 -這會安裝一個非常輕量的🤗 Transformers。裡面沒有安裝任何像是PyTorch或TensorFlow等的機器學習框架。因為我們會用到很多函式庫裡的不同功能,所以我們建議安裝包含了大部分使用情境所需資源的開發用版本:
+這會安裝一個非常輕量的 🤗 Transformers。裡面沒有安裝任何像是 PyTorch 或 TensorFlow 等的機器學習框架。因為我們會用到很多函式庫裡的不同功能,所以我們建議安裝包含了大部分使用情境所需資源的開發用版本:
```
@@ -50,16 +50,16 @@ import transformers
## 使用Python虛擬環境
-如果你比較想用Python虛擬環境的話,第一步就是安裝Python。我們建議跟著[這篇教學](https://realpython.com/installing-python/)做為起手式。
+如果你比較想用 Python 虛擬環境的話,第一步就是安裝 Python。我們建議跟著[這篇教學](https://realpython.com/installing-python/)做為起手式。
-當你安裝好Python後,你應該就能從終端機執行Python指令了。在進行下一步之前你可以先執行以下指令來確認Python有沒有安裝好:`python --version` 這條指令會讓終端機顯示你所安裝的Python版本。
+當你安裝好 Python 後,你應該就能從終端機執行 Python 指令了。在進行下一步之前你可以先執行以下指令來確認 Python 有沒有安裝好:`python --version` 這條指令會讓終端機顯示你所安裝的 Python 版本。
-在終端機執行像是`python --version`的Python指令時,你應該把你的指令想成是用你系統上主要的Python版本來執行。我們建議不要在這個版本上安裝任何資源包,讓每個專案在各自獨立的環境裡運行就可以了。這樣每個專案都可以有各自的相依性跟資源包,你也不用擔心不同專案之間使用同一個環境時潛在的相容性問題。
+在終端機執行像是`python --version`的 Python 指令時,你應該把你的指令想成是用你系統上主要的 Python 版本來執行。我們建議不要在這個版本上安裝任何資源包,讓每個專案在各自獨立的環境裡運行就可以了。這樣每個專案都可以有各自的相依性跟資源包,你也不用擔心不同專案之間使用同一個環境時潛在的相容性問題。
-在Python我們可以用[*虛擬環境*](https://docs.python.org/3/tutorial/venv.html)來做這件事。虛擬環境是一個獨立包裝的樹狀目錄,每一個目錄下都有安裝特定版本的Python跟它需要的所有資源包。創建這樣的虛擬環境可以用很多不同的工具,不過我們會用一個叫做[`venv`](https://docs.python.org/3/library/venv.html#module-venv)的Python官方資源包。
+在 Python 我們可以用[*虛擬環境*](https://docs.python.org/3/tutorial/venv.html)來做這件事。虛擬環境是一個獨立包裝的樹狀目錄,每一個目錄下都有安裝特定版本的Python跟它需要的所有資源包。創建這樣的虛擬環境可以用很多不同的工具,不過我們會用一個叫做[`venv`](https://docs.python.org/3/library/venv.html#module-venv)的Python官方資源包。
首先,創建你希望你的程式執行時所在的目錄 - 舉例來說,你可能想要在你的家目錄下新增一個叫*transformers-course*的目錄:
@@ -103,7 +103,7 @@ which python
### 安裝相依性資源包
-在之前的段落中提到的使用Google Colab的情況裡,你會需要安裝相依性資源包才能繼續。你可以用 `pip` 這個資源管理工具來安裝開發版的🤗 Transformers:
+在之前的段落中提到的使用 Google Colab 的情況裡,你會需要安裝相依性資源包才能繼續。你可以用 `pip` 這個資源管理工具來安裝開發版的🤗 Transformers:
```
pip install "transformers[sentencepiece]"
diff --git a/chapters/zh-TW/chapter1/1.mdx b/chapters/zh-TW/chapter1/1.mdx
new file mode 100644
index 000000000..f779a48d0
--- /dev/null
+++ b/chapters/zh-TW/chapter1/1.mdx
@@ -0,0 +1,57 @@
+# 本章簡介
+
+
-這會安裝一個非常輕量的🤗 Transformers。裡面沒有安裝任何像是PyTorch或TensorFlow等的機器學習框架。因為我們會用到很多函式庫裡的不同功能,所以我們建議安裝包含了大部分使用情境所需資源的開發用版本:
+這會安裝一個非常輕量的 🤗 Transformers。裡面沒有安裝任何像是 PyTorch 或 TensorFlow 等的機器學習框架。因為我們會用到很多函式庫裡的不同功能,所以我們建議安裝包含了大部分使用情境所需資源的開發用版本:
```
@@ -50,16 +50,16 @@ import transformers
## 使用Python虛擬環境
-如果你比較想用Python虛擬環境的話,第一步就是安裝Python。我們建議跟著[這篇教學](https://realpython.com/installing-python/)做為起手式。
+如果你比較想用 Python 虛擬環境的話,第一步就是安裝 Python。我們建議跟著[這篇教學](https://realpython.com/installing-python/)做為起手式。
-當你安裝好Python後,你應該就能從終端機執行Python指令了。在進行下一步之前你可以先執行以下指令來確認Python有沒有安裝好:`python --version` 這條指令會讓終端機顯示你所安裝的Python版本。
+當你安裝好 Python 後,你應該就能從終端機執行 Python 指令了。在進行下一步之前你可以先執行以下指令來確認 Python 有沒有安裝好:`python --version` 這條指令會讓終端機顯示你所安裝的 Python 版本。
-在終端機執行像是`python --version`的Python指令時,你應該把你的指令想成是用你系統上主要的Python版本來執行。我們建議不要在這個版本上安裝任何資源包,讓每個專案在各自獨立的環境裡運行就可以了。這樣每個專案都可以有各自的相依性跟資源包,你也不用擔心不同專案之間使用同一個環境時潛在的相容性問題。
+在終端機執行像是`python --version`的 Python 指令時,你應該把你的指令想成是用你系統上主要的 Python 版本來執行。我們建議不要在這個版本上安裝任何資源包,讓每個專案在各自獨立的環境裡運行就可以了。這樣每個專案都可以有各自的相依性跟資源包,你也不用擔心不同專案之間使用同一個環境時潛在的相容性問題。
-在Python我們可以用[*虛擬環境*](https://docs.python.org/3/tutorial/venv.html)來做這件事。虛擬環境是一個獨立包裝的樹狀目錄,每一個目錄下都有安裝特定版本的Python跟它需要的所有資源包。創建這樣的虛擬環境可以用很多不同的工具,不過我們會用一個叫做[`venv`](https://docs.python.org/3/library/venv.html#module-venv)的Python官方資源包。
+在 Python 我們可以用[*虛擬環境*](https://docs.python.org/3/tutorial/venv.html)來做這件事。虛擬環境是一個獨立包裝的樹狀目錄,每一個目錄下都有安裝特定版本的Python跟它需要的所有資源包。創建這樣的虛擬環境可以用很多不同的工具,不過我們會用一個叫做[`venv`](https://docs.python.org/3/library/venv.html#module-venv)的Python官方資源包。
首先,創建你希望你的程式執行時所在的目錄 - 舉例來說,你可能想要在你的家目錄下新增一個叫*transformers-course*的目錄:
@@ -103,7 +103,7 @@ which python
### 安裝相依性資源包
-在之前的段落中提到的使用Google Colab的情況裡,你會需要安裝相依性資源包才能繼續。你可以用 `pip` 這個資源管理工具來安裝開發版的🤗 Transformers:
+在之前的段落中提到的使用 Google Colab 的情況裡,你會需要安裝相依性資源包才能繼續。你可以用 `pip` 這個資源管理工具來安裝開發版的🤗 Transformers:
```
pip install "transformers[sentencepiece]"
diff --git a/chapters/zh-TW/chapter1/1.mdx b/chapters/zh-TW/chapter1/1.mdx
new file mode 100644
index 000000000..f779a48d0
--- /dev/null
+++ b/chapters/zh-TW/chapter1/1.mdx
@@ -0,0 +1,57 @@
+# 本章簡介
+
+ +
+ +
+text-generation pipeline將會返回這些.",
+ },
+ {
+ text: "它將返回代表人員、組織或位置的單詞。",
+ explain: "此外,使用 grouped_entities=True,它會將屬於同一實體的單詞組合在一起,例如“Hugging Face”。",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. 在此代碼示例中...的地方應該填寫什麼?
+
+```py
+from transformers import pipeline
+
+filler = pipeline("fill-mask", model="bert-base-cased")
+result = filler("...")
+```
+
+bert-base-cased 模型卡片,然後再嘗試找找錯在哪裏。"
+ },
+ {
+ text: "This [MASK] has been waiting for you.",
+ explain: "正解! 這個模型的mask的掩碼是[MASK].",
+ correct: true
+ },
+ {
+ text: "This man has been waiting for you.",
+ explain: "這個選項是不對的。 這個pipeline的作用是填充經過mask的文字,因此它需要在輸入的文本中存在mask的token。"
+ }
+ ]}
+/>
+
+### 4. 爲什麼這段代碼會無法運行?
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+result = classifier("This is a course about the Transformers library")
+```
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+  +
+ +
+  +
+ +
+  +
+AutoModel只需要知道初始化的Checkpoint(檢查點)就可以返回正確的體系結構。",
+ correct: true
+ },
+ {
+ text: "一種可以自動檢測輸入語言來加載正確權重的模型",
+ explain: "不正確; 雖然有些Checkpoint(檢查點)和模型能夠處理多種語言,但是沒有內置的工具可以根據語言自動選擇Checkpoint(檢查點)。您應該前往 Model Hub 尋找完成所需任務的最佳Checkpoint(檢查點)!"
+ }
+ ]}
+/>
+
+{:else}
+### 5.什麼是 TFAutoModel?
+TFAutoModel只需要知道初始化的Checkpoint(檢查點)就可以返回正確的體系結構。",
+ correct: true
+ },
+ {
+ text: "一種可以自動檢測輸入語言來加載正確權重的模型",
+ explain: "不正確; 雖然有些Checkpoint(檢查點)和模型能夠處理多種語言,但是沒有內置的工具可以根據語言自動選擇Checkpoint(檢查點)。您應該前往 Model Hub 尋找完成所需任務的最佳Checkpoint(檢查點)!"
+ }
+ ]}
+/>
+
+{/if}
+
+### 6.當將不同長度的序列批處理在一起時,需要進行哪些處理?
+編碼 方法確實存在於標記器中,但是它不存在於模型中。"
+ },
+ {
+ text: "直接調用標記器(Tokenizer)對象。",
+ explain: "完全正確!標記化器(Tokenizer) 的 __call__方法是一個非常強大的方法,可以處理幾乎任何事情。它也是從模型中獲取預測的方法。",
+ correct: true
+ },
+ {
+ text: "pad(填充)",
+ explain: "錯! pad(填充)非常有用,但它只是標記器(Tokenizer) API的一部分。"
+ },
+ {
+ text: "tokenize(標記)",
+ explain: "可以說,tokenize(標記)方法是最有用的方法之一,但它不是標記器(Tokenizer) API的核心方法。"
+ }
+ ]}
+/>
+
+### 9.這個代碼示例中的`result`變量包含什麼?
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+result = tokenizer.tokenize("Hello!")
+```
+
+convert_tokens_to_ids方法的作用!"
+ },
+ {
+ text: "包含所有標記(Token)的字符串",
+ explain: "這將是次優的,因為Tokenizer會將字符串拆分為多個標記的列表。"
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+### 10.下面的代碼有什麼錯誤嗎?
+```py
+from transformers import AutoTokenizer, AutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+model = AutoModel.from_pretrained("gpt2")
+
+encoded = tokenizer("Hey!", return_tensors="pt")
+result = model(**encoded)
+```
+
+DataLoader. We used the DataCollatorWithPadding function, which pads all items in a batch so they have the same length.",
+ correct: true
+ },
+ {
+ text: "它預處理整個數據集。",
+ explain: "這將是一個預處理函數,而不是校對函數。"
+ },
+ {
+ text: "它截斷數據集中的序列。",
+ explain: "校對函數用於處理單個批處理,而不是整個數據集。如果您對截斷感興趣,可以使用 < code > tokenizer 的 < truncate 參數。"
+ }
+ ]}
+/>
+
+### 7.當你用一個預先訓練過的語言模型(例如‘ bert-base-uncased’)實例化一個‘ AutoModelForXxx’類,這個類對應於一個不同於它所被訓練的任務時會發生什麼?
+evaluation_strategy as well, so this impacts evaluation. 再試一次!"
+ }
+ ]}
+/>
+
+### 9.為什麼要使用 Accelerate 庫?
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
data_files 參數來加載本地數據集。",
+ correct: true
+ },
+ {
+ text: "Hugging Face Hub",
+ explain: "正確! 你可以通過提供數據集 ID 在 Hub 上加載數據集, 例如 < code > load _ dataset ('em otion') 。",
+ correct: true
+ },
+ {
+ text: "遠程服務器",
+ explain: "正確! 你可以將URL傳遞給 load_dataset() 函數的 data_files 參數來加載遠程文件。",
+ correct: true
+ },
+ ]}
+/>
+
+### 2.假設您加載了 GLUE 任務,如下所示:
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("glue", "mrpc", split="train")
+```
+
+以下哪個命令將從 `dataset` 中生成50個元素的隨機樣本?
+
+dataset.shuffle().select(range(50))",
+ explain: "正確! 正如你在本章中看待的, 你首先打亂了數據集, 然後從中選擇樣本。",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "這是不正確的——儘管代碼會運行, 但它只會隨機處理數據集中的前50個元素。"
+ }
+ ]}
+/>
+
+### 3.假設你有一個叫做寵物數據集的家庭寵物數據集,它有一個名字列表示每個寵物的名字。下列哪種方法可以讓你過濾所有名字以字母"L"開頭的寵物的數據?
+ +
+ +
+ +
+ +
+ +
+ +
+
+
+
+
+ +
+ +
+
+您可以[在這裡](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).找到我們將訓練並上傳到 Hub的模型,可以嘗試輸入一些句子看看模型的預測結果。
+
+## 準備數據
+
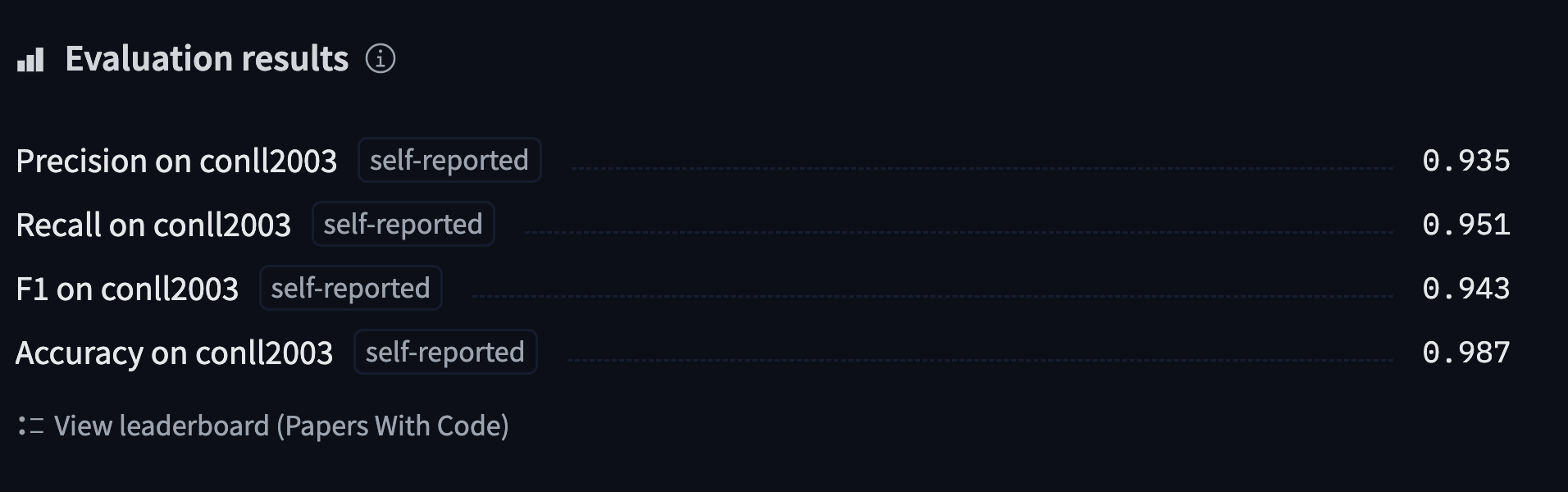
+首先,我們需要一個適合標記分類的數據集。在本節中,我們將使用[CoNLL-2003 數據集](https://huggingface.co/datasets/conll2003), 其中包含來自路透社的新聞報道。
+
+
+
+
+您可以[在這裡](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).找到我們將訓練並上傳到 Hub的模型,可以嘗試輸入一些句子看看模型的預測結果。
+
+## 準備數據
+
+首先,我們需要一個適合標記分類的數據集。在本節中,我們將使用[CoNLL-2003 數據集](https://huggingface.co/datasets/conll2003), 其中包含來自路透社的新聞報道。
+
+ +
+ +
+ +
+ +
+ +
+
+與前面的部分一樣,您可以使用以下代碼找到我們將訓練並上傳到 Hub 的實際模型,並[在這裡](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.)查看模型輸出的結果
+
+## 準備數據
+
+為了從頭開始微調或訓練翻譯模型,我們需要一個適合該任務的數據集。如前所述,我們將使用[KDE4 數據集](https://huggingface.co/datasets/kde4)在本節中,但您可以很容易地調整代碼以使用您自己的數據,只要您有要互譯的兩種語言的句子對。如果您需要複習如何將自定義數據加載到 **Dataset** 可以複習一下[第五章](/course/chapter5).
+
+### KDE4 數據集
+
+像往常一樣,我們使用 **load_dataset()** 函數:
+
+```py
+from datasets import load_dataset, load_metric
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+如果您想使用不同的語言對,您可以使用它們的代碼來指定它們。該數據集共有 92 種語言可用;您可以通過[數據集卡片](https://huggingface.co/datasets/kde4)展開其上的語言標籤來查看它們.
+
+
+
+
+與前面的部分一樣,您可以使用以下代碼找到我們將訓練並上傳到 Hub 的實際模型,並[在這裡](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.)查看模型輸出的結果
+
+## 準備數據
+
+為了從頭開始微調或訓練翻譯模型,我們需要一個適合該任務的數據集。如前所述,我們將使用[KDE4 數據集](https://huggingface.co/datasets/kde4)在本節中,但您可以很容易地調整代碼以使用您自己的數據,只要您有要互譯的兩種語言的句子對。如果您需要複習如何將自定義數據加載到 **Dataset** 可以複習一下[第五章](/course/chapter5).
+
+### KDE4 數據集
+
+像往常一樣,我們使用 **load_dataset()** 函數:
+
+```py
+from datasets import load_dataset, load_metric
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+如果您想使用不同的語言對,您可以使用它們的代碼來指定它們。該數據集共有 92 種語言可用;您可以通過[數據集卡片](https://huggingface.co/datasets/kde4)展開其上的語言標籤來查看它們.
+
+ +
+我們來看看數據集:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+我們有 210,173 對句子,但在一次訓練過程中,我們需要創建自己的驗證集。正如我們在[第五章](/course/chapter5)學的的那樣, **Dataset** 有一個 **train_test_split()** 方法,可以幫我們拆分數據集。我們將設定固定的隨機數種子:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+我們可以將 **test** 的鍵重命名為 **validation** 像這樣:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+現在讓我們看一下數據集的一個元素:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+我們得到一個字典,其中包含我們請求的兩種語言的兩個句子。這個充滿技術計算機科學術語的數據集的一個特殊之處在於它們都完全用法語翻譯。然而,法國工程師通常很懶惰,在交談時,大多數計算機科學專用詞彙都用英語表述。例如,“threads”這個詞很可能出現在法語句子中,尤其是在技術對話中;但在這個數據集中,它被翻譯成更正確的“fils de Discussion”。我們使用的預訓練模型已經在一個更大的法語和英語句子語料庫上進行了預訓練,採用了更簡單的選擇,即保留單詞的原樣:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+這種情況的另一個例子是“plugin”這個詞,它不是正式的法語詞,但大多數母語人士都能理解,也不會費心去翻譯。
+在 KDE4 數據集中,這個詞在法語中被翻譯成更正式的“module d’extension”:
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+然而,我們的預訓練模型堅持使用簡練而熟悉的英文單詞:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+看看我們的微調模型是否能識別數據集的這些特殊性。(劇透警告:它會)。
+
+
+
+我們來看看數據集:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+我們有 210,173 對句子,但在一次訓練過程中,我們需要創建自己的驗證集。正如我們在[第五章](/course/chapter5)學的的那樣, **Dataset** 有一個 **train_test_split()** 方法,可以幫我們拆分數據集。我們將設定固定的隨機數種子:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+我們可以將 **test** 的鍵重命名為 **validation** 像這樣:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+現在讓我們看一下數據集的一個元素:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+我們得到一個字典,其中包含我們請求的兩種語言的兩個句子。這個充滿技術計算機科學術語的數據集的一個特殊之處在於它們都完全用法語翻譯。然而,法國工程師通常很懶惰,在交談時,大多數計算機科學專用詞彙都用英語表述。例如,“threads”這個詞很可能出現在法語句子中,尤其是在技術對話中;但在這個數據集中,它被翻譯成更正確的“fils de Discussion”。我們使用的預訓練模型已經在一個更大的法語和英語句子語料庫上進行了預訓練,採用了更簡單的選擇,即保留單詞的原樣:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+這種情況的另一個例子是“plugin”這個詞,它不是正式的法語詞,但大多數母語人士都能理解,也不會費心去翻譯。
+在 KDE4 數據集中,這個詞在法語中被翻譯成更正式的“module d’extension”:
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+然而,我們的預訓練模型堅持使用簡練而熟悉的英文單詞:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+看看我們的微調模型是否能識別數據集的這些特殊性。(劇透警告:它會)。
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+generate() method.",
+ correct: true
+ },
+ {
+ text: "文本是作為單詞給出的,所以我們只需要應用子詞的標記。",
+ explain: "< code > Trainer 並不關心這些,因為它們以前已經被預處理過。"
+ },
+ {
+ text: "因為我們在序列到序列問題中使用了兩個模型",
+ explain: "我們確實在某種程度上使用了兩種模型,編碼器和解碼器,但是它們被組合在一個模型中。"
+ }
+ ]}
+/>
+
+{:else}
+
+### 9.為什麼在 Transformer 模型上調用“ compile ()”時通常不需要指定損失?
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+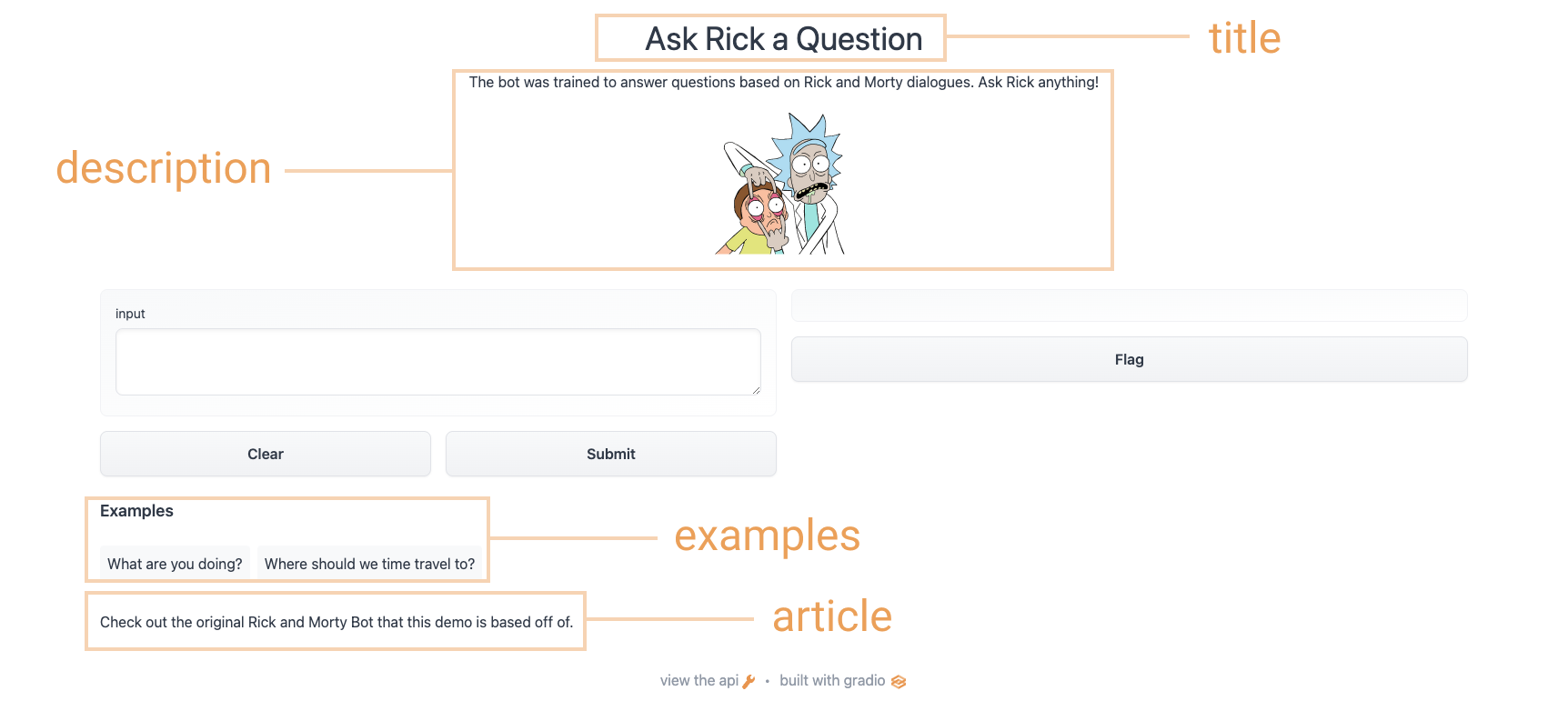 +
+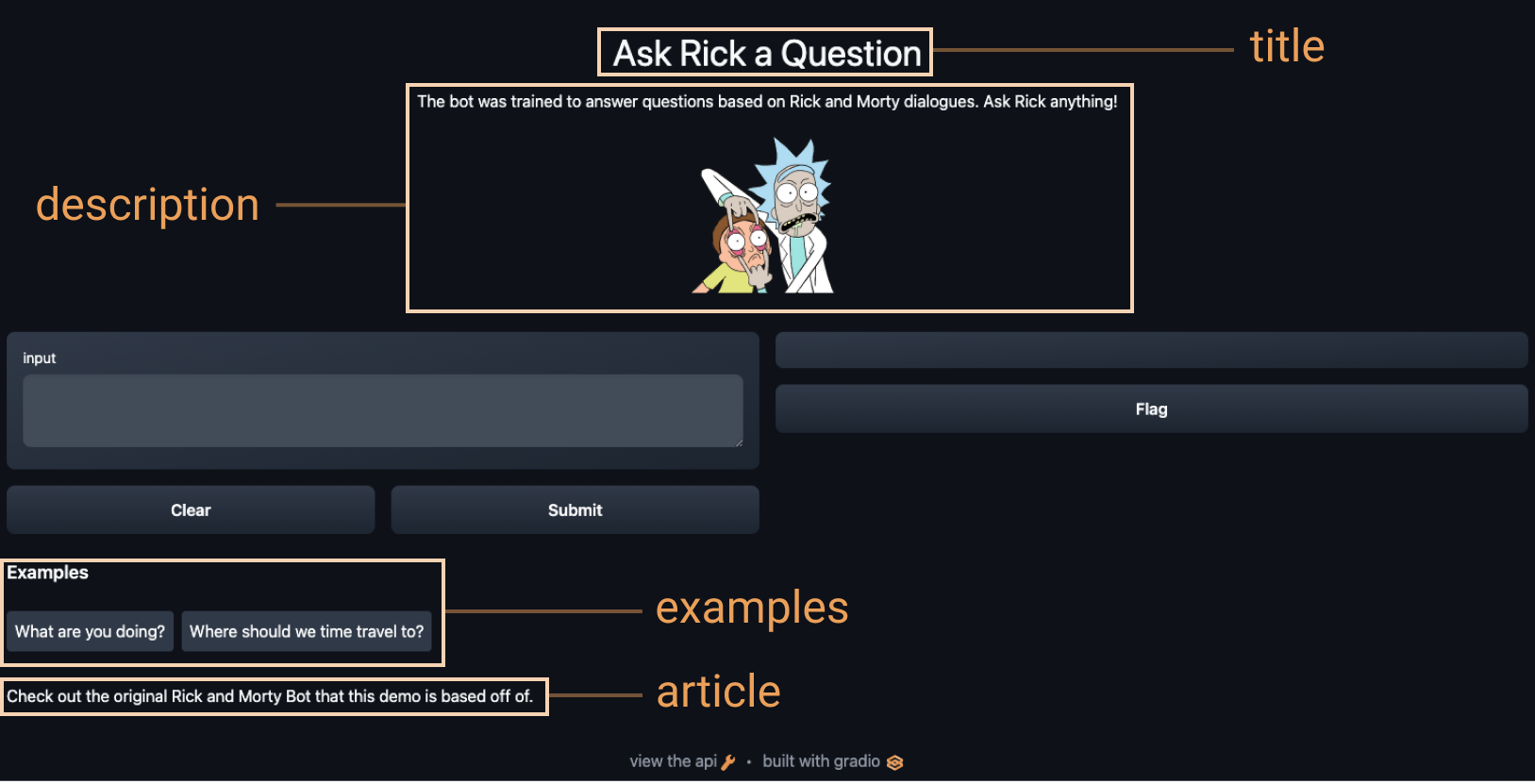 +
+ +"""
+
+article = "Check out [the original Rick and Morty Bot](https://huggingface.co/spaces/kingabzpro/Rick_and_Morty_Bot) that this demo is based off of."
+
+gr.Interface(
+ fn=predict,
+ inputs="textbox",
+ outputs="text",
+ title=title,
+ description=description,
+ article=article,
+ examples=[["What are you doing?"], ["Where should we time travel to?"]],
+).launch()
+```
+
+使用上面的選項,我們最終得到了一個更完整的界面。 試試下面的界面:
+
+
+
+### 使用臨時鏈接分享您的演示
+現在我們已經有了機器學習模型的工作演示,讓我們學習如何輕鬆共享指向我們界面的鏈接。
+通過在 `launch()` 方法中設置 `share=True` 可以輕鬆地公開共享接口:
+
+```python
+gr.Interface(classify_image, "image", "label").launch(share=True)
+```
+
+這會生成一個公開的、可共享的鏈接,您可以將其發送給任何人! 當您發送此鏈接時,另一方的用戶可以在瀏覽器中試用該模型長達 72 小時。 因為處理發生在您的設備上(只要您的設備保持開啟!),您不必擔心打包任何依賴項。 如果您使用 Google Colab 筆記本工作,則始終會自動創建共享鏈接。 它通常看起來像這樣:**XXXXX.gradio.app**。 雖然鏈接是通過 Gradio 鏈接提供的,但我們只是您本地服務器的代理,不會存儲通過接口發送的任何數據。
+
+但是請記住,這些鏈接是可公開訪問的,這意味著任何人都可以使用您的模型進行預測! 因此,請確保不要通過您編寫的函數公開任何敏感信息,或允許在您的設備上發生任何關鍵更改。 如果設置 `share=False`(默認值),則僅創建本地鏈接。
+
+### 在 Hugging Face Spaces 上託管您的演示
+
+可以傳遞給同事的共享鏈接很酷,但是如何永久託管您的演示並讓它存在於互聯網上自己的“空間”中?
+
+Hugging Face Spaces 提供了在互聯網上永久託管 Gradio 模型的基礎設施,**免費**! Spaces 允許您創建並推送到(公共或私人)存儲庫,
+你的 Gradio 在哪裡
+接口代碼將存在於 `app.py` 文件中。 [閱讀分步教程](https://huggingface.co/blog/gradio-spaces) 開始使用,或觀看下面的示例視頻。
+
+
+"""
+
+article = "Check out [the original Rick and Morty Bot](https://huggingface.co/spaces/kingabzpro/Rick_and_Morty_Bot) that this demo is based off of."
+
+gr.Interface(
+ fn=predict,
+ inputs="textbox",
+ outputs="text",
+ title=title,
+ description=description,
+ article=article,
+ examples=[["What are you doing?"], ["Where should we time travel to?"]],
+).launch()
+```
+
+使用上面的選項,我們最終得到了一個更完整的界面。 試試下面的界面:
+
+
+
+### 使用臨時鏈接分享您的演示
+現在我們已經有了機器學習模型的工作演示,讓我們學習如何輕鬆共享指向我們界面的鏈接。
+通過在 `launch()` 方法中設置 `share=True` 可以輕鬆地公開共享接口:
+
+```python
+gr.Interface(classify_image, "image", "label").launch(share=True)
+```
+
+這會生成一個公開的、可共享的鏈接,您可以將其發送給任何人! 當您發送此鏈接時,另一方的用戶可以在瀏覽器中試用該模型長達 72 小時。 因為處理發生在您的設備上(只要您的設備保持開啟!),您不必擔心打包任何依賴項。 如果您使用 Google Colab 筆記本工作,則始終會自動創建共享鏈接。 它通常看起來像這樣:**XXXXX.gradio.app**。 雖然鏈接是通過 Gradio 鏈接提供的,但我們只是您本地服務器的代理,不會存儲通過接口發送的任何數據。
+
+但是請記住,這些鏈接是可公開訪問的,這意味著任何人都可以使用您的模型進行預測! 因此,請確保不要通過您編寫的函數公開任何敏感信息,或允許在您的設備上發生任何關鍵更改。 如果設置 `share=False`(默認值),則僅創建本地鏈接。
+
+### 在 Hugging Face Spaces 上託管您的演示
+
+可以傳遞給同事的共享鏈接很酷,但是如何永久託管您的演示並讓它存在於互聯網上自己的“空間”中?
+
+Hugging Face Spaces 提供了在互聯網上永久託管 Gradio 模型的基礎設施,**免費**! Spaces 允許您創建並推送到(公共或私人)存儲庫,
+你的 Gradio 在哪裡
+接口代碼將存在於 `app.py` 文件中。 [閱讀分步教程](https://huggingface.co/blog/gradio-spaces) 開始使用,或觀看下面的示例視頻。
+
+Sketch Recognition | Demo Model
", + live=True, +) +interface.launch(share=True) +``` + + + + +注意 `Interface` 中的 `live=True` 參數,這意味著草圖演示使 +每次有人在畫板上畫畫時的預測(沒有提交按鈕!)。 + +此外,我們還在 `launch()` 方法中設置了 `share=True` 參數。 +這將創建一個公共鏈接,您可以發送給任何人! 當您發送此鏈接時,對方的用戶可以嘗試草圖識別模型。 重申一下,您還可以在 Hugging Face Spaces 上託管模型,這就是我們能夠嵌入上面的演示的方式。 + +接下來,我們將介紹 Gradio 可用於 Hugging Face 生態系統的其他方式! \ No newline at end of file diff --git a/chapters/zh-TW/chapter9/5.mdx b/chapters/zh-TW/chapter9/5.mdx new file mode 100644 index 000000000..af733d52f --- /dev/null +++ b/chapters/zh-TW/chapter9/5.mdx @@ -0,0 +1,66 @@ +# 與 Hugging Face Hub 整合 + +GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model
" +examples = [ + ["The tower is 324 metres (1,063 ft) tall,"], + ["The Moon's orbit around Earth has"], + ["The smooth Borealis basin in the Northern Hemisphere covers 40%"], +] +gr.Interface.load( + "huggingface/EleutherAI/gpt-j-6B", + inputs=gr.Textbox(lines=5, label="Input Text"), + title=title, + description=description, + article=article, + examples=examples, + enable_queue=True, +).launch() +``` + +上述代碼將生成以下界面: + + + +以這種方式加載模型使用 Hugging Face 的 [Inference API](https://huggingface.co/inference-api),而不是將模型加載到內存中。這對於像 GPT-J 或 T0pp這樣需要大量 RAM 的大型模型是理想的。 + +### 從 Hugging Face Spaces 空間加載 +要從hugs Face Hub加載任何空間並在本地重新創建它, 你可以將 `spaces/` 傳遞給 `Interface`, 再加上空間的名稱。 + +還記得第 1 節中刪除圖像背景的演示嗎? 讓我們從 Hugging Face Spaces 加載它: + +```py +gr.Interface.load("spaces/abidlabs/remove-bg").launch() +``` + + + +從Hub或Spaces加載演示的一個很酷的地方是, 你可以通過覆蓋任何參數來自定義它們。在這裡, 我們添加一個標題並讓它與網絡攝像頭一起使用: + +```py +gr.Interface.load( + "spaces/abidlabs/remove-bg", inputs="webcam", title="Remove your webcam background!" +).launch() +``` + + + +現在我們已經探索了幾種將Gradio與hugs Face Hub集成的方法, 讓我們來看看 `Interface` 類的一些高級功能。這就是下一節的主題! \ No newline at end of file diff --git a/chapters/zh-TW/chapter9/6.mdx b/chapters/zh-TW/chapter9/6.mdx new file mode 100644 index 000000000..77ad805e8 --- /dev/null +++ b/chapters/zh-TW/chapter9/6.mdx @@ -0,0 +1,97 @@ +# 高級接口功能 + +
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+