd_baseline == "mean":
+ group_baseline = torch.mean(group_rewards)
+ else:
+ group_baseline = self.tau * (
+ torch.logsumexp(group_rewards / self.tau, dim=-1)
+ - torch.log(torch.tensor(len(exps)))
+ )
+ for exp in exps:
+ score = exp.reward - group_baseline
+ exp.advantages = score * exp.action_mask
+ exp.returns = exp.advantages.clone()
+ metrics = {
+ "group_baseline": group_baseline.item(),
+ }
+ return exps, metrics
+
+ @classmethod
+ def default_args(cls) -> dict:
+ return {"opmd_baseline": "mean", "tau": 1.0}
+```
+
+After implementation, you need to register this module through {class}`trinity.algorithm.ADVANTAGE_FN`. Once registered, the module can be configured in the configuration file using the registered name.
+
+
+#### Step 1.2: Implement `PolicyLossFn`
+
+Developers need to implement the {class}`trinity.algorithm.PolicyLossFn` interface, which is similar to `AdvantageFn` and includes two methods:
+
+- `__call__`: Calculates the loss based on input parameters. Unlike `AdvantageFn`, the input parameters here are all `torch.Tensor`. This interface automatically scans the parameter list of the `__call__` method and converts it to the corresponding fields in the experience data. Therefore, please write all tensor names needed for loss calculation directly in the parameter list, rather than selecting parameters from `kwargs`.
+- `default_args`: Returns default initialization parameters in dictionary form, which will be used by default when users don't specify initialization parameters in the configuration file.
+
+Similarly, after implementation, you need to register this module through {class}`trinity.algorithm.POLICY_LOSS_FN`.
+
+Here's an implementation example for the OPMD algorithm's Policy Loss Fn. Since OPMD's Policy Loss only requires logprob, action_mask, and advantages, only these three items are specified in the parameter list of the `__call__` method:
+
+
+```python
+@POLICY_LOSS_FN.register_module("opmd")
+class OPMDPolicyLossFn(PolicyLossFn):
+ def __init__(self, tau: float = 1.0) -> None:
+ self.tau = tau
+
+ def __call__( # type: ignore
+ self,
+ logprob: torch.Tensor,
+ action_mask: torch.Tensor,
+ advantages: torch.Tensor,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Dict]:
+ pg_losses = -advantages * logprob
+ opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
+ opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
+ return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
+
+ @classmethod
+ def default_args(cls) -> Dict:
+ return {"tau": 1.0, "loss_agg_mode": "token-mean"}
+```
+
+---
+
+### Step 2: Register Your Algorithm
+
+The above steps implement the components needed for the algorithm, but these components are scattered and need to be configured in multiple places to take effect.
+
+To simplify configuration, Trinity-RFT provides {class}`trinity.algorithm.AlgorithmType` to describe a complete algorithm and registers it in {class}`trinity.algorithm.ALGORITHM_TYPE`, enabling one-click configuration.
+
+The `AlgorithmType` class includes the following attributes and methods:
+
+- `use_critic`: Whether to use the Critic model
+- `use_reference`: Whether to use the Reference model
+- `compute_advantage_in_trainer`: Whether to calculate Advantages in Trainer; if False, the `AdvantageFn` call in trainer will be skipped
+- `can_balance_batch`: Whether the algorithm allows automatic balancing when splitting a batch into microbatches (which permute the order of samples)
+- `schema`: The format of experience data corresponding to the algorithm
+- `default_config`: Gets the default configuration of the algorithm, which will override attributes with the same name in `ALGORITHM_TYPE`
+
+Similarly, after implementation, you need to register this module through `ALGORITHM_TYPE`.
+
+Below is the implementation for the OPMD algorithm.
+Since the OPMD algorithm doesn't need to use the Critic model, `use_critic` is set to `False`.
+The dictionary returned by the `default_config` method indicates that OPMD will use the `opmd` type `AdvantageFn` and `PolicyLossFn` implemented in Step 1, will not apply KL Penalty on rewards, but will add a `k2` type KL loss when calculating the final loss.
+
+```python
+@ALGORITHM_TYPE.register_module("opmd")
+class OPMDAlgorithm(AlgorithmType):
+ """OPMD algorithm."""
+
+ use_critic: bool = False
+ use_reference: bool = True
+ compute_advantage_in_trainer: bool = False
+ can_balance_batch: bool = True
+ schema: str = "experience"
+
+ @classmethod
+ def default_config(cls) -> Dict:
+ return {
+ "repeat_times": 2,
+ "advantage_fn": "opmd",
+ "sample_strategy": "warmup",
+ "policy_loss_fn": "opmd",
+ "kl_penalty_fn": "none",
+ "kl_loss_fn": "k2",
+ "entropy_loss_fn": "default",
+ }
+```
+
+```{tip}
+To ensure the registration takes effect, please make sure to import the newly implemented modules in the corresponding `__init__.py` files, for example:
+
+- Import `OPMDGroupAdvantage` in `trinity/algorithm/advantage_fn/__init__.py`
+- Import `OPMDPolicyLossFn` in `trinity/algorithm/policy_loss_fn/__init__.py`
+- Import `OPMDAlgorithm` in `trinity/algorithm/__init__.py`
+
+You can also place these classes in the `trinity/plugins` directory, and Trinity-RFT will automatically load all modules in the `plugins` directory at startup, without needing to import them in `__init__.py`.
+```
+
+---
+
+### Step 3: Use Your Algorithm
+
+After completing all the above steps, you can use the newly registered algorithm through a YAML configuration file.
+
+For default configurations, you just need to add the following content to your `config.yaml` file:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+# some other configs
+```
+
+If you need to modify certain parameters, you can simply add the corresponding parameters within the `algorithm` section. For example, if you need to modify `repeat_times` and the initialization parameters of `AdvantageFn` and `PolicyLossFn`, the modified `config.yaml` file would be as follows:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+ repeat_times: 8
+ advantage_fn_args:
+ opmd_baseline: "logavgexp"
+ tau: 0.99
+ policy_loss_fn_args:
+ tau: 0.99
+# some other configs
+```
diff --git a/docs/sphinx_doc/source/tutorial/develop_operator.md b/docs/sphinx_doc/source/tutorial/develop_operator.md
new file mode 100644
index 0000000000..f658e5bff6
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_operator.md
@@ -0,0 +1,82 @@
+## Operator Development Guide
+
+### Step 0: Basic Concepts of Operator Module
+
+In Trinity-RFT, the operator module is responsible for processing experience data in the buffer module. It supports existing data processing capabilities from [Data-Juicer](https://github.com/modelscope/data-juicer) naturally, and allows developers to implement their own operators as well.
+By customizing operators, developers can implement various data processing functionalities, such as data augmentation, filtering, and transformation. You can even implement advantages/returns calculation as operators, as shown in {ref}`Algorithms ` section.
+
+- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`): The operator that wraps the data processing operators from Data-Juicer. It provides a simple interface for developers to list the Data-Juicer operators they want to use. The full list of Data-Juicer operators can be found [here](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html).
+- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`): The base class for all operators used in experience data processing. It defines the interface and common functionalities that all operators should have. Each operator processes a batch of experience data and returns the processed data with metrics for logging.
+- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`): The experience data processing pipeline that manages a sequence of operators. It takes raw experiences from the `Explorer`, passes them through each operator in the pipeline, and writes the final processed experiences into the input buffer of the `Trainer`.
+
+```{note}
+Except for `ExperiencePipeline`, Trinity-RFT also provides `TaskPipeline` for task data processing.
+In the current version, the `TaskPipeline` only supports using Data-Juicer operators. Please see this {ref}`section ` for details.
+```
+---
+
+Developers can implement and use their own operators by following the steps below.
+
+### Step 1: Implement Operator
+
+The `ExperienceOperator` interface includes only one `process` method. The `ExperiencePipeline` will call this method with a list of `Experience` generated by the `Explorer` in one explore step. The `process` method should return a tuple containing the processed list of `Experience` and a dictionary of metrics for logging.
+
+```python
+class ExperienceOperator(ABC):
+
+ @abstractmethod
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ """Process a list of experiences and return a transformed list.
+
+ Args:
+ exps (List[Experience]): List of experiences to process, which contains
+ all experiences generated by the Explorer in one explore step.
+ Returns:
+ Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
+ """
+```
+
+Here is an implementation of a simple operator that filters out experiences with rewards below a certain threshold:
+
+```python
+from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
+from trinity.common.experience import Experience
+
+
+@EXPERIENCE_OPERATORS.register_module("reward_filter")
+class RewardFilter(ExperienceOperator):
+
+ def __init__(self, threshold: float = 0.0) -> None:
+ self.threshold = threshold
+
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
+ metrics = {"filtered_count": len(exps) - len(filtered_exps)}
+ return filtered_exps, metrics
+```
+
+After implementation, you need to register this module through {class}`trinity.data.operators.EXPERIENCE_OPERATORS`. Once registered, the module can be configured in the configuration file using the registered name.
+
+### Step 2: Use Your Operator
+
+After completing the above steps, you can use the newly registered operator through a YAML configuration file.
+
+```yaml
+# some other configs
+data_processor:
+ experience_pipeline:
+ operators:
+ - name: "reward_filter"
+ args:
+ threshold: 0.1
+synchronizer:
+ sync_method: nccl
+ sync_style: dynamic_by_explorer
+ sync_interval: 2
+# some other configs
+```
+
+```{tip}
+The `RewardFilter` reduces the number of experiences, which may cause the trainer can't get enough experiences to start a training step. To avoid the issue, you can use the advanced {ref}`Dynamic Synchronization ` feature provided by Trinity-RFT as shown in the above configuration file.
+The above setting means that the `Explorer` will sync with the `Trainer` every 2 steps and will continue running regardless of how many steps the `Trainer` has completed. This ensures that the `Trainer` can always get enough experiences to start a training step as long as the `Explorer` is running.
+```
diff --git a/docs/sphinx_doc/source/tutorial/develop_overview.md b/docs/sphinx_doc/source/tutorial/develop_overview.md
new file mode 100644
index 0000000000..f47cb967ff
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_overview.md
@@ -0,0 +1,31 @@
+# Developer Guide
+
+Trinity-RFT divides the RL training process into three modules: **Explorer**, **Trainer**, and **Buffer**.
+
+Explorer provides the `Workflow` interface to customize agent-environment interaction, Trainer provides the `Algorithm` interface to customize RL algorithms, and Buffer provides the `Operator` interface to customize data processing operators.
+
+The table below lists the main functions of each extension interface, its target users, and the corresponding development tutorials. Developers can refer to the respective module development tutorials and extend Trinity-RFT based on their needs.
+
+| Extension Interface | Target Users | Main Functions | Tutorial Link |
+|---------------------|-------------------|------------------------------------------|----------------------------|
+| `Workflow` | Agent Application Developers | Enhance agent's ability to complete tasks in a specified environment | [🔗](./develop_workflow.md) |
+| `Algorithm` | RL Algorithm Researchers | Design new RL algorithms | [🔗](./develop_algorithm.md) |
+| `Operator` | Data Engineers | Design new data cleaning and augmentation strategies | [🔗](./develop_operator.md) |
+
+```{tip}
+Trinity-RFT provides a modular development approach, allowing you to flexibly add custom modules without modifying the framework code.
+You can place your module code in the `trinity/plugins` directory. Trinity-RFT will automatically load all Python files in that directory at runtime and register the custom modules within them.
+Trinity-RFT also supports specifying other directories at runtime by setting the `--plugin-dir` option, for example: `trinity run --config --plugin-dir `.
+```
+
+For modules you plan to contribute to Trinity-RFT, please follow these steps:
+
+1. Implement your code in the appropriate directory, such as `trinity/common/workflows` for `Workflow`, `trinity/algorithm` for `Algorithm`, and `trinity/buffer/operators` for `Operator`.
+
+2. Register your module in the corresponding `__init__.py` file of the directory.
+
+3. Add tests for your module in the `tests` directory, following the naming conventions and structure of existing tests.
+
+4. Before submitting your code, ensure it passes the code style check by running `pre-commit run --all-files`.
+
+5. Submit a Pull Request to the Trinity-RFT repository, providing a detailed description of your module's functionality and purpose.
diff --git a/docs/sphinx_doc/source/tutorial/develop_workflow.md b/docs/sphinx_doc/source/tutorial/develop_workflow.md
new file mode 100644
index 0000000000..0b3201b322
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/develop_workflow.md
@@ -0,0 +1,291 @@
+(Workflows)=
+## Workflow Development Guide
+
+In Trinity-RFT, workflows are the core components that define the interaction between Agents and Environments.
+A qualified workflow needs to use the trained model to complete the specified task and obtain feedback information (reward) from the environment. Below are the steps to create a new workflow:
+
+---
+
+### Step 0: Basic Concepts
+
+Before starting development, it's important to understand several core concepts:
+
+- **Task** ({class}`trinity.common.workflows.Task`): Represents a data structure that can be converted into a `Workflow`. The content of the `Task` varies depending on the task type:
+ - **Math problems**: A `Task` contains the problem description and the golden answer.
+ - **Programming scenarios**: A `Task` includes the problem description, test cases, runtime environment, and other complex information.
+
+- **Workflow** ({class}`trinity.common.workflows.Workflow`): Describes how a `Task` is executed. It defines the interaction flow between Agents and Environments, including logic similar to *Rollout* and *Reward* calculations in other frameworks. After execution, it generates a list of `Experience`. Trinity-RFT includes several built-in workflows:
+ - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`): For math scenarios, submits problems to LLM, parses LLM responses, and calculates scores (rewards).
+ - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`): For webshop scenarios, it contains multi-turn interaction with environment.
+ - `AgentScopeReactMathWorkflow` ({class}`trinity.common.workflows.AgentScopeReactMathWorkflow`): For math scenarios, it directly uses a pre-implemented ReActAgent (based on AgentScope) to solve math problems.
+
+- **Experience** ({class}`trinity.common.experience.Experience`): The output of running a `Workflow`. The internal data format depends on the training algorithm used. For example, for common PPO/GRPO algorithms, `Experience` includes lists of token IDs, action masks (identifying which tokens were generated by the LLM), log probabilities, rewards, etc.
+
+---
+
+### Step 1: Prepare Task Dataset
+
+The task dataset is loaded via the `buffer.explorer_input.taskset` configuration entry in your YAML config file.
+To handle differences in `Task` contents, Trinity-RFT provides a unified `Task` interface containing the following fields.
+
+- **`workflow`** (`str`): The registered name of your workflow class. You can specify it in `buffer.explorer_input.taskset.default_workflow_type` of your YAML config file.
+- **`reward_fn`** (`Optional[str]`): The registered name of your reward function. You can specify it in `buffer.explorer_input.taskset.default_reward_fn_type`. Note that some workflows already include built-in reward calculation; in such cases, you can omit this field.
+- **`raw_task`** (`Dict`): A record of raw data in `Dict` format. For highly customized workflow, you can directly use `raw_task` to initialize your `Workflow` instance without relying on the following fields.
+- **`format_args`** ({class}`trinity.common.config.FormatConfig`): Parameters to facilitate the construction of `Workflow` instances. For example, the `prompt_key` and `response_key` can be used to get the prompt and response from `raw_task`. These settings come from the YAML configuration file and can be set in `buffer.explorer_input.task_set.format`.
+- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`): Parameters that control the rollout process, such as `temperature`. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.rollout_args`.
+- **`workflow_args`** (`Dict`): A dictionary of parameters to facilitate the construction of `Workflow` instances. Provides more flexibility than `format_args` and `rollout_args` by using a dictionary. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.workflow_args`. Normally, you do not need to set this field.
+
+```{tip}
+`workflow`, `workflow_args` and `raw_task` provide different levels of customization.
+
+- `workflow` provides the global settings for all tasks that uses the same workflow. (Global Level)
+- `workflow_args` can be set for each task dataset, allowing different task datasets using the same workflow to behave differently. (Dataset Level)
+- `raw_task` provides the ability to customize the behavior of each task, which is most flexible. (Data Sample Level)
+```
+
+In the math problem scenario, the `Task` dataset can be a `jsonl` file, where each line contains JSON with `question` and `answer` fields representing the problem description and standard answer, respectively. For example:
+
+```json
+{"question": "1+1=", "answer": "2"}
+{"question": "2+2=", "answer": "4"}
+...
+```
+
+Example configuration snippet:
+
+```yaml
+# some config
+buffer:
+ explorer_input:
+ taskset:
+ default_workflow: "math_workflow"
+ path: ${oc.env:TRINITY_TASKSET_PATH}
+ format:
+ prompt_key: "question"
+ response_key: "answer"
+ rollout_args:
+ temperature: 1.0
+ # some other configs
+```
+
+In this example, each task object's `raw_task` is a `Dict` with two keys (`question` and `answer`). The `MathWorkflow` uses the `prompt_key` and `response_key` to extract the question and answer from the `raw_task` and use the `rollout_args` to generate the response.
+
+---
+
+### Step 2: Implement a New Workflow
+
+The `Workflow` base class interface is as follows:
+
+```python
+class Workflow(ABC):
+
+ def __init__(
+ self,
+ *,
+ task: Task,
+ model: ModelWrapper,
+ auxiliary_models: Optional[List[openai.OpenAI]] = None,
+ ):
+ self.task = task
+ self.model = model
+ self.auxiliary_models = auxiliary_models
+
+ @abstractmethod
+ def run(self) -> List[Experience]:
+ """Run the workflow and return a list of Experiences."""
+```
+
+#### Initialize Your Workflow
+
+During initialization, `Workflow` receives the following parameters:
+
+- `task`({class}`trinity.common.workflows.Task`): A single data item from the task dataset.
+- `model`({class}`trinity.common.models.model.ModelWrapper`): The model being trained, which provides an interface similar to OpenAI, capable of receiving a list of conversation messages and returning content generated by the LLM (including reply text `response_text`, full sequence token ids `tokens`, prompt part token length `prompt_length`, and a list of output token logprobs `logprobs`).
+- `auxiliary_models`(`List[openai.OpenAI]`):A list of auxiliary models not involved in training. All are provided via OpenAI-compatible APIs.
+
+```{tip}
+You can switch to using the OpenAI API by setting `explorer.rollout_model.enable_openai_api` to `true` in your config file and calling `model.get_openai_client()` to get an `openai.OpenAI` instance in your workflow.
+And the `model` field when calling openai API can be obtained via `openai_client.models.list().data[0].id` or `openai_client.model_path`.
+```
+
+Here's an example of initializing a simple workflow using only `raw_task` and `rollout_args`. In more complex cases, you can use the `format_args` for further customization.
+
+```python
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+ # Optional: If you want to use OpenAI API in your workflow
+ # self.openai_client = self.model.get_openai_client()
+```
+
+#### Implementing the `run` method
+
+The `run` method is the core of your workflow. It returns a list of `Experience`.
+Below is a simple implementation for a math workflow.
+
+We first call the model to generate multiple response using the provided question and rollout arguments.
+Then we calculate the reward for each response using the `calculate_reward` function.
+Finally, we construct a list of `Experience` with the responses and rewards and return it.
+
+```python
+class ExampleWorkflow(Workflow):
+
+ # the __init__ function
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+```
+
+#### Registering Your Workflow
+
+Register your workflow using the `WORKFLOWS.register_module` decorator.
+Ensure the name does not conflict with existing workflows.
+
+```python
+# import some packages
+from trinity.common.workflows.workflow import WORKFLOWS
+
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ pass
+```
+
+For workflows that are prepared to be contributed to Trinity-RFT project, you need to place the above code in `trinity/common/workflows` folder, e.g., `trinity/common/workflows/example_workflow.py`. And add the following line to `trinity/common/workflows/__init__.py`:
+
+```python
+# existing import lines
+from trinity.common.workflows.example_workflow import ExampleWorkflow
+
+__all__ = [
+ # existing __all__ lines
+ "ExampleWorkflow",
+]
+```
+
+#### Avoid Re-initialization
+
+For heavy workflows, re-initializing every time can incurs extra computational costs.
+In this case, you can implement the `resettable` and `reset` methods to avoid re-initialization.
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ # some code
+ # ...
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+#### Full Code Example
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+---
+
+### Step 3: Use Your Workflow
+
+After implementing and registering your workflow, you need to update the configuration file to set the `default_workflow_type` in the `buffer.explorer_input.taskset` domain to the newly registered `Workflow` name.
+
+```yaml
+buffer:
+ # Other fields
+ explorer_input:
+ taskset:
+ path: /path/to/taskset
+ default_workflow_type: example_workflow
+ # Other fields
+```
+
+Now you can run your workflow in Trinity-RFT using the command:
+
+```
+trinity run --config
+```
diff --git a/docs/sphinx_doc/source/tutorial/example_megatron.md b/docs/sphinx_doc/source/tutorial/example_megatron.md
index b7ed7ba22e..fb5fd0a121 100644
--- a/docs/sphinx_doc/source/tutorial/example_megatron.md
+++ b/docs/sphinx_doc/source/tutorial/example_megatron.md
@@ -1,48 +1,17 @@
+(Megatron-LM)=
# Megatron-LM Backend
This guide walks you through how to train models using **Megatron-LM** in a clear way.
----
-
-## Step 1: Installation
-
-### Minimum Requirements
-
-Before you begin, make sure your system meets these requirements:
-
-- **GPUs**: At least 2 GPUs (for distributed training)
-- **CUDA**: Version 12.4 or higher
-- **Python**: Version 3.10 or higher
-
----
-
-### Install Dependencies
-
-Start by cloning the repository and setting up a virtual environment:
-
-```bash
-# Clone the repository
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
+```{note}
+This guide assumes you have already set up your environment following {ref}`Installation `. If you haven't done so, please refer to that guide first.
```
-#### Option A: Using Conda
-
-```bash
-# Create and activate a new environment
-conda create -n trinity python=3.10
-conda activate trinity
-```
+---
-#### Option B: Using venv
+## Step 1: Installation
-```bash
-# Create and activate a virtual environment
-python3.10 -m venv .venv
-source .venv/bin/activate
-```
-#### Install the Package
Install the project in editable mode with Megatron support:
@@ -54,19 +23,6 @@ pip install -e .[megatron]
pip install -e .\[megatron\]
```
-#### Install Flash Attention
-
-After installing the base dependencies, install `flash-attn`. This may take several minutes to compile — please be patient!
-
-```bash
-pip install flash-attn==2.8.1 -v
-```
-
-If you run into installation issues, try this alternative:
-
-```bash
-pip install flash-attn -v --no-build-isolation
-```
#### Install Apex (from NVIDIA)
diff --git a/docs/sphinx_doc/source/tutorial/example_mix_algo.md b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
index 4203cb8734..56312a7b98 100644
--- a/docs/sphinx_doc/source/tutorial/example_mix_algo.md
+++ b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
@@ -1,4 +1,4 @@
-# Algorithm Development
+# Advanced Algorithm Development
```{note}
This guide is an advanced version of the {ref}`Algorithms ` section in the Developer Guide.
diff --git a/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md b/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
index 4041c78761..0e85550e55 100644
--- a/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
+++ b/docs/sphinx_doc/source/tutorial/example_reasoning_basic.md
@@ -4,62 +4,7 @@ This tutorial shows a quick start guide for running RFT with Trinity-RFT.
## Step 0: Environment Preparation
-Minimal environment requirements:
-
-- GPUs: At least 2 GPUs
-- CUDA: Version >= 12.4
-- Python: Version >= 3.10
-
-```shell
-# Pull the source code from GitHub
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# Create a new environment using Conda or venv
-# Option 1: Conda
-conda create -n trinity python=3.10
-conda activate trinity
-
-# Option 2: venv
-python3.10 -m venv .venv
-source .venv/bin/activate
-
-# Install the package in editable mode
-# for bash
-pip install -e .[dev]
-# for zsh
-pip install -e .\[dev\]
-
-# Install flash-attn after all dependencies are installed
-# Note: flash-attn will take a long time to compile, please be patient.
-pip install flash-attn -v
-# Try the following command if you encounter errors during installation
-# pip install flash-attn -v --no-build-isolation
-```
-
-Installation using pip:
-
-```shell
-pip install trinity-rft
-```
-
-Installation from docker:
-
-We provided a dockerfile for Trinity-RFT.
-
-```shell
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# build the docker image
-# Note: you can edit the dockerfile to customize the environment
-# e.g., use pip mirrors or set api key
-docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-
-# run the docker image
-docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v :/data trinity-rft:latest
-```
-
+Please follow the instructions in [Installation](./trinity_installation.md) to set up the environment.
## Step 1: Model and Data Preparation
diff --git a/docs/sphinx_doc/source/tutorial/trinity_configs.md b/docs/sphinx_doc/source/tutorial/trinity_configs.md
index 88579f2fcc..731f5c2de4 100644
--- a/docs/sphinx_doc/source/tutorial/trinity_configs.md
+++ b/docs/sphinx_doc/source/tutorial/trinity_configs.md
@@ -658,3 +658,126 @@ trainer:
- `trainer.del_local_ckpt_after_load`: Whether to delete local checkpoints after loading.
- `trainer.max_actor_ckpt_to_keep`: Maximum number of actor checkpoints to keep.
- `trainer.max_critic_ckpt_to_keep`: Maximum number of critic checkpoints to keep.
+
+
+## Adding New Config Entries for the Config Generator (Advanced)
+
+This section introduces how to add new configuration parameters to the Config Generator page of Trinity-RFT.
+
+### Step 0: Understanding Streamlit
+
+Before adding new parameters to the Config Generator page, it is essential to familiarize yourself with the relevant API and mechanisms of [Streamlit](https://docs.streamlit.io/develop/api-reference). This project primarily utilizes various input components from Streamlit and employs `st.session_state` to store user-input parameters.
+
+### Step 1: Implement New Config Entries
+
+To illustrate the process of creating a new parameter setting for the Config Generator page, we will use `train_batch_size` as an example.
+
+1. Determine the appropriate scope for the parameter. Currently, parameters are categorized into four files:
+ - `trinity/manager/config_registry/buffer_config_manager.py`
+ - `trinity/manager/config_registry/explorer_config_manager.py`
+ - `trinity/manager/config_registry/model_config_manager.py`
+ - `trinity/manager/config_registry/trainer_config_manager.py`
+
+ In this case, `train_batch_size` should be placed in the `buffer_config_manager.py` file.
+
+2. Create a parameter setting function using Streamlit. The function name must follow the convention of starting with 'set_', and the remainder of the name becomes the config name.
+
+3. Decorate the parameter setting function with the `CONFIG_GENERATORS.register_config` decorator. This decorator requires the following information:
+ - Default value of the parameter
+ - Visibility condition (if applicable)
+ - Additional config parameters (if needed)
+
+```{note}
+The `CONFIG_GENERATORS.register_config` decorator automatically passes `key=config_name` as an argument to the registered configuration function. Ensure that your function accepts this keyword argument.
+```
+
+For `train_batch_size`, we will use the following settings:
+
+- Default value: 96
+- Visibility condition: `lambda: st.session_state["trainer_gpu_num"] > 0`
+- Additional config: `{"_train_batch_size_per_gpu": 16}`
+
+Here's the complete code for the `train_batch_size` parameter:
+
+```python
+@CONFIG_GENERATORS.register_config(
+ default_value=96,
+ visible=lambda: st.session_state["trainer_gpu_num"] > 0,
+ other_configs={"_train_batch_size_per_gpu": 16},
+)
+def set_train_batch_size(**kwargs):
+ key = kwargs.get("key")
+ trainer_gpu_num = st.session_state["trainer_gpu_num"]
+ st.session_state[key] = (
+ st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
+ )
+
+ def on_change():
+ st.session_state["_train_batch_size_per_gpu"] = max(
+ st.session_state[key] // st.session_state["trainer_gpu_num"], 1
+ )
+
+ st.number_input(
+ "Train Batch Size",
+ min_value=trainer_gpu_num,
+ step=trainer_gpu_num,
+ help=_str_for_train_batch_size(),
+ on_change=on_change,
+ **kwargs,
+ )
+```
+
+If the parameter requires validation, create a check function. For `train_batch_size`, we need to ensure it is divisible by `trainer_gpu_num`. If not, a warning should be displayed, and the parameter should be added to `unfinished_fields`.
+
+Decorate the check function with the `CONFIG_GENERATORS.register_check` decorator:
+
+```python
+@CONFIG_GENERATORS.register_check()
+def check_train_batch_size(unfinished_fields: set, key: str):
+ if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
+ unfinished_fields.add(key)
+ st.warning(_str_for_train_batch_size())
+```
+
+```{note}
+The `CONFIG_GENERATORS.register_check` decorator automatically receives `key=config_name` and `unfinished_fields=self.unfinished_fields` as arguments. Ensure your function accepts these keyword arguments.
+```
+
+### Step 2: Integrating New Parameters into `config_manager.py`
+
+To successfully integrate new parameters into the `config_manager.py` file, please adhere to the following procedure:
+
+1. Parameter Categorization:
+ Determine the appropriate section for the new parameter based on its functionality. The config generator page is structured into two primary modes:
+ - Beginner Mode: Comprises "Essential Configs" and "Important Configs" sections.
+ - Expert Mode: Includes "Model", "Buffer", "Explorer and Synchronizer", and "Trainer" sections.
+
+2. Parameter Addition:
+ Incorporate the new parameter into the relevant section using the `self.get_configs` method within the `ConfigManager` class.
+
+ Example:
+
+ ```python
+ class ConfigManager:
+ def _expert_buffer_part(self):
+ self.get_configs("total_epochs", "train_batch_size")
+ ```
+
+3. YAML File Integration:
+ Locate the appropriate position for the new parameter within the YAML file structure. This should be done in the `generate_config` function and its associated sub-functions.
+
+4. Parameter Value Assignment:
+ Utilize `st.session_state` to retrieve the parameter value from the config generator page and assign it to the corresponding field in the YAML.
+
+ Example:
+
+ ```python
+ class ConfigManager:
+ def _gen_buffer_config(self):
+ buffer_config = {
+ "batch_size": st.session_state["train_batch_size"],
+ # Additional configuration parameters
+ }
+ ```
+
+By following these steps, you can successfully add new parameters to the Config Generator page and ensure they are properly integrated into the configuration management system.
diff --git a/docs/sphinx_doc/source/tutorial/trinity_installation.md b/docs/sphinx_doc/source/tutorial/trinity_installation.md
new file mode 100644
index 0000000000..f4c13a2ce7
--- /dev/null
+++ b/docs/sphinx_doc/source/tutorial/trinity_installation.md
@@ -0,0 +1,111 @@
+(Installation)=
+# Installation
+
+For installing Trinity-RFT, you have three options: from source (recommended), via PyPI, or using Docker.
+
+Before installing, ensure your system meets the following requirements:
+
+- **Python**: Version 3.10 to 3.12 (inclusive)
+- **CUDA**: Version 12.4 to 12.8 (inclusive)
+- **GPUs**: At least 2 GPUs
+
+---
+
+## From Source (Recommended)
+
+This method is best if you plan to customize or contribute to Trinity-RFT.
+
+### 1. Clone the Repository
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+```
+
+### 2. Set Up a Virtual Environment
+
+Choose one of the following options:
+
+#### Using Conda
+
+```bash
+conda create -n trinity python=3.10
+conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### Using venv
+
+```bash
+python3.10 -m venv .venv
+source .venv/bin/activate
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# if you encounter issues when installing flash-attn, try:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### Using `uv`
+
+[`uv`](https://github.com/astral-sh/uv) is a modern Python package installer.
+
+```bash
+uv sync --extra dev --extra flash_attn
+```
+
+---
+
+## Via PyPI
+
+If you just want to use the package without modifying the code:
+
+```bash
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
+```
+
+Or with `uv`:
+
+```bash
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
+```
+
+---
+
+## Using Docker
+
+We provide a Docker setup for hassle-free environment configuration.
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+
+# Build the Docker image
+## Tip: You can modify the Dockerfile to add mirrors or set API keys
+docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
+
+# Run the container, replacing with your actual path
+docker run -it \
+ --gpus all \
+ --shm-size="64g" \
+ --rm \
+ -v $PWD:/workspace \
+ -v :/data \
+ trinity-rft:latest
+```
+
+```{note}
+For training with **Megatron-LM**, please refer to {ref}`Megatron-LM Backend `.
+```
+
+---
+
+## Troubleshooting
+
+If you encounter installation issues, refer to the FAQ or [GitHub Issues](https://github.com/modelscope/Trinity-RFT/issues).
diff --git a/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md b/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md
deleted file mode 100644
index 2b1ffac957..0000000000
--- a/docs/sphinx_doc/source/tutorial/trinity_programming_guide.md
+++ /dev/null
@@ -1,746 +0,0 @@
-# Developer Guide
-
-This guide introduces how to develop new modules in Trinity-RFT and provides relevant development guidelines.
-
-In Trinity-RFT, we decompose the RL pipeline into three main modules (**Explorer**, **Trainer** and **Buffer**) to facilitate customization and extension.
-Below is a table summarizing the modules and components that developers with different targets need to focus on.
-
-| Development Target | Core Module | Key Component |
-|--------------------|-------------|---------------|
-| Apply existing RL algorithms to new environments. | *Explorer* | `Workflow` |
-| Design new RL algorithms. | *Trainer* | `Algorithm` |
-| Enhance the RL process from the data perspective. | *Buffer* | `Operator` |
-
-```{note}
-Trinity-RFT is under active development, and the following interfaces may change. Please refer to the latest code when using this guide.
-```
-
-```{tip}
-For modules that only used for local testing or not intended for contribution, you can place them in the `trinity/plugins` directory. Trinity-RFT will automatically load all modules in this directory, and you can use those modules without adding them to the `__init__.py` file. You can specify another directory by setting the `--plugin-dir` option when running Trinity-RFT, e.g., `trinity run --config /path/to/your/config --plugin-dir /path/to/your/plugins`.
-```
-
----
-
-(Workflows)=
-## Workflows (For RL Environment Developers)
-
-In Trinity-RFT, workflows are the core components that define the interaction between Agents and Environments.
-A qualified workflow needs to use the trained model to complete the specified task and obtain feedback information (reward) from the environment. Below are the steps to create a new workflow:
-
----
-
-### Step 0: Basic Concepts
-
-Before starting development, it's important to understand several core concepts:
-
-- **Task** ({class}`trinity.common.workflows.Task`): Represents a data structure that can be converted into a `Workflow`. The content of the `Task` varies depending on the task type:
- - **Math problems**: A `Task` contains the problem description and the golden answer.
- - **Programming scenarios**: A `Task` includes the problem description, test cases, runtime environment, and other complex information.
-
-- **Workflow** ({class}`trinity.common.workflows.Workflow`): Describes how a `Task` is executed. It defines the interaction flow between Agents and Environments, including logic similar to *Rollout* and *Reward* calculations in other frameworks. After execution, it generates a list of `Experience`. Trinity-RFT includes several built-in workflows:
- - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`): For math scenarios, submits problems to LLM, parses LLM responses, and calculates scores (rewards).
- - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`): For webshop scenarios, it contains multi-turn interaction with environment.
- - `CodeWorkflow` (Coming soon): For coding scenarios, executes returned code, runs tests, and calculates rewards based on test results.
- - ...
-
-- **Experience** ({class}`trinity.common.experience.Experience`): The output of running a `Workflow`. The internal data format depends on the training algorithm used. For example, for common PPO/GRPO algorithms, `Experience` includes lists of token IDs, action masks (identifying which tokens were generated by the LLM), log probabilities, rewards, etc.
-
----
-
-### Step 1: Prepare Task Dataset
-
-The task dataset is loaded via the `buffer.explorer_input.taskset` configuration entry in your YAML config file.
-To handle differences in `Task` contents, Trinity-RFT provides a unified `Task` interface containing the following fields.
-
-- **`workflow`** (`str`): The registered name of your workflow class. You can specify it in `buffer.explorer_input.taskset.default_workflow_type` of your YAML config file.
-- **`reward_fn`** (`Optional[str]`): The registered name of your reward function. You can specify it in `buffer.explorer_input.taskset.default_reward_fn_type`. Note that some workflows already include built-in reward calculation; in such cases, you can omit this field.
-- **`raw_task`** (`Dict`): A record of raw data in `Dict` format. For highly customized workflow, you can directly use `raw_task` to initialize your `Workflow` instance without relying on the following fields.
-- **`format_args`** ({class}`trinity.common.config.FormatConfig`): Parameters to facilitate the construction of `Workflow` instances. For example, the `prompt_key` and `response_key` can be used to get the prompt and response from `raw_task`. These settings come from the YAML configuration file and can be set in `buffer.explorer_input.task_set.format`.
-- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`): Parameters that control the rollout process, such as `temperature`. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.rollout_args`.
-- **`workflow_args`** (`Dict`): A dictionary of parameters to facilitate the construction of `Workflow` instances. Provides more flexibility than `format_args` and `rollout_args` by using a dictionary. This field also comes from the YAML configuration file and can be set in `buffer.explorer_input.task_set.workflow_args`. Normally, you do not need to set this field.
-
-```{tip}
-`workflow`, `workflow_args` and `raw_task` provide different levels of customization.
-
-- `workflow` provides the global settings for all tasks that uses the same workflow. (Global Level)
-- `workflow_args` can be set for each task dataset, allowing different task datasets using the same workflow to behave differently. (Dataset Level)
-- `raw_task` provides the ability to customize the behavior of each task, which is most flexible. (Data Sample Level)
-```
-
-In the math problem scenario, the `Task` dataset can be a `jsonl` file, where each line contains JSON with `question` and `answer` fields representing the problem description and standard answer, respectively. For example:
-
-```json
-{"question": "1+1=", "answer": "2"}
-{"question": "2+2=", "answer": "4"}
-...
-```
-
-Example configuration snippet:
-
-```yaml
-# some config
-buffer:
- explorer_input:
- taskset:
- default_workflow: "math_workflow"
- path: ${oc.env:TRINITY_TASKSET_PATH}
- format:
- prompt_key: "question"
- response_key: "answer"
- rollout_args:
- temperature: 1.0
- # some other configs
-```
-
-In this example, each task object's `raw_task` is a `Dict` with two keys (`question` and `answer`). The `MathWorkflow` uses the `prompt_key` and `response_key` to extract the question and answer from the `raw_task` and use the `rollout_args` to generate the response.
-
----
-
-### Step 2: Implement a New Workflow
-
-The `Workflow` base class interface is as follows:
-
-```python
-class Workflow(ABC):
-
- def __init__(
- self,
- *,
- task: Task,
- model: ModelWrapper,
- auxiliary_models: Optional[List[openai.OpenAI]] = None,
- ):
- self.task = task
- self.model = model
- self.auxiliary_models = auxiliary_models
-
- @abstractmethod
- def run(self) -> List[Experience]:
- """Run the workflow and return a list of Experiences."""
-```
-
-#### Initialize Your Workflow
-
-During initialization, `Workflow` receives the following parameters:
-
-- `task`({class}`trinity.common.workflows.Task`): A single data item from the task dataset.
-- `model`({class}`trinity.common.models.model.ModelWrapper`): The model being trained, which provides an interface similar to OpenAI, capable of receiving a list of conversation messages and returning content generated by the LLM (including reply text `response_text`, full sequence token ids `tokens`, prompt part token length `prompt_length`, and a list of output token logprobs `logprobs`).
-- `auxiliary_models`(`List[openai.OpenAI]`):A list of auxiliary models not involved in training. All are provided via OpenAI-compatible APIs.
-
-```{tip}
-You can switch to using the OpenAI API by setting `explorer.rollout_model.enable_openai_api` to `true` in your config file and calling `model.get_openai_client()` to get an `openai.OpenAI` instance in your workflow.
-And the `model` field when calling openai API can be obtained via `openai_client.models.list().data[0].id` or `openai_client.model_path`.
-```
-
-Here's an example of initializing a simple workflow using only `raw_task` and `rollout_args`. In more complex cases, you can use the `format_args` for further customization.
-
-```python
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
- # Optional: If you want to use OpenAI API in your workflow
- # self.openai_client = self.model.get_openai_client()
-```
-
-#### Implementing the `run` method
-
-The `run` method is the core of your workflow. It returns a list of `Experience`.
-Below is a simple implementation for a math workflow.
-
-We first call the model to generate multiple response using the provided question and rollout arguments.
-Then we calculate the reward for each response using the `calculate_reward` function.
-Finally, we construct a list of `Experience` with the responses and rewards and return it.
-
-```python
-class ExampleWorkflow(Workflow):
-
- # the __init__ function
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-```
-
-#### Registering Your Workflow
-
-Register your workflow using the `WORKFLOWS.register_module` decorator.
-Ensure the name does not conflict with existing workflows.
-
-```python
-# import some packages
-from trinity.common.workflows.workflow import WORKFLOWS
-
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- pass
-```
-
-For workflows that are prepared to be contributed to Trinity-RFT project, you need to place the above code in `trinity/common/workflows` folder, e.g., `trinity/common/workflows/example_workflow.py`. And add the following line to `trinity/common/workflows/__init__.py`:
-
-```python
-# existing import lines
-from trinity.common.workflows.example_workflow import ExampleWorkflow
-
-__all__ = [
- # existing __all__ lines
- "ExampleWorkflow",
-]
-```
-
-#### Avoid Re-initialization
-
-For heavy workflows, re-initializing every time can incurs extra computational costs.
-In this case, you can implement the `resettable` and `reset` methods to avoid re-initialization.
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- # some code
- # ...
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
-#### Full Code Example
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
----
-
-### Step 3: Use Your Workflow
-
-After implementing and registering your workflow, you need to update the configuration file to set the `default_workflow_type` in the `buffer.explorer_input.taskset` domain to the newly registered `Workflow` name.
-
-```yaml
-buffer:
- # Other fields
- explorer_input:
- taskset:
- path: /path/to/taskset
- default_workflow_type: example_workflow
- # Other fields
-```
-
-Now you can run your workflow in Trinity-RFT using the command:
-
-```
-trinity run --config
-```
-
----
-
-(Algorithms)=
-## Algorithms (For RL Algorithm Developers)
-
-Trinity-RFT provides a standardized process for implementing new algorithms.
-
-### Step 0: Basic Concepts of Algorithm Module
-
-In Trinity-RFT, the algorithm module is primarily responsible for extracting experience data from the Replay Buffer during the RL process and calculating the loss to update models based on this data.
-To avoid implementing a new Trainer class each time a new algorithm is added, we have decomposed the representative PPO algorithm process into multiple sub-modules to adapt to various algorithms.
-
-- **Sample Strategy** ({class}`trinity.algorithm.SampleStrategy`): Responsible for sampling experience data from the buffer module. By customizing this module, you can implement functionalities like filtering experience data or mixed sampling from multiple data sources.
-- **Advantage Fn**({class}`trinity.algorithm.AdvantageFn`): Responsible for calculating the Advantage and Returns of experience data.
-- **Policy Loss Fn**({class}`trinity.algorithm.PolicyLossFn`): Responsible for calculating the core training loss of the policy network.
-- **KL Fn**({class}`trinity.algorithm.KLFn`): Responsible for calculating KL Divergence, which is generally used in two places in existing RL algorithms: Reward Penalty and Actor Loss.
-- **Entropy Loss Fn**({class}`trinity.algorithm.EntropyLossFn`): Responsible for calculating the entropy loss of the policy network.
-
-We provide several implementations of above modules in `trinity/algorithm`.
-
----
-
-### Step 1: Implement Algorithm Components
-
-
-Trinity-RFT allows developers to customize all the above modules. Developers only need to implement specific modules according to the requirements of their new algorithm. This section will provide a simple introduction using the {ref}`OPMD ` algorithm as an example.
-
-The main difference between OPMD and PPO algorithms lies in the calculation of Advantage and Policy Loss.
-OPMD relies on a group-based advantage calculation and does not use the Critic model.
-To implement OPMD, developers need to implement advantage calculation in `AdvantageFn` and policy loss calculation in `PolicyLossFn`.
-
----
-
-#### Step 1.1: Implement `AdvantageFn`
-
-The {class}`trinity.algorithm.AdvantageFn` interface includes three methods:
-
-- `__call__`: The main entrance for advantage calculation. It receives a list of experiences ({class}`trinity.common.experience.Experience`) and returns a list of experiences with calculated advantages and returns, along with a metrics dictionary for logging.
-- `default_args`: A class method that returns the default initialization parameters in dictionary form. It will be used by default when users don't specify initialization parameters in the configuration file.
-- `compute_in_trainer`: This class method indicates whether to compute advantages in the Trainer. If it returns `False`, the `AdvantageFn` will be called in the experience data processing pipeline.
-
-For convenience, Trinity-RFT provides an abstract class {class}`trinity.algorithm.advantage_fn.GroupAdvantage` that implements the `__call__` method for group-based advantage calculation, you can focus on how to group the experiences and calculate advantages on grouped experiences with the following two methods:
-
-- `group_experiences`: This method groups a experiences generated in a step into multiple sub-groups.
-
-- `calculate_group_advantage`: This method calculates the advantage for each group of experiences.
-
-Here's an implementation example for the OPMD algorithm's advantage function:
-
-```python
-from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
-
-@ADVANTAGE_FN.register_module("opmd")
-class OPMDGroupAdvantage(GroupAdvantage):
- """OPMD Group Advantage computation"""
-
- def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
- super().__init__(**kwargs)
- self.opmd_baseline = opmd_baseline
- self.tau = tau
-
- def group_experiences(self, exps):
- return group_by(exps, id_type="task")
-
- def calculate_group_advantage(
- self, group_id: str, exps: List[Experience]
- ) -> Tuple[List[Experience], Dict]:
- with torch.no_grad():
- if len(exps) == 1:
- group_baseline = torch.tensor(0.0)
- else:
- group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
- if self.opmd_baseline == "mean":
- group_baseline = torch.mean(group_rewards)
- else:
- group_baseline = self.tau * (
- torch.logsumexp(group_rewards / self.tau, dim=-1)
- - torch.log(torch.tensor(len(exps)))
- )
- for exp in exps:
- score = exp.reward - group_baseline
- exp.advantages = score * exp.action_mask
- exp.returns = exp.advantages.clone()
- metrics = {
- "group_baseline": group_baseline.item(),
- }
- return exps, metrics
-
- @classmethod
- def default_args(cls) -> dict:
- return {"opmd_baseline": "mean", "tau": 1.0}
-```
-
-After implementation, you need to register this module through {class}`trinity.algorithm.ADVANTAGE_FN`. Once registered, the module can be configured in the configuration file using the registered name.
-
-
-#### Step 1.3: Implement `PolicyLossFn`
-
-Developers need to implement the {class}`trinity.algorithm.PolicyLossFn` interface, which is similar to `AdvantageFn` and includes two methods:
-
-- `__call__`: Calculates the loss based on input parameters. Unlike `AdvantageFn`, the input parameters here are all `torch.Tensor`. This interface automatically scans the parameter list of the `__call__` method and converts it to the corresponding fields in the experience data. Therefore, please write all tensor names needed for loss calculation directly in the parameter list, rather than selecting parameters from `kwargs`.
-- `default_args`: Returns default initialization parameters in dictionary form, which will be used by default when users don't specify initialization parameters in the configuration file.
-
-Similarly, after implementation, you need to register this module through {class}`trinity.algorithm.POLICY_LOSS_FN`.
-
-Here's an implementation example for the OPMD algorithm's Policy Loss Fn. Since OPMD's Policy Loss only requires logprob, action_mask, and advantages, only these three items are specified in the parameter list of the `__call__` method:
-
-
-```python
-@POLICY_LOSS_FN.register_module("opmd")
-class OPMDPolicyLossFn(PolicyLossFn):
- def __init__(self, tau: float = 1.0) -> None:
- self.tau = tau
-
- def __call__( # type: ignore
- self,
- logprob: torch.Tensor,
- action_mask: torch.Tensor,
- advantages: torch.Tensor,
- **kwargs,
- ) -> Tuple[torch.Tensor, Dict]:
- pg_losses = -advantages * logprob
- opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
- opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
- return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
-
- @classmethod
- def default_args(cls) -> Dict:
- return {"tau": 1.0, "loss_agg_mode": "token-mean"}
-```
-
----
-
-### Step 2: Register Your Algorithm
-
-The above steps implement the components needed for the algorithm, but these components are scattered and need to be configured in multiple places to take effect.
-
-To simplify configuration, Trinity-RFT provides {class}`trinity.algorithm.AlgorithmType` to describe a complete algorithm and registers it in {class}`trinity.algorithm.ALGORITHM_TYPE`, enabling one-click configuration.
-
-The `AlgorithmType` class includes the following attributes and methods:
-
-- `use_critic`: Whether to use the Critic model
-- `use_reference`: Whether to use the Reference model
-- `compute_advantage_in_trainer`: Whether to calculate Advantages in Trainer; if False, the `AdvantageFn` call in trainer will be skipped
-- `can_balance_batch`: Whether the algorithm allows automatic balancing when splitting a batch into microbatches (which permute the order of samples)
-- `schema`: The format of experience data corresponding to the algorithm
-- `default_config`: Gets the default configuration of the algorithm, which will override attributes with the same name in `ALGORITHM_TYPE`
-
-Similarly, after implementation, you need to register this module through `ALGORITHM_TYPE`.
-
-Below is the implementation for the OPMD algorithm.
-Since the OPMD algorithm doesn't need to use the Critic model, `use_critic` is set to `False`.
-The dictionary returned by the `default_config` method indicates that OPMD will use the `opmd` type `AdvantageFn` and `PolicyLossFn` implemented in Step 1, will not apply KL Penalty on rewards, but will add a `k2` type KL loss when calculating the final loss.
-
-```python
-@ALGORITHM_TYPE.register_module("opmd")
-class OPMDAlgorithm(AlgorithmType):
- """OPMD algorithm."""
-
- use_critic: bool = False
- use_reference: bool = True
- compute_advantage_in_trainer: bool = False
- can_balance_batch: bool = True
- schema: str = "experience"
-
- @classmethod
- def default_config(cls) -> Dict:
- return {
- "repeat_times": 2,
- "advantage_fn": "opmd",
- "sample_strategy": "warmup",
- "policy_loss_fn": "opmd",
- "kl_penalty_fn": "none",
- "kl_loss_fn": "k2",
- "entropy_loss_fn": "default",
- }
-```
-
----
-
-### Step 3: Use Your Algorithm
-
-After completing all the above steps, you can use the newly registered algorithm through a YAML configuration file.
-
-For default configurations, you just need to add the following content to your `config.yaml` file:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
-# some other configs
-```
-
-If you need to modify certain parameters, you can simply add the corresponding parameters within the `algorithm` section. For example, if you need to modify `repeat_times` and the initialization parameters of `AdvantageFn` and `PolicyLossFn`, the modified `config.yaml` file would be as follows:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
- repeat_times: 8
- advantage_fn_args:
- opmd_baseline: "logavgexp"
- tau: 0.99
- policy_loss_fn_args:
- tau: 0.99
-# some other configs
-```
-
----
-
-## Operators (For Data Developers)
-
-### Step 0: Basic Concepts of Operator Module
-
-In Trinity-RFT, the operator module is responsible for processing experience data in the buffer module. It supports existing data processing capabilities from [Data-Juicer](https://github.com/modelscope/data-juicer) naturally, and allows developers to implement their own operators as well.
-By customizing operators, developers can implement various data processing functionalities, such as data augmentation, filtering, and transformation. You can even implement advantages/returns calculation as operators, as shown in {ref}`Algorithms ` section.
-
-- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`): The operator that wraps the data processing operators from Data-Juicer. It provides a simple interface for developers to list the Data-Juicer operators they want to use. The full list of Data-Juicer operators can be found [here](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html).
-- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`): The base class for all operators used in experience data processing. It defines the interface and common functionalities that all operators should have. Each operator processes a batch of experience data and returns the processed data with metrics for logging.
-- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`): The experience data processing pipeline that manages a sequence of operators. It takes raw experiences from the `Explorer`, passes them through each operator in the pipeline, and writes the final processed experiences into the input buffer of the `Trainer`.
-
-```{note}
-Except for `ExperiencePipeline`, Trinity-RFT also provides `TaskPipeline` for task data processing.
-In the current version, the `TaskPipeline` only supports using Data-Juicer operators. Please see this {ref}`section ` for details.
-```
----
-
-Developers can implement and use their own operators by following the steps below.
-
-### Step 1: Implement Operator
-
-The `ExperienceOperator` interface includes only one `process` method. The `ExperiencePipeline` will call this method with a list of `Experience` generated by the `Explorer` in one explore step. The `process` method should return a tuple containing the processed list of `Experience` and a dictionary of metrics for logging.
-
-```python
-class ExperienceOperator(ABC):
-
- @abstractmethod
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- """Process a list of experiences and return a transformed list.
-
- Args:
- exps (List[Experience]): List of experiences to process, which contains
- all experiences generated by the Explorer in one explore step.
- Returns:
- Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
- """
-```
-
-Here is an implementation of a simple operator that filters out experiences with rewards below a certain threshold:
-
-```python
-from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
-from trinity.common.experience import Experience
-
-
-@EXPERIENCE_OPERATORS.register_module("reward_filter")
-class RewardFilter(ExperienceOperator):
-
- def __init__(self, threshold: float = 0.0) -> None:
- self.threshold = threshold
-
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
- metrics = {"filtered_count": len(exps) - len(filtered_exps)}
- return filtered_exps, metrics
-```
-
-After implementation, you need to register this module through {class}`trinity.data.operators.EXPERIENCE_OPERATORS`. Once registered, the module can be configured in the configuration file using the registered name.
-
-### Step 2: Use Your Operator
-
-After completing the above steps, you can use the newly registered operator through a YAML configuration file.
-
-```yaml
-# some other configs
-data_processor:
- experience_pipeline:
- operators:
- - name: "reward_filter"
- args:
- threshold: 0.1
-synchronizer:
- sync_method: nccl
- sync_style: dynamic_by_explorer
- sync_interval: 2
-# some other configs
-```
-
-```{tip}
-The `RewardFilter` reduces the number of experiences, which may cause the trainer can't get enough experiences to start a training step. To avoid the issue, you can use the advanced {ref}`Dynamic Synchronization ` feature provided by Trinity-RFT as shown in the above configuration file.
-The above setting means that the `Explorer` will sync with the `Trainer` every 2 steps and will continue running regardless of how many steps the `Trainer` has completed. This ensures that the `Trainer` can always get enough experiences to start a training step as long as the `Explorer` is running.
-```
-
----
-
-## Adding New Config Entries for the Config Generator (Advanced)
-
-### Step 0: Understanding Streamlit
-
-Before adding new parameters to the Config Generator page, it is essential to familiarize yourself with the relevant API and mechanisms of [Streamlit](https://docs.streamlit.io/develop/api-reference). This project primarily utilizes various input components from Streamlit and employs `st.session_state` to store user-input parameters.
-
-### Step 1: Implement New Config Entries
-
-To illustrate the process of creating a new parameter setting for the Config Generator page, we will use `train_batch_size` as an example.
-
-1. Determine the appropriate scope for the parameter. Currently, parameters are categorized into four files:
- - `trinity/manager/config_registry/buffer_config_manager.py`
- - `trinity/manager/config_registry/explorer_config_manager.py`
- - `trinity/manager/config_registry/model_config_manager.py`
- - `trinity/manager/config_registry/trainer_config_manager.py`
-
- In this case, `train_batch_size` should be placed in the `buffer_config_manager.py` file.
-
-2. Create a parameter setting function using Streamlit. The function name must follow the convention of starting with 'set_', and the remainder of the name becomes the config name.
-
-3. Decorate the parameter setting function with the `CONFIG_GENERATORS.register_config` decorator. This decorator requires the following information:
- - Default value of the parameter
- - Visibility condition (if applicable)
- - Additional config parameters (if needed)
-
-```{note}
-The `CONFIG_GENERATORS.register_config` decorator automatically passes `key=config_name` as an argument to the registered configuration function. Ensure that your function accepts this keyword argument.
-```
-
-For `train_batch_size`, we will use the following settings:
-
-- Default value: 96
-- Visibility condition: `lambda: st.session_state["trainer_gpu_num"] > 0`
-- Additional config: `{"_train_batch_size_per_gpu": 16}`
-
-Here's the complete code for the `train_batch_size` parameter:
-
-```python
-@CONFIG_GENERATORS.register_config(
- default_value=96,
- visible=lambda: st.session_state["trainer_gpu_num"] > 0,
- other_configs={"_train_batch_size_per_gpu": 16},
-)
-def set_train_batch_size(**kwargs):
- key = kwargs.get("key")
- trainer_gpu_num = st.session_state["trainer_gpu_num"]
- st.session_state[key] = (
- st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
- )
-
- def on_change():
- st.session_state["_train_batch_size_per_gpu"] = max(
- st.session_state[key] // st.session_state["trainer_gpu_num"], 1
- )
-
- st.number_input(
- "Train Batch Size",
- min_value=trainer_gpu_num,
- step=trainer_gpu_num,
- help=_str_for_train_batch_size(),
- on_change=on_change,
- **kwargs,
- )
-```
-
-If the parameter requires validation, create a check function. For `train_batch_size`, we need to ensure it is divisible by `trainer_gpu_num`. If not, a warning should be displayed, and the parameter should be added to `unfinished_fields`.
-
-Decorate the check function with the `CONFIG_GENERATORS.register_check` decorator:
-
-```python
-@CONFIG_GENERATORS.register_check()
-def check_train_batch_size(unfinished_fields: set, key: str):
- if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
- unfinished_fields.add(key)
- st.warning(_str_for_train_batch_size())
-```
-
-```{note}
-The `CONFIG_GENERATORS.register_check` decorator automatically receives `key=config_name` and `unfinished_fields=self.unfinished_fields` as arguments. Ensure your function accepts these keyword arguments.
-```
-
-### Step 2: Integrating New Parameters into `config_manager.py`
-
-To successfully integrate new parameters into the `config_manager.py` file, please adhere to the following procedure:
-
-1. Parameter Categorization:
- Determine the appropriate section for the new parameter based on its functionality. The config generator page is structured into two primary modes:
- - Beginner Mode: Comprises "Essential Configs" and "Important Configs" sections.
- - Expert Mode: Includes "Model", "Buffer", "Explorer and Synchronizer", and "Trainer" sections.
-
-2. Parameter Addition:
- Incorporate the new parameter into the relevant section using the `self.get_configs` method within the `ConfigManager` class.
-
- Example:
-
- ```python
- class ConfigManager:
- def _expert_buffer_part(self):
- self.get_configs("total_epochs", "train_batch_size")
- ```
-
-3. YAML File Integration:
- Locate the appropriate position for the new parameter within the YAML file structure. This should be done in the `generate_config` function and its associated sub-functions.
-
-4. Parameter Value Assignment:
- Utilize `st.session_state` to retrieve the parameter value from the config generator page and assign it to the corresponding field in the YAML.
-
- Example:
-
- ```python
- class ConfigManager:
- def _gen_buffer_config(self):
- buffer_config = {
- "batch_size": st.session_state["train_batch_size"],
- # Additional configuration parameters
- }
- ```
-
-By meticulously following these steps, you can ensure that new parameters are successfully added to the Config Generator page and properly integrated into the configuration system. This process maintains the integrity and functionality of the configuration management framework.
-
----
-
-## Contributing your Code
-
-For modules that are prepared to be contributed to the Trinity-RFT project, please follow the steps below:
-
-1. Implement your code in the appropriate directory, such as `trinity/common/workflows` for workflows, `trinity/algorithm` for algorithms, `trinity/buffer/operators` for operators.
-
-2. Register your module in the corresponding `__init__.py` file of the directory.
-
-3. Add tests for your module in the `tests` directory, following the naming conventions and structure of existing tests.
-
-4. Before submitting the code, make sure it passes the code style check with `pre-commit run --all-files`.
-
-5. Submit a pull request to the Trinity-RFT repository, including a clear description of your changes.
diff --git a/docs/sphinx_doc/source_zh/index.rst b/docs/sphinx_doc/source_zh/index.rst
index a05d73ebf1..3e0a929e08 100644
--- a/docs/sphinx_doc/source_zh/index.rst
+++ b/docs/sphinx_doc/source_zh/index.rst
@@ -8,12 +8,26 @@
.. include:: main.md
:parser: myst_parser.sphinx_
+.. toctree::
+ :maxdepth: 2
+ :glob:
+ :hidden:
+ :caption: 教程
+
+ tutorial/trinity_installation.md
+ tutorial/develop_overview.md
+ tutorial/develop_workflow.md
+ tutorial/develop_algorithm.md
+ tutorial/example_mix_algo.md
+ tutorial/develop_operator.md
+ tutorial/trinity_configs.md
+ tutorial/synchronizer.md
.. toctree::
:maxdepth: 1
:glob:
:hidden:
- :caption: 教程
+ :caption: 样例
tutorial/example_reasoning_basic.md
tutorial/example_reasoning_advanced.md
@@ -26,17 +40,6 @@
tutorial/example_megatron.md
tutorial/example_data_functionalities.md
-.. toctree::
- :maxdepth: 2
- :glob:
- :hidden:
- :caption: 帮助文档
-
- tutorial/trinity_programming_guide.md
- tutorial/trinity_configs.md
- tutorial/example_mix_algo.md
- tutorial/synchronizer.md
-
.. toctree::
:maxdepth: 2
:hidden:
diff --git a/docs/sphinx_doc/source_zh/main.md b/docs/sphinx_doc/source_zh/main.md
index 2c39a5c75c..eb89d59d17 100644
--- a/docs/sphinx_doc/source_zh/main.md
+++ b/docs/sphinx_doc/source_zh/main.md
@@ -1,43 +1,32 @@
-## 🚀 新闻
-
-* [2025-09] ✨ [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.3.0)] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
-* [2025-08] 🎵 推出 [CHORD](https://github.com/modelscope/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
-* [2025-08] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.1)] Trinity-RFT v0.2.1 发布。
-* [2025-07] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.2.0)] Trinity-RFT v0.2.0 发布。
-* [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
-* [2025-06] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.1)] Trinity-RFT v0.1.1 发布。
-* [2025-05] [[发布说明](https://github.com/modelscope/Trinity-RFT/releases/tag/v0.1.0)] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
-* [2025-04] Trinity-RFT 开源。
-
-
## 💡 什么是 Trinity-RFT?
-Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。它支持广泛的应用场景,并为 [Experience 时代](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf) 的 RL 研究提供统一平台。
-
-RFT 流程被模块化为三个核心组件:
+Trinity-RFT 是一个灵活、通用的大语言模型(LLM)强化微调(RFT)框架。其提供三个独立模块,满足不同用户的需求:
-* **Explorer**:负责智能体与环境的交互
-* **Trainer**:负责模型训练
-* **Buffer**:负责数据存储与处理
+* 🤖 **Explorer**:面向智能体应用开发者。[[教程]](/tutorial/develop_workflow.md)
+ - 训练智能体应用,以增强其在指定环境中完成任务的能力
+ - 示例:[多轮交互](/tutorial/example_multi_turn.md),[ReAct 智能体](/tutorial/example_react.md)
+* 🧠 **Trainer**:面向 RL 算法研究者。[[教程]](/tutorial/develop_algorithm.md)
+ - 在简洁、可插拔的类中设计和验证新的 RL 算法
+ - 示例:[混合 RL 算法](/tutorial/example_mix_algo.md)
-
+* 🗄️ **Buffer**:面向数据工程师。[[教程]](/tutorial/develop_operator.md)
+ - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景
+ - 示例:[数据功能](/tutorial/example_data_functionalities.md)
-
-
-## ✨ 核心特性
+Trinity-RFT 统一了上述三个模块,并提供以下核心特性:
* **灵活的 RFT 模式:**
- 支持同步/异步、on-policy/off-policy 以及在线/离线训练。采样与训练可分离运行,并可在多设备上独立扩展。
-* **兼容 Agent 框架的工作流:**
- - 支持拼接式和通用多轮智能体工作流。可自动收集来自模型 API 客户端(如 OpenAI)的训练数据,并兼容 AgentScope 等智能体框架。
+* **通用 Agentic-RL:**
+ - 支持拼接式和通用多轮交互,能够直接训练使用 AgentScope 等智能体框架开发的 Agent 应用。
-* **强大的数据流水线:**
+* **全流程的数据流水线:**
- 支持 rollout 和经验数据的流水线处理,贯穿 RFT 生命周期实现主动管理(优先级、清洗、增强等)。
@@ -47,22 +36,6 @@ RFT 流程被模块化为三个核心组件:
-
-
-
-## 🛠️ Trinity-RFT 能做什么?
-
-* **用 RL 训练智能体应用**
- - 在 Workflow 中实现智能体-环境交互逻辑 ([示例1](tutorial/example_multi_turn.md),[示例2](tutorial/example_step_wise.md)),
- - 或直接使用 Agent 框架(如 AgentScope)编写好的工作流 ([示例](tutorial/example_react.md))。
-
-* **快速设计和验证 RL 算法**
- - 在简洁、可插拔的类中开发自定义 RL 算法(损失、采样及其他技巧) ([教程](tutorial/trinity_programming_guide.md#algorithms-for-rl-algorithm-developers),[示例](tutorial/example_mix_algo.md))。
-
-* **为 RFT 定制数据集和数据流水线**
- - 设计任务定制数据集,构建数据流水线以支持清洗、增强和人类参与场景 ([教程](tutorial/trinity_programming_guide.md#operators-for-data-developers),[示例](tutorial/example_data_functionalities.md))。
-
-
## 致谢
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md b/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md
new file mode 100644
index 0000000000..d003d6e2fd
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_algorithm.md
@@ -0,0 +1,214 @@
+(Algorithms)=
+## Algorithm 开发指南
+
+在 Trinity-RFT 中,Algorithm 模块主要负责在 RL 过程中从 Buffer 提取 experience 数据,并基于这些数据计算损失以更新模型。为了避免每次添加新算法时都实现新的 Trainer 类,我们将典型的 PPO 算法流程分解为多个子模块,以适应各种 RL 算法。
+
+### 步骤 0:Algorithm 子模块概览
+
+Trinity-RFT 将 Algorithm 模块拆分为以下几个子模块:
+
+- **采样策略(Sample Strategy)** ({class}`trinity.algorithm.SampleStrategy`):负责从缓冲区模块中采样 experience 数据。通过自定义此模块,你可以实现过滤 experience 数据或从多个数据源混合采样的功能。
+- **优势函数(Advantage Fn)**({class}`trinity.algorithm.AdvantageFn`):负责计算 experience 数据的优势值(Advantage)和回报值(Returns)。
+- **策略损失函数(Policy Loss Fn)**({class}`trinity.algorithm.PolicyLossFn`):负责计算策略网络的核心训练损失。
+- **KL 函数(KL Fn)**({class}`trinity.algorithm.KLFn`):负责计算 KL 散度,通常在现有 RL 算法中用于两个地方:奖励惩罚和 Actor 损失。
+- **熵损失函数(Entropy Loss Fn)**({class}`trinity.algorithm.EntropyLossFn`):负责计算策略网络的熵损失。
+
+我们在 `trinity/algorithm` 中提供了上述模块的若干实现。
+
+---
+
+### 步骤 1:实现算法组件
+
+Trinity-RFT 允许开发者自定义所有上述模块。开发者只需根据新算法的需求实现特定模块。本节将以 {ref}`OPMD ` 算法为例进行简要介绍。
+
+OPMD 与 PPO 算法的主要区别在于优势值和策略损失的计算。OPMD 依赖于基于组的优势值计算,且不使用 Critic 模型。为此,开发者需要实现新的优势函数 (`AdvantageFn`) 以及策略损失函数 (`PolicyLossFn`)。
+
+---
+
+#### 步骤 1.1:实现 `AdvantageFn`
+
+{class}`trinity.algorithm.AdvantageFn` 接口包含三个方法:
+
+- `__call__`:优势值计算的主要入口。接收一个 experience 列表 ({class}`trinity.common.experience.Experience`),返回一个包含计算出的优势值和回报值的 experience 列表,以及一个用于日志记录的指标字典。
+- `default_args`:类方法,返回默认初始化参数(字典形式)。当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
+- `compute_in_trainer`:类方法,指示是否在 Trainer 中计算优势值。若返回 `False`,则 `AdvantageFn` 将在 experience 数据处理流水线中被调用。
+
+为方便起见,Trinity-RFT 提供了一个抽象类 {class}`trinity.algorithm.advantage_fn.GroupAdvantage`,它实现了基于组的优势值计算的 `__call__` 方法,你可以专注于如何对 experience 进行分组以及如何在分组后的 experience 上计算优势值,通过以下两个方法实现:
+
+- `group_experiences`:此方法将一步生成的 experience 划分为多个子组。
+
+- `calculate_group_advantage`:此方法计算每组 experience 的优势值。
+
+以下是 OPMD 算法优势函数的实现示例:
+
+```python
+from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
+
+@ADVANTAGE_FN.register_module("opmd")
+class OPMDGroupAdvantage(GroupAdvantage):
+ """OPMD Group Advantage computation"""
+
+ def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.opmd_baseline = opmd_baseline
+ self.tau = tau
+
+ def group_experiences(self, exps):
+ return group_by(exps, id_type="task")
+
+ def calculate_group_advantage(
+ self, group_id: str, exps: List[Experience]
+ ) -> Tuple[List[Experience], Dict]:
+ with torch.no_grad():
+ if len(exps) == 1:
+ group_baseline = torch.tensor(0.0)
+ else:
+ group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
+ if self.opmd_baseline == "mean":
+ group_baseline = torch.mean(group_rewards)
+ else:
+ group_baseline = self.tau * (
+ torch.logsumexp(group_rewards / self.tau, dim=-1)
+ - torch.log(torch.tensor(len(exps)))
+ )
+ for exp in exps:
+ score = exp.reward - group_baseline
+ exp.advantages = score * exp.action_mask
+ exp.returns = exp.advantages.clone()
+ metrics = {
+ "group_baseline": group_baseline.item(),
+ }
+ return exps, metrics
+
+ @classmethod
+ def default_args(cls) -> dict:
+ return {"opmd_baseline": "mean", "tau": 1.0}
+```
+
+实现后,你需要通过 {class}`trinity.algorithm.ADVANTAGE_FN` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
+
+#### 步骤 1.2:实现 `PolicyLossFn`
+
+开发者需要实现 {class}`trinity.algorithm.PolicyLossFn` 接口,其与 `AdvantageFn` 类似,包含两个方法:
+
+- `__call__`:根据输入参数计算损失。与 `AdvantageFn` 不同,这里的输入参数均为 `torch.Tensor`。该接口会自动扫描 `__call__` 方法的参数列表,并将其转换为 experience 数据中的对应字段。因此,请直接在参数列表中写出损失计算所需的所有张量名称,而不是从 `kwargs` 中选择参数。
+- `default_args`:返回默认初始化参数(字典形式),当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
+
+同样,实现后需要通过 {class}`trinity.algorithm.POLICY_LOSS_FN` 注册此模块。
+
+以下是 OPMD 算法策略损失函数的实现示例。由于 OPMD 的策略损失仅需 logprob、action_mask 和 advantages,因此 `__call__` 方法的参数列表中仅指定这三个项:
+
+```python
+@POLICY_LOSS_FN.register_module("opmd")
+class OPMDPolicyLossFn(PolicyLossFn):
+ def __init__(
+ self, backend: str = "verl", tau: float = 1.0, loss_agg_mode: str = "token-mean"
+ ) -> None:
+ super().__init__(backend=backend)
+ self.tau = tau
+ self.loss_agg_mode = loss_agg_mode
+
+ def __call__( # type: ignore
+ self,
+ logprob: torch.Tensor,
+ action_mask: torch.Tensor,
+ advantages: torch.Tensor,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Dict]:
+ pg_losses = -advantages * logprob
+ opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
+ opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
+ return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
+
+ @classmethod
+ def default_args(cls) -> Dict:
+ return {"tau": 1.0}
+```
+
+---
+
+### 步骤 2:注册新算法
+
+上述步骤实现了算法所需的组件,但这些组件是分散的,需要在多个地方配置才能生效。
+
+为简化配置,Trinity-RFT 提供了 {class}`trinity.algorithm.AlgorithmType` 来描述完整算法,并在 {class}`trinity.algorithm.ALGORITHM_TYPE` 中注册,实现一键配置。
+
+`AlgorithmType` 类包含以下属性和方法:
+
+- `use_critic`:是否使用 Critic 模型
+- `use_reference`:是否使用 Reference 模型
+- `compute_advantage_in_trainer`:是否在 Trainer 中计算优势值;若为 False,则跳过 Trainer 中的 `AdvantageFn` 调用
+- `can_balance_batch`:算法是否允许在将批次拆分为微批次时自动平衡(打乱样本顺序)
+- `schema`:算法对应的 experience 数据格式
+- `default_config`:获取算法的默认配置,将覆盖 `ALGORITHM_TYPE` 中同名属性
+
+同样,实现后需要通过 `ALGORITHM_TYPE` 注册此模块。
+
+以下是 OPMD 算法的实现。
+由于 OPMD 算法不需要使用 Critic 模型,`use_critic` 设置为 `False`。
+`default_config` 方法返回的字典表明 OPMD 将使用步骤 1 中实现的 `opmd` 类型的 `AdvantageFn` 和 `PolicyLossFn`,不会对奖励应用 KL 惩罚,但在计算最终损失时会添加 `k2` 类型的 KL 损失。
+
+```python
+@ALGORITHM_TYPE.register_module("opmd")
+class OPMDAlgorithm(AlgorithmType):
+ """OPMD algorithm."""
+
+ use_critic: bool = False
+ use_reference: bool = True
+ compute_advantage_in_trainer: bool = False
+ can_balance_batch: bool = True
+ schema: str = "experience"
+
+ @classmethod
+ def default_config(cls) -> Dict:
+ return {
+ "repeat_times": 2,
+ "advantage_fn": "opmd",
+ "sample_strategy": "warmup",
+ "policy_loss_fn": "opmd",
+ "kl_penalty_fn": "none",
+ "kl_loss_fn": "k2",
+ "entropy_loss_fn": "default",
+ }
+```
+
+
+```{tip}
+为了保证注册生效,请确保在对应的 __init__.py 文件中导入了新实现的模块,例如:
+
+- 在 `trinity/algorithm/advantage_fn/__init__.py` 中导入 `OPMDGroupAdvantage`
+- 在 `trinity/algorithm/policy_loss_fn/__init__.py` 中导入 `OPMDPolicyLossFn`
+- 在 `trinity/algorithm/__init__.py` 中导入 `OPMDAlgorithm`
+
+也可以将这些类放在 `trinity/plugins` 目录下,Trinity-RFT 会在启动时自动加载 `plugins` 目录中的所有模块,无需在 `__init__.py` 中导入。
+```
+
+---
+
+### 步骤 3:使用新算法
+
+完成上述所有步骤后,你可以通过 YAML 配置文件使用新注册的算法。
+
+对于默认配置,你只需在 `config.yaml` 文件中添加以下内容:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+# some other configs
+```
+
+如果需要修改某些参数,可以在 `algorithm` 部分直接添加对应参数。例如,若需要修改 `repeat_times` 以及 `AdvantageFn` 和 `PolicyLossFn` 的初始化参数,修改后的 `config.yaml` 文件如下:
+
+```yaml
+# some other configs
+algorithm:
+ algorithm_type: "opmd"
+ repeat_times: 8
+ advantage_fn_args:
+ opmd_baseline: "logavgexp"
+ tau: 0.99
+ policy_loss_fn_args:
+ tau: 0.99
+# some other configs
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_operator.md b/docs/sphinx_doc/source_zh/tutorial/develop_operator.md
new file mode 100644
index 0000000000..692e6432f2
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_operator.md
@@ -0,0 +1,84 @@
+(Operators)=
+## Operator 开发指南
+
+
+### 步骤 0:Operator 模块基本概念
+
+Operator 模块负责处理由 Explorer 所生成的轨迹数据(我们称之为 `Experience`)。它原生支持来自 [Data-Juicer](https://github.com/modelscope/data-juicer) 的数据处理功能,也允许开发者实现自己的算子。
+通过自定义数据处理算子,开发者可以实现各种数据处理功能,如数据增强、过滤和转换。你甚至可以将优势值/回报值计算实现为 Operator,如 {ref}`算法 ` 部分所示。
+
+- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`):封装后的 Data-Juicer 算子,使用时只需在配置文件中标明想要使用的 Data-Juicer 算子列表即可。完整的 Data-Juicer 算子列表请见 [此处](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html)。
+- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`):用于 experience 数据处理的所有数据处理算子的基类。定义了所有数据处理算子应具备的接口和通用功能。每个算子处理一批 experience 数据,并返回处理后的数据及用于日志记录的指标。
+- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`):管理一系列数据处理算子的 experience 数据处理流水线。它从 `Explorer` 获取原始 experience,通过流水线中的每个算子处理,最后将最终处理过的 experience 写入 `Trainer` 的输入缓冲区。
+
+```{note}
+除了 `ExperiencePipeline`,Trinity-RFT 还提供 `TaskPipeline` 用于任务数据处理。
+当前版本中,`TaskPipeline` 仅支持使用 Data-Juicer 算子。详情请参见 {ref}`数据处理 ` 部分。
+```
+---
+
+开发者可通过以下步骤实现并使用自己的算子。
+
+### 步骤 1:实现数据处理算子
+
+`ExperienceOperator` 接口仅包含一个 `process` 方法。`ExperiencePipeline` 将调用此方法,传入 `Explorer` 在一次探索步骤中生成的一组 `Experience`。`process` 方法应返回一个元组,包含处理后的 `Experience` 列表和用于日志记录的指标字典。
+
+```python
+class ExperienceOperator(ABC):
+
+ @abstractmethod
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ """Process a list of experiences and return a transformed list.
+
+ Args:
+ exps (List[Experience]): List of experiences to process, which contains
+ all experiences generated by the Explorer in one explore step.
+ Returns:
+ Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
+ """
+```
+
+以下是一个简单数据处理算子的实现示例,该算子过滤掉奖励低于某一阈值的 experience:
+
+```python
+from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
+from trinity.common.experience import Experience
+
+
+@EXPERIENCE_OPERATORS.register_module("reward_filter")
+class RewardFilter(ExperienceOperator):
+
+ def __init__(self, threshold: float = 0.0) -> None:
+ self.threshold = threshold
+
+ def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
+ filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
+ metrics = {"filtered_count": len(exps) - len(filtered_exps)}
+ return filtered_exps, metrics
+```
+
+实现后,你需要通过 {class}`trinity.data.operators.EXPERIENCE_OPERATORS` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
+
+### 步骤 2:使用此算子
+
+完成上述步骤后,你可以通过 YAML 配置文件使用新注册的算子。
+
+```yaml
+# some other configs
+data_processor:
+ experience_pipeline:
+ operators:
+ - name: "reward_filter"
+ args:
+ threshold: 0.1
+synchronizer:
+ sync_method: nccl
+ sync_style: dynamic_by_explorer
+ sync_interval: 2
+# some other configs
+```
+
+```{tip}
+`RewardFilter` 会减少 experience 数量,可能导致 Trainer 无法获得足够的 experience 来启动训练流程。为避免此问题,你可以使用 Trinity-RFT 提供的 {ref}`动态同步 ` 功能 (`dynamic_by_explorer`)。
+上述设置意味着 `Explorer` 每运行 2 步就会与 `Trainer` 同步一次,且无论 `Trainer` 当前完成了多少步都会继续运行。这确保了只要 `Explorer` 在运行,`Trainer` 就总能获得足够的 experience 来启动训练步骤。
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_overview.md b/docs/sphinx_doc/source_zh/tutorial/develop_overview.md
new file mode 100644
index 0000000000..9e79780758
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_overview.md
@@ -0,0 +1,31 @@
+# 开发者指南
+
+Trinity-RFT 将 RL 训练过程拆分为了三个模块:**Explorer**、**Trainer** 和 **Buffer**。
+
+其中 Explorer 提供了能够自定义智能体与环境交互的 `Workflow` 接口,Trainer 提供了能够自定义 RL 算法的 `Algorithm` 接口,Buffer 提供了能够自定义数据处理算子的 `Operator` 接口。
+
+下表列出了各扩展接口的主要目标用户、功能以及对应的开发教程。开发者可以参考对应的模块开发教程,并根据自身需求对 Trinity-RFT 进行扩展。
+
+| 扩展接口 | 目标用户 | 主要功能 | 教程链接 |
+|--------------|----------------|-----------------------------------|------------------|
+| `Workflow` | 智能体应用开发者 | 提升 Agent 在指定环境中完成任务的能力 | [🔗](./develop_workflow.md) |
+| `Algorithm` | RL 算法研究者 | 设计新的 RL 算法 | [🔗](./develop_algorithm.md) |
+| `Operator` | 数据工程师 | 设计新的数据清洗、增强策略 | [🔗](./develop_operator.md) |
+
+```{tip}
+Trinity-RFT 提供了插件化的开发方式,可以在不修改框架代码的前提下,灵活地添加自定义模块。
+开发者可以将自己编写的模块代码放在 `trinity/plugins` 目录下。Trinity-RFT 会在运行时自动加载该目录下的所有 Python 文件,并注册其中的自定义模块。
+Trinity-RFT 也支持在运行时通过设置 `--plugin-dir` 选项来指定其他目录,例如:`trinity run --config --plugin-dir `。
+```
+
+对于准备向 Trinity-RFT 提交的模块,请遵循以下步骤:
+
+1. 在适当目录中实现你的代码,例如 `trinity/common/workflows` 用于 `Workflow`,`trinity/algorithm` 用于 `Algorithm`,`trinity/buffer/operators` 用于 `Operator`。
+
+2. 在目录对应的 `__init__.py` 文件中注册你的模块。
+
+3. 在 `tests` 目录中为你的模块添加测试,遵循现有测试的命名约定和结构。
+
+4. 提交代码前,确保通过 `pre-commit run --all-files` 完成代码风格检查。
+
+5. 向 Trinity-RFT 仓库提交 Pull Request,在描述中详细说明你的模块功能和用途。
diff --git a/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md b/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md
new file mode 100644
index 0000000000..9e45393a78
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/develop_workflow.md
@@ -0,0 +1,291 @@
+(Workflows)=
+## Workflow 开发指南
+
+在 Trinity-RFT 中,工作流(Workflow)是定义 Agent 与 Environment 之间交互的核心组件。
+一个合格的工作流需要使用训练好的模型完成指定任务,并从环境中获取反馈信息(奖励)。以下是创建新工作流的步骤:
+
+---
+
+### 步骤 0:基本概念
+
+在开始开发之前,理解以下几个核心概念非常重要:
+
+- **任务(Task)** ({class}`trinity.common.workflows.Task`):表示可转换为 `Workflow` 的数据结构。`Task` 的内容根据任务类型而异:
+ - **数学问题**:`Task` 包含问题描述和标准答案。
+ - **编程场景**:`Task` 包括问题描述、测试用例、运行环境等复杂信息。
+
+- **工作流(Workflow)** ({class}`trinity.common.workflows.Workflow`):描述 `Task` 如何执行。它定义了 Agent 与 Environment 的交互流程,包括类似其他框架中的 *Rollout* 和 *Reward* 计算逻辑。执行后生成一组 `Experience`。Trinity-RFT 包含多个内置工作流:
+ - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`):用于数学场景,将问题提交给 LLM,解析 LLM 响应,并计算分数(奖励)。
+ - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`):用于 webshop 场景,包含与环境的多轮交互。
+ - `AgentScopeReactMathWorkflow` ({class}`trinity.common.workflows.AgentScopeReactMathWorkflow`):用于数学场景,直接使用现有的 ReActAgent(基于 AgentScope)来解决数学问题。
+
+- **经验(Experience)** ({class}`trinity.common.experience.Experience`):运行 `Workflow` 的输出。内部数据格式取决于所使用的训练算法。例如,对于常见的 PPO/GRPO 算法,`Experience` 包含 token ID 列表、动作掩码(标识哪些 token 是由 LLM 生成的)、对数概率、奖励等。
+
+---
+
+### 步骤 1:准备任务数据集
+
+任务数据集通过 YAML 配置文件中的 `buffer.explorer_input.taskset` 配置项加载。
+为处理 `Task` 内容的差异,Trinity-RFT 提供了一个统一的 `Task` 接口,包含以下字段:
+
+- **`workflow`** (`str`):你的工作流类的注册名称。你可以在 YAML 配置文件的 `buffer.explorer_input.taskset.default_workflow_type` 中指定。
+- **`reward_fn`** (`Optional[str]`):你的奖励函数的注册名称。你可以在 `buffer.explorer_input.taskset.default_reward_fn_type` 中指定。注意某些工作流已内置奖励计算;此时可省略该字段。
+- **`raw_task`** (`Dict`):原始数据的记录,以 `Dict` 格式存储。对于高度定制化的工作流,你可以直接使用 `raw_task` 初始化 `Workflow` 实例,而不依赖以下字段。
+- **`format_args`** ({class}`trinity.common.config.FormatConfig`):便于构造 `Workflow` 实例的参数。例如,`prompt_key` 和 `response_key` 可用于从 `raw_task` 中提取 prompt 和 response。这些设置来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.format` 中设置。
+- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`):控制 rollout 过程的参数,如 `temperature`。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.rollout_args` 中设置。
+- **`workflow_args`** (`Dict`):用于构造 `Workflow` 实例的参数字典。相比 `format_args` 和 `rollout_args` 更灵活。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.workflow_args` 中设置。通常无需设置此字段。
+
+```{tip}
+`workflow`、`workflow_args` 和 `raw_task` 提供了不同级别的自定义能力。
+
+- `workflow` 为使用相同工作流的所有任务提供全局设置。(全局级别)
+- `workflow_args` 可为每个任务数据集设置,允许使用相同工作流的不同任务数据集表现出不同行为。(数据集级别)
+- `raw_task` 提供对每个任务行为的自定义能力,最为灵活。(数据样本级别)
+```
+
+在数学问题场景中,`Task` 数据集可以是一个 `jsonl` 文件,每行包含带有 `question` 和 `answer` 字段的 JSON,分别表示问题描述和标准答案。例如:
+
+```json
+{"question": "1+1=", "answer": "2"}
+{"question": "2+2=", "answer": "4"}
+...
+```
+
+配置示例片段:
+
+```yaml
+# some config
+buffer:
+ explorer_input:
+ taskset:
+ default_workflow: "math_workflow"
+ path: ${oc.env:TRINITY_TASKSET_PATH}
+ format:
+ prompt_key: "question"
+ response_key: "answer"
+ rollout_args:
+ temperature: 1.0
+ # some other configs
+```
+
+在此示例中,每个任务对象的 `raw_task` 是一个包含两个键(`question` 和 `answer`)的 `Dict`。`MathWorkflow` 使用 `prompt_key` 和 `response_key` 从 `raw_task` 中提取问题和答案,并使用 `rollout_args` 生成响应。
+
+---
+
+### 步骤 2:实现新的工作流
+
+`Workflow` 基类接口如下:
+
+```python
+class Workflow(ABC):
+
+ def __init__(
+ self,
+ *,
+ task: Task,
+ model: ModelWrapper,
+ auxiliary_models: Optional[List[openai.OpenAI]] = None,
+ ):
+ self.task = task
+ self.model = model
+ self.auxiliary_models = auxiliary_models
+
+ @abstractmethod
+ def run(self) -> List[Experience]:
+ """Run the workflow and return a list of Experiences."""
+```
+
+#### 初始化你的工作流
+
+`Workflow` 接受以下初始化参数:
+
+- `task`({class}`trinity.common.workflows.Task`):数据集中的单个任务。
+- `model`({class}`trinity.common.models.model.ModelWrapper`):正在训练的模型,提供类似于 OpenAI 的接口,能够接收对话消息列表并返回 LLM 生成的内容(包括回复文本 `response_text`、完整序列 token id `tokens`、prompt 部分 token 长度 `prompt_length`,以及输出 token 对数概率列表 `logprobs`)。
+- `auxiliary_models`(`List[openai.OpenAI]`):未参与训练的辅助模型列表。所有模型均通过兼容 OpenAI 的 API 提供。
+
+```{tip}
+你可以在配置文件中将 `explorer.rollout_model.enable_openai_api` 设置为 `true`,并在工作流中调用 `model.get_openai_client()` 获取 `openai.OpenAI` 实例,从而切换为使用 OpenAI API。
+调用 OpenAI API 时,`model` 字段可通过 `openai_client.models.list().data[0].id` 或 `openai_client.model_path` 获取。
+```
+
+以下是一个仅使用 `raw_task` 和 `rollout_args` 初始化简单工作流的示例。在更复杂的情况下,你可以使用 `format_args` 进行进一步自定义。
+
+```python
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+ # Optional: If you want to use OpenAI API in your workflow
+ # self.openai_client = self.model.get_openai_client()
+```
+
+#### 实现 `run` 方法
+
+`run` 方法是工作流的核心方法。它返回一个 `Experience` 列表。
+以下是一个数学工作流的简单实现。
+
+我们首先调用模型,使用给定的问题和 rollout 参数生成多个响应。
+然后使用 `calculate_reward` 函数计算每个响应的奖励。
+最后,我们构建一个包含响应和奖励的 `Experience` 列表并返回。
+
+```python
+class ExampleWorkflow(Workflow):
+
+ # the __init__ function
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+```
+
+#### 注册你的工作流
+
+使用 `WORKFLOWS.register_module` 装饰器注册你的工作流。
+确保名称不与现有工作流冲突。
+
+```python
+# import some packages
+from trinity.common.workflows.workflow import WORKFLOWS
+
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ pass
+```
+
+对于准备贡献给 Trinity-RFT 项目的模块,你需要将上述代码放入 `trinity/common/workflows` 文件夹中,例如 `trinity/common/workflows/example_workflow.py`。并在 `trinity/common/workflows/__init__.py` 中添加以下行:
+
+```python
+# existing import lines
+from .example_workflow import ExampleWorkflow
+
+__all__ = [
+ # existing __all__ lines
+ "ExampleWorkflow",
+]
+```
+
+#### 避免重复初始化
+
+对于重型工作流,每次重新初始化会带来额外计算开销。
+此时,你可以实现 `resettable` 和 `reset` 方法以避免重复初始化。
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+ # some code
+ # ...
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+#### 完整代码示例
+
+```python
+@WORKFLOWS.register_module("example_workflow")
+class ExampleWorkflow(Workflow):
+
+ def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
+ super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+ self.rollout_args = task.rollout_args
+
+ def calculate_reward(self, response: str, truth: str) -> float:
+ if response == truth:
+ return 1.0
+ else:
+ return 0.0
+
+ def run(self) -> List[Experience]:
+ # call the model to generate multiple responses
+ responses = self.model.chat(
+ [
+ {
+ "role": "user",
+ "content": f"Question:\n{self.question}",
+ }
+ ],
+ n=self.rollout_args.n,
+ temperature=self.rollout_args.temperature,
+ )
+ experiences = []
+ for response in responses:
+ # calulcate reward
+ reward: float = self.calculate_reward(response.response_text, self.answer)
+ # construct Experience
+ experiences.append(
+ Experience(
+ tokens=response.tokens,
+ prompt_length=response.prompt_length,
+ reward=reward,
+ logprobs=response.logprobs,
+ )
+ )
+ return experiences
+
+ def resettable(self):
+ return True
+
+ def reset(self, task: Task):
+ self.question = task.raw_task.get("question")
+ self.answer = task.raw_task.get("answer")
+```
+
+---
+
+### 步骤 3:使用你的工作流
+
+实现并注册工作流后,你需要更新配置文件,将 `buffer.explorer_input.taskset` 域中的 `default_workflow_type` 设置为新注册的 `Workflow` 名称。
+
+```yaml
+buffer:
+ # Other fields
+ explorer_input:
+ taskset:
+ path: /path/to/taskset
+ default_workflow_type: example_workflow
+ # Other fields
+```
+
+现在你可以使用以下命令在 Trinity-RFT 中运行你的工作流:
+
+```
+trinity run --config
+```
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_megatron.md b/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
index befbb7f5d6..1c34b27cb4 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_megatron.md
@@ -1,7 +1,12 @@
+(Megatron-LM)=
# Megatron-LM 支持
本指南将清晰地引导你如何使用 **Megatron-LM** 来训练模型。
+```{note}
+本指南假设你已经按照 {ref}`安装指南 ` 设置好了环境。如果还没有,请先参考该指南。
+```
+
---
## 步骤 1:安装
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md b/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
index 66272d1559..4c0b575fd5 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_mix_algo.md
@@ -1,10 +1,6 @@
-# 集成新算法
+# Algorithm 进阶开发
-```{note}
-本指南是开发者指南中 {ref}`算法模块 ` 部分的进阶版本。
-```
-
-本指南介绍了如何将新算法集成到 Trinity-RFT 中。
+本指南将会介绍如何将相对复杂的 RL 算法集成到 Trinity-RFT 中。
作为示例,我们引入了由更高级别的 LLM 生成的一些“专家”数据,并提出了一种名为 MIX 的算法,该算法优化以下策略目标:
$$
diff --git a/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md b/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
index a98fff2b69..961c9c43c6 100644
--- a/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
+++ b/docs/sphinx_doc/source_zh/tutorial/example_reasoning_basic.md
@@ -4,61 +4,7 @@
## 第 0 步:环境准备
-最低环境要求:
-
-- GPU:至少 2 块 GPU
-- CUDA:版本 >= 12.4
-- Python:版本 >= 3.10
-
-```shell
-# 从 GitHub 拉取源码
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# 使用 Conda 或 venv 创建新环境
-# 选项 1: Conda
-conda create -n trinity python=3.10
-conda activate trinity
-
-# 选项 2: venv
-python3.10 -m venv .venv
-source .venv/bin/activate
-
-# 以可编辑模式安装包
-# 对于 bash
-pip install -e .[dev]
-# 对于 zsh
-pip install -e .\[dev\]
-
-# 在所有依赖安装完成后安装 flash-attn
-# 注意:flash-attn 编译时间较长,请耐心等待。
-pip install flash-attn -v
-# 如果安装过程中遇到错误,可尝试以下命令
-# pip install flash-attn -v --no-build-isolation
-```
-
-使用 pip 安装:
-
-```shell
-pip install trinity-rft
-```
-
-通过 Docker 安装:
-
-我们为 Trinity-RFT 提供了 Dockerfile。
-
-```shell
-git clone https://github.com/modelscope/Trinity-RFT
-cd Trinity-RFT
-
-# 构建 Docker 镜像
-# 注意:你可以编辑 Dockerfile 来自定义环境
-# 例如,使用 pip 镜像或设置 API key
-docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
-
-# 运行 Docker 镜像
-docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v :/data trinity-rft:latest
-```
+请按照[安装指南](./trinity_installation.md)中的说明进行环境设置。
## 第 1 步:模型和数据准备
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md b/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
index b7151020de..1f2ed9f114 100644
--- a/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
+++ b/docs/sphinx_doc/source_zh/tutorial/trinity_configs.md
@@ -418,7 +418,7 @@ trainer:
---
-## 服务配置
+## Service 配置
配置 Trinity-RFT 使用的服务。目前仅支持 Data Juicer 服务。
@@ -469,7 +469,7 @@ data_processor:
--
-## 日志配置
+## Log 配置
Ray actor 日志配置。
@@ -484,7 +484,7 @@ log:
---
-## 阶段配置
+## Stage 配置
对于多阶段训练,可以在 `stages` 字段中定义多个阶段。每个阶段可以有自己的 `algorithm`、`buffer` 和其他配置。如果某个参数未在阶段中指定,则继承自全局配置。多个阶段将按定义顺序依次执行。
@@ -657,3 +657,126 @@ trainer:
- `trainer.del_local_ckpt_after_load`: 加载后是否删除本地检查点。
- `trainer.max_actor_ckpt_to_keep`: 最多保留的 actor 检查点数量。
- `trainer.max_critic_ckpt_to_keep`: 最多保留的 critic 检查点数量。
+
+
+## 图形化配置生成器(高级)
+
+本节将介绍如何为配置生成器页面添加新的配置参数。
+
+### 步骤 0:了解 Streamlit
+
+在为配置生成器页面添加新参数之前,需要先了解 [Streamlit](https://docs.streamlit.io/develop/api-reference) 的相关 API 和机制。本项目主要使用 Streamlit 的各种输入组件,并利用 `st.session_state` 存储用户输入的参数。
+
+### 步骤 1:实现新配置项
+
+为了说明如何为配置生成器页面创建新参数设置,我们以 `train_batch_size` 为例。
+
+1. 确定参数的合适作用域。目前参数分为四个文件:
+ - `trinity/manager/config_registry/buffer_config_manager.py`
+ - `trinity/manager/config_registry/explorer_config_manager.py`
+ - `trinity/manager/config_registry/model_config_manager.py`
+ - `trinity/manager/config_registry/trainer_config_manager.py`
+
+ 本例中,`train_batch_size` 应放在 `buffer_config_manager.py` 文件中。
+
+2. 使用 Streamlit 创建参数设置函数。函数名必须以 'set_' 开头,其余部分成为配置名称。
+
+3. 使用 `CONFIG_GENERATORS.register_config` 装饰器装饰参数设置函数。该装饰器需要以下信息:
+ - 参数的默认值
+ - 可见性条件(如适用)
+ - 额外配置参数(如需要)
+
+```{note}
+`CONFIG_GENERATORS.register_config` 装饰器会自动将 `key=config_name` 作为参数传递给注册的配置函数。确保你的函数接受此关键字参数。
+```
+
+对于 `train_batch_size`,我们将使用以下设置:
+
+- 默认值:96
+- 可见性条件:`lambda: st.session_state["trainer_gpu_num"] > 0`
+- 额外配置:`{"_train_batch_size_per_gpu": 16}`
+
+以下是 `train_batch_size` 参数的完整代码:
+
+```python
+@CONFIG_GENERATORS.register_config(
+ default_value=96,
+ visible=lambda: st.session_state["trainer_gpu_num"] > 0,
+ other_configs={"_train_batch_size_per_gpu": 16},
+)
+def set_train_batch_size(**kwargs):
+ key = kwargs.get("key")
+ trainer_gpu_num = st.session_state["trainer_gpu_num"]
+ st.session_state[key] = (
+ st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
+ )
+
+ def on_change():
+ st.session_state["_train_batch_size_per_gpu"] = max(
+ st.session_state[key] // st.session_state["trainer_gpu_num"], 1
+ )
+
+ st.number_input(
+ "Train Batch Size",
+ min_value=trainer_gpu_num,
+ step=trainer_gpu_num,
+ help=_str_for_train_batch_size(),
+ on_change=on_change,
+ **kwargs,
+ )
+```
+
+如果参数需要验证,创建一个检查函数。对于 `train_batch_size`,我们需要确保它能被 `trainer_gpu_num` 整除。若不能,则显示警告,并将参数添加到 `unfinished_fields`。
+
+使用 `CONFIG_GENERATORS.register_check` 装饰器装饰检查函数:
+
+```python
+@CONFIG_GENERATORS.register_check()
+def check_train_batch_size(unfinished_fields: set, key: str):
+ if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
+ unfinished_fields.add(key)
+ st.warning(_str_for_train_batch_size())
+```
+
+```{note}
+`CONFIG_GENERATORS.register_check` 装饰器会自动接收 `key=config_name` 和 `unfinished_fields=self.unfinished_fields` 作为参数。确保你的函数接受这些关键字参数。
+```
+
+### 步骤 2:将新参数集成到 `config_manager.py`
+
+要成功将新参数集成到 `config_manager.py` 文件中,请遵循以下步骤:
+
+1. **参数分类**:
+ 根据其功能确定新参数的合适部分。配置生成器页面分为两种主要模式:
+ - 初学者模式:包含“基本配置”和“重要配置”部分。
+ - 专家模式:包含“模型”、“缓冲区”、“Explorer 和 Synchronizer”以及“Trainer”部分。
+
+2. **添加参数**:
+ 在 `ConfigManager` 类的 `self.get_configs` 方法中,将新参数添加到相应部分。
+
+ 示例:
+
+ ```python
+ class ConfigManager:
+ def _expert_buffer_part(self):
+ self.get_configs("total_epochs", "train_batch_size")
+ ```
+
+3. **集成到 YAML 文件**:
+ 在 YAML 文件结构中找到新参数的合适位置。应在 `generate_config` 函数及其关联子函数中完成。
+
+4. **赋值参数值**:
+ 使用 `st.session_state` 从配置生成器页面获取参数值,并将其赋给 YAML 中的对应字段。
+
+ 示例:
+
+ ```python
+ class ConfigManager:
+ def _gen_buffer_config(self):
+ buffer_config = {
+ "batch_size": st.session_state["train_batch_size"],
+ # Additional configuration parameters
+ }
+ ```
+
+严格遵循这些步骤,你可以确保新参数成功添加到配置生成器页面,并正确集成到配置系统中。
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md b/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md
new file mode 100644
index 0000000000..fd7130ecb3
--- /dev/null
+++ b/docs/sphinx_doc/source_zh/tutorial/trinity_installation.md
@@ -0,0 +1,111 @@
+(Installation)=
+# 安装指南
+
+安装 Trinity-RFT 有三种方式:源码安装(推荐)、通过 PyPI 安装,或使用 Docker。
+
+在安装前,请确保您的系统满足以下要求:
+
+- **Python**:3.10 至 3.12(包含)
+- **CUDA**:12.4 至 12.8(包含)
+- **GPU**:至少 2 块 GPU
+
+---
+
+## 源码安装(推荐)
+
+如需修改、扩展 Trinity-RFT,推荐使用此方法。
+
+### 1. 克隆仓库
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+```
+
+### 2. 创建虚拟环境
+
+可选择以下任一方式:
+
+#### 使用 Conda
+
+```bash
+conda create -n trinity python=3.10
+conda activate trinity
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### 使用 venv
+
+```bash
+python3.10 -m venv .venv
+source .venv/bin/activate
+
+pip install -e ".[dev]"
+pip install -e ".[flash_attn]"
+# 如果安装 flash-attn 时遇到问题,可尝试:
+# pip install flash-attn==2.8.1 --no-build-isolation
+```
+
+#### 使用 `uv`
+
+[`uv`](https://github.com/astral-sh/uv) 是现代的 Python 包管理工具。
+
+```bash
+uv sync --extra dev --extra flash_attn
+```
+
+---
+
+## 通过 PyPI 安装
+
+如果您只需使用 Trinity-RFT 而不打算修改代码:
+
+```bash
+pip install trinity-rft==0.3.0
+pip install flash-attn==2.8.1
+```
+
+或使用 `uv`:
+
+```bash
+uv pip install trinity-rft==0.3.0
+uv pip install flash-attn==2.8.1
+```
+
+---
+
+## 使用 Docker
+
+我们提供了 Docker 环境,方便快速配置。
+
+```bash
+git clone https://github.com/modelscope/Trinity-RFT
+cd Trinity-RFT
+
+# 构建 Docker 镜像
+## 提示:可根据需要修改 Dockerfile 添加镜像源或设置 API 密钥
+docker build -f scripts/docker/Dockerfile -t trinity-rft:latest .
+
+# 运行容器,请将 替换为实际需要挂载的路径
+docker run -it \
+ --gpus all \
+ --shm-size="64g" \
+ --rm \
+ -v $PWD:/workspace \
+ -v :/data \
+ trinity-rft:latest
+```
+
+```{note}
+如需使用 **Megatron-LM** 进行训练,请参考 {ref}`Megatron-LM Backend `。
+```
+
+---
+
+## 常见问题
+
+如遇安装问题,请参考 FAQ 或 [GitHub Issues](https://github.com/modelscope/Trinity-RFT/issues)。
diff --git a/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md b/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md
deleted file mode 100644
index b9b88e65e0..0000000000
--- a/docs/sphinx_doc/source_zh/tutorial/trinity_programming_guide.md
+++ /dev/null
@@ -1,747 +0,0 @@
-# 开发者指南
-
-本指南介绍了如何在 Trinity-RFT 中开发新模块,并提供相关的开发规范。
-
-在 Trinity-RFT 中,我们将 RL 流程分解为三个主要模块(**Explorer**、**Trainer** 和 **Buffer**),以便于自定义和扩展。
-下表总结了不同开发目标的开发者需要关注的核心模块和关键组件。
-
-| 开发目标 | 核心模块 | 关键组件 |
-|--------------------|-------------|---------------|
-| 将现有 RL 算法应用于新环境 | *Explorer* | `Workflow` |
-| 设计新的 RL 算法 | *Trainer* | `Algorithm` |
-| 从数据角度增强 RL 流程 | *Buffer* | `Operator` |
-
-```{note}
-Trinity-RFT 正在积极开发中,以下接口可能会发生变化。使用本指南时请参考最新代码。
-```
-
-```{tip}
-对于仅用于本地测试或不打算贡献的模块,你可以将其放在 `trinity/plugins` 目录中。Trinity-RFT 会自动加载该目录下的所有模块,且无需将其添加到 `__init__.py` 文件中。你也可以通过运行 Trinity-RFT 时设置 `--plugin-dir` 选项来指定其他目录,例如:`trinity run --config /path/to/your/config --plugin-dir /path/to/your/plugins`。
-```
-
----
-
-(Workflows)=
-## 工作流(适用于 RL 环境开发者)
-
-在 Trinity-RFT 中,工作流(Workflow)是定义 Agent 与 Environment 之间交互的核心组件。
-一个合格的工作流需要使用训练好的模型完成指定任务,并从环境中获取反馈信息(奖励)。以下是创建新工作流的步骤:
-
----
-
-### 步骤 0:基本概念
-
-在开始开发之前,理解以下几个核心概念非常重要:
-
-- **任务(Task)** ({class}`trinity.common.workflows.Task`):表示可转换为 `Workflow` 的数据结构。`Task` 的内容根据任务类型而异:
- - **数学问题**:`Task` 包含问题描述和标准答案。
- - **编程场景**:`Task` 包括问题描述、测试用例、运行环境等复杂信息。
-
-- **工作流(Workflow)** ({class}`trinity.common.workflows.Workflow`):描述 `Task` 如何执行。它定义了 Agent 与 Environment 的交互流程,包括类似其他框架中的 *Rollout* 和 *Reward* 计算逻辑。执行后生成一组 `Experience`。Trinity-RFT 包含多个内置工作流:
- - `MathWorkflow` ({class}`trinity.common.workflows.MathWorkflow`):用于数学场景,将问题提交给 LLM,解析 LLM 响应,并计算分数(奖励)。
- - `WebShopWorkflow` ({class}`trinity.common.workflows.WebShopWorkflow`):用于 webshop 场景,包含与环境的多轮交互。
- - `CodeWorkflow`(即将推出):用于编码场景,执行返回的代码,运行测试,并根据测试结果计算奖励。
- - ...
-
-- **经验(Experience)** ({class}`trinity.common.experience.Experience`):运行 `Workflow` 的输出。内部数据格式取决于所使用的训练算法。例如,对于常见的 PPO/GRPO 算法,`Experience` 包含 token ID 列表、动作掩码(标识哪些 token 是由 LLM 生成的)、对数概率、奖励等。
-
----
-
-### 步骤 1:准备任务数据集
-
-任务数据集通过 YAML 配置文件中的 `buffer.explorer_input.taskset` 配置项加载。
-为处理 `Task` 内容的差异,Trinity-RFT 提供了一个统一的 `Task` 接口,包含以下字段:
-
-- **`workflow`** (`str`):你的工作流类的注册名称。你可以在 YAML 配置文件的 `buffer.explorer_input.taskset.default_workflow_type` 中指定。
-- **`reward_fn`** (`Optional[str]`):你的奖励函数的注册名称。你可以在 `buffer.explorer_input.taskset.default_reward_fn_type` 中指定。注意某些工作流已内置奖励计算;此时可省略该字段。
-- **`raw_task`** (`Dict`):原始数据的记录,以 `Dict` 格式存储。对于高度定制化的工作流,你可以直接使用 `raw_task` 初始化 `Workflow` 实例,而不依赖以下字段。
-- **`format_args`** ({class}`trinity.common.config.FormatConfig`):便于构造 `Workflow` 实例的参数。例如,`prompt_key` 和 `response_key` 可用于从 `raw_task` 中提取 prompt 和 response。这些设置来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.format` 中设置。
-- **`rollout_args`** ({class}`trinity.common.config.GenerationConfig`):控制 rollout 过程的参数,如 `temperature`。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.rollout_args` 中设置。
-- **`workflow_args`** (`Dict`):用于构造 `Workflow` 实例的参数字典。相比 `format_args` 和 `rollout_args` 更灵活。该字段也来自 YAML 配置文件,可在 `buffer.explorer_input.task_set.workflow_args` 中设置。通常无需设置此字段。
-
-```{tip}
-`workflow`、`workflow_args` 和 `raw_task` 提供了不同级别的自定义能力。
-
-- `workflow` 为使用相同工作流的所有任务提供全局设置。(全局级别)
-- `workflow_args` 可为每个任务数据集设置,允许使用相同工作流的不同任务数据集表现出不同行为。(数据集级别)
-- `raw_task` 提供对每个任务行为的自定义能力,最为灵活。(数据样本级别)
-```
-
-在数学问题场景中,`Task` 数据集可以是一个 `jsonl` 文件,每行包含带有 `question` 和 `answer` 字段的 JSON,分别表示问题描述和标准答案。例如:
-
-```json
-{"question": "1+1=", "answer": "2"}
-{"question": "2+2=", "answer": "4"}
-...
-```
-
-配置示例片段:
-
-```yaml
-# some config
-buffer:
- explorer_input:
- taskset:
- default_workflow: "math_workflow"
- path: ${oc.env:TRINITY_TASKSET_PATH}
- format:
- prompt_key: "question"
- response_key: "answer"
- rollout_args:
- temperature: 1.0
- # some other configs
-```
-
-在此示例中,每个任务对象的 `raw_task` 是一个包含两个键(`question` 和 `answer`)的 `Dict`。`MathWorkflow` 使用 `prompt_key` 和 `response_key` 从 `raw_task` 中提取问题和答案,并使用 `rollout_args` 生成响应。
-
----
-
-### 步骤 2:实现新的工作流
-
-`Workflow` 基类接口如下:
-
-```python
-class Workflow(ABC):
-
- def __init__(
- self,
- *,
- task: Task,
- model: ModelWrapper,
- auxiliary_models: Optional[List[openai.OpenAI]] = None,
- ):
- self.task = task
- self.model = model
- self.auxiliary_models = auxiliary_models
-
- @abstractmethod
- def run(self) -> List[Experience]:
- """Run the workflow and return a list of Experiences."""
-```
-
-#### 初始化你的工作流
-
-`Workflow` 接受以下初始化参数:
-
-- `task`({class}`trinity.common.workflows.Task`):数据集中的单个任务。
-- `model`({class}`trinity.common.models.model.ModelWrapper`):正在训练的模型,提供类似于 OpenAI 的接口,能够接收对话消息列表并返回 LLM 生成的内容(包括回复文本 `response_text`、完整序列 token id `tokens`、prompt 部分 token 长度 `prompt_length`,以及输出 token 对数概率列表 `logprobs`)。
-- `auxiliary_models`(`List[openai.OpenAI]`):未参与训练的辅助模型列表。所有模型均通过兼容 OpenAI 的 API 提供。
-
-```{tip}
-你可以在配置文件中将 `explorer.rollout_model.enable_openai_api` 设置为 `true`,并在工作流中调用 `model.get_openai_client()` 获取 `openai.OpenAI` 实例,从而切换为使用 OpenAI API。
-调用 OpenAI API 时,`model` 字段可通过 `openai_client.models.list().data[0].id` 或 `openai_client.model_path` 获取。
-```
-
-以下是一个仅使用 `raw_task` 和 `rollout_args` 初始化简单工作流的示例。在更复杂的情况下,你可以使用 `format_args` 进行进一步自定义。
-
-```python
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
- # Optional: If you want to use OpenAI API in your workflow
- # self.openai_client = self.model.get_openai_client()
-```
-
-#### 实现 `run` 方法
-
-`run` 方法是工作流的核心方法。它返回一个 `Experience` 列表。
-以下是一个数学工作流的简单实现。
-
-我们首先调用模型,使用给定的问题和 rollout 参数生成多个响应。
-然后使用 `calculate_reward` 函数计算每个响应的奖励。
-最后,我们构建一个包含响应和奖励的 `Experience` 列表并返回。
-
-```python
-class ExampleWorkflow(Workflow):
-
- # the __init__ function
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-```
-
-#### 注册你的工作流
-
-使用 `WORKFLOWS.register_module` 装饰器注册你的工作流。
-确保名称不与现有工作流冲突。
-
-```python
-# import some packages
-from trinity.common.workflows.workflow import WORKFLOWS
-
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- pass
-```
-
-对于准备贡献给 Trinity-RFT 项目的模块,你需要将上述代码放入 `trinity/common/workflows` 文件夹中,例如 `trinity/common/workflows/example_workflow.py`。并在 `trinity/common/workflows/__init__.py` 中添加以下行:
-
-```python
-# existing import lines
-from .example_workflow import ExampleWorkflow
-
-__all__ = [
- # existing __all__ lines
- "ExampleWorkflow",
-]
-```
-
-#### 避免重复初始化
-
-对于重型工作流,每次重新初始化会带来额外计算开销。
-此时,你可以实现 `resettable` 和 `reset` 方法以避免重复初始化。
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
- # some code
- # ...
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
-#### 完整代码示例
-
-```python
-@WORKFLOWS.register_module("example_workflow")
-class ExampleWorkflow(Workflow):
-
- def __init__(self, task: Task, model: ModelWrapper, auxiliary_models: List):
- super().__init__(task=task, model=model, auxiliary_models=auxiliary_models)
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
- self.rollout_args = task.rollout_args
-
- def calculate_reward(self, response: str, truth: str) -> float:
- if response == truth:
- return 1.0
- else:
- return 0.0
-
- def run(self) -> List[Experience]:
- # call the model to generate multiple responses
- responses = self.model.chat(
- [
- {
- "role": "user",
- "content": f"Question:\n{self.question}",
- }
- ],
- n=self.rollout_args.n,
- temperature=self.rollout_args.temperature,
- )
- experiences = []
- for response in responses:
- # calulcate reward
- reward: float = self.calculate_reward(response.response_text, self.answer)
- # construct Experience
- experiences.append(
- Experience(
- tokens=response.tokens,
- prompt_length=response.prompt_length,
- reward=reward,
- logprobs=response.logprobs,
- )
- )
- return experiences
-
- def resettable(self):
- return True
-
- def reset(self, task: Task):
- self.question = task.raw_task.get("question")
- self.answer = task.raw_task.get("answer")
-```
-
----
-
-### 步骤 3:使用你的工作流
-
-实现并注册工作流后,你需要更新配置文件,将 `buffer.explorer_input.taskset` 域中的 `default_workflow_type` 设置为新注册的 `Workflow` 名称。
-
-```yaml
-buffer:
- # Other fields
- explorer_input:
- taskset:
- path: /path/to/taskset
- default_workflow_type: example_workflow
- # Other fields
-```
-
-现在你可以使用以下命令在 Trinity-RFT 中运行你的工作流:
-
-```
-trinity run --config
-```
-
----
-
-(Algorithms)=
-## 算法(适用于 RL 算法开发者)
-
-Trinity-RFT 提供了实现新算法的标准化流程。
-
-### 步骤 0:算法模块基本概念
-
-在 Trinity-RFT 中,算法模块主要负责在 RL 过程中从回放缓冲区提取 experience 数据,并基于这些数据计算损失以更新模型。
-为了避免每次添加新算法时都实现新的 Trainer 类,我们将典型的 PPO 算法流程分解为多个子模块,以适应各种算法。
-
-- **采样策略(Sample Strategy)** ({class}`trinity.algorithm.SampleStrategy`):负责从缓冲区模块中采样 experience 数据。通过自定义此模块,你可以实现过滤 experience 数据或从多个数据源混合采样的功能。
-- **优势函数(Advantage Fn)**({class}`trinity.algorithm.AdvantageFn`):负责计算 experience 数据的优势值(Advantage)和回报值(Returns)。
-- **策略损失函数(Policy Loss Fn)**({class}`trinity.algorithm.PolicyLossFn`):负责计算策略网络的核心训练损失。
-- **KL 函数(KL Fn)**({class}`trinity.algorithm.KLFn`):负责计算 KL 散度,通常在现有 RL 算法中用于两个地方:奖励惩罚和 Actor 损失。
-- **熵损失函数(Entropy Loss Fn)**({class}`trinity.algorithm.EntropyLossFn`):负责计算策略网络的熵损失。
-
-我们在 `trinity/algorithm` 中提供了上述模块的若干实现。
-
----
-
-### 步骤 1:实现算法组件
-
-Trinity-RFT 允许开发者自定义所有上述模块。开发者只需根据新算法的需求实现特定模块。本节将以 {ref}`OPMD ` 算法为例进行简要介绍。
-
-OPMD 与 PPO 算法的主要区别在于优势值和策略损失的计算。
-OPMD 依赖于基于组的优势值计算,且不使用 Critic 模型。
-要实现 OPMD,开发者需要在 `AdvantageFn` 中实现优势值计算,在 `PolicyLossFn` 中实现策略损失计算。
-
----
-
-#### 步骤 1.1:实现 `AdvantageFn`
-
-{class}`trinity.algorithm.AdvantageFn` 接口包含三个方法:
-
-- `__call__`:优势值计算的主要入口。接收一个 experience 列表 ({class}`trinity.common.experience.Experience`),返回一个包含计算出的优势值和回报值的 experience 列表,以及一个用于日志记录的指标字典。
-- `default_args`:类方法,返回默认初始化参数(字典形式)。当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
-- `compute_in_trainer`:类方法,指示是否在 Trainer 中计算优势值。若返回 `False`,则 `AdvantageFn` 将在 experience 数据处理流水线中被调用。
-
-为方便起见,Trinity-RFT 提供了一个抽象类 {class}`trinity.algorithm.advantage_fn.GroupAdvantage`,它实现了基于组的优势值计算的 `__call__` 方法,你可以专注于如何对 experience 进行分组以及如何在分组后的 experience 上计算优势值,通过以下两个方法实现:
-
-- `group_experiences`:此方法将一步生成的 experience 划分为多个子组。
-
-- `calculate_group_advantage`:此方法计算每组 experience 的优势值。
-
-以下是 OPMD 算法优势函数的实现示例:
-
-```python
-from trinity.algorithm.advantage_fn import ADVANTAGE_FN, GroupAdvantage
-
-@ADVANTAGE_FN.register_module("opmd")
-class OPMDGroupAdvantage(GroupAdvantage):
- """OPMD Group Advantage computation"""
-
- def __init__(self, opmd_baseline: str = "mean", tau: float = 1.0, **kwargs) -> None:
- super().__init__(**kwargs)
- self.opmd_baseline = opmd_baseline
- self.tau = tau
-
- def group_experiences(self, exps):
- return group_by(exps, id_type="task")
-
- def calculate_group_advantage(
- self, group_id: str, exps: List[Experience]
- ) -> Tuple[List[Experience], Dict]:
- with torch.no_grad():
- if len(exps) == 1:
- group_baseline = torch.tensor(0.0)
- else:
- group_rewards = torch.tensor([exp.reward for exp in exps], dtype=torch.float32)
- if self.opmd_baseline == "mean":
- group_baseline = torch.mean(group_rewards)
- else:
- group_baseline = self.tau * (
- torch.logsumexp(group_rewards / self.tau, dim=-1)
- - torch.log(torch.tensor(len(exps)))
- )
- for exp in exps:
- score = exp.reward - group_baseline
- exp.advantages = score * exp.action_mask
- exp.returns = exp.advantages.clone()
- metrics = {
- "group_baseline": group_baseline.item(),
- }
- return exps, metrics
-
- @classmethod
- def default_args(cls) -> dict:
- return {"opmd_baseline": "mean", "tau": 1.0}
-```
-
-实现后,你需要通过 {class}`trinity.algorithm.ADVANTAGE_FN` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
-
-#### 步骤 1.3:实现 `PolicyLossFn`
-
-开发者需要实现 {class}`trinity.algorithm.PolicyLossFn` 接口,其与 `AdvantageFn` 类似,包含两个方法:
-
-- `__call__`:根据输入参数计算损失。与 `AdvantageFn` 不同,这里的输入参数均为 `torch.Tensor`。该接口会自动扫描 `__call__` 方法的参数列表,并将其转换为 experience 数据中的对应字段。因此,请直接在参数列表中写出损失计算所需的所有张量名称,而不是从 `kwargs` 中选择参数。
-- `default_args`:返回默认初始化参数(字典形式),当用户未在配置文件中指定初始化参数时,默认使用此方法返回的参数。
-
-同样,实现后需要通过 {class}`trinity.algorithm.POLICY_LOSS_FN` 注册此模块。
-
-以下是 OPMD 算法策略损失函数的实现示例。由于 OPMD 的策略损失仅需 logprob、action_mask 和 advantages,因此 `__call__` 方法的参数列表中仅指定这三个项:
-
-```python
-@POLICY_LOSS_FN.register_module("opmd")
-class OPMDPolicyLossFn(PolicyLossFn):
- def __init__(
- self, backend: str = "verl", tau: float = 1.0, loss_agg_mode: str = "token-mean"
- ) -> None:
- super().__init__(backend=backend)
- self.tau = tau
- self.loss_agg_mode = loss_agg_mode
-
- def __call__( # type: ignore
- self,
- logprob: torch.Tensor,
- action_mask: torch.Tensor,
- advantages: torch.Tensor,
- **kwargs,
- ) -> Tuple[torch.Tensor, Dict]:
- pg_losses = -advantages * logprob
- opmd_loss = masked_loss(pg_losses, action_mask, loss_agg_mode=self.loss_agg_mode)
- opmd_loss = opmd_loss / (1.0 + self.tau) # for regularization (w.r.t. current pi_theta)
- return opmd_loss, {"opmd_loss": opmd_loss.detach().item()}
-
- @classmethod
- def default_args(cls) -> Dict:
- return {"tau": 1.0}
-```
-
----
-
-### 步骤 2:注册你的算法
-
-上述步骤实现了算法所需的组件,但这些组件是分散的,需要在多个地方配置才能生效。
-
-为简化配置,Trinity-RFT 提供了 {class}`trinity.algorithm.AlgorithmType` 来描述完整算法,并在 {class}`trinity.algorithm.ALGORITHM_TYPE` 中注册,实现一键配置。
-
-`AlgorithmType` 类包含以下属性和方法:
-
-- `use_critic`:是否使用 Critic 模型
-- `use_reference`:是否使用 Reference 模型
-- `compute_advantage_in_trainer`:是否在 Trainer 中计算优势值;若为 False,则跳过 Trainer 中的 `AdvantageFn` 调用
-- `can_balance_batch`:算法是否允许在将批次拆分为微批次时自动平衡(打乱样本顺序)
-- `schema`:算法对应的 experience 数据格式
-- `default_config`:获取算法的默认配置,将覆盖 `ALGORITHM_TYPE` 中同名属性
-
-同样,实现后需要通过 `ALGORITHM_TYPE` 注册此模块。
-
-以下是 OPMD 算法的实现。
-由于 OPMD 算法不需要使用 Critic 模型,`use_critic` 设置为 `False`。
-`default_config` 方法返回的字典表明 OPMD 将使用步骤 1 中实现的 `opmd` 类型的 `AdvantageFn` 和 `PolicyLossFn`,不会对奖励应用 KL 惩罚,但在计算最终损失时会添加 `k2` 类型的 KL 损失。
-
-```python
-@ALGORITHM_TYPE.register_module("opmd")
-class OPMDAlgorithm(AlgorithmType):
- """OPMD algorithm."""
-
- use_critic: bool = False
- use_reference: bool = True
- compute_advantage_in_trainer: bool = False
- can_balance_batch: bool = True
- schema: str = "experience"
-
- @classmethod
- def default_config(cls) -> Dict:
- return {
- "repeat_times": 2,
- "advantage_fn": "opmd",
- "sample_strategy": "warmup",
- "policy_loss_fn": "opmd",
- "kl_penalty_fn": "none",
- "kl_loss_fn": "k2",
- "entropy_loss_fn": "default",
- }
-```
-
----
-
-### 步骤 3:使用你的算法
-
-完成上述所有步骤后,你可以通过 YAML 配置文件使用新注册的算法。
-
-对于默认配置,你只需在 `config.yaml` 文件中添加以下内容:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
-# some other configs
-```
-
-如果需要修改某些参数,可以在 `algorithm` 部分直接添加对应参数。例如,若需要修改 `repeat_times` 以及 `AdvantageFn` 和 `PolicyLossFn` 的初始化参数,修改后的 `config.yaml` 文件如下:
-
-```yaml
-# some other configs
-algorithm:
- algorithm_type: "opmd"
- repeat_times: 8
- advantage_fn_args:
- opmd_baseline: "logavgexp"
- tau: 0.99
- policy_loss_fn_args:
- tau: 0.99
-# some other configs
-```
-
----
-
-## 数据处理算子(适用于数据开发者)
-
-### 步骤 0:Operator 模块基本概念
-
-在 Trinity-RFT 中,Operator 模块负责处理缓冲区模块中的 experience 数据。它天然支持来自 [Data-Juicer](https://github.com/modelscope/data-juicer) 的现有数据处理功能,也允许开发者实现自己的算子。
-通过自定义数据处理算子,开发者可以实现各种数据处理功能,如数据增强、过滤和转换。你甚至可以将优势值/回报值计算实现为 Operator,如 {ref}`算法 ` 部分所示。
-
-- **DataJuicerOperator** ({class}`trinity.data.operators.DataJuicerOperator`):封装来自 Data-Juicer 的数据处理算子。为开发者提供简单接口,列出想要使用的 Data-Juicer 算子。完整的 Data-Juicer 算子列表请见 [此处](https://modelscope.github.io/data-juicer/en/main/docs/Operators.html)。
-- **ExperienceOperator** ({class}`trinity.data.operators.ExperienceOperator`):用于 experience 数据处理的所有数据处理算子的基类。定义了所有数据处理算子应具备的接口和通用功能。每个算子处理一批 experience 数据,并返回处理后的数据及用于日志记录的指标。
-- **ExperiencePipeline** ({class}`trinity.data.pipelines.ExperiencePipeline`):管理一系列数据处理算子的 experience 数据处理流水线。它从 `Explorer` 获取原始 experience,通过流水线中的每个算子处理,最后将最终处理过的 experience 写入 `Trainer` 的输入缓冲区。
-
-```{note}
-除了 `ExperiencePipeline`,Trinity-RFT 还提供 `TaskPipeline` 用于任务数据处理。
-当前版本中,`TaskPipeline` 仅支持使用 Data-Juicer 算子。详情请参见 {ref}`数据处理 ` 部分。
-```
----
-
-开发者可通过以下步骤实现并使用自己的算子。
-
-### 步骤 1:实现数据处理算子
-
-`ExperienceOperator` 接口仅包含一个 `process` 方法。`ExperiencePipeline` 将调用此方法,传入 `Explorer` 在一次探索步骤中生成的一组 `Experience`。`process` 方法应返回一个元组,包含处理后的 `Experience` 列表和用于日志记录的指标字典。
-
-```python
-class ExperienceOperator(ABC):
-
- @abstractmethod
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- """Process a list of experiences and return a transformed list.
-
- Args:
- exps (List[Experience]): List of experiences to process, which contains
- all experiences generated by the Explorer in one explore step.
- Returns:
- Tuple[List[Experience], Dict]: A tuple containing the processed list of experiences and a dictionary of metrics.
- """
-```
-
-以下是一个简单数据处理算子的实现示例,该算子过滤掉奖励低于某一阈值的 experience:
-
-```python
-from trinity.buffer.operators import EXPERIENCE_OPERATORS, ExperienceOperator
-from trinity.common.experience import Experience
-
-
-@EXPERIENCE_OPERATORS.register_module("reward_filter")
-class RewardFilter(ExperienceOperator):
-
- def __init__(self, threshold: float = 0.0) -> None:
- self.threshold = threshold
-
- def process(self, exps: List[Experience]) -> Tuple[List[Experience], Dict]:
- filtered_exps = [exp for exp in exps if exp.reward >= self.threshold]
- metrics = {"filtered_count": len(exps) - len(filtered_exps)}
- return filtered_exps, metrics
-```
-
-实现后,你需要通过 {class}`trinity.data.operators.EXPERIENCE_OPERATORS` 注册此模块。注册后,该模块可在配置文件中使用注册名称进行配置。
-
-### 步骤 2:使用此算子
-
-完成上述步骤后,你可以通过 YAML 配置文件使用新注册的算子。
-
-```yaml
-# some other configs
-data_processor:
- experience_pipeline:
- operators:
- - name: "reward_filter"
- args:
- threshold: 0.1
-synchronizer:
- sync_method: nccl
- sync_style: dynamic_by_explorer
- sync_interval: 2
-# some other configs
-```
-
-```{tip}
-`RewardFilter` 会减少 experience 数量,可能导致 Trainer 无法获得足够的 experience 启动训练步骤。为避免此问题,你可以使用 Trinity-RFT 提供的高级 {ref}`动态同步 ` 功能,如上配置所示。
-上述设置意味着 `Explorer` 每 2 步与 `Trainer` 同步一次,且无论 `Trainer` 完成了多少步都会继续运行。这确保了只要 `Explorer` 在运行,`Trainer` 就总能获得足够的 experience 来启动训练步骤。
-```
-
----
-
-## 为配置生成器添加新配置项(高级)
-
-### 步骤 0:了解 Streamlit
-
-在为配置生成器页面添加新参数之前,必须熟悉 [Streamlit](https://docs.streamlit.io/develop/api-reference) 的相关 API 和机制。本项目主要使用 Streamlit 的各种输入组件,并利用 `st.session_state` 存储用户输入的参数。
-
-### 步骤 1:实现新配置项
-
-为了说明如何为配置生成器页面创建新参数设置,我们以 `train_batch_size` 为例。
-
-1. 确定参数的合适作用域。目前参数分为四个文件:
- - `trinity/manager/config_registry/buffer_config_manager.py`
- - `trinity/manager/config_registry/explorer_config_manager.py`
- - `trinity/manager/config_registry/model_config_manager.py`
- - `trinity/manager/config_registry/trainer_config_manager.py`
-
- 本例中,`train_batch_size` 应放在 `buffer_config_manager.py` 文件中。
-
-2. 使用 Streamlit 创建参数设置函数。函数名必须以 'set_' 开头,其余部分成为配置名称。
-
-3. 使用 `CONFIG_GENERATORS.register_config` 装饰器装饰参数设置函数。该装饰器需要以下信息:
- - 参数的默认值
- - 可见性条件(如适用)
- - 额外配置参数(如需要)
-
-```{note}
-`CONFIG_GENERATORS.register_config` 装饰器会自动将 `key=config_name` 作为参数传递给注册的配置函数。确保你的函数接受此关键字参数。
-```
-
-对于 `train_batch_size`,我们将使用以下设置:
-
-- 默认值:96
-- 可见性条件:`lambda: st.session_state["trainer_gpu_num"] > 0`
-- 额外配置:`{"_train_batch_size_per_gpu": 16}`
-
-以下是 `train_batch_size` 参数的完整代码:
-
-```python
-@CONFIG_GENERATORS.register_config(
- default_value=96,
- visible=lambda: st.session_state["trainer_gpu_num"] > 0,
- other_configs={"_train_batch_size_per_gpu": 16},
-)
-def set_train_batch_size(**kwargs):
- key = kwargs.get("key")
- trainer_gpu_num = st.session_state["trainer_gpu_num"]
- st.session_state[key] = (
- st.session_state["_train_batch_size_per_gpu"] * st.session_state["trainer_gpu_num"]
- )
-
- def on_change():
- st.session_state["_train_batch_size_per_gpu"] = max(
- st.session_state[key] // st.session_state["trainer_gpu_num"], 1
- )
-
- st.number_input(
- "Train Batch Size",
- min_value=trainer_gpu_num,
- step=trainer_gpu_num,
- help=_str_for_train_batch_size(),
- on_change=on_change,
- **kwargs,
- )
-```
-
-如果参数需要验证,创建一个检查函数。对于 `train_batch_size`,我们需要确保它能被 `trainer_gpu_num` 整除。若不能,则显示警告,并将参数添加到 `unfinished_fields`。
-
-使用 `CONFIG_GENERATORS.register_check` 装饰器装饰检查函数:
-
-```python
-@CONFIG_GENERATORS.register_check()
-def check_train_batch_size(unfinished_fields: set, key: str):
- if st.session_state[key] % st.session_state["trainer_gpu_num"] != 0:
- unfinished_fields.add(key)
- st.warning(_str_for_train_batch_size())
-```
-
-```{note}
-`CONFIG_GENERATORS.register_check` 装饰器会自动接收 `key=config_name` 和 `unfinished_fields=self.unfinished_fields` 作为参数。确保你的函数接受这些关键字参数。
-```
-
-### 步骤 2:将新参数集成到 `config_manager.py`
-
-要成功将新参数集成到 `config_manager.py` 文件中,请遵循以下步骤:
-
-1. **参数分类**:
- 根据其功能确定新参数的合适部分。配置生成器页面分为两种主要模式:
- - 初学者模式:包含“基本配置”和“重要配置”部分。
- - 专家模式:包含“模型”、“缓冲区”、“Explorer 和 Synchronizer”以及“Trainer”部分。
-
-2. **添加参数**:
- 在 `ConfigManager` 类的 `self.get_configs` 方法中,将新参数添加到相应部分。
-
- 示例:
-
- ```python
- class ConfigManager:
- def _expert_buffer_part(self):
- self.get_configs("total_epochs", "train_batch_size")
- ```
-
-3. **集成到 YAML 文件**:
- 在 YAML 文件结构中找到新参数的合适位置。应在 `generate_config` 函数及其关联子函数中完成。
-
-4. **赋值参数值**:
- 使用 `st.session_state` 从配置生成器页面获取参数值,并将其赋给 YAML 中的对应字段。
-
- 示例:
-
- ```python
- class ConfigManager:
- def _gen_buffer_config(self):
- buffer_config = {
- "batch_size": st.session_state["train_batch_size"],
- # Additional configuration parameters
- }
- ```
-
-严格遵循这些步骤,你可以确保新参数成功添加到配置生成器页面,并正确集成到配置系统中。此过程保持了配置管理框架的完整性和功能性。
-
----
-
-## 贡献你的代码
-
-对于准备贡献给 Trinity-RFT 项目的模块,请遵循以下步骤:
-
-1. 在适当目录中实现你的代码,例如 `trinity/common/workflows` 用于工作流,`trinity/algorithm` 用于算法,`trinity/buffer/operators` 用于操作符。
-
-2. 在目录对应的 `__init__.py` 文件中注册你的模块。
-
-3. 在 `tests` 目录中为你的模块添加测试,遵循现有测试的命名约定和结构。
-
-4. 提交代码前,确保通过 `pre-commit run --all-files` 完成代码风格检查。
-
-5. 向 Trinity-RFT 仓库提交 Pull Request,包含对你更改的清晰描述。
diff --git a/pyproject.toml b/pyproject.toml
index 451be9db4f..5e78e3e8b4 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -120,6 +120,9 @@ exclude = '''
[tool.isort]
known_third_party = ["wandb"]
+[tool.uv.extra-build-dependencies]
+flash-attn = ["torch", "numpy"]
+
[project.urls]
"Homepage" = "https://github.com/modelscope/Trinity-RFT"
"Documentation" = "https://modelscope.github.io/Trinity-RFT/"