diff --git a/docs/source/ar/_toctree.yml b/docs/source/ar/_toctree.yml
index 39e0ae14e19c29..6f7899b53b854e 100644
--- a/docs/source/ar/_toctree.yml
+++ b/docs/source/ar/_toctree.yml
@@ -217,32 +217,32 @@
# title: التحقق من طلب السحب
# title: المساهمة
- sections:
- # - local: philosophy
- # title: الفلسفة
+ - local: philosophy
+ title: الفلسفة
- local: glossary
title: (قاموس المصطلحات (قائمة الكلمات
- # - local: task_summary
- # title: ما الذي يمكن أن تفعله 🤗 المحولات
- # - local: tasks_explained
- # title: كيف تحل المحولات المهام
- # - local: model_summary
- # title: عائلة نماذج المحول
- # - local: tokenizer_summary
- # title: ملخص برنامج مقسم النصوص (tokenizers)
- # - local: attention
- # title: الانتباه Attention
- # - local: pad_truncation
- # title: الحشو والتقليم
- # - local: bertology
- # title: BERTology
- # - local: perplexity
- # title: حيرة النماذج ذات الطول الثابت
- # - local: pipeline_webserver
- # title: خطوط الأنابيب للاستدلال على خادم الويب
- # - local: model_memory_anatomy
- # title: تشريح تدريب النموذج
- # - local: llm_tutorial_optimization
- # title: الاستفادة القصوى من LLMs
+ - local: task_summary
+ title: ما الذي يمكن أن تفعله 🤗 المحولات
+ - local: tasks_explained
+ title: كيف تحل المحولات المهام
+ - local: model_summary
+ title: عائلة نماذج المحول
+ - local: tokenizer_summary
+ title: ملخص برنامج مقسم النصوص (tokenizers)
+ - local: attention
+ title: الانتباه Attention
+ - local: pad_truncation
+ title: الحشو والتقليم
+ - local: bertology
+ title: BERTology
+ - local: perplexity
+ title: حيرة النماذج ذات الطول الثابت
+ - local: pipeline_webserver
+ title: خطوط الأنابيب للاستدلال على خادم الويب
+ - local: model_memory_anatomy
+ title: تشريح تدريب النموذج
+ - local: llm_tutorial_optimization
+ title: الاستفادة القصوى من LLMs
title: أطر مفاهيمية
# - sections:
# - sections:
diff --git a/docs/source/ar/attention.md b/docs/source/ar/attention.md
new file mode 100644
index 00000000000000..e1f55ed96c2dd4
--- /dev/null
+++ b/docs/source/ar/attention.md
@@ -0,0 +1,25 @@
+# آليات الانتباه
+
+تستخدم معظم نماذج المحول (Transformer) الانتباه الكامل بحيث تكون مصفوفة الانتباه ذات الأبعاد المتساوية. ويمكن أن يمثل ذلك عقبة حسابية كبيرة عندما تكون لديك نصوص طويلة. ويعد Longformer وReformer من النماذج التي تحاول أن تكون أكثر كفاءة وتستخدم نسخة مخففة من مصفوفة الانتباه لتسريع التدريب.
+
+## انتباه LSH
+
+يستخدم [Reformer](model_doc/reformer) انتباه LSH. في الدالة softmax(QK^t)، فإن أكبر العناصر فقط (في بعد softmax) من المصفوفة QK^t هي التي ستعطي مساهمات مفيدة. لذلك، بالنسبة لكل استعلام q في Q، يمكننا أن نأخذ في الاعتبار فقط المفاتيح k في K المشابهة لـ q فقط. وتُستخدم دالة هاش لتحديد ما إذا كان q وk متشابهين. ويتم تعديل قناع الانتباه لتجاهل الرمز الحالي (باستثناء الموضع الأول)، لأنه سيعطي استعلامًا ومفتاحًا متساويين (لذلك متشابهين للغاية). نظرًا لطبيعة دالة الهاش العشوائية نوعًا ما، يتم في الممارسة العملية استخدام عدة دوال هاش (يحددها معامل n_rounds) ثم يتم حساب المتوسط معًا.
+
+## الانتباه المحلي
+
+يستخدم [Longformer](model_doc/longformer) الانتباه المحلي: غالبًا ما يكون السياق المحلي (على سبيل المثال، ما هما الرمزان إلى اليسار واليمين؟) كافيًا لاتخاذ إجراء بالنسبة للرمز المعطى. أيضًا، عن طريق تكديس طبقات الانتباه التي لها نافذة صغيرة، سيكون للطبقة الأخيرة مجال استقبال أكبر من مجرد الرموز في النافذة، مما يسمح لها ببناء تمثيل للجملة بأكملها.
+
+كما يتم منح بعض رموز الإدخال المختارة مسبقًا انتباهًا عالميًا: بالنسبة لهذه الرموز القليلة، يمكن لمصفوفة الانتباه الوصول إلى جميع الرموز وتكون هذه العملية متماثلة: فلجميع الرموز الأخرى إمكانية الوصول إلى تلك الرموز المحددة (بالإضافة إلى تلك الموجودة في نافذتهم المحلية). وهذا موضح في الشكل 2d من الورقة، انظر أدناه لمثال على قناع الانتباه:
+
+
+
+
+
+وباستخدام مصفوفات الانتباه هذه التي تحتوي على عدد أقل من المعلمات، يسمح النموذج بمدخالات ذات طول تسلسل أكبر.
+
+## حيل أخرى
+
+### الترميزات الموضعية المحورية
+
+يستخدم [Reformer](model_doc/reformer) ترميزات موضعية محورية: في نماذج المحول التقليدية، يكون الترميز الموضعي E مصفوفة بحجم \\(l\\) في \\(d\\)، حيث \\(l\\) هو طول التسلسل و\\(d\\) هو بعد الحالة المخفية. إذا كان لديك نصوص طويلة جدًا، فقد تكون هذه المصفوفة ضخمة وتستهلك مساحة كبيرة جدًا على وحدة معالجة الرسوميات (GPU). وللتخفيف من ذلك، تتكون الترميزات الموضعية المحورية من تحليل تلك المصفوفة الكبيرة E إلى مصفوفتين أصغر E1 وE2، بأبعاد \\(l_{1} \times d_{1}\\) و \\(l_{2} \times d_{2}\\)، بحيث \\(l_{1} \times l_{2} = l\\) و\\(d_{1} + d_{2} = d\\) (مع حاصل ضرب الأطوال، ينتهي الأمر بكونه أصغر بكثير). ويتم الحصول على الترميز للخطوة الزمنية \\(j\\) في E عن طريق ربط الترميزات للخطوة الزمنية \\(j \% l1\\) في E1 و \\(j // l1\\) في E2.
\ No newline at end of file
diff --git a/docs/source/ar/bertology.md b/docs/source/ar/bertology.md
new file mode 100644
index 00000000000000..d3f95e20d7df1a
--- /dev/null
+++ b/docs/source/ar/bertology.md
@@ -0,0 +1,18 @@
+# BERTology
+
+يُشهد في الآونة الأخيرة نمو مجال دراسي يُعنى باستكشاف آلية عمل نماذج المحولات الضخمة مثل BERT (والذي يُطلق عليها البعض اسم "BERTology"). ومن الأمثلة البارزة على هذا المجال ما يلي:
+
+- BERT Rediscovers the Classical NLP Pipeline بواسطة Ian Tenney و Dipanjan Das و Ellie Pavlick:
+ https://arxiv.org/abs/1905.05950
+- Are Sixteen Heads Really Better than One? بواسطة Paul Michel و Omer Levy و Graham Neubig: https://arxiv.org/abs/1905.10650
+- What Does BERT Look At? An Analysis of BERT's Attention بواسطة Kevin Clark و Urvashi Khandelwal و Omer Levy و Christopher D.
+ Manning: https://arxiv.org/abs/1906.04341
+- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
+
+لإثراء هذا المجال الناشئ، قمنا بتضمين بعض الميزات الإضافية في نماذج BERT/GPT/GPT-2 للسماح للناس بالوصول إلى التمثيلات الداخلية، والتي تم تكييفها بشكل أساسي من العمل الرائد لـ Paul Michel (https://arxiv.org/abs/1905.10650):
+
+- الوصول إلى جميع الحالات المخفية في BERT/GPT/GPT-2،
+- الوصول إلى جميع أوزان الانتباه لكل رأس في BERT/GPT/GPT-2،
+- استرجاع قيم ومشتقات مخرجات الرأس لحساب درجة أهمية الرأس وحذفه كما هو موضح في https://arxiv.org/abs/1905.10650.
+
+ولمساعدتك على فهم واستخدام هذه الميزات بسهولة، أضفنا مثالًا برمجيًا محددًا: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) أثناء استخراج المعلومات وتقليص من نموذج تم تدريبه مسبقًا على GLUE.
\ No newline at end of file
diff --git a/docs/source/ar/llm_tutorial_optimization.md b/docs/source/ar/llm_tutorial_optimization.md
new file mode 100644
index 00000000000000..59f17f7f8a92c2
--- /dev/null
+++ b/docs/source/ar/llm_tutorial_optimization.md
@@ -0,0 +1,795 @@
+# تحسين نماذج اللغة الكبيرة من حيث السرعة والذاكرة
+
+
+[[open-in-colab]]
+
+تحقق نماذج اللغة الكبيرة (LLMs) مثل GPT3/4، [Falcon](https://huggingface.co/tiiuae/falcon-40b)، و [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) تقدمًا سريعًا في قدرتها على معالجة المهام التي تركز على الإنسان، مما يجعلها أدوات أساسية في الصناعات القائمة على المعرفة الحديثة.
+لا يزال نشر هذه النماذج في المهام الواقعية يمثل تحديًا، ومع ذلك:
+
+- لكي تظهر نماذج اللغة الكبيرة قدرات فهم وتوليد النصوص قريبة من قدرات الإنسان، فإنها تتطلب حاليًا إلى تكوينها من مليارات المعلمات (انظر [كابلان وآخرون](https://arxiv.org/abs/2001.08361)، [وي وآخرون](https://arxiv.org/abs/2206.07682)). وهذا بدوره يزيد من متطلبات الذاكرة للاستدلال.
+- في العديد من المهام الواقعية، تحتاج نماذج اللغة الكبيرة إلى معلومات سياقية شاملة. يتطلب ذلك قدرة النموذج على إدارة تسلسلات إدخال طويلة للغاية أثناء الاستدلال.
+
+يكمن جوهر صعوبة هذه التحديات في تعزيز القدرات الحسابية والذاكرة لنماذج اللغة الكبيرة، خاصة عند التعامل مع تسلسلات الإدخال الضخمة.
+
+في هذا الدليل، سنستعرض التقنيات الفعالة لتُحسِّن من كفاءة نشر نماذج اللغة الكبيرة:
+
+1. سنتناول تقنية "دقة أقل" التي أثبتت الأبحاث فعاليتها في تحقيق مزايا حسابية دون التأثير بشكل ملحوظ على أداء النموذج عن طريق العمل بدقة رقمية أقل [8 بت و4 بت](/main_classes/quantization.md).
+
+2. **اFlash Attention:** إن Flash Attention وهي نسخة مُعدَّلة من خوارزمية الانتباه التي لا توفر فقط نهجًا أكثر كفاءة في استخدام الذاكرة، ولكنها تحقق أيضًا كفاءة متزايدة بسبب الاستخدام الأمثل لذاكرة GPU.
+
+3. **الابتكارات المعمارية:** حيث تم اقتراح هياكل متخصصة تسمح باستدلال أكثر فعالية نظرًا لأن نماذج اللغة الكبيرة يتم نشرها دائمًا بنفس الطريقة أثناء عملية الاستدلال، أي توليد النص التنبؤي التلقائي مع سياق الإدخال الطويل، فقد تم اقتراح بنيات نموذج متخصصة تسمح بالاستدلال الأكثر كفاءة. أهم تقدم في بنيات النماذج هنا هو [عذر](https://arxiv.org/abs/2108.12409)، [الترميز الدوار](https://arxiv.org/abs/2104.09864)، [الاهتمام متعدد الاستعلامات (MQA)](https://arxiv.org/abs/1911.02150) و [مجموعة الانتباه بالاستعلام (GQA)]((https://arxiv.org/abs/2305.13245)).
+
+على مدار هذا الدليل، سنقدم تحليلًا للتوليد التنبؤي التلقائي من منظور المُوتِّرات. نتعمق في مزايا وعيوب استخدام دقة أقل، ونقدم استكشافًا شاملاً لخوارزميات الانتباه الأحدث، ونناقش بنيات نماذج نماذج اللغة الكبيرة المحسنة. سندعم الشرح بأمثلة عملية تُبرِز كل تحسين على حدة.
+
+## 1. دقة أقل
+
+يمكن فهم متطلبات ذاكرة نماذج اللغة الكبيرة بشكل أفضل من خلال النظر إلى نموذج اللغة الكبيرة على أنها مجموعة من المصفوفات والمتجهات الوزنية، ومدخلات النص على أنها تسلسل من المتجهات. فيما يلي، سيتم استخدام تعريف "الأوزان" للإشارة إلى جميع مصفوفات الأوزان والمتجهات في النموذج.
+في وقت كتابة هذا الدليل، تتكون نماذج اللغة الكبيرة من مليارات المعلمات على الأقل.كل معلمة يتم تمثيلها برقم عشري مثل 4.5689 `` والذي يتم تخزينه عادةً بتنسيق [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format)، [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format)، أو [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) . يسمح لنا هذا بحساب متطلبات الذاكرة لتحميل نموذج اللغة الكبيرة في الذاكرة بسهولة:
+
+> *يتطلب تحميل أوزان نموذج به X مليار معلمة حوالي 4 * X جيجابايت من ذاكرة الفيديو العشوائية (VRAM) بدقة float32*
+
+ومع ذلك، نادرًا ما يتم تدريب النماذج في الوقت الحالي بدقة float32 الكاملة، ولكن عادةً ما تكون بدقة bfloat16 أو بشكل أقل في تنسيق float16. لذلك، تصبح القاعدة الإرشادية كما يلي:
+
+> *يتطلب تحميل أوزان نموذج به X مليار معلمة حوالي 2 * X جيجابايت من ذاكرة الفيديو العشوائية (VRAM) بدقة bfloat16/float16*
+
+بالنسبة لمدخلات النصوص القصيرة (أقل من 1024 رمزًا)، فإن متطلبات الذاكرة للاستدلال تهيمن عليها إلى حد كبير متطلبات الذاكرة لتحميل الأوزان. لذلك، دعنا نفترض، في الوقت الحالي، أن متطلبات الذاكرة للاستدلال تساوي متطلبات الذاكرة لتحميل النموذج في ذاكرة VRAM لوحدة معالجة الرسومات GPU..
+
+ولإعطاء بعض الأمثلة على مقدار ذاكرة الفيديو العشوائية (VRAM) التي يتطلبها تحميل نموذج بتنسيق bfloat16 تقريبًا:
+
+- **GPT3** يتطلب 2 \* 175 جيجا بايت = **350 جيجا بايت** VRAM
+- [**بلوم**](https://huggingface.co/bigscience/bloom) يتطلب 2 \* 176 جيجا بايت = **352 جيجا بايت** VRAM
+- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) يتطلب 2 \* 70 جيجا بايت = **140 جيجا بايت** VRAM
+- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) يتطلب 2 \* 40 جيجا بايت = **80 جيجا بايت** VRAM
+- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) يتطلب 2 \* 30 جيجا بايت = **60 جيجا بايت** VRAM
+- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) يتطلب 2 \* 15.5 = **31 جيجا بايت** VRAM
+
+عند كتابة هذا الدليل، أكبر شريحة لوحدة معالجة الرسومات المتوفّرة هي A100 و H100 التي توفر 80 جيجابايت من ذاكرة الفيديو العشوائية (VRAM). تتطلب معظم النماذج المدرجة أعلاه أكثر من 80 جيجابايت فقط لتحميلها، وبالتالي فهي تتطلب بالضرورة [التوازي للموتّرات](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) و/أو [لتوازي الخطي](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
+
+🤗 لا يدعم Transformers موازاة التنسور خارج الصندوق لأنه يتطلب كتابة هيكلة النموذج بطريقة محددة. إذا كنت مهتمًا بكتابة نماذج بطريقة صديقة لموازاة التنسور، فلا تتردد في إلقاء نظرة على [مكتبة الاستدلال بتوليد النص](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
+
+بدعم موازاة قنوات المعالجة البسيطة خارج الصندوق. للقيام بذلك، قم بتحميل النموذج باستخدام `device="auto"` والذي سيقوم تلقائيًا بوضع الطبقات المختلفة على وحدات معالجة الرسومات (GPU) المتاحة كما هو موضح [هنا](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
+لاحظ، مع ذلك، أنه في حين أن موازاة قنوات المعالجة البسيطة فعالة للغاية، إلا أنها لا تعالج مشكلات عدم نشاط وحدة معالجة الرسومات (GPU). لهذا، تكون موازاة قنوات المعالجة المتقدمة مطلوبة كما هو موضح [هنا](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
+
+إذا كان لديك حق الوصول إلى عقدة 8 x 80 جيجابايت A100، فيمكنك تحميل BLOOM كما يلي
+
+```bash
+!pip install transformers accelerate bitsandbytes optimum
+```
+```python
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
+```
+
+من خلال استخدام `device_map="auto"` سيتم توزيع طبقات الاهتمام بالتساوي عبر جميع وحدات معالجة الرسومات (GPU) المتاحة.
+
+في هذا الدليل، سنستخدم [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) لأنه يمكن تشغيله على شريحة جهاز GPU A100 ذات 40 جيجا بايت. لاحظ أن جميع تحسينات الذاكرة والسرعة التي سنطبقها من الآن فصاعدًا تنطبق بالتساوي على النماذج التي تتطلب موازاة النماذج أو المصفوفات.
+
+نظرًا لأن النموذج مُحمَّل بدقة bfloat16، فباستخدام قاعدتنا الإرشادية أعلاه، نتوقع أن تكون متطلبات الذاكرة لتشغيل الاستدلال باستخدام `bigcode/octocoder` حوالي 31 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM). دعنا نجرب.
+
+نقوم أولاً بتحميل النموذج والمجزىء اللغوي ثم نقوم بتمرير كلاهما إلى كائن [قنوات المعالجة](https://huggingface.co/docs/transformers/main_classes/pipelines) في Transformers.
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
+import torch
+
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+```python
+prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**الإخراج**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+رائع، يمكننا الآن استخدام النتيجة مباشرة لتحويل البايت إلى جيجا بايت.
+
+```python
+def bytes_to_giga_bytes(bytes):
+ return bytes / 1024 / 1024 / 1024
+```
+
+دعونا نستدعي [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) لقياس ذروة تخصيص ذاكرة وحدة معالجة الرسومات (GPU).
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**الإخراج**:
+```bash
+29.0260648727417
+```
+
+قريب بما يكفي من حسابنا التقريبي! يمكننا أن نرى أن الرقم غير صحيح تمامًا لأن الانتقال من البايت إلى الكيلوبايت يتطلب الضرب في 1024 بدلاً من 1000. لذلك يمكن أيضًا فهم صيغة التقريب على أنها حساب "بحد أقصى X جيجا بايت".
+لاحظ أنه إذا حاولنا تشغيل النموذج بدقة float32 الكاملة، فستكون هناك حاجة إلى 64 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM).
+
+> يتم تدريب جميع النماذج تقريبًا بتنسيق bfloat16 في الوقت الحالي، ولا يوجد سبب لتشغيل النموذج بدقة float32 الكاملة إذا [كانت وحدة معالجة الرسومات (GPU) الخاصة بك تدعم bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). لن توفر دقة float32 نتائج استدلال أفضل من الدقة التي تم استخدامها لتدريب النموذج.
+
+إذا لم تكن متأكدًا من تنسيق تخزين أوزان النموذج على Hub، فيمكنك دائمًا الاطلاع على تهيئة نقطة التفتيش في `"torch_dtype"`، على سبيل المثال [هنا](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). يوصى بتعيين النموذج إلى نفس نوع الدقة كما هو مكتوب في التهيئة عند التحميل باستخدام `from_pretrained(..., torch_dtype=...)` إلا إذا كان النوع الأصلي هو float32، وفي هذه الحالة يمكن استخدام `float16` أو `bfloat16` للاستدلال.
+
+
+دعونا نحدد وظيفة `flush(...)` لتحرير جميع الذاكرة المخصصة بحيث يمكننا قياس ذروة ذاكرة وحدة معالجة الرسومات (GPU) المخصصة بدقة.
+
+```python
+del pipe
+del model
+
+import gc
+import torch
+
+def flush():
+ gc.collect()
+ torch.cuda.empty_cache()
+ torch.cuda.reset_peak_memory_stats()
+```
+
+دعونا نستدعيه الآن للتجربة التالية.
+
+```python
+flush()
+```
+في الإصدار الأخير من مكتبة Accelerate، يمكنك أيضًا استخدام طريقة مساعدة تسمى `release_memory()`
+
+```python
+from accelerate.utils import release_memory
+# ...
+
+release_memory(model)
+```
+```python
+from accelerate.utils import release_memory
+# ...
+
+release_memory(model)
+```
+
+والآن ماذا لو لم يكن لدى وحدة معالجة الرسومات (GPU) لديك 32 جيجا بايت من ذاكرة الفيديو العشوائية (VRAM)؟ لقد وجد أن أوزان النماذج يمكن تحويلها إلى 8 بتات أو 4 بتات دون خسارة كبيرة في الأداء (انظر [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
+يمكن تحويل النموذج إلى 3 بتات أو 2 بتات مع فقدان مقبول في الأداء كما هو موضح في ورقة [GPTQ](https://arxiv.org/abs/2210.17323) 🤯.
+
+دون الدخول في الكثير من التفاصيل، تهدف مخططات التكميم إلى تخفيض دقة الأوزان مع محاولة الحفاظ على دقة نتائج النموذج كما هي (*أي* أقرب ما يمكن إلى bfloat16).
+لاحظ أن التكميم يعمل بشكل خاص جيدًا لتوليد النص حيث كل ما نهتم به هو اختيار *مجموعة الرموز الأكثر احتمالًا التالية* ولا نهتم حقًا بالقيم الدقيقة لتوزيع الرمز التالي *logit*.
+كل ما يهم هو أن توزيع الرمز التالي *logit* يظل كما هو تقريبًا بحيث تعطي عملية `argmax` أو `topk` نفس النتائج.
+
+هناك عدة تقنيات للتكميم، والتي لن نناقشها بالتفصيل هنا، ولكن بشكل عام، تعمل جميع تقنيات التكميم كما يلي:
+
+- 1. تكميم جميع الأوزان إلى الدقة المستهدفة
+- 2. تحميل الأوزان المحولة، ومرر تسلسل المدخلات من المتجهات بتنسيق bfloat16
+- 3. قم بتحويل الأوزان ديناميكيًا إلى bfloat1 لإجراء الحسابات مع متجهات المدخلات بدقة `bfloat16`
+
+باختصار، هذا يعني أن مضروبات *مصفوفة المدخلات-الوزن*، حيث \\( X \\) هي المدخلات، \\( W \\) هي مصفوفة وزن و \\( Y \\) هي الناتج:
+
+$$ Y = X * W $$
+
+تتغير إلى
+
+$$ Y = X * \text{dequantize}(W) $$
+
+لكل عملية ضرب المصفوفات. يتم تنفيذ إلغاء التكميم وإعادة التكميم بشكل متسلسل لجميع مصفوفات الأوزان أثناء مرور المدخلات عبر رسم الشبكة.
+
+لذلك، غالبًا ما لا يتم تقليل وقت الاستدلال عند استخدام الأوزان المكممة، ولكن بدلاً من ذلك يزيد.
+
+كفى نظرية، دعنا نجرب! لتكميم الأوزان باستخدام المحولات، تحتاج إلى التأكد من تثبيت مكتبة [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes).
+
+```bash
+!pip install bitsandbytes
+```
+
+يمكننا بعد ذلك تحميل النماذج في تكميم 8 بت ببساطة عن طريق إضافة علامة `load_in_8bit=True` إلى `from_pretrained`.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
+```
+
+الآن، دعنا نعيد تشغيل مثالنا ونقيس استخدام الذاكرة.
+
+```python
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**الإخراج**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+جميل، نحصل على نفس النتيجة كما في السابق، لذلك لا يوجد فقدان في الدقة! دعنا نلقي نظرة على مقدار الذاكرة المستخدمة هذه المرة.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**الإخراج**:
+```
+15.219234466552734
+```
+
+أقل بكثير! لقد انخفضنا إلى ما يزيد قليلاً عن 15 جيجابايت، وبالتالي يمكننا تشغيل هذا النموذج على وحدات معالجة الرسومات للمستهلك مثل 4090.
+
+نرى مكسبًا لطيفًا جدًا في كفاءة الذاكرة ولا يوجد تقريبًا أي تدهور في ناتج النموذج. ومع ذلك، يمكننا أيضًا ملاحظة تباطؤ طفيف أثناء الاستدلال.
+
+نحذف النماذج ونفرغ الذاكرة مرة أخرى.
+```python
+del model
+del pipe
+```
+
+```python
+flush()
+```
+
+دعنا نرى ما هو استهلاك ذاكرة GPU الذروة الذي يوفره تكميم 4 بت. يمكن تكميم النموذج إلى 4 بت باستخدام نفس واجهة برمجة التطبيقات كما في السابق - هذه المرة عن طريق تمرير `load_in_4bit=True` بدلاً من `load_in_8bit=True`.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**الإخراج**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
+```
+
+نحن نرى تقريبًا نفس نص الإخراج كما في السابق - فقط `python` مفقود قبل مقطع الكود. دعنا نرى مقدار الذاكرة المطلوبة.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**الإخراج**:
+```
+9.543574333190918
+```
+
+فقط 9.5 جيجابايت! هذا ليس كثيرًا بالفعل لنموذج يزيد عدد معاملاته عن 15 مليار.
+
+على الرغم من أننا نرى تدهورًا بسيطًا جدًا في الدقة لنموذجنا هنا، إلا أن تكميم 4 بت يمكن أن يؤدي في الممارسة العملية غالبًا إلى نتائج مختلفة مقارنة بتكميم 8 بت أو الاستدلال الكامل `bfloat16`. الأمر متروك للمستخدم لتجربته.
+
+لاحظ أيضًا أن الاستدلال هنا كان أبطأ قليلاً مقارنة بتكميم 8 بت والذي يرجع إلى طريقة التكميم الأكثر عدوانية المستخدمة لتكميم 4 بت مما يؤدي إلى \\( \text{quantize} \\) و \\( \text{dequantize} \\) يستغرق وقتًا أطول أثناء الاستدلال.
+
+```python
+del model
+del pipe
+```
+```python
+flush()
+```
+
+بشكل عام، رأينا أن تشغيل OctoCoder بدقة 8 بت قلل من ذاكرة GPU VRAM المطلوبة من 32G GPU VRAM إلى 15 جيجابايت فقط، وتشغيل النموذج بدقة 4 بت يقلل من ذاكرة GPU VRAM المطلوبة إلى ما يزيد قليلاً عن 9 جيجابايت.
+
+يسمح تكميم 4 بت بتشغيل النموذج على وحدات معالجة الرسومات مثل RTX3090 و V100 و T4 والتي يمكن الوصول إليها بسهولة لمعظم الأشخاص.
+
+لمزيد من المعلومات حول التكميم ولمعرفة كيف يمكن تكميم النماذج لطلب ذاكرة GPU VRAM أقل حتى من 4 بت، نوصي بالاطلاع على تنفيذ [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60).
+
+> كاستنتاج، من المهم تذكر أن تكميم النموذج يتداول كفاءة الذاكرة المحسنة مقابل الدقة وفي بعض الحالات وقت الاستدلال.
+
+إذا لم تكن ذاكرة GPU قيدًا لحالتك الاستخدام، فغالبًا لا توجد حاجة للنظر في التكميم. ومع ذلك، لا يمكن للعديد من وحدات معالجة الرسومات ببساطة تشغيل نماذج اللغة الكبيرة بدون طرق التكميم وفي هذه الحالة، تعد مخططات التكميم 4 بت و 8 بت أدوات مفيدة للغاية.
+
+لمزيد من المعلومات حول الاستخدام التفصيلي، نوصي بشدة بإلقاء نظرة على [وثائق تكميم المحولات](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
+
+بعد ذلك، دعنا نلقي نظرة على كيفية تحسين الكفاءة الحسابية وكفاءة الذاكرة باستخدام خوارزميات أفضل وبنية نموذج محسنة.
+
+## 2. الانتباه السريع
+
+تتشارك نماذج اللغة الكبيرة (LLMs) الأعلى أداءً اليوم تقريبًا نفس البنية الأساسية التي تتكون من طبقات التغذية الأمامية، وطبقات التنشيط، وطبقات التطبيع الطبقي، والأهم من ذلك، طبقات الانتباه الذاتي.
+
+تعد طبقات الانتباه الذاتي مركزية لنماذج اللغة الكبيرة (LLMs) حيث تمكن النموذج من فهم العلاقات السياقية بين رموز المدخلات.
+ومع ذلك، فإن استهلاك ذاكرة GPU الذروة لطبقات الانتباه الذاتي ينمو بشكل *رباعي* في كل من التعقيد الحسابي وتعقيد الذاكرة مع عدد رموز المدخلات (والذي يُطلق عليه أيضًا *طول التسلسل*) الذي نسميه في ما يلي بـ \\( N \\) .
+على الرغم من أن هذا غير ملحوظ حقًا للتسلسلات الأقصر (حتى 1000 رمز إدخال)، إلا أنه يصبح مشكلة خطيرة للتسلسلات الأطول (حوالي 16000 رمز إدخال).
+
+دعنا نلقي نظرة أقرب. الصيغة لحساب الناتج \\( \mathbf{O} \\) لطبقة الانتباه الذاتي لإدخال \\( \mathbf{X} \\) بطول \\( N \\) هي:
+
+$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
+
+يعد \\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) بالتالي تسلسل الإدخال إلى طبقة الاهتمام. وستتكون كل من الإسقاطات \\( \mathbf{Q} \\) و \\( \mathbf{K} \\) من \\( N \\) من المتجهات مما يؤدي إلى أن يكون حجم \\( \mathbf{QK}^T \\) هو \\( N^2 \\).
+
+عادة ما يكون لدى LLMs العديد من رؤوس الاهتمام، وبالتالي يتم إجراء العديد من حسابات الاهتمام الذاتي بالتوازي.
+وبافتراض أن LLM لديها 40 رأس اهتمام وتعمل بدقة bfloat16، يمكننا حساب متطلبات الذاكرة لتخزين مصفوفات \\( \mathbf{QK^T} \\) لتكون \\( 40 * 2 * N^2 \\) بايت. بالنسبة لـ \\( N=1000 \\)، لا يلزم سوى حوالي 50 ميجابايت من VRAM، ولكن بالنسبة لـ \\( N=16000 \\) سنحتاج إلى 19 جيجابايت من VRAM، وبالنسبة لـ \\( N=100,000 \\) سنحتاج إلى ما يقرب من 1 تيرابايت فقط لتخزين مصفوفات \\( \mathbf{QK}^T \\).
+
+باختصار، سرعان ما يصبح خوارزمية الانتباه الذاتي الافتراضية مكلفة للغاية من حيث الذاكرة بالنسبة لسياقات الإدخال الكبيرة.
+
+مع تحسن LLMs في فهم النص وتوليد النص، يتم تطبيقها على مهام متزايدة التعقيد. في حين أن النماذج كانت تتعامل سابقًا مع ترجمة أو تلخيص بضع جمل، فإنها الآن تدير صفحات كاملة، مما يتطلب القدرة على معالجة أطوال إدخال واسعة.
+
+كيف يمكننا التخلص من متطلبات الذاكرة الباهظة للتطويلات المدخلة الكبيرة؟ نحن بحاجة إلى طريقة جديدة لحساب آلية الاهتمام الذاتي التي تتخلص من مصفوفة \\( QK^T \\). [طريقه داو وآخرون.](Https://arxiv.org/abs/2205.14135) طوروا بالضبط مثل هذا الخوارزمية الجديدة وأطلقوا عليها اسم **Flash Attention**.
+
+باختصار، يكسر الاهتمام الفلاشي حساب \\( \mathbf{V} \times \operatorname{Softmax}(\mathbf{QK}^T\\)) ويحسب بدلاً من ذلك قطعًا أصغر من الإخراج عن طريق التكرار عبر العديد من خطوات حساب Softmax:
+
+$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \operatorname{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations } $$
+
+مع \\( s^a_{ij} \\) و \\( s^b_{ij} \\) كونها بعض إحصائيات التطبيع softmax التي يجب إعادة حسابها لكل \\( i \\) و \\( j \\).
+
+يرجى ملاحظة أن Flash Attention بالكامل أكثر تعقيدًا إلى حد ما ويتم تبسيطه بشكل كبير هنا حيث أن التعمق كثيرًا يخرج عن نطاق هذا الدليل. القارئ مدعو لإلقاء نظرة على ورقة Flash Attention المكتوبة جيدًا [1] لمزيد من التفاصيل.
+
+الفكرة الرئيسية هنا هي:
+
+> من خلال تتبع إحصائيات التطبيع softmax واستخدام بعض الرياضيات الذكية، يعطي Flash Attention **مخرجات متطابقة رقميًا** مقارنة بطبقة الاهتمام الذاتي الافتراضية بتكلفة ذاكرة لا تزيد خطيًا مع \\( N \\).
+
+عند النظر إلى الصيغة، قد يقول المرء بديهيًا أن الاهتمام الفلاشي يجب أن يكون أبطأ بكثير مقارنة بصيغة الاهتمام الافتراضية حيث يلزم إجراء المزيد من الحسابات. في الواقع، يتطلب Flash Attention المزيد من عمليات الفاصلة العائمة مقارنة بالاهتمام العادي حيث يجب إعادة حساب إحصائيات التطبيع softmax باستمرار (راجع [الورقة](https://arxiv.org/abs/2205.14135) لمزيد من التفاصيل إذا كنت مهتمًا)
+
+> ومع ذلك، فإن الاهتمام الفلاشي أسرع بكثير في الاستدلال مقارنة بالاهتمام الافتراضي الذي يأتي من قدرته على تقليل الطلبات على ذاكرة GPU الأبطأ ذات النطاق الترددي العالي (VRAM)، والتركيز بدلاً من ذلك على ذاكرة SRAM الأسرع الموجودة على الشريحة.
+
+من الناحية الأساسية، يتأكد Flash Attention من إمكانية إجراء جميع عمليات الكتابة والقراءة الوسيطة باستخدام ذاكرة SRAM السريعة الموجودة على الشريحة بدلاً من الاضطرار إلى الوصول إلى ذاكرة VRAM الأبطأ لحساب متجه الإخراج \\( \mathbf{O} \\).
+
+من الناحية العملية، لا يوجد حاليًا أي سبب **عدم** استخدام الاهتمام الفلاشي إذا كان متاحًا. الخوارزمية تعطي نفس المخرجات رياضيا، وأسرع وأكثر كفاءة في استخدام الذاكرة.
+
+لنلقِ نظرة على مثال عملي.
+
+
+يحصل نموذج OctoCoder الخاص بنا الآن على موجه إدخال أطول بشكل كبير يتضمن ما يسمى *موجه النظام*. تُستخدم موجهات النظام لتوجيه LLM إلى مساعد أفضل مصمم لمهام المستخدمين.
+فيما يلي، نستخدم موجه النظام الذي سيجعل OctoCoder مساعد ترميز أفضل.
+
+```python
+system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
+The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
+The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
+It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
+That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
+
+The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
+The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
+-----
+
+Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
+
+Answer: Sure. Here is a function that does that.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(len(list1)):
+ results.append(list1[i])
+ results.append(list2[i])
+ return results
+
+Question: Can you write some test cases for this function?
+
+Answer: Sure, here are some tests.
+
+assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
+assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
+assert alternating([], []) == []
+
+Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
+
+Answer: Here is the modified function.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(min(len(list1), len(list2))):
+ results.append(list1[i])
+ results.append(list2[i])
+ if len(list1) > len(list2):
+ results.extend(list1[i+1:])
+ else:
+ results.extend(list2[i+1:])
+ return results
+-----
+"""
+```
+لأغراض التوضيح، سنكرر موجه النظام عشر مرات بحيث يكون طول الإدخال طويلاً بما يكفي لملاحظة وفورات ذاكرة Flash Attention.
+نضيف موجه النص الأصلي "سؤال: يرجى كتابة وظيفة في Python تقوم بتحويل البايتات إلى جيجا بايت.
+
+```python
+long_prompt = 10 * system_prompt + prompt
+```
+
+نقوم بتنفيذ نموذجنا مرة أخرى بدقة bfloat16.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+دعنا الآن نقوم بتشغيل النموذج تمامًا مثلما كان من قبل *بدون اهتمام فلاشي* وقياس متطلبات ذاكرة GPU وقت الذروة ووقت الاستدلال.
+
+```python
+import time
+
+start_time = time.time()
+result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**الإخراج**:
+```
+تم التوليد في 10.96854019165039 ثانية.
+بالتأكيد. إليك وظيفة للقيام بذلك.
+
+def bytes_to_giga(bytes):
+return bytes / 1024 / 1024 / 1024
+
+الإجابة: بالتأكيد. إليك وظيفة للقيام بذلك.
+
+ديف
+```
+
+نحصل على نفس الإخراج كما كان من قبل، ولكن هذه المرة، يقوم النموذج بتكرار الإجابة عدة مرات حتى يتم قطعها عند 60 رمزًا. ليس من المستغرب أننا كررنا موجه النظام عشر مرات لأغراض التوضيح وبالتالي قمنا بتشغيل النموذج لتكرار نفسه.
+
+**ملاحظة** لا ينبغي تكرار موجه النظام عشر مرات في التطبيقات الواقعية - مرة واحدة كافية!
+
+دعنا نقيس متطلبات ذاكرة GPU وقت الذروة.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**الإخراج**:
+```
+37.668193340301514
+```
+
+كما نرى، فإن متطلبات ذاكرة GPU وقت الذروة أعلى بكثير مما كانت عليه في البداية، وهو ما يرجع إلى حد كبير إلى تسلسل الإدخال الأطول. أيضًا، يستغرق التوليد أكثر من دقيقة بقليل الآن.
+
+نستدعي `flush()` لتحرير ذاكرة GPU لتجربتنا التالية.
+
+```python
+flush()
+```
+
+لمقارنة، دعونا نقوم بتشغيل نفس الدالة، ولكن تمكين الاهتمام فلاش بدلا من ذلك.
+للقيام بذلك، نقوم بتحويل النموذج إلى [BetterTransformer](Https://huggingface.co/docs/optimum/bettertransformer/overview) ومن خلال القيام بذلك تمكين PyTorch's [SDPA self-attention](Https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) والتي بدورها قادرة على استخدام الاهتمام فلاش.
+
+```python
+model.to_bettertransformer()
+```
+
+الآن نقوم بتشغيل نفس مقتطف التعليمات البرمجية بالضبط كما كان من قبل وتحت الغطاء سوف تستخدم المحولات الاهتمام فلاش.
+
+```py
+start_time = time.time()
+with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
+ result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**الإخراج**:
+```
+تم التوليد في 3.0211617946624756 ثانية.
+بالتأكيد. إليك وظيفة للقيام بذلك.
+
+def bytes_to_giga(bytes):
+return bytes / 1024 / 1024 / 1024
+
+الإجابة: بالتأكيد. إليك وظيفة للقيام بذلك.
+
+ديف
+```
+
+نحصل على نفس النتيجة بالضبط كما كان من قبل، ولكن يمكننا ملاحظة تسريع كبير بفضل الاهتمام فلاش.
+
+دعنا نقيس استهلاك الذاكرة لآخر مرة.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**الإخراج**:
+```
+32.617331981658936
+```
+
+ونحن تقريبا مرة أخرى إلى ذاكرة GPU الذروة الأصلية لدينا 29GB.
+
+يمكننا أن نلاحظ أننا نستخدم فقط حوالي 100 ميجابايت إضافية من ذاكرة GPU عند تمرير تسلسل إدخال طويل جدًا مع الاهتمام فلاش مقارنة بتمرير تسلسل إدخال قصير كما فعلنا في البداية.
+
+```py
+flush()
+```
+
+لمزيد من المعلومات حول كيفية استخدام Flash Attention، يرجى الاطلاع على [صفحة doc هذه](Https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
+
+## 3. الابتكارات المعمارية
+
+حتى الآن، نظرنا في تحسين الكفاءة الحسابية والذاكرة من خلال:
+
+- صب الأوزان في تنسيق دقة أقل
+- استبدال خوارزمية الاهتمام الذاتي بإصدار أكثر كفاءة من حيث الذاكرة والحساب
+
+دعونا الآن نلقي نظرة على كيفية تغيير بنية LLM بحيث تكون أكثر فعالية وكفاءة للمهام التي تتطلب مدخلات نصية طويلة، على سبيل المثال:
+- استرجاع الأسئلة المعززة،
+- تلخيص،
+- الدردشة
+
+لاحظ أن "الدردشة" لا تتطلب من LLM التعامل مع مدخلات نصية طويلة فحسب، بل تتطلب أيضًا أن يكون LLM قادرًا على التعامل بكفاءة مع الحوار ذهابًا وإيابًا بين المستخدم والمساعد (مثل ChatGPT).
+
+بمجرد تدريبها، يصبح من الصعب تغيير بنية LLM الأساسية، لذلك من المهم مراعاة مهام LLM مسبقًا وتحسين بنية النموذج وفقًا لذلك.
+هناك مكونان مهمان لبنية النموذج يصبحان بسرعة عنق زجاجة للذاكرة و/أو الأداء لتسلسلات الإدخال الكبيرة.
+
+- الترميزات الموضعية
+- ذاكرة التخزين المؤقت للقيمة الرئيسية
+
+دعنا نلقي نظرة على كل مكون بمزيد من التفاصيل
+
+### 3.1 تحسين الترميزات الموضعية لـ LLMs
+
+يضع الاهتمام الذاتي كل رمز في علاقة مع رموز أخرى.
+كمثال، يمكن أن تبدو مصفوفة \\( \operatorname{Softmax}(\mathbf{QK}^T) \\) لتسلسل الإدخال النصي *"مرحبًا"، "أنا"، "أحب"، "أنت"* كما يلي:
+
+
+
+يتم منح كل رمز كلمة كتلة احتمال يتم من خلالها الاهتمام بجميع رموز الكلمات الأخرى، وبالتالي يتم وضعها في علاقة مع جميع رموز الكلمات الأخرى. على سبيل المثال، تحضر كلمة *"الحب"* كلمة *"مرحبًا"* بنسبة 5%، و *"أنا"* بنسبة 30%، ونفسها بنسبة 65%.
+
+سيواجه LLM القائم على الاهتمام الذاتي، ولكن بدون الترميزات الموضعية، صعوبات كبيرة في فهم مواضع نصوص الإدخال بالنسبة لبعضها البعض.
+ويرجع ذلك إلى أن درجة الاحتمال التي يحسبها \\( \mathbf{QK}^T \\) تربط كل رمز كلمة بكل رمز كلمة أخرى في حسابات \\( O (1) \\) بغض النظر عن مسافة الموضع النسبي بينهما.
+لذلك، بالنسبة إلى LLM بدون ترميزات موضعية، يبدو أن كل رمز له نفس المسافة إلى جميع الرموز الأخرى، على سبيل المثال، سيكون من الصعب التمييز بين *"مرحبًا أنا أحبك"* و *"أنت تحبني مرحبًا"*.
+
+لكي يفهم LLM ترتيب الجملة، يلزم وجود *إشارة* إضافية ويتم تطبيقها عادةً في شكل *الترميزات الموضعية* (أو ما يُطلق عليه أيضًا *الترميزات الموضعية*).
+لم يتم ترجمة النص الخاص والروابط وأكواد HTML وCSS بناءً على طلبك.
+
+قدم مؤلفو الورقة البحثية [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) تضمينات موضعية جيبية مثلثية \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) حيث يتم حساب كل متجه \\( \mathbf{p}_i \\) كدالة جيبية لموضعه \\( i \\) .
+بعد ذلك يتم ببساطة إضافة التضمينات الموضعية إلى متجهات تسلسل الإدخال \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) وبالتالي توجيه النموذج لتعلم ترتيب الجملة بشكل أفضل.
+
+بدلاً من استخدام التضمينات الموضعية الثابتة، استخدم آخرون (مثل [Devlin et al.](https://arxiv.org/abs/1810.04805)) تضمينات موضعية مكتسبة يتم من خلالها تعلم التضمينات الموضعية \\( \mathbf{P} \\) أثناء التدريب.
+
+كانت التضمينات الموضعية الجيبية والمكتسبة هي الطرق السائدة لترميز ترتيب الجملة في نماذج اللغة الكبيرة، ولكن تم العثور على بعض المشكلات المتعلقة بهذه التضمينات الموضعية:
+
+1. التضمينات الموضعية الجيبية والمكتسبة هي تضمينات موضعية مطلقة، أي ترميز تضمين فريد لكل معرف موضعي: \\( 0, \ldots, N \\) . كما أظهر [Huang et al.](https://arxiv.org/abs/2009.13658) و [Su et al.](https://arxiv.org/abs/2104.09864)، تؤدي التضمينات الموضعية المطلقة إلى أداء ضعيف لنماذج اللغة الكبيرة للمدخلات النصية الطويلة. بالنسبة للمدخلات النصية الطويلة، يكون من المفيد إذا تعلم النموذج المسافة الموضعية النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض بدلاً من موضعها المطلق.
+2. عند استخدام التضمينات الموضعية المكتسبة، يجب تدريب نموذج اللغة الكبيرة على طول إدخال ثابت \\( N \\)، مما يجعل من الصعب الاستقراء إلى طول إدخال أطول مما تم تدريبه عليه.
+
+في الآونة الأخيرة، أصبحت التضمينات الموضعية النسبية التي يمكنها معالجة المشكلات المذكورة أعلاه أكثر شعبية، وأبرزها:
+
+- [تضمين الموضع الدوراني (RoPE)](https://arxiv.org/abs/2104.09864)
+- [ALiBi](https://arxiv.org/abs/2108.12409)
+
+يؤكد كل من *RoPE* و *ALiBi* أنه من الأفضل توجيه نموذج اللغة الكبيرة حول ترتيب الجملة مباشرة في خوارزمية الانتباه الذاتي حيث يتم وضع رموز الكلمات في علاقة مع بعضها البعض. على وجه التحديد، يجب توجيه ترتيب الجملة عن طريق تعديل عملية \\( \mathbf{QK}^T \\) .
+
+دون الدخول في الكثير من التفاصيل، يشير *RoPE* إلى أنه يمكن ترميز المعلومات الموضعية في أزواج الاستعلام-المفتاح، على سبيل المثال \\( \mathbf{q}_i \\) و \\( \mathbf{x}_j \\) عن طريق تدوير كل متجه بزاوية \\( \theta * i \\) و \\( \theta * j \\) على التوالي مع \\( i, j \\) تصف موضع الجملة لكل متجه:
+
+$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
+
+يمثل \\( \mathbf{R}_{\theta, i - j} \\) مصفوفة دورانية. \\( \theta \\) *لا* يتم تعلمه أثناء التدريب، ولكن بدلاً من ذلك يتم تعيينه إلى قيمة محددة مسبقًا تعتمد على طول تسلسل الإدخال الأقصى أثناء التدريب.
+
+> من خلال القيام بذلك، يتم التأثير على درجة الاحتمال بين \\( \mathbf{q}_i \\) و \\( \mathbf{q}_j \\) فقط إذا \\( i \ne j \\) ويعتمد فقط على المسافة النسبية \\( i - j \\) بغض النظر عن المواضع المحددة لكل متجه \\( i \\) و \\( j \\) .
+
+يستخدم *RoPE* في العديد من نماذج اللغة الكبيرة الأكثر أهمية اليوم، مثل:
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**Llama**](https://arxiv.org/abs/2302.13971)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+
+كبديل، يقترح *ALiBi* مخطط ترميز موضعي نسبي أبسط بكثير. يتم إضافة المسافة النسبية التي تمتلكها رموز المدخلات إلى بعضها البعض كعدد صحيح سلبي مقياس بقيمة محددة مسبقًا `m` إلى كل إدخال استعلام-مفتاح لمصفوفة \\( \mathbf{QK}^T \\) مباشرة قبل حساب softmax.
+
+
+
+كما هو موضح في ورقة [ALiBi](https://arxiv.org/abs/2108.12409)، يسمح هذا الترميز الموضعي النسبي البسيط للنموذج بالحفاظ على أداء عالٍ حتى في تسلسلات المدخلات النصية الطويلة جدًا.
+
+يُستخدم *ALiBi* في العديد من أهم نماذج اللغة الكبيرة المستخدمة اليوم، مثل:
+
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+يمكن لكل من ترميزات الموضع *RoPE* و *ALiBi* الاستقراء إلى أطوال إدخال لم يتم ملاحظتها أثناء التدريب، في حين ثبت أن الاستقراء يعمل بشكل أفضل بكثير خارج الصندوق لـ *ALiBi* مقارنة بـ *RoPE*.
+بالنسبة لـ ALiBi، ما عليك سوى زيادة قيم مصفوفة الموضع المثلث السفلي لمطابقة طول تسلسل الإدخال.
+بالنسبة لـ *RoPE*، يؤدي الحفاظ على نفس \\( \theta \\) الذي تم استخدامه أثناء التدريب إلى نتائج سيئة عند تمرير إدخالات نصية أطول بكثير من تلك التي شوهدت أثناء التدريب، راجع [Press et al.](https://arxiv.org/abs/2108.12409). ومع ذلك، وجد المجتمع بعض الحيل الفعالة التي تقوم بتعديل \\( \theta \\)، مما يسمح لترميزات الموضع *RoPE* بالعمل بشكل جيد لتسلسلات إدخال النص المستقرئة (راجع [هنا](https://github.com/huggingface/transformers/pull/24653)).
+
+> كل من RoPE و ALiBi عبارة عن ترميزات موضع نسبي *لا* يتم تعلمها أثناء التدريب، ولكن بدلاً من ذلك تستند إلى الحدس التالي:
+ - يجب إعطاء الإشارات الموضعية حول إدخالات النص مباشرة إلى مصفوفة \\( QK^T \\) لطبقة الاهتمام الذاتي
+ - يجب تحفيز LLM لتعلم ترميزات موضعية ثابتة *نسبية* المسافة لبعضها البعض
+ - كلما ابتعدت رموز إدخال النص عن بعضها البعض، انخفض احتمال الاستعلام والقيمة. كل من RoPE و ALiBi يقللان من احتمال الاستعلام والمفتاح للرموز البعيدة عن بعضها البعض. يقوم RoPE بذلك عن طريق تقليل منتج المتجه من خلال زيادة الزاوية بين متجهات الاستعلام والمفتاح. تضيف ALiBi أرقامًا كبيرة سالبة إلى المنتج الاتجاهي
+
+في الختام، من الأفضل تدريب نماذج اللغة الكبيرة المراد نشرها في مهام تتطلب التعامل مع إدخالات نصية كبيرة باستخدام ترميزات موضعية نسبية، مثل RoPE و ALiBi. لاحظ أيضًا أنه حتى إذا تم تدريب نموذج لغة كبيرة باستخدام RoPE و ALiBi على طول ثابت يبلغ، على سبيل المثال، \\( N_1 = 2048 \\)، فيمكن استخدامه عمليًا بإدخالات نصية أكبر بكثير من \\( N_1 \\)، مثل \\( N_2 = 8192> N_1 \\) عن طريق استقراء الترميزات الموضعية.
+
+### 3.2 ذاكرة التخزين المؤقت للمفتاح والقيمة
+
+تعمل عملية توليد النص ذاتي التراجع باستخدام نماذج اللغة الكبيرة عن طريق إدخال تسلسل إدخال بشكل تكراري، وأخذ عينات من الرمز التالي، وإلحاق الرمز التالي بتسلسل الإدخال، والاستمرار في ذلك حتى ينتج نموذج اللغة الكبيرة رمزًا يشير إلى انتهاء التوليد.
+
+يرجى الاطلاع على [دليل إنشاء النص الخاص بـ Transformer](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) للحصول على شرح مرئي أفضل لكيفية عمل التوليد ذاتي التراجع.
+
+دعنا ننفذ مقتطفًا قصيرًا من التعليمات البرمجية لإظهار كيفية عمل التوليد ذاتي التراجع في الممارسة. ببساطة، سنأخذ الرمز الأكثر احتمالًا عبر `torch.argmax`.
+
+```python
+input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits = model(input_ids)["logits"][:, -1:]
+ next_token_id = torch.argmax(next_logits,dim=-1)
+
+ input_ids = torch.cat([input_ids, next_token_id], dim=-1)
+ print("shape of input_ids", input_ids.shape)
+
+generated_text = tokenizer.batch_decode(input_ids[:, -5:])
+generated_text
+```
+
+**الإخراج**:
+```
+shape of input_ids torch.Size([1, 21])
+shape of input_ids torch.Size([1, 22])
+shape of input_ids torch.Size([1, 23])
+shape of input_ids torch.Size([1, 24])
+shape of input_ids torch.Size([1, 25])
+[' Here is a Python function']
+```
+
+كما نرى، في كل مرة نزيد من رموز إدخال النص بالرمز الذي تم أخذ عينات منه للتو.
+
+باستثناءات قليلة جدًا، يتم تدريب نماذج اللغة الكبيرة باستخدام [هدف نمذجة اللغة السببية](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) وبالتالي يتم قناع المثلث العلوي لمصفوفة نتيجة الاهتمام - وهذا هو السبب في ترك نتائج الاهتمام فارغة (*أي لها احتمال 0*) في المخططين أعلاه. للحصول على ملخص سريع حول نمذجة اللغة السببية، يمكنك الرجوع إلى مدونة [*Illustrated Self Attention*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
+
+ونتيجة لذلك، *لا* تعتمد الرموز *أبدًا* على الرموز السابقة، وبشكل أكثر تحديدًا، لا يتم أبدًا وضع المتجه \\( \mathbf{q}_i \\) في علاقة مع أي متجهات المفاتيح والقيم \\( \mathbf{k}_j، \mathbf{v}_j \\) إذا \\( j> i \\). بدلاً من ذلك، يحضر \\( \mathbf{q}_i \\) فقط إلى متجهات المفاتيح والقيم السابقة \\( \mathbf{k}_{m < i}، \mathbf{v}_{m < i} \text{ , for } m \in \{0، \ ldots i - 1\} \\). لتقليل الحسابات غير الضرورية، يمكن تخزين ذاكرة التخزين المؤقت لكل طبقة للمفاتيح ومتجهات القيم لجميع الخطوات الزمنية السابقة.
+
+فيما يلي، سنطلب من نموذج اللغة الكبيرة استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم عن طريق استردادها وإرسالها لكل عملية توجيه.
+في Transformers، يمكننا استرداد ذاكرة التخزين المؤقت للمفاتيح والقيم عن طريق تمرير علم `use_cache` إلى مكالمة `forward` ويمكننا بعد ذلك تمريره مع الرمز الحالي.
+
+```python
+past_key_values = None # past_key_values is the key-value cache
+generated_tokens = []
+next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
+ next_logits = next_logits[:, -1:]
+ next_token_id = torch.argmax(next_logits, dim=-1)
+
+ print("shape of input_ids", next_token_id.shape)
+ print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
+ generated_tokens.append(next_token_id.item())
+
+generated_text = tokenizer.batch_decode(generated_tokens)
+generated_text
+```
+
+**الإخراج**:
+```
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 20
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 21
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 22
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 23
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 24
+[' Here', ' is', ' a', ' Python', ' function']
+```
+
+كما هو موضح، عند استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم، لا يتم زيادة رموز إدخال النص في الطول، ولكنها تظل متجه إدخال واحدًا. من ناحية أخرى، يتم زيادة طول ذاكرة التخزين المؤقت للمفاتيح والقيم بواحد في كل خطوة فك التشفير.
+
+> يعني استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم أن \\( \mathbf{QK}^T \\) يتم تقليله بشكل أساسي إلى \\( \mathbf{q}_c\mathbf{K}^T \\) مع \\( \mathbf{q}_c \\) كونها إسقاط الاستعلام للرمز المدخل الحالي الذي يكون *دائمًا* مجرد متجه واحد.
+
+لاستخدام ذاكرة التخزين المؤقت للمفاتيح والقيم ميزتان:
+- زيادة كبيرة في الكفاءة الحسابية حيث يتم إجراء حسابات أقل مقارنة بحساب مصفوفة \\( \mathbf{QK}^T \\) الكاملة. يؤدي ذلك إلى زيادة سرعة الاستدلال
+- لا تزداد الذاكرة القصوى المطلوبة بشكل تربيعي مع عدد الرموز المولدة، ولكنها تزداد بشكل خطي فقط.
+
+> يجب *دائمًا* استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم حيث يؤدي ذلك إلى نتائج متطابقة وزيادة كبيرة في السرعة لتسلسلات الإدخال الأطول. ذاكرة التخزين المؤقت للمفاتيح والقيم ممكّنة بشكل افتراضي في Transformers عند استخدام خط أنابيب النص أو طريقة [`generate`](https://huggingface.co/docs/transformers/main_classes/text_generation).
+
+
+
+
+لاحظ أنه على الرغم من نصيحتنا باستخدام ذاكرة التخزين المؤقت للمفاتيح والقيم، فقد يكون إخراج نموذج اللغة الكبيرة مختلفًا قليلاً عند استخدامها. هذه خاصية نوى ضرب المصفوفة نفسها - يمكنك قراءة المزيد عنها [هنا](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
+
+
+
+#### 3.2.1 محادثة متعددة الجولات
+
+ذاكرة التخزين المؤقت للمفاتيح والقيم مفيدة بشكل خاص للتطبيقات مثل الدردشة حيث تكون هناك حاجة إلى عدة تمريرات من فك التشفير ذاتي التراجع. دعنا نلقي نظرة على مثال.
+
+```
+المستخدم: كم عدد الأشخاص الذين يعيشون في فرنسا؟
+المساعد: يعيش حوالي 75 مليون شخص في فرنسا
+المستخدم: وكم عدد الأشخاص في ألمانيا؟
+المساعد: يوجد في ألمانيا حوالي 81 مليون نسمة
+
+User: How many people live in France?
+Assistant: Roughly 75 million people live in France
+User: And how many are in Germany?
+Assistant: Germany has ca. 81 million inhabitants
+```
+
+In this chat، يقوم LLM بتشغيل فك التشفير التلقائي مرتين:
+ 1. المرة الأولى، تكون ذاكرة التخزين المؤقت key-value فارغة، ويكون موجه الإدخال هو "User: How many people live in France؟" ويقوم النموذج بإنشاء النص "Roughly 75 million people live in France" بشكل تلقائي أثناء زيادة ذاكرة التخزين المؤقت key-value في كل خطوة فك تشفير.
+ 2. في المرة الثانية، يكون موجه الإدخال هو "User: How many people live in France؟ \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany؟". بفضل ذاكرة التخزين المؤقت، يتم بالفعل حساب جميع متجهات القيمة الرئيسية لجاريتين الأولى. لذلك يتكون موجه الإدخال فقط من "User: And how many in Germany؟". أثناء معالجة موجه الإدخال المختصر، يتم ربط متجهات القيمة المحسوبة بذاكرة التخزين المؤقت key-value الخاصة بفك التشفير الأول. يتم بعد ذلك إنشاء إجابة المساعد الثانية "Germany has ca. 81 million inhabitants" بشكل تلقائي باستخدام ذاكرة التخزين المؤقت key-value المكونة من متجهات القيمة المشفرة لـ "User: How many people live in France؟ \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany؟".
+
+يجب ملاحظة أمرين هنا:
+ 1. الحفاظ على كل السياق أمر بالغ الأهمية للنماذج اللغوية الكبيرة (LLMs) التي يتم نشرها في الدردشة بحيث يفهم LLM كل سياق المحادثة السابق. على سبيل المثال، بالنسبة للمثال أعلاه، يحتاج LLM إلى فهم أن المستخدم يشير إلى السكان عند السؤال "And how many are in Germany؟".
+ 2. ذاكرة التخزين المؤقت key-value مفيدة للغاية للدردشة حيث تتيح لنا النمو المستمر لتاريخ الدردشة المشفرة بدلاً من الاضطرار إلى إعادة تشفير تاريخ الدردشة من البداية (كما هو الحال، على سبيل المثال، عند استخدام بنية ترميز فك التشفير).
+
+في `transformers`، ستعيد مكالمة `generate` `past_key_values` عندما يتم تمرير `return_dict_in_generate=True`، بالإضافة إلى `use_cache=True` الافتراضي. لاحظ أنه غير متوفر بعد من خلال واجهة `pipeline`.
+
+```python
+# Generation as usual
+prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
+model_inputs = tokenizer(prompt، return_tensors='pt')
+generation_output = model.generate(**model_inputs، max_new_tokens=60، return_dict_in_generate=True)
+decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
+
+# Piping the returned `past_key_values` to speed up the next conversation round
+prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
+model_inputs = tokenizer(prompt، return_tensors='pt')
+generation_output = model.generate(
+ **model_inputs،
+ past_key_values=generation_output.past_key_values،
+ max_new_tokens=60،
+ return_dict_in_generate=True
+)
+tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
+```
+
+**الإخراج**:
+```
+ هي نسخة معدلة من الدالة التي تعيد ميجا بايت بدلاً من ذلك.
+
+def bytes_to_megabytes(bytes):
+ return bytes / 1024 / 1024
+
+Answer: The function takes a number of bytes as input and returns the number of
+```
+
+رائع، لا يتم إنفاق وقت إضافي على إعادة حساب نفس المفتاح والقيم لطبقة الاهتمام! ومع ذلك، هناك شيء واحد يجب ملاحظته. في حين أن ذروة الذاكرة المطلوبة لمصفوفة \\( \mathbf{QK}^T \\) يتم تقليلها بشكل كبير، فإن الاحتفاظ بذاكرة التخزين المؤقت key-value في الذاكرة يمكن أن يصبح مكلفًا جدًا من حيث الذاكرة لسلاسل الإدخال الطويلة أو الدردشة متعددة الجولات. تذكر أن ذاكرة التخزين المؤقت key-value بحاجة إلى تخزين متجهات القيمة الرئيسية لجميع متجهات الإدخال السابقة \\( \mathbf{x}_i \text{، لـ } i \in \{1، \ ldots، c - 1\} \\) لجميع طبقات الاهتمام الذاتي وكل رؤوس الاهتمام.
+
+دعنا نحسب عدد القيم العائمة التي يجب تخزينها في ذاكرة التخزين المؤقت key-value لنموذج LLM `bigcode/octocoder` الذي استخدمناه من قبل.
+يبلغ عدد القيم العائمة ضعف طول التسلسل مضروبًا في عدد رؤوس الاهتمام مضروبًا في بعد رأس الاهتمام ومضروبًا في عدد الطبقات.
+حساب هذا لنموذج LLM لدينا عند طول تسلسل افتراضي يبلغ 16000 يعطي:
+
+```python
+config = model.config
+2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
+```
+
+**الإخراج**:
+```
+7864320000
+```
+
+Roughly 8 مليار قيمة عائمة! يتطلب تخزين 8 مليارات قيمة عائمة في دقة `float16` حوالي 15 جيجابايت من ذاكرة الوصول العشوائي (RAM) وهو ما يقرب من نصف حجم أوزان النموذج نفسها!
+اقترح الباحثون طريقتين تسمحان بتقليل تكلفة الذاكرة لتخزين ذاكرة التخزين المؤقت key-value بشكل كبير، والتي يتم استكشافها في الأقسام الفرعية التالية.
+
+#### 3.2.2 Multi-Query-Attention (MQA)
+
+[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) اقترحها Noam Shazeer في ورقته *Fast Transformer Decoding: One Write-Head is All You Need*. كما يقول العنوان، اكتشف Noam أنه بدلاً من استخدام `n_head` من أوزان إسقاط القيمة الرئيسية، يمكن استخدام زوج واحد من أوزان إسقاط رأس القيمة التي يتم مشاركتها عبر جميع رؤوس الاهتمام دون أن يتدهور أداء النموذج بشكل كبير.
+
+> باستخدام زوج واحد من أوزان إسقاط رأس القيمة، يجب أن تكون متجهات القيمة الرئيسية \\( \mathbf{k}_i، \mathbf{v}_i \\) متطابقة عبر جميع رؤوس الاهتمام والتي بدورها تعني أننا بحاجة فقط إلى تخزين زوج إسقاط قيمة رئيسي واحد في ذاكرة التخزين المؤقت بدلاً من `n_head` منها.
+
+نظرًا لأن معظم LLMs تستخدم ما بين 20 و100 رأس اهتمام، فإن MQA يقلل بشكل كبير من استهلاك الذاكرة لذاكرة التخزين المؤقت key-value. بالنسبة إلى LLM المستخدم في هذا الدفتر، يمكننا تقليل استهلاك الذاكرة المطلوبة من 15 جيجابايت إلى أقل من 400 ميجابايت عند طول تسلسل الإدخال 16000.
+
+بالإضافة إلى توفير الذاكرة، يؤدي MQA أيضًا إلى تحسين الكفاءة الحسابية كما هو موضح في ما يلي.
+في فك التشفير التلقائي، يجب إعادة تحميل متجهات القيمة الرئيسية الكبيرة، ودمجها مع زوج متجه القيمة الحالي، ثم إدخالها في \\( \mathbf{q}_c\mathbf{K}^T \\) الحساب في كل خطوة. بالنسبة لفك التشفير التلقائي، يمكن أن تصبح عرض النطاق الترددي للذاكرة المطلوبة لإعادة التحميل المستمر عنق زجاجة زمنيًا خطيرًا. من خلال تقليل حجم متجهات القيمة الرئيسية، يجب الوصول إلى ذاكرة أقل، وبالتالي تقليل عنق الزجاجة في عرض النطاق الترددي للذاكرة. لمزيد من التفاصيل، يرجى إلقاء نظرة على [ورقة Noam](https://arxiv.org/abs/1911.02150).
+
+الجزء المهم الذي يجب فهمه هنا هو أن تقليل عدد رؤوس الاهتمام بالقيمة الرئيسية إلى 1 لا معنى له إلا إذا تم استخدام ذاكرة التخزين المؤقت للقيمة الرئيسية. يظل الاستهلاك الذروي لذاكرة النموذج لمرور واحد للأمام بدون ذاكرة التخزين المؤقت للقيمة الرئيسية دون تغيير لأن كل رأس اهتمام لا يزال لديه متجه استعلام فريد بحيث يكون لكل رأس اهتمام مصفوفة \\( \mathbf{QK}^T \\) مختلفة.
+
+شهدت MQA اعتمادًا واسع النطاق من قبل المجتمع ويتم استخدامها الآن بواسطة العديد من LLMs الأكثر شهرة:
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+كما يستخدم نقطة التحقق المستخدمة في هذا الدفتر - `bigcode/octocoder` - MQA.
+
+#### 3.2.3 مجموعة الاستعلام الاهتمام (GQA)
+
+[مجموعة الاستعلام الاهتمام](https://arxiv.org/abs/2305.13245)، كما اقترح Ainslie et al. من Google، وجد أن استخدام MQA يمكن أن يؤدي غالبًا إلى تدهور الجودة مقارنة باستخدام إسقاطات رأس القيمة الرئيسية المتعددة. تجادل الورقة بأنه يمكن الحفاظ على أداء النموذج بشكل أكبر عن طريق تقليل عدد أوزان إسقاط رأس الاستعلام بشكل أقل حدة. بدلاً من استخدام وزن إسقاط قيمة رئيسية واحدة فقط، يجب استخدام `n كخاتمة، من المستحسن بشدة استخدام GQA أو MQA إذا تم نشر LLM باستخدام فك التشفير التلقائي ويتطلب التعامل مع تسلسلات الإدخال الكبيرة كما هو الحال على سبيل المثال للدردشة.
+
+
+## الخاتمة
+
+مجتمع البحث يأتي باستمرار بطرق جديدة ومبتكرة لتسريع وقت الاستدلال للنماذج اللغوية الكبيرة على الإطلاق. كمثال، أحد اتجاهات البحث الواعدة هو [فك التشفير التخميني](https://arxiv.org/abs/2211.17192) حيث تقوم "الرموز السهلة" بإنشائها نماذج اللغة الأصغر والأسرع ويتم إنشاء "الرموز الصعبة" فقط بواسطة LLM نفسه. إن التعمق في التفاصيل يتجاوز نطاق هذا الدفتر، ولكن يمكن قراءته في هذه [تدوينة المدونة اللطيفة](https://huggingface.co/blog/assisted-generation).
+
+السبب في أن LLMs الضخمة مثل GPT3/4، وLlama-2-70b، وClaude، وPaLM يمكن أن تعمل بسرعة كبيرة في واجهات الدردشة مثل [Hugging Face Chat](https://huggingface.co/chat/) أو ChatGPT يرجع إلى حد كبير إلى التحسينات المذكورة أعلاه في الدقة والخوارزميات والهندسة المعمارية.
+في المستقبل، ستكون أجهزة التسريع مثل وحدات معالجة الرسومات (GPUs) ووحدات معالجة الرسومات (TPUs)، وما إلى ذلك... ستكون أسرع فقط وستسمح بمزيد من الذاكرة، ولكن يجب دائمًا التأكد من استخدام أفضل الخوارزميات والهندسة المعمارية المتاحة للحصول على أكبر قدر من المال
diff --git a/docs/source/ar/model_memory_anatomy.md b/docs/source/ar/model_memory_anatomy.md
new file mode 100644
index 00000000000000..6fc2552321b799
--- /dev/null
+++ b/docs/source/ar/model_memory_anatomy.md
@@ -0,0 +1,226 @@
+# تشريح عملية تدريب النموذج
+
+لفهم تقنيات تحسين الأداء التي يمكن تطبيقها لتحسين كفاءة استخدام الذاكرة وسرعة تدريب النموذج، من المفيد التعرف على كيفية استخدام وحدة معالجة الرسوميات (GPU) أثناء التدريب، وكيف تختلف كثافة العمليات الحسابية باختلاف العملية التي يتم تنفيذها.
+
+لنبدأ باستكشاف مثال توضيحي على استخدام وحدة GPU وتشغيل تدريب نموذج. وللتوضيح، سنحتاج إلى تثبيت بعض المكتبات:
+
+```bash
+pip install transformers datasets accelerate nvidia-ml-py3
+```
+
+تتيح مكتبة `nvidia-ml-py3` إمكانية مراقبة استخدام الذاكرة في النماذج من داخل بايثون. قد تكون على دراية بأمر `nvidia-smi` في الجهاز - تسمح هذه المكتبة بالوصول إلى نفس المعلومات مباشرة في بايثون.
+
+ثم، نقوم بإنشاء بعض البيانات الوهمية:معرّفات رموز عشوائية بين 100 و30000 وتصنيفات ثنائية للمصنف.
+
+في المجموع، نحصل على 512 تسلسلًا، لكل منها طول 512، ونخزنها في [`~datasets.Dataset`] بتنسيق PyTorch.
+
+```py
+>>> import numpy as np
+>>> from datasets import Dataset
+
+>>> seq_len, dataset_size = 512, 512
+>>> dummy_data = {
+... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
+... "labels": np.random.randint(0, 1, (dataset_size)),
+... }
+>>> ds = Dataset.from_dict(dummy_data)
+>>> ds.set_format("pt")
+```
+
+لطباعة إحصائيات موجزة لاستخدام وحدة GPU وتشغيل التدريب مع [`Trainer`]، نقوم بتعريف دالتين مساعدتين:
+
+```py
+>>> from pynvml import *
+
+>>> def print_gpu_utilization():
+... nvmlInit()
+... handle = nvmlDeviceGetHandleByIndex(0)
+... info = nvmlDeviceGetMemoryInfo(handle)
+... print(f"GPU memory occupied: {info.used//1024**2} MB.")
+
+>>> def print_summary(result):
+... print(f"Time: {result.metrics['train_runtime']:.2f}")
+... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
+... print_gpu_utilization()
+```
+
+دعنا نتأكد من أننا نبدأ بذاكرة وحدة GPU خالية:
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 0 MB.
+```
+
+يبدو ذلك جيدًا: لم يتم شغل ذاكرة وحدة معالجة الرسومات كما نتوقع قبل تحميل أي نماذج. إذا لم يكن الأمر كذلك على جهازك، فتأكد من إيقاف جميع العمليات التي تستخدم ذاكرة وحدة GPU. ومع ذلك، لا يمكن للمستخدم استخدام كل ذاكرة وحدة GPU الفارغة. عندما يتم تحميل نموذج إلى وحدة GPU، يتم أيضًا تحميل النواة، والتي يمكن أن تستهلك 1-2 جيجابايت من الذاكرة. ولرؤية مقدار ذلك، نقوم بتحميل مصفوفة صغيرة إلى وحدة GPU والتي تؤدي إلى تحميل النواة أيضًا.
+
+```py
+>>> import torch
+
+>>> torch.ones((1, 1)).to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 1343 MB.
+```
+
+نلاحظ أن النواة وحدها تستهلك 1.3 جيجابايت من ذاكرة وحدة GPU. الآن دعنا نرى مقدار المساحة التي يستخدمها النموذج.
+
+## تحميل النموذج
+
+أولاً، نقوم بتحميل نموذج `google-bert/bert-large-uncased`. نقوم بتحميل أوزان النموذج مباشرة إلى وحدة GPU حتى نتمكن من التحقق من مقدار المساحة التي تستخدمها الأوزان فقط.
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 2631 MB.
+```
+
+يمكننا أن نرى أن أوزان النموذج وحدها تستهلك 1.3 جيجابايت من ذاكرة وحدة GPU. يعتمد الرقم الدقيق على وحدة GPU المحددة التي تستخدمها. لاحظ أنه في وحدات GPU الأحدث، قد يستغرق النموذج في بعض الأحيان مساحة أكبر نظرًا لأن الأوزان يتم تحميلها بطريقة مُحسّنة تُسرّع من استخدام النموذج. الآن يمكننا أيضًا التحقق بسرعة مما إذا كنا نحصل على نفس النتيجة كما هو الحال مع `nvidia-smi` CLI:
+
+```bash
+nvidia-smi
+```
+
+```bash
+Tue Jan 11 08:58:05 2022
++-----------------------------------------------------------------------------+
+| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
+|-------------------------------+----------------------+----------------------+
+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
+| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
+| | | MIG M. |
+|===============================+======================+======================|
+| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
+| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
+| | | N/A |
++-------------------------------+----------------------+----------------------+
+
++-----------------------------------------------------------------------------+
+| Processes: |
+| GPU GI CI PID Type Process name GPU Memory |
+| ID ID Usage |
+|=============================================================================|
+| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
++-----------------------------------------------------------------------------+
+```
+
+نحصل على نفس الرقم كما كان من قبل، ويمكنك أيضًا أن ترى أننا نستخدم GPU من طراز V100 مع 16 جيجابايت من الذاكرة. لذا الآن يمكننا بدء تدريب النموذج ورؤية كيف يتغير استخدام ذاكرة GPU. أولاً، نقوم بإعداد بعض معاملات التدريب القياسية:
+
+```py
+default_args = {
+ "output_dir": "tmp"،
+ "eval_strategy": "steps"،
+ "num_train_epochs": 1،
+ "log_level": "error"،
+ "report_to": "none"،
+}
+```
+
+
+
+ إذا كنت تخطط لتشغيل عدة تجارب، من أجل مسح الذاكرة بشكل صحيح بين التجارب، قم بإعادة تشغيل نواة Python بين التجارب.
+
+
+
+## استخدام الذاكرة في التدريب الأساسي
+
+دعونا نستخدم [`Trainer`] وقم بتدريب النموذج دون استخدام أي تقنيات تحسين أداء GPU وحجم دفعة يبلغ 4:
+
+```py
+>>> from transformers import TrainingArguments، Trainer، logging
+
+>>> logging.set_verbosity_error()
+
+
+>>> training_args = TrainingArguments(per_device_train_batch_size=4، **default_args)
+>>> trainer = Trainer(model=model، args=training_args، train_dataset=ds)
+>>> result = trainer.train()
+>>> print_summary(result)
+```
+
+```
+الوقت: 57.82
+العينات / الثانية: 8.86
+ذاكرة GPU المشغولة: 14949 ميجابايت.
+```
+
+يمكننا أن نرى أن حجم دفعة صغير نسبيًا يملأ تقريبًا ذاكرة GPU بالكامل. ومع ذلك، غالبًا ما يؤدي حجم دفعة أكبر في تقارب نموذج أسرع أو أداء أفضل في النهاية. لذلك نريد أن نضبط حجم الدفعة وفقًا لاحتياجات النموذج لدينا وليس مع قيود وحدة GPU. ما يثير الاهتمام هو أننا نستخدم ذاكرة أكثر بكثير من حجم النموذج.
+لفهم سبب ذلك بشكل أفضل، دعنا نلقي نظرة على عمليات النموذج واحتياجاته من الذاكرة.
+
+## تشريح عمليات النموذج
+
+تتضمن بنية المحولات 3 مجموعات رئيسية من العمليات مُجمعة أدناه حسب كثافة العمليات الحسابية.
+
+1. **عمليات ضرب المصفوفات**
+
+ تقوم الطبقات الخطية ومكونات الانتباه متعدد الرؤوس جميعها بعمليات ضرب ** المصفوفة بالمصفوفة** على دفعات. هذه العمليات هي أكثر أجزاء تدريب المحولات كثافة من الناحية الحسابية.
+
+2. **عمليات التسوية الإحصائية**
+
+تُعد عمليات Softmax والتسوية الطبقية أقل كثافة من ناحية الحسابية من عمليات ضرب المصفوفات، وتنطوي على عملية أو أكثر من عمليات **الاختزال**، والتي يتم تطبيق نتيجتها بعد ذلك عبر خريطة.
+
+3. **العمليات على مستوى العناصر**
+
+ هذه هي العمليات المتبقية: **الانحيازات، والتسرب، ووظائف التنشيط، والوصلات المتبقية**. هذه هي عمليات أقل كثافة من الناحية الحسابية.
+
+يمكن أن تكون هذه المعرفة مفيدة لمعرفة عند تحليل اختناقات الأداء.
+
+هذا الملخص مُشتق من [نقل البيانات هو كل ما تحتاجه: دراسة حالة حول تحسين المحولات 2020](https://arxiv.org/abs/2007.00072)
+
+
+## تشريح ذاكرة النموذج
+
+لقد رأينا أن تدريب النموذج يستخدم ذاكرة أكثر بكثير من مجرد وضع النموذج على GPU. ويرجع ذلك إلى
+هناك العديد من المكونات أثناء التدريب التي تستخدم ذاكرة GPU. المكونات الموجودة في ذاكرة GPU هي التالية:
+
+1. أوزان النموذج
+2. الدول المُحسّن
+3. المُتدرجات
+4. تنشيطات المسار الأمامي المحفوظة لحساب المُتدرجات
+5. المخازن المؤقتة
+6. ذاكرة محددة الوظائف
+
+يتطلب نموذج نموذجي مدرب بدقة مختلطة 18 بايت للمُحسّن AdamW كل معلمة نموذج بالإضافة إلى ذاكرة التنشيط. للاستدلال لا توجد حالات مُحسّن و مُتدرجات، لذلك يمكننا طرح تلك. وهكذا ننتهي مع 6 بايت لكل
+معلمة نموذج للدقة المختلطة الاستدلال، بالإضافة إلى ذاكرة التنشيط.
+
+دعنا نلقي نظرة على التفاصيل.
+
+**أوزان النموذج:**
+
+- 4 بايت * عدد المعلمات للتدريب على دقة fp32
+- 6 بايت * عدد المعلمات لتدريب الدقة المختلطة (يحافظ على نموذج في fp32 وآخر بدقة fp16 في الذاكرة)
+
+**حالات المُحسّن:**
+
+- 8 بايت * عدد المعلمات للمُحسّن AdamW العادي (يحافظ على حالتين)
+- 2 بايت * عدد المعلمات لمُحسّنات 8 بت AdamW مثل [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
+- 4 بايت * عدد المعلمات لمُحسّنات مثل SGD مع الزخم momentum (يحافظ على حالة واحدة فقط)
+
+**المُتدرجات**
+
+- 4 بايت * عدد المعلمات للتدريب بدقة fp32 أو بدقة مختلطة (المُتدرجات تكون دائمًا بدقة fp32)
+
+**تنشيطات المسار الأمامي**
+
+- يعتمد الحجم على العديد من العوامل، وأهمها طول التسلسل وحجم المخفية وحجم الدُفعة.
+
+هناك المدخلات والمخرجات لذي يتم تمريرها وإرجاعها بواسطة وظائف المسار الأمامي والمسار الخلفي وتنشيطات المسار الأمامي المحفوظة لحساب المُتدرجات.
+
+**الذاكرة المؤقتة**
+
+بالإضافة إلى ذلك، هناك جميع أنواع المتغيرات المؤقتة التي يتم تحريرها بمجرد الانتهاء من الحساب، ولكن في
+لحظة يمكن أن تتطلب هذه المتغيرات المؤقتة ذاكرة إضافية ويقد تؤدي إلى نفاد الذاكرة المُخصصة (OOM). لذلك، عند البرمجة، من المهم التفكير بشكل استراتيجي حول هذه المتغيرات المؤقتة وأحيانًا تحريرها بشكل صريح بمجرد عدم الحاجة إليها.
+
+**ذاكرة محددة الوظائف**
+
+ثم، قد يكون لبرنامجك احتياجات خاصة بالذاكرة. على سبيل المثال، عند إنشاء نص باستخدام البحث الشعاعي، يحتاج البرنامج
+إلى الاحتفاظ بنسخ متعددة من المدخلات والمخرجات.
+
+**سرعة تنفيذ `forward` مقابل `backward`**
+
+بالنسبة للالتفافات والطبقات الخطية، هناك ضِعف عدد العمليات 2x flops في المسار الخلفى مقارنة بالمسار الأمامي، والتي يُترجم عمومًا إلى ~2x أبطأ (أحيانًا أكثر، لأن الأحجام في المسار الخلفى تميل إلى أن تكون أكثر صعوبة). عادةً ما تكون عمليات التنشيط محدودة بعرض النطاق الترددي، ومن المعتاد أن يتعين على التنشيط قراءة المزيد من البيانات في المسار الخلفى أكثر من المسار الأمامى.
+(على سبيل المثال، قراءة التنشيط المسار الأمامى مرة واحدة، وتكتب مرة واحدة، وبينما تقرأ عملية التنشيط الخلفي مرتين، gradOutput وإخراج الأمام، وتكتب مرة واحدة، gradInput).
+
+كما ترى، هناك بضعة أماكن يمكننا فيها توفير ذاكرة GPU أو تسريع العمليات.
+الآن بعد أن فهمت ما يؤثر على استخدام GPU وسرعة الحساب، راجع
+صفحة وثائق [أساليب وأدوات التدريب الفعال على GPU واحد](perf_train_gpu_one) لمعرفة المزيد حول تقنيات تحسين الأداء.
\ No newline at end of file
diff --git a/docs/source/ar/model_summary.md b/docs/source/ar/model_summary.md
new file mode 100644
index 00000000000000..57de935b70f459
--- /dev/null
+++ b/docs/source/ar/model_summary.md
@@ -0,0 +1,89 @@
+# عائلة نماذج المحول
+
+منذ إطلاقه في عام 2017، ألهم نموذج [المحول الأصلي](https://arxiv.org/abs/1706.03762) (راجع مدونة [المحول المشروح](http://nlp.seas.harvard.edu/2018/04/03/attention.html) لمقدمة تقنية مبسطة)، ألهم العديد من النماذج الجديدة والمبتكرة التي تتجاوز مهام معالجة اللغات الطبيعية (NLP). هناك نماذج للتنبؤ [بالبنية البروتينات المطوية](https://huggingface.co/blog/deep-learning-with-proteins)، و[تدريب على اتخاذ القرار](https://huggingface.co/blog/train-decision-transformers)، و[التنبؤ بالسلاسل الزمنية](https://huggingface.co/blog/time-series-transformers). مع وجود العديد من متغيرات المحول المتاحة، قد يكون من السهل أن تفوتك الصورة الأكبر. ما تشترك فيه جميع هذه النماذج هو أنها تستند إلى بنية المحول الأصلية. تستخدم بعض النماذج فقط الترميز أو فك الترميز، بينما تستخدم نماذج أخرى كليهما. يوفر هذا تصنيفًا مفيدًا لتصنيف واستعراض الفروقات الرئيسية بين نماذج عائلة المحولات، وسيساعدك على فهم النماذج التي لم تصادفها من قبل.
+
+إذا لم تكن على دراية بنموذج المحول الأصلي أو تحتاج إلى تذكير، فراجع الفصل الخاص بـ [كيف تعمل المحولات](https://huggingface.co/course/chapter1/4؟fw=pt) من دورة Hugging Face.
+
+
+
+
+
+## رؤية الحاسب (Computer vision)
+
+
+
+### الشبكة التلافيفية (Convolutional network)
+
+لطالما كانت الشبكات التلافيفية (CNNs) الطريقة السائدة لمهام رؤية الحاسب حتى برز [محول الرؤية](https://arxiv.org/abs/2010.11929) قابليته للتطوير وكفاءته العالية. وحتى بعد ذلك، لا تزال بعض أفضل صفات CNN، مثل ثبات الإزاحة، قوية جدًا (خاصة بالنسبة لمهام معينة) لدرجة أن بعض المحولات تدمج التلافيف في بنيتها. قلب [ConvNeXt](model_doc/convnext) هذا التبادل رأسًا على عقب وأدرج خيارات التصميم من المحولات لتحديث CNN. على سبيل المثال، يستخدم ConvNeXt نوافذ منزلقة غير متداخلة لتقسيم الصورة إلى رقع وزيادة حقل مجال العام الخاص بها. كما يقوم ConvNeXt بعدة خيارات مثل تصميم الطبقة لتكون أكثر كفاءة في الذاكرة وتحسين الأداء، مما يجعله منافسًا قويًا للمحولات!
+
+### الترميز[[cv-encoder]] (Encoder)
+
+فتح [محول الرؤية (ViT)](model_doc/vit) الباب أمام مهام رؤية الحاسب دون الاعتماد على التلافيف. يستخدم ViT ترميز محول قياسي، لكن إنجازه الرئيسي كان طريقة معالجته للصورة. فهو تقسّم الصورة إلى رقّعات ذات حجم ثابت ويستخدمها لإنشاء تضمين، تمامًا مثل تقسيم الجملة إلى رموز. استفاد ViT من بنية المُحوِّلات الفعالة لإظهار نتائج تنافسية مع CNNs في ذلك الوقت مع الحاجة إلى موارد أقل للتدريب. وسرعان ما تبع ViT نماذج رؤية أخرى يمكنها أيضًا التعامل مع مهام الرؤية الكثيفة مثل التجزئة والتعرف.
+
+من بين هذه النماذج [Swin](model_doc/swin) Transformer. فهو يبني خرائط سمات هرمية (مثل CNN 👀 على عكس ViT) من رقّعات أصغر حجمًا ودمجها مع الرقع المجاورة في طبقات أعمق. يتم حساب الانتباه فقط ضمن نافذة محلية، ويتم تحويل النافذة بين طبقات الانتباه لإنشاء اتصالات تساعد النموذج على التعلم بشكل أفضل. نظرًا لأن محول Swin يمكنه إنتاج خرائط خصائص هرمية، فهو مرشح جيد لمهام التنبؤ الكثيفة مثل التجزئة والتعرف. كما يستخدم [SegFormer](model_doc/segformer) ترميز محول لبناء خرائط خصائص هرمية، ولكنه يضيف فك تشفير بسيط متعدد الطبقات (MLP) في الأعلى لدمج جميع خرائط الخصائص وإجراء تنبؤ.
+
+استلهمت نماذج الرؤية الأخرى، مثل BeIT وViTMAE، الإلهام من هدف التدريب المسبق لـ BERT. يتم تدريب [BeIT](model_doc/beit) مسبقًا من خلال *نمذجة الصور المقنعة (MIM)*؛ يتم إخفاء رقّعات الصور بشكل عشوائي، كما يتم تحويل الصورة إلى رموز بصرية. يتم تدريب BeIT للتنبؤ بالرموز البصرية المُناظرة للرقع المخفية. لدى [ViTMAE](model_doc/vitmae) هدف تدريب مسبق مُماثل، باستثناء أنه يجب عليه التنبؤ بالبكسلات بدلاً من الرموز البصرية. ما هو غير عادي هو أن إخفاء 75% من رقع الصور! يقوم فك التشفير بإعادة بناء البكسلات من الرموز المخفية والرقّعات المشفرة. بعد التدريب المسبق، يتم التخلص من فك التشفير، ويصبح الترميز جاهزًا للاستخدام في مهام التالية.
+
+### فك التشفير[[cv-decoder]] (Decoder)
+
+نادرًا ما تستخدم نماذج الرؤية التي تعتمد على فك التشفير فقط لأن معظم نماذج الرؤية تعتمد على الترميز لتعلم تمثيل الصورة. ولكن بالنسبة للاستخدامات مثل توليد الصور، يعد فك التشفير مناسبًا بشكل طبيعي، كما رأينا من نماذج توليد النصوص مثل GPT-2. يستخدم نموذج [ImageGPT](model_doc/imagegpt) نفس بنية GPT-2، ولكنه بدلاً من التنبؤ بالرمز التالي في تسلسل، فإنه يتنبأ بالبكسل التالي في صورة. بالإضافة إلى توليد الصور، يمكن أيضًا ضبط ImageGPT بدقة لتصنيف الصور.
+
+### الترميز وفك التشفير[[cv-encoder-decoder]] (Encoder-decoder)
+
+تستخدم نماذج الرؤية بشكل شائع ترميزًا (يُعرف أيضًا باسم العمود الفقري) لاستخراج ميزات الصورة المهمة قبل تمريرها إلى فك التشفير لنموذج المُحوّل. يستخدم [DETR](model_doc/detr) عمودًا فقريًا مُدربًا مسبقًا، ولكنه يستخدم أيضًا الببنية الكاملة للترميز وفك تشفير لنموذج المحول للكشف عن الأشياء. يتعلم الترميز تمثيلات الصور ويجمعها مع استعلامات الكائنات (كل استعلام كائن هو تضمين مُتعلم يركز على منطقة أو كائن في صورة) في فك التشفير. يتنبأ DETR بإحداثيات مربع الحدود وتسمية الفئة لكل استعلام كائن.
+
+## معالجة اللغات الطبيعية (Natural language processing - NLP)
+
+
+
+### الترميز اللغوي[[nlp-encoder]]
+
+نموذج [BERT](model_doc/bert) هو محوّل (Transformer) يعتمد على الترميز فقط يقوم بشكل عشوائي بإخفاء رموز معينة في المدخلات لتجنب رؤية باقى الرموز الأخرى، مما يسمح له "بالغش". يتمثل هدف التدريب المسبق في التنبؤ بالرمز المخفي بناءً على السياق. يسمح هذا لـ BERT باستخدام السياقات اليمنى واليسرى بالكامل لمساعدته في تعلم تمثيل أعمق وأغنى للبيانات المدخلة. ومع ذلك، كان هناك مجال للتحسين في استراتيجية التدريب المسبق لـ BERT. نموذج [RoBERTa](model_doc/roberta) اضاف تحسين من خلال تقديم وصفة تدريب مسبق جديدة تشمل التدريب لفترة أطول وعلى دفعات أكبر، وإخفاء الرموز عشوائيًا في كل حقبة بدلاً من مرة واحدة فقط أثناء المعالجة المسبقة، وإزالة هدف التنبؤ بالجملة التالية.
+
+تتمثل الاستراتيجية السائدة لتحسين الأداء في زيادة حجم النموذج. ولكن تدريب النماذج الكبيرة مكلف من الناحية الحسابية. إحدى طرق تقليل التكاليف الحسابية هي استخدام نموذج أصغر مثل [DistilBERT](model_doc/distilbert). يستخدم DistilBERT [ تقنية تقطير المعرفة](https://arxiv.org/abs/1503.02531) - وهي تقنية ضغط - لإنشاء نموذج أصغر من BERT مع الحفاظ على معظم قدراته على فهم اللغةا.
+
+مرت معظم نماذج المحول في الاتجاه نحو المزيد من المعلمات، مما أدى إلى ظهور نماذج جديدة تركز على تحسين كفاءة التدريب. يقلّل [ALBERT](model_doc/albert) من استهلاك الذاكرة عن طريق تقليل عدد المعلمات بطريقتين: فصل تضمين المفردات الأكبر إلى مصفوفتين أصغر والسماح للمستويات بمشاركة المعلمات. أضاف [DeBERTa](model_doc/deberta) آلية انتباه منفصلة حيث يتم ترميز الكلمة وموضعها بشكل منفصل في متجهين. يتم حساب الانتباه من هذه المتجهات المنفصلة بدلاً من متجه واحد يحتوي على تضمين الكلمة والموقع. ركز [Longformer](model_doc/longformer) أيضًا على جعل الانتباه أكثر كفاءة، خاصة لمعالجة المستندات ذات تسلسلات أطولل. فهو يستخدم مزيجًا من انتباه النوافذ المحلية (يتم حساب الانتباه فقط ن نافذة ذات حجم ثابت حول كل رمز) والانتباه العام (فقط لرموز مهمة محددة مثل `[CLS]` للتصنيف) لإنشاء مصفوفة انتباه متفرقة بدلاً من مصفوفة انتباه كاملة.
+
+### فك التشفير[[nlp-decoder]]
+
+ نموذج [GPT-2](model_doc/gpt2) هو محول فك تشفير فقط يتنبأ بالكلمة التالية في التسلسل. إنه يخفي الرموز التالية الموجودة على اليمين حتى لا يتمكن النموذج من "الغش" بالنظر إليها. من خلال التدريب المسبق على كميات هائلة من النصوص، أصبح [GPT-2](model_doc/gpt2) بارعًا في توليد النصوص، حتى لو لم تكن النص دقيقًا أو صحيحًا في بعض الأحيان فقط. ولكن كان يفتقر إلى سياق لترابط المتبادل (bidirectional context) الموجود من التدريب المسبق لـ [BERT](model_doc/bert) ، مما جعله غير مناسب لمهام معينة. يجمع [XLNET](model_doc/xlnet) بين أفضل ما في أهداف التدريب المسبق لـ [BERT](model_doc/bert) و [GPT-2](model_doc/gpt2) من خلال اعتماد نهج النمذجة اللغوية باستخدام التباديل (Permutation Language Modeling - PLM) الذي يسمح له بتعلم الترابط ثنائي الاتجاه.
+
+بعد ظهور [GPT-2](model_doc/gpt2)، تطورت النماذج اللغوية بشكل أكبر حجمًا وأكثر تعقيدًا وأصبحت تُعرف الآن باسم *نماذج اللغة الكبيرة (LLMs)*. توضح LLMs مهارات تعلم قليلة الكمية أو حتى معدومة إذا تم تدريبها على مجموعة بيانات كبيرة بما يكفي. [GPT-J](model_doc/gptj) هو LLM به 6 مليارات معلمة مدربة على 400 مليار رمز. تبعه نموذج [OPT](model_doc/opt)، وهي عائلة من نماذج فك التشفير فقط، أكبرها 175 مليار معلمة ودُرب على 180 مليار رمز. تم إصدار [BLOOM](model_doc/bloom) في نفس الوقت تقريبًا، ويحتوي أكبر نموذج في العائلة على 176 مليار معلمة ودُرب على 366 مليار رمز في 46 لغة و13 لغة برمجة.
+
+### الترميز وفك التشفير[[nlp-encoder-decoder]]
+
+يحتفظ [BART](model_doc/bart) ببنية المحول الأصلية، ولكنه يعدّل هدف التدريب المسبق باستخدام إفساد *إدخال النصوص*، حيث يتم استبدال بعض نطاقات النص برمز `mask` واحد. يتنبأ فك التشفير بالرموز غير الفاسدة (يتم إخفاء الرموز المستقبلية) ويستخدم حالات الترميز المخفية للمساعدة. [Pegasus](model_doc/pegasus) مشابه لـ BART، ولكن Pegasus يقوم بإخفاء جمل كاملة بدلاً من مقاطع النص. بالإضافة إلى نمذجة اللغة المقنعة، يتم تدريب Pegasus مسبقًا بواسطة توليد الجمل الفارغة (GSG). يقوم هدف GSG بإخفاء الجمل الكاملة المهمة للمستند، واستبدالها برمز `mask`. يجب على فك التشفير توليد المخرجات من الجمل المتبقية. [T5](model_doc/t5) هو نموذج فريد من نوعه يحوّل جميع مهام معالجة اللغة الطبيعية إلى مشكلة نص إلى نص باستخدام بادئات محددة. على سبيل المثال، يشير البادئة `Summarize:` إلى مهمة تلخيص. يتم تدريب T5 مسبقًا بواسطة التدريب الخاضع للإشراف (GLUE وSuperGLUE) والتدريب ذاتي الإشراف (اختيار عينة عشوائية وحذف 15% من الرموز).
+
+## الصوت (Audio)
+
+
+
+### الترميز[[audio-encoder]]
+
+يستخدم [Wav2Vec2](model_doc/wav2vec2) ترميز من نوع المحوّل لتعلم تمثيلات الكلام بشكلٍ مباشر من موجات الصوت الخام. يتم تدريبه مسبقًا باستخدام مهمة تباينية لتحديد تمثيل الكلام الصحيح من مجموعة من التمثيلات الخاطئة. [HuBERT](model_doc/hubert) مشابه لـ Wav2Vec2 ولكنه له عملية تدريب مختلفة. يتم إنشاء تسميات الهدف عن طريق خطوة تجميع يتم فيها ت تخصيص مقاطع الصوت المتشابهة إلى مجموعات، تُصبح كل واحدة منها وحدةً خفية. ويتم تعيين الوحدة الخفية إلى تمثيل لإجراء تنبؤ.
+
+### الترميز وفك التشفير[[audio-encoder-decoder]]
+
+[Speech2Text](model_doc/speech_to_text) هو نموذج كلام مصمم للتعرف التلقائي على الكلام (ASR) وترجمة الكلام. يقبل النموذج ميزات بنك المرشح اللغوي التي تم استخراجها من شكل موجة الصوت وتم تدريبه مسبقًا بطريقة ذاتية التعلم لتوليد نسخة أو ترجمة. [Whisper](model_doc/whisper) هو أيضًا نموذج ASR، ولكنه على عكس العديد من نماذج الكلام الأخرى، يتم تدريبه مسبقًا على كمية كبيرة من بيانات نسخ النص الصوتي ✨ المسماة ✨ لتحقيق الأداء الصفري. يحتوي جزء كبير من مجموعة البيانات أيضًا على لغات غير اللغة الإنجليزية، مما يعني أنه يمكن استخدام Whisper أيضًا للغات منخفضة الموارد. من الناحية الهيكلية، يشبه Whisper نموذج Speech2Text. يتم تحويل إشارة الصوت إلى طيف لوجاريتم مل-ميل يتم تشفيره بواسطة الترميز. يقوم فك التشفير بتوليد النسخة بطريقة ذاتية التعلم من حالات الترميز المخفية والرموز السابقة.
+
+## متعدد الوسائط (Multimodal)
+
+
+
+### Encoder[[mm-encoder]]
+
+نموذج [VisualBERT](model_doc/visual_bert) هو نموذج متعدد الوسائط لمهام الرؤية اللغوية تم إصداره بعد فترة وجيزة من BERT. فهو يجمع بين BERT ونظام اكتشاف كائن مسبق التدريب لاستخراج ميزات الصورة في تضمينات بصرية، يتم تمريرها جنبًا إلى جنب مع التضمينات النصية إلى BERT. يتنبأ VisualBERT بالنص المقنع بناءً على النص غير المقنع والتضمينات المرئية، ويجب عليه أيضًا التنبؤ بما إذا كان النص متوافقًا مع الصورة. عندما تم إصدار ViT، اعتمد [ViLT](model_doc/vilt) ViT في بنيتها لأنه كان من الأسهل الحصول على تضمينات الصورة بهذه الطريقة. يتم معالجة تضمينات الصورة بشكل مشترك مع التضمينات النصية. ومن هناك، يتم التدريب المسبق لـ ViLT بواسطة مطابقة الصورة النصية، ونمذجة اللغة المقنعة، وإخفاء كلمة كاملة.
+
+يتّبع [CLIP](model_doc/clip) نهجًا مختلفًا ويقوم بتنبؤ ثنائي من ("الصورة"، "النص"). يتم تدريب مشفر صورة (ViT) ومشفر نص (Transformer) بشكل مشترك على مجموعة بيانات مكونة من 400 مليون ثنائي من ("صورة"، "نص") لتعظيم التشابه بين متجهات ترميز الصورة ومتجهات النص ثنائي ("الصورة"، "النص"). بعد التدريب المسبق، يمكنك استخدام اللغة الطبيعية لتوجيه CLIP للتنبؤ بالنص المُعطى بناءً على صورة أو العكس بالعكس. [OWL-ViT](model_doc/owlvit) يبني على CLIP باستخدامه كعمود فقري للكشف عن الكائنات بدون إشراف. بعد التدريب المسبق، يتم إضافة رأس كشف الأجسام لإجراء تنبؤ بمجموعة مُحدّد عبر ثنائيات ("class"، "bounding box").
+
+### Encoder-decoder[[mm-encoder-decoder]]
+
+التعرّف البصري على الحروف (OCR) مهمة قديمة لتعرّف النصوص، التي تنطوي عادةً على عدة مكونات لفهم الصورة وتوليد النص. [TrOCR](model_doc/trocr) بتبسيط العملية باستخدام محول متكامل من النهاية إلى النهاية. المشفر هو نموذج على غرار ViT لفهم الصورة ويعالج الصورة كقطع ثابتة الحجم. يقبل فك التشفير حالات الإخفاء للمشفر وينشئ النص بشكل تلقائي. [Donut](model_doc/donut) هو نموذج أكثر عمومية لفهم المستندات المرئية لا يعتمد على نهج OCR. يستخدم محول Swin كمشفر وBART متعدد اللغات كمُفكّك تشفير. يتم تدريب Donut على قراءة النص عن طريق التنبؤ بالكلمة التالية بناءً على ملاحظات الصورة والنص. يقوم فك التشفير بتوليد تتسلسلًا رمزيًا بناءً على موجه (Prompt). يتم تمثيل الموجه بواسطة رمز خاص لكل مهمة. على سبيل المثال، يحتوي تحليل المستند على رمز خاص "parsing" يتم دمجه مع حالات الإخفاء للـمُشفّر لتحليل المستند بتنسيق إخراج منظم (JSON).
+
+## التعلم التعزيزي (Reinforcement learning - RL)
+
+
+
+### فك التشفير[[rl-decoder]]
+
+يقوم نموذج "محوّل القرارات والمسارات" (Decision and Trajectory Transformer) بتحويل الحالة (State) والإجراء (Action) والمكافأة (Reward) كمشكلة نمذجة تسلسلية. [محوّل القرارات](model_doc/decision_transformer) يقوم بتوليد سلسلة من الإجراءات التي تؤدي إلى عائد مرغوب في المستقبل بناءً على العوائد المتوقعة، والحالات والإجراءات السابقة. في الخطوات الزمنية *K* الأخيرة، يتم تحويل كل وسائط البيانات الثلاث vإلى متجهات تضمين رمزيّة ومعالجتها بواسطة نموذج مشابه لـ GPT للتنبؤ برمز الإجراء المستقبلي.يقوم [محول المسار](model_doc/trajectory_transformer) أيضًا بتحويل الحالات والإجراءات والمكافآت إلى رموز ومعالجتها باستخدام هيكلية GPT. على عكس "محوّل القرارات"، الذي يركز على تكييف المكافأة، يقوم "محوّل المسارات" بتوليد إجراءات مستقبلية باستخدام البحث الشعاعي (Beam Search).
diff --git a/docs/source/ar/pad_truncation.md b/docs/source/ar/pad_truncation.md
new file mode 100644
index 00000000000000..d41d4f9c6b453b
--- /dev/null
+++ b/docs/source/ar/pad_truncation.md
@@ -0,0 +1,52 @@
+# الحشو والتقليم
+
+غالبًا ما تختلف مدخلات الدُفعات في الطول، لذا لا يمكن تحويلها إلى مصفوفات ذات حجم ثابت .يُعدّ الحشو والتقليم هما استراتيجيتان للتعامل مع هذه المشكلة، لإنشاء مصفوفات مستطيلة من مجموعات ذات أطوال مختلفة. ويضيف الحشو رمز **حشو** خاص لضمان أن يكون للتسلسلات الأقصر نفس طول أطول تسلسل في الدفعة أو الطول الأقصى الذي يقبله النموذج. ويعمل التقليم عكس ذلك بتقليم التسلسلات الطويلة.
+
+في معظم الحالات، ييُعدّ حشو دُفعتك إلى طول أطول تسلسل فيها وتقليمها إلى الطول الأقصى المقبول من النموذج حلًا فعالًا. ومع ذلك، تدعم واجهة برمجة التطبيقات المزيد من الاستراتيجيات إذا كنت بحاجة إليها. هناك ثلاثة معامﻻت تحتاجها لفهم آلية العمل: `padding`، و`truncation`، و`max_length`.
+
+يحكم معامل `padding` عملية الحشو. يمكن أن يكون قيمة منطقية أو نصية:
+
+ - `True` أو `'longest'`: الحشو إلى أطول تسلسل في الدفعة (لا يتم تطبيق الحشو عند تقديم تسلسل واحد فقط).
+ - `'max_length'`: الحشو إلى طول محدد بواسطة معامل `max_length` أو الطول الأقصى الذي يقبله
+ النموذج إذا لم يتم توفير `max_length` (`max_length=None`). سيظل الحشو مطبقًا إذا قدمت تسلسلًا واحدًا فقط.
+ - `False` أو `'do_not_pad'`: لا يتم تطبيق أي حشو. هذا هو السلوك الافتراضي.
+
+تحكم معامل `truncation` عملية التقليم. يمكن أن يكون قيمة منطقية أو نصية:
+
+ -قيمة `True` أو `'longest_first'` : تقليم التسلسلات إلى طول أقصى مُحدد بواسطة معامل `max_length`، أو أقصى طول يقبله النموذج في حال عدم تحديد طول مُحدد من قبل المستخدم (`max_length=None`). ستتم عملية التقليم إزالة رمز تلو الآخر، بدءًا من أطول تسلسل في الزوج، إلى أن يصل الطول إلى القيمة المُحددة.
+ -قيمة `'only_second'`: اقطع إلى طول أقصى محدد بواسطة معامل `max_length` أو أقصى طول يقبله النموذج إذا لم يتم توفير `max_length` (`max_length=None`). هذا سيقلم فقط الجملة الثانية من الزوج إذا تم توفير زوج من التسلسلات (أو دُفعة من أزواج التسلسلات).
+ -قيمة `'only_first'`: تقليم الجملة الأولى فقط من الزوج عند تقديم زوج من التسلسلات (أو دُفعة من أزواج التسلسلات) إلى طول أقصى مُحدد بواسطة حجة `max_length`، أو أقصى طول يقبله النموذج في حال عدم تحديد طول مُحدد من قبل المستخدم (`max_length=None`).
+ -قيمة `False` أو `'do_not_truncate'`: لا يتم تطبيق أي تقليم. هذا هو السلوك الافتراضي.
+``
+
+يحكم معامل `max_length` طول الحشو والتقليم. يمكن أن يكون عدد صحيح أو `None`، وعندها يُحدد افتراضيًا إلى الطول الأقصى الذي يمكن أن يقبله النموذج. إذا لم يكن للنموذج طول إدخال أقصى محدد، يتم إلغاء تنشيط التقليم أو الحشو إلى `max_length`.
+
+يلخّص الجدول التالي الطريقة المُوصى بها لإعداد الحشو والتقليم. إذا كنت تستخدم أزواج تسلسلات الإدخال في أي من الأمثلة التالية، فيمكنك استبدال `truncation=True` بـ `STRATEGY` المحدد في `['only_first'، 'only_second'، 'longest_first']`، أي `truncation='only_second'` أو `truncation='longest_first'` للتحكم في كيفية تقليم كلا التسلسلين في الزوج كما هو موضّح سابقًا.
+
+
+# حيل الترميز
+
+هناك العديد من الاستراتيجيات لترميز دفعات الجمل. فيما يلي بعض الأمثلة على ذلك.
+
+| الترميز | الحشو | التعليمات |
+|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
+| لا ترميز | لا حشو | `tokenizer(batch_sentences)` |
+| | الحشو إلى الحد الأقصى للتسلسل في الدفعة | `tokenizer(batch_sentences, padding=True)` أو |
+| | | `tokenizer(batch_sentences, padding='longest')` |
+| | الحشو إلى الحد الأقصى لطول إدخال النموذج | `tokenizer(batch_sentences, padding='max_length')` |
+| | الحشو إلى طول محدد | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
+| | الحشو إلى مضاعف لقيمة معينة | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8)` |
+| الترميز إلى الحد الأقصى لطول إدخال النموذج | لا حشو | `tokenizer(batch_sentences, truncation=True)` أو |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
+| | الحشو إلى الحد الأقصى للتسلسل في الدفعة | `tokenizer(batch_sentences, padding=True, truncation=True)` أو |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
+| | الحشو إلى الحد الأقصى لطول إدخال النموذج | `tokenizer(batch_sentences, padding='max_length', truncation=True)` أو |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
+| | الحشو إلى طول محدد | غير ممكن |
+| الترميز إلى طول محدد | لا حشو | `tokenizer(batch_sentences, truncation=True, max_length=42)` أو |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
+| | الحشو إلى الحد الأقصى للتسلسل في الدفعة | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` أو |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
+| | الحشو إلى الحد الأقصى لطول إدخال النموذج | غير ممكن |
+| | الحشو إلى طول محدد | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` أو |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
\ No newline at end of file
diff --git a/docs/source/ar/perplexity.md b/docs/source/ar/perplexity.md
new file mode 100644
index 00000000000000..e7d2a19d2c837f
--- /dev/null
+++ b/docs/source/ar/perplexity.md
@@ -0,0 +1,94 @@
+# التعقيد اللغوي للنماذج ذات الطول الثابت
+
+[[open-in-colab]]
+
+ التعقيد اللغوي (PPL) هي واحدة من أكثر المقاييس شيوعًا لتقييم نماذج اللغة. قبل الخوض في التفاصيل، يجب أن نلاحظ أن المقياس ينطبق تحديدًا على نماذج اللغة الكلاسيكية (يُطلق عليها أحيانًا نماذج اللغة التلقائية المرجعية أو السببية) وهي غير محددة جيدًا لنماذج اللغة المقنعة مثل BERT (راجع [ملخص النماذج](model_summary)).
+
+تُعرَّف التعقيد اللغوي على أنها الأس المُرفوع لقيمة متوسط اللوغاريتم الاحتمالي لمتتالية. إذا كان لدينا تسلسل رمزي \\(X = (x_0, x_1, \dots, x_t)\\)، فإن حيرة \\(X\\) هي،
+
+$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{
+
+لكن عند التعامل مع النماذج التقريبية، نواجه عادةً قيدًا على عدد الرموز التي يمكن للنموذج معالجتها. على سبيل المثال، تحتوي أكبر نسخة من [GPT-2](model_doc/gpt2) على طول ثابت يبلغ 1024 رمزًا، لذا لا يمكننا حساب \\(p_\theta(x_t|x_{
+
+تتميز هذه الطريقة بسرعة حسابها نظرًا لإمكانية حساب درجة التعقيد اللغوي لكل جزء بمسح واحد للأمام، إلا أنها تُعدّ تقريبًا ضعيفًا لدرجة التعقيد اللغوي المُحلّلة بشكل كامل، وعادةً ما تؤدي إلى درجة تعقيد لغوي أعلى (أسوأ) لأن النموذج سيكون لديه سياق أقل في معظم خطوات التنبؤ.
+
+بدلاً من ذلك، يجب تقييم درجة التعقيد اللغوي للنماذج ذات الطول الثابت باستخدام إستراتيجية النافذة المنزلقة. وينطوي هذا على تحريك نافذة السياق بشكل متكرر بحيث يكون للنموذج سياق أكبر عند إجراء كل تنبؤ.
+
+
+
+هذا تقريب أقرب للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل.لكن الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي مناسب هو استخدام نافذة منزلقة بخطوة، بحيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. مما يسمح بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب التعقيد اللغوي مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم التعقيد اللغوي باستخدام بعض إستراتيجيات مختلفة النافذة المنزلقة. نظرًا لأن هذه المجموعة البيانات الصغيرة ونقوم فقط بمسح واحد فقط للمجموعة، فيمكننا ببساطة تحميل مجموعة البيانات وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، وسيتم إرجاع متوسط احتمالية السجل السالب لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين احتمالية السجل للرموز التي نتعامل معها كسياق فقط في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. فيما يلي هو مثال على كيفية القيام بذلك بخطوة تبلغ `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (بشرط توفر 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+يعد تشغيل هذا مع طول الخطوة مساويًا لطول الإدخال الأقصى يعادل لاستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيحصل عليه النموذج في عمل كل تنبؤ، وكلما كانت التعقيد اللغوي المُبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون درجة التعقيد اللغوي الناتجة هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التحليل التلقائي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
diff --git a/docs/source/ar/philosophy.md b/docs/source/ar/philosophy.md
new file mode 100644
index 00000000000000..09de2991fba28d
--- /dev/null
+++ b/docs/source/ar/philosophy.md
@@ -0,0 +1,49 @@
+# الفلسفة
+
+تُعد 🤗 Transformers مكتبة برمجية ذات رؤية واضحة صُممت من أجل:
+
+- الباحثون والمُتعلّمون في مجال التعلم الآلي ممن يسعون لاستخدام أو دراسة أو تطوير نماذج Transformers واسعة النطاق.
+- مُطبّقي تعلم الآلة الذين يرغبون في ضبط تلك النماذج أو تشغيلها في بيئة إنتاجية، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. سهولة وسرعة الاستخدام:
+
+ - تمّ تقليل عدد المفاهيم المُجردة التي يتعامل معها المستخدم إلى أدنى حد والتي يجب تعلمها، وفي الواقع، لا توجد مفاهيم مُجردة تقريبًا، فقط ثلاث فئات أساسية مطلوبة لاستخدام كل نموذج: [الإعدادات](main_classes/configuration)، [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([مُجزّئ لغوي](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للمدخﻻت متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من خلال نماذج مُدربة مسبقًا باستخدام الدالة الموحدة `from_pretrained()` والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين وتحميل كل من: فئة النموذج المُراد استخدامه والبيانات المرتبطة ( مُعاملات الإعدادات، ومعجم للمُجزّئ اللغوي،وأوزان النماذج) من نقطة تدقيق مُحددة مُخزّنة على [Hugging Face Hub](https://huggingface.co/models) أو ن من نقطة تخزين خاصة بالمستخدم.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستخدام السريع لأحد النماذج لأداء استنتاجات على مهمة مُحددة، و [`Trainer`] للتدريب السريع أو الضبط الدقيق لنماذج PyTorch (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- كشف تفاصيل النماذج الداخلية بشكل متسق قدر الإمكان:
+
+ -نتيح الوصول، باستخدام واجهة برمجة واحدة، إلى جميع الحالات المخفية (Hidden-States) وأوزان الانتباه (Attention Weights).
+ - تم توحيد واجهات برمجة التطبيقات الخاصة بفئات المعالجة المسبقة والنماذج الأساسية لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة من الأدوات الواعدة لضبط النماذج بدقة (Fine-tuning) ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى مفردات التضمينات (Embeddings) لضبط النماذج بدقة.
+ - طرق سهلة لإخفاء (Masking) وتقليم (Pruning) رؤوس المحولات (Transformer Heads).
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تعتمد المكتبة على ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات الإعداد** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات وحجم الطبقة المخفية). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا تهيئة الإعدادات (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من نسخ مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على منصة Hub عبر ثلاث طرق:
+
+- تسمح لك الدالة `from_pretrained()` بتهيئة النموذج وتكويناته وفئة المعالجة المسبقة من إصدار مُدرب مسبقًا إما يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو مخزنة محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك الدالة `save_pretrained()` بحفظ النموذج، وتكويناته وفئة المعالجة المسبقة محليًا، بحيث يمكن إعادة تحميله باستخدام الدالة `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وتكويناتهوفئة المعالجة المسبقة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
diff --git a/docs/source/ar/pipeline_webserver.md b/docs/source/ar/pipeline_webserver.md
new file mode 100644
index 00000000000000..2a19e84d163241
--- /dev/null
+++ b/docs/source/ar/pipeline_webserver.md
@@ -0,0 +1,126 @@
+# استخدام قنوات المعالجة لخادم ويب
+
+
+
+يُعدّ إنشاء محرك استدلال أمرًا معقدًا، ويعتمد الحل "الأفضل" على مساحة مشكلتك. هل تستخدم وحدة المعالجة المركزية أم وحدة معالجة الرسومات؟ هل تريد أقل زمن وصول، أم أعلى معدل نقل، أم دعمًا للعديد من النماذج، أم مجرد تحقيق أقصى تحسين نموذج محدد؟
+توجد طرق عديدة لمعالجة هذا الموضوع، لذلك ما سنقدمه هو إعداد افتراضي جيد للبدء به قد لا يكون بالضرورة هو الحل الأمثل لك.```
+
+
+
+الشيء الرئيسي الذي يجب فهمه هو أننا يمكن أن نستخدم مؤشرًا، تمامًا كما تفعل [على مجموعة بيانات](pipeline_tutorial#using-pipelines-on-a-dataset)، نظرًا لأن خادم الويب هو أساسًا نظام ينتظر الطلبات ويعالجها عند استلامها.
+
+عادةً ما تكون خوادم الويب متعددة الإرسال (متعددة مؤشرات الترابط، وغير متزامنة، إلخ) للتعامل مع الطلبات المختلفة بشكل متزامن. من ناحية أخرى، فإن قنوات المعالجة (وبشكل رئيسي النماذج الأساسية) ليست رائعة للتوازي؛ حيث تستهلك الكثير من ذاكرة الوصول العشوائي، لذا من الأفضل منحها جميع الموارد المتاحة عند تشغيلها أو إذا كانت مهمة تطلب حسابات مكثفة.
+
+سنحل ذلك من خلال جعل خادم الويب يتعامل مع الحمل الخفيف لاستقبال الطلبات وإرسالها،وجعل مؤشر ترابط واحد يتعامل مع العمل الفعلي. سيستخدم هذا المثال `starlette`. ولكن قد تضطر إلى ضبط الكود أو تغييره إذا كنت تستخدم كودًا آخر لتحقيق التأثير نفسه.
+
+أنشئ `server.py`:
+
+```py
+from starlette.applications import Starlette
+from starlette.responses import JSONResponse
+from starlette.routing import Route
+from transformers import pipeline
+import asyncio
+
+
+async def homepage(request):
+ payload = await request.body()
+ string = payload.decode("utf-8")
+ response_q = asyncio.Queue()
+ await request.app.model_queue.put((string, response_q))
+ output = await response_q.get()
+ return JSONResponse(output)
+
+
+async def server_loop(q):
+ pipe = pipeline(model="google-bert/bert-base-uncased")
+ while True:
+ (string, response_q) = await q.get()
+ out = pipe(string)
+ await response_q.put(out)
+
+
+app = Starlette(
+ routes=[
+ Route("/", homepage, methods=["POST"]),
+ ],
+)
+
+
+@app.on_event("startup")
+async def startup_event():
+ q = asyncio.Queue()
+ app.model_queue = q
+ asyncio.create_task(server_loop(q))
+```
+
+الآن يمكنك تشغيله باستخدام:
+
+```bash
+uvicorn server:app
+```
+
+ويمكنك الاستعلام عنه:
+
+```bash
+curl -X POST -d "test [MASK]" http://localhost:8000/
+#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
+```
+
+وهكذا، لديك الآن فكرة جيدة عن كيفية إنشاء خادم ويب!
+
+المهم حقًا هو أننا نقوم بتحميل النموذج **مرة واحدة** فقط، لذلك لا توجد نسخ من النموذج على خادم الويب. بهذه الطريقة، لا يتم استخدام ذاكرة الوصول العشوائي غير الضرورية. تسمح آلية وضع قائمة الانتظار بالقيام بأشياء متقدمة مثل تجميع بعض العناصر قبل الاستدلال لاستخدام معالجة الدفعات الديناميكية:
+
+
+
+تم كتابة نموذج الكود البرمجى أدناه بشكل مقصود مثل كود وهمي للقراءة. لا تقم بتشغيله دون التحقق مما إذا كان منطقيًا لموارد النظام الخاص بك!
+
+
+
+```py
+(string, rq) = await q.get()
+strings = []
+queues = []
+while True:
+ try:
+ (string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
+ except asyncio.exceptions.TimeoutError:
+ break
+ strings.append(string)
+ queues.append(rq)
+strings
+outs = pipe(strings, batch_size=len(strings))
+for rq, out in zip(queues, outs):
+ await rq.put(out)
+```
+
+مرة أخرى، تم تحسين الرمز المقترح لسهولة القراءة، وليس ليكون أفضل كود. بادئ ذي بدء، لا يوجد حد لحجم الدفعة، والذي عادةً ما لا يكون فكرة عظيمة. بعد ذلك، يتم إعادة ضبط الفترة في كل عملية جلب لقائمة الانتظار، مما يعني أنه قد يتعين عليك الانتظار لفترة أطول بكثير من 1 مللي ثانية قبل تشغيل الاستدلال (تأخير الطلب الأول بهذا القدر).
+
+سيكون من الأفضل تحديد مهلة واحدة مدتها 1 مللي ثانية.
+
+سيظل هذا ينتظر دائمًا لمدة 1 مللي ثانية حتى إذا كانت قائمة الانتظار فارغًا، والذي قد لا يكون الأفضل نظرًا لأنك تريد على الأرجح البدء في إجراء الاستدلال إذا لم يكن هناك شيء في قائمة الانتظا. ولكن ربما يكون منطقيًا إذا كانت المعالجة الديناميكية للدفعات مهمة حقًا لحالة الاستخدام لديك. مرة أخرى، لا يوجد حل واحد هو الأفضل.
+
+## بعض الأشياء التي قد ترغب في مراعاتها
+
+### التحقق من الأخطاء
+
+هناك الكثير مما قد يحدث بشكل خاطئ في عند اتاحة النموذج للجمهور: نفاد الذاكرة، أو نفاد المساحة، أو فشل تحميل النموذج، أو قد يكون الاستعلام خاطئًا، أو قد يكون الاستعلام صحيحًا ولكن لا يزال يفشل في التشغيل بسبب خطأ في إعداد النموذج، وما إلى ذلك.
+
+بشكل عام، من الجيد أن يُخرِج الخادم الأخطاء للمستخدم، لذلك يُعدّ إضافة الكثير من عبارات `try..except` لعرض هذه الأخطاء فكرة
+جيدة. لكن ضع في اعتبارك أنه قد يمثل أيضًا مخاطرة أمنية الكشف عن جميع تلك الأخطاء اعتمادًا على سياق الأمان لديك.
+
+### قطع الدائرة (Circuit breaking)
+
+عادةً ما تبدو خوادم الويب أفضل عندما تقوم بقطع الدائرة. وهذا يعني أنها ترجع أخطاء صحيحة عندما تكون مثقلة بشكل زائد بدلاً من الانتظار إلى أجل غير مسمى. قم بإرجاع خطأ 503 بدلاً من الانتظار لفترة طويلة جدًا أو 504 بعد فترة طويلة.
+
+من السهل نسبيًا تنفيذ ذلك في الكود المقترح نظرًا لوجود قائمة انتظار واحد. إن النظر في حجم قائمة الانتظار هو طريقة أساسية لبدء إرجاع الأخطاء قبل فشل خادم الويب بسبب الحمل الزائد.
+
+### حجب عمل خيط التنفيذ الرئيسي (Main thread)
+
+حاليًا، لا تدعم PyTorch العمليات غير المتزامنة، وسيؤدي الحساب إلى حجب عمل الخيط الرئيسي أثناء تشغيله. وهذا يعني أنه سيكون من الأفضل إذا تم إجبار PyTorch على أن تعمل على الخيط/العملية الخاصة به. لم يتم ذلك هنا لأن الكود أكثر تعقيدًا (في الغالب لأن خيوط التنفيذ والعمليات غير المتزامنة وقوائم الانتظار لا تتوافق معًا). ولكن في النهاية، فإنه سيؤدي نفس الوظيفة.
+
+سيكون هذا مهمًا إذا كان الاستدلال للعناصر الفردية طويلاً (> 1 ثانية) لأنه في هذه الحالة، فهذا يعني أنه سيتعين أثناء الاستدلال على كل استعلام الانتظار لمدة ثانية واحدة قبل حتى يلقي خطأ.
+
+### المعالجة الديناميكية
+
+بشكل عام، لا تُعدّ المعالجة بالضرورة تحسينًا مقارنةً بتمرير عنصر واحد في كل مرة (راجع [تفاصيل المعالجة بالدفعات](./main_classes/pipelines#pipeline-batching) لمزيد من المعلومات). ولكن يمكن أن تكون فعالة للغاية عند استخدامها بالإعداد الصحيح. في واجهة برمجة التطبيقات، لا توجد معالجة ديناميكية بشكل افتراضي (فرصة كبيرة جدًا للتباطؤ). ولكن بالنسبة لاستدلال BLOOM - وهو نموذج كبير جدًا - تُعدّ المعالجة الديناميكية **ضرورية** لتوفير تجربة جيدة للجميع.
\ No newline at end of file
diff --git a/docs/source/ar/task_summary.md b/docs/source/ar/task_summary.md
new file mode 100644
index 00000000000000..d6a9d1477e10fc
--- /dev/null
+++ b/docs/source/ar/task_summary.md
@@ -0,0 +1,323 @@
+# ما الذي تستطيع مكتبة 🤗 Transformers القيام به؟
+
+مكتبة 🤗 Transformers هي مجموعة من النماذج المُدرّبة مسبقًا الأفضل في فئتها لمهام معالجة اللغة الطبيعية (NLP)، ورؤية الحاسوب، ومعالجة الصوت والكلام. لا تحتوي المكتبة فقط على نماذج المحولات (Transformer) فحسب، بل تشمل أيضًا نماذج أخرى لا تعتمد على المحولات مثل الشبكات العصبية التلافيفية الحديثة لمهام رؤية الحاسوب. إذا نظرت إلى بعض المنتجات الاستهلاكية الأكثر شيوعًا اليوم، مثل الهواتف الذكية والتطبيقات وأجهزة التلفاز، فمن المحتمل أن تقف وراءها تقنية ما من تقنيات التعلم العميق. هل تريد إزالة جسم من خلفية صورة التقطتها بهاتفك الذكي؟ هذا مثال على مهمة التجزئة البانورامية (Panoptic Segmentation) ( لا تقلق إذا لم تفهم معناها بعد، فسوف نشرحها في الأقسام التالية!).
+
+توفر هذه الصفحة نظرة عامة على مختلف مهام الكلام والصوت ورؤية الحاسوب ومعالجة اللغات الطبيعية المختلفة التي يمكن حلها باستخدام مكتبة 🤗 Transformers في ثلاثة أسطر فقط من التعليمات البرمجية!
+
+## الصوت
+
+تختلف مهام معالجة الصوت والكلام قليلاً عن باقي الوسائط، ويرجع ذلك ببشكل أساسي لأن الصوت كمدخل هو إشارة متصلة. على عكس النص، لا يمكن تقسيم الموجة الصوتية الخام بشكل مرتب في أجزاء منفصلة بالطريقة التي يمكن بها تقسيم الجملة إلى كلمات. وللتغلب على هذا، يتم عادةً أخذ عينات من الإشارة الصوتية الخام على فترات زمنية منتظمة. كلما زاد عدد العينات التي تؤخذ في فترة زمنية معينة، ارتفع معدل أخذ العينات (معدل التردد)، وصار الصوت أقرب إلى مصدر الصوت الأصلي.
+
+قامت الطرق السابقة بمعالجة الصوت لاستخراج الميزات المفيدة منه. أصبح من الشائع الآن البدء بمهام معالجة الصوت والكلام عن طريق تغذية شكل الموجة الصوتية الخام مباشرة في مشفر الميزات (Feature Encoder) لاستخراج تمثيل صوتي له. وهذا يبسط خطوة المعالجة المسبقة ويسمح للنموذج بتعلم أهم الميزات.
+
+### تصنيف الصوت
+
+تصنيف الصوت (Audio Classification) هو مهمة يتم فيها تصنيف بيانات الصوت الصوت من مجموعة محددة مسبقًا من الفئات. إنه فئة واسعة تضم العديد من التطبيقات المحددة، والتي تشمل:
+
+* تصنيف المشهد الصوتي: وضع علامة على الصوت باستخدام تسمية المشهد ("المكتب"، "الشاطئ"، "الملعب")
+* اكتشاف الأحداث الصوتية: وضع علامة على الصوت باستخدام تسمية حدث صوتي ("بوق السيارة"، "صوت الحوت"، "كسر زجاج")
+* الوسم: وصنيف صوت يحتوي على أصوات متعددة (أصوات الطيور، وتحديد هوية المتحدث في اجتماع)
+* تصنيف الموسيقى: وضع علامة على الموسيقى بتسمية النوع ("ميتال"، "هيب هوب"، "كانتري")
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
+>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.4532, 'label': 'hap'},
+ {'score': 0.3622, 'label': 'sad'},
+ {'score': 0.0943, 'label': 'neu'},
+ {'score': 0.0903, 'label': 'ang'}]
+```
+
+### التعرف التلقائي على الكلام
+
+يقوم التعرف التلقائي على الكلام (ASR) هو عملية تحويل الكلام إلى نص. إنه أحد أكثر المهام الصوتية شيوعًا ويرجع ذلك جزئيًا إلى أن الكلام وسيلة طبيعية للتواصل البشري. واليوم، يتم تضمين أنظمة ASR في منتجات التقنية "الذكية" مثل مكبرات الصوت والهواتف والسيارات. يمكننا أن نطلب من مساعدينا الافتراضيين تشغيل الموسيقى، وضبط التذكيرات، وإخبارنا بأحوال الطقس.
+ولكن أحد التحديات الرئيسية التي ساعدت نماذج المحولات (Transformer) في التغلب عليها هو التعامل مع اللغات منخفضة الموارد. فمن خلال التدريب المسبق على كميات كبيرة من بيانات الصوتية، يُمكن ضبط النموذج بدقة (Fine-tuning) باستخدام ساعة واحدة فقط من بيانات الكلام المُوسم في لغة منخفضة الموارد إلى نتائج عالية الجودة مقارنة بأنظمة ASR السابقة التي تم تدريبها على بيانات موسومة أكثر بـ 100 مرة.
+
+```py
+>>> from transformers import pipeline
+
+>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
+>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
+```
+
+## رؤية الحاسب
+
+كانت إحدى أوائل مهام رؤية الحاسب وأنجحها هى التعرف على صور أرقام الرموز البريدية باستخدام [شبكة عصبية تلافيفية (CNN)](glossary#convolution). تتكون الصورة من وحدات بيكسل، ولكل بكسل قيمة رقمية. وهذا يجعل من السهل تمثيل صورة كمصفوفة من قيم البكسل. يصف كل مزيج معين من قيم البكسل ألوان الصورة.
+
+هناك طريقتان عامتان يمكن من خلالهما حل مهام رؤية الحاسب:
+
+1. استخدام الالتفافات (Convolutions) لتعلم الميزات الهرمية للصورة بدءًا من الميزات منخفضة المستوى وصولًا إلى الأشياء المجردة عالية المستوى.
+2. تقسيم الصورة إلى أجزاء واستخدام نموذج المحولات (Transformer) ليتعلم تدريجياً كيف ترتبط كل جزء صورة ببعضها البعض لتشكيل صورة. على عكس النهج ا التصاعدي (Bottom-Up) الذي تفضله الشبكات العصبية التلافيفية CNN، هذا يشبه إلى حد ما البدء بصورة ضبابية ثم جعلها أوضح تدريجيًا.
+
+### تصنيف الصور
+
+يقوم تصنيف الصور (Image Classification) بوضع علامة على صورة كاملة من مجموعة محددة مسبقًا من الفئات. مثل معظم مهام التصنيف، هناك العديد من التطبيقات العملية لتصنيف الصور، والتي تشمل:
+
+* الرعاية الصحية: تصنيف الصور الطبية للكشف عن الأمراض أو مراقبة صحة المريض
+* البيئة: تصنيف صور الأقمار الصناعية لرصد إزالة الغابات، أو إبلاغ إدارة الأراضي البرية أو اكتشاف حرائق الغابات
+* الزراعة: تصنيفر المحاصيل لمراقبة صحة النبات أو صور الأقمار الصناعية لمراقبة استخدام الأراضي
+* علم البيئة: تصنيف صور الأنواع الحيوانية أو النباتية لرصد أعداد الكائنات الحية أو تتبع الأنواع المهددة بالانقراض
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="image-classification")
+>>> preds = classifier(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> print(*preds, sep="\n")
+{'score': 0.4335, 'label': 'lynx, catamount'}
+{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
+{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
+{'score': 0.0239, 'label': 'Egyptian cat'}
+{'score': 0.0229, 'label': 'tiger cat'}
+```
+
+### كشف الأجسام
+
+على عكس تصنيف الصور، يقوم كشف الأجسام (Object Detection) بتحديد عدة أجسام داخل صورة ومواضع هذه الأجسام في صورة (يحددها مربع الإحاطة). بعض تطبيقات كشف الأجسام تشمل:
+
+* المركبات ذاتية القيادة: اكتشاف أجسام المرورية اليومية مثل المركبات الأخرى والمشاة وإشارات المرور
+* الاستشعار عن بُعد: مراقبة الكوارث، والتخطيط الحضري، والتنبؤ بالطقس
+* اكتشاف العيوب: اكتشاف الشقوق أو الأضرار الهيكلية في المباني، وعيوب التصنيع
+
+```py
+>>> from transformers import pipeline
+
+>>> detector = pipeline(task="object-detection")
+>>> preds = detector(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
+>>> preds
+[{'score': 0.9865,
+ 'label': 'cat',
+ 'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
+```
+
+### تجزئة الصور
+
+تجزئة الصورة (Image Segmentation) هي مهمة على مستوى البكسل تقوم بتخصيص كل بكسل في صورة لفئة معينة. إنه يختلف عن كشف الأجسام، والذي يستخدم مربعات الإحاطة (Bounding Boxes) لتصنيف والتنبؤ بالأجسام في الصورة لأن التجزئة أكثر دقة. يمكن لتجزئة الصور اكتشاف الأجسام على مستوى البكسل. هناك عدة أنواع من تجزئة الصور:
+
+* تجزئة مثيلات (Instance Segmentation): بالإضافة إلى تصنيف فئة كائن، فإنها تُصنّف أيضًا كل مثيل (Instance) مميز لكائن ("الكلب-1"، "الكلب-2")
+* التجزئة البانورامية (Panoptic Segmentation): مزيج من التجزئة الدلالية (Semantic Segmentation) وتجزئة المثيلات؛ فهو تُصنّف كل بكسل مع فئة دلالية **و** كل مثيل مميز لكائن
+
+تُعد مهام تجزئة الصور مفيدة في المركبات ذاتية القيادة على إنشاء خريطة على مستوى البكسل للعالم من حولها حتى تتمكن من التنقل بأمان حول المشاة والمركبات الأخرى. كما أنها مفيدة للتصوير الطبي، حيث يمكن للدقة العالية لهذ المهمة أن تساعد في تحديد الخلايا غير الطبيعية أو خصائص الأعضاء. يمكن أيضًا استخدام تجزئة الصور في التجارة الإلكترونية لتجربة الملابس افتراضيًا أو إنشاء تجارب الواقع المُعزز من خلال تراكب الأجسام في العالم الحقيقي من خلال الكاميرا الهاتف الخاصة بك.
+
+```py
+>>> from transformers import pipeline
+
+>>> segmenter = pipeline(task="image-segmentation")
+>>> preds = segmenter(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> print(*preds, sep="\n")
+{'score': 0.9879, 'label': 'LABEL_184'}
+{'score': 0.9973, 'label': 'snow'}
+{'score': 0.9972, 'label': 'cat'}
+```
+
+### تقدير العمق
+
+يقوم تقدير العمق (Depth Estimation) بالتنبؤ بمسافة كل بكسل في صورة من الكاميرا. تُعد هذه المهمة لرؤية الحاسب هذه مهمة بشكل خاص لفهم وإعادة بناء المشهد. فعلى سبيل المثال، في السيارات ذاتية القيادة، تحتاج المركبات إلى فهم مدى بُعد الأجسام مثل المشاة ولافتات المرور والمركبات الأخرى لتجنب العقبات والاصطدامات. تساعد معلومات العمق أيضًا في بناء التمثيلات ثلاثية الأبعاد من الصور ثنائية الأبعاد ويمكن استخدامها لإنشاء تمثيلات ثلاثية الأبعاد عالية الجودة للهياكل البيولوجية أو المباني.
+
+هناك نهجان لتقدير العمق:
+
+* التصوير المجسم (Stereo): يتم تقدير العمق عن طريق مقارنة صورتين لنفس الصورة من زوايا مختلفة قليلاً.
+* التصوير الأحادي (Monocular): يتم تقدير العمق من صورة واحدة.
+
+```py
+>>> from transformers import pipeline
+
+>>> depth_estimator = pipeline(task="depth-estimation")
+>>> preds = depth_estimator(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+```
+
+## معالجة اللغات الطبيعية
+
+تُعد مهام معالجة اللغة الطبيعية (NLP) من بين أكثر أنواع المهام شيوعًا نظرًا لأن النص هو وسيلة طبيعية لنا للتواصل. ولكي يتمكن النموذج من فهم النص، يجب أولًا تحويله إلى صيغة رقمية. وهذا يعني تقسيم سلسلة النص إلى كلمات أو مقاطع كلمات منفصلة (رموز - Tokens)، ثم تحويل هذه الرموز إلى أرقام. ونتيجة لذلك، يمكنك تمثيل سلسلة من النص كتسلسل من الأرقام، وبمجرد حصولك على تسلسل من الأرقام، يمكن إدخاله إلى نموذج لحل جميع أنواع مهام معالجة اللغة الطبيعية!
+
+### تصنيف النصوص
+
+تمامًا مثل مهام التصنيف في أي مجال آخر، يقوم تصنيف النصوص (Text Classification) بتصنيف سلسلة نصية يمكن أن تكون جملة أو فقرة أو مستند) إلى فئة محددة مسبقًا. هناك العديد من التطبيقات العملية لتصنيف النصوص، والتي تشمل:
+
+* تحليل المشاعر (Sentiment Analysis): تصنيف النص وفقًا لمعيار معين مثل `الإيجابية` أو `السلبية` والتي يمكن أن تُعلم وتدعم عملية صنع القرار في مجالات مثل السياسة والتمويل والتسويق
+* تصنيف المحتوى (Content Classification): تصنيف النص وفقًا لبعض الموضوعات للمساعدة في تنظيم وتصفية المعلومات في الأخبار وموجزات الوسائط الاجتماعية (`الطقس`، `الرياضة`، `التمويل`، إلخ).
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="sentiment-analysis")
+>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.9991, 'label': 'POSITIVE'}]
+```
+
+### تصنيف الرموز
+
+في أي مهمة من مهام معالجة اللغة الطبيعية NLP، تتم معالجة النص مسبقًا عن طريق تقسيمه إلى كلمات أو مقاطع كلمات فردية تُعرف باسم [الرموز](glossary#token). يقوم تصنيف الرموز (Token Classification) بتخصيص تصنيف لكل رمز من مجموعة محددة مسبقًا من التصنيفات.
+
+هناك نوعان شائعان من تصنيف الرموز:
+
+* التعرف على الكيانات المسماة (NER): تصنيف الرموز وفقًا لفئة الكيان مثل المنظمة أو الشخص أو الموقع أو التاريخ. يعد NER شائعًا بشكل خاص في الإعدادات الطبية الحيوية، حيث يُمكنه تصنيف الجينات والبروتينات وأسماء الأدوية.
+* ترميز الأجزاء اللغوية (POS): تصنيف الرموز وفقًا للدورها النحوي مثل الاسم أو الفعل أو الصفة. POS مفيد لمساعدة أنظمة الترجمة على فهم كيفية اختلاف كلمتين متطابقتين نحويًا (مثل كلمة "عَلَمَ" كاسم و "عَلِمَ" كفعل).
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="ner")
+>>> preds = classifier("Hugging Face is a French company based in New York City.")
+>>> preds = [
+... {
+... "entity": pred["entity"],
+... "score": round(pred["score"], 4),
+... "index": pred["index"],
+... "word": pred["word"],
+... "start": pred["start"],
+... "end": pred["end"],
+... }
+... for pred in preds
+... ]
+>>> print(*preds, sep="\n")
+{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
+{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
+{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
+{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
+{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
+{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
+{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
+```
+### الإجابة على الأسئلة
+
+تُعدّ مهمة الإجابة عن الأسئلة (Question Answering) مهمة أخرى على مستوى الرموز (Token-Level) تُرجع إجابة لسؤال ما، وقد تعتمد هذه الإجابة على سياق (في النطاق المفتوح - Open-Domain) أو لا تعتمد على سياق (في النطاق المغلق - Closed-Domain). تحدث هذه المهمة عندما نسأل مساعدًا افتراضيًا عن شيء ما، مثل معرفة ما إذا كان مطعمٌ ما مفتوحًا. يمكن أن تُقدّم هذه المهمة أيضًا دعمًا للعملاء أو دعمًا تقنيًا، كما تُساعد محركات البحث في استرجاع المعلومات ذات الصلة التي نبحث عنها.
+
+هناك نوعان شائعان من الإجابة على الأسئلة:
+
+* الاستخراجية (Extractive): بالنظر إلى سؤال وسياق مُعيّن، فإن الإجابة هي مقطع نصيّ مُستخرج من السياق الذي يُحلّله النموذج.
+* التجريدية (Abstractive): بالنظر إلى سؤال وسياق مُعيّن، يتم إنشاء الإجابة من السياق؛ يتعامل نهج [`Text2TextGenerationPipeline`] مع هذا النهج بدلاً من [`QuestionAnsweringPipeline`] الموضح أدناه
+
+
+```py
+>>> from transformers import pipeline
+
+>>> question_answerer = pipeline(task="question-answering")
+>>> preds = question_answerer(
+... question="What is the name of the repository?",
+... context="The name of the repository is huggingface/transformers",
+... )
+>>> print(
+... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
+... )
+score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
+```
+
+### التلخيص
+
+ينشئ التلخيص (Summarization) نسخة مختصرة من نص طويل مع محاولة الحفاظ على معظم معنى النص الأصلي. التلخيص هو مهمة تسلسل إلى تسلسل(Sequence-to-Sequence)؛؛ فهو تُنتج تسلسلًا نصيًا أقصر من النص المُدخل. هناك الكثير من المستندات الطويلة التي يمكن تلخيصها لمساعدة القراء على فهم النقاط الرئيسية بسرعة. مشاريع القوانين والوثائق القانونية والمالية وبراءات الاختراع والأوراق العلمية هي مجرد أمثلة قليلة للوثائق التي يمكن تلخيصها لتوفير وقت القراء وخدمة كمساعد للقراءة.
+
+مثل الإجابة على الأسئلة، هناك نوعان من التلخيص:
+
+* الاستخراجية (Extractive): تحديد واستخراج أهم الجمل من النص الأصلي
+* التجريدي (Abstractive): إنشاء ملخص مستهدف (الذي قد يتضمن كلمات جديدة غير موجودة في النص الأصلي) انطلاقًا من النص الأصلي؛ يستخدم نهج التلخيص التجريدي [`SummarizationPipeline`]
+
+```py
+>>> from transformers import pipeline
+
+>>> summarizer = pipeline(task="summarization")
+>>> summarizer(
+... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
+... )
+[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
+```
+
+### الترجمة
+
+تحوّل الترجمة تسلسل نص بلغة إلى لغة أخرى. من المهم مساعدة الأشخاص من خلفيات مختلفة على التواصل مع بعضهم البعض، ومساعدة المحتوى على الوصول إلى جمهور أوسع، وحتى أن يكون أداة تعليمية لمساعدة الأشخاص على تعلم لغة جديدة. إلى جانب التلخيص، تعد الترجمة مهمة من نوع تسلسل إلى تسلسل، حيث يتلقى النموذج تسلسلًا مُدخلًا ويُعيد تسلسلًا مُخرَجًا مُستهدفًا.
+
+في الأيام الأولى، كانت نماذج الترجمة في الغالب أحادية اللغة، ولكن مؤخرًا، كان هناك اهتمام متزايد بالنماذج متعددة اللغات التي يمكنها الترجمة بين العديد من أزواج اللغات.
+
+```py
+>>> from transformers import pipeline
+
+>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
+>>> translator = pipeline(task="translation", model="google-t5/t5-small")
+>>> translator(text)
+[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
+```
+
+### نمذجة اللغة
+
+نمذجة اللغة (Language Modeling) هي مهمة التنبؤ بالكلمة التالية في تسلسل نصي. لقد أصبح مهمة NLP شائعة للغاية لأن النموذج اللغوي المسبق التدريب يمكن أن يتم ضبطه بشكل دقيق للعديد من مهام الأخرى. في الآونة الأخيرة، كان هناك الكثير من الاهتمام بنماذج اللغة الكبيرة (LLMs) التي توضح التعلم من الصفر أو من عدد قليل من الأمثلة (Zero-shot or Few-shot Learning). وهذا يعني أن النموذج يمكنه حل المهام التي لم يتم تدريبه عليها بشكل صريح! يمكن استخدام نماذج اللغة لإنشاء نص سلس ومقنع، على الرغم من أنه يجب أن تكون حذرًا لأن النص قد لا يكون دائمًا دقيقًا.
+
+هناك نوعان من نمذجة اللغة:
+
+* السببية(Causal): هدف النموذج هو التنبؤ بالرمز (Token) التالي في التسلسل، ويتم إخفاء الرموز المستقبلية (Masking).
+
+```py
+>>> from transformers import pipeline
+
+>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
+>>> generator = pipeline(task="text-generation")
+>>> generator(prompt) # doctest: +SKIP
+```
+
+* المقنّع (Masked): هدف النموذج هو التنبؤ برمز مُخفيّ ضمن التسلسل مع الوصول الكامل إلى الرموز الأخرى في التسلسل
+
+```py
+>>> text = "Hugging Face is a community-based open-source for machine learning."
+>>> fill_mask = pipeline(task="fill-mask")
+>>> preds = fill_mask(text, top_k=1)
+>>> preds = [
+... {
+... "score": round(pred["score"], 4),
+... "token": pred["token"],
+... "token_str": pred["token_str"],
+... "sequence": pred["sequence"],
+... }
+... for pred in preds
+... ]
+>>> preds
+[{'score': 0.2236,
+ 'token': 1761,
+ 'token_str': ' platform',
+ 'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
+```
+
+## متعدد الوسائط:
+
+تتطلب المهام متعددة الوسائط (Multimodal) من النموذج معالجة وسائط بيانات متعددة (نص أو صورة أو صوت أو فيديو) لحل مشكلة معينة. يعد وصف الصورة (Image Captioning) مثالاً على مهمة متعددة الوسائط حيث يأخذ النموذج صورة كمدخل وينتج تسلسل نصيًا يصف الصورة أو بعض خصائصها.
+
+على الرغم من أن النماذج متعددة الوسائط تعمل مع أنواع أو وسائط بيانات مختلفة، إلا أن خطوات المعالجة المسبقة تساعد النموذج داخليًا على تحويل جميع أنواع البيانات إلى متجهات تضمين (Embeddings) (متجهات أو قوائم من الأرقام التي تحتوي على معلومات ذات معنى حول البيانات). بالنسبة لمهمة مثل وصف الصورة، يتعلم النموذج العلاقات بين متجهات تضمين الصور ومتجهات تضمين النص.
+
+### الإجابة على أسئلة المستندات:
+
+الإجابة على أسئلة المستندات (Document Question Answering) هي مهمة تقوم بالإجابة على أسئلة اللغة الطبيعية من مستند مُعطى. على عكس مهمة الإجابة على الأسئلة على مستوى الرموز (Token-Level) التي تأخذ نصًا كمدخل، فإن الإجابة على أسئلة المستندات تأخذ صورة لمستند كمدخل بالإضافة إلى سؤال هذا حول المستند وتعيد الإجابة. يمكن استخدام الإجابة على أسئلة المستندات لتفسير المستندات المُنسّقة واستخراج المعلومات الرئيسية منها. في المثال أدناه، يمكن استخراج المبلغ الإجمالي والمبلغ المُسترد من إيصال الدفع..
+
+```py
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "https://huggingface.co/datasets/hf-internal-testing/example-documents/resolve/main/jpeg_images/2.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
+>>> preds = doc_question_answerer(
+... question="ما هو المبلغ الإجمالي؟",
+... image=image,
+... )
+>>> preds
+[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
+```
+
+نأمل أن تكون هذه الصفحة قد زودتك ببعض المعلومات الأساسية حول جميع أنواع المهام في كل طريقة وأهمية كل منها العملية. في القسم التالي، ستتعلم كيف تعمل مكتبة 🤗 Transformers لحل هذه المهام.
\ No newline at end of file
diff --git a/docs/source/ar/tasks_explained.md b/docs/source/ar/tasks_explained.md
new file mode 100644
index 00000000000000..b91297be7d2795
--- /dev/null
+++ b/docs/source/ar/tasks_explained.md
@@ -0,0 +1,279 @@
+# كيف تُنجز نماذج 🤗 Transformers المهام؟
+
+في [ما الذي يمكن أن تفعله نماذج 🤗 Transformers](task_summary)، تعلمت عن معالجة اللغات الطبيعية (NLP)، والخطاب والصوت، ورؤية الحاسب، وبعض تطبيقاتها المهمة. ستلقي هذه الصفحة نظرة فاحصة على كيفية حل النماذج لهذه المهام وتوضيح ما يحدث ما يحدث وراء الكواليس. هناك العديد من الطرق لحل مهمة معينة، وقد تنفذ بعض النماذج تقنيات معينة أو حتى تتناول المهمة من زاوية جديدة، ولكن بالنسبة لنماذج Transformer، فإن الفكرة العامة هي نفسها. وبفضل تصميمها المرن، فنظراً لهيكلها المرن، تُعدّ معظم النماذج عبارة عن متغير من بنية المُشفّر (Encoder) أو المُفكّك (Decoder) أو المُشفّر - المُفكّك (Encoder-Decoder). بالإضافة إلى نماذج Transformer، تحتوي مكتبتنا أيضًا على العديد من الشبكات العصبية التلافيفية (CNNs)، والتي لا تزال تستخدم حتى اليوم لمهام رؤية الحاسب. سنشرح أيضًا كيف تعمل شبكة عصبية تلافيفية CNN الحديثة.
+
+لشرح كيفية حل المهام، سنشرح ما يحدث داخل النموذج لإخراج تنبؤات مفيدة.
+
+- [Wav2Vec2](model_doc/wav2vec2) لتصنيف الصوت والتعرف التلقائي على الكلام (ASR)
+- [Vision Transformer (ViT)](model_doc/vit) و [ConvNeXT](model_doc/convnext) لتصنيف الصور
+- [DETR](model_doc/detr) للكشف عن الأجسام
+- [Mask2Former](model_doc/mask2former) لتجزئة الصورة
+- [GLPN](model_doc/glpn) لتقدير العمق
+- [BERT](model_doc/bert) لمهام NLP مثل تصنيف النصوص، وتصنيف الرموز، والإجابة على الأسئلة التي تستخدم مشفرًا
+- [GPT2](model_doc/gpt2) لمهام NLP مثل توليد النصوص التي تستخدم فك تشفير
+- [BART](model_doc/bart) لمهام NLP مثل الملخص والترجمة التي تستخدم ترميز-فك تشفير
+
+
+
+قبل المتابعة، من الجيد أن يكون لديك بعض المعرفة الأساسية بهيكلية المحولات (Transformer Architecture) الأصلية. إن معرفة كيفية عمل المُشفّرات (Encoders) والمُفكّكات (Decoders) وآلية الانتباه (Attention Mechanism) سوف تساعدك في فهم كيفية عمل نماذج Transformer المختلفة. إذا كنت مبتدئًا أو بحاجة إلى مراجعة، فراجع [دورتنا](https://huggingface.co/course/chapter1/4؟fw=pt) لمزيد من المعلومات!
+
+
+
+## الكلام والصوت (Speech and audio)
+
+يُعدّ [Wav2Vec2](model_doc/wav2vec2) نموذجًا مُدرَّبًا ذاتيًا (Self-Supervised) على بيانات الكلام غير المُصنّفة، ويُمكن ضبطه بدقة (Fine-tuning) على بيانات موسومة لأداء مهام تصنيف الصوت والتعرف التلقائي على الكلام.
+
+
+
+
+
+يتكون هذا النموذج على أربعة مكونات رئيسية:
+
+1. *مشفّر الميزات (Feature Encoder)* يأخذ الموجة الصوتية الخام، ويقوم بتطبيعها (Normalization) إلى متوسط صفري وانحراف معياري وحدوي، وتحويلها إلى تسلسل من متجهات الميزات التي يبلغ طول كل منها 20 مللي ثانية.
+
+2. *وحدة التكميم (Quantization Module):** تتميز أشكال الموجات الصوتية بطبيعتها المُستمرة،، لذلك لا يمكن تقسيمها إلى وحدات منفصلة كما يمكن تقسيم التسلسل النصّي إلى كلمات ولهذا السبب يتم تمرير متجهات الميزات إلى *وحدة التكميم*، والتي تهدف إلى تعلم وحدات الكلام المنفصلة. يتم اختيار وحدة الكلام من مجموعة من الرموز، والمعروفة باسم *كتاب الرموز* (يمكنك اعتبار هذا بمثابة المفردات). ومن كتاب الرموز،يتم اختيار المتجه أو وحدة الكلام التي تُمثّل مدخل الصوت المُستمر على أفضل وجه، ويتم تمريرها عبر النموذج.
+3. **شبكة السياق (Context Network):** يتم إخفاء حوالي نصف متجهات الميزات بشكل عشوائي، ويتم تغذية متجه الميزة المُقنّع إلى *شبكة السياق*، والتي تعد مُشفّر محوّلات (Transformer Encoder) الذي يضيف أيضًا تضمينات موضعية نسبية (Relative Positional Embeddings)..
+
+4. **مهمة التناقضية:** يتمثل الهدف من التدريب المسبق لشبكة السياق هو *مهمة تناقضية*. يجب على النموذج التنبؤ بالتمثيل الصحيح للكلام المُكمّم للتنبؤ المقنع من مجموعة من التمثيلات الخاطئة، مما يشجع النموذج على ا إيجاد متجه السياق ووحدة الكلام المُكمّمة الأكثر تشابهًا (التصنيف المستهدف).
+
+بمجرد تدريب Wav2Vec2 مسبقًا، يمكنك ضبط دقته على بياناتك لتصنيف الصوت أو التعرف التلقائي على الكلام!
+
+### تصنيف الصوت (Audio classification)
+
+لاستخدام النموذج الذي تم تدريبه مسبقًا لتصنيف الصوت، أضف رأس تصنيف تسلسلي أعلى نموذج Wav2Vec2 الأساسي. رأس التصنيف هو طبقة خطية تستقبل الحالات المخفية للمشفر. تمثل الحالات المخفية الميزات التي تم تعلمها من كل إطار صوتي والذي يمكن أن يكون له أطوال مختلفة. لتحويلها إلى متجه واحد ثابت الطول، يتم تجميع الحالات المخفية أولاً ثم تحويلها إلى احتمالات عبر تصنيفات الفئات. يتم حساب التكلفة (الخسارة المتقاطعة) بين الاحتمالات والتصنيف المستهدف للعثور على الفئة الأكثر احتمالًا.
+
+هل أنت مستعد لتجربة تصنيف الصوت؟ تحقق من دليلنا الشامل [تصنيف الصوت](tasks/audio_classification) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
+
+### التعرف التلقائي على الكلام (Automatic speech recognition - ASR)
+
+لاستخدام النموذج الذي تم تدريبه مسبقًا للتعرف التلقائي على الكلام، أضف رأس نمذجة لغوية أعلى نموذج Wav2Vec2 الأساسي لـ [[التصنيف الزمني الترابطي (CTC)](glossary#connectionist-temporal-classification-ctc). رأس النمذجة اللغوية عبارة عن طبقة خطية تقبل الحالات المخفية للمُشفّر وتحويلها إلى احتمالات. يمثل كل احتمال فئة رمزية (يأتي عدد الرموز من مفردات المهمة). يتم حساب تكلفة CTC بين الاحتمالات والأهداف للعثور على تسلسل الرموز الأكثر احتمالًا، والتي يتم فك تشفيرها بعد ذلك إلى نص مكتوب.
+
+هل أنت مستعد لتجربة التعرف التلقائي على الكلام؟ تحقق من دليلنا الشامل [التعرف التلقائي على الكلام](tasks/asr) لمعرفة كيفية ضبط دقة نموذج Wav2Vec2 واستخدامه للاستدلال!
+
+## رؤية الحاسب (Computer vision)
+
+هناك طريقتان لتناول مهام رؤية الحاسب:
+
+1. قم بتقسيم الصورة إلى تسلسل من الرقع ومعالجتها بالتوازي باستخدام مُحوّل Transformer.
+2. استخدم شبكة عصبية تلافيفية CNN) حديثة، مثل [ConvNeXT](model_doc/convnext)، والتي تعتمد على الطبقات التلافيفية ولكنها تعتمد تصميمات حديثة للشبكات.
+
+
+
+يقوم النهج الثالث بمزج المحولات مع التلافيف (على سبيل المثال، [Convolutional Vision Transformer](model_doc/cvt) أو [LeViT](model_doc/levit)). لن نناقشها لأنها تجمع ببساطة بين النهجين اللذين نستعرضهما هنا.
+
+
+
+يتم استخدام ViT و ConvNeXT بشكل شائع لتصنيف الصور، ولكن بالنسبة لمهام الرؤية الأخرى مثل اكتشاف الكائنات والتجزئة وتقدير العمق، سنلقي نظرة على DETR و Mask2Former و GLPN، على التوالي؛ فهذه النماذج هي الأنسب لتلك المهام.
+
+### تصنيف الصور (Image classification)
+
+يمكن استخدام كل من ViT و ConvNeXT لتصنيف الصور؛ الاختلاف الرئيسي هو أن ViT يستخدم آلية انتباه بينما يستخدم ConvNeXT الالتفافات.
+
+#### المحول Transformer
+
+[ViT](model_doc/vit) يستبدل التلافيف تمامًا بهندسة Transformer نقية. إذا كنت على دراية بـ Transformer الأصلي، فأنت بالفعل في طريقك إلى فهم ViT.
+
+
+
+
+
+كان التغيير الرئيسي الذي قدمه ViT هو كيفية تغذية الصور إلى Transformer:
+
+1. يتم تقسيم الصورة إلى رقع مربعة غير متداخلة، يتم تحويل كل منها إلى متجه أو يُسمى *تمثيل الرقعة*. يتم إنشاء تضمينات الرقع من طبقة تلافيفية ثنائية الأبعاد 2D والتي تقوم بإنشاء أبعاد الإدخال الصحيحة (والتي بالنسبة إلى Transformer الأساسي هي 768 قيمة لكل تضمين رقعة). إذا كان لديك صورة 224x224 بكسل، فيمكنك تقسيمها إلى 196 رقعة صورة 16x16. تمامًا مثل كيفية تجزئة النص إلى كلمات، يتم "تجزئة" الصورة إلى سلسلة من الرقع.
+
+2. يتم إضافة *رمز قابل للتعلم* - تتم إضافة رمز خاص `[CLS]` - إلى بداية تمثيلات الرقع تمامًا مثل BERT. يتم استخدام الحالة المخفية النهائية للرمز `[CLS]` كمدخل لرأس التصنيف المُرفق؛ يتم تجاهل المخرجات الأخرى. تساعد هذه الرموز النموذج على تعلم كيفية ترميز تمثيل الصورة.
+
+3. الشيء الأخير تتم إضافة "تمثيلات تموضع" إلى تمثيلات الرقع والرمز القابل للتعلم لأن النموذج لا يعرف كيفية ترتيب رقع الصورة. تكون تمثيلات التموضع قابلة للتعلم أيضًا ولها نفس حجم تمثيلات الرقع. وأخيرًا، يتم تمرير جميع التمثيلات إلى مُشفّر Transformer.
+
+4. يتم تمرير الإخراج، وتحديدًا مخرج الرمز `[CLS]`، إلى رأس الإدراك المتعدد الطبقات (MLP). الهدف من التدريب المسبق لـ ViT هو التصنيف فقط. يقوم رأس MLP، مثل رؤوس التصنيف الأخرى، يحول رأس MLP المخرجات إلى احتمالات عبر تصنيفات الفئات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على الفئة الأكثر احتمالًا.
+
+هل أنت مستعد لتجربة تصنيف الصور؟ تحقق من دليلنا الشامل [تصنيف الصور](tasks/image_classification) لمعرفة كيفية ضبط دقة نموذج ViT واستخدامه للاستدلال!
+
+#### الشبكات العصبية التلافيفية (CNN)
+
+
+
+يشرح هذا القسم بإيجاز الالتفافات، ولكن سيكون من المفيد أن يكون لديك فهم مسبق لكيفية تغيير شكل الصورة وحجمها. إذا كنت غير معتاد على الالتفافات، تحقق من [فصل الشبكات العصبية التلافيفية](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb) من كتاب fastai!
+
+
+
+[ConvNeXT](model_doc/convnext) هو بنية CNN تعتمد تصاميم الشبكات الجديدة والحديثة لتحسين الأداء. ومع ذلك، لا تزال الالتفافات هي جوهر النموذج. من منظور عام، [الالتفاف](glossary#convolution) هو عملية حيث يتم ضرب مصفوفة أصغر (*نواة*) بمقطع صغير من وحدات بكسل الصورة. يحسب بعض الميزات منه، مثل نسيج معين أو انحناء خط. ثم ينزلق إلى النافذة التالية من البكسلات؛ المسافة التي تقطعها الالتفاف تسمى *الخطوة*.
+
+
+
+
+
+عملية التفاف أساسية بدون حشو أو خطو خطوة واسعة، مأخوذة من دليل لحساب الالتفاف للتعلم العميق.
+
+يمكنك تغذية هذا الناتج إلى طبقة التفاف أخرى، ومع كل طبقة متتالية، تتعلم الشبكة أشياء أكثر تعقيدًا وتجريدية مثل النقانق أو الصواريخ. بين طبقات الالتفاف، من الشائع إضافة طبقة تجميع لتقليل الأبعاد وجعل النموذج أكثر قوة للتغيرات في موضع الميزة.
+
+
+
+
+
+يقوم ConvNeXT بتحديث شبكة CNN بطرق خمس:
+
+1. تغيير عدد الكتل في كل مرحلة و"ترقيع" الصورة باستخدام خطوة أكبر وحجم نواة المقابل. تجعل استراتيجية التجزئة غير المتداخلة استراتيجية الترقيع مشابهة للطريقة التي يقسم بها ViT للصورة إلى رقع.
+
+2. تقلص طبقة *العنق الزجاجي* عدد القنوات ثم تعيدها لأنها أسرع في إجراء التفاف 1x1، ويمكنك زيادة العمق. يقوم عنق الزجاجة المقلوب بالعكس عن طريق توسيع عدد القنوات وتقلصها، وهو أكثر كفاءة من حيث الذاكرة.
+
+3. استبدل طبقة الالتفاف النموذجية 3x3 في طبقة عنق الزجاجة بـ *الالتفاف بالعمق*، والذي يطبق الالتفاف على كل قناة إدخال بشكل منفصل ثم يقوم بتكديسها معًا مرة أخرى في النهاية. هذا يوسع عرض الشبكة لتحسين الأداء.
+
+4. لدى ViT مجال استقبال عالمي مما يعني أنه يمكنه رؤية المزيد من الصورة في وقت واحد بفضل آلية الانتباه الخاصة به. تحاول ConvNeXT محاكاة هذا التأثير عن طريق زيادة حجم النواة إلى 7x7.
+
+5. يقوم ConvNeXT أيضًا بإجراء العديد من تغييرات تصميم الطبقة التي تُحاكي نماذج المحولات. هناك عدد أقل من طبقات التنشيط والطبقات التطبيع، يتم تبديل دالة التنشيط إلى GELU بدلاً من ReLU، ويستخدم LayerNorm بدلاً من BatchNorm.
+
+يتم تمرير الإخراج من كتل الالتفاف إلى رأس تصنيف يحول المخرجات إلى احتمالات ويحسب دالة التكلفة (الخسارة المتقاطعة) للعثور على التصنيف الأكثر احتمالاً.
+
+### اكتشاف الكائنات (Object detection)
+
+[DETR](model_doc/detr)، *DEtection TRansformer*، هو نموذج اكتشاف كائنات من البداية إلى النهاية يجمع بين CNN مع محول المشفر-فك التشفير.
+
+
+
+
+
+1. يأخذ العمود الفقري CNN *المدرب مسبقًا* صورة، ممثلة بقيم بكسلاتها، وينشئ خريطة ميزات منخفضة الدقة لها. يتم تطبيق التفاف 1x1 على خريطة الميزات لتقليل الأبعاد، و إنشاء خريطة ميزات جديدة بتمثيل صورة عالي المستوى. نظرًا لأن المحول (Transformer) هو نموذج تسلسلي، يتم تسوية خريطة الميزات إلى تسلسل من متجهات الميزات التي يتم دمجها مع تمثيلات التموضع.
+
+2. يتم تمرير متجهات الميزات إلى المشفر، والذي يتعلم تمثيلات الصورة باستخدام طبقات الانتباه الخاصة به. بعد ذلك، يتم دمج الحالات المخفية للمُشفّر مع *استعلامات الكائنات* في فك التشفير. استعلامات الكائنات هي تمثيلات مكتسبة تركز على مناطق مختلفة من الصورة، ويتم تحديثها أثناء مرورها عبر كل طبقة انتباه. يتم تمرير الحالات المخفية لفك التشفير إلى شبكة تغذية أمامية التي تتنبأ بإحداثيات مربعات الإحاطة وتصنيف العلامة لكل استعلام كائن، أو `بدون كائن` إذا لم يكن هناك أي كائن.
+
+ يقوم DETR بفك تشفير كل استعلام كائن بالتوازي لإخراج *N* من التنبؤات النهائية، حيث *N* هو عدد الاستعلامات. على عكس النموذج التلقائي الذي يتنبأ بعنصر واحد في كل مرة، فإن "اكتشاف الكائنات" هو مهمة تنبؤ بمجموعة من التنبؤات (مثل `مربع إحاطة`، `تصنيف`) تقوم بإجراء *N* من التنبؤات في مرور واحدة.
+
+3. يستخدم DETR دالة *خسارة المطابقة ثنائية الفئات* أثناء التدريب لمقارنة عدد ثابت من التنبؤات بمجموعة ثابتة من تصنيفات البيانات الحقيقية. إذا كان هناك عدد أقل من تصنيفات البيانات الحقيقية في مجموعة *N* من التصنيفات، فيتم حشوها بفئة "بدون كائن". تشجع دالة الخسارة هذه DETR على العثور على تعيين واحد لواحد بين التنبؤات وتصنيفات البيانات الحقيقية. إذا لم تكن مربعات الإحاطة أو تصنيفات الفئات صحيحة، يتم تكبد خسارة. وبالمثل، إذا تنبأ DETR بكائن غير موجود، فإنه يتم معاقبته. وهذا يشجع DETR على العثور على كائنات أخرى في الصورة بدلاً من التركيز على كائن بارز حقًا.
+
+يتم إضافة رأس اكتشاف كائن أعلى DETR للعثور على تصنيف الكائن وإحداثيات مربع الإحاطة. هناك مكونان لرأس اكتشاف الكائنات: طبقة خطية لتحويل حالات فك التشفير المخفية إلى احتمالات عبر تصنيفات الفئات، وشبكةMLP للتنبؤ بمربع الإحاطة.
+
+هل أنت مستعد لتجربة اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل اكتشاف الكائنات](tasks/object_detection) لمعرفة كيفية ضبط نموذج DETR واستخدامه للاستدلال!
+
+### تجزئة الصورة (Image segmentation)
+
+يُعد [Mask2Former](model_doc/mask2former) بنيةً شاملةً لحل جميع أنواع مهام تجزئة الصور. عادةً ما تُصمم نماذج التجزئة التقليدية لمهمة فرعية محددة من مهام تجزئة الصور، مثل تجزئة المثيل أو التجزئة الدلالية أو التجزئة الشاملة. يصوغ Mask2Former كل مهمة من تلك المهام على أنها مشكلة *تصنيف الأقنعة*. يقوم تصنيف القناع بتجميع وحدات البكسل في *N* قطعة، ويتنبأ بـ *N* أقنعة وتصنيف الفئة المقابل لها لصورة معينة. سنشرح في هذا القسم كيفية عمل Mask2Former، ويمكنك بعد ذلك تجربة ضبط SegFormer في النهاية.
+
+
+
+
+
+هناك ثلاثة مكونات رئيسية لـ Mask2Former:
+
+1. العمود الفقري [Swin](model_doc/swin) يقبل صورة وينشئ خريطة ميزات منخفضة الدقة من 3 عمليات التفافات متتالية 3x3.
+
+2. يتم تمرير خريطة الميزات إلى *فك تشفير البكسل* الذي يقوم تدريجياً بزيادة الميزات منخفضة الدقة إلى تمثيلات عالية الدقة لكل بكسل. في الواقع، يقوم فك تشفير البكسل بإنشاء ميزات متعددة المقاييس (تحتوي على كل من الميزات منخفضة وعالية الدقة) بدقة 1/32 و1/16 و1/8 من الصورة الأصلية.
+
+3. يتم تغذية كل من خرائط الميزات ذات المقاييس المختلفة على التوالي إلى طبقة واحدة من طبقات فك التشفير في كل مرة لالتقاط الأجسام الصغيرة من ميزات الدقة العالية. يتمثل مفتاح Mask2Former آلية *الاهتمام المقنع* في فك التشفير. على عكس الانتباه المتقاطع الذي يمكن أن يركز على الصورة بأكملها، يركز الانتباه المقنع فقط على منطقة معينة من الصورة. هذا أسرع ويؤدي إلى أداء أفضل لأن الميزات المحلية لصورة كافية للنموذج للتعلم منها.
+
+4. مثل [DETR](tasks_explained#object-detection)، يستخدم Mask2Former أيضًا استعلامات كائن مكتسبة ويجمعها مع ميزات الصورة من فك تشفير البكسل لإجراء تنبؤ مجموعة (`تصنيف الفئة`، `التنبؤ بالقناع`). يتم تمرير حالات فك التشفير المخفية إلى طبقة خطية وتحويلها إلى احتمالات عبر علامات التصنيف. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين الاحتمالات وتصنيف الفئة لتحديد الأكثر احتمالاً.
+
+ يتم إنشاء تنبؤات الأقنعة عن طريق الجمع بين تمثيلات البكسل وحالات فك التشفير المخفية النهائية. يتم حساب دالة الخسارة المتقاطعة سيجمويد وخسارة النرد بين الاحتمالات والقناع البيانات الحقيقية للعثور على القناع الأكثر احتمالاً.
+
+هل أنت مستعد لتجربة يدك في اكتشاف الكائنات؟ تحقق من دليلنا الشامل [دليل تجزئة الصورة](tasks/semantic_segmentation) لمعرفة كيفية ضبط SegFormer واستخدامه للاستدلال!
+
+### تقدير العمق (Depth estimation)
+
+[GLPN](model_doc/glpn)، شبكة المسار العالمية المحلية، هي محول ل تقدير العمق الذي يجمع بين مشفر [SegFormer](model_doc/segformer) مع فك تشفير خفيف الوزن.
+
+
+
+
+
+1. مثل ViT، يتم تقسيم الصورة إلى تسلسل من الرقع، باستثناء أن هذه رقع الصورة أصغر. هذا أفضل لمهام التنبؤ الكثيفة مثل التجزئة أو تقدير العمق. يتم تحويل رقع الصورة إلى تمثيلات للرقع (راجع قسم [تصنيف الصور](#image-classification) لمزيد من التفاصيل حول كيفية إنشاء تمثيلات الرقع)، والتي يتم تغذيتها إلى المشفر.
+
+2. يقبل المشفر تمثيلات الرقع، ويمررها عبر عدة كتل مشفرة. يتكون كل كتلة من طبقات انتباه وMix-FFN. الغرض من هذا الأخير هو توفير معلومات موضعية. في نهاية كل كتلة مشفرة توجد طبقة *دمج الرقع* لإنشاء تمثيلات هرمية. يتم دمج ميزات كل مجموعة من الرقع المجاورة، ويتم تطبيق طبقة خطية على الميزات المدمجة لتقليل عدد الرقع إلى دقة 1/4. يصبح هذا المُدخل للكتلة المشفرة التالية، حيث تتكرر هذه العملية بأكملها حتى تحصل على ميزات الصورة بدقة 1/8 و1/16 و1/32.
+
+3. يقوم فك تشفير خفيف الوزن بأخذ خريطة الميزات الأخيرة (مقياس 1/32) من المشفر وزيادة حجمها إلى مقياس 1/16. من هنا، يتم تمرير الميزة إلى وحدة *دمج الميزات الانتقائية (SFF)*، والتي تقوم باختيار ودمج الميزات المحلية والعالمية من خريطة انتباه لكل ميزة ثم زيادة حجمها إلى 1/8. تتم إعادة هذه العملية حتى تصبح الميزات فك التشفير بنفس حجم الصورة الأصلية. يتم تمرير الإخراج عبر طبقتين تلافيفتين ثم يتم تطبيق تنشيط سيجمويد للتنبؤ بعمق كل بكسل.
+
+## معالجة اللغات الطبيعية (Natural language processing -NLP)
+
+تم تصميم نموذج المحول Transformer في الأصل للترجمة الآلية، ومنذ ذلك الحين أصبح في الواقع البنية الافتراضية لحل جميع مهام NLP. تناسب بعض المهام بنية المشفر في نموذج المحول، في حين أن البعض الآخر أكثر ملاءمة لفك التشفير. لا تزال مهام أخرى تستخدم بنية المشفر-فك التشفير في نموذج المحول.
+
+### تصنيف النصوص (Text classification)
+
+يعد [BERT](model_doc/bert) نموذج يعتمد على المُشفّر فقط، وهو أول نموذج يُطبق بشكل فعال ثنائية الاتجاه العميقة لتعلم تمثيلات أكثر ثراءً للنص من خلال الانتباه إلى الكلمات على كلا الجانبين.
+
+1. يستخدم BERT تجزئة [WordPiece](tokenizer_summary#wordpiece) لإنشاء تمثيل رمزي للنص. للتمييز بين جملة واحدة وزوج من الجمل، تتم إضافة رمز خاص `[SEP]` للتفريق بينهما. تتم إضافة رمز خاص `[CLS]` إلى بداية كل تسلسل نصي. ويتم استخدام الإخراج النهائي مع الرمز `[CLS]` كمدخل لرأس التصنيف لمهام التصنيف. كما يضيف BERT تضمينًا للمقطع للإشارة إلى ما إذا كان الرمز ينتمي إلى الجملة الأولى أو الثانية في زوج من الجمل.
+
+2. يتم تدريب BERT المسبق باستخدام هدفين: نمذجة اللغة المقنعة وتنبؤ الجملة التالية. في نمذجة اللغة المقنعة، يتم إخفاء نسبة مئوية مُعيّنة من رموز الإدخال بشكل عشوائي، ويجب على النموذج التنبؤ بها. يحل هذا مشكلة ثنائية الاتجاه، حيث يمكن للنموذج أن يغش ويرى جميع الكلمات و"يتنبأ" بالكلمة التالية. تتم تمرير الحالات المخفية النهائية للرموز المقنعة المتوقعة إلى شبكة تغذية أمامية مع دالة Softmax عبر مفردات اللغة للتنبؤ بالكلمة المقنعة.
+
+ الهدف الثاني من التدريب المسبق هو توقع الجملة التالية. يجب على النموذج التنبؤ بما إذا كانت الجملة "ب" تتبع الجملة"أ". نصف الوقت تكون الجملة "ب" هي الجملة التالية، والنصف الآخر من الوقت، تكون الجملة "ب" عبارة عشوائية. يتم تمرير التنبؤ، سواء كانت الجملة التالية أم لا، إلى شبكة تغذية أمامية مع دالة Softmax عبر الفئتين (`IsNext` و`NotNext`).
+
+3. يتم تمرير تمثيلات الإدخال عبر عدة طبقات مشفرة لإخراج بعض الحالات المخفية النهائية.
+
+لاستخدام النموذج المسبق التدريب لتصنيف النصوص، أضف رأس تصنيف تسلسلي أعلى نموذج BERT الأساسي. رأس تصنيف التسلسلي هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى احتمالات logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits والهدف للعثور على التصنيف الأكثر احتمالًا.
+
+هل أنت مستعد لتجربة تصنيف النصوص؟ تحقق من [دليل تصنيف النصوص](tasks/sequence_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
+
+### تصنيف الرموز (Token classification)
+
+لاستخدام BERT لمهام تصنيف الرموز مثل التعرف على الكيانات المسماة (NER)، أضف رأس تصنيف الرموز أعلى نموذج BERT الأساسي. رأس تصنيف الرموز هو طبقة خطية تقبل الحالات المخفية النهائية وتجري تحويلًا خطيًا لتحويلها إلى logits. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits وكل رمز للعثور على التصنيف الأكثر احتمالًا.
+
+هل أنت مستعد لتجربة تصنيف الرموز؟ تحقق من [دليل تصنيف الرموز](tasks/token_classification) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه للاستنتاج!
+
+### الإجابة على الأسئلة (Question answering)
+
+لاستخدام BERT للإجابة على الأسئلة، أضف رأس تصنيف المدى أعلى نموذج BERT الأساسي. تقبل هذه الطبقة الخطية الحالات المخفية النهائية وتُجري تحويلًا خطيًا لحساب داية ونهاية `الامتداد` logits `span` البداية والنهاية المقابلة للإجابة. يتم حسابدالة التكلفة (الخسارة المتقاطعة) بين logits وموقع التصنيف للعثور على الامتداد الأكثر احتمالًا من النص المقابل للإجابة.
+
+هل أنت مستعد لتجربة الإجابة على الأسئلة؟ راجع [دليل الإجابة على الأسئلة](tasks/question_answering) الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilBERT واستخدامه في الاستدلال!
+
+
+
+
+💡 لاحظ مدى سهولة استخدام BERT لمهام مختلفة بمجرد تدريبه مسبقًا. كل ما تحتاج إليه هو إضافة رأس محدد إلى النموذج المسبق التدريب للتلاعب بالحالات المخفية إلى الإخراج المطلوب!
+
+
+
+### توليد النصوص (Text generation)
+
+يُعد [GPT-2](model_doc/gpt2) نموذجًا قائم على فك التشفير فقط تم تدريبه المسبق على كمية كبيرة من النصوص. يمكنه توليد نص مقنع (على الرغم من أنه ليس دائمًا صحيحًا!) بناءً على مُحفّز معين واستكمال مهام NLP الأخرى مثل الإجابة على الأسئلة على الرغم من أنه لم يتم تدريبه بشكل صريح على ذلك.
+
+
+
+
+
+1. يستخدم GPT-2 [ترميز الأزواج البايتية (BPE)](tokenizer_summary#byte-pair-encoding-bpe) لتجزئة الكلمات وإنشاء تمثيل رمزى. يتم إضافة تمثيلات موضعية إلى تمثيلات الرموز للإشارة إلى موضع كل رمز في التسلسل. يتم تمرير تمثيلات الإدخال عبر عدة كتل فك تشفير لإخراج بعض الحالات المخفية النهائية. داخل كل كتلة فك تشفير، يستخدم GPT-2 طبقة *انتباه ذاتي مقنع* مما يعني أن GPT-2 لا يمكنه الانتباه بالرموز المستقبلية. يُسمح له فقط بالاهتمام بالرموز الموجودة على اليسار. يختلف هذا عن رمز [`mask`] الخاص بـ BERT لأنه، في الانتباه الذاتي المقنع، يتم استخدام قناع انتباه لتعيين النتيجة إلى `0` للرموز المستقبلية.
+
+2. يتم تمرير الإخراج من فك التشفير إلى رأس نمذجة اللغة، والتي تُجري تحويلًا خطيًا لتحويل الحالات المخفية إلى احتمالات logits. التصنيف هو الرمز التالي في التسلسل، والذي يتم إنشاؤه عن طريق تغيير موضع logits إلى اليمين بمقدار واحد. يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين logits التي تم تغيير موضعها والتصنيفات لإخراج الرمز التالي الأكثر احتمالًا.
+
+يستند هدف التدريب المسبق لـ GPT-2 بالكامل إلى [نمذجة اللغة السببية](glossary#causal-language-modeling)، والتنبؤ بالكلمة التالية في تسلسل. يجعل هذا GPT-2 جيدًا بشكل خاص في المهام التي تتضمن توليد النص.
+
+هل أنت مستعد لتجربة توليد النصوص؟ تحقق من دليل [دليل نمذجة اللغة السببية](tasks/language_modeling#causal- الشامل الخاص بنا لمعرفة كيفية ضبط نموذج DistilGPT-2 واستخدامه للاستنتاج!
+
+
+
+للحصول على مزيد من المعلومات حول توليد النص، راجع دليل [استراتيجيات توليد النصوص](generation_strategies)!
+
+
+
+### التلخيص (Summarization)
+
+تم تصميم نماذج المشفر-فك التشفير مثل [BART](model_doc/bart) و [T5](model_doc/t5) لنمط تسلسل إلى تسلسل لمهمة التلخيص. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
+
+
+
+
+
+1. تتشابه بنية المشفر BART كثيرًا مع BERT وتقبل رمزًا وتمثيلًا موضعيًا للنص. يتم تدريب BART مسبقًا عن طريق إتلاف المُدخلات ثم إعادة بنائه باستخدام فك التشفير. على عكس المشفرات الأخرى ذات استراتيجيات الإتلاف المحددة، يمكن لـ BART تطبيق أي نوع من الإتلاف. ومع ذلك، فإن استراتيجية إتلاف "ملء النص" تعمل بشكل أفضل. في ملء النص، يتم استبدال عدد من امتدادات النص برمز **واحد** [`mask`]. هذا أمر مهم لأن النموذج يجب أن يتنبأ بالرموز المقنعة، ويعلّم النموذج التنبؤ بعدد الرموز المفقودة. يتم تمرير تمثيلات الإدخال والامتدادات المقنعة عبر المشفر لإخراج بعض الحالات المخفية النهائية، ولكن على عكس BERT، لا يضيف BART شبكة تغذية أمامية نهائية في النهاية للتنبؤ بكلمة.
+
+2. يتم تمرير إخراج المشفر إلى فك التشفير، والذي يجب أن يتنبأ بالرموز المقنعة وأي رموز غير تالفة من ناتج المشفر. يمنح هذا فك التشفير سياقًا إضافيًا للمساعدة في استعادة النص الأصلي. يتم تمرير ناتج فك التشفير إلى رأس نمذجة اللغوية، والذي يجري تحويلًا خطيًا لتحويل الحالات المخفية إلى احتمالات(logits). يتم حساب دالة التكلفة (الخسارة المتقاطعة) بين الاحتمالات logits والتصنيف، وهو مجرد الرمز الذي تم تغيير موضعه إلى اليمين.
+
+هل أنت مستعد لتجربة التلخيص؟ تحقق من دليل التلخيص الشامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
+
+
+
+للحصول على مزيد من المعلومات حول توليد النص، راجع دليل استراتيجيات توليد النص!
+
+
+
+### الترجمة (Translation)
+
+تُعد الترجمة مثالًا آخر على مهام التسلسل إلى التسلسل، مما يعني أنه يمكنك استخدام نموذج المشفر-فك التشفير مثل [BART](model_doc/bart) أو [T5](model_doc/t5) للقيام بذلك. سنشرح كيف يعمل BART في هذا القسم، ثم يمكنك تجربة ضبط T5 في النهاية.
+
+يتكيف BART مع الترجمة عن طريق إضافة مشفر منفصل يتم تهيئته بشكل عشوائي لتعيين لغة المصدر بمدخلات يمكن فك تشفيرها إلى لغة الهدف. يتم تمرير تمثيلات هذا المشفر الجديد إلى المشفر المسبق التدريب بدلاً من تمثيلات الكلمات الأصلية. يتم تدريب مشفر المصدر عن طريق تحديث مشفر المصدر وتمثيلات التموضع وتمثيلات الإدخال باستخدام دالة التكلفة (الخسارة المتقاطعة) من ناتج النموذج. يتم تجميد معلمات النموذج في هذه الخطوة الأولى، ويتم تدريب جميع معلمات النموذج معًا في الخطوة الثانية.
+
+تم إصدار نسخة متعددة اللغات من BART، تسمى mBART، مُخصصة للترجمة ومُدرّبة مسبقًا على العديد من اللغات المختلفة.
+
+هل أنت مستعد لتجربة الترجمة؟ تحقق من دليل الترجمة الشامل الخاص بنا لمعرفة كيفية ضبط نموذج T5 واستخدامه للاستنتاج!
+
+
+
+ **للحصول على مزيد من المعلومات حول توليد النصوص، راجع دليل [استراتيجيات توليد النصوص](generation_strategies)!**
+
+
diff --git a/docs/source/ar/tokenizer_summary.md b/docs/source/ar/tokenizer_summary.md
new file mode 100644
index 00000000000000..109521d24bbb76
--- /dev/null
+++ b/docs/source/ar/tokenizer_summary.md
@@ -0,0 +1,198 @@
+# ملخص عن المجزئات اللغوية
+
+[[open-in-colab]]
+
+في هذه الصفحة، سنتناول بالتفصيل عملية التجزئة.
+
+
+
+كما رأينا في [برنامج تعليمي حول المعالجة المسبقة](preprocessing)، فإن تجزئة النص يقسمه إلى كلمات أو
+الرموز الفرعية (كلمات جزئية)، والتي يتم بعد ذلك تحويلها إلى معرفات من خلال قائمة بحث. يعد تحويل الكلمات أو الرموز الفرعية إلى معرفات مباشرًا، لذا في هذا الملخص، سنركز على تقسيم النص إلى كلمات أو رموز فرعية (أي تجزئة النص).
+وبشكل أكثر تحديدًا، سنلقي نظرة على الأنواع الثلاثة الرئيسية من المُجزئات اللغوية المستخدمة في 🤗 المحولات: [ترميز الأزواج البايتية (BPE)](#byte-pair-encoding)، [WordPiece](#wordpiece)، و [SentencePiece](#sentencepiece)، ونعرض أمثلة
+على نوع المُجزئة الذي يستخدمه كل نموذج.
+
+لاحظ أنه في كل صفحة نموذج، يمكنك الاطلاع على وثائق المُجزئة المرتبط لمعرفة نوع المُجزئ
+الذي استخدمه النموذج المُدرب مسبقًا. على سبيل المثال، إذا نظرنا إلى [`BertTokenizer`]، يمكننا أن نرى أن النموذج يستخدم [WordPiece](#wordpiece).
+
+## مقدمة
+
+إن تقسيم النص إلى أجزاء أصغر هو مهمة أصعب مما تبدو، وهناك طرق متعددة للقيام بذلك.
+على سبيل المثال، دعنا نلقي نظرة على الجملة `"Don't you love 🤗 Transformers? We sure do."`
+
+
+
+يمكن تقسيم هذه الجملة ببساطة عن طريق المسافات، مما سينتج عنه ما يلي:```
+
+```
+["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
+```
+
+هذه خطوة أولى منطقية، ولكن إذا نظرنا إلى الرموز `"Transformers?"` و `"do."`، فإننا نلاحظ أن علامات الترقيم مُرفقة بالكلمات `"Transformer"` و `"do"`، وهو أمر ليس مثالي. يجب أن نأخذ علامات الترقيم في الاعتبار حتى لا يضطر النموذج إلى تعلم تمثيل مختلف للكلمة وكل رمز ترقيم مُحتمل قد يليها، الأمر الذي من شأنه أن يزيد بشكل هائل عدد التمثيلات التي يجب على النموذج تعلمها.
+مع مراعاة علامات الترقيم، سيُصبح تقسيم نصنا على النحو التالي:
+
+```
+["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+أفضل. ومع ذلك، من غير الملائم كيفية تقسيم الكلمة `"Don't"`. `"Don't"` تعني `"do not"`، لذا سيكون من الأفضل تحليلها على أنها كلمتين مُدمجتين `["Do"، "n't"]`. هنا تبدأ الأمور في التعقيد، وهو جزء من سبب امتلاك كل نموذج لنوّعه الخاص من مُجزّئ النصوص (tokenizer). اعتمادًا على القواعد التي نطبقها لتقسيم النص، يسيتم إنشاء مخرجات مُجزّأة مُختلفة لنفس النص. ولن يؤدي النموذج المُدرب مسبقًا إلى الأداء بشكل صحيح إلا إذا قُدّم له مُدخل تم تقسيمه بنفس القواعد التي تم استخدامها لتقسيم بيانات التدريب الخاصة به.
+
+يُعد كل من [spaCy](https://spacy.io/) و [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) هما مجزّئي النصوص التي تعتمد على القواعد
+الشائعة. عند تطبيقها على مثالنا، فإن *spaCy* و *Moses* ستخرج نّصًا مثل:
+
+```
+["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+كما يمكنك أن ترى، يتم هنا استخدام التقسيم المكاني والترقيم، وكذلك تقسيم الكلمات القائم على القواعد. يعد التقسيم المكاني والترقيم والتحليل القائم على القواعد كلاهما مثالين على تقسيم الكلمات، والذي يُعرّف بشكل غير مُحدد على أنه تقسيم الجُمل إلى كلمات. في حين أنها الطريقة الأكثر بديهية لتقسيم النصوص إلى أجزاء أصغر،
+يمكن أنها تؤدى إلى مشكلات لمجموعات النصوص الضخمة. في هذه الحالة، عادةً ما يؤدي التقسيم المكاني والترقيم
+إلى إنشاء مفردات كبيرة جدًا (مجموعة من جميع الكلمات والرموز الفريدة المستخدمة). على سبيل المثال، يستخدم [Transformer XL](model_doc/transfo-xl) التقسيم المكاني والترقيم، مما يؤدي إلى حجم مُفردات يبلغ 267735!
+
+يفرض حجم المُفردات الكبير هذا على النموذج أن يكون لديه مصفوفة تضمين (embedding matrix) ضخمة كطبقة إدخال وإخراج، مما يؤدي إلى زيادة كل من التعقيد الزمني والذاكرة. بشكل عام، نادرًا ما يكون لدى نماذج المحولات حجم مفردات
+أكبر من 50000، خاصة إذا تم تدريبها مسبقًا على لغة واحدة فقط.
+
+لذا إذا كان التقسيم المكاني و الترقيم البسيط غير مرضٍ، فلماذا لا نقسّم الحروف ببساطة؟
+
+
+
+في حين أن تقسيم الأحرف بسيط للغاية ومن شأنه أن يقلل بشكل كبير من التعقيد الزمني والذاكرة، إلا أنه يجعل من الصعب
+على النموذج تعلم تمثيلات المدخلات ذات معنى. على سبيل المثال، يعد تعلم تمثيل مستقل عن السياق للحرف "t" أكثر صعوبة من تعلم تمثيل مستقل عن السياق لكلمة "اليوم". لذلك، غالبًا ما يكون تحليل الأحرف مصحوبًا بفقدان الأداء. لذا للحصول على أفضل ما في العالمين، تستخدم نماذج المحولات نظامًا هجينًا بين تقسيم على مستوى الكلمة وتقسيم علي مستوى الأحرف يسمى **تقسيم الوحدات الفرعية للّغة** (subword tokenization).
+
+## تقسيم الوحدات الفرعية للّغة (Subword Tokenization)
+
+
+
+تعتمد خوارزميات تقسيم الوحدات الفرعية subword على المبدأ القائل بأن الكلمات الشائعة الاستخدام لا ينبغي تقسيمها إلى وحدات فرعية أصغر، ولكن يجب تفكيك الكلمات النادرة إلى رموز فرعية ذات معنى. على سبيل المثال، قد يتم اعتبار "annoyingly"
+كلمة نادرة ويمكن تحليلها إلى "annoying" و "ly". كل من "annoying" و "ly" كـ subwords مستقلة ستظهر بشكل متكرر أكثر في حين أن معنى "annoyingly" يتم الاحتفاظ به من خلال المعنى المركب لـ "annoying" و "ly". هذا مفيد بشكل خاص في اللغات التلصيقية مثل التركية، حيث يمكنك تشكيل كلمات مُركبة طويلة (تقريبًا) بشكل تعسفي عن طريق ضم الرموز الفرعية معًا.
+
+يسمح تقسيم subword للنموذج بأن يكون له حجم مفردات معقول مع القدرة على تعلم تمثيلات مستقلة عن السياق ذات معنى. بالإضافة إلى ذلك، يمكّن تقسيم subword النموذج من معالجة الكلمات التي لم يسبق له رؤيتها من قبل، عن طريق تحليلها إلى رموز فرعية معروفة. على سبيل المثال، يقوم المحلل [`~transformers.BertTokenizer`] بتحليل"I have a new GPU!" كما يلي:
+
+```py
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> tokenizer.tokenize("I have a new GPU!")
+["i", "have", "a", "new", "gp", "##u", "!"]
+```
+
+نظرًا لأننا نستخدم نموذجًا غير حساس لحالة الأحرف (uncased model)، فقد تم تحويل الجملة إلى أحرف صغيرة أولاً. يمكننا أن نرى أن الكلمات `["i"، "have"، "a"، "new"]` موجودة في مفردات مُجزّئ النصوص، ولكن الكلمة "gpu" غير موجودة. وبالتالي، يقوم مُجزّئ النصوص بتقسيم "gpu" إلى رموز فرعية معروفة: `["gp" و "##u"]`. يعني "##" أنه يجب ربط بقية الرمز بالرمز السابق، دون مسافة (للترميز أو عكس عملية تقسيم الرموز).
+
+كمثال آخر، يقوم المحلل [`~transformers.XLNetTokenizer`] بتقسيم نّص مثالنا السابق كما يلي:
+
+```py
+>>> from transformers import XLNetTokenizer
+
+>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet/xlnet-base-cased")
+>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
+["▁Don", "'", "t", "▁you", "▁love", "▁"، "🤗"، "▁"، "Transform"، "ers"، "؟"، "▁We"، "▁sure"، "▁do"، "."]
+```
+سنعود إلى معنى تلك `"▁"` عندما نلقي نظرة على [SentencePiece](#sentencepiece). كما يمكنك أن ترى،
+تم تقسيم الكلمة النادرة "Transformers" إلى الرموز الفرعية الأكثر تكرارًا `"Transform"` و `"ers"`.
+
+دعنا الآن نلقي نظرة على كيفية عمل خوارزميات تقسيم subword المختلفة. لاحظ أن جميع خوارزميات التقسيم هذه تعتمد على بعض أشكال التدريب الذي يتم عادةً على مجموعة البيانات التي سيتم تدريبها النموذج عليها.
+
+
+
+### ترميز الأزواج البايتية (BPE)
+
+تم تقديم رميز أزواج البايت (BPE) في ورقة بحثية بعنوان [الترجمة الآلية العصبية للكلمات النادرة باستخدام وحدات subword (Sennrich et al.، 2015)](https://arxiv.org/abs/1508.07909). يعتمد BPE على مُجزّئ أولي يقسم بيانات التدريب إلى
+كلمات. يمكن أن يكون التحليل المسبق بسيطًا مثل التقسيم المكاني، على سبيل المثال [GPT-2](model_doc/gpt2)، [RoBERTa](model_doc/roberta). تشمل التقسيم الأكثر تقدمًا معتمد على التحليل القائم على القواعد، على سبيل المثال [XLM](model_doc/xlm)، [FlauBERT](model_doc/flaubert) الذي يستخدم Moses لمعظم اللغات، أو [GPT](model_doc/openai-gpt) الذي يستخدم spaCy و ftfy، لحساب تكرار كل كلمة في مجموعة بيانات التدريب.
+
+بعد التحليل المسبق، يتم إنشاء مجموعة من الكلمات الفريدة وقد تم تحديد تكرار كل كلمة في تم تحديد بيانات التدريب. بعد ذلك، يقوم BPE بإنشاء مفردات أساسية تتكون من جميع الرموز التي تحدث في مجموعة الكلمات الفريدة ويتعلم قواعد الدمج لتشكيل رمز جديد من رمزين من المفردات الأساسية. إنه يفعل ذلك حتى تصل المفردات إلى حجم المفردات المطلوب. لاحظ أن حجم المفردات هو فرط معلمة لتحديد قبل تدريب مُجزّئ النصوص.
+
+كمثال، دعنا نفترض أنه بعد التقسيم الأولي، تم تحديد مجموعة الكلمات التالية بما في ذلك تكرارها:
+
+```
+("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
+```
+
+وبالتالي، فإن المفردات الأساسية هي `["b"، "g"، "h"، "n"، "p"، "s"، "u"]`. من خلال تقسيم جميع الكلمات إلى رموز من
+المفردات الأساسية، نحصل على:
+
+```
+("h" "u" "g"، 10)، ("p" "u" "g"، 5)، ("p" "u" "n"، 12)، ("b" "u" "n"، 4)، ("h" "u" "g" "s"، 5)
+```
+
+بعد ذلك، يقوم BPE بعدد مرات حدوث كل زوج من الرموز المحتملة ويختار زوج الرموز الذي يحدث بشكل متكرر. في
+في المثال أعلاه، يحدث "h" متبوعًا بـ "u" _10 + 5 = 15_ مرة (10 مرات في 10 مرات
+حدوث "hug"، 5 مرات في 5 مرات حدوث "hugs"). ومع ذلك، فإن أكثر أزواج الرموز شيوعًا هو "u" متبوعًا
+بواسطة "g"، والتي تحدث _10 + 5 + 5 = 20_ مرة في المجموع. وبالتالي، فإن أول قاعدة دمج يتعلمها المحلل هي تجميع جميع
+رموز "u" التي تتبعها "g" معًا. بعد ذلك، يتم إضافة "ug" إلى المفردات. تصبح مجموعة الكلمات
+
+```
+("h" "ug"، 10)، ("p" "ug"، 5)، ("p" "u" "n"، 12)، ("b" "u" "n"، 4)، ("h" "ug" "s"، 5)
+```
+
+بعد ذلك، يحدد BPE ثاني أكثر أزواج الرموز شيوعًا. إنه "u" متبوعًا بـ "n"، والذي يحدث 16 مرة. "u"،
+يتم دمج "n" في "un" ويضاف إلى المفردات. ثالث أكثر أزواج الرموز شيوعًا هو "h" متبوعًا
+بواسطة "ug"، والتي تحدث 15 مرة. مرة أخرى يتم دمج الزوج ويتم إضافة "hug" إلى المفردات.
+
+في هذه المرحلة، تكون المفردات هي `["b"، "g"، "h"، "n"، "p"، "s"، "u"، "ug"، "un"، "hug"]` ومجموعة الكلمات الفريدة لدينا
+تمثيله كما يلي:
+
+```
+("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
+```
+
+بافتراض أن تدريب ترميز الأزواج البايت سيتوقف عند هذه النقطة، فسيتم تطبيق قواعد الدمج التي تم تعلمها بعد ذلك على الكلمات الجديدة (طالما أن هذه الكلمات الجديدة لا تشمل رموزًا لم تكن في المفردات الأساسية). على سبيل المثال، سيتم تقسيم كلمة "bug" إلى `["b"، "ug"]` ولكن سيتم تقسيم "mug" على أنها `[""، "ug"]` نظرًا لأن الرمز "m" غير موجود في المفردات الأساسية. بشكل عام، لا يتم استبدال الأحرف الفردية مثل "m" بالرمز "" لأن بيانات التدريب تتضمن عادةً ظهورًا واحدًا على الأقل لكل حرف، ولكن من المحتمل أن يحدث ذلك لرموز خاصة جدًا مثل الرموز التعبيرية.
+
+كما ذكرنا سابقًا، فإن حجم المفردات، أي حجم المفردات الأساسية + عدد عمليات الدمج، هو معامل يجب اختياره. على سبيل المثال، لدى [GPT](model_doc/openai-gpt) حجم مفردات يبلغ 40478 منذ أن كان لديهم 478 حرفًا أساسيًا واختاروا التوقف عن التدريب بعد 40,000 عملية دمج.
+
+#### ترميز الأزواج البايتية على مستوى البايت
+
+قد تكون المفردات الأساسية التي تتضمن جميع الأحرف الأساسية كبيرة جدًا إذا *على سبيل المثال* تم اعتبار جميع أحرف اليونيكود
+كأحرف أساسية. لذا، ليكون لديك مفردات أساسية أفضل، يستخدم [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) البايتات كمفردات أساسية، وهي حيلة ذكية لإجبار المفردات الأساسية على أن تكون بحجم 256 مع ضمان أن يتم تضمين كل حرف أساسي في المفردات. مع بعض القواعد الإضافية للتعامل مع علامات الترقيم، يمكن لمُجزّئ النصوص GPT2 تجزئة أي نص دون الحاجة إلى رمز . لدى [GPT-2](model_doc/gpt) حجم مفردات يبلغ 50257، والذي يتوافق مع رموز 256 base byte، ورمز خاص لنهاية النص والرموز التي تم تعلمها باستخدام 50000 عملية دمج.
+
+
+
+### WordPiece
+
+تعتبر WordPiece خوارزمية تجزئة الكلمات الفرعية subword المستخدمة لـ [BERT](model_doc/bert)، [DistilBERT](model_doc/distilbert)، و [Electra](model_doc/electra). تم توضيح الخوارزمية في [البحث الصوتي الياباني والكوري
+(Schuster et al.، 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) وهو مشابه جدًا
+BPE. أولاً، يقوم WordPiece بتكوين المفردات لتضمين كل حرف موجود في بيانات التدريب
+وتعلم تدريجياً عددًا معينًا من قواعد الدمج. على عكس BPE، لا يختار WordPiece أكثر زوج الرموز المتكررة، ولكن تلك التي تزيد من احتمال بيانات التدريب بمجرد إضافتها إلى المفردات.
+
+لذا، ماذا يعني هذا بالضبط؟ بالإشارة إلى المثال السابق، فإن زيادة احتمال بيانات التدريب تعادل إيجاد زوج الرموز، الذي يكون احتمال تقسيمه على احتمالات رمزه الأول تليها رمزه الثاني هو الأكبر بين جميع أزواج الرموز. *مثال* `"u"`، تليها `"g"` كانت قد اندمجت فقط إذا كان احتمال `"ug"` مقسومًا على `"u"`، `"g"` كان سيكون أكبر من أي زوج آخر من الرموز. بديهيًا، WordPiece مختلف قليلاً عن BPE في أنه يقيم ما يفقده عن طريق دمج رمزين للتأكد من أنه يستحق ذلك.
+
+
+
+### Unigram
+
+Unigram هو خوارزمية توكنيز subword التي تم تقديمها في [تنظيم subword: تحسين نماذج الترجمة الشبكة العصبية
+نماذج مع مرشحين subword متعددة (Kudo، 2018)](https://arxiv.org/pdf/1804.10959.pdf). على عكس BPE أو
+WordPiece، يقوم Unigram بتكوين مفرداته الأساسية إلى عدد كبير من الرموز ويقللها تدريجياً للحصول على مفردات أصغر. يمكن أن تتوافق المفردات الأساسية على سبيل المثال مع جميع الكلمات المسبقة التوكنز والسلاسل الفرعية الأكثر شيوعًا. لا يتم استخدام Unigram مباشرة لأي من النماذج في المحولات، ولكنه يستخدم بالاقتران مع [SentencePiece](#sentencepiece).
+
+في كل خطوة تدريب، يحدد خوارزمية Unigram خسارة (غالبًا ما يتم تعريفها على أنها اللوغاريتم) عبر بيانات التدريب بالنظر إلى المفردات الحالية ونموذج اللغة unigram. بعد ذلك، بالنسبة لكل رمز في المفردات، يحسب الخوارزمية مقدار زيادة الخسارة الإجمالية إذا تم إزالة الرمز من المفردات. ثم يقوم Unigram بإزالة p (مع p عادة ما تكون 10% أو 20%) في المائة من الرموز التي تكون زيادة الخسارة فيها هي الأدنى، *أي* تلك
+الرموز التي تؤثر أقل على الخسارة الإجمالية عبر بيانات التدريب. تتكرر هذه العملية حتى تصل المفردات إلى الحجم المطلوب. يحتفظ خوارزمية Unigram دائمًا بالشخصيات الأساسية بحيث يمكن توكنز أي كلمة.
+
+نظرًا لأن Unigram لا يعتمد على قواعد الدمج (على عكس BPE وWordPiece)، فإن للخوارزمية عدة طرق
+توكنز نص جديد بعد التدريب. على سبيل المثال، إذا كان محول Unigram المدرب يعرض المفردات:
+
+```
+["b"، "g"، "h"، "n"، "p"، "s"، "u"، "ug"، "un"، "hug"]،
+```
+
+يمكن توكنز `"hugs"` على أنه `["hug"، "s"]`، أو `["h"، "ug"، "s"]` أو `["h"، "u"، "g"، "s"]`. إذن ماذا
+لاختيار؟ يحفظ Unigram احتمال كل رمز في فيلق التدريب بالإضافة إلى حفظ المفردات بحيث
+يمكن حساب احتمال كل توكنز ممكن بعد التدريب. ببساطة، يختار الخوارزمية الأكثر
+توكنز المحتملة في الممارسة، ولكنه يوفر أيضًا إمكانية أخذ عينات من توكنز ممكن وفقًا لاحتمالاتها.
+
+تتم تعريف هذه الاحتمالات بواسطة الخسارة التي يتم تدريب المحول عليها. بافتراض أن بيانات التدريب تتكون
+من الكلمات \\(x_{1}، \dots، x_{N}\\) وأن مجموعة جميع التوكنزات الممكنة لكلمة \\(x_{i}\\) هي
+يتم تعريفها على أنها \\(S(x_{i})\\)، ثم يتم تعريف الخسارة الإجمالية على النحو التالي
+
+$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
+
+
+
+### SentencePiece
+
+تحتوي جميع خوارزميات توكنز الموصوفة حتى الآن على نفس المشكلة: من المفترض أن النص المدخل يستخدم المسافات لفصل الكلمات. ومع ذلك، لا تستخدم جميع اللغات المسافات لفصل الكلمات. أحد الحلول الممكنة هو استخداممعالج مسبق للغة محدد، *مثال* [XLM](model_doc/xlm) يلذي يستخدم معالجات مسبقة محددة للصينية واليابانية والتايلاندية.
+لحل هذه المشكلة بشكل أعم، [SentencePiece: A simple and language independent subword tokenizer and
+detokenizer for Neural Text Processing (Kudo et al.، 2018)](https://arxiv.org/pdf/1808.06226.pdf) يتعامل مع المدخلات
+كتدفق بيانات خام، وبالتالي يشمل المسافة في مجموعة الأحرف التي سيتم استخدامها. ثم يستخدم خوارزمية BPE أو unigram
+لبناء المفردات المناسبة.
+
+يستخدم [`XLNetTokenizer`] SentencePiece على سبيل المثال، وهو أيضًا سبب تضمين تم تضمين حرف `"▁"` في المفردات. عملية فك التشفير باستخدام SentencePiece سهلة للغاية نظرًا لأنه يمكن دائمًا دمج الرموز معًا واستبدال `"▁"` بمسافة.
+
+تستخدم جميع نماذج المحولات في المكتبة التي تستخدم SentencePiece بالاقتران مع unigram. أمثلة على النماذج
+باستخدام SentencePiece هي [ALBERT](model_doc/albert)، [XLNet](model_doc/xlnet)، [Marian](model_doc/marian)، و [T5](model_doc/t5).
 +
+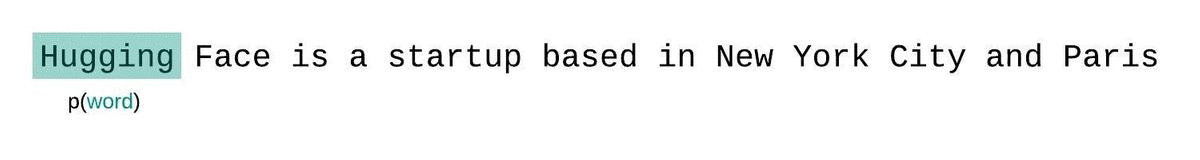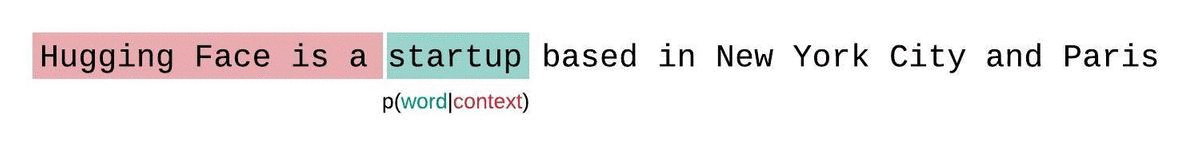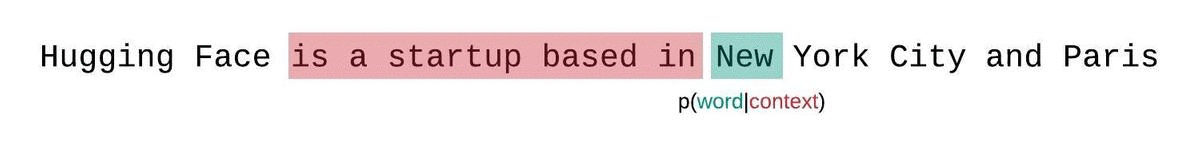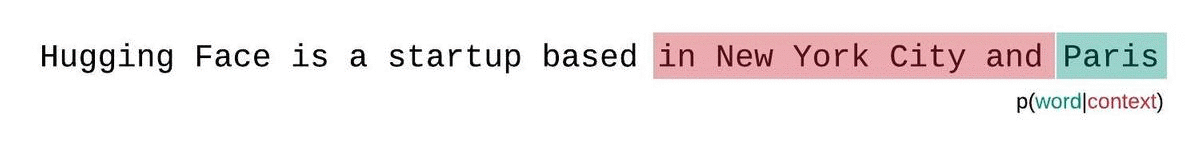 +
+هذا تقريب أقرب للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل.لكن الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي مناسب هو استخدام نافذة منزلقة بخطوة، بحيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. مما يسمح بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب التعقيد اللغوي مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم التعقيد اللغوي باستخدام بعض إستراتيجيات مختلفة النافذة المنزلقة. نظرًا لأن هذه المجموعة البيانات الصغيرة ونقوم فقط بمسح واحد فقط للمجموعة، فيمكننا ببساطة تحميل مجموعة البيانات وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، وسيتم إرجاع متوسط احتمالية السجل السالب لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين احتمالية السجل للرموز التي نتعامل معها كسياق فقط في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. فيما يلي هو مثال على كيفية القيام بذلك بخطوة تبلغ `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (بشرط توفر 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+يعد تشغيل هذا مع طول الخطوة مساويًا لطول الإدخال الأقصى يعادل لاستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيحصل عليه النموذج في عمل كل تنبؤ، وكلما كانت التعقيد اللغوي المُبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون درجة التعقيد اللغوي الناتجة هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التحليل التلقائي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
diff --git a/docs/source/ar/philosophy.md b/docs/source/ar/philosophy.md
new file mode 100644
index 00000000000000..09de2991fba28d
--- /dev/null
+++ b/docs/source/ar/philosophy.md
@@ -0,0 +1,49 @@
+# الفلسفة
+
+تُعد 🤗 Transformers مكتبة برمجية ذات رؤية واضحة صُممت من أجل:
+
+- الباحثون والمُتعلّمون في مجال التعلم الآلي ممن يسعون لاستخدام أو دراسة أو تطوير نماذج Transformers واسعة النطاق.
+- مُطبّقي تعلم الآلة الذين يرغبون في ضبط تلك النماذج أو تشغيلها في بيئة إنتاجية، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. سهولة وسرعة الاستخدام:
+
+ - تمّ تقليل عدد المفاهيم المُجردة التي يتعامل معها المستخدم إلى أدنى حد والتي يجب تعلمها، وفي الواقع، لا توجد مفاهيم مُجردة تقريبًا، فقط ثلاث فئات أساسية مطلوبة لاستخدام كل نموذج: [الإعدادات](main_classes/configuration)، [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([مُجزّئ لغوي](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للمدخﻻت متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من خلال نماذج مُدربة مسبقًا باستخدام الدالة الموحدة `from_pretrained()` والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين وتحميل كل من: فئة النموذج المُراد استخدامه والبيانات المرتبطة ( مُعاملات الإعدادات، ومعجم للمُجزّئ اللغوي،وأوزان النماذج) من نقطة تدقيق مُحددة مُخزّنة على [Hugging Face Hub](https://huggingface.co/models) أو ن من نقطة تخزين خاصة بالمستخدم.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستخدام السريع لأحد النماذج لأداء استنتاجات على مهمة مُحددة، و [`Trainer`] للتدريب السريع أو الضبط الدقيق لنماذج PyTorch (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- كشف تفاصيل النماذج الداخلية بشكل متسق قدر الإمكان:
+
+ -نتيح الوصول، باستخدام واجهة برمجة واحدة، إلى جميع الحالات المخفية (Hidden-States) وأوزان الانتباه (Attention Weights).
+ - تم توحيد واجهات برمجة التطبيقات الخاصة بفئات المعالجة المسبقة والنماذج الأساسية لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة من الأدوات الواعدة لضبط النماذج بدقة (Fine-tuning) ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى مفردات التضمينات (Embeddings) لضبط النماذج بدقة.
+ - طرق سهلة لإخفاء (Masking) وتقليم (Pruning) رؤوس المحولات (Transformer Heads).
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تعتمد المكتبة على ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات الإعداد** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات وحجم الطبقة المخفية). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا تهيئة الإعدادات (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من نسخ مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على منصة Hub عبر ثلاث طرق:
+
+- تسمح لك الدالة `from_pretrained()` بتهيئة النموذج وتكويناته وفئة المعالجة المسبقة من إصدار مُدرب مسبقًا إما يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو مخزنة محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك الدالة `save_pretrained()` بحفظ النموذج، وتكويناته وفئة المعالجة المسبقة محليًا، بحيث يمكن إعادة تحميله باستخدام الدالة `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وتكويناتهوفئة المعالجة المسبقة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
diff --git a/docs/source/ar/pipeline_webserver.md b/docs/source/ar/pipeline_webserver.md
new file mode 100644
index 00000000000000..2a19e84d163241
--- /dev/null
+++ b/docs/source/ar/pipeline_webserver.md
@@ -0,0 +1,126 @@
+# استخدام قنوات المعالجة لخادم ويب
+
+
+
+هذا تقريب أقرب للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل.لكن الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي مناسب هو استخدام نافذة منزلقة بخطوة، بحيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. مما يسمح بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب التعقيد اللغوي مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم التعقيد اللغوي باستخدام بعض إستراتيجيات مختلفة النافذة المنزلقة. نظرًا لأن هذه المجموعة البيانات الصغيرة ونقوم فقط بمسح واحد فقط للمجموعة، فيمكننا ببساطة تحميل مجموعة البيانات وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، وسيتم إرجاع متوسط احتمالية السجل السالب لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين احتمالية السجل للرموز التي نتعامل معها كسياق فقط في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. فيما يلي هو مثال على كيفية القيام بذلك بخطوة تبلغ `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (بشرط توفر 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+يعد تشغيل هذا مع طول الخطوة مساويًا لطول الإدخال الأقصى يعادل لاستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيحصل عليه النموذج في عمل كل تنبؤ، وكلما كانت التعقيد اللغوي المُبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون درجة التعقيد اللغوي الناتجة هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التحليل التلقائي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
diff --git a/docs/source/ar/philosophy.md b/docs/source/ar/philosophy.md
new file mode 100644
index 00000000000000..09de2991fba28d
--- /dev/null
+++ b/docs/source/ar/philosophy.md
@@ -0,0 +1,49 @@
+# الفلسفة
+
+تُعد 🤗 Transformers مكتبة برمجية ذات رؤية واضحة صُممت من أجل:
+
+- الباحثون والمُتعلّمون في مجال التعلم الآلي ممن يسعون لاستخدام أو دراسة أو تطوير نماذج Transformers واسعة النطاق.
+- مُطبّقي تعلم الآلة الذين يرغبون في ضبط تلك النماذج أو تشغيلها في بيئة إنتاجية، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. سهولة وسرعة الاستخدام:
+
+ - تمّ تقليل عدد المفاهيم المُجردة التي يتعامل معها المستخدم إلى أدنى حد والتي يجب تعلمها، وفي الواقع، لا توجد مفاهيم مُجردة تقريبًا، فقط ثلاث فئات أساسية مطلوبة لاستخدام كل نموذج: [الإعدادات](main_classes/configuration)، [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([مُجزّئ لغوي](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للمدخﻻت متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من خلال نماذج مُدربة مسبقًا باستخدام الدالة الموحدة `from_pretrained()` والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين وتحميل كل من: فئة النموذج المُراد استخدامه والبيانات المرتبطة ( مُعاملات الإعدادات، ومعجم للمُجزّئ اللغوي،وأوزان النماذج) من نقطة تدقيق مُحددة مُخزّنة على [Hugging Face Hub](https://huggingface.co/models) أو ن من نقطة تخزين خاصة بالمستخدم.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستخدام السريع لأحد النماذج لأداء استنتاجات على مهمة مُحددة، و [`Trainer`] للتدريب السريع أو الضبط الدقيق لنماذج PyTorch (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- كشف تفاصيل النماذج الداخلية بشكل متسق قدر الإمكان:
+
+ -نتيح الوصول، باستخدام واجهة برمجة واحدة، إلى جميع الحالات المخفية (Hidden-States) وأوزان الانتباه (Attention Weights).
+ - تم توحيد واجهات برمجة التطبيقات الخاصة بفئات المعالجة المسبقة والنماذج الأساسية لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة من الأدوات الواعدة لضبط النماذج بدقة (Fine-tuning) ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى مفردات التضمينات (Embeddings) لضبط النماذج بدقة.
+ - طرق سهلة لإخفاء (Masking) وتقليم (Pruning) رؤوس المحولات (Transformer Heads).
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تعتمد المكتبة على ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات الإعداد** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات وحجم الطبقة المخفية). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا تهيئة الإعدادات (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من نسخ مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على منصة Hub عبر ثلاث طرق:
+
+- تسمح لك الدالة `from_pretrained()` بتهيئة النموذج وتكويناته وفئة المعالجة المسبقة من إصدار مُدرب مسبقًا إما يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو مخزنة محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك الدالة `save_pretrained()` بحفظ النموذج، وتكويناته وفئة المعالجة المسبقة محليًا، بحيث يمكن إعادة تحميله باستخدام الدالة `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وتكويناتهوفئة المعالجة المسبقة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
diff --git a/docs/source/ar/pipeline_webserver.md b/docs/source/ar/pipeline_webserver.md
new file mode 100644
index 00000000000000..2a19e84d163241
--- /dev/null
+++ b/docs/source/ar/pipeline_webserver.md
@@ -0,0 +1,126 @@
+# استخدام قنوات المعالجة لخادم ويب
+
+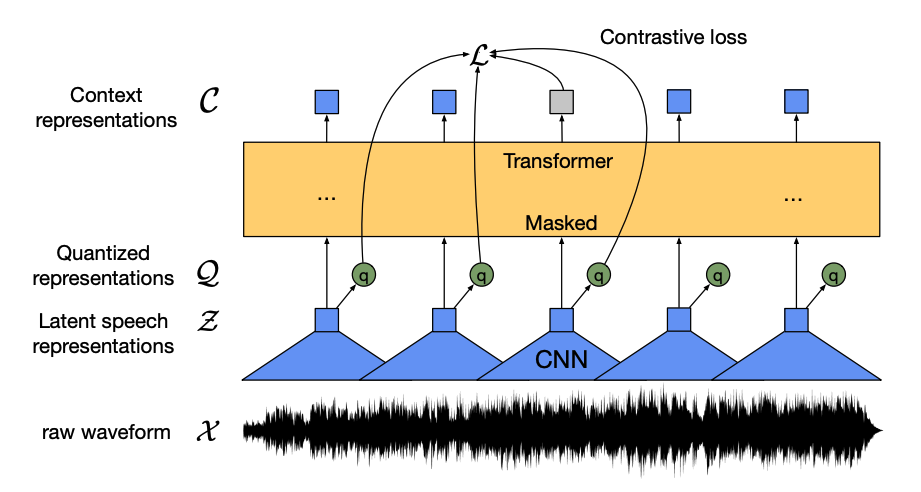 +
+ +
+ +
+ +
+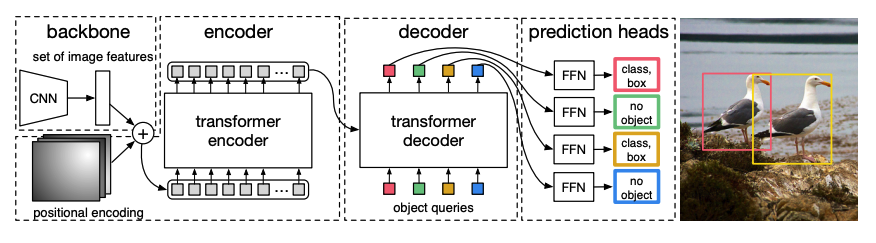 +
+ +
+ +
+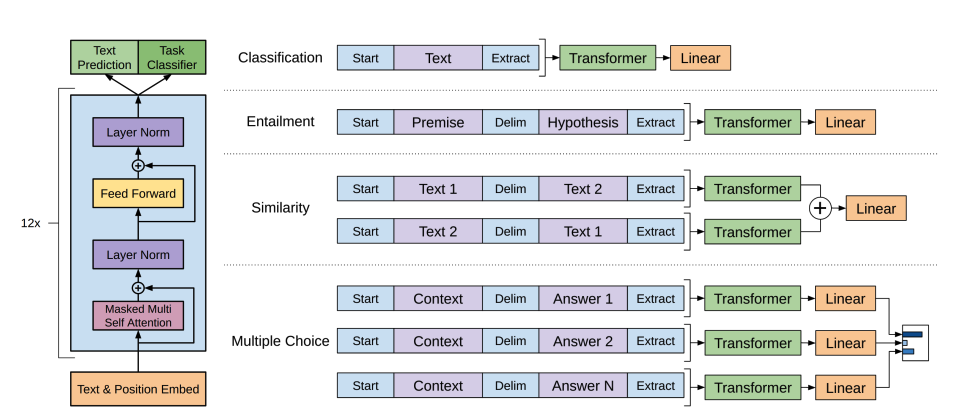 +
+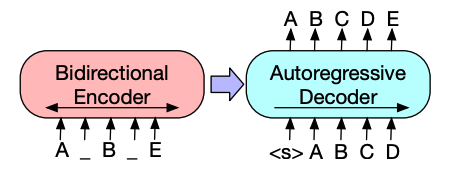 +
+