Disk Corruption #51
Comments
|
Same experience here. Haven't seen this on |
@deiwin How long have you been running v22 without encountering this issue? |
|
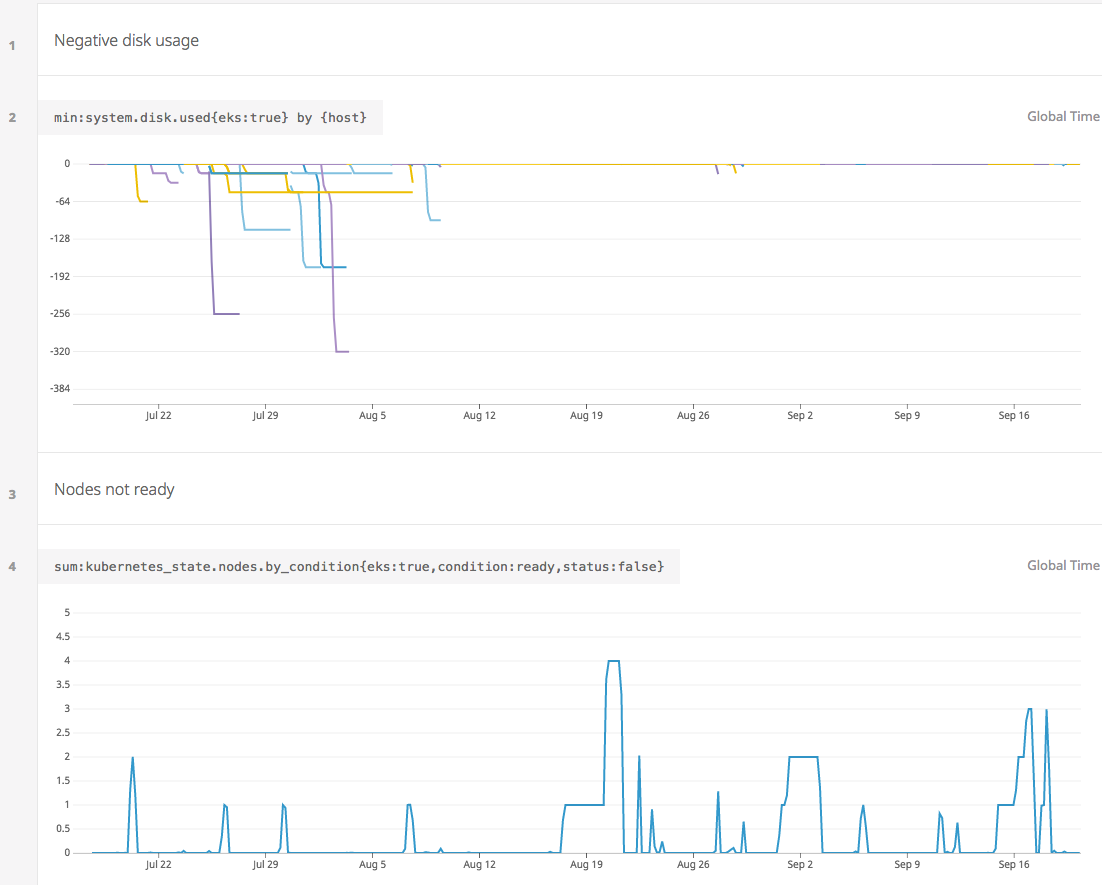
A bit over a month. An illustration: |

|
Although v22 isn't all roses either - we've seen a somewhat related issue of docker freezing up (node not ready with "PLEG is not healthy", We're currently experimenting with a different Docker version ( |
|
What is running on the affected worker nodes? Does this only happen on heavily loaded nodes or would this happen on an idle node? Instance types? Are there any messages in |
|
@brycecarman It does seem to happen more frequently on nodes that have more traffic and churn on the deployment images. Instance type's are r4.xl and r4.2xl. Nothing of note in dmesg. |
|
I'm wondering if it could be related to xfs, but ideally I'd like to reproduce this first. Do you have any reliable reproduction for this? |
|
I don't have a reliable way to test which makes it hard to confirm a fix and confirm the problem. However, I converted the root fs to ext4 to see if I would still have issues and my nodes are much more stable, so I believe it is xfs related. In regards to that link, I did check the dd_type and that was set correctly as far as I could tell. |
|
@deiwin are you seeing any difference with ext4? Do you have a repro for this? |
|
We also believe that it's something to do with xfs. Mostly because of this mail thread, which describes a very similar issue. I haven't tried ext4 and don't have a repro, although it does fail reliably in our setup. We're currently using v22 of the AMI + Docker 18.06.1ce, which has been a stable combination thus far. However, I have provided information about specific instances and occurrences to AWS support. They told me that the EKS team has passed the issue onto the EC2 team. Waiting to see where that gets us. For what it's worth, according to this, a patch should be available in newer kernel versions (4.19) and should fix the effect, although cause isn't known. |
Because of issue awslabs#51, we may want to use a distro that defaults to ext4 instead of xfs, since the former tends to be more stable.
|
We have seen a similar disk corruption issue occur roughly once every two weeks in a cluster of six m5.xlarge nodes. The nodes are lightly loaded: ~5% CPU usage, ~50% memory usage, ~50 pods. We haven't been able to track down any causal pattern or unusual system logs; the corruption appears to occur at random. This doesn't immediately impact service, only monitoring, so while we lack a repro we have obtained a snapshot of an affected volume. We use 100G root volumes, which after corruption are consistently reported as Attaching the affected volume to a separate instance and running an Comparing those two numbers: This looks like a bit-flip in the superblock free data block count, just as described in the above mail thread. The origin of that thread is https://phabricator.wikimedia.org/T199198, in which the authors appear to have narrowed down the issue to the free inode btree (finobt) feature. However, in our case it is already disabled: |
|
This doesn't appear to be specifically related to the AMI, so I'm going to close it. Feel free to re-open or contact AWS support if you are still experiencing this issue. |
Not sure if this is the proper place to open an issue as I am unclear where the issue is actually happening, but we are experiencing disk corruption on the worker nodes. We have tried v20, v23, and v24 and the root volumes showed corruption in as little as a couple hours and up to 4 days.
What ends up happening is that we start to see that these errors in the logs:
Then eventually the node runs out of disk space, fails instance status checks, and it gets replaced by the auto scaling group.
Any help would be appreciated.
Thanks.
The text was updated successfully, but these errors were encountered: