diff --git a/datahub-web-react/package.json b/datahub-web-react/package.json
index ca53932eba518..f641706c7661e 100644
--- a/datahub-web-react/package.json
+++ b/datahub-web-react/package.json
@@ -89,7 +89,7 @@
"test": "vitest",
"generate": "graphql-codegen --config codegen.yml",
"lint": "eslint . --ext .ts,.tsx --quiet && yarn format-check && yarn type-check",
- "lint-fix": "eslint '*/**/*.{ts,tsx}' --quiet --fix",
+ "lint-fix": "eslint '*/**/*.{ts,tsx}' --quiet --fix && yarn format",
"format-check": "prettier --check src",
"format": "prettier --write src",
"type-check": "tsc --noEmit",
diff --git a/datahub-web-react/src/app/entity/shared/tabs/Dataset/Validations/contract/FreshnessScheduleSummary.tsx b/datahub-web-react/src/app/entity/shared/tabs/Dataset/Validations/contract/FreshnessScheduleSummary.tsx
index 434ccb985574f..5009587c0d277 100644
--- a/datahub-web-react/src/app/entity/shared/tabs/Dataset/Validations/contract/FreshnessScheduleSummary.tsx
+++ b/datahub-web-react/src/app/entity/shared/tabs/Dataset/Validations/contract/FreshnessScheduleSummary.tsx
@@ -13,16 +13,29 @@ type Props = {
};
export const FreshnessScheduleSummary = ({ definition, evaluationSchedule }: Props) => {
- const scheduleText =
- definition.type === FreshnessAssertionScheduleType.Cron
- ? `${capitalizeFirstLetter(cronstrue.toString(definition.cron?.cron as string))}.`
- : `In the past ${
- definition.fixedInterval?.multiple
- } ${definition.fixedInterval?.unit.toLocaleLowerCase()}s${
- (evaluationSchedule &&
- `, as of ${cronstrue.toString(evaluationSchedule.cron as string).toLowerCase()}`) ||
- ''
- }`;
+ let scheduleText = '';
+ const cronStr = definition.cron?.cron ?? evaluationSchedule?.cron;
+ switch (definition.type) {
+ case FreshnessAssertionScheduleType.Cron:
+ scheduleText = cronStr
+ ? `${capitalizeFirstLetter(cronstrue.toString(cronStr))}.`
+ : `Unknown freshness schedule.`;
+ break;
+ case FreshnessAssertionScheduleType.SinceTheLastCheck:
+ scheduleText = cronStr
+ ? `Since the previous check, as of ${cronstrue.toString(cronStr).toLowerCase()}`
+ : 'Since the previous check';
+ break;
+ case FreshnessAssertionScheduleType.FixedInterval:
+ scheduleText = `In the past ${
+ definition.fixedInterval?.multiple
+ } ${definition.fixedInterval?.unit.toLocaleLowerCase()}s${
+ cronStr ? `, as of ${cronstrue.toString(cronStr).toLowerCase()}` : ''
+ }`;
+ break;
+ default:
+ break;
+ }
return <>{scheduleText};
};
diff --git a/docs-website/sidebars.js b/docs-website/sidebars.js
index e58dbd4d99b0b..8e48062af6d4d 100644
--- a/docs-website/sidebars.js
+++ b/docs-website/sidebars.js
@@ -209,11 +209,6 @@ module.exports = {
},
items: [
"docs/managed-datahub/welcome-acryl",
- {
- type: "doc",
- id: "docs/managed-datahub/saas-slack-setup",
- className: "saasOnly",
- },
{
type: "doc",
id: "docs/managed-datahub/approval-workflows",
@@ -247,6 +242,20 @@ module.exports = {
},
],
},
+ {
+ Slack: [
+ {
+ type: "doc",
+ id: "docs/managed-datahub/slack/saas-slack-setup",
+ className: "saasOnly",
+ },
+ {
+ type: "doc",
+ id: "docs/managed-datahub/slack/saas-slack-app",
+ className: "saasOnly",
+ },
+ ],
+ },
{
"Operator Guide": [
{
diff --git a/docs/actions/actions/slack.md b/docs/actions/actions/slack.md
index bdea1c479e8aa..a89439825d2da 100644
--- a/docs/actions/actions/slack.md
+++ b/docs/actions/actions/slack.md
@@ -138,7 +138,7 @@ In the next steps, we'll show you how to configure the Slack Action based on the
#### Managed DataHub
-Head over to the [Configuring Notifications](../../managed-datahub/saas-slack-setup.md#configuring-notifications) section in the Managed DataHub guide to configure Slack notifications for your Managed DataHub instance.
+Head over to the [Configuring Notifications](../../managed-datahub/slack/saas-slack-setup.md#configuring-notifications) section in the Managed DataHub guide to configure Slack notifications for your Managed DataHub instance.
#### Quickstart
diff --git a/docs/incidents/incidents.md b/docs/incidents/incidents.md
index 578571289cd2e..41b4df10b7828 100644
--- a/docs/incidents/incidents.md
+++ b/docs/incidents/incidents.md
@@ -427,5 +427,5 @@ These notifications are also able to tag the immediate asset's owners, along wit
 -To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
+To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/slack/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
diff --git a/docs/managed-datahub/managed-datahub-overview.md b/docs/managed-datahub/managed-datahub-overview.md
index 087238097dd9f..4efc96eaf17a7 100644
--- a/docs/managed-datahub/managed-datahub-overview.md
+++ b/docs/managed-datahub/managed-datahub-overview.md
@@ -56,7 +56,8 @@ know.
| Monitor Freshness SLAs | ❌ | ✅ |
| Monitor Table Schemas | ❌ | ✅ |
| Monitor Table Volume | ❌ | ✅ |
-| Validate Table Columns | ❌ | ✅ |
+| Monitor Table Column Integrity | ❌ | ✅ |
+| Monitor Table with Custom SQL | ❌ | ✅ |
| Receive Notifications via Email & Slack | ❌ | ✅ |
| Manage Data Incidents via Slack | ❌ | ✅ |
| View Data Health Dashboard | ❌ | ✅ |
@@ -115,7 +116,7 @@ Fill out
## Additional Integrations
-- [Slack Integration](docs/managed-datahub/saas-slack-setup.md)
+- [Slack Integration](docs/managed-datahub/slack/saas-slack-setup.md)
- [Remote Ingestion Executor](docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor.md)
- [AWS Privatelink](docs/managed-datahub/integrations/aws-privatelink.md)
- [AWS Eventbridge](docs/managed-datahub/operator-guide/setting-up-events-api-on-aws-eventbridge.md)
diff --git a/docs/managed-datahub/observe/assertions.md b/docs/managed-datahub/observe/assertions.md
index b74d524dff1bd..e63d051a0096b 100644
--- a/docs/managed-datahub/observe/assertions.md
+++ b/docs/managed-datahub/observe/assertions.md
@@ -38,7 +38,7 @@ If you opt for a 3rd party tool, it will be your responsibility to ensure the as
## Alerts
-Beyond the ability to see the results of the assertion checks (and history of the results) both on the physical asset’s page in the DataHub UI and as the result of DataHub API calls, you can also get notified via [slack messages](/docs/managed-datahub/saas-slack-setup.md) (DMs or to a team channel) based on your [subscription](https://youtu.be/VNNZpkjHG_I?t=79) to an assertion change event. In the future, we’ll also provide the ability to subscribe directly to contracts.
+Beyond the ability to see the results of the assertion checks (and history of the results) both on the physical asset’s page in the DataHub UI and as the result of DataHub API calls, you can also get notified via [Slack messages](/docs/managed-datahub/slack/saas-slack-setup.md) (DMs or to a team channel) based on your [subscription](https://youtu.be/VNNZpkjHG_I?t=79) to an assertion change event. In the future, we’ll also provide the ability to subscribe directly to contracts.
With Acryl Observe, you can get the Assertion Change event by getting API events via [AWS EventBridge](/docs/managed-datahub/operator-guide/setting-up-events-api-on-aws-eventbridge.md) (the availability and simplicity of setup of each solution dependent on your current Acryl setup – chat with your Acryl representative to learn more).
diff --git a/docs/managed-datahub/saas-slack-setup.md b/docs/managed-datahub/saas-slack-setup.md
deleted file mode 100644
index 1b98f3a30773a..0000000000000
--- a/docs/managed-datahub/saas-slack-setup.md
+++ /dev/null
@@ -1,113 +0,0 @@
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
-
-# Configure Slack For Notifications
-
-
-
-## Install the DataHub Slack App into your Slack workspace
-
-The following steps should be performed by a Slack Workspace Admin.
-- Navigate to https://api.slack.com/apps/
-- Click Create New App
-- Use “From an app manifest” option
-- Select your workspace
-- Paste this Manifest in YAML. Suggest changing name and `display_name` to be `DataHub App YOUR_TEAM_NAME` but not required. This name will show up in your slack workspace
-```yml
-display_information:
- name: DataHub App
- description: An app to integrate DataHub with Slack
- background_color: "#000000"
-features:
- bot_user:
- display_name: DataHub App
- always_online: false
-oauth_config:
- scopes:
- bot:
- - channels:read
- - chat:write
- - commands
- - groups:read
- - im:read
- - mpim:read
- - team:read
- - users:read
- - users:read.email
-settings:
- org_deploy_enabled: false
- socket_mode_enabled: false
- token_rotation_enabled: false
-```
-
-Confirm you see the Basic Information Tab
-
-
-
-- Click **Install to Workspace**
-- It will show you permissions the Slack App is asking for, what they mean and a default channel in which you want to add the slack app
- - Note that the Slack App will only be able to post in channels that the app has been added to. This is made clear by slack’s Authentication screen also.
-- Select the channel you'd like notifications to go to and click **Allow**
-- Go to DataHub App page
- - You can find your workspace's list of apps at https://api.slack.com/apps/
-
-## Generating a Bot Token
-
-- Go to **OAuth & Permissions** Tab
-
-
-
-Here you'll find a “Bot User OAuth Token” which DataHub will need to communicate with your slack through the bot.
-In the next steps, we'll show you how to configure the Slack Integration inside of Acryl DataHub.
-
-## Configuring Notifications
-
-> In order to set up the Slack integration, the user must have the `Manage Platform Settings` privilege.
-
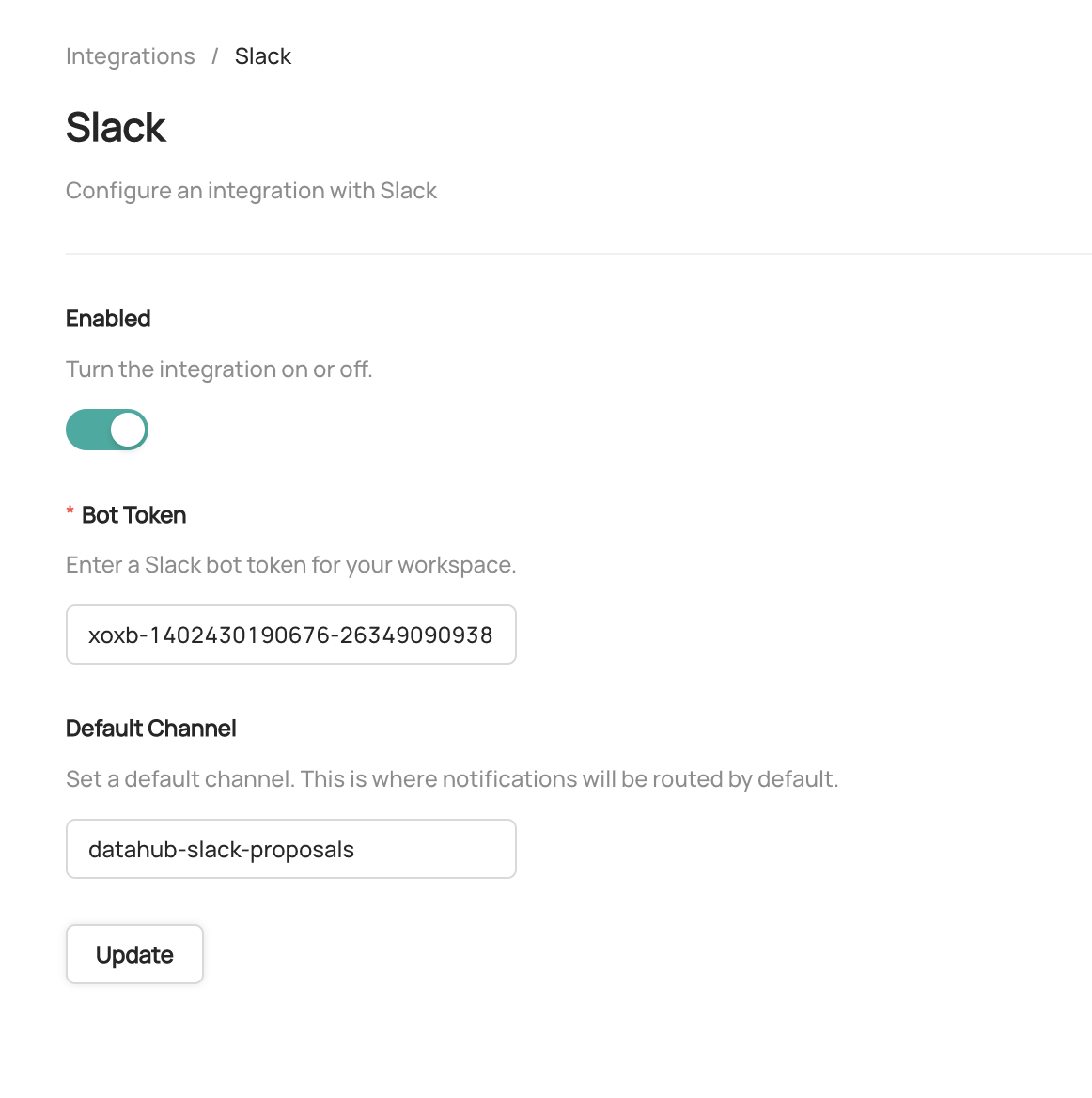
-To enable the integration with slack
-- Navigate to **Settings > Integrations**
-- Click **Slack**
-- Enable the Integration
-- Enter the **Bot Token** obtained in the previous steps
-- Enter a **Default Slack Channel** - this is where all notifications will be routed unless
-- Click **Update** to save your settings
-
-
-To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
+To do so, simply follow the [Slack Integration Guide](docs/managed-datahub/slack/saas-slack-setup.md) and contact your Acryl customer success team to enable the feature!
diff --git a/docs/managed-datahub/managed-datahub-overview.md b/docs/managed-datahub/managed-datahub-overview.md
index 087238097dd9f..4efc96eaf17a7 100644
--- a/docs/managed-datahub/managed-datahub-overview.md
+++ b/docs/managed-datahub/managed-datahub-overview.md
@@ -56,7 +56,8 @@ know.
| Monitor Freshness SLAs | ❌ | ✅ |
| Monitor Table Schemas | ❌ | ✅ |
| Monitor Table Volume | ❌ | ✅ |
-| Validate Table Columns | ❌ | ✅ |
+| Monitor Table Column Integrity | ❌ | ✅ |
+| Monitor Table with Custom SQL | ❌ | ✅ |
| Receive Notifications via Email & Slack | ❌ | ✅ |
| Manage Data Incidents via Slack | ❌ | ✅ |
| View Data Health Dashboard | ❌ | ✅ |
@@ -115,7 +116,7 @@ Fill out
## Additional Integrations
-- [Slack Integration](docs/managed-datahub/saas-slack-setup.md)
+- [Slack Integration](docs/managed-datahub/slack/saas-slack-setup.md)
- [Remote Ingestion Executor](docs/managed-datahub/operator-guide/setting-up-remote-ingestion-executor.md)
- [AWS Privatelink](docs/managed-datahub/integrations/aws-privatelink.md)
- [AWS Eventbridge](docs/managed-datahub/operator-guide/setting-up-events-api-on-aws-eventbridge.md)
diff --git a/docs/managed-datahub/observe/assertions.md b/docs/managed-datahub/observe/assertions.md
index b74d524dff1bd..e63d051a0096b 100644
--- a/docs/managed-datahub/observe/assertions.md
+++ b/docs/managed-datahub/observe/assertions.md
@@ -38,7 +38,7 @@ If you opt for a 3rd party tool, it will be your responsibility to ensure the as
## Alerts
-Beyond the ability to see the results of the assertion checks (and history of the results) both on the physical asset’s page in the DataHub UI and as the result of DataHub API calls, you can also get notified via [slack messages](/docs/managed-datahub/saas-slack-setup.md) (DMs or to a team channel) based on your [subscription](https://youtu.be/VNNZpkjHG_I?t=79) to an assertion change event. In the future, we’ll also provide the ability to subscribe directly to contracts.
+Beyond the ability to see the results of the assertion checks (and history of the results) both on the physical asset’s page in the DataHub UI and as the result of DataHub API calls, you can also get notified via [Slack messages](/docs/managed-datahub/slack/saas-slack-setup.md) (DMs or to a team channel) based on your [subscription](https://youtu.be/VNNZpkjHG_I?t=79) to an assertion change event. In the future, we’ll also provide the ability to subscribe directly to contracts.
With Acryl Observe, you can get the Assertion Change event by getting API events via [AWS EventBridge](/docs/managed-datahub/operator-guide/setting-up-events-api-on-aws-eventbridge.md) (the availability and simplicity of setup of each solution dependent on your current Acryl setup – chat with your Acryl representative to learn more).
diff --git a/docs/managed-datahub/saas-slack-setup.md b/docs/managed-datahub/saas-slack-setup.md
deleted file mode 100644
index 1b98f3a30773a..0000000000000
--- a/docs/managed-datahub/saas-slack-setup.md
+++ /dev/null
@@ -1,113 +0,0 @@
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
-
-# Configure Slack For Notifications
-
-
-
-## Install the DataHub Slack App into your Slack workspace
-
-The following steps should be performed by a Slack Workspace Admin.
-- Navigate to https://api.slack.com/apps/
-- Click Create New App
-- Use “From an app manifest” option
-- Select your workspace
-- Paste this Manifest in YAML. Suggest changing name and `display_name` to be `DataHub App YOUR_TEAM_NAME` but not required. This name will show up in your slack workspace
-```yml
-display_information:
- name: DataHub App
- description: An app to integrate DataHub with Slack
- background_color: "#000000"
-features:
- bot_user:
- display_name: DataHub App
- always_online: false
-oauth_config:
- scopes:
- bot:
- - channels:read
- - chat:write
- - commands
- - groups:read
- - im:read
- - mpim:read
- - team:read
- - users:read
- - users:read.email
-settings:
- org_deploy_enabled: false
- socket_mode_enabled: false
- token_rotation_enabled: false
-```
-
-Confirm you see the Basic Information Tab
-
-
-
-- Click **Install to Workspace**
-- It will show you permissions the Slack App is asking for, what they mean and a default channel in which you want to add the slack app
- - Note that the Slack App will only be able to post in channels that the app has been added to. This is made clear by slack’s Authentication screen also.
-- Select the channel you'd like notifications to go to and click **Allow**
-- Go to DataHub App page
- - You can find your workspace's list of apps at https://api.slack.com/apps/
-
-## Generating a Bot Token
-
-- Go to **OAuth & Permissions** Tab
-
-
-
-Here you'll find a “Bot User OAuth Token” which DataHub will need to communicate with your slack through the bot.
-In the next steps, we'll show you how to configure the Slack Integration inside of Acryl DataHub.
-
-## Configuring Notifications
-
-> In order to set up the Slack integration, the user must have the `Manage Platform Settings` privilege.
-
-To enable the integration with slack
-- Navigate to **Settings > Integrations**
-- Click **Slack**
-- Enable the Integration
-- Enter the **Bot Token** obtained in the previous steps
-- Enter a **Default Slack Channel** - this is where all notifications will be routed unless
-- Click **Update** to save your settings
-
- -
-To enable and disable specific types of notifications, or configure custom routing for notifications, start by navigating to **Settings > Notifications**.
-To enable or disable a specific notification type in Slack, simply click the check mark. By default, all notification types are enabled.
-To customize the channel where notifications are send, click the button to the right of the check box.
-
-
-
-To enable and disable specific types of notifications, or configure custom routing for notifications, start by navigating to **Settings > Notifications**.
-To enable or disable a specific notification type in Slack, simply click the check mark. By default, all notification types are enabled.
-To customize the channel where notifications are send, click the button to the right of the check box.
-
-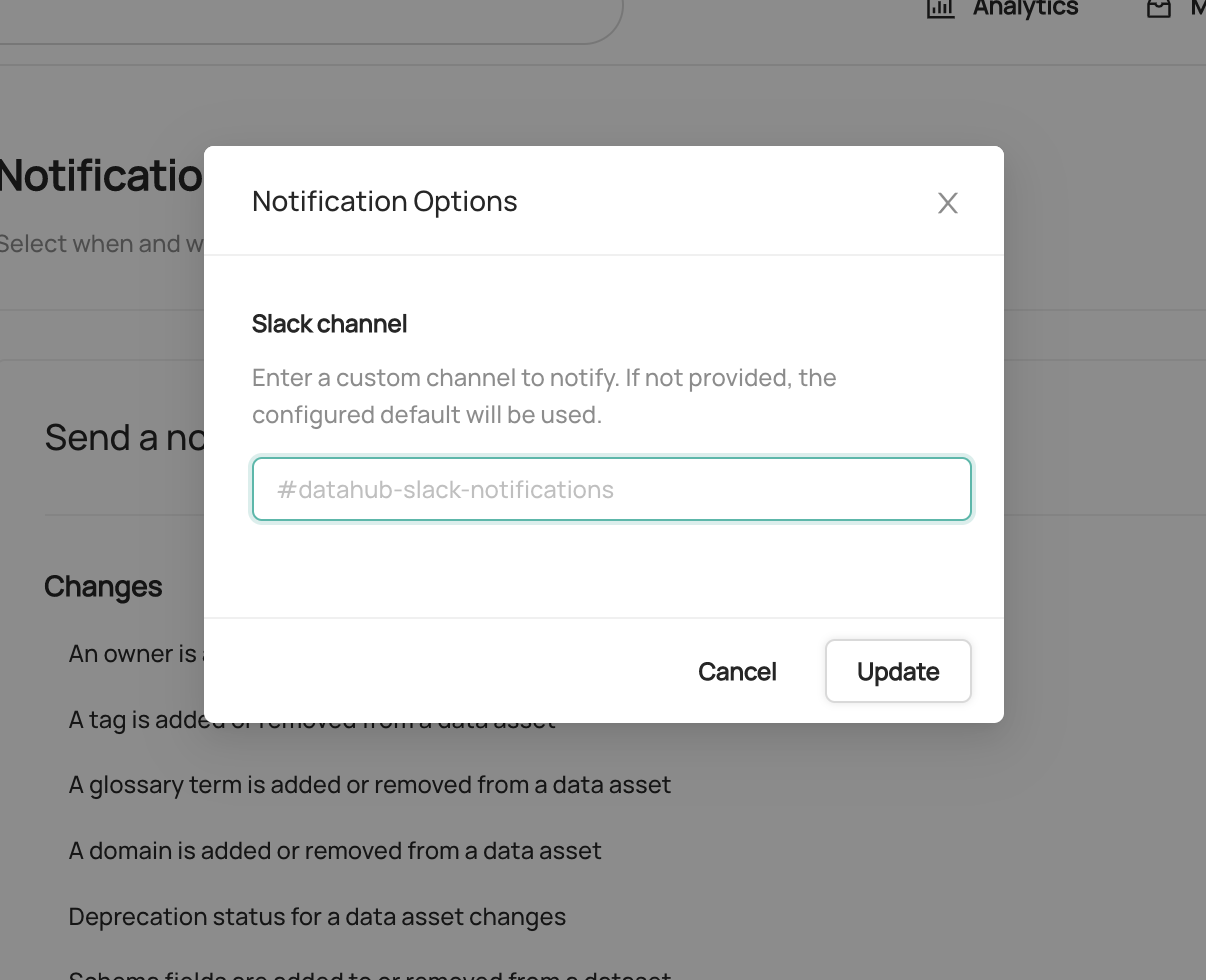 -
-If provided, a custom channel will be used to route notifications of the given type. If not provided, the default channel will be used.
-That's it! You should begin to receive notifications on Slack. Note that it may take up to 1 minute for notification settings to take effect after saving.
-
-## Sending Notifications
-
-For now we support sending notifications to
-- Slack Channel ID (e.g. `C029A3M079U`)
-- Slack Channel Name (e.g. `#troubleshoot`)
-- Specific Users (aka Direct Messages or DMs) via user ID
-
-By default, the Slack app will be able to send notifications to public channels. If you want to send notifications to private channels or DMs, you will need to invite the Slack app to those channels.
-
-## How to find Team ID and Channel ID in Slack
-
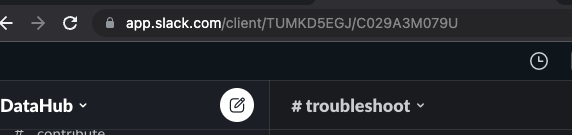
-- Go to the Slack channel for which you want to get channel ID
-- Check the URL e.g. for the troubleshoot channel in OSS DataHub slack
-
-
-
-- Notice `TUMKD5EGJ/C029A3M079U` in the URL
- - Team ID = `TUMKD5EGJ` from above
- - Channel ID = `C029A3M079U` from above
-
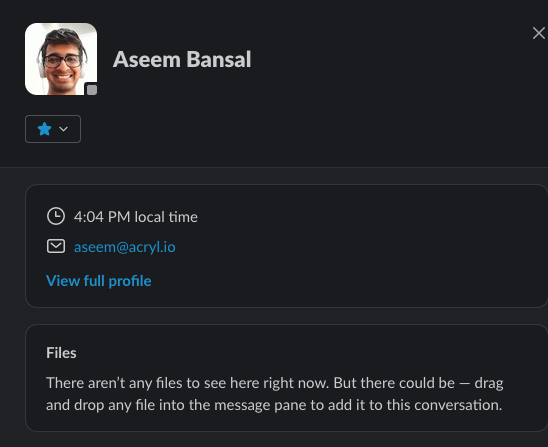
-## How to find User ID in Slack
-
-- Go to user DM
-- Click on their profile picture
-- Click on View Full Profile
-- Click on “More”
-- Click on “Copy member ID”
-
-
\ No newline at end of file
diff --git a/docs/managed-datahub/slack/saas-slack-app.md b/docs/managed-datahub/slack/saas-slack-app.md
new file mode 100644
index 0000000000000..5e16fed901e72
--- /dev/null
+++ b/docs/managed-datahub/slack/saas-slack-app.md
@@ -0,0 +1,59 @@
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+# Slack App Features
+
+
+
+## Overview
+The DataHub Slack App brings several of DataHub's key capabilities directly into your Slack experience. These include:
+1. Searching for Data Assets
+2. Subscribing to notifications for Data Assets
+3. Managing Data Incidents
+
+*Our goal with the Slack app is to make data discovery easier and more accessible for you.*
+
+## Slack App Commands
+The command-based capabilities on the Slack App revolve around search.
+
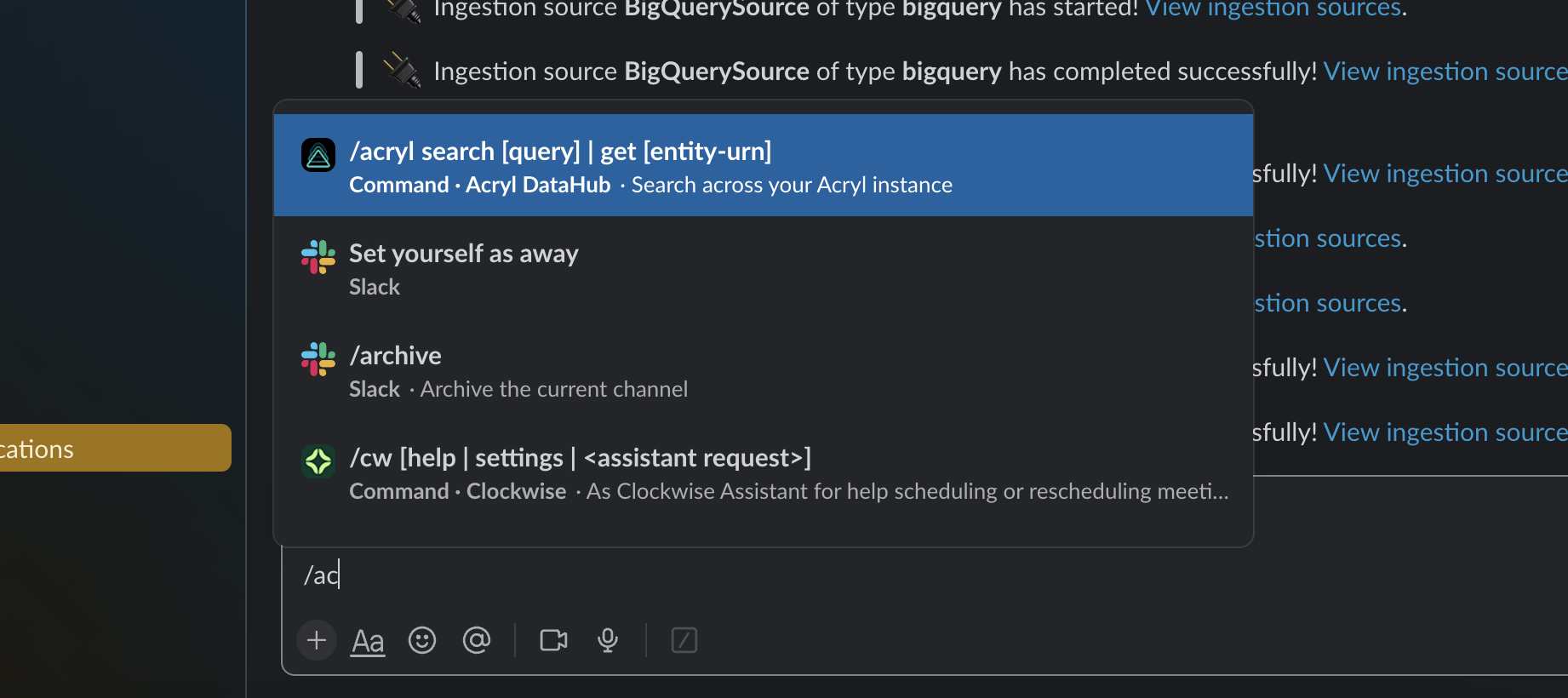
+### Querying for Assets
+You can trigger a search by simplying typing `/acryl my favorite table`.
+
-
-If provided, a custom channel will be used to route notifications of the given type. If not provided, the default channel will be used.
-That's it! You should begin to receive notifications on Slack. Note that it may take up to 1 minute for notification settings to take effect after saving.
-
-## Sending Notifications
-
-For now we support sending notifications to
-- Slack Channel ID (e.g. `C029A3M079U`)
-- Slack Channel Name (e.g. `#troubleshoot`)
-- Specific Users (aka Direct Messages or DMs) via user ID
-
-By default, the Slack app will be able to send notifications to public channels. If you want to send notifications to private channels or DMs, you will need to invite the Slack app to those channels.
-
-## How to find Team ID and Channel ID in Slack
-
-- Go to the Slack channel for which you want to get channel ID
-- Check the URL e.g. for the troubleshoot channel in OSS DataHub slack
-
-
-
-- Notice `TUMKD5EGJ/C029A3M079U` in the URL
- - Team ID = `TUMKD5EGJ` from above
- - Channel ID = `C029A3M079U` from above
-
-## How to find User ID in Slack
-
-- Go to user DM
-- Click on their profile picture
-- Click on View Full Profile
-- Click on “More”
-- Click on “Copy member ID”
-
-
\ No newline at end of file
diff --git a/docs/managed-datahub/slack/saas-slack-app.md b/docs/managed-datahub/slack/saas-slack-app.md
new file mode 100644
index 0000000000000..5e16fed901e72
--- /dev/null
+++ b/docs/managed-datahub/slack/saas-slack-app.md
@@ -0,0 +1,59 @@
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+# Slack App Features
+
+
+
+## Overview
+The DataHub Slack App brings several of DataHub's key capabilities directly into your Slack experience. These include:
+1. Searching for Data Assets
+2. Subscribing to notifications for Data Assets
+3. Managing Data Incidents
+
+*Our goal with the Slack app is to make data discovery easier and more accessible for you.*
+
+## Slack App Commands
+The command-based capabilities on the Slack App revolve around search.
+
+### Querying for Assets
+You can trigger a search by simplying typing `/acryl my favorite table`.
+
+  +
+
+
+Right within Slack, you'll be presented with results matching your query, and a handful of quick-actions for your convenience.
+
+ 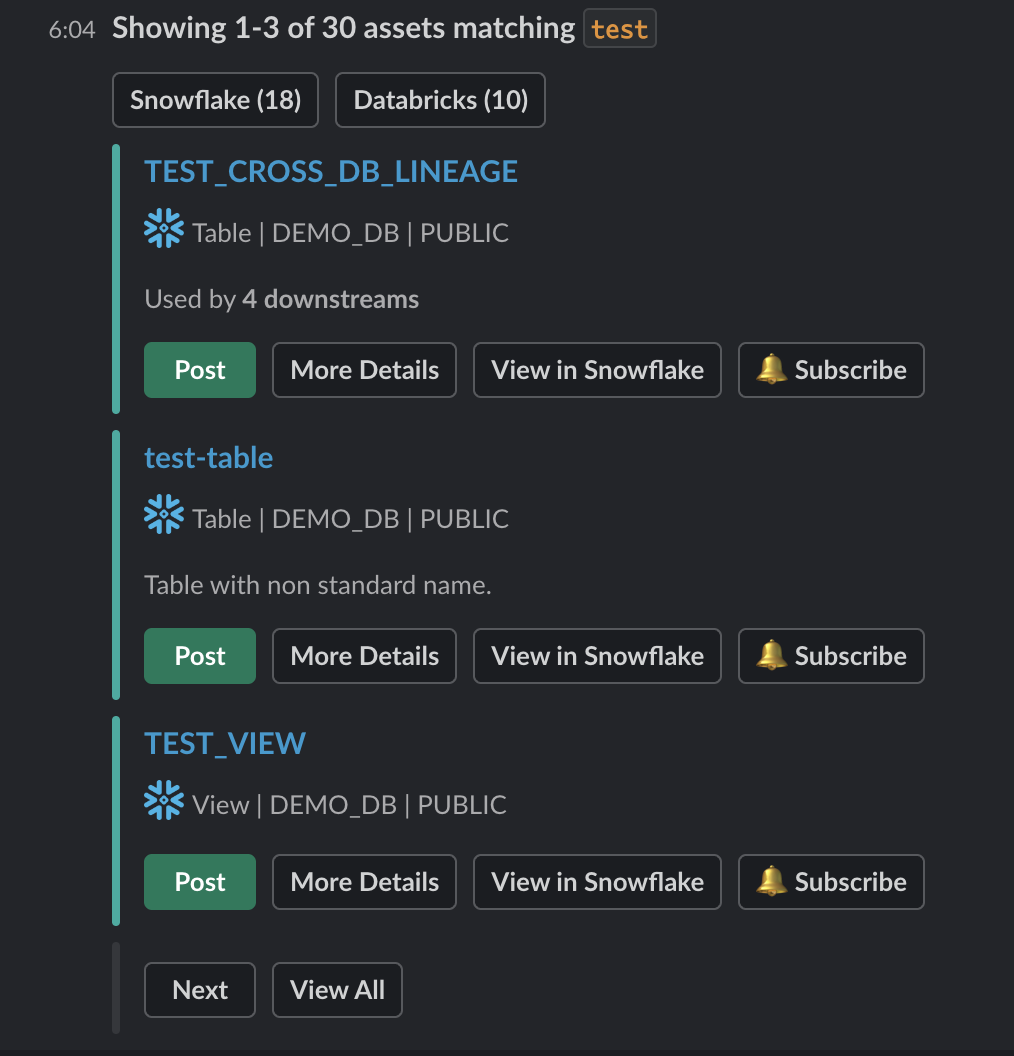 +
+
+
+By selecting **'More Details'** you can preview in-depth information about an asset without leaving Slack.
+
+ 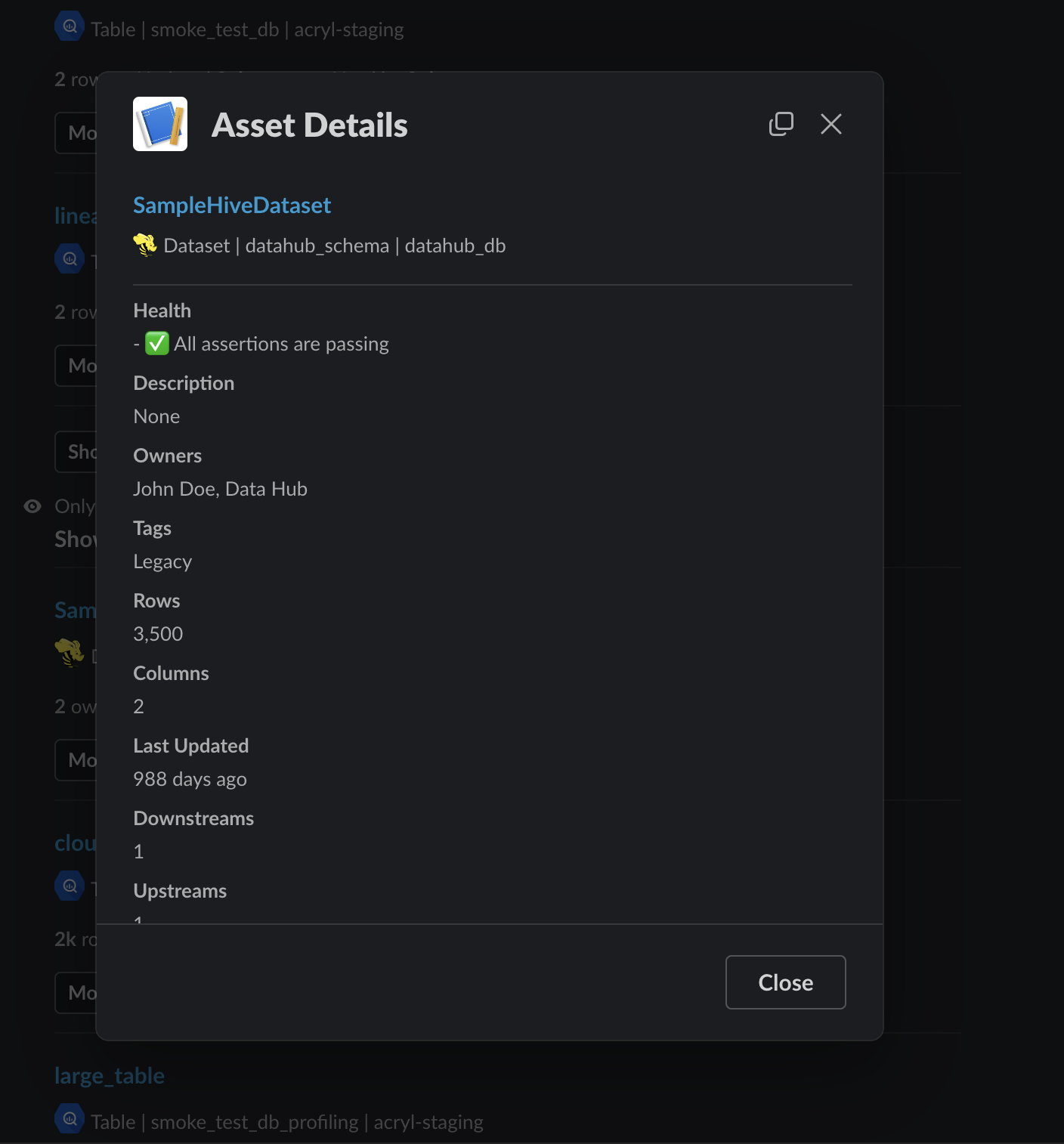 +
+
+
+### Subscribing to be notified about an Asset
+You can hit the **'Subscribe'** button on a specific search result to subscribe to it directly from within Slack.
+
+
+
+
+
+## Manage Data Incidents
+Some of the most commonly used features within our Slack app are the Incidents management capabilities.
+The DataHub UI offers a rich set of [Incident tracking and management](https://datahubproject.io/docs/incidents/incidents/) features.
+When a Slack member or channel receives notifications about an Incident, many of these features are made accessible right within the Slack app.
+
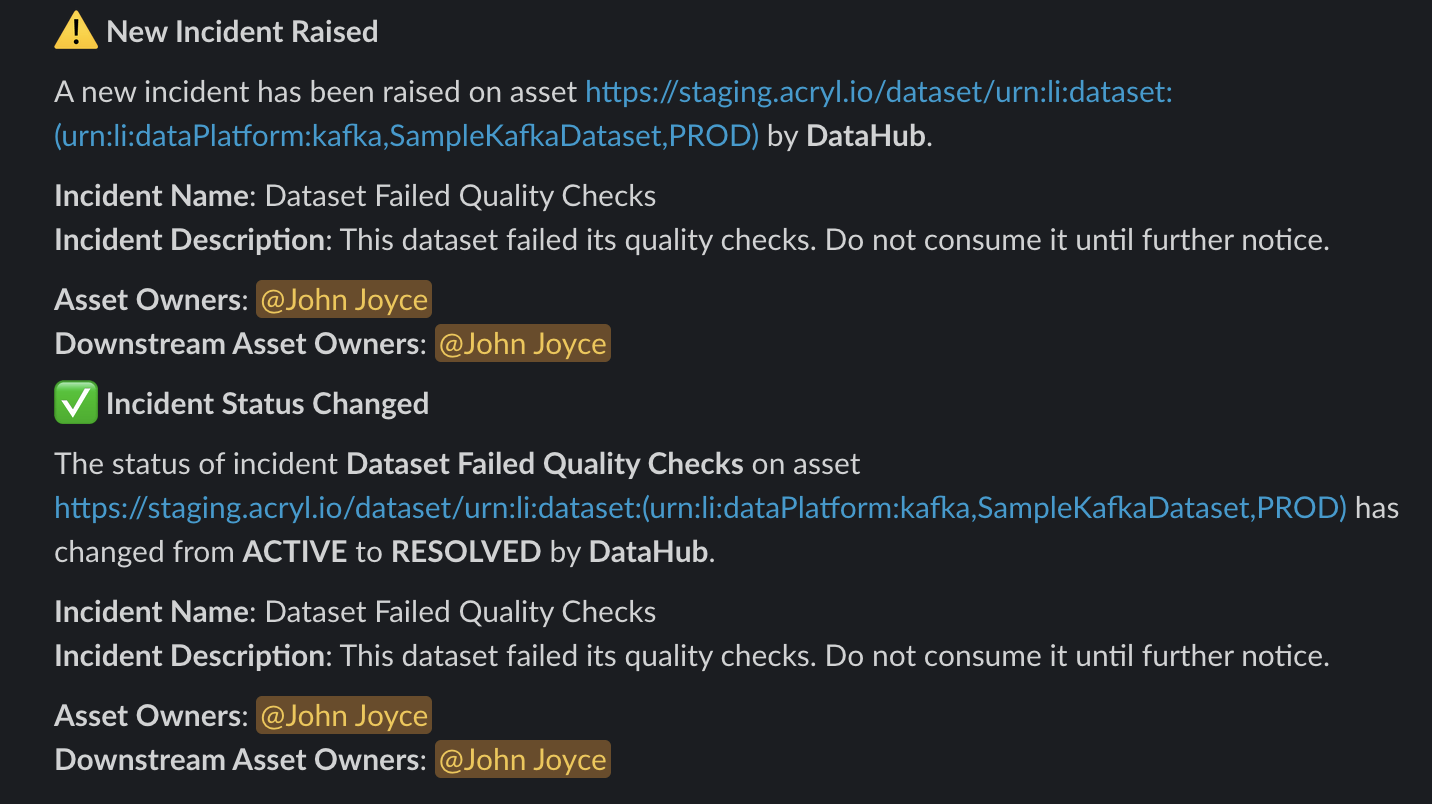
+When an incident is raised, you will recieve rich context about the incident in the Slack message itself. You will also be able to `Mark as Resolved`, update the `Priorty`, set a triage `Stage` and `View Details` - directly from the Slack message.
+
+ 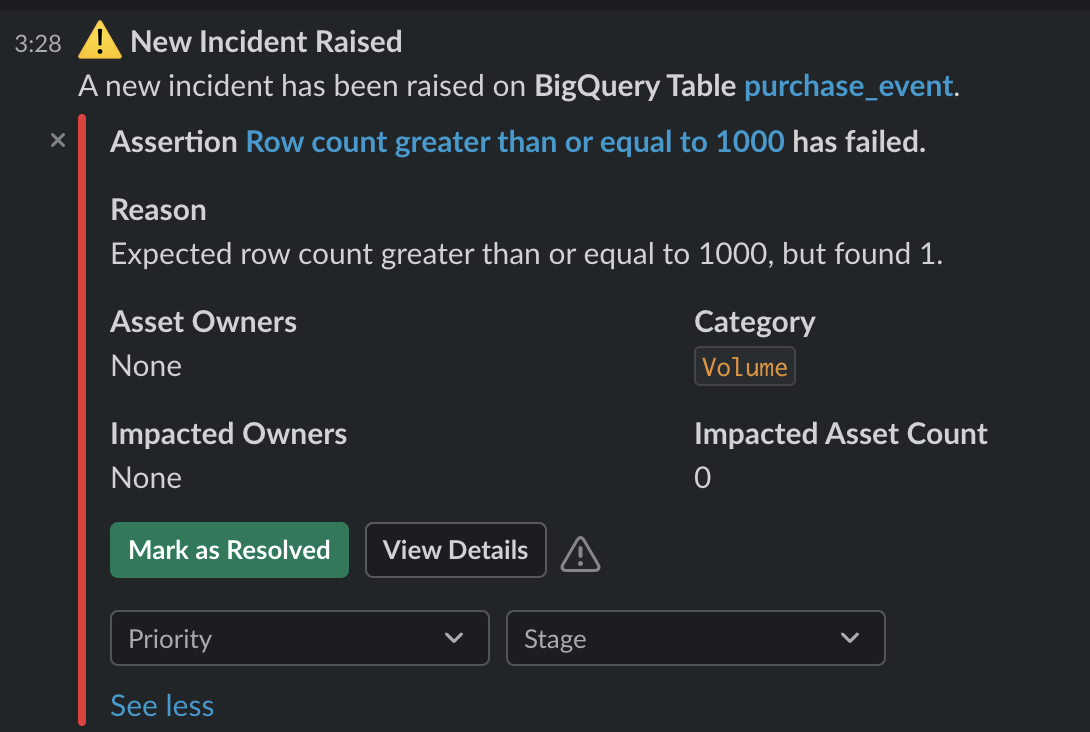 +
+
+
+If you choose to `Mark as Resolved` the message will update in-place, and you will be presented with the ability to `Reopen Incident` should you choose.
+
+ 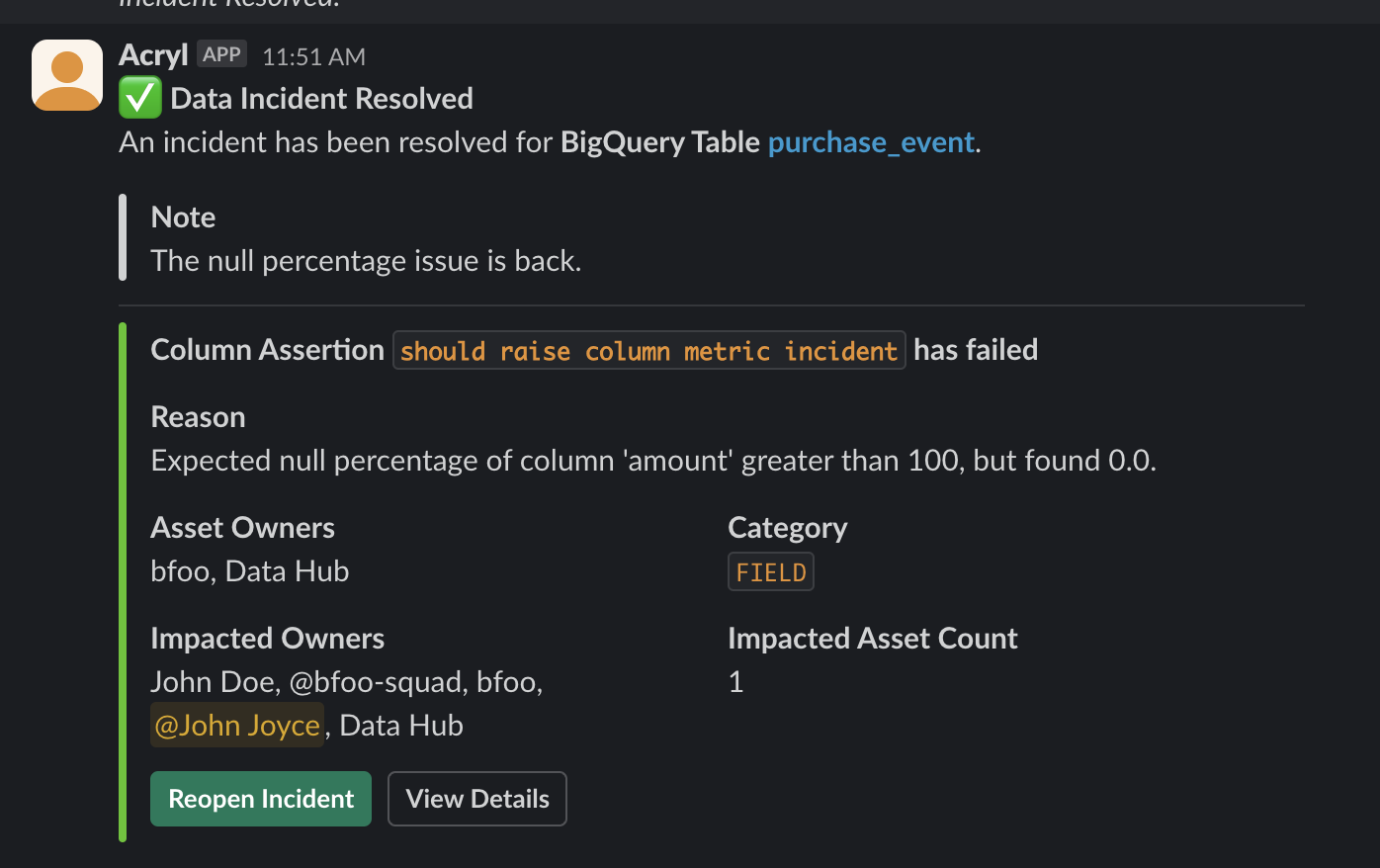 +
+
+
+
+## Coming Soon
+We're constantly working on rolling out new features for the Slack app, stay tuned!
+
diff --git a/docs/managed-datahub/slack/saas-slack-setup.md b/docs/managed-datahub/slack/saas-slack-setup.md
new file mode 100644
index 0000000000000..6db6a77c3a1f3
--- /dev/null
+++ b/docs/managed-datahub/slack/saas-slack-setup.md
@@ -0,0 +1,176 @@
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+# Configure Slack For Notifications
+
+
+
+## Install the DataHub Slack App into your Slack workspace
+
+
+### Video Walkthrough
+
+
+### Step-by-step guide
+The following steps should be performed by a Slack Workspace Admin.
+1. Navigate to [https://api.slack.com/reference/manifests#config-tokens](https://api.slack.com/reference/manifests#config-tokens)
+2. Under **Managing configuration tokens**, select **'Generate Token'**
+
+  +
+
+3. Select your workspace, then hit **'Generate'**
+
+  +
+
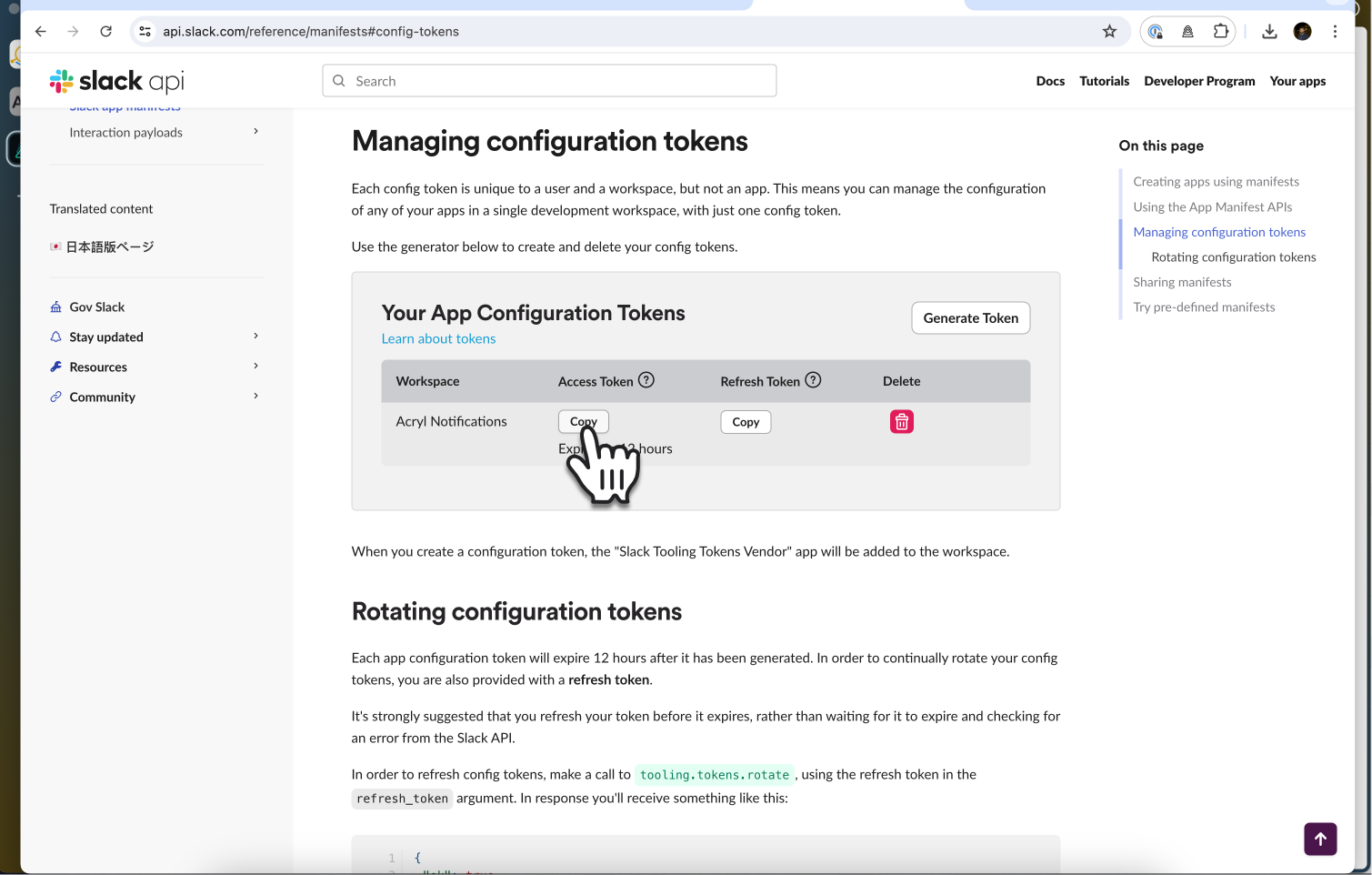
+4. Now you will see two tokens available for you to copy, an *Access Token* and a *Refresh Token*
+
+  +
+
+5. Navigate back to your DataHub [Slack Integration setup page](https://longtailcompanions.acryl.io/settings/integrations/slack), and paste the tokens into their respective boxes, and click **'Connect'**.
+
+  +
+
+6. You will be automatically re-directed to Slack to confirm DataHub Slack App's permissions and complete the installation process:
+
+  +
+
+7. Congrats 🎉 Slack is set up! Now try it out by going to the **Platform Notifications** page
+
+  +
+
+8. Enter your channel in, and click **'Send a test notification'**
+
+  +
+
+
+Now proceed to the [Subscriptions and Notifications page](https://datahubproject.io/docs/managed-datahub/subscription-and-notification) to see how you can subscribe to be notified about events on the platform, or visit the [Slack App page](saas-slack-app.md) to see how you can use DataHub's powerful capabilities directly within Slack.
+
+
+
+## Sending Notifications
+
+For now, we support sending notifications to
+- Slack Channel Name (e.g. `#troubleshoot`)
+- Slack Channel ID (e.g. `C029A3M079U`)
+- Specific Users (aka Direct Messages or DMs) via user ID
+
+By default, the Slack app will be able to send notifications to public channels. If you want to send notifications to private channels or DMs, you will need to invite the Slack app to those channels.
+
+## How to find Team ID and Channel ID in Slack
+:::note
+We recommend just using the Slack channel name for simplicity (e.g. `#troubleshoot`).
+:::
+
+**Via Slack App:**
+1. Go to the Slack channel for which you want to get a channel ID
+2. Click the channel name at the top
+
+  +
+
+3. At the bottom of the modal that pops up, you will see the Channel ID as well as a button to copy it
+
+ 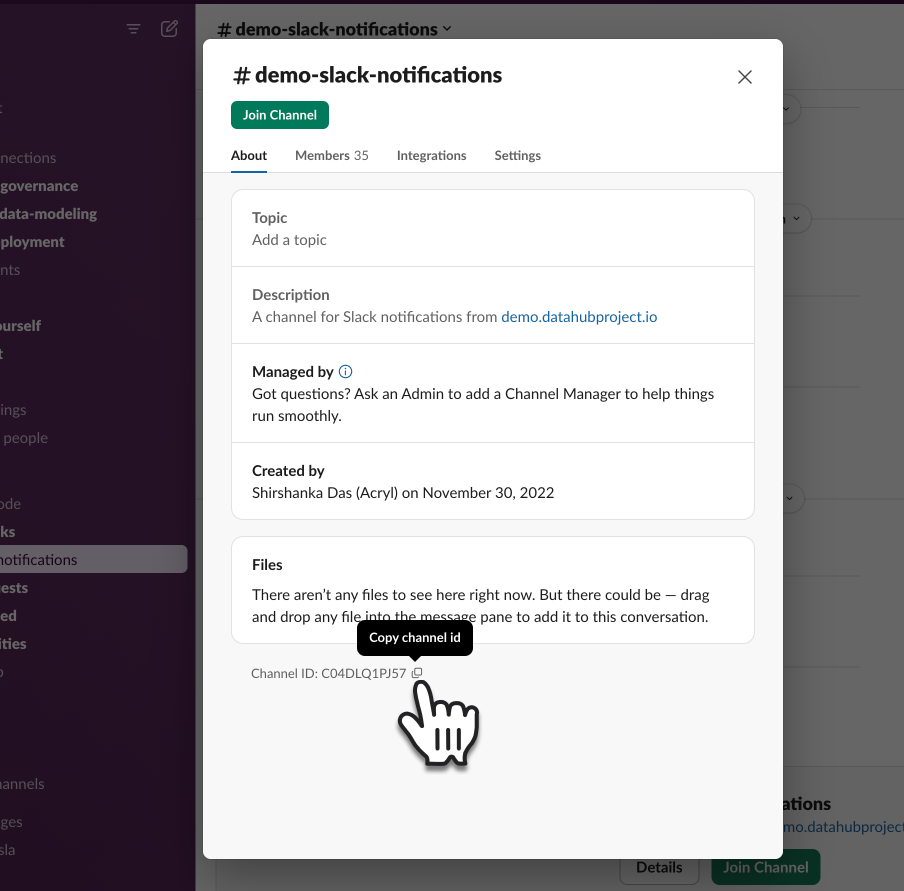 +
+
+
+**Via Web:**
+1. Go to the Slack channel for which you want to get a channel ID
+2. Check the URL e.g. for the troubleshoot channel in OSS DataHub Slack
+
+
+3. Notice `TUMKD5EGJ/C029A3M079U` in the URL
+ - Team ID = `TUMKD5EGJ` from above
+ - Channel ID = `C029A3M079U` from above
+
+## How to find User ID in Slack
+
+**Your User ID**
+1. Click your profile picture, then select **'Profile'**
+
+  +
+
+2. Now hit the **'...'** and select **'Copy member ID'**
+
+  +
+
+
+**Someone else's User ID**
+1. Click their profile picture in the Slack message
+
+  +
+
+2. Now hit the **'...'** and select **'Copy member ID'**
+
+  +
+
diff --git a/docs/managed-datahub/subscription-and-notification.md b/docs/managed-datahub/subscription-and-notification.md
index 81648d4298ec1..0e456fe415b2c 100644
--- a/docs/managed-datahub/subscription-and-notification.md
+++ b/docs/managed-datahub/subscription-and-notification.md
@@ -5,7 +5,10 @@ import FeatureAvailability from '@site/src/components/FeatureAvailability';
DataHub's Subscriptions and Notifications feature gives you real-time change alerts on data assets of your choice.
-With this feature, you can set up subscriptions to specific changes for an Entity – and DataHub will notify you when those changes happen. Currently, DataHub supports notifications on Slack, with support for Microsoft Teams and email subscriptions forthcoming.
+With this feature, you can set up subscriptions to specific changes for an Entity – and DataHub will notify you when those changes happen. Currently, DataHub supports notifications on Slack and Email, with support for Microsoft Teams forthcoming.
+
+Email will work out of box. For installing the DataHub Slack App, see:
+👉 [Configure Slack for Notifications](slack/saas-slack-setup.md)
 @@ -16,7 +19,7 @@ As a user, you can subscribe to and receive notifications about changes such as
## Prerequisites
-Once you have [configured Slack within your DataHub instance](saas-slack-setup.md), you will be able to subscribe to any Entity in DataHub and begin recieving notifications via DM.
+Once you have [configured Slack within your DataHub instance](slack/saas-slack-setup.md), you will be able to subscribe to any Entity in DataHub and begin recieving notifications via DM.
To begin receiving personal notifications, go to Settings > "My Notifications". From here, toggle on Slack Notifications and input your Slack Member ID.
If you want to create and manage group-level Subscriptions for your team, you will need [the following privileges](../../docs/authorization/roles.md#role-privileges):
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
index 342b5376d8a75..106596bf80ccf 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
@@ -5,6 +5,7 @@
import com.linkedin.data.template.RecordTemplate;
import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
+import com.linkedin.mxe.GenericAspect;
import com.linkedin.mxe.SystemMetadata;
import java.lang.reflect.InvocationTargetException;
import javax.annotation.Nonnull;
@@ -26,6 +27,9 @@ public interface ReadItem {
*/
@Nonnull
default String getAspectName() {
+ if (getAspectSpec() == null) {
+ return GenericAspect.dataSchema().getName();
+ }
return getAspectSpec().getName();
}
@@ -72,6 +76,6 @@ static T getAspect(Class clazz, @Nullable RecordTemplate recordTemplate)
*
* @return aspect's specification
*/
- @Nonnull
+ @Nullable
AspectSpec getAspectSpec();
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
index a302632e1936f..fc4ac90dfabad 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
@@ -9,6 +9,7 @@
import com.linkedin.util.Pair;
import java.util.ArrayList;
import java.util.Collection;
+import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
@@ -84,6 +85,13 @@ static void applyWriteMutationHooks(
}
}
+ default Stream applyProposalMutationHooks(
+ Collection proposedItems, @Nonnull RetrieverContext retrieverContext) {
+ return retrieverContext.getAspectRetriever().getEntityRegistry().getAllMutationHooks().stream()
+ .flatMap(
+ mutationHook -> mutationHook.applyProposalMutation(proposedItems, retrieverContext));
+ }
+
default ValidationExceptionCollection validateProposed(
Collection mcpItems) {
return validateProposed(mcpItems, getRetrieverContext());
@@ -191,16 +199,12 @@ default Map> getNewUrnAspectsMap(
static Map> merge(
@Nonnull Map> a, @Nonnull Map> b) {
- return Stream.concat(a.entrySet().stream(), b.entrySet().stream())
- .flatMap(
- entry ->
- entry.getValue().entrySet().stream()
- .map(innerEntry -> Pair.of(entry.getKey(), innerEntry)))
- .collect(
- Collectors.groupingBy(
- Pair::getKey,
- Collectors.mapping(
- Pair::getValue, Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue))));
+ Map> mergedMap = new HashMap<>();
+ for (Map.Entry> entry :
+ Stream.concat(a.entrySet().stream(), b.entrySet().stream()).collect(Collectors.toList())) {
+ mergedMap.computeIfAbsent(entry.getKey(), k -> new HashMap<>()).putAll(entry.getValue());
+ }
+ return mergedMap;
}
default String toAbbreviatedString(int maxWidth) {
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
index 1adb1be81ecc1..f99dd18d3c9c1 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
@@ -3,7 +3,6 @@
import com.linkedin.common.urn.Urn;
import com.linkedin.events.metadata.ChangeType;
import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
-import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
import javax.annotation.Nonnull;
import javax.annotation.Nullable;
@@ -25,20 +24,13 @@ public boolean enabled() {
}
public boolean shouldApply(
- @Nullable ChangeType changeType, @Nonnull Urn entityUrn, @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entityUrn.getEntityType(), aspectSpec);
+ @Nullable ChangeType changeType, @Nonnull Urn entityUrn, @Nonnull String aspectName) {
+ return shouldApply(changeType, entityUrn.getEntityType(), aspectName);
}
public boolean shouldApply(
- @Nullable ChangeType changeType,
- @Nonnull EntitySpec entitySpec,
- @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entitySpec.getName(), aspectSpec.getName());
- }
-
- public boolean shouldApply(
- @Nullable ChangeType changeType, @Nonnull String entityName, @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entityName, aspectSpec.getName());
+ @Nullable ChangeType changeType, @Nonnull EntitySpec entitySpec, @Nonnull String aspectName) {
+ return shouldApply(changeType, entitySpec.getName(), aspectName);
}
public boolean shouldApply(
@@ -49,8 +41,8 @@ && isChangeTypeSupported(changeType)
}
protected boolean isEntityAspectSupported(
- @Nonnull EntitySpec entitySpec, @Nonnull AspectSpec aspectSpec) {
- return isEntityAspectSupported(entitySpec.getName(), aspectSpec.getName());
+ @Nonnull EntitySpec entitySpec, @Nonnull String aspectName) {
+ return isEntityAspectSupported(entitySpec.getName(), aspectName);
}
protected boolean isEntityAspectSupported(
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
index 57016404648d5..853c2ef5f796c 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
@@ -24,7 +24,7 @@ public final Stream apply(
@Nonnull Collection batchItems, @Nonnull RetrieverContext retrieverContext) {
return applyMCLSideEffect(
batchItems.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
index 52920d8c6f396..ce49dd057bc3e 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
@@ -25,7 +25,7 @@ public final Stream apply(
Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return applyMCPSideEffect(
changeMCPS.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -41,7 +41,7 @@ public final Stream postApply(
Collection mclItems, @Nonnull RetrieverContext retrieverContext) {
return postMCPSideEffect(
mclItems.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
index c067954912a03..b2fd997d49444 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
@@ -3,6 +3,7 @@
import com.linkedin.metadata.aspect.ReadItem;
import com.linkedin.metadata.aspect.RetrieverContext;
import com.linkedin.metadata.aspect.batch.ChangeMCP;
+import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.PluginSpec;
import com.linkedin.util.Pair;
import java.util.Collection;
@@ -24,7 +25,7 @@ public final Stream> applyWriteMutation(
@Nonnull Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return writeMutation(
changeMCPS.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -34,7 +35,23 @@ public final Stream> applyReadMutation(
@Nonnull Collection items, @Nonnull RetrieverContext retrieverContext) {
return readMutation(
items.stream()
- .filter(i -> isEntityAspectSupported(i.getEntitySpec(), i.getAspectSpec()))
+ .filter(i -> isEntityAspectSupported(i.getEntitySpec(), i.getAspectName()))
+ .collect(Collectors.toList()),
+ retrieverContext);
+ }
+
+ /**
+ * Apply Proposal mutations prior to validation
+ *
+ * @param mcpItems wrapper for MCP
+ * @param retrieverContext retriever context
+ * @return stream of mutated Proposal items
+ */
+ public final Stream applyProposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return proposalMutation(
+ mcpItems.stream()
+ .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -48,4 +65,9 @@ protected Stream> writeMutation(
@Nonnull Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return changeMCPS.stream().map(i -> Pair.of(i, false));
}
+
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return Stream.empty();
+ }
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
index b39c38c2768a7..4083329899fee 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
@@ -22,7 +22,7 @@ public final Stream validateProposed(
@Nonnull RetrieverContext retrieverContext) {
return validateProposedAspects(
mcpItems.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -37,7 +37,7 @@ public final Stream validatePreCommit(
@Nonnull Collection changeMCPs, @Nonnull RetrieverContext retrieverContext) {
return validatePreCommitAspects(
changeMCPs.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
index 8aa154dc267b6..e9f93c0c1eab0 100644
--- a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
+++ b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
@@ -127,6 +127,10 @@ def _get_dependencies(
)
return upstream_tasks
+ @staticmethod
+ def _extract_owners(dag: "DAG") -> List[str]:
+ return [owner.strip() for owner in dag.owner.split(",")]
+
@staticmethod
def generate_dataflow(
config: DatahubLineageConfig,
@@ -175,7 +179,7 @@ def generate_dataflow(
data_flow.url = f"{base_url}/tree?dag_id={dag.dag_id}"
if config.capture_ownership_info and dag.owner:
- owners = [owner.strip() for owner in dag.owner.split(",")]
+ owners = AirflowGenerator._extract_owners(dag)
if config.capture_ownership_as_group:
data_flow.group_owners.update(owners)
else:
@@ -282,10 +286,12 @@ def generate_datajob(
datajob.url = f"{base_url}/taskinstance/list/?flt1_dag_id_equals={datajob.flow_urn.flow_id}&_flt_3_task_id={task.task_id}"
if capture_owner and dag.owner:
- if config and config.capture_ownership_as_group:
- datajob.group_owners.add(dag.owner)
- else:
- datajob.owners.add(dag.owner)
+ if config and config.capture_ownership_info:
+ owners = AirflowGenerator._extract_owners(dag)
+ if config.capture_ownership_as_group:
+ datajob.group_owners.update(owners)
+ else:
+ datajob.owners.update(owners)
if capture_tags and dag.tags:
datajob.tags.update(dag.tags)
diff --git a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
index 6ef4f831522cb..c87f7f8fb1a8e 100644
--- a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
+++ b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
@@ -362,8 +362,13 @@ def on_task_instance_running(
# Render templates in a copy of the task instance.
# This is necessary to get the correct operator args in the extractors.
- task_instance = copy.deepcopy(task_instance)
- task_instance.render_templates()
+ try:
+ task_instance = copy.deepcopy(task_instance)
+ task_instance.render_templates()
+ except Exception as e:
+ logger.info(
+ f"Error rendering templates in DataHub listener. Jinja-templated variables will not be extracted correctly: {e}"
+ )
# The type ignore is to placate mypy on Airflow 2.1.x.
dagrun: "DagRun" = task_instance.dag_run # type: ignore[attr-defined]
diff --git a/metadata-ingestion/docs/dev_guides/classification.md b/metadata-ingestion/docs/dev_guides/classification.md
index f20638a2ab5bd..39eac229a6601 100644
--- a/metadata-ingestion/docs/dev_guides/classification.md
+++ b/metadata-ingestion/docs/dev_guides/classification.md
@@ -10,7 +10,7 @@ Note that a `.` is used to denote nested fields in the YAML recipe.
| ------------------------- | -------- | --------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
| enabled | | boolean | Whether classification should be used to auto-detect glossary terms | False |
| sample_size | | int | Number of sample values used for classification. | 100 |
-| max_workers | | int | Number of worker threads to use for classification. Set to 1 to disable. | Number of cpu cores or 4 |
+| max_workers | | int | Number of worker processes to use for classification. Set to 1 to disable. | Number of cpu cores or 4 |
| info_type_to_term | | Dict[str,string] | Optional mapping to provide glossary term identifier for info type. | By default, info type is used as glossary term identifier. |
| classifiers | | Array of object | Classifiers to use to auto-detect glossary terms. If more than one classifier, infotype predictions from the classifier defined later in sequence take precedance. | [{'type': 'datahub', 'config': None}] |
| table_pattern | | AllowDenyPattern (see below for fields) | Regex patterns to filter tables for classification. This is used in combination with other patterns in parent config. Specify regex to match the entire table name in `database.schema.table` format. e.g. to match all tables starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*' | {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
diff --git a/metadata-ingestion/docs/sources/abs/README.md b/metadata-ingestion/docs/sources/abs/README.md
new file mode 100644
index 0000000000000..46a234ed305e0
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/README.md
@@ -0,0 +1,40 @@
+This connector ingests Azure Blob Storage (abbreviated to abs) datasets into DataHub. It allows mapping an individual
+file or a folder of files to a dataset in DataHub.
+To specify the group of files that form a dataset, use `path_specs` configuration in ingestion recipe. Refer
+section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
+
+### Concept Mapping
+
+This ingestion source maps the following Source System Concepts to DataHub Concepts:
+
+| Source Concept | DataHub Concept | Notes |
+|----------------------------------------|--------------------------------------------------------------------------------------------|------------------|
+| `"abs"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataplatform/) | |
+| abs blob / Folder containing abs blobs | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
+| abs container | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `Folder` |
+
+This connector supports both local files and those stored on Azure Blob Storage (which must be identified using the
+prefix `http(s)://.blob.core.windows.net/` or `azure://`).
+
+### Supported file types
+
+Supported file types are as follows:
+
+- CSV (*.csv)
+- TSV (*.tsv)
+- JSONL (*.jsonl)
+- JSON (*.json)
+- Parquet (*.parquet)
+- Apache Avro (*.avro)
+
+Schemas for Parquet and Avro files are extracted as provided.
+
+Schemas for schemaless formats (CSV, TSV, JSONL, JSON) are inferred. For CSV, TSV and JSONL files, we consider the first
+100 rows by default, which can be controlled via the `max_rows` recipe parameter (see [below](#config-details))
+JSON file schemas are inferred on the basis of the entire file (given the difficulty in extracting only the first few
+objects of the file), which may impact performance.
+We are working on using iterator-based JSON parsers to avoid reading in the entire JSON object.
+
+### Profiling
+
+Profiling is not available in the current release.
diff --git a/metadata-ingestion/docs/sources/abs/abs.md b/metadata-ingestion/docs/sources/abs/abs.md
new file mode 100644
index 0000000000000..613ace280c8ba
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/abs.md
@@ -0,0 +1,204 @@
+
+### Path Specs
+
+Path Specs (`path_specs`) is a list of Path Spec (`path_spec`) objects, where each individual `path_spec` represents one or more datasets. The include path (`path_spec.include`) represents a formatted path to the dataset. This path must end with `*.*` or `*.[ext]` to represent the leaf level. If `*.[ext]` is provided, then only files with the specified extension type will be scanned. "`.[ext]`" can be any of the [supported file types](#supported-file-types). Refer to [example 1](#example-1---individual-file-as-dataset) below for more details.
+
+All folder levels need to be specified in the include path. You can use `/*/` to represent a folder level and avoid specifying the exact folder name. To map a folder as a dataset, use the `{table}` placeholder to represent the folder level for which the dataset is to be created. For a partitioned dataset, you can use the placeholder `{partition_key[i]}` to represent the name of the `i`th partition and `{partition[i]}` to represent the value of the `i`th partition. During ingestion, `i` will be used to match the partition_key to the partition. Refer to [examples 2 and 3](#example-2---folder-of-files-as-dataset-without-partitions) below for more details.
+
+Exclude paths (`path_spec.exclude`) can be used to ignore paths that are not relevant to the current `path_spec`. This path cannot have named variables (`{}`). The exclude path can have `**` to represent multiple folder levels. Refer to [example 4](#example-4---folder-of-files-as-dataset-with-partitions-and-exclude-filter) below for more details.
+
+Refer to [example 5](#example-5---advanced---either-individual-file-or-folder-of-files-as-dataset) if your container has a more complex dataset representation.
+
+**Additional points to note**
+- Folder names should not contain {, }, *, / in their names.
+- Named variable {folder} is reserved for internal working. please do not use in named variables.
+
+
+### Path Specs - Examples
+#### Example 1 - Individual file as Dataset
+
+Container structure:
+
+```
+test-container
+├── employees.csv
+├── departments.json
+└── food_items.csv
+```
+
+Path specs config to ingest `employees.csv` and `food_items.csv` as datasets:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/*.csv
+
+```
+This will automatically ignore `departments.json` file. To include it, use `*.*` instead of `*.csv`.
+
+#### Example 2 - Folder of files as Dataset (without Partitions)
+
+Container structure:
+```
+test-container
+└── offers
+ ├── 1.avro
+ └── 2.avro
+
+```
+
+Path specs config to ingest folder `offers` as dataset:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*.avro
+```
+
+`{table}` represents folder for which dataset will be created.
+
+#### Example 3 - Folder of files as Dataset (with Partitions)
+
+Container structure:
+```
+test-container
+├── orders
+│ └── year=2022
+│ └── month=2
+│ ├── 1.parquet
+│ └── 2.parquet
+└── returns
+ └── year=2021
+ └── month=2
+ └── 1.parquet
+
+```
+
+Path specs config to ingest folders `orders` and `returns` as datasets:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+```
+
+One can also use `include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*/*/*.parquet` here however above format is preferred as it allows declaring partitions explicitly.
+
+#### Example 4 - Folder of files as Dataset (with Partitions), and Exclude Filter
+
+Container structure:
+```
+test-container
+├── orders
+│ └── year=2022
+│ └── month=2
+│ ├── 1.parquet
+│ └── 2.parquet
+└── tmp_orders
+ └── year=2021
+ └── month=2
+ └── 1.parquet
+
+
+```
+
+Path specs config to ingest folder `orders` as dataset but not folder `tmp_orders`:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+ exclude:
+ - **/tmp_orders/**
+```
+
+
+#### Example 5 - Advanced - Either Individual file OR Folder of files as Dataset
+
+Container structure:
+```
+test-container
+├── customers
+│ ├── part1.json
+│ ├── part2.json
+│ ├── part3.json
+│ └── part4.json
+├── employees.csv
+├── food_items.csv
+├── tmp_10101000.csv
+└── orders
+ └── year=2022
+ └── month=2
+ ├── 1.parquet
+ ├── 2.parquet
+ └── 3.parquet
+
+```
+
+Path specs config:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/*.csv
+ exclude:
+ - **/tmp_10101000.csv
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*.json
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+```
+
+Above config has 3 path_specs and will ingest following datasets
+- `employees.csv` - Single File as Dataset
+- `food_items.csv` - Single File as Dataset
+- `customers` - Folder as Dataset
+- `orders` - Folder as Dataset
+ and will ignore file `tmp_10101000.csv`
+
+**Valid path_specs.include**
+
+```python
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/bar.avro # single file table
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/*.* # mulitple file level tables
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*.avro #table without partition
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*/*.avro #table where partitions are not specified
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*.* # table where no partitions as well as data type specified
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/*.avro # specifying keywords to be used in display name
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.avro # specify partition key and value format
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.avro # specify partition value only format
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # for all extensions
+https://storageaccountname.blob.core.windows.net/my-container/*/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # table is present at 2 levels down in container
+https://storageaccountname.blob.core.windows.net/my-container/*/*/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # table is present at 3 levels down in container
+```
+
+**Valid path_specs.exclude**
+- \**/tests/**
+- https://storageaccountname.blob.core.windows.net/my-container/hr/**
+- **/tests/*.csv
+- https://storageaccountname.blob.core.windows.net/my-container/foo/*/my_table/**
+
+
+
+If you would like to write a more complicated function for resolving file names, then a {transformer} would be a good fit.
+
+:::caution
+
+Specify as long fixed prefix ( with out /*/ ) as possible in `path_specs.include`. This will reduce the scanning time and cost, specifically on AWS S3
+
+:::
+
+:::caution
+
+Running profiling against many tables or over many rows can run up significant costs.
+While we've done our best to limit the expensiveness of the queries the profiler runs, you
+should be prudent about the set of tables profiling is enabled on or the frequency
+of the profiling runs.
+
+:::
+
+:::caution
+
+If you are ingesting datasets from AWS S3, we recommend running the ingestion on a server in the same region to avoid high egress costs.
+
+:::
+
+### Compatibility
+
+Profiles are computed with PyDeequ, which relies on PySpark. Therefore, for computing profiles, we currently require Spark 3.0.3 with Hadoop 3.2 to be installed and the `SPARK_HOME` and `SPARK_VERSION` environment variables to be set. The Spark+Hadoop binary can be downloaded [here](https://www.apache.org/dyn/closer.lua/spark/spark-3.0.3/spark-3.0.3-bin-hadoop3.2.tgz).
+
+For an example guide on setting up PyDeequ on AWS, see [this guide](https://aws.amazon.com/blogs/big-data/testing-data-quality-at-scale-with-pydeequ/).
+
+:::caution
+
+From Spark 3.2.0+, Avro reader fails on column names that don't start with a letter and contains other character than letters, number, and underscore. [https://github.com/apache/spark/blob/72c62b6596d21e975c5597f8fff84b1a9d070a02/connector/avro/src/main/scala/org/apache/spark/sql/avro/AvroFileFormat.scala#L158]
+Avro files that contain such columns won't be profiled.
+:::
\ No newline at end of file
diff --git a/metadata-ingestion/docs/sources/abs/abs_recipe.yml b/metadata-ingestion/docs/sources/abs/abs_recipe.yml
new file mode 100644
index 0000000000000..4c4e5c678238f
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/abs_recipe.yml
@@ -0,0 +1,13 @@
+source:
+ type: abs
+ config:
+ path_specs:
+ - include: "https://storageaccountname.blob.core.windows.net/covid19-lake/covid_knowledge_graph/csv/nodes/*.*"
+
+ azure_config:
+ account_name: "*****"
+ sas_token: "*****"
+ container_name: "covid_knowledge_graph"
+ env: "PROD"
+
+# sink configs
diff --git a/metadata-ingestion/docs/sources/s3/README.md b/metadata-ingestion/docs/sources/s3/README.md
index b0d354a9b3c2a..5feda74107024 100644
--- a/metadata-ingestion/docs/sources/s3/README.md
+++ b/metadata-ingestion/docs/sources/s3/README.md
@@ -1,5 +1,5 @@
This connector ingests AWS S3 datasets into DataHub. It allows mapping an individual file or a folder of files to a dataset in DataHub.
-To specify the group of files that form a dataset, use `path_specs` configuration in ingestion recipe. Refer section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
+Refer to the section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
:::tip
This connector can also be used to ingest local files.
diff --git a/metadata-ingestion/scripts/modeldocgen.py b/metadata-ingestion/scripts/modeldocgen.py
index ea7813f0ca85b..ee5f06cb801ba 100644
--- a/metadata-ingestion/scripts/modeldocgen.py
+++ b/metadata-ingestion/scripts/modeldocgen.py
@@ -8,12 +8,12 @@
from dataclasses import Field, dataclass, field
from enum import auto
from pathlib import Path
-from typing import Any, Dict, List, Optional, Tuple, Iterable
+from typing import Any, Dict, Iterable, List, Optional, Tuple
import avro.schema
import click
-from datahub.configuration.common import ConfigEnum, ConfigModel
+from datahub.configuration.common import ConfigEnum, PermissiveConfigModel
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
@@ -22,7 +22,9 @@
from datahub.ingestion.extractor.schema_util import avro_schema_to_mce_fields
from datahub.ingestion.sink.file import FileSink, FileSinkConfig
from datahub.metadata.schema_classes import (
+ BrowsePathEntryClass,
BrowsePathsClass,
+ BrowsePathsV2Class,
DatasetPropertiesClass,
DatasetSnapshotClass,
ForeignKeyConstraintClass,
@@ -34,8 +36,6 @@
StringTypeClass,
SubTypesClass,
TagAssociationClass,
- BrowsePathsV2Class,
- BrowsePathEntryClass,
)
logger = logging.getLogger(__name__)
@@ -493,30 +493,29 @@ def strip_types(field_path: str) -> str:
],
)
+
@dataclass
class EntityAspectName:
entityName: str
aspectName: str
-@dataclass
-class AspectPluginConfig:
+class AspectPluginConfig(PermissiveConfigModel):
className: str
enabled: bool
- supportedEntityAspectNames: List[EntityAspectName]
+ supportedEntityAspectNames: List[EntityAspectName] = []
packageScan: Optional[List[str]] = None
supportedOperations: Optional[List[str]] = None
-@dataclass
-class PluginConfiguration:
+class PluginConfiguration(PermissiveConfigModel):
aspectPayloadValidators: Optional[List[AspectPluginConfig]] = None
mutationHooks: Optional[List[AspectPluginConfig]] = None
mclSideEffects: Optional[List[AspectPluginConfig]] = None
mcpSideEffects: Optional[List[AspectPluginConfig]] = None
-class EntityRegistry(ConfigModel):
+class EntityRegistry(PermissiveConfigModel):
entities: List[EntityDefinition]
events: Optional[List[EventDefinition]]
plugins: Optional[PluginConfiguration] = None
diff --git a/metadata-ingestion/setup.py b/metadata-ingestion/setup.py
index 41c04ca4a433c..e1a9e6a55909d 100644
--- a/metadata-ingestion/setup.py
+++ b/metadata-ingestion/setup.py
@@ -258,6 +258,13 @@
*path_spec_common,
}
+abs_base = {
+ "azure-core==1.29.4",
+ "azure-identity>=1.14.0",
+ "azure-storage-blob>=12.19.0",
+ "azure-storage-file-datalake>=12.14.0",
+}
+
data_lake_profiling = {
"pydeequ~=1.1.0",
"pyspark~=3.3.0",
@@ -265,6 +272,7 @@
delta_lake = {
*s3_base,
+ *abs_base,
# Version 0.18.0 broken on ARM Macs: https://github.com/delta-io/delta-rs/issues/2577
"deltalake>=0.6.3, != 0.6.4, < 0.18.0; platform_system == 'Darwin' and platform_machine == 'arm64'",
"deltalake>=0.6.3, != 0.6.4; platform_system != 'Darwin' or platform_machine != 'arm64'",
@@ -407,6 +415,7 @@
| {"cachetools"},
"s3": {*s3_base, *data_lake_profiling},
"gcs": {*s3_base, *data_lake_profiling},
+ "abs": {*abs_base},
"sagemaker": aws_common,
"salesforce": {"simple-salesforce"},
"snowflake": snowflake_common | usage_common | sqlglot_lib,
@@ -686,6 +695,7 @@
"demo-data = datahub.ingestion.source.demo_data.DemoDataSource",
"unity-catalog = datahub.ingestion.source.unity.source:UnityCatalogSource",
"gcs = datahub.ingestion.source.gcs.gcs_source:GCSSource",
+ "abs = datahub.ingestion.source.abs.source:ABSSource",
"sql-queries = datahub.ingestion.source.sql_queries:SqlQueriesSource",
"fivetran = datahub.ingestion.source.fivetran.fivetran:FivetranSource",
"qlik-sense = datahub.ingestion.source.qlik_sense.qlik_sense:QlikSenseSource",
diff --git a/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py b/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
index afeedb83f7998..f9a188c65feef 100644
--- a/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
+++ b/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
@@ -259,56 +259,56 @@ def generate_mcp(
)
yield mcp
- if self.schema_metadata.fields:
- for field in self.schema_metadata.fields:
- field_urn = field.urn or make_schema_field_urn(
- self.urn, field.id # type: ignore[arg-type]
+ if self.schema_metadata.fields:
+ for field in self.schema_metadata.fields:
+ field_urn = field.urn or make_schema_field_urn(
+ self.urn, field.id # type: ignore[arg-type]
+ )
+ assert field_urn.startswith("urn:li:schemaField:")
+
+ if field.globalTags:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=GlobalTagsClass(
+ tags=[
+ TagAssociationClass(tag=make_tag_urn(tag))
+ for tag in field.globalTags
+ ]
+ ),
)
- assert field_urn.startswith("urn:li:schemaField:")
-
- if field.globalTags:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=GlobalTagsClass(
- tags=[
- TagAssociationClass(tag=make_tag_urn(tag))
- for tag in field.globalTags
- ]
- ),
- )
- yield mcp
-
- if field.glossaryTerms:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=GlossaryTermsClass(
- terms=[
- GlossaryTermAssociationClass(
- urn=make_term_urn(term)
- )
- for term in field.glossaryTerms
- ],
- auditStamp=self._mint_auditstamp("yaml"),
- ),
- )
- yield mcp
-
- if field.structured_properties:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=StructuredPropertiesClass(
- properties=[
- StructuredPropertyValueAssignmentClass(
- propertyUrn=f"urn:li:structuredProperty:{prop_key}",
- values=prop_value
- if isinstance(prop_value, list)
- else [prop_value],
- )
- for prop_key, prop_value in field.structured_properties.items()
- ]
- ),
- )
- yield mcp
+ yield mcp
+
+ if field.glossaryTerms:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=GlossaryTermsClass(
+ terms=[
+ GlossaryTermAssociationClass(
+ urn=make_term_urn(term)
+ )
+ for term in field.glossaryTerms
+ ],
+ auditStamp=self._mint_auditstamp("yaml"),
+ ),
+ )
+ yield mcp
+
+ if field.structured_properties:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=StructuredPropertiesClass(
+ properties=[
+ StructuredPropertyValueAssignmentClass(
+ propertyUrn=f"urn:li:structuredProperty:{prop_key}",
+ values=prop_value
+ if isinstance(prop_value, list)
+ else [prop_value],
+ )
+ for prop_key, prop_value in field.structured_properties.items()
+ ]
+ ),
+ )
+ yield mcp
if self.subtype or self.subtypes:
mcp = MetadataChangeProposalWrapper(
diff --git a/metadata-ingestion/src/datahub/ingestion/api/source.py b/metadata-ingestion/src/datahub/ingestion/api/source.py
index ad1b312ef445c..788bec97a6488 100644
--- a/metadata-ingestion/src/datahub/ingestion/api/source.py
+++ b/metadata-ingestion/src/datahub/ingestion/api/source.py
@@ -1,3 +1,4 @@
+import contextlib
import datetime
import logging
from abc import ABCMeta, abstractmethod
@@ -10,6 +11,7 @@
Dict,
Generic,
Iterable,
+ Iterator,
List,
Optional,
Sequence,
@@ -97,6 +99,7 @@ def report_log(
context: Optional[str] = None,
exc: Optional[BaseException] = None,
log: bool = False,
+ stacklevel: int = 1,
) -> None:
"""
Report a user-facing warning for the ingestion run.
@@ -109,7 +112,8 @@ def report_log(
exc: The exception associated with the event. We'll show the stack trace when in debug mode.
"""
- stacklevel = 2
+ # One for this method, and one for the containing report_* call.
+ stacklevel = stacklevel + 2
log_key = f"{title}-{message}"
entries = self._entries[level]
@@ -118,6 +122,8 @@ def report_log(
context = f"{context[:_MAX_CONTEXT_STRING_LENGTH]} ..."
log_content = f"{message} => {context}" if context else message
+ if title:
+ log_content = f"{title}: {log_content}"
if exc:
log_content += f"{log_content}: {exc}"
@@ -255,9 +261,10 @@ def report_failure(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.ERROR, message, title, context, exc, log=False
+ StructuredLogLevel.ERROR, message, title, context, exc, log=log
)
def failure(
@@ -266,9 +273,10 @@ def failure(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.ERROR, message, title, context, exc, log=True
+ StructuredLogLevel.ERROR, message, title, context, exc, log=log
)
def info(
@@ -277,11 +285,30 @@ def info(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.INFO, message, title, context, exc, log=True
+ StructuredLogLevel.INFO, message, title, context, exc, log=log
)
+ @contextlib.contextmanager
+ def report_exc(
+ self,
+ message: LiteralString,
+ title: Optional[LiteralString] = None,
+ context: Optional[str] = None,
+ level: StructuredLogLevel = StructuredLogLevel.ERROR,
+ ) -> Iterator[None]:
+ # Convenience method that helps avoid boilerplate try/except blocks.
+ # TODO: I'm not super happy with the naming here - it's not obvious that this
+ # suppresses the exception in addition to reporting it.
+ try:
+ yield
+ except Exception as exc:
+ self._structured_logs.report_log(
+ level, message=message, title=title, context=context, exc=exc
+ )
+
def __post_init__(self) -> None:
self.start_time = datetime.datetime.now()
self.running_time: datetime.timedelta = datetime.timedelta(seconds=0)
diff --git a/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py b/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
index 99789a49c0b43..ddcb74e354613 100644
--- a/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
+++ b/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
@@ -39,7 +39,7 @@ class ClassificationConfig(ConfigModel):
max_workers: int = Field(
default=(os.cpu_count() or 4),
- description="Number of worker threads to use for classification. Set to 1 to disable.",
+ description="Number of worker processes to use for classification. Set to 1 to disable.",
)
table_pattern: AllowDenyPattern = Field(
diff --git a/metadata-ingestion/src/datahub/ingestion/graph/client.py b/metadata-ingestion/src/datahub/ingestion/graph/client.py
index 7ba412b3e772c..1d6097da231f8 100644
--- a/metadata-ingestion/src/datahub/ingestion/graph/client.py
+++ b/metadata-ingestion/src/datahub/ingestion/graph/client.py
@@ -1241,6 +1241,7 @@ def parse_sql_lineage(
env: str = DEFAULT_ENV,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> "SqlParsingResult":
from datahub.sql_parsing.sqlglot_lineage import sqlglot_lineage
@@ -1254,6 +1255,7 @@ def parse_sql_lineage(
schema_resolver=schema_resolver,
default_db=default_db,
default_schema=default_schema,
+ default_dialect=default_dialect,
)
def create_tag(self, tag_name: str) -> str:
diff --git a/metadata-ingestion/src/datahub/ingestion/run/pipeline.py b/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
index e61ffa46b3c10..60930f03763ed 100644
--- a/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
+++ b/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
@@ -379,13 +379,19 @@ def _notify_reporters_on_ingestion_completion(self) -> None:
for reporter in self.reporters:
try:
reporter.on_completion(
- status="CANCELLED"
- if self.final_status == PipelineStatus.CANCELLED
- else "FAILURE"
- if self.has_failures()
- else "SUCCESS"
- if self.final_status == PipelineStatus.COMPLETED
- else "UNKNOWN",
+ status=(
+ "CANCELLED"
+ if self.final_status == PipelineStatus.CANCELLED
+ else (
+ "FAILURE"
+ if self.has_failures()
+ else (
+ "SUCCESS"
+ if self.final_status == PipelineStatus.COMPLETED
+ else "UNKNOWN"
+ )
+ )
+ ),
report=self._get_structured_report(),
ctx=self.ctx,
)
@@ -425,7 +431,7 @@ def _time_to_print(self) -> bool:
return True
return False
- def run(self) -> None:
+ def run(self) -> None: # noqa: C901
with contextlib.ExitStack() as stack:
if self.config.flags.generate_memory_profiles:
import memray
@@ -436,6 +442,8 @@ def run(self) -> None:
)
)
+ stack.enter_context(self.sink)
+
self.final_status = PipelineStatus.UNKNOWN
self._notify_reporters_on_ingestion_start()
callback = None
@@ -460,7 +468,17 @@ def run(self) -> None:
if not self.dry_run:
self.sink.handle_work_unit_start(wu)
try:
- record_envelopes = self.extractor.get_records(wu)
+ # Most of this code is meant to be fully stream-based instead of generating all records into memory.
+ # However, the extractor in particular will never generate a particularly large list. We want the
+ # exception reporting to be associated with the source, and not the transformer. As such, we
+ # need to materialize the generator returned by get_records().
+ record_envelopes = list(self.extractor.get_records(wu))
+ except Exception as e:
+ self.source.get_report().failure(
+ "Source produced bad metadata", context=wu.id, exc=e
+ )
+ continue
+ try:
for record_envelope in self.transform(record_envelopes):
if not self.dry_run:
try:
@@ -482,9 +500,9 @@ def run(self) -> None:
)
# TODO: Transformer errors should cause the pipeline to fail.
- self.extractor.close()
if not self.dry_run:
self.sink.handle_work_unit_end(wu)
+ self.extractor.close()
self.source.close()
# no more data is coming, we need to let the transformers produce any additional records if they are holding on to state
for record_envelope in self.transform(
@@ -518,8 +536,6 @@ def run(self) -> None:
self._notify_reporters_on_ingestion_completion()
- self.sink.close()
-
def transform(self, records: Iterable[RecordEnvelope]) -> Iterable[RecordEnvelope]:
"""
Transforms the given sequence of records by passing the records through the transformers
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/__init__.py b/metadata-ingestion/src/datahub/ingestion/source/abs/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/config.py b/metadata-ingestion/src/datahub/ingestion/source/abs/config.py
new file mode 100644
index 0000000000000..c62239527a120
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/config.py
@@ -0,0 +1,163 @@
+import logging
+from typing import Any, Dict, List, Optional, Union
+
+import pydantic
+from pydantic.fields import Field
+
+from datahub.configuration.common import AllowDenyPattern
+from datahub.configuration.source_common import DatasetSourceConfigMixin
+from datahub.configuration.validate_field_deprecation import pydantic_field_deprecated
+from datahub.configuration.validate_field_rename import pydantic_renamed_field
+from datahub.ingestion.source.abs.datalake_profiler_config import DataLakeProfilerConfig
+from datahub.ingestion.source.azure.azure_common import AzureConnectionConfig
+from datahub.ingestion.source.data_lake_common.config import PathSpecsConfigMixin
+from datahub.ingestion.source.data_lake_common.path_spec import PathSpec
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StatefulStaleMetadataRemovalConfig,
+)
+from datahub.ingestion.source.state.stateful_ingestion_base import (
+ StatefulIngestionConfigBase,
+)
+from datahub.ingestion.source_config.operation_config import is_profiling_enabled
+
+# hide annoying debug errors from py4j
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+class DataLakeSourceConfig(
+ StatefulIngestionConfigBase, DatasetSourceConfigMixin, PathSpecsConfigMixin
+):
+ platform: str = Field(
+ default="",
+ description="The platform that this source connects to (either 'abs' or 'file'). "
+ "If not specified, the platform will be inferred from the path_specs.",
+ )
+
+ azure_config: Optional[AzureConnectionConfig] = Field(
+ default=None, description="Azure configuration"
+ )
+
+ stateful_ingestion: Optional[StatefulStaleMetadataRemovalConfig] = None
+ # Whether to create Datahub Azure Container properties
+ use_abs_container_properties: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs container properties",
+ )
+ # Whether to create Datahub Azure blob tags
+ use_abs_blob_tags: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs blob tags",
+ )
+ # Whether to create Datahub Azure blob properties
+ use_abs_blob_properties: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs blob properties",
+ )
+
+ # Whether to update the table schema when schema in files within the partitions are updated
+ _update_schema_on_partition_file_updates_deprecation = pydantic_field_deprecated(
+ "update_schema_on_partition_file_updates",
+ message="update_schema_on_partition_file_updates is deprecated. This behaviour is the default now.",
+ )
+
+ profile_patterns: AllowDenyPattern = Field(
+ default=AllowDenyPattern.allow_all(),
+ description="regex patterns for tables to profile ",
+ )
+ profiling: DataLakeProfilerConfig = Field(
+ default=DataLakeProfilerConfig(), description="Data profiling configuration"
+ )
+
+ spark_driver_memory: str = Field(
+ default="4g", description="Max amount of memory to grant Spark."
+ )
+
+ spark_config: Dict[str, Any] = Field(
+ description='Spark configuration properties to set on the SparkSession. Put config property names into quotes. For example: \'"spark.executor.memory": "2g"\'',
+ default={},
+ )
+
+ max_rows: int = Field(
+ default=100,
+ description="Maximum number of rows to use when inferring schemas for TSV and CSV files.",
+ )
+ add_partition_columns_to_schema: bool = Field(
+ default=False,
+ description="Whether to add partition fields to the schema.",
+ )
+ verify_ssl: Union[bool, str] = Field(
+ default=True,
+ description="Either a boolean, in which case it controls whether we verify the server's TLS certificate, or a string, in which case it must be a path to a CA bundle to use.",
+ )
+
+ number_of_files_to_sample: int = Field(
+ default=100,
+ description="Number of files to list to sample for schema inference. This will be ignored if sample_files is set to False in the pathspec.",
+ )
+
+ _rename_path_spec_to_plural = pydantic_renamed_field(
+ "path_spec", "path_specs", lambda path_spec: [path_spec]
+ )
+
+ def is_profiling_enabled(self) -> bool:
+ return self.profiling.enabled and is_profiling_enabled(
+ self.profiling.operation_config
+ )
+
+ @pydantic.validator("path_specs", always=True)
+ def check_path_specs_and_infer_platform(
+ cls, path_specs: List[PathSpec], values: Dict
+ ) -> List[PathSpec]:
+ if len(path_specs) == 0:
+ raise ValueError("path_specs must not be empty")
+
+ # Check that all path specs have the same platform.
+ guessed_platforms = set(
+ "abs" if path_spec.is_abs else "file" for path_spec in path_specs
+ )
+ if len(guessed_platforms) > 1:
+ raise ValueError(
+ f"Cannot have multiple platforms in path_specs: {guessed_platforms}"
+ )
+ guessed_platform = guessed_platforms.pop()
+
+ # Ensure abs configs aren't used for file sources.
+ if guessed_platform != "abs" and (
+ values.get("use_abs_container_properties")
+ or values.get("use_abs_blob_tags")
+ or values.get("use_abs_blob_properties")
+ ):
+ raise ValueError(
+ "Cannot grab abs blob/container tags when platform is not abs. Remove the flag or use abs."
+ )
+
+ # Infer platform if not specified.
+ if values.get("platform") and values["platform"] != guessed_platform:
+ raise ValueError(
+ f"All path_specs belong to {guessed_platform} platform, but platform is set to {values['platform']}"
+ )
+ else:
+ logger.debug(f'Setting config "platform": {guessed_platform}')
+ values["platform"] = guessed_platform
+
+ return path_specs
+
+ @pydantic.validator("platform", always=True)
+ def platform_not_empty(cls, platform: str, values: dict) -> str:
+ inferred_platform = values.get(
+ "platform", None
+ ) # we may have inferred it above
+ platform = platform or inferred_platform
+ if not platform:
+ raise ValueError("platform must not be empty")
+ return platform
+
+ @pydantic.root_validator()
+ def ensure_profiling_pattern_is_passed_to_profiling(
+ cls, values: Dict[str, Any]
+ ) -> Dict[str, Any]:
+ profiling: Optional[DataLakeProfilerConfig] = values.get("profiling")
+ if profiling is not None and profiling.enabled:
+ profiling._allow_deny_patterns = values["profile_patterns"]
+ return values
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py b/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py
new file mode 100644
index 0000000000000..9f6d13a08b182
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py
@@ -0,0 +1,92 @@
+from typing import Any, Dict, Optional
+
+import pydantic
+from pydantic.fields import Field
+
+from datahub.configuration import ConfigModel
+from datahub.configuration.common import AllowDenyPattern
+from datahub.ingestion.source_config.operation_config import OperationConfig
+
+
+class DataLakeProfilerConfig(ConfigModel):
+ enabled: bool = Field(
+ default=False, description="Whether profiling should be done."
+ )
+ operation_config: OperationConfig = Field(
+ default_factory=OperationConfig,
+ description="Experimental feature. To specify operation configs.",
+ )
+
+ # These settings will override the ones below.
+ profile_table_level_only: bool = Field(
+ default=False,
+ description="Whether to perform profiling at table-level only or include column-level profiling as well.",
+ )
+
+ _allow_deny_patterns: AllowDenyPattern = pydantic.PrivateAttr(
+ default=AllowDenyPattern.allow_all(),
+ )
+
+ max_number_of_fields_to_profile: Optional[pydantic.PositiveInt] = Field(
+ default=None,
+ description="A positive integer that specifies the maximum number of columns to profile for any table. `None` implies all columns. The cost of profiling goes up significantly as the number of columns to profile goes up.",
+ )
+
+ include_field_null_count: bool = Field(
+ default=True,
+ description="Whether to profile for the number of nulls for each column.",
+ )
+ include_field_min_value: bool = Field(
+ default=True,
+ description="Whether to profile for the min value of numeric columns.",
+ )
+ include_field_max_value: bool = Field(
+ default=True,
+ description="Whether to profile for the max value of numeric columns.",
+ )
+ include_field_mean_value: bool = Field(
+ default=True,
+ description="Whether to profile for the mean value of numeric columns.",
+ )
+ include_field_median_value: bool = Field(
+ default=True,
+ description="Whether to profile for the median value of numeric columns.",
+ )
+ include_field_stddev_value: bool = Field(
+ default=True,
+ description="Whether to profile for the standard deviation of numeric columns.",
+ )
+ include_field_quantiles: bool = Field(
+ default=True,
+ description="Whether to profile for the quantiles of numeric columns.",
+ )
+ include_field_distinct_value_frequencies: bool = Field(
+ default=True, description="Whether to profile for distinct value frequencies."
+ )
+ include_field_histogram: bool = Field(
+ default=True,
+ description="Whether to profile for the histogram for numeric fields.",
+ )
+ include_field_sample_values: bool = Field(
+ default=True,
+ description="Whether to profile for the sample values for all columns.",
+ )
+
+ @pydantic.root_validator()
+ def ensure_field_level_settings_are_normalized(
+ cls: "DataLakeProfilerConfig", values: Dict[str, Any]
+ ) -> Dict[str, Any]:
+ max_num_fields_to_profile_key = "max_number_of_fields_to_profile"
+ max_num_fields_to_profile = values.get(max_num_fields_to_profile_key)
+
+ # Disable all field-level metrics.
+ if values.get("profile_table_level_only"):
+ for field_level_metric in cls.__fields__:
+ if field_level_metric.startswith("include_field_"):
+ values.setdefault(field_level_metric, False)
+
+ assert (
+ max_num_fields_to_profile is None
+ ), f"{max_num_fields_to_profile_key} should be set to None"
+
+ return values
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py b/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py
new file mode 100644
index 0000000000000..c969b229989e8
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py
@@ -0,0 +1,472 @@
+import dataclasses
+from typing import Any, List, Optional
+
+from pandas import DataFrame
+from pydeequ.analyzers import (
+ AnalysisRunBuilder,
+ AnalysisRunner,
+ AnalyzerContext,
+ ApproxCountDistinct,
+ ApproxQuantile,
+ ApproxQuantiles,
+ Histogram,
+ Maximum,
+ Mean,
+ Minimum,
+ StandardDeviation,
+)
+from pyspark.sql import SparkSession
+from pyspark.sql.functions import col, count, isnan, when
+from pyspark.sql.types import (
+ DataType as SparkDataType,
+ DateType,
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ NullType,
+ ShortType,
+ StringType,
+ TimestampType,
+)
+
+from datahub.emitter.mce_builder import get_sys_time
+from datahub.ingestion.source.profiling.common import (
+ Cardinality,
+ convert_to_cardinality,
+)
+from datahub.ingestion.source.s3.datalake_profiler_config import DataLakeProfilerConfig
+from datahub.ingestion.source.s3.report import DataLakeSourceReport
+from datahub.metadata.schema_classes import (
+ DatasetFieldProfileClass,
+ DatasetProfileClass,
+ HistogramClass,
+ QuantileClass,
+ ValueFrequencyClass,
+)
+from datahub.telemetry import stats, telemetry
+
+NUM_SAMPLE_ROWS = 20
+QUANTILES = [0.05, 0.25, 0.5, 0.75, 0.95]
+MAX_HIST_BINS = 25
+
+
+def null_str(value: Any) -> Optional[str]:
+ # str() with a passthrough for None.
+ return str(value) if value is not None else None
+
+
+@dataclasses.dataclass
+class _SingleColumnSpec:
+ column: str
+ column_profile: DatasetFieldProfileClass
+
+ # if the histogram is a list of value frequencies (discrete data) or bins (continuous data)
+ histogram_distinct: Optional[bool] = None
+
+ type_: SparkDataType = NullType # type:ignore
+
+ unique_count: Optional[int] = None
+ non_null_count: Optional[int] = None
+ cardinality: Optional[Cardinality] = None
+
+
+class _SingleTableProfiler:
+ spark: SparkSession
+ dataframe: DataFrame
+ analyzer: AnalysisRunBuilder
+ column_specs: List[_SingleColumnSpec]
+ row_count: int
+ profiling_config: DataLakeProfilerConfig
+ file_path: str
+ columns_to_profile: List[str]
+ ignored_columns: List[str]
+ profile: DatasetProfileClass
+ report: DataLakeSourceReport
+
+ def __init__(
+ self,
+ dataframe: DataFrame,
+ spark: SparkSession,
+ profiling_config: DataLakeProfilerConfig,
+ report: DataLakeSourceReport,
+ file_path: str,
+ ):
+ self.spark = spark
+ self.dataframe = dataframe
+ self.analyzer = AnalysisRunner(spark).onData(dataframe)
+ self.column_specs = []
+ self.row_count = dataframe.count()
+ self.profiling_config = profiling_config
+ self.file_path = file_path
+ self.columns_to_profile = []
+ self.ignored_columns = []
+ self.profile = DatasetProfileClass(timestampMillis=get_sys_time())
+ self.report = report
+
+ self.profile.rowCount = self.row_count
+ self.profile.columnCount = len(dataframe.columns)
+
+ column_types = {x.name: x.dataType for x in dataframe.schema.fields}
+
+ if self.profiling_config.profile_table_level_only:
+ return
+
+ # get column distinct counts
+ for column in dataframe.columns:
+ if not self.profiling_config._allow_deny_patterns.allowed(column):
+ self.ignored_columns.append(column)
+ continue
+
+ self.columns_to_profile.append(column)
+ # Normal CountDistinct is ridiculously slow
+ self.analyzer.addAnalyzer(ApproxCountDistinct(column))
+
+ if self.profiling_config.max_number_of_fields_to_profile is not None:
+ if (
+ len(self.columns_to_profile)
+ > self.profiling_config.max_number_of_fields_to_profile
+ ):
+ columns_being_dropped = self.columns_to_profile[
+ self.profiling_config.max_number_of_fields_to_profile :
+ ]
+ self.columns_to_profile = self.columns_to_profile[
+ : self.profiling_config.max_number_of_fields_to_profile
+ ]
+
+ self.report.report_file_dropped(
+ f"The max_number_of_fields_to_profile={self.profiling_config.max_number_of_fields_to_profile} reached. Profile of columns {self.file_path}({', '.join(sorted(columns_being_dropped))})"
+ )
+
+ analysis_result = self.analyzer.run()
+ analysis_metrics = AnalyzerContext.successMetricsAsJson(
+ self.spark, analysis_result
+ )
+
+ # reshape distinct counts into dictionary
+ column_distinct_counts = {
+ x["instance"]: int(x["value"])
+ for x in analysis_metrics
+ if x["name"] == "ApproxCountDistinct"
+ }
+
+ select_numeric_null_counts = [
+ count(
+ when(
+ isnan(c) | col(c).isNull(),
+ c,
+ )
+ ).alias(c)
+ for c in self.columns_to_profile
+ if column_types[column] in [DoubleType, FloatType]
+ ]
+
+ # PySpark doesn't support isnan() on non-float/double columns
+ select_nonnumeric_null_counts = [
+ count(
+ when(
+ col(c).isNull(),
+ c,
+ )
+ ).alias(c)
+ for c in self.columns_to_profile
+ if column_types[column] not in [DoubleType, FloatType]
+ ]
+
+ null_counts = dataframe.select(
+ select_numeric_null_counts + select_nonnumeric_null_counts
+ )
+ column_null_counts = null_counts.toPandas().T[0].to_dict()
+ column_null_fractions = {
+ c: column_null_counts[c] / self.row_count if self.row_count != 0 else 0
+ for c in self.columns_to_profile
+ }
+ column_nonnull_counts = {
+ c: self.row_count - column_null_counts[c] for c in self.columns_to_profile
+ }
+
+ column_unique_proportions = {
+ c: (
+ column_distinct_counts[c] / column_nonnull_counts[c]
+ if column_nonnull_counts[c] > 0
+ else 0
+ )
+ for c in self.columns_to_profile
+ }
+
+ if self.profiling_config.include_field_sample_values:
+ # take sample and convert to Pandas DataFrame
+ if self.row_count < NUM_SAMPLE_ROWS:
+ # if row count is less than number to sample, just take all rows
+ rdd_sample = dataframe.rdd.take(self.row_count)
+ else:
+ rdd_sample = dataframe.rdd.takeSample(False, NUM_SAMPLE_ROWS, seed=0)
+
+ # init column specs with profiles
+ for column in self.columns_to_profile:
+ column_profile = DatasetFieldProfileClass(fieldPath=column)
+
+ column_spec = _SingleColumnSpec(column, column_profile)
+
+ column_profile.uniqueCount = column_distinct_counts.get(column)
+ column_profile.uniqueProportion = column_unique_proportions.get(column)
+ column_profile.nullCount = column_null_counts.get(column)
+ column_profile.nullProportion = column_null_fractions.get(column)
+ if self.profiling_config.include_field_sample_values:
+ column_profile.sampleValues = sorted(
+ [str(x[column]) for x in rdd_sample]
+ )
+
+ column_spec.type_ = column_types[column]
+ column_spec.cardinality = convert_to_cardinality(
+ column_distinct_counts[column],
+ column_null_fractions[column],
+ )
+
+ self.column_specs.append(column_spec)
+
+ def prep_min_value(self, column: str) -> None:
+ if self.profiling_config.include_field_min_value:
+ self.analyzer.addAnalyzer(Minimum(column))
+
+ def prep_max_value(self, column: str) -> None:
+ if self.profiling_config.include_field_max_value:
+ self.analyzer.addAnalyzer(Maximum(column))
+
+ def prep_mean_value(self, column: str) -> None:
+ if self.profiling_config.include_field_mean_value:
+ self.analyzer.addAnalyzer(Mean(column))
+
+ def prep_median_value(self, column: str) -> None:
+ if self.profiling_config.include_field_median_value:
+ self.analyzer.addAnalyzer(ApproxQuantile(column, 0.5))
+
+ def prep_stdev_value(self, column: str) -> None:
+ if self.profiling_config.include_field_stddev_value:
+ self.analyzer.addAnalyzer(StandardDeviation(column))
+
+ def prep_quantiles(self, column: str) -> None:
+ if self.profiling_config.include_field_quantiles:
+ self.analyzer.addAnalyzer(ApproxQuantiles(column, QUANTILES))
+
+ def prep_distinct_value_frequencies(self, column: str) -> None:
+ if self.profiling_config.include_field_distinct_value_frequencies:
+ self.analyzer.addAnalyzer(Histogram(column))
+
+ def prep_field_histogram(self, column: str) -> None:
+ if self.profiling_config.include_field_histogram:
+ self.analyzer.addAnalyzer(Histogram(column, maxDetailBins=MAX_HIST_BINS))
+
+ def prepare_table_profiles(self) -> None:
+ row_count = self.row_count
+
+ telemetry.telemetry_instance.ping(
+ "profile_data_lake_table",
+ {"rows_profiled": stats.discretize(row_count)},
+ )
+
+ # loop through the columns and add the analyzers
+ for column_spec in self.column_specs:
+ column = column_spec.column
+ column_profile = column_spec.column_profile
+ type_ = column_spec.type_
+ cardinality = column_spec.cardinality
+
+ non_null_count = column_spec.non_null_count
+ unique_count = column_spec.unique_count
+
+ if (
+ self.profiling_config.include_field_null_count
+ and non_null_count is not None
+ ):
+ null_count = row_count - non_null_count
+ assert null_count >= 0
+ column_profile.nullCount = null_count
+ if row_count > 0:
+ column_profile.nullProportion = null_count / row_count
+
+ if unique_count is not None:
+ column_profile.uniqueCount = unique_count
+ if non_null_count is not None and non_null_count > 0:
+ column_profile.uniqueProportion = unique_count / non_null_count
+
+ if isinstance(
+ type_,
+ (
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ ShortType,
+ ),
+ ):
+ if cardinality == Cardinality.UNIQUE:
+ pass
+ elif cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ column_spec.histogram_distinct = True
+ self.prep_distinct_value_frequencies(column)
+ elif cardinality in [
+ Cardinality.MANY,
+ Cardinality.VERY_MANY,
+ Cardinality.UNIQUE,
+ ]:
+ column_spec.histogram_distinct = False
+ self.prep_min_value(column)
+ self.prep_max_value(column)
+ self.prep_mean_value(column)
+ self.prep_median_value(column)
+ self.prep_stdev_value(column)
+ self.prep_quantiles(column)
+ self.prep_field_histogram(column)
+ else: # unknown cardinality - skip
+ pass
+
+ elif isinstance(type_, StringType):
+ if cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ column_spec.histogram_distinct = True
+ self.prep_distinct_value_frequencies(
+ column,
+ )
+
+ elif isinstance(type_, (DateType, TimestampType)):
+ self.prep_min_value(column)
+ self.prep_max_value(column)
+
+ # FIXME: Re-add histogram once kl_divergence has been modified to support datetimes
+
+ if cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ self.prep_distinct_value_frequencies(
+ column,
+ )
+
+ def extract_table_profiles(
+ self,
+ analysis_metrics: DataFrame,
+ ) -> None:
+ self.profile.fieldProfiles = []
+
+ analysis_metrics = analysis_metrics.toPandas()
+ # DataFrame with following columns:
+ # entity: "Column" for column profile, "Table" for table profile
+ # instance: name of column being profiled. "*" for table profiles
+ # name: name of metric. Histogram metrics are formatted as "Histogram.."
+ # value: value of metric
+
+ column_metrics = analysis_metrics[analysis_metrics["entity"] == "Column"]
+
+ # resolve histogram types for grouping
+ column_metrics["kind"] = column_metrics["name"].apply(
+ lambda x: "Histogram" if x.startswith("Histogram.") else x
+ )
+
+ column_histogram_metrics = column_metrics[column_metrics["kind"] == "Histogram"]
+ column_nonhistogram_metrics = column_metrics[
+ column_metrics["kind"] != "Histogram"
+ ]
+
+ histogram_columns = set()
+
+ if len(column_histogram_metrics) > 0:
+ # we only want the absolute counts for each histogram for now
+ column_histogram_metrics = column_histogram_metrics[
+ column_histogram_metrics["name"].apply(
+ lambda x: x.startswith("Histogram.abs.")
+ )
+ ]
+ # get the histogram bins by chopping off the "Histogram.abs." prefix
+ column_histogram_metrics["bin"] = column_histogram_metrics["name"].apply(
+ lambda x: x[14:]
+ )
+
+ # reshape histogram counts for easier access
+ histogram_counts = column_histogram_metrics.set_index(["instance", "bin"])[
+ "value"
+ ]
+
+ histogram_columns = set(histogram_counts.index.get_level_values(0))
+
+ profiled_columns = set()
+
+ if len(column_nonhistogram_metrics) > 0:
+ # reshape other metrics for easier access
+ nonhistogram_metrics = column_nonhistogram_metrics.set_index(
+ ["instance", "name"]
+ )["value"]
+
+ profiled_columns = set(nonhistogram_metrics.index.get_level_values(0))
+ # histogram_columns = set(histogram_counts.index.get_level_values(0))
+
+ for column_spec in self.column_specs:
+ column = column_spec.column
+ column_profile = column_spec.column_profile
+
+ if column not in profiled_columns:
+ continue
+
+ # convert to Dict so we can use .get
+ deequ_column_profile = nonhistogram_metrics.loc[column].to_dict()
+
+ # uniqueCount, uniqueProportion, nullCount, nullProportion, sampleValues already set in TableWrapper
+ column_profile.min = null_str(deequ_column_profile.get("Minimum"))
+ column_profile.max = null_str(deequ_column_profile.get("Maximum"))
+ column_profile.mean = null_str(deequ_column_profile.get("Mean"))
+ column_profile.median = null_str(
+ deequ_column_profile.get("ApproxQuantiles-0.5")
+ )
+ column_profile.stdev = null_str(
+ deequ_column_profile.get("StandardDeviation")
+ )
+ if all(
+ deequ_column_profile.get(f"ApproxQuantiles-{quantile}") is not None
+ for quantile in QUANTILES
+ ):
+ column_profile.quantiles = [
+ QuantileClass(
+ quantile=str(quantile),
+ value=str(deequ_column_profile[f"ApproxQuantiles-{quantile}"]),
+ )
+ for quantile in QUANTILES
+ ]
+
+ if column in histogram_columns:
+ column_histogram = histogram_counts.loc[column]
+ # sort so output is deterministic
+ column_histogram = column_histogram.sort_index()
+
+ if column_spec.histogram_distinct:
+ column_profile.distinctValueFrequencies = [
+ ValueFrequencyClass(
+ value=value, frequency=int(column_histogram.loc[value])
+ )
+ for value in column_histogram.index
+ ]
+ # sort so output is deterministic
+ column_profile.distinctValueFrequencies = sorted(
+ column_profile.distinctValueFrequencies, key=lambda x: x.value
+ )
+
+ else:
+ column_profile.histogram = HistogramClass(
+ [str(x) for x in column_histogram.index],
+ [float(x) for x in column_histogram],
+ )
+
+ # append the column profile to the dataset profile
+ self.profile.fieldProfiles.append(column_profile)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/report.py b/metadata-ingestion/src/datahub/ingestion/source/abs/report.py
new file mode 100644
index 0000000000000..c24e2f9706091
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/report.py
@@ -0,0 +1,19 @@
+import dataclasses
+from dataclasses import field as dataclass_field
+from typing import List
+
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StaleEntityRemovalSourceReport,
+)
+
+
+@dataclasses.dataclass
+class DataLakeSourceReport(StaleEntityRemovalSourceReport):
+ files_scanned = 0
+ filtered: List[str] = dataclass_field(default_factory=list)
+
+ def report_file_scanned(self) -> None:
+ self.files_scanned += 1
+
+ def report_file_dropped(self, file: str) -> None:
+ self.filtered.append(file)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/source.py b/metadata-ingestion/src/datahub/ingestion/source/abs/source.py
new file mode 100644
index 0000000000000..07cc694e1b162
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/source.py
@@ -0,0 +1,700 @@
+import dataclasses
+import functools
+import logging
+import os
+import pathlib
+import re
+import time
+from collections import OrderedDict
+from datetime import datetime
+from pathlib import PurePath
+from typing import Any, Dict, Iterable, List, Optional, Tuple
+
+import smart_open.compression as so_compression
+from more_itertools import peekable
+from pyspark.sql.types import (
+ ArrayType,
+ BinaryType,
+ BooleanType,
+ ByteType,
+ DateType,
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ MapType,
+ NullType,
+ ShortType,
+ StringType,
+ StructField,
+ StructType,
+ TimestampType,
+)
+from smart_open import open as smart_open
+
+from datahub.emitter.mce_builder import (
+ make_data_platform_urn,
+ make_dataplatform_instance_urn,
+ make_dataset_urn_with_platform_instance,
+)
+from datahub.emitter.mcp import MetadataChangeProposalWrapper
+from datahub.ingestion.api.common import PipelineContext
+from datahub.ingestion.api.decorators import (
+ SourceCapability,
+ SupportStatus,
+ capability,
+ config_class,
+ platform_name,
+ support_status,
+)
+from datahub.ingestion.api.source import MetadataWorkUnitProcessor, SourceReport
+from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.source.abs.config import DataLakeSourceConfig, PathSpec
+from datahub.ingestion.source.abs.report import DataLakeSourceReport
+from datahub.ingestion.source.azure.abs_util import (
+ get_abs_properties,
+ get_abs_tags,
+ get_container_name,
+ get_container_relative_path,
+ get_key_prefix,
+ list_folders,
+ strip_abs_prefix,
+)
+from datahub.ingestion.source.data_lake_common.data_lake_utils import ContainerWUCreator
+from datahub.ingestion.source.schema_inference import avro, csv_tsv, json, parquet
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StaleEntityRemovalHandler,
+)
+from datahub.ingestion.source.state.stateful_ingestion_base import (
+ StatefulIngestionSourceBase,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.schema import (
+ BooleanTypeClass,
+ BytesTypeClass,
+ DateTypeClass,
+ NullTypeClass,
+ NumberTypeClass,
+ RecordTypeClass,
+ SchemaField,
+ SchemaFieldDataType,
+ SchemaMetadata,
+ StringTypeClass,
+ TimeTypeClass,
+)
+from datahub.metadata.schema_classes import (
+ DataPlatformInstanceClass,
+ DatasetPropertiesClass,
+ MapTypeClass,
+ OperationClass,
+ OperationTypeClass,
+ OtherSchemaClass,
+ _Aspect,
+)
+from datahub.telemetry import telemetry
+from datahub.utilities.perf_timer import PerfTimer
+
+# hide annoying debug errors from py4j
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+# for a list of all types, see https://spark.apache.org/docs/3.0.3/api/python/_modules/pyspark/sql/types.html
+_field_type_mapping = {
+ NullType: NullTypeClass,
+ StringType: StringTypeClass,
+ BinaryType: BytesTypeClass,
+ BooleanType: BooleanTypeClass,
+ DateType: DateTypeClass,
+ TimestampType: TimeTypeClass,
+ DecimalType: NumberTypeClass,
+ DoubleType: NumberTypeClass,
+ FloatType: NumberTypeClass,
+ ByteType: BytesTypeClass,
+ IntegerType: NumberTypeClass,
+ LongType: NumberTypeClass,
+ ShortType: NumberTypeClass,
+ ArrayType: NullTypeClass,
+ MapType: MapTypeClass,
+ StructField: RecordTypeClass,
+ StructType: RecordTypeClass,
+}
+PAGE_SIZE = 1000
+
+# Hack to support the .gzip extension with smart_open.
+so_compression.register_compressor(".gzip", so_compression._COMPRESSOR_REGISTRY[".gz"])
+
+
+def get_column_type(
+ report: SourceReport, dataset_name: str, column_type: str
+) -> SchemaFieldDataType:
+ """
+ Maps known Spark types to datahub types
+ """
+ TypeClass: Any = None
+
+ for field_type, type_class in _field_type_mapping.items():
+ if isinstance(column_type, field_type):
+ TypeClass = type_class
+ break
+
+ # if still not found, report the warning
+ if TypeClass is None:
+ report.report_warning(
+ dataset_name, f"unable to map type {column_type} to metadata schema"
+ )
+ TypeClass = NullTypeClass
+
+ return SchemaFieldDataType(type=TypeClass())
+
+
+# config flags to emit telemetry for
+config_options_to_report = [
+ "platform",
+ "use_relative_path",
+ "ignore_dotfiles",
+]
+
+
+def partitioned_folder_comparator(folder1: str, folder2: str) -> int:
+ # Try to convert to number and compare if the folder name is a number
+ try:
+ # Stripping = from the folder names as it most probably partition name part like year=2021
+ if "=" in folder1 and "=" in folder2:
+ if folder1.rsplit("=", 1)[0] == folder2.rsplit("=", 1)[0]:
+ folder1 = folder1.rsplit("=", 1)[-1]
+ folder2 = folder2.rsplit("=", 1)[-1]
+
+ num_folder1 = int(folder1)
+ num_folder2 = int(folder2)
+ if num_folder1 == num_folder2:
+ return 0
+ else:
+ return 1 if num_folder1 > num_folder2 else -1
+ except Exception:
+ # If folder name is not a number then do string comparison
+ if folder1 == folder2:
+ return 0
+ else:
+ return 1 if folder1 > folder2 else -1
+
+
+@dataclasses.dataclass
+class TableData:
+ display_name: str
+ is_abs: bool
+ full_path: str
+ rel_path: str
+ partitions: Optional[OrderedDict]
+ timestamp: datetime
+ table_path: str
+ size_in_bytes: int
+ number_of_files: int
+
+
+@platform_name("ABS Data Lake", id="abs")
+@config_class(DataLakeSourceConfig)
+@support_status(SupportStatus.INCUBATING)
+@capability(SourceCapability.DATA_PROFILING, "Optionally enabled via configuration")
+@capability(SourceCapability.TAGS, "Can extract ABS object/container tags if enabled")
+@capability(
+ SourceCapability.DELETION_DETECTION,
+ "Optionally enabled via `stateful_ingestion.remove_stale_metadata`",
+ supported=True,
+)
+class ABSSource(StatefulIngestionSourceBase):
+ source_config: DataLakeSourceConfig
+ report: DataLakeSourceReport
+ profiling_times_taken: List[float]
+ container_WU_creator: ContainerWUCreator
+
+ def __init__(self, config: DataLakeSourceConfig, ctx: PipelineContext):
+ super().__init__(config, ctx)
+ self.source_config = config
+ self.report = DataLakeSourceReport()
+ self.profiling_times_taken = []
+ config_report = {
+ config_option: config.dict().get(config_option)
+ for config_option in config_options_to_report
+ }
+ config_report = {
+ **config_report,
+ "profiling_enabled": config.is_profiling_enabled(),
+ }
+
+ telemetry.telemetry_instance.ping(
+ "data_lake_config",
+ config_report,
+ )
+
+ @classmethod
+ def create(cls, config_dict, ctx):
+ config = DataLakeSourceConfig.parse_obj(config_dict)
+
+ return cls(config, ctx)
+
+ def get_fields(self, table_data: TableData, path_spec: PathSpec) -> List:
+ if self.is_abs_platform():
+ if self.source_config.azure_config is None:
+ raise ValueError("Azure config is required for ABS file sources")
+
+ abs_client = self.source_config.azure_config.get_blob_service_client()
+ file = smart_open(
+ f"azure://{self.source_config.azure_config.container_name}/{table_data.rel_path}",
+ "rb",
+ transport_params={"client": abs_client},
+ )
+ else:
+ # We still use smart_open here to take advantage of the compression
+ # capabilities of smart_open.
+ file = smart_open(table_data.full_path, "rb")
+
+ fields = []
+
+ extension = pathlib.Path(table_data.full_path).suffix
+ from datahub.ingestion.source.data_lake_common.path_spec import (
+ SUPPORTED_COMPRESSIONS,
+ )
+
+ if path_spec.enable_compression and (extension[1:] in SUPPORTED_COMPRESSIONS):
+ # Removing the compression extension and using the one before that like .json.gz -> .json
+ extension = pathlib.Path(table_data.full_path).with_suffix("").suffix
+ if extension == "" and path_spec.default_extension:
+ extension = f".{path_spec.default_extension}"
+
+ try:
+ if extension == ".parquet":
+ fields = parquet.ParquetInferrer().infer_schema(file)
+ elif extension == ".csv":
+ fields = csv_tsv.CsvInferrer(
+ max_rows=self.source_config.max_rows
+ ).infer_schema(file)
+ elif extension == ".tsv":
+ fields = csv_tsv.TsvInferrer(
+ max_rows=self.source_config.max_rows
+ ).infer_schema(file)
+ elif extension == ".json":
+ fields = json.JsonInferrer().infer_schema(file)
+ elif extension == ".avro":
+ fields = avro.AvroInferrer().infer_schema(file)
+ else:
+ self.report.report_warning(
+ table_data.full_path,
+ f"file {table_data.full_path} has unsupported extension",
+ )
+ file.close()
+ except Exception as e:
+ self.report.report_warning(
+ table_data.full_path,
+ f"could not infer schema for file {table_data.full_path}: {e}",
+ )
+ file.close()
+ logger.debug(f"Extracted fields in schema: {fields}")
+ fields = sorted(fields, key=lambda f: f.fieldPath)
+
+ if self.source_config.add_partition_columns_to_schema:
+ self.add_partition_columns_to_schema(
+ fields=fields, path_spec=path_spec, full_path=table_data.full_path
+ )
+
+ return fields
+
+ def add_partition_columns_to_schema(
+ self, path_spec: PathSpec, full_path: str, fields: List[SchemaField]
+ ) -> None:
+ vars = path_spec.get_named_vars(full_path)
+ if vars is not None and "partition" in vars:
+ for partition in vars["partition"].values():
+ partition_arr = partition.split("=")
+ if len(partition_arr) != 2:
+ logger.debug(
+ f"Could not derive partition key from partition field {partition}"
+ )
+ continue
+ partition_key = partition_arr[0]
+ fields.append(
+ SchemaField(
+ fieldPath=f"{partition_key}",
+ nativeDataType="string",
+ type=SchemaFieldDataType(StringTypeClass()),
+ isPartitioningKey=True,
+ nullable=True,
+ recursive=False,
+ )
+ )
+
+ def _create_table_operation_aspect(self, table_data: TableData) -> OperationClass:
+ reported_time = int(time.time() * 1000)
+
+ operation = OperationClass(
+ timestampMillis=reported_time,
+ lastUpdatedTimestamp=int(table_data.timestamp.timestamp() * 1000),
+ operationType=OperationTypeClass.UPDATE,
+ )
+
+ return operation
+
+ def ingest_table(
+ self, table_data: TableData, path_spec: PathSpec
+ ) -> Iterable[MetadataWorkUnit]:
+ aspects: List[Optional[_Aspect]] = []
+
+ logger.info(f"Extracting table schema from file: {table_data.full_path}")
+ browse_path: str = (
+ strip_abs_prefix(table_data.table_path)
+ if self.is_abs_platform()
+ else table_data.table_path.strip("/")
+ )
+
+ data_platform_urn = make_data_platform_urn(self.source_config.platform)
+ logger.info(f"Creating dataset urn with name: {browse_path}")
+ dataset_urn = make_dataset_urn_with_platform_instance(
+ self.source_config.platform,
+ browse_path,
+ self.source_config.platform_instance,
+ self.source_config.env,
+ )
+
+ if self.source_config.platform_instance:
+ data_platform_instance = DataPlatformInstanceClass(
+ platform=data_platform_urn,
+ instance=make_dataplatform_instance_urn(
+ self.source_config.platform, self.source_config.platform_instance
+ ),
+ )
+ aspects.append(data_platform_instance)
+
+ container = get_container_name(table_data.table_path)
+ key_prefix = (
+ get_key_prefix(table_data.table_path)
+ if table_data.full_path == table_data.table_path
+ else None
+ )
+
+ custom_properties = get_abs_properties(
+ container,
+ key_prefix,
+ full_path=str(table_data.full_path),
+ number_of_files=table_data.number_of_files,
+ size_in_bytes=table_data.size_in_bytes,
+ sample_files=path_spec.sample_files,
+ azure_config=self.source_config.azure_config,
+ use_abs_container_properties=self.source_config.use_abs_container_properties,
+ use_abs_blob_properties=self.source_config.use_abs_blob_properties,
+ )
+
+ dataset_properties = DatasetPropertiesClass(
+ description="",
+ name=table_data.display_name,
+ customProperties=custom_properties,
+ )
+ aspects.append(dataset_properties)
+ if table_data.size_in_bytes > 0:
+ try:
+ fields = self.get_fields(table_data, path_spec)
+ schema_metadata = SchemaMetadata(
+ schemaName=table_data.display_name,
+ platform=data_platform_urn,
+ version=0,
+ hash="",
+ fields=fields,
+ platformSchema=OtherSchemaClass(rawSchema=""),
+ )
+ aspects.append(schema_metadata)
+ except Exception as e:
+ logger.error(
+ f"Failed to extract schema from file {table_data.full_path}. The error was:{e}"
+ )
+ else:
+ logger.info(
+ f"Skipping schema extraction for empty file {table_data.full_path}"
+ )
+
+ if (
+ self.source_config.use_abs_container_properties
+ or self.source_config.use_abs_blob_tags
+ ):
+ abs_tags = get_abs_tags(
+ container,
+ key_prefix,
+ dataset_urn,
+ self.source_config.azure_config,
+ self.ctx,
+ self.source_config.use_abs_blob_tags,
+ )
+ if abs_tags:
+ aspects.append(abs_tags)
+
+ operation = self._create_table_operation_aspect(table_data)
+ aspects.append(operation)
+ for mcp in MetadataChangeProposalWrapper.construct_many(
+ entityUrn=dataset_urn,
+ aspects=aspects,
+ ):
+ yield mcp.as_workunit()
+
+ yield from self.container_WU_creator.create_container_hierarchy(
+ table_data.table_path, dataset_urn
+ )
+
+ def get_prefix(self, relative_path: str) -> str:
+ index = re.search(r"[\*|\{]", relative_path)
+ if index:
+ return relative_path[: index.start()]
+ else:
+ return relative_path
+
+ def extract_table_name(self, path_spec: PathSpec, named_vars: dict) -> str:
+ if path_spec.table_name is None:
+ raise ValueError("path_spec.table_name is not set")
+ return path_spec.table_name.format_map(named_vars)
+
+ def extract_table_data(
+ self,
+ path_spec: PathSpec,
+ path: str,
+ rel_path: str,
+ timestamp: datetime,
+ size: int,
+ ) -> TableData:
+ logger.debug(f"Getting table data for path: {path}")
+ table_name, table_path = path_spec.extract_table_name_and_path(path)
+ table_data = TableData(
+ display_name=table_name,
+ is_abs=self.is_abs_platform(),
+ full_path=path,
+ rel_path=rel_path,
+ partitions=None,
+ timestamp=timestamp,
+ table_path=table_path,
+ number_of_files=1,
+ size_in_bytes=size,
+ )
+ return table_data
+
+ def resolve_templated_folders(
+ self, container_name: str, prefix: str
+ ) -> Iterable[str]:
+ folder_split: List[str] = prefix.split("*", 1)
+ # If the len of split is 1 it means we don't have * in the prefix
+ if len(folder_split) == 1:
+ yield prefix
+ return
+
+ folders: Iterable[str] = list_folders(
+ container_name, folder_split[0], self.source_config.azure_config
+ )
+ for folder in folders:
+ yield from self.resolve_templated_folders(
+ container_name, f"{folder}{folder_split[1]}"
+ )
+
+ def get_dir_to_process(
+ self,
+ container_name: str,
+ folder: str,
+ path_spec: PathSpec,
+ protocol: str,
+ ) -> str:
+ iterator = list_folders(
+ container_name=container_name,
+ prefix=folder,
+ azure_config=self.source_config.azure_config,
+ )
+ iterator = peekable(iterator)
+ if iterator:
+ sorted_dirs = sorted(
+ iterator,
+ key=functools.cmp_to_key(partitioned_folder_comparator),
+ reverse=True,
+ )
+ for dir in sorted_dirs:
+ if path_spec.dir_allowed(f"{protocol}{container_name}/{dir}/"):
+ return self.get_dir_to_process(
+ container_name=container_name,
+ folder=dir + "/",
+ path_spec=path_spec,
+ protocol=protocol,
+ )
+ return folder
+ else:
+ return folder
+
+ def abs_browser(
+ self, path_spec: PathSpec, sample_size: int
+ ) -> Iterable[Tuple[str, str, datetime, int]]:
+ if self.source_config.azure_config is None:
+ raise ValueError("azure_config not set. Cannot browse Azure Blob Storage")
+ abs_blob_service_client = (
+ self.source_config.azure_config.get_blob_service_client()
+ )
+ container_client = abs_blob_service_client.get_container_client(
+ self.source_config.azure_config.container_name
+ )
+
+ container_name = self.source_config.azure_config.container_name
+ logger.debug(f"Scanning container: {container_name}")
+
+ prefix = self.get_prefix(get_container_relative_path(path_spec.include))
+ logger.debug(f"Scanning objects with prefix:{prefix}")
+
+ matches = re.finditer(r"{\s*\w+\s*}", path_spec.include, re.MULTILINE)
+ matches_list = list(matches)
+ if matches_list and path_spec.sample_files:
+ max_start: int = -1
+ include: str = path_spec.include
+ max_match: str = ""
+ for match in matches_list:
+ pos = include.find(match.group())
+ if pos > max_start:
+ if max_match:
+ include = include.replace(max_match, "*")
+ max_start = match.start()
+ max_match = match.group()
+
+ table_index = include.find(max_match)
+
+ for folder in self.resolve_templated_folders(
+ container_name,
+ get_container_relative_path(include[:table_index]),
+ ):
+ try:
+ for f in list_folders(
+ container_name, f"{folder}", self.source_config.azure_config
+ ):
+ logger.info(f"Processing folder: {f}")
+ protocol = ContainerWUCreator.get_protocol(path_spec.include)
+ dir_to_process = self.get_dir_to_process(
+ container_name=container_name,
+ folder=f + "/",
+ path_spec=path_spec,
+ protocol=protocol,
+ )
+ logger.info(f"Getting files from folder: {dir_to_process}")
+ dir_to_process = dir_to_process.rstrip("\\")
+ for obj in container_client.list_blobs(
+ name_starts_with=f"{dir_to_process}",
+ results_per_page=PAGE_SIZE,
+ ):
+ abs_path = self.create_abs_path(obj.name)
+ logger.debug(f"Sampling file: {abs_path}")
+ yield abs_path, obj.name, obj.last_modified, obj.size,
+ except Exception as e:
+ # This odd check if being done because boto does not have a proper exception to catch
+ # The exception that appears in stacktrace cannot actually be caught without a lot more work
+ # https://github.com/boto/boto3/issues/1195
+ if "NoSuchBucket" in repr(e):
+ logger.debug(
+ f"Got NoSuchBucket exception for {container_name}", e
+ )
+ self.get_report().report_warning(
+ "Missing bucket", f"No bucket found {container_name}"
+ )
+ else:
+ raise e
+ else:
+ logger.debug(
+ "No template in the pathspec can't do sampling, fallbacking to do full scan"
+ )
+ path_spec.sample_files = False
+ for obj in container_client.list_blobs(
+ prefix=f"{prefix}", results_per_page=PAGE_SIZE
+ ):
+ abs_path = self.create_abs_path(obj.name)
+ logger.debug(f"Path: {abs_path}")
+ # the following line if using the file_system_client
+ # yield abs_path, obj.last_modified, obj.content_length,
+ yield abs_path, obj.name, obj.last_modified, obj.size
+
+ def create_abs_path(self, key: str) -> str:
+ if self.source_config.azure_config:
+ account_name = self.source_config.azure_config.account_name
+ container_name = self.source_config.azure_config.container_name
+ return (
+ f"https://{account_name}.blob.core.windows.net/{container_name}/{key}"
+ )
+ return ""
+
+ def local_browser(
+ self, path_spec: PathSpec
+ ) -> Iterable[Tuple[str, str, datetime, int]]:
+ prefix = self.get_prefix(path_spec.include)
+ if os.path.isfile(prefix):
+ logger.debug(f"Scanning single local file: {prefix}")
+ file_name = prefix
+ yield prefix, file_name, datetime.utcfromtimestamp(
+ os.path.getmtime(prefix)
+ ), os.path.getsize(prefix)
+ else:
+ logger.debug(f"Scanning files under local folder: {prefix}")
+ for root, dirs, files in os.walk(prefix):
+ dirs.sort(key=functools.cmp_to_key(partitioned_folder_comparator))
+
+ for file in sorted(files):
+ # We need to make sure the path is in posix style which is not true on windows
+ full_path = PurePath(
+ os.path.normpath(os.path.join(root, file))
+ ).as_posix()
+ yield full_path, file, datetime.utcfromtimestamp(
+ os.path.getmtime(full_path)
+ ), os.path.getsize(full_path)
+
+ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
+ self.container_WU_creator = ContainerWUCreator(
+ self.source_config.platform,
+ self.source_config.platform_instance,
+ self.source_config.env,
+ )
+ with PerfTimer():
+ assert self.source_config.path_specs
+ for path_spec in self.source_config.path_specs:
+ file_browser = (
+ self.abs_browser(
+ path_spec, self.source_config.number_of_files_to_sample
+ )
+ if self.is_abs_platform()
+ else self.local_browser(path_spec)
+ )
+ table_dict: Dict[str, TableData] = {}
+ for file, name, timestamp, size in file_browser:
+ if not path_spec.allowed(file):
+ continue
+ table_data = self.extract_table_data(
+ path_spec, file, name, timestamp, size
+ )
+ if table_data.table_path not in table_dict:
+ table_dict[table_data.table_path] = table_data
+ else:
+ table_dict[table_data.table_path].number_of_files = (
+ table_dict[table_data.table_path].number_of_files + 1
+ )
+ table_dict[table_data.table_path].size_in_bytes = (
+ table_dict[table_data.table_path].size_in_bytes
+ + table_data.size_in_bytes
+ )
+ if (
+ table_dict[table_data.table_path].timestamp
+ < table_data.timestamp
+ ) and (table_data.size_in_bytes > 0):
+ table_dict[
+ table_data.table_path
+ ].full_path = table_data.full_path
+ table_dict[
+ table_data.table_path
+ ].timestamp = table_data.timestamp
+
+ for guid, table_data in table_dict.items():
+ yield from self.ingest_table(table_data, path_spec)
+
+ def get_workunit_processors(self) -> List[Optional[MetadataWorkUnitProcessor]]:
+ return [
+ *super().get_workunit_processors(),
+ StaleEntityRemovalHandler.create(
+ self, self.source_config, self.ctx
+ ).workunit_processor,
+ ]
+
+ def is_abs_platform(self):
+ return self.source_config.platform == "abs"
+
+ def get_report(self):
+ return self.report
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/__init__.py b/metadata-ingestion/src/datahub/ingestion/source/azure/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py b/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py
new file mode 100644
index 0000000000000..34faa0f0979ef
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py
@@ -0,0 +1,286 @@
+import logging
+import os
+import re
+from typing import Dict, Iterable, List, Optional
+
+from azure.storage.blob import BlobProperties
+
+from datahub.emitter.mce_builder import make_tag_urn
+from datahub.ingestion.api.common import PipelineContext
+from datahub.ingestion.source.azure.azure_common import AzureConnectionConfig
+from datahub.metadata.schema_classes import GlobalTagsClass, TagAssociationClass
+
+ABS_PREFIXES_REGEX = re.compile(
+ r"(http[s]?://[a-z0-9]{3,24}\.blob\.core\.windows\.net/)"
+)
+
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+def is_abs_uri(uri: str) -> bool:
+ return bool(ABS_PREFIXES_REGEX.match(uri))
+
+
+def get_abs_prefix(abs_uri: str) -> Optional[str]:
+ result = re.search(ABS_PREFIXES_REGEX, abs_uri)
+ if result and result.groups():
+ return result.group(1)
+ return None
+
+
+def strip_abs_prefix(abs_uri: str) -> str:
+ # remove abs prefix https://.blob.core.windows.net
+ abs_prefix = get_abs_prefix(abs_uri)
+ if not abs_prefix:
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ length_abs_prefix = len(abs_prefix)
+ return abs_uri[length_abs_prefix:]
+
+
+def make_abs_urn(abs_uri: str, env: str) -> str:
+ abs_name = strip_abs_prefix(abs_uri)
+
+ if abs_name.endswith("/"):
+ abs_name = abs_name[:-1]
+
+ name, extension = os.path.splitext(abs_name)
+
+ if extension != "":
+ extension = extension[1:] # remove the dot
+ return f"urn:li:dataset:(urn:li:dataPlatform:abs,{name}_{extension},{env})"
+
+ return f"urn:li:dataset:(urn:li:dataPlatform:abs,{abs_name},{env})"
+
+
+def get_container_name(abs_uri: str) -> str:
+ if not is_abs_uri(abs_uri):
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ return strip_abs_prefix(abs_uri).split("/")[0]
+
+
+def get_key_prefix(abs_uri: str) -> str:
+ if not is_abs_uri(abs_uri):
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ return strip_abs_prefix(abs_uri).split("/", maxsplit=1)[1]
+
+
+def get_abs_properties(
+ container_name: str,
+ blob_name: Optional[str],
+ full_path: str,
+ number_of_files: int,
+ size_in_bytes: int,
+ sample_files: bool,
+ azure_config: Optional[AzureConnectionConfig],
+ use_abs_container_properties: Optional[bool] = False,
+ use_abs_blob_properties: Optional[bool] = False,
+) -> Dict[str, str]:
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ blob_service_client = azure_config.get_blob_service_client()
+ container_client = blob_service_client.get_container_client(
+ container=container_name
+ )
+
+ custom_properties = {"schema_inferred_from": full_path}
+ if not sample_files:
+ custom_properties.update(
+ {
+ "number_of_files": str(number_of_files),
+ "size_in_bytes": str(size_in_bytes),
+ }
+ )
+
+ if use_abs_blob_properties and blob_name is not None:
+ blob_client = container_client.get_blob_client(blob=blob_name)
+ blob_properties = blob_client.get_blob_properties()
+ if blob_properties:
+ create_properties(
+ data=blob_properties,
+ prefix="blob",
+ custom_properties=custom_properties,
+ resource_name=blob_name,
+ json_properties=[
+ "metadata",
+ "content_settings",
+ "lease",
+ "copy",
+ "immutability_policy",
+ ],
+ )
+ else:
+ logger.warning(
+ f"No blob properties found for container={container_name}, blob={blob_name}."
+ )
+
+ if use_abs_container_properties:
+ container_properties = container_client.get_container_properties()
+ if container_properties:
+ create_properties(
+ data=container_properties,
+ prefix="container",
+ custom_properties=custom_properties,
+ resource_name=container_name,
+ json_properties=["metadata"],
+ )
+ else:
+ logger.warning(
+ f"No container properties found for container={container_name}."
+ )
+
+ return custom_properties
+
+
+def add_property(
+ key: str, value: str, custom_properties: Dict[str, str], resource_name: str
+) -> Dict[str, str]:
+ if key in custom_properties:
+ key = f"{key}_{resource_name}"
+ if value is not None:
+ custom_properties[key] = str(value)
+ return custom_properties
+
+
+def create_properties(
+ data: BlobProperties,
+ prefix: str,
+ custom_properties: Dict[str, str],
+ resource_name: str,
+ json_properties: List[str],
+) -> None:
+ for item in data.items():
+ key = item[0]
+ transformed_key = f"{prefix}_{key}"
+ value = item[1]
+ if value is None:
+ continue
+ try:
+ # These are known properties with a json value, we process these recursively...
+ if key in json_properties:
+ create_properties(
+ data=value,
+ prefix=f"{prefix}_{key}",
+ custom_properties=custom_properties,
+ resource_name=resource_name,
+ json_properties=json_properties,
+ )
+ else:
+ custom_properties = add_property(
+ key=transformed_key,
+ value=value,
+ custom_properties=custom_properties,
+ resource_name=resource_name,
+ )
+ except Exception as exception:
+ logger.debug(
+ f"Could not create property {key} value {value}, from resource {resource_name}: {exception}."
+ )
+
+
+def get_abs_tags(
+ container_name: str,
+ key_name: Optional[str],
+ dataset_urn: str,
+ azure_config: Optional[AzureConnectionConfig],
+ ctx: PipelineContext,
+ use_abs_blob_tags: Optional[bool] = False,
+) -> Optional[GlobalTagsClass]:
+ # Todo add the service_client, when building out this get_abs_tags
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ tags_to_add: List[str] = []
+ blob_service_client = azure_config.get_blob_service_client()
+ container_client = blob_service_client.get_container_client(container_name)
+ blob_client = container_client.get_blob_client(blob=key_name)
+
+ if use_abs_blob_tags and key_name is not None:
+ tag_set = blob_client.get_blob_tags()
+ if tag_set:
+ tags_to_add.extend(
+ make_tag_urn(f"""{key}:{value}""") for key, value in tag_set.items()
+ )
+ else:
+ # Unlike container tags, if an object does not have tags, it will just return an empty array
+ # as opposed to an exception.
+ logger.info(f"No tags found for container={container_name} key={key_name}")
+
+ if len(tags_to_add) == 0:
+ return None
+
+ if ctx.graph is not None:
+ logger.debug("Connected to DatahubApi, grabbing current tags to maintain.")
+ current_tags: Optional[GlobalTagsClass] = ctx.graph.get_aspect(
+ entity_urn=dataset_urn,
+ aspect_type=GlobalTagsClass,
+ )
+ if current_tags:
+ tags_to_add.extend([current_tag.tag for current_tag in current_tags.tags])
+ else:
+ logger.warning("Could not connect to DatahubApi. No current tags to maintain")
+
+ # Sort existing tags
+ tags_to_add = sorted(list(set(tags_to_add)))
+ # Remove duplicate tags
+ new_tags = GlobalTagsClass(
+ tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
+ )
+ return new_tags
+
+
+def list_folders(
+ container_name: str, prefix: str, azure_config: Optional[AzureConnectionConfig]
+) -> Iterable[str]:
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ abs_blob_service_client = azure_config.get_blob_service_client()
+ container_client = abs_blob_service_client.get_container_client(container_name)
+
+ current_level = prefix.count("/")
+ blob_list = container_client.list_blobs(name_starts_with=prefix)
+
+ this_dict = {}
+ for blob in blob_list:
+ blob_name = blob.name[: blob.name.rfind("/") + 1]
+ folder_structure_arr = blob_name.split("/")
+
+ folder_name = ""
+ if len(folder_structure_arr) > current_level:
+ folder_name = f"{folder_name}/{folder_structure_arr[current_level]}"
+ else:
+ continue
+
+ folder_name = folder_name[1 : len(folder_name)]
+
+ if folder_name.endswith("/"):
+ folder_name = folder_name[:-1]
+
+ if folder_name == "":
+ continue
+
+ folder_name = f"{prefix}{folder_name}"
+ if folder_name in this_dict:
+ continue
+ else:
+ this_dict[folder_name] = folder_name
+
+ yield f"{folder_name}"
+
+
+def get_container_relative_path(abs_uri: str) -> str:
+ return "/".join(strip_abs_prefix(abs_uri).split("/")[1:])
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py b/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py
new file mode 100644
index 0000000000000..46de4e09d7ee5
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py
@@ -0,0 +1,98 @@
+from typing import Dict, Optional, Union
+
+from azure.identity import ClientSecretCredential
+from azure.storage.blob import BlobServiceClient
+from azure.storage.filedatalake import DataLakeServiceClient, FileSystemClient
+from pydantic import Field, root_validator
+
+from datahub.configuration import ConfigModel
+from datahub.configuration.common import ConfigurationError
+
+
+class AzureConnectionConfig(ConfigModel):
+ """
+ Common Azure credentials config.
+
+ https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-directory-file-acl-python
+ """
+
+ base_path: str = Field(
+ default="/",
+ description="Base folder in hierarchical namespaces to start from.",
+ )
+ container_name: str = Field(
+ description="Azure storage account container name.",
+ )
+ account_name: str = Field(
+ description="Name of the Azure storage account. See [Microsoft official documentation on how to create a storage account.](https://docs.microsoft.com/en-us/azure/storage/blobs/create-data-lake-storage-account)",
+ )
+ account_key: Optional[str] = Field(
+ description="Azure storage account access key that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ sas_token: Optional[str] = Field(
+ description="Azure storage account Shared Access Signature (SAS) token that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ client_secret: Optional[str] = Field(
+ description="Azure client secret that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ client_id: Optional[str] = Field(
+ description="Azure client (Application) ID required when a `client_secret` is used as a credential.",
+ default=None,
+ )
+ tenant_id: Optional[str] = Field(
+ description="Azure tenant (Directory) ID required when a `client_secret` is used as a credential.",
+ default=None,
+ )
+
+ def get_abfss_url(self, folder_path: str = "") -> str:
+ if not folder_path.startswith("/"):
+ folder_path = f"/{folder_path}"
+ return f"abfss://{self.container_name}@{self.account_name}.dfs.core.windows.net{folder_path}"
+
+ # TODO DEX-1010
+ def get_filesystem_client(self) -> FileSystemClient:
+ return self.get_data_lake_service_client().get_file_system_client(
+ file_system=self.container_name
+ )
+
+ def get_blob_service_client(self):
+ return BlobServiceClient(
+ account_url=f"https://{self.account_name}.blob.core.windows.net",
+ credential=f"{self.get_credentials()}",
+ )
+
+ def get_data_lake_service_client(self) -> DataLakeServiceClient:
+ return DataLakeServiceClient(
+ account_url=f"https://{self.account_name}.dfs.core.windows.net",
+ credential=f"{self.get_credentials()}",
+ )
+
+ def get_credentials(
+ self,
+ ) -> Union[Optional[str], ClientSecretCredential]:
+ if self.client_id and self.client_secret and self.tenant_id:
+ return ClientSecretCredential(
+ tenant_id=self.tenant_id,
+ client_id=self.client_id,
+ client_secret=self.client_secret,
+ )
+ return self.sas_token if self.sas_token is not None else self.account_key
+
+ @root_validator()
+ def _check_credential_values(cls, values: Dict) -> Dict:
+ if (
+ values.get("account_key")
+ or values.get("sas_token")
+ or (
+ values.get("client_id")
+ and values.get("client_secret")
+ and values.get("tenant_id")
+ )
+ ):
+ return values
+ raise ConfigurationError(
+ "credentials missing, requires one combination of account_key or sas_token or (client_id and client_secret and tenant_id)"
+ )
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
index 5046f52cdce26..7a96b2f0643ab 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
@@ -2,24 +2,9 @@
import functools
import logging
import os
-import re
-import traceback
-from collections import defaultdict
-from datetime import datetime, timedelta
-from typing import Dict, Iterable, List, Optional, Set, Type, Union, cast
+from typing import Iterable, List, Optional
-from google.cloud import bigquery
-from google.cloud.bigquery.table import TableListItem
-
-from datahub.configuration.pattern_utils import is_schema_allowed, is_tag_allowed
-from datahub.emitter.mce_builder import (
- make_data_platform_urn,
- make_dataplatform_instance_urn,
- make_dataset_urn,
- make_tag_urn,
-)
-from datahub.emitter.mcp import MetadataChangeProposalWrapper
-from datahub.emitter.mcp_builder import BigQueryDatasetKey, ContainerKey, ProjectIdKey
+from datahub.emitter.mce_builder import make_dataset_urn
from datahub.ingestion.api.common import PipelineContext
from datahub.ingestion.api.decorators import (
SupportStatus,
@@ -30,54 +15,31 @@
)
from datahub.ingestion.api.incremental_lineage_helper import auto_incremental_lineage
from datahub.ingestion.api.source import (
- CapabilityReport,
MetadataWorkUnitProcessor,
SourceCapability,
TestableSource,
TestConnectionReport,
)
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.glossary.classification_mixin import (
- SAMPLE_SIZE_MULTIPLIER,
- ClassificationHandler,
- classification_workunit_processor,
-)
from datahub.ingestion.source.bigquery_v2.bigquery_audit import (
BigqueryTableIdentifier,
BigQueryTableRef,
)
from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
-from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
-from datahub.ingestion.source.bigquery_v2.bigquery_helper import (
- unquote_and_decode_unicode_escape_seq,
-)
from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
- BigqueryColumn,
- BigqueryDataset,
BigqueryProject,
BigQuerySchemaApi,
- BigqueryTable,
- BigqueryTableSnapshot,
- BigqueryView,
)
-from datahub.ingestion.source.bigquery_v2.common import (
- BQ_EXTERNAL_DATASET_URL_TEMPLATE,
- BQ_EXTERNAL_TABLE_URL_TEMPLATE,
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_test_connection import (
+ BigQueryTestConnection,
)
from datahub.ingestion.source.bigquery_v2.lineage import BigqueryLineageExtractor
from datahub.ingestion.source.bigquery_v2.profiler import BigqueryProfiler
from datahub.ingestion.source.bigquery_v2.usage import BigQueryUsageExtractor
-from datahub.ingestion.source.common.subtypes import (
- DatasetContainerSubTypes,
- DatasetSubTypes,
-)
-from datahub.ingestion.source.sql.sql_utils import (
- add_table_to_schema_container,
- gen_database_container,
- gen_schema_container,
- get_domain_wu,
-)
from datahub.ingestion.source.state.profiling_state_handler import ProfilingHandler
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantLineageRunSkipHandler,
@@ -89,57 +51,11 @@
from datahub.ingestion.source.state.stateful_ingestion_base import (
StatefulIngestionSourceBase,
)
-from datahub.ingestion.source_report.ingestion_stage import (
- METADATA_EXTRACTION,
- PROFILING,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.common import (
- Status,
- SubTypes,
- TimeStamp,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
- DatasetProperties,
- ViewProperties,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.schema import (
- ArrayType,
- BooleanType,
- BytesType,
- DateType,
- MySqlDDL,
- NullType,
- NumberType,
- RecordType,
- SchemaField,
- SchemaFieldDataType,
- SchemaMetadata,
- StringType,
- TimeType,
-)
-from datahub.metadata.schema_classes import (
- DataPlatformInstanceClass,
- GlobalTagsClass,
- TagAssociationClass,
-)
from datahub.sql_parsing.schema_resolver import SchemaResolver
-from datahub.utilities.file_backed_collections import FileBackedDict
-from datahub.utilities.hive_schema_to_avro import (
- HiveColumnToAvroConverter,
- get_schema_fields_for_hive_column,
-)
-from datahub.utilities.mapping import Constants
-from datahub.utilities.perf_timer import PerfTimer
-from datahub.utilities.ratelimiter import RateLimiter
from datahub.utilities.registries.domain_registry import DomainRegistry
logger: logging.Logger = logging.getLogger(__name__)
-# Handle table snapshots
-# See https://cloud.google.com/bigquery/docs/table-snapshots-intro.
-SNAPSHOT_TABLE_REGEX = re.compile(r"^(.+)@(\d{13})$")
-CLUSTERING_COLUMN_TAG = "CLUSTERING_COLUMN"
-
# We can't use close as it is not called if the ingestion is not successful
def cleanup(config: BigQueryV2Config) -> None:
@@ -178,58 +94,18 @@ def cleanup(config: BigQueryV2Config) -> None:
supported=True,
)
class BigqueryV2Source(StatefulIngestionSourceBase, TestableSource):
- # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
- # Note: We use the hive schema parser to parse nested BigQuery types. We also have
- # some extra type mappings in that file.
- BIGQUERY_FIELD_TYPE_MAPPINGS: Dict[
- str,
- Type[
- Union[
- ArrayType,
- BytesType,
- BooleanType,
- NumberType,
- RecordType,
- StringType,
- TimeType,
- DateType,
- NullType,
- ]
- ],
- ] = {
- "BYTES": BytesType,
- "BOOL": BooleanType,
- "DECIMAL": NumberType,
- "NUMERIC": NumberType,
- "BIGNUMERIC": NumberType,
- "BIGDECIMAL": NumberType,
- "FLOAT64": NumberType,
- "INT": NumberType,
- "INT64": NumberType,
- "SMALLINT": NumberType,
- "INTEGER": NumberType,
- "BIGINT": NumberType,
- "TINYINT": NumberType,
- "BYTEINT": NumberType,
- "STRING": StringType,
- "TIME": TimeType,
- "TIMESTAMP": TimeType,
- "DATE": DateType,
- "DATETIME": TimeType,
- "GEOGRAPHY": NullType,
- "JSON": RecordType,
- "INTERVAL": NullType,
- "ARRAY": ArrayType,
- "STRUCT": RecordType,
- }
-
def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
super().__init__(config, ctx)
self.config: BigQueryV2Config = config
self.report: BigQueryV2Report = BigQueryV2Report()
- self.classification_handler = ClassificationHandler(self.config, self.report)
self.platform: str = "bigquery"
+ self.domain_registry: Optional[DomainRegistry] = None
+ if self.config.domain:
+ self.domain_registry = DomainRegistry(
+ cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
+ )
+
BigqueryTableIdentifier._BIGQUERY_DEFAULT_SHARDED_TABLE_REGEX = (
self.config.sharded_table_pattern
)
@@ -247,12 +123,6 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
self.sql_parser_schema_resolver = self._init_schema_resolver()
- self.data_reader: Optional[BigQueryDataReader] = None
- if self.classification_handler.is_classification_enabled():
- self.data_reader = BigQueryDataReader.create(
- self.config.get_bigquery_client()
- )
-
redundant_lineage_run_skip_handler: Optional[
RedundantLineageRunSkipHandler
] = None
@@ -289,12 +159,6 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
redundant_run_skip_handler=redundant_usage_run_skip_handler,
)
- self.domain_registry: Optional[DomainRegistry] = None
- if self.config.domain:
- self.domain_registry = DomainRegistry(
- cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
- )
-
self.profiling_state_handler: Optional[ProfilingHandler] = None
if self.config.enable_stateful_profiling:
self.profiling_state_handler = ProfilingHandler(
@@ -307,17 +171,15 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
config, self.report, self.profiling_state_handler
)
- # Global store of table identifiers for lineage filtering
- self.table_refs: Set[str] = set()
-
- # Maps project -> view_ref, so we can find all views in a project
- self.view_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
- # Maps project -> snapshot_ref, so we can find all snapshots in a project
- self.snapshot_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
- # Maps view ref -> actual sql
- self.view_definitions: FileBackedDict[str] = FileBackedDict()
- # Maps snapshot ref -> Snapshot
- self.snapshots_by_ref: FileBackedDict[BigqueryTableSnapshot] = FileBackedDict()
+ self.bq_schema_extractor = BigQuerySchemaGenerator(
+ self.config,
+ self.report,
+ self.bigquery_data_dictionary,
+ self.domain_registry,
+ self.sql_parser_schema_resolver,
+ self.profiler,
+ self.gen_dataset_urn,
+ )
self.add_config_to_report()
atexit.register(cleanup, config)
@@ -327,161 +189,9 @@ def create(cls, config_dict: dict, ctx: PipelineContext) -> "BigqueryV2Source":
config = BigQueryV2Config.parse_obj(config_dict)
return cls(ctx, config)
- @staticmethod
- def connectivity_test(client: bigquery.Client) -> CapabilityReport:
- ret = client.query("select 1")
- if ret.error_result:
- return CapabilityReport(
- capable=False, failure_reason=f"{ret.error_result['message']}"
- )
- else:
- return CapabilityReport(capable=True)
-
- @property
- def store_table_refs(self):
- return self.config.include_table_lineage or self.config.include_usage_statistics
-
- @staticmethod
- def metadata_read_capability_test(
- project_ids: List[str], config: BigQueryV2Config
- ) -> CapabilityReport:
- for project_id in project_ids:
- try:
- logger.info(f"Metadata read capability test for project {project_id}")
- client: bigquery.Client = config.get_bigquery_client()
- assert client
- bigquery_data_dictionary = BigQuerySchemaApi(
- BigQueryV2Report().schema_api_perf, client
- )
- result = bigquery_data_dictionary.get_datasets_for_project_id(
- project_id, 10
- )
- if len(result) == 0:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Dataset query returned empty dataset. It is either empty or no dataset in project {project_id}",
- )
- tables = bigquery_data_dictionary.get_tables_for_dataset(
- project_id=project_id,
- dataset_name=result[0].name,
- tables={},
- with_data_read_permission=config.have_table_data_read_permission,
- )
- if len(list(tables)) == 0:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Tables query did not return any table. It is either empty or no tables in project {project_id}.{result[0].name}",
- )
-
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Dataset query failed with error: {e}",
- )
-
- return CapabilityReport(capable=True)
-
- @staticmethod
- def lineage_capability_test(
- connection_conf: BigQueryV2Config,
- project_ids: List[str],
- report: BigQueryV2Report,
- ) -> CapabilityReport:
- lineage_extractor = BigqueryLineageExtractor(
- connection_conf, report, lambda ref: ""
- )
- for project_id in project_ids:
- try:
- logger.info(f"Lineage capability test for project {project_id}")
- lineage_extractor.test_capability(project_id)
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Lineage capability test failed with: {e}",
- )
-
- return CapabilityReport(capable=True)
-
- @staticmethod
- def usage_capability_test(
- connection_conf: BigQueryV2Config,
- project_ids: List[str],
- report: BigQueryV2Report,
- ) -> CapabilityReport:
- usage_extractor = BigQueryUsageExtractor(
- connection_conf,
- report,
- schema_resolver=SchemaResolver(platform="bigquery"),
- dataset_urn_builder=lambda ref: "",
- )
- for project_id in project_ids:
- try:
- logger.info(f"Usage capability test for project {project_id}")
- failures_before_test = len(report.failures)
- usage_extractor.test_capability(project_id)
- if failures_before_test != len(report.failures):
- return CapabilityReport(
- capable=False,
- failure_reason="Usage capability test failed. Check the logs for further info",
- )
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Usage capability test failed with: {e} for project {project_id}",
- )
- return CapabilityReport(capable=True)
-
@staticmethod
def test_connection(config_dict: dict) -> TestConnectionReport:
- test_report = TestConnectionReport()
- _report: Dict[Union[SourceCapability, str], CapabilityReport] = dict()
-
- try:
- connection_conf = BigQueryV2Config.parse_obj_allow_extras(config_dict)
- client: bigquery.Client = connection_conf.get_bigquery_client()
- assert client
-
- test_report.basic_connectivity = BigqueryV2Source.connectivity_test(client)
-
- connection_conf.start_time = datetime.now()
- connection_conf.end_time = datetime.now() + timedelta(minutes=1)
-
- report: BigQueryV2Report = BigQueryV2Report()
- project_ids: List[str] = []
- projects = client.list_projects()
-
- for project in projects:
- if connection_conf.project_id_pattern.allowed(project.project_id):
- project_ids.append(project.project_id)
-
- metadata_read_capability = BigqueryV2Source.metadata_read_capability_test(
- project_ids, connection_conf
- )
- if SourceCapability.SCHEMA_METADATA not in _report:
- _report[SourceCapability.SCHEMA_METADATA] = metadata_read_capability
-
- if connection_conf.include_table_lineage:
- lineage_capability = BigqueryV2Source.lineage_capability_test(
- connection_conf, project_ids, report
- )
- if SourceCapability.LINEAGE_COARSE not in _report:
- _report[SourceCapability.LINEAGE_COARSE] = lineage_capability
-
- if connection_conf.include_usage_statistics:
- usage_capability = BigqueryV2Source.usage_capability_test(
- connection_conf, project_ids, report
- )
- if SourceCapability.USAGE_STATS not in _report:
- _report[SourceCapability.USAGE_STATS] = usage_capability
-
- test_report.capability_report = _report
- return test_report
-
- except Exception as e:
- test_report.basic_connectivity = CapabilityReport(
- capable=False, failure_reason=f"{e}"
- )
- return test_report
+ return BigQueryTestConnection.test_connection(config_dict)
def _init_schema_resolver(self) -> SchemaResolver:
schema_resolution_required = (
@@ -509,83 +219,6 @@ def _init_schema_resolver(self) -> SchemaResolver:
)
return SchemaResolver(platform=self.platform, env=self.config.env)
- def get_dataplatform_instance_aspect(
- self, dataset_urn: str, project_id: str
- ) -> MetadataWorkUnit:
- aspect = DataPlatformInstanceClass(
- platform=make_data_platform_urn(self.platform),
- instance=(
- make_dataplatform_instance_urn(self.platform, project_id)
- if self.config.include_data_platform_instance
- else None
- ),
- )
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=aspect
- ).as_workunit()
-
- def gen_dataset_key(self, db_name: str, schema: str) -> ContainerKey:
- return BigQueryDatasetKey(
- project_id=db_name,
- dataset_id=schema,
- platform=self.platform,
- env=self.config.env,
- backcompat_env_as_instance=True,
- )
-
- def gen_project_id_key(self, database: str) -> ContainerKey:
- return ProjectIdKey(
- project_id=database,
- platform=self.platform,
- env=self.config.env,
- backcompat_env_as_instance=True,
- )
-
- def gen_project_id_containers(self, database: str) -> Iterable[MetadataWorkUnit]:
- database_container_key = self.gen_project_id_key(database)
-
- yield from gen_database_container(
- database=database,
- name=database,
- sub_types=[DatasetContainerSubTypes.BIGQUERY_PROJECT],
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- database_container_key=database_container_key,
- )
-
- def gen_dataset_containers(
- self, dataset: str, project_id: str, tags: Optional[Dict[str, str]] = None
- ) -> Iterable[MetadataWorkUnit]:
- schema_container_key = self.gen_dataset_key(project_id, dataset)
-
- tags_joined: Optional[List[str]] = None
- if tags and self.config.capture_dataset_label_as_tag:
- tags_joined = [
- f"{k}:{v}"
- for k, v in tags.items()
- if is_tag_allowed(self.config.capture_dataset_label_as_tag, k)
- ]
-
- database_container_key = self.gen_project_id_key(database=project_id)
-
- yield from gen_schema_container(
- database=project_id,
- schema=dataset,
- sub_types=[DatasetContainerSubTypes.BIGQUERY_DATASET],
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- schema_container_key=schema_container_key,
- database_container_key=database_container_key,
- external_url=(
- BQ_EXTERNAL_DATASET_URL_TEMPLATE.format(
- project=project_id, dataset=dataset
- )
- if self.config.include_external_url
- else None
- ),
- tags=tags_joined,
- )
-
def get_workunit_processors(self) -> List[Optional[MetadataWorkUnitProcessor]]:
return [
*super().get_workunit_processors(),
@@ -603,25 +236,23 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
return
if self.config.include_schema_metadata:
- for project_id in projects:
- self.report.set_ingestion_stage(project_id.id, METADATA_EXTRACTION)
- logger.info(f"Processing project: {project_id.id}")
- yield from self._process_project(project_id)
+ for project in projects:
+ yield from self.bq_schema_extractor.get_project_workunits(project)
if self.config.include_usage_statistics:
yield from self.usage_extractor.get_usage_workunits(
- [p.id for p in projects], self.table_refs
+ [p.id for p in projects], self.bq_schema_extractor.table_refs
)
if self.config.include_table_lineage:
yield from self.lineage_extractor.get_lineage_workunits(
[p.id for p in projects],
self.sql_parser_schema_resolver,
- self.view_refs_by_project,
- self.view_definitions,
- self.snapshot_refs_by_project,
- self.snapshots_by_ref,
- self.table_refs,
+ self.bq_schema_extractor.view_refs_by_project,
+ self.bq_schema_extractor.view_definitions,
+ self.bq_schema_extractor.snapshot_refs_by_project,
+ self.bq_schema_extractor.snapshots_by_ref,
+ self.bq_schema_extractor.table_refs,
)
def _get_projects(self) -> List[BigqueryProject]:
@@ -636,15 +267,25 @@ def _get_projects(self) -> List[BigqueryProject]:
return list(self._query_project_list())
def _query_project_list(self) -> Iterable[BigqueryProject]:
- projects = self.bigquery_data_dictionary.get_projects()
- if not projects: # Report failure on exception and if empty list is returned
- self.report.report_failure(
- "metadata-extraction",
- "Get projects didn't return any project. "
- "Maybe resourcemanager.projects.get permission is missing for the service account. "
+ try:
+ projects = self.bigquery_data_dictionary.get_projects()
+
+ if (
+ not projects
+ ): # Report failure on exception and if empty list is returned
+ self.report.failure(
+ title="Get projects didn't return any project. ",
+ message="Maybe resourcemanager.projects.get permission is missing for the service account. "
+ "You can assign predefined roles/bigquery.metadataViewer role to your service account.",
+ )
+ except Exception as e:
+ self.report.failure(
+ title="Failed to get BigQuery Projects",
+ message="Maybe resourcemanager.projects.get permission is missing for the service account. "
"You can assign predefined roles/bigquery.metadataViewer role to your service account.",
+ exc=e,
)
- return
+ projects = []
for project in projects:
if self.config.project_id_pattern.allowed(project.id):
@@ -652,567 +293,6 @@ def _query_project_list(self) -> Iterable[BigqueryProject]:
else:
self.report.report_dropped(project.id)
- def _process_project(
- self, bigquery_project: BigqueryProject
- ) -> Iterable[MetadataWorkUnit]:
- db_tables: Dict[str, List[BigqueryTable]] = {}
- db_views: Dict[str, List[BigqueryView]] = {}
- db_snapshots: Dict[str, List[BigqueryTableSnapshot]] = {}
-
- project_id = bigquery_project.id
- try:
- bigquery_project.datasets = (
- self.bigquery_data_dictionary.get_datasets_for_project_id(project_id)
- )
- except Exception as e:
- error_message = f"Unable to get datasets for project {project_id}, skipping. The error was: {e}"
- if self.config.is_profiling_enabled():
- error_message = f"Unable to get datasets for project {project_id}, skipping. Does your service account has bigquery.datasets.get permission? The error was: {e}"
- logger.error(error_message)
- self.report.report_failure(
- "metadata-extraction",
- f"{project_id} - {error_message}",
- )
- return None
-
- if len(bigquery_project.datasets) == 0:
- more_info = (
- "Either there are no datasets in this project or missing bigquery.datasets.get permission. "
- "You can assign predefined roles/bigquery.metadataViewer role to your service account."
- )
- if self.config.exclude_empty_projects:
- self.report.report_dropped(project_id)
- warning_message = f"Excluded project '{project_id}' since no were datasets found. {more_info}"
- else:
- yield from self.gen_project_id_containers(project_id)
- warning_message = (
- f"No datasets found in project '{project_id}'. {more_info}"
- )
- logger.warning(warning_message)
- return
-
- yield from self.gen_project_id_containers(project_id)
-
- self.report.num_project_datasets_to_scan[project_id] = len(
- bigquery_project.datasets
- )
- for bigquery_dataset in bigquery_project.datasets:
- if not is_schema_allowed(
- self.config.dataset_pattern,
- bigquery_dataset.name,
- project_id,
- self.config.match_fully_qualified_names,
- ):
- self.report.report_dropped(f"{bigquery_dataset.name}.*")
- continue
- try:
- # db_tables, db_views, and db_snapshots are populated in the this method
- yield from self._process_schema(
- project_id, bigquery_dataset, db_tables, db_views, db_snapshots
- )
-
- except Exception as e:
- error_message = f"Unable to get tables for dataset {bigquery_dataset.name} in project {project_id}, skipping. Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission? The error was: {e}"
- if self.config.is_profiling_enabled():
- error_message = f"Unable to get tables for dataset {bigquery_dataset.name} in project {project_id}, skipping. Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission, bigquery.tables.getData permission? The error was: {e}"
-
- trace = traceback.format_exc()
- logger.error(trace)
- logger.error(error_message)
- self.report.report_failure(
- "metadata-extraction",
- f"{project_id}.{bigquery_dataset.name} - {error_message} - {trace}",
- )
- continue
-
- if self.config.is_profiling_enabled():
- logger.info(f"Starting profiling project {project_id}")
- self.report.set_ingestion_stage(project_id, PROFILING)
- yield from self.profiler.get_workunits(
- project_id=project_id,
- tables=db_tables,
- )
-
- def _process_schema(
- self,
- project_id: str,
- bigquery_dataset: BigqueryDataset,
- db_tables: Dict[str, List[BigqueryTable]],
- db_views: Dict[str, List[BigqueryView]],
- db_snapshots: Dict[str, List[BigqueryTableSnapshot]],
- ) -> Iterable[MetadataWorkUnit]:
- dataset_name = bigquery_dataset.name
-
- yield from self.gen_dataset_containers(
- dataset_name, project_id, bigquery_dataset.labels
- )
-
- columns = None
-
- rate_limiter: Optional[RateLimiter] = None
- if self.config.rate_limit:
- rate_limiter = RateLimiter(
- max_calls=self.config.requests_per_min, period=60
- )
-
- if (
- self.config.include_tables
- or self.config.include_views
- or self.config.include_table_snapshots
- ):
- columns = self.bigquery_data_dictionary.get_columns_for_dataset(
- project_id=project_id,
- dataset_name=dataset_name,
- column_limit=self.config.column_limit,
- run_optimized_column_query=self.config.run_optimized_column_query,
- extract_policy_tags_from_catalog=self.config.extract_policy_tags_from_catalog,
- report=self.report,
- rate_limiter=rate_limiter,
- )
-
- if self.config.include_tables:
- db_tables[dataset_name] = list(
- self.get_tables_for_dataset(project_id, dataset_name)
- )
-
- for table in db_tables[dataset_name]:
- table_columns = columns.get(table.name, []) if columns else []
- table_wu_generator = self._process_table(
- table=table,
- columns=table_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
- yield from classification_workunit_processor(
- table_wu_generator,
- self.classification_handler,
- self.data_reader,
- [project_id, dataset_name, table.name],
- data_reader_kwargs=dict(
- sample_size_percent=(
- self.config.classification.sample_size
- * SAMPLE_SIZE_MULTIPLIER
- / table.rows_count
- if table.rows_count
- else None
- )
- ),
- )
- elif self.store_table_refs:
- # Need table_refs to calculate lineage and usage
- for table_item in self.bigquery_data_dictionary.list_tables(
- dataset_name, project_id
- ):
- identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=table_item.table_id,
- )
- if not self.config.table_pattern.allowed(identifier.raw_table_name()):
- self.report.report_dropped(identifier.raw_table_name())
- continue
- try:
- self.table_refs.add(
- str(BigQueryTableRef(identifier).get_sanitized_table_ref())
- )
- except Exception as e:
- logger.warning(
- f"Could not create table ref for {table_item.path}: {e}"
- )
-
- if self.config.include_views:
- db_views[dataset_name] = list(
- self.bigquery_data_dictionary.get_views_for_dataset(
- project_id,
- dataset_name,
- self.config.is_profiling_enabled(),
- self.report,
- )
- )
-
- for view in db_views[dataset_name]:
- view_columns = columns.get(view.name, []) if columns else []
- yield from self._process_view(
- view=view,
- columns=view_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- if self.config.include_table_snapshots:
- db_snapshots[dataset_name] = list(
- self.bigquery_data_dictionary.get_snapshots_for_dataset(
- project_id,
- dataset_name,
- self.config.is_profiling_enabled(),
- self.report,
- )
- )
-
- for snapshot in db_snapshots[dataset_name]:
- snapshot_columns = columns.get(snapshot.name, []) if columns else []
- yield from self._process_snapshot(
- snapshot=snapshot,
- columns=snapshot_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- # This method is used to generate the ignore list for datatypes the profiler doesn't support we have to do it here
- # because the profiler doesn't have access to columns
- def generate_profile_ignore_list(self, columns: List[BigqueryColumn]) -> List[str]:
- ignore_list: List[str] = []
- for column in columns:
- if not column.data_type or any(
- word in column.data_type.lower()
- for word in ["array", "struct", "geography", "json"]
- ):
- ignore_list.append(column.field_path)
- return ignore_list
-
- def _process_table(
- self,
- table: BigqueryTable,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(project_id, dataset_name, table.name)
-
- self.report.report_entity_scanned(table_identifier.raw_table_name())
-
- if not self.config.table_pattern.allowed(table_identifier.raw_table_name()):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- if self.store_table_refs:
- self.table_refs.add(
- str(BigQueryTableRef(table_identifier).get_sanitized_table_ref())
- )
- table.column_count = len(columns)
-
- # We only collect profile ignore list if profiling is enabled and profile_table_level_only is false
- if (
- self.config.is_profiling_enabled()
- and not self.config.profiling.profile_table_level_only
- ):
- table.columns_ignore_from_profiling = self.generate_profile_ignore_list(
- columns
- )
-
- if not table.column_count:
- logger.warning(
- f"Table doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- # If table has time partitioning, set the data type of the partitioning field
- if table.partition_info:
- table.partition_info.column = next(
- (
- column
- for column in columns
- if column.name == table.partition_info.field
- ),
- None,
- )
- yield from self.gen_table_dataset_workunits(
- table, columns, project_id, dataset_name
- )
-
- def _process_view(
- self,
- view: BigqueryView,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(project_id, dataset_name, view.name)
-
- self.report.report_entity_scanned(table_identifier.raw_table_name(), "view")
-
- if not self.config.view_pattern.allowed(table_identifier.raw_table_name()):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- if self.store_table_refs:
- table_ref = str(
- BigQueryTableRef(table_identifier).get_sanitized_table_ref()
- )
- self.table_refs.add(table_ref)
- if self.config.lineage_parse_view_ddl and view.view_definition:
- self.view_refs_by_project[project_id].add(table_ref)
- self.view_definitions[table_ref] = view.view_definition
-
- view.column_count = len(columns)
- if not view.column_count:
- logger.warning(
- f"View doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- yield from self.gen_view_dataset_workunits(
- table=view,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- def _process_snapshot(
- self,
- snapshot: BigqueryTableSnapshot,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(
- project_id, dataset_name, snapshot.name
- )
-
- self.report.snapshots_scanned += 1
-
- if not self.config.table_snapshot_pattern.allowed(
- table_identifier.raw_table_name()
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- snapshot.columns = columns
- snapshot.column_count = len(columns)
- if not snapshot.column_count:
- logger.warning(
- f"Snapshot doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- if self.store_table_refs:
- table_ref = str(
- BigQueryTableRef(table_identifier).get_sanitized_table_ref()
- )
- self.table_refs.add(table_ref)
- if snapshot.base_table_identifier:
- self.snapshot_refs_by_project[project_id].add(table_ref)
- self.snapshots_by_ref[table_ref] = snapshot
-
- yield from self.gen_snapshot_dataset_workunits(
- table=snapshot,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- def gen_table_dataset_workunits(
- self,
- table: BigqueryTable,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- custom_properties: Dict[str, str] = {}
- if table.expires:
- custom_properties["expiration_date"] = str(table.expires)
-
- if table.partition_info:
- custom_properties["partition_info"] = str(table.partition_info)
-
- if table.size_in_bytes:
- custom_properties["size_in_bytes"] = str(table.size_in_bytes)
-
- if table.active_billable_bytes:
- custom_properties["billable_bytes_active"] = str(
- table.active_billable_bytes
- )
-
- if table.long_term_billable_bytes:
- custom_properties["billable_bytes_long_term"] = str(
- table.long_term_billable_bytes
- )
-
- if table.max_partition_id:
- custom_properties["number_of_partitions"] = str(table.num_partitions)
- custom_properties["max_partition_id"] = str(table.max_partition_id)
- custom_properties["is_partitioned"] = str(True)
-
- sub_types: List[str] = [DatasetSubTypes.TABLE]
- if table.max_shard_id:
- custom_properties["max_shard_id"] = str(table.max_shard_id)
- custom_properties["is_sharded"] = str(True)
- sub_types = ["sharded table"] + sub_types
-
- tags_to_add = None
- if table.labels and self.config.capture_table_label_as_tag:
- tags_to_add = []
- tags_to_add.extend(
- [
- make_tag_urn(f"""{k}:{v}""")
- for k, v in table.labels.items()
- if is_tag_allowed(self.config.capture_table_label_as_tag, k)
- ]
- )
-
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- sub_types=sub_types,
- tags_to_add=tags_to_add,
- custom_properties=custom_properties,
- )
-
- def gen_view_dataset_workunits(
- self,
- table: BigqueryView,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- tags_to_add = None
- if table.labels and self.config.capture_view_label_as_tag:
- tags_to_add = [
- make_tag_urn(f"{k}:{v}")
- for k, v in table.labels.items()
- if is_tag_allowed(self.config.capture_view_label_as_tag, k)
- ]
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- tags_to_add=tags_to_add,
- sub_types=[DatasetSubTypes.VIEW],
- )
-
- view = cast(BigqueryView, table)
- view_definition_string = view.view_definition
- view_properties_aspect = ViewProperties(
- materialized=view.materialized,
- viewLanguage="SQL",
- viewLogic=view_definition_string or "",
- )
- yield MetadataChangeProposalWrapper(
- entityUrn=self.gen_dataset_urn(
- project_id=project_id, dataset_name=dataset_name, table=table.name
- ),
- aspect=view_properties_aspect,
- ).as_workunit()
-
- def gen_snapshot_dataset_workunits(
- self,
- table: BigqueryTableSnapshot,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- custom_properties: Dict[str, str] = {}
- if table.ddl:
- custom_properties["snapshot_ddl"] = table.ddl
- if table.snapshot_time:
- custom_properties["snapshot_time"] = str(table.snapshot_time)
- if table.size_in_bytes:
- custom_properties["size_in_bytes"] = str(table.size_in_bytes)
- if table.rows_count:
- custom_properties["rows_count"] = str(table.rows_count)
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- sub_types=[DatasetSubTypes.BIGQUERY_TABLE_SNAPSHOT],
- custom_properties=custom_properties,
- )
-
- def gen_dataset_workunits(
- self,
- table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- sub_types: List[str],
- tags_to_add: Optional[List[str]] = None,
- custom_properties: Optional[Dict[str, str]] = None,
- ) -> Iterable[MetadataWorkUnit]:
- dataset_urn = self.gen_dataset_urn(
- project_id=project_id, dataset_name=dataset_name, table=table.name
- )
-
- status = Status(removed=False)
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=status
- ).as_workunit()
-
- datahub_dataset_name = BigqueryTableIdentifier(
- project_id, dataset_name, table.name
- )
-
- yield self.gen_schema_metadata(
- dataset_urn, table, columns, datahub_dataset_name
- )
-
- dataset_properties = DatasetProperties(
- name=datahub_dataset_name.get_table_display_name(),
- description=(
- unquote_and_decode_unicode_escape_seq(table.comment)
- if table.comment
- else ""
- ),
- qualifiedName=str(datahub_dataset_name),
- created=(
- TimeStamp(time=int(table.created.timestamp() * 1000))
- if table.created is not None
- else None
- ),
- lastModified=(
- TimeStamp(time=int(table.last_altered.timestamp() * 1000))
- if table.last_altered is not None
- else None
- ),
- externalUrl=(
- BQ_EXTERNAL_TABLE_URL_TEMPLATE.format(
- project=project_id, dataset=dataset_name, table=table.name
- )
- if self.config.include_external_url
- else None
- ),
- )
- if custom_properties:
- dataset_properties.customProperties.update(custom_properties)
-
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=dataset_properties
- ).as_workunit()
-
- if tags_to_add:
- yield self.gen_tags_aspect_workunit(dataset_urn, tags_to_add)
-
- yield from add_table_to_schema_container(
- dataset_urn=dataset_urn,
- parent_container_key=self.gen_dataset_key(project_id, dataset_name),
- )
- yield self.get_dataplatform_instance_aspect(
- dataset_urn=dataset_urn, project_id=project_id
- )
-
- subTypes = SubTypes(typeNames=sub_types)
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=subTypes
- ).as_workunit()
-
- if self.domain_registry:
- yield from get_domain_wu(
- dataset_name=str(datahub_dataset_name),
- entity_urn=dataset_urn,
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- )
-
- def gen_tags_aspect_workunit(
- self, dataset_urn: str, tags_to_add: List[str]
- ) -> MetadataWorkUnit:
- tags = GlobalTagsClass(
- tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
- )
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=tags
- ).as_workunit()
-
def gen_dataset_urn(
self, project_id: str, dataset_name: str, table: str, use_raw_name: bool = False
) -> str:
@@ -1235,241 +315,9 @@ def gen_dataset_urn_from_raw_ref(self, ref: BigQueryTableRef) -> str:
use_raw_name=True,
)
- def gen_dataset_urn_from_ref(self, ref: BigQueryTableRef) -> str:
- return self.gen_dataset_urn(
- ref.table_identifier.project_id,
- ref.table_identifier.dataset,
- ref.table_identifier.table,
- )
-
- def gen_schema_fields(self, columns: List[BigqueryColumn]) -> List[SchemaField]:
- schema_fields: List[SchemaField] = []
-
- # Below line affects HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR in global scope
- # TODO: Refractor this such that
- # converter = HiveColumnToAvroConverter(struct_type_separator=" ");
- # converter.get_schema_fields_for_hive_column(...)
- original_struct_type_separator = (
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR
- )
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = " "
- _COMPLEX_TYPE = re.compile("^(struct|array)")
- last_id = -1
- for col in columns:
- # if col.data_type is empty that means this column is part of a complex type
- if col.data_type is None or _COMPLEX_TYPE.match(col.data_type.lower()):
- # If the we have seen the ordinal position that most probably means we already processed this complex type
- if last_id != col.ordinal_position:
- schema_fields.extend(
- get_schema_fields_for_hive_column(
- col.name, col.data_type.lower(), description=col.comment
- )
- )
-
- # We have to add complex type comments to the correct level
- if col.comment:
- for idx, field in enumerate(schema_fields):
- # Remove all the [version=2.0].[type=struct]. tags to get the field path
- if (
- re.sub(
- r"\[.*?\]\.",
- "",
- field.fieldPath.lower(),
- 0,
- re.MULTILINE,
- )
- == col.field_path.lower()
- ):
- field.description = col.comment
- schema_fields[idx] = field
- break
- else:
- tags = []
- if col.is_partition_column:
- tags.append(
- TagAssociationClass(make_tag_urn(Constants.TAG_PARTITION_KEY))
- )
-
- if col.cluster_column_position is not None:
- tags.append(
- TagAssociationClass(
- make_tag_urn(
- f"{CLUSTERING_COLUMN_TAG}_{col.cluster_column_position}"
- )
- )
- )
-
- if col.policy_tags:
- for policy_tag in col.policy_tags:
- tags.append(TagAssociationClass(make_tag_urn(policy_tag)))
- field = SchemaField(
- fieldPath=col.name,
- type=SchemaFieldDataType(
- self.BIGQUERY_FIELD_TYPE_MAPPINGS.get(col.data_type, NullType)()
- ),
- nativeDataType=col.data_type,
- description=col.comment,
- nullable=col.is_nullable,
- globalTags=GlobalTagsClass(tags=tags),
- )
- schema_fields.append(field)
- last_id = col.ordinal_position
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = (
- original_struct_type_separator
- )
- return schema_fields
-
- def gen_schema_metadata(
- self,
- dataset_urn: str,
- table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
- columns: List[BigqueryColumn],
- dataset_name: BigqueryTableIdentifier,
- ) -> MetadataWorkUnit:
- schema_metadata = SchemaMetadata(
- schemaName=str(dataset_name),
- platform=make_data_platform_urn(self.platform),
- version=0,
- hash="",
- platformSchema=MySqlDDL(tableSchema=""),
- # fields=[],
- fields=self.gen_schema_fields(columns),
- )
-
- if self.config.lineage_parse_view_ddl or self.config.lineage_use_sql_parser:
- self.sql_parser_schema_resolver.add_schema_metadata(
- dataset_urn, schema_metadata
- )
-
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=schema_metadata
- ).as_workunit()
-
def get_report(self) -> BigQueryV2Report:
return self.report
- def get_tables_for_dataset(
- self,
- project_id: str,
- dataset_name: str,
- ) -> Iterable[BigqueryTable]:
- # In bigquery there is no way to query all tables in a Project id
- with PerfTimer() as timer:
- # Partitions view throw exception if we try to query partition info for too many tables
- # so we have to limit the number of tables we query partition info.
- # The conn.list_tables returns table infos that information_schema doesn't contain and this
- # way we can merge that info with the queried one.
- # https://cloud.google.com/bigquery/docs/information-schema-partitions
- max_batch_size: int = (
- self.config.number_of_datasets_process_in_batch
- if not self.config.is_profiling_enabled()
- else self.config.number_of_datasets_process_in_batch_if_profiling_enabled
- )
-
- # We get the list of tables in the dataset to get core table properties and to be able to process the tables in batches
- # We collect only the latest shards from sharded tables (tables with _YYYYMMDD suffix) and ignore temporary tables
- table_items = self.get_core_table_details(
- dataset_name, project_id, self.config.temp_table_dataset_prefix
- )
-
- items_to_get: Dict[str, TableListItem] = {}
- for table_item in table_items.keys():
- items_to_get[table_item] = table_items[table_item]
- if len(items_to_get) % max_batch_size == 0:
- yield from self.bigquery_data_dictionary.get_tables_for_dataset(
- project_id,
- dataset_name,
- items_to_get,
- with_data_read_permission=self.config.have_table_data_read_permission,
- )
- items_to_get.clear()
-
- if items_to_get:
- yield from self.bigquery_data_dictionary.get_tables_for_dataset(
- project_id,
- dataset_name,
- items_to_get,
- with_data_read_permission=self.config.have_table_data_read_permission,
- )
-
- self.report.metadata_extraction_sec[f"{project_id}.{dataset_name}"] = round(
- timer.elapsed_seconds(), 2
- )
-
- def get_core_table_details(
- self, dataset_name: str, project_id: str, temp_table_dataset_prefix: str
- ) -> Dict[str, TableListItem]:
- table_items: Dict[str, TableListItem] = {}
- # Dict to store sharded table and the last seen max shard id
- sharded_tables: Dict[str, TableListItem] = {}
-
- for table in self.bigquery_data_dictionary.list_tables(
- dataset_name, project_id
- ):
- table_identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=table.table_id,
- )
-
- if table.table_type == "VIEW":
- if (
- not self.config.include_views
- or not self.config.view_pattern.allowed(
- table_identifier.raw_table_name()
- )
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
- else:
- if not self.config.table_pattern.allowed(
- table_identifier.raw_table_name()
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
-
- _, shard = BigqueryTableIdentifier.get_table_and_shard(
- table_identifier.table
- )
- table_name = table_identifier.get_table_name().split(".")[-1]
-
- # Sharded tables look like: table_20220120
- # For sharded tables we only process the latest shard and ignore the rest
- # to find the latest shard we iterate over the list of tables and store the maximum shard id
- # We only have one special case where the table name is a date `20220110`
- # in this case we merge all these tables under dataset name as table name.
- # For example some_dataset.20220110 will be turned to some_dataset.some_dataset
- # It seems like there are some bigquery user who uses this non-standard way of sharding the tables.
- if shard:
- if table_name not in sharded_tables:
- sharded_tables[table_name] = table
- continue
-
- stored_table_identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=sharded_tables[table_name].table_id,
- )
- _, stored_shard = BigqueryTableIdentifier.get_table_and_shard(
- stored_table_identifier.table
- )
- # When table is none, we use dataset_name as table_name
- assert stored_shard
- if stored_shard < shard:
- sharded_tables[table_name] = table
- continue
- elif str(table_identifier).startswith(temp_table_dataset_prefix):
- logger.debug(f"Dropping temporary table {table_identifier.table}")
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
-
- table_items[table.table_id] = table
-
- # Adding maximum shards to the list of tables
- table_items.update({value.table_id: value for value in sharded_tables.values()})
-
- return table_items
-
def add_config_to_report(self):
self.report.include_table_lineage = self.config.include_table_lineage
self.report.use_date_sharded_audit_log_tables = (
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
index 75e116773df96..7d2f8ee0e1fd8 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
@@ -66,6 +66,7 @@ def get_exported_bigquery_audit_metadata(
rate_limiter = RateLimiter(max_calls=self.requests_per_min, period=60)
with self.report.get_exported_log_entries as current_timer:
+ self.report.num_get_exported_log_entries_api_requests += 1
for dataset in bigquery_audit_metadata_datasets:
logger.info(
f"Start loading log entries from BigQueryAuditMetadata in {dataset}"
@@ -115,6 +116,7 @@ def get_bigquery_log_entries_via_gcp_logging(
)
with self.report.list_log_entries as current_timer:
+ self.report.num_list_log_entries_api_requests += 1
list_entries = client.list_entries(
filter_=filter,
page_size=log_page_size,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
index 578c9dddbd2e4..fe961dbd780f6 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
@@ -24,6 +24,10 @@
logger = logging.getLogger(__name__)
+DEFAULT_BQ_SCHEMA_PARALLELISM = int(
+ os.getenv("DATAHUB_BIGQUERY_SCHEMA_PARALLELISM", 20)
+)
+
class BigQueryUsageConfig(BaseUsageConfig):
_query_log_delay_removed = pydantic_removed_field("query_log_delay")
@@ -175,12 +179,12 @@ class BigQueryV2Config(
number_of_datasets_process_in_batch: int = Field(
hidden_from_docs=True,
- default=500,
+ default=10000,
description="Number of table queried in batch when getting metadata. This is a low level config property which should be touched with care.",
)
number_of_datasets_process_in_batch_if_profiling_enabled: int = Field(
- default=200,
+ default=1000,
description="Number of partitioned table queried in batch when getting metadata. This is a low level config property which should be touched with care. This restriction is needed because we query partitions system view which throws error if we try to touch too many tables.",
)
@@ -313,6 +317,12 @@ def have_table_data_read_permission(self) -> bool:
hidden_from_schema=True,
)
+ max_threads_dataset_parallelism: int = Field(
+ default=DEFAULT_BQ_SCHEMA_PARALLELISM,
+ description="Number of worker threads to use to parallelize BigQuery Dataset Metadata Extraction."
+ " Set to 1 to disable.",
+ )
+
@root_validator(skip_on_failure=True)
def profile_default_settings(cls, values: Dict) -> Dict:
# Extra default SQLAlchemy option for better connection pooling and threading.
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
index bbdf32da13621..507e1d917d206 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
@@ -10,14 +10,27 @@ def unquote_and_decode_unicode_escape_seq(
"""
If string starts and ends with a quote, unquote it and decode Unicode escape sequences
"""
+ unicode_seq_pattern = re.compile(r"\\(u|U)[0-9a-fA-F]{4}")
trailing_quote = trailing_quote if trailing_quote else leading_quote
if string.startswith(leading_quote) and string.endswith(trailing_quote):
string = string[1:-1]
- cleaned_string = string.encode().decode("unicode-escape")
-
- return cleaned_string
+ # Decode Unicode escape sequences. This avoid issues with encoding
+ # This process does not handle unicode from "\U00010000" to "\U0010FFFF"
+ while unicode_seq_pattern.search(string):
+ # Get the first Unicode escape sequence.
+ # mypy: unicode_seq_pattern.search(string) is not None because of the while loop
+ unicode_seq = unicode_seq_pattern.search(string).group(0) # type: ignore
+ # Replace the Unicode escape sequence with the decoded character
+ try:
+ string = string.replace(
+ unicode_seq, unicode_seq.encode("utf-8").decode("unicode-escape")
+ )
+ except UnicodeDecodeError:
+ # Skip decoding if is not possible to decode the Unicode escape sequence
+ break # avoid infinite loop
+ return string
def parse_labels(labels_str: str) -> Dict[str, str]:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
index 8a1bf9e5f3d1d..4cfcc3922ddc3 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
@@ -20,20 +20,32 @@
@dataclass
class BigQuerySchemaApiPerfReport(Report):
- num_list_projects: int = 0
+ num_listed_projects: int = 0
num_list_projects_retry_request: int = 0
+ num_list_projects_api_requests: int = 0
+ num_list_datasets_api_requests: int = 0
+ num_get_columns_for_dataset_api_requests: int = 0
+ num_get_tables_for_dataset_api_requests: int = 0
+ num_list_tables_api_requests: int = 0
+ num_get_views_for_dataset_api_requests: int = 0
+ num_get_snapshots_for_dataset_api_requests: int = 0
+
list_projects: PerfTimer = field(default_factory=PerfTimer)
list_datasets: PerfTimer = field(default_factory=PerfTimer)
- get_columns_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- get_tables_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- list_tables: PerfTimer = field(default_factory=PerfTimer)
- get_views_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- get_snapshots_for_dataset: PerfTimer = field(default_factory=PerfTimer)
+
+ get_columns_for_dataset_sec: float = 0
+ get_tables_for_dataset_sec: float = 0
+ list_tables_sec: float = 0
+ get_views_for_dataset_sec: float = 0
+ get_snapshots_for_dataset_sec: float = 0
@dataclass
class BigQueryAuditLogApiPerfReport(Report):
+ num_get_exported_log_entries_api_requests: int = 0
get_exported_log_entries: PerfTimer = field(default_factory=PerfTimer)
+
+ num_list_log_entries_api_requests: int = 0
list_log_entries: PerfTimer = field(default_factory=PerfTimer)
@@ -85,7 +97,6 @@ class BigQueryV2Report(
num_usage_parsed_log_entries: TopKDict[str, int] = field(
default_factory=int_top_k_dict
)
- usage_error_count: Dict[str, int] = field(default_factory=int_top_k_dict)
num_usage_resources_dropped: int = 0
num_usage_operations_dropped: int = 0
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
index fe9bbc134a147..d73ac46c862ea 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
@@ -24,6 +24,7 @@
BigqueryTableType,
)
from datahub.ingestion.source.sql.sql_generic import BaseColumn, BaseTable, BaseView
+from datahub.utilities.perf_timer import PerfTimer
from datahub.utilities.ratelimiter import RateLimiter
logger: logging.Logger = logging.getLogger(__name__)
@@ -154,7 +155,7 @@ def get_query_result(self, query: str) -> RowIterator:
resp = self.bq_client.query(query)
return resp.result()
- def get_projects(self) -> List[BigqueryProject]:
+ def get_projects(self, max_results_per_page: int = 100) -> List[BigqueryProject]:
def _should_retry(exc: BaseException) -> bool:
logger.debug(
f"Exception occured for project.list api. Reason: {exc}. Retrying api request..."
@@ -162,34 +163,50 @@ def _should_retry(exc: BaseException) -> bool:
self.report.num_list_projects_retry_request += 1
return True
+ page_token = None
+ projects: List[BigqueryProject] = []
with self.report.list_projects:
- try:
- # Bigquery API has limit in calling project.list request i.e. 2 request per second.
- # https://cloud.google.com/bigquery/quotas#api_request_quotas
- # Whenever this limit reached an exception occur with msg
- # 'Quota exceeded: Your user exceeded quota for concurrent project.lists requests.'
- # Hence, added the api request retry of 15 min.
- # We already tried adding rate_limit externally, proving max_result and page_size
- # to restrict the request calls inside list_project but issue still occured.
- projects_iterator = self.bq_client.list_projects(
- retry=retry.Retry(
- predicate=_should_retry, initial=10, maximum=180, timeout=900
+ while True:
+ try:
+ self.report.num_list_projects_api_requests += 1
+ # Bigquery API has limit in calling project.list request i.e. 2 request per second.
+ # https://cloud.google.com/bigquery/quotas#api_request_quotas
+ # Whenever this limit reached an exception occur with msg
+ # 'Quota exceeded: Your user exceeded quota for concurrent project.lists requests.'
+ # Hence, added the api request retry of 15 min.
+ # We already tried adding rate_limit externally, proving max_result and page_size
+ # to restrict the request calls inside list_project but issue still occured.
+ projects_iterator = self.bq_client.list_projects(
+ max_results=max_results_per_page,
+ page_token=page_token,
+ timeout=900,
+ retry=retry.Retry(
+ predicate=_should_retry,
+ initial=10,
+ maximum=180,
+ multiplier=4,
+ timeout=900,
+ ),
)
- )
- projects: List[BigqueryProject] = [
- BigqueryProject(id=p.project_id, name=p.friendly_name)
- for p in projects_iterator
- ]
- self.report.num_list_projects = len(projects)
- return projects
- except Exception as e:
- logger.error(f"Error getting projects. {e}", exc_info=True)
- return []
+ _projects: List[BigqueryProject] = [
+ BigqueryProject(id=p.project_id, name=p.friendly_name)
+ for p in projects_iterator
+ ]
+ projects.extend(_projects)
+ self.report.num_listed_projects = len(projects)
+ page_token = projects_iterator.next_page_token
+ if not page_token:
+ break
+ except Exception as e:
+ logger.error(f"Error getting projects. {e}", exc_info=True)
+ return []
+ return projects
def get_datasets_for_project_id(
self, project_id: str, maxResults: Optional[int] = None
) -> List[BigqueryDataset]:
with self.report.list_datasets:
+ self.report.num_list_datasets_api_requests += 1
datasets = self.bq_client.list_datasets(project_id, max_results=maxResults)
return [
BigqueryDataset(name=d.dataset_id, labels=d.labels) for d in datasets
@@ -222,50 +239,42 @@ def get_datasets_for_project_id_with_information_schema(
def list_tables(
self, dataset_name: str, project_id: str
) -> Iterator[TableListItem]:
- with self.report.list_tables as current_timer:
+ with PerfTimer() as current_timer:
for table in self.bq_client.list_tables(f"{project_id}.{dataset_name}"):
with current_timer.pause():
yield table
+ self.report.num_list_tables_api_requests += 1
+ self.report.list_tables_sec += current_timer.elapsed_seconds()
def get_tables_for_dataset(
self,
project_id: str,
dataset_name: str,
tables: Dict[str, TableListItem],
+ report: BigQueryV2Report,
with_data_read_permission: bool = False,
- report: Optional[BigQueryV2Report] = None,
) -> Iterator[BigqueryTable]:
- with self.report.get_tables_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
filter_clause: str = ", ".join(f"'{table}'" for table in tables.keys())
if with_data_read_permission:
- # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
- # and skip the others. Sharded tables are tables with suffix _20220102
- cur = self.get_query_result(
- BigqueryQuery.tables_for_dataset.format(
- project_id=project_id,
- dataset_name=dataset_name,
- table_filter=(
- f" and t.table_name in ({filter_clause})"
- if filter_clause
- else ""
- ),
- ),
- )
+ query_template = BigqueryQuery.tables_for_dataset
else:
- # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
- # and skip the others. Sharded tables are tables with suffix _20220102
- cur = self.get_query_result(
- BigqueryQuery.tables_for_dataset_without_partition_data.format(
- project_id=project_id,
- dataset_name=dataset_name,
- table_filter=(
- f" and t.table_name in ({filter_clause})"
- if filter_clause
- else ""
- ),
+ query_template = BigqueryQuery.tables_for_dataset_without_partition_data
+
+ # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
+ # and skip the others. Sharded tables are tables with suffix _20220102
+ cur = self.get_query_result(
+ query_template.format(
+ project_id=project_id,
+ dataset_name=dataset_name,
+ table_filter=(
+ f" and t.table_name in ({filter_clause})"
+ if filter_clause
+ else ""
),
- )
+ ),
+ )
for table in cur:
try:
@@ -275,15 +284,14 @@ def get_tables_for_dataset(
)
except Exception as e:
table_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing table {table_name}",
- exc_info=True,
+ report.warning(
+ title="Failed to process table",
+ message="Error encountered while processing table",
+ context=table_name,
+ exc=e,
)
- if report:
- report.report_warning(
- "metadata-extraction",
- f"Failed to get table {table_name}: {e}",
- )
+ self.report.num_get_tables_for_dataset_api_requests += 1
+ self.report.get_tables_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_table(
@@ -332,7 +340,7 @@ def get_views_for_dataset(
has_data_read: bool,
report: BigQueryV2Report,
) -> Iterator[BigqueryView]:
- with self.report.get_views_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
if has_data_read:
# If profiling is enabled
cur = self.get_query_result(
@@ -353,14 +361,14 @@ def get_views_for_dataset(
yield BigQuerySchemaApi._make_bigquery_view(table)
except Exception as e:
view_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing view {view_name}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to get view {view_name}: {e}",
+ report.warning(
+ title="Failed to process view",
+ message="Error encountered while processing view",
+ context=view_name,
+ exc=e,
)
+ self.report.num_get_views_for_dataset_api_requests += 1
+ self.report.get_views_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_view(view: bigquery.Row) -> BigqueryView:
@@ -416,22 +424,18 @@ def get_policy_tags_for_column(
)
yield policy_tag.display_name
except Exception as e:
- logger.warning(
- f"Unexpected error when retrieving policy tag {policy_tag_name} for column {column_name} in table {table_name}: {e}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to retrieve policy tag {policy_tag_name} for column {column_name} in table {table_name} due to unexpected error: {e}",
+ report.warning(
+ title="Failed to retrieve policy tag",
+ message="Unexpected error when retrieving policy tag for column",
+ context=f"policy tag {policy_tag_name} for column {column_name} in table {table_ref}",
+ exc=e,
)
except Exception as e:
- logger.error(
- f"Unexpected error retrieving schema for table {table_name} in dataset {dataset_name}, project {project_id}: {e}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to retrieve schema for table {table_name} in dataset {dataset_name}, project {project_id} due to unexpected error: {e}",
+ report.warning(
+ title="Failed to retrieve policy tag for table",
+ message="Unexpected error retrieving policy tag for table",
+ context=table_ref,
+ exc=e,
)
def get_columns_for_dataset(
@@ -445,7 +449,7 @@ def get_columns_for_dataset(
rate_limiter: Optional[RateLimiter] = None,
) -> Optional[Dict[str, List[BigqueryColumn]]]:
columns: Dict[str, List[BigqueryColumn]] = defaultdict(list)
- with self.report.get_columns_for_dataset:
+ with PerfTimer() as timer:
try:
cur = self.get_query_result(
(
@@ -461,89 +465,57 @@ def get_columns_for_dataset(
),
)
except Exception as e:
- logger.warning(f"Columns for dataset query failed with exception: {e}")
- # Error - Information schema query returned too much data.
- # Please repeat query with more selective predicates.
+ report.warning(
+ title="Failed to retrieve columns for dataset",
+ message="Query to get columns for dataset failed with exception",
+ context=f"{project_id}.{dataset_name}",
+ exc=e,
+ )
return None
last_seen_table: str = ""
for column in cur:
- if (
- column_limit
- and column.table_name in columns
- and len(columns[column.table_name]) >= column_limit
- ):
- if last_seen_table != column.table_name:
- logger.warning(
- f"{project_id}.{dataset_name}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
- )
- last_seen_table = column.table_name
- else:
- columns[column.table_name].append(
- BigqueryColumn(
- name=column.column_name,
- ordinal_position=column.ordinal_position,
- field_path=column.field_path,
- is_nullable=column.is_nullable == "YES",
- data_type=column.data_type,
- comment=column.comment,
- is_partition_column=column.is_partitioning_column == "YES",
- cluster_column_position=column.clustering_ordinal_position,
- policy_tags=(
- list(
- self.get_policy_tags_for_column(
- project_id,
- dataset_name,
- column.table_name,
- column.column_name,
- report,
- rate_limiter,
+ with timer.pause():
+ if (
+ column_limit
+ and column.table_name in columns
+ and len(columns[column.table_name]) >= column_limit
+ ):
+ if last_seen_table != column.table_name:
+ logger.warning(
+ f"{project_id}.{dataset_name}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
+ )
+ last_seen_table = column.table_name
+ else:
+ columns[column.table_name].append(
+ BigqueryColumn(
+ name=column.column_name,
+ ordinal_position=column.ordinal_position,
+ field_path=column.field_path,
+ is_nullable=column.is_nullable == "YES",
+ data_type=column.data_type,
+ comment=column.comment,
+ is_partition_column=column.is_partitioning_column
+ == "YES",
+ cluster_column_position=column.clustering_ordinal_position,
+ policy_tags=(
+ list(
+ self.get_policy_tags_for_column(
+ project_id,
+ dataset_name,
+ column.table_name,
+ column.column_name,
+ report,
+ rate_limiter,
+ )
)
- )
- if extract_policy_tags_from_catalog
- else []
- ),
+ if extract_policy_tags_from_catalog
+ else []
+ ),
+ )
)
- )
-
- return columns
-
- # This is not used anywhere
- def get_columns_for_table(
- self,
- table_identifier: BigqueryTableIdentifier,
- column_limit: Optional[int],
- ) -> List[BigqueryColumn]:
- cur = self.get_query_result(
- BigqueryQuery.columns_for_table.format(table_identifier=table_identifier),
- )
-
- columns: List[BigqueryColumn] = []
- last_seen_table: str = ""
- for column in cur:
- if (
- column_limit
- and column.table_name in columns
- and len(columns[column.table_name]) >= column_limit
- ):
- if last_seen_table != column.table_name:
- logger.warning(
- f"{table_identifier.project_id}.{table_identifier.dataset}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
- )
- else:
- columns.append(
- BigqueryColumn(
- name=column.column_name,
- ordinal_position=column.ordinal_position,
- is_nullable=column.is_nullable == "YES",
- field_path=column.field_path,
- data_type=column.data_type,
- comment=column.comment,
- is_partition_column=column.is_partitioning_column == "YES",
- cluster_column_position=column.clustering_ordinal_position,
- )
- )
- last_seen_table = column.table_name
+ self.report.num_get_columns_for_dataset_api_requests += 1
+ self.report.get_columns_for_dataset_sec += timer.elapsed_seconds()
return columns
@@ -554,7 +526,7 @@ def get_snapshots_for_dataset(
has_data_read: bool,
report: BigQueryV2Report,
) -> Iterator[BigqueryTableSnapshot]:
- with self.report.get_snapshots_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
if has_data_read:
# If profiling is enabled
cur = self.get_query_result(
@@ -575,14 +547,14 @@ def get_snapshots_for_dataset(
yield BigQuerySchemaApi._make_bigquery_table_snapshot(table)
except Exception as e:
snapshot_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing view {snapshot_name}",
- exc_info=True,
- )
report.report_warning(
- "metadata-extraction",
- f"Failed to get view {snapshot_name}: {e}",
+ title="Failed to process snapshot",
+ message="Error encountered while processing snapshot",
+ context=snapshot_name,
+ exc=e,
)
+ self.report.num_get_snapshots_for_dataset_api_requests += 1
+ self.report.get_snapshots_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_table_snapshot(snapshot: bigquery.Row) -> BigqueryTableSnapshot:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
new file mode 100644
index 0000000000000..3ffcb225db1c2
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
@@ -0,0 +1,1090 @@
+import logging
+import re
+from collections import defaultdict
+from typing import Callable, Dict, Iterable, List, Optional, Set, Type, Union, cast
+
+from google.cloud.bigquery.table import TableListItem
+
+from datahub.configuration.pattern_utils import is_schema_allowed, is_tag_allowed
+from datahub.emitter.mce_builder import (
+ make_data_platform_urn,
+ make_dataplatform_instance_urn,
+ make_tag_urn,
+)
+from datahub.emitter.mcp import MetadataChangeProposalWrapper
+from datahub.emitter.mcp_builder import BigQueryDatasetKey, ContainerKey, ProjectIdKey
+from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.glossary.classification_mixin import (
+ SAMPLE_SIZE_MULTIPLIER,
+ ClassificationHandler,
+ classification_workunit_processor,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_audit import (
+ BigqueryTableIdentifier,
+ BigQueryTableRef,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
+from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
+from datahub.ingestion.source.bigquery_v2.bigquery_helper import (
+ unquote_and_decode_unicode_escape_seq,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
+from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
+ BigqueryColumn,
+ BigqueryDataset,
+ BigqueryProject,
+ BigQuerySchemaApi,
+ BigqueryTable,
+ BigqueryTableSnapshot,
+ BigqueryView,
+)
+from datahub.ingestion.source.bigquery_v2.common import (
+ BQ_EXTERNAL_DATASET_URL_TEMPLATE,
+ BQ_EXTERNAL_TABLE_URL_TEMPLATE,
+)
+from datahub.ingestion.source.bigquery_v2.profiler import BigqueryProfiler
+from datahub.ingestion.source.common.subtypes import (
+ DatasetContainerSubTypes,
+ DatasetSubTypes,
+)
+from datahub.ingestion.source.sql.sql_utils import (
+ add_table_to_schema_container,
+ gen_database_container,
+ gen_schema_container,
+ get_domain_wu,
+)
+from datahub.ingestion.source_report.ingestion_stage import (
+ METADATA_EXTRACTION,
+ PROFILING,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.common import (
+ Status,
+ SubTypes,
+ TimeStamp,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
+ DatasetProperties,
+ ViewProperties,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.schema import (
+ ArrayType,
+ BooleanType,
+ BytesType,
+ DateType,
+ MySqlDDL,
+ NullType,
+ NumberType,
+ RecordType,
+ SchemaField,
+ SchemaFieldDataType,
+ SchemaMetadata,
+ StringType,
+ TimeType,
+)
+from datahub.metadata.schema_classes import (
+ DataPlatformInstanceClass,
+ GlobalTagsClass,
+ TagAssociationClass,
+)
+from datahub.sql_parsing.schema_resolver import SchemaResolver
+from datahub.utilities.file_backed_collections import FileBackedDict
+from datahub.utilities.hive_schema_to_avro import (
+ HiveColumnToAvroConverter,
+ get_schema_fields_for_hive_column,
+)
+from datahub.utilities.mapping import Constants
+from datahub.utilities.perf_timer import PerfTimer
+from datahub.utilities.ratelimiter import RateLimiter
+from datahub.utilities.registries.domain_registry import DomainRegistry
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
+
+logger: logging.Logger = logging.getLogger(__name__)
+# Handle table snapshots
+# See https://cloud.google.com/bigquery/docs/table-snapshots-intro.
+SNAPSHOT_TABLE_REGEX = re.compile(r"^(.+)@(\d{13})$")
+CLUSTERING_COLUMN_TAG = "CLUSTERING_COLUMN"
+
+
+class BigQuerySchemaGenerator:
+ # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
+ # Note: We use the hive schema parser to parse nested BigQuery types. We also have
+ # some extra type mappings in that file.
+ BIGQUERY_FIELD_TYPE_MAPPINGS: Dict[
+ str,
+ Type[
+ Union[
+ ArrayType,
+ BytesType,
+ BooleanType,
+ NumberType,
+ RecordType,
+ StringType,
+ TimeType,
+ DateType,
+ NullType,
+ ]
+ ],
+ ] = {
+ "BYTES": BytesType,
+ "BOOL": BooleanType,
+ "INT": NumberType,
+ "INT64": NumberType,
+ "SMALLINT": NumberType,
+ "INTEGER": NumberType,
+ "BIGINT": NumberType,
+ "TINYINT": NumberType,
+ "BYTEINT": NumberType,
+ "STRING": StringType,
+ "TIME": TimeType,
+ "TIMESTAMP": TimeType,
+ "DATE": DateType,
+ "DATETIME": TimeType,
+ "GEOGRAPHY": NullType,
+ "JSON": RecordType,
+ "INTERVAL": NullType,
+ "ARRAY": ArrayType,
+ "STRUCT": RecordType,
+ }
+
+ def __init__(
+ self,
+ config: BigQueryV2Config,
+ report: BigQueryV2Report,
+ bigquery_data_dictionary: BigQuerySchemaApi,
+ domain_registry: Optional[DomainRegistry],
+ sql_parser_schema_resolver: SchemaResolver,
+ profiler: BigqueryProfiler,
+ dataset_urn_builder: Callable[[str, str, str], str],
+ ):
+ self.config = config
+ self.report = report
+ self.bigquery_data_dictionary = bigquery_data_dictionary
+ self.domain_registry = domain_registry
+ self.sql_parser_schema_resolver = sql_parser_schema_resolver
+ self.profiler = profiler
+ self.gen_dataset_urn = dataset_urn_builder
+ self.platform: str = "bigquery"
+
+ self.classification_handler = ClassificationHandler(self.config, self.report)
+ self.data_reader: Optional[BigQueryDataReader] = None
+ if self.classification_handler.is_classification_enabled():
+ self.data_reader = BigQueryDataReader.create(
+ self.config.get_bigquery_client()
+ )
+
+ # Global store of table identifiers for lineage filtering
+ self.table_refs: Set[str] = set()
+
+ # Maps project -> view_ref, so we can find all views in a project
+ self.view_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
+ # Maps project -> snapshot_ref, so we can find all snapshots in a project
+ self.snapshot_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
+ # Maps view ref -> actual sql
+ self.view_definitions: FileBackedDict[str] = FileBackedDict()
+ # Maps snapshot ref -> Snapshot
+ self.snapshots_by_ref: FileBackedDict[BigqueryTableSnapshot] = FileBackedDict()
+
+ @property
+ def store_table_refs(self):
+ return self.config.include_table_lineage or self.config.include_usage_statistics
+
+ def get_project_workunits(
+ self, project: BigqueryProject
+ ) -> Iterable[MetadataWorkUnit]:
+ self.report.set_ingestion_stage(project.id, METADATA_EXTRACTION)
+ logger.info(f"Processing project: {project.id}")
+ yield from self._process_project(project)
+
+ def get_dataplatform_instance_aspect(
+ self, dataset_urn: str, project_id: str
+ ) -> MetadataWorkUnit:
+ aspect = DataPlatformInstanceClass(
+ platform=make_data_platform_urn(self.platform),
+ instance=(
+ make_dataplatform_instance_urn(self.platform, project_id)
+ if self.config.include_data_platform_instance
+ else None
+ ),
+ )
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=aspect
+ ).as_workunit()
+
+ def gen_dataset_key(self, db_name: str, schema: str) -> ContainerKey:
+ return BigQueryDatasetKey(
+ project_id=db_name,
+ dataset_id=schema,
+ platform=self.platform,
+ env=self.config.env,
+ backcompat_env_as_instance=True,
+ )
+
+ def gen_project_id_key(self, database: str) -> ContainerKey:
+ return ProjectIdKey(
+ project_id=database,
+ platform=self.platform,
+ env=self.config.env,
+ backcompat_env_as_instance=True,
+ )
+
+ def gen_project_id_containers(self, database: str) -> Iterable[MetadataWorkUnit]:
+ database_container_key = self.gen_project_id_key(database)
+
+ yield from gen_database_container(
+ database=database,
+ name=database,
+ sub_types=[DatasetContainerSubTypes.BIGQUERY_PROJECT],
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ database_container_key=database_container_key,
+ )
+
+ def gen_dataset_containers(
+ self, dataset: str, project_id: str, tags: Optional[Dict[str, str]] = None
+ ) -> Iterable[MetadataWorkUnit]:
+ schema_container_key = self.gen_dataset_key(project_id, dataset)
+
+ tags_joined: Optional[List[str]] = None
+ if tags and self.config.capture_dataset_label_as_tag:
+ tags_joined = [
+ f"{k}:{v}"
+ for k, v in tags.items()
+ if is_tag_allowed(self.config.capture_dataset_label_as_tag, k)
+ ]
+
+ database_container_key = self.gen_project_id_key(database=project_id)
+
+ yield from gen_schema_container(
+ database=project_id,
+ schema=dataset,
+ sub_types=[DatasetContainerSubTypes.BIGQUERY_DATASET],
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ schema_container_key=schema_container_key,
+ database_container_key=database_container_key,
+ external_url=(
+ BQ_EXTERNAL_DATASET_URL_TEMPLATE.format(
+ project=project_id, dataset=dataset
+ )
+ if self.config.include_external_url
+ else None
+ ),
+ tags=tags_joined,
+ )
+
+ def _process_project(
+ self, bigquery_project: BigqueryProject
+ ) -> Iterable[MetadataWorkUnit]:
+ db_tables: Dict[str, List[BigqueryTable]] = {}
+
+ project_id = bigquery_project.id
+ try:
+ bigquery_project.datasets = (
+ self.bigquery_data_dictionary.get_datasets_for_project_id(project_id)
+ )
+ except Exception as e:
+
+ if (
+ self.config.project_id or self.config.project_ids
+ ) and "not enabled BigQuery." in str(e):
+ action_mesage = (
+ "The project has not enabled BigQuery API. "
+ "Did you mistype project id in recipe ?"
+ )
+ else:
+ action_mesage = (
+ "Does your service account have `bigquery.datasets.get` permission ? "
+ "Assign predefined role `roles/bigquery.metadataViewer` to your service account."
+ )
+
+ self.report.failure(
+ title="Unable to get datasets for project",
+ message=action_mesage,
+ context=project_id,
+ exc=e,
+ )
+ return None
+
+ if len(bigquery_project.datasets) == 0:
+ action_message = (
+ "Either there are no datasets in this project or missing `bigquery.datasets.get` permission. "
+ "You can assign predefined roles/bigquery.metadataViewer role to your service account."
+ )
+ if self.config.exclude_empty_projects:
+ self.report.report_dropped(project_id)
+ logger.info(
+ f"Excluded project '{project_id}' since no datasets were found. {action_message}"
+ )
+ else:
+ yield from self.gen_project_id_containers(project_id)
+ self.report.warning(
+ title="No datasets found in project",
+ message=action_message,
+ context=project_id,
+ )
+ return
+
+ yield from self.gen_project_id_containers(project_id)
+
+ self.report.num_project_datasets_to_scan[project_id] = len(
+ bigquery_project.datasets
+ )
+ yield from self._process_project_datasets(bigquery_project, db_tables)
+
+ if self.config.is_profiling_enabled():
+ logger.info(f"Starting profiling project {project_id}")
+ self.report.set_ingestion_stage(project_id, PROFILING)
+ yield from self.profiler.get_workunits(
+ project_id=project_id,
+ tables=db_tables,
+ )
+
+ def _process_project_datasets(
+ self,
+ bigquery_project: BigqueryProject,
+ db_tables: Dict[str, List[BigqueryTable]],
+ ) -> Iterable[MetadataWorkUnit]:
+
+ db_views: Dict[str, List[BigqueryView]] = {}
+ db_snapshots: Dict[str, List[BigqueryTableSnapshot]] = {}
+ project_id = bigquery_project.id
+
+ def _process_schema_worker(
+ bigquery_dataset: BigqueryDataset,
+ ) -> Iterable[MetadataWorkUnit]:
+ if not is_schema_allowed(
+ self.config.dataset_pattern,
+ bigquery_dataset.name,
+ project_id,
+ self.config.match_fully_qualified_names,
+ ):
+ self.report.report_dropped(f"{bigquery_dataset.name}.*")
+ return
+ try:
+ # db_tables, db_views, and db_snapshots are populated in the this method
+ for wu in self._process_schema(
+ project_id, bigquery_dataset, db_tables, db_views, db_snapshots
+ ):
+ yield wu
+ except Exception as e:
+ if self.config.is_profiling_enabled():
+ action_mesage = "Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission, bigquery.tables.getData permission?"
+ else:
+ action_mesage = "Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission?"
+
+ self.report.failure(
+ title="Unable to get tables for dataset",
+ message=action_mesage,
+ context=f"{project_id}.{bigquery_dataset.name}",
+ exc=e,
+ )
+
+ for wu in ThreadedIteratorExecutor.process(
+ worker_func=_process_schema_worker,
+ args_list=[(bq_dataset,) for bq_dataset in bigquery_project.datasets],
+ max_workers=self.config.max_threads_dataset_parallelism,
+ ):
+ yield wu
+
+ def _process_schema(
+ self,
+ project_id: str,
+ bigquery_dataset: BigqueryDataset,
+ db_tables: Dict[str, List[BigqueryTable]],
+ db_views: Dict[str, List[BigqueryView]],
+ db_snapshots: Dict[str, List[BigqueryTableSnapshot]],
+ ) -> Iterable[MetadataWorkUnit]:
+ dataset_name = bigquery_dataset.name
+
+ yield from self.gen_dataset_containers(
+ dataset_name, project_id, bigquery_dataset.labels
+ )
+
+ columns = None
+
+ rate_limiter: Optional[RateLimiter] = None
+ if self.config.rate_limit:
+ rate_limiter = RateLimiter(
+ max_calls=self.config.requests_per_min, period=60
+ )
+
+ if (
+ self.config.include_tables
+ or self.config.include_views
+ or self.config.include_table_snapshots
+ ):
+ columns = self.bigquery_data_dictionary.get_columns_for_dataset(
+ project_id=project_id,
+ dataset_name=dataset_name,
+ column_limit=self.config.column_limit,
+ run_optimized_column_query=self.config.run_optimized_column_query,
+ extract_policy_tags_from_catalog=self.config.extract_policy_tags_from_catalog,
+ report=self.report,
+ rate_limiter=rate_limiter,
+ )
+
+ if self.config.include_tables:
+ db_tables[dataset_name] = list(
+ self.get_tables_for_dataset(project_id, dataset_name)
+ )
+
+ for table in db_tables[dataset_name]:
+ table_columns = columns.get(table.name, []) if columns else []
+ table_wu_generator = self._process_table(
+ table=table,
+ columns=table_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+ yield from classification_workunit_processor(
+ table_wu_generator,
+ self.classification_handler,
+ self.data_reader,
+ [project_id, dataset_name, table.name],
+ data_reader_kwargs=dict(
+ sample_size_percent=(
+ self.config.classification.sample_size
+ * SAMPLE_SIZE_MULTIPLIER
+ / table.rows_count
+ if table.rows_count
+ else None
+ )
+ ),
+ )
+ elif self.store_table_refs:
+ # Need table_refs to calculate lineage and usage
+ for table_item in self.bigquery_data_dictionary.list_tables(
+ dataset_name, project_id
+ ):
+ identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=table_item.table_id,
+ )
+ if not self.config.table_pattern.allowed(identifier.raw_table_name()):
+ self.report.report_dropped(identifier.raw_table_name())
+ continue
+ try:
+ self.table_refs.add(
+ str(BigQueryTableRef(identifier).get_sanitized_table_ref())
+ )
+ except Exception as e:
+ logger.warning(
+ f"Could not create table ref for {table_item.path}: {e}"
+ )
+
+ if self.config.include_views:
+ db_views[dataset_name] = list(
+ self.bigquery_data_dictionary.get_views_for_dataset(
+ project_id,
+ dataset_name,
+ self.config.is_profiling_enabled(),
+ self.report,
+ )
+ )
+
+ for view in db_views[dataset_name]:
+ view_columns = columns.get(view.name, []) if columns else []
+ yield from self._process_view(
+ view=view,
+ columns=view_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ if self.config.include_table_snapshots:
+ db_snapshots[dataset_name] = list(
+ self.bigquery_data_dictionary.get_snapshots_for_dataset(
+ project_id,
+ dataset_name,
+ self.config.is_profiling_enabled(),
+ self.report,
+ )
+ )
+
+ for snapshot in db_snapshots[dataset_name]:
+ snapshot_columns = columns.get(snapshot.name, []) if columns else []
+ yield from self._process_snapshot(
+ snapshot=snapshot,
+ columns=snapshot_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ # This method is used to generate the ignore list for datatypes the profiler doesn't support we have to do it here
+ # because the profiler doesn't have access to columns
+ def generate_profile_ignore_list(self, columns: List[BigqueryColumn]) -> List[str]:
+ ignore_list: List[str] = []
+ for column in columns:
+ if not column.data_type or any(
+ word in column.data_type.lower()
+ for word in ["array", "struct", "geography", "json"]
+ ):
+ ignore_list.append(column.field_path)
+ return ignore_list
+
+ def _process_table(
+ self,
+ table: BigqueryTable,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(project_id, dataset_name, table.name)
+
+ self.report.report_entity_scanned(table_identifier.raw_table_name())
+
+ if not self.config.table_pattern.allowed(table_identifier.raw_table_name()):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ if self.store_table_refs:
+ self.table_refs.add(
+ str(BigQueryTableRef(table_identifier).get_sanitized_table_ref())
+ )
+ table.column_count = len(columns)
+
+ # We only collect profile ignore list if profiling is enabled and profile_table_level_only is false
+ if (
+ self.config.is_profiling_enabled()
+ and not self.config.profiling.profile_table_level_only
+ ):
+ table.columns_ignore_from_profiling = self.generate_profile_ignore_list(
+ columns
+ )
+
+ if not table.column_count:
+ logger.warning(
+ f"Table doesn't have any column or unable to get columns for table: {table_identifier}"
+ )
+
+ # If table has time partitioning, set the data type of the partitioning field
+ if table.partition_info:
+ table.partition_info.column = next(
+ (
+ column
+ for column in columns
+ if column.name == table.partition_info.field
+ ),
+ None,
+ )
+ yield from self.gen_table_dataset_workunits(
+ table, columns, project_id, dataset_name
+ )
+
+ def _process_view(
+ self,
+ view: BigqueryView,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(project_id, dataset_name, view.name)
+
+ self.report.report_entity_scanned(table_identifier.raw_table_name(), "view")
+
+ if not self.config.view_pattern.allowed(table_identifier.raw_table_name()):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ if self.store_table_refs:
+ table_ref = str(
+ BigQueryTableRef(table_identifier).get_sanitized_table_ref()
+ )
+ self.table_refs.add(table_ref)
+ if self.config.lineage_parse_view_ddl and view.view_definition:
+ self.view_refs_by_project[project_id].add(table_ref)
+ self.view_definitions[table_ref] = view.view_definition
+
+ view.column_count = len(columns)
+ if not view.column_count:
+ logger.warning(
+ f"View doesn't have any column or unable to get columns for view: {table_identifier}"
+ )
+
+ yield from self.gen_view_dataset_workunits(
+ table=view,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ def _process_snapshot(
+ self,
+ snapshot: BigqueryTableSnapshot,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(
+ project_id, dataset_name, snapshot.name
+ )
+
+ self.report.snapshots_scanned += 1
+
+ if not self.config.table_snapshot_pattern.allowed(
+ table_identifier.raw_table_name()
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ snapshot.columns = columns
+ snapshot.column_count = len(columns)
+ if not snapshot.column_count:
+ logger.warning(
+ f"Snapshot doesn't have any column or unable to get columns for snapshot: {table_identifier}"
+ )
+
+ if self.store_table_refs:
+ table_ref = str(
+ BigQueryTableRef(table_identifier).get_sanitized_table_ref()
+ )
+ self.table_refs.add(table_ref)
+ if snapshot.base_table_identifier:
+ self.snapshot_refs_by_project[project_id].add(table_ref)
+ self.snapshots_by_ref[table_ref] = snapshot
+
+ yield from self.gen_snapshot_dataset_workunits(
+ table=snapshot,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ def gen_table_dataset_workunits(
+ self,
+ table: BigqueryTable,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ custom_properties: Dict[str, str] = {}
+ if table.expires:
+ custom_properties["expiration_date"] = str(table.expires)
+
+ if table.partition_info:
+ custom_properties["partition_info"] = str(table.partition_info)
+
+ if table.size_in_bytes:
+ custom_properties["size_in_bytes"] = str(table.size_in_bytes)
+
+ if table.active_billable_bytes:
+ custom_properties["billable_bytes_active"] = str(
+ table.active_billable_bytes
+ )
+
+ if table.long_term_billable_bytes:
+ custom_properties["billable_bytes_long_term"] = str(
+ table.long_term_billable_bytes
+ )
+
+ if table.max_partition_id:
+ custom_properties["number_of_partitions"] = str(table.num_partitions)
+ custom_properties["max_partition_id"] = str(table.max_partition_id)
+ custom_properties["is_partitioned"] = str(True)
+
+ sub_types: List[str] = [DatasetSubTypes.TABLE]
+ if table.max_shard_id:
+ custom_properties["max_shard_id"] = str(table.max_shard_id)
+ custom_properties["is_sharded"] = str(True)
+ sub_types = ["sharded table"] + sub_types
+
+ tags_to_add = None
+ if table.labels and self.config.capture_table_label_as_tag:
+ tags_to_add = []
+ tags_to_add.extend(
+ [
+ make_tag_urn(f"""{k}:{v}""")
+ for k, v in table.labels.items()
+ if is_tag_allowed(self.config.capture_table_label_as_tag, k)
+ ]
+ )
+
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ sub_types=sub_types,
+ tags_to_add=tags_to_add,
+ custom_properties=custom_properties,
+ )
+
+ def gen_view_dataset_workunits(
+ self,
+ table: BigqueryView,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ tags_to_add = None
+ if table.labels and self.config.capture_view_label_as_tag:
+ tags_to_add = [
+ make_tag_urn(f"{k}:{v}")
+ for k, v in table.labels.items()
+ if is_tag_allowed(self.config.capture_view_label_as_tag, k)
+ ]
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ tags_to_add=tags_to_add,
+ sub_types=[DatasetSubTypes.VIEW],
+ )
+
+ view = cast(BigqueryView, table)
+ view_definition_string = view.view_definition
+ view_properties_aspect = ViewProperties(
+ materialized=view.materialized,
+ viewLanguage="SQL",
+ viewLogic=view_definition_string or "",
+ )
+ yield MetadataChangeProposalWrapper(
+ entityUrn=self.gen_dataset_urn(project_id, dataset_name, table.name),
+ aspect=view_properties_aspect,
+ ).as_workunit()
+
+ def gen_snapshot_dataset_workunits(
+ self,
+ table: BigqueryTableSnapshot,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ custom_properties: Dict[str, str] = {}
+ if table.ddl:
+ custom_properties["snapshot_ddl"] = table.ddl
+ if table.snapshot_time:
+ custom_properties["snapshot_time"] = str(table.snapshot_time)
+ if table.size_in_bytes:
+ custom_properties["size_in_bytes"] = str(table.size_in_bytes)
+ if table.rows_count:
+ custom_properties["rows_count"] = str(table.rows_count)
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ sub_types=[DatasetSubTypes.BIGQUERY_TABLE_SNAPSHOT],
+ custom_properties=custom_properties,
+ )
+
+ def gen_dataset_workunits(
+ self,
+ table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ sub_types: List[str],
+ tags_to_add: Optional[List[str]] = None,
+ custom_properties: Optional[Dict[str, str]] = None,
+ ) -> Iterable[MetadataWorkUnit]:
+ dataset_urn = self.gen_dataset_urn(project_id, dataset_name, table.name)
+
+ status = Status(removed=False)
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=status
+ ).as_workunit()
+
+ datahub_dataset_name = BigqueryTableIdentifier(
+ project_id, dataset_name, table.name
+ )
+
+ yield self.gen_schema_metadata(
+ dataset_urn, table, columns, datahub_dataset_name
+ )
+
+ dataset_properties = DatasetProperties(
+ name=datahub_dataset_name.get_table_display_name(),
+ description=(
+ unquote_and_decode_unicode_escape_seq(table.comment)
+ if table.comment
+ else ""
+ ),
+ qualifiedName=str(datahub_dataset_name),
+ created=(
+ TimeStamp(time=int(table.created.timestamp() * 1000))
+ if table.created is not None
+ else None
+ ),
+ lastModified=(
+ TimeStamp(time=int(table.last_altered.timestamp() * 1000))
+ if table.last_altered is not None
+ else None
+ ),
+ externalUrl=(
+ BQ_EXTERNAL_TABLE_URL_TEMPLATE.format(
+ project=project_id, dataset=dataset_name, table=table.name
+ )
+ if self.config.include_external_url
+ else None
+ ),
+ )
+ if custom_properties:
+ dataset_properties.customProperties.update(custom_properties)
+
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=dataset_properties
+ ).as_workunit()
+
+ if tags_to_add:
+ yield self.gen_tags_aspect_workunit(dataset_urn, tags_to_add)
+
+ yield from add_table_to_schema_container(
+ dataset_urn=dataset_urn,
+ parent_container_key=self.gen_dataset_key(project_id, dataset_name),
+ )
+ yield self.get_dataplatform_instance_aspect(
+ dataset_urn=dataset_urn, project_id=project_id
+ )
+
+ subTypes = SubTypes(typeNames=sub_types)
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=subTypes
+ ).as_workunit()
+
+ if self.domain_registry:
+ yield from get_domain_wu(
+ dataset_name=str(datahub_dataset_name),
+ entity_urn=dataset_urn,
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ )
+
+ def gen_tags_aspect_workunit(
+ self, dataset_urn: str, tags_to_add: List[str]
+ ) -> MetadataWorkUnit:
+ tags = GlobalTagsClass(
+ tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
+ )
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=tags
+ ).as_workunit()
+
+ def gen_schema_fields(self, columns: List[BigqueryColumn]) -> List[SchemaField]:
+ schema_fields: List[SchemaField] = []
+
+ # Below line affects HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR in global scope
+ # TODO: Refractor this such that
+ # converter = HiveColumnToAvroConverter(struct_type_separator=" ");
+ # converter.get_schema_fields_for_hive_column(...)
+ original_struct_type_separator = (
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR
+ )
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = " "
+ _COMPLEX_TYPE = re.compile("^(struct|array)")
+ last_id = -1
+ for col in columns:
+ # if col.data_type is empty that means this column is part of a complex type
+ if col.data_type is None or _COMPLEX_TYPE.match(col.data_type.lower()):
+ # If the we have seen the ordinal position that most probably means we already processed this complex type
+ if last_id != col.ordinal_position:
+ schema_fields.extend(
+ get_schema_fields_for_hive_column(
+ col.name, col.data_type.lower(), description=col.comment
+ )
+ )
+
+ # We have to add complex type comments to the correct level
+ if col.comment:
+ for idx, field in enumerate(schema_fields):
+ # Remove all the [version=2.0].[type=struct]. tags to get the field path
+ if (
+ re.sub(
+ r"\[.*?\]\.",
+ repl="",
+ string=field.fieldPath.lower(),
+ count=0,
+ flags=re.MULTILINE,
+ )
+ == col.field_path.lower()
+ ):
+ field.description = col.comment
+ schema_fields[idx] = field
+ break
+ else:
+ tags = []
+ if col.is_partition_column:
+ tags.append(
+ TagAssociationClass(make_tag_urn(Constants.TAG_PARTITION_KEY))
+ )
+
+ if col.cluster_column_position is not None:
+ tags.append(
+ TagAssociationClass(
+ make_tag_urn(
+ f"{CLUSTERING_COLUMN_TAG}_{col.cluster_column_position}"
+ )
+ )
+ )
+
+ if col.policy_tags:
+ for policy_tag in col.policy_tags:
+ tags.append(TagAssociationClass(make_tag_urn(policy_tag)))
+ field = SchemaField(
+ fieldPath=col.name,
+ type=SchemaFieldDataType(
+ self.BIGQUERY_FIELD_TYPE_MAPPINGS.get(col.data_type, NullType)()
+ ),
+ nativeDataType=col.data_type,
+ description=col.comment,
+ nullable=col.is_nullable,
+ globalTags=GlobalTagsClass(tags=tags),
+ )
+ schema_fields.append(field)
+ last_id = col.ordinal_position
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = (
+ original_struct_type_separator
+ )
+ return schema_fields
+
+ def gen_schema_metadata(
+ self,
+ dataset_urn: str,
+ table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
+ columns: List[BigqueryColumn],
+ dataset_name: BigqueryTableIdentifier,
+ ) -> MetadataWorkUnit:
+ schema_metadata = SchemaMetadata(
+ schemaName=str(dataset_name),
+ platform=make_data_platform_urn(self.platform),
+ version=0,
+ hash="",
+ platformSchema=MySqlDDL(tableSchema=""),
+ # fields=[],
+ fields=self.gen_schema_fields(columns),
+ )
+
+ if self.config.lineage_parse_view_ddl or self.config.lineage_use_sql_parser:
+ self.sql_parser_schema_resolver.add_schema_metadata(
+ dataset_urn, schema_metadata
+ )
+
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=schema_metadata
+ ).as_workunit()
+
+ def get_tables_for_dataset(
+ self,
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[BigqueryTable]:
+ # In bigquery there is no way to query all tables in a Project id
+ with PerfTimer() as timer:
+ # Partitions view throw exception if we try to query partition info for too many tables
+ # so we have to limit the number of tables we query partition info.
+ # The conn.list_tables returns table infos that information_schema doesn't contain and this
+ # way we can merge that info with the queried one.
+ # https://cloud.google.com/bigquery/docs/information-schema-partitions
+ max_batch_size: int = (
+ self.config.number_of_datasets_process_in_batch
+ if not self.config.is_profiling_enabled()
+ else self.config.number_of_datasets_process_in_batch_if_profiling_enabled
+ )
+
+ # We get the list of tables in the dataset to get core table properties and to be able to process the tables in batches
+ # We collect only the latest shards from sharded tables (tables with _YYYYMMDD suffix) and ignore temporary tables
+ table_items = self.get_core_table_details(
+ dataset_name, project_id, self.config.temp_table_dataset_prefix
+ )
+
+ items_to_get: Dict[str, TableListItem] = {}
+ for table_item in table_items:
+ items_to_get[table_item] = table_items[table_item]
+ if len(items_to_get) % max_batch_size == 0:
+ yield from self.bigquery_data_dictionary.get_tables_for_dataset(
+ project_id,
+ dataset_name,
+ items_to_get,
+ with_data_read_permission=self.config.have_table_data_read_permission,
+ report=self.report,
+ )
+ items_to_get.clear()
+
+ if items_to_get:
+ yield from self.bigquery_data_dictionary.get_tables_for_dataset(
+ project_id,
+ dataset_name,
+ items_to_get,
+ with_data_read_permission=self.config.have_table_data_read_permission,
+ report=self.report,
+ )
+
+ self.report.metadata_extraction_sec[f"{project_id}.{dataset_name}"] = round(
+ timer.elapsed_seconds(), 2
+ )
+
+ def get_core_table_details(
+ self, dataset_name: str, project_id: str, temp_table_dataset_prefix: str
+ ) -> Dict[str, TableListItem]:
+ table_items: Dict[str, TableListItem] = {}
+ # Dict to store sharded table and the last seen max shard id
+ sharded_tables: Dict[str, TableListItem] = {}
+
+ for table in self.bigquery_data_dictionary.list_tables(
+ dataset_name, project_id
+ ):
+ table_identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=table.table_id,
+ )
+
+ if table.table_type == "VIEW":
+ if (
+ not self.config.include_views
+ or not self.config.view_pattern.allowed(
+ table_identifier.raw_table_name()
+ )
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+ else:
+ if not self.config.table_pattern.allowed(
+ table_identifier.raw_table_name()
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+
+ _, shard = BigqueryTableIdentifier.get_table_and_shard(
+ table_identifier.table
+ )
+ table_name = table_identifier.get_table_name().split(".")[-1]
+
+ # Sharded tables look like: table_20220120
+ # For sharded tables we only process the latest shard and ignore the rest
+ # to find the latest shard we iterate over the list of tables and store the maximum shard id
+ # We only have one special case where the table name is a date `20220110`
+ # in this case we merge all these tables under dataset name as table name.
+ # For example some_dataset.20220110 will be turned to some_dataset.some_dataset
+ # It seems like there are some bigquery user who uses this non-standard way of sharding the tables.
+ if shard:
+ if table_name not in sharded_tables:
+ sharded_tables[table_name] = table
+ continue
+
+ stored_table_identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=sharded_tables[table_name].table_id,
+ )
+ _, stored_shard = BigqueryTableIdentifier.get_table_and_shard(
+ stored_table_identifier.table
+ )
+ # When table is none, we use dataset_name as table_name
+ assert stored_shard
+ if stored_shard < shard:
+ sharded_tables[table_name] = table
+ continue
+ elif str(table_identifier).startswith(temp_table_dataset_prefix):
+ logger.debug(f"Dropping temporary table {table_identifier.table}")
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+
+ table_items[table.table_id] = table
+
+ # Adding maximum shards to the list of tables
+ table_items.update({value.table_id: value for value in sharded_tables.values()})
+
+ return table_items
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py
new file mode 100644
index 0000000000000..3aac78c154b2e
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py
@@ -0,0 +1,178 @@
+import logging
+from datetime import datetime, timedelta
+from typing import Dict, List, Union
+
+from google.cloud import bigquery
+
+from datahub.ingestion.api.source import (
+ CapabilityReport,
+ SourceCapability,
+ TestConnectionReport,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
+from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
+from datahub.ingestion.source.bigquery_v2.bigquery_schema import BigQuerySchemaApi
+from datahub.ingestion.source.bigquery_v2.lineage import BigqueryLineageExtractor
+from datahub.ingestion.source.bigquery_v2.usage import BigQueryUsageExtractor
+from datahub.sql_parsing.schema_resolver import SchemaResolver
+
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+class BigQueryTestConnection:
+ @staticmethod
+ def test_connection(config_dict: dict) -> TestConnectionReport:
+ test_report = TestConnectionReport()
+ _report: Dict[Union[SourceCapability, str], CapabilityReport] = dict()
+
+ try:
+ connection_conf = BigQueryV2Config.parse_obj_allow_extras(config_dict)
+ client: bigquery.Client = connection_conf.get_bigquery_client()
+ assert client
+
+ test_report.basic_connectivity = BigQueryTestConnection.connectivity_test(
+ client
+ )
+
+ connection_conf.start_time = datetime.now()
+ connection_conf.end_time = datetime.now() + timedelta(minutes=1)
+
+ report: BigQueryV2Report = BigQueryV2Report()
+ project_ids: List[str] = []
+ projects = client.list_projects()
+
+ for project in projects:
+ if connection_conf.project_id_pattern.allowed(project.project_id):
+ project_ids.append(project.project_id)
+
+ metadata_read_capability = (
+ BigQueryTestConnection.metadata_read_capability_test(
+ project_ids, connection_conf
+ )
+ )
+ if SourceCapability.SCHEMA_METADATA not in _report:
+ _report[SourceCapability.SCHEMA_METADATA] = metadata_read_capability
+
+ if connection_conf.include_table_lineage:
+ lineage_capability = BigQueryTestConnection.lineage_capability_test(
+ connection_conf, project_ids, report
+ )
+ if SourceCapability.LINEAGE_COARSE not in _report:
+ _report[SourceCapability.LINEAGE_COARSE] = lineage_capability
+
+ if connection_conf.include_usage_statistics:
+ usage_capability = BigQueryTestConnection.usage_capability_test(
+ connection_conf, project_ids, report
+ )
+ if SourceCapability.USAGE_STATS not in _report:
+ _report[SourceCapability.USAGE_STATS] = usage_capability
+
+ test_report.capability_report = _report
+ return test_report
+
+ except Exception as e:
+ test_report.basic_connectivity = CapabilityReport(
+ capable=False, failure_reason=f"{e}"
+ )
+ return test_report
+
+ @staticmethod
+ def connectivity_test(client: bigquery.Client) -> CapabilityReport:
+ ret = client.query("select 1")
+ if ret.error_result:
+ return CapabilityReport(
+ capable=False, failure_reason=f"{ret.error_result['message']}"
+ )
+ else:
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def metadata_read_capability_test(
+ project_ids: List[str], config: BigQueryV2Config
+ ) -> CapabilityReport:
+ for project_id in project_ids:
+ try:
+ logger.info(f"Metadata read capability test for project {project_id}")
+ client: bigquery.Client = config.get_bigquery_client()
+ assert client
+ bigquery_data_dictionary = BigQuerySchemaApi(
+ BigQueryV2Report().schema_api_perf, client
+ )
+ result = bigquery_data_dictionary.get_datasets_for_project_id(
+ project_id, 10
+ )
+ if len(result) == 0:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Dataset query returned empty dataset. It is either empty or no dataset in project {project_id}",
+ )
+ tables = bigquery_data_dictionary.get_tables_for_dataset(
+ project_id=project_id,
+ dataset_name=result[0].name,
+ tables={},
+ with_data_read_permission=config.have_table_data_read_permission,
+ report=BigQueryV2Report(),
+ )
+ if len(list(tables)) == 0:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Tables query did not return any table. It is either empty or no tables in project {project_id}.{result[0].name}",
+ )
+
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Dataset query failed with error: {e}",
+ )
+
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def lineage_capability_test(
+ connection_conf: BigQueryV2Config,
+ project_ids: List[str],
+ report: BigQueryV2Report,
+ ) -> CapabilityReport:
+ lineage_extractor = BigqueryLineageExtractor(
+ connection_conf, report, lambda ref: ""
+ )
+ for project_id in project_ids:
+ try:
+ logger.info(f"Lineage capability test for project {project_id}")
+ lineage_extractor.test_capability(project_id)
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Lineage capability test failed with: {e}",
+ )
+
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def usage_capability_test(
+ connection_conf: BigQueryV2Config,
+ project_ids: List[str],
+ report: BigQueryV2Report,
+ ) -> CapabilityReport:
+ usage_extractor = BigQueryUsageExtractor(
+ connection_conf,
+ report,
+ schema_resolver=SchemaResolver(platform="bigquery"),
+ dataset_urn_builder=lambda ref: "",
+ )
+ for project_id in project_ids:
+ try:
+ logger.info(f"Usage capability test for project {project_id}")
+ failures_before_test = len(report.failures)
+ usage_extractor.test_capability(project_id)
+ if failures_before_test != len(report.failures):
+ return CapabilityReport(
+ capable=False,
+ failure_reason="Usage capability test failed. Check the logs for further info",
+ )
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Usage capability test failed with: {e} for project {project_id}",
+ )
+ return CapabilityReport(capable=True)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
index c41207ec67f62..496bd64d3b4fe 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
@@ -251,11 +251,6 @@ def get_time_window(self) -> Tuple[datetime, datetime]:
else:
return self.config.start_time, self.config.end_time
- def error(self, log: logging.Logger, key: str, reason: str) -> None:
- # TODO: Remove this method.
- # Note that this downgrades the error to a warning.
- self.report.warning(key, reason)
-
def _should_ingest_lineage(self) -> bool:
if (
self.redundant_run_skip_handler
@@ -265,9 +260,9 @@ def _should_ingest_lineage(self) -> bool:
)
):
# Skip this run
- self.report.report_warning(
- "lineage-extraction",
- "Skip this run as there was already a run for current ingestion window.",
+ self.report.warning(
+ title="Skipped redundant lineage extraction",
+ message="Skip this run as there was already a run for current ingestion window.",
)
return False
@@ -345,12 +340,12 @@ def generate_lineage(
events, sql_parser_schema_resolver
)
except Exception as e:
- if project_id:
- self.report.lineage_failed_extraction.append(project_id)
- self.error(
- logger,
- "lineage",
- f"{project_id}: {e}",
+ self.report.lineage_failed_extraction.append(project_id)
+ self.report.warning(
+ title="Failed to extract lineage",
+ message="Unexpected error encountered",
+ context=project_id,
+ exc=e,
)
lineage = {}
@@ -481,98 +476,88 @@ def lineage_via_catalog_lineage_api(
# Regions to search for BigQuery tables: projects/{project_id}/locations/{region}
enabled_regions: List[str] = ["US", "EU"]
- try:
- lineage_client: lineage_v1.LineageClient = lineage_v1.LineageClient()
+ lineage_client: lineage_v1.LineageClient = lineage_v1.LineageClient()
+
+ data_dictionary = BigQuerySchemaApi(
+ self.report.schema_api_perf, self.config.get_bigquery_client()
+ )
- data_dictionary = BigQuerySchemaApi(
- self.report.schema_api_perf, self.config.get_bigquery_client()
+ # Filtering datasets
+ datasets = list(data_dictionary.get_datasets_for_project_id(project_id))
+ project_tables = []
+ for dataset in datasets:
+ # Enables only tables where type is TABLE, VIEW or MATERIALIZED_VIEW (not EXTERNAL)
+ project_tables.extend(
+ [
+ table
+ for table in data_dictionary.list_tables(dataset.name, project_id)
+ if table.table_type in ["TABLE", "VIEW", "MATERIALIZED_VIEW"]
+ ]
)
- # Filtering datasets
- datasets = list(data_dictionary.get_datasets_for_project_id(project_id))
- project_tables = []
- for dataset in datasets:
- # Enables only tables where type is TABLE, VIEW or MATERIALIZED_VIEW (not EXTERNAL)
- project_tables.extend(
+ lineage_map: Dict[str, Set[LineageEdge]] = {}
+ curr_date = datetime.now()
+ for project_table in project_tables:
+ # Convert project table to .. format
+ table = f"{project_table.project}.{project_table.dataset_id}.{project_table.table_id}"
+
+ if not is_schema_allowed(
+ self.config.dataset_pattern,
+ schema_name=project_table.dataset_id,
+ db_name=project_table.project,
+ match_fully_qualified_schema_name=self.config.match_fully_qualified_names,
+ ) or not self.config.table_pattern.allowed(table):
+ self.report.num_skipped_lineage_entries_not_allowed[
+ project_table.project
+ ] += 1
+ continue
+
+ logger.info("Creating lineage map for table %s", table)
+ upstreams = set()
+ downstream_table = lineage_v1.EntityReference()
+ # fully_qualified_name in format: "bigquery:.."
+ downstream_table.fully_qualified_name = f"bigquery:{table}"
+ # Searches in different regions
+ for region in enabled_regions:
+ location_request = lineage_v1.SearchLinksRequest(
+ target=downstream_table,
+ parent=f"projects/{project_id}/locations/{region.lower()}",
+ )
+ response = lineage_client.search_links(request=location_request)
+ upstreams.update(
[
- table
- for table in data_dictionary.list_tables(
- dataset.name, project_id
+ str(lineage.source.fully_qualified_name).replace(
+ "bigquery:", ""
)
- if table.table_type in ["TABLE", "VIEW", "MATERIALIZED_VIEW"]
+ for lineage in response
]
)
- lineage_map: Dict[str, Set[LineageEdge]] = {}
- curr_date = datetime.now()
- for project_table in project_tables:
- # Convert project table to .. format
- table = f"{project_table.project}.{project_table.dataset_id}.{project_table.table_id}"
-
- if not is_schema_allowed(
- self.config.dataset_pattern,
- schema_name=project_table.dataset_id,
- db_name=project_table.project,
- match_fully_qualified_schema_name=self.config.match_fully_qualified_names,
- ) or not self.config.table_pattern.allowed(table):
- self.report.num_skipped_lineage_entries_not_allowed[
- project_table.project
- ] += 1
- continue
-
- logger.info("Creating lineage map for table %s", table)
- upstreams = set()
- downstream_table = lineage_v1.EntityReference()
- # fully_qualified_name in format: "bigquery:.."
- downstream_table.fully_qualified_name = f"bigquery:{table}"
- # Searches in different regions
- for region in enabled_regions:
- location_request = lineage_v1.SearchLinksRequest(
- target=downstream_table,
- parent=f"projects/{project_id}/locations/{region.lower()}",
- )
- response = lineage_client.search_links(request=location_request)
- upstreams.update(
- [
- str(lineage.source.fully_qualified_name).replace(
- "bigquery:", ""
- )
- for lineage in response
- ]
- )
-
- # Downstream table identifier
- destination_table_str = str(
- BigQueryTableRef(
- table_identifier=BigqueryTableIdentifier(*table.split("."))
- )
+ # Downstream table identifier
+ destination_table_str = str(
+ BigQueryTableRef(
+ table_identifier=BigqueryTableIdentifier(*table.split("."))
)
+ )
- # Only builds lineage map when the table has upstreams
- logger.debug("Found %d upstreams for table %s", len(upstreams), table)
- if upstreams:
- lineage_map[destination_table_str] = {
- LineageEdge(
- table=str(
- BigQueryTableRef(
- table_identifier=BigqueryTableIdentifier.from_string_name(
- source_table
- )
+ # Only builds lineage map when the table has upstreams
+ logger.debug("Found %d upstreams for table %s", len(upstreams), table)
+ if upstreams:
+ lineage_map[destination_table_str] = {
+ LineageEdge(
+ table=str(
+ BigQueryTableRef(
+ table_identifier=BigqueryTableIdentifier.from_string_name(
+ source_table
)
- ),
- column_mapping=frozenset(),
- auditStamp=curr_date,
- )
- for source_table in upstreams
- }
- return lineage_map
- except Exception as e:
- self.error(
- logger,
- "lineage-exported-catalog-lineage-api",
- f"Error: {e}",
- )
- raise e
+ )
+ ),
+ column_mapping=frozenset(),
+ auditStamp=curr_date,
+ )
+ for source_table in upstreams
+ }
+ return lineage_map
def _get_parsed_audit_log_events(self, project_id: str) -> Iterable[QueryEvent]:
# We adjust the filter values a bit, since we need to make sure that the join
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
index 8c393d1e8a436..582c312f99098 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
@@ -227,8 +227,9 @@ def get_profile_request(
if partition is None and bq_table.partition_info:
self.report.report_warning(
- "profile skipped as partitioned table is empty or partition id or type was invalid",
- profile_request.pretty_name,
+ title="Profile skipped for partitioned table",
+ message="profile skipped as partitioned table is empty or partition id or type was invalid",
+ context=profile_request.pretty_name,
)
return None
if (
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
index 1b95cbf505016..6824d630a2277 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
@@ -358,9 +358,9 @@ def _should_ingest_usage(self) -> bool:
)
):
# Skip this run
- self.report.report_warning(
- "usage-extraction",
- "Skip this run as there was already a run for current ingestion window.",
+ self.report.warning(
+ title="Skipped redundant usage extraction",
+ message="Skip this run as there was already a run for current ingestion window.",
)
return False
@@ -410,8 +410,7 @@ def _get_workunits_internal(
)
usage_state.report_disk_usage(self.report)
except Exception as e:
- logger.error("Error processing usage", exc_info=True)
- self.report.report_warning("usage-ingestion", str(e))
+ self.report.warning(message="Error processing usage", exc=e)
self.report_status("usage-ingestion", False)
def generate_read_events_from_query(
@@ -477,10 +476,12 @@ def _ingest_events(
)
except Exception as e:
- logger.warning(
- f"Unable to store usage event {audit_event}", exc_info=True
+ self.report.warning(
+ message="Unable to store usage event",
+ context=f"{audit_event}",
+ exc=e,
)
- self._report_error("store-event", e)
+
logger.info(f"Total number of events aggregated = {num_aggregated}.")
if self.report.num_view_query_events > 0:
@@ -500,11 +501,11 @@ def _generate_operational_workunits(
yield operational_wu
self.report.num_operational_stats_workunits_emitted += 1
except Exception as e:
- logger.warning(
- f"Unable to generate operation workunit for event {audit_event}",
- exc_info=True,
+ self.report.warning(
+ message="Unable to generate operation workunit",
+ context=f"{audit_event}",
+ exc=e,
)
- self._report_error("operation-workunit", e)
def _generate_usage_workunits(
self, usage_state: BigQueryUsageState
@@ -541,11 +542,11 @@ def _generate_usage_workunits(
)
self.report.num_usage_workunits_emitted += 1
except Exception as e:
- logger.warning(
- f"Unable to generate usage workunit for bucket {entry.timestamp}, {entry.resource}",
- exc_info=True,
+ self.report.warning(
+ message="Unable to generate usage statistics workunit",
+ context=f"{entry.timestamp}, {entry.resource}",
+ exc=e,
)
- self._report_error("statistics-workunit", e)
def _get_usage_events(self, projects: Iterable[str]) -> Iterable[AuditEvent]:
if self.config.use_exported_bigquery_audit_metadata:
@@ -559,12 +560,12 @@ def _get_usage_events(self, projects: Iterable[str]) -> Iterable[AuditEvent]:
)
yield from self._get_parsed_bigquery_log_events(project_id)
except Exception as e:
- logger.error(
- f"Error getting usage events for project {project_id}",
- exc_info=True,
- )
self.report.usage_failed_extraction.append(project_id)
- self.report.report_warning(f"usage-extraction-{project_id}", str(e))
+ self.report.warning(
+ message="Failed to get some or all usage events for project",
+ context=project_id,
+ exc=e,
+ )
self.report_status(f"usage-extraction-{project_id}", False)
self.report.usage_extraction_sec[project_id] = round(
@@ -898,12 +899,10 @@ def _get_parsed_bigquery_log_events(
self.report.num_usage_parsed_log_entries[project_id] += 1
yield event
except Exception as e:
- logger.warning(
- f"Unable to parse log entry `{entry}` for project {project_id}",
- exc_info=True,
- )
- self._report_error(
- f"log-parse-{project_id}", e, group="usage-log-parse"
+ self.report.warning(
+ message="Unable to parse usage log entry",
+ context=f"`{entry}` for project {project_id}",
+ exc=e,
)
def _generate_filter(self, corrected_start_time, corrected_end_time):
@@ -946,13 +945,6 @@ def get_tables_from_query(
return parsed_table_refs
- def _report_error(
- self, label: str, e: Exception, group: Optional[str] = None
- ) -> None:
- """Report an error that does not constitute a major failure."""
- self.report.usage_error_count[label] += 1
- self.report.report_warning(group or f"usage-{label}", str(e))
-
def test_capability(self, project_id: str) -> None:
for entry in self._get_parsed_bigquery_log_events(project_id, limit=1):
logger.debug(f"Connection test got one {entry}")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py b/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
index 84547efe37a62..0d9fc8225532c 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
@@ -35,6 +35,7 @@ class DatasetContainerSubTypes(str, Enum):
FOLDER = "Folder"
S3_BUCKET = "S3 bucket"
GCS_BUCKET = "GCS bucket"
+ ABS_CONTAINER = "ABS container"
class BIContainerSubTypes(str, Enum):
diff --git a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
index 5393dd4835d8c..2ebdd2b4126bb 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
@@ -16,6 +16,12 @@
get_s3_prefix,
is_s3_uri,
)
+from datahub.ingestion.source.azure.abs_util import (
+ get_abs_prefix,
+ get_container_name,
+ get_container_relative_path,
+ is_abs_uri,
+)
from datahub.ingestion.source.common.subtypes import DatasetContainerSubTypes
from datahub.ingestion.source.gcs.gcs_utils import (
get_gcs_bucket_name,
@@ -29,6 +35,7 @@
PLATFORM_S3 = "s3"
PLATFORM_GCS = "gcs"
+PLATFORM_ABS = "abs"
class ContainerWUCreator:
@@ -85,6 +92,8 @@ def get_protocol(path: str) -> str:
protocol = get_s3_prefix(path)
elif is_gcs_uri(path):
protocol = get_gcs_prefix(path)
+ elif is_abs_uri(path):
+ protocol = get_abs_prefix(path)
if protocol:
return protocol
@@ -99,7 +108,25 @@ def get_bucket_name(path: str) -> str:
return get_bucket_name(path)
elif is_gcs_uri(path):
return get_gcs_bucket_name(path)
- raise ValueError(f"Unable to get get bucket name form path: {path}")
+ elif is_abs_uri(path):
+ return get_container_name(path)
+ raise ValueError(f"Unable to get bucket name from path: {path}")
+
+ def get_sub_types(self) -> str:
+ if self.platform == PLATFORM_S3:
+ return DatasetContainerSubTypes.S3_BUCKET
+ elif self.platform == PLATFORM_GCS:
+ return DatasetContainerSubTypes.GCS_BUCKET
+ elif self.platform == PLATFORM_ABS:
+ return DatasetContainerSubTypes.ABS_CONTAINER
+ raise ValueError(f"Unable to sub type for platform: {self.platform}")
+
+ def get_base_full_path(self, path: str) -> str:
+ if self.platform == "s3" or self.platform == "gcs":
+ return get_bucket_relative_path(path)
+ elif self.platform == "abs":
+ return get_container_relative_path(path)
+ raise ValueError(f"Unable to get base full path from path: {path}")
def create_container_hierarchy(
self, path: str, dataset_urn: str
@@ -107,22 +134,18 @@ def create_container_hierarchy(
logger.debug(f"Creating containers for {dataset_urn}")
base_full_path = path
parent_key = None
- if self.platform in (PLATFORM_S3, PLATFORM_GCS):
+ if self.platform in (PLATFORM_S3, PLATFORM_GCS, PLATFORM_ABS):
bucket_name = self.get_bucket_name(path)
bucket_key = self.gen_bucket_key(bucket_name)
yield from self.create_emit_containers(
container_key=bucket_key,
name=bucket_name,
- sub_types=[
- DatasetContainerSubTypes.S3_BUCKET
- if self.platform == "s3"
- else DatasetContainerSubTypes.GCS_BUCKET
- ],
+ sub_types=[self.get_sub_types()],
parent_container_key=None,
)
parent_key = bucket_key
- base_full_path = get_bucket_relative_path(path)
+ base_full_path = self.get_base_full_path(path)
parent_folder_path = (
base_full_path[: base_full_path.rfind("/")]
diff --git a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
index 7a807bde2ed0a..e21cdac1edf75 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
@@ -11,6 +11,7 @@
from datahub.configuration.common import ConfigModel
from datahub.ingestion.source.aws.s3_util import is_s3_uri
+from datahub.ingestion.source.azure.abs_util import is_abs_uri
from datahub.ingestion.source.gcs.gcs_utils import is_gcs_uri
# hide annoying debug errors from py4j
@@ -107,7 +108,7 @@ def dir_allowed(self, path: str) -> bool:
# glob_include = self.glob_include.rsplit("/", 1)[0]
glob_include = self.glob_include
- for i in range(slash_to_remove_from_glob):
+ for _ in range(slash_to_remove_from_glob):
glob_include = glob_include.rsplit("/", 1)[0]
logger.debug(f"Checking dir to inclusion: {path}")
@@ -169,7 +170,8 @@ def validate_default_extension(cls, v):
def turn_off_sampling_for_non_s3(cls, v, values):
is_s3 = is_s3_uri(values.get("include") or "")
is_gcs = is_gcs_uri(values.get("include") or "")
- if not is_s3 and not is_gcs:
+ is_abs = is_abs_uri(values.get("include") or "")
+ if not is_s3 and not is_gcs and not is_abs:
# Sampling only makes sense on s3 and gcs currently
v = False
return v
@@ -213,6 +215,10 @@ def is_s3(self):
def is_gcs(self):
return is_gcs_uri(self.include)
+ @cached_property
+ def is_abs(self):
+ return is_abs_uri(self.include)
+
@cached_property
def compiled_include(self):
parsable_include = PathSpec.get_parsable_include(self.include)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py b/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
index 1b6619b4c4d28..bc069bd1e59ac 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
@@ -31,15 +31,12 @@ def __init__(
reporter: LookMLSourceReport,
liquid_variable: Dict[Any, Any],
) -> None:
- self.viewfile_cache: Dict[str, LookerViewFile] = {}
+ self.viewfile_cache: Dict[str, Optional[LookerViewFile]] = {}
self._root_project_name = root_project_name
self._base_projects_folder = base_projects_folder
self.reporter = reporter
self.liquid_variable = liquid_variable
- def is_view_seen(self, path: str) -> bool:
- return path in self.viewfile_cache
-
def _load_viewfile(
self, project_name: str, path: str, reporter: LookMLSourceReport
) -> Optional[LookerViewFile]:
@@ -56,17 +53,15 @@ def _load_viewfile(
)
return None
- if self.is_view_seen(str(path)):
+ if path in self.viewfile_cache:
return self.viewfile_cache[path]
try:
with open(path) as file:
raw_file_content = file.read()
except Exception as e:
- logger.debug(f"An error occurred while reading path {path}", exc_info=True)
- self.reporter.report_failure(
- path, f"failed to load view file {path} from disk: {e}"
- )
+ self.reporter.failure("Failed to read lkml file", path, exc=e)
+ self.viewfile_cache[path] = None
return None
try:
logger.debug(f"Loading viewfile {path}")
@@ -91,8 +86,8 @@ def _load_viewfile(
self.viewfile_cache[path] = looker_viewfile
return looker_viewfile
except Exception as e:
- logger.debug(f"An error occurred while parsing path {path}", exc_info=True)
- self.reporter.report_failure(path, f"failed to load view file {path}: {e}")
+ self.reporter.failure("Failed to parse lkml file", path, exc=e)
+ self.viewfile_cache[path] = None
return None
def load_viewfile(
diff --git a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
index 3d6c746183fd9..bd0bbe742a219 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
@@ -419,7 +419,7 @@ def generate(self) -> Iterable[MetadataWorkUnit]:
for mcp in self.aggregator.gen_metadata():
yield mcp.as_workunit()
if len(self.aggregator.report.observed_query_parse_failures) > 0:
- self.report.report_failure(
+ self.report.report_warning(
title="Failed to extract some SQL lineage",
message="Unexpected error(s) while attempting to extract lineage from SQL queries. See the full logs for more details.",
context=f"Query Parsing Failures: {self.aggregator.report.observed_query_parse_failures}",
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
index 2a1d18c83e6fa..a7c008d932a71 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
@@ -11,14 +11,13 @@
)
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.source.snowflake.snowflake_config import (
- SnowflakeIdentifierConfig,
- SnowflakeV2Config,
-)
+from datahub.ingestion.source.snowflake.snowflake_config import SnowflakeV2Config
from datahub.ingestion.source.snowflake.snowflake_connection import SnowflakeConnection
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeIdentifierMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeIdentifierBuilder,
+)
from datahub.metadata.com.linkedin.pegasus2avro.assertion import (
AssertionResult,
AssertionResultType,
@@ -40,23 +39,20 @@ class DataQualityMonitoringResult(BaseModel):
VALUE: int
-class SnowflakeAssertionsHandler(SnowflakeIdentifierMixin):
+class SnowflakeAssertionsHandler:
def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
+ identifiers: SnowflakeIdentifierBuilder,
) -> None:
self.config = config
self.report = report
- self.logger = logger
self.connection = connection
+ self.identifiers = identifiers
self._urns_processed: List[str] = []
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
-
def get_assertion_workunits(
self, discovered_datasets: List[str]
) -> Iterable[MetadataWorkUnit]:
@@ -80,10 +76,10 @@ def _gen_platform_instance_wu(self, urn: str) -> MetadataWorkUnit:
return MetadataChangeProposalWrapper(
entityUrn=urn,
aspect=DataPlatformInstance(
- platform=make_data_platform_urn(self.platform),
+ platform=make_data_platform_urn(self.identifiers.platform),
instance=(
make_dataplatform_instance_urn(
- self.platform, self.config.platform_instance
+ self.identifiers.platform, self.config.platform_instance
)
if self.config.platform_instance
else None
@@ -98,7 +94,7 @@ def _process_result_row(
result = DataQualityMonitoringResult.parse_obj(result_row)
assertion_guid = result.METRIC_NAME.split("__")[-1].lower()
status = bool(result.VALUE) # 1 if PASS, 0 if FAIL
- assertee = self.get_dataset_identifier(
+ assertee = self.identifiers.get_dataset_identifier(
result.TABLE_NAME, result.TABLE_SCHEMA, result.TABLE_DATABASE
)
if assertee in discovered_datasets:
@@ -107,7 +103,7 @@ def _process_result_row(
aspect=AssertionRunEvent(
timestampMillis=datetime_to_ts_millis(result.MEASUREMENT_TIME),
runId=result.MEASUREMENT_TIME.strftime("%Y-%m-%dT%H:%M:%SZ"),
- asserteeUrn=self.gen_dataset_urn(assertee),
+ asserteeUrn=self.identifiers.gen_dataset_urn(assertee),
status=AssertionRunStatus.COMPLETE,
assertionUrn=make_assertion_urn(assertion_guid),
result=AssertionResult(
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
index f6247eb949417..ac9164cd0a000 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
@@ -131,6 +131,7 @@ class SnowflakeIdentifierConfig(
# Changing default value here.
convert_urns_to_lowercase: bool = Field(
default=True,
+ description="Whether to convert dataset urns to lowercase.",
)
@@ -181,6 +182,11 @@ class SnowflakeV2Config(
description="If enabled, populates the snowflake usage statistics. Requires appropriate grants given to the role.",
)
+ include_view_definitions: bool = Field(
+ default=True,
+ description="If enabled, populates the ingested views' definitions.",
+ )
+
include_technical_schema: bool = Field(
default=True,
description="If enabled, populates the snowflake technical schema and descriptions.",
@@ -205,8 +211,13 @@ class SnowflakeV2Config(
description="Populates view->view and table->view column lineage using DataHub's sql parser.",
)
- lazy_schema_resolver: bool = Field(
+ use_queries_v2: bool = Field(
default=False,
+ description="If enabled, uses the new queries extractor to extract queries from snowflake.",
+ )
+
+ lazy_schema_resolver: bool = Field(
+ default=True,
description="If enabled, uses lazy schema resolver to resolve schemas for tables and views. "
"This is useful if you have a large number of schemas and want to avoid bulk fetching the schema for each table/view.",
)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
index 3e65f06200418..151e9fb631620 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
@@ -2,7 +2,7 @@
import logging
from dataclasses import dataclass
from datetime import datetime
-from typing import Any, Callable, Collection, Iterable, List, Optional, Set, Tuple, Type
+from typing import Any, Collection, Iterable, List, Optional, Set, Tuple, Type
from pydantic import BaseModel, validator
@@ -21,7 +21,11 @@
)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeCommonMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantLineageRunSkipHandler,
)
@@ -119,18 +123,19 @@ def __init__(
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
redundant_run_skip_handler: Optional[RedundantLineageRunSkipHandler],
sql_aggregator: SqlParsingAggregator,
) -> None:
self.config = config
self.report = report
- self.logger = logger
- self.dataset_urn_builder = dataset_urn_builder
self.connection = connection
+ self.filters = filters
+ self.identifiers = identifiers
+ self.redundant_run_skip_handler = redundant_run_skip_handler
self.sql_aggregator = sql_aggregator
- self.redundant_run_skip_handler = redundant_run_skip_handler
self.start_time, self.end_time = (
self.report.lineage_start_time,
self.report.lineage_end_time,
@@ -210,7 +215,7 @@ def populate_known_query_lineage(
results: Iterable[UpstreamLineageEdge],
) -> None:
for db_row in results:
- dataset_name = self.get_dataset_identifier_from_qualified_name(
+ dataset_name = self.identifiers.get_dataset_identifier_from_qualified_name(
db_row.DOWNSTREAM_TABLE_NAME
)
if dataset_name not in discovered_assets or not db_row.QUERIES:
@@ -233,7 +238,7 @@ def get_known_query_lineage(
if not db_row.UPSTREAM_TABLES:
return None
- downstream_table_urn = self.dataset_urn_builder(dataset_name)
+ downstream_table_urn = self.identifiers.gen_dataset_urn(dataset_name)
known_lineage = KnownQueryLineageInfo(
query_text=query.query_text,
@@ -288,7 +293,7 @@ def _populate_external_lineage_from_show_query(
external_tables_query: str = SnowflakeQuery.show_external_tables()
try:
for db_row in self.connection.query(external_tables_query):
- key = self.get_dataset_identifier(
+ key = self.identifiers.get_dataset_identifier(
db_row["name"], db_row["schema_name"], db_row["database_name"]
)
@@ -299,16 +304,16 @@ def _populate_external_lineage_from_show_query(
upstream_urn=make_s3_urn_for_lineage(
db_row["location"], self.config.env
),
- downstream_urn=self.dataset_urn_builder(key),
+ downstream_urn=self.identifiers.gen_dataset_urn(key),
)
self.report.num_external_table_edges_scanned += 1
self.report.num_external_table_edges_scanned += 1
except Exception as e:
logger.debug(e, exc_info=e)
- self.report_warning(
- "external_lineage",
- f"Populating external table lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Error populating external table lineage from Snowflake",
+ exc=e,
)
self.report_status(EXTERNAL_LINEAGE, False)
@@ -328,41 +333,47 @@ def _populate_external_lineage_from_copy_history(
try:
for db_row in self.connection.query(query):
known_lineage_mapping = self._process_external_lineage_result_row(
- db_row, discovered_tables
+ db_row, discovered_tables, identifiers=self.identifiers
)
if known_lineage_mapping:
+ self.report.num_external_table_edges_scanned += 1
yield known_lineage_mapping
except Exception as e:
if isinstance(e, SnowflakePermissionError):
error_msg = "Failed to get external lineage. Please grant imported privileges on SNOWFLAKE database. "
self.warn_if_stateful_else_error(LINEAGE_PERMISSION_ERROR, error_msg)
else:
- logger.debug(e, exc_info=e)
- self.report_warning(
- "external_lineage",
- f"Populating table external lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Error fetching external lineage from Snowflake",
+ exc=e,
)
self.report_status(EXTERNAL_LINEAGE, False)
+ @classmethod
def _process_external_lineage_result_row(
- self, db_row: dict, discovered_tables: List[str]
+ cls,
+ db_row: dict,
+ discovered_tables: Optional[List[str]],
+ identifiers: SnowflakeIdentifierBuilder,
) -> Optional[KnownLineageMapping]:
# key is the down-stream table name
- key: str = self.get_dataset_identifier_from_qualified_name(
+ key: str = identifiers.get_dataset_identifier_from_qualified_name(
db_row["DOWNSTREAM_TABLE_NAME"]
)
- if key not in discovered_tables:
+ if discovered_tables is not None and key not in discovered_tables:
return None
if db_row["UPSTREAM_LOCATIONS"] is not None:
external_locations = json.loads(db_row["UPSTREAM_LOCATIONS"])
+ loc: str
for loc in external_locations:
if loc.startswith("s3://"):
- self.report.num_external_table_edges_scanned += 1
return KnownLineageMapping(
- upstream_urn=make_s3_urn_for_lineage(loc, self.config.env),
- downstream_urn=self.dataset_urn_builder(key),
+ upstream_urn=make_s3_urn_for_lineage(
+ loc, identifiers.identifier_config.env
+ ),
+ downstream_urn=identifiers.gen_dataset_urn(key),
)
return None
@@ -388,10 +399,9 @@ def _fetch_upstream_lineages_for_tables(self) -> Iterable[UpstreamLineageEdge]:
error_msg = "Failed to get table/view to table lineage. Please grant imported privileges on SNOWFLAKE database. "
self.warn_if_stateful_else_error(LINEAGE_PERMISSION_ERROR, error_msg)
else:
- logger.debug(e, exc_info=e)
- self.report_warning(
- "table-upstream-lineage",
- f"Extracting lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Failed to extract table/view -> table lineage from Snowflake",
+ exc=e,
)
self.report_status(TABLE_LINEAGE, False)
@@ -402,9 +412,10 @@ def _process_upstream_lineage_row(
return UpstreamLineageEdge.parse_obj(db_row)
except Exception as e:
self.report.num_upstream_lineage_edge_parsing_failed += 1
- self.report_warning(
- f"Parsing lineage edge failed due to error {e}",
- db_row.get("DOWNSTREAM_TABLE_NAME") or "",
+ self.structured_reporter.warning(
+ "Failed to parse lineage edge",
+ context=db_row.get("DOWNSTREAM_TABLE_NAME") or None,
+ exc=e,
)
return None
@@ -417,17 +428,21 @@ def map_query_result_upstreams(
for upstream_table in upstream_tables:
if upstream_table and upstream_table.query_id == query_id:
try:
- upstream_name = self.get_dataset_identifier_from_qualified_name(
- upstream_table.upstream_object_name
+ upstream_name = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ upstream_table.upstream_object_name
+ )
)
if upstream_name and (
not self.config.validate_upstreams_against_patterns
- or self.is_dataset_pattern_allowed(
+ or self.filters.is_dataset_pattern_allowed(
upstream_name,
upstream_table.upstream_object_domain,
)
):
- upstreams.append(self.dataset_urn_builder(upstream_name))
+ upstreams.append(
+ self.identifiers.gen_dataset_urn(upstream_name)
+ )
except Exception as e:
logger.debug(e, exc_info=e)
return upstreams
@@ -491,7 +506,7 @@ def build_finegrained_lineage(
return None
column_lineage = ColumnLineageInfo(
downstream=DownstreamColumnRef(
- table=dataset_urn, column=self.snowflake_identifier(col)
+ table=dataset_urn, column=self.identifiers.snowflake_identifier(col)
),
upstreams=sorted(column_upstreams),
)
@@ -508,19 +523,23 @@ def build_finegrained_lineage_upstreams(
and upstream_col.column_name
and (
not self.config.validate_upstreams_against_patterns
- or self.is_dataset_pattern_allowed(
+ or self.filters.is_dataset_pattern_allowed(
upstream_col.object_name,
upstream_col.object_domain,
)
)
):
- upstream_dataset_name = self.get_dataset_identifier_from_qualified_name(
- upstream_col.object_name
+ upstream_dataset_name = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ upstream_col.object_name
+ )
)
column_upstreams.append(
ColumnRef(
- table=self.dataset_urn_builder(upstream_dataset_name),
- column=self.snowflake_identifier(upstream_col.column_name),
+ table=self.identifiers.gen_dataset_urn(upstream_dataset_name),
+ column=self.identifiers.snowflake_identifier(
+ upstream_col.column_name
+ ),
)
)
return column_upstreams
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
index 4deeb9f96f48e..422bda5284dbc 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
@@ -37,7 +37,6 @@ def __init__(
super().__init__(config, report, self.platform, state_handler)
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
- self.logger = logger
self.database_default_schema: Dict[str, str] = dict()
def get_workunits(
@@ -86,7 +85,7 @@ def get_workunits(
)
def get_dataset_name(self, table_name: str, schema_name: str, db_name: str) -> str:
- return self.get_dataset_identifier(table_name, schema_name, db_name)
+ return self.identifiers.get_dataset_identifier(table_name, schema_name, db_name)
def get_batch_kwargs(
self, table: BaseTable, schema_name: str, db_name: str
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
index c647a624a5467..d5b8f98e40075 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
@@ -1,3 +1,4 @@
+import dataclasses
import functools
import json
import logging
@@ -11,6 +12,7 @@
import pydantic
from typing_extensions import Self
+from datahub.configuration.common import ConfigModel
from datahub.configuration.time_window_config import (
BaseTimeWindowConfig,
BucketDuration,
@@ -20,6 +22,7 @@
from datahub.ingestion.api.source import Source, SourceReport
from datahub.ingestion.api.source_helpers import auto_workunit
from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.graph.client import DataHubGraph
from datahub.ingestion.source.snowflake.constants import SnowflakeObjectDomain
from datahub.ingestion.source.snowflake.snowflake_config import (
DEFAULT_TEMP_TABLES_PATTERNS,
@@ -30,13 +33,18 @@
SnowflakeConnection,
SnowflakeConnectionConfig,
)
+from datahub.ingestion.source.snowflake.snowflake_lineage_v2 import (
+ SnowflakeLineageExtractor,
+)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_utils import (
- SnowflakeFilterMixin,
- SnowflakeIdentifierMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+ SnowflakeStructuredReportMixin,
)
from datahub.ingestion.source.usage.usage_common import BaseUsageConfig
from datahub.metadata.urns import CorpUserUrn
+from datahub.sql_parsing.schema_resolver import SchemaResolver
from datahub.sql_parsing.sql_parsing_aggregator import (
KnownLineageMapping,
PreparsedQuery,
@@ -50,11 +58,12 @@
DownstreamColumnRef,
)
from datahub.utilities.file_backed_collections import ConnectionWrapper, FileBackedList
+from datahub.utilities.perf_timer import PerfTimer
logger = logging.getLogger(__name__)
-class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilterConfig):
+class SnowflakeQueriesExtractorConfig(ConfigModel):
# TODO: Support stateful ingestion for the time windows.
window: BaseTimeWindowConfig = BaseTimeWindowConfig()
@@ -76,12 +85,6 @@ class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilter
hidden_from_docs=True,
)
- convert_urns_to_lowercase: bool = pydantic.Field(
- # Override the default.
- default=True,
- description="Whether to convert dataset urns to lowercase.",
- )
-
include_lineage: bool = True
include_queries: bool = True
include_usage_statistics: bool = True
@@ -89,40 +92,56 @@ class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilter
include_operations: bool = True
-class SnowflakeQueriesSourceConfig(SnowflakeQueriesExtractorConfig):
+class SnowflakeQueriesSourceConfig(
+ SnowflakeQueriesExtractorConfig, SnowflakeIdentifierConfig, SnowflakeFilterConfig
+):
connection: SnowflakeConnectionConfig
@dataclass
class SnowflakeQueriesExtractorReport(Report):
- window: Optional[BaseTimeWindowConfig] = None
+ copy_history_fetch_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ query_log_fetch_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ audit_log_load_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
sql_aggregator: Optional[SqlAggregatorReport] = None
@dataclass
class SnowflakeQueriesSourceReport(SourceReport):
+ window: Optional[BaseTimeWindowConfig] = None
queries_extractor: Optional[SnowflakeQueriesExtractorReport] = None
-class SnowflakeQueriesExtractor(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
+class SnowflakeQueriesExtractor(SnowflakeStructuredReportMixin):
def __init__(
self,
connection: SnowflakeConnection,
config: SnowflakeQueriesExtractorConfig,
structured_report: SourceReport,
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
+ graph: Optional[DataHubGraph] = None,
+ schema_resolver: Optional[SchemaResolver] = None,
+ discovered_tables: Optional[List[str]] = None,
):
self.connection = connection
self.config = config
self.report = SnowflakeQueriesExtractorReport()
+ self.filters = filters
+ self.identifiers = identifiers
+ self.discovered_tables = discovered_tables
+
self._structured_report = structured_report
self.aggregator = SqlParsingAggregator(
- platform=self.platform,
- platform_instance=self.config.platform_instance,
- env=self.config.env,
- # graph=self.ctx.graph,
+ platform=self.identifiers.platform,
+ platform_instance=self.identifiers.identifier_config.platform_instance,
+ env=self.identifiers.identifier_config.env,
+ schema_resolver=schema_resolver,
+ graph=graph,
+ eager_graph_load=False,
generate_lineage=self.config.include_lineage,
generate_queries=self.config.include_queries,
generate_usage_statistics=self.config.include_usage_statistics,
@@ -144,14 +163,6 @@ def __init__(
def structured_reporter(self) -> SourceReport:
return self._structured_report
- @property
- def filter_config(self) -> SnowflakeFilterConfig:
- return self.config
-
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
-
@functools.cached_property
def local_temp_path(self) -> pathlib.Path:
if self.config.local_temp_path:
@@ -170,13 +181,16 @@ def is_temp_table(self, name: str) -> bool:
)
def is_allowed_table(self, name: str) -> bool:
- return self.is_dataset_pattern_allowed(name, SnowflakeObjectDomain.TABLE)
+ if self.discovered_tables and name not in self.discovered_tables:
+ return False
+
+ return self.filters.is_dataset_pattern_allowed(
+ name, SnowflakeObjectDomain.TABLE
+ )
def get_workunits_internal(
self,
) -> Iterable[MetadataWorkUnit]:
- self.report.window = self.config.window
-
# TODO: Add some logic to check if the cached audit log is stale or not.
audit_log_file = self.local_temp_path / "audit_log.sqlite"
use_cached_audit_log = audit_log_file.exists()
@@ -191,74 +205,90 @@ def get_workunits_internal(
shared_connection = ConnectionWrapper(audit_log_file)
queries = FileBackedList(shared_connection)
+ entry: Union[KnownLineageMapping, PreparsedQuery]
+
+ with self.report.copy_history_fetch_timer:
+ for entry in self.fetch_copy_history():
+ queries.append(entry)
- logger.info("Fetching audit log")
- for entry in self.fetch_audit_log():
- queries.append(entry)
+ # TODO: Add "show external tables" lineage to the main schema extractor.
+ # Because it's not a time-based thing, it doesn't really make sense in the snowflake-queries extractor.
- for query in queries:
- self.aggregator.add(query)
+ with self.report.query_log_fetch_timer:
+ for entry in self.fetch_query_log():
+ queries.append(entry)
+
+ with self.report.audit_log_load_timer:
+ for query in queries:
+ self.aggregator.add(query)
yield from auto_workunit(self.aggregator.gen_metadata())
- def fetch_audit_log(
- self,
- ) -> Iterable[Union[KnownLineageMapping, PreparsedQuery]]:
- """
- # TODO: we need to fetch this info from somewhere
- discovered_tables = []
-
- snowflake_lineage_v2 = SnowflakeLineageExtractor(
- config=self.config, # type: ignore
- report=self.report, # type: ignore
- dataset_urn_builder=self.gen_dataset_urn,
- redundant_run_skip_handler=None,
- sql_aggregator=self.aggregator, # TODO this should be unused
- )
+ def fetch_copy_history(self) -> Iterable[KnownLineageMapping]:
+ # Derived from _populate_external_lineage_from_copy_history.
- for (
- known_lineage_mapping
- ) in snowflake_lineage_v2._populate_external_lineage_from_copy_history(
- discovered_tables=discovered_tables
- ):
- interim_results.append(known_lineage_mapping)
+ query: str = SnowflakeQuery.copy_lineage_history(
+ start_time_millis=int(self.config.window.start_time.timestamp() * 1000),
+ end_time_millis=int(self.config.window.end_time.timestamp() * 1000),
+ downstreams_deny_pattern=self.config.temporary_tables_pattern,
+ )
- for (
- known_lineage_mapping
- ) in snowflake_lineage_v2._populate_external_lineage_from_show_query(
- discovered_tables=discovered_tables
+ with self.structured_reporter.report_exc(
+ "Error fetching copy history from Snowflake"
):
- interim_results.append(known_lineage_mapping)
- """
+ logger.info("Fetching copy history from Snowflake")
+ resp = self.connection.query(query)
+
+ for row in resp:
+ try:
+ result = (
+ SnowflakeLineageExtractor._process_external_lineage_result_row(
+ row,
+ discovered_tables=self.discovered_tables,
+ identifiers=self.identifiers,
+ )
+ )
+ except Exception as e:
+ self.structured_reporter.warning(
+ "Error parsing copy history row",
+ context=f"{row}",
+ exc=e,
+ )
+ else:
+ if result:
+ yield result
- audit_log_query = _build_enriched_audit_log_query(
+ def fetch_query_log(
+ self,
+ ) -> Iterable[PreparsedQuery]:
+ query_log_query = _build_enriched_query_log_query(
start_time=self.config.window.start_time,
end_time=self.config.window.end_time,
bucket_duration=self.config.window.bucket_duration,
deny_usernames=self.config.deny_usernames,
)
- resp = self.connection.query(audit_log_query)
-
- for i, row in enumerate(resp):
- if i % 1000 == 0:
- logger.info(f"Processed {i} audit log rows")
-
- assert isinstance(row, dict)
- try:
- entry = self._parse_audit_log_row(row)
- except Exception as e:
- self.structured_reporter.warning(
- "Error parsing audit log row",
- context=f"{row}",
- exc=e,
- )
- else:
- yield entry
-
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- # Copied from SnowflakeCommonMixin.
- return self.snowflake_identifier(self.cleanup_qualified_name(qualified_name))
+ with self.structured_reporter.report_exc(
+ "Error fetching query log from Snowflake"
+ ):
+ logger.info("Fetching query log from Snowflake")
+ resp = self.connection.query(query_log_query)
+
+ for i, row in enumerate(resp):
+ if i % 1000 == 0:
+ logger.info(f"Processed {i} query log rows")
+
+ assert isinstance(row, dict)
+ try:
+ entry = self._parse_audit_log_row(row)
+ except Exception as e:
+ self.structured_reporter.warning(
+ "Error parsing query log row",
+ context=f"{row}",
+ exc=e,
+ )
+ else:
+ yield entry
def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
json_fields = {
@@ -280,13 +310,17 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
column_usage = {}
for obj in direct_objects_accessed:
- dataset = self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(obj["objectName"])
+ dataset = self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ obj["objectName"]
+ )
)
columns = set()
for modified_column in obj["columns"]:
- columns.add(self.snowflake_identifier(modified_column["columnName"]))
+ columns.add(
+ self.identifiers.snowflake_identifier(modified_column["columnName"])
+ )
upstreams.append(dataset)
column_usage[dataset] = columns
@@ -301,8 +335,10 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
context=f"{row}",
)
- downstream = self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(obj["objectName"])
+ downstream = self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ obj["objectName"]
+ )
)
column_lineage = []
for modified_column in obj["columns"]:
@@ -310,18 +346,18 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
ColumnLineageInfo(
downstream=DownstreamColumnRef(
dataset=downstream,
- column=self.snowflake_identifier(
+ column=self.identifiers.snowflake_identifier(
modified_column["columnName"]
),
),
upstreams=[
ColumnRef(
- table=self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(
+ table=self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
upstream["objectName"]
)
),
- column=self.snowflake_identifier(
+ column=self.identifiers.snowflake_identifier(
upstream["columnName"]
),
)
@@ -332,12 +368,9 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
)
)
- # TODO: Support filtering the table names.
- # if objects_modified:
- # breakpoint()
-
- # TODO implement email address mapping
- user = CorpUserUrn(res["user_name"])
+ # TODO: Fetch email addresses from Snowflake to map user -> email
+ # TODO: Support email_domain fallback for generating user urns.
+ user = CorpUserUrn(self.identifiers.snowflake_identifier(res["user_name"]))
timestamp: datetime = res["query_start_time"]
timestamp = timestamp.astimezone(timezone.utc)
@@ -348,14 +381,18 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
)
entry = PreparsedQuery(
- query_id=res["query_fingerprint"],
+ # Despite having Snowflake's fingerprints available, our own fingerprinting logic does a better
+ # job at eliminating redundant / repetitive queries. As such, we don't include the fingerprint
+ # here so that the aggregator auto-generates one.
+ # query_id=res["query_fingerprint"],
+ query_id=None,
query_text=res["query_text"],
upstreams=upstreams,
downstream=downstream,
column_lineage=column_lineage,
column_usage=column_usage,
inferred_schema=None,
- confidence_score=1,
+ confidence_score=1.0,
query_count=res["query_count"],
user=user,
timestamp=timestamp,
@@ -371,7 +408,14 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeQueriesSourceConfig):
self.config = config
self.report = SnowflakeQueriesSourceReport()
- self.platform = "snowflake"
+ self.filters = SnowflakeFilter(
+ filter_config=self.config,
+ structured_reporter=self.report,
+ )
+ self.identifiers = SnowflakeIdentifierBuilder(
+ identifier_config=self.config,
+ structured_reporter=self.report,
+ )
self.connection = self.config.connection.get_connection()
@@ -379,6 +423,9 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeQueriesSourceConfig):
connection=self.connection,
config=self.config,
structured_report=self.report,
+ filters=self.filters,
+ identifiers=self.identifiers,
+ graph=self.ctx.graph,
)
self.report.queries_extractor = self.queries_extractor.report
@@ -388,6 +435,8 @@ def create(cls, config_dict: dict, ctx: PipelineContext) -> Self:
return cls(ctx, config)
def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
+ self.report.window = self.config.window
+
# TODO: Disable auto status processor?
return self.queries_extractor.get_workunits_internal()
@@ -399,7 +448,7 @@ def get_report(self) -> SnowflakeQueriesSourceReport:
_MAX_TABLES_PER_QUERY = 20
-def _build_enriched_audit_log_query(
+def _build_enriched_query_log_query(
start_time: datetime,
end_time: datetime,
bucket_duration: BucketDuration,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
index 4924546383aa4..80b6be36e5ffa 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
@@ -15,6 +15,9 @@
from datahub.utilities.perf_timer import PerfTimer
if TYPE_CHECKING:
+ from datahub.ingestion.source.snowflake.snowflake_queries import (
+ SnowflakeQueriesExtractorReport,
+ )
from datahub.ingestion.source.snowflake.snowflake_schema import (
SnowflakeDataDictionary,
)
@@ -113,6 +116,8 @@ class SnowflakeV2Report(
data_dictionary_cache: Optional["SnowflakeDataDictionary"] = None
+ queries_extractor: Optional["SnowflakeQueriesExtractorReport"] = None
+
# These will be non-zero if snowflake information_schema queries fail with error -
# "Information schema query returned too much data. Please repeat query with more selective predicates.""
# This will result in overall increase in time complexity
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
index ce8f20d23aa6b..600292c2c9942 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
@@ -185,8 +185,6 @@ def get_column_tags_for_table(
class SnowflakeDataDictionary(SupportsAsObj):
def __init__(self, connection: SnowflakeConnection) -> None:
- self.logger = logger
-
self.connection = connection
def as_obj(self) -> Dict[str, Dict[str, int]]:
@@ -514,7 +512,7 @@ def get_tags_for_database_without_propagation(
)
else:
# This should never happen.
- self.logger.error(f"Encountered an unexpected domain: {domain}")
+ logger.error(f"Encountered an unexpected domain: {domain}")
continue
return tags
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
index e604ed96b8eb6..1d4a5b377da14 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
@@ -1,8 +1,6 @@
-import concurrent.futures
import itertools
import logging
-import queue
-from typing import Callable, Dict, Iterable, List, Optional, Union
+from typing import Dict, Iterable, List, Optional, Union
from datahub.configuration.pattern_utils import is_schema_allowed
from datahub.emitter.mce_builder import (
@@ -28,8 +26,6 @@
SnowflakeObjectDomain,
)
from datahub.ingestion.source.snowflake.snowflake_config import (
- SnowflakeFilterConfig,
- SnowflakeIdentifierConfig,
SnowflakeV2Config,
TagOption,
)
@@ -54,8 +50,9 @@
)
from datahub.ingestion.source.snowflake.snowflake_tag import SnowflakeTagExtractor
from datahub.ingestion.source.snowflake.snowflake_utils import (
- SnowflakeFilterMixin,
- SnowflakeIdentifierMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+ SnowflakeStructuredReportMixin,
SnowsightUrlBuilder,
)
from datahub.ingestion.source.sql.sql_utils import (
@@ -101,6 +98,7 @@
from datahub.metadata.com.linkedin.pegasus2avro.tag import TagProperties
from datahub.sql_parsing.sql_parsing_aggregator import SqlParsingAggregator
from datahub.utilities.registries.domain_registry import DomainRegistry
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
logger = logging.getLogger(__name__)
@@ -143,13 +141,16 @@
}
-class SnowflakeSchemaGenerator(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
+class SnowflakeSchemaGenerator(SnowflakeStructuredReportMixin):
+ platform = "snowflake"
+
def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
domain_registry: Optional[DomainRegistry],
profiler: Optional[SnowflakeProfiler],
aggregator: Optional[SqlParsingAggregator],
@@ -158,7 +159,8 @@ def __init__(
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
self.connection: SnowflakeConnection = connection
- self.dataset_urn_builder = dataset_urn_builder
+ self.filters: SnowflakeFilter = filters
+ self.identifiers: SnowflakeIdentifierBuilder = identifiers
self.data_dictionary: SnowflakeDataDictionary = SnowflakeDataDictionary(
connection=self.connection
@@ -186,19 +188,17 @@ def get_connection(self) -> SnowflakeConnection:
def structured_reporter(self) -> SourceReport:
return self.report
- @property
- def filter_config(self) -> SnowflakeFilterConfig:
- return self.config
+ def gen_dataset_urn(self, dataset_identifier: str) -> str:
+ return self.identifiers.gen_dataset_urn(dataset_identifier)
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
+ def snowflake_identifier(self, identifier: str) -> str:
+ return self.identifiers.snowflake_identifier(identifier)
def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
self.databases = []
for database in self.get_databases() or []:
self.report.report_entity_scanned(database.name, "database")
- if not self.filter_config.database_pattern.allowed(database.name):
+ if not self.filters.filter_config.database_pattern.allowed(database.name):
self.report.report_dropped(f"{database.name}.*")
else:
self.databases.append(database)
@@ -212,7 +212,10 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
yield from self._process_database(snowflake_db)
except SnowflakePermissionError as e:
- self.report_error(GENERIC_PERMISSION_ERROR_KEY, str(e))
+ self.structured_reporter.failure(
+ GENERIC_PERMISSION_ERROR_KEY,
+ exc=e,
+ )
return
def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
@@ -221,10 +224,9 @@ def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
# whose information_schema can be queried to start with.
databases = self.data_dictionary.show_databases()
except Exception as e:
- logger.debug(f"Failed to list databases due to error {e}", exc_info=e)
- self.report_error(
- "list-databases",
- f"Failed to list databases due to error {e}",
+ self.structured_reporter.failure(
+ "Failed to list databases",
+ exc=e,
)
return None
else:
@@ -233,7 +235,7 @@ def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
] = self.get_databases_from_ischema(databases)
if len(ischema_databases) == 0:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
"No databases found. Please check permissions.",
)
@@ -276,7 +278,7 @@ def _process_database(
# This may happen if REFERENCE_USAGE permissions are set
# We can not run show queries on database in such case.
# This need not be a failure case.
- self.report_warning(
+ self.structured_reporter.warning(
"Insufficient privileges to operate on database, skipping. Please grant USAGE permissions on database to extract its metadata.",
db_name,
)
@@ -285,9 +287,8 @@ def _process_database(
f"Failed to use database {db_name} due to error {e}",
exc_info=e,
)
- self.report_warning(
- "Failed to get schemas for database",
- db_name,
+ self.structured_reporter.warning(
+ "Failed to get schemas for database", db_name, exc=e
)
return
@@ -318,41 +319,22 @@ def _process_db_schemas(
snowflake_db: SnowflakeDatabase,
db_tables: Dict[str, List[SnowflakeTable]],
) -> Iterable[MetadataWorkUnit]:
- q: "queue.Queue[MetadataWorkUnit]" = queue.Queue(maxsize=100)
-
- def _process_schema_worker(snowflake_schema: SnowflakeSchema) -> None:
+ def _process_schema_worker(
+ snowflake_schema: SnowflakeSchema,
+ ) -> Iterable[MetadataWorkUnit]:
for wu in self._process_schema(
snowflake_schema, snowflake_db.name, db_tables
):
- q.put(wu)
-
- with concurrent.futures.ThreadPoolExecutor(
- max_workers=SCHEMA_PARALLELISM
- ) as executor:
- futures = []
- for snowflake_schema in snowflake_db.schemas:
- f = executor.submit(_process_schema_worker, snowflake_schema)
- futures.append(f)
-
- # Read from the queue and yield the work units until all futures are done.
- while True:
- if not q.empty():
- while not q.empty():
- yield q.get_nowait()
- else:
- try:
- yield q.get(timeout=0.2)
- except queue.Empty:
- pass
-
- # Filter out the done futures.
- futures = [f for f in futures if not f.done()]
- if not futures:
- break
+ yield wu
- # Yield the remaining work units. This theoretically should not happen, but adding it just in case.
- while not q.empty():
- yield q.get_nowait()
+ for wu in ThreadedIteratorExecutor.process(
+ worker_func=_process_schema_worker,
+ args_list=[
+ (snowflake_schema,) for snowflake_schema in snowflake_db.schemas
+ ],
+ max_workers=SCHEMA_PARALLELISM,
+ ):
+ yield wu
def fetch_schemas_for_database(
self, snowflake_db: SnowflakeDatabase, db_name: str
@@ -362,10 +344,10 @@ def fetch_schemas_for_database(
for schema in self.data_dictionary.get_schemas_for_database(db_name):
self.report.report_entity_scanned(schema.name, "schema")
if not is_schema_allowed(
- self.filter_config.schema_pattern,
+ self.filters.filter_config.schema_pattern,
schema.name,
db_name,
- self.filter_config.match_fully_qualified_names,
+ self.filters.filter_config.match_fully_qualified_names,
):
self.report.report_dropped(f"{db_name}.{schema.name}.*")
else:
@@ -376,17 +358,14 @@ def fetch_schemas_for_database(
# Ideal implementation would use PEP 678 – Enriching Exceptions with Notes
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get schemas for database {db_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get schemas for database",
db_name,
+ exc=e,
)
if not schemas:
- self.report_warning(
+ self.structured_reporter.warning(
"No schemas found in database. If schemas exist, please grant USAGE permissions on them.",
db_name,
)
@@ -441,12 +420,12 @@ def _process_schema(
and self.config.parse_view_ddl
):
for view in views:
- view_identifier = self.get_dataset_identifier(
+ view_identifier = self.identifiers.get_dataset_identifier(
view.name, schema_name, db_name
)
if view.view_definition:
self.aggregator.add_view_definition(
- view_urn=self.dataset_urn_builder(view_identifier),
+ view_urn=self.identifiers.gen_dataset_urn(view_identifier),
view_definition=view.view_definition,
default_db=db_name,
default_schema=schema_name,
@@ -461,9 +440,10 @@ def _process_schema(
yield from self._process_tag(tag)
if not snowflake_schema.views and not snowflake_schema.tables:
- self.report_warning(
- "No tables/views found in schema. If tables exist, please grant REFERENCES or SELECT permissions on them.",
- f"{db_name}.{schema_name}",
+ self.structured_reporter.warning(
+ title="No tables/views found in schema",
+ message="If tables exist, please grant REFERENCES or SELECT permissions on them.",
+ context=f"{db_name}.{schema_name}",
)
def fetch_views_for_schema(
@@ -472,11 +452,13 @@ def fetch_views_for_schema(
try:
views: List[SnowflakeView] = []
for view in self.get_views_for_schema(schema_name, db_name):
- view_name = self.get_dataset_identifier(view.name, schema_name, db_name)
+ view_name = self.identifiers.get_dataset_identifier(
+ view.name, schema_name, db_name
+ )
self.report.report_entity_scanned(view_name, "view")
- if not self.filter_config.view_pattern.allowed(view_name):
+ if not self.filters.filter_config.view_pattern.allowed(view_name):
self.report.report_dropped(view_name)
else:
views.append(view)
@@ -489,13 +471,10 @@ def fetch_views_for_schema(
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get views for schema {db_name}.{schema_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get views for schema",
f"{db_name}.{schema_name}",
+ exc=e,
)
return []
@@ -505,11 +484,13 @@ def fetch_tables_for_schema(
try:
tables: List[SnowflakeTable] = []
for table in self.get_tables_for_schema(schema_name, db_name):
- table_identifier = self.get_dataset_identifier(
+ table_identifier = self.identifiers.get_dataset_identifier(
table.name, schema_name, db_name
)
self.report.report_entity_scanned(table_identifier)
- if not self.filter_config.table_pattern.allowed(table_identifier):
+ if not self.filters.filter_config.table_pattern.allowed(
+ table_identifier
+ ):
self.report.report_dropped(table_identifier)
else:
tables.append(table)
@@ -521,13 +502,10 @@ def fetch_tables_for_schema(
error_msg = f"Failed to get tables for schema {db_name}.{schema_name}. Please check permissions."
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get tables for schema {db_name}.{schema_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get tables for schema",
f"{db_name}.{schema_name}",
+ exc=e,
)
return []
@@ -546,7 +524,9 @@ def _process_table(
db_name: str,
) -> Iterable[MetadataWorkUnit]:
schema_name = snowflake_schema.name
- table_identifier = self.get_dataset_identifier(table.name, schema_name, db_name)
+ table_identifier = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
try:
table.columns = self.get_columns_for_table(
@@ -558,11 +538,9 @@ def _process_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get columns for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get columns for table", table_identifier, exc=e
)
- self.report_warning("Failed to get columns for table", table_identifier)
if self.config.extract_tags != TagOption.skip:
table.tags = self.tag_extractor.get_tags_on_object(
@@ -595,11 +573,9 @@ def fetch_foreign_keys_for_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get foreign key for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get foreign keys for table", table_identifier, exc=e
)
- self.report_warning("Failed to get foreign key for table", table_identifier)
def fetch_pk_for_table(
self,
@@ -613,11 +589,9 @@ def fetch_pk_for_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get primary key for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get primary key for table", table_identifier, exc=e
)
- self.report_warning("Failed to get primary key for table", table_identifier)
def _process_view(
self,
@@ -626,7 +600,9 @@ def _process_view(
db_name: str,
) -> Iterable[MetadataWorkUnit]:
schema_name = snowflake_schema.name
- view_name = self.get_dataset_identifier(view.name, schema_name, db_name)
+ view_name = self.identifiers.get_dataset_identifier(
+ view.name, schema_name, db_name
+ )
try:
view.columns = self.get_columns_for_table(
@@ -637,11 +613,9 @@ def _process_view(
view.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get columns for view {view_name} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get columns for view", view_name, exc=e
)
- self.report_warning("Failed to get columns for view", view_name)
if self.config.extract_tags != TagOption.skip:
view.tags = self.tag_extractor.get_tags_on_object(
@@ -677,8 +651,10 @@ def gen_dataset_workunits(
for tag in table.column_tags[column_name]:
yield from self._process_tag(tag)
- dataset_name = self.get_dataset_identifier(table.name, schema_name, db_name)
- dataset_urn = self.dataset_urn_builder(dataset_name)
+ dataset_name = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
+ dataset_urn = self.identifiers.gen_dataset_urn(dataset_name)
status = Status(removed=False)
yield MetadataChangeProposalWrapper(
@@ -753,7 +729,11 @@ def gen_dataset_workunits(
view_properties_aspect = ViewProperties(
materialized=table.materialized,
viewLanguage="SQL",
- viewLogic=table.view_definition,
+ viewLogic=(
+ table.view_definition
+ if self.config.include_view_definitions
+ else ""
+ ),
)
yield MetadataChangeProposalWrapper(
@@ -815,8 +795,10 @@ def gen_schema_metadata(
schema_name: str,
db_name: str,
) -> SchemaMetadata:
- dataset_name = self.get_dataset_identifier(table.name, schema_name, db_name)
- dataset_urn = self.dataset_urn_builder(dataset_name)
+ dataset_name = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
+ dataset_urn = self.identifiers.gen_dataset_urn(dataset_name)
foreign_keys: Optional[List[ForeignKeyConstraint]] = None
if isinstance(table, SnowflakeTable) and len(table.foreign_keys) > 0:
@@ -875,7 +857,7 @@ def build_foreign_keys(
for fk in table.foreign_keys:
foreign_dataset = make_dataset_urn_with_platform_instance(
platform=self.platform,
- name=self.get_dataset_identifier(
+ name=self.identifiers.get_dataset_identifier(
fk.referred_table, fk.referred_schema, fk.referred_database
),
env=self.config.env,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
index dad0ce7b59ee1..794a6f4a59f46 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
@@ -1,5 +1,5 @@
import logging
-from typing import Callable, Iterable, List
+from typing import Iterable, List
from datahub.emitter.mce_builder import make_dataset_urn_with_platform_instance
from datahub.emitter.mcp import MetadataChangeProposalWrapper
@@ -26,12 +26,9 @@ def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
- dataset_urn_builder: Callable[[str], str],
) -> None:
self.config = config
self.report = report
- self.logger = logger
- self.dataset_urn_builder = dataset_urn_builder
def get_shares_workunits(
self, databases: List[SnowflakeDatabase]
@@ -94,9 +91,10 @@ def report_missing_databases(
missing_dbs = [db for db in inbounds + outbounds if db not in db_names]
if missing_dbs and self.config.platform_instance:
- self.report_warning(
- "snowflake-shares",
- f"Databases {missing_dbs} were not ingested. Siblings/Lineage will not be set for these.",
+ self.report.warning(
+ title="Extra Snowflake share configurations",
+ message="Some databases referenced by the share configs were not ingested. Siblings/lineage will not be set for these.",
+ context=f"{missing_dbs}",
)
elif missing_dbs:
logger.debug(
@@ -113,15 +111,15 @@ def gen_siblings(
) -> Iterable[MetadataWorkUnit]:
if not sibling_databases:
return
- dataset_identifier = self.get_dataset_identifier(
+ dataset_identifier = self.identifiers.get_dataset_identifier(
table_name, schema_name, database_name
)
- urn = self.dataset_urn_builder(dataset_identifier)
+ urn = self.identifiers.gen_dataset_urn(dataset_identifier)
sibling_urns = [
make_dataset_urn_with_platform_instance(
- self.platform,
- self.get_dataset_identifier(
+ self.identifiers.platform,
+ self.identifiers.get_dataset_identifier(
table_name, schema_name, sibling_db.database
),
sibling_db.platform_instance,
@@ -141,14 +139,14 @@ def get_upstream_lineage_with_primary_sibling(
table_name: str,
primary_sibling_db: DatabaseId,
) -> MetadataWorkUnit:
- dataset_identifier = self.get_dataset_identifier(
+ dataset_identifier = self.identifiers.get_dataset_identifier(
table_name, schema_name, database_name
)
- urn = self.dataset_urn_builder(dataset_identifier)
+ urn = self.identifiers.gen_dataset_urn(dataset_identifier)
upstream_urn = make_dataset_urn_with_platform_instance(
- self.platform,
- self.get_dataset_identifier(
+ self.identifiers.platform,
+ self.identifiers.get_dataset_identifier(
table_name, schema_name, primary_sibling_db.database
),
primary_sibling_db.platform_instance,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
index f78ae70291f8a..72952f6b76e8b 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
@@ -1,5 +1,4 @@
import dataclasses
-import logging
from collections import defaultdict
from typing import Dict, Iterable, List, Optional
@@ -9,7 +8,10 @@
from datahub.ingestion.api.decorators import SupportStatus, config_class, support_status
from datahub.ingestion.api.source import Source, SourceReport
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.source.snowflake.snowflake_config import SnowflakeFilterConfig
+from datahub.ingestion.source.snowflake.snowflake_config import (
+ SnowflakeFilterConfig,
+ SnowflakeIdentifierConfig,
+)
from datahub.ingestion.source.snowflake.snowflake_connection import (
SnowflakeConnectionConfig,
)
@@ -17,6 +19,9 @@
from datahub.ingestion.source.snowflake.snowflake_schema_gen import (
SnowflakeSchemaGenerator,
)
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source_report.time_window import BaseTimeWindowReport
from datahub.utilities.lossy_collections import LossyList
@@ -59,7 +64,6 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeSummaryConfig):
super().__init__(ctx)
self.config: SnowflakeSummaryConfig = config
self.report: SnowflakeSummaryReport = SnowflakeSummaryReport()
- self.logger = logging.getLogger(__name__)
self.connection = self.config.get_connection()
@@ -69,7 +73,10 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
config=self.config, # type: ignore
report=self.report, # type: ignore
connection=self.connection,
- dataset_urn_builder=lambda x: "",
+ identifiers=SnowflakeIdentifierBuilder(
+ identifier_config=SnowflakeIdentifierConfig(),
+ structured_reporter=self.report,
+ ),
domain_registry=None,
profiler=None,
aggregator=None,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
index e6b4ef1fd9607..9307eb607be26 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
@@ -27,7 +27,6 @@ def __init__(
self.config = config
self.data_dictionary = data_dictionary
self.report = report
- self.logger = logger
self.tag_cache: Dict[str, _SnowflakeTagCache] = {}
@@ -69,16 +68,18 @@ def _get_tags_on_object_with_propagation(
) -> List[SnowflakeTag]:
identifier = ""
if domain == SnowflakeObjectDomain.DATABASE:
- identifier = self.get_quoted_identifier_for_database(db_name)
+ identifier = self.identifiers.get_quoted_identifier_for_database(db_name)
elif domain == SnowflakeObjectDomain.SCHEMA:
assert schema_name is not None
- identifier = self.get_quoted_identifier_for_schema(db_name, schema_name)
+ identifier = self.identifiers.get_quoted_identifier_for_schema(
+ db_name, schema_name
+ )
elif (
domain == SnowflakeObjectDomain.TABLE
): # Views belong to this domain as well.
assert schema_name is not None
assert table_name is not None
- identifier = self.get_quoted_identifier_for_table(
+ identifier = self.identifiers.get_quoted_identifier_for_table(
db_name, schema_name, table_name
)
else:
@@ -140,7 +141,7 @@ def get_column_tags_for_table(
elif self.config.extract_tags == TagOption.with_lineage:
self.report.num_get_tags_on_columns_for_table_queries += 1
temp_column_tags = self.data_dictionary.get_tags_on_columns_for_table(
- quoted_table_name=self.get_quoted_identifier_for_table(
+ quoted_table_name=self.identifiers.get_quoted_identifier_for_table(
db_name, schema_name, table_name
),
db_name=db_name,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
index c5e0994059f2e..aff15386c5083 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
@@ -2,7 +2,7 @@
import logging
import time
from datetime import datetime, timezone
-from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
+from typing import Any, Dict, Iterable, List, Optional, Tuple
import pydantic
@@ -20,7 +20,11 @@
)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeCommonMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantUsageRunSkipHandler,
)
@@ -112,13 +116,14 @@ def __init__(
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filter: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
redundant_run_skip_handler: Optional[RedundantUsageRunSkipHandler],
) -> None:
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
- self.dataset_urn_builder = dataset_urn_builder
- self.logger = logger
+ self.filter = filter
+ self.identifiers = identifiers
self.connection = connection
self.redundant_run_skip_handler = redundant_run_skip_handler
@@ -171,7 +176,7 @@ def get_usage_workunits(
bucket_duration=self.config.bucket_duration,
),
dataset_urns={
- self.dataset_urn_builder(dataset_identifier)
+ self.identifiers.gen_dataset_urn(dataset_identifier)
for dataset_identifier in discovered_datasets
},
)
@@ -232,7 +237,7 @@ def _get_workunits_internal(
logger.debug(f"Processing usage row number {results.rownumber}")
logger.debug(self.report.usage_aggregation.as_string())
- if not self.is_dataset_pattern_allowed(
+ if not self.filter.is_dataset_pattern_allowed(
row["OBJECT_NAME"],
row["OBJECT_DOMAIN"],
):
@@ -242,7 +247,7 @@ def _get_workunits_internal(
continue
dataset_identifier = (
- self.get_dataset_identifier_from_qualified_name(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
row["OBJECT_NAME"]
)
)
@@ -279,7 +284,8 @@ def build_usage_statistics_for_dataset(
fieldCounts=self._map_field_counts(row["FIELD_COUNTS"]),
)
return MetadataChangeProposalWrapper(
- entityUrn=self.dataset_urn_builder(dataset_identifier), aspect=stats
+ entityUrn=self.identifiers.gen_dataset_urn(dataset_identifier),
+ aspect=stats,
).as_workunit()
except Exception as e:
logger.debug(
@@ -356,7 +362,9 @@ def _map_field_counts(self, field_counts_str: str) -> List[DatasetFieldUsageCoun
return sorted(
[
DatasetFieldUsageCounts(
- fieldPath=self.snowflake_identifier(field_count["col"]),
+ fieldPath=self.identifiers.snowflake_identifier(
+ field_count["col"]
+ ),
count=field_count["total"],
)
for field_count in field_counts
@@ -454,8 +462,10 @@ def _get_operation_aspect_work_unit(
for obj in event.objects_modified:
resource = obj.objectName
- dataset_identifier = self.get_dataset_identifier_from_qualified_name(
- resource
+ dataset_identifier = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ resource
+ )
)
if dataset_identifier not in discovered_datasets:
@@ -476,7 +486,7 @@ def _get_operation_aspect_work_unit(
),
)
mcp = MetadataChangeProposalWrapper(
- entityUrn=self.dataset_urn_builder(dataset_identifier),
+ entityUrn=self.identifiers.gen_dataset_urn(dataset_identifier),
aspect=operation_aspect,
)
wu = MetadataWorkUnit(
@@ -561,7 +571,7 @@ def _is_unsupported_object_accessed(self, obj: Dict[str, Any]) -> bool:
def _is_object_valid(self, obj: Dict[str, Any]) -> bool:
if self._is_unsupported_object_accessed(
obj
- ) or not self.is_dataset_pattern_allowed(
+ ) or not self.filter.is_dataset_pattern_allowed(
obj.get("objectName"), obj.get("objectDomain")
):
return False
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
index c33fbb3d0bfc8..a1878963d3798 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
@@ -1,8 +1,7 @@
import abc
+from functools import cached_property
from typing import ClassVar, Literal, Optional, Tuple
-from typing_extensions import Protocol
-
from datahub.configuration.pattern_utils import is_schema_allowed
from datahub.emitter.mce_builder import make_dataset_urn_with_platform_instance
from datahub.ingestion.api.source import SourceReport
@@ -25,42 +24,6 @@ class SnowflakeStructuredReportMixin(abc.ABC):
def structured_reporter(self) -> SourceReport:
...
- # TODO: Eventually I want to deprecate these methods and use the structured_reporter directly.
- def report_warning(self, key: str, reason: str) -> None:
- self.structured_reporter.warning(key, reason)
-
- def report_error(self, key: str, reason: str) -> None:
- self.structured_reporter.failure(key, reason)
-
-
-# Required only for mypy, since we are using mixin classes, and not inheritance.
-# Reference - https://mypy.readthedocs.io/en/latest/more_types.html#mixin-classes
-class SnowflakeCommonProtocol(Protocol):
- platform: str = "snowflake"
-
- config: SnowflakeV2Config
- report: SnowflakeV2Report
-
- def get_dataset_identifier(
- self, table_name: str, schema_name: str, db_name: str
- ) -> str:
- ...
-
- def cleanup_qualified_name(self, qualified_name: str) -> str:
- ...
-
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- ...
-
- def snowflake_identifier(self, identifier: str) -> str:
- ...
-
- def report_warning(self, key: str, reason: str) -> None:
- ...
-
- def report_error(self, key: str, reason: str) -> None:
- ...
-
class SnowsightUrlBuilder:
CLOUD_REGION_IDS_WITHOUT_CLOUD_SUFFIX: ClassVar = [
@@ -140,17 +103,14 @@ def get_external_url_for_database(self, db_name: str) -> Optional[str]:
return f"{self.snowsight_base_url}#/data/databases/{db_name}/"
-class SnowflakeFilterMixin(SnowflakeStructuredReportMixin):
- @property
- @abc.abstractmethod
- def filter_config(self) -> SnowflakeFilterConfig:
- ...
+class SnowflakeFilter:
+ def __init__(
+ self, filter_config: SnowflakeFilterConfig, structured_reporter: SourceReport
+ ) -> None:
+ self.filter_config = filter_config
+ self.structured_reporter = structured_reporter
- @staticmethod
- def _combine_identifier_parts(
- table_name: str, schema_name: str, db_name: str
- ) -> str:
- return f"{db_name}.{schema_name}.{table_name}"
+ # TODO: Refactor remaining filtering logic into this class.
def is_dataset_pattern_allowed(
self,
@@ -167,28 +127,35 @@ def is_dataset_pattern_allowed(
SnowflakeObjectDomain.MATERIALIZED_VIEW,
):
return False
+
if len(dataset_params) != 3:
- self.report_warning(
- "invalid-dataset-pattern",
- f"Found {dataset_params} of type {dataset_type}",
+ self.structured_reporter.info(
+ title="Unexpected dataset pattern",
+ message=f"Found a {dataset_type} with an unexpected number of parts. Database and schema filtering will not work as expected, but table filtering will still work.",
+ context=dataset_name,
)
- # NOTE: this case returned `True` earlier when extracting lineage
- return False
+ # We fall-through here so table/view filtering still works.
- if not self.filter_config.database_pattern.allowed(
- dataset_params[0].strip('"')
- ) or not is_schema_allowed(
- self.filter_config.schema_pattern,
- dataset_params[1].strip('"'),
- dataset_params[0].strip('"'),
- self.filter_config.match_fully_qualified_names,
+ if (
+ len(dataset_params) >= 1
+ and not self.filter_config.database_pattern.allowed(
+ dataset_params[0].strip('"')
+ )
+ ) or (
+ len(dataset_params) >= 2
+ and not is_schema_allowed(
+ self.filter_config.schema_pattern,
+ dataset_params[1].strip('"'),
+ dataset_params[0].strip('"'),
+ self.filter_config.match_fully_qualified_names,
+ )
):
return False
if dataset_type.lower() in {
SnowflakeObjectDomain.TABLE
} and not self.filter_config.table_pattern.allowed(
- self.cleanup_qualified_name(dataset_name)
+ _cleanup_qualified_name(dataset_name, self.structured_reporter)
):
return False
@@ -196,41 +163,53 @@ def is_dataset_pattern_allowed(
SnowflakeObjectDomain.VIEW,
SnowflakeObjectDomain.MATERIALIZED_VIEW,
} and not self.filter_config.view_pattern.allowed(
- self.cleanup_qualified_name(dataset_name)
+ _cleanup_qualified_name(dataset_name, self.structured_reporter)
):
return False
return True
- # Qualified Object names from snowflake audit logs have quotes for for snowflake quoted identifiers,
- # For example "test-database"."test-schema".test_table
- # whereas we generate urns without quotes even for quoted identifiers for backward compatibility
- # and also unavailability of utility function to identify whether current table/schema/database
- # name should be quoted in above method get_dataset_identifier
- def cleanup_qualified_name(self, qualified_name: str) -> str:
- name_parts = qualified_name.split(".")
- if len(name_parts) != 3:
- self.structured_reporter.report_warning(
- title="Unexpected dataset pattern",
- message="We failed to parse a Snowflake qualified name into its constituent parts. "
- "DB/schema/table filtering may not work as expected on these entities.",
- context=f"{qualified_name} has {len(name_parts)} parts",
- )
- return qualified_name.replace('"', "")
- return SnowflakeFilterMixin._combine_identifier_parts(
- table_name=name_parts[2].strip('"'),
- schema_name=name_parts[1].strip('"'),
- db_name=name_parts[0].strip('"'),
+
+def _combine_identifier_parts(
+ *, table_name: str, schema_name: str, db_name: str
+) -> str:
+ return f"{db_name}.{schema_name}.{table_name}"
+
+
+# Qualified Object names from snowflake audit logs have quotes for for snowflake quoted identifiers,
+# For example "test-database"."test-schema".test_table
+# whereas we generate urns without quotes even for quoted identifiers for backward compatibility
+# and also unavailability of utility function to identify whether current table/schema/database
+# name should be quoted in above method get_dataset_identifier
+def _cleanup_qualified_name(
+ qualified_name: str, structured_reporter: SourceReport
+) -> str:
+ name_parts = qualified_name.split(".")
+ if len(name_parts) != 3:
+ structured_reporter.info(
+ title="Unexpected dataset pattern",
+ message="We failed to parse a Snowflake qualified name into its constituent parts. "
+ "DB/schema/table filtering may not work as expected on these entities.",
+ context=f"{qualified_name} has {len(name_parts)} parts",
)
+ return qualified_name.replace('"', "")
+ return _combine_identifier_parts(
+ db_name=name_parts[0].strip('"'),
+ schema_name=name_parts[1].strip('"'),
+ table_name=name_parts[2].strip('"'),
+ )
-class SnowflakeIdentifierMixin(abc.ABC):
+class SnowflakeIdentifierBuilder:
platform = "snowflake"
- @property
- @abc.abstractmethod
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- ...
+ def __init__(
+ self,
+ identifier_config: SnowflakeIdentifierConfig,
+ structured_reporter: SourceReport,
+ ) -> None:
+ self.identifier_config = identifier_config
+ self.structured_reporter = structured_reporter
def snowflake_identifier(self, identifier: str) -> str:
# to be in in sync with older connector, convert name to lowercase
@@ -242,7 +221,7 @@ def get_dataset_identifier(
self, table_name: str, schema_name: str, db_name: str
) -> str:
return self.snowflake_identifier(
- SnowflakeCommonMixin._combine_identifier_parts(
+ _combine_identifier_parts(
table_name=table_name, schema_name=schema_name, db_name=db_name
)
)
@@ -255,20 +234,10 @@ def gen_dataset_urn(self, dataset_identifier: str) -> str:
env=self.identifier_config.env,
)
-
-# TODO: We're most of the way there on fully removing SnowflakeCommonProtocol.
-class SnowflakeCommonMixin(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
- @property
- def structured_reporter(self: SnowflakeCommonProtocol) -> SourceReport:
- return self.report
-
- @property
- def filter_config(self: SnowflakeCommonProtocol) -> SnowflakeFilterConfig:
- return self.config
-
- @property
- def identifier_config(self: SnowflakeCommonProtocol) -> SnowflakeIdentifierConfig:
- return self.config
+ def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
+ return self.snowflake_identifier(
+ _cleanup_qualified_name(qualified_name, self.structured_reporter)
+ )
@staticmethod
def get_quoted_identifier_for_database(db_name):
@@ -278,40 +247,51 @@ def get_quoted_identifier_for_database(db_name):
def get_quoted_identifier_for_schema(db_name, schema_name):
return f'"{db_name}"."{schema_name}"'
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- return self.snowflake_identifier(self.cleanup_qualified_name(qualified_name))
-
@staticmethod
def get_quoted_identifier_for_table(db_name, schema_name, table_name):
return f'"{db_name}"."{schema_name}"."{table_name}"'
+
+class SnowflakeCommonMixin(SnowflakeStructuredReportMixin):
+ platform = "snowflake"
+
+ config: SnowflakeV2Config
+ report: SnowflakeV2Report
+
+ @property
+ def structured_reporter(self) -> SourceReport:
+ return self.report
+
+ @cached_property
+ def identifiers(self) -> SnowflakeIdentifierBuilder:
+ return SnowflakeIdentifierBuilder(self.config, self.report)
+
# Note - decide how to construct user urns.
# Historically urns were created using part before @ from user's email.
# Users without email were skipped from both user entries as well as aggregates.
# However email is not mandatory field in snowflake user, user_name is always present.
def get_user_identifier(
- self: SnowflakeCommonProtocol,
+ self,
user_name: str,
user_email: Optional[str],
email_as_user_identifier: bool,
) -> str:
if user_email:
- return self.snowflake_identifier(
+ return self.identifiers.snowflake_identifier(
user_email
if email_as_user_identifier is True
else user_email.split("@")[0]
)
- return self.snowflake_identifier(user_name)
+ return self.identifiers.snowflake_identifier(user_name)
# TODO: Revisit this after stateful ingestion can commit checkpoint
# for failures that do not affect the checkpoint
- def warn_if_stateful_else_error(
- self: SnowflakeCommonProtocol, key: str, reason: str
- ) -> None:
+ # TODO: Add additional parameters to match the signature of the .warning and .failure methods
+ def warn_if_stateful_else_error(self, key: str, reason: str) -> None:
if (
self.config.stateful_ingestion is not None
and self.config.stateful_ingestion.enabled
):
- self.report_warning(key, reason)
+ self.structured_reporter.warning(key, reason)
else:
- self.report_error(key, reason)
+ self.structured_reporter.failure(key, reason)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
index d8eda98da422b..1881e1da5be68 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
@@ -25,6 +25,7 @@
TestableSource,
TestConnectionReport,
)
+from datahub.ingestion.api.source_helpers import auto_workunit
from datahub.ingestion.api.workunit import MetadataWorkUnit
from datahub.ingestion.source.snowflake.constants import (
GENERIC_PERMISSION_ERROR_KEY,
@@ -42,6 +43,10 @@
SnowflakeLineageExtractor,
)
from datahub.ingestion.source.snowflake.snowflake_profiler import SnowflakeProfiler
+from datahub.ingestion.source.snowflake.snowflake_queries import (
+ SnowflakeQueriesExtractor,
+ SnowflakeQueriesExtractorConfig,
+)
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
from datahub.ingestion.source.snowflake.snowflake_schema import (
SnowflakeDataDictionary,
@@ -56,6 +61,8 @@
)
from datahub.ingestion.source.snowflake.snowflake_utils import (
SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
SnowsightUrlBuilder,
)
from datahub.ingestion.source.state.profiling_state_handler import ProfilingHandler
@@ -72,6 +79,7 @@
from datahub.ingestion.source_report.ingestion_stage import (
LINEAGE_EXTRACTION,
METADATA_EXTRACTION,
+ QUERIES_EXTRACTION,
)
from datahub.sql_parsing.sql_parsing_aggregator import SqlParsingAggregator
from datahub.utilities.registries.domain_registry import DomainRegistry
@@ -127,9 +135,13 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
super().__init__(config, ctx)
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = SnowflakeV2Report()
- self.logger = logger
- self.connection = self.config.get_connection()
+ self.filters = SnowflakeFilter(
+ filter_config=self.config, structured_reporter=self.report
+ )
+ self.identifiers = SnowflakeIdentifierBuilder(
+ identifier_config=self.config, structured_reporter=self.report
+ )
self.domain_registry: Optional[DomainRegistry] = None
if self.config.domain:
@@ -137,28 +149,29 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
)
+ self.connection = self.config.get_connection()
+
# For database, schema, tables, views, etc
self.data_dictionary = SnowflakeDataDictionary(connection=self.connection)
self.lineage_extractor: Optional[SnowflakeLineageExtractor] = None
self.aggregator: Optional[SqlParsingAggregator] = None
- if self.config.include_table_lineage:
+ if self.config.use_queries_v2 or self.config.include_table_lineage:
self.aggregator = SqlParsingAggregator(
- platform=self.platform,
+ platform=self.identifiers.platform,
platform_instance=self.config.platform_instance,
env=self.config.env,
- graph=(
+ graph=self.ctx.graph,
+ eager_graph_load=(
# If we're ingestion schema metadata for tables/views, then we will populate
# schemas into the resolver as we go. We only need to do a bulk fetch
# if we're not ingesting schema metadata as part of ingestion.
- self.ctx.graph
- if not (
+ (
self.config.include_technical_schema
and self.config.include_tables
and self.config.include_views
)
and not self.config.lazy_schema_resolver
- else None
),
generate_usage_statistics=False,
generate_operations=False,
@@ -166,6 +179,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
)
self.report.sql_aggregator = self.aggregator.report
+ if self.config.include_table_lineage:
+ assert self.aggregator is not None
redundant_lineage_run_skip_handler: Optional[
RedundantLineageRunSkipHandler
] = None
@@ -180,7 +195,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
config,
self.report,
connection=self.connection,
- dataset_urn_builder=self.gen_dataset_urn,
+ filters=self.filters,
+ identifiers=self.identifiers,
redundant_run_skip_handler=redundant_lineage_run_skip_handler,
sql_aggregator=self.aggregator,
)
@@ -201,7 +217,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
config,
self.report,
connection=self.connection,
- dataset_urn_builder=self.gen_dataset_urn,
+ filter=self.filters,
+ identifiers=self.identifiers,
redundant_run_skip_handler=redundant_usage_run_skip_handler,
)
@@ -277,10 +294,12 @@ class SnowflakePrivilege:
capabilities: List[SourceCapability] = [c.capability for c in SnowflakeV2Source.get_capabilities() if c.capability not in (SourceCapability.PLATFORM_INSTANCE, SourceCapability.DOMAINS, SourceCapability.DELETION_DETECTION)] # type: ignore
cur = conn.query("select current_role()")
- current_role = [row[0] for row in cur][0]
+ current_role = [row["CURRENT_ROLE()"] for row in cur][0]
cur = conn.query("select current_secondary_roles()")
- secondary_roles_str = json.loads([row[0] for row in cur][0])["roles"]
+ secondary_roles_str = json.loads(
+ [row["CURRENT_SECONDARY_ROLES()"] for row in cur][0]
+ )["roles"]
secondary_roles = (
[] if secondary_roles_str == "" else secondary_roles_str.split(",")
)
@@ -299,7 +318,9 @@ class SnowflakePrivilege:
cur = conn.query(f'show grants to role "{role}"')
for row in cur:
privilege = SnowflakePrivilege(
- privilege=row[1], object_type=row[2], object_name=row[3]
+ privilege=row["privilege"],
+ object_type=row["granted_on"],
+ object_name=row["name"],
)
privileges.append(privilege)
@@ -362,7 +383,7 @@ class SnowflakePrivilege:
roles.append(privilege.object_name)
cur = conn.query("select current_warehouse()")
- current_warehouse = [row[0] for row in cur][0]
+ current_warehouse = [row["CURRENT_WAREHOUSE()"] for row in cur][0]
default_failure_messages = {
SourceCapability.SCHEMA_METADATA: "Either no tables exist or current role does not have permissions to access them",
@@ -445,7 +466,8 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
profiler=self.profiler,
aggregator=self.aggregator,
snowsight_url_builder=snowsight_url_builder,
- dataset_urn_builder=self.gen_dataset_urn,
+ filters=self.filters,
+ identifiers=self.identifiers,
)
self.report.set_ingestion_stage("*", METADATA_EXTRACTION)
@@ -453,30 +475,28 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
databases = schema_extractor.databases
- self.connection.close()
-
# TODO: The checkpoint state for stale entity detection can be committed here.
if self.config.shares:
yield from SnowflakeSharesHandler(
- self.config, self.report, self.gen_dataset_urn
+ self.config, self.report
).get_shares_workunits(databases)
discovered_tables: List[str] = [
- self.get_dataset_identifier(table_name, schema.name, db.name)
+ self.identifiers.get_dataset_identifier(table_name, schema.name, db.name)
for db in databases
for schema in db.schemas
for table_name in schema.tables
]
discovered_views: List[str] = [
- self.get_dataset_identifier(table_name, schema.name, db.name)
+ self.identifiers.get_dataset_identifier(table_name, schema.name, db.name)
for db in databases
for schema in db.schemas
for table_name in schema.views
]
if len(discovered_tables) == 0 and len(discovered_views) == 0:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
"No tables/views found. Please check permissions.",
)
@@ -484,33 +504,66 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
discovered_datasets = discovered_tables + discovered_views
- if self.config.include_table_lineage and self.lineage_extractor:
- self.report.set_ingestion_stage("*", LINEAGE_EXTRACTION)
- yield from self.lineage_extractor.get_workunits(
- discovered_tables=discovered_tables,
- discovered_views=discovered_views,
+ if self.config.use_queries_v2:
+ self.report.set_ingestion_stage("*", "View Parsing")
+ assert self.aggregator is not None
+ yield from auto_workunit(self.aggregator.gen_metadata())
+
+ self.report.set_ingestion_stage("*", QUERIES_EXTRACTION)
+
+ schema_resolver = self.aggregator._schema_resolver
+
+ queries_extractor = SnowflakeQueriesExtractor(
+ connection=self.connection,
+ config=SnowflakeQueriesExtractorConfig(
+ window=self.config,
+ temporary_tables_pattern=self.config.temporary_tables_pattern,
+ include_lineage=self.config.include_table_lineage,
+ include_usage_statistics=self.config.include_usage_stats,
+ include_operations=self.config.include_operational_stats,
+ ),
+ structured_report=self.report,
+ filters=self.filters,
+ identifiers=self.identifiers,
+ schema_resolver=schema_resolver,
)
- if (
- self.config.include_usage_stats or self.config.include_operational_stats
- ) and self.usage_extractor:
- yield from self.usage_extractor.get_usage_workunits(discovered_datasets)
+ # TODO: This is slightly suboptimal because we create two SqlParsingAggregator instances with different configs
+ # but a shared schema resolver. That's fine for now though - once we remove the old lineage/usage extractors,
+ # it should be pretty straightforward to refactor this and only initialize the aggregator once.
+ self.report.queries_extractor = queries_extractor.report
+ yield from queries_extractor.get_workunits_internal()
+
+ else:
+ if self.config.include_table_lineage and self.lineage_extractor:
+ self.report.set_ingestion_stage("*", LINEAGE_EXTRACTION)
+ yield from self.lineage_extractor.get_workunits(
+ discovered_tables=discovered_tables,
+ discovered_views=discovered_views,
+ )
+
+ if (
+ self.config.include_usage_stats or self.config.include_operational_stats
+ ) and self.usage_extractor:
+ yield from self.usage_extractor.get_usage_workunits(discovered_datasets)
if self.config.include_assertion_results:
yield from SnowflakeAssertionsHandler(
- self.config, self.report, self.connection
+ self.config, self.report, self.connection, self.identifiers
).get_assertion_workunits(discovered_datasets)
+ self.connection.close()
+
def report_warehouse_failure(self) -> None:
if self.config.warehouse is not None:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
f"Current role does not have permissions to use warehouse {self.config.warehouse}. Please update permissions.",
)
else:
- self.report_error(
- "no-active-warehouse",
- "No default warehouse set for user. Either set default warehouse for user or configure warehouse in recipe.",
+ self.structured_reporter.failure(
+ "Could not use a Snowflake warehouse",
+ "No default warehouse set for user. Either set a default warehouse for the user or configure a warehouse in the recipe.",
)
def get_report(self) -> SourceReport:
@@ -541,19 +594,28 @@ def inspect_session_metadata(self, connection: SnowflakeConnection) -> None:
for db_row in connection.query(SnowflakeQuery.current_version()):
self.report.saas_version = db_row["CURRENT_VERSION()"]
except Exception as e:
- self.report_error("version", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake version",
+ exc=e,
+ )
try:
logger.info("Checking current role")
for db_row in connection.query(SnowflakeQuery.current_role()):
self.report.role = db_row["CURRENT_ROLE()"]
except Exception as e:
- self.report_error("version", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake role",
+ exc=e,
+ )
try:
logger.info("Checking current warehouse")
for db_row in connection.query(SnowflakeQuery.current_warehouse()):
self.report.default_warehouse = db_row["CURRENT_WAREHOUSE()"]
except Exception as e:
- self.report_error("current_warehouse", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake warehouse",
+ exc=e,
+ )
try:
logger.info("Checking current edition")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py b/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
index ae17cff60fedd..9ddc671e21133 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
@@ -251,11 +251,6 @@ class AthenaConfig(SQLCommonConfig):
"queries executed by DataHub."
)
- # overwrite default behavior of SQLAlchemyConfing
- include_views: Optional[bool] = pydantic.Field(
- default=True, description="Whether views should be ingested."
- )
-
_s3_staging_dir_population = pydantic_renamed_field(
old_name="s3_staging_dir",
new_name="query_result_location",
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py b/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
index 0589a5e39d68e..12c98ef11a654 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
@@ -276,3 +276,19 @@ def get_identifier(
return f"{self.config.database}.{regular}"
current_database = self.get_db_name(inspector)
return f"{current_database}.{regular}"
+
+ def add_profile_metadata(self, inspector: Inspector) -> None:
+ try:
+ with inspector.engine.connect() as conn:
+ for row in conn.execute(
+ """SELECT table_catalog, table_schema, table_name, pg_table_size('"' || table_catalog || '"."' || table_schema || '"."' || table_name || '"') AS table_size FROM information_schema.TABLES"""
+ ):
+ self.profile_metadata_info.dataset_name_to_storage_bytes[
+ self.get_identifier(
+ schema=row.table_schema,
+ entity=row.table_name,
+ inspector=inspector,
+ )
+ ] = row.table_size
+ except Exception as e:
+ logger.error(f"failed to fetch profile metadata: {e}")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
index 93c7025aeee4e..3ead59eed2d39 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
@@ -83,10 +83,10 @@ class SQLCommonConfig(
description='Attach domains to databases, schemas or tables during ingestion using regex patterns. Domain key can be a guid like *urn:li:domain:ec428203-ce86-4db3-985d-5a8ee6df32ba* or a string like "Marketing".) If you provide strings, then datahub will attempt to resolve this name to a guid, and will error out if this fails. There can be multiple domain keys specified.',
)
- include_views: Optional[bool] = Field(
+ include_views: bool = Field(
default=True, description="Whether views should be ingested."
)
- include_tables: Optional[bool] = Field(
+ include_tables: bool = Field(
default=True, description="Whether tables should be ingested."
)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/tableau.py b/metadata-ingestion/src/datahub/ingestion/source/tableau.py
index b14a4a8586c7d..1655724f2d402 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/tableau.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/tableau.py
@@ -1009,10 +1009,34 @@ def get_connection_object_page(
error and (error.get(c.EXTENSIONS) or {}).get(c.SEVERITY) == c.WARNING
for error in errors
):
- self.report.warning(
- message=f"Received error fetching Query Connection {connection_type}",
- context=f"Errors: {errors}",
- )
+ # filter out PERMISSIONS_MODE_SWITCHED to report error in human-readable format
+ other_errors = []
+ permission_mode_errors = []
+ for error in errors:
+ if (
+ error.get("extensions")
+ and error["extensions"].get("code")
+ == "PERMISSIONS_MODE_SWITCHED"
+ ):
+ permission_mode_errors.append(error)
+ else:
+ other_errors.append(error)
+
+ if other_errors:
+ self.report.warning(
+ message=f"Received error fetching Query Connection {connection_type}",
+ context=f"Errors: {other_errors}",
+ )
+
+ if permission_mode_errors:
+ self.report.warning(
+ title="Derived Permission Error",
+ message="Turn on your derived permissions. See for details "
+ "https://community.tableau.com/s/question/0D54T00000QnjHbSAJ/how-to-fix-the"
+ "-permissionsmodeswitched-error",
+ context=f"{permission_mode_errors}",
+ )
+
else:
raise RuntimeError(f"Query {connection_type} error: {errors}")
@@ -2255,7 +2279,7 @@ def emit_upstream_tables(self) -> Iterable[MetadataWorkUnit]:
yield from self.emit_table(database_table, tableau_columns)
- # Emmitting tables that were purely parsed from SQL queries
+ # Emitting tables that were purely parsed from SQL queries
for database_table in self.database_tables.values():
# Only tables purely parsed from SQL queries don't have ID
if database_table.id:
@@ -2278,10 +2302,11 @@ def emit_table(
tableau_columns: Optional[List[Dict[str, Any]]],
) -> Iterable[MetadataWorkUnit]:
logger.debug(
- f"Emiting external table {database_table} tableau_columns {tableau_columns}"
+ f"Emitting external table {database_table} tableau_columns {tableau_columns}"
)
+ dataset_urn = DatasetUrn.from_string(database_table.urn)
dataset_snapshot = DatasetSnapshot(
- urn=database_table.urn,
+ urn=str(dataset_urn),
aspects=[],
)
if database_table.paths:
@@ -2302,6 +2327,13 @@ def emit_table(
if schema_metadata is not None:
dataset_snapshot.aspects.append(schema_metadata)
+ if not dataset_snapshot.aspects:
+ # This should only happen with ingest_tables_external enabled.
+ logger.warning(
+ f"Urn {database_table.urn} has no real aspects, adding a key aspect to ensure materialization"
+ )
+ dataset_snapshot.aspects.append(dataset_urn.to_key_aspect())
+
yield self.get_metadata_change_event(dataset_snapshot)
def get_schema_metadata_for_table(
diff --git a/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py b/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
index 14dc428b65389..4308b405e46e3 100644
--- a/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
@@ -14,6 +14,7 @@
USAGE_EXTRACTION_INGESTION = "Usage Extraction Ingestion"
USAGE_EXTRACTION_OPERATIONAL_STATS = "Usage Extraction Operational Stats"
USAGE_EXTRACTION_USAGE_AGGREGATION = "Usage Extraction Usage Aggregation"
+QUERIES_EXTRACTION = "Queries Extraction"
PROFILING = "Profiling"
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
index 677b96269fe58..fbf6f954f82bb 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
@@ -251,7 +251,9 @@ def __init__(
platform: str,
platform_instance: Optional[str] = None,
env: str = builder.DEFAULT_ENV,
+ schema_resolver: Optional[SchemaResolver] = None,
graph: Optional[DataHubGraph] = None,
+ eager_graph_load: bool = True,
generate_lineage: bool = True,
generate_queries: bool = True,
generate_query_subject_fields: bool = True,
@@ -274,8 +276,12 @@ def __init__(
self.generate_usage_statistics = generate_usage_statistics
self.generate_query_usage_statistics = generate_query_usage_statistics
self.generate_operations = generate_operations
- if self.generate_queries and not self.generate_lineage:
- raise ValueError("Queries will only be generated if lineage is enabled")
+ if self.generate_queries and not (
+ self.generate_lineage or self.generate_query_usage_statistics
+ ):
+ logger.warning(
+ "Queries will not be generated, as neither lineage nor query usage statistics are enabled"
+ )
self.usage_config = usage_config
if (
@@ -297,17 +303,29 @@ def __init__(
# Set up the schema resolver.
self._schema_resolver: SchemaResolver
- if graph is None:
+ if schema_resolver is not None:
+ # If explicitly provided, use it.
+ assert self.platform.platform_name == schema_resolver.platform
+ assert self.platform_instance == schema_resolver.platform_instance
+ assert self.env == schema_resolver.env
+ self._schema_resolver = schema_resolver
+ elif graph is not None and eager_graph_load and self._need_schemas:
+ # Bulk load schemas using the graph client.
+ self._schema_resolver = graph.initialize_schema_resolver_from_datahub(
+ platform=self.platform.urn(),
+ platform_instance=self.platform_instance,
+ env=self.env,
+ )
+ else:
+ # Otherwise, use a lazy-loading schema resolver.
self._schema_resolver = self._exit_stack.enter_context(
SchemaResolver(
platform=self.platform.platform_name,
platform_instance=self.platform_instance,
env=self.env,
+ graph=graph,
)
)
- else:
- self._schema_resolver = None # type: ignore
- self._initialize_schema_resolver_from_graph(graph)
# Initialize internal data structures.
# This leans pretty heavily on the our query fingerprinting capabilities.
@@ -373,6 +391,8 @@ def __init__(
# Usage aggregator. This will only be initialized if usage statistics are enabled.
# TODO: Replace with FileBackedDict.
+ # TODO: The BaseUsageConfig class is much too broad for our purposes, and has a number of
+ # configs that won't be respected here. Using it is misleading.
self._usage_aggregator: Optional[UsageAggregator[UrnStr]] = None
if self.generate_usage_statistics:
assert self.usage_config is not None
@@ -392,7 +412,13 @@ def close(self) -> None:
@property
def _need_schemas(self) -> bool:
- return self.generate_lineage or self.generate_usage_statistics
+ # Unless the aggregator is totally disabled, we will need schema information.
+ return (
+ self.generate_lineage
+ or self.generate_usage_statistics
+ or self.generate_queries
+ or self.generate_operations
+ )
def register_schema(
self, urn: Union[str, DatasetUrn], schema: models.SchemaMetadataClass
@@ -414,35 +440,6 @@ def register_schemas_from_stream(
yield wu
- def _initialize_schema_resolver_from_graph(self, graph: DataHubGraph) -> None:
- # requires a graph instance
- # if no schemas are currently registered in the schema resolver
- # and we need the schema resolver (e.g. lineage or usage is enabled)
- # then use the graph instance to fetch all schemas for the
- # platform/instance/env combo
- if not self._need_schemas:
- return
-
- if (
- self._schema_resolver is not None
- and self._schema_resolver.schema_count() > 0
- ):
- # TODO: Have a mechanism to override this, e.g. when table ingestion is enabled but view ingestion is not.
- logger.info(
- "Not fetching any schemas from the graph, since "
- f"there are {self._schema_resolver.schema_count()} schemas already registered."
- )
- return
-
- # TODO: The initialize_schema_resolver_from_datahub method should take in a SchemaResolver
- # that it can populate or add to, rather than creating a new one and dropping any schemas
- # that were already loaded into the existing one.
- self._schema_resolver = graph.initialize_schema_resolver_from_datahub(
- platform=self.platform.urn(),
- platform_instance=self.platform_instance,
- env=self.env,
- )
-
def _maybe_format_query(self, query: str) -> str:
if self.format_queries:
with self.report.sql_formatting_timer:
@@ -660,10 +657,10 @@ def add_observed_query(
if parsed.debug_info.table_error:
self.report.num_observed_queries_failed += 1
return # we can't do anything with this query
- elif isinstance(parsed.debug_info.column_error, CooperativeTimeoutError):
- self.report.num_observed_queries_column_timeout += 1
elif parsed.debug_info.column_error:
self.report.num_observed_queries_column_failed += 1
+ if isinstance(parsed.debug_info.column_error, CooperativeTimeoutError):
+ self.report.num_observed_queries_column_timeout += 1
query_fingerprint = parsed.query_fingerprint
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
index 9c2a588a577cc..976ff8bcc9b3f 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
@@ -843,8 +843,14 @@ def _sqlglot_lineage_inner(
schema_resolver: SchemaResolverInterface,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> SqlParsingResult:
- dialect = get_dialect(schema_resolver.platform)
+
+ if not default_dialect:
+ dialect = get_dialect(schema_resolver.platform)
+ else:
+ dialect = get_dialect(default_dialect)
+
if is_dialect_instance(dialect, "snowflake"):
# in snowflake, table identifiers must be uppercased to match sqlglot's behavior.
if default_db:
@@ -1003,6 +1009,7 @@ def sqlglot_lineage(
schema_resolver: SchemaResolverInterface,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> SqlParsingResult:
"""Parse a SQL statement and generate lineage information.
@@ -1020,8 +1027,9 @@ def sqlglot_lineage(
can be brittle with respect to missing schema information and complex
SQL logic like UNNESTs.
- The SQL dialect is inferred from the schema_resolver's platform. The
- set of supported dialects is the same as sqlglot's. See their
+ The SQL dialect can be given as an argument called default_dialect or it can
+ be inferred from the schema_resolver's platform.
+ The set of supported dialects is the same as sqlglot's. See their
`documentation `_
for the full list.
@@ -1035,6 +1043,7 @@ def sqlglot_lineage(
schema_resolver: The schema resolver to use for resolving table schemas.
default_db: The default database to use for unqualified table names.
default_schema: The default schema to use for unqualified table names.
+ default_dialect: A default dialect to override the dialect provided by 'schema_resolver'.
Returns:
A SqlParsingResult object containing the parsed lineage information.
@@ -1059,6 +1068,7 @@ def sqlglot_lineage(
schema_resolver=schema_resolver,
default_db=default_db,
default_schema=default_schema,
+ default_dialect=default_dialect,
)
except Exception as e:
return SqlParsingResult.make_from_error(e)
diff --git a/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py b/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py
new file mode 100644
index 0000000000000..216fa155035d3
--- /dev/null
+++ b/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py
@@ -0,0 +1,52 @@
+import concurrent.futures
+import contextlib
+import queue
+from typing import Any, Callable, Generator, Iterable, Tuple, TypeVar
+
+T = TypeVar("T")
+
+
+class ThreadedIteratorExecutor:
+ """
+ Executes worker functions of type `Callable[..., Iterable[T]]` in parallel threads,
+ yielding items of type `T` as they become available.
+ """
+
+ @classmethod
+ def process(
+ cls,
+ worker_func: Callable[..., Iterable[T]],
+ args_list: Iterable[Tuple[Any, ...]],
+ max_workers: int,
+ ) -> Generator[T, None, None]:
+
+ out_q: queue.Queue[T] = queue.Queue()
+
+ def _worker_wrapper(
+ worker_func: Callable[..., Iterable[T]], *args: Any
+ ) -> None:
+ for item in worker_func(*args):
+ out_q.put(item)
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
+ futures = []
+ for args in args_list:
+ future = executor.submit(_worker_wrapper, worker_func, *args)
+ futures.append(future)
+ # Read from the queue and yield the work units until all futures are done.
+ while True:
+ if not out_q.empty():
+ while not out_q.empty():
+ yield out_q.get_nowait()
+ else:
+ with contextlib.suppress(queue.Empty):
+ yield out_q.get(timeout=0.2)
+
+ # Filter out the done futures.
+ futures = [f for f in futures if not f.done()]
+ if not futures:
+ break
+
+ # Yield the remaining work units. This theoretically should not happen, but adding it just in case.
+ while not out_q.empty():
+ yield out_q.get_nowait()
diff --git a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
index a24b6174eb925..762c73d2a55c6 100644
--- a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
+++ b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
@@ -11,7 +11,6 @@
DynamicTypedClassifierConfig,
)
from datahub.ingestion.glossary.datahub_classifier import DataHubClassifierConfig
-from datahub.ingestion.source.bigquery_v2.bigquery import BigqueryV2Source
from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
BigqueryColumn,
@@ -19,6 +18,9 @@
BigQuerySchemaApi,
BigqueryTable,
)
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
from tests.test_helpers import mce_helpers
from tests.test_helpers.state_helpers import run_and_get_pipeline
@@ -39,7 +41,7 @@ def random_email():
@freeze_time(FROZEN_TIME)
@patch.object(BigQuerySchemaApi, "get_tables_for_dataset")
-@patch.object(BigqueryV2Source, "get_core_table_details")
+@patch.object(BigQuerySchemaGenerator, "get_core_table_details")
@patch.object(BigQuerySchemaApi, "get_datasets_for_project_id")
@patch.object(BigQuerySchemaApi, "get_columns_for_dataset")
@patch.object(BigQueryDataReader, "get_sample_data_for_table")
diff --git a/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json b/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
index b9b2a3b2141a8..f35ff9fdb9d15 100644
--- a/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
+++ b/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
@@ -832,7 +832,8 @@
{
"fieldPath": "metadata_json"
}
- ]
+ ],
+ "sizeInBytes": 16384
}
},
"systemMetadata": {
diff --git a/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json b/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
index 832b46e096ae0..f47789fc470cd 100644
--- a/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
+++ b/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
@@ -600,7 +600,8 @@
},
"rowCount": 2,
"columnCount": 9,
- "fieldProfiles": []
+ "fieldProfiles": [],
+ "sizeInBytes": 16384
}
},
"systemMetadata": {
diff --git a/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json b/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json
new file mode 100644
index 0000000000000..a8593493a5ec7
--- /dev/null
+++ b/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json
@@ -0,0 +1,16 @@
+{
+ "errors":[
+ {
+ "message": "One or more of the attributes used in your filter contain sensitive data so your results have been automatically filtered to contain only the results you have permissions to see",
+ "extensions": {
+ "severity": "WARNING",
+ "code": "PERMISSIONS_MODE_SWITCHED",
+ "properties": {
+ "workbooksConnection": [
+ "projectNameWithin"
+ ]
+ }
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json b/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
index 5de4fe5f647d9..855f872838052 100644
--- a/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
+++ b/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
@@ -42958,6 +42958,50 @@
"pipelineName": "test_tableau_cll_ingest"
}
},
+{
+ "proposedSnapshot": {
+ "com.linkedin.pegasus2avro.metadata.snapshot.DatasetSnapshot": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:bigquery,demo-custom-323403.bigquery_demo.order_items,PROD)",
+ "aspects": [
+ {
+ "com.linkedin.pegasus2avro.metadata.key.DatasetKey": {
+ "platform": "urn:li:dataPlatform:bigquery",
+ "name": "demo-custom-323403.bigquery_demo.order_items",
+ "origin": "PROD"
+ }
+ }
+ ]
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1638860400000,
+ "runId": "tableau-test",
+ "lastRunId": "no-run-id-provided",
+ "pipelineName": "test_tableau_cll_ingest"
+ }
+},
+{
+ "proposedSnapshot": {
+ "com.linkedin.pegasus2avro.metadata.snapshot.DatasetSnapshot": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:bigquery,demo-custom-323403.bigquery_demo.sellers,PROD)",
+ "aspects": [
+ {
+ "com.linkedin.pegasus2avro.metadata.key.DatasetKey": {
+ "platform": "urn:li:dataPlatform:bigquery",
+ "name": "demo-custom-323403.bigquery_demo.sellers",
+ "origin": "PROD"
+ }
+ }
+ ]
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1638860400000,
+ "runId": "tableau-test",
+ "lastRunId": "no-run-id-provided",
+ "pipelineName": "test_tableau_cll_ingest"
+ }
+},
{
"entityType": "chart",
"entityUrn": "urn:li:chart:(tableau,130496dc-29ca-8a89-e32b-d73c4d8b65ff)",
diff --git a/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py b/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
index b64609b6ea605..0891a1e0cd593 100644
--- a/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
+++ b/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
@@ -2,7 +2,7 @@
import logging
import pathlib
import sys
-from typing import Any, Dict, cast
+from typing import Any, Dict, List, cast
from unittest import mock
import pytest
@@ -232,6 +232,41 @@ def side_effect_site_get_by_id(id, *arg, **kwargs):
return site
+def mock_sdk_client(
+ side_effect_query_metadata_response: List[dict],
+ datasources_side_effect: List[dict],
+ sign_out_side_effect: List[dict],
+) -> mock.MagicMock:
+
+ mock_client = mock.Mock()
+ mocked_metadata = mock.Mock()
+ mocked_metadata.query.side_effect = side_effect_query_metadata_response
+ mock_client.metadata = mocked_metadata
+
+ mock_client.auth = mock.Mock()
+ mock_client.site_id = "190a6a5c-63ed-4de1-8045-site1"
+ mock_client.views = mock.Mock()
+ mock_client.projects = mock.Mock()
+ mock_client.sites = mock.Mock()
+
+ mock_client.projects.get.side_effect = side_effect_project_data
+ mock_client.sites.get.side_effect = side_effect_site_data
+ mock_client.sites.get_by_id.side_effect = side_effect_site_get_by_id
+
+ mock_client.datasources = mock.Mock()
+ mock_client.datasources.get.side_effect = datasources_side_effect
+ mock_client.datasources.get_by_id.side_effect = side_effect_datasource_get_by_id
+
+ mock_client.workbooks = mock.Mock()
+ mock_client.workbooks.get.side_effect = side_effect_workbook_data
+
+ mock_client.views.get.side_effect = side_effect_usage_stat
+ mock_client.auth.sign_in.return_value = None
+ mock_client.auth.sign_out.side_effect = sign_out_side_effect
+
+ return mock_client
+
+
def tableau_ingest_common(
pytestconfig,
tmp_path,
@@ -251,30 +286,11 @@ def tableau_ingest_common(
mock_checkpoint.return_value = mock_datahub_graph
with mock.patch("datahub.ingestion.source.tableau.Server") as mock_sdk:
- mock_client = mock.Mock()
- mocked_metadata = mock.Mock()
- mocked_metadata.query.side_effect = side_effect_query_metadata_response
- mock_client.metadata = mocked_metadata
- mock_client.auth = mock.Mock()
- mock_client.site_id = "190a6a5c-63ed-4de1-8045-site1"
- mock_client.views = mock.Mock()
- mock_client.projects = mock.Mock()
- mock_client.sites = mock.Mock()
-
- mock_client.projects.get.side_effect = side_effect_project_data
- mock_client.sites.get.side_effect = side_effect_site_data
- mock_client.sites.get_by_id.side_effect = side_effect_site_get_by_id
- mock_client.datasources = mock.Mock()
- mock_client.datasources.get.side_effect = datasources_side_effect
- mock_client.datasources.get_by_id.side_effect = (
- side_effect_datasource_get_by_id
+ mock_sdk.return_value = mock_sdk_client(
+ side_effect_query_metadata_response=side_effect_query_metadata_response,
+ datasources_side_effect=datasources_side_effect,
+ sign_out_side_effect=sign_out_side_effect,
)
- mock_client.workbooks = mock.Mock()
- mock_client.workbooks.get.side_effect = side_effect_workbook_data
- mock_client.views.get.side_effect = side_effect_usage_stat
- mock_client.auth.sign_in.return_value = None
- mock_client.auth.sign_out.side_effect = sign_out_side_effect
- mock_sdk.return_value = mock_client
mock_sdk._auth_token = "ABC"
pipeline = Pipeline.create(
@@ -1106,3 +1122,51 @@ def test_site_name_pattern(pytestconfig, tmp_path, mock_datahub_graph):
pipeline_config=new_config,
pipeline_name="test_tableau_site_name_pattern_ingest",
)
+
+
+@freeze_time(FROZEN_TIME)
+@pytest.mark.integration
+def test_permission_mode_switched_error(pytestconfig, tmp_path, mock_datahub_graph):
+
+ with mock.patch(
+ "datahub.ingestion.source.state_provider.datahub_ingestion_checkpointing_provider.DataHubGraph",
+ mock_datahub_graph,
+ ) as mock_checkpoint:
+ mock_checkpoint.return_value = mock_datahub_graph
+
+ with mock.patch("datahub.ingestion.source.tableau.Server") as mock_sdk:
+ mock_sdk.return_value = mock_sdk_client(
+ side_effect_query_metadata_response=[
+ read_response(pytestconfig, "permission_mode_switched_error.json")
+ ],
+ sign_out_side_effect=[{}],
+ datasources_side_effect=[{}],
+ )
+
+ reporter = TableauSourceReport()
+ tableau_source = TableauSiteSource(
+ platform="tableau",
+ config=mock.MagicMock(),
+ ctx=mock.MagicMock(),
+ site=mock.MagicMock(),
+ server=mock_sdk.return_value,
+ report=reporter,
+ )
+
+ tableau_source.get_connection_object_page(
+ query=mock.MagicMock(),
+ connection_type=mock.MagicMock(),
+ query_filter=mock.MagicMock(),
+ retries_remaining=1,
+ )
+
+ warnings = list(reporter.warnings)
+
+ assert len(warnings) == 1
+
+ assert warnings[0].title == "Derived Permission Error"
+
+ assert warnings[0].message == (
+ "Turn on your derived permissions. See for details "
+ "https://community.tableau.com/s/question/0D54T00000QnjHbSAJ/how-to-fix-the-permissionsmodeswitched-error"
+ )
diff --git a/metadata-ingestion/tests/unit/test_bigquery_source.py b/metadata-ingestion/tests/unit/test_bigquery_source.py
index b58f35c0deef5..746cf9b0acfc3 100644
--- a/metadata-ingestion/tests/unit/test_bigquery_source.py
+++ b/metadata-ingestion/tests/unit/test_bigquery_source.py
@@ -32,6 +32,9 @@
BigqueryTableSnapshot,
BigqueryView,
)
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
from datahub.ingestion.source.bigquery_v2.lineage import (
LineageEdge,
LineageEdgeColumnMapping,
@@ -231,8 +234,9 @@ def test_get_dataplatform_instance_aspect_returns_project_id(get_bq_client_mock)
config = BigQueryV2Config.parse_obj({"include_data_platform_instance": True})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
- data_platform_instance = source.get_dataplatform_instance_aspect(
+ data_platform_instance = schema_gen.get_dataplatform_instance_aspect(
"urn:li:test", project_id
)
metadata = data_platform_instance.metadata
@@ -246,8 +250,9 @@ def test_get_dataplatform_instance_aspect_returns_project_id(get_bq_client_mock)
def test_get_dataplatform_instance_default_no_instance(get_bq_client_mock):
config = BigQueryV2Config.parse_obj({})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
- data_platform_instance = source.get_dataplatform_instance_aspect(
+ data_platform_instance = schema_gen.get_dataplatform_instance_aspect(
"urn:li:test", "project_id"
)
metadata = data_platform_instance.metadata
@@ -273,24 +278,35 @@ def test_get_projects_with_single_project_id(get_bq_client_mock):
def test_get_projects_by_list(get_bq_client_mock):
client_mock = MagicMock()
get_bq_client_mock.return_value = client_mock
- client_mock.list_projects.return_value = [
- SimpleNamespace(
- project_id="test-1",
- friendly_name="one",
- ),
- SimpleNamespace(
- project_id="test-2",
- friendly_name="two",
- ),
- ]
+
+ first_page = MagicMock()
+ first_page.__iter__.return_value = iter(
+ [
+ SimpleNamespace(project_id="test-1", friendly_name="one"),
+ SimpleNamespace(project_id="test-2", friendly_name="two"),
+ ]
+ )
+ first_page.next_page_token = "token1"
+
+ second_page = MagicMock()
+ second_page.__iter__.return_value = iter(
+ [
+ SimpleNamespace(project_id="test-3", friendly_name="three"),
+ SimpleNamespace(project_id="test-4", friendly_name="four"),
+ ]
+ )
+ second_page.next_page_token = None
+ client_mock.list_projects.side_effect = [first_page, second_page]
config = BigQueryV2Config.parse_obj({})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test1"))
assert source._get_projects() == [
BigqueryProject("test-1", "one"),
BigqueryProject("test-2", "two"),
+ BigqueryProject("test-3", "three"),
+ BigqueryProject("test-4", "four"),
]
- assert client_mock.list_projects.call_count == 1
+ assert client_mock.list_projects.call_count == 2
@patch.object(BigQuerySchemaApi, "get_projects")
@@ -342,7 +358,7 @@ def test_get_projects_list_failure(
caplog.clear()
with caplog.at_level(logging.ERROR):
projects = source._get_projects()
- assert len(caplog.records) == 1
+ assert len(caplog.records) == 2
assert error_str in caplog.records[0].msg
assert len(source.report.failures) == 1
assert projects == []
@@ -395,8 +411,9 @@ def test_gen_table_dataset_workunits(get_bq_client_mock, bigquery_table):
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_table_dataset_workunits(
+ gen = schema_gen.gen_table_dataset_workunits(
bigquery_table, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -710,9 +727,10 @@ def test_table_processing_logic(get_bq_client_mock, data_dictionary_mock):
data_dictionary_mock.get_tables_for_dataset.return_value = None
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
_ = list(
- source.get_tables_for_dataset(
+ schema_gen.get_tables_for_dataset(
project_id="test-project", dataset_name="test-dataset"
)
)
@@ -784,9 +802,10 @@ def test_table_processing_logic_date_named_tables(
data_dictionary_mock.get_tables_for_dataset.return_value = None
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
_ = list(
- source.get_tables_for_dataset(
+ schema_gen.get_tables_for_dataset(
project_id="test-project", dataset_name="test-dataset"
)
)
@@ -882,7 +901,9 @@ def test_get_views_for_dataset(
assert list(views) == [bigquery_view_1, bigquery_view_2]
-@patch.object(BigqueryV2Source, "gen_dataset_workunits", lambda *args, **kwargs: [])
+@patch.object(
+ BigQuerySchemaGenerator, "gen_dataset_workunits", lambda *args, **kwargs: []
+)
@patch.object(BigQueryV2Config, "get_bigquery_client")
def test_gen_view_dataset_workunits(
get_bq_client_mock, bigquery_view_1, bigquery_view_2
@@ -897,8 +918,9 @@ def test_gen_view_dataset_workunits(
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_view_dataset_workunits(
+ gen = schema_gen.gen_view_dataset_workunits(
bigquery_view_1, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -908,7 +930,7 @@ def test_gen_view_dataset_workunits(
viewLogic=bigquery_view_1.view_definition,
)
- gen = source.gen_view_dataset_workunits(
+ gen = schema_gen.gen_view_dataset_workunits(
bigquery_view_2, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -990,8 +1012,9 @@ def test_gen_snapshot_dataset_workunits(get_bq_client_mock, bigquery_snapshot):
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_snapshot_dataset_workunits(
+ gen = schema_gen.gen_snapshot_dataset_workunits(
bigquery_snapshot, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalWrapper, list(gen)[2].metadata)
diff --git a/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py b/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
index 8a3fa5ca46ea4..21787af1b0cb9 100644
--- a/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
+++ b/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
@@ -212,3 +212,29 @@ def test_unquote_and_decode_unicode_escape_seq():
expected_output = "No escape sequences here"
result = unquote_and_decode_unicode_escape_seq(input_string)
assert result == expected_output
+
+ # Test with invalid Unicode escape sequences
+ input_string = '"No escape \\u123 sequences here"'
+ expected_output = "No escape \\u123 sequences here"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with a string that has multiple Unicode escape sequences
+ input_string = '"Hello \\u003cWorld\\u003e \\u003cAgain\\u003e \\u003cAgain\\u003e \\u003cAgain\\u003e"'
+ expected_output = "Hello "
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with a string that has a Unicode escape sequence at the beginning
+ input_string = '"Hello \\utest"'
+ expected_output = "Hello \\utest"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with special characters
+ input_string = (
+ '"Hello \\u003cWorld\\u003e \\u003cçãâÁÁà|{}()[].,/;\\+=--_*&%$#@!?\\u003e"'
+ )
+ expected_output = "Hello <çãâÁÁà|{}()[].,/;\\+=--_*&%$#@!?>"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
diff --git a/metadata-ingestion/tests/unit/test_snowflake_shares.py b/metadata-ingestion/tests/unit/test_snowflake_shares.py
index fc753f99b7e8f..2e78f0bb3ae65 100644
--- a/metadata-ingestion/tests/unit/test_snowflake_shares.py
+++ b/metadata-ingestion/tests/unit/test_snowflake_shares.py
@@ -102,9 +102,7 @@ def test_snowflake_shares_workunit_no_shares(
config = SnowflakeV2Config(account_id="abc12345", platform_instance="instance1")
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x)
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -204,9 +202,7 @@ def test_snowflake_shares_workunit_inbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -262,9 +258,7 @@ def test_snowflake_shares_workunit_outbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -313,9 +307,7 @@ def test_snowflake_shares_workunit_inbound_and_outbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -376,9 +368,7 @@ def test_snowflake_shares_workunit_inbound_and_outbound_share_no_platform_instan
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x)
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
assert sorted(config.outbounds().keys()) == ["db1", "db2_main"]
assert sorted(config.inbounds().keys()) == [
diff --git a/metadata-ingestion/tests/unit/test_snowflake_source.py b/metadata-ingestion/tests/unit/test_snowflake_source.py
index 3353e74449c95..72b59a3a4e493 100644
--- a/metadata-ingestion/tests/unit/test_snowflake_source.py
+++ b/metadata-ingestion/tests/unit/test_snowflake_source.py
@@ -274,21 +274,31 @@ def test_test_connection_basic_success(mock_connect):
test_connection_helpers.assert_basic_connectivity_success(report)
-def setup_mock_connect(mock_connect, query_results=None):
- def default_query_results(query):
+class MissingQueryMock(Exception):
+ pass
+
+
+def setup_mock_connect(mock_connect, extra_query_results=None):
+ def query_results(query):
+ if extra_query_results is not None:
+ try:
+ return extra_query_results(query)
+ except MissingQueryMock:
+ pass
+
if query == "select current_role()":
- return [("TEST_ROLE",)]
+ return [{"CURRENT_ROLE()": "TEST_ROLE"}]
elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
+ return [{"CURRENT_SECONDARY_ROLES()": '{"roles":"","value":""}'}]
elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- raise ValueError(f"Unexpected query: {query}")
+ return [{"CURRENT_WAREHOUSE()": "TEST_WAREHOUSE"}]
+ elif query == 'show grants to role "PUBLIC"':
+ return []
+ raise MissingQueryMock(f"Unexpected query: {query}")
connection_mock = MagicMock()
cursor_mock = MagicMock()
- cursor_mock.execute.side_effect = (
- query_results if query_results is not None else default_query_results
- )
+ cursor_mock.execute.side_effect = query_results
connection_mock.cursor.return_value = cursor_mock
mock_connect.return_value = connection_mock
@@ -296,21 +306,11 @@ def default_query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_no_warehouse(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [(None,)]
+ if query == "select current_warehouse()":
+ return [{"CURRENT_WAREHOUSE()": None}]
elif query == 'show grants to role "TEST_ROLE"':
- return [
- ("", "USAGE", "DATABASE", "DB1"),
- ("", "USAGE", "SCHEMA", "DB1.SCHEMA1"),
- ("", "REFERENCES", "TABLE", "DB1.SCHEMA1.TABLE1"),
- ]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ return [{"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"}]
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
report = test_connection_helpers.run_test_connection(
@@ -330,17 +330,9 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_schema_failure(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE",)]
- elif query == 'show grants to role "TEST_ROLE"':
- return [("", "USAGE", "DATABASE", "DB1")]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ if query == 'show grants to role "TEST_ROLE"':
+ return [{"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"}]
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
@@ -361,21 +353,17 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_schema_success(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- elif query == 'show grants to role "TEST_ROLE"':
+ if query == 'show grants to role "TEST_ROLE"':
return [
- ["", "USAGE", "DATABASE", "DB1"],
- ["", "USAGE", "SCHEMA", "DB1.SCHEMA1"],
- ["", "REFERENCES", "TABLE", "DB1.SCHEMA1.TABLE1"],
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "DB1.SCHEMA1"},
+ {
+ "privilege": "REFERENCES",
+ "granted_on": "TABLE",
+ "name": "DB1.SCHEMA1.TABLE1",
+ },
]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
@@ -397,30 +385,38 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_all_success(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- elif query == 'show grants to role "TEST_ROLE"':
+ if query == 'show grants to role "TEST_ROLE"':
return [
- ("", "USAGE", "DATABASE", "DB1"),
- ("", "USAGE", "SCHEMA", "DB1.SCHEMA1"),
- ("", "SELECT", "TABLE", "DB1.SCHEMA1.TABLE1"),
- ("", "USAGE", "ROLE", "TEST_USAGE_ROLE"),
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "DB1.SCHEMA1"},
+ {
+ "privilege": "SELECT",
+ "granted_on": "TABLE",
+ "name": "DB1.SCHEMA1.TABLE1",
+ },
+ {"privilege": "USAGE", "granted_on": "ROLE", "name": "TEST_USAGE_ROLE"},
]
- elif query == 'show grants to role "PUBLIC"':
- return []
elif query == 'show grants to role "TEST_USAGE_ROLE"':
return [
- ["", "USAGE", "DATABASE", "SNOWFLAKE"],
- ["", "USAGE", "SCHEMA", "ACCOUNT_USAGE"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.OBJECT_DEPENDENCIES"],
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "SNOWFLAKE"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "ACCOUNT_USAGE"},
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY",
+ },
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY",
+ },
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.OBJECT_DEPENDENCIES",
+ },
]
- raise ValueError(f"Unexpected query: {query}")
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
diff --git a/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py b/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py
new file mode 100644
index 0000000000000..35c44c7b4a847
--- /dev/null
+++ b/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py
@@ -0,0 +1,14 @@
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
+
+
+def test_threaded_iterator_executor():
+ def table_of(i):
+ for j in range(1, 11):
+ yield f"{i}x{j}={i*j}"
+
+ assert {
+ res
+ for res in ThreadedIteratorExecutor.process(
+ table_of, [(i,) for i in range(1, 30)], max_workers=2
+ )
+ } == {x for i in range(1, 30) for x in table_of(i)}
diff --git a/metadata-integration/java/spark-lineage-beta/README.md b/metadata-integration/java/spark-lineage-beta/README.md
index a643919664b07..b0753936dd677 100644
--- a/metadata-integration/java/spark-lineage-beta/README.md
+++ b/metadata-integration/java/spark-lineage-beta/README.md
@@ -346,8 +346,10 @@ Use Java 8 to build the project. The project uses Gradle as the build tool. To b
+
## Changelog
+### Version 0.2.14
+- Fix warning about MeterFilter warning from Micrometer
-### Version 0.2.12
+### Version 0.2.13
- Silencing some chatty warnings in RddPathUtils
### Version 0.2.12
diff --git a/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java b/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
index 54bb3821edded..96fa74d1bca1f 100644
--- a/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
+++ b/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
@@ -287,13 +287,7 @@ private static void initializeMetrics(OpenLineageConfig openLineageConfig) {
} else {
disabledFacets = "";
}
- meterRegistry
- .config()
- .commonTags(
- Tags.of(
- Tag.of("openlineage.spark.integration.version", Versions.getVersion()),
- Tag.of("openlineage.spark.version", sparkVersion),
- Tag.of("openlineage.spark.disabled.facets", disabledFacets)));
+
((CompositeMeterRegistry) meterRegistry)
.getRegistries()
.forEach(
diff --git a/metadata-io/build.gradle b/metadata-io/build.gradle
index 6666e33544688..ff29cb5fff47d 100644
--- a/metadata-io/build.gradle
+++ b/metadata-io/build.gradle
@@ -21,6 +21,7 @@ dependencies {
api project(':metadata-service:services')
api project(':metadata-operation-context')
+ implementation spec.product.pegasus.restliServer
implementation spec.product.pegasus.data
implementation spec.product.pegasus.generator
diff --git a/metadata-io/metadata-io-api/build.gradle b/metadata-io/metadata-io-api/build.gradle
index bd79e8cb3ddef..b8028fad07bb6 100644
--- a/metadata-io/metadata-io-api/build.gradle
+++ b/metadata-io/metadata-io-api/build.gradle
@@ -8,4 +8,11 @@ dependencies {
implementation project(':metadata-utils')
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
+
+ testImplementation(externalDependency.testng)
+ testImplementation(externalDependency.mockito)
+ testImplementation(testFixtures(project(":entity-registry")))
+ testImplementation project(':metadata-operation-context')
+ testImplementation externalDependency.lombok
+ testAnnotationProcessor externalDependency.lombok
}
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
index 0914df744e413..a23f6ab175046 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
@@ -8,6 +8,7 @@
import com.linkedin.metadata.aspect.batch.AspectsBatch;
import com.linkedin.metadata.aspect.batch.BatchItem;
import com.linkedin.metadata.aspect.batch.ChangeMCP;
+import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.validation.ValidationExceptionCollection;
import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.util.Pair;
@@ -18,6 +19,7 @@
import java.util.Objects;
import java.util.Set;
import java.util.stream.Collectors;
+import java.util.stream.Stream;
import javax.annotation.Nonnull;
import lombok.Builder;
import lombok.Getter;
@@ -44,9 +46,20 @@ public class AspectsBatchImpl implements AspectsBatch {
public Pair>, List> toUpsertBatchItems(
final Map> latestAspects) {
+ // Process proposals to change items
+ Stream mutatedProposalsStream =
+ proposedItemsToChangeItemStream(
+ items.stream()
+ .filter(item -> item instanceof ProposedItem)
+ .map(item -> (MCPItem) item)
+ .collect(Collectors.toList()));
+ // Regular change items
+ Stream changeMCPStream =
+ items.stream().filter(item -> !(item instanceof ProposedItem));
+
// Convert patches to upserts if needed
LinkedList upsertBatchItems =
- items.stream()
+ Stream.concat(mutatedProposalsStream, changeMCPStream)
.map(
item -> {
final String urnStr = item.getUrn().toString();
@@ -85,6 +98,17 @@ public Pair>, List> toUpsertBatchItems(
return Pair.of(newUrnAspectNames, upsertBatchItems);
}
+ private Stream proposedItemsToChangeItemStream(List proposedItems) {
+ return applyProposalMutationHooks(proposedItems, retrieverContext)
+ .filter(mcpItem -> mcpItem.getMetadataChangeProposal() != null)
+ .map(
+ mcpItem ->
+ ChangeItemImpl.ChangeItemImplBuilder.build(
+ mcpItem.getMetadataChangeProposal(),
+ mcpItem.getAuditStamp(),
+ retrieverContext.getAspectRetriever()));
+ }
+
public static class AspectsBatchImplBuilder {
/**
* Just one aspect record template
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
new file mode 100644
index 0000000000000..452ed39ddf317
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
@@ -0,0 +1,80 @@
+package com.linkedin.metadata.entity.ebean.batch;
+
+import com.linkedin.common.AuditStamp;
+import com.linkedin.common.urn.Urn;
+import com.linkedin.data.template.RecordTemplate;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.models.AspectSpec;
+import com.linkedin.metadata.models.EntitySpec;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import javax.annotation.Nonnull;
+import javax.annotation.Nullable;
+import lombok.Builder;
+import lombok.Getter;
+import lombok.extern.slf4j.Slf4j;
+
+/** Represents an unvalidated wrapped MCP */
+@Slf4j
+@Getter
+@Builder(toBuilder = true)
+public class ProposedItem implements MCPItem {
+ @Nonnull private final MetadataChangeProposal metadataChangeProposal;
+ @Nonnull private final AuditStamp auditStamp;
+ // derived
+ @Nonnull private EntitySpec entitySpec;
+ @Nullable private AspectSpec aspectSpec;
+
+ @Nonnull
+ @Override
+ public String getAspectName() {
+ if (metadataChangeProposal.getAspectName() != null) {
+ return metadataChangeProposal.getAspectName();
+ } else {
+ return MCPItem.super.getAspectName();
+ }
+ }
+
+ @Nullable
+ public AspectSpec getAspectSpec() {
+ if (aspectSpec != null) {
+ return aspectSpec;
+ }
+ if (entitySpec.getAspectSpecMap().containsKey(getAspectName())) {
+ return entitySpec.getAspectSpecMap().get(getAspectName());
+ }
+ return null;
+ }
+
+ @Nullable
+ @Override
+ public RecordTemplate getRecordTemplate() {
+ if (getAspectSpec() != null) {
+ return GenericRecordUtils.deserializeAspect(
+ getMetadataChangeProposal().getAspect().getValue(),
+ getMetadataChangeProposal().getAspect().getContentType(),
+ getAspectSpec());
+ }
+ return null;
+ }
+
+ @Nonnull
+ @Override
+ public Urn getUrn() {
+ return metadataChangeProposal.getEntityUrn();
+ }
+
+ @Nullable
+ @Override
+ public SystemMetadata getSystemMetadata() {
+ return metadataChangeProposal.getSystemMetadata();
+ }
+
+ @Nonnull
+ @Override
+ public ChangeType getChangeType() {
+ return metadataChangeProposal.getChangeType();
+ }
+}
diff --git a/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java b/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java
new file mode 100644
index 0000000000000..d2e7243d04560
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java
@@ -0,0 +1,320 @@
+package com.linkedin.metadata.entity.ebean.batch;
+
+import static com.linkedin.metadata.Constants.DATASET_ENTITY_NAME;
+import static com.linkedin.metadata.Constants.STATUS_ASPECT_NAME;
+import static com.linkedin.metadata.Constants.STRUCTURED_PROPERTIES_ASPECT_NAME;
+import static org.mockito.Mockito.mock;
+import static org.mockito.Mockito.when;
+import static org.testng.Assert.assertEquals;
+
+import com.linkedin.common.Status;
+import com.linkedin.common.urn.UrnUtils;
+import com.linkedin.data.ByteString;
+import com.linkedin.data.schema.annotation.PathSpecBasedSchemaAnnotationVisitor;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.AspectRetriever;
+import com.linkedin.metadata.aspect.GraphRetriever;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.patch.GenericJsonPatch;
+import com.linkedin.metadata.aspect.patch.PatchOperationType;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import com.linkedin.metadata.entity.SearchRetriever;
+import com.linkedin.metadata.models.registry.ConfigEntityRegistry;
+import com.linkedin.metadata.models.registry.EntityRegistry;
+import com.linkedin.metadata.models.registry.EntityRegistryException;
+import com.linkedin.metadata.models.registry.MergedEntityRegistry;
+import com.linkedin.metadata.models.registry.SnapshotEntityRegistry;
+import com.linkedin.metadata.snapshot.Snapshot;
+import com.linkedin.metadata.utils.AuditStampUtils;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import com.linkedin.structured.StructuredProperties;
+import com.linkedin.structured.StructuredPropertyValueAssignmentArray;
+import com.linkedin.util.Pair;
+import io.datahubproject.metadata.context.RetrieverContext;
+import java.nio.charset.StandardCharsets;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Stream;
+import javax.annotation.Nonnull;
+import lombok.Getter;
+import lombok.Setter;
+import lombok.experimental.Accessors;
+import org.testng.annotations.BeforeMethod;
+import org.testng.annotations.BeforeTest;
+import org.testng.annotations.Test;
+
+public class AspectsBatchImplTest {
+ private EntityRegistry testRegistry;
+ private AspectRetriever mockAspectRetriever;
+ private RetrieverContext retrieverContext;
+
+ @BeforeTest
+ public void beforeTest() throws EntityRegistryException {
+ PathSpecBasedSchemaAnnotationVisitor.class
+ .getClassLoader()
+ .setClassAssertionStatus(PathSpecBasedSchemaAnnotationVisitor.class.getName(), false);
+
+ EntityRegistry snapshotEntityRegistry = new SnapshotEntityRegistry();
+ EntityRegistry configEntityRegistry =
+ new ConfigEntityRegistry(
+ Snapshot.class.getClassLoader().getResourceAsStream("AspectsBatchImplTest.yaml"));
+ this.testRegistry =
+ new MergedEntityRegistry(snapshotEntityRegistry).apply(configEntityRegistry);
+ }
+
+ @BeforeMethod
+ public void setup() {
+ this.mockAspectRetriever = mock(AspectRetriever.class);
+ when(this.mockAspectRetriever.getEntityRegistry()).thenReturn(testRegistry);
+ this.retrieverContext =
+ RetrieverContext.builder()
+ .searchRetriever(mock(SearchRetriever.class))
+ .aspectRetriever(mockAspectRetriever)
+ .graphRetriever(mock(GraphRetriever.class))
+ .build();
+ }
+
+ @Test
+ public void toUpsertBatchItemsChangeItemTest() {
+ List testItems =
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .recordTemplate(new Status().setRemoved(true))
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever));
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(Map.of(), testItems),
+ "Expected noop, pass through with no additional MCPs or changes");
+ }
+
+ @Test
+ public void toUpsertBatchItemsPatchItemTest() {
+ GenericJsonPatch.PatchOp testPatchOp = new GenericJsonPatch.PatchOp();
+ testPatchOp.setOp(PatchOperationType.REMOVE.getValue());
+ testPatchOp.setPath(
+ String.format(
+ "/properties/%s", "urn:li:structuredProperty:io.acryl.privacy.retentionTime"));
+
+ List testItems =
+ List.of(
+ PatchItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .patch(
+ GenericJsonPatch.builder()
+ .arrayPrimaryKeys(Map.of("properties", List.of("propertyUrn")))
+ .patch(List.of(testPatchOp))
+ .build()
+ .getJsonPatch())
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(retrieverContext.getAspectRetriever().getEntityRegistry()),
+ PatchItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .patch(
+ GenericJsonPatch.builder()
+ .arrayPrimaryKeys(Map.of("properties", List.of("propertyUrn")))
+ .patch(List.of(testPatchOp))
+ .build()
+ .getJsonPatch())
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(retrieverContext.getAspectRetriever().getEntityRegistry()));
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(
+ Map.of(),
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .auditStamp(testItems.get(0).getAuditStamp())
+ .recordTemplate(
+ new StructuredProperties()
+ .setProperties(new StructuredPropertyValueAssignmentArray()))
+ .systemMetadata(testItems.get(0).getSystemMetadata())
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .auditStamp(testItems.get(1).getAuditStamp())
+ .recordTemplate(
+ new StructuredProperties()
+ .setProperties(new StructuredPropertyValueAssignmentArray()))
+ .systemMetadata(testItems.get(1).getSystemMetadata())
+ .build(mockAspectRetriever))),
+ "Expected patch items converted to upsert change items");
+ }
+
+ @Test
+ public void toUpsertBatchItemsProposedItemTest() {
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .setAspectName("my-custom-aspect")
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\"}", StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(),
+ ProposedItem.builder()
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .setAspectName("my-custom-aspect")
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\"}", StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(
+ Map.of(),
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .systemMetadata(testItems.get(0).getSystemMetadata())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .systemMetadata(testItems.get(1).getSystemMetadata())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever))),
+ "Mutation to status aspect");
+ }
+
+ /** Converts unsupported to status aspect */
+ @Getter
+ @Setter
+ @Accessors(chain = true)
+ public static class TestMutator extends MutationHook {
+ private AspectPluginConfig config;
+
+ @Override
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems,
+ @Nonnull com.linkedin.metadata.aspect.RetrieverContext retrieverContext) {
+ return mcpItems.stream()
+ .peek(
+ item ->
+ item.getMetadataChangeProposal()
+ .setAspectName(STATUS_ASPECT_NAME)
+ .setAspect(
+ GenericRecordUtils.serializeAspect(new Status().setRemoved(false))));
+ }
+ }
+}
diff --git a/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml b/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml
new file mode 100644
index 0000000000000..9716b0cab9b2f
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml
@@ -0,0 +1,19 @@
+entities:
+ - name: dataset
+ doc: Datasets represent logical or physical data assets stored or represented in various data platforms. Tables, Views, Streams are all instances of datasets.
+ category: core
+ keyAspect: datasetKey
+ aspects:
+ - status
+ - structuredProperties
+plugins:
+ mutationHooks:
+ - className: 'com.linkedin.metadata.entity.ebean.batch.AspectsBatchImplTest$TestMutator'
+ packageScan:
+ - 'com.linkedin.metadata.entity.ebean.batch'
+ enabled: true
+ supportedOperations:
+ - UPSERT
+ supportedEntityAspectNames:
+ - entityName: 'dataset'
+ aspectName: '*'
\ No newline at end of file
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
new file mode 100644
index 0000000000000..8d6bdffceacb9
--- /dev/null
+++ b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
@@ -0,0 +1,80 @@
+package com.linkedin.metadata.aspect.hooks;
+
+import com.datahub.util.exception.ModelConversionException;
+import com.linkedin.data.template.RecordTemplate;
+import com.linkedin.data.transform.filter.request.MaskTree;
+import com.linkedin.metadata.aspect.RetrieverContext;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import com.linkedin.metadata.entity.validation.ValidationApiUtils;
+import com.linkedin.metadata.entity.validation.ValidationException;
+import com.linkedin.metadata.models.AspectSpec;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.restli.internal.server.util.RestUtils;
+import java.util.Collection;
+import java.util.stream.Stream;
+import javax.annotation.Nonnull;
+import lombok.Getter;
+import lombok.Setter;
+import lombok.experimental.Accessors;
+import lombok.extern.slf4j.Slf4j;
+
+/** This mutator will log and drop unknown aspects. It will also log and drop unknown fields. */
+@Slf4j
+@Setter
+@Getter
+@Accessors(chain = true)
+public class IgnoreUnknownMutator extends MutationHook {
+ @Nonnull private AspectPluginConfig config;
+
+ @Override
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return mcpItems.stream()
+ .filter(
+ item -> {
+ if (item.getEntitySpec().getAspectSpec(item.getAspectName()) == null) {
+ log.warn(
+ "Dropping unknown aspect {} on entity {}",
+ item.getAspectName(),
+ item.getAspectSpec().getName());
+ return false;
+ }
+ if (!"application/json"
+ .equals(item.getMetadataChangeProposal().getAspect().getContentType())) {
+ log.warn(
+ "Dropping unknown content type {} for aspect {} on entity {}",
+ item.getMetadataChangeProposal().getAspect().getContentType(),
+ item.getAspectName(),
+ item.getEntitySpec().getName());
+ return false;
+ }
+ return true;
+ })
+ .peek(
+ item -> {
+ try {
+ AspectSpec aspectSpec = item.getEntitySpec().getAspectSpec(item.getAspectName());
+ GenericAspect aspect = item.getMetadataChangeProposal().getAspect();
+ RecordTemplate recordTemplate =
+ GenericRecordUtils.deserializeAspect(
+ aspect.getValue(), aspect.getContentType(), aspectSpec);
+ try {
+ ValidationApiUtils.validateOrThrow(recordTemplate);
+ } catch (ValidationException | ModelConversionException e) {
+ log.warn(
+ "Failed to validate aspect. Coercing aspect {} on entity {}",
+ item.getAspectName(),
+ item.getEntitySpec().getName());
+ RestUtils.trimRecordTemplate(recordTemplate, new MaskTree(), false);
+ item.getMetadataChangeProposal()
+ .setAspect(GenericRecordUtils.serializeAspect(recordTemplate));
+ }
+ } catch (Exception e) {
+ throw new RuntimeException(e);
+ }
+ });
+ }
+}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java b/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java
new file mode 100644
index 0000000000000..11a3153abcaee
--- /dev/null
+++ b/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java
@@ -0,0 +1,143 @@
+package com.linkedin.metadata.aspect.hooks;
+
+import static com.linkedin.metadata.Constants.DATASET_ENTITY_NAME;
+import static com.linkedin.metadata.Constants.DATASET_PROPERTIES_ASPECT_NAME;
+import static com.linkedin.metadata.Constants.GLOBAL_TAGS_ASPECT_NAME;
+import static org.mockito.Mockito.mock;
+import static org.testng.Assert.assertEquals;
+
+import com.linkedin.common.GlobalTags;
+import com.linkedin.common.TagAssociation;
+import com.linkedin.common.TagAssociationArray;
+import com.linkedin.common.urn.TagUrn;
+import com.linkedin.common.urn.Urn;
+import com.linkedin.common.urn.UrnUtils;
+import com.linkedin.data.ByteString;
+import com.linkedin.data.template.StringMap;
+import com.linkedin.dataset.DatasetProperties;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.AspectRetriever;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.entity.SearchRetriever;
+import com.linkedin.metadata.entity.ebean.batch.ProposedItem;
+import com.linkedin.metadata.models.registry.EntityRegistry;
+import com.linkedin.metadata.utils.AuditStampUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import com.linkedin.test.metadata.aspect.TestEntityRegistry;
+import io.datahubproject.metadata.context.RetrieverContext;
+import io.datahubproject.test.metadata.context.TestOperationContexts;
+import java.net.URISyntaxException;
+import java.nio.charset.StandardCharsets;
+import java.util.List;
+import java.util.Map;
+import org.testng.annotations.BeforeMethod;
+import org.testng.annotations.Test;
+
+public class IgnoreUnknownMutatorTest {
+ private static final EntityRegistry TEST_REGISTRY = new TestEntityRegistry();
+ private static final AspectPluginConfig TEST_PLUGIN_CONFIG =
+ AspectPluginConfig.builder()
+ .className(IgnoreUnknownMutator.class.getName())
+ .enabled(true)
+ .supportedOperations(List.of("UPSERT"))
+ .supportedEntityAspectNames(
+ List.of(
+ AspectPluginConfig.EntityAspectName.builder()
+ .entityName(DATASET_ENTITY_NAME)
+ .aspectName("*")
+ .build()))
+ .build();
+ private static final Urn TEST_DATASET_URN =
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:postgres,calm-pagoda-323403.jaffle_shop.customers,PROD)");
+ private AspectRetriever mockAspectRetriever;
+ private RetrieverContext retrieverContext;
+
+ @BeforeMethod
+ public void setup() {
+ mockAspectRetriever = mock(AspectRetriever.class);
+ retrieverContext =
+ RetrieverContext.builder()
+ .searchRetriever(mock(SearchRetriever.class))
+ .aspectRetriever(mockAspectRetriever)
+ .graphRetriever(TestOperationContexts.emptyGraphRetriever)
+ .build();
+ }
+
+ @Test
+ public void testUnknownFieldInTagAssociationArray() throws URISyntaxException {
+ IgnoreUnknownMutator test = new IgnoreUnknownMutator();
+ test.setConfig(TEST_PLUGIN_CONFIG);
+
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(TEST_REGISTRY.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(TEST_DATASET_URN)
+ .setAspectName(GLOBAL_TAGS_ASPECT_NAME)
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"tags\":[{\"tag\":\"urn:li:tag:Legacy\",\"foo\":\"bar\"}]}",
+ StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ List result = test.proposalMutation(testItems, retrieverContext).toList();
+
+ assertEquals(1, result.size());
+ assertEquals(
+ result.get(0).getAspect(GlobalTags.class),
+ new GlobalTags()
+ .setTags(
+ new TagAssociationArray(
+ List.of(
+ new TagAssociation()
+ .setTag(TagUrn.createFromString("urn:li:tag:Legacy"))))));
+ }
+
+ @Test
+ public void testUnknownFieldDatasetProperties() throws URISyntaxException {
+ IgnoreUnknownMutator test = new IgnoreUnknownMutator();
+ test.setConfig(TEST_PLUGIN_CONFIG);
+
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(TEST_REGISTRY.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(TEST_DATASET_URN)
+ .setAspectName(DATASET_PROPERTIES_ASPECT_NAME)
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\",\"customProperties\":{\"prop2\":\"pikachu\",\"prop1\":\"fakeprop\"}}",
+ StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ List result = test.proposalMutation(testItems, retrieverContext).toList();
+
+ assertEquals(1, result.size());
+ assertEquals(
+ result.get(0).getAspect(DatasetProperties.class),
+ new DatasetProperties()
+ .setCustomProperties(new StringMap(Map.of("prop1", "fakeprop", "prop2", "pikachu"))));
+ }
+}
diff --git a/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java b/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
index 9a4c01dabf9a7..f6533a6ac1d8a 100644
--- a/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
+++ b/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
@@ -34,6 +34,7 @@
"com.linkedin.gms.factory.context",
"com.linkedin.gms.factory.timeseries",
"com.linkedin.gms.factory.assertion",
+ "com.linkedin.gms.factory.plugins"
},
excludeFilters = {
@ComponentScan.Filter(
diff --git a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
index 2666f58de862e..f6f71a12a6951 100644
--- a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
+++ b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
@@ -6,6 +6,7 @@
import com.datahub.authentication.Authentication;
import com.datahub.metadata.ingestion.IngestionScheduler;
import com.linkedin.entity.client.SystemEntityClient;
+import com.linkedin.gms.factory.plugins.SpringStandardPluginConfiguration;
import com.linkedin.metadata.boot.kafka.DataHubUpgradeKafkaListener;
import com.linkedin.metadata.graph.elastic.ElasticSearchGraphService;
import com.linkedin.metadata.models.registry.EntityRegistry;
@@ -85,4 +86,6 @@ public OperationContext operationContext(
indexConvention,
mock(RetrieverContext.class));
}
+
+ @MockBean SpringStandardPluginConfiguration springStandardPluginConfiguration;
}
diff --git a/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java b/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
index af3caecba865c..4ea5e6ea34d5b 100644
--- a/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
+++ b/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
@@ -33,7 +33,8 @@
"com.linkedin.gms.factory.form",
"com.linkedin.metadata.dao.producer",
"io.datahubproject.metadata.jobs.common.health.kafka",
- "com.linkedin.gms.factory.context"
+ "com.linkedin.gms.factory.context",
+ "com.linkedin.gms.factory.plugins"
},
excludeFilters = {
@ComponentScan.Filter(
diff --git a/metadata-models/src/main/resources/entity-registry.yml b/metadata-models/src/main/resources/entity-registry.yml
index c8344b7de1e12..6006ca179d162 100644
--- a/metadata-models/src/main/resources/entity-registry.yml
+++ b/metadata-models/src/main/resources/entity-registry.yml
@@ -665,3 +665,9 @@ plugins:
aspectName: 'schemaMetadata'
- entityName: '*'
aspectName: 'editableSchemaMetadata'
+ - className: 'com.linkedin.metadata.aspect.plugins.hooks.MutationHook'
+ enabled: true
+ spring:
+ enabled: true
+ packageScan:
+ - com.linkedin.gms.factory.plugins
\ No newline at end of file
diff --git a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
index dcea185fcbc7c..1eee0498f112a 100644
--- a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
+++ b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
@@ -35,6 +35,7 @@ public class RequestContext implements ContextInterface {
@Nonnull private final String requestID;
@Nonnull private final String userAgent;
+ @Builder.Default private boolean validated = true;
public RequestContext(
@Nonnull String actorUrn,
diff --git a/metadata-service/configuration/src/main/resources/application.yaml b/metadata-service/configuration/src/main/resources/application.yaml
index 599f7e7be344f..1d5b7c7904f97 100644
--- a/metadata-service/configuration/src/main/resources/application.yaml
+++ b/metadata-service/configuration/src/main/resources/application.yaml
@@ -466,6 +466,8 @@ businessAttribute:
keepAliveTime: ${BUSINESS_ATTRIBUTE_PROPAGATION_CONCURRENCY_KEEP_ALIVE:60} # Number of seconds to keep inactive threads alive
metadataChangeProposal:
+ validation:
+ ignoreUnknown: ${MCP_VALIDATION_IGNORE_UNKNOWN:true}
throttle:
updateIntervalMs: ${MCP_THROTTLE_UPDATE_INTERVAL_MS:60000}
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
index f1518f9c8f9d7..9f4dfb86c0fcd 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
@@ -1,6 +1,7 @@
package com.linkedin.gms.factory.entityregistry;
import com.datahub.plugins.metadata.aspect.SpringPluginFactory;
+import com.linkedin.gms.factory.plugins.SpringStandardPluginConfiguration;
import com.linkedin.metadata.aspect.plugins.PluginFactory;
import com.linkedin.metadata.aspect.plugins.config.PluginConfiguration;
import com.linkedin.metadata.models.registry.ConfigEntityRegistry;
@@ -29,7 +30,9 @@ public class ConfigEntityRegistryFactory {
@Bean(name = "configEntityRegistry")
@Nonnull
- protected ConfigEntityRegistry getInstance() throws IOException, EntityRegistryException {
+ protected ConfigEntityRegistry getInstance(
+ SpringStandardPluginConfiguration springStandardPluginConfiguration)
+ throws IOException, EntityRegistryException {
BiFunction, PluginFactory> pluginFactoryProvider =
(config, loaders) -> new SpringPluginFactory(applicationContext, config, loaders);
if (entityRegistryConfigPath != null) {
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
new file mode 100644
index 0000000000000..fa4f520dc88c7
--- /dev/null
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
@@ -0,0 +1,33 @@
+package com.linkedin.gms.factory.plugins;
+
+import com.linkedin.metadata.aspect.hooks.IgnoreUnknownMutator;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import java.util.List;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.context.annotation.Bean;
+import org.springframework.context.annotation.Configuration;
+
+@Configuration
+public class SpringStandardPluginConfiguration {
+
+ @Value("${metadataChangeProposal.validation.ignoreUnknown}")
+ private boolean ignoreUnknownEnabled;
+
+ @Bean
+ public MutationHook ignoreUnknownMutator() {
+ return new IgnoreUnknownMutator()
+ .setConfig(
+ AspectPluginConfig.builder()
+ .className(IgnoreUnknownMutator.class.getName())
+ .enabled(ignoreUnknownEnabled)
+ .supportedOperations(List.of("CREATE", "CREATE_ENTITY", "UPSERT"))
+ .supportedEntityAspectNames(
+ List.of(
+ AspectPluginConfig.EntityAspectName.builder()
+ .entityName("*")
+ .aspectName("*")
+ .build()))
+ .build());
+ }
+}
diff --git a/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java b/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
index 043b0016abaaa..f7e911c262908 100644
--- a/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
+++ b/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
@@ -78,6 +78,15 @@ private static Stream filterSpringConfigs(
config -> config.getSpring() != null && config.getSpring().isEnabled());
}
+ @Nonnull
+ @Override
+ public List getClassLoaders() {
+ if (!super.getClassLoaders().isEmpty()) {
+ return super.getClassLoaders();
+ }
+ return List.of(SpringPluginFactory.class.getClassLoader());
+ }
+
/**
* Override to inject classes from Spring
*
@@ -137,7 +146,8 @@ protected List build(
log.warn(
"Failed to load class {} from loader {}",
config.getClassName(),
- classLoader.getName());
+ classLoader.getName(),
+ e);
}
}
diff --git a/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java b/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
index c44cb4eaa1ac3..bc623c3cc983c 100644
--- a/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
+++ b/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
@@ -37,6 +37,7 @@
"com.linkedin.gms.factory.search",
"com.linkedin.gms.factory.secret",
"com.linkedin.gms.factory.timeseries",
+ "com.linkedin.gms.factory.plugins"
})
@PropertySource(value = "classpath:/application.yaml", factory = YamlPropertySourceFactory.class)
@Configuration
@@ -16,7 +19,7 @@ As a user, you can subscribe to and receive notifications about changes such as
## Prerequisites
-Once you have [configured Slack within your DataHub instance](saas-slack-setup.md), you will be able to subscribe to any Entity in DataHub and begin recieving notifications via DM.
+Once you have [configured Slack within your DataHub instance](slack/saas-slack-setup.md), you will be able to subscribe to any Entity in DataHub and begin recieving notifications via DM.
To begin receiving personal notifications, go to Settings > "My Notifications". From here, toggle on Slack Notifications and input your Slack Member ID.
If you want to create and manage group-level Subscriptions for your team, you will need [the following privileges](../../docs/authorization/roles.md#role-privileges):
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
index 342b5376d8a75..106596bf80ccf 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/ReadItem.java
@@ -5,6 +5,7 @@
import com.linkedin.data.template.RecordTemplate;
import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
+import com.linkedin.mxe.GenericAspect;
import com.linkedin.mxe.SystemMetadata;
import java.lang.reflect.InvocationTargetException;
import javax.annotation.Nonnull;
@@ -26,6 +27,9 @@ public interface ReadItem {
*/
@Nonnull
default String getAspectName() {
+ if (getAspectSpec() == null) {
+ return GenericAspect.dataSchema().getName();
+ }
return getAspectSpec().getName();
}
@@ -72,6 +76,6 @@ static T getAspect(Class clazz, @Nullable RecordTemplate recordTemplate)
*
* @return aspect's specification
*/
- @Nonnull
+ @Nullable
AspectSpec getAspectSpec();
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
index a302632e1936f..fc4ac90dfabad 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/batch/AspectsBatch.java
@@ -9,6 +9,7 @@
import com.linkedin.util.Pair;
import java.util.ArrayList;
import java.util.Collection;
+import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
@@ -84,6 +85,13 @@ static void applyWriteMutationHooks(
}
}
+ default Stream applyProposalMutationHooks(
+ Collection proposedItems, @Nonnull RetrieverContext retrieverContext) {
+ return retrieverContext.getAspectRetriever().getEntityRegistry().getAllMutationHooks().stream()
+ .flatMap(
+ mutationHook -> mutationHook.applyProposalMutation(proposedItems, retrieverContext));
+ }
+
default ValidationExceptionCollection validateProposed(
Collection mcpItems) {
return validateProposed(mcpItems, getRetrieverContext());
@@ -191,16 +199,12 @@ default Map> getNewUrnAspectsMap(
static Map> merge(
@Nonnull Map> a, @Nonnull Map> b) {
- return Stream.concat(a.entrySet().stream(), b.entrySet().stream())
- .flatMap(
- entry ->
- entry.getValue().entrySet().stream()
- .map(innerEntry -> Pair.of(entry.getKey(), innerEntry)))
- .collect(
- Collectors.groupingBy(
- Pair::getKey,
- Collectors.mapping(
- Pair::getValue, Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue))));
+ Map> mergedMap = new HashMap<>();
+ for (Map.Entry> entry :
+ Stream.concat(a.entrySet().stream(), b.entrySet().stream()).collect(Collectors.toList())) {
+ mergedMap.computeIfAbsent(entry.getKey(), k -> new HashMap<>()).putAll(entry.getValue());
+ }
+ return mergedMap;
}
default String toAbbreviatedString(int maxWidth) {
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
index 1adb1be81ecc1..f99dd18d3c9c1 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
@@ -3,7 +3,6 @@
import com.linkedin.common.urn.Urn;
import com.linkedin.events.metadata.ChangeType;
import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
-import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
import javax.annotation.Nonnull;
import javax.annotation.Nullable;
@@ -25,20 +24,13 @@ public boolean enabled() {
}
public boolean shouldApply(
- @Nullable ChangeType changeType, @Nonnull Urn entityUrn, @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entityUrn.getEntityType(), aspectSpec);
+ @Nullable ChangeType changeType, @Nonnull Urn entityUrn, @Nonnull String aspectName) {
+ return shouldApply(changeType, entityUrn.getEntityType(), aspectName);
}
public boolean shouldApply(
- @Nullable ChangeType changeType,
- @Nonnull EntitySpec entitySpec,
- @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entitySpec.getName(), aspectSpec.getName());
- }
-
- public boolean shouldApply(
- @Nullable ChangeType changeType, @Nonnull String entityName, @Nonnull AspectSpec aspectSpec) {
- return shouldApply(changeType, entityName, aspectSpec.getName());
+ @Nullable ChangeType changeType, @Nonnull EntitySpec entitySpec, @Nonnull String aspectName) {
+ return shouldApply(changeType, entitySpec.getName(), aspectName);
}
public boolean shouldApply(
@@ -49,8 +41,8 @@ && isChangeTypeSupported(changeType)
}
protected boolean isEntityAspectSupported(
- @Nonnull EntitySpec entitySpec, @Nonnull AspectSpec aspectSpec) {
- return isEntityAspectSupported(entitySpec.getName(), aspectSpec.getName());
+ @Nonnull EntitySpec entitySpec, @Nonnull String aspectName) {
+ return isEntityAspectSupported(entitySpec.getName(), aspectName);
}
protected boolean isEntityAspectSupported(
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
index 57016404648d5..853c2ef5f796c 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCLSideEffect.java
@@ -24,7 +24,7 @@ public final Stream apply(
@Nonnull Collection batchItems, @Nonnull RetrieverContext retrieverContext) {
return applyMCLSideEffect(
batchItems.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
index 52920d8c6f396..ce49dd057bc3e 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MCPSideEffect.java
@@ -25,7 +25,7 @@ public final Stream apply(
Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return applyMCPSideEffect(
changeMCPS.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -41,7 +41,7 @@ public final Stream postApply(
Collection mclItems, @Nonnull RetrieverContext retrieverContext) {
return postMCPSideEffect(
mclItems.stream()
- .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectSpec()))
+ .filter(item -> shouldApply(item.getChangeType(), item.getUrn(), item.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
index c067954912a03..b2fd997d49444 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/hooks/MutationHook.java
@@ -3,6 +3,7 @@
import com.linkedin.metadata.aspect.ReadItem;
import com.linkedin.metadata.aspect.RetrieverContext;
import com.linkedin.metadata.aspect.batch.ChangeMCP;
+import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.PluginSpec;
import com.linkedin.util.Pair;
import java.util.Collection;
@@ -24,7 +25,7 @@ public final Stream> applyWriteMutation(
@Nonnull Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return writeMutation(
changeMCPS.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -34,7 +35,23 @@ public final Stream> applyReadMutation(
@Nonnull Collection items, @Nonnull RetrieverContext retrieverContext) {
return readMutation(
items.stream()
- .filter(i -> isEntityAspectSupported(i.getEntitySpec(), i.getAspectSpec()))
+ .filter(i -> isEntityAspectSupported(i.getEntitySpec(), i.getAspectName()))
+ .collect(Collectors.toList()),
+ retrieverContext);
+ }
+
+ /**
+ * Apply Proposal mutations prior to validation
+ *
+ * @param mcpItems wrapper for MCP
+ * @param retrieverContext retriever context
+ * @return stream of mutated Proposal items
+ */
+ public final Stream applyProposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return proposalMutation(
+ mcpItems.stream()
+ .filter(i -> shouldApply(i.getChangeType(), i.getEntitySpec(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -48,4 +65,9 @@ protected Stream> writeMutation(
@Nonnull Collection changeMCPS, @Nonnull RetrieverContext retrieverContext) {
return changeMCPS.stream().map(i -> Pair.of(i, false));
}
+
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return Stream.empty();
+ }
}
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
index b39c38c2768a7..4083329899fee 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/validation/AspectPayloadValidator.java
@@ -22,7 +22,7 @@ public final Stream validateProposed(
@Nonnull RetrieverContext retrieverContext) {
return validateProposedAspects(
mcpItems.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
@@ -37,7 +37,7 @@ public final Stream validatePreCommit(
@Nonnull Collection changeMCPs, @Nonnull RetrieverContext retrieverContext) {
return validatePreCommitAspects(
changeMCPs.stream()
- .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectSpec()))
+ .filter(i -> shouldApply(i.getChangeType(), i.getUrn(), i.getAspectName()))
.collect(Collectors.toList()),
retrieverContext);
}
diff --git a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
index 8aa154dc267b6..e9f93c0c1eab0 100644
--- a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
+++ b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/client/airflow_generator.py
@@ -127,6 +127,10 @@ def _get_dependencies(
)
return upstream_tasks
+ @staticmethod
+ def _extract_owners(dag: "DAG") -> List[str]:
+ return [owner.strip() for owner in dag.owner.split(",")]
+
@staticmethod
def generate_dataflow(
config: DatahubLineageConfig,
@@ -175,7 +179,7 @@ def generate_dataflow(
data_flow.url = f"{base_url}/tree?dag_id={dag.dag_id}"
if config.capture_ownership_info and dag.owner:
- owners = [owner.strip() for owner in dag.owner.split(",")]
+ owners = AirflowGenerator._extract_owners(dag)
if config.capture_ownership_as_group:
data_flow.group_owners.update(owners)
else:
@@ -282,10 +286,12 @@ def generate_datajob(
datajob.url = f"{base_url}/taskinstance/list/?flt1_dag_id_equals={datajob.flow_urn.flow_id}&_flt_3_task_id={task.task_id}"
if capture_owner and dag.owner:
- if config and config.capture_ownership_as_group:
- datajob.group_owners.add(dag.owner)
- else:
- datajob.owners.add(dag.owner)
+ if config and config.capture_ownership_info:
+ owners = AirflowGenerator._extract_owners(dag)
+ if config.capture_ownership_as_group:
+ datajob.group_owners.update(owners)
+ else:
+ datajob.owners.update(owners)
if capture_tags and dag.tags:
datajob.tags.update(dag.tags)
diff --git a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
index 6ef4f831522cb..c87f7f8fb1a8e 100644
--- a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
+++ b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
@@ -362,8 +362,13 @@ def on_task_instance_running(
# Render templates in a copy of the task instance.
# This is necessary to get the correct operator args in the extractors.
- task_instance = copy.deepcopy(task_instance)
- task_instance.render_templates()
+ try:
+ task_instance = copy.deepcopy(task_instance)
+ task_instance.render_templates()
+ except Exception as e:
+ logger.info(
+ f"Error rendering templates in DataHub listener. Jinja-templated variables will not be extracted correctly: {e}"
+ )
# The type ignore is to placate mypy on Airflow 2.1.x.
dagrun: "DagRun" = task_instance.dag_run # type: ignore[attr-defined]
diff --git a/metadata-ingestion/docs/dev_guides/classification.md b/metadata-ingestion/docs/dev_guides/classification.md
index f20638a2ab5bd..39eac229a6601 100644
--- a/metadata-ingestion/docs/dev_guides/classification.md
+++ b/metadata-ingestion/docs/dev_guides/classification.md
@@ -10,7 +10,7 @@ Note that a `.` is used to denote nested fields in the YAML recipe.
| ------------------------- | -------- | --------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
| enabled | | boolean | Whether classification should be used to auto-detect glossary terms | False |
| sample_size | | int | Number of sample values used for classification. | 100 |
-| max_workers | | int | Number of worker threads to use for classification. Set to 1 to disable. | Number of cpu cores or 4 |
+| max_workers | | int | Number of worker processes to use for classification. Set to 1 to disable. | Number of cpu cores or 4 |
| info_type_to_term | | Dict[str,string] | Optional mapping to provide glossary term identifier for info type. | By default, info type is used as glossary term identifier. |
| classifiers | | Array of object | Classifiers to use to auto-detect glossary terms. If more than one classifier, infotype predictions from the classifier defined later in sequence take precedance. | [{'type': 'datahub', 'config': None}] |
| table_pattern | | AllowDenyPattern (see below for fields) | Regex patterns to filter tables for classification. This is used in combination with other patterns in parent config. Specify regex to match the entire table name in `database.schema.table` format. e.g. to match all tables starting with customer in Customer database and public schema, use the regex 'Customer.public.customer.*' | {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
diff --git a/metadata-ingestion/docs/sources/abs/README.md b/metadata-ingestion/docs/sources/abs/README.md
new file mode 100644
index 0000000000000..46a234ed305e0
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/README.md
@@ -0,0 +1,40 @@
+This connector ingests Azure Blob Storage (abbreviated to abs) datasets into DataHub. It allows mapping an individual
+file or a folder of files to a dataset in DataHub.
+To specify the group of files that form a dataset, use `path_specs` configuration in ingestion recipe. Refer
+section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
+
+### Concept Mapping
+
+This ingestion source maps the following Source System Concepts to DataHub Concepts:
+
+| Source Concept | DataHub Concept | Notes |
+|----------------------------------------|--------------------------------------------------------------------------------------------|------------------|
+| `"abs"` | [Data Platform](https://datahubproject.io/docs/generated/metamodel/entities/dataplatform/) | |
+| abs blob / Folder containing abs blobs | [Dataset](https://datahubproject.io/docs/generated/metamodel/entities/dataset/) | |
+| abs container | [Container](https://datahubproject.io/docs/generated/metamodel/entities/container/) | Subtype `Folder` |
+
+This connector supports both local files and those stored on Azure Blob Storage (which must be identified using the
+prefix `http(s)://.blob.core.windows.net/` or `azure://`).
+
+### Supported file types
+
+Supported file types are as follows:
+
+- CSV (*.csv)
+- TSV (*.tsv)
+- JSONL (*.jsonl)
+- JSON (*.json)
+- Parquet (*.parquet)
+- Apache Avro (*.avro)
+
+Schemas for Parquet and Avro files are extracted as provided.
+
+Schemas for schemaless formats (CSV, TSV, JSONL, JSON) are inferred. For CSV, TSV and JSONL files, we consider the first
+100 rows by default, which can be controlled via the `max_rows` recipe parameter (see [below](#config-details))
+JSON file schemas are inferred on the basis of the entire file (given the difficulty in extracting only the first few
+objects of the file), which may impact performance.
+We are working on using iterator-based JSON parsers to avoid reading in the entire JSON object.
+
+### Profiling
+
+Profiling is not available in the current release.
diff --git a/metadata-ingestion/docs/sources/abs/abs.md b/metadata-ingestion/docs/sources/abs/abs.md
new file mode 100644
index 0000000000000..613ace280c8ba
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/abs.md
@@ -0,0 +1,204 @@
+
+### Path Specs
+
+Path Specs (`path_specs`) is a list of Path Spec (`path_spec`) objects, where each individual `path_spec` represents one or more datasets. The include path (`path_spec.include`) represents a formatted path to the dataset. This path must end with `*.*` or `*.[ext]` to represent the leaf level. If `*.[ext]` is provided, then only files with the specified extension type will be scanned. "`.[ext]`" can be any of the [supported file types](#supported-file-types). Refer to [example 1](#example-1---individual-file-as-dataset) below for more details.
+
+All folder levels need to be specified in the include path. You can use `/*/` to represent a folder level and avoid specifying the exact folder name. To map a folder as a dataset, use the `{table}` placeholder to represent the folder level for which the dataset is to be created. For a partitioned dataset, you can use the placeholder `{partition_key[i]}` to represent the name of the `i`th partition and `{partition[i]}` to represent the value of the `i`th partition. During ingestion, `i` will be used to match the partition_key to the partition. Refer to [examples 2 and 3](#example-2---folder-of-files-as-dataset-without-partitions) below for more details.
+
+Exclude paths (`path_spec.exclude`) can be used to ignore paths that are not relevant to the current `path_spec`. This path cannot have named variables (`{}`). The exclude path can have `**` to represent multiple folder levels. Refer to [example 4](#example-4---folder-of-files-as-dataset-with-partitions-and-exclude-filter) below for more details.
+
+Refer to [example 5](#example-5---advanced---either-individual-file-or-folder-of-files-as-dataset) if your container has a more complex dataset representation.
+
+**Additional points to note**
+- Folder names should not contain {, }, *, / in their names.
+- Named variable {folder} is reserved for internal working. please do not use in named variables.
+
+
+### Path Specs - Examples
+#### Example 1 - Individual file as Dataset
+
+Container structure:
+
+```
+test-container
+├── employees.csv
+├── departments.json
+└── food_items.csv
+```
+
+Path specs config to ingest `employees.csv` and `food_items.csv` as datasets:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/*.csv
+
+```
+This will automatically ignore `departments.json` file. To include it, use `*.*` instead of `*.csv`.
+
+#### Example 2 - Folder of files as Dataset (without Partitions)
+
+Container structure:
+```
+test-container
+└── offers
+ ├── 1.avro
+ └── 2.avro
+
+```
+
+Path specs config to ingest folder `offers` as dataset:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*.avro
+```
+
+`{table}` represents folder for which dataset will be created.
+
+#### Example 3 - Folder of files as Dataset (with Partitions)
+
+Container structure:
+```
+test-container
+├── orders
+│ └── year=2022
+│ └── month=2
+│ ├── 1.parquet
+│ └── 2.parquet
+└── returns
+ └── year=2021
+ └── month=2
+ └── 1.parquet
+
+```
+
+Path specs config to ingest folders `orders` and `returns` as datasets:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+```
+
+One can also use `include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*/*/*.parquet` here however above format is preferred as it allows declaring partitions explicitly.
+
+#### Example 4 - Folder of files as Dataset (with Partitions), and Exclude Filter
+
+Container structure:
+```
+test-container
+├── orders
+│ └── year=2022
+│ └── month=2
+│ ├── 1.parquet
+│ └── 2.parquet
+└── tmp_orders
+ └── year=2021
+ └── month=2
+ └── 1.parquet
+
+
+```
+
+Path specs config to ingest folder `orders` as dataset but not folder `tmp_orders`:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+ exclude:
+ - **/tmp_orders/**
+```
+
+
+#### Example 5 - Advanced - Either Individual file OR Folder of files as Dataset
+
+Container structure:
+```
+test-container
+├── customers
+│ ├── part1.json
+│ ├── part2.json
+│ ├── part3.json
+│ └── part4.json
+├── employees.csv
+├── food_items.csv
+├── tmp_10101000.csv
+└── orders
+ └── year=2022
+ └── month=2
+ ├── 1.parquet
+ ├── 2.parquet
+ └── 3.parquet
+
+```
+
+Path specs config:
+```
+path_specs:
+ - include: https://storageaccountname.blob.core.windows.net/test-container/*.csv
+ exclude:
+ - **/tmp_10101000.csv
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/*.json
+ - include: https://storageaccountname.blob.core.windows.net/test-container/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.parquet
+```
+
+Above config has 3 path_specs and will ingest following datasets
+- `employees.csv` - Single File as Dataset
+- `food_items.csv` - Single File as Dataset
+- `customers` - Folder as Dataset
+- `orders` - Folder as Dataset
+ and will ignore file `tmp_10101000.csv`
+
+**Valid path_specs.include**
+
+```python
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/bar.avro # single file table
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/*.* # mulitple file level tables
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*.avro #table without partition
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*/*.avro #table where partitions are not specified
+https://storageaccountname.blob.core.windows.net/my-container/foo/tests/{table}/*.* # table where no partitions as well as data type specified
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/*.avro # specifying keywords to be used in display name
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition_key[0]}={partition[0]}/{partition_key[1]}={partition[1]}/*.avro # specify partition key and value format
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.avro # specify partition value only format
+https://storageaccountname.blob.core.windows.net/my-container/{dept}/tests/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # for all extensions
+https://storageaccountname.blob.core.windows.net/my-container/*/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # table is present at 2 levels down in container
+https://storageaccountname.blob.core.windows.net/my-container/*/*/{table}/{partition[0]}/{partition[1]}/{partition[2]}/*.* # table is present at 3 levels down in container
+```
+
+**Valid path_specs.exclude**
+- \**/tests/**
+- https://storageaccountname.blob.core.windows.net/my-container/hr/**
+- **/tests/*.csv
+- https://storageaccountname.blob.core.windows.net/my-container/foo/*/my_table/**
+
+
+
+If you would like to write a more complicated function for resolving file names, then a {transformer} would be a good fit.
+
+:::caution
+
+Specify as long fixed prefix ( with out /*/ ) as possible in `path_specs.include`. This will reduce the scanning time and cost, specifically on AWS S3
+
+:::
+
+:::caution
+
+Running profiling against many tables or over many rows can run up significant costs.
+While we've done our best to limit the expensiveness of the queries the profiler runs, you
+should be prudent about the set of tables profiling is enabled on or the frequency
+of the profiling runs.
+
+:::
+
+:::caution
+
+If you are ingesting datasets from AWS S3, we recommend running the ingestion on a server in the same region to avoid high egress costs.
+
+:::
+
+### Compatibility
+
+Profiles are computed with PyDeequ, which relies on PySpark. Therefore, for computing profiles, we currently require Spark 3.0.3 with Hadoop 3.2 to be installed and the `SPARK_HOME` and `SPARK_VERSION` environment variables to be set. The Spark+Hadoop binary can be downloaded [here](https://www.apache.org/dyn/closer.lua/spark/spark-3.0.3/spark-3.0.3-bin-hadoop3.2.tgz).
+
+For an example guide on setting up PyDeequ on AWS, see [this guide](https://aws.amazon.com/blogs/big-data/testing-data-quality-at-scale-with-pydeequ/).
+
+:::caution
+
+From Spark 3.2.0+, Avro reader fails on column names that don't start with a letter and contains other character than letters, number, and underscore. [https://github.com/apache/spark/blob/72c62b6596d21e975c5597f8fff84b1a9d070a02/connector/avro/src/main/scala/org/apache/spark/sql/avro/AvroFileFormat.scala#L158]
+Avro files that contain such columns won't be profiled.
+:::
\ No newline at end of file
diff --git a/metadata-ingestion/docs/sources/abs/abs_recipe.yml b/metadata-ingestion/docs/sources/abs/abs_recipe.yml
new file mode 100644
index 0000000000000..4c4e5c678238f
--- /dev/null
+++ b/metadata-ingestion/docs/sources/abs/abs_recipe.yml
@@ -0,0 +1,13 @@
+source:
+ type: abs
+ config:
+ path_specs:
+ - include: "https://storageaccountname.blob.core.windows.net/covid19-lake/covid_knowledge_graph/csv/nodes/*.*"
+
+ azure_config:
+ account_name: "*****"
+ sas_token: "*****"
+ container_name: "covid_knowledge_graph"
+ env: "PROD"
+
+# sink configs
diff --git a/metadata-ingestion/docs/sources/s3/README.md b/metadata-ingestion/docs/sources/s3/README.md
index b0d354a9b3c2a..5feda74107024 100644
--- a/metadata-ingestion/docs/sources/s3/README.md
+++ b/metadata-ingestion/docs/sources/s3/README.md
@@ -1,5 +1,5 @@
This connector ingests AWS S3 datasets into DataHub. It allows mapping an individual file or a folder of files to a dataset in DataHub.
-To specify the group of files that form a dataset, use `path_specs` configuration in ingestion recipe. Refer section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
+Refer to the section [Path Specs](https://datahubproject.io/docs/generated/ingestion/sources/s3/#path-specs) for more details.
:::tip
This connector can also be used to ingest local files.
diff --git a/metadata-ingestion/scripts/modeldocgen.py b/metadata-ingestion/scripts/modeldocgen.py
index ea7813f0ca85b..ee5f06cb801ba 100644
--- a/metadata-ingestion/scripts/modeldocgen.py
+++ b/metadata-ingestion/scripts/modeldocgen.py
@@ -8,12 +8,12 @@
from dataclasses import Field, dataclass, field
from enum import auto
from pathlib import Path
-from typing import Any, Dict, List, Optional, Tuple, Iterable
+from typing import Any, Dict, Iterable, List, Optional, Tuple
import avro.schema
import click
-from datahub.configuration.common import ConfigEnum, ConfigModel
+from datahub.configuration.common import ConfigEnum, PermissiveConfigModel
from datahub.emitter.mce_builder import make_data_platform_urn, make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
@@ -22,7 +22,9 @@
from datahub.ingestion.extractor.schema_util import avro_schema_to_mce_fields
from datahub.ingestion.sink.file import FileSink, FileSinkConfig
from datahub.metadata.schema_classes import (
+ BrowsePathEntryClass,
BrowsePathsClass,
+ BrowsePathsV2Class,
DatasetPropertiesClass,
DatasetSnapshotClass,
ForeignKeyConstraintClass,
@@ -34,8 +36,6 @@
StringTypeClass,
SubTypesClass,
TagAssociationClass,
- BrowsePathsV2Class,
- BrowsePathEntryClass,
)
logger = logging.getLogger(__name__)
@@ -493,30 +493,29 @@ def strip_types(field_path: str) -> str:
],
)
+
@dataclass
class EntityAspectName:
entityName: str
aspectName: str
-@dataclass
-class AspectPluginConfig:
+class AspectPluginConfig(PermissiveConfigModel):
className: str
enabled: bool
- supportedEntityAspectNames: List[EntityAspectName]
+ supportedEntityAspectNames: List[EntityAspectName] = []
packageScan: Optional[List[str]] = None
supportedOperations: Optional[List[str]] = None
-@dataclass
-class PluginConfiguration:
+class PluginConfiguration(PermissiveConfigModel):
aspectPayloadValidators: Optional[List[AspectPluginConfig]] = None
mutationHooks: Optional[List[AspectPluginConfig]] = None
mclSideEffects: Optional[List[AspectPluginConfig]] = None
mcpSideEffects: Optional[List[AspectPluginConfig]] = None
-class EntityRegistry(ConfigModel):
+class EntityRegistry(PermissiveConfigModel):
entities: List[EntityDefinition]
events: Optional[List[EventDefinition]]
plugins: Optional[PluginConfiguration] = None
diff --git a/metadata-ingestion/setup.py b/metadata-ingestion/setup.py
index 41c04ca4a433c..e1a9e6a55909d 100644
--- a/metadata-ingestion/setup.py
+++ b/metadata-ingestion/setup.py
@@ -258,6 +258,13 @@
*path_spec_common,
}
+abs_base = {
+ "azure-core==1.29.4",
+ "azure-identity>=1.14.0",
+ "azure-storage-blob>=12.19.0",
+ "azure-storage-file-datalake>=12.14.0",
+}
+
data_lake_profiling = {
"pydeequ~=1.1.0",
"pyspark~=3.3.0",
@@ -265,6 +272,7 @@
delta_lake = {
*s3_base,
+ *abs_base,
# Version 0.18.0 broken on ARM Macs: https://github.com/delta-io/delta-rs/issues/2577
"deltalake>=0.6.3, != 0.6.4, < 0.18.0; platform_system == 'Darwin' and platform_machine == 'arm64'",
"deltalake>=0.6.3, != 0.6.4; platform_system != 'Darwin' or platform_machine != 'arm64'",
@@ -407,6 +415,7 @@
| {"cachetools"},
"s3": {*s3_base, *data_lake_profiling},
"gcs": {*s3_base, *data_lake_profiling},
+ "abs": {*abs_base},
"sagemaker": aws_common,
"salesforce": {"simple-salesforce"},
"snowflake": snowflake_common | usage_common | sqlglot_lib,
@@ -686,6 +695,7 @@
"demo-data = datahub.ingestion.source.demo_data.DemoDataSource",
"unity-catalog = datahub.ingestion.source.unity.source:UnityCatalogSource",
"gcs = datahub.ingestion.source.gcs.gcs_source:GCSSource",
+ "abs = datahub.ingestion.source.abs.source:ABSSource",
"sql-queries = datahub.ingestion.source.sql_queries:SqlQueriesSource",
"fivetran = datahub.ingestion.source.fivetran.fivetran:FivetranSource",
"qlik-sense = datahub.ingestion.source.qlik_sense.qlik_sense:QlikSenseSource",
diff --git a/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py b/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
index afeedb83f7998..f9a188c65feef 100644
--- a/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
+++ b/metadata-ingestion/src/datahub/api/entities/dataset/dataset.py
@@ -259,56 +259,56 @@ def generate_mcp(
)
yield mcp
- if self.schema_metadata.fields:
- for field in self.schema_metadata.fields:
- field_urn = field.urn or make_schema_field_urn(
- self.urn, field.id # type: ignore[arg-type]
+ if self.schema_metadata.fields:
+ for field in self.schema_metadata.fields:
+ field_urn = field.urn or make_schema_field_urn(
+ self.urn, field.id # type: ignore[arg-type]
+ )
+ assert field_urn.startswith("urn:li:schemaField:")
+
+ if field.globalTags:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=GlobalTagsClass(
+ tags=[
+ TagAssociationClass(tag=make_tag_urn(tag))
+ for tag in field.globalTags
+ ]
+ ),
)
- assert field_urn.startswith("urn:li:schemaField:")
-
- if field.globalTags:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=GlobalTagsClass(
- tags=[
- TagAssociationClass(tag=make_tag_urn(tag))
- for tag in field.globalTags
- ]
- ),
- )
- yield mcp
-
- if field.glossaryTerms:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=GlossaryTermsClass(
- terms=[
- GlossaryTermAssociationClass(
- urn=make_term_urn(term)
- )
- for term in field.glossaryTerms
- ],
- auditStamp=self._mint_auditstamp("yaml"),
- ),
- )
- yield mcp
-
- if field.structured_properties:
- mcp = MetadataChangeProposalWrapper(
- entityUrn=field_urn,
- aspect=StructuredPropertiesClass(
- properties=[
- StructuredPropertyValueAssignmentClass(
- propertyUrn=f"urn:li:structuredProperty:{prop_key}",
- values=prop_value
- if isinstance(prop_value, list)
- else [prop_value],
- )
- for prop_key, prop_value in field.structured_properties.items()
- ]
- ),
- )
- yield mcp
+ yield mcp
+
+ if field.glossaryTerms:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=GlossaryTermsClass(
+ terms=[
+ GlossaryTermAssociationClass(
+ urn=make_term_urn(term)
+ )
+ for term in field.glossaryTerms
+ ],
+ auditStamp=self._mint_auditstamp("yaml"),
+ ),
+ )
+ yield mcp
+
+ if field.structured_properties:
+ mcp = MetadataChangeProposalWrapper(
+ entityUrn=field_urn,
+ aspect=StructuredPropertiesClass(
+ properties=[
+ StructuredPropertyValueAssignmentClass(
+ propertyUrn=f"urn:li:structuredProperty:{prop_key}",
+ values=prop_value
+ if isinstance(prop_value, list)
+ else [prop_value],
+ )
+ for prop_key, prop_value in field.structured_properties.items()
+ ]
+ ),
+ )
+ yield mcp
if self.subtype or self.subtypes:
mcp = MetadataChangeProposalWrapper(
diff --git a/metadata-ingestion/src/datahub/ingestion/api/source.py b/metadata-ingestion/src/datahub/ingestion/api/source.py
index ad1b312ef445c..788bec97a6488 100644
--- a/metadata-ingestion/src/datahub/ingestion/api/source.py
+++ b/metadata-ingestion/src/datahub/ingestion/api/source.py
@@ -1,3 +1,4 @@
+import contextlib
import datetime
import logging
from abc import ABCMeta, abstractmethod
@@ -10,6 +11,7 @@
Dict,
Generic,
Iterable,
+ Iterator,
List,
Optional,
Sequence,
@@ -97,6 +99,7 @@ def report_log(
context: Optional[str] = None,
exc: Optional[BaseException] = None,
log: bool = False,
+ stacklevel: int = 1,
) -> None:
"""
Report a user-facing warning for the ingestion run.
@@ -109,7 +112,8 @@ def report_log(
exc: The exception associated with the event. We'll show the stack trace when in debug mode.
"""
- stacklevel = 2
+ # One for this method, and one for the containing report_* call.
+ stacklevel = stacklevel + 2
log_key = f"{title}-{message}"
entries = self._entries[level]
@@ -118,6 +122,8 @@ def report_log(
context = f"{context[:_MAX_CONTEXT_STRING_LENGTH]} ..."
log_content = f"{message} => {context}" if context else message
+ if title:
+ log_content = f"{title}: {log_content}"
if exc:
log_content += f"{log_content}: {exc}"
@@ -255,9 +261,10 @@ def report_failure(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.ERROR, message, title, context, exc, log=False
+ StructuredLogLevel.ERROR, message, title, context, exc, log=log
)
def failure(
@@ -266,9 +273,10 @@ def failure(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.ERROR, message, title, context, exc, log=True
+ StructuredLogLevel.ERROR, message, title, context, exc, log=log
)
def info(
@@ -277,11 +285,30 @@ def info(
context: Optional[str] = None,
title: Optional[LiteralString] = None,
exc: Optional[BaseException] = None,
+ log: bool = True,
) -> None:
self._structured_logs.report_log(
- StructuredLogLevel.INFO, message, title, context, exc, log=True
+ StructuredLogLevel.INFO, message, title, context, exc, log=log
)
+ @contextlib.contextmanager
+ def report_exc(
+ self,
+ message: LiteralString,
+ title: Optional[LiteralString] = None,
+ context: Optional[str] = None,
+ level: StructuredLogLevel = StructuredLogLevel.ERROR,
+ ) -> Iterator[None]:
+ # Convenience method that helps avoid boilerplate try/except blocks.
+ # TODO: I'm not super happy with the naming here - it's not obvious that this
+ # suppresses the exception in addition to reporting it.
+ try:
+ yield
+ except Exception as exc:
+ self._structured_logs.report_log(
+ level, message=message, title=title, context=context, exc=exc
+ )
+
def __post_init__(self) -> None:
self.start_time = datetime.datetime.now()
self.running_time: datetime.timedelta = datetime.timedelta(seconds=0)
diff --git a/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py b/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
index 99789a49c0b43..ddcb74e354613 100644
--- a/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
+++ b/metadata-ingestion/src/datahub/ingestion/glossary/classifier.py
@@ -39,7 +39,7 @@ class ClassificationConfig(ConfigModel):
max_workers: int = Field(
default=(os.cpu_count() or 4),
- description="Number of worker threads to use for classification. Set to 1 to disable.",
+ description="Number of worker processes to use for classification. Set to 1 to disable.",
)
table_pattern: AllowDenyPattern = Field(
diff --git a/metadata-ingestion/src/datahub/ingestion/graph/client.py b/metadata-ingestion/src/datahub/ingestion/graph/client.py
index 7ba412b3e772c..1d6097da231f8 100644
--- a/metadata-ingestion/src/datahub/ingestion/graph/client.py
+++ b/metadata-ingestion/src/datahub/ingestion/graph/client.py
@@ -1241,6 +1241,7 @@ def parse_sql_lineage(
env: str = DEFAULT_ENV,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> "SqlParsingResult":
from datahub.sql_parsing.sqlglot_lineage import sqlglot_lineage
@@ -1254,6 +1255,7 @@ def parse_sql_lineage(
schema_resolver=schema_resolver,
default_db=default_db,
default_schema=default_schema,
+ default_dialect=default_dialect,
)
def create_tag(self, tag_name: str) -> str:
diff --git a/metadata-ingestion/src/datahub/ingestion/run/pipeline.py b/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
index e61ffa46b3c10..60930f03763ed 100644
--- a/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
+++ b/metadata-ingestion/src/datahub/ingestion/run/pipeline.py
@@ -379,13 +379,19 @@ def _notify_reporters_on_ingestion_completion(self) -> None:
for reporter in self.reporters:
try:
reporter.on_completion(
- status="CANCELLED"
- if self.final_status == PipelineStatus.CANCELLED
- else "FAILURE"
- if self.has_failures()
- else "SUCCESS"
- if self.final_status == PipelineStatus.COMPLETED
- else "UNKNOWN",
+ status=(
+ "CANCELLED"
+ if self.final_status == PipelineStatus.CANCELLED
+ else (
+ "FAILURE"
+ if self.has_failures()
+ else (
+ "SUCCESS"
+ if self.final_status == PipelineStatus.COMPLETED
+ else "UNKNOWN"
+ )
+ )
+ ),
report=self._get_structured_report(),
ctx=self.ctx,
)
@@ -425,7 +431,7 @@ def _time_to_print(self) -> bool:
return True
return False
- def run(self) -> None:
+ def run(self) -> None: # noqa: C901
with contextlib.ExitStack() as stack:
if self.config.flags.generate_memory_profiles:
import memray
@@ -436,6 +442,8 @@ def run(self) -> None:
)
)
+ stack.enter_context(self.sink)
+
self.final_status = PipelineStatus.UNKNOWN
self._notify_reporters_on_ingestion_start()
callback = None
@@ -460,7 +468,17 @@ def run(self) -> None:
if not self.dry_run:
self.sink.handle_work_unit_start(wu)
try:
- record_envelopes = self.extractor.get_records(wu)
+ # Most of this code is meant to be fully stream-based instead of generating all records into memory.
+ # However, the extractor in particular will never generate a particularly large list. We want the
+ # exception reporting to be associated with the source, and not the transformer. As such, we
+ # need to materialize the generator returned by get_records().
+ record_envelopes = list(self.extractor.get_records(wu))
+ except Exception as e:
+ self.source.get_report().failure(
+ "Source produced bad metadata", context=wu.id, exc=e
+ )
+ continue
+ try:
for record_envelope in self.transform(record_envelopes):
if not self.dry_run:
try:
@@ -482,9 +500,9 @@ def run(self) -> None:
)
# TODO: Transformer errors should cause the pipeline to fail.
- self.extractor.close()
if not self.dry_run:
self.sink.handle_work_unit_end(wu)
+ self.extractor.close()
self.source.close()
# no more data is coming, we need to let the transformers produce any additional records if they are holding on to state
for record_envelope in self.transform(
@@ -518,8 +536,6 @@ def run(self) -> None:
self._notify_reporters_on_ingestion_completion()
- self.sink.close()
-
def transform(self, records: Iterable[RecordEnvelope]) -> Iterable[RecordEnvelope]:
"""
Transforms the given sequence of records by passing the records through the transformers
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/__init__.py b/metadata-ingestion/src/datahub/ingestion/source/abs/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/config.py b/metadata-ingestion/src/datahub/ingestion/source/abs/config.py
new file mode 100644
index 0000000000000..c62239527a120
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/config.py
@@ -0,0 +1,163 @@
+import logging
+from typing import Any, Dict, List, Optional, Union
+
+import pydantic
+from pydantic.fields import Field
+
+from datahub.configuration.common import AllowDenyPattern
+from datahub.configuration.source_common import DatasetSourceConfigMixin
+from datahub.configuration.validate_field_deprecation import pydantic_field_deprecated
+from datahub.configuration.validate_field_rename import pydantic_renamed_field
+from datahub.ingestion.source.abs.datalake_profiler_config import DataLakeProfilerConfig
+from datahub.ingestion.source.azure.azure_common import AzureConnectionConfig
+from datahub.ingestion.source.data_lake_common.config import PathSpecsConfigMixin
+from datahub.ingestion.source.data_lake_common.path_spec import PathSpec
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StatefulStaleMetadataRemovalConfig,
+)
+from datahub.ingestion.source.state.stateful_ingestion_base import (
+ StatefulIngestionConfigBase,
+)
+from datahub.ingestion.source_config.operation_config import is_profiling_enabled
+
+# hide annoying debug errors from py4j
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+class DataLakeSourceConfig(
+ StatefulIngestionConfigBase, DatasetSourceConfigMixin, PathSpecsConfigMixin
+):
+ platform: str = Field(
+ default="",
+ description="The platform that this source connects to (either 'abs' or 'file'). "
+ "If not specified, the platform will be inferred from the path_specs.",
+ )
+
+ azure_config: Optional[AzureConnectionConfig] = Field(
+ default=None, description="Azure configuration"
+ )
+
+ stateful_ingestion: Optional[StatefulStaleMetadataRemovalConfig] = None
+ # Whether to create Datahub Azure Container properties
+ use_abs_container_properties: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs container properties",
+ )
+ # Whether to create Datahub Azure blob tags
+ use_abs_blob_tags: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs blob tags",
+ )
+ # Whether to create Datahub Azure blob properties
+ use_abs_blob_properties: Optional[bool] = Field(
+ None,
+ description="Whether to create tags in datahub from the abs blob properties",
+ )
+
+ # Whether to update the table schema when schema in files within the partitions are updated
+ _update_schema_on_partition_file_updates_deprecation = pydantic_field_deprecated(
+ "update_schema_on_partition_file_updates",
+ message="update_schema_on_partition_file_updates is deprecated. This behaviour is the default now.",
+ )
+
+ profile_patterns: AllowDenyPattern = Field(
+ default=AllowDenyPattern.allow_all(),
+ description="regex patterns for tables to profile ",
+ )
+ profiling: DataLakeProfilerConfig = Field(
+ default=DataLakeProfilerConfig(), description="Data profiling configuration"
+ )
+
+ spark_driver_memory: str = Field(
+ default="4g", description="Max amount of memory to grant Spark."
+ )
+
+ spark_config: Dict[str, Any] = Field(
+ description='Spark configuration properties to set on the SparkSession. Put config property names into quotes. For example: \'"spark.executor.memory": "2g"\'',
+ default={},
+ )
+
+ max_rows: int = Field(
+ default=100,
+ description="Maximum number of rows to use when inferring schemas for TSV and CSV files.",
+ )
+ add_partition_columns_to_schema: bool = Field(
+ default=False,
+ description="Whether to add partition fields to the schema.",
+ )
+ verify_ssl: Union[bool, str] = Field(
+ default=True,
+ description="Either a boolean, in which case it controls whether we verify the server's TLS certificate, or a string, in which case it must be a path to a CA bundle to use.",
+ )
+
+ number_of_files_to_sample: int = Field(
+ default=100,
+ description="Number of files to list to sample for schema inference. This will be ignored if sample_files is set to False in the pathspec.",
+ )
+
+ _rename_path_spec_to_plural = pydantic_renamed_field(
+ "path_spec", "path_specs", lambda path_spec: [path_spec]
+ )
+
+ def is_profiling_enabled(self) -> bool:
+ return self.profiling.enabled and is_profiling_enabled(
+ self.profiling.operation_config
+ )
+
+ @pydantic.validator("path_specs", always=True)
+ def check_path_specs_and_infer_platform(
+ cls, path_specs: List[PathSpec], values: Dict
+ ) -> List[PathSpec]:
+ if len(path_specs) == 0:
+ raise ValueError("path_specs must not be empty")
+
+ # Check that all path specs have the same platform.
+ guessed_platforms = set(
+ "abs" if path_spec.is_abs else "file" for path_spec in path_specs
+ )
+ if len(guessed_platforms) > 1:
+ raise ValueError(
+ f"Cannot have multiple platforms in path_specs: {guessed_platforms}"
+ )
+ guessed_platform = guessed_platforms.pop()
+
+ # Ensure abs configs aren't used for file sources.
+ if guessed_platform != "abs" and (
+ values.get("use_abs_container_properties")
+ or values.get("use_abs_blob_tags")
+ or values.get("use_abs_blob_properties")
+ ):
+ raise ValueError(
+ "Cannot grab abs blob/container tags when platform is not abs. Remove the flag or use abs."
+ )
+
+ # Infer platform if not specified.
+ if values.get("platform") and values["platform"] != guessed_platform:
+ raise ValueError(
+ f"All path_specs belong to {guessed_platform} platform, but platform is set to {values['platform']}"
+ )
+ else:
+ logger.debug(f'Setting config "platform": {guessed_platform}')
+ values["platform"] = guessed_platform
+
+ return path_specs
+
+ @pydantic.validator("platform", always=True)
+ def platform_not_empty(cls, platform: str, values: dict) -> str:
+ inferred_platform = values.get(
+ "platform", None
+ ) # we may have inferred it above
+ platform = platform or inferred_platform
+ if not platform:
+ raise ValueError("platform must not be empty")
+ return platform
+
+ @pydantic.root_validator()
+ def ensure_profiling_pattern_is_passed_to_profiling(
+ cls, values: Dict[str, Any]
+ ) -> Dict[str, Any]:
+ profiling: Optional[DataLakeProfilerConfig] = values.get("profiling")
+ if profiling is not None and profiling.enabled:
+ profiling._allow_deny_patterns = values["profile_patterns"]
+ return values
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py b/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py
new file mode 100644
index 0000000000000..9f6d13a08b182
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/datalake_profiler_config.py
@@ -0,0 +1,92 @@
+from typing import Any, Dict, Optional
+
+import pydantic
+from pydantic.fields import Field
+
+from datahub.configuration import ConfigModel
+from datahub.configuration.common import AllowDenyPattern
+from datahub.ingestion.source_config.operation_config import OperationConfig
+
+
+class DataLakeProfilerConfig(ConfigModel):
+ enabled: bool = Field(
+ default=False, description="Whether profiling should be done."
+ )
+ operation_config: OperationConfig = Field(
+ default_factory=OperationConfig,
+ description="Experimental feature. To specify operation configs.",
+ )
+
+ # These settings will override the ones below.
+ profile_table_level_only: bool = Field(
+ default=False,
+ description="Whether to perform profiling at table-level only or include column-level profiling as well.",
+ )
+
+ _allow_deny_patterns: AllowDenyPattern = pydantic.PrivateAttr(
+ default=AllowDenyPattern.allow_all(),
+ )
+
+ max_number_of_fields_to_profile: Optional[pydantic.PositiveInt] = Field(
+ default=None,
+ description="A positive integer that specifies the maximum number of columns to profile for any table. `None` implies all columns. The cost of profiling goes up significantly as the number of columns to profile goes up.",
+ )
+
+ include_field_null_count: bool = Field(
+ default=True,
+ description="Whether to profile for the number of nulls for each column.",
+ )
+ include_field_min_value: bool = Field(
+ default=True,
+ description="Whether to profile for the min value of numeric columns.",
+ )
+ include_field_max_value: bool = Field(
+ default=True,
+ description="Whether to profile for the max value of numeric columns.",
+ )
+ include_field_mean_value: bool = Field(
+ default=True,
+ description="Whether to profile for the mean value of numeric columns.",
+ )
+ include_field_median_value: bool = Field(
+ default=True,
+ description="Whether to profile for the median value of numeric columns.",
+ )
+ include_field_stddev_value: bool = Field(
+ default=True,
+ description="Whether to profile for the standard deviation of numeric columns.",
+ )
+ include_field_quantiles: bool = Field(
+ default=True,
+ description="Whether to profile for the quantiles of numeric columns.",
+ )
+ include_field_distinct_value_frequencies: bool = Field(
+ default=True, description="Whether to profile for distinct value frequencies."
+ )
+ include_field_histogram: bool = Field(
+ default=True,
+ description="Whether to profile for the histogram for numeric fields.",
+ )
+ include_field_sample_values: bool = Field(
+ default=True,
+ description="Whether to profile for the sample values for all columns.",
+ )
+
+ @pydantic.root_validator()
+ def ensure_field_level_settings_are_normalized(
+ cls: "DataLakeProfilerConfig", values: Dict[str, Any]
+ ) -> Dict[str, Any]:
+ max_num_fields_to_profile_key = "max_number_of_fields_to_profile"
+ max_num_fields_to_profile = values.get(max_num_fields_to_profile_key)
+
+ # Disable all field-level metrics.
+ if values.get("profile_table_level_only"):
+ for field_level_metric in cls.__fields__:
+ if field_level_metric.startswith("include_field_"):
+ values.setdefault(field_level_metric, False)
+
+ assert (
+ max_num_fields_to_profile is None
+ ), f"{max_num_fields_to_profile_key} should be set to None"
+
+ return values
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py b/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py
new file mode 100644
index 0000000000000..c969b229989e8
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/profiling.py
@@ -0,0 +1,472 @@
+import dataclasses
+from typing import Any, List, Optional
+
+from pandas import DataFrame
+from pydeequ.analyzers import (
+ AnalysisRunBuilder,
+ AnalysisRunner,
+ AnalyzerContext,
+ ApproxCountDistinct,
+ ApproxQuantile,
+ ApproxQuantiles,
+ Histogram,
+ Maximum,
+ Mean,
+ Minimum,
+ StandardDeviation,
+)
+from pyspark.sql import SparkSession
+from pyspark.sql.functions import col, count, isnan, when
+from pyspark.sql.types import (
+ DataType as SparkDataType,
+ DateType,
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ NullType,
+ ShortType,
+ StringType,
+ TimestampType,
+)
+
+from datahub.emitter.mce_builder import get_sys_time
+from datahub.ingestion.source.profiling.common import (
+ Cardinality,
+ convert_to_cardinality,
+)
+from datahub.ingestion.source.s3.datalake_profiler_config import DataLakeProfilerConfig
+from datahub.ingestion.source.s3.report import DataLakeSourceReport
+from datahub.metadata.schema_classes import (
+ DatasetFieldProfileClass,
+ DatasetProfileClass,
+ HistogramClass,
+ QuantileClass,
+ ValueFrequencyClass,
+)
+from datahub.telemetry import stats, telemetry
+
+NUM_SAMPLE_ROWS = 20
+QUANTILES = [0.05, 0.25, 0.5, 0.75, 0.95]
+MAX_HIST_BINS = 25
+
+
+def null_str(value: Any) -> Optional[str]:
+ # str() with a passthrough for None.
+ return str(value) if value is not None else None
+
+
+@dataclasses.dataclass
+class _SingleColumnSpec:
+ column: str
+ column_profile: DatasetFieldProfileClass
+
+ # if the histogram is a list of value frequencies (discrete data) or bins (continuous data)
+ histogram_distinct: Optional[bool] = None
+
+ type_: SparkDataType = NullType # type:ignore
+
+ unique_count: Optional[int] = None
+ non_null_count: Optional[int] = None
+ cardinality: Optional[Cardinality] = None
+
+
+class _SingleTableProfiler:
+ spark: SparkSession
+ dataframe: DataFrame
+ analyzer: AnalysisRunBuilder
+ column_specs: List[_SingleColumnSpec]
+ row_count: int
+ profiling_config: DataLakeProfilerConfig
+ file_path: str
+ columns_to_profile: List[str]
+ ignored_columns: List[str]
+ profile: DatasetProfileClass
+ report: DataLakeSourceReport
+
+ def __init__(
+ self,
+ dataframe: DataFrame,
+ spark: SparkSession,
+ profiling_config: DataLakeProfilerConfig,
+ report: DataLakeSourceReport,
+ file_path: str,
+ ):
+ self.spark = spark
+ self.dataframe = dataframe
+ self.analyzer = AnalysisRunner(spark).onData(dataframe)
+ self.column_specs = []
+ self.row_count = dataframe.count()
+ self.profiling_config = profiling_config
+ self.file_path = file_path
+ self.columns_to_profile = []
+ self.ignored_columns = []
+ self.profile = DatasetProfileClass(timestampMillis=get_sys_time())
+ self.report = report
+
+ self.profile.rowCount = self.row_count
+ self.profile.columnCount = len(dataframe.columns)
+
+ column_types = {x.name: x.dataType for x in dataframe.schema.fields}
+
+ if self.profiling_config.profile_table_level_only:
+ return
+
+ # get column distinct counts
+ for column in dataframe.columns:
+ if not self.profiling_config._allow_deny_patterns.allowed(column):
+ self.ignored_columns.append(column)
+ continue
+
+ self.columns_to_profile.append(column)
+ # Normal CountDistinct is ridiculously slow
+ self.analyzer.addAnalyzer(ApproxCountDistinct(column))
+
+ if self.profiling_config.max_number_of_fields_to_profile is not None:
+ if (
+ len(self.columns_to_profile)
+ > self.profiling_config.max_number_of_fields_to_profile
+ ):
+ columns_being_dropped = self.columns_to_profile[
+ self.profiling_config.max_number_of_fields_to_profile :
+ ]
+ self.columns_to_profile = self.columns_to_profile[
+ : self.profiling_config.max_number_of_fields_to_profile
+ ]
+
+ self.report.report_file_dropped(
+ f"The max_number_of_fields_to_profile={self.profiling_config.max_number_of_fields_to_profile} reached. Profile of columns {self.file_path}({', '.join(sorted(columns_being_dropped))})"
+ )
+
+ analysis_result = self.analyzer.run()
+ analysis_metrics = AnalyzerContext.successMetricsAsJson(
+ self.spark, analysis_result
+ )
+
+ # reshape distinct counts into dictionary
+ column_distinct_counts = {
+ x["instance"]: int(x["value"])
+ for x in analysis_metrics
+ if x["name"] == "ApproxCountDistinct"
+ }
+
+ select_numeric_null_counts = [
+ count(
+ when(
+ isnan(c) | col(c).isNull(),
+ c,
+ )
+ ).alias(c)
+ for c in self.columns_to_profile
+ if column_types[column] in [DoubleType, FloatType]
+ ]
+
+ # PySpark doesn't support isnan() on non-float/double columns
+ select_nonnumeric_null_counts = [
+ count(
+ when(
+ col(c).isNull(),
+ c,
+ )
+ ).alias(c)
+ for c in self.columns_to_profile
+ if column_types[column] not in [DoubleType, FloatType]
+ ]
+
+ null_counts = dataframe.select(
+ select_numeric_null_counts + select_nonnumeric_null_counts
+ )
+ column_null_counts = null_counts.toPandas().T[0].to_dict()
+ column_null_fractions = {
+ c: column_null_counts[c] / self.row_count if self.row_count != 0 else 0
+ for c in self.columns_to_profile
+ }
+ column_nonnull_counts = {
+ c: self.row_count - column_null_counts[c] for c in self.columns_to_profile
+ }
+
+ column_unique_proportions = {
+ c: (
+ column_distinct_counts[c] / column_nonnull_counts[c]
+ if column_nonnull_counts[c] > 0
+ else 0
+ )
+ for c in self.columns_to_profile
+ }
+
+ if self.profiling_config.include_field_sample_values:
+ # take sample and convert to Pandas DataFrame
+ if self.row_count < NUM_SAMPLE_ROWS:
+ # if row count is less than number to sample, just take all rows
+ rdd_sample = dataframe.rdd.take(self.row_count)
+ else:
+ rdd_sample = dataframe.rdd.takeSample(False, NUM_SAMPLE_ROWS, seed=0)
+
+ # init column specs with profiles
+ for column in self.columns_to_profile:
+ column_profile = DatasetFieldProfileClass(fieldPath=column)
+
+ column_spec = _SingleColumnSpec(column, column_profile)
+
+ column_profile.uniqueCount = column_distinct_counts.get(column)
+ column_profile.uniqueProportion = column_unique_proportions.get(column)
+ column_profile.nullCount = column_null_counts.get(column)
+ column_profile.nullProportion = column_null_fractions.get(column)
+ if self.profiling_config.include_field_sample_values:
+ column_profile.sampleValues = sorted(
+ [str(x[column]) for x in rdd_sample]
+ )
+
+ column_spec.type_ = column_types[column]
+ column_spec.cardinality = convert_to_cardinality(
+ column_distinct_counts[column],
+ column_null_fractions[column],
+ )
+
+ self.column_specs.append(column_spec)
+
+ def prep_min_value(self, column: str) -> None:
+ if self.profiling_config.include_field_min_value:
+ self.analyzer.addAnalyzer(Minimum(column))
+
+ def prep_max_value(self, column: str) -> None:
+ if self.profiling_config.include_field_max_value:
+ self.analyzer.addAnalyzer(Maximum(column))
+
+ def prep_mean_value(self, column: str) -> None:
+ if self.profiling_config.include_field_mean_value:
+ self.analyzer.addAnalyzer(Mean(column))
+
+ def prep_median_value(self, column: str) -> None:
+ if self.profiling_config.include_field_median_value:
+ self.analyzer.addAnalyzer(ApproxQuantile(column, 0.5))
+
+ def prep_stdev_value(self, column: str) -> None:
+ if self.profiling_config.include_field_stddev_value:
+ self.analyzer.addAnalyzer(StandardDeviation(column))
+
+ def prep_quantiles(self, column: str) -> None:
+ if self.profiling_config.include_field_quantiles:
+ self.analyzer.addAnalyzer(ApproxQuantiles(column, QUANTILES))
+
+ def prep_distinct_value_frequencies(self, column: str) -> None:
+ if self.profiling_config.include_field_distinct_value_frequencies:
+ self.analyzer.addAnalyzer(Histogram(column))
+
+ def prep_field_histogram(self, column: str) -> None:
+ if self.profiling_config.include_field_histogram:
+ self.analyzer.addAnalyzer(Histogram(column, maxDetailBins=MAX_HIST_BINS))
+
+ def prepare_table_profiles(self) -> None:
+ row_count = self.row_count
+
+ telemetry.telemetry_instance.ping(
+ "profile_data_lake_table",
+ {"rows_profiled": stats.discretize(row_count)},
+ )
+
+ # loop through the columns and add the analyzers
+ for column_spec in self.column_specs:
+ column = column_spec.column
+ column_profile = column_spec.column_profile
+ type_ = column_spec.type_
+ cardinality = column_spec.cardinality
+
+ non_null_count = column_spec.non_null_count
+ unique_count = column_spec.unique_count
+
+ if (
+ self.profiling_config.include_field_null_count
+ and non_null_count is not None
+ ):
+ null_count = row_count - non_null_count
+ assert null_count >= 0
+ column_profile.nullCount = null_count
+ if row_count > 0:
+ column_profile.nullProportion = null_count / row_count
+
+ if unique_count is not None:
+ column_profile.uniqueCount = unique_count
+ if non_null_count is not None and non_null_count > 0:
+ column_profile.uniqueProportion = unique_count / non_null_count
+
+ if isinstance(
+ type_,
+ (
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ ShortType,
+ ),
+ ):
+ if cardinality == Cardinality.UNIQUE:
+ pass
+ elif cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ column_spec.histogram_distinct = True
+ self.prep_distinct_value_frequencies(column)
+ elif cardinality in [
+ Cardinality.MANY,
+ Cardinality.VERY_MANY,
+ Cardinality.UNIQUE,
+ ]:
+ column_spec.histogram_distinct = False
+ self.prep_min_value(column)
+ self.prep_max_value(column)
+ self.prep_mean_value(column)
+ self.prep_median_value(column)
+ self.prep_stdev_value(column)
+ self.prep_quantiles(column)
+ self.prep_field_histogram(column)
+ else: # unknown cardinality - skip
+ pass
+
+ elif isinstance(type_, StringType):
+ if cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ column_spec.histogram_distinct = True
+ self.prep_distinct_value_frequencies(
+ column,
+ )
+
+ elif isinstance(type_, (DateType, TimestampType)):
+ self.prep_min_value(column)
+ self.prep_max_value(column)
+
+ # FIXME: Re-add histogram once kl_divergence has been modified to support datetimes
+
+ if cardinality in [
+ Cardinality.ONE,
+ Cardinality.TWO,
+ Cardinality.VERY_FEW,
+ Cardinality.FEW,
+ ]:
+ self.prep_distinct_value_frequencies(
+ column,
+ )
+
+ def extract_table_profiles(
+ self,
+ analysis_metrics: DataFrame,
+ ) -> None:
+ self.profile.fieldProfiles = []
+
+ analysis_metrics = analysis_metrics.toPandas()
+ # DataFrame with following columns:
+ # entity: "Column" for column profile, "Table" for table profile
+ # instance: name of column being profiled. "*" for table profiles
+ # name: name of metric. Histogram metrics are formatted as "Histogram.."
+ # value: value of metric
+
+ column_metrics = analysis_metrics[analysis_metrics["entity"] == "Column"]
+
+ # resolve histogram types for grouping
+ column_metrics["kind"] = column_metrics["name"].apply(
+ lambda x: "Histogram" if x.startswith("Histogram.") else x
+ )
+
+ column_histogram_metrics = column_metrics[column_metrics["kind"] == "Histogram"]
+ column_nonhistogram_metrics = column_metrics[
+ column_metrics["kind"] != "Histogram"
+ ]
+
+ histogram_columns = set()
+
+ if len(column_histogram_metrics) > 0:
+ # we only want the absolute counts for each histogram for now
+ column_histogram_metrics = column_histogram_metrics[
+ column_histogram_metrics["name"].apply(
+ lambda x: x.startswith("Histogram.abs.")
+ )
+ ]
+ # get the histogram bins by chopping off the "Histogram.abs." prefix
+ column_histogram_metrics["bin"] = column_histogram_metrics["name"].apply(
+ lambda x: x[14:]
+ )
+
+ # reshape histogram counts for easier access
+ histogram_counts = column_histogram_metrics.set_index(["instance", "bin"])[
+ "value"
+ ]
+
+ histogram_columns = set(histogram_counts.index.get_level_values(0))
+
+ profiled_columns = set()
+
+ if len(column_nonhistogram_metrics) > 0:
+ # reshape other metrics for easier access
+ nonhistogram_metrics = column_nonhistogram_metrics.set_index(
+ ["instance", "name"]
+ )["value"]
+
+ profiled_columns = set(nonhistogram_metrics.index.get_level_values(0))
+ # histogram_columns = set(histogram_counts.index.get_level_values(0))
+
+ for column_spec in self.column_specs:
+ column = column_spec.column
+ column_profile = column_spec.column_profile
+
+ if column not in profiled_columns:
+ continue
+
+ # convert to Dict so we can use .get
+ deequ_column_profile = nonhistogram_metrics.loc[column].to_dict()
+
+ # uniqueCount, uniqueProportion, nullCount, nullProportion, sampleValues already set in TableWrapper
+ column_profile.min = null_str(deequ_column_profile.get("Minimum"))
+ column_profile.max = null_str(deequ_column_profile.get("Maximum"))
+ column_profile.mean = null_str(deequ_column_profile.get("Mean"))
+ column_profile.median = null_str(
+ deequ_column_profile.get("ApproxQuantiles-0.5")
+ )
+ column_profile.stdev = null_str(
+ deequ_column_profile.get("StandardDeviation")
+ )
+ if all(
+ deequ_column_profile.get(f"ApproxQuantiles-{quantile}") is not None
+ for quantile in QUANTILES
+ ):
+ column_profile.quantiles = [
+ QuantileClass(
+ quantile=str(quantile),
+ value=str(deequ_column_profile[f"ApproxQuantiles-{quantile}"]),
+ )
+ for quantile in QUANTILES
+ ]
+
+ if column in histogram_columns:
+ column_histogram = histogram_counts.loc[column]
+ # sort so output is deterministic
+ column_histogram = column_histogram.sort_index()
+
+ if column_spec.histogram_distinct:
+ column_profile.distinctValueFrequencies = [
+ ValueFrequencyClass(
+ value=value, frequency=int(column_histogram.loc[value])
+ )
+ for value in column_histogram.index
+ ]
+ # sort so output is deterministic
+ column_profile.distinctValueFrequencies = sorted(
+ column_profile.distinctValueFrequencies, key=lambda x: x.value
+ )
+
+ else:
+ column_profile.histogram = HistogramClass(
+ [str(x) for x in column_histogram.index],
+ [float(x) for x in column_histogram],
+ )
+
+ # append the column profile to the dataset profile
+ self.profile.fieldProfiles.append(column_profile)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/report.py b/metadata-ingestion/src/datahub/ingestion/source/abs/report.py
new file mode 100644
index 0000000000000..c24e2f9706091
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/report.py
@@ -0,0 +1,19 @@
+import dataclasses
+from dataclasses import field as dataclass_field
+from typing import List
+
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StaleEntityRemovalSourceReport,
+)
+
+
+@dataclasses.dataclass
+class DataLakeSourceReport(StaleEntityRemovalSourceReport):
+ files_scanned = 0
+ filtered: List[str] = dataclass_field(default_factory=list)
+
+ def report_file_scanned(self) -> None:
+ self.files_scanned += 1
+
+ def report_file_dropped(self, file: str) -> None:
+ self.filtered.append(file)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/abs/source.py b/metadata-ingestion/src/datahub/ingestion/source/abs/source.py
new file mode 100644
index 0000000000000..07cc694e1b162
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/abs/source.py
@@ -0,0 +1,700 @@
+import dataclasses
+import functools
+import logging
+import os
+import pathlib
+import re
+import time
+from collections import OrderedDict
+from datetime import datetime
+from pathlib import PurePath
+from typing import Any, Dict, Iterable, List, Optional, Tuple
+
+import smart_open.compression as so_compression
+from more_itertools import peekable
+from pyspark.sql.types import (
+ ArrayType,
+ BinaryType,
+ BooleanType,
+ ByteType,
+ DateType,
+ DecimalType,
+ DoubleType,
+ FloatType,
+ IntegerType,
+ LongType,
+ MapType,
+ NullType,
+ ShortType,
+ StringType,
+ StructField,
+ StructType,
+ TimestampType,
+)
+from smart_open import open as smart_open
+
+from datahub.emitter.mce_builder import (
+ make_data_platform_urn,
+ make_dataplatform_instance_urn,
+ make_dataset_urn_with_platform_instance,
+)
+from datahub.emitter.mcp import MetadataChangeProposalWrapper
+from datahub.ingestion.api.common import PipelineContext
+from datahub.ingestion.api.decorators import (
+ SourceCapability,
+ SupportStatus,
+ capability,
+ config_class,
+ platform_name,
+ support_status,
+)
+from datahub.ingestion.api.source import MetadataWorkUnitProcessor, SourceReport
+from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.source.abs.config import DataLakeSourceConfig, PathSpec
+from datahub.ingestion.source.abs.report import DataLakeSourceReport
+from datahub.ingestion.source.azure.abs_util import (
+ get_abs_properties,
+ get_abs_tags,
+ get_container_name,
+ get_container_relative_path,
+ get_key_prefix,
+ list_folders,
+ strip_abs_prefix,
+)
+from datahub.ingestion.source.data_lake_common.data_lake_utils import ContainerWUCreator
+from datahub.ingestion.source.schema_inference import avro, csv_tsv, json, parquet
+from datahub.ingestion.source.state.stale_entity_removal_handler import (
+ StaleEntityRemovalHandler,
+)
+from datahub.ingestion.source.state.stateful_ingestion_base import (
+ StatefulIngestionSourceBase,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.schema import (
+ BooleanTypeClass,
+ BytesTypeClass,
+ DateTypeClass,
+ NullTypeClass,
+ NumberTypeClass,
+ RecordTypeClass,
+ SchemaField,
+ SchemaFieldDataType,
+ SchemaMetadata,
+ StringTypeClass,
+ TimeTypeClass,
+)
+from datahub.metadata.schema_classes import (
+ DataPlatformInstanceClass,
+ DatasetPropertiesClass,
+ MapTypeClass,
+ OperationClass,
+ OperationTypeClass,
+ OtherSchemaClass,
+ _Aspect,
+)
+from datahub.telemetry import telemetry
+from datahub.utilities.perf_timer import PerfTimer
+
+# hide annoying debug errors from py4j
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+# for a list of all types, see https://spark.apache.org/docs/3.0.3/api/python/_modules/pyspark/sql/types.html
+_field_type_mapping = {
+ NullType: NullTypeClass,
+ StringType: StringTypeClass,
+ BinaryType: BytesTypeClass,
+ BooleanType: BooleanTypeClass,
+ DateType: DateTypeClass,
+ TimestampType: TimeTypeClass,
+ DecimalType: NumberTypeClass,
+ DoubleType: NumberTypeClass,
+ FloatType: NumberTypeClass,
+ ByteType: BytesTypeClass,
+ IntegerType: NumberTypeClass,
+ LongType: NumberTypeClass,
+ ShortType: NumberTypeClass,
+ ArrayType: NullTypeClass,
+ MapType: MapTypeClass,
+ StructField: RecordTypeClass,
+ StructType: RecordTypeClass,
+}
+PAGE_SIZE = 1000
+
+# Hack to support the .gzip extension with smart_open.
+so_compression.register_compressor(".gzip", so_compression._COMPRESSOR_REGISTRY[".gz"])
+
+
+def get_column_type(
+ report: SourceReport, dataset_name: str, column_type: str
+) -> SchemaFieldDataType:
+ """
+ Maps known Spark types to datahub types
+ """
+ TypeClass: Any = None
+
+ for field_type, type_class in _field_type_mapping.items():
+ if isinstance(column_type, field_type):
+ TypeClass = type_class
+ break
+
+ # if still not found, report the warning
+ if TypeClass is None:
+ report.report_warning(
+ dataset_name, f"unable to map type {column_type} to metadata schema"
+ )
+ TypeClass = NullTypeClass
+
+ return SchemaFieldDataType(type=TypeClass())
+
+
+# config flags to emit telemetry for
+config_options_to_report = [
+ "platform",
+ "use_relative_path",
+ "ignore_dotfiles",
+]
+
+
+def partitioned_folder_comparator(folder1: str, folder2: str) -> int:
+ # Try to convert to number and compare if the folder name is a number
+ try:
+ # Stripping = from the folder names as it most probably partition name part like year=2021
+ if "=" in folder1 and "=" in folder2:
+ if folder1.rsplit("=", 1)[0] == folder2.rsplit("=", 1)[0]:
+ folder1 = folder1.rsplit("=", 1)[-1]
+ folder2 = folder2.rsplit("=", 1)[-1]
+
+ num_folder1 = int(folder1)
+ num_folder2 = int(folder2)
+ if num_folder1 == num_folder2:
+ return 0
+ else:
+ return 1 if num_folder1 > num_folder2 else -1
+ except Exception:
+ # If folder name is not a number then do string comparison
+ if folder1 == folder2:
+ return 0
+ else:
+ return 1 if folder1 > folder2 else -1
+
+
+@dataclasses.dataclass
+class TableData:
+ display_name: str
+ is_abs: bool
+ full_path: str
+ rel_path: str
+ partitions: Optional[OrderedDict]
+ timestamp: datetime
+ table_path: str
+ size_in_bytes: int
+ number_of_files: int
+
+
+@platform_name("ABS Data Lake", id="abs")
+@config_class(DataLakeSourceConfig)
+@support_status(SupportStatus.INCUBATING)
+@capability(SourceCapability.DATA_PROFILING, "Optionally enabled via configuration")
+@capability(SourceCapability.TAGS, "Can extract ABS object/container tags if enabled")
+@capability(
+ SourceCapability.DELETION_DETECTION,
+ "Optionally enabled via `stateful_ingestion.remove_stale_metadata`",
+ supported=True,
+)
+class ABSSource(StatefulIngestionSourceBase):
+ source_config: DataLakeSourceConfig
+ report: DataLakeSourceReport
+ profiling_times_taken: List[float]
+ container_WU_creator: ContainerWUCreator
+
+ def __init__(self, config: DataLakeSourceConfig, ctx: PipelineContext):
+ super().__init__(config, ctx)
+ self.source_config = config
+ self.report = DataLakeSourceReport()
+ self.profiling_times_taken = []
+ config_report = {
+ config_option: config.dict().get(config_option)
+ for config_option in config_options_to_report
+ }
+ config_report = {
+ **config_report,
+ "profiling_enabled": config.is_profiling_enabled(),
+ }
+
+ telemetry.telemetry_instance.ping(
+ "data_lake_config",
+ config_report,
+ )
+
+ @classmethod
+ def create(cls, config_dict, ctx):
+ config = DataLakeSourceConfig.parse_obj(config_dict)
+
+ return cls(config, ctx)
+
+ def get_fields(self, table_data: TableData, path_spec: PathSpec) -> List:
+ if self.is_abs_platform():
+ if self.source_config.azure_config is None:
+ raise ValueError("Azure config is required for ABS file sources")
+
+ abs_client = self.source_config.azure_config.get_blob_service_client()
+ file = smart_open(
+ f"azure://{self.source_config.azure_config.container_name}/{table_data.rel_path}",
+ "rb",
+ transport_params={"client": abs_client},
+ )
+ else:
+ # We still use smart_open here to take advantage of the compression
+ # capabilities of smart_open.
+ file = smart_open(table_data.full_path, "rb")
+
+ fields = []
+
+ extension = pathlib.Path(table_data.full_path).suffix
+ from datahub.ingestion.source.data_lake_common.path_spec import (
+ SUPPORTED_COMPRESSIONS,
+ )
+
+ if path_spec.enable_compression and (extension[1:] in SUPPORTED_COMPRESSIONS):
+ # Removing the compression extension and using the one before that like .json.gz -> .json
+ extension = pathlib.Path(table_data.full_path).with_suffix("").suffix
+ if extension == "" and path_spec.default_extension:
+ extension = f".{path_spec.default_extension}"
+
+ try:
+ if extension == ".parquet":
+ fields = parquet.ParquetInferrer().infer_schema(file)
+ elif extension == ".csv":
+ fields = csv_tsv.CsvInferrer(
+ max_rows=self.source_config.max_rows
+ ).infer_schema(file)
+ elif extension == ".tsv":
+ fields = csv_tsv.TsvInferrer(
+ max_rows=self.source_config.max_rows
+ ).infer_schema(file)
+ elif extension == ".json":
+ fields = json.JsonInferrer().infer_schema(file)
+ elif extension == ".avro":
+ fields = avro.AvroInferrer().infer_schema(file)
+ else:
+ self.report.report_warning(
+ table_data.full_path,
+ f"file {table_data.full_path} has unsupported extension",
+ )
+ file.close()
+ except Exception as e:
+ self.report.report_warning(
+ table_data.full_path,
+ f"could not infer schema for file {table_data.full_path}: {e}",
+ )
+ file.close()
+ logger.debug(f"Extracted fields in schema: {fields}")
+ fields = sorted(fields, key=lambda f: f.fieldPath)
+
+ if self.source_config.add_partition_columns_to_schema:
+ self.add_partition_columns_to_schema(
+ fields=fields, path_spec=path_spec, full_path=table_data.full_path
+ )
+
+ return fields
+
+ def add_partition_columns_to_schema(
+ self, path_spec: PathSpec, full_path: str, fields: List[SchemaField]
+ ) -> None:
+ vars = path_spec.get_named_vars(full_path)
+ if vars is not None and "partition" in vars:
+ for partition in vars["partition"].values():
+ partition_arr = partition.split("=")
+ if len(partition_arr) != 2:
+ logger.debug(
+ f"Could not derive partition key from partition field {partition}"
+ )
+ continue
+ partition_key = partition_arr[0]
+ fields.append(
+ SchemaField(
+ fieldPath=f"{partition_key}",
+ nativeDataType="string",
+ type=SchemaFieldDataType(StringTypeClass()),
+ isPartitioningKey=True,
+ nullable=True,
+ recursive=False,
+ )
+ )
+
+ def _create_table_operation_aspect(self, table_data: TableData) -> OperationClass:
+ reported_time = int(time.time() * 1000)
+
+ operation = OperationClass(
+ timestampMillis=reported_time,
+ lastUpdatedTimestamp=int(table_data.timestamp.timestamp() * 1000),
+ operationType=OperationTypeClass.UPDATE,
+ )
+
+ return operation
+
+ def ingest_table(
+ self, table_data: TableData, path_spec: PathSpec
+ ) -> Iterable[MetadataWorkUnit]:
+ aspects: List[Optional[_Aspect]] = []
+
+ logger.info(f"Extracting table schema from file: {table_data.full_path}")
+ browse_path: str = (
+ strip_abs_prefix(table_data.table_path)
+ if self.is_abs_platform()
+ else table_data.table_path.strip("/")
+ )
+
+ data_platform_urn = make_data_platform_urn(self.source_config.platform)
+ logger.info(f"Creating dataset urn with name: {browse_path}")
+ dataset_urn = make_dataset_urn_with_platform_instance(
+ self.source_config.platform,
+ browse_path,
+ self.source_config.platform_instance,
+ self.source_config.env,
+ )
+
+ if self.source_config.platform_instance:
+ data_platform_instance = DataPlatformInstanceClass(
+ platform=data_platform_urn,
+ instance=make_dataplatform_instance_urn(
+ self.source_config.platform, self.source_config.platform_instance
+ ),
+ )
+ aspects.append(data_platform_instance)
+
+ container = get_container_name(table_data.table_path)
+ key_prefix = (
+ get_key_prefix(table_data.table_path)
+ if table_data.full_path == table_data.table_path
+ else None
+ )
+
+ custom_properties = get_abs_properties(
+ container,
+ key_prefix,
+ full_path=str(table_data.full_path),
+ number_of_files=table_data.number_of_files,
+ size_in_bytes=table_data.size_in_bytes,
+ sample_files=path_spec.sample_files,
+ azure_config=self.source_config.azure_config,
+ use_abs_container_properties=self.source_config.use_abs_container_properties,
+ use_abs_blob_properties=self.source_config.use_abs_blob_properties,
+ )
+
+ dataset_properties = DatasetPropertiesClass(
+ description="",
+ name=table_data.display_name,
+ customProperties=custom_properties,
+ )
+ aspects.append(dataset_properties)
+ if table_data.size_in_bytes > 0:
+ try:
+ fields = self.get_fields(table_data, path_spec)
+ schema_metadata = SchemaMetadata(
+ schemaName=table_data.display_name,
+ platform=data_platform_urn,
+ version=0,
+ hash="",
+ fields=fields,
+ platformSchema=OtherSchemaClass(rawSchema=""),
+ )
+ aspects.append(schema_metadata)
+ except Exception as e:
+ logger.error(
+ f"Failed to extract schema from file {table_data.full_path}. The error was:{e}"
+ )
+ else:
+ logger.info(
+ f"Skipping schema extraction for empty file {table_data.full_path}"
+ )
+
+ if (
+ self.source_config.use_abs_container_properties
+ or self.source_config.use_abs_blob_tags
+ ):
+ abs_tags = get_abs_tags(
+ container,
+ key_prefix,
+ dataset_urn,
+ self.source_config.azure_config,
+ self.ctx,
+ self.source_config.use_abs_blob_tags,
+ )
+ if abs_tags:
+ aspects.append(abs_tags)
+
+ operation = self._create_table_operation_aspect(table_data)
+ aspects.append(operation)
+ for mcp in MetadataChangeProposalWrapper.construct_many(
+ entityUrn=dataset_urn,
+ aspects=aspects,
+ ):
+ yield mcp.as_workunit()
+
+ yield from self.container_WU_creator.create_container_hierarchy(
+ table_data.table_path, dataset_urn
+ )
+
+ def get_prefix(self, relative_path: str) -> str:
+ index = re.search(r"[\*|\{]", relative_path)
+ if index:
+ return relative_path[: index.start()]
+ else:
+ return relative_path
+
+ def extract_table_name(self, path_spec: PathSpec, named_vars: dict) -> str:
+ if path_spec.table_name is None:
+ raise ValueError("path_spec.table_name is not set")
+ return path_spec.table_name.format_map(named_vars)
+
+ def extract_table_data(
+ self,
+ path_spec: PathSpec,
+ path: str,
+ rel_path: str,
+ timestamp: datetime,
+ size: int,
+ ) -> TableData:
+ logger.debug(f"Getting table data for path: {path}")
+ table_name, table_path = path_spec.extract_table_name_and_path(path)
+ table_data = TableData(
+ display_name=table_name,
+ is_abs=self.is_abs_platform(),
+ full_path=path,
+ rel_path=rel_path,
+ partitions=None,
+ timestamp=timestamp,
+ table_path=table_path,
+ number_of_files=1,
+ size_in_bytes=size,
+ )
+ return table_data
+
+ def resolve_templated_folders(
+ self, container_name: str, prefix: str
+ ) -> Iterable[str]:
+ folder_split: List[str] = prefix.split("*", 1)
+ # If the len of split is 1 it means we don't have * in the prefix
+ if len(folder_split) == 1:
+ yield prefix
+ return
+
+ folders: Iterable[str] = list_folders(
+ container_name, folder_split[0], self.source_config.azure_config
+ )
+ for folder in folders:
+ yield from self.resolve_templated_folders(
+ container_name, f"{folder}{folder_split[1]}"
+ )
+
+ def get_dir_to_process(
+ self,
+ container_name: str,
+ folder: str,
+ path_spec: PathSpec,
+ protocol: str,
+ ) -> str:
+ iterator = list_folders(
+ container_name=container_name,
+ prefix=folder,
+ azure_config=self.source_config.azure_config,
+ )
+ iterator = peekable(iterator)
+ if iterator:
+ sorted_dirs = sorted(
+ iterator,
+ key=functools.cmp_to_key(partitioned_folder_comparator),
+ reverse=True,
+ )
+ for dir in sorted_dirs:
+ if path_spec.dir_allowed(f"{protocol}{container_name}/{dir}/"):
+ return self.get_dir_to_process(
+ container_name=container_name,
+ folder=dir + "/",
+ path_spec=path_spec,
+ protocol=protocol,
+ )
+ return folder
+ else:
+ return folder
+
+ def abs_browser(
+ self, path_spec: PathSpec, sample_size: int
+ ) -> Iterable[Tuple[str, str, datetime, int]]:
+ if self.source_config.azure_config is None:
+ raise ValueError("azure_config not set. Cannot browse Azure Blob Storage")
+ abs_blob_service_client = (
+ self.source_config.azure_config.get_blob_service_client()
+ )
+ container_client = abs_blob_service_client.get_container_client(
+ self.source_config.azure_config.container_name
+ )
+
+ container_name = self.source_config.azure_config.container_name
+ logger.debug(f"Scanning container: {container_name}")
+
+ prefix = self.get_prefix(get_container_relative_path(path_spec.include))
+ logger.debug(f"Scanning objects with prefix:{prefix}")
+
+ matches = re.finditer(r"{\s*\w+\s*}", path_spec.include, re.MULTILINE)
+ matches_list = list(matches)
+ if matches_list and path_spec.sample_files:
+ max_start: int = -1
+ include: str = path_spec.include
+ max_match: str = ""
+ for match in matches_list:
+ pos = include.find(match.group())
+ if pos > max_start:
+ if max_match:
+ include = include.replace(max_match, "*")
+ max_start = match.start()
+ max_match = match.group()
+
+ table_index = include.find(max_match)
+
+ for folder in self.resolve_templated_folders(
+ container_name,
+ get_container_relative_path(include[:table_index]),
+ ):
+ try:
+ for f in list_folders(
+ container_name, f"{folder}", self.source_config.azure_config
+ ):
+ logger.info(f"Processing folder: {f}")
+ protocol = ContainerWUCreator.get_protocol(path_spec.include)
+ dir_to_process = self.get_dir_to_process(
+ container_name=container_name,
+ folder=f + "/",
+ path_spec=path_spec,
+ protocol=protocol,
+ )
+ logger.info(f"Getting files from folder: {dir_to_process}")
+ dir_to_process = dir_to_process.rstrip("\\")
+ for obj in container_client.list_blobs(
+ name_starts_with=f"{dir_to_process}",
+ results_per_page=PAGE_SIZE,
+ ):
+ abs_path = self.create_abs_path(obj.name)
+ logger.debug(f"Sampling file: {abs_path}")
+ yield abs_path, obj.name, obj.last_modified, obj.size,
+ except Exception as e:
+ # This odd check if being done because boto does not have a proper exception to catch
+ # The exception that appears in stacktrace cannot actually be caught without a lot more work
+ # https://github.com/boto/boto3/issues/1195
+ if "NoSuchBucket" in repr(e):
+ logger.debug(
+ f"Got NoSuchBucket exception for {container_name}", e
+ )
+ self.get_report().report_warning(
+ "Missing bucket", f"No bucket found {container_name}"
+ )
+ else:
+ raise e
+ else:
+ logger.debug(
+ "No template in the pathspec can't do sampling, fallbacking to do full scan"
+ )
+ path_spec.sample_files = False
+ for obj in container_client.list_blobs(
+ prefix=f"{prefix}", results_per_page=PAGE_SIZE
+ ):
+ abs_path = self.create_abs_path(obj.name)
+ logger.debug(f"Path: {abs_path}")
+ # the following line if using the file_system_client
+ # yield abs_path, obj.last_modified, obj.content_length,
+ yield abs_path, obj.name, obj.last_modified, obj.size
+
+ def create_abs_path(self, key: str) -> str:
+ if self.source_config.azure_config:
+ account_name = self.source_config.azure_config.account_name
+ container_name = self.source_config.azure_config.container_name
+ return (
+ f"https://{account_name}.blob.core.windows.net/{container_name}/{key}"
+ )
+ return ""
+
+ def local_browser(
+ self, path_spec: PathSpec
+ ) -> Iterable[Tuple[str, str, datetime, int]]:
+ prefix = self.get_prefix(path_spec.include)
+ if os.path.isfile(prefix):
+ logger.debug(f"Scanning single local file: {prefix}")
+ file_name = prefix
+ yield prefix, file_name, datetime.utcfromtimestamp(
+ os.path.getmtime(prefix)
+ ), os.path.getsize(prefix)
+ else:
+ logger.debug(f"Scanning files under local folder: {prefix}")
+ for root, dirs, files in os.walk(prefix):
+ dirs.sort(key=functools.cmp_to_key(partitioned_folder_comparator))
+
+ for file in sorted(files):
+ # We need to make sure the path is in posix style which is not true on windows
+ full_path = PurePath(
+ os.path.normpath(os.path.join(root, file))
+ ).as_posix()
+ yield full_path, file, datetime.utcfromtimestamp(
+ os.path.getmtime(full_path)
+ ), os.path.getsize(full_path)
+
+ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
+ self.container_WU_creator = ContainerWUCreator(
+ self.source_config.platform,
+ self.source_config.platform_instance,
+ self.source_config.env,
+ )
+ with PerfTimer():
+ assert self.source_config.path_specs
+ for path_spec in self.source_config.path_specs:
+ file_browser = (
+ self.abs_browser(
+ path_spec, self.source_config.number_of_files_to_sample
+ )
+ if self.is_abs_platform()
+ else self.local_browser(path_spec)
+ )
+ table_dict: Dict[str, TableData] = {}
+ for file, name, timestamp, size in file_browser:
+ if not path_spec.allowed(file):
+ continue
+ table_data = self.extract_table_data(
+ path_spec, file, name, timestamp, size
+ )
+ if table_data.table_path not in table_dict:
+ table_dict[table_data.table_path] = table_data
+ else:
+ table_dict[table_data.table_path].number_of_files = (
+ table_dict[table_data.table_path].number_of_files + 1
+ )
+ table_dict[table_data.table_path].size_in_bytes = (
+ table_dict[table_data.table_path].size_in_bytes
+ + table_data.size_in_bytes
+ )
+ if (
+ table_dict[table_data.table_path].timestamp
+ < table_data.timestamp
+ ) and (table_data.size_in_bytes > 0):
+ table_dict[
+ table_data.table_path
+ ].full_path = table_data.full_path
+ table_dict[
+ table_data.table_path
+ ].timestamp = table_data.timestamp
+
+ for guid, table_data in table_dict.items():
+ yield from self.ingest_table(table_data, path_spec)
+
+ def get_workunit_processors(self) -> List[Optional[MetadataWorkUnitProcessor]]:
+ return [
+ *super().get_workunit_processors(),
+ StaleEntityRemovalHandler.create(
+ self, self.source_config, self.ctx
+ ).workunit_processor,
+ ]
+
+ def is_abs_platform(self):
+ return self.source_config.platform == "abs"
+
+ def get_report(self):
+ return self.report
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/__init__.py b/metadata-ingestion/src/datahub/ingestion/source/azure/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py b/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py
new file mode 100644
index 0000000000000..34faa0f0979ef
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/azure/abs_util.py
@@ -0,0 +1,286 @@
+import logging
+import os
+import re
+from typing import Dict, Iterable, List, Optional
+
+from azure.storage.blob import BlobProperties
+
+from datahub.emitter.mce_builder import make_tag_urn
+from datahub.ingestion.api.common import PipelineContext
+from datahub.ingestion.source.azure.azure_common import AzureConnectionConfig
+from datahub.metadata.schema_classes import GlobalTagsClass, TagAssociationClass
+
+ABS_PREFIXES_REGEX = re.compile(
+ r"(http[s]?://[a-z0-9]{3,24}\.blob\.core\.windows\.net/)"
+)
+
+logging.getLogger("py4j").setLevel(logging.ERROR)
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+def is_abs_uri(uri: str) -> bool:
+ return bool(ABS_PREFIXES_REGEX.match(uri))
+
+
+def get_abs_prefix(abs_uri: str) -> Optional[str]:
+ result = re.search(ABS_PREFIXES_REGEX, abs_uri)
+ if result and result.groups():
+ return result.group(1)
+ return None
+
+
+def strip_abs_prefix(abs_uri: str) -> str:
+ # remove abs prefix https://.blob.core.windows.net
+ abs_prefix = get_abs_prefix(abs_uri)
+ if not abs_prefix:
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ length_abs_prefix = len(abs_prefix)
+ return abs_uri[length_abs_prefix:]
+
+
+def make_abs_urn(abs_uri: str, env: str) -> str:
+ abs_name = strip_abs_prefix(abs_uri)
+
+ if abs_name.endswith("/"):
+ abs_name = abs_name[:-1]
+
+ name, extension = os.path.splitext(abs_name)
+
+ if extension != "":
+ extension = extension[1:] # remove the dot
+ return f"urn:li:dataset:(urn:li:dataPlatform:abs,{name}_{extension},{env})"
+
+ return f"urn:li:dataset:(urn:li:dataPlatform:abs,{abs_name},{env})"
+
+
+def get_container_name(abs_uri: str) -> str:
+ if not is_abs_uri(abs_uri):
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ return strip_abs_prefix(abs_uri).split("/")[0]
+
+
+def get_key_prefix(abs_uri: str) -> str:
+ if not is_abs_uri(abs_uri):
+ raise ValueError(
+ f"Not an Azure Blob Storage URI. Must match the following regular expression: {str(ABS_PREFIXES_REGEX)}"
+ )
+ return strip_abs_prefix(abs_uri).split("/", maxsplit=1)[1]
+
+
+def get_abs_properties(
+ container_name: str,
+ blob_name: Optional[str],
+ full_path: str,
+ number_of_files: int,
+ size_in_bytes: int,
+ sample_files: bool,
+ azure_config: Optional[AzureConnectionConfig],
+ use_abs_container_properties: Optional[bool] = False,
+ use_abs_blob_properties: Optional[bool] = False,
+) -> Dict[str, str]:
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ blob_service_client = azure_config.get_blob_service_client()
+ container_client = blob_service_client.get_container_client(
+ container=container_name
+ )
+
+ custom_properties = {"schema_inferred_from": full_path}
+ if not sample_files:
+ custom_properties.update(
+ {
+ "number_of_files": str(number_of_files),
+ "size_in_bytes": str(size_in_bytes),
+ }
+ )
+
+ if use_abs_blob_properties and blob_name is not None:
+ blob_client = container_client.get_blob_client(blob=blob_name)
+ blob_properties = blob_client.get_blob_properties()
+ if blob_properties:
+ create_properties(
+ data=blob_properties,
+ prefix="blob",
+ custom_properties=custom_properties,
+ resource_name=blob_name,
+ json_properties=[
+ "metadata",
+ "content_settings",
+ "lease",
+ "copy",
+ "immutability_policy",
+ ],
+ )
+ else:
+ logger.warning(
+ f"No blob properties found for container={container_name}, blob={blob_name}."
+ )
+
+ if use_abs_container_properties:
+ container_properties = container_client.get_container_properties()
+ if container_properties:
+ create_properties(
+ data=container_properties,
+ prefix="container",
+ custom_properties=custom_properties,
+ resource_name=container_name,
+ json_properties=["metadata"],
+ )
+ else:
+ logger.warning(
+ f"No container properties found for container={container_name}."
+ )
+
+ return custom_properties
+
+
+def add_property(
+ key: str, value: str, custom_properties: Dict[str, str], resource_name: str
+) -> Dict[str, str]:
+ if key in custom_properties:
+ key = f"{key}_{resource_name}"
+ if value is not None:
+ custom_properties[key] = str(value)
+ return custom_properties
+
+
+def create_properties(
+ data: BlobProperties,
+ prefix: str,
+ custom_properties: Dict[str, str],
+ resource_name: str,
+ json_properties: List[str],
+) -> None:
+ for item in data.items():
+ key = item[0]
+ transformed_key = f"{prefix}_{key}"
+ value = item[1]
+ if value is None:
+ continue
+ try:
+ # These are known properties with a json value, we process these recursively...
+ if key in json_properties:
+ create_properties(
+ data=value,
+ prefix=f"{prefix}_{key}",
+ custom_properties=custom_properties,
+ resource_name=resource_name,
+ json_properties=json_properties,
+ )
+ else:
+ custom_properties = add_property(
+ key=transformed_key,
+ value=value,
+ custom_properties=custom_properties,
+ resource_name=resource_name,
+ )
+ except Exception as exception:
+ logger.debug(
+ f"Could not create property {key} value {value}, from resource {resource_name}: {exception}."
+ )
+
+
+def get_abs_tags(
+ container_name: str,
+ key_name: Optional[str],
+ dataset_urn: str,
+ azure_config: Optional[AzureConnectionConfig],
+ ctx: PipelineContext,
+ use_abs_blob_tags: Optional[bool] = False,
+) -> Optional[GlobalTagsClass]:
+ # Todo add the service_client, when building out this get_abs_tags
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ tags_to_add: List[str] = []
+ blob_service_client = azure_config.get_blob_service_client()
+ container_client = blob_service_client.get_container_client(container_name)
+ blob_client = container_client.get_blob_client(blob=key_name)
+
+ if use_abs_blob_tags and key_name is not None:
+ tag_set = blob_client.get_blob_tags()
+ if tag_set:
+ tags_to_add.extend(
+ make_tag_urn(f"""{key}:{value}""") for key, value in tag_set.items()
+ )
+ else:
+ # Unlike container tags, if an object does not have tags, it will just return an empty array
+ # as opposed to an exception.
+ logger.info(f"No tags found for container={container_name} key={key_name}")
+
+ if len(tags_to_add) == 0:
+ return None
+
+ if ctx.graph is not None:
+ logger.debug("Connected to DatahubApi, grabbing current tags to maintain.")
+ current_tags: Optional[GlobalTagsClass] = ctx.graph.get_aspect(
+ entity_urn=dataset_urn,
+ aspect_type=GlobalTagsClass,
+ )
+ if current_tags:
+ tags_to_add.extend([current_tag.tag for current_tag in current_tags.tags])
+ else:
+ logger.warning("Could not connect to DatahubApi. No current tags to maintain")
+
+ # Sort existing tags
+ tags_to_add = sorted(list(set(tags_to_add)))
+ # Remove duplicate tags
+ new_tags = GlobalTagsClass(
+ tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
+ )
+ return new_tags
+
+
+def list_folders(
+ container_name: str, prefix: str, azure_config: Optional[AzureConnectionConfig]
+) -> Iterable[str]:
+ if azure_config is None:
+ raise ValueError(
+ "Azure configuration is not provided. Cannot retrieve container client."
+ )
+
+ abs_blob_service_client = azure_config.get_blob_service_client()
+ container_client = abs_blob_service_client.get_container_client(container_name)
+
+ current_level = prefix.count("/")
+ blob_list = container_client.list_blobs(name_starts_with=prefix)
+
+ this_dict = {}
+ for blob in blob_list:
+ blob_name = blob.name[: blob.name.rfind("/") + 1]
+ folder_structure_arr = blob_name.split("/")
+
+ folder_name = ""
+ if len(folder_structure_arr) > current_level:
+ folder_name = f"{folder_name}/{folder_structure_arr[current_level]}"
+ else:
+ continue
+
+ folder_name = folder_name[1 : len(folder_name)]
+
+ if folder_name.endswith("/"):
+ folder_name = folder_name[:-1]
+
+ if folder_name == "":
+ continue
+
+ folder_name = f"{prefix}{folder_name}"
+ if folder_name in this_dict:
+ continue
+ else:
+ this_dict[folder_name] = folder_name
+
+ yield f"{folder_name}"
+
+
+def get_container_relative_path(abs_uri: str) -> str:
+ return "/".join(strip_abs_prefix(abs_uri).split("/")[1:])
diff --git a/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py b/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py
new file mode 100644
index 0000000000000..46de4e09d7ee5
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/azure/azure_common.py
@@ -0,0 +1,98 @@
+from typing import Dict, Optional, Union
+
+from azure.identity import ClientSecretCredential
+from azure.storage.blob import BlobServiceClient
+from azure.storage.filedatalake import DataLakeServiceClient, FileSystemClient
+from pydantic import Field, root_validator
+
+from datahub.configuration import ConfigModel
+from datahub.configuration.common import ConfigurationError
+
+
+class AzureConnectionConfig(ConfigModel):
+ """
+ Common Azure credentials config.
+
+ https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-directory-file-acl-python
+ """
+
+ base_path: str = Field(
+ default="/",
+ description="Base folder in hierarchical namespaces to start from.",
+ )
+ container_name: str = Field(
+ description="Azure storage account container name.",
+ )
+ account_name: str = Field(
+ description="Name of the Azure storage account. See [Microsoft official documentation on how to create a storage account.](https://docs.microsoft.com/en-us/azure/storage/blobs/create-data-lake-storage-account)",
+ )
+ account_key: Optional[str] = Field(
+ description="Azure storage account access key that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ sas_token: Optional[str] = Field(
+ description="Azure storage account Shared Access Signature (SAS) token that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ client_secret: Optional[str] = Field(
+ description="Azure client secret that can be used as a credential. **An account key, a SAS token or a client secret is required for authentication.**",
+ default=None,
+ )
+ client_id: Optional[str] = Field(
+ description="Azure client (Application) ID required when a `client_secret` is used as a credential.",
+ default=None,
+ )
+ tenant_id: Optional[str] = Field(
+ description="Azure tenant (Directory) ID required when a `client_secret` is used as a credential.",
+ default=None,
+ )
+
+ def get_abfss_url(self, folder_path: str = "") -> str:
+ if not folder_path.startswith("/"):
+ folder_path = f"/{folder_path}"
+ return f"abfss://{self.container_name}@{self.account_name}.dfs.core.windows.net{folder_path}"
+
+ # TODO DEX-1010
+ def get_filesystem_client(self) -> FileSystemClient:
+ return self.get_data_lake_service_client().get_file_system_client(
+ file_system=self.container_name
+ )
+
+ def get_blob_service_client(self):
+ return BlobServiceClient(
+ account_url=f"https://{self.account_name}.blob.core.windows.net",
+ credential=f"{self.get_credentials()}",
+ )
+
+ def get_data_lake_service_client(self) -> DataLakeServiceClient:
+ return DataLakeServiceClient(
+ account_url=f"https://{self.account_name}.dfs.core.windows.net",
+ credential=f"{self.get_credentials()}",
+ )
+
+ def get_credentials(
+ self,
+ ) -> Union[Optional[str], ClientSecretCredential]:
+ if self.client_id and self.client_secret and self.tenant_id:
+ return ClientSecretCredential(
+ tenant_id=self.tenant_id,
+ client_id=self.client_id,
+ client_secret=self.client_secret,
+ )
+ return self.sas_token if self.sas_token is not None else self.account_key
+
+ @root_validator()
+ def _check_credential_values(cls, values: Dict) -> Dict:
+ if (
+ values.get("account_key")
+ or values.get("sas_token")
+ or (
+ values.get("client_id")
+ and values.get("client_secret")
+ and values.get("tenant_id")
+ )
+ ):
+ return values
+ raise ConfigurationError(
+ "credentials missing, requires one combination of account_key or sas_token or (client_id and client_secret and tenant_id)"
+ )
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
index 5046f52cdce26..7a96b2f0643ab 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery.py
@@ -2,24 +2,9 @@
import functools
import logging
import os
-import re
-import traceback
-from collections import defaultdict
-from datetime import datetime, timedelta
-from typing import Dict, Iterable, List, Optional, Set, Type, Union, cast
+from typing import Iterable, List, Optional
-from google.cloud import bigquery
-from google.cloud.bigquery.table import TableListItem
-
-from datahub.configuration.pattern_utils import is_schema_allowed, is_tag_allowed
-from datahub.emitter.mce_builder import (
- make_data_platform_urn,
- make_dataplatform_instance_urn,
- make_dataset_urn,
- make_tag_urn,
-)
-from datahub.emitter.mcp import MetadataChangeProposalWrapper
-from datahub.emitter.mcp_builder import BigQueryDatasetKey, ContainerKey, ProjectIdKey
+from datahub.emitter.mce_builder import make_dataset_urn
from datahub.ingestion.api.common import PipelineContext
from datahub.ingestion.api.decorators import (
SupportStatus,
@@ -30,54 +15,31 @@
)
from datahub.ingestion.api.incremental_lineage_helper import auto_incremental_lineage
from datahub.ingestion.api.source import (
- CapabilityReport,
MetadataWorkUnitProcessor,
SourceCapability,
TestableSource,
TestConnectionReport,
)
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.glossary.classification_mixin import (
- SAMPLE_SIZE_MULTIPLIER,
- ClassificationHandler,
- classification_workunit_processor,
-)
from datahub.ingestion.source.bigquery_v2.bigquery_audit import (
BigqueryTableIdentifier,
BigQueryTableRef,
)
from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
-from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
-from datahub.ingestion.source.bigquery_v2.bigquery_helper import (
- unquote_and_decode_unicode_escape_seq,
-)
from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
- BigqueryColumn,
- BigqueryDataset,
BigqueryProject,
BigQuerySchemaApi,
- BigqueryTable,
- BigqueryTableSnapshot,
- BigqueryView,
)
-from datahub.ingestion.source.bigquery_v2.common import (
- BQ_EXTERNAL_DATASET_URL_TEMPLATE,
- BQ_EXTERNAL_TABLE_URL_TEMPLATE,
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_test_connection import (
+ BigQueryTestConnection,
)
from datahub.ingestion.source.bigquery_v2.lineage import BigqueryLineageExtractor
from datahub.ingestion.source.bigquery_v2.profiler import BigqueryProfiler
from datahub.ingestion.source.bigquery_v2.usage import BigQueryUsageExtractor
-from datahub.ingestion.source.common.subtypes import (
- DatasetContainerSubTypes,
- DatasetSubTypes,
-)
-from datahub.ingestion.source.sql.sql_utils import (
- add_table_to_schema_container,
- gen_database_container,
- gen_schema_container,
- get_domain_wu,
-)
from datahub.ingestion.source.state.profiling_state_handler import ProfilingHandler
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantLineageRunSkipHandler,
@@ -89,57 +51,11 @@
from datahub.ingestion.source.state.stateful_ingestion_base import (
StatefulIngestionSourceBase,
)
-from datahub.ingestion.source_report.ingestion_stage import (
- METADATA_EXTRACTION,
- PROFILING,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.common import (
- Status,
- SubTypes,
- TimeStamp,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
- DatasetProperties,
- ViewProperties,
-)
-from datahub.metadata.com.linkedin.pegasus2avro.schema import (
- ArrayType,
- BooleanType,
- BytesType,
- DateType,
- MySqlDDL,
- NullType,
- NumberType,
- RecordType,
- SchemaField,
- SchemaFieldDataType,
- SchemaMetadata,
- StringType,
- TimeType,
-)
-from datahub.metadata.schema_classes import (
- DataPlatformInstanceClass,
- GlobalTagsClass,
- TagAssociationClass,
-)
from datahub.sql_parsing.schema_resolver import SchemaResolver
-from datahub.utilities.file_backed_collections import FileBackedDict
-from datahub.utilities.hive_schema_to_avro import (
- HiveColumnToAvroConverter,
- get_schema_fields_for_hive_column,
-)
-from datahub.utilities.mapping import Constants
-from datahub.utilities.perf_timer import PerfTimer
-from datahub.utilities.ratelimiter import RateLimiter
from datahub.utilities.registries.domain_registry import DomainRegistry
logger: logging.Logger = logging.getLogger(__name__)
-# Handle table snapshots
-# See https://cloud.google.com/bigquery/docs/table-snapshots-intro.
-SNAPSHOT_TABLE_REGEX = re.compile(r"^(.+)@(\d{13})$")
-CLUSTERING_COLUMN_TAG = "CLUSTERING_COLUMN"
-
# We can't use close as it is not called if the ingestion is not successful
def cleanup(config: BigQueryV2Config) -> None:
@@ -178,58 +94,18 @@ def cleanup(config: BigQueryV2Config) -> None:
supported=True,
)
class BigqueryV2Source(StatefulIngestionSourceBase, TestableSource):
- # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
- # Note: We use the hive schema parser to parse nested BigQuery types. We also have
- # some extra type mappings in that file.
- BIGQUERY_FIELD_TYPE_MAPPINGS: Dict[
- str,
- Type[
- Union[
- ArrayType,
- BytesType,
- BooleanType,
- NumberType,
- RecordType,
- StringType,
- TimeType,
- DateType,
- NullType,
- ]
- ],
- ] = {
- "BYTES": BytesType,
- "BOOL": BooleanType,
- "DECIMAL": NumberType,
- "NUMERIC": NumberType,
- "BIGNUMERIC": NumberType,
- "BIGDECIMAL": NumberType,
- "FLOAT64": NumberType,
- "INT": NumberType,
- "INT64": NumberType,
- "SMALLINT": NumberType,
- "INTEGER": NumberType,
- "BIGINT": NumberType,
- "TINYINT": NumberType,
- "BYTEINT": NumberType,
- "STRING": StringType,
- "TIME": TimeType,
- "TIMESTAMP": TimeType,
- "DATE": DateType,
- "DATETIME": TimeType,
- "GEOGRAPHY": NullType,
- "JSON": RecordType,
- "INTERVAL": NullType,
- "ARRAY": ArrayType,
- "STRUCT": RecordType,
- }
-
def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
super().__init__(config, ctx)
self.config: BigQueryV2Config = config
self.report: BigQueryV2Report = BigQueryV2Report()
- self.classification_handler = ClassificationHandler(self.config, self.report)
self.platform: str = "bigquery"
+ self.domain_registry: Optional[DomainRegistry] = None
+ if self.config.domain:
+ self.domain_registry = DomainRegistry(
+ cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
+ )
+
BigqueryTableIdentifier._BIGQUERY_DEFAULT_SHARDED_TABLE_REGEX = (
self.config.sharded_table_pattern
)
@@ -247,12 +123,6 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
self.sql_parser_schema_resolver = self._init_schema_resolver()
- self.data_reader: Optional[BigQueryDataReader] = None
- if self.classification_handler.is_classification_enabled():
- self.data_reader = BigQueryDataReader.create(
- self.config.get_bigquery_client()
- )
-
redundant_lineage_run_skip_handler: Optional[
RedundantLineageRunSkipHandler
] = None
@@ -289,12 +159,6 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
redundant_run_skip_handler=redundant_usage_run_skip_handler,
)
- self.domain_registry: Optional[DomainRegistry] = None
- if self.config.domain:
- self.domain_registry = DomainRegistry(
- cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
- )
-
self.profiling_state_handler: Optional[ProfilingHandler] = None
if self.config.enable_stateful_profiling:
self.profiling_state_handler = ProfilingHandler(
@@ -307,17 +171,15 @@ def __init__(self, ctx: PipelineContext, config: BigQueryV2Config):
config, self.report, self.profiling_state_handler
)
- # Global store of table identifiers for lineage filtering
- self.table_refs: Set[str] = set()
-
- # Maps project -> view_ref, so we can find all views in a project
- self.view_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
- # Maps project -> snapshot_ref, so we can find all snapshots in a project
- self.snapshot_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
- # Maps view ref -> actual sql
- self.view_definitions: FileBackedDict[str] = FileBackedDict()
- # Maps snapshot ref -> Snapshot
- self.snapshots_by_ref: FileBackedDict[BigqueryTableSnapshot] = FileBackedDict()
+ self.bq_schema_extractor = BigQuerySchemaGenerator(
+ self.config,
+ self.report,
+ self.bigquery_data_dictionary,
+ self.domain_registry,
+ self.sql_parser_schema_resolver,
+ self.profiler,
+ self.gen_dataset_urn,
+ )
self.add_config_to_report()
atexit.register(cleanup, config)
@@ -327,161 +189,9 @@ def create(cls, config_dict: dict, ctx: PipelineContext) -> "BigqueryV2Source":
config = BigQueryV2Config.parse_obj(config_dict)
return cls(ctx, config)
- @staticmethod
- def connectivity_test(client: bigquery.Client) -> CapabilityReport:
- ret = client.query("select 1")
- if ret.error_result:
- return CapabilityReport(
- capable=False, failure_reason=f"{ret.error_result['message']}"
- )
- else:
- return CapabilityReport(capable=True)
-
- @property
- def store_table_refs(self):
- return self.config.include_table_lineage or self.config.include_usage_statistics
-
- @staticmethod
- def metadata_read_capability_test(
- project_ids: List[str], config: BigQueryV2Config
- ) -> CapabilityReport:
- for project_id in project_ids:
- try:
- logger.info(f"Metadata read capability test for project {project_id}")
- client: bigquery.Client = config.get_bigquery_client()
- assert client
- bigquery_data_dictionary = BigQuerySchemaApi(
- BigQueryV2Report().schema_api_perf, client
- )
- result = bigquery_data_dictionary.get_datasets_for_project_id(
- project_id, 10
- )
- if len(result) == 0:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Dataset query returned empty dataset. It is either empty or no dataset in project {project_id}",
- )
- tables = bigquery_data_dictionary.get_tables_for_dataset(
- project_id=project_id,
- dataset_name=result[0].name,
- tables={},
- with_data_read_permission=config.have_table_data_read_permission,
- )
- if len(list(tables)) == 0:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Tables query did not return any table. It is either empty or no tables in project {project_id}.{result[0].name}",
- )
-
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Dataset query failed with error: {e}",
- )
-
- return CapabilityReport(capable=True)
-
- @staticmethod
- def lineage_capability_test(
- connection_conf: BigQueryV2Config,
- project_ids: List[str],
- report: BigQueryV2Report,
- ) -> CapabilityReport:
- lineage_extractor = BigqueryLineageExtractor(
- connection_conf, report, lambda ref: ""
- )
- for project_id in project_ids:
- try:
- logger.info(f"Lineage capability test for project {project_id}")
- lineage_extractor.test_capability(project_id)
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Lineage capability test failed with: {e}",
- )
-
- return CapabilityReport(capable=True)
-
- @staticmethod
- def usage_capability_test(
- connection_conf: BigQueryV2Config,
- project_ids: List[str],
- report: BigQueryV2Report,
- ) -> CapabilityReport:
- usage_extractor = BigQueryUsageExtractor(
- connection_conf,
- report,
- schema_resolver=SchemaResolver(platform="bigquery"),
- dataset_urn_builder=lambda ref: "",
- )
- for project_id in project_ids:
- try:
- logger.info(f"Usage capability test for project {project_id}")
- failures_before_test = len(report.failures)
- usage_extractor.test_capability(project_id)
- if failures_before_test != len(report.failures):
- return CapabilityReport(
- capable=False,
- failure_reason="Usage capability test failed. Check the logs for further info",
- )
- except Exception as e:
- return CapabilityReport(
- capable=False,
- failure_reason=f"Usage capability test failed with: {e} for project {project_id}",
- )
- return CapabilityReport(capable=True)
-
@staticmethod
def test_connection(config_dict: dict) -> TestConnectionReport:
- test_report = TestConnectionReport()
- _report: Dict[Union[SourceCapability, str], CapabilityReport] = dict()
-
- try:
- connection_conf = BigQueryV2Config.parse_obj_allow_extras(config_dict)
- client: bigquery.Client = connection_conf.get_bigquery_client()
- assert client
-
- test_report.basic_connectivity = BigqueryV2Source.connectivity_test(client)
-
- connection_conf.start_time = datetime.now()
- connection_conf.end_time = datetime.now() + timedelta(minutes=1)
-
- report: BigQueryV2Report = BigQueryV2Report()
- project_ids: List[str] = []
- projects = client.list_projects()
-
- for project in projects:
- if connection_conf.project_id_pattern.allowed(project.project_id):
- project_ids.append(project.project_id)
-
- metadata_read_capability = BigqueryV2Source.metadata_read_capability_test(
- project_ids, connection_conf
- )
- if SourceCapability.SCHEMA_METADATA not in _report:
- _report[SourceCapability.SCHEMA_METADATA] = metadata_read_capability
-
- if connection_conf.include_table_lineage:
- lineage_capability = BigqueryV2Source.lineage_capability_test(
- connection_conf, project_ids, report
- )
- if SourceCapability.LINEAGE_COARSE not in _report:
- _report[SourceCapability.LINEAGE_COARSE] = lineage_capability
-
- if connection_conf.include_usage_statistics:
- usage_capability = BigqueryV2Source.usage_capability_test(
- connection_conf, project_ids, report
- )
- if SourceCapability.USAGE_STATS not in _report:
- _report[SourceCapability.USAGE_STATS] = usage_capability
-
- test_report.capability_report = _report
- return test_report
-
- except Exception as e:
- test_report.basic_connectivity = CapabilityReport(
- capable=False, failure_reason=f"{e}"
- )
- return test_report
+ return BigQueryTestConnection.test_connection(config_dict)
def _init_schema_resolver(self) -> SchemaResolver:
schema_resolution_required = (
@@ -509,83 +219,6 @@ def _init_schema_resolver(self) -> SchemaResolver:
)
return SchemaResolver(platform=self.platform, env=self.config.env)
- def get_dataplatform_instance_aspect(
- self, dataset_urn: str, project_id: str
- ) -> MetadataWorkUnit:
- aspect = DataPlatformInstanceClass(
- platform=make_data_platform_urn(self.platform),
- instance=(
- make_dataplatform_instance_urn(self.platform, project_id)
- if self.config.include_data_platform_instance
- else None
- ),
- )
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=aspect
- ).as_workunit()
-
- def gen_dataset_key(self, db_name: str, schema: str) -> ContainerKey:
- return BigQueryDatasetKey(
- project_id=db_name,
- dataset_id=schema,
- platform=self.platform,
- env=self.config.env,
- backcompat_env_as_instance=True,
- )
-
- def gen_project_id_key(self, database: str) -> ContainerKey:
- return ProjectIdKey(
- project_id=database,
- platform=self.platform,
- env=self.config.env,
- backcompat_env_as_instance=True,
- )
-
- def gen_project_id_containers(self, database: str) -> Iterable[MetadataWorkUnit]:
- database_container_key = self.gen_project_id_key(database)
-
- yield from gen_database_container(
- database=database,
- name=database,
- sub_types=[DatasetContainerSubTypes.BIGQUERY_PROJECT],
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- database_container_key=database_container_key,
- )
-
- def gen_dataset_containers(
- self, dataset: str, project_id: str, tags: Optional[Dict[str, str]] = None
- ) -> Iterable[MetadataWorkUnit]:
- schema_container_key = self.gen_dataset_key(project_id, dataset)
-
- tags_joined: Optional[List[str]] = None
- if tags and self.config.capture_dataset_label_as_tag:
- tags_joined = [
- f"{k}:{v}"
- for k, v in tags.items()
- if is_tag_allowed(self.config.capture_dataset_label_as_tag, k)
- ]
-
- database_container_key = self.gen_project_id_key(database=project_id)
-
- yield from gen_schema_container(
- database=project_id,
- schema=dataset,
- sub_types=[DatasetContainerSubTypes.BIGQUERY_DATASET],
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- schema_container_key=schema_container_key,
- database_container_key=database_container_key,
- external_url=(
- BQ_EXTERNAL_DATASET_URL_TEMPLATE.format(
- project=project_id, dataset=dataset
- )
- if self.config.include_external_url
- else None
- ),
- tags=tags_joined,
- )
-
def get_workunit_processors(self) -> List[Optional[MetadataWorkUnitProcessor]]:
return [
*super().get_workunit_processors(),
@@ -603,25 +236,23 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
return
if self.config.include_schema_metadata:
- for project_id in projects:
- self.report.set_ingestion_stage(project_id.id, METADATA_EXTRACTION)
- logger.info(f"Processing project: {project_id.id}")
- yield from self._process_project(project_id)
+ for project in projects:
+ yield from self.bq_schema_extractor.get_project_workunits(project)
if self.config.include_usage_statistics:
yield from self.usage_extractor.get_usage_workunits(
- [p.id for p in projects], self.table_refs
+ [p.id for p in projects], self.bq_schema_extractor.table_refs
)
if self.config.include_table_lineage:
yield from self.lineage_extractor.get_lineage_workunits(
[p.id for p in projects],
self.sql_parser_schema_resolver,
- self.view_refs_by_project,
- self.view_definitions,
- self.snapshot_refs_by_project,
- self.snapshots_by_ref,
- self.table_refs,
+ self.bq_schema_extractor.view_refs_by_project,
+ self.bq_schema_extractor.view_definitions,
+ self.bq_schema_extractor.snapshot_refs_by_project,
+ self.bq_schema_extractor.snapshots_by_ref,
+ self.bq_schema_extractor.table_refs,
)
def _get_projects(self) -> List[BigqueryProject]:
@@ -636,15 +267,25 @@ def _get_projects(self) -> List[BigqueryProject]:
return list(self._query_project_list())
def _query_project_list(self) -> Iterable[BigqueryProject]:
- projects = self.bigquery_data_dictionary.get_projects()
- if not projects: # Report failure on exception and if empty list is returned
- self.report.report_failure(
- "metadata-extraction",
- "Get projects didn't return any project. "
- "Maybe resourcemanager.projects.get permission is missing for the service account. "
+ try:
+ projects = self.bigquery_data_dictionary.get_projects()
+
+ if (
+ not projects
+ ): # Report failure on exception and if empty list is returned
+ self.report.failure(
+ title="Get projects didn't return any project. ",
+ message="Maybe resourcemanager.projects.get permission is missing for the service account. "
+ "You can assign predefined roles/bigquery.metadataViewer role to your service account.",
+ )
+ except Exception as e:
+ self.report.failure(
+ title="Failed to get BigQuery Projects",
+ message="Maybe resourcemanager.projects.get permission is missing for the service account. "
"You can assign predefined roles/bigquery.metadataViewer role to your service account.",
+ exc=e,
)
- return
+ projects = []
for project in projects:
if self.config.project_id_pattern.allowed(project.id):
@@ -652,567 +293,6 @@ def _query_project_list(self) -> Iterable[BigqueryProject]:
else:
self.report.report_dropped(project.id)
- def _process_project(
- self, bigquery_project: BigqueryProject
- ) -> Iterable[MetadataWorkUnit]:
- db_tables: Dict[str, List[BigqueryTable]] = {}
- db_views: Dict[str, List[BigqueryView]] = {}
- db_snapshots: Dict[str, List[BigqueryTableSnapshot]] = {}
-
- project_id = bigquery_project.id
- try:
- bigquery_project.datasets = (
- self.bigquery_data_dictionary.get_datasets_for_project_id(project_id)
- )
- except Exception as e:
- error_message = f"Unable to get datasets for project {project_id}, skipping. The error was: {e}"
- if self.config.is_profiling_enabled():
- error_message = f"Unable to get datasets for project {project_id}, skipping. Does your service account has bigquery.datasets.get permission? The error was: {e}"
- logger.error(error_message)
- self.report.report_failure(
- "metadata-extraction",
- f"{project_id} - {error_message}",
- )
- return None
-
- if len(bigquery_project.datasets) == 0:
- more_info = (
- "Either there are no datasets in this project or missing bigquery.datasets.get permission. "
- "You can assign predefined roles/bigquery.metadataViewer role to your service account."
- )
- if self.config.exclude_empty_projects:
- self.report.report_dropped(project_id)
- warning_message = f"Excluded project '{project_id}' since no were datasets found. {more_info}"
- else:
- yield from self.gen_project_id_containers(project_id)
- warning_message = (
- f"No datasets found in project '{project_id}'. {more_info}"
- )
- logger.warning(warning_message)
- return
-
- yield from self.gen_project_id_containers(project_id)
-
- self.report.num_project_datasets_to_scan[project_id] = len(
- bigquery_project.datasets
- )
- for bigquery_dataset in bigquery_project.datasets:
- if not is_schema_allowed(
- self.config.dataset_pattern,
- bigquery_dataset.name,
- project_id,
- self.config.match_fully_qualified_names,
- ):
- self.report.report_dropped(f"{bigquery_dataset.name}.*")
- continue
- try:
- # db_tables, db_views, and db_snapshots are populated in the this method
- yield from self._process_schema(
- project_id, bigquery_dataset, db_tables, db_views, db_snapshots
- )
-
- except Exception as e:
- error_message = f"Unable to get tables for dataset {bigquery_dataset.name} in project {project_id}, skipping. Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission? The error was: {e}"
- if self.config.is_profiling_enabled():
- error_message = f"Unable to get tables for dataset {bigquery_dataset.name} in project {project_id}, skipping. Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission, bigquery.tables.getData permission? The error was: {e}"
-
- trace = traceback.format_exc()
- logger.error(trace)
- logger.error(error_message)
- self.report.report_failure(
- "metadata-extraction",
- f"{project_id}.{bigquery_dataset.name} - {error_message} - {trace}",
- )
- continue
-
- if self.config.is_profiling_enabled():
- logger.info(f"Starting profiling project {project_id}")
- self.report.set_ingestion_stage(project_id, PROFILING)
- yield from self.profiler.get_workunits(
- project_id=project_id,
- tables=db_tables,
- )
-
- def _process_schema(
- self,
- project_id: str,
- bigquery_dataset: BigqueryDataset,
- db_tables: Dict[str, List[BigqueryTable]],
- db_views: Dict[str, List[BigqueryView]],
- db_snapshots: Dict[str, List[BigqueryTableSnapshot]],
- ) -> Iterable[MetadataWorkUnit]:
- dataset_name = bigquery_dataset.name
-
- yield from self.gen_dataset_containers(
- dataset_name, project_id, bigquery_dataset.labels
- )
-
- columns = None
-
- rate_limiter: Optional[RateLimiter] = None
- if self.config.rate_limit:
- rate_limiter = RateLimiter(
- max_calls=self.config.requests_per_min, period=60
- )
-
- if (
- self.config.include_tables
- or self.config.include_views
- or self.config.include_table_snapshots
- ):
- columns = self.bigquery_data_dictionary.get_columns_for_dataset(
- project_id=project_id,
- dataset_name=dataset_name,
- column_limit=self.config.column_limit,
- run_optimized_column_query=self.config.run_optimized_column_query,
- extract_policy_tags_from_catalog=self.config.extract_policy_tags_from_catalog,
- report=self.report,
- rate_limiter=rate_limiter,
- )
-
- if self.config.include_tables:
- db_tables[dataset_name] = list(
- self.get_tables_for_dataset(project_id, dataset_name)
- )
-
- for table in db_tables[dataset_name]:
- table_columns = columns.get(table.name, []) if columns else []
- table_wu_generator = self._process_table(
- table=table,
- columns=table_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
- yield from classification_workunit_processor(
- table_wu_generator,
- self.classification_handler,
- self.data_reader,
- [project_id, dataset_name, table.name],
- data_reader_kwargs=dict(
- sample_size_percent=(
- self.config.classification.sample_size
- * SAMPLE_SIZE_MULTIPLIER
- / table.rows_count
- if table.rows_count
- else None
- )
- ),
- )
- elif self.store_table_refs:
- # Need table_refs to calculate lineage and usage
- for table_item in self.bigquery_data_dictionary.list_tables(
- dataset_name, project_id
- ):
- identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=table_item.table_id,
- )
- if not self.config.table_pattern.allowed(identifier.raw_table_name()):
- self.report.report_dropped(identifier.raw_table_name())
- continue
- try:
- self.table_refs.add(
- str(BigQueryTableRef(identifier).get_sanitized_table_ref())
- )
- except Exception as e:
- logger.warning(
- f"Could not create table ref for {table_item.path}: {e}"
- )
-
- if self.config.include_views:
- db_views[dataset_name] = list(
- self.bigquery_data_dictionary.get_views_for_dataset(
- project_id,
- dataset_name,
- self.config.is_profiling_enabled(),
- self.report,
- )
- )
-
- for view in db_views[dataset_name]:
- view_columns = columns.get(view.name, []) if columns else []
- yield from self._process_view(
- view=view,
- columns=view_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- if self.config.include_table_snapshots:
- db_snapshots[dataset_name] = list(
- self.bigquery_data_dictionary.get_snapshots_for_dataset(
- project_id,
- dataset_name,
- self.config.is_profiling_enabled(),
- self.report,
- )
- )
-
- for snapshot in db_snapshots[dataset_name]:
- snapshot_columns = columns.get(snapshot.name, []) if columns else []
- yield from self._process_snapshot(
- snapshot=snapshot,
- columns=snapshot_columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- # This method is used to generate the ignore list for datatypes the profiler doesn't support we have to do it here
- # because the profiler doesn't have access to columns
- def generate_profile_ignore_list(self, columns: List[BigqueryColumn]) -> List[str]:
- ignore_list: List[str] = []
- for column in columns:
- if not column.data_type or any(
- word in column.data_type.lower()
- for word in ["array", "struct", "geography", "json"]
- ):
- ignore_list.append(column.field_path)
- return ignore_list
-
- def _process_table(
- self,
- table: BigqueryTable,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(project_id, dataset_name, table.name)
-
- self.report.report_entity_scanned(table_identifier.raw_table_name())
-
- if not self.config.table_pattern.allowed(table_identifier.raw_table_name()):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- if self.store_table_refs:
- self.table_refs.add(
- str(BigQueryTableRef(table_identifier).get_sanitized_table_ref())
- )
- table.column_count = len(columns)
-
- # We only collect profile ignore list if profiling is enabled and profile_table_level_only is false
- if (
- self.config.is_profiling_enabled()
- and not self.config.profiling.profile_table_level_only
- ):
- table.columns_ignore_from_profiling = self.generate_profile_ignore_list(
- columns
- )
-
- if not table.column_count:
- logger.warning(
- f"Table doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- # If table has time partitioning, set the data type of the partitioning field
- if table.partition_info:
- table.partition_info.column = next(
- (
- column
- for column in columns
- if column.name == table.partition_info.field
- ),
- None,
- )
- yield from self.gen_table_dataset_workunits(
- table, columns, project_id, dataset_name
- )
-
- def _process_view(
- self,
- view: BigqueryView,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(project_id, dataset_name, view.name)
-
- self.report.report_entity_scanned(table_identifier.raw_table_name(), "view")
-
- if not self.config.view_pattern.allowed(table_identifier.raw_table_name()):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- if self.store_table_refs:
- table_ref = str(
- BigQueryTableRef(table_identifier).get_sanitized_table_ref()
- )
- self.table_refs.add(table_ref)
- if self.config.lineage_parse_view_ddl and view.view_definition:
- self.view_refs_by_project[project_id].add(table_ref)
- self.view_definitions[table_ref] = view.view_definition
-
- view.column_count = len(columns)
- if not view.column_count:
- logger.warning(
- f"View doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- yield from self.gen_view_dataset_workunits(
- table=view,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- def _process_snapshot(
- self,
- snapshot: BigqueryTableSnapshot,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- table_identifier = BigqueryTableIdentifier(
- project_id, dataset_name, snapshot.name
- )
-
- self.report.snapshots_scanned += 1
-
- if not self.config.table_snapshot_pattern.allowed(
- table_identifier.raw_table_name()
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- return
-
- snapshot.columns = columns
- snapshot.column_count = len(columns)
- if not snapshot.column_count:
- logger.warning(
- f"Snapshot doesn't have any column or unable to get columns for table: {table_identifier}"
- )
-
- if self.store_table_refs:
- table_ref = str(
- BigQueryTableRef(table_identifier).get_sanitized_table_ref()
- )
- self.table_refs.add(table_ref)
- if snapshot.base_table_identifier:
- self.snapshot_refs_by_project[project_id].add(table_ref)
- self.snapshots_by_ref[table_ref] = snapshot
-
- yield from self.gen_snapshot_dataset_workunits(
- table=snapshot,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- )
-
- def gen_table_dataset_workunits(
- self,
- table: BigqueryTable,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- custom_properties: Dict[str, str] = {}
- if table.expires:
- custom_properties["expiration_date"] = str(table.expires)
-
- if table.partition_info:
- custom_properties["partition_info"] = str(table.partition_info)
-
- if table.size_in_bytes:
- custom_properties["size_in_bytes"] = str(table.size_in_bytes)
-
- if table.active_billable_bytes:
- custom_properties["billable_bytes_active"] = str(
- table.active_billable_bytes
- )
-
- if table.long_term_billable_bytes:
- custom_properties["billable_bytes_long_term"] = str(
- table.long_term_billable_bytes
- )
-
- if table.max_partition_id:
- custom_properties["number_of_partitions"] = str(table.num_partitions)
- custom_properties["max_partition_id"] = str(table.max_partition_id)
- custom_properties["is_partitioned"] = str(True)
-
- sub_types: List[str] = [DatasetSubTypes.TABLE]
- if table.max_shard_id:
- custom_properties["max_shard_id"] = str(table.max_shard_id)
- custom_properties["is_sharded"] = str(True)
- sub_types = ["sharded table"] + sub_types
-
- tags_to_add = None
- if table.labels and self.config.capture_table_label_as_tag:
- tags_to_add = []
- tags_to_add.extend(
- [
- make_tag_urn(f"""{k}:{v}""")
- for k, v in table.labels.items()
- if is_tag_allowed(self.config.capture_table_label_as_tag, k)
- ]
- )
-
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- sub_types=sub_types,
- tags_to_add=tags_to_add,
- custom_properties=custom_properties,
- )
-
- def gen_view_dataset_workunits(
- self,
- table: BigqueryView,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- tags_to_add = None
- if table.labels and self.config.capture_view_label_as_tag:
- tags_to_add = [
- make_tag_urn(f"{k}:{v}")
- for k, v in table.labels.items()
- if is_tag_allowed(self.config.capture_view_label_as_tag, k)
- ]
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- tags_to_add=tags_to_add,
- sub_types=[DatasetSubTypes.VIEW],
- )
-
- view = cast(BigqueryView, table)
- view_definition_string = view.view_definition
- view_properties_aspect = ViewProperties(
- materialized=view.materialized,
- viewLanguage="SQL",
- viewLogic=view_definition_string or "",
- )
- yield MetadataChangeProposalWrapper(
- entityUrn=self.gen_dataset_urn(
- project_id=project_id, dataset_name=dataset_name, table=table.name
- ),
- aspect=view_properties_aspect,
- ).as_workunit()
-
- def gen_snapshot_dataset_workunits(
- self,
- table: BigqueryTableSnapshot,
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- ) -> Iterable[MetadataWorkUnit]:
- custom_properties: Dict[str, str] = {}
- if table.ddl:
- custom_properties["snapshot_ddl"] = table.ddl
- if table.snapshot_time:
- custom_properties["snapshot_time"] = str(table.snapshot_time)
- if table.size_in_bytes:
- custom_properties["size_in_bytes"] = str(table.size_in_bytes)
- if table.rows_count:
- custom_properties["rows_count"] = str(table.rows_count)
- yield from self.gen_dataset_workunits(
- table=table,
- columns=columns,
- project_id=project_id,
- dataset_name=dataset_name,
- sub_types=[DatasetSubTypes.BIGQUERY_TABLE_SNAPSHOT],
- custom_properties=custom_properties,
- )
-
- def gen_dataset_workunits(
- self,
- table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
- columns: List[BigqueryColumn],
- project_id: str,
- dataset_name: str,
- sub_types: List[str],
- tags_to_add: Optional[List[str]] = None,
- custom_properties: Optional[Dict[str, str]] = None,
- ) -> Iterable[MetadataWorkUnit]:
- dataset_urn = self.gen_dataset_urn(
- project_id=project_id, dataset_name=dataset_name, table=table.name
- )
-
- status = Status(removed=False)
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=status
- ).as_workunit()
-
- datahub_dataset_name = BigqueryTableIdentifier(
- project_id, dataset_name, table.name
- )
-
- yield self.gen_schema_metadata(
- dataset_urn, table, columns, datahub_dataset_name
- )
-
- dataset_properties = DatasetProperties(
- name=datahub_dataset_name.get_table_display_name(),
- description=(
- unquote_and_decode_unicode_escape_seq(table.comment)
- if table.comment
- else ""
- ),
- qualifiedName=str(datahub_dataset_name),
- created=(
- TimeStamp(time=int(table.created.timestamp() * 1000))
- if table.created is not None
- else None
- ),
- lastModified=(
- TimeStamp(time=int(table.last_altered.timestamp() * 1000))
- if table.last_altered is not None
- else None
- ),
- externalUrl=(
- BQ_EXTERNAL_TABLE_URL_TEMPLATE.format(
- project=project_id, dataset=dataset_name, table=table.name
- )
- if self.config.include_external_url
- else None
- ),
- )
- if custom_properties:
- dataset_properties.customProperties.update(custom_properties)
-
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=dataset_properties
- ).as_workunit()
-
- if tags_to_add:
- yield self.gen_tags_aspect_workunit(dataset_urn, tags_to_add)
-
- yield from add_table_to_schema_container(
- dataset_urn=dataset_urn,
- parent_container_key=self.gen_dataset_key(project_id, dataset_name),
- )
- yield self.get_dataplatform_instance_aspect(
- dataset_urn=dataset_urn, project_id=project_id
- )
-
- subTypes = SubTypes(typeNames=sub_types)
- yield MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=subTypes
- ).as_workunit()
-
- if self.domain_registry:
- yield from get_domain_wu(
- dataset_name=str(datahub_dataset_name),
- entity_urn=dataset_urn,
- domain_registry=self.domain_registry,
- domain_config=self.config.domain,
- )
-
- def gen_tags_aspect_workunit(
- self, dataset_urn: str, tags_to_add: List[str]
- ) -> MetadataWorkUnit:
- tags = GlobalTagsClass(
- tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
- )
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=tags
- ).as_workunit()
-
def gen_dataset_urn(
self, project_id: str, dataset_name: str, table: str, use_raw_name: bool = False
) -> str:
@@ -1235,241 +315,9 @@ def gen_dataset_urn_from_raw_ref(self, ref: BigQueryTableRef) -> str:
use_raw_name=True,
)
- def gen_dataset_urn_from_ref(self, ref: BigQueryTableRef) -> str:
- return self.gen_dataset_urn(
- ref.table_identifier.project_id,
- ref.table_identifier.dataset,
- ref.table_identifier.table,
- )
-
- def gen_schema_fields(self, columns: List[BigqueryColumn]) -> List[SchemaField]:
- schema_fields: List[SchemaField] = []
-
- # Below line affects HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR in global scope
- # TODO: Refractor this such that
- # converter = HiveColumnToAvroConverter(struct_type_separator=" ");
- # converter.get_schema_fields_for_hive_column(...)
- original_struct_type_separator = (
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR
- )
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = " "
- _COMPLEX_TYPE = re.compile("^(struct|array)")
- last_id = -1
- for col in columns:
- # if col.data_type is empty that means this column is part of a complex type
- if col.data_type is None or _COMPLEX_TYPE.match(col.data_type.lower()):
- # If the we have seen the ordinal position that most probably means we already processed this complex type
- if last_id != col.ordinal_position:
- schema_fields.extend(
- get_schema_fields_for_hive_column(
- col.name, col.data_type.lower(), description=col.comment
- )
- )
-
- # We have to add complex type comments to the correct level
- if col.comment:
- for idx, field in enumerate(schema_fields):
- # Remove all the [version=2.0].[type=struct]. tags to get the field path
- if (
- re.sub(
- r"\[.*?\]\.",
- "",
- field.fieldPath.lower(),
- 0,
- re.MULTILINE,
- )
- == col.field_path.lower()
- ):
- field.description = col.comment
- schema_fields[idx] = field
- break
- else:
- tags = []
- if col.is_partition_column:
- tags.append(
- TagAssociationClass(make_tag_urn(Constants.TAG_PARTITION_KEY))
- )
-
- if col.cluster_column_position is not None:
- tags.append(
- TagAssociationClass(
- make_tag_urn(
- f"{CLUSTERING_COLUMN_TAG}_{col.cluster_column_position}"
- )
- )
- )
-
- if col.policy_tags:
- for policy_tag in col.policy_tags:
- tags.append(TagAssociationClass(make_tag_urn(policy_tag)))
- field = SchemaField(
- fieldPath=col.name,
- type=SchemaFieldDataType(
- self.BIGQUERY_FIELD_TYPE_MAPPINGS.get(col.data_type, NullType)()
- ),
- nativeDataType=col.data_type,
- description=col.comment,
- nullable=col.is_nullable,
- globalTags=GlobalTagsClass(tags=tags),
- )
- schema_fields.append(field)
- last_id = col.ordinal_position
- HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = (
- original_struct_type_separator
- )
- return schema_fields
-
- def gen_schema_metadata(
- self,
- dataset_urn: str,
- table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
- columns: List[BigqueryColumn],
- dataset_name: BigqueryTableIdentifier,
- ) -> MetadataWorkUnit:
- schema_metadata = SchemaMetadata(
- schemaName=str(dataset_name),
- platform=make_data_platform_urn(self.platform),
- version=0,
- hash="",
- platformSchema=MySqlDDL(tableSchema=""),
- # fields=[],
- fields=self.gen_schema_fields(columns),
- )
-
- if self.config.lineage_parse_view_ddl or self.config.lineage_use_sql_parser:
- self.sql_parser_schema_resolver.add_schema_metadata(
- dataset_urn, schema_metadata
- )
-
- return MetadataChangeProposalWrapper(
- entityUrn=dataset_urn, aspect=schema_metadata
- ).as_workunit()
-
def get_report(self) -> BigQueryV2Report:
return self.report
- def get_tables_for_dataset(
- self,
- project_id: str,
- dataset_name: str,
- ) -> Iterable[BigqueryTable]:
- # In bigquery there is no way to query all tables in a Project id
- with PerfTimer() as timer:
- # Partitions view throw exception if we try to query partition info for too many tables
- # so we have to limit the number of tables we query partition info.
- # The conn.list_tables returns table infos that information_schema doesn't contain and this
- # way we can merge that info with the queried one.
- # https://cloud.google.com/bigquery/docs/information-schema-partitions
- max_batch_size: int = (
- self.config.number_of_datasets_process_in_batch
- if not self.config.is_profiling_enabled()
- else self.config.number_of_datasets_process_in_batch_if_profiling_enabled
- )
-
- # We get the list of tables in the dataset to get core table properties and to be able to process the tables in batches
- # We collect only the latest shards from sharded tables (tables with _YYYYMMDD suffix) and ignore temporary tables
- table_items = self.get_core_table_details(
- dataset_name, project_id, self.config.temp_table_dataset_prefix
- )
-
- items_to_get: Dict[str, TableListItem] = {}
- for table_item in table_items.keys():
- items_to_get[table_item] = table_items[table_item]
- if len(items_to_get) % max_batch_size == 0:
- yield from self.bigquery_data_dictionary.get_tables_for_dataset(
- project_id,
- dataset_name,
- items_to_get,
- with_data_read_permission=self.config.have_table_data_read_permission,
- )
- items_to_get.clear()
-
- if items_to_get:
- yield from self.bigquery_data_dictionary.get_tables_for_dataset(
- project_id,
- dataset_name,
- items_to_get,
- with_data_read_permission=self.config.have_table_data_read_permission,
- )
-
- self.report.metadata_extraction_sec[f"{project_id}.{dataset_name}"] = round(
- timer.elapsed_seconds(), 2
- )
-
- def get_core_table_details(
- self, dataset_name: str, project_id: str, temp_table_dataset_prefix: str
- ) -> Dict[str, TableListItem]:
- table_items: Dict[str, TableListItem] = {}
- # Dict to store sharded table and the last seen max shard id
- sharded_tables: Dict[str, TableListItem] = {}
-
- for table in self.bigquery_data_dictionary.list_tables(
- dataset_name, project_id
- ):
- table_identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=table.table_id,
- )
-
- if table.table_type == "VIEW":
- if (
- not self.config.include_views
- or not self.config.view_pattern.allowed(
- table_identifier.raw_table_name()
- )
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
- else:
- if not self.config.table_pattern.allowed(
- table_identifier.raw_table_name()
- ):
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
-
- _, shard = BigqueryTableIdentifier.get_table_and_shard(
- table_identifier.table
- )
- table_name = table_identifier.get_table_name().split(".")[-1]
-
- # Sharded tables look like: table_20220120
- # For sharded tables we only process the latest shard and ignore the rest
- # to find the latest shard we iterate over the list of tables and store the maximum shard id
- # We only have one special case where the table name is a date `20220110`
- # in this case we merge all these tables under dataset name as table name.
- # For example some_dataset.20220110 will be turned to some_dataset.some_dataset
- # It seems like there are some bigquery user who uses this non-standard way of sharding the tables.
- if shard:
- if table_name not in sharded_tables:
- sharded_tables[table_name] = table
- continue
-
- stored_table_identifier = BigqueryTableIdentifier(
- project_id=project_id,
- dataset=dataset_name,
- table=sharded_tables[table_name].table_id,
- )
- _, stored_shard = BigqueryTableIdentifier.get_table_and_shard(
- stored_table_identifier.table
- )
- # When table is none, we use dataset_name as table_name
- assert stored_shard
- if stored_shard < shard:
- sharded_tables[table_name] = table
- continue
- elif str(table_identifier).startswith(temp_table_dataset_prefix):
- logger.debug(f"Dropping temporary table {table_identifier.table}")
- self.report.report_dropped(table_identifier.raw_table_name())
- continue
-
- table_items[table.table_id] = table
-
- # Adding maximum shards to the list of tables
- table_items.update({value.table_id: value for value in sharded_tables.values()})
-
- return table_items
-
def add_config_to_report(self):
self.report.include_table_lineage = self.config.include_table_lineage
self.report.use_date_sharded_audit_log_tables = (
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
index 75e116773df96..7d2f8ee0e1fd8 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_audit_log_api.py
@@ -66,6 +66,7 @@ def get_exported_bigquery_audit_metadata(
rate_limiter = RateLimiter(max_calls=self.requests_per_min, period=60)
with self.report.get_exported_log_entries as current_timer:
+ self.report.num_get_exported_log_entries_api_requests += 1
for dataset in bigquery_audit_metadata_datasets:
logger.info(
f"Start loading log entries from BigQueryAuditMetadata in {dataset}"
@@ -115,6 +116,7 @@ def get_bigquery_log_entries_via_gcp_logging(
)
with self.report.list_log_entries as current_timer:
+ self.report.num_list_log_entries_api_requests += 1
list_entries = client.list_entries(
filter_=filter,
page_size=log_page_size,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
index 578c9dddbd2e4..fe961dbd780f6 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_config.py
@@ -24,6 +24,10 @@
logger = logging.getLogger(__name__)
+DEFAULT_BQ_SCHEMA_PARALLELISM = int(
+ os.getenv("DATAHUB_BIGQUERY_SCHEMA_PARALLELISM", 20)
+)
+
class BigQueryUsageConfig(BaseUsageConfig):
_query_log_delay_removed = pydantic_removed_field("query_log_delay")
@@ -175,12 +179,12 @@ class BigQueryV2Config(
number_of_datasets_process_in_batch: int = Field(
hidden_from_docs=True,
- default=500,
+ default=10000,
description="Number of table queried in batch when getting metadata. This is a low level config property which should be touched with care.",
)
number_of_datasets_process_in_batch_if_profiling_enabled: int = Field(
- default=200,
+ default=1000,
description="Number of partitioned table queried in batch when getting metadata. This is a low level config property which should be touched with care. This restriction is needed because we query partitions system view which throws error if we try to touch too many tables.",
)
@@ -313,6 +317,12 @@ def have_table_data_read_permission(self) -> bool:
hidden_from_schema=True,
)
+ max_threads_dataset_parallelism: int = Field(
+ default=DEFAULT_BQ_SCHEMA_PARALLELISM,
+ description="Number of worker threads to use to parallelize BigQuery Dataset Metadata Extraction."
+ " Set to 1 to disable.",
+ )
+
@root_validator(skip_on_failure=True)
def profile_default_settings(cls, values: Dict) -> Dict:
# Extra default SQLAlchemy option for better connection pooling and threading.
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
index bbdf32da13621..507e1d917d206 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_helper.py
@@ -10,14 +10,27 @@ def unquote_and_decode_unicode_escape_seq(
"""
If string starts and ends with a quote, unquote it and decode Unicode escape sequences
"""
+ unicode_seq_pattern = re.compile(r"\\(u|U)[0-9a-fA-F]{4}")
trailing_quote = trailing_quote if trailing_quote else leading_quote
if string.startswith(leading_quote) and string.endswith(trailing_quote):
string = string[1:-1]
- cleaned_string = string.encode().decode("unicode-escape")
-
- return cleaned_string
+ # Decode Unicode escape sequences. This avoid issues with encoding
+ # This process does not handle unicode from "\U00010000" to "\U0010FFFF"
+ while unicode_seq_pattern.search(string):
+ # Get the first Unicode escape sequence.
+ # mypy: unicode_seq_pattern.search(string) is not None because of the while loop
+ unicode_seq = unicode_seq_pattern.search(string).group(0) # type: ignore
+ # Replace the Unicode escape sequence with the decoded character
+ try:
+ string = string.replace(
+ unicode_seq, unicode_seq.encode("utf-8").decode("unicode-escape")
+ )
+ except UnicodeDecodeError:
+ # Skip decoding if is not possible to decode the Unicode escape sequence
+ break # avoid infinite loop
+ return string
def parse_labels(labels_str: str) -> Dict[str, str]:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
index 8a1bf9e5f3d1d..4cfcc3922ddc3 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_report.py
@@ -20,20 +20,32 @@
@dataclass
class BigQuerySchemaApiPerfReport(Report):
- num_list_projects: int = 0
+ num_listed_projects: int = 0
num_list_projects_retry_request: int = 0
+ num_list_projects_api_requests: int = 0
+ num_list_datasets_api_requests: int = 0
+ num_get_columns_for_dataset_api_requests: int = 0
+ num_get_tables_for_dataset_api_requests: int = 0
+ num_list_tables_api_requests: int = 0
+ num_get_views_for_dataset_api_requests: int = 0
+ num_get_snapshots_for_dataset_api_requests: int = 0
+
list_projects: PerfTimer = field(default_factory=PerfTimer)
list_datasets: PerfTimer = field(default_factory=PerfTimer)
- get_columns_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- get_tables_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- list_tables: PerfTimer = field(default_factory=PerfTimer)
- get_views_for_dataset: PerfTimer = field(default_factory=PerfTimer)
- get_snapshots_for_dataset: PerfTimer = field(default_factory=PerfTimer)
+
+ get_columns_for_dataset_sec: float = 0
+ get_tables_for_dataset_sec: float = 0
+ list_tables_sec: float = 0
+ get_views_for_dataset_sec: float = 0
+ get_snapshots_for_dataset_sec: float = 0
@dataclass
class BigQueryAuditLogApiPerfReport(Report):
+ num_get_exported_log_entries_api_requests: int = 0
get_exported_log_entries: PerfTimer = field(default_factory=PerfTimer)
+
+ num_list_log_entries_api_requests: int = 0
list_log_entries: PerfTimer = field(default_factory=PerfTimer)
@@ -85,7 +97,6 @@ class BigQueryV2Report(
num_usage_parsed_log_entries: TopKDict[str, int] = field(
default_factory=int_top_k_dict
)
- usage_error_count: Dict[str, int] = field(default_factory=int_top_k_dict)
num_usage_resources_dropped: int = 0
num_usage_operations_dropped: int = 0
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
index fe9bbc134a147..d73ac46c862ea 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema.py
@@ -24,6 +24,7 @@
BigqueryTableType,
)
from datahub.ingestion.source.sql.sql_generic import BaseColumn, BaseTable, BaseView
+from datahub.utilities.perf_timer import PerfTimer
from datahub.utilities.ratelimiter import RateLimiter
logger: logging.Logger = logging.getLogger(__name__)
@@ -154,7 +155,7 @@ def get_query_result(self, query: str) -> RowIterator:
resp = self.bq_client.query(query)
return resp.result()
- def get_projects(self) -> List[BigqueryProject]:
+ def get_projects(self, max_results_per_page: int = 100) -> List[BigqueryProject]:
def _should_retry(exc: BaseException) -> bool:
logger.debug(
f"Exception occured for project.list api. Reason: {exc}. Retrying api request..."
@@ -162,34 +163,50 @@ def _should_retry(exc: BaseException) -> bool:
self.report.num_list_projects_retry_request += 1
return True
+ page_token = None
+ projects: List[BigqueryProject] = []
with self.report.list_projects:
- try:
- # Bigquery API has limit in calling project.list request i.e. 2 request per second.
- # https://cloud.google.com/bigquery/quotas#api_request_quotas
- # Whenever this limit reached an exception occur with msg
- # 'Quota exceeded: Your user exceeded quota for concurrent project.lists requests.'
- # Hence, added the api request retry of 15 min.
- # We already tried adding rate_limit externally, proving max_result and page_size
- # to restrict the request calls inside list_project but issue still occured.
- projects_iterator = self.bq_client.list_projects(
- retry=retry.Retry(
- predicate=_should_retry, initial=10, maximum=180, timeout=900
+ while True:
+ try:
+ self.report.num_list_projects_api_requests += 1
+ # Bigquery API has limit in calling project.list request i.e. 2 request per second.
+ # https://cloud.google.com/bigquery/quotas#api_request_quotas
+ # Whenever this limit reached an exception occur with msg
+ # 'Quota exceeded: Your user exceeded quota for concurrent project.lists requests.'
+ # Hence, added the api request retry of 15 min.
+ # We already tried adding rate_limit externally, proving max_result and page_size
+ # to restrict the request calls inside list_project but issue still occured.
+ projects_iterator = self.bq_client.list_projects(
+ max_results=max_results_per_page,
+ page_token=page_token,
+ timeout=900,
+ retry=retry.Retry(
+ predicate=_should_retry,
+ initial=10,
+ maximum=180,
+ multiplier=4,
+ timeout=900,
+ ),
)
- )
- projects: List[BigqueryProject] = [
- BigqueryProject(id=p.project_id, name=p.friendly_name)
- for p in projects_iterator
- ]
- self.report.num_list_projects = len(projects)
- return projects
- except Exception as e:
- logger.error(f"Error getting projects. {e}", exc_info=True)
- return []
+ _projects: List[BigqueryProject] = [
+ BigqueryProject(id=p.project_id, name=p.friendly_name)
+ for p in projects_iterator
+ ]
+ projects.extend(_projects)
+ self.report.num_listed_projects = len(projects)
+ page_token = projects_iterator.next_page_token
+ if not page_token:
+ break
+ except Exception as e:
+ logger.error(f"Error getting projects. {e}", exc_info=True)
+ return []
+ return projects
def get_datasets_for_project_id(
self, project_id: str, maxResults: Optional[int] = None
) -> List[BigqueryDataset]:
with self.report.list_datasets:
+ self.report.num_list_datasets_api_requests += 1
datasets = self.bq_client.list_datasets(project_id, max_results=maxResults)
return [
BigqueryDataset(name=d.dataset_id, labels=d.labels) for d in datasets
@@ -222,50 +239,42 @@ def get_datasets_for_project_id_with_information_schema(
def list_tables(
self, dataset_name: str, project_id: str
) -> Iterator[TableListItem]:
- with self.report.list_tables as current_timer:
+ with PerfTimer() as current_timer:
for table in self.bq_client.list_tables(f"{project_id}.{dataset_name}"):
with current_timer.pause():
yield table
+ self.report.num_list_tables_api_requests += 1
+ self.report.list_tables_sec += current_timer.elapsed_seconds()
def get_tables_for_dataset(
self,
project_id: str,
dataset_name: str,
tables: Dict[str, TableListItem],
+ report: BigQueryV2Report,
with_data_read_permission: bool = False,
- report: Optional[BigQueryV2Report] = None,
) -> Iterator[BigqueryTable]:
- with self.report.get_tables_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
filter_clause: str = ", ".join(f"'{table}'" for table in tables.keys())
if with_data_read_permission:
- # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
- # and skip the others. Sharded tables are tables with suffix _20220102
- cur = self.get_query_result(
- BigqueryQuery.tables_for_dataset.format(
- project_id=project_id,
- dataset_name=dataset_name,
- table_filter=(
- f" and t.table_name in ({filter_clause})"
- if filter_clause
- else ""
- ),
- ),
- )
+ query_template = BigqueryQuery.tables_for_dataset
else:
- # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
- # and skip the others. Sharded tables are tables with suffix _20220102
- cur = self.get_query_result(
- BigqueryQuery.tables_for_dataset_without_partition_data.format(
- project_id=project_id,
- dataset_name=dataset_name,
- table_filter=(
- f" and t.table_name in ({filter_clause})"
- if filter_clause
- else ""
- ),
+ query_template = BigqueryQuery.tables_for_dataset_without_partition_data
+
+ # Tables are ordered by name and table suffix to make sure we always process the latest sharded table
+ # and skip the others. Sharded tables are tables with suffix _20220102
+ cur = self.get_query_result(
+ query_template.format(
+ project_id=project_id,
+ dataset_name=dataset_name,
+ table_filter=(
+ f" and t.table_name in ({filter_clause})"
+ if filter_clause
+ else ""
),
- )
+ ),
+ )
for table in cur:
try:
@@ -275,15 +284,14 @@ def get_tables_for_dataset(
)
except Exception as e:
table_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing table {table_name}",
- exc_info=True,
+ report.warning(
+ title="Failed to process table",
+ message="Error encountered while processing table",
+ context=table_name,
+ exc=e,
)
- if report:
- report.report_warning(
- "metadata-extraction",
- f"Failed to get table {table_name}: {e}",
- )
+ self.report.num_get_tables_for_dataset_api_requests += 1
+ self.report.get_tables_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_table(
@@ -332,7 +340,7 @@ def get_views_for_dataset(
has_data_read: bool,
report: BigQueryV2Report,
) -> Iterator[BigqueryView]:
- with self.report.get_views_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
if has_data_read:
# If profiling is enabled
cur = self.get_query_result(
@@ -353,14 +361,14 @@ def get_views_for_dataset(
yield BigQuerySchemaApi._make_bigquery_view(table)
except Exception as e:
view_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing view {view_name}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to get view {view_name}: {e}",
+ report.warning(
+ title="Failed to process view",
+ message="Error encountered while processing view",
+ context=view_name,
+ exc=e,
)
+ self.report.num_get_views_for_dataset_api_requests += 1
+ self.report.get_views_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_view(view: bigquery.Row) -> BigqueryView:
@@ -416,22 +424,18 @@ def get_policy_tags_for_column(
)
yield policy_tag.display_name
except Exception as e:
- logger.warning(
- f"Unexpected error when retrieving policy tag {policy_tag_name} for column {column_name} in table {table_name}: {e}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to retrieve policy tag {policy_tag_name} for column {column_name} in table {table_name} due to unexpected error: {e}",
+ report.warning(
+ title="Failed to retrieve policy tag",
+ message="Unexpected error when retrieving policy tag for column",
+ context=f"policy tag {policy_tag_name} for column {column_name} in table {table_ref}",
+ exc=e,
)
except Exception as e:
- logger.error(
- f"Unexpected error retrieving schema for table {table_name} in dataset {dataset_name}, project {project_id}: {e}",
- exc_info=True,
- )
- report.report_warning(
- "metadata-extraction",
- f"Failed to retrieve schema for table {table_name} in dataset {dataset_name}, project {project_id} due to unexpected error: {e}",
+ report.warning(
+ title="Failed to retrieve policy tag for table",
+ message="Unexpected error retrieving policy tag for table",
+ context=table_ref,
+ exc=e,
)
def get_columns_for_dataset(
@@ -445,7 +449,7 @@ def get_columns_for_dataset(
rate_limiter: Optional[RateLimiter] = None,
) -> Optional[Dict[str, List[BigqueryColumn]]]:
columns: Dict[str, List[BigqueryColumn]] = defaultdict(list)
- with self.report.get_columns_for_dataset:
+ with PerfTimer() as timer:
try:
cur = self.get_query_result(
(
@@ -461,89 +465,57 @@ def get_columns_for_dataset(
),
)
except Exception as e:
- logger.warning(f"Columns for dataset query failed with exception: {e}")
- # Error - Information schema query returned too much data.
- # Please repeat query with more selective predicates.
+ report.warning(
+ title="Failed to retrieve columns for dataset",
+ message="Query to get columns for dataset failed with exception",
+ context=f"{project_id}.{dataset_name}",
+ exc=e,
+ )
return None
last_seen_table: str = ""
for column in cur:
- if (
- column_limit
- and column.table_name in columns
- and len(columns[column.table_name]) >= column_limit
- ):
- if last_seen_table != column.table_name:
- logger.warning(
- f"{project_id}.{dataset_name}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
- )
- last_seen_table = column.table_name
- else:
- columns[column.table_name].append(
- BigqueryColumn(
- name=column.column_name,
- ordinal_position=column.ordinal_position,
- field_path=column.field_path,
- is_nullable=column.is_nullable == "YES",
- data_type=column.data_type,
- comment=column.comment,
- is_partition_column=column.is_partitioning_column == "YES",
- cluster_column_position=column.clustering_ordinal_position,
- policy_tags=(
- list(
- self.get_policy_tags_for_column(
- project_id,
- dataset_name,
- column.table_name,
- column.column_name,
- report,
- rate_limiter,
+ with timer.pause():
+ if (
+ column_limit
+ and column.table_name in columns
+ and len(columns[column.table_name]) >= column_limit
+ ):
+ if last_seen_table != column.table_name:
+ logger.warning(
+ f"{project_id}.{dataset_name}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
+ )
+ last_seen_table = column.table_name
+ else:
+ columns[column.table_name].append(
+ BigqueryColumn(
+ name=column.column_name,
+ ordinal_position=column.ordinal_position,
+ field_path=column.field_path,
+ is_nullable=column.is_nullable == "YES",
+ data_type=column.data_type,
+ comment=column.comment,
+ is_partition_column=column.is_partitioning_column
+ == "YES",
+ cluster_column_position=column.clustering_ordinal_position,
+ policy_tags=(
+ list(
+ self.get_policy_tags_for_column(
+ project_id,
+ dataset_name,
+ column.table_name,
+ column.column_name,
+ report,
+ rate_limiter,
+ )
)
- )
- if extract_policy_tags_from_catalog
- else []
- ),
+ if extract_policy_tags_from_catalog
+ else []
+ ),
+ )
)
- )
-
- return columns
-
- # This is not used anywhere
- def get_columns_for_table(
- self,
- table_identifier: BigqueryTableIdentifier,
- column_limit: Optional[int],
- ) -> List[BigqueryColumn]:
- cur = self.get_query_result(
- BigqueryQuery.columns_for_table.format(table_identifier=table_identifier),
- )
-
- columns: List[BigqueryColumn] = []
- last_seen_table: str = ""
- for column in cur:
- if (
- column_limit
- and column.table_name in columns
- and len(columns[column.table_name]) >= column_limit
- ):
- if last_seen_table != column.table_name:
- logger.warning(
- f"{table_identifier.project_id}.{table_identifier.dataset}.{column.table_name} contains more than {column_limit} columns, only processing {column_limit} columns"
- )
- else:
- columns.append(
- BigqueryColumn(
- name=column.column_name,
- ordinal_position=column.ordinal_position,
- is_nullable=column.is_nullable == "YES",
- field_path=column.field_path,
- data_type=column.data_type,
- comment=column.comment,
- is_partition_column=column.is_partitioning_column == "YES",
- cluster_column_position=column.clustering_ordinal_position,
- )
- )
- last_seen_table = column.table_name
+ self.report.num_get_columns_for_dataset_api_requests += 1
+ self.report.get_columns_for_dataset_sec += timer.elapsed_seconds()
return columns
@@ -554,7 +526,7 @@ def get_snapshots_for_dataset(
has_data_read: bool,
report: BigQueryV2Report,
) -> Iterator[BigqueryTableSnapshot]:
- with self.report.get_snapshots_for_dataset as current_timer:
+ with PerfTimer() as current_timer:
if has_data_read:
# If profiling is enabled
cur = self.get_query_result(
@@ -575,14 +547,14 @@ def get_snapshots_for_dataset(
yield BigQuerySchemaApi._make_bigquery_table_snapshot(table)
except Exception as e:
snapshot_name = f"{project_id}.{dataset_name}.{table.table_name}"
- logger.warning(
- f"Error while processing view {snapshot_name}",
- exc_info=True,
- )
report.report_warning(
- "metadata-extraction",
- f"Failed to get view {snapshot_name}: {e}",
+ title="Failed to process snapshot",
+ message="Error encountered while processing snapshot",
+ context=snapshot_name,
+ exc=e,
)
+ self.report.num_get_snapshots_for_dataset_api_requests += 1
+ self.report.get_snapshots_for_dataset_sec += current_timer.elapsed_seconds()
@staticmethod
def _make_bigquery_table_snapshot(snapshot: bigquery.Row) -> BigqueryTableSnapshot:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
new file mode 100644
index 0000000000000..3ffcb225db1c2
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
@@ -0,0 +1,1090 @@
+import logging
+import re
+from collections import defaultdict
+from typing import Callable, Dict, Iterable, List, Optional, Set, Type, Union, cast
+
+from google.cloud.bigquery.table import TableListItem
+
+from datahub.configuration.pattern_utils import is_schema_allowed, is_tag_allowed
+from datahub.emitter.mce_builder import (
+ make_data_platform_urn,
+ make_dataplatform_instance_urn,
+ make_tag_urn,
+)
+from datahub.emitter.mcp import MetadataChangeProposalWrapper
+from datahub.emitter.mcp_builder import BigQueryDatasetKey, ContainerKey, ProjectIdKey
+from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.glossary.classification_mixin import (
+ SAMPLE_SIZE_MULTIPLIER,
+ ClassificationHandler,
+ classification_workunit_processor,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_audit import (
+ BigqueryTableIdentifier,
+ BigQueryTableRef,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
+from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
+from datahub.ingestion.source.bigquery_v2.bigquery_helper import (
+ unquote_and_decode_unicode_escape_seq,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
+from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
+ BigqueryColumn,
+ BigqueryDataset,
+ BigqueryProject,
+ BigQuerySchemaApi,
+ BigqueryTable,
+ BigqueryTableSnapshot,
+ BigqueryView,
+)
+from datahub.ingestion.source.bigquery_v2.common import (
+ BQ_EXTERNAL_DATASET_URL_TEMPLATE,
+ BQ_EXTERNAL_TABLE_URL_TEMPLATE,
+)
+from datahub.ingestion.source.bigquery_v2.profiler import BigqueryProfiler
+from datahub.ingestion.source.common.subtypes import (
+ DatasetContainerSubTypes,
+ DatasetSubTypes,
+)
+from datahub.ingestion.source.sql.sql_utils import (
+ add_table_to_schema_container,
+ gen_database_container,
+ gen_schema_container,
+ get_domain_wu,
+)
+from datahub.ingestion.source_report.ingestion_stage import (
+ METADATA_EXTRACTION,
+ PROFILING,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.common import (
+ Status,
+ SubTypes,
+ TimeStamp,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
+ DatasetProperties,
+ ViewProperties,
+)
+from datahub.metadata.com.linkedin.pegasus2avro.schema import (
+ ArrayType,
+ BooleanType,
+ BytesType,
+ DateType,
+ MySqlDDL,
+ NullType,
+ NumberType,
+ RecordType,
+ SchemaField,
+ SchemaFieldDataType,
+ SchemaMetadata,
+ StringType,
+ TimeType,
+)
+from datahub.metadata.schema_classes import (
+ DataPlatformInstanceClass,
+ GlobalTagsClass,
+ TagAssociationClass,
+)
+from datahub.sql_parsing.schema_resolver import SchemaResolver
+from datahub.utilities.file_backed_collections import FileBackedDict
+from datahub.utilities.hive_schema_to_avro import (
+ HiveColumnToAvroConverter,
+ get_schema_fields_for_hive_column,
+)
+from datahub.utilities.mapping import Constants
+from datahub.utilities.perf_timer import PerfTimer
+from datahub.utilities.ratelimiter import RateLimiter
+from datahub.utilities.registries.domain_registry import DomainRegistry
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
+
+logger: logging.Logger = logging.getLogger(__name__)
+# Handle table snapshots
+# See https://cloud.google.com/bigquery/docs/table-snapshots-intro.
+SNAPSHOT_TABLE_REGEX = re.compile(r"^(.+)@(\d{13})$")
+CLUSTERING_COLUMN_TAG = "CLUSTERING_COLUMN"
+
+
+class BigQuerySchemaGenerator:
+ # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
+ # Note: We use the hive schema parser to parse nested BigQuery types. We also have
+ # some extra type mappings in that file.
+ BIGQUERY_FIELD_TYPE_MAPPINGS: Dict[
+ str,
+ Type[
+ Union[
+ ArrayType,
+ BytesType,
+ BooleanType,
+ NumberType,
+ RecordType,
+ StringType,
+ TimeType,
+ DateType,
+ NullType,
+ ]
+ ],
+ ] = {
+ "BYTES": BytesType,
+ "BOOL": BooleanType,
+ "INT": NumberType,
+ "INT64": NumberType,
+ "SMALLINT": NumberType,
+ "INTEGER": NumberType,
+ "BIGINT": NumberType,
+ "TINYINT": NumberType,
+ "BYTEINT": NumberType,
+ "STRING": StringType,
+ "TIME": TimeType,
+ "TIMESTAMP": TimeType,
+ "DATE": DateType,
+ "DATETIME": TimeType,
+ "GEOGRAPHY": NullType,
+ "JSON": RecordType,
+ "INTERVAL": NullType,
+ "ARRAY": ArrayType,
+ "STRUCT": RecordType,
+ }
+
+ def __init__(
+ self,
+ config: BigQueryV2Config,
+ report: BigQueryV2Report,
+ bigquery_data_dictionary: BigQuerySchemaApi,
+ domain_registry: Optional[DomainRegistry],
+ sql_parser_schema_resolver: SchemaResolver,
+ profiler: BigqueryProfiler,
+ dataset_urn_builder: Callable[[str, str, str], str],
+ ):
+ self.config = config
+ self.report = report
+ self.bigquery_data_dictionary = bigquery_data_dictionary
+ self.domain_registry = domain_registry
+ self.sql_parser_schema_resolver = sql_parser_schema_resolver
+ self.profiler = profiler
+ self.gen_dataset_urn = dataset_urn_builder
+ self.platform: str = "bigquery"
+
+ self.classification_handler = ClassificationHandler(self.config, self.report)
+ self.data_reader: Optional[BigQueryDataReader] = None
+ if self.classification_handler.is_classification_enabled():
+ self.data_reader = BigQueryDataReader.create(
+ self.config.get_bigquery_client()
+ )
+
+ # Global store of table identifiers for lineage filtering
+ self.table_refs: Set[str] = set()
+
+ # Maps project -> view_ref, so we can find all views in a project
+ self.view_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
+ # Maps project -> snapshot_ref, so we can find all snapshots in a project
+ self.snapshot_refs_by_project: Dict[str, Set[str]] = defaultdict(set)
+ # Maps view ref -> actual sql
+ self.view_definitions: FileBackedDict[str] = FileBackedDict()
+ # Maps snapshot ref -> Snapshot
+ self.snapshots_by_ref: FileBackedDict[BigqueryTableSnapshot] = FileBackedDict()
+
+ @property
+ def store_table_refs(self):
+ return self.config.include_table_lineage or self.config.include_usage_statistics
+
+ def get_project_workunits(
+ self, project: BigqueryProject
+ ) -> Iterable[MetadataWorkUnit]:
+ self.report.set_ingestion_stage(project.id, METADATA_EXTRACTION)
+ logger.info(f"Processing project: {project.id}")
+ yield from self._process_project(project)
+
+ def get_dataplatform_instance_aspect(
+ self, dataset_urn: str, project_id: str
+ ) -> MetadataWorkUnit:
+ aspect = DataPlatformInstanceClass(
+ platform=make_data_platform_urn(self.platform),
+ instance=(
+ make_dataplatform_instance_urn(self.platform, project_id)
+ if self.config.include_data_platform_instance
+ else None
+ ),
+ )
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=aspect
+ ).as_workunit()
+
+ def gen_dataset_key(self, db_name: str, schema: str) -> ContainerKey:
+ return BigQueryDatasetKey(
+ project_id=db_name,
+ dataset_id=schema,
+ platform=self.platform,
+ env=self.config.env,
+ backcompat_env_as_instance=True,
+ )
+
+ def gen_project_id_key(self, database: str) -> ContainerKey:
+ return ProjectIdKey(
+ project_id=database,
+ platform=self.platform,
+ env=self.config.env,
+ backcompat_env_as_instance=True,
+ )
+
+ def gen_project_id_containers(self, database: str) -> Iterable[MetadataWorkUnit]:
+ database_container_key = self.gen_project_id_key(database)
+
+ yield from gen_database_container(
+ database=database,
+ name=database,
+ sub_types=[DatasetContainerSubTypes.BIGQUERY_PROJECT],
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ database_container_key=database_container_key,
+ )
+
+ def gen_dataset_containers(
+ self, dataset: str, project_id: str, tags: Optional[Dict[str, str]] = None
+ ) -> Iterable[MetadataWorkUnit]:
+ schema_container_key = self.gen_dataset_key(project_id, dataset)
+
+ tags_joined: Optional[List[str]] = None
+ if tags and self.config.capture_dataset_label_as_tag:
+ tags_joined = [
+ f"{k}:{v}"
+ for k, v in tags.items()
+ if is_tag_allowed(self.config.capture_dataset_label_as_tag, k)
+ ]
+
+ database_container_key = self.gen_project_id_key(database=project_id)
+
+ yield from gen_schema_container(
+ database=project_id,
+ schema=dataset,
+ sub_types=[DatasetContainerSubTypes.BIGQUERY_DATASET],
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ schema_container_key=schema_container_key,
+ database_container_key=database_container_key,
+ external_url=(
+ BQ_EXTERNAL_DATASET_URL_TEMPLATE.format(
+ project=project_id, dataset=dataset
+ )
+ if self.config.include_external_url
+ else None
+ ),
+ tags=tags_joined,
+ )
+
+ def _process_project(
+ self, bigquery_project: BigqueryProject
+ ) -> Iterable[MetadataWorkUnit]:
+ db_tables: Dict[str, List[BigqueryTable]] = {}
+
+ project_id = bigquery_project.id
+ try:
+ bigquery_project.datasets = (
+ self.bigquery_data_dictionary.get_datasets_for_project_id(project_id)
+ )
+ except Exception as e:
+
+ if (
+ self.config.project_id or self.config.project_ids
+ ) and "not enabled BigQuery." in str(e):
+ action_mesage = (
+ "The project has not enabled BigQuery API. "
+ "Did you mistype project id in recipe ?"
+ )
+ else:
+ action_mesage = (
+ "Does your service account have `bigquery.datasets.get` permission ? "
+ "Assign predefined role `roles/bigquery.metadataViewer` to your service account."
+ )
+
+ self.report.failure(
+ title="Unable to get datasets for project",
+ message=action_mesage,
+ context=project_id,
+ exc=e,
+ )
+ return None
+
+ if len(bigquery_project.datasets) == 0:
+ action_message = (
+ "Either there are no datasets in this project or missing `bigquery.datasets.get` permission. "
+ "You can assign predefined roles/bigquery.metadataViewer role to your service account."
+ )
+ if self.config.exclude_empty_projects:
+ self.report.report_dropped(project_id)
+ logger.info(
+ f"Excluded project '{project_id}' since no datasets were found. {action_message}"
+ )
+ else:
+ yield from self.gen_project_id_containers(project_id)
+ self.report.warning(
+ title="No datasets found in project",
+ message=action_message,
+ context=project_id,
+ )
+ return
+
+ yield from self.gen_project_id_containers(project_id)
+
+ self.report.num_project_datasets_to_scan[project_id] = len(
+ bigquery_project.datasets
+ )
+ yield from self._process_project_datasets(bigquery_project, db_tables)
+
+ if self.config.is_profiling_enabled():
+ logger.info(f"Starting profiling project {project_id}")
+ self.report.set_ingestion_stage(project_id, PROFILING)
+ yield from self.profiler.get_workunits(
+ project_id=project_id,
+ tables=db_tables,
+ )
+
+ def _process_project_datasets(
+ self,
+ bigquery_project: BigqueryProject,
+ db_tables: Dict[str, List[BigqueryTable]],
+ ) -> Iterable[MetadataWorkUnit]:
+
+ db_views: Dict[str, List[BigqueryView]] = {}
+ db_snapshots: Dict[str, List[BigqueryTableSnapshot]] = {}
+ project_id = bigquery_project.id
+
+ def _process_schema_worker(
+ bigquery_dataset: BigqueryDataset,
+ ) -> Iterable[MetadataWorkUnit]:
+ if not is_schema_allowed(
+ self.config.dataset_pattern,
+ bigquery_dataset.name,
+ project_id,
+ self.config.match_fully_qualified_names,
+ ):
+ self.report.report_dropped(f"{bigquery_dataset.name}.*")
+ return
+ try:
+ # db_tables, db_views, and db_snapshots are populated in the this method
+ for wu in self._process_schema(
+ project_id, bigquery_dataset, db_tables, db_views, db_snapshots
+ ):
+ yield wu
+ except Exception as e:
+ if self.config.is_profiling_enabled():
+ action_mesage = "Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission, bigquery.tables.getData permission?"
+ else:
+ action_mesage = "Does your service account has bigquery.tables.list, bigquery.routines.get, bigquery.routines.list permission?"
+
+ self.report.failure(
+ title="Unable to get tables for dataset",
+ message=action_mesage,
+ context=f"{project_id}.{bigquery_dataset.name}",
+ exc=e,
+ )
+
+ for wu in ThreadedIteratorExecutor.process(
+ worker_func=_process_schema_worker,
+ args_list=[(bq_dataset,) for bq_dataset in bigquery_project.datasets],
+ max_workers=self.config.max_threads_dataset_parallelism,
+ ):
+ yield wu
+
+ def _process_schema(
+ self,
+ project_id: str,
+ bigquery_dataset: BigqueryDataset,
+ db_tables: Dict[str, List[BigqueryTable]],
+ db_views: Dict[str, List[BigqueryView]],
+ db_snapshots: Dict[str, List[BigqueryTableSnapshot]],
+ ) -> Iterable[MetadataWorkUnit]:
+ dataset_name = bigquery_dataset.name
+
+ yield from self.gen_dataset_containers(
+ dataset_name, project_id, bigquery_dataset.labels
+ )
+
+ columns = None
+
+ rate_limiter: Optional[RateLimiter] = None
+ if self.config.rate_limit:
+ rate_limiter = RateLimiter(
+ max_calls=self.config.requests_per_min, period=60
+ )
+
+ if (
+ self.config.include_tables
+ or self.config.include_views
+ or self.config.include_table_snapshots
+ ):
+ columns = self.bigquery_data_dictionary.get_columns_for_dataset(
+ project_id=project_id,
+ dataset_name=dataset_name,
+ column_limit=self.config.column_limit,
+ run_optimized_column_query=self.config.run_optimized_column_query,
+ extract_policy_tags_from_catalog=self.config.extract_policy_tags_from_catalog,
+ report=self.report,
+ rate_limiter=rate_limiter,
+ )
+
+ if self.config.include_tables:
+ db_tables[dataset_name] = list(
+ self.get_tables_for_dataset(project_id, dataset_name)
+ )
+
+ for table in db_tables[dataset_name]:
+ table_columns = columns.get(table.name, []) if columns else []
+ table_wu_generator = self._process_table(
+ table=table,
+ columns=table_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+ yield from classification_workunit_processor(
+ table_wu_generator,
+ self.classification_handler,
+ self.data_reader,
+ [project_id, dataset_name, table.name],
+ data_reader_kwargs=dict(
+ sample_size_percent=(
+ self.config.classification.sample_size
+ * SAMPLE_SIZE_MULTIPLIER
+ / table.rows_count
+ if table.rows_count
+ else None
+ )
+ ),
+ )
+ elif self.store_table_refs:
+ # Need table_refs to calculate lineage and usage
+ for table_item in self.bigquery_data_dictionary.list_tables(
+ dataset_name, project_id
+ ):
+ identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=table_item.table_id,
+ )
+ if not self.config.table_pattern.allowed(identifier.raw_table_name()):
+ self.report.report_dropped(identifier.raw_table_name())
+ continue
+ try:
+ self.table_refs.add(
+ str(BigQueryTableRef(identifier).get_sanitized_table_ref())
+ )
+ except Exception as e:
+ logger.warning(
+ f"Could not create table ref for {table_item.path}: {e}"
+ )
+
+ if self.config.include_views:
+ db_views[dataset_name] = list(
+ self.bigquery_data_dictionary.get_views_for_dataset(
+ project_id,
+ dataset_name,
+ self.config.is_profiling_enabled(),
+ self.report,
+ )
+ )
+
+ for view in db_views[dataset_name]:
+ view_columns = columns.get(view.name, []) if columns else []
+ yield from self._process_view(
+ view=view,
+ columns=view_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ if self.config.include_table_snapshots:
+ db_snapshots[dataset_name] = list(
+ self.bigquery_data_dictionary.get_snapshots_for_dataset(
+ project_id,
+ dataset_name,
+ self.config.is_profiling_enabled(),
+ self.report,
+ )
+ )
+
+ for snapshot in db_snapshots[dataset_name]:
+ snapshot_columns = columns.get(snapshot.name, []) if columns else []
+ yield from self._process_snapshot(
+ snapshot=snapshot,
+ columns=snapshot_columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ # This method is used to generate the ignore list for datatypes the profiler doesn't support we have to do it here
+ # because the profiler doesn't have access to columns
+ def generate_profile_ignore_list(self, columns: List[BigqueryColumn]) -> List[str]:
+ ignore_list: List[str] = []
+ for column in columns:
+ if not column.data_type or any(
+ word in column.data_type.lower()
+ for word in ["array", "struct", "geography", "json"]
+ ):
+ ignore_list.append(column.field_path)
+ return ignore_list
+
+ def _process_table(
+ self,
+ table: BigqueryTable,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(project_id, dataset_name, table.name)
+
+ self.report.report_entity_scanned(table_identifier.raw_table_name())
+
+ if not self.config.table_pattern.allowed(table_identifier.raw_table_name()):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ if self.store_table_refs:
+ self.table_refs.add(
+ str(BigQueryTableRef(table_identifier).get_sanitized_table_ref())
+ )
+ table.column_count = len(columns)
+
+ # We only collect profile ignore list if profiling is enabled and profile_table_level_only is false
+ if (
+ self.config.is_profiling_enabled()
+ and not self.config.profiling.profile_table_level_only
+ ):
+ table.columns_ignore_from_profiling = self.generate_profile_ignore_list(
+ columns
+ )
+
+ if not table.column_count:
+ logger.warning(
+ f"Table doesn't have any column or unable to get columns for table: {table_identifier}"
+ )
+
+ # If table has time partitioning, set the data type of the partitioning field
+ if table.partition_info:
+ table.partition_info.column = next(
+ (
+ column
+ for column in columns
+ if column.name == table.partition_info.field
+ ),
+ None,
+ )
+ yield from self.gen_table_dataset_workunits(
+ table, columns, project_id, dataset_name
+ )
+
+ def _process_view(
+ self,
+ view: BigqueryView,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(project_id, dataset_name, view.name)
+
+ self.report.report_entity_scanned(table_identifier.raw_table_name(), "view")
+
+ if not self.config.view_pattern.allowed(table_identifier.raw_table_name()):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ if self.store_table_refs:
+ table_ref = str(
+ BigQueryTableRef(table_identifier).get_sanitized_table_ref()
+ )
+ self.table_refs.add(table_ref)
+ if self.config.lineage_parse_view_ddl and view.view_definition:
+ self.view_refs_by_project[project_id].add(table_ref)
+ self.view_definitions[table_ref] = view.view_definition
+
+ view.column_count = len(columns)
+ if not view.column_count:
+ logger.warning(
+ f"View doesn't have any column or unable to get columns for view: {table_identifier}"
+ )
+
+ yield from self.gen_view_dataset_workunits(
+ table=view,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ def _process_snapshot(
+ self,
+ snapshot: BigqueryTableSnapshot,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ table_identifier = BigqueryTableIdentifier(
+ project_id, dataset_name, snapshot.name
+ )
+
+ self.report.snapshots_scanned += 1
+
+ if not self.config.table_snapshot_pattern.allowed(
+ table_identifier.raw_table_name()
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ return
+
+ snapshot.columns = columns
+ snapshot.column_count = len(columns)
+ if not snapshot.column_count:
+ logger.warning(
+ f"Snapshot doesn't have any column or unable to get columns for snapshot: {table_identifier}"
+ )
+
+ if self.store_table_refs:
+ table_ref = str(
+ BigQueryTableRef(table_identifier).get_sanitized_table_ref()
+ )
+ self.table_refs.add(table_ref)
+ if snapshot.base_table_identifier:
+ self.snapshot_refs_by_project[project_id].add(table_ref)
+ self.snapshots_by_ref[table_ref] = snapshot
+
+ yield from self.gen_snapshot_dataset_workunits(
+ table=snapshot,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ )
+
+ def gen_table_dataset_workunits(
+ self,
+ table: BigqueryTable,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ custom_properties: Dict[str, str] = {}
+ if table.expires:
+ custom_properties["expiration_date"] = str(table.expires)
+
+ if table.partition_info:
+ custom_properties["partition_info"] = str(table.partition_info)
+
+ if table.size_in_bytes:
+ custom_properties["size_in_bytes"] = str(table.size_in_bytes)
+
+ if table.active_billable_bytes:
+ custom_properties["billable_bytes_active"] = str(
+ table.active_billable_bytes
+ )
+
+ if table.long_term_billable_bytes:
+ custom_properties["billable_bytes_long_term"] = str(
+ table.long_term_billable_bytes
+ )
+
+ if table.max_partition_id:
+ custom_properties["number_of_partitions"] = str(table.num_partitions)
+ custom_properties["max_partition_id"] = str(table.max_partition_id)
+ custom_properties["is_partitioned"] = str(True)
+
+ sub_types: List[str] = [DatasetSubTypes.TABLE]
+ if table.max_shard_id:
+ custom_properties["max_shard_id"] = str(table.max_shard_id)
+ custom_properties["is_sharded"] = str(True)
+ sub_types = ["sharded table"] + sub_types
+
+ tags_to_add = None
+ if table.labels and self.config.capture_table_label_as_tag:
+ tags_to_add = []
+ tags_to_add.extend(
+ [
+ make_tag_urn(f"""{k}:{v}""")
+ for k, v in table.labels.items()
+ if is_tag_allowed(self.config.capture_table_label_as_tag, k)
+ ]
+ )
+
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ sub_types=sub_types,
+ tags_to_add=tags_to_add,
+ custom_properties=custom_properties,
+ )
+
+ def gen_view_dataset_workunits(
+ self,
+ table: BigqueryView,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ tags_to_add = None
+ if table.labels and self.config.capture_view_label_as_tag:
+ tags_to_add = [
+ make_tag_urn(f"{k}:{v}")
+ for k, v in table.labels.items()
+ if is_tag_allowed(self.config.capture_view_label_as_tag, k)
+ ]
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ tags_to_add=tags_to_add,
+ sub_types=[DatasetSubTypes.VIEW],
+ )
+
+ view = cast(BigqueryView, table)
+ view_definition_string = view.view_definition
+ view_properties_aspect = ViewProperties(
+ materialized=view.materialized,
+ viewLanguage="SQL",
+ viewLogic=view_definition_string or "",
+ )
+ yield MetadataChangeProposalWrapper(
+ entityUrn=self.gen_dataset_urn(project_id, dataset_name, table.name),
+ aspect=view_properties_aspect,
+ ).as_workunit()
+
+ def gen_snapshot_dataset_workunits(
+ self,
+ table: BigqueryTableSnapshot,
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[MetadataWorkUnit]:
+ custom_properties: Dict[str, str] = {}
+ if table.ddl:
+ custom_properties["snapshot_ddl"] = table.ddl
+ if table.snapshot_time:
+ custom_properties["snapshot_time"] = str(table.snapshot_time)
+ if table.size_in_bytes:
+ custom_properties["size_in_bytes"] = str(table.size_in_bytes)
+ if table.rows_count:
+ custom_properties["rows_count"] = str(table.rows_count)
+ yield from self.gen_dataset_workunits(
+ table=table,
+ columns=columns,
+ project_id=project_id,
+ dataset_name=dataset_name,
+ sub_types=[DatasetSubTypes.BIGQUERY_TABLE_SNAPSHOT],
+ custom_properties=custom_properties,
+ )
+
+ def gen_dataset_workunits(
+ self,
+ table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
+ columns: List[BigqueryColumn],
+ project_id: str,
+ dataset_name: str,
+ sub_types: List[str],
+ tags_to_add: Optional[List[str]] = None,
+ custom_properties: Optional[Dict[str, str]] = None,
+ ) -> Iterable[MetadataWorkUnit]:
+ dataset_urn = self.gen_dataset_urn(project_id, dataset_name, table.name)
+
+ status = Status(removed=False)
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=status
+ ).as_workunit()
+
+ datahub_dataset_name = BigqueryTableIdentifier(
+ project_id, dataset_name, table.name
+ )
+
+ yield self.gen_schema_metadata(
+ dataset_urn, table, columns, datahub_dataset_name
+ )
+
+ dataset_properties = DatasetProperties(
+ name=datahub_dataset_name.get_table_display_name(),
+ description=(
+ unquote_and_decode_unicode_escape_seq(table.comment)
+ if table.comment
+ else ""
+ ),
+ qualifiedName=str(datahub_dataset_name),
+ created=(
+ TimeStamp(time=int(table.created.timestamp() * 1000))
+ if table.created is not None
+ else None
+ ),
+ lastModified=(
+ TimeStamp(time=int(table.last_altered.timestamp() * 1000))
+ if table.last_altered is not None
+ else None
+ ),
+ externalUrl=(
+ BQ_EXTERNAL_TABLE_URL_TEMPLATE.format(
+ project=project_id, dataset=dataset_name, table=table.name
+ )
+ if self.config.include_external_url
+ else None
+ ),
+ )
+ if custom_properties:
+ dataset_properties.customProperties.update(custom_properties)
+
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=dataset_properties
+ ).as_workunit()
+
+ if tags_to_add:
+ yield self.gen_tags_aspect_workunit(dataset_urn, tags_to_add)
+
+ yield from add_table_to_schema_container(
+ dataset_urn=dataset_urn,
+ parent_container_key=self.gen_dataset_key(project_id, dataset_name),
+ )
+ yield self.get_dataplatform_instance_aspect(
+ dataset_urn=dataset_urn, project_id=project_id
+ )
+
+ subTypes = SubTypes(typeNames=sub_types)
+ yield MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=subTypes
+ ).as_workunit()
+
+ if self.domain_registry:
+ yield from get_domain_wu(
+ dataset_name=str(datahub_dataset_name),
+ entity_urn=dataset_urn,
+ domain_registry=self.domain_registry,
+ domain_config=self.config.domain,
+ )
+
+ def gen_tags_aspect_workunit(
+ self, dataset_urn: str, tags_to_add: List[str]
+ ) -> MetadataWorkUnit:
+ tags = GlobalTagsClass(
+ tags=[TagAssociationClass(tag_to_add) for tag_to_add in tags_to_add]
+ )
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=tags
+ ).as_workunit()
+
+ def gen_schema_fields(self, columns: List[BigqueryColumn]) -> List[SchemaField]:
+ schema_fields: List[SchemaField] = []
+
+ # Below line affects HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR in global scope
+ # TODO: Refractor this such that
+ # converter = HiveColumnToAvroConverter(struct_type_separator=" ");
+ # converter.get_schema_fields_for_hive_column(...)
+ original_struct_type_separator = (
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR
+ )
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = " "
+ _COMPLEX_TYPE = re.compile("^(struct|array)")
+ last_id = -1
+ for col in columns:
+ # if col.data_type is empty that means this column is part of a complex type
+ if col.data_type is None or _COMPLEX_TYPE.match(col.data_type.lower()):
+ # If the we have seen the ordinal position that most probably means we already processed this complex type
+ if last_id != col.ordinal_position:
+ schema_fields.extend(
+ get_schema_fields_for_hive_column(
+ col.name, col.data_type.lower(), description=col.comment
+ )
+ )
+
+ # We have to add complex type comments to the correct level
+ if col.comment:
+ for idx, field in enumerate(schema_fields):
+ # Remove all the [version=2.0].[type=struct]. tags to get the field path
+ if (
+ re.sub(
+ r"\[.*?\]\.",
+ repl="",
+ string=field.fieldPath.lower(),
+ count=0,
+ flags=re.MULTILINE,
+ )
+ == col.field_path.lower()
+ ):
+ field.description = col.comment
+ schema_fields[idx] = field
+ break
+ else:
+ tags = []
+ if col.is_partition_column:
+ tags.append(
+ TagAssociationClass(make_tag_urn(Constants.TAG_PARTITION_KEY))
+ )
+
+ if col.cluster_column_position is not None:
+ tags.append(
+ TagAssociationClass(
+ make_tag_urn(
+ f"{CLUSTERING_COLUMN_TAG}_{col.cluster_column_position}"
+ )
+ )
+ )
+
+ if col.policy_tags:
+ for policy_tag in col.policy_tags:
+ tags.append(TagAssociationClass(make_tag_urn(policy_tag)))
+ field = SchemaField(
+ fieldPath=col.name,
+ type=SchemaFieldDataType(
+ self.BIGQUERY_FIELD_TYPE_MAPPINGS.get(col.data_type, NullType)()
+ ),
+ nativeDataType=col.data_type,
+ description=col.comment,
+ nullable=col.is_nullable,
+ globalTags=GlobalTagsClass(tags=tags),
+ )
+ schema_fields.append(field)
+ last_id = col.ordinal_position
+ HiveColumnToAvroConverter._STRUCT_TYPE_SEPARATOR = (
+ original_struct_type_separator
+ )
+ return schema_fields
+
+ def gen_schema_metadata(
+ self,
+ dataset_urn: str,
+ table: Union[BigqueryTable, BigqueryView, BigqueryTableSnapshot],
+ columns: List[BigqueryColumn],
+ dataset_name: BigqueryTableIdentifier,
+ ) -> MetadataWorkUnit:
+ schema_metadata = SchemaMetadata(
+ schemaName=str(dataset_name),
+ platform=make_data_platform_urn(self.platform),
+ version=0,
+ hash="",
+ platformSchema=MySqlDDL(tableSchema=""),
+ # fields=[],
+ fields=self.gen_schema_fields(columns),
+ )
+
+ if self.config.lineage_parse_view_ddl or self.config.lineage_use_sql_parser:
+ self.sql_parser_schema_resolver.add_schema_metadata(
+ dataset_urn, schema_metadata
+ )
+
+ return MetadataChangeProposalWrapper(
+ entityUrn=dataset_urn, aspect=schema_metadata
+ ).as_workunit()
+
+ def get_tables_for_dataset(
+ self,
+ project_id: str,
+ dataset_name: str,
+ ) -> Iterable[BigqueryTable]:
+ # In bigquery there is no way to query all tables in a Project id
+ with PerfTimer() as timer:
+ # Partitions view throw exception if we try to query partition info for too many tables
+ # so we have to limit the number of tables we query partition info.
+ # The conn.list_tables returns table infos that information_schema doesn't contain and this
+ # way we can merge that info with the queried one.
+ # https://cloud.google.com/bigquery/docs/information-schema-partitions
+ max_batch_size: int = (
+ self.config.number_of_datasets_process_in_batch
+ if not self.config.is_profiling_enabled()
+ else self.config.number_of_datasets_process_in_batch_if_profiling_enabled
+ )
+
+ # We get the list of tables in the dataset to get core table properties and to be able to process the tables in batches
+ # We collect only the latest shards from sharded tables (tables with _YYYYMMDD suffix) and ignore temporary tables
+ table_items = self.get_core_table_details(
+ dataset_name, project_id, self.config.temp_table_dataset_prefix
+ )
+
+ items_to_get: Dict[str, TableListItem] = {}
+ for table_item in table_items:
+ items_to_get[table_item] = table_items[table_item]
+ if len(items_to_get) % max_batch_size == 0:
+ yield from self.bigquery_data_dictionary.get_tables_for_dataset(
+ project_id,
+ dataset_name,
+ items_to_get,
+ with_data_read_permission=self.config.have_table_data_read_permission,
+ report=self.report,
+ )
+ items_to_get.clear()
+
+ if items_to_get:
+ yield from self.bigquery_data_dictionary.get_tables_for_dataset(
+ project_id,
+ dataset_name,
+ items_to_get,
+ with_data_read_permission=self.config.have_table_data_read_permission,
+ report=self.report,
+ )
+
+ self.report.metadata_extraction_sec[f"{project_id}.{dataset_name}"] = round(
+ timer.elapsed_seconds(), 2
+ )
+
+ def get_core_table_details(
+ self, dataset_name: str, project_id: str, temp_table_dataset_prefix: str
+ ) -> Dict[str, TableListItem]:
+ table_items: Dict[str, TableListItem] = {}
+ # Dict to store sharded table and the last seen max shard id
+ sharded_tables: Dict[str, TableListItem] = {}
+
+ for table in self.bigquery_data_dictionary.list_tables(
+ dataset_name, project_id
+ ):
+ table_identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=table.table_id,
+ )
+
+ if table.table_type == "VIEW":
+ if (
+ not self.config.include_views
+ or not self.config.view_pattern.allowed(
+ table_identifier.raw_table_name()
+ )
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+ else:
+ if not self.config.table_pattern.allowed(
+ table_identifier.raw_table_name()
+ ):
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+
+ _, shard = BigqueryTableIdentifier.get_table_and_shard(
+ table_identifier.table
+ )
+ table_name = table_identifier.get_table_name().split(".")[-1]
+
+ # Sharded tables look like: table_20220120
+ # For sharded tables we only process the latest shard and ignore the rest
+ # to find the latest shard we iterate over the list of tables and store the maximum shard id
+ # We only have one special case where the table name is a date `20220110`
+ # in this case we merge all these tables under dataset name as table name.
+ # For example some_dataset.20220110 will be turned to some_dataset.some_dataset
+ # It seems like there are some bigquery user who uses this non-standard way of sharding the tables.
+ if shard:
+ if table_name not in sharded_tables:
+ sharded_tables[table_name] = table
+ continue
+
+ stored_table_identifier = BigqueryTableIdentifier(
+ project_id=project_id,
+ dataset=dataset_name,
+ table=sharded_tables[table_name].table_id,
+ )
+ _, stored_shard = BigqueryTableIdentifier.get_table_and_shard(
+ stored_table_identifier.table
+ )
+ # When table is none, we use dataset_name as table_name
+ assert stored_shard
+ if stored_shard < shard:
+ sharded_tables[table_name] = table
+ continue
+ elif str(table_identifier).startswith(temp_table_dataset_prefix):
+ logger.debug(f"Dropping temporary table {table_identifier.table}")
+ self.report.report_dropped(table_identifier.raw_table_name())
+ continue
+
+ table_items[table.table_id] = table
+
+ # Adding maximum shards to the list of tables
+ table_items.update({value.table_id: value for value in sharded_tables.values()})
+
+ return table_items
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py
new file mode 100644
index 0000000000000..3aac78c154b2e
--- /dev/null
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_test_connection.py
@@ -0,0 +1,178 @@
+import logging
+from datetime import datetime, timedelta
+from typing import Dict, List, Union
+
+from google.cloud import bigquery
+
+from datahub.ingestion.api.source import (
+ CapabilityReport,
+ SourceCapability,
+ TestConnectionReport,
+)
+from datahub.ingestion.source.bigquery_v2.bigquery_config import BigQueryV2Config
+from datahub.ingestion.source.bigquery_v2.bigquery_report import BigQueryV2Report
+from datahub.ingestion.source.bigquery_v2.bigquery_schema import BigQuerySchemaApi
+from datahub.ingestion.source.bigquery_v2.lineage import BigqueryLineageExtractor
+from datahub.ingestion.source.bigquery_v2.usage import BigQueryUsageExtractor
+from datahub.sql_parsing.schema_resolver import SchemaResolver
+
+logger: logging.Logger = logging.getLogger(__name__)
+
+
+class BigQueryTestConnection:
+ @staticmethod
+ def test_connection(config_dict: dict) -> TestConnectionReport:
+ test_report = TestConnectionReport()
+ _report: Dict[Union[SourceCapability, str], CapabilityReport] = dict()
+
+ try:
+ connection_conf = BigQueryV2Config.parse_obj_allow_extras(config_dict)
+ client: bigquery.Client = connection_conf.get_bigquery_client()
+ assert client
+
+ test_report.basic_connectivity = BigQueryTestConnection.connectivity_test(
+ client
+ )
+
+ connection_conf.start_time = datetime.now()
+ connection_conf.end_time = datetime.now() + timedelta(minutes=1)
+
+ report: BigQueryV2Report = BigQueryV2Report()
+ project_ids: List[str] = []
+ projects = client.list_projects()
+
+ for project in projects:
+ if connection_conf.project_id_pattern.allowed(project.project_id):
+ project_ids.append(project.project_id)
+
+ metadata_read_capability = (
+ BigQueryTestConnection.metadata_read_capability_test(
+ project_ids, connection_conf
+ )
+ )
+ if SourceCapability.SCHEMA_METADATA not in _report:
+ _report[SourceCapability.SCHEMA_METADATA] = metadata_read_capability
+
+ if connection_conf.include_table_lineage:
+ lineage_capability = BigQueryTestConnection.lineage_capability_test(
+ connection_conf, project_ids, report
+ )
+ if SourceCapability.LINEAGE_COARSE not in _report:
+ _report[SourceCapability.LINEAGE_COARSE] = lineage_capability
+
+ if connection_conf.include_usage_statistics:
+ usage_capability = BigQueryTestConnection.usage_capability_test(
+ connection_conf, project_ids, report
+ )
+ if SourceCapability.USAGE_STATS not in _report:
+ _report[SourceCapability.USAGE_STATS] = usage_capability
+
+ test_report.capability_report = _report
+ return test_report
+
+ except Exception as e:
+ test_report.basic_connectivity = CapabilityReport(
+ capable=False, failure_reason=f"{e}"
+ )
+ return test_report
+
+ @staticmethod
+ def connectivity_test(client: bigquery.Client) -> CapabilityReport:
+ ret = client.query("select 1")
+ if ret.error_result:
+ return CapabilityReport(
+ capable=False, failure_reason=f"{ret.error_result['message']}"
+ )
+ else:
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def metadata_read_capability_test(
+ project_ids: List[str], config: BigQueryV2Config
+ ) -> CapabilityReport:
+ for project_id in project_ids:
+ try:
+ logger.info(f"Metadata read capability test for project {project_id}")
+ client: bigquery.Client = config.get_bigquery_client()
+ assert client
+ bigquery_data_dictionary = BigQuerySchemaApi(
+ BigQueryV2Report().schema_api_perf, client
+ )
+ result = bigquery_data_dictionary.get_datasets_for_project_id(
+ project_id, 10
+ )
+ if len(result) == 0:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Dataset query returned empty dataset. It is either empty or no dataset in project {project_id}",
+ )
+ tables = bigquery_data_dictionary.get_tables_for_dataset(
+ project_id=project_id,
+ dataset_name=result[0].name,
+ tables={},
+ with_data_read_permission=config.have_table_data_read_permission,
+ report=BigQueryV2Report(),
+ )
+ if len(list(tables)) == 0:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Tables query did not return any table. It is either empty or no tables in project {project_id}.{result[0].name}",
+ )
+
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Dataset query failed with error: {e}",
+ )
+
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def lineage_capability_test(
+ connection_conf: BigQueryV2Config,
+ project_ids: List[str],
+ report: BigQueryV2Report,
+ ) -> CapabilityReport:
+ lineage_extractor = BigqueryLineageExtractor(
+ connection_conf, report, lambda ref: ""
+ )
+ for project_id in project_ids:
+ try:
+ logger.info(f"Lineage capability test for project {project_id}")
+ lineage_extractor.test_capability(project_id)
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Lineage capability test failed with: {e}",
+ )
+
+ return CapabilityReport(capable=True)
+
+ @staticmethod
+ def usage_capability_test(
+ connection_conf: BigQueryV2Config,
+ project_ids: List[str],
+ report: BigQueryV2Report,
+ ) -> CapabilityReport:
+ usage_extractor = BigQueryUsageExtractor(
+ connection_conf,
+ report,
+ schema_resolver=SchemaResolver(platform="bigquery"),
+ dataset_urn_builder=lambda ref: "",
+ )
+ for project_id in project_ids:
+ try:
+ logger.info(f"Usage capability test for project {project_id}")
+ failures_before_test = len(report.failures)
+ usage_extractor.test_capability(project_id)
+ if failures_before_test != len(report.failures):
+ return CapabilityReport(
+ capable=False,
+ failure_reason="Usage capability test failed. Check the logs for further info",
+ )
+ except Exception as e:
+ return CapabilityReport(
+ capable=False,
+ failure_reason=f"Usage capability test failed with: {e} for project {project_id}",
+ )
+ return CapabilityReport(capable=True)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
index c41207ec67f62..496bd64d3b4fe 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/lineage.py
@@ -251,11 +251,6 @@ def get_time_window(self) -> Tuple[datetime, datetime]:
else:
return self.config.start_time, self.config.end_time
- def error(self, log: logging.Logger, key: str, reason: str) -> None:
- # TODO: Remove this method.
- # Note that this downgrades the error to a warning.
- self.report.warning(key, reason)
-
def _should_ingest_lineage(self) -> bool:
if (
self.redundant_run_skip_handler
@@ -265,9 +260,9 @@ def _should_ingest_lineage(self) -> bool:
)
):
# Skip this run
- self.report.report_warning(
- "lineage-extraction",
- "Skip this run as there was already a run for current ingestion window.",
+ self.report.warning(
+ title="Skipped redundant lineage extraction",
+ message="Skip this run as there was already a run for current ingestion window.",
)
return False
@@ -345,12 +340,12 @@ def generate_lineage(
events, sql_parser_schema_resolver
)
except Exception as e:
- if project_id:
- self.report.lineage_failed_extraction.append(project_id)
- self.error(
- logger,
- "lineage",
- f"{project_id}: {e}",
+ self.report.lineage_failed_extraction.append(project_id)
+ self.report.warning(
+ title="Failed to extract lineage",
+ message="Unexpected error encountered",
+ context=project_id,
+ exc=e,
)
lineage = {}
@@ -481,98 +476,88 @@ def lineage_via_catalog_lineage_api(
# Regions to search for BigQuery tables: projects/{project_id}/locations/{region}
enabled_regions: List[str] = ["US", "EU"]
- try:
- lineage_client: lineage_v1.LineageClient = lineage_v1.LineageClient()
+ lineage_client: lineage_v1.LineageClient = lineage_v1.LineageClient()
+
+ data_dictionary = BigQuerySchemaApi(
+ self.report.schema_api_perf, self.config.get_bigquery_client()
+ )
- data_dictionary = BigQuerySchemaApi(
- self.report.schema_api_perf, self.config.get_bigquery_client()
+ # Filtering datasets
+ datasets = list(data_dictionary.get_datasets_for_project_id(project_id))
+ project_tables = []
+ for dataset in datasets:
+ # Enables only tables where type is TABLE, VIEW or MATERIALIZED_VIEW (not EXTERNAL)
+ project_tables.extend(
+ [
+ table
+ for table in data_dictionary.list_tables(dataset.name, project_id)
+ if table.table_type in ["TABLE", "VIEW", "MATERIALIZED_VIEW"]
+ ]
)
- # Filtering datasets
- datasets = list(data_dictionary.get_datasets_for_project_id(project_id))
- project_tables = []
- for dataset in datasets:
- # Enables only tables where type is TABLE, VIEW or MATERIALIZED_VIEW (not EXTERNAL)
- project_tables.extend(
+ lineage_map: Dict[str, Set[LineageEdge]] = {}
+ curr_date = datetime.now()
+ for project_table in project_tables:
+ # Convert project table to .. format
+ table = f"{project_table.project}.{project_table.dataset_id}.{project_table.table_id}"
+
+ if not is_schema_allowed(
+ self.config.dataset_pattern,
+ schema_name=project_table.dataset_id,
+ db_name=project_table.project,
+ match_fully_qualified_schema_name=self.config.match_fully_qualified_names,
+ ) or not self.config.table_pattern.allowed(table):
+ self.report.num_skipped_lineage_entries_not_allowed[
+ project_table.project
+ ] += 1
+ continue
+
+ logger.info("Creating lineage map for table %s", table)
+ upstreams = set()
+ downstream_table = lineage_v1.EntityReference()
+ # fully_qualified_name in format: "bigquery:.."
+ downstream_table.fully_qualified_name = f"bigquery:{table}"
+ # Searches in different regions
+ for region in enabled_regions:
+ location_request = lineage_v1.SearchLinksRequest(
+ target=downstream_table,
+ parent=f"projects/{project_id}/locations/{region.lower()}",
+ )
+ response = lineage_client.search_links(request=location_request)
+ upstreams.update(
[
- table
- for table in data_dictionary.list_tables(
- dataset.name, project_id
+ str(lineage.source.fully_qualified_name).replace(
+ "bigquery:", ""
)
- if table.table_type in ["TABLE", "VIEW", "MATERIALIZED_VIEW"]
+ for lineage in response
]
)
- lineage_map: Dict[str, Set[LineageEdge]] = {}
- curr_date = datetime.now()
- for project_table in project_tables:
- # Convert project table to .. format
- table = f"{project_table.project}.{project_table.dataset_id}.{project_table.table_id}"
-
- if not is_schema_allowed(
- self.config.dataset_pattern,
- schema_name=project_table.dataset_id,
- db_name=project_table.project,
- match_fully_qualified_schema_name=self.config.match_fully_qualified_names,
- ) or not self.config.table_pattern.allowed(table):
- self.report.num_skipped_lineage_entries_not_allowed[
- project_table.project
- ] += 1
- continue
-
- logger.info("Creating lineage map for table %s", table)
- upstreams = set()
- downstream_table = lineage_v1.EntityReference()
- # fully_qualified_name in format: "bigquery:.."
- downstream_table.fully_qualified_name = f"bigquery:{table}"
- # Searches in different regions
- for region in enabled_regions:
- location_request = lineage_v1.SearchLinksRequest(
- target=downstream_table,
- parent=f"projects/{project_id}/locations/{region.lower()}",
- )
- response = lineage_client.search_links(request=location_request)
- upstreams.update(
- [
- str(lineage.source.fully_qualified_name).replace(
- "bigquery:", ""
- )
- for lineage in response
- ]
- )
-
- # Downstream table identifier
- destination_table_str = str(
- BigQueryTableRef(
- table_identifier=BigqueryTableIdentifier(*table.split("."))
- )
+ # Downstream table identifier
+ destination_table_str = str(
+ BigQueryTableRef(
+ table_identifier=BigqueryTableIdentifier(*table.split("."))
)
+ )
- # Only builds lineage map when the table has upstreams
- logger.debug("Found %d upstreams for table %s", len(upstreams), table)
- if upstreams:
- lineage_map[destination_table_str] = {
- LineageEdge(
- table=str(
- BigQueryTableRef(
- table_identifier=BigqueryTableIdentifier.from_string_name(
- source_table
- )
+ # Only builds lineage map when the table has upstreams
+ logger.debug("Found %d upstreams for table %s", len(upstreams), table)
+ if upstreams:
+ lineage_map[destination_table_str] = {
+ LineageEdge(
+ table=str(
+ BigQueryTableRef(
+ table_identifier=BigqueryTableIdentifier.from_string_name(
+ source_table
)
- ),
- column_mapping=frozenset(),
- auditStamp=curr_date,
- )
- for source_table in upstreams
- }
- return lineage_map
- except Exception as e:
- self.error(
- logger,
- "lineage-exported-catalog-lineage-api",
- f"Error: {e}",
- )
- raise e
+ )
+ ),
+ column_mapping=frozenset(),
+ auditStamp=curr_date,
+ )
+ for source_table in upstreams
+ }
+ return lineage_map
def _get_parsed_audit_log_events(self, project_id: str) -> Iterable[QueryEvent]:
# We adjust the filter values a bit, since we need to make sure that the join
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
index 8c393d1e8a436..582c312f99098 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/profiler.py
@@ -227,8 +227,9 @@ def get_profile_request(
if partition is None and bq_table.partition_info:
self.report.report_warning(
- "profile skipped as partitioned table is empty or partition id or type was invalid",
- profile_request.pretty_name,
+ title="Profile skipped for partitioned table",
+ message="profile skipped as partitioned table is empty or partition id or type was invalid",
+ context=profile_request.pretty_name,
)
return None
if (
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
index 1b95cbf505016..6824d630a2277 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/usage.py
@@ -358,9 +358,9 @@ def _should_ingest_usage(self) -> bool:
)
):
# Skip this run
- self.report.report_warning(
- "usage-extraction",
- "Skip this run as there was already a run for current ingestion window.",
+ self.report.warning(
+ title="Skipped redundant usage extraction",
+ message="Skip this run as there was already a run for current ingestion window.",
)
return False
@@ -410,8 +410,7 @@ def _get_workunits_internal(
)
usage_state.report_disk_usage(self.report)
except Exception as e:
- logger.error("Error processing usage", exc_info=True)
- self.report.report_warning("usage-ingestion", str(e))
+ self.report.warning(message="Error processing usage", exc=e)
self.report_status("usage-ingestion", False)
def generate_read_events_from_query(
@@ -477,10 +476,12 @@ def _ingest_events(
)
except Exception as e:
- logger.warning(
- f"Unable to store usage event {audit_event}", exc_info=True
+ self.report.warning(
+ message="Unable to store usage event",
+ context=f"{audit_event}",
+ exc=e,
)
- self._report_error("store-event", e)
+
logger.info(f"Total number of events aggregated = {num_aggregated}.")
if self.report.num_view_query_events > 0:
@@ -500,11 +501,11 @@ def _generate_operational_workunits(
yield operational_wu
self.report.num_operational_stats_workunits_emitted += 1
except Exception as e:
- logger.warning(
- f"Unable to generate operation workunit for event {audit_event}",
- exc_info=True,
+ self.report.warning(
+ message="Unable to generate operation workunit",
+ context=f"{audit_event}",
+ exc=e,
)
- self._report_error("operation-workunit", e)
def _generate_usage_workunits(
self, usage_state: BigQueryUsageState
@@ -541,11 +542,11 @@ def _generate_usage_workunits(
)
self.report.num_usage_workunits_emitted += 1
except Exception as e:
- logger.warning(
- f"Unable to generate usage workunit for bucket {entry.timestamp}, {entry.resource}",
- exc_info=True,
+ self.report.warning(
+ message="Unable to generate usage statistics workunit",
+ context=f"{entry.timestamp}, {entry.resource}",
+ exc=e,
)
- self._report_error("statistics-workunit", e)
def _get_usage_events(self, projects: Iterable[str]) -> Iterable[AuditEvent]:
if self.config.use_exported_bigquery_audit_metadata:
@@ -559,12 +560,12 @@ def _get_usage_events(self, projects: Iterable[str]) -> Iterable[AuditEvent]:
)
yield from self._get_parsed_bigquery_log_events(project_id)
except Exception as e:
- logger.error(
- f"Error getting usage events for project {project_id}",
- exc_info=True,
- )
self.report.usage_failed_extraction.append(project_id)
- self.report.report_warning(f"usage-extraction-{project_id}", str(e))
+ self.report.warning(
+ message="Failed to get some or all usage events for project",
+ context=project_id,
+ exc=e,
+ )
self.report_status(f"usage-extraction-{project_id}", False)
self.report.usage_extraction_sec[project_id] = round(
@@ -898,12 +899,10 @@ def _get_parsed_bigquery_log_events(
self.report.num_usage_parsed_log_entries[project_id] += 1
yield event
except Exception as e:
- logger.warning(
- f"Unable to parse log entry `{entry}` for project {project_id}",
- exc_info=True,
- )
- self._report_error(
- f"log-parse-{project_id}", e, group="usage-log-parse"
+ self.report.warning(
+ message="Unable to parse usage log entry",
+ context=f"`{entry}` for project {project_id}",
+ exc=e,
)
def _generate_filter(self, corrected_start_time, corrected_end_time):
@@ -946,13 +945,6 @@ def get_tables_from_query(
return parsed_table_refs
- def _report_error(
- self, label: str, e: Exception, group: Optional[str] = None
- ) -> None:
- """Report an error that does not constitute a major failure."""
- self.report.usage_error_count[label] += 1
- self.report.report_warning(group or f"usage-{label}", str(e))
-
def test_capability(self, project_id: str) -> None:
for entry in self._get_parsed_bigquery_log_events(project_id, limit=1):
logger.debug(f"Connection test got one {entry}")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py b/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
index 84547efe37a62..0d9fc8225532c 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/common/subtypes.py
@@ -35,6 +35,7 @@ class DatasetContainerSubTypes(str, Enum):
FOLDER = "Folder"
S3_BUCKET = "S3 bucket"
GCS_BUCKET = "GCS bucket"
+ ABS_CONTAINER = "ABS container"
class BIContainerSubTypes(str, Enum):
diff --git a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
index 5393dd4835d8c..2ebdd2b4126bb 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/data_lake_utils.py
@@ -16,6 +16,12 @@
get_s3_prefix,
is_s3_uri,
)
+from datahub.ingestion.source.azure.abs_util import (
+ get_abs_prefix,
+ get_container_name,
+ get_container_relative_path,
+ is_abs_uri,
+)
from datahub.ingestion.source.common.subtypes import DatasetContainerSubTypes
from datahub.ingestion.source.gcs.gcs_utils import (
get_gcs_bucket_name,
@@ -29,6 +35,7 @@
PLATFORM_S3 = "s3"
PLATFORM_GCS = "gcs"
+PLATFORM_ABS = "abs"
class ContainerWUCreator:
@@ -85,6 +92,8 @@ def get_protocol(path: str) -> str:
protocol = get_s3_prefix(path)
elif is_gcs_uri(path):
protocol = get_gcs_prefix(path)
+ elif is_abs_uri(path):
+ protocol = get_abs_prefix(path)
if protocol:
return protocol
@@ -99,7 +108,25 @@ def get_bucket_name(path: str) -> str:
return get_bucket_name(path)
elif is_gcs_uri(path):
return get_gcs_bucket_name(path)
- raise ValueError(f"Unable to get get bucket name form path: {path}")
+ elif is_abs_uri(path):
+ return get_container_name(path)
+ raise ValueError(f"Unable to get bucket name from path: {path}")
+
+ def get_sub_types(self) -> str:
+ if self.platform == PLATFORM_S3:
+ return DatasetContainerSubTypes.S3_BUCKET
+ elif self.platform == PLATFORM_GCS:
+ return DatasetContainerSubTypes.GCS_BUCKET
+ elif self.platform == PLATFORM_ABS:
+ return DatasetContainerSubTypes.ABS_CONTAINER
+ raise ValueError(f"Unable to sub type for platform: {self.platform}")
+
+ def get_base_full_path(self, path: str) -> str:
+ if self.platform == "s3" or self.platform == "gcs":
+ return get_bucket_relative_path(path)
+ elif self.platform == "abs":
+ return get_container_relative_path(path)
+ raise ValueError(f"Unable to get base full path from path: {path}")
def create_container_hierarchy(
self, path: str, dataset_urn: str
@@ -107,22 +134,18 @@ def create_container_hierarchy(
logger.debug(f"Creating containers for {dataset_urn}")
base_full_path = path
parent_key = None
- if self.platform in (PLATFORM_S3, PLATFORM_GCS):
+ if self.platform in (PLATFORM_S3, PLATFORM_GCS, PLATFORM_ABS):
bucket_name = self.get_bucket_name(path)
bucket_key = self.gen_bucket_key(bucket_name)
yield from self.create_emit_containers(
container_key=bucket_key,
name=bucket_name,
- sub_types=[
- DatasetContainerSubTypes.S3_BUCKET
- if self.platform == "s3"
- else DatasetContainerSubTypes.GCS_BUCKET
- ],
+ sub_types=[self.get_sub_types()],
parent_container_key=None,
)
parent_key = bucket_key
- base_full_path = get_bucket_relative_path(path)
+ base_full_path = self.get_base_full_path(path)
parent_folder_path = (
base_full_path[: base_full_path.rfind("/")]
diff --git a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
index 7a807bde2ed0a..e21cdac1edf75 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/data_lake_common/path_spec.py
@@ -11,6 +11,7 @@
from datahub.configuration.common import ConfigModel
from datahub.ingestion.source.aws.s3_util import is_s3_uri
+from datahub.ingestion.source.azure.abs_util import is_abs_uri
from datahub.ingestion.source.gcs.gcs_utils import is_gcs_uri
# hide annoying debug errors from py4j
@@ -107,7 +108,7 @@ def dir_allowed(self, path: str) -> bool:
# glob_include = self.glob_include.rsplit("/", 1)[0]
glob_include = self.glob_include
- for i in range(slash_to_remove_from_glob):
+ for _ in range(slash_to_remove_from_glob):
glob_include = glob_include.rsplit("/", 1)[0]
logger.debug(f"Checking dir to inclusion: {path}")
@@ -169,7 +170,8 @@ def validate_default_extension(cls, v):
def turn_off_sampling_for_non_s3(cls, v, values):
is_s3 = is_s3_uri(values.get("include") or "")
is_gcs = is_gcs_uri(values.get("include") or "")
- if not is_s3 and not is_gcs:
+ is_abs = is_abs_uri(values.get("include") or "")
+ if not is_s3 and not is_gcs and not is_abs:
# Sampling only makes sense on s3 and gcs currently
v = False
return v
@@ -213,6 +215,10 @@ def is_s3(self):
def is_gcs(self):
return is_gcs_uri(self.include)
+ @cached_property
+ def is_abs(self):
+ return is_abs_uri(self.include)
+
@cached_property
def compiled_include(self):
parsable_include = PathSpec.get_parsable_include(self.include)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py b/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
index 1b6619b4c4d28..bc069bd1e59ac 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/looker/looker_file_loader.py
@@ -31,15 +31,12 @@ def __init__(
reporter: LookMLSourceReport,
liquid_variable: Dict[Any, Any],
) -> None:
- self.viewfile_cache: Dict[str, LookerViewFile] = {}
+ self.viewfile_cache: Dict[str, Optional[LookerViewFile]] = {}
self._root_project_name = root_project_name
self._base_projects_folder = base_projects_folder
self.reporter = reporter
self.liquid_variable = liquid_variable
- def is_view_seen(self, path: str) -> bool:
- return path in self.viewfile_cache
-
def _load_viewfile(
self, project_name: str, path: str, reporter: LookMLSourceReport
) -> Optional[LookerViewFile]:
@@ -56,17 +53,15 @@ def _load_viewfile(
)
return None
- if self.is_view_seen(str(path)):
+ if path in self.viewfile_cache:
return self.viewfile_cache[path]
try:
with open(path) as file:
raw_file_content = file.read()
except Exception as e:
- logger.debug(f"An error occurred while reading path {path}", exc_info=True)
- self.reporter.report_failure(
- path, f"failed to load view file {path} from disk: {e}"
- )
+ self.reporter.failure("Failed to read lkml file", path, exc=e)
+ self.viewfile_cache[path] = None
return None
try:
logger.debug(f"Loading viewfile {path}")
@@ -91,8 +86,8 @@ def _load_viewfile(
self.viewfile_cache[path] = looker_viewfile
return looker_viewfile
except Exception as e:
- logger.debug(f"An error occurred while parsing path {path}", exc_info=True)
- self.reporter.report_failure(path, f"failed to load view file {path}: {e}")
+ self.reporter.failure("Failed to parse lkml file", path, exc=e)
+ self.viewfile_cache[path] = None
return None
def load_viewfile(
diff --git a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
index 3d6c746183fd9..bd0bbe742a219 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
@@ -419,7 +419,7 @@ def generate(self) -> Iterable[MetadataWorkUnit]:
for mcp in self.aggregator.gen_metadata():
yield mcp.as_workunit()
if len(self.aggregator.report.observed_query_parse_failures) > 0:
- self.report.report_failure(
+ self.report.report_warning(
title="Failed to extract some SQL lineage",
message="Unexpected error(s) while attempting to extract lineage from SQL queries. See the full logs for more details.",
context=f"Query Parsing Failures: {self.aggregator.report.observed_query_parse_failures}",
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
index 2a1d18c83e6fa..a7c008d932a71 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_assertion.py
@@ -11,14 +11,13 @@
)
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.source.snowflake.snowflake_config import (
- SnowflakeIdentifierConfig,
- SnowflakeV2Config,
-)
+from datahub.ingestion.source.snowflake.snowflake_config import SnowflakeV2Config
from datahub.ingestion.source.snowflake.snowflake_connection import SnowflakeConnection
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeIdentifierMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeIdentifierBuilder,
+)
from datahub.metadata.com.linkedin.pegasus2avro.assertion import (
AssertionResult,
AssertionResultType,
@@ -40,23 +39,20 @@ class DataQualityMonitoringResult(BaseModel):
VALUE: int
-class SnowflakeAssertionsHandler(SnowflakeIdentifierMixin):
+class SnowflakeAssertionsHandler:
def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
+ identifiers: SnowflakeIdentifierBuilder,
) -> None:
self.config = config
self.report = report
- self.logger = logger
self.connection = connection
+ self.identifiers = identifiers
self._urns_processed: List[str] = []
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
-
def get_assertion_workunits(
self, discovered_datasets: List[str]
) -> Iterable[MetadataWorkUnit]:
@@ -80,10 +76,10 @@ def _gen_platform_instance_wu(self, urn: str) -> MetadataWorkUnit:
return MetadataChangeProposalWrapper(
entityUrn=urn,
aspect=DataPlatformInstance(
- platform=make_data_platform_urn(self.platform),
+ platform=make_data_platform_urn(self.identifiers.platform),
instance=(
make_dataplatform_instance_urn(
- self.platform, self.config.platform_instance
+ self.identifiers.platform, self.config.platform_instance
)
if self.config.platform_instance
else None
@@ -98,7 +94,7 @@ def _process_result_row(
result = DataQualityMonitoringResult.parse_obj(result_row)
assertion_guid = result.METRIC_NAME.split("__")[-1].lower()
status = bool(result.VALUE) # 1 if PASS, 0 if FAIL
- assertee = self.get_dataset_identifier(
+ assertee = self.identifiers.get_dataset_identifier(
result.TABLE_NAME, result.TABLE_SCHEMA, result.TABLE_DATABASE
)
if assertee in discovered_datasets:
@@ -107,7 +103,7 @@ def _process_result_row(
aspect=AssertionRunEvent(
timestampMillis=datetime_to_ts_millis(result.MEASUREMENT_TIME),
runId=result.MEASUREMENT_TIME.strftime("%Y-%m-%dT%H:%M:%SZ"),
- asserteeUrn=self.gen_dataset_urn(assertee),
+ asserteeUrn=self.identifiers.gen_dataset_urn(assertee),
status=AssertionRunStatus.COMPLETE,
assertionUrn=make_assertion_urn(assertion_guid),
result=AssertionResult(
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
index f6247eb949417..ac9164cd0a000 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_config.py
@@ -131,6 +131,7 @@ class SnowflakeIdentifierConfig(
# Changing default value here.
convert_urns_to_lowercase: bool = Field(
default=True,
+ description="Whether to convert dataset urns to lowercase.",
)
@@ -181,6 +182,11 @@ class SnowflakeV2Config(
description="If enabled, populates the snowflake usage statistics. Requires appropriate grants given to the role.",
)
+ include_view_definitions: bool = Field(
+ default=True,
+ description="If enabled, populates the ingested views' definitions.",
+ )
+
include_technical_schema: bool = Field(
default=True,
description="If enabled, populates the snowflake technical schema and descriptions.",
@@ -205,8 +211,13 @@ class SnowflakeV2Config(
description="Populates view->view and table->view column lineage using DataHub's sql parser.",
)
- lazy_schema_resolver: bool = Field(
+ use_queries_v2: bool = Field(
default=False,
+ description="If enabled, uses the new queries extractor to extract queries from snowflake.",
+ )
+
+ lazy_schema_resolver: bool = Field(
+ default=True,
description="If enabled, uses lazy schema resolver to resolve schemas for tables and views. "
"This is useful if you have a large number of schemas and want to avoid bulk fetching the schema for each table/view.",
)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
index 3e65f06200418..151e9fb631620 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_lineage_v2.py
@@ -2,7 +2,7 @@
import logging
from dataclasses import dataclass
from datetime import datetime
-from typing import Any, Callable, Collection, Iterable, List, Optional, Set, Tuple, Type
+from typing import Any, Collection, Iterable, List, Optional, Set, Tuple, Type
from pydantic import BaseModel, validator
@@ -21,7 +21,11 @@
)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeCommonMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantLineageRunSkipHandler,
)
@@ -119,18 +123,19 @@ def __init__(
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
redundant_run_skip_handler: Optional[RedundantLineageRunSkipHandler],
sql_aggregator: SqlParsingAggregator,
) -> None:
self.config = config
self.report = report
- self.logger = logger
- self.dataset_urn_builder = dataset_urn_builder
self.connection = connection
+ self.filters = filters
+ self.identifiers = identifiers
+ self.redundant_run_skip_handler = redundant_run_skip_handler
self.sql_aggregator = sql_aggregator
- self.redundant_run_skip_handler = redundant_run_skip_handler
self.start_time, self.end_time = (
self.report.lineage_start_time,
self.report.lineage_end_time,
@@ -210,7 +215,7 @@ def populate_known_query_lineage(
results: Iterable[UpstreamLineageEdge],
) -> None:
for db_row in results:
- dataset_name = self.get_dataset_identifier_from_qualified_name(
+ dataset_name = self.identifiers.get_dataset_identifier_from_qualified_name(
db_row.DOWNSTREAM_TABLE_NAME
)
if dataset_name not in discovered_assets or not db_row.QUERIES:
@@ -233,7 +238,7 @@ def get_known_query_lineage(
if not db_row.UPSTREAM_TABLES:
return None
- downstream_table_urn = self.dataset_urn_builder(dataset_name)
+ downstream_table_urn = self.identifiers.gen_dataset_urn(dataset_name)
known_lineage = KnownQueryLineageInfo(
query_text=query.query_text,
@@ -288,7 +293,7 @@ def _populate_external_lineage_from_show_query(
external_tables_query: str = SnowflakeQuery.show_external_tables()
try:
for db_row in self.connection.query(external_tables_query):
- key = self.get_dataset_identifier(
+ key = self.identifiers.get_dataset_identifier(
db_row["name"], db_row["schema_name"], db_row["database_name"]
)
@@ -299,16 +304,16 @@ def _populate_external_lineage_from_show_query(
upstream_urn=make_s3_urn_for_lineage(
db_row["location"], self.config.env
),
- downstream_urn=self.dataset_urn_builder(key),
+ downstream_urn=self.identifiers.gen_dataset_urn(key),
)
self.report.num_external_table_edges_scanned += 1
self.report.num_external_table_edges_scanned += 1
except Exception as e:
logger.debug(e, exc_info=e)
- self.report_warning(
- "external_lineage",
- f"Populating external table lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Error populating external table lineage from Snowflake",
+ exc=e,
)
self.report_status(EXTERNAL_LINEAGE, False)
@@ -328,41 +333,47 @@ def _populate_external_lineage_from_copy_history(
try:
for db_row in self.connection.query(query):
known_lineage_mapping = self._process_external_lineage_result_row(
- db_row, discovered_tables
+ db_row, discovered_tables, identifiers=self.identifiers
)
if known_lineage_mapping:
+ self.report.num_external_table_edges_scanned += 1
yield known_lineage_mapping
except Exception as e:
if isinstance(e, SnowflakePermissionError):
error_msg = "Failed to get external lineage. Please grant imported privileges on SNOWFLAKE database. "
self.warn_if_stateful_else_error(LINEAGE_PERMISSION_ERROR, error_msg)
else:
- logger.debug(e, exc_info=e)
- self.report_warning(
- "external_lineage",
- f"Populating table external lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Error fetching external lineage from Snowflake",
+ exc=e,
)
self.report_status(EXTERNAL_LINEAGE, False)
+ @classmethod
def _process_external_lineage_result_row(
- self, db_row: dict, discovered_tables: List[str]
+ cls,
+ db_row: dict,
+ discovered_tables: Optional[List[str]],
+ identifiers: SnowflakeIdentifierBuilder,
) -> Optional[KnownLineageMapping]:
# key is the down-stream table name
- key: str = self.get_dataset_identifier_from_qualified_name(
+ key: str = identifiers.get_dataset_identifier_from_qualified_name(
db_row["DOWNSTREAM_TABLE_NAME"]
)
- if key not in discovered_tables:
+ if discovered_tables is not None and key not in discovered_tables:
return None
if db_row["UPSTREAM_LOCATIONS"] is not None:
external_locations = json.loads(db_row["UPSTREAM_LOCATIONS"])
+ loc: str
for loc in external_locations:
if loc.startswith("s3://"):
- self.report.num_external_table_edges_scanned += 1
return KnownLineageMapping(
- upstream_urn=make_s3_urn_for_lineage(loc, self.config.env),
- downstream_urn=self.dataset_urn_builder(key),
+ upstream_urn=make_s3_urn_for_lineage(
+ loc, identifiers.identifier_config.env
+ ),
+ downstream_urn=identifiers.gen_dataset_urn(key),
)
return None
@@ -388,10 +399,9 @@ def _fetch_upstream_lineages_for_tables(self) -> Iterable[UpstreamLineageEdge]:
error_msg = "Failed to get table/view to table lineage. Please grant imported privileges on SNOWFLAKE database. "
self.warn_if_stateful_else_error(LINEAGE_PERMISSION_ERROR, error_msg)
else:
- logger.debug(e, exc_info=e)
- self.report_warning(
- "table-upstream-lineage",
- f"Extracting lineage from Snowflake failed due to error {e}.",
+ self.structured_reporter.warning(
+ "Failed to extract table/view -> table lineage from Snowflake",
+ exc=e,
)
self.report_status(TABLE_LINEAGE, False)
@@ -402,9 +412,10 @@ def _process_upstream_lineage_row(
return UpstreamLineageEdge.parse_obj(db_row)
except Exception as e:
self.report.num_upstream_lineage_edge_parsing_failed += 1
- self.report_warning(
- f"Parsing lineage edge failed due to error {e}",
- db_row.get("DOWNSTREAM_TABLE_NAME") or "",
+ self.structured_reporter.warning(
+ "Failed to parse lineage edge",
+ context=db_row.get("DOWNSTREAM_TABLE_NAME") or None,
+ exc=e,
)
return None
@@ -417,17 +428,21 @@ def map_query_result_upstreams(
for upstream_table in upstream_tables:
if upstream_table and upstream_table.query_id == query_id:
try:
- upstream_name = self.get_dataset_identifier_from_qualified_name(
- upstream_table.upstream_object_name
+ upstream_name = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ upstream_table.upstream_object_name
+ )
)
if upstream_name and (
not self.config.validate_upstreams_against_patterns
- or self.is_dataset_pattern_allowed(
+ or self.filters.is_dataset_pattern_allowed(
upstream_name,
upstream_table.upstream_object_domain,
)
):
- upstreams.append(self.dataset_urn_builder(upstream_name))
+ upstreams.append(
+ self.identifiers.gen_dataset_urn(upstream_name)
+ )
except Exception as e:
logger.debug(e, exc_info=e)
return upstreams
@@ -491,7 +506,7 @@ def build_finegrained_lineage(
return None
column_lineage = ColumnLineageInfo(
downstream=DownstreamColumnRef(
- table=dataset_urn, column=self.snowflake_identifier(col)
+ table=dataset_urn, column=self.identifiers.snowflake_identifier(col)
),
upstreams=sorted(column_upstreams),
)
@@ -508,19 +523,23 @@ def build_finegrained_lineage_upstreams(
and upstream_col.column_name
and (
not self.config.validate_upstreams_against_patterns
- or self.is_dataset_pattern_allowed(
+ or self.filters.is_dataset_pattern_allowed(
upstream_col.object_name,
upstream_col.object_domain,
)
)
):
- upstream_dataset_name = self.get_dataset_identifier_from_qualified_name(
- upstream_col.object_name
+ upstream_dataset_name = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ upstream_col.object_name
+ )
)
column_upstreams.append(
ColumnRef(
- table=self.dataset_urn_builder(upstream_dataset_name),
- column=self.snowflake_identifier(upstream_col.column_name),
+ table=self.identifiers.gen_dataset_urn(upstream_dataset_name),
+ column=self.identifiers.snowflake_identifier(
+ upstream_col.column_name
+ ),
)
)
return column_upstreams
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
index 4deeb9f96f48e..422bda5284dbc 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_profiler.py
@@ -37,7 +37,6 @@ def __init__(
super().__init__(config, report, self.platform, state_handler)
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
- self.logger = logger
self.database_default_schema: Dict[str, str] = dict()
def get_workunits(
@@ -86,7 +85,7 @@ def get_workunits(
)
def get_dataset_name(self, table_name: str, schema_name: str, db_name: str) -> str:
- return self.get_dataset_identifier(table_name, schema_name, db_name)
+ return self.identifiers.get_dataset_identifier(table_name, schema_name, db_name)
def get_batch_kwargs(
self, table: BaseTable, schema_name: str, db_name: str
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
index c647a624a5467..d5b8f98e40075 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_queries.py
@@ -1,3 +1,4 @@
+import dataclasses
import functools
import json
import logging
@@ -11,6 +12,7 @@
import pydantic
from typing_extensions import Self
+from datahub.configuration.common import ConfigModel
from datahub.configuration.time_window_config import (
BaseTimeWindowConfig,
BucketDuration,
@@ -20,6 +22,7 @@
from datahub.ingestion.api.source import Source, SourceReport
from datahub.ingestion.api.source_helpers import auto_workunit
from datahub.ingestion.api.workunit import MetadataWorkUnit
+from datahub.ingestion.graph.client import DataHubGraph
from datahub.ingestion.source.snowflake.constants import SnowflakeObjectDomain
from datahub.ingestion.source.snowflake.snowflake_config import (
DEFAULT_TEMP_TABLES_PATTERNS,
@@ -30,13 +33,18 @@
SnowflakeConnection,
SnowflakeConnectionConfig,
)
+from datahub.ingestion.source.snowflake.snowflake_lineage_v2 import (
+ SnowflakeLineageExtractor,
+)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_utils import (
- SnowflakeFilterMixin,
- SnowflakeIdentifierMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+ SnowflakeStructuredReportMixin,
)
from datahub.ingestion.source.usage.usage_common import BaseUsageConfig
from datahub.metadata.urns import CorpUserUrn
+from datahub.sql_parsing.schema_resolver import SchemaResolver
from datahub.sql_parsing.sql_parsing_aggregator import (
KnownLineageMapping,
PreparsedQuery,
@@ -50,11 +58,12 @@
DownstreamColumnRef,
)
from datahub.utilities.file_backed_collections import ConnectionWrapper, FileBackedList
+from datahub.utilities.perf_timer import PerfTimer
logger = logging.getLogger(__name__)
-class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilterConfig):
+class SnowflakeQueriesExtractorConfig(ConfigModel):
# TODO: Support stateful ingestion for the time windows.
window: BaseTimeWindowConfig = BaseTimeWindowConfig()
@@ -76,12 +85,6 @@ class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilter
hidden_from_docs=True,
)
- convert_urns_to_lowercase: bool = pydantic.Field(
- # Override the default.
- default=True,
- description="Whether to convert dataset urns to lowercase.",
- )
-
include_lineage: bool = True
include_queries: bool = True
include_usage_statistics: bool = True
@@ -89,40 +92,56 @@ class SnowflakeQueriesExtractorConfig(SnowflakeIdentifierConfig, SnowflakeFilter
include_operations: bool = True
-class SnowflakeQueriesSourceConfig(SnowflakeQueriesExtractorConfig):
+class SnowflakeQueriesSourceConfig(
+ SnowflakeQueriesExtractorConfig, SnowflakeIdentifierConfig, SnowflakeFilterConfig
+):
connection: SnowflakeConnectionConfig
@dataclass
class SnowflakeQueriesExtractorReport(Report):
- window: Optional[BaseTimeWindowConfig] = None
+ copy_history_fetch_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ query_log_fetch_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ audit_log_load_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
sql_aggregator: Optional[SqlAggregatorReport] = None
@dataclass
class SnowflakeQueriesSourceReport(SourceReport):
+ window: Optional[BaseTimeWindowConfig] = None
queries_extractor: Optional[SnowflakeQueriesExtractorReport] = None
-class SnowflakeQueriesExtractor(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
+class SnowflakeQueriesExtractor(SnowflakeStructuredReportMixin):
def __init__(
self,
connection: SnowflakeConnection,
config: SnowflakeQueriesExtractorConfig,
structured_report: SourceReport,
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
+ graph: Optional[DataHubGraph] = None,
+ schema_resolver: Optional[SchemaResolver] = None,
+ discovered_tables: Optional[List[str]] = None,
):
self.connection = connection
self.config = config
self.report = SnowflakeQueriesExtractorReport()
+ self.filters = filters
+ self.identifiers = identifiers
+ self.discovered_tables = discovered_tables
+
self._structured_report = structured_report
self.aggregator = SqlParsingAggregator(
- platform=self.platform,
- platform_instance=self.config.platform_instance,
- env=self.config.env,
- # graph=self.ctx.graph,
+ platform=self.identifiers.platform,
+ platform_instance=self.identifiers.identifier_config.platform_instance,
+ env=self.identifiers.identifier_config.env,
+ schema_resolver=schema_resolver,
+ graph=graph,
+ eager_graph_load=False,
generate_lineage=self.config.include_lineage,
generate_queries=self.config.include_queries,
generate_usage_statistics=self.config.include_usage_statistics,
@@ -144,14 +163,6 @@ def __init__(
def structured_reporter(self) -> SourceReport:
return self._structured_report
- @property
- def filter_config(self) -> SnowflakeFilterConfig:
- return self.config
-
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
-
@functools.cached_property
def local_temp_path(self) -> pathlib.Path:
if self.config.local_temp_path:
@@ -170,13 +181,16 @@ def is_temp_table(self, name: str) -> bool:
)
def is_allowed_table(self, name: str) -> bool:
- return self.is_dataset_pattern_allowed(name, SnowflakeObjectDomain.TABLE)
+ if self.discovered_tables and name not in self.discovered_tables:
+ return False
+
+ return self.filters.is_dataset_pattern_allowed(
+ name, SnowflakeObjectDomain.TABLE
+ )
def get_workunits_internal(
self,
) -> Iterable[MetadataWorkUnit]:
- self.report.window = self.config.window
-
# TODO: Add some logic to check if the cached audit log is stale or not.
audit_log_file = self.local_temp_path / "audit_log.sqlite"
use_cached_audit_log = audit_log_file.exists()
@@ -191,74 +205,90 @@ def get_workunits_internal(
shared_connection = ConnectionWrapper(audit_log_file)
queries = FileBackedList(shared_connection)
+ entry: Union[KnownLineageMapping, PreparsedQuery]
+
+ with self.report.copy_history_fetch_timer:
+ for entry in self.fetch_copy_history():
+ queries.append(entry)
- logger.info("Fetching audit log")
- for entry in self.fetch_audit_log():
- queries.append(entry)
+ # TODO: Add "show external tables" lineage to the main schema extractor.
+ # Because it's not a time-based thing, it doesn't really make sense in the snowflake-queries extractor.
- for query in queries:
- self.aggregator.add(query)
+ with self.report.query_log_fetch_timer:
+ for entry in self.fetch_query_log():
+ queries.append(entry)
+
+ with self.report.audit_log_load_timer:
+ for query in queries:
+ self.aggregator.add(query)
yield from auto_workunit(self.aggregator.gen_metadata())
- def fetch_audit_log(
- self,
- ) -> Iterable[Union[KnownLineageMapping, PreparsedQuery]]:
- """
- # TODO: we need to fetch this info from somewhere
- discovered_tables = []
-
- snowflake_lineage_v2 = SnowflakeLineageExtractor(
- config=self.config, # type: ignore
- report=self.report, # type: ignore
- dataset_urn_builder=self.gen_dataset_urn,
- redundant_run_skip_handler=None,
- sql_aggregator=self.aggregator, # TODO this should be unused
- )
+ def fetch_copy_history(self) -> Iterable[KnownLineageMapping]:
+ # Derived from _populate_external_lineage_from_copy_history.
- for (
- known_lineage_mapping
- ) in snowflake_lineage_v2._populate_external_lineage_from_copy_history(
- discovered_tables=discovered_tables
- ):
- interim_results.append(known_lineage_mapping)
+ query: str = SnowflakeQuery.copy_lineage_history(
+ start_time_millis=int(self.config.window.start_time.timestamp() * 1000),
+ end_time_millis=int(self.config.window.end_time.timestamp() * 1000),
+ downstreams_deny_pattern=self.config.temporary_tables_pattern,
+ )
- for (
- known_lineage_mapping
- ) in snowflake_lineage_v2._populate_external_lineage_from_show_query(
- discovered_tables=discovered_tables
+ with self.structured_reporter.report_exc(
+ "Error fetching copy history from Snowflake"
):
- interim_results.append(known_lineage_mapping)
- """
+ logger.info("Fetching copy history from Snowflake")
+ resp = self.connection.query(query)
+
+ for row in resp:
+ try:
+ result = (
+ SnowflakeLineageExtractor._process_external_lineage_result_row(
+ row,
+ discovered_tables=self.discovered_tables,
+ identifiers=self.identifiers,
+ )
+ )
+ except Exception as e:
+ self.structured_reporter.warning(
+ "Error parsing copy history row",
+ context=f"{row}",
+ exc=e,
+ )
+ else:
+ if result:
+ yield result
- audit_log_query = _build_enriched_audit_log_query(
+ def fetch_query_log(
+ self,
+ ) -> Iterable[PreparsedQuery]:
+ query_log_query = _build_enriched_query_log_query(
start_time=self.config.window.start_time,
end_time=self.config.window.end_time,
bucket_duration=self.config.window.bucket_duration,
deny_usernames=self.config.deny_usernames,
)
- resp = self.connection.query(audit_log_query)
-
- for i, row in enumerate(resp):
- if i % 1000 == 0:
- logger.info(f"Processed {i} audit log rows")
-
- assert isinstance(row, dict)
- try:
- entry = self._parse_audit_log_row(row)
- except Exception as e:
- self.structured_reporter.warning(
- "Error parsing audit log row",
- context=f"{row}",
- exc=e,
- )
- else:
- yield entry
-
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- # Copied from SnowflakeCommonMixin.
- return self.snowflake_identifier(self.cleanup_qualified_name(qualified_name))
+ with self.structured_reporter.report_exc(
+ "Error fetching query log from Snowflake"
+ ):
+ logger.info("Fetching query log from Snowflake")
+ resp = self.connection.query(query_log_query)
+
+ for i, row in enumerate(resp):
+ if i % 1000 == 0:
+ logger.info(f"Processed {i} query log rows")
+
+ assert isinstance(row, dict)
+ try:
+ entry = self._parse_audit_log_row(row)
+ except Exception as e:
+ self.structured_reporter.warning(
+ "Error parsing query log row",
+ context=f"{row}",
+ exc=e,
+ )
+ else:
+ yield entry
def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
json_fields = {
@@ -280,13 +310,17 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
column_usage = {}
for obj in direct_objects_accessed:
- dataset = self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(obj["objectName"])
+ dataset = self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ obj["objectName"]
+ )
)
columns = set()
for modified_column in obj["columns"]:
- columns.add(self.snowflake_identifier(modified_column["columnName"]))
+ columns.add(
+ self.identifiers.snowflake_identifier(modified_column["columnName"])
+ )
upstreams.append(dataset)
column_usage[dataset] = columns
@@ -301,8 +335,10 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
context=f"{row}",
)
- downstream = self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(obj["objectName"])
+ downstream = self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ obj["objectName"]
+ )
)
column_lineage = []
for modified_column in obj["columns"]:
@@ -310,18 +346,18 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
ColumnLineageInfo(
downstream=DownstreamColumnRef(
dataset=downstream,
- column=self.snowflake_identifier(
+ column=self.identifiers.snowflake_identifier(
modified_column["columnName"]
),
),
upstreams=[
ColumnRef(
- table=self.gen_dataset_urn(
- self.get_dataset_identifier_from_qualified_name(
+ table=self.identifiers.gen_dataset_urn(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
upstream["objectName"]
)
),
- column=self.snowflake_identifier(
+ column=self.identifiers.snowflake_identifier(
upstream["columnName"]
),
)
@@ -332,12 +368,9 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
)
)
- # TODO: Support filtering the table names.
- # if objects_modified:
- # breakpoint()
-
- # TODO implement email address mapping
- user = CorpUserUrn(res["user_name"])
+ # TODO: Fetch email addresses from Snowflake to map user -> email
+ # TODO: Support email_domain fallback for generating user urns.
+ user = CorpUserUrn(self.identifiers.snowflake_identifier(res["user_name"]))
timestamp: datetime = res["query_start_time"]
timestamp = timestamp.astimezone(timezone.utc)
@@ -348,14 +381,18 @@ def _parse_audit_log_row(self, row: Dict[str, Any]) -> PreparsedQuery:
)
entry = PreparsedQuery(
- query_id=res["query_fingerprint"],
+ # Despite having Snowflake's fingerprints available, our own fingerprinting logic does a better
+ # job at eliminating redundant / repetitive queries. As such, we don't include the fingerprint
+ # here so that the aggregator auto-generates one.
+ # query_id=res["query_fingerprint"],
+ query_id=None,
query_text=res["query_text"],
upstreams=upstreams,
downstream=downstream,
column_lineage=column_lineage,
column_usage=column_usage,
inferred_schema=None,
- confidence_score=1,
+ confidence_score=1.0,
query_count=res["query_count"],
user=user,
timestamp=timestamp,
@@ -371,7 +408,14 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeQueriesSourceConfig):
self.config = config
self.report = SnowflakeQueriesSourceReport()
- self.platform = "snowflake"
+ self.filters = SnowflakeFilter(
+ filter_config=self.config,
+ structured_reporter=self.report,
+ )
+ self.identifiers = SnowflakeIdentifierBuilder(
+ identifier_config=self.config,
+ structured_reporter=self.report,
+ )
self.connection = self.config.connection.get_connection()
@@ -379,6 +423,9 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeQueriesSourceConfig):
connection=self.connection,
config=self.config,
structured_report=self.report,
+ filters=self.filters,
+ identifiers=self.identifiers,
+ graph=self.ctx.graph,
)
self.report.queries_extractor = self.queries_extractor.report
@@ -388,6 +435,8 @@ def create(cls, config_dict: dict, ctx: PipelineContext) -> Self:
return cls(ctx, config)
def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
+ self.report.window = self.config.window
+
# TODO: Disable auto status processor?
return self.queries_extractor.get_workunits_internal()
@@ -399,7 +448,7 @@ def get_report(self) -> SnowflakeQueriesSourceReport:
_MAX_TABLES_PER_QUERY = 20
-def _build_enriched_audit_log_query(
+def _build_enriched_query_log_query(
start_time: datetime,
end_time: datetime,
bucket_duration: BucketDuration,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
index 4924546383aa4..80b6be36e5ffa 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_report.py
@@ -15,6 +15,9 @@
from datahub.utilities.perf_timer import PerfTimer
if TYPE_CHECKING:
+ from datahub.ingestion.source.snowflake.snowflake_queries import (
+ SnowflakeQueriesExtractorReport,
+ )
from datahub.ingestion.source.snowflake.snowflake_schema import (
SnowflakeDataDictionary,
)
@@ -113,6 +116,8 @@ class SnowflakeV2Report(
data_dictionary_cache: Optional["SnowflakeDataDictionary"] = None
+ queries_extractor: Optional["SnowflakeQueriesExtractorReport"] = None
+
# These will be non-zero if snowflake information_schema queries fail with error -
# "Information schema query returned too much data. Please repeat query with more selective predicates.""
# This will result in overall increase in time complexity
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
index ce8f20d23aa6b..600292c2c9942 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema.py
@@ -185,8 +185,6 @@ def get_column_tags_for_table(
class SnowflakeDataDictionary(SupportsAsObj):
def __init__(self, connection: SnowflakeConnection) -> None:
- self.logger = logger
-
self.connection = connection
def as_obj(self) -> Dict[str, Dict[str, int]]:
@@ -514,7 +512,7 @@ def get_tags_for_database_without_propagation(
)
else:
# This should never happen.
- self.logger.error(f"Encountered an unexpected domain: {domain}")
+ logger.error(f"Encountered an unexpected domain: {domain}")
continue
return tags
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
index e604ed96b8eb6..1d4a5b377da14 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_schema_gen.py
@@ -1,8 +1,6 @@
-import concurrent.futures
import itertools
import logging
-import queue
-from typing import Callable, Dict, Iterable, List, Optional, Union
+from typing import Dict, Iterable, List, Optional, Union
from datahub.configuration.pattern_utils import is_schema_allowed
from datahub.emitter.mce_builder import (
@@ -28,8 +26,6 @@
SnowflakeObjectDomain,
)
from datahub.ingestion.source.snowflake.snowflake_config import (
- SnowflakeFilterConfig,
- SnowflakeIdentifierConfig,
SnowflakeV2Config,
TagOption,
)
@@ -54,8 +50,9 @@
)
from datahub.ingestion.source.snowflake.snowflake_tag import SnowflakeTagExtractor
from datahub.ingestion.source.snowflake.snowflake_utils import (
- SnowflakeFilterMixin,
- SnowflakeIdentifierMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+ SnowflakeStructuredReportMixin,
SnowsightUrlBuilder,
)
from datahub.ingestion.source.sql.sql_utils import (
@@ -101,6 +98,7 @@
from datahub.metadata.com.linkedin.pegasus2avro.tag import TagProperties
from datahub.sql_parsing.sql_parsing_aggregator import SqlParsingAggregator
from datahub.utilities.registries.domain_registry import DomainRegistry
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
logger = logging.getLogger(__name__)
@@ -143,13 +141,16 @@
}
-class SnowflakeSchemaGenerator(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
+class SnowflakeSchemaGenerator(SnowflakeStructuredReportMixin):
+ platform = "snowflake"
+
def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filters: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
domain_registry: Optional[DomainRegistry],
profiler: Optional[SnowflakeProfiler],
aggregator: Optional[SqlParsingAggregator],
@@ -158,7 +159,8 @@ def __init__(
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
self.connection: SnowflakeConnection = connection
- self.dataset_urn_builder = dataset_urn_builder
+ self.filters: SnowflakeFilter = filters
+ self.identifiers: SnowflakeIdentifierBuilder = identifiers
self.data_dictionary: SnowflakeDataDictionary = SnowflakeDataDictionary(
connection=self.connection
@@ -186,19 +188,17 @@ def get_connection(self) -> SnowflakeConnection:
def structured_reporter(self) -> SourceReport:
return self.report
- @property
- def filter_config(self) -> SnowflakeFilterConfig:
- return self.config
+ def gen_dataset_urn(self, dataset_identifier: str) -> str:
+ return self.identifiers.gen_dataset_urn(dataset_identifier)
- @property
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- return self.config
+ def snowflake_identifier(self, identifier: str) -> str:
+ return self.identifiers.snowflake_identifier(identifier)
def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
self.databases = []
for database in self.get_databases() or []:
self.report.report_entity_scanned(database.name, "database")
- if not self.filter_config.database_pattern.allowed(database.name):
+ if not self.filters.filter_config.database_pattern.allowed(database.name):
self.report.report_dropped(f"{database.name}.*")
else:
self.databases.append(database)
@@ -212,7 +212,10 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
yield from self._process_database(snowflake_db)
except SnowflakePermissionError as e:
- self.report_error(GENERIC_PERMISSION_ERROR_KEY, str(e))
+ self.structured_reporter.failure(
+ GENERIC_PERMISSION_ERROR_KEY,
+ exc=e,
+ )
return
def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
@@ -221,10 +224,9 @@ def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
# whose information_schema can be queried to start with.
databases = self.data_dictionary.show_databases()
except Exception as e:
- logger.debug(f"Failed to list databases due to error {e}", exc_info=e)
- self.report_error(
- "list-databases",
- f"Failed to list databases due to error {e}",
+ self.structured_reporter.failure(
+ "Failed to list databases",
+ exc=e,
)
return None
else:
@@ -233,7 +235,7 @@ def get_databases(self) -> Optional[List[SnowflakeDatabase]]:
] = self.get_databases_from_ischema(databases)
if len(ischema_databases) == 0:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
"No databases found. Please check permissions.",
)
@@ -276,7 +278,7 @@ def _process_database(
# This may happen if REFERENCE_USAGE permissions are set
# We can not run show queries on database in such case.
# This need not be a failure case.
- self.report_warning(
+ self.structured_reporter.warning(
"Insufficient privileges to operate on database, skipping. Please grant USAGE permissions on database to extract its metadata.",
db_name,
)
@@ -285,9 +287,8 @@ def _process_database(
f"Failed to use database {db_name} due to error {e}",
exc_info=e,
)
- self.report_warning(
- "Failed to get schemas for database",
- db_name,
+ self.structured_reporter.warning(
+ "Failed to get schemas for database", db_name, exc=e
)
return
@@ -318,41 +319,22 @@ def _process_db_schemas(
snowflake_db: SnowflakeDatabase,
db_tables: Dict[str, List[SnowflakeTable]],
) -> Iterable[MetadataWorkUnit]:
- q: "queue.Queue[MetadataWorkUnit]" = queue.Queue(maxsize=100)
-
- def _process_schema_worker(snowflake_schema: SnowflakeSchema) -> None:
+ def _process_schema_worker(
+ snowflake_schema: SnowflakeSchema,
+ ) -> Iterable[MetadataWorkUnit]:
for wu in self._process_schema(
snowflake_schema, snowflake_db.name, db_tables
):
- q.put(wu)
-
- with concurrent.futures.ThreadPoolExecutor(
- max_workers=SCHEMA_PARALLELISM
- ) as executor:
- futures = []
- for snowflake_schema in snowflake_db.schemas:
- f = executor.submit(_process_schema_worker, snowflake_schema)
- futures.append(f)
-
- # Read from the queue and yield the work units until all futures are done.
- while True:
- if not q.empty():
- while not q.empty():
- yield q.get_nowait()
- else:
- try:
- yield q.get(timeout=0.2)
- except queue.Empty:
- pass
-
- # Filter out the done futures.
- futures = [f for f in futures if not f.done()]
- if not futures:
- break
+ yield wu
- # Yield the remaining work units. This theoretically should not happen, but adding it just in case.
- while not q.empty():
- yield q.get_nowait()
+ for wu in ThreadedIteratorExecutor.process(
+ worker_func=_process_schema_worker,
+ args_list=[
+ (snowflake_schema,) for snowflake_schema in snowflake_db.schemas
+ ],
+ max_workers=SCHEMA_PARALLELISM,
+ ):
+ yield wu
def fetch_schemas_for_database(
self, snowflake_db: SnowflakeDatabase, db_name: str
@@ -362,10 +344,10 @@ def fetch_schemas_for_database(
for schema in self.data_dictionary.get_schemas_for_database(db_name):
self.report.report_entity_scanned(schema.name, "schema")
if not is_schema_allowed(
- self.filter_config.schema_pattern,
+ self.filters.filter_config.schema_pattern,
schema.name,
db_name,
- self.filter_config.match_fully_qualified_names,
+ self.filters.filter_config.match_fully_qualified_names,
):
self.report.report_dropped(f"{db_name}.{schema.name}.*")
else:
@@ -376,17 +358,14 @@ def fetch_schemas_for_database(
# Ideal implementation would use PEP 678 – Enriching Exceptions with Notes
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get schemas for database {db_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get schemas for database",
db_name,
+ exc=e,
)
if not schemas:
- self.report_warning(
+ self.structured_reporter.warning(
"No schemas found in database. If schemas exist, please grant USAGE permissions on them.",
db_name,
)
@@ -441,12 +420,12 @@ def _process_schema(
and self.config.parse_view_ddl
):
for view in views:
- view_identifier = self.get_dataset_identifier(
+ view_identifier = self.identifiers.get_dataset_identifier(
view.name, schema_name, db_name
)
if view.view_definition:
self.aggregator.add_view_definition(
- view_urn=self.dataset_urn_builder(view_identifier),
+ view_urn=self.identifiers.gen_dataset_urn(view_identifier),
view_definition=view.view_definition,
default_db=db_name,
default_schema=schema_name,
@@ -461,9 +440,10 @@ def _process_schema(
yield from self._process_tag(tag)
if not snowflake_schema.views and not snowflake_schema.tables:
- self.report_warning(
- "No tables/views found in schema. If tables exist, please grant REFERENCES or SELECT permissions on them.",
- f"{db_name}.{schema_name}",
+ self.structured_reporter.warning(
+ title="No tables/views found in schema",
+ message="If tables exist, please grant REFERENCES or SELECT permissions on them.",
+ context=f"{db_name}.{schema_name}",
)
def fetch_views_for_schema(
@@ -472,11 +452,13 @@ def fetch_views_for_schema(
try:
views: List[SnowflakeView] = []
for view in self.get_views_for_schema(schema_name, db_name):
- view_name = self.get_dataset_identifier(view.name, schema_name, db_name)
+ view_name = self.identifiers.get_dataset_identifier(
+ view.name, schema_name, db_name
+ )
self.report.report_entity_scanned(view_name, "view")
- if not self.filter_config.view_pattern.allowed(view_name):
+ if not self.filters.filter_config.view_pattern.allowed(view_name):
self.report.report_dropped(view_name)
else:
views.append(view)
@@ -489,13 +471,10 @@ def fetch_views_for_schema(
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get views for schema {db_name}.{schema_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get views for schema",
f"{db_name}.{schema_name}",
+ exc=e,
)
return []
@@ -505,11 +484,13 @@ def fetch_tables_for_schema(
try:
tables: List[SnowflakeTable] = []
for table in self.get_tables_for_schema(schema_name, db_name):
- table_identifier = self.get_dataset_identifier(
+ table_identifier = self.identifiers.get_dataset_identifier(
table.name, schema_name, db_name
)
self.report.report_entity_scanned(table_identifier)
- if not self.filter_config.table_pattern.allowed(table_identifier):
+ if not self.filters.filter_config.table_pattern.allowed(
+ table_identifier
+ ):
self.report.report_dropped(table_identifier)
else:
tables.append(table)
@@ -521,13 +502,10 @@ def fetch_tables_for_schema(
error_msg = f"Failed to get tables for schema {db_name}.{schema_name}. Please check permissions."
raise SnowflakePermissionError(error_msg) from e.__cause__
else:
- logger.debug(
- f"Failed to get tables for schema {db_name}.{schema_name} due to error {e}",
- exc_info=e,
- )
- self.report_warning(
+ self.structured_reporter.warning(
"Failed to get tables for schema",
f"{db_name}.{schema_name}",
+ exc=e,
)
return []
@@ -546,7 +524,9 @@ def _process_table(
db_name: str,
) -> Iterable[MetadataWorkUnit]:
schema_name = snowflake_schema.name
- table_identifier = self.get_dataset_identifier(table.name, schema_name, db_name)
+ table_identifier = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
try:
table.columns = self.get_columns_for_table(
@@ -558,11 +538,9 @@ def _process_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get columns for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get columns for table", table_identifier, exc=e
)
- self.report_warning("Failed to get columns for table", table_identifier)
if self.config.extract_tags != TagOption.skip:
table.tags = self.tag_extractor.get_tags_on_object(
@@ -595,11 +573,9 @@ def fetch_foreign_keys_for_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get foreign key for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get foreign keys for table", table_identifier, exc=e
)
- self.report_warning("Failed to get foreign key for table", table_identifier)
def fetch_pk_for_table(
self,
@@ -613,11 +589,9 @@ def fetch_pk_for_table(
table.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get primary key for table {table_identifier} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get primary key for table", table_identifier, exc=e
)
- self.report_warning("Failed to get primary key for table", table_identifier)
def _process_view(
self,
@@ -626,7 +600,9 @@ def _process_view(
db_name: str,
) -> Iterable[MetadataWorkUnit]:
schema_name = snowflake_schema.name
- view_name = self.get_dataset_identifier(view.name, schema_name, db_name)
+ view_name = self.identifiers.get_dataset_identifier(
+ view.name, schema_name, db_name
+ )
try:
view.columns = self.get_columns_for_table(
@@ -637,11 +613,9 @@ def _process_view(
view.name, schema_name, db_name
)
except Exception as e:
- logger.debug(
- f"Failed to get columns for view {view_name} due to error {e}",
- exc_info=e,
+ self.structured_reporter.warning(
+ "Failed to get columns for view", view_name, exc=e
)
- self.report_warning("Failed to get columns for view", view_name)
if self.config.extract_tags != TagOption.skip:
view.tags = self.tag_extractor.get_tags_on_object(
@@ -677,8 +651,10 @@ def gen_dataset_workunits(
for tag in table.column_tags[column_name]:
yield from self._process_tag(tag)
- dataset_name = self.get_dataset_identifier(table.name, schema_name, db_name)
- dataset_urn = self.dataset_urn_builder(dataset_name)
+ dataset_name = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
+ dataset_urn = self.identifiers.gen_dataset_urn(dataset_name)
status = Status(removed=False)
yield MetadataChangeProposalWrapper(
@@ -753,7 +729,11 @@ def gen_dataset_workunits(
view_properties_aspect = ViewProperties(
materialized=table.materialized,
viewLanguage="SQL",
- viewLogic=table.view_definition,
+ viewLogic=(
+ table.view_definition
+ if self.config.include_view_definitions
+ else ""
+ ),
)
yield MetadataChangeProposalWrapper(
@@ -815,8 +795,10 @@ def gen_schema_metadata(
schema_name: str,
db_name: str,
) -> SchemaMetadata:
- dataset_name = self.get_dataset_identifier(table.name, schema_name, db_name)
- dataset_urn = self.dataset_urn_builder(dataset_name)
+ dataset_name = self.identifiers.get_dataset_identifier(
+ table.name, schema_name, db_name
+ )
+ dataset_urn = self.identifiers.gen_dataset_urn(dataset_name)
foreign_keys: Optional[List[ForeignKeyConstraint]] = None
if isinstance(table, SnowflakeTable) and len(table.foreign_keys) > 0:
@@ -875,7 +857,7 @@ def build_foreign_keys(
for fk in table.foreign_keys:
foreign_dataset = make_dataset_urn_with_platform_instance(
platform=self.platform,
- name=self.get_dataset_identifier(
+ name=self.identifiers.get_dataset_identifier(
fk.referred_table, fk.referred_schema, fk.referred_database
),
env=self.config.env,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
index dad0ce7b59ee1..794a6f4a59f46 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_shares.py
@@ -1,5 +1,5 @@
import logging
-from typing import Callable, Iterable, List
+from typing import Iterable, List
from datahub.emitter.mce_builder import make_dataset_urn_with_platform_instance
from datahub.emitter.mcp import MetadataChangeProposalWrapper
@@ -26,12 +26,9 @@ def __init__(
self,
config: SnowflakeV2Config,
report: SnowflakeV2Report,
- dataset_urn_builder: Callable[[str], str],
) -> None:
self.config = config
self.report = report
- self.logger = logger
- self.dataset_urn_builder = dataset_urn_builder
def get_shares_workunits(
self, databases: List[SnowflakeDatabase]
@@ -94,9 +91,10 @@ def report_missing_databases(
missing_dbs = [db for db in inbounds + outbounds if db not in db_names]
if missing_dbs and self.config.platform_instance:
- self.report_warning(
- "snowflake-shares",
- f"Databases {missing_dbs} were not ingested. Siblings/Lineage will not be set for these.",
+ self.report.warning(
+ title="Extra Snowflake share configurations",
+ message="Some databases referenced by the share configs were not ingested. Siblings/lineage will not be set for these.",
+ context=f"{missing_dbs}",
)
elif missing_dbs:
logger.debug(
@@ -113,15 +111,15 @@ def gen_siblings(
) -> Iterable[MetadataWorkUnit]:
if not sibling_databases:
return
- dataset_identifier = self.get_dataset_identifier(
+ dataset_identifier = self.identifiers.get_dataset_identifier(
table_name, schema_name, database_name
)
- urn = self.dataset_urn_builder(dataset_identifier)
+ urn = self.identifiers.gen_dataset_urn(dataset_identifier)
sibling_urns = [
make_dataset_urn_with_platform_instance(
- self.platform,
- self.get_dataset_identifier(
+ self.identifiers.platform,
+ self.identifiers.get_dataset_identifier(
table_name, schema_name, sibling_db.database
),
sibling_db.platform_instance,
@@ -141,14 +139,14 @@ def get_upstream_lineage_with_primary_sibling(
table_name: str,
primary_sibling_db: DatabaseId,
) -> MetadataWorkUnit:
- dataset_identifier = self.get_dataset_identifier(
+ dataset_identifier = self.identifiers.get_dataset_identifier(
table_name, schema_name, database_name
)
- urn = self.dataset_urn_builder(dataset_identifier)
+ urn = self.identifiers.gen_dataset_urn(dataset_identifier)
upstream_urn = make_dataset_urn_with_platform_instance(
- self.platform,
- self.get_dataset_identifier(
+ self.identifiers.platform,
+ self.identifiers.get_dataset_identifier(
table_name, schema_name, primary_sibling_db.database
),
primary_sibling_db.platform_instance,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
index f78ae70291f8a..72952f6b76e8b 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_summary.py
@@ -1,5 +1,4 @@
import dataclasses
-import logging
from collections import defaultdict
from typing import Dict, Iterable, List, Optional
@@ -9,7 +8,10 @@
from datahub.ingestion.api.decorators import SupportStatus, config_class, support_status
from datahub.ingestion.api.source import Source, SourceReport
from datahub.ingestion.api.workunit import MetadataWorkUnit
-from datahub.ingestion.source.snowflake.snowflake_config import SnowflakeFilterConfig
+from datahub.ingestion.source.snowflake.snowflake_config import (
+ SnowflakeFilterConfig,
+ SnowflakeIdentifierConfig,
+)
from datahub.ingestion.source.snowflake.snowflake_connection import (
SnowflakeConnectionConfig,
)
@@ -17,6 +19,9 @@
from datahub.ingestion.source.snowflake.snowflake_schema_gen import (
SnowflakeSchemaGenerator,
)
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source_report.time_window import BaseTimeWindowReport
from datahub.utilities.lossy_collections import LossyList
@@ -59,7 +64,6 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeSummaryConfig):
super().__init__(ctx)
self.config: SnowflakeSummaryConfig = config
self.report: SnowflakeSummaryReport = SnowflakeSummaryReport()
- self.logger = logging.getLogger(__name__)
self.connection = self.config.get_connection()
@@ -69,7 +73,10 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
config=self.config, # type: ignore
report=self.report, # type: ignore
connection=self.connection,
- dataset_urn_builder=lambda x: "",
+ identifiers=SnowflakeIdentifierBuilder(
+ identifier_config=SnowflakeIdentifierConfig(),
+ structured_reporter=self.report,
+ ),
domain_registry=None,
profiler=None,
aggregator=None,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
index e6b4ef1fd9607..9307eb607be26 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_tag.py
@@ -27,7 +27,6 @@ def __init__(
self.config = config
self.data_dictionary = data_dictionary
self.report = report
- self.logger = logger
self.tag_cache: Dict[str, _SnowflakeTagCache] = {}
@@ -69,16 +68,18 @@ def _get_tags_on_object_with_propagation(
) -> List[SnowflakeTag]:
identifier = ""
if domain == SnowflakeObjectDomain.DATABASE:
- identifier = self.get_quoted_identifier_for_database(db_name)
+ identifier = self.identifiers.get_quoted_identifier_for_database(db_name)
elif domain == SnowflakeObjectDomain.SCHEMA:
assert schema_name is not None
- identifier = self.get_quoted_identifier_for_schema(db_name, schema_name)
+ identifier = self.identifiers.get_quoted_identifier_for_schema(
+ db_name, schema_name
+ )
elif (
domain == SnowflakeObjectDomain.TABLE
): # Views belong to this domain as well.
assert schema_name is not None
assert table_name is not None
- identifier = self.get_quoted_identifier_for_table(
+ identifier = self.identifiers.get_quoted_identifier_for_table(
db_name, schema_name, table_name
)
else:
@@ -140,7 +141,7 @@ def get_column_tags_for_table(
elif self.config.extract_tags == TagOption.with_lineage:
self.report.num_get_tags_on_columns_for_table_queries += 1
temp_column_tags = self.data_dictionary.get_tags_on_columns_for_table(
- quoted_table_name=self.get_quoted_identifier_for_table(
+ quoted_table_name=self.identifiers.get_quoted_identifier_for_table(
db_name, schema_name, table_name
),
db_name=db_name,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
index c5e0994059f2e..aff15386c5083 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_usage_v2.py
@@ -2,7 +2,7 @@
import logging
import time
from datetime import datetime, timezone
-from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
+from typing import Any, Dict, Iterable, List, Optional, Tuple
import pydantic
@@ -20,7 +20,11 @@
)
from datahub.ingestion.source.snowflake.snowflake_query import SnowflakeQuery
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
-from datahub.ingestion.source.snowflake.snowflake_utils import SnowflakeCommonMixin
+from datahub.ingestion.source.snowflake.snowflake_utils import (
+ SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
+)
from datahub.ingestion.source.state.redundant_run_skip_handler import (
RedundantUsageRunSkipHandler,
)
@@ -112,13 +116,14 @@ def __init__(
config: SnowflakeV2Config,
report: SnowflakeV2Report,
connection: SnowflakeConnection,
- dataset_urn_builder: Callable[[str], str],
+ filter: SnowflakeFilter,
+ identifiers: SnowflakeIdentifierBuilder,
redundant_run_skip_handler: Optional[RedundantUsageRunSkipHandler],
) -> None:
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = report
- self.dataset_urn_builder = dataset_urn_builder
- self.logger = logger
+ self.filter = filter
+ self.identifiers = identifiers
self.connection = connection
self.redundant_run_skip_handler = redundant_run_skip_handler
@@ -171,7 +176,7 @@ def get_usage_workunits(
bucket_duration=self.config.bucket_duration,
),
dataset_urns={
- self.dataset_urn_builder(dataset_identifier)
+ self.identifiers.gen_dataset_urn(dataset_identifier)
for dataset_identifier in discovered_datasets
},
)
@@ -232,7 +237,7 @@ def _get_workunits_internal(
logger.debug(f"Processing usage row number {results.rownumber}")
logger.debug(self.report.usage_aggregation.as_string())
- if not self.is_dataset_pattern_allowed(
+ if not self.filter.is_dataset_pattern_allowed(
row["OBJECT_NAME"],
row["OBJECT_DOMAIN"],
):
@@ -242,7 +247,7 @@ def _get_workunits_internal(
continue
dataset_identifier = (
- self.get_dataset_identifier_from_qualified_name(
+ self.identifiers.get_dataset_identifier_from_qualified_name(
row["OBJECT_NAME"]
)
)
@@ -279,7 +284,8 @@ def build_usage_statistics_for_dataset(
fieldCounts=self._map_field_counts(row["FIELD_COUNTS"]),
)
return MetadataChangeProposalWrapper(
- entityUrn=self.dataset_urn_builder(dataset_identifier), aspect=stats
+ entityUrn=self.identifiers.gen_dataset_urn(dataset_identifier),
+ aspect=stats,
).as_workunit()
except Exception as e:
logger.debug(
@@ -356,7 +362,9 @@ def _map_field_counts(self, field_counts_str: str) -> List[DatasetFieldUsageCoun
return sorted(
[
DatasetFieldUsageCounts(
- fieldPath=self.snowflake_identifier(field_count["col"]),
+ fieldPath=self.identifiers.snowflake_identifier(
+ field_count["col"]
+ ),
count=field_count["total"],
)
for field_count in field_counts
@@ -454,8 +462,10 @@ def _get_operation_aspect_work_unit(
for obj in event.objects_modified:
resource = obj.objectName
- dataset_identifier = self.get_dataset_identifier_from_qualified_name(
- resource
+ dataset_identifier = (
+ self.identifiers.get_dataset_identifier_from_qualified_name(
+ resource
+ )
)
if dataset_identifier not in discovered_datasets:
@@ -476,7 +486,7 @@ def _get_operation_aspect_work_unit(
),
)
mcp = MetadataChangeProposalWrapper(
- entityUrn=self.dataset_urn_builder(dataset_identifier),
+ entityUrn=self.identifiers.gen_dataset_urn(dataset_identifier),
aspect=operation_aspect,
)
wu = MetadataWorkUnit(
@@ -561,7 +571,7 @@ def _is_unsupported_object_accessed(self, obj: Dict[str, Any]) -> bool:
def _is_object_valid(self, obj: Dict[str, Any]) -> bool:
if self._is_unsupported_object_accessed(
obj
- ) or not self.is_dataset_pattern_allowed(
+ ) or not self.filter.is_dataset_pattern_allowed(
obj.get("objectName"), obj.get("objectDomain")
):
return False
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
index c33fbb3d0bfc8..a1878963d3798 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_utils.py
@@ -1,8 +1,7 @@
import abc
+from functools import cached_property
from typing import ClassVar, Literal, Optional, Tuple
-from typing_extensions import Protocol
-
from datahub.configuration.pattern_utils import is_schema_allowed
from datahub.emitter.mce_builder import make_dataset_urn_with_platform_instance
from datahub.ingestion.api.source import SourceReport
@@ -25,42 +24,6 @@ class SnowflakeStructuredReportMixin(abc.ABC):
def structured_reporter(self) -> SourceReport:
...
- # TODO: Eventually I want to deprecate these methods and use the structured_reporter directly.
- def report_warning(self, key: str, reason: str) -> None:
- self.structured_reporter.warning(key, reason)
-
- def report_error(self, key: str, reason: str) -> None:
- self.structured_reporter.failure(key, reason)
-
-
-# Required only for mypy, since we are using mixin classes, and not inheritance.
-# Reference - https://mypy.readthedocs.io/en/latest/more_types.html#mixin-classes
-class SnowflakeCommonProtocol(Protocol):
- platform: str = "snowflake"
-
- config: SnowflakeV2Config
- report: SnowflakeV2Report
-
- def get_dataset_identifier(
- self, table_name: str, schema_name: str, db_name: str
- ) -> str:
- ...
-
- def cleanup_qualified_name(self, qualified_name: str) -> str:
- ...
-
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- ...
-
- def snowflake_identifier(self, identifier: str) -> str:
- ...
-
- def report_warning(self, key: str, reason: str) -> None:
- ...
-
- def report_error(self, key: str, reason: str) -> None:
- ...
-
class SnowsightUrlBuilder:
CLOUD_REGION_IDS_WITHOUT_CLOUD_SUFFIX: ClassVar = [
@@ -140,17 +103,14 @@ def get_external_url_for_database(self, db_name: str) -> Optional[str]:
return f"{self.snowsight_base_url}#/data/databases/{db_name}/"
-class SnowflakeFilterMixin(SnowflakeStructuredReportMixin):
- @property
- @abc.abstractmethod
- def filter_config(self) -> SnowflakeFilterConfig:
- ...
+class SnowflakeFilter:
+ def __init__(
+ self, filter_config: SnowflakeFilterConfig, structured_reporter: SourceReport
+ ) -> None:
+ self.filter_config = filter_config
+ self.structured_reporter = structured_reporter
- @staticmethod
- def _combine_identifier_parts(
- table_name: str, schema_name: str, db_name: str
- ) -> str:
- return f"{db_name}.{schema_name}.{table_name}"
+ # TODO: Refactor remaining filtering logic into this class.
def is_dataset_pattern_allowed(
self,
@@ -167,28 +127,35 @@ def is_dataset_pattern_allowed(
SnowflakeObjectDomain.MATERIALIZED_VIEW,
):
return False
+
if len(dataset_params) != 3:
- self.report_warning(
- "invalid-dataset-pattern",
- f"Found {dataset_params} of type {dataset_type}",
+ self.structured_reporter.info(
+ title="Unexpected dataset pattern",
+ message=f"Found a {dataset_type} with an unexpected number of parts. Database and schema filtering will not work as expected, but table filtering will still work.",
+ context=dataset_name,
)
- # NOTE: this case returned `True` earlier when extracting lineage
- return False
+ # We fall-through here so table/view filtering still works.
- if not self.filter_config.database_pattern.allowed(
- dataset_params[0].strip('"')
- ) or not is_schema_allowed(
- self.filter_config.schema_pattern,
- dataset_params[1].strip('"'),
- dataset_params[0].strip('"'),
- self.filter_config.match_fully_qualified_names,
+ if (
+ len(dataset_params) >= 1
+ and not self.filter_config.database_pattern.allowed(
+ dataset_params[0].strip('"')
+ )
+ ) or (
+ len(dataset_params) >= 2
+ and not is_schema_allowed(
+ self.filter_config.schema_pattern,
+ dataset_params[1].strip('"'),
+ dataset_params[0].strip('"'),
+ self.filter_config.match_fully_qualified_names,
+ )
):
return False
if dataset_type.lower() in {
SnowflakeObjectDomain.TABLE
} and not self.filter_config.table_pattern.allowed(
- self.cleanup_qualified_name(dataset_name)
+ _cleanup_qualified_name(dataset_name, self.structured_reporter)
):
return False
@@ -196,41 +163,53 @@ def is_dataset_pattern_allowed(
SnowflakeObjectDomain.VIEW,
SnowflakeObjectDomain.MATERIALIZED_VIEW,
} and not self.filter_config.view_pattern.allowed(
- self.cleanup_qualified_name(dataset_name)
+ _cleanup_qualified_name(dataset_name, self.structured_reporter)
):
return False
return True
- # Qualified Object names from snowflake audit logs have quotes for for snowflake quoted identifiers,
- # For example "test-database"."test-schema".test_table
- # whereas we generate urns without quotes even for quoted identifiers for backward compatibility
- # and also unavailability of utility function to identify whether current table/schema/database
- # name should be quoted in above method get_dataset_identifier
- def cleanup_qualified_name(self, qualified_name: str) -> str:
- name_parts = qualified_name.split(".")
- if len(name_parts) != 3:
- self.structured_reporter.report_warning(
- title="Unexpected dataset pattern",
- message="We failed to parse a Snowflake qualified name into its constituent parts. "
- "DB/schema/table filtering may not work as expected on these entities.",
- context=f"{qualified_name} has {len(name_parts)} parts",
- )
- return qualified_name.replace('"', "")
- return SnowflakeFilterMixin._combine_identifier_parts(
- table_name=name_parts[2].strip('"'),
- schema_name=name_parts[1].strip('"'),
- db_name=name_parts[0].strip('"'),
+
+def _combine_identifier_parts(
+ *, table_name: str, schema_name: str, db_name: str
+) -> str:
+ return f"{db_name}.{schema_name}.{table_name}"
+
+
+# Qualified Object names from snowflake audit logs have quotes for for snowflake quoted identifiers,
+# For example "test-database"."test-schema".test_table
+# whereas we generate urns without quotes even for quoted identifiers for backward compatibility
+# and also unavailability of utility function to identify whether current table/schema/database
+# name should be quoted in above method get_dataset_identifier
+def _cleanup_qualified_name(
+ qualified_name: str, structured_reporter: SourceReport
+) -> str:
+ name_parts = qualified_name.split(".")
+ if len(name_parts) != 3:
+ structured_reporter.info(
+ title="Unexpected dataset pattern",
+ message="We failed to parse a Snowflake qualified name into its constituent parts. "
+ "DB/schema/table filtering may not work as expected on these entities.",
+ context=f"{qualified_name} has {len(name_parts)} parts",
)
+ return qualified_name.replace('"', "")
+ return _combine_identifier_parts(
+ db_name=name_parts[0].strip('"'),
+ schema_name=name_parts[1].strip('"'),
+ table_name=name_parts[2].strip('"'),
+ )
-class SnowflakeIdentifierMixin(abc.ABC):
+class SnowflakeIdentifierBuilder:
platform = "snowflake"
- @property
- @abc.abstractmethod
- def identifier_config(self) -> SnowflakeIdentifierConfig:
- ...
+ def __init__(
+ self,
+ identifier_config: SnowflakeIdentifierConfig,
+ structured_reporter: SourceReport,
+ ) -> None:
+ self.identifier_config = identifier_config
+ self.structured_reporter = structured_reporter
def snowflake_identifier(self, identifier: str) -> str:
# to be in in sync with older connector, convert name to lowercase
@@ -242,7 +221,7 @@ def get_dataset_identifier(
self, table_name: str, schema_name: str, db_name: str
) -> str:
return self.snowflake_identifier(
- SnowflakeCommonMixin._combine_identifier_parts(
+ _combine_identifier_parts(
table_name=table_name, schema_name=schema_name, db_name=db_name
)
)
@@ -255,20 +234,10 @@ def gen_dataset_urn(self, dataset_identifier: str) -> str:
env=self.identifier_config.env,
)
-
-# TODO: We're most of the way there on fully removing SnowflakeCommonProtocol.
-class SnowflakeCommonMixin(SnowflakeFilterMixin, SnowflakeIdentifierMixin):
- @property
- def structured_reporter(self: SnowflakeCommonProtocol) -> SourceReport:
- return self.report
-
- @property
- def filter_config(self: SnowflakeCommonProtocol) -> SnowflakeFilterConfig:
- return self.config
-
- @property
- def identifier_config(self: SnowflakeCommonProtocol) -> SnowflakeIdentifierConfig:
- return self.config
+ def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
+ return self.snowflake_identifier(
+ _cleanup_qualified_name(qualified_name, self.structured_reporter)
+ )
@staticmethod
def get_quoted_identifier_for_database(db_name):
@@ -278,40 +247,51 @@ def get_quoted_identifier_for_database(db_name):
def get_quoted_identifier_for_schema(db_name, schema_name):
return f'"{db_name}"."{schema_name}"'
- def get_dataset_identifier_from_qualified_name(self, qualified_name: str) -> str:
- return self.snowflake_identifier(self.cleanup_qualified_name(qualified_name))
-
@staticmethod
def get_quoted_identifier_for_table(db_name, schema_name, table_name):
return f'"{db_name}"."{schema_name}"."{table_name}"'
+
+class SnowflakeCommonMixin(SnowflakeStructuredReportMixin):
+ platform = "snowflake"
+
+ config: SnowflakeV2Config
+ report: SnowflakeV2Report
+
+ @property
+ def structured_reporter(self) -> SourceReport:
+ return self.report
+
+ @cached_property
+ def identifiers(self) -> SnowflakeIdentifierBuilder:
+ return SnowflakeIdentifierBuilder(self.config, self.report)
+
# Note - decide how to construct user urns.
# Historically urns were created using part before @ from user's email.
# Users without email were skipped from both user entries as well as aggregates.
# However email is not mandatory field in snowflake user, user_name is always present.
def get_user_identifier(
- self: SnowflakeCommonProtocol,
+ self,
user_name: str,
user_email: Optional[str],
email_as_user_identifier: bool,
) -> str:
if user_email:
- return self.snowflake_identifier(
+ return self.identifiers.snowflake_identifier(
user_email
if email_as_user_identifier is True
else user_email.split("@")[0]
)
- return self.snowflake_identifier(user_name)
+ return self.identifiers.snowflake_identifier(user_name)
# TODO: Revisit this after stateful ingestion can commit checkpoint
# for failures that do not affect the checkpoint
- def warn_if_stateful_else_error(
- self: SnowflakeCommonProtocol, key: str, reason: str
- ) -> None:
+ # TODO: Add additional parameters to match the signature of the .warning and .failure methods
+ def warn_if_stateful_else_error(self, key: str, reason: str) -> None:
if (
self.config.stateful_ingestion is not None
and self.config.stateful_ingestion.enabled
):
- self.report_warning(key, reason)
+ self.structured_reporter.warning(key, reason)
else:
- self.report_error(key, reason)
+ self.structured_reporter.failure(key, reason)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
index d8eda98da422b..1881e1da5be68 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
@@ -25,6 +25,7 @@
TestableSource,
TestConnectionReport,
)
+from datahub.ingestion.api.source_helpers import auto_workunit
from datahub.ingestion.api.workunit import MetadataWorkUnit
from datahub.ingestion.source.snowflake.constants import (
GENERIC_PERMISSION_ERROR_KEY,
@@ -42,6 +43,10 @@
SnowflakeLineageExtractor,
)
from datahub.ingestion.source.snowflake.snowflake_profiler import SnowflakeProfiler
+from datahub.ingestion.source.snowflake.snowflake_queries import (
+ SnowflakeQueriesExtractor,
+ SnowflakeQueriesExtractorConfig,
+)
from datahub.ingestion.source.snowflake.snowflake_report import SnowflakeV2Report
from datahub.ingestion.source.snowflake.snowflake_schema import (
SnowflakeDataDictionary,
@@ -56,6 +61,8 @@
)
from datahub.ingestion.source.snowflake.snowflake_utils import (
SnowflakeCommonMixin,
+ SnowflakeFilter,
+ SnowflakeIdentifierBuilder,
SnowsightUrlBuilder,
)
from datahub.ingestion.source.state.profiling_state_handler import ProfilingHandler
@@ -72,6 +79,7 @@
from datahub.ingestion.source_report.ingestion_stage import (
LINEAGE_EXTRACTION,
METADATA_EXTRACTION,
+ QUERIES_EXTRACTION,
)
from datahub.sql_parsing.sql_parsing_aggregator import SqlParsingAggregator
from datahub.utilities.registries.domain_registry import DomainRegistry
@@ -127,9 +135,13 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
super().__init__(config, ctx)
self.config: SnowflakeV2Config = config
self.report: SnowflakeV2Report = SnowflakeV2Report()
- self.logger = logger
- self.connection = self.config.get_connection()
+ self.filters = SnowflakeFilter(
+ filter_config=self.config, structured_reporter=self.report
+ )
+ self.identifiers = SnowflakeIdentifierBuilder(
+ identifier_config=self.config, structured_reporter=self.report
+ )
self.domain_registry: Optional[DomainRegistry] = None
if self.config.domain:
@@ -137,28 +149,29 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
cached_domains=[k for k in self.config.domain], graph=self.ctx.graph
)
+ self.connection = self.config.get_connection()
+
# For database, schema, tables, views, etc
self.data_dictionary = SnowflakeDataDictionary(connection=self.connection)
self.lineage_extractor: Optional[SnowflakeLineageExtractor] = None
self.aggregator: Optional[SqlParsingAggregator] = None
- if self.config.include_table_lineage:
+ if self.config.use_queries_v2 or self.config.include_table_lineage:
self.aggregator = SqlParsingAggregator(
- platform=self.platform,
+ platform=self.identifiers.platform,
platform_instance=self.config.platform_instance,
env=self.config.env,
- graph=(
+ graph=self.ctx.graph,
+ eager_graph_load=(
# If we're ingestion schema metadata for tables/views, then we will populate
# schemas into the resolver as we go. We only need to do a bulk fetch
# if we're not ingesting schema metadata as part of ingestion.
- self.ctx.graph
- if not (
+ (
self.config.include_technical_schema
and self.config.include_tables
and self.config.include_views
)
and not self.config.lazy_schema_resolver
- else None
),
generate_usage_statistics=False,
generate_operations=False,
@@ -166,6 +179,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
)
self.report.sql_aggregator = self.aggregator.report
+ if self.config.include_table_lineage:
+ assert self.aggregator is not None
redundant_lineage_run_skip_handler: Optional[
RedundantLineageRunSkipHandler
] = None
@@ -180,7 +195,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
config,
self.report,
connection=self.connection,
- dataset_urn_builder=self.gen_dataset_urn,
+ filters=self.filters,
+ identifiers=self.identifiers,
redundant_run_skip_handler=redundant_lineage_run_skip_handler,
sql_aggregator=self.aggregator,
)
@@ -201,7 +217,8 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
config,
self.report,
connection=self.connection,
- dataset_urn_builder=self.gen_dataset_urn,
+ filter=self.filters,
+ identifiers=self.identifiers,
redundant_run_skip_handler=redundant_usage_run_skip_handler,
)
@@ -277,10 +294,12 @@ class SnowflakePrivilege:
capabilities: List[SourceCapability] = [c.capability for c in SnowflakeV2Source.get_capabilities() if c.capability not in (SourceCapability.PLATFORM_INSTANCE, SourceCapability.DOMAINS, SourceCapability.DELETION_DETECTION)] # type: ignore
cur = conn.query("select current_role()")
- current_role = [row[0] for row in cur][0]
+ current_role = [row["CURRENT_ROLE()"] for row in cur][0]
cur = conn.query("select current_secondary_roles()")
- secondary_roles_str = json.loads([row[0] for row in cur][0])["roles"]
+ secondary_roles_str = json.loads(
+ [row["CURRENT_SECONDARY_ROLES()"] for row in cur][0]
+ )["roles"]
secondary_roles = (
[] if secondary_roles_str == "" else secondary_roles_str.split(",")
)
@@ -299,7 +318,9 @@ class SnowflakePrivilege:
cur = conn.query(f'show grants to role "{role}"')
for row in cur:
privilege = SnowflakePrivilege(
- privilege=row[1], object_type=row[2], object_name=row[3]
+ privilege=row["privilege"],
+ object_type=row["granted_on"],
+ object_name=row["name"],
)
privileges.append(privilege)
@@ -362,7 +383,7 @@ class SnowflakePrivilege:
roles.append(privilege.object_name)
cur = conn.query("select current_warehouse()")
- current_warehouse = [row[0] for row in cur][0]
+ current_warehouse = [row["CURRENT_WAREHOUSE()"] for row in cur][0]
default_failure_messages = {
SourceCapability.SCHEMA_METADATA: "Either no tables exist or current role does not have permissions to access them",
@@ -445,7 +466,8 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
profiler=self.profiler,
aggregator=self.aggregator,
snowsight_url_builder=snowsight_url_builder,
- dataset_urn_builder=self.gen_dataset_urn,
+ filters=self.filters,
+ identifiers=self.identifiers,
)
self.report.set_ingestion_stage("*", METADATA_EXTRACTION)
@@ -453,30 +475,28 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
databases = schema_extractor.databases
- self.connection.close()
-
# TODO: The checkpoint state for stale entity detection can be committed here.
if self.config.shares:
yield from SnowflakeSharesHandler(
- self.config, self.report, self.gen_dataset_urn
+ self.config, self.report
).get_shares_workunits(databases)
discovered_tables: List[str] = [
- self.get_dataset_identifier(table_name, schema.name, db.name)
+ self.identifiers.get_dataset_identifier(table_name, schema.name, db.name)
for db in databases
for schema in db.schemas
for table_name in schema.tables
]
discovered_views: List[str] = [
- self.get_dataset_identifier(table_name, schema.name, db.name)
+ self.identifiers.get_dataset_identifier(table_name, schema.name, db.name)
for db in databases
for schema in db.schemas
for table_name in schema.views
]
if len(discovered_tables) == 0 and len(discovered_views) == 0:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
"No tables/views found. Please check permissions.",
)
@@ -484,33 +504,66 @@ def get_workunits_internal(self) -> Iterable[MetadataWorkUnit]:
discovered_datasets = discovered_tables + discovered_views
- if self.config.include_table_lineage and self.lineage_extractor:
- self.report.set_ingestion_stage("*", LINEAGE_EXTRACTION)
- yield from self.lineage_extractor.get_workunits(
- discovered_tables=discovered_tables,
- discovered_views=discovered_views,
+ if self.config.use_queries_v2:
+ self.report.set_ingestion_stage("*", "View Parsing")
+ assert self.aggregator is not None
+ yield from auto_workunit(self.aggregator.gen_metadata())
+
+ self.report.set_ingestion_stage("*", QUERIES_EXTRACTION)
+
+ schema_resolver = self.aggregator._schema_resolver
+
+ queries_extractor = SnowflakeQueriesExtractor(
+ connection=self.connection,
+ config=SnowflakeQueriesExtractorConfig(
+ window=self.config,
+ temporary_tables_pattern=self.config.temporary_tables_pattern,
+ include_lineage=self.config.include_table_lineage,
+ include_usage_statistics=self.config.include_usage_stats,
+ include_operations=self.config.include_operational_stats,
+ ),
+ structured_report=self.report,
+ filters=self.filters,
+ identifiers=self.identifiers,
+ schema_resolver=schema_resolver,
)
- if (
- self.config.include_usage_stats or self.config.include_operational_stats
- ) and self.usage_extractor:
- yield from self.usage_extractor.get_usage_workunits(discovered_datasets)
+ # TODO: This is slightly suboptimal because we create two SqlParsingAggregator instances with different configs
+ # but a shared schema resolver. That's fine for now though - once we remove the old lineage/usage extractors,
+ # it should be pretty straightforward to refactor this and only initialize the aggregator once.
+ self.report.queries_extractor = queries_extractor.report
+ yield from queries_extractor.get_workunits_internal()
+
+ else:
+ if self.config.include_table_lineage and self.lineage_extractor:
+ self.report.set_ingestion_stage("*", LINEAGE_EXTRACTION)
+ yield from self.lineage_extractor.get_workunits(
+ discovered_tables=discovered_tables,
+ discovered_views=discovered_views,
+ )
+
+ if (
+ self.config.include_usage_stats or self.config.include_operational_stats
+ ) and self.usage_extractor:
+ yield from self.usage_extractor.get_usage_workunits(discovered_datasets)
if self.config.include_assertion_results:
yield from SnowflakeAssertionsHandler(
- self.config, self.report, self.connection
+ self.config, self.report, self.connection, self.identifiers
).get_assertion_workunits(discovered_datasets)
+ self.connection.close()
+
def report_warehouse_failure(self) -> None:
if self.config.warehouse is not None:
- self.report_error(
+ self.structured_reporter.failure(
GENERIC_PERMISSION_ERROR_KEY,
f"Current role does not have permissions to use warehouse {self.config.warehouse}. Please update permissions.",
)
else:
- self.report_error(
- "no-active-warehouse",
- "No default warehouse set for user. Either set default warehouse for user or configure warehouse in recipe.",
+ self.structured_reporter.failure(
+ "Could not use a Snowflake warehouse",
+ "No default warehouse set for user. Either set a default warehouse for the user or configure a warehouse in the recipe.",
)
def get_report(self) -> SourceReport:
@@ -541,19 +594,28 @@ def inspect_session_metadata(self, connection: SnowflakeConnection) -> None:
for db_row in connection.query(SnowflakeQuery.current_version()):
self.report.saas_version = db_row["CURRENT_VERSION()"]
except Exception as e:
- self.report_error("version", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake version",
+ exc=e,
+ )
try:
logger.info("Checking current role")
for db_row in connection.query(SnowflakeQuery.current_role()):
self.report.role = db_row["CURRENT_ROLE()"]
except Exception as e:
- self.report_error("version", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake role",
+ exc=e,
+ )
try:
logger.info("Checking current warehouse")
for db_row in connection.query(SnowflakeQuery.current_warehouse()):
self.report.default_warehouse = db_row["CURRENT_WAREHOUSE()"]
except Exception as e:
- self.report_error("current_warehouse", f"Error: {e}")
+ self.structured_reporter.failure(
+ "Could not determine the current Snowflake warehouse",
+ exc=e,
+ )
try:
logger.info("Checking current edition")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py b/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
index ae17cff60fedd..9ddc671e21133 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/athena.py
@@ -251,11 +251,6 @@ class AthenaConfig(SQLCommonConfig):
"queries executed by DataHub."
)
- # overwrite default behavior of SQLAlchemyConfing
- include_views: Optional[bool] = pydantic.Field(
- default=True, description="Whether views should be ingested."
- )
-
_s3_staging_dir_population = pydantic_renamed_field(
old_name="s3_staging_dir",
new_name="query_result_location",
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py b/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
index 0589a5e39d68e..12c98ef11a654 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/postgres.py
@@ -276,3 +276,19 @@ def get_identifier(
return f"{self.config.database}.{regular}"
current_database = self.get_db_name(inspector)
return f"{current_database}.{regular}"
+
+ def add_profile_metadata(self, inspector: Inspector) -> None:
+ try:
+ with inspector.engine.connect() as conn:
+ for row in conn.execute(
+ """SELECT table_catalog, table_schema, table_name, pg_table_size('"' || table_catalog || '"."' || table_schema || '"."' || table_name || '"') AS table_size FROM information_schema.TABLES"""
+ ):
+ self.profile_metadata_info.dataset_name_to_storage_bytes[
+ self.get_identifier(
+ schema=row.table_schema,
+ entity=row.table_name,
+ inspector=inspector,
+ )
+ ] = row.table_size
+ except Exception as e:
+ logger.error(f"failed to fetch profile metadata: {e}")
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
index 93c7025aeee4e..3ead59eed2d39 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
@@ -83,10 +83,10 @@ class SQLCommonConfig(
description='Attach domains to databases, schemas or tables during ingestion using regex patterns. Domain key can be a guid like *urn:li:domain:ec428203-ce86-4db3-985d-5a8ee6df32ba* or a string like "Marketing".) If you provide strings, then datahub will attempt to resolve this name to a guid, and will error out if this fails. There can be multiple domain keys specified.',
)
- include_views: Optional[bool] = Field(
+ include_views: bool = Field(
default=True, description="Whether views should be ingested."
)
- include_tables: Optional[bool] = Field(
+ include_tables: bool = Field(
default=True, description="Whether tables should be ingested."
)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/tableau.py b/metadata-ingestion/src/datahub/ingestion/source/tableau.py
index b14a4a8586c7d..1655724f2d402 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/tableau.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/tableau.py
@@ -1009,10 +1009,34 @@ def get_connection_object_page(
error and (error.get(c.EXTENSIONS) or {}).get(c.SEVERITY) == c.WARNING
for error in errors
):
- self.report.warning(
- message=f"Received error fetching Query Connection {connection_type}",
- context=f"Errors: {errors}",
- )
+ # filter out PERMISSIONS_MODE_SWITCHED to report error in human-readable format
+ other_errors = []
+ permission_mode_errors = []
+ for error in errors:
+ if (
+ error.get("extensions")
+ and error["extensions"].get("code")
+ == "PERMISSIONS_MODE_SWITCHED"
+ ):
+ permission_mode_errors.append(error)
+ else:
+ other_errors.append(error)
+
+ if other_errors:
+ self.report.warning(
+ message=f"Received error fetching Query Connection {connection_type}",
+ context=f"Errors: {other_errors}",
+ )
+
+ if permission_mode_errors:
+ self.report.warning(
+ title="Derived Permission Error",
+ message="Turn on your derived permissions. See for details "
+ "https://community.tableau.com/s/question/0D54T00000QnjHbSAJ/how-to-fix-the"
+ "-permissionsmodeswitched-error",
+ context=f"{permission_mode_errors}",
+ )
+
else:
raise RuntimeError(f"Query {connection_type} error: {errors}")
@@ -2255,7 +2279,7 @@ def emit_upstream_tables(self) -> Iterable[MetadataWorkUnit]:
yield from self.emit_table(database_table, tableau_columns)
- # Emmitting tables that were purely parsed from SQL queries
+ # Emitting tables that were purely parsed from SQL queries
for database_table in self.database_tables.values():
# Only tables purely parsed from SQL queries don't have ID
if database_table.id:
@@ -2278,10 +2302,11 @@ def emit_table(
tableau_columns: Optional[List[Dict[str, Any]]],
) -> Iterable[MetadataWorkUnit]:
logger.debug(
- f"Emiting external table {database_table} tableau_columns {tableau_columns}"
+ f"Emitting external table {database_table} tableau_columns {tableau_columns}"
)
+ dataset_urn = DatasetUrn.from_string(database_table.urn)
dataset_snapshot = DatasetSnapshot(
- urn=database_table.urn,
+ urn=str(dataset_urn),
aspects=[],
)
if database_table.paths:
@@ -2302,6 +2327,13 @@ def emit_table(
if schema_metadata is not None:
dataset_snapshot.aspects.append(schema_metadata)
+ if not dataset_snapshot.aspects:
+ # This should only happen with ingest_tables_external enabled.
+ logger.warning(
+ f"Urn {database_table.urn} has no real aspects, adding a key aspect to ensure materialization"
+ )
+ dataset_snapshot.aspects.append(dataset_urn.to_key_aspect())
+
yield self.get_metadata_change_event(dataset_snapshot)
def get_schema_metadata_for_table(
diff --git a/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py b/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
index 14dc428b65389..4308b405e46e3 100644
--- a/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
+++ b/metadata-ingestion/src/datahub/ingestion/source_report/ingestion_stage.py
@@ -14,6 +14,7 @@
USAGE_EXTRACTION_INGESTION = "Usage Extraction Ingestion"
USAGE_EXTRACTION_OPERATIONAL_STATS = "Usage Extraction Operational Stats"
USAGE_EXTRACTION_USAGE_AGGREGATION = "Usage Extraction Usage Aggregation"
+QUERIES_EXTRACTION = "Queries Extraction"
PROFILING = "Profiling"
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
index 677b96269fe58..fbf6f954f82bb 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
@@ -251,7 +251,9 @@ def __init__(
platform: str,
platform_instance: Optional[str] = None,
env: str = builder.DEFAULT_ENV,
+ schema_resolver: Optional[SchemaResolver] = None,
graph: Optional[DataHubGraph] = None,
+ eager_graph_load: bool = True,
generate_lineage: bool = True,
generate_queries: bool = True,
generate_query_subject_fields: bool = True,
@@ -274,8 +276,12 @@ def __init__(
self.generate_usage_statistics = generate_usage_statistics
self.generate_query_usage_statistics = generate_query_usage_statistics
self.generate_operations = generate_operations
- if self.generate_queries and not self.generate_lineage:
- raise ValueError("Queries will only be generated if lineage is enabled")
+ if self.generate_queries and not (
+ self.generate_lineage or self.generate_query_usage_statistics
+ ):
+ logger.warning(
+ "Queries will not be generated, as neither lineage nor query usage statistics are enabled"
+ )
self.usage_config = usage_config
if (
@@ -297,17 +303,29 @@ def __init__(
# Set up the schema resolver.
self._schema_resolver: SchemaResolver
- if graph is None:
+ if schema_resolver is not None:
+ # If explicitly provided, use it.
+ assert self.platform.platform_name == schema_resolver.platform
+ assert self.platform_instance == schema_resolver.platform_instance
+ assert self.env == schema_resolver.env
+ self._schema_resolver = schema_resolver
+ elif graph is not None and eager_graph_load and self._need_schemas:
+ # Bulk load schemas using the graph client.
+ self._schema_resolver = graph.initialize_schema_resolver_from_datahub(
+ platform=self.platform.urn(),
+ platform_instance=self.platform_instance,
+ env=self.env,
+ )
+ else:
+ # Otherwise, use a lazy-loading schema resolver.
self._schema_resolver = self._exit_stack.enter_context(
SchemaResolver(
platform=self.platform.platform_name,
platform_instance=self.platform_instance,
env=self.env,
+ graph=graph,
)
)
- else:
- self._schema_resolver = None # type: ignore
- self._initialize_schema_resolver_from_graph(graph)
# Initialize internal data structures.
# This leans pretty heavily on the our query fingerprinting capabilities.
@@ -373,6 +391,8 @@ def __init__(
# Usage aggregator. This will only be initialized if usage statistics are enabled.
# TODO: Replace with FileBackedDict.
+ # TODO: The BaseUsageConfig class is much too broad for our purposes, and has a number of
+ # configs that won't be respected here. Using it is misleading.
self._usage_aggregator: Optional[UsageAggregator[UrnStr]] = None
if self.generate_usage_statistics:
assert self.usage_config is not None
@@ -392,7 +412,13 @@ def close(self) -> None:
@property
def _need_schemas(self) -> bool:
- return self.generate_lineage or self.generate_usage_statistics
+ # Unless the aggregator is totally disabled, we will need schema information.
+ return (
+ self.generate_lineage
+ or self.generate_usage_statistics
+ or self.generate_queries
+ or self.generate_operations
+ )
def register_schema(
self, urn: Union[str, DatasetUrn], schema: models.SchemaMetadataClass
@@ -414,35 +440,6 @@ def register_schemas_from_stream(
yield wu
- def _initialize_schema_resolver_from_graph(self, graph: DataHubGraph) -> None:
- # requires a graph instance
- # if no schemas are currently registered in the schema resolver
- # and we need the schema resolver (e.g. lineage or usage is enabled)
- # then use the graph instance to fetch all schemas for the
- # platform/instance/env combo
- if not self._need_schemas:
- return
-
- if (
- self._schema_resolver is not None
- and self._schema_resolver.schema_count() > 0
- ):
- # TODO: Have a mechanism to override this, e.g. when table ingestion is enabled but view ingestion is not.
- logger.info(
- "Not fetching any schemas from the graph, since "
- f"there are {self._schema_resolver.schema_count()} schemas already registered."
- )
- return
-
- # TODO: The initialize_schema_resolver_from_datahub method should take in a SchemaResolver
- # that it can populate or add to, rather than creating a new one and dropping any schemas
- # that were already loaded into the existing one.
- self._schema_resolver = graph.initialize_schema_resolver_from_datahub(
- platform=self.platform.urn(),
- platform_instance=self.platform_instance,
- env=self.env,
- )
-
def _maybe_format_query(self, query: str) -> str:
if self.format_queries:
with self.report.sql_formatting_timer:
@@ -660,10 +657,10 @@ def add_observed_query(
if parsed.debug_info.table_error:
self.report.num_observed_queries_failed += 1
return # we can't do anything with this query
- elif isinstance(parsed.debug_info.column_error, CooperativeTimeoutError):
- self.report.num_observed_queries_column_timeout += 1
elif parsed.debug_info.column_error:
self.report.num_observed_queries_column_failed += 1
+ if isinstance(parsed.debug_info.column_error, CooperativeTimeoutError):
+ self.report.num_observed_queries_column_timeout += 1
query_fingerprint = parsed.query_fingerprint
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
index 9c2a588a577cc..976ff8bcc9b3f 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
@@ -843,8 +843,14 @@ def _sqlglot_lineage_inner(
schema_resolver: SchemaResolverInterface,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> SqlParsingResult:
- dialect = get_dialect(schema_resolver.platform)
+
+ if not default_dialect:
+ dialect = get_dialect(schema_resolver.platform)
+ else:
+ dialect = get_dialect(default_dialect)
+
if is_dialect_instance(dialect, "snowflake"):
# in snowflake, table identifiers must be uppercased to match sqlglot's behavior.
if default_db:
@@ -1003,6 +1009,7 @@ def sqlglot_lineage(
schema_resolver: SchemaResolverInterface,
default_db: Optional[str] = None,
default_schema: Optional[str] = None,
+ default_dialect: Optional[str] = None,
) -> SqlParsingResult:
"""Parse a SQL statement and generate lineage information.
@@ -1020,8 +1027,9 @@ def sqlglot_lineage(
can be brittle with respect to missing schema information and complex
SQL logic like UNNESTs.
- The SQL dialect is inferred from the schema_resolver's platform. The
- set of supported dialects is the same as sqlglot's. See their
+ The SQL dialect can be given as an argument called default_dialect or it can
+ be inferred from the schema_resolver's platform.
+ The set of supported dialects is the same as sqlglot's. See their
`documentation `_
for the full list.
@@ -1035,6 +1043,7 @@ def sqlglot_lineage(
schema_resolver: The schema resolver to use for resolving table schemas.
default_db: The default database to use for unqualified table names.
default_schema: The default schema to use for unqualified table names.
+ default_dialect: A default dialect to override the dialect provided by 'schema_resolver'.
Returns:
A SqlParsingResult object containing the parsed lineage information.
@@ -1059,6 +1068,7 @@ def sqlglot_lineage(
schema_resolver=schema_resolver,
default_db=default_db,
default_schema=default_schema,
+ default_dialect=default_dialect,
)
except Exception as e:
return SqlParsingResult.make_from_error(e)
diff --git a/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py b/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py
new file mode 100644
index 0000000000000..216fa155035d3
--- /dev/null
+++ b/metadata-ingestion/src/datahub/utilities/threaded_iterator_executor.py
@@ -0,0 +1,52 @@
+import concurrent.futures
+import contextlib
+import queue
+from typing import Any, Callable, Generator, Iterable, Tuple, TypeVar
+
+T = TypeVar("T")
+
+
+class ThreadedIteratorExecutor:
+ """
+ Executes worker functions of type `Callable[..., Iterable[T]]` in parallel threads,
+ yielding items of type `T` as they become available.
+ """
+
+ @classmethod
+ def process(
+ cls,
+ worker_func: Callable[..., Iterable[T]],
+ args_list: Iterable[Tuple[Any, ...]],
+ max_workers: int,
+ ) -> Generator[T, None, None]:
+
+ out_q: queue.Queue[T] = queue.Queue()
+
+ def _worker_wrapper(
+ worker_func: Callable[..., Iterable[T]], *args: Any
+ ) -> None:
+ for item in worker_func(*args):
+ out_q.put(item)
+
+ with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
+ futures = []
+ for args in args_list:
+ future = executor.submit(_worker_wrapper, worker_func, *args)
+ futures.append(future)
+ # Read from the queue and yield the work units until all futures are done.
+ while True:
+ if not out_q.empty():
+ while not out_q.empty():
+ yield out_q.get_nowait()
+ else:
+ with contextlib.suppress(queue.Empty):
+ yield out_q.get(timeout=0.2)
+
+ # Filter out the done futures.
+ futures = [f for f in futures if not f.done()]
+ if not futures:
+ break
+
+ # Yield the remaining work units. This theoretically should not happen, but adding it just in case.
+ while not out_q.empty():
+ yield out_q.get_nowait()
diff --git a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
index a24b6174eb925..762c73d2a55c6 100644
--- a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
+++ b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
@@ -11,7 +11,6 @@
DynamicTypedClassifierConfig,
)
from datahub.ingestion.glossary.datahub_classifier import DataHubClassifierConfig
-from datahub.ingestion.source.bigquery_v2.bigquery import BigqueryV2Source
from datahub.ingestion.source.bigquery_v2.bigquery_data_reader import BigQueryDataReader
from datahub.ingestion.source.bigquery_v2.bigquery_schema import (
BigqueryColumn,
@@ -19,6 +18,9 @@
BigQuerySchemaApi,
BigqueryTable,
)
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
from tests.test_helpers import mce_helpers
from tests.test_helpers.state_helpers import run_and_get_pipeline
@@ -39,7 +41,7 @@ def random_email():
@freeze_time(FROZEN_TIME)
@patch.object(BigQuerySchemaApi, "get_tables_for_dataset")
-@patch.object(BigqueryV2Source, "get_core_table_details")
+@patch.object(BigQuerySchemaGenerator, "get_core_table_details")
@patch.object(BigQuerySchemaApi, "get_datasets_for_project_id")
@patch.object(BigQuerySchemaApi, "get_columns_for_dataset")
@patch.object(BigQueryDataReader, "get_sample_data_for_table")
diff --git a/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json b/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
index b9b2a3b2141a8..f35ff9fdb9d15 100644
--- a/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
+++ b/metadata-ingestion/tests/integration/postgres/postgres_all_db_mces_with_db_golden.json
@@ -832,7 +832,8 @@
{
"fieldPath": "metadata_json"
}
- ]
+ ],
+ "sizeInBytes": 16384
}
},
"systemMetadata": {
diff --git a/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json b/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
index 832b46e096ae0..f47789fc470cd 100644
--- a/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
+++ b/metadata-ingestion/tests/integration/postgres/postgres_mces_with_db_golden.json
@@ -600,7 +600,8 @@
},
"rowCount": 2,
"columnCount": 9,
- "fieldProfiles": []
+ "fieldProfiles": [],
+ "sizeInBytes": 16384
}
},
"systemMetadata": {
diff --git a/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json b/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json
new file mode 100644
index 0000000000000..a8593493a5ec7
--- /dev/null
+++ b/metadata-ingestion/tests/integration/tableau/setup/permission_mode_switched_error.json
@@ -0,0 +1,16 @@
+{
+ "errors":[
+ {
+ "message": "One or more of the attributes used in your filter contain sensitive data so your results have been automatically filtered to contain only the results you have permissions to see",
+ "extensions": {
+ "severity": "WARNING",
+ "code": "PERMISSIONS_MODE_SWITCHED",
+ "properties": {
+ "workbooksConnection": [
+ "projectNameWithin"
+ ]
+ }
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json b/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
index 5de4fe5f647d9..855f872838052 100644
--- a/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
+++ b/metadata-ingestion/tests/integration/tableau/tableau_cll_mces_golden.json
@@ -42958,6 +42958,50 @@
"pipelineName": "test_tableau_cll_ingest"
}
},
+{
+ "proposedSnapshot": {
+ "com.linkedin.pegasus2avro.metadata.snapshot.DatasetSnapshot": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:bigquery,demo-custom-323403.bigquery_demo.order_items,PROD)",
+ "aspects": [
+ {
+ "com.linkedin.pegasus2avro.metadata.key.DatasetKey": {
+ "platform": "urn:li:dataPlatform:bigquery",
+ "name": "demo-custom-323403.bigquery_demo.order_items",
+ "origin": "PROD"
+ }
+ }
+ ]
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1638860400000,
+ "runId": "tableau-test",
+ "lastRunId": "no-run-id-provided",
+ "pipelineName": "test_tableau_cll_ingest"
+ }
+},
+{
+ "proposedSnapshot": {
+ "com.linkedin.pegasus2avro.metadata.snapshot.DatasetSnapshot": {
+ "urn": "urn:li:dataset:(urn:li:dataPlatform:bigquery,demo-custom-323403.bigquery_demo.sellers,PROD)",
+ "aspects": [
+ {
+ "com.linkedin.pegasus2avro.metadata.key.DatasetKey": {
+ "platform": "urn:li:dataPlatform:bigquery",
+ "name": "demo-custom-323403.bigquery_demo.sellers",
+ "origin": "PROD"
+ }
+ }
+ ]
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1638860400000,
+ "runId": "tableau-test",
+ "lastRunId": "no-run-id-provided",
+ "pipelineName": "test_tableau_cll_ingest"
+ }
+},
{
"entityType": "chart",
"entityUrn": "urn:li:chart:(tableau,130496dc-29ca-8a89-e32b-d73c4d8b65ff)",
diff --git a/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py b/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
index b64609b6ea605..0891a1e0cd593 100644
--- a/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
+++ b/metadata-ingestion/tests/integration/tableau/test_tableau_ingest.py
@@ -2,7 +2,7 @@
import logging
import pathlib
import sys
-from typing import Any, Dict, cast
+from typing import Any, Dict, List, cast
from unittest import mock
import pytest
@@ -232,6 +232,41 @@ def side_effect_site_get_by_id(id, *arg, **kwargs):
return site
+def mock_sdk_client(
+ side_effect_query_metadata_response: List[dict],
+ datasources_side_effect: List[dict],
+ sign_out_side_effect: List[dict],
+) -> mock.MagicMock:
+
+ mock_client = mock.Mock()
+ mocked_metadata = mock.Mock()
+ mocked_metadata.query.side_effect = side_effect_query_metadata_response
+ mock_client.metadata = mocked_metadata
+
+ mock_client.auth = mock.Mock()
+ mock_client.site_id = "190a6a5c-63ed-4de1-8045-site1"
+ mock_client.views = mock.Mock()
+ mock_client.projects = mock.Mock()
+ mock_client.sites = mock.Mock()
+
+ mock_client.projects.get.side_effect = side_effect_project_data
+ mock_client.sites.get.side_effect = side_effect_site_data
+ mock_client.sites.get_by_id.side_effect = side_effect_site_get_by_id
+
+ mock_client.datasources = mock.Mock()
+ mock_client.datasources.get.side_effect = datasources_side_effect
+ mock_client.datasources.get_by_id.side_effect = side_effect_datasource_get_by_id
+
+ mock_client.workbooks = mock.Mock()
+ mock_client.workbooks.get.side_effect = side_effect_workbook_data
+
+ mock_client.views.get.side_effect = side_effect_usage_stat
+ mock_client.auth.sign_in.return_value = None
+ mock_client.auth.sign_out.side_effect = sign_out_side_effect
+
+ return mock_client
+
+
def tableau_ingest_common(
pytestconfig,
tmp_path,
@@ -251,30 +286,11 @@ def tableau_ingest_common(
mock_checkpoint.return_value = mock_datahub_graph
with mock.patch("datahub.ingestion.source.tableau.Server") as mock_sdk:
- mock_client = mock.Mock()
- mocked_metadata = mock.Mock()
- mocked_metadata.query.side_effect = side_effect_query_metadata_response
- mock_client.metadata = mocked_metadata
- mock_client.auth = mock.Mock()
- mock_client.site_id = "190a6a5c-63ed-4de1-8045-site1"
- mock_client.views = mock.Mock()
- mock_client.projects = mock.Mock()
- mock_client.sites = mock.Mock()
-
- mock_client.projects.get.side_effect = side_effect_project_data
- mock_client.sites.get.side_effect = side_effect_site_data
- mock_client.sites.get_by_id.side_effect = side_effect_site_get_by_id
- mock_client.datasources = mock.Mock()
- mock_client.datasources.get.side_effect = datasources_side_effect
- mock_client.datasources.get_by_id.side_effect = (
- side_effect_datasource_get_by_id
+ mock_sdk.return_value = mock_sdk_client(
+ side_effect_query_metadata_response=side_effect_query_metadata_response,
+ datasources_side_effect=datasources_side_effect,
+ sign_out_side_effect=sign_out_side_effect,
)
- mock_client.workbooks = mock.Mock()
- mock_client.workbooks.get.side_effect = side_effect_workbook_data
- mock_client.views.get.side_effect = side_effect_usage_stat
- mock_client.auth.sign_in.return_value = None
- mock_client.auth.sign_out.side_effect = sign_out_side_effect
- mock_sdk.return_value = mock_client
mock_sdk._auth_token = "ABC"
pipeline = Pipeline.create(
@@ -1106,3 +1122,51 @@ def test_site_name_pattern(pytestconfig, tmp_path, mock_datahub_graph):
pipeline_config=new_config,
pipeline_name="test_tableau_site_name_pattern_ingest",
)
+
+
+@freeze_time(FROZEN_TIME)
+@pytest.mark.integration
+def test_permission_mode_switched_error(pytestconfig, tmp_path, mock_datahub_graph):
+
+ with mock.patch(
+ "datahub.ingestion.source.state_provider.datahub_ingestion_checkpointing_provider.DataHubGraph",
+ mock_datahub_graph,
+ ) as mock_checkpoint:
+ mock_checkpoint.return_value = mock_datahub_graph
+
+ with mock.patch("datahub.ingestion.source.tableau.Server") as mock_sdk:
+ mock_sdk.return_value = mock_sdk_client(
+ side_effect_query_metadata_response=[
+ read_response(pytestconfig, "permission_mode_switched_error.json")
+ ],
+ sign_out_side_effect=[{}],
+ datasources_side_effect=[{}],
+ )
+
+ reporter = TableauSourceReport()
+ tableau_source = TableauSiteSource(
+ platform="tableau",
+ config=mock.MagicMock(),
+ ctx=mock.MagicMock(),
+ site=mock.MagicMock(),
+ server=mock_sdk.return_value,
+ report=reporter,
+ )
+
+ tableau_source.get_connection_object_page(
+ query=mock.MagicMock(),
+ connection_type=mock.MagicMock(),
+ query_filter=mock.MagicMock(),
+ retries_remaining=1,
+ )
+
+ warnings = list(reporter.warnings)
+
+ assert len(warnings) == 1
+
+ assert warnings[0].title == "Derived Permission Error"
+
+ assert warnings[0].message == (
+ "Turn on your derived permissions. See for details "
+ "https://community.tableau.com/s/question/0D54T00000QnjHbSAJ/how-to-fix-the-permissionsmodeswitched-error"
+ )
diff --git a/metadata-ingestion/tests/unit/test_bigquery_source.py b/metadata-ingestion/tests/unit/test_bigquery_source.py
index b58f35c0deef5..746cf9b0acfc3 100644
--- a/metadata-ingestion/tests/unit/test_bigquery_source.py
+++ b/metadata-ingestion/tests/unit/test_bigquery_source.py
@@ -32,6 +32,9 @@
BigqueryTableSnapshot,
BigqueryView,
)
+from datahub.ingestion.source.bigquery_v2.bigquery_schema_gen import (
+ BigQuerySchemaGenerator,
+)
from datahub.ingestion.source.bigquery_v2.lineage import (
LineageEdge,
LineageEdgeColumnMapping,
@@ -231,8 +234,9 @@ def test_get_dataplatform_instance_aspect_returns_project_id(get_bq_client_mock)
config = BigQueryV2Config.parse_obj({"include_data_platform_instance": True})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
- data_platform_instance = source.get_dataplatform_instance_aspect(
+ data_platform_instance = schema_gen.get_dataplatform_instance_aspect(
"urn:li:test", project_id
)
metadata = data_platform_instance.metadata
@@ -246,8 +250,9 @@ def test_get_dataplatform_instance_aspect_returns_project_id(get_bq_client_mock)
def test_get_dataplatform_instance_default_no_instance(get_bq_client_mock):
config = BigQueryV2Config.parse_obj({})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
- data_platform_instance = source.get_dataplatform_instance_aspect(
+ data_platform_instance = schema_gen.get_dataplatform_instance_aspect(
"urn:li:test", "project_id"
)
metadata = data_platform_instance.metadata
@@ -273,24 +278,35 @@ def test_get_projects_with_single_project_id(get_bq_client_mock):
def test_get_projects_by_list(get_bq_client_mock):
client_mock = MagicMock()
get_bq_client_mock.return_value = client_mock
- client_mock.list_projects.return_value = [
- SimpleNamespace(
- project_id="test-1",
- friendly_name="one",
- ),
- SimpleNamespace(
- project_id="test-2",
- friendly_name="two",
- ),
- ]
+
+ first_page = MagicMock()
+ first_page.__iter__.return_value = iter(
+ [
+ SimpleNamespace(project_id="test-1", friendly_name="one"),
+ SimpleNamespace(project_id="test-2", friendly_name="two"),
+ ]
+ )
+ first_page.next_page_token = "token1"
+
+ second_page = MagicMock()
+ second_page.__iter__.return_value = iter(
+ [
+ SimpleNamespace(project_id="test-3", friendly_name="three"),
+ SimpleNamespace(project_id="test-4", friendly_name="four"),
+ ]
+ )
+ second_page.next_page_token = None
+ client_mock.list_projects.side_effect = [first_page, second_page]
config = BigQueryV2Config.parse_obj({})
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test1"))
assert source._get_projects() == [
BigqueryProject("test-1", "one"),
BigqueryProject("test-2", "two"),
+ BigqueryProject("test-3", "three"),
+ BigqueryProject("test-4", "four"),
]
- assert client_mock.list_projects.call_count == 1
+ assert client_mock.list_projects.call_count == 2
@patch.object(BigQuerySchemaApi, "get_projects")
@@ -342,7 +358,7 @@ def test_get_projects_list_failure(
caplog.clear()
with caplog.at_level(logging.ERROR):
projects = source._get_projects()
- assert len(caplog.records) == 1
+ assert len(caplog.records) == 2
assert error_str in caplog.records[0].msg
assert len(source.report.failures) == 1
assert projects == []
@@ -395,8 +411,9 @@ def test_gen_table_dataset_workunits(get_bq_client_mock, bigquery_table):
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_table_dataset_workunits(
+ gen = schema_gen.gen_table_dataset_workunits(
bigquery_table, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -710,9 +727,10 @@ def test_table_processing_logic(get_bq_client_mock, data_dictionary_mock):
data_dictionary_mock.get_tables_for_dataset.return_value = None
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
_ = list(
- source.get_tables_for_dataset(
+ schema_gen.get_tables_for_dataset(
project_id="test-project", dataset_name="test-dataset"
)
)
@@ -784,9 +802,10 @@ def test_table_processing_logic_date_named_tables(
data_dictionary_mock.get_tables_for_dataset.return_value = None
source = BigqueryV2Source(config=config, ctx=PipelineContext(run_id="test"))
+ schema_gen = source.bq_schema_extractor
_ = list(
- source.get_tables_for_dataset(
+ schema_gen.get_tables_for_dataset(
project_id="test-project", dataset_name="test-dataset"
)
)
@@ -882,7 +901,9 @@ def test_get_views_for_dataset(
assert list(views) == [bigquery_view_1, bigquery_view_2]
-@patch.object(BigqueryV2Source, "gen_dataset_workunits", lambda *args, **kwargs: [])
+@patch.object(
+ BigQuerySchemaGenerator, "gen_dataset_workunits", lambda *args, **kwargs: []
+)
@patch.object(BigQueryV2Config, "get_bigquery_client")
def test_gen_view_dataset_workunits(
get_bq_client_mock, bigquery_view_1, bigquery_view_2
@@ -897,8 +918,9 @@ def test_gen_view_dataset_workunits(
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_view_dataset_workunits(
+ gen = schema_gen.gen_view_dataset_workunits(
bigquery_view_1, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -908,7 +930,7 @@ def test_gen_view_dataset_workunits(
viewLogic=bigquery_view_1.view_definition,
)
- gen = source.gen_view_dataset_workunits(
+ gen = schema_gen.gen_view_dataset_workunits(
bigquery_view_2, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalClass, next(iter(gen)).metadata)
@@ -990,8 +1012,9 @@ def test_gen_snapshot_dataset_workunits(get_bq_client_mock, bigquery_snapshot):
source: BigqueryV2Source = BigqueryV2Source(
config=config, ctx=PipelineContext(run_id="test")
)
+ schema_gen = source.bq_schema_extractor
- gen = source.gen_snapshot_dataset_workunits(
+ gen = schema_gen.gen_snapshot_dataset_workunits(
bigquery_snapshot, [], project_id, dataset_name
)
mcp = cast(MetadataChangeProposalWrapper, list(gen)[2].metadata)
diff --git a/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py b/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
index 8a3fa5ca46ea4..21787af1b0cb9 100644
--- a/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
+++ b/metadata-ingestion/tests/unit/test_bigqueryv2_usage_source.py
@@ -212,3 +212,29 @@ def test_unquote_and_decode_unicode_escape_seq():
expected_output = "No escape sequences here"
result = unquote_and_decode_unicode_escape_seq(input_string)
assert result == expected_output
+
+ # Test with invalid Unicode escape sequences
+ input_string = '"No escape \\u123 sequences here"'
+ expected_output = "No escape \\u123 sequences here"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with a string that has multiple Unicode escape sequences
+ input_string = '"Hello \\u003cWorld\\u003e \\u003cAgain\\u003e \\u003cAgain\\u003e \\u003cAgain\\u003e"'
+ expected_output = "Hello "
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with a string that has a Unicode escape sequence at the beginning
+ input_string = '"Hello \\utest"'
+ expected_output = "Hello \\utest"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
+
+ # Test with special characters
+ input_string = (
+ '"Hello \\u003cWorld\\u003e \\u003cçãâÁÁà|{}()[].,/;\\+=--_*&%$#@!?\\u003e"'
+ )
+ expected_output = "Hello <çãâÁÁà|{}()[].,/;\\+=--_*&%$#@!?>"
+ result = unquote_and_decode_unicode_escape_seq(input_string)
+ assert result == expected_output
diff --git a/metadata-ingestion/tests/unit/test_snowflake_shares.py b/metadata-ingestion/tests/unit/test_snowflake_shares.py
index fc753f99b7e8f..2e78f0bb3ae65 100644
--- a/metadata-ingestion/tests/unit/test_snowflake_shares.py
+++ b/metadata-ingestion/tests/unit/test_snowflake_shares.py
@@ -102,9 +102,7 @@ def test_snowflake_shares_workunit_no_shares(
config = SnowflakeV2Config(account_id="abc12345", platform_instance="instance1")
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x)
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -204,9 +202,7 @@ def test_snowflake_shares_workunit_inbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -262,9 +258,7 @@ def test_snowflake_shares_workunit_outbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -313,9 +307,7 @@ def test_snowflake_shares_workunit_inbound_and_outbound_share(
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x, "instance1")
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
wus = list(shares_handler.get_shares_workunits(snowflake_databases))
@@ -376,9 +368,7 @@ def test_snowflake_shares_workunit_inbound_and_outbound_share_no_platform_instan
)
report = SnowflakeV2Report()
- shares_handler = SnowflakeSharesHandler(
- config, report, lambda x: make_snowflake_urn(x)
- )
+ shares_handler = SnowflakeSharesHandler(config, report)
assert sorted(config.outbounds().keys()) == ["db1", "db2_main"]
assert sorted(config.inbounds().keys()) == [
diff --git a/metadata-ingestion/tests/unit/test_snowflake_source.py b/metadata-ingestion/tests/unit/test_snowflake_source.py
index 3353e74449c95..72b59a3a4e493 100644
--- a/metadata-ingestion/tests/unit/test_snowflake_source.py
+++ b/metadata-ingestion/tests/unit/test_snowflake_source.py
@@ -274,21 +274,31 @@ def test_test_connection_basic_success(mock_connect):
test_connection_helpers.assert_basic_connectivity_success(report)
-def setup_mock_connect(mock_connect, query_results=None):
- def default_query_results(query):
+class MissingQueryMock(Exception):
+ pass
+
+
+def setup_mock_connect(mock_connect, extra_query_results=None):
+ def query_results(query):
+ if extra_query_results is not None:
+ try:
+ return extra_query_results(query)
+ except MissingQueryMock:
+ pass
+
if query == "select current_role()":
- return [("TEST_ROLE",)]
+ return [{"CURRENT_ROLE()": "TEST_ROLE"}]
elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
+ return [{"CURRENT_SECONDARY_ROLES()": '{"roles":"","value":""}'}]
elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- raise ValueError(f"Unexpected query: {query}")
+ return [{"CURRENT_WAREHOUSE()": "TEST_WAREHOUSE"}]
+ elif query == 'show grants to role "PUBLIC"':
+ return []
+ raise MissingQueryMock(f"Unexpected query: {query}")
connection_mock = MagicMock()
cursor_mock = MagicMock()
- cursor_mock.execute.side_effect = (
- query_results if query_results is not None else default_query_results
- )
+ cursor_mock.execute.side_effect = query_results
connection_mock.cursor.return_value = cursor_mock
mock_connect.return_value = connection_mock
@@ -296,21 +306,11 @@ def default_query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_no_warehouse(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [(None,)]
+ if query == "select current_warehouse()":
+ return [{"CURRENT_WAREHOUSE()": None}]
elif query == 'show grants to role "TEST_ROLE"':
- return [
- ("", "USAGE", "DATABASE", "DB1"),
- ("", "USAGE", "SCHEMA", "DB1.SCHEMA1"),
- ("", "REFERENCES", "TABLE", "DB1.SCHEMA1.TABLE1"),
- ]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ return [{"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"}]
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
report = test_connection_helpers.run_test_connection(
@@ -330,17 +330,9 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_schema_failure(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE",)]
- elif query == 'show grants to role "TEST_ROLE"':
- return [("", "USAGE", "DATABASE", "DB1")]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ if query == 'show grants to role "TEST_ROLE"':
+ return [{"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"}]
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
@@ -361,21 +353,17 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_schema_success(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- elif query == 'show grants to role "TEST_ROLE"':
+ if query == 'show grants to role "TEST_ROLE"':
return [
- ["", "USAGE", "DATABASE", "DB1"],
- ["", "USAGE", "SCHEMA", "DB1.SCHEMA1"],
- ["", "REFERENCES", "TABLE", "DB1.SCHEMA1.TABLE1"],
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "DB1.SCHEMA1"},
+ {
+ "privilege": "REFERENCES",
+ "granted_on": "TABLE",
+ "name": "DB1.SCHEMA1.TABLE1",
+ },
]
- elif query == 'show grants to role "PUBLIC"':
- return []
- raise ValueError(f"Unexpected query: {query}")
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
@@ -397,30 +385,38 @@ def query_results(query):
@patch("snowflake.connector.connect")
def test_test_connection_capability_all_success(mock_connect):
def query_results(query):
- if query == "select current_role()":
- return [("TEST_ROLE",)]
- elif query == "select current_secondary_roles()":
- return [('{"roles":"","value":""}',)]
- elif query == "select current_warehouse()":
- return [("TEST_WAREHOUSE")]
- elif query == 'show grants to role "TEST_ROLE"':
+ if query == 'show grants to role "TEST_ROLE"':
return [
- ("", "USAGE", "DATABASE", "DB1"),
- ("", "USAGE", "SCHEMA", "DB1.SCHEMA1"),
- ("", "SELECT", "TABLE", "DB1.SCHEMA1.TABLE1"),
- ("", "USAGE", "ROLE", "TEST_USAGE_ROLE"),
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "DB1"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "DB1.SCHEMA1"},
+ {
+ "privilege": "SELECT",
+ "granted_on": "TABLE",
+ "name": "DB1.SCHEMA1.TABLE1",
+ },
+ {"privilege": "USAGE", "granted_on": "ROLE", "name": "TEST_USAGE_ROLE"},
]
- elif query == 'show grants to role "PUBLIC"':
- return []
elif query == 'show grants to role "TEST_USAGE_ROLE"':
return [
- ["", "USAGE", "DATABASE", "SNOWFLAKE"],
- ["", "USAGE", "SCHEMA", "ACCOUNT_USAGE"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY"],
- ["", "USAGE", "VIEW", "SNOWFLAKE.ACCOUNT_USAGE.OBJECT_DEPENDENCIES"],
+ {"privilege": "USAGE", "granted_on": "DATABASE", "name": "SNOWFLAKE"},
+ {"privilege": "USAGE", "granted_on": "SCHEMA", "name": "ACCOUNT_USAGE"},
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY",
+ },
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY",
+ },
+ {
+ "privilege": "USAGE",
+ "granted_on": "VIEW",
+ "name": "SNOWFLAKE.ACCOUNT_USAGE.OBJECT_DEPENDENCIES",
+ },
]
- raise ValueError(f"Unexpected query: {query}")
+ raise MissingQueryMock(f"Unexpected query: {query}")
setup_mock_connect(mock_connect, query_results)
diff --git a/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py b/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py
new file mode 100644
index 0000000000000..35c44c7b4a847
--- /dev/null
+++ b/metadata-ingestion/tests/unit/utilities/test_threaded_iterator_executor.py
@@ -0,0 +1,14 @@
+from datahub.utilities.threaded_iterator_executor import ThreadedIteratorExecutor
+
+
+def test_threaded_iterator_executor():
+ def table_of(i):
+ for j in range(1, 11):
+ yield f"{i}x{j}={i*j}"
+
+ assert {
+ res
+ for res in ThreadedIteratorExecutor.process(
+ table_of, [(i,) for i in range(1, 30)], max_workers=2
+ )
+ } == {x for i in range(1, 30) for x in table_of(i)}
diff --git a/metadata-integration/java/spark-lineage-beta/README.md b/metadata-integration/java/spark-lineage-beta/README.md
index a643919664b07..b0753936dd677 100644
--- a/metadata-integration/java/spark-lineage-beta/README.md
+++ b/metadata-integration/java/spark-lineage-beta/README.md
@@ -346,8 +346,10 @@ Use Java 8 to build the project. The project uses Gradle as the build tool. To b
+
## Changelog
+### Version 0.2.14
+- Fix warning about MeterFilter warning from Micrometer
-### Version 0.2.12
+### Version 0.2.13
- Silencing some chatty warnings in RddPathUtils
### Version 0.2.12
diff --git a/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java b/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
index 54bb3821edded..96fa74d1bca1f 100644
--- a/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
+++ b/metadata-integration/java/spark-lineage-beta/src/main/java/datahub/spark/DatahubSparkListener.java
@@ -287,13 +287,7 @@ private static void initializeMetrics(OpenLineageConfig openLineageConfig) {
} else {
disabledFacets = "";
}
- meterRegistry
- .config()
- .commonTags(
- Tags.of(
- Tag.of("openlineage.spark.integration.version", Versions.getVersion()),
- Tag.of("openlineage.spark.version", sparkVersion),
- Tag.of("openlineage.spark.disabled.facets", disabledFacets)));
+
((CompositeMeterRegistry) meterRegistry)
.getRegistries()
.forEach(
diff --git a/metadata-io/build.gradle b/metadata-io/build.gradle
index 6666e33544688..ff29cb5fff47d 100644
--- a/metadata-io/build.gradle
+++ b/metadata-io/build.gradle
@@ -21,6 +21,7 @@ dependencies {
api project(':metadata-service:services')
api project(':metadata-operation-context')
+ implementation spec.product.pegasus.restliServer
implementation spec.product.pegasus.data
implementation spec.product.pegasus.generator
diff --git a/metadata-io/metadata-io-api/build.gradle b/metadata-io/metadata-io-api/build.gradle
index bd79e8cb3ddef..b8028fad07bb6 100644
--- a/metadata-io/metadata-io-api/build.gradle
+++ b/metadata-io/metadata-io-api/build.gradle
@@ -8,4 +8,11 @@ dependencies {
implementation project(':metadata-utils')
compileOnly externalDependency.lombok
annotationProcessor externalDependency.lombok
+
+ testImplementation(externalDependency.testng)
+ testImplementation(externalDependency.mockito)
+ testImplementation(testFixtures(project(":entity-registry")))
+ testImplementation project(':metadata-operation-context')
+ testImplementation externalDependency.lombok
+ testAnnotationProcessor externalDependency.lombok
}
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
index 0914df744e413..a23f6ab175046 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
@@ -8,6 +8,7 @@
import com.linkedin.metadata.aspect.batch.AspectsBatch;
import com.linkedin.metadata.aspect.batch.BatchItem;
import com.linkedin.metadata.aspect.batch.ChangeMCP;
+import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.validation.ValidationExceptionCollection;
import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.util.Pair;
@@ -18,6 +19,7 @@
import java.util.Objects;
import java.util.Set;
import java.util.stream.Collectors;
+import java.util.stream.Stream;
import javax.annotation.Nonnull;
import lombok.Builder;
import lombok.Getter;
@@ -44,9 +46,20 @@ public class AspectsBatchImpl implements AspectsBatch {
public Pair>, List> toUpsertBatchItems(
final Map> latestAspects) {
+ // Process proposals to change items
+ Stream mutatedProposalsStream =
+ proposedItemsToChangeItemStream(
+ items.stream()
+ .filter(item -> item instanceof ProposedItem)
+ .map(item -> (MCPItem) item)
+ .collect(Collectors.toList()));
+ // Regular change items
+ Stream changeMCPStream =
+ items.stream().filter(item -> !(item instanceof ProposedItem));
+
// Convert patches to upserts if needed
LinkedList upsertBatchItems =
- items.stream()
+ Stream.concat(mutatedProposalsStream, changeMCPStream)
.map(
item -> {
final String urnStr = item.getUrn().toString();
@@ -85,6 +98,17 @@ public Pair>, List> toUpsertBatchItems(
return Pair.of(newUrnAspectNames, upsertBatchItems);
}
+ private Stream proposedItemsToChangeItemStream(List proposedItems) {
+ return applyProposalMutationHooks(proposedItems, retrieverContext)
+ .filter(mcpItem -> mcpItem.getMetadataChangeProposal() != null)
+ .map(
+ mcpItem ->
+ ChangeItemImpl.ChangeItemImplBuilder.build(
+ mcpItem.getMetadataChangeProposal(),
+ mcpItem.getAuditStamp(),
+ retrieverContext.getAspectRetriever()));
+ }
+
public static class AspectsBatchImplBuilder {
/**
* Just one aspect record template
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
new file mode 100644
index 0000000000000..452ed39ddf317
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
@@ -0,0 +1,80 @@
+package com.linkedin.metadata.entity.ebean.batch;
+
+import com.linkedin.common.AuditStamp;
+import com.linkedin.common.urn.Urn;
+import com.linkedin.data.template.RecordTemplate;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.models.AspectSpec;
+import com.linkedin.metadata.models.EntitySpec;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import javax.annotation.Nonnull;
+import javax.annotation.Nullable;
+import lombok.Builder;
+import lombok.Getter;
+import lombok.extern.slf4j.Slf4j;
+
+/** Represents an unvalidated wrapped MCP */
+@Slf4j
+@Getter
+@Builder(toBuilder = true)
+public class ProposedItem implements MCPItem {
+ @Nonnull private final MetadataChangeProposal metadataChangeProposal;
+ @Nonnull private final AuditStamp auditStamp;
+ // derived
+ @Nonnull private EntitySpec entitySpec;
+ @Nullable private AspectSpec aspectSpec;
+
+ @Nonnull
+ @Override
+ public String getAspectName() {
+ if (metadataChangeProposal.getAspectName() != null) {
+ return metadataChangeProposal.getAspectName();
+ } else {
+ return MCPItem.super.getAspectName();
+ }
+ }
+
+ @Nullable
+ public AspectSpec getAspectSpec() {
+ if (aspectSpec != null) {
+ return aspectSpec;
+ }
+ if (entitySpec.getAspectSpecMap().containsKey(getAspectName())) {
+ return entitySpec.getAspectSpecMap().get(getAspectName());
+ }
+ return null;
+ }
+
+ @Nullable
+ @Override
+ public RecordTemplate getRecordTemplate() {
+ if (getAspectSpec() != null) {
+ return GenericRecordUtils.deserializeAspect(
+ getMetadataChangeProposal().getAspect().getValue(),
+ getMetadataChangeProposal().getAspect().getContentType(),
+ getAspectSpec());
+ }
+ return null;
+ }
+
+ @Nonnull
+ @Override
+ public Urn getUrn() {
+ return metadataChangeProposal.getEntityUrn();
+ }
+
+ @Nullable
+ @Override
+ public SystemMetadata getSystemMetadata() {
+ return metadataChangeProposal.getSystemMetadata();
+ }
+
+ @Nonnull
+ @Override
+ public ChangeType getChangeType() {
+ return metadataChangeProposal.getChangeType();
+ }
+}
diff --git a/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java b/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java
new file mode 100644
index 0000000000000..d2e7243d04560
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/test/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImplTest.java
@@ -0,0 +1,320 @@
+package com.linkedin.metadata.entity.ebean.batch;
+
+import static com.linkedin.metadata.Constants.DATASET_ENTITY_NAME;
+import static com.linkedin.metadata.Constants.STATUS_ASPECT_NAME;
+import static com.linkedin.metadata.Constants.STRUCTURED_PROPERTIES_ASPECT_NAME;
+import static org.mockito.Mockito.mock;
+import static org.mockito.Mockito.when;
+import static org.testng.Assert.assertEquals;
+
+import com.linkedin.common.Status;
+import com.linkedin.common.urn.UrnUtils;
+import com.linkedin.data.ByteString;
+import com.linkedin.data.schema.annotation.PathSpecBasedSchemaAnnotationVisitor;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.AspectRetriever;
+import com.linkedin.metadata.aspect.GraphRetriever;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.patch.GenericJsonPatch;
+import com.linkedin.metadata.aspect.patch.PatchOperationType;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import com.linkedin.metadata.entity.SearchRetriever;
+import com.linkedin.metadata.models.registry.ConfigEntityRegistry;
+import com.linkedin.metadata.models.registry.EntityRegistry;
+import com.linkedin.metadata.models.registry.EntityRegistryException;
+import com.linkedin.metadata.models.registry.MergedEntityRegistry;
+import com.linkedin.metadata.models.registry.SnapshotEntityRegistry;
+import com.linkedin.metadata.snapshot.Snapshot;
+import com.linkedin.metadata.utils.AuditStampUtils;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import com.linkedin.structured.StructuredProperties;
+import com.linkedin.structured.StructuredPropertyValueAssignmentArray;
+import com.linkedin.util.Pair;
+import io.datahubproject.metadata.context.RetrieverContext;
+import java.nio.charset.StandardCharsets;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Stream;
+import javax.annotation.Nonnull;
+import lombok.Getter;
+import lombok.Setter;
+import lombok.experimental.Accessors;
+import org.testng.annotations.BeforeMethod;
+import org.testng.annotations.BeforeTest;
+import org.testng.annotations.Test;
+
+public class AspectsBatchImplTest {
+ private EntityRegistry testRegistry;
+ private AspectRetriever mockAspectRetriever;
+ private RetrieverContext retrieverContext;
+
+ @BeforeTest
+ public void beforeTest() throws EntityRegistryException {
+ PathSpecBasedSchemaAnnotationVisitor.class
+ .getClassLoader()
+ .setClassAssertionStatus(PathSpecBasedSchemaAnnotationVisitor.class.getName(), false);
+
+ EntityRegistry snapshotEntityRegistry = new SnapshotEntityRegistry();
+ EntityRegistry configEntityRegistry =
+ new ConfigEntityRegistry(
+ Snapshot.class.getClassLoader().getResourceAsStream("AspectsBatchImplTest.yaml"));
+ this.testRegistry =
+ new MergedEntityRegistry(snapshotEntityRegistry).apply(configEntityRegistry);
+ }
+
+ @BeforeMethod
+ public void setup() {
+ this.mockAspectRetriever = mock(AspectRetriever.class);
+ when(this.mockAspectRetriever.getEntityRegistry()).thenReturn(testRegistry);
+ this.retrieverContext =
+ RetrieverContext.builder()
+ .searchRetriever(mock(SearchRetriever.class))
+ .aspectRetriever(mockAspectRetriever)
+ .graphRetriever(mock(GraphRetriever.class))
+ .build();
+ }
+
+ @Test
+ public void toUpsertBatchItemsChangeItemTest() {
+ List testItems =
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .recordTemplate(new Status().setRemoved(true))
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever));
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(Map.of(), testItems),
+ "Expected noop, pass through with no additional MCPs or changes");
+ }
+
+ @Test
+ public void toUpsertBatchItemsPatchItemTest() {
+ GenericJsonPatch.PatchOp testPatchOp = new GenericJsonPatch.PatchOp();
+ testPatchOp.setOp(PatchOperationType.REMOVE.getValue());
+ testPatchOp.setPath(
+ String.format(
+ "/properties/%s", "urn:li:structuredProperty:io.acryl.privacy.retentionTime"));
+
+ List testItems =
+ List.of(
+ PatchItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .patch(
+ GenericJsonPatch.builder()
+ .arrayPrimaryKeys(Map.of("properties", List.of("propertyUrn")))
+ .patch(List.of(testPatchOp))
+ .build()
+ .getJsonPatch())
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(retrieverContext.getAspectRetriever().getEntityRegistry()),
+ PatchItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .patch(
+ GenericJsonPatch.builder()
+ .arrayPrimaryKeys(Map.of("properties", List.of("propertyUrn")))
+ .patch(List.of(testPatchOp))
+ .build()
+ .getJsonPatch())
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(retrieverContext.getAspectRetriever().getEntityRegistry()));
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(
+ Map.of(),
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .auditStamp(testItems.get(0).getAuditStamp())
+ .recordTemplate(
+ new StructuredProperties()
+ .setProperties(new StructuredPropertyValueAssignmentArray()))
+ .systemMetadata(testItems.get(0).getSystemMetadata())
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STRUCTURED_PROPERTIES_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STRUCTURED_PROPERTIES_ASPECT_NAME))
+ .auditStamp(testItems.get(1).getAuditStamp())
+ .recordTemplate(
+ new StructuredProperties()
+ .setProperties(new StructuredPropertyValueAssignmentArray()))
+ .systemMetadata(testItems.get(1).getSystemMetadata())
+ .build(mockAspectRetriever))),
+ "Expected patch items converted to upsert change items");
+ }
+
+ @Test
+ public void toUpsertBatchItemsProposedItemTest() {
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .setAspectName("my-custom-aspect")
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\"}", StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build(),
+ ProposedItem.builder()
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .setAspectName("my-custom-aspect")
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\"}", StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ AspectsBatchImpl testBatch =
+ AspectsBatchImpl.builder().items(testItems).retrieverContext(retrieverContext).build();
+
+ assertEquals(
+ testBatch.toUpsertBatchItems(Map.of()),
+ Pair.of(
+ Map.of(),
+ List.of(
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .systemMetadata(testItems.get(0).getSystemMetadata())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever),
+ ChangeItemImpl.builder()
+ .urn(
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)"))
+ .changeType(ChangeType.UPSERT)
+ .aspectName(STATUS_ASPECT_NAME)
+ .entitySpec(testRegistry.getEntitySpec(DATASET_ENTITY_NAME))
+ .aspectSpec(
+ testRegistry
+ .getEntitySpec(DATASET_ENTITY_NAME)
+ .getAspectSpec(STATUS_ASPECT_NAME))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .systemMetadata(testItems.get(1).getSystemMetadata())
+ .recordTemplate(new Status().setRemoved(false))
+ .build(mockAspectRetriever))),
+ "Mutation to status aspect");
+ }
+
+ /** Converts unsupported to status aspect */
+ @Getter
+ @Setter
+ @Accessors(chain = true)
+ public static class TestMutator extends MutationHook {
+ private AspectPluginConfig config;
+
+ @Override
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems,
+ @Nonnull com.linkedin.metadata.aspect.RetrieverContext retrieverContext) {
+ return mcpItems.stream()
+ .peek(
+ item ->
+ item.getMetadataChangeProposal()
+ .setAspectName(STATUS_ASPECT_NAME)
+ .setAspect(
+ GenericRecordUtils.serializeAspect(new Status().setRemoved(false))));
+ }
+ }
+}
diff --git a/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml b/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml
new file mode 100644
index 0000000000000..9716b0cab9b2f
--- /dev/null
+++ b/metadata-io/metadata-io-api/src/test/resources/AspectsBatchImplTest.yaml
@@ -0,0 +1,19 @@
+entities:
+ - name: dataset
+ doc: Datasets represent logical or physical data assets stored or represented in various data platforms. Tables, Views, Streams are all instances of datasets.
+ category: core
+ keyAspect: datasetKey
+ aspects:
+ - status
+ - structuredProperties
+plugins:
+ mutationHooks:
+ - className: 'com.linkedin.metadata.entity.ebean.batch.AspectsBatchImplTest$TestMutator'
+ packageScan:
+ - 'com.linkedin.metadata.entity.ebean.batch'
+ enabled: true
+ supportedOperations:
+ - UPSERT
+ supportedEntityAspectNames:
+ - entityName: 'dataset'
+ aspectName: '*'
\ No newline at end of file
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
new file mode 100644
index 0000000000000..8d6bdffceacb9
--- /dev/null
+++ b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
@@ -0,0 +1,80 @@
+package com.linkedin.metadata.aspect.hooks;
+
+import com.datahub.util.exception.ModelConversionException;
+import com.linkedin.data.template.RecordTemplate;
+import com.linkedin.data.transform.filter.request.MaskTree;
+import com.linkedin.metadata.aspect.RetrieverContext;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import com.linkedin.metadata.entity.validation.ValidationApiUtils;
+import com.linkedin.metadata.entity.validation.ValidationException;
+import com.linkedin.metadata.models.AspectSpec;
+import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.restli.internal.server.util.RestUtils;
+import java.util.Collection;
+import java.util.stream.Stream;
+import javax.annotation.Nonnull;
+import lombok.Getter;
+import lombok.Setter;
+import lombok.experimental.Accessors;
+import lombok.extern.slf4j.Slf4j;
+
+/** This mutator will log and drop unknown aspects. It will also log and drop unknown fields. */
+@Slf4j
+@Setter
+@Getter
+@Accessors(chain = true)
+public class IgnoreUnknownMutator extends MutationHook {
+ @Nonnull private AspectPluginConfig config;
+
+ @Override
+ protected Stream proposalMutation(
+ @Nonnull Collection mcpItems, @Nonnull RetrieverContext retrieverContext) {
+ return mcpItems.stream()
+ .filter(
+ item -> {
+ if (item.getEntitySpec().getAspectSpec(item.getAspectName()) == null) {
+ log.warn(
+ "Dropping unknown aspect {} on entity {}",
+ item.getAspectName(),
+ item.getAspectSpec().getName());
+ return false;
+ }
+ if (!"application/json"
+ .equals(item.getMetadataChangeProposal().getAspect().getContentType())) {
+ log.warn(
+ "Dropping unknown content type {} for aspect {} on entity {}",
+ item.getMetadataChangeProposal().getAspect().getContentType(),
+ item.getAspectName(),
+ item.getEntitySpec().getName());
+ return false;
+ }
+ return true;
+ })
+ .peek(
+ item -> {
+ try {
+ AspectSpec aspectSpec = item.getEntitySpec().getAspectSpec(item.getAspectName());
+ GenericAspect aspect = item.getMetadataChangeProposal().getAspect();
+ RecordTemplate recordTemplate =
+ GenericRecordUtils.deserializeAspect(
+ aspect.getValue(), aspect.getContentType(), aspectSpec);
+ try {
+ ValidationApiUtils.validateOrThrow(recordTemplate);
+ } catch (ValidationException | ModelConversionException e) {
+ log.warn(
+ "Failed to validate aspect. Coercing aspect {} on entity {}",
+ item.getAspectName(),
+ item.getEntitySpec().getName());
+ RestUtils.trimRecordTemplate(recordTemplate, new MaskTree(), false);
+ item.getMetadataChangeProposal()
+ .setAspect(GenericRecordUtils.serializeAspect(recordTemplate));
+ }
+ } catch (Exception e) {
+ throw new RuntimeException(e);
+ }
+ });
+ }
+}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java b/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java
new file mode 100644
index 0000000000000..11a3153abcaee
--- /dev/null
+++ b/metadata-io/src/test/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutatorTest.java
@@ -0,0 +1,143 @@
+package com.linkedin.metadata.aspect.hooks;
+
+import static com.linkedin.metadata.Constants.DATASET_ENTITY_NAME;
+import static com.linkedin.metadata.Constants.DATASET_PROPERTIES_ASPECT_NAME;
+import static com.linkedin.metadata.Constants.GLOBAL_TAGS_ASPECT_NAME;
+import static org.mockito.Mockito.mock;
+import static org.testng.Assert.assertEquals;
+
+import com.linkedin.common.GlobalTags;
+import com.linkedin.common.TagAssociation;
+import com.linkedin.common.TagAssociationArray;
+import com.linkedin.common.urn.TagUrn;
+import com.linkedin.common.urn.Urn;
+import com.linkedin.common.urn.UrnUtils;
+import com.linkedin.data.ByteString;
+import com.linkedin.data.template.StringMap;
+import com.linkedin.dataset.DatasetProperties;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.AspectRetriever;
+import com.linkedin.metadata.aspect.batch.MCPItem;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.entity.SearchRetriever;
+import com.linkedin.metadata.entity.ebean.batch.ProposedItem;
+import com.linkedin.metadata.models.registry.EntityRegistry;
+import com.linkedin.metadata.utils.AuditStampUtils;
+import com.linkedin.mxe.GenericAspect;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.mxe.SystemMetadata;
+import com.linkedin.test.metadata.aspect.TestEntityRegistry;
+import io.datahubproject.metadata.context.RetrieverContext;
+import io.datahubproject.test.metadata.context.TestOperationContexts;
+import java.net.URISyntaxException;
+import java.nio.charset.StandardCharsets;
+import java.util.List;
+import java.util.Map;
+import org.testng.annotations.BeforeMethod;
+import org.testng.annotations.Test;
+
+public class IgnoreUnknownMutatorTest {
+ private static final EntityRegistry TEST_REGISTRY = new TestEntityRegistry();
+ private static final AspectPluginConfig TEST_PLUGIN_CONFIG =
+ AspectPluginConfig.builder()
+ .className(IgnoreUnknownMutator.class.getName())
+ .enabled(true)
+ .supportedOperations(List.of("UPSERT"))
+ .supportedEntityAspectNames(
+ List.of(
+ AspectPluginConfig.EntityAspectName.builder()
+ .entityName(DATASET_ENTITY_NAME)
+ .aspectName("*")
+ .build()))
+ .build();
+ private static final Urn TEST_DATASET_URN =
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:postgres,calm-pagoda-323403.jaffle_shop.customers,PROD)");
+ private AspectRetriever mockAspectRetriever;
+ private RetrieverContext retrieverContext;
+
+ @BeforeMethod
+ public void setup() {
+ mockAspectRetriever = mock(AspectRetriever.class);
+ retrieverContext =
+ RetrieverContext.builder()
+ .searchRetriever(mock(SearchRetriever.class))
+ .aspectRetriever(mockAspectRetriever)
+ .graphRetriever(TestOperationContexts.emptyGraphRetriever)
+ .build();
+ }
+
+ @Test
+ public void testUnknownFieldInTagAssociationArray() throws URISyntaxException {
+ IgnoreUnknownMutator test = new IgnoreUnknownMutator();
+ test.setConfig(TEST_PLUGIN_CONFIG);
+
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(TEST_REGISTRY.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(TEST_DATASET_URN)
+ .setAspectName(GLOBAL_TAGS_ASPECT_NAME)
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"tags\":[{\"tag\":\"urn:li:tag:Legacy\",\"foo\":\"bar\"}]}",
+ StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ List result = test.proposalMutation(testItems, retrieverContext).toList();
+
+ assertEquals(1, result.size());
+ assertEquals(
+ result.get(0).getAspect(GlobalTags.class),
+ new GlobalTags()
+ .setTags(
+ new TagAssociationArray(
+ List.of(
+ new TagAssociation()
+ .setTag(TagUrn.createFromString("urn:li:tag:Legacy"))))));
+ }
+
+ @Test
+ public void testUnknownFieldDatasetProperties() throws URISyntaxException {
+ IgnoreUnknownMutator test = new IgnoreUnknownMutator();
+ test.setConfig(TEST_PLUGIN_CONFIG);
+
+ List testItems =
+ List.of(
+ ProposedItem.builder()
+ .entitySpec(TEST_REGISTRY.getEntitySpec(DATASET_ENTITY_NAME))
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(TEST_DATASET_URN)
+ .setAspectName(DATASET_PROPERTIES_ASPECT_NAME)
+ .setEntityType(DATASET_ENTITY_NAME)
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(
+ new GenericAspect()
+ .setContentType("application/json")
+ .setValue(
+ ByteString.copyString(
+ "{\"foo\":\"bar\",\"customProperties\":{\"prop2\":\"pikachu\",\"prop1\":\"fakeprop\"}}",
+ StandardCharsets.UTF_8)))
+ .setSystemMetadata(new SystemMetadata()))
+ .auditStamp(AuditStampUtils.createDefaultAuditStamp())
+ .build());
+
+ List result = test.proposalMutation(testItems, retrieverContext).toList();
+
+ assertEquals(1, result.size());
+ assertEquals(
+ result.get(0).getAspect(DatasetProperties.class),
+ new DatasetProperties()
+ .setCustomProperties(new StringMap(Map.of("prop1", "fakeprop", "prop2", "pikachu"))));
+ }
+}
diff --git a/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java b/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
index 9a4c01dabf9a7..f6533a6ac1d8a 100644
--- a/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
+++ b/metadata-jobs/mae-consumer-job/src/main/java/com/linkedin/metadata/kafka/MaeConsumerApplication.java
@@ -34,6 +34,7 @@
"com.linkedin.gms.factory.context",
"com.linkedin.gms.factory.timeseries",
"com.linkedin.gms.factory.assertion",
+ "com.linkedin.gms.factory.plugins"
},
excludeFilters = {
@ComponentScan.Filter(
diff --git a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
index 2666f58de862e..f6f71a12a6951 100644
--- a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
+++ b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
@@ -6,6 +6,7 @@
import com.datahub.authentication.Authentication;
import com.datahub.metadata.ingestion.IngestionScheduler;
import com.linkedin.entity.client.SystemEntityClient;
+import com.linkedin.gms.factory.plugins.SpringStandardPluginConfiguration;
import com.linkedin.metadata.boot.kafka.DataHubUpgradeKafkaListener;
import com.linkedin.metadata.graph.elastic.ElasticSearchGraphService;
import com.linkedin.metadata.models.registry.EntityRegistry;
@@ -85,4 +86,6 @@ public OperationContext operationContext(
indexConvention,
mock(RetrieverContext.class));
}
+
+ @MockBean SpringStandardPluginConfiguration springStandardPluginConfiguration;
}
diff --git a/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java b/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
index af3caecba865c..4ea5e6ea34d5b 100644
--- a/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
+++ b/metadata-jobs/mce-consumer-job/src/main/java/com/linkedin/metadata/kafka/MceConsumerApplication.java
@@ -33,7 +33,8 @@
"com.linkedin.gms.factory.form",
"com.linkedin.metadata.dao.producer",
"io.datahubproject.metadata.jobs.common.health.kafka",
- "com.linkedin.gms.factory.context"
+ "com.linkedin.gms.factory.context",
+ "com.linkedin.gms.factory.plugins"
},
excludeFilters = {
@ComponentScan.Filter(
diff --git a/metadata-models/src/main/resources/entity-registry.yml b/metadata-models/src/main/resources/entity-registry.yml
index c8344b7de1e12..6006ca179d162 100644
--- a/metadata-models/src/main/resources/entity-registry.yml
+++ b/metadata-models/src/main/resources/entity-registry.yml
@@ -665,3 +665,9 @@ plugins:
aspectName: 'schemaMetadata'
- entityName: '*'
aspectName: 'editableSchemaMetadata'
+ - className: 'com.linkedin.metadata.aspect.plugins.hooks.MutationHook'
+ enabled: true
+ spring:
+ enabled: true
+ packageScan:
+ - com.linkedin.gms.factory.plugins
\ No newline at end of file
diff --git a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
index dcea185fcbc7c..1eee0498f112a 100644
--- a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
+++ b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/RequestContext.java
@@ -35,6 +35,7 @@ public class RequestContext implements ContextInterface {
@Nonnull private final String requestID;
@Nonnull private final String userAgent;
+ @Builder.Default private boolean validated = true;
public RequestContext(
@Nonnull String actorUrn,
diff --git a/metadata-service/configuration/src/main/resources/application.yaml b/metadata-service/configuration/src/main/resources/application.yaml
index 599f7e7be344f..1d5b7c7904f97 100644
--- a/metadata-service/configuration/src/main/resources/application.yaml
+++ b/metadata-service/configuration/src/main/resources/application.yaml
@@ -466,6 +466,8 @@ businessAttribute:
keepAliveTime: ${BUSINESS_ATTRIBUTE_PROPAGATION_CONCURRENCY_KEEP_ALIVE:60} # Number of seconds to keep inactive threads alive
metadataChangeProposal:
+ validation:
+ ignoreUnknown: ${MCP_VALIDATION_IGNORE_UNKNOWN:true}
throttle:
updateIntervalMs: ${MCP_THROTTLE_UPDATE_INTERVAL_MS:60000}
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
index f1518f9c8f9d7..9f4dfb86c0fcd 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/entityregistry/ConfigEntityRegistryFactory.java
@@ -1,6 +1,7 @@
package com.linkedin.gms.factory.entityregistry;
import com.datahub.plugins.metadata.aspect.SpringPluginFactory;
+import com.linkedin.gms.factory.plugins.SpringStandardPluginConfiguration;
import com.linkedin.metadata.aspect.plugins.PluginFactory;
import com.linkedin.metadata.aspect.plugins.config.PluginConfiguration;
import com.linkedin.metadata.models.registry.ConfigEntityRegistry;
@@ -29,7 +30,9 @@ public class ConfigEntityRegistryFactory {
@Bean(name = "configEntityRegistry")
@Nonnull
- protected ConfigEntityRegistry getInstance() throws IOException, EntityRegistryException {
+ protected ConfigEntityRegistry getInstance(
+ SpringStandardPluginConfiguration springStandardPluginConfiguration)
+ throws IOException, EntityRegistryException {
BiFunction, PluginFactory> pluginFactoryProvider =
(config, loaders) -> new SpringPluginFactory(applicationContext, config, loaders);
if (entityRegistryConfigPath != null) {
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
new file mode 100644
index 0000000000000..fa4f520dc88c7
--- /dev/null
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
@@ -0,0 +1,33 @@
+package com.linkedin.gms.factory.plugins;
+
+import com.linkedin.metadata.aspect.hooks.IgnoreUnknownMutator;
+import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
+import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
+import java.util.List;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.context.annotation.Bean;
+import org.springframework.context.annotation.Configuration;
+
+@Configuration
+public class SpringStandardPluginConfiguration {
+
+ @Value("${metadataChangeProposal.validation.ignoreUnknown}")
+ private boolean ignoreUnknownEnabled;
+
+ @Bean
+ public MutationHook ignoreUnknownMutator() {
+ return new IgnoreUnknownMutator()
+ .setConfig(
+ AspectPluginConfig.builder()
+ .className(IgnoreUnknownMutator.class.getName())
+ .enabled(ignoreUnknownEnabled)
+ .supportedOperations(List.of("CREATE", "CREATE_ENTITY", "UPSERT"))
+ .supportedEntityAspectNames(
+ List.of(
+ AspectPluginConfig.EntityAspectName.builder()
+ .entityName("*")
+ .aspectName("*")
+ .build()))
+ .build());
+ }
+}
diff --git a/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java b/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
index 043b0016abaaa..f7e911c262908 100644
--- a/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
+++ b/metadata-service/plugin/src/main/java/com/datahub/plugins/metadata/aspect/SpringPluginFactory.java
@@ -78,6 +78,15 @@ private static Stream filterSpringConfigs(
config -> config.getSpring() != null && config.getSpring().isEnabled());
}
+ @Nonnull
+ @Override
+ public List getClassLoaders() {
+ if (!super.getClassLoaders().isEmpty()) {
+ return super.getClassLoaders();
+ }
+ return List.of(SpringPluginFactory.class.getClassLoader());
+ }
+
/**
* Override to inject classes from Spring
*
@@ -137,7 +146,8 @@ protected List build(
log.warn(
"Failed to load class {} from loader {}",
config.getClassName(),
- classLoader.getName());
+ classLoader.getName(),
+ e);
}
}
diff --git a/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java b/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
index c44cb4eaa1ac3..bc623c3cc983c 100644
--- a/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
+++ b/metadata-service/war/src/main/java/com/linkedin/gms/CommonApplicationConfig.java
@@ -37,6 +37,7 @@
"com.linkedin.gms.factory.search",
"com.linkedin.gms.factory.secret",
"com.linkedin.gms.factory.timeseries",
+ "com.linkedin.gms.factory.plugins"
})
@PropertySource(value = "classpath:/application.yaml", factory = YamlPropertySourceFactory.class)
@Configuration