![]()




Deployment Tutorial · Usage · Feedback · Screenshots · Live Demo · FAQ · Related Projects · Donate
Warning: This README is translated by ChatGPT. Please feel free to submit a PR if you find any translation errors.
Warning: The Docker image for English version is
justsong/one-api-en.
Note: The latest image pulled from Docker may be an
alpharelease. Specify the version manually if you require stability.
- Support for multiple large models:
- Supports access to multiple channels through load balancing.
- Supports stream mode that enables typewriter-like effect through stream transmission.
- Supports multi-machine deployment. See here for more details.
- Supports token management that allows setting token expiration time and usage count.
- Supports voucher management that enables batch generation and export of vouchers. Vouchers can be used for account balance replenishment.
- Supports channel management that allows bulk creation of channels.
- Supports user grouping and channel grouping for setting different rates for different groups.
- Supports channel model list configuration.
- Supports quota details checking.
- Supports user invite rewards.
- Allows display of balance in USD.
- Supports announcement publishing, recharge link setting, and initial balance setting for new users.
- Offers rich customization options:
- Supports customization of system name, logo, and footer.
- Supports customization of homepage and about page using HTML & Markdown code, or embedding a standalone webpage through iframe.
- Supports management API access through system access tokens.
- Supports Cloudflare Turnstile user verification.
- Supports user management and multiple user login/registration methods:
- Email login/registration and password reset via email.
- GitHub OAuth.
- WeChat Official Account authorization (requires additional deployment of WeChat Server).
- Immediate support and encapsulation of other major model APIs as they become available.
Deployment command: docker run --name one-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api-en
Update command: docker run --rm -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower -cR
The first 3000 in -p 3000:3000 is the port of the host, which can be modified as needed.
Data will be saved in the /home/ubuntu/data/one-api directory on the host. Ensure that the directory exists and has write permissions, or change it to a suitable directory.
Nginx reference configuration:
server{
server_name openai.justsong.cn; # Modify your domain name accordingly
location / {
client_max_body_size 64m;
proxy_http_version 1.1;
proxy_pass http://localhost:3000; # Modify your port accordingly
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_cache_bypass $http_upgrade;
proxy_set_header Accept-Encoding gzip;
}
}
Next, configure HTTPS with Let's Encrypt certbot:
# Install certbot on Ubuntu:
sudo snap install --classic certbot
sudo ln -s /snap/bin/certbot /usr/bin/certbot
# Generate certificates & modify Nginx configuration
sudo certbot --nginx
# Follow the prompts
# Restart Nginx
sudo service nginx restartThe initial account username is root and password is 123456.
- Download the executable file from GitHub Releases or compile from source:
git clone https://github.com/songquanpeng/one-api.git # Build the frontend cd one-api/web/default npm install npm run build # Build the backend cd ../.. go mod download go build -ldflags "-s -w" -o one-api
- Run:
chmod u+x one-api ./one-api --port 3000 --log-dir ./logs
- Access http://localhost:3000/ and log in. The initial account username is
rootand password is123456.
For more detailed deployment tutorials, please refer to this page.
- Set the same
SESSION_SECRETfor all servers. - Set
SQL_DSNand use MySQL instead of SQLite. All servers should connect to the same database. - Set the
NODE_TYPEfor all non-master nodes toslave. - Set
SYNC_FREQUENCYfor servers to periodically sync configurations from the database. - Non-master nodes can optionally set
FRONTEND_BASE_URLto redirect page requests to the master server. - Install Redis separately on non-master nodes, and configure
REDIS_CONN_STRINGso that the database can be accessed with zero latency when the cache has not expired. - If the main server also has high latency accessing the database, Redis must be enabled and
SYNC_FREQUENCYmust be set to periodically sync configurations from the database.
Please refer to the environment variables section for details on using environment variables.
Refer to #175 for detailed instructions.
If you encounter a blank page after deployment, refer to #97 for possible solutions.
Deploy on Sealos
Sealos supports high concurrency, dynamic scaling, and stable operations for millions of users.
Click the button below to deploy with one click.👇

Deployment on Zeabur
Zeabur's servers are located overseas, automatically solving network issues, and the free quota is sufficient for personal usage.

- First, fork the code.
- Go to Zeabur, log in, and enter the console.
- Create a new project. In Service -> Add Service, select Marketplace, and choose MySQL. Note down the connection parameters (username, password, address, and port).
- Copy the connection parameters and run
create database `one-api`to create the database. - Then, in Service -> Add Service, select Git (authorization is required for the first use) and choose your forked repository.
- Automatic deployment will start, but please cancel it for now. Go to the Variable tab, add a
PORTwith a value of3000, and then add aSQL_DSNwith a value of<username>:<password>@tcp(<addr>:<port>)/one-api. Save the changes. Please note that ifSQL_DSNis not set, data will not be persisted, and the data will be lost after redeployment. - Select Redeploy.
- In the Domains tab, select a suitable domain name prefix, such as "my-one-api". The final domain name will be "my-one-api.zeabur.app". You can also CNAME your own domain name.
- Wait for the deployment to complete, and click on the generated domain name to access One API.
The system is ready to use out of the box.
You can configure it by setting environment variables or command line parameters.
After the system starts, log in as the root user to further configure the system.
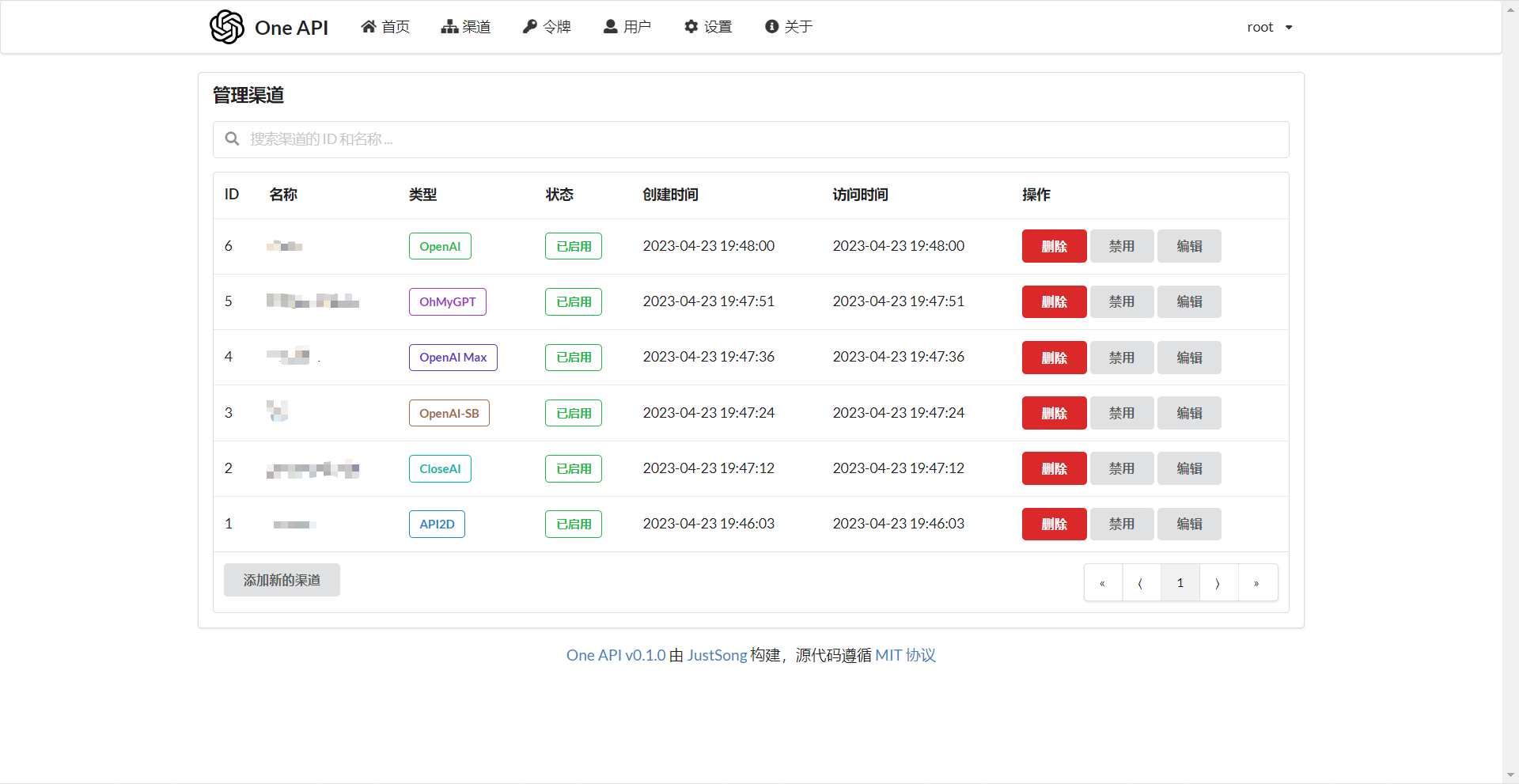
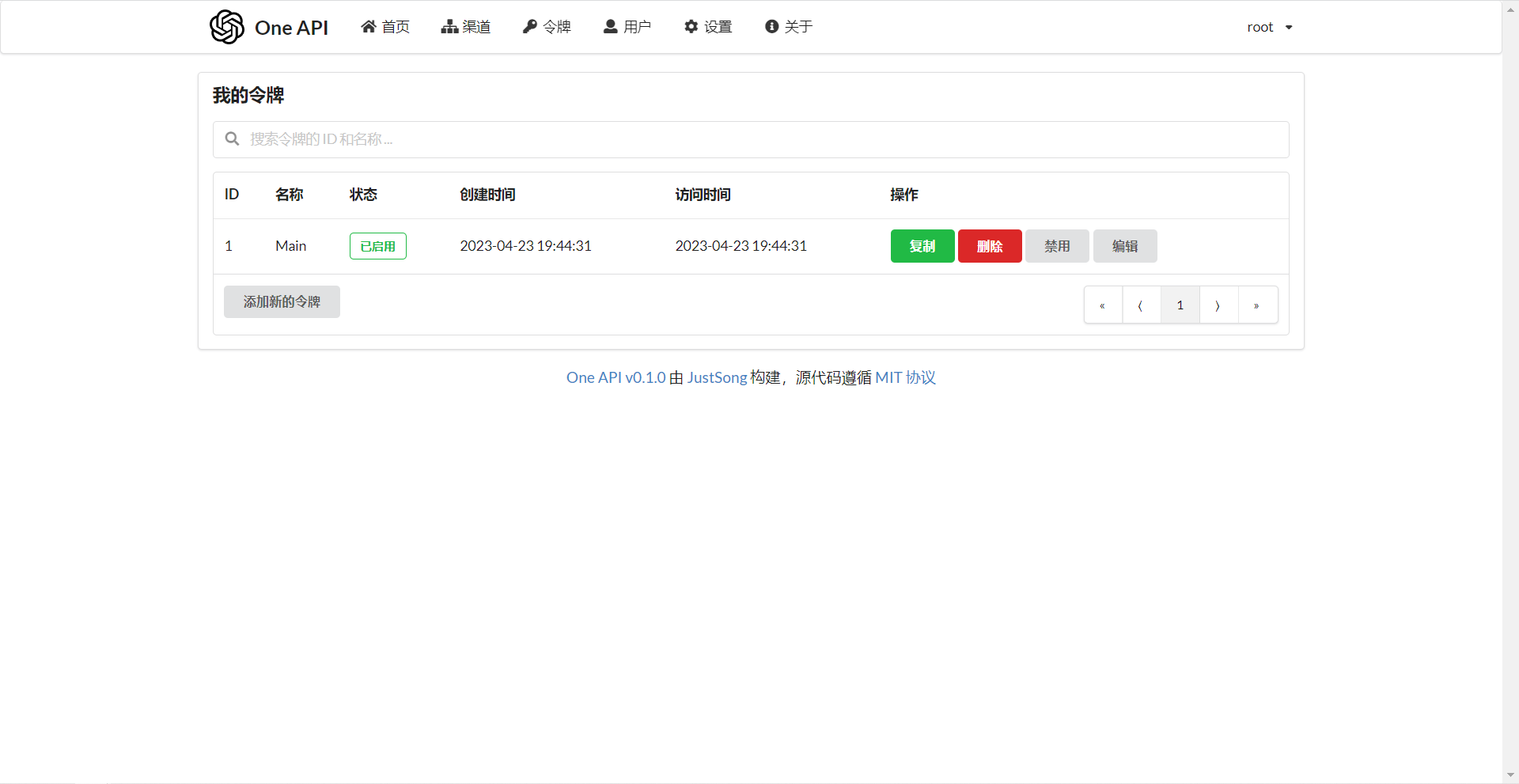
Add your API Key on the Channels page, and then add an access token on the Tokens page.
You can then use your access token to access One API. The usage is consistent with the OpenAI API.
In places where the OpenAI API is used, remember to set the API Base to your One API deployment address, for example: https://openai.justsong.cn. The API Key should be the token generated in One API.
Note that the specific API Base format depends on the client you are using.
graph LR
A(User)
A --->|Request| B(One API)
B -->|Relay Request| C(OpenAI)
B -->|Relay Request| D(Azure)
B -->|Relay Request| E(Other downstream channels)
To specify which channel to use for the current request, you can add the channel ID after the token, for example: Authorization: Bearer ONE_API_KEY-CHANNEL_ID.
Note that the token needs to be created by an administrator to specify the channel ID.
If the channel ID is not provided, load balancing will be used to distribute the requests to multiple channels.
REDIS_CONN_STRING: When set, Redis will be used as the storage for request rate limiting instead of memory.- Example:
REDIS_CONN_STRING=redis://default:redispw@localhost:49153
- Example:
SESSION_SECRET: When set, a fixed session key will be used to ensure that cookies of logged-in users are still valid after the system restarts.- Example:
SESSION_SECRET=random_string
- Example:
SQL_DSN: When set, the specified database will be used instead of SQLite. Please use MySQL version 8.0.- Example:
SQL_DSN=root:123456@tcp(localhost:3306)/oneapi
- Example:
LOG_SQL_DSN: When set, a separate database will be used for thelogstable; please use MySQL or PostgreSQL.- Example:
LOG_SQL_DSN=root:123456@tcp(localhost:3306)/oneapi-logs
- Example:
FRONTEND_BASE_URL: When set, the specified frontend address will be used instead of the backend address.- Example:
FRONTEND_BASE_URL=https://openai.justsong.cn
- Example:
- 'MEMORY_CACHE_ENABLED': Enabling memory caching can cause a certain delay in updating user quotas, with optional values of 'true' and 'false'. If not set, it defaults to 'false'.
SYNC_FREQUENCY: When set, the system will periodically sync configurations from the database, with the unit in seconds. If not set, no sync will happen.- Example:
SYNC_FREQUENCY=60
- Example:
NODE_TYPE: When set, specifies the node type. Valid values aremasterandslave. If not set, it defaults tomaster.- Example:
NODE_TYPE=slave
- Example:
CHANNEL_UPDATE_FREQUENCY: When set, it periodically updates the channel balances, with the unit in minutes. If not set, no update will happen.- Example:
CHANNEL_UPDATE_FREQUENCY=1440
- Example:
CHANNEL_TEST_FREQUENCY: When set, it periodically tests the channels, with the unit in minutes. If not set, no test will happen.- Example:
CHANNEL_TEST_FREQUENCY=1440
- Example:
POLLING_INTERVAL: The time interval (in seconds) between requests when updating channel balances and testing channel availability. Default is no interval.- Example:
POLLING_INTERVAL=5
- Example:
BATCH_UPDATE_ENABLED: Enabling batch database update aggregation can cause a certain delay in updating user quotas. The optional values are 'true' and 'false', but if not set, it defaults to 'false'. +Example:BATCH_UPDATE_ENABLED=true+If you encounter an issue with too many database connections, you can try enabling this option.BATCH_UPDATE_INTERVAL=5: The time interval for batch updating aggregates, measured in seconds, defaults to '5'. +Example:BATCH_UPDATE_INTERVAL=5- Request frequency limit:
GLOBAL_API_RATE_LIMIT: Global API rate limit (excluding relay requests), the maximum number of requests within three minutes per IP, default to 180.GLOBAL_WEL_RATE_LIMIT: Global web speed limit, the maximum number of requests within three minutes per IP, default to 60.
- Encoder cache settings:
+
TIKTOKEN_CACHE_DIR: By default, when the program starts, it will download the encoding of some common word elements online, such as' gpt-3.5 turbo '. In some unstable network environments or offline situations, it may cause startup problems. This directory can be configured to cache data and can be migrated to an offline environment. +DATA_GYM_CACHE_DIR: Currently, this configuration has the same function as' TIKTOKEN-CACHE-DIR ', but its priority is not as high as it. RELAY_TIMEOUT: Relay timeout setting, measured in seconds, with no default timeout time set.RELAY_PROXY: After setting up, use this proxy to request APIs.USER_CONTENT_REQUEST_TIMEOUT: The timeout period for users to upload and download content, measured in seconds.USER_CONTENT_REQUEST_PROXY: After setting up, use this agent to request content uploaded by users, such as images.SQLITE_BUSY_TIMEOUT: SQLite lock wait timeout setting, measured in milliseconds, default to '3000'.GEMINI_SAFETY_SETTING: Gemini's security settings are set to 'BLOCK-NONE' by default.GEMINI_VERSION: The Gemini version used by the One API, which defaults to 'v1'.THE: The system's theme setting, default to 'default', specific optional values refer to [here] (./web/README. md).ENABLE_METRIC: Whether to disable channels based on request success rate, default not enabled, optional values are 'true' and 'false'.METRIC_QUEUE_SIZE: Request success rate statistics queue size, default to '10'.METRIC_SUCCESS_RATE_THRESHOLD: Request success rate threshold, default to '0.8'.INITIAL_ROOT_TOKEN: If this value is set, a root user token with the value of the environment variable will be automatically created when the system starts for the first time.INITIAL_ROOT_ACCESS_TOKEN: If this value is set, a system management token will be automatically created for the root user with a value of the environment variable when the system starts for the first time.
--port <port_number>: Specifies the port number on which the server listens. Defaults to3000.- Example:
--port 3000
- Example:
--log-dir <log_dir>: Specifies the log directory. If not set, the logs will not be saved.- Example:
--log-dir ./logs
- Example:
--version: Prints the system version number and exits.--help: Displays the command usage help and parameter descriptions.
- What is quota? How is it calculated? Does One API have quota calculation issues?
- Quota = Group multiplier * Model multiplier * (number of prompt tokens + number of completion tokens * completion multiplier)
- The completion multiplier is fixed at 1.33 for GPT3.5 and 2 for GPT4, consistent with the official definition.
- If it is not a stream mode, the official API will return the total number of tokens consumed. However, please note that the consumption multipliers for prompts and completions are different.
- Why does it prompt "insufficient quota" even though my account balance is sufficient?
- Please check if your token quota is sufficient. It is separate from the account balance.
- The token quota is used to set the maximum usage and can be freely set by the user.
- It says "No available channels" when trying to use a channel. What should I do?
- Please check the user and channel group settings.
- Also check the channel model settings.
- Channel testing reports an error: "invalid character '<' looking for beginning of value"
- This error occurs when the returned value is not valid JSON but an HTML page.
- Most likely, the IP of your deployment site or the node of the proxy has been blocked by CloudFlare.
- ChatGPT Next Web reports an error: "Failed to fetch"
- Do not set
BASE_URLduring deployment. - Double-check that your interface address and API Key are correct.
- Do not set
- FastGPT: Knowledge question answering system based on the LLM
- VChart: More than just a cross-platform charting library, but also an expressive data storyteller.
- VMind: Not just automatic, but also fantastic. Open-source solution for intelligent visualization.
This project is an open-source project. Please use it in compliance with OpenAI's Terms of Use and applicable laws and regulations. It must not be used for illegal purposes.
This project is released under the MIT license. Based on this, attribution and a link to this project must be included at the bottom of the page.
The same applies to derivative projects based on this project.
If you do not wish to include attribution, prior authorization must be obtained.
According to the MIT license, users should bear the risk and responsibility of using this project, and the developer of this open-source project is not responsible for this.