Model with ZeRO-1 converges worse than model without ZeRO-1 #1217
Description
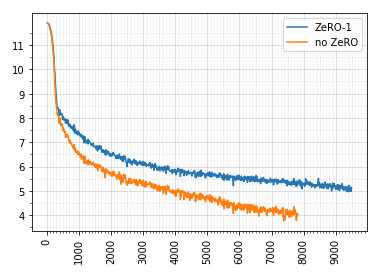
This result was obtained when training Megatron LM from the examples.
Here is DS configuration:
{ "train_batch_size": 32, "train_micro_batch_size_per_gpu":1, "steps_per_print":10, "prescale_gradients":false, "gradient_clipping":1.0, "wall_clock_breakdown":false, "fp16": { "enabled":true, "loss_scale":0 }, "zero_optimization": { "stage":1 }, "gradient_predivide_factor": 1, "zero_allow_untested_optimizer": true }
We use apex Lamb as optimizer.