diff --git a/3rdparty/ps-lite b/3rdparty/ps-lite
index 862f8a664..7672fdc62 160000
--- a/3rdparty/ps-lite
+++ b/3rdparty/ps-lite
@@ -1 +1 @@
-Subproject commit 862f8a6644ddee9a2220244097e18a9bccf9e1da
+Subproject commit 7672fdc62c50ff7bb13586bee6872a8efd98d966
diff --git a/README.md b/README.md
index 395e2364d..f49d901f2 100644
--- a/README.md
+++ b/README.md
@@ -5,32 +5,27 @@
BytePS is a high performance and general distributed training framework. It supports TensorFlow, Keras, PyTorch, and MXNet, and can run on either TCP or RDMA network.
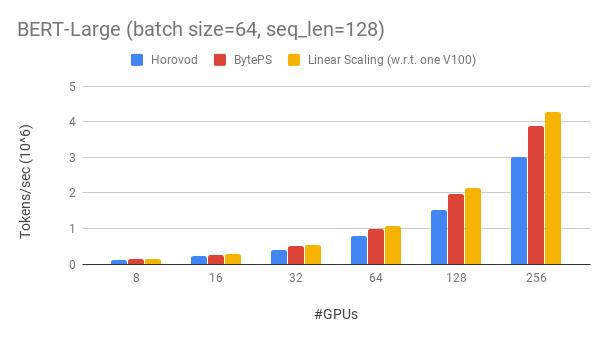
-BytePS outperforms existing open-sourced distributed training frameworks by a large margin. For example, on a popular public cloud and with the same number of GPUs, BytePS can *double the training speed* (see below), compared with [Horovod](https://github.com/horovod/horovod)+[NCCL](https://github.com/NVIDIA/nccl).
+BytePS outperforms existing open-sourced distributed training frameworks by a large margin. For example, on BERT-large training, BytePS can achieve ~90% scaling efficiency with 256 GPUs (see below), which is much higher than [Horovod](https://github.com/horovod/horovod)+[NCCL](https://github.com/NVIDIA/nccl).
## News
-- Use [the ssh launcher](launcher/) to launch your distributed jobs
-- Asynchronous training support for
-[PyTorch](https://github.com/bytedance/byteps/pull/121),
-[TensorFlow](https://github.com/bytedance/byteps/pull/122),
-[MXNet](https://github.com/bytedance/byteps/pull/114)
-- Find your training stragglers using [server timeline](docs/timeline.md)
-- [Improved key distribution strategy for better load-balancing](https://github.com/bytedance/byteps/pull/116)
+- [New Server](https://github.com/bytedance/byteps/pull/151): We improve the server performance by a large margin, and it is now independent of MXNet KVStore. Try our [new docker images](docker/).
+- Use [the ssh launcher](launcher/) to launch your distributed jobs
+- [Improved key distribution strategy for better load-balancing](https://github.com/bytedance/byteps/pull/116)
- [Improved RDMA robustness](https://github.com/bytedance/byteps/pull/91)
## Performance
-For demonstration, we test two models: VGG16 (communication-intensive) and Resnet50 (computation-intensive). Both models are trained using fp32.
+We show our experiment on BERT-large training, which is based on GluonNLP toolkit. The model uses mixed precision.
-We use Tesla V100 16GB GPUs and set batch size equal to 64 *per GPU*. The machines are in fact VMs on a popular public cloud. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 20 Gbps TCP/IP network.
+We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs (32GB memory) with NVLink-enabled. Machines are inter-connected with 100 Gbps RoCEv2 network.
-BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.
+BytePS achieves ~90% scaling efficiency for BERT-large. The code is available [here](https://github.com/ymjiang/gluon-nlp/tree/bert-byteps/scripts/bert).
-
 +
-You can reproduce the results using the Dockerfiles and example scripts we provide.
-Evaluation on RDMA networks can be found at [performance.md](docs/performance.md).
+More evaluation in different scenarios can be found at [performance.md](docs/performance.md).
## Goodbye MPI, Hello Cloud
diff --git a/byteps/common/common.h b/byteps/common/common.h
index 6a39a4663..739e2ac28 100644
--- a/byteps/common/common.h
+++ b/byteps/common/common.h
@@ -17,8 +17,11 @@
#ifndef BYTEPS_COMMON_H
#define BYTEPS_COMMON_H
+#ifndef BYTEPS_BUILDING_SERVER
#include
#include
+#endif
+
#include
#include
#include
@@ -217,7 +220,9 @@ enum class RequestType {
int GetCommandType(RequestType requestType, int d);
+#ifndef BYTEPS_BUILDING_SERVER
ncclDataType_t getNcclDataType(DataType dtype);
+#endif
int getDataTypeLength(int dtype);
diff --git a/byteps/common/cpu_reducer.cc b/byteps/common/cpu_reducer.cc
index a7699fb79..d145b5341 100644
--- a/byteps/common/cpu_reducer.cc
+++ b/byteps/common/cpu_reducer.cc
@@ -13,19 +13,32 @@
// limitations under the License.
// =============================================================================
+#ifndef BYTEPS_BUILDING_SERVER
#include "global.h"
+#endif
+
+#include "cpu_reducer.h"
namespace byteps {
namespace common {
CpuReducer::CpuReducer(std::shared_ptr comm) {
+
+#ifndef BYTEPS_BUILDING_SERVER
std::vector peers;
auto pcie_size = BytePSGlobal::GetPcieSwitchSize();
for (int i = BytePSGlobal::GetLocalRank() % pcie_size;
i < BytePSGlobal::GetLocalSize(); i += pcie_size) {
peers.push_back(i);
}
- _comm = std::make_shared(comm, std::string("cpu"), peers);
+ if (comm) {
+ _comm = std::make_shared(comm, std::string("cpu"), peers);
+ }
+ else {
+ _comm = nullptr;
+ }
+#endif
+
if (getenv("BYTEPS_OMP_THREAD_PER_GPU")) {
_num_threads = atoi(getenv("BYTEPS_OMP_THREAD_PER_GPU"));
} else {
@@ -34,9 +47,14 @@ CpuReducer::CpuReducer(std::shared_ptr comm) {
return;
}
+#ifndef BYTEPS_BUILDING_SERVER
bool CpuReducer::isRoot() {
+ if (!_comm) {
+ return false;
+ }
return (_comm->getRoot() == BytePSGlobal::GetLocalRank());
}
+#endif
int CpuReducer::sum(void* dst, void* src, size_t len, DataType dtype) {
switch (dtype) {
@@ -64,7 +82,7 @@ int CpuReducer::sum(void* dst, void* src, size_t len, DataType dtype) {
BPS_CHECK(0) << "Unsupported data type: " << dtype;
}
return 0;
-}
+}
template
int CpuReducer::_sum(T* dst, T* src, size_t len) {
@@ -190,5 +208,19 @@ int CpuReducer::_sum_float16(void* dst, void* src1, void* src2, size_t len) {
return 0;
}
+int CpuReducer::copy(void* dst, void* src, size_t len) {
+ auto in = (float*)src;
+ auto out = (float*)dst;
+#pragma omp parallel for simd num_threads(_num_threads)
+ for (size_t i = 0; i < len / 4; ++i) {
+ out[i] = in[i];
+ }
+ if (len % 4) {
+ std::memcpy(out + len / 4, in + len / 4, len % 4);
+ }
+ return 0;
+}
+
+
} // namespace common
} // namespace byteps
diff --git a/byteps/common/cpu_reducer.h b/byteps/common/cpu_reducer.h
index 92e8bdd7a..a6e682c55 100644
--- a/byteps/common/cpu_reducer.h
+++ b/byteps/common/cpu_reducer.h
@@ -22,10 +22,16 @@
#endif
#include
+#include
#include "common.h"
-#include "communicator.h"
#include "logging.h"
+#ifndef BYTEPS_BUILDING_SERVER
+#include "communicator.h"
+#else
+typedef void BytePSComm;
+#endif
+
#include
namespace byteps {
@@ -41,8 +47,17 @@ class CpuReducer {
int sum(void* dst, void* src, size_t len, DataType dtype);
int sum(void* dst, void* src1, void* src2, size_t len, DataType dtype);
+ int copy(void* dst, void* src, size_t len);
+
+#ifndef BYTEPS_BUILDING_SERVER
bool isRoot();
std::shared_ptr getComm() { return _comm; }
+#endif
+
+
+ DataType GetDataType(int dtype) {
+ return static_cast(dtype);
+ }
private:
#if __AVX__ && __F16C__
diff --git a/byteps/common/global.cc b/byteps/common/global.cc
index 3e3d080f9..03e4a0fe3 100644
--- a/byteps/common/global.cc
+++ b/byteps/common/global.cc
@@ -338,7 +338,7 @@ uint64_t BytePSGlobal::Hash_DJB2(uint64_t key) {
auto str = std::to_string(key).c_str();
uint64_t hash = 5381;
int c;
- while (c = *str) { // hash(i) = hash(i-1) * 33 ^ str[i]
+ while ((c = *str)) { // hash(i) = hash(i-1) * 33 ^ str[i]
hash = ((hash << 5) + hash) + c;
str++;
}
@@ -349,7 +349,7 @@ uint64_t BytePSGlobal::Hash_SDBM(uint64_t key) {
auto str = std::to_string(key).c_str();
uint64_t hash = 0;
int c;
- while (c = *str) { // hash(i) = hash(i-1) * 65599 + str[i]
+ while ((c = *str)) { // hash(i) = hash(i-1) * 65599 + str[i]
hash = c + (hash << 6) + (hash << 16) - hash;
str++;
}
diff --git a/byteps/common/shared_memory.cc b/byteps/common/shared_memory.cc
index ec86d166f..e4ff185f2 100644
--- a/byteps/common/shared_memory.cc
+++ b/byteps/common/shared_memory.cc
@@ -54,22 +54,26 @@ std::vector BytePSSharedMemory::openPcieSharedMemory(uint64_t key,
for (int i = 0; i < BytePSGlobal::GetPcieSwitchNum(); i++) {
auto prefix = std::string("BytePS_Pcie") + std::to_string(i) + "_Shm_";
if (BytePSGlobal::IsDistributed()) {
- if (i <= numa_max_node()) {
- numa_set_preferred(i);
+ if (BytePSGlobal::IsCrossPcieSwitch()) {
+ if (i <= numa_max_node()) {
+ numa_set_preferred(i);
+ r.push_back(openSharedMemory(prefix, key, size));
+ numa_set_preferred(-1);
+ } else {
+ numa_set_preferred(numa_max_node());
+ r.push_back(openSharedMemory(prefix, key, size));
+ numa_set_preferred(-1);
+ }
} else {
- numa_set_preferred(numa_max_node());
+ r.push_back(openSharedMemory(prefix, key, size));
}
- r.push_back(openSharedMemory(prefix, key, size));
- numa_set_preferred(-1);
} else {
if (BytePSGlobal::IsCrossPcieSwitch()) {
numa_set_interleave_mask(numa_all_nodes_ptr);
r.push_back(openSharedMemory(prefix, key, size));
numa_set_interleave_mask(numa_no_nodes_ptr);
} else {
- numa_set_preferred(0);
r.push_back(openSharedMemory(prefix, key, size));
- numa_set_preferred(-1);
}
}
}
diff --git a/byteps/server/__init__.py b/byteps/server/__init__.py
new file mode 100644
index 000000000..bb9500d64
--- /dev/null
+++ b/byteps/server/__init__.py
@@ -0,0 +1,23 @@
+# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import ctypes
+import os
+from byteps.common import get_ext_suffix
+
+dll_path = os.path.join(os.path.dirname(__file__),
+ 'c_lib' + get_ext_suffix())
+SERVER_LIB_CTYPES = ctypes.CDLL(dll_path, ctypes.RTLD_GLOBAL)
+SERVER_LIB_CTYPES.byteps_server()
diff --git a/byteps/server/queue.h b/byteps/server/queue.h
new file mode 100644
index 000000000..fe3f7f57c
--- /dev/null
+++ b/byteps/server/queue.h
@@ -0,0 +1,110 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef BYTEPS_SERVER_QUEUE_H
+#define BYTEPS_SERVER_QUEUE_H
+
+#include
+#include
+#include
+#include
+#include
+
+namespace byteps {
+namespace server {
+
+/**
+ * \brief thread-safe queue allowing push and waited pop
+ */
+class PriorityQueue {
+ public:
+ PriorityQueue(bool is_schedule) {
+ enable_schedule_ = is_schedule;
+ if (enable_schedule_) {
+ std::make_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ }
+ }
+ ~PriorityQueue() { }
+
+ /**
+ * \brief push an value and sort using heap. threadsafe.
+ * \param new_value the value
+ */
+ void Push(BytePSEngineMessage new_value) {
+ mu_.lock();
+ queue_.push_back(std::move(new_value));
+ if (enable_schedule_) {
+ ++push_cnt_[new_value.key];
+ std::push_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ }
+ mu_.unlock();
+ cond_.notify_all();
+ }
+
+ /**
+ * \brief wait until pop an element from the beginning, threadsafe
+ * \param value the poped value
+ */
+ void WaitAndPop(BytePSEngineMessage* value) {
+ std::unique_lock lk(mu_);
+ cond_.wait(lk, [this]{return !queue_.empty();});
+ if (enable_schedule_) {
+ std::pop_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ *value = queue_.back();
+ queue_.pop_back();
+ } else {
+ *value = std::move(queue_.front());
+ queue_.erase(queue_.begin());
+ }
+ }
+
+ void ClearCounter(uint64_t key) {
+ if (!enable_schedule_) return;
+ std::unique_lock lk(mu_);
+ push_cnt_[key] = 0;
+ }
+
+ bool ComparePriority(const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ if (push_cnt_[a.key] == push_cnt_[b.key]) {
+ return (a.id > b.id);
+ } else {
+ return (push_cnt_[a.key] > push_cnt_[b.key]);
+ }
+ }
+
+ private:
+ mutable std::mutex mu_;
+ std::vector queue_;
+ std::condition_variable cond_;
+ std::unordered_map push_cnt_;
+ volatile bool enable_schedule_ = false;
+};
+
+} // namespace server
+} // namespace byteps
+
+#endif // BYTEPS_SERVER_QUEUE_H
\ No newline at end of file
diff --git a/byteps/server/server.cc b/byteps/server/server.cc
new file mode 100644
index 000000000..3f91fcdfe
--- /dev/null
+++ b/byteps/server/server.cc
@@ -0,0 +1,403 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#include "server.h"
+#include "queue.h"
+
+namespace byteps {
+namespace server {
+
+using namespace ps;
+
+// engine related
+std::vector engine_queues_;
+std::vector engine_threads_;
+
+void SendPushResponse(uint64_t key, const ps::KVMeta& req, ps::KVServer* server){
+ auto iterator = push_response_map_.find(key);
+ if (iterator == push_response_map_.end()) { // new key
+ ps::KVPairs response;
+ response.keys.push_back(key);
+ push_response_map_[key] = response; // add to the map
+ server->Response(req, response);
+ } else { // not new key, then reuse the memory address to avoid ibv_reg_mr on RDMA data path
+ ps::KVPairs *response = &iterator->second;
+ response->keys[0] = key;
+ server->Response(req, *response);
+ }
+}
+
+void SendPullResponse(const DataHandleType type,
+ const uint64_t key,
+ const ps::KVMeta& req_meta,
+ ps::KVServer* server) {
+ std::lock_guard lock(pullresp_mu_);
+ auto& stored = store_[key];
+ CHECK(stored.tensor) << "init " << key << " first";
+ // as server returns when store_realt is ready in this case
+ auto len = stored.len;
+ // send pull response
+ auto iterator = pull_response_map_.find(key);
+ if (iterator == pull_response_map_.end()) { // new key
+ ps::KVPairs response;
+ response.keys = {EncodeKey(key)};
+ response.lens = {len};
+ response.vals = ps::SArray(stored.tensor, len, false); // zero copy
+ pull_response_map_[key] = response; // add to the map
+ server->Response(req_meta, response);
+ } else { // not new key, then reuse the memory address to avoid ibv_reg_mr on RDMA data path
+ ps::KVPairs *response = &iterator->second;
+ // keys and lens remain unchanged, just update vals
+ auto p = static_cast(stored.tensor);
+ CHECK(p);
+ response->vals = ps::SArray(p, len, false);
+ server->Response(req_meta, *response);
+ }
+}
+
+void BytePSServerEngineThread(int i) {
+ auto& q = engine_queues_[i];
+ while (true) {
+ BytePSEngineMessage msg;
+ q->WaitAndPop(&msg);
+ if (msg.ops == TERMINATE) break;
+ // do some check
+ CHECK(msg.dst);
+ CHECK(msg.src);
+
+ bool is_debug = (debug_mode_ && (debug_key_ == msg.key));
+ switch (msg.ops) {
+ case COPY_MERGED: {
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_COPY_MERGED_TO_STORE_BEFORE \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ bps_reducer_->copy(msg.dst, msg.src, msg.len);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_COPY_MERGED_TO_STORE_AFTER \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ std::lock_guard lock(flag_mu_[i]);
+ if (is_push_finished_[i].find(msg.key) == is_push_finished_[i].end()) {
+ is_push_finished_[i][msg.key] = false;
+ pull_cnt_[i][msg.key] = 0;
+ }
+ is_push_finished_[i][msg.key] = true;
+ for (auto& req_meta : q_pull_reqmeta_[i][msg.key]) {
+ SendPullResponse(msg.type, msg.key, req_meta, byteps_server_);
+ pull_cnt_[i][msg.key] += 1;
+ if (pull_cnt_[i][msg.key] == (size_t) ps::NumWorkers()) {
+ is_push_finished_[i][msg.key] = false;
+ pull_cnt_[i][msg.key] = 0;
+ }
+ }
+ q_pull_reqmeta_[i][msg.key].clear();
+ break;
+ }
+ case SUM_RECV: {
+ auto bps_type = bps_reducer_->GetDataType(msg.type.dtype);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_SUM_RECV_BEFORE \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ CHECK_GE(bps_reducer_->sum(msg.dst,
+ msg.src,
+ msg.len,
+ bps_type), 0);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_SUM_RECV_AFTER \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ break;
+ }
+ default:
+ CHECK(0);
+ }
+ }
+}
+
+void BytePSHandler(const ps::KVMeta& req_meta,
+ const ps::KVPairs &req_data, ps::KVServer* server) {
+ std::lock_guard lock(handle_mu_); // push & pull may have racing
+ DataHandleType type = DepairDataHandleType(req_meta.cmd);
+ CHECK_EQ(type.requestType, RequestType::kDefaultPushPull);
+ // do some check
+ CHECK_EQ(req_data.keys.size(), (size_t)1);
+ if (log_key_info_) {
+ if (req_meta.push) {
+ CHECK_EQ(req_data.lens.size(), (size_t)1);
+ CHECK_EQ(req_data.vals.size(), (size_t)req_data.lens[0]);
+ LOG(INFO) << "push key="
+ << DecodeKey(req_data.keys[0])
+ << "\t sender=" << req_meta.sender
+ << "\t size=" << (size_t) req_data.lens[0];
+ } else {
+ LOG(INFO) << "pull key="
+ << (uint64_t) DecodeKey(req_data.keys[0])
+ << "\t sender=" << req_meta.sender;
+ }
+ }
+ uint64_t key = DecodeKey(req_data.keys[0]);
+ if (req_meta.push) { // push request
+ CHECK_EQ(req_data.lens.size(), (size_t)1);
+ CHECK_EQ(req_data.vals.size(), (size_t)req_data.lens[0]);
+ auto& stored = store_[key];
+ auto len = (size_t) req_data.lens[0];
+ auto recved = reinterpret_cast(req_data.vals.data());
+ if (!stored.tensor) {
+ if (sync_mode_ && (update_buf_.find(key) == update_buf_.end())) {
+ update_buf_[key].merged.len = len;
+ update_buf_[key].merged.dtype = type.dtype;
+ }
+ // buffer the request meta
+ auto &updates = update_buf_[key];
+ updates.request.push_back(req_meta);
+ // should send response after collecting all init push
+ if (updates.request.size() < (size_t) ps::NumWorkers()) return;
+ if (log_key_info_) {
+ LOG(INFO) << "Collected all " << updates.request.size()
+ << " requests for key=" << key
+ << ", init the store buffer size=" << (size_t) req_data.lens[0];
+ }
+ // initialization
+ stored.tensor = (char*) malloc(len);
+ stored.len = len;
+ stored.dtype = type.dtype;
+ CHECK(stored.tensor);
+ bps_reducer_->copy(stored.tensor, recved, len); // we may not need this copy
+ for (const auto& req : updates.request) {
+ SendPushResponse(key, req, server);
+ }
+ updates.request.clear();
+ } else {
+ auto &updates = update_buf_[key];
+ auto tid = GetThreadID(key, len);
+ if (updates.request.empty()) { // from the first incoming worker
+ if (sync_mode_) {
+ if (is_engine_blocking_) {
+ bps_reducer_->copy(updates.merged.tensor, recved, len);
+ } else { // non-blocking
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: FIRST_WORKER_RECV \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved) << "\t"
+ << "len: " << len << "\t"
+ << "addr: " << DEBUG_PRINT_TENSOR_ADDRESS(recved);
+ }
+ // zero copy
+ updates.merged.tensor = recved;
+ updates.merged.tmp_sarray = req_data;
+ }
+ } else { // async mode, directly add to the buffer
+ if (is_engine_blocking_) {
+ CHECK_GE(bps_reducer_->sum((void *) stored.tensor,
+ (void *) recved,
+ len,
+ bps_reducer_->GetDataType(stored.dtype)), 0);
+ } else {
+ BytePSEngineMessage msg = {timestamp_++, type, key, stored.tensor, recved, len, SUM_RECV, req_data};
+ engine_queues_[tid]->Push(msg);
+ }
+ }
+ } else { // from other workers
+ CHECK(sync_mode_);
+ CHECK(updates.merged.tensor);
+ if (is_engine_blocking_) {
+ CHECK_GE(bps_reducer_->sum((void *) updates.merged.tensor,
+ (void *) recved,
+ len,
+ bps_reducer_->GetDataType(updates.merged.dtype)), 0);
+ } else { // non-blocking
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: OTHER_WORKER_SUM \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "merged: " << DEBUG_PRINT_TENSOR_VALUE(updates.merged.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved) << "\t"
+ << "len: " << len << "\t"
+ << "addr: " << DEBUG_PRINT_TENSOR_ADDRESS(recved);
+ }
+ BytePSEngineMessage msg = {timestamp_++, type, key, updates.merged.tensor, recved, len, SUM_RECV, req_data, req_meta};
+ engine_queues_[tid]->Push(msg);
+ }
+ }
+ // add a worker information (request.size() is the # workers received)
+ updates.request.push_back(req_meta);
+ SendPushResponse(key, req_meta, server);
+ if (sync_mode_ && updates.request.size() == (size_t) ps::NumWorkers()) {
+ auto& stored = store_[key];
+ auto& update = updates.merged;
+ if (is_engine_blocking_) {
+ bps_reducer_->copy(stored.tensor, updates.merged.tensor, len);
+ } else {
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: COPY_MERGED_TO_STORE \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "merged: " << DEBUG_PRINT_TENSOR_VALUE(updates.merged.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved);
+ }
+ BytePSEngineMessage msg = {timestamp_++, type, key, stored.tensor, update.tensor, len, COPY_MERGED};
+ engine_queues_[tid]->Push(msg);
+ engine_queues_[tid]->ClearCounter(key);
+ }
+ updates.request.clear();
+ } else if (!sync_mode_) {
+ // async: clean the request buffer
+ updates.request.clear();
+ engine_queues_[tid]->ClearCounter(key);
+ }
+ }
+ } else { // pull request
+ auto& stored = store_[key];
+ CHECK(stored.tensor) << "Processing pull request when the NDArray of key "
+ << key << " has not been inited yet, which is not expected.";
+ if (is_engine_blocking_) {
+ SendPullResponse(type, key, req_meta, server);
+ } else {
+ auto tid = GetThreadID(key, 0);
+ std::lock_guard lock(flag_mu_[tid]);
+ if (is_push_finished_[tid].find(key) == is_push_finished_[tid].end()) {
+ is_push_finished_[tid][key] = false;
+ pull_cnt_[tid][key] = 0;
+ }
+ if (is_push_finished_[tid][key]) { // push already finished
+ SendPullResponse(type, key, req_meta, server);
+ pull_cnt_[tid][key] += 1;
+ if (pull_cnt_[tid][key] == (size_t) ps::NumWorkers()) {
+ is_push_finished_[tid][key] = false;
+ pull_cnt_[tid][key] = 0;
+ // check: remain should be 0
+ auto remain = q_pull_reqmeta_[tid][key].size();
+ CHECK_EQ(remain, 0) << remain;
+ }
+ } else { // push not finished, put into the queue, and wait for the engine
+ q_pull_reqmeta_[tid][key].push_back(req_meta);
+ }
+ }
+ }
+}
+
+void init_global_env() {
+ // enable to print key profile
+ log_key_info_ = GetEnv("PS_KEY_LOG", false);
+
+ // sync or async training
+ sync_mode_ = GetEnv("BYTEPS_ENABLE_ASYNC", true);
+ if (!sync_mode_) LOG(INFO) << "BytePS server is enabled asynchronous training";
+
+ // debug mode
+ debug_mode_ = GetEnv("BYTEPS_SERVER_DEBUG", false);
+ debug_key_ = GetEnv("BYTEPS_SERVER_DEBUG_KEY", 0);
+ if (debug_mode_) LOG(INFO) << "Debug mode enabled! Printing key " << debug_key_;
+
+ // enable engine block mode (default disabled)
+ is_engine_blocking_ = GetEnv("BYTEPS_SERVER_ENGINE_BLOCKING", false);
+ if (is_engine_blocking_) LOG(INFO) << "Enable blocking mode of the server engine";
+
+ // number of engine thread
+ // invalid if is_engine_blocking = true
+ engine_thread_num_ = GetEnv("BYTEPS_SERVER_ENGINE_THREAD", 4);
+ LOG(INFO) << "BytePS server engine uses " << engine_thread_num_ << " threads"
+ << ", consider increasing BYTEPS_SERVER_ENGINE_THREAD for higher performance";
+ CHECK_GE(engine_thread_num_, 1);
+
+ // enable scheduling for server engine
+ enable_schedule_ = GetEnv("BYTEPS_SERVER_ENABLE_SCHEDULE", false);
+ if (enable_schedule_) LOG(INFO) << "Enable engine scheduling for BytePS server";
+}
+
+extern "C" void byteps_server() {
+ init_global_env();
+
+ // cpu reducer
+ bps_reducer_ = new byteps::common::CpuReducer(nullptr);
+
+ // flag mu and its protected map
+ std::vector tmp_flagmu(engine_thread_num_);
+ std::vector > tmp_ispushfinished(engine_thread_num_);
+ std::vector > > tmp_qpullreqmeta(engine_thread_num_);
+ std::vector > tmp_pullcnt(engine_thread_num_);
+ flag_mu_.swap(tmp_flagmu);
+ is_push_finished_.swap(tmp_ispushfinished);
+ q_pull_reqmeta_.swap(tmp_qpullreqmeta);
+ pull_cnt_.swap(tmp_pullcnt);
+ CHECK_EQ(flag_mu_.size(), engine_thread_num_);
+ CHECK_EQ(is_push_finished_.size(), engine_thread_num_);
+ CHECK_EQ(q_pull_reqmeta_.size(), engine_thread_num_);
+ CHECK_EQ(pull_cnt_.size(), engine_thread_num_);
+
+ // init the engine
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ acc_load_.push_back(0);
+ }
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ auto q = new PriorityQueue(enable_schedule_);
+ engine_queues_.push_back(q);
+ }
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ auto t = new std::thread(&BytePSServerEngineThread, i);
+ engine_threads_.push_back(t);
+ }
+
+ // init server instance
+ byteps_server_ = new KVServer(0);
+ byteps_server_->set_request_handle(BytePSHandler);
+ StartAsync(0, "byteps_server\0");
+ if (!Postoffice::Get()->is_recovery()) {
+ Postoffice::Get()->Barrier(0,
+ ps::kWorkerGroup + ps::kServerGroup + ps::kScheduler);
+ }
+
+ // clean the server resource
+ Finalize(0, true);
+ if (byteps_server_) {
+ delete byteps_server_;
+ byteps_server_ = nullptr;
+ }
+ if (bps_reducer_) {
+ delete bps_reducer_;
+ bps_reducer_ = nullptr;
+ }
+ BytePSEngineMessage msg;
+ msg.ops = TERMINATE;
+ for (auto q : engine_queues_) q->Push(msg);
+ for (auto t : engine_threads_) t->join();
+ for (auto& it : store_) free(it.second.tensor);
+ for (auto& it : update_buf_) free(it.second.merged.tensor);
+ LOG(INFO) << "byteps has been shutdown";
+
+ return;
+}
+
+} // namespace server
+} // namespace byteps
diff --git a/byteps/server/server.h b/byteps/server/server.h
new file mode 100644
index 000000000..5b6e30fcf
--- /dev/null
+++ b/byteps/server/server.h
@@ -0,0 +1,169 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef BYTEPS_SERVER_H
+#define BYTEPS_SERVER_H
+
+#include
+#include
+#include
+#include "ps/ps.h"
+#include "../common/cpu_reducer.h"
+
+namespace byteps {
+namespace server {
+
+#define SERVER_KEY_TYPE uint64_t
+#define SERVER_DATA_TYPE char
+#define DEBUG_PRINT_TENSOR_VALUE(X) (*((float *)(X) + 0))
+#define DEBUG_PRINT_TENSOR_ADDRESS(X) (reinterpret_cast(X))
+
+using namespace ps;
+
+enum class RequestType {
+ kDefaultPushPull, kRowSparsePushPull, kCompressedPushPull
+};
+
+enum BytePSEngineOperation {
+ SUM_RECV, COPY_MERGED, TERMINATE
+};
+
+struct PSKV {
+ SArray keys; // n keys
+ SArray lens; // the length of the i-th value
+};
+
+struct DataHandleType {
+ RequestType requestType;
+ int dtype;
+};
+
+struct BytePSArray {
+ char* tensor;
+ size_t len;
+ int dtype;
+ ps::KVPairs tmp_sarray;
+};
+
+struct UpdateBuf {
+ std::vector request;
+ BytePSArray merged;
+};
+
+struct BytePSEngineMessage {
+ uint64_t id;
+ DataHandleType type;
+ uint64_t key;
+ void* dst;
+ void* src;
+ size_t len;
+ BytePSEngineOperation ops;
+ ps::KVPairs sarray; // to temporarily hold it and auto release
+ ps::KVMeta req_meta;
+};
+
+static DataHandleType DepairDataHandleType(int cmd) {
+ int w = std::floor((std::sqrt(8 * cmd + 1) - 1)/2);
+ int t = ((w * w) + w) / 2;
+ int y = cmd - t;
+ int x = w - y;
+ CHECK_GE(x, 0);
+ CHECK_GE(y, 0);
+ DataHandleType type;
+ type.requestType = static_cast(x);
+ type.dtype = y;
+ return type;
+}
+
+
+KVServer* byteps_server_;
+byteps::common::CpuReducer* bps_reducer_;
+std::unordered_map > mem_map_;
+std::mutex pullresp_mu_;
+std::unordered_map > push_response_map_;
+std::unordered_map > pull_response_map_;
+
+// push & pull flag
+std::vector flag_mu_;
+std::vector > is_push_finished_;
+std::vector > > q_pull_reqmeta_;
+std::vector > pull_cnt_;
+
+// address map
+std::mutex handle_mu_;
+std::unordered_map store_;
+std::unordered_map update_buf_;
+
+// hash function
+std::mutex hash_mu_;
+std::unordered_map hash_cache_;
+std::vector acc_load_; // accumulated tensor size for an engine thread
+
+// global knob
+uint64_t timestamp_ = 0;
+size_t engine_thread_num_ = 4;
+volatile bool is_engine_blocking_ = false;
+volatile bool log_key_info_ = false;
+volatile bool sync_mode_ = true;
+volatile bool debug_mode_ = false;
+volatile bool enable_schedule_ = false;
+
+// debug
+uint64_t debug_key_;
+std::mutex debug_mu_;
+
+
+uint64_t DecodeKey(ps::Key key) {
+ auto kr = ps::Postoffice::Get()->GetServerKeyRanges()[ps::MyRank()];
+ return key - kr.begin();
+}
+
+uint64_t EncodeKey(ps::Key key) {
+ auto kr = ps::Postoffice::Get()->GetServerKeyRanges()[ps::MyRank()];
+ return key + kr.begin();
+}
+
+size_t GetThreadID(uint64_t key, size_t len) {
+ std::lock_guard lock(hash_mu_);
+ if (len == 0) { // pull
+ CHECK_NE(hash_cache_.find(key), hash_cache_.end());
+ return hash_cache_[key];
+ }
+ if (hash_cache_.find(key) != hash_cache_.end()) {
+ return hash_cache_[key];
+ }
+ CHECK_GT(len, 0);
+ CHECK_EQ(acc_load_.size(), engine_thread_num_);
+ auto min_index = -1;
+ auto min_load = std::numeric_limits::max();
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ if (acc_load_[i] < min_load) {
+ min_load = acc_load_[i];
+ min_index = i;
+ }
+ }
+ CHECK_GE(min_index, 0);
+ CHECK_LT(min_index, engine_thread_num_);
+ acc_load_[min_index] += len;
+ hash_cache_[key] = min_index;
+ return hash_cache_[key];
+}
+
+extern "C" void byteps_server();
+
+} // namespace server
+} // namespace byteps
+
+#endif // BYTEPS_SERVER_H
diff --git a/docker/Dockerfile.mix.mxnet15 b/docker/Dockerfile.mix.mxnet15
deleted file mode 100644
index 683ec86c1..000000000
--- a/docker/Dockerfile.mix.mxnet15
+++ /dev/null
@@ -1,172 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends --fix-missing \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-pip \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base \
- python3 \
- python3-dev \
- python3-pip \
- python3-setuptools
-
-
-RUN python -m pip install --upgrade pip &&\
- pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-RUN pip3 install --upgrade pip &&\
- python3 -m pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-############ build server
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.5.0
-RUN python -m pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-RUN pip3 --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python3 setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python3 setup.py bdist_wheel
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
diff --git a/docker/Dockerfile.worker.mxnet.cu100.rdma b/docker/Dockerfile.mxnet
similarity index 65%
rename from docker/Dockerfile.worker.mxnet.cu100.rdma
rename to docker/Dockerfile.mxnet
index a38055c71..68ed1639e 100644
--- a/docker/Dockerfile.worker.mxnet.cu100.rdma
+++ b/docker/Dockerfile.mxnet
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,31 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -147,12 +79,32 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install mxnet
+ARG FRAMEWORK_VERSION=1.5.0
+RUN python3 -m pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_PYTORCH=1
+ARG BYTEPS_WITHOUT_TENSORFLOW=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
@@ -162,5 +114,3 @@ RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu100.rdma b/docker/Dockerfile.pytorch
similarity index 64%
rename from docker/Dockerfile.worker.pytorch.cu100.rdma
rename to docker/Dockerfile.pytorch
index e67c9a359..a6f0c1d28 100644
--- a/docker/Dockerfile.worker.pytorch.cu100.rdma
+++ b/docker/Dockerfile.pytorch
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,40 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -156,12 +79,33 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install pytorch
+ARG FRAMEWORK_VERSION=1.1.0
+ARG TORCHVISION_VERSION=0.2.2
+RUN python3 -m pip --no-cache-dir install torch==$FRAMEWORK_VERSION torchvision==$TORCHVISION_VERSION
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_TENSORFLOW=1
+ARG BYTEPS_WITHOUT_MXNET=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
diff --git a/docker/Dockerfile.server b/docker/Dockerfile.server
deleted file mode 100644
index f6bf291f2..000000000
--- a/docker/Dockerfile.server
+++ /dev/null
@@ -1,86 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM ubuntu:16.04
-
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV LD_LIBRARY_PATH /root/incubator-mxnet/lib/:/usr/local/lib:$LD_LIBRARY_PATH
-
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-RUN apt-get update && apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- cd python && \
- python setup.py build && \
- python setup.py install &&\
- python setup.py bdist_wheel
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
diff --git a/docker/Dockerfile.server.rdma b/docker/Dockerfile.server.rdma
deleted file mode 100644
index f86c2abc4..000000000
--- a/docker/Dockerfile.server.rdma
+++ /dev/null
@@ -1,89 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM ubuntu:18.04
-
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV LD_LIBRARY_PATH /root/incubator-mxnet/lib/:/usr/local/lib:$LD_LIBRARY_PATH
-
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1 USE_RDMA=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update && apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends \
- tzdata \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- librdmacm-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip ibverbs-providers &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- cd python && \
- python setup.py build && \
- python setup.py install &&\
- python setup.py bdist_wheel
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu100.rdma b/docker/Dockerfile.tensorflow
similarity index 65%
rename from docker/Dockerfile.worker.tensorflow.cu100.rdma
rename to docker/Dockerfile.tensorflow
index e07f902b0..1159b4d9a 100644
--- a/docker/Dockerfile.worker.tensorflow.cu100.rdma
+++ b/docker/Dockerfile.tensorflow
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,33 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.14.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -149,12 +79,33 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install tensorflow
+ARG FRAMEWORK_VERSION=1.14.0
+RUN python3 -m pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION &&\
+ rm -rf /tmp/pip && rm -rf /root/.cache
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_PYTORCH=1
+ARG BYTEPS_WITHOUT_MXNET=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
diff --git a/docker/Dockerfile.worker.mxnet.cu100 b/docker/Dockerfile.worker.mxnet.cu100
deleted file mode 100644
index 38cd85c2e..000000000
--- a/docker/Dockerfile.worker.mxnet.cu100
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.mxnet.cu90 b/docker/Dockerfile.worker.mxnet.cu90
deleted file mode 100644
index 08c3a5578..000000000
--- a/docker/Dockerfile.worker.mxnet.cu90
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu90==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu100 b/docker/Dockerfile.worker.pytorch.cu100
deleted file mode 100644
index 73a74db1d..000000000
--- a/docker/Dockerfile.worker.pytorch.cu100
+++ /dev/null
@@ -1,149 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu90 b/docker/Dockerfile.worker.pytorch.cu90
deleted file mode 100644
index df2833793..000000000
--- a/docker/Dockerfile.worker.pytorch.cu90
+++ /dev/null
@@ -1,149 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu100 b/docker/Dockerfile.worker.tensorflow.cu100
deleted file mode 100644
index 7ff2fae93..000000000
--- a/docker/Dockerfile.worker.tensorflow.cu100
+++ /dev/null
@@ -1,142 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.12.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu90 b/docker/Dockerfile.worker.tensorflow.cu90
deleted file mode 100644
index 50b393a5a..000000000
--- a/docker/Dockerfile.worker.tensorflow.cu90
+++ /dev/null
@@ -1,142 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.12.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/README.md b/docker/README.md
index a84763ee2..16b8ddcaf 100644
--- a/docker/README.md
+++ b/docker/README.md
@@ -5,13 +5,6 @@ You may need to manually build them to get the latest functionalities of BytePS,
| Docker Image Name | Source Dockerfile | Description |
| --- | --- | --- |
-| bytepsimage/worker_mxnet | Dockerfile.worker.mxnet.cu90 | worker image for MXNet (CUDA 9.0) |
-| bytepsimage/worker_pytorch | Dockerfile.worker.pytorch.cu90 | worker image for PyTorch (CUDA 9.0) |
-| bytepsimage/worker_tensorflow | Dockerfile.worker.tensorflow.cu90 | worker image for TensorFlow (CUDA 9.0) |
-| bytepsimage/worker_mxnet_rdma | Dockerfile.worker.mxnet.cu100.rdma | worker image for MXNet with RDMA support (CUDA 10.0) |
-| bytepsimage/worker_pytorch_rdma | Dockerfile.worker.pytorch.cu100.rdma | worker image for PyTorch with RDMA support (CUDA 10.0) |
-| bytepsimage/worker_tensorflow_rdma | Dockerfile.worker.tensorflow.cu100.rdma | worker image for TensorFlow with RDMA support (CUDA 10.0) |
-| bytepsimage/byteps_server | Dockerfile.server | server/scheduler image |
-| bytepsimage/byteps_server_rdma | Dockerfile.server.rdma | server/scheduler image with RDMA support |
-| bytepsimage/mxnet15 | Dockerfile.mix.mxnet15 | all-in-one image with MXNet 1.5.0 (CUDA 10.0), applicable to worker/server/scheduler |
-
+| bytepsimage/mxnet | Dockerfile.mxnet | Image for MXNet |
+| bytepsimage/pytorch | Dockerfile.pytorch | Image for PyTorch |
+| bytepsimage/tensorflow | Dockerfile.tensorflow | Image for TensorFlow |
diff --git a/docs/architecture.md b/docs/architecture.md
index ff2e21f80..e6a7dd940 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -5,7 +5,8 @@ We highly recommend you to read [BytePS's rationale](./rationale.md) first befor
From application views, BytePS is a communication library just like Horovod. The plugins handle framework-specific transformation (e.g., on data structure), and
put communication tasks into BytePS priority queues. The BytePS Core then gets the tasks (priority-aware, not FIFO) and handles the actual communication.
-
+
-You can reproduce the results using the Dockerfiles and example scripts we provide.
-Evaluation on RDMA networks can be found at [performance.md](docs/performance.md).
+More evaluation in different scenarios can be found at [performance.md](docs/performance.md).
## Goodbye MPI, Hello Cloud
diff --git a/byteps/common/common.h b/byteps/common/common.h
index 6a39a4663..739e2ac28 100644
--- a/byteps/common/common.h
+++ b/byteps/common/common.h
@@ -17,8 +17,11 @@
#ifndef BYTEPS_COMMON_H
#define BYTEPS_COMMON_H
+#ifndef BYTEPS_BUILDING_SERVER
#include
#include
+#endif
+
#include
#include
#include
@@ -217,7 +220,9 @@ enum class RequestType {
int GetCommandType(RequestType requestType, int d);
+#ifndef BYTEPS_BUILDING_SERVER
ncclDataType_t getNcclDataType(DataType dtype);
+#endif
int getDataTypeLength(int dtype);
diff --git a/byteps/common/cpu_reducer.cc b/byteps/common/cpu_reducer.cc
index a7699fb79..d145b5341 100644
--- a/byteps/common/cpu_reducer.cc
+++ b/byteps/common/cpu_reducer.cc
@@ -13,19 +13,32 @@
// limitations under the License.
// =============================================================================
+#ifndef BYTEPS_BUILDING_SERVER
#include "global.h"
+#endif
+
+#include "cpu_reducer.h"
namespace byteps {
namespace common {
CpuReducer::CpuReducer(std::shared_ptr comm) {
+
+#ifndef BYTEPS_BUILDING_SERVER
std::vector peers;
auto pcie_size = BytePSGlobal::GetPcieSwitchSize();
for (int i = BytePSGlobal::GetLocalRank() % pcie_size;
i < BytePSGlobal::GetLocalSize(); i += pcie_size) {
peers.push_back(i);
}
- _comm = std::make_shared(comm, std::string("cpu"), peers);
+ if (comm) {
+ _comm = std::make_shared(comm, std::string("cpu"), peers);
+ }
+ else {
+ _comm = nullptr;
+ }
+#endif
+
if (getenv("BYTEPS_OMP_THREAD_PER_GPU")) {
_num_threads = atoi(getenv("BYTEPS_OMP_THREAD_PER_GPU"));
} else {
@@ -34,9 +47,14 @@ CpuReducer::CpuReducer(std::shared_ptr comm) {
return;
}
+#ifndef BYTEPS_BUILDING_SERVER
bool CpuReducer::isRoot() {
+ if (!_comm) {
+ return false;
+ }
return (_comm->getRoot() == BytePSGlobal::GetLocalRank());
}
+#endif
int CpuReducer::sum(void* dst, void* src, size_t len, DataType dtype) {
switch (dtype) {
@@ -64,7 +82,7 @@ int CpuReducer::sum(void* dst, void* src, size_t len, DataType dtype) {
BPS_CHECK(0) << "Unsupported data type: " << dtype;
}
return 0;
-}
+}
template
int CpuReducer::_sum(T* dst, T* src, size_t len) {
@@ -190,5 +208,19 @@ int CpuReducer::_sum_float16(void* dst, void* src1, void* src2, size_t len) {
return 0;
}
+int CpuReducer::copy(void* dst, void* src, size_t len) {
+ auto in = (float*)src;
+ auto out = (float*)dst;
+#pragma omp parallel for simd num_threads(_num_threads)
+ for (size_t i = 0; i < len / 4; ++i) {
+ out[i] = in[i];
+ }
+ if (len % 4) {
+ std::memcpy(out + len / 4, in + len / 4, len % 4);
+ }
+ return 0;
+}
+
+
} // namespace common
} // namespace byteps
diff --git a/byteps/common/cpu_reducer.h b/byteps/common/cpu_reducer.h
index 92e8bdd7a..a6e682c55 100644
--- a/byteps/common/cpu_reducer.h
+++ b/byteps/common/cpu_reducer.h
@@ -22,10 +22,16 @@
#endif
#include
+#include
#include "common.h"
-#include "communicator.h"
#include "logging.h"
+#ifndef BYTEPS_BUILDING_SERVER
+#include "communicator.h"
+#else
+typedef void BytePSComm;
+#endif
+
#include
namespace byteps {
@@ -41,8 +47,17 @@ class CpuReducer {
int sum(void* dst, void* src, size_t len, DataType dtype);
int sum(void* dst, void* src1, void* src2, size_t len, DataType dtype);
+ int copy(void* dst, void* src, size_t len);
+
+#ifndef BYTEPS_BUILDING_SERVER
bool isRoot();
std::shared_ptr getComm() { return _comm; }
+#endif
+
+
+ DataType GetDataType(int dtype) {
+ return static_cast(dtype);
+ }
private:
#if __AVX__ && __F16C__
diff --git a/byteps/common/global.cc b/byteps/common/global.cc
index 3e3d080f9..03e4a0fe3 100644
--- a/byteps/common/global.cc
+++ b/byteps/common/global.cc
@@ -338,7 +338,7 @@ uint64_t BytePSGlobal::Hash_DJB2(uint64_t key) {
auto str = std::to_string(key).c_str();
uint64_t hash = 5381;
int c;
- while (c = *str) { // hash(i) = hash(i-1) * 33 ^ str[i]
+ while ((c = *str)) { // hash(i) = hash(i-1) * 33 ^ str[i]
hash = ((hash << 5) + hash) + c;
str++;
}
@@ -349,7 +349,7 @@ uint64_t BytePSGlobal::Hash_SDBM(uint64_t key) {
auto str = std::to_string(key).c_str();
uint64_t hash = 0;
int c;
- while (c = *str) { // hash(i) = hash(i-1) * 65599 + str[i]
+ while ((c = *str)) { // hash(i) = hash(i-1) * 65599 + str[i]
hash = c + (hash << 6) + (hash << 16) - hash;
str++;
}
diff --git a/byteps/common/shared_memory.cc b/byteps/common/shared_memory.cc
index ec86d166f..e4ff185f2 100644
--- a/byteps/common/shared_memory.cc
+++ b/byteps/common/shared_memory.cc
@@ -54,22 +54,26 @@ std::vector BytePSSharedMemory::openPcieSharedMemory(uint64_t key,
for (int i = 0; i < BytePSGlobal::GetPcieSwitchNum(); i++) {
auto prefix = std::string("BytePS_Pcie") + std::to_string(i) + "_Shm_";
if (BytePSGlobal::IsDistributed()) {
- if (i <= numa_max_node()) {
- numa_set_preferred(i);
+ if (BytePSGlobal::IsCrossPcieSwitch()) {
+ if (i <= numa_max_node()) {
+ numa_set_preferred(i);
+ r.push_back(openSharedMemory(prefix, key, size));
+ numa_set_preferred(-1);
+ } else {
+ numa_set_preferred(numa_max_node());
+ r.push_back(openSharedMemory(prefix, key, size));
+ numa_set_preferred(-1);
+ }
} else {
- numa_set_preferred(numa_max_node());
+ r.push_back(openSharedMemory(prefix, key, size));
}
- r.push_back(openSharedMemory(prefix, key, size));
- numa_set_preferred(-1);
} else {
if (BytePSGlobal::IsCrossPcieSwitch()) {
numa_set_interleave_mask(numa_all_nodes_ptr);
r.push_back(openSharedMemory(prefix, key, size));
numa_set_interleave_mask(numa_no_nodes_ptr);
} else {
- numa_set_preferred(0);
r.push_back(openSharedMemory(prefix, key, size));
- numa_set_preferred(-1);
}
}
}
diff --git a/byteps/server/__init__.py b/byteps/server/__init__.py
new file mode 100644
index 000000000..bb9500d64
--- /dev/null
+++ b/byteps/server/__init__.py
@@ -0,0 +1,23 @@
+# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import ctypes
+import os
+from byteps.common import get_ext_suffix
+
+dll_path = os.path.join(os.path.dirname(__file__),
+ 'c_lib' + get_ext_suffix())
+SERVER_LIB_CTYPES = ctypes.CDLL(dll_path, ctypes.RTLD_GLOBAL)
+SERVER_LIB_CTYPES.byteps_server()
diff --git a/byteps/server/queue.h b/byteps/server/queue.h
new file mode 100644
index 000000000..fe3f7f57c
--- /dev/null
+++ b/byteps/server/queue.h
@@ -0,0 +1,110 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef BYTEPS_SERVER_QUEUE_H
+#define BYTEPS_SERVER_QUEUE_H
+
+#include
+#include
+#include
+#include
+#include
+
+namespace byteps {
+namespace server {
+
+/**
+ * \brief thread-safe queue allowing push and waited pop
+ */
+class PriorityQueue {
+ public:
+ PriorityQueue(bool is_schedule) {
+ enable_schedule_ = is_schedule;
+ if (enable_schedule_) {
+ std::make_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ }
+ }
+ ~PriorityQueue() { }
+
+ /**
+ * \brief push an value and sort using heap. threadsafe.
+ * \param new_value the value
+ */
+ void Push(BytePSEngineMessage new_value) {
+ mu_.lock();
+ queue_.push_back(std::move(new_value));
+ if (enable_schedule_) {
+ ++push_cnt_[new_value.key];
+ std::push_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ }
+ mu_.unlock();
+ cond_.notify_all();
+ }
+
+ /**
+ * \brief wait until pop an element from the beginning, threadsafe
+ * \param value the poped value
+ */
+ void WaitAndPop(BytePSEngineMessage* value) {
+ std::unique_lock lk(mu_);
+ cond_.wait(lk, [this]{return !queue_.empty();});
+ if (enable_schedule_) {
+ std::pop_heap(queue_.begin(), queue_.end(),
+ [this](const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ return ComparePriority(a, b);
+ }
+ );
+ *value = queue_.back();
+ queue_.pop_back();
+ } else {
+ *value = std::move(queue_.front());
+ queue_.erase(queue_.begin());
+ }
+ }
+
+ void ClearCounter(uint64_t key) {
+ if (!enable_schedule_) return;
+ std::unique_lock lk(mu_);
+ push_cnt_[key] = 0;
+ }
+
+ bool ComparePriority(const BytePSEngineMessage& a, const BytePSEngineMessage& b) {
+ if (push_cnt_[a.key] == push_cnt_[b.key]) {
+ return (a.id > b.id);
+ } else {
+ return (push_cnt_[a.key] > push_cnt_[b.key]);
+ }
+ }
+
+ private:
+ mutable std::mutex mu_;
+ std::vector queue_;
+ std::condition_variable cond_;
+ std::unordered_map push_cnt_;
+ volatile bool enable_schedule_ = false;
+};
+
+} // namespace server
+} // namespace byteps
+
+#endif // BYTEPS_SERVER_QUEUE_H
\ No newline at end of file
diff --git a/byteps/server/server.cc b/byteps/server/server.cc
new file mode 100644
index 000000000..3f91fcdfe
--- /dev/null
+++ b/byteps/server/server.cc
@@ -0,0 +1,403 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#include "server.h"
+#include "queue.h"
+
+namespace byteps {
+namespace server {
+
+using namespace ps;
+
+// engine related
+std::vector engine_queues_;
+std::vector engine_threads_;
+
+void SendPushResponse(uint64_t key, const ps::KVMeta& req, ps::KVServer* server){
+ auto iterator = push_response_map_.find(key);
+ if (iterator == push_response_map_.end()) { // new key
+ ps::KVPairs response;
+ response.keys.push_back(key);
+ push_response_map_[key] = response; // add to the map
+ server->Response(req, response);
+ } else { // not new key, then reuse the memory address to avoid ibv_reg_mr on RDMA data path
+ ps::KVPairs *response = &iterator->second;
+ response->keys[0] = key;
+ server->Response(req, *response);
+ }
+}
+
+void SendPullResponse(const DataHandleType type,
+ const uint64_t key,
+ const ps::KVMeta& req_meta,
+ ps::KVServer* server) {
+ std::lock_guard lock(pullresp_mu_);
+ auto& stored = store_[key];
+ CHECK(stored.tensor) << "init " << key << " first";
+ // as server returns when store_realt is ready in this case
+ auto len = stored.len;
+ // send pull response
+ auto iterator = pull_response_map_.find(key);
+ if (iterator == pull_response_map_.end()) { // new key
+ ps::KVPairs response;
+ response.keys = {EncodeKey(key)};
+ response.lens = {len};
+ response.vals = ps::SArray(stored.tensor, len, false); // zero copy
+ pull_response_map_[key] = response; // add to the map
+ server->Response(req_meta, response);
+ } else { // not new key, then reuse the memory address to avoid ibv_reg_mr on RDMA data path
+ ps::KVPairs *response = &iterator->second;
+ // keys and lens remain unchanged, just update vals
+ auto p = static_cast(stored.tensor);
+ CHECK(p);
+ response->vals = ps::SArray(p, len, false);
+ server->Response(req_meta, *response);
+ }
+}
+
+void BytePSServerEngineThread(int i) {
+ auto& q = engine_queues_[i];
+ while (true) {
+ BytePSEngineMessage msg;
+ q->WaitAndPop(&msg);
+ if (msg.ops == TERMINATE) break;
+ // do some check
+ CHECK(msg.dst);
+ CHECK(msg.src);
+
+ bool is_debug = (debug_mode_ && (debug_key_ == msg.key));
+ switch (msg.ops) {
+ case COPY_MERGED: {
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_COPY_MERGED_TO_STORE_BEFORE \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ bps_reducer_->copy(msg.dst, msg.src, msg.len);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_COPY_MERGED_TO_STORE_AFTER \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ std::lock_guard lock(flag_mu_[i]);
+ if (is_push_finished_[i].find(msg.key) == is_push_finished_[i].end()) {
+ is_push_finished_[i][msg.key] = false;
+ pull_cnt_[i][msg.key] = 0;
+ }
+ is_push_finished_[i][msg.key] = true;
+ for (auto& req_meta : q_pull_reqmeta_[i][msg.key]) {
+ SendPullResponse(msg.type, msg.key, req_meta, byteps_server_);
+ pull_cnt_[i][msg.key] += 1;
+ if (pull_cnt_[i][msg.key] == (size_t) ps::NumWorkers()) {
+ is_push_finished_[i][msg.key] = false;
+ pull_cnt_[i][msg.key] = 0;
+ }
+ }
+ q_pull_reqmeta_[i][msg.key].clear();
+ break;
+ }
+ case SUM_RECV: {
+ auto bps_type = bps_reducer_->GetDataType(msg.type.dtype);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_SUM_RECV_BEFORE \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ CHECK_GE(bps_reducer_->sum(msg.dst,
+ msg.src,
+ msg.len,
+ bps_type), 0);
+ if (is_debug) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: ENGINE_SUM_RECV_AFTER \t"
+ << "dst: " << DEBUG_PRINT_TENSOR_VALUE(msg.dst) << "\t"
+ << "src: " << DEBUG_PRINT_TENSOR_VALUE(msg.src) << "\t"
+ << "dst_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.dst) << "\t"
+ << "src_addr: " << DEBUG_PRINT_TENSOR_ADDRESS(msg.src) << "\t";
+ }
+ break;
+ }
+ default:
+ CHECK(0);
+ }
+ }
+}
+
+void BytePSHandler(const ps::KVMeta& req_meta,
+ const ps::KVPairs &req_data, ps::KVServer* server) {
+ std::lock_guard lock(handle_mu_); // push & pull may have racing
+ DataHandleType type = DepairDataHandleType(req_meta.cmd);
+ CHECK_EQ(type.requestType, RequestType::kDefaultPushPull);
+ // do some check
+ CHECK_EQ(req_data.keys.size(), (size_t)1);
+ if (log_key_info_) {
+ if (req_meta.push) {
+ CHECK_EQ(req_data.lens.size(), (size_t)1);
+ CHECK_EQ(req_data.vals.size(), (size_t)req_data.lens[0]);
+ LOG(INFO) << "push key="
+ << DecodeKey(req_data.keys[0])
+ << "\t sender=" << req_meta.sender
+ << "\t size=" << (size_t) req_data.lens[0];
+ } else {
+ LOG(INFO) << "pull key="
+ << (uint64_t) DecodeKey(req_data.keys[0])
+ << "\t sender=" << req_meta.sender;
+ }
+ }
+ uint64_t key = DecodeKey(req_data.keys[0]);
+ if (req_meta.push) { // push request
+ CHECK_EQ(req_data.lens.size(), (size_t)1);
+ CHECK_EQ(req_data.vals.size(), (size_t)req_data.lens[0]);
+ auto& stored = store_[key];
+ auto len = (size_t) req_data.lens[0];
+ auto recved = reinterpret_cast(req_data.vals.data());
+ if (!stored.tensor) {
+ if (sync_mode_ && (update_buf_.find(key) == update_buf_.end())) {
+ update_buf_[key].merged.len = len;
+ update_buf_[key].merged.dtype = type.dtype;
+ }
+ // buffer the request meta
+ auto &updates = update_buf_[key];
+ updates.request.push_back(req_meta);
+ // should send response after collecting all init push
+ if (updates.request.size() < (size_t) ps::NumWorkers()) return;
+ if (log_key_info_) {
+ LOG(INFO) << "Collected all " << updates.request.size()
+ << " requests for key=" << key
+ << ", init the store buffer size=" << (size_t) req_data.lens[0];
+ }
+ // initialization
+ stored.tensor = (char*) malloc(len);
+ stored.len = len;
+ stored.dtype = type.dtype;
+ CHECK(stored.tensor);
+ bps_reducer_->copy(stored.tensor, recved, len); // we may not need this copy
+ for (const auto& req : updates.request) {
+ SendPushResponse(key, req, server);
+ }
+ updates.request.clear();
+ } else {
+ auto &updates = update_buf_[key];
+ auto tid = GetThreadID(key, len);
+ if (updates.request.empty()) { // from the first incoming worker
+ if (sync_mode_) {
+ if (is_engine_blocking_) {
+ bps_reducer_->copy(updates.merged.tensor, recved, len);
+ } else { // non-blocking
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: FIRST_WORKER_RECV \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved) << "\t"
+ << "len: " << len << "\t"
+ << "addr: " << DEBUG_PRINT_TENSOR_ADDRESS(recved);
+ }
+ // zero copy
+ updates.merged.tensor = recved;
+ updates.merged.tmp_sarray = req_data;
+ }
+ } else { // async mode, directly add to the buffer
+ if (is_engine_blocking_) {
+ CHECK_GE(bps_reducer_->sum((void *) stored.tensor,
+ (void *) recved,
+ len,
+ bps_reducer_->GetDataType(stored.dtype)), 0);
+ } else {
+ BytePSEngineMessage msg = {timestamp_++, type, key, stored.tensor, recved, len, SUM_RECV, req_data};
+ engine_queues_[tid]->Push(msg);
+ }
+ }
+ } else { // from other workers
+ CHECK(sync_mode_);
+ CHECK(updates.merged.tensor);
+ if (is_engine_blocking_) {
+ CHECK_GE(bps_reducer_->sum((void *) updates.merged.tensor,
+ (void *) recved,
+ len,
+ bps_reducer_->GetDataType(updates.merged.dtype)), 0);
+ } else { // non-blocking
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: OTHER_WORKER_SUM \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "merged: " << DEBUG_PRINT_TENSOR_VALUE(updates.merged.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved) << "\t"
+ << "len: " << len << "\t"
+ << "addr: " << DEBUG_PRINT_TENSOR_ADDRESS(recved);
+ }
+ BytePSEngineMessage msg = {timestamp_++, type, key, updates.merged.tensor, recved, len, SUM_RECV, req_data, req_meta};
+ engine_queues_[tid]->Push(msg);
+ }
+ }
+ // add a worker information (request.size() is the # workers received)
+ updates.request.push_back(req_meta);
+ SendPushResponse(key, req_meta, server);
+ if (sync_mode_ && updates.request.size() == (size_t) ps::NumWorkers()) {
+ auto& stored = store_[key];
+ auto& update = updates.merged;
+ if (is_engine_blocking_) {
+ bps_reducer_->copy(stored.tensor, updates.merged.tensor, len);
+ } else {
+ if (debug_mode_ && (debug_key_ == key)) {
+ std::lock_guard lock(debug_mu_);
+ LOG(INFO) << "stage: COPY_MERGED_TO_STORE \t"
+ << "stored: " << DEBUG_PRINT_TENSOR_VALUE(stored.tensor) << "\t"
+ << "merged: " << DEBUG_PRINT_TENSOR_VALUE(updates.merged.tensor) << "\t"
+ << "recved: " << DEBUG_PRINT_TENSOR_VALUE(recved);
+ }
+ BytePSEngineMessage msg = {timestamp_++, type, key, stored.tensor, update.tensor, len, COPY_MERGED};
+ engine_queues_[tid]->Push(msg);
+ engine_queues_[tid]->ClearCounter(key);
+ }
+ updates.request.clear();
+ } else if (!sync_mode_) {
+ // async: clean the request buffer
+ updates.request.clear();
+ engine_queues_[tid]->ClearCounter(key);
+ }
+ }
+ } else { // pull request
+ auto& stored = store_[key];
+ CHECK(stored.tensor) << "Processing pull request when the NDArray of key "
+ << key << " has not been inited yet, which is not expected.";
+ if (is_engine_blocking_) {
+ SendPullResponse(type, key, req_meta, server);
+ } else {
+ auto tid = GetThreadID(key, 0);
+ std::lock_guard lock(flag_mu_[tid]);
+ if (is_push_finished_[tid].find(key) == is_push_finished_[tid].end()) {
+ is_push_finished_[tid][key] = false;
+ pull_cnt_[tid][key] = 0;
+ }
+ if (is_push_finished_[tid][key]) { // push already finished
+ SendPullResponse(type, key, req_meta, server);
+ pull_cnt_[tid][key] += 1;
+ if (pull_cnt_[tid][key] == (size_t) ps::NumWorkers()) {
+ is_push_finished_[tid][key] = false;
+ pull_cnt_[tid][key] = 0;
+ // check: remain should be 0
+ auto remain = q_pull_reqmeta_[tid][key].size();
+ CHECK_EQ(remain, 0) << remain;
+ }
+ } else { // push not finished, put into the queue, and wait for the engine
+ q_pull_reqmeta_[tid][key].push_back(req_meta);
+ }
+ }
+ }
+}
+
+void init_global_env() {
+ // enable to print key profile
+ log_key_info_ = GetEnv("PS_KEY_LOG", false);
+
+ // sync or async training
+ sync_mode_ = GetEnv("BYTEPS_ENABLE_ASYNC", true);
+ if (!sync_mode_) LOG(INFO) << "BytePS server is enabled asynchronous training";
+
+ // debug mode
+ debug_mode_ = GetEnv("BYTEPS_SERVER_DEBUG", false);
+ debug_key_ = GetEnv("BYTEPS_SERVER_DEBUG_KEY", 0);
+ if (debug_mode_) LOG(INFO) << "Debug mode enabled! Printing key " << debug_key_;
+
+ // enable engine block mode (default disabled)
+ is_engine_blocking_ = GetEnv("BYTEPS_SERVER_ENGINE_BLOCKING", false);
+ if (is_engine_blocking_) LOG(INFO) << "Enable blocking mode of the server engine";
+
+ // number of engine thread
+ // invalid if is_engine_blocking = true
+ engine_thread_num_ = GetEnv("BYTEPS_SERVER_ENGINE_THREAD", 4);
+ LOG(INFO) << "BytePS server engine uses " << engine_thread_num_ << " threads"
+ << ", consider increasing BYTEPS_SERVER_ENGINE_THREAD for higher performance";
+ CHECK_GE(engine_thread_num_, 1);
+
+ // enable scheduling for server engine
+ enable_schedule_ = GetEnv("BYTEPS_SERVER_ENABLE_SCHEDULE", false);
+ if (enable_schedule_) LOG(INFO) << "Enable engine scheduling for BytePS server";
+}
+
+extern "C" void byteps_server() {
+ init_global_env();
+
+ // cpu reducer
+ bps_reducer_ = new byteps::common::CpuReducer(nullptr);
+
+ // flag mu and its protected map
+ std::vector tmp_flagmu(engine_thread_num_);
+ std::vector > tmp_ispushfinished(engine_thread_num_);
+ std::vector > > tmp_qpullreqmeta(engine_thread_num_);
+ std::vector > tmp_pullcnt(engine_thread_num_);
+ flag_mu_.swap(tmp_flagmu);
+ is_push_finished_.swap(tmp_ispushfinished);
+ q_pull_reqmeta_.swap(tmp_qpullreqmeta);
+ pull_cnt_.swap(tmp_pullcnt);
+ CHECK_EQ(flag_mu_.size(), engine_thread_num_);
+ CHECK_EQ(is_push_finished_.size(), engine_thread_num_);
+ CHECK_EQ(q_pull_reqmeta_.size(), engine_thread_num_);
+ CHECK_EQ(pull_cnt_.size(), engine_thread_num_);
+
+ // init the engine
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ acc_load_.push_back(0);
+ }
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ auto q = new PriorityQueue(enable_schedule_);
+ engine_queues_.push_back(q);
+ }
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ auto t = new std::thread(&BytePSServerEngineThread, i);
+ engine_threads_.push_back(t);
+ }
+
+ // init server instance
+ byteps_server_ = new KVServer(0);
+ byteps_server_->set_request_handle(BytePSHandler);
+ StartAsync(0, "byteps_server\0");
+ if (!Postoffice::Get()->is_recovery()) {
+ Postoffice::Get()->Barrier(0,
+ ps::kWorkerGroup + ps::kServerGroup + ps::kScheduler);
+ }
+
+ // clean the server resource
+ Finalize(0, true);
+ if (byteps_server_) {
+ delete byteps_server_;
+ byteps_server_ = nullptr;
+ }
+ if (bps_reducer_) {
+ delete bps_reducer_;
+ bps_reducer_ = nullptr;
+ }
+ BytePSEngineMessage msg;
+ msg.ops = TERMINATE;
+ for (auto q : engine_queues_) q->Push(msg);
+ for (auto t : engine_threads_) t->join();
+ for (auto& it : store_) free(it.second.tensor);
+ for (auto& it : update_buf_) free(it.second.merged.tensor);
+ LOG(INFO) << "byteps has been shutdown";
+
+ return;
+}
+
+} // namespace server
+} // namespace byteps
diff --git a/byteps/server/server.h b/byteps/server/server.h
new file mode 100644
index 000000000..5b6e30fcf
--- /dev/null
+++ b/byteps/server/server.h
@@ -0,0 +1,169 @@
+// Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+// =============================================================================
+
+#ifndef BYTEPS_SERVER_H
+#define BYTEPS_SERVER_H
+
+#include
+#include
+#include
+#include "ps/ps.h"
+#include "../common/cpu_reducer.h"
+
+namespace byteps {
+namespace server {
+
+#define SERVER_KEY_TYPE uint64_t
+#define SERVER_DATA_TYPE char
+#define DEBUG_PRINT_TENSOR_VALUE(X) (*((float *)(X) + 0))
+#define DEBUG_PRINT_TENSOR_ADDRESS(X) (reinterpret_cast(X))
+
+using namespace ps;
+
+enum class RequestType {
+ kDefaultPushPull, kRowSparsePushPull, kCompressedPushPull
+};
+
+enum BytePSEngineOperation {
+ SUM_RECV, COPY_MERGED, TERMINATE
+};
+
+struct PSKV {
+ SArray keys; // n keys
+ SArray lens; // the length of the i-th value
+};
+
+struct DataHandleType {
+ RequestType requestType;
+ int dtype;
+};
+
+struct BytePSArray {
+ char* tensor;
+ size_t len;
+ int dtype;
+ ps::KVPairs tmp_sarray;
+};
+
+struct UpdateBuf {
+ std::vector request;
+ BytePSArray merged;
+};
+
+struct BytePSEngineMessage {
+ uint64_t id;
+ DataHandleType type;
+ uint64_t key;
+ void* dst;
+ void* src;
+ size_t len;
+ BytePSEngineOperation ops;
+ ps::KVPairs sarray; // to temporarily hold it and auto release
+ ps::KVMeta req_meta;
+};
+
+static DataHandleType DepairDataHandleType(int cmd) {
+ int w = std::floor((std::sqrt(8 * cmd + 1) - 1)/2);
+ int t = ((w * w) + w) / 2;
+ int y = cmd - t;
+ int x = w - y;
+ CHECK_GE(x, 0);
+ CHECK_GE(y, 0);
+ DataHandleType type;
+ type.requestType = static_cast(x);
+ type.dtype = y;
+ return type;
+}
+
+
+KVServer* byteps_server_;
+byteps::common::CpuReducer* bps_reducer_;
+std::unordered_map > mem_map_;
+std::mutex pullresp_mu_;
+std::unordered_map > push_response_map_;
+std::unordered_map > pull_response_map_;
+
+// push & pull flag
+std::vector flag_mu_;
+std::vector > is_push_finished_;
+std::vector > > q_pull_reqmeta_;
+std::vector > pull_cnt_;
+
+// address map
+std::mutex handle_mu_;
+std::unordered_map store_;
+std::unordered_map update_buf_;
+
+// hash function
+std::mutex hash_mu_;
+std::unordered_map hash_cache_;
+std::vector acc_load_; // accumulated tensor size for an engine thread
+
+// global knob
+uint64_t timestamp_ = 0;
+size_t engine_thread_num_ = 4;
+volatile bool is_engine_blocking_ = false;
+volatile bool log_key_info_ = false;
+volatile bool sync_mode_ = true;
+volatile bool debug_mode_ = false;
+volatile bool enable_schedule_ = false;
+
+// debug
+uint64_t debug_key_;
+std::mutex debug_mu_;
+
+
+uint64_t DecodeKey(ps::Key key) {
+ auto kr = ps::Postoffice::Get()->GetServerKeyRanges()[ps::MyRank()];
+ return key - kr.begin();
+}
+
+uint64_t EncodeKey(ps::Key key) {
+ auto kr = ps::Postoffice::Get()->GetServerKeyRanges()[ps::MyRank()];
+ return key + kr.begin();
+}
+
+size_t GetThreadID(uint64_t key, size_t len) {
+ std::lock_guard lock(hash_mu_);
+ if (len == 0) { // pull
+ CHECK_NE(hash_cache_.find(key), hash_cache_.end());
+ return hash_cache_[key];
+ }
+ if (hash_cache_.find(key) != hash_cache_.end()) {
+ return hash_cache_[key];
+ }
+ CHECK_GT(len, 0);
+ CHECK_EQ(acc_load_.size(), engine_thread_num_);
+ auto min_index = -1;
+ auto min_load = std::numeric_limits::max();
+ for (size_t i = 0; i < engine_thread_num_; ++i) {
+ if (acc_load_[i] < min_load) {
+ min_load = acc_load_[i];
+ min_index = i;
+ }
+ }
+ CHECK_GE(min_index, 0);
+ CHECK_LT(min_index, engine_thread_num_);
+ acc_load_[min_index] += len;
+ hash_cache_[key] = min_index;
+ return hash_cache_[key];
+}
+
+extern "C" void byteps_server();
+
+} // namespace server
+} // namespace byteps
+
+#endif // BYTEPS_SERVER_H
diff --git a/docker/Dockerfile.mix.mxnet15 b/docker/Dockerfile.mix.mxnet15
deleted file mode 100644
index 683ec86c1..000000000
--- a/docker/Dockerfile.mix.mxnet15
+++ /dev/null
@@ -1,172 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends --fix-missing \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-pip \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base \
- python3 \
- python3-dev \
- python3-pip \
- python3-setuptools
-
-
-RUN python -m pip install --upgrade pip &&\
- pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-RUN pip3 install --upgrade pip &&\
- python3 -m pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-############ build server
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.5.0
-RUN python -m pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-RUN pip3 --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python3 setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python3 setup.py bdist_wheel
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
diff --git a/docker/Dockerfile.worker.mxnet.cu100.rdma b/docker/Dockerfile.mxnet
similarity index 65%
rename from docker/Dockerfile.worker.mxnet.cu100.rdma
rename to docker/Dockerfile.mxnet
index a38055c71..68ed1639e 100644
--- a/docker/Dockerfile.worker.mxnet.cu100.rdma
+++ b/docker/Dockerfile.mxnet
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,31 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -147,12 +79,32 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install mxnet
+ARG FRAMEWORK_VERSION=1.5.0
+RUN python3 -m pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_PYTORCH=1
+ARG BYTEPS_WITHOUT_TENSORFLOW=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
@@ -162,5 +114,3 @@ RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu100.rdma b/docker/Dockerfile.pytorch
similarity index 64%
rename from docker/Dockerfile.worker.pytorch.cu100.rdma
rename to docker/Dockerfile.pytorch
index e67c9a359..a6f0c1d28 100644
--- a/docker/Dockerfile.worker.pytorch.cu100.rdma
+++ b/docker/Dockerfile.pytorch
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,40 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -156,12 +79,33 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install pytorch
+ARG FRAMEWORK_VERSION=1.1.0
+ARG TORCHVISION_VERSION=0.2.2
+RUN python3 -m pip --no-cache-dir install torch==$FRAMEWORK_VERSION torchvision==$TORCHVISION_VERSION
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_TENSORFLOW=1
+ARG BYTEPS_WITHOUT_MXNET=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
diff --git a/docker/Dockerfile.server b/docker/Dockerfile.server
deleted file mode 100644
index f6bf291f2..000000000
--- a/docker/Dockerfile.server
+++ /dev/null
@@ -1,86 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM ubuntu:16.04
-
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV LD_LIBRARY_PATH /root/incubator-mxnet/lib/:/usr/local/lib:$LD_LIBRARY_PATH
-
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-RUN apt-get update && apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- cd python && \
- python setup.py build && \
- python setup.py install &&\
- python setup.py bdist_wheel
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
diff --git a/docker/Dockerfile.server.rdma b/docker/Dockerfile.server.rdma
deleted file mode 100644
index f86c2abc4..000000000
--- a/docker/Dockerfile.server.rdma
+++ /dev/null
@@ -1,89 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM ubuntu:18.04
-
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV LD_LIBRARY_PATH /root/incubator-mxnet/lib/:/usr/local/lib:$LD_LIBRARY_PATH
-
-# To enable RDMA, add `USE_RDMA=1` to `SERVER_BUILD_OPTS` below.
-ENV SERVER_BUILD_OPTS "USE_BLAS=openblas USE_MKL=1 USE_DIST_KVSTORE=1 USE_RDMA=1"
-ENV BYTEPS_SERVER_MXNET_PATH /root/incubator-mxnet
-ENV MXNET_SERVER_LINK https://github.com/bytedance/incubator-mxnet
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update && apt-get install -y --allow-downgrades --allow-change-held-packages --no-install-recommends \
- tzdata \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- librdmacm-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip ibverbs-providers &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-WORKDIR /root/
-
-RUN git clone --single-branch --branch byteps --recurse-submodules $MXNET_SERVER_LINK
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- make clean_all && make -j16 $SERVER_BUILD_OPTS
-
-RUN cd $BYTEPS_SERVER_MXNET_PATH && \
- cd python && \
- python setup.py build && \
- python setup.py install &&\
- python setup.py bdist_wheel
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu100.rdma b/docker/Dockerfile.tensorflow
similarity index 65%
rename from docker/Dockerfile.worker.tensorflow.cu100.rdma
rename to docker/Dockerfile.tensorflow
index e07f902b0..1159b4d9a 100644
--- a/docker/Dockerfile.worker.tensorflow.cu100.rdma
+++ b/docker/Dockerfile.tensorflow
@@ -1,25 +1,7 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
FROM nvidia/cuda:10.0-devel-ubuntu18.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
+ARG https_proxy
+ARG http_proxy
ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
@@ -30,11 +12,9 @@ ENV BYTEPS_BASE_PATH /usr/local
ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
ARG DEBIAN_FRONTEND=noninteractive
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
+RUN apt-get update -qq
+RUN apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
build-essential \
tzdata \
ca-certificates \
@@ -42,47 +22,22 @@ RUN apt-get update &&\
curl \
wget \
vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- ibverbs-providers \
- librdmacm-dev \
- ibverbs-utils \
- rdmacm-utils \
- libibverbs-dev
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
+ libcudnn7=7.6.0.64-1+cuda10.0 \
+ libnuma-dev \
+ ibverbs-providers \
+ librdmacm-dev \
+ ibverbs-utils \
+ rdmacm-utils \
+ libibverbs-dev \
+ python3 \
+ python3-dev \
+ python3-pip \
+ python3-setuptools
# Install NCCL
ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
RUN cd / && \
wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
@@ -91,33 +46,8 @@ RUN cd / && \
echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
ldconfig && rm -rf /nccl-$NCCL_VERSION
-
WORKDIR /root/
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.14.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
# install gcc 4.9
RUN mkdir -p /root/gcc/ && cd /root/gcc &&\
wget http://launchpadlibrarian.net/247707088/libmpfr4_3.1.4-1_amd64.deb &&\
@@ -149,12 +79,33 @@ RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
+
+RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
+ echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
+ echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
+ ldconfig
+
+RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
+ ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
+ ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
+ ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
+
+# install tensorflow
+ARG FRAMEWORK_VERSION=1.14.0
+RUN python3 -m pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION &&\
+ rm -rf /tmp/pip && rm -rf /root/.cache
+
# Install BytePS
ARG BYTEPS_NCCL_LINK=shared
ARG BYTEPS_USE_RDMA=1
+ARG BYTEPS_WITHOUT_PYTORCH=1
+ARG BYTEPS_WITHOUT_MXNET=1
+ARG BYTEPS_BRANCH=master
+RUN cd $BYTEPS_BASE_PATH &&\
+ git clone --recursive -b $BYTEPS_BRANCH $BYTEPS_GIT_LINK
RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
+ python3 setup.py install
# Remove GCC pinning
RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
diff --git a/docker/Dockerfile.worker.mxnet.cu100 b/docker/Dockerfile.worker.mxnet.cu100
deleted file mode 100644
index 38cd85c2e..000000000
--- a/docker/Dockerfile.worker.mxnet.cu100
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu100==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.mxnet.cu90 b/docker/Dockerfile.worker.mxnet.cu90
deleted file mode 100644
index 08c3a5578..000000000
--- a/docker/Dockerfile.worker.mxnet.cu90
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install mxnet
-ARG FRAMEWORK_VERSION=1.4.1
-RUN pip --no-cache-dir install mxnet-cu90==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu100 b/docker/Dockerfile.worker.pytorch.cu100
deleted file mode 100644
index 73a74db1d..000000000
--- a/docker/Dockerfile.worker.pytorch.cu100
+++ /dev/null
@@ -1,149 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.pytorch.cu90 b/docker/Dockerfile.worker.pytorch.cu90
deleted file mode 100644
index df2833793..000000000
--- a/docker/Dockerfile.worker.pytorch.cu90
+++ /dev/null
@@ -1,149 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install pytorch
-ARG FRAMEWORK_VERSION=1.0.1
-RUN pip --no-cache-dir install \
- future \
- numpy \
- pyyaml \
- setuptools \
- six \
- typing \
- protobuf \
- torchvision==0.2.2 \
- torch==$FRAMEWORK_VERSION
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py install &&\
- BYTEPS_WITHOUT_TENSORFLOW=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu100 b/docker/Dockerfile.worker.tensorflow.cu100
deleted file mode 100644
index 7ff2fae93..000000000
--- a/docker/Dockerfile.worker.tensorflow.cu100
+++ /dev/null
@@ -1,142 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:10.0-devel-ubuntu16.04
-ENV CUDA_VERSION=10.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.12.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/Dockerfile.worker.tensorflow.cu90 b/docker/Dockerfile.worker.tensorflow.cu90
deleted file mode 100644
index 50b393a5a..000000000
--- a/docker/Dockerfile.worker.tensorflow.cu90
+++ /dev/null
@@ -1,142 +0,0 @@
-# Copyright 2019 Bytedance Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# =============================================================================
-
-FROM nvidia/cuda:9.0-devel-ubuntu16.04
-ENV CUDA_VERSION=9.0
-ARG REGION
-
-RUN rm -f /tmp/pip.conf &&\
- echo -e '[global]\nindex-url = https://pypi.douban.com/simple' >> /tmp/pip.conf
-
-RUN if [ "x$REGION" = "xchina" ]; then mkdir -p ~/.pip && mv /tmp/pip.conf ~/.pip/; fi
-
-ENV USE_CUDA_PATH /usr/local/cuda:/usr/local/cudnn/lib64
-ENV PATH /usr/local/cuda/bin:/usr/local/nvidia/bin:${PATH}
-ENV LD_LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:/usr/local/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/nccl/lib:$LD_LIBRARY_PATH
-ENV LIBRARY_PATH /usr/local/cudnn/lib64:/usr/local/cuda/lib64:$LIBRARY_PATH
-
-ENV BYTEPS_BASE_PATH /usr/local
-ENV BYTEPS_PATH $BYTEPS_BASE_PATH/byteps
-ENV BYTEPS_GIT_LINK https://github.com/bytedance/byteps
-
-ARG CUDNN_VERSION=7.4.1.5-1+cuda$CUDA_VERSION
-
-RUN apt-get update &&\
- apt-get install -y --allow-unauthenticated --allow-downgrades --allow-change-held-packages --no-install-recommends \
- build-essential \
- ca-certificates \
- git \
- curl \
- wget \
- vim \
- libopenblas-dev \
- liblapack-dev \
- libopencv-dev \
- python \
- python-dev \
- python-setuptools \
- libjemalloc-dev \
- graphviz \
- cmake \
- libjpeg-dev \
- libpng-dev \
- iftop \
- lsb-release \
- libcudnn7=${CUDNN_VERSION} \
- libnuma-dev \
- gcc-4.9 \
- g++-4.9 \
- gcc-4.9-base
-
-RUN apt-get update &&\
- apt-get -y install python-pip &&\
- pip install --upgrade pip
-
-RUN pip --no-cache-dir install \
- matplotlib \
- numpy==1.15.2 \
- scipy \
- sklearn \
- pandas \
- graphviz==0.9.0 \
- mxboard \
- tensorboard==1.0.0a6
-
-# Install NCCL
-ENV NCCL_VERSION=d7a58cfa5865c4f627a128c3238cc72502649881
-
-RUN cd / && \
- wget -q -O - https://github.com/NVIDIA/nccl/archive/$NCCL_VERSION.tar.gz | tar -xzf - && \
- cd nccl-$NCCL_VERSION && make -j src.build && make pkg.txz.build && \
- mkdir -p /usr/local/nccl && \
- tar -Jxf /nccl-$NCCL_VERSION/build/pkg/txz/nccl*.txz -C /usr/local/nccl/ --strip-components 1 && \
- echo "/usr/local/nccl/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig && rm -rf /nccl-$NCCL_VERSION
-
-
-WORKDIR /root/
-
-RUN echo "/usr/local/cuda/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/cudnn/lib64" >> /etc/ld.so.conf.d/cuda.conf && \
- echo "/usr/local/nvidia/lib" >> /etc/ld.so.conf.d/nvidia.conf && \
- echo "/usr/local/nvidia/lib64" >> /etc/ld.so.conf.d/nvidia.conf && \
- ldconfig
-
-RUN ln -sf /usr/local/cudnn/include/cudnn.h /usr/local/cuda/include/ && \
- ln -sf /usr/local/cudnn/lib64/libcudnn* /usr/local/cuda/lib64 &&\
- ln -sf /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/libcuda.so && \
- ln -sf /usr/local/cuda/lib64/libcuda.so /usr/local/cuda/lib64/libcuda.so.1
-
-
-################################ install your framework ################################
-# install tensorflow
-ARG FRAMEWORK_VERSION=1.12.0
-RUN pip --no-cache-dir install tensorflow-gpu==$FRAMEWORK_VERSION && \
- rm -rf /tmp/pip && \
- rm -rf /root/.cache
-
-################################ install your framework ################################
-
-
-RUN cd $BYTEPS_BASE_PATH &&\
- git clone --recurse-submodules $BYTEPS_GIT_LINK
-
-# Pin GCC to 4.9 (priority 200) to compile correctly against TensorFlow, PyTorch, and MXNet.
-RUN update-alternatives --install /usr/bin/gcc gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc $(readlink -f $(which gcc)) 100 && \
- update-alternatives --install /usr/bin/g++ g++ $(readlink -f $(which g++)) 100 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ $(readlink -f $(which g++)) 100
-RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-gcc x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 200 && \
- update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 200 && \
- update-alternatives --install /usr/bin/x86_64-linux-gnu-g++ x86_64-linux-gnu-g++ /usr/bin/g++-4.9 200
-
-
-# Install BytePS
-ARG BYTEPS_NCCL_LINK=shared
-RUN cd $BYTEPS_PATH &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py install &&\
- BYTEPS_WITHOUT_PYTORCH=1 python setup.py bdist_wheel
-
-# Remove GCC pinning
-RUN update-alternatives --remove gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-gcc /usr/bin/gcc-4.9 && \
- update-alternatives --remove g++ /usr/bin/g++-4.9 && \
- update-alternatives --remove x86_64-linux-gnu-g++ /usr/bin/g++-4.9
-
-RUN rm -rf /usr/local/cuda/lib64/libcuda.so && \
- rm -rf /usr/local/cuda/lib64/libcuda.so.1
-
-
diff --git a/docker/README.md b/docker/README.md
index a84763ee2..16b8ddcaf 100644
--- a/docker/README.md
+++ b/docker/README.md
@@ -5,13 +5,6 @@ You may need to manually build them to get the latest functionalities of BytePS,
| Docker Image Name | Source Dockerfile | Description |
| --- | --- | --- |
-| bytepsimage/worker_mxnet | Dockerfile.worker.mxnet.cu90 | worker image for MXNet (CUDA 9.0) |
-| bytepsimage/worker_pytorch | Dockerfile.worker.pytorch.cu90 | worker image for PyTorch (CUDA 9.0) |
-| bytepsimage/worker_tensorflow | Dockerfile.worker.tensorflow.cu90 | worker image for TensorFlow (CUDA 9.0) |
-| bytepsimage/worker_mxnet_rdma | Dockerfile.worker.mxnet.cu100.rdma | worker image for MXNet with RDMA support (CUDA 10.0) |
-| bytepsimage/worker_pytorch_rdma | Dockerfile.worker.pytorch.cu100.rdma | worker image for PyTorch with RDMA support (CUDA 10.0) |
-| bytepsimage/worker_tensorflow_rdma | Dockerfile.worker.tensorflow.cu100.rdma | worker image for TensorFlow with RDMA support (CUDA 10.0) |
-| bytepsimage/byteps_server | Dockerfile.server | server/scheduler image |
-| bytepsimage/byteps_server_rdma | Dockerfile.server.rdma | server/scheduler image with RDMA support |
-| bytepsimage/mxnet15 | Dockerfile.mix.mxnet15 | all-in-one image with MXNet 1.5.0 (CUDA 10.0), applicable to worker/server/scheduler |
-
+| bytepsimage/mxnet | Dockerfile.mxnet | Image for MXNet |
+| bytepsimage/pytorch | Dockerfile.pytorch | Image for PyTorch |
+| bytepsimage/tensorflow | Dockerfile.tensorflow | Image for TensorFlow |
diff --git a/docs/architecture.md b/docs/architecture.md
index ff2e21f80..e6a7dd940 100644
--- a/docs/architecture.md
+++ b/docs/architecture.md
@@ -5,7 +5,8 @@ We highly recommend you to read [BytePS's rationale](./rationale.md) first befor
From application views, BytePS is a communication library just like Horovod. The plugins handle framework-specific transformation (e.g., on data structure), and
put communication tasks into BytePS priority queues. The BytePS Core then gets the tasks (priority-aware, not FIFO) and handles the actual communication.
- +
+
## General Workflow
To demonstrate the work flow of BytePS, below we use a common data-parallel training scenario as an example. Say we have multiple worker machines (we refer them as "**workers**"), and each machine (worker) has multiple GPUs. We also have some CPU machines that serve as PS (we refer them as "**servers**").
diff --git a/docs/cross-barrier.md b/docs/cross-barrier.md
index c8baba2e6..09e2dba51 100644
--- a/docs/cross-barrier.md
+++ b/docs/cross-barrier.md
@@ -19,14 +19,15 @@ completion of all parameters.
Fig.1 shows the dependency graph with global barrier. Machine learning frameworks such as PyTorch and TensorFlow have
similar dependencies when using BytePS for push and pull.
-
+
*Fig.1: Dependency Graph With Global Barrier*
Fig. 2 shows the dependency graph after removing global barrier. What we do here is to change the dependency
graph from Fig. 1 to Fig. 2 by removing the barrier, building layer-wise dependencies while guaranteeing computation correctness.
-
+
+
*Fig.2: Dependency Graph After Removing Global Barrier*
diff --git a/docs/images/byteps_architecture.png b/docs/images/byteps_architecture.png
deleted file mode 100644
index 93bf14bb9..000000000
Binary files a/docs/images/byteps_architecture.png and /dev/null differ
diff --git a/docs/images/dag_barrier.png b/docs/images/dag_barrier.png
deleted file mode 100644
index 6137cb8c8..000000000
Binary files a/docs/images/dag_barrier.png and /dev/null differ
diff --git a/docs/images/dag_without_barrier.png b/docs/images/dag_without_barrier.png
deleted file mode 100644
index 04df725b3..000000000
Binary files a/docs/images/dag_without_barrier.png and /dev/null differ
diff --git a/docs/images/perf_tcp_resnet50.png b/docs/images/perf_tcp_resnet50.png
deleted file mode 100644
index 9fe181a0d..000000000
Binary files a/docs/images/perf_tcp_resnet50.png and /dev/null differ
diff --git a/docs/images/perf_tcp_vgg16.png b/docs/images/perf_tcp_vgg16.png
deleted file mode 100644
index 7812a74a3..000000000
Binary files a/docs/images/perf_tcp_vgg16.png and /dev/null differ
diff --git a/docs/performance.md b/docs/performance.md
index f8f0a62c0..124525592 100644
--- a/docs/performance.md
+++ b/docs/performance.md
@@ -1,15 +1,19 @@
# BytePS Performance with 100Gbps RDMA
-## NVLink + RDMA
+## NVLink + TCP
-We show our experiment on BERT-large training, which is based on GluonNLP toolkit. The model uses mixed precision.
+We test two models: VGG16 (communication-intensive) and Resnet50 (computation-intensive) on a popular public cloud. Both models are trained using fp32.
-We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs (32GB memory) with NVLink-enabled.
-Machines are inter-connected with 100 Gbps RoCEv2 network.
+We use Tesla V100 16GB GPUs and set batch size equal to 64 *per GPU*. The machines are in fact VMs on the cloud. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 20 Gbps TCP/IP network.
-BytePS outperforms Horovod (after carefully tuned) by 16% in this case, both with RDMA enabled.
+BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.
-
+
+
+
+
+
+You can reproduce the results using the Dockerfiles and example scripts we provide.
## PCIe + RDMA
diff --git a/docs/step-by-step-tutorial.md b/docs/step-by-step-tutorial.md
index b24733404..67e5d3100 100644
--- a/docs/step-by-step-tutorial.md
+++ b/docs/step-by-step-tutorial.md
@@ -8,89 +8,85 @@ When you have successfully run through these examples, read the [best practice](
### TensorFlow
```
-docker pull bytepsimage/worker_tensorflow
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_tensorflow bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-# can also try: export EVAL_TYPE=mnist
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
### PyTorch
```
-docker pull bytepsimage/worker_pytorch
+docker pull bytepsimage/pytorch
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_pytorch bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/pytorch bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
### MXNet
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/mxnet
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/mxnet bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
## Distributed Training (TCP)
-Let's say you have two workers, and each one with 4 GPUs. For simplicity we use one server.
+Let's say you have two workers, and each one with 4 GPUs. For simplicity we use one server. In practice, you need more servers (at least equal to the number of workers) to achieve high performance.
-The way to launch the scheduler and the server are the same for any framework.
+
+For the workers, you need to pay attention to `DMLC_WORKER_ID`. This is the main difference compared to single machine jobs. Let's say the 2 workers are using TensorFlow.
For the scheduler:
```
-# scheduler can use the same image as servers
-docker pull bytepsimage/byteps_server
+docker pull bytepsimage/tensorflow
-docker run -it --net=host bytepsimage/byteps_server bash
+docker run -it --net=host bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_NUM_WORKER=2
@@ -99,14 +95,14 @@ export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For the server:
```
-docker pull bytepsimage/byteps_server
+docker pull bytepsimage/tensorflow
-docker run -it --net=host bytepsimage/byteps_server bash
+docker run -it --net=host bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_NUM_WORKER=2
@@ -115,85 +111,78 @@ export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-# 4 threads should be enough for a server
-export MXNET_OMP_MAX_THREADS=4
-
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
-For the workers, you need to pay attention to `DMLC_WORKER_ID`. This is the main difference compared to single machine jobs. Let's say the 2 workers are using MXNet.
For worker-0:
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
-# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
-export DMLC_WORKER_ID=0 # worker-0
-export DMLC_NUM_WORKER=2 # 2 workers
-export DMLC_ROLE=worker # your role is worker
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3
+export DMLC_WORKER_ID=0
+export DMLC_NUM_WORKER=2
+export DMLC_ROLE=worker
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
For worker-1:
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
-# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
-export DMLC_WORKER_ID=1 # worker-1
-export DMLC_NUM_WORKER=2 # 2 workers
-export DMLC_ROLE=worker # your role is worker
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3
+export DMLC_WORKER_ID=1
+export DMLC_NUM_WORKER=2
+export DMLC_ROLE=worker
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
-If your workers use TensorFlow, you need to change the image name to `bytepsimage/worker_tensorflow`, and replace the python script with
+
+If your workers use PyTorch, you need to change the image name to `bytepsimage/pytorch`, and replace the python script of the workers with
+
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
-If your workers use PyTorch, you need to change the image name to `bytepsimage/worker_pytorch`, and replace the python script with
+If your workers use MXNet, you need to change the image name to `bytepsimage/mxnet`, and replace the python script of the workers with
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
## Distributed Training with RDMA
-The steps to launch RDMA tasks are basically similar to the above. The main differences are that (1) you need to specify your RDMA devices when running a docker, and (2) you need to set `DMLC_ENABLE_RDMA=1`. To run this example, your `nvidia-docker` need to support cuda 10.
+The steps to launch RDMA tasks are basically similar to the above. The main differences are that (1) you need to specify your RDMA devices when running a docker, and (2) you need to set `DMLC_ENABLE_RDMA=1`.
-In the following, let's continue to use the example: you have two workers and one server, and the workers are using MXNet.
+In the following, let's continue to use the example: you have two workers and one server, and the workers are using TensorFlow.
For the scheduler:
```
-# the scheduler may use the same image as servers
-docker pull bytepsimage/byteps_server_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/byteps_server_rdma bash
+docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_ENABLE_RDMA=1
@@ -209,15 +198,15 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For the server:
```
-docker pull bytepsimage/byteps_server_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/byteps_server_rdma bash
+docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_ENABLE_RDMA=1
@@ -228,24 +217,21 @@ export DMLC_NUM_SERVER=1
# the RDMA interface name of the server
export DMLC_INTERFACE=eth5
-# 4 threads should be enough for a server
-export MXNET_OMP_MAX_THREADS=4
-
# your scheduler's RDMA NIC information (IP, port)
export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For worker-0:
```
-docker pull bytepsimage/worker_mxnet_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/worker_mxnet_rdma bash
+nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export NVIDIA_VISIBLE_DEVICES=0,1,2,3
@@ -264,20 +250,19 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
For worker-1:
```
-docker pull bytepsimage/worker_mxnet_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/worker_mxnet_rdma bash
+nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export NVIDIA_VISIBLE_DEVICES=0,1,2,3
@@ -296,24 +281,25 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
-If your workers use TensorFlow, you need to change the image name to `bytepsimage/worker_tensorflow_rdma`, and replace the python script with
+
+If your workers use PyTorch, you need to change the image name to `bytepsimage/pytorch`, and replace the python script of the workers with
+
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
-If your workers use PyTorch, you need to change the image name to `bytepsimage/worker_pytorch_rdma`, and replace the python script with
+If your workers use MXNet, you need to change the image name to `bytepsimage/mxnet`, and replace the python script of the workers with
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
\ No newline at end of file
diff --git a/example/keras/run_keras.sh b/example/keras/run_keras.sh
deleted file mode 100755
index 3d4ca705f..000000000
--- a/example/keras/run_keras.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "imagenet" ]; then
- echo "Run Keras ImageNet ..."
- python $path/keras_imagenet_resnet50.py $@
-elif [ "$EVAL_TYPE" == "mnist" ]; then
- echo "Run Keras MNIST ..."
- python $path/keras_mnist.py $@
-elif [ "$EVAL_TYPE" == "mnist_advanced" ]; then
- echo "Run Keras MNIST-advanced ..."
- python $path/keras_mnist_advanced.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/example/mxnet-gluon/run_mnist_gluon.sh b/example/mxnet-gluon/run_mnist_gluon.sh
deleted file mode 100644
index 2632e358c..000000000
--- a/example/mxnet-gluon/run_mnist_gluon.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/bin/bash
-
-export NVIDIA_VISIBLE_DEVICES=0,1
-export DMLC_WORKER_ID=0
-export DMLC_NUM_WORKER=1
-export DMLC_ROLE=worker
-
-# the following value does not matter for non-distributed jobs
-export DMLC_NUM_SERVER=1
-export DMLC_PS_ROOT_URI=127.0.0.1
-export DMLC_PS_ROOT_PORT=9000
-
-path="`dirname $0`"
-echo $path
-
-python $path/../../launcher/launch.py \
- python $path/train_mnist_byteps.py
\ No newline at end of file
diff --git a/example/mxnet/start_mxnet_byteps.sh b/example/mxnet/start_mxnet_byteps.sh
deleted file mode 100755
index ff1c537d3..000000000
--- a/example/mxnet/start_mxnet_byteps.sh
+++ /dev/null
@@ -1,5 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-python $path/train_imagenet_byteps.py $@
diff --git a/example/mxnet-gluon/train_mnist_byteps.py b/example/mxnet/train_gluon_mnist_byteps.py
similarity index 100%
rename from example/mxnet-gluon/train_mnist_byteps.py
rename to example/mxnet/train_gluon_mnist_byteps.py
diff --git a/example/pytorch/microbenchmark-byteps.py b/example/pytorch/microbenchmark-byteps.py
deleted file mode 100644
index 1a1ae05a1..000000000
--- a/example/pytorch/microbenchmark-byteps.py
+++ /dev/null
@@ -1,82 +0,0 @@
-from __future__ import print_function
-
-import torch
-import argparse
-import torch.backends.cudnn as cudnn
-from byteps.torch.ops import push_pull_async_inplace, poll, synchronize
-import byteps.torch as bps
-import time
-import numpy as np
-
-
-parser = argparse.ArgumentParser(description='PyTorch BytePS Synthetic Benchmark',
- formatter_class=argparse.ArgumentDefaultsHelpFormatter)
-parser.add_argument('--num-warmup', type=int, default=10,
- help='number of warm-up steps that don\'t count towards benchmark')
-parser.add_argument('--num-iters', type=int, default=1000,
- help='number of benchmark iterations')
-parser.add_argument('--no-cuda', action='store_true', default=False,
- help='disables CUDA')
-parser.add_argument('--no-wait', type=bool, default=True,
- help='wait for other worker request first')
-parser.add_argument('--gpu', type=int, default=-1,
- help='use a specified gpu')
-
-args = parser.parse_args()
-args.cuda = not args.no_cuda and torch.cuda.is_available()
-
-bps.init()
-
-# BytePS: pin GPU to local rank.
-if args.gpu >= 0:
- torch.cuda.set_device(args.gpu)
-else:
- torch.cuda.set_device(bps.local_rank())
-
-cudnn.benchmark = True
-
-
-def log(s, nl=True):
- if bps.rank() != 0:
- return
- print(s, end='\n' if nl else '')
-
-
-def benchmark(tensor, average, name):
- if not args.no_wait and bps.rank() == 0:
- time.sleep(0.01)
- start = time.time()
- handle = push_pull_async_inplace(tensor, average, name)
- while True:
- if poll(handle):
- synchronize(handle)
- break
- end = time.time()
- return (end - start) * 1000
-
-
-log('Number of GPUs: %d' % (bps.size()))
-
-# Benchmark
-log('Running benchmark...')
-
-log('size (Byte) \t avg. time (ms) \t std.dev (ms)')
-for i in range(8):
- size = 10**i
- data = torch.rand(size, dtype=torch.float32)
- if args.cuda:
- data = data.cuda()
- # warm up
- for j in range(args.num_warmup):
- benchmark(tensor=data, average=True, name=str(i))
- # timeit
- durations = []
- for j in range(args.num_iters):
- t = benchmark(tensor=data, average=True, name=str(i))
- durations.append(t)
- avg = np.mean(durations)
- std = np.std(durations)
-
- log('%d \t %s \t %s' % (4*size, '%.3f'%avg, '%.3f'%std))
-
-log('End benchmark.')
diff --git a/example/pytorch/start_pytorch_byteps.sh b/example/pytorch/start_pytorch_byteps.sh
deleted file mode 100755
index f82a279cc..000000000
--- a/example/pytorch/start_pytorch_byteps.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "mnist" ]; then
- echo "training mnist..."
- python $path/train_mnist_byteps.py $@
-elif [ "$EVAL_TYPE" == "imagenet" ]; then
- echo "training imagenet..."
- python $path/train_imagenet_resnet50_byteps.py $@
-elif [ "$EVAL_TYPE" == "benchmark" ]; then
- echo "running benchmark..."
- python $path/benchmark_byteps.py $@
-elif [ "$EVAL_TYPE" == "nobarrierbenchmark" ]; then
- echo "running benchmark without global barrier..."
- python $path/benchmark_cross_barrier_byteps.py $@
-elif [ "$EVAL_TYPE" == "microbenchmark" ]; then
- echo "running microbenchmark"
- python $path/microbenchmark-byteps.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/example/tensorflow/run_tensorflow_byteps.sh b/example/tensorflow/run_tensorflow_byteps.sh
deleted file mode 100755
index 68ff57cd4..000000000
--- a/example/tensorflow/run_tensorflow_byteps.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "benchmark" ]; then
- echo "Run synthetic benchmark..."
- python3 $path/synthetic_benchmark.py $@
-elif [ "$EVAL_TYPE" == "mnist" ]; then
- echo "Run MNIST ..."
- python3 $path/tensorflow_mnist.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/launcher/launch.py b/launcher/launch.py
index 51541d019..927c78c3d 100644
--- a/launcher/launch.py
+++ b/launcher/launch.py
@@ -10,7 +10,6 @@
COMMON_REQUIRED_ENVS = ["DMLC_ROLE", "DMLC_NUM_WORKER", "DMLC_NUM_SERVER",
"DMLC_PS_ROOT_URI", "DMLC_PS_ROOT_PORT"]
WORKER_REQUIRED_ENVS = ["DMLC_WORKER_ID"]
-SERVER_REQUIRED_ENVS = ["BYTEPS_SERVER_MXNET_PATH"]
def check_env():
assert "DMLC_ROLE" in os.environ and \
@@ -23,8 +22,6 @@ def check_env():
if num_worker == 1:
required_envs = []
required_envs += WORKER_REQUIRED_ENVS
- else:
- required_envs += SERVER_REQUIRED_ENVS
for env in required_envs:
if env not in os.environ:
print("The env " + env + " is missing")
@@ -60,5 +57,4 @@ def worker(local_rank, local_size, command):
t[i].join()
else:
- sys.path.insert(0, os.getenv("BYTEPS_SERVER_MXNET_PATH")+"/python")
- import mxnet
+ import byteps.server
diff --git a/setup.py b/setup.py
index 9df9176da..8319c45ff 100644
--- a/setup.py
+++ b/setup.py
@@ -20,6 +20,7 @@
from distutils.version import LooseVersion
import traceback
+server_lib = Extension('byteps.server.c_lib', [])
tensorflow_lib = Extension('byteps.tensorflow.c_lib', [])
mxnet_lib = Extension('byteps.mxnet.c_lib', [])
pytorch_lib = Extension('byteps.torch.c_lib', [])
@@ -280,6 +281,25 @@ def get_common_options(build_ext):
EXTRA_OBJECTS=EXTRA_OBJECTS)
+def build_server(build_ext, options):
+ server_lib.define_macros = options['MACROS']
+ server_lib.include_dirs = options['INCLUDES']
+ server_lib.sources = ['byteps/server/server.cc',
+ 'byteps/common/cpu_reducer.cc',
+ 'byteps/common/logging.cc']
+ server_lib.extra_compile_args = options['COMPILE_FLAGS'] + \
+ ['-DBYTEPS_BUILDING_SERVER']
+ server_lib.extra_link_args = options['LINK_FLAGS']
+ server_lib.extra_objects = options['EXTRA_OBJECTS']
+ server_lib.library_dirs = options['LIBRARY_DIRS']
+ if int(os.environ.get('BYTEPS_USE_RDMA', 0)):
+ server_lib.libraries = ['rdmacm', 'ibverbs']
+ else:
+ server_lib.libraries = []
+
+ build_ext.build_extension(server_lib)
+
+
def check_tf_version():
try:
import tensorflow as tf
@@ -775,6 +795,12 @@ def build_extensions(self):
options = get_common_options(self)
built_plugins = []
+ try:
+ build_server(self, options)
+ except:
+ raise DistutilsSetupError('An ERROR occured while building the server module.\n\n'
+ '%s' % traceback.format_exc())
+
# If PyTorch is installed, it must be imported before others, otherwise
# we may get an error: dlopen: cannot load any more object with static TLS
if not int(os.environ.get('BYTEPS_WITHOUT_PYTORCH', 0)):
@@ -818,8 +844,9 @@ def build_extensions(self):
raise
if not built_plugins:
- raise DistutilsError(
- 'TensorFlow, MXNet, PyTorch plugins were excluded from build. Aborting.')
+ print('INFO: Only server module is built.')
+ return
+
if not any(built_plugins):
raise DistutilsError(
'None of TensorFlow, MXNet, PyTorch plugins were built. See errors above.')
@@ -851,7 +878,7 @@ def build_extensions(self):
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy'
],
- ext_modules=[tensorflow_lib, mxnet_lib, pytorch_lib],
+ ext_modules=[server_lib, tensorflow_lib, mxnet_lib, pytorch_lib],
# $ setup.py publish support.
cmdclass={
'upload': UploadCommand,
+
+
## General Workflow
To demonstrate the work flow of BytePS, below we use a common data-parallel training scenario as an example. Say we have multiple worker machines (we refer them as "**workers**"), and each machine (worker) has multiple GPUs. We also have some CPU machines that serve as PS (we refer them as "**servers**").
diff --git a/docs/cross-barrier.md b/docs/cross-barrier.md
index c8baba2e6..09e2dba51 100644
--- a/docs/cross-barrier.md
+++ b/docs/cross-barrier.md
@@ -19,14 +19,15 @@ completion of all parameters.
Fig.1 shows the dependency graph with global barrier. Machine learning frameworks such as PyTorch and TensorFlow have
similar dependencies when using BytePS for push and pull.
-
+
*Fig.1: Dependency Graph With Global Barrier*
Fig. 2 shows the dependency graph after removing global barrier. What we do here is to change the dependency
graph from Fig. 1 to Fig. 2 by removing the barrier, building layer-wise dependencies while guaranteeing computation correctness.
-
+
+
*Fig.2: Dependency Graph After Removing Global Barrier*
diff --git a/docs/images/byteps_architecture.png b/docs/images/byteps_architecture.png
deleted file mode 100644
index 93bf14bb9..000000000
Binary files a/docs/images/byteps_architecture.png and /dev/null differ
diff --git a/docs/images/dag_barrier.png b/docs/images/dag_barrier.png
deleted file mode 100644
index 6137cb8c8..000000000
Binary files a/docs/images/dag_barrier.png and /dev/null differ
diff --git a/docs/images/dag_without_barrier.png b/docs/images/dag_without_barrier.png
deleted file mode 100644
index 04df725b3..000000000
Binary files a/docs/images/dag_without_barrier.png and /dev/null differ
diff --git a/docs/images/perf_tcp_resnet50.png b/docs/images/perf_tcp_resnet50.png
deleted file mode 100644
index 9fe181a0d..000000000
Binary files a/docs/images/perf_tcp_resnet50.png and /dev/null differ
diff --git a/docs/images/perf_tcp_vgg16.png b/docs/images/perf_tcp_vgg16.png
deleted file mode 100644
index 7812a74a3..000000000
Binary files a/docs/images/perf_tcp_vgg16.png and /dev/null differ
diff --git a/docs/performance.md b/docs/performance.md
index f8f0a62c0..124525592 100644
--- a/docs/performance.md
+++ b/docs/performance.md
@@ -1,15 +1,19 @@
# BytePS Performance with 100Gbps RDMA
-## NVLink + RDMA
+## NVLink + TCP
-We show our experiment on BERT-large training, which is based on GluonNLP toolkit. The model uses mixed precision.
+We test two models: VGG16 (communication-intensive) and Resnet50 (computation-intensive) on a popular public cloud. Both models are trained using fp32.
-We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs (32GB memory) with NVLink-enabled.
-Machines are inter-connected with 100 Gbps RoCEv2 network.
+We use Tesla V100 16GB GPUs and set batch size equal to 64 *per GPU*. The machines are in fact VMs on the cloud. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 20 Gbps TCP/IP network.
-BytePS outperforms Horovod (after carefully tuned) by 16% in this case, both with RDMA enabled.
+BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.
-
+
+
+
+
+
+You can reproduce the results using the Dockerfiles and example scripts we provide.
## PCIe + RDMA
diff --git a/docs/step-by-step-tutorial.md b/docs/step-by-step-tutorial.md
index b24733404..67e5d3100 100644
--- a/docs/step-by-step-tutorial.md
+++ b/docs/step-by-step-tutorial.md
@@ -8,89 +8,85 @@ When you have successfully run through these examples, read the [best practice](
### TensorFlow
```
-docker pull bytepsimage/worker_tensorflow
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_tensorflow bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-# can also try: export EVAL_TYPE=mnist
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
### PyTorch
```
-docker pull bytepsimage/worker_pytorch
+docker pull bytepsimage/pytorch
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_pytorch bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/pytorch bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
### MXNet
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/mxnet
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/mxnet bash
# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
-export DMLC_NUM_WORKER=1 # you only have one worker
-export DMLC_ROLE=worker # your role is worker
+export DMLC_NUM_WORKER=1 # one worker
+export DMLC_ROLE=worker
# the following value does not matter for non-distributed jobs
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
## Distributed Training (TCP)
-Let's say you have two workers, and each one with 4 GPUs. For simplicity we use one server.
+Let's say you have two workers, and each one with 4 GPUs. For simplicity we use one server. In practice, you need more servers (at least equal to the number of workers) to achieve high performance.
-The way to launch the scheduler and the server are the same for any framework.
+
+For the workers, you need to pay attention to `DMLC_WORKER_ID`. This is the main difference compared to single machine jobs. Let's say the 2 workers are using TensorFlow.
For the scheduler:
```
-# scheduler can use the same image as servers
-docker pull bytepsimage/byteps_server
+docker pull bytepsimage/tensorflow
-docker run -it --net=host bytepsimage/byteps_server bash
+docker run -it --net=host bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_NUM_WORKER=2
@@ -99,14 +95,14 @@ export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For the server:
```
-docker pull bytepsimage/byteps_server
+docker pull bytepsimage/tensorflow
-docker run -it --net=host bytepsimage/byteps_server bash
+docker run -it --net=host bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_NUM_WORKER=2
@@ -115,85 +111,78 @@ export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-# 4 threads should be enough for a server
-export MXNET_OMP_MAX_THREADS=4
-
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
-For the workers, you need to pay attention to `DMLC_WORKER_ID`. This is the main difference compared to single machine jobs. Let's say the 2 workers are using MXNet.
For worker-0:
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
-# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
-export DMLC_WORKER_ID=0 # worker-0
-export DMLC_NUM_WORKER=2 # 2 workers
-export DMLC_ROLE=worker # your role is worker
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3
+export DMLC_WORKER_ID=0
+export DMLC_NUM_WORKER=2
+export DMLC_ROLE=worker
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
For worker-1:
```
-docker pull bytepsimage/worker_mxnet
+docker pull bytepsimage/tensorflow
-nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/worker_mxnet bash
+nvidia-docker run -it --net=host --shm-size=32768m bytepsimage/tensorflow bash
-# now you are in docker environment
-export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # say you have 4 GPUs
-export DMLC_WORKER_ID=1 # worker-1
-export DMLC_NUM_WORKER=2 # 2 workers
-export DMLC_ROLE=worker # your role is worker
+export NVIDIA_VISIBLE_DEVICES=0,1,2,3
+export DMLC_WORKER_ID=1
+export DMLC_NUM_WORKER=2
+export DMLC_ROLE=worker
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1 # the scheduler IP
export DMLC_PS_ROOT_PORT=1234 # the scheduler port
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
-If your workers use TensorFlow, you need to change the image name to `bytepsimage/worker_tensorflow`, and replace the python script with
+
+If your workers use PyTorch, you need to change the image name to `bytepsimage/pytorch`, and replace the python script of the workers with
+
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
-If your workers use PyTorch, you need to change the image name to `bytepsimage/worker_pytorch`, and replace the python script with
+If your workers use MXNet, you need to change the image name to `bytepsimage/mxnet`, and replace the python script of the workers with
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
## Distributed Training with RDMA
-The steps to launch RDMA tasks are basically similar to the above. The main differences are that (1) you need to specify your RDMA devices when running a docker, and (2) you need to set `DMLC_ENABLE_RDMA=1`. To run this example, your `nvidia-docker` need to support cuda 10.
+The steps to launch RDMA tasks are basically similar to the above. The main differences are that (1) you need to specify your RDMA devices when running a docker, and (2) you need to set `DMLC_ENABLE_RDMA=1`.
-In the following, let's continue to use the example: you have two workers and one server, and the workers are using MXNet.
+In the following, let's continue to use the example: you have two workers and one server, and the workers are using TensorFlow.
For the scheduler:
```
-# the scheduler may use the same image as servers
-docker pull bytepsimage/byteps_server_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/byteps_server_rdma bash
+docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_ENABLE_RDMA=1
@@ -209,15 +198,15 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For the server:
```
-docker pull bytepsimage/byteps_server_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/byteps_server_rdma bash
+docker run -it --net=host --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export DMLC_ENABLE_RDMA=1
@@ -228,24 +217,21 @@ export DMLC_NUM_SERVER=1
# the RDMA interface name of the server
export DMLC_INTERFACE=eth5
-# 4 threads should be enough for a server
-export MXNET_OMP_MAX_THREADS=4
-
# your scheduler's RDMA NIC information (IP, port)
export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-python /usr/local/byteps/launcher/launch.py
+python3 /usr/local/byteps/launcher/launch.py
```
For worker-0:
```
-docker pull bytepsimage/worker_mxnet_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/worker_mxnet_rdma bash
+nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export NVIDIA_VISIBLE_DEVICES=0,1,2,3
@@ -264,20 +250,19 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
For worker-1:
```
-docker pull bytepsimage/worker_mxnet_rdma
+docker pull bytepsimage/tensorflow
# specify your rdma device (usually under /dev/infiniband, but depend on your system configurations)
-nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/worker_mxnet_rdma bash
+nvidia-docker run -it --net=host --shm-size=32768m --device /dev/infiniband/rdma_cm --device /dev/infiniband/issm0 --device /dev/infiniband/ucm0 --device /dev/infiniband/umad0 --device /dev/infiniband/uverbs0 --cap-add IPC_LOCK bytepsimage/tensorflow bash
# now you are in docker environment
export NVIDIA_VISIBLE_DEVICES=0,1,2,3
@@ -296,24 +281,25 @@ export DMLC_PS_ROOT_URI=10.0.0.100
export DMLC_PS_ROOT_PORT=9000
# launch the job
-export EVAL_TYPE=benchmark
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/mxnet/start_mxnet_byteps.sh \
- --benchmark 1 --batch-size=32
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/tensorflow/synthetic_benchmark.py \
+ --model ResNet50 --num-iters 1000000
```
-If your workers use TensorFlow, you need to change the image name to `bytepsimage/worker_tensorflow_rdma`, and replace the python script with
+
+If your workers use PyTorch, you need to change the image name to `bytepsimage/pytorch`, and replace the python script of the workers with
+
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/tensorflow/run_tensorflow_byteps.sh \
- --model ResNet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/pytorch/benchmark_byteps.py \
+ --model resnet50 --num-iters 1000000
```
-If your workers use PyTorch, you need to change the image name to `bytepsimage/worker_pytorch_rdma`, and replace the python script with
+If your workers use MXNet, you need to change the image name to `bytepsimage/mxnet`, and replace the python script of the workers with
```
-python /usr/local/byteps/launcher/launch.py \
- /usr/local/byteps/example/pytorch/start_pytorch_byteps.sh \
- --model resnet50 --num-iters 1000000
+python3 /usr/local/byteps/launcher/launch.py \
+ python3 /usr/local/byteps/example/mxnet/train_imagenet_byteps.py \
+ --benchmark 1 --batch-size=32
```
\ No newline at end of file
diff --git a/example/keras/run_keras.sh b/example/keras/run_keras.sh
deleted file mode 100755
index 3d4ca705f..000000000
--- a/example/keras/run_keras.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "imagenet" ]; then
- echo "Run Keras ImageNet ..."
- python $path/keras_imagenet_resnet50.py $@
-elif [ "$EVAL_TYPE" == "mnist" ]; then
- echo "Run Keras MNIST ..."
- python $path/keras_mnist.py $@
-elif [ "$EVAL_TYPE" == "mnist_advanced" ]; then
- echo "Run Keras MNIST-advanced ..."
- python $path/keras_mnist_advanced.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/example/mxnet-gluon/run_mnist_gluon.sh b/example/mxnet-gluon/run_mnist_gluon.sh
deleted file mode 100644
index 2632e358c..000000000
--- a/example/mxnet-gluon/run_mnist_gluon.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/bin/bash
-
-export NVIDIA_VISIBLE_DEVICES=0,1
-export DMLC_WORKER_ID=0
-export DMLC_NUM_WORKER=1
-export DMLC_ROLE=worker
-
-# the following value does not matter for non-distributed jobs
-export DMLC_NUM_SERVER=1
-export DMLC_PS_ROOT_URI=127.0.0.1
-export DMLC_PS_ROOT_PORT=9000
-
-path="`dirname $0`"
-echo $path
-
-python $path/../../launcher/launch.py \
- python $path/train_mnist_byteps.py
\ No newline at end of file
diff --git a/example/mxnet/start_mxnet_byteps.sh b/example/mxnet/start_mxnet_byteps.sh
deleted file mode 100755
index ff1c537d3..000000000
--- a/example/mxnet/start_mxnet_byteps.sh
+++ /dev/null
@@ -1,5 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-python $path/train_imagenet_byteps.py $@
diff --git a/example/mxnet-gluon/train_mnist_byteps.py b/example/mxnet/train_gluon_mnist_byteps.py
similarity index 100%
rename from example/mxnet-gluon/train_mnist_byteps.py
rename to example/mxnet/train_gluon_mnist_byteps.py
diff --git a/example/pytorch/microbenchmark-byteps.py b/example/pytorch/microbenchmark-byteps.py
deleted file mode 100644
index 1a1ae05a1..000000000
--- a/example/pytorch/microbenchmark-byteps.py
+++ /dev/null
@@ -1,82 +0,0 @@
-from __future__ import print_function
-
-import torch
-import argparse
-import torch.backends.cudnn as cudnn
-from byteps.torch.ops import push_pull_async_inplace, poll, synchronize
-import byteps.torch as bps
-import time
-import numpy as np
-
-
-parser = argparse.ArgumentParser(description='PyTorch BytePS Synthetic Benchmark',
- formatter_class=argparse.ArgumentDefaultsHelpFormatter)
-parser.add_argument('--num-warmup', type=int, default=10,
- help='number of warm-up steps that don\'t count towards benchmark')
-parser.add_argument('--num-iters', type=int, default=1000,
- help='number of benchmark iterations')
-parser.add_argument('--no-cuda', action='store_true', default=False,
- help='disables CUDA')
-parser.add_argument('--no-wait', type=bool, default=True,
- help='wait for other worker request first')
-parser.add_argument('--gpu', type=int, default=-1,
- help='use a specified gpu')
-
-args = parser.parse_args()
-args.cuda = not args.no_cuda and torch.cuda.is_available()
-
-bps.init()
-
-# BytePS: pin GPU to local rank.
-if args.gpu >= 0:
- torch.cuda.set_device(args.gpu)
-else:
- torch.cuda.set_device(bps.local_rank())
-
-cudnn.benchmark = True
-
-
-def log(s, nl=True):
- if bps.rank() != 0:
- return
- print(s, end='\n' if nl else '')
-
-
-def benchmark(tensor, average, name):
- if not args.no_wait and bps.rank() == 0:
- time.sleep(0.01)
- start = time.time()
- handle = push_pull_async_inplace(tensor, average, name)
- while True:
- if poll(handle):
- synchronize(handle)
- break
- end = time.time()
- return (end - start) * 1000
-
-
-log('Number of GPUs: %d' % (bps.size()))
-
-# Benchmark
-log('Running benchmark...')
-
-log('size (Byte) \t avg. time (ms) \t std.dev (ms)')
-for i in range(8):
- size = 10**i
- data = torch.rand(size, dtype=torch.float32)
- if args.cuda:
- data = data.cuda()
- # warm up
- for j in range(args.num_warmup):
- benchmark(tensor=data, average=True, name=str(i))
- # timeit
- durations = []
- for j in range(args.num_iters):
- t = benchmark(tensor=data, average=True, name=str(i))
- durations.append(t)
- avg = np.mean(durations)
- std = np.std(durations)
-
- log('%d \t %s \t %s' % (4*size, '%.3f'%avg, '%.3f'%std))
-
-log('End benchmark.')
diff --git a/example/pytorch/start_pytorch_byteps.sh b/example/pytorch/start_pytorch_byteps.sh
deleted file mode 100755
index f82a279cc..000000000
--- a/example/pytorch/start_pytorch_byteps.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "mnist" ]; then
- echo "training mnist..."
- python $path/train_mnist_byteps.py $@
-elif [ "$EVAL_TYPE" == "imagenet" ]; then
- echo "training imagenet..."
- python $path/train_imagenet_resnet50_byteps.py $@
-elif [ "$EVAL_TYPE" == "benchmark" ]; then
- echo "running benchmark..."
- python $path/benchmark_byteps.py $@
-elif [ "$EVAL_TYPE" == "nobarrierbenchmark" ]; then
- echo "running benchmark without global barrier..."
- python $path/benchmark_cross_barrier_byteps.py $@
-elif [ "$EVAL_TYPE" == "microbenchmark" ]; then
- echo "running microbenchmark"
- python $path/microbenchmark-byteps.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/example/tensorflow/run_tensorflow_byteps.sh b/example/tensorflow/run_tensorflow_byteps.sh
deleted file mode 100755
index 68ff57cd4..000000000
--- a/example/tensorflow/run_tensorflow_byteps.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-#!/bin/bash
-
-path="`dirname $0`"
-
-if [ "$EVAL_TYPE" == "benchmark" ]; then
- echo "Run synthetic benchmark..."
- python3 $path/synthetic_benchmark.py $@
-elif [ "$EVAL_TYPE" == "mnist" ]; then
- echo "Run MNIST ..."
- python3 $path/tensorflow_mnist.py $@
-else
- echo "Error: unsupported $EVAL_TYPE"
- exit 1
-fi
diff --git a/launcher/launch.py b/launcher/launch.py
index 51541d019..927c78c3d 100644
--- a/launcher/launch.py
+++ b/launcher/launch.py
@@ -10,7 +10,6 @@
COMMON_REQUIRED_ENVS = ["DMLC_ROLE", "DMLC_NUM_WORKER", "DMLC_NUM_SERVER",
"DMLC_PS_ROOT_URI", "DMLC_PS_ROOT_PORT"]
WORKER_REQUIRED_ENVS = ["DMLC_WORKER_ID"]
-SERVER_REQUIRED_ENVS = ["BYTEPS_SERVER_MXNET_PATH"]
def check_env():
assert "DMLC_ROLE" in os.environ and \
@@ -23,8 +22,6 @@ def check_env():
if num_worker == 1:
required_envs = []
required_envs += WORKER_REQUIRED_ENVS
- else:
- required_envs += SERVER_REQUIRED_ENVS
for env in required_envs:
if env not in os.environ:
print("The env " + env + " is missing")
@@ -60,5 +57,4 @@ def worker(local_rank, local_size, command):
t[i].join()
else:
- sys.path.insert(0, os.getenv("BYTEPS_SERVER_MXNET_PATH")+"/python")
- import mxnet
+ import byteps.server
diff --git a/setup.py b/setup.py
index 9df9176da..8319c45ff 100644
--- a/setup.py
+++ b/setup.py
@@ -20,6 +20,7 @@
from distutils.version import LooseVersion
import traceback
+server_lib = Extension('byteps.server.c_lib', [])
tensorflow_lib = Extension('byteps.tensorflow.c_lib', [])
mxnet_lib = Extension('byteps.mxnet.c_lib', [])
pytorch_lib = Extension('byteps.torch.c_lib', [])
@@ -280,6 +281,25 @@ def get_common_options(build_ext):
EXTRA_OBJECTS=EXTRA_OBJECTS)
+def build_server(build_ext, options):
+ server_lib.define_macros = options['MACROS']
+ server_lib.include_dirs = options['INCLUDES']
+ server_lib.sources = ['byteps/server/server.cc',
+ 'byteps/common/cpu_reducer.cc',
+ 'byteps/common/logging.cc']
+ server_lib.extra_compile_args = options['COMPILE_FLAGS'] + \
+ ['-DBYTEPS_BUILDING_SERVER']
+ server_lib.extra_link_args = options['LINK_FLAGS']
+ server_lib.extra_objects = options['EXTRA_OBJECTS']
+ server_lib.library_dirs = options['LIBRARY_DIRS']
+ if int(os.environ.get('BYTEPS_USE_RDMA', 0)):
+ server_lib.libraries = ['rdmacm', 'ibverbs']
+ else:
+ server_lib.libraries = []
+
+ build_ext.build_extension(server_lib)
+
+
def check_tf_version():
try:
import tensorflow as tf
@@ -775,6 +795,12 @@ def build_extensions(self):
options = get_common_options(self)
built_plugins = []
+ try:
+ build_server(self, options)
+ except:
+ raise DistutilsSetupError('An ERROR occured while building the server module.\n\n'
+ '%s' % traceback.format_exc())
+
# If PyTorch is installed, it must be imported before others, otherwise
# we may get an error: dlopen: cannot load any more object with static TLS
if not int(os.environ.get('BYTEPS_WITHOUT_PYTORCH', 0)):
@@ -818,8 +844,9 @@ def build_extensions(self):
raise
if not built_plugins:
- raise DistutilsError(
- 'TensorFlow, MXNet, PyTorch plugins were excluded from build. Aborting.')
+ print('INFO: Only server module is built.')
+ return
+
if not any(built_plugins):
raise DistutilsError(
'None of TensorFlow, MXNet, PyTorch plugins were built. See errors above.')
@@ -851,7 +878,7 @@ def build_extensions(self):
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy'
],
- ext_modules=[tensorflow_lib, mxnet_lib, pytorch_lib],
+ ext_modules=[server_lib, tensorflow_lib, mxnet_lib, pytorch_lib],
# $ setup.py publish support.
cmdclass={
'upload': UploadCommand,