diff --git a/chapters/ru/_toctree.yml b/chapters/ru/_toctree.yml
index edfd8d605..9aef5a09d 100644
--- a/chapters/ru/_toctree.yml
+++ b/chapters/ru/_toctree.yml
@@ -57,3 +57,12 @@
title: Hugging Face Hub
- local: chapter4/2
title: Использование предобученных моделей
+ - local: chapter4/3
+ title: Публикация предобученных моделей в общий доступ
+ - local: chapter4/4
+ title: Создание карточки модели
+ - local: chapter4/5
+ title: Первая часть завершена!
+ - local: chapter4/6
+ title: Итоговый тест по главе
+ quiz: 4
\ No newline at end of file
diff --git a/chapters/ru/chapter4/3.mdx b/chapters/ru/chapter4/3.mdx
new file mode 100644
index 000000000..601aa06b5
--- /dev/null
+++ b/chapters/ru/chapter4/3.mdx
@@ -0,0 +1,634 @@
+
+
+# Публикация обученых моделей в общий доступ
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Далее мы рассмотрим самые простые способы публикации предварительно обученных моделей в 🤗 Hub: доступные инструменты и утилиты, упрощающие совместное использование и обновление моделей непосредственно в Hub.
+
+
+
+Мы призываем всех пользователей, которые обучают модели, вносить свой вклад, делясь ими с сообществом — совместное использование моделей, даже если они обучены на очень конкретных наборах данных, поможет другим, сэкономив им время и вычислительные ресурсы! В свою очередь, вы можете извлечь выгоду из работы, которую проделали другие!
+
+Есть три пути создания репозитория с моделью:
+
+- С использованием API `push_to_hub`
+- С использованием python-библиотеки `huggingface_hub`
+- С использованием веб-интерфейса
+
+После создания репозитория вы можете загружать в него файлы через git и git-lfs. В следующих разделах мы познакомим вас с созданием репозиториев моделей и загрузкой в них файлов.
+
+## Использование API `push_to_hub`
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Простейший путь загрузки файлов на Hub – `push_to_hub` API.
+
+Перед тем, как пойдем дальше, необходимо сгенерировать токен аутентификации. Это необходимо сделать для того, чтобы `huggingface_hub` API «узнал» вас и предоставил вам необходимые права на запись. Убедитесь, что вы находитесь в окружении, в котором установлена библиотека `transformers` (см. [Установка](/course/ru/chapter0)). Если вы работаете в Jupyter'е, вы можете использовать следующую функцию для авторизации:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+В терминале можно запустить:
+
+```bash
+huggingface-cli login
+```
+
+В обоих случаях вам будет предложено ввести свой логин и пароль (это должны быть те же данные, которые вы используете для входа на Hub). Если у вас нет учетной записи HuggingFace, вы можете создать ее [здесь](https://huggingface.co/join).
+
+Отлично! После авторизации ваш токен сохранится во временную папку. Давайте создадим репозитории!
+
+{#if fw === 'pt'}
+
+Если вы уже пользовались `Trainer` API для обучения модели, то самый простой способ загрузить модель на Hub – установить аргумент `push_to_hub=True` во время инициализации `TrainingArguments`:
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments(
+ "bert-finetuned-mrpc", save_strategy="epoch", push_to_hub=True
+)
+```
+
+При вызове `trainer.train()` `Trainer` будет загружать модель на Hub каждый раз, когда она будет сохраняться (в данном примере каждую эпоху). Репозиторий будет назван так же, как вы назовете папку для сохранения (в примере это `bert-finetuned-mrpc`), но вы можете задать имя репозитория самостоятельно: задайте аргумент `hub_model_id = "a_different_name"`.
+
+Для загрузки модели в репозиторий организации, представитем которой вы являетесь, укажите `hub_model_id = "my_organization/my_repo_name"`.
+
+После окончания обучения следует вызвать метод `trainer.push_to_hub()`, который загрузит последнюю версию вашей модели в репозиторий. Также он сгенерирует карточку модели со всей необходимой информацией, использованными гиперпараметрами и результатами валидации. Ниже приведено то, что вы можете найти в подобной карточке модели:
+
+
+

+
+

+
+
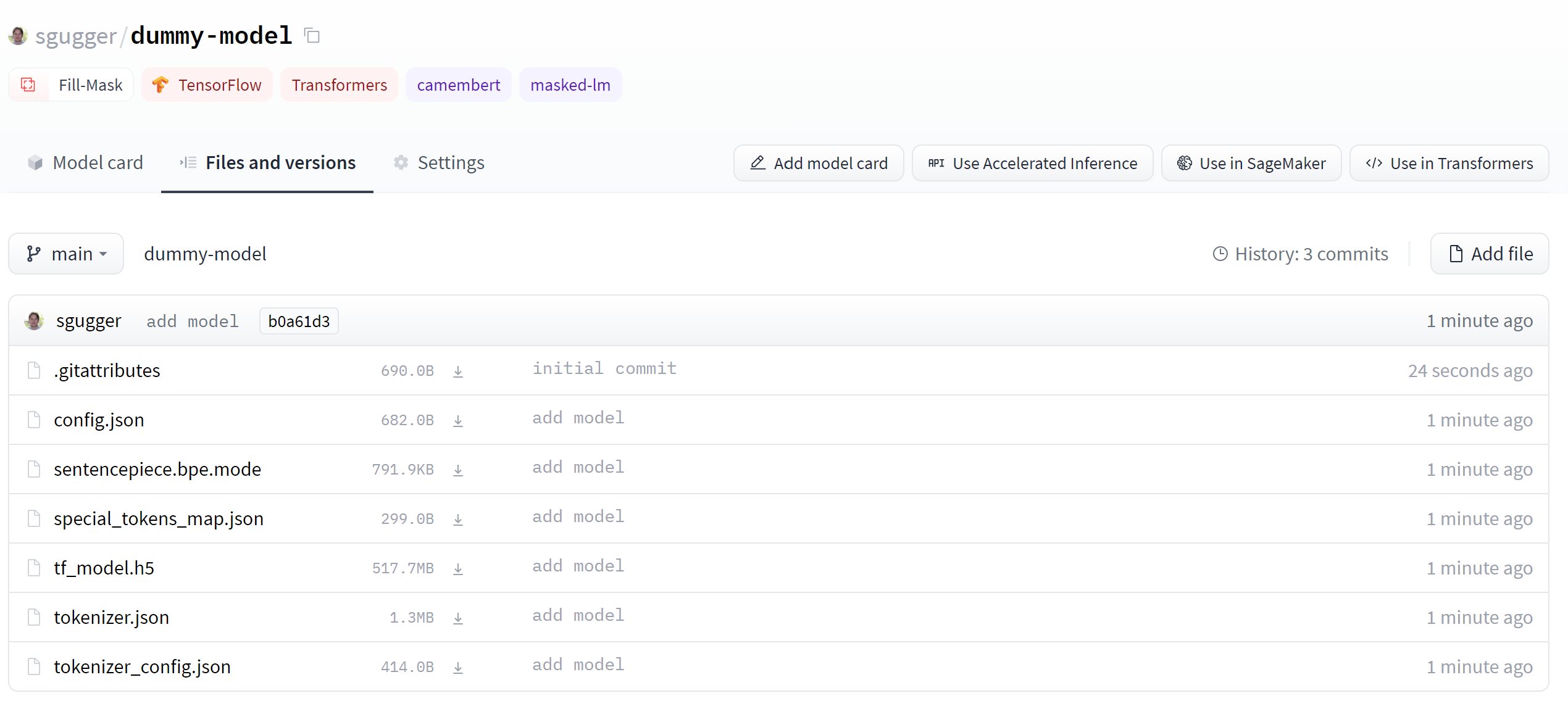
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
push_to_hub, его применение отправит необходимые файлы в указанный репозиторий. Тем не менее, это не единственный верный ответ!",
+ correct: true
+ },
+ {
+ text: "Модель",
+ explain: "Верно! Все модели обладают методом push_to_hub, его применение отправит сответствующие файлы и конфигурации в указанный репозиторий. Но это не всё, чем вы можете поделиться!",
+ correct: true
+ },
+ {
+ text: "Экземпляр Trainer",
+ explain: "Правильно: Trainer также обладает методом push_to_hub, его применение загрузит модель, конфигурацию, токенизатор и черновик карточки модели в указанный репозиторий. Попробуйте и другие ответы!",
+ correct: true
+ }
+ ]}
+/>
+{:else}
+push_to_hub, его применение отправит все файлы токенизатора (словарь, архитектуру и пр.) в указанный репозиторий. Тем не менее, это не единственный верный ответ!",
+ correct: true
+ },
+ {
+ text: "Конфигурация модели",
+ explain: "Верно! Все конфигурации моделей обладают методом push_to_hub, его применение отправит необходимые файлы в указанный репозиторий. Тем не менее, это не единственный верный ответ!",
+ correct: true
+ },
+ {
+ text: "Модель",
+ explain: "Верно! Все модели обладают методом push_to_hub, его применение отправит сответствующие файлы и конфигурации в указанный репозиторий. Но это не всё, чем вы можете поделиться!",
+ correct: true
+ },
+ {
+ text: "Все вышеперечисленной с помощью специального callback",
+ explain: "Верно: PushToHubCallback будет регулярно отсылать все объекты в репозиторий во время обучения.",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. Какой первый шаг при использовани `push_to_hub()` метода или инструментов командной строки?
+
+
+
+### 7.Если вы используете модель и токенизатор – как вы можете загрузить их на Hub?
+
+huggingface_hub утилиту.",
+ explain: "Модели и токенизаторы уже используют утилиты huggingface_hub: нет необходимости в дополнительных утилитах!"
+ },
+ {
+ text: "Сохранив их на диск и вызвав transformers-cli upload-model",
+ explain: "Команды upload-model не существует."
+ }
+ ]}
+/>
+
+### 8. Какие операции git вы можете проводить с экземпляром класса `Repository`?
+
+git_commit() метод как раз для этого.",
+ correct: true
+ },
+ {
+ text: "Pull",
+ explain: "Это предназначение метода git_pull().",
+ correct: true
+ },
+ {
+ text: "Push",
+ explain: "Метод git_push() делает это.",
+ correct: true
+ },
+ {
+ text: "Merge",
+ explain: "Нет, такая операция невозможная с данным API."
+ }
+ ]}
+/>