From 83de13fe6d59223f1db62cb5a7c20efac2fb65ff Mon Sep 17 00:00:00 2001
From: Aleksandar Petrov <8142643+aleks-p@users.noreply.github.com>
Date: Fri, 12 Apr 2024 08:36:29 -0300
Subject: [PATCH] Improve wording in docs / examples (#3200)
* Improve wording, fix typos
* Generate reference help
* Apply suggestions from code review
Co-authored-by: Kim Nylander <104772500+knylander-grafana@users.noreply.github.com>
---------
Co-authored-by: Kim Nylander <104772500+knylander-grafana@users.noreply.github.com>
---
README.md | 6 ++--
cmd/pyroscope/help-all.txt.tmpl | 4 +--
cmd/pyroscope/help.txt.tmpl | 4 +--
docs/internal/RELEASE.md | 8 ++---
docs/internal/contributing/README.md | 6 ++--
docs/sources/configure-client/_index.md | 2 +-
docs/sources/configure-client/aws-lambda.md | 4 +--
.../ebpf/configuration/_index.md | 2 +-
.../grafana-agent/sampling.md | 2 +-
.../configure-client/language-sdks/_index.md | 2 +-
.../configure-client/language-sdks/dotnet.md | 4 +--
.../configure-client/language-sdks/go_push.md | 2 +-
.../configure-client/language-sdks/java.md | 2 +-
.../configure-client/language-sdks/nodejs.md | 20 ++++++-------
.../configure-client/language-sdks/python.md | 2 +-
.../configure-client/language-sdks/ruby.md | 2 +-
.../configure-client/language-sdks/rust.md | 8 ++---
.../trace-span-profiles/go-span-profiles.md | 6 ++--
.../trace-span-profiles/java-span-profiles.md | 8 ++---
.../trace-span-profiles/ruby-span-profiles.md | 10 +++----
docs/sources/configure-server/_index.md | 2 +-
.../configure-server/about-configurations.md | 2 +-
.../configure-server/about-server-api.md | 24 +++++++--------
.../configure-server/about-tenant-ids.md | 2 +-
.../configure-shuffle-sharding/index.md | 2 +-
.../index.md | 4 +--
docs/sources/deploy-kubernetes/helm.md | 8 ++---
.../deploy-kubernetes/tanka-jsonnet.md | 4 +--
.../continuous-profiling/_index.md | 10 +++----
docs/sources/introduction/profiling.md | 6 ++--
.../block-format/_index.md | 2 +-
.../components/compactor/index.md | 2 +-
.../components/query-frontend/index.md | 2 +-
.../hash-ring/index.md | 8 ++---
docs/sources/release-notes/v1-1.md | 4 +--
docs/sources/release-notes/v1-2.md | 2 +-
docs/sources/release-notes/v1-3.md | 4 +--
docs/sources/release-notes/v1-4.md | 4 +--
docs/sources/upgrade-guide/_index.md | 4 +--
.../view-and-analyze-profile-data/_index.md | 4 +--
.../analyze-profiles/_index.md | 4 +--
.../flamegraphs.md | 30 +++++++++----------
.../profiling-types/_index.md | 18 +++++------
.../pyroscope-ui.md | 26 ++++++++--------
.../self-vs-total.md | 4 +--
.../golang-push/README.md | 10 +++----
.../java/rideshare/README.md | 12 ++++----
.../python/README.md | 10 +++----
.../python/rideshare/README.md | 20 ++++++-------
.../ruby/README.md | 8 ++---
.../ruby/rideshare/README.md | 8 ++---
pkg/querier/vcs/github.md | 6 ++--
pkg/validation/limits.go | 10 +++----
53 files changed, 185 insertions(+), 185 deletions(-)
diff --git a/README.md b/README.md
index ac2cb97987..dbf4e458dc 100644
--- a/README.md
+++ b/README.md
@@ -77,7 +77,7 @@ For more documentation on how to add the Pyroscope agent to your code, see the [

- NodeJS
+ Node.js
Documentation
Examples
|
@@ -136,11 +136,11 @@ Pyroscope is possible thanks to the excellent work of many people, including but
* Brendan Gregg — inventor of Flame Graphs
* Julia Evans — creator of rbspy — sampling profiler for Ruby
-* Vladimir Agafonkin — creator of flamebearer — fast flamegraph renderer
+* Vladimir Agafonkin — creator of flamebearer — fast flame graph renderer
* Ben Frederickson — creator of py-spy — sampling profiler for Python
* Adam Saponara — creator of phpspy — sampling profiler for PHP
* Alexei Starovoitov, Brendan Gregg, and many others who made BPF based profiling in Linux kernel possible
-* Jamie Wong — creator of speedscope — interactive flamegraph visualizer
+* Jamie Wong — creator of speedscope — interactive flame graph visualizer
## Contributing
diff --git a/cmd/pyroscope/help-all.txt.tmpl b/cmd/pyroscope/help-all.txt.tmpl
index 8eede47f3c..a4ecc98189 100644
--- a/cmd/pyroscope/help-all.txt.tmpl
+++ b/cmd/pyroscope/help-all.txt.tmpl
@@ -542,9 +542,9 @@ Usage of ./pyroscope:
-querier.max-concurrent int
The maximum number of concurrent queries allowed. (default 4)
-querier.max-flamegraph-nodes-default int
- Maximum number of flamegraph nodes by default. 0 to disable. (default 8192)
+ Maximum number of flame graph nodes by default. 0 to disable. (default 8192)
-querier.max-flamegraph-nodes-max int
- Maximum number of flamegraph nodes allowed. 0 to disable.
+ Maximum number of flame graph nodes allowed. 0 to disable.
-querier.max-query-length duration
The limit to length of queries. 0 to disable. (default 1d)
-querier.max-query-lookback duration
diff --git a/cmd/pyroscope/help.txt.tmpl b/cmd/pyroscope/help.txt.tmpl
index 368c78ee53..bcf5fcd771 100644
--- a/cmd/pyroscope/help.txt.tmpl
+++ b/cmd/pyroscope/help.txt.tmpl
@@ -150,9 +150,9 @@ Usage of ./pyroscope:
-querier.health-check-timeout duration
Timeout for ingester client healthcheck RPCs. (default 5s)
-querier.max-flamegraph-nodes-default int
- Maximum number of flamegraph nodes by default. 0 to disable. (default 8192)
+ Maximum number of flame graph nodes by default. 0 to disable. (default 8192)
-querier.max-flamegraph-nodes-max int
- Maximum number of flamegraph nodes allowed. 0 to disable.
+ Maximum number of flame graph nodes allowed. 0 to disable.
-querier.max-query-length duration
The limit to length of queries. 0 to disable. (default 1d)
-querier.max-query-lookback duration
diff --git a/docs/internal/RELEASE.md b/docs/internal/RELEASE.md
index 65e7bb5ae0..a3c6ed82ee 100644
--- a/docs/internal/RELEASE.md
+++ b/docs/internal/RELEASE.md
@@ -18,9 +18,9 @@ To release a new version of the project you need to follow the following steps:
>
> ⚠️ Incorrect: `release/v1.3.0`
-The CI will automatically handle the build and create a draft github release.
+The CI will automatically handle the build and create a draft GitHub release.
-Once ready, you can edit and publish the draft release on Github. You will need to take the release notes and append them to the `CHANGELOG.md` file in the root of the repository.
+Once ready, you can edit and publish the draft release on GitHub. You will need to take the release notes and append them to the `CHANGELOG.md` file in the root of the repository.
The list of changes from the CHANGELOG.md file form the basis of the public-facing release notes. Release notes are added to the [public Pyroscope documentation](https://grafana.com/docs/pyroscope/latest/release-notes/). These release notes follow the same pattern for each release:
@@ -50,7 +50,7 @@ To create a new release first prepare the release using:
make release/prepare
```
-This will build and packages all artifacts without pushing or creating the github release.
+This will build and packages all artifacts without pushing or creating the GitHub release.
Once you're ready you can then tag your release.
@@ -64,6 +64,6 @@ And finally push the release using:
make release
```
-> Make sure to have a [Github Token](https://goreleaser.com/scm/github/?h=github#github) `GITHUB_TOKEN` correctly set.
+> Make sure to have a [GitHub Token](https://goreleaser.com/scm/github/?h=github#github) `GITHUB_TOKEN` correctly set.
Make sure to create the release notes and CHANGELOG for any manual release.
diff --git a/docs/internal/contributing/README.md b/docs/internal/contributing/README.md
index 4e08515e30..44192cf4fe 100644
--- a/docs/internal/contributing/README.md
+++ b/docs/internal/contributing/README.md
@@ -41,7 +41,7 @@ To build:
make go/bin
```
-To run the unit tests suite:
+To run the unit test suite:
```
make go/test
@@ -124,7 +124,7 @@ will be able to interact with it.
### Dependency management
We use [Go modules](https://golang.org/cmd/go/#hdr-Modules__module_versions__and_more) to manage dependencies on external packages.
-However we don't commit the `vendor/` folder.
+However, we don't commit the `vendor/` folder.
To add or update a new dependency, use the `go get` command:
@@ -150,4 +150,4 @@ The Grafana Pyroscope documentation is compiled into a website published at [gra
To start the website locally you can use `make docs/docs` and follow console instructions to access the website.
-Note: if you attempt to view pages on Github, it's likely that you might find broken links or pages. That is expected and should not be addressed unless it is causing issues with the site that occur as part of the build.
+Note: if you attempt to view pages on GitHub, it's likely that you might find broken links or pages. That is expected and should not be addressed unless it is causing issues with the site that occur as part of the build.
diff --git a/docs/sources/configure-client/_index.md b/docs/sources/configure-client/_index.md
index 5cfb668dd8..be17cb61f5 100644
--- a/docs/sources/configure-client/_index.md
+++ b/docs/sources/configure-client/_index.md
@@ -97,7 +97,7 @@ To get started, choose one of the integrations below:
Examples
- NodeJS
+ Node.js
Documentation
Examples
|
diff --git a/docs/sources/configure-client/aws-lambda.md b/docs/sources/configure-client/aws-lambda.md
index db040654ea..0df0b54c9f 100644
--- a/docs/sources/configure-client/aws-lambda.md
+++ b/docs/sources/configure-client/aws-lambda.md
@@ -35,9 +35,9 @@ For more details, refer to the [Building Extensions for AWS Lambda blog post](ht
## Set up the Pyroscope Lambda extension
-To set up the Pyroscope Lamnda extension, you need to:
+To set up the Pyroscope Lambda extension, you need to:
-1. Configure your Lamda function
+1. Configure your Lambda function
1. Set up your environment variables
1. Integrate the Pyroscope SDK
diff --git a/docs/sources/configure-client/grafana-agent/ebpf/configuration/_index.md b/docs/sources/configure-client/grafana-agent/ebpf/configuration/_index.md
index beb020441b..1375757bef 100644
--- a/docs/sources/configure-client/grafana-agent/ebpf/configuration/_index.md
+++ b/docs/sources/configure-client/grafana-agent/ebpf/configuration/_index.md
@@ -121,6 +121,6 @@ The `pyroscope.ebpf` component exposes the following Prometheus metrics:
Check out the following resources to learn more about eBPF profiling:
-- [The pros and cons of eBPF profiling](https://pyroscope.io/blog/ebpf-profiling-pros-cons) blog post (for more context on flamegraphs below)
+- [The pros and cons of eBPF profiling](https://pyroscope.io/blog/ebpf-profiling-pros-cons) blog post (for more context on flame graphs below)
- [Demo](https://play-pyroscope.grafana.org) showing breakdown of our examples cluster
- Grafana Agent documentation for [pyroscope.ebpf](/docs/agent/latest/flow/reference/components/pyroscope.ebpf/), [pyroscope.write](/docs/agent/latest/flow/reference/components/pyroscope.write/), [discovery.kubernetes](/docs/agent/latest/flow/reference/components/discovery.kubernetes/), [discovery.relabel](/docs/agent/latest/flow/reference/components/discovery.relabel/) components
diff --git a/docs/sources/configure-client/grafana-agent/sampling.md b/docs/sources/configure-client/grafana-agent/sampling.md
index 488b4e2e96..ab8c5c39d5 100644
--- a/docs/sources/configure-client/grafana-agent/sampling.md
+++ b/docs/sources/configure-client/grafana-agent/sampling.md
@@ -9,7 +9,7 @@ weight: 30
Applications often have many instances deployed. While Pyroscope is designed to handle large amounts of profiling data, you may want only a subset of the application's instances to be scraped.
-For example, the volume of profiling data your application generates may make it unreasonable to profile every instance or you might be targeting cost-reduction.
+For example, the volume of profiling data your application generates may make it unreasonable to profile every instance, or you might be targeting cost-reduction.
Through configuration of the Grafana Agent, Pyroscope can sample scrape targets.
diff --git a/docs/sources/configure-client/language-sdks/_index.md b/docs/sources/configure-client/language-sdks/_index.md
index 9e0f00dafc..a48ef66cf5 100644
--- a/docs/sources/configure-client/language-sdks/_index.md
+++ b/docs/sources/configure-client/language-sdks/_index.md
@@ -36,7 +36,7 @@ The following languages SDKs provide support for sending profiles from your appl
- NodeJS
+ Node.js
Documentation
Examples
|
diff --git a/docs/sources/configure-client/language-sdks/dotnet.md b/docs/sources/configure-client/language-sdks/dotnet.md
index bf3cb248cc..dfd23298c4 100644
--- a/docs/sources/configure-client/language-sdks/dotnet.md
+++ b/docs/sources/configure-client/language-sdks/dotnet.md
@@ -31,7 +31,7 @@ Our .NET profiler works with the following .NET versions:
## Before you begin
-To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pryoscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
+To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pyroscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
The Pyroscope server can be a local server for development or a remote server for production use.
@@ -143,7 +143,7 @@ It is possible to dynamically change authorization credentials:
Pyroscope.Profiler.Instance.SetBasicAuth(basicAuthUser, BasicAuthPassword);
```
-Here is a simple [example](https://github.com/grafana/pyroscope/blob/main/examples/language-sdk-instrumentation/dotnet/rideshare/example/Program.cs) exposing this APIs as an http endpoint.
+Here is a simple [example](https://github.com/grafana/pyroscope/blob/main/examples/language-sdk-instrumentation/dotnet/rideshare/example/Program.cs) exposing these APIs as HTTP endpoints.
### Configuration options
diff --git a/docs/sources/configure-client/language-sdks/go_push.md b/docs/sources/configure-client/language-sdks/go_push.md
index 29d884eef0..b0516cf977 100644
--- a/docs/sources/configure-client/language-sdks/go_push.md
+++ b/docs/sources/configure-client/language-sdks/go_push.md
@@ -97,7 +97,7 @@ pprof.Do(context.Background(), pprof.Labels("controller", "slow_controller"), fu
### Mutex profiling
-Mutex profiling is useful for finding sources of contention within your application. It helps you to find out which mutexes are being held by which goroutines.
+Mutex profiling is useful for finding sources of contention within your application. It helps you find out which mutexes are being held by which goroutines.
To enable mutex profiling, you need to add the following code to your application:
diff --git a/docs/sources/configure-client/language-sdks/java.md b/docs/sources/configure-client/language-sdks/java.md
index 1544283e26..6198998654 100644
--- a/docs/sources/configure-client/language-sdks/java.md
+++ b/docs/sources/configure-client/language-sdks/java.md
@@ -34,7 +34,7 @@ The latest release is also available on [Maven Central](https://search.maven.org
## Configure the Java client
-You can start Pyroscope either from your apps's Java code or attach it as javaagent.
+You can start Pyroscope either from your application's code or attach it as javaagent.
### Start Pyroscope from app's Java code
diff --git a/docs/sources/configure-client/language-sdks/nodejs.md b/docs/sources/configure-client/language-sdks/nodejs.md
index c67f169bbe..60904cc3f4 100644
--- a/docs/sources/configure-client/language-sdks/nodejs.md
+++ b/docs/sources/configure-client/language-sdks/nodejs.md
@@ -1,25 +1,25 @@
---
-title: "NodeJS"
-menuTitle: "NodeJS"
-description: "Instrumenting nodeJS applications for continuous profiling."
+title: "Node.js"
+menuTitle: "Node.js"
+description: "Instrumenting Node.js applications for continuous profiling."
weight: 80
aliases:
- /docs/phlare/latest/configure-client/language-sdks/nodejs
---
-# NodeJS
+# Node.js
Enhance your Node.js application's performance with our Node.js Profiler. Seamlessly integrated with Pyroscope, it provides real-time insights into your application’s operation, helping you identify and resolve performance bottlenecks. This integration is key for Node.js developers aiming to boost efficiency, reduce latency, and maintain optimal application performance.
## Before you begin
-To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pryoscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
+To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pyroscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
The Pyroscope server can be a local server for development or a remote server for production use.
-## Add NodeJS profiling to your application
+## Add Node.js profiling to your application
-To start profiling a NodeJS application, you need to include the npm module in your app:
+To start profiling a Node.js application, you need to include the npm module in your app:
```
npm install @pyroscope/nodejs
@@ -28,7 +28,7 @@ npm install @pyroscope/nodejs
yarn add @pyroscope/nodejs
```
-## Configure the NodeJS client
+## Configure the Node.js client
Add the following code to your application:
@@ -45,7 +45,7 @@ Pyroscope.start()
Note: If you'd prefer to use Pull mode you can do so using the [Grafana Agent]({{< relref "../grafana-agent" >}}).
-### Add profiling labels to NodeJS applications
+### Add profiling labels to Node.js applications
It is possible to add tags (labels) to the profiling data. These tags can be used to filter the data in the UI. Dynamic tagging isn't supported yet.
@@ -79,7 +79,7 @@ Pyroscope.init({
Pyroscope.start()
```
-To configure the NodeJS SDK to send data to Pyroscope, replace the `serverAddress` placeholder with the appropriate server URL. This could be the Grafana Cloud Pyroscope URL or your own custom Pyroscope server URL.
+To configure the Node.js SDK to send data to Pyroscope, replace the `serverAddress` placeholder with the appropriate server URL. This could be the Grafana Cloud Pyroscope URL or your own custom Pyroscope server URL.
If you need to send data to Grafana Cloud, you’ll have to configure HTTP Basic authentication. Replace `basicAuthUser` with your Grafana Cloud stack user ID and `basicAuthPassword` with your Grafana Cloud API key.
diff --git a/docs/sources/configure-client/language-sdks/python.md b/docs/sources/configure-client/language-sdks/python.md
index 988bc0a8fe..98cc4ab621 100644
--- a/docs/sources/configure-client/language-sdks/python.md
+++ b/docs/sources/configure-client/language-sdks/python.md
@@ -13,7 +13,7 @@ Our Python Profiler, when integrated with Pyroscope, transforms the way you anal
## Before you begin
-To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pryoscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
+To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pyroscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
The Pyroscope server can be a local server for development or a remote server for production use.
diff --git a/docs/sources/configure-client/language-sdks/ruby.md b/docs/sources/configure-client/language-sdks/ruby.md
index 8b950fae60..9c045d0519 100644
--- a/docs/sources/configure-client/language-sdks/ruby.md
+++ b/docs/sources/configure-client/language-sdks/ruby.md
@@ -13,7 +13,7 @@ The Ruby Profiler revolutionizes performance tuning in Ruby applications. Integr
## Before you begin
-To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pryoscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
+To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pyroscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
The Pyroscope server can be a local server for development or a remote server for production use.
diff --git a/docs/sources/configure-client/language-sdks/rust.md b/docs/sources/configure-client/language-sdks/rust.md
index b4ea59b98e..b188d73942 100644
--- a/docs/sources/configure-client/language-sdks/rust.md
+++ b/docs/sources/configure-client/language-sdks/rust.md
@@ -13,7 +13,7 @@ Optimize your Rust applications with our advanced Rust Profiler. In collaboratio
## Before you begin
-To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pryoscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
+To capture and analyze profiling data, you need either a hosted Pyroscope OSS server or a hosted [Pyroscope instance with Grafana Cloud Profiles](/products/cloud/profiles-for-continuous-profiling/) (requires a free Grafana Cloud account).
The Pyroscope server can be a local server for development or a remote server for production use.
@@ -73,7 +73,7 @@ The agent can be stopped at any point, and it'll send a last report to the serve
let agent_ready = agent.stop().unwrap();
```
-It's recommended to shutdown the agent before exiting the application. A last
+It's recommended to shut down the agent before exiting the application. A last
request to the server might be missed if the agent is not shutdown properly.
```rust
@@ -142,10 +142,10 @@ PyroscopeAgent::builder("http://localhost:4040", "myapp")
- **Backend**: The Pyroscope Agent uses [pprof-rs](https://github.com/tikv/pprof-rs) as a backend. As a result, the [limitations](https://github.com/tikv/pprof-rs#why-not-) for pprof-rs also applies.
As of 0.5.0, the Pyroscope Agent supports tagging within threads. Check the [tags](https://github.com/pyroscope-io/pyroscope-rs/blob/main/examples/tags.rs) and [multi-thread](https://github.com/pyroscope-io/pyroscope-rs/blob/main/examples/multi-thread.rs) examples for usage.
- **Timer**: epoll (for Linux) and kqueue (for macOS) are required for a more precise timer.
-- **Shutdown**: The Pyroscope Agent might take some time (usually less than 10 seconds) to shutdown properly and drop its threads. For a proper shutdown, it's recommended that you run the `shutdown` function before dropping the agent.
+- **Shutdown**: The Pyroscope Agent might take some time (usually less than 10 seconds) to shut down properly and drop its threads. For a proper shutdown, it's recommended that you run the `shutdown` function before dropping the agent.
- **Relevant Links**
- - [Github Repository](https://github.com/pyroscope-io/pyroscope-rs)
+ - [GitHub Repository](https://github.com/pyroscope-io/pyroscope-rs)
- [Cargo crate](https://crates.io/crates/pyroscope)
- [Crate documentation](https://docs.rs/pyroscope/latest/pyroscope/index.html)
diff --git a/docs/sources/configure-client/trace-span-profiles/go-span-profiles.md b/docs/sources/configure-client/trace-span-profiles/go-span-profiles.md
index a010ef1274..fad1bb908b 100644
--- a/docs/sources/configure-client/trace-span-profiles/go-span-profiles.md
+++ b/docs/sources/configure-client/trace-span-profiles/go-span-profiles.md
@@ -30,7 +30,7 @@ To use Span Profiles, you need to:
Your applications must be instrumented for profiling and tracing before you can use span profiles.
-* Profiling: Your application must be instrumented with Pyroscopes Go SDK. If you haven't done this yet, please refer to the [Go (push mode)]({{< relref "../language-sdks/go_push" >}}) guide.
+* Profiling: Your application must be instrumented with Pyroscope's Go SDK. If you haven't done this yet, please refer to the [Go (push mode)]({{< relref "../language-sdks/go_push" >}}) guide.
* Tracing: Your application must be instrumented with OpenTelemetry traces. If you haven't done this yet, please refer to the [OpenTelemetry](https://opentelemetry.io/docs/go/getting-started/) guide.
### OpenTelemetry support
@@ -103,11 +103,11 @@ Check out the [examples](https://github.com/grafana/pyroscope/tree/main/examples
\ No newline at end of file
+`"8474e98b95013e4f"` can be any ID that you use to identify execution contexts (individual HTTP / GRPC requests). -->
diff --git a/docs/sources/configure-client/trace-span-profiles/java-span-profiles.md b/docs/sources/configure-client/trace-span-profiles/java-span-profiles.md
index fa70c16790..be3f2bc592 100644
--- a/docs/sources/configure-client/trace-span-profiles/java-span-profiles.md
+++ b/docs/sources/configure-client/trace-span-profiles/java-span-profiles.md
@@ -13,7 +13,7 @@ weight: 100
Your applications must be instrumented for profiling and tracing before you can use span profiles.
-* Profiling: Your application must be instrumented with Pyroscopes Java client SDK. If you haven't done this yet, please refer to the [Java ()]({{< relref "../language-sdks/java" >}}) guide.
+* Profiling: Your application must be instrumented with Pyroscope's Java client SDK. If you haven't done this yet, please refer to the [Java ()]({{< relref "../language-sdks/java" >}}) guide.
* Tracing: Your application must be instrumented with OpenTelemetry traces. If you haven't done this yet, please refer to the [OpenTelemetry](https://opentelemetry.io/docs/java/getting-started/) guide.
## OpenTelemetry support
@@ -84,13 +84,13 @@ To use a simple configuration, follow these steps:
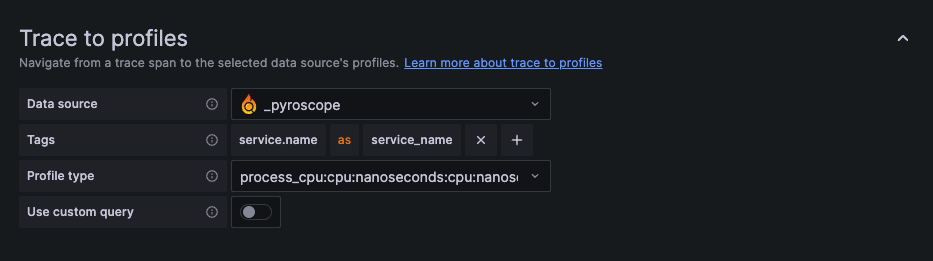
1. Select a Pyroscope data source from the Data source drop-down.
-2. Optional: Choose any tags to use in the query. If left blank, the default values of service.name and service.namespace are used.
+2. Optional: Choose any tags to use in the query. If left blank, the default values of `service.name` and `service.namespace` are used.
-The tags you configure must be present in the spans attributes or resources for a trace to profiles span link to appear. You can optionally configure a new name for the tag. This is useful for example if the tag has dots in the name and the target data source doesn’t allow using dots in labels. In that case you can for example remap service.name to service_name.
+The tags you configure must be present in the spans attributes or resources for a trace to profiles span link to appear. You can optionally configure a new name for the tag. This is useful for example if the tag has dots in the name and the target data source doesn't allow using dots in labels. In that case you can for example remap service.name to service_name.
3. Select one or more profile types to use in the query. Select the drop-down and choose options from the menu.
-The profile type or app must be selected for the query to be valid. Grafana doesn’t show any data if the profile type or app isn’t selected when a query runs.
+The profile type or app must be selected for the query to be valid. Grafana doesn't show any data if the profile type or app isn’t selected when a query runs.
diff --git a/docs/sources/configure-client/trace-span-profiles/ruby-span-profiles.md b/docs/sources/configure-client/trace-span-profiles/ruby-span-profiles.md
index 7056a742c6..5ff2a3d731 100644
--- a/docs/sources/configure-client/trace-span-profiles/ruby-span-profiles.md
+++ b/docs/sources/configure-client/trace-span-profiles/ruby-span-profiles.md
@@ -13,7 +13,7 @@ weight: 100
Your applications must be instrumented for profiling and tracing before you can use span profiles.
-* Profiling: Your application must be instrumented with Pyroscopes Ruby SDK. If you haven't done this yet, please refer to the [Ruby (push mode)]({{< relref "../language-sdks/ruby" >}}) guide.
+* Profiling: Your application must be instrumented with Pyroscope's Ruby SDK. If you haven't done this yet, please refer to the [Ruby (push mode)]({{< relref "../language-sdks/ruby" >}}) guide.
* Tracing: Your application must be instrumented with OpenTelemetry traces. If you haven't done this yet, please refer to the [OpenTelemetry](https://opentelemetry.io/docs/ruby/getting-started/) guide.
## OpenTelemetry support
@@ -63,16 +63,16 @@ To use a simple configuration, follow these steps:
1. Select a Pyroscope data source from the Data source drop-down.
-2. Optional: Choose any tags to use in the query. If left blank, the default values of service.name and service.namespace are used.
+2. Optional: Choose any tags to use in the query. If left blank, the default values of `service.name` and `service.namespace` are used.
-The tags you configure must be present in the spans attributes or resources for a trace to profiles span link to appear. You can optionally configure a new name for the tag. This is useful for example if the tag has dots in the name and the target data source doesn’t allow using dots in labels. In that case you can for example remap service.name to service_name.
+The tags you configure must be present in the spans attributes or resources for a trace to profiles span link to appear. You can optionally configure a new name for the tag. This is useful for example if the tag has dots in the name and the target data source doesn't allow using dots in labels. In that case you can for example remap service.name to service_name.
3. Select one or more profile types to use in the query. Select the drop-down and choose options from the menu.
-The profile type or app must be selected for the query to be valid. Grafana doesn’t show any data if the profile type or app isn’t selected when a query runs.
+The profile type or app must be selected for the query to be valid. Grafana doesn't show any data if the profile type or app isn’t selected when a query runs.

## Examples
-Check out the [examples](https://github.com/grafana/pyroscope/tree/main/examples/tracing/tempo) directory for a complete demo application that shows tracing integration features.
\ No newline at end of file
+Check out the [examples](https://github.com/grafana/pyroscope/tree/main/examples/tracing/tempo) directory for a complete demo application that shows tracing integration features.
diff --git a/docs/sources/configure-server/_index.md b/docs/sources/configure-server/_index.md
index 0a537f7ba1..597f51c94d 100644
--- a/docs/sources/configure-server/_index.md
+++ b/docs/sources/configure-server/_index.md
@@ -13,6 +13,6 @@ weight: 40
# Configure the Pyroscope server
-Pyroscope's server is built to be horizontally scalable and to support organizations of all sizes.
+The Pyroscope server is built to be horizontally scalable and to support organizations of all sizes.
{{< section menuTitle="true" >}}
diff --git a/docs/sources/configure-server/about-configurations.md b/docs/sources/configure-server/about-configurations.md
index eb9d0b9093..f22ca2746b 100644
--- a/docs/sources/configure-server/about-configurations.md
+++ b/docs/sources/configure-server/about-configurations.md
@@ -22,7 +22,7 @@ It is recommended to use a single configuration file and either pass it to all r
This helps avoid a common misconfiguration pitfall: while certain configuration parameters might look like they’re only needed by one type of component, they might in fact be used by multiple components. For example, the `-distributor.replication-factor` CLI flag is not only required by ingesters, but also by distributors and queriers.
-By using a single configuration file, you ensure that each component gets all of the configuration that it needs without needing to track which parameter belongs to which component.
+By using a single configuration file, you ensure that each component gets all the configuration that it needs without needing to track which parameter belongs to which component.
There is no harm in passing a configuration that is specific to one component (such as an ingester) to another component (such as a querier). In such case, the configuration is simply ignored.
If necessary, you can use advanced CLI flags to override specific values on a particular Pyroscope component or replica. This can be helpful if you want to change a parameter that is specific to a certain component, without having to do a full restart of all other components.
diff --git a/docs/sources/configure-server/about-server-api.md b/docs/sources/configure-server/about-server-api.md
index 8b996bfc6b..280d4e4f31 100644
--- a/docs/sources/configure-server/about-server-api.md
+++ b/docs/sources/configure-server/about-server-api.md
@@ -30,7 +30,7 @@ The following query parameters are accepted:
| `sampleRate` | sample rate used in Hz | optional (default is `100` Hz) |
| `spyName` | name of the spy used | optional |
| `units` | name of the profiling data unit | optional (default is `samples` |
-| `aggregrationType` | type of aggregration to merge profiles | optional (default is `sum`) |
+| `aggregrationType` | type of aggregation to merge profiles | optional (default is `sum`) |
`name` specifies application name. For example:
@@ -218,20 +218,20 @@ curl -X POST \
There is one primary endpoint for querying profile data: `GET /pyroscope/render`.
The search input is provided via query parameters.
-The output is typically a JSON object containing one or more time series and a flamegraph.
+The output is typically a JSON object containing one or more time series and a flame graph.
### Query parameters
Here is an overview of the accepted query parameters:
-| Name | Description | Notes |
-|:---------------|:--------------------------------------------------------------------------------------|:-----------------------------------------------------|
-| `query` | contains the profile type and label selectors | required |
-| `from` | UNIX time for the start of the search window | required |
-| `until` | UNIX time for the end of the search window | optional (default is `now`) |
-| `format` | format of the profiling data | optional (default is `json`) |
-| `maxNodes` | the maximum number of nodes the resulting flamegraph will contain | optional (default is `max_flamegraph_nodes_default`) |
-| `groupBy` | one or more label names to group the time series by (doesn't apply to the flamegraph) | optional (default is no grouping) |
+| Name | Description | Notes |
+|:-----------|:---------------------------------------------------------------------------------------|:-----------------------------------------------------|
+| `query` | contains the profile type and label selectors | required |
+| `from` | UNIX time for the start of the search window | required |
+| `until` | UNIX time for the end of the search window | optional (default is `now`) |
+| `format` | format of the profiling data | optional (default is `json`) |
+| `maxNodes` | the maximum number of nodes the resulting flame graph will contain | optional (default is `max_flamegraph_nodes_default`) |
+| `groupBy` | one or more label names to group the time series by (doesn't apply to the flame graph) | optional (default is no grouping) |
#### `query`
@@ -331,8 +331,8 @@ type FlamebearerProfileV1 struct {
#### `flamebearer`
-The `flamebearer` field contains data in a form suitable for rendering a flamegraph.
-Data within the flamebearer is organized in separate arrays containing the profile symbols and the sample values.
+The `flamebearer` field contains data in a form suitable for rendering a flame graph.
+Data within the `flamebearer` is organized in separate arrays containing the profile symbols and the sample values.
#### `metadata`
diff --git a/docs/sources/configure-server/about-tenant-ids.md b/docs/sources/configure-server/about-tenant-ids.md
index 0f667c92e2..3ef4e11562 100644
--- a/docs/sources/configure-server/about-tenant-ids.md
+++ b/docs/sources/configure-server/about-tenant-ids.md
@@ -16,7 +16,7 @@ The query takes the tenant ID from the `X-Scope-OrgID` parameter that exists in
To push profiles to Grafana Pyroscope for a specific tenant, refer to [Configure the Agent]({{< relref "../configure-client" >}}).
-> By default multi-tenancy is disabled, the tenant ID is ignored and all profiles are stored and retrieved with the same tenant (`anonymous`).
+> By default, multi-tenancy is disabled, the tenant ID is ignored and all profiles are stored and retrieved with the same tenant (`anonymous`).
>
>To enable multi-tenancy, add the `multitenancy_enabled` parameter to the Grafana Pyroscope configuration file and set it to `true`. Alternatively you can also use command line arguments to enable multi-tenancy, for example `--auth.multitenancy-enabled=true`.
diff --git a/docs/sources/configure-server/configure-shuffle-sharding/index.md b/docs/sources/configure-server/configure-shuffle-sharding/index.md
index 54110e8bc7..c0f7ef5949 100644
--- a/docs/sources/configure-server/configure-shuffle-sharding/index.md
+++ b/docs/sources/configure-server/configure-shuffle-sharding/index.md
@@ -36,7 +36,7 @@ Shuffle sharding provides the following benefits:
- A misbehaving tenant only affects its shard instances.
Assuming that each tenant shard is relatively small compared to the total number of instances in the cluster, it’s likely that any other tenant runs on different instances or that only a subset of instances match the affected instances.
-Using shuffle sharding doesn’t require more resources, but can result in unbalanced instances.
+Using shuffle sharding doesn't require more resources, but can result in unbalanced instances.
### Low overlapping instances probability
diff --git a/docs/sources/configure-server/reference-configuration-parameters/index.md b/docs/sources/configure-server/reference-configuration-parameters/index.md
index a318f43a05..32c32f05ac 100644
--- a/docs/sources/configure-server/reference-configuration-parameters/index.md
+++ b/docs/sources/configure-server/reference-configuration-parameters/index.md
@@ -1883,11 +1883,11 @@ The `limits` block configures default and per-tenant limits imposed by component
# CLI flag: -querier.max-query-parallelism
[max_query_parallelism: | default = 0]
-# Maximum number of flamegraph nodes by default. 0 to disable.
+# Maximum number of flame graph nodes by default. 0 to disable.
# CLI flag: -querier.max-flamegraph-nodes-default
[max_flamegraph_nodes_default: | default = 8192]
-# Maximum number of flamegraph nodes allowed. 0 to disable.
+# Maximum number of flame graph nodes allowed. 0 to disable.
# CLI flag: -querier.max-flamegraph-nodes-max
[max_flamegraph_nodes_max: | default = 0]
diff --git a/docs/sources/deploy-kubernetes/helm.md b/docs/sources/deploy-kubernetes/helm.md
index 4a36a76d6e..dfc842c0dd 100644
--- a/docs/sources/deploy-kubernetes/helm.md
+++ b/docs/sources/deploy-kubernetes/helm.md
@@ -71,7 +71,7 @@ Use a custom namespace so that you don't have to overwrite the default namespace
```
{{% /admonition %}}
- - Option B: Install Pyroscope as micro-services. In this mode, as you scale out the number of instances, they will share a singular backend for storage and querying.
+ - Option B: Install Pyroscope as multiple microservices. In this mode, as you scale out the number of instances, they will share a singular backend for storage and querying.
```bash
# Gather the default config for micro-services
@@ -80,7 +80,7 @@ Use a custom namespace so that you don't have to overwrite the default namespace
```
{{% admonition type="note" %}}
- The output of the command contains the query URLs necessary for the following steps, so for a micro-service setup, it will look like this:
+ The output of the command contains the query URLs necessary for the following steps, so for a microservice setup, it will look like this:
```
[...]
@@ -96,7 +96,7 @@ Use a custom namespace so that you don't have to overwrite the default namespace
kubectl -n pyroscope-test get pods
```
- The results look similar to this when you are in micro-services mode:
+ The results look similar to this when you are in microservices mode:
```bash
kubectl -n pyroscope-test get pods
@@ -113,7 +113,7 @@ Use a custom namespace so that you don't have to overwrite the default namespace
pyroscope-querier-66bf58dfcc-zbggm 1/1 Running 0 3m23s
```
-1. Wait until all of the pods have a status of `Running` or `Completed`, which might take a few minutes.
+1. Wait until all the pods have a status of `Running` or `Completed`, which might take a few minutes.
## Query profiles in Grafana
diff --git a/docs/sources/deploy-kubernetes/tanka-jsonnet.md b/docs/sources/deploy-kubernetes/tanka-jsonnet.md
index 2e64c6f2a3..a5172638b3 100644
--- a/docs/sources/deploy-kubernetes/tanka-jsonnet.md
+++ b/docs/sources/deploy-kubernetes/tanka-jsonnet.md
@@ -54,7 +54,7 @@ You can use [Tanka](https://tanka.dev/) and [jsonnet-bundler](https://github.com
tk env set environments/default --server-from-context=$(kubectl config current-context)
```
-1. Decide if you want to run Pyroscope in the monolithic or the micro-services mode
+1. Decide if you want to run Pyroscope in the monolithic or the microservices mode
- Option A) For monolithic mode the file `environments/default/main.jsonnet`, should look like;
@@ -67,7 +67,7 @@ You can use [Tanka](https://tanka.dev/) and [jsonnet-bundler](https://github.com
})
```
- - Option B) For micro services mode the file `environments/default/main.jsonnet`, should look like;
+ - Option B) For microservices mode the file `environments/default/main.jsonnet`, should look like;
```jsonnet
local pyroscope = import 'pyroscope/jsonnet/pyroscope/pyroscope.libsonnet';
diff --git a/docs/sources/introduction/continuous-profiling/_index.md b/docs/sources/introduction/continuous-profiling/_index.md
index 78e829dbe6..18bdbea487 100644
--- a/docs/sources/introduction/continuous-profiling/_index.md
+++ b/docs/sources/introduction/continuous-profiling/_index.md
@@ -7,7 +7,7 @@ keywords:
- pyroscope
- phlare
- continuous profiling
- - flamegraphs
+ - flame graphs
---
## When to use continuous profiling
@@ -15,13 +15,13 @@ keywords:
Continuous profiling is a systematic method of collecting and analyzing performance data from production systems.
Traditionally, profiling is used as an ad-hoc debugging tool in languages like Go and Java.
-You are probably used to running a benchmark tool locally and getting a pprof file in Go or maybe connecting into a misbehaving prod instance and pulling a flamegraph from a JFR file in Java.
+You are probably used to running a benchmark tool locally and getting a pprof file in Go or maybe connecting into a misbehaving prod instance and pulling a flame graph from a JFR file in Java.
This is great for debugging but not so great for production.
-
+
{{% admonition type="note" %}}
-To learn more about flamegraphs, refer to [Flamegraphs: Visualizing performance data]({{< relref "../../view-and-analyze-profile-data/flamegraphs" >}}).
+To learn more about flame graphs, refer to [Flame graphs: Visualizing performance data]({{< relref "../../view-and-analyze-profile-data/flamegraphs" >}}).
{{% /admonition %}}
Continuous profiling is a modern approach which is safer and more scalable for production environments.
@@ -69,4 +69,4 @@ This granular insight allows for targeted optimization, leading to faster applic
### Enhanced incident management
Pyroscope streamlines incident management by offering immediate, actionable insights into application performance issues.
-With continuous profiling, teams can quickly pinpoint the root cause of an incident, reducing the mean time to resolution (MTTR) and enhancing overall system reliability and user satisfaction.
\ No newline at end of file
+With continuous profiling, teams can quickly pinpoint the root cause of an incident, reducing the mean time to resolution (MTTR) and enhancing overall system reliability and user satisfaction.
diff --git a/docs/sources/introduction/profiling.md b/docs/sources/introduction/profiling.md
index 14f119b8e0..892ed9740d 100644
--- a/docs/sources/introduction/profiling.md
+++ b/docs/sources/introduction/profiling.md
@@ -6,7 +6,7 @@ weight: 20
keywords:
- pyroscope
- continuous profiling
- - flamegraphs
+ - flame graphs
---
# Profiling fundamentals
@@ -53,7 +53,7 @@ Continuous profiling provides:
- **Economical advantages**:
- **Resource optimization**: Continual monitoring ensures resources aren't wasted, leading to cost savings.
- **Rapid problem resolution**: Faster troubleshooting means reduced time and monetary investment in issue rectification, letting developers channel their efforts into productive endeavors.
-- **Unintrusive operation**: Specifically designed to work quietly in the background, continuous profiling doesn't compromise the performance of live environments.
+- **Non-intrusive operation**: Specifically designed to work quietly in the background, continuous profiling doesn't compromise the performance of live environments.
7. **Real-time response**: It equips teams with the ability to act instantly, addressing issues as they arise rather than post-occurrence, which is crucial for maintaining high system availability.
## How to choose between traditional and continuous profiling
@@ -70,4 +70,4 @@ In many modern development workflows, both methods are useful.
- **When**: In production environments or during extended performance tests.
- **Advantages**: Provides a continuous view of system performance, often with minimal overhead, making it suitable for live environments.
- - **Disadvantages**: It might be less detailed than traditional profiling due to the need to minimize impact on the running system.
\ No newline at end of file
+ - **Disadvantages**: It might be less detailed than traditional profiling due to the need to minimize impact on the running system.
diff --git a/docs/sources/reference-pyroscope-architecture/block-format/_index.md b/docs/sources/reference-pyroscope-architecture/block-format/_index.md
index 3154b4e932..915c6b1b9e 100644
--- a/docs/sources/reference-pyroscope-architecture/block-format/_index.md
+++ b/docs/sources/reference-pyroscope-architecture/block-format/_index.md
@@ -36,7 +36,7 @@ The data model within the block is fairly aligned to Google's [proto definition]
Profile series labels contain additional information gathered at ingestion time and can
-be used to select certain profiles. They are comparable to Prometeus'/Loki's labels
+be used to select certain profiles. They are comparable to Prometheus/Loki labels
and typical label names are `namespace` and `pod` to describe which workload the profiles
are coming from.
diff --git a/docs/sources/reference-pyroscope-architecture/components/compactor/index.md b/docs/sources/reference-pyroscope-architecture/components/compactor/index.md
index 284f7cdf35..67a2030e18 100644
--- a/docs/sources/reference-pyroscope-architecture/components/compactor/index.md
+++ b/docs/sources/reference-pyroscope-architecture/components/compactor/index.md
@@ -106,7 +106,7 @@ The compactor allows configuring of the compaction jobs order via the `-compacto
## Blocks deletion
-Following a successful compaction, the original blocks are deleted from the storage. Block deletion is not immediate; it follows a two step process:
+Following a successful compaction, the original blocks are deleted from the storage. Block deletion is not immediate; it follows a two-step process:
1. An original block is marked for deletion; this is a soft delete
1. Once a block has been marked for deletion for longer than the configurable `-compactor.deletion-delay`, the block is deleted from storage; this is a hard delete
diff --git a/docs/sources/reference-pyroscope-architecture/components/query-frontend/index.md b/docs/sources/reference-pyroscope-architecture/components/query-frontend/index.md
index 9ac0fdb71c..ffd289ef34 100644
--- a/docs/sources/reference-pyroscope-architecture/components/query-frontend/index.md
+++ b/docs/sources/reference-pyroscope-architecture/components/query-frontend/index.md
@@ -18,6 +18,6 @@ We recommend that you run at least two query-frontend replicas for high-availabi
The following steps describe how a query moves through the query-frontend.
1. A query-frontend receives a query.
-1. The query-frontend places the query in an queue by communicating with the query-scheduler, where it waits to be picked up by a querier.
+1. The query-frontend places the query in a queue by communicating with the query-scheduler, where it waits to be picked up by a querier.
1. A querier picks up the query from the queue and executes it.
1. A querier or queriers return the result to query-frontend, which then aggregates and forwards the results to the client.
diff --git a/docs/sources/reference-pyroscope-architecture/hash-ring/index.md b/docs/sources/reference-pyroscope-architecture/hash-ring/index.md
index 48d644011e..a411031df0 100644
--- a/docs/sources/reference-pyroscope-architecture/hash-ring/index.md
+++ b/docs/sources/reference-pyroscope-architecture/hash-ring/index.md
@@ -20,7 +20,7 @@ The token determines the location on the hash ring deterministically.
This allows independent determination of what instance of Pyroscope is the authoritative owner of any specific data.
For example, profiles are sharded across [ingesters]({{< relref "../components/ingester.md" >}}).
-The token of a given profile is computed by hashing all of the profile’ labels and the tenant ID: the result of which is an unsigned 32-bit integer within the space of the tokens.
+The token of a given profile is computed by hashing all of the profile’s labels and the tenant ID: the result of which is an unsigned 32-bit integer within the space of the tokens.
The ingester that owns that series is the instance that owns the range of the tokens, including the profile token.
To divide up set of possible tokens (`2^32`) across the available instances within the cluster, all of the running instances of a given Pyroscope component, such as the ingesters, join a hash ring.
@@ -28,7 +28,7 @@ The hash ring is a data structure that splits the space of the tokens into multi
Upon startup, an instance generates random token values, and it registers them into the ring.
The values that each instance registers determine which instance owns a given token.
-A token is owned by the instance that registered the smallest value that is higher than the token being looked up (by wrapping around zero when it reaches `(2^32)-1)`.
+A token is owned by the instance that registered the smallest value that is higher than the token being looked up (by wrapping around zero when it reaches `(2^32)-1)`).
To replicate the data across multiple instances, Pyroscope finds the replicas by starting from the authoritative owner of the data and walking the ring clockwise.
Data is replicated to the next instances found while walking the ring.
@@ -43,7 +43,7 @@ To better understand how it works, take four ingesters and a tokens space betwee
- Ingester #4 is registered in the ring with the token `9`
Pyroscope receives an incoming performance profile with labels `{__name__="process_cpu", instance="1.1.1.1"}`.
-It hashes the profile’ labels, and the result of the hashing function is the token `3`.
+It hashes the profile’s labels, and the result of the hashing function is the token `3`.
To find which ingester owns token `3`, Pyroscope looks up the token `3` in the ring and finds the ingester that is registered with the smallest token larger than `3`.
The ingester #2, which is registered with token `4`, is the authoritative owner of the profile `{__name__="process_cpu",instance="1.1.1.1"}`.
@@ -89,4 +89,4 @@ Pyroscope primarily uses the hash ring for sharding and replication.
Features that are built using the hash ring:
- **Service discovery**: Instances can discover each other looking up who is registered in the ring.
-- **Heartbeating**: Instances periodically send an heartbeat to the ring to signal they're up and running. An instance is considered unhealthy if misses the heartbeat for some period of time.
+- **Heartbeats**: Instances periodically send a heartbeat to the ring to signal they're up and running. An instance is considered unhealthy if it misses the heartbeat for some period of time.
diff --git a/docs/sources/release-notes/v1-1.md b/docs/sources/release-notes/v1-1.md
index 79ec052c9e..d14297ea19 100644
--- a/docs/sources/release-notes/v1-1.md
+++ b/docs/sources/release-notes/v1-1.md
@@ -31,7 +31,7 @@ You can reach out to the team using:
- Updated multiple dependencies including Go, Ruby, Django, Rust, and more.
- Introduced meta fetcher that synchronizes filtered metadata locally.
- Introduced pyroscope packaging via nfpm.
-- Use Grafana flamegraph component.
+- Use Grafana flame graph component.
- 'ExportData' now respects the 'flamegraph.com' related prop.
- Introduced option to disable RBAC.
- Introduced a tenant scanner.
@@ -62,4 +62,4 @@ You can reach out to the team using:
- Automation added for brew releases.
- Helm improvements: setting correct namespace, adding initContainers, hostNetwork, etc.
- Refactored after dskit upgrade.
-- Updated rideshare examples for ingesting to grafana.com.
\ No newline at end of file
+- Updated rideshare examples for ingesting to grafana.com.
diff --git a/docs/sources/release-notes/v1-2.md b/docs/sources/release-notes/v1-2.md
index a6db04549e..d56e69dc1b 100644
--- a/docs/sources/release-notes/v1-2.md
+++ b/docs/sources/release-notes/v1-2.md
@@ -11,7 +11,7 @@ We are excited to present this release of Grafana Pyroscope packed with 150 comm
In this release, we've introduced significant enhancements to our microservice mode, aiming to boost performance and streamline operations. The **compactor** component has been added to optimize block management, improving query speed and reducing replication factor overhead.
-Our physical planning has undergone optimization, ensuring that data deduplication occurs only when necessary. Additionally, we've initiated tracing integrations, allowing for the inclusion of span ids in profiling samples and enabling flamegraph filtering.
+Our physical planning has undergone optimization, ensuring that data deduplication occurs only when necessary. Additionally, we've initiated tracing integrations, allowing for the inclusion of span ids in profiling samples and enabling flame graph filtering.
For users leveraging Function as a Service (FaaS) environments, we've enhanced profiling data ingestion by automatically aggregating profiles. This not only reduces the number of profiles but also contributes to improved overall efficiency.
diff --git a/docs/sources/release-notes/v1-3.md b/docs/sources/release-notes/v1-3.md
index ca7a747ca6..c98576c9ac 100644
--- a/docs/sources/release-notes/v1-3.md
+++ b/docs/sources/release-notes/v1-3.md
@@ -61,8 +61,8 @@ Version 1.3 includes the following fixes:
Version 1.3 includes the following documentation updates:
* Enhanced memory overhead documentation: Deeper insights into system performance ([#2895](https://github.com/grafana/pyroscope/pull/2895)).
-* Updated NodeJS documentation: Fixed Markdown link issues for better clarity ([#2890](https://github.com/grafana/pyroscope/pull/2890)).
+* Updated Node.js documentation: Fixed Markdown link issues for better clarity ([#2890](https://github.com/grafana/pyroscope/pull/2890)).
* Expanded java.md documentation: Comprehensive Java profiling guidance ([#2904](https://github.com/grafana/pyroscope/pull/2904)).
* Removed dependency on Grafana Agent: Streamlined Pyroscope architecture ([#2913](https://github.com/grafana/pyroscope/pull/2913)).
* Updated various sections: Intro, analyze, sampling, and SDK pages now offer clearer and more detailed information ([#2855](https://github.com/grafana/pyroscope/pull/2855), [#2844](https://github.com/grafana/pyroscope/pull/2844), [#2854](https://github.com/grafana/pyroscope/pull/2854), [#2851](https://github.com/grafana/pyroscope/pull/2851), [#2861](https://github.com/grafana/pyroscope/pull/2861)).
-* Launched a 1-minute YouTube short on eBPF: Providing a quick and informative overview of eBPF ([#2893](https://github.com/grafana/pyroscope/pull/2893)).
\ No newline at end of file
+* Launched a 1-minute YouTube short on eBPF: Providing a quick and informative overview of eBPF ([#2893](https://github.com/grafana/pyroscope/pull/2893)).
diff --git a/docs/sources/release-notes/v1-4.md b/docs/sources/release-notes/v1-4.md
index 742a3e660e..4b37a31ed1 100644
--- a/docs/sources/release-notes/v1-4.md
+++ b/docs/sources/release-notes/v1-4.md
@@ -12,7 +12,7 @@ We are excited to present Grafana Pyroscope 1.4.
This release includes several new features which are precursors to larger projects like:
* Adhoc profiling
-* Time series scoped to a flamegraph function
+* Time series scoped to a flame graph function
* Traces to profiles tooling
Additionally, numerous other changes improve stability, performance, and documentation.
@@ -26,7 +26,7 @@ Features and enhancements for version 1.4 include:
* Adhoc profiles API ([#2963](https://github.com/grafana/pyroscope/pull/2963))
* Add query-tracer to profilecli ([#2966](https://github.com/grafana/pyroscope/pull/2966))
* Add ServiceMonitor support to Helm chart ([#2944](https://github.com/grafana/pyroscope/pull/2944), [#2929](https://github.com/grafana/pyroscope/pull/2929), [#2967](https://github.com/grafana/pyroscope/pull/2967))
-* Scope time series to flamegraph node API ([#2961](https://github.com/grafana/pyroscope/pull/2961))
+* Scope time series to flame graph node API ([#2961](https://github.com/grafana/pyroscope/pull/2961))
### Improvements and updates
diff --git a/docs/sources/upgrade-guide/_index.md b/docs/sources/upgrade-guide/_index.md
index 88bab4c0f3..25a3dbf24c 100644
--- a/docs/sources/upgrade-guide/_index.md
+++ b/docs/sources/upgrade-guide/_index.md
@@ -24,7 +24,7 @@ This upgrade guide applies to on-premise installations and not for Grafana Cloud
Version 1.0 of Pyroscope is a major release that includes breaking changes.
This guide explains how to upgrade to v1.0 from previous versions.
-This document describes in detail the changes that we've made to Pyroscope and how they affect you. For convinience, at the end of this guide we provide short checklists for you to follow.
+This document describes in detail the changes that we've made to Pyroscope and how they affect you. For convenience, at the end of this guide we provide short checklists for you to follow.
### New architecture
@@ -91,7 +91,7 @@ We provide the following checklists to help you upgrade to v1.0.
When upgrading to v1.0, we suggest that you follow this checklist:
* Migrate your configuration from the old format to the new format (old config is usually located at `/etc/pyroscope/server.yml` and the new config is at `/etc/pyroscope/config.yaml`). There's a detailed description of all configuration parameters [here]({{< relref "../configure-server/reference-configuration-parameters" >}}).
-* Upgrade docker image image from `pyroscope/pyroscope` to `grafana/pyroscope`. Link to the new docker image is [here](https://hub.docker.com/r/grafana/pyroscope).
+* Upgrade docker image from `pyroscope/pyroscope` to `grafana/pyroscope`. Link to the new docker image is [here](https://hub.docker.com/r/grafana/pyroscope).
* Delete old data (typically found at `/var/lib/pyroscope`).
#### Upgrade Checklist for Helm deployments
diff --git a/docs/sources/view-and-analyze-profile-data/_index.md b/docs/sources/view-and-analyze-profile-data/_index.md
index 690edcaa57..0409567c1c 100644
--- a/docs/sources/view-and-analyze-profile-data/_index.md
+++ b/docs/sources/view-and-analyze-profile-data/_index.md
@@ -9,14 +9,14 @@ keywords:
- pyroscope
- UI
- performance analysis
- - flamegraphs
+ - flame graphs
- CLI
---
# View and analyze profile data
Profiling data can be presented in a variety of formats presents such as:
-- **Flamegraphs**: Visualize call relationships and identify hotspots.
+- **Flame graphs**: Visualize call relationships and identify hotspots.
- **Tables**: View detailed statistics for specific functions or time periods.
- **Charts and graphs**: Analyze trends and compare performance across different metrics.
diff --git a/docs/sources/view-and-analyze-profile-data/analyze-profiles/_index.md b/docs/sources/view-and-analyze-profile-data/analyze-profiles/_index.md
index 657c4cf5e0..ade1a1851b 100644
--- a/docs/sources/view-and-analyze-profile-data/analyze-profiles/_index.md
+++ b/docs/sources/view-and-analyze-profile-data/analyze-profiles/_index.md
@@ -9,7 +9,7 @@ draft: true
keywords:
- pyroscope
- performance analysis
- - flamegraphs
+ - flame graphs
---
@@ -36,4 +36,4 @@ With traditional profiling getting any of this information is much more difficul
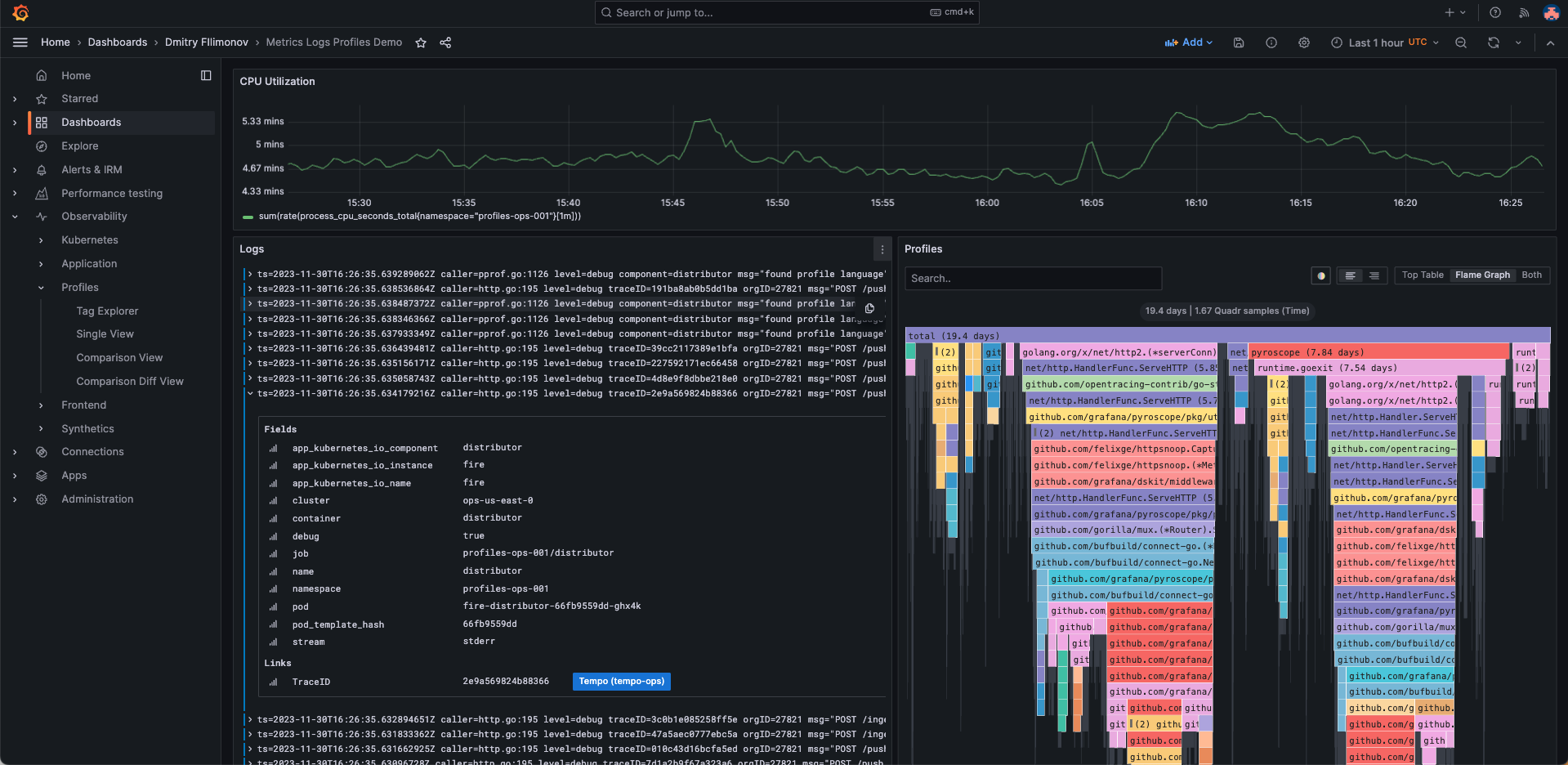
-Pyroscope enhances its value through seamless integration with leading observability tools like Grafana, Prometheus, and Loki. This integration facilitates deeper insights into application performance and aids in addressing issues identified through other monitoring methods.
\ No newline at end of file
+Pyroscope enhances its value through seamless integration with leading observability tools like Grafana, Prometheus, and Loki. This integration facilitates deeper insights into application performance and aids in addressing issues identified through other monitoring methods.
diff --git a/docs/sources/view-and-analyze-profile-data/flamegraphs.md b/docs/sources/view-and-analyze-profile-data/flamegraphs.md
index 9ce1a251ed..7ff64defff 100644
--- a/docs/sources/view-and-analyze-profile-data/flamegraphs.md
+++ b/docs/sources/view-and-analyze-profile-data/flamegraphs.md
@@ -1,7 +1,7 @@
---
-title: "Flamegraphs: Visualizing performance data"
-menuTitle: Flamegraphs
-description: Learn about flamegraphs to help visualize performance data.
+title: "Flame graphs: Visualizing performance data"
+menuTitle: Flame graphs
+description: Learn about flame graphs to help visualize performance data.
weight: 33
aliases:
- ../introduction/flamegraphs/
@@ -10,33 +10,33 @@ keywords:
- Profiling
---
-# Flamegraphs: Visualizing performance data
+# Flame graphs: Visualizing performance data
-A fundamental aspect of continuous profiling is the flamegraph, a convenient way to visualize performance data.
+A fundamental aspect of continuous profiling is the flame graph, a convenient way to visualize performance data.
These graphs provide a clear, intuitive understanding of resource allocation and bottlenecks within the application. Pyroscope extends this functionality with additional visualization formats like tree graphs and top lists.
-## How is a flamegraph created?
+## How is a flame graph created?
-
+
-This diagram shows how code is turned into a flamegraph. In this case Pyroscope would sample the stacktrace of your application to understand how many CPU cycles are being spent in each function. It would then aggregate this data and turn it into a flamegraph. This is a very simplified example but it gives you an idea of how Pyroscope works.
+This diagram shows how code is turned into a flame graph. In this case Pyroscope would sample the stacktrace of your application to understand how many CPU cycles are being spent in each function. It would then aggregate this data and turn it into a flame graph. This is a very simplified example but it gives you an idea of how Pyroscope works.
-## What does a flamegraph represent?
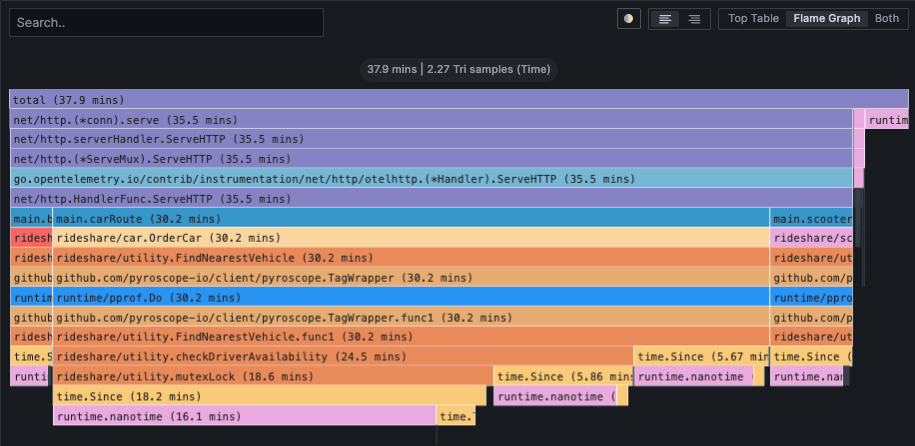
+## What does a flame graph represent?
-
+
-Horizontally, the flamegraph represents 100% of the time that this application was running.
+Horizontally, the flame graph represents 100% of the time that this application was running.
The width of each node represents the amount of time spent in that function.
The wider the node, the more time spent in that function. The narrower the node, the less time spent in that function.
-Vertically, the nodes in the flamegraph represent the hierarchy of which functions were called and how much time was spent in each function.
+Vertically, the nodes in the flame graph represent the hierarchy of which functions were called and how much time was spent in each function.
The top node is the root node and represents the total amount of time spent in the application.
The nodes below it represent the functions that were called and how much time was spent in each function.
The nodes below those represent the functions that were called from those functions and how much time was spent in each function.
-This continues until you reach the bottom of the flamegraph.
+This continues until you reach the bottom of the flame graph.
This is a CPU profile, but profiles can represent many other types of resource such as memory, network, disk, etc.
-## Flamegraph visualization panel UI
+## Flame graph visualization panel UI
-To learn more about the flamegraph user interface, refer to [Flame graph visualization panel](https://grafana.com/docs/grafana-cloud/visualizations/panels-visualizations/visualizations/flame-graph).
\ No newline at end of file
+To learn more about the flame graph user interface, refer to [Flame graph visualization panel](https://grafana.com/docs/grafana-cloud/visualizations/panels-visualizations/visualizations/flame-graph).
diff --git a/docs/sources/view-and-analyze-profile-data/profiling-types/_index.md b/docs/sources/view-and-analyze-profile-data/profiling-types/_index.md
index 080cea0510..66d4d3c03c 100644
--- a/docs/sources/view-and-analyze-profile-data/profiling-types/_index.md
+++ b/docs/sources/view-and-analyze-profile-data/profiling-types/_index.md
@@ -9,7 +9,7 @@ keywords:
- pyroscope
- profiling types
- application performance
- - flamegraphs
+ - flame graphs
---
# Understand profiling types and their uses in Pyroscope
@@ -49,12 +49,12 @@ Various languages support different profiling types. Pyroscope supports the foll
CPU profiling measures the amount of CPU time consumed by different parts of your application code. High CPU usage can indicate inefficient code, leading to poor performance and increased operational costs. It's used to identify and optimize CPU-intensive functions in your application.
- **When to use**: To identify and optimize CPU-intensive functions
-- **Flamegraph insight**: The width of blocks indicates the CPU time consumed by each function
+- **Flame graph insight**: The width of blocks indicates the CPU time consumed by each function
-As you can see here, the UI is showing a spike in CPU along with the flamegraph associated with that spike.
+As you can see here, the UI is showing a spike in CPU along with the flame graph associated with that spike.
Often times without profiling you may get similar insights from metrics, but with profiling you have more details into the specific cause of a spike in CPU usage at the line level
-
+
@@ -66,7 +66,7 @@ Excessive or inefficient memory allocation can lead to memory leaks and high gar
- **Types**: Alloc Objects, Alloc Space
- **When to use**: For identifying and optimizing memory usage patterns
-- **Flamegraph insight**: Highlights functions where memory allocation is high
+- **Flame graph insight**: Highlights functions where memory allocation is high
The timeline shows memory allocations over time and is great for debugging memory related issues.
A common example is when a memory leak is created due to improper handling of memory in a function.
@@ -75,14 +75,14 @@ This is a clear indicator of a memory leak.
-Without profiling, this is may be something that's exhibited in metrics or out-of-memory errors (OOM) logs but with profiling you have more details into the specific function that's allocating the memory which is causing the leak at the line level.
+Without profiling, this may be something that's exhibited in metrics or out-of-memory errors (OOM) logs but with profiling you have more details into the specific function that's allocating the memory which is causing the leak at the line level.
## Goroutine profiling
Goroutines are lightweight threads in Go, used for concurrent operations. Goroutine profiling measures the usage and performance of these threads. Poor management can lead to issues like deadlocks and excessive resource usage.
- **When to use**: Especially useful in Go applications for concurrency management
-- **Flamegraph insight**: Provides a view of goroutine distribution and issues
+- **Flame graph insight**: Provides a view of goroutine distribution and issues
## Mutex profiling
@@ -90,7 +90,7 @@ Mutex profiling involves analyzing mutex (mutual exclusion) locks, used to preve
- **Types**: Mutex Count, Mutex Duration
- **When to use**: To optimize thread synchronization and reduce lock contention
-- **Flamegraph insight**: Shows frequency and duration of mutex operations
+- **Flame graph insight**: Shows frequency and duration of mutex operations
## Block profiling
@@ -98,6 +98,6 @@ Block profiling measures the frequency and duration of blocking operations, wher
- **Types**: Block Count, Block Duration
- **When to use**: To identify and reduce blocking delays
-- **Flamegraph insight**: Identifies where and how long threads are blocked
+- **Flame graph insight**: Identifies where and how long threads are blocked
diff --git a/docs/sources/view-and-analyze-profile-data/pyroscope-ui.md b/docs/sources/view-and-analyze-profile-data/pyroscope-ui.md
index d0d2593476..2d45c2fe85 100644
--- a/docs/sources/view-and-analyze-profile-data/pyroscope-ui.md
+++ b/docs/sources/view-and-analyze-profile-data/pyroscope-ui.md
@@ -8,7 +8,7 @@ aliases:
keywords:
- pyroscope
- performance analysis
- - flamegraphs
+ - flame graphs
---
# Use the Pyroscope UI to explore profiling data
@@ -51,7 +51,7 @@ To use the Tag Explorer:
## Single view
-The Single View page in Pyroscope's UI is built for in-depth profile analysis. Here, you can explore a single flamegraph with multiple viewing options and functionalities:
+The Single View page in Pyroscope's UI is built for in-depth profile analysis. Here, you can explore a single flame graph with multiple viewing options and functionalities:
Table view
: Breaks down the profiling data into a sortable table format.
@@ -59,20 +59,20 @@ Table view
Sandwich view
: Displays both the callers and callees for a selected function, offering a comprehensive view of function interactions.
-Flamegraph view
-: Visualizes profiling data in a flamegraph format, allowing easy identification of resource-intensive functions.
+Flame graph view
+: Visualizes profiling data in a flame graph format, allowing easy identification of resource-intensive functions.
Export & share
-: Options to export the flamegraph for offline analysis or share it via a flamegraph.com link for collaborative review.
+: Options to export the flame graph for offline analysis or share it via a flamegraph.com link for collaborative review.
The screenshot above shows a spike in CPU usage.
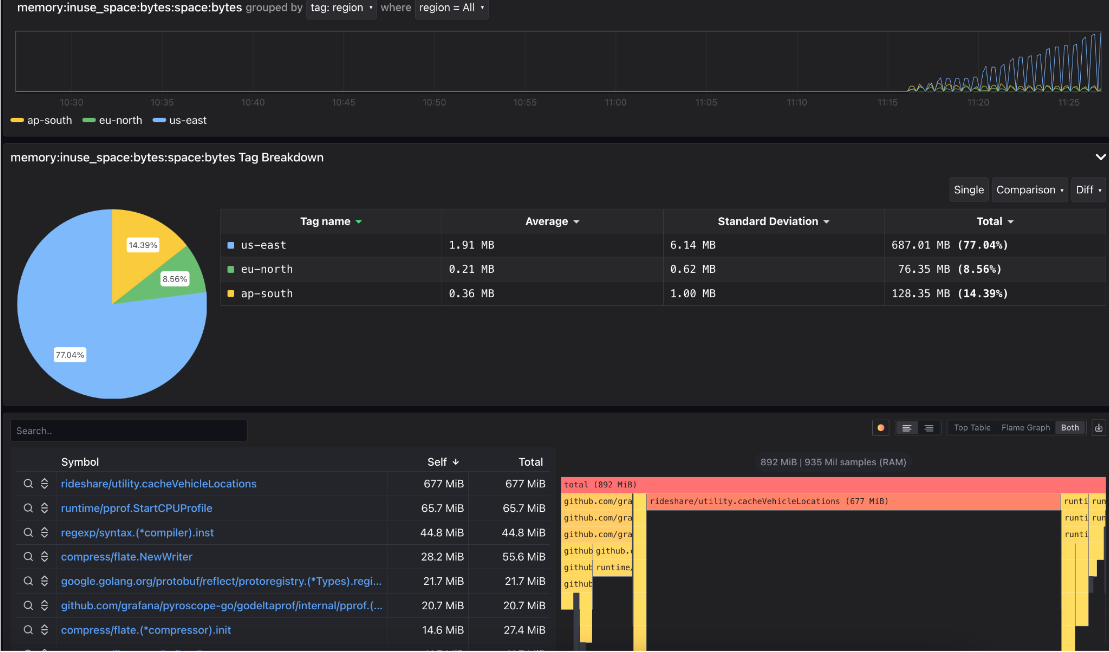
-Without profiling, we would go from a memory spike to digging through code or guessing what the cause of it is. However, with profiling, you can use the flamegraph and table to see exactly which function is most responsible for the spike. Often this will show up as a single node taking up a noticeably disproportionate width in the flamegraph as seen below with the "checkDriverAvailability" function.
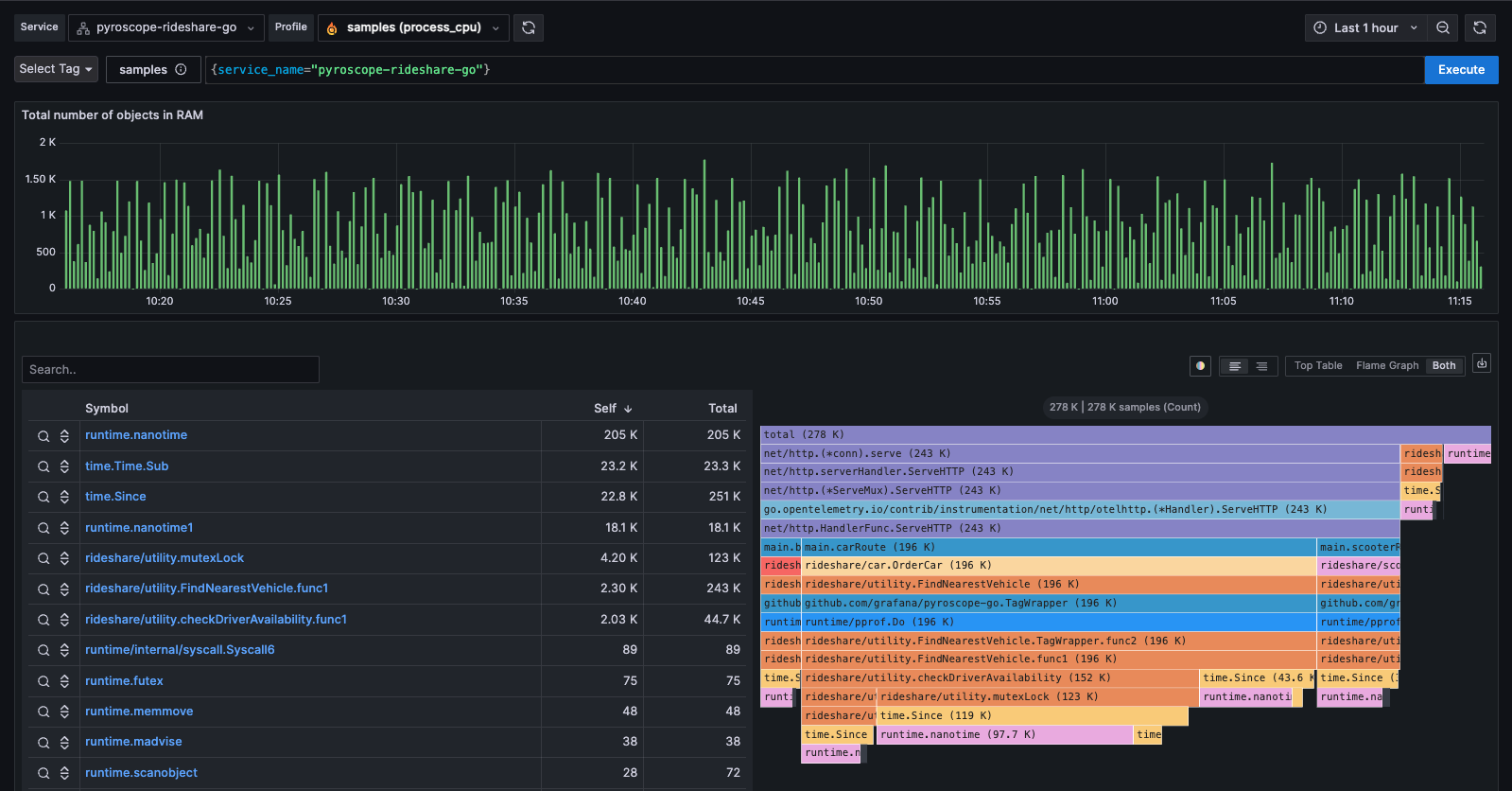
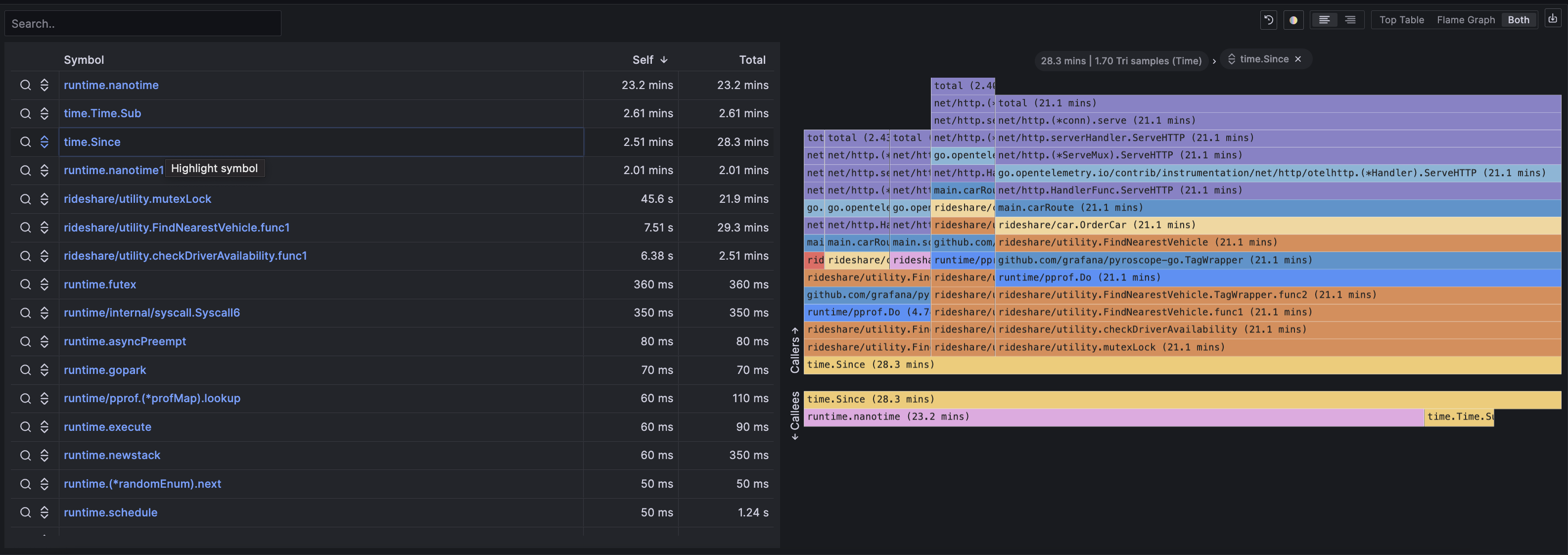
+Without profiling, we would go from a memory spike to digging through code or guessing what the cause of it is. However, with profiling, you can use the flame graph and table to see exactly which function is most responsible for the spike. Often this will show up as a single node taking up a noticeably disproportionate width in the flame graph as seen below with the "checkDriverAvailability" function.

-However, in some instances it may be a function that is called many times and is taking up a large amount of space in the flamegraph.
+However, in some instances it may be a function that is called many times and is taking up a large amount of space in the flame graph.
In this case, you can use the sandwich view to see that a logging function called throughout many functions in the codebase is the culprit.
@@ -83,8 +83,8 @@ The Comparison page facilitates side-by-side comparison of profiles either based
To run a comparison:
-1. Select two different sets of labels (for example, `env:production` vs. `env:development`) and or time periods, reflected by the sub-timelines above each flamegraph.
-2. View the resulting flamegraphs side by side to identify disparities in performance.
+1. Select two different sets of labels (for example, `env:production` vs. `env:development`) and or time periods, reflected by the sub-timelines above each flame graph.
+2. View the resulting flame graphs side by side to identify disparities in performance.
There are many practical use cases for comparison for companies using Pyroscope.
Some examples of labels below expressed as `label:value` are:
@@ -101,7 +101,7 @@ Release analysis
Region
: Compare `region:us-east-1` vs. `region:us-west-1`
-Another example where time is more important than labels is when you want to compare two different time periods. For example, in investigating the cause of a memory leak you would see something like the following where the timeline shows an steadily increasing amount of memory allocations over time. This is a clear indicator of a memory leak.
+Another example where time is more important than labels is when you want to compare two different time periods. For example, in investigating the cause of a memory leak you would see something like the following where the timeline shows a steadily increasing amount of memory allocations over time. This is a clear indicator of a memory leak.
You can then use the comparison page to compare the memory allocations between two different time periods where allocations were low and where allocations were high which would allow you to identify the function that is causing the memory leak.
@@ -110,13 +110,13 @@ You can then use the comparison page to compare the memory allocations between t
## Diff page: Identify changes with differential analysis
The Diff page is an extension of the comparison page, crucial for more easily visually showing the differences between two profiling data sets.
-It normalizes the data by comparing the percentage of total time spent in each function so that the resulting flamegraph is comparing the __share__ of time spent in each function rather than the absolute amount of time spent in each function.
+It normalizes the data by comparing the percentage of total time spent in each function so that the resulting flame graph is comparing the __share__ of time spent in each function rather than the absolute amount of time spent in each function.
This is important because it allows you to compare two different queries that may have different total amounts of time spent in each function.
-Similar to a git diff it takes the flamegraphs from the comparison page and highlights the differences between the two flamegraphs where red represents an increase in CPU usage from the baseline to the comparison and green represents a decrease.
+Similar to a git diff it takes the flame graphs from the comparison page and highlights the differences between the two flame graphs where red represents an increase in CPU usage from the baseline to the comparison and green represents a decrease.
Using the same examples from above, here is a diff between two label sets:
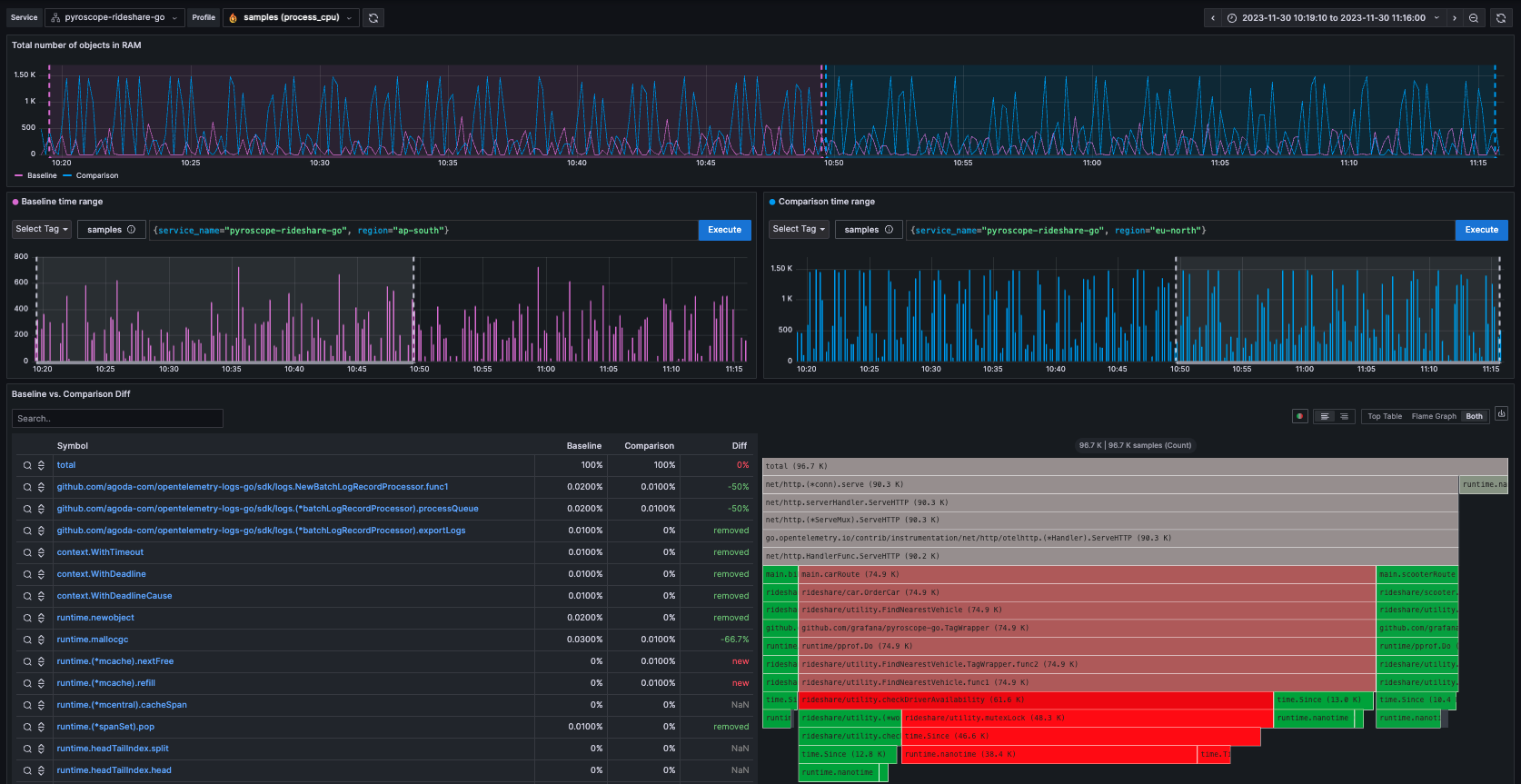
-
diff --git a/docs/sources/view-and-analyze-profile-data/self-vs-total.md b/docs/sources/view-and-analyze-profile-data/self-vs-total.md
index bec7645398..23fbb60769 100644
--- a/docs/sources/view-and-analyze-profile-data/self-vs-total.md
+++ b/docs/sources/view-and-analyze-profile-data/self-vs-total.md
@@ -15,7 +15,7 @@ keywords:
# Understand 'self' vs. 'total' metrics in profiling with Pyroscope
-Profiling in Pyroscope provideds many different ways of analyzing your profiling data. One of the key pieces of this analysis are the metrics 'self' and 'total', whose understanding is key for accurate interpretation of profiling data in both CPU and memory contexts. These metrics can be seen both within the table and the flamegraph view of the UI.
+Profiling in Pyroscope provides many different ways of analyzing your profiling data. One of the key pieces of this analysis are the metrics 'self' and 'total', whose understanding is key for accurate interpretation of profiling data in both CPU and memory contexts. These metrics can be seen both within the table and the flame graph view of the UI.
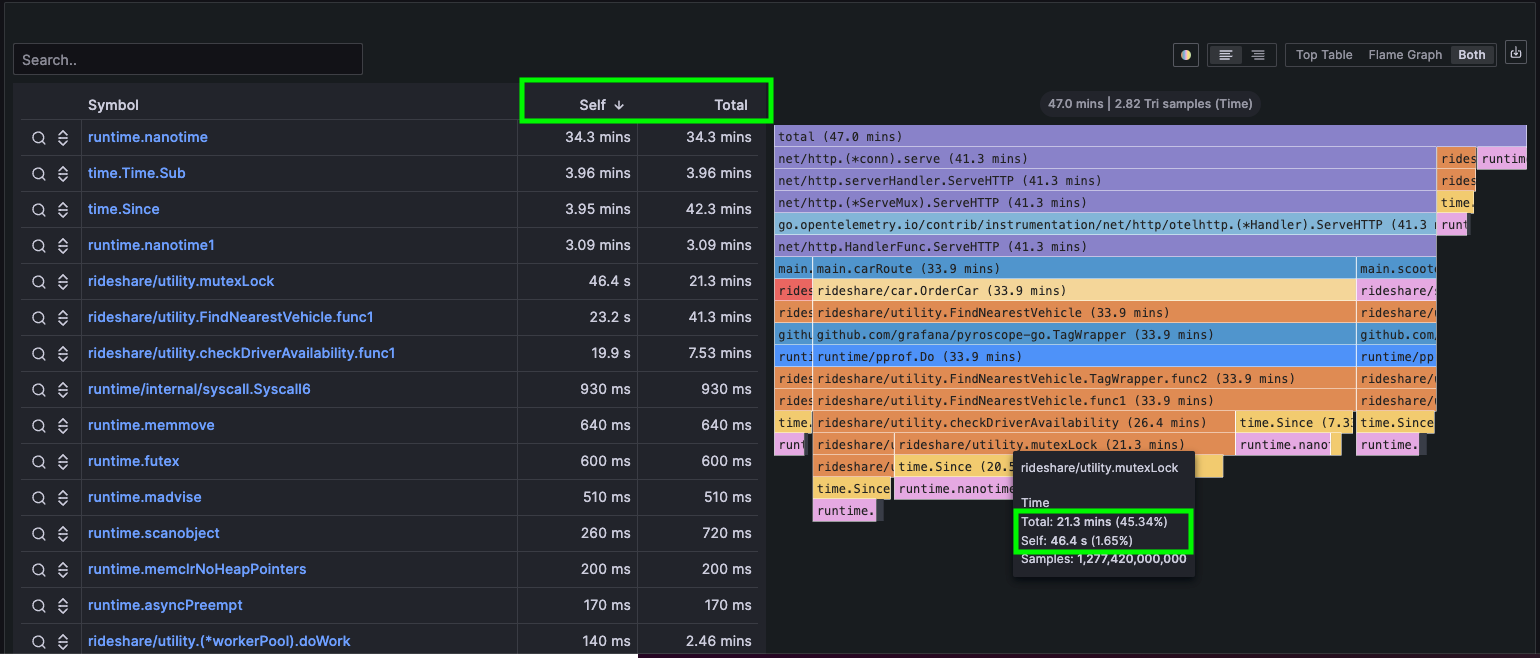
@@ -74,7 +74,7 @@ handle_request()
## 'Self' and 'Total' in memory profiling
- **Self in Memory**: For memory profiling, 'self' measures the memory allocated by the function itself, vital for detecting direct memory allocation issues.
-- **Total in Memory**: 'Total' memory includes allocations by the function and its called functions, essential for assessing overall memory footprint.
+- **Total in Memory**: 'Total' memory includes allocations by the function and it's called functions, essential for assessing overall memory footprint.
The same example from the CPU profiling section can be used to illustrate the concepts of 'self' and 'total' in memory profiling, just with memory units instead of CPU.
diff --git a/examples/language-sdk-instrumentation/golang-push/README.md b/examples/language-sdk-instrumentation/golang-push/README.md
index 4d526995e8..1a243cb03a 100644
--- a/examples/language-sdk-instrumentation/golang-push/README.md
+++ b/examples/language-sdk-instrumentation/golang-push/README.md
@@ -51,7 +51,7 @@ What this block does, is:
2. execute the `FindNearestVehicle()` function
3. Before the block ends it will (behind the scenes) remove the `pyroscope.Labels("vehicle", vehicle)` from the application since that block is complete
-## Resulting flamegraph / performance results from the example
+## Resulting flame graph / performance results from the example
### Running the example
To run the example run the following commands:
```
@@ -65,7 +65,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flamegraph that looks like this (below). After we give 20-30 seconds for the flamegraph to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flame graph that looks like this (below). After we give 20-30 seconds for the flame graph to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
## Where's the performance bottleneck?
@@ -89,14 +89,14 @@ We can also see that the `mutexLock()` function is consuming almost 70% of CPU r

## Comparing two time periods
-Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flamegraphs. The pink section on the left timeline results in the left flamegraph, and the blue section on the right represents the right flamegraph.
+Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flame graphs. The pink section on the left timeline results in the left flame graph, and the blue section on the right represents the right flame graph.
When we select a period of low-cpu utilization and a period of high-cpu utilization we can see that there is clearly different behavior in the `mutexLock()` function where it takes **33% of CPU** during low-cpu times and **71% of CPU** during high-cpu times.

-## Visualizing Diff Between Two Flamegraphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flamegraphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+## Visualizing Diff Between Two Flame graphs
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.

diff --git a/examples/language-sdk-instrumentation/java/rideshare/README.md b/examples/language-sdk-instrumentation/java/rideshare/README.md
index f1c77892af..eb1d5a9d43 100644
--- a/examples/language-sdk-instrumentation/java/rideshare/README.md
+++ b/examples/language-sdk-instrumentation/java/rideshare/README.md
@@ -45,7 +45,7 @@ What this block does, is:
2. execute the code to find the nearest `vehicle`
3. Before the block ends it will (behind the scenes) remove the `LabelsSet("vehicle", vehicle)` from the application since that block is complete
-## Resulting flamegraph / performance results from the example
+## Resulting flame graph / performance results from the example
### Running the example
To run the example run the following commands:
```
@@ -59,7 +59,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `rideshare.java.push.app.itimer` from the dropdown, you should see a flamegraph that looks like this (below). After we give the flamegraph some time to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `searchRadius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `rideshare.java.push.app.itimer` from the dropdown, you should see a flame graph that looks like this (below). After we give the flame graph some time to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `searchRadius` parameters.
## Where's the performance bottleneck?

@@ -79,8 +79,8 @@ Knowing there is an issue with the `orderCar()` function we automatically select
We can also see that the `mutexLock()` function is consuming 76% of CPU resources during this time period.

-## Comparing Two Tag Sets with FlameQL
-Using Pyroscope's "comparison view" we can actually select two different sets of tags using Pyroscope's prometheus-inspired query language [FlameQL](https://pyroscope.io/docs/flameql/) to compare the resulting flamegraphs. The pink section on the left timeline contains all data where to region is **not equal to** eu-north
+## Comparing two tag sets with FlameQL
+Using Pyroscope's "comparison view" we can actually select two different sets of tags using Pyroscope's prometheus-inspired query language [FlameQL](https://pyroscope.io/docs/flameql/) to compare the resulting flame graphs. The pink section on the left timeline contains all data where to region is **not equal to** eu-north
```
REGION != "eu-north"
```
@@ -94,8 +94,8 @@ In the graph where `REGION = "eu-north"`, `checkDriverAvailability()` takes ~92%

-## Visualizing Diff Between Two Flamegraphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two tagsets/flamegraphs is better visualized via a diff flamegraph, where red represents cpu time added and green represents cpu time removed. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+## Visualizing diff between two flame graphs
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized via a diff flame graph, where red represents cpu time added and green represents cpu time removed. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.

diff --git a/examples/language-sdk-instrumentation/python/README.md b/examples/language-sdk-instrumentation/python/README.md
index 7d83e1381c..5660c4baae 100644
--- a/examples/language-sdk-instrumentation/python/README.md
+++ b/examples/language-sdk-instrumentation/python/README.md
@@ -50,7 +50,7 @@ What this block does, is:
2. execute the `find_nearest_vehicle()` function
3. Before the block ends it will (behind the scenes) remove the `{ "vehicle" => "car" }` from the application since that block is complete
-## Resulting flamegraph / performance results from the example
+## Resulting flame graph / performance results from the example
### Running the example
To run the example run the following commands:
```
@@ -64,7 +64,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flamegraph that looks like this (below). After we give 20-30 seconds for the flamegraph to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flame graph that looks like this (below). After we give 20-30 seconds for the flame graph to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
## Where's the performance bottleneck?
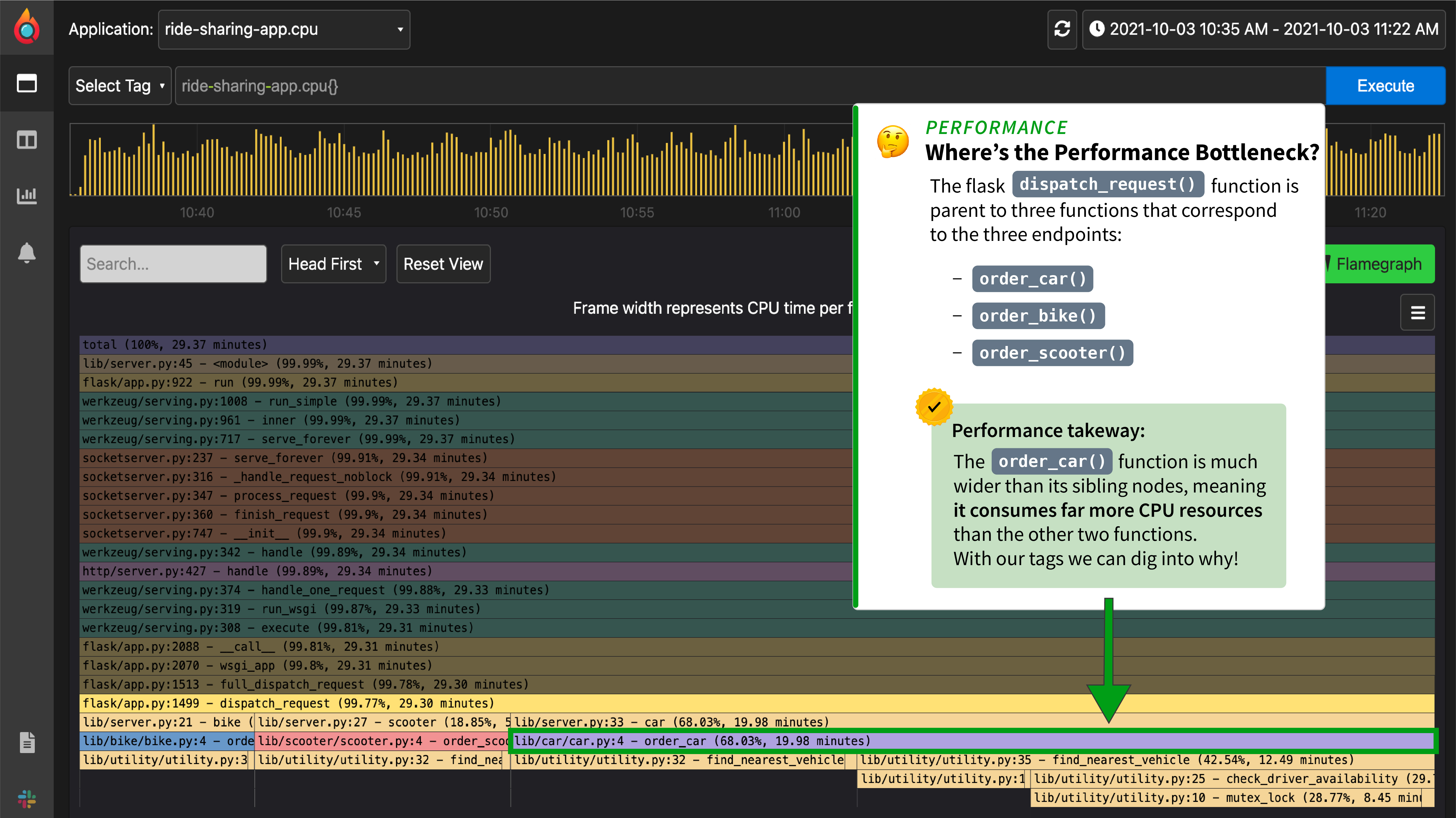
@@ -86,13 +86,13 @@ We can also see that the `mutex_lock()` function is consuming almost 70% of CPU
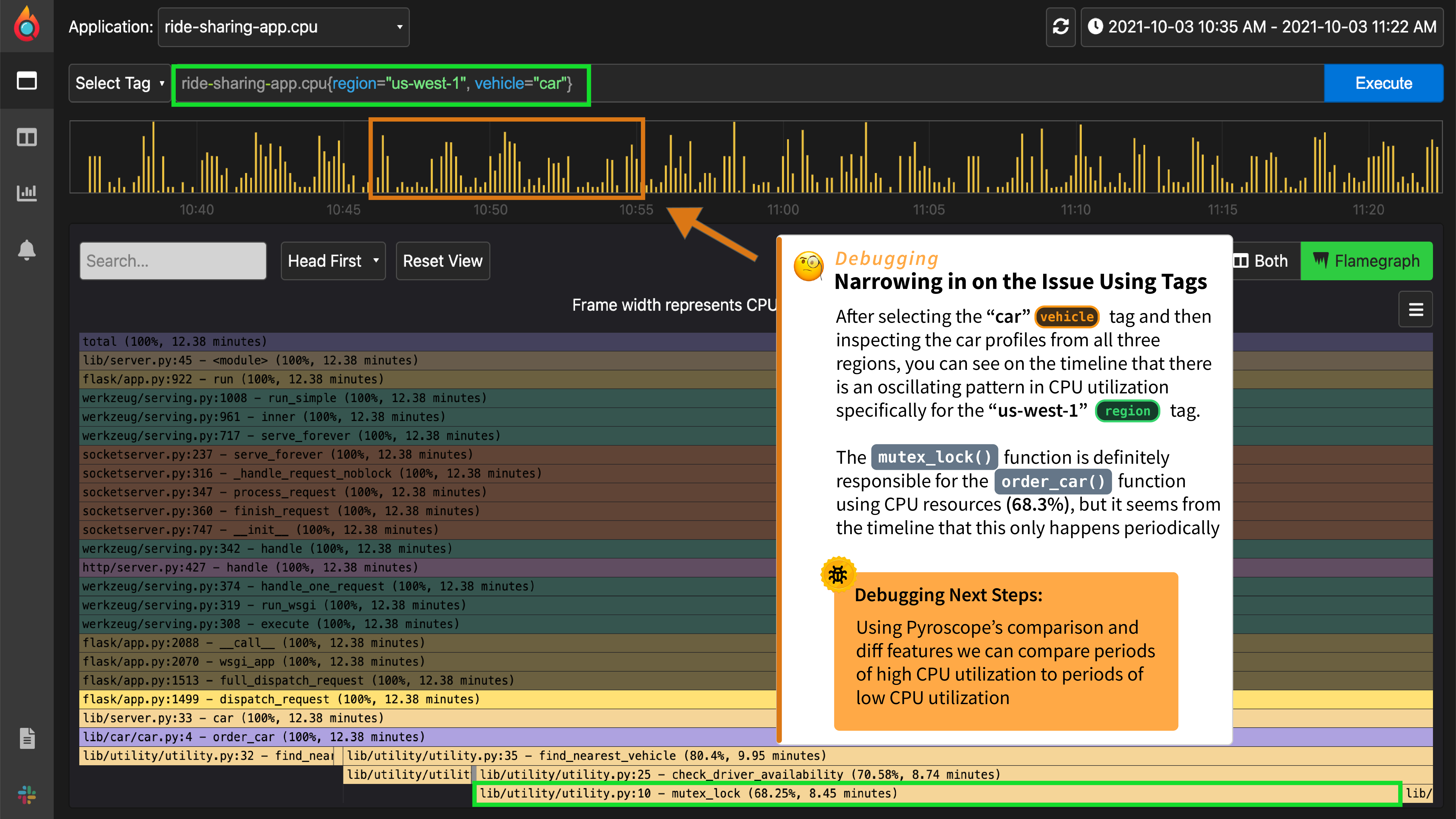
## Comparing two time periods
-Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flamegraphs. The pink section on the left timeline results in the left flamegraph, and the blue section on the right represents the right flamegraph.
+Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flame graphs. The pink section on the left timeline results in the left flame graph, and the blue section on the right represents the right flame graph.
When we select a period of low-cpu utilization and a period of high-cpu utilization we can see that there is clearly different behavior in the `mutex_lock()` function where it takes **51% of CPU** during low-cpu times and **78% of CPU** during high-cpu times.
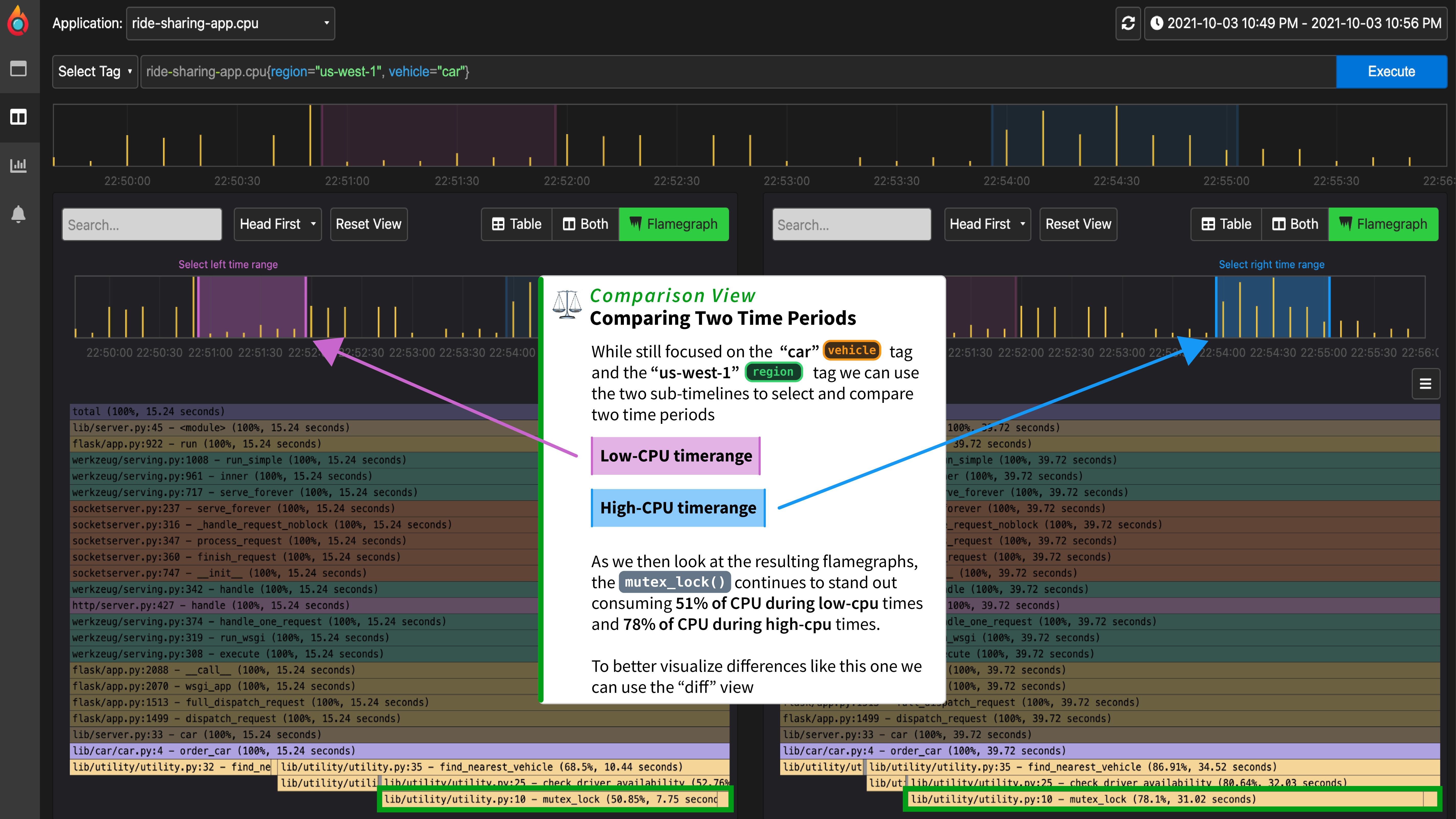
-## Visualizing Diff Between Two Flamegraphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flamegraphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+## Visualizing diff between two flame graphs
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.
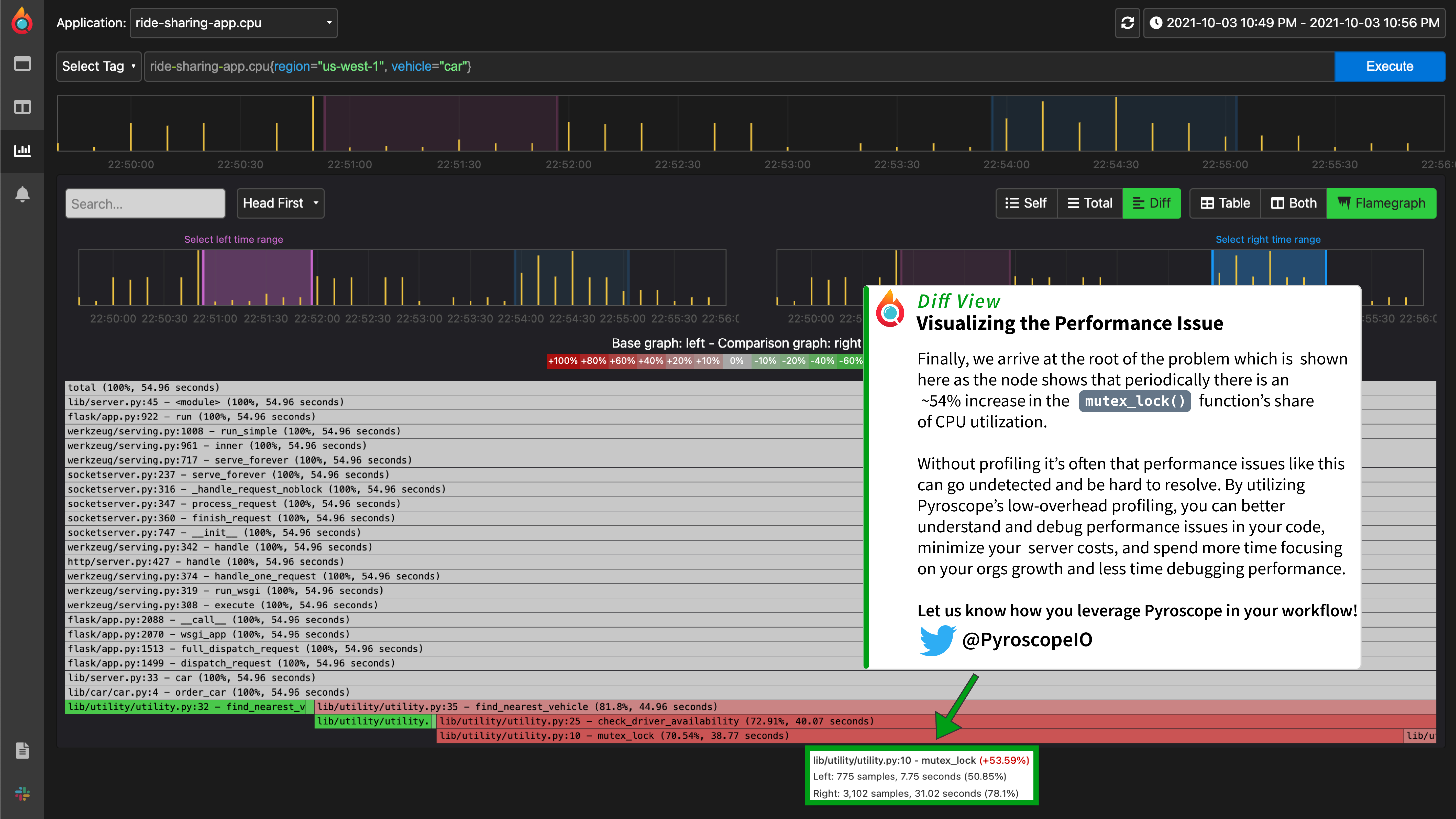
### More use cases
diff --git a/examples/language-sdk-instrumentation/python/rideshare/README.md b/examples/language-sdk-instrumentation/python/rideshare/README.md
index b77b7fa77d..33ced7ae94 100644
--- a/examples/language-sdk-instrumentation/python/rideshare/README.md
+++ b/examples/language-sdk-instrumentation/python/rideshare/README.md
@@ -62,7 +62,7 @@ What this block does, is:
2. execute the `find_nearest_vehicle()` function
3. Before the block ends it will (behind the scenes) remove the `{ "vehicle" => "car" }` from the application since that block is complete
-## Resulting flamegraph / performance results from the example
+## Resulting flame graph / performance results from the example
### Running the example
@@ -79,7 +79,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flamegraph that looks like this (below). After we give 20-30 seconds for the flamegraph to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flame graph that looks like this (below). After we give 20-30 seconds for the flame graph to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
## Where's the performance bottleneck?
@@ -94,23 +94,23 @@ The benefit of using Pyroscope, is that by tagging both `region` and `vehicle` a
- Something is wrong with the `/car` endpoint code where `car` vehicle tag is consuming **68% of CPU**
- Something is wrong with one of our regions where `eu-north` region tag is consuming **54% of CPU**
-From the flamegraph we can see that for the `eu-north` tag the biggest performance impact comes from the `find_nearest_vehicle()` function which consumes close to **68% of cpu**. To analyze this we can go directly to the comparison page using the comparison dropdown.
+From the flame graph we can see that for the `eu-north` tag the biggest performance impact comes from the `find_nearest_vehicle()` function which consumes close to **68% of cpu**. To analyze this we can go directly to the comparison page using the comparison dropdown.
## Comparing two time periods
-Using Pyroscope's "comparison view" we can actually select two different queries and compare the resulting flamegraphs:
-- Left flamegraph: `{ region != "eu-north", ... }`
-- Right flamegraph: `{ region = "eu-north", ... }`
+Using Pyroscope's "comparison view" we can actually select two different queries and compare the resulting flame graphs:
+- Left flame graph: `{ region != "eu-north", ... }`
+- Right flame graph: `{ region = "eu-north", ... }`
When we select a period of low-cpu utilization and a period of high-cpu utilization we can see that there is clearly different behavior in the `find_nearest_vehicle()` function where it takes:
-- Left flamegraph: **22% of CPU** when `{ region != "eu-north", ... }`
-- right flamgraph: **82% of CPU** when `{ region = "eu-north", ... }`
+- Left flame graph: **22% of CPU** when `{ region != "eu-north", ... }`
+- right flame graph: **82% of CPU** when `{ region = "eu-north", ... }`
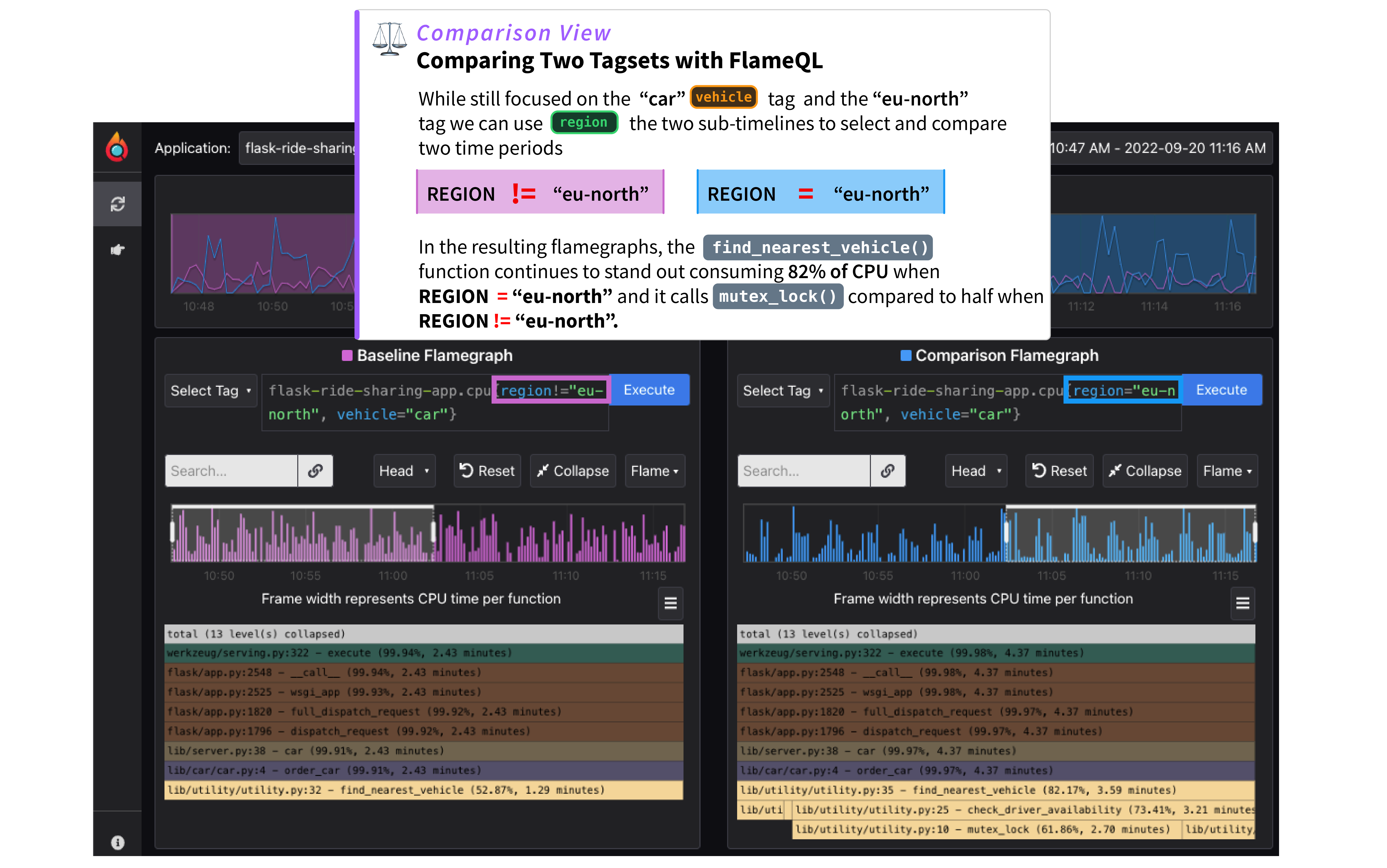
-## Visualizing Diff Between Two Flamegraphs
+## Visualizing diff between two flame graphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flamegraphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.
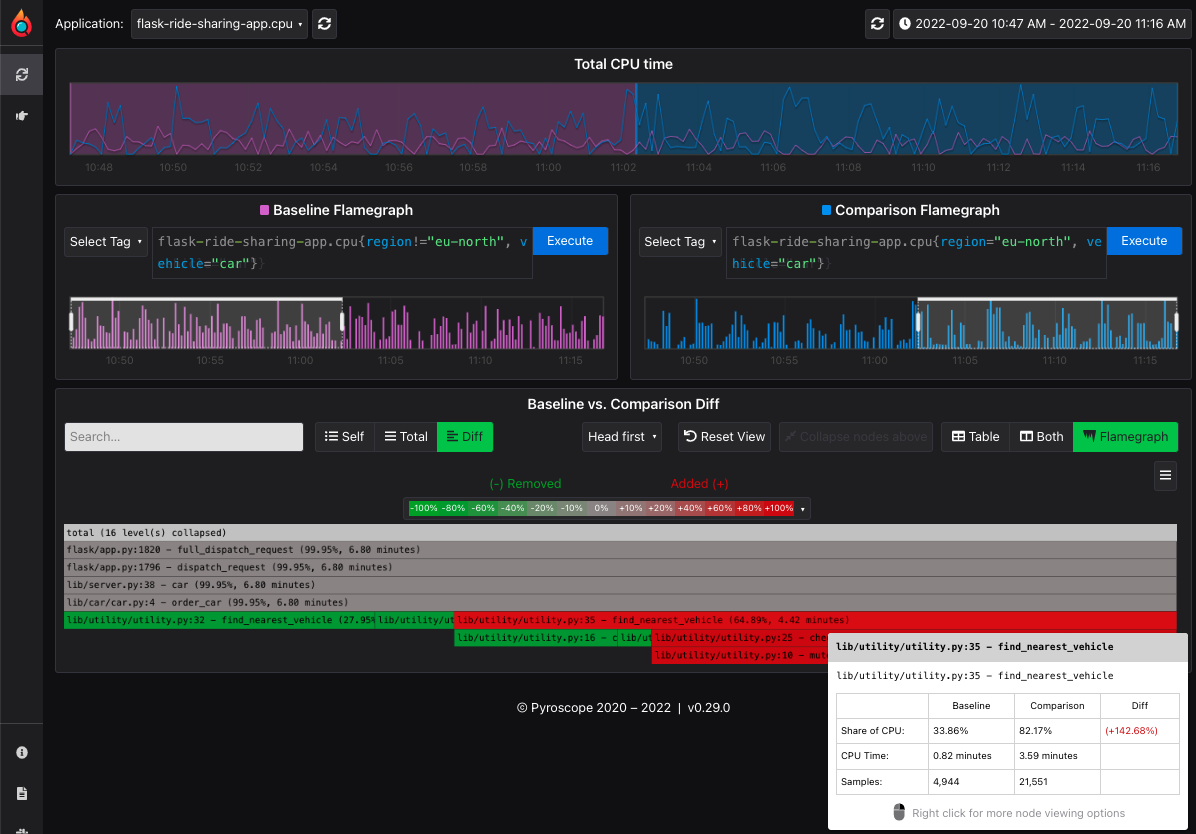
diff --git a/examples/language-sdk-instrumentation/ruby/README.md b/examples/language-sdk-instrumentation/ruby/README.md
index 5c30b1e6bb..968dfba2ee 100644
--- a/examples/language-sdk-instrumentation/ruby/README.md
+++ b/examples/language-sdk-instrumentation/ruby/README.md
@@ -60,7 +60,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flamegraph that looks like this. After we give 20-30 seconds for the flamegraph to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flame graph that looks like this. After we give 20-30 seconds for the flame graph to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
## Where's the performance bottleneck?

@@ -84,14 +84,14 @@ We can also see that the `mutex_lock()` function is consuming almost 70% of CPU

## Comparing two time periods
-Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flamegraphs. The pink section on the left timeline results in the left flamegraph and the blue section on the right represents the right flamegraph.
+Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flame graphs. The pink section on the left timeline results in the left flame graph and the blue section on the right represents the right flame graph.
When we select a period of low-cpu utilization, and a period of high-cpu utilization we can see that there is clearly different behavior in the `mutex_lock()` function where it takes **23% of CPU** during low-cpu times and **70% of CPU** during high-cpu times.

-## Visualizing Diff Between Two Flamegraphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flamegraphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+## Visualizing diff between two flame graphs
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.

diff --git a/examples/language-sdk-instrumentation/ruby/rideshare/README.md b/examples/language-sdk-instrumentation/ruby/rideshare/README.md
index 93b2fc89ac..cfb080a751 100644
--- a/examples/language-sdk-instrumentation/ruby/rideshare/README.md
+++ b/examples/language-sdk-instrumentation/ruby/rideshare/README.md
@@ -60,7 +60,7 @@ docker-compose up --build
# docker-compose down
```
-What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flamegraph that looks like this. After we give 20-30 seconds for the flamegraph to update and then click the refresh button we see our 3 functions at the bottom of the flamegraph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
+What this example will do is run all the code mentioned above and also send some mock-load to the 3 servers as well as their respective 3 endpoints. If you select our application: `ride-sharing-app.cpu` from the dropdown, you should see a flame graph that looks like this. After we give 20-30 seconds for the flame graph to update and then click the refresh button we see our 3 functions at the bottom of the flame graph taking CPU resources _proportional to the size_ of their respective `search_radius` parameters.
## Where's the performance bottleneck?

@@ -84,14 +84,14 @@ We can also see that the `mutex_lock()` function is consuming almost 70% of CPU

## Comparing two time periods
-Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flamegraphs. The pink section on the left timeline results in the left flamegraph and the blue section on the right represents the right flamegraph.
+Using Pyroscope's "comparison view" we can actually select two different time ranges from the timeline to compare the resulting flame graphs. The pink section on the left timeline results in the left flame graph and the blue section on the right represents the right flame graph.
When we select a period of low-cpu utilization, and a period of high-cpu utilization we can see that there is clearly different behavior in the `mutex_lock()` function where it takes **23% of CPU** during low-cpu times and **70% of CPU** during high-cpu times.

-## Visualizing Diff Between Two Flamegraphs
-While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flamegraphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flamegraph.
+## Visualizing diff between two flame graphs
+While the difference _in this case_ is stark enough to see in the comparison view, sometimes the diff between the two flame graphs is better visualized with them overlayed over each other. Without changing any parameters, we can simply select the diff view tab and see the difference represented in a color-coded diff flame graph.

diff --git a/pkg/querier/vcs/github.md b/pkg/querier/vcs/github.md
index 217e625bb4..6361da61ab 100644
--- a/pkg/querier/vcs/github.md
+++ b/pkg/querier/vcs/github.md
@@ -9,9 +9,9 @@ sequenceDiagram
participant Client
participant Pyroscope
participant GitHub
- User->>Client: Select a Flamegraph Node
- Client->>Pyroscope: Request Flamegraph Data For Node
- Pyroscope-->>Client: Flamegraph Data
+ User->>Client: Select a Flame graph Node
+ Client->>Pyroscope: Request Flame graph Data For Node
+ Pyroscope-->>Client: Flame graph Data
Client-->Client: if the data has source code information
Client->>Pyroscope: Request Github App client ID
Pyroscope-->>Client: Github App client ID
diff --git a/pkg/validation/limits.go b/pkg/validation/limits.go
index 7e4d031298..1b269963b4 100644
--- a/pkg/validation/limits.go
+++ b/pkg/validation/limits.go
@@ -59,7 +59,7 @@ type Limits struct {
MaxQueryLength model.Duration `yaml:"max_query_length" json:"max_query_length"`
MaxQueryParallelism int `yaml:"max_query_parallelism" json:"max_query_parallelism"`
- // FlameGraph enforced limits.
+ // Flame graph enforced limits.
MaxFlameGraphNodesDefault int `yaml:"max_flamegraph_nodes_default" json:"max_flamegraph_nodes_default"`
MaxFlameGraphNodesMax int `yaml:"max_flamegraph_nodes_max" json:"max_flamegraph_nodes_max"`
@@ -130,8 +130,8 @@ func (l *Limits) RegisterFlags(f *flag.FlagSet) {
f.IntVar(&l.MaxProfileStacktraceDepth, "validation.max-profile-stacktrace-depth", 1000, "Maximum depth of a profile stacktrace. Profiles are not rejected instead stacktraces are truncated. 0 to disable.")
f.IntVar(&l.MaxProfileSymbolValueLength, "validation.max-profile-symbol-value-length", 65535, "Maximum length of a profile symbol value (labels, function names and filenames, etc...). Profiles are not rejected instead symbol values are truncated. 0 to disable.")
- f.IntVar(&l.MaxFlameGraphNodesDefault, "querier.max-flamegraph-nodes-default", 8<<10, "Maximum number of flamegraph nodes by default. 0 to disable.")
- f.IntVar(&l.MaxFlameGraphNodesMax, "querier.max-flamegraph-nodes-max", 0, "Maximum number of flamegraph nodes allowed. 0 to disable.")
+ f.IntVar(&l.MaxFlameGraphNodesDefault, "querier.max-flamegraph-nodes-default", 8<<10, "Maximum number of flame graph nodes by default. 0 to disable.")
+ f.IntVar(&l.MaxFlameGraphNodesMax, "querier.max-flamegraph-nodes-max", 0, "Maximum number of flame graph nodes allowed. 0 to disable.")
f.Var(&l.DistributorAggregationWindow, "distributor.aggregation-window", "Duration of the distributor aggregation window. Requires aggregation period to be specified. 0 to disable.")
f.Var(&l.DistributorAggregationPeriod, "distributor.aggregation-period", "Duration of the distributor aggregation period. Requires aggregation window to be specified. 0 to disable.")
@@ -317,12 +317,12 @@ func (o *Overrides) MaxQueryLookback(tenantID string) time.Duration {
return time.Duration(o.getOverridesForTenant(tenantID).MaxQueryLookback)
}
-// MaxFlameGraphNodesDefault returns the max flamegraph nodes used by default.
+// MaxFlameGraphNodesDefault returns the max flame graph nodes used by default.
func (o *Overrides) MaxFlameGraphNodesDefault(tenantID string) int {
return o.getOverridesForTenant(tenantID).MaxFlameGraphNodesDefault
}
-// MaxFlameGraphNodesMax returns the max flamegraph nodes allowed.
+// MaxFlameGraphNodesMax returns the max flame graph nodes allowed.
func (o *Overrides) MaxFlameGraphNodesMax(tenantID string) int {
return o.getOverridesForTenant(tenantID).MaxFlameGraphNodesMax
}