+
همان طور که در [فصل اول](/course/chapter1) دیدید، مدلهای ترنسفورمر معمولا بسیار بزرگ هستند. با داشتن میلیونها یا حتی دهها میلیارد پارامتر، تعلیم و بکارگیری این مدلها کار بسیار پیچیدهای است. علاوه بر این، تقریبا هر روز مدلهای جدیدی عرضه میشوند که هرکدام شیوه پیادهسازی خود را دارند و امتحان کردن تمام آنها کار آسانی نیست.
کتابخانه ترنسفومرهای هاگینگفِیس برای حل این مشکل تولید شده است. هدف آن، ارائه یک API واحد برای بارگذاری، تعلیم و ذخیرهسازی مدلهای ترنسفورمر است. ویژگی های اصلی این کتابخانه از این قرار است:
diff --git a/chapters/fa/chapter2/2.mdx b/chapters/fa/chapter2/2.mdx
index 71abc5e16..9ae1d64e2 100644
--- a/chapters/fa/chapter2/2.mdx
+++ b/chapters/fa/chapter2/2.mdx
@@ -5,18 +5,18 @@
{#if fw === 'pt'}
-
diff --git a/chapters/fa/chapter2/3.mdx b/chapters/fa/chapter2/3.mdx
index 0155c5634..eace2dc12 100644
--- a/chapters/fa/chapter2/3.mdx
+++ b/chapters/fa/chapter2/3.mdx
@@ -5,18 +5,18 @@
{#if fw === 'pt'}
-
diff --git a/chapters/fa/chapter3/1.mdx b/chapters/fa/chapter3/1.mdx
index b3f520423..cf96cdbf8 100644
--- a/chapters/fa/chapter3/1.mdx
+++ b/chapters/fa/chapter3/1.mdx
@@ -4,6 +4,11 @@
# مقدمه
+
+
در [فصل ۲](/course/chapter2) نحوه استفاده از توکِنایزرها و مدلهای از پیش تعلیم دیده را جهت انجام پیشبینیهای جدید بررسی کردیم. اما چگونه میتوانید یک مدل از پیش تعلیم دیده را خودتان کوک کنید؟
{#if fw === 'pt'}
diff --git a/chapters/fa/chapter3/2.mdx b/chapters/fa/chapter3/2.mdx
index 092a92b30..deabbc5f0 100644
--- a/chapters/fa/chapter3/2.mdx
+++ b/chapters/fa/chapter3/2.mdx
@@ -6,18 +6,18 @@
{#if fw === 'pt'}
-
diff --git a/chapters/fa/chapter4/1.mdx b/chapters/fa/chapter4/1.mdx
index b071b63df..7f6995ac0 100644
--- a/chapters/fa/chapter4/1.mdx
+++ b/chapters/fa/chapter4/1.mdx
@@ -1,6 +1,11 @@
# هاب هاگینگفِیس
+
+
[هاب هاگینگفِیس](https://huggingface.co/) –- وبسایت اصلی ما –- پلتفرمی مرکزی است که به همه امکان مشارکت، کشف و استفاده از جدیدترین و بهترین مدلها و دیتاسِتها را میدهد. این هاب طیف گستردهای از مدلها را در خود جای داده، که بالغ بر ۱۰ هزار مورد از آنها در دسترس عموم قرار دارد. در این فصل بر روی مدلها متمرکز شده و در فصل ۵ نیز نگاهی به دیتاسِتها خواهیم داشت.
مدلهای موجود در هاب، محدود به ترنسفورمرهای هاگینگفِیس یا حتی NLP نیستند. از جمله آنها میتوان مدلهایی از قبیل [Flair](https://github.com/flairNLP/flair) و [AllenNLP](https://github.com/allenai/allennlp) برای پردازش زبان طبیعی، [Asteroid](https://github.com/asteroid-team/asteroid) و [pyannote](https://github.com/pyannote/pyannote-audio) برای پردازش گفتار، و [timm](https://github.com/rwightman/pytorch-image-models) را برای پردازش تصویر برشمرد.
diff --git a/chapters/fa/chapter4/2.mdx b/chapters/fa/chapter4/2.mdx
index 01960357d..2514c1849 100644
--- a/chapters/fa/chapter4/2.mdx
+++ b/chapters/fa/chapter4/2.mdx
@@ -5,18 +5,18 @@
{#if fw === 'pt'}
-
{:else}
-
diff --git a/chapters/fr/chapter1/1.mdx b/chapters/fr/chapter1/1.mdx
index a0ff68898..6dd1423c5 100644
--- a/chapters/fr/chapter1/1.mdx
+++ b/chapters/fr/chapter1/1.mdx
@@ -1,55 +1,60 @@
-# Introduction
-
-## Bienvenue au cours 🤗 !
-
-
-
-Ce cours vous apprendra à utiliser les bibliothèques de NLP de l'écosystème [Hugging Face](https://huggingface.co/) : [🤗 *Transformers*](https://github.com/huggingface/transformers), [🤗 *Datasets*](https://github.com/huggingface/datasets), [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers) et [🤗 *Accelerate*](https://github.com/huggingface/accelerate), ainsi que le [*Hub*](https://huggingface.co/models). C'est totalement gratuit et sans publicité.
-
-## À quoi s'attendre ?
-
-Voici un bref aperçu du cours :
-
-
-

-

-
-
-- Les chapitres 1 à 4 présentent les principaux concepts de la bibliothèque 🤗 *Transformers*. À la fin de ce chapitre, vous serez familier avec le fonctionnement des *transformers* et vous saurez comment utiliser un modèle présent sur le [*Hub*](https://huggingface.co/models), le *finetuner* sur un jeu de données, et partager vos résultats sur le *Hub* !
-- Les chapitres 5 à 8 présentent les bases des librairies 🤗 *Datasets* et 🤗 *Tokenizers* ainsi qu'une découverte des problèmes classiques de NLP. À la fin de ce chapitre, vous serez capable de résoudre les problèmes de NLP les plus communs par vous-même.
-- Les chapitres 9 à 12 proposent d'aller plus loin et d'explorer comment les *transformers* peuvent être utilisés pour résoudre des problèmes de traitement de la parole et de vision par ordinateur. En suivant ces chapitres, vous apprendrez à construire et à partager vos modèles via des démonstrateurs, et vous serez capable d'optimiser ces modèles pour des environnements de production. Enfin, vous serez prêt à appliquer 🤗 *Transformers* à (presque) n'importe quel problème d'apprentissage automatique !
-
-Ce cours :
-
-* requiert un bon niveau en Python,
-* se comprend mieux si vous avez déjà suivi un cours d'introduction à l'apprentissage profond comme [fast.ai's](https://www.fast.ai/), [*Practical Deep Learning for Coders*](https://course.fast.ai/) ou un des cours développés par [*DeepLearning.AI*](https://www.deeplearning.ai/),
-* n'attend pas une connaissance appronfondie de [PyTorch](https://pytorch.org/) ou de [TensorFlow](https://www.tensorflow.org/), bien qu'être familiarisé avec l'un d'entre eux peut aider.
-
-Après avoir terminé ce cours, nous vous recommandons de suivre la [Spécialisation en NLP](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh) dispensée par DeepLearning.AI, qui couvre une grande partie des modèles traditionnels de NLP comme le Bayésien naïf et les LSTMs qui sont importants à connaître!
-
-## Qui sommes-nous ?
-
-À propos des auteurs de ce cours :
-
-*Abubakar Abid** a obtenu son doctorat à Stanford en apprentissage automatique appliqué. Pendant son doctorat, il a fondé [Gradio](https://github.com/gradio-app/gradio), une bibliothèque Python open-source qui a été utilisée pour construire plus de 600 000 démos d'apprentissage automatique. Gradio a été rachetée par Hugging Face, où Abubakar occupe désormais le poste de responsable de l'équipe d'apprentissage automatique.
-
-**Matthew Carrigan** est ingénieur en apprentissage machine chez Hugging Face. Il vit à Dublin en Irlande. Il a travaillé auparavant comme ingénieur en apprentissage machine chez Parse.ly et avant cela comme chercheur postdoctoral au Trinity College Dublin. Il ne croit pas que nous arrivions à l'*AGI* en mettant à l'échelle les architectures existantes mais a tout de même beaucoup d'espoir dans l'immortalité des robots.
-
-**Lysandre Debut** est ingénieur en apprentissage machine chez Hugging Face et a travaillé sur la bibliothèque 🤗 *Transformers* depuis les premières phases de développement. Son but est de rendre le NLP accessible à tous en développant des outils disposant d'une API très simple.
-
-**Sylvain Gugger** est ingénieur recherche chez Hugging Face et un des principaux responsables de la bibliothèque 🤗 *Transformers*. Avant cela, il était chercheur en en apprentissage machine chez fast.ai et a écrit le livre [*Deep Learning for Coders with fastai and PyTorch*](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/) avec Jeremy Howard. Son but est de rendre l'apprentissage profond plus accessible, en développant et en améliorant des techniques permettant aux modèles d'apprendre rapidement sur des ressources limitées.
-
-**Dawood Khan** est un ingénieur en apprentissage automatique chez Hugging Face. Il vient de New York et est diplômé de l'Université de New York en informatique. Après avoir travaillé comme ingénieur iOS pendant quelques années, Dawood a quitté son poste pour créer Gradio avec ses cofondateurs. Gradio a finalement été acquis par Hugging Face.
-
-**Merve Noyan** est développeuse *advocate* chez Hugging Face et travaille à la création d'outils et de contenus visant à démocratiser l'apprentissage machine pour tous.
-
-**Lucile Saulnier** est ingénieure en apprentissage machine chez Hugging Face et travaille au développement et à l'implémentation de nombreux outils *open source*. Elle est également activement impliquée dans de nombreux projets de recherche dans le domaine du NLP comme l'entraînement collaboratif de modèles et le projet BigScience.
-
-**Lewis Tunstall** est ingénieur en apprentissage machine chez Hugging Face et dévoué au développement d'outils open source avec la volonté de les rendre accessibles à une communauté plus large. Il est également co-auteur du livre [*Natural Language Processing with Transformers*](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/).
-
-**Leandro von Werra** est ingénieur en apprentissage machine dans l'équipe *open source* d'Hugging Face et également co-auteur du livre [*Natural Language Processing with Transformers*](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/). Il a plusieurs années d'expérience dans l'industrie où il a pu déployer des projets de NLP en production et travailler sur toutes les étapes clefs du déploiement.
-
-Êtes-vous prêt à commencer ? Dans ce chapitre, vous apprendrez :
-* à utiliser la fonction `pipeline()` pour résoudre des problèmes de NLP comme la génération de texte et la classification,
-* l'architecture d'un *transformer*,
-* comment faire la distinction entre les différentes architectures d'encodeur, de décodeur et d'encodeur-décodeur ainsi que leurs différents cas d'usage.
+# Introduction
+
+
+
+## Bienvenue au cours 🤗 !
+
+
+
+Ce cours vous apprendra à utiliser les bibliothèques de NLP de l'écosystème [Hugging Face](https://huggingface.co/) : [🤗 *Transformers*](https://github.com/huggingface/transformers), [🤗 *Datasets*](https://github.com/huggingface/datasets), [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers) et [🤗 *Accelerate*](https://github.com/huggingface/accelerate), ainsi que le [*Hub*](https://huggingface.co/models). C'est totalement gratuit et sans publicité.
+
+## À quoi s'attendre ?
+
+Voici un bref aperçu du cours :
+
+
+
+
+
+
+- Les chapitres 1 à 4 présentent les principaux concepts de la bibliothèque 🤗 *Transformers*. À la fin de ce chapitre, vous serez familier avec le fonctionnement des *transformers* et vous saurez comment utiliser un modèle présent sur le [*Hub*](https://huggingface.co/models), le *finetuner* sur un jeu de données, et partager vos résultats sur le *Hub* !
+- Les chapitres 5 à 8 présentent les bases des librairies 🤗 *Datasets* et 🤗 *Tokenizers* ainsi qu'une découverte des problèmes classiques de NLP. À la fin de ce chapitre, vous serez capable de résoudre les problèmes de NLP les plus communs par vous-même.
+- Les chapitres 9 à 12 proposent d'aller plus loin et d'explorer comment les *transformers* peuvent être utilisés pour résoudre des problèmes de traitement de la parole et de vision par ordinateur. En suivant ces chapitres, vous apprendrez à construire et à partager vos modèles via des démonstrateurs, et vous serez capable d'optimiser ces modèles pour des environnements de production. Enfin, vous serez prêt à appliquer 🤗 *Transformers* à (presque) n'importe quel problème d'apprentissage automatique !
+
+Ce cours :
+
+* requiert un bon niveau en Python,
+* se comprend mieux si vous avez déjà suivi un cours d'introduction à l'apprentissage profond comme [fast.ai's](https://www.fast.ai/), [*Practical Deep Learning for Coders*](https://course.fast.ai/) ou un des cours développés par [*DeepLearning.AI*](https://www.deeplearning.ai/),
+* n'attend pas une connaissance appronfondie de [PyTorch](https://pytorch.org/) ou de [TensorFlow](https://www.tensorflow.org/), bien qu'être familiarisé avec l'un d'entre eux peut aider.
+
+Après avoir terminé ce cours, nous vous recommandons de suivre la [Spécialisation en NLP](https://www.coursera.org/specializations/natural-language-processing?utm_source=deeplearning-ai&utm_medium=institutions&utm_campaign=20211011-nlp-2-hugging_face-page-nlp-refresh) dispensée par DeepLearning.AI, qui couvre une grande partie des modèles traditionnels de NLP comme le Bayésien naïf et les LSTMs qui sont importants à connaître!
+
+## Qui sommes-nous ?
+
+À propos des auteurs de ce cours :
+
+*Abubakar Abid** a obtenu son doctorat à Stanford en apprentissage automatique appliqué. Pendant son doctorat, il a fondé [Gradio](https://github.com/gradio-app/gradio), une bibliothèque Python open-source qui a été utilisée pour construire plus de 600 000 démos d'apprentissage automatique. Gradio a été rachetée par Hugging Face, où Abubakar occupe désormais le poste de responsable de l'équipe d'apprentissage automatique.
+
+**Matthew Carrigan** est ingénieur en apprentissage machine chez Hugging Face. Il vit à Dublin en Irlande. Il a travaillé auparavant comme ingénieur en apprentissage machine chez Parse.ly et avant cela comme chercheur postdoctoral au Trinity College Dublin. Il ne croit pas que nous arrivions à l'*AGI* en mettant à l'échelle les architectures existantes mais a tout de même beaucoup d'espoir dans l'immortalité des robots.
+
+**Lysandre Debut** est ingénieur en apprentissage machine chez Hugging Face et a travaillé sur la bibliothèque 🤗 *Transformers* depuis les premières phases de développement. Son but est de rendre le NLP accessible à tous en développant des outils disposant d'une API très simple.
+
+**Sylvain Gugger** est ingénieur recherche chez Hugging Face et un des principaux responsables de la bibliothèque 🤗 *Transformers*. Avant cela, il était chercheur en en apprentissage machine chez fast.ai et a écrit le livre [*Deep Learning for Coders with fastai and PyTorch*](https://learning.oreilly.com/library/view/deep-learning-for/9781492045519/) avec Jeremy Howard. Son but est de rendre l'apprentissage profond plus accessible, en développant et en améliorant des techniques permettant aux modèles d'apprendre rapidement sur des ressources limitées.
+
+**Dawood Khan** est un ingénieur en apprentissage automatique chez Hugging Face. Il vient de New York et est diplômé de l'Université de New York en informatique. Après avoir travaillé comme ingénieur iOS pendant quelques années, Dawood a quitté son poste pour créer Gradio avec ses cofondateurs. Gradio a finalement été acquis par Hugging Face.
+
+**Merve Noyan** est développeuse *advocate* chez Hugging Face et travaille à la création d'outils et de contenus visant à démocratiser l'apprentissage machine pour tous.
+
+**Lucile Saulnier** est ingénieure en apprentissage machine chez Hugging Face et travaille au développement et à l'implémentation de nombreux outils *open source*. Elle est également activement impliquée dans de nombreux projets de recherche dans le domaine du NLP comme l'entraînement collaboratif de modèles et le projet BigScience.
+
+**Lewis Tunstall** est ingénieur en apprentissage machine chez Hugging Face et dévoué au développement d'outils open source avec la volonté de les rendre accessibles à une communauté plus large. Il est également co-auteur du livre [*Natural Language Processing with Transformers*](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/).
+
+**Leandro von Werra** est ingénieur en apprentissage machine dans l'équipe *open source* d'Hugging Face et également co-auteur du livre [*Natural Language Processing with Transformers*](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/). Il a plusieurs années d'expérience dans l'industrie où il a pu déployer des projets de NLP en production et travailler sur toutes les étapes clefs du déploiement.
+
+Êtes-vous prêt à commencer ? Dans ce chapitre, vous apprendrez :
+* à utiliser la fonction `pipeline()` pour résoudre des problèmes de NLP comme la génération de texte et la classification,
+* l'architecture d'un *transformer*,
+* comment faire la distinction entre les différentes architectures d'encodeur, de décodeur et d'encodeur-décodeur ainsi que leurs différents cas d'usage.
diff --git a/chapters/fr/chapter1/10.mdx b/chapters/fr/chapter1/10.mdx
index d48d06003..889612715 100644
--- a/chapters/fr/chapter1/10.mdx
+++ b/chapters/fr/chapter1/10.mdx
@@ -1,258 +1,263 @@
-
-
-# Quiz de fin de chapitre
-
-Ce chapitre a couvert un grand nombre de notions ! Ne vous inquiétez pas si vous n'avez pas compris tous les détails, les chapitres suivants vous aideront à comprendre comment les choses fonctionnent concrètement.
-
-Mais avant d'aller plus loin, prenons un instant pour voir ce que vous avez appris dans ce chapitre !
-
-
-### 1. Explorez le *Hub* et cherchez le modèle `roberta-large-mnli`. Quelle tâche accomplit-il ?
-
-
-
page roberta-large-mnli."
- },
- {
- text: "Classification de texte",
- explain: "Pour être plus précis, il classifie si deux phrases sont logiquement liées entre elles parmis trois possibilités (contradiction, neutre, lien). Il s'agit d'une tâche aussi appelée inference de langage naturel.",
- correct: true
- },
- {
- text: "Génération de texte",
- explain: "Regardez à nouveau sur la page roberta-large-mnli."
- }
- ]}
-/>
-
-### 2. Que renvoie le code suivant ?
-
-```py
-from transformers import pipeline
-
-ner = pipeline("ner", grouped_entities=True)
-ner(
- "My name is Sylvain and I work at Hugging Face in Brooklyn."
-) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
-```
-
-d'analyse de sentiment (sentiment-analysis dans la documentation d'Hugging-Face)."
- },
- {
- text: "Il renvoie un texte généré qui complète cette phrase.",
- explain: "Cela correspondrait au pipeline de génération de texte (text-generation dans la documentation d'Hugging-Face)."
- },
- {
- text: "Il renvoie les entités nommées dans cette phrase, telles que les personnes, les organisations ou lieux.",
- explain: "De plus, avec grouped_entities=True, cela regroupe les mots appartenant à la même entité, comme par exemple \"Hugging Face\".",
- correct: true
- }
- ]}
-/>
-
-### 3. Que remplace « ... » dans ce code ?
-
-```py
-from transformers import pipeline
-
-filler = pipeline("fill-mask", model="bert-base-cased")
-result = filler("...")
-```
-
- has been waiting for you. # Ce <mask> vous attend.",
- explain: "Regardez la description du modèle bert-base-cased et essayez de trouver votre erreur."
- },
- {
- text: "This [MASK] has been waiting for you. # Ce [MASK] vous attend.",
- explain: "Le modèle utilise [MASK] comme mot-masque.",
- correct: true
- },
- {
- text: "This man has been waiting for you. # Cet homme vous attend.",
- explain: "Ce pipeline permet de remplacer les mot manquants donc il a besoin d'un mot-masque."
- }
- ]}
-/>
-
-### 4. Pourquoi ce code ne fonctionne-t-il pas ?
-
-```py
-from transformers import pipeline
-
-classifier = pipeline("zero-shot-classification")
-result = classifier(
- "This is a course about the Transformers library"
-) # C'est un cours sur la bibliothèque Transformers
-```
-
-candidate_labels=[...].",
- correct: true
- },
- {
- text: "Ce pipeline nécessite que des phrases soient données, pas juste une phrase.",
- explain: "Bien que ce pipeline puisse prendre une liste de phrases à traiter (comme tous les autres pipelines)."
- },
- {
- text: "La bibliothèque 🤗 Transformers est cassée, comme d'habitude.",
- explain: "Nous n'avons aucun commentaire pour cette réponse !",
- },
- {
- text: "Ce pipeline nécessite des phrases plus longues, celle-ci est trop courte.",
- explain: "Notez que si un texte est très long, il est tronqué par le pipeline."
- }
- ]}
-/>
-
-### 5. Que signifie « apprentissage par transfert » ?
-
-
-
-### 6. Vrai ou faux ? Un modèle de langage n'a généralement pas besoin d'étiquettes pour son pré-entraînement.
-
-
-autosupervisé, ce qui signifie que les étiquettes sont créées automatiquement à partir des données d'entrée (comme prédire le mot suivant ou remplacer des mots masqués).",
- correct: true
- },
- {
- text: "Faux",
- explain: "Ce n'est pas la bonne réponse."
- }
- ]}
-/>
-
-### 7. Sélectionnez la phrase qui décrit le mieux les termes « modèle », « architecture » et « poids ».
-
-
-
-
-### 8. Parmi ces types de modèles, quel est le plus approprié pour générer du texte à partir d'une instruction (*prompt*) ?
-
-
-
-### 9. Parmi ces types de modèles, quel est le plus approprié pour le résumé de texte ?
-
-
-
-### 10. Quel type de modèle utiliseriez-vous pour classifier des entrées de texte en fonction de certains labels ?
-
-
-
-### 11. De quelle source possible peut être le biais observé dans un modèle ?
-
-finetunée d'un modèle pré-entraîné et il a conservé ses biais.",
- explain: "Avec l'apprentissage par transfert, les biais du modèle pré-entraîné perdurent dans le modèle finetuné.",
- correct: true
- },
- {
- text: "Le modèle a été entraîné sur des données qui sont biaisées.",
- explain: "Ceci représente la source de biais la plus évidente mais n'est pas la seule possible.",
- correct: true
- },
- {
- text: "La métrique optimisée lors de l'entraînement du modèle est biaisée.",
- explain: "Une source moins évidente est la façon dont le modèle est entraîné. Votre modèle va de façon aveugle optimiser la métrique que vous avez sélectionnée, sans prendre aucun recul.",
- correct: true
- }
- ]}
-/>
+
+
+# Quiz de fin de chapitre
+
+
+
+Ce chapitre a couvert un grand nombre de notions ! Ne vous inquiétez pas si vous n'avez pas compris tous les détails, les chapitres suivants vous aideront à comprendre comment les choses fonctionnent concrètement.
+
+Mais avant d'aller plus loin, prenons un instant pour voir ce que vous avez appris dans ce chapitre !
+
+
+### 1. Explorez le *Hub* et cherchez le modèle `roberta-large-mnli`. Quelle tâche accomplit-il ?
+
+
+page roberta-large-mnli."
+ },
+ {
+ text: "Classification de texte",
+ explain: "Pour être plus précis, il classifie si deux phrases sont logiquement liées entre elles parmis trois possibilités (contradiction, neutre, lien). Il s'agit d'une tâche aussi appelée inference de langage naturel.",
+ correct: true
+ },
+ {
+ text: "Génération de texte",
+ explain: "Regardez à nouveau sur la page roberta-large-mnli."
+ }
+ ]}
+/>
+
+### 2. Que renvoie le code suivant ?
+
+```py
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner(
+ "My name is Sylvain and I work at Hugging Face in Brooklyn."
+) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
+```
+
+d'analyse de sentiment (sentiment-analysis dans la documentation d'Hugging-Face)."
+ },
+ {
+ text: "Il renvoie un texte généré qui complète cette phrase.",
+ explain: "Cela correspondrait au pipeline de génération de texte (text-generation dans la documentation d'Hugging-Face)."
+ },
+ {
+ text: "Il renvoie les entités nommées dans cette phrase, telles que les personnes, les organisations ou lieux.",
+ explain: "De plus, avec grouped_entities=True, cela regroupe les mots appartenant à la même entité, comme par exemple \"Hugging Face\".",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Que remplace « ... » dans ce code ?
+
+```py
+from transformers import pipeline
+
+filler = pipeline("fill-mask", model="bert-base-cased")
+result = filler("...")
+```
+
+ has been waiting for you. # Ce <mask> vous attend.",
+ explain: "Regardez la description du modèle bert-base-cased et essayez de trouver votre erreur."
+ },
+ {
+ text: "This [MASK] has been waiting for you. # Ce [MASK] vous attend.",
+ explain: "Le modèle utilise [MASK] comme mot-masque.",
+ correct: true
+ },
+ {
+ text: "This man has been waiting for you. # Cet homme vous attend.",
+ explain: "Ce pipeline permet de remplacer les mot manquants donc il a besoin d'un mot-masque."
+ }
+ ]}
+/>
+
+### 4. Pourquoi ce code ne fonctionne-t-il pas ?
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+result = classifier(
+ "This is a course about the Transformers library"
+) # C'est un cours sur la bibliothèque Transformers
+```
+
+candidate_labels=[...].",
+ correct: true
+ },
+ {
+ text: "Ce pipeline nécessite que des phrases soient données, pas juste une phrase.",
+ explain: "Bien que ce pipeline puisse prendre une liste de phrases à traiter (comme tous les autres pipelines)."
+ },
+ {
+ text: "La bibliothèque 🤗 Transformers est cassée, comme d'habitude.",
+ explain: "Nous n'avons aucun commentaire pour cette réponse !",
+ },
+ {
+ text: "Ce pipeline nécessite des phrases plus longues, celle-ci est trop courte.",
+ explain: "Notez que si un texte est très long, il est tronqué par le pipeline."
+ }
+ ]}
+/>
+
+### 5. Que signifie « apprentissage par transfert » ?
+
+
+
+### 6. Vrai ou faux ? Un modèle de langage n'a généralement pas besoin d'étiquettes pour son pré-entraînement.
+
+
+autosupervisé, ce qui signifie que les étiquettes sont créées automatiquement à partir des données d'entrée (comme prédire le mot suivant ou remplacer des mots masqués).",
+ correct: true
+ },
+ {
+ text: "Faux",
+ explain: "Ce n'est pas la bonne réponse."
+ }
+ ]}
+/>
+
+### 7. Sélectionnez la phrase qui décrit le mieux les termes « modèle », « architecture » et « poids ».
+
+
+
+
+### 8. Parmi ces types de modèles, quel est le plus approprié pour générer du texte à partir d'une instruction (*prompt*) ?
+
+
+
+### 9. Parmi ces types de modèles, quel est le plus approprié pour le résumé de texte ?
+
+
+
+### 10. Quel type de modèle utiliseriez-vous pour classifier des entrées de texte en fonction de certains labels ?
+
+
+
+### 11. De quelle source possible peut être le biais observé dans un modèle ?
+
+finetunée d'un modèle pré-entraîné et il a conservé ses biais.",
+ explain: "Avec l'apprentissage par transfert, les biais du modèle pré-entraîné perdurent dans le modèle finetuné.",
+ correct: true
+ },
+ {
+ text: "Le modèle a été entraîné sur des données qui sont biaisées.",
+ explain: "Ceci représente la source de biais la plus évidente mais n'est pas la seule possible.",
+ correct: true
+ },
+ {
+ text: "La métrique optimisée lors de l'entraînement du modèle est biaisée.",
+ explain: "Une source moins évidente est la façon dont le modèle est entraîné. Votre modèle va de façon aveugle optimiser la métrique que vous avez sélectionnée, sans prendre aucun recul.",
+ correct: true
+ }
+ ]}
+/>
diff --git a/chapters/fr/chapter1/2.mdx b/chapters/fr/chapter1/2.mdx
index ef5803d79..c3b8db6ac 100644
--- a/chapters/fr/chapter1/2.mdx
+++ b/chapters/fr/chapter1/2.mdx
@@ -1,21 +1,26 @@
-# Traitement du langage naturel (NLP pour Natural Language Processing)
-
-Avant de commencer avec les *transformers*, voyons succinctement ce qu'est le traitement du langage naturel et pourquoi il est important.
-
-## Le NLP, qu'est-ce que c'est ?
-
-Le traitement du langage naturel est un domaine de linguistique et d'apprentissage automatique se concentrant sur la compréhension de tout ce qui est lié à la langue humaine. L'objectif des tâches de NLP est non seulement de comprendre individuellement chaque mot, mais aussi de comprendre le contexte associé à l'utilisation de ces mots.
-
-La liste suivante regroupe les tâches de NLP les plus courantes, avec pour chacune quelques exemples :
-
-- **Classification de phrases entières** : analyser le sentiment d'un avis, détecter si un email est un spam, déterminer si une phrase est grammaticalement correcte, déterminer si deux phrases sont logiquement reliées ou non, etc.
-- **Classification de chaque mot d'une phrase** : identifier les composants grammaticaux d'une phrase (nom, verbe, adjectif), identifier les entités nommées (personne, lieu, organisation), etc.
-- **Génération de texte** : compléter le début d'un texte avec un texte généré automatiquement, remplacer les mots manquants ou masqués dans un texte, etc.
-- **Extraction d'une réponse à partir d'un texte** : étant donné une question et un contexte extraire la réponse à la question en fonction des informations fournies par le contexte, etc.
-- **Génération de nouvelles phrases à partir d'un texte** : traduire un texte dans une autre langue, faire le résumé d'un texte, etc.
-
-Le traitement du langage naturel ne se limite pas qu'à la compréhension du texte. Il s'intéresse aussi aux problèmes complexes de reconnaissance de la parole et de vision par ordinateur tels que la génération d'une transcription à partir d'un échantillon audio ou la description d'une image.
-
-## Pourquoi est-ce difficile ?
-
-Les ordinateurs ne traitent pas les informations de la même manière que les humains. Par exemple, lorsque nous lisons la phrase « j'ai faim », nous comprenons très facilement son sens. De même, lorsque nous lisons deux phrases telles que « j'ai faim » et « je suis triste », nous pouvons facilement déterminer s'il existe des similitudes entre elles. Pour les modèles d'apprentissage automatique, ces tâches sont plus difficiles. Le texte doit être traité de manière à permettre au modèle d'apprendre. Et parce que le langage est complexe, nous devons prendre soin de réfléchir à la meilleure façon de faire ce traitement. Il y a eu beaucoup de recherches sur la façon de représenter le texte et nous allons voir quelques-unes de ces méthodes dans le chapitre suivant.
+# Traitement du langage naturel (NLP pour Natural Language Processing)
+
+
+
+Avant de commencer avec les *transformers*, voyons succinctement ce qu'est le traitement du langage naturel et pourquoi il est important.
+
+## Le NLP, qu'est-ce que c'est ?
+
+Le traitement du langage naturel est un domaine de linguistique et d'apprentissage automatique se concentrant sur la compréhension de tout ce qui est lié à la langue humaine. L'objectif des tâches de NLP est non seulement de comprendre individuellement chaque mot, mais aussi de comprendre le contexte associé à l'utilisation de ces mots.
+
+La liste suivante regroupe les tâches de NLP les plus courantes, avec pour chacune quelques exemples :
+
+- **Classification de phrases entières** : analyser le sentiment d'un avis, détecter si un email est un spam, déterminer si une phrase est grammaticalement correcte, déterminer si deux phrases sont logiquement reliées ou non, etc.
+- **Classification de chaque mot d'une phrase** : identifier les composants grammaticaux d'une phrase (nom, verbe, adjectif), identifier les entités nommées (personne, lieu, organisation), etc.
+- **Génération de texte** : compléter le début d'un texte avec un texte généré automatiquement, remplacer les mots manquants ou masqués dans un texte, etc.
+- **Extraction d'une réponse à partir d'un texte** : étant donné une question et un contexte extraire la réponse à la question en fonction des informations fournies par le contexte, etc.
+- **Génération de nouvelles phrases à partir d'un texte** : traduire un texte dans une autre langue, faire le résumé d'un texte, etc.
+
+Le traitement du langage naturel ne se limite pas qu'à la compréhension du texte. Il s'intéresse aussi aux problèmes complexes de reconnaissance de la parole et de vision par ordinateur tels que la génération d'une transcription à partir d'un échantillon audio ou la description d'une image.
+
+## Pourquoi est-ce difficile ?
+
+Les ordinateurs ne traitent pas les informations de la même manière que les humains. Par exemple, lorsque nous lisons la phrase « j'ai faim », nous comprenons très facilement son sens. De même, lorsque nous lisons deux phrases telles que « j'ai faim » et « je suis triste », nous pouvons facilement déterminer s'il existe des similitudes entre elles. Pour les modèles d'apprentissage automatique, ces tâches sont plus difficiles. Le texte doit être traité de manière à permettre au modèle d'apprendre. Et parce que le langage est complexe, nous devons prendre soin de réfléchir à la meilleure façon de faire ce traitement. Il y a eu beaucoup de recherches sur la façon de représenter le texte et nous allons voir quelques-unes de ces méthodes dans le chapitre suivant.
diff --git a/chapters/fr/chapter1/3.mdx b/chapters/fr/chapter1/3.mdx
index 5428aff2b..d10b714e2 100644
--- a/chapters/fr/chapter1/3.mdx
+++ b/chapters/fr/chapter1/3.mdx
@@ -1,381 +1,381 @@
-# Que peuvent faire les transformers ?
-
-
-
-Dans cette section, nous allons voir ce que peuvent faire les *transformers* et utiliser notre premier outil de la bibliothèque 🤗 *Transformers* : la fonction `pipeline()`.
-
-
-👀 Vous voyez ce bouton Open in Colab en haut à droite ? Cliquez dessus pour ouvrir un notebook Colab avec tous les exemples de code de cette section. Ce bouton sera présent dans n'importe quelle section contenant des exemples de code.
-
-Si vous souhaitez exécuter les codes en local, nous vous recommandons de jeter un œil au chapitre configuration.
-
-
-## Les transformers sont partout !
-
-Les *transformers* sont utilisés pour résoudre toute sorte de tâches de NLP comme celles mentionnées dans la section précédente. Voici quelques-unes des entreprises et organisations qui utilisent Hugging Face, les *transformers* et qui contribuent aussi à la communauté en partageant leurs modèles :
-
- -
-La bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers) fournit toutes les fonctionnalités nécessaires pour créer et utiliser les modèles partagés. Le [*Hub*](https://huggingface.co/models) contient des milliers de modèles pré-entraînés que n'importe qui peut télécharger et utiliser. Vous pouvez également transférer vos propres modèles vers le Hub !
-
-
- ⚠️ Le Hub n'est pas limité aux transformers. Tout le monde peut partager n'importe quel modèle ou jeu de données s'il le souhaite ! Créez un compte sur huggingface.co pour bénéficier de toutes les fonctionnalités disponibles !
-
-
-Avant de découvrir en détail comment les *transformers* fonctionnent, nous allons voir quelques exemples de comment ils peuvent être utilisés pour résoudre des problèmes intéressants de NLP.
-
-## Travailler avec les pipelines
-
-
-
-L'outil le plus basique de la bibliothèque 🤗 *Transformers* est la fonction `pipeline()`. Elle relie un modèle avec ses étapes de pré-traitement et de post-traitement, permettant d'entrer n'importe quel texte et d'obtenir une réponse compréhensible :
-
-```python
-from transformers import pipeline
-
-classifier = pipeline("sentiment-analysis")
-classifier(
- "I've been waiting for a HuggingFace course my whole life."
-) # J'ai attendu un cours d'HuggingFace toute ma vie.
-```
-
-```python out
-[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
-```
-
-On peut même passer plusieurs phrases !
-
-```python
-classifier(
- [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
- ] # « J'ai attendu un cours d'HuggingFace toute ma vie. », « Je déteste tellement ça ! »
-)
-```
-
-```python out
-[{'label': 'POSITIVE', 'score': 0.9598047137260437},
- {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
-```
-
-Par défaut, ce pipeline sélectionne un modèle pré-entraîné qui a été spécifiquement entraîné pour l'analyse de sentiment en anglais. Le modèle est téléchargé et mis en cache lorsque vous créez l'objet `classifier`. Si vous réexécutez la commande, c'est le modèle mis en cache qui sera utilisé et il n'y a pas besoin de télécharger le modèle à nouveau.
-
-Il y a trois étapes principales lorsque vous passez du texte à un pipeline :
-
-1. le texte est prétraité pour qu'il ait un format compréhensible par le modèle,
-2. les données prétraitées sont passées au modèle,
-3. les prédictions du modèle sont post-traitées de sorte que vous puissiez les comprendre.
-
-
-Voici une liste non-exhaustive des [pipelines disponibles](https://huggingface.co/transformers/main_classes/pipelines.html) :
-
-- `feature-extraction` (pour obtenir la représentation vectorielle d'un texte)
-- `fill-mask`
-- `ner` (*named entity recognition* ou reconnaissance d'entités nommées en français)
-- `question-answering`
-- `sentiment-analysis`
-- `summarization`
-- `text-generation`
-- `translation`
-- `zero-shot-classification`
-
-Regardons de plus près certains d'entre eux !
-
-## Zero-shot classification
-
-Nous allons commencer par nous attaquer à une tâche plus difficile où nous devons classer des textes qui n'ont pas été annotés. C'est un scénario très répandu dans les projets réels car l'annotation de textes est généralement longue et nécessite parfois une expertise dans un domaine. Pour ce cas d'usage, le pipeline `zero-shot-classification` est très puissant : il vous permet de spécifier les labels à utiliser pour la classification, de sorte que vous n'ayez pas à vous soucier des labels du modèle pré-entraîné. Nous avons déjà vu comment le modèle peut classer un texte comme positif ou négatif en utilisant ces deux labels mais il peut également classer le texte en utilisant n'importe quel autre ensemble de labels que vous souhaitez.
-
-```python
-from transformers import pipeline
-
-classifier = pipeline("zero-shot-classification")
-classifier(
- "This is a course about the Transformers library",
- # C'est un cours sur la bibliothèque Transformers
- candidate_labels=["education", "politics", "business"],
-)
-```
-
-```python out
-{'sequence': 'This is a course about the Transformers library',
-# C'est un cours sur la bibliothèque Transformers
- 'labels': ['education', 'business', 'politics'],
- 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
-```
-
-Ce pipeline est appelé _zero-shot_ car vous n'avez pas besoin d'entraîner spécifiquement le modèle sur vos données pour l'utiliser. Il peut directement retourner des scores de probabilité pour n'importe quel ensemble de labels que vous choisissez !
-
-
-
-✏️ **Essayez !** Jouez avec vos propres séquences et labels et voyez comment le modèle fonctionne.
-
-
-
-
-## Génération de texte
-
-Maintenant, nous allons voir comment utiliser un pipeline pour générer du texte. L'idée principale ici est que vous fournissez seulement un extrait de texte qui va être complété par du texte généré automatiquement par le modèle. Cette fonction est similaire à la fonction de texte prédictif que l'on trouve sur de nombreux téléphones portables. La génération de texte implique de l'aléatoire, donc il est normal que vous n'obteniez pas les mêmes résultats que ceux présentés ci-dessous.
-
-```python
-from transformers import pipeline
-
-generator = pipeline("text-generation")
-generator(
- "In this course, we will teach you how to"
-) # Dans ce cours, nous vous enseignerons comment
-```
-
-```python out
-[{'generated_text': 'In this course, we will teach you how to understand and use '
- # Dans ce cours, nous vous enseignerons comment comprendre et utiliser
- 'data flow and data interchange when handling user data. We '
- # flux de données et l'échange de données lors de la manipulation des données utilisateur. Nous
- 'will be working with one or more of the most commonly used '
- # travailleront avec un ou plusieurs des plus couramment utilisés
- 'data flows — data flows of various types, as seen by the '
- # flux de données - flux de données de différents types, tels qu'ils sont vus par
- 'HTTP'}] # HTTP
-```
-
-Il est possible de contrôler le nombre de séquences générées avec l'argument `num_return_sequences` et la longueur totale du texte généré avec l'argument `max_length`.
-
-
-
-✏️ **Essayez !** Utilisez les arguments `num_return_sequences` et `max_length` pour générer deux phrases de 15 mots chacune.
-
-
-
-
-## Utiliser n'importe quel modèle du Hub dans un pipeline
-
-Les exemples précédents utilisaient le modèle par défaut pour la tâche en question mais vous pouvez aussi choisir un modèle particulier du *Hub* et l'utiliser dans un pipeline pour une tâche spécifique comme par exemple la génération de texte. Rendez-vous sur le [*Hub*](https://huggingface.co/models) et cliquez sur le *filtre* correspondant sur la gauche pour afficher seulement les modèles supportés pour cette tâche. Vous devriez arriver sur une page comme [celle-ci](https://huggingface.co/models?pipeline_tag=text-generation).
-
-Essayons le modèle [`distilgpt2`](https://huggingface.co/distilgpt2) ! Voici comment charger le modèle dans le même pipeline que précédemment :
-
-```python
-from transformers import pipeline
-
-generator = pipeline("text-generation", model="distilgpt2")
-generator(
- "In this course, we will teach you how to",
- # Dans ce cours, nous vous enseignerons comment
- max_length=30,
- num_return_sequences=2,
-)
-```
-
-```python out
-[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
- # Dans ce cours, nous vous enseignerons comment manipuler le monde et
- 'move your mental and physical capabilities to your advantage.'},
- # utiliser vos capacités mentales et physiques à votre avantage.
- {'generated_text': 'In this course, we will teach you how to become an expert and '
- # Dans ce cours, nous vous apprendrons comment devenir un expert et
- 'practice realtime, and with a hands on experience on both real '
- # pratique en temps réel, et avec une expérience pratique à la fois sur de vrais
- 'time and real'}]
- # temps et réel
-```
-
-Vous pouvez améliorer votre recherche de modèle en cliquant sur les *filtres* de langue et choisir un modèle qui génère du texte dans une autre langue. Le *Hub* contient également des *checkpoints* pour des modèles multilingues qui supportent plusieurs langues.
-
-Une fois que vous avez choisi un modèle, vous verrez que vous pouvez tester son fonctionnement en ligne directement. Cela vous permet de tester rapidement les capacités du modèle avant de le télécharger.
-
-
-
-✏️ **Essayez !** Utilisez les filtres pour trouver un modèle de génération de texte pour une autre langue. N'hésitez pas à jouer avec le *widget* et l'utiliser dans un pipeline !
-
-
-
-### L'API d'inférence
-
-Tous les modèles peuvent être testé directement depuis votre navigateur en utilisant l'API d'inférence qui est disponible sur le site [Hugging Face](https://huggingface.co/). Vous pouvez jouer avec le modèle directement sur sa page en entrant du texte personnalisé et en regardant le modèle traiter les données d'entrée.
-
-L'API d'inférence qui est utilisée par le *widget* est également disponible en tant que produit payant si vous avez besoin de l'API pour votre travail. Consultez la [page des prix](https://huggingface.co/pricing) pour plus de détails.
-
-## Remplacement des mots manquants
-
-Le prochain pipeline que vous allez essayer est celui de `fill-mask`. L'idée de cette tâche est de remplir les mots manquants d'un texte donné :
-
-```python
-from transformers import pipeline
-
-unmasker = pipeline("fill-mask")
-unmasker("This course will teach you all about models.", top_k=2)
-```
-
-```python out
-[{'sequence': 'This course will teach you all about mathematical models.',
-# Ce cours vous apprendra tout sur les modèles mathématiques.
- 'score': 0.19619831442832947,
- 'token': 30412,
- 'token_str': ' mathematical'},
- {'sequence': 'This course will teach you all about computational models.',
- # Ce cours vous apprendra tout sur les modèles mathématiques.
- 'score': 0.04052725434303284,
- 'token': 38163,
- 'token_str': ' computational'}]
-```
-
-L'argument `top_k` permet de contrôler le nombre de possibilités que vous souhaitez afficher. Notez que dans ce cas, le modèle remplace le mot spécial ``, qui est souvent appelé un *mot masqué*. D'autres modèles permettant de remplacer les mots manquants peuvent avoir des mots masqués différents, donc il est toujours bon de vérifier le mot masqué approprié lorsque vous comparez d'autres modèles. Une façon de le vérifier est de regarder le mot masqué utilisé dans l'outil de test de la page du modèle.
-
-
-
-✏️ **Essayez !** Recherchez le modèle `bert-base-cased` sur le *Hub* et identifiez le mot masqué dans l'outil d'inférence. Que prédit le modèle pour la phrase dans notre exemple de pipeline au-dessus ?
-
-
-
-## Reconnaissance d'entités nommées
-
-La reconnaissance d'entités nommées ou NER (pour *Named Entity Recognition*) est une tâche où le modèle doit trouver les parties du texte d'entrée qui correspondent à des entités telles que des personnes, des lieux ou des organisations. Voyons un exemple :
-
-```python
-from transformers import pipeline
-
-ner = pipeline("ner", grouped_entities=True)
-ner(
- "My name is Sylvain and I work at Hugging Face in Brooklyn."
-) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
-```
-
-```python out
-[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
-]
-```
-
-Nous pouvons voir que le modèle a correctement identifié Sylvain comme une personne (PER), Hugging Face comme une organisation (ORG) et Brooklyn comme un lieu (LOC).
-
-Il est possible d'utiliser l'option `grouped_entities=True` lors de la création du pipeline pour regrouper les parties du texte qui correspondent à la même entité : ici le modèle à correctement regroupé `Hugging` et `Face` comme une seule organisation, même si le nom comporte plusieurs mots. En effet, comme nous allons voir dans le prochain chapitre, la prétraitement du texte sépare parfois certains mots en plus petites parties. Par exemple, `Sylvain` est séparé en quatre morceaux : `S`, `##yl`, `##va`, et `##in`. Dans l'étape de post-traitement, le pipeline a réussi à regrouper ces morceaux.
-
-
-
-✏️ **Essayez !** Recherchez sur le *Hub* un modèle capable de reconnaître les différentes parties du langage (généralement abrégé en POS pour *Part-of-speech*) en anglais. Que prédit le modèle pour la phrase dans notre exemple du pipeline au-dessus ?
-
-
-
-## Réponse à des questions
-
-Le pipeline `question-answering` répond à des questions en utilisant des informations données en contexte :
-
-```python
-from transformers import pipeline
-
-question_answerer = pipeline("question-answering")
-question_answerer(
- question="Where do I work?", # Où est-ce que je travaille ?
- context="My name is Sylvain and I work at Hugging Face in Brooklyn",
- # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
-)
-```
-
-```python out
-{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
-```
-
-Notez que ce pipeline fonctionne par extraction d'information depuis le contexte fourni, il ne génère pas la réponse.
-
-## Résumé
-
-Le résumé est une tâche de réduction d'un texte en un texte plus court, tout en gardant tous (ou presque tous) les aspects importants référencés dans le texte. Voici un exemple :
-
-```python
-from transformers import pipeline
-
-summarizer = pipeline("summarization")
-summarizer(
- """
- America has changed dramatically during recent years. Not only has the number of
- graduates in traditional engineering disciplines such as mechanical, civil,
- electrical, chemical, and aeronautical engineering declined, but in most of
- the premier American universities engineering curricula now concentrate on
- and encourage largely the study of engineering science. As a result, there
- are declining offerings in engineering subjects dealing with infrastructure,
- the environment, and related issues, and greater concentration on high
- technology subjects, largely supporting increasingly complex scientific
- developments. While the latter is important, it should not be at the expense
- of more traditional engineering.
-
- Rapidly developing economies such as China and India, as well as other
- industrial countries in Europe and Asia, continue to encourage and advance
- the teaching of engineering. Both China and India, respectively, graduate
- six and eight times as many traditional engineers as does the United States.
- Other industrial countries at minimum maintain their output, while America
- suffers an increasingly serious decline in the number of engineering graduates
- and a lack of well-educated engineers.
-"""
-)
-
-"""
- L'Amérique a changé de façon spectaculaire au cours des dernières années. Non seulement le nombre de
- diplômés dans les disciplines traditionnelles de l'ingénierie telles que le génie mécanique, civil,
- l'électricité, la chimie et l'aéronautique a diminué, mais dans la plupart
- des grandes universités américaines, les programmes d'études d'ingénierie se concentrent désormais sur
- et encouragent largement l'étude des sciences de l'ingénieur. Par conséquent, il y a
- de moins en moins d'offres dans les sujets d'ingénierie traitant de l'infrastructure,
- l'environnement et les questions connexes, et une plus grande concentration sur les sujets de haute
- technologie, qui soutiennent en grande partie des développements scientifiques de plus en plus
- complexes. Si cette dernière est importante, elle ne doit pas se faire au détriment
- de l'ingénierie plus traditionnelle.
-
- Les économies en développement rapide telles que la Chine et l'Inde, ainsi que d'autres
- pays industrialisés d'Europe et d'Asie, continuent d'encourager et de promouvoir
- l'enseignement de l'ingénierie. La Chine et l'Inde, respectivement, diplôment
- six et huit fois plus d'ingénieurs traditionnels que les États-Unis.
- Les autres pays industriels maintiennent au minimum leur production, tandis que l'Amérique
- souffre d'une baisse de plus en plus importante du nombre de diplômés en ingénierie
- et un manque d'ingénieurs bien formés.
-"""
-```
-
-```python out
-[{'summary_text': ' America has changed dramatically during recent years . The '
- # L'Amérique a changé de façon spectaculaire au cours des dernières années. Le
- 'number of engineering graduates in the U.S. has declined in '
- # nombre de diplômés en ingénierie aux États-Unis a diminué dans
- 'traditional engineering disciplines such as mechanical, civil '
- # dans les disciplines traditionnelles de l'ingénierie, telles que le génie mécanique, civil
- ', electrical, chemical, and aeronautical engineering . Rapidly '
- # l'électricité, la chimie et l'aéronautique. Les économies
- 'developing economies such as China and India, as well as other '
- # en développement rapide comme la Chine et l'Inde, ainsi que d'autres
- 'industrial countries in Europe and Asia, continue to encourage '
- # pays industriels d'Europe et d'Asie, continuent d'encourager
- 'and advance engineering.'}]
- # et à faire progresser l'ingénierie.
-```
-
-Comme pour la génération de texte, vous pouvez spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
-
-
-## Traduction
-
-Pour la traduction, vous pouvez utiliser un modèle par défaut si vous fournissez un couple de langues dans le nom de la tâche (comme `"translation_en_to_fr"`), mais le plus simple reste d'utiliser un modèle adéquat disponible sur le [*Hub*](https://huggingface.co/models). Ici, nous allons essayer de traduire du français en anglais :
-
-```python
-from transformers import pipeline
-
-translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
-translator("Ce cours est produit par Hugging Face.")
-```
-
-```python out
-[{'translation_text': 'This course is produced by Hugging Face.'}]
-```
-
-Comme pour la génération de texte et le résumé de texte, il est possible de spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
-
-
-
-✏️ **Essayez !** Recherchez d'autres modèles de traduction sur le Hub et essayez de traduire la phrase précédente en plusieurs langues différentes.
-
-
-
-Les pipelines présentés jusqu'ici sont principalement destinés à des fins de démonstration. Ils ont été programmés pour des tâches spécifiques et ne peuvent pas effectuer de variations de celles-ci. Dans le chapitre suivant, vous apprendrez ce qu'il y a dans un `pipeline()` et comment modifier son comportement.
+# Que peuvent faire les transformers ?
+
+
+
+Dans cette section, nous allons voir ce que peuvent faire les *transformers* et utiliser notre premier outil de la bibliothèque 🤗 *Transformers* : la fonction `pipeline()`.
+
+
+👀 Vous voyez ce bouton Open in Colab en haut à droite ? Cliquez dessus pour ouvrir un notebook Colab avec tous les exemples de code de cette section. Ce bouton sera présent dans n'importe quelle section contenant des exemples de code.
+
+Si vous souhaitez exécuter les codes en local, nous vous recommandons de jeter un œil au chapitre configuration.
+
+
+## Les transformers sont partout !
+
+Les *transformers* sont utilisés pour résoudre toute sorte de tâches de NLP comme celles mentionnées dans la section précédente. Voici quelques-unes des entreprises et organisations qui utilisent Hugging Face, les *transformers* et qui contribuent aussi à la communauté en partageant leurs modèles :
+
+
+
+La bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers) fournit toutes les fonctionnalités nécessaires pour créer et utiliser les modèles partagés. Le [*Hub*](https://huggingface.co/models) contient des milliers de modèles pré-entraînés que n'importe qui peut télécharger et utiliser. Vous pouvez également transférer vos propres modèles vers le Hub !
+
+
+ ⚠️ Le Hub n'est pas limité aux transformers. Tout le monde peut partager n'importe quel modèle ou jeu de données s'il le souhaite ! Créez un compte sur huggingface.co pour bénéficier de toutes les fonctionnalités disponibles !
+
+
+Avant de découvrir en détail comment les *transformers* fonctionnent, nous allons voir quelques exemples de comment ils peuvent être utilisés pour résoudre des problèmes intéressants de NLP.
+
+## Travailler avec les pipelines
+
+
+
+L'outil le plus basique de la bibliothèque 🤗 *Transformers* est la fonction `pipeline()`. Elle relie un modèle avec ses étapes de pré-traitement et de post-traitement, permettant d'entrer n'importe quel texte et d'obtenir une réponse compréhensible :
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("sentiment-analysis")
+classifier(
+ "I've been waiting for a HuggingFace course my whole life."
+) # J'ai attendu un cours d'HuggingFace toute ma vie.
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
+```
+
+On peut même passer plusieurs phrases !
+
+```python
+classifier(
+ [
+ "I've been waiting for a HuggingFace course my whole life.",
+ "I hate this so much!",
+ ] # « J'ai attendu un cours d'HuggingFace toute ma vie. », « Je déteste tellement ça ! »
+)
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437},
+ {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
+```
+
+Par défaut, ce pipeline sélectionne un modèle pré-entraîné qui a été spécifiquement entraîné pour l'analyse de sentiment en anglais. Le modèle est téléchargé et mis en cache lorsque vous créez l'objet `classifier`. Si vous réexécutez la commande, c'est le modèle mis en cache qui sera utilisé et il n'y a pas besoin de télécharger le modèle à nouveau.
+
+Il y a trois étapes principales lorsque vous passez du texte à un pipeline :
+
+1. le texte est prétraité pour qu'il ait un format compréhensible par le modèle,
+2. les données prétraitées sont passées au modèle,
+3. les prédictions du modèle sont post-traitées de sorte que vous puissiez les comprendre.
+
+
+Voici une liste non-exhaustive des [pipelines disponibles](https://huggingface.co/transformers/main_classes/pipelines.html) :
+
+- `feature-extraction` (pour obtenir la représentation vectorielle d'un texte)
+- `fill-mask`
+- `ner` (*named entity recognition* ou reconnaissance d'entités nommées en français)
+- `question-answering`
+- `sentiment-analysis`
+- `summarization`
+- `text-generation`
+- `translation`
+- `zero-shot-classification`
+
+Regardons de plus près certains d'entre eux !
+
+## Zero-shot classification
+
+Nous allons commencer par nous attaquer à une tâche plus difficile où nous devons classer des textes qui n'ont pas été annotés. C'est un scénario très répandu dans les projets réels car l'annotation de textes est généralement longue et nécessite parfois une expertise dans un domaine. Pour ce cas d'usage, le pipeline `zero-shot-classification` est très puissant : il vous permet de spécifier les labels à utiliser pour la classification, de sorte que vous n'ayez pas à vous soucier des labels du modèle pré-entraîné. Nous avons déjà vu comment le modèle peut classer un texte comme positif ou négatif en utilisant ces deux labels mais il peut également classer le texte en utilisant n'importe quel autre ensemble de labels que vous souhaitez.
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+classifier(
+ "This is a course about the Transformers library",
+ # C'est un cours sur la bibliothèque Transformers
+ candidate_labels=["education", "politics", "business"],
+)
+```
+
+```python out
+{'sequence': 'This is a course about the Transformers library',
+# C'est un cours sur la bibliothèque Transformers
+ 'labels': ['education', 'business', 'politics'],
+ 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
+```
+
+Ce pipeline est appelé _zero-shot_ car vous n'avez pas besoin d'entraîner spécifiquement le modèle sur vos données pour l'utiliser. Il peut directement retourner des scores de probabilité pour n'importe quel ensemble de labels que vous choisissez !
+
+
+
+✏️ **Essayez !** Jouez avec vos propres séquences et labels et voyez comment le modèle fonctionne.
+
+
+
+
+## Génération de texte
+
+Maintenant, nous allons voir comment utiliser un pipeline pour générer du texte. L'idée principale ici est que vous fournissez seulement un extrait de texte qui va être complété par du texte généré automatiquement par le modèle. Cette fonction est similaire à la fonction de texte prédictif que l'on trouve sur de nombreux téléphones portables. La génération de texte implique de l'aléatoire, donc il est normal que vous n'obteniez pas les mêmes résultats que ceux présentés ci-dessous.
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation")
+generator(
+ "In this course, we will teach you how to"
+) # Dans ce cours, nous vous enseignerons comment
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to understand and use '
+ # Dans ce cours, nous vous enseignerons comment comprendre et utiliser
+ 'data flow and data interchange when handling user data. We '
+ # flux de données et l'échange de données lors de la manipulation des données utilisateur. Nous
+ 'will be working with one or more of the most commonly used '
+ # travailleront avec un ou plusieurs des plus couramment utilisés
+ 'data flows — data flows of various types, as seen by the '
+ # flux de données - flux de données de différents types, tels qu'ils sont vus par
+ 'HTTP'}] # HTTP
+```
+
+Il est possible de contrôler le nombre de séquences générées avec l'argument `num_return_sequences` et la longueur totale du texte généré avec l'argument `max_length`.
+
+
+
+✏️ **Essayez !** Utilisez les arguments `num_return_sequences` et `max_length` pour générer deux phrases de 15 mots chacune.
+
+
+
+
+## Utiliser n'importe quel modèle du Hub dans un pipeline
+
+Les exemples précédents utilisaient le modèle par défaut pour la tâche en question mais vous pouvez aussi choisir un modèle particulier du *Hub* et l'utiliser dans un pipeline pour une tâche spécifique comme par exemple la génération de texte. Rendez-vous sur le [*Hub*](https://huggingface.co/models) et cliquez sur le *filtre* correspondant sur la gauche pour afficher seulement les modèles supportés pour cette tâche. Vous devriez arriver sur une page comme [celle-ci](https://huggingface.co/models?pipeline_tag=text-generation).
+
+Essayons le modèle [`distilgpt2`](https://huggingface.co/distilgpt2) ! Voici comment charger le modèle dans le même pipeline que précédemment :
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation", model="distilgpt2")
+generator(
+ "In this course, we will teach you how to",
+ # Dans ce cours, nous vous enseignerons comment
+ max_length=30,
+ num_return_sequences=2,
+)
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
+ # Dans ce cours, nous vous enseignerons comment manipuler le monde et
+ 'move your mental and physical capabilities to your advantage.'},
+ # utiliser vos capacités mentales et physiques à votre avantage.
+ {'generated_text': 'In this course, we will teach you how to become an expert and '
+ # Dans ce cours, nous vous apprendrons comment devenir un expert et
+ 'practice realtime, and with a hands on experience on both real '
+ # pratique en temps réel, et avec une expérience pratique à la fois sur de vrais
+ 'time and real'}]
+ # temps et réel
+```
+
+Vous pouvez améliorer votre recherche de modèle en cliquant sur les *filtres* de langue et choisir un modèle qui génère du texte dans une autre langue. Le *Hub* contient également des *checkpoints* pour des modèles multilingues qui supportent plusieurs langues.
+
+Une fois que vous avez choisi un modèle, vous verrez que vous pouvez tester son fonctionnement en ligne directement. Cela vous permet de tester rapidement les capacités du modèle avant de le télécharger.
+
+
+
+✏️ **Essayez !** Utilisez les filtres pour trouver un modèle de génération de texte pour une autre langue. N'hésitez pas à jouer avec le *widget* et l'utiliser dans un pipeline !
+
+
+
+### L'API d'inférence
+
+Tous les modèles peuvent être testé directement depuis votre navigateur en utilisant l'API d'inférence qui est disponible sur le site [Hugging Face](https://huggingface.co/). Vous pouvez jouer avec le modèle directement sur sa page en entrant du texte personnalisé et en regardant le modèle traiter les données d'entrée.
+
+L'API d'inférence qui est utilisée par le *widget* est également disponible en tant que produit payant si vous avez besoin de l'API pour votre travail. Consultez la [page des prix](https://huggingface.co/pricing) pour plus de détails.
+
+## Remplacement des mots manquants
+
+Le prochain pipeline que vous allez essayer est celui de `fill-mask`. L'idée de cette tâche est de remplir les mots manquants d'un texte donné :
+
+```python
+from transformers import pipeline
+
+unmasker = pipeline("fill-mask")
+unmasker("This course will teach you all about models.", top_k=2)
+```
+
+```python out
+[{'sequence': 'This course will teach you all about mathematical models.',
+# Ce cours vous apprendra tout sur les modèles mathématiques.
+ 'score': 0.19619831442832947,
+ 'token': 30412,
+ 'token_str': ' mathematical'},
+ {'sequence': 'This course will teach you all about computational models.',
+ # Ce cours vous apprendra tout sur les modèles mathématiques.
+ 'score': 0.04052725434303284,
+ 'token': 38163,
+ 'token_str': ' computational'}]
+```
+
+L'argument `top_k` permet de contrôler le nombre de possibilités que vous souhaitez afficher. Notez que dans ce cas, le modèle remplace le mot spécial ``, qui est souvent appelé un *mot masqué*. D'autres modèles permettant de remplacer les mots manquants peuvent avoir des mots masqués différents, donc il est toujours bon de vérifier le mot masqué approprié lorsque vous comparez d'autres modèles. Une façon de le vérifier est de regarder le mot masqué utilisé dans l'outil de test de la page du modèle.
+
+
+
+✏️ **Essayez !** Recherchez le modèle `bert-base-cased` sur le *Hub* et identifiez le mot masqué dans l'outil d'inférence. Que prédit le modèle pour la phrase dans notre exemple de pipeline au-dessus ?
+
+
+
+## Reconnaissance d'entités nommées
+
+La reconnaissance d'entités nommées ou NER (pour *Named Entity Recognition*) est une tâche où le modèle doit trouver les parties du texte d'entrée qui correspondent à des entités telles que des personnes, des lieux ou des organisations. Voyons un exemple :
+
+```python
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner(
+ "My name is Sylvain and I work at Hugging Face in Brooklyn."
+) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
+]
+```
+
+Nous pouvons voir que le modèle a correctement identifié Sylvain comme une personne (PER), Hugging Face comme une organisation (ORG) et Brooklyn comme un lieu (LOC).
+
+Il est possible d'utiliser l'option `grouped_entities=True` lors de la création du pipeline pour regrouper les parties du texte qui correspondent à la même entité : ici le modèle à correctement regroupé `Hugging` et `Face` comme une seule organisation, même si le nom comporte plusieurs mots. En effet, comme nous allons voir dans le prochain chapitre, la prétraitement du texte sépare parfois certains mots en plus petites parties. Par exemple, `Sylvain` est séparé en quatre morceaux : `S`, `##yl`, `##va`, et `##in`. Dans l'étape de post-traitement, le pipeline a réussi à regrouper ces morceaux.
+
+
+
+✏️ **Essayez !** Recherchez sur le *Hub* un modèle capable de reconnaître les différentes parties du langage (généralement abrégé en POS pour *Part-of-speech*) en anglais. Que prédit le modèle pour la phrase dans notre exemple du pipeline au-dessus ?
+
+
+
+## Réponse à des questions
+
+Le pipeline `question-answering` répond à des questions en utilisant des informations données en contexte :
+
+```python
+from transformers import pipeline
+
+question_answerer = pipeline("question-answering")
+question_answerer(
+ question="Where do I work?", # Où est-ce que je travaille ?
+ context="My name is Sylvain and I work at Hugging Face in Brooklyn",
+ # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
+)
+```
+
+```python out
+{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
+```
+
+Notez que ce pipeline fonctionne par extraction d'information depuis le contexte fourni, il ne génère pas la réponse.
+
+## Résumé
+
+Le résumé est une tâche de réduction d'un texte en un texte plus court, tout en gardant tous (ou presque tous) les aspects importants référencés dans le texte. Voici un exemple :
+
+```python
+from transformers import pipeline
+
+summarizer = pipeline("summarization")
+summarizer(
+ """
+ America has changed dramatically during recent years. Not only has the number of
+ graduates in traditional engineering disciplines such as mechanical, civil,
+ electrical, chemical, and aeronautical engineering declined, but in most of
+ the premier American universities engineering curricula now concentrate on
+ and encourage largely the study of engineering science. As a result, there
+ are declining offerings in engineering subjects dealing with infrastructure,
+ the environment, and related issues, and greater concentration on high
+ technology subjects, largely supporting increasingly complex scientific
+ developments. While the latter is important, it should not be at the expense
+ of more traditional engineering.
+
+ Rapidly developing economies such as China and India, as well as other
+ industrial countries in Europe and Asia, continue to encourage and advance
+ the teaching of engineering. Both China and India, respectively, graduate
+ six and eight times as many traditional engineers as does the United States.
+ Other industrial countries at minimum maintain their output, while America
+ suffers an increasingly serious decline in the number of engineering graduates
+ and a lack of well-educated engineers.
+"""
+)
+
+"""
+ L'Amérique a changé de façon spectaculaire au cours des dernières années. Non seulement le nombre de
+ diplômés dans les disciplines traditionnelles de l'ingénierie telles que le génie mécanique, civil,
+ l'électricité, la chimie et l'aéronautique a diminué, mais dans la plupart
+ des grandes universités américaines, les programmes d'études d'ingénierie se concentrent désormais sur
+ et encouragent largement l'étude des sciences de l'ingénieur. Par conséquent, il y a
+ de moins en moins d'offres dans les sujets d'ingénierie traitant de l'infrastructure,
+ l'environnement et les questions connexes, et une plus grande concentration sur les sujets de haute
+ technologie, qui soutiennent en grande partie des développements scientifiques de plus en plus
+ complexes. Si cette dernière est importante, elle ne doit pas se faire au détriment
+ de l'ingénierie plus traditionnelle.
+
+ Les économies en développement rapide telles que la Chine et l'Inde, ainsi que d'autres
+ pays industrialisés d'Europe et d'Asie, continuent d'encourager et de promouvoir
+ l'enseignement de l'ingénierie. La Chine et l'Inde, respectivement, diplôment
+ six et huit fois plus d'ingénieurs traditionnels que les États-Unis.
+ Les autres pays industriels maintiennent au minimum leur production, tandis que l'Amérique
+ souffre d'une baisse de plus en plus importante du nombre de diplômés en ingénierie
+ et un manque d'ingénieurs bien formés.
+"""
+```
+
+```python out
+[{'summary_text': ' America has changed dramatically during recent years . The '
+ # L'Amérique a changé de façon spectaculaire au cours des dernières années. Le
+ 'number of engineering graduates in the U.S. has declined in '
+ # nombre de diplômés en ingénierie aux États-Unis a diminué dans
+ 'traditional engineering disciplines such as mechanical, civil '
+ # dans les disciplines traditionnelles de l'ingénierie, telles que le génie mécanique, civil
+ ', electrical, chemical, and aeronautical engineering . Rapidly '
+ # l'électricité, la chimie et l'aéronautique. Les économies
+ 'developing economies such as China and India, as well as other '
+ # en développement rapide comme la Chine et l'Inde, ainsi que d'autres
+ 'industrial countries in Europe and Asia, continue to encourage '
+ # pays industriels d'Europe et d'Asie, continuent d'encourager
+ 'and advance engineering.'}]
+ # et à faire progresser l'ingénierie.
+```
+
+Comme pour la génération de texte, vous pouvez spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
+
+
+## Traduction
+
+Pour la traduction, vous pouvez utiliser un modèle par défaut si vous fournissez un couple de langues dans le nom de la tâche (comme `"translation_en_to_fr"`), mais le plus simple reste d'utiliser un modèle adéquat disponible sur le [*Hub*](https://huggingface.co/models). Ici, nous allons essayer de traduire du français en anglais :
+
+```python
+from transformers import pipeline
+
+translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
+translator("Ce cours est produit par Hugging Face.")
+```
+
+```python out
+[{'translation_text': 'This course is produced by Hugging Face.'}]
+```
+
+Comme pour la génération de texte et le résumé de texte, il est possible de spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
+
+
+
+✏️ **Essayez !** Recherchez d'autres modèles de traduction sur le Hub et essayez de traduire la phrase précédente en plusieurs langues différentes.
+
+
+
+Les pipelines présentés jusqu'ici sont principalement destinés à des fins de démonstration. Ils ont été programmés pour des tâches spécifiques et ne peuvent pas effectuer de variations de celles-ci. Dans le chapitre suivant, vous apprendrez ce qu'il y a dans un `pipeline()` et comment modifier son comportement.
diff --git a/chapters/fr/chapter1/4.mdx b/chapters/fr/chapter1/4.mdx
index dc996234e..28de8aa80 100644
--- a/chapters/fr/chapter1/4.mdx
+++ b/chapters/fr/chapter1/4.mdx
@@ -1,169 +1,174 @@
-# Comment fonctionnent les transformers ?
-
-Dans cette partie, nous allons jeter un coup d'œil à l'architecture des *transformers*.
-
-## Court historique des transformers
-
-Voici quelques dates clefs dans la courte histoire des *transformers* :
-
-
-
-La bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers) fournit toutes les fonctionnalités nécessaires pour créer et utiliser les modèles partagés. Le [*Hub*](https://huggingface.co/models) contient des milliers de modèles pré-entraînés que n'importe qui peut télécharger et utiliser. Vous pouvez également transférer vos propres modèles vers le Hub !
-
-
- ⚠️ Le Hub n'est pas limité aux transformers. Tout le monde peut partager n'importe quel modèle ou jeu de données s'il le souhaite ! Créez un compte sur huggingface.co pour bénéficier de toutes les fonctionnalités disponibles !
-
-
-Avant de découvrir en détail comment les *transformers* fonctionnent, nous allons voir quelques exemples de comment ils peuvent être utilisés pour résoudre des problèmes intéressants de NLP.
-
-## Travailler avec les pipelines
-
-
-
-L'outil le plus basique de la bibliothèque 🤗 *Transformers* est la fonction `pipeline()`. Elle relie un modèle avec ses étapes de pré-traitement et de post-traitement, permettant d'entrer n'importe quel texte et d'obtenir une réponse compréhensible :
-
-```python
-from transformers import pipeline
-
-classifier = pipeline("sentiment-analysis")
-classifier(
- "I've been waiting for a HuggingFace course my whole life."
-) # J'ai attendu un cours d'HuggingFace toute ma vie.
-```
-
-```python out
-[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
-```
-
-On peut même passer plusieurs phrases !
-
-```python
-classifier(
- [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
- ] # « J'ai attendu un cours d'HuggingFace toute ma vie. », « Je déteste tellement ça ! »
-)
-```
-
-```python out
-[{'label': 'POSITIVE', 'score': 0.9598047137260437},
- {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
-```
-
-Par défaut, ce pipeline sélectionne un modèle pré-entraîné qui a été spécifiquement entraîné pour l'analyse de sentiment en anglais. Le modèle est téléchargé et mis en cache lorsque vous créez l'objet `classifier`. Si vous réexécutez la commande, c'est le modèle mis en cache qui sera utilisé et il n'y a pas besoin de télécharger le modèle à nouveau.
-
-Il y a trois étapes principales lorsque vous passez du texte à un pipeline :
-
-1. le texte est prétraité pour qu'il ait un format compréhensible par le modèle,
-2. les données prétraitées sont passées au modèle,
-3. les prédictions du modèle sont post-traitées de sorte que vous puissiez les comprendre.
-
-
-Voici une liste non-exhaustive des [pipelines disponibles](https://huggingface.co/transformers/main_classes/pipelines.html) :
-
-- `feature-extraction` (pour obtenir la représentation vectorielle d'un texte)
-- `fill-mask`
-- `ner` (*named entity recognition* ou reconnaissance d'entités nommées en français)
-- `question-answering`
-- `sentiment-analysis`
-- `summarization`
-- `text-generation`
-- `translation`
-- `zero-shot-classification`
-
-Regardons de plus près certains d'entre eux !
-
-## Zero-shot classification
-
-Nous allons commencer par nous attaquer à une tâche plus difficile où nous devons classer des textes qui n'ont pas été annotés. C'est un scénario très répandu dans les projets réels car l'annotation de textes est généralement longue et nécessite parfois une expertise dans un domaine. Pour ce cas d'usage, le pipeline `zero-shot-classification` est très puissant : il vous permet de spécifier les labels à utiliser pour la classification, de sorte que vous n'ayez pas à vous soucier des labels du modèle pré-entraîné. Nous avons déjà vu comment le modèle peut classer un texte comme positif ou négatif en utilisant ces deux labels mais il peut également classer le texte en utilisant n'importe quel autre ensemble de labels que vous souhaitez.
-
-```python
-from transformers import pipeline
-
-classifier = pipeline("zero-shot-classification")
-classifier(
- "This is a course about the Transformers library",
- # C'est un cours sur la bibliothèque Transformers
- candidate_labels=["education", "politics", "business"],
-)
-```
-
-```python out
-{'sequence': 'This is a course about the Transformers library',
-# C'est un cours sur la bibliothèque Transformers
- 'labels': ['education', 'business', 'politics'],
- 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
-```
-
-Ce pipeline est appelé _zero-shot_ car vous n'avez pas besoin d'entraîner spécifiquement le modèle sur vos données pour l'utiliser. Il peut directement retourner des scores de probabilité pour n'importe quel ensemble de labels que vous choisissez !
-
-
-
-✏️ **Essayez !** Jouez avec vos propres séquences et labels et voyez comment le modèle fonctionne.
-
-
-
-
-## Génération de texte
-
-Maintenant, nous allons voir comment utiliser un pipeline pour générer du texte. L'idée principale ici est que vous fournissez seulement un extrait de texte qui va être complété par du texte généré automatiquement par le modèle. Cette fonction est similaire à la fonction de texte prédictif que l'on trouve sur de nombreux téléphones portables. La génération de texte implique de l'aléatoire, donc il est normal que vous n'obteniez pas les mêmes résultats que ceux présentés ci-dessous.
-
-```python
-from transformers import pipeline
-
-generator = pipeline("text-generation")
-generator(
- "In this course, we will teach you how to"
-) # Dans ce cours, nous vous enseignerons comment
-```
-
-```python out
-[{'generated_text': 'In this course, we will teach you how to understand and use '
- # Dans ce cours, nous vous enseignerons comment comprendre et utiliser
- 'data flow and data interchange when handling user data. We '
- # flux de données et l'échange de données lors de la manipulation des données utilisateur. Nous
- 'will be working with one or more of the most commonly used '
- # travailleront avec un ou plusieurs des plus couramment utilisés
- 'data flows — data flows of various types, as seen by the '
- # flux de données - flux de données de différents types, tels qu'ils sont vus par
- 'HTTP'}] # HTTP
-```
-
-Il est possible de contrôler le nombre de séquences générées avec l'argument `num_return_sequences` et la longueur totale du texte généré avec l'argument `max_length`.
-
-
-
-✏️ **Essayez !** Utilisez les arguments `num_return_sequences` et `max_length` pour générer deux phrases de 15 mots chacune.
-
-
-
-
-## Utiliser n'importe quel modèle du Hub dans un pipeline
-
-Les exemples précédents utilisaient le modèle par défaut pour la tâche en question mais vous pouvez aussi choisir un modèle particulier du *Hub* et l'utiliser dans un pipeline pour une tâche spécifique comme par exemple la génération de texte. Rendez-vous sur le [*Hub*](https://huggingface.co/models) et cliquez sur le *filtre* correspondant sur la gauche pour afficher seulement les modèles supportés pour cette tâche. Vous devriez arriver sur une page comme [celle-ci](https://huggingface.co/models?pipeline_tag=text-generation).
-
-Essayons le modèle [`distilgpt2`](https://huggingface.co/distilgpt2) ! Voici comment charger le modèle dans le même pipeline que précédemment :
-
-```python
-from transformers import pipeline
-
-generator = pipeline("text-generation", model="distilgpt2")
-generator(
- "In this course, we will teach you how to",
- # Dans ce cours, nous vous enseignerons comment
- max_length=30,
- num_return_sequences=2,
-)
-```
-
-```python out
-[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
- # Dans ce cours, nous vous enseignerons comment manipuler le monde et
- 'move your mental and physical capabilities to your advantage.'},
- # utiliser vos capacités mentales et physiques à votre avantage.
- {'generated_text': 'In this course, we will teach you how to become an expert and '
- # Dans ce cours, nous vous apprendrons comment devenir un expert et
- 'practice realtime, and with a hands on experience on both real '
- # pratique en temps réel, et avec une expérience pratique à la fois sur de vrais
- 'time and real'}]
- # temps et réel
-```
-
-Vous pouvez améliorer votre recherche de modèle en cliquant sur les *filtres* de langue et choisir un modèle qui génère du texte dans une autre langue. Le *Hub* contient également des *checkpoints* pour des modèles multilingues qui supportent plusieurs langues.
-
-Une fois que vous avez choisi un modèle, vous verrez que vous pouvez tester son fonctionnement en ligne directement. Cela vous permet de tester rapidement les capacités du modèle avant de le télécharger.
-
-
-
-✏️ **Essayez !** Utilisez les filtres pour trouver un modèle de génération de texte pour une autre langue. N'hésitez pas à jouer avec le *widget* et l'utiliser dans un pipeline !
-
-
-
-### L'API d'inférence
-
-Tous les modèles peuvent être testé directement depuis votre navigateur en utilisant l'API d'inférence qui est disponible sur le site [Hugging Face](https://huggingface.co/). Vous pouvez jouer avec le modèle directement sur sa page en entrant du texte personnalisé et en regardant le modèle traiter les données d'entrée.
-
-L'API d'inférence qui est utilisée par le *widget* est également disponible en tant que produit payant si vous avez besoin de l'API pour votre travail. Consultez la [page des prix](https://huggingface.co/pricing) pour plus de détails.
-
-## Remplacement des mots manquants
-
-Le prochain pipeline que vous allez essayer est celui de `fill-mask`. L'idée de cette tâche est de remplir les mots manquants d'un texte donné :
-
-```python
-from transformers import pipeline
-
-unmasker = pipeline("fill-mask")
-unmasker("This course will teach you all about models.", top_k=2)
-```
-
-```python out
-[{'sequence': 'This course will teach you all about mathematical models.',
-# Ce cours vous apprendra tout sur les modèles mathématiques.
- 'score': 0.19619831442832947,
- 'token': 30412,
- 'token_str': ' mathematical'},
- {'sequence': 'This course will teach you all about computational models.',
- # Ce cours vous apprendra tout sur les modèles mathématiques.
- 'score': 0.04052725434303284,
- 'token': 38163,
- 'token_str': ' computational'}]
-```
-
-L'argument `top_k` permet de contrôler le nombre de possibilités que vous souhaitez afficher. Notez que dans ce cas, le modèle remplace le mot spécial ``, qui est souvent appelé un *mot masqué*. D'autres modèles permettant de remplacer les mots manquants peuvent avoir des mots masqués différents, donc il est toujours bon de vérifier le mot masqué approprié lorsque vous comparez d'autres modèles. Une façon de le vérifier est de regarder le mot masqué utilisé dans l'outil de test de la page du modèle.
-
-
-
-✏️ **Essayez !** Recherchez le modèle `bert-base-cased` sur le *Hub* et identifiez le mot masqué dans l'outil d'inférence. Que prédit le modèle pour la phrase dans notre exemple de pipeline au-dessus ?
-
-
-
-## Reconnaissance d'entités nommées
-
-La reconnaissance d'entités nommées ou NER (pour *Named Entity Recognition*) est une tâche où le modèle doit trouver les parties du texte d'entrée qui correspondent à des entités telles que des personnes, des lieux ou des organisations. Voyons un exemple :
-
-```python
-from transformers import pipeline
-
-ner = pipeline("ner", grouped_entities=True)
-ner(
- "My name is Sylvain and I work at Hugging Face in Brooklyn."
-) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
-```
-
-```python out
-[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
-]
-```
-
-Nous pouvons voir que le modèle a correctement identifié Sylvain comme une personne (PER), Hugging Face comme une organisation (ORG) et Brooklyn comme un lieu (LOC).
-
-Il est possible d'utiliser l'option `grouped_entities=True` lors de la création du pipeline pour regrouper les parties du texte qui correspondent à la même entité : ici le modèle à correctement regroupé `Hugging` et `Face` comme une seule organisation, même si le nom comporte plusieurs mots. En effet, comme nous allons voir dans le prochain chapitre, la prétraitement du texte sépare parfois certains mots en plus petites parties. Par exemple, `Sylvain` est séparé en quatre morceaux : `S`, `##yl`, `##va`, et `##in`. Dans l'étape de post-traitement, le pipeline a réussi à regrouper ces morceaux.
-
-
-
-✏️ **Essayez !** Recherchez sur le *Hub* un modèle capable de reconnaître les différentes parties du langage (généralement abrégé en POS pour *Part-of-speech*) en anglais. Que prédit le modèle pour la phrase dans notre exemple du pipeline au-dessus ?
-
-
-
-## Réponse à des questions
-
-Le pipeline `question-answering` répond à des questions en utilisant des informations données en contexte :
-
-```python
-from transformers import pipeline
-
-question_answerer = pipeline("question-answering")
-question_answerer(
- question="Where do I work?", # Où est-ce que je travaille ?
- context="My name is Sylvain and I work at Hugging Face in Brooklyn",
- # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
-)
-```
-
-```python out
-{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
-```
-
-Notez que ce pipeline fonctionne par extraction d'information depuis le contexte fourni, il ne génère pas la réponse.
-
-## Résumé
-
-Le résumé est une tâche de réduction d'un texte en un texte plus court, tout en gardant tous (ou presque tous) les aspects importants référencés dans le texte. Voici un exemple :
-
-```python
-from transformers import pipeline
-
-summarizer = pipeline("summarization")
-summarizer(
- """
- America has changed dramatically during recent years. Not only has the number of
- graduates in traditional engineering disciplines such as mechanical, civil,
- electrical, chemical, and aeronautical engineering declined, but in most of
- the premier American universities engineering curricula now concentrate on
- and encourage largely the study of engineering science. As a result, there
- are declining offerings in engineering subjects dealing with infrastructure,
- the environment, and related issues, and greater concentration on high
- technology subjects, largely supporting increasingly complex scientific
- developments. While the latter is important, it should not be at the expense
- of more traditional engineering.
-
- Rapidly developing economies such as China and India, as well as other
- industrial countries in Europe and Asia, continue to encourage and advance
- the teaching of engineering. Both China and India, respectively, graduate
- six and eight times as many traditional engineers as does the United States.
- Other industrial countries at minimum maintain their output, while America
- suffers an increasingly serious decline in the number of engineering graduates
- and a lack of well-educated engineers.
-"""
-)
-
-"""
- L'Amérique a changé de façon spectaculaire au cours des dernières années. Non seulement le nombre de
- diplômés dans les disciplines traditionnelles de l'ingénierie telles que le génie mécanique, civil,
- l'électricité, la chimie et l'aéronautique a diminué, mais dans la plupart
- des grandes universités américaines, les programmes d'études d'ingénierie se concentrent désormais sur
- et encouragent largement l'étude des sciences de l'ingénieur. Par conséquent, il y a
- de moins en moins d'offres dans les sujets d'ingénierie traitant de l'infrastructure,
- l'environnement et les questions connexes, et une plus grande concentration sur les sujets de haute
- technologie, qui soutiennent en grande partie des développements scientifiques de plus en plus
- complexes. Si cette dernière est importante, elle ne doit pas se faire au détriment
- de l'ingénierie plus traditionnelle.
-
- Les économies en développement rapide telles que la Chine et l'Inde, ainsi que d'autres
- pays industrialisés d'Europe et d'Asie, continuent d'encourager et de promouvoir
- l'enseignement de l'ingénierie. La Chine et l'Inde, respectivement, diplôment
- six et huit fois plus d'ingénieurs traditionnels que les États-Unis.
- Les autres pays industriels maintiennent au minimum leur production, tandis que l'Amérique
- souffre d'une baisse de plus en plus importante du nombre de diplômés en ingénierie
- et un manque d'ingénieurs bien formés.
-"""
-```
-
-```python out
-[{'summary_text': ' America has changed dramatically during recent years . The '
- # L'Amérique a changé de façon spectaculaire au cours des dernières années. Le
- 'number of engineering graduates in the U.S. has declined in '
- # nombre de diplômés en ingénierie aux États-Unis a diminué dans
- 'traditional engineering disciplines such as mechanical, civil '
- # dans les disciplines traditionnelles de l'ingénierie, telles que le génie mécanique, civil
- ', electrical, chemical, and aeronautical engineering . Rapidly '
- # l'électricité, la chimie et l'aéronautique. Les économies
- 'developing economies such as China and India, as well as other '
- # en développement rapide comme la Chine et l'Inde, ainsi que d'autres
- 'industrial countries in Europe and Asia, continue to encourage '
- # pays industriels d'Europe et d'Asie, continuent d'encourager
- 'and advance engineering.'}]
- # et à faire progresser l'ingénierie.
-```
-
-Comme pour la génération de texte, vous pouvez spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
-
-
-## Traduction
-
-Pour la traduction, vous pouvez utiliser un modèle par défaut si vous fournissez un couple de langues dans le nom de la tâche (comme `"translation_en_to_fr"`), mais le plus simple reste d'utiliser un modèle adéquat disponible sur le [*Hub*](https://huggingface.co/models). Ici, nous allons essayer de traduire du français en anglais :
-
-```python
-from transformers import pipeline
-
-translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
-translator("Ce cours est produit par Hugging Face.")
-```
-
-```python out
-[{'translation_text': 'This course is produced by Hugging Face.'}]
-```
-
-Comme pour la génération de texte et le résumé de texte, il est possible de spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
-
-
-
-✏️ **Essayez !** Recherchez d'autres modèles de traduction sur le Hub et essayez de traduire la phrase précédente en plusieurs langues différentes.
-
-
-
-Les pipelines présentés jusqu'ici sont principalement destinés à des fins de démonstration. Ils ont été programmés pour des tâches spécifiques et ne peuvent pas effectuer de variations de celles-ci. Dans le chapitre suivant, vous apprendrez ce qu'il y a dans un `pipeline()` et comment modifier son comportement.
+# Que peuvent faire les transformers ?
+
+
+
+Dans cette section, nous allons voir ce que peuvent faire les *transformers* et utiliser notre premier outil de la bibliothèque 🤗 *Transformers* : la fonction `pipeline()`.
+
+
+👀 Vous voyez ce bouton Open in Colab en haut à droite ? Cliquez dessus pour ouvrir un notebook Colab avec tous les exemples de code de cette section. Ce bouton sera présent dans n'importe quelle section contenant des exemples de code.
+
+Si vous souhaitez exécuter les codes en local, nous vous recommandons de jeter un œil au chapitre configuration.
+
+
+## Les transformers sont partout !
+
+Les *transformers* sont utilisés pour résoudre toute sorte de tâches de NLP comme celles mentionnées dans la section précédente. Voici quelques-unes des entreprises et organisations qui utilisent Hugging Face, les *transformers* et qui contribuent aussi à la communauté en partageant leurs modèles :
+
+
+
+La bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers) fournit toutes les fonctionnalités nécessaires pour créer et utiliser les modèles partagés. Le [*Hub*](https://huggingface.co/models) contient des milliers de modèles pré-entraînés que n'importe qui peut télécharger et utiliser. Vous pouvez également transférer vos propres modèles vers le Hub !
+
+
+ ⚠️ Le Hub n'est pas limité aux transformers. Tout le monde peut partager n'importe quel modèle ou jeu de données s'il le souhaite ! Créez un compte sur huggingface.co pour bénéficier de toutes les fonctionnalités disponibles !
+
+
+Avant de découvrir en détail comment les *transformers* fonctionnent, nous allons voir quelques exemples de comment ils peuvent être utilisés pour résoudre des problèmes intéressants de NLP.
+
+## Travailler avec les pipelines
+
+
+
+L'outil le plus basique de la bibliothèque 🤗 *Transformers* est la fonction `pipeline()`. Elle relie un modèle avec ses étapes de pré-traitement et de post-traitement, permettant d'entrer n'importe quel texte et d'obtenir une réponse compréhensible :
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("sentiment-analysis")
+classifier(
+ "I've been waiting for a HuggingFace course my whole life."
+) # J'ai attendu un cours d'HuggingFace toute ma vie.
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
+```
+
+On peut même passer plusieurs phrases !
+
+```python
+classifier(
+ [
+ "I've been waiting for a HuggingFace course my whole life.",
+ "I hate this so much!",
+ ] # « J'ai attendu un cours d'HuggingFace toute ma vie. », « Je déteste tellement ça ! »
+)
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437},
+ {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
+```
+
+Par défaut, ce pipeline sélectionne un modèle pré-entraîné qui a été spécifiquement entraîné pour l'analyse de sentiment en anglais. Le modèle est téléchargé et mis en cache lorsque vous créez l'objet `classifier`. Si vous réexécutez la commande, c'est le modèle mis en cache qui sera utilisé et il n'y a pas besoin de télécharger le modèle à nouveau.
+
+Il y a trois étapes principales lorsque vous passez du texte à un pipeline :
+
+1. le texte est prétraité pour qu'il ait un format compréhensible par le modèle,
+2. les données prétraitées sont passées au modèle,
+3. les prédictions du modèle sont post-traitées de sorte que vous puissiez les comprendre.
+
+
+Voici une liste non-exhaustive des [pipelines disponibles](https://huggingface.co/transformers/main_classes/pipelines.html) :
+
+- `feature-extraction` (pour obtenir la représentation vectorielle d'un texte)
+- `fill-mask`
+- `ner` (*named entity recognition* ou reconnaissance d'entités nommées en français)
+- `question-answering`
+- `sentiment-analysis`
+- `summarization`
+- `text-generation`
+- `translation`
+- `zero-shot-classification`
+
+Regardons de plus près certains d'entre eux !
+
+## Zero-shot classification
+
+Nous allons commencer par nous attaquer à une tâche plus difficile où nous devons classer des textes qui n'ont pas été annotés. C'est un scénario très répandu dans les projets réels car l'annotation de textes est généralement longue et nécessite parfois une expertise dans un domaine. Pour ce cas d'usage, le pipeline `zero-shot-classification` est très puissant : il vous permet de spécifier les labels à utiliser pour la classification, de sorte que vous n'ayez pas à vous soucier des labels du modèle pré-entraîné. Nous avons déjà vu comment le modèle peut classer un texte comme positif ou négatif en utilisant ces deux labels mais il peut également classer le texte en utilisant n'importe quel autre ensemble de labels que vous souhaitez.
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+classifier(
+ "This is a course about the Transformers library",
+ # C'est un cours sur la bibliothèque Transformers
+ candidate_labels=["education", "politics", "business"],
+)
+```
+
+```python out
+{'sequence': 'This is a course about the Transformers library',
+# C'est un cours sur la bibliothèque Transformers
+ 'labels': ['education', 'business', 'politics'],
+ 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
+```
+
+Ce pipeline est appelé _zero-shot_ car vous n'avez pas besoin d'entraîner spécifiquement le modèle sur vos données pour l'utiliser. Il peut directement retourner des scores de probabilité pour n'importe quel ensemble de labels que vous choisissez !
+
+
+
+✏️ **Essayez !** Jouez avec vos propres séquences et labels et voyez comment le modèle fonctionne.
+
+
+
+
+## Génération de texte
+
+Maintenant, nous allons voir comment utiliser un pipeline pour générer du texte. L'idée principale ici est que vous fournissez seulement un extrait de texte qui va être complété par du texte généré automatiquement par le modèle. Cette fonction est similaire à la fonction de texte prédictif que l'on trouve sur de nombreux téléphones portables. La génération de texte implique de l'aléatoire, donc il est normal que vous n'obteniez pas les mêmes résultats que ceux présentés ci-dessous.
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation")
+generator(
+ "In this course, we will teach you how to"
+) # Dans ce cours, nous vous enseignerons comment
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to understand and use '
+ # Dans ce cours, nous vous enseignerons comment comprendre et utiliser
+ 'data flow and data interchange when handling user data. We '
+ # flux de données et l'échange de données lors de la manipulation des données utilisateur. Nous
+ 'will be working with one or more of the most commonly used '
+ # travailleront avec un ou plusieurs des plus couramment utilisés
+ 'data flows — data flows of various types, as seen by the '
+ # flux de données - flux de données de différents types, tels qu'ils sont vus par
+ 'HTTP'}] # HTTP
+```
+
+Il est possible de contrôler le nombre de séquences générées avec l'argument `num_return_sequences` et la longueur totale du texte généré avec l'argument `max_length`.
+
+
+
+✏️ **Essayez !** Utilisez les arguments `num_return_sequences` et `max_length` pour générer deux phrases de 15 mots chacune.
+
+
+
+
+## Utiliser n'importe quel modèle du Hub dans un pipeline
+
+Les exemples précédents utilisaient le modèle par défaut pour la tâche en question mais vous pouvez aussi choisir un modèle particulier du *Hub* et l'utiliser dans un pipeline pour une tâche spécifique comme par exemple la génération de texte. Rendez-vous sur le [*Hub*](https://huggingface.co/models) et cliquez sur le *filtre* correspondant sur la gauche pour afficher seulement les modèles supportés pour cette tâche. Vous devriez arriver sur une page comme [celle-ci](https://huggingface.co/models?pipeline_tag=text-generation).
+
+Essayons le modèle [`distilgpt2`](https://huggingface.co/distilgpt2) ! Voici comment charger le modèle dans le même pipeline que précédemment :
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation", model="distilgpt2")
+generator(
+ "In this course, we will teach you how to",
+ # Dans ce cours, nous vous enseignerons comment
+ max_length=30,
+ num_return_sequences=2,
+)
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
+ # Dans ce cours, nous vous enseignerons comment manipuler le monde et
+ 'move your mental and physical capabilities to your advantage.'},
+ # utiliser vos capacités mentales et physiques à votre avantage.
+ {'generated_text': 'In this course, we will teach you how to become an expert and '
+ # Dans ce cours, nous vous apprendrons comment devenir un expert et
+ 'practice realtime, and with a hands on experience on both real '
+ # pratique en temps réel, et avec une expérience pratique à la fois sur de vrais
+ 'time and real'}]
+ # temps et réel
+```
+
+Vous pouvez améliorer votre recherche de modèle en cliquant sur les *filtres* de langue et choisir un modèle qui génère du texte dans une autre langue. Le *Hub* contient également des *checkpoints* pour des modèles multilingues qui supportent plusieurs langues.
+
+Une fois que vous avez choisi un modèle, vous verrez que vous pouvez tester son fonctionnement en ligne directement. Cela vous permet de tester rapidement les capacités du modèle avant de le télécharger.
+
+
+
+✏️ **Essayez !** Utilisez les filtres pour trouver un modèle de génération de texte pour une autre langue. N'hésitez pas à jouer avec le *widget* et l'utiliser dans un pipeline !
+
+
+
+### L'API d'inférence
+
+Tous les modèles peuvent être testé directement depuis votre navigateur en utilisant l'API d'inférence qui est disponible sur le site [Hugging Face](https://huggingface.co/). Vous pouvez jouer avec le modèle directement sur sa page en entrant du texte personnalisé et en regardant le modèle traiter les données d'entrée.
+
+L'API d'inférence qui est utilisée par le *widget* est également disponible en tant que produit payant si vous avez besoin de l'API pour votre travail. Consultez la [page des prix](https://huggingface.co/pricing) pour plus de détails.
+
+## Remplacement des mots manquants
+
+Le prochain pipeline que vous allez essayer est celui de `fill-mask`. L'idée de cette tâche est de remplir les mots manquants d'un texte donné :
+
+```python
+from transformers import pipeline
+
+unmasker = pipeline("fill-mask")
+unmasker("This course will teach you all about models.", top_k=2)
+```
+
+```python out
+[{'sequence': 'This course will teach you all about mathematical models.',
+# Ce cours vous apprendra tout sur les modèles mathématiques.
+ 'score': 0.19619831442832947,
+ 'token': 30412,
+ 'token_str': ' mathematical'},
+ {'sequence': 'This course will teach you all about computational models.',
+ # Ce cours vous apprendra tout sur les modèles mathématiques.
+ 'score': 0.04052725434303284,
+ 'token': 38163,
+ 'token_str': ' computational'}]
+```
+
+L'argument `top_k` permet de contrôler le nombre de possibilités que vous souhaitez afficher. Notez que dans ce cas, le modèle remplace le mot spécial ``, qui est souvent appelé un *mot masqué*. D'autres modèles permettant de remplacer les mots manquants peuvent avoir des mots masqués différents, donc il est toujours bon de vérifier le mot masqué approprié lorsque vous comparez d'autres modèles. Une façon de le vérifier est de regarder le mot masqué utilisé dans l'outil de test de la page du modèle.
+
+
+
+✏️ **Essayez !** Recherchez le modèle `bert-base-cased` sur le *Hub* et identifiez le mot masqué dans l'outil d'inférence. Que prédit le modèle pour la phrase dans notre exemple de pipeline au-dessus ?
+
+
+
+## Reconnaissance d'entités nommées
+
+La reconnaissance d'entités nommées ou NER (pour *Named Entity Recognition*) est une tâche où le modèle doit trouver les parties du texte d'entrée qui correspondent à des entités telles que des personnes, des lieux ou des organisations. Voyons un exemple :
+
+```python
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner(
+ "My name is Sylvain and I work at Hugging Face in Brooklyn."
+) # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
+]
+```
+
+Nous pouvons voir que le modèle a correctement identifié Sylvain comme une personne (PER), Hugging Face comme une organisation (ORG) et Brooklyn comme un lieu (LOC).
+
+Il est possible d'utiliser l'option `grouped_entities=True` lors de la création du pipeline pour regrouper les parties du texte qui correspondent à la même entité : ici le modèle à correctement regroupé `Hugging` et `Face` comme une seule organisation, même si le nom comporte plusieurs mots. En effet, comme nous allons voir dans le prochain chapitre, la prétraitement du texte sépare parfois certains mots en plus petites parties. Par exemple, `Sylvain` est séparé en quatre morceaux : `S`, `##yl`, `##va`, et `##in`. Dans l'étape de post-traitement, le pipeline a réussi à regrouper ces morceaux.
+
+
+
+✏️ **Essayez !** Recherchez sur le *Hub* un modèle capable de reconnaître les différentes parties du langage (généralement abrégé en POS pour *Part-of-speech*) en anglais. Que prédit le modèle pour la phrase dans notre exemple du pipeline au-dessus ?
+
+
+
+## Réponse à des questions
+
+Le pipeline `question-answering` répond à des questions en utilisant des informations données en contexte :
+
+```python
+from transformers import pipeline
+
+question_answerer = pipeline("question-answering")
+question_answerer(
+ question="Where do I work?", # Où est-ce que je travaille ?
+ context="My name is Sylvain and I work at Hugging Face in Brooklyn",
+ # Je m'appelle Sylvain et je travaille à Hugging Face à Brooklyn.
+)
+```
+
+```python out
+{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
+```
+
+Notez que ce pipeline fonctionne par extraction d'information depuis le contexte fourni, il ne génère pas la réponse.
+
+## Résumé
+
+Le résumé est une tâche de réduction d'un texte en un texte plus court, tout en gardant tous (ou presque tous) les aspects importants référencés dans le texte. Voici un exemple :
+
+```python
+from transformers import pipeline
+
+summarizer = pipeline("summarization")
+summarizer(
+ """
+ America has changed dramatically during recent years. Not only has the number of
+ graduates in traditional engineering disciplines such as mechanical, civil,
+ electrical, chemical, and aeronautical engineering declined, but in most of
+ the premier American universities engineering curricula now concentrate on
+ and encourage largely the study of engineering science. As a result, there
+ are declining offerings in engineering subjects dealing with infrastructure,
+ the environment, and related issues, and greater concentration on high
+ technology subjects, largely supporting increasingly complex scientific
+ developments. While the latter is important, it should not be at the expense
+ of more traditional engineering.
+
+ Rapidly developing economies such as China and India, as well as other
+ industrial countries in Europe and Asia, continue to encourage and advance
+ the teaching of engineering. Both China and India, respectively, graduate
+ six and eight times as many traditional engineers as does the United States.
+ Other industrial countries at minimum maintain their output, while America
+ suffers an increasingly serious decline in the number of engineering graduates
+ and a lack of well-educated engineers.
+"""
+)
+
+"""
+ L'Amérique a changé de façon spectaculaire au cours des dernières années. Non seulement le nombre de
+ diplômés dans les disciplines traditionnelles de l'ingénierie telles que le génie mécanique, civil,
+ l'électricité, la chimie et l'aéronautique a diminué, mais dans la plupart
+ des grandes universités américaines, les programmes d'études d'ingénierie se concentrent désormais sur
+ et encouragent largement l'étude des sciences de l'ingénieur. Par conséquent, il y a
+ de moins en moins d'offres dans les sujets d'ingénierie traitant de l'infrastructure,
+ l'environnement et les questions connexes, et une plus grande concentration sur les sujets de haute
+ technologie, qui soutiennent en grande partie des développements scientifiques de plus en plus
+ complexes. Si cette dernière est importante, elle ne doit pas se faire au détriment
+ de l'ingénierie plus traditionnelle.
+
+ Les économies en développement rapide telles que la Chine et l'Inde, ainsi que d'autres
+ pays industrialisés d'Europe et d'Asie, continuent d'encourager et de promouvoir
+ l'enseignement de l'ingénierie. La Chine et l'Inde, respectivement, diplôment
+ six et huit fois plus d'ingénieurs traditionnels que les États-Unis.
+ Les autres pays industriels maintiennent au minimum leur production, tandis que l'Amérique
+ souffre d'une baisse de plus en plus importante du nombre de diplômés en ingénierie
+ et un manque d'ingénieurs bien formés.
+"""
+```
+
+```python out
+[{'summary_text': ' America has changed dramatically during recent years . The '
+ # L'Amérique a changé de façon spectaculaire au cours des dernières années. Le
+ 'number of engineering graduates in the U.S. has declined in '
+ # nombre de diplômés en ingénierie aux États-Unis a diminué dans
+ 'traditional engineering disciplines such as mechanical, civil '
+ # dans les disciplines traditionnelles de l'ingénierie, telles que le génie mécanique, civil
+ ', electrical, chemical, and aeronautical engineering . Rapidly '
+ # l'électricité, la chimie et l'aéronautique. Les économies
+ 'developing economies such as China and India, as well as other '
+ # en développement rapide comme la Chine et l'Inde, ainsi que d'autres
+ 'industrial countries in Europe and Asia, continue to encourage '
+ # pays industriels d'Europe et d'Asie, continuent d'encourager
+ 'and advance engineering.'}]
+ # et à faire progresser l'ingénierie.
+```
+
+Comme pour la génération de texte, vous pouvez spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
+
+
+## Traduction
+
+Pour la traduction, vous pouvez utiliser un modèle par défaut si vous fournissez un couple de langues dans le nom de la tâche (comme `"translation_en_to_fr"`), mais le plus simple reste d'utiliser un modèle adéquat disponible sur le [*Hub*](https://huggingface.co/models). Ici, nous allons essayer de traduire du français en anglais :
+
+```python
+from transformers import pipeline
+
+translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
+translator("Ce cours est produit par Hugging Face.")
+```
+
+```python out
+[{'translation_text': 'This course is produced by Hugging Face.'}]
+```
+
+Comme pour la génération de texte et le résumé de texte, il est possible de spécifier une `max_length` (longueur maximale) ou une `min_length` (longueur minimale) pour le résultat.
+
+
+
+✏️ **Essayez !** Recherchez d'autres modèles de traduction sur le Hub et essayez de traduire la phrase précédente en plusieurs langues différentes.
+
+
+
+Les pipelines présentés jusqu'ici sont principalement destinés à des fins de démonstration. Ils ont été programmés pour des tâches spécifiques et ne peuvent pas effectuer de variations de celles-ci. Dans le chapitre suivant, vous apprendrez ce qu'il y a dans un `pipeline()` et comment modifier son comportement.
diff --git a/chapters/fr/chapter1/4.mdx b/chapters/fr/chapter1/4.mdx
index dc996234e..28de8aa80 100644
--- a/chapters/fr/chapter1/4.mdx
+++ b/chapters/fr/chapter1/4.mdx
@@ -1,169 +1,174 @@
-# Comment fonctionnent les transformers ?
-
-Dans cette partie, nous allons jeter un coup d'œil à l'architecture des *transformers*.
-
-## Court historique des transformers
-
-Voici quelques dates clefs dans la courte histoire des *transformers* :
-
-
-

-

-
-

-

-
-

-

-
-

-
-

-

-
-

-

-
-

-

-
-

-

-
-

-

-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
-

-

-
-

-

-
+
+
+
+
+
+
-

-

-
-

-

-
-

-

-
+
+
+
+
+
+
+
+
+
encode existe sur les tokenizer, elle n'existe pas sur les modèles."
- },
- {
- text: "Appeler directement l'objet tokenizer",
- explain: "La méthode __call__ du tokenizer est une méthode très puissante qui peut traiter à peu près tout. C'est également la méthode utilisée pour récupérer les prédictions d'un modèle.",
- correct: true
- },
- {
- text: "pad",
- explain: "Le padding est très utile mais ce n'est qu'une partie de l'API tokenizer."
- },
- {
- text: "tokenize",
- explain: "La méthode tokenize est est sans doute l'une des méthodes les plus utiles, mais elle ne constitue pas le cœur de l'API tokenizer."
- }
- ]}
-/>
-
-### 9. Que contient la variable `result` dans cet exemple de code ?
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-result = tokenizer.tokenize("Hello!")
-```
-
-token.",
- explain: "Convertissez cela en identifiants, et donnez-les à un modèle !",
- correct: true
- },
- {
- text: "Une liste d'identifiants",
- explain: "C'est à cela que la méthode __call__ ou la méthode convert_tokens_to_ids sert !"
- },
- {
- text: "Une chaîne contenant tous les tokens",
- explain: "Ce serait sous-optimal car le but est de diviser la chaîne de caractères en plusieurs éléments."
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 10. Y a-t-il un problème avec le code suivant ?
-
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = AutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-tokenizer qui a été entraîné avec un checkpoint différent est rarement une bonne idée. Le modèle n'a pas été entraîné pour donner du sens à la sortie de ce tokenizer donc la sortie du modèle (s'il peut même fonctionner !) n'aura aucun sens."
- },
- {
- text: " Le tokenizer et le modèle doivent toujours provenir du même checkpoint.",
- explain: "",
- correct: true
- },
- {
- text: " C'est une bonne pratique de faire du padding et de troncage avec le tokenizer car chaque entrée est un batch.",
- explain: "Il est vrai que chaque entrée de modèle doit être un batch. Cependant, tronquer ou compléter cette séquence n'aurait pas nécessairement de sens puisqu'il n'y en a qu'une seule. Il s'agit là de techniques permettant de mettre en batch une liste de phrases."
- }
- ]}
-/>
-
-{:else}
-### 10. Y a-t-il un problème avec le code suivant ?
-
-```py
-from transformers import AutoTokenizer, TFAutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = TFAutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-tokenizer qui a été entraîné avec un checkpoint différent est rarement une bonne idée. Le modèle n'a pas été entraîné pour donner du sens à la sortie de ce tokenizer donc la sortie du modèle (s'il peut même fonctionner !) n'aura aucun sens."
- },
- {
- text: " Le tokenizer et le modèle doivent toujours provenir du même checkpoint.",
- explain: "",
- correct: true
- },
- {
- text: " C'est une bonne pratique de faire du padding et de troncage avec le tokenizer car chaque entrée est un batch.",
- explain: "Il est vrai que chaque entrée de modèle doit être un batch. Cependant, tronquer ou compléter cette séquence n'aurait pas nécessairement de sens puisqu'il n'y en a qu'une seule. Il s'agit là de techniques permettant de mettre en batch une liste de phrases."
- }
- ]}
-/>
-
-{/if}
+
+
+
+
+# Quiz de fin de chapitre
+
+
+
+### 1. Quel est l'ordre du pipeline de modélisation du langage ?
+
+
+tokenizer donne un sens à ces prédictions et les reconvertit en texte si nécessaire.",
+ explain: " Le modèle ne peut pas comprendre le texte ! Le tokenizer doit d'abord tokeniser le texte et le convertir en identifiants afin qu'il soit compréhensible par le modèle."},
+ {
+ text: " Tout d'abord, le tokenizer, qui traite le texte et renvoie des identifiants. Puis le modèle traite ces identifiants et produit une prédiction, qui peut être du texte.",
+ explain: " La prédiction du modèle ne peut pas être du texte immédiatement. Le tokenizer doit être utilisé afin de reconvertir la prédiction en texte !"},
+ {
+ text: " Le tokenizer traite le texte et renvoie des identifiants. Le modèle traite ces identifiants et produit une prédiction. Le tokenizer peut alors être utilisé à nouveau pour reconvertir ces prédictions en texte.",
+ explain: " Le tokenizer peut être utilisé à la fois pour la tokenisation et la dé-tokénisation.",
+ correct: true
+ }
+ ]}
+/>
+
+### 2. Combien de dimensions le tenseur produit par le transformer de base possède-t-il et quelles sont-elles ?
+
+
+transformers gèrent les batchs, même avec une seule séquence ce serait une taille de batch de 1 !"
+ },
+ {
+ text: "3: la longueur de la séquence, la taille du batch et la taille cachée.",
+ explain: "",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Lequel des éléments suivants est un exemple de tokenisation en sous-mots ?
+
+
+
+### 4. Qu'est-ce qu'une tête de modèle ?
+
+transformer de base qui redirige les tenseurs vers leurs couches correctes.",
+ explain: "Il n'y a pas de tel composant."
+ },
+ {
+ text: "Également connu sous le nom de mécanisme d'auto-attention, il adapte la représentation d'un token en fonction des autres tokens de la séquence.",
+ explain: "La couche d'auto-attention contient des têtes d'attention mais ce ne sont pas des têtes d'adaptation."
+ },
+ {
+ text: "Un composant supplémentaire, généralement constitué d'une ou plusieurs couches, pour convertir les prédictions du transformer en une sortie spécifique à la tâche.",
+ explain: "Les têtes d'adaptation, aussi appelées simplement têtes, se présentent sous différentes formes : têtes de modélisation du langage, têtes de réponse aux questions, têtes de classification des séquences, etc.",
+ correct: true
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 5. Qu'est-ce qu'un AutoModel?
+
+checkpoints et modèles soient capables de gérer plusieurs langues, il n'existe pas d'outils intégrés pour la sélection automatique des checkpoints en fonction de la langue. Vous devez vous rendre sur le Hub des modèles pour trouver le meilleur checkpoint pour votre tâche !"
+ }
+ ]}
+/>
+
+{:else}
+### 5. What is an AutoModel?
+
+checkpoints et modèles soient capables de gérer plusieurs langues, il n'existe pas d'outils intégrés pour la sélection automatique des checkpoints en fonction de la langue. Vous devez vous rendre sur le Hub des modèles pour trouver le meilleur checkpoint pour votre tâche !"
+ }
+ ]}
+/>
+
+{/if}
+
+### 6. Quelles sont les techniques à connaître lors de la mise en batch de séquences de longueurs différentes ?
+
+
+padding",
+ explain: "Le padding est une façon correcte d'égaliser les séquences pour qu'elles tiennent dans une forme rectangulaire. Mais est-ce le seul moyen ?",
+ correct: true
+ },
+ {
+ text: "Les masques d'attention ",
+ explain: "Les masques d'attention sont d'une importance capitale lorsqu'on manipule des séquences de longueurs différentes. Ce n'est cependant pas la seule technique à laquelle il faut faire attention.",
+ correct: true
+ }
+ ]}
+/>
+
+### 7. Quel est l'intérêt d'appliquer une fonction SoftMax aux logits produits par un modèle de classification de séquences ?
+
+
+
+### 8. Autour de quelle méthode s'articule la majeure partie de l'API tokenizer ?
+
+encode, car elle peut encoder du texte en identifiants et des identifiants en prédictions.",
+ explain: "Bien que la méthode encode existe sur les tokenizer, elle n'existe pas sur les modèles."
+ },
+ {
+ text: "Appeler directement l'objet tokenizer",
+ explain: "La méthode __call__ du tokenizer est une méthode très puissante qui peut traiter à peu près tout. C'est également la méthode utilisée pour récupérer les prédictions d'un modèle.",
+ correct: true
+ },
+ {
+ text: "pad",
+ explain: "Le padding est très utile mais ce n'est qu'une partie de l'API tokenizer."
+ },
+ {
+ text: "tokenize",
+ explain: "La méthode tokenize est est sans doute l'une des méthodes les plus utiles, mais elle ne constitue pas le cœur de l'API tokenizer."
+ }
+ ]}
+/>
+
+### 9. Que contient la variable `result` dans cet exemple de code ?
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+result = tokenizer.tokenize("Hello!")
+```
+
+token.",
+ explain: "Convertissez cela en identifiants, et donnez-les à un modèle !",
+ correct: true
+ },
+ {
+ text: "Une liste d'identifiants",
+ explain: "C'est à cela que la méthode __call__ ou la méthode convert_tokens_to_ids sert !"
+ },
+ {
+ text: "Une chaîne contenant tous les tokens",
+ explain: "Ce serait sous-optimal car le but est de diviser la chaîne de caractères en plusieurs éléments."
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 10. Y a-t-il un problème avec le code suivant ?
+
+
+```py
+from transformers import AutoTokenizer, AutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+model = AutoModel.from_pretrained("gpt2")
+
+encoded = tokenizer("Hey!", return_tensors="pt")
+result = model(**encoded)
+```
+
+tokenizer qui a été entraîné avec un checkpoint différent est rarement une bonne idée. Le modèle n'a pas été entraîné pour donner du sens à la sortie de ce tokenizer donc la sortie du modèle (s'il peut même fonctionner !) n'aura aucun sens."
+ },
+ {
+ text: " Le tokenizer et le modèle doivent toujours provenir du même checkpoint.",
+ explain: "",
+ correct: true
+ },
+ {
+ text: " C'est une bonne pratique de faire du padding et de troncage avec le tokenizer car chaque entrée est un batch.",
+ explain: "Il est vrai que chaque entrée de modèle doit être un batch. Cependant, tronquer ou compléter cette séquence n'aurait pas nécessairement de sens puisqu'il n'y en a qu'une seule. Il s'agit là de techniques permettant de mettre en batch une liste de phrases."
+ }
+ ]}
+/>
+
+{:else}
+### 10. Y a-t-il un problème avec le code suivant ?
+
+```py
+from transformers import AutoTokenizer, TFAutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+model = TFAutoModel.from_pretrained("gpt2")
+
+encoded = tokenizer("Hey!", return_tensors="pt")
+result = model(**encoded)
+```
+
+tokenizer qui a été entraîné avec un checkpoint différent est rarement une bonne idée. Le modèle n'a pas été entraîné pour donner du sens à la sortie de ce tokenizer donc la sortie du modèle (s'il peut même fonctionner !) n'aura aucun sens."
+ },
+ {
+ text: " Le tokenizer et le modèle doivent toujours provenir du même checkpoint.",
+ explain: "",
+ correct: true
+ },
+ {
+ text: " C'est une bonne pratique de faire du padding et de troncage avec le tokenizer car chaque entrée est un batch.",
+ explain: "Il est vrai que chaque entrée de modèle doit être un batch. Cependant, tronquer ou compléter cette séquence n'aurait pas nécessairement de sens puisqu'il n'y en a qu'une seule. Il s'agit là de techniques permettant de mettre en batch une liste de phrases."
+ }
+ ]}
+/>
+
+{/if}
diff --git a/chapters/fr/chapter3/1.mdx b/chapters/fr/chapter3/1.mdx
index 3ce9c58f7..3b9d16505 100644
--- a/chapters/fr/chapter3/1.mdx
+++ b/chapters/fr/chapter3/1.mdx
@@ -1,23 +1,28 @@
-
-
-# Introduction
-
-Dans le [chapitre 2](/course/fr/chapter2) nous avons étudié comment utiliser les *tokenizers* et les modèles pré-entraînés pour faire des prédictions.
-Mais que faire si vous souhaitez *finetuner* un modèle pré-entraîné pour votre propre jeu de données ? C'est le sujet de ce chapitre ! Vous allez apprendre à :
-
-{#if fw === 'pt'}
-* savoir comment préparer un très grand jeu de données à partir du *Hub*,
-* savoir comment utiliser l'API de haut niveau `Trainer` pour *finetuner* un modèle,
-* savoir comment utiliser une boucle d'entraînement personnalisée,
-* savoir comment tirer parti de la bibliothèque 🤗 *Accelerate* pour exécuter facilement cette boucle d'entraînement personnalisée sur n'importe quelle configuration distribuée.
-configuration distribuée
-
-{:else}
-* savoir comment préparer un très grand jeu de données à partir du *Hub*,
-* savoir comment utiliser Keras pour *finetuner* un modèle,
-* savoir comment utiliser Keras pour obtenir des prédictions,
-* savoir comment utiliser des métriques personnalisées.
-
-{/if}
-
+
+
+# Introduction
+
+
+
+Dans le [chapitre 2](/course/fr/chapter2) nous avons étudié comment utiliser les *tokenizers* et les modèles pré-entraînés pour faire des prédictions.
+Mais que faire si vous souhaitez *finetuner* un modèle pré-entraîné pour votre propre jeu de données ? C'est le sujet de ce chapitre ! Vous allez apprendre à :
+
+{#if fw === 'pt'}
+* savoir comment préparer un très grand jeu de données à partir du *Hub*,
+* savoir comment utiliser l'API de haut niveau `Trainer` pour *finetuner* un modèle,
+* savoir comment utiliser une boucle d'entraînement personnalisée,
+* savoir comment tirer parti de la bibliothèque 🤗 *Accelerate* pour exécuter facilement cette boucle d'entraînement personnalisée sur n'importe quelle configuration distribuée.
+configuration distribuée
+
+{:else}
+* savoir comment préparer un très grand jeu de données à partir du *Hub*,
+* savoir comment utiliser Keras pour *finetuner* un modèle,
+* savoir comment utiliser Keras pour obtenir des prédictions,
+* savoir comment utiliser des métriques personnalisées.
+
+{/if}
+
Afin de télécharger vos *checkpoints* entraînés sur le *Hub* Hugging Face, vous aurez besoin d'un compte huggingface.co : [créer un compte](https://huggingface.co/join)
\ No newline at end of file
diff --git a/chapters/fr/chapter3/2.mdx b/chapters/fr/chapter3/2.mdx
index 297c260f5..5a3186a74 100644
--- a/chapters/fr/chapter3/2.mdx
+++ b/chapters/fr/chapter3/2.mdx
@@ -1,385 +1,385 @@
-
-
-# Préparer les données
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-{#if fw === 'pt'}
-
-En continuant avec l'exemple du [chapitre précédent](/course/fr/chapter2), voici comment entraîner un classifieur de séquences sur un batch avec PyTorch :
-
-```python
-import torch
-from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
-
-# Même chose que précédemment
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
-sequences = [
- "I've been waiting for a HuggingFace course my whole life.",
- # J'ai attendu un cours de HuggingFace toute ma vie.
- "This course is amazing!", # Ce cours est incroyable !
-]
-batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
-
-# Ceci est nouveau
-batch["labels"] = torch.tensor([1, 1])
-
-optimizer = AdamW(model.parameters())
-loss = model(**batch).loss
-loss.backward()
-optimizer.step()
-```
-{:else}
-
-En continuant avec l'exemple du [chapitre précédent](/course/fr/chapter2), voici comment entraîner un classifieur de séquences sur un batch avec TensorFlow :
-
-```python
-import tensorflow as tf
-import numpy as np
-from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-
-# Même chose que précédemment
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-sequences = [
- "I've been waiting for a HuggingFace course my whole life.",
- # J'ai attendu un cours de HuggingFace toute ma vie.
- "This course is amazing!", # Ce cours est incroyable !
-]
-batch = dict(tokenizer(sequences, padding=True, truncation=True, return_tensors="tf"))
-
-# Ceci est nouveau
-model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
-labels = tf.convert_to_tensor([1, 1])
-model.train_on_batch(batch, labels)
-```
-{/if}
-Evidemment, entraîner un modèle avec seulement deux phrases ne va pas donner de bons résultats. Pour obtenir de meilleurs résultats, vous allez avoir à préparer un plus grand jeu de données.
-
-Dans cette section, nous allons utiliser comme exemple le jeu de données MRPC (*Microsoft Research Paraphrase Corpus*) présenté dans un [papier](https://www.aclweb.org/anthology/I05-5002.pdf) par William B. Dolan et Chris Brockett. Ce jeu de données contient 5801 paires de phrases avec un label indiquant si ces paires sont des paraphrases ou non (i.e. si elles ont la même signification). Nous l'avons choisi pour ce chapitre parce que c'est un petit jeu de données et cela rend donc simples les expériences d'entraînement sur ce jeu de données.
-
-### Charger un jeu de données depuis le Hub
-
-{#if fw === 'pt'}
-
-{:else}
-
-{/if}
-
-Le *Hub* ne contient pas seulement des modèles mais aussi plusieurs jeux de données dans un tas de langues différentes. Vous pouvez explorer les jeux de données [ici](https://huggingface.co/datasets) et nous vous conseillons d'essayer de charger un nouveau jeu de données une fois que vous avez étudié cette section (voir la documentation générale [ici](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)). Mais pour l'instant, concentrons-nous sur le jeu de données MRPC ! Il s'agit de l'un des 10 jeux de données qui constituent le [*benchmark* GLUE](https://gluebenchmark.com/) qui est un *benchmark* académique utilisé pour mesurer les performances des modèles d'apprentissage automatique sur 10 différentes tâches de classification de textes.
-
-La bibliothèque 🤗 *Datasets* propose une commande très simple pour télécharger et mettre en cache un jeu de données à partir du *Hub*. On peut télécharger le jeu de données MRPC comme ceci :
-
-```py
-from datasets import load_dataset
-
-raw_datasets = load_dataset("glue", "mrpc")
-raw_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['sentence1', 'sentence2', 'label', 'idx'],
- num_rows: 3668
- })
- validation: Dataset({
- features: ['sentence1', 'sentence2', 'label', 'idx'],
- num_rows: 408
- })
- test: Dataset({
- features: ['sentence1', 'sentence2', 'label', 'idx'],
- num_rows: 1725
- })
-})
-```
-
-Comme vous le voyez, on obtient un objet de type `DatasetDict` qui contient le jeu de données d'entraînement, celui de validation et celui de test. Chacun d'eux contient plusieurs colonnes (`sentence1`, `sentence2`, `label` et `idx`) et une variable nombre de lignes qui contient le nombre d'éléments dans chaque jeu de données (il y a donc 3.668 paires de phrases dans le jeu d'entraînement, 408 dans celui de validation et 1.725 dans celui de test).
-
-Cette commande télécharge et met en cache le jeu de données dans *~/.cache/huggingface/dataset*. Rappelez-vous que comme vu au chapitre 2, vous pouvez personnaliser votre dossier cache en modifiant la variable d'environnement `HF_HOME`.
-
-Nous pouvons accéder à chaque paire de phrase de notre objet `raw_datasets` par les indices, comme avec un dictionnaire :
-
-```py
-raw_train_dataset = raw_datasets["train"]
-raw_train_dataset[0]
-```
-
-```python out
-{'idx': 0,
- 'label': 1,
- 'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
- # Amrozi a accusé son frère, qu'il a appelé « le témoin », de déformer délibérément son témoignage.
- 'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
- # Se référant à lui uniquement comme « le témoin », Amrozi a accusé son frère de déformer délibérément son témoignage.
-```
-
-Nous pouvons voir que les étiquettes sont déjà des entiers, donc nous n'aurons pas à faire de prétraitement ici. Pour savoir quel entier correspond à quel label, nous pouvons inspecter les `features` de notre `raw_train_dataset`. Cela nous indiquera le type de chaque colonne :
-
-```py
-raw_train_dataset.features
-```
-
-```python out
-{'sentence1': Value(dtype='string', id=None),
- 'sentence2': Value(dtype='string', id=None),
- 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
- 'idx': Value(dtype='int32', id=None)}
-```
-
-En réalité, `label` est de type `ClassLabel` et la correspondance des entiers aux noms des labels est enregistrée le dossier *names*. `0` correspond à `not_equivalent` et `1` correspond à `equivalent`.
-
-
-
-✏️ **Essayez !** Regardez l'élément 15 de l'ensemble d'entraînement et l'élément 87 de l'ensemble de validation. Quelles sont leurs étiquettes ?
-
-
-### Prétraitement d'un jeu de données
-
-{#if fw === 'pt'}
-
-{:else}
-
-{/if}
-
-Pour prétraiter le jeu de données, nous devons convertir le texte en chiffres compréhensibles par le modèle. Comme vous l'avez vu dans le [chapitre précédent](/course/fr/chapter2), cette conversion est effectuée par un *tokenizer*. Nous pouvons fournir au *tokenizer* une phrase ou une liste de phrases, de sorte que nous pouvons directement tokeniser toutes les premières phrases et toutes les secondes phrases de chaque paire comme ceci :
-
-```py
-from transformers import AutoTokenizer
-
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
-tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
-```
-
-Cependant, nous ne pouvons pas simplement passer deux séquences au modèle et obtenir une prédiction pour savoir si les deux phrases sont des paraphrases ou non. Nous devons traiter les deux séquences comme une paire, et appliquer le prétraitement approprié. Heureusement, le *tokenizer* peut également prendre une paire de séquences et la préparer de la manière attendue par notre modèle BERT :
-
-```py
-inputs = tokenizer(
- "This is the first sentence.", "This is the second one."
-) # "C'est la première phrase.", "C'est la deuxième."
-inputs
-```
-
-```python out
-{
- 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
- 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
- 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
-}
-```
-
-Nous avons discuté des clés `input_ids` et `attention_mask` dans le [chapitre 2](/course/fr/chapter2), mais nous avons laissé de côté les `token_type_ids`. Dans cet exemple, c'est ce qui indique au modèle quelle partie de l'entrée est la première phrase et quelle partie est la deuxième phrase.
-
-
-
-✏️ **Essayez !** Prenez l'élément 15 de l'ensemble d'entraînement et tokenisez les deux phrases séparément et par paire. Quelle est la différence entre les deux résultats ?
-
-
-
-Si on décode les IDs dans `input_ids` en mots :
-
-```py
-tokenizer.convert_ids_to_tokens(inputs["input_ids"])
-```
-
-nous aurons :
-
-```python out
-['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
-```
-
-Nous voyons donc que le modèle s'attend à ce que les entrées soient de la forme `[CLS] phrase1 [SEP] phrase2 [SEP]` lorsqu'il y a deux phrases. En alignant cela avec les `token_type_ids`, on obtient :
-
-```python out
-['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
-[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
-```
-
-Comme vous pouvez le voir, les parties de l'entrée correspondant à `[CLS] sentence1 [SEP]` ont toutes un *token* de type ID de `0`, tandis que les autres parties, correspondant à `sentence2 [SEP]`, ont toutes un *token* de type ID de `1`.
-
-Notez que si vous choisissez un autre *checkpoint*, vous n'aurez pas nécessairement les `token_type_ids` dans vos entrées tokenisées (par exemple, ils ne sont pas retournés si vous utilisez un modèle DistilBERT). Ils ne sont retournés que lorsque le modèle sait quoi faire avec eux, parce qu'il les a vus pendant son pré-entraînement.
-
-Ici, BERT est pré-entraîné avec les *tokens* de type ID et en plus de l'objectif de modélisation du langage masqué dont nous avons abordé dans [chapitre 1](/course/fr/chapter1), il a un objectif supplémentaire appelé _prédiction de la phrase suivante_. Le but de cette tâche est de modéliser la relation entre des paires de phrases.
-
-Avec la prédiction de la phrase suivante, on fournit au modèle des paires de phrases (avec des *tokens* masqués de manière aléatoire) et on lui demande de prédire si la deuxième phrase suit la première. Pour rendre la tâche non triviale, la moitié du temps, les phrases se suivent dans le document d'origine dont elles ont été extraites, et l'autre moitié du temps, les deux phrases proviennent de deux documents différents.
-
-En général, vous n'avez pas besoin de vous inquiéter de savoir s'il y a ou non des `token_type_ids` dans vos entrées tokenisées : tant que vous utilisez le même *checkpoint* pour le *tokenizer* et le modèle, tout ira bien puisque le *tokenizer* sait quoi fournir à son modèle.
-
-Maintenant que nous avons vu comment notre *tokenizer* peut traiter une paire de phrases, nous pouvons l'utiliser pour tokeniser l'ensemble de notre jeu de données : comme dans le [chapitre précédent](/course/fr/chapter2), nous pouvons fournir au *tokenizer* une liste de paires de phrases en lui donnant la liste des premières phrases, puis la liste des secondes phrases. Ceci est également compatible avec les options de remplissage et de troncature que nous avons vues dans le [chapitre 2](/course/fr/chapter2). Voici donc une façon de prétraiter le jeu de données d'entraînement :
-
-```py
-tokenized_dataset = tokenizer(
- raw_datasets["train"]["sentence1"],
- raw_datasets["train"]["sentence2"],
- padding=True,
- truncation=True,
-)
-```
-
-Cela fonctionne bien, mais a l'inconvénient de retourner un dictionnaire (avec nos clés, `input_ids`, `attention_mask`, et `token_type_ids`, et des valeurs qui sont des listes de listes). Cela ne fonctionnera également que si vous avez assez de RAM pour stocker l'ensemble de votre jeu de données pendant la tokenisation (alors que les jeux de données de la bibliothèque 🤗 *Datasets* sont des fichiers [Apache Arrow](https://arrow.apache.org/) stockés sur le disque, vous ne gardez donc en mémoire que les échantillons que vous demandez).
-
-Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
-
-```py
-def tokenize_function(example):
- return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
-```
-
-Cette fonction prend un dictionnaire (comme les éléments de notre jeu de données) et retourne un nouveau dictionnaire avec les clés `input_ids`, `attention_mask`, et `token_type_ids`. Notez que cela fonctionne également si le dictionnaire `example` contient plusieurs échantillons (chaque clé étant une liste de phrases) puisque le `tokenizer` travaille sur des listes de paires de phrases, comme vu précédemment. Cela nous permettra d'utiliser l'option `batched=True` dans notre appel à `map()`, ce qui accélérera grandement la tokénisation. Le `tokenizer` est soutenu par un *tokenizer* écrit en Rust à partir de la bibliothèque [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers). Ce *tokenizer* peut être très rapide, mais seulement si on lui donne beaucoup d'entrées en même temps.
-
-Notez que nous avons laissé l'argument `padding` hors de notre fonction de *tokenizer* pour le moment. C'est parce que le *padding* de tous les échantillons à la longueur maximale n'est pas efficace : il est préférable de remplir les échantillons lorsque nous construisons un batch, car alors nous avons seulement besoin de remplir à la longueur maximale dans ce batch, et non la longueur maximale dans l'ensemble des données. Cela peut permettre de gagner beaucoup de temps et de puissance de traitement lorsque les entrées ont des longueurs très variables !
-
-Voici comment nous appliquons la fonction de tokenization sur tous nos jeux de données en même temps. Nous utilisons `batched=True` dans notre appel à `map` pour que la fonction soit appliquée à plusieurs éléments de notre jeu de données en une fois, et non à chaque élément séparément. Cela permet un prétraitement plus rapide.
-
-```py
-tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
-tokenized_datasets
-```
-
-La façon dont la bibliothèque 🤗 *Datasets* applique ce traitement consiste à ajouter de nouveaux champs aux jeux de données, un pour chaque clé du dictionnaire renvoyé par la fonction de prétraitement :
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
- num_rows: 3668
- })
- validation: Dataset({
- features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
- num_rows: 408
- })
- test: Dataset({
- features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
- num_rows: 1725
- })
-})
-```
-
-Vous pouvez même utiliser le multitraitement lorsque vous appliquez votre fonction de prétraitement avec `map()` en passant un argument `num_proc`. Nous ne l'avons pas fait ici parce que la bibliothèque 🤗 *Tokenizers* utilise déjà plusieurs *threads* pour tokeniser nos échantillons plus rapidement, mais si vous n'utilisez pas un *tokenizer* rapide soutenu par cette bibliothèque, cela pourrait accélérer votre prétraitement.
-
-Notre `tokenize_function` retourne un dictionnaire avec les clés `input_ids`, `attention_mask`, et `token_type_ids`, donc ces trois champs sont ajoutés à toutes les divisions de notre jeu de données. Notez que nous aurions également pu modifier des champs existants si notre fonction de prétraitement avait retourné une nouvelle valeur pour une clé existante dans l'ensemble de données auquel nous avons appliqué `map()`.
-
-La dernière chose que nous devrons faire est de remplir tous les exemples à la longueur de l'élément le plus long lorsque nous regroupons les éléments, une technique que nous appelons le *padding dynamique*.
-
-### Padding dynamique
-
-
-
-{#if fw === 'pt'}
-La fonction qui est responsable de l'assemblage des échantillons dans un batch est appelée *fonction de rassemblement*. C'est un argument que vous pouvez passer quand vous construisez un `DataLoader`, la valeur par défaut étant une fonction qui va juste convertir vos échantillons en tenseurs PyTorch et les concaténer (récursivement si vos éléments sont des listes, des *tuples* ou des dictionnaires). Cela ne sera pas possible dans notre cas puisque les entrées que nous avons ne seront pas toutes de la même taille. Nous avons délibérément reporté le *padding*, pour ne l'appliquer que si nécessaire sur chaque batch et éviter d'avoir des entrées trop longues avec beaucoup de remplissage. Cela accélère considérablement l'entraînement, mais notez que si vous vous entraînez sur un TPU, cela peut poser des problèmes. En effet, les TPU préfèrent les formes fixes, même si cela nécessite un *padding* supplémentaire.
-
-{:else}
-La fonction qui est responsable de l'assemblage des échantillons dans un batch est appelée *fonction de rassemblement*. C'est un argument que vous pouvez passer quand vous construisez un `DataLoader`, la valeur par défaut étant une fonction qui va juste convertir vos échantillons en type tf.Tensor et les concaténer (récursivement si les éléments sont des listes, des *tuples* ou des dictionnaires). Cela ne sera pas possible dans notre cas puisque les entrées que nous avons ne seront pas toutes de la même taille. Nous avons délibérément reporté le *padding*, pour ne l'appliquer que si nécessaire sur chaque batch et éviter d'avoir des entrées trop longues avec beaucoup de remplissage. Cela accélère considérablement l'entraînement, mais notez que si vous vous entraînez sur un TPU, cela peut poser des problèmes. En effet, les TPU préfèrent les formes fixes, même si cela nécessite un *padding* supplémentaire.
-
-{/if}
-Pour faire cela en pratique, nous devons définir une fonction de rassemblement qui appliquera la bonne quantité de *padding* aux éléments du jeu de données que nous voulons regrouper. Heureusement, la bibliothèque 🤗 *Transformers* nous fournit une telle fonction via `DataCollatorWithPadding`. Elle prend un *tokenizer* lorsque vous l'instanciez (pour savoir quel *token* de *padding* utiliser et si le modèle s'attend à ce que le *padding* soit à gauche ou à droite des entrées) et fera tout ce dont vous avez besoin :
-
-{#if fw === 'pt'}
-```py
-from transformers import DataCollatorWithPadding
-
-data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
-```
-{:else}
-```py
-from transformers import DataCollatorWithPadding
-
-data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
-```
-{/if}
-
-Pour tester notre nouveau jouet, prenons quelques éléments de notre jeu d'entraînement avec lesquels nous allons former un batch. Ici, on supprime les colonnes `idx`, `sentence1` et `sentence2` puisque nous n'en aurons pas besoin et qu'elles contiennent des *strings* (et nous ne pouvons pas créer des tenseurs avec des *strings*) et on regarde la longueur de chaque entrée du batch :
-
-```py
-samples = tokenized_datasets["train"][:8]
-samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
-[len(x) for x in samples["input_ids"]]
-```
-
-```python out
-[50, 59, 47, 67, 59, 50, 62, 32]
-```
-
-Sans surprise, nous obtenons des échantillons de longueur variable, de 32 à 67. Le *padding* dynamique signifie que les échantillons de ce batch doivent tous être rembourrés à une longueur de 67, la longueur maximale dans le batch. Sans le *padding* dynamique, tous les échantillons devraient être rembourrés à la longueur maximale du jeu de données entier, ou à la longueur maximale que le modèle peut accepter. Vérifions à nouveau que notre `data_collator` rembourre dynamiquement le batch correctement :
-
-```py
-batch = data_collator(samples)
-{k: v.shape for k, v in batch.items()}
-```
-
-{#if fw === 'tf'}
-
-```python out
-{'attention_mask': TensorShape([8, 67]),
- 'input_ids': TensorShape([8, 67]),
- 'token_type_ids': TensorShape([8, 67]),
- 'labels': TensorShape([8])}
-```
-
-{:else}
-
-```python out
-{'attention_mask': torch.Size([8, 67]),
- 'input_ids': torch.Size([8, 67]),
- 'token_type_ids': torch.Size([8, 67]),
- 'labels': torch.Size([8])}
-```
-
-C'est beau ! Maintenant que nous sommes passés du texte brut à des batchs que notre modèle peut traiter, nous sommes prêts à le *finetuner* !
-
-{/if}
-
-
-
-✏️ **Essayez !** Reproduisez le prétraitement sur le jeu de données GLUE SST-2. C'est un peu différent puisqu'il est composé de phrases simples au lieu de paires, mais le reste de ce que nous avons fait devrait être identique. Pour un défi plus difficile, essayez d'écrire une fonction de prétraitement qui fonctionne sur toutes les tâches GLUE.
-
-
-
-{#if fw === 'tf'}
-
-Maintenant que nous disposons de notre jeu de données et d'un collecteur de données, nous devons les assembler. Nous pourrions charger manuellement des batchs et les assembler mais c'est beaucoup de travail et probablement pas très performant non plus. A la place, il existe une méthode simple qui offre une solution performante à ce problème : `to_tf_dataset()`. Cela va envelopper un `tf.data.Dataset` autour de votre jeu de données, avec une fonction de collation optionnelle. `tf.data.Dataset` est un format natif de TensorFlow que Keras peut utiliser pour `model.fit()`, donc cette seule méthode convertit immédiatement un *dataset* en un format prêt pour l'entraînement. Voyons cela en action avec notre jeu de données !
-
-```py
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "token_type_ids"],
- label_cols=["labels"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-
-tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "token_type_ids"],
- label_cols=["labels"],
- shuffle=False,
- collate_fn=data_collator,
- batch_size=8,
-)
-```
-
-Et c'est tout ! Nous pouvons utiliser ces jeux de données dans le prochain cours, où l'entraînement sera agréablement simple après tout le dur travail de prétraitement des données.
-
-{/if}
+
+
+# Préparer les données
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+{#if fw === 'pt'}
+
+En continuant avec l'exemple du [chapitre précédent](/course/fr/chapter2), voici comment entraîner un classifieur de séquences sur un batch avec PyTorch :
+
+```python
+import torch
+from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
+
+# Même chose que précédemment
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
+sequences = [
+ "I've been waiting for a HuggingFace course my whole life.",
+ # J'ai attendu un cours de HuggingFace toute ma vie.
+ "This course is amazing!", # Ce cours est incroyable !
+]
+batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
+
+# Ceci est nouveau
+batch["labels"] = torch.tensor([1, 1])
+
+optimizer = AdamW(model.parameters())
+loss = model(**batch).loss
+loss.backward()
+optimizer.step()
+```
+{:else}
+
+En continuant avec l'exemple du [chapitre précédent](/course/fr/chapter2), voici comment entraîner un classifieur de séquences sur un batch avec TensorFlow :
+
+```python
+import tensorflow as tf
+import numpy as np
+from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+# Même chose que précédemment
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
+sequences = [
+ "I've been waiting for a HuggingFace course my whole life.",
+ # J'ai attendu un cours de HuggingFace toute ma vie.
+ "This course is amazing!", # Ce cours est incroyable !
+]
+batch = dict(tokenizer(sequences, padding=True, truncation=True, return_tensors="tf"))
+
+# Ceci est nouveau
+model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
+labels = tf.convert_to_tensor([1, 1])
+model.train_on_batch(batch, labels)
+```
+{/if}
+Evidemment, entraîner un modèle avec seulement deux phrases ne va pas donner de bons résultats. Pour obtenir de meilleurs résultats, vous allez avoir à préparer un plus grand jeu de données.
+
+Dans cette section, nous allons utiliser comme exemple le jeu de données MRPC (*Microsoft Research Paraphrase Corpus*) présenté dans un [papier](https://www.aclweb.org/anthology/I05-5002.pdf) par William B. Dolan et Chris Brockett. Ce jeu de données contient 5801 paires de phrases avec un label indiquant si ces paires sont des paraphrases ou non (i.e. si elles ont la même signification). Nous l'avons choisi pour ce chapitre parce que c'est un petit jeu de données et cela rend donc simples les expériences d'entraînement sur ce jeu de données.
+
+### Charger un jeu de données depuis le Hub
+
+{#if fw === 'pt'}
+
+{:else}
+
+{/if}
+
+Le *Hub* ne contient pas seulement des modèles mais aussi plusieurs jeux de données dans un tas de langues différentes. Vous pouvez explorer les jeux de données [ici](https://huggingface.co/datasets) et nous vous conseillons d'essayer de charger un nouveau jeu de données une fois que vous avez étudié cette section (voir la documentation générale [ici](https://huggingface.co/docs/datasets/loading_datasets.html#from-the-huggingface-hub)). Mais pour l'instant, concentrons-nous sur le jeu de données MRPC ! Il s'agit de l'un des 10 jeux de données qui constituent le [*benchmark* GLUE](https://gluebenchmark.com/) qui est un *benchmark* académique utilisé pour mesurer les performances des modèles d'apprentissage automatique sur 10 différentes tâches de classification de textes.
+
+La bibliothèque 🤗 *Datasets* propose une commande très simple pour télécharger et mettre en cache un jeu de données à partir du *Hub*. On peut télécharger le jeu de données MRPC comme ceci :
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("glue", "mrpc")
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['sentence1', 'sentence2', 'label', 'idx'],
+ num_rows: 3668
+ })
+ validation: Dataset({
+ features: ['sentence1', 'sentence2', 'label', 'idx'],
+ num_rows: 408
+ })
+ test: Dataset({
+ features: ['sentence1', 'sentence2', 'label', 'idx'],
+ num_rows: 1725
+ })
+})
+```
+
+Comme vous le voyez, on obtient un objet de type `DatasetDict` qui contient le jeu de données d'entraînement, celui de validation et celui de test. Chacun d'eux contient plusieurs colonnes (`sentence1`, `sentence2`, `label` et `idx`) et une variable nombre de lignes qui contient le nombre d'éléments dans chaque jeu de données (il y a donc 3.668 paires de phrases dans le jeu d'entraînement, 408 dans celui de validation et 1.725 dans celui de test).
+
+Cette commande télécharge et met en cache le jeu de données dans *~/.cache/huggingface/dataset*. Rappelez-vous que comme vu au chapitre 2, vous pouvez personnaliser votre dossier cache en modifiant la variable d'environnement `HF_HOME`.
+
+Nous pouvons accéder à chaque paire de phrase de notre objet `raw_datasets` par les indices, comme avec un dictionnaire :
+
+```py
+raw_train_dataset = raw_datasets["train"]
+raw_train_dataset[0]
+```
+
+```python out
+{'idx': 0,
+ 'label': 1,
+ 'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
+ # Amrozi a accusé son frère, qu'il a appelé « le témoin », de déformer délibérément son témoignage.
+ 'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
+ # Se référant à lui uniquement comme « le témoin », Amrozi a accusé son frère de déformer délibérément son témoignage.
+```
+
+Nous pouvons voir que les étiquettes sont déjà des entiers, donc nous n'aurons pas à faire de prétraitement ici. Pour savoir quel entier correspond à quel label, nous pouvons inspecter les `features` de notre `raw_train_dataset`. Cela nous indiquera le type de chaque colonne :
+
+```py
+raw_train_dataset.features
+```
+
+```python out
+{'sentence1': Value(dtype='string', id=None),
+ 'sentence2': Value(dtype='string', id=None),
+ 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
+ 'idx': Value(dtype='int32', id=None)}
+```
+
+En réalité, `label` est de type `ClassLabel` et la correspondance des entiers aux noms des labels est enregistrée le dossier *names*. `0` correspond à `not_equivalent` et `1` correspond à `equivalent`.
+
+
+
+✏️ **Essayez !** Regardez l'élément 15 de l'ensemble d'entraînement et l'élément 87 de l'ensemble de validation. Quelles sont leurs étiquettes ?
+
+
+### Prétraitement d'un jeu de données
+
+{#if fw === 'pt'}
+
+{:else}
+
+{/if}
+
+Pour prétraiter le jeu de données, nous devons convertir le texte en chiffres compréhensibles par le modèle. Comme vous l'avez vu dans le [chapitre précédent](/course/fr/chapter2), cette conversion est effectuée par un *tokenizer*. Nous pouvons fournir au *tokenizer* une phrase ou une liste de phrases, de sorte que nous pouvons directement tokeniser toutes les premières phrases et toutes les secondes phrases de chaque paire comme ceci :
+
+```py
+from transformers import AutoTokenizer
+
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
+tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
+```
+
+Cependant, nous ne pouvons pas simplement passer deux séquences au modèle et obtenir une prédiction pour savoir si les deux phrases sont des paraphrases ou non. Nous devons traiter les deux séquences comme une paire, et appliquer le prétraitement approprié. Heureusement, le *tokenizer* peut également prendre une paire de séquences et la préparer de la manière attendue par notre modèle BERT :
+
+```py
+inputs = tokenizer(
+ "This is the first sentence.", "This is the second one."
+) # "C'est la première phrase.", "C'est la deuxième."
+inputs
+```
+
+```python out
+{
+ 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+}
+```
+
+Nous avons discuté des clés `input_ids` et `attention_mask` dans le [chapitre 2](/course/fr/chapter2), mais nous avons laissé de côté les `token_type_ids`. Dans cet exemple, c'est ce qui indique au modèle quelle partie de l'entrée est la première phrase et quelle partie est la deuxième phrase.
+
+
+
+✏️ **Essayez !** Prenez l'élément 15 de l'ensemble d'entraînement et tokenisez les deux phrases séparément et par paire. Quelle est la différence entre les deux résultats ?
+
+
+
+Si on décode les IDs dans `input_ids` en mots :
+
+```py
+tokenizer.convert_ids_to_tokens(inputs["input_ids"])
+```
+
+nous aurons :
+
+```python out
+['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
+```
+
+Nous voyons donc que le modèle s'attend à ce que les entrées soient de la forme `[CLS] phrase1 [SEP] phrase2 [SEP]` lorsqu'il y a deux phrases. En alignant cela avec les `token_type_ids`, on obtient :
+
+```python out
+['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
+[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
+```
+
+Comme vous pouvez le voir, les parties de l'entrée correspondant à `[CLS] sentence1 [SEP]` ont toutes un *token* de type ID de `0`, tandis que les autres parties, correspondant à `sentence2 [SEP]`, ont toutes un *token* de type ID de `1`.
+
+Notez que si vous choisissez un autre *checkpoint*, vous n'aurez pas nécessairement les `token_type_ids` dans vos entrées tokenisées (par exemple, ils ne sont pas retournés si vous utilisez un modèle DistilBERT). Ils ne sont retournés que lorsque le modèle sait quoi faire avec eux, parce qu'il les a vus pendant son pré-entraînement.
+
+Ici, BERT est pré-entraîné avec les *tokens* de type ID et en plus de l'objectif de modélisation du langage masqué dont nous avons abordé dans [chapitre 1](/course/fr/chapter1), il a un objectif supplémentaire appelé _prédiction de la phrase suivante_. Le but de cette tâche est de modéliser la relation entre des paires de phrases.
+
+Avec la prédiction de la phrase suivante, on fournit au modèle des paires de phrases (avec des *tokens* masqués de manière aléatoire) et on lui demande de prédire si la deuxième phrase suit la première. Pour rendre la tâche non triviale, la moitié du temps, les phrases se suivent dans le document d'origine dont elles ont été extraites, et l'autre moitié du temps, les deux phrases proviennent de deux documents différents.
+
+En général, vous n'avez pas besoin de vous inquiéter de savoir s'il y a ou non des `token_type_ids` dans vos entrées tokenisées : tant que vous utilisez le même *checkpoint* pour le *tokenizer* et le modèle, tout ira bien puisque le *tokenizer* sait quoi fournir à son modèle.
+
+Maintenant que nous avons vu comment notre *tokenizer* peut traiter une paire de phrases, nous pouvons l'utiliser pour tokeniser l'ensemble de notre jeu de données : comme dans le [chapitre précédent](/course/fr/chapter2), nous pouvons fournir au *tokenizer* une liste de paires de phrases en lui donnant la liste des premières phrases, puis la liste des secondes phrases. Ceci est également compatible avec les options de remplissage et de troncature que nous avons vues dans le [chapitre 2](/course/fr/chapter2). Voici donc une façon de prétraiter le jeu de données d'entraînement :
+
+```py
+tokenized_dataset = tokenizer(
+ raw_datasets["train"]["sentence1"],
+ raw_datasets["train"]["sentence2"],
+ padding=True,
+ truncation=True,
+)
+```
+
+Cela fonctionne bien, mais a l'inconvénient de retourner un dictionnaire (avec nos clés, `input_ids`, `attention_mask`, et `token_type_ids`, et des valeurs qui sont des listes de listes). Cela ne fonctionnera également que si vous avez assez de RAM pour stocker l'ensemble de votre jeu de données pendant la tokenisation (alors que les jeux de données de la bibliothèque 🤗 *Datasets* sont des fichiers [Apache Arrow](https://arrow.apache.org/) stockés sur le disque, vous ne gardez donc en mémoire que les échantillons que vous demandez).
+
+Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
+
+```py
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+```
+
+Cette fonction prend un dictionnaire (comme les éléments de notre jeu de données) et retourne un nouveau dictionnaire avec les clés `input_ids`, `attention_mask`, et `token_type_ids`. Notez que cela fonctionne également si le dictionnaire `example` contient plusieurs échantillons (chaque clé étant une liste de phrases) puisque le `tokenizer` travaille sur des listes de paires de phrases, comme vu précédemment. Cela nous permettra d'utiliser l'option `batched=True` dans notre appel à `map()`, ce qui accélérera grandement la tokénisation. Le `tokenizer` est soutenu par un *tokenizer* écrit en Rust à partir de la bibliothèque [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers). Ce *tokenizer* peut être très rapide, mais seulement si on lui donne beaucoup d'entrées en même temps.
+
+Notez que nous avons laissé l'argument `padding` hors de notre fonction de *tokenizer* pour le moment. C'est parce que le *padding* de tous les échantillons à la longueur maximale n'est pas efficace : il est préférable de remplir les échantillons lorsque nous construisons un batch, car alors nous avons seulement besoin de remplir à la longueur maximale dans ce batch, et non la longueur maximale dans l'ensemble des données. Cela peut permettre de gagner beaucoup de temps et de puissance de traitement lorsque les entrées ont des longueurs très variables !
+
+Voici comment nous appliquons la fonction de tokenization sur tous nos jeux de données en même temps. Nous utilisons `batched=True` dans notre appel à `map` pour que la fonction soit appliquée à plusieurs éléments de notre jeu de données en une fois, et non à chaque élément séparément. Cela permet un prétraitement plus rapide.
+
+```py
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+tokenized_datasets
+```
+
+La façon dont la bibliothèque 🤗 *Datasets* applique ce traitement consiste à ajouter de nouveaux champs aux jeux de données, un pour chaque clé du dictionnaire renvoyé par la fonction de prétraitement :
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
+ num_rows: 3668
+ })
+ validation: Dataset({
+ features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
+ num_rows: 408
+ })
+ test: Dataset({
+ features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
+ num_rows: 1725
+ })
+})
+```
+
+Vous pouvez même utiliser le multitraitement lorsque vous appliquez votre fonction de prétraitement avec `map()` en passant un argument `num_proc`. Nous ne l'avons pas fait ici parce que la bibliothèque 🤗 *Tokenizers* utilise déjà plusieurs *threads* pour tokeniser nos échantillons plus rapidement, mais si vous n'utilisez pas un *tokenizer* rapide soutenu par cette bibliothèque, cela pourrait accélérer votre prétraitement.
+
+Notre `tokenize_function` retourne un dictionnaire avec les clés `input_ids`, `attention_mask`, et `token_type_ids`, donc ces trois champs sont ajoutés à toutes les divisions de notre jeu de données. Notez que nous aurions également pu modifier des champs existants si notre fonction de prétraitement avait retourné une nouvelle valeur pour une clé existante dans l'ensemble de données auquel nous avons appliqué `map()`.
+
+La dernière chose que nous devrons faire est de remplir tous les exemples à la longueur de l'élément le plus long lorsque nous regroupons les éléments, une technique que nous appelons le *padding dynamique*.
+
+### Padding dynamique
+
+
+
+{#if fw === 'pt'}
+La fonction qui est responsable de l'assemblage des échantillons dans un batch est appelée *fonction de rassemblement*. C'est un argument que vous pouvez passer quand vous construisez un `DataLoader`, la valeur par défaut étant une fonction qui va juste convertir vos échantillons en tenseurs PyTorch et les concaténer (récursivement si vos éléments sont des listes, des *tuples* ou des dictionnaires). Cela ne sera pas possible dans notre cas puisque les entrées que nous avons ne seront pas toutes de la même taille. Nous avons délibérément reporté le *padding*, pour ne l'appliquer que si nécessaire sur chaque batch et éviter d'avoir des entrées trop longues avec beaucoup de remplissage. Cela accélère considérablement l'entraînement, mais notez que si vous vous entraînez sur un TPU, cela peut poser des problèmes. En effet, les TPU préfèrent les formes fixes, même si cela nécessite un *padding* supplémentaire.
+
+{:else}
+La fonction qui est responsable de l'assemblage des échantillons dans un batch est appelée *fonction de rassemblement*. C'est un argument que vous pouvez passer quand vous construisez un `DataLoader`, la valeur par défaut étant une fonction qui va juste convertir vos échantillons en type tf.Tensor et les concaténer (récursivement si les éléments sont des listes, des *tuples* ou des dictionnaires). Cela ne sera pas possible dans notre cas puisque les entrées que nous avons ne seront pas toutes de la même taille. Nous avons délibérément reporté le *padding*, pour ne l'appliquer que si nécessaire sur chaque batch et éviter d'avoir des entrées trop longues avec beaucoup de remplissage. Cela accélère considérablement l'entraînement, mais notez que si vous vous entraînez sur un TPU, cela peut poser des problèmes. En effet, les TPU préfèrent les formes fixes, même si cela nécessite un *padding* supplémentaire.
+
+{/if}
+Pour faire cela en pratique, nous devons définir une fonction de rassemblement qui appliquera la bonne quantité de *padding* aux éléments du jeu de données que nous voulons regrouper. Heureusement, la bibliothèque 🤗 *Transformers* nous fournit une telle fonction via `DataCollatorWithPadding`. Elle prend un *tokenizer* lorsque vous l'instanciez (pour savoir quel *token* de *padding* utiliser et si le modèle s'attend à ce que le *padding* soit à gauche ou à droite des entrées) et fera tout ce dont vous avez besoin :
+
+{#if fw === 'pt'}
+```py
+from transformers import DataCollatorWithPadding
+
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+{:else}
+```py
+from transformers import DataCollatorWithPadding
+
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+```
+{/if}
+
+Pour tester notre nouveau jouet, prenons quelques éléments de notre jeu d'entraînement avec lesquels nous allons former un batch. Ici, on supprime les colonnes `idx`, `sentence1` et `sentence2` puisque nous n'en aurons pas besoin et qu'elles contiennent des *strings* (et nous ne pouvons pas créer des tenseurs avec des *strings*) et on regarde la longueur de chaque entrée du batch :
+
+```py
+samples = tokenized_datasets["train"][:8]
+samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
+[len(x) for x in samples["input_ids"]]
+```
+
+```python out
+[50, 59, 47, 67, 59, 50, 62, 32]
+```
+
+Sans surprise, nous obtenons des échantillons de longueur variable, de 32 à 67. Le *padding* dynamique signifie que les échantillons de ce batch doivent tous être rembourrés à une longueur de 67, la longueur maximale dans le batch. Sans le *padding* dynamique, tous les échantillons devraient être rembourrés à la longueur maximale du jeu de données entier, ou à la longueur maximale que le modèle peut accepter. Vérifions à nouveau que notre `data_collator` rembourre dynamiquement le batch correctement :
+
+```py
+batch = data_collator(samples)
+{k: v.shape for k, v in batch.items()}
+```
+
+{#if fw === 'tf'}
+
+```python out
+{'attention_mask': TensorShape([8, 67]),
+ 'input_ids': TensorShape([8, 67]),
+ 'token_type_ids': TensorShape([8, 67]),
+ 'labels': TensorShape([8])}
+```
+
+{:else}
+
+```python out
+{'attention_mask': torch.Size([8, 67]),
+ 'input_ids': torch.Size([8, 67]),
+ 'token_type_ids': torch.Size([8, 67]),
+ 'labels': torch.Size([8])}
+```
+
+C'est beau ! Maintenant que nous sommes passés du texte brut à des batchs que notre modèle peut traiter, nous sommes prêts à le *finetuner* !
+
+{/if}
+
+
+
+✏️ **Essayez !** Reproduisez le prétraitement sur le jeu de données GLUE SST-2. C'est un peu différent puisqu'il est composé de phrases simples au lieu de paires, mais le reste de ce que nous avons fait devrait être identique. Pour un défi plus difficile, essayez d'écrire une fonction de prétraitement qui fonctionne sur toutes les tâches GLUE.
+
+
+
+{#if fw === 'tf'}
+
+Maintenant que nous disposons de notre jeu de données et d'un collecteur de données, nous devons les assembler. Nous pourrions charger manuellement des batchs et les assembler mais c'est beaucoup de travail et probablement pas très performant non plus. A la place, il existe une méthode simple qui offre une solution performante à ce problème : `to_tf_dataset()`. Cela va envelopper un `tf.data.Dataset` autour de votre jeu de données, avec une fonction de collation optionnelle. `tf.data.Dataset` est un format natif de TensorFlow que Keras peut utiliser pour `model.fit()`, donc cette seule méthode convertit immédiatement un *dataset* en un format prêt pour l'entraînement. Voyons cela en action avec notre jeu de données !
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+
+tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=False,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+```
+
+Et c'est tout ! Nous pouvons utiliser ces jeux de données dans le prochain cours, où l'entraînement sera agréablement simple après tout le dur travail de prétraitement des données.
+
+{/if}
diff --git a/chapters/fr/chapter3/3.mdx b/chapters/fr/chapter3/3.mdx
index 2624cdd5a..eba84e1b1 100644
--- a/chapters/fr/chapter3/3.mdx
+++ b/chapters/fr/chapter3/3.mdx
@@ -1,171 +1,171 @@
-
-
-# Finetuner un modèle avec l'API Trainer
-
-
-
-
-
-La bibliothèque 🤗 *Transformers* fournit une classe `Trainer` pour vous aider à *finetuner* n'importe lequel des modèles pré-entraînés qu'elle met à disposition sur votre jeu de données. Une fois que vous avez fait tout le travail de prétraitement des données dans la dernière section, il ne vous reste que quelques étapes pour définir le `Trainer`. La partie la plus difficile sera probablement de préparer l'environnement pour exécuter `Trainer.train()`, car elle fonctionnera très lentement sur un CPU. Si vous n'avez pas de GPU, vous pouvez avoir accès à des GPUs ou TPUs gratuits sur [Google Colab](https://colab.research.google.com/).
-
-Les exemples de code ci-dessous supposent que vous avez déjà exécuté les exemples de la section précédente. Voici un bref résumé de ce dont vous avez besoin :
-
-```py
-from datasets import load_dataset
-from transformers import AutoTokenizer, DataCollatorWithPadding
-
-raw_datasets = load_dataset("glue", "mrpc")
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-
-
-def tokenize_function(example):
- return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
-
-
-tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
-data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
-```
-
-### Entraînement
-
-La première étape avant de pouvoir définir notre `Trainer` est de définir une classe `TrainingArguments` qui contiendra tous les hyperparamètres que le `Trainer` utilisera pour l'entraînement et l'évaluation. Le seul argument que vous devez fournir est un répertoire où le modèle entraîné sera sauvegardé, ainsi que les *checkpoints*. Pour tout le reste, vous pouvez laisser les valeurs par défaut, qui devraient fonctionner assez bien pour un *finetuning* de base.
-
-```py
-from transformers import TrainingArguments
-
-training_args = TrainingArguments("test-trainer")
-```
-
-
-
-💡 Si vous voulez télécharger automatiquement votre modèle sur le *Hub* pendant l'entraînement, passez `push_to_hub=True` dans le `TrainingArguments`. Nous en apprendrons plus à ce sujet au [chapitre 4](/course/fr/chapter4/3).
-
-
-
-La deuxième étape consiste à définir notre modèle. Comme dans le [chapitre précédent](/course/fr/chapter2), nous utiliserons la classe `AutoModelForSequenceClassification`, avec deux labels :
-
-```py
-from transformers import AutoModelForSequenceClassification
-
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-```
-
-Vous remarquerez que contrairement au [chapitre 2](/course/fr/chapter2), vous obtenez un message d'avertissement après l'instanciation de ce modèle pré-entraîné. C'est parce que BERT n'a pas été pré-entraîné à la classification de paires de phrases, donc la tête du modèle pré-entraîné a été supprimée et une nouvelle tête adaptée à la classification de séquences a été ajoutée à la place. Les messages d'avertissement indiquent que certains poids n'ont pas été utilisés (ceux correspondant à la tête de pré-entraînement abandonnée) et que d'autres ont été initialisés de manière aléatoire (ceux pour la nouvelle tête). Il conclut en vous encourageant à entraîner le modèle, ce qui est exactement ce que nous allons faire maintenant.
-
-Une fois que nous avons notre modèle, nous pouvons définir un `Trainer` en lui passant tous les objets construits jusqu'à présent : le `model`, le `training_args`, les jeux de données d'entraînement et de validation, notre `data_collator`, et notre `tokenizer` :
-
-```py
-from transformers import Trainer
-
-trainer = Trainer(
- model,
- training_args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- tokenizer=tokenizer,
-)
-```
-
-Notez que lorsque vous passez le `tokenizer` comme nous l'avons fait ici, le `data_collator` par défaut utilisé par le `Trainer` sera un `DataCollatorWithPadding` comme défini précédemment. Ainsi, vous pouvez sauter la ligne `data_collator=data_collator` dans cet appel. Il était quand même important de vous montrer cette partie du traitement dans la section 2 !
-
-Pour *finetuner* le modèle sur notre jeu de données, il suffit d'appeler la méthode `train()` de notre `Trainer` :
-
-```py
-trainer.train()
-```
-
-Cela lancera le *finetuning* (qui devrait prendre quelques minutes sur un GPU) et indiquera la perte d'entraînement tous les 500 pas. Cependant, elle ne vous dira pas si votre modèle fonctionne bien (ou mal). Ceci est dû au fait que :
-
-1. nous n'avons pas dit au `Trainer` d'évaluer pendant l'entraînement en réglant `evaluation_strategy` à soit `"steps"` (évaluer chaque `eval_steps`) ou `"epoch"` (évaluer à la fin de chaque *epoch*).
-2. nous n'avons pas fourni au `Trainer` une fonction `compute_metrics()` pour calculer une métrique pendant ladite évaluation (sinon l'évaluation aurait juste affiché la perte, qui n'est pas un nombre très intuitif).
-
-
-### Evaluation
-
-Voyons comment nous pouvons construire une fonction `compute_metrics()` utile et l'utiliser la prochaine fois que nous entraînons. La fonction doit prendre un objet `EvalPrediction` (qui est un *tuple* nommé avec un champ `predictions` et un champ `label_ids`) et retournera un dictionnaire de chaînes de caractères vers des flottants (les chaînes de caractères étant les noms des métriques retournées, et les flottants leurs valeurs). Pour obtenir des prédictions de notre modèle, nous pouvons utiliser la commande `Trainer.predict()` :
-
-```py
-predictions = trainer.predict(tokenized_datasets["validation"])
-print(predictions.predictions.shape, predictions.label_ids.shape)
-```
-
-```python out
-(408, 2) (408,)
-```
-
-La sortie de la méthode `predict()` est un autre *tuple* nommé avec trois champs : `predictions`, `label_ids`, et `metrics`. Le champ `metrics` contiendra juste la perte sur le jeu de données passé, ainsi que quelques mesures de temps (combien de temps il a fallu pour prédire, au total et en moyenne). Une fois que nous aurons complété notre fonction `compute_metrics()` et que nous l'aurons passé au `Trainer`, ce champ contiendra également les métriques retournées par `compute_metrics()`.
-
-Comme vous pouvez le voir, `predictions` est un tableau bidimensionnel de forme 408 x 2 (408 étant le nombre d'éléments dans le jeu de données que nous avons utilisé). Ce sont les logits pour chaque élément du jeu de données que nous avons passé à `predict()` (comme vous l'avez vu dans le [chapitre précédent](/course/fr/chapter2), tous les *transformers* retournent des logits). Pour les transformer en prédictions que nous pouvons comparer à nos étiquettes, nous devons prendre l'indice avec la valeur maximale sur le second axe :
-
-```py
-import numpy as np
-
-preds = np.argmax(predictions.predictions, axis=-1)
-```
-
-Nous pouvons maintenant comparer ces `preds` aux étiquettes. Pour construire notre fonction `compute_metric()`, nous allons nous appuyer sur les métriques de la bibliothèque 🤗 [*Evaluate*](https://github.com/huggingface/evaluate/). Nous pouvons charger les métriques associées au jeu de données MRPC aussi facilement que nous avons chargé le jeu de données, cette fois avec la fonction `evaluate.load()`. L'objet retourné possède une méthode `compute()` que nous pouvons utiliser pour effectuer le calcul de la métrique :
-
-```py
-import evaluate
-
-metric = evaluate.load("glue", "mrpc")
-metric.compute(predictions=preds, references=predictions.label_ids)
-```
-
-```python out
-{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
-```
-
-Les résultats exacts que vous obtiendrez peuvent varier, car l'initialisation aléatoire de la tête du modèle peut modifier les métriques obtenues. Ici, nous pouvons voir que notre modèle a une précision de 85,78% sur l'ensemble de validation et un score F1 de 89,97. Ce sont les deux métriques utilisées pour évaluer les résultats sur le jeu de données MRPC pour le benchmark GLUE. Le tableau du papier de [BERT](https://arxiv.org/pdf/1810.04805.pdf) indique un score F1 de 88,9 pour le modèle de base. Il s'agissait du modèle `uncased` alors que nous utilisons actuellement le modèle `cased`, ce qui explique le meilleur résultat.
-
-En regroupant le tout, nous obtenons notre fonction `compute_metrics()` :
-
-```py
-def compute_metrics(eval_preds):
- metric = evaluate.load("glue", "mrpc")
- logits, labels = eval_preds
- predictions = np.argmax(logits, axis=-1)
- return metric.compute(predictions=predictions, references=labels)
-```
-
-Et pour le voir utilisé en action pour rapporter les métriques à la fin de chaque époque, voici comment nous définissons un nouveau `Trainer` avec cette fonction `compute_metrics()` :
-
-```py
-training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-
-trainer = Trainer(
- model,
- training_args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- tokenizer=tokenizer,
- compute_metrics=compute_metrics,
-)
-```
-
-Notez que nous créons un nouveau `TrainingArguments` avec sa `evaluation_strategy` définie sur `"epoch"` et un nouveau modèle. Sinon, nous ne ferions que continuer l'entraînement du modèle que nous avons déjà entraîné. Pour lancer un nouveau cycle d'entraînement, nous exécutons :
-
-```
-trainer.train()
-```
-
-Cette fois, il indiquera la perte et les mesures de validation à la fin de chaque époque, en plus de la perte d'entraînement. Encore une fois, le score exact de précision/F1 que vous atteignez peut être un peu différent de ce que nous avons trouvé, en raison de l'initialisation aléatoire de la tête du modèle, mais il devrait être dans la même fourchette.
-
-Le `Trainer` fonctionnera sur plusieurs GPUs ou TPUs et fournit beaucoup d'options, comme l'entraînement en précision mixte (utilisez `fp16 = True` dans vos arguments d'entraînement). Nous passerons en revue tout ce qu'il supporte dans le chapitre 10.
-
-Ceci conclut l'introduction au *fine-tuning* en utilisant l'API `Trainer`. Un exemple d'utilisation pour les tâches de NLP les plus communes es donné dans le [chapitre 7](/course/fr/chapter7), mais pour l'instant regardons comment faire la même chose en PyTorch pur.
-
-
-
-✏️ **Essayez !** *Finetunez* un modèle sur le jeu de données GLUE SST-2, en utilisant le traitement des données que vous avez fait dans la section 2.
-
-
+
+
+# Finetuner un modèle avec l'API Trainer
+
+
+
+
+
+La bibliothèque 🤗 *Transformers* fournit une classe `Trainer` pour vous aider à *finetuner* n'importe lequel des modèles pré-entraînés qu'elle met à disposition sur votre jeu de données. Une fois que vous avez fait tout le travail de prétraitement des données dans la dernière section, il ne vous reste que quelques étapes pour définir le `Trainer`. La partie la plus difficile sera probablement de préparer l'environnement pour exécuter `Trainer.train()`, car elle fonctionnera très lentement sur un CPU. Si vous n'avez pas de GPU, vous pouvez avoir accès à des GPUs ou TPUs gratuits sur [Google Colab](https://colab.research.google.com/).
+
+Les exemples de code ci-dessous supposent que vous avez déjà exécuté les exemples de la section précédente. Voici un bref résumé de ce dont vous avez besoin :
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+### Entraînement
+
+La première étape avant de pouvoir définir notre `Trainer` est de définir une classe `TrainingArguments` qui contiendra tous les hyperparamètres que le `Trainer` utilisera pour l'entraînement et l'évaluation. Le seul argument que vous devez fournir est un répertoire où le modèle entraîné sera sauvegardé, ainsi que les *checkpoints*. Pour tout le reste, vous pouvez laisser les valeurs par défaut, qui devraient fonctionner assez bien pour un *finetuning* de base.
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments("test-trainer")
+```
+
+
+
+💡 Si vous voulez télécharger automatiquement votre modèle sur le *Hub* pendant l'entraînement, passez `push_to_hub=True` dans le `TrainingArguments`. Nous en apprendrons plus à ce sujet au [chapitre 4](/course/fr/chapter4/3).
+
+
+
+La deuxième étape consiste à définir notre modèle. Comme dans le [chapitre précédent](/course/fr/chapter2), nous utiliserons la classe `AutoModelForSequenceClassification`, avec deux labels :
+
+```py
+from transformers import AutoModelForSequenceClassification
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+Vous remarquerez que contrairement au [chapitre 2](/course/fr/chapter2), vous obtenez un message d'avertissement après l'instanciation de ce modèle pré-entraîné. C'est parce que BERT n'a pas été pré-entraîné à la classification de paires de phrases, donc la tête du modèle pré-entraîné a été supprimée et une nouvelle tête adaptée à la classification de séquences a été ajoutée à la place. Les messages d'avertissement indiquent que certains poids n'ont pas été utilisés (ceux correspondant à la tête de pré-entraînement abandonnée) et que d'autres ont été initialisés de manière aléatoire (ceux pour la nouvelle tête). Il conclut en vous encourageant à entraîner le modèle, ce qui est exactement ce que nous allons faire maintenant.
+
+Une fois que nous avons notre modèle, nous pouvons définir un `Trainer` en lui passant tous les objets construits jusqu'à présent : le `model`, le `training_args`, les jeux de données d'entraînement et de validation, notre `data_collator`, et notre `tokenizer` :
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+)
+```
+
+Notez que lorsque vous passez le `tokenizer` comme nous l'avons fait ici, le `data_collator` par défaut utilisé par le `Trainer` sera un `DataCollatorWithPadding` comme défini précédemment. Ainsi, vous pouvez sauter la ligne `data_collator=data_collator` dans cet appel. Il était quand même important de vous montrer cette partie du traitement dans la section 2 !
+
+Pour *finetuner* le modèle sur notre jeu de données, il suffit d'appeler la méthode `train()` de notre `Trainer` :
+
+```py
+trainer.train()
+```
+
+Cela lancera le *finetuning* (qui devrait prendre quelques minutes sur un GPU) et indiquera la perte d'entraînement tous les 500 pas. Cependant, elle ne vous dira pas si votre modèle fonctionne bien (ou mal). Ceci est dû au fait que :
+
+1. nous n'avons pas dit au `Trainer` d'évaluer pendant l'entraînement en réglant `evaluation_strategy` à soit `"steps"` (évaluer chaque `eval_steps`) ou `"epoch"` (évaluer à la fin de chaque *epoch*).
+2. nous n'avons pas fourni au `Trainer` une fonction `compute_metrics()` pour calculer une métrique pendant ladite évaluation (sinon l'évaluation aurait juste affiché la perte, qui n'est pas un nombre très intuitif).
+
+
+### Evaluation
+
+Voyons comment nous pouvons construire une fonction `compute_metrics()` utile et l'utiliser la prochaine fois que nous entraînons. La fonction doit prendre un objet `EvalPrediction` (qui est un *tuple* nommé avec un champ `predictions` et un champ `label_ids`) et retournera un dictionnaire de chaînes de caractères vers des flottants (les chaînes de caractères étant les noms des métriques retournées, et les flottants leurs valeurs). Pour obtenir des prédictions de notre modèle, nous pouvons utiliser la commande `Trainer.predict()` :
+
+```py
+predictions = trainer.predict(tokenized_datasets["validation"])
+print(predictions.predictions.shape, predictions.label_ids.shape)
+```
+
+```python out
+(408, 2) (408,)
+```
+
+La sortie de la méthode `predict()` est un autre *tuple* nommé avec trois champs : `predictions`, `label_ids`, et `metrics`. Le champ `metrics` contiendra juste la perte sur le jeu de données passé, ainsi que quelques mesures de temps (combien de temps il a fallu pour prédire, au total et en moyenne). Une fois que nous aurons complété notre fonction `compute_metrics()` et que nous l'aurons passé au `Trainer`, ce champ contiendra également les métriques retournées par `compute_metrics()`.
+
+Comme vous pouvez le voir, `predictions` est un tableau bidimensionnel de forme 408 x 2 (408 étant le nombre d'éléments dans le jeu de données que nous avons utilisé). Ce sont les logits pour chaque élément du jeu de données que nous avons passé à `predict()` (comme vous l'avez vu dans le [chapitre précédent](/course/fr/chapter2), tous les *transformers* retournent des logits). Pour les transformer en prédictions que nous pouvons comparer à nos étiquettes, nous devons prendre l'indice avec la valeur maximale sur le second axe :
+
+```py
+import numpy as np
+
+preds = np.argmax(predictions.predictions, axis=-1)
+```
+
+Nous pouvons maintenant comparer ces `preds` aux étiquettes. Pour construire notre fonction `compute_metric()`, nous allons nous appuyer sur les métriques de la bibliothèque 🤗 [*Evaluate*](https://github.com/huggingface/evaluate/). Nous pouvons charger les métriques associées au jeu de données MRPC aussi facilement que nous avons chargé le jeu de données, cette fois avec la fonction `evaluate.load()`. L'objet retourné possède une méthode `compute()` que nous pouvons utiliser pour effectuer le calcul de la métrique :
+
+```py
+import evaluate
+
+metric = evaluate.load("glue", "mrpc")
+metric.compute(predictions=preds, references=predictions.label_ids)
+```
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+Les résultats exacts que vous obtiendrez peuvent varier, car l'initialisation aléatoire de la tête du modèle peut modifier les métriques obtenues. Ici, nous pouvons voir que notre modèle a une précision de 85,78% sur l'ensemble de validation et un score F1 de 89,97. Ce sont les deux métriques utilisées pour évaluer les résultats sur le jeu de données MRPC pour le benchmark GLUE. Le tableau du papier de [BERT](https://arxiv.org/pdf/1810.04805.pdf) indique un score F1 de 88,9 pour le modèle de base. Il s'agissait du modèle `uncased` alors que nous utilisons actuellement le modèle `cased`, ce qui explique le meilleur résultat.
+
+En regroupant le tout, nous obtenons notre fonction `compute_metrics()` :
+
+```py
+def compute_metrics(eval_preds):
+ metric = evaluate.load("glue", "mrpc")
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+ return metric.compute(predictions=predictions, references=labels)
+```
+
+Et pour le voir utilisé en action pour rapporter les métriques à la fin de chaque époque, voici comment nous définissons un nouveau `Trainer` avec cette fonction `compute_metrics()` :
+
+```py
+training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+
+trainer = Trainer(
+ model,
+ training_args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+Notez que nous créons un nouveau `TrainingArguments` avec sa `evaluation_strategy` définie sur `"epoch"` et un nouveau modèle. Sinon, nous ne ferions que continuer l'entraînement du modèle que nous avons déjà entraîné. Pour lancer un nouveau cycle d'entraînement, nous exécutons :
+
+```
+trainer.train()
+```
+
+Cette fois, il indiquera la perte et les mesures de validation à la fin de chaque époque, en plus de la perte d'entraînement. Encore une fois, le score exact de précision/F1 que vous atteignez peut être un peu différent de ce que nous avons trouvé, en raison de l'initialisation aléatoire de la tête du modèle, mais il devrait être dans la même fourchette.
+
+Le `Trainer` fonctionnera sur plusieurs GPUs ou TPUs et fournit beaucoup d'options, comme l'entraînement en précision mixte (utilisez `fp16 = True` dans vos arguments d'entraînement). Nous passerons en revue tout ce qu'il supporte dans le chapitre 10.
+
+Ceci conclut l'introduction au *fine-tuning* en utilisant l'API `Trainer`. Un exemple d'utilisation pour les tâches de NLP les plus communes es donné dans le [chapitre 7](/course/fr/chapter7), mais pour l'instant regardons comment faire la même chose en PyTorch pur.
+
+
+
+✏️ **Essayez !** *Finetunez* un modèle sur le jeu de données GLUE SST-2, en utilisant le traitement des données que vous avez fait dans la section 2.
+
+
diff --git a/chapters/fr/chapter3/3_tf.mdx b/chapters/fr/chapter3/3_tf.mdx
index 9a84d533d..bace781f0 100644
--- a/chapters/fr/chapter3/3_tf.mdx
+++ b/chapters/fr/chapter3/3_tf.mdx
@@ -1,190 +1,190 @@
-
-
-# Finetuner un modèle avec Keras
-
-
-
-Une fois que vous avez fait tout le travail de prétraitement des données dans la dernière section, il ne vous reste que quelques étapes pour entraîner le modèle. Notez, cependant, que la commande `model.fit()` s'exécutera très lentement sur un CPU. Si vous n'avez pas de GPU, vous pouvez avoir accès à des GPUs ou TPUs gratuits sur [Google Colab](https://colab.research.google.com/).
-
-Les exemples de code ci-dessous supposent que vous avez déjà exécuté les exemples de la section précédente. Voici un bref résumé de ce dont vous avez besoin :
-
-```py
-from datasets import load_dataset
-from transformers import AutoTokenizer, DataCollatorWithPadding
-import numpy as np
-
-raw_datasets = load_dataset("glue", "mrpc")
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-
-
-def tokenize_function(example):
- return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
-
-
-tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
-
-data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
-
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "token_type_ids"],
- label_cols=["labels"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-
-tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "token_type_ids"],
- label_cols=["labels"],
- shuffle=False,
- collate_fn=data_collator,
- batch_size=8,
-)
-```
-
-### Entraînement
-
-Les modèles TensorFlow importés depuis 🤗 *Transformers* sont déjà des modèles Keras. Voici une courte introduction à Keras.
-
-
-
-Cela signifie qu'une fois que nous disposons de nos données, très peu de travail est nécessaire pour commencer à entraîner sur celles-ci.
-
-
-
-Comme dans le [chapitre précédent](/course/fr/chapter2), nous allons utiliser la classe `TFAutoModelForSequenceClassification`, avec deux étiquettes :
-
-```py
-from transformers import TFAutoModelForSequenceClassification
-
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-```
-
-Vous remarquerez que, contrairement au [chapitre 2](/course/fr/chapter2), vous obtenez un message d'avertissement après l'instanciation de ce modèle pré-entraîné. Ceci est dû au fait que BERT n'a pas été pré-entraîné à la classification de paires de phrases, donc la tête du modèle pré-entraîné a été supprimée et une nouvelle tête adaptée à la classification de séquences a été insérée à la place. Les messages d'avertissement indiquent que certains poids n'ont pas été utilisés (ceux correspondant à la tête de pré-entraînement abandonnée) et que d'autres ont été initialisés de manière aléatoire (ceux pour la nouvelle tête). Il conclut en vous encourageant à entraîner le modèle, ce qui est exactement ce que nous allons faire maintenant.
-
-Pour *finetuner* le modèle sur notre jeu de données, nous devons simplement `compiler()` notre modèle et ensuite passer nos données à la méthode `fit()`. Cela va démarrer le processus de *finetuning* (qui devrait prendre quelques minutes sur un GPU) et rapporter la perte d'entraînement au fur et à mesure, plus la perte de validation à la fin de chaque époque.
-
-
-
-Notez que les modèles 🤗 *Transformers* ont une capacité spéciale que la plupart des modèles Keras n'ont pas. Ils peuvent automatiquement utiliser une perte appropriée qu'ils calculent en interne. Ils utiliseront cette perte par défaut si vous ne définissez pas un argument de perte dans `compile()`. Notez que pour utiliser la perte interne, vous devrez passer vos labels comme faisant partie de l'entrée, et non pas comme un label séparé, ce qui est la façon normale d'utiliser les labels avec les modèles Keras. Vous verrez des exemples de cela dans la partie 2 du cours, où la définition de la fonction de perte correcte peut être délicate. Pour la classification des séquences, cependant, une fonction de perte standard de Keras fonctionne bien, et c'est donc ce que nous utiliserons ici.
-
-
-
-```py
-from tensorflow.keras.losses import SparseCategoricalCrossentropy
-
-model.compile(
- optimizer="adam",
- loss=SparseCategoricalCrossentropy(from_logits=True),
- metrics=["accuracy"],
-)
-model.fit(
- tf_train_dataset,
- validation_data=tf_validation_dataset,
-)
-```
-
-
-
-Notez un piège très commun ici. Vous *pouvez* simplement passer le nom de la perte comme une chaîne à Keras, mais par défaut Keras supposera que vous avez déjà appliqué une fonction softmax à vos sorties. Cependant, de nombreux modèles produisent les valeurs juste avant l'application de la softmax, que l'on appelle aussi les *logits*. Nous devons indiquer à la fonction de perte que c'est ce que fait notre modèle, et la seule façon de le faire est de l'appeler directement, plutôt que par son nom avec une chaîne.
-
-
-
-
-### Améliorer les performances d'entraînement
-
-
-
-Si vous essayez le code ci-dessus, il fonctionne certainement, mais vous constaterez que la perte ne diminue que lentement ou sporadiquement. La cause principale est le *taux d'apprentissage*. Comme pour la perte, lorsque nous transmettons à Keras le nom d'un optimiseur sous forme de chaîne de caractères, Keras initialise cet optimiseur avec des valeurs par défaut pour tous les paramètres, y compris le taux d'apprentissage. Cependant, nous savons depuis longtemps que les *transformers* bénéficient d'un taux d'apprentissage beaucoup plus faible que celui par défaut d'Adam, qui est de 1e-3, également écrit comme 10 à la puissance -3, ou 0,001. 5e-5 (0,00005), qui est environ vingt fois inférieur, est un bien meilleur point de départ.
-
-En plus de réduire le taux d'apprentissage, nous avons une deuxième astuce dans notre manche : nous pouvons réduire lentement le taux d'apprentissage au cours de l'entraînement. Dans la littérature, on parle parfois de *décroissance* ou d'*annulation* du taux d'apprentissage.le taux d'apprentissage. Dans Keras, la meilleure façon de le faire est d'utiliser un *planificateur du taux d'apprentissage*. Un bon planificateur à utiliser est `PolynomialDecay`. Malgré son nom, avec les paramètres par défaut, il diminue simplement de façon linéaire le taux d'apprentissage de la valeur initiale à la valeur finale au cours de l'entraînement, ce qui est exactement ce que nous voulons. Afin d'utiliser correctement un planificateur, nous devons lui dire combien de temps l'entraînement va durer. Nous calculons cela comme `num_train_steps` ci-dessous.
-
-```py
-from tensorflow.keras.optimizers.schedules import PolynomialDecay
-
-batch_size = 8
-num_epochs = 3
-# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié
-# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un lot tf.data.Dataset
-# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size.
-num_train_steps = len(tf_train_dataset) * num_epochs
-lr_scheduler = PolynomialDecay(
- initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
-)
-from tensorflow.keras.optimizers import Adam
-
-opt = Adam(learning_rate=lr_scheduler)
-```
-
-
-
-La bibliothèque 🤗 *Transformers* possède également une fonction `create_optimizer()` qui créera un optimiseur `AdamW` avec un taux d'apprentissage décroissant. Il s'agit d'un raccourci pratique que vous verrez en détail dans les prochaines sections du cours.
-
-
-
-Nous avons maintenant notre tout nouvel optimiseur et nous pouvons essayer de nous entraîner avec lui. Tout d'abord, rechargeons le modèle pour réinitialiser les modifications apportées aux poids lors de l'entraînement que nous venons d'effectuer, puis nous pouvons le compiler avec le nouvel optimiseur :
-
-```py
-import tensorflow as tf
-
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
-model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])
-```
-
-Maintenant, on *fit* :
-
-```py
-model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
-```
-
-
-
-💡 Si vous voulez télécharger automatiquement votre modèle sur le *Hub* pendant l'entraînement, vous pouvez passer un `PushToHubCallback` dans la méthode `model.fit()`. Nous en apprendrons davantage à ce sujet au [chapitre 4](/course/fr/chapter4/3).
-
-
-
-### Prédictions du modèle
-
-
-
-
-Entraîner et regarder la perte diminuer, c'est très bien, mais que faire si l'on veut réellement obtenir des résultats du modèle entraîné, soit pour calculer des métriques, soit pour utiliser le modèle en production ? Pour ce faire, nous pouvons simplement utiliser la méthode `predict()`. Ceci retournera les *logits* de la tête de sortie du modèle, un par classe.
-
-```py
-preds = model.predict(tf_validation_dataset)["logits"]
-```
-
-Nous pouvons convertir ces logits en prédictions de classe du modèle en utilisant `argmax` pour trouver le logit le plus élevé, qui correspond à la classe la plus probable :
-
-```py
-class_preds = np.argmax(preds, axis=1)
-print(preds.shape, class_preds.shape)
-```
-
-```python out
-(408, 2) (408,)
-```
-
-Maintenant, utilisons ces `preds` pour calculer des métriques ! Nous pouvons charger les métriques associées au jeu de données MRPC aussi facilement que nous avons chargé le jeu de données, cette fois avec la fonction `evaluate.load()`. L'objet retourné a une méthode `compute()` que nous pouvons utiliser pour faire le calcul de la métrique :
-
-```py
-import evaluate
-
-metric = evaluate.load("glue", "mrpc")
-metric.compute(predictions=class_preds, references=raw_datasets["validation"]["label"])
-```
-
-```python out
-{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
-```
-
-Les résultats exacts que vous obtiendrez peuvent varier, car l'initialisation aléatoire de la tête du modèle peut modifier les métriques obtenues. Ici, nous pouvons voir que notre modèle a une précision de 85,78% sur l'ensemble de validation et un score F1 de 89,97. Ce sont les deux métriques utilisées pour évaluer les résultats sur le jeu de données MRPC pour le benchmark GLUE. Le tableau du papier de [BERT](https://arxiv.org/pdf/1810.04805.pdf) indique un score F1 de 88,9 pour le modèle de base. Il s'agissait du modèle `uncased` alors que nous utilisons actuellement le modèle `cased`, ce qui explique le meilleur résultat.
-
-Ceci conclut l'introduction à le *finetuning* en utilisant l'API Keras. Un exemple d'application de cette méthode aux tâches les plus courantes du traitement automatique des langues sera présenté au [chapitre 7](/course/fr/chapter7). Si vous souhaitez affiner vos connaissances de l'API Keras, essayez *finetuner* un modèle sur le jeu de données GLUE SST-2, en utilisant le traitement des données que vous avez effectué dans la section 2.
+
+
+# Finetuner un modèle avec Keras
+
+
+
+Une fois que vous avez fait tout le travail de prétraitement des données dans la dernière section, il ne vous reste que quelques étapes pour entraîner le modèle. Notez, cependant, que la commande `model.fit()` s'exécutera très lentement sur un CPU. Si vous n'avez pas de GPU, vous pouvez avoir accès à des GPUs ou TPUs gratuits sur [Google Colab](https://colab.research.google.com/).
+
+Les exemples de code ci-dessous supposent que vous avez déjà exécuté les exemples de la section précédente. Voici un bref résumé de ce dont vous avez besoin :
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+import numpy as np
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+
+tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "token_type_ids"],
+ label_cols=["labels"],
+ shuffle=False,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+```
+
+### Entraînement
+
+Les modèles TensorFlow importés depuis 🤗 *Transformers* sont déjà des modèles Keras. Voici une courte introduction à Keras.
+
+
+
+Cela signifie qu'une fois que nous disposons de nos données, très peu de travail est nécessaire pour commencer à entraîner sur celles-ci.
+
+
+
+Comme dans le [chapitre précédent](/course/fr/chapter2), nous allons utiliser la classe `TFAutoModelForSequenceClassification`, avec deux étiquettes :
+
+```py
+from transformers import TFAutoModelForSequenceClassification
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+Vous remarquerez que, contrairement au [chapitre 2](/course/fr/chapter2), vous obtenez un message d'avertissement après l'instanciation de ce modèle pré-entraîné. Ceci est dû au fait que BERT n'a pas été pré-entraîné à la classification de paires de phrases, donc la tête du modèle pré-entraîné a été supprimée et une nouvelle tête adaptée à la classification de séquences a été insérée à la place. Les messages d'avertissement indiquent que certains poids n'ont pas été utilisés (ceux correspondant à la tête de pré-entraînement abandonnée) et que d'autres ont été initialisés de manière aléatoire (ceux pour la nouvelle tête). Il conclut en vous encourageant à entraîner le modèle, ce qui est exactement ce que nous allons faire maintenant.
+
+Pour *finetuner* le modèle sur notre jeu de données, nous devons simplement `compiler()` notre modèle et ensuite passer nos données à la méthode `fit()`. Cela va démarrer le processus de *finetuning* (qui devrait prendre quelques minutes sur un GPU) et rapporter la perte d'entraînement au fur et à mesure, plus la perte de validation à la fin de chaque époque.
+
+
+
+Notez que les modèles 🤗 *Transformers* ont une capacité spéciale que la plupart des modèles Keras n'ont pas. Ils peuvent automatiquement utiliser une perte appropriée qu'ils calculent en interne. Ils utiliseront cette perte par défaut si vous ne définissez pas un argument de perte dans `compile()`. Notez que pour utiliser la perte interne, vous devrez passer vos labels comme faisant partie de l'entrée, et non pas comme un label séparé, ce qui est la façon normale d'utiliser les labels avec les modèles Keras. Vous verrez des exemples de cela dans la partie 2 du cours, où la définition de la fonction de perte correcte peut être délicate. Pour la classification des séquences, cependant, une fonction de perte standard de Keras fonctionne bien, et c'est donc ce que nous utiliserons ici.
+
+
+
+```py
+from tensorflow.keras.losses import SparseCategoricalCrossentropy
+
+model.compile(
+ optimizer="adam",
+ loss=SparseCategoricalCrossentropy(from_logits=True),
+ metrics=["accuracy"],
+)
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_validation_dataset,
+)
+```
+
+
+
+Notez un piège très commun ici. Vous *pouvez* simplement passer le nom de la perte comme une chaîne à Keras, mais par défaut Keras supposera que vous avez déjà appliqué une fonction softmax à vos sorties. Cependant, de nombreux modèles produisent les valeurs juste avant l'application de la softmax, que l'on appelle aussi les *logits*. Nous devons indiquer à la fonction de perte que c'est ce que fait notre modèle, et la seule façon de le faire est de l'appeler directement, plutôt que par son nom avec une chaîne.
+
+
+
+
+### Améliorer les performances d'entraînement
+
+
+
+Si vous essayez le code ci-dessus, il fonctionne certainement, mais vous constaterez que la perte ne diminue que lentement ou sporadiquement. La cause principale est le *taux d'apprentissage*. Comme pour la perte, lorsque nous transmettons à Keras le nom d'un optimiseur sous forme de chaîne de caractères, Keras initialise cet optimiseur avec des valeurs par défaut pour tous les paramètres, y compris le taux d'apprentissage. Cependant, nous savons depuis longtemps que les *transformers* bénéficient d'un taux d'apprentissage beaucoup plus faible que celui par défaut d'Adam, qui est de 1e-3, également écrit comme 10 à la puissance -3, ou 0,001. 5e-5 (0,00005), qui est environ vingt fois inférieur, est un bien meilleur point de départ.
+
+En plus de réduire le taux d'apprentissage, nous avons une deuxième astuce dans notre manche : nous pouvons réduire lentement le taux d'apprentissage au cours de l'entraînement. Dans la littérature, on parle parfois de *décroissance* ou d'*annulation* du taux d'apprentissage.le taux d'apprentissage. Dans Keras, la meilleure façon de le faire est d'utiliser un *planificateur du taux d'apprentissage*. Un bon planificateur à utiliser est `PolynomialDecay`. Malgré son nom, avec les paramètres par défaut, il diminue simplement de façon linéaire le taux d'apprentissage de la valeur initiale à la valeur finale au cours de l'entraînement, ce qui est exactement ce que nous voulons. Afin d'utiliser correctement un planificateur, nous devons lui dire combien de temps l'entraînement va durer. Nous calculons cela comme `num_train_steps` ci-dessous.
+
+```py
+from tensorflow.keras.optimizers.schedules import PolynomialDecay
+
+batch_size = 8
+num_epochs = 3
+# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié
+# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un lot tf.data.Dataset
+# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size.
+num_train_steps = len(tf_train_dataset) * num_epochs
+lr_scheduler = PolynomialDecay(
+ initial_learning_rate=5e-5, end_learning_rate=0.0, decay_steps=num_train_steps
+)
+from tensorflow.keras.optimizers import Adam
+
+opt = Adam(learning_rate=lr_scheduler)
+```
+
+
+
+La bibliothèque 🤗 *Transformers* possède également une fonction `create_optimizer()` qui créera un optimiseur `AdamW` avec un taux d'apprentissage décroissant. Il s'agit d'un raccourci pratique que vous verrez en détail dans les prochaines sections du cours.
+
+
+
+Nous avons maintenant notre tout nouvel optimiseur et nous pouvons essayer de nous entraîner avec lui. Tout d'abord, rechargeons le modèle pour réinitialiser les modifications apportées aux poids lors de l'entraînement que nous venons d'effectuer, puis nous pouvons le compiler avec le nouvel optimiseur :
+
+```py
+import tensorflow as tf
+
+model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])
+```
+
+Maintenant, on *fit* :
+
+```py
+model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+💡 Si vous voulez télécharger automatiquement votre modèle sur le *Hub* pendant l'entraînement, vous pouvez passer un `PushToHubCallback` dans la méthode `model.fit()`. Nous en apprendrons davantage à ce sujet au [chapitre 4](/course/fr/chapter4/3).
+
+
+
+### Prédictions du modèle
+
+
+
+
+Entraîner et regarder la perte diminuer, c'est très bien, mais que faire si l'on veut réellement obtenir des résultats du modèle entraîné, soit pour calculer des métriques, soit pour utiliser le modèle en production ? Pour ce faire, nous pouvons simplement utiliser la méthode `predict()`. Ceci retournera les *logits* de la tête de sortie du modèle, un par classe.
+
+```py
+preds = model.predict(tf_validation_dataset)["logits"]
+```
+
+Nous pouvons convertir ces logits en prédictions de classe du modèle en utilisant `argmax` pour trouver le logit le plus élevé, qui correspond à la classe la plus probable :
+
+```py
+class_preds = np.argmax(preds, axis=1)
+print(preds.shape, class_preds.shape)
+```
+
+```python out
+(408, 2) (408,)
+```
+
+Maintenant, utilisons ces `preds` pour calculer des métriques ! Nous pouvons charger les métriques associées au jeu de données MRPC aussi facilement que nous avons chargé le jeu de données, cette fois avec la fonction `evaluate.load()`. L'objet retourné a une méthode `compute()` que nous pouvons utiliser pour faire le calcul de la métrique :
+
+```py
+import evaluate
+
+metric = evaluate.load("glue", "mrpc")
+metric.compute(predictions=class_preds, references=raw_datasets["validation"]["label"])
+```
+
+```python out
+{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
+```
+
+Les résultats exacts que vous obtiendrez peuvent varier, car l'initialisation aléatoire de la tête du modèle peut modifier les métriques obtenues. Ici, nous pouvons voir que notre modèle a une précision de 85,78% sur l'ensemble de validation et un score F1 de 89,97. Ce sont les deux métriques utilisées pour évaluer les résultats sur le jeu de données MRPC pour le benchmark GLUE. Le tableau du papier de [BERT](https://arxiv.org/pdf/1810.04805.pdf) indique un score F1 de 88,9 pour le modèle de base. Il s'agissait du modèle `uncased` alors que nous utilisons actuellement le modèle `cased`, ce qui explique le meilleur résultat.
+
+Ceci conclut l'introduction à le *finetuning* en utilisant l'API Keras. Un exemple d'application de cette méthode aux tâches les plus courantes du traitement automatique des langues sera présenté au [chapitre 7](/course/fr/chapter7). Si vous souhaitez affiner vos connaissances de l'API Keras, essayez *finetuner* un modèle sur le jeu de données GLUE SST-2, en utilisant le traitement des données que vous avez effectué dans la section 2.
diff --git a/chapters/fr/chapter3/4.mdx b/chapters/fr/chapter3/4.mdx
index e66caa6db..b04812639 100644
--- a/chapters/fr/chapter3/4.mdx
+++ b/chapters/fr/chapter3/4.mdx
@@ -1,359 +1,359 @@
-# Un entraînement complet
-
-
-
-
-
-Maintenant nous allons voir comment obtenir les mêmes résultats que dans la dernière section sans utiliser la classe `Trainer`. Encore une fois, nous supposons que vous avez fait le traitement des données dans la section 2. Voici un court résumé couvrant tout ce dont vous aurez besoin :
-
-```py
-from datasets import load_dataset
-from transformers import AutoTokenizer, DataCollatorWithPadding
-
-raw_datasets = load_dataset("glue", "mrpc")
-checkpoint = "bert-base-uncased"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-
-
-def tokenize_function(example):
- return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
-
-
-tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
-data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
-```
-
-### Préparer l'entraînement
-
-Avant d'écrire réellement notre boucle d'entraînement, nous devons définir quelques objets. Les premiers sont les *dataloaders* que nous utiliserons pour itérer sur les batchs. Mais avant de pouvoir définir ces chargeurs de données, nous devons appliquer un peu de post-traitement à nos `tokenized_datasets`, pour prendre soin de certaines choses que le `Trainer` fait pour nous automatiquement. Spécifiquement, nous devons :
-
-- supprimer les colonnes correspondant aux valeurs que le modèle n'attend pas (comme les colonnes `sentence1` et `sentence2`),
-- renommer la colonne `label` en `labels` (parce que le modèle s'attend à ce que l'argument soit nommé `labels`),
-- définir le format des jeux de données pour qu'ils retournent des tenseurs PyTorch au lieu de listes.
-
-Notre `tokenized_datasets` a une méthode pour chacune de ces étapes :
-
-```py
-tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
-tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
-tokenized_datasets.set_format("torch")
-tokenized_datasets["train"].column_names
-```
-
-Nous pouvons alors vérifier que le résultat ne comporte que des colonnes que notre modèle acceptera :
-
-```python
-["attention_mask", "input_ids", "labels", "token_type_ids"]
-```
-
-Maintenant que cela est fait, nous pouvons facilement définir nos *dataloaders* :
-
-```py
-from torch.utils.data import DataLoader
-
-train_dataloader = DataLoader(
- tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
-)
-eval_dataloader = DataLoader(
- tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
-)
-```
-
-Pour vérifier rapidement qu'il n'y a pas d'erreur dans le traitement des données, nous pouvons inspecter un batch comme celui-ci :
-
-```py
-for batch in train_dataloader:
- break
-{k: v.shape for k, v in batch.items()}
-```
-
-```python out
-{'attention_mask': torch.Size([8, 65]),
- 'input_ids': torch.Size([8, 65]),
- 'labels': torch.Size([8]),
- 'token_type_ids': torch.Size([8, 65])}
-```
-
-Notez que les formes réelles seront probablement légèrement différentes pour vous puisque nous avons défini `shuffle=True` pour le chargeur de données d'entraînement et que nous *paddons* à la longueur maximale dans le batch.
-
-Maintenant que nous en avons terminé avec le prétraitement des données (un objectif satisfaisant mais difficile à atteindre pour tout praticien d'apprentissage automatique), passons au modèle. Nous l'instancions exactement comme nous l'avons fait dans la section précédente :
-
-```py
-from transformers import AutoModelForSequenceClassification
-
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-```
-
-Pour s'assurer que tout se passera bien pendant l'entraînement, nous transmettons notre batch à ce modèle :
-
-```py
-outputs = model(**batch)
-print(outputs.loss, outputs.logits.shape)
-```
-
-```python out
-tensor(0.5441, grad_fn=) torch.Size([8, 2])
-```
-
-Tous les modèles 🤗 *Transformers* renvoient la perte lorsque les `labels` sont fournis. Nous obtenons également les logits (deux pour chaque entrée de notre batch, donc un tenseur de taille 8 x 2).
-
-Nous sommes presque prêts à écrire notre boucle d'entraînement ! Il nous manque juste deux choses : un optimiseur et un planificateur de taux d'apprentissage. Puisque nous essayons de reproduire à la main ce que fait la fonction `Trainer`, utilisons les mêmes paramètres par défaut. L'optimiseur utilisé par `Trainer` est `AdamW`, qui est le même qu'Adam, mais avec une torsion pour la régularisation par décroissance de poids (voir [*Decoupled Weight Decay Regularization*](https://arxiv.org/abs/1711.05101) par Ilya Loshchilov et Frank Hutter) :
-
-```py
-from transformers import AdamW
-
-optimizer = AdamW(model.parameters(), lr=5e-5)
-```
-
-Enfin, le planificateur du taux d'apprentissage utilisé par défaut est juste une décroissance linéaire de la valeur maximale (5e-5) à 0. Pour le définir correctement, nous devons connaître le nombre d'étapes d'entraînement que nous prendrons, qui est le nombre d'époques que nous voulons exécuter multiplié par le nombre de batch d'entraînement (qui est la longueur de notre *dataloader* d'entraînement). Le `Trainer` utilise trois époques par défaut, nous allons donc suivre ça :
-
-```py
-from transformers import get_scheduler
-
-num_epochs = 3
-num_training_steps = num_epochs * len(train_dataloader)
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-print(num_training_steps)
-```
-
-```python out
-1377
-```
-
-### La boucle d'entraînement
-
-Une dernière chose : nous voulons utiliser le GPU si nous en avons un (sur un CPU, l'entraînement peut prendre plusieurs heures au lieu de quelques minutes). Pour ce faire, nous définissons un `device` sur lequel nous allons placer notre modèle et nos batchs :
-
-```py
-import torch
-
-device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
-model.to(device)
-device
-```
-
-```python out
-device(type='cuda')
-```
-
-Nous sommes maintenant prêts à entraîner ! Pour avoir une idée du moment où l'entraînement sera terminé, nous ajoutons une barre de progression sur le nombre d'étapes d'entraînement, en utilisant la bibliothèque `tqdm` :
-
-```py
-from tqdm.auto import tqdm
-
-progress_bar = tqdm(range(num_training_steps))
-
-model.train()
-for epoch in range(num_epochs):
- for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
- outputs = model(**batch)
- loss = outputs.loss
- loss.backward()
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-```
-
-Vous pouvez voir que le cœur de la boucle d'entraînement ressemble beaucoup à celui de l'introduction. Nous n'avons pas demandé de rapport, donc cette boucle d'entraînement ne nous dira rien sur les résultats du modèle. Pour cela, nous devons ajouter une boucle d'évaluation.
-
-
-### La boucle d'évaluation
-
-Comme nous l'avons fait précédemment, nous allons utiliser une métrique fournie par la bibliothèque 🤗 *Evaluate*. Nous avons déjà vu la méthode `metric.compute()`, mais les métriques peuvent en fait accumuler des batchs pour nous au fur et à mesure que nous parcourons la boucle de prédiction avec la méthode `add_batch()`. Une fois que nous avons accumulé tous les batchs, nous pouvons obtenir le résultat final avec `metric.compute()`. Voici comment implémenter tout cela dans une boucle d'évaluation :
-
-```py
-import evaluate
-
-metric = evaluate.load("glue", "mrpc")
-model.eval()
-for batch in eval_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
- with torch.no_grad():
- outputs = model(**batch)
-
- logits = outputs.logits
- predictions = torch.argmax(logits, dim=-1)
- metric.add_batch(predictions=predictions, references=batch["labels"])
-
-metric.compute()
-```
-
-```python out
-{'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}
-```
-
-Une fois encore, vos résultats seront légèrement différents en raison du caractère aléatoire de l'initialisation de la tête du modèle et du mélange des données, mais ils devraient se situer dans la même fourchette.
-
-
-
-✏️ **Essayez** Modifiez la boucle d'entraînement précédente pour *finetuner* votre modèle sur le jeu de données SST-2.
-
-
-
-### Optimisez votre boucle d'entraînement avec 🤗 Accelerate
-
-
-
-La boucle d'entraînement que nous avons définie précédemment fonctionne bien sur un seul CPU ou GPU. Mais en utilisant la bibliothèque [🤗 *Accelerate*](https://github.com/huggingface/accelerate), il suffit de quelques ajustements pour permettre un entraînement distribué sur plusieurs GPUs ou TPUs. En partant de la création des *dataloaders* d'entraînement et de validation, voici à quoi ressemble notre boucle d'entraînement manuel :
-
-```py
-from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
-
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-optimizer = AdamW(model.parameters(), lr=3e-5)
-
-device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
-model.to(device)
-
-num_epochs = 3
-num_training_steps = num_epochs * len(train_dataloader)
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-
-progress_bar = tqdm(range(num_training_steps))
-
-model.train()
-for epoch in range(num_epochs):
- for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
- outputs = model(**batch)
- loss = outputs.loss
- loss.backward()
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-```
-
-Et voici les changements :
-
-```diff
-+ from accelerate import Accelerator
- from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
-
-+ accelerator = Accelerator()
-
- model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
- optimizer = AdamW(model.parameters(), lr=3e-5)
-
-- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
-- model.to(device)
-
-+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
-+ train_dataloader, eval_dataloader, model, optimizer
-+ )
-
- num_epochs = 3
- num_training_steps = num_epochs * len(train_dataloader)
- lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps
- )
-
- progress_bar = tqdm(range(num_training_steps))
-
- model.train()
- for epoch in range(num_epochs):
- for batch in train_dataloader:
-- batch = {k: v.to(device) for k, v in batch.items()}
- outputs = model(**batch)
- loss = outputs.loss
-- loss.backward()
-+ accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-```
-
-La première ligne à ajouter est la ligne d'importation. La deuxième ligne instancie un objet `Accelerator` qui va regarder l'environnement et initialiser la bonne configuration distribuée. 🤗 *Accelerate* gère le placement des périphériques pour vous, donc vous pouvez enlever les lignes qui placent le modèle sur le périphérique (ou, si vous préférez, les changer pour utiliser `accelerator.device` au lieu de `device`).
-
-Ensuite, le gros du travail est fait dans la ligne qui envoie les *dataloaders*, le modèle, et l'optimiseur à `accelerator.prepare()`. Cela va envelopper ces objets dans le conteneur approprié pour s'assurer que votre entraînement distribué fonctionne comme prévu. Les changements restants à faire sont la suppression de la ligne qui met le batch sur le `device` (encore une fois, si vous voulez le garder, vous pouvez juste le changer pour utiliser `accelerator.device`) et le remplacement de `loss.backward()` par `accelerator.backward(loss)`.
-
-
-⚠️ Afin de bénéficier de la rapidité offerte par les TPUs du Cloud, nous vous recommandons de rembourrer vos échantillons à une longueur fixe avec les arguments `padding="max_length"` et `max_length` du tokenizer.
-
-
-Si vous souhaitez faire un copier-coller pour jouer, voici à quoi ressemble la boucle d'entraînement complète avec 🤗 Accelerate :
-
-```py
-from accelerate import Accelerator
-from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
-
-accelerator = Accelerator()
-
-model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
-optimizer = AdamW(model.parameters(), lr=3e-5)
-
-train_dl, eval_dl, model, optimizer = accelerator.prepare(
- train_dataloader, eval_dataloader, model, optimizer
-)
-
-num_epochs = 3
-num_training_steps = num_epochs * len(train_dl)
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-
-progress_bar = tqdm(range(num_training_steps))
-
-model.train()
-for epoch in range(num_epochs):
- for batch in train_dl:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-```
-
-En plaçant ceci dans un script `train.py`, cela sera exécutable sur n'importe quel type d'installation distribuée. Pour l'essayer dans votre installation distribuée, exécutez la commande :
-
-```bash
-accelerate config
-```
-
-qui vous demandera de répondre à quelques questions et enregistrera vos réponses dans un fichier de configuration utilisé par cette commande :
-
-```
-accelerate launch train.py
-```
-
-qui lancera l'entraînement distribué.
-
-Si vous voulez essayer ceci dans un *notebook* (par exemple, pour le tester avec des TPUs sur Colab), collez simplement le code dans une `training_function()` et lancez une dernière cellule avec :
-
-```python
-from accelerate import notebook_launcher
-
-notebook_launcher(training_function)
-```
-
-Vous trouverez d'autres exemples dans le dépôt d'[🤗 *Accelerate*](https://github.com/huggingface/accelerate/tree/main/examples).
+# Un entraînement complet
+
+
+
+
+
+Maintenant nous allons voir comment obtenir les mêmes résultats que dans la dernière section sans utiliser la classe `Trainer`. Encore une fois, nous supposons que vous avez fait le traitement des données dans la section 2. Voici un court résumé couvrant tout ce dont vous aurez besoin :
+
+```py
+from datasets import load_dataset
+from transformers import AutoTokenizer, DataCollatorWithPadding
+
+raw_datasets = load_dataset("glue", "mrpc")
+checkpoint = "bert-base-uncased"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+
+def tokenize_function(example):
+ return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
+
+
+tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
+data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+### Préparer l'entraînement
+
+Avant d'écrire réellement notre boucle d'entraînement, nous devons définir quelques objets. Les premiers sont les *dataloaders* que nous utiliserons pour itérer sur les batchs. Mais avant de pouvoir définir ces chargeurs de données, nous devons appliquer un peu de post-traitement à nos `tokenized_datasets`, pour prendre soin de certaines choses que le `Trainer` fait pour nous automatiquement. Spécifiquement, nous devons :
+
+- supprimer les colonnes correspondant aux valeurs que le modèle n'attend pas (comme les colonnes `sentence1` et `sentence2`),
+- renommer la colonne `label` en `labels` (parce que le modèle s'attend à ce que l'argument soit nommé `labels`),
+- définir le format des jeux de données pour qu'ils retournent des tenseurs PyTorch au lieu de listes.
+
+Notre `tokenized_datasets` a une méthode pour chacune de ces étapes :
+
+```py
+tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
+tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+tokenized_datasets.set_format("torch")
+tokenized_datasets["train"].column_names
+```
+
+Nous pouvons alors vérifier que le résultat ne comporte que des colonnes que notre modèle acceptera :
+
+```python
+["attention_mask", "input_ids", "labels", "token_type_ids"]
+```
+
+Maintenant que cela est fait, nous pouvons facilement définir nos *dataloaders* :
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
+)
+```
+
+Pour vérifier rapidement qu'il n'y a pas d'erreur dans le traitement des données, nous pouvons inspecter un batch comme celui-ci :
+
+```py
+for batch in train_dataloader:
+ break
+{k: v.shape for k, v in batch.items()}
+```
+
+```python out
+{'attention_mask': torch.Size([8, 65]),
+ 'input_ids': torch.Size([8, 65]),
+ 'labels': torch.Size([8]),
+ 'token_type_ids': torch.Size([8, 65])}
+```
+
+Notez que les formes réelles seront probablement légèrement différentes pour vous puisque nous avons défini `shuffle=True` pour le chargeur de données d'entraînement et que nous *paddons* à la longueur maximale dans le batch.
+
+Maintenant que nous en avons terminé avec le prétraitement des données (un objectif satisfaisant mais difficile à atteindre pour tout praticien d'apprentissage automatique), passons au modèle. Nous l'instancions exactement comme nous l'avons fait dans la section précédente :
+
+```py
+from transformers import AutoModelForSequenceClassification
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+```
+
+Pour s'assurer que tout se passera bien pendant l'entraînement, nous transmettons notre batch à ce modèle :
+
+```py
+outputs = model(**batch)
+print(outputs.loss, outputs.logits.shape)
+```
+
+```python out
+tensor(0.5441, grad_fn=) torch.Size([8, 2])
+```
+
+Tous les modèles 🤗 *Transformers* renvoient la perte lorsque les `labels` sont fournis. Nous obtenons également les logits (deux pour chaque entrée de notre batch, donc un tenseur de taille 8 x 2).
+
+Nous sommes presque prêts à écrire notre boucle d'entraînement ! Il nous manque juste deux choses : un optimiseur et un planificateur de taux d'apprentissage. Puisque nous essayons de reproduire à la main ce que fait la fonction `Trainer`, utilisons les mêmes paramètres par défaut. L'optimiseur utilisé par `Trainer` est `AdamW`, qui est le même qu'Adam, mais avec une torsion pour la régularisation par décroissance de poids (voir [*Decoupled Weight Decay Regularization*](https://arxiv.org/abs/1711.05101) par Ilya Loshchilov et Frank Hutter) :
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Enfin, le planificateur du taux d'apprentissage utilisé par défaut est juste une décroissance linéaire de la valeur maximale (5e-5) à 0. Pour le définir correctement, nous devons connaître le nombre d'étapes d'entraînement que nous prendrons, qui est le nombre d'époques que nous voulons exécuter multiplié par le nombre de batch d'entraînement (qui est la longueur de notre *dataloader* d'entraînement). Le `Trainer` utilise trois époques par défaut, nous allons donc suivre ça :
+
+```py
+from transformers import get_scheduler
+
+num_epochs = 3
+num_training_steps = num_epochs * len(train_dataloader)
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+print(num_training_steps)
+```
+
+```python out
+1377
+```
+
+### La boucle d'entraînement
+
+Une dernière chose : nous voulons utiliser le GPU si nous en avons un (sur un CPU, l'entraînement peut prendre plusieurs heures au lieu de quelques minutes). Pour ce faire, nous définissons un `device` sur lequel nous allons placer notre modèle et nos batchs :
+
+```py
+import torch
+
+device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+model.to(device)
+device
+```
+
+```python out
+device(type='cuda')
+```
+
+Nous sommes maintenant prêts à entraîner ! Pour avoir une idée du moment où l'entraînement sera terminé, nous ajoutons une barre de progression sur le nombre d'étapes d'entraînement, en utilisant la bibliothèque `tqdm` :
+
+```py
+from tqdm.auto import tqdm
+
+progress_bar = tqdm(range(num_training_steps))
+
+model.train()
+for epoch in range(num_epochs):
+ for batch in train_dataloader:
+ batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss.backward()
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+Vous pouvez voir que le cœur de la boucle d'entraînement ressemble beaucoup à celui de l'introduction. Nous n'avons pas demandé de rapport, donc cette boucle d'entraînement ne nous dira rien sur les résultats du modèle. Pour cela, nous devons ajouter une boucle d'évaluation.
+
+
+### La boucle d'évaluation
+
+Comme nous l'avons fait précédemment, nous allons utiliser une métrique fournie par la bibliothèque 🤗 *Evaluate*. Nous avons déjà vu la méthode `metric.compute()`, mais les métriques peuvent en fait accumuler des batchs pour nous au fur et à mesure que nous parcourons la boucle de prédiction avec la méthode `add_batch()`. Une fois que nous avons accumulé tous les batchs, nous pouvons obtenir le résultat final avec `metric.compute()`. Voici comment implémenter tout cela dans une boucle d'évaluation :
+
+```py
+import evaluate
+
+metric = evaluate.load("glue", "mrpc")
+model.eval()
+for batch in eval_dataloader:
+ batch = {k: v.to(device) for k, v in batch.items()}
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ logits = outputs.logits
+ predictions = torch.argmax(logits, dim=-1)
+ metric.add_batch(predictions=predictions, references=batch["labels"])
+
+metric.compute()
+```
+
+```python out
+{'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}
+```
+
+Une fois encore, vos résultats seront légèrement différents en raison du caractère aléatoire de l'initialisation de la tête du modèle et du mélange des données, mais ils devraient se situer dans la même fourchette.
+
+
+
+✏️ **Essayez** Modifiez la boucle d'entraînement précédente pour *finetuner* votre modèle sur le jeu de données SST-2.
+
+
+
+### Optimisez votre boucle d'entraînement avec 🤗 Accelerate
+
+
+
+La boucle d'entraînement que nous avons définie précédemment fonctionne bien sur un seul CPU ou GPU. Mais en utilisant la bibliothèque [🤗 *Accelerate*](https://github.com/huggingface/accelerate), il suffit de quelques ajustements pour permettre un entraînement distribué sur plusieurs GPUs ou TPUs. En partant de la création des *dataloaders* d'entraînement et de validation, voici à quoi ressemble notre boucle d'entraînement manuel :
+
+```py
+from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+optimizer = AdamW(model.parameters(), lr=3e-5)
+
+device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+model.to(device)
+
+num_epochs = 3
+num_training_steps = num_epochs * len(train_dataloader)
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+
+progress_bar = tqdm(range(num_training_steps))
+
+model.train()
+for epoch in range(num_epochs):
+ for batch in train_dataloader:
+ batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss.backward()
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+Et voici les changements :
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+La première ligne à ajouter est la ligne d'importation. La deuxième ligne instancie un objet `Accelerator` qui va regarder l'environnement et initialiser la bonne configuration distribuée. 🤗 *Accelerate* gère le placement des périphériques pour vous, donc vous pouvez enlever les lignes qui placent le modèle sur le périphérique (ou, si vous préférez, les changer pour utiliser `accelerator.device` au lieu de `device`).
+
+Ensuite, le gros du travail est fait dans la ligne qui envoie les *dataloaders*, le modèle, et l'optimiseur à `accelerator.prepare()`. Cela va envelopper ces objets dans le conteneur approprié pour s'assurer que votre entraînement distribué fonctionne comme prévu. Les changements restants à faire sont la suppression de la ligne qui met le batch sur le `device` (encore une fois, si vous voulez le garder, vous pouvez juste le changer pour utiliser `accelerator.device`) et le remplacement de `loss.backward()` par `accelerator.backward(loss)`.
+
+
+⚠️ Afin de bénéficier de la rapidité offerte par les TPUs du Cloud, nous vous recommandons de rembourrer vos échantillons à une longueur fixe avec les arguments `padding="max_length"` et `max_length` du tokenizer.
+
+
+Si vous souhaitez faire un copier-coller pour jouer, voici à quoi ressemble la boucle d'entraînement complète avec 🤗 Accelerate :
+
+```py
+from accelerate import Accelerator
+from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
+accelerator = Accelerator()
+
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+optimizer = AdamW(model.parameters(), lr=3e-5)
+
+train_dl, eval_dl, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+)
+
+num_epochs = 3
+num_training_steps = num_epochs * len(train_dl)
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+
+progress_bar = tqdm(range(num_training_steps))
+
+model.train()
+for epoch in range(num_epochs):
+ for batch in train_dl:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+En plaçant ceci dans un script `train.py`, cela sera exécutable sur n'importe quel type d'installation distribuée. Pour l'essayer dans votre installation distribuée, exécutez la commande :
+
+```bash
+accelerate config
+```
+
+qui vous demandera de répondre à quelques questions et enregistrera vos réponses dans un fichier de configuration utilisé par cette commande :
+
+```
+accelerate launch train.py
+```
+
+qui lancera l'entraînement distribué.
+
+Si vous voulez essayer ceci dans un *notebook* (par exemple, pour le tester avec des TPUs sur Colab), collez simplement le code dans une `training_function()` et lancez une dernière cellule avec :
+
+```python
+from accelerate import notebook_launcher
+
+notebook_launcher(training_function)
+```
+
+Vous trouverez d'autres exemples dans le dépôt d'[🤗 *Accelerate*](https://github.com/huggingface/accelerate/tree/main/examples).
diff --git a/chapters/fr/chapter3/5.mdx b/chapters/fr/chapter3/5.mdx
index db244e545..782e3f5d8 100644
--- a/chapters/fr/chapter3/5.mdx
+++ b/chapters/fr/chapter3/5.mdx
@@ -1,20 +1,25 @@
-
-
-# Finetuning, coché !
-
-C'était amusant ! Dans les deux premiers chapitres, vous avez appris à connaître les modèles et les *tokenizers*, et vous savez maintenant comment les *finetuner* pour vos propres données. Pour récapituler, dans ce chapitre vous :
-
-{#if fw === 'pt'}
-* avez appris à connaître les jeux de données dans le [*Hub*](https://huggingface.co/datasets),
-* avez appris à charger et à prétraiter des jeux de données, notamment en utilisant le remplissage dynamique et les assembleurs,
-* avez implémenté votre propre *finetuning* et évaluation d'un modèle,
-* avez implémenté une boucle d'entraînement de niveau inférieur,
-* avez utilisé 🤗 *Accelerate* pour adapter facilement votre boucle d'entraînement afin qu'elle fonctionne pour plusieurs GPUs ou TPUs.
-
-{:else}
-* avez appris à connaître les jeux de données dans le [*Hub*](https://huggingface.co/datasets),
-* avez appris comment charger et prétraiter les jeux de données,
-* avez appris comment *finetuner* et évaluer un modèle avec Keras,
-* avez implémenté une métrique personnalisée.
-
+
+
+# Finetuning, coché !
+
+
+
+C'était amusant ! Dans les deux premiers chapitres, vous avez appris à connaître les modèles et les *tokenizers*, et vous savez maintenant comment les *finetuner* pour vos propres données. Pour récapituler, dans ce chapitre vous :
+
+{#if fw === 'pt'}
+* avez appris à connaître les jeux de données dans le [*Hub*](https://huggingface.co/datasets),
+* avez appris à charger et à prétraiter des jeux de données, notamment en utilisant le remplissage dynamique et les assembleurs,
+* avez implémenté votre propre *finetuning* et évaluation d'un modèle,
+* avez implémenté une boucle d'entraînement de niveau inférieur,
+* avez utilisé 🤗 *Accelerate* pour adapter facilement votre boucle d'entraînement afin qu'elle fonctionne pour plusieurs GPUs ou TPUs.
+
+{:else}
+* avez appris à connaître les jeux de données dans le [*Hub*](https://huggingface.co/datasets),
+* avez appris comment charger et prétraiter les jeux de données,
+* avez appris comment *finetuner* et évaluer un modèle avec Keras,
+* avez implémenté une métrique personnalisée.
+
{/if}
\ No newline at end of file
diff --git a/chapters/fr/chapter3/6.mdx b/chapters/fr/chapter3/6.mdx
index 44c0fdf44..5379a1fbe 100644
--- a/chapters/fr/chapter3/6.mdx
+++ b/chapters/fr/chapter3/6.mdx
@@ -1,296 +1,301 @@
-
-
-
-
-# Quiz de fin de chapitre
-
-Testez ce que vous avez appris dans ce chapitre !
-
-### 1. Le jeu de données `emotion` contient des messages Twitter étiquetés avec des émotions. Cherchez-le dans le [*Hub*](https://huggingface.co/datasets) et lisez la carte du jeu de données. Laquelle de ces émotions n'est pas une de ses émotions de base ?
-
-
-
-### 2. Cherchez le jeu de données `ar_sarcasme` dans le [*Hub*](https://huggingface.co/datasets). Quelle tâche prend-il en charge ?
-
-tags.",
- correct: true
- },
- {
- text: "Traduction automatique",
- explain: "Ce n'est pas ça. Jetez un autre coup d'œil à la carte du jeu de données !"
- },
- {
- text: "Reconnaissance des entités nommées",
- explain: "Ce n'est pas ça. Jetez un autre coup d'œil à la carte du jeu de données !"
- },
- {
- text: "Réponse aux questions",
- explain: "Hélas, cette question n'a pas reçu de réponse correcte. Essayez à nouveau !"
- }
- ]}
-/>
-
-### 3. Comment le modèle BERT attend-il qu'une paire de phrases soit traitée ?
-
-[SEP] est nécessaire pour séparer les deux phrases, mais ce n'est pas tout !"
- },
- {
- text: "[CLS] Tokens_de_la_phrase_1 Tokens_de_la_phrase_2",
- explain: "Un jeton spécial [CLS] est requis au début, mais ce n'est pas la seule chose !"
- },
- {
- text: "[CLS] Tokens_de_la_phrase_1 [SEP] Tokens_de_la_phrase_2 [SEP]",
- explain: "C'est exact !",
- correct: true
- },
- {
- text: "[CLS] Tokens_de_la_phrase_1 [SEP] Tokens_de_la_phrase_2",
- explain: "Un jeton spécial [CLS] est nécessaire au début, ainsi qu'un jeton spécial [SEP] pour séparer les deux phrases, mais ce n'est pas tout !"
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 4. Quels sont les avantages de la méthode `Dataset.map()` ?
-
-
-
-### 5. Que signifie le remplissage (*padding*) dynamique ?
-
-tokens que la précédente dans le jeu de données.",
- explain: "Cela n'a pas de sens de regarder l'ordre dans le jeu de données puisque nous le mélangeons pendant l'entraînement."
- },
- ]}
-/>
-
-### 6. Quel est le but d'une fonction de rassemblement ?
-
-DataCollatorWithPadding."
- },
- {
- text: "Elle rassemble tous les échantillons dans un batch.",
- explain: "Vous pouvez passer la fonction de rassemblement comme argument d'une fonction DataLoader. Nous avons utilisé la fonction DataCollatorWithPadding qui remplit tous les éléments d'un batch pour qu'ils aient la même longueur.",
- correct: true
- },
- {
- text: "Elle pré-traite tout le jeu de données.",
- explain: "Ce serait une fonction de prétraitement, pas une fonction de rassemblement."
- },
- {
- text: "Elle tronque les séquences dans le jeu de données.",
- explain: "Une fonction de rassemblement est impliquée dans le traitement des batchs individuels, et non de tout le jeu de données. Si vous êtes intéressé par la troncature, vous pouvez utiliser la fonction truncate en argument du tokenizer."
- }
- ]}
-/>
-
-### 7. Que se passe-t-il lorsque vous instanciez une des classes `AutoModelForXxx` avec un modèle de langage pré-entraîné (tel que `bert-base-uncased`) qui correspond à une tâche différente de celle pour laquelle il a été entraîné ?
-
-AutoModelForSequenceClassification avec bert-base-uncased, nous avons eu des messages d'avertissement lors de l'instanciation du modèle. La tête pré-entraînée n'est pas utilisée pour la tâche de classification de séquences, elle est donc supprimée et une nouvelle tête est instanciée avec des poids aléatoires..",
- correct: true
- },
- {
- text: "La tête du modèle pré-entraîné est supprimée.",
- explain: "Quelque chose d'autre doit se produire. Essayez encore !"
- },
- {
- text: "Rien, puisque le modèle peut encore être finetuné pour les différentes tâches.",
- explain: "La tête du modèle pré-entraîné n'a pas été entraînée à résoudre cette tâche, nous devons donc la supprimer !"
- }
- ]}
-/>
-
-### 8. Quel est le but de `TrainingArguments` ?
-
-Trainer.",
- explain: "",
- correct: true
- },
- {
- text: "Préciser la taille du modèle.",
- explain: "La taille du modèle est définie par la configuration du modèle, et non par la classe TrainingArguments."
- },
- {
- text: "Juste contenir les hyperparamètres utilisés pour l'évaluation.",
- explain: "Dans l'exemple, nous avons spécifié où le modèle et ses checkpoints seront sauvegardés. Essayez à nouveau !"
- },
- {
- text: "Contenir seulement les hyperparamètres utilisés pour l'entraînement.",
- explain: "Dans l'exemple, nous avons utilisé une evaluation_strategy également, ce qui a un impact sur l'évaluation. Essayez à nouveau !"
- }
- ]}
-/>
-
-### 9. Pourquoi devriez-vous utiliser la librairie 🤗 *Accelerate* ?
-
-Accelerate ne fournit aucun modèles."
- },
- {
- text: "Elle fournit une API de haut niveau qui évite d'avoir à mettre en place sa propre boucle d'entraînement.",
- explain: "C'est ce que nous avons fait avec le Trainer mais pas avec la librairie 🤗 Accelerate. Essayez à nouveau !"
- },
- {
- text: "Elle permet à nos boucles d'entraînement de fonctionner avec des stratégies distribuées.",
- explain: "Avec 🤗 Accelerate, vos boucles d'entraînement fonctionneront pour plusieurs GPUs et TPUs.",
- correct: true
- },
- {
- text: "Elle offre davantage de fonctions d'optimisation.",
- explain: "Non, la librairie 🤗 Accelerate ne fournit pas de fonctions d'optimisation."
- }
- ]}
-/>
-
-{:else}
-### 4. Que se passe-t-il lorsque vous instanciez une des classes `TFAutoModelForXxx` avec un modèle de langage pré-entraîné (tel que `bert-base-uncased`) qui correspond à une tâche différente de celle pour laquelle il a été entraîné ?
-
-TFAutoModelForSequenceClassification avec bert-base-uncased, nous avons eu des messages d'avertissement lors de l'instanciation du modèle. La tête pré-entraînée n'est pas utilisée pour la tâche de classification de séquences, elle est donc supprimée et une nouvelle tête est instanciée avec des poids aléatoires..",
- correct: true
- },
- {
- text: "La tête du modèle pré-entraîné est supprimée.",
- explain: "Quelque chose d'autre doit se produire. Essayez encore !"
- },
- {
- text: "Rien, puisque le modèle peut encore être finetuné pour les différentes tâches.",
- explain: "La tête du modèle pré-entraîné n'a pas été entraînée à résoudre cette tâche, nous devons donc la supprimer !"
- }
- ]}
-/>
-
-### 5. Les modèles TensorFlow de `transformers` sont déjà des modèles Keras. Quel avantage cela offre-t-il ?
-
-TPUStrategy, y compris l'initialisation du modèle."
- },
- {
- text: "Vous pouvez tirer parti des méthodes existantes telles que compile(), fit() et predict().",
- explain: "Une fois que vous disposez des données, l'entraînement sur celles-ci ne demande que très peu de travail.",
- correct: true
- },
- {
- text: "Vous apprendrez à connaître Keras ainsi que transformers.",
- explain: "Mais nous cherchons quelque chose d'autre :)",
- correct: true
- },
- {
- text: "Vous pouvez facilement calculer les métriques liées au jeu de données.",
- explain: "Keras nous aide à entraîner et à évaluer le modèle, et non à calculer les paramètres liés aux jeux de données."
- }
- ]}
-/>
-
-### 6. Comment pouvez-vous définir votre propre métrique personnalisée ?
-
-tf.keras.metrics.Metric.",
- explain: "Excellent !",
- correct: true
- },
- {
- text: "Utilisation de l'API fonctionnelle de Keras.",
- explain: "Essayez à nouveau !"
- },
- {
- text: "En utilisant un callable avec la signature metric_fn(y_true, y_pred).",
- explain: " ",
- correct: true
- },
- {
- text: "En le googlant.",
- explain: "Ce n'est pas la réponse que nous cherchons, mais cela devrait vous aider à la trouver.",
- correct: true
- }
- ]}
-/>
-
-{/if}
+
+
+
+
+# Quiz de fin de chapitre
+
+
+
+Testez ce que vous avez appris dans ce chapitre !
+
+### 1. Le jeu de données `emotion` contient des messages Twitter étiquetés avec des émotions. Cherchez-le dans le [*Hub*](https://huggingface.co/datasets) et lisez la carte du jeu de données. Laquelle de ces émotions n'est pas une de ses émotions de base ?
+
+
+
+### 2. Cherchez le jeu de données `ar_sarcasme` dans le [*Hub*](https://huggingface.co/datasets). Quelle tâche prend-il en charge ?
+
+tags.",
+ correct: true
+ },
+ {
+ text: "Traduction automatique",
+ explain: "Ce n'est pas ça. Jetez un autre coup d'œil à la carte du jeu de données !"
+ },
+ {
+ text: "Reconnaissance des entités nommées",
+ explain: "Ce n'est pas ça. Jetez un autre coup d'œil à la carte du jeu de données !"
+ },
+ {
+ text: "Réponse aux questions",
+ explain: "Hélas, cette question n'a pas reçu de réponse correcte. Essayez à nouveau !"
+ }
+ ]}
+/>
+
+### 3. Comment le modèle BERT attend-il qu'une paire de phrases soit traitée ?
+
+[SEP] est nécessaire pour séparer les deux phrases, mais ce n'est pas tout !"
+ },
+ {
+ text: "[CLS] Tokens_de_la_phrase_1 Tokens_de_la_phrase_2",
+ explain: "Un jeton spécial [CLS] est requis au début, mais ce n'est pas la seule chose !"
+ },
+ {
+ text: "[CLS] Tokens_de_la_phrase_1 [SEP] Tokens_de_la_phrase_2 [SEP]",
+ explain: "C'est exact !",
+ correct: true
+ },
+ {
+ text: "[CLS] Tokens_de_la_phrase_1 [SEP] Tokens_de_la_phrase_2",
+ explain: "Un jeton spécial [CLS] est nécessaire au début, ainsi qu'un jeton spécial [SEP] pour séparer les deux phrases, mais ce n'est pas tout !"
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 4. Quels sont les avantages de la méthode `Dataset.map()` ?
+
+
+
+### 5. Que signifie le remplissage (*padding*) dynamique ?
+
+tokens que la précédente dans le jeu de données.",
+ explain: "Cela n'a pas de sens de regarder l'ordre dans le jeu de données puisque nous le mélangeons pendant l'entraînement."
+ },
+ ]}
+/>
+
+### 6. Quel est le but d'une fonction de rassemblement ?
+
+DataCollatorWithPadding."
+ },
+ {
+ text: "Elle rassemble tous les échantillons dans un batch.",
+ explain: "Vous pouvez passer la fonction de rassemblement comme argument d'une fonction DataLoader. Nous avons utilisé la fonction DataCollatorWithPadding qui remplit tous les éléments d'un batch pour qu'ils aient la même longueur.",
+ correct: true
+ },
+ {
+ text: "Elle pré-traite tout le jeu de données.",
+ explain: "Ce serait une fonction de prétraitement, pas une fonction de rassemblement."
+ },
+ {
+ text: "Elle tronque les séquences dans le jeu de données.",
+ explain: "Une fonction de rassemblement est impliquée dans le traitement des batchs individuels, et non de tout le jeu de données. Si vous êtes intéressé par la troncature, vous pouvez utiliser la fonction truncate en argument du tokenizer."
+ }
+ ]}
+/>
+
+### 7. Que se passe-t-il lorsque vous instanciez une des classes `AutoModelForXxx` avec un modèle de langage pré-entraîné (tel que `bert-base-uncased`) qui correspond à une tâche différente de celle pour laquelle il a été entraîné ?
+
+AutoModelForSequenceClassification avec bert-base-uncased, nous avons eu des messages d'avertissement lors de l'instanciation du modèle. La tête pré-entraînée n'est pas utilisée pour la tâche de classification de séquences, elle est donc supprimée et une nouvelle tête est instanciée avec des poids aléatoires..",
+ correct: true
+ },
+ {
+ text: "La tête du modèle pré-entraîné est supprimée.",
+ explain: "Quelque chose d'autre doit se produire. Essayez encore !"
+ },
+ {
+ text: "Rien, puisque le modèle peut encore être finetuné pour les différentes tâches.",
+ explain: "La tête du modèle pré-entraîné n'a pas été entraînée à résoudre cette tâche, nous devons donc la supprimer !"
+ }
+ ]}
+/>
+
+### 8. Quel est le but de `TrainingArguments` ?
+
+Trainer.",
+ explain: "",
+ correct: true
+ },
+ {
+ text: "Préciser la taille du modèle.",
+ explain: "La taille du modèle est définie par la configuration du modèle, et non par la classe TrainingArguments."
+ },
+ {
+ text: "Juste contenir les hyperparamètres utilisés pour l'évaluation.",
+ explain: "Dans l'exemple, nous avons spécifié où le modèle et ses checkpoints seront sauvegardés. Essayez à nouveau !"
+ },
+ {
+ text: "Contenir seulement les hyperparamètres utilisés pour l'entraînement.",
+ explain: "Dans l'exemple, nous avons utilisé une evaluation_strategy également, ce qui a un impact sur l'évaluation. Essayez à nouveau !"
+ }
+ ]}
+/>
+
+### 9. Pourquoi devriez-vous utiliser la librairie 🤗 *Accelerate* ?
+
+Accelerate ne fournit aucun modèles."
+ },
+ {
+ text: "Elle fournit une API de haut niveau qui évite d'avoir à mettre en place sa propre boucle d'entraînement.",
+ explain: "C'est ce que nous avons fait avec le Trainer mais pas avec la librairie 🤗 Accelerate. Essayez à nouveau !"
+ },
+ {
+ text: "Elle permet à nos boucles d'entraînement de fonctionner avec des stratégies distribuées.",
+ explain: "Avec 🤗 Accelerate, vos boucles d'entraînement fonctionneront pour plusieurs GPUs et TPUs.",
+ correct: true
+ },
+ {
+ text: "Elle offre davantage de fonctions d'optimisation.",
+ explain: "Non, la librairie 🤗 Accelerate ne fournit pas de fonctions d'optimisation."
+ }
+ ]}
+/>
+
+{:else}
+### 4. Que se passe-t-il lorsque vous instanciez une des classes `TFAutoModelForXxx` avec un modèle de langage pré-entraîné (tel que `bert-base-uncased`) qui correspond à une tâche différente de celle pour laquelle il a été entraîné ?
+
+TFAutoModelForSequenceClassification avec bert-base-uncased, nous avons eu des messages d'avertissement lors de l'instanciation du modèle. La tête pré-entraînée n'est pas utilisée pour la tâche de classification de séquences, elle est donc supprimée et une nouvelle tête est instanciée avec des poids aléatoires..",
+ correct: true
+ },
+ {
+ text: "La tête du modèle pré-entraîné est supprimée.",
+ explain: "Quelque chose d'autre doit se produire. Essayez encore !"
+ },
+ {
+ text: "Rien, puisque le modèle peut encore être finetuné pour les différentes tâches.",
+ explain: "La tête du modèle pré-entraîné n'a pas été entraînée à résoudre cette tâche, nous devons donc la supprimer !"
+ }
+ ]}
+/>
+
+### 5. Les modèles TensorFlow de `transformers` sont déjà des modèles Keras. Quel avantage cela offre-t-il ?
+
+TPUStrategy, y compris l'initialisation du modèle."
+ },
+ {
+ text: "Vous pouvez tirer parti des méthodes existantes telles que compile(), fit() et predict().",
+ explain: "Une fois que vous disposez des données, l'entraînement sur celles-ci ne demande que très peu de travail.",
+ correct: true
+ },
+ {
+ text: "Vous apprendrez à connaître Keras ainsi que transformers.",
+ explain: "Mais nous cherchons quelque chose d'autre :)",
+ correct: true
+ },
+ {
+ text: "Vous pouvez facilement calculer les métriques liées au jeu de données.",
+ explain: "Keras nous aide à entraîner et à évaluer le modèle, et non à calculer les paramètres liés aux jeux de données."
+ }
+ ]}
+/>
+
+### 6. Comment pouvez-vous définir votre propre métrique personnalisée ?
+
+tf.keras.metrics.Metric.",
+ explain: "Excellent !",
+ correct: true
+ },
+ {
+ text: "Utilisation de l'API fonctionnelle de Keras.",
+ explain: "Essayez à nouveau !"
+ },
+ {
+ text: "En utilisant un callable avec la signature metric_fn(y_true, y_pred).",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "En le googlant.",
+ explain: "Ce n'est pas la réponse que nous cherchons, mais cela devrait vous aider à la trouver.",
+ correct: true
+ }
+ ]}
+/>
+
+{/if}
diff --git a/chapters/fr/chapter4/1.mdx b/chapters/fr/chapter4/1.mdx
index 7a0420461..b27ba639e 100644
--- a/chapters/fr/chapter4/1.mdx
+++ b/chapters/fr/chapter4/1.mdx
@@ -1,17 +1,22 @@
-# Le Hub d'Hugging Face
-
-Le [*Hub* d'Hugging Face](https://huggingface.co/), notre site internet principal, est une plateforme centrale qui permet à quiconque de découvrir, d'utiliser et de contribuer à de nouveaux modèles et jeux de données de pointe. Il héberge une grande variété de modèles, dont plus de 10 000 sont accessibles au public. Nous nous concentrerons sur les modèles dans ce chapitre, et nous examinerons les jeux de données au chapitre 5.
-
-Les modèles présents dans le *Hub* ne sont pas limités à 🤗 *Transformers* ou même au NLP. Il existe des modèles de [Flair](https://github.com/flairNLP/flair) et [AllenNLP](https://github.com/allenai/allennlp) pour le NLP, [Asteroid](https://github.com/asteroid-team/asteroid) et [pyannote](https://github.com/pyannote/pyannote-audio) pour l'audio, et [timm](https://github.com/rwightman/pytorch-image-models) pour la vision, pour n'en citer que quelques-uns.
-
-Chacun de ces modèles est hébergé sous forme de dépôt Git, ce qui permet le suivi des versions et la reproductibilité. Partager un modèle sur le *Hub*, c'est l'ouvrir à la communauté et le rendre accessible à tous ceux qui souhaitent l'utiliser facilement, ce qui leur évite d'avoir à entraîner eux-mêmes un modèle et simplifie le partage et l'utilisation.
-
-En outre, le partage d'un modèle sur le *Hub* déploie automatiquement une API d'inférence hébergée pour ce modèle. Toute personne de la communauté est libre de la tester directement sur la page du modèle, avec des entrées personnalisées et des *widgets* appropriés.
-
-La meilleure partie est que le partage ainsi que l'utilisation de n'importe quel modèle public sur le *Hub* sont totalement gratuits ! [Des plans payants](https://huggingface.co/pricing) existent également si vous souhaitez partager des modèles en privé.
-
-La vidéo ci-dessous montre comment naviguer sur le *Hub* :
-
-
-
+# Le Hub d'Hugging Face
+
+
+
+Le [*Hub* d'Hugging Face](https://huggingface.co/), notre site internet principal, est une plateforme centrale qui permet à quiconque de découvrir, d'utiliser et de contribuer à de nouveaux modèles et jeux de données de pointe. Il héberge une grande variété de modèles, dont plus de 10 000 sont accessibles au public. Nous nous concentrerons sur les modèles dans ce chapitre, et nous examinerons les jeux de données au chapitre 5.
+
+Les modèles présents dans le *Hub* ne sont pas limités à 🤗 *Transformers* ou même au NLP. Il existe des modèles de [Flair](https://github.com/flairNLP/flair) et [AllenNLP](https://github.com/allenai/allennlp) pour le NLP, [Asteroid](https://github.com/asteroid-team/asteroid) et [pyannote](https://github.com/pyannote/pyannote-audio) pour l'audio, et [timm](https://github.com/rwightman/pytorch-image-models) pour la vision, pour n'en citer que quelques-uns.
+
+Chacun de ces modèles est hébergé sous forme de dépôt Git, ce qui permet le suivi des versions et la reproductibilité. Partager un modèle sur le *Hub*, c'est l'ouvrir à la communauté et le rendre accessible à tous ceux qui souhaitent l'utiliser facilement, ce qui leur évite d'avoir à entraîner eux-mêmes un modèle et simplifie le partage et l'utilisation.
+
+En outre, le partage d'un modèle sur le *Hub* déploie automatiquement une API d'inférence hébergée pour ce modèle. Toute personne de la communauté est libre de la tester directement sur la page du modèle, avec des entrées personnalisées et des *widgets* appropriés.
+
+La meilleure partie est que le partage ainsi que l'utilisation de n'importe quel modèle public sur le *Hub* sont totalement gratuits ! [Des plans payants](https://huggingface.co/pricing) existent également si vous souhaitez partager des modèles en privé.
+
+La vidéo ci-dessous montre comment naviguer sur le *Hub* :
+
+
+
Avoir un compte huggingface.co est nécessaire pour suivre cette partie car nous allons créer et gérer des répertoires sur le *Hub* : [créer un compte](https://huggingface.co/join)
\ No newline at end of file
diff --git a/chapters/fr/chapter4/2.mdx b/chapters/fr/chapter4/2.mdx
index 86579685f..6f86e8f4f 100644
--- a/chapters/fr/chapter4/2.mdx
+++ b/chapters/fr/chapter4/2.mdx
@@ -1,97 +1,97 @@
-
-
-# Utilisation de modèles pré-entraînés
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-Le *Hub* rend simple la sélection d'un modèle et permet alors que celui-ci puisse être utilisé dans toute bibliothèque en aval en seulement quelques lignes de code. Voyons comment utiliser concrètement l'un de ces modèles et comment contribuer au développement de la communauté.
-
-Supposons que nous recherchions un modèle basé sur le français, capable de remplir des masques.
-
-
-

-
-

-
+
+
+
+
-

-
-

-
-
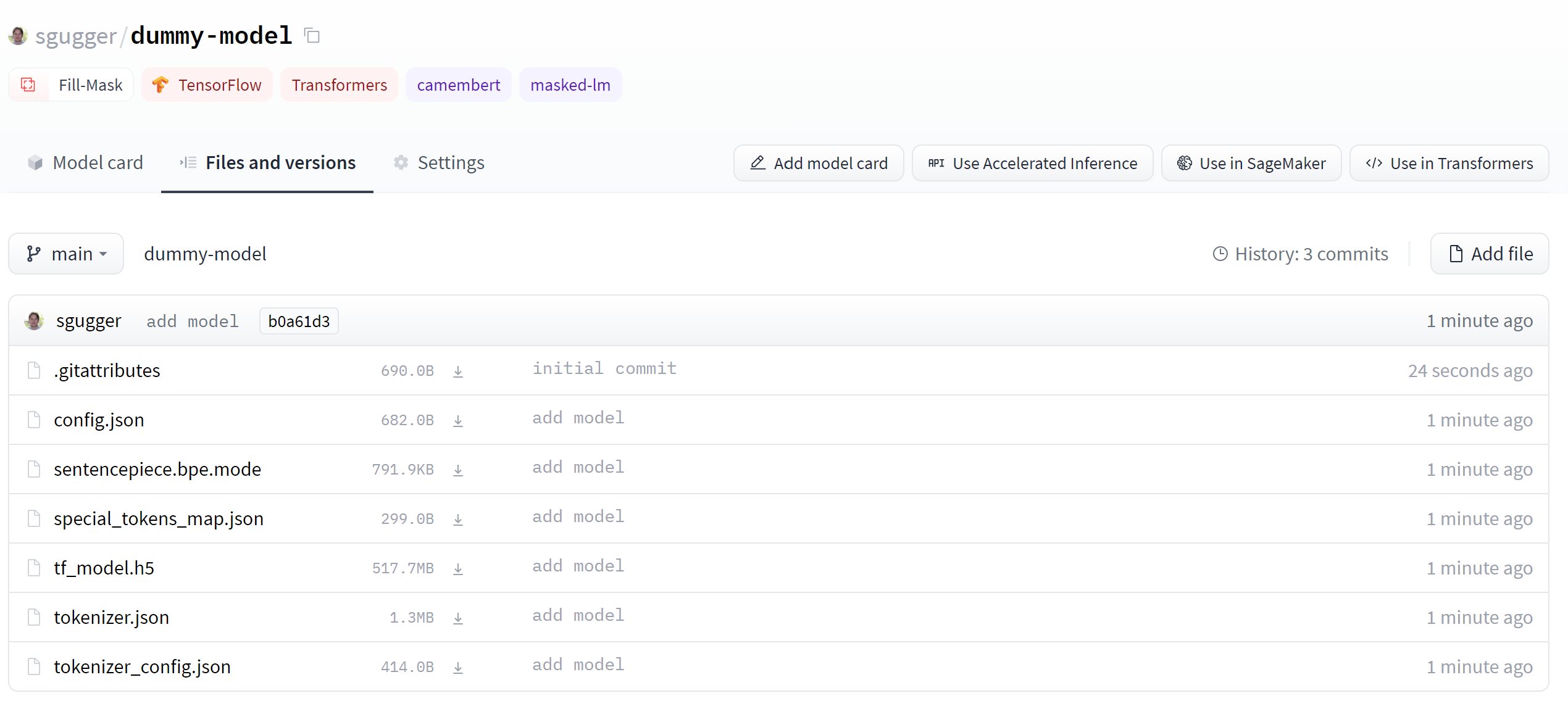
-
-

-
-

-
-

-
-

-
-

-
-

-
-

-
-

-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
git-lfs pour les fichiers volumineux.",
- correct: true
- }
- ]}
-/>
-
-### 3. Que pouvez-vous faire en utilisant l'interface web du *Hub* ?
-
-Forker » un dépôt existant.",
- explain: "« Forker » un dépôt n'est pas possible sur le Hub."
- },
- {
- text: "Créer un nouveau dépôt de modèles.",
- explain: "Ce n'est pas tout ce que vous pouvez faire, cependant.",
- correct: true
- },
- {
- text: "Gérer et modifier des fichiers.",
- explain: "Ce n'est pas la seule bonne réponse, cependant.",
- correct: true
- },
- {
- text: "Télécharger des fichiers.",
- explain: "Mais ce n'est pas tout.",
- correct: true
- },
- {
- text: "Voir les différences entre les versions.",
- explain: "Ce n'est pas tout ce que vous pouvez faire.",
- correct: true
- }
- ]}
-/>
-
-### 4. Qu'est-ce qu'une carte de modèle ?
-
-tokenizer.",
- explain: "Il s'agit bien d'une description du modèle, mais c'est un élément important : s'il est incomplet ou absent, l'utilité du modèle est considérablement réduite."
- },
- {
- text: "Un moyen d'assurer la reproductibilité, la réutilisation et l'équité..",
- explain: "Le fait de partager les bonnes informations dans la fiche du modèle aidera les utilisateurs à tirer parti de votre modèle et à être conscients de ses limites et de ses biais.",
- correct: true
- },
- {
- text: "Un fichier Python qui peut être exécuté pour récupérer des informations sur le modèle.",
- explain: "Les cartes de modèle sont de simples fichiers Markdown."
- }
- ]}
-/>
-
-### 5. Lesquels de ces objets de la bibliothèque 🤗 *Transformers* peuvent être directement partagés sur le Hub avec `push_to_hub()` ?
-
-{#if fw === 'pt'}
-tokenizer",
- explain: "Tous les tokenizers ont la méthode push_to_hub et l'utiliser poussera tous les fichiers du tokenizer (vocabulaire, architecture du tokenizer, etc.) vers un dépôt donné. Ce n'est pas la seule bonne réponse, cependant !",
- correct: true
- },
- {
- text: "Une configuration de modèle",
- explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
- correct: true
- },
- {
- text: "Un modèle",
- explain: "Tous les modèles ont la méthode push_to_hub qui le pushra ainsi que leurs fichiers de configuration, vers un dépôt donné. Ce n'est pas tout ce que vous pouvez partager, cependant.",
- correct: true
- },
- {
- text: "Trainer",
- explain: "Le Trainer implémente aussi la méthode push_to_hub. L'utiliser téléchargera le modèle, sa configuration, le tokenizer et une ébauche de carte de modèle vers un dépôt donné. Essayez une autre réponse !",
- correct: true
- }
- ]}
-/>
-{:else}
-tokenizer",
- explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
- correct: true
- },
- {
- text: "Une configuration de modèle",
- explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
- correct: true
- },
- {
- text: "Un modèle",
- explain: "Tous les modèles ont la méthode push_to_hub qui le pushra ainsi que leurs fichiers de configuration, vers un dépôt donné. Ce n'est pas tout ce que vous pouvez partager, cependant.",
- correct: true
- },
- {
- text: "Tout ce qui précède avec un callback dédié",
- explain: "Le PushToHubCallback enverra régulièrement tous ces objets à un dépôt pendant l'entraînement.",
- correct: true
- }
- ]}
-/>
-{/if}
-
-### 6. Quelle est la première étape lorsqu'on utilise la méthode `push_to_hub()` ou les outils CLI ?
-
-notebook.",
- explain: "Cela affichera un widget pour vous permettre de vous authentifier.",
- correct: true
- },
- ]}
-/>
-
-### 7. Vous utilisez un modèle et un *tokenizer*, comment pouvez-vous les télécharger sur le *Hub* ?
-
-tokenizer.",
- explain: " ",
- correct: true
- },
- {
- text: "Au sein du moteur d'exécution Python, en les enveloppant dans une balise huggingface_hub.",
- explain: "Les modèles et les tokenizers bénéficient déjà de huggingface_hub : pas besoin d'emballage supplémentaire !"
- },
- {
- text: "En les sauvegardant sur le disque et en appelant transformers-cli upload-model.",
- explain: "La commande upload-model n'existe pas."
- }
- ]}
-/>
-
-### 8. Quelles opérations git pouvez-vous faire avec la classe `Repository` ?
-
-commit.",
- explain: "La méthode git_commit() est là pour ça.",
- correct: true
- },
- {
- text: "Un pull.",
- explain: "C'est le but de la méthode git_pull().",
- correct: true
- },
- {
- text: "Un push.",
- explain: "La méthode git_push() fait ça.",
- correct: true
- },
- {
- text: "Un merge.",
- explain: "Cette opération ne sera jamais possible avec cette API."
- }
- ]}
+
+
+
+
+# Quiz de fin de chapitre
+
+
+
+Testons ce que vous avez appris dans ce chapitre !
+
+### 1. A quoi sont limités les modèles du *Hub* ?
+
+Transformers.",
+ explain: "Si les modèles de la bibliothèque 🤗 Transformers sont pris en charge sur le Hub, ils ne sont pas les seuls !"
+ },
+ {
+ text: "Tous les modèles avec une interface similaire à 🤗 Transformers.",
+ explain: "Aucune exigence d'interface n'est fixée lors du téléchargement de modèles vers le Hub."
+ },
+ {
+ text: "Il n'y a pas de limites.",
+ explain: "Il n'y a pas de limites au téléchargement de modèles sur le Hub.",
+ correct: true
+ },
+ {
+ text: "Des modèles qui sont d'une certaine manière liés au NLP.",
+ explain: "Aucune exigence n'est fixée concernant le domaine d'application !"
+ }
+ ]}
+/>
+
+### 2. Comment pouvez-vous gérer les modèles sur le *Hub* ?
+
+Hub sont de simples dépôts Git exploitant git-lfs pour les fichiers volumineux.",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Que pouvez-vous faire en utilisant l'interface web du *Hub* ?
+
+Forker » un dépôt existant.",
+ explain: "« Forker » un dépôt n'est pas possible sur le Hub."
+ },
+ {
+ text: "Créer un nouveau dépôt de modèles.",
+ explain: "Ce n'est pas tout ce que vous pouvez faire, cependant.",
+ correct: true
+ },
+ {
+ text: "Gérer et modifier des fichiers.",
+ explain: "Ce n'est pas la seule bonne réponse, cependant.",
+ correct: true
+ },
+ {
+ text: "Télécharger des fichiers.",
+ explain: "Mais ce n'est pas tout.",
+ correct: true
+ },
+ {
+ text: "Voir les différences entre les versions.",
+ explain: "Ce n'est pas tout ce que vous pouvez faire.",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Qu'est-ce qu'une carte de modèle ?
+
+tokenizer.",
+ explain: "Il s'agit bien d'une description du modèle, mais c'est un élément important : s'il est incomplet ou absent, l'utilité du modèle est considérablement réduite."
+ },
+ {
+ text: "Un moyen d'assurer la reproductibilité, la réutilisation et l'équité..",
+ explain: "Le fait de partager les bonnes informations dans la fiche du modèle aidera les utilisateurs à tirer parti de votre modèle et à être conscients de ses limites et de ses biais.",
+ correct: true
+ },
+ {
+ text: "Un fichier Python qui peut être exécuté pour récupérer des informations sur le modèle.",
+ explain: "Les cartes de modèle sont de simples fichiers Markdown."
+ }
+ ]}
+/>
+
+### 5. Lesquels de ces objets de la bibliothèque 🤗 *Transformers* peuvent être directement partagés sur le Hub avec `push_to_hub()` ?
+
+{#if fw === 'pt'}
+tokenizer",
+ explain: "Tous les tokenizers ont la méthode push_to_hub et l'utiliser poussera tous les fichiers du tokenizer (vocabulaire, architecture du tokenizer, etc.) vers un dépôt donné. Ce n'est pas la seule bonne réponse, cependant !",
+ correct: true
+ },
+ {
+ text: "Une configuration de modèle",
+ explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
+ correct: true
+ },
+ {
+ text: "Un modèle",
+ explain: "Tous les modèles ont la méthode push_to_hub qui le pushra ainsi que leurs fichiers de configuration, vers un dépôt donné. Ce n'est pas tout ce que vous pouvez partager, cependant.",
+ correct: true
+ },
+ {
+ text: "Trainer",
+ explain: "Le Trainer implémente aussi la méthode push_to_hub. L'utiliser téléchargera le modèle, sa configuration, le tokenizer et une ébauche de carte de modèle vers un dépôt donné. Essayez une autre réponse !",
+ correct: true
+ }
+ ]}
+/>
+{:else}
+tokenizer",
+ explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
+ correct: true
+ },
+ {
+ text: "Une configuration de modèle",
+ explain: "Toutes les configurations de modèles ont la méthode push_to_hub et son utilisation les poussera vers un dépôt donné. Que pouvez-vous partager d'autre ?",
+ correct: true
+ },
+ {
+ text: "Un modèle",
+ explain: "Tous les modèles ont la méthode push_to_hub qui le pushra ainsi que leurs fichiers de configuration, vers un dépôt donné. Ce n'est pas tout ce que vous pouvez partager, cependant.",
+ correct: true
+ },
+ {
+ text: "Tout ce qui précède avec un callback dédié",
+ explain: "Le PushToHubCallback enverra régulièrement tous ces objets à un dépôt pendant l'entraînement.",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. Quelle est la première étape lorsqu'on utilise la méthode `push_to_hub()` ou les outils CLI ?
+
+notebook.",
+ explain: "Cela affichera un widget pour vous permettre de vous authentifier.",
+ correct: true
+ },
+ ]}
+/>
+
+### 7. Vous utilisez un modèle et un *tokenizer*, comment pouvez-vous les télécharger sur le *Hub* ?
+
+tokenizer.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "Au sein du moteur d'exécution Python, en les enveloppant dans une balise huggingface_hub.",
+ explain: "Les modèles et les tokenizers bénéficient déjà de huggingface_hub : pas besoin d'emballage supplémentaire !"
+ },
+ {
+ text: "En les sauvegardant sur le disque et en appelant transformers-cli upload-model.",
+ explain: "La commande upload-model n'existe pas."
+ }
+ ]}
+/>
+
+### 8. Quelles opérations git pouvez-vous faire avec la classe `Repository` ?
+
+commit.",
+ explain: "La méthode git_commit() est là pour ça.",
+ correct: true
+ },
+ {
+ text: "Un pull.",
+ explain: "C'est le but de la méthode git_pull().",
+ correct: true
+ },
+ {
+ text: "Un push.",
+ explain: "La méthode git_push() fait ça.",
+ correct: true
+ },
+ {
+ text: "Un merge.",
+ explain: "Cette opération ne sera jamais possible avec cette API."
+ }
+ ]}
/>
\ No newline at end of file
diff --git a/chapters/fr/chapter5/1.mdx b/chapters/fr/chapter5/1.mdx
index 2817734c9..3b1d9718f 100644
--- a/chapters/fr/chapter5/1.mdx
+++ b/chapters/fr/chapter5/1.mdx
@@ -1,17 +1,22 @@
-# Introduction
-
-Dans le [chapitre 3](/course/fr/chapter3) vous avez eu un premier aperçu de la bibliothèque 🤗 *Datasets* et des trois étapes principales pour *finetuner* un modèle :
-
-1. chargement d'un jeu de données à partir du *Hub* d’Hugging Face,
-2. prétraitement des données avec `Dataset.map()`,
-3. chargement et calcul des métriques.
-
-Mais ce n'est qu'effleurer la surface de ce que 🤗 *Datasets* peut faire ! Dans ce chapitre, nous allons plonger profondément dans cette bibliothèque. En cours de route, nous trouverons des réponses aux questions suivantes :
-
-* que faire lorsque votre jeu de données n'est pas sur le *Hub* ?
-* comment découper et trancher un jeu de données ? (Et si on a _vraiment_ besoin d'utiliser Pandas ?)
-* que faire lorsque votre jeu de données est énorme et va monopoliser la RAM de votre ordinateur portable ?
-* qu'est-ce que c'est que le « *memory mapping* » et Apache Arrow ?
-* comment créer votre propre jeu de données et le pousser sur le *Hub* ?
-
+# Introduction
+
+
+
+Dans le [chapitre 3](/course/fr/chapter3) vous avez eu un premier aperçu de la bibliothèque 🤗 *Datasets* et des trois étapes principales pour *finetuner* un modèle :
+
+1. chargement d'un jeu de données à partir du *Hub* d’Hugging Face,
+2. prétraitement des données avec `Dataset.map()`,
+3. chargement et calcul des métriques.
+
+Mais ce n'est qu'effleurer la surface de ce que 🤗 *Datasets* peut faire ! Dans ce chapitre, nous allons plonger profondément dans cette bibliothèque. En cours de route, nous trouverons des réponses aux questions suivantes :
+
+* que faire lorsque votre jeu de données n'est pas sur le *Hub* ?
+* comment découper et trancher un jeu de données ? (Et si on a _vraiment_ besoin d'utiliser Pandas ?)
+* que faire lorsque votre jeu de données est énorme et va monopoliser la RAM de votre ordinateur portable ?
+* qu'est-ce que c'est que le « *memory mapping* » et Apache Arrow ?
+* comment créer votre propre jeu de données et le pousser sur le *Hub* ?
+
Les techniques apprises dans ce chapitre vous prépareront aux tâches avancées de tokenisation du [chapitre 6](/course/fr/chapter6) et de *finetuning* du [chapitre 7](/course/fr/chapter7). Alors prenez un café et commençons !
\ No newline at end of file
diff --git a/chapters/fr/chapter5/2.mdx b/chapters/fr/chapter5/2.mdx
index f05424005..ee20d7800 100644
--- a/chapters/fr/chapter5/2.mdx
+++ b/chapters/fr/chapter5/2.mdx
@@ -1,167 +1,167 @@
-# Que faire si mon jeu de données n'est pas sur le Hub ?
-
-
-
-Vous savez comment utiliser le [*Hub*](https://huggingface.co/datasets) pour télécharger des jeux de données mais en pratique vous vous retrouverez souvent à travailler avec des données stockées sur votre ordinateur portable ou sur un serveur distant. Dans cette section, nous allons vous montrer comment 🤗 *Datasets* peut être utilisé pour charger des jeux de données qui ne sont pas disponibles sur le *Hub* d’Hugging Face.
-
-
-
-## Travailler avec des jeux de données locaux et distants
-
-🤗 *Datasets* fournit des scripts de chargement de jeux de données locaux et distants. La bibliothèque prend en charge plusieurs formats de données courants, tels que :
-
-| Format des données | Script de chargement | Exemple |
-| :----------------: | :------------------: | :-----------------------------------------------------: |
-| CSV & TSV | `csv` | `load_dataset("csv", data_files="my_file.csv")` |
-| Fichiers texte | `text` | `load_dataset("text", data_files="my_file.txt")` |
-| JSON & JSON Lines | `json` | `load_dataset("json", data_files="my_file.jsonl")` |
-| DataFrames en Pickle | `pandas` | `load_dataset("pandas", data_files="my_dataframe.pkl")` |
-
-Comme indiqué dans le tableau, pour chaque format de données, nous avons juste besoin de spécifier le type de script de chargement dans la fonction `load_dataset()`, ainsi qu'un argument `data_files` qui spécifie le chemin vers un ou plusieurs fichiers. Commençons par charger un jeu de données à partir de fichiers locaux puis plus tard comment faire la même chose avec des fichiers distants.
-
-## Charger un jeu de données local
-
-Pour cet exemple, nous utilisons le jeu de données [SQuAD-it](https://github.com/crux82/squad-it/) qui est un grand jeu de données pour la tâche de *Question Awnswering* en italien.
-
-Les échantillons d’entraînement et de test sont hébergés sur GitHub, nous pouvons donc les télécharger avec une simple commande `wget` :
-
-```python
-!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
-!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
-```
-
-Cela télécharge deux fichiers compressés appelés *SQuAD_it-train.json.gz* et *SQuAD_it-test.json.gz* que nous pouvons décompresser avec la commande Linux `gzip` :
-
-```python
-!gzip -dkv SQuAD_it-*.json.gz
-```
-
-```bash
-SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
-SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json
-```
-
-Nous pouvons voir que les fichiers compressés ont été remplacés par _SQuAD_it-train.json_ et _SQuAD_it-text.json_, et que les données sont stockées au format JSON.
-
-
-
-✎ Si vous vous demandez pourquoi il y a un caractère `!` dans les commandes *shell* ci-dessus, c'est parce que nous les exécutons dans un *notebook* Jupyter. Supprimez simplement le préfixe si vous souhaitez télécharger et décompresser le jeu de données dans un terminal.
-
-
-
-Pour charger un fichier JSON avec la fonction `load_dataset()`, nous avons juste besoin de savoir si nous avons affaire à du JSON ordinaire (similaire à un dictionnaire imbriqué) ou à des lignes JSON (JSON séparé par des lignes). Comme de nombreux jeux de données de questions-réponses, SQuAD-it utilise le format imbriqué où tout le texte est stocké dans un champ `data`. Cela signifie que nous pouvons charger le jeu de données en spécifiant l'argument `field` comme suit :
-
-```py
-from datasets import load_dataset
-
-squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
-```
-
-Par défaut, le chargement de fichiers locaux crée un objet `DatasetDict` avec un échantillon `train`. Nous pouvons le voir en inspectant l'objet `squad_it_dataset` :
-
-```py
-squad_it_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['title', 'paragraphs'],
- num_rows: 442
- })
-})
-```
-
-Cela nous montre le nombre de lignes et les noms de colonnes associés à l’échantillon d’entraînement. Nous pouvons afficher l'un des exemples en indexant l’échantillon `train` comme suit :
-
-```py
-squad_it_dataset["train"][0]
-```
-
-```python out
-{
- "title": "Terremoto del Sichuan del 2008", # Séisme du Sichuan 2008
- "paragraphs": [
- {
- "context": "Il terremoto del Sichuan del 2008 o il terremoto...",
- # Le tremblement de terre du Sichuan de 2008 ou le...
- "qas": [
- {
- "answers": [{"answer_start": 29, "text": "2008"}],
- "id": "56cdca7862d2951400fa6826",
- "question": "In quale anno si è verificato il terremoto nel Sichuan?",
- # En quelle année le tremblement de terre du Sichuan a-t-il eu lieu ?
- },
- ...
- ],
- },
- ...
- ],
-}
-```
-
-Super, nous avons chargé notre premier jeu de données local ! Mais ce que nous voulons vraiment, c'est inclure à la fois les échantillons `train` et `test` dans un seul objet `DatasetDict` afin que nous puissions appliquer les fonctions `Dataset.map()` sur les deux à la fois . Pour ce faire, nous pouvons fournir un dictionnaire à l'argument `data_files` qui associe chaque nom des échantillons à un fichier associé à cet échantillon :
-
-```py
-data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
-squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-squad_it_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['title', 'paragraphs'],
- num_rows: 442
- })
- test: Dataset({
- features: ['title', 'paragraphs'],
- num_rows: 48
- })
-})
-```
-
-C'est exactement ce que nous voulions. Désormais, nous pouvons appliquer diverses techniques de prétraitement pour nettoyer les données, tokeniser les avis, etc.
-
-
-
-L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
-
-
-
-Les scripts de chargement de 🤗 *Datasets* prennent en charge la décompression automatique des fichiers d'entrée. Nous aurions donc pu ignorer l'utilisation de `gzip` en pointant l'argument `data_files` directement sur les fichiers compressés :
-
-```py
-data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
-squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-```
-
-Cela peut être utile si vous ne souhaitez pas décompresser manuellement de nombreux fichiers GZIP. La décompression automatique s'applique également à d'autres formats courants tels que ZIP et TAR. Il vous suffit donc de pointer `data_files` vers les fichiers compressés et vous êtes prêt à partir !
-
-Maintenant que vous savez comment charger des fichiers locaux sur votre ordinateur portable ou de bureau, examinons le chargement de fichiers distants.
-
-## Charger un jeu de données distant
-
-Si vous travaillez en tant que *data scientist* ou codeur dans une entreprise, il y a de fortes chances que les jeux de données que vous souhaitez analyser soient stockés sur un serveur distant. Heureusement, charger des fichiers distants est aussi simple que de charger des fichiers locaux ! Au lieu de fournir un chemin vers les fichiers locaux, nous pointons l'argument `data_files` de `load_dataset()` vers une ou plusieurs URL où les fichiers distants sont stockés. Par exemple, pour le jeu de données SQuAD-it hébergé sur GitHub, nous pouvons simplement faire pointer `data_files` vers les URL _SQuAD_it-*.json.gz_ comme suit :
-
-```py
-url = "https://github.com/crux82/squad-it/raw/master/"
-data_files = {
- "train": url + "SQuAD_it-train.json.gz",
- "test": url + "SQuAD_it-test.json.gz",
-}
-squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-```
-
-Cela renvoie le même objet `DatasetDict` obtenu ci-dessus mais nous évite de télécharger et de décompresser manuellement les fichiers _SQuAD_it-*.json.gz_. Ceci conclut notre incursion dans les différentes façons de charger des jeux de données qui ne sont pas hébergés sur le *Hub*. Maintenant que nous avons un jeu de données avec lequel jouer, mettons la main à la pâte avec diverses techniques de gestion des données !
-
-
-
-✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) pour plus d'informations sur ces formats).
-
-
+# Que faire si mon jeu de données n'est pas sur le Hub ?
+
+
+
+Vous savez comment utiliser le [*Hub*](https://huggingface.co/datasets) pour télécharger des jeux de données mais en pratique vous vous retrouverez souvent à travailler avec des données stockées sur votre ordinateur portable ou sur un serveur distant. Dans cette section, nous allons vous montrer comment 🤗 *Datasets* peut être utilisé pour charger des jeux de données qui ne sont pas disponibles sur le *Hub* d’Hugging Face.
+
+
+
+## Travailler avec des jeux de données locaux et distants
+
+🤗 *Datasets* fournit des scripts de chargement de jeux de données locaux et distants. La bibliothèque prend en charge plusieurs formats de données courants, tels que :
+
+| Format des données | Script de chargement | Exemple |
+| :----------------: | :------------------: | :-----------------------------------------------------: |
+| CSV & TSV | `csv` | `load_dataset("csv", data_files="my_file.csv")` |
+| Fichiers texte | `text` | `load_dataset("text", data_files="my_file.txt")` |
+| JSON & JSON Lines | `json` | `load_dataset("json", data_files="my_file.jsonl")` |
+| DataFrames en Pickle | `pandas` | `load_dataset("pandas", data_files="my_dataframe.pkl")` |
+
+Comme indiqué dans le tableau, pour chaque format de données, nous avons juste besoin de spécifier le type de script de chargement dans la fonction `load_dataset()`, ainsi qu'un argument `data_files` qui spécifie le chemin vers un ou plusieurs fichiers. Commençons par charger un jeu de données à partir de fichiers locaux puis plus tard comment faire la même chose avec des fichiers distants.
+
+## Charger un jeu de données local
+
+Pour cet exemple, nous utilisons le jeu de données [SQuAD-it](https://github.com/crux82/squad-it/) qui est un grand jeu de données pour la tâche de *Question Awnswering* en italien.
+
+Les échantillons d’entraînement et de test sont hébergés sur GitHub, nous pouvons donc les télécharger avec une simple commande `wget` :
+
+```python
+!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
+!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
+```
+
+Cela télécharge deux fichiers compressés appelés *SQuAD_it-train.json.gz* et *SQuAD_it-test.json.gz* que nous pouvons décompresser avec la commande Linux `gzip` :
+
+```python
+!gzip -dkv SQuAD_it-*.json.gz
+```
+
+```bash
+SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
+SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json
+```
+
+Nous pouvons voir que les fichiers compressés ont été remplacés par _SQuAD_it-train.json_ et _SQuAD_it-text.json_, et que les données sont stockées au format JSON.
+
+
+
+✎ Si vous vous demandez pourquoi il y a un caractère `!` dans les commandes *shell* ci-dessus, c'est parce que nous les exécutons dans un *notebook* Jupyter. Supprimez simplement le préfixe si vous souhaitez télécharger et décompresser le jeu de données dans un terminal.
+
+
+
+Pour charger un fichier JSON avec la fonction `load_dataset()`, nous avons juste besoin de savoir si nous avons affaire à du JSON ordinaire (similaire à un dictionnaire imbriqué) ou à des lignes JSON (JSON séparé par des lignes). Comme de nombreux jeux de données de questions-réponses, SQuAD-it utilise le format imbriqué où tout le texte est stocké dans un champ `data`. Cela signifie que nous pouvons charger le jeu de données en spécifiant l'argument `field` comme suit :
+
+```py
+from datasets import load_dataset
+
+squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
+```
+
+Par défaut, le chargement de fichiers locaux crée un objet `DatasetDict` avec un échantillon `train`. Nous pouvons le voir en inspectant l'objet `squad_it_dataset` :
+
+```py
+squad_it_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['title', 'paragraphs'],
+ num_rows: 442
+ })
+})
+```
+
+Cela nous montre le nombre de lignes et les noms de colonnes associés à l’échantillon d’entraînement. Nous pouvons afficher l'un des exemples en indexant l’échantillon `train` comme suit :
+
+```py
+squad_it_dataset["train"][0]
+```
+
+```python out
+{
+ "title": "Terremoto del Sichuan del 2008", # Séisme du Sichuan 2008
+ "paragraphs": [
+ {
+ "context": "Il terremoto del Sichuan del 2008 o il terremoto...",
+ # Le tremblement de terre du Sichuan de 2008 ou le...
+ "qas": [
+ {
+ "answers": [{"answer_start": 29, "text": "2008"}],
+ "id": "56cdca7862d2951400fa6826",
+ "question": "In quale anno si è verificato il terremoto nel Sichuan?",
+ # En quelle année le tremblement de terre du Sichuan a-t-il eu lieu ?
+ },
+ ...
+ ],
+ },
+ ...
+ ],
+}
+```
+
+Super, nous avons chargé notre premier jeu de données local ! Mais ce que nous voulons vraiment, c'est inclure à la fois les échantillons `train` et `test` dans un seul objet `DatasetDict` afin que nous puissions appliquer les fonctions `Dataset.map()` sur les deux à la fois . Pour ce faire, nous pouvons fournir un dictionnaire à l'argument `data_files` qui associe chaque nom des échantillons à un fichier associé à cet échantillon :
+
+```py
+data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
+squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
+squad_it_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['title', 'paragraphs'],
+ num_rows: 442
+ })
+ test: Dataset({
+ features: ['title', 'paragraphs'],
+ num_rows: 48
+ })
+})
+```
+
+C'est exactement ce que nous voulions. Désormais, nous pouvons appliquer diverses techniques de prétraitement pour nettoyer les données, tokeniser les avis, etc.
+
+
+
+L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
+
+
+
+Les scripts de chargement de 🤗 *Datasets* prennent en charge la décompression automatique des fichiers d'entrée. Nous aurions donc pu ignorer l'utilisation de `gzip` en pointant l'argument `data_files` directement sur les fichiers compressés :
+
+```py
+data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
+squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
+```
+
+Cela peut être utile si vous ne souhaitez pas décompresser manuellement de nombreux fichiers GZIP. La décompression automatique s'applique également à d'autres formats courants tels que ZIP et TAR. Il vous suffit donc de pointer `data_files` vers les fichiers compressés et vous êtes prêt à partir !
+
+Maintenant que vous savez comment charger des fichiers locaux sur votre ordinateur portable ou de bureau, examinons le chargement de fichiers distants.
+
+## Charger un jeu de données distant
+
+Si vous travaillez en tant que *data scientist* ou codeur dans une entreprise, il y a de fortes chances que les jeux de données que vous souhaitez analyser soient stockés sur un serveur distant. Heureusement, charger des fichiers distants est aussi simple que de charger des fichiers locaux ! Au lieu de fournir un chemin vers les fichiers locaux, nous pointons l'argument `data_files` de `load_dataset()` vers une ou plusieurs URL où les fichiers distants sont stockés. Par exemple, pour le jeu de données SQuAD-it hébergé sur GitHub, nous pouvons simplement faire pointer `data_files` vers les URL _SQuAD_it-*.json.gz_ comme suit :
+
+```py
+url = "https://github.com/crux82/squad-it/raw/master/"
+data_files = {
+ "train": url + "SQuAD_it-train.json.gz",
+ "test": url + "SQuAD_it-test.json.gz",
+}
+squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
+```
+
+Cela renvoie le même objet `DatasetDict` obtenu ci-dessus mais nous évite de télécharger et de décompresser manuellement les fichiers _SQuAD_it-*.json.gz_. Ceci conclut notre incursion dans les différentes façons de charger des jeux de données qui ne sont pas hébergés sur le *Hub*. Maintenant que nous avons un jeu de données avec lequel jouer, mettons la main à la pâte avec diverses techniques de gestion des données !
+
+
+
+✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) pour plus d'informations sur ces formats).
+
+
diff --git a/chapters/fr/chapter5/3.mdx b/chapters/fr/chapter5/3.mdx
index 1962c4dad..443681291 100644
--- a/chapters/fr/chapter5/3.mdx
+++ b/chapters/fr/chapter5/3.mdx
@@ -1,752 +1,752 @@
-# Il est temps de trancher et de découper
-
-
-
-La plupart du temps, les données avec lesquelles vous travaillez ne sont pas parfaitement préparées pour l’entraînements de modèles. Dans cette section, nous allons explorer les différentes fonctionnalités fournies par 🤗 *Datasets* pour nettoyer vos jeux de données.
-
-
-
-## Trancher et découper nos données
-
-Semblable à Pandas, 🤗 *Datasets* fournit plusieurs fonctions pour manipuler le contenu des objets `Dataset` et `DatasetDict`. Nous avons déjà rencontré la méthode `Dataset.map()` dans le [chapitre 3](/course/fr/chapter3) et dans cette section nous allons explorer certaines des autres fonctions à notre disposition.
-
-Pour cet exemple, nous utiliserons le [*Drug Review Dataset*](https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+%28Drugs.com%29) qui est hébergé sur [*UC Irvine Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et contenant des avis de patients sur divers médicaments ainsi que la condition traitée et une note de 10 étoiles sur la satisfaction du patient.
-
-Nous devons d'abord télécharger et extraire les données, ce qui peut être fait avec les commandes `wget` et `unzip` :
-
-```py
-!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip"
-!unzip drugsCom_raw.zip
-```
-
-Étant donné que TSV n'est qu'une variante de CSV qui utilise des tabulations au lieu de virgules comme séparateurs, nous pouvons charger ces fichiers en utilisant le script de chargement `csv` et en spécifiant l'argument `delimiter` dans la fonction `load_dataset()` comme suit :
-
-```py
-from datasets import load_dataset
-
-data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
-# \t is the tab character in Python
-drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
-```
-
-Une bonne pratique lors de toute sorte d'analyse de données consiste à prélever un petit échantillon aléatoire pour avoir une idée rapide du type de données avec lesquelles vous travaillez. Dans 🤗 *Datasets*, nous pouvons créer un échantillon aléatoire en enchaînant les fonctions `Dataset.shuffle()` et `Dataset.select()` :
-
-```py
-drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
-# Un coup d'œil sur les premiers exemples
-drug_sample[:3]
-```
-
-```python out
-{'Unnamed: 0': [87571, 178045, 80482],
- 'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],
- 'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],
- #['Goutte aiguë', 'ibromyalgie', 'Affections inflammatoires']
- 'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"',
- # comme la personne précédente l'a mentionné, je suis un fervent partisan de l'aleve, il fonctionne plus rapidement pour ma goutte que les médicaments sur ordonnance que je prends. Je n'ai plus besoin d'aller chez le médecin pour des renouvellements.....Aleve fonctionne !"
- '"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."',
- # J'ai pris du Cymbalta pendant environ un an et demi pour des douleurs de la fibromyalgie. C'est un excellent analgésique et un antidépresseur, mais les effets secondaires l'ont emporté sur tous les avantages que j'en ai tirés. J'ai eu des problèmes d'agitation, de fatigue constante, de vertiges, de bouche sèche, d'engourdissement, de picotements dans les pieds, et de transpiration horrible. Je suis en train de m'en sevrer maintenant. Je suis passée de 60 mg à 30 mg et maintenant à 15 mg. Je l'arrêterai complètement dans environ une semaine. La douleur de la fibrose revient, mais je préfère la supporter plutôt que les effets secondaires.
- '"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],
- # J'ai pris Mobic pendant plus d'un an sans effets secondaires autres qu'une pression sanguine élevée. J'avais de fortes douleurs au genou et à la cheville qui ont complètement disparu après avoir pris Mobic. J'ai essayé d'arrêter le médicament mais la douleur est revenue après quelques jours."
- 'rating': [9.0, 3.0, 10.0],
- 'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],
- #['2 septembre 2015', '7 novembre 2011', '5 juin 2013']
- 'usefulCount': [36, 13, 128]}
-```
-
-Notez que nous avons corrigé la graine dans `Dataset.shuffle()` à des fins de reproductibilité. `Dataset.select()` attend un itérable d'indices, nous avons donc passé `range(1000)` pour récupérer les 1 000 premiers exemples du jeu de données mélangé. À partir de cet échantillon, nous pouvons déjà voir quelques bizarreries dans notre jeu de données :
-
-* la colonne `Unnamed: 0` ressemble étrangement à un identifiant anonyme pour chaque patient,
-* la colonne `condition` comprend un mélange d'étiquettes en majuscules et en minuscules,
-* les avis sont de longueur variable et contiennent un mélange de séparateurs de lignes Python (`\r\n`) ainsi que des codes de caractères HTML comme `&\#039;`.
-
-Voyons comment nous pouvons utiliser 🤗 *Datasets* pour traiter chacun de ces problèmes. Pour tester l'hypothèse de l'ID patient pour la colonne `Unnamed : 0`, nous pouvons utiliser la fonction `Dataset.unique()` pour vérifier que le nombre d'ID correspond au nombre de lignes dans chaque division :
-
-```py
-for split in drug_dataset.keys():
- assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
-```
-
-Cela semble confirmer notre hypothèse, alors nettoyons un peu en renommant la colonne `Unnamed: 0` en quelque chose d'un peu plus interprétable. Nous pouvons utiliser la fonction `DatasetDict.rename_column()` pour renommer la colonne sur les deux divisions en une seule fois :
-
-```py
-drug_dataset = drug_dataset.rename_column(
- original_column_name="Unnamed: 0", new_column_name="patient_id"
-)
-drug_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
- num_rows: 161297
- })
- test: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
- num_rows: 53766
- })
-})
-```
-
-
-
-✏️ **Essayez !** Utilisez la fonction ` Dataset.unique()` pour trouver le nombre de médicaments et de conditions uniques dans les échantillons d'entraînement et de test.
-
-
-
-Ensuite, normalisons toutes les étiquettes `condition` en utilisant `Dataset.map()`. Comme nous l'avons fait avec la tokenisation dans le [chapitre 3](/course/fr/chapter3), nous pouvons définir une fonction simple qui peut être appliquée sur toutes les lignes de chaque division dans `drug_dataset` :
-
-```py
-def lowercase_condition(example):
- return {"condition": example["condition"].lower()}
-
-
-drug_dataset.map(lowercase_condition)
-```
-
-```python out
-AttributeError: 'NoneType' object has no attribute 'lower'
-```
-
-Oh non, nous rencontrons un problème avec notre fonction ! À partir de l'erreur, nous pouvons déduire que certaines des entrées de la colonne `condition` sont `None` ne pouvant donc pas être mises en minuscules car ce ne sont pas des chaînes. Supprimons ces lignes en utilisant `Dataset.filter()`, qui fonctionne de manière similaire à `Dataset.map()` et attend une fonction qui reçoit un seul exemple issu du jeu de données. Au lieu d'écrire une fonction explicite comme :
-
-```py
-def filter_nones(x):
- return x["condition"] is not None
-```
-
-puis exécuter `drug_dataset.filter(filter_nones)`, nous pouvons le faire en une seule ligne en utilisant une _fonction lambda_. En Python, les fonctions lambda sont de petites fonctions que vous pouvez définir sans les nommer explicitement. Ils prennent la forme générale :
-
-```
-lambda :
-```
-
-où `lambda` est l'un des [mots clés](https://docs.python.org/3/reference/lexical_analysis.html#keywords) spéciaux de Python, `` est une liste/ensemble de valeurs séparées par des virgules qui définissent les entrées de la fonction et `` représente les opérations que vous souhaitez exécuter. Par exemple, nous pouvons définir une simple fonction lambda qui met au carré un nombre comme suit :
-
-```
-lambda x : x * x
-```
-
-Pour appliquer cette fonction à une entrée, nous devons l'envelopper ainsi que l'entrée entre parenthèses :
-
-```py
-(lambda x: x * x)(3)
-```
-
-```python out
-9
-```
-
-De même, nous pouvons définir des fonctions lambda avec plusieurs arguments en les séparant par des virgules. Par exemple, nous pouvons calculer l'aire d'un triangle comme suit :
-
-```py
-(lambda base, height: 0.5 * base * height)(4, 8)
-```
-
-```python out
-16.0
-```
-
-Les fonctions lambda sont pratiques lorsque vous souhaitez définir de petites fonctions à usage unique (pour plus d'informations à leur sujet, nous vous recommandons de lire l'excellent [tutoriel Real Python](https://realpython.com/python-lambda/) d'André Burgaud) . Dans le contexte de la bibliothèque 🤗 *Datasets*, nous pouvons utiliser des fonctions lambda pour définir des opérations simples de « mappage » et de filtrage. Utilisons cette astuce pour éliminer les entrées `None` dans notre jeu de données :
-
-```py
-drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
-```
-
-Avec les entrées `None` supprimées, nous pouvons normaliser notre colonne `condition` :
-
-```py
-drug_dataset = drug_dataset.map(lowercase_condition)
-# Vérification que la mise en minuscule a fonctionné
-drug_dataset["train"]["condition"][:3]
-```
-
-```python out
-['left ventricular dysfunction', 'adhd', 'birth control']
-```
-
-Ça marche ! Maintenant que nous avons nettoyé les étiquettes, examinons le nettoyage des avis eux-mêmes.
-
-## Création de nouvelles colonnes
-
-Chaque fois que vous avez affaire à des avis de clients, une bonne pratique consiste à vérifier le nombre de mots dans chaque avis. Une critique peut être un simple mot comme « Génial ! » ou un essai complet avec des milliers de mots. Selon le cas d'usage, vous devrez gérer ces extrêmes différemment. Pour calculer le nombre de mots dans chaque révision, nous utiliserons une heuristique approximative basée sur la division de chaque texte par des espaces.
-
-Définissons une fonction simple qui compte le nombre de mots dans chaque avis :
-
-```py
-def compute_review_length(example):
- return {"review_length": len(example["review"].split())}
-```
-
-Contrairement à notre fonction `lowercase_condition()`, `compute_review_length()` renvoie un dictionnaire dont la clé ne correspond pas à l'un des noms de colonne du jeu de données. Dans ce cas, lorsque `compute_review_length()` est passé à `Dataset.map()`, il est appliqué à toutes les lignes du jeu de données pour créer une nouvelle colonne `review_length` :
-
-```py
-drug_dataset = drug_dataset.map(compute_review_length)
-# Inspecter le premier exemple d'entraînement
-drug_dataset["train"][0]
-```
-
-```python out
-{'patient_id': 206461,
- 'drugName': 'Valsartan',
- 'condition': 'left ventricular dysfunction', # dysfonctionnement du ventricule gauche
- 'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
- # Il n'a aucun effet secondaire, je le prends en combinaison avec Bystolic 5 mg et de l'huile de poisson.
- 'rating': 9.0,
- 'date': 'May 20, 2012', # 20 mai 2012
- 'usefulCount': 27,
- 'review_length': 17}
-```
-
-Comme prévu, nous pouvons voir qu'une colonne `review_length` a été ajoutée à notre jeu d'entraînement. Nous pouvons trier cette nouvelle colonne avec `Dataset.sort()` pour voir à quoi ressemblent les valeurs extrêmes :
-
-```py
-drug_dataset["train"].sort("review_length")[:3]
-```
-
-```python out
-{'patient_id': [103488, 23627, 20558],
- 'drugName': ['Loestrin 21 1 / 20', 'Chlorzoxazone', 'Nucynta'],
- 'condition': ['birth control', 'muscle spasm', 'pain'],
- # contraception, spasme musculaire, douleur.
- 'review': ['"Excellent."', '"useless"', '"ok"'], # Excellent, inutile, ok
- 'rating': [10.0, 1.0, 6.0],
- 'date': ['November 4, 2008', 'March 24, 2017', 'August 20, 2016'],
- # 4 novembre 2008, 24 mars 2017, 20 août 2016
- 'usefulCount': [5, 2, 10],
- 'review_length': [1, 1, 1]}
-```
-
-Comme nous le soupçonnions, certaines critiques ne contiennent qu'un seul mot, ce qui, bien que cela puisse convenir à l'analyse des sentiments, n’est pas informatif si nous voulons prédire la condition.
-
-
-
-🙋 Une autre façon d'ajouter de nouvelles colonnes à un jeu de données consiste à utiliser la fonction `Dataset.add_column()`. Cela vous permet de donner la colonne sous forme de liste Python ou de tableau NumPy et peut être utile dans les situations où `Dataset.map()` n'est pas bien adapté à votre analyse.
-
-
-
-Utilisons la fonction `Dataset.filter()` pour supprimer les avis contenant moins de 30 mots. De la même manière que nous l'avons fait avec la colonne `condition`, nous pouvons filtrer les avis très courts en exigeant que les avis aient une longueur supérieure à ce seuil :
-
-```py
-drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
-print(drug_dataset.num_rows)
-```
-
-```python out
-{'train': 138514, 'test': 46108}
-```
-
-Comme vous pouvez le constater, cela a supprimé environ 15 % des avis de nos jeux d'entraînement et de test d'origine.
-
-
-
-✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
-
-
-
-La dernière chose à laquelle nous devons faire face est la présence de caractères HTML dans nos avis. Nous pouvons utiliser le module `html` de Python pour supprimer ces caractères, comme ceci :
-
-```py
-import html
-
-text = "I'm a transformer called BERT"
-html.unescape(text)
-```
-
-```python out
-"I'm a transformer called BERT"
-```
-
-Nous utilisons `Dataset.map()` pour démasquer tous les caractères HTML de notre corpus :
-
-```python
-drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
-```
-
-Comme vous pouvez le voir, la méthode `Dataset.map()` est très utile pour le traitement des données. Et nous n'avons même pas effleuré la surface de tout ce qu'elle peut faire !
-
-## Les superpouvoirs de la méthode `map()`
-
-La méthode `Dataset.map()` prend un argument `batched` qui, s'il est défini sur `True`, l'amène à envoyer un batch d'exemples à la fonction *map* en une seule fois (la taille du batch est configurable mais est fixé par défaut à 1 000). Par exemple, la fonction `map()` précédente qui supprime tout le code HTML prend un peu de temps à s'exécuter (vous pouvez lire le temps pris dans les barres de progression). On peut accélérer cela en traitant plusieurs éléments en même temps à l'aide d'une compréhension de liste.
-
-Lorsque vous spécifiez `batched=True`, la fonction reçoit un dictionnaire avec les champs du jeu de données mais chaque valeur est maintenant une _liste de valeurs_ et non plus une seule valeur. La valeur retournée par `Dataset.map()` devrait être la même : un dictionnaire avec les champs que nous voulons mettre à jour ou ajouter à notre jeu de données, et une liste de valeurs. Par exemple, voici une autre façon de supprimer tous les caractères HTML, mais en utilisant `batched=True` :
-
-```python
-new_drug_dataset = drug_dataset.map(
- lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True
-)
-```
-
-Si vous exécutez ce code dans un *notebook*, vous verrez que cette commande s'exécute beaucoup plus rapidement que la précédente. Et ce n'est pas parce que nos critiques ont déjà été scannées au format HTML. Si vous ré-exécutez l'instruction de la section précédente (sans `batched=True`), cela prendra le même temps qu'avant. En effet, les compréhensions de liste sont généralement plus rapides que l'exécution du même code dans une boucle `for` et nous gagnons également en performances en accédant à de nombreux éléments en même temps au lieu d'un par un.
-
-L'utilisation de `Dataset.map()` avec `batched=True` est essentielle pour les *tokenizers rapides* que nous rencontrerons dans le [chapitre 6](/course/fr/chapter6) et qui peuvent rapidement tokeniser de grandes listes de textes. Par exemple, pour tokeniser toutes les critiques de médicaments avec un *tokenizer* rapide nous pouvons utiliser une fonction comme celle-ci :
-
-```python
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-
-
-def tokenize_function(examples):
- return tokenizer(examples["review"], truncation=True)
-```
-
-Comme vous l'avez vu dans le [chapitre 3](/course/fr/chapter3), nous pouvons passer un ou plusieurs exemples au *tokenizer*. Nous pouvons donc utiliser cette fonction avec ou sans `batched=True`. Profitons-en pour comparer les performances des différentes options. Dans un *notebook*, vous pouvez chronométrer une instruction d'une ligne en ajoutant `%time` avant la ligne de code que vous souhaitez mesurer :
-
-```python no-format
-%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
-```
-
-Vous pouvez également chronométrer une cellule entière en mettant `%%time` au début de la cellule. Sur le matériel sur lequel nous avons exécuté cela, cela affichait 10,8 s pour cette instruction (c'est le nombre écrit après "Wall time").
-
-
-
-✏️ **Essayez !** Exécutez la même instruction avec et sans `batched=True`, puis essayez-le avec un *tokenizer* lent (ajoutez `use_fast=False` dans la méthode `AutoTokenizer.from_pretrained()`) afin que vous puissiez voir quels temps vous obtenez sur votre matériel.
-
-
-
-Voici les résultats que nous avons obtenus avec et sans *batching*, avec un *tokenizer* rapide et un lent :
-
-Options | *Tokenizer* rapide | *Tokenizer* lent
-:--------------:|:----------------:|:-----------------:
-`batched=True` | 10.8s | 4min41s
-`batched=False` | 59.2s | 5min3s
-
-Cela signifie que l'utilisation d'un *tokenizer* rapide avec l'option `batched=True` est 30 fois plus rapide que son homologue lent sans batch. C'est vraiment incroyable ! C'est la raison principale pour laquelle les *tokenizers* rapides sont la valeur par défaut lors de l'utilisation de `AutoTokenizer` (et pourquoi ils sont appelés « rapides »). Ils sont capables d'atteindre une telle vitesse car en coulisses le code de tokenisation est exécuté en Rust qui est un langage facilitant la parallélisation de l'exécution du code.
-
-La parallélisation est également la raison du gain de vitesse de près de 6 fois obtenue par le *tokenizer* rapide avec batch. Vous ne pouvez pas paralléliser une seule opération de tokenisation, mais lorsque vous souhaitez tokeniser de nombreux textes en même temps, vous pouvez simplement répartir l'exécution sur plusieurs processus. Chacun responsable de ses propres textes.
-
-`Dataset.map()` possède aussi ses propres capacités de parallélisation. Comme elles ne sont pas soutenus par Rust, un *tokenizer* lent ne peut pas rattraper un rapide mais cela peut toujours être utile (surtout si vous utilisez un *tokenizer* qui n'a pas de version rapide). Pour activer le multitraitement, utilisez l'argument `num_proc` et spécifiez le nombre de processus à utiliser dans votre appel à `Dataset.map()` :
-
-```py
-slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
-
-
-def slow_tokenize_function(examples):
- return slow_tokenizer(examples["review"], truncation=True)
-
-
-tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)
-```
-
-Vous pouvez faire des tests pour déterminer le nombre optimal de processus à utiliser. Dans notre cas 8 semble produire le meilleur gain de vitesse. Voici les chiffres que nous avons obtenus avec et sans multitraitement :
-
-Options | *Tokenizer* rapide | *Tokenizer* lent
-:----------------------------:|:----------------:|:---------------:
-`batched=True` | 10.8s | 4min41s
-`batched=False` | 59.2s | 5min3s
-`batched=True`, `num_proc=8` | 6.52s | 41.3s
-`batched=False`, `num_proc=8` | 9.49s | 45.2s
-
-Ce sont des résultats beaucoup plus raisonnables pour le *tokenizer* lent mais les performances du *tokenizer* rapide ont également été considérablement améliorées. Notez, cependant, que ce ne sera pas toujours le cas : pour des valeurs de `num_proc` autres que 8, nos tests ont montré qu'il était plus rapide d'utiliser `batched=True` sans cette option. En général, nous ne recommandons pas d'utiliser le multitraitement pour les *tokenizers* rapides avec `batched=True`.
-
-
-
-Utiliser `num_proc` pour accélérer votre traitement est généralement une bonne idée tant que la fonction que vous utilisez n'effectue pas déjà une sorte de multitraitement.
-
-
-
-Toutes ces fonctionnalités condensées en une seule méthode sont déjà assez étonnantes, mais il y a plus ! Avec `Dataset.map()` et `batched=True` vous pouvez modifier le nombre d'éléments dans votre jeu de données. Ceci est très utile dans de nombreuses situations où vous souhaitez créer plusieurs fonctionnalités d'entraînement à partir d'un exemple. Nous devrons le faire dans le cadre du prétraitement de plusieurs des tâches de traitement du langage naturel que nous entreprendrons dans le [chapitre 7](/course/fr/chapter7).
-
-
-
-💡 En apprentissage automatique, un _exemple_ est généralement défini comme l'ensemble de _features_ que nous donnons au modèle. Dans certains contextes, ces caractéristiques seront l'ensemble des colonnes d'un `Dataset`, mais dans d'autres (comme ici et pour la réponse aux questions), plusieurs caractéristiques peuvent être extraites d'un seul exemple et appartenir à une seule colonne.
-
-
-
-Voyons comment cela fonctionne ! Ici, nous allons tokeniser nos exemples et les tronquer à une longueur maximale de 128 mais nous demanderons au *tokenizer* de renvoyer *tous* les morceaux des textes au lieu du premier. Cela peut être fait avec `return_overflowing_tokens=True` :
-
-```py
-def tokenize_and_split(examples):
- return tokenizer(
- examples["review"],
- truncation=True,
- max_length=128,
- return_overflowing_tokens=True,
- )
-```
-
-Testons cela sur un exemple avant d'utiliser `Dataset.map()` sur le jeu de données :
-
-```py
-result = tokenize_and_split(drug_dataset["train"][0])
-[len(inp) for inp in result["input_ids"]]
-```
-
-```python out
-[128, 49]
-```
-
-Notre premier exemple du jeu d’entraînement est devenu deux caractéristiques car il a été segmenté à plus que le nombre maximum de *tokens* que nous avons spécifié : le premier de longueur 128 et le second de longueur 49. Faisons maintenant cela pour tous les éléments du jeu de données !
-
-```py
-tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
-```
-
-```python out
-ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
-```
-
-Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
-
-Le problème est que nous essayons de mélanger deux jeux de données différents de tailles différentes : les colonnes `drug_dataset` auront un certain nombre d'exemples (les 1 000 dans notre erreur), mais le `tokenized_dataset` que nous construisons en aura plus (le 1 463 dans le message d'erreur). Cela ne fonctionne pas pour un `Dataset`, nous devons donc soit supprimer les colonnes de l'ancien jeu de données, soit leur donner la même taille que dans le nouveau jeu de données. Nous pouvons faire la première option avec l'argument `remove_columns` :
-
-```py
-tokenized_dataset = drug_dataset.map(
- tokenize_and_split, batched=True, remove_columns=drug_dataset["train"].column_names
-)
-```
-
-Maintenant, cela fonctionne sans erreur. Nous pouvons vérifier que notre nouveau jeu de données contient beaucoup plus d'éléments que le jeu de données d'origine en comparant les longueurs :
-
-```py
-len(tokenized_dataset["train"]), len(drug_dataset["train"])
-```
-
-```python out
-(206772, 138514)
-```
-
-Nous avons mentionné que nous pouvions également résoudre le problème de longueur non concordante en donnant aux anciennes colonnes la même taille que les nouvelles. Pour ce faire, nous avons besoin du champ `overflow_to_sample_mapping` que le *tokenizer* renvoie lorsque nous définissons `return_overflowing_tokens=True`. Il nous donne une correspondance entre un nouvel index de caractéristique et l'index de l'échantillon dont il est issu. Grâce à cela, nous pouvons associer chaque clé présente dans notre jeu de données d'origine à une liste de valeurs de la bonne taille en répétant les valeurs de chaque exemple autant de fois qu'il génère de nouvelles caractéristiques :
-
-```py
-def tokenize_and_split(examples):
- result = tokenizer(
- examples["review"],
- truncation=True,
- max_length=128,
- return_overflowing_tokens=True,
- )
- # Extract mapping between new and old indices
- sample_map = result.pop("overflow_to_sample_mapping")
- for key, values in examples.items():
- result[key] = [values[i] for i in sample_map]
- return result
-```
-
-Nous pouvons voir que cela fonctionne avec `Dataset.map()` sans que nous ayons besoin de supprimer les anciennes colonnes :
-
-```py
-tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
-tokenized_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
- num_rows: 206772
- })
- test: Dataset({
- features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
- num_rows: 68876
- })
-})
-```
-
-Nous obtenons le même nombre de caractéristiques d'entraînement qu'auparavant, mais ici nous avons conservé tous les anciens champs. Si vous en avez besoin pour un post-traitement après l'application de votre modèle, vous pouvez utiliser cette approche.
-
-Vous avez maintenant vu comment 🤗 *Datasets* peut être utilisé pour prétraiter un jeu de données de différentes manières. Bien que les fonctions de traitement de 🤗 *Datasets* couvrent la plupart de vos besoins, il peut arriver que vous deviez passer à Pandas pour accéder à des fonctionnalités plus puissantes, telles que `DataFrame.groupby()` ou des API de haut niveau pour la visualisation. Heureusement, 🤗 *Datasets* est conçu pour être interopérable avec des bibliothèques telles que Pandas, NumPy, PyTorch, TensorFlow et JAX. Voyons comment cela fonctionne.
-
-## De `Dataset` à `DataFrame` et vice versa
-
-
-
-Pour permettre la conversion entre diverses bibliothèques tierces, 🤗 *Datasets* fournit une fonction `Dataset.set_format()`. Cette fonction ne modifie que le _format de sortie_ du jeu de données. Vous pouvez donc facilement passer à un autre format sans affecter le _format de données_ sous-jacent, qui est Apache Arrow. Le formatage se fait sur place. Pour démontrer, convertissons notre jeu de données vers Pandas :
-
-```py
-drug_dataset.set_format("pandas")
-```
-
-Maintenant, lorsque nous accédons aux éléments du jeu de données, nous obtenons un `pandas.DataFrame` au lieu d'un dictionnaire :
-
-```py
-drug_dataset["train"][:3]
-```
-
-
-
-
- |
- patient_id |
- drugName |
- condition |
- review |
- rating |
- date |
- usefulCount |
- review_length |
-
-
-
-
- | 0 |
- 95260 |
- Guanfacine |
- adhd |
- "My son is halfway through his fourth week of Intuniv..." |
- 8.0 |
- April 27, 2010 |
- 192 |
- 141 |
-
-
- | 1 |
- 92703 |
- Lybrel |
- birth control |
- "I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." |
- 5.0 |
- December 14, 2009 |
- 17 |
- 134 |
-
-
- | 2 |
- 138000 |
- Ortho Evra |
- birth control |
- "This is my first time using any form of birth control..." |
- 8.0 |
- November 3, 2015 |
- 10 |
- 89 |
-
-
-
-
-Créons un `pandas.DataFrame` pour l'ensemble d'entraînement en sélectionnant tous les éléments de `drug_dataset["train"]` :
-
-```py
-train_df = drug_dataset["train"][:]
-```
-
-
-
-🚨 Sous le capot, `Dataset.set_format()` change le format de retour pour la méthode `__getitem__()`. Cela signifie que lorsque nous voulons créer un nouvel objet comme `train_df` à partir d'un `Dataset` au format `"pandas"`, nous devons découper tout le jeu de données pour obtenir un `pandas.DataFrame`. Vous pouvez vérifier par vous-même que le type de `drug_dataset["train"]` est `Dataset`, quel que soit le format de sortie.
-
-
-
-
-De là, nous pouvons utiliser toutes les fonctionnalités Pandas que nous voulons. Par exemple, nous pouvons faire un chaînage sophistiqué pour calculer la distribution de classe parmi les entrées `condition` :
-
-```py
-frequencies = (
- train_df["condition"]
- .value_counts()
- .to_frame()
- .reset_index()
- .rename(columns={"index": "condition", "condition": "frequency"})
-)
-frequencies.head()
-```
-
-
-
-
- |
- condition |
- frequency |
-
-
-
-
- | 0 |
- birth control |
- 27655 |
-
-
- | 1 |
- depression |
- 8023 |
-
-
- | 2 |
- acne |
- 5209 |
-
-
- | 3 |
- anxiety |
- 4991 |
-
-
- | 4 |
- pain |
- 4744 |
-
-
-
-
-
-Et une fois que nous avons terminé notre analyse Pandas, nous pouvons toujours créer un nouvel objet `Dataset` en utilisant la fonction `Dataset.from_pandas()` comme suit :
-
-
-```py
-from datasets import Dataset
-
-freq_dataset = Dataset.from_pandas(frequencies)
-freq_dataset
-```
-
-```python out
-Dataset({
- features: ['condition', 'frequency'],
- num_rows: 819
-})
-```
-
-
-
-✏️ **Essayez !** Calculez la note moyenne par médicament et stockez le résultat dans un nouveau jeu de données.
-
-
-
-Ceci conclut notre visite des différentes techniques de prétraitement disponibles dans 🤗 *Datasets*. Pour compléter la section, créons un ensemble de validation pour préparer le jeu de données à l’entraînement d'un classifieur. Avant cela, nous allons réinitialiser le format de sortie de `drug_dataset` de `"pandas"` à `"arrow"` :
-
-```python
-drug_dataset.reset_format()
-```
-
-## Création d'un ensemble de validation
-
-Bien que nous ayons un jeu de test que nous pourrions utiliser pour l'évaluation, il est recommandé de ne pas toucher au jeu de test et de créer un jeu de validation séparé pendant le développement. Une fois que vous êtes satisfait des performances de vos modèles sur l'ensemble de validation, vous pouvez effectuer une dernière vérification d'intégrité sur l'ensemble test. Ce processus permet d'atténuer le risque de surentraînement sur le jeu de test et de déployer un modèle qui échoue sur des données du monde réel.
-
-🤗 *Datasets* fournit une fonction `Dataset.train_test_split()` basée sur la célèbre fonctionnalité de `scikit-learn`. Utilisons-la pour diviser notre ensemble d'entraînement `train` et `validation` (nous définissons l'argument `seed` pour la reproductibilité) :
-
-```py
-drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
-# Rename the default "test" split to "validation"
-drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
-# Add the "test" set to our `DatasetDict`
-drug_dataset_clean["test"] = drug_dataset["test"]
-drug_dataset_clean
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
- num_rows: 110811
- })
- validation: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
- num_rows: 27703
- })
- test: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
- num_rows: 46108
- })
-})
-```
-
-Génial, nous avons maintenant préparé un jeu de données prêt pour l'entraînement de certains modèles ! Dans la [section 5](/course/fr/chapter5/5), nous vous montrerons comment télécharger des jeux de données sur le *Hub*. Mais pour l'instant, terminons notre analyse en examinant quelques façons d'enregistrer des jeux de données sur votre ordinateur local.
-
-## Enregistrer un jeu de données
-
-
-
-Bien que 🤗 *Datasets* mette en cache chaque jeu de données téléchargé et les opérations qui y sont effectuées, il y a des moments où vous voudrez enregistrer un jeu de données sur le disque (par exemple, au cas où le cache serait supprimé). Comme indiqué dans le tableau ci-dessous, 🤗 *Datasets* fournit trois fonctions principales pour enregistrer votre jeu de données dans différents formats :
-
-| Format de données | Fonction |
-| :---------------: | :----------------------: |
-| Arrow | `Dataset.save_to_disk()` |
-| CSV | `Dataset.to_csv()` |
-| JSON | `Dataset.to_json()` |
-
-Par exemple, enregistrons notre jeu de données nettoyé au format Arrow :
-
-```py
-drug_dataset_clean.save_to_disk("drug-reviews")
-```
-
-Cela créera un répertoire avec la structure suivante :
-
-```
-drug-reviews/
-├── dataset_dict.json
-├── test
-│ ├── dataset.arrow
-│ ├── dataset_info.json
-│ └── state.json
-├── train
-│ ├── dataset.arrow
-│ ├── dataset_info.json
-│ ├── indices.arrow
-│ └── state.json
-└── validation
- ├── dataset.arrow
- ├── dataset_info.json
- ├── indices.arrow
- └── state.json
-```
-
-où nous pouvons voir que chaque division est associée à sa propre table *dataset.arrow* et à certaines métadonnées dans *dataset_info.json* et *state.json*. Vous pouvez considérer le format Arrow comme un tableau sophistiqué de colonnes et de lignes optimisé pour la création d'applications hautes performances qui traitent et transportent de grands ensembles de données.
-
-Une fois le jeu de données enregistré, nous pouvons le charger en utilisant la fonction `load_from_disk()` comme suit :
-
-```py
-from datasets import load_from_disk
-
-drug_dataset_reloaded = load_from_disk("drug-reviews")
-drug_dataset_reloaded
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
- num_rows: 110811
- })
- validation: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
- num_rows: 27703
- })
- test: Dataset({
- features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
- num_rows: 46108
- })
-})
-```
-
-Pour les formats CSV et JSON, nous devons stocker chaque fractionnement dans un fichier séparé. Pour ce faire, vous pouvez parcourir les clés et les valeurs de l'objet `DatasetDict` :
-
-```py
-for split, dataset in drug_dataset_clean.items():
- dataset.to_json(f"drug-reviews-{split}.jsonl")
-```
-
-Cela enregistre chaque fractionnement au [format JSON Lines](https://jsonlines.org), où chaque ligne du jeu de données est stockée sous la forme d'une seule ligne de JSON. Voici à quoi ressemble le premier exemple :
-
-```py
-!head -n 1 drug-reviews-train.jsonl
-```
-
-```python out
-{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
- # Il semble que je ressente les effets secondaires habituels de LEXAPRO : insomnie, baisse de la libido, somnolence pendant la journée. Je le prends le soir parce que mon médecin m'a dit de le prendre le soir s'il me fatiguait. J'ai supposé que ce serait le cas et j'ai commencé à le prendre la nuit. Rêves étranges, certains agréables. On m'a diagnostiqué une fibromyalgie. Il semble que ce médicament aide à soulager la douleur. J'ai eu de l'anxiété et de la dépression dans ma famille, et j'ai essayé plusieurs autres médicaments qui n'ont pas fonctionné. Cela ne fait que deux semaines que je prends ce médicament, mais je me sens plus positif dans mon esprit et je veux accomplir davantage dans ma vie. J'espère que les effets secondaires vont s'estomper, cela vaut la peine de s'y tenir d'après les réponses des autres. C'est un excellent médicament.
-```
-
-Nous pouvons ensuite utiliser les techniques de [section 2](/course/fr/chapter5/2) pour charger les fichiers JSON comme suit :
-
-```py
-data_files = {
- "train": "drug-reviews-train.jsonl",
- "validation": "drug-reviews-validation.jsonl",
- "test": "drug-reviews-test.jsonl",
-}
-drug_dataset_reloaded = load_dataset("json", data_files=data_files)
-```
-
-Et c'est tout pour notre excursion dans la manipulation des données avec 🤗 *Datasets* ! Maintenant que nous disposons d'un ensemble de données nettoyé pour entraîner un modèle, voici quelques idées que vous pouvez essayer :
-
-1. Utilisez les techniques du [chapitre 3](/course/fr/chapter3) pour entraîner un classifieur capable de prédire l'état du patient en fonction de l'examen du médicament.
-2. Utilisez le pipeline `summarization` du [chapitre 1](/course/fr/chapter1) pour générer des résumés des révisions.
-
-Ensuite, nous verrons comment 🤗 *Datasets* peut vous permettre de travailler avec d'énormes jeux de données sans faire exploser votre ordinateur portable !
+# Il est temps de trancher et de découper
+
+
+
+La plupart du temps, les données avec lesquelles vous travaillez ne sont pas parfaitement préparées pour l’entraînements de modèles. Dans cette section, nous allons explorer les différentes fonctionnalités fournies par 🤗 *Datasets* pour nettoyer vos jeux de données.
+
+
+
+## Trancher et découper nos données
+
+Semblable à Pandas, 🤗 *Datasets* fournit plusieurs fonctions pour manipuler le contenu des objets `Dataset` et `DatasetDict`. Nous avons déjà rencontré la méthode `Dataset.map()` dans le [chapitre 3](/course/fr/chapter3) et dans cette section nous allons explorer certaines des autres fonctions à notre disposition.
+
+Pour cet exemple, nous utiliserons le [*Drug Review Dataset*](https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+%28Drugs.com%29) qui est hébergé sur [*UC Irvine Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et contenant des avis de patients sur divers médicaments ainsi que la condition traitée et une note de 10 étoiles sur la satisfaction du patient.
+
+Nous devons d'abord télécharger et extraire les données, ce qui peut être fait avec les commandes `wget` et `unzip` :
+
+```py
+!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip"
+!unzip drugsCom_raw.zip
+```
+
+Étant donné que TSV n'est qu'une variante de CSV qui utilise des tabulations au lieu de virgules comme séparateurs, nous pouvons charger ces fichiers en utilisant le script de chargement `csv` et en spécifiant l'argument `delimiter` dans la fonction `load_dataset()` comme suit :
+
+```py
+from datasets import load_dataset
+
+data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
+# \t is the tab character in Python
+drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
+```
+
+Une bonne pratique lors de toute sorte d'analyse de données consiste à prélever un petit échantillon aléatoire pour avoir une idée rapide du type de données avec lesquelles vous travaillez. Dans 🤗 *Datasets*, nous pouvons créer un échantillon aléatoire en enchaînant les fonctions `Dataset.shuffle()` et `Dataset.select()` :
+
+```py
+drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
+# Un coup d'œil sur les premiers exemples
+drug_sample[:3]
+```
+
+```python out
+{'Unnamed: 0': [87571, 178045, 80482],
+ 'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],
+ 'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],
+ #['Goutte aiguë', 'ibromyalgie', 'Affections inflammatoires']
+ 'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"',
+ # comme la personne précédente l'a mentionné, je suis un fervent partisan de l'aleve, il fonctionne plus rapidement pour ma goutte que les médicaments sur ordonnance que je prends. Je n'ai plus besoin d'aller chez le médecin pour des renouvellements.....Aleve fonctionne !"
+ '"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."',
+ # J'ai pris du Cymbalta pendant environ un an et demi pour des douleurs de la fibromyalgie. C'est un excellent analgésique et un antidépresseur, mais les effets secondaires l'ont emporté sur tous les avantages que j'en ai tirés. J'ai eu des problèmes d'agitation, de fatigue constante, de vertiges, de bouche sèche, d'engourdissement, de picotements dans les pieds, et de transpiration horrible. Je suis en train de m'en sevrer maintenant. Je suis passée de 60 mg à 30 mg et maintenant à 15 mg. Je l'arrêterai complètement dans environ une semaine. La douleur de la fibrose revient, mais je préfère la supporter plutôt que les effets secondaires.
+ '"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],
+ # J'ai pris Mobic pendant plus d'un an sans effets secondaires autres qu'une pression sanguine élevée. J'avais de fortes douleurs au genou et à la cheville qui ont complètement disparu après avoir pris Mobic. J'ai essayé d'arrêter le médicament mais la douleur est revenue après quelques jours."
+ 'rating': [9.0, 3.0, 10.0],
+ 'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],
+ #['2 septembre 2015', '7 novembre 2011', '5 juin 2013']
+ 'usefulCount': [36, 13, 128]}
+```
+
+Notez que nous avons corrigé la graine dans `Dataset.shuffle()` à des fins de reproductibilité. `Dataset.select()` attend un itérable d'indices, nous avons donc passé `range(1000)` pour récupérer les 1 000 premiers exemples du jeu de données mélangé. À partir de cet échantillon, nous pouvons déjà voir quelques bizarreries dans notre jeu de données :
+
+* la colonne `Unnamed: 0` ressemble étrangement à un identifiant anonyme pour chaque patient,
+* la colonne `condition` comprend un mélange d'étiquettes en majuscules et en minuscules,
+* les avis sont de longueur variable et contiennent un mélange de séparateurs de lignes Python (`\r\n`) ainsi que des codes de caractères HTML comme `&\#039;`.
+
+Voyons comment nous pouvons utiliser 🤗 *Datasets* pour traiter chacun de ces problèmes. Pour tester l'hypothèse de l'ID patient pour la colonne `Unnamed : 0`, nous pouvons utiliser la fonction `Dataset.unique()` pour vérifier que le nombre d'ID correspond au nombre de lignes dans chaque division :
+
+```py
+for split in drug_dataset.keys():
+ assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
+```
+
+Cela semble confirmer notre hypothèse, alors nettoyons un peu en renommant la colonne `Unnamed: 0` en quelque chose d'un peu plus interprétable. Nous pouvons utiliser la fonction `DatasetDict.rename_column()` pour renommer la colonne sur les deux divisions en une seule fois :
+
+```py
+drug_dataset = drug_dataset.rename_column(
+ original_column_name="Unnamed: 0", new_column_name="patient_id"
+)
+drug_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
+ num_rows: 161297
+ })
+ test: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
+ num_rows: 53766
+ })
+})
+```
+
+
+
+✏️ **Essayez !** Utilisez la fonction ` Dataset.unique()` pour trouver le nombre de médicaments et de conditions uniques dans les échantillons d'entraînement et de test.
+
+
+
+Ensuite, normalisons toutes les étiquettes `condition` en utilisant `Dataset.map()`. Comme nous l'avons fait avec la tokenisation dans le [chapitre 3](/course/fr/chapter3), nous pouvons définir une fonction simple qui peut être appliquée sur toutes les lignes de chaque division dans `drug_dataset` :
+
+```py
+def lowercase_condition(example):
+ return {"condition": example["condition"].lower()}
+
+
+drug_dataset.map(lowercase_condition)
+```
+
+```python out
+AttributeError: 'NoneType' object has no attribute 'lower'
+```
+
+Oh non, nous rencontrons un problème avec notre fonction ! À partir de l'erreur, nous pouvons déduire que certaines des entrées de la colonne `condition` sont `None` ne pouvant donc pas être mises en minuscules car ce ne sont pas des chaînes. Supprimons ces lignes en utilisant `Dataset.filter()`, qui fonctionne de manière similaire à `Dataset.map()` et attend une fonction qui reçoit un seul exemple issu du jeu de données. Au lieu d'écrire une fonction explicite comme :
+
+```py
+def filter_nones(x):
+ return x["condition"] is not None
+```
+
+puis exécuter `drug_dataset.filter(filter_nones)`, nous pouvons le faire en une seule ligne en utilisant une _fonction lambda_. En Python, les fonctions lambda sont de petites fonctions que vous pouvez définir sans les nommer explicitement. Ils prennent la forme générale :
+
+```
+lambda :
+```
+
+où `lambda` est l'un des [mots clés](https://docs.python.org/3/reference/lexical_analysis.html#keywords) spéciaux de Python, `` est une liste/ensemble de valeurs séparées par des virgules qui définissent les entrées de la fonction et `` représente les opérations que vous souhaitez exécuter. Par exemple, nous pouvons définir une simple fonction lambda qui met au carré un nombre comme suit :
+
+```
+lambda x : x * x
+```
+
+Pour appliquer cette fonction à une entrée, nous devons l'envelopper ainsi que l'entrée entre parenthèses :
+
+```py
+(lambda x: x * x)(3)
+```
+
+```python out
+9
+```
+
+De même, nous pouvons définir des fonctions lambda avec plusieurs arguments en les séparant par des virgules. Par exemple, nous pouvons calculer l'aire d'un triangle comme suit :
+
+```py
+(lambda base, height: 0.5 * base * height)(4, 8)
+```
+
+```python out
+16.0
+```
+
+Les fonctions lambda sont pratiques lorsque vous souhaitez définir de petites fonctions à usage unique (pour plus d'informations à leur sujet, nous vous recommandons de lire l'excellent [tutoriel Real Python](https://realpython.com/python-lambda/) d'André Burgaud) . Dans le contexte de la bibliothèque 🤗 *Datasets*, nous pouvons utiliser des fonctions lambda pour définir des opérations simples de « mappage » et de filtrage. Utilisons cette astuce pour éliminer les entrées `None` dans notre jeu de données :
+
+```py
+drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
+```
+
+Avec les entrées `None` supprimées, nous pouvons normaliser notre colonne `condition` :
+
+```py
+drug_dataset = drug_dataset.map(lowercase_condition)
+# Vérification que la mise en minuscule a fonctionné
+drug_dataset["train"]["condition"][:3]
+```
+
+```python out
+['left ventricular dysfunction', 'adhd', 'birth control']
+```
+
+Ça marche ! Maintenant que nous avons nettoyé les étiquettes, examinons le nettoyage des avis eux-mêmes.
+
+## Création de nouvelles colonnes
+
+Chaque fois que vous avez affaire à des avis de clients, une bonne pratique consiste à vérifier le nombre de mots dans chaque avis. Une critique peut être un simple mot comme « Génial ! » ou un essai complet avec des milliers de mots. Selon le cas d'usage, vous devrez gérer ces extrêmes différemment. Pour calculer le nombre de mots dans chaque révision, nous utiliserons une heuristique approximative basée sur la division de chaque texte par des espaces.
+
+Définissons une fonction simple qui compte le nombre de mots dans chaque avis :
+
+```py
+def compute_review_length(example):
+ return {"review_length": len(example["review"].split())}
+```
+
+Contrairement à notre fonction `lowercase_condition()`, `compute_review_length()` renvoie un dictionnaire dont la clé ne correspond pas à l'un des noms de colonne du jeu de données. Dans ce cas, lorsque `compute_review_length()` est passé à `Dataset.map()`, il est appliqué à toutes les lignes du jeu de données pour créer une nouvelle colonne `review_length` :
+
+```py
+drug_dataset = drug_dataset.map(compute_review_length)
+# Inspecter le premier exemple d'entraînement
+drug_dataset["train"][0]
+```
+
+```python out
+{'patient_id': 206461,
+ 'drugName': 'Valsartan',
+ 'condition': 'left ventricular dysfunction', # dysfonctionnement du ventricule gauche
+ 'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
+ # Il n'a aucun effet secondaire, je le prends en combinaison avec Bystolic 5 mg et de l'huile de poisson.
+ 'rating': 9.0,
+ 'date': 'May 20, 2012', # 20 mai 2012
+ 'usefulCount': 27,
+ 'review_length': 17}
+```
+
+Comme prévu, nous pouvons voir qu'une colonne `review_length` a été ajoutée à notre jeu d'entraînement. Nous pouvons trier cette nouvelle colonne avec `Dataset.sort()` pour voir à quoi ressemblent les valeurs extrêmes :
+
+```py
+drug_dataset["train"].sort("review_length")[:3]
+```
+
+```python out
+{'patient_id': [103488, 23627, 20558],
+ 'drugName': ['Loestrin 21 1 / 20', 'Chlorzoxazone', 'Nucynta'],
+ 'condition': ['birth control', 'muscle spasm', 'pain'],
+ # contraception, spasme musculaire, douleur.
+ 'review': ['"Excellent."', '"useless"', '"ok"'], # Excellent, inutile, ok
+ 'rating': [10.0, 1.0, 6.0],
+ 'date': ['November 4, 2008', 'March 24, 2017', 'August 20, 2016'],
+ # 4 novembre 2008, 24 mars 2017, 20 août 2016
+ 'usefulCount': [5, 2, 10],
+ 'review_length': [1, 1, 1]}
+```
+
+Comme nous le soupçonnions, certaines critiques ne contiennent qu'un seul mot, ce qui, bien que cela puisse convenir à l'analyse des sentiments, n’est pas informatif si nous voulons prédire la condition.
+
+
+
+🙋 Une autre façon d'ajouter de nouvelles colonnes à un jeu de données consiste à utiliser la fonction `Dataset.add_column()`. Cela vous permet de donner la colonne sous forme de liste Python ou de tableau NumPy et peut être utile dans les situations où `Dataset.map()` n'est pas bien adapté à votre analyse.
+
+
+
+Utilisons la fonction `Dataset.filter()` pour supprimer les avis contenant moins de 30 mots. De la même manière que nous l'avons fait avec la colonne `condition`, nous pouvons filtrer les avis très courts en exigeant que les avis aient une longueur supérieure à ce seuil :
+
+```py
+drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
+print(drug_dataset.num_rows)
+```
+
+```python out
+{'train': 138514, 'test': 46108}
+```
+
+Comme vous pouvez le constater, cela a supprimé environ 15 % des avis de nos jeux d'entraînement et de test d'origine.
+
+
+
+✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
+
+
+
+La dernière chose à laquelle nous devons faire face est la présence de caractères HTML dans nos avis. Nous pouvons utiliser le module `html` de Python pour supprimer ces caractères, comme ceci :
+
+```py
+import html
+
+text = "I'm a transformer called BERT"
+html.unescape(text)
+```
+
+```python out
+"I'm a transformer called BERT"
+```
+
+Nous utilisons `Dataset.map()` pour démasquer tous les caractères HTML de notre corpus :
+
+```python
+drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
+```
+
+Comme vous pouvez le voir, la méthode `Dataset.map()` est très utile pour le traitement des données. Et nous n'avons même pas effleuré la surface de tout ce qu'elle peut faire !
+
+## Les superpouvoirs de la méthode `map()`
+
+La méthode `Dataset.map()` prend un argument `batched` qui, s'il est défini sur `True`, l'amène à envoyer un batch d'exemples à la fonction *map* en une seule fois (la taille du batch est configurable mais est fixé par défaut à 1 000). Par exemple, la fonction `map()` précédente qui supprime tout le code HTML prend un peu de temps à s'exécuter (vous pouvez lire le temps pris dans les barres de progression). On peut accélérer cela en traitant plusieurs éléments en même temps à l'aide d'une compréhension de liste.
+
+Lorsque vous spécifiez `batched=True`, la fonction reçoit un dictionnaire avec les champs du jeu de données mais chaque valeur est maintenant une _liste de valeurs_ et non plus une seule valeur. La valeur retournée par `Dataset.map()` devrait être la même : un dictionnaire avec les champs que nous voulons mettre à jour ou ajouter à notre jeu de données, et une liste de valeurs. Par exemple, voici une autre façon de supprimer tous les caractères HTML, mais en utilisant `batched=True` :
+
+```python
+new_drug_dataset = drug_dataset.map(
+ lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True
+)
+```
+
+Si vous exécutez ce code dans un *notebook*, vous verrez que cette commande s'exécute beaucoup plus rapidement que la précédente. Et ce n'est pas parce que nos critiques ont déjà été scannées au format HTML. Si vous ré-exécutez l'instruction de la section précédente (sans `batched=True`), cela prendra le même temps qu'avant. En effet, les compréhensions de liste sont généralement plus rapides que l'exécution du même code dans une boucle `for` et nous gagnons également en performances en accédant à de nombreux éléments en même temps au lieu d'un par un.
+
+L'utilisation de `Dataset.map()` avec `batched=True` est essentielle pour les *tokenizers rapides* que nous rencontrerons dans le [chapitre 6](/course/fr/chapter6) et qui peuvent rapidement tokeniser de grandes listes de textes. Par exemple, pour tokeniser toutes les critiques de médicaments avec un *tokenizer* rapide nous pouvons utiliser une fonction comme celle-ci :
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+
+
+def tokenize_function(examples):
+ return tokenizer(examples["review"], truncation=True)
+```
+
+Comme vous l'avez vu dans le [chapitre 3](/course/fr/chapter3), nous pouvons passer un ou plusieurs exemples au *tokenizer*. Nous pouvons donc utiliser cette fonction avec ou sans `batched=True`. Profitons-en pour comparer les performances des différentes options. Dans un *notebook*, vous pouvez chronométrer une instruction d'une ligne en ajoutant `%time` avant la ligne de code que vous souhaitez mesurer :
+
+```python no-format
+%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
+```
+
+Vous pouvez également chronométrer une cellule entière en mettant `%%time` au début de la cellule. Sur le matériel sur lequel nous avons exécuté cela, cela affichait 10,8 s pour cette instruction (c'est le nombre écrit après "Wall time").
+
+
+
+✏️ **Essayez !** Exécutez la même instruction avec et sans `batched=True`, puis essayez-le avec un *tokenizer* lent (ajoutez `use_fast=False` dans la méthode `AutoTokenizer.from_pretrained()`) afin que vous puissiez voir quels temps vous obtenez sur votre matériel.
+
+
+
+Voici les résultats que nous avons obtenus avec et sans *batching*, avec un *tokenizer* rapide et un lent :
+
+Options | *Tokenizer* rapide | *Tokenizer* lent
+:--------------:|:----------------:|:-----------------:
+`batched=True` | 10.8s | 4min41s
+`batched=False` | 59.2s | 5min3s
+
+Cela signifie que l'utilisation d'un *tokenizer* rapide avec l'option `batched=True` est 30 fois plus rapide que son homologue lent sans batch. C'est vraiment incroyable ! C'est la raison principale pour laquelle les *tokenizers* rapides sont la valeur par défaut lors de l'utilisation de `AutoTokenizer` (et pourquoi ils sont appelés « rapides »). Ils sont capables d'atteindre une telle vitesse car en coulisses le code de tokenisation est exécuté en Rust qui est un langage facilitant la parallélisation de l'exécution du code.
+
+La parallélisation est également la raison du gain de vitesse de près de 6 fois obtenue par le *tokenizer* rapide avec batch. Vous ne pouvez pas paralléliser une seule opération de tokenisation, mais lorsque vous souhaitez tokeniser de nombreux textes en même temps, vous pouvez simplement répartir l'exécution sur plusieurs processus. Chacun responsable de ses propres textes.
+
+`Dataset.map()` possède aussi ses propres capacités de parallélisation. Comme elles ne sont pas soutenus par Rust, un *tokenizer* lent ne peut pas rattraper un rapide mais cela peut toujours être utile (surtout si vous utilisez un *tokenizer* qui n'a pas de version rapide). Pour activer le multitraitement, utilisez l'argument `num_proc` et spécifiez le nombre de processus à utiliser dans votre appel à `Dataset.map()` :
+
+```py
+slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
+
+
+def slow_tokenize_function(examples):
+ return slow_tokenizer(examples["review"], truncation=True)
+
+
+tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)
+```
+
+Vous pouvez faire des tests pour déterminer le nombre optimal de processus à utiliser. Dans notre cas 8 semble produire le meilleur gain de vitesse. Voici les chiffres que nous avons obtenus avec et sans multitraitement :
+
+Options | *Tokenizer* rapide | *Tokenizer* lent
+:----------------------------:|:----------------:|:---------------:
+`batched=True` | 10.8s | 4min41s
+`batched=False` | 59.2s | 5min3s
+`batched=True`, `num_proc=8` | 6.52s | 41.3s
+`batched=False`, `num_proc=8` | 9.49s | 45.2s
+
+Ce sont des résultats beaucoup plus raisonnables pour le *tokenizer* lent mais les performances du *tokenizer* rapide ont également été considérablement améliorées. Notez, cependant, que ce ne sera pas toujours le cas : pour des valeurs de `num_proc` autres que 8, nos tests ont montré qu'il était plus rapide d'utiliser `batched=True` sans cette option. En général, nous ne recommandons pas d'utiliser le multitraitement pour les *tokenizers* rapides avec `batched=True`.
+
+
+
+Utiliser `num_proc` pour accélérer votre traitement est généralement une bonne idée tant que la fonction que vous utilisez n'effectue pas déjà une sorte de multitraitement.
+
+
+
+Toutes ces fonctionnalités condensées en une seule méthode sont déjà assez étonnantes, mais il y a plus ! Avec `Dataset.map()` et `batched=True` vous pouvez modifier le nombre d'éléments dans votre jeu de données. Ceci est très utile dans de nombreuses situations où vous souhaitez créer plusieurs fonctionnalités d'entraînement à partir d'un exemple. Nous devrons le faire dans le cadre du prétraitement de plusieurs des tâches de traitement du langage naturel que nous entreprendrons dans le [chapitre 7](/course/fr/chapter7).
+
+
+
+💡 En apprentissage automatique, un _exemple_ est généralement défini comme l'ensemble de _features_ que nous donnons au modèle. Dans certains contextes, ces caractéristiques seront l'ensemble des colonnes d'un `Dataset`, mais dans d'autres (comme ici et pour la réponse aux questions), plusieurs caractéristiques peuvent être extraites d'un seul exemple et appartenir à une seule colonne.
+
+
+
+Voyons comment cela fonctionne ! Ici, nous allons tokeniser nos exemples et les tronquer à une longueur maximale de 128 mais nous demanderons au *tokenizer* de renvoyer *tous* les morceaux des textes au lieu du premier. Cela peut être fait avec `return_overflowing_tokens=True` :
+
+```py
+def tokenize_and_split(examples):
+ return tokenizer(
+ examples["review"],
+ truncation=True,
+ max_length=128,
+ return_overflowing_tokens=True,
+ )
+```
+
+Testons cela sur un exemple avant d'utiliser `Dataset.map()` sur le jeu de données :
+
+```py
+result = tokenize_and_split(drug_dataset["train"][0])
+[len(inp) for inp in result["input_ids"]]
+```
+
+```python out
+[128, 49]
+```
+
+Notre premier exemple du jeu d’entraînement est devenu deux caractéristiques car il a été segmenté à plus que le nombre maximum de *tokens* que nous avons spécifié : le premier de longueur 128 et le second de longueur 49. Faisons maintenant cela pour tous les éléments du jeu de données !
+
+```py
+tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
+```
+
+```python out
+ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
+```
+
+Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
+
+Le problème est que nous essayons de mélanger deux jeux de données différents de tailles différentes : les colonnes `drug_dataset` auront un certain nombre d'exemples (les 1 000 dans notre erreur), mais le `tokenized_dataset` que nous construisons en aura plus (le 1 463 dans le message d'erreur). Cela ne fonctionne pas pour un `Dataset`, nous devons donc soit supprimer les colonnes de l'ancien jeu de données, soit leur donner la même taille que dans le nouveau jeu de données. Nous pouvons faire la première option avec l'argument `remove_columns` :
+
+```py
+tokenized_dataset = drug_dataset.map(
+ tokenize_and_split, batched=True, remove_columns=drug_dataset["train"].column_names
+)
+```
+
+Maintenant, cela fonctionne sans erreur. Nous pouvons vérifier que notre nouveau jeu de données contient beaucoup plus d'éléments que le jeu de données d'origine en comparant les longueurs :
+
+```py
+len(tokenized_dataset["train"]), len(drug_dataset["train"])
+```
+
+```python out
+(206772, 138514)
+```
+
+Nous avons mentionné que nous pouvions également résoudre le problème de longueur non concordante en donnant aux anciennes colonnes la même taille que les nouvelles. Pour ce faire, nous avons besoin du champ `overflow_to_sample_mapping` que le *tokenizer* renvoie lorsque nous définissons `return_overflowing_tokens=True`. Il nous donne une correspondance entre un nouvel index de caractéristique et l'index de l'échantillon dont il est issu. Grâce à cela, nous pouvons associer chaque clé présente dans notre jeu de données d'origine à une liste de valeurs de la bonne taille en répétant les valeurs de chaque exemple autant de fois qu'il génère de nouvelles caractéristiques :
+
+```py
+def tokenize_and_split(examples):
+ result = tokenizer(
+ examples["review"],
+ truncation=True,
+ max_length=128,
+ return_overflowing_tokens=True,
+ )
+ # Extract mapping between new and old indices
+ sample_map = result.pop("overflow_to_sample_mapping")
+ for key, values in examples.items():
+ result[key] = [values[i] for i in sample_map]
+ return result
+```
+
+Nous pouvons voir que cela fonctionne avec `Dataset.map()` sans que nous ayons besoin de supprimer les anciennes colonnes :
+
+```py
+tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
+tokenized_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
+ num_rows: 206772
+ })
+ test: Dataset({
+ features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
+ num_rows: 68876
+ })
+})
+```
+
+Nous obtenons le même nombre de caractéristiques d'entraînement qu'auparavant, mais ici nous avons conservé tous les anciens champs. Si vous en avez besoin pour un post-traitement après l'application de votre modèle, vous pouvez utiliser cette approche.
+
+Vous avez maintenant vu comment 🤗 *Datasets* peut être utilisé pour prétraiter un jeu de données de différentes manières. Bien que les fonctions de traitement de 🤗 *Datasets* couvrent la plupart de vos besoins, il peut arriver que vous deviez passer à Pandas pour accéder à des fonctionnalités plus puissantes, telles que `DataFrame.groupby()` ou des API de haut niveau pour la visualisation. Heureusement, 🤗 *Datasets* est conçu pour être interopérable avec des bibliothèques telles que Pandas, NumPy, PyTorch, TensorFlow et JAX. Voyons comment cela fonctionne.
+
+## De `Dataset` à `DataFrame` et vice versa
+
+
+
+Pour permettre la conversion entre diverses bibliothèques tierces, 🤗 *Datasets* fournit une fonction `Dataset.set_format()`. Cette fonction ne modifie que le _format de sortie_ du jeu de données. Vous pouvez donc facilement passer à un autre format sans affecter le _format de données_ sous-jacent, qui est Apache Arrow. Le formatage se fait sur place. Pour démontrer, convertissons notre jeu de données vers Pandas :
+
+```py
+drug_dataset.set_format("pandas")
+```
+
+Maintenant, lorsque nous accédons aux éléments du jeu de données, nous obtenons un `pandas.DataFrame` au lieu d'un dictionnaire :
+
+```py
+drug_dataset["train"][:3]
+```
+
+
+
+
+ |
+ patient_id |
+ drugName |
+ condition |
+ review |
+ rating |
+ date |
+ usefulCount |
+ review_length |
+
+
+
+
+ | 0 |
+ 95260 |
+ Guanfacine |
+ adhd |
+ "My son is halfway through his fourth week of Intuniv..." |
+ 8.0 |
+ April 27, 2010 |
+ 192 |
+ 141 |
+
+
+ | 1 |
+ 92703 |
+ Lybrel |
+ birth control |
+ "I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." |
+ 5.0 |
+ December 14, 2009 |
+ 17 |
+ 134 |
+
+
+ | 2 |
+ 138000 |
+ Ortho Evra |
+ birth control |
+ "This is my first time using any form of birth control..." |
+ 8.0 |
+ November 3, 2015 |
+ 10 |
+ 89 |
+
+
+
+
+Créons un `pandas.DataFrame` pour l'ensemble d'entraînement en sélectionnant tous les éléments de `drug_dataset["train"]` :
+
+```py
+train_df = drug_dataset["train"][:]
+```
+
+
+
+🚨 Sous le capot, `Dataset.set_format()` change le format de retour pour la méthode `__getitem__()`. Cela signifie que lorsque nous voulons créer un nouvel objet comme `train_df` à partir d'un `Dataset` au format `"pandas"`, nous devons découper tout le jeu de données pour obtenir un `pandas.DataFrame`. Vous pouvez vérifier par vous-même que le type de `drug_dataset["train"]` est `Dataset`, quel que soit le format de sortie.
+
+
+
+
+De là, nous pouvons utiliser toutes les fonctionnalités Pandas que nous voulons. Par exemple, nous pouvons faire un chaînage sophistiqué pour calculer la distribution de classe parmi les entrées `condition` :
+
+```py
+frequencies = (
+ train_df["condition"]
+ .value_counts()
+ .to_frame()
+ .reset_index()
+ .rename(columns={"index": "condition", "condition": "frequency"})
+)
+frequencies.head()
+```
+
+
+
+
+ |
+ condition |
+ frequency |
+
+
+
+
+ | 0 |
+ birth control |
+ 27655 |
+
+
+ | 1 |
+ depression |
+ 8023 |
+
+
+ | 2 |
+ acne |
+ 5209 |
+
+
+ | 3 |
+ anxiety |
+ 4991 |
+
+
+ | 4 |
+ pain |
+ 4744 |
+
+
+
+
+
+Et une fois que nous avons terminé notre analyse Pandas, nous pouvons toujours créer un nouvel objet `Dataset` en utilisant la fonction `Dataset.from_pandas()` comme suit :
+
+
+```py
+from datasets import Dataset
+
+freq_dataset = Dataset.from_pandas(frequencies)
+freq_dataset
+```
+
+```python out
+Dataset({
+ features: ['condition', 'frequency'],
+ num_rows: 819
+})
+```
+
+
+
+✏️ **Essayez !** Calculez la note moyenne par médicament et stockez le résultat dans un nouveau jeu de données.
+
+
+
+Ceci conclut notre visite des différentes techniques de prétraitement disponibles dans 🤗 *Datasets*. Pour compléter la section, créons un ensemble de validation pour préparer le jeu de données à l’entraînement d'un classifieur. Avant cela, nous allons réinitialiser le format de sortie de `drug_dataset` de `"pandas"` à `"arrow"` :
+
+```python
+drug_dataset.reset_format()
+```
+
+## Création d'un ensemble de validation
+
+Bien que nous ayons un jeu de test que nous pourrions utiliser pour l'évaluation, il est recommandé de ne pas toucher au jeu de test et de créer un jeu de validation séparé pendant le développement. Une fois que vous êtes satisfait des performances de vos modèles sur l'ensemble de validation, vous pouvez effectuer une dernière vérification d'intégrité sur l'ensemble test. Ce processus permet d'atténuer le risque de surentraînement sur le jeu de test et de déployer un modèle qui échoue sur des données du monde réel.
+
+🤗 *Datasets* fournit une fonction `Dataset.train_test_split()` basée sur la célèbre fonctionnalité de `scikit-learn`. Utilisons-la pour diviser notre ensemble d'entraînement `train` et `validation` (nous définissons l'argument `seed` pour la reproductibilité) :
+
+```py
+drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
+# Rename the default "test" split to "validation"
+drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
+# Add the "test" set to our `DatasetDict`
+drug_dataset_clean["test"] = drug_dataset["test"]
+drug_dataset_clean
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
+ num_rows: 110811
+ })
+ validation: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
+ num_rows: 27703
+ })
+ test: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
+ num_rows: 46108
+ })
+})
+```
+
+Génial, nous avons maintenant préparé un jeu de données prêt pour l'entraînement de certains modèles ! Dans la [section 5](/course/fr/chapter5/5), nous vous montrerons comment télécharger des jeux de données sur le *Hub*. Mais pour l'instant, terminons notre analyse en examinant quelques façons d'enregistrer des jeux de données sur votre ordinateur local.
+
+## Enregistrer un jeu de données
+
+
+
+Bien que 🤗 *Datasets* mette en cache chaque jeu de données téléchargé et les opérations qui y sont effectuées, il y a des moments où vous voudrez enregistrer un jeu de données sur le disque (par exemple, au cas où le cache serait supprimé). Comme indiqué dans le tableau ci-dessous, 🤗 *Datasets* fournit trois fonctions principales pour enregistrer votre jeu de données dans différents formats :
+
+| Format de données | Fonction |
+| :---------------: | :----------------------: |
+| Arrow | `Dataset.save_to_disk()` |
+| CSV | `Dataset.to_csv()` |
+| JSON | `Dataset.to_json()` |
+
+Par exemple, enregistrons notre jeu de données nettoyé au format Arrow :
+
+```py
+drug_dataset_clean.save_to_disk("drug-reviews")
+```
+
+Cela créera un répertoire avec la structure suivante :
+
+```
+drug-reviews/
+├── dataset_dict.json
+├── test
+│ ├── dataset.arrow
+│ ├── dataset_info.json
+│ └── state.json
+├── train
+│ ├── dataset.arrow
+│ ├── dataset_info.json
+│ ├── indices.arrow
+│ └── state.json
+└── validation
+ ├── dataset.arrow
+ ├── dataset_info.json
+ ├── indices.arrow
+ └── state.json
+```
+
+où nous pouvons voir que chaque division est associée à sa propre table *dataset.arrow* et à certaines métadonnées dans *dataset_info.json* et *state.json*. Vous pouvez considérer le format Arrow comme un tableau sophistiqué de colonnes et de lignes optimisé pour la création d'applications hautes performances qui traitent et transportent de grands ensembles de données.
+
+Une fois le jeu de données enregistré, nous pouvons le charger en utilisant la fonction `load_from_disk()` comme suit :
+
+```py
+from datasets import load_from_disk
+
+drug_dataset_reloaded = load_from_disk("drug-reviews")
+drug_dataset_reloaded
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
+ num_rows: 110811
+ })
+ validation: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
+ num_rows: 27703
+ })
+ test: Dataset({
+ features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
+ num_rows: 46108
+ })
+})
+```
+
+Pour les formats CSV et JSON, nous devons stocker chaque fractionnement dans un fichier séparé. Pour ce faire, vous pouvez parcourir les clés et les valeurs de l'objet `DatasetDict` :
+
+```py
+for split, dataset in drug_dataset_clean.items():
+ dataset.to_json(f"drug-reviews-{split}.jsonl")
+```
+
+Cela enregistre chaque fractionnement au [format JSON Lines](https://jsonlines.org), où chaque ligne du jeu de données est stockée sous la forme d'une seule ligne de JSON. Voici à quoi ressemble le premier exemple :
+
+```py
+!head -n 1 drug-reviews-train.jsonl
+```
+
+```python out
+{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
+ # Il semble que je ressente les effets secondaires habituels de LEXAPRO : insomnie, baisse de la libido, somnolence pendant la journée. Je le prends le soir parce que mon médecin m'a dit de le prendre le soir s'il me fatiguait. J'ai supposé que ce serait le cas et j'ai commencé à le prendre la nuit. Rêves étranges, certains agréables. On m'a diagnostiqué une fibromyalgie. Il semble que ce médicament aide à soulager la douleur. J'ai eu de l'anxiété et de la dépression dans ma famille, et j'ai essayé plusieurs autres médicaments qui n'ont pas fonctionné. Cela ne fait que deux semaines que je prends ce médicament, mais je me sens plus positif dans mon esprit et je veux accomplir davantage dans ma vie. J'espère que les effets secondaires vont s'estomper, cela vaut la peine de s'y tenir d'après les réponses des autres. C'est un excellent médicament.
+```
+
+Nous pouvons ensuite utiliser les techniques de [section 2](/course/fr/chapter5/2) pour charger les fichiers JSON comme suit :
+
+```py
+data_files = {
+ "train": "drug-reviews-train.jsonl",
+ "validation": "drug-reviews-validation.jsonl",
+ "test": "drug-reviews-test.jsonl",
+}
+drug_dataset_reloaded = load_dataset("json", data_files=data_files)
+```
+
+Et c'est tout pour notre excursion dans la manipulation des données avec 🤗 *Datasets* ! Maintenant que nous disposons d'un ensemble de données nettoyé pour entraîner un modèle, voici quelques idées que vous pouvez essayer :
+
+1. Utilisez les techniques du [chapitre 3](/course/fr/chapter3) pour entraîner un classifieur capable de prédire l'état du patient en fonction de l'examen du médicament.
+2. Utilisez le pipeline `summarization` du [chapitre 1](/course/fr/chapter1) pour générer des résumés des révisions.
+
+Ensuite, nous verrons comment 🤗 *Datasets* peut vous permettre de travailler avec d'énormes jeux de données sans faire exploser votre ordinateur portable !
diff --git a/chapters/fr/chapter5/4.mdx b/chapters/fr/chapter5/4.mdx
index dc286c718..0b369438c 100644
--- a/chapters/fr/chapter5/4.mdx
+++ b/chapters/fr/chapter5/4.mdx
@@ -1,296 +1,296 @@
-# Données massives ? 🤗 Datasets à la rescousse !
-
-
-
-
-De nos jours, il n'est pas rare de travailler avec des jeux de données de plusieurs gigaoctets surtout si vous envisagez de pré-entraîner un *transformer* comme BERT ou GPT-2 à partir de zéro. Dans ces cas, même _charger_ les données peut être un défi. Par exemple, le corpus WebText utilisé pour pré-entraîner GPT-2 se compose de plus de 8 millions de documents et de 40 Go de texte. Le charger dans la RAM de votre ordinateur portable est susceptible de lui donner une crise cardiaque !
-
-Heureusement, 🤗 *Datasets* a été conçu pour surmonter ces limitations. Il vous libère des problèmes de gestion de la mémoire en traitant les jeux de données comme des fichiers _mappés en mémoire_, ainsi que des limites du disque dur en faisant du _streaming_ sur les entrées dans un corpus.
-
-
-
-Dans cette section, nous allons explorer ces fonctionnalités de 🤗 *Datasets* avec un énorme corpus de 825 Go connu sous le nom de [*The Pile*](https://pile.eleuther.ai). Commençons !
-
-## Qu'est-ce que The Pile ?
-
-*The Pile* est un corpus de texte en anglais créé par [EleutherAI](https://www.eleuther.ai) pour entraîner des modèles de langage à grande échelle. Il comprend une gamme variée de jeux de données, couvrant des articles scientifiques, des référentiels de code GitHub et du texte Web filtré. Le corpus d’entraînement est disponible en [morceaux de 14 Go](https://mystic.the-eye.eu/public/AI/pile/) et vous pouvez aussi télécharger plusieurs des [composants individuels]( https://mystic.the-eye.eu/public/AI/pile_preliminary_components/). Commençons par jeter un coup d'œil au jeu de données *PubMed Abstracts*, qui est un corpus de résumés de 15 millions de publications biomédicales sur [PubMed](https://pubmed.ncbi.nlm.nih.gov/). Le jeu de données est au [format JSON Lines](https://jsonlines.org) et est compressé à l'aide de la bibliothèque `zstandard`. Nous devons donc d'abord installer cette bibliothèque :
-
-```py
-!pip install zstandard
-```
-
-Ensuite, nous pouvons charger le jeu de données en utilisant la méthode pour les fichiers distants que nous avons apprise dans [section 2](/course/fr/chapter5/2) :
-
-```py
-from datasets import load_dataset
-
-# Cela prend quelques minutes à exécuter, alors allez prendre un thé ou un café en attendant :)
-data_files = "https://mystic.the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
-pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
-pubmed_dataset
-```
-
-```python out
-Dataset({
- features: ['meta', 'text'],
- num_rows: 15518009
-})
-```
-
-Nous pouvons voir qu'il y a 15 518 009 lignes et 2 colonnes dans notre jeu de données. C'est beaucoup !
-
-
-
-✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) pour plus de détails.
-
-
-
-Inspectons le contenu du premier exemple :
-
-```py
-pubmed_dataset[0]
-```
-
-```python out
-{'meta': {'pmid': 11409574, 'language': 'eng'},
- 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'
-# Épidémiologie de l'hypoxémie chez les enfants souffrant d'une infection aiguë des voies respiratoires inférieures. Déterminer la prévalence de l'hypoxémie chez les enfants de moins de 5 ans souffrant d'une infection aiguë des voies respiratoires inférieures (IAVI), les facteurs de risque de l'hypoxémie chez les enfants de moins de 5 ans souffrant d'une IAVI, et l'association de l'hypoxémie à un risque accru de décès chez les enfants du même âge ...
-}
-```
-
-Cela ressemble au résumé d'un article médical. Voyons maintenant combien de RAM nous avons utilisé pour charger le jeu de données !
-
-## La magie du memory mapping
-
-Un moyen simple de mesurer l'utilisation de la mémoire dans Python consiste à utiliser la bibliothèque [`psutil`](https://psutil.readthedocs.io/en/latest/) qui peut être installée avec `pip` comme suit :
-
-```python
-!pip install psutil
-```
-
-Elle fournit une classe `Process` qui permet de vérifier l'utilisation de la mémoire du processus en cours :
-
-```py
-import psutil
-
-# Process.memory_info est exprimé en octets, donc convertir en mégaoctets
-print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
-```
-
-```python out
-RAM used: 5678.33 MB
-```
-
-Ici, l'attribut `rss` fait référence à la _taille de l'ensemble résident_, qui est la fraction de mémoire qu'un processus occupe dans la RAM. Cette mesure inclut également la mémoire utilisée par l'interpréteur Python et les bibliothèques que nous avons chargées, de sorte que la quantité réelle de mémoire utilisée pour charger le jeu de données est un peu plus petite. À titre de comparaison, voyons la taille du jeu de données sur le disque en utilisant l'attribut `dataset_size`. Comme le résultat est exprimé en octets comme précédemment, nous devons le convertir manuellement en gigaoctets :
-
-```py
-print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
-size_gb = pubmed_dataset.dataset_size / (1024**3)
-print(f"Dataset size (cache file) : {size_gb:.2f} GB")
-```
-
-```python out
-Number of files in dataset : 20979437051
-Dataset size (cache file) : 19.54 GB
-```
-
-Malgré sa taille de près de 20 Go, nous pouvons charger et accéder au jeu de données avec beaucoup moins de RAM !
-
-
-
-✏️ **Essayez !** Choisissez l'un des [sous-ensembles](https://mystic.the-eye.eu/public/AI/pile_preliminary_components/) de *The Pile* qui est plus grand que la RAM de votre ordinateur portable ou de bureau. Chargez-le avec 🤗 *Datasets* et mesurez la quantité de RAM utilisée. Notez que pour obtenir une mesure précise, vous devrez le faire dans un nouveau processus. Vous pouvez trouver les tailles décompressées de chaque sous-ensemble dans le tableau 1 du papier de [*The Pile*](https://arxiv.org/abs/2101.00027).
-
-
-
-Si vous êtes familier avec Pandas, ce résultat pourrait surprendre en raison de la célèbre [règle d'or](https://wesmckinney.com/blog/apache-arrow-pandas-internals/) de Wes Kinney selon laquelle vous avez généralement besoin de 5 à 10 fois plus de RAM que la taille de votre jeu de données. Alors, comment 🤗 *Datasets* résout-il ce problème de gestion de la mémoire ? 🤗 *Datasets* traite chaque jeu de données comme un [fichier mappé en mémoire](https://en.wikipedia.org/wiki/Memory-mapped_file). Cela fournit un mappage entre la RAM et le stockage du système de fichiers permettant à la bibliothèque d'accéder et d'opérer sur des éléments du jeu de données sans avoir besoin de le charger entièrement en mémoire.
-
-Les fichiers mappés en mémoire peuvent également être partagés entre plusieurs processus ce qui permet de paralléliser des méthodes telles que `Dataset.map()` sans avoir à déplacer ou copier le jeu de données. Sous le capot, ces capacités sont toutes réalisées par le format de mémoire [Apache Arrow](https://arrow.apache.org) et [`pyarrow`](https://arrow.apache.org/docs/python/index.html), qui accélèrent le chargement et le traitement des données. (Pour plus de détails sur Apache Arrow et les comparaisons avec Pandas, consultez [l'article de blog de Dejan Simic](https://towardsdatascience.com/apache-arrow-read-dataframe-with-zero-memory-69634092b1a)). Pour voir ceci en action, effectuons un petit test de vitesse en itérant sur tous les éléments du jeu de données *PubMed Abstracts* :
-
-```py
-import timeit
-
-code_snippet = """batch_size = 1000
-
-for idx in range(0, len(pubmed_dataset), batch_size):
- _ = pubmed_dataset[idx:idx + batch_size]
-"""
-
-time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
-print(
- f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
- f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
-)
-```
-
-```python out
-'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
-```
-
-Ici, nous avons utilisé le module `timeit` de Python pour mesurer le temps d'exécution pris par `code_snippet`. Vous pourrez généralement itérer sur un jeu de données à une vitesse de quelques dixièmes de Go/s à plusieurs Go/s. Cela fonctionne très bien pour la grande majorité des applications, mais vous devrez parfois travailler avec un jeu de données trop volumineux pour être même stocké sur le disque dur de votre ordinateur portable. Par exemple, si nous essayions de télécharger *The Pile* dans son intégralité, nous aurions besoin de 825 Go d'espace disque libre ! Pour gérer ces cas, 🤗 *Datasets* fournit une fonctionnalité de streaming qui nous permet de télécharger et d'accéder aux éléments à la volée, sans avoir besoin de télécharger l'intégralité du jeu de données. Voyons comment cela fonctionne.
-
-
-
-💡 Dans les *notebooks* Jupyter, vous pouvez également chronométrer les cellules à l'aide de la fonction magique [`%%timeit`](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit).
-
-
-
-## Jeux de données en continu
-
-Pour activer le streaming du jeu de données, il vous suffit de passer l'argument `streaming=True` à la fonction `load_dataset()`. Par exemple, chargeons à nouveau le jeu de données *PubMed Abstracts* mais en mode streaming :
-
-```py
-pubmed_dataset_streamed = load_dataset(
- "json", data_files=data_files, split="train", streaming=True
-)
-```
-
-Au lieu du familier `Dataset` que nous avons rencontré ailleurs dans ce chapitre, l'objet retourné avec `streaming=True` est un `IterableDataset`. Comme son nom l'indique, pour accéder aux éléments d'un `IterableDataset`, nous devons parcourir celui-ci. Nous pouvons accéder au premier élément de notre jeu de données diffusé comme suit :
-
-
-```py
-next(iter(pubmed_dataset_streamed))
-```
-
-```python out
-{'meta': {'pmid': 11409574, 'language': 'eng'},
- 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
-```
-
-Les éléments d'un jeu de données diffusé en continu peuvent être traités à la volée à l'aide de `IterableDataset.map()`, ce qui est utile pendant l’entraînement si vous avez besoin de tokeniser les entrées. Le processus est exactement le même que celui que nous avons utilisé pour tokeniser notre jeu de données dans le [chapitre 3](/course/fr/chapter3), à la seule différence que les sorties sont renvoyées une par une :
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
-tokenized_dataset = pubmed_dataset_streamed.map(lambda x: tokenizer(x["text"]))
-next(iter(tokenized_dataset))
-```
-
-```python out
-{'input_ids': [101, 4958, 5178, 4328, 6779, ...], 'attention_mask': [1, 1, 1, 1, 1, ...]}
-```
-
-
-
-💡 Pour accélérer la tokenisation avec le streaming, vous pouvez passer `batched=True`, comme nous l'avons vu dans la dernière section. Il traitera les exemples batch par batch. La taille de batch par défaut est de 1 000 et peut être spécifiée avec l'argument `batch_size`.
-
-
-
-Vous pouvez également mélanger un jeu de données diffusé en continu à l'aide de `IterableDataset.shuffle()`, mais contrairement à `Dataset.shuffle()`, cela ne mélange que les éléments dans un `buffer_size` prédéfini :
-
-```py
-shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
-next(iter(shuffled_dataset))
-```
-
-```python out
-{'meta': {'pmid': 11410799, 'language': 'eng'},
- 'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'
-# Étude randomisée sur la modification de la dose ou du calendrier d'administration du facteur de stimulation des colonies de granulocytes dans le cadre d'une chimiothérapie à base de platine chez les patients âgés atteints de cancer du poumon ...
-}
-```
-
-Dans cet exemple, nous avons sélectionné un exemple aléatoire parmi les 10 000 premiers exemples du tampon. Une fois qu'un exemple est accédé, sa place dans le tampon est remplie avec l'exemple suivant dans le corpus (c'est-à-dire le 10 001e exemple dans le cas ci-dessus). Vous pouvez également sélectionner des éléments d'un jeu de données diffusé en continu à l'aide des fonctions `IterableDataset.take()` et `IterableDataset.skip()`, qui agissent de la même manière que `Dataset.select()`. Par exemple, pour sélectionner les 5 premiers exemples dans le jeu de données *PubMed Abstracts*, nous pouvons procéder comme suit :
-
-```py
-dataset_head = pubmed_dataset_streamed.take(5)
-list(dataset_head)
-```
-
-```python out
-[{'meta': {'pmid': 11409574, 'language': 'eng'},
- 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'
-# Épidémiologie de l'hypoxémie chez les enfants atteints d'une infection aiguë des voies respiratoires inférieures ...},
- {'meta': {'pmid': 11409575, 'language': 'eng'},
- 'text': 'Clinical signs of hypoxaemia in children with acute lower respiratory infection: indicators of oxygen therapy ...'
-# Signes cliniques d'hypoxémie chez les enfants atteints d'une infection aiguë des voies respiratoires inférieures : indicateurs de l'oxygénothérapie ...},
- {'meta': {'pmid': 11409576, 'language': 'eng'},
- 'text': "Hypoxaemia in children with severe pneumonia in Papua New Guinea ..."
-# Hypoxémie chez les enfants atteints de pneumonie grave en Papouasie-Nouvelle-Guinée ...},
- {'meta': {'pmid': 11409577, 'language': 'eng'},
- 'text': 'Oxygen concentrators and cylinders ...'
-# Concentrateurs et bouteilles d'oxygène...},
- {'meta': {'pmid': 11409578, 'language': 'eng'},
- 'text': 'Oxygen supply in rural africa: a personal experience ...'
-# L'approvisionnement en oxygène dans les zones rurales africaines : une expérience personnelle ...}]
-```
-
-De même, vous pouvez utiliser la fonction `IterableDataset.skip()` pour créer des fractionnements d'entraînement et de validation à partir d'un jeu de données mélangé comme suit :
-
-```py
-# Ignorer les 1 000 premiers exemples et inclure le reste dans l'ensemble d'apprentissage.
-train_dataset = shuffled_dataset.skip(1000)
-# Prendre les 1 000 premiers exemples pour l'ensemble de validation.
-validation_dataset = shuffled_dataset.take(1000)
-```
-
-Terminons notre exploration du streaming des jeux de données avec une application commune : combiner plusieurs jeux de données pour créer un seul corpus. 🤗 *Datasets* fournit une fonction `interleave_datasets()` qui convertit une liste d'objets `IterableDataset` en un seul `IterableDataset`, où les éléments du nouveau jeu de données sont obtenus en alternant entre les exemples source. Cette fonction est particulièrement utile lorsque vous essayez de combiner de grands jeux de données. Par exemple, streamons FreeLaw, un sous-ensemble de *The Pile* et qui est un jeu de données de 51 Go d'avis juridiques de tribunaux américains :
-
-```py
-law_dataset_streamed = load_dataset(
- "json",
- data_files="https://mystic.the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
- split="train",
- streaming=True,
-)
-next(iter(law_dataset_streamed))
-```
-
-```python out
-{'meta': {'case_ID': '110921.json',
- 'case_jurisdiction': 'scotus.tar.gz',
- 'date_created': '2010-04-28T17:12:49Z'},
- 'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
-```
-
-Ce jeu de données est suffisamment volumineux pour solliciter la RAM de la plupart des ordinateurs portables, mais nous avons pu le charger et y accéder sans transpirer ! Combinons maintenant les jeux de données FreeLaw et *PubMed Abstracts* avec la fonction `interleave_datasets()` :
-
-```py
-from itertools import islice
-from datasets import interleave_datasets
-
-combined_dataset = interleave_datasets([pubmed_dataset_streamed, law_dataset_streamed])
-list(islice(combined_dataset, 2))
-```
-
-```python out
-[{'meta': {'pmid': 11409574, 'language': 'eng'},
- 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
- {'meta': {'case_ID': '110921.json',
- 'case_jurisdiction': 'scotus.tar.gz',
- 'date_created': '2010-04-28T17:12:49Z'},
- 'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
-```
-
-Ici, nous avons utilisé la fonction `islice()` du module `itertools` de Python pour sélectionner les deux premiers exemples du jeu de données combiné. Nous pouvons voir qu'ils correspondent aux premiers exemples de chacun des deux jeux de données source.
-
-Enfin, si vous souhaitez streamer *The Pile* dans son intégralité de 825 Go, vous pouvez récupérer tous les fichiers préparés comme suit :
-
-```py
-base_url = "https://mystic.the-eye.eu/public/AI/pile/"
-data_files = {
- "train": [base_url + "train/" + f"{idx:02d}.jsonl.zst" for idx in range(30)],
- "validation": base_url + "val.jsonl.zst",
- "test": base_url + "test.jsonl.zst",
-}
-pile_dataset = load_dataset("json", data_files=data_files, streaming=True)
-next(iter(pile_dataset["train"]))
-```
-
-```python out
-{'meta': {'pile_set_name': 'Pile-CC'},
- 'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web...'}
-```
-
-
-
-✏️ **Essayez !** Utilisez l'un des grands corpus Common Crawl comme [`mc4`](https://huggingface.co/datasets/mc4) ou [`oscar`](https://huggingface.co/datasets/oscar) pour créer en streaming un jeu de données multilingue représentant les proportions de langues parlées dans un pays de votre choix. Par exemple, les quatre langues nationales en Suisse sont l'allemand, le français, l'italien et le romanche. Vous pouvez donc essayer de créer un corpus suisse en échantillonnant les sous-ensembles Oscar en fonction de leur proportion parlée.
-
-
-
-Vous disposez maintenant de tous les outils dont vous avez besoin pour charger et traiter des jeux de données de toutes formes et tailles. Cependant à moins que vous ne soyez exceptionnellement chanceux, il arrivera un moment dans votre cheminement en traitement du langage naturel où vous devrez réellement créer un jeu de données pour résoudre un problème donné. C'est le sujet de la section suivante !
+# Données massives ? 🤗 Datasets à la rescousse !
+
+
+
+
+De nos jours, il n'est pas rare de travailler avec des jeux de données de plusieurs gigaoctets surtout si vous envisagez de pré-entraîner un *transformer* comme BERT ou GPT-2 à partir de zéro. Dans ces cas, même _charger_ les données peut être un défi. Par exemple, le corpus WebText utilisé pour pré-entraîner GPT-2 se compose de plus de 8 millions de documents et de 40 Go de texte. Le charger dans la RAM de votre ordinateur portable est susceptible de lui donner une crise cardiaque !
+
+Heureusement, 🤗 *Datasets* a été conçu pour surmonter ces limitations. Il vous libère des problèmes de gestion de la mémoire en traitant les jeux de données comme des fichiers _mappés en mémoire_, ainsi que des limites du disque dur en faisant du _streaming_ sur les entrées dans un corpus.
+
+
+
+Dans cette section, nous allons explorer ces fonctionnalités de 🤗 *Datasets* avec un énorme corpus de 825 Go connu sous le nom de [*The Pile*](https://pile.eleuther.ai). Commençons !
+
+## Qu'est-ce que The Pile ?
+
+*The Pile* est un corpus de texte en anglais créé par [EleutherAI](https://www.eleuther.ai) pour entraîner des modèles de langage à grande échelle. Il comprend une gamme variée de jeux de données, couvrant des articles scientifiques, des référentiels de code GitHub et du texte Web filtré. Le corpus d’entraînement est disponible en [morceaux de 14 Go](https://mystic.the-eye.eu/public/AI/pile/) et vous pouvez aussi télécharger plusieurs des [composants individuels]( https://mystic.the-eye.eu/public/AI/pile_preliminary_components/). Commençons par jeter un coup d'œil au jeu de données *PubMed Abstracts*, qui est un corpus de résumés de 15 millions de publications biomédicales sur [PubMed](https://pubmed.ncbi.nlm.nih.gov/). Le jeu de données est au [format JSON Lines](https://jsonlines.org) et est compressé à l'aide de la bibliothèque `zstandard`. Nous devons donc d'abord installer cette bibliothèque :
+
+```py
+!pip install zstandard
+```
+
+Ensuite, nous pouvons charger le jeu de données en utilisant la méthode pour les fichiers distants que nous avons apprise dans [section 2](/course/fr/chapter5/2) :
+
+```py
+from datasets import load_dataset
+
+# Cela prend quelques minutes à exécuter, alors allez prendre un thé ou un café en attendant :)
+data_files = "https://mystic.the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
+pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
+pubmed_dataset
+```
+
+```python out
+Dataset({
+ features: ['meta', 'text'],
+ num_rows: 15518009
+})
+```
+
+Nous pouvons voir qu'il y a 15 518 009 lignes et 2 colonnes dans notre jeu de données. C'est beaucoup !
+
+
+
+✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) pour plus de détails.
+
+
+
+Inspectons le contenu du premier exemple :
+
+```py
+pubmed_dataset[0]
+```
+
+```python out
+{'meta': {'pmid': 11409574, 'language': 'eng'},
+ 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'
+# Épidémiologie de l'hypoxémie chez les enfants souffrant d'une infection aiguë des voies respiratoires inférieures. Déterminer la prévalence de l'hypoxémie chez les enfants de moins de 5 ans souffrant d'une infection aiguë des voies respiratoires inférieures (IAVI), les facteurs de risque de l'hypoxémie chez les enfants de moins de 5 ans souffrant d'une IAVI, et l'association de l'hypoxémie à un risque accru de décès chez les enfants du même âge ...
+}
+```
+
+Cela ressemble au résumé d'un article médical. Voyons maintenant combien de RAM nous avons utilisé pour charger le jeu de données !
+
+## La magie du memory mapping
+
+Un moyen simple de mesurer l'utilisation de la mémoire dans Python consiste à utiliser la bibliothèque [`psutil`](https://psutil.readthedocs.io/en/latest/) qui peut être installée avec `pip` comme suit :
+
+```python
+!pip install psutil
+```
+
+Elle fournit une classe `Process` qui permet de vérifier l'utilisation de la mémoire du processus en cours :
+
+```py
+import psutil
+
+# Process.memory_info est exprimé en octets, donc convertir en mégaoctets
+print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
+```
+
+```python out
+RAM used: 5678.33 MB
+```
+
+Ici, l'attribut `rss` fait référence à la _taille de l'ensemble résident_, qui est la fraction de mémoire qu'un processus occupe dans la RAM. Cette mesure inclut également la mémoire utilisée par l'interpréteur Python et les bibliothèques que nous avons chargées, de sorte que la quantité réelle de mémoire utilisée pour charger le jeu de données est un peu plus petite. À titre de comparaison, voyons la taille du jeu de données sur le disque en utilisant l'attribut `dataset_size`. Comme le résultat est exprimé en octets comme précédemment, nous devons le convertir manuellement en gigaoctets :
+
+```py
+print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
+size_gb = pubmed_dataset.dataset_size / (1024**3)
+print(f"Dataset size (cache file) : {size_gb:.2f} GB")
+```
+
+```python out
+Number of files in dataset : 20979437051
+Dataset size (cache file) : 19.54 GB
+```
+
+Malgré sa taille de près de 20 Go, nous pouvons charger et accéder au jeu de données avec beaucoup moins de RAM !
+
+
+
+✏️ **Essayez !** Choisissez l'un des [sous-ensembles](https://mystic.the-eye.eu/public/AI/pile_preliminary_components/) de *The Pile* qui est plus grand que la RAM de votre ordinateur portable ou de bureau. Chargez-le avec 🤗 *Datasets* et mesurez la quantité de RAM utilisée. Notez que pour obtenir une mesure précise, vous devrez le faire dans un nouveau processus. Vous pouvez trouver les tailles décompressées de chaque sous-ensemble dans le tableau 1 du papier de [*The Pile*](https://arxiv.org/abs/2101.00027).
+
+
+
+Si vous êtes familier avec Pandas, ce résultat pourrait surprendre en raison de la célèbre [règle d'or](https://wesmckinney.com/blog/apache-arrow-pandas-internals/) de Wes Kinney selon laquelle vous avez généralement besoin de 5 à 10 fois plus de RAM que la taille de votre jeu de données. Alors, comment 🤗 *Datasets* résout-il ce problème de gestion de la mémoire ? 🤗 *Datasets* traite chaque jeu de données comme un [fichier mappé en mémoire](https://en.wikipedia.org/wiki/Memory-mapped_file). Cela fournit un mappage entre la RAM et le stockage du système de fichiers permettant à la bibliothèque d'accéder et d'opérer sur des éléments du jeu de données sans avoir besoin de le charger entièrement en mémoire.
+
+Les fichiers mappés en mémoire peuvent également être partagés entre plusieurs processus ce qui permet de paralléliser des méthodes telles que `Dataset.map()` sans avoir à déplacer ou copier le jeu de données. Sous le capot, ces capacités sont toutes réalisées par le format de mémoire [Apache Arrow](https://arrow.apache.org) et [`pyarrow`](https://arrow.apache.org/docs/python/index.html), qui accélèrent le chargement et le traitement des données. (Pour plus de détails sur Apache Arrow et les comparaisons avec Pandas, consultez [l'article de blog de Dejan Simic](https://towardsdatascience.com/apache-arrow-read-dataframe-with-zero-memory-69634092b1a)). Pour voir ceci en action, effectuons un petit test de vitesse en itérant sur tous les éléments du jeu de données *PubMed Abstracts* :
+
+```py
+import timeit
+
+code_snippet = """batch_size = 1000
+
+for idx in range(0, len(pubmed_dataset), batch_size):
+ _ = pubmed_dataset[idx:idx + batch_size]
+"""
+
+time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
+print(
+ f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
+ f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
+)
+```
+
+```python out
+'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
+```
+
+Ici, nous avons utilisé le module `timeit` de Python pour mesurer le temps d'exécution pris par `code_snippet`. Vous pourrez généralement itérer sur un jeu de données à une vitesse de quelques dixièmes de Go/s à plusieurs Go/s. Cela fonctionne très bien pour la grande majorité des applications, mais vous devrez parfois travailler avec un jeu de données trop volumineux pour être même stocké sur le disque dur de votre ordinateur portable. Par exemple, si nous essayions de télécharger *The Pile* dans son intégralité, nous aurions besoin de 825 Go d'espace disque libre ! Pour gérer ces cas, 🤗 *Datasets* fournit une fonctionnalité de streaming qui nous permet de télécharger et d'accéder aux éléments à la volée, sans avoir besoin de télécharger l'intégralité du jeu de données. Voyons comment cela fonctionne.
+
+
+
+💡 Dans les *notebooks* Jupyter, vous pouvez également chronométrer les cellules à l'aide de la fonction magique [`%%timeit`](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit).
+
+
+
+## Jeux de données en continu
+
+Pour activer le streaming du jeu de données, il vous suffit de passer l'argument `streaming=True` à la fonction `load_dataset()`. Par exemple, chargeons à nouveau le jeu de données *PubMed Abstracts* mais en mode streaming :
+
+```py
+pubmed_dataset_streamed = load_dataset(
+ "json", data_files=data_files, split="train", streaming=True
+)
+```
+
+Au lieu du familier `Dataset` que nous avons rencontré ailleurs dans ce chapitre, l'objet retourné avec `streaming=True` est un `IterableDataset`. Comme son nom l'indique, pour accéder aux éléments d'un `IterableDataset`, nous devons parcourir celui-ci. Nous pouvons accéder au premier élément de notre jeu de données diffusé comme suit :
+
+
+```py
+next(iter(pubmed_dataset_streamed))
+```
+
+```python out
+{'meta': {'pmid': 11409574, 'language': 'eng'},
+ 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
+```
+
+Les éléments d'un jeu de données diffusé en continu peuvent être traités à la volée à l'aide de `IterableDataset.map()`, ce qui est utile pendant l’entraînement si vous avez besoin de tokeniser les entrées. Le processus est exactement le même que celui que nous avons utilisé pour tokeniser notre jeu de données dans le [chapitre 3](/course/fr/chapter3), à la seule différence que les sorties sont renvoyées une par une :
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+tokenized_dataset = pubmed_dataset_streamed.map(lambda x: tokenizer(x["text"]))
+next(iter(tokenized_dataset))
+```
+
+```python out
+{'input_ids': [101, 4958, 5178, 4328, 6779, ...], 'attention_mask': [1, 1, 1, 1, 1, ...]}
+```
+
+
+
+💡 Pour accélérer la tokenisation avec le streaming, vous pouvez passer `batched=True`, comme nous l'avons vu dans la dernière section. Il traitera les exemples batch par batch. La taille de batch par défaut est de 1 000 et peut être spécifiée avec l'argument `batch_size`.
+
+
+
+Vous pouvez également mélanger un jeu de données diffusé en continu à l'aide de `IterableDataset.shuffle()`, mais contrairement à `Dataset.shuffle()`, cela ne mélange que les éléments dans un `buffer_size` prédéfini :
+
+```py
+shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
+next(iter(shuffled_dataset))
+```
+
+```python out
+{'meta': {'pmid': 11410799, 'language': 'eng'},
+ 'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'
+# Étude randomisée sur la modification de la dose ou du calendrier d'administration du facteur de stimulation des colonies de granulocytes dans le cadre d'une chimiothérapie à base de platine chez les patients âgés atteints de cancer du poumon ...
+}
+```
+
+Dans cet exemple, nous avons sélectionné un exemple aléatoire parmi les 10 000 premiers exemples du tampon. Une fois qu'un exemple est accédé, sa place dans le tampon est remplie avec l'exemple suivant dans le corpus (c'est-à-dire le 10 001e exemple dans le cas ci-dessus). Vous pouvez également sélectionner des éléments d'un jeu de données diffusé en continu à l'aide des fonctions `IterableDataset.take()` et `IterableDataset.skip()`, qui agissent de la même manière que `Dataset.select()`. Par exemple, pour sélectionner les 5 premiers exemples dans le jeu de données *PubMed Abstracts*, nous pouvons procéder comme suit :
+
+```py
+dataset_head = pubmed_dataset_streamed.take(5)
+list(dataset_head)
+```
+
+```python out
+[{'meta': {'pmid': 11409574, 'language': 'eng'},
+ 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'
+# Épidémiologie de l'hypoxémie chez les enfants atteints d'une infection aiguë des voies respiratoires inférieures ...},
+ {'meta': {'pmid': 11409575, 'language': 'eng'},
+ 'text': 'Clinical signs of hypoxaemia in children with acute lower respiratory infection: indicators of oxygen therapy ...'
+# Signes cliniques d'hypoxémie chez les enfants atteints d'une infection aiguë des voies respiratoires inférieures : indicateurs de l'oxygénothérapie ...},
+ {'meta': {'pmid': 11409576, 'language': 'eng'},
+ 'text': "Hypoxaemia in children with severe pneumonia in Papua New Guinea ..."
+# Hypoxémie chez les enfants atteints de pneumonie grave en Papouasie-Nouvelle-Guinée ...},
+ {'meta': {'pmid': 11409577, 'language': 'eng'},
+ 'text': 'Oxygen concentrators and cylinders ...'
+# Concentrateurs et bouteilles d'oxygène...},
+ {'meta': {'pmid': 11409578, 'language': 'eng'},
+ 'text': 'Oxygen supply in rural africa: a personal experience ...'
+# L'approvisionnement en oxygène dans les zones rurales africaines : une expérience personnelle ...}]
+```
+
+De même, vous pouvez utiliser la fonction `IterableDataset.skip()` pour créer des fractionnements d'entraînement et de validation à partir d'un jeu de données mélangé comme suit :
+
+```py
+# Ignorer les 1 000 premiers exemples et inclure le reste dans l'ensemble d'apprentissage.
+train_dataset = shuffled_dataset.skip(1000)
+# Prendre les 1 000 premiers exemples pour l'ensemble de validation.
+validation_dataset = shuffled_dataset.take(1000)
+```
+
+Terminons notre exploration du streaming des jeux de données avec une application commune : combiner plusieurs jeux de données pour créer un seul corpus. 🤗 *Datasets* fournit une fonction `interleave_datasets()` qui convertit une liste d'objets `IterableDataset` en un seul `IterableDataset`, où les éléments du nouveau jeu de données sont obtenus en alternant entre les exemples source. Cette fonction est particulièrement utile lorsque vous essayez de combiner de grands jeux de données. Par exemple, streamons FreeLaw, un sous-ensemble de *The Pile* et qui est un jeu de données de 51 Go d'avis juridiques de tribunaux américains :
+
+```py
+law_dataset_streamed = load_dataset(
+ "json",
+ data_files="https://mystic.the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
+ split="train",
+ streaming=True,
+)
+next(iter(law_dataset_streamed))
+```
+
+```python out
+{'meta': {'case_ID': '110921.json',
+ 'case_jurisdiction': 'scotus.tar.gz',
+ 'date_created': '2010-04-28T17:12:49Z'},
+ 'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
+```
+
+Ce jeu de données est suffisamment volumineux pour solliciter la RAM de la plupart des ordinateurs portables, mais nous avons pu le charger et y accéder sans transpirer ! Combinons maintenant les jeux de données FreeLaw et *PubMed Abstracts* avec la fonction `interleave_datasets()` :
+
+```py
+from itertools import islice
+from datasets import interleave_datasets
+
+combined_dataset = interleave_datasets([pubmed_dataset_streamed, law_dataset_streamed])
+list(islice(combined_dataset, 2))
+```
+
+```python out
+[{'meta': {'pmid': 11409574, 'language': 'eng'},
+ 'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
+ {'meta': {'case_ID': '110921.json',
+ 'case_jurisdiction': 'scotus.tar.gz',
+ 'date_created': '2010-04-28T17:12:49Z'},
+ 'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
+```
+
+Ici, nous avons utilisé la fonction `islice()` du module `itertools` de Python pour sélectionner les deux premiers exemples du jeu de données combiné. Nous pouvons voir qu'ils correspondent aux premiers exemples de chacun des deux jeux de données source.
+
+Enfin, si vous souhaitez streamer *The Pile* dans son intégralité de 825 Go, vous pouvez récupérer tous les fichiers préparés comme suit :
+
+```py
+base_url = "https://mystic.the-eye.eu/public/AI/pile/"
+data_files = {
+ "train": [base_url + "train/" + f"{idx:02d}.jsonl.zst" for idx in range(30)],
+ "validation": base_url + "val.jsonl.zst",
+ "test": base_url + "test.jsonl.zst",
+}
+pile_dataset = load_dataset("json", data_files=data_files, streaming=True)
+next(iter(pile_dataset["train"]))
+```
+
+```python out
+{'meta': {'pile_set_name': 'Pile-CC'},
+ 'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web...'}
+```
+
+
+
+✏️ **Essayez !** Utilisez l'un des grands corpus Common Crawl comme [`mc4`](https://huggingface.co/datasets/mc4) ou [`oscar`](https://huggingface.co/datasets/oscar) pour créer en streaming un jeu de données multilingue représentant les proportions de langues parlées dans un pays de votre choix. Par exemple, les quatre langues nationales en Suisse sont l'allemand, le français, l'italien et le romanche. Vous pouvez donc essayer de créer un corpus suisse en échantillonnant les sous-ensembles Oscar en fonction de leur proportion parlée.
+
+
+
+Vous disposez maintenant de tous les outils dont vous avez besoin pour charger et traiter des jeux de données de toutes formes et tailles. Cependant à moins que vous ne soyez exceptionnellement chanceux, il arrivera un moment dans votre cheminement en traitement du langage naturel où vous devrez réellement créer un jeu de données pour résoudre un problème donné. C'est le sujet de la section suivante !
diff --git a/chapters/fr/chapter5/5.mdx b/chapters/fr/chapter5/5.mdx
index 4781cd83c..3b1f96a41 100644
--- a/chapters/fr/chapter5/5.mdx
+++ b/chapters/fr/chapter5/5.mdx
@@ -1,467 +1,467 @@
-# Création de votre propre jeu de données
-
-
-
-Parfois, le jeu de données dont vous avez besoin pour créer une application de NLP n'existe pas. Vous devrez donc le créer vous-même. Dans cette section, nous allons vous montrer comment créer un corpus de [problèmes GitHub](https://github.com/features/issues/), qui sont couramment utilisés pour suivre les bogues ou les fonctionnalités dans les dépôts GitHub. Ce corpus pourrait être utilisé à diverses fins, notamment :
-
-* explorer combien de temps il faut pour fermer les problèmes ouverts ou les *pull requests*
-* entraîner d'un _classificateur multilabel_ capable d'étiqueter les problèmes avec des métadonnées basées sur la description du problème (par exemple : « bug », « amélioration » ou « question »)
-* créer un moteur de recherche sémantique pour trouver les problèmes correspondant à la requête d'un utilisateur
-
-Ici, nous nous concentrerons sur la création du corpus, et dans la section suivante, nous aborderons l'application de recherche sémantique. Pour garder les choses méta, nous utiliserons les problèmes GitHub associés à un projet open source populaire : 🤗 *Datasets* ! Voyons comment obtenir les données et explorons les informations contenues dans ces problèmes.
-
-## Obtenir les données
-
-Vous pouvez trouver tous les problèmes dans 🤗 *Datasets* en accédant à l'[onglet « Issues »](https://github.com/huggingface/datasets/issues) du dépôt. Comme le montre la capture d'écran suivante, au moment de la rédaction, il y avait 331 problèmes ouverts et 668 problèmes fermés.
-
-
-

-
-

-
-

-
-
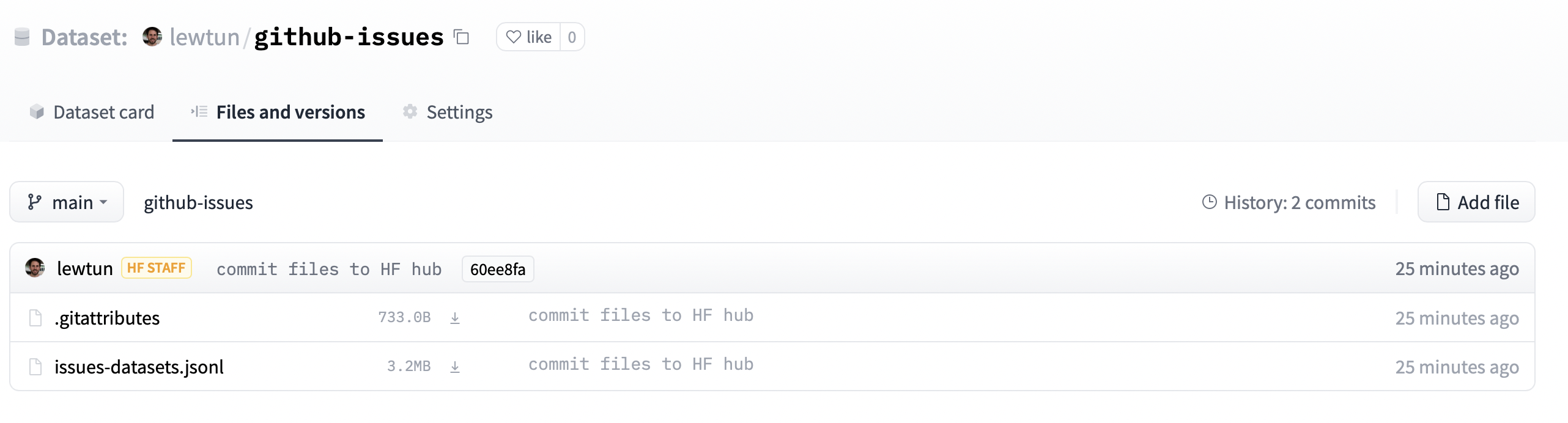
-
-

-
-

-
+
+
+
+
+
+
+
+
+
+
+
+
-

-

-
-
-
- |
- html_url |
- title |
- comments |
- body |
-
-
-
-
- | 0 |
- https://github.com/huggingface/datasets/issues/2787 |
- ConnectionError: Couldn't reach https://raw.githubusercontent.com |
- the bug code locate in :\r\n if data_args.task_name is not None... |
- Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
-
-
- | 1 |
- https://github.com/huggingface/datasets/issues/2787 |
- ConnectionError: Couldn't reach https://raw.githubusercontent.com |
- Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... |
- Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
-
-
- | 2 |
- https://github.com/huggingface/datasets/issues/2787 |
- ConnectionError: Couldn't reach https://raw.githubusercontent.com |
- cannot connect,even by Web browser,please check that there is some problems。 |
- Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
-
-
- | 3 |
- https://github.com/huggingface/datasets/issues/2787 |
- ConnectionError: Couldn't reach https://raw.githubusercontent.com |
- I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... |
- Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
-
-
-
-
-Génial, nous pouvons voir que les lignes ont été répliquées, avec la colonne `comments` contenant les commentaires individuels ! Maintenant que nous en avons fini avec Pandas, nous pouvons rapidement revenir à un `Dataset` en chargeant le `DataFrame` en mémoire :
-
-```py
-from datasets import Dataset
-
-comments_dataset = Dataset.from_pandas(comments_df)
-comments_dataset
-```
-
-```python out
-Dataset({
- features: ['html_url', 'title', 'comments', 'body'],
- num_rows: 2842
-})
-```
-
-D'accord, cela nous a donné quelques milliers de commentaires avec lesquels travailler !
-
-
-
-
-✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
-
-
-
-Maintenant que nous avons un commentaire par ligne, créons une nouvelle colonne `comments_length` contenant le nombre de mots par commentaire :
-
-```py
-comments_dataset = comments_dataset.map(
- lambda x: {"comment_length": len(x["comments"].split())}
-)
-```
-
-Nous pouvons utiliser cette nouvelle colonne pour filtrer les commentaires courts incluant généralement des éléments tels que « cc @lewtun » ou « Merci ! » qui ne sont pas pertinents pour notre moteur de recherche. Il n'y a pas de nombre précis à sélectionner pour le filtre mais 15 mots semblent être un bon début :
-
-```py
-comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
-comments_dataset
-```
-
-```python out
-Dataset({
- features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
- num_rows: 2098
-})
-```
-
-Après avoir un peu nettoyé notre jeu de données, concaténons le titre, la description et les commentaires du problème dans une nouvelle colonne `text`. Comme d'habitude, nous allons écrire une fonction simple que nous pouvons passer à `Dataset.map()` :
-
-```py
-def concatenate_text(examples):
- return {
- "text": examples["title"]
- + " \n "
- + examples["body"]
- + " \n "
- + examples["comments"]
- }
-
-
-comments_dataset = comments_dataset.map(concatenate_text)
-```
-
-Nous sommes enfin prêts à créer des enchâssements ! Jetons un coup d'œil.
-
-## Création d’enchâssements pour les textes
-
-Nous avons vu dans [chapitre 2](/course/fr/chapter2) que nous pouvons obtenir des enchâssements de *tokens* en utilisant la classe `AutoModel`. Tout ce que nous avons à faire est de choisir un *checkpoint* approprié à partir duquel charger le modèle. Heureusement, il existe une bibliothèque appelée `sentence-transformers` dédiée à la création d’enchâssements. Comme décrit dans la [documentation de la bibliothèque](https://www.sbert.net/examples/applications/semantic-search/README.html#symmetric-vs-asymmetric-semantic-search), notre cas d'utilisation est un exemple de _recherche sémantique asymétrique_. En effet, nous avons une requête courte dont nous aimerions trouver la réponse dans un document plus long, par exemple un commentaire à un problème. Le [tableau de présentation des modèles](https://www.sbert.net/docs/pretrained_models.html#model-overview) de la documentation indique que le *checkpoint* `multi-qa-mpnet-base-dot-v1` a les meilleures performances pour la recherche sémantique. Utilisons donc le pour notre application. Nous allons également charger le *tokenizer* en utilisant le même *checkpoint* :
-
-{#if fw === 'pt'}
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
-tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
-model = AutoModel.from_pretrained(model_ckpt)
-```
-
-Pour accélérer le processus, il est utile de placer le modèle et les entrées sur un périphérique GPU, alors faisons-le maintenant :
-
-```py
-import torch
-
-device = torch.device("cuda")
-model.to(device)
-```
-
-{:else}
-
-```py
-from transformers import AutoTokenizer, TFAutoModel
-
-model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
-tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
-model = TFAutoModel.from_pretrained(model_ckpt, from_pt=True)
-```
-
-Notez que nous avons défini `from_pt=True` comme argument de la méthode `from_pretrained()`. C'est parce que le point de contrôle `multi-qa-mpnet-base-dot-v1` n'a que des poids PyTorch. Donc définir `from_pt=True` converti automatiquement au format TensorFlow pour nous. Comme vous pouvez le voir, il est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
-
-{/if}
-
-Comme nous l'avons mentionné précédemment, nous aimerions représenter chaque entrée dans notre corpus de problèmes GitHub comme un vecteur unique. Nous devons donc regrouper ou faire la moyenne de nos enchâssements de *tokens* d'une manière ou d'une autre. Une approche populaire consiste à effectuer un *regroupement CLS* sur les sorties de notre modèle, où nous collectons simplement le dernier état caché pour le *token* spécial `[CLS]`. La fonction suivante fait ça pour nous :
-
-```py
-def cls_pooling(model_output):
- return model_output.last_hidden_state[:, 0]
-```
-
-Ensuite, nous allons créer une fonction utile qui va tokeniser une liste de documents, placer les tenseurs dans le GPU, les donner au modèle et enfin appliquer le regroupement CLS aux sorties :
-
-{#if fw === 'pt'}
-
-```py
-def get_embeddings(text_list):
- encoded_input = tokenizer(
- text_list, padding=True, truncation=True, return_tensors="pt"
- )
- encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
- model_output = model(**encoded_input)
- return cls_pooling(model_output)
-```
-
-Nous pouvons tester le fonctionnement de la fonction en lui donnant la première entrée textuelle de notre corpus et en inspectant la forme de sortie :
-
-```py
-embedding = get_embeddings(comments_dataset["text"][0])
-embedding.shape
-```
-
-```python out
-torch.Size([1, 768])
-```
-
-Super ! Nous avons converti la première entrée de notre corpus en un vecteur à 768 dimensions. Nous pouvons utiliser `Dataset.map()` pour appliquer notre fonction `get_embeddings()` à chaque ligne de notre corpus. Créons donc une nouvelle colonne `embeddings` comme suit :
-
-```py
-embeddings_dataset = comments_dataset.map(
- lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
-)
-```
-
-{:else}
-
-```py
-def get_embeddings(text_list):
- encoded_input = tokenizer(
- text_list, padding=True, truncation=True, return_tensors="tf"
- )
- encoded_input = {k: v for k, v in encoded_input.items()}
- model_output = model(**encoded_input)
- return cls_pooling(model_output)
-```
-
-Nous pouvons tester le fonctionnement de la fonction en lui donnant la première entrée textuelle de notre corpus et en inspectant la forme de sortie :
-
-```py
-embedding = get_embeddings(comments_dataset["text"][0])
-embedding.shape
-```
-
-```python out
-TensorShape([1, 768])
-```
-
-Super ! Nous avons converti la première entrée de notre corpus en un vecteur à 768 dimensions. Nous pouvons utiliser `Dataset.map()` pour appliquer notre fonction `get_embeddings()` à chaque ligne de notre corpus. Créons donc une nouvelle colonne `embeddings` comme suit :
-
-```py
-embeddings_dataset = comments_dataset.map(
- lambda x: {"embeddings": get_embeddings(x["text"]).numpy()[0]}
-)
-```
-
-{/if}
-
-
-Notez que nous avons converti les enchâssements en tableaux NumPy. C'est parce que 🤗 *Datasets* nécessite ce format lorsque nous essayons de les indexer avec FAISS, ce que nous ferons ensuite.
-
-## Utilisation de FAISS pour une recherche de similarité efficace
-
-Maintenant que nous avons un jeu de données d'incorporations, nous avons besoin d'un moyen de les rechercher. Pour ce faire, nous utiliserons une structure de données spéciale dans 🤗 *Datasets* appelée _FAISS index_. [FAISS](https://faiss.ai/) (abréviation de *Facebook AI Similarity Search*) est une bibliothèque qui fournit des algorithmes efficaces pour rechercher et regrouper rapidement des vecteurs d'intégration.
-
-L'idée de base derrière FAISS est de créer une structure de données spéciale appelée un _index_ qui permet de trouver quels plongements sont similaires à un plongement d'entrée. Créer un index FAISS dans 🤗 *Datasets* est simple -- nous utilisons la fonction `Dataset.add_faiss_index()` et spécifions quelle colonne de notre jeu de données nous aimerions indexer :
-
-```py
-embeddings_dataset.add_faiss_index(column="embeddings")
-```
-
-Nous pouvons maintenant effectuer des requêtes sur cet index en effectuant une recherche des voisins les plus proches avec la fonction `Dataset.get_nearest_examples()`. Testons cela en enchâssant d'abord une question comme suit :
-
-{#if fw === 'pt'}
-
-```py
-question = "How can I load a dataset offline?"
-question_embedding = get_embeddings([question]).cpu().detach().numpy()
-question_embedding.shape
-```
-
-```python out
-torch.Size([1, 768])
-```
-
-{:else}
-
-```py
-question = "How can I load a dataset offline?"
-question_embedding = get_embeddings([question]).numpy()
-question_embedding.shape
-```
-
-```python out
-(1, 768)
-```
-
-{/if}
-
-Tout comme avec les documents, nous avons maintenant un vecteur de 768 dimensions représentant la requête. Nous pouvons le comparer à l’ensemble du corpus pour trouver les enchâssements les plus similaires :
-
-```py
-scores, samples = embeddings_dataset.get_nearest_examples(
- "embeddings", question_embedding, k=5
-)
-```
-
-La fonction `Dataset.get_nearest_examples()` renvoie un *tuple* de scores qui classent le chevauchement entre la requête et le document, et un jeu correspondant d'échantillons (ici, les 5 meilleures correspondances). Collectons-les dans un `pandas.DataFrame` afin de pouvoir les trier facilement :
-
-```py
-import pandas as pd
-
-samples_df = pd.DataFrame.from_dict(samples)
-samples_df["scores"] = scores
-samples_df.sort_values("scores", ascending=False, inplace=True)
-```
-
-Nous pouvons maintenant parcourir les premières lignes pour voir dans quelle mesure notre requête correspond aux commentaires disponibles :
-
-```py
-for _, row in samples_df.iterrows():
- print(f"COMMENT: {row.comments}")
- print(f"SCORE: {row.scores}")
- print(f"TITLE: {row.title}")
- print(f"URL: {row.html_url}")
- print("=" * 50)
- print()
-```
-
-```python out
-"""
-COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
-
-@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
-SCORE: 25.505046844482422
-TITLE: Discussion using datasets in offline mode
-URL: https://github.com/huggingface/datasets/issues/824
-==================================================
-
-COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
-You can now use them offline
-\`\`\`python
-datasets = load_dataset("text", data_files=data_files)
-\`\`\`
-
-We'll do a new release soon
-SCORE: 24.555509567260742
-TITLE: Discussion using datasets in offline mode
-URL: https://github.com/huggingface/datasets/issues/824
-==================================================
-
-COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
-
-Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
-
-I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
-
-----------
-
-> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
-
-Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
-For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
-\`\`\`python
-load_dataset("./my_dataset")
-\`\`\`
-and the dataset script will generate your dataset once and for all.
-
-----------
-
-About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
-cf #1724
-SCORE: 24.14896583557129
-TITLE: Discussion using datasets in offline mode
-URL: https://github.com/huggingface/datasets/issues/824
-==================================================
-
-COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
->
-> 1. (online machine)
->
-> ```
->
-> import datasets
->
-> data = datasets.load_dataset(...)
->
-> data.save_to_disk(/YOUR/DATASET/DIR)
->
-> ```
->
-> 2. copy the dir from online to the offline machine
->
-> 3. (offline machine)
->
-> ```
->
-> import datasets
->
-> data = datasets.load_from_disk(/SAVED/DATA/DIR)
->
-> ```
->
->
->
-> HTH.
-
-
-SCORE: 22.893993377685547
-TITLE: Discussion using datasets in offline mode
-URL: https://github.com/huggingface/datasets/issues/824
-==================================================
-
-COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
-1. (online machine)
-\`\`\`
-import datasets
-data = datasets.load_dataset(...)
-data.save_to_disk(/YOUR/DATASET/DIR)
-\`\`\`
-2. copy the dir from online to the offline machine
-3. (offline machine)
-\`\`\`
-import datasets
-data = datasets.load_from_disk(/SAVED/DATA/DIR)
-\`\`\`
-
-HTH.
-SCORE: 22.406635284423828
-TITLE: Discussion using datasets in offline mode
-URL: https://github.com/huggingface/datasets/issues/824
-==================================================
-"""
-```
-
-Pas mal ! Notre deuxième résultat semble correspondre à la requête.
-
-
-
-✏️ **Essayez !** Créez votre propre requête et voyez si vous pouvez trouver une réponse dans les documents récupérés. Vous devrez peut-être augmenter le paramètre `k` dans `Dataset.get_nearest_examples()` pour élargir la recherche.
-
-
+
+
+# Recherche sémantique avec FAISS
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Dans [section 5](/course/fr/chapter5/5), nous avons créé un jeu de données de problèmes et de commentaires GitHub à partir du dépôt 🤗 *Datasets*. Dans cette section, nous utilisons ces informations pour créer un moteur de recherche qui peut nous aider à trouver des réponses à nos questions les plus urgentes sur la bibliothèque !
+
+
+
+## Utilisation des enchâssements pour la recherche sémantique
+
+Comme nous l'avons vu dans le [chapitre 1](/course/fr/chapter1), les modèles de langage basés sur les *transformers* représentent chaque *token* dans une étendue de texte sous la forme d'un _enchâssement_. Il s'avère que l'on peut regrouper les enchâssements individuels pour créer une représentation vectorielle pour des phrases entières, des paragraphes ou (dans certains cas) des documents. Ces enchâssements peuvent ensuite être utilisés pour trouver des documents similaires dans le corpus en calculant la similarité du produit scalaire (ou une autre métrique de similarité) entre chaque enchâssement et en renvoyant les documents avec le plus grand chevauchement.
+
+Dans cette section, nous utilisons les enchâssements pour développer un moteur de recherche sémantique. Ces moteurs de recherche offrent plusieurs avantages par rapport aux approches conventionnelles basées sur la correspondance des mots-clés dans une requête avec les documents.
+
+
+
+
+
+
+
+ |
+ html_url |
+ title |
+ comments |
+ body |
+
+
+
+
+ | 0 |
+ https://github.com/huggingface/datasets/issues/2787 |
+ ConnectionError: Couldn't reach https://raw.githubusercontent.com |
+ the bug code locate in :\r\n if data_args.task_name is not None... |
+ Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
+
+
+ | 1 |
+ https://github.com/huggingface/datasets/issues/2787 |
+ ConnectionError: Couldn't reach https://raw.githubusercontent.com |
+ Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... |
+ Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
+
+
+ | 2 |
+ https://github.com/huggingface/datasets/issues/2787 |
+ ConnectionError: Couldn't reach https://raw.githubusercontent.com |
+ cannot connect,even by Web browser,please check that there is some problems。 |
+ Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
+
+
+ | 3 |
+ https://github.com/huggingface/datasets/issues/2787 |
+ ConnectionError: Couldn't reach https://raw.githubusercontent.com |
+ I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... |
+ Hello,\r\nI am trying to run run_glue.py and it gives me this error... |
+
+
+
+
+Génial, nous pouvons voir que les lignes ont été répliquées, avec la colonne `comments` contenant les commentaires individuels ! Maintenant que nous en avons fini avec Pandas, nous pouvons rapidement revenir à un `Dataset` en chargeant le `DataFrame` en mémoire :
+
+```py
+from datasets import Dataset
+
+comments_dataset = Dataset.from_pandas(comments_df)
+comments_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 2842
+})
+```
+
+D'accord, cela nous a donné quelques milliers de commentaires avec lesquels travailler !
+
+
+
+
+✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
+
+
+
+Maintenant que nous avons un commentaire par ligne, créons une nouvelle colonne `comments_length` contenant le nombre de mots par commentaire :
+
+```py
+comments_dataset = comments_dataset.map(
+ lambda x: {"comment_length": len(x["comments"].split())}
+)
+```
+
+Nous pouvons utiliser cette nouvelle colonne pour filtrer les commentaires courts incluant généralement des éléments tels que « cc @lewtun » ou « Merci ! » qui ne sont pas pertinents pour notre moteur de recherche. Il n'y a pas de nombre précis à sélectionner pour le filtre mais 15 mots semblent être un bon début :
+
+```py
+comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
+comments_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
+ num_rows: 2098
+})
+```
+
+Après avoir un peu nettoyé notre jeu de données, concaténons le titre, la description et les commentaires du problème dans une nouvelle colonne `text`. Comme d'habitude, nous allons écrire une fonction simple que nous pouvons passer à `Dataset.map()` :
+
+```py
+def concatenate_text(examples):
+ return {
+ "text": examples["title"]
+ + " \n "
+ + examples["body"]
+ + " \n "
+ + examples["comments"]
+ }
+
+
+comments_dataset = comments_dataset.map(concatenate_text)
+```
+
+Nous sommes enfin prêts à créer des enchâssements ! Jetons un coup d'œil.
+
+## Création d’enchâssements pour les textes
+
+Nous avons vu dans [chapitre 2](/course/fr/chapter2) que nous pouvons obtenir des enchâssements de *tokens* en utilisant la classe `AutoModel`. Tout ce que nous avons à faire est de choisir un *checkpoint* approprié à partir duquel charger le modèle. Heureusement, il existe une bibliothèque appelée `sentence-transformers` dédiée à la création d’enchâssements. Comme décrit dans la [documentation de la bibliothèque](https://www.sbert.net/examples/applications/semantic-search/README.html#symmetric-vs-asymmetric-semantic-search), notre cas d'utilisation est un exemple de _recherche sémantique asymétrique_. En effet, nous avons une requête courte dont nous aimerions trouver la réponse dans un document plus long, par exemple un commentaire à un problème. Le [tableau de présentation des modèles](https://www.sbert.net/docs/pretrained_models.html#model-overview) de la documentation indique que le *checkpoint* `multi-qa-mpnet-base-dot-v1` a les meilleures performances pour la recherche sémantique. Utilisons donc le pour notre application. Nous allons également charger le *tokenizer* en utilisant le même *checkpoint* :
+
+{#if fw === 'pt'}
+
+```py
+from transformers import AutoTokenizer, AutoModel
+
+model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
+tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
+model = AutoModel.from_pretrained(model_ckpt)
+```
+
+Pour accélérer le processus, il est utile de placer le modèle et les entrées sur un périphérique GPU, alors faisons-le maintenant :
+
+```py
+import torch
+
+device = torch.device("cuda")
+model.to(device)
+```
+
+{:else}
+
+```py
+from transformers import AutoTokenizer, TFAutoModel
+
+model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
+tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
+model = TFAutoModel.from_pretrained(model_ckpt, from_pt=True)
+```
+
+Notez que nous avons défini `from_pt=True` comme argument de la méthode `from_pretrained()`. C'est parce que le point de contrôle `multi-qa-mpnet-base-dot-v1` n'a que des poids PyTorch. Donc définir `from_pt=True` converti automatiquement au format TensorFlow pour nous. Comme vous pouvez le voir, il est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
+
+{/if}
+
+Comme nous l'avons mentionné précédemment, nous aimerions représenter chaque entrée dans notre corpus de problèmes GitHub comme un vecteur unique. Nous devons donc regrouper ou faire la moyenne de nos enchâssements de *tokens* d'une manière ou d'une autre. Une approche populaire consiste à effectuer un *regroupement CLS* sur les sorties de notre modèle, où nous collectons simplement le dernier état caché pour le *token* spécial `[CLS]`. La fonction suivante fait ça pour nous :
+
+```py
+def cls_pooling(model_output):
+ return model_output.last_hidden_state[:, 0]
+```
+
+Ensuite, nous allons créer une fonction utile qui va tokeniser une liste de documents, placer les tenseurs dans le GPU, les donner au modèle et enfin appliquer le regroupement CLS aux sorties :
+
+{#if fw === 'pt'}
+
+```py
+def get_embeddings(text_list):
+ encoded_input = tokenizer(
+ text_list, padding=True, truncation=True, return_tensors="pt"
+ )
+ encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
+ model_output = model(**encoded_input)
+ return cls_pooling(model_output)
+```
+
+Nous pouvons tester le fonctionnement de la fonction en lui donnant la première entrée textuelle de notre corpus et en inspectant la forme de sortie :
+
+```py
+embedding = get_embeddings(comments_dataset["text"][0])
+embedding.shape
+```
+
+```python out
+torch.Size([1, 768])
+```
+
+Super ! Nous avons converti la première entrée de notre corpus en un vecteur à 768 dimensions. Nous pouvons utiliser `Dataset.map()` pour appliquer notre fonction `get_embeddings()` à chaque ligne de notre corpus. Créons donc une nouvelle colonne `embeddings` comme suit :
+
+```py
+embeddings_dataset = comments_dataset.map(
+ lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
+)
+```
+
+{:else}
+
+```py
+def get_embeddings(text_list):
+ encoded_input = tokenizer(
+ text_list, padding=True, truncation=True, return_tensors="tf"
+ )
+ encoded_input = {k: v for k, v in encoded_input.items()}
+ model_output = model(**encoded_input)
+ return cls_pooling(model_output)
+```
+
+Nous pouvons tester le fonctionnement de la fonction en lui donnant la première entrée textuelle de notre corpus et en inspectant la forme de sortie :
+
+```py
+embedding = get_embeddings(comments_dataset["text"][0])
+embedding.shape
+```
+
+```python out
+TensorShape([1, 768])
+```
+
+Super ! Nous avons converti la première entrée de notre corpus en un vecteur à 768 dimensions. Nous pouvons utiliser `Dataset.map()` pour appliquer notre fonction `get_embeddings()` à chaque ligne de notre corpus. Créons donc une nouvelle colonne `embeddings` comme suit :
+
+```py
+embeddings_dataset = comments_dataset.map(
+ lambda x: {"embeddings": get_embeddings(x["text"]).numpy()[0]}
+)
+```
+
+{/if}
+
+
+Notez que nous avons converti les enchâssements en tableaux NumPy. C'est parce que 🤗 *Datasets* nécessite ce format lorsque nous essayons de les indexer avec FAISS, ce que nous ferons ensuite.
+
+## Utilisation de FAISS pour une recherche de similarité efficace
+
+Maintenant que nous avons un jeu de données d'incorporations, nous avons besoin d'un moyen de les rechercher. Pour ce faire, nous utiliserons une structure de données spéciale dans 🤗 *Datasets* appelée _FAISS index_. [FAISS](https://faiss.ai/) (abréviation de *Facebook AI Similarity Search*) est une bibliothèque qui fournit des algorithmes efficaces pour rechercher et regrouper rapidement des vecteurs d'intégration.
+
+L'idée de base derrière FAISS est de créer une structure de données spéciale appelée un _index_ qui permet de trouver quels plongements sont similaires à un plongement d'entrée. Créer un index FAISS dans 🤗 *Datasets* est simple -- nous utilisons la fonction `Dataset.add_faiss_index()` et spécifions quelle colonne de notre jeu de données nous aimerions indexer :
+
+```py
+embeddings_dataset.add_faiss_index(column="embeddings")
+```
+
+Nous pouvons maintenant effectuer des requêtes sur cet index en effectuant une recherche des voisins les plus proches avec la fonction `Dataset.get_nearest_examples()`. Testons cela en enchâssant d'abord une question comme suit :
+
+{#if fw === 'pt'}
+
+```py
+question = "How can I load a dataset offline?"
+question_embedding = get_embeddings([question]).cpu().detach().numpy()
+question_embedding.shape
+```
+
+```python out
+torch.Size([1, 768])
+```
+
+{:else}
+
+```py
+question = "How can I load a dataset offline?"
+question_embedding = get_embeddings([question]).numpy()
+question_embedding.shape
+```
+
+```python out
+(1, 768)
+```
+
+{/if}
+
+Tout comme avec les documents, nous avons maintenant un vecteur de 768 dimensions représentant la requête. Nous pouvons le comparer à l’ensemble du corpus pour trouver les enchâssements les plus similaires :
+
+```py
+scores, samples = embeddings_dataset.get_nearest_examples(
+ "embeddings", question_embedding, k=5
+)
+```
+
+La fonction `Dataset.get_nearest_examples()` renvoie un *tuple* de scores qui classent le chevauchement entre la requête et le document, et un jeu correspondant d'échantillons (ici, les 5 meilleures correspondances). Collectons-les dans un `pandas.DataFrame` afin de pouvoir les trier facilement :
+
+```py
+import pandas as pd
+
+samples_df = pd.DataFrame.from_dict(samples)
+samples_df["scores"] = scores
+samples_df.sort_values("scores", ascending=False, inplace=True)
+```
+
+Nous pouvons maintenant parcourir les premières lignes pour voir dans quelle mesure notre requête correspond aux commentaires disponibles :
+
+```py
+for _, row in samples_df.iterrows():
+ print(f"COMMENT: {row.comments}")
+ print(f"SCORE: {row.scores}")
+ print(f"TITLE: {row.title}")
+ print(f"URL: {row.html_url}")
+ print("=" * 50)
+ print()
+```
+
+```python out
+"""
+COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
+
+@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
+SCORE: 25.505046844482422
+TITLE: Discussion using datasets in offline mode
+URL: https://github.com/huggingface/datasets/issues/824
+==================================================
+
+COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
+You can now use them offline
+\`\`\`python
+datasets = load_dataset("text", data_files=data_files)
+\`\`\`
+
+We'll do a new release soon
+SCORE: 24.555509567260742
+TITLE: Discussion using datasets in offline mode
+URL: https://github.com/huggingface/datasets/issues/824
+==================================================
+
+COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
+
+Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
+
+I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
+
+----------
+
+> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
+
+Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
+For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
+\`\`\`python
+load_dataset("./my_dataset")
+\`\`\`
+and the dataset script will generate your dataset once and for all.
+
+----------
+
+About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
+cf #1724
+SCORE: 24.14896583557129
+TITLE: Discussion using datasets in offline mode
+URL: https://github.com/huggingface/datasets/issues/824
+==================================================
+
+COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
+>
+> 1. (online machine)
+>
+> ```
+>
+> import datasets
+>
+> data = datasets.load_dataset(...)
+>
+> data.save_to_disk(/YOUR/DATASET/DIR)
+>
+> ```
+>
+> 2. copy the dir from online to the offline machine
+>
+> 3. (offline machine)
+>
+> ```
+>
+> import datasets
+>
+> data = datasets.load_from_disk(/SAVED/DATA/DIR)
+>
+> ```
+>
+>
+>
+> HTH.
+
+
+SCORE: 22.893993377685547
+TITLE: Discussion using datasets in offline mode
+URL: https://github.com/huggingface/datasets/issues/824
+==================================================
+
+COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
+1. (online machine)
+\`\`\`
+import datasets
+data = datasets.load_dataset(...)
+data.save_to_disk(/YOUR/DATASET/DIR)
+\`\`\`
+2. copy the dir from online to the offline machine
+3. (offline machine)
+\`\`\`
+import datasets
+data = datasets.load_from_disk(/SAVED/DATA/DIR)
+\`\`\`
+
+HTH.
+SCORE: 22.406635284423828
+TITLE: Discussion using datasets in offline mode
+URL: https://github.com/huggingface/datasets/issues/824
+==================================================
+"""
+```
+
+Pas mal ! Notre deuxième résultat semble correspondre à la requête.
+
+
+
+✏️ **Essayez !** Créez votre propre requête et voyez si vous pouvez trouver une réponse dans les documents récupérés. Vous devrez peut-être augmenter le paramètre `k` dans `Dataset.get_nearest_examples()` pour élargir la recherche.
+
+
diff --git a/chapters/fr/chapter5/7.mdx b/chapters/fr/chapter5/7.mdx
index 55083fffa..e205ff607 100644
--- a/chapters/fr/chapter5/7.mdx
+++ b/chapters/fr/chapter5/7.mdx
@@ -1,10 +1,15 @@
-# 🤗 Datasets, coché !
-
-Eh bien, ce fut une sacrée visite de la bibliothèque 🤗 *Datasets*. Félicitations d’être arrivé jusqu'ici ! Avec les connaissances que vous avez acquises dans ce chapitre, vous devriez être en mesure de :
-- charger des jeux de données depuis n'importe où, que ce soit le *Hub* d’Hugging Face, votre ordinateur portable ou un serveur distant de votre entreprise,
-- manipuler vos données en utilisant un mélange des fonctions Dataset.map() et Dataset.filter(),
-- passer rapidement d'un format de données à un autre, comme Pandas et NumPy, en utilisant Dataset.set_format(),
-- créer votre propre jeu de données et l’envoyer vers le *Hub*,
-- enchâsser vos documents en utilisant un *transformer* et construire un moteur de recherche sémantique en utilisant FAISS.
-
-Dans le [chapitre 7](/course/fr/chapter7), nous mettrons tout cela à profit en plongeant dans les tâches de traitement du langage naturel de base pour lesquelles les *transformers* sont parfaits. Avant cela mettez vos connaissances sur la librairie 🤗 *Datasets* à l'épreuve avec un petit quiz !
+# 🤗 Datasets, coché !
+
+
+
+Eh bien, ce fut une sacrée visite de la bibliothèque 🤗 *Datasets*. Félicitations d’être arrivé jusqu'ici ! Avec les connaissances que vous avez acquises dans ce chapitre, vous devriez être en mesure de :
+- charger des jeux de données depuis n'importe où, que ce soit le *Hub* d’Hugging Face, votre ordinateur portable ou un serveur distant de votre entreprise,
+- manipuler vos données en utilisant un mélange des fonctions Dataset.map() et Dataset.filter(),
+- passer rapidement d'un format de données à un autre, comme Pandas et NumPy, en utilisant Dataset.set_format(),
+- créer votre propre jeu de données et l’envoyer vers le *Hub*,
+- enchâsser vos documents en utilisant un *transformer* et construire un moteur de recherche sémantique en utilisant FAISS.
+
+Dans le [chapitre 7](/course/fr/chapter7), nous mettrons tout cela à profit en plongeant dans les tâches de traitement du langage naturel de base pour lesquelles les *transformers* sont parfaits. Avant cela mettez vos connaissances sur la librairie 🤗 *Datasets* à l'épreuve avec un petit quiz !
diff --git a/chapters/fr/chapter5/8.mdx b/chapters/fr/chapter5/8.mdx
index 54f4e770f..6abf66b0a 100644
--- a/chapters/fr/chapter5/8.mdx
+++ b/chapters/fr/chapter5/8.mdx
@@ -1,226 +1,231 @@
-
-
-# Quiz de fin de chapitre
-
-Ce chapitre a couvert beaucoup de terrain ! Ne vous inquiétez pas si vous n'avez pas saisi tous les détails, les chapitres suivants vous aideront à comprendre comment les choses fonctionnent sous le capot.
-
-Avant de poursuivre, testons ce que vous avez appris dans ce chapitre.
-
-### 1. La fonction `load_dataset()` dans 🤗 *Datasets* vous permet de charger un jeu de données depuis lequel des emplacements suivants ?
-
-data_files de load_dataset() pour charger les jeux de données locaux.",
- correct: true
- },
- {
- text: "Le Hub d’Hugging Face.",
- explain: "Vous pouvez charger des jeux de données sur le Hub en fournissant l'ID du jeu de données. Par exemple : load_dataset('emotion').",
- correct: true
- },
- {
- text: "Un serveur distant.",
- explain: "Vous pouvez passer des URLs à l'argument data_files de load_dataset() pour charger des fichiers distants.",
- correct: true
- },
- ]}
-/>
-
-### 2. Supposons que vous chargiez l'une des tâches du jeu de données GLUE comme suit :
-
-```py
-from datasets import load_dataset
-
-dataset = load_dataset("glue", "mrpc", split="train")
-```
-
-Laquelle des commandes suivantes produira un échantillon aléatoire de 50 éléments à partir de `dataset` ?
-
-dataset.sample(50)",
- explain: "Il n'y a pas de méthode Dataset.sample()."
- },
- {
- text: "dataset.shuffle().select(range(50))",
- explain: "Comme vous l'avez vu dans ce chapitre, vous mélangez d'abord le jeu de données puis sélectionnez les échantillons à partir de celui-ci.",
- correct: true
- },
- {
- text: "dataset.select(range(50)).shuffle()",
- explain: "Bien que le code s'exécute, il ne mélange que les 50 premiers éléments du jeu de données."
- }
- ]}
-/>
-
-### 3. Supposons que vous disposiez d'un jeu de données sur les animaux domestiques appelé `pets_dataset` qui comporte une colonne `name` indiquant le nom de chaque animal. Parmi les approches suivantes, laquelle vous permettrait de filtrer le jeu de données pour tous les animaux dont le nom commence par la lettre « L » ?
-
-pets_dataset.filter(lambda x : x['name'].startswith('L'))",
- explain: "L'utilisation d'une fonction Python lambda pour ces filtres rapides est une excellente idée. Pouvez-vous penser à une autre solution ?",
- correct: true
- },
- {
- text: "pets_dataset.filter(lambda x['name'].startswith('L'))",
- explain: "Une fonction lambda prend la forme générale lambda *arguments* : *expression*, vous devez donc fournir des arguments dans ce cas."
- },
- {
- text: "Créer une fonction comme def filter_names(x): return x['name'].startswith('L') et exécuter pets_dataset.filter(filter_names).",
- explain: "Tout comme avec Dataset.map(), vous pouvez passer des fonctions explicites à Dataset.filter(). Ceci est utile lorsque vous avez une logique complexe qui ne convient pas à une fonction lambda courte. Parmi les autres solutions, laquelle fonctionnerait ?",
- correct: true
- }
- ]}
-/>
-
-### 4. Qu'est-ce que le *memory mapping* ?
-
-mapping entre la RAM CPU et GPU.",
- explain: "Ce n'est pas ça, réessayez !",
- },
- {
- text: "Un mapping entre la RAM et le stockage du système de fichiers.",
- explain: "🤗 Datasets traite chaque jeu de données comme un fichier mappé en mémoire. Cela permet à la bibliothèque d'accéder et d'opérer sur des éléments du jeu de données sans avoir à le charger complètement en mémoire.",
- correct: true
- },
- {
- text: "Un mapping entre deux fichiers dans le cache 🤗 Datasets.",
- explain: "Ce n'est pas ça, réessayez !"
- }
- ]}
-/>
-
-### 5. Parmi les éléments suivants, lesquels sont les principaux avantages du *memory mapping* ?
-
-Datasets d'être extrêmement rapide. Ce n'est cependant pas le seul avantage.",
- correct: true
- },
- {
- text: "Les applications peuvent accéder à des segments de données dans un fichier extrêmement volumineux sans avoir à lire tout le fichier dans la RAM au préalable.",
- explain: "Cela permet à 🤗 Datasets de charger des jeux de données de plusieurs Go sur votre ordinateur portable sans faire exploser votre CPU. Quel autre avantage cette technique offre-t-elle ?",
- correct: true
- },
- {
- text: "Cela consomme moins d'énergie, donc votre batterie dure plus longtemps.",
- explain: "Ce n'est pas ça, réessayez !"
- }
- ]}
-/>
-
-### 6. Pourquoi le code suivant échoue-t-il ?
-
-```py
-from datasets import load_dataset
-
-dataset = load_dataset("allocine", streaming=True, split="train")
-dataset[0]
-```
-
-IterableDataset.",
- explain: "Un IterableDataset est un générateur, pas un conteneur. Vous devez donc accéder à ses éléments en utilisant next(iter(dataset)).",
- correct: true
- },
- {
- text: "Le jeu de données allocine n'a pas d’échantillon train.",
- explain: "Consultez le jeu de données allocine sur le Hub (https://huggingface.co/datasets/allocine) pour voir quels échantillons il contient."
- }
- ]}
-/>
-
-### 7. Parmi les avantages suivants, lesquels sont les principaux pour la création d'une fiche pour les jeux de données ?
-
-
-
-
-### 8. Qu'est-ce que la recherche sémantique ?
-
-recherche lexicale et c'est ce que vous voyez généralement avec les moteurs de recherche traditionnels."
- },
- {
- text: "Un moyen de rechercher des documents correspondants en comprenant la signification contextuelle d'une requête.",
- explain: "La recherche sémantique utilise des vecteurs d’enchâssement pour représenter les requêtes et les documents. Elle utilise ensuite une métrique de similarité pour mesurer la quantité de chevauchement entre eux. Comment la décrire autrement ?",
- correct: true
- },
- {
- text: "Un moyen d'améliorer la précision de la recherche.",
- explain: "Les moteurs de recherche sémantique peuvent capturer l'intention d'une requête bien mieux que la correspondance des mots clés et récupèrent généralement les documents avec une plus grande précision. Mais ce n'est pas la seule bonne réponse. Qu'est-ce que la recherche sémantique apporte d'autre ?",
- correct: true
- }
- ]}
-/>
-
-### 9. Pour la recherche sémantique asymétrique, vous avez généralement :
-
-
-
-### 10. Puis-je utiliser 🤗 *Datasets* pour charger des données à utiliser dans d'autres domaines, comme le traitement de la parole ?
-
-Datasets prend actuellement en charge les données tabulaires, l'audio et la vision par ordinateur. Consultez le jeu de données MNIST sur le Hub pour un exemple de vision par ordinateur."
- },
- {
- text: "Oui.",
- explain: "Découvrez les développements passionnants concernant la parole et la vision dans la bibliothèque 🤗 Transformers pour voir comment 🤗 Datasets est utilisé dans ces domaines.",
- correct : true
- },
- ]}
-/>
+
+
+# Quiz de fin de chapitre
+
+
+
+Ce chapitre a couvert beaucoup de terrain ! Ne vous inquiétez pas si vous n'avez pas saisi tous les détails, les chapitres suivants vous aideront à comprendre comment les choses fonctionnent sous le capot.
+
+Avant de poursuivre, testons ce que vous avez appris dans ce chapitre.
+
+### 1. La fonction `load_dataset()` dans 🤗 *Datasets* vous permet de charger un jeu de données depuis lequel des emplacements suivants ?
+
+data_files de load_dataset() pour charger les jeux de données locaux.",
+ correct: true
+ },
+ {
+ text: "Le Hub d’Hugging Face.",
+ explain: "Vous pouvez charger des jeux de données sur le Hub en fournissant l'ID du jeu de données. Par exemple : load_dataset('emotion').",
+ correct: true
+ },
+ {
+ text: "Un serveur distant.",
+ explain: "Vous pouvez passer des URLs à l'argument data_files de load_dataset() pour charger des fichiers distants.",
+ correct: true
+ },
+ ]}
+/>
+
+### 2. Supposons que vous chargiez l'une des tâches du jeu de données GLUE comme suit :
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("glue", "mrpc", split="train")
+```
+
+Laquelle des commandes suivantes produira un échantillon aléatoire de 50 éléments à partir de `dataset` ?
+
+dataset.sample(50)",
+ explain: "Il n'y a pas de méthode Dataset.sample()."
+ },
+ {
+ text: "dataset.shuffle().select(range(50))",
+ explain: "Comme vous l'avez vu dans ce chapitre, vous mélangez d'abord le jeu de données puis sélectionnez les échantillons à partir de celui-ci.",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "Bien que le code s'exécute, il ne mélange que les 50 premiers éléments du jeu de données."
+ }
+ ]}
+/>
+
+### 3. Supposons que vous disposiez d'un jeu de données sur les animaux domestiques appelé `pets_dataset` qui comporte une colonne `name` indiquant le nom de chaque animal. Parmi les approches suivantes, laquelle vous permettrait de filtrer le jeu de données pour tous les animaux dont le nom commence par la lettre « L » ?
+
+pets_dataset.filter(lambda x : x['name'].startswith('L'))",
+ explain: "L'utilisation d'une fonction Python lambda pour ces filtres rapides est une excellente idée. Pouvez-vous penser à une autre solution ?",
+ correct: true
+ },
+ {
+ text: "pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "Une fonction lambda prend la forme générale lambda *arguments* : *expression*, vous devez donc fournir des arguments dans ce cas."
+ },
+ {
+ text: "Créer une fonction comme def filter_names(x): return x['name'].startswith('L') et exécuter pets_dataset.filter(filter_names).",
+ explain: "Tout comme avec Dataset.map(), vous pouvez passer des fonctions explicites à Dataset.filter(). Ceci est utile lorsque vous avez une logique complexe qui ne convient pas à une fonction lambda courte. Parmi les autres solutions, laquelle fonctionnerait ?",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Qu'est-ce que le *memory mapping* ?
+
+mapping entre la RAM CPU et GPU.",
+ explain: "Ce n'est pas ça, réessayez !",
+ },
+ {
+ text: "Un mapping entre la RAM et le stockage du système de fichiers.",
+ explain: "🤗 Datasets traite chaque jeu de données comme un fichier mappé en mémoire. Cela permet à la bibliothèque d'accéder et d'opérer sur des éléments du jeu de données sans avoir à le charger complètement en mémoire.",
+ correct: true
+ },
+ {
+ text: "Un mapping entre deux fichiers dans le cache 🤗 Datasets.",
+ explain: "Ce n'est pas ça, réessayez !"
+ }
+ ]}
+/>
+
+### 5. Parmi les éléments suivants, lesquels sont les principaux avantages du *memory mapping* ?
+
+Datasets d'être extrêmement rapide. Ce n'est cependant pas le seul avantage.",
+ correct: true
+ },
+ {
+ text: "Les applications peuvent accéder à des segments de données dans un fichier extrêmement volumineux sans avoir à lire tout le fichier dans la RAM au préalable.",
+ explain: "Cela permet à 🤗 Datasets de charger des jeux de données de plusieurs Go sur votre ordinateur portable sans faire exploser votre CPU. Quel autre avantage cette technique offre-t-elle ?",
+ correct: true
+ },
+ {
+ text: "Cela consomme moins d'énergie, donc votre batterie dure plus longtemps.",
+ explain: "Ce n'est pas ça, réessayez !"
+ }
+ ]}
+/>
+
+### 6. Pourquoi le code suivant échoue-t-il ?
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("allocine", streaming=True, split="train")
+dataset[0]
+```
+
+IterableDataset.",
+ explain: "Un IterableDataset est un générateur, pas un conteneur. Vous devez donc accéder à ses éléments en utilisant next(iter(dataset)).",
+ correct: true
+ },
+ {
+ text: "Le jeu de données allocine n'a pas d’échantillon train.",
+ explain: "Consultez le jeu de données allocine sur le Hub (https://huggingface.co/datasets/allocine) pour voir quels échantillons il contient."
+ }
+ ]}
+/>
+
+### 7. Parmi les avantages suivants, lesquels sont les principaux pour la création d'une fiche pour les jeux de données ?
+
+
+
+
+### 8. Qu'est-ce que la recherche sémantique ?
+
+recherche lexicale et c'est ce que vous voyez généralement avec les moteurs de recherche traditionnels."
+ },
+ {
+ text: "Un moyen de rechercher des documents correspondants en comprenant la signification contextuelle d'une requête.",
+ explain: "La recherche sémantique utilise des vecteurs d’enchâssement pour représenter les requêtes et les documents. Elle utilise ensuite une métrique de similarité pour mesurer la quantité de chevauchement entre eux. Comment la décrire autrement ?",
+ correct: true
+ },
+ {
+ text: "Un moyen d'améliorer la précision de la recherche.",
+ explain: "Les moteurs de recherche sémantique peuvent capturer l'intention d'une requête bien mieux que la correspondance des mots clés et récupèrent généralement les documents avec une plus grande précision. Mais ce n'est pas la seule bonne réponse. Qu'est-ce que la recherche sémantique apporte d'autre ?",
+ correct: true
+ }
+ ]}
+/>
+
+### 9. Pour la recherche sémantique asymétrique, vous avez généralement :
+
+
+
+### 10. Puis-je utiliser 🤗 *Datasets* pour charger des données à utiliser dans d'autres domaines, comme le traitement de la parole ?
+
+Datasets prend actuellement en charge les données tabulaires, l'audio et la vision par ordinateur. Consultez le jeu de données MNIST sur le Hub pour un exemple de vision par ordinateur."
+ },
+ {
+ text: "Oui.",
+ explain: "Découvrez les développements passionnants concernant la parole et la vision dans la bibliothèque 🤗 Transformers pour voir comment 🤗 Datasets est utilisé dans ces domaines.",
+ correct : true
+ },
+ ]}
+/>
diff --git a/chapters/fr/chapter6/1.mdx b/chapters/fr/chapter6/1.mdx
index 6869cc815..730e89a3f 100644
--- a/chapters/fr/chapter6/1.mdx
+++ b/chapters/fr/chapter6/1.mdx
@@ -1,13 +1,18 @@
-# Introduction
-
-Dans le [chapitre 3](/course/fr/chapter3), nous avons vu comment *finetuner* un modèle sur une tâche donnée. Pour ce faire, nous utilisons le même *tokenizer* que celui avec lequel le modèle a été pré-entraîné. Mais que faisons-nous lorsque nous voulons entraîner un modèle à partir de zéro ? Dans ces cas, l'utilisation d'un *tokenizer* qui a été pré-entraîné sur un corpus d'un autre domaine ou d'une autre langue est généralement sous-optimale. Par exemple, un *tokenizer* entraîné sur un corpus anglais sera peu performant sur un corpus de textes japonais car l'utilisation des espaces et de la ponctuation est très différente entre les deux langues.
-
-Dans ce chapitre, vous apprendrez à entraîner un tout nouveau *tokenizer* sur un corpus de textes afin qu'il puisse ensuite être utilisé pour pré-entraîner un modèle de langue. Tout cela se fera à l'aide de la bibliothèque [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers), qui fournit les *tokenizers* « rapides » de la bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers). Nous examinerons de près les fonctionnalités offertes par cette bibliothèque et nous étudierons comment les *tokenizers* rapides diffèrent des versions « lentes ».
-
-Les sujets que nous couvrirons comprennent :
-* comment entraîner sur un nouveau corpus de textes, un nouveau *tokenizer* similaire à celui utilisé par un *checkpoint* donné,
-* les caractéristiques spéciales des *tokenizers* rapides,
-* les différences entre les trois principaux algorithmes de tokénisation utilisés aujourd'hui en NLP,
-* comment construire un *tokenizer* à partir de zéro avec la bibliothèque 🤗 *Tokenizers* et l'entraîner sur des données.
-
+# Introduction
+
+
+
+Dans le [chapitre 3](/course/fr/chapter3), nous avons vu comment *finetuner* un modèle sur une tâche donnée. Pour ce faire, nous utilisons le même *tokenizer* que celui avec lequel le modèle a été pré-entraîné. Mais que faisons-nous lorsque nous voulons entraîner un modèle à partir de zéro ? Dans ces cas, l'utilisation d'un *tokenizer* qui a été pré-entraîné sur un corpus d'un autre domaine ou d'une autre langue est généralement sous-optimale. Par exemple, un *tokenizer* entraîné sur un corpus anglais sera peu performant sur un corpus de textes japonais car l'utilisation des espaces et de la ponctuation est très différente entre les deux langues.
+
+Dans ce chapitre, vous apprendrez à entraîner un tout nouveau *tokenizer* sur un corpus de textes afin qu'il puisse ensuite être utilisé pour pré-entraîner un modèle de langue. Tout cela se fera à l'aide de la bibliothèque [🤗 *Tokenizers*](https://github.com/huggingface/tokenizers), qui fournit les *tokenizers* « rapides » de la bibliothèque [🤗 *Transformers*](https://github.com/huggingface/transformers). Nous examinerons de près les fonctionnalités offertes par cette bibliothèque et nous étudierons comment les *tokenizers* rapides diffèrent des versions « lentes ».
+
+Les sujets que nous couvrirons comprennent :
+* comment entraîner sur un nouveau corpus de textes, un nouveau *tokenizer* similaire à celui utilisé par un *checkpoint* donné,
+* les caractéristiques spéciales des *tokenizers* rapides,
+* les différences entre les trois principaux algorithmes de tokénisation utilisés aujourd'hui en NLP,
+* comment construire un *tokenizer* à partir de zéro avec la bibliothèque 🤗 *Tokenizers* et l'entraîner sur des données.
+
Les techniques présentées dans ce chapitre vous prépareront à la section du [chapitre 7](/course/fr/chapter7/6) où nous verrons comment créer un modèle de langue pour le langage Python. Commençons par examiner ce que signifie « entraîner » un *tokenizer*.
\ No newline at end of file
diff --git a/chapters/fr/chapter6/10.mdx b/chapters/fr/chapter6/10.mdx
index 062b51f16..4846966e4 100644
--- a/chapters/fr/chapter6/10.mdx
+++ b/chapters/fr/chapter6/10.mdx
@@ -1,278 +1,283 @@
-
-
-# Quiz de fin de chapitre
-
-Testons ce que vous avez appris dans ce chapitre !
-
-### 1. Quand devez-vous entraîner un nouveau tokenizer ?
-
-tokenizer que le modèle pré-entraîné et de finetuner ce modèle à la place."
- },
- {
- text: "Lorsque votre jeu de données est similaire à celui utilisé par un modèle pré-entraîné existant et que vous souhaitez finetuner un nouveau modèle en utilisant ce modèle pré-entraîné.",
- explain: "Pour finetuner un modèle à partir d'un modèle pré-entraîné, vous devez toujours utiliser le même tokenizer."
- },
- {
- text: "Lorsque votre jeu de données est différent de celui utilisé par un modèle pré-entraîné existant et que vous souhaitez pré-entraîner un nouveau modèle.",
- explain: "Dans ce cas, il n'y a aucun avantage à utiliser le même tokenizer.",
- correct: true
- },
- {
- text: "Lorsque votre jeu de données est différent de celui utilisé par un modèle pré-entraîné existant mais que vous souhaitez finetuner un nouveau modèle en utilisant ce modèle pré-entraîné.",
- explain: "Pour finetuner un modèle à partir d'un modèle pré-entraîné, vous devez toujours utiliser le même tokenizer."
- }
- ]}
-/>
-
-### 2. Quel est l'avantage d'utiliser un générateur de listes par rapport à une liste de listes lors de l'utilisation de train_new_from_iterator() ?
-
-train_new_from_iterator() accepte.",
- explain: "Une liste de listes de textes est un type particulier de générateur de listes de textes, la méthode l'acceptera donc aussi. Essayez à nouveau !"
- },
- {
- text: "Vous éviterez de charger l'ensemble des données en mémoire en une seule fois.",
- explain: "Chaque batch de textes sera libéré de la mémoire lorsque vous itérerez et le gain sera particulièrement visible si vous utilisez des 🤗 Datasets pour stocker vos textes.",
- correct: true
- },
- {
- text: "Cela permettra à la bibliothèque 🤗 Tokenizers d'utiliser le multitraitement.",
- explain: "Il utilisera le multiprocesseur dans tous les cas."
- },
- {
- text: "Le tokenizer que vous entraînez générera de meilleurs textes.",
- explain: "Le tokenizer ne génère pas de texte. Vous le confondez avec un modèle de langage ?"
- }
- ]}
-/>
-
-### 3. Quels sont les avantages d'utiliser un tokenizer « rapide » ?
-
-tokenizer lent lorsque vous faites des batchs d'entrées.",
- explain: "Grâce au parallélisme implémenté dans Rust, il sera plus rapide sur les batchs d'entrées. Quel autre avantage pouvez-vous imaginer ?",
- correct: true
- },
- {
- text: "Les tokenizers rapides sont toujours plus rapides que leurs homologues lents.",
- explain: "Un tokenizer rapide peut en fait être plus lent si vous ne lui donnez qu'un seul ou très peu de textes, car il ne peut pas utiliser le parallélisme."
- },
- {
- text: "Il peut appliquer le padding et la troncature.",
- explain: "C'est vrai, mais les tokenizers lents le font aussi."
- },
- {
- text: "Il possède des fonctionnalités supplémentaires qui vous permettent d'associer les tokens à l'extrait de texte qui les a créés.",
- explain: "En effet, c'est ce qu'on appelle des correspondances d'offset. Ce n'est pas le seul avantage, cependant.",
- correct: true
- }
- ]}
-/>
-
-### 4. Comment le pipeline `token-classification` gère-t-il les entités qui s'étendent sur plusieurs tokens ?
-
-token porte l'étiquette de l'entité, le mot entier est considéré comme étiqueté avec cette entité.",
- explain: "C'est une stratégie pour gérer les entités. Quelles autres réponses s'appliquent ici ?",
- correct: true
- },
- {
- text: "Lorsqu'un token a l'étiquette d'une entité donnée, tout autre token suivant ayant la même étiquette est considéré comme faisant partie de la même entité, à moins qu'il ne soit étiqueté comme le début d'une nouvelle entité.",
- explain: "C'est la façon la plus courante de regrouper des entités, mais ce n'est pas la seule bonne réponse.",
- correct: true
- }
- ]}
-/>
-
-### 5. Comment le pipeline `question-answering` gère-t-il les contextes longs ?
-
-
-
-### 6. Qu'est-ce que la normalisation ?
-
-tokenizer effectue sur les textes lors des étapes initiales.",
- explain: "Par exemple, il peut s'agir de supprimer les accents ou les espaces, ou de mettre les entrées en minuscules.",
- correct: true
- },
- {
- text: "Il s'agit d'une technique d'augmentation de données qui consiste à rendre le texte plus normal en supprimant les mots rares.",
- explain: "Essayez encore."
- },
- {
- text: "C'est l'étape finale du post-traitement où le tokenizer ajoute les tokens spéciaux.",
- explain: "Cette étape est simplement appelée post-traitement."
- },
- {
- text: "C'est lorsque les enchâssements sont faits avec une moyenne nulle et un écart-type de 1, en soustrayant la moyenne et en divisant par l'écart-type.",
- explain: "Ce processus est communément appelé normalisation lorsqu'il est appliqué aux valeurs des pixels en vision par ordinateur, mais ce n'est pas ce que signifie la normalisation en NLP."
- }
- ]}
-/>
-
-### 7. Qu'est-ce que la pré-tokénisation pour un tokenizer en sous-mots ?
-
-tokenizer, pour diviser l'entrée en mots.",
- explain: "C'est la bonne réponse !",
- correct: true
- },
- {
- text: "Il s'agit de l'étape précédant l'application du modèle tokenizer, qui divise l'entrée en tokens.",
- explain: "La division en tokens est le travail du modèle tokenizer."
- }
- ]}
-/>
-
-### 8. Sélectionnez les phrases qui s'appliquent au tokenizer BPE.
-
-tokens.",
- explain: "C'est l'approche adoptée par un algorithme de tokénisation différent."
- },
- {
- text: "Un tokenizer BPE apprend les règles de fusion en fusionnant la paire de tokens la plus fréquente.",
- explain: "C'est exact !",
- correct: true
- },
- {
- text: "Un tokenizer BPE apprend une règle de fusion en fusionnant la paire de tokens qui maximise un score qui privilégie les paires fréquentes avec des parties individuelles moins fréquentes.",
- explain: "C'est la stratégie appliquée par un autre algorithme de tokenization."
- },
- {
- text: "BPE tokenise les mots en sous-mots en les divisant en caractères, puis en appliquant les règles de fusion.",
- explain: " ",
- correct: true
- },
- {
- text: "BPE tokenise les mots en sous-mots en trouvant le plus long sous-mot du vocabulaire en commençant par le début, puis en répétant le processus pour le reste du texte.",
- explain: "C'est la façon de faire d'un autre algorithme de tokenization."
- },
- ]}
-/>
-
-### 9. Sélectionnez les phrases qui s'appliquent au tokenizer WordPiece.
-
-tokens.",
- explain: "C'est la façon de faire d'un autre algorithme de tokenization."
- },
- {
- text: "WordPiece Les tokenizer apprennent les règles de fusion en fusionnant la paire de tokens la plus fréquente.",
- explain: "C'est la façon de faire d'un autre algorithme de tokenization."
- },
- {
- text: "Un tokenizer WordPiece apprend une règle de fusion en fusionnant la paire de tokens qui maximise un score qui privilégie les paires fréquentes avec des parties individuelles moins fréquentes.",
- explain: " ",
- correct: true
- },
- {
- text: "WordPiece tokenise les mots en sous-mots en trouvant la segmentation en tokens la plus probable, selon le modèle.",
- explain: "C'est la façon de faire d'un autre algorithme de tokenization."
- },
- {
- text: "WordPiece tokenise les mots en sous-mots en trouvant le plus long sous-mot du vocabulaire en commençant par le début, puis en répétant le processus pour le reste du texte.",
- explain: "C'est ainsi que WordPiece procède pour l'encodage.",
- correct: true
- },
- ]}
-/>
-
-### 10. Sélectionnez les phrases qui s'appliquent au tokenizer Unigram.
-
-tokens.",
- explain: " ",
- correct: true
- },
- {
- text: "Unigram adapte son vocabulaire en minimisant une perte calculée sur l'ensemble du corpus.",
- explain: " ",
- correct: true
- },
- {
- text: "Unigram adapte son vocabulaire en conservant les sous-mots les plus fréquents.",
- explain: " "
- },
- {
- text: "Unigram segmente les mots en sous-mots en trouvant la segmentation la plus probable en tokens, selon le modèle.",
- explain: " ",
- correct: true
- },
- {
- text: "Unigram décompose les mots en sous-mots en les divisant en caractères puis en appliquant les règles de fusion.",
- explain: "C'est la façon de faire d'un autre algorithme de tokenization."
- },
- ]}
-/>
+
+
+# Quiz de fin de chapitre
+
+
+
+Testons ce que vous avez appris dans ce chapitre !
+
+### 1. Quand devez-vous entraîner un nouveau tokenizer ?
+
+tokenizer que le modèle pré-entraîné et de finetuner ce modèle à la place."
+ },
+ {
+ text: "Lorsque votre jeu de données est similaire à celui utilisé par un modèle pré-entraîné existant et que vous souhaitez finetuner un nouveau modèle en utilisant ce modèle pré-entraîné.",
+ explain: "Pour finetuner un modèle à partir d'un modèle pré-entraîné, vous devez toujours utiliser le même tokenizer."
+ },
+ {
+ text: "Lorsque votre jeu de données est différent de celui utilisé par un modèle pré-entraîné existant et que vous souhaitez pré-entraîner un nouveau modèle.",
+ explain: "Dans ce cas, il n'y a aucun avantage à utiliser le même tokenizer.",
+ correct: true
+ },
+ {
+ text: "Lorsque votre jeu de données est différent de celui utilisé par un modèle pré-entraîné existant mais que vous souhaitez finetuner un nouveau modèle en utilisant ce modèle pré-entraîné.",
+ explain: "Pour finetuner un modèle à partir d'un modèle pré-entraîné, vous devez toujours utiliser le même tokenizer."
+ }
+ ]}
+/>
+
+### 2. Quel est l'avantage d'utiliser un générateur de listes par rapport à une liste de listes lors de l'utilisation de train_new_from_iterator() ?
+
+train_new_from_iterator() accepte.",
+ explain: "Une liste de listes de textes est un type particulier de générateur de listes de textes, la méthode l'acceptera donc aussi. Essayez à nouveau !"
+ },
+ {
+ text: "Vous éviterez de charger l'ensemble des données en mémoire en une seule fois.",
+ explain: "Chaque batch de textes sera libéré de la mémoire lorsque vous itérerez et le gain sera particulièrement visible si vous utilisez des 🤗 Datasets pour stocker vos textes.",
+ correct: true
+ },
+ {
+ text: "Cela permettra à la bibliothèque 🤗 Tokenizers d'utiliser le multitraitement.",
+ explain: "Il utilisera le multiprocesseur dans tous les cas."
+ },
+ {
+ text: "Le tokenizer que vous entraînez générera de meilleurs textes.",
+ explain: "Le tokenizer ne génère pas de texte. Vous le confondez avec un modèle de langage ?"
+ }
+ ]}
+/>
+
+### 3. Quels sont les avantages d'utiliser un tokenizer « rapide » ?
+
+tokenizer lent lorsque vous faites des batchs d'entrées.",
+ explain: "Grâce au parallélisme implémenté dans Rust, il sera plus rapide sur les batchs d'entrées. Quel autre avantage pouvez-vous imaginer ?",
+ correct: true
+ },
+ {
+ text: "Les tokenizers rapides sont toujours plus rapides que leurs homologues lents.",
+ explain: "Un tokenizer rapide peut en fait être plus lent si vous ne lui donnez qu'un seul ou très peu de textes, car il ne peut pas utiliser le parallélisme."
+ },
+ {
+ text: "Il peut appliquer le padding et la troncature.",
+ explain: "C'est vrai, mais les tokenizers lents le font aussi."
+ },
+ {
+ text: "Il possède des fonctionnalités supplémentaires qui vous permettent d'associer les tokens à l'extrait de texte qui les a créés.",
+ explain: "En effet, c'est ce qu'on appelle des correspondances d'offset. Ce n'est pas le seul avantage, cependant.",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Comment le pipeline `token-classification` gère-t-il les entités qui s'étendent sur plusieurs tokens ?
+
+token porte l'étiquette de l'entité, le mot entier est considéré comme étiqueté avec cette entité.",
+ explain: "C'est une stratégie pour gérer les entités. Quelles autres réponses s'appliquent ici ?",
+ correct: true
+ },
+ {
+ text: "Lorsqu'un token a l'étiquette d'une entité donnée, tout autre token suivant ayant la même étiquette est considéré comme faisant partie de la même entité, à moins qu'il ne soit étiqueté comme le début d'une nouvelle entité.",
+ explain: "C'est la façon la plus courante de regrouper des entités, mais ce n'est pas la seule bonne réponse.",
+ correct: true
+ }
+ ]}
+/>
+
+### 5. Comment le pipeline `question-answering` gère-t-il les contextes longs ?
+
+
+
+### 6. Qu'est-ce que la normalisation ?
+
+tokenizer effectue sur les textes lors des étapes initiales.",
+ explain: "Par exemple, il peut s'agir de supprimer les accents ou les espaces, ou de mettre les entrées en minuscules.",
+ correct: true
+ },
+ {
+ text: "Il s'agit d'une technique d'augmentation de données qui consiste à rendre le texte plus normal en supprimant les mots rares.",
+ explain: "Essayez encore."
+ },
+ {
+ text: "C'est l'étape finale du post-traitement où le tokenizer ajoute les tokens spéciaux.",
+ explain: "Cette étape est simplement appelée post-traitement."
+ },
+ {
+ text: "C'est lorsque les enchâssements sont faits avec une moyenne nulle et un écart-type de 1, en soustrayant la moyenne et en divisant par l'écart-type.",
+ explain: "Ce processus est communément appelé normalisation lorsqu'il est appliqué aux valeurs des pixels en vision par ordinateur, mais ce n'est pas ce que signifie la normalisation en NLP."
+ }
+ ]}
+/>
+
+### 7. Qu'est-ce que la pré-tokénisation pour un tokenizer en sous-mots ?
+
+tokenizer, pour diviser l'entrée en mots.",
+ explain: "C'est la bonne réponse !",
+ correct: true
+ },
+ {
+ text: "Il s'agit de l'étape précédant l'application du modèle tokenizer, qui divise l'entrée en tokens.",
+ explain: "La division en tokens est le travail du modèle tokenizer."
+ }
+ ]}
+/>
+
+### 8. Sélectionnez les phrases qui s'appliquent au tokenizer BPE.
+
+tokens.",
+ explain: "C'est l'approche adoptée par un algorithme de tokénisation différent."
+ },
+ {
+ text: "Un tokenizer BPE apprend les règles de fusion en fusionnant la paire de tokens la plus fréquente.",
+ explain: "C'est exact !",
+ correct: true
+ },
+ {
+ text: "Un tokenizer BPE apprend une règle de fusion en fusionnant la paire de tokens qui maximise un score qui privilégie les paires fréquentes avec des parties individuelles moins fréquentes.",
+ explain: "C'est la stratégie appliquée par un autre algorithme de tokenization."
+ },
+ {
+ text: "BPE tokenise les mots en sous-mots en les divisant en caractères, puis en appliquant les règles de fusion.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "BPE tokenise les mots en sous-mots en trouvant le plus long sous-mot du vocabulaire en commençant par le début, puis en répétant le processus pour le reste du texte.",
+ explain: "C'est la façon de faire d'un autre algorithme de tokenization."
+ },
+ ]}
+/>
+
+### 9. Sélectionnez les phrases qui s'appliquent au tokenizer WordPiece.
+
+tokens.",
+ explain: "C'est la façon de faire d'un autre algorithme de tokenization."
+ },
+ {
+ text: "WordPiece Les tokenizer apprennent les règles de fusion en fusionnant la paire de tokens la plus fréquente.",
+ explain: "C'est la façon de faire d'un autre algorithme de tokenization."
+ },
+ {
+ text: "Un tokenizer WordPiece apprend une règle de fusion en fusionnant la paire de tokens qui maximise un score qui privilégie les paires fréquentes avec des parties individuelles moins fréquentes.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "WordPiece tokenise les mots en sous-mots en trouvant la segmentation en tokens la plus probable, selon le modèle.",
+ explain: "C'est la façon de faire d'un autre algorithme de tokenization."
+ },
+ {
+ text: "WordPiece tokenise les mots en sous-mots en trouvant le plus long sous-mot du vocabulaire en commençant par le début, puis en répétant le processus pour le reste du texte.",
+ explain: "C'est ainsi que WordPiece procède pour l'encodage.",
+ correct: true
+ },
+ ]}
+/>
+
+### 10. Sélectionnez les phrases qui s'appliquent au tokenizer Unigram.
+
+tokens.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "Unigram adapte son vocabulaire en minimisant une perte calculée sur l'ensemble du corpus.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "Unigram adapte son vocabulaire en conservant les sous-mots les plus fréquents.",
+ explain: " "
+ },
+ {
+ text: "Unigram segmente les mots en sous-mots en trouvant la segmentation la plus probable en tokens, selon le modèle.",
+ explain: " ",
+ correct: true
+ },
+ {
+ text: "Unigram décompose les mots en sous-mots en les divisant en caractères puis en appliquant les règles de fusion.",
+ explain: "C'est la façon de faire d'un autre algorithme de tokenization."
+ },
+ ]}
+/>
diff --git a/chapters/fr/chapter6/2.mdx b/chapters/fr/chapter6/2.mdx
index 9a29792dd..8eba2f385 100644
--- a/chapters/fr/chapter6/2.mdx
+++ b/chapters/fr/chapter6/2.mdx
@@ -1,265 +1,265 @@
-# Entraîner un nouveau tokenizer à partir d'un ancien
-
-
-
-Si un modèle de langue n'est pas disponible dans la langue qui vous intéresse ou si votre corpus est très différent de celui sur lequel votre modèle de langue a été entraîné, vous voudrez très probablement réentraîner le modèle à partir de zéro en utilisant un *tokenizer* adapté à vos données. Pour ce faire, vous devrez entraîner un nouveau *tokenizer* sur votre jeu de données. Mais qu'est-ce que cela signifie exactement ? Lorsque nous avons examiné pour la première fois les *tokenizers* dans le [chapitre 2](/course/fr/chapter2), nous avons vu que la plupart des *transformers* utilisent un _algorithme de tokenisation en sous-mots_. Pour identifier les sous-mots qui sont intéressants et qui apparaissent le plus fréquemment dans un corpus donné, le *tokenizer* doit examiner attentivement tous les textes du corpus. C'est un processus que nous appelons *entraînement*. Les règles exactes qui régissent cet apprentissage dépendent du type de *tokenizer* utilisé. Nous passerons en revue les trois principaux algorithmes plus loin dans ce chapitre.
-
-
-
-
-
-⚠️ Entraîner un *tokenizer* n'est pas la même chose qu'entraîner un modèle ! L'entraînement du modèle utilise la descente de gradient stochastique pour réduire un peu plus la perte à chaque batch. Il est par nature aléatoire (ce qui signifie que vous devez définir des graines pour obtenir les mêmes résultats lorsque vous effectuez deux fois le même entraînement). Entraîner un *tokenizer* est un processus statistique qui identifie les meilleurs sous-mots à choisir pour un corpus donné. Les règles exactes utilisées pour les choisir dépendent de l'algorithme de tokénisation. Le processus est déterministe, ce qui signifie que vous obtenez toujours les mêmes résultats lorsque vous vous entraînez avec le même algorithme sur le même corpus.
-
-
-
-
-## Assemblage d'un corpus
-
-Il y a une API très simple dans 🤗 *Transformers* que vous pouvez utiliser pour entraîner un nouveau *tokenizer* avec les mêmes caractéristiques qu'un déjà existant : `AutoTokenizer.train_new_from_iterator()`. Pour illustrer cela, disons que nous voulons entraîner GPT-2 à partir de zéro mais dans une langue autre que l'anglais. Notre première tâche est de rassembler des batchs de données dans cette langue dans un corpus d'entraînement. Pour avoir des exemples que tout le monde puisse comprendre, nous n'utiliserons pas ici une langue comme le russe ou le chinois mais plutôt une langue anglaise spécialisée : le langage Python.
-
-La bibliothèque [🤗 *Datasets*](https://github.com/huggingface/datasets) peut nous aider à assembler un corpus de code source Python. Nous allons utiliser la fonction habituelle `load_dataset()` pour télécharger et mettre en cache le jeu de données [CodeSearchNet](https://huggingface.co/datasets/code_search_net). Ce jeu de données a été créé pour le [CodeSearchNet challenge](https://wandb.ai/github/CodeSearchNet/benchmark) et contient des millions de fonctions provenant de bibliothèques open source sur GitHub dans plusieurs langages de programmation. Ici, nous allons charger la partie Python de ce jeu de données :
-
-```py
-from datasets import load_dataset
-
-# Cela peut prendre quelques minutes alors prenez un thé ou un café pendant que vous patientez !
-raw_datasets = load_dataset("code_search_net", "python")
-```
-
-Nous pouvons jeter un coup d'œil au jeu d'entraînement pour voir quelles sont les colonnes auxquelles nous avons accès :
-
-```py
-raw_datasets["train"]
-```
-
-```python out
-Dataset({
- features: ['repository_name', 'func_path_in_repository', 'func_name', 'whole_func_string', 'language',
- 'func_code_string', 'func_code_tokens', 'func_documentation_string', 'func_documentation_tokens', 'split_name',
- 'func_code_url'
- ],
- num_rows: 412178
-})
-```
-
-Nous pouvons voir que le jeu de données sépare les chaînes de documents du code et suggère une tokenization des deux. Ici, nous utiliserons simplement la colonne `whole_func_string` pour entraîner notre *tokenizer*. Nous pouvons regarder un exemple de la façon suivante :
-
-```py
-print(raw_datasets["train"][123456]["whole_func_string"])
-```
-
-qui nous affiche ce qui suit :
-
-```out
-def handle_simple_responses(
- self, timeout_ms=None, info_cb=DEFAULT_MESSAGE_CALLBACK):
- """Accepts normal responses from the device.
-
- Args:
- timeout_ms: Timeout in milliseconds to wait for each response.
- info_cb: Optional callback for text sent from the bootloader.
-
- Returns:
- OKAY packet's message.
- """
- return self._accept_responses('OKAY', info_cb, timeout_ms=timeout_ms)
-```
-
-La première chose à faire est de transformer le jeu de données en un _itérateur_ de listes de textes. Par exemple, une liste de listes de textes. L'utilisation de listes de textes permet à notre *tokenizer* d'aller plus vite (l'entraînement a alors lieu sur des batchs de textes au lieu de traiter des textes un par un). Et le fait que ce soit un itérateur permet d'éviter d'avoir tout en mémoire en même temps. Si votre corpus est énorme, vous voudrez profiter du fait que 🤗 *Datasets* ne charge pas tout en RAM mais stocke les éléments du jeu de données sur le disque.
-
-Faire ce qui suit créerait une liste de listes de 1 000 textes chacune mais chargerait tout en mémoire :
-
-
-```py
-# Ne décommentez pas la ligne suivante à moins que votre jeu de données soit petit !
-# training_corpus = [raw_datasets["train"][i: i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000)]
-```
-
-En utilisant un générateur, nous pouvons éviter que Python ne charge quoi que ce soit en mémoire à moins que cela soit réellement nécessaire. Pour créer un tel générateur, il suffit de remplacer les crochets par des parenthèses :
-
-```py
-training_corpus = (
- raw_datasets["train"][i : i + 1000]["whole_func_string"]
- for i in range(0, len(raw_datasets["train"]), 1000)
-)
-```
-
-Cette ligne de code ne récupère aucun élément du jeu de données. Elle crée simplement un objet que vous pouvez utiliser dans une boucle `for` Python. Les textes ne seront chargés que lorsque vous en aurez besoin (c'est-à-dire lorsque vous serez à l'étape de la boucle `for` qui les requiert) et seulement 1 000 textes à la fois. De cette façon, vous n'épuiserez pas toute votre mémoire, même si vous traitez un énorme jeu de données.
-
-Le problème avec un objet générateur est qu'il ne peut être utilisé qu'une seule fois. Ainsi, au lieu que cet objet nous donne deux fois la liste des 10 premiers chiffres :
-
-
-```py
-gen = (i for i in range(10))
-print(list(gen))
-print(list(gen))
-```
-
-on les reçoit une fois et ensuite une liste vide :
-
-```python out
-[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
-[]
-```
-
-C'est pourquoi nous définissons une fonction qui renvoie un générateur à la place :
-
-```py
-def get_training_corpus():
- return (
- raw_datasets["train"][i : i + 1000]["whole_func_string"]
- for i in range(0, len(raw_datasets["train"]), 1000)
- )
-
-
-training_corpus = get_training_corpus()
-```
-
-Vous pouvez également définir votre générateur à l'intérieur d'une boucle `for` en utilisant l'instruction `yield` :
-
-```py
-def get_training_corpus():
- dataset = raw_datasets["train"]
- for start_idx in range(0, len(dataset), 1000):
- samples = dataset[start_idx : start_idx + 1000]
- yield samples["whole_func_string"]
-```
-
-qui produit exactement le même générateur que précédemment mais permet d'utiliser une logique plus complexe que celle que vous pouvez utiliser dans une compréhension de liste.
-
-
-## Entraînement d'un nouveau tokenizer
-
-Maintenant que nous avons notre corpus sous la forme d'un itérateur de batchs de textes, nous sommes prêts à entraîner un nouveau *tokenizer*. Pour ce faire, nous devons d'abord charger le *tokenizer* que nous voulons coupler avec notre modèle (ici, le GPT-2) :
-
-
-```py
-from transformers import AutoTokenizer
-
-old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
-```
-
-Même si nous allons entraîner un nouveau *tokenizer*, c'est une bonne idée de faire ça pour éviter de partir entièrement de zéro. De cette façon, nous n'aurons pas à spécifier l'algorithme de tokénisation ou les jetons spéciaux que nous voulons utiliser. Notre nouveau *tokenizer* sera exactement le même que celui du GPT-2. La seule chose qui changera sera le vocabulaire qui sera déterminé lors de l'entraînement sur notre corpus.
-
-Voyons d'abord comment ce *tokenizer* traiterait un exemple de fonction :
-
-
-```py
-example = '''def add_numbers(a, b):
- """Add the two numbers `a` and `b`."""
- return a + b'''
-
-tokens = old_tokenizer.tokenize(example)
-tokens
-```
-
-```python out
-['def', 'Ġadd', '_', 'n', 'umbers', '(', 'a', ',', 'Ġb', '):', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo',
- 'Ġnumbers', 'Ġ`', 'a', '`', 'Ġand', 'Ġ`', 'b', '`', '."', '""', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
-```
-
-Ce *tokenizer* possède quelques symboles spéciaux, comme `Ġ` et `Ċ`, qui désignent respectivement les espaces et les retours à la ligne. Comme on peut le voir, ce n'est pas très efficace. Le *tokenizer* renvoie des jetons individuels pour chaque espace alors qu'il pourrait regrouper ceux des indentations (puisqu’avoir des ensembles de quatre ou huit espaces est très courant dans du code). Il divise également le nom de la fonction de façon un peu bizarre car pas habitué à voir des mots avec le caractère `_`.
-
-Entraînons un nouveau *tokenizer* et voyons s'il résout ces problèmes. Pour cela, nous allons utiliser la méthode `train_new_from_iterator()` :
-
-
-```py
-tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
-```
-
-Cette commande peut prendre un peu de temps si votre corpus est très grand. Pour ce jeu de données de 1,6 Go de textes, elle est très rapide (1 minute 16 secondes sur un CPU AMD Ryzen 9 3900X avec 12 cœurs).
-
-Notez que `AutoTokenizer.train_new_from_iterator()` ne fonctionne que si le *tokenizer* que vous utilisez est un *tokenizer* « rapide ». Comme vous le verrez dans la section suivante, la bibliothèque 🤗 *Transformers* contient deux types de *tokenizers* : certains sont écrits en pur Python et d'autres (les rapides) sont soutenus par la bibliothèque 🤗 *Tokenizers* qui est écrite dans le langage [Rust](https://www.rust-lang.org). Python est le langage le plus souvent utilisé pour les applications de science des données et d'apprentissage profond, mais lorsque quelque chose doit être parallélisé pour être rapide, il faut que cela soit écrit dans un autre langage. Par exemple, les multiplications matricielles qui sont au cœur du calcul du modèle sont écrites en CUDA, une bibliothèque en C optimisée pour les GPUs.
-
-Entraîner un tout nouveau *tokenizer* en Python pur est atrocement lent, c'est pourquoi nous avons développé la bibliothèque 🤗 *Tokenizers*. Notez que, tout comme vous n'avez pas eu à apprendre le langage CUDA pour pouvoir exécuter votre modèle sur un batch d'entrées sur un GPU, vous n'aurez pas besoin d'apprendre Rust pour utiliser un *tokenizer* rapide. La bibliothèque 🤗 *Tokenizers* fournit des liaisons Python pour de nombreuses méthodes qui appellent en interne un morceau de code en Rust. Par exemple, pour paralléliser l'entraînement de votre nouveau *tokenizer* ou, comme nous l'avons vu dans le [chapitre 3](/course/fr/chapter3), la tokenisation d'un lot d'entrées.
-
-La plupart des *transformers* ont un *tokenizer* rapide de disponible. Il y a quelques exceptions que vous pouvez vérifier [ici](https://huggingface.co/transformers/#supported-frameworks). S'il est disponible, l'API `AutoTokenizer` sélectionne toujours pour vous le *tokenizer* rapide. Dans la prochaine section, nous allons jeter un coup d'oeil à certaines des autres caractéristiques spéciales des *tokenizers* rapides, qui seront très utiles pour des tâches comme la classification de *tokens* et la réponse aux questions. Mais avant cela, essayons notre tout nouveau *tokenizer* sur l'exemple précédent :
-
-```py
-tokens = tokenizer.tokenize(example)
-tokens
-```
-
-```python out
-['def', 'Ġadd', '_', 'numbers', '(', 'a', ',', 'Ġb', '):', 'ĊĠĠĠ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo', 'Ġnumbers', 'Ġ`',
- 'a', '`', 'Ġand', 'Ġ`', 'b', '`."""', 'ĊĠĠĠ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
-```
-
-Ici, nous voyons à nouveau les symboles spéciaux `Ġ` et `Ċ` qui indiquent les espaces et les retours à la ligne. Nous pouvons également voir que notre *tokenizer* a appris certains *tokens* qui sont très spécifiques à un corpus de fonctions Python. Par exemple, il y a un token `ĊĠĠĠ` qui représente une indentation et un *token* `Ġ"""` qui représente les trois guillemets qui commencent une *docstring*. Le *tokenizer* divise également correctement le nom de la fonction sur `_`. Il s'agit d'une représentation assez compacte. En comparaison, l'utilisation du *tokenizer* en anglais « simple » sur le même exemple nous donnera une phrase plus longue :
-
-```py
-print(len(tokens))
-print(len(old_tokenizer.tokenize(example)))
-```
-
-```python out
-27
-36
-```
-
-Prenons un autre exemple :
-
-```python
-example = """class LinearLayer():
- def __init__(self, input_size, output_size):
- self.weight = torch.randn(input_size, output_size)
- self.bias = torch.zeros(output_size)
-
- def __call__(self, x):
- return x @ self.weights + self.bias
- """
-tokenizer.tokenize(example)
-```
-
-```python out
-['class', 'ĠLinear', 'Layer', '():', 'ĊĠĠĠ', 'Ġdef', 'Ġ__', 'init', '__(', 'self', ',', 'Ġinput', '_', 'size', ',',
- 'Ġoutput', '_', 'size', '):', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'weight', 'Ġ=', 'Ġtorch', '.', 'randn', '(', 'input', '_',
- 'size', ',', 'Ġoutput', '_', 'size', ')', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'bias', 'Ġ=', 'Ġtorch', '.', 'zeros', '(',
- 'output', '_', 'size', ')', 'ĊĊĠĠĠ', 'Ġdef', 'Ġ__', 'call', '__(', 'self', ',', 'Ġx', '):', 'ĊĠĠĠĠĠĠĠ',
- 'Ġreturn', 'Ġx', 'Ġ@', 'Ġself', '.', 'weights', 'Ġ+', 'Ġself', '.', 'bias', 'ĊĠĠĠĠ']
-```
-
-En plus du *token* correspondant à une indentation, on peut également voir ici un *token* pour une double indentation : `ĊĠĠĠĠĠĠĠĠĠ`. Les mots spéciaux de Python comme `class`, `init`, `call`, `self`, et `return` sont tous tokenizés comme un seul *token*. Nous pouvons voir qu'en plus de séparer sur `_` et `.` le tokenizer sépare correctement même les noms en minuscules. Par exemple `LinearLayer` est tokenisé comme `["ĠLinear", "Layer"]`.
-
-## Sauvegarde du tokenizer
-
-Pour être sûr de pouvoir l'utiliser plus tard, nous devons sauvegarder notre nouveau *tokenizer*. Comme pour les modèles, ceci est fait avec la méthode `save_pretrained()` :
-
-
-```py
-tokenizer.save_pretrained("code-search-net-tokenizer")
-```
-
-Cela créera un nouveau dossier nommé *code-search-net-tokenizer* contenant tous les fichiers dont le *tokenizer* a besoin pour être rechargé. Si vous souhaitez partager ce *tokenizer* avec vos collègues et amis, vous pouvez le télécharger sur le *Hub* en vous connectant à votre compte. Si vous travaillez dans un *notebook*, il existe une fonction pratique pour vous aider à le faire :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face. Si vous ne travaillez pas sur un ordinateur portable, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-Une fois connecté, vous pouvez pousser votre *tokenizer* en exécutant la commande suivante :
-
-```py
-tokenizer.push_to_hub("code-search-net-tokenizer")
-```
-
-Cela créera un nouveau dépôt dans votre espace avec le nom `code-search-net-tokenizer` contenant le fichier *tokenizer*. Vous pouvez ensuite charger le *tokenizer* de n'importe où avec la méthode `from_pretrained()` :
-
-```py
-# Remplacez "huggingface-course" ci-dessous par votre espace réel pour utiliser votre propre tokenizer
-tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
-```
-
+# Entraîner un nouveau tokenizer à partir d'un ancien
+
+
+
+Si un modèle de langue n'est pas disponible dans la langue qui vous intéresse ou si votre corpus est très différent de celui sur lequel votre modèle de langue a été entraîné, vous voudrez très probablement réentraîner le modèle à partir de zéro en utilisant un *tokenizer* adapté à vos données. Pour ce faire, vous devrez entraîner un nouveau *tokenizer* sur votre jeu de données. Mais qu'est-ce que cela signifie exactement ? Lorsque nous avons examiné pour la première fois les *tokenizers* dans le [chapitre 2](/course/fr/chapter2), nous avons vu que la plupart des *transformers* utilisent un _algorithme de tokenisation en sous-mots_. Pour identifier les sous-mots qui sont intéressants et qui apparaissent le plus fréquemment dans un corpus donné, le *tokenizer* doit examiner attentivement tous les textes du corpus. C'est un processus que nous appelons *entraînement*. Les règles exactes qui régissent cet apprentissage dépendent du type de *tokenizer* utilisé. Nous passerons en revue les trois principaux algorithmes plus loin dans ce chapitre.
+
+
+
+
+
+⚠️ Entraîner un *tokenizer* n'est pas la même chose qu'entraîner un modèle ! L'entraînement du modèle utilise la descente de gradient stochastique pour réduire un peu plus la perte à chaque batch. Il est par nature aléatoire (ce qui signifie que vous devez définir des graines pour obtenir les mêmes résultats lorsque vous effectuez deux fois le même entraînement). Entraîner un *tokenizer* est un processus statistique qui identifie les meilleurs sous-mots à choisir pour un corpus donné. Les règles exactes utilisées pour les choisir dépendent de l'algorithme de tokénisation. Le processus est déterministe, ce qui signifie que vous obtenez toujours les mêmes résultats lorsque vous vous entraînez avec le même algorithme sur le même corpus.
+
+
+
+
+## Assemblage d'un corpus
+
+Il y a une API très simple dans 🤗 *Transformers* que vous pouvez utiliser pour entraîner un nouveau *tokenizer* avec les mêmes caractéristiques qu'un déjà existant : `AutoTokenizer.train_new_from_iterator()`. Pour illustrer cela, disons que nous voulons entraîner GPT-2 à partir de zéro mais dans une langue autre que l'anglais. Notre première tâche est de rassembler des batchs de données dans cette langue dans un corpus d'entraînement. Pour avoir des exemples que tout le monde puisse comprendre, nous n'utiliserons pas ici une langue comme le russe ou le chinois mais plutôt une langue anglaise spécialisée : le langage Python.
+
+La bibliothèque [🤗 *Datasets*](https://github.com/huggingface/datasets) peut nous aider à assembler un corpus de code source Python. Nous allons utiliser la fonction habituelle `load_dataset()` pour télécharger et mettre en cache le jeu de données [CodeSearchNet](https://huggingface.co/datasets/code_search_net). Ce jeu de données a été créé pour le [CodeSearchNet challenge](https://wandb.ai/github/CodeSearchNet/benchmark) et contient des millions de fonctions provenant de bibliothèques open source sur GitHub dans plusieurs langages de programmation. Ici, nous allons charger la partie Python de ce jeu de données :
+
+```py
+from datasets import load_dataset
+
+# Cela peut prendre quelques minutes alors prenez un thé ou un café pendant que vous patientez !
+raw_datasets = load_dataset("code_search_net", "python")
+```
+
+Nous pouvons jeter un coup d'œil au jeu d'entraînement pour voir quelles sont les colonnes auxquelles nous avons accès :
+
+```py
+raw_datasets["train"]
+```
+
+```python out
+Dataset({
+ features: ['repository_name', 'func_path_in_repository', 'func_name', 'whole_func_string', 'language',
+ 'func_code_string', 'func_code_tokens', 'func_documentation_string', 'func_documentation_tokens', 'split_name',
+ 'func_code_url'
+ ],
+ num_rows: 412178
+})
+```
+
+Nous pouvons voir que le jeu de données sépare les chaînes de documents du code et suggère une tokenization des deux. Ici, nous utiliserons simplement la colonne `whole_func_string` pour entraîner notre *tokenizer*. Nous pouvons regarder un exemple de la façon suivante :
+
+```py
+print(raw_datasets["train"][123456]["whole_func_string"])
+```
+
+qui nous affiche ce qui suit :
+
+```out
+def handle_simple_responses(
+ self, timeout_ms=None, info_cb=DEFAULT_MESSAGE_CALLBACK):
+ """Accepts normal responses from the device.
+
+ Args:
+ timeout_ms: Timeout in milliseconds to wait for each response.
+ info_cb: Optional callback for text sent from the bootloader.
+
+ Returns:
+ OKAY packet's message.
+ """
+ return self._accept_responses('OKAY', info_cb, timeout_ms=timeout_ms)
+```
+
+La première chose à faire est de transformer le jeu de données en un _itérateur_ de listes de textes. Par exemple, une liste de listes de textes. L'utilisation de listes de textes permet à notre *tokenizer* d'aller plus vite (l'entraînement a alors lieu sur des batchs de textes au lieu de traiter des textes un par un). Et le fait que ce soit un itérateur permet d'éviter d'avoir tout en mémoire en même temps. Si votre corpus est énorme, vous voudrez profiter du fait que 🤗 *Datasets* ne charge pas tout en RAM mais stocke les éléments du jeu de données sur le disque.
+
+Faire ce qui suit créerait une liste de listes de 1 000 textes chacune mais chargerait tout en mémoire :
+
+
+```py
+# Ne décommentez pas la ligne suivante à moins que votre jeu de données soit petit !
+# training_corpus = [raw_datasets["train"][i: i + 1000]["whole_func_string"] for i in range(0, len(raw_datasets["train"]), 1000)]
+```
+
+En utilisant un générateur, nous pouvons éviter que Python ne charge quoi que ce soit en mémoire à moins que cela soit réellement nécessaire. Pour créer un tel générateur, il suffit de remplacer les crochets par des parenthèses :
+
+```py
+training_corpus = (
+ raw_datasets["train"][i : i + 1000]["whole_func_string"]
+ for i in range(0, len(raw_datasets["train"]), 1000)
+)
+```
+
+Cette ligne de code ne récupère aucun élément du jeu de données. Elle crée simplement un objet que vous pouvez utiliser dans une boucle `for` Python. Les textes ne seront chargés que lorsque vous en aurez besoin (c'est-à-dire lorsque vous serez à l'étape de la boucle `for` qui les requiert) et seulement 1 000 textes à la fois. De cette façon, vous n'épuiserez pas toute votre mémoire, même si vous traitez un énorme jeu de données.
+
+Le problème avec un objet générateur est qu'il ne peut être utilisé qu'une seule fois. Ainsi, au lieu que cet objet nous donne deux fois la liste des 10 premiers chiffres :
+
+
+```py
+gen = (i for i in range(10))
+print(list(gen))
+print(list(gen))
+```
+
+on les reçoit une fois et ensuite une liste vide :
+
+```python out
+[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
+[]
+```
+
+C'est pourquoi nous définissons une fonction qui renvoie un générateur à la place :
+
+```py
+def get_training_corpus():
+ return (
+ raw_datasets["train"][i : i + 1000]["whole_func_string"]
+ for i in range(0, len(raw_datasets["train"]), 1000)
+ )
+
+
+training_corpus = get_training_corpus()
+```
+
+Vous pouvez également définir votre générateur à l'intérieur d'une boucle `for` en utilisant l'instruction `yield` :
+
+```py
+def get_training_corpus():
+ dataset = raw_datasets["train"]
+ for start_idx in range(0, len(dataset), 1000):
+ samples = dataset[start_idx : start_idx + 1000]
+ yield samples["whole_func_string"]
+```
+
+qui produit exactement le même générateur que précédemment mais permet d'utiliser une logique plus complexe que celle que vous pouvez utiliser dans une compréhension de liste.
+
+
+## Entraînement d'un nouveau tokenizer
+
+Maintenant que nous avons notre corpus sous la forme d'un itérateur de batchs de textes, nous sommes prêts à entraîner un nouveau *tokenizer*. Pour ce faire, nous devons d'abord charger le *tokenizer* que nous voulons coupler avec notre modèle (ici, le GPT-2) :
+
+
+```py
+from transformers import AutoTokenizer
+
+old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
+```
+
+Même si nous allons entraîner un nouveau *tokenizer*, c'est une bonne idée de faire ça pour éviter de partir entièrement de zéro. De cette façon, nous n'aurons pas à spécifier l'algorithme de tokénisation ou les jetons spéciaux que nous voulons utiliser. Notre nouveau *tokenizer* sera exactement le même que celui du GPT-2. La seule chose qui changera sera le vocabulaire qui sera déterminé lors de l'entraînement sur notre corpus.
+
+Voyons d'abord comment ce *tokenizer* traiterait un exemple de fonction :
+
+
+```py
+example = '''def add_numbers(a, b):
+ """Add the two numbers `a` and `b`."""
+ return a + b'''
+
+tokens = old_tokenizer.tokenize(example)
+tokens
+```
+
+```python out
+['def', 'Ġadd', '_', 'n', 'umbers', '(', 'a', ',', 'Ġb', '):', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo',
+ 'Ġnumbers', 'Ġ`', 'a', '`', 'Ġand', 'Ġ`', 'b', '`', '."', '""', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
+```
+
+Ce *tokenizer* possède quelques symboles spéciaux, comme `Ġ` et `Ċ`, qui désignent respectivement les espaces et les retours à la ligne. Comme on peut le voir, ce n'est pas très efficace. Le *tokenizer* renvoie des jetons individuels pour chaque espace alors qu'il pourrait regrouper ceux des indentations (puisqu’avoir des ensembles de quatre ou huit espaces est très courant dans du code). Il divise également le nom de la fonction de façon un peu bizarre car pas habitué à voir des mots avec le caractère `_`.
+
+Entraînons un nouveau *tokenizer* et voyons s'il résout ces problèmes. Pour cela, nous allons utiliser la méthode `train_new_from_iterator()` :
+
+
+```py
+tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
+```
+
+Cette commande peut prendre un peu de temps si votre corpus est très grand. Pour ce jeu de données de 1,6 Go de textes, elle est très rapide (1 minute 16 secondes sur un CPU AMD Ryzen 9 3900X avec 12 cœurs).
+
+Notez que `AutoTokenizer.train_new_from_iterator()` ne fonctionne que si le *tokenizer* que vous utilisez est un *tokenizer* « rapide ». Comme vous le verrez dans la section suivante, la bibliothèque 🤗 *Transformers* contient deux types de *tokenizers* : certains sont écrits en pur Python et d'autres (les rapides) sont soutenus par la bibliothèque 🤗 *Tokenizers* qui est écrite dans le langage [Rust](https://www.rust-lang.org). Python est le langage le plus souvent utilisé pour les applications de science des données et d'apprentissage profond, mais lorsque quelque chose doit être parallélisé pour être rapide, il faut que cela soit écrit dans un autre langage. Par exemple, les multiplications matricielles qui sont au cœur du calcul du modèle sont écrites en CUDA, une bibliothèque en C optimisée pour les GPUs.
+
+Entraîner un tout nouveau *tokenizer* en Python pur est atrocement lent, c'est pourquoi nous avons développé la bibliothèque 🤗 *Tokenizers*. Notez que, tout comme vous n'avez pas eu à apprendre le langage CUDA pour pouvoir exécuter votre modèle sur un batch d'entrées sur un GPU, vous n'aurez pas besoin d'apprendre Rust pour utiliser un *tokenizer* rapide. La bibliothèque 🤗 *Tokenizers* fournit des liaisons Python pour de nombreuses méthodes qui appellent en interne un morceau de code en Rust. Par exemple, pour paralléliser l'entraînement de votre nouveau *tokenizer* ou, comme nous l'avons vu dans le [chapitre 3](/course/fr/chapter3), la tokenisation d'un lot d'entrées.
+
+La plupart des *transformers* ont un *tokenizer* rapide de disponible. Il y a quelques exceptions que vous pouvez vérifier [ici](https://huggingface.co/transformers/#supported-frameworks). S'il est disponible, l'API `AutoTokenizer` sélectionne toujours pour vous le *tokenizer* rapide. Dans la prochaine section, nous allons jeter un coup d'oeil à certaines des autres caractéristiques spéciales des *tokenizers* rapides, qui seront très utiles pour des tâches comme la classification de *tokens* et la réponse aux questions. Mais avant cela, essayons notre tout nouveau *tokenizer* sur l'exemple précédent :
+
+```py
+tokens = tokenizer.tokenize(example)
+tokens
+```
+
+```python out
+['def', 'Ġadd', '_', 'numbers', '(', 'a', ',', 'Ġb', '):', 'ĊĠĠĠ', 'Ġ"""', 'Add', 'Ġthe', 'Ġtwo', 'Ġnumbers', 'Ġ`',
+ 'a', '`', 'Ġand', 'Ġ`', 'b', '`."""', 'ĊĠĠĠ', 'Ġreturn', 'Ġa', 'Ġ+', 'Ġb']
+```
+
+Ici, nous voyons à nouveau les symboles spéciaux `Ġ` et `Ċ` qui indiquent les espaces et les retours à la ligne. Nous pouvons également voir que notre *tokenizer* a appris certains *tokens* qui sont très spécifiques à un corpus de fonctions Python. Par exemple, il y a un token `ĊĠĠĠ` qui représente une indentation et un *token* `Ġ"""` qui représente les trois guillemets qui commencent une *docstring*. Le *tokenizer* divise également correctement le nom de la fonction sur `_`. Il s'agit d'une représentation assez compacte. En comparaison, l'utilisation du *tokenizer* en anglais « simple » sur le même exemple nous donnera une phrase plus longue :
+
+```py
+print(len(tokens))
+print(len(old_tokenizer.tokenize(example)))
+```
+
+```python out
+27
+36
+```
+
+Prenons un autre exemple :
+
+```python
+example = """class LinearLayer():
+ def __init__(self, input_size, output_size):
+ self.weight = torch.randn(input_size, output_size)
+ self.bias = torch.zeros(output_size)
+
+ def __call__(self, x):
+ return x @ self.weights + self.bias
+ """
+tokenizer.tokenize(example)
+```
+
+```python out
+['class', 'ĠLinear', 'Layer', '():', 'ĊĠĠĠ', 'Ġdef', 'Ġ__', 'init', '__(', 'self', ',', 'Ġinput', '_', 'size', ',',
+ 'Ġoutput', '_', 'size', '):', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'weight', 'Ġ=', 'Ġtorch', '.', 'randn', '(', 'input', '_',
+ 'size', ',', 'Ġoutput', '_', 'size', ')', 'ĊĠĠĠĠĠĠĠ', 'Ġself', '.', 'bias', 'Ġ=', 'Ġtorch', '.', 'zeros', '(',
+ 'output', '_', 'size', ')', 'ĊĊĠĠĠ', 'Ġdef', 'Ġ__', 'call', '__(', 'self', ',', 'Ġx', '):', 'ĊĠĠĠĠĠĠĠ',
+ 'Ġreturn', 'Ġx', 'Ġ@', 'Ġself', '.', 'weights', 'Ġ+', 'Ġself', '.', 'bias', 'ĊĠĠĠĠ']
+```
+
+En plus du *token* correspondant à une indentation, on peut également voir ici un *token* pour une double indentation : `ĊĠĠĠĠĠĠĠĠĠ`. Les mots spéciaux de Python comme `class`, `init`, `call`, `self`, et `return` sont tous tokenizés comme un seul *token*. Nous pouvons voir qu'en plus de séparer sur `_` et `.` le tokenizer sépare correctement même les noms en minuscules. Par exemple `LinearLayer` est tokenisé comme `["ĠLinear", "Layer"]`.
+
+## Sauvegarde du tokenizer
+
+Pour être sûr de pouvoir l'utiliser plus tard, nous devons sauvegarder notre nouveau *tokenizer*. Comme pour les modèles, ceci est fait avec la méthode `save_pretrained()` :
+
+
+```py
+tokenizer.save_pretrained("code-search-net-tokenizer")
+```
+
+Cela créera un nouveau dossier nommé *code-search-net-tokenizer* contenant tous les fichiers dont le *tokenizer* a besoin pour être rechargé. Si vous souhaitez partager ce *tokenizer* avec vos collègues et amis, vous pouvez le télécharger sur le *Hub* en vous connectant à votre compte. Si vous travaillez dans un *notebook*, il existe une fonction pratique pour vous aider à le faire :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face. Si vous ne travaillez pas sur un ordinateur portable, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+Une fois connecté, vous pouvez pousser votre *tokenizer* en exécutant la commande suivante :
+
+```py
+tokenizer.push_to_hub("code-search-net-tokenizer")
+```
+
+Cela créera un nouveau dépôt dans votre espace avec le nom `code-search-net-tokenizer` contenant le fichier *tokenizer*. Vous pouvez ensuite charger le *tokenizer* de n'importe où avec la méthode `from_pretrained()` :
+
+```py
+# Remplacez "huggingface-course" ci-dessous par votre espace réel pour utiliser votre propre tokenizer
+tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
+```
+
Vous êtes maintenant prêt à entraîner un modèle de langue à partir de zéro et à le *finetuner* sur votre tâche ! Nous verrons cela dans le [chapitre 7](/course/fr/chapter7), mais d'abord, dans le reste de ce chapitre, nous allons examiner de plus près les *tokenizers* rapides et explorer en détail ce qui se passe lorsque nous appelons la méthode `train_new_from_iterator()`.
\ No newline at end of file
diff --git a/chapters/fr/chapter6/3.mdx b/chapters/fr/chapter6/3.mdx
index c37fc06ff..41d437a8d 100644
--- a/chapters/fr/chapter6/3.mdx
+++ b/chapters/fr/chapter6/3.mdx
@@ -1,477 +1,477 @@
-
-
-# Pouvoirs spéciaux des tokenizers rapides
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-Dans cette section, nous allons examiner de plus près les capacités des *tokenizers* dans 🤗 *Transformers*.
-Jusqu'à présent, nous ne les avons utilisés que pour tokeniser les entrées ou décoder les identifiants pour revenir à du texte. Mais les *tokenizers*, et surtout ceux soutenus par la bibliothèque 🤗 *Tokenizers*, peuvent faire beaucoup plus. Pour illustrer ces fonctionnalités supplémentaires, nous allons explorer comment reproduire les résultats des pipelines `token-classification` (que nous avons appelé `ner`) et `question-answering` que nous avons rencontrés pour la première fois dans le [chapitre 1](/course/fr/chapter1).
-
-
-
-Dans la discussion qui suit, nous ferons souvent la distinction entre les *tokenizers* « lents » et les « rapides ». Les *tokenizers* lents sont ceux écrits en Python à l'intérieur de la bibliothèque 🤗 *Transformers*, tandis que les rapides sont ceux fournis par 🤗 *Tokenizers* et sont codés en Rust. Si vous vous souvenez du tableau du [chapitre 5](/course/fr/chapter5/3) qui indiquait combien de temps il fallait à un *tokenizer* rapide et à un *tokenizer* lent pour tokeniser le jeu de données *Drug Review*, vous devriez avoir une idée de la raison pour laquelle nous les appelons rapides et lents :
-
- | *Tokenizer* rapide | *Tokenizer* lent
-:--------------:|:--------------:|:-------------:
-`batched=True` | 10.8s | 4min41s
-`batched=False` | 59.2s | 5min3s
-
-
-
-⚠️ Lors de la tokenisation d'une seule phrase, vous ne verrez pas toujours une différence de vitesse entre les versions lente et rapide d'un même *tokenizer*. En fait, la version rapide peut même être plus lente ! Ce n'est que lorsque vous tokenisez beaucoup de textes en parallèle et en même temps que vous pourrez clairement voir la différence.
-
-
-
-## L'objet BatchEncoding
-
-
-
-La sortie d'un *tokenizer* n'est pas un simple dictionnaire Python. Ce que nous obtenons est en fait un objet spécial `BatchEncoding`. C'est une sous-classe d'un dictionnaire (c'est pourquoi nous avons pu indexer ce résultat sans problème auparavant), mais avec des méthodes supplémentaires qui sont principalement utilisées par les *tokenizers* rapides.
-
-En plus de leurs capacités de parallélisation, la fonctionnalité clé des *tokenizers* rapides est qu'ils gardent toujours la trace de l'étendue originale des textes d'où proviennent les *tokens* finaux, une fonctionnalité que nous appelons *mapping offset*. Cela permet de débloquer des fonctionnalités telles que le mappage de chaque mot aux *tokens* qu'il a générés ou le mappage de chaque caractère du texte original au *token* qu'il contient, et vice versa.
-
-Prenons un exemple :
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
-# Je m'appelle Sylvain et je travaille chez Hugging Face à Brooklyn.
-encoding = tokenizer(example)
-print(type(encoding))
-```
-
-Comme mentionné précédemment, nous obtenons un objet `BatchEncoding` dans la sortie du *tokenizer* :
-
-```python out
-
-```
-
-Puisque la classe `AutoTokenizer` choisit un *tokenizer* rapide par défaut, nous pouvons utiliser les méthodes supplémentaires que cet objet `BatchEncoding` fournit. Nous avons deux façons de vérifier si notre *tokenizer* est rapide ou lent. Nous pouvons soit vérifier l'attribut `is_fast` du *tokenizer* comme suit :
-
-```python
-tokenizer.is_fast
-```
-
-```python out
-True
-```
-
-soit vérifier le même attribut mais avec notre `encoding` :
-
-```python
-encoding.is_fast
-```
-
-```python out
-True
-```
-
-Voyons ce qu'un *tokenizer* rapide nous permet de faire. Tout d'abord, nous pouvons accéder aux *tokens* sans avoir à reconvertir les identifiants en *tokens* :
-
-```py
-encoding.tokens()
-```
-
-```python out
-['[CLS]', 'My', 'name', 'is', 'S', '##yl', '##va', '##in', 'and', 'I', 'work', 'at', 'Hu', '##gging', 'Face', 'in',
- 'Brooklyn', '.', '[SEP]']
-```
-
-Dans ce cas, le *token* à l'index 5 est `##yl` et fait partie du mot « Sylvain » dans la phrase originale. Nous pouvons également utiliser la méthode `word_ids()` pour obtenir l'index du mot dont provient chaque *token* :
-
-```py
-encoding.word_ids()
-```
-
-```python out
-[None, 0, 1, 2, 3, 3, 3, 3, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12, None]
-```
-
-On peut voir que les *tokens* spéciaux du *tokenizer*, `[CLS]` et `[SEP]`, sont mis en correspondance avec `None` et que chaque *token* est mis en correspondance avec le mot dont il provient. Ceci est particulièrement utile pour déterminer si un *token* est au début d'un mot ou si deux *tokens* sont dans le même mot. Nous pourrions nous appuyer sur le préfixe `##` pour cela, mais il ne fonctionne que pour les *tokenizers* de type BERT. Cette méthode fonctionne pour n'importe quel type de *tokenizer*, du moment qu'il est rapide. Dans le chapitre suivant, nous verrons comment utiliser cette capacité pour appliquer correctement les étiquettes que nous avons pour chaque mot aux *tokens* dans des tâches comme la reconnaissance d'entités nommées et le POS (*Part-of-speech*). Nous pouvons également l'utiliser pour masquer tous les *tokens* provenant du même mot dans la modélisation du langage masqué (une technique appelée _whole word masking_).
-
-
-
-La notion de ce qu'est un mot est compliquée. Par exemple, est-ce que « I'll » (contraction de « I will ») compte pour un ou deux mots ? Cela dépend en fait du *tokenizer* et de l'opération de prétokénisation qu'il applique. Certains *tokenizer* se contentent de séparer les espaces et considèrent donc qu'il s'agit d'un seul mot. D'autres utilisent la ponctuation en plus des espaces et considèrent donc qu'il s'agit de deux mots.
-
-
-
-✏️ **Essayez !** Créez un *tokenizer* à partir des checkpoints `bert-base-cased` et `roberta-base` et tokenisez « 81s » avec. Qu'observez-vous ? Quels sont les identifiants des mots ?
-
-
-
-De même, il existe une méthode `sentence_ids()` que nous pouvons utiliser pour associer un *token* à la phrase dont il provient (bien que dans ce cas, le `token_type_ids` retourné par le *tokenizer* peut nous donner la même information).
-
-Enfin, nous pouvons faire correspondre n'importe quel mot ou *token* aux caractères du texte d'origine (et vice versa) grâce aux méthodes `word_to_chars()` ou `token_to_chars()` et `char_to_word()` ou `char_to_token()`. Par exemple, la méthode `word_ids()` nous a dit que `##yl` fait partie du mot à l'indice 3, mais de quel mot s'agit-il dans la phrase ? Nous pouvons le découvrir comme ceci :
-
-```py
-start, end = encoding.word_to_chars(3)
-example[start:end]
-```
-
-```python out
-Sylvain
-```
-
-Comme nous l'avons mentionné précédemment, tout ceci est rendu possible par le fait que le *tokenizer* rapide garde la trace de la partie du texte d'où provient chaque *token* dans une liste d'*offsets*. Pour illustrer leur utilisation, nous allons maintenant vous montrer comment reproduire manuellement les résultats du pipeline `token-classification`.
-
-
-
-✏️ **Essayez !** Rédigez votre propre texte et voyez si vous pouvez comprendre quels *tokens* sont associés à l'identifiant du mot et comment extraire les étendues de caractères pour un seul mot. Pour obtenir des points bonus, essayez d'utiliser deux phrases en entrée et voyez si les identifiants ont un sens pour vous.
-
-
-
-## A l'intérieur du pipeline `token-classification`
-
-Dans le [chapitre 1](/course/fr/chapter1), nous avons eu un premier aperçu de la NER (où la tâche est d'identifier les parties du texte qui correspondent à des entités telles que des personnes, des lieux ou des organisations) avec la fonction `pipeline()` de 🤗 *Transformers*. Puis, dans le [chapitre 2](/course/fr/chapter2), nous avons vu comment un pipeline regroupe les trois étapes nécessaires pour obtenir les prédictions à partir d'un texte brut : la tokenisation, le passage des entrées dans le modèle et le post-traitement. Les deux premières étapes du pipeline de `token-classification` sont les mêmes que dans tout autre pipeline mais le post-traitement est un peu plus complexe. Voyons comment !
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-### Obtenir les résultats de base avec le pipeline
-
-Tout d'abord, prenons un pipeline de classification de *tokens* afin d'obtenir des résultats à comparer manuellement. Le modèle utilisé par défaut est [`dbmdz/bert-large-cased-finetuned-conll03-english`](https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english). Il effectue une NER sur les phrases :
-
-```py
-from transformers import pipeline
-
-token_classifier = pipeline("token-classification")
-token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
-```
-
-```python out
-[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
- {'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
- {'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
- {'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
- {'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
- {'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
- {'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
- {'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-Le modèle a correctement identifié chaque *token* généré par « Sylvain » comme une personne, chaque *token* généré par « Hugging Face » comme une organisation, et le *token* « Brooklyn » comme un lieu. Nous pouvons également demander au pipeline de regrouper les *tokens* qui correspondent à la même entité :
-
-```py
-from transformers import pipeline
-
-token_classifier = pipeline("token-classification", aggregation_strategy="simple")
-token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
-```
-
-```python out
-[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-La propriété `aggregation_strategy` choisie va changer les scores calculés pour chaque entité groupée. Avec `"simple"` le score est juste la moyenne des scores de chaque *token* dans l'entité donnée. Par exemple, le score de « Sylvain » est la moyenne des scores que nous avons vu dans l'exemple précédent pour les tokens `S`, `##yl`, `##va`, et `##in`. D'autres stratégies sont disponibles :
-
-- `"first"`, où le score de chaque entité est le score du premier *token* de cette entité (donc pour « Sylvain » ce serait 0.993828, le score du token `S`)
-- `"max"`, où le score de chaque entité est le score maximal des *tokens* de cette entité (ainsi, pour « Hugging Face », le score de « Face » serait de 0,98879766).
-- `"average"`, où le score de chaque entité est la moyenne des scores des mots qui composent cette entité (ainsi, pour « Sylvain », il n'y aurait pas de différence avec la stratégie `"simple"`, mais "Hugging Face" aurait un score de 0,9819, la moyenne des scores de « Hugging », 0,975, et « Face », 0,98879).
-
-Voyons maintenant comment obtenir ces résultats sans utiliser la fonction `pipeline()` !
-
-### Des entrées aux prédictions
-
-{#if fw === 'pt'}
-
-D'abord, nous devons tokeniser notre entrée et la faire passer dans le modèle. Cela se fait exactement comme dans le [chapitre 2](/course/fr/chapter2). Nous instancions le *tokenizer* et le modèle en utilisant les classes `TFAutoXxx` et les utilisons ensuite dans notre exemple :
-
-```py
-from transformers import AutoTokenizer, AutoModelForTokenClassification
-
-model_checkpoint = "dbmdz/bert-large-cased-finetuned-conll03-english"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
-model = AutoModelForTokenClassification.from_pretrained(model_checkpoint)
-
-example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
-inputs = tokenizer(example, return_tensors="pt")
-outputs = model(**inputs)
-```
-
-Puisque nous utilisons `AutoModelForTokenClassification`, nous obtenons un ensemble de logits pour chaque *token* dans la séquence d'entrée :
-
-```py
-print(inputs["input_ids"].shape)
-print(outputs.logits.shape)
-```
-
-```python out
-torch.Size([1, 19])
-torch.Size([1, 19, 9])
-```
-
-{:else}
-
-D'abord, nous devons tokeniser notre entrée et la faire passer dans le modèle. Cela se fait exactement comme dans le [chapitre 2](/course/fr/chapter2). Nous instancions le *tokenizer* et le modèle en utilisant les classes `TFAutoXxx` et les utilisons ensuite dans notre exemple :
-
-```py
-from transformers import AutoTokenizer, TFAutoModelForTokenClassification
-
-model_checkpoint = "dbmdz/bert-large-cased-finetuned-conll03-english"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
-model = TFAutoModelForTokenClassification.from_pretrained(model_checkpoint)
-
-example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
-inputs = tokenizer(example, return_tensors="tf")
-outputs = model(**inputs)
-```
-
-Puisque nous utilisons `TFAutoModelForTokenClassification`, nous obtenons un ensemble de logits pour chaque *token* dans la séquence d'entrée :
-
-```py
-print(inputs["input_ids"].shape)
-print(outputs.logits.shape)
-```
-
-```python out
-(1, 19)
-(1, 19, 9)
-```
-
-{/if}
-
-Nous avons un batch avec 1 séquence de 19 *tokens* et le modèle a 9 étiquettes différentes. Ainsi, la sortie du modèle a une forme de 1 x 19 x 9. Comme pour le pipeline de classification de texte, nous utilisons une fonction softmax pour convertir ces logits en probabilités et nous prenons l'argmax pour obtenir des prédictions (notez que nous pouvons prendre l'argmax sur les logits car la fonction softmax ne change pas l'ordre) :
-
-{#if fw === 'pt'}
-
-```py
-import torch
-
-probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)[0].tolist()
-predictions = outputs.logits.argmax(dim=-1)[0].tolist()
-print(predictions)
-```
-
-{:else}
-
-```py
-import tensorflow as tf
-
-probabilities = tf.math.softmax(outputs.logits, axis=-1)[0]
-probabilities = probabilities.numpy().tolist()
-predictions = tf.math.argmax(outputs.logits, axis=-1)[0]
-predictions = predictions.numpy().tolist()
-print(predictions)
-```
-
-{/if}
-
-```python out
-[0, 0, 0, 0, 4, 4, 4, 4, 0, 0, 0, 0, 6, 6, 6, 0, 8, 0, 0]
-```
-
-L'attribut `model.config.id2label` contient la correspondance entre les index et les étiquettes que nous pouvons utiliser pour donner un sens aux prédictions :
-
-```py
-model.config.id2label
-```
-
-```python out
-{0: 'O',
- 1: 'B-MISC',
- 2: 'I-MISC',
- 3: 'B-PER',
- 4: 'I-PER',
- 5: 'B-ORG',
- 6: 'I-ORG',
- 7: 'B-LOC',
- 8: 'I-LOC'}
-```
-
-Comme nous l'avons vu précédemment, il y a 9 étiquettes : `O` est le label pour les *tokens* qui ne sont dans aucune entité nommée (il signifie *outside* (en dehors)) et nous avons ensuite deux labels pour chaque type d'entité (divers, personne, organisation et lieu). L'étiquette `B-XXX` indique que le *token* est au début d'une entité `XXX` et l'étiquette `I-XXX` indique que le *token* est à l'intérieur de l'entité `XXX`. Par exemple, dans l'exemple actuel, nous nous attendons à ce que notre modèle classe le *token* `S` comme `B-PER` (début d'une entité personne) et les *tokens* `##yl`, `##va` et `##in` comme `I-PER` (à l'intérieur d'une entité personne).
-
-Vous pourriez penser que le modèle s'est trompé ici car il a attribué l'étiquette `I-PER` à ces quatre *tokens* mais ce n'est pas tout à fait vrai. Il existe en fait deux formats pour ces étiquettes `B-` et `I-` : *IOB1* et *IOB2*. Le format IOB2 (en rose ci-dessous) est celui que nous avons introduit alors que dans le format IOB1 (en bleu), les étiquettes commençant par `B-` ne sont jamais utilisées que pour séparer deux entités adjacentes du même type. Le modèle que nous utilisons a été *finetuné* sur un jeu de données utilisant ce format, c'est pourquoi il attribue le label `I-PER` au *token* `S`.
-
-
-

-

-
+
+
+
-

-

-
+
+
+
-

-

-
+
+
+
-
-
-
`` et '' par " et toute séquence de deux espaces ou plus par un seul espace, de plus il supprime les accents.
-
-Le prétokenizer à utiliser pour tout *tokenizer SentencePiece* est `Metaspace` :
-
-```python
-tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
-```
-
-Nous pouvons jeter un coup d'oeil à la prétokénisation sur le même exemple de texte que précédemment :
-
-```python
-tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
-```
-
-```python out
-[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
-```
-
-Vient ensuite le modèle, qui doit être entraîné. XLNet possède un certain nombre de *tokens* spéciaux :
-
-```python
-special_tokens = ["", "", "", "", "", "", ""]
-trainer = trainers.UnigramTrainer(
- vocab_size=25000, special_tokens=special_tokens, unk_token=""
-)
-tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
-```
-
-Un argument très important à ne pas oublier pour le `UnigramTrainer` est le `unk_token`. Nous pouvons aussi passer d'autres arguments spécifiques à l'algorithme *Unigram*, comme le `shrinking_factor` pour chaque étape où nous enlevons des *tokens* (par défaut 0.75) ou le `max_piece_length` pour spécifier la longueur maximale d'un *token* donné (par défaut 16).
-
-Ce *tokenizer* peut aussi être entraîné sur des fichiers texte :
-
-```python
-tokenizer.model = models.Unigram()
-tokenizer.train(["wikitext-2.txt"], trainer=trainer)
-```
-
-Regardons la tokenisation de notre exemple :
-
-```python
-encoding = tokenizer.encode("Let's test this tokenizer.")
-print(encoding.tokens)
-```
-
-```python out
-['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.']
-```
-
-Une particularité de XLNet est qu'il place le *token* `` à la fin de la phrase, avec un identifiant de 2 (pour le distinguer des autres *tokens*). Le résultat est un remplissage à gauche. Nous pouvons traiter tous les *tokens* spéciaux et les types d'identifiant de *token* avec un modèle, comme pour BERT. Mais d'abord nous devons obtenir les identifiants des *tokens* `` et `` :
-
-```python
-cls_token_id = tokenizer.token_to_id("")
-sep_token_id = tokenizer.token_to_id("")
-print(cls_token_id, sep_token_id)
-```
-
-```python out
-0 1
-```
-
-Le modèle ressemble à ceci :
-
-```python
-tokenizer.post_processor = processors.TemplateProcessing(
- single="$A:0 :0 :2",
- pair="$A:0 :0 $B:1 :1 :2",
- special_tokens=[("", sep_token_id), ("", cls_token_id)],
-)
-```
-
-Et nous pouvons tester son fonctionnement en codant une paire de phrases :
-
-```python
-encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences!")
-print(encoding.tokens)
-print(encoding.type_ids)
-```
-
-```python out
-['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.', '.', '.', '', '▁', 'on', '▁', 'a', '▁pair',
- '▁of', '▁sentence', 's', '!', '', '']
-[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]
-```
-
-Enfin, nous ajoutons un décodeur `Metaspace` :
-
-```python
-tokenizer.decoder = decoders.Metaspace()
-```
-
-et on en a fini avec ce *tokenizer* ! On peut le sauvegarder et l'envelopper dans un `PreTrainedTokenizerFast` ou `XLNetTokenizerFast` si on veut l'utiliser dans 🤗 *Transformers*. Une chose à noter lors de l'utilisation de `PreTrainedTokenizerFast` est qu'en plus des *tokens* spéciaux, nous devons dire à la bibliothèque 🤗 *Transformers* de rembourrer à gauche :
-
-```python
-from transformers import PreTrainedTokenizerFast
-
-wrapped_tokenizer = PreTrainedTokenizerFast(
- tokenizer_object=tokenizer,
- bos_token="",
- eos_token="",
- unk_token="",
- pad_token="",
- cls_token="",
- sep_token="",
- mask_token="",
- padding_side="left",
-)
-```
-
-Ou alternativement :
-
-```python
-from transformers import XLNetTokenizerFast
-
-wrapped_tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer)
-```
-
-Maintenant que vous avez vu comment les différentes briques sont utilisées pour construire des *tokenizers* existants, vous devriez être capable d'écrire n'importe quel *tokenizer* que vous voulez avec la bibliothèque 🤗 *Tokenizers* et pouvoir l'utiliser dans 🤗 *Transformers*.
+# Construction d'un tokenizer, bloc par bloc
+
+
+
+Comme nous l'avons vu dans les sections précédentes, la tokenisation comprend plusieurs étapes :
+
+- normalisation (tout nettoyage du texte jugé nécessaire, comme la suppression des espaces ou des accents, la normalisation Unicode, etc.),
+- prétokénisation (division de l'entrée en mots),
+- passage de l'entrée dans le modèle (utilisation des mots prétokénisés pour produire une séquence de *tokens*),
+- post-traitement (ajout des *tokens* spéciaux du *tokenizer*, génération du masque d'attention et des identifiants du type de *token*).
+
+Pour mémoire, voici un autre aperçu du processus global :
+
+
+
+
+
`` et '' par " et toute séquence de deux espaces ou plus par un seul espace, de plus il supprime les accents.
+
+Le prétokenizer à utiliser pour tout *tokenizer SentencePiece* est `Metaspace` :
+
+```python
+tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
+```
+
+Nous pouvons jeter un coup d'oeil à la prétokénisation sur le même exemple de texte que précédemment :
+
+```python
+tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
+```
+
+```python out
+[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
+```
+
+Vient ensuite le modèle, qui doit être entraîné. XLNet possède un certain nombre de *tokens* spéciaux :
+
+```python
+special_tokens = ["", "", "", "", "", "", ""]
+trainer = trainers.UnigramTrainer(
+ vocab_size=25000, special_tokens=special_tokens, unk_token=""
+)
+tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
+```
+
+Un argument très important à ne pas oublier pour le `UnigramTrainer` est le `unk_token`. Nous pouvons aussi passer d'autres arguments spécifiques à l'algorithme *Unigram*, comme le `shrinking_factor` pour chaque étape où nous enlevons des *tokens* (par défaut 0.75) ou le `max_piece_length` pour spécifier la longueur maximale d'un *token* donné (par défaut 16).
+
+Ce *tokenizer* peut aussi être entraîné sur des fichiers texte :
+
+```python
+tokenizer.model = models.Unigram()
+tokenizer.train(["wikitext-2.txt"], trainer=trainer)
+```
+
+Regardons la tokenisation de notre exemple :
+
+```python
+encoding = tokenizer.encode("Let's test this tokenizer.")
+print(encoding.tokens)
+```
+
+```python out
+['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.']
+```
+
+Une particularité de XLNet est qu'il place le *token* `` à la fin de la phrase, avec un identifiant de 2 (pour le distinguer des autres *tokens*). Le résultat est un remplissage à gauche. Nous pouvons traiter tous les *tokens* spéciaux et les types d'identifiant de *token* avec un modèle, comme pour BERT. Mais d'abord nous devons obtenir les identifiants des *tokens* `` et `` :
+
+```python
+cls_token_id = tokenizer.token_to_id("")
+sep_token_id = tokenizer.token_to_id("")
+print(cls_token_id, sep_token_id)
+```
+
+```python out
+0 1
+```
+
+Le modèle ressemble à ceci :
+
+```python
+tokenizer.post_processor = processors.TemplateProcessing(
+ single="$A:0 :0 :2",
+ pair="$A:0 :0 $B:1 :1 :2",
+ special_tokens=[("", sep_token_id), ("", cls_token_id)],
+)
+```
+
+Et nous pouvons tester son fonctionnement en codant une paire de phrases :
+
+```python
+encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences!")
+print(encoding.tokens)
+print(encoding.type_ids)
+```
+
+```python out
+['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.', '.', '.', '', '▁', 'on', '▁', 'a', '▁pair',
+ '▁of', '▁sentence', 's', '!', '', '']
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]
+```
+
+Enfin, nous ajoutons un décodeur `Metaspace` :
+
+```python
+tokenizer.decoder = decoders.Metaspace()
+```
+
+et on en a fini avec ce *tokenizer* ! On peut le sauvegarder et l'envelopper dans un `PreTrainedTokenizerFast` ou `XLNetTokenizerFast` si on veut l'utiliser dans 🤗 *Transformers*. Une chose à noter lors de l'utilisation de `PreTrainedTokenizerFast` est qu'en plus des *tokens* spéciaux, nous devons dire à la bibliothèque 🤗 *Transformers* de rembourrer à gauche :
+
+```python
+from transformers import PreTrainedTokenizerFast
+
+wrapped_tokenizer = PreTrainedTokenizerFast(
+ tokenizer_object=tokenizer,
+ bos_token="",
+ eos_token="",
+ unk_token="",
+ pad_token="",
+ cls_token="",
+ sep_token="",
+ mask_token="",
+ padding_side="left",
+)
+```
+
+Ou alternativement :
+
+```python
+from transformers import XLNetTokenizerFast
+
+wrapped_tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer)
+```
+
+Maintenant que vous avez vu comment les différentes briques sont utilisées pour construire des *tokenizers* existants, vous devriez être capable d'écrire n'importe quel *tokenizer* que vous voulez avec la bibliothèque 🤗 *Tokenizers* et pouvoir l'utiliser dans 🤗 *Transformers*.
diff --git a/chapters/fr/chapter6/9.mdx b/chapters/fr/chapter6/9.mdx
index 11e4beeab..2d586dc7b 100644
--- a/chapters/fr/chapter6/9.mdx
+++ b/chapters/fr/chapter6/9.mdx
@@ -1,11 +1,16 @@
-# Tokenizer, coché !
-
-Bon travail pour finir ce chapitre !
-
-Après cette plongée en profondeur dans les *tokenizers*, vous devriez :
-
-- être capable d'entraîner un nouveau tokenizer en utilisant un ancien tokenizer comme modèle,
-- comprendre comment utiliser les *offsets* pour faire correspondre la position des *tokens* à l'étendue de texte d'origine,
-- connaître les différences entre BPE, *WordPiece* et *Unigram*,
-- être capable de combiner les blocs fournis par la bibliothèque 🤗 *Tokenizers* pour construire votre propre *tokenizer*,
-- être capable d'utiliser ce *tokenizer* dans la bibliothèque 🤗 *Transformers*.
+# Tokenizer, coché !
+
+
+
+Bon travail pour finir ce chapitre !
+
+Après cette plongée en profondeur dans les *tokenizers*, vous devriez :
+
+- être capable d'entraîner un nouveau tokenizer en utilisant un ancien tokenizer comme modèle,
+- comprendre comment utiliser les *offsets* pour faire correspondre la position des *tokens* à l'étendue de texte d'origine,
+- connaître les différences entre BPE, *WordPiece* et *Unigram*,
+- être capable de combiner les blocs fournis par la bibliothèque 🤗 *Tokenizers* pour construire votre propre *tokenizer*,
+- être capable d'utiliser ce *tokenizer* dans la bibliothèque 🤗 *Transformers*.
diff --git a/chapters/fr/chapter7/1.mdx b/chapters/fr/chapter7/1.mdx
index 49c7a7a84..603659553 100644
--- a/chapters/fr/chapter7/1.mdx
+++ b/chapters/fr/chapter7/1.mdx
@@ -1,33 +1,38 @@
-
-
-# Introduction
-
-Dans le [chapitre 3](/course/fr/chapter3), vous avez vu comment *finetuner* un modèle de classification de texte. Dans ce chapitre, nous nous attaquons aux tâches de NLP courantes suivantes :
-
-- la classification de *tokens*,
-- la modélisation du langage masqué (comme BERT),
-- les résumés,
-- la traduction,
-- le pré-entraînement à la modélisation causale du langage (comme GPT-2),
-- la réponse aux questions.
-
-{#if fw === 'pt'}
-
-Pour ce faire, vous devrez tirer parti de tout ce que vous avez appris sur l'API `Trainer`, sur la bibliothèque 🤗 *Accelerate* au [chapitre 3](/course/fr/chapitre3), sur la bibliothèque 🤗 *Datasets* au [chapitre 5](/course/fr/chapiter5) et sur la bibliothèque 🤗 *Tokenizers* au [chapitre 6](/course/fr/chapiter6). Nous téléchargerons également nos résultats sur le *Hub*, comme nous l'avons fait dans le [chapitre 4](/course/fr/chapiter4), donc c'est vraiment le chapitre où tout est réuni !
-
-Chaque section peut être lue indépendamment et vous montrera comment entraîner un modèle avec l'API `Trainer` ou avec 🤗 *Accelerate* et votre propre boucle d'entraînement. N'hésitez pas à sauter l'une ou l'autre partie et à vous concentrer sur celle qui vous intéresse le plus. L'API `Trainer` est idéale pour *finetuner* ou entraîner votre modèle sans vous soucier de ce qui se passe en coulisses, tandis que la boucle d'entraînement avec `Accelerate` vous permettra de personnaliser plus facilement toutes les parties que vous souhaitez.
-
-{:else}
-
-Pour ce faire, vous devrez tirer parti de tout ce que vous avez appris sur l'entraînement des modèles avec l'API Keras dans le [chapitre 3](/course/fr/chapiter3), sur la bibliothèque 🤗 *Accelerate* au [chapitre 3](/course/fr/chapitre3), sur la bibliothèque 🤗 *Datasets* au [chapitre 5](/course/fr/chapiter5) et sur la bibliothèque 🤗 *Tokenizers* au [chapitre 6](/course/fr/chapiter6). Nous téléchargerons également nos résultats sur le *Hub*, comme nous l'avons fait dans le [chapitre 4](/course/fr/chapiter4), donc c'est vraiment le chapitre où tout est réuni !
-
-Chaque section peut être lue indépendamment.
-
-{/if}
-
-
-
-
-Si vous lisez les sections dans l'ordre, vous remarquerez qu'elles ont beaucoup de code et de prose en commun. La répétition est intentionnelle, afin de vous permettre de vous plonger (ou de revenir plus tard) dans une tâche qui vous intéresse et de trouver un exemple fonctionnel complet.
-
-
+
+
+# Introduction
+
+
+
+Dans le [chapitre 3](/course/fr/chapter3), vous avez vu comment *finetuner* un modèle de classification de texte. Dans ce chapitre, nous nous attaquons aux tâches de NLP courantes suivantes :
+
+- la classification de *tokens*,
+- la modélisation du langage masqué (comme BERT),
+- les résumés,
+- la traduction,
+- le pré-entraînement à la modélisation causale du langage (comme GPT-2),
+- la réponse aux questions.
+
+{#if fw === 'pt'}
+
+Pour ce faire, vous devrez tirer parti de tout ce que vous avez appris sur l'API `Trainer`, sur la bibliothèque 🤗 *Accelerate* au [chapitre 3](/course/fr/chapitre3), sur la bibliothèque 🤗 *Datasets* au [chapitre 5](/course/fr/chapiter5) et sur la bibliothèque 🤗 *Tokenizers* au [chapitre 6](/course/fr/chapiter6). Nous téléchargerons également nos résultats sur le *Hub*, comme nous l'avons fait dans le [chapitre 4](/course/fr/chapiter4), donc c'est vraiment le chapitre où tout est réuni !
+
+Chaque section peut être lue indépendamment et vous montrera comment entraîner un modèle avec l'API `Trainer` ou avec 🤗 *Accelerate* et votre propre boucle d'entraînement. N'hésitez pas à sauter l'une ou l'autre partie et à vous concentrer sur celle qui vous intéresse le plus. L'API `Trainer` est idéale pour *finetuner* ou entraîner votre modèle sans vous soucier de ce qui se passe en coulisses, tandis que la boucle d'entraînement avec `Accelerate` vous permettra de personnaliser plus facilement toutes les parties que vous souhaitez.
+
+{:else}
+
+Pour ce faire, vous devrez tirer parti de tout ce que vous avez appris sur l'entraînement des modèles avec l'API Keras dans le [chapitre 3](/course/fr/chapiter3), sur la bibliothèque 🤗 *Accelerate* au [chapitre 3](/course/fr/chapitre3), sur la bibliothèque 🤗 *Datasets* au [chapitre 5](/course/fr/chapiter5) et sur la bibliothèque 🤗 *Tokenizers* au [chapitre 6](/course/fr/chapiter6). Nous téléchargerons également nos résultats sur le *Hub*, comme nous l'avons fait dans le [chapitre 4](/course/fr/chapiter4), donc c'est vraiment le chapitre où tout est réuni !
+
+Chaque section peut être lue indépendamment.
+
+{/if}
+
+
+
+
+Si vous lisez les sections dans l'ordre, vous remarquerez qu'elles ont beaucoup de code et de prose en commun. La répétition est intentionnelle, afin de vous permettre de vous plonger (ou de revenir plus tard) dans une tâche qui vous intéresse et de trouver un exemple fonctionnel complet.
+
+
diff --git a/chapters/fr/chapter7/2.mdx b/chapters/fr/chapter7/2.mdx
index 921f9629f..8a4cdc83a 100644
--- a/chapters/fr/chapter7/2.mdx
+++ b/chapters/fr/chapter7/2.mdx
@@ -1,982 +1,982 @@
-
-
-# Classification de tokens
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-La première application que nous allons explorer est la classification de *tokens*. Cette tâche générique englobe tous les problèmes qui peuvent être formulés comme l'attribution d'une étiquette à chaque *token* d'une phrase, tels que :
-
-- la **reconnaissance d'entités nommées (NER de l'anglais *Named Entity Recognition*)**, c'est-à-dire trouver les entités (telles que des personnes, des lieux ou des organisations) dans une phrase. Ce tâche peut être formulée comme l'attribution d'une étiquette à chaque *token* faisant parti d'une entité en ayant une classe spécifique par entité, et une classe pour les *tokens* ne faisant pas parti d'entité.
-- le ***part-of-speech tagging* (POS)**, c'est-à-dire marquer chaque mot dans une phrase comme correspondant à une partie particulière (comme un nom, un verbe, un adjectif, etc.).
-- le ***chunking***, c'est-à-dire trouver les *tokens* qui appartiennent à la même entité. Cette tâche (qui peut être combinée avec le POS ou la NER) peut être formulée comme l'attribution d'une étiquette (habituellement `B-`) à tous les *tokens* qui sont au début d'un morceau, une autre étiquette (habituellement `I-`) aux *tokens* qui sont à l'intérieur d'un morceau, et une troisième étiquette (habituellement `O`) aux *tokens* qui n'appartiennent à aucun morceau.
-
-
-
-Bien sûr, il existe de nombreux autres types de problèmes de classification de *tokens*. Ce ne sont là que quelques exemples représentatifs. Dans cette section, nous allons *finetuner* un modèle (BERT) sur la tâche de NER. Il sera alors capable de calculer des prédictions comme celle-ci :
-
-
-
-
-
-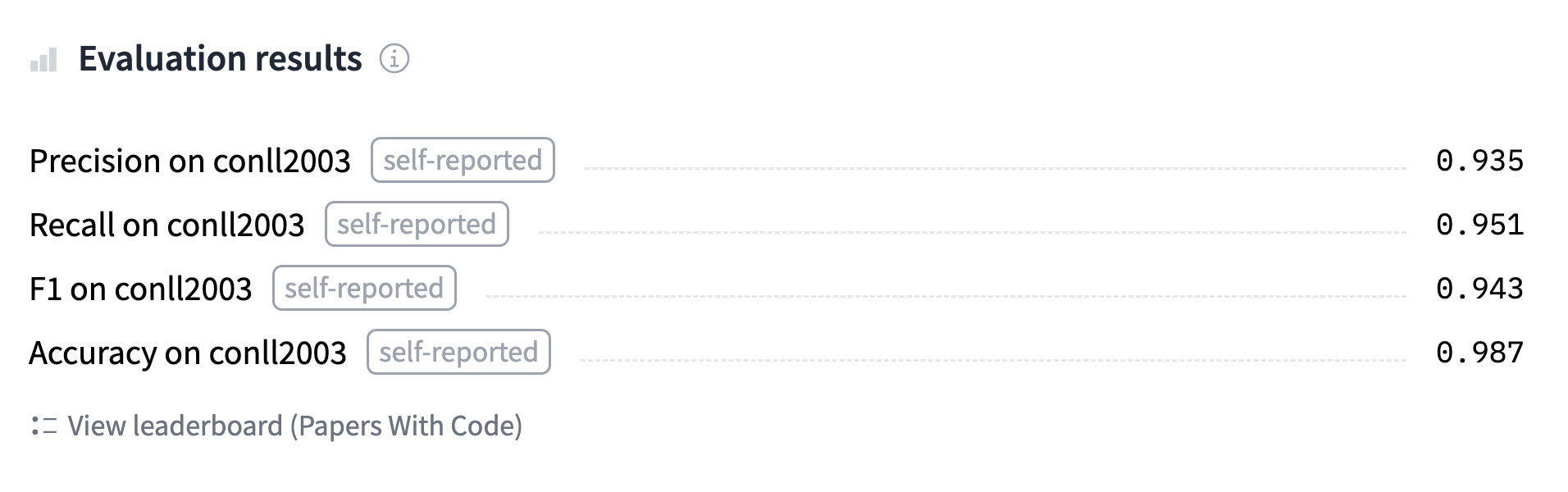 -
-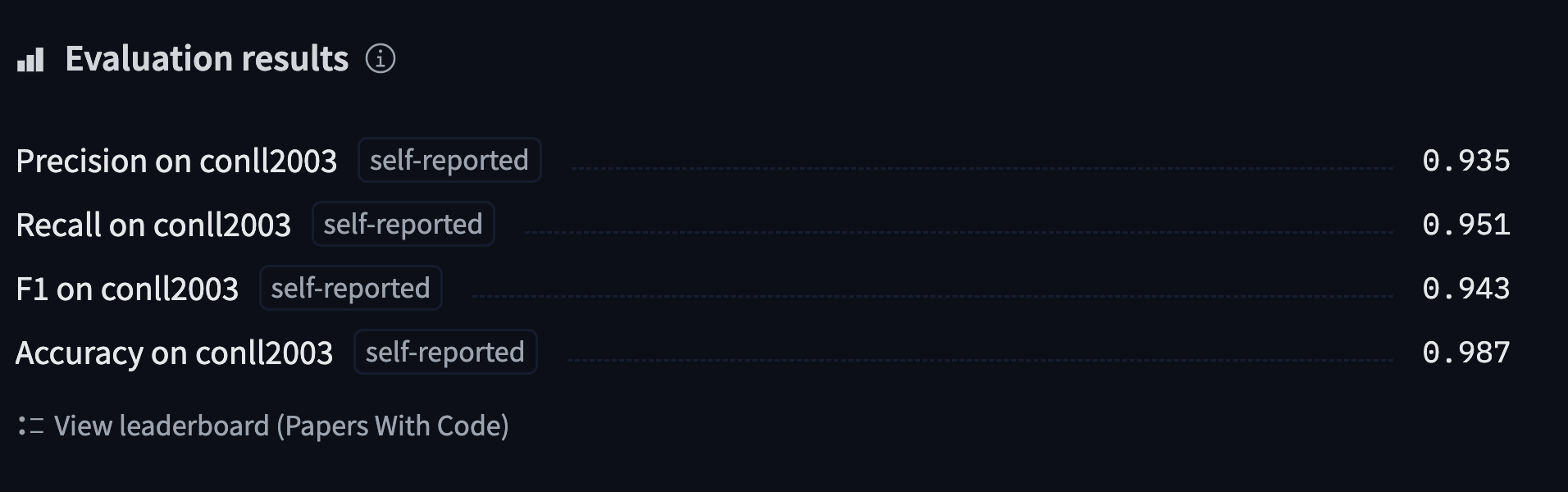 -
-
-Vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+nom+est+Sylvain+et+je+travaille+à+Hugging+Face+in+Brooklyn) les prédictions du modèle que nous allons entraîner.
-
-## Préparation des données
-
-Tout d'abord, nous avons besoin d'un jeu de données adapté à la classification des *tokens*. Dans cette section, nous utiliserons le jeu de données [CoNLL-2003](https://huggingface.co/datasets/conll2003), qui contient des articles de presse de Reuters.
-
-
-
-💡 Tant que votre jeu de données consiste en des textes divisés en mots avec leurs étiquettes correspondantes, vous pourrez adapter les procédures de traitement des données décrites ici à votre propre jeu de données. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rafraîchissement sur la façon de charger vos propres données personnalisées dans un `Dataset`.
-
-
-
-### Le jeu de données CoNLL-2003
-
-Pour charger le jeu de données CoNLL-2003, nous utilisons la méthode `load_dataset()` de la bibliothèque 🤗 *Datasets* :
-
-```py
-from datasets import load_dataset
-
-raw_datasets = load_dataset("conll2003")
-```
-
-Cela va télécharger et mettre en cache le jeu de données, comme nous l'avons vu dans [chapitre 3](/course/fr/chapter3) pour le jeu de données GLUE MRPC. L'inspection de cet objet nous montre les colonnes présentes dans ce jeu de données et la répartition entre les ensembles d'entraînement, de validation et de test :
-
-```py
-raw_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 14041
- })
- validation: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 3250
- })
- test: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 3453
- })
-})
-```
-
-En particulier, nous pouvons voir que le jeu de données contient des étiquettes pour les trois tâches que nous avons mentionnées précédemment : NER, POS et *chunking*. Une grande différence avec les autres jeux de données est que les entrées textuelles ne sont pas présentés comme des phrases ou des documents, mais comme des listes de mots (la dernière colonne est appelée `tokens`, mais elle contient des mots dans le sens où ce sont des entrées prétokénisées qui doivent encore passer par le *tokenizer* pour la tokenisation en sous-mots).
-
-Regardons le premier élément de l'ensemble d'entraînement :
-
-```py
-raw_datasets["train"][0]["tokens"]
-```
-
-```python out
-['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
-```
-
-Puisque nous voulons effectuer reconnaître des entités nommées, nous allons examiner les balises NER :
-
-```py
-raw_datasets["train"][0]["ner_tags"]
-```
-
-```python out
-[3, 0, 7, 0, 0, 0, 7, 0, 0]
-```
-
-Ce sont les étiquettes sous forme d'entiers disponibles pour l'entraînement mais ne sont pas nécessairement utiles lorsque nous voulons inspecter les données. Comme pour la classification de texte, nous pouvons accéder à la correspondance entre ces entiers et les noms des étiquettes en regardant l'attribut `features` de notre jeu de données :
-
-```py
-ner_feature = raw_datasets["train"].features["ner_tags"]
-ner_feature
-```
-
-```python out
-Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
-```
-
-Cette colonne contient donc des éléments qui sont des séquences de `ClassLabel`. Le type des éléments de la séquence se trouve dans l'attribut `feature` de cette `ner_feature`, et nous pouvons accéder à la liste des noms en regardant l'attribut `names` de cette `feature` :
-
-```py
-label_names = ner_feature.feature.names
-label_names
-```
-
-```python out
-['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
-```
-
-Nous avons déjà vu ces étiquettes au [chapitre 6](/course/fr/chapter6/3) lorsque nous nous sommes intéressés au pipeline `token-classification` mais nosu pouvons tout de même faire un rapide rappel :
-
-- `O` signifie que le mot ne correspond à aucune entité.
-- `B-PER`/`I-PER` signifie que le mot correspond au début/est à l'intérieur d'une entité *personne*.
-- `B-ORG`/`I-ORG` signifie que le mot correspond au début/est à l'intérieur d'une entité *organisation*.
-- `B-LOC`/`I-LOC` signifie que le mot correspond au début/est à l'intérieur d'une entité *location*.
-- `B-MISC`/`I-MISC` signifie que le mot correspond au début/est à l'intérieur d'une entité *divers*.
-
-Maintenant, le décodage des étiquettes que nous avons vues précédemment nous donne ceci :
-
-```python
-words = raw_datasets["train"][0]["tokens"]
-labels = raw_datasets["train"][0]["ner_tags"]
-line1 = ""
-line2 = ""
-for word, label in zip(words, labels):
- full_label = label_names[label]
- max_length = max(len(word), len(full_label))
- line1 += word + " " * (max_length - len(word) + 1)
- line2 += full_label + " " * (max_length - len(full_label) + 1)
-
-print(line1)
-print(line2)
-```
-
-```python out
-'EU rejects German call to boycott British lamb .'
-'B-ORG O B-MISC O O O B-MISC O O'
-```
-
-Et pour un exemple mélangeant les étiquettes `B-` et `I-`, voici ce que le même code nous donne sur le quatrième élément du jeu d'entraînement :
-
-```python out
-'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
-'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
-```
-
-Comme on peut le voir, les entités couvrant deux mots, comme « European Union » et « Werner Zwingmann », se voient attribuer une étiquette `B-` pour le premier mot et une étiquette `I-` pour le second.
-
-
-
-✏️ *A votre tour !* Affichez les deux mêmes phrases avec leurs étiquettes POS ou *chunking*.
-
-
-
-### Traitement des données
-
-
-
-Comme d'habitude, nos textes doivent être convertis en identifiants de *tokens* avant que le modèle puisse leur donner un sens. Comme nous l'avons vu au [chapitre 6](/course/fr/chapter6/), une grande différence dans le cas des tâches de classification de *tokens* est que nous avons des entrées prétokénisées. Heureusement, l'API `tokenizer` peut gérer cela assez facilement. Nous devons juste avertir le `tokenizer` avec un drapeau spécial.
-
-Pour commencer, nous allons créer notre objet `tokenizer`. Comme nous l'avons dit précédemment, nous allons utiliser un modèle BERT pré-entraîné, donc nous allons commencer par télécharger et mettre en cache le *tokenizer* associé :
-
-```python
-from transformers import AutoTokenizer
-
-model_checkpoint = "bert-base-cased"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
-```
-
-Vous pouvez remplacer le `model_checkpoint` par tout autre modèle que vous préférez à partir du [*Hub*](https://huggingface.co/models), ou par un dossier local dans lequel vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*. La seule contrainte est que le *tokenizer* doit être soutenu par la bibliothèque 🤗 *Tokenizers*. Il y a donc une version rapide disponible. Vous pouvez voir toutes les architectures qui ont une version rapide dans [ce tableau](https://huggingface.co/transformers/#supported-frameworks), et pour vérifier que l'objet `tokenizer` que vous utilisez est bien soutenu par 🤗 *Tokenizers* vous pouvez regarder son attribut `is_fast` :
-
-```py
-tokenizer.is_fast
-```
-
-```python out
-True
-```
-
-Pour tokeniser une entrée prétokenisée, nous pouvons utiliser notre `tokenizer` comme d'habitude et juste ajouter `is_split_into_words=True` :
-
-```py
-inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
-inputs.tokens()
-```
-
-```python out
-['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
-```
-
-Comme on peut le voir, le *tokenizer* a ajouté les *tokens* spéciaux utilisés par le modèle (`[CLS]` au début et `[SEP]` à la fin) et n'a pas touché à la plupart des mots. Le mot `lamb`, cependant, a été tokenisé en deux sous-mots, `la` et `##mb`. Cela introduit un décalage entre nos entrées et les étiquettes : la liste des étiquettes n'a que 9 éléments, alors que notre entrée a maintenant 12 *tokens*. Il est facile de tenir compte des *tokens* spéciaux (nous savons qu'ils sont au début et à la fin), mais nous devons également nous assurer que nous alignons toutes les étiquettes avec les mots appropriés.
-
-Heureusement, comme nous utilisons un *tokenizer* rapide, nous avons accès aux superpouvoirs des 🤗 *Tokenizers*, ce qui signifie que nous pouvons facilement faire correspondre chaque *token* au mot correspondant (comme on le voit au [chapitre 6](/course/fr/chapter6/3)) :
-
-```py
-inputs.word_ids()
-```
-
-```python out
-[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
-```
-
-Avec un peu de travail, nous pouvons étendre notre liste d'étiquettes pour qu'elle corresponde aux *tokens*. La première règle que nous allons appliquer est que les *tokens* spéciaux reçoivent une étiquette de `-100`. En effet, par défaut, `-100` est un indice qui est ignoré dans la fonction de perte que nous allons utiliser (l'entropie croisée). Ensuite, chaque *token* reçoit la même étiquette que le *token* qui a commencé le mot dans lequel il se trouve puisqu'ils font partie de la même entité. Pour les *tokens* à l'intérieur d'un mot mais pas au début, nous remplaçons le `B-` par `I-` (puisque le *token* ne commence pas l'entité) :
-
-```python
-def align_labels_with_tokens(labels, word_ids):
- new_labels = []
- current_word = None
- for word_id in word_ids:
- if word_id != current_word:
- # Début d'un nouveau mot !
- current_word = word_id
- label = -100 if word_id is None else labels[word_id]
- new_labels.append(label)
- elif word_id is None:
- # Token spécial
- new_labels.append(-100)
- else:
- # Même mot que le token précédent
- label = labels[word_id]
- # Si l'étiquette est B-XXX, nous la changeons en I-XXX
- if label % 2 == 1:
- label += 1
- new_labels.append(label)
-
- return new_labels
-```
-
-Essayons-le sur notre première phrase :
-
-```py
-labels = raw_datasets["train"][0]["ner_tags"]
-word_ids = inputs.word_ids()
-print(labels)
-print(align_labels_with_tokens(labels, word_ids))
-```
-
-```python out
-[3, 0, 7, 0, 0, 0, 7, 0, 0]
-[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
-```
-
-Comme nous pouvons le voir, notre fonction a ajouté `-100` pour les deux *tokens* spéciaux du début et de fin, et un nouveau `0` pour notre mot qui a été divisé en deux *tokens*.
-
-
-
-✏️ *A votre tour !* Certains chercheurs préfèrent n'attribuer qu'une seule étiquette par mot et attribuer `-100` aux autres sous-*tokens* dans un mot donné. Ceci afin d'éviter que les longs mots qui se divisent en plusieurs batchs ne contribuent fortement à la perte. Changez la fonction précédente pour aligner les étiquettes avec les identifiants d'entrée en suivant cette règle.
-
-
-Pour prétraiter notre jeu de données, nous devons tokeniser toutes les entrées et appliquer `align_labels_with_tokens()` sur toutes les étiquettes. Pour profiter de la vitesse de notre *tokenizer* rapide, il est préférable de tokeniser beaucoup de textes en même temps. Nous allons donc écrire une fonction qui traite une liste d'exemples et utiliser la méthode `Dataset.map()` avec l'option `batched=True`. La seule chose qui diffère de notre exemple précédent est que la fonction `word_ids()` a besoin de récupérer l'index de l'exemple dont nous voulons les identifiants de mots lorsque les entrées du *tokenizer* sont des listes de textes (ou dans notre cas, des listes de mots), donc nous l'ajoutons aussi :
-
-```py
-def tokenize_and_align_labels(examples):
- tokenized_inputs = tokenizer(
- examples["tokens"], truncation=True, is_split_into_words=True
- )
- all_labels = examples["ner_tags"]
- new_labels = []
- for i, labels in enumerate(all_labels):
- word_ids = tokenized_inputs.word_ids(i)
- new_labels.append(align_labels_with_tokens(labels, word_ids))
-
- tokenized_inputs["labels"] = new_labels
- return tokenized_inputs
-```
-
-Notez que nous n'avons pas encore rembourré nos entrées. Nous le ferons plus tard lors de la création des batchs avec un collateur de données.
-
-Nous pouvons maintenant appliquer tout ce prétraitement en une seule fois sur les autres divisions de notre jeu de données :
-
-```py
-tokenized_datasets = raw_datasets.map(
- tokenize_and_align_labels,
- batched=True,
- remove_columns=raw_datasets["train"].column_names,
-)
-```
-
-Nous avons fait la partie la plus difficile ! Maintenant que les données ont été prétraitées, l'entraînement ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3).
-
-{#if fw === 'pt'}
-
-## Finetuning du modèle avec l'API `Trainer`
-
-Le code utilisant `Trainer` sera le même que précédemment. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
-
-{:else}
-
-## Finetuning du modèle avec Keras
-
-Le code utilisant Keras sera très similaire au précédent. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
-
-{/if}
-
-
-### Collation des données
-
-Nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne fait que rembourrer les entrées (identifiants d'entrée, masque d'attention et *token* de type identifiants). Ici, nos étiquettes doivent être rembourréés exactement de la même manière que les entrées afin qu'elles gardent la même taille, en utilisant `-100` comme valeur afin que les prédictions correspondantes soient ignorées dans le calcul de la perte.
-
-Tout ceci est fait par un [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées :
-
-{#if fw === 'pt'}
-
-```py
-from transformers import DataCollatorForTokenClassification
-
-data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
-```
-
-{:else}
-
-```py
-from transformers import DataCollatorForTokenClassification
-
-data_collator = DataCollatorForTokenClassification(
- tokenizer=tokenizer, return_tensors="tf"
-)
-```
-
-{/if}
-
-Pour tester cette fonction sur quelques échantillons, nous pouvons simplement l'appeler sur une liste d'exemples provenant de notre jeu d'entraînement tokénisé :
-
-```py
-batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
-batch["labels"]
-```
-
-```python out
-tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
- [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
-```
-
-Comparons cela aux étiquettes des premier et deuxième éléments de notre jeu de données :
-
-```py
-for i in range(2):
- print(tokenized_datasets["train"][i]["labels"])
-```
-
-```python out
-[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
-[-100, 1, 2, -100]
-```
-
-{#if fw === 'pt'}
-
-Comme nous pouvons le voir, le deuxième jeu d'étiquettes a été complété à la longueur du premier en utilisant des `-100`.
-
-{:else}
-
-Notre collateur de données est prêt à fonctionner ! Maintenant, utilisons-le pour créer un `tf.data.Dataset` avec la méthode `to_tf_dataset()`.
-
-```py
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
- collate_fn=data_collator,
- shuffle=True,
- batch_size=16,
-)
-
-tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=16,
-)
-```
-
-
-Prochain arrêt : le modèle lui-même.
-
-{/if}
-
-{#if fw === 'tf'}
-
-### Définir le modèle
-
-Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `TFAutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances correctes des étiquettes à la place.
-
-Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent la correspondance de l'identifiant à l'étiquette et vice versa :
-
-```py
-id2label = {str(i): label for i, label in enumerate(label_names)}
-label2id = {v: k for k, v in id2label.items()}
-```
-
-Maintenant, nous pouvons simplement les passer à la méthode `TFAutoModelForTokenClassification.from_pretrained()`, et ils seront définis dans la configuration du modèle puis correctement enregistrés et téléchargés vers le *Hub* :
-
-```py
-from transformers import TFAutoModelForTokenClassification
-
-model = TFAutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Comme lorsque nous avons défini notre `TFAutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
-
-```python
-model.config.num_labels
-```
-
-```python out
-9
-```
-
-
-
-⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez plus tard une erreur obscure lors de l'appel de `model.fit()`. Cela peut être ennuyeux à déboguer donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
-
-
-
-### Finetuning du modèle
-
-Nous sommes maintenant prêts à entraîner notre modèle ! Mais nous devons d'abord faire un peu de ménage : nous devons nous connecter à Hugging Face et définir nos hyperparamètres d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-Après s'être connecté, nous pouvons préparer tout ce dont nous avons besoin pour compiler notre modèle. 🤗 *Transformers* fournit une fonction pratique `create_optimizer()` qui vous donnera un optimiseur `AdamW` avec des paramètres appropriés pour le taux de décroissance des poids et le taux de décroissance de l'apprentissage, les deux améliorant les performances de votre modèle par rapport à l'optimiseur `Adam` :
-
-```python
-from transformers import create_optimizer
-import tensorflow as tf
-
-# Entraîner en mixed-precision float16
-# Commentez cette ligne si vous utilisez un GPU qui ne bénéficiera pas de cette fonction
-tf.keras.mixed_precision.set_global_policy("mixed_float16")
-
-# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié par le nombre total d'époques
-# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un batchtf.data.Dataset,
-# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size
-num_epochs = 3
-num_train_steps = len(tf_train_dataset) * num_epochs
-
-optimizer, schedule = create_optimizer(
- init_lr=2e-5,
- num_warmup_steps=0,
- num_train_steps=num_train_steps,
- weight_decay_rate=0.01,
-)
-model.compile(optimizer=optimizer)
-```
-
-Notez également que nous ne fournissons pas d'argument `loss` à `compile()`. C'est parce que les modèles peuvent en fait calculer la perte en interne. Si vous compilez sans perte et fournissez vos étiquettes dans le dictionnaire d'entrée (comme nous le faisons dans nos jeux de données), alors le modèle s'entraînera en utilisant cette perte interne, qui sera appropriée pour la tâche et le type de modèle que vous avez choisi.
-
-Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle vers le *Hub* pendant l'entraînement, et nous ajustons le modèle avec ce *callback* :
-
-```python
-from transformers.keras_callbacks import PushToHubCallback
-
-callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
-
-model.fit(
- tf_train_dataset,
- validation_data=tf_eval_dataset,
- callbacks=[callback],
- epochs=num_epochs,
-)
-```
-
-Vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, par exemple `"cool_huggingface_user/bert-finetuned-ner"`.
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
-
-
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous pourrez reprendre votre entraînement sur une autre machine si nécessaire.
-
-A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de classification de *tokens*. Félicitations ! Mais quelle est la qualité réelle de notre modèle ? Nous devons évaluer certaines métriques pour le découvrir.
-
-{/if}
-
-
-### Métriques
-
-{#if fw === 'pt'}
-
-Pour que le `Trainer` calcule une métrique à chaque époque, nous devrons définir une fonction `compute_metrics()` qui prend les tableaux de prédictions et d'étiquettes, et retourne un dictionnaire avec les noms et les valeurs des métriques.
-
-Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
-
-```py
-!pip install seqeval
-```
-
-Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-{:else}
-
-Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
-
-```py
-!pip install seqeval
-```
-
-Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-{/if}
-
-```py
-import evaluate
-
-metric = evaluate.load("seqeval")
-```
-
-Cette métrique ne se comporte pas comme la précision standard : elle prend les listes d'étiquettes comme des chaînes de caractères et non comme des entiers. Nous devrons donc décoder complètement les prédictions et les étiquettes avant de les transmettre à la métrique. Voyons comment cela fonctionne. Tout d'abord, nous allons obtenir les étiquettes pour notre premier exemple d'entraînement :
-
-```py
-labels = raw_datasets["train"][0]["ner_tags"]
-labels = [label_names[i] for i in labels]
-labels
-```
-
-```python out
-['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
-```
-
-Nous pouvons alors créer de fausses prédictions pour celles-ci en changeant simplement la valeur de l'indice 2 :
-
-```py
-predictions = labels.copy()
-predictions[2] = "O"
-metric.compute(predictions=[predictions], references=[labels])
-```
-
-Notez que la métrique prend une liste de prédictions (pas seulement une) et une liste d'étiquettes. Voici la sortie :
-
-```python out
-{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
- 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
- 'overall_precision': 1.0,
- 'overall_recall': 0.67,
- 'overall_f1': 0.8,
- 'overall_accuracy': 0.89}
-```
-
-{#if fw === 'pt'}
-
-Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que le score global. Pour notre calcul de métrique, nous ne garderons que le score global, mais n'hésitez pas à modifier la fonction `compute_metrics()` pour retourner toutes les métriques que vous souhaitez.
-
-Cette fonction `compute_metrics()` prend d'abord l'argmax des logits pour les convertir en prédictions (comme d'habitude, les logits et les probabilités sont dans le même ordre, donc nous n'avons pas besoin d'appliquer la fonction softmax). Ensuite, nous devons convertir les étiquettes et les prédictions des entiers en chaînes de caractères. Nous supprimons toutes les valeurs dont l'étiquette est `-100`, puis nous passons les résultats à la méthode `metric.compute()` :
-
-```py
-import numpy as np
-
-
-def compute_metrics(eval_preds):
- logits, labels = eval_preds
- predictions = np.argmax(logits, axis=-1)
-
- # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
- true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
- true_predictions = [
- [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
- for prediction, label in zip(predictions, labels)
- ]
- all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
- return {
- "precision": all_metrics["overall_precision"],
- "recall": all_metrics["overall_recall"],
- "f1": all_metrics["overall_f1"],
- "accuracy": all_metrics["overall_accuracy"],
- }
-```
-
-Maintenant que ceci est fait, nous sommes presque prêts à définir notre `Trainer`. Nous avons juste besoin d'un objet `model` pour *finetuner* !
-
-{:else}
-
-Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que pour l'ensemble. Voyons maintenant ce qui se passe si nous essayons d'utiliser les prédictions de notre modèle pour calculer des scores réels.
-
-TensorFlow n'aime pas concaténer nos prédictions ensemble car elles ont des longueurs de séquence variables. Cela signifie que nous ne pouvons pas simplement utiliser `model.predict()`. Mais cela ne va pas nous arrêter. Nous obtiendrons des prédictions un batch à la fois et les concaténerons en une grande liste longue au fur et à mesure et en laissant de côté les *tokens* `-100` qui indiquent le masquage/le remplissage. Puis nous calculerons les métriques sur la liste à la fin :
-
-```py
-import numpy as np
-
-all_predictions = []
-all_labels = []
-for batch in tf_eval_dataset:
- logits = model.predict(batch)["logits"]
- labels = batch["labels"]
- predictions = np.argmax(logits, axis=-1)
- for prediction, label in zip(predictions, labels):
- for predicted_idx, label_idx in zip(prediction, label):
- if label_idx == -100:
- continue
- all_predictions.append(label_names[predicted_idx])
- all_labels.append(label_names[label_idx])
-metric.compute(predictions=[all_predictions], references=[all_labels])
-```
-
-
-```python out
-{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
- 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
- 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
- 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
- 'overall_precision': 0.87,
- 'overall_recall': 0.91,
- 'overall_f1': 0.89,
- 'overall_accuracy': 0.97}
-```
-
-Comment s'est comporté votre modèle, comparé au nôtre ? Si vous avez obtenu des chiffres similaires, votre entraînement a été un succès !
-
-{/if}
-
-{#if fw === 'pt'}
-
-### Définir le modèle
-
-Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `AutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances des étiquettes à la place.
-
-Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent les correspondances entre identifiants et étiquettes et vice versa :
-
-```py
-id2label = {str(i): label for i, label in enumerate(label_names)}
-label2id = {v: k for k, v in id2label.items()}
-```
-
-Maintenant nous pouvons simplement les passer à la méthode `AutoModelForTokenClassification.from_pretrained()`, ils seront définis dans la configuration du modèle puis correctement sauvegardés et téléchargés vers le *Hub* :
-
-```py
-from transformers import AutoModelForTokenClassification
-
-model = AutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Comme lorsque nous avons défini notre `AutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute, mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
-
-```python
-model.config.num_labels
-```
-
-```python out
-9
-```
-
-
-
-⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez une erreur obscure lors de l'appel de la méthode `Trainer.train()` (quelque chose comme "CUDA error : device-side assert triggered"). C'est la première cause de bogues signalés par les utilisateurs pour de telles erreurs, donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
-
-
-
-### Finetuning du modèle
-
-Nous sommes maintenant prêts à entraîner notre modèle ! Nous devons juste faire deux dernières choses avant de définir notre `Trainer` : se connecter à Hugging Face et définir nos arguments d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-Une fois ceci fait, nous pouvons définir nos `TrainingArguments` :
-
-```python
-from transformers import TrainingArguments
-
-args = TrainingArguments(
- "bert-finetuned-ner",
- evaluation_strategy="epoch",
- save_strategy="epoch",
- learning_rate=2e-5,
- num_train_epochs=3,
- weight_decay=0.01,
- push_to_hub=True,
-)
-```
-
-Vous avez déjà vu la plupart d'entre eux. Nous définissons quelques hyperparamètres (comme le taux d'apprentissage, le nombre d'époques à entraîner, et le taux de décroissance des poids), et nous spécifions `push_to_hub=True` pour indiquer que nous voulons sauvegarder le modèle, l'évaluer à la fin de chaque époque, et que nous voulons télécharger nos résultats vers le *Hub*. Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"``TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé d'après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"sgugger/bert-finetuned-ner"`.
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Trainer` et devrez définir un nouveau nom.
-
-
-
-Enfin, nous passons tout au `Trainer` et lançons l'entraînement :
-
-```python
-from transformers import Trainer
-
-trainer = Trainer(
- model=model,
- args=args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- compute_metrics=compute_metrics,
- tokenizer=tokenizer,
-)
-trainer.train()
-```
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
-
-Une fois l'entraînement terminé, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la version la plus récente du modèle :
-
-```py
-trainer.push_to_hub(commit_message="Training complete")
-```
-
-Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
-
-```python out
-'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
-```
-
-Le `Trainer` rédige également une carte modèle avec tous les résultats de l'évaluation et la télécharge. A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à affiner un modèle sur une tâche de classification de *tokens*. Félicitations !
-
-Si vous voulez plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
-
-## Une boucle d'entraînement personnalisée
-
-Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3/4) avec quelques changements pour l'évaluation.
-
-### Préparer tout pour l'entraînement
-
-D'abord nous devons construire le `DataLoader`s à partir de nos jeux de données. Nous réutilisons notre `data_collator` comme un `collate_fn` et mélanger l'ensemble d'entraînement, mais pas l'ensemble de validation :
-
-```py
-from torch.utils.data import DataLoader
-
-train_dataloader = DataLoader(
- tokenized_datasets["train"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-eval_dataloader = DataLoader(
- tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
-)
-```
-
-Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne continuons pas le *finetuning* d'avant et que nous repartons bien du modèle pré-entraîné de BERT :
-
-```py
-model = AutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Ensuite, nous avons besoin d'un optimiseur. Nous utilisons le classique `AdamW`, qui est comme `Adam`, mais avec un correctif dans la façon dont le taux de décroissance des poids est appliquée :
-
-```py
-from torch.optim import AdamW
-
-optimizer = AdamW(model.parameters(), lr=2e-5)
-```
-
-Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()` :
-
-```py
-from accelerate import Accelerator
-
-accelerator = Accelerator()
-model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
-)
-```
-
-
-
-🚨 Si vous entraînez sur un TPU, vous devrez déplacer tout le code à partir de la cellule ci-dessus dans une fonction d'entraînement dédiée. Voir le [chapitre 3](/course/fr/chapter3) pour plus de détails.
-
-
-
-Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le *dataloader* car cette méthode modifiera sa longueur. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
-
-```py
-from transformers import get_scheduler
-
-num_train_epochs = 3
-num_update_steps_per_epoch = len(train_dataloader)
-num_training_steps = num_train_epochs * num_update_steps_per_epoch
-
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-```
-
-Enfin, pour pousser notre modèle vers le *Hub*, nous avons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous à Hugging Face si vous n'êtes pas déjà connecté. Nous déterminons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur et ce que fait la fonction `get_full_repo_name()`) :
-
-```py
-from huggingface_hub import Repository, get_full_repo_name
-
-model_name = "bert-finetuned-ner-accelerate"
-repo_name = get_full_repo_name(model_name)
-repo_name
-```
-
-```python out
-'sgugger/bert-finetuned-ner-accelerate'
-```
-
-Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone existant du dépôt avec lequel nous travaillons :
-
-```py
-output_dir = "bert-finetuned-ner-accelerate"
-repo = Repository(output_dir, clone_from=repo_name)
-```
-
-Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
-
-### Boucle d'entraînement
-
-Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes, et les convertit en listes de chaînes de caractères comme notre objet `metric` l'attend :
-
-```py
-def postprocess(predictions, labels):
- predictions = predictions.detach().cpu().clone().numpy()
- labels = labels.detach().cpu().clone().numpy()
-
- # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
- true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
- true_predictions = [
- [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
- for prediction, label in zip(predictions, labels)
- ]
- return true_labels, true_predictions
-```
-
-Ensuite, nous pouvons écrire la boucle d'entraînement. Après avoir défini une barre de progression pour suivre l'évolution de l'entraînement, la boucle comporte trois parties :
-
-- L'entraînement proprement dit, qui est l'itération classique sur le `train_dataloader`, passage en avant, puis passage en arrière et étape d'optimisation.
-- L'évaluation, dans laquelle il y a une nouveauté après avoir obtenu les sorties de notre modèle sur un batch : puisque deux processus peuvent avoir paddé les entrées et les étiquettes à des formes différentes, nous devons utiliser `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne le faisons pas, l'évaluation va soit se tromper, soit se bloquer pour toujours. Ensuite, nous envoyons les résultats à `metric.add_batch()` et appelons `metric.compute()` une fois que la boucle d'évaluation est terminée.
-- Sauvegarde et téléchargement, où nous sauvegardons d'abord le modèle et le *tokenizer*, puis appelons `repo.push_to_hub()`. Remarquez que nous utilisons l'argument `blocking=False` pour indiquer à la bibliothèque 🤗 *Hub* de pousser dans un processus asynchrone. De cette façon, l'entraînement continue normalement et cette (longue) instruction est exécutée en arrière-plan.
-
-Voici le code complet de la boucle d'entraînement :
-
-```py
-from tqdm.auto import tqdm
-import torch
-
-progress_bar = tqdm(range(num_training_steps))
-
-for epoch in range(num_train_epochs):
- # Entraînement
- model.train()
- for batch in train_dataloader:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-
- # Evaluation
- model.eval()
- for batch in eval_dataloader:
- with torch.no_grad():
- outputs = model(**batch)
-
- predictions = outputs.logits.argmax(dim=-1)
- labels = batch["labels"]
-
- # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
- predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
- labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
-
- predictions_gathered = accelerator.gather(predictions)
- labels_gathered = accelerator.gather(labels)
-
- true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
- metric.add_batch(predictions=true_predictions, references=true_labels)
-
- results = metric.compute()
- print(
- f"epoch {epoch}:",
- {
- key: results[f"overall_{key}"]
- for key in ["precision", "recall", "f1", "accuracy"]
- },
- )
-
- # Sauvegarder et télécharger
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False
- )
-```
-
-Au cas où ce serait la première fois que vous verriez un modèle enregistré avec 🤗 *Accelerate*, prenons un moment pour inspecter les trois lignes de code qui l'accompagnent :
-
-```py
-accelerator.wait_for_everyone()
-unwrapped_model = accelerator.unwrap_model(model)
-unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
-```
-
-La première ligne est explicite : elle indique à tous les processus d'attendre que tout le monde soit à ce stade avant de continuer. C'est pour s'assurer que nous avons le même modèle dans chaque processus avant de sauvegarder. Ensuite, nous prenons le `unwrapped_model` qui est le modèle de base que nous avons défini. La méthode `accelerator.prepare()` modifie le modèle pour qu'il fonctionne dans l'entraînement distribué, donc il n'aura plus la méthode `save_pretrained()` ; la méthode `accelerator.unwrap_model()` annule cette étape. Enfin, nous appelons `save_pretrained()` mais nous disons à cette méthode d'utiliser `accelerator.save()` au lieu de `torch.save()`.
-
-Une fois ceci fait, vous devriez avoir un modèle qui produit des résultats assez similaires à celui entraîné avec le `Trainer`. Vous pouvez vérifier le modèle que nous avons formé en utilisant ce code à [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les implémenter directement en modifiant le code ci-dessus !
-
-{/if}
-
-### Utilisation du modèle finetuné
-
-Nous vous avons déjà montré comment vous pouvez utiliser le modèle *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, vous devez juste spécifier l'identifiant de modèle approprié :
-
-```py
-from transformers import pipeline
-
-# Remplacez ceci par votre propre checkpoint
-model_checkpoint = "huggingface-course/bert-finetuned-ner"
-token_classifier = pipeline(
- "token-classification", model=model_checkpoint, aggregation_strategy="simple"
-)
-token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
-```
-
-```python out
-[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-Super ! Notre modèle fonctionne aussi bien que le modèle par défaut pour ce pipeline !
-
+
+
+# Classification de tokens
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+La première application que nous allons explorer est la classification de *tokens*. Cette tâche générique englobe tous les problèmes qui peuvent être formulés comme l'attribution d'une étiquette à chaque *token* d'une phrase, tels que :
+
+- la **reconnaissance d'entités nommées (NER de l'anglais *Named Entity Recognition*)**, c'est-à-dire trouver les entités (telles que des personnes, des lieux ou des organisations) dans une phrase. Ce tâche peut être formulée comme l'attribution d'une étiquette à chaque *token* faisant parti d'une entité en ayant une classe spécifique par entité, et une classe pour les *tokens* ne faisant pas parti d'entité.
+- le ***part-of-speech tagging* (POS)**, c'est-à-dire marquer chaque mot dans une phrase comme correspondant à une partie particulière (comme un nom, un verbe, un adjectif, etc.).
+- le ***chunking***, c'est-à-dire trouver les *tokens* qui appartiennent à la même entité. Cette tâche (qui peut être combinée avec le POS ou la NER) peut être formulée comme l'attribution d'une étiquette (habituellement `B-`) à tous les *tokens* qui sont au début d'un morceau, une autre étiquette (habituellement `I-`) aux *tokens* qui sont à l'intérieur d'un morceau, et une troisième étiquette (habituellement `O`) aux *tokens* qui n'appartiennent à aucun morceau.
+
+
+
+Bien sûr, il existe de nombreux autres types de problèmes de classification de *tokens*. Ce ne sont là que quelques exemples représentatifs. Dans cette section, nous allons *finetuner* un modèle (BERT) sur la tâche de NER. Il sera alors capable de calculer des prédictions comme celle-ci :
+
+
+
+
+
+
+
+
+
+Vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+nom+est+Sylvain+et+je+travaille+à+Hugging+Face+in+Brooklyn) les prédictions du modèle que nous allons entraîner.
+
+## Préparation des données
+
+Tout d'abord, nous avons besoin d'un jeu de données adapté à la classification des *tokens*. Dans cette section, nous utiliserons le jeu de données [CoNLL-2003](https://huggingface.co/datasets/conll2003), qui contient des articles de presse de Reuters.
+
+
+
+💡 Tant que votre jeu de données consiste en des textes divisés en mots avec leurs étiquettes correspondantes, vous pourrez adapter les procédures de traitement des données décrites ici à votre propre jeu de données. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rafraîchissement sur la façon de charger vos propres données personnalisées dans un `Dataset`.
+
+
+
+### Le jeu de données CoNLL-2003
+
+Pour charger le jeu de données CoNLL-2003, nous utilisons la méthode `load_dataset()` de la bibliothèque 🤗 *Datasets* :
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("conll2003")
+```
+
+Cela va télécharger et mettre en cache le jeu de données, comme nous l'avons vu dans [chapitre 3](/course/fr/chapter3) pour le jeu de données GLUE MRPC. L'inspection de cet objet nous montre les colonnes présentes dans ce jeu de données et la répartition entre les ensembles d'entraînement, de validation et de test :
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 14041
+ })
+ validation: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3250
+ })
+ test: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3453
+ })
+})
+```
+
+En particulier, nous pouvons voir que le jeu de données contient des étiquettes pour les trois tâches que nous avons mentionnées précédemment : NER, POS et *chunking*. Une grande différence avec les autres jeux de données est que les entrées textuelles ne sont pas présentés comme des phrases ou des documents, mais comme des listes de mots (la dernière colonne est appelée `tokens`, mais elle contient des mots dans le sens où ce sont des entrées prétokénisées qui doivent encore passer par le *tokenizer* pour la tokenisation en sous-mots).
+
+Regardons le premier élément de l'ensemble d'entraînement :
+
+```py
+raw_datasets["train"][0]["tokens"]
+```
+
+```python out
+['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
+```
+
+Puisque nous voulons effectuer reconnaître des entités nommées, nous allons examiner les balises NER :
+
+```py
+raw_datasets["train"][0]["ner_tags"]
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+```
+
+Ce sont les étiquettes sous forme d'entiers disponibles pour l'entraînement mais ne sont pas nécessairement utiles lorsque nous voulons inspecter les données. Comme pour la classification de texte, nous pouvons accéder à la correspondance entre ces entiers et les noms des étiquettes en regardant l'attribut `features` de notre jeu de données :
+
+```py
+ner_feature = raw_datasets["train"].features["ner_tags"]
+ner_feature
+```
+
+```python out
+Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
+```
+
+Cette colonne contient donc des éléments qui sont des séquences de `ClassLabel`. Le type des éléments de la séquence se trouve dans l'attribut `feature` de cette `ner_feature`, et nous pouvons accéder à la liste des noms en regardant l'attribut `names` de cette `feature` :
+
+```py
+label_names = ner_feature.feature.names
+label_names
+```
+
+```python out
+['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
+```
+
+Nous avons déjà vu ces étiquettes au [chapitre 6](/course/fr/chapter6/3) lorsque nous nous sommes intéressés au pipeline `token-classification` mais nosu pouvons tout de même faire un rapide rappel :
+
+- `O` signifie que le mot ne correspond à aucune entité.
+- `B-PER`/`I-PER` signifie que le mot correspond au début/est à l'intérieur d'une entité *personne*.
+- `B-ORG`/`I-ORG` signifie que le mot correspond au début/est à l'intérieur d'une entité *organisation*.
+- `B-LOC`/`I-LOC` signifie que le mot correspond au début/est à l'intérieur d'une entité *location*.
+- `B-MISC`/`I-MISC` signifie que le mot correspond au début/est à l'intérieur d'une entité *divers*.
+
+Maintenant, le décodage des étiquettes que nous avons vues précédemment nous donne ceci :
+
+```python
+words = raw_datasets["train"][0]["tokens"]
+labels = raw_datasets["train"][0]["ner_tags"]
+line1 = ""
+line2 = ""
+for word, label in zip(words, labels):
+ full_label = label_names[label]
+ max_length = max(len(word), len(full_label))
+ line1 += word + " " * (max_length - len(word) + 1)
+ line2 += full_label + " " * (max_length - len(full_label) + 1)
+
+print(line1)
+print(line2)
+```
+
+```python out
+'EU rejects German call to boycott British lamb .'
+'B-ORG O B-MISC O O O B-MISC O O'
+```
+
+Et pour un exemple mélangeant les étiquettes `B-` et `I-`, voici ce que le même code nous donne sur le quatrième élément du jeu d'entraînement :
+
+```python out
+'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
+'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
+```
+
+Comme on peut le voir, les entités couvrant deux mots, comme « European Union » et « Werner Zwingmann », se voient attribuer une étiquette `B-` pour le premier mot et une étiquette `I-` pour le second.
+
+
+
+✏️ *A votre tour !* Affichez les deux mêmes phrases avec leurs étiquettes POS ou *chunking*.
+
+
+
+### Traitement des données
+
+
+
+Comme d'habitude, nos textes doivent être convertis en identifiants de *tokens* avant que le modèle puisse leur donner un sens. Comme nous l'avons vu au [chapitre 6](/course/fr/chapter6/), une grande différence dans le cas des tâches de classification de *tokens* est que nous avons des entrées prétokénisées. Heureusement, l'API `tokenizer` peut gérer cela assez facilement. Nous devons juste avertir le `tokenizer` avec un drapeau spécial.
+
+Pour commencer, nous allons créer notre objet `tokenizer`. Comme nous l'avons dit précédemment, nous allons utiliser un modèle BERT pré-entraîné, donc nous allons commencer par télécharger et mettre en cache le *tokenizer* associé :
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Vous pouvez remplacer le `model_checkpoint` par tout autre modèle que vous préférez à partir du [*Hub*](https://huggingface.co/models), ou par un dossier local dans lequel vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*. La seule contrainte est que le *tokenizer* doit être soutenu par la bibliothèque 🤗 *Tokenizers*. Il y a donc une version rapide disponible. Vous pouvez voir toutes les architectures qui ont une version rapide dans [ce tableau](https://huggingface.co/transformers/#supported-frameworks), et pour vérifier que l'objet `tokenizer` que vous utilisez est bien soutenu par 🤗 *Tokenizers* vous pouvez regarder son attribut `is_fast` :
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+Pour tokeniser une entrée prétokenisée, nous pouvons utiliser notre `tokenizer` comme d'habitude et juste ajouter `is_split_into_words=True` :
+
+```py
+inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
+inputs.tokens()
+```
+
+```python out
+['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
+```
+
+Comme on peut le voir, le *tokenizer* a ajouté les *tokens* spéciaux utilisés par le modèle (`[CLS]` au début et `[SEP]` à la fin) et n'a pas touché à la plupart des mots. Le mot `lamb`, cependant, a été tokenisé en deux sous-mots, `la` et `##mb`. Cela introduit un décalage entre nos entrées et les étiquettes : la liste des étiquettes n'a que 9 éléments, alors que notre entrée a maintenant 12 *tokens*. Il est facile de tenir compte des *tokens* spéciaux (nous savons qu'ils sont au début et à la fin), mais nous devons également nous assurer que nous alignons toutes les étiquettes avec les mots appropriés.
+
+Heureusement, comme nous utilisons un *tokenizer* rapide, nous avons accès aux superpouvoirs des 🤗 *Tokenizers*, ce qui signifie que nous pouvons facilement faire correspondre chaque *token* au mot correspondant (comme on le voit au [chapitre 6](/course/fr/chapter6/3)) :
+
+```py
+inputs.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
+```
+
+Avec un peu de travail, nous pouvons étendre notre liste d'étiquettes pour qu'elle corresponde aux *tokens*. La première règle que nous allons appliquer est que les *tokens* spéciaux reçoivent une étiquette de `-100`. En effet, par défaut, `-100` est un indice qui est ignoré dans la fonction de perte que nous allons utiliser (l'entropie croisée). Ensuite, chaque *token* reçoit la même étiquette que le *token* qui a commencé le mot dans lequel il se trouve puisqu'ils font partie de la même entité. Pour les *tokens* à l'intérieur d'un mot mais pas au début, nous remplaçons le `B-` par `I-` (puisque le *token* ne commence pas l'entité) :
+
+```python
+def align_labels_with_tokens(labels, word_ids):
+ new_labels = []
+ current_word = None
+ for word_id in word_ids:
+ if word_id != current_word:
+ # Début d'un nouveau mot !
+ current_word = word_id
+ label = -100 if word_id is None else labels[word_id]
+ new_labels.append(label)
+ elif word_id is None:
+ # Token spécial
+ new_labels.append(-100)
+ else:
+ # Même mot que le token précédent
+ label = labels[word_id]
+ # Si l'étiquette est B-XXX, nous la changeons en I-XXX
+ if label % 2 == 1:
+ label += 1
+ new_labels.append(label)
+
+ return new_labels
+```
+
+Essayons-le sur notre première phrase :
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+word_ids = inputs.word_ids()
+print(labels)
+print(align_labels_with_tokens(labels, word_ids))
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+```
+
+Comme nous pouvons le voir, notre fonction a ajouté `-100` pour les deux *tokens* spéciaux du début et de fin, et un nouveau `0` pour notre mot qui a été divisé en deux *tokens*.
+
+
+
+✏️ *A votre tour !* Certains chercheurs préfèrent n'attribuer qu'une seule étiquette par mot et attribuer `-100` aux autres sous-*tokens* dans un mot donné. Ceci afin d'éviter que les longs mots qui se divisent en plusieurs batchs ne contribuent fortement à la perte. Changez la fonction précédente pour aligner les étiquettes avec les identifiants d'entrée en suivant cette règle.
+
+
+Pour prétraiter notre jeu de données, nous devons tokeniser toutes les entrées et appliquer `align_labels_with_tokens()` sur toutes les étiquettes. Pour profiter de la vitesse de notre *tokenizer* rapide, il est préférable de tokeniser beaucoup de textes en même temps. Nous allons donc écrire une fonction qui traite une liste d'exemples et utiliser la méthode `Dataset.map()` avec l'option `batched=True`. La seule chose qui diffère de notre exemple précédent est que la fonction `word_ids()` a besoin de récupérer l'index de l'exemple dont nous voulons les identifiants de mots lorsque les entrées du *tokenizer* sont des listes de textes (ou dans notre cas, des listes de mots), donc nous l'ajoutons aussi :
+
+```py
+def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples["tokens"], truncation=True, is_split_into_words=True
+ )
+ all_labels = examples["ner_tags"]
+ new_labels = []
+ for i, labels in enumerate(all_labels):
+ word_ids = tokenized_inputs.word_ids(i)
+ new_labels.append(align_labels_with_tokens(labels, word_ids))
+
+ tokenized_inputs["labels"] = new_labels
+ return tokenized_inputs
+```
+
+Notez que nous n'avons pas encore rembourré nos entrées. Nous le ferons plus tard lors de la création des batchs avec un collateur de données.
+
+Nous pouvons maintenant appliquer tout ce prétraitement en une seule fois sur les autres divisions de notre jeu de données :
+
+```py
+tokenized_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+```
+
+Nous avons fait la partie la plus difficile ! Maintenant que les données ont été prétraitées, l'entraînement ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3).
+
+{#if fw === 'pt'}
+
+## Finetuning du modèle avec l'API `Trainer`
+
+Le code utilisant `Trainer` sera le même que précédemment. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
+
+{:else}
+
+## Finetuning du modèle avec Keras
+
+Le code utilisant Keras sera très similaire au précédent. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
+
+{/if}
+
+
+### Collation des données
+
+Nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne fait que rembourrer les entrées (identifiants d'entrée, masque d'attention et *token* de type identifiants). Ici, nos étiquettes doivent être rembourréés exactement de la même manière que les entrées afin qu'elles gardent la même taille, en utilisant `-100` comme valeur afin que les prédictions correspondantes soient ignorées dans le calcul de la perte.
+
+Tout ceci est fait par un [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées :
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(
+ tokenizer=tokenizer, return_tensors="tf"
+)
+```
+
+{/if}
+
+Pour tester cette fonction sur quelques échantillons, nous pouvons simplement l'appeler sur une liste d'exemples provenant de notre jeu d'entraînement tokénisé :
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
+batch["labels"]
+```
+
+```python out
+tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
+ [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
+```
+
+Comparons cela aux étiquettes des premier et deuxième éléments de notre jeu de données :
+
+```py
+for i in range(2):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+[-100, 1, 2, -100]
+```
+
+{#if fw === 'pt'}
+
+Comme nous pouvons le voir, le deuxième jeu d'étiquettes a été complété à la longueur du premier en utilisant des `-100`.
+
+{:else}
+
+Notre collateur de données est prêt à fonctionner ! Maintenant, utilisons-le pour créer un `tf.data.Dataset` avec la méthode `to_tf_dataset()`.
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+
+Prochain arrêt : le modèle lui-même.
+
+{/if}
+
+{#if fw === 'tf'}
+
+### Définir le modèle
+
+Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `TFAutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances correctes des étiquettes à la place.
+
+Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent la correspondance de l'identifiant à l'étiquette et vice versa :
+
+```py
+id2label = {str(i): label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Maintenant, nous pouvons simplement les passer à la méthode `TFAutoModelForTokenClassification.from_pretrained()`, et ils seront définis dans la configuration du modèle puis correctement enregistrés et téléchargés vers le *Hub* :
+
+```py
+from transformers import TFAutoModelForTokenClassification
+
+model = TFAutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Comme lorsque nous avons défini notre `TFAutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez plus tard une erreur obscure lors de l'appel de `model.fit()`. Cela peut être ennuyeux à déboguer donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
+
+
+
+### Finetuning du modèle
+
+Nous sommes maintenant prêts à entraîner notre modèle ! Mais nous devons d'abord faire un peu de ménage : nous devons nous connecter à Hugging Face et définir nos hyperparamètres d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+Après s'être connecté, nous pouvons préparer tout ce dont nous avons besoin pour compiler notre modèle. 🤗 *Transformers* fournit une fonction pratique `create_optimizer()` qui vous donnera un optimiseur `AdamW` avec des paramètres appropriés pour le taux de décroissance des poids et le taux de décroissance de l'apprentissage, les deux améliorant les performances de votre modèle par rapport à l'optimiseur `Adam` :
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Entraîner en mixed-precision float16
+# Commentez cette ligne si vous utilisez un GPU qui ne bénéficiera pas de cette fonction
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié par le nombre total d'époques
+# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un batchtf.data.Dataset,
+# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+```
+
+Notez également que nous ne fournissons pas d'argument `loss` à `compile()`. C'est parce que les modèles peuvent en fait calculer la perte en interne. Si vous compilez sans perte et fournissez vos étiquettes dans le dictionnaire d'entrée (comme nous le faisons dans nos jeux de données), alors le modèle s'entraînera en utilisant cette perte interne, qui sera appropriée pour la tâche et le type de modèle que vous avez choisi.
+
+Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle vers le *Hub* pendant l'entraînement, et nous ajustons le modèle avec ce *callback* :
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+Vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, par exemple `"cool_huggingface_user/bert-finetuned-ner"`.
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
+
+
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous pourrez reprendre votre entraînement sur une autre machine si nécessaire.
+
+A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de classification de *tokens*. Félicitations ! Mais quelle est la qualité réelle de notre modèle ? Nous devons évaluer certaines métriques pour le découvrir.
+
+{/if}
+
+
+### Métriques
+
+{#if fw === 'pt'}
+
+Pour que le `Trainer` calcule une métrique à chaque époque, nous devrons définir une fonction `compute_metrics()` qui prend les tableaux de prédictions et d'étiquettes, et retourne un dictionnaire avec les noms et les valeurs des métriques.
+
+Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
+
+```py
+!pip install seqeval
+```
+
+Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+{:else}
+
+Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
+
+```py
+!pip install seqeval
+```
+
+Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+{/if}
+
+```py
+import evaluate
+
+metric = evaluate.load("seqeval")
+```
+
+Cette métrique ne se comporte pas comme la précision standard : elle prend les listes d'étiquettes comme des chaînes de caractères et non comme des entiers. Nous devrons donc décoder complètement les prédictions et les étiquettes avant de les transmettre à la métrique. Voyons comment cela fonctionne. Tout d'abord, nous allons obtenir les étiquettes pour notre premier exemple d'entraînement :
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+labels = [label_names[i] for i in labels]
+labels
+```
+
+```python out
+['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
+```
+
+Nous pouvons alors créer de fausses prédictions pour celles-ci en changeant simplement la valeur de l'indice 2 :
+
+```py
+predictions = labels.copy()
+predictions[2] = "O"
+metric.compute(predictions=[predictions], references=[labels])
+```
+
+Notez que la métrique prend une liste de prédictions (pas seulement une) et une liste d'étiquettes. Voici la sortie :
+
+```python out
+{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
+ 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
+ 'overall_precision': 1.0,
+ 'overall_recall': 0.67,
+ 'overall_f1': 0.8,
+ 'overall_accuracy': 0.89}
+```
+
+{#if fw === 'pt'}
+
+Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que le score global. Pour notre calcul de métrique, nous ne garderons que le score global, mais n'hésitez pas à modifier la fonction `compute_metrics()` pour retourner toutes les métriques que vous souhaitez.
+
+Cette fonction `compute_metrics()` prend d'abord l'argmax des logits pour les convertir en prédictions (comme d'habitude, les logits et les probabilités sont dans le même ordre, donc nous n'avons pas besoin d'appliquer la fonction softmax). Ensuite, nous devons convertir les étiquettes et les prédictions des entiers en chaînes de caractères. Nous supprimons toutes les valeurs dont l'étiquette est `-100`, puis nous passons les résultats à la méthode `metric.compute()` :
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+
+ # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
+ return {
+ "precision": all_metrics["overall_precision"],
+ "recall": all_metrics["overall_recall"],
+ "f1": all_metrics["overall_f1"],
+ "accuracy": all_metrics["overall_accuracy"],
+ }
+```
+
+Maintenant que ceci est fait, nous sommes presque prêts à définir notre `Trainer`. Nous avons juste besoin d'un objet `model` pour *finetuner* !
+
+{:else}
+
+Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que pour l'ensemble. Voyons maintenant ce qui se passe si nous essayons d'utiliser les prédictions de notre modèle pour calculer des scores réels.
+
+TensorFlow n'aime pas concaténer nos prédictions ensemble car elles ont des longueurs de séquence variables. Cela signifie que nous ne pouvons pas simplement utiliser `model.predict()`. Mais cela ne va pas nous arrêter. Nous obtiendrons des prédictions un batch à la fois et les concaténerons en une grande liste longue au fur et à mesure et en laissant de côté les *tokens* `-100` qui indiquent le masquage/le remplissage. Puis nous calculerons les métriques sur la liste à la fin :
+
+```py
+import numpy as np
+
+all_predictions = []
+all_labels = []
+for batch in tf_eval_dataset:
+ logits = model.predict(batch)["logits"]
+ labels = batch["labels"]
+ predictions = np.argmax(logits, axis=-1)
+ for prediction, label in zip(predictions, labels):
+ for predicted_idx, label_idx in zip(prediction, label):
+ if label_idx == -100:
+ continue
+ all_predictions.append(label_names[predicted_idx])
+ all_labels.append(label_names[label_idx])
+metric.compute(predictions=[all_predictions], references=[all_labels])
+```
+
+
+```python out
+{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
+ 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
+ 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
+ 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
+ 'overall_precision': 0.87,
+ 'overall_recall': 0.91,
+ 'overall_f1': 0.89,
+ 'overall_accuracy': 0.97}
+```
+
+Comment s'est comporté votre modèle, comparé au nôtre ? Si vous avez obtenu des chiffres similaires, votre entraînement a été un succès !
+
+{/if}
+
+{#if fw === 'pt'}
+
+### Définir le modèle
+
+Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `AutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances des étiquettes à la place.
+
+Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent les correspondances entre identifiants et étiquettes et vice versa :
+
+```py
+id2label = {str(i): label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Maintenant nous pouvons simplement les passer à la méthode `AutoModelForTokenClassification.from_pretrained()`, ils seront définis dans la configuration du modèle puis correctement sauvegardés et téléchargés vers le *Hub* :
+
+```py
+from transformers import AutoModelForTokenClassification
+
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Comme lorsque nous avons défini notre `AutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute, mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez une erreur obscure lors de l'appel de la méthode `Trainer.train()` (quelque chose comme "CUDA error : device-side assert triggered"). C'est la première cause de bogues signalés par les utilisateurs pour de telles erreurs, donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
+
+
+
+### Finetuning du modèle
+
+Nous sommes maintenant prêts à entraîner notre modèle ! Nous devons juste faire deux dernières choses avant de définir notre `Trainer` : se connecter à Hugging Face et définir nos arguments d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+Une fois ceci fait, nous pouvons définir nos `TrainingArguments` :
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-ner",
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ push_to_hub=True,
+)
+```
+
+Vous avez déjà vu la plupart d'entre eux. Nous définissons quelques hyperparamètres (comme le taux d'apprentissage, le nombre d'époques à entraîner, et le taux de décroissance des poids), et nous spécifions `push_to_hub=True` pour indiquer que nous voulons sauvegarder le modèle, l'évaluer à la fin de chaque époque, et que nous voulons télécharger nos résultats vers le *Hub*. Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"``TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé d'après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"sgugger/bert-finetuned-ner"`.
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Trainer` et devrez définir un nouveau nom.
+
+
+
+Enfin, nous passons tout au `Trainer` et lançons l'entraînement :
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
+
+Une fois l'entraînement terminé, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la version la plus récente du modèle :
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
+```
+
+Le `Trainer` rédige également une carte modèle avec tous les résultats de l'évaluation et la télécharge. A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à affiner un modèle sur une tâche de classification de *tokens*. Félicitations !
+
+Si vous voulez plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
+
+## Une boucle d'entraînement personnalisée
+
+Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3/4) avec quelques changements pour l'évaluation.
+
+### Préparer tout pour l'entraînement
+
+D'abord nous devons construire le `DataLoader`s à partir de nos jeux de données. Nous réutilisons notre `data_collator` comme un `collate_fn` et mélanger l'ensemble d'entraînement, mais pas l'ensemble de validation :
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne continuons pas le *finetuning* d'avant et que nous repartons bien du modèle pré-entraîné de BERT :
+
+```py
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Ensuite, nous avons besoin d'un optimiseur. Nous utilisons le classique `AdamW`, qui est comme `Adam`, mais avec un correctif dans la façon dont le taux de décroissance des poids est appliquée :
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()` :
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 Si vous entraînez sur un TPU, vous devrez déplacer tout le code à partir de la cellule ci-dessus dans une fonction d'entraînement dédiée. Voir le [chapitre 3](/course/fr/chapter3) pour plus de détails.
+
+
+
+Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le *dataloader* car cette méthode modifiera sa longueur. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Enfin, pour pousser notre modèle vers le *Hub*, nous avons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous à Hugging Face si vous n'êtes pas déjà connecté. Nous déterminons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur et ce que fait la fonction `get_full_repo_name()`) :
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-ner-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-ner-accelerate'
+```
+
+Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone existant du dépôt avec lequel nous travaillons :
+
+```py
+output_dir = "bert-finetuned-ner-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
+
+### Boucle d'entraînement
+
+Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes, et les convertit en listes de chaînes de caractères comme notre objet `metric` l'attend :
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.detach().cpu().clone().numpy()
+ labels = labels.detach().cpu().clone().numpy()
+
+ # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ return true_labels, true_predictions
+```
+
+Ensuite, nous pouvons écrire la boucle d'entraînement. Après avoir défini une barre de progression pour suivre l'évolution de l'entraînement, la boucle comporte trois parties :
+
+- L'entraînement proprement dit, qui est l'itération classique sur le `train_dataloader`, passage en avant, puis passage en arrière et étape d'optimisation.
+- L'évaluation, dans laquelle il y a une nouveauté après avoir obtenu les sorties de notre modèle sur un batch : puisque deux processus peuvent avoir paddé les entrées et les étiquettes à des formes différentes, nous devons utiliser `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne le faisons pas, l'évaluation va soit se tromper, soit se bloquer pour toujours. Ensuite, nous envoyons les résultats à `metric.add_batch()` et appelons `metric.compute()` une fois que la boucle d'évaluation est terminée.
+- Sauvegarde et téléchargement, où nous sauvegardons d'abord le modèle et le *tokenizer*, puis appelons `repo.push_to_hub()`. Remarquez que nous utilisons l'argument `blocking=False` pour indiquer à la bibliothèque 🤗 *Hub* de pousser dans un processus asynchrone. De cette façon, l'entraînement continue normalement et cette (longue) instruction est exécutée en arrière-plan.
+
+Voici le code complet de la boucle d'entraînement :
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Entraînement
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in eval_dataloader:
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+
+ # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(predictions)
+ labels_gathered = accelerator.gather(labels)
+
+ true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=true_predictions, references=true_labels)
+
+ results = metric.compute()
+ print(
+ f"epoch {epoch}:",
+ {
+ key: results[f"overall_{key}"]
+ for key in ["precision", "recall", "f1", "accuracy"]
+ },
+ )
+
+ # Sauvegarder et télécharger
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+Au cas où ce serait la première fois que vous verriez un modèle enregistré avec 🤗 *Accelerate*, prenons un moment pour inspecter les trois lignes de code qui l'accompagnent :
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+La première ligne est explicite : elle indique à tous les processus d'attendre que tout le monde soit à ce stade avant de continuer. C'est pour s'assurer que nous avons le même modèle dans chaque processus avant de sauvegarder. Ensuite, nous prenons le `unwrapped_model` qui est le modèle de base que nous avons défini. La méthode `accelerator.prepare()` modifie le modèle pour qu'il fonctionne dans l'entraînement distribué, donc il n'aura plus la méthode `save_pretrained()` ; la méthode `accelerator.unwrap_model()` annule cette étape. Enfin, nous appelons `save_pretrained()` mais nous disons à cette méthode d'utiliser `accelerator.save()` au lieu de `torch.save()`.
+
+Une fois ceci fait, vous devriez avoir un modèle qui produit des résultats assez similaires à celui entraîné avec le `Trainer`. Vous pouvez vérifier le modèle que nous avons formé en utilisant ce code à [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les implémenter directement en modifiant le code ci-dessus !
+
+{/if}
+
+### Utilisation du modèle finetuné
+
+Nous vous avons déjà montré comment vous pouvez utiliser le modèle *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, vous devez juste spécifier l'identifiant de modèle approprié :
+
+```py
+from transformers import pipeline
+
+# Remplacez ceci par votre propre checkpoint
+model_checkpoint = "huggingface-course/bert-finetuned-ner"
+token_classifier = pipeline(
+ "token-classification", model=model_checkpoint, aggregation_strategy="simple"
+)
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Super ! Notre modèle fonctionne aussi bien que le modèle par défaut pour ce pipeline !
+
diff --git a/chapters/fr/chapter7/3.mdx b/chapters/fr/chapter7/3.mdx
index 89cd6a843..96f3b04ff 100644
--- a/chapters/fr/chapter7/3.mdx
+++ b/chapters/fr/chapter7/3.mdx
@@ -1,1042 +1,1042 @@
-
-
-# Finetuner un modèle de langage masqué
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-Pour de nombreuses applications de NLP impliquant des *transformers*, vous pouvez simplement prendre un modèle pré-entraîné du *Hub* et le *finetuner* directement sur vos données pour la tâche à accomplir. Pour autant que le corpus utilisé pour le pré-entraînement ne soit pas trop différent du corpus utilisé pour le *finetuning*. L'apprentissage par transfert produira généralement de bons résultats.
-
-Cependant, il existe quelques cas où vous voudrez d'abord *finetuner* les modèles de langue sur vos données, avant d'entraîner une tête spécifique à la tâche. Par exemple, si votre jeu de données contient des contrats légaux ou des articles scientifiques, un *transformer* classique comme BERT traitera généralement les mots spécifiques au domaine dans votre corpus comme des *tokens* rares et les performances résultantes peuvent être moins que satisfaisantes. En *finetunant* le modèle de langage sur les données du domaine, vous pouvez améliorer les performances de nombreuses tâches en aval, ce qui signifie que vous ne devez généralement effectuer cette étape qu'une seule fois !
-
-Ce processus de *finetuning* d'un modèle de langage pré-entraîné sur des données *dans le domaine* est généralement appelé _adaptation au domaine_. Il a été popularisé en 2018 par [ULMFiT](https://arxiv.org/abs/1801.06146) qui a été l'une des premières architectures neuronales (basées sur des LSTMs) à faire en sorte que l'apprentissage par transfert fonctionne réellement pour le NLP. Un exemple d'adaptation de domaine avec ULMFiT est présenté dans l'image ci-dessous. Dans cette section, nous ferons quelque chose de similaire mais avec un *transformer* au lieu d'une LSTM !
-
-
-
-
-Vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+nom+est+Sylvain+et+je+travaille+à+Hugging+Face+in+Brooklyn) les prédictions du modèle que nous allons entraîner.
-
-## Préparation des données
-
-Tout d'abord, nous avons besoin d'un jeu de données adapté à la classification des *tokens*. Dans cette section, nous utiliserons le jeu de données [CoNLL-2003](https://huggingface.co/datasets/conll2003), qui contient des articles de presse de Reuters.
-
-
-
-💡 Tant que votre jeu de données consiste en des textes divisés en mots avec leurs étiquettes correspondantes, vous pourrez adapter les procédures de traitement des données décrites ici à votre propre jeu de données. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rafraîchissement sur la façon de charger vos propres données personnalisées dans un `Dataset`.
-
-
-
-### Le jeu de données CoNLL-2003
-
-Pour charger le jeu de données CoNLL-2003, nous utilisons la méthode `load_dataset()` de la bibliothèque 🤗 *Datasets* :
-
-```py
-from datasets import load_dataset
-
-raw_datasets = load_dataset("conll2003")
-```
-
-Cela va télécharger et mettre en cache le jeu de données, comme nous l'avons vu dans [chapitre 3](/course/fr/chapter3) pour le jeu de données GLUE MRPC. L'inspection de cet objet nous montre les colonnes présentes dans ce jeu de données et la répartition entre les ensembles d'entraînement, de validation et de test :
-
-```py
-raw_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 14041
- })
- validation: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 3250
- })
- test: Dataset({
- features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
- num_rows: 3453
- })
-})
-```
-
-En particulier, nous pouvons voir que le jeu de données contient des étiquettes pour les trois tâches que nous avons mentionnées précédemment : NER, POS et *chunking*. Une grande différence avec les autres jeux de données est que les entrées textuelles ne sont pas présentés comme des phrases ou des documents, mais comme des listes de mots (la dernière colonne est appelée `tokens`, mais elle contient des mots dans le sens où ce sont des entrées prétokénisées qui doivent encore passer par le *tokenizer* pour la tokenisation en sous-mots).
-
-Regardons le premier élément de l'ensemble d'entraînement :
-
-```py
-raw_datasets["train"][0]["tokens"]
-```
-
-```python out
-['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
-```
-
-Puisque nous voulons effectuer reconnaître des entités nommées, nous allons examiner les balises NER :
-
-```py
-raw_datasets["train"][0]["ner_tags"]
-```
-
-```python out
-[3, 0, 7, 0, 0, 0, 7, 0, 0]
-```
-
-Ce sont les étiquettes sous forme d'entiers disponibles pour l'entraînement mais ne sont pas nécessairement utiles lorsque nous voulons inspecter les données. Comme pour la classification de texte, nous pouvons accéder à la correspondance entre ces entiers et les noms des étiquettes en regardant l'attribut `features` de notre jeu de données :
-
-```py
-ner_feature = raw_datasets["train"].features["ner_tags"]
-ner_feature
-```
-
-```python out
-Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
-```
-
-Cette colonne contient donc des éléments qui sont des séquences de `ClassLabel`. Le type des éléments de la séquence se trouve dans l'attribut `feature` de cette `ner_feature`, et nous pouvons accéder à la liste des noms en regardant l'attribut `names` de cette `feature` :
-
-```py
-label_names = ner_feature.feature.names
-label_names
-```
-
-```python out
-['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
-```
-
-Nous avons déjà vu ces étiquettes au [chapitre 6](/course/fr/chapter6/3) lorsque nous nous sommes intéressés au pipeline `token-classification` mais nosu pouvons tout de même faire un rapide rappel :
-
-- `O` signifie que le mot ne correspond à aucune entité.
-- `B-PER`/`I-PER` signifie que le mot correspond au début/est à l'intérieur d'une entité *personne*.
-- `B-ORG`/`I-ORG` signifie que le mot correspond au début/est à l'intérieur d'une entité *organisation*.
-- `B-LOC`/`I-LOC` signifie que le mot correspond au début/est à l'intérieur d'une entité *location*.
-- `B-MISC`/`I-MISC` signifie que le mot correspond au début/est à l'intérieur d'une entité *divers*.
-
-Maintenant, le décodage des étiquettes que nous avons vues précédemment nous donne ceci :
-
-```python
-words = raw_datasets["train"][0]["tokens"]
-labels = raw_datasets["train"][0]["ner_tags"]
-line1 = ""
-line2 = ""
-for word, label in zip(words, labels):
- full_label = label_names[label]
- max_length = max(len(word), len(full_label))
- line1 += word + " " * (max_length - len(word) + 1)
- line2 += full_label + " " * (max_length - len(full_label) + 1)
-
-print(line1)
-print(line2)
-```
-
-```python out
-'EU rejects German call to boycott British lamb .'
-'B-ORG O B-MISC O O O B-MISC O O'
-```
-
-Et pour un exemple mélangeant les étiquettes `B-` et `I-`, voici ce que le même code nous donne sur le quatrième élément du jeu d'entraînement :
-
-```python out
-'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
-'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
-```
-
-Comme on peut le voir, les entités couvrant deux mots, comme « European Union » et « Werner Zwingmann », se voient attribuer une étiquette `B-` pour le premier mot et une étiquette `I-` pour le second.
-
-
-
-✏️ *A votre tour !* Affichez les deux mêmes phrases avec leurs étiquettes POS ou *chunking*.
-
-
-
-### Traitement des données
-
-
-
-Comme d'habitude, nos textes doivent être convertis en identifiants de *tokens* avant que le modèle puisse leur donner un sens. Comme nous l'avons vu au [chapitre 6](/course/fr/chapter6/), une grande différence dans le cas des tâches de classification de *tokens* est que nous avons des entrées prétokénisées. Heureusement, l'API `tokenizer` peut gérer cela assez facilement. Nous devons juste avertir le `tokenizer` avec un drapeau spécial.
-
-Pour commencer, nous allons créer notre objet `tokenizer`. Comme nous l'avons dit précédemment, nous allons utiliser un modèle BERT pré-entraîné, donc nous allons commencer par télécharger et mettre en cache le *tokenizer* associé :
-
-```python
-from transformers import AutoTokenizer
-
-model_checkpoint = "bert-base-cased"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
-```
-
-Vous pouvez remplacer le `model_checkpoint` par tout autre modèle que vous préférez à partir du [*Hub*](https://huggingface.co/models), ou par un dossier local dans lequel vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*. La seule contrainte est que le *tokenizer* doit être soutenu par la bibliothèque 🤗 *Tokenizers*. Il y a donc une version rapide disponible. Vous pouvez voir toutes les architectures qui ont une version rapide dans [ce tableau](https://huggingface.co/transformers/#supported-frameworks), et pour vérifier que l'objet `tokenizer` que vous utilisez est bien soutenu par 🤗 *Tokenizers* vous pouvez regarder son attribut `is_fast` :
-
-```py
-tokenizer.is_fast
-```
-
-```python out
-True
-```
-
-Pour tokeniser une entrée prétokenisée, nous pouvons utiliser notre `tokenizer` comme d'habitude et juste ajouter `is_split_into_words=True` :
-
-```py
-inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
-inputs.tokens()
-```
-
-```python out
-['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
-```
-
-Comme on peut le voir, le *tokenizer* a ajouté les *tokens* spéciaux utilisés par le modèle (`[CLS]` au début et `[SEP]` à la fin) et n'a pas touché à la plupart des mots. Le mot `lamb`, cependant, a été tokenisé en deux sous-mots, `la` et `##mb`. Cela introduit un décalage entre nos entrées et les étiquettes : la liste des étiquettes n'a que 9 éléments, alors que notre entrée a maintenant 12 *tokens*. Il est facile de tenir compte des *tokens* spéciaux (nous savons qu'ils sont au début et à la fin), mais nous devons également nous assurer que nous alignons toutes les étiquettes avec les mots appropriés.
-
-Heureusement, comme nous utilisons un *tokenizer* rapide, nous avons accès aux superpouvoirs des 🤗 *Tokenizers*, ce qui signifie que nous pouvons facilement faire correspondre chaque *token* au mot correspondant (comme on le voit au [chapitre 6](/course/fr/chapter6/3)) :
-
-```py
-inputs.word_ids()
-```
-
-```python out
-[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
-```
-
-Avec un peu de travail, nous pouvons étendre notre liste d'étiquettes pour qu'elle corresponde aux *tokens*. La première règle que nous allons appliquer est que les *tokens* spéciaux reçoivent une étiquette de `-100`. En effet, par défaut, `-100` est un indice qui est ignoré dans la fonction de perte que nous allons utiliser (l'entropie croisée). Ensuite, chaque *token* reçoit la même étiquette que le *token* qui a commencé le mot dans lequel il se trouve puisqu'ils font partie de la même entité. Pour les *tokens* à l'intérieur d'un mot mais pas au début, nous remplaçons le `B-` par `I-` (puisque le *token* ne commence pas l'entité) :
-
-```python
-def align_labels_with_tokens(labels, word_ids):
- new_labels = []
- current_word = None
- for word_id in word_ids:
- if word_id != current_word:
- # Début d'un nouveau mot !
- current_word = word_id
- label = -100 if word_id is None else labels[word_id]
- new_labels.append(label)
- elif word_id is None:
- # Token spécial
- new_labels.append(-100)
- else:
- # Même mot que le token précédent
- label = labels[word_id]
- # Si l'étiquette est B-XXX, nous la changeons en I-XXX
- if label % 2 == 1:
- label += 1
- new_labels.append(label)
-
- return new_labels
-```
-
-Essayons-le sur notre première phrase :
-
-```py
-labels = raw_datasets["train"][0]["ner_tags"]
-word_ids = inputs.word_ids()
-print(labels)
-print(align_labels_with_tokens(labels, word_ids))
-```
-
-```python out
-[3, 0, 7, 0, 0, 0, 7, 0, 0]
-[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
-```
-
-Comme nous pouvons le voir, notre fonction a ajouté `-100` pour les deux *tokens* spéciaux du début et de fin, et un nouveau `0` pour notre mot qui a été divisé en deux *tokens*.
-
-
-
-✏️ *A votre tour !* Certains chercheurs préfèrent n'attribuer qu'une seule étiquette par mot et attribuer `-100` aux autres sous-*tokens* dans un mot donné. Ceci afin d'éviter que les longs mots qui se divisent en plusieurs batchs ne contribuent fortement à la perte. Changez la fonction précédente pour aligner les étiquettes avec les identifiants d'entrée en suivant cette règle.
-
-
-Pour prétraiter notre jeu de données, nous devons tokeniser toutes les entrées et appliquer `align_labels_with_tokens()` sur toutes les étiquettes. Pour profiter de la vitesse de notre *tokenizer* rapide, il est préférable de tokeniser beaucoup de textes en même temps. Nous allons donc écrire une fonction qui traite une liste d'exemples et utiliser la méthode `Dataset.map()` avec l'option `batched=True`. La seule chose qui diffère de notre exemple précédent est que la fonction `word_ids()` a besoin de récupérer l'index de l'exemple dont nous voulons les identifiants de mots lorsque les entrées du *tokenizer* sont des listes de textes (ou dans notre cas, des listes de mots), donc nous l'ajoutons aussi :
-
-```py
-def tokenize_and_align_labels(examples):
- tokenized_inputs = tokenizer(
- examples["tokens"], truncation=True, is_split_into_words=True
- )
- all_labels = examples["ner_tags"]
- new_labels = []
- for i, labels in enumerate(all_labels):
- word_ids = tokenized_inputs.word_ids(i)
- new_labels.append(align_labels_with_tokens(labels, word_ids))
-
- tokenized_inputs["labels"] = new_labels
- return tokenized_inputs
-```
-
-Notez que nous n'avons pas encore rembourré nos entrées. Nous le ferons plus tard lors de la création des batchs avec un collateur de données.
-
-Nous pouvons maintenant appliquer tout ce prétraitement en une seule fois sur les autres divisions de notre jeu de données :
-
-```py
-tokenized_datasets = raw_datasets.map(
- tokenize_and_align_labels,
- batched=True,
- remove_columns=raw_datasets["train"].column_names,
-)
-```
-
-Nous avons fait la partie la plus difficile ! Maintenant que les données ont été prétraitées, l'entraînement ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3).
-
-{#if fw === 'pt'}
-
-## Finetuning du modèle avec l'API `Trainer`
-
-Le code utilisant `Trainer` sera le même que précédemment. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
-
-{:else}
-
-## Finetuning du modèle avec Keras
-
-Le code utilisant Keras sera très similaire au précédent. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
-
-{/if}
-
-
-### Collation des données
-
-Nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne fait que rembourrer les entrées (identifiants d'entrée, masque d'attention et *token* de type identifiants). Ici, nos étiquettes doivent être rembourréés exactement de la même manière que les entrées afin qu'elles gardent la même taille, en utilisant `-100` comme valeur afin que les prédictions correspondantes soient ignorées dans le calcul de la perte.
-
-Tout ceci est fait par un [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées :
-
-{#if fw === 'pt'}
-
-```py
-from transformers import DataCollatorForTokenClassification
-
-data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
-```
-
-{:else}
-
-```py
-from transformers import DataCollatorForTokenClassification
-
-data_collator = DataCollatorForTokenClassification(
- tokenizer=tokenizer, return_tensors="tf"
-)
-```
-
-{/if}
-
-Pour tester cette fonction sur quelques échantillons, nous pouvons simplement l'appeler sur une liste d'exemples provenant de notre jeu d'entraînement tokénisé :
-
-```py
-batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
-batch["labels"]
-```
-
-```python out
-tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
- [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
-```
-
-Comparons cela aux étiquettes des premier et deuxième éléments de notre jeu de données :
-
-```py
-for i in range(2):
- print(tokenized_datasets["train"][i]["labels"])
-```
-
-```python out
-[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
-[-100, 1, 2, -100]
-```
-
-{#if fw === 'pt'}
-
-Comme nous pouvons le voir, le deuxième jeu d'étiquettes a été complété à la longueur du premier en utilisant des `-100`.
-
-{:else}
-
-Notre collateur de données est prêt à fonctionner ! Maintenant, utilisons-le pour créer un `tf.data.Dataset` avec la méthode `to_tf_dataset()`.
-
-```py
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
- collate_fn=data_collator,
- shuffle=True,
- batch_size=16,
-)
-
-tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=16,
-)
-```
-
-
-Prochain arrêt : le modèle lui-même.
-
-{/if}
-
-{#if fw === 'tf'}
-
-### Définir le modèle
-
-Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `TFAutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances correctes des étiquettes à la place.
-
-Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent la correspondance de l'identifiant à l'étiquette et vice versa :
-
-```py
-id2label = {str(i): label for i, label in enumerate(label_names)}
-label2id = {v: k for k, v in id2label.items()}
-```
-
-Maintenant, nous pouvons simplement les passer à la méthode `TFAutoModelForTokenClassification.from_pretrained()`, et ils seront définis dans la configuration du modèle puis correctement enregistrés et téléchargés vers le *Hub* :
-
-```py
-from transformers import TFAutoModelForTokenClassification
-
-model = TFAutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Comme lorsque nous avons défini notre `TFAutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
-
-```python
-model.config.num_labels
-```
-
-```python out
-9
-```
-
-
-
-⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez plus tard une erreur obscure lors de l'appel de `model.fit()`. Cela peut être ennuyeux à déboguer donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
-
-
-
-### Finetuning du modèle
-
-Nous sommes maintenant prêts à entraîner notre modèle ! Mais nous devons d'abord faire un peu de ménage : nous devons nous connecter à Hugging Face et définir nos hyperparamètres d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-Après s'être connecté, nous pouvons préparer tout ce dont nous avons besoin pour compiler notre modèle. 🤗 *Transformers* fournit une fonction pratique `create_optimizer()` qui vous donnera un optimiseur `AdamW` avec des paramètres appropriés pour le taux de décroissance des poids et le taux de décroissance de l'apprentissage, les deux améliorant les performances de votre modèle par rapport à l'optimiseur `Adam` :
-
-```python
-from transformers import create_optimizer
-import tensorflow as tf
-
-# Entraîner en mixed-precision float16
-# Commentez cette ligne si vous utilisez un GPU qui ne bénéficiera pas de cette fonction
-tf.keras.mixed_precision.set_global_policy("mixed_float16")
-
-# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié par le nombre total d'époques
-# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un batchtf.data.Dataset,
-# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size
-num_epochs = 3
-num_train_steps = len(tf_train_dataset) * num_epochs
-
-optimizer, schedule = create_optimizer(
- init_lr=2e-5,
- num_warmup_steps=0,
- num_train_steps=num_train_steps,
- weight_decay_rate=0.01,
-)
-model.compile(optimizer=optimizer)
-```
-
-Notez également que nous ne fournissons pas d'argument `loss` à `compile()`. C'est parce que les modèles peuvent en fait calculer la perte en interne. Si vous compilez sans perte et fournissez vos étiquettes dans le dictionnaire d'entrée (comme nous le faisons dans nos jeux de données), alors le modèle s'entraînera en utilisant cette perte interne, qui sera appropriée pour la tâche et le type de modèle que vous avez choisi.
-
-Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle vers le *Hub* pendant l'entraînement, et nous ajustons le modèle avec ce *callback* :
-
-```python
-from transformers.keras_callbacks import PushToHubCallback
-
-callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
-
-model.fit(
- tf_train_dataset,
- validation_data=tf_eval_dataset,
- callbacks=[callback],
- epochs=num_epochs,
-)
-```
-
-Vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, par exemple `"cool_huggingface_user/bert-finetuned-ner"`.
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
-
-
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous pourrez reprendre votre entraînement sur une autre machine si nécessaire.
-
-A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de classification de *tokens*. Félicitations ! Mais quelle est la qualité réelle de notre modèle ? Nous devons évaluer certaines métriques pour le découvrir.
-
-{/if}
-
-
-### Métriques
-
-{#if fw === 'pt'}
-
-Pour que le `Trainer` calcule une métrique à chaque époque, nous devrons définir une fonction `compute_metrics()` qui prend les tableaux de prédictions et d'étiquettes, et retourne un dictionnaire avec les noms et les valeurs des métriques.
-
-Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
-
-```py
-!pip install seqeval
-```
-
-Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-{:else}
-
-Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
-
-```py
-!pip install seqeval
-```
-
-Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-{/if}
-
-```py
-import evaluate
-
-metric = evaluate.load("seqeval")
-```
-
-Cette métrique ne se comporte pas comme la précision standard : elle prend les listes d'étiquettes comme des chaînes de caractères et non comme des entiers. Nous devrons donc décoder complètement les prédictions et les étiquettes avant de les transmettre à la métrique. Voyons comment cela fonctionne. Tout d'abord, nous allons obtenir les étiquettes pour notre premier exemple d'entraînement :
-
-```py
-labels = raw_datasets["train"][0]["ner_tags"]
-labels = [label_names[i] for i in labels]
-labels
-```
-
-```python out
-['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
-```
-
-Nous pouvons alors créer de fausses prédictions pour celles-ci en changeant simplement la valeur de l'indice 2 :
-
-```py
-predictions = labels.copy()
-predictions[2] = "O"
-metric.compute(predictions=[predictions], references=[labels])
-```
-
-Notez que la métrique prend une liste de prédictions (pas seulement une) et une liste d'étiquettes. Voici la sortie :
-
-```python out
-{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
- 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
- 'overall_precision': 1.0,
- 'overall_recall': 0.67,
- 'overall_f1': 0.8,
- 'overall_accuracy': 0.89}
-```
-
-{#if fw === 'pt'}
-
-Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que le score global. Pour notre calcul de métrique, nous ne garderons que le score global, mais n'hésitez pas à modifier la fonction `compute_metrics()` pour retourner toutes les métriques que vous souhaitez.
-
-Cette fonction `compute_metrics()` prend d'abord l'argmax des logits pour les convertir en prédictions (comme d'habitude, les logits et les probabilités sont dans le même ordre, donc nous n'avons pas besoin d'appliquer la fonction softmax). Ensuite, nous devons convertir les étiquettes et les prédictions des entiers en chaînes de caractères. Nous supprimons toutes les valeurs dont l'étiquette est `-100`, puis nous passons les résultats à la méthode `metric.compute()` :
-
-```py
-import numpy as np
-
-
-def compute_metrics(eval_preds):
- logits, labels = eval_preds
- predictions = np.argmax(logits, axis=-1)
-
- # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
- true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
- true_predictions = [
- [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
- for prediction, label in zip(predictions, labels)
- ]
- all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
- return {
- "precision": all_metrics["overall_precision"],
- "recall": all_metrics["overall_recall"],
- "f1": all_metrics["overall_f1"],
- "accuracy": all_metrics["overall_accuracy"],
- }
-```
-
-Maintenant que ceci est fait, nous sommes presque prêts à définir notre `Trainer`. Nous avons juste besoin d'un objet `model` pour *finetuner* !
-
-{:else}
-
-Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que pour l'ensemble. Voyons maintenant ce qui se passe si nous essayons d'utiliser les prédictions de notre modèle pour calculer des scores réels.
-
-TensorFlow n'aime pas concaténer nos prédictions ensemble car elles ont des longueurs de séquence variables. Cela signifie que nous ne pouvons pas simplement utiliser `model.predict()`. Mais cela ne va pas nous arrêter. Nous obtiendrons des prédictions un batch à la fois et les concaténerons en une grande liste longue au fur et à mesure et en laissant de côté les *tokens* `-100` qui indiquent le masquage/le remplissage. Puis nous calculerons les métriques sur la liste à la fin :
-
-```py
-import numpy as np
-
-all_predictions = []
-all_labels = []
-for batch in tf_eval_dataset:
- logits = model.predict(batch)["logits"]
- labels = batch["labels"]
- predictions = np.argmax(logits, axis=-1)
- for prediction, label in zip(predictions, labels):
- for predicted_idx, label_idx in zip(prediction, label):
- if label_idx == -100:
- continue
- all_predictions.append(label_names[predicted_idx])
- all_labels.append(label_names[label_idx])
-metric.compute(predictions=[all_predictions], references=[all_labels])
-```
-
-
-```python out
-{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
- 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
- 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
- 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
- 'overall_precision': 0.87,
- 'overall_recall': 0.91,
- 'overall_f1': 0.89,
- 'overall_accuracy': 0.97}
-```
-
-Comment s'est comporté votre modèle, comparé au nôtre ? Si vous avez obtenu des chiffres similaires, votre entraînement a été un succès !
-
-{/if}
-
-{#if fw === 'pt'}
-
-### Définir le modèle
-
-Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `AutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances des étiquettes à la place.
-
-Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent les correspondances entre identifiants et étiquettes et vice versa :
-
-```py
-id2label = {str(i): label for i, label in enumerate(label_names)}
-label2id = {v: k for k, v in id2label.items()}
-```
-
-Maintenant nous pouvons simplement les passer à la méthode `AutoModelForTokenClassification.from_pretrained()`, ils seront définis dans la configuration du modèle puis correctement sauvegardés et téléchargés vers le *Hub* :
-
-```py
-from transformers import AutoModelForTokenClassification
-
-model = AutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Comme lorsque nous avons défini notre `AutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute, mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
-
-```python
-model.config.num_labels
-```
-
-```python out
-9
-```
-
-
-
-⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez une erreur obscure lors de l'appel de la méthode `Trainer.train()` (quelque chose comme "CUDA error : device-side assert triggered"). C'est la première cause de bogues signalés par les utilisateurs pour de telles erreurs, donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
-
-
-
-### Finetuning du modèle
-
-Nous sommes maintenant prêts à entraîner notre modèle ! Nous devons juste faire deux dernières choses avant de définir notre `Trainer` : se connecter à Hugging Face et définir nos arguments d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-Une fois ceci fait, nous pouvons définir nos `TrainingArguments` :
-
-```python
-from transformers import TrainingArguments
-
-args = TrainingArguments(
- "bert-finetuned-ner",
- evaluation_strategy="epoch",
- save_strategy="epoch",
- learning_rate=2e-5,
- num_train_epochs=3,
- weight_decay=0.01,
- push_to_hub=True,
-)
-```
-
-Vous avez déjà vu la plupart d'entre eux. Nous définissons quelques hyperparamètres (comme le taux d'apprentissage, le nombre d'époques à entraîner, et le taux de décroissance des poids), et nous spécifions `push_to_hub=True` pour indiquer que nous voulons sauvegarder le modèle, l'évaluer à la fin de chaque époque, et que nous voulons télécharger nos résultats vers le *Hub*. Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"``TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé d'après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"sgugger/bert-finetuned-ner"`.
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Trainer` et devrez définir un nouveau nom.
-
-
-
-Enfin, nous passons tout au `Trainer` et lançons l'entraînement :
-
-```python
-from transformers import Trainer
-
-trainer = Trainer(
- model=model,
- args=args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- compute_metrics=compute_metrics,
- tokenizer=tokenizer,
-)
-trainer.train()
-```
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
-
-Une fois l'entraînement terminé, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la version la plus récente du modèle :
-
-```py
-trainer.push_to_hub(commit_message="Training complete")
-```
-
-Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
-
-```python out
-'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
-```
-
-Le `Trainer` rédige également une carte modèle avec tous les résultats de l'évaluation et la télécharge. A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à affiner un modèle sur une tâche de classification de *tokens*. Félicitations !
-
-Si vous voulez plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
-
-## Une boucle d'entraînement personnalisée
-
-Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3/4) avec quelques changements pour l'évaluation.
-
-### Préparer tout pour l'entraînement
-
-D'abord nous devons construire le `DataLoader`s à partir de nos jeux de données. Nous réutilisons notre `data_collator` comme un `collate_fn` et mélanger l'ensemble d'entraînement, mais pas l'ensemble de validation :
-
-```py
-from torch.utils.data import DataLoader
-
-train_dataloader = DataLoader(
- tokenized_datasets["train"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-eval_dataloader = DataLoader(
- tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
-)
-```
-
-Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne continuons pas le *finetuning* d'avant et que nous repartons bien du modèle pré-entraîné de BERT :
-
-```py
-model = AutoModelForTokenClassification.from_pretrained(
- model_checkpoint,
- id2label=id2label,
- label2id=label2id,
-)
-```
-
-Ensuite, nous avons besoin d'un optimiseur. Nous utilisons le classique `AdamW`, qui est comme `Adam`, mais avec un correctif dans la façon dont le taux de décroissance des poids est appliquée :
-
-```py
-from torch.optim import AdamW
-
-optimizer = AdamW(model.parameters(), lr=2e-5)
-```
-
-Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()` :
-
-```py
-from accelerate import Accelerator
-
-accelerator = Accelerator()
-model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
-)
-```
-
-
-
-🚨 Si vous entraînez sur un TPU, vous devrez déplacer tout le code à partir de la cellule ci-dessus dans une fonction d'entraînement dédiée. Voir le [chapitre 3](/course/fr/chapter3) pour plus de détails.
-
-
-
-Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le *dataloader* car cette méthode modifiera sa longueur. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
-
-```py
-from transformers import get_scheduler
-
-num_train_epochs = 3
-num_update_steps_per_epoch = len(train_dataloader)
-num_training_steps = num_train_epochs * num_update_steps_per_epoch
-
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-```
-
-Enfin, pour pousser notre modèle vers le *Hub*, nous avons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous à Hugging Face si vous n'êtes pas déjà connecté. Nous déterminons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur et ce que fait la fonction `get_full_repo_name()`) :
-
-```py
-from huggingface_hub import Repository, get_full_repo_name
-
-model_name = "bert-finetuned-ner-accelerate"
-repo_name = get_full_repo_name(model_name)
-repo_name
-```
-
-```python out
-'sgugger/bert-finetuned-ner-accelerate'
-```
-
-Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone existant du dépôt avec lequel nous travaillons :
-
-```py
-output_dir = "bert-finetuned-ner-accelerate"
-repo = Repository(output_dir, clone_from=repo_name)
-```
-
-Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
-
-### Boucle d'entraînement
-
-Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes, et les convertit en listes de chaînes de caractères comme notre objet `metric` l'attend :
-
-```py
-def postprocess(predictions, labels):
- predictions = predictions.detach().cpu().clone().numpy()
- labels = labels.detach().cpu().clone().numpy()
-
- # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
- true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
- true_predictions = [
- [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
- for prediction, label in zip(predictions, labels)
- ]
- return true_labels, true_predictions
-```
-
-Ensuite, nous pouvons écrire la boucle d'entraînement. Après avoir défini une barre de progression pour suivre l'évolution de l'entraînement, la boucle comporte trois parties :
-
-- L'entraînement proprement dit, qui est l'itération classique sur le `train_dataloader`, passage en avant, puis passage en arrière et étape d'optimisation.
-- L'évaluation, dans laquelle il y a une nouveauté après avoir obtenu les sorties de notre modèle sur un batch : puisque deux processus peuvent avoir paddé les entrées et les étiquettes à des formes différentes, nous devons utiliser `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne le faisons pas, l'évaluation va soit se tromper, soit se bloquer pour toujours. Ensuite, nous envoyons les résultats à `metric.add_batch()` et appelons `metric.compute()` une fois que la boucle d'évaluation est terminée.
-- Sauvegarde et téléchargement, où nous sauvegardons d'abord le modèle et le *tokenizer*, puis appelons `repo.push_to_hub()`. Remarquez que nous utilisons l'argument `blocking=False` pour indiquer à la bibliothèque 🤗 *Hub* de pousser dans un processus asynchrone. De cette façon, l'entraînement continue normalement et cette (longue) instruction est exécutée en arrière-plan.
-
-Voici le code complet de la boucle d'entraînement :
-
-```py
-from tqdm.auto import tqdm
-import torch
-
-progress_bar = tqdm(range(num_training_steps))
-
-for epoch in range(num_train_epochs):
- # Entraînement
- model.train()
- for batch in train_dataloader:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-
- # Evaluation
- model.eval()
- for batch in eval_dataloader:
- with torch.no_grad():
- outputs = model(**batch)
-
- predictions = outputs.logits.argmax(dim=-1)
- labels = batch["labels"]
-
- # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
- predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
- labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
-
- predictions_gathered = accelerator.gather(predictions)
- labels_gathered = accelerator.gather(labels)
-
- true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
- metric.add_batch(predictions=true_predictions, references=true_labels)
-
- results = metric.compute()
- print(
- f"epoch {epoch}:",
- {
- key: results[f"overall_{key}"]
- for key in ["precision", "recall", "f1", "accuracy"]
- },
- )
-
- # Sauvegarder et télécharger
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False
- )
-```
-
-Au cas où ce serait la première fois que vous verriez un modèle enregistré avec 🤗 *Accelerate*, prenons un moment pour inspecter les trois lignes de code qui l'accompagnent :
-
-```py
-accelerator.wait_for_everyone()
-unwrapped_model = accelerator.unwrap_model(model)
-unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
-```
-
-La première ligne est explicite : elle indique à tous les processus d'attendre que tout le monde soit à ce stade avant de continuer. C'est pour s'assurer que nous avons le même modèle dans chaque processus avant de sauvegarder. Ensuite, nous prenons le `unwrapped_model` qui est le modèle de base que nous avons défini. La méthode `accelerator.prepare()` modifie le modèle pour qu'il fonctionne dans l'entraînement distribué, donc il n'aura plus la méthode `save_pretrained()` ; la méthode `accelerator.unwrap_model()` annule cette étape. Enfin, nous appelons `save_pretrained()` mais nous disons à cette méthode d'utiliser `accelerator.save()` au lieu de `torch.save()`.
-
-Une fois ceci fait, vous devriez avoir un modèle qui produit des résultats assez similaires à celui entraîné avec le `Trainer`. Vous pouvez vérifier le modèle que nous avons formé en utilisant ce code à [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les implémenter directement en modifiant le code ci-dessus !
-
-{/if}
-
-### Utilisation du modèle finetuné
-
-Nous vous avons déjà montré comment vous pouvez utiliser le modèle *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, vous devez juste spécifier l'identifiant de modèle approprié :
-
-```py
-from transformers import pipeline
-
-# Remplacez ceci par votre propre checkpoint
-model_checkpoint = "huggingface-course/bert-finetuned-ner"
-token_classifier = pipeline(
- "token-classification", model=model_checkpoint, aggregation_strategy="simple"
-)
-token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
-```
-
-```python out
-[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
- {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
- {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
-```
-
-Super ! Notre modèle fonctionne aussi bien que le modèle par défaut pour ce pipeline !
-
+
+
+# Classification de tokens
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+La première application que nous allons explorer est la classification de *tokens*. Cette tâche générique englobe tous les problèmes qui peuvent être formulés comme l'attribution d'une étiquette à chaque *token* d'une phrase, tels que :
+
+- la **reconnaissance d'entités nommées (NER de l'anglais *Named Entity Recognition*)**, c'est-à-dire trouver les entités (telles que des personnes, des lieux ou des organisations) dans une phrase. Ce tâche peut être formulée comme l'attribution d'une étiquette à chaque *token* faisant parti d'une entité en ayant une classe spécifique par entité, et une classe pour les *tokens* ne faisant pas parti d'entité.
+- le ***part-of-speech tagging* (POS)**, c'est-à-dire marquer chaque mot dans une phrase comme correspondant à une partie particulière (comme un nom, un verbe, un adjectif, etc.).
+- le ***chunking***, c'est-à-dire trouver les *tokens* qui appartiennent à la même entité. Cette tâche (qui peut être combinée avec le POS ou la NER) peut être formulée comme l'attribution d'une étiquette (habituellement `B-`) à tous les *tokens* qui sont au début d'un morceau, une autre étiquette (habituellement `I-`) aux *tokens* qui sont à l'intérieur d'un morceau, et une troisième étiquette (habituellement `O`) aux *tokens* qui n'appartiennent à aucun morceau.
+
+
+
+Bien sûr, il existe de nombreux autres types de problèmes de classification de *tokens*. Ce ne sont là que quelques exemples représentatifs. Dans cette section, nous allons *finetuner* un modèle (BERT) sur la tâche de NER. Il sera alors capable de calculer des prédictions comme celle-ci :
+
+
+
+
+
+
+
+
+
+Vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+nom+est+Sylvain+et+je+travaille+à+Hugging+Face+in+Brooklyn) les prédictions du modèle que nous allons entraîner.
+
+## Préparation des données
+
+Tout d'abord, nous avons besoin d'un jeu de données adapté à la classification des *tokens*. Dans cette section, nous utiliserons le jeu de données [CoNLL-2003](https://huggingface.co/datasets/conll2003), qui contient des articles de presse de Reuters.
+
+
+
+💡 Tant que votre jeu de données consiste en des textes divisés en mots avec leurs étiquettes correspondantes, vous pourrez adapter les procédures de traitement des données décrites ici à votre propre jeu de données. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rafraîchissement sur la façon de charger vos propres données personnalisées dans un `Dataset`.
+
+
+
+### Le jeu de données CoNLL-2003
+
+Pour charger le jeu de données CoNLL-2003, nous utilisons la méthode `load_dataset()` de la bibliothèque 🤗 *Datasets* :
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("conll2003")
+```
+
+Cela va télécharger et mettre en cache le jeu de données, comme nous l'avons vu dans [chapitre 3](/course/fr/chapter3) pour le jeu de données GLUE MRPC. L'inspection de cet objet nous montre les colonnes présentes dans ce jeu de données et la répartition entre les ensembles d'entraînement, de validation et de test :
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 14041
+ })
+ validation: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3250
+ })
+ test: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3453
+ })
+})
+```
+
+En particulier, nous pouvons voir que le jeu de données contient des étiquettes pour les trois tâches que nous avons mentionnées précédemment : NER, POS et *chunking*. Une grande différence avec les autres jeux de données est que les entrées textuelles ne sont pas présentés comme des phrases ou des documents, mais comme des listes de mots (la dernière colonne est appelée `tokens`, mais elle contient des mots dans le sens où ce sont des entrées prétokénisées qui doivent encore passer par le *tokenizer* pour la tokenisation en sous-mots).
+
+Regardons le premier élément de l'ensemble d'entraînement :
+
+```py
+raw_datasets["train"][0]["tokens"]
+```
+
+```python out
+['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
+```
+
+Puisque nous voulons effectuer reconnaître des entités nommées, nous allons examiner les balises NER :
+
+```py
+raw_datasets["train"][0]["ner_tags"]
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+```
+
+Ce sont les étiquettes sous forme d'entiers disponibles pour l'entraînement mais ne sont pas nécessairement utiles lorsque nous voulons inspecter les données. Comme pour la classification de texte, nous pouvons accéder à la correspondance entre ces entiers et les noms des étiquettes en regardant l'attribut `features` de notre jeu de données :
+
+```py
+ner_feature = raw_datasets["train"].features["ner_tags"]
+ner_feature
+```
+
+```python out
+Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
+```
+
+Cette colonne contient donc des éléments qui sont des séquences de `ClassLabel`. Le type des éléments de la séquence se trouve dans l'attribut `feature` de cette `ner_feature`, et nous pouvons accéder à la liste des noms en regardant l'attribut `names` de cette `feature` :
+
+```py
+label_names = ner_feature.feature.names
+label_names
+```
+
+```python out
+['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
+```
+
+Nous avons déjà vu ces étiquettes au [chapitre 6](/course/fr/chapter6/3) lorsque nous nous sommes intéressés au pipeline `token-classification` mais nosu pouvons tout de même faire un rapide rappel :
+
+- `O` signifie que le mot ne correspond à aucune entité.
+- `B-PER`/`I-PER` signifie que le mot correspond au début/est à l'intérieur d'une entité *personne*.
+- `B-ORG`/`I-ORG` signifie que le mot correspond au début/est à l'intérieur d'une entité *organisation*.
+- `B-LOC`/`I-LOC` signifie que le mot correspond au début/est à l'intérieur d'une entité *location*.
+- `B-MISC`/`I-MISC` signifie que le mot correspond au début/est à l'intérieur d'une entité *divers*.
+
+Maintenant, le décodage des étiquettes que nous avons vues précédemment nous donne ceci :
+
+```python
+words = raw_datasets["train"][0]["tokens"]
+labels = raw_datasets["train"][0]["ner_tags"]
+line1 = ""
+line2 = ""
+for word, label in zip(words, labels):
+ full_label = label_names[label]
+ max_length = max(len(word), len(full_label))
+ line1 += word + " " * (max_length - len(word) + 1)
+ line2 += full_label + " " * (max_length - len(full_label) + 1)
+
+print(line1)
+print(line2)
+```
+
+```python out
+'EU rejects German call to boycott British lamb .'
+'B-ORG O B-MISC O O O B-MISC O O'
+```
+
+Et pour un exemple mélangeant les étiquettes `B-` et `I-`, voici ce que le même code nous donne sur le quatrième élément du jeu d'entraînement :
+
+```python out
+'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
+'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
+```
+
+Comme on peut le voir, les entités couvrant deux mots, comme « European Union » et « Werner Zwingmann », se voient attribuer une étiquette `B-` pour le premier mot et une étiquette `I-` pour le second.
+
+
+
+✏️ *A votre tour !* Affichez les deux mêmes phrases avec leurs étiquettes POS ou *chunking*.
+
+
+
+### Traitement des données
+
+
+
+Comme d'habitude, nos textes doivent être convertis en identifiants de *tokens* avant que le modèle puisse leur donner un sens. Comme nous l'avons vu au [chapitre 6](/course/fr/chapter6/), une grande différence dans le cas des tâches de classification de *tokens* est que nous avons des entrées prétokénisées. Heureusement, l'API `tokenizer` peut gérer cela assez facilement. Nous devons juste avertir le `tokenizer` avec un drapeau spécial.
+
+Pour commencer, nous allons créer notre objet `tokenizer`. Comme nous l'avons dit précédemment, nous allons utiliser un modèle BERT pré-entraîné, donc nous allons commencer par télécharger et mettre en cache le *tokenizer* associé :
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Vous pouvez remplacer le `model_checkpoint` par tout autre modèle que vous préférez à partir du [*Hub*](https://huggingface.co/models), ou par un dossier local dans lequel vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*. La seule contrainte est que le *tokenizer* doit être soutenu par la bibliothèque 🤗 *Tokenizers*. Il y a donc une version rapide disponible. Vous pouvez voir toutes les architectures qui ont une version rapide dans [ce tableau](https://huggingface.co/transformers/#supported-frameworks), et pour vérifier que l'objet `tokenizer` que vous utilisez est bien soutenu par 🤗 *Tokenizers* vous pouvez regarder son attribut `is_fast` :
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+Pour tokeniser une entrée prétokenisée, nous pouvons utiliser notre `tokenizer` comme d'habitude et juste ajouter `is_split_into_words=True` :
+
+```py
+inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
+inputs.tokens()
+```
+
+```python out
+['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
+```
+
+Comme on peut le voir, le *tokenizer* a ajouté les *tokens* spéciaux utilisés par le modèle (`[CLS]` au début et `[SEP]` à la fin) et n'a pas touché à la plupart des mots. Le mot `lamb`, cependant, a été tokenisé en deux sous-mots, `la` et `##mb`. Cela introduit un décalage entre nos entrées et les étiquettes : la liste des étiquettes n'a que 9 éléments, alors que notre entrée a maintenant 12 *tokens*. Il est facile de tenir compte des *tokens* spéciaux (nous savons qu'ils sont au début et à la fin), mais nous devons également nous assurer que nous alignons toutes les étiquettes avec les mots appropriés.
+
+Heureusement, comme nous utilisons un *tokenizer* rapide, nous avons accès aux superpouvoirs des 🤗 *Tokenizers*, ce qui signifie que nous pouvons facilement faire correspondre chaque *token* au mot correspondant (comme on le voit au [chapitre 6](/course/fr/chapter6/3)) :
+
+```py
+inputs.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
+```
+
+Avec un peu de travail, nous pouvons étendre notre liste d'étiquettes pour qu'elle corresponde aux *tokens*. La première règle que nous allons appliquer est que les *tokens* spéciaux reçoivent une étiquette de `-100`. En effet, par défaut, `-100` est un indice qui est ignoré dans la fonction de perte que nous allons utiliser (l'entropie croisée). Ensuite, chaque *token* reçoit la même étiquette que le *token* qui a commencé le mot dans lequel il se trouve puisqu'ils font partie de la même entité. Pour les *tokens* à l'intérieur d'un mot mais pas au début, nous remplaçons le `B-` par `I-` (puisque le *token* ne commence pas l'entité) :
+
+```python
+def align_labels_with_tokens(labels, word_ids):
+ new_labels = []
+ current_word = None
+ for word_id in word_ids:
+ if word_id != current_word:
+ # Début d'un nouveau mot !
+ current_word = word_id
+ label = -100 if word_id is None else labels[word_id]
+ new_labels.append(label)
+ elif word_id is None:
+ # Token spécial
+ new_labels.append(-100)
+ else:
+ # Même mot que le token précédent
+ label = labels[word_id]
+ # Si l'étiquette est B-XXX, nous la changeons en I-XXX
+ if label % 2 == 1:
+ label += 1
+ new_labels.append(label)
+
+ return new_labels
+```
+
+Essayons-le sur notre première phrase :
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+word_ids = inputs.word_ids()
+print(labels)
+print(align_labels_with_tokens(labels, word_ids))
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+```
+
+Comme nous pouvons le voir, notre fonction a ajouté `-100` pour les deux *tokens* spéciaux du début et de fin, et un nouveau `0` pour notre mot qui a été divisé en deux *tokens*.
+
+
+
+✏️ *A votre tour !* Certains chercheurs préfèrent n'attribuer qu'une seule étiquette par mot et attribuer `-100` aux autres sous-*tokens* dans un mot donné. Ceci afin d'éviter que les longs mots qui se divisent en plusieurs batchs ne contribuent fortement à la perte. Changez la fonction précédente pour aligner les étiquettes avec les identifiants d'entrée en suivant cette règle.
+
+
+Pour prétraiter notre jeu de données, nous devons tokeniser toutes les entrées et appliquer `align_labels_with_tokens()` sur toutes les étiquettes. Pour profiter de la vitesse de notre *tokenizer* rapide, il est préférable de tokeniser beaucoup de textes en même temps. Nous allons donc écrire une fonction qui traite une liste d'exemples et utiliser la méthode `Dataset.map()` avec l'option `batched=True`. La seule chose qui diffère de notre exemple précédent est que la fonction `word_ids()` a besoin de récupérer l'index de l'exemple dont nous voulons les identifiants de mots lorsque les entrées du *tokenizer* sont des listes de textes (ou dans notre cas, des listes de mots), donc nous l'ajoutons aussi :
+
+```py
+def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples["tokens"], truncation=True, is_split_into_words=True
+ )
+ all_labels = examples["ner_tags"]
+ new_labels = []
+ for i, labels in enumerate(all_labels):
+ word_ids = tokenized_inputs.word_ids(i)
+ new_labels.append(align_labels_with_tokens(labels, word_ids))
+
+ tokenized_inputs["labels"] = new_labels
+ return tokenized_inputs
+```
+
+Notez que nous n'avons pas encore rembourré nos entrées. Nous le ferons plus tard lors de la création des batchs avec un collateur de données.
+
+Nous pouvons maintenant appliquer tout ce prétraitement en une seule fois sur les autres divisions de notre jeu de données :
+
+```py
+tokenized_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+```
+
+Nous avons fait la partie la plus difficile ! Maintenant que les données ont été prétraitées, l'entraînement ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3).
+
+{#if fw === 'pt'}
+
+## Finetuning du modèle avec l'API `Trainer`
+
+Le code utilisant `Trainer` sera le même que précédemment. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
+
+{:else}
+
+## Finetuning du modèle avec Keras
+
+Le code utilisant Keras sera très similaire au précédent. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
+
+{/if}
+
+
+### Collation des données
+
+Nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne fait que rembourrer les entrées (identifiants d'entrée, masque d'attention et *token* de type identifiants). Ici, nos étiquettes doivent être rembourréés exactement de la même manière que les entrées afin qu'elles gardent la même taille, en utilisant `-100` comme valeur afin que les prédictions correspondantes soient ignorées dans le calcul de la perte.
+
+Tout ceci est fait par un [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées :
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(
+ tokenizer=tokenizer, return_tensors="tf"
+)
+```
+
+{/if}
+
+Pour tester cette fonction sur quelques échantillons, nous pouvons simplement l'appeler sur une liste d'exemples provenant de notre jeu d'entraînement tokénisé :
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
+batch["labels"]
+```
+
+```python out
+tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
+ [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
+```
+
+Comparons cela aux étiquettes des premier et deuxième éléments de notre jeu de données :
+
+```py
+for i in range(2):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+[-100, 1, 2, -100]
+```
+
+{#if fw === 'pt'}
+
+Comme nous pouvons le voir, le deuxième jeu d'étiquettes a été complété à la longueur du premier en utilisant des `-100`.
+
+{:else}
+
+Notre collateur de données est prêt à fonctionner ! Maintenant, utilisons-le pour créer un `tf.data.Dataset` avec la méthode `to_tf_dataset()`.
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+
+Prochain arrêt : le modèle lui-même.
+
+{/if}
+
+{#if fw === 'tf'}
+
+### Définir le modèle
+
+Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `TFAutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances correctes des étiquettes à la place.
+
+Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent la correspondance de l'identifiant à l'étiquette et vice versa :
+
+```py
+id2label = {str(i): label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Maintenant, nous pouvons simplement les passer à la méthode `TFAutoModelForTokenClassification.from_pretrained()`, et ils seront définis dans la configuration du modèle puis correctement enregistrés et téléchargés vers le *Hub* :
+
+```py
+from transformers import TFAutoModelForTokenClassification
+
+model = TFAutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Comme lorsque nous avons défini notre `TFAutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez plus tard une erreur obscure lors de l'appel de `model.fit()`. Cela peut être ennuyeux à déboguer donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
+
+
+
+### Finetuning du modèle
+
+Nous sommes maintenant prêts à entraîner notre modèle ! Mais nous devons d'abord faire un peu de ménage : nous devons nous connecter à Hugging Face et définir nos hyperparamètres d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+Après s'être connecté, nous pouvons préparer tout ce dont nous avons besoin pour compiler notre modèle. 🤗 *Transformers* fournit une fonction pratique `create_optimizer()` qui vous donnera un optimiseur `AdamW` avec des paramètres appropriés pour le taux de décroissance des poids et le taux de décroissance de l'apprentissage, les deux améliorant les performances de votre modèle par rapport à l'optimiseur `Adam` :
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Entraîner en mixed-precision float16
+# Commentez cette ligne si vous utilisez un GPU qui ne bénéficiera pas de cette fonction
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans l'ensemble de données, divisé par la taille du batch puis multiplié par le nombre total d'époques
+# par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un batchtf.data.Dataset,
+# et non le jeu de données original Hugging Face Dataset, donc son len() est déjà num_samples // batch_size
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+```
+
+Notez également que nous ne fournissons pas d'argument `loss` à `compile()`. C'est parce que les modèles peuvent en fait calculer la perte en interne. Si vous compilez sans perte et fournissez vos étiquettes dans le dictionnaire d'entrée (comme nous le faisons dans nos jeux de données), alors le modèle s'entraînera en utilisant cette perte interne, qui sera appropriée pour la tâche et le type de modèle que vous avez choisi.
+
+Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle vers le *Hub* pendant l'entraînement, et nous ajustons le modèle avec ce *callback* :
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+Vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, par exemple `"cool_huggingface_user/bert-finetuned-ner"`.
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
+
+
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous pourrez reprendre votre entraînement sur une autre machine si nécessaire.
+
+A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de classification de *tokens*. Félicitations ! Mais quelle est la qualité réelle de notre modèle ? Nous devons évaluer certaines métriques pour le découvrir.
+
+{/if}
+
+
+### Métriques
+
+{#if fw === 'pt'}
+
+Pour que le `Trainer` calcule une métrique à chaque époque, nous devrons définir une fonction `compute_metrics()` qui prend les tableaux de prédictions et d'étiquettes, et retourne un dictionnaire avec les noms et les valeurs des métriques.
+
+Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
+
+```py
+!pip install seqeval
+```
+
+Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+{:else}
+
+Le *framework* traditionnel utilisé pour évaluer la prédiction de la classification des *tokens* est [*seqeval*](https://github.com/chakki-works/seqeval). Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *seqeval* :
+
+```py
+!pip install seqeval
+```
+
+Nous pouvons ensuite le charger via la fonction `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+{/if}
+
+```py
+import evaluate
+
+metric = evaluate.load("seqeval")
+```
+
+Cette métrique ne se comporte pas comme la précision standard : elle prend les listes d'étiquettes comme des chaînes de caractères et non comme des entiers. Nous devrons donc décoder complètement les prédictions et les étiquettes avant de les transmettre à la métrique. Voyons comment cela fonctionne. Tout d'abord, nous allons obtenir les étiquettes pour notre premier exemple d'entraînement :
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+labels = [label_names[i] for i in labels]
+labels
+```
+
+```python out
+['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
+```
+
+Nous pouvons alors créer de fausses prédictions pour celles-ci en changeant simplement la valeur de l'indice 2 :
+
+```py
+predictions = labels.copy()
+predictions[2] = "O"
+metric.compute(predictions=[predictions], references=[labels])
+```
+
+Notez que la métrique prend une liste de prédictions (pas seulement une) et une liste d'étiquettes. Voici la sortie :
+
+```python out
+{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
+ 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
+ 'overall_precision': 1.0,
+ 'overall_recall': 0.67,
+ 'overall_f1': 0.8,
+ 'overall_accuracy': 0.89}
+```
+
+{#if fw === 'pt'}
+
+Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que le score global. Pour notre calcul de métrique, nous ne garderons que le score global, mais n'hésitez pas à modifier la fonction `compute_metrics()` pour retourner toutes les métriques que vous souhaitez.
+
+Cette fonction `compute_metrics()` prend d'abord l'argmax des logits pour les convertir en prédictions (comme d'habitude, les logits et les probabilités sont dans le même ordre, donc nous n'avons pas besoin d'appliquer la fonction softmax). Ensuite, nous devons convertir les étiquettes et les prédictions des entiers en chaînes de caractères. Nous supprimons toutes les valeurs dont l'étiquette est `-100`, puis nous passons les résultats à la méthode `metric.compute()` :
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+
+ # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
+ return {
+ "precision": all_metrics["overall_precision"],
+ "recall": all_metrics["overall_recall"],
+ "f1": all_metrics["overall_f1"],
+ "accuracy": all_metrics["overall_accuracy"],
+ }
+```
+
+Maintenant que ceci est fait, nous sommes presque prêts à définir notre `Trainer`. Nous avons juste besoin d'un objet `model` pour *finetuner* !
+
+{:else}
+
+Cela renvoie un batch d'informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que pour l'ensemble. Voyons maintenant ce qui se passe si nous essayons d'utiliser les prédictions de notre modèle pour calculer des scores réels.
+
+TensorFlow n'aime pas concaténer nos prédictions ensemble car elles ont des longueurs de séquence variables. Cela signifie que nous ne pouvons pas simplement utiliser `model.predict()`. Mais cela ne va pas nous arrêter. Nous obtiendrons des prédictions un batch à la fois et les concaténerons en une grande liste longue au fur et à mesure et en laissant de côté les *tokens* `-100` qui indiquent le masquage/le remplissage. Puis nous calculerons les métriques sur la liste à la fin :
+
+```py
+import numpy as np
+
+all_predictions = []
+all_labels = []
+for batch in tf_eval_dataset:
+ logits = model.predict(batch)["logits"]
+ labels = batch["labels"]
+ predictions = np.argmax(logits, axis=-1)
+ for prediction, label in zip(predictions, labels):
+ for predicted_idx, label_idx in zip(prediction, label):
+ if label_idx == -100:
+ continue
+ all_predictions.append(label_names[predicted_idx])
+ all_labels.append(label_names[label_idx])
+metric.compute(predictions=[all_predictions], references=[all_labels])
+```
+
+
+```python out
+{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
+ 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
+ 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
+ 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
+ 'overall_precision': 0.87,
+ 'overall_recall': 0.91,
+ 'overall_f1': 0.89,
+ 'overall_accuracy': 0.97}
+```
+
+Comment s'est comporté votre modèle, comparé au nôtre ? Si vous avez obtenu des chiffres similaires, votre entraînement a été un succès !
+
+{/if}
+
+{#if fw === 'pt'}
+
+### Définir le modèle
+
+Puisque nous travaillons sur un problème de classification de *tokens*, nous allons utiliser la classe `AutoModelForTokenClassification`. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d'étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l'argument `num_labels`, mais si nous voulons un joli *widget* d'inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances des étiquettes à la place.
+
+Elles devraient être définies par deux dictionnaires, `id2label` et `label2id`, qui contiennent les correspondances entre identifiants et étiquettes et vice versa :
+
+```py
+id2label = {str(i): label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Maintenant nous pouvons simplement les passer à la méthode `AutoModelForTokenClassification.from_pretrained()`, ils seront définis dans la configuration du modèle puis correctement sauvegardés et téléchargés vers le *Hub* :
+
+```py
+from transformers import AutoModelForTokenClassification
+
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Comme lorsque nous avons défini notre `AutoModelForSequenceClassification` au [chapitre 3](/course/fr/chapter3), la création du modèle émet un avertissement indiquant que certains poids n'ont pas été utilisés (ceux de la tête de pré-entraînement) et que d'autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux *tokens*), et que ce modèle doit être entraîné. Nous ferons cela dans une minute, mais vérifions d'abord que notre modèle a le bon nombre d'étiquettes :
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Si vous avez un modèle avec le mauvais nombre d'étiquettes, vous obtiendrez une erreur obscure lors de l'appel de la méthode `Trainer.train()` (quelque chose comme "CUDA error : device-side assert triggered"). C'est la première cause de bogues signalés par les utilisateurs pour de telles erreurs, donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d'étiquettes attendu.
+
+
+
+### Finetuning du modèle
+
+Nous sommes maintenant prêts à entraîner notre modèle ! Nous devons juste faire deux dernières choses avant de définir notre `Trainer` : se connecter à Hugging Face et définir nos arguments d'entraînement. Si vous travaillez dans un *notebook*, il y a une fonction pratique pour vous aider à le faire :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+Une fois ceci fait, nous pouvons définir nos `TrainingArguments` :
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-ner",
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ push_to_hub=True,
+)
+```
+
+Vous avez déjà vu la plupart d'entre eux. Nous définissons quelques hyperparamètres (comme le taux d'apprentissage, le nombre d'époques à entraîner, et le taux de décroissance des poids), et nous spécifions `push_to_hub=True` pour indiquer que nous voulons sauvegarder le modèle, l'évaluer à la fin de chaque époque, et que nous voulons télécharger nos résultats vers le *Hub*. Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/bert-finetuned-ner"``TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé d'après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"sgugger/bert-finetuned-ner"`.
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Trainer` et devrez définir un nouveau nom.
+
+
+
+Enfin, nous passons tout au `Trainer` et lançons l'entraînement :
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
+
+Une fois l'entraînement terminé, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la version la plus récente du modèle :
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
+```
+
+Le `Trainer` rédige également une carte modèle avec tous les résultats de l'évaluation et la télécharge. A ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à affiner un modèle sur une tâche de classification de *tokens*. Félicitations !
+
+Si vous voulez plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
+
+## Une boucle d'entraînement personnalisée
+
+Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans le [chapitre 3](/course/fr/chapter3/4) avec quelques changements pour l'évaluation.
+
+### Préparer tout pour l'entraînement
+
+D'abord nous devons construire le `DataLoader`s à partir de nos jeux de données. Nous réutilisons notre `data_collator` comme un `collate_fn` et mélanger l'ensemble d'entraînement, mais pas l'ensemble de validation :
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne continuons pas le *finetuning* d'avant et que nous repartons bien du modèle pré-entraîné de BERT :
+
+```py
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Ensuite, nous avons besoin d'un optimiseur. Nous utilisons le classique `AdamW`, qui est comme `Adam`, mais avec un correctif dans la façon dont le taux de décroissance des poids est appliquée :
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()` :
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 Si vous entraînez sur un TPU, vous devrez déplacer tout le code à partir de la cellule ci-dessus dans une fonction d'entraînement dédiée. Voir le [chapitre 3](/course/fr/chapter3) pour plus de détails.
+
+
+
+Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le *dataloader* car cette méthode modifiera sa longueur. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Enfin, pour pousser notre modèle vers le *Hub*, nous avons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous à Hugging Face si vous n'êtes pas déjà connecté. Nous déterminons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur et ce que fait la fonction `get_full_repo_name()`) :
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-ner-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-ner-accelerate'
+```
+
+Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone existant du dépôt avec lequel nous travaillons :
+
+```py
+output_dir = "bert-finetuned-ner-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
+
+### Boucle d'entraînement
+
+Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes, et les convertit en listes de chaînes de caractères comme notre objet `metric` l'attend :
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.detach().cpu().clone().numpy()
+ labels = labels.detach().cpu().clone().numpy()
+
+ # Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ return true_labels, true_predictions
+```
+
+Ensuite, nous pouvons écrire la boucle d'entraînement. Après avoir défini une barre de progression pour suivre l'évolution de l'entraînement, la boucle comporte trois parties :
+
+- L'entraînement proprement dit, qui est l'itération classique sur le `train_dataloader`, passage en avant, puis passage en arrière et étape d'optimisation.
+- L'évaluation, dans laquelle il y a une nouveauté après avoir obtenu les sorties de notre modèle sur un batch : puisque deux processus peuvent avoir paddé les entrées et les étiquettes à des formes différentes, nous devons utiliser `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne le faisons pas, l'évaluation va soit se tromper, soit se bloquer pour toujours. Ensuite, nous envoyons les résultats à `metric.add_batch()` et appelons `metric.compute()` une fois que la boucle d'évaluation est terminée.
+- Sauvegarde et téléchargement, où nous sauvegardons d'abord le modèle et le *tokenizer*, puis appelons `repo.push_to_hub()`. Remarquez que nous utilisons l'argument `blocking=False` pour indiquer à la bibliothèque 🤗 *Hub* de pousser dans un processus asynchrone. De cette façon, l'entraînement continue normalement et cette (longue) instruction est exécutée en arrière-plan.
+
+Voici le code complet de la boucle d'entraînement :
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Entraînement
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in eval_dataloader:
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+
+ # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(predictions)
+ labels_gathered = accelerator.gather(labels)
+
+ true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=true_predictions, references=true_labels)
+
+ results = metric.compute()
+ print(
+ f"epoch {epoch}:",
+ {
+ key: results[f"overall_{key}"]
+ for key in ["precision", "recall", "f1", "accuracy"]
+ },
+ )
+
+ # Sauvegarder et télécharger
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+Au cas où ce serait la première fois que vous verriez un modèle enregistré avec 🤗 *Accelerate*, prenons un moment pour inspecter les trois lignes de code qui l'accompagnent :
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+La première ligne est explicite : elle indique à tous les processus d'attendre que tout le monde soit à ce stade avant de continuer. C'est pour s'assurer que nous avons le même modèle dans chaque processus avant de sauvegarder. Ensuite, nous prenons le `unwrapped_model` qui est le modèle de base que nous avons défini. La méthode `accelerator.prepare()` modifie le modèle pour qu'il fonctionne dans l'entraînement distribué, donc il n'aura plus la méthode `save_pretrained()` ; la méthode `accelerator.unwrap_model()` annule cette étape. Enfin, nous appelons `save_pretrained()` mais nous disons à cette méthode d'utiliser `accelerator.save()` au lieu de `torch.save()`.
+
+Une fois ceci fait, vous devriez avoir un modèle qui produit des résultats assez similaires à celui entraîné avec le `Trainer`. Vous pouvez vérifier le modèle que nous avons formé en utilisant ce code à [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les implémenter directement en modifiant le code ci-dessus !
+
+{/if}
+
+### Utilisation du modèle finetuné
+
+Nous vous avons déjà montré comment vous pouvez utiliser le modèle *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, vous devez juste spécifier l'identifiant de modèle approprié :
+
+```py
+from transformers import pipeline
+
+# Remplacez ceci par votre propre checkpoint
+model_checkpoint = "huggingface-course/bert-finetuned-ner"
+token_classifier = pipeline(
+ "token-classification", model=model_checkpoint, aggregation_strategy="simple"
+)
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Super ! Notre modèle fonctionne aussi bien que le modèle par défaut pour ce pipeline !
+
diff --git a/chapters/fr/chapter7/3.mdx b/chapters/fr/chapter7/3.mdx
index 89cd6a843..96f3b04ff 100644
--- a/chapters/fr/chapter7/3.mdx
+++ b/chapters/fr/chapter7/3.mdx
@@ -1,1042 +1,1042 @@
-
-
-# Finetuner un modèle de langage masqué
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-Pour de nombreuses applications de NLP impliquant des *transformers*, vous pouvez simplement prendre un modèle pré-entraîné du *Hub* et le *finetuner* directement sur vos données pour la tâche à accomplir. Pour autant que le corpus utilisé pour le pré-entraînement ne soit pas trop différent du corpus utilisé pour le *finetuning*. L'apprentissage par transfert produira généralement de bons résultats.
-
-Cependant, il existe quelques cas où vous voudrez d'abord *finetuner* les modèles de langue sur vos données, avant d'entraîner une tête spécifique à la tâche. Par exemple, si votre jeu de données contient des contrats légaux ou des articles scientifiques, un *transformer* classique comme BERT traitera généralement les mots spécifiques au domaine dans votre corpus comme des *tokens* rares et les performances résultantes peuvent être moins que satisfaisantes. En *finetunant* le modèle de langage sur les données du domaine, vous pouvez améliorer les performances de nombreuses tâches en aval, ce qui signifie que vous ne devez généralement effectuer cette étape qu'une seule fois !
-
-Ce processus de *finetuning* d'un modèle de langage pré-entraîné sur des données *dans le domaine* est généralement appelé _adaptation au domaine_. Il a été popularisé en 2018 par [ULMFiT](https://arxiv.org/abs/1801.06146) qui a été l'une des premières architectures neuronales (basées sur des LSTMs) à faire en sorte que l'apprentissage par transfert fonctionne réellement pour le NLP. Un exemple d'adaptation de domaine avec ULMFiT est présenté dans l'image ci-dessous. Dans cette section, nous ferons quelque chose de similaire mais avec un *transformer* au lieu d'une LSTM !
-
-
-

-

-
-
-
Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
-'>>> Label: 0'
-
-'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.
The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
-'>>> Label: 0'
-
-'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version.
My 4 and 6 year old children love this movie and have been asking again and again to watch it.
I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.
I do not have older children so I do not know what they would think of it.
The songs are very cute. My daughter keeps singing them over and over.
Hope this helps.'
-'>>> Label: 1'
-```
-
-Oui, ce sont bien des critiques de films, et si vous êtes assez âgés, vous pouvez même comprendre le commentaire dans la dernière critique sur le fait de posséder une version VHS 😜 ! Bien que nous n'ayons pas besoin des étiquettes pour la modélisation du langage, nous pouvons déjà voir qu'un `0` dénote une critique négative, tandis qu'un `1` correspond à une critique positive.
-
-
-
-✏️ **Essayez !** Créez un échantillon aléatoire de la répartition `unsupervised` et vérifiez que les étiquettes ne sont ni `0` ni `1`. Pendant que vous y êtes, vous pouvez aussi vérifier que les étiquettes dans les échantillons `train` et `test` sont bien `0` ou `1`. C'est un contrôle utile que tout praticien en NLP devrait effectuer au début d'un nouveau projet !
-
-
-
-Maintenant que nous avons jeté un coup d'œil rapide aux données, plongeons dans leur préparation pour la modélisation du langage masqué. Comme nous allons le voir, il y a quelques étapes supplémentaires à suivre par rapport aux tâches de classification de séquences que nous avons vues au [chapitre 3](/course/fr/chapter3). Allons-y !
-
-## Prétraitement des données
-
-
-
-Pour la modélisation autorégressive et la modélisation du langage masqué, une étape commune de prétraitement consiste à concaténer tous les exemples, puis à diviser le corpus entier en morceaux de taille égale. C'est très différent de notre approche habituelle, où nous nous contentons de *tokenizer* les exemples individuels. Pourquoi tout concaténer ? La raison est que les exemples individuels peuvent être tronqués s'ils sont trop longs, ce qui entraînerait la perte d'informations qui pourraient être utiles pour la tâche de modélisation du langage !
-
-Donc pour commencer, nous allons d'abord tokeniser notre corpus comme d'habitude, mais _sans_ mettre l'option `truncation=True` dans notre *tokenizer*. Nous allons aussi récupérer les identifiants des mots s'ils sont disponibles (ce qui sera le cas si nous utilisons un *tokenizer* rapide, comme décrit dans le [chapitre 6](/course/fr/chapter6/3)), car nous en aurons besoin plus tard pour faire le masquage de mots entiers. Nous allons envelopper cela dans une simple fonction, et pendant que nous y sommes, nous allons supprimer les colonnes `text` et `label` puisque nous n'en avons plus besoin :
-
-```python
-def tokenize_function(examples):
- result = tokenizer(examples["text"])
- if tokenizer.is_fast:
- result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
- return result
-
-
-# Utilisation de batched=True pour activer le multithreading rapide !
-tokenized_datasets = imdb_dataset.map(
- tokenize_function, batched=True, remove_columns=["text", "label"]
-)
-tokenized_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['attention_mask', 'input_ids', 'word_ids'],
- num_rows: 25000
- })
- test: Dataset({
- features: ['attention_mask', 'input_ids', 'word_ids'],
- num_rows: 25000
- })
- unsupervised: Dataset({
- features: ['attention_mask', 'input_ids', 'word_ids'],
- num_rows: 50000
- })
-})
-```
-
-Comme DistilBERT est un modèle de type BERT, nous pouvons voir que les textes encodés sont constitués des `input_ids` et des `attention_mask` que nous avons vus dans d'autres chapitres, ainsi que des `word_ids` que nous avons ajoutés.
-
-Maintenant que nos critiques de films ont été tokenisées, l'étape suivante consiste à les regrouper et à diviser le résultat en chunks. Mais quelle taille doivent avoir ces *chunks* ? Cela sera finalement déterminé par la quantité de mémoire GPU dont vous disposez, mais un bon point de départ est de voir quelle est la taille maximale du contexte du modèle. Cela peut être déduit en inspectant l'attribut `model_max_length` du *tokenizer* :
-
-```python
-tokenizer.model_max_length
-```
-
-
-```python out
-512
-```
-
-Cette valeur est dérivée du fichier *tokenizer_config.json* associé à un *checkpoint*. Dans ce cas, nous pouvons voir que la taille du contexte est de 512 *tokens*, tout comme avec BERT.
-
-
-
-✏️ **Essayez !** Certains *transformers*, comme [BigBird](https://huggingface.co/google/bigbird-roberta-base) et [Longformer](hf.co/allenai/longformer-base-4096), ont une longueur de contexte beaucoup plus longue que BERT et les autres premiers *transformers*. Instanciez le *tokenizer* pour l'un de ces *checkpoints* et vérifiez que le `model_max_length` correspond à ce qui est indiqué sur sa carte.
-
-
-
-Ainsi, pour réaliser nos expériences sur des GPUs comme ceux disponibles sur Google Colab, nous choisirons quelque chose d'un peu plus petit qui peut tenir en mémoire :
-
-```python
-chunk_size = 128
-```
-
-
-
-Notez que l'utilisation d'une petite taille peut être préjudiciable dans les scénarios du monde réel. Vous devez donc utiliser une taille qui correspond au cas d'utilisation auquel vous appliquerez votre modèle.
-
-
-
-Maintenant vient la partie amusante. Pour montrer comment la concaténation fonctionne, prenons quelques commentaires de notre ensemble d'entraînement et affichons le nombre de *tokens* par commentaire :
-
-```python
-# Le découpage produit une liste de listes pour chaque caractéristique
-tokenized_samples = tokenized_datasets["train"][:3]
-
-for idx, sample in enumerate(tokenized_samples["input_ids"]):
- print(f"'>>> Review {idx} length: {len(sample)}'")
-```
-
-```python out
-'>>> Review 0 length: 200'
-'>>> Review 1 length: 559'
-'>>> Review 2 length: 192'
-```
-
-Nous pouvons ensuite concaténer tous ces exemples avec une simple compréhension du dictionnaire, comme suit :
-
-```python
-concatenated_examples = {
- k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
-}
-total_length = len(concatenated_examples["input_ids"])
-print(f"'>>> Longueur des critiques concaténées : {total_length}'")
-```
-
-```python out
-'>>> Longueur des critiques concaténées : 951'
-```
-
-Super, la longueur totale est correcte. Donc maintenant, nous allons diviser les exemples concaténés en morceaux de la taille donnée par `block_size`. Pour ce faire, nous itérons sur les caractéristiques de `concatenated_examples` et utilisons une compréhension de liste pour créer des *chunks* de chaque caractéristique. Le résultat est un dictionnaire de *chunks* pour chaque caractéristique :
-
-```python
-chunks = {
- k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
- for k, t in concatenated_examples.items()
-}
-
-for chunk in chunks["input_ids"]:
- print(f"'>>> Chunk length: {len(chunk)}'")
-```
-
-```python out
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 128'
-'>>> Chunk length: 55'
-```
-
-Comme vous pouvez le voir dans cet exemple, le dernier *chunk* sera généralement plus petit que la taille maximale des morceaux. Il y a deux stratégies principales pour gérer cela :
-
-* Abandonner le dernier morceau s'il est plus petit que `chunk_size`.
-* Rembourrer le dernier morceau jusqu'à ce que sa longueur soit égale à `chunk_size`.
-
-Nous adopterons la première approche ici, donc nous allons envelopper toute la logique ci-dessus dans une seule fonction que nous pouvons appliquer à nos jeux de données tokenisés :
-
-```python
-def group_texts(examples):
- # Concaténation de tous les textes
- concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
- # Calcule la longueur des textes concaténés
- total_length = len(concatenated_examples[list(examples.keys())[0]])
- # Nous laissons tomber le dernier morceau s'il est plus petit que chunk_size
- total_length = (total_length // chunk_size) * chunk_size
- # Fractionnement par chunk de max_len
- result = {
- k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
- for k, t in concatenated_examples.items()
- }
- # Créer une nouvelle colonne d'étiquettes
- result["labels"] = result["input_ids"].copy()
- return result
-```
-
-Notez que dans la dernière étape de `group_texts()` nous créons une nouvelle colonne `labels` qui est une copie de la colonne `input_ids`. Comme nous le verrons bientôt, c'est parce que dans la modélisation du langage masqué, l'objectif est de prédire des *tokens* masqués aléatoirement dans le batch d'entrée, et en créant une colonne `labels`, nous fournissons la vérité de base pour notre modèle de langage à apprendre.
-
-Appliquons maintenant `group_texts()` à nos jeux de données tokenisés en utilisant notre fidèle fonction `Dataset.map()` :
-
-```python
-lm_datasets = tokenized_datasets.map(group_texts, batched=True)
-lm_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
- num_rows: 61289
- })
- test: Dataset({
- features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
- num_rows: 59905
- })
- unsupervised: Dataset({
- features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
- num_rows: 122963
- })
-})
-```
-
-Vous pouvez voir que le regroupement puis le découpage des textes a produit beaucoup plus d'exemples que nos 25 000 exemples initiaux pour les divisions `train` et `test`. C'est parce que nous avons maintenant des exemples impliquant des *tokens* contigus qui s'étendent sur plusieurs exemples du corpus original. Vous pouvez le voir explicitement en cherchant les *tokens* spéciaux `[SEP]` et `[CLS]` dans l'un des *chunks* :
-
-```python
-tokenizer.decode(lm_datasets["train"][1]["input_ids"])
-```
-
-```python out
-".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
-```
-
-Dans cet exemple, vous pouvez voir deux critiques de films qui se chevauchent, l'une sur un film de lycée et l'autre sur les sans-abri. Voyons également à quoi ressemblent les étiquettes pour la modélisation du langage masqué :
-
-```python out
-tokenizer.decode(lm_datasets["train"][1]["labels"])
-```
-
-```python out
-".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
-```
-
-Comme prévu par notre fonction `group_texts()` ci-dessus, cela semble identique aux `input_ids` décodés. Mais alors comment notre modèle peut-il apprendre quoi que ce soit ? Il nous manque une étape clé : insérer des *tokens* à des positions aléatoires dans les entrées ! Voyons comment nous pouvons le faire à la volée pendant le *finetuning* en utilisant un collateur de données spécial.
-
-## Finetuning de DistilBERT avec l'API `Trainer`
-
-Le *finetuning* d'un modèle de langage masqué est presque identique au *finetuning* d'un modèle de classification de séquences, comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3). La seule différence est que nous avons besoin d'un collecteur de données spécial qui peut masquer de manière aléatoire certains des *tokens* dans chaque batch de textes. Heureusement, 🤗 *Transformers* est livré préparé avec un `DataCollatorForLanguageModeling` dédié à cette tâche. Nous devons juste lui passer le *tokenizer* et un argument `mlm_probability` qui spécifie quelle fraction des *tokens* à masquer. Nous choisirons 15%, qui est la quantité utilisée pour BERT et un choix commun dans la littérature :
-
-```python
-from transformers import DataCollatorForLanguageModeling
-
-data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
-```
-
-Pour voir comment le masquage aléatoire fonctionne, nous allons donner quelques exemples au collateur de données. Puisqu'il s'attend à une liste de `dict` où chaque `dict` représente un seul morceau de texte contigu, nous itérons d'abord sur le jeu de données avant de donner le batch au collateur. Nous supprimons la clé `"word_ids"` pour ce collateur de données car il ne l'attend pas :
-
-```python
-samples = [lm_datasets["train"][i] for i in range(2)]
-for sample in samples:
- _ = sample.pop("word_ids")
-
-for chunk in data_collator(samples)["input_ids"]:
- print(f"\n'>>> {tokenizer.decode(chunk)}'")
-```
-
-```python output
-'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
-
-'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
-```
-
-Super, ça a marché ! Nous pouvons voir que le *token* `[MASK]` a été inséré de façon aléatoire à différents endroits dans notre texte. Ce seront les *tokens* que notre modèle devra prédire pendant l'entraînement. Et la beauté du collecteur de données est qu'il va rendre aléatoire l'insertion du `[MASK]` à chaque batch !
-
-
-
-✏️ **Essayez** Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode `tokenizer.decode()` par `tokenizer.convert_ids_to_tokens()` pour voir que parfois un seul *token* d'un mot donné est masqué et pas les autres.
-
-
-
-{#if fw === 'pt'}
-
-Un effet secondaire du masquage aléatoire est que nos métriques d'évaluation ne seront pas déterministes lorsque nous utilisons la fonction `Trainer` puisque nous utilisons le même collateur de données pour les échantillons d'entraînement et de test. Nous verrons plus tard, lorsque nous examinerons le *finetuning* avec 🤗 *Accelerate*, comment nous pouvons utiliser la flexibilité d'une boucle d'évaluation personnalisée pour geler le caractère aléatoire.
-
-{/if}
-
-Lors de l'entraînement des modèles pour la modélisation du langage masqué, une technique qui peut être utilisée est de masquer des mots entiers ensemble et pas seulement des *tokens* individuels. Cette approche est appelée _masquage de mots entiers_. Si nous voulons utiliser le masquage de mots entiers, nous devons construire nous-mêmes un collateur de données. Un collateur de données est simplement une fonction qui prend une liste d'échantillons et les convertit en un batch. Faisons-le ! Nous utiliserons les identifiants des mots calculés plus tôt pour faire une correspondance entre les indices des mots et les *tokens*, puis nous déciderons aléatoirement quels mots masquer et appliquerons ce masque sur les entrées. Notez que les étiquettes sont toutes `-100` sauf celles qui correspondent aux mots masqués.
-
-{#if fw === 'pt'}
-
-```py
-import collections
-import numpy as np
-
-from transformers import default_data_collator
-
-wwm_probability = 0.2
-
-
-def whole_word_masking_data_collator(features):
- for feature in features:
- word_ids = feature.pop("word_ids")
-
- # Création d'une correspondance entre les mots et les indices des tokens correspondants
- mapping = collections.defaultdict(list)
- current_word_index = -1
- current_word = None
- for idx, word_id in enumerate(word_ids):
- if word_id is not None:
- if word_id != current_word:
- current_word = word_id
- current_word_index += 1
- mapping[current_word_index].append(idx)
-
- # Masquer des mots de façon aléatoire
- mask = np.random.binomial(1, wwm_probability, (len(mapping),))
- input_ids = feature["input_ids"]
- labels = feature["labels"]
- new_labels = [-100] * len(labels)
- for word_id in np.where(mask)[0]:
- word_id = word_id.item()
- for idx in mapping[word_id]:
- new_labels[idx] = labels[idx]
- input_ids[idx] = tokenizer.mask_token_id
-
- return default_data_collator(features)
-```
-
-{:else}
-
-```py
-import collections
-import numpy as np
-
-from transformers.data.data_collator import tf_default_data_collator
-
-wwm_probability = 0.2
-
-
-def whole_word_masking_data_collator(features):
- for feature in features:
- word_ids = feature.pop("word_ids")
-
- # Création d'une correspondance entre les mots et les indices des tokens correspondants
- mapping = collections.defaultdict(list)
- current_word_index = -1
- current_word = None
- for idx, word_id in enumerate(word_ids):
- if word_id is not None:
- if word_id != current_word:
- current_word = word_id
- current_word_index += 1
- mapping[current_word_index].append(idx)
-
- # Masquer des mots de façon aléatoire
- mask = np.random.binomial(1, wwm_probability, (len(mapping),))
- input_ids = feature["input_ids"]
- labels = feature["labels"]
- new_labels = [-100] * len(labels)
- for word_id in np.where(mask)[0]:
- word_id = word_id.item()
- for idx in mapping[word_id]:
- new_labels[idx] = labels[idx]
- input_ids[idx] = tokenizer.mask_token_id
-
- return tf_default_data_collator(features)
-```
-
-{/if}
-
-Ensuite, nous pouvons l'essayer sur les mêmes échantillons que précédemment :
-
-```py
-samples = [lm_datasets["train"][i] for i in range(2)]
-batch = whole_word_masking_data_collator(samples)
-
-for chunk in batch["input_ids"]:
- print(f"\n'>>> {tokenizer.decode(chunk)}'")
-```
-
-```python out
-'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
-
-'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'
-```
-
-
-
-✏️ **Essayez** Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode `tokenizer.decode()` par `tokenizer.convert_ids_to_tokens()` pour voir que les *tokens* d'un mot donné sont toujours masqués ensemble.
-
-
-
-Maintenant que nous avons deux collateurs de données, les étapes restantes du *finetuning* sont standards. L'entraînement peut prendre un certain temps sur Google Colab si vous n'avez pas la chance de tomber sur un mythique GPU P100 😭. Ainsi nous allons d'abord réduire la taille du jeu d'entraînement à quelques milliers d'exemples. Ne vous inquiétez pas, nous obtiendrons quand même un modèle de langage assez décent ! Un moyen rapide de réduire la taille d'un jeu de données dans 🤗 *Datasets* est la fonction `Dataset.train_test_split()` que nous avons vue au [chapitre 5](/course/fr/chapter5) :
-
-```python
-train_size = 10_000
-test_size = int(0.1 * train_size)
-
-downsampled_dataset = lm_datasets["train"].train_test_split(
- train_size=train_size, test_size=test_size, seed=42
-)
-downsampled_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
- num_rows: 10000
- })
- test: Dataset({
- features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
- num_rows: 1000
- })
-})
-```
-
-Cela a automatiquement créé de nouvelles divisions `train` et `test` avec la taille du jeu d'entraînement fixée à 10.000 exemples et la validation fixée à 10% de cela. N'hésitez pas à augmenter la taille si vous avez un GPU puissant ! La prochaine chose que nous devons faire est de nous connecter au *Hub*. Si vous exécutez ce code dans un *notebook*, vous pouvez le faire avec la fonction suivante :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-qui affichera un *widget* où vous pourrez saisir vos informations d'identification. Alternativement, vous pouvez exécuter :
-
-```
-huggingface-cli login
-```
-
-dans votre terminal préféré et connectez-vous là.
-
-{#if fw === 'tf'}
-
-Une fois que nous sommes connectés, nous pouvons créer nos jeux de données `tf.data`. Nous n'utiliserons ici que le collecteur de données standard, mais vous pouvez également essayer le collecteur de masquage de mots entiers et comparer les résultats à titre d'exercice :
-
-```python
-tf_train_dataset = downsampled_dataset["train"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=True,
- batch_size=32,
-)
-
-tf_eval_dataset = downsampled_dataset["test"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=32,
-)
-```
-
-Ensuite, nous configurons nos hyperparamètres d'entraînement et compilons notre modèle. Nous utilisons la fonction `create_optimizer()` de la bibliothèque 🤗 *Transformers*, qui nous donne un optimiseur `AdamW` avec une décroissance linéaire du taux d'apprentissage. Nous utilisons également la perte intégrée au modèle, qui est la perte par défaut lorsqu'aucune perte n'est spécifiée comme argument de `compile()`, et nous définissons la précision d'entraînement à `"mixed_float16"`. Notez que si vous utilisez un GPU Colab ou un autre GPU qui n'a pas le support accéléré en float16, vous devriez probablement commenter cette ligne.
-
-De plus, nous mettons en place un `PushToHubCallback` qui sauvegardera le modèle sur le *Hub* après chaque époque. Vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, pour pousser le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/distilbert-finetuned-imdb"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, donc dans notre cas, ce sera `"lewtun/distilbert-finetuned-imdb"`.
-
-```python
-from transformers import create_optimizer
-from transformers.keras_callbacks import PushToHubCallback
-import tensorflow as tf
-
-num_train_steps = len(tf_train_dataset)
-optimizer, schedule = create_optimizer(
- init_lr=2e-5,
- num_warmup_steps=1_000,
- num_train_steps=num_train_steps,
- weight_decay_rate=0.01,
-)
-model.compile(optimizer=optimizer)
-
-# Entraîner en mixed-precision float16
-tf.keras.mixed_precision.set_global_policy("mixed_float16")
-
-callback = PushToHubCallback(
- output_dir=f"{model_name}-finetuned-imdb", tokenizer=tokenizer
-)
-```
-
-Nous sommes maintenant prêts à exécuter `model.fit()`. Mais avant, regardons brièvement la _perplexité_ qui est une métrique commune pour évaluer la performance des modèles de langage.
-
-{:else}
-
-Une fois que nous sommes connectés, nous pouvons spécifier les arguments pour le `Trainer` :
-
-```python
-from transformers import TrainingArguments
-
-batch_size = 64
-# Montrer la perte d'entraînement à chaque époque
-logging_steps = len(downsampled_dataset["train"]) // batch_size
-model_name = model_checkpoint.split("/")[-1]
-
-training_args = TrainingArguments(
- output_dir=f"{model_name}-finetuned-imdb",
- overwrite_output_dir=True,
- evaluation_strategy="epoch",
- learning_rate=2e-5,
- weight_decay=0.01,
- per_device_train_batch_size=batch_size,
- per_device_eval_batch_size=batch_size,
- push_to_hub=True,
- fp16=True,
- logging_steps=logging_steps,
-)
-```
-
-Ici, nous avons modifié quelques options par défaut, y compris `logging_steps` pour s'assurer que nous suivons la perte d'entraînement à chaque époque. Nous avons également utilisé `fp16=True` pour activer l'entraînement en précision mixte, ce qui nous donne un autre gain de vitesse. Par défaut, `Trainer` va supprimer toutes les colonnes qui ne font pas partie de la méthode `forward()` du modèle. Cela signifie que si vous utilisez le collateur de masquage de mots entiers, vous devrez également définir `remove_unused_columns=False` pour vous assurer que nous ne perdons pas la colonne `word_ids` pendant l'entraînement.
-
-Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` `TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"lewtun/distilbert-finetuned-imdb"`.
-
-Nous avons maintenant tous les ingrédients pour instancier le `Trainer`. Ici, nous utilisons juste le collateur standard `data_collator`, mais vous pouvez essayer le collateur de masquage de mots entiers et comparer les résultats comme exercice :
-
-```python
-from transformers import Trainer
-
-trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=downsampled_dataset["train"],
- eval_dataset=downsampled_dataset["test"],
- data_collator=data_collator,
-)
-```
-
-Nous sommes maintenant prêts à exécuter `trainer.train()`. Mais avant, regardons brièvement la _perplexité_ qui est une métrique commune pour évaluer la performance des modèles de langage.
-
-{/if}
-
-### Perplexité pour les modèles de langage
-
-
-
-Contrairement à d'autres tâches, comme la classification de textes ou la réponse à des questions, sur lesquelles nous disposons d'un corpus étiqueté pour entraîner, la modélisation du langage ne s'appuie sur aucune étiquette explicite. Alors comment déterminer ce qui fait un bon modèle de langage ? Comme pour la fonction de correction automatique de votre téléphone, un bon modèle de langage est celui qui attribue des probabilités élevées aux phrases grammaticalement correctes et des probabilités faibles aux phrases absurdes. Pour vous donner une meilleure idée de ce à quoi cela ressemble, vous pouvez trouver en ligne des séries entières de « ratés d'autocorrection » où le modèle d'un téléphone produit des compléments plutôt amusants (et souvent inappropriés) !
-
-{#if fw === 'pt'}
-
-En supposant que notre ensemble de test se compose principalement de phrases grammaticalement correctes, une façon de mesurer la qualité de notre modèle de langage est de calculer les probabilités qu'il attribue au mot suivant dans toutes les phrases de l'ensemble de test. Des probabilités élevées indiquent que le modèle n'est pas « surpris » ou « perplexe » vis-à-vis des exemples non vus, et suggèrent qu'il a appris les modèles de base de la grammaire de la langue. Il existe plusieurs définitions mathématiques de la perplexité. Celle que nous utiliserons la définit comme l'exponentielle de la perte d'entropie croisée. Ainsi, nous pouvons calculer la perplexité de notre modèle pré-entraîné en utilisant la fonction `Trainer.evaluate()` pour calculer la perte d'entropie croisée sur l'ensemble de test, puis en prenant l'exponentielle du résultat :
-
-```python
-import math
-
-eval_results = trainer.evaluate()
-print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
-```
-
-{:else}
-
-En supposant que notre ensemble de test se compose principalement de phrases grammaticalement correctes, une façon de mesurer la qualité de notre modèle de langage est de calculer les probabilités qu'il attribue au mot suivant dans toutes les phrases de l'ensemble de test. Des probabilités élevées indiquent que le modèle n'est pas « surpris » ou « perplexe » vis-à-vis des exemples non vus, et suggèrent qu'il a appris les modèles de base de la grammaire de la langue. Il existe plusieurs définitions mathématiques de la perplexité. Celle que nous utiliserons la définit comme l'exponentielle de la perte d'entropie croisée. Ainsi, nous pouvons calculer la perplexité de notre modèle pré-entraîné en utilisant la fonction `model.evaluate()` pour calculer la perte d'entropie croisée sur l'ensemble de test, puis en prenant l'exponentielle du résultat :
-
-```python
-import math
-
-eval_loss = model.evaluate(tf_eval_dataset)
-print(f"Perplexité : {math.exp(eval_loss):.2f}")
-```
-
-{/if}
-
-```python out
->>> Perplexité : 21.75
-```
-
-Un score de perplexité faible signifie un meilleur modèle de langue. Nous pouvons voir ici que notre modèle de départ a une valeur assez élevée. Voyons si nous pouvons la réduire en l'affinant ! Pour ce faire, nous commençons par exécuter la boucle d'entraînement :
-
-{#if fw === 'pt'}
-
-```python
-trainer.train()
-```
-
-{:else}
-
-```python
-model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
-```
-
-{/if}
-
-et ensuite calculer la perplexité résultante sur l'ensemble de test comme précédemment :
-
-{#if fw === 'pt'}
-
-```python
-eval_results = trainer.evaluate()
-print(f">>> Perplexité : {math.exp(eval_results['eval_loss']):.2f}")
-```
-
-{:else}
-
-```python
-eval_loss = model.evaluate(tf_eval_dataset)
-print(f"Perplexité : {math.exp(eval_loss):.2f}")
-```
-
-{/if}
-
-```python out
->>> Perplexité : 11.32
-```
-
-Joli. C'est une réduction considérable de la perplexité, ce qui nous indique que le modèle a appris quelque chose sur le domaine des critiques de films !
-
-{#if fw === 'pt'}
-
-Une fois l'entraînement terminé, nous pouvons pousser la carte de modèle avec les informations d'entraînement vers le *Hub* (les *checkpoints* sont sauvegardés pendant l'entraînement lui-même) :
-
-```python
-trainer.push_to_hub()
-```
-
-{/if}
-
-
-
-✏️ **A votre tour !** Exécutez l'entraînement ci-dessus après avoir remplacé le collecteur de données par le collecteur de mots entiers masqués. Obtenez-vous de meilleurs résultats ?
-
-
-
-{#if fw === 'pt'}
-
-Dans notre cas d'utilisation, nous n'avons pas eu besoin de faire quelque chose de spécial avec la boucle d'entraînement, mais dans certains cas, vous pourriez avoir besoin de mettre en œuvre une logique personnalisée. Pour ces applications, vous pouvez utiliser 🤗 *Accelerate*. Jetons un coup d'œil !
-
-## Finetuning de DistilBERT avec 🤗 Accelerate
-
-Comme nous l'avons vu, avec `Trainer` le *finetuning* d'un modèle de langage masqué est très similaire à l'exemple de classification de texte du [chapitre 3](/course/fr/chapter3). En fait, la seule subtilité est l'utilisation d'un collateur de données spécial, et nous l'avons déjà couvert plus tôt dans cette section !
-
-Cependant, nous avons vu que `DataCollatorForLanguageModeling` applique aussi un masquage aléatoire à chaque évaluation. Nous verrons donc quelques fluctuations dans nos scores de perplexité à chaque entrainement. Une façon d'éliminer cette source d'aléat est d'appliquer le masquage _une fois_ sur l'ensemble de test, puis d'utiliser le collateur de données par défaut dans 🤗 *Transformers* pour collecter les batchs pendant l'évaluation. Pour voir comment cela fonctionne, implémentons une fonction simple qui applique le masquage sur un batch, similaire à notre première rencontre avec `DataCollatorForLanguageModeling` :
-
-```python
-def insert_random_mask(batch):
- features = [dict(zip(batch, t)) for t in zip(*batch.values())]
- masked_inputs = data_collator(features)
- # Créer une nouvelle colonne "masquée" pour chaque colonne du jeu de données
- return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
-```
-
-Ensuite, nous allons appliquer cette fonction à notre jeu de test et laisser tomber les colonnes non masquées afin de les remplacer par les colonnes masquées. Vous pouvez utiliser le masquage de mots entiers en remplaçant le `data_collator` ci-dessus par celui qui est approprié. Dans ce cas vous devez supprimer la première ligne ici :
-
-```py
-downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
-eval_dataset = downsampled_dataset["test"].map(
- insert_random_mask,
- batched=True,
- remove_columns=downsampled_dataset["test"].column_names,
-)
-eval_dataset = eval_dataset.rename_columns(
- {
- "masked_input_ids": "input_ids",
- "masked_attention_mask": "attention_mask",
- "masked_labels": "labels",
- }
-)
-```
-
-Nous pouvons ensuite configurer les *dataloaders* comme d'habitude, mais nous utiliserons le `default_data_collator` de 🤗 *Transformers* pour le jeu d'évaluation :
-
-```python
-from torch.utils.data import DataLoader
-from transformers import default_data_collator
-
-batch_size = 64
-train_dataloader = DataLoader(
- downsampled_dataset["train"],
- shuffle=True,
- batch_size=batch_size,
- collate_fn=data_collator,
-)
-eval_dataloader = DataLoader(
- eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
-)
-```
-
-Nous suivons les étapes standard avec 🤗 *Accelerate*. La première est de charger une version fraîche du modèle pré-entraîné :
-
-```
-model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
-```
-
-Ensuite, nous devons spécifier l'optimiseur. Nous utiliserons le standard `AdamW` :
-
-```python
-from torch.optim import AdamW
-
-optimizer = AdamW(model.parameters(), lr=5e-5)
-```
-
-Avec ces objets, nous pouvons maintenant tout préparer pour l'entraînement avec l'objet `Accelerator` :
-
-```python
-from accelerate import Accelerator
-
-accelerator = Accelerator()
-model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
-)
-```
-
-Maintenant que notre modèle, notre optimiseur et nos chargeurs de données sont configurés, nous pouvons spécifier le planificateur du taux d'apprentissage comme suit :
-
-```python
-from transformers import get_scheduler
-
-num_train_epochs = 3
-num_update_steps_per_epoch = len(train_dataloader)
-num_training_steps = num_train_epochs * num_update_steps_per_epoch
-
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-```
-
-Il ne reste qu'une dernière chose à faire avant de s'entraîner : créer un dépôt de modèles sur le *Hub* d'Hugging Face ! Nous pouvons utiliser la bibliothèque 🤗 *Hub* pour générer d'abord le nom complet de notre dépôt :
-
-```python
-from huggingface_hub import get_full_repo_name
-
-model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
-repo_name = get_full_repo_name(model_name)
-repo_name
-```
-
-```python out
-'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
-```
-
-puis créer et cloner le dépôt en utilisant la classe `Repository` du 🤗 *Hub* :
-
-```python
-from huggingface_hub import Repository
-
-output_dir = model_name
-repo = Repository(output_dir, clone_from=repo_name)
-```
-
-Une fois cela fait, il ne reste plus qu'à rédiger la boucle complète d'entraînement et d'évaluation :
-
-```python
-from tqdm.auto import tqdm
-import torch
-import math
-
-progress_bar = tqdm(range(num_training_steps))
-
-for epoch in range(num_train_epochs):
- # Entraînement
- model.train()
- for batch in train_dataloader:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-
- # Evaluation
- model.eval()
- losses = []
- for step, batch in enumerate(eval_dataloader):
- with torch.no_grad():
- outputs = model(**batch)
-
- loss = outputs.loss
- losses.append(accelerator.gather(loss.repeat(batch_size)))
-
- losses = torch.cat(losses)
- losses = losses[: len(eval_dataset)]
- try:
- perplexity = math.exp(torch.mean(losses))
- except OverflowError:
- perplexity = float("inf")
-
- print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
-
- # Sauvegarder et télécharger
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False
- )
-```
-
-```python out
->>> Epoch 0: Perplexity: 11.397545307900472
->>> Epoch 1: Perplexity: 10.904909330983092
->>> Epoch 2: Perplexity: 10.729503505340409
-```
-
-Cool, nous avons été en mesure d'évaluer la perplexité à chaque époque et de garantir la reproductibilité des entraînements multiples !
-
-{/if}
-
-### Utilisation de notre modèle finetuné
-
-Vous pouvez interagir avec votre modèle *finetuné* soit en utilisant son *widget* sur le *Hub*, soit localement avec le `pipeline` de 🤗 *Transformers*. Utilisons ce dernier pour télécharger notre modèle en utilisant le pipeline `fill-mask` :
-
-```python
-from transformers import pipeline
-
-mask_filler = pipeline(
- "fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
-)
-```
-
-Nous pouvons ensuite donner au pipeline notre exemple de texte « this is a great [MASK] » et voir quelles sont les 5 premières prédictions :
-
-```python
-preds = mask_filler(text)
-
-for pred in preds:
- print(f">>> {pred['sequence']}")
-```
-
-```python out
-'>>> this is a great movie.'
-'>>> this is a great film.'
-'>>> this is a great story.'
-'>>> this is a great movies.'
-'>>> this is a great character.'
-```
-
-Notre modèle a clairement adapté ses pondérations pour prédire les mots qui sont plus fortement associés aux films !
-
-
-
-Ceci conclut notre première expérience d'entraînement d'un modèle de langage. Dans la [section 6](/course/fr/chapter7/section6), vous apprendrez comment entraîner à partir de zéro un modèle autorégressif comme GPT-2. Allez-y si vous voulez voir comment vous pouvez pré-entraîner votre propre *transformer* !
-
-
-
-✏️ **Essayez !** Pour quantifier les avantages de l'adaptation au domaine, finetunez un classifieur sur le jeu de données IMDb pour à la fois, le checkpoint de DistilBERT pré-entraîné et e checkpoint de DistilBERT finetuné. Si vous avez besoin d'un rafraîchissement sur la classification de texte, consultez le [chapitre 3](/course/fr/chapter3).
-
-
+
+
+# Finetuner un modèle de langage masqué
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Pour de nombreuses applications de NLP impliquant des *transformers*, vous pouvez simplement prendre un modèle pré-entraîné du *Hub* et le *finetuner* directement sur vos données pour la tâche à accomplir. Pour autant que le corpus utilisé pour le pré-entraînement ne soit pas trop différent du corpus utilisé pour le *finetuning*. L'apprentissage par transfert produira généralement de bons résultats.
+
+Cependant, il existe quelques cas où vous voudrez d'abord *finetuner* les modèles de langue sur vos données, avant d'entraîner une tête spécifique à la tâche. Par exemple, si votre jeu de données contient des contrats légaux ou des articles scientifiques, un *transformer* classique comme BERT traitera généralement les mots spécifiques au domaine dans votre corpus comme des *tokens* rares et les performances résultantes peuvent être moins que satisfaisantes. En *finetunant* le modèle de langage sur les données du domaine, vous pouvez améliorer les performances de nombreuses tâches en aval, ce qui signifie que vous ne devez généralement effectuer cette étape qu'une seule fois !
+
+Ce processus de *finetuning* d'un modèle de langage pré-entraîné sur des données *dans le domaine* est généralement appelé _adaptation au domaine_. Il a été popularisé en 2018 par [ULMFiT](https://arxiv.org/abs/1801.06146) qui a été l'une des premières architectures neuronales (basées sur des LSTMs) à faire en sorte que l'apprentissage par transfert fonctionne réellement pour le NLP. Un exemple d'adaptation de domaine avec ULMFiT est présenté dans l'image ci-dessous. Dans cette section, nous ferons quelque chose de similaire mais avec un *transformer* au lieu d'une LSTM !
+
+
+
+
+
+
+
Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
+'>>> Label: 0'
+
+'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.
The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
+'>>> Label: 0'
+
+'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version.
My 4 and 6 year old children love this movie and have been asking again and again to watch it.
I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.
I do not have older children so I do not know what they would think of it.
The songs are very cute. My daughter keeps singing them over and over.
Hope this helps.'
+'>>> Label: 1'
+```
+
+Oui, ce sont bien des critiques de films, et si vous êtes assez âgés, vous pouvez même comprendre le commentaire dans la dernière critique sur le fait de posséder une version VHS 😜 ! Bien que nous n'ayons pas besoin des étiquettes pour la modélisation du langage, nous pouvons déjà voir qu'un `0` dénote une critique négative, tandis qu'un `1` correspond à une critique positive.
+
+
+
+✏️ **Essayez !** Créez un échantillon aléatoire de la répartition `unsupervised` et vérifiez que les étiquettes ne sont ni `0` ni `1`. Pendant que vous y êtes, vous pouvez aussi vérifier que les étiquettes dans les échantillons `train` et `test` sont bien `0` ou `1`. C'est un contrôle utile que tout praticien en NLP devrait effectuer au début d'un nouveau projet !
+
+
+
+Maintenant que nous avons jeté un coup d'œil rapide aux données, plongeons dans leur préparation pour la modélisation du langage masqué. Comme nous allons le voir, il y a quelques étapes supplémentaires à suivre par rapport aux tâches de classification de séquences que nous avons vues au [chapitre 3](/course/fr/chapter3). Allons-y !
+
+## Prétraitement des données
+
+
+
+Pour la modélisation autorégressive et la modélisation du langage masqué, une étape commune de prétraitement consiste à concaténer tous les exemples, puis à diviser le corpus entier en morceaux de taille égale. C'est très différent de notre approche habituelle, où nous nous contentons de *tokenizer* les exemples individuels. Pourquoi tout concaténer ? La raison est que les exemples individuels peuvent être tronqués s'ils sont trop longs, ce qui entraînerait la perte d'informations qui pourraient être utiles pour la tâche de modélisation du langage !
+
+Donc pour commencer, nous allons d'abord tokeniser notre corpus comme d'habitude, mais _sans_ mettre l'option `truncation=True` dans notre *tokenizer*. Nous allons aussi récupérer les identifiants des mots s'ils sont disponibles (ce qui sera le cas si nous utilisons un *tokenizer* rapide, comme décrit dans le [chapitre 6](/course/fr/chapter6/3)), car nous en aurons besoin plus tard pour faire le masquage de mots entiers. Nous allons envelopper cela dans une simple fonction, et pendant que nous y sommes, nous allons supprimer les colonnes `text` et `label` puisque nous n'en avons plus besoin :
+
+```python
+def tokenize_function(examples):
+ result = tokenizer(examples["text"])
+ if tokenizer.is_fast:
+ result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
+ return result
+
+
+# Utilisation de batched=True pour activer le multithreading rapide !
+tokenized_datasets = imdb_dataset.map(
+ tokenize_function, batched=True, remove_columns=["text", "label"]
+)
+tokenized_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 50000
+ })
+})
+```
+
+Comme DistilBERT est un modèle de type BERT, nous pouvons voir que les textes encodés sont constitués des `input_ids` et des `attention_mask` que nous avons vus dans d'autres chapitres, ainsi que des `word_ids` que nous avons ajoutés.
+
+Maintenant que nos critiques de films ont été tokenisées, l'étape suivante consiste à les regrouper et à diviser le résultat en chunks. Mais quelle taille doivent avoir ces *chunks* ? Cela sera finalement déterminé par la quantité de mémoire GPU dont vous disposez, mais un bon point de départ est de voir quelle est la taille maximale du contexte du modèle. Cela peut être déduit en inspectant l'attribut `model_max_length` du *tokenizer* :
+
+```python
+tokenizer.model_max_length
+```
+
+
+```python out
+512
+```
+
+Cette valeur est dérivée du fichier *tokenizer_config.json* associé à un *checkpoint*. Dans ce cas, nous pouvons voir que la taille du contexte est de 512 *tokens*, tout comme avec BERT.
+
+
+
+✏️ **Essayez !** Certains *transformers*, comme [BigBird](https://huggingface.co/google/bigbird-roberta-base) et [Longformer](hf.co/allenai/longformer-base-4096), ont une longueur de contexte beaucoup plus longue que BERT et les autres premiers *transformers*. Instanciez le *tokenizer* pour l'un de ces *checkpoints* et vérifiez que le `model_max_length` correspond à ce qui est indiqué sur sa carte.
+
+
+
+Ainsi, pour réaliser nos expériences sur des GPUs comme ceux disponibles sur Google Colab, nous choisirons quelque chose d'un peu plus petit qui peut tenir en mémoire :
+
+```python
+chunk_size = 128
+```
+
+
+
+Notez que l'utilisation d'une petite taille peut être préjudiciable dans les scénarios du monde réel. Vous devez donc utiliser une taille qui correspond au cas d'utilisation auquel vous appliquerez votre modèle.
+
+
+
+Maintenant vient la partie amusante. Pour montrer comment la concaténation fonctionne, prenons quelques commentaires de notre ensemble d'entraînement et affichons le nombre de *tokens* par commentaire :
+
+```python
+# Le découpage produit une liste de listes pour chaque caractéristique
+tokenized_samples = tokenized_datasets["train"][:3]
+
+for idx, sample in enumerate(tokenized_samples["input_ids"]):
+ print(f"'>>> Review {idx} length: {len(sample)}'")
+```
+
+```python out
+'>>> Review 0 length: 200'
+'>>> Review 1 length: 559'
+'>>> Review 2 length: 192'
+```
+
+Nous pouvons ensuite concaténer tous ces exemples avec une simple compréhension du dictionnaire, comme suit :
+
+```python
+concatenated_examples = {
+ k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
+}
+total_length = len(concatenated_examples["input_ids"])
+print(f"'>>> Longueur des critiques concaténées : {total_length}'")
+```
+
+```python out
+'>>> Longueur des critiques concaténées : 951'
+```
+
+Super, la longueur totale est correcte. Donc maintenant, nous allons diviser les exemples concaténés en morceaux de la taille donnée par `block_size`. Pour ce faire, nous itérons sur les caractéristiques de `concatenated_examples` et utilisons une compréhension de liste pour créer des *chunks* de chaque caractéristique. Le résultat est un dictionnaire de *chunks* pour chaque caractéristique :
+
+```python
+chunks = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+}
+
+for chunk in chunks["input_ids"]:
+ print(f"'>>> Chunk length: {len(chunk)}'")
+```
+
+```python out
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 55'
+```
+
+Comme vous pouvez le voir dans cet exemple, le dernier *chunk* sera généralement plus petit que la taille maximale des morceaux. Il y a deux stratégies principales pour gérer cela :
+
+* Abandonner le dernier morceau s'il est plus petit que `chunk_size`.
+* Rembourrer le dernier morceau jusqu'à ce que sa longueur soit égale à `chunk_size`.
+
+Nous adopterons la première approche ici, donc nous allons envelopper toute la logique ci-dessus dans une seule fonction que nous pouvons appliquer à nos jeux de données tokenisés :
+
+```python
+def group_texts(examples):
+ # Concaténation de tous les textes
+ concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+ # Calcule la longueur des textes concaténés
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # Nous laissons tomber le dernier morceau s'il est plus petit que chunk_size
+ total_length = (total_length // chunk_size) * chunk_size
+ # Fractionnement par chunk de max_len
+ result = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+ }
+ # Créer une nouvelle colonne d'étiquettes
+ result["labels"] = result["input_ids"].copy()
+ return result
+```
+
+Notez que dans la dernière étape de `group_texts()` nous créons une nouvelle colonne `labels` qui est une copie de la colonne `input_ids`. Comme nous le verrons bientôt, c'est parce que dans la modélisation du langage masqué, l'objectif est de prédire des *tokens* masqués aléatoirement dans le batch d'entrée, et en créant une colonne `labels`, nous fournissons la vérité de base pour notre modèle de langage à apprendre.
+
+Appliquons maintenant `group_texts()` à nos jeux de données tokenisés en utilisant notre fidèle fonction `Dataset.map()` :
+
+```python
+lm_datasets = tokenized_datasets.map(group_texts, batched=True)
+lm_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 61289
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 59905
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 122963
+ })
+})
+```
+
+Vous pouvez voir que le regroupement puis le découpage des textes a produit beaucoup plus d'exemples que nos 25 000 exemples initiaux pour les divisions `train` et `test`. C'est parce que nous avons maintenant des exemples impliquant des *tokens* contigus qui s'étendent sur plusieurs exemples du corpus original. Vous pouvez le voir explicitement en cherchant les *tokens* spéciaux `[SEP]` et `[CLS]` dans l'un des *chunks* :
+
+```python
+tokenizer.decode(lm_datasets["train"][1]["input_ids"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+Dans cet exemple, vous pouvez voir deux critiques de films qui se chevauchent, l'une sur un film de lycée et l'autre sur les sans-abri. Voyons également à quoi ressemblent les étiquettes pour la modélisation du langage masqué :
+
+```python out
+tokenizer.decode(lm_datasets["train"][1]["labels"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+Comme prévu par notre fonction `group_texts()` ci-dessus, cela semble identique aux `input_ids` décodés. Mais alors comment notre modèle peut-il apprendre quoi que ce soit ? Il nous manque une étape clé : insérer des *tokens* à des positions aléatoires dans les entrées ! Voyons comment nous pouvons le faire à la volée pendant le *finetuning* en utilisant un collateur de données spécial.
+
+## Finetuning de DistilBERT avec l'API `Trainer`
+
+Le *finetuning* d'un modèle de langage masqué est presque identique au *finetuning* d'un modèle de classification de séquences, comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3). La seule différence est que nous avons besoin d'un collecteur de données spécial qui peut masquer de manière aléatoire certains des *tokens* dans chaque batch de textes. Heureusement, 🤗 *Transformers* est livré préparé avec un `DataCollatorForLanguageModeling` dédié à cette tâche. Nous devons juste lui passer le *tokenizer* et un argument `mlm_probability` qui spécifie quelle fraction des *tokens* à masquer. Nous choisirons 15%, qui est la quantité utilisée pour BERT et un choix commun dans la littérature :
+
+```python
+from transformers import DataCollatorForLanguageModeling
+
+data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+Pour voir comment le masquage aléatoire fonctionne, nous allons donner quelques exemples au collateur de données. Puisqu'il s'attend à une liste de `dict` où chaque `dict` représente un seul morceau de texte contigu, nous itérons d'abord sur le jeu de données avant de donner le batch au collateur. Nous supprimons la clé `"word_ids"` pour ce collateur de données car il ne l'attend pas :
+
+```python
+samples = [lm_datasets["train"][i] for i in range(2)]
+for sample in samples:
+ _ = sample.pop("word_ids")
+
+for chunk in data_collator(samples)["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python output
+'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
+
+'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
+```
+
+Super, ça a marché ! Nous pouvons voir que le *token* `[MASK]` a été inséré de façon aléatoire à différents endroits dans notre texte. Ce seront les *tokens* que notre modèle devra prédire pendant l'entraînement. Et la beauté du collecteur de données est qu'il va rendre aléatoire l'insertion du `[MASK]` à chaque batch !
+
+
+
+✏️ **Essayez** Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode `tokenizer.decode()` par `tokenizer.convert_ids_to_tokens()` pour voir que parfois un seul *token* d'un mot donné est masqué et pas les autres.
+
+
+
+{#if fw === 'pt'}
+
+Un effet secondaire du masquage aléatoire est que nos métriques d'évaluation ne seront pas déterministes lorsque nous utilisons la fonction `Trainer` puisque nous utilisons le même collateur de données pour les échantillons d'entraînement et de test. Nous verrons plus tard, lorsque nous examinerons le *finetuning* avec 🤗 *Accelerate*, comment nous pouvons utiliser la flexibilité d'une boucle d'évaluation personnalisée pour geler le caractère aléatoire.
+
+{/if}
+
+Lors de l'entraînement des modèles pour la modélisation du langage masqué, une technique qui peut être utilisée est de masquer des mots entiers ensemble et pas seulement des *tokens* individuels. Cette approche est appelée _masquage de mots entiers_. Si nous voulons utiliser le masquage de mots entiers, nous devons construire nous-mêmes un collateur de données. Un collateur de données est simplement une fonction qui prend une liste d'échantillons et les convertit en un batch. Faisons-le ! Nous utiliserons les identifiants des mots calculés plus tôt pour faire une correspondance entre les indices des mots et les *tokens*, puis nous déciderons aléatoirement quels mots masquer et appliquerons ce masque sur les entrées. Notez que les étiquettes sont toutes `-100` sauf celles qui correspondent aux mots masqués.
+
+{#if fw === 'pt'}
+
+```py
+import collections
+import numpy as np
+
+from transformers import default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Création d'une correspondance entre les mots et les indices des tokens correspondants
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Masquer des mots de façon aléatoire
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+
+ return default_data_collator(features)
+```
+
+{:else}
+
+```py
+import collections
+import numpy as np
+
+from transformers.data.data_collator import tf_default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Création d'une correspondance entre les mots et les indices des tokens correspondants
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Masquer des mots de façon aléatoire
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+
+ return tf_default_data_collator(features)
+```
+
+{/if}
+
+Ensuite, nous pouvons l'essayer sur les mêmes échantillons que précédemment :
+
+```py
+samples = [lm_datasets["train"][i] for i in range(2)]
+batch = whole_word_masking_data_collator(samples)
+
+for chunk in batch["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python out
+'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
+
+'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'
+```
+
+
+
+✏️ **Essayez** Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode `tokenizer.decode()` par `tokenizer.convert_ids_to_tokens()` pour voir que les *tokens* d'un mot donné sont toujours masqués ensemble.
+
+
+
+Maintenant que nous avons deux collateurs de données, les étapes restantes du *finetuning* sont standards. L'entraînement peut prendre un certain temps sur Google Colab si vous n'avez pas la chance de tomber sur un mythique GPU P100 😭. Ainsi nous allons d'abord réduire la taille du jeu d'entraînement à quelques milliers d'exemples. Ne vous inquiétez pas, nous obtiendrons quand même un modèle de langage assez décent ! Un moyen rapide de réduire la taille d'un jeu de données dans 🤗 *Datasets* est la fonction `Dataset.train_test_split()` que nous avons vue au [chapitre 5](/course/fr/chapter5) :
+
+```python
+train_size = 10_000
+test_size = int(0.1 * train_size)
+
+downsampled_dataset = lm_datasets["train"].train_test_split(
+ train_size=train_size, test_size=test_size, seed=42
+)
+downsampled_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 10000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 1000
+ })
+})
+```
+
+Cela a automatiquement créé de nouvelles divisions `train` et `test` avec la taille du jeu d'entraînement fixée à 10.000 exemples et la validation fixée à 10% de cela. N'hésitez pas à augmenter la taille si vous avez un GPU puissant ! La prochaine chose que nous devons faire est de nous connecter au *Hub*. Si vous exécutez ce code dans un *notebook*, vous pouvez le faire avec la fonction suivante :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+qui affichera un *widget* où vous pourrez saisir vos informations d'identification. Alternativement, vous pouvez exécuter :
+
+```
+huggingface-cli login
+```
+
+dans votre terminal préféré et connectez-vous là.
+
+{#if fw === 'tf'}
+
+Une fois que nous sommes connectés, nous pouvons créer nos jeux de données `tf.data`. Nous n'utiliserons ici que le collecteur de données standard, mais vous pouvez également essayer le collecteur de masquage de mots entiers et comparer les résultats à titre d'exercice :
+
+```python
+tf_train_dataset = downsampled_dataset["train"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+
+tf_eval_dataset = downsampled_dataset["test"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=32,
+)
+```
+
+Ensuite, nous configurons nos hyperparamètres d'entraînement et compilons notre modèle. Nous utilisons la fonction `create_optimizer()` de la bibliothèque 🤗 *Transformers*, qui nous donne un optimiseur `AdamW` avec une décroissance linéaire du taux d'apprentissage. Nous utilisons également la perte intégrée au modèle, qui est la perte par défaut lorsqu'aucune perte n'est spécifiée comme argument de `compile()`, et nous définissons la précision d'entraînement à `"mixed_float16"`. Notez que si vous utilisez un GPU Colab ou un autre GPU qui n'a pas le support accéléré en float16, vous devriez probablement commenter cette ligne.
+
+De plus, nous mettons en place un `PushToHubCallback` qui sauvegardera le modèle sur le *Hub* après chaque époque. Vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, pour pousser le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/distilbert-finetuned-imdb"`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, donc dans notre cas, ce sera `"lewtun/distilbert-finetuned-imdb"`.
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+num_train_steps = len(tf_train_dataset)
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=1_000,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Entraîner en mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+callback = PushToHubCallback(
+ output_dir=f"{model_name}-finetuned-imdb", tokenizer=tokenizer
+)
+```
+
+Nous sommes maintenant prêts à exécuter `model.fit()`. Mais avant, regardons brièvement la _perplexité_ qui est une métrique commune pour évaluer la performance des modèles de langage.
+
+{:else}
+
+Une fois que nous sommes connectés, nous pouvons spécifier les arguments pour le `Trainer` :
+
+```python
+from transformers import TrainingArguments
+
+batch_size = 64
+# Montrer la perte d'entraînement à chaque époque
+logging_steps = len(downsampled_dataset["train"]) // batch_size
+model_name = model_checkpoint.split("/")[-1]
+
+training_args = TrainingArguments(
+ output_dir=f"{model_name}-finetuned-imdb",
+ overwrite_output_dir=True,
+ evaluation_strategy="epoch",
+ learning_rate=2e-5,
+ weight_decay=0.01,
+ per_device_train_batch_size=batch_size,
+ per_device_eval_batch_size=batch_size,
+ push_to_hub=True,
+ fp16=True,
+ logging_steps=logging_steps,
+)
+```
+
+Ici, nous avons modifié quelques options par défaut, y compris `logging_steps` pour s'assurer que nous suivons la perte d'entraînement à chaque époque. Nous avons également utilisé `fp16=True` pour activer l'entraînement en précision mixte, ce qui nous donne un autre gain de vitesse. Par défaut, `Trainer` va supprimer toutes les colonnes qui ne font pas partie de la méthode `forward()` du modèle. Cela signifie que si vous utilisez le collateur de masquage de mots entiers, vous devrez également définir `remove_unused_columns=False` pour vous assurer que nous ne perdons pas la colonne `word_ids` pendant l'entraînement.
+
+Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` `TrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera `"lewtun/distilbert-finetuned-imdb"`.
+
+Nous avons maintenant tous les ingrédients pour instancier le `Trainer`. Ici, nous utilisons juste le collateur standard `data_collator`, mais vous pouvez essayer le collateur de masquage de mots entiers et comparer les résultats comme exercice :
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=downsampled_dataset["train"],
+ eval_dataset=downsampled_dataset["test"],
+ data_collator=data_collator,
+)
+```
+
+Nous sommes maintenant prêts à exécuter `trainer.train()`. Mais avant, regardons brièvement la _perplexité_ qui est une métrique commune pour évaluer la performance des modèles de langage.
+
+{/if}
+
+### Perplexité pour les modèles de langage
+
+
+
+Contrairement à d'autres tâches, comme la classification de textes ou la réponse à des questions, sur lesquelles nous disposons d'un corpus étiqueté pour entraîner, la modélisation du langage ne s'appuie sur aucune étiquette explicite. Alors comment déterminer ce qui fait un bon modèle de langage ? Comme pour la fonction de correction automatique de votre téléphone, un bon modèle de langage est celui qui attribue des probabilités élevées aux phrases grammaticalement correctes et des probabilités faibles aux phrases absurdes. Pour vous donner une meilleure idée de ce à quoi cela ressemble, vous pouvez trouver en ligne des séries entières de « ratés d'autocorrection » où le modèle d'un téléphone produit des compléments plutôt amusants (et souvent inappropriés) !
+
+{#if fw === 'pt'}
+
+En supposant que notre ensemble de test se compose principalement de phrases grammaticalement correctes, une façon de mesurer la qualité de notre modèle de langage est de calculer les probabilités qu'il attribue au mot suivant dans toutes les phrases de l'ensemble de test. Des probabilités élevées indiquent que le modèle n'est pas « surpris » ou « perplexe » vis-à-vis des exemples non vus, et suggèrent qu'il a appris les modèles de base de la grammaire de la langue. Il existe plusieurs définitions mathématiques de la perplexité. Celle que nous utiliserons la définit comme l'exponentielle de la perte d'entropie croisée. Ainsi, nous pouvons calculer la perplexité de notre modèle pré-entraîné en utilisant la fonction `Trainer.evaluate()` pour calculer la perte d'entropie croisée sur l'ensemble de test, puis en prenant l'exponentielle du résultat :
+
+```python
+import math
+
+eval_results = trainer.evaluate()
+print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+En supposant que notre ensemble de test se compose principalement de phrases grammaticalement correctes, une façon de mesurer la qualité de notre modèle de langage est de calculer les probabilités qu'il attribue au mot suivant dans toutes les phrases de l'ensemble de test. Des probabilités élevées indiquent que le modèle n'est pas « surpris » ou « perplexe » vis-à-vis des exemples non vus, et suggèrent qu'il a appris les modèles de base de la grammaire de la langue. Il existe plusieurs définitions mathématiques de la perplexité. Celle que nous utiliserons la définit comme l'exponentielle de la perte d'entropie croisée. Ainsi, nous pouvons calculer la perplexité de notre modèle pré-entraîné en utilisant la fonction `model.evaluate()` pour calculer la perte d'entropie croisée sur l'ensemble de test, puis en prenant l'exponentielle du résultat :
+
+```python
+import math
+
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexité : {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexité : 21.75
+```
+
+Un score de perplexité faible signifie un meilleur modèle de langue. Nous pouvons voir ici que notre modèle de départ a une valeur assez élevée. Voyons si nous pouvons la réduire en l'affinant ! Pour ce faire, nous commençons par exécuter la boucle d'entraînement :
+
+{#if fw === 'pt'}
+
+```python
+trainer.train()
+```
+
+{:else}
+
+```python
+model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
+```
+
+{/if}
+
+et ensuite calculer la perplexité résultante sur l'ensemble de test comme précédemment :
+
+{#if fw === 'pt'}
+
+```python
+eval_results = trainer.evaluate()
+print(f">>> Perplexité : {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+```python
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexité : {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexité : 11.32
+```
+
+Joli. C'est une réduction considérable de la perplexité, ce qui nous indique que le modèle a appris quelque chose sur le domaine des critiques de films !
+
+{#if fw === 'pt'}
+
+Une fois l'entraînement terminé, nous pouvons pousser la carte de modèle avec les informations d'entraînement vers le *Hub* (les *checkpoints* sont sauvegardés pendant l'entraînement lui-même) :
+
+```python
+trainer.push_to_hub()
+```
+
+{/if}
+
+
+
+✏️ **A votre tour !** Exécutez l'entraînement ci-dessus après avoir remplacé le collecteur de données par le collecteur de mots entiers masqués. Obtenez-vous de meilleurs résultats ?
+
+
+
+{#if fw === 'pt'}
+
+Dans notre cas d'utilisation, nous n'avons pas eu besoin de faire quelque chose de spécial avec la boucle d'entraînement, mais dans certains cas, vous pourriez avoir besoin de mettre en œuvre une logique personnalisée. Pour ces applications, vous pouvez utiliser 🤗 *Accelerate*. Jetons un coup d'œil !
+
+## Finetuning de DistilBERT avec 🤗 Accelerate
+
+Comme nous l'avons vu, avec `Trainer` le *finetuning* d'un modèle de langage masqué est très similaire à l'exemple de classification de texte du [chapitre 3](/course/fr/chapter3). En fait, la seule subtilité est l'utilisation d'un collateur de données spécial, et nous l'avons déjà couvert plus tôt dans cette section !
+
+Cependant, nous avons vu que `DataCollatorForLanguageModeling` applique aussi un masquage aléatoire à chaque évaluation. Nous verrons donc quelques fluctuations dans nos scores de perplexité à chaque entrainement. Une façon d'éliminer cette source d'aléat est d'appliquer le masquage _une fois_ sur l'ensemble de test, puis d'utiliser le collateur de données par défaut dans 🤗 *Transformers* pour collecter les batchs pendant l'évaluation. Pour voir comment cela fonctionne, implémentons une fonction simple qui applique le masquage sur un batch, similaire à notre première rencontre avec `DataCollatorForLanguageModeling` :
+
+```python
+def insert_random_mask(batch):
+ features = [dict(zip(batch, t)) for t in zip(*batch.values())]
+ masked_inputs = data_collator(features)
+ # Créer une nouvelle colonne "masquée" pour chaque colonne du jeu de données
+ return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
+```
+
+Ensuite, nous allons appliquer cette fonction à notre jeu de test et laisser tomber les colonnes non masquées afin de les remplacer par les colonnes masquées. Vous pouvez utiliser le masquage de mots entiers en remplaçant le `data_collator` ci-dessus par celui qui est approprié. Dans ce cas vous devez supprimer la première ligne ici :
+
+```py
+downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
+eval_dataset = downsampled_dataset["test"].map(
+ insert_random_mask,
+ batched=True,
+ remove_columns=downsampled_dataset["test"].column_names,
+)
+eval_dataset = eval_dataset.rename_columns(
+ {
+ "masked_input_ids": "input_ids",
+ "masked_attention_mask": "attention_mask",
+ "masked_labels": "labels",
+ }
+)
+```
+
+Nous pouvons ensuite configurer les *dataloaders* comme d'habitude, mais nous utiliserons le `default_data_collator` de 🤗 *Transformers* pour le jeu d'évaluation :
+
+```python
+from torch.utils.data import DataLoader
+from transformers import default_data_collator
+
+batch_size = 64
+train_dataloader = DataLoader(
+ downsampled_dataset["train"],
+ shuffle=True,
+ batch_size=batch_size,
+ collate_fn=data_collator,
+)
+eval_dataloader = DataLoader(
+ eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
+)
+```
+
+Nous suivons les étapes standard avec 🤗 *Accelerate*. La première est de charger une version fraîche du modèle pré-entraîné :
+
+```
+model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+Ensuite, nous devons spécifier l'optimiseur. Nous utiliserons le standard `AdamW` :
+
+```python
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Avec ces objets, nous pouvons maintenant tout préparer pour l'entraînement avec l'objet `Accelerator` :
+
+```python
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Maintenant que notre modèle, notre optimiseur et nos chargeurs de données sont configurés, nous pouvons spécifier le planificateur du taux d'apprentissage comme suit :
+
+```python
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Il ne reste qu'une dernière chose à faire avant de s'entraîner : créer un dépôt de modèles sur le *Hub* d'Hugging Face ! Nous pouvons utiliser la bibliothèque 🤗 *Hub* pour générer d'abord le nom complet de notre dépôt :
+
+```python
+from huggingface_hub import get_full_repo_name
+
+model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
+```
+
+puis créer et cloner le dépôt en utilisant la classe `Repository` du 🤗 *Hub* :
+
+```python
+from huggingface_hub import Repository
+
+output_dir = model_name
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Une fois cela fait, il ne reste plus qu'à rédiger la boucle complète d'entraînement et d'évaluation :
+
+```python
+from tqdm.auto import tqdm
+import torch
+import math
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Entraînement
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather(loss.repeat(batch_size)))
+
+ losses = torch.cat(losses)
+ losses = losses[: len(eval_dataset)]
+ try:
+ perplexity = math.exp(torch.mean(losses))
+ except OverflowError:
+ perplexity = float("inf")
+
+ print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
+
+ # Sauvegarder et télécharger
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+>>> Epoch 0: Perplexity: 11.397545307900472
+>>> Epoch 1: Perplexity: 10.904909330983092
+>>> Epoch 2: Perplexity: 10.729503505340409
+```
+
+Cool, nous avons été en mesure d'évaluer la perplexité à chaque époque et de garantir la reproductibilité des entraînements multiples !
+
+{/if}
+
+### Utilisation de notre modèle finetuné
+
+Vous pouvez interagir avec votre modèle *finetuné* soit en utilisant son *widget* sur le *Hub*, soit localement avec le `pipeline` de 🤗 *Transformers*. Utilisons ce dernier pour télécharger notre modèle en utilisant le pipeline `fill-mask` :
+
+```python
+from transformers import pipeline
+
+mask_filler = pipeline(
+ "fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
+)
+```
+
+Nous pouvons ensuite donner au pipeline notre exemple de texte « this is a great [MASK] » et voir quelles sont les 5 premières prédictions :
+
+```python
+preds = mask_filler(text)
+
+for pred in preds:
+ print(f">>> {pred['sequence']}")
+```
+
+```python out
+'>>> this is a great movie.'
+'>>> this is a great film.'
+'>>> this is a great story.'
+'>>> this is a great movies.'
+'>>> this is a great character.'
+```
+
+Notre modèle a clairement adapté ses pondérations pour prédire les mots qui sont plus fortement associés aux films !
+
+
+
+Ceci conclut notre première expérience d'entraînement d'un modèle de langage. Dans la [section 6](/course/fr/chapter7/section6), vous apprendrez comment entraîner à partir de zéro un modèle autorégressif comme GPT-2. Allez-y si vous voulez voir comment vous pouvez pré-entraîner votre propre *transformer* !
+
+
+
+✏️ **Essayez !** Pour quantifier les avantages de l'adaptation au domaine, finetunez un classifieur sur le jeu de données IMDb pour à la fois, le checkpoint de DistilBERT pré-entraîné et e checkpoint de DistilBERT finetuné. Si vous avez besoin d'un rafraîchissement sur la classification de texte, consultez le [chapitre 3](/course/fr/chapter3).
+
+
diff --git a/chapters/fr/chapter7/4.mdx b/chapters/fr/chapter7/4.mdx
index e28cf05d5..8f0659328 100644
--- a/chapters/fr/chapter7/4.mdx
+++ b/chapters/fr/chapter7/4.mdx
@@ -1,998 +1,998 @@
-
-
-# Traduction
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-Plongeons maintenant dans la traduction. Il s'agit d'une autre [tâche de séquence à séquence](/course/fr/chapitre1/7), ce qui signifie que c'est un problème qui peut être formulé comme le passage d'une séquence à une autre. En ce sens, le problème est assez proche de la tâche de [résumé](/course/fr/chapitre7/6) et vous pouvez adapter ce que nous allons voir ici à d'autres problèmes de séquence à séquence tels que :
-
-- Le **transfert de style** ? c'est-à-dire créer un modèle qui *traduit* des textes écrits dans un certain style vers un autre (par exemple, du formel au décontracté ou de l'anglais shakespearien à l'anglais moderne).
-- La **génération de réponse à des questions** c'est-à-dire créer un modèle qui génère des réponses à des questions compte tenu d'un contexte.
-
-
-
-Si vous disposez d'un corpus de textes suffisamment important en deux langues différentes (ou plus), vous pouvez entraîner un nouveau modèle de traduction à partir de zéro, comme nous le ferons dans la section sur la [modélisation causale du langage](/course/fr/chapitre7/6). Il est toutefois plus rapide de *finetuner* un modèle de traduction existant, qu'il s'agisse d'un modèle multilingue comme mT5 ou mBART que vous souhaitez adapter à une paire de langues spécifique, ou même d'un modèle spécialisé dans la traduction d'une langue vers une autre que vous souhaitez adapter à votre corpus spécifique.
-
-Dans cette section, nous allons *finetuner* un modèle Marian pré-entraîné pour traduire de l'anglais au français (puisque de nombreux employés de Hugging Face parlent ces deux langues) sur le jeu de données [KDE4](https://huggingface.co/datasets/kde4) qui est un jeu de données de fichiers localisés pour les applications [KDE](https://apps.kde.org/). Le modèle que nous utiliserons a été pré-entraîné sur un large corpus de textes français et anglais provenant du jeu de données [Opus](https://opus.nlpl.eu/) qui contient en fait le jeu de données KDE4. A noter que même si le modèle pré-entraîné que nous utilisons a vu ces données pendant son pré-entraînement, nous verrons que nous pouvons obtenir une meilleure version de ce modèle après un *finetuning*.
-
-Une fois que nous aurons terminé, nous aurons un modèle capable de faire des prédictions comme celle-ci :
-
-
-
-
-
- -
- -
-
-Comme dans les sections précédentes, vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
-
-## Préparation des données
-
-Pour *finetuner* ou entraîner un modèle de traduction à partir de zéro, nous avons besoin d'un jeu de données adapté à cette tâche. Comme mentionné précédemment, nous utiliserons le jeu de données [KDE4](https://huggingface.co/datasets/kde4) dans cette section. Notez que vous pouvez adapter assez facilement le code pour utiliser vos propres données du moment que vous disposez de paires de phrases dans les deux langues que vous voulez traduire. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rappel sur la façon de charger vos données personnalisées dans un `Dataset`.
-
-### Le jeu de données KDE4
-
-Comme d'habitude, nous téléchargeons notre jeu de données en utilisant la fonction `load_dataset()` :
-
-```py
-from datasets import load_dataset
-
-raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
-```
-
-Si vous souhaitez travailler avec une autre paire de langues, 92 langues sont disponibles au total pour ce jeu de données. Vous pouvez les voir dans la [carte du jeu de données](https://huggingface.co/datasets/kde4).
-
-
-
-
-Comme dans les sections précédentes, vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
-
-## Préparation des données
-
-Pour *finetuner* ou entraîner un modèle de traduction à partir de zéro, nous avons besoin d'un jeu de données adapté à cette tâche. Comme mentionné précédemment, nous utiliserons le jeu de données [KDE4](https://huggingface.co/datasets/kde4) dans cette section. Notez que vous pouvez adapter assez facilement le code pour utiliser vos propres données du moment que vous disposez de paires de phrases dans les deux langues que vous voulez traduire. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rappel sur la façon de charger vos données personnalisées dans un `Dataset`.
-
-### Le jeu de données KDE4
-
-Comme d'habitude, nous téléchargeons notre jeu de données en utilisant la fonction `load_dataset()` :
-
-```py
-from datasets import load_dataset
-
-raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
-```
-
-Si vous souhaitez travailler avec une autre paire de langues, 92 langues sont disponibles au total pour ce jeu de données. Vous pouvez les voir dans la [carte du jeu de données](https://huggingface.co/datasets/kde4).
-
- -
-Jetons un coup d'œil au jeu de données :
-
-```py
-raw_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['id', 'translation'],
- num_rows: 210173
- })
-})
-```
-
-Nous avons 210 173 paires de phrases. Cependant regroupées dans un seul échantillon. Nous devrons donc créer notre propre jeu de validation. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), un `Dataset` possède une méthode `train_test_split()` qui peut nous aider. Nous allons fournir une graine pour la reproductibilité :
-
-```py
-split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
-split_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['id', 'translation'],
- num_rows: 189155
- })
- test: Dataset({
- features: ['id', 'translation'],
- num_rows: 21018
- })
-})
-```
-
-Nous pouvons renommer la clé `test` en `validation` comme ceci :
-
-```py
-split_datasets["validation"] = split_datasets.pop("test")
-```
-
-Examinons maintenant un élément de ce jeu de données :
-
-```py
-split_datasets["train"][1]["translation"]
-```
-
-```python out
-{'en': 'Default to expanded threads',
- 'fr': 'Par défaut, développer les fils de discussion'}
-```
-
-Nous obtenons un dictionnaire contenant deux phrases dans la paire de langues qui nous intéresse.
-Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français sont souvent paresseux et laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
-
-```py
-from transformers import pipeline
-
-model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
-translator = pipeline("translation", model=model_checkpoint)
-translator("Default to expanded threads")
-```
-
-```python out
-[{'translation_text': 'Par défaut pour les threads élargis'}]
-```
-
-Un autre exemple de ce comportement peut être observé avec le mot « *plugin* » qui n'est pas officiellement un mot français mais que la plupart des francophones comprendront et ne prendront pas la peine de traduire.
-Dans le jeu de données KDE4, ce mot a été traduit en français par le plus officiel « module d'extension » :
-
-```py
-split_datasets["train"][172]["translation"]
-```
-
-```python out
-{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
- 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
-```
-
-Notre modèle pré-entraîné, lui, s'en tient au mot anglais :
-
-```py
-translator(
- "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
-)
-```
-
-```python out
-[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
-```
-
-Il sera intéressant de voir si notre modèle *finetuné* tient compte de ces particularités (alerte *spoiler* : il le fera).
-
-
-
-
-
-✏️ **A votre tour !** Un autre mot anglais souvent utilisé en français est « *email* ». Trouvez le premier échantillon dans l'échantillon d'entraînement qui utilise ce mot. Comment est-il traduit ? Comment le modèle pré-entraîné traduit-il cette même phrase ?
-
-
-
-### Traitement des données
-
-
-
-Vous devriez maintenant connaître le principe : les textes doivent tous être convertis en ensembles d'ID de *tokens* pour que le modèle puisse leur donner un sens. Pour cette tâche, nous aurons besoin de tokeniser les entrées et les cibles. Notre première tâche est de créer notre objet `tokenizer`. Comme indiqué précédemment, nous utiliserons un modèle pré-entraîné Marian English to French. Si vous essayez ce code avec une autre paire de langues, assurez-vous d'adapter le *checkpoint* du modèle. L'organisation [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) fournit plus de mille modèles dans plusieurs langues.
-
-```python
-from transformers import AutoTokenizer
-
-model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")
-```
-
-Vous pouvez remplacer le `model_checkpoint` par un tout autre modèle disponible sur le [*Hub*](https://huggingface.co/models) qui aurait votre préférence, ou par un dossier en local où vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*.
-
-
-
-💡 Si vous utilisez un *tokenizer* multilingue tel que mBART, mBART-50 ou M2M100, vous devrez définir les codes de langue de vos entrées et cibles dans le *tokenizer* en définissant `tokenizer.src_lang` et `tokenizer.tgt_lang` aux bonnes valeurs.
-
-
-
-La préparation de nos données est assez simple. Il y a juste une chose à retenir : vous traitez les entrées comme d'habitude, mais pour les cibles, vous devez envelopper le *tokenizer* dans le gestionnaire de contexte `as_target_tokenizer()`.
-
-Un gestionnaire de contexte en Python est introduit avec l'instruction `with` et est utile lorsque vous avez deux opérations liées à exécuter en paire. L'exemple le plus courant est lorsque vous écrivez ou lisez un fichier, ce qui est souvent fait dans une instruction comme :
-
-```
-with open(file_path) as f:
- content = f.read()
-```
-
-Ici, les deux opérations connexes qui sont exécutées en paire sont les actions d'ouverture et de fermeture du fichier. L'objet correspondant au fichier ouvert `f` n'existe qu'à l'intérieur du bloc indenté sous le `with`. L'ouverture se produit avant ce bloc et la fermeture à la fin du bloc.
-
-Dans le cas présent, le gestionnaire de contexte `as_target_tokenizer()` va définir le *tokenizer* dans la langue de sortie (ici, le français) avant l'exécution du bloc indenté, puis le redéfinir dans la langue d'entrée (ici, l'anglais).
-
-Ainsi, le prétraitement d'un échantillon ressemble à ceci :
-
-```python
-en_sentence = split_datasets["train"][1]["translation"]["en"]
-fr_sentence = split_datasets["train"][1]["translation"]["fr"]
-
-inputs = tokenizer(en_sentence)
-with tokenizer.as_target_tokenizer():
- targets = tokenizer(fr_sentence)
-```
-
-Si nous oublions de tokeniser les cibles dans le gestionnaire de contexte, elles seront tokenisées par le *tokenizer* d'entrée, ce qui dans le cas d'un modèle Marian, ne va pas du tout bien se passer :
-
-```python
-wrong_targets = tokenizer(fr_sentence)
-print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
-print(tokenizer.convert_ids_to_tokens(targets["input_ids"]))
-```
-
-```python out
-['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
-['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
-```
-
-Comme on peut le voir, utiliser le *tokenizer* anglais pour prétraiter une phrase française donne un batch de *tokens* plus important, puisque le *tokenizer* ne connaît aucun mot français (sauf ceux qui apparaissent aussi en anglais, comme « discussion »).
-
-Les `inputs` et les `targets` sont des dictionnaires avec nos clés habituelles (identifiants d'entrée, masque d'attention, etc.). La dernière étape est de définir une clé `"labels"` dans les entrées. Nous faisons cela dans la fonction de prétraitement que nous allons appliquer sur les jeux de données :
-
-```python
-max_input_length = 128
-max_target_length = 128
-
-
-def preprocess_function(examples):
- inputs = [ex["en"] for ex in examples["translation"]]
- targets = [ex["fr"] for ex in examples["translation"]]
- model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
-
- # Configurer le tokenizer pour les cibles.
- with tokenizer.as_target_tokenizer():
- labels = tokenizer(targets, max_length=max_target_length, truncation=True)
-
- model_inputs["labels"] = labels["input_ids"]
- return model_inputs
-```
-
-Notez que nous avons fixé des longueurs maximales similaires pour nos entrées et nos sorties. Comme les textes que nous traitons semblent assez courts, nous utilisons 128.
-
-
-
-💡 Si vous utilisez un modèle T5 (plus précisément, un des *checkpoints* `t5-xxx`), le modèle s'attendra à ce que les entrées aient un préfixe indiquant la tâche à accomplir, comme `translate: English to French:`.
-
-
-
-
-
-⚠️ Nous ne faisons pas attention au masque d'attention des cibles car le modèle ne s'y attend pas. Au lieu de cela, les étiquettes correspondant à un *token* de *padding* doivent être mises à `-100` afin qu'elles soient ignorées dans le calcul de la perte. Cela sera fait par notre collateur de données plus tard puisque nous appliquons le *padding* dynamique, mais si vous utilisez le *padding* ici, vous devriez adapter la fonction de prétraitement pour mettre toutes les étiquettes qui correspondent au *token* de *padding* à `-100`.
-
-
-
-Nous pouvons maintenant appliquer ce prétraitement en une seule fois sur toutes les échantillons de notre jeu de données :
-
-```py
-tokenized_datasets = split_datasets.map(
- preprocess_function,
- batched=True,
- remove_columns=split_datasets["train"].column_names,
-)
-```
-
-Maintenant que les données ont été prétraitées, nous sommes prêts à *finetuner* notre modèle pré-entraîné !
-
-{#if fw === 'pt'}
-
-## Finetuner le modèle avec l'API `Trainer`
-
-Le code actuel utilisant `Trainer` sera le même que précédemment, avec juste un petit changement : nous utilisons ici [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) qui est une sous-classe de `Trainer` qui nous permet de traiter correctement l'évaluation, en utilisant la méthode `generate()` pour prédire les sorties à partir des entrées. Nous y reviendrons plus en détail lorsque nous parlerons du calcul de la métrique.
-
-Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
-```
-
-{:else}
-
-## Finetuner du modèle avec Keras
-
-Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
-
-```py
-from transformers import TFAutoModelForSeq2SeqLM
-
-model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
-```
-
-
-
-💡 Le *checkpoint* `Helsinki-NLP/opus-mt-en-fr` ne dispose que de poids PyTorch, vous aurez donc une erreur si vous essayez de charger le modèle sans utiliser l'argument `from_pt=True` dans la méthode `from_pretrained()`. Lorsque vous spécifiez `from_pt=True`, la bibliothèque téléchargera et convertira automatiquement les poids PyTorch pour vous. Comme vous pouvez le constater, c'est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
-
-
-
-{/if}
-
-Notez que cette fois-ci, nous utilisons un modèle qui a été entraîné sur une tâche de traduction et qui peut déjà être utilisé, donc il n'y a pas d'avertissement concernant les poids manquants ou ceux nouvellement initialisés.
-
-### Collecte des données
-
-Nous aurons besoin d'un assembleur de données pour gérer le rembourrage pour la mise en batchs dynamique. Ici, nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne rembourre que les entrées (identifiants d'entrée, masque d'attention, et *token* de type identifiants). Nos étiquettes doivent également être rembourrées à la longueur maximale rencontrée dans les étiquettes. Et, comme mentionné précédemment, la valeur de remplissage utilisée pour remplir les étiquettes doit être `-100` et non le *token* de *padding* du *tokenizer* afin de s'assurer que ces valeurs soient ignorées dans le calcul de la perte.
-
-Tout ceci est réalisé par un [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées, mais également le `model`. C'est parce que ce collateur de données est également responsable de la préparation des identifiants d'entrée du décodeur, qui sont des versions décalées des étiquettes avec un *token* spécial au début. Comme ce décalage est effectué de manière légèrement différente selon les architectures, le `DataCollatorForSeq2Seq` a besoin de connaître l'objet `model` :
-
-{#if fw === 'pt'}
-
-```py
-from transformers import DataCollatorForSeq2Seq
-
-data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
-```
-
-{:else}
-
-```py
-from transformers import DataCollatorForSeq2Seq
-
-data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
-```
-
-{/if}
-
-Pour le tester sur quelques échantillons, nous l'appelons simplement sur une liste d'exemples de notre échantillon d'entrainement tokénisé :
-
-```py
-batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
-batch.keys()
-```
-
-```python out
-dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
-```
-
-Nous pouvons vérifier que nos étiquettes ont été rembourrées à la longueur maximale du batch, en utilisant `-100` :
-
-```py
-batch["labels"]
-```
-
-```python out
-tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
- -100, -100, -100, -100, -100, -100],
- [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
- 550, 7032, 5821, 7907, 12649, 0]])
-```
-
-Nous pouvons aussi jeter un coup d'œil aux identifiants d'entrée du décodeur, pour voir qu'il s'agit de versions décalées des étiquettes :
-
-```py
-batch["decoder_input_ids"]
-```
-
-```python out
-tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
- 59513, 59513, 59513, 59513, 59513, 59513],
- [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
- 817, 550, 7032, 5821, 7907, 12649]])
-```
-
-Voici les étiquettes des premier et deuxième éléments de notre jeu de données :
-
-```py
-for i in range(1, 3):
- print(tokenized_datasets["train"][i]["labels"])
-```
-
-```python out
-[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
-[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
-```
-
-{#if fw === 'pt'}
-
-Nous allons transmettre ce `data_collator` au `Seq2SeqTrainer`. Ensuite, jetons un coup d'oeil à la métrique.
-
-{:else}
-
-Nous pouvons maintenant utiliser ce `data_collator` pour convertir chacun de nos jeux de données en un `tf.data.Dataset`, prêt pour l'entraînement :
-
-```python
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=True,
- batch_size=32,
-)
-tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=16,
-)
-```
-
-{/if}
-
-
-### Métriques
-
-
-
-{#if fw === 'pt'}
-
-La fonctionnalité que `Seq2SeqTrainer` ajoute à sa superclasse `Trainer` est la possibilité d'utiliser la méthode `generate()` pendant l'évaluation ou la prédiction. Pendant l'entraînement, le modèle utilisera les `decoder_input_ids` avec un masque d'attention assurant qu'il n'utilise pas les *tokens* après le *token* qu'il essaie de prédire, pour accélérer l'entraînement. Pendant l'inférence, nous ne pourrons pas les utiliser puisque nous n'aurons pas d'étiquettes. Ainsi c'est une bonne idée d'évaluer notre modèle avec la même configuration.
-
-Comme nous l'avons vu dans le [chapitre 1](/course/fr/chapter1/6), le décodeur effectue l'inférence en prédisant les *tokens* un par un. C'est quelque chose qui est implémenté en coulisses dans 🤗 *Transformers* par la méthode `generate()`. Le `Seq2SeqTrainer` nous laissera utiliser cette méthode pour l'évaluation si nous indiquons `predict_with_generate=True`.
-
-{/if}
-
-La métrique traditionnelle utilisée pour la traduction est le [score BLEU](https://en.wikipedia.org/wiki/BLEU), introduit dans [un article de 2002](https://aclanthology.org/P02-1040.pdf) par Kishore Papineni et al. Le score BLEU évalue dans quelle mesure les traductions sont proches de leurs étiquettes. Il ne mesure pas l'intelligibilité ou l'exactitude grammaticale des résultats générés par le modèle, mais utilise des règles statistiques pour garantir que tous les mots des résultats générés apparaissent également dans les cibles. En outre, il existe des règles qui pénalisent les répétitions des mêmes mots s'ils ne sont pas également répétés dans les cibles (pour éviter que le modèle ne produise des phrases telles que « the the the the the the the ») et les phrases produites qui sont plus courtes que celles des cibles (pour éviter que le modèle ne produise des phrases telles que « the »).
-
-L'une des faiblesses de BLEU est qu'il s'attend à ce que le texte soit déjà tokenisé, ce qui rend difficile la comparaison des scores entre les modèles qui utilisent différents *tokenizers*. Par conséquent, la mesure la plus couramment utilisée aujourd'hui pour évaluer les modèles de traduction est [SacreBLEU](https://github.com/mjpost/sacrebleu) qui remédie à cette faiblesse (et à d'autres) en standardisant l'étape de tokenisation. Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *SacreBLEU* :
-
-```py
-!pip install sacrebleu
-```
-
-Nous pouvons ensuite charger ce score via `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-```py
-import evaluate
-
-metric = evaluate.load("sacrebleu")
-```
-
-Cette métrique prend des textes comme entrées et cibles. Elle est conçue pour accepter plusieurs cibles acceptables car il y a souvent plusieurs traductions possibles d'une même phrase. Le jeu de données que nous utilisons n'en fournit qu'une seule, mais en NLP, il n'est pas rare de trouver des jeux de données ayant plusieurs phrases comme étiquettes. Ainsi, les prédictions doivent être une liste de phrases mais les références doivent être une liste de listes de phrases.
-
-Essayons un exemple :
-
-```py
-predictions = [
- "This plugin lets you translate web pages between several languages automatically."
-]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 46.750469682990165,
- 'counts': [11, 6, 4, 3],
- 'totals': [12, 11, 10, 9],
- 'precisions': [91.67, 54.54, 40.0, 33.33],
- 'bp': 0.9200444146293233,
- 'sys_len': 12,
- 'ref_len': 13}
-```
-
-Cela donne un score BLEU de 46.75, ce qui est plutôt bon. A titre de comparaison, le *Transformer* original dans l'article [*Attention Is All You Need*](https://arxiv.org/pdf/1706.03762.pdf) a obtenu un score BLEU de 41.8 sur une tâche de traduction similaire entre l'anglais et le français ! (Pour plus d'informations sur les métriques individuelles, comme `counts` et `bp`, voir le [dépôt SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74). D'autre part, si nous essayons avec les deux mauvais types de prédictions (répétitions ou prédiction trop courte) qui sortent souvent des modèles de traduction, nous obtiendrons des scores BLEU plutôt mauvais :
-
-```py
-predictions = ["This This This This"]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 1.683602693167689,
- 'counts': [1, 0, 0, 0],
- 'totals': [4, 3, 2, 1],
- 'precisions': [25.0, 16.67, 12.5, 12.5],
- 'bp': 0.10539922456186433,
- 'sys_len': 4,
- 'ref_len': 13}
-```
-
-```py
-predictions = ["This plugin"]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 0.0,
- 'counts': [2, 1, 0, 0],
- 'totals': [2, 1, 0, 0],
- 'precisions': [100.0, 100.0, 0.0, 0.0],
- 'bp': 0.004086771438464067,
- 'sys_len': 2,
- 'ref_len': 13}
-```
-
-Le score peut aller de 0 à 100. Plus il est élevé, mieux c'est.
-
-{#if fw === 'tf'}
-
-Pour passer des sorties du modèle aux textes que la métrique peut utiliser, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding*. Définissons une fonction qui prend notre modèle et un jeu de données et calcule des métriques sur ceux-ci. Comme la génération de longues séquences peut être lente, nous sous-échantillonnons l'ensemble de validation pour nous assurer que cela ne prend pas une éternité :
-
-```py
-import numpy as np
-
-
-def compute_metrics():
- all_preds = []
- all_labels = []
- sampled_dataset = tokenized_datasets["validation"].shuffle().select(range(200))
- tf_generate_dataset = sampled_dataset.to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=4,
- )
- for batch in tf_generate_dataset:
- predictions = model.generate(
- input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
- )
- decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
- labels = batch["labels"].numpy()
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
- all_preds.extend(decoded_preds)
- all_labels.extend(decoded_labels)
-
- result = metric.compute(predictions=all_preds, references=all_labels)
- return {"bleu": result["score"]}
-```
-
-{:else}
-
-Pour passer des sorties du modèle aux textes utilisables par la métrique, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding* :
-
-```py
-import numpy as np
-
-
-def compute_metrics(eval_preds):
- preds, labels = eval_preds
- # Dans le cas où le modèle retourne plus que les logits de prédiction
- if isinstance(preds, tuple):
- preds = preds[0]
-
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
-
- # Remplacer les -100 dans les étiquettes car nous ne pouvons pas les décoder
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Quelques post-traitements simples
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
-
- result = metric.compute(predictions=decoded_preds, references=decoded_labels)
- return {"bleu": result["score"]}
-```
-
-{/if}
-
-Maintenant que c'est fait, nous sommes prêts à *finetuner* notre modèle !
-
-
-### Finetuner le modèle
-
-La première étape consiste à se connecter à Hugging Face, afin de pouvoir télécharger vos résultats sur le *Hub*. Il y a une fonction pratique pour vous aider à le faire dans un *notebook* :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-{#if fw === 'tf'}
-
-Avant de commencer, voyons quel type de résultats nous obtenons avec notre modèle sans entraînement :
-
-```py
-print(compute_metrics())
-```
-
-```
-{'bleu': 33.26983701454733}
-```
-
-Une fois ceci fait, nous pouvons préparer tout ce dont nous avons besoin pour compiler et entraîner notre modèle. Notez l'utilisation de `tf.keras.mixed_precision.set_global_policy("mixed_float16")`. Ceci indiquera à Keras de s'entraîner en utilisant float16, ce qui peut donner un gain de vitesse significatif sur les GPUs qui le supportent (Nvidia 20xx/V100 ou plus récent).
-
-```python
-from transformers import create_optimizer
-from transformers.keras_callbacks import PushToHubCallback
-import tensorflow as tf
-
-# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans le jeu de données, divisé par la taille du batch,
-# puis multiplié par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un tf.data.Dataset,
-# et non le jeu de données original donc son len() est déjà num_samples // batch_size.
-num_epochs = 3
-num_train_steps = len(tf_train_dataset) * num_epochs
-
-optimizer, schedule = create_optimizer(
- init_lr=5e-5,
- num_warmup_steps=0,
- num_train_steps=num_train_steps,
- weight_decay_rate=0.01,
-)
-model.compile(optimizer=optimizer)
-
-# Entraîner en mixed-precision float16
-tf.keras.mixed_precision.set_global_policy("mixed_float16")
-```
-
-Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle sur le *Hub* pendant l'entraînement, comme nous l'avons vu dans la [section 2](/course/fr/chapter7/2), puis nous entraînons simplement le modèle avec ce *callback* :
-
-```python
-from transformers.keras_callbacks import PushToHubCallback
-
-callback = PushToHubCallback(
- output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
-)
-
-model.fit(
- tf_train_dataset,
- validation_data=tf_eval_dataset,
- callbacks=[callback],
- epochs=num_epochs,
-)
-```
-
-Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser le modèle avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` dans `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé après le répertoire de sortie que vous avez défini. Ici ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
-
-
-
-Enfin, voyons à quoi ressemblent nos métriques maintenant que l'entraînement est terminé :
-
-```py
-print(compute_metrics())
-```
-
-```
-{'bleu': 57.334066271545865}
-```
-
-À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
-
-{:else}
-
-Une fois ceci fait, nous pouvons définir notre `Seq2SeqTrainingArguments`. Comme pour le `Trainer`, nous utilisons une sous-classe de `TrainingArguments` qui contient quelques champs supplémentaires :
-
-```python
-from transformers import Seq2SeqTrainingArguments
-
-args = Seq2SeqTrainingArguments(
- f"marian-finetuned-kde4-en-to-fr",
- evaluation_strategy="no",
- save_strategy="epoch",
- learning_rate=2e-5,
- per_device_train_batch_size=32,
- per_device_eval_batch_size=64,
- weight_decay=0.01,
- save_total_limit=3,
- num_train_epochs=3,
- predict_with_generate=True,
- fp16=True,
- push_to_hub=True,
-)
-```
-
-En dehors des hyperparamètres habituels (comme le taux d'apprentissage, le nombre d'époques, la taille des batchs et une le taux de décroissance des poids), voici quelques changements par rapport à ce que nous avons vu dans les sections précédentes :
-
-- Nous ne définissons pas d'évaluation car elle prend du temps. Nous allons juste évaluer une fois notre modèle avant l'entraînement et après.
-- Nous avons mis `fp16=True`, ce qui accélère l'entraînement sur les GPUs modernes.
-- Nous définissons `predict_with_generate=True`, comme discuté ci-dessus.
-- Nous utilisons `push_to_hub=True` pour télécharger le modèle sur le *Hub* à la fin de chaque époque.
-
-Notez que vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` à `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé d'après le répertoire de sortie que vous avez défini. Dans notre cas ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Seq2SeqTrainer` et devrez définir un nouveau nom.
-
-
-
-
-Enfin, nous passons tout au `Seq2SeqTrainer` :
-
-```python
-from transformers import Seq2SeqTrainer
-
-trainer = Seq2SeqTrainer(
- model,
- args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- tokenizer=tokenizer,
- compute_metrics=compute_metrics,
-)
-```
-
-Avant d'entraîner, nous allons d'abord regarder le score obtenu par notre modèle, pour vérifier que nous n'aggravons pas les choses avec notre *finetuning*. Cette commande va prendre un peu de temps, vous pouvez donc prendre un café pendant qu'elle s'exécute :
-
-```python
-trainer.evaluate(max_length=max_target_length)
-```
-
-```python out
-{'eval_loss': 1.6964408159255981,
- 'eval_bleu': 39.26865061007616,
- 'eval_runtime': 965.8884,
- 'eval_samples_per_second': 21.76,
- 'eval_steps_per_second': 0.341}
-```
-
-Un score BLEU de 39 n'est pas trop mauvais, ce qui reflète le fait que notre modèle est déjà bon pour traduire des phrases anglaises en phrases françaises.
-
-Vient ensuite l'entraînement, qui prendra également un peu de temps :
-
-```python
-trainer.train()
-```
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
-
-Une fois l'entraînement terminé, nous évaluons à nouveau notre modèle. Avec un peu de chance, nous verrons une amélioration du score BLEU !
-
-```py
-trainer.evaluate(max_length=max_target_length)
-```
-
-```python out
-{'eval_loss': 0.8558505773544312,
- 'eval_bleu': 52.94161337775576,
- 'eval_runtime': 714.2576,
- 'eval_samples_per_second': 29.426,
- 'eval_steps_per_second': 0.461,
- 'epoch': 3.0}
-```
-
-C'est une amélioration de près de 14 points, ce qui est formidable.
-
-Enfin, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la dernière version du modèle. `Trainer` rédige également une carte de modèle avec tous les résultats de l'évaluation et la télécharge. Cette carte de modèle contient des métadonnées qui aident le *Hub* à choisir le *widget* pour l'inférence. Habituellement, il n'y a pas besoin de dire quoi que ce soit car il peut inférer le bon *widget* à partir de la classe du modèle, mais dans ce cas, la même classe de modèle peut être utilisée pour toutes sortes de problèmes de séquence à séquence. Ainsi nous spécifions que c'est un modèle de traduction :
-
-```py
-trainer.push_to_hub(tags="translation", commit_message="Training complete")
-```
-
-Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
-
-```python out
-'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
-```
-
-À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
-
-Si vous souhaitez vous plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
-
-{/if}
-
-{#if fw === 'pt'}
-
-## Une boucle d'entraînement personnalisée
-
-Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans la [section 2](/course/fr/chapter7/2) et dans le [chapitre 3](/course/fr/chapter3/4).
-
-### Préparer le tout pour l'entraînement
-
-Vous avez vu tout cela plusieurs fois maintenant, donc nous allons passer en revue le code assez rapidement. D'abord, nous allons construire le `DataLoader` à partir de nos jeux de données, après avoir configuré les jeux de données au format `"torch"` pour obtenir les tenseurs PyTorch :
-
-```py
-from torch.utils.data import DataLoader
-
-tokenized_datasets.set_format("torch")
-train_dataloader = DataLoader(
- tokenized_datasets["train"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-eval_dataloader = DataLoader(
- tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
-)
-```
-
-Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne poursuivons pas le *finetuning* précédent et que nous repartons du modèle pré-entraîné :
-
-```py
-model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
-```
-
-Nous aurons alors besoin d'un optimiseur :
-
-```py
-from transformers import AdamW
-
-optimizer = AdamW(model.parameters(), lr=2e-5)
-```
-
-Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()`. Rappelez-vous que si vous voulez entraîner sur des TPUs dans un *notebook* de Colab, vous devez déplacer tout ce code dans une fonction d'entraînement et ne devrait pas exécuter une cellule qui instancie un `Accelerator`.
-
-```py
-from accelerate import Accelerator
-
-accelerator = Accelerator()
-model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
-)
-```
-
-Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le chargeur de données car cette méthode va changer la longueur du `DataLoader`. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
-
-```py
-from transformers import get_scheduler
-
-num_train_epochs = 3
-num_update_steps_per_epoch = len(train_dataloader)
-num_training_steps = num_train_epochs * num_update_steps_per_epoch
-
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-```
-
-Enfin, pour pousser notre modèle vers le *Hub*, nous aurons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous au *Hub* si vous n'êtes pas déjà connecté. Nous déterminerons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur, ce que fait la fonction `get_full_repo_name()`) :
-
-```py
-from huggingface_hub import Repository, get_full_repo_name
-
-model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
-repo_name = get_full_repo_name(model_name)
-repo_name
-```
-
-```python out
-'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
-```
-
-Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone du dépôt avec lequel nous travaillons :
-
-```py
-output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
-repo = Repository(output_dir, clone_from=repo_name)
-```
-
-Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
-
-### Boucle d'entraînement
-
-Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes et les convertit en listes de chaînes de caractères que notre objet `metric` attend :
-
-```py
-def postprocess(predictions, labels):
- predictions = predictions.cpu().numpy()
- labels = labels.cpu().numpy()
-
- decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
-
- # Remplace -100 dans les étiquettes car nous ne pouvons pas les décoder
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Quelques post-traitements simples
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
- return decoded_preds, decoded_labels
-```
-
-La boucle d'entraînement ressemble beaucoup à celles de la [section 2](/course/fr/chapter7/2) et du [chapitre 3](/course/fr/chapter3), avec quelques différences dans la partie évaluation. Donc concentrons-nous sur cela !
-
-La première chose à noter est que nous utilisons la méthode `generate()` pour calculer les prédictions. C'est une méthode sur notre modèle de base et non pas le modèle enveloppé créé dans la méthode `prepare()`. C'est pourquoi nous déballons d'abord le modèle, puis nous appelons cette méthode.
-
-La deuxième chose est que, comme avec la classification de [*token*](/course/fr/chapter7/2), deux processus peuvent avoir rembourrés les entrées et les étiquettes à des formes différentes. Ainsi nous utilisons `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne faisons pas cela, l'évaluation va soit se tromper, soit se bloquer pour toujours.
-
-```py
-from tqdm.auto import tqdm
-import torch
-
-progress_bar = tqdm(range(num_training_steps))
-
-for epoch in range(num_train_epochs):
- # Entraînement
- model.train()
- for batch in train_dataloader:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-
- # Evaluation
- model.eval()
- for batch in tqdm(eval_dataloader):
- with torch.no_grad():
- generated_tokens = accelerator.unwrap_model(model).generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- max_length=128,
- )
- labels = batch["labels"]
-
- # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
- generated_tokens = accelerator.pad_across_processes(
- generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
- )
- labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
-
- predictions_gathered = accelerator.gather(generated_tokens)
- labels_gathered = accelerator.gather(labels)
-
- decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
- metric.add_batch(predictions=decoded_preds, references=decoded_labels)
-
- results = metric.compute()
- print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
-
- # Sauvegarder et télécharger
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False
- )
-```
-
-```python out
-epoch 0, BLEU score: 53.47
-epoch 1, BLEU score: 54.24
-epoch 2, BLEU score: 54.44
-```
-
-Une fois que c'est fait, vous devriez avoir un modèle qui a des résultats assez similaires à celui entraîné avec `Seq2SeqTrainer`. Vous pouvez vérifier celui que nous avons entraîné en utilisant ce code sur [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les mettre en œuvre directement en modifiant le code ci-dessus !
-
-{/if}
-
-### Utilisation du modèle finetuné
-
-Nous vous avons déjà montré comment vous pouvez utiliser le modèle que nous avons *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, nous devons juste spécifier l'identifiant de modèle approprié :
-
-```py
-from transformers import pipeline
-
-# Remplacez ceci par votre propre checkpoint
-model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
-translator = pipeline("translation", model=model_checkpoint)
-translator("Default to expanded threads")
-```
-
-```python out
-[{'translation_text': 'Par défaut, développer les fils de discussion'}]
-```
-
-Comme prévu, notre modèle pré-entraîné a adapté ses connaissances au corpus sur lequel nous l'avons *finetuné*. Et au lieu de laisser le mot anglais « *threads* », le modèle le traduit maintenant par la version française officielle. Il en va de même pour « *plugin* » :
-
-```py
-translator(
- "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
-)
-```
-
-```python out
-[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
-```
-
-Un autre excellent exemple d'adaptation au domaine !
-
-
-
-✏️ **A votre tour !** Que retourne le modèle sur l'échantillon avec le mot « *email* » que vous avez identifié plus tôt ?
-
-
+
+
+# Traduction
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Plongeons maintenant dans la traduction. Il s'agit d'une autre [tâche de séquence à séquence](/course/fr/chapitre1/7), ce qui signifie que c'est un problème qui peut être formulé comme le passage d'une séquence à une autre. En ce sens, le problème est assez proche de la tâche de [résumé](/course/fr/chapitre7/6) et vous pouvez adapter ce que nous allons voir ici à d'autres problèmes de séquence à séquence tels que :
+
+- Le **transfert de style** ? c'est-à-dire créer un modèle qui *traduit* des textes écrits dans un certain style vers un autre (par exemple, du formel au décontracté ou de l'anglais shakespearien à l'anglais moderne).
+- La **génération de réponse à des questions** c'est-à-dire créer un modèle qui génère des réponses à des questions compte tenu d'un contexte.
+
+
+
+Si vous disposez d'un corpus de textes suffisamment important en deux langues différentes (ou plus), vous pouvez entraîner un nouveau modèle de traduction à partir de zéro, comme nous le ferons dans la section sur la [modélisation causale du langage](/course/fr/chapitre7/6). Il est toutefois plus rapide de *finetuner* un modèle de traduction existant, qu'il s'agisse d'un modèle multilingue comme mT5 ou mBART que vous souhaitez adapter à une paire de langues spécifique, ou même d'un modèle spécialisé dans la traduction d'une langue vers une autre que vous souhaitez adapter à votre corpus spécifique.
+
+Dans cette section, nous allons *finetuner* un modèle Marian pré-entraîné pour traduire de l'anglais au français (puisque de nombreux employés de Hugging Face parlent ces deux langues) sur le jeu de données [KDE4](https://huggingface.co/datasets/kde4) qui est un jeu de données de fichiers localisés pour les applications [KDE](https://apps.kde.org/). Le modèle que nous utiliserons a été pré-entraîné sur un large corpus de textes français et anglais provenant du jeu de données [Opus](https://opus.nlpl.eu/) qui contient en fait le jeu de données KDE4. A noter que même si le modèle pré-entraîné que nous utilisons a vu ces données pendant son pré-entraînement, nous verrons que nous pouvons obtenir une meilleure version de ce modèle après un *finetuning*.
+
+Une fois que nous aurons terminé, nous aurons un modèle capable de faire des prédictions comme celle-ci :
+
+
+
+
+
+
+
+
+
+Comme dans les sections précédentes, vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## Préparation des données
+
+Pour *finetuner* ou entraîner un modèle de traduction à partir de zéro, nous avons besoin d'un jeu de données adapté à cette tâche. Comme mentionné précédemment, nous utiliserons le jeu de données [KDE4](https://huggingface.co/datasets/kde4) dans cette section. Notez que vous pouvez adapter assez facilement le code pour utiliser vos propres données du moment que vous disposez de paires de phrases dans les deux langues que vous voulez traduire. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rappel sur la façon de charger vos données personnalisées dans un `Dataset`.
+
+### Le jeu de données KDE4
+
+Comme d'habitude, nous téléchargeons notre jeu de données en utilisant la fonction `load_dataset()` :
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+Si vous souhaitez travailler avec une autre paire de langues, 92 langues sont disponibles au total pour ce jeu de données. Vous pouvez les voir dans la [carte du jeu de données](https://huggingface.co/datasets/kde4).
+
+
+
+Jetons un coup d'œil au jeu de données :
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+Nous avons 210 173 paires de phrases. Cependant regroupées dans un seul échantillon. Nous devrons donc créer notre propre jeu de validation. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), un `Dataset` possède une méthode `train_test_split()` qui peut nous aider. Nous allons fournir une graine pour la reproductibilité :
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+Nous pouvons renommer la clé `test` en `validation` comme ceci :
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Examinons maintenant un élément de ce jeu de données :
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+Nous obtenons un dictionnaire contenant deux phrases dans la paire de langues qui nous intéresse.
+Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français sont souvent paresseux et laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Un autre exemple de ce comportement peut être observé avec le mot « *plugin* » qui n'est pas officiellement un mot français mais que la plupart des francophones comprendront et ne prendront pas la peine de traduire.
+Dans le jeu de données KDE4, ce mot a été traduit en français par le plus officiel « module d'extension » :
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Notre modèle pré-entraîné, lui, s'en tient au mot anglais :
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Il sera intéressant de voir si notre modèle *finetuné* tient compte de ces particularités (alerte *spoiler* : il le fera).
+
+
+
+
+
+✏️ **A votre tour !** Un autre mot anglais souvent utilisé en français est « *email* ». Trouvez le premier échantillon dans l'échantillon d'entraînement qui utilise ce mot. Comment est-il traduit ? Comment le modèle pré-entraîné traduit-il cette même phrase ?
+
+
+
+### Traitement des données
+
+
+
+Vous devriez maintenant connaître le principe : les textes doivent tous être convertis en ensembles d'ID de *tokens* pour que le modèle puisse leur donner un sens. Pour cette tâche, nous aurons besoin de tokeniser les entrées et les cibles. Notre première tâche est de créer notre objet `tokenizer`. Comme indiqué précédemment, nous utiliserons un modèle pré-entraîné Marian English to French. Si vous essayez ce code avec une autre paire de langues, assurez-vous d'adapter le *checkpoint* du modèle. L'organisation [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) fournit plus de mille modèles dans plusieurs langues.
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")
+```
+
+Vous pouvez remplacer le `model_checkpoint` par un tout autre modèle disponible sur le [*Hub*](https://huggingface.co/models) qui aurait votre préférence, ou par un dossier en local où vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*.
+
+
+
+💡 Si vous utilisez un *tokenizer* multilingue tel que mBART, mBART-50 ou M2M100, vous devrez définir les codes de langue de vos entrées et cibles dans le *tokenizer* en définissant `tokenizer.src_lang` et `tokenizer.tgt_lang` aux bonnes valeurs.
+
+
+
+La préparation de nos données est assez simple. Il y a juste une chose à retenir : vous traitez les entrées comme d'habitude, mais pour les cibles, vous devez envelopper le *tokenizer* dans le gestionnaire de contexte `as_target_tokenizer()`.
+
+Un gestionnaire de contexte en Python est introduit avec l'instruction `with` et est utile lorsque vous avez deux opérations liées à exécuter en paire. L'exemple le plus courant est lorsque vous écrivez ou lisez un fichier, ce qui est souvent fait dans une instruction comme :
+
+```
+with open(file_path) as f:
+ content = f.read()
+```
+
+Ici, les deux opérations connexes qui sont exécutées en paire sont les actions d'ouverture et de fermeture du fichier. L'objet correspondant au fichier ouvert `f` n'existe qu'à l'intérieur du bloc indenté sous le `with`. L'ouverture se produit avant ce bloc et la fermeture à la fin du bloc.
+
+Dans le cas présent, le gestionnaire de contexte `as_target_tokenizer()` va définir le *tokenizer* dans la langue de sortie (ici, le français) avant l'exécution du bloc indenté, puis le redéfinir dans la langue d'entrée (ici, l'anglais).
+
+Ainsi, le prétraitement d'un échantillon ressemble à ceci :
+
+```python
+en_sentence = split_datasets["train"][1]["translation"]["en"]
+fr_sentence = split_datasets["train"][1]["translation"]["fr"]
+
+inputs = tokenizer(en_sentence)
+with tokenizer.as_target_tokenizer():
+ targets = tokenizer(fr_sentence)
+```
+
+Si nous oublions de tokeniser les cibles dans le gestionnaire de contexte, elles seront tokenisées par le *tokenizer* d'entrée, ce qui dans le cas d'un modèle Marian, ne va pas du tout bien se passer :
+
+```python
+wrong_targets = tokenizer(fr_sentence)
+print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
+print(tokenizer.convert_ids_to_tokens(targets["input_ids"]))
+```
+
+```python out
+['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
+['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
+```
+
+Comme on peut le voir, utiliser le *tokenizer* anglais pour prétraiter une phrase française donne un batch de *tokens* plus important, puisque le *tokenizer* ne connaît aucun mot français (sauf ceux qui apparaissent aussi en anglais, comme « discussion »).
+
+Les `inputs` et les `targets` sont des dictionnaires avec nos clés habituelles (identifiants d'entrée, masque d'attention, etc.). La dernière étape est de définir une clé `"labels"` dans les entrées. Nous faisons cela dans la fonction de prétraitement que nous allons appliquer sur les jeux de données :
+
+```python
+max_input_length = 128
+max_target_length = 128
+
+
+def preprocess_function(examples):
+ inputs = [ex["en"] for ex in examples["translation"]]
+ targets = [ex["fr"] for ex in examples["translation"]]
+ model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
+
+ # Configurer le tokenizer pour les cibles.
+ with tokenizer.as_target_tokenizer():
+ labels = tokenizer(targets, max_length=max_target_length, truncation=True)
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+```
+
+Notez que nous avons fixé des longueurs maximales similaires pour nos entrées et nos sorties. Comme les textes que nous traitons semblent assez courts, nous utilisons 128.
+
+
+
+💡 Si vous utilisez un modèle T5 (plus précisément, un des *checkpoints* `t5-xxx`), le modèle s'attendra à ce que les entrées aient un préfixe indiquant la tâche à accomplir, comme `translate: English to French:`.
+
+
+
+
+
+⚠️ Nous ne faisons pas attention au masque d'attention des cibles car le modèle ne s'y attend pas. Au lieu de cela, les étiquettes correspondant à un *token* de *padding* doivent être mises à `-100` afin qu'elles soient ignorées dans le calcul de la perte. Cela sera fait par notre collateur de données plus tard puisque nous appliquons le *padding* dynamique, mais si vous utilisez le *padding* ici, vous devriez adapter la fonction de prétraitement pour mettre toutes les étiquettes qui correspondent au *token* de *padding* à `-100`.
+
+
+
+Nous pouvons maintenant appliquer ce prétraitement en une seule fois sur toutes les échantillons de notre jeu de données :
+
+```py
+tokenized_datasets = split_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=split_datasets["train"].column_names,
+)
+```
+
+Maintenant que les données ont été prétraitées, nous sommes prêts à *finetuner* notre modèle pré-entraîné !
+
+{#if fw === 'pt'}
+
+## Finetuner le modèle avec l'API `Trainer`
+
+Le code actuel utilisant `Trainer` sera le même que précédemment, avec juste un petit changement : nous utilisons ici [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) qui est une sous-classe de `Trainer` qui nous permet de traiter correctement l'évaluation, en utilisant la méthode `generate()` pour prédire les sorties à partir des entrées. Nous y reviendrons plus en détail lorsque nous parlerons du calcul de la métrique.
+
+Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## Finetuner du modèle avec Keras
+
+Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
+
+```py
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
+```
+
+
+
+💡 Le *checkpoint* `Helsinki-NLP/opus-mt-en-fr` ne dispose que de poids PyTorch, vous aurez donc une erreur si vous essayez de charger le modèle sans utiliser l'argument `from_pt=True` dans la méthode `from_pretrained()`. Lorsque vous spécifiez `from_pt=True`, la bibliothèque téléchargera et convertira automatiquement les poids PyTorch pour vous. Comme vous pouvez le constater, c'est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
+
+
+
+{/if}
+
+Notez que cette fois-ci, nous utilisons un modèle qui a été entraîné sur une tâche de traduction et qui peut déjà être utilisé, donc il n'y a pas d'avertissement concernant les poids manquants ou ceux nouvellement initialisés.
+
+### Collecte des données
+
+Nous aurons besoin d'un assembleur de données pour gérer le rembourrage pour la mise en batchs dynamique. Ici, nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne rembourre que les entrées (identifiants d'entrée, masque d'attention, et *token* de type identifiants). Nos étiquettes doivent également être rembourrées à la longueur maximale rencontrée dans les étiquettes. Et, comme mentionné précédemment, la valeur de remplissage utilisée pour remplir les étiquettes doit être `-100` et non le *token* de *padding* du *tokenizer* afin de s'assurer que ces valeurs soient ignorées dans le calcul de la perte.
+
+Tout ceci est réalisé par un [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées, mais également le `model`. C'est parce que ce collateur de données est également responsable de la préparation des identifiants d'entrée du décodeur, qui sont des versions décalées des étiquettes avec un *token* spécial au début. Comme ce décalage est effectué de manière légèrement différente selon les architectures, le `DataCollatorForSeq2Seq` a besoin de connaître l'objet `model` :
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+Pour le tester sur quelques échantillons, nous l'appelons simplement sur une liste d'exemples de notre échantillon d'entrainement tokénisé :
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
+batch.keys()
+```
+
+```python out
+dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
+```
+
+Nous pouvons vérifier que nos étiquettes ont été rembourrées à la longueur maximale du batch, en utilisant `-100` :
+
+```py
+batch["labels"]
+```
+
+```python out
+tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
+ -100, -100, -100, -100, -100, -100],
+ [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
+ 550, 7032, 5821, 7907, 12649, 0]])
+```
+
+Nous pouvons aussi jeter un coup d'œil aux identifiants d'entrée du décodeur, pour voir qu'il s'agit de versions décalées des étiquettes :
+
+```py
+batch["decoder_input_ids"]
+```
+
+```python out
+tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
+ 59513, 59513, 59513, 59513, 59513, 59513],
+ [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
+ 817, 550, 7032, 5821, 7907, 12649]])
+```
+
+Voici les étiquettes des premier et deuxième éléments de notre jeu de données :
+
+```py
+for i in range(1, 3):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
+[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
+```
+
+{#if fw === 'pt'}
+
+Nous allons transmettre ce `data_collator` au `Seq2SeqTrainer`. Ensuite, jetons un coup d'oeil à la métrique.
+
+{:else}
+
+Nous pouvons maintenant utiliser ce `data_collator` pour convertir chacun de nos jeux de données en un `tf.data.Dataset`, prêt pour l'entraînement :
+
+```python
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+{/if}
+
+
+### Métriques
+
+
+
+{#if fw === 'pt'}
+
+La fonctionnalité que `Seq2SeqTrainer` ajoute à sa superclasse `Trainer` est la possibilité d'utiliser la méthode `generate()` pendant l'évaluation ou la prédiction. Pendant l'entraînement, le modèle utilisera les `decoder_input_ids` avec un masque d'attention assurant qu'il n'utilise pas les *tokens* après le *token* qu'il essaie de prédire, pour accélérer l'entraînement. Pendant l'inférence, nous ne pourrons pas les utiliser puisque nous n'aurons pas d'étiquettes. Ainsi c'est une bonne idée d'évaluer notre modèle avec la même configuration.
+
+Comme nous l'avons vu dans le [chapitre 1](/course/fr/chapter1/6), le décodeur effectue l'inférence en prédisant les *tokens* un par un. C'est quelque chose qui est implémenté en coulisses dans 🤗 *Transformers* par la méthode `generate()`. Le `Seq2SeqTrainer` nous laissera utiliser cette méthode pour l'évaluation si nous indiquons `predict_with_generate=True`.
+
+{/if}
+
+La métrique traditionnelle utilisée pour la traduction est le [score BLEU](https://en.wikipedia.org/wiki/BLEU), introduit dans [un article de 2002](https://aclanthology.org/P02-1040.pdf) par Kishore Papineni et al. Le score BLEU évalue dans quelle mesure les traductions sont proches de leurs étiquettes. Il ne mesure pas l'intelligibilité ou l'exactitude grammaticale des résultats générés par le modèle, mais utilise des règles statistiques pour garantir que tous les mots des résultats générés apparaissent également dans les cibles. En outre, il existe des règles qui pénalisent les répétitions des mêmes mots s'ils ne sont pas également répétés dans les cibles (pour éviter que le modèle ne produise des phrases telles que « the the the the the the the ») et les phrases produites qui sont plus courtes que celles des cibles (pour éviter que le modèle ne produise des phrases telles que « the »).
+
+L'une des faiblesses de BLEU est qu'il s'attend à ce que le texte soit déjà tokenisé, ce qui rend difficile la comparaison des scores entre les modèles qui utilisent différents *tokenizers*. Par conséquent, la mesure la plus couramment utilisée aujourd'hui pour évaluer les modèles de traduction est [SacreBLEU](https://github.com/mjpost/sacrebleu) qui remédie à cette faiblesse (et à d'autres) en standardisant l'étape de tokenisation. Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *SacreBLEU* :
+
+```py
+!pip install sacrebleu
+```
+
+Nous pouvons ensuite charger ce score via `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+```py
+import evaluate
+
+metric = evaluate.load("sacrebleu")
+```
+
+Cette métrique prend des textes comme entrées et cibles. Elle est conçue pour accepter plusieurs cibles acceptables car il y a souvent plusieurs traductions possibles d'une même phrase. Le jeu de données que nous utilisons n'en fournit qu'une seule, mais en NLP, il n'est pas rare de trouver des jeux de données ayant plusieurs phrases comme étiquettes. Ainsi, les prédictions doivent être une liste de phrases mais les références doivent être une liste de listes de phrases.
+
+Essayons un exemple :
+
+```py
+predictions = [
+ "This plugin lets you translate web pages between several languages automatically."
+]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 46.750469682990165,
+ 'counts': [11, 6, 4, 3],
+ 'totals': [12, 11, 10, 9],
+ 'precisions': [91.67, 54.54, 40.0, 33.33],
+ 'bp': 0.9200444146293233,
+ 'sys_len': 12,
+ 'ref_len': 13}
+```
+
+Cela donne un score BLEU de 46.75, ce qui est plutôt bon. A titre de comparaison, le *Transformer* original dans l'article [*Attention Is All You Need*](https://arxiv.org/pdf/1706.03762.pdf) a obtenu un score BLEU de 41.8 sur une tâche de traduction similaire entre l'anglais et le français ! (Pour plus d'informations sur les métriques individuelles, comme `counts` et `bp`, voir le [dépôt SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74). D'autre part, si nous essayons avec les deux mauvais types de prédictions (répétitions ou prédiction trop courte) qui sortent souvent des modèles de traduction, nous obtiendrons des scores BLEU plutôt mauvais :
+
+```py
+predictions = ["This This This This"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 1.683602693167689,
+ 'counts': [1, 0, 0, 0],
+ 'totals': [4, 3, 2, 1],
+ 'precisions': [25.0, 16.67, 12.5, 12.5],
+ 'bp': 0.10539922456186433,
+ 'sys_len': 4,
+ 'ref_len': 13}
+```
+
+```py
+predictions = ["This plugin"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 0.0,
+ 'counts': [2, 1, 0, 0],
+ 'totals': [2, 1, 0, 0],
+ 'precisions': [100.0, 100.0, 0.0, 0.0],
+ 'bp': 0.004086771438464067,
+ 'sys_len': 2,
+ 'ref_len': 13}
+```
+
+Le score peut aller de 0 à 100. Plus il est élevé, mieux c'est.
+
+{#if fw === 'tf'}
+
+Pour passer des sorties du modèle aux textes que la métrique peut utiliser, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding*. Définissons une fonction qui prend notre modèle et un jeu de données et calcule des métriques sur ceux-ci. Comme la génération de longues séquences peut être lente, nous sous-échantillonnons l'ensemble de validation pour nous assurer que cela ne prend pas une éternité :
+
+```py
+import numpy as np
+
+
+def compute_metrics():
+ all_preds = []
+ all_labels = []
+ sampled_dataset = tokenized_datasets["validation"].shuffle().select(range(200))
+ tf_generate_dataset = sampled_dataset.to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=4,
+ )
+ for batch in tf_generate_dataset:
+ predictions = model.generate(
+ input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
+ )
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = batch["labels"].numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+
+ result = metric.compute(predictions=all_preds, references=all_labels)
+ return {"bleu": result["score"]}
+```
+
+{:else}
+
+Pour passer des sorties du modèle aux textes utilisables par la métrique, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding* :
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # Dans le cas où le modèle retourne plus que les logits de prédiction
+ if isinstance(preds, tuple):
+ preds = preds[0]
+
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Remplacer les -100 dans les étiquettes car nous ne pouvons pas les décoder
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Quelques post-traitements simples
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": result["score"]}
+```
+
+{/if}
+
+Maintenant que c'est fait, nous sommes prêts à *finetuner* notre modèle !
+
+
+### Finetuner le modèle
+
+La première étape consiste à se connecter à Hugging Face, afin de pouvoir télécharger vos résultats sur le *Hub*. Il y a une fonction pratique pour vous aider à le faire dans un *notebook* :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'tf'}
+
+Avant de commencer, voyons quel type de résultats nous obtenons avec notre modèle sans entraînement :
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 33.26983701454733}
+```
+
+Une fois ceci fait, nous pouvons préparer tout ce dont nous avons besoin pour compiler et entraîner notre modèle. Notez l'utilisation de `tf.keras.mixed_precision.set_global_policy("mixed_float16")`. Ceci indiquera à Keras de s'entraîner en utilisant float16, ce qui peut donner un gain de vitesse significatif sur les GPUs qui le supportent (Nvidia 20xx/V100 ou plus récent).
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans le jeu de données, divisé par la taille du batch,
+# puis multiplié par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un tf.data.Dataset,
+# et non le jeu de données original donc son len() est déjà num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Entraîner en mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle sur le *Hub* pendant l'entraînement, comme nous l'avons vu dans la [section 2](/course/fr/chapter7/2), puis nous entraînons simplement le modèle avec ce *callback* :
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser le modèle avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` dans `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé après le répertoire de sortie que vous avez défini. Ici ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
+
+
+
+Enfin, voyons à quoi ressemblent nos métriques maintenant que l'entraînement est terminé :
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 57.334066271545865}
+```
+
+À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
+
+{:else}
+
+Une fois ceci fait, nous pouvons définir notre `Seq2SeqTrainingArguments`. Comme pour le `Trainer`, nous utilisons une sous-classe de `TrainingArguments` qui contient quelques champs supplémentaires :
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+args = Seq2SeqTrainingArguments(
+ f"marian-finetuned-kde4-en-to-fr",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=64,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=3,
+ predict_with_generate=True,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+En dehors des hyperparamètres habituels (comme le taux d'apprentissage, le nombre d'époques, la taille des batchs et une le taux de décroissance des poids), voici quelques changements par rapport à ce que nous avons vu dans les sections précédentes :
+
+- Nous ne définissons pas d'évaluation car elle prend du temps. Nous allons juste évaluer une fois notre modèle avant l'entraînement et après.
+- Nous avons mis `fp16=True`, ce qui accélère l'entraînement sur les GPUs modernes.
+- Nous définissons `predict_with_generate=True`, comme discuté ci-dessus.
+- Nous utilisons `push_to_hub=True` pour télécharger le modèle sur le *Hub* à la fin de chaque époque.
+
+Notez que vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` à `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé d'après le répertoire de sortie que vous avez défini. Dans notre cas ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Seq2SeqTrainer` et devrez définir un nouveau nom.
+
+
+
+
+Enfin, nous passons tout au `Seq2SeqTrainer` :
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+Avant d'entraîner, nous allons d'abord regarder le score obtenu par notre modèle, pour vérifier que nous n'aggravons pas les choses avec notre *finetuning*. Cette commande va prendre un peu de temps, vous pouvez donc prendre un café pendant qu'elle s'exécute :
+
+```python
+trainer.evaluate(max_length=max_target_length)
+```
+
+```python out
+{'eval_loss': 1.6964408159255981,
+ 'eval_bleu': 39.26865061007616,
+ 'eval_runtime': 965.8884,
+ 'eval_samples_per_second': 21.76,
+ 'eval_steps_per_second': 0.341}
+```
+
+Un score BLEU de 39 n'est pas trop mauvais, ce qui reflète le fait que notre modèle est déjà bon pour traduire des phrases anglaises en phrases françaises.
+
+Vient ensuite l'entraînement, qui prendra également un peu de temps :
+
+```python
+trainer.train()
+```
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
+
+Une fois l'entraînement terminé, nous évaluons à nouveau notre modèle. Avec un peu de chance, nous verrons une amélioration du score BLEU !
+
+```py
+trainer.evaluate(max_length=max_target_length)
+```
+
+```python out
+{'eval_loss': 0.8558505773544312,
+ 'eval_bleu': 52.94161337775576,
+ 'eval_runtime': 714.2576,
+ 'eval_samples_per_second': 29.426,
+ 'eval_steps_per_second': 0.461,
+ 'epoch': 3.0}
+```
+
+C'est une amélioration de près de 14 points, ce qui est formidable.
+
+Enfin, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la dernière version du modèle. `Trainer` rédige également une carte de modèle avec tous les résultats de l'évaluation et la télécharge. Cette carte de modèle contient des métadonnées qui aident le *Hub* à choisir le *widget* pour l'inférence. Habituellement, il n'y a pas besoin de dire quoi que ce soit car il peut inférer le bon *widget* à partir de la classe du modèle, mais dans ce cas, la même classe de modèle peut être utilisée pour toutes sortes de problèmes de séquence à séquence. Ainsi nous spécifions que c'est un modèle de traduction :
+
+```py
+trainer.push_to_hub(tags="translation", commit_message="Training complete")
+```
+
+Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
+
+```python out
+'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
+```
+
+À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
+
+Si vous souhaitez vous plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
+
+{/if}
+
+{#if fw === 'pt'}
+
+## Une boucle d'entraînement personnalisée
+
+Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans la [section 2](/course/fr/chapter7/2) et dans le [chapitre 3](/course/fr/chapter3/4).
+
+### Préparer le tout pour l'entraînement
+
+Vous avez vu tout cela plusieurs fois maintenant, donc nous allons passer en revue le code assez rapidement. D'abord, nous allons construire le `DataLoader` à partir de nos jeux de données, après avoir configuré les jeux de données au format `"torch"` pour obtenir les tenseurs PyTorch :
+
+```py
+from torch.utils.data import DataLoader
+
+tokenized_datasets.set_format("torch")
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne poursuivons pas le *finetuning* précédent et que nous repartons du modèle pré-entraîné :
+
+```py
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+Nous aurons alors besoin d'un optimiseur :
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()`. Rappelez-vous que si vous voulez entraîner sur des TPUs dans un *notebook* de Colab, vous devez déplacer tout ce code dans une fonction d'entraînement et ne devrait pas exécuter une cellule qui instancie un `Accelerator`.
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le chargeur de données car cette méthode va changer la longueur du `DataLoader`. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Enfin, pour pousser notre modèle vers le *Hub*, nous aurons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous au *Hub* si vous n'êtes pas déjà connecté. Nous déterminerons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur, ce que fait la fonction `get_full_repo_name()`) :
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
+```
+
+Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone du dépôt avec lequel nous travaillons :
+
+```py
+output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
+
+### Boucle d'entraînement
+
+Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes et les convertit en listes de chaînes de caractères que notre objet `metric` attend :
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+
+ # Remplace -100 dans les étiquettes car nous ne pouvons pas les décoder
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Quelques post-traitements simples
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ return decoded_preds, decoded_labels
+```
+
+La boucle d'entraînement ressemble beaucoup à celles de la [section 2](/course/fr/chapter7/2) et du [chapitre 3](/course/fr/chapter3), avec quelques différences dans la partie évaluation. Donc concentrons-nous sur cela !
+
+La première chose à noter est que nous utilisons la méthode `generate()` pour calculer les prédictions. C'est une méthode sur notre modèle de base et non pas le modèle enveloppé créé dans la méthode `prepare()`. C'est pourquoi nous déballons d'abord le modèle, puis nous appelons cette méthode.
+
+La deuxième chose est que, comme avec la classification de [*token*](/course/fr/chapter7/2), deux processus peuvent avoir rembourrés les entrées et les étiquettes à des formes différentes. Ainsi nous utilisons `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne faisons pas cela, l'évaluation va soit se tromper, soit se bloquer pour toujours.
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Entraînement
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_length=128,
+ )
+ labels = batch["labels"]
+
+ # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(generated_tokens)
+ labels_gathered = accelerator.gather(labels)
+
+ decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ results = metric.compute()
+ print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
+
+ # Sauvegarder et télécharger
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+epoch 0, BLEU score: 53.47
+epoch 1, BLEU score: 54.24
+epoch 2, BLEU score: 54.44
+```
+
+Une fois que c'est fait, vous devriez avoir un modèle qui a des résultats assez similaires à celui entraîné avec `Seq2SeqTrainer`. Vous pouvez vérifier celui que nous avons entraîné en utilisant ce code sur [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les mettre en œuvre directement en modifiant le code ci-dessus !
+
+{/if}
+
+### Utilisation du modèle finetuné
+
+Nous vous avons déjà montré comment vous pouvez utiliser le modèle que nous avons *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, nous devons juste spécifier l'identifiant de modèle approprié :
+
+```py
+from transformers import pipeline
+
+# Remplacez ceci par votre propre checkpoint
+model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut, développer les fils de discussion'}]
+```
+
+Comme prévu, notre modèle pré-entraîné a adapté ses connaissances au corpus sur lequel nous l'avons *finetuné*. Et au lieu de laisser le mot anglais « *threads* », le modèle le traduit maintenant par la version française officielle. Il en va de même pour « *plugin* » :
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Un autre excellent exemple d'adaptation au domaine !
+
+
+
+✏️ **A votre tour !** Que retourne le modèle sur l'échantillon avec le mot « *email* » que vous avez identifié plus tôt ?
+
+
diff --git a/chapters/fr/chapter7/5.mdx b/chapters/fr/chapter7/5.mdx
index c2177fb07..d2d570667 100644
--- a/chapters/fr/chapter7/5.mdx
+++ b/chapters/fr/chapter7/5.mdx
@@ -1,1083 +1,1083 @@
-
-
-# Résumé de textes
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-
-Dans cette section, nous allons voir comment les *transformers* peuvent être utilisés pour condenser de longs documents en résumés, une tâche connue sous le nom de _résumé de texte_. Il s'agit de l'une des tâches de NLP les plus difficiles car elle requiert une série de capacités, telles que la compréhension de longs passages et la génération d'un texte cohérent qui capture les sujets principaux d'un document. Cependant, lorsqu'il est bien fait, le résumé de texte est un outil puissant qui peut accélérer divers processus commerciaux en soulageant les experts du domaine de la lecture détaillée de longs documents.
-
-
-
-Bien qu'il existe déjà plusieurs modèles *finetunés* pour le résumé sur le [*Hub*](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads), la plupart d'entre eux ne sont adaptés qu'aux documents en anglais. Ainsi, pour ajouter une touche d'originalité à cette section, nous allons entraîner un modèle bilingue pour l'anglais et l'espagnol. À la fin de cette section, vous disposerez d'un [modèle](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) capable de résumer les commentaires des clients comme celui présenté ici :
-
-
-
-
-Comme nous allons le voir, ces résumés sont concis car ils sont appris à partir des titres que les clients fournissent dans leurs commentaires sur les produits. Commençons par constituer un corpus bilingue approprié pour cette tâche.
-
-## Préparation d'un corpus multilingue
-
-Nous allons utiliser le [*Multilingual Amazon Reviews Corpus*](https://huggingface.co/datasets/amazon_reviews_multi) pour créer notre résumeur bilingue. Ce corpus est constitué de critiques de produits Amazon en six langues et est généralement utilisé pour évaluer les classifieurs multilingues. Cependant, comme chaque critique est accompagnée d'un titre court, nous pouvons utiliser les titres comme résumés cibles pour l'apprentissage de notre modèle ! Pour commencer, téléchargeons les sous-ensembles anglais et espagnols depuis le *Hub* :
-
-```python
-from datasets import load_dataset
-
-spanish_dataset = load_dataset("amazon_reviews_multi", "es")
-english_dataset = load_dataset("amazon_reviews_multi", "en")
-english_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 200000
- })
- validation: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 5000
- })
- test: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 5000
- })
-})
-```
-
-Comme vous pouvez le voir, pour chaque langue, il y a 200 000 critiques pour la partie entraînement et 5 000 critiques pour chacune des parties validation et test. Les informations qui nous intéressent sont contenues dans les colonnes `review_body` et `review_title`. Voyons quelques exemples en créant une fonction simple qui prend un échantillon aléatoire de l'ensemble d'entraînement avec les techniques apprises au [chapitre 5](/course/fr/chapter5) :
-
-```python
-def show_samples(dataset, num_samples=3, seed=42):
- sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
- for example in sample:
- print(f"\n'>> Title: {example['review_title']}'")
- print(f"'>> Review: {example['review_body']}'")
-
-
-show_samples(english_dataset)
-```
-
-```python out
-'>> Title: Worked in front position, not rear'
-# Travaillé en position avant, pas arrière
-'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
-# 3 étoiles car ce ne sont pas des freins arrière comme indiqué dans la description de l'article. Au moins, l'adaptateur de montage ne fonctionnait que sur la fourche avant du vélo pour lequel je l'ai acheté.
-
-'>> Title: meh'
-'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
-# Il fait son travail et il est magnifique mais le mien est en train de tomber en morceaux, j'ai dû le recoller avec de la colle chaude.
-
-'>> Title: Can\'t beat these for the money'
-# On ne peut pas faire mieux pour le prix
-'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
-# Je l'ai acheté pour manipuler diverses pièces d'avion et des "trucs" de hangar que je devais organiser ; il a vraiment fait l'affaire. L'unité est arrivée rapidement, était bien emballée et est arrivée intacte (toujours un bon signe). Il y a cinq supports muraux - trois sur le dessus et deux sur le dessous. Je voulais le monter sur le mur, alors tout ce que j'ai eu à faire était d'enlever les deux couches supérieures de tiroirs en plastique, ainsi que les tiroirs d'angle inférieurs, de le placer où je voulais et de le marquer ; j'ai ensuite utilisé quelques-uns des nouveaux ancrages muraux à vis en plastique (la variété de 50 livres) et il s'est facilement monté sur le mur. Certains ont fait remarquer qu'ils voulaient des séparateurs pour les tiroirs, et qu'ils les ont fabriqués. Bonne idée. Pour ma part, j'avais besoin de quelque chose dont je pouvais voir le contenu à hauteur des yeux, et je voulais donc des tiroirs plus grands. J'aime aussi le fait qu'il s'agisse du nouveau plastique qui ne se fragilise pas et ne se fend pas comme mes anciens tiroirs en plastique. J'aime la construction entièrement en plastique. Elle est suffisamment résistante pour contenir des pièces métalliques, mais étant en plastique, elle n'est pas aussi lourde qu'un cadre métallique, ce qui permet de la fixer facilement au mur et de la charger d'objets lourds ou légers. Aucun problème. Pour le prix, c'est imbattable. C'est le meilleur que j'ai acheté à ce jour, et j'utilise des versions de ce type depuis plus de quarante ans.
-```
-
-
-
-✏️ **Essayez !** Changez la graine aléatoire dans la commande `Dataset.shuffle()` pour explorer d'autres critiques dans le corpus. Si vous parlez espagnol, jetez un coup d'œil à certaines des critiques dans `spanish_dataset` pour voir si les titres semblent aussi être des résumés raisonnables.
-
-
-
-Cet échantillon montre la diversité des critiques que l'on trouve généralement en ligne, allant du positif au négatif (et tout ce qui se trouve entre les deux !). Bien que l'exemple avec le titre « meh » ne soit pas très informatif, les autres titres semblent être des résumés décents des critiques. Entraîner un modèle de résumé sur l'ensemble des 400 000 avis prendrait beaucoup trop de temps sur un seul GPU, nous allons donc nous concentrer sur la génération de résumés pour un seul domaine de produits. Pour avoir une idée des domaines parmi lesquels nous pouvons choisir, convertissons `english_dataset` en `pandas.DataFrame` et calculons le nombre d'avis par catégorie de produits :
-
-```python
-english_dataset.set_format("pandas")
-english_df = english_dataset["train"][:]
-# Afficher le compte des 20 premiers produits
-english_df["product_category"].value_counts()[:20]
-```
-
-```python out
-home 17679 # maison
-apparel 15951 # vêtements
-wireless 15717 # sans fil
-other 13418 # autres
-beauty 12091 # beauté
-drugstore 11730 # pharmacie
-kitchen 10382 # cuisine
-toy 8745 # jouets
-sports 8277 # sports
-automotive 7506 # automobile
-lawn_and_garden 7327 # pelouse_et_jardin
-home_improvement 7136 # amélioration_de_la_maison
-pet_products 7082 # produits_pour_animaux_de_compagnie
-digital_ebook_purchase 6749 # achat_de_livres_numériques
-pc 6401 # ordinateur_personnel
-electronics 6186 # électronique
-office_product 5521 # produits_de_bureau
-shoes 5197 # chaussures
-grocery 4730 # épicerie
-book 3756 # livre
-Name: product_category, dtype: int64
-```
-
-Les produits les plus populaires du jeu de données anglais concernent les articles ménagers, les vêtements et l'électronique sans fil. Pour rester dans le thème d'Amazon, nous allons nous concentrer sur le résumé des critiques de livres. Après tout, c'est la raison d'être de l'entreprise ! Nous pouvons voir deux catégories de produits qui correspondent à nos besoins (`book` et `digital_ebook_purchase`). Nous allons donc filtrer les jeux de données dans les deux langues pour ces produits uniquement. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), la fonction `Dataset.filter()` nous permet de découper un jeu de données de manière très efficace. Nous pouvons donc définir une fonction simple pour le faire :
-
-```python
-def filter_books(example):
- return (
- example["product_category"] == "book"
- or example["product_category"] == "digital_ebook_purchase"
- )
-```
-
-Maintenant, lorsque nous appliquons cette fonction à `english_dataset` et `spanish_dataset`, le résultat ne contient que les lignes impliquant les catégories de livres. Avant d'appliquer le filtre, changeons le format de `english_dataset` de `"pandas"` à `"arrow"` :
-
-```python
-english_dataset.reset_format()
-```
-
-Nous pouvons ensuite appliquer la fonction de filtrage et, à titre de vérification, inspecter un échantillon de critiques pour voir si elles portent bien sur des livres :
-
-```python
-spanish_books = spanish_dataset.filter(filter_books)
-english_books = english_dataset.filter(filter_books)
-show_samples(english_books)
-```
-
-```python out
-'>> Title: I\'m dissapointed.'
-# Je suis déçu
-'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
-# Je suppose que j'avais de plus grandes attentes pour ce livre d'après les critiques. Je pensais vraiment que j'allais au moins l'aimer. L'idée de l'intrigue était géniale. J'aimais Ash, mais ça n'allait nulle part. La plus grande partie du livre était consacrée à leur émission de radio et aux conversations avec les auditeurs. Je voulais que l'auteur creuse plus profondément pour que nous puissions vraiment connaître les personnages. Tout ce que nous savons de Grace, c'est qu'elle est séduisante, qu'elle est latino et qu'elle est une sorte de garce. Je suis déçue.
-
-'>> Title: Good art, good price, poor design'
-# Un bon art, un bon prix, un mauvais design
-'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
-# J'ai eu le calendrier DC Vintage ces deux dernières années, mais il était en rupture de stock pour toujours cette année et j'ai vu qu'ils avaient réduit les dimensions sans raison valable. Celui-ci a de bons choix artistiques mais le design a le pli qui traverse l'image, donc c'est moins esthétique, surtout si vous voulez garder une image à accrocher. Pour le prix, c'est un bon calendrier.
-
-'>> Title: Helpful'
-# Utile
-'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
-# Presque tous les conseils sont utiles et. Je me considère comme un utilisateur intermédiaire à avancé de OneNote. Je le recommande vivement.
-```
-
-D'accord, nous pouvons voir que les critiques ne concernent pas strictement les livres et peuvent se référer à des choses comme des calendriers et des applications électroniques telles que OneNote. Néanmoins, le domaine semble approprié pour entraîner un modèle de résumé. Avant de regarder les différents modèles qui conviennent à cette tâche, nous avons une dernière préparation de données à faire : combiner les critiques anglaises et espagnoles en un seul objet `DatasetDict`. 🤗 *Datasets* fournit une fonction pratique `concatenate_datasets()` qui (comme son nom l'indique) va empiler deux objets `Dataset` l'un sur l'autre. Ainsi, pour créer notre jeu de données bilingue, nous allons boucler sur chaque division, concaténer les jeux de données pour cette division, et mélanger le résultat pour s'assurer que notre modèle ne s'adapte pas trop à une seule langue :
-
-```python
-from datasets import concatenate_datasets, DatasetDict
-
-books_dataset = DatasetDict()
-
-for split in english_books.keys():
- books_dataset[split] = concatenate_datasets(
- [english_books[split], spanish_books[split]]
- )
- books_dataset[split] = books_dataset[split].shuffle(seed=42)
-
-# Quelques exemples
-show_samples(books_dataset)
-```
-
-```python out
-'>> Title: Easy to follow!!!!'
-# Facile à suivre!!!!
-'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
-# J'ai adoré The dash diet weight loss Solution. Jamais faim. Je recommande ce régime. Les menus sont également bien arrondis. Essayez-le. Il contient beaucoup d'informations, merci.
-
-'>> Title: PARCIALMENTE DAÑADO'
-# PARTIELLEMENT ENDOMMAGÉ
-'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
-# Il est arrivé le jour prévu, avec d'autres livres que j'avais commandés, mais la boîte est arrivée en mauvais état, ce qui a endommagé les coins des livres car ils étaient livrés sans protection (doublure).
-
-'>> Title: no lo he podido descargar'
-# Je n'ai pas pu le télécharger
-'>> Review: igual que el anterior'
-# même chose que ci-dessus
-```
-
-Cela ressemble certainement à un mélange de critiques anglaises et espagnoles ! Maintenant que nous avons un corpus d'entraînement, une dernière chose à vérifier est la distribution des mots dans les critiques et leurs titres. Ceci est particulièrement important pour les tâches de résumé, où les résumés de référence courts dans les données peuvent biaiser le modèle pour qu'il ne produise qu'un ou deux mots dans les résumés générés. Les graphiques ci-dessous montrent les distributions de mots, et nous pouvons voir que les titres sont fortement biaisés vers seulement 1 ou 2 mots :
-
-
-
-Jetons un coup d'œil au jeu de données :
-
-```py
-raw_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['id', 'translation'],
- num_rows: 210173
- })
-})
-```
-
-Nous avons 210 173 paires de phrases. Cependant regroupées dans un seul échantillon. Nous devrons donc créer notre propre jeu de validation. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), un `Dataset` possède une méthode `train_test_split()` qui peut nous aider. Nous allons fournir une graine pour la reproductibilité :
-
-```py
-split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
-split_datasets
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['id', 'translation'],
- num_rows: 189155
- })
- test: Dataset({
- features: ['id', 'translation'],
- num_rows: 21018
- })
-})
-```
-
-Nous pouvons renommer la clé `test` en `validation` comme ceci :
-
-```py
-split_datasets["validation"] = split_datasets.pop("test")
-```
-
-Examinons maintenant un élément de ce jeu de données :
-
-```py
-split_datasets["train"][1]["translation"]
-```
-
-```python out
-{'en': 'Default to expanded threads',
- 'fr': 'Par défaut, développer les fils de discussion'}
-```
-
-Nous obtenons un dictionnaire contenant deux phrases dans la paire de langues qui nous intéresse.
-Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français sont souvent paresseux et laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
-
-```py
-from transformers import pipeline
-
-model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
-translator = pipeline("translation", model=model_checkpoint)
-translator("Default to expanded threads")
-```
-
-```python out
-[{'translation_text': 'Par défaut pour les threads élargis'}]
-```
-
-Un autre exemple de ce comportement peut être observé avec le mot « *plugin* » qui n'est pas officiellement un mot français mais que la plupart des francophones comprendront et ne prendront pas la peine de traduire.
-Dans le jeu de données KDE4, ce mot a été traduit en français par le plus officiel « module d'extension » :
-
-```py
-split_datasets["train"][172]["translation"]
-```
-
-```python out
-{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
- 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
-```
-
-Notre modèle pré-entraîné, lui, s'en tient au mot anglais :
-
-```py
-translator(
- "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
-)
-```
-
-```python out
-[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
-```
-
-Il sera intéressant de voir si notre modèle *finetuné* tient compte de ces particularités (alerte *spoiler* : il le fera).
-
-
-
-
-
-✏️ **A votre tour !** Un autre mot anglais souvent utilisé en français est « *email* ». Trouvez le premier échantillon dans l'échantillon d'entraînement qui utilise ce mot. Comment est-il traduit ? Comment le modèle pré-entraîné traduit-il cette même phrase ?
-
-
-
-### Traitement des données
-
-
-
-Vous devriez maintenant connaître le principe : les textes doivent tous être convertis en ensembles d'ID de *tokens* pour que le modèle puisse leur donner un sens. Pour cette tâche, nous aurons besoin de tokeniser les entrées et les cibles. Notre première tâche est de créer notre objet `tokenizer`. Comme indiqué précédemment, nous utiliserons un modèle pré-entraîné Marian English to French. Si vous essayez ce code avec une autre paire de langues, assurez-vous d'adapter le *checkpoint* du modèle. L'organisation [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) fournit plus de mille modèles dans plusieurs langues.
-
-```python
-from transformers import AutoTokenizer
-
-model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
-tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")
-```
-
-Vous pouvez remplacer le `model_checkpoint` par un tout autre modèle disponible sur le [*Hub*](https://huggingface.co/models) qui aurait votre préférence, ou par un dossier en local où vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*.
-
-
-
-💡 Si vous utilisez un *tokenizer* multilingue tel que mBART, mBART-50 ou M2M100, vous devrez définir les codes de langue de vos entrées et cibles dans le *tokenizer* en définissant `tokenizer.src_lang` et `tokenizer.tgt_lang` aux bonnes valeurs.
-
-
-
-La préparation de nos données est assez simple. Il y a juste une chose à retenir : vous traitez les entrées comme d'habitude, mais pour les cibles, vous devez envelopper le *tokenizer* dans le gestionnaire de contexte `as_target_tokenizer()`.
-
-Un gestionnaire de contexte en Python est introduit avec l'instruction `with` et est utile lorsque vous avez deux opérations liées à exécuter en paire. L'exemple le plus courant est lorsque vous écrivez ou lisez un fichier, ce qui est souvent fait dans une instruction comme :
-
-```
-with open(file_path) as f:
- content = f.read()
-```
-
-Ici, les deux opérations connexes qui sont exécutées en paire sont les actions d'ouverture et de fermeture du fichier. L'objet correspondant au fichier ouvert `f` n'existe qu'à l'intérieur du bloc indenté sous le `with`. L'ouverture se produit avant ce bloc et la fermeture à la fin du bloc.
-
-Dans le cas présent, le gestionnaire de contexte `as_target_tokenizer()` va définir le *tokenizer* dans la langue de sortie (ici, le français) avant l'exécution du bloc indenté, puis le redéfinir dans la langue d'entrée (ici, l'anglais).
-
-Ainsi, le prétraitement d'un échantillon ressemble à ceci :
-
-```python
-en_sentence = split_datasets["train"][1]["translation"]["en"]
-fr_sentence = split_datasets["train"][1]["translation"]["fr"]
-
-inputs = tokenizer(en_sentence)
-with tokenizer.as_target_tokenizer():
- targets = tokenizer(fr_sentence)
-```
-
-Si nous oublions de tokeniser les cibles dans le gestionnaire de contexte, elles seront tokenisées par le *tokenizer* d'entrée, ce qui dans le cas d'un modèle Marian, ne va pas du tout bien se passer :
-
-```python
-wrong_targets = tokenizer(fr_sentence)
-print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
-print(tokenizer.convert_ids_to_tokens(targets["input_ids"]))
-```
-
-```python out
-['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
-['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
-```
-
-Comme on peut le voir, utiliser le *tokenizer* anglais pour prétraiter une phrase française donne un batch de *tokens* plus important, puisque le *tokenizer* ne connaît aucun mot français (sauf ceux qui apparaissent aussi en anglais, comme « discussion »).
-
-Les `inputs` et les `targets` sont des dictionnaires avec nos clés habituelles (identifiants d'entrée, masque d'attention, etc.). La dernière étape est de définir une clé `"labels"` dans les entrées. Nous faisons cela dans la fonction de prétraitement que nous allons appliquer sur les jeux de données :
-
-```python
-max_input_length = 128
-max_target_length = 128
-
-
-def preprocess_function(examples):
- inputs = [ex["en"] for ex in examples["translation"]]
- targets = [ex["fr"] for ex in examples["translation"]]
- model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
-
- # Configurer le tokenizer pour les cibles.
- with tokenizer.as_target_tokenizer():
- labels = tokenizer(targets, max_length=max_target_length, truncation=True)
-
- model_inputs["labels"] = labels["input_ids"]
- return model_inputs
-```
-
-Notez que nous avons fixé des longueurs maximales similaires pour nos entrées et nos sorties. Comme les textes que nous traitons semblent assez courts, nous utilisons 128.
-
-
-
-💡 Si vous utilisez un modèle T5 (plus précisément, un des *checkpoints* `t5-xxx`), le modèle s'attendra à ce que les entrées aient un préfixe indiquant la tâche à accomplir, comme `translate: English to French:`.
-
-
-
-
-
-⚠️ Nous ne faisons pas attention au masque d'attention des cibles car le modèle ne s'y attend pas. Au lieu de cela, les étiquettes correspondant à un *token* de *padding* doivent être mises à `-100` afin qu'elles soient ignorées dans le calcul de la perte. Cela sera fait par notre collateur de données plus tard puisque nous appliquons le *padding* dynamique, mais si vous utilisez le *padding* ici, vous devriez adapter la fonction de prétraitement pour mettre toutes les étiquettes qui correspondent au *token* de *padding* à `-100`.
-
-
-
-Nous pouvons maintenant appliquer ce prétraitement en une seule fois sur toutes les échantillons de notre jeu de données :
-
-```py
-tokenized_datasets = split_datasets.map(
- preprocess_function,
- batched=True,
- remove_columns=split_datasets["train"].column_names,
-)
-```
-
-Maintenant que les données ont été prétraitées, nous sommes prêts à *finetuner* notre modèle pré-entraîné !
-
-{#if fw === 'pt'}
-
-## Finetuner le modèle avec l'API `Trainer`
-
-Le code actuel utilisant `Trainer` sera le même que précédemment, avec juste un petit changement : nous utilisons ici [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) qui est une sous-classe de `Trainer` qui nous permet de traiter correctement l'évaluation, en utilisant la méthode `generate()` pour prédire les sorties à partir des entrées. Nous y reviendrons plus en détail lorsque nous parlerons du calcul de la métrique.
-
-Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
-```
-
-{:else}
-
-## Finetuner du modèle avec Keras
-
-Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
-
-```py
-from transformers import TFAutoModelForSeq2SeqLM
-
-model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
-```
-
-
-
-💡 Le *checkpoint* `Helsinki-NLP/opus-mt-en-fr` ne dispose que de poids PyTorch, vous aurez donc une erreur si vous essayez de charger le modèle sans utiliser l'argument `from_pt=True` dans la méthode `from_pretrained()`. Lorsque vous spécifiez `from_pt=True`, la bibliothèque téléchargera et convertira automatiquement les poids PyTorch pour vous. Comme vous pouvez le constater, c'est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
-
-
-
-{/if}
-
-Notez que cette fois-ci, nous utilisons un modèle qui a été entraîné sur une tâche de traduction et qui peut déjà être utilisé, donc il n'y a pas d'avertissement concernant les poids manquants ou ceux nouvellement initialisés.
-
-### Collecte des données
-
-Nous aurons besoin d'un assembleur de données pour gérer le rembourrage pour la mise en batchs dynamique. Ici, nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne rembourre que les entrées (identifiants d'entrée, masque d'attention, et *token* de type identifiants). Nos étiquettes doivent également être rembourrées à la longueur maximale rencontrée dans les étiquettes. Et, comme mentionné précédemment, la valeur de remplissage utilisée pour remplir les étiquettes doit être `-100` et non le *token* de *padding* du *tokenizer* afin de s'assurer que ces valeurs soient ignorées dans le calcul de la perte.
-
-Tout ceci est réalisé par un [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées, mais également le `model`. C'est parce que ce collateur de données est également responsable de la préparation des identifiants d'entrée du décodeur, qui sont des versions décalées des étiquettes avec un *token* spécial au début. Comme ce décalage est effectué de manière légèrement différente selon les architectures, le `DataCollatorForSeq2Seq` a besoin de connaître l'objet `model` :
-
-{#if fw === 'pt'}
-
-```py
-from transformers import DataCollatorForSeq2Seq
-
-data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
-```
-
-{:else}
-
-```py
-from transformers import DataCollatorForSeq2Seq
-
-data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
-```
-
-{/if}
-
-Pour le tester sur quelques échantillons, nous l'appelons simplement sur une liste d'exemples de notre échantillon d'entrainement tokénisé :
-
-```py
-batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
-batch.keys()
-```
-
-```python out
-dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
-```
-
-Nous pouvons vérifier que nos étiquettes ont été rembourrées à la longueur maximale du batch, en utilisant `-100` :
-
-```py
-batch["labels"]
-```
-
-```python out
-tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
- -100, -100, -100, -100, -100, -100],
- [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
- 550, 7032, 5821, 7907, 12649, 0]])
-```
-
-Nous pouvons aussi jeter un coup d'œil aux identifiants d'entrée du décodeur, pour voir qu'il s'agit de versions décalées des étiquettes :
-
-```py
-batch["decoder_input_ids"]
-```
-
-```python out
-tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
- 59513, 59513, 59513, 59513, 59513, 59513],
- [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
- 817, 550, 7032, 5821, 7907, 12649]])
-```
-
-Voici les étiquettes des premier et deuxième éléments de notre jeu de données :
-
-```py
-for i in range(1, 3):
- print(tokenized_datasets["train"][i]["labels"])
-```
-
-```python out
-[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
-[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
-```
-
-{#if fw === 'pt'}
-
-Nous allons transmettre ce `data_collator` au `Seq2SeqTrainer`. Ensuite, jetons un coup d'oeil à la métrique.
-
-{:else}
-
-Nous pouvons maintenant utiliser ce `data_collator` pour convertir chacun de nos jeux de données en un `tf.data.Dataset`, prêt pour l'entraînement :
-
-```python
-tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=True,
- batch_size=32,
-)
-tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=16,
-)
-```
-
-{/if}
-
-
-### Métriques
-
-
-
-{#if fw === 'pt'}
-
-La fonctionnalité que `Seq2SeqTrainer` ajoute à sa superclasse `Trainer` est la possibilité d'utiliser la méthode `generate()` pendant l'évaluation ou la prédiction. Pendant l'entraînement, le modèle utilisera les `decoder_input_ids` avec un masque d'attention assurant qu'il n'utilise pas les *tokens* après le *token* qu'il essaie de prédire, pour accélérer l'entraînement. Pendant l'inférence, nous ne pourrons pas les utiliser puisque nous n'aurons pas d'étiquettes. Ainsi c'est une bonne idée d'évaluer notre modèle avec la même configuration.
-
-Comme nous l'avons vu dans le [chapitre 1](/course/fr/chapter1/6), le décodeur effectue l'inférence en prédisant les *tokens* un par un. C'est quelque chose qui est implémenté en coulisses dans 🤗 *Transformers* par la méthode `generate()`. Le `Seq2SeqTrainer` nous laissera utiliser cette méthode pour l'évaluation si nous indiquons `predict_with_generate=True`.
-
-{/if}
-
-La métrique traditionnelle utilisée pour la traduction est le [score BLEU](https://en.wikipedia.org/wiki/BLEU), introduit dans [un article de 2002](https://aclanthology.org/P02-1040.pdf) par Kishore Papineni et al. Le score BLEU évalue dans quelle mesure les traductions sont proches de leurs étiquettes. Il ne mesure pas l'intelligibilité ou l'exactitude grammaticale des résultats générés par le modèle, mais utilise des règles statistiques pour garantir que tous les mots des résultats générés apparaissent également dans les cibles. En outre, il existe des règles qui pénalisent les répétitions des mêmes mots s'ils ne sont pas également répétés dans les cibles (pour éviter que le modèle ne produise des phrases telles que « the the the the the the the ») et les phrases produites qui sont plus courtes que celles des cibles (pour éviter que le modèle ne produise des phrases telles que « the »).
-
-L'une des faiblesses de BLEU est qu'il s'attend à ce que le texte soit déjà tokenisé, ce qui rend difficile la comparaison des scores entre les modèles qui utilisent différents *tokenizers*. Par conséquent, la mesure la plus couramment utilisée aujourd'hui pour évaluer les modèles de traduction est [SacreBLEU](https://github.com/mjpost/sacrebleu) qui remédie à cette faiblesse (et à d'autres) en standardisant l'étape de tokenisation. Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *SacreBLEU* :
-
-```py
-!pip install sacrebleu
-```
-
-Nous pouvons ensuite charger ce score via `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
-
-```py
-import evaluate
-
-metric = evaluate.load("sacrebleu")
-```
-
-Cette métrique prend des textes comme entrées et cibles. Elle est conçue pour accepter plusieurs cibles acceptables car il y a souvent plusieurs traductions possibles d'une même phrase. Le jeu de données que nous utilisons n'en fournit qu'une seule, mais en NLP, il n'est pas rare de trouver des jeux de données ayant plusieurs phrases comme étiquettes. Ainsi, les prédictions doivent être une liste de phrases mais les références doivent être une liste de listes de phrases.
-
-Essayons un exemple :
-
-```py
-predictions = [
- "This plugin lets you translate web pages between several languages automatically."
-]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 46.750469682990165,
- 'counts': [11, 6, 4, 3],
- 'totals': [12, 11, 10, 9],
- 'precisions': [91.67, 54.54, 40.0, 33.33],
- 'bp': 0.9200444146293233,
- 'sys_len': 12,
- 'ref_len': 13}
-```
-
-Cela donne un score BLEU de 46.75, ce qui est plutôt bon. A titre de comparaison, le *Transformer* original dans l'article [*Attention Is All You Need*](https://arxiv.org/pdf/1706.03762.pdf) a obtenu un score BLEU de 41.8 sur une tâche de traduction similaire entre l'anglais et le français ! (Pour plus d'informations sur les métriques individuelles, comme `counts` et `bp`, voir le [dépôt SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74). D'autre part, si nous essayons avec les deux mauvais types de prédictions (répétitions ou prédiction trop courte) qui sortent souvent des modèles de traduction, nous obtiendrons des scores BLEU plutôt mauvais :
-
-```py
-predictions = ["This This This This"]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 1.683602693167689,
- 'counts': [1, 0, 0, 0],
- 'totals': [4, 3, 2, 1],
- 'precisions': [25.0, 16.67, 12.5, 12.5],
- 'bp': 0.10539922456186433,
- 'sys_len': 4,
- 'ref_len': 13}
-```
-
-```py
-predictions = ["This plugin"]
-references = [
- [
- "This plugin allows you to automatically translate web pages between several languages."
- ]
-]
-metric.compute(predictions=predictions, references=references)
-```
-
-```python out
-{'score': 0.0,
- 'counts': [2, 1, 0, 0],
- 'totals': [2, 1, 0, 0],
- 'precisions': [100.0, 100.0, 0.0, 0.0],
- 'bp': 0.004086771438464067,
- 'sys_len': 2,
- 'ref_len': 13}
-```
-
-Le score peut aller de 0 à 100. Plus il est élevé, mieux c'est.
-
-{#if fw === 'tf'}
-
-Pour passer des sorties du modèle aux textes que la métrique peut utiliser, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding*. Définissons une fonction qui prend notre modèle et un jeu de données et calcule des métriques sur ceux-ci. Comme la génération de longues séquences peut être lente, nous sous-échantillonnons l'ensemble de validation pour nous assurer que cela ne prend pas une éternité :
-
-```py
-import numpy as np
-
-
-def compute_metrics():
- all_preds = []
- all_labels = []
- sampled_dataset = tokenized_datasets["validation"].shuffle().select(range(200))
- tf_generate_dataset = sampled_dataset.to_tf_dataset(
- columns=["input_ids", "attention_mask", "labels"],
- collate_fn=data_collator,
- shuffle=False,
- batch_size=4,
- )
- for batch in tf_generate_dataset:
- predictions = model.generate(
- input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
- )
- decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
- labels = batch["labels"].numpy()
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
- all_preds.extend(decoded_preds)
- all_labels.extend(decoded_labels)
-
- result = metric.compute(predictions=all_preds, references=all_labels)
- return {"bleu": result["score"]}
-```
-
-{:else}
-
-Pour passer des sorties du modèle aux textes utilisables par la métrique, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding* :
-
-```py
-import numpy as np
-
-
-def compute_metrics(eval_preds):
- preds, labels = eval_preds
- # Dans le cas où le modèle retourne plus que les logits de prédiction
- if isinstance(preds, tuple):
- preds = preds[0]
-
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
-
- # Remplacer les -100 dans les étiquettes car nous ne pouvons pas les décoder
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Quelques post-traitements simples
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
-
- result = metric.compute(predictions=decoded_preds, references=decoded_labels)
- return {"bleu": result["score"]}
-```
-
-{/if}
-
-Maintenant que c'est fait, nous sommes prêts à *finetuner* notre modèle !
-
-
-### Finetuner le modèle
-
-La première étape consiste à se connecter à Hugging Face, afin de pouvoir télécharger vos résultats sur le *Hub*. Il y a une fonction pratique pour vous aider à le faire dans un *notebook* :
-
-```python
-from huggingface_hub import notebook_login
-
-notebook_login()
-```
-
-Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
-
-Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
-
-```bash
-huggingface-cli login
-```
-
-{#if fw === 'tf'}
-
-Avant de commencer, voyons quel type de résultats nous obtenons avec notre modèle sans entraînement :
-
-```py
-print(compute_metrics())
-```
-
-```
-{'bleu': 33.26983701454733}
-```
-
-Une fois ceci fait, nous pouvons préparer tout ce dont nous avons besoin pour compiler et entraîner notre modèle. Notez l'utilisation de `tf.keras.mixed_precision.set_global_policy("mixed_float16")`. Ceci indiquera à Keras de s'entraîner en utilisant float16, ce qui peut donner un gain de vitesse significatif sur les GPUs qui le supportent (Nvidia 20xx/V100 ou plus récent).
-
-```python
-from transformers import create_optimizer
-from transformers.keras_callbacks import PushToHubCallback
-import tensorflow as tf
-
-# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans le jeu de données, divisé par la taille du batch,
-# puis multiplié par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un tf.data.Dataset,
-# et non le jeu de données original donc son len() est déjà num_samples // batch_size.
-num_epochs = 3
-num_train_steps = len(tf_train_dataset) * num_epochs
-
-optimizer, schedule = create_optimizer(
- init_lr=5e-5,
- num_warmup_steps=0,
- num_train_steps=num_train_steps,
- weight_decay_rate=0.01,
-)
-model.compile(optimizer=optimizer)
-
-# Entraîner en mixed-precision float16
-tf.keras.mixed_precision.set_global_policy("mixed_float16")
-```
-
-Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle sur le *Hub* pendant l'entraînement, comme nous l'avons vu dans la [section 2](/course/fr/chapter7/2), puis nous entraînons simplement le modèle avec ce *callback* :
-
-```python
-from transformers.keras_callbacks import PushToHubCallback
-
-callback = PushToHubCallback(
- output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
-)
-
-model.fit(
- tf_train_dataset,
- validation_data=tf_eval_dataset,
- callbacks=[callback],
- epochs=num_epochs,
-)
-```
-
-Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser le modèle avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` dans `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé après le répertoire de sortie que vous avez défini. Ici ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
-
-
-
-Enfin, voyons à quoi ressemblent nos métriques maintenant que l'entraînement est terminé :
-
-```py
-print(compute_metrics())
-```
-
-```
-{'bleu': 57.334066271545865}
-```
-
-À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
-
-{:else}
-
-Une fois ceci fait, nous pouvons définir notre `Seq2SeqTrainingArguments`. Comme pour le `Trainer`, nous utilisons une sous-classe de `TrainingArguments` qui contient quelques champs supplémentaires :
-
-```python
-from transformers import Seq2SeqTrainingArguments
-
-args = Seq2SeqTrainingArguments(
- f"marian-finetuned-kde4-en-to-fr",
- evaluation_strategy="no",
- save_strategy="epoch",
- learning_rate=2e-5,
- per_device_train_batch_size=32,
- per_device_eval_batch_size=64,
- weight_decay=0.01,
- save_total_limit=3,
- num_train_epochs=3,
- predict_with_generate=True,
- fp16=True,
- push_to_hub=True,
-)
-```
-
-En dehors des hyperparamètres habituels (comme le taux d'apprentissage, le nombre d'époques, la taille des batchs et une le taux de décroissance des poids), voici quelques changements par rapport à ce que nous avons vu dans les sections précédentes :
-
-- Nous ne définissons pas d'évaluation car elle prend du temps. Nous allons juste évaluer une fois notre modèle avant l'entraînement et après.
-- Nous avons mis `fp16=True`, ce qui accélère l'entraînement sur les GPUs modernes.
-- Nous définissons `predict_with_generate=True`, comme discuté ci-dessus.
-- Nous utilisons `push_to_hub=True` pour télécharger le modèle sur le *Hub* à la fin de chaque époque.
-
-Notez que vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` à `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé d'après le répertoire de sortie que vous avez défini. Dans notre cas ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
-
-
-
-💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Seq2SeqTrainer` et devrez définir un nouveau nom.
-
-
-
-
-Enfin, nous passons tout au `Seq2SeqTrainer` :
-
-```python
-from transformers import Seq2SeqTrainer
-
-trainer = Seq2SeqTrainer(
- model,
- args,
- train_dataset=tokenized_datasets["train"],
- eval_dataset=tokenized_datasets["validation"],
- data_collator=data_collator,
- tokenizer=tokenizer,
- compute_metrics=compute_metrics,
-)
-```
-
-Avant d'entraîner, nous allons d'abord regarder le score obtenu par notre modèle, pour vérifier que nous n'aggravons pas les choses avec notre *finetuning*. Cette commande va prendre un peu de temps, vous pouvez donc prendre un café pendant qu'elle s'exécute :
-
-```python
-trainer.evaluate(max_length=max_target_length)
-```
-
-```python out
-{'eval_loss': 1.6964408159255981,
- 'eval_bleu': 39.26865061007616,
- 'eval_runtime': 965.8884,
- 'eval_samples_per_second': 21.76,
- 'eval_steps_per_second': 0.341}
-```
-
-Un score BLEU de 39 n'est pas trop mauvais, ce qui reflète le fait que notre modèle est déjà bon pour traduire des phrases anglaises en phrases françaises.
-
-Vient ensuite l'entraînement, qui prendra également un peu de temps :
-
-```python
-trainer.train()
-```
-
-Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
-
-Une fois l'entraînement terminé, nous évaluons à nouveau notre modèle. Avec un peu de chance, nous verrons une amélioration du score BLEU !
-
-```py
-trainer.evaluate(max_length=max_target_length)
-```
-
-```python out
-{'eval_loss': 0.8558505773544312,
- 'eval_bleu': 52.94161337775576,
- 'eval_runtime': 714.2576,
- 'eval_samples_per_second': 29.426,
- 'eval_steps_per_second': 0.461,
- 'epoch': 3.0}
-```
-
-C'est une amélioration de près de 14 points, ce qui est formidable.
-
-Enfin, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la dernière version du modèle. `Trainer` rédige également une carte de modèle avec tous les résultats de l'évaluation et la télécharge. Cette carte de modèle contient des métadonnées qui aident le *Hub* à choisir le *widget* pour l'inférence. Habituellement, il n'y a pas besoin de dire quoi que ce soit car il peut inférer le bon *widget* à partir de la classe du modèle, mais dans ce cas, la même classe de modèle peut être utilisée pour toutes sortes de problèmes de séquence à séquence. Ainsi nous spécifions que c'est un modèle de traduction :
-
-```py
-trainer.push_to_hub(tags="translation", commit_message="Training complete")
-```
-
-Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
-
-```python out
-'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
-```
-
-À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
-
-Si vous souhaitez vous plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
-
-{/if}
-
-{#if fw === 'pt'}
-
-## Une boucle d'entraînement personnalisée
-
-Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans la [section 2](/course/fr/chapter7/2) et dans le [chapitre 3](/course/fr/chapter3/4).
-
-### Préparer le tout pour l'entraînement
-
-Vous avez vu tout cela plusieurs fois maintenant, donc nous allons passer en revue le code assez rapidement. D'abord, nous allons construire le `DataLoader` à partir de nos jeux de données, après avoir configuré les jeux de données au format `"torch"` pour obtenir les tenseurs PyTorch :
-
-```py
-from torch.utils.data import DataLoader
-
-tokenized_datasets.set_format("torch")
-train_dataloader = DataLoader(
- tokenized_datasets["train"],
- shuffle=True,
- collate_fn=data_collator,
- batch_size=8,
-)
-eval_dataloader = DataLoader(
- tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
-)
-```
-
-Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne poursuivons pas le *finetuning* précédent et que nous repartons du modèle pré-entraîné :
-
-```py
-model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
-```
-
-Nous aurons alors besoin d'un optimiseur :
-
-```py
-from transformers import AdamW
-
-optimizer = AdamW(model.parameters(), lr=2e-5)
-```
-
-Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()`. Rappelez-vous que si vous voulez entraîner sur des TPUs dans un *notebook* de Colab, vous devez déplacer tout ce code dans une fonction d'entraînement et ne devrait pas exécuter une cellule qui instancie un `Accelerator`.
-
-```py
-from accelerate import Accelerator
-
-accelerator = Accelerator()
-model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
-)
-```
-
-Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le chargeur de données car cette méthode va changer la longueur du `DataLoader`. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
-
-```py
-from transformers import get_scheduler
-
-num_train_epochs = 3
-num_update_steps_per_epoch = len(train_dataloader)
-num_training_steps = num_train_epochs * num_update_steps_per_epoch
-
-lr_scheduler = get_scheduler(
- "linear",
- optimizer=optimizer,
- num_warmup_steps=0,
- num_training_steps=num_training_steps,
-)
-```
-
-Enfin, pour pousser notre modèle vers le *Hub*, nous aurons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous au *Hub* si vous n'êtes pas déjà connecté. Nous déterminerons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur, ce que fait la fonction `get_full_repo_name()`) :
-
-```py
-from huggingface_hub import Repository, get_full_repo_name
-
-model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
-repo_name = get_full_repo_name(model_name)
-repo_name
-```
-
-```python out
-'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
-```
-
-Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone du dépôt avec lequel nous travaillons :
-
-```py
-output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
-repo = Repository(output_dir, clone_from=repo_name)
-```
-
-Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
-
-### Boucle d'entraînement
-
-Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes et les convertit en listes de chaînes de caractères que notre objet `metric` attend :
-
-```py
-def postprocess(predictions, labels):
- predictions = predictions.cpu().numpy()
- labels = labels.cpu().numpy()
-
- decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
-
- # Remplace -100 dans les étiquettes car nous ne pouvons pas les décoder
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Quelques post-traitements simples
- decoded_preds = [pred.strip() for pred in decoded_preds]
- decoded_labels = [[label.strip()] for label in decoded_labels]
- return decoded_preds, decoded_labels
-```
-
-La boucle d'entraînement ressemble beaucoup à celles de la [section 2](/course/fr/chapter7/2) et du [chapitre 3](/course/fr/chapter3), avec quelques différences dans la partie évaluation. Donc concentrons-nous sur cela !
-
-La première chose à noter est que nous utilisons la méthode `generate()` pour calculer les prédictions. C'est une méthode sur notre modèle de base et non pas le modèle enveloppé créé dans la méthode `prepare()`. C'est pourquoi nous déballons d'abord le modèle, puis nous appelons cette méthode.
-
-La deuxième chose est que, comme avec la classification de [*token*](/course/fr/chapter7/2), deux processus peuvent avoir rembourrés les entrées et les étiquettes à des formes différentes. Ainsi nous utilisons `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne faisons pas cela, l'évaluation va soit se tromper, soit se bloquer pour toujours.
-
-```py
-from tqdm.auto import tqdm
-import torch
-
-progress_bar = tqdm(range(num_training_steps))
-
-for epoch in range(num_train_epochs):
- # Entraînement
- model.train()
- for batch in train_dataloader:
- outputs = model(**batch)
- loss = outputs.loss
- accelerator.backward(loss)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
-
- # Evaluation
- model.eval()
- for batch in tqdm(eval_dataloader):
- with torch.no_grad():
- generated_tokens = accelerator.unwrap_model(model).generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- max_length=128,
- )
- labels = batch["labels"]
-
- # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
- generated_tokens = accelerator.pad_across_processes(
- generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
- )
- labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
-
- predictions_gathered = accelerator.gather(generated_tokens)
- labels_gathered = accelerator.gather(labels)
-
- decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
- metric.add_batch(predictions=decoded_preds, references=decoded_labels)
-
- results = metric.compute()
- print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
-
- # Sauvegarder et télécharger
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False
- )
-```
-
-```python out
-epoch 0, BLEU score: 53.47
-epoch 1, BLEU score: 54.24
-epoch 2, BLEU score: 54.44
-```
-
-Une fois que c'est fait, vous devriez avoir un modèle qui a des résultats assez similaires à celui entraîné avec `Seq2SeqTrainer`. Vous pouvez vérifier celui que nous avons entraîné en utilisant ce code sur [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les mettre en œuvre directement en modifiant le code ci-dessus !
-
-{/if}
-
-### Utilisation du modèle finetuné
-
-Nous vous avons déjà montré comment vous pouvez utiliser le modèle que nous avons *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, nous devons juste spécifier l'identifiant de modèle approprié :
-
-```py
-from transformers import pipeline
-
-# Remplacez ceci par votre propre checkpoint
-model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
-translator = pipeline("translation", model=model_checkpoint)
-translator("Default to expanded threads")
-```
-
-```python out
-[{'translation_text': 'Par défaut, développer les fils de discussion'}]
-```
-
-Comme prévu, notre modèle pré-entraîné a adapté ses connaissances au corpus sur lequel nous l'avons *finetuné*. Et au lieu de laisser le mot anglais « *threads* », le modèle le traduit maintenant par la version française officielle. Il en va de même pour « *plugin* » :
-
-```py
-translator(
- "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
-)
-```
-
-```python out
-[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
-```
-
-Un autre excellent exemple d'adaptation au domaine !
-
-
-
-✏️ **A votre tour !** Que retourne le modèle sur l'échantillon avec le mot « *email* » que vous avez identifié plus tôt ?
-
-
+
+
+# Traduction
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Plongeons maintenant dans la traduction. Il s'agit d'une autre [tâche de séquence à séquence](/course/fr/chapitre1/7), ce qui signifie que c'est un problème qui peut être formulé comme le passage d'une séquence à une autre. En ce sens, le problème est assez proche de la tâche de [résumé](/course/fr/chapitre7/6) et vous pouvez adapter ce que nous allons voir ici à d'autres problèmes de séquence à séquence tels que :
+
+- Le **transfert de style** ? c'est-à-dire créer un modèle qui *traduit* des textes écrits dans un certain style vers un autre (par exemple, du formel au décontracté ou de l'anglais shakespearien à l'anglais moderne).
+- La **génération de réponse à des questions** c'est-à-dire créer un modèle qui génère des réponses à des questions compte tenu d'un contexte.
+
+
+
+Si vous disposez d'un corpus de textes suffisamment important en deux langues différentes (ou plus), vous pouvez entraîner un nouveau modèle de traduction à partir de zéro, comme nous le ferons dans la section sur la [modélisation causale du langage](/course/fr/chapitre7/6). Il est toutefois plus rapide de *finetuner* un modèle de traduction existant, qu'il s'agisse d'un modèle multilingue comme mT5 ou mBART que vous souhaitez adapter à une paire de langues spécifique, ou même d'un modèle spécialisé dans la traduction d'une langue vers une autre que vous souhaitez adapter à votre corpus spécifique.
+
+Dans cette section, nous allons *finetuner* un modèle Marian pré-entraîné pour traduire de l'anglais au français (puisque de nombreux employés de Hugging Face parlent ces deux langues) sur le jeu de données [KDE4](https://huggingface.co/datasets/kde4) qui est un jeu de données de fichiers localisés pour les applications [KDE](https://apps.kde.org/). Le modèle que nous utiliserons a été pré-entraîné sur un large corpus de textes français et anglais provenant du jeu de données [Opus](https://opus.nlpl.eu/) qui contient en fait le jeu de données KDE4. A noter que même si le modèle pré-entraîné que nous utilisons a vu ces données pendant son pré-entraînement, nous verrons que nous pouvons obtenir une meilleure version de ce modèle après un *finetuning*.
+
+Une fois que nous aurons terminé, nous aurons un modèle capable de faire des prédictions comme celle-ci :
+
+
+
+
+
+
+
+
+
+Comme dans les sections précédentes, vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le [*Hub*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## Préparation des données
+
+Pour *finetuner* ou entraîner un modèle de traduction à partir de zéro, nous avons besoin d'un jeu de données adapté à cette tâche. Comme mentionné précédemment, nous utiliserons le jeu de données [KDE4](https://huggingface.co/datasets/kde4) dans cette section. Notez que vous pouvez adapter assez facilement le code pour utiliser vos propres données du moment que vous disposez de paires de phrases dans les deux langues que vous voulez traduire. Reportez-vous au [chapitre 5](/course/fr/chapter5) si vous avez besoin d'un rappel sur la façon de charger vos données personnalisées dans un `Dataset`.
+
+### Le jeu de données KDE4
+
+Comme d'habitude, nous téléchargeons notre jeu de données en utilisant la fonction `load_dataset()` :
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+Si vous souhaitez travailler avec une autre paire de langues, 92 langues sont disponibles au total pour ce jeu de données. Vous pouvez les voir dans la [carte du jeu de données](https://huggingface.co/datasets/kde4).
+
+
+
+Jetons un coup d'œil au jeu de données :
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+Nous avons 210 173 paires de phrases. Cependant regroupées dans un seul échantillon. Nous devrons donc créer notre propre jeu de validation. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), un `Dataset` possède une méthode `train_test_split()` qui peut nous aider. Nous allons fournir une graine pour la reproductibilité :
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+Nous pouvons renommer la clé `test` en `validation` comme ceci :
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Examinons maintenant un élément de ce jeu de données :
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+Nous obtenons un dictionnaire contenant deux phrases dans la paire de langues qui nous intéresse.
+Une particularité de ce jeu de données rempli de termes techniques informatiques est qu'ils sont tous entièrement traduits en français. Cependant, les ingénieurs français sont souvent paresseux et laissent la plupart des mots spécifiques à l'informatique en anglais lorsqu'ils parlent. Ici, par exemple, le mot « *threads* » pourrait très bien apparaître dans une phrase française, surtout dans une conversation technique. Mais dans ce jeu de données, il a été traduit en « fils de discussion ». Le modèle pré-entraîné que nous utilisons (qui a été pré-entraîné sur un plus grand corpus de phrases françaises et anglaises) prend l'option de laisser le mot tel quel :
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Un autre exemple de ce comportement peut être observé avec le mot « *plugin* » qui n'est pas officiellement un mot français mais que la plupart des francophones comprendront et ne prendront pas la peine de traduire.
+Dans le jeu de données KDE4, ce mot a été traduit en français par le plus officiel « module d'extension » :
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Notre modèle pré-entraîné, lui, s'en tient au mot anglais :
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Il sera intéressant de voir si notre modèle *finetuné* tient compte de ces particularités (alerte *spoiler* : il le fera).
+
+
+
+
+
+✏️ **A votre tour !** Un autre mot anglais souvent utilisé en français est « *email* ». Trouvez le premier échantillon dans l'échantillon d'entraînement qui utilise ce mot. Comment est-il traduit ? Comment le modèle pré-entraîné traduit-il cette même phrase ?
+
+
+
+### Traitement des données
+
+
+
+Vous devriez maintenant connaître le principe : les textes doivent tous être convertis en ensembles d'ID de *tokens* pour que le modèle puisse leur donner un sens. Pour cette tâche, nous aurons besoin de tokeniser les entrées et les cibles. Notre première tâche est de créer notre objet `tokenizer`. Comme indiqué précédemment, nous utiliserons un modèle pré-entraîné Marian English to French. Si vous essayez ce code avec une autre paire de langues, assurez-vous d'adapter le *checkpoint* du modèle. L'organisation [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) fournit plus de mille modèles dans plusieurs langues.
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="tf")
+```
+
+Vous pouvez remplacer le `model_checkpoint` par un tout autre modèle disponible sur le [*Hub*](https://huggingface.co/models) qui aurait votre préférence, ou par un dossier en local où vous avez sauvegardé un modèle pré-entraîné et un *tokenizer*.
+
+
+
+💡 Si vous utilisez un *tokenizer* multilingue tel que mBART, mBART-50 ou M2M100, vous devrez définir les codes de langue de vos entrées et cibles dans le *tokenizer* en définissant `tokenizer.src_lang` et `tokenizer.tgt_lang` aux bonnes valeurs.
+
+
+
+La préparation de nos données est assez simple. Il y a juste une chose à retenir : vous traitez les entrées comme d'habitude, mais pour les cibles, vous devez envelopper le *tokenizer* dans le gestionnaire de contexte `as_target_tokenizer()`.
+
+Un gestionnaire de contexte en Python est introduit avec l'instruction `with` et est utile lorsque vous avez deux opérations liées à exécuter en paire. L'exemple le plus courant est lorsque vous écrivez ou lisez un fichier, ce qui est souvent fait dans une instruction comme :
+
+```
+with open(file_path) as f:
+ content = f.read()
+```
+
+Ici, les deux opérations connexes qui sont exécutées en paire sont les actions d'ouverture et de fermeture du fichier. L'objet correspondant au fichier ouvert `f` n'existe qu'à l'intérieur du bloc indenté sous le `with`. L'ouverture se produit avant ce bloc et la fermeture à la fin du bloc.
+
+Dans le cas présent, le gestionnaire de contexte `as_target_tokenizer()` va définir le *tokenizer* dans la langue de sortie (ici, le français) avant l'exécution du bloc indenté, puis le redéfinir dans la langue d'entrée (ici, l'anglais).
+
+Ainsi, le prétraitement d'un échantillon ressemble à ceci :
+
+```python
+en_sentence = split_datasets["train"][1]["translation"]["en"]
+fr_sentence = split_datasets["train"][1]["translation"]["fr"]
+
+inputs = tokenizer(en_sentence)
+with tokenizer.as_target_tokenizer():
+ targets = tokenizer(fr_sentence)
+```
+
+Si nous oublions de tokeniser les cibles dans le gestionnaire de contexte, elles seront tokenisées par le *tokenizer* d'entrée, ce qui dans le cas d'un modèle Marian, ne va pas du tout bien se passer :
+
+```python
+wrong_targets = tokenizer(fr_sentence)
+print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
+print(tokenizer.convert_ids_to_tokens(targets["input_ids"]))
+```
+
+```python out
+['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
+['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
+```
+
+Comme on peut le voir, utiliser le *tokenizer* anglais pour prétraiter une phrase française donne un batch de *tokens* plus important, puisque le *tokenizer* ne connaît aucun mot français (sauf ceux qui apparaissent aussi en anglais, comme « discussion »).
+
+Les `inputs` et les `targets` sont des dictionnaires avec nos clés habituelles (identifiants d'entrée, masque d'attention, etc.). La dernière étape est de définir une clé `"labels"` dans les entrées. Nous faisons cela dans la fonction de prétraitement que nous allons appliquer sur les jeux de données :
+
+```python
+max_input_length = 128
+max_target_length = 128
+
+
+def preprocess_function(examples):
+ inputs = [ex["en"] for ex in examples["translation"]]
+ targets = [ex["fr"] for ex in examples["translation"]]
+ model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
+
+ # Configurer le tokenizer pour les cibles.
+ with tokenizer.as_target_tokenizer():
+ labels = tokenizer(targets, max_length=max_target_length, truncation=True)
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+```
+
+Notez que nous avons fixé des longueurs maximales similaires pour nos entrées et nos sorties. Comme les textes que nous traitons semblent assez courts, nous utilisons 128.
+
+
+
+💡 Si vous utilisez un modèle T5 (plus précisément, un des *checkpoints* `t5-xxx`), le modèle s'attendra à ce que les entrées aient un préfixe indiquant la tâche à accomplir, comme `translate: English to French:`.
+
+
+
+
+
+⚠️ Nous ne faisons pas attention au masque d'attention des cibles car le modèle ne s'y attend pas. Au lieu de cela, les étiquettes correspondant à un *token* de *padding* doivent être mises à `-100` afin qu'elles soient ignorées dans le calcul de la perte. Cela sera fait par notre collateur de données plus tard puisque nous appliquons le *padding* dynamique, mais si vous utilisez le *padding* ici, vous devriez adapter la fonction de prétraitement pour mettre toutes les étiquettes qui correspondent au *token* de *padding* à `-100`.
+
+
+
+Nous pouvons maintenant appliquer ce prétraitement en une seule fois sur toutes les échantillons de notre jeu de données :
+
+```py
+tokenized_datasets = split_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=split_datasets["train"].column_names,
+)
+```
+
+Maintenant que les données ont été prétraitées, nous sommes prêts à *finetuner* notre modèle pré-entraîné !
+
+{#if fw === 'pt'}
+
+## Finetuner le modèle avec l'API `Trainer`
+
+Le code actuel utilisant `Trainer` sera le même que précédemment, avec juste un petit changement : nous utilisons ici [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) qui est une sous-classe de `Trainer` qui nous permet de traiter correctement l'évaluation, en utilisant la méthode `generate()` pour prédire les sorties à partir des entrées. Nous y reviendrons plus en détail lorsque nous parlerons du calcul de la métrique.
+
+Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## Finetuner du modèle avec Keras
+
+Tout d'abord, nous avons besoin d'un modèle à *finetuner*. Nous allons utiliser l'API habituelle `AutoModel` :
+
+```py
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
+```
+
+
+
+💡 Le *checkpoint* `Helsinki-NLP/opus-mt-en-fr` ne dispose que de poids PyTorch, vous aurez donc une erreur si vous essayez de charger le modèle sans utiliser l'argument `from_pt=True` dans la méthode `from_pretrained()`. Lorsque vous spécifiez `from_pt=True`, la bibliothèque téléchargera et convertira automatiquement les poids PyTorch pour vous. Comme vous pouvez le constater, c'est très simple de passer d'un *framework* à l'autre dans 🤗 *Transformers* !
+
+
+
+{/if}
+
+Notez que cette fois-ci, nous utilisons un modèle qui a été entraîné sur une tâche de traduction et qui peut déjà être utilisé, donc il n'y a pas d'avertissement concernant les poids manquants ou ceux nouvellement initialisés.
+
+### Collecte des données
+
+Nous aurons besoin d'un assembleur de données pour gérer le rembourrage pour la mise en batchs dynamique. Ici, nous ne pouvons pas simplement utiliser un `DataCollatorWithPadding` comme dans le [chapitre 3](/course/fr/chapter3) car cela ne rembourre que les entrées (identifiants d'entrée, masque d'attention, et *token* de type identifiants). Nos étiquettes doivent également être rembourrées à la longueur maximale rencontrée dans les étiquettes. Et, comme mentionné précédemment, la valeur de remplissage utilisée pour remplir les étiquettes doit être `-100` et non le *token* de *padding* du *tokenizer* afin de s'assurer que ces valeurs soient ignorées dans le calcul de la perte.
+
+Tout ceci est réalisé par un [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Comme le `DataCollatorWithPadding`, il prend le `tokenizer` utilisé pour prétraiter les entrées, mais également le `model`. C'est parce que ce collateur de données est également responsable de la préparation des identifiants d'entrée du décodeur, qui sont des versions décalées des étiquettes avec un *token* spécial au début. Comme ce décalage est effectué de manière légèrement différente selon les architectures, le `DataCollatorForSeq2Seq` a besoin de connaître l'objet `model` :
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+Pour le tester sur quelques échantillons, nous l'appelons simplement sur une liste d'exemples de notre échantillon d'entrainement tokénisé :
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
+batch.keys()
+```
+
+```python out
+dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
+```
+
+Nous pouvons vérifier que nos étiquettes ont été rembourrées à la longueur maximale du batch, en utilisant `-100` :
+
+```py
+batch["labels"]
+```
+
+```python out
+tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
+ -100, -100, -100, -100, -100, -100],
+ [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
+ 550, 7032, 5821, 7907, 12649, 0]])
+```
+
+Nous pouvons aussi jeter un coup d'œil aux identifiants d'entrée du décodeur, pour voir qu'il s'agit de versions décalées des étiquettes :
+
+```py
+batch["decoder_input_ids"]
+```
+
+```python out
+tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
+ 59513, 59513, 59513, 59513, 59513, 59513],
+ [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
+ 817, 550, 7032, 5821, 7907, 12649]])
+```
+
+Voici les étiquettes des premier et deuxième éléments de notre jeu de données :
+
+```py
+for i in range(1, 3):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
+[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
+```
+
+{#if fw === 'pt'}
+
+Nous allons transmettre ce `data_collator` au `Seq2SeqTrainer`. Ensuite, jetons un coup d'oeil à la métrique.
+
+{:else}
+
+Nous pouvons maintenant utiliser ce `data_collator` pour convertir chacun de nos jeux de données en un `tf.data.Dataset`, prêt pour l'entraînement :
+
+```python
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+{/if}
+
+
+### Métriques
+
+
+
+{#if fw === 'pt'}
+
+La fonctionnalité que `Seq2SeqTrainer` ajoute à sa superclasse `Trainer` est la possibilité d'utiliser la méthode `generate()` pendant l'évaluation ou la prédiction. Pendant l'entraînement, le modèle utilisera les `decoder_input_ids` avec un masque d'attention assurant qu'il n'utilise pas les *tokens* après le *token* qu'il essaie de prédire, pour accélérer l'entraînement. Pendant l'inférence, nous ne pourrons pas les utiliser puisque nous n'aurons pas d'étiquettes. Ainsi c'est une bonne idée d'évaluer notre modèle avec la même configuration.
+
+Comme nous l'avons vu dans le [chapitre 1](/course/fr/chapter1/6), le décodeur effectue l'inférence en prédisant les *tokens* un par un. C'est quelque chose qui est implémenté en coulisses dans 🤗 *Transformers* par la méthode `generate()`. Le `Seq2SeqTrainer` nous laissera utiliser cette méthode pour l'évaluation si nous indiquons `predict_with_generate=True`.
+
+{/if}
+
+La métrique traditionnelle utilisée pour la traduction est le [score BLEU](https://en.wikipedia.org/wiki/BLEU), introduit dans [un article de 2002](https://aclanthology.org/P02-1040.pdf) par Kishore Papineni et al. Le score BLEU évalue dans quelle mesure les traductions sont proches de leurs étiquettes. Il ne mesure pas l'intelligibilité ou l'exactitude grammaticale des résultats générés par le modèle, mais utilise des règles statistiques pour garantir que tous les mots des résultats générés apparaissent également dans les cibles. En outre, il existe des règles qui pénalisent les répétitions des mêmes mots s'ils ne sont pas également répétés dans les cibles (pour éviter que le modèle ne produise des phrases telles que « the the the the the the the ») et les phrases produites qui sont plus courtes que celles des cibles (pour éviter que le modèle ne produise des phrases telles que « the »).
+
+L'une des faiblesses de BLEU est qu'il s'attend à ce que le texte soit déjà tokenisé, ce qui rend difficile la comparaison des scores entre les modèles qui utilisent différents *tokenizers*. Par conséquent, la mesure la plus couramment utilisée aujourd'hui pour évaluer les modèles de traduction est [SacreBLEU](https://github.com/mjpost/sacrebleu) qui remédie à cette faiblesse (et à d'autres) en standardisant l'étape de tokenisation. Pour utiliser cette métrique, nous devons d'abord installer la bibliothèque *SacreBLEU* :
+
+```py
+!pip install sacrebleu
+```
+
+Nous pouvons ensuite charger ce score via `evaluate.load()` comme nous l'avons fait dans le [chapitre 3](/course/fr/chapter3) :
+
+```py
+import evaluate
+
+metric = evaluate.load("sacrebleu")
+```
+
+Cette métrique prend des textes comme entrées et cibles. Elle est conçue pour accepter plusieurs cibles acceptables car il y a souvent plusieurs traductions possibles d'une même phrase. Le jeu de données que nous utilisons n'en fournit qu'une seule, mais en NLP, il n'est pas rare de trouver des jeux de données ayant plusieurs phrases comme étiquettes. Ainsi, les prédictions doivent être une liste de phrases mais les références doivent être une liste de listes de phrases.
+
+Essayons un exemple :
+
+```py
+predictions = [
+ "This plugin lets you translate web pages between several languages automatically."
+]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 46.750469682990165,
+ 'counts': [11, 6, 4, 3],
+ 'totals': [12, 11, 10, 9],
+ 'precisions': [91.67, 54.54, 40.0, 33.33],
+ 'bp': 0.9200444146293233,
+ 'sys_len': 12,
+ 'ref_len': 13}
+```
+
+Cela donne un score BLEU de 46.75, ce qui est plutôt bon. A titre de comparaison, le *Transformer* original dans l'article [*Attention Is All You Need*](https://arxiv.org/pdf/1706.03762.pdf) a obtenu un score BLEU de 41.8 sur une tâche de traduction similaire entre l'anglais et le français ! (Pour plus d'informations sur les métriques individuelles, comme `counts` et `bp`, voir le [dépôt SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74). D'autre part, si nous essayons avec les deux mauvais types de prédictions (répétitions ou prédiction trop courte) qui sortent souvent des modèles de traduction, nous obtiendrons des scores BLEU plutôt mauvais :
+
+```py
+predictions = ["This This This This"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 1.683602693167689,
+ 'counts': [1, 0, 0, 0],
+ 'totals': [4, 3, 2, 1],
+ 'precisions': [25.0, 16.67, 12.5, 12.5],
+ 'bp': 0.10539922456186433,
+ 'sys_len': 4,
+ 'ref_len': 13}
+```
+
+```py
+predictions = ["This plugin"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 0.0,
+ 'counts': [2, 1, 0, 0],
+ 'totals': [2, 1, 0, 0],
+ 'precisions': [100.0, 100.0, 0.0, 0.0],
+ 'bp': 0.004086771438464067,
+ 'sys_len': 2,
+ 'ref_len': 13}
+```
+
+Le score peut aller de 0 à 100. Plus il est élevé, mieux c'est.
+
+{#if fw === 'tf'}
+
+Pour passer des sorties du modèle aux textes que la métrique peut utiliser, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding*. Définissons une fonction qui prend notre modèle et un jeu de données et calcule des métriques sur ceux-ci. Comme la génération de longues séquences peut être lente, nous sous-échantillonnons l'ensemble de validation pour nous assurer que cela ne prend pas une éternité :
+
+```py
+import numpy as np
+
+
+def compute_metrics():
+ all_preds = []
+ all_labels = []
+ sampled_dataset = tokenized_datasets["validation"].shuffle().select(range(200))
+ tf_generate_dataset = sampled_dataset.to_tf_dataset(
+ columns=["input_ids", "attention_mask", "labels"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=4,
+ )
+ for batch in tf_generate_dataset:
+ predictions = model.generate(
+ input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
+ )
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = batch["labels"].numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+
+ result = metric.compute(predictions=all_preds, references=all_labels)
+ return {"bleu": result["score"]}
+```
+
+{:else}
+
+Pour passer des sorties du modèle aux textes utilisables par la métrique, nous allons utiliser la méthode `tokenizer.batch_decode()`. Nous devons juste nettoyer tous les `-100` dans les étiquettes. Le *tokenizer* fera automatiquement la même chose pour le *token* de *padding* :
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # Dans le cas où le modèle retourne plus que les logits de prédiction
+ if isinstance(preds, tuple):
+ preds = preds[0]
+
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Remplacer les -100 dans les étiquettes car nous ne pouvons pas les décoder
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Quelques post-traitements simples
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": result["score"]}
+```
+
+{/if}
+
+Maintenant que c'est fait, nous sommes prêts à *finetuner* notre modèle !
+
+
+### Finetuner le modèle
+
+La première étape consiste à se connecter à Hugging Face, afin de pouvoir télécharger vos résultats sur le *Hub*. Il y a une fonction pratique pour vous aider à le faire dans un *notebook* :
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Cela affichera un *widget* où vous pourrez entrer vos identifiants de connexion à Hugging Face.
+
+Si vous ne travaillez pas dans un *notebook*, tapez simplement la ligne suivante dans votre terminal :
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'tf'}
+
+Avant de commencer, voyons quel type de résultats nous obtenons avec notre modèle sans entraînement :
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 33.26983701454733}
+```
+
+Une fois ceci fait, nous pouvons préparer tout ce dont nous avons besoin pour compiler et entraîner notre modèle. Notez l'utilisation de `tf.keras.mixed_precision.set_global_policy("mixed_float16")`. Ceci indiquera à Keras de s'entraîner en utilisant float16, ce qui peut donner un gain de vitesse significatif sur les GPUs qui le supportent (Nvidia 20xx/V100 ou plus récent).
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# Le nombre d'étapes d'entraînement est le nombre d'échantillons dans le jeu de données, divisé par la taille du batch,
+# puis multiplié par le nombre total d'époques. Notez que le jeu de données tf_train_dataset est ici un tf.data.Dataset,
+# et non le jeu de données original donc son len() est déjà num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Entraîner en mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+Ensuite, nous définissons un `PushToHubCallback` pour télécharger notre modèle sur le *Hub* pendant l'entraînement, comme nous l'avons vu dans la [section 2](/course/fr/chapter7/2), puis nous entraînons simplement le modèle avec ce *callback* :
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser le modèle avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` dans `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé après le répertoire de sortie que vous avez défini. Ici ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de l'appel de `model.fit()` et devrez définir un nouveau nom.
+
+
+
+Enfin, voyons à quoi ressemblent nos métriques maintenant que l'entraînement est terminé :
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 57.334066271545865}
+```
+
+À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
+
+{:else}
+
+Une fois ceci fait, nous pouvons définir notre `Seq2SeqTrainingArguments`. Comme pour le `Trainer`, nous utilisons une sous-classe de `TrainingArguments` qui contient quelques champs supplémentaires :
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+args = Seq2SeqTrainingArguments(
+ f"marian-finetuned-kde4-en-to-fr",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=64,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=3,
+ predict_with_generate=True,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+En dehors des hyperparamètres habituels (comme le taux d'apprentissage, le nombre d'époques, la taille des batchs et une le taux de décroissance des poids), voici quelques changements par rapport à ce que nous avons vu dans les sections précédentes :
+
+- Nous ne définissons pas d'évaluation car elle prend du temps. Nous allons juste évaluer une fois notre modèle avant l'entraînement et après.
+- Nous avons mis `fp16=True`, ce qui accélère l'entraînement sur les GPUs modernes.
+- Nous définissons `predict_with_generate=True`, comme discuté ci-dessus.
+- Nous utilisons `push_to_hub=True` pour télécharger le modèle sur le *Hub* à la fin de chaque époque.
+
+Notez que vous pouvez spécifier le nom complet du dépôt vers lequel vous voulez pousser avec l'argument `hub_model_id` (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l'organisation [`huggingface-course`](https://huggingface.co/huggingface-course), nous avons ajouté `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` à `Seq2SeqTrainingArguments`. Par défaut, le dépôt utilisé sera dans votre espace et nommé d'après le répertoire de sortie que vous avez défini. Dans notre cas ce sera `"sgugger/marian-finetuned-kde4-en-to-fr"` (qui est le modèle que nous avons lié au début de cette section).
+
+
+
+💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S'il ne l'est pas, vous obtiendrez une erreur lors de la définition de votre `Seq2SeqTrainer` et devrez définir un nouveau nom.
+
+
+
+
+Enfin, nous passons tout au `Seq2SeqTrainer` :
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+Avant d'entraîner, nous allons d'abord regarder le score obtenu par notre modèle, pour vérifier que nous n'aggravons pas les choses avec notre *finetuning*. Cette commande va prendre un peu de temps, vous pouvez donc prendre un café pendant qu'elle s'exécute :
+
+```python
+trainer.evaluate(max_length=max_target_length)
+```
+
+```python out
+{'eval_loss': 1.6964408159255981,
+ 'eval_bleu': 39.26865061007616,
+ 'eval_runtime': 965.8884,
+ 'eval_samples_per_second': 21.76,
+ 'eval_steps_per_second': 0.341}
+```
+
+Un score BLEU de 39 n'est pas trop mauvais, ce qui reflète le fait que notre modèle est déjà bon pour traduire des phrases anglaises en phrases françaises.
+
+Vient ensuite l'entraînement, qui prendra également un peu de temps :
+
+```python
+trainer.train()
+```
+
+Notez que pendant l'entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le *Hub* en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
+
+Une fois l'entraînement terminé, nous évaluons à nouveau notre modèle. Avec un peu de chance, nous verrons une amélioration du score BLEU !
+
+```py
+trainer.evaluate(max_length=max_target_length)
+```
+
+```python out
+{'eval_loss': 0.8558505773544312,
+ 'eval_bleu': 52.94161337775576,
+ 'eval_runtime': 714.2576,
+ 'eval_samples_per_second': 29.426,
+ 'eval_steps_per_second': 0.461,
+ 'epoch': 3.0}
+```
+
+C'est une amélioration de près de 14 points, ce qui est formidable.
+
+Enfin, nous utilisons la méthode `push_to_hub()` pour nous assurer que nous téléchargeons la dernière version du modèle. `Trainer` rédige également une carte de modèle avec tous les résultats de l'évaluation et la télécharge. Cette carte de modèle contient des métadonnées qui aident le *Hub* à choisir le *widget* pour l'inférence. Habituellement, il n'y a pas besoin de dire quoi que ce soit car il peut inférer le bon *widget* à partir de la classe du modèle, mais dans ce cas, la même classe de modèle peut être utilisée pour toutes sortes de problèmes de séquence à séquence. Ainsi nous spécifions que c'est un modèle de traduction :
+
+```py
+trainer.push_to_hub(tags="translation", commit_message="Training complete")
+```
+
+Cette commande renvoie l'URL du commit qu'elle vient de faire, si vous voulez l'inspecter :
+
+```python out
+'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
+```
+
+À ce stade, vous pouvez utiliser le *widget* d'inférence sur le *Hub* pour tester votre modèle et le partager avec vos amis. Vous avez réussi à *finetuner* un modèle sur une tâche de traduction. Félicitations !
+
+Si vous souhaitez vous plonger un peu plus profondément dans la boucle d'entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 *Accelerate*.
+
+{/if}
+
+{#if fw === 'pt'}
+
+## Une boucle d'entraînement personnalisée
+
+Jetons maintenant un coup d'œil à la boucle d'entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans la [section 2](/course/fr/chapter7/2) et dans le [chapitre 3](/course/fr/chapter3/4).
+
+### Préparer le tout pour l'entraînement
+
+Vous avez vu tout cela plusieurs fois maintenant, donc nous allons passer en revue le code assez rapidement. D'abord, nous allons construire le `DataLoader` à partir de nos jeux de données, après avoir configuré les jeux de données au format `"torch"` pour obtenir les tenseurs PyTorch :
+
+```py
+from torch.utils.data import DataLoader
+
+tokenized_datasets.set_format("torch")
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne poursuivons pas le *finetuning* précédent et que nous repartons du modèle pré-entraîné :
+
+```py
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+Nous aurons alors besoin d'un optimiseur :
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode `accelerator.prepare()`. Rappelez-vous que si vous voulez entraîner sur des TPUs dans un *notebook* de Colab, vous devez déplacer tout ce code dans une fonction d'entraînement et ne devrait pas exécuter une cellule qui instancie un `Accelerator`.
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Maintenant que nous avons envoyé notre `train_dataloader` à `accelerator.prepare()`, nous pouvons utiliser sa longueur pour calculer le nombre d'étapes d'entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le chargeur de données car cette méthode va changer la longueur du `DataLoader`. Nous utilisons un programme linéaire classique du taux d'apprentissage à 0 :
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Enfin, pour pousser notre modèle vers le *Hub*, nous aurons besoin de créer un objet `Repository` dans un dossier de travail. Tout d'abord, connectez-vous au *Hub* si vous n'êtes pas déjà connecté. Nous déterminerons le nom du dépôt à partir de l'identifiant du modèle que nous voulons donner à notre modèle (n'hésitez pas à remplacer le `repo_name` par votre propre choix, il doit juste contenir votre nom d'utilisateur, ce que fait la fonction `get_full_repo_name()`) :
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
+```
+
+Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S'il existe déjà, ce dossier local doit être un clone du dépôt avec lequel nous travaillons :
+
+```py
+output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans `output_dir` en appelant la méthode `repo.push_to_hub()`. Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
+
+### Boucle d'entraînement
+
+Nous sommes maintenant prêts à écrire la boucle d'entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction `postprocess()` qui prend les prédictions et les étiquettes et les convertit en listes de chaînes de caractères que notre objet `metric` attend :
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+
+ # Remplace -100 dans les étiquettes car nous ne pouvons pas les décoder
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Quelques post-traitements simples
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ return decoded_preds, decoded_labels
+```
+
+La boucle d'entraînement ressemble beaucoup à celles de la [section 2](/course/fr/chapter7/2) et du [chapitre 3](/course/fr/chapter3), avec quelques différences dans la partie évaluation. Donc concentrons-nous sur cela !
+
+La première chose à noter est que nous utilisons la méthode `generate()` pour calculer les prédictions. C'est une méthode sur notre modèle de base et non pas le modèle enveloppé créé dans la méthode `prepare()`. C'est pourquoi nous déballons d'abord le modèle, puis nous appelons cette méthode.
+
+La deuxième chose est que, comme avec la classification de [*token*](/course/fr/chapter7/2), deux processus peuvent avoir rembourrés les entrées et les étiquettes à des formes différentes. Ainsi nous utilisons `accelerator.pad_across_processes()` pour rendre les prédictions et les étiquettes de la même forme avant d'appeler la méthode `gather()`. Si nous ne faisons pas cela, l'évaluation va soit se tromper, soit se bloquer pour toujours.
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Entraînement
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_length=128,
+ )
+ labels = batch["labels"]
+
+ # Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(generated_tokens)
+ labels_gathered = accelerator.gather(labels)
+
+ decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ results = metric.compute()
+ print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
+
+ # Sauvegarder et télécharger
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+epoch 0, BLEU score: 53.47
+epoch 1, BLEU score: 54.24
+epoch 2, BLEU score: 54.44
+```
+
+Une fois que c'est fait, vous devriez avoir un modèle qui a des résultats assez similaires à celui entraîné avec `Seq2SeqTrainer`. Vous pouvez vérifier celui que nous avons entraîné en utilisant ce code sur [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). Et si vous voulez tester des modifications de la boucle d'entraînement, vous pouvez les mettre en œuvre directement en modifiant le code ci-dessus !
+
+{/if}
+
+### Utilisation du modèle finetuné
+
+Nous vous avons déjà montré comment vous pouvez utiliser le modèle que nous avons *finetuné* sur le *Hub* avec le *widget* d'inférence. Pour l'utiliser localement dans un `pipeline`, nous devons juste spécifier l'identifiant de modèle approprié :
+
+```py
+from transformers import pipeline
+
+# Remplacez ceci par votre propre checkpoint
+model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut, développer les fils de discussion'}]
+```
+
+Comme prévu, notre modèle pré-entraîné a adapté ses connaissances au corpus sur lequel nous l'avons *finetuné*. Et au lieu de laisser le mot anglais « *threads* », le modèle le traduit maintenant par la version française officielle. Il en va de même pour « *plugin* » :
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Un autre excellent exemple d'adaptation au domaine !
+
+
+
+✏️ **A votre tour !** Que retourne le modèle sur l'échantillon avec le mot « *email* » que vous avez identifié plus tôt ?
+
+
diff --git a/chapters/fr/chapter7/5.mdx b/chapters/fr/chapter7/5.mdx
index c2177fb07..d2d570667 100644
--- a/chapters/fr/chapter7/5.mdx
+++ b/chapters/fr/chapter7/5.mdx
@@ -1,1083 +1,1083 @@
-
-
-# Résumé de textes
-
-{#if fw === 'pt'}
-
-
-
-{:else}
-
-
-
-{/if}
-
-
-Dans cette section, nous allons voir comment les *transformers* peuvent être utilisés pour condenser de longs documents en résumés, une tâche connue sous le nom de _résumé de texte_. Il s'agit de l'une des tâches de NLP les plus difficiles car elle requiert une série de capacités, telles que la compréhension de longs passages et la génération d'un texte cohérent qui capture les sujets principaux d'un document. Cependant, lorsqu'il est bien fait, le résumé de texte est un outil puissant qui peut accélérer divers processus commerciaux en soulageant les experts du domaine de la lecture détaillée de longs documents.
-
-
-
-Bien qu'il existe déjà plusieurs modèles *finetunés* pour le résumé sur le [*Hub*](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads), la plupart d'entre eux ne sont adaptés qu'aux documents en anglais. Ainsi, pour ajouter une touche d'originalité à cette section, nous allons entraîner un modèle bilingue pour l'anglais et l'espagnol. À la fin de cette section, vous disposerez d'un [modèle](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) capable de résumer les commentaires des clients comme celui présenté ici :
-
-
-
-
-Comme nous allons le voir, ces résumés sont concis car ils sont appris à partir des titres que les clients fournissent dans leurs commentaires sur les produits. Commençons par constituer un corpus bilingue approprié pour cette tâche.
-
-## Préparation d'un corpus multilingue
-
-Nous allons utiliser le [*Multilingual Amazon Reviews Corpus*](https://huggingface.co/datasets/amazon_reviews_multi) pour créer notre résumeur bilingue. Ce corpus est constitué de critiques de produits Amazon en six langues et est généralement utilisé pour évaluer les classifieurs multilingues. Cependant, comme chaque critique est accompagnée d'un titre court, nous pouvons utiliser les titres comme résumés cibles pour l'apprentissage de notre modèle ! Pour commencer, téléchargeons les sous-ensembles anglais et espagnols depuis le *Hub* :
-
-```python
-from datasets import load_dataset
-
-spanish_dataset = load_dataset("amazon_reviews_multi", "es")
-english_dataset = load_dataset("amazon_reviews_multi", "en")
-english_dataset
-```
-
-```python out
-DatasetDict({
- train: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 200000
- })
- validation: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 5000
- })
- test: Dataset({
- features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
- num_rows: 5000
- })
-})
-```
-
-Comme vous pouvez le voir, pour chaque langue, il y a 200 000 critiques pour la partie entraînement et 5 000 critiques pour chacune des parties validation et test. Les informations qui nous intéressent sont contenues dans les colonnes `review_body` et `review_title`. Voyons quelques exemples en créant une fonction simple qui prend un échantillon aléatoire de l'ensemble d'entraînement avec les techniques apprises au [chapitre 5](/course/fr/chapter5) :
-
-```python
-def show_samples(dataset, num_samples=3, seed=42):
- sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
- for example in sample:
- print(f"\n'>> Title: {example['review_title']}'")
- print(f"'>> Review: {example['review_body']}'")
-
-
-show_samples(english_dataset)
-```
-
-```python out
-'>> Title: Worked in front position, not rear'
-# Travaillé en position avant, pas arrière
-'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
-# 3 étoiles car ce ne sont pas des freins arrière comme indiqué dans la description de l'article. Au moins, l'adaptateur de montage ne fonctionnait que sur la fourche avant du vélo pour lequel je l'ai acheté.
-
-'>> Title: meh'
-'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
-# Il fait son travail et il est magnifique mais le mien est en train de tomber en morceaux, j'ai dû le recoller avec de la colle chaude.
-
-'>> Title: Can\'t beat these for the money'
-# On ne peut pas faire mieux pour le prix
-'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
-# Je l'ai acheté pour manipuler diverses pièces d'avion et des "trucs" de hangar que je devais organiser ; il a vraiment fait l'affaire. L'unité est arrivée rapidement, était bien emballée et est arrivée intacte (toujours un bon signe). Il y a cinq supports muraux - trois sur le dessus et deux sur le dessous. Je voulais le monter sur le mur, alors tout ce que j'ai eu à faire était d'enlever les deux couches supérieures de tiroirs en plastique, ainsi que les tiroirs d'angle inférieurs, de le placer où je voulais et de le marquer ; j'ai ensuite utilisé quelques-uns des nouveaux ancrages muraux à vis en plastique (la variété de 50 livres) et il s'est facilement monté sur le mur. Certains ont fait remarquer qu'ils voulaient des séparateurs pour les tiroirs, et qu'ils les ont fabriqués. Bonne idée. Pour ma part, j'avais besoin de quelque chose dont je pouvais voir le contenu à hauteur des yeux, et je voulais donc des tiroirs plus grands. J'aime aussi le fait qu'il s'agisse du nouveau plastique qui ne se fragilise pas et ne se fend pas comme mes anciens tiroirs en plastique. J'aime la construction entièrement en plastique. Elle est suffisamment résistante pour contenir des pièces métalliques, mais étant en plastique, elle n'est pas aussi lourde qu'un cadre métallique, ce qui permet de la fixer facilement au mur et de la charger d'objets lourds ou légers. Aucun problème. Pour le prix, c'est imbattable. C'est le meilleur que j'ai acheté à ce jour, et j'utilise des versions de ce type depuis plus de quarante ans.
-```
-
-
-
-✏️ **Essayez !** Changez la graine aléatoire dans la commande `Dataset.shuffle()` pour explorer d'autres critiques dans le corpus. Si vous parlez espagnol, jetez un coup d'œil à certaines des critiques dans `spanish_dataset` pour voir si les titres semblent aussi être des résumés raisonnables.
-
-
-
-Cet échantillon montre la diversité des critiques que l'on trouve généralement en ligne, allant du positif au négatif (et tout ce qui se trouve entre les deux !). Bien que l'exemple avec le titre « meh » ne soit pas très informatif, les autres titres semblent être des résumés décents des critiques. Entraîner un modèle de résumé sur l'ensemble des 400 000 avis prendrait beaucoup trop de temps sur un seul GPU, nous allons donc nous concentrer sur la génération de résumés pour un seul domaine de produits. Pour avoir une idée des domaines parmi lesquels nous pouvons choisir, convertissons `english_dataset` en `pandas.DataFrame` et calculons le nombre d'avis par catégorie de produits :
-
-```python
-english_dataset.set_format("pandas")
-english_df = english_dataset["train"][:]
-# Afficher le compte des 20 premiers produits
-english_df["product_category"].value_counts()[:20]
-```
-
-```python out
-home 17679 # maison
-apparel 15951 # vêtements
-wireless 15717 # sans fil
-other 13418 # autres
-beauty 12091 # beauté
-drugstore 11730 # pharmacie
-kitchen 10382 # cuisine
-toy 8745 # jouets
-sports 8277 # sports
-automotive 7506 # automobile
-lawn_and_garden 7327 # pelouse_et_jardin
-home_improvement 7136 # amélioration_de_la_maison
-pet_products 7082 # produits_pour_animaux_de_compagnie
-digital_ebook_purchase 6749 # achat_de_livres_numériques
-pc 6401 # ordinateur_personnel
-electronics 6186 # électronique
-office_product 5521 # produits_de_bureau
-shoes 5197 # chaussures
-grocery 4730 # épicerie
-book 3756 # livre
-Name: product_category, dtype: int64
-```
-
-Les produits les plus populaires du jeu de données anglais concernent les articles ménagers, les vêtements et l'électronique sans fil. Pour rester dans le thème d'Amazon, nous allons nous concentrer sur le résumé des critiques de livres. Après tout, c'est la raison d'être de l'entreprise ! Nous pouvons voir deux catégories de produits qui correspondent à nos besoins (`book` et `digital_ebook_purchase`). Nous allons donc filtrer les jeux de données dans les deux langues pour ces produits uniquement. Comme nous l'avons vu dans le [chapitre 5](/course/fr/chapter5), la fonction `Dataset.filter()` nous permet de découper un jeu de données de manière très efficace. Nous pouvons donc définir une fonction simple pour le faire :
-
-```python
-def filter_books(example):
- return (
- example["product_category"] == "book"
- or example["product_category"] == "digital_ebook_purchase"
- )
-```
-
-Maintenant, lorsque nous appliquons cette fonction à `english_dataset` et `spanish_dataset`, le résultat ne contient que les lignes impliquant les catégories de livres. Avant d'appliquer le filtre, changeons le format de `english_dataset` de `"pandas"` à `"arrow"` :
-
-```python
-english_dataset.reset_format()
-```
-
-Nous pouvons ensuite appliquer la fonction de filtrage et, à titre de vérification, inspecter un échantillon de critiques pour voir si elles portent bien sur des livres :
-
-```python
-spanish_books = spanish_dataset.filter(filter_books)
-english_books = english_dataset.filter(filter_books)
-show_samples(english_books)
-```
-
-```python out
-'>> Title: I\'m dissapointed.'
-# Je suis déçu
-'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
-# Je suppose que j'avais de plus grandes attentes pour ce livre d'après les critiques. Je pensais vraiment que j'allais au moins l'aimer. L'idée de l'intrigue était géniale. J'aimais Ash, mais ça n'allait nulle part. La plus grande partie du livre était consacrée à leur émission de radio et aux conversations avec les auditeurs. Je voulais que l'auteur creuse plus profondément pour que nous puissions vraiment connaître les personnages. Tout ce que nous savons de Grace, c'est qu'elle est séduisante, qu'elle est latino et qu'elle est une sorte de garce. Je suis déçue.
-
-'>> Title: Good art, good price, poor design'
-# Un bon art, un bon prix, un mauvais design
-'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
-# J'ai eu le calendrier DC Vintage ces deux dernières années, mais il était en rupture de stock pour toujours cette année et j'ai vu qu'ils avaient réduit les dimensions sans raison valable. Celui-ci a de bons choix artistiques mais le design a le pli qui traverse l'image, donc c'est moins esthétique, surtout si vous voulez garder une image à accrocher. Pour le prix, c'est un bon calendrier.
-
-'>> Title: Helpful'
-# Utile
-'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
-# Presque tous les conseils sont utiles et. Je me considère comme un utilisateur intermédiaire à avancé de OneNote. Je le recommande vivement.
-```
-
-D'accord, nous pouvons voir que les critiques ne concernent pas strictement les livres et peuvent se référer à des choses comme des calendriers et des applications électroniques telles que OneNote. Néanmoins, le domaine semble approprié pour entraîner un modèle de résumé. Avant de regarder les différents modèles qui conviennent à cette tâche, nous avons une dernière préparation de données à faire : combiner les critiques anglaises et espagnoles en un seul objet `DatasetDict`. 🤗 *Datasets* fournit une fonction pratique `concatenate_datasets()` qui (comme son nom l'indique) va empiler deux objets `Dataset` l'un sur l'autre. Ainsi, pour créer notre jeu de données bilingue, nous allons boucler sur chaque division, concaténer les jeux de données pour cette division, et mélanger le résultat pour s'assurer que notre modèle ne s'adapte pas trop à une seule langue :
-
-```python
-from datasets import concatenate_datasets, DatasetDict
-
-books_dataset = DatasetDict()
-
-for split in english_books.keys():
- books_dataset[split] = concatenate_datasets(
- [english_books[split], spanish_books[split]]
- )
- books_dataset[split] = books_dataset[split].shuffle(seed=42)
-
-# Quelques exemples
-show_samples(books_dataset)
-```
-
-```python out
-'>> Title: Easy to follow!!!!'
-# Facile à suivre!!!!
-'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
-# J'ai adoré The dash diet weight loss Solution. Jamais faim. Je recommande ce régime. Les menus sont également bien arrondis. Essayez-le. Il contient beaucoup d'informations, merci.
-
-'>> Title: PARCIALMENTE DAÑADO'
-# PARTIELLEMENT ENDOMMAGÉ
-'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
-# Il est arrivé le jour prévu, avec d'autres livres que j'avais commandés, mais la boîte est arrivée en mauvais état, ce qui a endommagé les coins des livres car ils étaient livrés sans protection (doublure).
-
-'>> Title: no lo he podido descargar'
-# Je n'ai pas pu le télécharger
-'>> Review: igual que el anterior'
-# même chose que ci-dessus
-```
-
-Cela ressemble certainement à un mélange de critiques anglaises et espagnoles ! Maintenant que nous avons un corpus d'entraînement, une dernière chose à vérifier est la distribution des mots dans les critiques et leurs titres. Ceci est particulièrement important pour les tâches de résumé, où les résumés de référence courts dans les données peuvent biaiser le modèle pour qu'il ne produise qu'un ou deux mots dans les résumés générés. Les graphiques ci-dessous montrent les distributions de mots, et nous pouvons voir que les titres sont fortement biaisés vers seulement 1 ou 2 mots :
-
-
-

-

-
-

-

-
+
+
+
+
+
+
-

-

-
+
+
+
-

-

-
+
+
+
-100 comme étiquette pour les tokens que nous voulons ignorer dans la perte."
- },
- {
- text: "Nous devons nous assurer que les étiquettes sont tronquées ou rembourrées à la même taille que les entrées, lorsque nous appliquons la troncature/le padding.",
- explain: "En effet mais ce n'est pas la seule différence.",
- correct: true
- }
- ]}
-/>
-
-### 3. Quel problème se pose lorsque nous tokenisons les mots dans un problème de classification de tokens et que nous voulons étiqueter les tokens ?
-
-tokenizer ajoute des tokens spéciaux et nous n'avons pas d'étiquettes pour eux.",
- explain: "Nous les étiquetons par -100 ils sont donc ignorés dans la perte."
- },
- {
- text: "Chaque mot peut produire plusieurs tokens, ce qui fait que nous nous retrouvons avec plus de tokens que d'étiquettes.",
- explain: "C'est le problème principal et nous devons aligner les étiquettes originales avec les tokens.",
- correct: true
- },
- {
- text: "Les tokens ajoutés n'ont pas d'étiquettes, il n'y a donc pas de problème.",
- explain: "Nous avons besoin d'autant d'étiquettes que de tokens, sinon nos modèles se tromperont."
- }
- ]}
-/>
-
-### 4. Que signifie « adaptation au domaine » ?
-
-finetunons un modèle pré-entraîné sur un nouveau jeu de données et qu'il donne des prédictions qui sont plus adaptées à ce nouveau jeu de données.",
- explain: "Le modèle a adapté ses connaissances au nouveau jeu de données.",
- correct: true
- },
- {
- text: "C'est lorsque nous ajoutons des échantillons mal classés à un jeu de données pour rendre notre modèle plus robuste.",
- explain: "C'est certainement quelque chose que vous devriez faire si vous réentraînez votre modèle régulièrement, mais ce n'est pas une adaptation au domaine."
- }
- ]}
-/>
-
-### 5. Quelles sont les étiquettes dans un problème de modélisation du langage masqué ?
-
-tokens de la phrase d'entrée sont masqués de manière aléatoire et les étiquettes sont les tokens d'entrée originaux.",
- explain: "C'est ça !",
- correct: true
- },
- {
- text: "Certains des tokens de la phrase d'entrée sont masqués de manière aléatoire et les étiquettes sont les tokens d'entrée originaux, décalés vers la gauche.",
- explain: "Non, le déplacement des étiquettes vers la gauche correspond à la prédiction du mot suivant, ce qui est une modélisation causale du langage."
- },
- {
- text: "Certains des tokens de la phrase d'entrée sont masqués de manière aléatoire et l'étiquette indique si la phrase est positive ou négative.",
- explain: "Il s'agit d'un problème de classification de séquences avec une certaine augmentation de données et non d'une modélisation du langage masqué."
- },
- {
- text: "Certains des tokens des deux phrases d'entrée sont masqués de manière aléatoire et l'étiquette indique si les deux phrases sont similaires ou non.",
- explain: "Il s'agit d'un problème de classification de séquences avec une certaine augmentation de données et non d'une modélisation du langage masqué."
- }
- ]}
-/>
-
-### 6. Laquelle de ces tâches peut être considérée comme un problème de séquence à séquence ?
-
-
-
-### 7. Quelle est la bonne façon de prétraiter les données pour un problème de séquence à séquence ?
-
-tokenizer avec les éléments suivants inputs=... et targets=....",
- explain: "Nous pourrions ajouter cette API à l'avenir mais ce n'est pas possible pour le moment."
- },
- {
- text: "Les entrées et les cibles doivent être prétraitées, en deux appels séparés au tokenizer.",
- explain: "C'est vrai, mais incomplet. Il y a quelque chose que vous devez faire pour vous assurer que le tokenizer traite les deux correctement."
- },
- {
- text: "Comme d'habitude, nous devons simplement tokeniser les entrées.",
- explain: "Pas dans un problème de classification de séquences. Les cibles sont aussi des textes que nous devons convertir en chiffres !"
- },
- {
- text: "Les entrées doivent être envoyées au tokenizer, et les cibles aussi, mais sous un gestionnaire de contexte spécial.",
- explain: "C'est exact, le tokenizer doit être mis en mode cible par ce gestionnaire de contexte.",
- correct: true
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-
-### 8. Pourquoi existe-t-il une sous-classe spécifique de Trainer pour les problèmes de séquence à séquence ?
-
--100.",
- explain: "Ce n'est pas du tout une perte personnalisée mais la façon dont la perte est toujours calculée."
- },
- {
- text: "Parce que les problèmes de séquence à séquence nécessitent une boucle d'évaluation spéciale.",
- explain: "Les prédictions des modèles de séquence à séquence sont souvent exécutées en utilisant la méthode generate().",
- correct: true
- },
- {
- text: "Parce que les cibles sont des textes dans des problèmes de séquence à séquence.",
- explain: "Trainer ne se soucie pas vraiment de cela puisqu'elles ont été prétraités auparavant."
- },
- {
- text: "Parce que nous utilisons deux modèles dans les problèmes de séquence à séquence.",
- explain: "Nous utilisons en quelque sorte deux modèles, un encodeur et un décodeur, mais ils sont regroupés dans un seul modèle."
- }
- ]}
-/>
-
-{:else}
-
-### 9. Pourquoi est-il souvent inutile de spécifier une perte quand on appelle compile() sur un transformer ?
-
-tranformers sont entraînés avec un apprentissage autosupervisé.",
- explain: "Pas tout à fait. Même l'apprentissage autosupervisé a besoin d'une fonction de perte !"
- },
- {
- text: "Parce que la sortie de perte interne du modèle est utilisée par défaut.",
- explain: " ",
- correct: true
- },
- {
- text: "Parce que nous calculons les mesures après l'entraînement au lieu de le faire.",
- explain: "Nous le faisons souvent mais cela n'explique pas d'où vient la valeur de perte que nous optimisons dans l'entraînement."
- },
- {
- text: "Parce que la perte est spécifiée dans model.fit().",
- explain: "La fonction de perte est toujours fixée une fois que vous exécutez model.compile() et ne peut pas être modifiée dans model.fit()."
- }
- ]}
-/>
-
-{/if}
-
-### 10. Quand devez-vous pré-entraîner un nouveau modèle ?
-
-finetuner sur vos données afin d'éviter d'énormes coûts de calcul."
- },
- {
- text: "Lorsque vous avez des doutes sur le biais du modèle pré-entraîné que vous utilisez.",
- explain: "C'est vrai mais vous devez vous assurer que les données que vous utiliserez pour l'entraînement sont vraiment meilleures.",
- correct: true
- },
- {
- text: "Lorsque les modèles pré-entraînés disponibles ne sont tout simplement pas assez bons.",
- explain: "Vous êtes sûr d'avoir bien débogué votre entraînement ?"
- }
- ]}
-/>
-
-### 11. Pourquoi est-il facile de prétraîner un modèle de langage sur des batchs de textes ?
-
-Transformers ne nécessite que quelques lignes de code pour démarrer l'entraînement.",
- explain: "Bien que vrai, cela ne répond pas vraiment à la question posée. Essayez une autre réponse !"
- }
- ]}
-/>
-
-### 12. Quels sont les principaux défis lors du prétraitement des données pour une tâche de réponse à des questions ?
-
-
-
-### 13. Comment le post-traitement est-il généralement effectué dans les réponses aux questions ?
-
-tokens correspondant.",
- explain: "Ce pourrait être une façon de faire mais c'est un peu trop simpliste."
- },
- {
- text: "Le modèle vous donne les positions de début et de fin de la réponse pour chaque caractéristique créée par un exemple et il vous suffit de décoder la plage de tokens correspondant dans celui qui a le meilleur score.",
- explain: "C'est proche du post-traitement que nous avons étudié, mais ce n'est pas tout à fait exact."
- },
- {
- text: "Le modèle vous donne les positions de début et de fin de la réponse pour chaque caractéristique créée par un exemple et vous n'avez plus qu'à les faire correspondre à la portée dans le contexte de celui qui a le meilleur score.",
- explain: "C'est ça en résumé !",
- correct: true
- },
- {
- text: "Le modèle génère une réponse et il vous suffit de la décoder.",
- explain: "A moins que vous ne formuliez votre problème de réponse aux questions comme une tâche de séquence à séquence."
- }
- ]}
-/>
+
+
+
+
+# Quiz de fin de chapitre
+
+
+
+Testons ce que vous avez appris dans ce chapitre !
+
+### 1. Laquelle des tâches suivantes peut être considérée comme un problème de classification de tokens ?
+
+
+
+### 2. Quelle partie du prétraitement pour la classification de tokens diffère des autres pipelines de prétraitement ?
+
+-100 pour étiqueter les tokens spéciaux.",
+ explain: "Ce n'est pas spécifique à la classification de tokens. Nous utilisons toujours -100 comme étiquette pour les tokens que nous voulons ignorer dans la perte."
+ },
+ {
+ text: "Nous devons nous assurer que les étiquettes sont tronquées ou rembourrées à la même taille que les entrées, lorsque nous appliquons la troncature/le padding.",
+ explain: "En effet mais ce n'est pas la seule différence.",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Quel problème se pose lorsque nous tokenisons les mots dans un problème de classification de tokens et que nous voulons étiqueter les tokens ?
+
+tokenizer ajoute des