diff --git a/README.md b/README.md
index daab3d1f9d6bbe..94826c061133ea 100644
--- a/README.md
+++ b/README.md
@@ -458,6 +458,7 @@ Current number of checkpoints: ** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
@@ -475,7 +476,7 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
@@ -518,6 +519,7 @@ Current number of checkpoints: ** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
diff --git a/README_es.md b/README_es.md
index 9e1ac93b4a99ab..185cf908afd68f 100644
--- a/README_es.md
+++ b/README_es.md
@@ -433,6 +433,7 @@ Número actual de puntos de control: ** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
@@ -450,7 +451,7 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
@@ -493,6 +494,7 @@ Número actual de puntos de control: ** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
diff --git a/README_hd.md b/README_hd.md
index 92935efb589cee..84664b21f3a6ae 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -407,6 +407,7 @@ conda install conda-forge::transformers
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [ProphetNet: प्रेडिक्टिंग फ्यूचर एन-ग्राम फॉर सीक्वेंस-टू-सीक्वेंस प्री-ट्रेनिंग ](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा पोस्ट किया गया।
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. से) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. द्वाराअनुसंधान पत्र [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) के साथ जारी किया गया
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA से) साथ वाला पेपर [डीप लर्निंग इंफ़ेक्शन के लिए इंटीजर क्वांटिज़ेशन: प्रिंसिपल्स एंड एम्पिरिकल इवैल्यूएशन](https:// arxiv.org/abs/2004.09602) हाओ वू, पैट्रिक जुड, जिआओजी झांग, मिखाइल इसेव और पॉलियस माइकेविसियस द्वारा।
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group से) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. द्वाराअनुसंधान पत्र [Qwen Technical Report](https://arxiv.org/abs/2309.16609) के साथ जारी किया गया
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (फेसबुक से) साथ में कागज [रिट्रीवल-ऑगमेंटेड जेनरेशन फॉर नॉलेज-इंटेंसिव एनएलपी टास्क](https://arxiv .org/abs/2005.11401) पैट्रिक लुईस, एथन पेरेज़, अलेक्जेंड्रा पिक्टस, फैबियो पेट्रोनी, व्लादिमीर कारपुखिन, नमन गोयल, हेनरिक कुटलर, माइक लुईस, वेन-ताउ यिह, टिम रॉकटाशेल, सेबस्टियन रिडेल, डौवे कीला द्वारा।
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google अनुसंधान से) केल्विन गु, केंटन ली, ज़ोरा तुंग, पानुपोंग पसुपत और मिंग-वेई चांग द्वारा साथ में दिया गया पेपर [REALM: रिट्रीवल-ऑगमेंटेड लैंग्वेज मॉडल प्री-ट्रेनिंग](https://arxiv.org/abs/2002.08909)।
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
@@ -424,7 +425,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI से) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. द्वाराअनुसंधान पत्र [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) के साथ जारी किया गया
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https ://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP से) साथ में पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स] (https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योआव आर्टज़ी द्वारा पोस्ट किया गया।
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI से) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. द्वाराअनुसंधान पत्र [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) के साथ जारी किया गया
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (Google AI से) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. द्वाराअनुसंधान पत्र [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) के साथ जारी किया गया
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (फेसबुक से), साथ में पेपर [फेयरसेक S2T: फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग विद फेयरसेक](https: //arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया。
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (फेसबुक से) साथ में पेपर [लार्ज-स्केल सेल्फ- एंड सेमी-सुपरवाइज्ड लर्निंग फॉर स्पीच ट्रांसलेशन](https://arxiv.org/abs/2104.06678) चांगहान वांग, ऐनी वू, जुआन पिनो, एलेक्सी बेवस्की, माइकल औली, एलेक्सिस द्वारा Conneau द्वारा पोस्ट किया गया।
@@ -467,6 +468,7 @@ conda install conda-forge::transformers
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise से) Jaehyeon Kim, Jungil Kong, Juhee Son. द्वाराअनुसंधान पत्र [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) के साथ जारी किया गया
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (फेसबुक एआई से) साथ में पेपर [wav2vec 2.0: ए फ्रेमवर्क फॉर सेल्फ-सुपरवाइज्ड लर्निंग ऑफ स्पीच रिप्रेजेंटेशन](https://arxiv.org/abs/2006.11477) एलेक्सी बेवस्की, हेनरी झोउ, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI से) साथ वाला पेपर [FAIRSEQ S2T: FAIRSEQ के साथ फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग ](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, सरव्या पोपुरी, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया।
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI से) साथ वाला पेपर [सरल और प्रभावी जीरो-शॉट क्रॉस-लिंगुअल फोनेम रिकॉग्निशन](https://arxiv.org/abs/2109.11680) कियानटोंग जू, एलेक्सी बाएव्स्की, माइकल औली द्वारा।
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (माइक्रोसॉफ्ट रिसर्च से) पेपर के साथ जारी किया गया [WavLM: फुल स्टैक के लिए बड़े पैमाने पर स्व-पर्यवेक्षित पूर्व-प्रशिक्षण स्पीच प्रोसेसिंग](https://arxiv.org/abs/2110.13900) सानयुआन चेन, चेंगयी वांग, झेंगयांग चेन, यू वू, शुजी लियू, ज़ुओ चेन, जिन्यु ली, नाओयुकी कांडा, ताकुया योशियोका, ज़िओंग जिओ, जियान वू, लॉन्ग झोउ, शुओ रेन, यानमिन कियान, याओ कियान, जियान वू, माइकल ज़ेंग, फुरु वेई।
diff --git a/README_ja.md b/README_ja.md
index f43dda021c6f19..ff2f124dba1192 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -467,6 +467,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group から) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. から公開された研究論文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
@@ -484,7 +485,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI から) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. から公開された研究論文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (Google AI から) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. から公開された研究論文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (Microsoft Research から) Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei. から公開された研究論文 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205)
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
@@ -527,6 +528,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise から) Jaehyeon Kim, Jungil Kong, Juhee Son. から公開された研究論文 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103)
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171)
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research から) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei から公開された研究論文: [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
diff --git a/README_ko.md b/README_ko.md
index c2e53a1b81ce95..7b4c4410f2c83b 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -382,6 +382,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research 에서) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 의 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 논문과 함께 발표했습니다.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. 에서 제공)은 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.의 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)논문과 함께 발표했습니다.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA 에서) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 의 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 논문과 함께 발표했습니다.
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group 에서 제공)은 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.의 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)논문과 함께 발표했습니다.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook 에서) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 의 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 논문과 함께 발표했습니다.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research 에서) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 의 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 논문과 함께 발표했습니다.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research 에서) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 의 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 논문과 함께 발표했습니다.
@@ -399,7 +400,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI 에서 제공)은 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.의 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)논문과 함께 발표했습니다.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI 에서 제공)은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.의 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)논문과 함께 발표했습니다.
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (Google AI 에서 제공)은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.의 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)논문과 함께 발표했습니다.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (Microsoft Research 에서 제공)은 Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.의 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205)논문과 함께 발표했습니다.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook 에서) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino 의 [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) 논문과 함께 발표했습니다.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook 에서) Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 의 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 논문과 함께 발표했습니다.
@@ -442,6 +443,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise 에서 제공)은 Jaehyeon Kim, Jungil Kong, Juhee Son.의 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103)논문과 함께 발표했습니다.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI 에서) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli 의 [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) 논문과 함께 발표했습니다.
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI 에서) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino 의 [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) 논문과 함께 발표했습니다.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI 에서) Qiantong Xu, Alexei Baevski, Michael Auli 의 [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) 논문과 함께 발표했습니다.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research 에서) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei 의 [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) 논문과 함께 발표했습니다.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 972f3a386f420e..c6d949d60a72e9 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -406,6 +406,7 @@ conda install conda-forge::transformers
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (来自 Nanjing University, The University of Hong Kong etc.) 伴随论文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) 由 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao 发布。
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (来自 the Qwen team, Alibaba Group) 伴随论文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609) 由 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu 发布。
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (来自 Facebook) 伴随论文 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 由 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 发布。
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (来自 Google Research) 伴随论文 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 由 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 发布。
@@ -423,7 +424,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (来自 Meta AI) 伴随论文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) 由 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick 发布。
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (来自 Google AI) 伴随论文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) 由 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer 发布。
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (来自 Google AI) 伴随论文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) 由 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer 发布。
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (来自 Microsoft Research) 伴随论文 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) 由 Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei 发布。
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (来自 Facebook), 伴随论文 [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) 由 Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino 发布。
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (来自 Facebook) 伴随论文 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 由 Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 发布。
@@ -466,6 +467,7 @@ conda install conda-forge::transformers
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (来自 Kakao Enterprise) 伴随论文 [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) 由 Jaehyeon Kim, Jungil Kong, Juhee Son 发布。
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (来自 Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) 由 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (来自 Facebook AI) 伴随论文 [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) 由 Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli 发布。
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (来自 Facebook AI) 伴随论文 [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) 由 Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino 发布。
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (来自 Facebook AI) 伴随论文 [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) 由 Qiantong Xu, Alexei Baevski, Michael Auli 发布。
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
diff --git a/README_zh-hant.md b/README_zh-hant.md
index b17c8946bc3e30..2b51db15a552ec 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -418,6 +418,7 @@ conda install conda-forge::transformers
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
@@ -435,7 +436,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
-1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
+1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook) released with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
@@ -478,6 +479,7 @@ conda install conda-forge::transformers
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 86cffb9a7e35cf..2f973b4c436a09 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -446,6 +446,8 @@
title: ProphetNet
- local: model_doc/qdqbert
title: QDQBert
+ - local: model_doc/qwen2
+ title: Qwen2
- local: model_doc/rag
title: RAG
- local: model_doc/realm
@@ -648,6 +650,8 @@
title: VITS
- local: model_doc/wav2vec2
title: Wav2Vec2
+ - local: model_doc/wav2vec2-bert
+ title: Wav2Vec2-BERT
- local: model_doc/wav2vec2-conformer
title: Wav2Vec2-Conformer
- local: model_doc/wav2vec2_phoneme
diff --git a/docs/source/en/custom_models.md b/docs/source/en/custom_models.md
index 22ba58b9d9ddc4..c64b2af5c2de02 100644
--- a/docs/source/en/custom_models.md
+++ b/docs/source/en/custom_models.md
@@ -34,6 +34,16 @@ Before we dive into the model, let's first write its configuration. The configur
will contain all the necessary information to build the model. As we will see in the next section, the model can only
take a `config` to be initialized, so we really need that object to be as complete as possible.
+
+
+Models in the `transformers` library itself generally follow the convention that they accept a `config` object
+in their `__init__` method, and then pass the whole `config` to sub-layers in the model, rather than breaking the
+config object into multiple arguments that are all passed individually to sub-layers. Writing your model in this
+style results in simpler code with a clear "source of truth" for any hyperparameters, and also makes it easier
+to reuse code from other models in `transformers`.
+
+
+
In our example, we will take a couple of arguments of the ResNet class that we might want to tweak. Different
configurations will then give us the different types of ResNets that are possible. We then just store those arguments,
after checking the validity of a few of them.
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index 52b5df6e59ba14..6fc472cc040451 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -232,6 +232,7 @@ Flax), PyTorch, and/or TensorFlow.
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
@@ -295,6 +296,7 @@ Flax), PyTorch, and/or TensorFlow.
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/phi.md b/docs/source/en/model_doc/phi.md
index ecfa5f6bf11a31..96efe4a303a84f 100644
--- a/docs/source/en/model_doc/phi.md
+++ b/docs/source/en/model_doc/phi.md
@@ -23,15 +23,15 @@ The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/a
The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
### Summary
+
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
-They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
-to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
+They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
+to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
to “think step by step” or perform some rudimentary in-context learning.
With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
-
The abstract from the Phi-1 paper is the following:
*We introduce phi-1, a new large language model for code, with significantly smaller size than
@@ -60,32 +60,32 @@ including hallucinations and the potential for toxic and biased generations –e
are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
promote further research on these urgent topics.*
-
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
-The original code for Phi-1 and Phi-1.5 can be found [here](https://huggingface.co/microsoft/phi-1/blob/main/modeling_mixformer_sequential.py) and [here](https://huggingface.co/microsoft/phi-1_5/blob/main/modeling_mixformer_sequential.py) respectively.
-
-The original code for Phi-2 can be found [here](https://huggingface.co/microsoft/phi-2).
+The original code for Phi-1, Phi-1.5 and Phi-2 can be found [here](https://huggingface.co/microsoft/phi-1), [here](https://huggingface.co/microsoft/phi-1_5) and [here](https://huggingface.co/microsoft/phi-2), respectively.
## Usage tips
- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
-
## How to use Phi-2
-The current weights at [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) are not in proper order to be used with the library model. Until that is resolved, please use [susnato/phi-2](https://huggingface.co/susnato/phi-2) to load using the library `phi` model.
+Phi-2 has been integrated in the development version (4.37.0.dev) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
+
+* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
+
+* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
->>> model = AutoModelForCausalLM.from_pretrained("susnato/phi-2")
->>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-2")
+>>> model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
>>> inputs = tokenizer('Can you help me write a formal email to a potential business partner proposing a joint venture?', return_tensors="pt", return_attention_mask=False)
@@ -95,15 +95,14 @@ The current weights at [microsoft/phi-2](https://huggingface.co/microsoft/phi-2)
'Can you help me write a formal email to a potential business partner proposing a joint venture?\nInput: Company A: ABC Inc.\nCompany B: XYZ Ltd.\nJoint Venture: A new online platform for e-commerce'
```
-
### Example :
```python
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
->>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
->>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
+>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5")
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
@@ -118,7 +117,6 @@ The current weights at [microsoft/phi-2](https://huggingface.co/microsoft/phi-2)
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
-
## Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
@@ -136,8 +134,8 @@ To load and run a model using Flash Attention 2, refer to the snippet below:
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
->>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
->>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
+>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
@@ -153,12 +151,13 @@ To load and run a model using Flash Attention 2, refer to the snippet below:
```
### Expected speedups
-Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `susnato/phi-1_dev` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `microsoft/phi-1` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
+
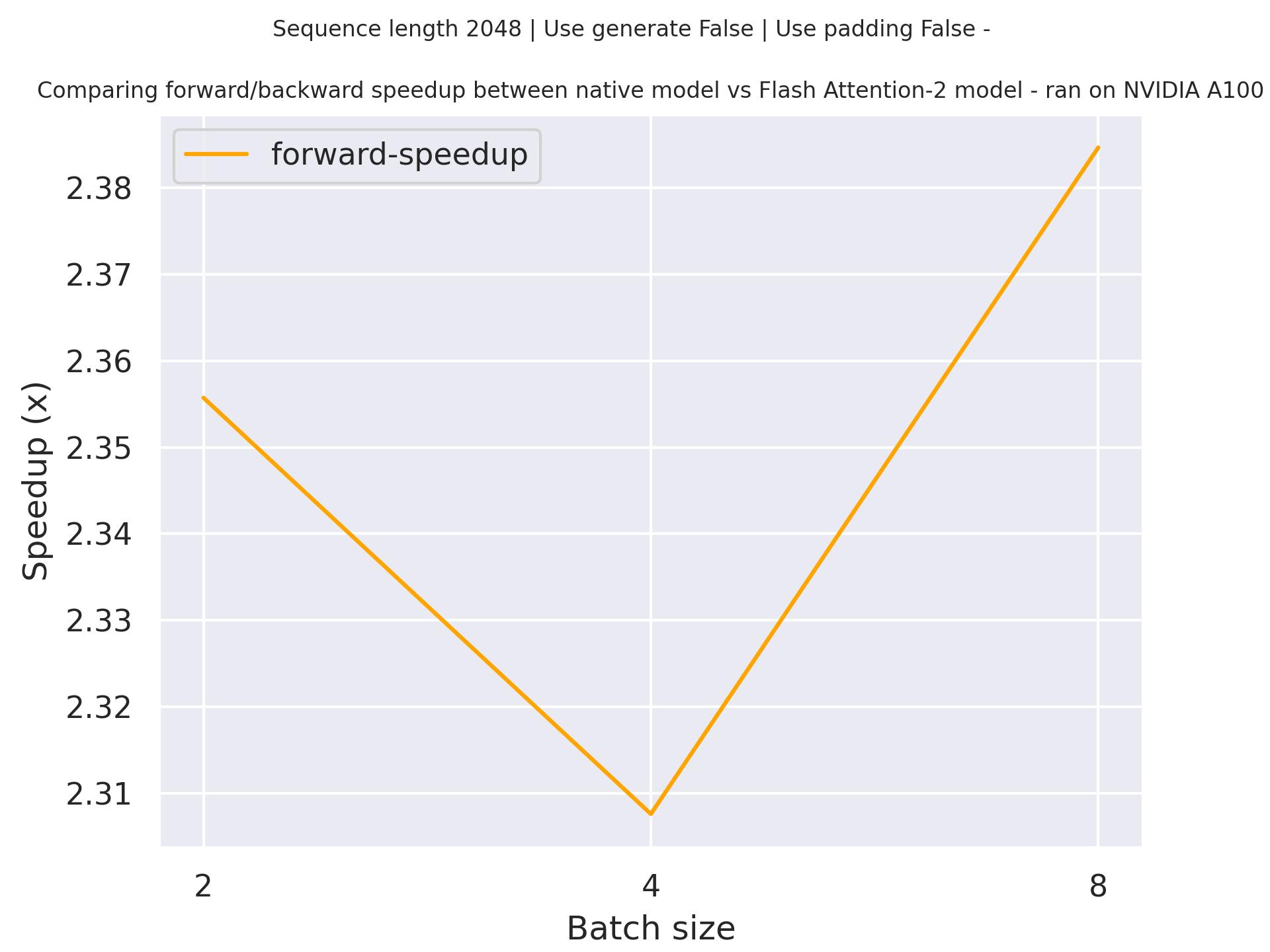
-
## PhiConfig
[[autodoc]] PhiConfig
diff --git a/docs/source/en/model_doc/qwen2.md b/docs/source/en/model_doc/qwen2.md
new file mode 100644
index 00000000000000..61e45fd9c2c8e2
--- /dev/null
+++ b/docs/source/en/model_doc/qwen2.md
@@ -0,0 +1,82 @@
+
+
+# Qwen2
+
+## Overview
+
+Qwen2 is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
+
+### Model Details
+
+Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
+
+
+## Usage tips
+
+`Qwen2-7B-beta` and `Qwen2-7B-Chat-beta` can be found on the [Huggingface Hub](https://huggingface.co/Qwen)
+
+In the following, we demonstrate how to use `Qwen2-7B-Chat-beta` for the inference. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("Qwen2/Qwen2-7B-Chat-beta", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("Qwen2/Qwen2-7B-Chat-beta")
+
+>>> prompt = "Give me a short introduction to large language model."
+
+>>> messages = [{"role": "user", "content": prompt}]
+
+>>> text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+
+>>> model_inputs = tokenizer([text], return_tensors="pt").to(device)
+
+>>> generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
+
+>>> generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
+
+>>> response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+## Qwen2Config
+
+[[autodoc]] Qwen2Config
+
+## Qwen2Tokenizer
+
+[[autodoc]] Qwen2Tokenizer
+ - save_vocabulary
+
+## Qwen2TokenizerFast
+
+[[autodoc]] Qwen2TokenizerFast
+
+## Qwen2Model
+
+[[autodoc]] Qwen2Model
+ - forward
+
+## Qwen2ForCausalLM
+
+[[autodoc]] Qwen2ForCausalLM
+ - forward
+
+## Qwen2ForSequenceClassification
+
+[[autodoc]] Qwen2ForSequenceClassification
+ - forward
diff --git a/docs/source/en/model_doc/siglip.md b/docs/source/en/model_doc/siglip.md
index 5cebbf97848e9b..28f96b02f1faf2 100644
--- a/docs/source/en/model_doc/siglip.md
+++ b/docs/source/en/model_doc/siglip.md
@@ -28,7 +28,7 @@ The abstract from the paper is the following:
- Usage of SigLIP is similar to [CLIP](clip). The main difference is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
- Training is not yet supported. If you want to fine-tune SigLIP or train from scratch, refer to the loss function from [OpenCLIP](https://github.com/mlfoundations/open_clip/blob/73ad04ae7fb93ede1c02dc9040a828634cb1edf1/src/open_clip/loss.py#L307), which leverages various `torch.distributed` utilities.
-- When using the standalone [`SiglipTokenizer`], make sure to pass `padding="max_length"` as that's how the model was trained. The multimodal [`SiglipProcessor`] takes care of this behind the scenes.
+- When using the standalone [`SiglipTokenizer`] or [`SiglipProcessor`], make sure to pass `padding="max_length"` as that's how the model was trained.
 @@ -82,7 +82,8 @@ If you want to do the pre- and postprocessing yourself, here's how to do that:
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
->>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> # important: we pass `padding=max_length` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/docs/source/en/model_doc/wav2vec2-bert.md b/docs/source/en/model_doc/wav2vec2-bert.md
new file mode 100644
index 00000000000000..6514133330a9d4
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2-bert.md
@@ -0,0 +1,90 @@
+
+
+# Wav2Vec2-BERT
+
+## Overview
+
+The Wav2Vec2-BERT model was proposed in [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team from Meta AI.
+
+This model was pre-trained on 4.5M hours of unlabeled audio data covering more than 143 languages. It requires finetuning to be used for downstream tasks such as Automatic Speech Recognition (ASR), or Audio Classification.
+
+The official results of the model can be found in Section 3.2.1 of the paper.
+
+The abstract from the paper is the following:
+
+*Recent advancements in automatic speech translation have dramatically expanded language coverage, improved multimodal capabilities, and enabled a wide range of tasks and functionalities. That said, large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model—SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. The expanded version of SeamlessAlign adds 114,800 hours of automatically aligned data for a total of 76 languages. SeamlessM4T v2 provides the foundation on which our two newest models, SeamlessExpressive and SeamlessStreaming, are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one’s voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention (EMMA) mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To understand the performance of these models, we combined novel and modified versions of existing automatic metrics to evaluate prosody, latency, and robustness. For human evaluations, we adapted existing protocols tailored for measuring the most relevant attributes in the preservation of meaning, naturalness, and expressivity. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. In sum, Seamless gives us a pivotal look at the technical foundation needed to turn the Universal Speech Translator from a science fiction concept into a real-world technology. Finally, contributions in this work—including models, code, and a watermark detector—are publicly released and accessible at the link below.*
+
+This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/seamless_communication).
+
+## Usage tips
+
+- Wav2Vec2-BERT follows the same architecture as Wav2Vec2-Conformer, but employs a causal depthwise convolutional layer and uses as input a mel-spectrogram representation of the audio instead of the raw waveform.
+- Wav2Vec2-BERT can use either no relative position embeddings, Shaw-like position embeddings, Transformer-XL-like position embeddings, or
+ rotary position embeddings by setting the correct `config.position_embeddings_type`.
+- Wav2Vec2-BERT also introduces a Conformer-based adapter network instead of a simple convolutional network.
+
+## Resources
+
+
+
+- [`Wav2Vec2BertForCTC`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
+- You can also adapt these notebooks on [how to finetune a speech recognition model in English](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb), and [how to finetune a speech recognition model in any language](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb).
+
+
+
+- [`Wav2Vec2BertForSequenceClassification`] can be used by adapting this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification).
+- See also: [Audio classification task guide](../tasks/audio_classification)
+
+
+## Wav2Vec2BertConfig
+
+[[autodoc]] Wav2Vec2BertConfig
+
+## Wav2Vec2BertProcessor
+
+[[autodoc]] Wav2Vec2BertProcessor
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## Wav2Vec2BertModel
+
+[[autodoc]] Wav2Vec2BertModel
+ - forward
+
+## Wav2Vec2BertForCTC
+
+[[autodoc]] Wav2Vec2BertForCTC
+ - forward
+
+## Wav2Vec2BertForSequenceClassification
+
+[[autodoc]] Wav2Vec2BertForSequenceClassification
+ - forward
+
+## Wav2Vec2BertForAudioFrameClassification
+
+[[autodoc]] Wav2Vec2BertForAudioFrameClassification
+ - forward
+
+## Wav2Vec2BertForXVector
+
+[[autodoc]] Wav2Vec2BertForXVector
+ - forward
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 5cc9cd208d8aa3..899e5b52f002ce 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -52,6 +52,7 @@ FlashAttention-2 is currently supported for the following architectures:
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
+* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
@@ -174,6 +175,7 @@ For now, Transformers supports SDPA inference and training for the following arc
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
+* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
diff --git a/docs/source/en/tasks/asr.md b/docs/source/en/tasks/asr.md
index d01269ba60a696..737460ed297bcf 100644
--- a/docs/source/en/tasks/asr.md
+++ b/docs/source/en/tasks/asr.md
@@ -32,7 +32,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
+[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-BERT](../model_doc/wav2vec2-bert), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
diff --git a/docs/source/en/tasks/audio_classification.md b/docs/source/en/tasks/audio_classification.md
index 743a797fc53fa8..678af90c4fa079 100644
--- a/docs/source/en/tasks/audio_classification.md
+++ b/docs/source/en/tasks/audio_classification.md
@@ -32,7 +32,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
+[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-BERT](../model_doc/wav2vec2-bert), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
diff --git a/docs/source/en/tasks/language_modeling.md b/docs/source/en/tasks/language_modeling.md
index a50555dfcf941a..02b5f2ca73f613 100644
--- a/docs/source/en/tasks/language_modeling.md
+++ b/docs/source/en/tasks/language_modeling.md
@@ -37,7 +37,7 @@ You can finetune other architectures for causal language modeling following the
Choose one of the following architectures:
-[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
+[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
diff --git a/docs/source/en/tasks/sequence_classification.md b/docs/source/en/tasks/sequence_classification.md
index 4a0e5b611c9136..0acbf7bfb1e8d5 100644
--- a/docs/source/en/tasks/sequence_classification.md
+++ b/docs/source/en/tasks/sequence_classification.md
@@ -33,7 +33,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
+[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
diff --git a/examples/flax/question-answering/run_qa.py b/examples/flax/question-answering/run_qa.py
index fdba1c3ba49fdb..8e6eb2580dc9ed 100644
--- a/examples/flax/question-answering/run_qa.py
+++ b/examples/flax/question-answering/run_qa.py
@@ -62,7 +62,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
Array = Any
Dataset = datasets.arrow_dataset.Dataset
diff --git a/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py b/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
index 5172bcb0beba0f..31780e8ff213e9 100644
--- a/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
+++ b/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
@@ -60,7 +60,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=2.14.0", "To fix: pip install -r examples/flax/speech-recogintion/requirements.txt")
diff --git a/examples/flax/text-classification/run_flax_glue.py b/examples/flax/text-classification/run_flax_glue.py
index 9c51c828363515..b9ebc3344a33bd 100755
--- a/examples/flax/text-classification/run_flax_glue.py
+++ b/examples/flax/text-classification/run_flax_glue.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
Array = Any
Dataset = datasets.arrow_dataset.Dataset
diff --git a/examples/flax/token-classification/run_flax_ner.py b/examples/flax/token-classification/run_flax_ner.py
index ac14b5c2854702..b3eeba8d789dc6 100644
--- a/examples/flax/token-classification/run_flax_ner.py
+++ b/examples/flax/token-classification/run_flax_ner.py
@@ -56,7 +56,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/audio-classification/run_audio_classification.py b/examples/pytorch/audio-classification/run_audio_classification.py
index da31bd0ec29687..4171ea8e3c17eb 100644
--- a/examples/pytorch/audio-classification/run_audio_classification.py
+++ b/examples/pytorch/audio-classification/run_audio_classification.py
@@ -45,7 +45,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.14.0", "To fix: pip install -r examples/pytorch/audio-classification/requirements.txt")
diff --git a/examples/pytorch/contrastive-image-text/run_clip.py b/examples/pytorch/contrastive-image-text/run_clip.py
index a6c1551316daec..d992453edceff5 100644
--- a/examples/pytorch/contrastive-image-text/run_clip.py
+++ b/examples/pytorch/contrastive-image-text/run_clip.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")
diff --git a/examples/pytorch/image-classification/run_image_classification.py b/examples/pytorch/image-classification/run_image_classification.py
index db13dc988ed591..36d8864f19af06 100755
--- a/examples/pytorch/image-classification/run_image_classification.py
+++ b/examples/pytorch/image-classification/run_image_classification.py
@@ -57,7 +57,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
diff --git a/examples/pytorch/image-classification/run_image_classification_no_trainer.py b/examples/pytorch/image-classification/run_image_classification_no_trainer.py
index 963a01b77cf7fc..7c3aa725ea46ed 100644
--- a/examples/pytorch/image-classification/run_image_classification_no_trainer.py
+++ b/examples/pytorch/image-classification/run_image_classification_no_trainer.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -438,8 +438,8 @@ def collate_fn(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 5e3ba45e6c06b3..95e28a5b6025fd 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -44,7 +44,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
index e644cf48e47bae..01d592887ab547 100644
--- a/examples/pytorch/image-pretraining/run_mim.py
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -49,7 +49,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
diff --git a/examples/pytorch/image-pretraining/run_mim_no_trainer.py b/examples/pytorch/image-pretraining/run_mim_no_trainer.py
index ddce78940aecb0..6d5c1849e5b3b2 100644
--- a/examples/pytorch/image-pretraining/run_mim_no_trainer.py
+++ b/examples/pytorch/image-pretraining/run_mim_no_trainer.py
@@ -54,7 +54,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
@@ -626,8 +626,8 @@ def preprocess_images(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_clm.py b/examples/pytorch/language-modeling/run_clm.py
index e9e44af3a37aac..7c73fd741f2c9d 100755
--- a/examples/pytorch/language-modeling/run_clm.py
+++ b/examples/pytorch/language-modeling/run_clm.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/language-modeling/run_clm_no_trainer.py b/examples/pytorch/language-modeling/run_clm_no_trainer.py
index 7a18814e65049e..a8e9b608e466d9 100755
--- a/examples/pytorch/language-modeling/run_clm_no_trainer.py
+++ b/examples/pytorch/language-modeling/run_clm_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -526,8 +526,8 @@ def group_texts(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_mlm.py b/examples/pytorch/language-modeling/run_mlm.py
index 87898963fe89f9..bdee374424d0d9 100755
--- a/examples/pytorch/language-modeling/run_mlm.py
+++ b/examples/pytorch/language-modeling/run_mlm.py
@@ -54,7 +54,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/language-modeling/run_mlm_no_trainer.py b/examples/pytorch/language-modeling/run_mlm_no_trainer.py
index 8ef5eb3a2c0008..97860cd2666abb 100755
--- a/examples/pytorch/language-modeling/run_mlm_no_trainer.py
+++ b/examples/pytorch/language-modeling/run_mlm_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
@@ -563,8 +563,8 @@ def group_texts(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_plm.py b/examples/pytorch/language-modeling/run_plm.py
index af0d5f06a0b5f2..66451247e06a7f 100755
--- a/examples/pytorch/language-modeling/run_plm.py
+++ b/examples/pytorch/language-modeling/run_plm.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/multiple-choice/run_swag.py b/examples/pytorch/multiple-choice/run_swag.py
index 5b7aaa0a705d0d..a1cfcfdddafa4a 100755
--- a/examples/pytorch/multiple-choice/run_swag.py
+++ b/examples/pytorch/multiple-choice/run_swag.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/pytorch/multiple-choice/run_swag_no_trainer.py b/examples/pytorch/multiple-choice/run_swag_no_trainer.py
index e15cc9da9a3606..533072fc0af15a 100755
--- a/examples/pytorch/multiple-choice/run_swag_no_trainer.py
+++ b/examples/pytorch/multiple-choice/run_swag_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
# You should update this to your particular problem to have better documentation of `model_type`
@@ -510,8 +510,8 @@ def preprocess_function(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_qa.py b/examples/pytorch/question-answering/run_qa.py
index b134d95765c538..c43fec14f4ec04 100755
--- a/examples/pytorch/question-answering/run_qa.py
+++ b/examples/pytorch/question-answering/run_qa.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/question-answering/run_qa_beam_search.py b/examples/pytorch/question-answering/run_qa_beam_search.py
index 23a2231e9acc3d..d75e394e8d94dc 100755
--- a/examples/pytorch/question-answering/run_qa_beam_search.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py b/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
index ed92bccbd202ce..65c38edca295df 100644
--- a/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
@@ -750,8 +750,8 @@ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_qa_no_trainer.py b/examples/pytorch/question-answering/run_qa_no_trainer.py
index 2ae3eb6c45c872..5cb00d5225cb8f 100755
--- a/examples/pytorch/question-answering/run_qa_no_trainer.py
+++ b/examples/pytorch/question-answering/run_qa_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
@@ -780,8 +780,8 @@ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_seq2seq_qa.py b/examples/pytorch/question-answering/run_seq2seq_qa.py
index 92ba31efdd8312..55f9c65988c077 100644
--- a/examples/pytorch/question-answering/run_seq2seq_qa.py
+++ b/examples/pytorch/question-answering/run_seq2seq_qa.py
@@ -47,7 +47,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
index 5b12a98c7e0a68..af62d75f764b02 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
@@ -52,7 +52,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
index 99e24de7312229..315c0ce4611cd2 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -513,8 +513,8 @@ def preprocess_val(example_batch):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index 1c658904e71e30..def937450fbca2 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
@@ -132,6 +132,20 @@ class ModelArguments:
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
)
+ ctc_zero_infinity: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`. Infinite losses mainly"
+ " occur when the inputs are too short to be aligned to the targets."
+ },
+ )
+ add_adapter: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether a convolutional attention network should be stacked on top of the Wav2Vec2Bert Encoder. Can be very"
+ "useful to downsample the output length."
+ },
+ )
@dataclass
@@ -309,11 +323,14 @@ class DataCollatorCTCWithPadding:
padding: Union[bool, str] = "longest"
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
+ feature_extractor_input_name: Optional[str] = "input_values"
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
+ input_features = [
+ {self.feature_extractor_input_name: feature[self.feature_extractor_input_name]} for feature in features
+ ]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
@@ -599,9 +616,11 @@ def remove_special_characters(batch):
"gradient_checkpointing": training_args.gradient_checkpointing,
"layerdrop": model_args.layerdrop,
"ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "ctc_zero_infinity": model_args.ctc_zero_infinity,
"pad_token_id": tokenizer.pad_token_id,
"vocab_size": len(tokenizer),
"activation_dropout": model_args.activation_dropout,
+ "add_adapter": model_args.add_adapter,
}
)
@@ -635,6 +654,7 @@ def remove_special_characters(batch):
min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
audio_column_name = data_args.audio_column_name
num_workers = data_args.preprocessing_num_workers
+ feature_extractor_input_name = feature_extractor.model_input_names[0]
# `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
phoneme_language = data_args.phoneme_language
@@ -646,8 +666,9 @@ def prepare_dataset(batch):
sample = batch[audio_column_name]
inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
+ batch[feature_extractor_input_name] = getattr(inputs, feature_extractor_input_name)[0]
+ # take length of raw audio waveform
+ batch["input_length"] = len(sample["array"].squeeze())
# encode targets
additional_kwargs = {}
@@ -728,7 +749,9 @@ def compute_metrics(pred):
processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
# Instantiate custom data collator
- data_collator = DataCollatorCTCWithPadding(processor=processor)
+ data_collator = DataCollatorCTCWithPadding(
+ processor=processor, feature_extractor_input_name=feature_extractor_input_name
+ )
# Initialize Trainer
trainer = Trainer(
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
index 5708f524a3180f..f311d97987c062 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index 9ffb48638d3672..50f27e41bfc139 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
diff --git a/examples/pytorch/summarization/run_summarization.py b/examples/pytorch/summarization/run_summarization.py
index fcd6c69de848d1..993c4d4cfcbeda 100755
--- a/examples/pytorch/summarization/run_summarization.py
+++ b/examples/pytorch/summarization/run_summarization.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/examples/pytorch/summarization/run_summarization_no_trainer.py b/examples/pytorch/summarization/run_summarization_no_trainer.py
index 30c1b887e80eec..3212ef1af52b04 100644
--- a/examples/pytorch/summarization/run_summarization_no_trainer.py
+++ b/examples/pytorch/summarization/run_summarization_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
@@ -580,8 +580,8 @@ def postprocess_text(preds, labels):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/text-classification/run_classification.py b/examples/pytorch/text-classification/run_classification.py
index 4ce7bfab3a518b..a080df108ebf8e 100755
--- a/examples/pytorch/text-classification/run_classification.py
+++ b/examples/pytorch/text-classification/run_classification.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
@@ -545,7 +545,7 @@ def main():
"run. You can ignore this if you are doing finetuning."
)
model.config.label2id = label_to_id
- model.config.id2label = {id: label for label, id in config.label2id.items()}
+ model.config.id2label = {id: label for label, id in label_to_id.items()}
elif not is_regression: # classification, but not training
logger.info("using label infos in the model config")
logger.info("label2id: {}".format(model.config.label2id))
diff --git a/examples/pytorch/text-classification/run_glue.py b/examples/pytorch/text-classification/run_glue.py
index 8fa821c49ae89f..c9381824018ec8 100755
--- a/examples/pytorch/text-classification/run_glue.py
+++ b/examples/pytorch/text-classification/run_glue.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
diff --git a/examples/pytorch/text-classification/run_glue_no_trainer.py b/examples/pytorch/text-classification/run_glue_no_trainer.py
index 870eeb31e99f1e..711494d85c066d 100644
--- a/examples/pytorch/text-classification/run_glue_no_trainer.py
+++ b/examples/pytorch/text-classification/run_glue_no_trainer.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
diff --git a/examples/pytorch/text-classification/run_xnli.py b/examples/pytorch/text-classification/run_xnli.py
index 8260645764184a..b716744297fccb 100755
--- a/examples/pytorch/text-classification/run_xnli.py
+++ b/examples/pytorch/text-classification/run_xnli.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
diff --git a/examples/pytorch/token-classification/run_ner.py b/examples/pytorch/token-classification/run_ner.py
index 40028f779cc14e..8d7a67cd1571a6 100755
--- a/examples/pytorch/token-classification/run_ner.py
+++ b/examples/pytorch/token-classification/run_ner.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/token-classification/run_ner_no_trainer.py b/examples/pytorch/token-classification/run_ner_no_trainer.py
index 7d2939f81bf39b..02bbd12d22ba50 100755
--- a/examples/pytorch/token-classification/run_ner_no_trainer.py
+++ b/examples/pytorch/token-classification/run_ner_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/translation/run_translation.py b/examples/pytorch/translation/run_translation.py
index cb9fa48e84a747..04f26cb72f589a 100755
--- a/examples/pytorch/translation/run_translation.py
+++ b/examples/pytorch/translation/run_translation.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
diff --git a/examples/pytorch/translation/run_translation_no_trainer.py b/examples/pytorch/translation/run_translation_no_trainer.py
index 1e8009d42d86dd..c4764b5ee4a7d7 100644
--- a/examples/pytorch/translation/run_translation_no_trainer.py
+++ b/examples/pytorch/translation/run_translation_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
diff --git a/examples/research_projects/codeparrot/README.md b/examples/research_projects/codeparrot/README.md
index 6c57c4350fbc02..3259041ba5404a 100644
--- a/examples/research_projects/codeparrot/README.md
+++ b/examples/research_projects/codeparrot/README.md
@@ -50,7 +50,7 @@ The raw dataset contains many duplicates. We deduplicated and filtered the datas
- fraction of alphanumeric characters < 0.25
- containing the word "auto-generated" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with a mention of "test file" or "configuration file" or similar in the first 5 lines
-- filtering with a probability of 0.7 of files with high occurence of the keywords "test " or "config"
+- filtering with a probability of 0.7 of files with high occurrence of the keywords "test " or "config"
- filtering with a probability of 0.7 of files without a mention of the keywords `def` , `for`, `while` and `class`
- filtering files that use the assignment operator `=` less than 5 times
- filtering files with ratio between number of characters and number of tokens after tokenization < 1.5 (the average ratio is 3.6)
diff --git a/examples/research_projects/jax-projects/README.md b/examples/research_projects/jax-projects/README.md
index 420a97f7682a9c..71f9a7a4e0e2a1 100644
--- a/examples/research_projects/jax-projects/README.md
+++ b/examples/research_projects/jax-projects/README.md
@@ -1153,7 +1153,7 @@ In the following, we will describe how to do so using a standard console, but yo
2. Once you've installed the google cloud sdk, you should set your account by running the following command. Make sure that `` corresponds to the gmail address you used to sign up for this event.
```bash
-$ gcloud config set account
+$ gcloud config set account
```
3. Let's also make sure the correct project is set in case your email is used for multiple gcloud projects:
diff --git a/examples/research_projects/jax-projects/big_bird/README.md b/examples/research_projects/jax-projects/big_bird/README.md
index e8ef274bbe07cd..42586e49580ebb 100644
--- a/examples/research_projects/jax-projects/big_bird/README.md
+++ b/examples/research_projects/jax-projects/big_bird/README.md
@@ -57,4 +57,4 @@ wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/r
python3 evaluate.py
```
-You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repositary](https://github.com/thevasudevgupta/bigbird).
+You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repository](https://github.com/thevasudevgupta/bigbird).
diff --git a/examples/research_projects/jax-projects/model_parallel/README.md b/examples/research_projects/jax-projects/model_parallel/README.md
index b63b93862db06f..97f3cdb047741a 100644
--- a/examples/research_projects/jax-projects/model_parallel/README.md
+++ b/examples/research_projects/jax-projects/model_parallel/README.md
@@ -27,7 +27,7 @@ To adapt the script for other models, we need to also change the `ParitionSpec`
TODO: Add more explantion.
-Before training, let's prepare our model first. To be able to shard the model, the sharded dimention needs to be a multiple of devices it'll be sharded on. But GPTNeo's vocab size is 50257, so we need to resize the embeddings accordingly.
+Before training, let's prepare our model first. To be able to shard the model, the sharded dimension needs to be a multiple of devices it'll be sharded on. But GPTNeo's vocab size is 50257, so we need to resize the embeddings accordingly.
```python
from transformers import FlaxGPTNeoForCausalLM, GPTNeoConfig
diff --git a/examples/research_projects/mlm_wwm/README.md b/examples/research_projects/mlm_wwm/README.md
index 9426be7c27be1f..0144b1ad309206 100644
--- a/examples/research_projects/mlm_wwm/README.md
+++ b/examples/research_projects/mlm_wwm/README.md
@@ -95,4 +95,4 @@ python run_mlm_wwm.py \
**Note1:** On TPU, you should the flag `--pad_to_max_length` to make sure all your batches have the same length.
-**Note2:** And if you have any questions or something goes wrong when runing this code, don't hesitate to pin @wlhgtc.
+**Note2:** And if you have any questions or something goes wrong when running this code, don't hesitate to pin @wlhgtc.
diff --git a/examples/tensorflow/contrastive-image-text/run_clip.py b/examples/tensorflow/contrastive-image-text/run_clip.py
index d63712133ca559..e94f4b6b44fb0a 100644
--- a/examples/tensorflow/contrastive-image-text/run_clip.py
+++ b/examples/tensorflow/contrastive-image-text/run_clip.py
@@ -52,7 +52,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version(
"datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/contrastive-image-text/requirements.txt"
diff --git a/examples/tensorflow/image-classification/run_image_classification.py b/examples/tensorflow/image-classification/run_image_classification.py
index 41cb0ffe9568c8..11f35ceacc0221 100644
--- a/examples/tensorflow/image-classification/run_image_classification.py
+++ b/examples/tensorflow/image-classification/run_image_classification.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
diff --git a/examples/tensorflow/multiple-choice/run_swag.py b/examples/tensorflow/multiple-choice/run_swag.py
index e170daa97938ca..8572ec98e1ae96 100644
--- a/examples/tensorflow/multiple-choice/run_swag.py
+++ b/examples/tensorflow/multiple-choice/run_swag.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/tensorflow/question-answering/run_qa.py b/examples/tensorflow/question-answering/run_qa.py
index 6aaf45f00fd3b0..19e00c3dc42031 100755
--- a/examples/tensorflow/question-answering/run_qa.py
+++ b/examples/tensorflow/question-answering/run_qa.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/tensorflow/summarization/run_summarization.py b/examples/tensorflow/summarization/run_summarization.py
index 39c8f7f89f4b89..84ba7f2e7b9656 100644
--- a/examples/tensorflow/summarization/run_summarization.py
+++ b/examples/tensorflow/summarization/run_summarization.py
@@ -54,7 +54,7 @@
# region Checking dependencies
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/examples/tensorflow/text-classification/run_glue.py b/examples/tensorflow/text-classification/run_glue.py
index 3662d6aaac10a3..198bec7da382e2 100644
--- a/examples/tensorflow/text-classification/run_glue.py
+++ b/examples/tensorflow/text-classification/run_glue.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
task_to_keys = {
"cola": ("sentence", None),
diff --git a/examples/tensorflow/translation/run_translation.py b/examples/tensorflow/translation/run_translation.py
index b34a8624051909..2d0c06f57e7e25 100644
--- a/examples/tensorflow/translation/run_translation.py
+++ b/examples/tensorflow/translation/run_translation.py
@@ -57,7 +57,7 @@
# region Dependencies and constants
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/setup.py b/setup.py
index 65b84fe938f787..91ad923ec3e74c 100644
--- a/setup.py
+++ b/setup.py
@@ -428,7 +428,7 @@ def run(self):
setup(
name="transformers",
- version="4.37.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
+ version="4.38.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
author="The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)",
author_email="transformers@huggingface.co",
description="State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow",
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 4941d724455dfe..41d2c3632c039a 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -18,7 +18,7 @@
# to defer the actual importing for when the objects are requested. This way `import transformers` provides the names
# in the namespace without actually importing anything (and especially none of the backends).
-__version__ = "4.37.0.dev0"
+__version__ = "4.38.0.dev0"
from typing import TYPE_CHECKING
@@ -711,6 +711,11 @@
],
"models.pvt": ["PVT_PRETRAINED_CONFIG_ARCHIVE_MAP", "PvtConfig"],
"models.qdqbert": ["QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "QDQBertConfig"],
+ "models.qwen2": [
+ "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Qwen2Config",
+ "Qwen2Tokenizer",
+ ],
"models.rag": ["RagConfig", "RagRetriever", "RagTokenizer"],
"models.realm": [
"REALM_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -909,6 +914,11 @@
"Wav2Vec2Processor",
"Wav2Vec2Tokenizer",
],
+ "models.wav2vec2_bert": [
+ "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Wav2Vec2BertConfig",
+ "Wav2Vec2BertProcessor",
+ ],
"models.wav2vec2_conformer": [
"WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
"Wav2Vec2ConformerConfig",
@@ -1185,6 +1195,7 @@
_import_structure["models.nougat"].append("NougatTokenizerFast")
_import_structure["models.openai"].append("OpenAIGPTTokenizerFast")
_import_structure["models.pegasus"].append("PegasusTokenizerFast")
+ _import_structure["models.qwen2"].append("Qwen2TokenizerFast")
_import_structure["models.realm"].append("RealmTokenizerFast")
_import_structure["models.reformer"].append("ReformerTokenizerFast")
_import_structure["models.rembert"].append("RemBertTokenizerFast")
@@ -2971,6 +2982,14 @@
"load_tf_weights_in_qdqbert",
]
)
+ _import_structure["models.qwen2"].extend(
+ [
+ "Qwen2ForCausalLM",
+ "Qwen2ForSequenceClassification",
+ "Qwen2Model",
+ "Qwen2PreTrainedModel",
+ ]
+ )
_import_structure["models.rag"].extend(
[
"RagModel",
@@ -3501,6 +3520,17 @@
"Wav2Vec2PreTrainedModel",
]
)
+ _import_structure["models.wav2vec2_bert"].extend(
+ [
+ "WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Wav2Vec2BertForAudioFrameClassification",
+ "Wav2Vec2BertForCTC",
+ "Wav2Vec2BertForSequenceClassification",
+ "Wav2Vec2BertForXVector",
+ "Wav2Vec2BertModel",
+ "Wav2Vec2BertPreTrainedModel",
+ ]
+ )
_import_structure["models.wav2vec2_conformer"].extend(
[
"WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -5404,6 +5434,7 @@
)
from .models.pvt import PVT_PRETRAINED_CONFIG_ARCHIVE_MAP, PvtConfig
from .models.qdqbert import QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, QDQBertConfig
+ from .models.qwen2 import QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP, Qwen2Config, Qwen2Tokenizer
from .models.rag import RagConfig, RagRetriever, RagTokenizer
from .models.realm import (
REALM_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5602,6 +5633,11 @@
Wav2Vec2Processor,
Wav2Vec2Tokenizer,
)
+ from .models.wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ Wav2Vec2BertConfig,
+ Wav2Vec2BertProcessor,
+ )
from .models.wav2vec2_conformer import (
WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
Wav2Vec2ConformerConfig,
@@ -5871,6 +5907,7 @@
from .models.nougat import NougatTokenizerFast
from .models.openai import OpenAIGPTTokenizerFast
from .models.pegasus import PegasusTokenizerFast
+ from .models.qwen2 import Qwen2TokenizerFast
from .models.realm import RealmTokenizerFast
from .models.reformer import ReformerTokenizerFast
from .models.rembert import RemBertTokenizerFast
@@ -7373,6 +7410,12 @@
QDQBertPreTrainedModel,
load_tf_weights_in_qdqbert,
)
+ from .models.qwen2 import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ Qwen2PreTrainedModel,
+ )
from .models.rag import (
RagModel,
RagPreTrainedModel,
@@ -7799,6 +7842,15 @@
Wav2Vec2Model,
Wav2Vec2PreTrainedModel,
)
+ from .models.wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertPreTrainedModel,
+ )
from .models.wav2vec2_conformer import (
WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
Wav2Vec2ConformerForAudioFrameClassification,
diff --git a/src/transformers/convert_pytorch_checkpoint_to_tf2.py b/src/transformers/convert_pytorch_checkpoint_to_tf2.py
index f300b0bb92c661..c10dd44ed853fa 100755
--- a/src/transformers/convert_pytorch_checkpoint_to_tf2.py
+++ b/src/transformers/convert_pytorch_checkpoint_to_tf2.py
@@ -129,6 +129,7 @@
XLMWithLMHeadModel,
XLNetLMHeadModel,
)
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13
logging.set_verbosity_info()
@@ -329,7 +330,11 @@ def convert_pt_checkpoint_to_tf(
if compare_with_pt_model:
tfo = tf_model(tf_model.dummy_inputs, training=False) # build the network
- state_dict = torch.load(pytorch_checkpoint_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ pytorch_checkpoint_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
pt_model = pt_model_class.from_pretrained(
pretrained_model_name_or_path=None, config=config, state_dict=state_dict
)
diff --git a/src/transformers/convert_slow_tokenizer.py b/src/transformers/convert_slow_tokenizer.py
index 76ac66ceb9efcc..53dbfeb6b64cb7 100644
--- a/src/transformers/convert_slow_tokenizer.py
+++ b/src/transformers/convert_slow_tokenizer.py
@@ -355,6 +355,48 @@ def converted(self) -> Tokenizer:
return tokenizer
+class Qwen2Converter(Converter):
+ def converted(self) -> Tokenizer:
+ vocab = self.original_tokenizer.encoder
+ merges = list(self.original_tokenizer.bpe_ranks.keys())
+
+ tokenizer = Tokenizer(
+ BPE(
+ vocab=vocab,
+ merges=merges,
+ dropout=None,
+ unk_token=None,
+ continuing_subword_prefix="",
+ end_of_word_suffix="",
+ fuse_unk=False,
+ byte_fallback=False,
+ )
+ )
+
+ tokenizer.normalizer = normalizers.NFC()
+
+ tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
+ [
+ pre_tokenizers.Split(
+ Regex(
+ r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
+ ),
+ behavior="isolated",
+ invert=False,
+ ),
+ pre_tokenizers.ByteLevel(
+ add_prefix_space=getattr(self.original_tokenizer, "add_prefix_space", False),
+ use_regex=False,
+ ),
+ ]
+ )
+
+ tokenizer.decoder = decoders.ByteLevel()
+ tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
+
+ return tokenizer
+
+
class RobertaConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
@@ -510,15 +552,22 @@ def tokenizer(self, proto):
def normalizer(self, proto):
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
+ _normalizers = [
+ normalizers.Strip(left=False, right=True), # stripping is important
+ normalizers.Replace(Regex(" {2,}"), "▁"),
+ ]
if not precompiled_charsmap:
- return normalizers.Sequence([normalizers.Replace(Regex(" {2,}"), " ")])
+ return normalizers.Sequence(_normalizers)
else:
- return normalizers.Sequence(
- [normalizers.Precompiled(precompiled_charsmap), normalizers.Replace(Regex(" {2,}"), " ")]
- )
+ return normalizers.Sequence([normalizers.Precompiled(precompiled_charsmap)] + _normalizers)
def pre_tokenizer(self, replacement, add_prefix_space):
- return pre_tokenizers.Metaspace(replacement=replacement, add_prefix_space=add_prefix_space)
+ prepend_scheme = "always"
+ if hasattr(self.original_tokenizer, "legacy") and not self.original_tokenizer.legacy:
+ prepend_scheme = "first"
+ return pre_tokenizers.Metaspace(
+ replacement=replacement, add_prefix_space=add_prefix_space, prepend_scheme=prepend_scheme
+ )
def post_processor(self):
return None
@@ -1289,6 +1338,7 @@ def converted(self) -> Tokenizer:
"NllbTokenizer": NllbConverter,
"OpenAIGPTTokenizer": OpenAIGPTConverter,
"PegasusTokenizer": PegasusConverter,
+ "Qwen2Tokenizer": Qwen2Converter,
"RealmTokenizer": BertConverter,
"ReformerTokenizer": ReformerConverter,
"RemBertTokenizer": RemBertConverter,
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index 01ad4b5314c827..75a9f59a07bf18 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -171,12 +171,16 @@ def get_candidates(self, input_ids: torch.LongTensor, max_new_tokens=None) -> Tu
"""
input_ids = input_ids.to(self.assistant_model.device)
+ # Don't generate more than `max_length - 1` candidates since the target model generates one extra token.
+ new_cur_len = input_ids.shape[-1]
+ max_new_tokens = min(int(self.num_assistant_tokens), self.generation_config.max_length - new_cur_len - 1)
+ if max_new_tokens == 0:
+ return input_ids, None
+
# 1. If it is not the first round of candidate generation, prepare the inputs based on the input_ids length
# (which implicitly contains the number of accepted candidates from the previous round)
has_past_key_values = self.assistant_kwargs.get("past_key_values", None) is not None
if has_past_key_values:
- new_cur_len = input_ids.shape[-1]
-
new_cache_size = new_cur_len - 1
self.assistant_kwargs["past_key_values"] = _crop_past_key_values(
self.assistant_model, self.assistant_kwargs["past_key_values"], new_cache_size - 1
diff --git a/src/transformers/generation/configuration_utils.py b/src/transformers/generation/configuration_utils.py
index 4353a113223870..abc118aa8c1d60 100644
--- a/src/transformers/generation/configuration_utils.py
+++ b/src/transformers/generation/configuration_utils.py
@@ -200,7 +200,8 @@ class GenerationConfig(PushToHubMixin):
Higher guidance scale encourages the model to generate samples that are more closely linked to the input
prompt, usually at the expense of poorer quality.
low_memory (`bool`, *optional*):
- Switch to sequential topk for contrastive search to reduce peak memory. Used with contrastive search.
+ Switch to sequential beam search and sequential topk for contrastive search to reduce peak memory.
+ Used with beam search and contrastive search.
> Parameters that define the output variables of `generate`
diff --git a/src/transformers/generation/logits_process.py b/src/transformers/generation/logits_process.py
index 2b1b9f5a50b6ef..04120e39fbd27c 100644
--- a/src/transformers/generation/logits_process.py
+++ b/src/transformers/generation/logits_process.py
@@ -95,6 +95,7 @@ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwa
scores = processor(input_ids, scores, **kwargs)
else:
scores = processor(input_ids, scores)
+
return scores
@@ -1657,6 +1658,9 @@ def __init__(self, begin_suppress_tokens, begin_index):
self.begin_suppress_tokens = list(begin_suppress_tokens)
self.begin_index = begin_index
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
+
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if input_ids.shape[1] == self.begin_index:
@@ -1778,6 +1782,7 @@ class WhisperTimeStampLogitsProcessor(LogitsProcessor):
max_initial_timestamp_index (`int`, *optional*, defaults to 1):
Used to set the maximum value of the initial timestamp. This is used to prevent the model from
predicting timestamps that are too far in the future.
+ begin_index (`Optional`, *optional*): Token index of the first token that is generated by the model.
_detect_timestamp_from_logprob (`bool`, *optional*): Whether timestamps can be predicted from logprobs over all timestamps.
Examples:
@@ -1810,11 +1815,11 @@ class WhisperTimeStampLogitsProcessor(LogitsProcessor):
"""
def __init__(
- self, generate_config, _detect_timestamp_from_logprob: Optional[bool] = None
+ self, generate_config, begin_index: Optional[int] = None, _detect_timestamp_from_logprob: Optional[bool] = None
): # support for the kwargs
- self.eos_token_id = generate_config.eos_token_id
self.no_timestamps_token_id = generate_config.no_timestamps_token_id
self.timestamp_begin = generate_config.no_timestamps_token_id + 1
+ self.eos_token_id = generate_config.eos_token_id or generate_config.bos_token_id
# this variable is mostly just used for testing
self._detect_timestamp_from_logprob = (
@@ -1823,10 +1828,17 @@ def __init__(
else getattr(generate_config, "_detect_timestamp_from_logprob", True)
)
- self.begin_index = (
- len(generate_config.forced_decoder_ids) + 1 if generate_config.forced_decoder_ids is not None else 1
+ num_forced_ids = (
+ len(generate_config.forced_decoder_ids) if generate_config.forced_decoder_ids is not None else 0
)
+ self.begin_index = begin_index or (num_forced_ids + 1)
+
self.max_initial_timestamp_index = getattr(generate_config, "max_initial_timestamp_index", None)
+ # TODO(Patrick): Make sure that official models have max_initial_timestamp_index set to 50
+ # self.max_initial_timestamp_index = 50
+
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
@@ -1878,6 +1890,60 @@ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> to
return scores
+class WhisperNoSpeechDetection(LogitsProcessor):
+ r"""This processor can be used to detect silence when using Whisper. It should take as input unprocessed logits to follow the original implementation"""
+
+ def __init__(self, no_speech_token: int, begin_index: int, scores_is_logprobs: bool = False):
+ self.no_speech_token = no_speech_token
+ # offset between token, , in paper and first generated token
+ # is equal to the position of the first generated token index
+ self.start_of_trans_offset = begin_index
+
+ # `self.begin_index` is a running value that is changed on the fly
+ self.begin_index = begin_index
+ self._no_speech_prob = [0.0]
+ self.is_scores_logprobs = scores_is_logprobs
+
+ # overwritten dynamically
+ self.model = None
+ self.inputs = None
+
+ def set_model(self, model):
+ self.model = model
+
+ def set_inputs(self, inputs):
+ self.inputs = {**self.model.prepare_inputs_for_generation(**inputs), **inputs}
+ self.inputs["input_features"] = self.inputs.pop("inputs")
+
+ @property
+ def no_speech_prob(self):
+ return self._no_speech_prob
+
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
+
+ @add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
+ if input_ids.shape[1] == self.begin_index:
+ if self.start_of_trans_offset > 1:
+ with torch.no_grad():
+ logits = self.model(**self.inputs).logits
+
+ no_speech_index = self.begin_index - self.start_of_trans_offset
+ no_speech_scores = logits[:, no_speech_index]
+ else:
+ no_speech_scores = scores
+
+ if self.is_scores_logprobs:
+ probs = no_speech_scores.exp()
+ else:
+ probs = no_speech_scores.float().softmax(dim=-1)
+
+ self._no_speech_prob = probs[:, self.no_speech_token]
+
+ return scores
+
+
class ClassifierFreeGuidanceLogitsProcessor(LogitsProcessor):
r"""
[`LogitsProcessor`] for classifier free guidance (CFG). The scores are split over the batch dimension,
diff --git a/src/transformers/generation/utils.py b/src/transformers/generation/utils.py
index 0534f5c8d6bc73..f8a70d71e676a6 100644
--- a/src/transformers/generation/utils.py
+++ b/src/transformers/generation/utils.py
@@ -518,6 +518,8 @@ def _prepare_decoder_input_ids_for_generation(
# exception: Donut checkpoints have task-specific decoder starts and don't expect a BOS token
elif self.config.model_type == "vision-encoder-decoder" and "donut" in self.name_or_path.lower():
pass
+ elif self.config.model_type in ["whisper"]:
+ pass
# user input but doesn't start with decoder_start_token_id -> prepend decoder_start_token_id (and adjust
# decoder_attention_mask if provided)
elif (decoder_input_ids[:, 0] != decoder_start_token_id).all().item():
@@ -1558,6 +1560,7 @@ def generate(
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
synced_gpus=synced_gpus,
+ sequential=generation_config.low_memory,
**model_kwargs,
)
@@ -1951,8 +1954,7 @@ def contrastive_search(
model_kwargs["past_key_values"] = tuple(new_key_values)
if sequential:
- all_outputs = {key: [] for key in outputs} # defined in first loop iteration
- all_last_hstates, all_hstates, all_logits = [], [], []
+ all_outputs = []
for i in range(top_k):
# compute the candidate tokens by the language model and collect their hidden_states
next_model_inputs = self.prepare_inputs_for_generation(top_k_ids[:, i].view(-1, 1), **model_kwargs)
@@ -1963,32 +1965,8 @@ def contrastive_search(
output_hidden_states=True,
output_attentions=output_attentions,
)
- for key in all_outputs:
- all_outputs[key].append(outputs[key])
-
- if self.config.is_encoder_decoder:
- next_hidden = outputs.decoder_hidden_states[-1]
- full_hidden_states = outputs.decoder_hidden_states
-
- else:
- next_hidden = outputs.hidden_states[-1]
- full_hidden_states = outputs.hidden_states
-
- all_last_hstates.append(torch.squeeze(next_hidden, 0))
- all_hstates.append(full_hidden_states)
- all_logits.append(outputs.logits[:, -1, :])
-
- # stack hidden states
- next_hidden = torch.stack([all_last_hstates[i] for i in range(top_k)], dim=0)
- final_full_hstates = [0 for i in range(len(full_hidden_states))]
- for layer in range(len(full_hidden_states)):
- final_full_hstates[layer] = torch.stack(
- [torch.squeeze(all_hstates[i][layer], 0) for i in range(top_k)], dim=0
- )
- full_hidden_states = tuple(final_full_hstates)
-
- # stack logits
- logits = torch.cat(all_logits, dim=0)
+ all_outputs.append(outputs)
+ outputs = stack_model_outputs(all_outputs)
else:
# compute the candidate tokens by the language model and collect their hidden_states
@@ -2001,15 +1979,15 @@ def contrastive_search(
output_hidden_states=True,
output_attentions=output_attentions,
)
- # name is different for encoder-decoder and decoder-only models
- if self.config.is_encoder_decoder:
- next_hidden = outputs.decoder_hidden_states[-1]
- full_hidden_states = outputs.decoder_hidden_states
- else:
- next_hidden = outputs.hidden_states[-1]
- full_hidden_states = outputs.hidden_states
+ # name is different for encoder-decoder and decoder-only models
+ if self.config.is_encoder_decoder:
+ next_hidden = outputs.decoder_hidden_states[-1]
+ full_hidden_states = outputs.decoder_hidden_states
+ else:
+ next_hidden = outputs.hidden_states[-1]
+ full_hidden_states = outputs.hidden_states
- logits = outputs.logits[:, -1, :]
+ logits = outputs.logits[:, -1, :]
context_hidden = last_hidden_states.repeat_interleave(top_k, dim=0)
@@ -2747,6 +2725,7 @@ def beam_search(
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
synced_gpus: bool = False,
+ sequential: Optional[bool] = None,
**model_kwargs,
) -> Union[GenerateBeamOutput, torch.LongTensor]:
r"""
@@ -2792,6 +2771,10 @@ def beam_search(
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ sequential (`bool`, defaults to `False`):
+ By default, beam search has `batch_size * num_beams` as effective batch size (see `beam_search()` for
+ more details). This flag will avoid parallelizing the beam search and will instead run beam search
+ sequentially.
model_kwargs:
Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
an encoder-decoder model the kwargs should include `encoder_outputs`.
@@ -2858,6 +2841,7 @@ def beam_search(
# init values
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ sequential = sequential if sequential is not None else self.generation_config.low_memory
if max_length is not None:
warnings.warn(
"`max_length` is deprecated in this function, use"
@@ -2932,12 +2916,39 @@ def beam_search(
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
- outputs = self(
- **model_inputs,
- return_dict=True,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- )
+ # if sequential is True, split the input to batches of batch_size and run sequentially
+ if sequential:
+ if any(
+ model_name in self.__class__.__name__.lower()
+ for model_name in ["fsmt", "reformer", "bloom", "ctrl", "gpt_bigcode", "transo_xl", "xlnet", "cpm"]
+ ):
+ raise RuntimeError(
+ f"Currently generation for {self.__class__.__name__} is not supported "
+ f"for `low_memory beam_search`. Please open an issue on GitHub if you need this feature."
+ )
+
+ inputs_per_sub_batches = _split_model_inputs(
+ model_inputs, split_size=batch_size, full_batch_size=batch_beam_size
+ )
+ outputs_per_sub_batch = [
+ self(
+ **inputs_per_sub_batch,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ for inputs_per_sub_batch in inputs_per_sub_batches
+ ]
+
+ outputs = stack_model_outputs(outputs_per_sub_batch)
+
+ else: # Unchanged original behavior
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
if synced_gpus and this_peer_finished:
cur_len = cur_len + 1
@@ -4395,7 +4406,7 @@ def assisted_decoding(
else:
selected_tokens = new_logits.argmax(dim=-1)
- candidate_new_tokens = candidate_input_ids[:, -candidate_length:]
+ candidate_new_tokens = candidate_input_ids[:, cur_len:]
n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
# Ensure we don't generate beyond max_len or an EOS token
@@ -4531,12 +4542,13 @@ def _speculative_sampling(
NOTE: Unless otherwise stated, the variable names match those in the paper.
"""
+ new_candidate_input_ids = candidate_input_ids[:, -candidate_length:]
# Gets the probabilities from the logits. q_i and p_i denote the assistant and model probabilities of the tokens
# selected by the assistant, respectively.
q = candidate_logits.softmax(dim=-1)
- q_i = q[:, torch.arange(candidate_length), candidate_input_ids[:, -candidate_length:]].squeeze(0, 1)
+ q_i = q[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
p = new_logits.softmax(dim=-1)
- p_i = p[:, torch.arange(candidate_length), candidate_input_ids[:, -candidate_length:]].squeeze(0, 1)
+ p_i = p[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
probability_ratio = p_i / q_i
# When probability_ratio > 1 (i.e. q_i(x) < p_i(x), or "assistant probability of the candidate token is smaller
@@ -4544,28 +4556,33 @@ def _speculative_sampling(
# (= keep with p = probability_ratio). Keep all the tokens until the first rejection
r_i = torch.rand_like(probability_ratio)
is_accepted = r_i <= probability_ratio
- n_matches = (~is_accepted.cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
+ n_matches = ((~is_accepted).cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
# Ensure we don't generate beyond max_len or an EOS token (not in algorithm 1, but needed for correct behavior)
if last_assistant_token_is_eos and n_matches == candidate_length:
+ # Output length is assumed to be `n_matches + 1`. Since we won't generate another token with the target model
+ # due to acceptance on EOS we fix `n_matches`
n_matches -= 1
- n_matches = min(n_matches, max_matches)
-
- # Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
- gamma = candidate_logits.shape[1]
- p_n_plus_1 = p[:, n_matches, :]
- if n_matches < gamma:
- q_n_plus_1 = q[:, n_matches, :]
- p_prime = torch.clamp((p_n_plus_1 - q_n_plus_1), min=0).softmax(dim=-1)
+ valid_tokens = new_candidate_input_ids[:, : n_matches + 1]
else:
- p_prime = p_n_plus_1
- t = torch.multinomial(p_prime, num_samples=1).squeeze(1)[None, :]
+ n_matches = min(n_matches, max_matches)
+
+ # Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
+ gamma = min(candidate_logits.shape[1], max_matches)
+ p_n_plus_1 = p[:, n_matches, :]
+ if n_matches < gamma:
+ q_n_plus_1 = q[:, n_matches, :]
+ p_prime = torch.clamp((p_n_plus_1 - q_n_plus_1), min=0)
+ p_prime.div_(p_prime.sum())
+ else:
+ p_prime = p_n_plus_1
+ t = torch.multinomial(p_prime, num_samples=1).squeeze(1)[None, :]
- # The selected tokens include the matches (if any) plus the next sampled tokens
- if n_matches > 0:
- valid_tokens = torch.cat((candidate_input_ids[:, -n_matches:], t), dim=-1)
- else:
- valid_tokens = t
+ # The selected tokens include the matches (if any) plus the next sampled tokens
+ if n_matches > 0:
+ valid_tokens = torch.cat((new_candidate_input_ids[:, :n_matches], t), dim=-1)
+ else:
+ valid_tokens = t
return valid_tokens, n_matches
@@ -4658,3 +4675,139 @@ def _ranking_fast(
contrastive_score = torch.stack(torch.split(contrastive_score, beam_width)) # [B, K]
_, selected_idx = contrastive_score.max(dim=-1) # [B]
return selected_idx
+
+
+def _split(data, full_batch_size: int, split_size: int = None):
+ """
+ Takes care of three cases:
+ 1. data is a tensor: e.g. last_hidden_state, pooler_output etc. split them on the batch_size dim
+ 2. data is a tuple: e.g. hidden_states, attentions etc. Keep the tuple as it is and split each tensor in it and
+ return a list of tuples
+ 3. data is a tuple of tuples, e.g. past_key_values. Keep the tuple as it is and split each tuple in it and
+ return a list of tuples of tuples
+ (see documentation of ModelOutput)
+ """
+ if data is None:
+ return [None] * (full_batch_size // split_size)
+ if isinstance(data, torch.Tensor):
+ return [data[i : i + split_size] for i in range(0, full_batch_size, split_size)]
+ elif isinstance(data, tuple):
+ # If the elements of the tuple are also tuples (e.g., past_key_values in our earlier example)
+ if isinstance(data[0], tuple):
+ return [
+ tuple(tuple(tensor[i : i + split_size] for tensor in inner_tuple) for inner_tuple in data)
+ for i in range(0, full_batch_size, split_size)
+ ]
+
+ else:
+ return [
+ tuple(sub_tensor[i : i + split_size] for sub_tensor in data)
+ for i in range(0, full_batch_size, split_size)
+ ]
+ else:
+ raise ValueError(f"Unexpected attribute type: {type(data)}")
+
+
+def _split_model_inputs(
+ model_input: Union[ModelOutput, Dict], split_size: int, full_batch_size: int
+) -> List[Union[ModelOutput, Dict]]:
+ """
+ Split a ModelOutput object (or its subclasses) or Dict into a list of same-class objects based on a specified split
+ size. The input object is dict when it was prepared for forward pass and ModelOutput when it was returned from
+ previous forward pass.
+ """
+ # Edge case: if model_input is None, return a list of Nones
+ # this happens with Whisper where encoder_outputs is None
+ if model_input is None:
+ return [model_input] * (full_batch_size // split_size)
+ # Infer the class from the object
+ model_output_cls = type(model_input)
+ if (full_batch_size % split_size) != 0:
+ raise ValueError("`full_batch_size` must be divisible by `split_size`")
+
+ if split_size > full_batch_size:
+ raise ValueError("`split_size` must be smaller or equal to `full_batch_size`")
+
+ # Helper function to split tensors or tuples of tensors
+
+ # Find all the dataclass fields (e.g., last_hidden_state, pooler_output etc.) and split them
+ keys = (
+ model_input.__dataclass_fields__.keys() if hasattr(model_input, "__dataclass_fields__") else model_input.keys()
+ )
+ # We only keep keys that are in the model_input
+ keys = [k for k in keys if k in model_input]
+ # Here we can have four types of values: tensors, tuples of tensors and booleans, and encoder_outputs which is a
+ # ModelOutput object.
+ # bool should not be split but replicated for each split
+ bool_keys = [k for k in keys if isinstance(model_input[k], bool)]
+ non_bool_keys = [k for k in keys if not isinstance(model_input[k], bool) and not k == "encoder_outputs"]
+
+ # we split the tensors and tuples of tensors
+ data_split_list = [
+ {k: _split(model_input[k], full_batch_size, split_size)[i] for k in non_bool_keys}
+ for i in range(full_batch_size // split_size)
+ ]
+ # bool values are the same and replicated for each split
+ bool_data = {k: model_input[k] for k in bool_keys}
+ # encoder_outputs is a ModelOutput object and should be split by its own
+ if "encoder_outputs" in model_input:
+ encoder_outputs_split = _split_model_inputs(model_input["encoder_outputs"], split_size, full_batch_size)
+ data_split_list = [
+ {**data_split, "encoder_outputs": encoder_outputs_split[i]} for i, data_split in enumerate(data_split_list)
+ ]
+
+ # Convert each dictionary in the list to an object of the inferred class
+ split_model_inputs: List[Union[ModelOutput, Dict]] = [
+ model_output_cls(**data_split, **bool_data) for data_split in data_split_list
+ ]
+
+ return split_model_inputs
+
+
+def stack_model_outputs(model_outputs: List[ModelOutput]) -> ModelOutput:
+ """
+ Stack a list of ModelOutput objects (or its subclasses) along the batch_size dimension. The function infers the
+ specific ModelOutput subclass from the list provided.
+ """
+ if not model_outputs:
+ raise ValueError("Input list is empty.")
+
+ # Infer the class from the first object in the list
+ model_output_cls = type(model_outputs[0])
+
+ # Ensure all objects are of the same type
+ if not all(isinstance(obj, model_output_cls) for obj in model_outputs):
+ raise ValueError("All elements in the list should be of the same type.")
+
+ # Helper function to concat tensors or tuples of tensors
+ def _concat(data):
+ """
+ Reverse of `_split` function above.
+ """
+ if any(data is None for data in data):
+ return None
+ if isinstance(data[0], torch.Tensor):
+ return torch.cat(data, dim=0)
+ elif isinstance(data[0], tuple):
+ # If the elements of the tuple are also tuples (e.g., past_key_values in our earlier example)
+ if isinstance(data[0][0], tuple):
+ return tuple(
+ tuple(torch.cat([attr[i][j] for attr in data], dim=0) for j in range(len(data[0][0])))
+ for i in range(len(data[0]))
+ )
+ else:
+ return tuple(torch.cat([attr[i] for attr in data], dim=0) for i in range(len(data[0])))
+ elif isinstance(data[0], (int, float)):
+ # If the elements are integers or floats, return a tensor
+ return torch.tensor(data)
+ else:
+ raise ValueError(f"Unexpected attribute type: {type(data[0])}")
+
+ # Use a dictionary comprehension to gather attributes from all objects and concatenate them
+ concatenated_data = {
+ k: _concat([getattr(model_output, k) for model_output in model_outputs])
+ for k in model_output_cls.__dataclass_fields__.keys()
+ }
+
+ # Return a new object of the inferred class with the concatenated attributes
+ return model_output_cls(**concatenated_data)
diff --git a/src/transformers/modeling_flax_pytorch_utils.py b/src/transformers/modeling_flax_pytorch_utils.py
index f6014d7c208ab6..830d222928b9ee 100644
--- a/src/transformers/modeling_flax_pytorch_utils.py
+++ b/src/transformers/modeling_flax_pytorch_utils.py
@@ -50,6 +50,8 @@ def load_pytorch_checkpoint_in_flax_state_dict(
"""Load pytorch checkpoints in a flax model"""
try:
import torch # noqa: F401
+
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13 # noqa: F401
except (ImportError, ModuleNotFoundError):
logger.error(
"Loading a PyTorch model in Flax, requires both PyTorch and Flax to be installed. Please see"
@@ -68,7 +70,7 @@ def load_pytorch_checkpoint_in_flax_state_dict(
for k in f.keys():
pt_state_dict[k] = f.get_tensor(k)
else:
- pt_state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+ pt_state_dict = torch.load(pt_path, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters.")
flax_state_dict = convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model)
@@ -245,11 +247,13 @@ def convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model):
def convert_pytorch_sharded_state_dict_to_flax(shard_filenames, flax_model):
import torch
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13
+
# Load the index
flax_state_dict = {}
for shard_file in shard_filenames:
# load using msgpack utils
- pt_state_dict = torch.load(shard_file, weights_only=True)
+ pt_state_dict = torch.load(shard_file, weights_only=is_torch_greater_or_equal_than_1_13)
pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()}
model_prefix = flax_model.base_model_prefix
diff --git a/src/transformers/modeling_tf_pytorch_utils.py b/src/transformers/modeling_tf_pytorch_utils.py
index bab8e70d99a5b5..e68b02bc7ab401 100644
--- a/src/transformers/modeling_tf_pytorch_utils.py
+++ b/src/transformers/modeling_tf_pytorch_utils.py
@@ -167,6 +167,8 @@ def load_pytorch_checkpoint_in_tf2_model(
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from safetensors.torch import load_file as safe_load_file # noqa: F401
+
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13 # noqa: F401
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
@@ -186,7 +188,7 @@ def load_pytorch_checkpoint_in_tf2_model(
if pt_path.endswith(".safetensors"):
state_dict = safe_load_file(pt_path)
else:
- state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(pt_path, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
pt_state_dict.update(state_dict)
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 3f19ec1884e71e..9c4639b475dfc2 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -48,6 +48,7 @@
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
id_tensor_storage,
+ is_torch_greater_or_equal_than_1_13,
prune_conv1d_layer,
prune_layer,
prune_linear_layer,
@@ -481,7 +482,11 @@ def load_sharded_checkpoint(model, folder, strict=True, prefer_safe=True):
error_message += f"\nMissing key(s): {str_unexpected_keys}."
raise RuntimeError(error_message)
- loader = safe_load_file if load_safe else partial(torch.load, map_location="cpu", weights_only=True)
+ loader = (
+ safe_load_file
+ if load_safe
+ else partial(torch.load, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
+ )
for shard_file in shard_files:
state_dict = loader(os.path.join(folder, shard_file))
@@ -525,7 +530,12 @@ def load_state_dict(checkpoint_file: Union[str, os.PathLike]):
and is_zipfile(checkpoint_file)
):
extra_args = {"mmap": True}
- return torch.load(checkpoint_file, map_location=map_location, weights_only=True, **extra_args)
+ return torch.load(
+ checkpoint_file,
+ map_location=map_location,
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ **extra_args,
+ )
except Exception as e:
try:
with open(checkpoint_file) as f:
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 2c20873c2ed79d..09f5bb543ab043 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -176,6 +176,7 @@
prophetnet,
pvt,
qdqbert,
+ qwen2,
rag,
realm,
reformer,
@@ -234,6 +235,7 @@
vits,
vivit,
wav2vec2,
+ wav2vec2_bert,
wav2vec2_conformer,
wav2vec2_phoneme,
wav2vec2_with_lm,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 9eb3f1985c8536..060d3057f518fa 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -182,6 +182,7 @@
("prophetnet", "ProphetNetConfig"),
("pvt", "PvtConfig"),
("qdqbert", "QDQBertConfig"),
+ ("qwen2", "Qwen2Config"),
("rag", "RagConfig"),
("realm", "RealmConfig"),
("reformer", "ReformerConfig"),
@@ -245,6 +246,7 @@
("vits", "VitsConfig"),
("vivit", "VivitConfig"),
("wav2vec2", "Wav2Vec2Config"),
+ ("wav2vec2-bert", "Wav2Vec2BertConfig"),
("wav2vec2-conformer", "Wav2Vec2ConformerConfig"),
("wavlm", "WavLMConfig"),
("whisper", "WhisperConfig"),
@@ -405,6 +407,7 @@
("prophetnet", "PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("pvt", "PVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("qdqbert", "QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("qwen2", "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("realm", "REALM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("regnet", "REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("rembert", "REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -457,6 +460,7 @@
("vits", "VITS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vivit", "VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("wav2vec2", "WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("wav2vec2-bert", "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("wav2vec2-conformer", "WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("whisper", "WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("xclip", "XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -649,6 +653,7 @@
("prophetnet", "ProphetNet"),
("pvt", "PVT"),
("qdqbert", "QDQBert"),
+ ("qwen2", "Qwen2"),
("rag", "RAG"),
("realm", "REALM"),
("reformer", "Reformer"),
@@ -715,6 +720,7 @@
("vits", "VITS"),
("vivit", "ViViT"),
("wav2vec2", "Wav2Vec2"),
+ ("wav2vec2-bert", "Wav2Vec2-BERT"),
("wav2vec2-conformer", "Wav2Vec2-Conformer"),
("wav2vec2_phoneme", "Wav2Vec2Phoneme"),
("wavlm", "WavLM"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 457217566e7cfa..b3461e8b56a7a9 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -100,6 +100,7 @@
("vit_mae", "ViTFeatureExtractor"),
("vit_msn", "ViTFeatureExtractor"),
("wav2vec2", "Wav2Vec2FeatureExtractor"),
+ ("wav2vec2-bert", "Wav2Vec2FeatureExtractor"),
("wav2vec2-conformer", "Wav2Vec2FeatureExtractor"),
("wavlm", "Wav2Vec2FeatureExtractor"),
("whisper", "WhisperFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 7bf50a4518fa88..9332497732a4ce 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -177,6 +177,7 @@
("prophetnet", "ProphetNetModel"),
("pvt", "PvtModel"),
("qdqbert", "QDQBertModel"),
+ ("qwen2", "Qwen2Model"),
("reformer", "ReformerModel"),
("regnet", "RegNetModel"),
("rembert", "RemBertModel"),
@@ -231,6 +232,7 @@
("vits", "VitsModel"),
("vivit", "VivitModel"),
("wav2vec2", "Wav2Vec2Model"),
+ ("wav2vec2-bert", "Wav2Vec2BertModel"),
("wav2vec2-conformer", "Wav2Vec2ConformerModel"),
("wavlm", "WavLMModel"),
("whisper", "WhisperModel"),
@@ -449,6 +451,7 @@
("plbart", "PLBartForCausalLM"),
("prophetnet", "ProphetNetForCausalLM"),
("qdqbert", "QDQBertLMHeadModel"),
+ ("qwen2", "Qwen2ForCausalLM"),
("reformer", "ReformerModelWithLMHead"),
("rembert", "RemBertForCausalLM"),
("roberta", "RobertaForCausalLM"),
@@ -792,6 +795,7 @@
("phi", "PhiForSequenceClassification"),
("plbart", "PLBartForSequenceClassification"),
("qdqbert", "QDQBertForSequenceClassification"),
+ ("qwen2", "Qwen2ForSequenceClassification"),
("reformer", "ReformerForSequenceClassification"),
("rembert", "RemBertForSequenceClassification"),
("roberta", "RobertaForSequenceClassification"),
@@ -1031,6 +1035,7 @@
("unispeech", "UniSpeechForSequenceClassification"),
("unispeech-sat", "UniSpeechSatForSequenceClassification"),
("wav2vec2", "Wav2Vec2ForSequenceClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForSequenceClassification"),
("wav2vec2-conformer", "Wav2Vec2ConformerForSequenceClassification"),
("wavlm", "WavLMForSequenceClassification"),
("whisper", "WhisperForAudioClassification"),
@@ -1048,6 +1053,7 @@
("unispeech", "UniSpeechForCTC"),
("unispeech-sat", "UniSpeechSatForCTC"),
("wav2vec2", "Wav2Vec2ForCTC"),
+ ("wav2vec2-bert", "Wav2Vec2BertForCTC"),
("wav2vec2-conformer", "Wav2Vec2ConformerForCTC"),
("wavlm", "WavLMForCTC"),
]
@@ -1059,6 +1065,7 @@
("data2vec-audio", "Data2VecAudioForAudioFrameClassification"),
("unispeech-sat", "UniSpeechSatForAudioFrameClassification"),
("wav2vec2", "Wav2Vec2ForAudioFrameClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForAudioFrameClassification"),
("wav2vec2-conformer", "Wav2Vec2ConformerForAudioFrameClassification"),
("wavlm", "WavLMForAudioFrameClassification"),
]
@@ -1070,6 +1077,7 @@
("data2vec-audio", "Data2VecAudioForXVector"),
("unispeech-sat", "UniSpeechSatForXVector"),
("wav2vec2", "Wav2Vec2ForXVector"),
+ ("wav2vec2-bert", "Wav2Vec2BertForXVector"),
("wav2vec2-conformer", "Wav2Vec2ConformerForXVector"),
("wavlm", "WavLMForXVector"),
]
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index eee8af931e99ac..2a8823fea7c0ee 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -25,8 +25,9 @@
from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
from ...feature_extraction_utils import FeatureExtractionMixin
from ...image_processing_utils import ImageProcessingMixin
+from ...processing_utils import ProcessorMixin
from ...tokenization_utils import TOKENIZER_CONFIG_FILE
-from ...utils import FEATURE_EXTRACTOR_NAME, get_file_from_repo, logging
+from ...utils import FEATURE_EXTRACTOR_NAME, PROCESSOR_NAME, get_file_from_repo, logging
from .auto_factory import _LazyAutoMapping
from .configuration_auto import (
CONFIG_MAPPING_NAMES,
@@ -90,6 +91,7 @@
("vipllava", "LlavaProcessor"),
("vision-text-dual-encoder", "VisionTextDualEncoderProcessor"),
("wav2vec2", "Wav2Vec2Processor"),
+ ("wav2vec2-bert", "Wav2Vec2Processor"),
("wav2vec2-conformer", "Wav2Vec2Processor"),
("wavlm", "Wav2Vec2Processor"),
("whisper", "WhisperProcessor"),
@@ -227,27 +229,41 @@ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
processor_class = None
processor_auto_map = None
- # First, let's see if we have a preprocessor config.
+ # First, let's see if we have a processor or preprocessor config.
# Filter the kwargs for `get_file_from_repo`.
get_file_from_repo_kwargs = {
key: kwargs[key] for key in inspect.signature(get_file_from_repo).parameters.keys() if key in kwargs
}
- # Let's start by checking whether the processor class is saved in an image processor
- preprocessor_config_file = get_file_from_repo(
- pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
+
+ # Let's start by checking whether the processor class is saved in a processor config
+ processor_config_file = get_file_from_repo(
+ pretrained_model_name_or_path, PROCESSOR_NAME, **get_file_from_repo_kwargs
)
- if preprocessor_config_file is not None:
- config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ if processor_config_file is not None:
+ config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs)
processor_class = config_dict.get("processor_class", None)
if "AutoProcessor" in config_dict.get("auto_map", {}):
processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
- # If not found, let's check whether the processor class is saved in a feature extractor config
- if preprocessor_config_file is not None and processor_class is None:
- config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
- processor_class = config_dict.get("processor_class", None)
- if "AutoProcessor" in config_dict.get("auto_map", {}):
- processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+ if processor_class is None:
+ # If not found, let's check whether the processor class is saved in an image processor config
+ preprocessor_config_file = get_file_from_repo(
+ pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
+ )
+ if preprocessor_config_file is not None:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ # If not found, let's check whether the processor class is saved in a feature extractor config
+ if preprocessor_config_file is not None and processor_class is None:
+ config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(
+ pretrained_model_name_or_path, **kwargs
+ )
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
if processor_class is None:
# Next, let's check whether the processor class is saved in a tokenizer
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index ac09eecd1e0e99..4823cf41fc7731 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -333,6 +333,13 @@
("plbart", ("PLBartTokenizer" if is_sentencepiece_available() else None, None)),
("prophetnet", ("ProphetNetTokenizer", None)),
("qdqbert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "qwen2",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
("rag", ("RagTokenizer", None)),
("realm", ("RealmTokenizer", "RealmTokenizerFast" if is_tokenizers_available() else None)),
(
@@ -372,7 +379,7 @@
"SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
),
),
- ("siglip", ("SiglipTokenizer", None)),
+ ("siglip", ("SiglipTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text", ("Speech2TextTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text_2", ("Speech2Text2Tokenizer", None)),
("speecht5", ("SpeechT5Tokenizer" if is_sentencepiece_available() else None, None)),
@@ -411,6 +418,7 @@
("visual_bert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
("vits", ("VitsTokenizer", None)),
("wav2vec2", ("Wav2Vec2CTCTokenizer", None)),
+ ("wav2vec2-bert", ("Wav2Vec2CTCTokenizer", None)),
("wav2vec2-conformer", ("Wav2Vec2CTCTokenizer", None)),
("wav2vec2_phoneme", ("Wav2Vec2PhonemeCTCTokenizer", None)),
("whisper", ("WhisperTokenizer", "WhisperTokenizerFast" if is_tokenizers_available() else None)),
diff --git a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
index 2fe33db810890a..70e12b0ddc474b 100644
--- a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
@@ -1414,13 +1414,14 @@ def post_process_object_detection(
boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
# and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
results = []
for s, l, b in zip(scores, labels, boxes):
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index d903abffafb455..b74f6accadfcfc 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -1874,8 +1874,8 @@ def forward(
intermediate = outputs.intermediate_hidden_states if return_dict else outputs[4]
outputs_class = self.class_labels_classifier(intermediate)
- for lvl in range(hs.shape[0]):
- tmp = self.bbox_predictor(hs[lvl])
+ for lvl in range(intermediate.shape[0]):
+ tmp = self.bbox_predictor(intermediate[lvl])
tmp[..., :2] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
@@ -2118,9 +2118,9 @@ def forward(
outputs_loss["pred_masks"] = pred_masks
if self.config.auxiliary_loss:
intermediate = decoder_outputs.intermediate_hidden_states if return_dict else decoder_outputs[-1]
- outputs_class = self.class_labels_classifier(intermediate)
- outputs_coord = self.bbox_predictor(intermediate).sigmoid()
- auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_class = self.conditional_detr.class_labels_classifier(intermediate)
+ outputs_coord = self.conditional_detr.bbox_predictor(intermediate).sigmoid()
+ auxiliary_outputs = self.conditional_detr._set_aux_loss(outputs_class, outputs_coord)
outputs_loss["auxiliary_outputs"] = auxiliary_outputs
loss_dict = criterion(outputs_loss, labels)
diff --git a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
index 8c40d20c816ad3..52611700623f2d 100644
--- a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
@@ -1411,13 +1411,14 @@ def post_process_object_detection(
boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
# and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
results = []
for s, l, b in zip(scores, labels, boxes):
diff --git a/src/transformers/models/dinov2/modeling_dinov2.py b/src/transformers/models/dinov2/modeling_dinov2.py
index 66bac639f6731b..ddf70f08b750fb 100644
--- a/src/transformers/models/dinov2/modeling_dinov2.py
+++ b/src/transformers/models/dinov2/modeling_dinov2.py
@@ -103,12 +103,13 @@ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width:
height, width = height + 0.1, width + 0.1
patch_pos_embed = patch_pos_embed.reshape(1, int(math.sqrt(num_positions)), int(math.sqrt(num_positions)), dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+ target_dtype = patch_pos_embed.dtype
patch_pos_embed = nn.functional.interpolate(
- patch_pos_embed,
+ patch_pos_embed.to(dtype=torch.float32),
scale_factor=(float(height / math.sqrt(num_positions)), float(width / math.sqrt(num_positions))),
mode="bicubic",
align_corners=False,
- )
+ ).to(dtype=target_dtype)
if int(height) != patch_pos_embed.shape[-2] or int(width) != patch_pos_embed.shape[-1]:
raise ValueError("Width or height does not match with the interpolated position embeddings")
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
@@ -116,7 +117,8 @@ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width:
def forward(self, pixel_values: torch.Tensor, bool_masked_pos: Optional[torch.Tensor] = None) -> torch.Tensor:
batch_size, _, height, width = pixel_values.shape
- embeddings = self.patch_embeddings(pixel_values)
+ target_dtype = self.patch_embeddings.projection.weight.dtype
+ embeddings = self.patch_embeddings(pixel_values.to(dtype=target_dtype))
if bool_masked_pos is not None:
embeddings = torch.where(
diff --git a/src/transformers/models/esm/tokenization_esm.py b/src/transformers/models/esm/tokenization_esm.py
index 065eaae1d50520..478527c0ecd17f 100644
--- a/src/transformers/models/esm/tokenization_esm.py
+++ b/src/transformers/models/esm/tokenization_esm.py
@@ -14,10 +14,9 @@
# limitations under the License.
"""Tokenization classes for ESM."""
import os
-from typing import List, Optional, Union
+from typing import List, Optional
from ...tokenization_utils import PreTrainedTokenizer
-from ...tokenization_utils_base import AddedToken
from ...utils import logging
@@ -91,11 +90,10 @@ def _convert_token_to_id(self, token: str) -> int:
def _tokenize(self, text, **kwargs):
return text.split()
- def get_vocab_size(self, with_added_tokens=False):
- return len(self._id_to_token)
-
def get_vocab(self):
- return {token: i for i, token in enumerate(self.all_tokens)}
+ base_vocab = self._token_to_id.copy()
+ base_vocab.update(self.added_tokens_encoder)
+ return base_vocab
def token_to_id(self, token: str) -> int:
return self._token_to_id.get(token, self._token_to_id.get(self.unk_token))
@@ -156,7 +154,4 @@ def save_vocabulary(self, save_directory, filename_prefix):
@property
def vocab_size(self) -> int:
- return self.get_vocab_size(with_added_tokens=False)
-
- def _add_tokens(self, new_tokens: Union[List[str], List[AddedToken]], special_tokens: bool = False) -> int:
- return super()._add_tokens(new_tokens, special_tokens=True)
+ return len(self.all_tokens)
diff --git a/src/transformers/models/gpt_neox/modeling_gpt_neox.py b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
index dc255b34851b23..0d4a8ae8ad9dc4 100755
--- a/src/transformers/models/gpt_neox/modeling_gpt_neox.py
+++ b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
@@ -390,7 +390,7 @@ def forward(
elif hasattr(self.config, "_pre_quantization_dtype"):
target_dtype = self.config._pre_quantization_dtype
else:
- target_dtype = self.q_proj.weight.dtype
+ target_dtype = self.query_key_value.weight.dtype
logger.warning_once(
f"The input hidden states seems to be silently casted in float32, this might be related to"
@@ -526,8 +526,8 @@ def attention_mask_func(attention_scores, ltor_mask):
return attention_scores
-# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with LlamaRotary->GPTNeoXRotary
class GPTNeoXRotaryEmbedding(nn.Module):
+ # Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
@@ -549,8 +549,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
@@ -558,15 +558,15 @@ def forward(self, x, seq_len=None):
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
- self.cos_cached[:seq_len].to(dtype=x.dtype),
- self.sin_cached[:seq_len].to(dtype=x.dtype),
+ self.cos_cached[:seq_len],
+ self.sin_cached[:seq_len],
)
-# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->GPTNeoX
class GPTNeoXLinearScalingRotaryEmbedding(GPTNeoXRotaryEmbedding):
"""GPTNeoXRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+ # Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
@@ -579,14 +579,14 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
-# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->GPTNeoX
class GPTNeoXDynamicNTKScalingRotaryEmbedding(GPTNeoXRotaryEmbedding):
"""GPTNeoXRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
+ # Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
@@ -606,8 +606,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def rotate_half(x):
diff --git a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
index d92787677161e0..dbef70021d5c40 100755
--- a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
+++ b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
@@ -235,6 +235,7 @@ def _attn(self, query, key, value, attention_mask=None, head_mask=None):
# Copied from transformers.models.gpt_neox.modeling_gpt_neox.GPTNeoXRotaryEmbedding with GPTNeoXRotaryEmbedding->RotaryEmbedding
class RotaryEmbedding(nn.Module):
+ # Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
@@ -256,8 +257,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
@@ -265,8 +266,8 @@ def forward(self, x, seq_len=None):
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
- self.cos_cached[:seq_len].to(dtype=x.dtype),
- self.sin_cached[:seq_len].to(dtype=x.dtype),
+ self.cos_cached[:seq_len],
+ self.sin_cached[:seq_len],
)
diff --git a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
index b6c765851213bd..f5edb52520045b 100644
--- a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
@@ -944,6 +944,12 @@ class TFLayoutLMPreTrainedModel(TFPreTrainedModel):
config_class = LayoutLMConfig
base_model_prefix = "layoutlm"
+ @property
+ def input_signature(self):
+ signature = super().input_signature
+ signature["bbox"] = tf.TensorSpec(shape=(None, None, 4), dtype=tf.int32, name="bbox")
+ return signature
+
LAYOUTLM_START_DOCSTRING = r"""
diff --git a/src/transformers/models/llava/convert_llava_weights_to_hf.py b/src/transformers/models/llava/convert_llava_weights_to_hf.py
index 65b58236db1053..bb40668f32c7d0 100644
--- a/src/transformers/models/llava/convert_llava_weights_to_hf.py
+++ b/src/transformers/models/llava/convert_llava_weights_to_hf.py
@@ -27,6 +27,25 @@
)
+EPILOG_TXT = """Example:
+ python transformers/src/transformers/models/llava/convert_llava_weights_to_hf.py --text_model_id lmsys/vicuna-7b-v1.5 --vision_model_id openai/clip-vit-large-patch14-336 --output_hub_path org/llava-v1.5-7b-conv --old_state_dict_id liuhaotian/llava-v1.5-7b
+
+Example for creating the old state dict file with Python:
+
+ import torch
+ from llava.model.language_model.llava_llama import LlavaLlamaForCausalLM
+
+ # load model
+ kwargs = {"device_map": "auto", "torch_dtype": torch.float16}
+ model = LlavaLlamaForCausalLM.from_pretrained("liuhaotian/llava-v1.5-7b", low_cpu_mem_usage=True, **kwargs)
+
+ # load vision tower
+ model.get_vision_tower().load_model()
+
+ # Save state dict
+ torch.save(model.state_dict(), "tmp/hf_models/llava-v1.5-7b/model_state_dict.bin")
+"""
+
KEYS_TO_MODIFY_MAPPING = {
"model.vision_tower.": "",
"model.mm_projector": "multi_modal_projector",
@@ -42,6 +61,8 @@
def convert_state_dict_to_hf(state_dict):
new_state_dict = {}
for key, value in state_dict.items():
+ if key.endswith(".inv_freq"):
+ continue
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
if key_to_modify in key:
key = key.replace(key_to_modify, new_key)
@@ -55,7 +76,7 @@ def convert_llava_llama_to_hf(text_model_id, vision_model_id, output_hub_path, o
text_config = AutoConfig.from_pretrained(text_model_id)
tokenizer = AutoTokenizer.from_pretrained(text_model_id)
- tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special=True)
+ tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special_tokens=True)
tokenizer.add_special_tokens({"pad_token": ""})
image_processor = CLIPImageProcessor.from_pretrained(vision_model_id)
@@ -93,15 +114,16 @@ def convert_llava_llama_to_hf(text_model_id, vision_model_id, output_hub_path, o
tuple((dist.sample() for _ in range(model.language_model.lm_head.weight.data[32000:].shape[0]))),
dim=0,
)
- model.config.vocab_size = model.config.vocab_size + pad_shape
- model.config.text_config.vocab_size = model.config.text_config.vocab_size + pad_shape
model.push_to_hub(output_hub_path)
processor.push_to_hub(output_hub_path)
def main():
- parser = argparse.ArgumentParser()
+ parser = argparse.ArgumentParser(
+ epilog=EPILOG_TXT,
+ formatter_class=argparse.RawDescriptionHelpFormatter,
+ )
parser.add_argument(
"--text_model_id",
help="Hub location of the text model",
diff --git a/src/transformers/models/phi/modeling_phi.py b/src/transformers/models/phi/modeling_phi.py
index d6ad4e46608eb9..823807a475db4f 100644
--- a/src/transformers/models/phi/modeling_phi.py
+++ b/src/transformers/models/phi/modeling_phi.py
@@ -506,7 +506,7 @@ def forward(
value_states = value_states.to(target_dtype)
attn_output = self._flash_attention_forward(
- query_states, key_states, value_states, attention_mask, q_len, dropout=attn_dropout, softmax_scale=1.0
+ query_states, key_states, value_states, attention_mask, q_len, dropout=attn_dropout, softmax_scale=None
)
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
diff --git a/src/transformers/models/qwen2/__init__.py b/src/transformers/models/qwen2/__init__.py
new file mode 100644
index 00000000000000..9fd51aaffee86c
--- /dev/null
+++ b/src/transformers/models/qwen2/__init__.py
@@ -0,0 +1,80 @@
+# Copyright 2024 The Qwen Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_tokenizers_available,
+ is_torch_available,
+)
+
+
+_import_structure = {
+ "configuration_qwen2": ["QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP", "Qwen2Config"],
+ "tokenization_qwen2": ["Qwen2Tokenizer"],
+}
+
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_qwen2_fast"] = ["Qwen2TokenizerFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_qwen2"] = [
+ "Qwen2ForCausalLM",
+ "Qwen2Model",
+ "Qwen2PreTrainedModel",
+ "Qwen2ForSequenceClassification",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_qwen2 import QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP, Qwen2Config
+ from .tokenization_qwen2 import Qwen2Tokenizer
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_qwen2_fast import Qwen2TokenizerFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_qwen2 import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ Qwen2PreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/qwen2/configuration_qwen2.py b/src/transformers/models/qwen2/configuration_qwen2.py
new file mode 100644
index 00000000000000..0bbfd1cf1601ed
--- /dev/null
+++ b/src/transformers/models/qwen2/configuration_qwen2.py
@@ -0,0 +1,144 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Qwen2 model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "Qwen/Qwen2-7B-beta": "https://huggingface.co/Qwen/Qwen2-7B-beta/resolve/main/config.json",
+}
+
+
+class Qwen2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen2Model`]. It is used to instantiate a
+ Qwen2 model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of
+ Qwen2-7B-beta [Qwen/Qwen2-7B-beta](https://huggingface.co/Qwen/Qwen2-7B-beta).
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 151936):
+ Vocabulary size of the Qwen2 model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`Qwen2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 22016):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 32):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 32768):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ use_sliding_window (`bool`, *optional*, defaults to `False`):
+ Whether to use sliding window attention.
+ sliding_window (`int`, *optional*, defaults to 4096):
+ Sliding window attention (SWA) window size. If not specified, will default to `4096`.
+ max_window_layers (`int`, *optional*, defaults to 28):
+ The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+
+ ```python
+ >>> from transformers import Qwen2Model, Qwen2Config
+
+ >>> # Initializing a Qwen2 style configuration
+ >>> configuration = Qwen2Config()
+
+ >>> # Initializing a model from the Qwen2-7B style configuration
+ >>> model = Qwen2Model(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "qwen2"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ def __init__(
+ self,
+ vocab_size=151936,
+ hidden_size=4096,
+ intermediate_size=22016,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=32,
+ hidden_act="silu",
+ max_position_embeddings=32768,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ use_sliding_window=False,
+ sliding_window=4096,
+ max_window_layers=28,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.max_window_layers = max_window_layers
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_dropout = attention_dropout
+
+ super().__init__(
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/src/transformers/models/qwen2/modeling_qwen2.py b/src/transformers/models/qwen2/modeling_qwen2.py
new file mode 100644
index 00000000000000..f8290928a5ca9e
--- /dev/null
+++ b/src/transformers/models/qwen2/modeling_qwen2.py
@@ -0,0 +1,1401 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Qwen2 model."""
+import inspect
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache
+from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
+from ...modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_qwen2 import Qwen2Config
+
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
+
+
+logger = logging.get_logger(__name__)
+
+
+_CHECKPOINT_FOR_DOC = "Qwen/Qwen2-7B-beta"
+_CONFIG_FOR_DOC = "Qwen2Config"
+
+QWEN2_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "Qwen/Qwen2-7B-beta",
+ # See all Qwen2 models at https://huggingface.co/models?filter=qwen2
+]
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Qwen2
+class Qwen2RMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Qwen2RMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Qwen2
+class Qwen2RotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
+ )
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralMLP with Mistral->Qwen2
+class Qwen2MLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+class Qwen2Attention(nn.Module):
+ """
+ Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
+ and "Generating Long Sequences with Sparse Transformers".
+ """
+
+ def __init__(self, config: Qwen2Config, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
+ "to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
+ "when creating this class."
+ )
+
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+ self.attention_dropout = config.attention_dropout
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+ self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
+ self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
+
+ self.rotary_emb = Qwen2RotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class Qwen2FlashAttention2(Qwen2Attention):
+ """
+ Qwen2 flash attention module, following Qwen2 attention module. This module inherits from `Qwen2Attention`
+ as the weights of the module stays untouched. The only required change would be on the forward pass
+ where it needs to correctly call the public API of flash attention and deal with padding tokens
+ in case the input contains any of them. Additionally, for sliding window attention, we apply SWA only to the bottom
+ config.max_window_layers layers.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ):
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window
+ )
+
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ "The current flash attention version does not support sliding window attention, for a more memory efficient implementation"
+ " make sure to upgrade flash-attn library."
+ )
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (
+ getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents
+ ):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
+ f" {past_key.shape}"
+ )
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
+
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ use_sliding_windows=False,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_sliding_windows (`bool`, *optional*):
+ Whether to activate sliding window attention.
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Decide whether to use SWA or not by layer index.
+ if use_sliding_windows and self.layer_idx >= self.config.max_window_layers:
+ use_sliding_windows = False
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ if not use_sliding_windows:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ if not use_sliding_windows:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.mistral.modeling_mistral.MistralFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ batch_size, kv_seq_len, num_heads, head_dim = key_layer.shape
+
+ # On the first iteration we need to properly re-create the padding mask
+ # by slicing it on the proper place
+ if kv_seq_len != attention_mask.shape[-1]:
+ attention_mask_num_tokens = attention_mask.shape[-1]
+ attention_mask = attention_mask[:, attention_mask_num_tokens - kv_seq_len :]
+
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+
+ key_layer = index_first_axis(key_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+ value_layer = index_first_axis(value_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaSdpaAttention with Llama->Qwen2
+class Qwen2SdpaAttention(Qwen2Attention):
+ """
+ Qwen2 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
+ `Qwen2Attention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
+ SDPA API.
+ """
+
+ # Adapted from Qwen2Attention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "Qwen2Model is using Qwen2SdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if query_states.device.type == "cuda" and attention_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.attention_dropout if self.training else 0.0,
+ # The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
+ is_causal=self.is_causal and attention_mask is None and q_len > 1,
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+QWEN2_ATTENTION_CLASSES = {
+ "eager": Qwen2Attention,
+ "flash_attention_2": Qwen2FlashAttention2,
+ "sdpa": Qwen2SdpaAttention,
+}
+
+
+class Qwen2DecoderLayer(nn.Module):
+ def __init__(self, config: Qwen2Config, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ if config.use_sliding_window and config._attn_implementation != "flash_attention_2":
+ logger.warning_once(
+ f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; "
+ "unexpected results may be encountered."
+ )
+ self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
+
+ self.mlp = Qwen2MLP(config)
+ self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+QWEN2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`Qwen2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2PreTrainedModel(PreTrainedModel):
+ config_class = Qwen2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["Qwen2DecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+QWEN2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance;
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2Model(Qwen2PreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen2DecoderLayer`]
+
+ Args:
+ config: Qwen2Config
+ """
+
+ def __init__(self, config: Qwen2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self._attn_implementation = config._attn_implementation
+ self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ " this may lead to unexpected behaviour for Flash Attention version of Qwen2. Make sure to "
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+
+ if self._attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class Qwen2ForCausalLM(Qwen2PreTrainedModel):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = Qwen2Model(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, Qwen2ForCausalLM
+
+ >>> model = Qwen2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ # Omit tokens covered by past_key_values
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
+ input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (
+ max_cache_length is not None
+ and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length
+ ):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
+ )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Qwen2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`Qwen2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2ForSequenceClassification(Qwen2PreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = Qwen2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ # if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
+ sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
+ sequence_lengths = sequence_lengths % input_ids.shape[-1]
+ sequence_lengths = sequence_lengths.to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/src/transformers/models/qwen2/tokenization_qwen2.py b/src/transformers/models/qwen2/tokenization_qwen2.py
new file mode 100644
index 00000000000000..fe8e5ded8363cd
--- /dev/null
+++ b/src/transformers/models/qwen2/tokenization_qwen2.py
@@ -0,0 +1,345 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for Qwen2."""
+
+import json
+import os
+import unicodedata
+from functools import lru_cache
+from typing import Optional, Tuple
+
+import regex as re
+
+from ...tokenization_utils import AddedToken, PreTrainedTokenizer
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {
+ "vocab_file": "vocab.json",
+ "merges_file": "merges.txt",
+}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
+ "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
+}
+
+MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
+
+PRETOKENIZE_REGEX = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
+
+
+@lru_cache()
+# Copied from transformers.models.gpt2.tokenization_gpt2.bytes_to_unicode
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
+ characters the bpe code barfs on.
+
+ The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab
+ if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for
+ decent coverage. This is a significant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup
+ tables between utf-8 bytes and unicode strings.
+ """
+ bs = (
+ list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ )
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+# Copied from transformers.models.gpt2.tokenization_gpt2.get_pairs
+def get_pairs(word):
+ """
+ Return set of symbol pairs in a word.
+
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+class Qwen2Tokenizer(PreTrainedTokenizer):
+ """
+ Construct a Qwen2 tokenizer. Based on byte-level Byte-Pair-Encoding.
+
+ Same with GPT2Tokenzier, this tokenizer has been trained to treat spaces like parts of the tokens so a word will
+ be encoded differently whether it is at the beginning of the sentence (without space) or not:
+
+ ```python
+ >>> from transformers import Qwen2Tokenizer
+
+ >>> tokenizer = Qwen2Tokenizer.from_pretrained("Qwen/Qwen-tokenizer")
+ >>> tokenizer("Hello world")["input_ids"]
+ [9707, 1879]
+
+ >>> tokenizer(" Hello world")["input_ids"]
+ [21927, 1879]
+ ```
+ This is expected.
+
+ You should not use GPT2Tokenizer instead, because of the different pretokenization rules.
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+ merges_file (`str`):
+ Path to the merges file.
+ errors (`str`, *optional*, defaults to `"replace"`):
+ Paradigm to follow when decoding bytes to UTF-8. See
+ [bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
+ unk_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ bos_token (`str`, *optional*):
+ The beginning of sequence token. Not applicable for this tokenizer.
+ eos_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The end of sequence token.
+ pad_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The token used for padding, for example when batching sequences of different lengths.
+ clean_up_tokenization_spaces (`bool`, *optional*, defaults to `False`):
+ Whether or not the model should cleanup the spaces that were added when splitting the input text during the
+ tokenization process. Not applicable to this tokenizer, since tokenization does not add spaces.
+ split_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the special tokens should be split during the tokenization process. The default behavior is
+ to not split special tokens. This means that if `<|endoftext|>` is the `eos_token`, then `tokenizer.tokenize("<|endoftext|>") =
+ ['<|endoftext|>`]. Otherwise, if `split_special_tokens=True`, then `tokenizer.tokenize("<|endoftext|>")` will be give `['<',
+ '|', 'endo', 'ft', 'ext', '|', '>']`. This argument is only supported for `slow` tokenizers for the moment.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = MAX_MODEL_INPUT_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+
+ def __init__(
+ self,
+ vocab_file,
+ merges_file,
+ errors="replace",
+ unk_token="<|endoftext|>",
+ bos_token=None,
+ eos_token="<|endoftext|>",
+ pad_token="<|endoftext|>",
+ clean_up_tokenization_spaces=False,
+ split_special_tokens=False,
+ **kwargs,
+ ):
+ # Qwen vocab does not contain control tokens; added tokens need to be special
+ bos_token = (
+ AddedToken(bos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(bos_token, str)
+ else bos_token
+ )
+ eos_token = (
+ AddedToken(eos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+ unk_token = (
+ AddedToken(unk_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ pad_token = (
+ AddedToken(pad_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+
+ with open(vocab_file, encoding="utf-8") as vocab_handle:
+ self.encoder = json.load(vocab_handle)
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.errors = errors # how to handle errors in decoding
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ bpe_merges = []
+ with open(merges_file, encoding="utf-8") as merges_handle:
+ for line in merges_handle:
+ line = line.strip()
+ if not line or line.startswith("#"):
+ continue
+ bpe_merges.append(tuple(line.split()))
+ self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
+ # NOTE: the cache can grow without bound and will get really large for long running processes
+ # (esp. for texts of language that do not use space between word, e.g. Chinese); technically
+ # not a memory leak but appears as one.
+ # GPT2Tokenizer has the same problem, so let's be consistent.
+ self.cache = {}
+
+ self.pat = re.compile(PRETOKENIZE_REGEX)
+
+ if kwargs.get("add_prefix_space", False):
+ logger.warning_once(
+ f"{self.__class__.__name} does not support `add_prefix_space`, setting it to True has no effect."
+ )
+
+ super().__init__(
+ errors=errors,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ pad_token=pad_token,
+ unk_token=unk_token,
+ clean_up_tokenization_spaces=clean_up_tokenization_spaces,
+ split_special_tokens=split_special_tokens,
+ **kwargs,
+ )
+
+ @property
+ def vocab_size(self) -> int:
+ return len(self.encoder)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.get_vocab
+ def get_vocab(self):
+ return dict(self.encoder, **self.added_tokens_encoder)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.bpe
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token)
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ except ValueError:
+ new_word.extend(word[i:])
+ break
+ else:
+ new_word.extend(word[i:j])
+ i = j
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = " ".join(word)
+ self.cache[token] = word
+ return word
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._tokenize
+ def _tokenize(self, text):
+ """Tokenize a string."""
+ bpe_tokens = []
+ for token in re.findall(self.pat, text):
+ token = "".join(
+ self.byte_encoder[b] for b in token.encode("utf-8")
+ ) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
+ bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
+ return bpe_tokens
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_token_to_id
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.encoder.get(token, self.encoder.get(self.unk_token))
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_id_to_token
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ return self.decoder.get(index)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.convert_tokens_to_string
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ text = "".join(tokens)
+ text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
+ return text
+
+ def decode(
+ self,
+ token_ids,
+ skip_special_tokens: bool = False,
+ clean_up_tokenization_spaces: Optional[bool] = False,
+ spaces_between_special_tokens: bool = False,
+ **kwargs,
+ ) -> str:
+ # `spaces_between_special_tokens` defaults to True for _decode in slow tokenizers
+ # and cannot be configured elsewhere, but it should default to False for Qwen2Tokenizer
+ return super().decode(
+ token_ids,
+ skip_special_tokens=skip_special_tokens,
+ clean_up_tokenization_spaces=clean_up_tokenization_spaces,
+ spaces_between_special_tokens=spaces_between_special_tokens,
+ **kwargs,
+ )
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+ merge_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
+ )
+
+ with open(vocab_file, "w", encoding="utf-8") as f:
+ f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
+
+ index = 0
+ with open(merge_file, "w", encoding="utf-8") as writer:
+ writer.write("#version: 0.2\n")
+ for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
+ if index != token_index:
+ logger.warning(
+ f"Saving vocabulary to {merge_file}: BPE merge indices are not consecutive."
+ " Please check that the tokenizer is not corrupted!"
+ )
+ index = token_index
+ writer.write(" ".join(bpe_tokens) + "\n")
+ index += 1
+
+ return vocab_file, merge_file
+
+ def prepare_for_tokenization(self, text, **kwargs):
+ text = unicodedata.normalize("NFC", text)
+ return (text, kwargs)
diff --git a/src/transformers/models/qwen2/tokenization_qwen2_fast.py b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
new file mode 100644
index 00000000000000..178af4e62f2bfa
--- /dev/null
+++ b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
@@ -0,0 +1,143 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for Qwen2."""
+
+from typing import Optional, Tuple
+
+from ...tokenization_utils import AddedToken
+from ...tokenization_utils_fast import PreTrainedTokenizerFast
+from ...utils import logging
+from .tokenization_qwen2 import Qwen2Tokenizer
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {
+ "vocab_file": "vocab.json",
+ "merges_file": "merges.txt",
+ "tokenizer_file": "tokenizer.json",
+}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
+ "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
+ "tokenizer_file": {
+ "qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/tokenizer.json"
+ },
+}
+
+MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
+
+
+class Qwen2TokenizerFast(PreTrainedTokenizerFast):
+ """
+ Construct a "fast" Qwen2 tokenizer (backed by HuggingFace's *tokenizers* library). Based on byte-level
+ Byte-Pair-Encoding.
+
+ Same with GPT2Tokenzier, this tokenizer has been trained to treat spaces like parts of the tokens so a word will
+ be encoded differently whether it is at the beginning of the sentence (without space) or not:
+
+ ```python
+ >>> from transformers import Qwen2TokenizerFast
+
+ >>> tokenizer = Qwen2TokenizerFast.from_pretrained("Qwen/Qwen-tokenizer")
+ >>> tokenizer("Hello world")["input_ids"]
+ [9707, 1879]
+
+ >>> tokenizer(" Hello world")["input_ids"]
+ [21927, 1879]
+ ```
+ This is expected.
+
+ This tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should
+ refer to this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`, *optional*):
+ Path to the vocabulary file.
+ merges_file (`str`, *optional*):
+ Path to the merges file.
+ tokenizer_file (`str`, *optional*):
+ Path to [tokenizers](https://github.com/huggingface/tokenizers) file (generally has a .json extension) that
+ contains everything needed to load the tokenizer.
+ unk_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead. Not applicable to this tokenizer.
+ bos_token (`str`, *optional*):
+ The beginning of sequence token. Not applicable for this tokenizer.
+ eos_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The end of sequence token.
+ pad_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The token used for padding, for example when batching sequences of different lengths.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = MAX_MODEL_INPUT_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+ slow_tokenizer_class = Qwen2Tokenizer
+
+ def __init__(
+ self,
+ vocab_file=None,
+ merges_file=None,
+ tokenizer_file=None,
+ unk_token="<|endoftext|>",
+ bos_token=None,
+ eos_token="<|endoftext|>",
+ pad_token="<|endoftext|>",
+ **kwargs,
+ ):
+ # We need to at least pass vocab_file and merges_file to base class
+ # in case a slow tokenizer needs to be initialized; other can be
+ # configured through files.
+ # following GPT2TokenizerFast, also adding unk_token, bos_token, and eos_token
+
+ bos_token = (
+ AddedToken(bos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(bos_token, str)
+ else bos_token
+ )
+ eos_token = (
+ AddedToken(eos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+ unk_token = (
+ AddedToken(unk_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ pad_token = (
+ AddedToken(pad_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+
+ super().__init__(
+ vocab_file,
+ merges_file,
+ tokenizer_file=tokenizer_file,
+ unk_token=unk_token,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ pad_token=pad_token,
+ **kwargs,
+ )
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2_fast.GPT2TokenizerFast.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ files = self._tokenizer.model.save(save_directory, name=filename_prefix)
+ return tuple(files)
diff --git a/src/transformers/models/rwkv/modeling_rwkv.py b/src/transformers/models/rwkv/modeling_rwkv.py
index 35fd7976ccf653..ef3f294c0d5d82 100644
--- a/src/transformers/models/rwkv/modeling_rwkv.py
+++ b/src/transformers/models/rwkv/modeling_rwkv.py
@@ -778,6 +778,24 @@ def get_output_embeddings(self):
def set_output_embeddings(self, new_embeddings):
self.head = new_embeddings
+ def generate(self, *args, **kwargs):
+ # Thin wrapper to raise exceptions when trying to generate with methods that manipulate `past_key_values`.
+ # RWKV is one of the few models that don't have it (it has `state` instead, which has different properties and
+ # usage).
+ try:
+ gen_output = super().generate(*args, **kwargs)
+ except AttributeError as exc:
+ # Expected exception: "AttributeError: '(object name)' object has no attribute 'past_key_values'"
+ if "past_key_values" in str(exc):
+ raise AttributeError(
+ "You tried to call `generate` with a decoding strategy that manipulates `past_key_values`. RWKV "
+ "doesn't have that attribute, try another generation strategy instead. For the available "
+ "generation strategies, check this doc: https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
+ )
+ else:
+ raise exc
+ return gen_output
+
def prepare_inputs_for_generation(self, input_ids, state=None, inputs_embeds=None, **kwargs):
# only last token for inputs_ids if the state is passed along.
if state is not None:
diff --git a/src/transformers/models/siglip/modeling_siglip.py b/src/transformers/models/siglip/modeling_siglip.py
index b497b57fe2157a..1df70200d32bd5 100644
--- a/src/transformers/models/siglip/modeling_siglip.py
+++ b/src/transformers/models/siglip/modeling_siglip.py
@@ -1123,7 +1123,8 @@ def forward(
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
- >>> inputs = processor(text=texts, images=image, return_tensors="pt")
+ >>> # important: we pass `padding=max_length` since the model was trained with this
+ >>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/siglip/processing_siglip.py b/src/transformers/models/siglip/processing_siglip.py
index ecb229d28a57c9..f21cf735480212 100644
--- a/src/transformers/models/siglip/processing_siglip.py
+++ b/src/transformers/models/siglip/processing_siglip.py
@@ -50,9 +50,9 @@ def __call__(
self,
text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
images: ImageInput = None,
- padding: Union[bool, str, PaddingStrategy] = "max_length",
+ padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
- max_length=None,
+ max_length: int = None,
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
) -> BatchFeature:
"""
@@ -71,7 +71,7 @@ def __call__(
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
number of channels, H and W are image height and width.
- padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `max_length`):
+ padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `False`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding
index) among:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
diff --git a/src/transformers/models/switch_transformers/modeling_switch_transformers.py b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
index b123a6de2341e1..416549b7b75c72 100644
--- a/src/transformers/models/switch_transformers/modeling_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
@@ -898,7 +898,7 @@ def __init__(self, config, embed_tokens=None):
config.num_layers = config.num_decoder_layers if self.is_decoder else config.num_layers
self.block = nn.ModuleList()
for i in range(config.num_layers):
- is_sparse = (i % sparse_step == 1) if sparse_step > 0 else False
+ is_sparse = (i % sparse_step == 1 or sparse_step == 1) if sparse_step > 0 else False
self.block.append(
SwitchTransformersBlock(config, has_relative_attention_bias=bool(i == 0), is_sparse=is_sparse)
diff --git a/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py b/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
index a96d56084ce008..2914cfdfcd4b42 100644
--- a/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
+++ b/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
@@ -46,6 +46,8 @@
def convert_state_dict_to_hf(state_dict):
new_state_dict = {}
for key, value in state_dict.items():
+ if key.endswith(".inv_freq"):
+ continue
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
if key_to_modify in key:
key = key.replace(key_to_modify, new_key)
@@ -58,7 +60,7 @@ def convert_vipllava_llama_to_hf(text_model_id, vision_model_id, output_hub_path
text_config = AutoConfig.from_pretrained(text_model_id)
tokenizer = AutoTokenizer.from_pretrained(text_model_id)
- tokenizer.add_tokens(AddedToken("", special=True, normalized=False))
+ tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special_tokens=True)
tokenizer.add_special_tokens({"pad_token": ""})
image_processor = CLIPImageProcessor.from_pretrained(vision_model_id)
@@ -97,8 +99,6 @@ def convert_vipllava_llama_to_hf(text_model_id, vision_model_id, output_hub_path
tuple((dist.sample() for _ in range(model.language_model.lm_head.weight.data[32000:].shape[0]))),
dim=0,
)
- model.config.vocab_size = model.config.vocab_size + pad_shape
- model.config.text_config.vocab_size = model.config.text_config.vocab_size + pad_shape
model.push_to_hub(output_hub_path)
processor.push_to_hub(output_hub_path)
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index ddfa2e21263f0f..6d4501ce97f5d8 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -37,6 +37,7 @@
XVectorOutput,
)
from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import is_torch_greater_or_equal_than_1_13
from ...utils import (
ModelOutput,
add_code_sample_docstrings,
@@ -1333,7 +1334,11 @@ def load_adapter(self, target_lang: str, force_load=True, **kwargs):
cache_dir=cache_dir,
)
- state_dict = torch.load(weight_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weight_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
except EnvironmentError:
# Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
diff --git a/src/transformers/models/wav2vec2_bert/__init__.py b/src/transformers/models/wav2vec2_bert/__init__.py
new file mode 100644
index 00000000000000..594f108bcaad96
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/__init__.py
@@ -0,0 +1,70 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_wav2vec2_bert": [
+ "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Wav2Vec2BertConfig",
+ ],
+ "processing_wav2vec2_bert": ["Wav2Vec2BertProcessor"],
+}
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_wav2vec2_bert"] = [
+ "WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Wav2Vec2BertForAudioFrameClassification",
+ "Wav2Vec2BertForCTC",
+ "Wav2Vec2BertForSequenceClassification",
+ "Wav2Vec2BertForXVector",
+ "Wav2Vec2BertModel",
+ "Wav2Vec2BertPreTrainedModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ Wav2Vec2BertConfig,
+ )
+ from .processing_wav2vec2_bert import Wav2Vec2BertProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
new file mode 100644
index 00000000000000..12593107ef939d
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
@@ -0,0 +1,314 @@
+# coding=utf-8
+# Copyright 2024 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Wav2Vec2Bert model configuration"""
+
+import functools
+import operator
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/w2v-bert-2.0": "https://huggingface.co/facebook/w2v-bert-2.0/resolve/main/config.json",
+}
+
+
+class Wav2Vec2BertConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Wav2Vec2BertModel`]. It is used to
+ instantiate an Wav2Vec2Bert model according to the specified arguments, defining the model architecture.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the Wav2Vec2Bert
+ [facebook/wav2vec2-bert-rel-pos-large](https://huggingface.co/facebook/wav2vec2-bert-rel-pos-large)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*):
+ Vocabulary size of the Wav2Vec2Bert model. Defines the number of different tokens that can be
+ represented by the `inputs_ids` passed when calling [`Wav2Vec2BertModel`]. Vocabulary size of the
+ model. Defines the different tokens that can be represented by the *inputs_ids* passed to the forward
+ method of [`Wav2Vec2BertModel`].
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 4096):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ feature_projection_input_dim (`int`, *optional*, defaults to 160):
+ Input dimension of this model, i.e the dimension after processing input audios with [`SeamlessM4TFeatureExtractor`] or [`Wav2Vec2BertProcessor`].
+ hidden_act (`str` or `function`, *optional*, defaults to `"swish"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"`, `"swish"` and `"gelu_new"` are supported.
+ hidden_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ activation_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for activations inside the fully connected layer.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ feat_proj_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for the feature projection.
+ final_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for the final projection layer of [`Wav2Vec2BertForCTC`].
+ layerdrop (`float`, *optional*, defaults to 0.1):
+ The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ details.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+ apply_spec_augment (`bool`, *optional*, defaults to `True`):
+ Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
+ [SpecAugment: A Simple Data Augmentation Method for Automatic Speech
+ Recognition](https://arxiv.org/abs/1904.08779).
+ mask_time_prob (`float`, *optional*, defaults to 0.05):
+ Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
+ procecure generates `mask_time_prob*len(time_axis)/mask_time_length ``independent masks over the axis. If
+ reasoning from the propability of each feature vector to be chosen as the start of the vector span to be
+ masked, *mask_time_prob* should be `prob_vector_start*mask_time_length`. Note that overlap may decrease the
+ actual percentage of masked vectors. This is only relevant if `apply_spec_augment is True`.
+ mask_time_length (`int`, *optional*, defaults to 10):
+ Length of vector span along the time axis.
+ mask_time_min_masks (`int`, *optional*, defaults to 2):
+ The minimum number of masks of length `mask_feature_length` generated along the time axis, each time step,
+ irrespectively of `mask_feature_prob`. Only relevant if `mask_time_prob*len(time_axis)/mask_time_length <
+ mask_time_min_masks`.
+ mask_feature_prob (`float`, *optional*, defaults to 0.0):
+ Percentage (between 0 and 1) of all feature vectors along the feature axis which will be masked. The
+ masking procecure generates `mask_feature_prob*len(feature_axis)/mask_time_length` independent masks over
+ the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector
+ span to be masked, *mask_feature_prob* should be `prob_vector_start*mask_feature_length`. Note that overlap
+ may decrease the actual percentage of masked vectors. This is only relevant if `apply_spec_augment is
+ True`.
+ mask_feature_length (`int`, *optional*, defaults to 10):
+ Length of vector span along the feature axis.
+ mask_feature_min_masks (`int`, *optional*, defaults to 0):
+ The minimum number of masks of length `mask_feature_length` generated along the feature axis, each time
+ step, irrespectively of `mask_feature_prob`. Only relevant if
+ `mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks`.
+ ctc_loss_reduction (`str`, *optional*, defaults to `"sum"`):
+ Specifies the reduction to apply to the output of `torch.nn.CTCLoss`. Only relevant when training an
+ instance of [`Wav2Vec2BertForCTC`].
+ ctc_zero_infinity (`bool`, *optional*, defaults to `False`):
+ Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`. Infinite losses mainly
+ occur when the inputs are too short to be aligned to the targets. Only relevant when training an instance
+ of [`Wav2Vec2BertForCTC`].
+ use_weighted_layer_sum (`bool`, *optional*, defaults to `False`):
+ Whether to use a weighted average of layer outputs with learned weights. Only relevant when using an
+ instance of [`Wav2Vec2BertForSequenceClassification`].
+ classifier_proj_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the projection before token mean-pooling for classification.
+ tdnn_dim (`Tuple[int]` or `List[int]`, *optional*, defaults to `(512, 512, 512, 512, 1500)`):
+ A tuple of integers defining the number of output channels of each 1D convolutional layer in the *TDNN*
+ module of the *XVector* model. The length of *tdnn_dim* defines the number of *TDNN* layers.
+ tdnn_kernel (`Tuple[int]` or `List[int]`, *optional*, defaults to `(5, 3, 3, 1, 1)`):
+ A tuple of integers defining the kernel size of each 1D convolutional layer in the *TDNN* module of the
+ *XVector* model. The length of *tdnn_kernel* has to match the length of *tdnn_dim*.
+ tdnn_dilation (`Tuple[int]` or `List[int]`, *optional*, defaults to `(1, 2, 3, 1, 1)`):
+ A tuple of integers defining the dilation factor of each 1D convolutional layer in *TDNN* module of the
+ *XVector* model. The length of *tdnn_dilation* has to match the length of *tdnn_dim*.
+ xvector_output_dim (`int`, *optional*, defaults to 512):
+ Dimensionality of the *XVector* embedding vectors.
+ pad_token_id (`int`, *optional*, defaults to 0): The id of the _beginning-of-stream_ token.
+ bos_token_id (`int`, *optional*, defaults to 1): The id of the _padding_ token.
+ eos_token_id (`int`, *optional*, defaults to 2): The id of the _end-of-stream_ token.
+ add_adapter (`bool`, *optional*, defaults to `False`):
+ Whether a convolutional attention network should be stacked on top of the Wav2Vec2Bert Encoder. Can be very
+ useful for warm-starting Wav2Vec2Bert for SpeechEncoderDecoder models.
+ adapter_kernel_size (`int`, *optional*, defaults to 3):
+ Kernel size of the convolutional layers in the adapter network. Only relevant if `add_adapter is True`.
+ adapter_stride (`int`, *optional*, defaults to 2):
+ Stride of the convolutional layers in the adapter network. Only relevant if `add_adapter is True`.
+ num_adapter_layers (`int`, *optional*, defaults to 1):
+ Number of convolutional layers that should be used in the adapter network. Only relevant if `add_adapter is
+ True`.
+ adapter_act (`str` or `function`, *optional*, defaults to `"relu"`):
+ The non-linear activation function (function or string) in the adapter layers. If string, `"gelu"`,
+ `"relu"`, `"selu"`, `"swish"` and `"gelu_new"` are supported.
+ use_intermediate_ffn_before_adapter (`bool`, *optional*, defaults to `False`):
+ Whether an intermediate feed-forward block should be stacked on top of the Wav2Vec2Bert Encoder and before the adapter network.
+ Only relevant if `add_adapter is True`.
+ output_hidden_size (`int`, *optional*):
+ Dimensionality of the encoder output layer. If not defined, this defaults to *hidden-size*. Only relevant
+ if `add_adapter is True`.
+ position_embeddings_type (`str`, *optional*, defaults to `"relative_key"`):
+ Can be specified to :
+ - `rotary`, for rotary position embeddings.
+ - `relative`, for relative position embeddings.
+ - `relative_key`, for relative position embeddings as defined by Shaw in [Self-Attention
+ with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ If left to `None`, no relative position embeddings is applied.
+ rotary_embedding_base (`int`, *optional*, defaults to 10000):
+ If `"rotary"` position embeddings are used, defines the size of the embedding base.
+ max_source_positions (`int`, *optional*, defaults to 5000):
+ if `"relative"` position embeddings are used, defines the maximum source input positions.
+ left_max_position_embeddings (`int`, *optional*, defaults to 64):
+ If `"relative_key"` (aka Shaw) position embeddings are used, defines the left clipping value for relative positions.
+ right_max_position_embeddings (`int`, *optional*, defaults to 8):
+ If `"relative_key"` (aka Shaw) position embeddings are used, defines the right clipping value for relative positions.
+ conv_depthwise_kernel_size (`int`, *optional*, defaults to 31):
+ Kernel size of convolutional depthwise 1D layer in Conformer blocks.
+ conformer_conv_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all convolutional layers in Conformer blocks.
+ Example:
+
+ ```python
+ >>> from transformers import Wav2Vec2BertConfig, Wav2Vec2BertModel
+
+ >>> # Initializing a Wav2Vec2Bert facebook/wav2vec2-bert-rel-pos-large style configuration
+ >>> configuration = Wav2Vec2BertConfig()
+
+ >>> # Initializing a model (with random weights) from the facebook/wav2vec2-bert-rel-pos-large style configuration
+ >>> model = Wav2Vec2BertModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "wav2vec2-bert"
+
+ def __init__(
+ self,
+ vocab_size=None,
+ hidden_size=1024,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ intermediate_size=4096,
+ feature_projection_input_dim=160,
+ hidden_act="swish",
+ hidden_dropout=0.0,
+ activation_dropout=0.0,
+ attention_dropout=0.0,
+ feat_proj_dropout=0.0,
+ final_dropout=0.1,
+ layerdrop=0.1,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ apply_spec_augment=True,
+ mask_time_prob=0.05,
+ mask_time_length=10,
+ mask_time_min_masks=2,
+ mask_feature_prob=0.0,
+ mask_feature_length=10,
+ mask_feature_min_masks=0,
+ ctc_loss_reduction="sum",
+ ctc_zero_infinity=False,
+ use_weighted_layer_sum=False,
+ classifier_proj_size=768,
+ tdnn_dim=(512, 512, 512, 512, 1500),
+ tdnn_kernel=(5, 3, 3, 1, 1),
+ tdnn_dilation=(1, 2, 3, 1, 1),
+ xvector_output_dim=512,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ add_adapter=False,
+ adapter_kernel_size=3,
+ adapter_stride=2,
+ num_adapter_layers=1,
+ adapter_act="relu",
+ use_intermediate_ffn_before_adapter=False,
+ output_hidden_size=None,
+ position_embeddings_type="relative_key",
+ rotary_embedding_base=10000,
+ max_source_positions=5000,
+ left_max_position_embeddings=64,
+ right_max_position_embeddings=8,
+ conv_depthwise_kernel_size=31,
+ conformer_conv_dropout=0.1,
+ **kwargs,
+ ):
+ super().__init__(**kwargs, pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id)
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.num_attention_heads = num_attention_heads
+ self.feature_projection_input_dim = feature_projection_input_dim
+ self.hidden_dropout = hidden_dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.feat_proj_dropout = feat_proj_dropout
+ self.final_dropout = final_dropout
+ self.layerdrop = layerdrop
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.vocab_size = vocab_size
+ self.use_weighted_layer_sum = use_weighted_layer_sum
+ self.max_source_positions = max_source_positions
+
+ if position_embeddings_type is not None and position_embeddings_type not in [
+ "rotary",
+ "relative",
+ "relative_key",
+ ]:
+ raise ValueError(
+ """
+ `position_embeddings_type` is not valid. It must be one of the following values:
+ `["rotary", "relative", "relative_key"]` or left as `None`.
+ """
+ )
+ self.position_embeddings_type = position_embeddings_type
+ self.rotary_embedding_base = rotary_embedding_base
+ self.left_max_position_embeddings = left_max_position_embeddings
+ self.right_max_position_embeddings = right_max_position_embeddings
+
+ # Conformer-block related
+ self.conv_depthwise_kernel_size = conv_depthwise_kernel_size
+ self.conformer_conv_dropout = conformer_conv_dropout
+
+ # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ self.apply_spec_augment = apply_spec_augment
+ self.mask_time_prob = mask_time_prob
+ self.mask_time_length = mask_time_length
+ self.mask_time_min_masks = mask_time_min_masks
+ self.mask_feature_prob = mask_feature_prob
+ self.mask_feature_length = mask_feature_length
+ self.mask_feature_min_masks = mask_feature_min_masks
+
+ # ctc loss
+ self.ctc_loss_reduction = ctc_loss_reduction
+ self.ctc_zero_infinity = ctc_zero_infinity
+
+ # adapter
+ self.add_adapter = add_adapter
+ self.adapter_kernel_size = adapter_kernel_size
+ self.adapter_stride = adapter_stride
+ self.num_adapter_layers = num_adapter_layers
+ self.adapter_act = adapter_act
+ self.output_hidden_size = output_hidden_size if output_hidden_size is not None else hidden_size
+ if use_intermediate_ffn_before_adapter and not add_adapter:
+ raise ValueError("`use_intermediate_ffn_before_adapter` is `True` but `add_adapter` is `False`.")
+ self.use_intermediate_ffn_before_adapter = use_intermediate_ffn_before_adapter
+
+ # SequenceClassification-specific parameter. Feel free to ignore for other classes.
+ self.classifier_proj_size = classifier_proj_size
+
+ # XVector-specific parameters. Feel free to ignore for other classes.
+ self.tdnn_dim = list(tdnn_dim)
+ self.tdnn_kernel = list(tdnn_kernel)
+ self.tdnn_dilation = list(tdnn_dilation)
+ self.xvector_output_dim = xvector_output_dim
+
+ @property
+ def inputs_to_logits_ratio(self):
+ return functools.reduce(operator.mul, self.conv_stride, 1)
diff --git a/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py b/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
new file mode 100644
index 00000000000000..8b77cd71f7f7e0
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
@@ -0,0 +1,218 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Wav2Vec2Bert BERT checkpoint."""
+
+
+import argparse
+
+import torch
+import torchaudio
+from fairseq2.data import Collater
+from fairseq2.data.audio import WaveformToFbankConverter
+from fairseq2.nn.padding import get_seqs_and_padding_mask
+from seamless_communication.models.conformer_shaw import load_conformer_shaw_model
+
+from transformers import (
+ SeamlessM4TFeatureExtractor,
+ Wav2Vec2BertConfig,
+ Wav2Vec2BertModel,
+ logging,
+)
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+wav2vec_convert_list = [
+ ("encoder_frontend.model_dim_proj", "feature_projection.projection"),
+ ("encoder_frontend.post_extract_layer_norm", "feature_projection.layer_norm"),
+ ("encoder_frontend.pos_encoder.conv", "encoder.pos_conv_embed.conv"),
+ ("encoder.inner.layers", "encoder.layers"),
+ ("encoder.inner_layer_norm", "encoder.layer_norm"),
+ ("encoder.adaptor_layers", "adapter.layers"),
+ ("inner_proj", "intermediate_dense"),
+ ("self_attn.output_proj", "self_attn.linear_out"),
+ ("output_proj", "output_dense"),
+ ("self_attn.k_proj", "self_attn.linear_k"),
+ ("self_attn.v_proj", "self_attn.linear_v"),
+ ("self_attn.q_proj", "self_attn.linear_q"),
+ ("self_attn.sdpa.u_bias", "self_attn.pos_bias_u"),
+ ("self_attn.sdpa.v_bias", "self_attn.pos_bias_v"),
+ ("self_attn.sdpa.rel_k_embed", "self_attn.distance_embedding"),
+ ("self_attn.sdpa.r_proj", "self_attn.linear_pos"),
+ ("conv.pointwise_conv1", "conv_module.pointwise_conv1"),
+ ("conv.pointwise_conv2", "conv_module.pointwise_conv2"),
+ ("conv.depthwise_conv", "conv_module.depthwise_conv"),
+ ("conv.layer_norm", "conv_module.depthwise_layer_norm"),
+ ("conv_layer_norm", "conv_module.layer_norm"),
+ ("encoder.proj1", "intermediate_ffn.intermediate_dense"),
+ ("encoder.proj2", "intermediate_ffn.output_dense"),
+ ("encoder.layer_norm", "inner_layer_norm"),
+ ("masker.temporal_mask_embed", "masked_spec_embed"),
+]
+
+keys_to_remove = {
+ "quantizer.entry_proj",
+ "final_proj",
+ "final_target_proj",
+ "quantizer.entries",
+ "quantizer.num_updates",
+}
+
+
+def param_count(model):
+ return sum(p[1].numel() for p in model.named_parameters() if "final_proj" not in p[0])
+
+
+def _convert_model(
+ original_model,
+ hf_model,
+ convert_list,
+):
+ state_dict = original_model.state_dict()
+
+ for k, v in list(state_dict.items()):
+ new_key = k
+ for old_layer_name, new_layer_name in convert_list:
+ if old_layer_name in new_key:
+ new_key = new_key.replace(old_layer_name, new_layer_name)
+
+ # must do it by hand
+ if ".layer_norm" in new_key and new_key.split(".layer_norm")[0][-1].isnumeric():
+ new_key = new_key.replace("layer_norm", "final_layer_norm")
+
+ add_key = True
+ for key in keys_to_remove:
+ if key in new_key:
+ state_dict.pop(k)
+ add_key = False
+ break
+
+ if add_key:
+ state_dict[new_key] = state_dict.pop(k)
+
+ extra_keys = set(state_dict.keys()) - set(hf_model.state_dict().keys())
+ extra_keys = set({k for k in extra_keys if "num_updates" not in k}) # filter unecessary param
+ missing_keys = set(hf_model.state_dict().keys()) - set(state_dict.keys())
+ if len(extra_keys) != 0:
+ raise ValueError(f"extra keys found: {extra_keys}")
+ if len(missing_keys) != 0:
+ raise ValueError(f"missing keys: {missing_keys}")
+ hf_model.load_state_dict(state_dict, strict=True)
+ n_params = param_count(hf_model)
+
+ logger.info(f"model loaded: {round(n_params/1e6,1)}M params")
+
+ hf_model.eval()
+ del state_dict
+
+ return hf_model
+
+
+@torch.no_grad()
+def convert_wav2vec2_bert_checkpoint(
+ checkpoint_path,
+ pytorch_dump_folder_path,
+ config_path=None,
+ repo_id=None,
+):
+ """
+ Copy/paste/tweak model's weights to transformers design.
+ """
+ if config_path is not None:
+ config = Wav2Vec2BertConfig.from_pretrained(config_path, hidden_act="swish")
+ else:
+ config = Wav2Vec2BertConfig(apply_spec_augment=False)
+
+ hf_wav2vec = Wav2Vec2BertModel(config)
+
+ model = load_conformer_shaw_model(checkpoint_path, dtype=torch.float32)
+ model.eval()
+
+ hf_wav2vec = _convert_model(model, hf_wav2vec, wav2vec_convert_list)
+
+ hf_wav2vec.save_pretrained(pytorch_dump_folder_path)
+
+ if repo_id:
+ hf_wav2vec.push_to_hub(repo_id, create_pr=True)
+
+ # save feature extractor
+ fe = SeamlessM4TFeatureExtractor(padding_value=1)
+ fe._set_processor_class("Wav2Vec2BertProcessor")
+ fe.save_pretrained(pytorch_dump_folder_path)
+
+ if repo_id:
+ fe.push_to_hub(repo_id, create_pr=True)
+
+ if args.audio_path:
+ waveform, sample_rate = torchaudio.load(args.audio_path)
+ waveform = torchaudio.functional.resample(waveform, sample_rate, fe.sampling_rate)
+
+ fbank_converter = WaveformToFbankConverter(
+ num_mel_bins=80,
+ waveform_scale=2**15,
+ channel_last=True,
+ standardize=True,
+ dtype=torch.float32,
+ )
+ collater = Collater(pad_value=1)
+
+ decoded_audio = {"waveform": waveform.T, "sample_rate": fe.sampling_rate, "format": -1}
+ src = collater(fbank_converter(decoded_audio))["fbank"]
+ seqs, padding_mask = get_seqs_and_padding_mask(src)
+
+ with torch.inference_mode():
+ seqs, padding_mask = model.encoder_frontend(seqs, padding_mask)
+ original_output, padding_mask = model.encoder(seqs, padding_mask)
+
+ hf_wav2vec.eval()
+
+ inputs = fe(waveform, return_tensors="pt", padding=True)
+ with torch.no_grad():
+ outputs = hf_wav2vec(**inputs)
+
+ torch.testing.assert_close(original_output, outputs.last_hidden_state, atol=5e-3, rtol=5e-3)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ help="Path to the output PyTorch model.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default="conformer_shaw", type=str, help="Path to seamless communication checkpoint"
+ )
+ parser.add_argument(
+ "--config_path",
+ default=None,
+ type=str,
+ help="Path to hf config.json of model to convert",
+ )
+ parser.add_argument("--repo_id", default=None, type=str, help="Push to this repo id if precised.")
+ parser.add_argument(
+ "--audio_path",
+ default=None,
+ type=str,
+ help="If specified, check that the original model and the converted model produce the same outputs.",
+ )
+
+ args = parser.parse_args()
+ convert_wav2vec2_bert_checkpoint(
+ args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path, args.repo_id
+ )
diff --git a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
new file mode 100644
index 00000000000000..034da900ee8ab3
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
@@ -0,0 +1,1667 @@
+# coding=utf-8
+# Copyright 2024 The Seamless Authors and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Wav2Vec2-BERT model."""
+
+import math
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss
+
+from ...activations import ACT2FN
+from ...integrations.deepspeed import is_deepspeed_zero3_enabled
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_outputs import (
+ BaseModelOutput,
+ CausalLMOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+ Wav2Vec2BaseModelOutput,
+ XVectorOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+)
+from .configuration_wav2vec2_bert import Wav2Vec2BertConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+_HIDDEN_STATES_START_POSITION = 2
+
+# General docstring
+_CONFIG_FOR_DOC = "Wav2Vec2BertConfig"
+
+# Base docstring
+_BASE_CHECKPOINT_FOR_DOC = "facebook/w2v-bert-2.0"
+_PRETRAINED_CHECKPOINT_FOR_DOC = "hf-audio/wav2vec2-bert-CV16-en"
+_EXPECTED_OUTPUT_SHAPE = [1, 146, 1024]
+
+# CTC docstring
+_CTC_EXPECTED_OUTPUT = "'mr quilter is the apostle of the middle classes and we are glad to welcome his gospel'"
+_CTC_EXPECTED_LOSS = 17.04
+
+
+WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/w2v-bert-2.0",
+ # See all Wav2Vec2-BERT models at https://huggingface.co/models?filter=wav2vec2-bert
+]
+
+
+# Copied from transformers.models.seamless_m4t_v2.modeling_seamless_m4t_v2._compute_new_attention_mask
+def _compute_new_attention_mask(hidden_states: torch.Tensor, seq_lens: torch.Tensor):
+ """
+ Computes an attention mask of the form `(batch, seq_len)` with an attention for each element in the batch that
+ stops at the corresponding element in `seq_lens`.
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch, seq_len, *)`):
+ The sequences to mask, where `*` is any number of sequence-specific dimensions including none.
+ seq_lens (`torch.Tensor` of shape `(batch)`:
+ Each element represents the length of the sequence at the same index in `hidden_states`
+ Returns:
+ `torch.FloatTensor`: The float attention mask of shape `(batch, seq_len)`
+ """
+ batch_size, mask_seq_len = hidden_states.shape[:2]
+
+ indices = torch.arange(mask_seq_len, device=seq_lens.device).expand(batch_size, -1)
+
+ bool_mask = indices >= seq_lens.unsqueeze(1).expand(-1, mask_seq_len)
+
+ mask = hidden_states.new_ones((batch_size, mask_seq_len))
+
+ mask = mask.masked_fill(bool_mask, 0)
+
+ return mask
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
+def _compute_mask_indices(
+ shape: Tuple[int, int],
+ mask_prob: float,
+ mask_length: int,
+ attention_mask: Optional[torch.LongTensor] = None,
+ min_masks: int = 0,
+) -> np.ndarray:
+ """
+ Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
+ ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ CPU as part of the preprocessing during training.
+
+ Args:
+ shape: The shape for which to compute masks. This should be of a tuple of size 2 where
+ the first element is the batch size and the second element is the length of the axis to span.
+ mask_prob: The percentage of the whole axis (between 0 and 1) which will be masked. The number of
+ independently generated mask spans of length `mask_length` is computed by
+ `mask_prob*shape[1]/mask_length`. Note that due to overlaps, `mask_prob` is an upper bound and the
+ actual percentage will be smaller.
+ mask_length: size of the mask
+ min_masks: minimum number of masked spans
+ attention_mask: A (right-padded) attention mask which independently shortens the feature axis of
+ each batch dimension.
+ """
+ batch_size, sequence_length = shape
+
+ if mask_length < 1:
+ raise ValueError("`mask_length` has to be bigger than 0.")
+
+ if mask_length > sequence_length:
+ raise ValueError(
+ f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length}"
+ f" and `sequence_length`: {sequence_length}`"
+ )
+
+ # epsilon is used for probabilistic rounding
+ epsilon = np.random.rand(1).item()
+
+ def compute_num_masked_span(input_length):
+ """Given input length, compute how many spans should be masked"""
+ num_masked_span = int(mask_prob * input_length / mask_length + epsilon)
+ num_masked_span = max(num_masked_span, min_masks)
+
+ # make sure num masked span <= sequence_length
+ if num_masked_span * mask_length > sequence_length:
+ num_masked_span = sequence_length // mask_length
+
+ # make sure num_masked span is also <= input_length - (mask_length - 1)
+ if input_length - (mask_length - 1) < num_masked_span:
+ num_masked_span = max(input_length - (mask_length - 1), 0)
+
+ return num_masked_span
+
+ # compute number of masked spans in batch
+ input_lengths = (
+ attention_mask.sum(-1).detach().tolist()
+ if attention_mask is not None
+ else [sequence_length for _ in range(batch_size)]
+ )
+
+ # SpecAugment mask to fill
+ spec_aug_mask = np.zeros((batch_size, sequence_length), dtype=bool)
+ spec_aug_mask_idxs = []
+
+ max_num_masked_span = compute_num_masked_span(sequence_length)
+
+ if max_num_masked_span == 0:
+ return spec_aug_mask
+
+ for input_length in input_lengths:
+ # compute num of masked spans for this input
+ num_masked_span = compute_num_masked_span(input_length)
+
+ # get random indices to mask
+ spec_aug_mask_idx = np.random.choice(
+ np.arange(input_length - (mask_length - 1)), num_masked_span, replace=False
+ )
+
+ # pick first sampled index that will serve as a dummy index to pad vector
+ # to ensure same dimension for all batches due to probabilistic rounding
+ # Picking first sample just pads those vectors twice.
+ if len(spec_aug_mask_idx) == 0:
+ # this case can only happen if `input_length` is strictly smaller then
+ # `sequence_length` in which case the last token has to be a padding
+ # token which we can use as a dummy mask id
+ dummy_mask_idx = sequence_length - 1
+ else:
+ dummy_mask_idx = spec_aug_mask_idx[0]
+
+ spec_aug_mask_idx = np.concatenate(
+ [spec_aug_mask_idx, np.ones(max_num_masked_span - num_masked_span, dtype=np.int32) * dummy_mask_idx]
+ )
+ spec_aug_mask_idxs.append(spec_aug_mask_idx)
+
+ spec_aug_mask_idxs = np.array(spec_aug_mask_idxs)
+
+ # expand masked indices to masked spans
+ spec_aug_mask_idxs = np.broadcast_to(
+ spec_aug_mask_idxs[:, :, None], (batch_size, max_num_masked_span, mask_length)
+ )
+ spec_aug_mask_idxs = spec_aug_mask_idxs.reshape(batch_size, max_num_masked_span * mask_length)
+
+ # add offset to the starting indexes so that indexes now create a span
+ offsets = np.arange(mask_length)[None, None, :]
+ offsets = np.broadcast_to(offsets, (batch_size, max_num_masked_span, mask_length)).reshape(
+ batch_size, max_num_masked_span * mask_length
+ )
+ spec_aug_mask_idxs = spec_aug_mask_idxs + offsets
+
+ # ensure that we cannot have indices larger than sequence_length
+ if spec_aug_mask_idxs.max() > sequence_length - 1:
+ spec_aug_mask_idxs[spec_aug_mask_idxs > sequence_length - 1] = sequence_length - 1
+
+ # scatter indices to mask
+ np.put_along_axis(spec_aug_mask, spec_aug_mask_idxs, 1, -1)
+
+ return spec_aug_mask
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2._sample_negative_indices
+def _sample_negative_indices(
+ features_shape: Tuple, num_negatives: int, mask_time_indices: Optional[np.ndarray] = None
+):
+ """
+ Sample `num_negatives` vectors from feature vectors.
+ """
+ batch_size, sequence_length = features_shape
+
+ # generate indices of the positive vectors themselves, repeat them `num_negatives` times
+ sequence_length_range = np.arange(sequence_length)
+
+ # get `num_negatives` random vector indices from the same utterance
+ sampled_negative_indices = np.zeros(shape=(batch_size, sequence_length, num_negatives), dtype=np.int32)
+
+ mask_time_indices = (
+ mask_time_indices.astype(bool) if mask_time_indices is not None else np.ones(features_shape, dtype=bool)
+ )
+
+ for batch_idx in range(batch_size):
+ high = mask_time_indices[batch_idx].sum() - 1
+ mapped_masked_indices = sequence_length_range[mask_time_indices[batch_idx]]
+
+ feature_indices = np.broadcast_to(np.arange(high + 1)[:, None], (high + 1, num_negatives))
+ sampled_indices = np.random.randint(0, high, size=(high + 1, num_negatives))
+ # avoid sampling the same positive vector, but keep the distribution uniform
+ sampled_indices[sampled_indices >= feature_indices] += 1
+
+ # remap to actual indices
+ sampled_negative_indices[batch_idx][mask_time_indices[batch_idx]] = mapped_masked_indices[sampled_indices]
+
+ # correct for batch size
+ sampled_negative_indices[batch_idx] += batch_idx * sequence_length
+
+ return sampled_negative_indices
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerRotaryPositionalEmbedding with Wav2Vec2Conformer->Wav2Vec2Bert
+class Wav2Vec2BertRotaryPositionalEmbedding(nn.Module):
+ """Rotary positional embedding
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ dim = config.hidden_size // config.num_attention_heads
+ base = config.rotary_embedding_base
+
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
+ # Ignore copy
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.cached_sequence_length = None
+ self.cached_rotary_positional_embedding = None
+
+ def forward(self, hidden_states):
+ sequence_length = hidden_states.shape[1]
+
+ if sequence_length == self.cached_sequence_length and self.cached_rotary_positional_embedding is not None:
+ return self.cached_rotary_positional_embedding
+
+ self.cached_sequence_length = sequence_length
+ # Embeddings are computed in the dtype of the inv_freq constant
+ time_stamps = torch.arange(sequence_length).type_as(self.inv_freq)
+ freqs = torch.einsum("i,j->ij", time_stamps, self.inv_freq)
+ embeddings = torch.cat((freqs, freqs), dim=-1)
+
+ cos_embeddings = embeddings.cos()[:, None, None, :]
+ sin_embeddings = embeddings.sin()[:, None, None, :]
+ # Computed embeddings are cast to the dtype of the hidden state inputs
+ self.cached_rotary_positional_embedding = torch.stack([cos_embeddings, sin_embeddings]).type_as(hidden_states)
+ return self.cached_rotary_positional_embedding
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerRelPositionalEmbedding with Wav2Vec2Conformer->Wav2Vec2Bert
+class Wav2Vec2BertRelPositionalEmbedding(nn.Module):
+ """Relative positional encoding module."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.max_len = config.max_source_positions
+ self.d_model = config.hidden_size
+ self.pe = None
+ self.extend_pe(torch.tensor(0.0).expand(1, self.max_len))
+
+ def extend_pe(self, x):
+ # Reset the positional encodings
+ if self.pe is not None:
+ # self.pe contains both positive and negative parts
+ # the length of self.pe is 2 * input_len - 1
+ if self.pe.size(1) >= x.size(1) * 2 - 1:
+ if self.pe.dtype != x.dtype or self.pe.device != x.device:
+ self.pe = self.pe.to(dtype=x.dtype, device=x.device)
+ return
+ # Suppose `i` is the position of query vector and `j` is the
+ # position of key vector. We use positive relative positions when keys
+ # are to the left (i>j) and negative relative positions otherwise (i (batch, 2*channel, dim)
+ hidden_states = self.pointwise_conv1(hidden_states)
+ # => (batch, channel, dim)
+ hidden_states = self.glu(hidden_states)
+
+ # Pad the sequence entirely on the left because of causal convolution.
+ hidden_states = torch.nn.functional.pad(hidden_states, (self.depthwise_conv.kernel_size[0] - 1, 0))
+
+ # 1D Depthwise Conv
+ hidden_states = self.depthwise_conv(hidden_states)
+
+ hidden_states = self.depthwise_layer_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
+
+ hidden_states = self.activation(hidden_states)
+
+ hidden_states = self.pointwise_conv2(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = hidden_states.transpose(1, 2)
+ return hidden_states
+
+
+class Wav2Vec2BertSelfAttention(nn.Module):
+ """Construct an Wav2Vec2BertSelfAttention object.
+ Can be enhanced with rotary or relative position embeddings.
+ """
+
+ def __init__(self, config, is_adapter_attention=False):
+ super().__init__()
+ hidden_size = config.hidden_size if not is_adapter_attention else config.output_hidden_size
+
+ self.head_size = hidden_size // config.num_attention_heads
+ self.num_heads = config.num_attention_heads
+ self.position_embeddings_type = config.position_embeddings_type if not is_adapter_attention else None
+
+ self.linear_q = nn.Linear(hidden_size, hidden_size)
+ self.linear_k = nn.Linear(hidden_size, hidden_size)
+ self.linear_v = nn.Linear(hidden_size, hidden_size)
+ self.linear_out = nn.Linear(hidden_size, hidden_size)
+
+ self.dropout = nn.Dropout(p=config.attention_dropout)
+
+ if self.position_embeddings_type == "relative":
+ # linear transformation for positional encoding
+ self.linear_pos = nn.Linear(hidden_size, hidden_size, bias=False)
+ # these two learnable bias are used in matrix c and matrix d
+ # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
+ self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
+
+ if self.position_embeddings_type == "relative_key":
+ self.left_max_position_embeddings = config.left_max_position_embeddings
+ self.right_max_position_embeddings = config.right_max_position_embeddings
+ num_positions = self.left_max_position_embeddings + self.right_max_position_embeddings + 1
+ self.distance_embedding = nn.Embedding(num_positions, self.head_size)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ relative_position_embeddings: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # self-attention mechanism
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+
+ # make sure query/key states can be != value states
+ query_key_states = hidden_states
+ value_states = hidden_states
+
+ if self.position_embeddings_type == "rotary":
+ if relative_position_embeddings is None:
+ raise ValueError(
+ "`relative_position_embeddings` has to be defined when `self.position_embeddings_type == 'rotary'"
+ )
+ query_key_states = self._apply_rotary_embedding(query_key_states, relative_position_embeddings)
+
+ # project query_key_states and value_states
+ query = self.linear_q(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
+ key = self.linear_k(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
+ value = self.linear_v(value_states).view(batch_size, -1, self.num_heads, self.head_size)
+
+ # => (batch, head, time1, d_k)
+ query = query.transpose(1, 2)
+ key = key.transpose(1, 2)
+ value = value.transpose(1, 2)
+
+ if self.position_embeddings_type == "relative":
+ if relative_position_embeddings is None:
+ raise ValueError(
+ "`relative_position_embeddings` has to be defined when `self.position_embeddings_type =="
+ " 'relative'"
+ )
+ # apply relative_position_embeddings to qk scores
+ # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ scores = self._apply_relative_embeddings(
+ query=query, key=key, relative_position_embeddings=relative_position_embeddings
+ )
+ else:
+ scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_size)
+
+ if self.position_embeddings_type == "relative_key":
+ query_length, key_length = query.shape[2], key.shape[2]
+
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_r - position_ids_l
+ distance = torch.clamp(distance, -self.left_max_position_embeddings, self.right_max_position_embeddings)
+
+ positional_embedding = self.distance_embedding(distance + self.left_max_position_embeddings)
+ positional_embedding = positional_embedding.to(dtype=query.dtype) # fp16 compatibility
+
+ relative_position_attn_weights = torch.einsum("bhld,lrd->bhlr", query, positional_embedding)
+ scores = scores + (relative_position_attn_weights / math.sqrt(self.head_size))
+
+ # apply attention_mask if necessary
+ if attention_mask is not None:
+ scores = scores + attention_mask
+
+ # => (batch, head, time1, time2)
+ probs = torch.softmax(scores, dim=-1)
+ probs = self.dropout(probs)
+
+ # => (batch, head, time1, d_k)
+ hidden_states = torch.matmul(probs, value)
+
+ # => (batch, time1, hidden_size)
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, self.num_heads * self.head_size)
+ hidden_states = self.linear_out(hidden_states)
+
+ return hidden_states, probs
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerSelfAttention._apply_rotary_embedding
+ def _apply_rotary_embedding(self, hidden_states, relative_position_embeddings):
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+ hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads, self.head_size)
+
+ cos = relative_position_embeddings[0, :sequence_length, ...]
+ sin = relative_position_embeddings[1, :sequence_length, ...]
+
+ # rotate hidden_states with rotary embeddings
+ hidden_states = hidden_states.transpose(0, 1)
+ rotated_states_begin = hidden_states[..., : self.head_size // 2]
+ rotated_states_end = hidden_states[..., self.head_size // 2 :]
+ rotated_states = torch.cat((-rotated_states_end, rotated_states_begin), dim=rotated_states_begin.ndim - 1)
+ hidden_states = (hidden_states * cos) + (rotated_states * sin)
+ hidden_states = hidden_states.transpose(0, 1)
+
+ hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads * self.head_size)
+
+ return hidden_states
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerSelfAttention._apply_relative_embeddings
+ def _apply_relative_embeddings(self, query, key, relative_position_embeddings):
+ # 1. project positional embeddings
+ # => (batch, head, 2*time1-1, d_k)
+ proj_relative_position_embeddings = self.linear_pos(relative_position_embeddings)
+ proj_relative_position_embeddings = proj_relative_position_embeddings.view(
+ relative_position_embeddings.size(0), -1, self.num_heads, self.head_size
+ )
+ proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(1, 2)
+ proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(2, 3)
+
+ # 2. Add bias to query
+ # => (batch, head, time1, d_k)
+ query = query.transpose(1, 2)
+ q_with_bias_u = (query + self.pos_bias_u).transpose(1, 2)
+ q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
+
+ # 3. attention score: first compute matrix a and matrix c
+ # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # => (batch, head, time1, time2)
+ scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
+
+ # 4. then compute matrix b and matrix d
+ # => (batch, head, time1, 2*time1-1)
+ scores_bd = torch.matmul(q_with_bias_v, proj_relative_position_embeddings)
+
+ # 5. shift matrix b and matrix d
+ zero_pad = torch.zeros((*scores_bd.size()[:3], 1), device=scores_bd.device, dtype=scores_bd.dtype)
+ scores_bd_padded = torch.cat([zero_pad, scores_bd], dim=-1)
+ scores_bd_padded_shape = scores_bd.size()[:2] + (scores_bd.shape[3] + 1, scores_bd.shape[2])
+ scores_bd_padded = scores_bd_padded.view(*scores_bd_padded_shape)
+ scores_bd = scores_bd_padded[:, :, 1:].view_as(scores_bd)
+ scores_bd = scores_bd[:, :, :, : scores_bd.size(-1) // 2 + 1]
+
+ # 6. sum matrices
+ # => (batch, head, time1, time2)
+ scores = (scores_ac + scores_bd) / math.sqrt(self.head_size)
+
+ return scores
+
+
+class Wav2Vec2BertEncoderLayer(nn.Module):
+ """Conformer block based on https://arxiv.org/abs/2005.08100."""
+
+ def __init__(self, config):
+ super().__init__()
+ embed_dim = config.hidden_size
+ dropout = config.attention_dropout
+
+ # Feed-forward 1
+ self.ffn1_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn1 = Wav2Vec2BertFeedForward(config)
+
+ # Self-Attention
+ self.self_attn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.self_attn_dropout = nn.Dropout(dropout)
+ self.self_attn = Wav2Vec2BertSelfAttention(config)
+
+ # Conformer Convolution
+ self.conv_module = Wav2Vec2BertConvolutionModule(config)
+
+ # Feed-forward 2
+ self.ffn2_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn2 = Wav2Vec2BertFeedForward(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask: Optional[torch.Tensor] = None,
+ relative_position_embeddings: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ conv_attention_mask: Optional[torch.Tensor] = None,
+ ):
+ hidden_states = hidden_states
+
+ # 1. Feed-Forward 1 layer
+ residual = hidden_states
+ hidden_states = self.ffn1_layer_norm(hidden_states)
+ hidden_states = self.ffn1(hidden_states)
+ hidden_states = hidden_states * 0.5 + residual
+ residual = hidden_states
+
+ # 2. Self-Attention layer
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weigts = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ relative_position_embeddings=relative_position_embeddings,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.self_attn_dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ # 3. Convolutional Layer
+ residual = hidden_states
+ hidden_states = self.conv_module(hidden_states, attention_mask=conv_attention_mask)
+ hidden_states = residual + hidden_states
+
+ # 4. Feed-Forward 2 Layer
+ residual = hidden_states
+ hidden_states = self.ffn2_layer_norm(hidden_states)
+ hidden_states = self.ffn2(hidden_states)
+ hidden_states = hidden_states * 0.5 + residual
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ return hidden_states, attn_weigts
+
+
+class Wav2Vec2BertEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ if config.position_embeddings_type == "relative":
+ self.embed_positions = Wav2Vec2BertRelPositionalEmbedding(config)
+ elif config.position_embeddings_type == "rotary":
+ self.embed_positions = Wav2Vec2BertRotaryPositionalEmbedding(config)
+ else:
+ self.embed_positions = None
+
+ self.dropout = nn.Dropout(config.hidden_dropout)
+ self.layers = nn.ModuleList([Wav2Vec2BertEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ conv_attention_mask = attention_mask
+ if attention_mask is not None:
+ # make sure padded tokens output 0
+ hidden_states = hidden_states.masked_fill(~attention_mask.bool().unsqueeze(-1), 0.0)
+
+ # extend attention_mask
+ attention_mask = 1.0 - attention_mask[:, None, None, :].to(dtype=hidden_states.dtype)
+ attention_mask = attention_mask * torch.finfo(hidden_states.dtype).min
+ attention_mask = attention_mask.expand(
+ attention_mask.shape[0], 1, attention_mask.shape[-1], attention_mask.shape[-1]
+ )
+
+ hidden_states = self.dropout(hidden_states)
+
+ if self.embed_positions is not None:
+ relative_position_embeddings = self.embed_positions(hidden_states)
+ else:
+ relative_position_embeddings = None
+
+ deepspeed_zero3_is_enabled = is_deepspeed_zero3_enabled()
+
+ for i, layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ dropout_probability = torch.rand([])
+
+ skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
+ if not skip_the_layer or deepspeed_zero3_is_enabled:
+ # under deepspeed zero3 all gpus must run in sync
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer.__call__,
+ hidden_states,
+ attention_mask,
+ relative_position_embeddings,
+ output_attentions,
+ conv_attention_mask,
+ )
+ else:
+ layer_outputs = layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ relative_position_embeddings=relative_position_embeddings,
+ output_attentions=output_attentions,
+ conv_attention_mask=conv_attention_mask,
+ )
+ hidden_states = layer_outputs[0]
+
+ if skip_the_layer:
+ layer_outputs = (None, None)
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class Wav2Vec2BertAdapter(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ # feature dim might need to be down-projected
+ if config.output_hidden_size != config.hidden_size:
+ self.proj = nn.Linear(config.hidden_size, config.output_hidden_size)
+ self.proj_layer_norm = nn.LayerNorm(config.output_hidden_size, eps=config.layer_norm_eps)
+ else:
+ self.proj = self.proj_layer_norm = None
+ self.layers = nn.ModuleList(Wav2Vec2BertAdapterLayer(config) for _ in range(config.num_adapter_layers))
+ self.layerdrop = config.layerdrop
+
+ self.kernel_size = config.adapter_kernel_size
+ self.stride = config.adapter_stride
+
+ def _compute_sub_sample_lengths_from_attention_mask(self, seq_lens):
+ if seq_lens is None:
+ return seq_lens
+ pad = self.kernel_size // 2
+ seq_lens = ((seq_lens + 2 * pad - self.kernel_size) / self.stride) + 1
+ return seq_lens.floor()
+
+ def forward(self, hidden_states, attention_mask=None):
+ # down project hidden_states if necessary
+ if self.proj is not None and self.proj_layer_norm is not None:
+ hidden_states = self.proj(hidden_states)
+ hidden_states = self.proj_layer_norm(hidden_states)
+
+ sub_sampled_lengths = None
+ if attention_mask is not None:
+ sub_sampled_lengths = (attention_mask.size(1) - (1 - attention_mask.int()).sum(1)).to(hidden_states.device)
+
+ for layer in self.layers:
+ layerdrop_prob = torch.rand([])
+ sub_sampled_lengths = self._compute_sub_sample_lengths_from_attention_mask(sub_sampled_lengths)
+ if not self.training or (layerdrop_prob > self.layerdrop):
+ hidden_states = layer(
+ hidden_states, attention_mask=attention_mask, sub_sampled_lengths=sub_sampled_lengths
+ )
+
+ return hidden_states
+
+
+class Wav2Vec2BertAdapterLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ embed_dim = config.output_hidden_size
+ dropout = config.conformer_conv_dropout
+
+ self.kernel_size = config.adapter_kernel_size
+ self.stride = config.adapter_stride
+
+ # 1. residual convolution
+ self.residual_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.residual_conv = nn.Conv1d(
+ embed_dim,
+ 2 * embed_dim,
+ self.kernel_size,
+ stride=self.stride,
+ padding=self.stride // 2,
+ )
+ self.activation = nn.GLU(dim=1)
+
+ # Self-Attention
+ self.self_attn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.self_attn_conv = nn.Conv1d(
+ embed_dim,
+ 2 * embed_dim,
+ self.kernel_size,
+ stride=self.stride,
+ padding=self.stride // 2,
+ )
+ self.self_attn = Wav2Vec2BertSelfAttention(config, is_adapter_attention=True)
+ self.self_attn_dropout = nn.Dropout(dropout)
+
+ # Feed-forward
+ self.ffn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn = Wav2Vec2BertFeedForward(config, act_fn=config.adapter_act, hidden_size=embed_dim)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ sub_sampled_lengths: Optional[torch.Tensor] = None,
+ ):
+ residual = self.residual_layer_norm(hidden_states)
+
+ # Apply pooling to the residual to match the sequence length of the
+ # multi-head attention output.
+ # (batch, seq_len, feature_dim) -> (batch, feature_dim, seq_len)
+ residual = residual.transpose(1, 2)
+ residual = self.residual_conv(residual)
+ residual = self.activation(residual)
+ # (batch, feature_dim, seq_len) -> (batch, seq_len, feature_dim)
+ residual = residual.transpose(1, 2)
+
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ # Apply pooling before feeding to the multihead-attention layer.
+ # (batch, seq_len, feature_dim) -> (batch, feature_dim, seq_len)
+ hidden_states = hidden_states.transpose(1, 2)
+ hidden_states = self.self_attn_conv(hidden_states)
+ hidden_states = self.activation(hidden_states)
+ # (batch, feature_dim, seq_len) -> (batch, seq_len, feature_dim)
+ hidden_states = hidden_states.transpose(1, 2)
+
+ if attention_mask is not None:
+ attention_mask = _compute_new_attention_mask(hidden_states=hidden_states, seq_lens=sub_sampled_lengths)
+ attention_mask = _prepare_4d_attention_mask(
+ attention_mask,
+ hidden_states.dtype,
+ )
+
+ # The rest of the computation is identical to a vanilla Transformer
+ # encoder layer.
+ hidden_states, attn_weigths = self.self_attn(
+ hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.self_attn_dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ residual = hidden_states
+
+ hidden_states = self.ffn_layer_norm(hidden_states)
+ hidden_states = self.ffn(hidden_states) + residual
+
+ return hidden_states
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerPreTrainedModel with Wav2Vec2Conformer->Wav2Vec2Bert,wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+class Wav2Vec2BertPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = Wav2Vec2BertConfig
+ base_model_prefix = "wav2vec2_bert"
+ main_input_name = "input_features"
+ supports_gradient_checkpointing = True
+
+ # Ignore copy
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, Wav2Vec2BertSelfAttention):
+ if hasattr(module, "pos_bias_u"):
+ nn.init.xavier_uniform_(module.pos_bias_u)
+ if hasattr(module, "pos_bias_v"):
+ nn.init.xavier_uniform_(module.pos_bias_v)
+ elif isinstance(module, Wav2Vec2BertFeatureProjection):
+ k = math.sqrt(1 / module.projection.in_features)
+ nn.init.uniform_(module.projection.weight, a=-k, b=k)
+ nn.init.uniform_(module.projection.bias, a=-k, b=k)
+ elif isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (nn.LayerNorm, nn.GroupNorm)):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, nn.Conv1d):
+ nn.init.kaiming_normal_(module.weight)
+
+ if module.bias is not None:
+ k = math.sqrt(module.groups / (module.in_channels * module.kernel_size[0]))
+ nn.init.uniform_(module.bias, a=-k, b=k)
+
+ # Ignore copy
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[torch.LongTensor, int], add_adapter: Optional[bool] = None
+ ):
+ """
+ Computes the output length of the convolutional layers
+ """
+
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
+ def _conv_out_length(input_length, kernel_size, stride, padding):
+ # 1D convolutional layer output length formula taken
+ # from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
+ return torch.div(input_length + 2 * padding - kernel_size, stride, rounding_mode="floor") + 1
+
+ if add_adapter:
+ padding = self.config.adapter_kernel_size // 2
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(
+ input_lengths, self.config.adapter_kernel_size, self.config.adapter_stride, padding
+ )
+
+ return input_lengths
+
+ def _get_feature_vector_attention_mask(
+ self, feature_vector_length: int, attention_mask: torch.LongTensor, add_adapter=None
+ ):
+ # Effectively attention_mask.sum(-1), but not inplace to be able to run
+ # on inference mode.
+ non_padded_lengths = attention_mask.cumsum(dim=-1)[:, -1]
+
+ output_lengths = self._get_feat_extract_output_lengths(non_padded_lengths, add_adapter=add_adapter)
+ output_lengths = output_lengths.to(torch.long)
+
+ batch_size = attention_mask.shape[0]
+
+ attention_mask = torch.zeros(
+ (batch_size, feature_vector_length), dtype=attention_mask.dtype, device=attention_mask.device
+ )
+ # these two operations makes sure that all values before the output lengths idxs are attended to
+ attention_mask[(torch.arange(attention_mask.shape[0], device=attention_mask.device), output_lengths - 1)] = 1
+ attention_mask = attention_mask.flip([-1]).cumsum(-1).flip([-1]).bool()
+ return attention_mask
+
+
+WAV2VEC2_BERT_START_DOCSTRING = r"""
+ Wav2Vec2Bert was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
+ Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
+ Auli.
+
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving etc.).
+
+ This model is a PyTorch [nn.Module](https://pytorch.org/docs/stable/nn.html#nn.Module) sub-class. Use it as a
+ regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
+
+ Parameters:
+ config ([`Wav2Vec2BertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+WAV2VEC2_BERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_features (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Float values of input raw speech waveform. Values can be obtained by loading a `.flac` or `.wav` audio file
+ into an array of type `List[float]` or a `numpy.ndarray`, *e.g.* via the soundfile library (`pip install
+ soundfile`). To prepare the array into `input_features`, the [`AutoProcessor`] should be used for padding and
+ conversion into a tensor of type `torch.FloatTensor`. See [`Wav2Vec2BertProcessor.__call__`] for details.
+ attention_mask (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing convolution and attention on padding token indices. Mask values selected in `[0,
+ 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Wav2Vec2Bert Model transformer outputting raw hidden-states without any specific head on top.",
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertModel(Wav2Vec2BertPreTrainedModel):
+ def __init__(self, config: Wav2Vec2BertConfig):
+ super().__init__(config)
+ self.config = config
+ self.feature_projection = Wav2Vec2BertFeatureProjection(config)
+
+ # model only needs masking vector if mask prob is > 0.0
+ if config.mask_time_prob > 0.0 or config.mask_feature_prob > 0.0:
+ self.masked_spec_embed = nn.Parameter(torch.FloatTensor(config.hidden_size).uniform_())
+
+ self.encoder = Wav2Vec2BertEncoder(config)
+
+ self.adapter = Wav2Vec2BertAdapter(config) if config.add_adapter else None
+
+ self.intermediate_ffn = None
+ if config.use_intermediate_ffn_before_adapter:
+ self.intermediate_ffn = Wav2Vec2BertFeedForward(config, act_fn="relu")
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2Model._mask_hidden_states
+ def _mask_hidden_states(
+ self,
+ hidden_states: torch.FloatTensor,
+ mask_time_indices: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.LongTensor] = None,
+ ):
+ """
+ Masks extracted features along time axis and/or along feature axis according to
+ [SpecAugment](https://arxiv.org/abs/1904.08779).
+ """
+
+ # `config.apply_spec_augment` can set masking to False
+ if not getattr(self.config, "apply_spec_augment", True):
+ return hidden_states
+
+ # generate indices & apply SpecAugment along time axis
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+
+ if mask_time_indices is not None:
+ # apply SpecAugment along time axis with given mask_time_indices
+ hidden_states[mask_time_indices] = self.masked_spec_embed.to(hidden_states.dtype)
+ elif self.config.mask_time_prob > 0 and self.training:
+ mask_time_indices = _compute_mask_indices(
+ (batch_size, sequence_length),
+ mask_prob=self.config.mask_time_prob,
+ mask_length=self.config.mask_time_length,
+ attention_mask=attention_mask,
+ min_masks=self.config.mask_time_min_masks,
+ )
+ mask_time_indices = torch.tensor(mask_time_indices, device=hidden_states.device, dtype=torch.bool)
+ hidden_states[mask_time_indices] = self.masked_spec_embed.to(hidden_states.dtype)
+
+ if self.config.mask_feature_prob > 0 and self.training:
+ # generate indices & apply SpecAugment along feature axis
+ mask_feature_indices = _compute_mask_indices(
+ (batch_size, hidden_size),
+ mask_prob=self.config.mask_feature_prob,
+ mask_length=self.config.mask_feature_length,
+ min_masks=self.config.mask_feature_min_masks,
+ )
+ mask_feature_indices = torch.tensor(mask_feature_indices, device=hidden_states.device, dtype=torch.bool)
+ mask_feature_indices = mask_feature_indices[:, None].expand(-1, sequence_length, -1)
+ hidden_states[mask_feature_indices] = 0
+
+ return hidden_states
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_PRETRAINED_CHECKPOINT_FOR_DOC,
+ output_type=Wav2Vec2BaseModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ mask_time_indices: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, Wav2Vec2BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ hidden_states, extract_features = self.feature_projection(input_features)
+ hidden_states = self._mask_hidden_states(
+ hidden_states, mask_time_indices=mask_time_indices, attention_mask=attention_mask
+ )
+
+ encoder_outputs = self.encoder(
+ hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+
+ if self.intermediate_ffn:
+ expanded_hidden_states = self.intermediate_ffn(hidden_states)
+ hidden_states = hidden_states + 0.5 * expanded_hidden_states
+
+ if self.adapter is not None:
+ hidden_states = self.adapter(hidden_states, attention_mask=attention_mask)
+
+ if not return_dict:
+ return (hidden_states, extract_features) + encoder_outputs[1:]
+
+ return Wav2Vec2BaseModelOutput(
+ last_hidden_state=hidden_states,
+ extract_features=extract_features,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """Wav2Vec2Bert Model with a `language modeling` head on top for Connectionist Temporal Classification (CTC).""",
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForCTC(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForCTC.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config, target_lang: Optional[str] = None):
+ super().__init__(config)
+
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ self.dropout = nn.Dropout(config.final_dropout)
+
+ self.target_lang = target_lang
+
+ if config.vocab_size is None:
+ raise ValueError(
+ f"You are trying to instantiate {self.__class__} with a configuration that "
+ "does not define the vocabulary size of the language model head. Please "
+ "instantiate the model as follows: `Wav2Vec2BertForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
+ "or define `vocab_size` of your model's configuration."
+ )
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_PRETRAINED_CHECKPOINT_FOR_DOC,
+ output_type=CausalLMOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_CTC_EXPECTED_OUTPUT,
+ expected_loss=_CTC_EXPECTED_LOSS,
+ )
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, CausalLMOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, target_length)`, *optional*):
+ Labels for connectionist temporal classification. Note that `target_length` has to be smaller or equal to
+ the sequence length of the output logits. Indices are selected in `[-100, 0, ..., config.vocab_size - 1]`.
+ All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ...,
+ config.vocab_size - 1]`.
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ hidden_states = self.dropout(hidden_states)
+
+ logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ if labels.max() >= self.config.vocab_size:
+ raise ValueError(f"Label values must be <= vocab_size: {self.config.vocab_size}")
+
+ # retrieve loss input_lengths from attention_mask
+ attention_mask = (
+ attention_mask
+ if attention_mask is not None
+ else torch.ones(input_features.shape[:2], device=input_features.device, dtype=torch.long)
+ )
+ input_lengths = self._get_feat_extract_output_lengths(attention_mask.sum([-1])).to(torch.long)
+
+ # assuming that padded tokens are filled with -100
+ # when not being attended to
+ labels_mask = labels >= 0
+ target_lengths = labels_mask.sum(-1)
+ flattened_targets = labels.masked_select(labels_mask)
+
+ # ctc_loss doesn't support fp16
+ log_probs = nn.functional.log_softmax(logits, dim=-1, dtype=torch.float32).transpose(0, 1)
+
+ with torch.backends.cudnn.flags(enabled=False):
+ loss = nn.functional.ctc_loss(
+ log_probs,
+ flattened_targets,
+ input_lengths,
+ target_lengths,
+ blank=self.config.pad_token_id,
+ reduction=self.config.ctc_loss_reduction,
+ zero_infinity=self.config.ctc_zero_infinity,
+ )
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return CausalLMOutput(
+ loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions
+ )
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with a sequence classification head on top (a linear layer over the pooled output) for
+ tasks like SUPERB Keyword Spotting.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForSequenceClassification(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForSequenceClassification.__init__ with Wav2Vec2->Wav2Vec2Bert,wav2vec2->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Wav2Vec2Bert adapters (config.add_adapter=True)"
+ )
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.projector = nn.Linear(config.hidden_size, config.classifier_proj_size)
+ self.classifier = nn.Linear(config.classifier_proj_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForSequenceClassification.forward with Wav2Vec2->Wav2Vec2Bert,wav2vec2->wav2vec2_bert,WAV_2_VEC_2->WAV2VEC2_BERT, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ hidden_states = self.projector(hidden_states)
+ if attention_mask is None:
+ pooled_output = hidden_states.mean(dim=1)
+ else:
+ padding_mask = self._get_feature_vector_attention_mask(hidden_states.shape[1], attention_mask)
+ hidden_states[~padding_mask] = 0.0
+ pooled_output = hidden_states.sum(dim=1) / padding_mask.sum(dim=1).view(-1, 1)
+
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with a frame classification head on top for tasks like Speaker Diarization.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForAudioFrameClassification(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of Wav2Vec2Bert adapters (config.add_adapter=True)"
+ )
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+ self.num_labels = config.num_labels
+
+ self.init_weights()
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.freeze_base_model with wav2vec2_conformer->wav2vec2_bert
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=TokenClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.forward with wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, TokenClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ logits = self.classifier(hidden_states)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), torch.argmax(labels.view(-1, self.num_labels), axis=1))
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2.AMSoftmaxLoss
+class AMSoftmaxLoss(nn.Module):
+ def __init__(self, input_dim, num_labels, scale=30.0, margin=0.4):
+ super(AMSoftmaxLoss, self).__init__()
+ self.scale = scale
+ self.margin = margin
+ self.num_labels = num_labels
+ self.weight = nn.Parameter(torch.randn(input_dim, num_labels), requires_grad=True)
+ self.loss = nn.CrossEntropyLoss()
+
+ def forward(self, hidden_states, labels):
+ labels = labels.flatten()
+ weight = nn.functional.normalize(self.weight, dim=0)
+ hidden_states = nn.functional.normalize(hidden_states, dim=1)
+ cos_theta = torch.mm(hidden_states, weight)
+ psi = cos_theta - self.margin
+
+ onehot = nn.functional.one_hot(labels, self.num_labels)
+ logits = self.scale * torch.where(onehot.bool(), psi, cos_theta)
+ loss = self.loss(logits, labels)
+
+ return loss
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2.TDNNLayer
+class TDNNLayer(nn.Module):
+ def __init__(self, config, layer_id=0):
+ super().__init__()
+ self.in_conv_dim = config.tdnn_dim[layer_id - 1] if layer_id > 0 else config.tdnn_dim[layer_id]
+ self.out_conv_dim = config.tdnn_dim[layer_id]
+ self.kernel_size = config.tdnn_kernel[layer_id]
+ self.dilation = config.tdnn_dilation[layer_id]
+
+ self.kernel = nn.Linear(self.in_conv_dim * self.kernel_size, self.out_conv_dim)
+ self.activation = nn.ReLU()
+
+ def forward(self, hidden_states):
+ hidden_states = hidden_states.unsqueeze(1)
+ hidden_states = nn.functional.unfold(
+ hidden_states,
+ (self.kernel_size, self.in_conv_dim),
+ stride=(1, self.in_conv_dim),
+ dilation=(self.dilation, 1),
+ )
+ hidden_states = hidden_states.transpose(1, 2)
+ hidden_states = self.kernel(hidden_states)
+
+ hidden_states = self.activation(hidden_states)
+ return hidden_states
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with an XVector feature extraction head on top for tasks like Speaker Verification.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForXVector(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.projector = nn.Linear(config.hidden_size, config.tdnn_dim[0])
+
+ tdnn_layers = [TDNNLayer(config, i) for i in range(len(config.tdnn_dim))]
+ self.tdnn = nn.ModuleList(tdnn_layers)
+
+ self.feature_extractor = nn.Linear(config.tdnn_dim[-1] * 2, config.xvector_output_dim)
+ self.classifier = nn.Linear(config.xvector_output_dim, config.xvector_output_dim)
+
+ self.objective = AMSoftmaxLoss(config.xvector_output_dim, config.num_labels)
+
+ self.init_weights()
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.freeze_base_model with wav2vec2_conformer->wav2vec2_bert
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector._get_tdnn_output_lengths
+ def _get_tdnn_output_lengths(self, input_lengths: Union[torch.LongTensor, int]):
+ """
+ Computes the output length of the TDNN layers
+ """
+
+ def _conv_out_length(input_length, kernel_size, stride):
+ # 1D convolutional layer output length formula taken
+ # from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
+ return (input_length - kernel_size) // stride + 1
+
+ for kernel_size in self.config.tdnn_kernel:
+ input_lengths = _conv_out_length(input_lengths, kernel_size, 1)
+
+ return input_lengths
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=XVectorOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.forward with wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, XVectorOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ hidden_states = self.projector(hidden_states)
+
+ for tdnn_layer in self.tdnn:
+ hidden_states = tdnn_layer(hidden_states)
+
+ # Statistic Pooling
+ if attention_mask is None:
+ mean_features = hidden_states.mean(dim=1)
+ std_features = hidden_states.std(dim=1)
+ else:
+ feat_extract_output_lengths = self._get_feat_extract_output_lengths(attention_mask.sum(dim=1))
+ tdnn_output_lengths = self._get_tdnn_output_lengths(feat_extract_output_lengths)
+ mean_features = []
+ std_features = []
+ for i, length in enumerate(tdnn_output_lengths):
+ mean_features.append(hidden_states[i, :length].mean(dim=0))
+ std_features.append(hidden_states[i, :length].std(dim=0))
+ mean_features = torch.stack(mean_features)
+ std_features = torch.stack(std_features)
+ statistic_pooling = torch.cat([mean_features, std_features], dim=-1)
+
+ output_embeddings = self.feature_extractor(statistic_pooling)
+ logits = self.classifier(output_embeddings)
+
+ loss = None
+ if labels is not None:
+ loss = self.objective(logits, labels)
+
+ if not return_dict:
+ output = (logits, output_embeddings) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return XVectorOutput(
+ loss=loss,
+ logits=logits,
+ embeddings=output_embeddings,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py
new file mode 100644
index 00000000000000..ec792ce75a0248
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py
@@ -0,0 +1,145 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Speech processor class for Wav2Vec2-BERT
+"""
+import warnings
+
+from ...processing_utils import ProcessorMixin
+from ..seamless_m4t.feature_extraction_seamless_m4t import SeamlessM4TFeatureExtractor
+from ..wav2vec2.tokenization_wav2vec2 import Wav2Vec2CTCTokenizer
+
+
+class Wav2Vec2BertProcessor(ProcessorMixin):
+ r"""
+ Constructs a Wav2Vec2-BERT processor which wraps a Wav2Vec2-BERT feature extractor and a Wav2Vec2 CTC tokenizer into a single
+ processor.
+
+ [`Wav2Vec2Processor`] offers all the functionalities of [`SeamlessM4TFeatureExtractor`] and [`PreTrainedTokenizer`].
+ See the docstring of [`~Wav2Vec2Processor.__call__`] and [`~Wav2Vec2Processor.decode`] for more information.
+
+ Args:
+ feature_extractor (`SeamlessM4TFeatureExtractor`):
+ An instance of [`SeamlessM4TFeatureExtractor`]. The feature extractor is a required input.
+ tokenizer ([`PreTrainedTokenizer`]):
+ An instance of [`PreTrainedTokenizer`]. The tokenizer is a required input.
+ """
+
+ feature_extractor_class = "SeamlessM4TFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer):
+ super().__init__(feature_extractor, tokenizer)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ try:
+ return super().from_pretrained(pretrained_model_name_or_path, **kwargs)
+ except OSError:
+ warnings.warn(
+ f"Loading a tokenizer inside {cls.__name__} from a config that does not"
+ " include a `tokenizer_class` attribute is deprecated and will be "
+ "removed in v5. Please add `'tokenizer_class': 'Wav2Vec2CTCTokenizer'`"
+ " attribute to either your `config.json` or `tokenizer_config.json` "
+ "file to suppress this warning: ",
+ FutureWarning,
+ )
+
+ feature_extractor = SeamlessM4TFeatureExtractor.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
+
+ return cls(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ def __call__(self, audio=None, text=None, **kwargs):
+ """
+ Main method to prepare for the model one or several sequences(s) and audio(s). This method forwards the `audio`
+ and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.__call__`] if `audio` is not
+ `None` to pre-process the audio. To prepare the target sequences(s), this method forwards the `text` and `kwargs` arguments to
+ PreTrainedTokenizer's [`~PreTrainedTokenizer.__call__`] if `text` is not `None`. Please refer to the doctsring of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ audio (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The audio or batch of audios to be prepared. Each audio can be NumPy array or PyTorch tensor. In case
+ of a NumPy array/PyTorch tensor, each audio should be of shape (C, T), where C is a number of channels,
+ and T the sample length of the audio.
+ kwargs (*optional*):
+ Remaining dictionary of keyword arguments that will be passed to the feature extractor and/or the
+ tokenizer.
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+ - **input_features** -- Audio input features to be fed to a model. Returned when `audio` is not `None`.
+ - **attention_mask** -- List of indices specifying which timestamps should be attended to by the model when `audio` is not `None`.
+ When only `text` is specified, returns the token attention mask.
+ - **labels** -- List of token ids to be fed to a model. Returned when both `text` and `audio` are not `None`.
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None` and `audio` is `None`.
+ """
+
+ sampling_rate = kwargs.pop("sampling_rate", None)
+
+ if audio is None and text is None:
+ raise ValueError("You need to specify either an `audio` or `text` input to process.")
+
+ if audio is not None:
+ inputs = self.feature_extractor(audio, sampling_rate=sampling_rate, **kwargs)
+ if text is not None:
+ encodings = self.tokenizer(text, **kwargs)
+
+ if text is None:
+ return inputs
+ elif audio is None:
+ return encodings
+ else:
+ inputs["labels"] = encodings["input_ids"]
+ return inputs
+
+ def pad(self, input_features=None, labels=None, **kwargs):
+ """
+ If `input_features` is not `None`, this method forwards the `input_features` and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.pad`] to pad the input features.
+ If `labels` is not `None`, this method forwards the `labels` and `kwargs` arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.pad`] to pad the label(s).
+ Please refer to the doctsring of the above two methods for more information.
+ """
+ if input_features is None and labels is None:
+ raise ValueError("You need to specify either an `input_features` or `labels` input to pad.")
+
+ if input_features is not None:
+ input_features = self.feature_extractor.pad(input_features, **kwargs)
+ if labels is not None:
+ labels = self.tokenizer.pad(labels, **kwargs)
+
+ if labels is None:
+ return input_features
+ elif input_features is None:
+ return labels
+ else:
+ input_features["labels"] = labels["input_ids"]
+ return input_features
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer
+ to the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/transformers/models/whisper/generation_whisper.py b/src/transformers/models/whisper/generation_whisper.py
new file mode 100644
index 00000000000000..c45fffb984b113
--- /dev/null
+++ b/src/transformers/models/whisper/generation_whisper.py
@@ -0,0 +1,1493 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import math
+import warnings
+import zlib
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ...generation.configuration_utils import GenerationConfig
+from ...generation.logits_process import (
+ ForceTokensLogitsProcessor,
+ LogitsProcessorList,
+ SuppressTokensAtBeginLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+ WhisperNoSpeechDetection,
+ WhisperTimeStampLogitsProcessor,
+)
+from ...generation.stopping_criteria import StoppingCriteriaList
+from ...modeling_outputs import BaseModelOutput
+from ...utils import logging
+from .tokenization_whisper import TASK_IDS, TO_LANGUAGE_CODE
+
+
+logger = logging.get_logger(__name__)
+
+
+def _median_filter(inputs: torch.Tensor, filter_width: int) -> torch.Tensor:
+ """
+ Applies a median filter of width `filter_width` along the last dimension of the input.
+
+ The `inputs` tensor is assumed to be 3- or 4-dimensional.
+ """
+ if filter_width <= 0 or filter_width % 2 != 1:
+ raise ValueError("`filter_width` should be an odd number")
+
+ pad_width = filter_width // 2
+ if inputs.shape[-1] <= pad_width:
+ return inputs
+
+ # Pad the left and right edges.
+ inputs = nn.functional.pad(inputs, (pad_width, pad_width, 0, 0), mode="reflect")
+
+ # sort() is faster than torch.median (https://github.com/pytorch/pytorch/issues/51450)
+ result = inputs.unfold(-1, filter_width, 1).sort()[0][..., pad_width]
+ return result
+
+
+def _dynamic_time_warping(matrix: np.ndarray):
+ """
+ Measures similarity between two temporal sequences: the input audio and the output tokens. Used to generate
+ token-level timestamps.
+ """
+ output_length, input_length = matrix.shape
+ cost = np.ones((output_length + 1, input_length + 1), dtype=np.float32) * np.inf
+ trace = -np.ones((output_length + 1, input_length + 1), dtype=np.float32)
+
+ cost[0, 0] = 0
+ for j in range(1, input_length + 1):
+ for i in range(1, output_length + 1):
+ c0 = cost[i - 1, j - 1]
+ c1 = cost[i - 1, j]
+ c2 = cost[i, j - 1]
+
+ if c0 < c1 and c0 < c2:
+ c, t = c0, 0
+ elif c1 < c0 and c1 < c2:
+ c, t = c1, 1
+ else:
+ c, t = c2, 2
+
+ cost[i, j] = matrix[i - 1, j - 1] + c
+ trace[i, j] = t
+
+ # backtrace
+ i = trace.shape[0] - 1
+ j = trace.shape[1] - 1
+ trace[0, :] = 2
+ trace[:, 0] = 1
+
+ text_indices = []
+ time_indices = []
+ while i > 0 or j > 0:
+ text_indices.append(i - 1)
+ time_indices.append(j - 1)
+ if trace[i, j] == 0:
+ i -= 1
+ j -= 1
+ elif trace[i, j] == 1:
+ i -= 1
+ elif trace[i, j] == 2:
+ j -= 1
+ else:
+ raise RuntimeError(
+ f"Internal error in dynamic time warping. Unexpected trace[{i}, {j}]. Please file a bug report."
+ )
+
+ text_indices = np.array(text_indices)[::-1]
+ time_indices = np.array(time_indices)[::-1]
+ return text_indices, time_indices
+
+
+def _get_attr_from_logit_processors(logits_processor, logit_processor_class, attribute_name):
+ logit_processor = next((cls for cls in logits_processor if isinstance(cls, logit_processor_class)), None)
+ if logit_processor:
+ return getattr(logit_processor, attribute_name, None)
+ return None
+
+
+def _pad_to_max_length(current_segments, pad_token_id, padding="right", bos_token_tensor=None, cut_off_length=None):
+ max_total_length = 0
+ sequences = []
+ if padding not in ["right", "left"]:
+ raise ValueError(f"`padding` must be either 'right' or 'left', not {padding}")
+
+ for current_segment_list in current_segments:
+ if current_segment_list is not None and len([d["tokens"] for d in current_segment_list]) > 0:
+ sequence = torch.cat([d["tokens"] for d in current_segment_list], dim=-1)
+
+ if cut_off_length is not None:
+ sequence = sequence[-cut_off_length:]
+
+ if bos_token_tensor is not None:
+ sequence = torch.cat([bos_token_tensor, sequence])
+
+ sequences.append(sequence)
+ max_total_length = max(max_total_length, len(sequences[-1]))
+ else:
+ sequences.append(bos_token_tensor)
+
+ for i in range(len(current_segments)):
+ pad_length = max_total_length - len(sequences[i])
+ pad = (0, pad_length) if padding == "right" else (pad_length, 0)
+ sequences[i] = F.pad(sequences[i], pad=pad, value=pad_token_id)
+
+ sequences = torch.stack(sequences, dim=0)
+ return sequences
+
+
+class WhisperGenerationMixin:
+ def _extract_token_timestamps(self, generate_outputs, alignment_heads, time_precision=0.02, num_frames=None):
+ """
+ Calculates token-level timestamps using the encoder-decoder cross-attentions and dynamic time-warping (DTW) to
+ map each output token to a position in the input audio. If `num_frames` is specified, the encoder-decoder
+ cross-attentions will be cropped before applying DTW.
+
+ Returns:
+ tensor containing the timestamps in seconds for each predicted token
+ """
+ # Create a list with `decoder_layers` elements, each a tensor of shape
+ # (batch size, attention_heads, output length, input length).
+ cross_attentions = []
+ for i in range(self.config.decoder_layers):
+ cross_attentions.append(torch.cat([x[i] for x in generate_outputs.cross_attentions], dim=2))
+
+ # Select specific cross-attention layers and heads. This is a tensor
+ # of shape (batch size, num selected, output length, input length).
+ weights = torch.stack([cross_attentions[l][:, h] for l, h in alignment_heads])
+ weights = weights.permute([1, 0, 2, 3])
+
+ if "beam_indices" in generate_outputs:
+ # If beam search has been used, the output sequences may have been generated for more timesteps than their sequence_lengths
+ # since the beam search strategy chooses the most probable sequences at the end of the search.
+ # In that case, the cross_attentions weights are too long and we have to make sure that they have the right output_length
+ weight_length = (generate_outputs.beam_indices != -1).sum(-1).max()
+ weights = weights[:, :, :weight_length]
+
+ # If beam index is still -1, it means that the associated token id is EOS
+ # We need to replace the index with 0 since index_select gives an error if any of the indexes is -1.
+ beam_indices = generate_outputs.beam_indices[:, :weight_length]
+ beam_indices = beam_indices.masked_fill(beam_indices == -1, 0)
+
+ # Select the cross attention from the right beam for each output sequences
+ weights = torch.stack(
+ [
+ torch.index_select(weights[:, :, i, :], dim=0, index=beam_indices[:, i])
+ for i in range(beam_indices.shape[1])
+ ],
+ dim=2,
+ )
+
+ timestamps = torch.zeros_like(generate_outputs.sequences, dtype=torch.float32)
+ batch_size = timestamps.shape[0]
+
+ if num_frames is not None:
+ # two cases:
+ # 1. num_frames is the same for each sample -> compute the DTW matrix for each sample in parallel
+ # 2. num_frames is different, compute the DTW matrix for each sample sequentially
+
+ # we're using np.unique because num_frames can be int/list/tuple
+ if len(np.unique(num_frames)) == 1:
+ # if num_frames is the same, no need to recompute matrix, std and mean for each element of the batch
+ num_frames = num_frames if isinstance(num_frames, int) else num_frames[0]
+
+ weights = weights[..., : num_frames // 2]
+ else:
+ # num_frames is of shape (batch_size,) whereas batch_size is truely batch_size*num_return_sequences
+ repeat_time = batch_size if isinstance(num_frames, int) else batch_size // len(num_frames)
+ num_frames = np.repeat(num_frames, repeat_time)
+
+ if num_frames is None or isinstance(num_frames, int):
+ # Normalize and smoothen the weights.
+ std = torch.std(weights, dim=-2, keepdim=True, unbiased=False)
+ mean = torch.mean(weights, dim=-2, keepdim=True)
+ weights = (weights - mean) / std
+ weights = _median_filter(weights, self.config.median_filter_width)
+
+ # Average the different cross-attention heads.
+ weights = weights.mean(dim=1)
+
+ # Perform dynamic time warping on each element of the batch.
+ for batch_idx in range(batch_size):
+ if num_frames is not None and isinstance(num_frames, (tuple, list, np.ndarray)):
+ matrix = weights[batch_idx, ..., : num_frames[batch_idx] // 2]
+
+ # Normalize and smoothen the weights.
+ std = torch.std(matrix, dim=-2, keepdim=True, unbiased=False)
+ mean = torch.mean(matrix, dim=-2, keepdim=True)
+ matrix = (matrix - mean) / std
+ matrix = _median_filter(matrix, self.config.median_filter_width)
+
+ # Average the different cross-attention heads.
+ matrix = matrix.mean(dim=0)
+ else:
+ matrix = weights[batch_idx]
+
+ text_indices, time_indices = _dynamic_time_warping(-matrix.cpu().double().numpy())
+ jumps = np.pad(np.diff(text_indices), (1, 0), constant_values=1).astype(bool)
+ jump_times = time_indices[jumps] * time_precision
+ timestamps[batch_idx, 1:] = torch.tensor(jump_times)
+
+ return timestamps
+
+ def generate(
+ self,
+ input_features: Optional[torch.Tensor] = None,
+ generation_config: Optional[GenerationConfig] = None,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
+ synced_gpus: bool = False,
+ return_timestamps: Optional[bool] = None,
+ task: Optional[str] = None,
+ language: Optional[str] = None,
+ is_multilingual: Optional[bool] = None,
+ prompt_ids: Optional[torch.Tensor] = None,
+ condition_on_prev_tokens: Optional[bool] = None,
+ temperature: Optional[Union[float, Tuple[float, ...]]] = None,
+ compression_ratio_threshold: Optional[float] = None,
+ logprob_threshold: Optional[float] = None,
+ no_speech_threshold: Optional[float] = None,
+ num_segment_frames: Optional[int] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ time_precision: float = 0.02,
+ return_token_timestamps: Optional[bool] = None,
+ return_segments: bool = False,
+ return_dict_in_generate: Optional[bool] = None,
+ **kwargs,
+ ):
+ """
+ Transcribes or translates log-mel input features to a sequence of auto-regressively generated token ids.
+
+
+
+ Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
+ model's default generation configuration. You can override any `generation_config` by passing the corresponding
+ parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
+
+ For an overview of generation strategies and code examples, check out the [following
+ guide](./generation_strategies).
+
+
+
+ Parameters:
+ input_features (`torch.Tensor` of shape `(batch_size, feature_size, sequence_length)`, *optional*):
+ Float values of log-mel features extracted from the raw speech waveform. The raw speech waveform can be obtained by
+ loading a `.flac` or `.wav` audio file into an array of type `List[float]` or a `numpy.ndarray`, *e.g.* via
+ the soundfile library (`pip install soundfile`). To prepare the array into `input_features`, the
+ [`AutoFeatureExtractor`] should be used for extracting the mel features, padding and conversion into a
+ tensor of type `torch.FloatTensor`. See [`~WhisperFeatureExtractor.__call__`] for details.
+ generation_config (`~generation.GenerationConfig`, *optional*):
+ The generation configuration to be used as base parametrization for the generation call. `**kwargs`
+ passed to generate matching the attributes of `generation_config` will override them. If
+ `generation_config` is not provided, the default will be used, which had the following loading
+ priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
+ configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
+ default values, whose documentation should be checked to parameterize generation.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ Custom logits processors that complement the default logits processors built from arguments and
+ generation config. If a logit processor is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ Custom stopping criteria that complement the default stopping criteria built from arguments and a
+ generation config. If a stopping criteria is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
+ If provided, this function constraints the beam search to allowed tokens only at each step. If not
+ provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
+ `input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
+ on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
+ for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
+ Retrieval](https://arxiv.org/abs/2010.00904).
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ return_timestamps (`bool`, *optional*):
+ Whether to return the timestamps with the text. This enables the `WhisperTimestampsLogitsProcessor`.
+ task (`str`, *optional*):
+ Task to use for generation, either "translate" or "transcribe". The `model.config.forced_decoder_ids`
+ will be updated accordingly.
+ language (`str`, *optional*):
+ Language token to use for generation, can be either in the form of `<|en|>`, `en` or `english`. You can
+ find all the possible language tokens in the `model.generation_config.lang_to_id` dictionary.
+ is_multilingual (`bool`, *optional*):
+ Whether or not the model is multilingual.
+ prompt_ids (`torch.Tensor`, *optional*):
+ Rank-1 tensor of token IDs created by passing text to [`~WhisperProcessor.get_prompt_ids`] that is
+ provided as a prompt to each chunk. This can be used to provide or "prompt-engineer" a context for
+ transcription, e.g. custom vocabularies or proper nouns to make it more likely to predict those words
+ correctly. It cannot be used in conjunction with `decoder_start_token_id` as it overwrites this value.
+ condition_on_prev_tokens (`bool`, *optional*):
+ Only relevant for long-form transcription. Whether to condition each segment on the previous segment.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ temperature (`float` or list of `float`, *optional*):
+ The temperature to be used for generation. Passing a single `float` value and `do_sample=True` activates
+ generation using sampling. For long-form transcription, temperature fallback can be activated by passing
+ a list of float values such as (0.0, 0.2, 0.4, 0.6, 0.8, 1.0). As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ compression_ratio_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the zlib compression rate of each segment will be computed. If the compression rate of
+ a segment is higher than `compression_ratio_threshold`, temperature fallback is activated: the generated segment is discarded and the generation is
+ repeated using a higher temperature. The intuition behind this feature is that segments with very high compression rates
+ suffer from a lot of repetition. The unwanted repetition can be reduced by injecting more randomness by increasing the temperature. If `compression_ratio_threshold` is defined
+ make sure that `temperature` is a list of values. A common value for `compression_ratio_threshold` is 1.35.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ logprob_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the average log-probability of each segment will be computed. If the log-probability of
+ a given segment is lower than `logprob_threshold`, temperature fallback is activated: the generated segment is discarded and the generation is
+ repeated using a higher temperature. The intuition behind this feature is that segments of low log-probability
+ can be improved by injecting more randomness by increasing the temperature. If `logprob_threshold` is defined
+ make sure that `temperature` is a list of values. A common value for `logprob_threshold` is -1.0.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ no_speech_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the "no-speech" token combined with the `logprob_threshold`
+ is used to determine whether a segment contains only silence. In this case, the transcription for this segment
+ is skipped.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ num_segment_frames (`int`, *optional*):
+ The number of frames a single segment is made of. If not defined, `num_segment_frames` defaults to the model's stride
+ times the maximum input length.
+ attention_mask (`torch.Tensor`, *optional*):
+ `attention_mask` needs to be passed when doing long-form transcription using a batch size > 1.
+ time_precision (`int`, *optional*, defaults to 0.02):
+ The duration of output token in seconds. *E.g.* 0.02 means that a generated token on average accounts
+ for 20 ms.
+ return_token_timestamps (`bool`, *optional*):
+ Whether to return token-level timestamps with the text. This can be used with or without the
+ `return_timestamps` option. To get word-level timestamps, use the tokenizer to group the tokens into
+ words.
+ return_segments (`bool`, *optional*, defaults to `False`):
+ Whether to additionally return a list of all segments. Note that this option can only be enabled
+ when doing long-form transcription.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of just returning the generated tokens.
+ Note that when doing long-form transcription, `return_dict_in_generate` can only be enabled when
+ `return_segments` is set True. In this case the generation outputs of each segment is added to each
+ segment.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
+ forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
+ specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
+
+ Return:
+ [`~utils.ModelOutput`] or `torch.LongTensor` or `Dict[str, Any]`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
+ or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor` or a dict of segments when `return_segments=True`.
+
+ If the passed input is > 30 seconds / > 3000 mel input features and `return_segments=True` then a dictionary of generated sequence ids, called `sequences` and a list of each generated segment is returned.
+
+ else if the passed input is <= 30 seconds / >= 3000 mel input features, the possible [`~utils.ModelOutput`] types are:
+
+ - [`~generation.GenerateEncoderDecoderOutput`],
+ - [`~generation.GenerateBeamEncoderDecoderOutput`]
+
+ else only the generated output sequence ids are returned.
+
+ Example:
+
+ - *Longform transcription*: To transcribe or translate audios longer than 30 seconds, process the audio files without truncation and pass all mel features at once to generate.
+
+ ```python
+ >>> import torch
+ >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
+ >>> from datasets import load_dataset, Audio
+
+ >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
+ >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ >>> model.cuda()
+
+ >>> # load audios > 30 seconds
+ >>> ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
+ >>> # resample to 16kHz
+ >>> ds = ds.cast_column("audio", Audio(sampling_rate=16000))
+ >>> # take first 8 audios and retrieve array
+ >>> audio = ds[:8]["audio"]
+ >>> audio = [x["array"] for x in audio]
+
+ >>> # make sure to NOT truncate the input audio, to return the `attention_mask` and to pad to the longest audio
+ >>> inputs = processor(audio, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True, sampling_rate=16_000)
+ >>> inputs = inputs.to("cuda", torch.float32)
+
+ >>> # transcribe audio to ids
+ >>> generated_ids = model.generate(**inputs)
+
+ >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ >>> transcription[0]
+ ' Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!'
+ ```
+
+ - *Shortform transcription*: If passed mel input features are < 30 seconds, the whole audio will be transcribed with a single call to generate.
+
+ ```python
+ >>> import torch
+ >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
+ >>> from datasets import load_dataset
+
+ >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
+ >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+
+ >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+
+ >>> inputs = processor(ds[0]["audio"]["array"], return_tensors="pt")
+ >>> input_features = inputs.input_features
+
+ >>> generated_ids = model.generate(inputs=input_features)
+
+ >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+ >>> transcription
+ ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
+ ```
+
+ """
+ # 0. deprecate old inputs
+ if "inputs" in kwargs:
+ input_features = kwargs.pop("inputs")
+ warnings.warn(
+ "The input name `inputs` is deprecated. Please make sure to use `input_features` instead.",
+ FutureWarning,
+ )
+ # 1. copy generation config
+ if generation_config is None:
+ generation_config = copy.deepcopy(self.generation_config)
+ else:
+ generation_config = copy.deepcopy(generation_config)
+
+ # 2. set global generate variables
+ input_stride = self.model.encoder.conv1.stride[0] * self.model.encoder.conv2.stride[0]
+ num_segment_frames = input_stride * self.config.max_source_positions
+ total_input_frames = self._retrieve_total_input_frames(
+ input_features=input_features, input_stride=input_stride, kwargs=kwargs
+ )
+ is_shortform = total_input_frames <= num_segment_frames
+
+ if is_shortform:
+ # warn user of ignored inputs
+ self._maybe_warn_unused_inputs(
+ condition_on_prev_tokens=condition_on_prev_tokens,
+ temperature=temperature,
+ compression_ratio_threshold=compression_ratio_threshold,
+ logprob_threshold=logprob_threshold,
+ no_speech_threshold=no_speech_threshold,
+ total_input_frames=total_input_frames,
+ )
+
+ # 3. Make sure generation config is correctly set
+ # Make sure the generation config is correctly set depending on whether timestamps are to be returned or not
+ self._set_return_outputs(
+ return_dict_in_generate=return_dict_in_generate,
+ return_token_timestamps=return_token_timestamps,
+ is_shortform=is_shortform,
+ logprob_threshold=logprob_threshold,
+ generation_config=generation_config,
+ )
+ self._set_return_timestamps(
+ return_timestamps=return_timestamps, is_shortform=is_shortform, generation_config=generation_config
+ )
+ self._set_language_and_task(
+ language=language, task=task, is_multilingual=is_multilingual, generation_config=generation_config
+ )
+ # pass self.config for backward compatibility
+ self._set_forced_decoder_ids(
+ task=task,
+ language=language,
+ prompt_ids=prompt_ids,
+ generation_config=generation_config,
+ config=self.config,
+ kwargs=kwargs,
+ )
+ self._set_token_ids(generation_config=generation_config, config=self.config, kwargs=kwargs)
+ self._set_num_frames(
+ return_token_timestamps=return_token_timestamps, generation_config=generation_config, kwargs=kwargs
+ )
+ self._set_thresholds_and_condition(
+ generation_config=generation_config,
+ logprob_threshold=logprob_threshold,
+ compression_ratio_threshold=compression_ratio_threshold,
+ no_speech_threshold=no_speech_threshold,
+ condition_on_prev_tokens=condition_on_prev_tokens,
+ )
+
+ # 4. Retrieve logits processors
+ logits_processor = self._retrieve_logit_processors(
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ no_speech_threshold=no_speech_threshold,
+ is_shortform=is_shortform,
+ num_beams=kwargs.get("num_beams", 1),
+ )
+
+ # 5. If we're in shortform mode, simple generate the whole input at once and return the output
+ if is_shortform:
+ if temperature is not None:
+ kwargs["temperature"] = temperature
+
+ outputs = super().generate(
+ input_features,
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ synced_gpus=synced_gpus,
+ **kwargs,
+ )
+
+ if generation_config.return_token_timestamps and hasattr(generation_config, "alignment_heads"):
+ outputs["token_timestamps"] = self._extract_token_timestamps(
+ outputs, generation_config.alignment_heads, num_frames=generation_config.num_frames
+ )
+
+ return outputs
+
+ # 6. Else we're in longform mode which is more complex.
+ # We need to chunk the audio input depending on when the model generates timestamp tokens
+
+ # 6.1 Set and retrieve global longform generation variables
+ self._set_condition_on_prev_tokens(
+ condition_on_prev_tokens=condition_on_prev_tokens, generation_config=generation_config
+ )
+
+ timestamp_begin = generation_config.no_timestamps_token_id + 1
+ temperatures = [temperature] if not isinstance(temperature, (list, tuple)) else temperature
+ temperature = temperatures[0]
+ batch_size = input_features.shape[0]
+
+ max_frames, seek = self._retrieve_max_frames_and_seek(
+ batch_size=batch_size, attention_mask=attention_mask, total_input_frames=total_input_frames
+ )
+ init_tokens = self._retrieve_init_tokens_from_forced_decoder_ids(generation_config=generation_config)
+
+ # 6.2 Preppare running variables, list for generation
+ cur_bsz = batch_size
+ current_segments = [[] for _ in range(batch_size)]
+ batch_idx_map = list(range(batch_size))
+ do_condition_on_prev_tokens = [condition_on_prev_tokens for _ in range(batch_size)]
+
+ # 6.2 Transcribe audio until we reach the end of all input audios
+ while (seek < max_frames).any():
+ # 6.3 NOTE: When in longform transcription mode and batch size > 1 we need to dynamically reduce the batch size during the loop
+ # in case one audio finished earlier than another one. Thus, we need to keep a table of "previous-index-2-current-index" in order
+ # to know which original audio is being decoded
+ # Set updated index map, duration of previously decoded chunks and number of max frames of current decoding chunk
+ input_features, cur_bsz, batch_idx_map = self._maybe_reduce_batch(
+ input_features=input_features,
+ seek=seek,
+ max_frames=max_frames,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ )
+ time_offset = seek * time_precision / input_stride
+ seek_num_frames = (max_frames - seek).clamp(max=num_segment_frames)
+
+ # 6.4 cut out next 30s segment from input features
+ segment_input = self._get_input_segment(
+ input_features=input_features,
+ seek=seek,
+ seek_num_frames=seek_num_frames,
+ num_segment_frames=num_segment_frames,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ )
+
+ # 6.5 prepare decoder input ids
+ suppress_tokens = _get_attr_from_logit_processors(
+ logits_processor, SuppressTokensLogitsProcessor, "suppress_tokens"
+ )
+ decoder_input_ids, kwargs = self._prepare_decoder_input_ids(
+ cur_bsz=cur_bsz,
+ init_tokens=init_tokens,
+ current_segments=current_segments,
+ batch_idx_map=batch_idx_map,
+ do_condition_on_prev_tokens=do_condition_on_prev_tokens,
+ generation_config=generation_config,
+ config=self.config,
+ device=segment_input.device,
+ suppress_tokens=suppress_tokens,
+ kwargs=kwargs,
+ )
+
+ # 6.6 set max new tokens or max length
+ kwargs = self._set_max_new_tokens_and_length(
+ config=self.config,
+ decoder_input_ids=decoder_input_ids,
+ generation_config=generation_config,
+ kwargs=kwargs,
+ )
+
+ # 6.7 Set current `begin_index` for all logit processors
+ for proc in logits_processor:
+ if hasattr(proc, "set_begin_index"):
+ proc.set_begin_index(decoder_input_ids.shape[-1])
+
+ # 6.8 Run generate with fallback
+ seek_sequences, seek_outputs, should_skip, do_condition_on_prev_tokens = self.generate_with_fallback(
+ segment_input=segment_input,
+ decoder_input_ids=decoder_input_ids,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ seek=seek,
+ num_segment_frames=num_segment_frames,
+ max_frames=max_frames,
+ temperatures=temperatures,
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ synced_gpus=synced_gpus,
+ return_token_timestamps=return_token_timestamps,
+ do_condition_on_prev_tokens=do_condition_on_prev_tokens,
+ kwargs=kwargs,
+ )
+
+ # 6.9 In every generated sequence, split by timestamp tokens and extract segments
+ for i, seek_sequence in enumerate(seek_sequences):
+ prev_i = batch_idx_map[i]
+
+ if should_skip[i]:
+ seek[prev_i] += seek_num_frames[prev_i]
+ continue
+
+ segments, segment_offset = self._retrieve_segment(
+ seek_sequence=seek_sequence,
+ seek_outputs=seek_outputs,
+ time_offset=time_offset,
+ timestamp_begin=timestamp_begin,
+ seek_num_frames=seek_num_frames,
+ time_precision=time_precision,
+ input_stride=input_stride,
+ prev_idx=prev_i,
+ idx=i,
+ )
+
+ current_segments[prev_i] += segments
+ seek[prev_i] += segment_offset
+
+ # 7. Once all segments are added to the list of all segments, called `current_segments`, we extract the predicted
+ # output tokens from the list of dicts. If we use batch size > 1, we make sure to pad the output
+ sequences = _pad_to_max_length(current_segments, generation_config.pad_token_id, padding="right")
+
+ # 8. If we return all segments, the predicted output sequences are put under `"sequences"`.
+ if return_segments:
+ return {"sequences": sequences, "segments": current_segments}
+
+ return sequences
+
+ def generate_with_fallback(
+ self,
+ segment_input,
+ decoder_input_ids,
+ cur_bsz,
+ batch_idx_map,
+ seek,
+ num_segment_frames,
+ max_frames,
+ temperatures,
+ generation_config,
+ logits_processor,
+ stopping_criteria,
+ prefix_allowed_tokens_fn,
+ synced_gpus,
+ return_token_timestamps,
+ do_condition_on_prev_tokens,
+ kwargs,
+ ):
+ # 6.6 Batch generate current chunk
+ seek_sequence_list = [None for _ in range(cur_bsz)]
+ seek_outputs_list = [None for _ in range(cur_bsz)]
+ needs_fallback = [False for _ in range(cur_bsz)]
+ should_skip = [False for _ in range(cur_bsz)]
+ fallback_index_map = list(range(cur_bsz))
+
+ if generation_config.no_speech_threshold is not None:
+ self._setup_no_speech_detection(logits_processor, segment_input, decoder_input_ids, kwargs)
+
+ for fallback_idx, temperature in enumerate(temperatures):
+ generation_config.do_sample = temperature is not None and temperature > 0.0
+ generation_config.temperature = temperature
+ generation_config.num_beams = kwargs.pop("num_beams", 1) if not generation_config.do_sample else 1
+
+ seek_outputs = super().generate(
+ segment_input,
+ generation_config,
+ logits_processor,
+ stopping_criteria,
+ prefix_allowed_tokens_fn,
+ synced_gpus,
+ decoder_input_ids=decoder_input_ids,
+ **kwargs,
+ )
+
+ # post-process sequence tokens and outputs to be in list form
+ sequence_tokens, seek_outputs = self._postprocess_outputs(
+ seek_outputs, return_token_timestamps, generation_config
+ )
+
+ # remove all previously passed decoder input ids
+ seek_sequences = sequence_tokens[:, decoder_input_ids.shape[-1] :]
+
+ # 6.7 Extract cut sequences from every sequence and check if fallback should be applied
+ # Loop over each decoded audio individually as each decoding can be of a different length
+ new_fallback_index_map = []
+ new_segment_input = []
+ new_decoder_input_ids = []
+ new_decoder_attention_mask = []
+
+ for i, seek_sequence in enumerate(seek_sequences):
+ # make sure we cut a predicted EOS token if we are not finished with the generation yet
+ prev_i = batch_idx_map[fallback_index_map[i]]
+ is_not_final = (seek[prev_i] + num_segment_frames) < max_frames[prev_i]
+
+ # remove eos token id
+ if is_not_final and seek_sequence[-1] == generation_config.eos_token_id:
+ seek_sequence = seek_sequence[:-1]
+
+ # remove all padding tokens
+ if seek_sequence[-1] == generation_config.pad_token_id:
+ num_paddings = (seek_sequence == generation_config.pad_token_id).sum()
+ seek_sequence = seek_sequence[:-num_paddings]
+
+ # check which sequences in batch need fallback & which should be skipped
+ needs_fallback[i], should_skip[i] = self._need_fallback(
+ seek_sequence,
+ seek_outputs,
+ i,
+ logits_processor,
+ generation_config,
+ self.config.vocab_size,
+ temperature,
+ )
+
+ seek_sequence_list[fallback_index_map[i]] = seek_sequence
+ seek_outputs_list[fallback_index_map[i]] = seek_outputs[i]
+ do_condition_on_prev_tokens[fallback_index_map[i]] = (
+ generation_config.condition_on_prev_tokens and temperature is not None and temperature < 0.5
+ )
+
+ if needs_fallback[i]:
+ new_fallback_index_map.append(fallback_index_map[i])
+ new_segment_input.append(segment_input[i])
+ new_decoder_input_ids.append(decoder_input_ids[i])
+ if "decoder_attention_mask" in kwargs:
+ new_decoder_attention_mask.append(kwargs["decoder_attention_mask"][i])
+
+ fallback_index_map = new_fallback_index_map
+
+ # if no sequence needs to be run with temperature fallback, we're finished
+ if len(fallback_index_map) == 0 or fallback_idx == len(temperatures) - 1:
+ seek_sequences = seek_sequence_list
+ seek_outputs = seek_outputs_list
+ break
+
+ # if we're still in the loop, make sure that decoder_input_ids and segment inputs are tensors
+ decoder_input_ids = torch.stack(new_decoder_input_ids)
+ segment_input = torch.stack(new_segment_input)
+ if "decoder_attention_mask" in kwargs:
+ kwargs["decoder_attention_mask"] = torch.stack(new_decoder_attention_mask)
+
+ return seek_sequences, seek_outputs, should_skip, do_condition_on_prev_tokens
+
+ def _postprocess_outputs(self, seek_outputs, return_token_timestamps, generation_config):
+ if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
+ num_frames = getattr(generation_config, "num_frames", None)
+ seek_outputs["token_timestamps"] = self._extract_token_timestamps(
+ seek_outputs, generation_config.alignment_heads, num_frames=num_frames
+ )
+
+ if generation_config.return_dict_in_generate:
+
+ def split_by_batch_index(values, key, batch_idx):
+ if key == "scores":
+ return [v[batch_idx].cpu() for v in values]
+ if key == "past_key_values":
+ # we don't save `past_key_values` as this is too costly
+ return None
+ return values[batch_idx].cpu()
+
+ sequence_tokens = seek_outputs["sequences"]
+ seek_outputs = [
+ {k: split_by_batch_index(v, k, i) for k, v in seek_outputs.items()}
+ for i in range(sequence_tokens.shape[0])
+ ]
+ else:
+ sequence_tokens = seek_outputs
+
+ return sequence_tokens, seek_outputs
+
+ def _need_fallback(
+ self,
+ seek_sequence,
+ seek_outputs,
+ index,
+ logits_processor,
+ generation_config,
+ vocab_size,
+ temperature,
+ ):
+ needs_fallback = False
+ should_skip = False
+ if generation_config.compression_ratio_threshold is not None:
+ compression_ratio = self._retrieve_compression_ratio(seek_sequence, vocab_size)
+
+ if compression_ratio > generation_config.compression_ratio_threshold:
+ needs_fallback = True
+
+ if generation_config.logprob_threshold is not None:
+ if "sequences_scores" in seek_outputs[0]:
+ logprobs = [s["sequences_scores"] for s in seek_outputs][index]
+ else:
+ scores = seek_outputs[index]["scores"]
+ logprobs = self._retrieve_avg_logprobs(
+ scores, seek_sequence, generation_config.eos_token_id, temperature
+ )
+
+ if logprobs < generation_config.logprob_threshold:
+ needs_fallback = True
+
+ if generation_config.no_speech_threshold is not None:
+ no_speech_prob = _get_attr_from_logit_processors(
+ logits_processor, WhisperNoSpeechDetection, "no_speech_prob"
+ )
+
+ if (
+ logprobs < generation_config.logprob_threshold
+ and no_speech_prob[index] > generation_config.no_speech_threshold
+ ):
+ needs_fallback = False
+ should_skip = True
+
+ return needs_fallback, should_skip
+
+ @staticmethod
+ def _setup_no_speech_detection(logits_processor, segment_input, decoder_input_ids, kwargs):
+ set_inputs = _get_attr_from_logit_processors(logits_processor, WhisperNoSpeechDetection, "set_inputs")
+ extra_kwargs = {k: v for k, v in kwargs.items() if torch.is_tensor(v)}
+ set_inputs({"inputs": segment_input, "decoder_input_ids": decoder_input_ids, **extra_kwargs})
+
+ @staticmethod
+ def _retrieve_total_input_frames(input_features, input_stride, kwargs):
+ if input_features is not None:
+ return input_features.shape[-1]
+
+ if "encoder_outputs" in kwargs:
+ encoder_outputs_shape = (
+ kwargs["encoder_outputs"][0].shape
+ if isinstance(kwargs["encoder_outputs"], BaseModelOutput)
+ else kwargs["encoder_outputs"].shape
+ )
+ return encoder_outputs_shape[1] * input_stride
+
+ raise ValueError("Make sure to provide either `input_features` or `encoder_outputs` to `generate`.")
+
+ @staticmethod
+ def _maybe_warn_unused_inputs(
+ condition_on_prev_tokens,
+ temperature,
+ compression_ratio_threshold,
+ logprob_threshold,
+ no_speech_threshold,
+ total_input_frames,
+ ):
+ warning_prefix = (
+ f"Audio input consists of only {total_input_frames}. "
+ "Short-form transcription is activated."
+ "{}, but will be ignored."
+ )
+ if condition_on_prev_tokens is not None:
+ logger.warn(warning_prefix.format(f"condition_on_prev_tokens is set to {condition_on_prev_tokens}"))
+
+ if compression_ratio_threshold is not None:
+ logger.warn(warning_prefix.format(f"compression_ratio_threshold is set to {compression_ratio_threshold}"))
+
+ if logprob_threshold is not None:
+ logger.warn(warning_prefix.format(f"logprob_threshold is set to {logprob_threshold}"))
+
+ if no_speech_threshold is not None:
+ logger.warn(warning_prefix.format(f"no_speech_threshold is set to {no_speech_threshold}"))
+
+ # when passing temperature as a list it cannot just be ignored => throw error in this case
+ if isinstance(temperature, (list, tuple)):
+ raise ValueError(
+ f"Audio input consists of only {total_input_frames}. Short-form transcription is activated."
+ f"temperature cannot be set to {temperature} which can only be used for temperature fallback for long-form generation. Make sure to set `temperature` to a float value or `None` for short-form generation."
+ )
+
+ @staticmethod
+ def _set_return_outputs(
+ return_dict_in_generate, return_token_timestamps, is_shortform, logprob_threshold, generation_config
+ ):
+ if return_dict_in_generate is None:
+ return_dict_in_generate = generation_config.return_dict_in_generate
+
+ generation_config.return_token_timestamps = return_token_timestamps
+ if return_token_timestamps:
+ return_dict_in_generate = True
+ generation_config.output_attentions = True
+ generation_config.output_scores = True
+
+ if not is_shortform and logprob_threshold is not None:
+ return_dict_in_generate = True
+ generation_config.output_scores = True
+
+ generation_config.return_dict_in_generate = return_dict_in_generate
+
+ @staticmethod
+ def _set_return_timestamps(return_timestamps, is_shortform, generation_config):
+ if return_timestamps is True:
+ if not hasattr(generation_config, "no_timestamps_token_id"):
+ raise ValueError(
+ "You are trying to return timestamps, but the generation config is not properly set. "
+ "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
+ "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
+ )
+ generation_config.return_timestamps = True
+ elif not is_shortform:
+ if return_timestamps is False:
+ raise ValueError(
+ "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
+ "requires the model to predict timestamp tokens. Please either pass `return_timestamps=True` or make sure to pass no more than 3000 mel input features."
+ )
+
+ if not hasattr(generation_config, "no_timestamps_token_id"):
+ raise ValueError(
+ "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
+ "requires the generation config to have `no_timestamps_token_id` correctly. "
+ "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
+ "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
+ "or make sure to pass no more than 3000 mel input features."
+ )
+
+ logger.info("Setting `return_timestamps=True` for long-form generation.")
+ generation_config.return_timestamps = True
+ else:
+ generation_config.return_timestamps = False
+
+ @staticmethod
+ def _set_language_and_task(language, task, is_multilingual, generation_config):
+ if is_multilingual is not None:
+ if not hasattr(generation_config, "is_multilingual"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `is_multilingual` argument "
+ "to `generate`. Please update the generation config as per the instructions "
+ "https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ generation_config.is_multilingual = is_multilingual
+
+ if hasattr(generation_config, "is_multilingual") and not generation_config.is_multilingual:
+ if task is not None or language is not None:
+ raise ValueError(
+ "Cannot specify `task` or `language` for an English-only model. If the model is intended to be "
+ "multilingual, pass `is_multilingual=True` to generate, or update the generation config."
+ )
+
+ if language is not None:
+ if not hasattr(generation_config, "lang_to_id"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `language` argument "
+ "to `generate`. Either set the language using the `forced_decoder_ids` in the model config, "
+ "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ language = language.lower()
+ generation_config.language = language
+
+ if task is not None:
+ if not hasattr(generation_config, "task_to_id"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `task` argument "
+ "to `generate`. Either set the task using the `forced_decoder_ids` in the model config, "
+ "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ generation_config.task = task
+
+ @staticmethod
+ def _set_forced_decoder_ids(task, language, prompt_ids, generation_config, config, kwargs):
+ forced_decoder_ids = None
+ # Legacy code for backward compatibility
+ if hasattr(config, "forced_decoder_ids") and config.forced_decoder_ids is not None:
+ forced_decoder_ids = config.forced_decoder_ids
+ elif hasattr(generation_config, "forced_decoder_ids") and generation_config.forced_decoder_ids is not None:
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ else:
+ forced_decoder_ids = kwargs.pop("forced_decoder_ids", None)
+
+ if task is not None or language is not None or (forced_decoder_ids is None and prompt_ids is not None):
+ forced_decoder_ids = []
+ if hasattr(generation_config, "language"):
+ if generation_config.language in generation_config.lang_to_id.keys():
+ language_token = generation_config.language
+ elif generation_config.language in TO_LANGUAGE_CODE.keys():
+ language_token = f"<|{TO_LANGUAGE_CODE[generation_config.language]}|>"
+ elif generation_config.language in TO_LANGUAGE_CODE.values():
+ language_token = f"<|{generation_config.language}|>"
+ else:
+ is_language_code = len(generation_config.language) == 2
+ raise ValueError(
+ f"Unsupported language: {generation_config.language}. Language should be one of:"
+ f" {list(TO_LANGUAGE_CODE.values()) if is_language_code else list(TO_LANGUAGE_CODE.keys())}."
+ )
+ if language_token not in generation_config.lang_to_id:
+ raise ValueError(
+ f"{language_token} is not supported by this specific model as it is not in the `generation_config.lang_to_id`."
+ "(You should just add it to the generation config)"
+ )
+ forced_decoder_ids.append((1, generation_config.lang_to_id[language_token]))
+ else:
+ forced_decoder_ids.append((1, None)) # automatically detect the language
+
+ if hasattr(generation_config, "task"):
+ if generation_config.task in TASK_IDS:
+ forced_decoder_ids.append((2, generation_config.task_to_id[generation_config.task]))
+ else:
+ raise ValueError(
+ f"The `{generation_config.task}`task is not supported. The task should be one of `{TASK_IDS}`"
+ )
+ elif hasattr(generation_config, "task_to_id"):
+ forced_decoder_ids.append((2, generation_config.task_to_id["transcribe"])) # defaults to transcribe
+ if hasattr(generation_config, "no_timestamps_token_id") and not generation_config.return_timestamps:
+ idx = forced_decoder_ids[-1][0] + 1 if forced_decoder_ids else 1
+ forced_decoder_ids.append((idx, generation_config.no_timestamps_token_id))
+
+ if forced_decoder_ids is not None:
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ if prompt_ids is not None:
+ if kwargs.get("decoder_start_token_id") is not None:
+ raise ValueError(
+ "When specifying `prompt_ids`, you cannot also specify `decoder_start_token_id` as it gets overwritten."
+ )
+ prompt_ids = prompt_ids.tolist()
+ decoder_start_token_id, *text_prompt_ids = prompt_ids
+ # Slicing the text prompt ids in a manner consistent with the OpenAI implementation
+ # to accomodate context space for the prefix (see https://github.com/openai/whisper/blob/c09a7ae299c4c34c5839a76380ae407e7d785914/whisper/decoding.py#L599)
+ text_prompt_ids = text_prompt_ids[-config.max_target_positions // 2 - 1 :]
+ # Set the decoder_start_token_id to <|startofprev|>
+ kwargs.update({"decoder_start_token_id": decoder_start_token_id})
+
+ # If the user passes `max_new_tokens`, increase its number to account for the prompt
+ if kwargs.get("max_new_tokens", None) is not None:
+ kwargs["max_new_tokens"] += len(text_prompt_ids)
+ if kwargs["max_new_tokens"] >= config.max_target_positions:
+ raise ValueError(
+ f"The length of the sliced `prompt_ids` is {len(text_prompt_ids)}, and the `max_new_tokens` "
+ f"{kwargs['max_new_tokens'] - len(text_prompt_ids)}. Thus, the combined length of the sliced "
+ f"`prompt_ids` and `max_new_tokens` is: {kwargs['max_new_tokens']}. This exceeds the "
+ f"`max_target_positions` of the Whisper model: {config.max_target_positions}. "
+ "You should either reduce the length of your prompt, or reduce the value of `max_new_tokens`, "
+ f"so that their combined length is less that {config.max_target_positions}."
+ )
+
+ # Reformat the forced_decoder_ids to incorporate the prompt
+ non_prompt_forced_decoder_ids = (
+ kwargs.pop("forced_decoder_ids", None) or generation_config.forced_decoder_ids
+ )
+ forced_decoder_ids = [
+ *text_prompt_ids,
+ generation_config.decoder_start_token_id,
+ *[token for _, token in non_prompt_forced_decoder_ids],
+ ]
+ forced_decoder_ids = [(rank + 1, token) for rank, token in enumerate(forced_decoder_ids)]
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ @staticmethod
+ def _set_token_ids(generation_config, config, kwargs):
+ eos_token_id = kwargs.pop("eos_token_id", None)
+ decoder_start_token_id = kwargs.pop("decoder_start_token_id", None)
+
+ eos_token_id = eos_token_id if eos_token_id is not None else generation_config.eos_token_id
+ decoder_start_token_id = (
+ decoder_start_token_id if decoder_start_token_id is not None else generation_config.decoder_start_token_id
+ )
+
+ generation_config.eos_token_id = eos_token_id if eos_token_id is not None else config.eos_token_id
+ generation_config.decoder_start_token_id = (
+ decoder_start_token_id if decoder_start_token_id is not None else config.decoder_start_token_id
+ )
+
+ @staticmethod
+ def _set_num_frames(return_token_timestamps, generation_config, kwargs):
+ if return_token_timestamps:
+ if getattr(generation_config, "task", None) == "translate":
+ logger.warning("Token-level timestamps may not be reliable for task 'translate'.")
+ if not hasattr(generation_config, "alignment_heads"):
+ raise ValueError(
+ "Model generation config has no `alignment_heads`, token-level timestamps not available. "
+ "See https://gist.github.com/hollance/42e32852f24243b748ae6bc1f985b13a on how to add this property to the generation config."
+ )
+
+ generation_config.num_frames = kwargs.pop("num_frames", None)
+
+ @staticmethod
+ def _set_thresholds_and_condition(
+ generation_config,
+ logprob_threshold,
+ compression_ratio_threshold,
+ no_speech_threshold,
+ condition_on_prev_tokens,
+ ):
+ generation_config.logprob_threshold = (
+ logprob_threshold
+ if logprob_threshold is not None
+ else getattr(generation_config, "logprob_threshold", None)
+ )
+ generation_config.compression_ratio_threshold = (
+ compression_ratio_threshold
+ if compression_ratio_threshold is not None
+ else getattr(generation_config, "compression_ratio_threshold", None)
+ )
+ generation_config.no_speech_threshold = (
+ no_speech_threshold
+ if no_speech_threshold is not None
+ else getattr(generation_config, "no_speech_threshold", None)
+ )
+ generation_config.condition_on_prev_tokens = (
+ condition_on_prev_tokens
+ if condition_on_prev_tokens is not None
+ else getattr(generation_config, "condition_on_prev_tokens", None)
+ )
+
+ @staticmethod
+ def _set_condition_on_prev_tokens(condition_on_prev_tokens, generation_config):
+ condition_on_prev_tokens = (
+ condition_on_prev_tokens
+ if condition_on_prev_tokens is not None
+ else getattr(generation_config, "condition_on_prev_tokens", False)
+ )
+ generation_config.condition_on_prev_tokens = condition_on_prev_tokens
+
+ @staticmethod
+ def _retrieve_max_frames_and_seek(batch_size, attention_mask, total_input_frames):
+ if batch_size > 1 and attention_mask is None:
+ raise ValueError(
+ "When doing long-form audio transcription, make sure to pass an `attention_mask`. You can retrieve the `attention_mask` by doing `processor(audio, ..., return_attention_mask=True)` "
+ )
+ elif batch_size > 1:
+ max_frames = attention_mask.sum(-1).cpu().to(torch.long)
+ seek = torch.zeros((batch_size,), dtype=torch.long)
+ else:
+ max_frames = torch.ones((1,), dtype=torch.long) * total_input_frames
+ seek = torch.zeros((1,), dtype=torch.long)
+
+ return max_frames, seek
+
+ @staticmethod
+ def _retrieve_init_tokens_from_forced_decoder_ids(generation_config):
+ init_tokens = [generation_config.decoder_start_token_id]
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ if forced_decoder_ids is not None and forced_decoder_ids[0][0] == 1:
+ i = 1
+ while len(forced_decoder_ids) > 0 and forced_decoder_ids[0][0] == i:
+ init_tokens += [forced_decoder_ids[0][1]]
+ forced_decoder_ids = forced_decoder_ids[1:]
+ i += 1
+
+ forced_decoder_ids = forced_decoder_ids if len(forced_decoder_ids) > 0 else None
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ return init_tokens
+
+ def _retrieve_logit_processors(
+ self, generation_config, logits_processor, no_speech_threshold, is_shortform, num_beams
+ ):
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ if generation_config.return_timestamps is True:
+ last_forced_decoder_ids = forced_decoder_ids[-1][-1] if forced_decoder_ids is not None else None
+ if last_forced_decoder_ids == generation_config.no_timestamps_token_id:
+ # remove no_timestamp to be forcefully generated if we want to return timestamps
+ # this is also important to make sure `WhisperTimeStampLogitsProcessor` functions correctly
+ forced_decoder_ids = forced_decoder_ids[:-1] if len(forced_decoder_ids) > 1 else None
+ # Make sure that if list is empty we set it to None
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ begin_index = len(forced_decoder_ids) + 1 if forced_decoder_ids is not None else 1
+
+ if generation_config.return_timestamps is True:
+ timestamp_processor = WhisperTimeStampLogitsProcessor(generation_config, begin_index=begin_index)
+ logits_processor = (
+ [timestamp_processor] if logits_processor is None else [timestamp_processor] + logits_processor
+ )
+
+ if generation_config.suppress_tokens is not None:
+ suppress_tokens_processor = SuppressTokensLogitsProcessor(generation_config.suppress_tokens)
+ logits_processor = (
+ [suppress_tokens_processor]
+ if logits_processor is None
+ else [suppress_tokens_processor] + logits_processor
+ )
+ generation_config.suppress_tokens = None
+
+ if generation_config.begin_suppress_tokens is not None:
+ begin_suppress_processor = SuppressTokensAtBeginLogitsProcessor(
+ generation_config.begin_suppress_tokens, begin_index=begin_index
+ )
+ logits_processor = (
+ [begin_suppress_processor]
+ if logits_processor is None
+ else [begin_suppress_processor] + logits_processor
+ )
+ generation_config.begin_suppress_tokens = None
+
+ if no_speech_threshold is not None and not is_shortform:
+ no_speech_detector = WhisperNoSpeechDetection(
+ no_speech_token=generation_config.no_timestamps_token_id - 1,
+ begin_index=begin_index,
+ scores_is_logprobs=num_beams > 1,
+ )
+ logits_processor = (
+ [no_speech_detector] if logits_processor is None else [no_speech_detector] + logits_processor
+ )
+ no_speech_detector.set_model(self)
+
+ if is_shortform and generation_config.forced_decoder_ids is not None:
+ forced_tokens_proc = ForceTokensLogitsProcessor(generation_config.forced_decoder_ids)
+ # TODO(Patrick): It's important that the `forced_tokens_proc` processor is appended after
+ # the suppress_tokens processor or else it might happen that all token logits are suppressed to -inf
+ # which would lead to unexpected behavior
+ # The better approach here is to NOT make use of the `forced_tokens_proc` for Whisper and instead
+ # initialize all of them as `decoder_input_ids`.
+ logits_processor = (
+ [forced_tokens_proc] if logits_processor is None else logits_processor + [forced_tokens_proc]
+ )
+ generation_config.forced_decoder_ids = None
+
+ return logits_processor
+
+ @staticmethod
+ def _maybe_reduce_batch(input_features, seek, max_frames, cur_bsz, batch_idx_map):
+ prev_bsz = cur_bsz
+ new_batch_idx_map = []
+ for i in range(prev_bsz):
+ prev_i = batch_idx_map[i]
+ if seek[prev_i] >= max_frames[prev_i]:
+ cut_index = i + (cur_bsz - prev_bsz)
+ cur_bsz -= 1
+ input_features = torch.cat([input_features[:cut_index], input_features[cut_index + 1 :]], dim=0)
+ else:
+ # cut out index that goes away
+ new_batch_idx_map.append(prev_i)
+
+ return input_features, cur_bsz, new_batch_idx_map
+
+ @staticmethod
+ def _get_input_segment(input_features, seek, seek_num_frames, num_segment_frames, cur_bsz, batch_idx_map):
+ segment_input = []
+ for i in range(cur_bsz):
+ prev_i = batch_idx_map[i]
+ segment_input_slice = input_features[i : i + 1, :, seek[prev_i] : seek[prev_i] + seek_num_frames[prev_i]]
+
+ if segment_input_slice.shape[-1] < num_segment_frames:
+ # pad to 3000 if necessary
+ segment_input_slice = F.pad(
+ segment_input_slice, pad=(0, num_segment_frames - segment_input_slice.shape[-1])
+ )
+
+ segment_input.append(segment_input_slice)
+
+ segment_input = torch.cat(segment_input, dim=0)
+
+ return segment_input
+
+ @staticmethod
+ def _prepare_decoder_input_ids(
+ cur_bsz,
+ init_tokens,
+ current_segments,
+ batch_idx_map,
+ do_condition_on_prev_tokens,
+ generation_config,
+ config,
+ device,
+ suppress_tokens,
+ kwargs,
+ ):
+ cut_off_length = config.max_target_positions // 2 - 1
+
+ one_tensor = torch.ones((cur_bsz, 1), device=device, dtype=torch.long)
+ decoder_input_ids = torch.cat([t * one_tensor for t in init_tokens], dim=-1)
+
+ prev_start_of_text = getattr(generation_config, "prev_sot_token_id", None)
+ if prev_start_of_text is None:
+ prev_start_of_text = suppress_tokens[-2] if suppress_tokens is not None else None
+
+ if any(do_condition_on_prev_tokens) and len(current_segments[0]) > 0:
+ # according to https://github.com/openai/whisper/blob/e58f28804528831904c3b6f2c0e473f346223433/whisper/decoding.py#L609
+ active_segments = [current_segments[i] if do_condition_on_prev_tokens[i] else None for i in batch_idx_map]
+ prev_start_of_text = getattr(generation_config, "prev_bos_token_id", None) or prev_start_of_text
+
+ bos_token_tensor = prev_start_of_text * one_tensor[0]
+ prev_tokens = _pad_to_max_length(
+ active_segments,
+ generation_config.pad_token_id,
+ padding="left",
+ bos_token_tensor=bos_token_tensor,
+ cut_off_length=cut_off_length,
+ )
+ decoder_input_ids = torch.cat([prev_tokens, decoder_input_ids], dim=-1)
+
+ kwargs["decoder_attention_mask"] = decoder_input_ids != generation_config.pad_token_id
+ else:
+ # make sure `"decoder_attention_mask"` is not passed to forward
+ kwargs.pop("decoder_attention_mask", None)
+
+ return decoder_input_ids, kwargs
+
+ @staticmethod
+ def _set_max_new_tokens_and_length(config, decoder_input_ids, generation_config, kwargs):
+ num_initial_tokens = min(config.max_target_positions // 2 - 1, decoder_input_ids.shape[-1] - 1)
+
+ passed_max_length = kwargs.pop("max_length", None)
+ passed_max_new_tokens = kwargs.pop("max_new_tokens", None)
+ max_length_config = getattr(generation_config, "max_length", None)
+ max_new_tokens_config = getattr(generation_config, "max_new_tokens", None)
+
+ max_new_tokens = None
+ max_length = None
+
+ # Make sure we don't get larger than `max_length`
+ if passed_max_length is not None and passed_max_new_tokens is None:
+ max_length = min(passed_max_length + num_initial_tokens, config.max_target_positions)
+ logger.info(
+ f"Increase max_length from {passed_max_length} to {max_length} since input is conditioned on previous segment."
+ )
+ elif max_length_config is not None and passed_max_new_tokens is None and max_new_tokens_config is None:
+ max_length = min(generation_config.max_length + num_initial_tokens, config.max_target_positions)
+ logger.info(
+ f"Increase max_length from {max_length_config} to {max_length} since input is conditioned on previous segment."
+ )
+ elif (
+ passed_max_new_tokens is not None
+ and passed_max_new_tokens + decoder_input_ids.shape[-1] > config.max_target_positions
+ ):
+ max_new_tokens = config.max_target_positions - decoder_input_ids.shape[-1]
+ elif (
+ passed_max_new_tokens is None
+ and max_new_tokens_config is not None
+ and max_new_tokens_config + decoder_input_ids.shape[-1] > config.max_target_positions
+ ):
+ max_new_tokens = config.max_target_positions - decoder_input_ids.shape[-1]
+
+ if max_new_tokens is not None:
+ kwargs["max_new_tokens"] = max_new_tokens
+
+ if max_length is not None:
+ kwargs["max_length"] = max_length
+
+ return kwargs
+
+ @staticmethod
+ def _retrieve_compression_ratio(tokens, vocab_size):
+ """Compute byte length of zlib compressed token bytes vs. byte length of raw token bytes"""
+ length = int(math.log2(vocab_size) / 8) + 1
+ token_bytes = b"".join([t.to_bytes(length, "little") for t in tokens.tolist()])
+ compression_ratio = len(token_bytes) / len(zlib.compress(token_bytes))
+
+ return compression_ratio
+
+ @staticmethod
+ def _retrieve_avg_logprobs(scores, tokens, eos_token_id, temperature):
+ rescale_temperature = temperature if temperature > 0.0 else 1
+ scores = torch.stack(scores).to(tokens.device)
+
+ if scores.shape[0] > tokens.shape[0]:
+ scores = scores[: tokens.shape[0]]
+ else:
+ tokens = tokens[-scores.shape[0] :]
+
+ logprobs = F.log_softmax((scores * rescale_temperature).float(), dim=-1).to(scores.dtype)
+
+ # retrieve logprob of selected tokens and sum
+ sum_logprobs = sum((logprobs[i][tokens[i]] * (tokens[i] != eos_token_id)) for i in range(logprobs.shape[0]))
+ length = (tokens != eos_token_id).sum(-1) if eos_token_id is not None else tokens.shape[0]
+
+ avg_logprobs = sum_logprobs / (length + 1)
+ return avg_logprobs
+
+ @staticmethod
+ def _retrieve_segment(
+ seek_sequence,
+ seek_outputs,
+ time_offset,
+ timestamp_begin,
+ seek_num_frames,
+ time_precision,
+ input_stride,
+ prev_idx,
+ idx,
+ ):
+ # find the predicted "end of segment" predictions of Whisper
+ # "end of segment" predictions occur whenever Whisper predicts a timestamp token
+ timestamp_tokens: torch.Tensor = seek_sequence.ge(timestamp_begin)
+ single_timestamp_ending = timestamp_tokens[-2:].tolist() == [False, True]
+ timestamp_segment_indices = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0]
+ timestamp_segment_indices.add_(1)
+
+ # If whisper predicted a "end of segment" via a timestep token, let's go ever each
+ # "end of segment" prediction and slice the decoding into segments accordingly
+ if len(timestamp_segment_indices) > 0:
+ # if the output contains two consecutive timestamp tokens
+ slices = timestamp_segment_indices.tolist()
+ segments = []
+ if single_timestamp_ending:
+ slices.append(len(seek_sequence))
+
+ last_slice = 0
+ # Add each segment to list of all segments
+ for current_slice in slices:
+ sliced_tokens = seek_sequence[last_slice:current_slice]
+ start_timestamp_pos = sliced_tokens[0].item() - timestamp_begin
+ end_timestamp_pos = sliced_tokens[-1].item() - timestamp_begin
+ segments.append(
+ {
+ "start": time_offset[prev_idx] + start_timestamp_pos * time_precision,
+ "end": time_offset[prev_idx] + end_timestamp_pos * time_precision,
+ "tokens": sliced_tokens,
+ "result": seek_outputs[idx],
+ }
+ )
+ last_slice = current_slice
+
+ if single_timestamp_ending:
+ # single timestamp at the end means no speech after the last timestamp.
+ segment_offset = seek_num_frames[prev_idx]
+ else:
+ # otherwise, ignore the unfinished segment and seek to the last timestamp
+ # here we throw away all predictions after the last predicted "end of segment"
+ # since we are cutting right in the middle of an audio
+ last_timestamp_pos = seek_sequence[last_slice - 1].item() - timestamp_begin
+ segment_offset = last_timestamp_pos * input_stride
+ else:
+ # If whisper does not predict any "end of segment" token, then
+ # the whole decoding is considered a segment and we add it to the list of segments
+ timestamps = seek_sequence[timestamp_tokens.nonzero().flatten()]
+ last_timestamp_pos = seek_num_frames[prev_idx]
+ if timestamps.numel() > 0 and timestamps[-1].item() != timestamp_begin:
+ # no consecutive timestamps but it has a timestamp; use the last one.
+ last_timestamp_pos = timestamps[-1].item() - timestamp_begin
+
+ segments = [
+ {
+ "start": time_offset[prev_idx],
+ "end": time_offset[prev_idx] + last_timestamp_pos * time_precision,
+ "tokens": seek_sequence,
+ "result": seek_outputs[idx],
+ }
+ ]
+ segment_offset = seek_num_frames[prev_idx]
+
+ return segments, segment_offset
diff --git a/src/transformers/models/whisper/modeling_whisper.py b/src/transformers/models/whisper/modeling_whisper.py
index a3550c791c7318..76ea27a954a84a 100644
--- a/src/transformers/models/whisper/modeling_whisper.py
+++ b/src/transformers/models/whisper/modeling_whisper.py
@@ -13,10 +13,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch Whisper model."""
-
-import copy
import math
-import warnings
from typing import Optional, Tuple, Union
import numpy as np
@@ -27,7 +24,6 @@
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
-from ...generation.logits_process import WhisperTimeStampLogitsProcessor
from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
from ...modeling_outputs import (
BaseModelOutput,
@@ -47,7 +43,7 @@
replace_return_docstrings,
)
from .configuration_whisper import WhisperConfig
-from .tokenization_whisper import TASK_IDS, TO_LANGUAGE_CODE
+from .generation_whisper import WhisperGenerationMixin
if is_flash_attn_2_available():
@@ -57,6 +53,8 @@
logger = logging.get_logger(__name__)
+_HIDDEN_STATES_START_POSITION = 1
+
_CONFIG_FOR_DOC = "WhisperConfig"
_CHECKPOINT_FOR_DOC = "openai/whisper-tiny"
@@ -229,87 +227,15 @@ def compute_num_masked_span(input_length):
return spec_aug_mask
-def _median_filter(inputs: torch.Tensor, filter_width: int) -> torch.Tensor:
- """
- Applies a median filter of width `filter_width` along the last dimension of the input.
-
- The `inputs` tensor is assumed to be 3- or 4-dimensional.
- """
- if filter_width <= 0 or filter_width % 2 != 1:
- raise ValueError("`filter_width` should be an odd number")
-
- pad_width = filter_width // 2
- if inputs.shape[-1] <= pad_width:
- return inputs
-
- # Pad the left and right edges.
- inputs = nn.functional.pad(inputs, (pad_width, pad_width, 0, 0), mode="reflect")
-
- # sort() is faster than torch.median (https://github.com/pytorch/pytorch/issues/51450)
- result = inputs.unfold(-1, filter_width, 1).sort()[0][..., pad_width]
- return result
-
-
-def _dynamic_time_warping(matrix: np.ndarray):
- """
- Measures similarity between two temporal sequences: the input audio and the output tokens. Used to generate
- token-level timestamps.
- """
- output_length, input_length = matrix.shape
- cost = np.ones((output_length + 1, input_length + 1), dtype=np.float32) * np.inf
- trace = -np.ones((output_length + 1, input_length + 1), dtype=np.float32)
-
- cost[0, 0] = 0
- for j in range(1, input_length + 1):
- for i in range(1, output_length + 1):
- c0 = cost[i - 1, j - 1]
- c1 = cost[i - 1, j]
- c2 = cost[i, j - 1]
-
- if c0 < c1 and c0 < c2:
- c, t = c0, 0
- elif c1 < c0 and c1 < c2:
- c, t = c1, 1
- else:
- c, t = c2, 2
-
- cost[i, j] = matrix[i - 1, j - 1] + c
- trace[i, j] = t
-
- # backtrace
- i = trace.shape[0] - 1
- j = trace.shape[1] - 1
- trace[0, :] = 2
- trace[:, 0] = 1
-
- text_indices = []
- time_indices = []
- while i > 0 or j > 0:
- text_indices.append(i - 1)
- time_indices.append(j - 1)
- if trace[i, j] == 0:
- i -= 1
- j -= 1
- elif trace[i, j] == 1:
- i -= 1
- elif trace[i, j] == 2:
- j -= 1
- else:
- raise RuntimeError(
- f"Internal error in dynamic time warping. Unexpected trace[{i}, {j}]. Please file a bug report."
- )
-
- text_indices = np.array(text_indices)[::-1]
- time_indices = np.array(time_indices)[::-1]
- return text_indices, time_indices
-
-
class WhisperPositionalEmbedding(nn.Embedding):
def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):
super().__init__(num_positions, embedding_dim)
- def forward(self, input_ids, past_key_values_length=0):
- return self.weight[past_key_values_length : past_key_values_length + input_ids.shape[1]]
+ def forward(self, input_ids, past_key_values_length=0, position_ids=None):
+ if position_ids is None:
+ return self.weight[past_key_values_length : past_key_values_length + input_ids.shape[1]]
+ else:
+ return self.weight[position_ids]
class WhisperAttention(nn.Module):
@@ -1356,6 +1282,7 @@ def forward(
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
+ position_ids=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
@@ -1459,9 +1386,13 @@ def forward(
# embed positions
if input_ids is not None:
- positions = self.embed_positions(input_ids, past_key_values_length=past_key_values_length)
+ positions = self.embed_positions(
+ input_ids, past_key_values_length=past_key_values_length, position_ids=position_ids
+ )
else:
- positions = self.embed_positions(inputs_embeds, past_key_values_length=past_key_values_length)
+ positions = self.embed_positions(
+ inputs_embeds, past_key_values_length=past_key_values_length, position_ids=position_ids
+ )
hidden_states = inputs_embeds + positions
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
@@ -1643,6 +1574,7 @@ def forward(
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
decoder_inputs_embeds: Optional[Tuple[torch.FloatTensor]] = None,
+ decoder_position_ids: Optional[Tuple[torch.LongTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
@@ -1701,6 +1633,7 @@ def forward(
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
+ position_ids=decoder_position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
@@ -1726,7 +1659,7 @@ def forward(
"The Whisper Model with a language modeling head. Can be used for automatic speech recognition.",
WHISPER_START_DOCSTRING,
)
-class WhisperForConditionalGeneration(WhisperPreTrainedModel):
+class WhisperForConditionalGeneration(WhisperGenerationMixin, WhisperPreTrainedModel):
base_model_prefix = "model"
_tied_weights_keys = ["proj_out.weight"]
@@ -1774,6 +1707,7 @@ def forward(
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
decoder_inputs_embeds: Optional[Tuple[torch.FloatTensor]] = None,
+ decoder_position_ids: Optional[Tuple[torch.LongTensor]] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
@@ -1828,6 +1762,7 @@ def forward(
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
decoder_inputs_embeds=decoder_inputs_embeds,
+ decoder_position_ids=decoder_position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
@@ -1858,647 +1793,6 @@ def forward(
encoder_attentions=outputs.encoder_attentions,
)
- def generate(
- self,
- input_features: Optional[torch.Tensor] = None,
- generation_config=None,
- logits_processor=None,
- stopping_criteria=None,
- prefix_allowed_tokens_fn=None,
- synced_gpus=False,
- return_timestamps=None,
- task=None,
- language=None,
- is_multilingual=None,
- prompt_ids: Optional[torch.Tensor] = None,
- num_segment_frames: Optional[int] = None,
- return_token_timestamps: Optional[bool] = None,
- return_segments: bool = False,
- attention_mask: Optional[torch.Tensor] = None,
- time_precision: int = 0.02,
- return_dict_in_generate: Optional[bool] = None,
- **kwargs,
- ):
- """
- Transcribes or translates passed mel input features to a sequence of token ids.
-
-
-
- Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
- model's default generation configuration. You can override any `generation_config` by passing the corresponding
- parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
-
- For an overview of generation strategies and code examples, check out the [following
- guide](./generation_strategies).
-
-
-
- Parameters:
- inputs (`torch.Tensor` of varying shape depending on the modality, *optional*):
- The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
- method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
- should of in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
- `input_ids`, `input_values`, `input_features`, or `pixel_values`.
- generation_config (`~generation.GenerationConfig`, *optional*):
- The generation configuration to be used as base parametrization for the generation call. `**kwargs`
- passed to generate matching the attributes of `generation_config` will override them. If
- `generation_config` is not provided, the default will be used, which had the following loading
- priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
- configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
- default values, whose documentation should be checked to parameterize generation.
- logits_processor (`LogitsProcessorList`, *optional*):
- Custom logits processors that complement the default logits processors built from arguments and
- generation config. If a logit processor is passed that is already created with the arguments or a
- generation config an error is thrown. This feature is intended for advanced users.
- stopping_criteria (`StoppingCriteriaList`, *optional*):
- Custom stopping criteria that complement the default stopping criteria built from arguments and a
- generation config. If a stopping criteria is passed that is already created with the arguments or a
- generation config an error is thrown. This feature is intended for advanced users.
- prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
- If provided, this function constraints the beam search to allowed tokens only at each step. If not
- provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
- `input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
- on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
- for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
- synced_gpus (`bool`, *optional*, defaults to `False`):
- Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
- return_timestamps (`bool`, *optional*):
- Whether to return the timestamps with the text. This enables the `WhisperTimestampsLogitsProcessor`.
- task (`str`, *optional*):
- Task to use for generation, either "translate" or "transcribe". The `model.config.forced_decoder_ids`
- will be updated accordingly.
- language (`str`, *optional*):
- Language token to use for generation, can be either in the form of `<|en|>`, `en` or `english`. You can
- find all the possible language tokens in the `model.generation_config.lang_to_id` dictionary.
- is_multilingual (`bool`, *optional*):
- Whether or not the model is multilingual.
- prompt_ids (`torch.Tensor`, *optional*):
- Rank-1 tensor of token IDs created by passing text to [`~WhisperProcessor.get_prompt_ids`] that is
- provided as a prompt to each chunk. This can be used to provide or "prompt-engineer" a context for
- transcription, e.g. custom vocabularies or proper nouns to make it more likely to predict those words
- correctly. It cannot be used in conjunction with `decoder_start_token_id` as it overwrites this value.
- return_token_timestamps (`bool`, *optional*):
- Whether to return token-level timestamps with the text. This can be used with or without the
- `return_timestamps` option. To get word-level timestamps, use the tokenizer to group the tokens into
- words.
- return_segments (`bool`, *optional*, defaults to `False`):
- Whether to additionally return a list of all segments. Note that this option can only be enabled
- when doing long-form transcription.
- attention_mask (`torch.Tensor`, *optional*):
- `attention_mask` needs to be passed when doing long-form transcription using a batch size > 1.
- time_precision (`int`, *optional*, defaults to 0.02):
- The duration of output token in seconds. *E.g.* 0.02 means that a generated token on average accounts
- for 20 ms.
- return_dict_in_generate (`bool`, *optional*, defaults to `False`):
- Whether or not to return a [`~utils.ModelOutput`] instead of just returning the generated tokens.
- Note that when doing long-form transcription, `return_dict_in_generate` can only be enabled when
- `return_segments` is set True. In this case the generation outputs of each segment is added to each
- segment.
- kwargs (`Dict[str, Any]`, *optional*):
- Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
- forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
- specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
-
- Return:
- [`~utils.ModelOutput`] or `torch.LongTensor` or `Dict[str, Any]`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
- or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor` or a dict of segments when `return_segments=True`.
-
- If the passed input is > 30 seconds / > 3000 mel input features and `return_segments=True` then a dictionary of generated sequence ids, called `sequences` and a list of each generated segment is returned.
-
- else if the passed input is <= 30 seconds / >= 3000 mel input features, the possible [`~utils.ModelOutput`] types are:
-
- - [`~generation.GenerateEncoderDecoderOutput`],
- - [`~generation.GenerateBeamEncoderDecoderOutput`]
-
- else only the generated output sequence ids are returned.
-
- Example:
-
- - *Longform transcription*: To transcribe or translate audios longer than 30 seconds, process the audio files without truncation and pass all mel features at once to generate.
-
- ```python
- >>> import torch
- >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
- >>> from datasets import load_dataset, Audio
-
- >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
- >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
- >>> model.cuda()
-
- >>> # load audios > 30 seconds
- >>> ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
- >>> # resample to 16kHz
- >>> ds = ds.cast_column("audio", Audio(sampling_rate=16000))
- >>> # take first 8 audios and retrieve array
- >>> audio = ds[:8]["audio"]
- >>> audio = [x["array"] for x in audio]
-
- >>> # make sure to NOT truncate the input audio, to return the `attention_mask` and to pad to the longest audio
- >>> inputs = processor(audio, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True, sampling_rate=16_000)
- >>> inputs = inputs.to("cuda", torch.float32)
-
- >>> # transcribe audio to ids
- >>> generated_ids = model.generate(**inputs)
-
- >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
- >>> transcription[0]
- ' Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!'
- ```
-
- - *Shortform transcription*: If passed mel input features are < 30 seconds, the whole audio will be transcribed with a single call to generate.
-
- ```python
- >>> import torch
- >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
- >>> from datasets import load_dataset
-
- >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
- >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
-
- >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
-
- >>> inputs = processor(ds[0]["audio"]["array"], return_tensors="pt")
- >>> input_features = inputs.input_features
-
- >>> generated_ids = model.generate(inputs=input_features)
-
- >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
- >>> transcription
- ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
- ```
-
- """
-
- if "inputs" in kwargs:
- input_features = kwargs.pop("inputs")
- warnings.warn(
- "The input name `inputs` is deprecated. Please make sure to use `input_features` instead.",
- FutureWarning,
- )
-
- if generation_config is None:
- generation_config = copy.deepcopy(self.generation_config)
-
- return_dict_in_generate = (
- return_dict_in_generate
- if return_dict_in_generate is not None
- else generation_config.return_dict_in_generate
- )
-
- input_stride = self.model.encoder.conv1.stride[0] * self.model.encoder.conv2.stride[0]
- if num_segment_frames is None:
- num_segment_frames = input_stride * self.config.max_source_positions
-
- # 1. Check whether we're in shortform or longform mode
- if input_features is not None:
- total_input_frames = input_features.shape[-1]
- elif "encoder_outputs" in kwargs:
- encoder_outputs_shape = (
- kwargs["encoder_outputs"][0].shape
- if isinstance(kwargs["encoder_outputs"], BaseModelOutput)
- else kwargs["encoder_outputs"].shape
- )
- total_input_frames = encoder_outputs_shape[1] * input_stride
- else:
- raise ValueError("Make sure to provide either `input_features` or `encoder_outputs` to `generate`.")
-
- is_shortform = total_input_frames <= num_segment_frames
-
- # 2. Make sure the generation config is correctly set depending on whether timestamps are to be returned or not
- if return_timestamps is True:
- if not hasattr(generation_config, "no_timestamps_token_id"):
- raise ValueError(
- "You are trying to return timestamps, but the generation config is not properly set. "
- "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
- "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
- )
- generation_config.return_timestamps = return_timestamps
- elif not is_shortform:
- if return_timestamps is False:
- raise ValueError(
- "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
- "requires the model to predict timestamp tokens. Please either pass `return_timestamps=True` or make sure to pass no more than 3000 mel input features."
- )
-
- if not hasattr(generation_config, "no_timestamps_token_id"):
- raise ValueError(
- "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
- "requires the generation config to have `no_timestamps_token_id` correctly. "
- "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
- "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
- "or make sure to pass no more than 3000 mel input features."
- )
-
- logger.info("Setting `return_timestamps=True` for long-form generation.")
- generation_config.return_timestamps = True
- else:
- generation_config.return_timestamps = False
-
- # 3. Make sure to correctly set language-related parameters
- if is_multilingual is not None:
- if not hasattr(generation_config, "is_multilingual"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `is_multilingual` argument "
- "to `generate`. Please update the generation config as per the instructions "
- "https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- generation_config.is_multilingual = is_multilingual
-
- if hasattr(generation_config, "is_multilingual") and not generation_config.is_multilingual:
- if task is not None or language is not None:
- raise ValueError(
- "Cannot specify `task` or `language` for an English-only model. If the model is intended to be "
- "multilingual, pass `is_multilingual=True` to generate, or update the generation config."
- )
-
- if language is not None:
- if not hasattr(generation_config, "lang_to_id"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `language` argument "
- "to `generate`. Either set the language using the `forced_decoder_ids` in the model config, "
- "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- language = language.lower()
- generation_config.language = language
- if task is not None:
- if not hasattr(generation_config, "task_to_id"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `task` argument "
- "to `generate`. Either set the task using the `forced_decoder_ids` in the model config, "
- "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- generation_config.task = task
-
- # 4. Add forced decoder ids depending on passed `language`, `task`,`prompt_ids`, `return_token_timestamps` and `return_timestamps`
- forced_decoder_ids = None
- # Legacy code for backward compatibility
- if hasattr(self.config, "forced_decoder_ids") and self.config.forced_decoder_ids is not None:
- forced_decoder_ids = self.config.forced_decoder_ids
- elif (
- hasattr(self.generation_config, "forced_decoder_ids")
- and self.generation_config.forced_decoder_ids is not None
- ):
- forced_decoder_ids = self.generation_config.forced_decoder_ids
- else:
- forced_decoder_ids = kwargs.get("forced_decoder_ids", None)
-
- if task is not None or language is not None or (forced_decoder_ids is None and prompt_ids is not None):
- forced_decoder_ids = []
- if hasattr(generation_config, "language"):
- if generation_config.language in generation_config.lang_to_id.keys():
- language_token = generation_config.language
- elif generation_config.language in TO_LANGUAGE_CODE.keys():
- language_token = f"<|{TO_LANGUAGE_CODE[generation_config.language]}|>"
- elif generation_config.language in TO_LANGUAGE_CODE.values():
- language_token = f"<|{generation_config.language}|>"
- else:
- is_language_code = len(generation_config.language) == 2
- raise ValueError(
- f"Unsupported language: {generation_config.language}. Language should be one of:"
- f" {list(TO_LANGUAGE_CODE.values()) if is_language_code else list(TO_LANGUAGE_CODE.keys())}."
- )
- if language_token not in generation_config.lang_to_id:
- raise ValueError(
- f"{language_token} is not supported by this specific model as it is not in the `generation_config.lang_to_id`."
- "(You should just add it to the generation config)"
- )
- forced_decoder_ids.append((1, generation_config.lang_to_id[language_token]))
- else:
- forced_decoder_ids.append((1, None)) # automatically detect the language
-
- if hasattr(generation_config, "task"):
- if generation_config.task in TASK_IDS:
- forced_decoder_ids.append((2, generation_config.task_to_id[generation_config.task]))
- else:
- raise ValueError(
- f"The `{generation_config.task}`task is not supported. The task should be one of `{TASK_IDS}`"
- )
- elif hasattr(generation_config, "task_to_id"):
- forced_decoder_ids.append((2, generation_config.task_to_id["transcribe"])) # defaults to transcribe
- if hasattr(generation_config, "no_timestamps_token_id") and not generation_config.return_timestamps:
- idx = forced_decoder_ids[-1][0] + 1 if forced_decoder_ids else 1
- forced_decoder_ids.append((idx, generation_config.no_timestamps_token_id))
-
- if forced_decoder_ids is not None:
- generation_config.forced_decoder_ids = forced_decoder_ids
-
- if prompt_ids is not None:
- if kwargs.get("decoder_start_token_id") is not None:
- raise ValueError(
- "When specifying `prompt_ids`, you cannot also specify `decoder_start_token_id` as it gets overwritten."
- )
- prompt_ids = prompt_ids.tolist()
- decoder_start_token_id, *text_prompt_ids = prompt_ids
- # Slicing the text prompt ids in a manner consistent with the OpenAI implementation
- # to accomodate context space for the prefix (see https://github.com/openai/whisper/blob/c09a7ae299c4c34c5839a76380ae407e7d785914/whisper/decoding.py#L599)
- text_prompt_ids = text_prompt_ids[-self.config.max_target_positions // 2 - 1 :]
- # Set the decoder_start_token_id to <|startofprev|>
- kwargs.update({"decoder_start_token_id": decoder_start_token_id})
-
- # If the user passes `max_new_tokens`, increase its number to account for the prompt
- if kwargs.get("max_new_tokens", None) is not None:
- kwargs["max_new_tokens"] += len(text_prompt_ids)
- if kwargs["max_new_tokens"] >= self.config.max_target_positions:
- raise ValueError(
- f"The length of the sliced `prompt_ids` is {len(text_prompt_ids)}, and the `max_new_tokens` "
- f"{kwargs['max_new_tokens'] - len(text_prompt_ids)}. Thus, the combined length of the sliced "
- f"`prompt_ids` and `max_new_tokens` is: {kwargs['max_new_tokens']}. This exceeds the "
- f"`max_target_positions` of the Whisper model: {self.config.max_target_positions}. "
- "You should either reduce the length of your prompt, or reduce the value of `max_new_tokens`, "
- f"so that their combined length is less that {self.config.max_target_positions}."
- )
-
- # Reformat the forced_decoder_ids to incorporate the prompt
- non_prompt_forced_decoder_ids = (
- kwargs.pop("forced_decoder_ids", None) or generation_config.forced_decoder_ids
- )
- forced_decoder_ids = [
- *text_prompt_ids,
- generation_config.decoder_start_token_id,
- *[token for _rank, token in non_prompt_forced_decoder_ids],
- ]
- forced_decoder_ids = [(rank + 1, token) for rank, token in enumerate(forced_decoder_ids)]
- generation_config.forced_decoder_ids = forced_decoder_ids
-
- if return_token_timestamps:
- kwargs["output_attentions"] = True
- return_dict_in_generate = True
- kwargs["output_scores"] = True
-
- if getattr(generation_config, "task", None) == "translate":
- logger.warning("Token-level timestamps may not be reliable for task 'translate'.")
- if not hasattr(generation_config, "alignment_heads"):
- raise ValueError(
- "Model generation config has no `alignment_heads`, token-level timestamps not available. "
- "See https://gist.github.com/hollance/42e32852f24243b748ae6bc1f985b13a on how to add this property to the generation config."
- )
-
- if kwargs.get("num_frames") is not None:
- generation_config.num_frames = kwargs.pop("num_frames")
-
- if generation_config.return_timestamps is True:
- last_forced_decoder_ids = (
- generation_config.forced_decoder_ids[-1][-1]
- if hasattr(self.config, "forced_decoder_ids") and self.config.forced_decoder_ids
- else None
- )
- if last_forced_decoder_ids == self.generation_config.no_timestamps_token_id:
- # remove no_timestamp to be forcefully generated if we want to return timestamps
- # this is also important to make sure `WhisperTimeStampLogitsProcessor` functions correctly
- forced_decoder_ids = generation_config.forced_decoder_ids[:-1]
- # Make sure that if list is empty we set it to None
- generation_config.forced_decoder_ids = None if len(forced_decoder_ids) == 0 else forced_decoder_ids
-
- timestamp_processor = [WhisperTimeStampLogitsProcessor(generation_config)]
- logits_processor = (
- timestamp_processor if logits_processor is None else timestamp_processor + logits_processor
- )
-
- # 5. If we're in shortform mode, simple generate the whole input at once and return the output
- if is_shortform:
- outputs = super().generate(
- input_features,
- generation_config,
- logits_processor,
- stopping_criteria,
- prefix_allowed_tokens_fn,
- synced_gpus,
- return_dict_in_generate=return_dict_in_generate,
- **kwargs,
- )
-
- if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
- num_frames = getattr(generation_config, "num_frames", None)
- outputs["token_timestamps"] = self._extract_token_timestamps(
- outputs, generation_config.alignment_heads, num_frames=num_frames
- )
-
- return outputs
-
- # 6. Else we're in longform mode which is more complex. We need to chunk the audio input depending on when the model generated
- # timestamp tokens
- # 6.1 Set running parameters for while loop
- if not return_segments and return_dict_in_generate:
- raise ValueError(
- "Make sure to set `return_segments=True` to return generation outputs as part of the `'segments' key.`"
- )
-
- # if input is longer than 30 seconds we default to long-form generation
- timestamp_begin = self.generation_config.no_timestamps_token_id + 1
- # input stride is mel frames per encoder output vector which is the product of all conv strides
- batch_size = input_features.shape[0]
-
- if batch_size > 1 and attention_mask is None:
- raise ValueError(
- "When doing long-form audio transcription, make sure to pass an `attention_mask`. You can retrieve the `attention_mask` by doing `processor(audio, ..., return_attention_mask=True)` "
- )
- elif batch_size > 1:
- max_frames = attention_mask.sum(-1).cpu().to(torch.long)
- seek = torch.zeros((batch_size,), dtype=torch.long)
- else:
- max_frames = torch.ones((1,), dtype=torch.long) * total_input_frames
- seek = torch.zeros((1,), dtype=torch.long)
-
- current_segments = [[] for _ in range(batch_size)]
- cur_to_prev_index_map = list(range(batch_size))
-
- # batch size can decrease during the run
- cur_bsz = prev_bsz = batch_size
-
- # 6.2 Transcribe audio until we reach the end of all input audios
- while (seek < max_frames).any():
- prev_bsz = cur_bsz
-
- # 6.3 NOTE: When in longform transcription mode and batch size > 1 we need to dynamically reduce the batch size during the loop
- # in case one audio finished earlier than another one. Thus, we need to keep a table of "previous-index-2-current-index" in order
- # to know which original audio is being decoded
- new_cur_to_prev_index_map = []
- for i in range(prev_bsz):
- prev_i = cur_to_prev_index_map[i]
- if seek[prev_i] >= max_frames[prev_i]:
- cut_index = i + (cur_bsz - prev_bsz)
- cur_bsz -= 1
- input_features = torch.cat([input_features[:cut_index], input_features[cut_index + 1 :]], dim=0)
- else:
- # cut out index that goes away
- new_cur_to_prev_index_map.append(prev_i)
-
- # 6.4 Set updated index map, duration of previously decoded chunks and number of max frames of current decoding chunk
- cur_to_prev_index_map = new_cur_to_prev_index_map
- time_offset = seek * time_precision / input_stride
- seek_num_frames = (max_frames - seek).clamp(max=num_segment_frames)
-
- # 6.5 Make sure that all inputs are padded to the same input length
- segment_input = []
- for i in range(cur_bsz):
- prev_i = cur_to_prev_index_map[i]
- segment_input_slice = input_features[
- i : i + 1, :, seek[prev_i] : seek[prev_i] + seek_num_frames[prev_i]
- ]
-
- if segment_input_slice.shape[-1] < num_segment_frames:
- # pad to 3000 if necessary
- segment_input_slice = F.pad(
- segment_input_slice, pad=(0, num_segment_frames - segment_input_slice.shape[-1])
- )
-
- segment_input.append(segment_input_slice)
-
- segment_input = torch.cat(segment_input, dim=0)
-
- # 6.6 Batch generate current chunk
- seek_outputs = super().generate(
- segment_input,
- generation_config,
- logits_processor,
- stopping_criteria,
- prefix_allowed_tokens_fn,
- synced_gpus,
- return_dict_in_generate=return_dict_in_generate,
- **kwargs,
- )
-
- if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
- num_frames = getattr(generation_config, "num_frames", None)
- seek_outputs["token_timestamps"] = self._extract_token_timestamps(
- seek_outputs, generation_config.alignment_heads, num_frames=num_frames
- )
-
- if return_dict_in_generate:
- seek_sequences = seek_outputs["sequences"]
- seek_outputs = [
- {k: v[i] for k, v in seek_outputs.items()}
- for i in range(next(iter(seek_outputs.values())).size(0))
- ]
- else:
- seek_sequences = seek_outputs
-
- # 6.7 Loop over each decoded audio individually as each decoding can be of a different length
- for i, seek_sequence in enumerate(seek_sequences):
- prev_i = cur_to_prev_index_map[i]
-
- # make sure we cut a predicted EOS token if we are not finished with the generation yet
- is_not_final = (seek[prev_i] + num_segment_frames) < max_frames[prev_i]
- if is_not_final and seek_sequence[-1] == self.generation_config.eos_token_id:
- seek_sequence = seek_sequence[:-1]
-
- # remove all padding tokens
- if seek_sequence[-1] == self.generation_config.pad_token_id:
- num_paddings = (seek_sequence == self.generation_config.pad_token_id).sum()
- seek_sequence = seek_sequence[:-num_paddings]
-
- segments, segment_offset = self._retrieve_segment(
- seek_sequence=seek_sequence,
- seek_outputs=seek_outputs,
- time_offset=time_offset,
- timestamp_begin=timestamp_begin,
- seek_num_frames=seek_num_frames,
- cur_bsz=cur_bsz,
- time_precision=time_precision,
- input_stride=input_stride,
- prev_idx=prev_i,
- idx=i,
- )
-
- current_segments[prev_i] += segments
- seek[prev_i] += segment_offset
-
- # 7. Once all segments are added to the list of all segments, called `current_segments`, we extract the predicted
- # output tokens from the list of dicts. If we use batch size > 1, we make sure to pad the output
- sequences = []
- max_total_length = 0
- for current_segment_list in current_segments:
- sequences.append(torch.cat([d["tokens"] for d in current_segment_list], dim=-1))
- max_total_length = max(max_total_length, len(sequences[-1]))
-
- for i in range(batch_size):
- sequences[i] = F.pad(
- sequences[i], pad=(0, max_total_length - len(sequences[i])), value=self.generation_config.pad_token_id
- )
-
- sequences = torch.stack(sequences, dim=0)
-
- # 8. If we return all segments, the predicted output sequences are put under `"sequences"`.
- if return_segments:
- return {"sequences": sequences, "segments": current_segments}
-
- return sequences
-
- @staticmethod
- def _retrieve_segment(
- seek_sequence,
- seek_outputs,
- time_offset,
- timestamp_begin,
- seek_num_frames,
- cur_bsz,
- time_precision,
- input_stride,
- prev_idx,
- idx,
- ):
- # find the predicted "end of segment" predictions of Whisper
- # "end of segment" predictions occur whenever Whisper predicts a timestamp token
- timestamp_tokens: torch.Tensor = seek_sequence.ge(timestamp_begin)
- single_timestamp_ending = timestamp_tokens[-2:].tolist() == cur_bsz * [[False, True]]
- timestamp_segment_indices = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0]
-
- # If whisper predicted a "end of segment" via a timestep token, let's go ever each
- # "end of segment" prediction and slice the decoding into segments accordingly
- if len(timestamp_segment_indices) > 0:
- # if the output contains two consecutive timestamp tokens
- slices = timestamp_segment_indices.tolist()
- segments = []
- if single_timestamp_ending:
- slices.append(len(seek_sequence))
-
- last_slice = 0
- # Add each segment to list of all segments
- for current_slice in slices:
- sliced_tokens = seek_sequence[last_slice + 1 : current_slice + 1]
- start_timestamp_pos = sliced_tokens[0].item() - timestamp_begin
- end_timestamp_pos = sliced_tokens[-1].item() - timestamp_begin
- segments.append(
- {
- "start": time_offset[prev_idx] + start_timestamp_pos * time_precision,
- "end": time_offset[prev_idx] + end_timestamp_pos * time_precision,
- "tokens": sliced_tokens,
- "result": seek_outputs[idx],
- }
- )
- last_slice = current_slice
-
- if single_timestamp_ending:
- # single timestamp at the end means no speech after the last timestamp.
- segment_offset = seek_num_frames[prev_idx]
- else:
- # otherwise, ignore the unfinished segment and seek to the last timestamp
- # here we throw away all predictions after the last predicted "end of segment"
- # since we are cutting right in the middle of an audio
- last_timestamp_pos = seek_sequence[last_slice].item() - timestamp_begin
- segment_offset = last_timestamp_pos * input_stride
- else:
- # If whisper does not predict any "end of segment" token, then
- # the whole decoding is considered a segment and we add it to the list of segments
- timestamps = seek_sequence[timestamp_tokens.nonzero().flatten()]
- last_timestamp_pos = seek_num_frames[prev_idx]
- if timestamps.numel() > 0 and timestamps[-1].item() != timestamp_begin:
- # no consecutive timestamps but it has a timestamp; use the last one.
- last_timestamp_pos = timestamps[-1].item() - timestamp_begin
-
- segments = [
- {
- "start": time_offset[prev_idx],
- "end": time_offset[prev_idx] + last_timestamp_pos * time_precision,
- "tokens": seek_sequence,
- "result": seek_outputs[idx],
- }
- ]
- segment_offset = seek_num_frames[prev_idx]
-
- return segments, segment_offset
-
def prepare_inputs_for_generation(
self,
decoder_input_ids,
@@ -2506,8 +1800,13 @@ def prepare_inputs_for_generation(
use_cache=None,
encoder_outputs=None,
attention_mask=None,
+ decoder_attention_mask=None,
**kwargs,
):
+ decoder_position_ids = None
+ if decoder_attention_mask is not None:
+ decoder_position_ids = (decoder_attention_mask.cumsum(-1) - 1).clamp(min=0)
+
if past_key_values is not None:
past_length = past_key_values[0][0].shape[2]
@@ -2520,12 +1819,16 @@ def prepare_inputs_for_generation(
decoder_input_ids = decoder_input_ids[:, remove_prefix_length:]
+ if decoder_position_ids is not None and decoder_position_ids.shape[1] > decoder_input_ids.shape[1]:
+ decoder_position_ids = decoder_position_ids[:, remove_prefix_length:]
+
return {
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"use_cache": use_cache,
- "decoder_attention_mask": None,
+ "decoder_attention_mask": decoder_attention_mask,
+ "decoder_position_ids": decoder_position_ids,
}
@staticmethod
@@ -2537,99 +1840,6 @@ def _reorder_cache(past_key_values, beam_idx):
)
return reordered_past
- def _extract_token_timestamps(self, generate_outputs, alignment_heads, time_precision=0.02, num_frames=None):
- """
- Calculates token-level timestamps using the encoder-decoder cross-attentions and dynamic time-warping (DTW) to
- map each output token to a position in the input audio. If `num_frames` is specified, the encoder-decoder
- cross-attentions will be cropped before applying DTW.
-
- Returns:
- tensor containing the timestamps in seconds for each predicted token
- """
- # Create a list with `decoder_layers` elements, each a tensor of shape
- # (batch size, attention_heads, output length, input length).
- cross_attentions = []
- for i in range(self.config.decoder_layers):
- cross_attentions.append(torch.cat([x[i] for x in generate_outputs.cross_attentions], dim=2))
-
- # Select specific cross-attention layers and heads. This is a tensor
- # of shape (batch size, num selected, output length, input length).
- weights = torch.stack([cross_attentions[l][:, h] for l, h in alignment_heads])
- weights = weights.permute([1, 0, 2, 3])
-
- if "beam_indices" in generate_outputs:
- # If beam search has been used, the output sequences may have been generated for more timesteps than their sequence_lengths
- # since the beam search strategy chooses the most probable sequences at the end of the search.
- # In that case, the cross_attentions weights are too long and we have to make sure that they have the right output_length
- weight_length = (generate_outputs.beam_indices != -1).sum(-1).max()
- weights = weights[:, :, :weight_length]
-
- # If beam index is still -1, it means that the associated token id is EOS
- # We need to replace the index with 0 since index_select gives an error if any of the indexes is -1.
- beam_indices = generate_outputs.beam_indices[:, :weight_length]
- beam_indices = beam_indices.masked_fill(beam_indices == -1, 0)
-
- # Select the cross attention from the right beam for each output sequences
- weights = torch.stack(
- [
- torch.index_select(weights[:, :, i, :], dim=0, index=beam_indices[:, i])
- for i in range(beam_indices.shape[1])
- ],
- dim=2,
- )
-
- timestamps = torch.zeros_like(generate_outputs.sequences, dtype=torch.float32)
- batch_size = timestamps.shape[0]
-
- if num_frames is not None:
- # two cases:
- # 1. num_frames is the same for each sample -> compute the DTW matrix for each sample in parallel
- # 2. num_frames is different, compute the DTW matrix for each sample sequentially
-
- # we're using np.unique because num_frames can be int/list/tuple
- if len(np.unique(num_frames)) == 1:
- # if num_frames is the same, no need to recompute matrix, std and mean for each element of the batch
- num_frames = num_frames if isinstance(num_frames, int) else num_frames[0]
-
- weights = weights[..., : num_frames // 2]
- else:
- # num_frames is of shape (batch_size,) whereas batch_size is truely batch_size*num_return_sequences
- repeat_time = batch_size if isinstance(num_frames, int) else batch_size // len(num_frames)
- num_frames = np.repeat(num_frames, repeat_time)
-
- if num_frames is None or isinstance(num_frames, int):
- # Normalize and smoothen the weights.
- std = torch.std(weights, dim=-2, keepdim=True, unbiased=False)
- mean = torch.mean(weights, dim=-2, keepdim=True)
- weights = (weights - mean) / std
- weights = _median_filter(weights, self.config.median_filter_width)
-
- # Average the different cross-attention heads.
- weights = weights.mean(dim=1)
-
- # Perform dynamic time warping on each element of the batch.
- for batch_idx in range(batch_size):
- if num_frames is not None and isinstance(num_frames, (tuple, list, np.ndarray)):
- matrix = weights[batch_idx, ..., : num_frames[batch_idx] // 2]
-
- # Normalize and smoothen the weights.
- std = torch.std(matrix, dim=-2, keepdim=True, unbiased=False)
- mean = torch.mean(matrix, dim=-2, keepdim=True)
- matrix = (matrix - mean) / std
- matrix = _median_filter(matrix, self.config.median_filter_width)
-
- # Average the different cross-attention heads.
- matrix = matrix.mean(dim=0)
- else:
- matrix = weights[batch_idx]
-
- text_indices, time_indices = _dynamic_time_warping(-matrix.cpu().double().numpy())
- jumps = np.pad(np.diff(text_indices), (1, 0), constant_values=1).astype(bool)
- jump_times = time_indices[jumps] * time_precision
- timestamps[batch_idx, 1:] = torch.tensor(jump_times)
-
- return timestamps
-
class WhisperDecoderWrapper(WhisperPreTrainedModel):
"""
@@ -2957,6 +2167,11 @@ def forward(
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ if self.config.use_weighted_layer_sum:
+ output_hidden_states = True
+ elif output_hidden_states is None:
+ output_hidden_states = self.config.output_hidden_states
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if encoder_outputs is None:
@@ -2969,7 +2184,8 @@ def forward(
)
if self.config.use_weighted_layer_sum:
- hidden_states = torch.stack(encoder_outputs, dim=1)
+ hidden_states = encoder_outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
else:
diff --git a/src/transformers/models/whisper/tokenization_whisper.py b/src/transformers/models/whisper/tokenization_whisper.py
index a54103ccef8f53..127f5be6193d72 100644
--- a/src/transformers/models/whisper/tokenization_whisper.py
+++ b/src/transformers/models/whisper/tokenization_whisper.py
@@ -530,10 +530,21 @@ def _decode_with_timestamps(self, token_ids, skip_special_tokens=False, time_pre
"""
timestamp_begin = self.all_special_ids[-1] + 1
outputs = [[]]
+
+ cur_max_timestamp = 0.0
+ prev_segments_len = 0.0
+
for token in token_ids:
if token >= timestamp_begin:
- timestamp = f"<|{(token - timestamp_begin) * time_precision:.2f}|>"
- outputs.append(timestamp)
+ timestamp = float((token - timestamp_begin) * time_precision)
+
+ if timestamp < cur_max_timestamp:
+ # next segment has started
+ prev_segments_len += cur_max_timestamp
+
+ cur_max_timestamp = timestamp
+
+ outputs.append(f"<|{(timestamp + prev_segments_len):.2f}|>")
outputs.append([])
else:
outputs[-1].append(token)
@@ -553,6 +564,9 @@ def _compute_offsets(self, token_ids, time_precision=0.02):
The time ratio to convert from token to time.
"""
offsets = []
+ # ensure torch tensor of token ids is placed on cpu
+ if "torch" in str(type(token_ids)) and (hasattr(token_ids, "cpu") and callable(token_ids.cpu)):
+ token_ids = token_ids.cpu()
token_ids = np.array(token_ids)
if token_ids.shape[0] > 1 and len(token_ids.shape) > 1:
raise ValueError("Can only process a single input at a time")
@@ -628,7 +642,7 @@ def decode(
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_offsets: bool = False,
- time_precision=0.02,
+ time_precision: float = 0.02,
decode_with_timestamps: bool = False,
normalize: bool = False,
basic_normalize: bool = False,
diff --git a/src/transformers/models/whisper/tokenization_whisper_fast.py b/src/transformers/models/whisper/tokenization_whisper_fast.py
index ee44bb5918d2b0..509175be994f75 100644
--- a/src/transformers/models/whisper/tokenization_whisper_fast.py
+++ b/src/transformers/models/whisper/tokenization_whisper_fast.py
@@ -224,10 +224,21 @@ def _decode_with_timestamps(self, token_ids, skip_special_tokens=False, time_pre
"""
timestamp_begin = self.all_special_ids[-1] + 1
outputs = [[]]
+
+ cur_max_timestamp = 0.0
+ prev_segments_len = 0.0
+
for token in token_ids:
if token >= timestamp_begin:
- timestamp = f"<|{(token - timestamp_begin) * time_precision:.2f}|>"
- outputs.append(timestamp)
+ timestamp = float((token - timestamp_begin) * time_precision)
+
+ if timestamp < cur_max_timestamp:
+ # next segment has started
+ prev_segments_len += cur_max_timestamp
+
+ cur_max_timestamp = timestamp
+
+ outputs.append(f"<|{(timestamp + prev_segments_len):.2f}|>")
outputs.append([])
else:
outputs[-1].append(token)
@@ -248,6 +259,9 @@ def _compute_offsets(self, token_ids, time_precision=0.02):
The time ratio to convert from token to time.
"""
offsets = []
+ # ensure torch tensor of token ids is placed on cpu
+ if "torch" in str(type(token_ids)) and (hasattr(token_ids, "cpu") and callable(token_ids.cpu)):
+ token_ids = token_ids.cpu()
token_ids = np.array(token_ids)
if token_ids.shape[0] > 1 and len(token_ids.shape) > 1:
raise ValueError("Can only process a single input at a time")
@@ -327,7 +341,7 @@ def decode(
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_offsets: bool = False,
- time_precision=0.02,
+ time_precision: float = 0.02,
decode_with_timestamps: bool = False,
normalize: bool = False,
basic_normalize: bool = False,
diff --git a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
index 582f3733d6e837..48bb28bf4ee2c6 100644
--- a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
@@ -47,7 +47,7 @@
logger = logging.get_logger(__name__)
-_CHECKPOINT_FOR_DOC = "xlm-roberta-xlarge"
+_CHECKPOINT_FOR_DOC = "facebook/xlm-roberta-xl"
_CONFIG_FOR_DOC = "XLMRobertaXLConfig"
XLM_ROBERTA_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
@@ -653,7 +653,7 @@ def _init_weights(self, module):
@add_start_docstrings(
- "The bare XLM-RoBERTa-xlarge Model transformer outputting raw hidden-states without any specific head on top.",
+ "The bare XLM-RoBERTa-XL Model transformer outputting raw hidden-states without any specific head on top.",
XLM_ROBERTA_XL_START_DOCSTRING,
)
class XLMRobertaXLModel(XLMRobertaXLPreTrainedModel):
@@ -833,7 +833,7 @@ def forward(
@add_start_docstrings(
- """XLM-RoBERTa-xlarge Model with a `language modeling` head on top for CLM fine-tuning.""",
+ """XLM-RoBERTa-XL Model with a `language modeling` head on top for CLM fine-tuning.""",
XLM_ROBERTA_XL_START_DOCSTRING,
)
class XLMRobertaXLForCausalLM(XLMRobertaXLPreTrainedModel):
@@ -990,7 +990,7 @@ def _reorder_cache(self, past_key_values, beam_idx):
@add_start_docstrings(
- """XLM-RoBERTa-xlarge Model with a `language modeling` head on top.""", XLM_ROBERTA_XL_START_DOCSTRING
+ """XLM-RoBERTa-XL Model with a `language modeling` head on top.""", XLM_ROBERTA_XL_START_DOCSTRING
)
class XLMRobertaXLForMaskedLM(XLMRobertaXLPreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.weight", "lm_head.decoder.bias"]
@@ -1081,7 +1081,7 @@ def forward(
class XLMRobertaXLLMHead(nn.Module):
- """XLM-Roberta-xlarge Head for masked language modeling."""
+ """XLM-RoBERTa-XL Head for masked language modeling."""
def __init__(self, config):
super().__init__()
@@ -1109,7 +1109,7 @@ def _tie_weights(self):
@add_start_docstrings(
"""
- XLM-RoBERTa-xlarge Model transformer with a sequence classification/regression head on top (a linear layer on top
+ XLM-RoBERTa-XL Model transformer with a sequence classification/regression head on top (a linear layer on top
of the pooled output) e.g. for GLUE tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1203,7 +1203,7 @@ def forward(
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a multiple choice classification head on top (a linear layer on top of the pooled
+ XLM-RoBERTa-XL Model with a multiple choice classification head on top (a linear layer on top of the pooled
output and a softmax) e.g. for RocStories/SWAG tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1294,7 +1294,7 @@ def forward(
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a token classification head on top (a linear layer on top of the hidden-states
+ XLM-RoBERTa-XL Model with a token classification head on top (a linear layer on top of the hidden-states
output) e.g. for Named-Entity-Recognition (NER) tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1405,7 +1405,7 @@ def forward(self, features, **kwargs):
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a span classification head on top for extractive question-answering tasks like SQuAD
+ XLM-RoBERTa-XL Model with a span classification head on top for extractive question-answering tasks like SQuAD
(a linear layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
XLM_ROBERTA_XL_START_DOCSTRING,
diff --git a/src/transformers/pipelines/automatic_speech_recognition.py b/src/transformers/pipelines/automatic_speech_recognition.py
index 32e61db42af5ff..2c8bf5e2ad9084 100644
--- a/src/transformers/pipelines/automatic_speech_recognition.py
+++ b/src/transformers/pipelines/automatic_speech_recognition.py
@@ -17,11 +17,10 @@
import numpy as np
import requests
-from ..modelcard import ModelCard
from ..tokenization_utils import PreTrainedTokenizer
from ..utils import is_torch_available, is_torchaudio_available, logging
from .audio_utils import ffmpeg_read
-from .base import ArgumentHandler, ChunkPipeline, infer_framework_load_model
+from .base import ChunkPipeline
if TYPE_CHECKING:
@@ -35,7 +34,7 @@
if is_torch_available():
import torch
- from ..models.auto.modeling_auto import MODEL_FOR_CTC_MAPPING_NAMES, MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
+ from ..models.auto.modeling_auto import MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
def rescale_stride(stride, ratio):
@@ -155,11 +154,15 @@ class AutomaticSpeechRecognitionPipeline(ChunkPipeline):
model ([`PreTrainedModel`] or [`TFPreTrainedModel`]):
The model that will be used by the pipeline to make predictions. This needs to be a model inheriting from
[`PreTrainedModel`] for PyTorch and [`TFPreTrainedModel`] for TensorFlow.
+ feature_extractor ([`SequenceFeatureExtractor`]):
+ The feature extractor that will be used by the pipeline to encode waveform for the model.
tokenizer ([`PreTrainedTokenizer`]):
The tokenizer that will be used by the pipeline to encode data for the model. This object inherits from
[`PreTrainedTokenizer`].
- feature_extractor ([`SequenceFeatureExtractor`]):
- The feature extractor that will be used by the pipeline to encode waveform for the model.
+ decoder (`pyctcdecode.BeamSearchDecoderCTC`, *optional*):
+ [PyCTCDecode's
+ BeamSearchDecoderCTC](https://github.com/kensho-technologies/pyctcdecode/blob/2fd33dc37c4111417e08d89ccd23d28e9b308d19/pyctcdecode/decoder.py#L180)
+ can be passed for language model boosted decoding. See [`Wav2Vec2ProcessorWithLM`] for more information.
chunk_length_s (`float`, *optional*, defaults to 0):
The input length for in each chunk. If `chunk_length_s = 0` then chunking is disabled (default).
@@ -190,10 +193,9 @@ class AutomaticSpeechRecognitionPipeline(ChunkPipeline):
device (Union[`int`, `torch.device`], *optional*):
Device ordinal for CPU/GPU supports. Setting this to `None` will leverage CPU, a positive will run the
model on the associated CUDA device id.
- decoder (`pyctcdecode.BeamSearchDecoderCTC`, *optional*):
- [PyCTCDecode's
- BeamSearchDecoderCTC](https://github.com/kensho-technologies/pyctcdecode/blob/2fd33dc37c4111417e08d89ccd23d28e9b308d19/pyctcdecode/decoder.py#L180)
- can be passed for language model boosted decoding. See [`Wav2Vec2ProcessorWithLM`] for more information.
+ torch_dtype (Union[`int`, `torch.dtype`], *optional*):
+ The data-type (dtype) of the computation. Setting this to `None` will use float32 precision. Set to
+ `torch.float16` or `torch.bfloat16` to use half-precision in the respective dtypes.
"""
@@ -203,77 +205,14 @@ def __init__(
feature_extractor: Union["SequenceFeatureExtractor", str] = None,
tokenizer: Optional[PreTrainedTokenizer] = None,
decoder: Optional[Union["BeamSearchDecoderCTC", str]] = None,
- modelcard: Optional[ModelCard] = None,
- framework: Optional[str] = None,
- task: str = "",
- args_parser: ArgumentHandler = None,
device: Union[int, "torch.device"] = None,
torch_dtype: Optional[Union[str, "torch.dtype"]] = None,
- binary_output: bool = False,
**kwargs,
):
- if framework is None:
- framework, model = infer_framework_load_model(model, config=model.config)
-
- self.task = task
- self.model = model
- self.tokenizer = tokenizer
- self.feature_extractor = feature_extractor
- self.modelcard = modelcard
- self.framework = framework
-
- # `accelerate` device map
- hf_device_map = getattr(self.model, "hf_device_map", None)
-
- if hf_device_map is not None and device is not None:
- raise ValueError(
- "The model has been loaded with `accelerate` and therefore cannot be moved to a specific device. Please "
- "discard the `device` argument when creating your pipeline object."
- )
-
- if self.framework == "tf":
- raise ValueError("The AutomaticSpeechRecognitionPipeline is only available in PyTorch.")
-
- # We shouldn't call `model.to()` for models loaded with accelerate
- if device is not None and not (isinstance(device, int) and device < 0):
- self.model.to(device)
-
- if device is None:
- if hf_device_map is not None:
- # Take the first device used by `accelerate`.
- device = next(iter(hf_device_map.values()))
- else:
- device = -1
-
- if is_torch_available() and self.framework == "pt":
- if isinstance(device, torch.device):
- self.device = device
- elif isinstance(device, str):
- self.device = torch.device(device)
- elif device < 0:
- self.device = torch.device("cpu")
- else:
- self.device = torch.device(f"cuda:{device}")
- else:
- self.device = device if device is not None else -1
- self.torch_dtype = torch_dtype
- self.binary_output = binary_output
-
- # Update config and generation_config with task specific parameters
- task_specific_params = self.model.config.task_specific_params
- if task_specific_params is not None and task in task_specific_params:
- self.model.config.update(task_specific_params.get(task))
- if self.model.can_generate():
- self.model.generation_config.update(**task_specific_params.get(task))
-
- self.call_count = 0
- self._batch_size = kwargs.pop("batch_size", None)
- self._num_workers = kwargs.pop("num_workers", None)
-
# set the model type so we can check we have the right pre- and post-processing parameters
- if self.model.config.model_type == "whisper":
+ if model.config.model_type == "whisper":
self.type = "seq2seq_whisper"
- elif self.model.__class__.__name__ in MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.values():
+ elif model.__class__.__name__ in MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.values():
self.type = "seq2seq"
elif (
feature_extractor._processor_class
@@ -285,11 +224,7 @@ def __init__(
else:
self.type = "ctc"
- self._preprocess_params, self._forward_params, self._postprocess_params = self._sanitize_parameters(**kwargs)
-
- mapping = MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.copy()
- mapping.update(MODEL_FOR_CTC_MAPPING_NAMES)
- self.check_model_type(mapping)
+ super().__init__(model, tokenizer, feature_extractor, device=device, torch_dtype=torch_dtype, **kwargs)
def __call__(
self,
@@ -582,8 +517,11 @@ def _forward(self, model_inputs, return_timestamps=False, generate_kwargs=None):
out["stride"] = stride
else:
- input_values = model_inputs.pop("input_values")
- outputs = self.model(input_values=input_values, attention_mask=attention_mask)
+ inputs = {
+ self.model.main_input_name: model_inputs.pop(self.model.main_input_name),
+ "attention_mask": attention_mask,
+ }
+ outputs = self.model(**inputs)
logits = outputs.logits
if self.type == "ctc_with_lm":
diff --git a/src/transformers/processing_utils.py b/src/transformers/processing_utils.py
index 41236fe9e1d3c9..f727f308ac3a20 100644
--- a/src/transformers/processing_utils.py
+++ b/src/transformers/processing_utils.py
@@ -16,14 +16,28 @@
Processing saving/loading class for common processors.
"""
+import copy
+import inspect
+import json
import os
import warnings
from pathlib import Path
-from typing import Optional, Union
+from typing import Any, Dict, Optional, Tuple, Union
from .dynamic_module_utils import custom_object_save
from .tokenization_utils_base import PreTrainedTokenizerBase
-from .utils import PushToHubMixin, copy_func, direct_transformers_import, logging
+from .utils import (
+ PROCESSOR_NAME,
+ PushToHubMixin,
+ add_model_info_to_auto_map,
+ cached_file,
+ copy_func,
+ direct_transformers_import,
+ download_url,
+ is_offline_mode,
+ is_remote_url,
+ logging,
+)
logger = logging.get_logger(__name__)
@@ -85,10 +99,70 @@ def __init__(self, *args, **kwargs):
setattr(self, attribute_name, arg)
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this processor instance.
+ """
+ output = copy.deepcopy(self.__dict__)
+
+ # Get the kwargs in `__init__`.
+ sig = inspect.signature(self.__init__)
+ # Only save the attributes that are presented in the kwargs of `__init__`.
+ attrs_to_save = sig.parameters
+ # Don't save attributes like `tokenizer`, `image processor` etc.
+ attrs_to_save = [x for x in attrs_to_save if x not in self.__class__.attributes]
+ # extra attributes to be kept
+ attrs_to_save += ["auto_map"]
+
+ output = {k: v for k, v in output.items() if k in attrs_to_save}
+
+ output["processor_class"] = self.__class__.__name__
+
+ if "tokenizer" in output:
+ del output["tokenizer"]
+ if "image_processor" in output:
+ del output["image_processor"]
+ if "feature_extractor" in output:
+ del output["feature_extractor"]
+
+ # Some attributes have different names but containing objects that are not simple strings
+ output = {
+ k: v
+ for k, v in output.items()
+ if not (isinstance(v, PushToHubMixin) or v.__class__.__name__ == "BeamSearchDecoderCTC")
+ }
+
+ return output
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this feature_extractor instance in JSON format.
+ """
+ dictionary = self.to_dict()
+
+ return json.dumps(dictionary, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this processor instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
def __repr__(self):
attributes_repr = [f"- {name}: {repr(getattr(self, name))}" for name in self.attributes]
attributes_repr = "\n".join(attributes_repr)
- return f"{self.__class__.__name__}:\n{attributes_repr}"
+ return f"{self.__class__.__name__}:\n{attributes_repr}\n\n{self.to_json_string()}"
def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
"""
@@ -139,6 +213,7 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
if self._auto_class is not None:
attrs = [getattr(self, attribute_name) for attribute_name in self.attributes]
configs = [(a.init_kwargs if isinstance(a, PreTrainedTokenizerBase) else a) for a in attrs]
+ configs.append(self)
custom_object_save(self, save_directory, config=configs)
for attribute_name in self.attributes:
@@ -156,6 +231,15 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
if isinstance(attribute, PreTrainedTokenizerBase):
del attribute.init_kwargs["auto_map"]
+ # If we save using the predefined names, we can load using `from_pretrained`
+ output_processor_file = os.path.join(save_directory, PROCESSOR_NAME)
+
+ # For now, let's not save to `processor_config.json` if the processor doesn't have extra attributes and
+ # `auto_map` is not specified.
+ if set(self.to_dict().keys()) != {"processor_class"}:
+ self.to_json_file(output_processor_file)
+ logger.info(f"processor saved in {output_processor_file}")
+
if push_to_hub:
self._upload_modified_files(
save_directory,
@@ -165,6 +249,152 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
token=kwargs.get("token"),
)
+ if set(self.to_dict().keys()) == {"processor_class"}:
+ return []
+ return [output_processor_file]
+
+ @classmethod
+ def get_processor_dict(
+ cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
+ ) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ """
+ From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
+ processor of type [`~processing_utils.ProcessingMixin`] using `from_args_and_dict`.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+
+ Returns:
+ `Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the processor object.
+ """
+ cache_dir = kwargs.pop("cache_dir", None)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ token = kwargs.pop("token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", "")
+
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+
+ user_agent = {"file_type": "processor", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if os.path.isdir(pretrained_model_name_or_path):
+ processor_file = os.path.join(pretrained_model_name_or_path, PROCESSOR_NAME)
+ if os.path.isfile(pretrained_model_name_or_path):
+ resolved_processor_file = pretrained_model_name_or_path
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ processor_file = pretrained_model_name_or_path
+ resolved_processor_file = download_url(pretrained_model_name_or_path)
+ else:
+ processor_file = PROCESSOR_NAME
+ try:
+ # Load from local folder or from cache or download from model Hub and cache
+ resolved_processor_file = cached_file(
+ pretrained_model_name_or_path,
+ processor_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ subfolder=subfolder,
+ )
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
+ # the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load processor for '{pretrained_model_name_or_path}'. If you were trying to load"
+ " it from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a {PROCESSOR_NAME} file"
+ )
+
+ try:
+ # Load processor dict
+ with open(resolved_processor_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ processor_dict = json.loads(text)
+
+ except json.JSONDecodeError:
+ raise EnvironmentError(
+ f"It looks like the config file at '{resolved_processor_file}' is not a valid JSON file."
+ )
+
+ if is_local:
+ logger.info(f"loading configuration file {resolved_processor_file}")
+ else:
+ logger.info(f"loading configuration file {processor_file} from cache at {resolved_processor_file}")
+
+ if "auto_map" in processor_dict and not is_local:
+ processor_dict["auto_map"] = add_model_info_to_auto_map(
+ processor_dict["auto_map"], pretrained_model_name_or_path
+ )
+
+ return processor_dict, kwargs
+
+ @classmethod
+ def from_args_and_dict(cls, args, processor_dict: Dict[str, Any], **kwargs):
+ """
+ Instantiates a type of [`~processing_utils.ProcessingMixin`] from a Python dictionary of parameters.
+
+ Args:
+ processor_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the processor object. Such a dictionary can be
+ retrieved from a pretrained checkpoint by leveraging the
+ [`~processing_utils.ProcessingMixin.to_dict`] method.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the processor object.
+
+ Returns:
+ [`~processing_utils.ProcessingMixin`]: The processor object instantiated from those
+ parameters.
+ """
+ processor_dict = processor_dict.copy()
+ return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
+
+ # Unlike image processors or feature extractors whose `__init__` accept `kwargs`, processor don't have `kwargs`.
+ # We have to pop up some unused (but specific) arguments to make it work.
+ if "processor_class" in processor_dict:
+ del processor_dict["processor_class"]
+
+ if "auto_map" in processor_dict:
+ del processor_dict["auto_map"]
+
+ processor = cls(*args, **processor_dict)
+
+ # Update processor with kwargs if needed
+ for key in set(kwargs.keys()):
+ if hasattr(processor, key):
+ setattr(processor, key, kwargs.pop(key))
+
+ logger.info(f"Processor {processor}")
+ if return_unused_kwargs:
+ return processor, kwargs
+ else:
+ return processor
+
@classmethod
def from_pretrained(
cls,
@@ -226,7 +456,19 @@ def from_pretrained(
kwargs["token"] = token
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
- return cls(*args)
+
+ # Existing processors on the Hub created before #27761 being merged don't have `processor_config.json` (if not
+ # updated afterward), and we need to keep `from_pretrained` work. So here it fallbacks to the empty dict.
+ # However, for models added in the future, we won't get the expected error if this file is missing.
+ try:
+ processor_dict, kwargs = cls.get_processor_dict(pretrained_model_name_or_path, **kwargs)
+ except EnvironmentError as e:
+ if "does not appear to have a file named processor_config.json." in str(e):
+ processor_dict, kwargs = {}, kwargs
+ else:
+ raise
+
+ return cls.from_args_and_dict(args, processor_dict, **kwargs)
@classmethod
def register_for_auto_class(cls, auto_class="AutoProcessor"):
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 6850f4dca067ea..f7a15a7fbff1fa 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -64,7 +64,7 @@
from .modeling_utils import PreTrainedModel, load_sharded_checkpoint, unwrap_model
from .models.auto.modeling_auto import MODEL_FOR_CAUSAL_LM_MAPPING_NAMES, MODEL_MAPPING_NAMES
from .optimization import Adafactor, get_scheduler
-from .pytorch_utils import ALL_LAYERNORM_LAYERS
+from .pytorch_utils import ALL_LAYERNORM_LAYERS, is_torch_greater_or_equal_than_1_13
from .tokenization_utils_base import PreTrainedTokenizerBase
from .trainer_callback import (
CallbackHandler,
@@ -2103,7 +2103,11 @@ def _load_from_checkpoint(self, resume_from_checkpoint, model=None):
logger.warning(
"Enabling FP16 and loading from smp < 1.10 checkpoint together is not suppported."
)
- state_dict = torch.load(weights_file, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weights_file,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# Required for smp to not auto-translate state_dict from hf to smp (is already smp).
state_dict["_smp_is_partial"] = False
load_result = model.load_state_dict(state_dict, strict=True)
@@ -2116,7 +2120,11 @@ def _load_from_checkpoint(self, resume_from_checkpoint, model=None):
if self.args.save_safetensors and os.path.isfile(safe_weights_file):
state_dict = safetensors.torch.load_file(safe_weights_file, device="cpu")
else:
- state_dict = torch.load(weights_file, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weights_file,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# workaround for FSDP bug https://github.com/pytorch/pytorch/issues/82963
# which takes *args instead of **kwargs
@@ -2184,7 +2192,11 @@ def _load_best_model(self):
if self.args.save_safetensors and os.path.isfile(best_safe_model_path):
state_dict = safetensors.torch.load_file(best_safe_model_path, device="cpu")
else:
- state_dict = torch.load(best_model_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ best_model_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
state_dict["_smp_is_partial"] = False
load_result = model.load_state_dict(state_dict, strict=True)
@@ -2213,7 +2225,11 @@ def _load_best_model(self):
if self.args.save_safetensors and os.path.isfile(best_safe_model_path):
state_dict = safetensors.torch.load_file(best_safe_model_path, device="cpu")
else:
- state_dict = torch.load(best_model_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ best_model_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# If the model is on the GPU, it still works!
# workaround for FSDP bug https://github.com/pytorch/pytorch/issues/82963
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index 0c1da8334ea706..463f134217582c 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -1844,11 +1844,6 @@ def _setup_devices(self) -> "torch.device":
device = torch.device("cuda", local_rank)
self._n_gpu = 1
torch.cuda.set_device(device)
- elif is_torch_xpu_available() and "ACCELERATE_USE_XPU" not in os.environ:
- os.environ["ACCELERATE_USE_XPU"] = "true"
- self.distributed_state = PartialState(timeout=timedelta(seconds=self.ddp_timeout))
- device = torch.device("xpu:0")
- self._n_gpu = 1
elif is_sagemaker_dp_enabled():
self.distributed_state = PartialState(_use_sagemaker_dp=True)
self._n_gpu = 1
@@ -1877,12 +1872,6 @@ def _setup_devices(self) -> "torch.device":
elif is_sagemaker_dp_enabled() or is_sagemaker_mp_enabled():
# Already set _n_gpu
pass
- elif self.distributed_state.distributed_type == DistributedType.MULTI_XPU:
- if "ACCELERATE_USE_XPU" not in os.environ:
- os.environ["ACCELERATE_USE_XPU"] = "true"
- self._n_gpu = 1
- device = torch.device("xpu:0")
- torch.xpu.set_device(device)
elif self.distributed_state.distributed_type == DistributedType.NO:
if self.use_mps_device:
warnings.warn(
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index 780090aec5e934..bb05dd28ef318c 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -217,6 +217,7 @@
CONFIG_NAME = "config.json"
FEATURE_EXTRACTOR_NAME = "preprocessor_config.json"
IMAGE_PROCESSOR_NAME = FEATURE_EXTRACTOR_NAME
+PROCESSOR_NAME = "processor_config.json"
GENERATION_CONFIG_NAME = "generation_config.json"
MODEL_CARD_NAME = "modelcard.json"
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 4d89b2942f7997..a897403d959655 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -6715,6 +6715,34 @@ def load_tf_weights_in_qdqbert(*args, **kwargs):
requires_backends(load_tf_weights_in_qdqbert, ["torch"])
+class Qwen2ForCausalLM(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2ForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2Model(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2PreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class RagModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -8730,6 +8758,51 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class Wav2Vec2BertForAudioFrameClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForCTC(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForXVector(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_tokenizers_objects.py b/src/transformers/utils/dummy_tokenizers_objects.py
index b8cc21303a815a..863cb3ad03ad55 100644
--- a/src/transformers/utils/dummy_tokenizers_objects.py
+++ b/src/transformers/utils/dummy_tokenizers_objects.py
@@ -331,6 +331,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["tokenizers"])
+class Qwen2TokenizerFast(metaclass=DummyObject):
+ _backends = ["tokenizers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["tokenizers"])
+
+
class RealmTokenizerFast(metaclass=DummyObject):
_backends = ["tokenizers"]
diff --git a/tests/generation/test_utils.py b/tests/generation/test_utils.py
index c41bc3b21a4ee3..2c16f41ae171dc 100644
--- a/tests/generation/test_utils.py
+++ b/tests/generation/test_utils.py
@@ -88,6 +88,7 @@
TopKLogitsWarper,
TopPLogitsWarper,
)
+ from transformers.generation.utils import _speculative_sampling
class GenerationTesterMixin:
@@ -1539,6 +1540,39 @@ def test_contrastive_generate_low_memory(self):
)
self.assertListEqual(low_output.tolist(), high_output.tolist())
+ def test_beam_search_low_memory(self):
+ # Check that choosing 'low_memory' does not change the model output
+ for model_class in self.all_generative_model_classes:
+ if any(model_name in model_class.__name__.lower() for model_name in ["fsmt", "reformer"]):
+ self.skipTest("Won't fix: old model with different cache format")
+ if any(
+ model_name in model_class.__name__.lower()
+ for model_name in [
+ "bloom",
+ "ctrl",
+ "gptbigcode",
+ "transo_xl",
+ "xlnet",
+ "cpm",
+ ]
+ ):
+ self.skipTest("May fix in the future: need model-specific fixes")
+ config, input_ids, attention_mask, max_length = self._get_input_ids_and_config(batch_size=2)
+ # batch_size=1 is ok, but batch_size>1 will cause non-identical output
+
+ config.use_cache = True
+ config.is_decoder = True
+
+ # test output equality of low versus high memory
+ model = model_class(config).to(torch_device).eval()
+
+ low_output = model.generate(input_ids, max_new_tokens=8, num_beams=5, early_stopping=True, low_memory=True)
+
+ high_output = model.generate(
+ input_ids, max_new_tokens=8, num_beams=5, early_stopping=True, low_memory=False
+ )
+ self.assertListEqual(low_output.tolist(), high_output.tolist())
+
@is_flaky() # Read NOTE (1) below. If there are API issues, all attempts will fail.
def test_assisted_decoding_matches_greedy_search(self):
# This test ensures that the assisted generation does not introduce output changes over greedy search.
@@ -2391,6 +2425,43 @@ def test_top_k_top_p_filtering_with_filter_value(self):
self.assertTrue(torch.allclose(expected_output, output, atol=1e-12))
+ def test_speculative_sampling(self):
+ # assume vocab size 10, input length 5 + 3 generated candidates
+ candidate_input_ids = torch.tensor([[8, 0, 3, 9, 8, 1, 4, 5]]) # input tokens
+ candidate_logits = torch.tensor(
+ [
+ [
+ [-10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # generated 1
+ [-10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # generated 4
+ [-10.0, -10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0], # generated 5
+ ]
+ ]
+ )
+ candidate_length = 3
+ inf = float("inf")
+ new_logits = torch.tensor(
+ [
+ [
+ [-10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # accepts 1
+ [-10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # accepts 4
+ [-inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, 10.0, -inf], # rejects 5, accepts 8
+ [-10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # N/A
+ ]
+ ]
+ )
+ last_assistant_token_is_eos = False
+ max_matches = 5
+ validated_tokens, n_matches = _speculative_sampling(
+ candidate_input_ids,
+ candidate_logits,
+ candidate_length,
+ new_logits,
+ last_assistant_token_is_eos,
+ max_matches,
+ )
+ self.assertTrue(n_matches.item() == 2)
+ self.assertTrue(validated_tokens.tolist()[0] == [1, 4, 8])
+
@require_torch
class GenerationIntegrationTests(unittest.TestCase, GenerationIntegrationTestsMixin):
@@ -2766,6 +2837,19 @@ def test_transition_scores_group_beam_search_encoder_decoder(self):
self.assertTrue(torch.allclose(transition_scores_sum, outputs.sequences_scores, atol=1e-3))
+ def test_beam_search_low_memory(self):
+ tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ tokenizer.pad_token_id = tokenizer.eos_token_id
+ model_inputs = tokenizer("I", return_tensors="pt")["input_ids"]
+
+ low_output = model.generate(model_inputs, max_new_tokens=40, num_beams=5, early_stopping=True, low_memory=True)
+
+ high_output = model.generate(
+ model_inputs, max_new_tokens=40, num_beams=5, early_stopping=True, low_memory=False
+ )
+ self.assertListEqual(low_output.tolist(), high_output.tolist())
+
@slow
def test_beam_search_example_integration(self):
# PT-only test: TF doesn't have a BeamSearchScorer
diff --git a/tests/models/auto/test_processor_auto.py b/tests/models/auto/test_processor_auto.py
index bf4a92475deec9..6cab1cbe817607 100644
--- a/tests/models/auto/test_processor_auto.py
+++ b/tests/models/auto/test_processor_auto.py
@@ -42,7 +42,7 @@
)
from transformers.testing_utils import TOKEN, USER, get_tests_dir, is_staging_test
from transformers.tokenization_utils import TOKENIZER_CONFIG_FILE
-from transformers.utils import FEATURE_EXTRACTOR_NAME, is_tokenizers_available
+from transformers.utils import FEATURE_EXTRACTOR_NAME, PROCESSOR_NAME, is_tokenizers_available
sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
@@ -91,6 +91,34 @@ def test_processor_from_local_directory_from_extractor_config(self):
self.assertIsInstance(processor, Wav2Vec2Processor)
+ def test_processor_from_processor_class(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ feature_extractor = Wav2Vec2FeatureExtractor()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
+
+ processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+
+ # save in new folder
+ processor.save_pretrained(tmpdirname)
+
+ if not os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # create one manually in order to perform this test's objective
+ config_dict = {"processor_class": "Wav2Vec2Processor"}
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as fp:
+ json.dump(config_dict, fp)
+
+ # drop `processor_class` in tokenizer config
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
def test_processor_from_feat_extr_processor_class(self):
with tempfile.TemporaryDirectory() as tmpdirname:
feature_extractor = Wav2Vec2FeatureExtractor()
@@ -101,6 +129,15 @@ def test_processor_from_feat_extr_processor_class(self):
# save in new folder
processor.save_pretrained(tmpdirname)
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
# drop `processor_class` in tokenizer
with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "r") as f:
config_dict = json.load(f)
@@ -123,6 +160,15 @@ def test_processor_from_tokenizer_processor_class(self):
# save in new folder
processor.save_pretrained(tmpdirname)
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
# drop `processor_class` in feature extractor
with open(os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME), "r") as f:
config_dict = json.load(f)
@@ -270,6 +316,45 @@ class NewProcessor(ProcessorMixin):
if CustomConfig in PROCESSOR_MAPPING._extra_content:
del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ def test_from_pretrained_dynamic_processor_with_extra_attributes(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ pass
+
+ class NewTokenizer(BertTokenizer):
+ pass
+
+ class NewProcessor(ProcessorMixin):
+ feature_extractor_class = "AutoFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer, processor_attr_1=1, processor_attr_2=True):
+ super().__init__(feature_extractor, tokenizer)
+
+ self.processor_attr_1 = processor_attr_1
+ self.processor_attr_2 = processor_attr_2
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoProcessor.register(CustomConfig, NewProcessor)
+ # If remote code is not set, the default is to use local classes.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", processor_attr_2=False
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertEqual(processor.processor_attr_1, 1)
+ self.assertEqual(processor.processor_attr_2, False)
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+
def test_auto_processor_creates_tokenizer(self):
processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-bert")
self.assertEqual(processor.__class__.__name__, "BertTokenizerFast")
diff --git a/tests/models/clip/test_processor_clip.py b/tests/models/clip/test_processor_clip.py
index fb88ef27053206..a76d3b33b829f4 100644
--- a/tests/models/clip/test_processor_clip.py
+++ b/tests/models/clip/test_processor_clip.py
@@ -26,6 +26,8 @@
from transformers.testing_utils import require_vision
from transformers.utils import IMAGE_PROCESSOR_NAME, is_vision_available
+from ...test_processing_common import ProcessorTesterMixin
+
if is_vision_available():
from PIL import Image
@@ -34,7 +36,9 @@
@require_vision
-class CLIPProcessorTest(unittest.TestCase):
+class CLIPProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = CLIPProcessor
+
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
diff --git a/tests/models/conditional_detr/test_modeling_conditional_detr.py b/tests/models/conditional_detr/test_modeling_conditional_detr.py
index 10d788bd692f0d..657b202fbfe626 100644
--- a/tests/models/conditional_detr/test_modeling_conditional_detr.py
+++ b/tests/models/conditional_detr/test_modeling_conditional_detr.py
@@ -399,6 +399,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/deformable_detr/test_modeling_deformable_detr.py b/tests/models/deformable_detr/test_modeling_deformable_detr.py
index 8cfe6ca451d91e..ffb1fc175c4063 100644
--- a/tests/models/deformable_detr/test_modeling_deformable_detr.py
+++ b/tests/models/deformable_detr/test_modeling_deformable_detr.py
@@ -476,6 +476,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/deta/test_modeling_deta.py b/tests/models/deta/test_modeling_deta.py
index 8db3485703d1fc..8025e65bd02d1c 100644
--- a/tests/models/deta/test_modeling_deta.py
+++ b/tests/models/deta/test_modeling_deta.py
@@ -449,6 +449,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/esm/test_tokenization_esm.py b/tests/models/esm/test_tokenization_esm.py
index 539baaf34150d9..aac03b535edce3 100644
--- a/tests/models/esm/test_tokenization_esm.py
+++ b/tests/models/esm/test_tokenization_esm.py
@@ -87,3 +87,25 @@ def test_tokenize_special_tokens(self):
self.assertEqual(len(token_2), 1)
self.assertEqual(token_1[0], SPECIAL_TOKEN_1)
self.assertEqual(token_2[0], SPECIAL_TOKEN_2)
+
+ def test_add_tokens(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ vocab_size = len(tokenizer)
+ self.assertEqual(tokenizer.add_tokens(""), 0)
+ self.assertEqual(tokenizer.add_tokens("testoken"), 1)
+ self.assertEqual(tokenizer.add_tokens(["testoken1", "testtoken2"]), 2)
+ self.assertEqual(len(tokenizer), vocab_size + 3)
+
+ self.assertEqual(tokenizer.add_special_tokens({}), 0)
+ self.assertEqual(tokenizer.add_special_tokens({"bos_token": "[BOS]", "eos_token": "[EOS]"}), 2)
+ self.assertRaises(AssertionError, tokenizer.add_special_tokens, {"additional_special_tokens": ""})
+ self.assertEqual(tokenizer.add_special_tokens({"additional_special_tokens": [""]}), 1)
+ self.assertEqual(
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", ""]}), 2
+ )
+ self.assertIn("", tokenizer.special_tokens_map["additional_special_tokens"])
+ self.assertIsInstance(tokenizer.special_tokens_map["additional_special_tokens"], list)
+ self.assertGreaterEqual(len(tokenizer.special_tokens_map["additional_special_tokens"]), 2)
+
+ self.assertEqual(len(tokenizer), vocab_size + 8)
diff --git a/tests/models/gpt_neox/test_modeling_gpt_neox.py b/tests/models/gpt_neox/test_modeling_gpt_neox.py
index 8777bd3abd629b..19e3db2a61fb91 100644
--- a/tests/models/gpt_neox/test_modeling_gpt_neox.py
+++ b/tests/models/gpt_neox/test_modeling_gpt_neox.py
@@ -355,3 +355,13 @@ def test_lm_generate_gptneox(self):
output_str = tokenizer.batch_decode(output_ids)[0]
self.assertEqual(output_str, expected_output)
+
+ def pythia_integration_test(self):
+ model_name_or_path = "EleutherAI/pythia-70m"
+ model = GPTNeoXForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16).to(torch_device)
+ EXPECTED_LOGITS = torch.tensor([1069.0000, 228.7500, 1072.0000, 1072.0000, 1069.0000, 1068.0000, 1068.0000, 1071.0000, 1071.0000, 1071.0000, 1073.0000, 1070.0000, 1071.0000, 1075.0000, 1073.0000, 1075.0000, 1074.0000, 1069.0000, 1072.0000, 1071.0000, 1071.0000, 1071.0000, 1070.0000, 1069.0000, 1069.0000, 1069.0000, 1070.0000, 1075.0000, 1073.0000, 1074.0000]) # fmt: skip
+ input_ids = [29, 93, 303, 64, 5478, 49651, 10394, 187, 34, 12939, 875]
+ # alternative: tokenizer('<|im_start|>system\nA chat between')
+ input_ids = torch.as_tensor(input_ids)[None].to(torch_device)
+ outputs = model(input_ids)["logits"][:, -1][0, :30]
+ self.assertTrue(torch.allclose(EXPECTED_LOGITS, outputs, atol=1e-5))
diff --git a/tests/models/llama/test_modeling_llama.py b/tests/models/llama/test_modeling_llama.py
index 2a52590369176a..c1cc479123f0a0 100644
--- a/tests/models/llama/test_modeling_llama.py
+++ b/tests/models/llama/test_modeling_llama.py
@@ -457,10 +457,10 @@ def test_eager_matches_sdpa_generate(self):
"""
max_new_tokens = 30
- tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
+ tokenizer = LlamaTokenizer.from_pretrained("saibo/llama-1B")
model_sdpa = LlamaForCausalLM.from_pretrained(
- "meta-llama/Llama-2-7b-hf",
+ "saibo/llama-1B",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(torch_device)
@@ -468,7 +468,7 @@ def test_eager_matches_sdpa_generate(self):
self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
model_eager = LlamaForCausalLM.from_pretrained(
- "meta-llama/Llama-2-7b-hf",
+ "saibo/llama-1B",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
attn_implementation="eager",
@@ -488,7 +488,11 @@ def test_eager_matches_sdpa_generate(self):
if not has_sdpa:
raise ValueError("The SDPA model should have SDPA attention layers")
- texts = ["hi", "Hello this is a very long sentence my friend", "Today I am in Paris and"]
+ texts = [
+ "hi here's a longer context, getting longer and",
+ "Hello this is a very long sentence my friend, very long for real",
+ "Today I am in Paris and",
+ ]
for padding_side in ["left", "right"]:
tokenizer.padding_side = padding_side
diff --git a/tests/models/maskformer/test_modeling_maskformer.py b/tests/models/maskformer/test_modeling_maskformer.py
index c4f014c5bbb5bb..7e48d761423830 100644
--- a/tests/models/maskformer/test_modeling_maskformer.py
+++ b/tests/models/maskformer/test_modeling_maskformer.py
@@ -362,6 +362,24 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(transformer_decoder_hidden_states.grad)
self.assertIsNotNone(attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_auxiliary_loss = True
+ config.output_auxiliary_logits = True
+ config.output_hidden_states = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_logits)
+ self.assertEqual(len(outputs.auxiliary_logits), self.model_tester.num_channels - 1)
+
TOLERANCE = 1e-4
diff --git a/tests/models/qwen2/__init__.py b/tests/models/qwen2/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/qwen2/test_modeling_qwen2.py b/tests/models/qwen2/test_modeling_qwen2.py
new file mode 100644
index 00000000000000..587312bfa21d73
--- /dev/null
+++ b/tests/models/qwen2/test_modeling_qwen2.py
@@ -0,0 +1,604 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Qwen2 model. """
+
+
+import gc
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, Qwen2Config, is_torch_available, set_seed
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_bitsandbytes,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ )
+
+
+class Qwen2ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ max_window_layers=3,
+ use_sliding_window=True,
+ sliding_window=2,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ bos_token_id=1,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.max_window_layers = max_window_layers
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.scope = scope
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return Qwen2Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ max_window_layers=self.max_window_layers,
+ use_sliding_window=self.use_sliding_window,
+ sliding_window=self.sliding_window,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ )
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Qwen2
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = Qwen2Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Qwen2
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = Qwen2Model(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Qwen2
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = Qwen2ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Qwen2
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = Qwen2ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTest with Mistral->Qwen2
+class Qwen2ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (Qwen2Model, Qwen2ForCausalLM, Qwen2ForSequenceClassification) if is_torch_available() else ()
+ all_generative_model_classes = (Qwen2ForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Qwen2Model,
+ "text-classification": Qwen2ForSequenceClassification,
+ "text-generation": Qwen2ForCausalLM,
+ "zero-shot": Qwen2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
+ def setUp(self):
+ self.model_tester = Qwen2ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Qwen2Config, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_Qwen2_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ print(config)
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ @unittest.skip("Qwen2 buffers include complex numbers, which breaks this test")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip("Qwen2 uses GQA on all models so the KV cache is a non standard format")
+ def test_past_key_values_format(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_padding_right(self):
+ import torch
+
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
+ dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device)
+
+ model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False)
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ with self.assertRaises(ValueError):
+ _ = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_use_cache(self):
+ import torch
+
+ max_new_tokens = 30
+
+ for model_class in self.all_generative_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # NOTE: Qwen2 apparently does not support right padding + use_cache with FA2.
+ dummy_attention_mask[:, -1] = 1
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_padding_right(self):
+ self.skipTest("Qwen2 flash attention does not support right padding")
+
+
+@require_torch
+class Qwen2IntegrationTest(unittest.TestCase):
+ @slow
+ def test_model_450m_logits(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto")
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ with torch.no_grad():
+ out = model(input_ids).logits.cpu()
+ # Expected mean on dim = -1
+ EXPECTED_MEAN = torch.tensor([[-2.5548, -2.5737, -3.0600, -2.5906, -2.8478, -2.8118, -2.9325, -2.7694]])
+ torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, atol=1e-2, rtol=1e-2)
+ # slicing logits[0, 0, 0:30]
+ EXPECTED_SLICE = torch.tensor([-5.8781, -5.8616, -0.1052, -4.7200, -5.8781, -5.8774, -5.8773, -5.8777, -5.8781, -5.8780, -5.8781, -5.8779, -1.0787, 1.7583, -5.8779, -5.8780, -5.8783, -5.8778, -5.8776, -5.8781, -5.8784, -5.8778, -5.8778, -5.8777, -5.8779, -5.8778, -5.8776, -5.8780, -5.8779, -5.8781]) # fmt: skip
+ print(out[0, 0, :30])
+ torch.testing.assert_close(out[0, 0, :30], EXPECTED_SLICE, atol=1e-4, rtol=1e-4)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_450m_generation(self):
+ EXPECTED_TEXT_COMPLETION = """My favourite condiment is 100% ketchup. I love it on everything. I’m not a big"""
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-450m-beta", use_fast=False)
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @require_bitsandbytes
+ @slow
+ @require_flash_attn
+ def test_model_450m_long_prompt(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta",
+ device_map="auto",
+ load_in_4bit=True,
+ attn_implementation="flash_attention_2",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ @require_torch_sdpa
+ def test_model_450m_long_prompt_sdpa(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta",
+ device_map="auto",
+ attn_implementation="sdpa",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = assistant_model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ EXPECTED_TEXT_COMPLETION = """My favourite condiment is 100% ketchup. I love it on everything. I’m not a big"""
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-450m-beta", use_fast=False)
+
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ def test_speculative_generation(self):
+ EXPECTED_TEXT_COMPLETION = (
+ "My favourite condiment is 100% Sriracha. I love the heat, the tang and the fact costs"
+ )
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-beta", use_fast=False)
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto", torch_dtype=torch.float16)
+ assistant_model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta", device_map="auto", torch_dtype=torch.float16
+ )
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ set_seed(0)
+ generated_ids = model.generate(
+ input_ids, max_new_tokens=20, do_sample=True, temperature=0.3, assistant_model=assistant_model
+ )
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/tests/models/qwen2/test_tokenization_qwen2.py b/tests/models/qwen2/test_tokenization_qwen2.py
new file mode 100644
index 00000000000000..565520367f57f4
--- /dev/null
+++ b/tests/models/qwen2/test_tokenization_qwen2.py
@@ -0,0 +1,204 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+
+from transformers import AddedToken, Qwen2Tokenizer, Qwen2TokenizerFast
+from transformers.models.qwen2.tokenization_qwen2 import VOCAB_FILES_NAMES, bytes_to_unicode
+from transformers.testing_utils import require_tokenizers, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_tokenizers
+class Qwen2TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = Qwen2Tokenizer
+ rust_tokenizer_class = Qwen2TokenizerFast
+ test_slow_tokenizer = True
+ test_rust_tokenizer = True
+ space_between_special_tokens = False
+ from_pretrained_kwargs = None
+ test_seq2seq = False
+
+ def setUp(self):
+ super().setUp()
+
+ # this make sure the vocabuary is complete at the byte level.
+ vocab = list(bytes_to_unicode().values())
+ # the vocabulary, note:
+ # - `"\u0120n"`, `"\u0120lowest"`, `"\u0120newer"`, and `"\u0120wider"` are ineffective, because there are
+ # not in the merges.
+ # - `"01"` is ineffective, because the merge is ineffective due to pretokenization.
+ vocab.extend(
+ [
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "01",
+ ";}",
+ ";}\u010a",
+ "\u00cf\u0135",
+ ]
+ )
+
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+
+ # note: `"0 1"` is in the merges, but the pretokenization rules render it ineffective
+ merges = [
+ "#version: 0.2",
+ "\u0120 l",
+ "\u0120l o",
+ "\u0120lo w",
+ "e r",
+ "0 1",
+ "; }",
+ ";} \u010a",
+ "\u00cf \u0135",
+ ]
+
+ self.special_tokens_map = {"eos_token": "<|endoftext|>"}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ def get_tokenizer(self, **kwargs):
+ kwargs.update(self.special_tokens_map)
+ return Qwen2Tokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs):
+ kwargs.update(self.special_tokens_map)
+ return Qwen2TokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ # this case should cover
+ # - NFC normalization (code point U+03D3 has different normalization forms under NFC, NFD, NFKC, and NFKD)
+ # - the pretokenization rules (spliting digits and merging symbols with \n\r)
+ input_text = "lower lower newer 010;}\n<|endoftext|>\u03d2\u0301"
+ output_text = "lower lower newer 010;}\n<|endoftext|>\u03d3"
+ return input_text, output_text
+
+ def test_python_full_tokenizer(self):
+ tokenizer = self.get_tokenizer()
+ sequence, _ = self.get_input_output_texts(tokenizer)
+ bpe_tokens = [
+ "l",
+ "o",
+ "w",
+ "er",
+ "\u0120low",
+ "er",
+ "\u0120",
+ "n",
+ "e",
+ "w",
+ "er",
+ "\u0120",
+ "0",
+ "1",
+ "0",
+ ";}\u010a",
+ "<|endoftext|>",
+ "\u00cf\u0135",
+ ]
+ tokens = tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens
+ input_bpe_tokens = [75, 78, 86, 260, 259, 260, 220, 77, 68, 86, 260, 220, 15, 16, 15, 266, 268, 267]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @unittest.skip("We disable the test of pretokenization as it is not reversible.")
+ def test_pretokenized_inputs(self):
+ # the test case in parent class uses str.split to "pretokenize",
+ # which eats the whitespaces, which, in turn, is not reversible.
+ # the results, by nature, should be different.
+ pass
+
+ def test_nfc_normalization(self):
+ # per https://unicode.org/faq/normalization.html, there are three characters whose normalization forms
+ # under NFC, NFD, NFKC, and NFKD are all different
+ # using these, we can make sure only NFC is applied
+ input_string = "\u03d2\u0301\u03d2\u0308\u017f\u0307" # the NFD form
+ output_string = "\u03d3\u03d4\u1e9b" # the NFC form
+
+ if self.test_slow_tokenizer:
+ tokenizer = self.get_tokenizer()
+ tokenizer_output_string, _ = tokenizer.prepare_for_tokenization(input_string)
+ self.assertEqual(tokenizer_output_string, output_string)
+
+ if self.test_rust_tokenizer:
+ tokenizer = self.get_rust_tokenizer()
+ # we can check the class of the normalizer, but it would be okay if Sequence([NFD, NFC]) is used
+ # let's check the output instead
+ tokenizer_output_string = tokenizer.backend_tokenizer.normalizer.normalize_str(input_string)
+ self.assertEqual(tokenizer_output_string, output_string)
+
+ def test_slow_tokenizer_decode_spaces_between_special_tokens_default(self):
+ # Qwen2Tokenzier changes the default `spaces_between_special_tokens` in `decode` to False
+ if not self.test_slow_tokenizer:
+ return
+
+ # tokenizer has a special token: `"<|endfotext|>"` as eos, but it is not `legacy_added_tokens`
+ # special tokens in `spaces_between_special_tokens` means spaces between `legacy_added_tokens`
+ # that would be `"<|im_start|>"` and `"<|im_end|>"` in Qwen/Qwen2 Models
+ token_ids = [259, 260, 268, 269, 26]
+ sequence = " lower<|endoftext|><|im_start|>;"
+ sequence_with_space = " lower<|endoftext|> <|im_start|> ;"
+
+ tokenizer = self.get_tokenizer()
+ # let's add a legacy_added_tokens
+ im_start = AddedToken(
+ "<|im_start|>", single_word=False, lstrip=False, rstrip=False, special=True, normalized=False
+ )
+ tokenizer.add_tokens([im_start])
+
+ # `spaces_between_special_tokens` defaults to False
+ self.assertEqual(tokenizer.decode(token_ids), sequence)
+
+ # but it can be set to True
+ self.assertEqual(tokenizer.decode(token_ids, spaces_between_special_tokens=True), sequence_with_space)
+
+ @slow
+ def test_tokenizer_integration(self):
+ sequences = [
+ "Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides "
+ "general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet...) for Natural "
+ "Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained "
+ "models in 100+ languages and deep interoperability between Jax, PyTorch and TensorFlow.",
+ "🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。",
+ """```python\ntokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-tokenizer")\n"""
+ """tokenizer("世界,你好!")```""",
+ ]
+
+ expected_encoding = {'input_ids': [[8963, 388, 320, 69514, 3881, 438, 4510, 27414, 32852, 388, 323, 4510, 27414, 21334, 35722, 1455, 529, 8, 5707, 4586, 58238, 77235, 320, 61437, 11, 479, 2828, 12, 17, 11, 11830, 61437, 64, 11, 1599, 10994, 11, 27604, 321, 33, 529, 11, 29881, 6954, 32574, 369, 18448, 11434, 45451, 320, 45, 23236, 8, 323, 18448, 11434, 23470, 320, 30042, 38, 8, 448, 916, 220, 18, 17, 10, 80669, 4119, 304, 220, 16, 15, 15, 10, 15459, 323, 5538, 94130, 2897, 1948, 619, 706, 11, 5355, 51, 21584, 323, 94986, 13], [144834, 80532, 93685, 83744, 34187, 73670, 104261, 29490, 62189, 103937, 104034, 102830, 98841, 104034, 104949, 9370, 5333, 58143, 102011, 1773, 37029, 98841, 104034, 104949, 73670, 101940, 100768, 104997, 33108, 100912, 105054, 90395, 100136, 106831, 45181, 64355, 104034, 113521, 101975, 33108, 85329, 1773, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643], [73594, 12669, 198, 85593, 284, 8979, 37434, 6387, 10442, 35722, 445, 48, 16948, 45274, 16948, 34841, 3135, 1138, 85593, 445, 99489, 3837, 108386, 6313, 899, 73594, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: off
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="Qwen/Qwen-tokenizer",
+ revision="5909c8222473b2c73b0b73fb054552cd4ef6a8eb",
+ sequences=sequences,
+ )
diff --git a/tests/models/t5/test_tokenization_t5.py b/tests/models/t5/test_tokenization_t5.py
index a141dea86b71a5..5fa0e19c792b29 100644
--- a/tests/models/t5/test_tokenization_t5.py
+++ b/tests/models/t5/test_tokenization_t5.py
@@ -424,6 +424,41 @@ def test_some_edge_cases(self):
self.assertEqual(tokens, [])
self.assertEqual(tokens, tokenizer.sp_model.encode("▁", out_type=str))
+ def test_fast_slow_edge_cases(self):
+ # We are testing spaces before and spaces after special tokens + space transformations
+ slow_tokenizer = T5Tokenizer.from_pretrained("t5-base", legacy=False)
+ fast_tokenizer = T5TokenizerFast.from_pretrained("t5-base", legacy=False, from_slow=True)
+ slow_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=False))
+ fast_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=False))
+
+ edge_case = "Hey!. HowHey !"
+ EXPECTED_SLOW = ["▁Hey", "!", "", ".", "▁How", "", "He", "y", "", "!"] # fmt: skip
+ with self.subTest(f"slow {edge_case} normalized = False"):
+ self.assertEqual(slow_tokenizer.tokenize(edge_case), EXPECTED_SLOW)
+ with self.subTest(f"Fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(edge_case), EXPECTED_SLOW)
+
+ hard_case = "Hey! . How Hey ! . "
+ EXPECTED_SLOW = ["▁Hey", "!", "", ".", "▁How", "", "▁Hey", "", "▁", "!", "▁", "."] # fmt: skip
+ with self.subTest(f"slow {edge_case} normalized = False"):
+ self.assertEqual(slow_tokenizer.tokenize(hard_case), EXPECTED_SLOW)
+ with self.subTest(f"fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(hard_case), EXPECTED_SLOW)
+
+ fast_tokenizer = T5TokenizerFast.from_pretrained("t5-base", legacy=False, from_slow=True)
+ fast_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=True))
+
+ # `normalized=True` is the default normalization scheme when adding a token. Normalize -> don't strip the space.
+ # the issue now is that our slow tokenizer should NOT strip the space if we want to simulate sentencepiece token addition.
+
+ EXPECTED_FAST = ["▁Hey", "!", "", ".", "▁How", "", "He", "y", "▁", "", "!"] # fmt: skip
+ with self.subTest(f"fast {edge_case} normalized = True"):
+ self.assertEqual(fast_tokenizer.tokenize(edge_case), EXPECTED_FAST)
+
+ EXPECTED_FAST = ['▁Hey', '!', '▁', '', '.', '▁How', '', '▁Hey','▁', '', '▁', '!', '▁', '.'] # fmt: skip
+ with self.subTest(f"fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(hard_case), EXPECTED_FAST)
+
@require_sentencepiece
@require_tokenizers
diff --git a/tests/models/table_transformer/test_modeling_table_transformer.py b/tests/models/table_transformer/test_modeling_table_transformer.py
index d81c52ff1307c9..851ef36a1a12d3 100644
--- a/tests/models/table_transformer/test_modeling_table_transformer.py
+++ b/tests/models/table_transformer/test_modeling_table_transformer.py
@@ -411,6 +411,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/wav2vec2_bert/__init__.py b/tests/models/wav2vec2_bert/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py b/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py
new file mode 100644
index 00000000000000..a4a0a95972c9f7
--- /dev/null
+++ b/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py
@@ -0,0 +1,913 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Wav2Vec2-BERT model. """
+import tempfile
+import unittest
+
+from datasets import load_dataset
+
+from transformers import Wav2Vec2BertConfig, is_torch_available
+from transformers.testing_utils import (
+ is_pt_flax_cross_test,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AutoFeatureExtractor,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ )
+ from transformers.models.wav2vec2_bert.modeling_wav2vec2_bert import (
+ _compute_mask_indices,
+ _sample_negative_indices,
+ )
+
+
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTester with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertModelTester:
+ # Ignore copy
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=200, # speech is longer
+ is_training=False,
+ hidden_size=16,
+ feature_projection_input_dim=16,
+ num_conv_pos_embeddings=16,
+ num_conv_pos_embedding_groups=2,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ hidden_dropout_prob=0.1,
+ intermediate_size=20,
+ layer_norm_eps=1e-5,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ mask_time_prob=0.5,
+ mask_time_length=2,
+ vocab_size=32,
+ do_stable_layer_norm=False,
+ num_adapter_layers=2,
+ adapter_stride=2,
+ tdnn_dim=(32, 32),
+ tdnn_kernel=(5, 3),
+ tdnn_dilation=(1, 2),
+ xvector_output_dim=32,
+ position_embeddings_type="relative",
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.feature_projection_input_dim = feature_projection_input_dim
+ self.num_conv_pos_embeddings = num_conv_pos_embeddings
+ self.num_conv_pos_embedding_groups = num_conv_pos_embedding_groups
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.intermediate_size = intermediate_size
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.vocab_size = vocab_size
+ self.do_stable_layer_norm = do_stable_layer_norm
+ self.num_adapter_layers = num_adapter_layers
+ self.adapter_stride = adapter_stride
+ self.mask_time_prob = mask_time_prob
+ self.mask_time_length = mask_time_length
+ self.scope = scope
+ self.tdnn_dim = tdnn_dim
+ self.tdnn_kernel = tdnn_kernel
+ self.tdnn_dilation = tdnn_dilation
+ self.xvector_output_dim = xvector_output_dim
+ self.position_embeddings_type = position_embeddings_type
+
+ self.output_seq_length = self.seq_length
+ self.encoder_seq_length = self.output_seq_length
+
+ self.adapter_output_seq_length = self.output_seq_length
+
+ for _ in range(num_adapter_layers):
+ self.adapter_output_seq_length = (self.adapter_output_seq_length - 1) // adapter_stride + 1
+
+ # Ignore copy
+ def prepare_config_and_inputs(self, position_embeddings_type="relative"):
+ input_shape = [self.batch_size, self.seq_length, self.feature_projection_input_dim]
+
+ input_features = floats_tensor(input_shape, self.vocab_size)
+ attention_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config(position_embeddings_type=position_embeddings_type)
+
+ return config, input_features, attention_mask
+
+ # Ignore copy
+ def get_config(self, position_embeddings_type="relative"):
+ return Wav2Vec2BertConfig(
+ hidden_size=self.hidden_size,
+ feature_projection_input_dim=self.feature_projection_input_dim,
+ mask_time_prob=self.mask_time_prob,
+ mask_time_length=self.mask_time_length,
+ num_conv_pos_embeddings=self.num_conv_pos_embeddings,
+ num_conv_pos_embedding_groups=self.num_conv_pos_embedding_groups,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ intermediate_size=self.intermediate_size,
+ layer_norm_eps=self.layer_norm_eps,
+ do_stable_layer_norm=self.do_stable_layer_norm,
+ hidden_act=self.hidden_act,
+ initializer_range=self.initializer_range,
+ vocab_size=self.vocab_size,
+ num_adapter_layers=self.num_adapter_layers,
+ adapter_stride=self.adapter_stride,
+ tdnn_dim=self.tdnn_dim,
+ tdnn_kernel=self.tdnn_kernel,
+ tdnn_dilation=self.tdnn_dilation,
+ xvector_output_dim=self.xvector_output_dim,
+ position_embeddings_type=position_embeddings_type,
+ )
+
+ def create_and_check_model(self, config, input_features, attention_mask):
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_model_with_adapter(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_model_with_adapter_for_ctc(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 2 * config.hidden_size
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size)
+ )
+
+ # Ignore copy
+ def create_and_check_model_with_intermediate_ffn_before_adapter(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.use_intermediate_ffn_before_adapter = True
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ # also try with different adapter proj dim
+ config.output_hidden_size = 8
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ def create_and_check_model_with_adapter_proj_dim(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 8
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ def create_and_check_model_float16(self, config, input_features, attention_mask):
+ model = Wav2Vec2BertModel(config=config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = Wav2Vec2BertModel.from_pretrained(tmpdirname, torch_dtype=torch.float16)
+
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ result = model(input_features.type(dtype=torch.float16), attention_mask=attention_mask)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_batch_inference(self, config, input_features, *args):
+ # test does not pass for models making use of `group_norm`
+ # check: https://github.com/pytorch/fairseq/issues/3227
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ input_features = input_features[:3]
+ attention_mask = torch.ones(input_features.shape, device=torch_device, dtype=torch.bool)
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0.0
+
+ batch_outputs = model(input_features, attention_mask=attention_mask).last_hidden_state
+
+ for i in range(input_features.shape[0]):
+ input_slice = input_features[i : i + 1, : input_lengths[i]]
+ output = model(input_slice).last_hidden_state
+
+ batch_output = batch_outputs[i : i + 1, : output.shape[1]]
+ self.parent.assertTrue(torch.allclose(output, batch_output, atol=1e-3))
+
+ def check_ctc_loss(self, config, input_features, *args):
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_features = input_features[:3]
+ # Ignore copy
+ attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], min(max_length_labels) - 1), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ model.config.ctc_loss_reduction = "sum"
+ sum_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+
+ model.config.ctc_loss_reduction = "mean"
+ mean_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(sum_loss, float))
+ self.parent.assertTrue(isinstance(mean_loss, float))
+
+ def check_seq_classifier_loss(self, config, input_features, *args):
+ model = Wav2Vec2BertForSequenceClassification(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_features = input_features[:3]
+ # Ignore copy
+ attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ masked_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+ unmasked_loss = model(input_features, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(masked_loss, float))
+ self.parent.assertTrue(isinstance(unmasked_loss, float))
+ self.parent.assertTrue(masked_loss != unmasked_loss)
+
+ def check_ctc_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # Ignore copy
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ if max_length_labels[i] < labels.shape[-1]:
+ # it's important that we make sure that target lengths are at least
+ # one shorter than logit lengths to prevent -inf
+ labels[i, max_length_labels[i] - 1 :] = -100
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_seq_classifier_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForSequenceClassification(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze everything but the classification head
+ model.freeze_base_model()
+
+ input_features = input_features[:3]
+
+ # Ignore copy
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_xvector_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForXVector(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze everything but the classification head
+ model.freeze_base_model()
+
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_labels_out_of_vocab(self, config, input_features, *args):
+ model = Wav2Vec2BertForCTC(config)
+ model.to(torch_device)
+ model.train()
+
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size + 100)
+
+ with self.parent.assertRaises(ValueError):
+ model(input_features, labels=labels)
+
+ def prepare_config_and_inputs_for_common(self):
+ config, input_features, attention_mask = self.prepare_config_and_inputs()
+ inputs_dict = {"input_features": input_features, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTest with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ # Ignore copy
+ all_model_classes = (
+ (
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForXVector,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ pipeline_model_mapping = (
+ {
+ "audio-classification": Wav2Vec2BertForSequenceClassification,
+ "automatic-speech-recognition": Wav2Vec2BertForCTC,
+ "feature-extraction": Wav2Vec2BertModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_headmasking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Wav2Vec2BertModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Wav2Vec2BertConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_relative(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ # Ignore copy
+ def test_model_with_relative_key(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_rotary(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_no_rel_pos(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type=None)
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_adapter(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter(*config_and_inputs)
+
+ def test_model_with_adapter_for_ctc(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs)
+
+ # Ignore copy
+ def test_model_with_intermediate_ffn_before_adapter(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_intermediate_ffn_before_adapter(*config_and_inputs)
+
+ def test_model_with_adapter_proj_dim(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_relative(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ # Ignore copy
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_relative_key(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_rotary(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ def test_ctc_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_loss(*config_and_inputs)
+
+ def test_seq_classifier_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_loss(*config_and_inputs)
+
+ def test_ctc_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_training(*config_and_inputs)
+
+ def test_seq_classifier_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_training(*config_and_inputs)
+
+ def test_xvector_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_xvector_training(*config_and_inputs)
+
+ def test_labels_out_of_vocab(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_labels_out_of_vocab(*config_and_inputs)
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="`input_ids` is renamed to `input_features`")
+ def test_forward_signature(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
+ def test_model_common_attributes(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="non-robust architecture does not exist in Flax")
+ @is_pt_flax_cross_test
+ def test_equivalence_flax_to_pt(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="non-robust architecture does not exist in Flax")
+ @is_pt_flax_cross_test
+ def test_equivalence_pt_to_flax(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ # set layer drop to 0
+ model.config.layerdrop = 0.0
+
+ input_features = inputs_dict["input_features"]
+
+ input_lengths = torch.tensor(
+ [input_features.shape[1] for _ in range(input_features.shape[0])], dtype=torch.long, device=torch_device
+ )
+ output_lengths = model._get_feat_extract_output_lengths(input_lengths)
+
+ labels = ids_tensor((input_features.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size)
+ inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"])
+ inputs_dict["labels"] = labels
+
+ outputs = model(**inputs_dict)
+
+ output = outputs[0]
+
+ # Encoder-/Decoder-only models
+ hidden_states = outputs.hidden_states[0]
+ attentions = outputs.attentions[0]
+
+ hidden_states.retain_grad()
+ attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+ self.assertIsNotNone(attentions.grad)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv.weight",
+ "conv.parametrizations.weight",
+ "masked_spec_embed",
+ "codevectors",
+ "quantizer.weight_proj.weight",
+ "project_hid.weight",
+ "project_hid.bias",
+ "project_q.weight",
+ "project_q.bias",
+ "pos_bias_v",
+ "pos_bias_u",
+ "pointwise_conv1",
+ "pointwise_conv2",
+ "feature_projection.projection.weight",
+ "feature_projection.projection.bias",
+ "objective.weight",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "weight_g") and module.weight_g is not None:
+ module.weight_g.data.fill_(3)
+ if hasattr(module, "weight_v") and module.weight_v is not None:
+ module.weight_v.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+ if hasattr(module, "pos_bias_u") and module.pos_bias_u is not None:
+ module.pos_bias_u.data.fill_(3)
+ if hasattr(module, "pos_bias_v") and module.pos_bias_v is not None:
+ module.pos_bias_v.data.fill_(3)
+ if hasattr(module, "codevectors") and module.codevectors is not None:
+ module.codevectors.data.fill_(3)
+ if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None:
+ module.masked_spec_embed.data.fill_(3)
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working")
+ def test_mask_feature_prob_ctc(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working")
+ def test_mask_time_prob_ctc(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ # Ignore copy
+ model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
+ self.assertIsNotNone(model)
+
+
+@require_torch
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerUtilsTest with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertUtilsTest(unittest.TestCase):
+ def test_compute_mask_indices(self):
+ batch_size = 4
+ sequence_length = 60
+ mask_prob = 0.5
+ mask_length = 1
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ self.assertListEqual(mask.sum(axis=-1).tolist(), [mask_prob * sequence_length for _ in range(batch_size)])
+
+ def test_compute_mask_indices_low_prob(self):
+ # with these settings num_masked_spans=0.5, which means probabilistic rounding
+ # ensures that in 5 out of 10 method calls, num_masked_spans=0, and in
+ # the other 5 out of 10, cases num_masked_spans=1
+ n_trials = 100
+ batch_size = 4
+ sequence_length = 100
+ mask_prob = 0.05
+ mask_length = 10
+
+ count_dimensions_masked = 0
+ count_dimensions_not_masked = 0
+
+ for _ in range(n_trials):
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ num_masks = torch.sum(mask).item()
+
+ if num_masks > 0:
+ count_dimensions_masked += 1
+ else:
+ count_dimensions_not_masked += 1
+
+ # as we test for at least 10 masked dimension and at least
+ # 10 non-masked dimension, this test could fail with probability:
+ # P(100 coin flips, at most 9 heads) = 1.66e-18
+ self.assertGreater(count_dimensions_masked, int(n_trials * 0.1))
+ self.assertGreater(count_dimensions_not_masked, int(n_trials * 0.1))
+
+ def test_compute_mask_indices_overlap(self):
+ batch_size = 4
+ sequence_length = 80
+ mask_prob = 0.5
+ mask_length = 4
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ # because of overlap mask don't have to add up exactly to `mask_prob * sequence_length`, but have to be smaller or equal
+ for batch_sum in mask.sum(axis=-1):
+ self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
+
+ def test_compute_mask_indices_attn_mask_overlap(self):
+ batch_size = 4
+ sequence_length = 80
+ mask_prob = 0.5
+ mask_length = 4
+
+ attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ attention_mask[:2, sequence_length // 2 :] = 0
+
+ mask = _compute_mask_indices(
+ (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask
+ )
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ for batch_sum in mask.sum(axis=-1):
+ self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
+
+ self.assertTrue(mask[:2, sequence_length // 2 :].sum() == 0)
+
+ def test_compute_mask_indices_short_audio(self):
+ batch_size = 4
+ sequence_length = 100
+ mask_prob = 0.05
+ mask_length = 10
+
+ attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ # force one example to be heavily padded
+ attention_mask[0, 5:] = 0
+
+ mask = _compute_mask_indices(
+ (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask, min_masks=2
+ )
+
+ # make sure that non-padded examples cannot be padded
+ self.assertFalse(mask[0][attention_mask[0].to(torch.bool).cpu()].any())
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working. Test a class used for pretraining, not yet supported.")
+ def test_compute_perplexity(self):
+ pass
+
+ def test_sample_negatives(self):
+ batch_size = 2
+ sequence_length = 10
+ hidden_size = 4
+ num_negatives = 3
+
+ features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
+ sequence_length, hidden_size
+ ) # each value in vector consits of same value
+ features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
+
+ # sample negative indices
+ sampled_negative_indices = _sample_negative_indices((batch_size, sequence_length), num_negatives, None)
+ sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
+ negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
+ negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
+ self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
+
+ # make sure no negatively sampled vector is actually a positive one
+ for negative in negatives:
+ self.assertTrue(((negative - features) == 0).sum() == 0.0)
+
+ # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
+ self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
+
+ def test_sample_negatives_with_mask(self):
+ batch_size = 2
+ sequence_length = 10
+ hidden_size = 4
+ num_negatives = 3
+
+ # second half of last input tensor is padded
+ mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ mask[-1, sequence_length // 2 :] = 0
+
+ features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
+ sequence_length, hidden_size
+ ) # each value in vector consits of same value
+ features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
+
+ # replace masked feature vectors with -100 to test that those are not sampled
+ features = torch.where(mask[:, :, None].expand(features.shape).bool(), features, -100)
+
+ # sample negative indices
+ sampled_negative_indices = _sample_negative_indices(
+ (batch_size, sequence_length), num_negatives, mask.cpu().numpy()
+ )
+ sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
+ negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
+ negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
+
+ self.assertTrue((negatives >= 0).all().item())
+
+ self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
+
+ # make sure no negatively sampled vector is actually a positive one
+ for negative in negatives:
+ self.assertTrue(((negative - features) == 0).sum() == 0.0)
+
+ # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
+ self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
+
+
+@require_torch
+@slow
+class Wav2Vec2BertModelIntegrationTest(unittest.TestCase):
+ def _load_datasamples(self, num_samples):
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").filter(lambda x: x["id"] in [f"1272-141231-000{i}" for i in range(num_samples)])
+ speech_samples = speech_samples[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ def test_inference_w2v2_bert(self):
+ model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
+ model.to(torch_device)
+ feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/w2v-bert-2.0")
+
+ input_speech = self._load_datasamples(2)
+
+ inputs = feature_extractor(input_speech, return_tensors="pt", padding=True).to(torch_device)
+
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**inputs, output_attentions=True)
+
+ # fmt: off
+ expected_slice_0 = torch.tensor(
+ [[-0.0098, -0.0570, -0.1286, 0.0439, -0.1037, -0.0235],
+ [-0.0767, 0.0574, -0.3224, 0.0482, 0.0440, -0.0193],
+ [ 0.0220, -0.0878, -0.2027, -0.0028, -0.0666, 0.0721],
+ [ 0.0307, -0.1099, 0.0273, -0.0416, -0.0715, 0.0094],
+ [ 0.0758, -0.0291, 0.1084, 0.0004, -0.0751, -0.0116],
+ [ 0.0349, -0.0343, -0.0098, 0.0415, -0.0617, 0.0241],
+ [-0.0193, -0.0171, 0.1965, 0.0797, -0.0308, 0.2033],
+ [-0.0323, -0.0315, 0.0948, 0.0944, -0.0254, 0.1241],
+ [-0.0493, 0.0010, -0.1762, 0.0034, -0.0787, 0.0832],
+ [ 0.0043, -0.1228, -0.0739, 0.0266, -0.0337, -0.0068]]
+ ).to(torch_device)
+ # fmt: on
+
+ # fmt: off
+ expected_slice_1 = torch.tensor(
+ [[-0.0348, -0.0521, -0.3036, 0.0285, -0.0715, -0.0453],
+ [-0.0102, 0.0114, -0.3266, 0.0027, -0.0558, 0.0038],
+ [ 0.0454, 0.0148, -0.2418, -0.0392, -0.0455, 0.0478],
+ [-0.0013, 0.0825, -0.1730, -0.0091, -0.0426, 0.0360],
+ [-0.0227, 0.0687, -0.1168, 0.0569, -0.0160, 0.0759],
+ [-0.0318, 0.0562, -0.0508, 0.0605, 0.0150, 0.0953],
+ [-0.0415, 0.0438, 0.0233, 0.0336, 0.0262, 0.0860],
+ [-0.0163, 0.0048, 0.0807, 0.0119, 0.0712, 0.0158],
+ [ 0.0244, -0.0145, 0.0262, -0.0237, 0.0283, -0.0125],
+ [-0.0587, -0.0516, -0.0368, -0.0196, 0.0307, -0.1434]]
+ ).to(torch_device)
+ # fmt: on
+
+ self.assertTrue((outputs.last_hidden_state[0, 25:35, 4:10] - expected_slice_0).abs().max() <= 1e-4)
+ self.assertTrue((outputs.last_hidden_state[1, 25:35, 4:10] - expected_slice_1).abs().max() <= 1e-4)
+
+ self.assertAlmostEqual(outputs.last_hidden_state[1].mean().item(), 3.3123e-05)
+ self.assertAlmostEqual(outputs.last_hidden_state[1].std().item(), 0.1545, delta=2e-5)
+
+ self.assertListEqual(list(outputs.last_hidden_state.shape), [2, 326, 1024])
diff --git a/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py b/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py
new file mode 100644
index 00000000000000..b6b1506f5e4d68
--- /dev/null
+++ b/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py
@@ -0,0 +1,156 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+from transformers.models.seamless_m4t import SeamlessM4TFeatureExtractor
+from transformers.models.wav2vec2 import Wav2Vec2CTCTokenizer
+from transformers.models.wav2vec2.tokenization_wav2vec2 import VOCAB_FILES_NAMES
+from transformers.models.wav2vec2_bert import Wav2Vec2BertProcessor
+from transformers.utils import FEATURE_EXTRACTOR_NAME
+
+from ..wav2vec2.test_feature_extraction_wav2vec2 import floats_list
+
+
+# Copied from tests.models.wav2vec2.test_processor_wav2vec2.Wav2Vec2ProcessorTest with Wav2Vec2FeatureExtractor->SeamlessM4TFeatureExtractor, Wav2Vec2Processor->Wav2Vec2BertProcessor
+class Wav2Vec2BertProcessorTest(unittest.TestCase):
+ def setUp(self):
+ vocab = "
@@ -82,7 +82,8 @@ If you want to do the pre- and postprocessing yourself, here's how to do that:
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
->>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> # important: we pass `padding=max_length` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/docs/source/en/model_doc/wav2vec2-bert.md b/docs/source/en/model_doc/wav2vec2-bert.md
new file mode 100644
index 00000000000000..6514133330a9d4
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2-bert.md
@@ -0,0 +1,90 @@
+
+
+# Wav2Vec2-BERT
+
+## Overview
+
+The Wav2Vec2-BERT model was proposed in [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team from Meta AI.
+
+This model was pre-trained on 4.5M hours of unlabeled audio data covering more than 143 languages. It requires finetuning to be used for downstream tasks such as Automatic Speech Recognition (ASR), or Audio Classification.
+
+The official results of the model can be found in Section 3.2.1 of the paper.
+
+The abstract from the paper is the following:
+
+*Recent advancements in automatic speech translation have dramatically expanded language coverage, improved multimodal capabilities, and enabled a wide range of tasks and functionalities. That said, large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model—SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. The expanded version of SeamlessAlign adds 114,800 hours of automatically aligned data for a total of 76 languages. SeamlessM4T v2 provides the foundation on which our two newest models, SeamlessExpressive and SeamlessStreaming, are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one’s voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention (EMMA) mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To understand the performance of these models, we combined novel and modified versions of existing automatic metrics to evaluate prosody, latency, and robustness. For human evaluations, we adapted existing protocols tailored for measuring the most relevant attributes in the preservation of meaning, naturalness, and expressivity. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. In sum, Seamless gives us a pivotal look at the technical foundation needed to turn the Universal Speech Translator from a science fiction concept into a real-world technology. Finally, contributions in this work—including models, code, and a watermark detector—are publicly released and accessible at the link below.*
+
+This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/seamless_communication).
+
+## Usage tips
+
+- Wav2Vec2-BERT follows the same architecture as Wav2Vec2-Conformer, but employs a causal depthwise convolutional layer and uses as input a mel-spectrogram representation of the audio instead of the raw waveform.
+- Wav2Vec2-BERT can use either no relative position embeddings, Shaw-like position embeddings, Transformer-XL-like position embeddings, or
+ rotary position embeddings by setting the correct `config.position_embeddings_type`.
+- Wav2Vec2-BERT also introduces a Conformer-based adapter network instead of a simple convolutional network.
+
+## Resources
+
+
+
+- [`Wav2Vec2BertForCTC`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
+- You can also adapt these notebooks on [how to finetune a speech recognition model in English](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb), and [how to finetune a speech recognition model in any language](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb).
+
+
+
+- [`Wav2Vec2BertForSequenceClassification`] can be used by adapting this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification).
+- See also: [Audio classification task guide](../tasks/audio_classification)
+
+
+## Wav2Vec2BertConfig
+
+[[autodoc]] Wav2Vec2BertConfig
+
+## Wav2Vec2BertProcessor
+
+[[autodoc]] Wav2Vec2BertProcessor
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## Wav2Vec2BertModel
+
+[[autodoc]] Wav2Vec2BertModel
+ - forward
+
+## Wav2Vec2BertForCTC
+
+[[autodoc]] Wav2Vec2BertForCTC
+ - forward
+
+## Wav2Vec2BertForSequenceClassification
+
+[[autodoc]] Wav2Vec2BertForSequenceClassification
+ - forward
+
+## Wav2Vec2BertForAudioFrameClassification
+
+[[autodoc]] Wav2Vec2BertForAudioFrameClassification
+ - forward
+
+## Wav2Vec2BertForXVector
+
+[[autodoc]] Wav2Vec2BertForXVector
+ - forward
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 5cc9cd208d8aa3..899e5b52f002ce 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -52,6 +52,7 @@ FlashAttention-2 is currently supported for the following architectures:
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
+* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
@@ -174,6 +175,7 @@ For now, Transformers supports SDPA inference and training for the following arc
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
+* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
diff --git a/docs/source/en/tasks/asr.md b/docs/source/en/tasks/asr.md
index d01269ba60a696..737460ed297bcf 100644
--- a/docs/source/en/tasks/asr.md
+++ b/docs/source/en/tasks/asr.md
@@ -32,7 +32,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
+[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-BERT](../model_doc/wav2vec2-bert), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
diff --git a/docs/source/en/tasks/audio_classification.md b/docs/source/en/tasks/audio_classification.md
index 743a797fc53fa8..678af90c4fa079 100644
--- a/docs/source/en/tasks/audio_classification.md
+++ b/docs/source/en/tasks/audio_classification.md
@@ -32,7 +32,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
+[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-BERT](../model_doc/wav2vec2-bert), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
diff --git a/docs/source/en/tasks/language_modeling.md b/docs/source/en/tasks/language_modeling.md
index a50555dfcf941a..02b5f2ca73f613 100644
--- a/docs/source/en/tasks/language_modeling.md
+++ b/docs/source/en/tasks/language_modeling.md
@@ -37,7 +37,7 @@ You can finetune other architectures for causal language modeling following the
Choose one of the following architectures:
-[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
+[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
diff --git a/docs/source/en/tasks/sequence_classification.md b/docs/source/en/tasks/sequence_classification.md
index 4a0e5b611c9136..0acbf7bfb1e8d5 100644
--- a/docs/source/en/tasks/sequence_classification.md
+++ b/docs/source/en/tasks/sequence_classification.md
@@ -33,7 +33,7 @@ The task illustrated in this tutorial is supported by the following model archit
-[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
+[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
diff --git a/examples/flax/question-answering/run_qa.py b/examples/flax/question-answering/run_qa.py
index fdba1c3ba49fdb..8e6eb2580dc9ed 100644
--- a/examples/flax/question-answering/run_qa.py
+++ b/examples/flax/question-answering/run_qa.py
@@ -62,7 +62,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
Array = Any
Dataset = datasets.arrow_dataset.Dataset
diff --git a/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py b/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
index 5172bcb0beba0f..31780e8ff213e9 100644
--- a/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
+++ b/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
@@ -60,7 +60,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=2.14.0", "To fix: pip install -r examples/flax/speech-recogintion/requirements.txt")
diff --git a/examples/flax/text-classification/run_flax_glue.py b/examples/flax/text-classification/run_flax_glue.py
index 9c51c828363515..b9ebc3344a33bd 100755
--- a/examples/flax/text-classification/run_flax_glue.py
+++ b/examples/flax/text-classification/run_flax_glue.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
Array = Any
Dataset = datasets.arrow_dataset.Dataset
diff --git a/examples/flax/token-classification/run_flax_ner.py b/examples/flax/token-classification/run_flax_ner.py
index ac14b5c2854702..b3eeba8d789dc6 100644
--- a/examples/flax/token-classification/run_flax_ner.py
+++ b/examples/flax/token-classification/run_flax_ner.py
@@ -56,7 +56,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/audio-classification/run_audio_classification.py b/examples/pytorch/audio-classification/run_audio_classification.py
index da31bd0ec29687..4171ea8e3c17eb 100644
--- a/examples/pytorch/audio-classification/run_audio_classification.py
+++ b/examples/pytorch/audio-classification/run_audio_classification.py
@@ -45,7 +45,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.14.0", "To fix: pip install -r examples/pytorch/audio-classification/requirements.txt")
diff --git a/examples/pytorch/contrastive-image-text/run_clip.py b/examples/pytorch/contrastive-image-text/run_clip.py
index a6c1551316daec..d992453edceff5 100644
--- a/examples/pytorch/contrastive-image-text/run_clip.py
+++ b/examples/pytorch/contrastive-image-text/run_clip.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")
diff --git a/examples/pytorch/image-classification/run_image_classification.py b/examples/pytorch/image-classification/run_image_classification.py
index db13dc988ed591..36d8864f19af06 100755
--- a/examples/pytorch/image-classification/run_image_classification.py
+++ b/examples/pytorch/image-classification/run_image_classification.py
@@ -57,7 +57,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
diff --git a/examples/pytorch/image-classification/run_image_classification_no_trainer.py b/examples/pytorch/image-classification/run_image_classification_no_trainer.py
index 963a01b77cf7fc..7c3aa725ea46ed 100644
--- a/examples/pytorch/image-classification/run_image_classification_no_trainer.py
+++ b/examples/pytorch/image-classification/run_image_classification_no_trainer.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -438,8 +438,8 @@ def collate_fn(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/image-pretraining/run_mae.py b/examples/pytorch/image-pretraining/run_mae.py
index 5e3ba45e6c06b3..95e28a5b6025fd 100644
--- a/examples/pytorch/image-pretraining/run_mae.py
+++ b/examples/pytorch/image-pretraining/run_mae.py
@@ -44,7 +44,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
diff --git a/examples/pytorch/image-pretraining/run_mim.py b/examples/pytorch/image-pretraining/run_mim.py
index e644cf48e47bae..01d592887ab547 100644
--- a/examples/pytorch/image-pretraining/run_mim.py
+++ b/examples/pytorch/image-pretraining/run_mim.py
@@ -49,7 +49,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
diff --git a/examples/pytorch/image-pretraining/run_mim_no_trainer.py b/examples/pytorch/image-pretraining/run_mim_no_trainer.py
index ddce78940aecb0..6d5c1849e5b3b2 100644
--- a/examples/pytorch/image-pretraining/run_mim_no_trainer.py
+++ b/examples/pytorch/image-pretraining/run_mim_no_trainer.py
@@ -54,7 +54,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
@@ -626,8 +626,8 @@ def preprocess_images(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_clm.py b/examples/pytorch/language-modeling/run_clm.py
index e9e44af3a37aac..7c73fd741f2c9d 100755
--- a/examples/pytorch/language-modeling/run_clm.py
+++ b/examples/pytorch/language-modeling/run_clm.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/language-modeling/run_clm_no_trainer.py b/examples/pytorch/language-modeling/run_clm_no_trainer.py
index 7a18814e65049e..a8e9b608e466d9 100755
--- a/examples/pytorch/language-modeling/run_clm_no_trainer.py
+++ b/examples/pytorch/language-modeling/run_clm_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -526,8 +526,8 @@ def group_texts(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_mlm.py b/examples/pytorch/language-modeling/run_mlm.py
index 87898963fe89f9..bdee374424d0d9 100755
--- a/examples/pytorch/language-modeling/run_mlm.py
+++ b/examples/pytorch/language-modeling/run_mlm.py
@@ -54,7 +54,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/language-modeling/run_mlm_no_trainer.py b/examples/pytorch/language-modeling/run_mlm_no_trainer.py
index 8ef5eb3a2c0008..97860cd2666abb 100755
--- a/examples/pytorch/language-modeling/run_mlm_no_trainer.py
+++ b/examples/pytorch/language-modeling/run_mlm_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
@@ -563,8 +563,8 @@ def group_texts(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/language-modeling/run_plm.py b/examples/pytorch/language-modeling/run_plm.py
index af0d5f06a0b5f2..66451247e06a7f 100755
--- a/examples/pytorch/language-modeling/run_plm.py
+++ b/examples/pytorch/language-modeling/run_plm.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
diff --git a/examples/pytorch/multiple-choice/run_swag.py b/examples/pytorch/multiple-choice/run_swag.py
index 5b7aaa0a705d0d..a1cfcfdddafa4a 100755
--- a/examples/pytorch/multiple-choice/run_swag.py
+++ b/examples/pytorch/multiple-choice/run_swag.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/pytorch/multiple-choice/run_swag_no_trainer.py b/examples/pytorch/multiple-choice/run_swag_no_trainer.py
index e15cc9da9a3606..533072fc0af15a 100755
--- a/examples/pytorch/multiple-choice/run_swag_no_trainer.py
+++ b/examples/pytorch/multiple-choice/run_swag_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
# You should update this to your particular problem to have better documentation of `model_type`
@@ -510,8 +510,8 @@ def preprocess_function(examples):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_qa.py b/examples/pytorch/question-answering/run_qa.py
index b134d95765c538..c43fec14f4ec04 100755
--- a/examples/pytorch/question-answering/run_qa.py
+++ b/examples/pytorch/question-answering/run_qa.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/question-answering/run_qa_beam_search.py b/examples/pytorch/question-answering/run_qa_beam_search.py
index 23a2231e9acc3d..d75e394e8d94dc 100755
--- a/examples/pytorch/question-answering/run_qa_beam_search.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py b/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
index ed92bccbd202ce..65c38edca295df 100644
--- a/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
+++ b/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
@@ -750,8 +750,8 @@ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_qa_no_trainer.py b/examples/pytorch/question-answering/run_qa_no_trainer.py
index 2ae3eb6c45c872..5cb00d5225cb8f 100755
--- a/examples/pytorch/question-answering/run_qa_no_trainer.py
+++ b/examples/pytorch/question-answering/run_qa_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
@@ -780,8 +780,8 @@ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/question-answering/run_seq2seq_qa.py b/examples/pytorch/question-answering/run_seq2seq_qa.py
index 92ba31efdd8312..55f9c65988c077 100644
--- a/examples/pytorch/question-answering/run_seq2seq_qa.py
+++ b/examples/pytorch/question-answering/run_seq2seq_qa.py
@@ -47,7 +47,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
index 5b12a98c7e0a68..af62d75f764b02 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
@@ -52,7 +52,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
diff --git a/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py b/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
index 99e24de7312229..315c0ce4611cd2 100644
--- a/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
+++ b/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
@@ -513,8 +513,8 @@ def preprocess_val(example_batch):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index 1c658904e71e30..def937450fbca2 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
@@ -132,6 +132,20 @@ class ModelArguments:
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
)
+ ctc_zero_infinity: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`. Infinite losses mainly"
+ " occur when the inputs are too short to be aligned to the targets."
+ },
+ )
+ add_adapter: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether a convolutional attention network should be stacked on top of the Wav2Vec2Bert Encoder. Can be very"
+ "useful to downsample the output length."
+ },
+ )
@dataclass
@@ -309,11 +323,14 @@ class DataCollatorCTCWithPadding:
padding: Union[bool, str] = "longest"
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
+ feature_extractor_input_name: Optional[str] = "input_values"
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
+ input_features = [
+ {self.feature_extractor_input_name: feature[self.feature_extractor_input_name]} for feature in features
+ ]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
@@ -599,9 +616,11 @@ def remove_special_characters(batch):
"gradient_checkpointing": training_args.gradient_checkpointing,
"layerdrop": model_args.layerdrop,
"ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "ctc_zero_infinity": model_args.ctc_zero_infinity,
"pad_token_id": tokenizer.pad_token_id,
"vocab_size": len(tokenizer),
"activation_dropout": model_args.activation_dropout,
+ "add_adapter": model_args.add_adapter,
}
)
@@ -635,6 +654,7 @@ def remove_special_characters(batch):
min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
audio_column_name = data_args.audio_column_name
num_workers = data_args.preprocessing_num_workers
+ feature_extractor_input_name = feature_extractor.model_input_names[0]
# `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
phoneme_language = data_args.phoneme_language
@@ -646,8 +666,9 @@ def prepare_dataset(batch):
sample = batch[audio_column_name]
inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
+ batch[feature_extractor_input_name] = getattr(inputs, feature_extractor_input_name)[0]
+ # take length of raw audio waveform
+ batch["input_length"] = len(sample["array"].squeeze())
# encode targets
additional_kwargs = {}
@@ -728,7 +749,9 @@ def compute_metrics(pred):
processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
# Instantiate custom data collator
- data_collator = DataCollatorCTCWithPadding(processor=processor)
+ data_collator = DataCollatorCTCWithPadding(
+ processor=processor, feature_extractor_input_name=feature_extractor_input_name
+ )
# Initialize Trainer
trainer = Trainer(
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
index 5708f524a3180f..f311d97987c062 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index 9ffb48638d3672..50f27e41bfc139 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
diff --git a/examples/pytorch/summarization/run_summarization.py b/examples/pytorch/summarization/run_summarization.py
index fcd6c69de848d1..993c4d4cfcbeda 100755
--- a/examples/pytorch/summarization/run_summarization.py
+++ b/examples/pytorch/summarization/run_summarization.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/examples/pytorch/summarization/run_summarization_no_trainer.py b/examples/pytorch/summarization/run_summarization_no_trainer.py
index 30c1b887e80eec..3212ef1af52b04 100644
--- a/examples/pytorch/summarization/run_summarization_no_trainer.py
+++ b/examples/pytorch/summarization/run_summarization_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
@@ -580,8 +580,8 @@ def postprocess_text(preds, labels):
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
- num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps if overrode_max_train_steps else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
diff --git a/examples/pytorch/text-classification/run_classification.py b/examples/pytorch/text-classification/run_classification.py
index 4ce7bfab3a518b..a080df108ebf8e 100755
--- a/examples/pytorch/text-classification/run_classification.py
+++ b/examples/pytorch/text-classification/run_classification.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
@@ -545,7 +545,7 @@ def main():
"run. You can ignore this if you are doing finetuning."
)
model.config.label2id = label_to_id
- model.config.id2label = {id: label for label, id in config.label2id.items()}
+ model.config.id2label = {id: label for label, id in label_to_id.items()}
elif not is_regression: # classification, but not training
logger.info("using label infos in the model config")
logger.info("label2id: {}".format(model.config.label2id))
diff --git a/examples/pytorch/text-classification/run_glue.py b/examples/pytorch/text-classification/run_glue.py
index 8fa821c49ae89f..c9381824018ec8 100755
--- a/examples/pytorch/text-classification/run_glue.py
+++ b/examples/pytorch/text-classification/run_glue.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
diff --git a/examples/pytorch/text-classification/run_glue_no_trainer.py b/examples/pytorch/text-classification/run_glue_no_trainer.py
index 870eeb31e99f1e..711494d85c066d 100644
--- a/examples/pytorch/text-classification/run_glue_no_trainer.py
+++ b/examples/pytorch/text-classification/run_glue_no_trainer.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
diff --git a/examples/pytorch/text-classification/run_xnli.py b/examples/pytorch/text-classification/run_xnli.py
index 8260645764184a..b716744297fccb 100755
--- a/examples/pytorch/text-classification/run_xnli.py
+++ b/examples/pytorch/text-classification/run_xnli.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
diff --git a/examples/pytorch/token-classification/run_ner.py b/examples/pytorch/token-classification/run_ner.py
index 40028f779cc14e..8d7a67cd1571a6 100755
--- a/examples/pytorch/token-classification/run_ner.py
+++ b/examples/pytorch/token-classification/run_ner.py
@@ -50,7 +50,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/token-classification/run_ner_no_trainer.py b/examples/pytorch/token-classification/run_ner_no_trainer.py
index 7d2939f81bf39b..02bbd12d22ba50 100755
--- a/examples/pytorch/token-classification/run_ner_no_trainer.py
+++ b/examples/pytorch/token-classification/run_ner_no_trainer.py
@@ -56,7 +56,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
diff --git a/examples/pytorch/translation/run_translation.py b/examples/pytorch/translation/run_translation.py
index cb9fa48e84a747..04f26cb72f589a 100755
--- a/examples/pytorch/translation/run_translation.py
+++ b/examples/pytorch/translation/run_translation.py
@@ -53,7 +53,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
diff --git a/examples/pytorch/translation/run_translation_no_trainer.py b/examples/pytorch/translation/run_translation_no_trainer.py
index 1e8009d42d86dd..c4764b5ee4a7d7 100644
--- a/examples/pytorch/translation/run_translation_no_trainer.py
+++ b/examples/pytorch/translation/run_translation_no_trainer.py
@@ -57,7 +57,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
diff --git a/examples/research_projects/codeparrot/README.md b/examples/research_projects/codeparrot/README.md
index 6c57c4350fbc02..3259041ba5404a 100644
--- a/examples/research_projects/codeparrot/README.md
+++ b/examples/research_projects/codeparrot/README.md
@@ -50,7 +50,7 @@ The raw dataset contains many duplicates. We deduplicated and filtered the datas
- fraction of alphanumeric characters < 0.25
- containing the word "auto-generated" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with a mention of "test file" or "configuration file" or similar in the first 5 lines
-- filtering with a probability of 0.7 of files with high occurence of the keywords "test " or "config"
+- filtering with a probability of 0.7 of files with high occurrence of the keywords "test " or "config"
- filtering with a probability of 0.7 of files without a mention of the keywords `def` , `for`, `while` and `class`
- filtering files that use the assignment operator `=` less than 5 times
- filtering files with ratio between number of characters and number of tokens after tokenization < 1.5 (the average ratio is 3.6)
diff --git a/examples/research_projects/jax-projects/README.md b/examples/research_projects/jax-projects/README.md
index 420a97f7682a9c..71f9a7a4e0e2a1 100644
--- a/examples/research_projects/jax-projects/README.md
+++ b/examples/research_projects/jax-projects/README.md
@@ -1153,7 +1153,7 @@ In the following, we will describe how to do so using a standard console, but yo
2. Once you've installed the google cloud sdk, you should set your account by running the following command. Make sure that `` corresponds to the gmail address you used to sign up for this event.
```bash
-$ gcloud config set account
+$ gcloud config set account
```
3. Let's also make sure the correct project is set in case your email is used for multiple gcloud projects:
diff --git a/examples/research_projects/jax-projects/big_bird/README.md b/examples/research_projects/jax-projects/big_bird/README.md
index e8ef274bbe07cd..42586e49580ebb 100644
--- a/examples/research_projects/jax-projects/big_bird/README.md
+++ b/examples/research_projects/jax-projects/big_bird/README.md
@@ -57,4 +57,4 @@ wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/r
python3 evaluate.py
```
-You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repositary](https://github.com/thevasudevgupta/bigbird).
+You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repository](https://github.com/thevasudevgupta/bigbird).
diff --git a/examples/research_projects/jax-projects/model_parallel/README.md b/examples/research_projects/jax-projects/model_parallel/README.md
index b63b93862db06f..97f3cdb047741a 100644
--- a/examples/research_projects/jax-projects/model_parallel/README.md
+++ b/examples/research_projects/jax-projects/model_parallel/README.md
@@ -27,7 +27,7 @@ To adapt the script for other models, we need to also change the `ParitionSpec`
TODO: Add more explantion.
-Before training, let's prepare our model first. To be able to shard the model, the sharded dimention needs to be a multiple of devices it'll be sharded on. But GPTNeo's vocab size is 50257, so we need to resize the embeddings accordingly.
+Before training, let's prepare our model first. To be able to shard the model, the sharded dimension needs to be a multiple of devices it'll be sharded on. But GPTNeo's vocab size is 50257, so we need to resize the embeddings accordingly.
```python
from transformers import FlaxGPTNeoForCausalLM, GPTNeoConfig
diff --git a/examples/research_projects/mlm_wwm/README.md b/examples/research_projects/mlm_wwm/README.md
index 9426be7c27be1f..0144b1ad309206 100644
--- a/examples/research_projects/mlm_wwm/README.md
+++ b/examples/research_projects/mlm_wwm/README.md
@@ -95,4 +95,4 @@ python run_mlm_wwm.py \
**Note1:** On TPU, you should the flag `--pad_to_max_length` to make sure all your batches have the same length.
-**Note2:** And if you have any questions or something goes wrong when runing this code, don't hesitate to pin @wlhgtc.
+**Note2:** And if you have any questions or something goes wrong when running this code, don't hesitate to pin @wlhgtc.
diff --git a/examples/tensorflow/contrastive-image-text/run_clip.py b/examples/tensorflow/contrastive-image-text/run_clip.py
index d63712133ca559..e94f4b6b44fb0a 100644
--- a/examples/tensorflow/contrastive-image-text/run_clip.py
+++ b/examples/tensorflow/contrastive-image-text/run_clip.py
@@ -52,7 +52,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version(
"datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/contrastive-image-text/requirements.txt"
diff --git a/examples/tensorflow/image-classification/run_image_classification.py b/examples/tensorflow/image-classification/run_image_classification.py
index 41cb0ffe9568c8..11f35ceacc0221 100644
--- a/examples/tensorflow/image-classification/run_image_classification.py
+++ b/examples/tensorflow/image-classification/run_image_classification.py
@@ -55,7 +55,7 @@
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
diff --git a/examples/tensorflow/multiple-choice/run_swag.py b/examples/tensorflow/multiple-choice/run_swag.py
index e170daa97938ca..8572ec98e1ae96 100644
--- a/examples/tensorflow/multiple-choice/run_swag.py
+++ b/examples/tensorflow/multiple-choice/run_swag.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/tensorflow/question-answering/run_qa.py b/examples/tensorflow/question-answering/run_qa.py
index 6aaf45f00fd3b0..19e00c3dc42031 100755
--- a/examples/tensorflow/question-answering/run_qa.py
+++ b/examples/tensorflow/question-answering/run_qa.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
logger = logging.getLogger(__name__)
diff --git a/examples/tensorflow/summarization/run_summarization.py b/examples/tensorflow/summarization/run_summarization.py
index 39c8f7f89f4b89..84ba7f2e7b9656 100644
--- a/examples/tensorflow/summarization/run_summarization.py
+++ b/examples/tensorflow/summarization/run_summarization.py
@@ -54,7 +54,7 @@
# region Checking dependencies
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/examples/tensorflow/text-classification/run_glue.py b/examples/tensorflow/text-classification/run_glue.py
index 3662d6aaac10a3..198bec7da382e2 100644
--- a/examples/tensorflow/text-classification/run_glue.py
+++ b/examples/tensorflow/text-classification/run_glue.py
@@ -48,7 +48,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
task_to_keys = {
"cola": ("sentence", None),
diff --git a/examples/tensorflow/translation/run_translation.py b/examples/tensorflow/translation/run_translation.py
index b34a8624051909..2d0c06f57e7e25 100644
--- a/examples/tensorflow/translation/run_translation.py
+++ b/examples/tensorflow/translation/run_translation.py
@@ -57,7 +57,7 @@
# region Dependencies and constants
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.37.0.dev0")
+check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
diff --git a/setup.py b/setup.py
index 65b84fe938f787..91ad923ec3e74c 100644
--- a/setup.py
+++ b/setup.py
@@ -428,7 +428,7 @@ def run(self):
setup(
name="transformers",
- version="4.37.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
+ version="4.38.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
author="The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)",
author_email="transformers@huggingface.co",
description="State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow",
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 4941d724455dfe..41d2c3632c039a 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -18,7 +18,7 @@
# to defer the actual importing for when the objects are requested. This way `import transformers` provides the names
# in the namespace without actually importing anything (and especially none of the backends).
-__version__ = "4.37.0.dev0"
+__version__ = "4.38.0.dev0"
from typing import TYPE_CHECKING
@@ -711,6 +711,11 @@
],
"models.pvt": ["PVT_PRETRAINED_CONFIG_ARCHIVE_MAP", "PvtConfig"],
"models.qdqbert": ["QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "QDQBertConfig"],
+ "models.qwen2": [
+ "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Qwen2Config",
+ "Qwen2Tokenizer",
+ ],
"models.rag": ["RagConfig", "RagRetriever", "RagTokenizer"],
"models.realm": [
"REALM_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -909,6 +914,11 @@
"Wav2Vec2Processor",
"Wav2Vec2Tokenizer",
],
+ "models.wav2vec2_bert": [
+ "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Wav2Vec2BertConfig",
+ "Wav2Vec2BertProcessor",
+ ],
"models.wav2vec2_conformer": [
"WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
"Wav2Vec2ConformerConfig",
@@ -1185,6 +1195,7 @@
_import_structure["models.nougat"].append("NougatTokenizerFast")
_import_structure["models.openai"].append("OpenAIGPTTokenizerFast")
_import_structure["models.pegasus"].append("PegasusTokenizerFast")
+ _import_structure["models.qwen2"].append("Qwen2TokenizerFast")
_import_structure["models.realm"].append("RealmTokenizerFast")
_import_structure["models.reformer"].append("ReformerTokenizerFast")
_import_structure["models.rembert"].append("RemBertTokenizerFast")
@@ -2971,6 +2982,14 @@
"load_tf_weights_in_qdqbert",
]
)
+ _import_structure["models.qwen2"].extend(
+ [
+ "Qwen2ForCausalLM",
+ "Qwen2ForSequenceClassification",
+ "Qwen2Model",
+ "Qwen2PreTrainedModel",
+ ]
+ )
_import_structure["models.rag"].extend(
[
"RagModel",
@@ -3501,6 +3520,17 @@
"Wav2Vec2PreTrainedModel",
]
)
+ _import_structure["models.wav2vec2_bert"].extend(
+ [
+ "WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Wav2Vec2BertForAudioFrameClassification",
+ "Wav2Vec2BertForCTC",
+ "Wav2Vec2BertForSequenceClassification",
+ "Wav2Vec2BertForXVector",
+ "Wav2Vec2BertModel",
+ "Wav2Vec2BertPreTrainedModel",
+ ]
+ )
_import_structure["models.wav2vec2_conformer"].extend(
[
"WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -5404,6 +5434,7 @@
)
from .models.pvt import PVT_PRETRAINED_CONFIG_ARCHIVE_MAP, PvtConfig
from .models.qdqbert import QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, QDQBertConfig
+ from .models.qwen2 import QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP, Qwen2Config, Qwen2Tokenizer
from .models.rag import RagConfig, RagRetriever, RagTokenizer
from .models.realm import (
REALM_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5602,6 +5633,11 @@
Wav2Vec2Processor,
Wav2Vec2Tokenizer,
)
+ from .models.wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ Wav2Vec2BertConfig,
+ Wav2Vec2BertProcessor,
+ )
from .models.wav2vec2_conformer import (
WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
Wav2Vec2ConformerConfig,
@@ -5871,6 +5907,7 @@
from .models.nougat import NougatTokenizerFast
from .models.openai import OpenAIGPTTokenizerFast
from .models.pegasus import PegasusTokenizerFast
+ from .models.qwen2 import Qwen2TokenizerFast
from .models.realm import RealmTokenizerFast
from .models.reformer import ReformerTokenizerFast
from .models.rembert import RemBertTokenizerFast
@@ -7373,6 +7410,12 @@
QDQBertPreTrainedModel,
load_tf_weights_in_qdqbert,
)
+ from .models.qwen2 import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ Qwen2PreTrainedModel,
+ )
from .models.rag import (
RagModel,
RagPreTrainedModel,
@@ -7799,6 +7842,15 @@
Wav2Vec2Model,
Wav2Vec2PreTrainedModel,
)
+ from .models.wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertPreTrainedModel,
+ )
from .models.wav2vec2_conformer import (
WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
Wav2Vec2ConformerForAudioFrameClassification,
diff --git a/src/transformers/convert_pytorch_checkpoint_to_tf2.py b/src/transformers/convert_pytorch_checkpoint_to_tf2.py
index f300b0bb92c661..c10dd44ed853fa 100755
--- a/src/transformers/convert_pytorch_checkpoint_to_tf2.py
+++ b/src/transformers/convert_pytorch_checkpoint_to_tf2.py
@@ -129,6 +129,7 @@
XLMWithLMHeadModel,
XLNetLMHeadModel,
)
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13
logging.set_verbosity_info()
@@ -329,7 +330,11 @@ def convert_pt_checkpoint_to_tf(
if compare_with_pt_model:
tfo = tf_model(tf_model.dummy_inputs, training=False) # build the network
- state_dict = torch.load(pytorch_checkpoint_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ pytorch_checkpoint_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
pt_model = pt_model_class.from_pretrained(
pretrained_model_name_or_path=None, config=config, state_dict=state_dict
)
diff --git a/src/transformers/convert_slow_tokenizer.py b/src/transformers/convert_slow_tokenizer.py
index 76ac66ceb9efcc..53dbfeb6b64cb7 100644
--- a/src/transformers/convert_slow_tokenizer.py
+++ b/src/transformers/convert_slow_tokenizer.py
@@ -355,6 +355,48 @@ def converted(self) -> Tokenizer:
return tokenizer
+class Qwen2Converter(Converter):
+ def converted(self) -> Tokenizer:
+ vocab = self.original_tokenizer.encoder
+ merges = list(self.original_tokenizer.bpe_ranks.keys())
+
+ tokenizer = Tokenizer(
+ BPE(
+ vocab=vocab,
+ merges=merges,
+ dropout=None,
+ unk_token=None,
+ continuing_subword_prefix="",
+ end_of_word_suffix="",
+ fuse_unk=False,
+ byte_fallback=False,
+ )
+ )
+
+ tokenizer.normalizer = normalizers.NFC()
+
+ tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
+ [
+ pre_tokenizers.Split(
+ Regex(
+ r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
+ ),
+ behavior="isolated",
+ invert=False,
+ ),
+ pre_tokenizers.ByteLevel(
+ add_prefix_space=getattr(self.original_tokenizer, "add_prefix_space", False),
+ use_regex=False,
+ ),
+ ]
+ )
+
+ tokenizer.decoder = decoders.ByteLevel()
+ tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
+
+ return tokenizer
+
+
class RobertaConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
@@ -510,15 +552,22 @@ def tokenizer(self, proto):
def normalizer(self, proto):
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
+ _normalizers = [
+ normalizers.Strip(left=False, right=True), # stripping is important
+ normalizers.Replace(Regex(" {2,}"), "▁"),
+ ]
if not precompiled_charsmap:
- return normalizers.Sequence([normalizers.Replace(Regex(" {2,}"), " ")])
+ return normalizers.Sequence(_normalizers)
else:
- return normalizers.Sequence(
- [normalizers.Precompiled(precompiled_charsmap), normalizers.Replace(Regex(" {2,}"), " ")]
- )
+ return normalizers.Sequence([normalizers.Precompiled(precompiled_charsmap)] + _normalizers)
def pre_tokenizer(self, replacement, add_prefix_space):
- return pre_tokenizers.Metaspace(replacement=replacement, add_prefix_space=add_prefix_space)
+ prepend_scheme = "always"
+ if hasattr(self.original_tokenizer, "legacy") and not self.original_tokenizer.legacy:
+ prepend_scheme = "first"
+ return pre_tokenizers.Metaspace(
+ replacement=replacement, add_prefix_space=add_prefix_space, prepend_scheme=prepend_scheme
+ )
def post_processor(self):
return None
@@ -1289,6 +1338,7 @@ def converted(self) -> Tokenizer:
"NllbTokenizer": NllbConverter,
"OpenAIGPTTokenizer": OpenAIGPTConverter,
"PegasusTokenizer": PegasusConverter,
+ "Qwen2Tokenizer": Qwen2Converter,
"RealmTokenizer": BertConverter,
"ReformerTokenizer": ReformerConverter,
"RemBertTokenizer": RemBertConverter,
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index 01ad4b5314c827..75a9f59a07bf18 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -171,12 +171,16 @@ def get_candidates(self, input_ids: torch.LongTensor, max_new_tokens=None) -> Tu
"""
input_ids = input_ids.to(self.assistant_model.device)
+ # Don't generate more than `max_length - 1` candidates since the target model generates one extra token.
+ new_cur_len = input_ids.shape[-1]
+ max_new_tokens = min(int(self.num_assistant_tokens), self.generation_config.max_length - new_cur_len - 1)
+ if max_new_tokens == 0:
+ return input_ids, None
+
# 1. If it is not the first round of candidate generation, prepare the inputs based on the input_ids length
# (which implicitly contains the number of accepted candidates from the previous round)
has_past_key_values = self.assistant_kwargs.get("past_key_values", None) is not None
if has_past_key_values:
- new_cur_len = input_ids.shape[-1]
-
new_cache_size = new_cur_len - 1
self.assistant_kwargs["past_key_values"] = _crop_past_key_values(
self.assistant_model, self.assistant_kwargs["past_key_values"], new_cache_size - 1
diff --git a/src/transformers/generation/configuration_utils.py b/src/transformers/generation/configuration_utils.py
index 4353a113223870..abc118aa8c1d60 100644
--- a/src/transformers/generation/configuration_utils.py
+++ b/src/transformers/generation/configuration_utils.py
@@ -200,7 +200,8 @@ class GenerationConfig(PushToHubMixin):
Higher guidance scale encourages the model to generate samples that are more closely linked to the input
prompt, usually at the expense of poorer quality.
low_memory (`bool`, *optional*):
- Switch to sequential topk for contrastive search to reduce peak memory. Used with contrastive search.
+ Switch to sequential beam search and sequential topk for contrastive search to reduce peak memory.
+ Used with beam search and contrastive search.
> Parameters that define the output variables of `generate`
diff --git a/src/transformers/generation/logits_process.py b/src/transformers/generation/logits_process.py
index 2b1b9f5a50b6ef..04120e39fbd27c 100644
--- a/src/transformers/generation/logits_process.py
+++ b/src/transformers/generation/logits_process.py
@@ -95,6 +95,7 @@ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwa
scores = processor(input_ids, scores, **kwargs)
else:
scores = processor(input_ids, scores)
+
return scores
@@ -1657,6 +1658,9 @@ def __init__(self, begin_suppress_tokens, begin_index):
self.begin_suppress_tokens = list(begin_suppress_tokens)
self.begin_index = begin_index
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
+
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if input_ids.shape[1] == self.begin_index:
@@ -1778,6 +1782,7 @@ class WhisperTimeStampLogitsProcessor(LogitsProcessor):
max_initial_timestamp_index (`int`, *optional*, defaults to 1):
Used to set the maximum value of the initial timestamp. This is used to prevent the model from
predicting timestamps that are too far in the future.
+ begin_index (`Optional`, *optional*): Token index of the first token that is generated by the model.
_detect_timestamp_from_logprob (`bool`, *optional*): Whether timestamps can be predicted from logprobs over all timestamps.
Examples:
@@ -1810,11 +1815,11 @@ class WhisperTimeStampLogitsProcessor(LogitsProcessor):
"""
def __init__(
- self, generate_config, _detect_timestamp_from_logprob: Optional[bool] = None
+ self, generate_config, begin_index: Optional[int] = None, _detect_timestamp_from_logprob: Optional[bool] = None
): # support for the kwargs
- self.eos_token_id = generate_config.eos_token_id
self.no_timestamps_token_id = generate_config.no_timestamps_token_id
self.timestamp_begin = generate_config.no_timestamps_token_id + 1
+ self.eos_token_id = generate_config.eos_token_id or generate_config.bos_token_id
# this variable is mostly just used for testing
self._detect_timestamp_from_logprob = (
@@ -1823,10 +1828,17 @@ def __init__(
else getattr(generate_config, "_detect_timestamp_from_logprob", True)
)
- self.begin_index = (
- len(generate_config.forced_decoder_ids) + 1 if generate_config.forced_decoder_ids is not None else 1
+ num_forced_ids = (
+ len(generate_config.forced_decoder_ids) if generate_config.forced_decoder_ids is not None else 0
)
+ self.begin_index = begin_index or (num_forced_ids + 1)
+
self.max_initial_timestamp_index = getattr(generate_config, "max_initial_timestamp_index", None)
+ # TODO(Patrick): Make sure that official models have max_initial_timestamp_index set to 50
+ # self.max_initial_timestamp_index = 50
+
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
@@ -1878,6 +1890,60 @@ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> to
return scores
+class WhisperNoSpeechDetection(LogitsProcessor):
+ r"""This processor can be used to detect silence when using Whisper. It should take as input unprocessed logits to follow the original implementation"""
+
+ def __init__(self, no_speech_token: int, begin_index: int, scores_is_logprobs: bool = False):
+ self.no_speech_token = no_speech_token
+ # offset between token, , in paper and first generated token
+ # is equal to the position of the first generated token index
+ self.start_of_trans_offset = begin_index
+
+ # `self.begin_index` is a running value that is changed on the fly
+ self.begin_index = begin_index
+ self._no_speech_prob = [0.0]
+ self.is_scores_logprobs = scores_is_logprobs
+
+ # overwritten dynamically
+ self.model = None
+ self.inputs = None
+
+ def set_model(self, model):
+ self.model = model
+
+ def set_inputs(self, inputs):
+ self.inputs = {**self.model.prepare_inputs_for_generation(**inputs), **inputs}
+ self.inputs["input_features"] = self.inputs.pop("inputs")
+
+ @property
+ def no_speech_prob(self):
+ return self._no_speech_prob
+
+ def set_begin_index(self, begin_index):
+ self.begin_index = begin_index
+
+ @add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
+ if input_ids.shape[1] == self.begin_index:
+ if self.start_of_trans_offset > 1:
+ with torch.no_grad():
+ logits = self.model(**self.inputs).logits
+
+ no_speech_index = self.begin_index - self.start_of_trans_offset
+ no_speech_scores = logits[:, no_speech_index]
+ else:
+ no_speech_scores = scores
+
+ if self.is_scores_logprobs:
+ probs = no_speech_scores.exp()
+ else:
+ probs = no_speech_scores.float().softmax(dim=-1)
+
+ self._no_speech_prob = probs[:, self.no_speech_token]
+
+ return scores
+
+
class ClassifierFreeGuidanceLogitsProcessor(LogitsProcessor):
r"""
[`LogitsProcessor`] for classifier free guidance (CFG). The scores are split over the batch dimension,
diff --git a/src/transformers/generation/utils.py b/src/transformers/generation/utils.py
index 0534f5c8d6bc73..f8a70d71e676a6 100644
--- a/src/transformers/generation/utils.py
+++ b/src/transformers/generation/utils.py
@@ -518,6 +518,8 @@ def _prepare_decoder_input_ids_for_generation(
# exception: Donut checkpoints have task-specific decoder starts and don't expect a BOS token
elif self.config.model_type == "vision-encoder-decoder" and "donut" in self.name_or_path.lower():
pass
+ elif self.config.model_type in ["whisper"]:
+ pass
# user input but doesn't start with decoder_start_token_id -> prepend decoder_start_token_id (and adjust
# decoder_attention_mask if provided)
elif (decoder_input_ids[:, 0] != decoder_start_token_id).all().item():
@@ -1558,6 +1560,7 @@ def generate(
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
synced_gpus=synced_gpus,
+ sequential=generation_config.low_memory,
**model_kwargs,
)
@@ -1951,8 +1954,7 @@ def contrastive_search(
model_kwargs["past_key_values"] = tuple(new_key_values)
if sequential:
- all_outputs = {key: [] for key in outputs} # defined in first loop iteration
- all_last_hstates, all_hstates, all_logits = [], [], []
+ all_outputs = []
for i in range(top_k):
# compute the candidate tokens by the language model and collect their hidden_states
next_model_inputs = self.prepare_inputs_for_generation(top_k_ids[:, i].view(-1, 1), **model_kwargs)
@@ -1963,32 +1965,8 @@ def contrastive_search(
output_hidden_states=True,
output_attentions=output_attentions,
)
- for key in all_outputs:
- all_outputs[key].append(outputs[key])
-
- if self.config.is_encoder_decoder:
- next_hidden = outputs.decoder_hidden_states[-1]
- full_hidden_states = outputs.decoder_hidden_states
-
- else:
- next_hidden = outputs.hidden_states[-1]
- full_hidden_states = outputs.hidden_states
-
- all_last_hstates.append(torch.squeeze(next_hidden, 0))
- all_hstates.append(full_hidden_states)
- all_logits.append(outputs.logits[:, -1, :])
-
- # stack hidden states
- next_hidden = torch.stack([all_last_hstates[i] for i in range(top_k)], dim=0)
- final_full_hstates = [0 for i in range(len(full_hidden_states))]
- for layer in range(len(full_hidden_states)):
- final_full_hstates[layer] = torch.stack(
- [torch.squeeze(all_hstates[i][layer], 0) for i in range(top_k)], dim=0
- )
- full_hidden_states = tuple(final_full_hstates)
-
- # stack logits
- logits = torch.cat(all_logits, dim=0)
+ all_outputs.append(outputs)
+ outputs = stack_model_outputs(all_outputs)
else:
# compute the candidate tokens by the language model and collect their hidden_states
@@ -2001,15 +1979,15 @@ def contrastive_search(
output_hidden_states=True,
output_attentions=output_attentions,
)
- # name is different for encoder-decoder and decoder-only models
- if self.config.is_encoder_decoder:
- next_hidden = outputs.decoder_hidden_states[-1]
- full_hidden_states = outputs.decoder_hidden_states
- else:
- next_hidden = outputs.hidden_states[-1]
- full_hidden_states = outputs.hidden_states
+ # name is different for encoder-decoder and decoder-only models
+ if self.config.is_encoder_decoder:
+ next_hidden = outputs.decoder_hidden_states[-1]
+ full_hidden_states = outputs.decoder_hidden_states
+ else:
+ next_hidden = outputs.hidden_states[-1]
+ full_hidden_states = outputs.hidden_states
- logits = outputs.logits[:, -1, :]
+ logits = outputs.logits[:, -1, :]
context_hidden = last_hidden_states.repeat_interleave(top_k, dim=0)
@@ -2747,6 +2725,7 @@ def beam_search(
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
synced_gpus: bool = False,
+ sequential: Optional[bool] = None,
**model_kwargs,
) -> Union[GenerateBeamOutput, torch.LongTensor]:
r"""
@@ -2792,6 +2771,10 @@ def beam_search(
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ sequential (`bool`, defaults to `False`):
+ By default, beam search has `batch_size * num_beams` as effective batch size (see `beam_search()` for
+ more details). This flag will avoid parallelizing the beam search and will instead run beam search
+ sequentially.
model_kwargs:
Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
an encoder-decoder model the kwargs should include `encoder_outputs`.
@@ -2858,6 +2841,7 @@ def beam_search(
# init values
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ sequential = sequential if sequential is not None else self.generation_config.low_memory
if max_length is not None:
warnings.warn(
"`max_length` is deprecated in this function, use"
@@ -2932,12 +2916,39 @@ def beam_search(
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
- outputs = self(
- **model_inputs,
- return_dict=True,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- )
+ # if sequential is True, split the input to batches of batch_size and run sequentially
+ if sequential:
+ if any(
+ model_name in self.__class__.__name__.lower()
+ for model_name in ["fsmt", "reformer", "bloom", "ctrl", "gpt_bigcode", "transo_xl", "xlnet", "cpm"]
+ ):
+ raise RuntimeError(
+ f"Currently generation for {self.__class__.__name__} is not supported "
+ f"for `low_memory beam_search`. Please open an issue on GitHub if you need this feature."
+ )
+
+ inputs_per_sub_batches = _split_model_inputs(
+ model_inputs, split_size=batch_size, full_batch_size=batch_beam_size
+ )
+ outputs_per_sub_batch = [
+ self(
+ **inputs_per_sub_batch,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ for inputs_per_sub_batch in inputs_per_sub_batches
+ ]
+
+ outputs = stack_model_outputs(outputs_per_sub_batch)
+
+ else: # Unchanged original behavior
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
if synced_gpus and this_peer_finished:
cur_len = cur_len + 1
@@ -4395,7 +4406,7 @@ def assisted_decoding(
else:
selected_tokens = new_logits.argmax(dim=-1)
- candidate_new_tokens = candidate_input_ids[:, -candidate_length:]
+ candidate_new_tokens = candidate_input_ids[:, cur_len:]
n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
# Ensure we don't generate beyond max_len or an EOS token
@@ -4531,12 +4542,13 @@ def _speculative_sampling(
NOTE: Unless otherwise stated, the variable names match those in the paper.
"""
+ new_candidate_input_ids = candidate_input_ids[:, -candidate_length:]
# Gets the probabilities from the logits. q_i and p_i denote the assistant and model probabilities of the tokens
# selected by the assistant, respectively.
q = candidate_logits.softmax(dim=-1)
- q_i = q[:, torch.arange(candidate_length), candidate_input_ids[:, -candidate_length:]].squeeze(0, 1)
+ q_i = q[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
p = new_logits.softmax(dim=-1)
- p_i = p[:, torch.arange(candidate_length), candidate_input_ids[:, -candidate_length:]].squeeze(0, 1)
+ p_i = p[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
probability_ratio = p_i / q_i
# When probability_ratio > 1 (i.e. q_i(x) < p_i(x), or "assistant probability of the candidate token is smaller
@@ -4544,28 +4556,33 @@ def _speculative_sampling(
# (= keep with p = probability_ratio). Keep all the tokens until the first rejection
r_i = torch.rand_like(probability_ratio)
is_accepted = r_i <= probability_ratio
- n_matches = (~is_accepted.cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
+ n_matches = ((~is_accepted).cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
# Ensure we don't generate beyond max_len or an EOS token (not in algorithm 1, but needed for correct behavior)
if last_assistant_token_is_eos and n_matches == candidate_length:
+ # Output length is assumed to be `n_matches + 1`. Since we won't generate another token with the target model
+ # due to acceptance on EOS we fix `n_matches`
n_matches -= 1
- n_matches = min(n_matches, max_matches)
-
- # Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
- gamma = candidate_logits.shape[1]
- p_n_plus_1 = p[:, n_matches, :]
- if n_matches < gamma:
- q_n_plus_1 = q[:, n_matches, :]
- p_prime = torch.clamp((p_n_plus_1 - q_n_plus_1), min=0).softmax(dim=-1)
+ valid_tokens = new_candidate_input_ids[:, : n_matches + 1]
else:
- p_prime = p_n_plus_1
- t = torch.multinomial(p_prime, num_samples=1).squeeze(1)[None, :]
+ n_matches = min(n_matches, max_matches)
+
+ # Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
+ gamma = min(candidate_logits.shape[1], max_matches)
+ p_n_plus_1 = p[:, n_matches, :]
+ if n_matches < gamma:
+ q_n_plus_1 = q[:, n_matches, :]
+ p_prime = torch.clamp((p_n_plus_1 - q_n_plus_1), min=0)
+ p_prime.div_(p_prime.sum())
+ else:
+ p_prime = p_n_plus_1
+ t = torch.multinomial(p_prime, num_samples=1).squeeze(1)[None, :]
- # The selected tokens include the matches (if any) plus the next sampled tokens
- if n_matches > 0:
- valid_tokens = torch.cat((candidate_input_ids[:, -n_matches:], t), dim=-1)
- else:
- valid_tokens = t
+ # The selected tokens include the matches (if any) plus the next sampled tokens
+ if n_matches > 0:
+ valid_tokens = torch.cat((new_candidate_input_ids[:, :n_matches], t), dim=-1)
+ else:
+ valid_tokens = t
return valid_tokens, n_matches
@@ -4658,3 +4675,139 @@ def _ranking_fast(
contrastive_score = torch.stack(torch.split(contrastive_score, beam_width)) # [B, K]
_, selected_idx = contrastive_score.max(dim=-1) # [B]
return selected_idx
+
+
+def _split(data, full_batch_size: int, split_size: int = None):
+ """
+ Takes care of three cases:
+ 1. data is a tensor: e.g. last_hidden_state, pooler_output etc. split them on the batch_size dim
+ 2. data is a tuple: e.g. hidden_states, attentions etc. Keep the tuple as it is and split each tensor in it and
+ return a list of tuples
+ 3. data is a tuple of tuples, e.g. past_key_values. Keep the tuple as it is and split each tuple in it and
+ return a list of tuples of tuples
+ (see documentation of ModelOutput)
+ """
+ if data is None:
+ return [None] * (full_batch_size // split_size)
+ if isinstance(data, torch.Tensor):
+ return [data[i : i + split_size] for i in range(0, full_batch_size, split_size)]
+ elif isinstance(data, tuple):
+ # If the elements of the tuple are also tuples (e.g., past_key_values in our earlier example)
+ if isinstance(data[0], tuple):
+ return [
+ tuple(tuple(tensor[i : i + split_size] for tensor in inner_tuple) for inner_tuple in data)
+ for i in range(0, full_batch_size, split_size)
+ ]
+
+ else:
+ return [
+ tuple(sub_tensor[i : i + split_size] for sub_tensor in data)
+ for i in range(0, full_batch_size, split_size)
+ ]
+ else:
+ raise ValueError(f"Unexpected attribute type: {type(data)}")
+
+
+def _split_model_inputs(
+ model_input: Union[ModelOutput, Dict], split_size: int, full_batch_size: int
+) -> List[Union[ModelOutput, Dict]]:
+ """
+ Split a ModelOutput object (or its subclasses) or Dict into a list of same-class objects based on a specified split
+ size. The input object is dict when it was prepared for forward pass and ModelOutput when it was returned from
+ previous forward pass.
+ """
+ # Edge case: if model_input is None, return a list of Nones
+ # this happens with Whisper where encoder_outputs is None
+ if model_input is None:
+ return [model_input] * (full_batch_size // split_size)
+ # Infer the class from the object
+ model_output_cls = type(model_input)
+ if (full_batch_size % split_size) != 0:
+ raise ValueError("`full_batch_size` must be divisible by `split_size`")
+
+ if split_size > full_batch_size:
+ raise ValueError("`split_size` must be smaller or equal to `full_batch_size`")
+
+ # Helper function to split tensors or tuples of tensors
+
+ # Find all the dataclass fields (e.g., last_hidden_state, pooler_output etc.) and split them
+ keys = (
+ model_input.__dataclass_fields__.keys() if hasattr(model_input, "__dataclass_fields__") else model_input.keys()
+ )
+ # We only keep keys that are in the model_input
+ keys = [k for k in keys if k in model_input]
+ # Here we can have four types of values: tensors, tuples of tensors and booleans, and encoder_outputs which is a
+ # ModelOutput object.
+ # bool should not be split but replicated for each split
+ bool_keys = [k for k in keys if isinstance(model_input[k], bool)]
+ non_bool_keys = [k for k in keys if not isinstance(model_input[k], bool) and not k == "encoder_outputs"]
+
+ # we split the tensors and tuples of tensors
+ data_split_list = [
+ {k: _split(model_input[k], full_batch_size, split_size)[i] for k in non_bool_keys}
+ for i in range(full_batch_size // split_size)
+ ]
+ # bool values are the same and replicated for each split
+ bool_data = {k: model_input[k] for k in bool_keys}
+ # encoder_outputs is a ModelOutput object and should be split by its own
+ if "encoder_outputs" in model_input:
+ encoder_outputs_split = _split_model_inputs(model_input["encoder_outputs"], split_size, full_batch_size)
+ data_split_list = [
+ {**data_split, "encoder_outputs": encoder_outputs_split[i]} for i, data_split in enumerate(data_split_list)
+ ]
+
+ # Convert each dictionary in the list to an object of the inferred class
+ split_model_inputs: List[Union[ModelOutput, Dict]] = [
+ model_output_cls(**data_split, **bool_data) for data_split in data_split_list
+ ]
+
+ return split_model_inputs
+
+
+def stack_model_outputs(model_outputs: List[ModelOutput]) -> ModelOutput:
+ """
+ Stack a list of ModelOutput objects (or its subclasses) along the batch_size dimension. The function infers the
+ specific ModelOutput subclass from the list provided.
+ """
+ if not model_outputs:
+ raise ValueError("Input list is empty.")
+
+ # Infer the class from the first object in the list
+ model_output_cls = type(model_outputs[0])
+
+ # Ensure all objects are of the same type
+ if not all(isinstance(obj, model_output_cls) for obj in model_outputs):
+ raise ValueError("All elements in the list should be of the same type.")
+
+ # Helper function to concat tensors or tuples of tensors
+ def _concat(data):
+ """
+ Reverse of `_split` function above.
+ """
+ if any(data is None for data in data):
+ return None
+ if isinstance(data[0], torch.Tensor):
+ return torch.cat(data, dim=0)
+ elif isinstance(data[0], tuple):
+ # If the elements of the tuple are also tuples (e.g., past_key_values in our earlier example)
+ if isinstance(data[0][0], tuple):
+ return tuple(
+ tuple(torch.cat([attr[i][j] for attr in data], dim=0) for j in range(len(data[0][0])))
+ for i in range(len(data[0]))
+ )
+ else:
+ return tuple(torch.cat([attr[i] for attr in data], dim=0) for i in range(len(data[0])))
+ elif isinstance(data[0], (int, float)):
+ # If the elements are integers or floats, return a tensor
+ return torch.tensor(data)
+ else:
+ raise ValueError(f"Unexpected attribute type: {type(data[0])}")
+
+ # Use a dictionary comprehension to gather attributes from all objects and concatenate them
+ concatenated_data = {
+ k: _concat([getattr(model_output, k) for model_output in model_outputs])
+ for k in model_output_cls.__dataclass_fields__.keys()
+ }
+
+ # Return a new object of the inferred class with the concatenated attributes
+ return model_output_cls(**concatenated_data)
diff --git a/src/transformers/modeling_flax_pytorch_utils.py b/src/transformers/modeling_flax_pytorch_utils.py
index f6014d7c208ab6..830d222928b9ee 100644
--- a/src/transformers/modeling_flax_pytorch_utils.py
+++ b/src/transformers/modeling_flax_pytorch_utils.py
@@ -50,6 +50,8 @@ def load_pytorch_checkpoint_in_flax_state_dict(
"""Load pytorch checkpoints in a flax model"""
try:
import torch # noqa: F401
+
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13 # noqa: F401
except (ImportError, ModuleNotFoundError):
logger.error(
"Loading a PyTorch model in Flax, requires both PyTorch and Flax to be installed. Please see"
@@ -68,7 +70,7 @@ def load_pytorch_checkpoint_in_flax_state_dict(
for k in f.keys():
pt_state_dict[k] = f.get_tensor(k)
else:
- pt_state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+ pt_state_dict = torch.load(pt_path, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters.")
flax_state_dict = convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model)
@@ -245,11 +247,13 @@ def convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model):
def convert_pytorch_sharded_state_dict_to_flax(shard_filenames, flax_model):
import torch
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13
+
# Load the index
flax_state_dict = {}
for shard_file in shard_filenames:
# load using msgpack utils
- pt_state_dict = torch.load(shard_file, weights_only=True)
+ pt_state_dict = torch.load(shard_file, weights_only=is_torch_greater_or_equal_than_1_13)
pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()}
model_prefix = flax_model.base_model_prefix
diff --git a/src/transformers/modeling_tf_pytorch_utils.py b/src/transformers/modeling_tf_pytorch_utils.py
index bab8e70d99a5b5..e68b02bc7ab401 100644
--- a/src/transformers/modeling_tf_pytorch_utils.py
+++ b/src/transformers/modeling_tf_pytorch_utils.py
@@ -167,6 +167,8 @@ def load_pytorch_checkpoint_in_tf2_model(
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from safetensors.torch import load_file as safe_load_file # noqa: F401
+
+ from .pytorch_utils import is_torch_greater_or_equal_than_1_13 # noqa: F401
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
@@ -186,7 +188,7 @@ def load_pytorch_checkpoint_in_tf2_model(
if pt_path.endswith(".safetensors"):
state_dict = safe_load_file(pt_path)
else:
- state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(pt_path, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
pt_state_dict.update(state_dict)
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 3f19ec1884e71e..9c4639b475dfc2 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -48,6 +48,7 @@
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
id_tensor_storage,
+ is_torch_greater_or_equal_than_1_13,
prune_conv1d_layer,
prune_layer,
prune_linear_layer,
@@ -481,7 +482,11 @@ def load_sharded_checkpoint(model, folder, strict=True, prefer_safe=True):
error_message += f"\nMissing key(s): {str_unexpected_keys}."
raise RuntimeError(error_message)
- loader = safe_load_file if load_safe else partial(torch.load, map_location="cpu", weights_only=True)
+ loader = (
+ safe_load_file
+ if load_safe
+ else partial(torch.load, map_location="cpu", weights_only=is_torch_greater_or_equal_than_1_13)
+ )
for shard_file in shard_files:
state_dict = loader(os.path.join(folder, shard_file))
@@ -525,7 +530,12 @@ def load_state_dict(checkpoint_file: Union[str, os.PathLike]):
and is_zipfile(checkpoint_file)
):
extra_args = {"mmap": True}
- return torch.load(checkpoint_file, map_location=map_location, weights_only=True, **extra_args)
+ return torch.load(
+ checkpoint_file,
+ map_location=map_location,
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ **extra_args,
+ )
except Exception as e:
try:
with open(checkpoint_file) as f:
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 2c20873c2ed79d..09f5bb543ab043 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -176,6 +176,7 @@
prophetnet,
pvt,
qdqbert,
+ qwen2,
rag,
realm,
reformer,
@@ -234,6 +235,7 @@
vits,
vivit,
wav2vec2,
+ wav2vec2_bert,
wav2vec2_conformer,
wav2vec2_phoneme,
wav2vec2_with_lm,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 9eb3f1985c8536..060d3057f518fa 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -182,6 +182,7 @@
("prophetnet", "ProphetNetConfig"),
("pvt", "PvtConfig"),
("qdqbert", "QDQBertConfig"),
+ ("qwen2", "Qwen2Config"),
("rag", "RagConfig"),
("realm", "RealmConfig"),
("reformer", "ReformerConfig"),
@@ -245,6 +246,7 @@
("vits", "VitsConfig"),
("vivit", "VivitConfig"),
("wav2vec2", "Wav2Vec2Config"),
+ ("wav2vec2-bert", "Wav2Vec2BertConfig"),
("wav2vec2-conformer", "Wav2Vec2ConformerConfig"),
("wavlm", "WavLMConfig"),
("whisper", "WhisperConfig"),
@@ -405,6 +407,7 @@
("prophetnet", "PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("pvt", "PVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("qdqbert", "QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("qwen2", "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("realm", "REALM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("regnet", "REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("rembert", "REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -457,6 +460,7 @@
("vits", "VITS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vivit", "VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("wav2vec2", "WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("wav2vec2-bert", "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("wav2vec2-conformer", "WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("whisper", "WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("xclip", "XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -649,6 +653,7 @@
("prophetnet", "ProphetNet"),
("pvt", "PVT"),
("qdqbert", "QDQBert"),
+ ("qwen2", "Qwen2"),
("rag", "RAG"),
("realm", "REALM"),
("reformer", "Reformer"),
@@ -715,6 +720,7 @@
("vits", "VITS"),
("vivit", "ViViT"),
("wav2vec2", "Wav2Vec2"),
+ ("wav2vec2-bert", "Wav2Vec2-BERT"),
("wav2vec2-conformer", "Wav2Vec2-Conformer"),
("wav2vec2_phoneme", "Wav2Vec2Phoneme"),
("wavlm", "WavLM"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 457217566e7cfa..b3461e8b56a7a9 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -100,6 +100,7 @@
("vit_mae", "ViTFeatureExtractor"),
("vit_msn", "ViTFeatureExtractor"),
("wav2vec2", "Wav2Vec2FeatureExtractor"),
+ ("wav2vec2-bert", "Wav2Vec2FeatureExtractor"),
("wav2vec2-conformer", "Wav2Vec2FeatureExtractor"),
("wavlm", "Wav2Vec2FeatureExtractor"),
("whisper", "WhisperFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 7bf50a4518fa88..9332497732a4ce 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -177,6 +177,7 @@
("prophetnet", "ProphetNetModel"),
("pvt", "PvtModel"),
("qdqbert", "QDQBertModel"),
+ ("qwen2", "Qwen2Model"),
("reformer", "ReformerModel"),
("regnet", "RegNetModel"),
("rembert", "RemBertModel"),
@@ -231,6 +232,7 @@
("vits", "VitsModel"),
("vivit", "VivitModel"),
("wav2vec2", "Wav2Vec2Model"),
+ ("wav2vec2-bert", "Wav2Vec2BertModel"),
("wav2vec2-conformer", "Wav2Vec2ConformerModel"),
("wavlm", "WavLMModel"),
("whisper", "WhisperModel"),
@@ -449,6 +451,7 @@
("plbart", "PLBartForCausalLM"),
("prophetnet", "ProphetNetForCausalLM"),
("qdqbert", "QDQBertLMHeadModel"),
+ ("qwen2", "Qwen2ForCausalLM"),
("reformer", "ReformerModelWithLMHead"),
("rembert", "RemBertForCausalLM"),
("roberta", "RobertaForCausalLM"),
@@ -792,6 +795,7 @@
("phi", "PhiForSequenceClassification"),
("plbart", "PLBartForSequenceClassification"),
("qdqbert", "QDQBertForSequenceClassification"),
+ ("qwen2", "Qwen2ForSequenceClassification"),
("reformer", "ReformerForSequenceClassification"),
("rembert", "RemBertForSequenceClassification"),
("roberta", "RobertaForSequenceClassification"),
@@ -1031,6 +1035,7 @@
("unispeech", "UniSpeechForSequenceClassification"),
("unispeech-sat", "UniSpeechSatForSequenceClassification"),
("wav2vec2", "Wav2Vec2ForSequenceClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForSequenceClassification"),
("wav2vec2-conformer", "Wav2Vec2ConformerForSequenceClassification"),
("wavlm", "WavLMForSequenceClassification"),
("whisper", "WhisperForAudioClassification"),
@@ -1048,6 +1053,7 @@
("unispeech", "UniSpeechForCTC"),
("unispeech-sat", "UniSpeechSatForCTC"),
("wav2vec2", "Wav2Vec2ForCTC"),
+ ("wav2vec2-bert", "Wav2Vec2BertForCTC"),
("wav2vec2-conformer", "Wav2Vec2ConformerForCTC"),
("wavlm", "WavLMForCTC"),
]
@@ -1059,6 +1065,7 @@
("data2vec-audio", "Data2VecAudioForAudioFrameClassification"),
("unispeech-sat", "UniSpeechSatForAudioFrameClassification"),
("wav2vec2", "Wav2Vec2ForAudioFrameClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForAudioFrameClassification"),
("wav2vec2-conformer", "Wav2Vec2ConformerForAudioFrameClassification"),
("wavlm", "WavLMForAudioFrameClassification"),
]
@@ -1070,6 +1077,7 @@
("data2vec-audio", "Data2VecAudioForXVector"),
("unispeech-sat", "UniSpeechSatForXVector"),
("wav2vec2", "Wav2Vec2ForXVector"),
+ ("wav2vec2-bert", "Wav2Vec2BertForXVector"),
("wav2vec2-conformer", "Wav2Vec2ConformerForXVector"),
("wavlm", "WavLMForXVector"),
]
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index eee8af931e99ac..2a8823fea7c0ee 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -25,8 +25,9 @@
from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
from ...feature_extraction_utils import FeatureExtractionMixin
from ...image_processing_utils import ImageProcessingMixin
+from ...processing_utils import ProcessorMixin
from ...tokenization_utils import TOKENIZER_CONFIG_FILE
-from ...utils import FEATURE_EXTRACTOR_NAME, get_file_from_repo, logging
+from ...utils import FEATURE_EXTRACTOR_NAME, PROCESSOR_NAME, get_file_from_repo, logging
from .auto_factory import _LazyAutoMapping
from .configuration_auto import (
CONFIG_MAPPING_NAMES,
@@ -90,6 +91,7 @@
("vipllava", "LlavaProcessor"),
("vision-text-dual-encoder", "VisionTextDualEncoderProcessor"),
("wav2vec2", "Wav2Vec2Processor"),
+ ("wav2vec2-bert", "Wav2Vec2Processor"),
("wav2vec2-conformer", "Wav2Vec2Processor"),
("wavlm", "Wav2Vec2Processor"),
("whisper", "WhisperProcessor"),
@@ -227,27 +229,41 @@ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
processor_class = None
processor_auto_map = None
- # First, let's see if we have a preprocessor config.
+ # First, let's see if we have a processor or preprocessor config.
# Filter the kwargs for `get_file_from_repo`.
get_file_from_repo_kwargs = {
key: kwargs[key] for key in inspect.signature(get_file_from_repo).parameters.keys() if key in kwargs
}
- # Let's start by checking whether the processor class is saved in an image processor
- preprocessor_config_file = get_file_from_repo(
- pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
+
+ # Let's start by checking whether the processor class is saved in a processor config
+ processor_config_file = get_file_from_repo(
+ pretrained_model_name_or_path, PROCESSOR_NAME, **get_file_from_repo_kwargs
)
- if preprocessor_config_file is not None:
- config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ if processor_config_file is not None:
+ config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs)
processor_class = config_dict.get("processor_class", None)
if "AutoProcessor" in config_dict.get("auto_map", {}):
processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
- # If not found, let's check whether the processor class is saved in a feature extractor config
- if preprocessor_config_file is not None and processor_class is None:
- config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
- processor_class = config_dict.get("processor_class", None)
- if "AutoProcessor" in config_dict.get("auto_map", {}):
- processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+ if processor_class is None:
+ # If not found, let's check whether the processor class is saved in an image processor config
+ preprocessor_config_file = get_file_from_repo(
+ pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **get_file_from_repo_kwargs
+ )
+ if preprocessor_config_file is not None:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ # If not found, let's check whether the processor class is saved in a feature extractor config
+ if preprocessor_config_file is not None and processor_class is None:
+ config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(
+ pretrained_model_name_or_path, **kwargs
+ )
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
if processor_class is None:
# Next, let's check whether the processor class is saved in a tokenizer
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index ac09eecd1e0e99..4823cf41fc7731 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -333,6 +333,13 @@
("plbart", ("PLBartTokenizer" if is_sentencepiece_available() else None, None)),
("prophetnet", ("ProphetNetTokenizer", None)),
("qdqbert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "qwen2",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
("rag", ("RagTokenizer", None)),
("realm", ("RealmTokenizer", "RealmTokenizerFast" if is_tokenizers_available() else None)),
(
@@ -372,7 +379,7 @@
"SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
),
),
- ("siglip", ("SiglipTokenizer", None)),
+ ("siglip", ("SiglipTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text", ("Speech2TextTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text_2", ("Speech2Text2Tokenizer", None)),
("speecht5", ("SpeechT5Tokenizer" if is_sentencepiece_available() else None, None)),
@@ -411,6 +418,7 @@
("visual_bert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
("vits", ("VitsTokenizer", None)),
("wav2vec2", ("Wav2Vec2CTCTokenizer", None)),
+ ("wav2vec2-bert", ("Wav2Vec2CTCTokenizer", None)),
("wav2vec2-conformer", ("Wav2Vec2CTCTokenizer", None)),
("wav2vec2_phoneme", ("Wav2Vec2PhonemeCTCTokenizer", None)),
("whisper", ("WhisperTokenizer", "WhisperTokenizerFast" if is_tokenizers_available() else None)),
diff --git a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
index 2fe33db810890a..70e12b0ddc474b 100644
--- a/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/image_processing_conditional_detr.py
@@ -1414,13 +1414,14 @@ def post_process_object_detection(
boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
# and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
results = []
for s, l, b in zip(scores, labels, boxes):
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index d903abffafb455..b74f6accadfcfc 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -1874,8 +1874,8 @@ def forward(
intermediate = outputs.intermediate_hidden_states if return_dict else outputs[4]
outputs_class = self.class_labels_classifier(intermediate)
- for lvl in range(hs.shape[0]):
- tmp = self.bbox_predictor(hs[lvl])
+ for lvl in range(intermediate.shape[0]):
+ tmp = self.bbox_predictor(intermediate[lvl])
tmp[..., :2] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
@@ -2118,9 +2118,9 @@ def forward(
outputs_loss["pred_masks"] = pred_masks
if self.config.auxiliary_loss:
intermediate = decoder_outputs.intermediate_hidden_states if return_dict else decoder_outputs[-1]
- outputs_class = self.class_labels_classifier(intermediate)
- outputs_coord = self.bbox_predictor(intermediate).sigmoid()
- auxiliary_outputs = self._set_aux_loss(outputs_class, outputs_coord)
+ outputs_class = self.conditional_detr.class_labels_classifier(intermediate)
+ outputs_coord = self.conditional_detr.bbox_predictor(intermediate).sigmoid()
+ auxiliary_outputs = self.conditional_detr._set_aux_loss(outputs_class, outputs_coord)
outputs_loss["auxiliary_outputs"] = auxiliary_outputs
loss_dict = criterion(outputs_loss, labels)
diff --git a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
index 8c40d20c816ad3..52611700623f2d 100644
--- a/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/image_processing_deformable_detr.py
@@ -1411,13 +1411,14 @@ def post_process_object_detection(
boxes = torch.gather(boxes, 1, topk_boxes.unsqueeze(-1).repeat(1, 1, 4))
# and from relative [0, 1] to absolute [0, height] coordinates
- if isinstance(target_sizes, List):
- img_h = torch.Tensor([i[0] for i in target_sizes])
- img_w = torch.Tensor([i[1] for i in target_sizes])
- else:
- img_h, img_w = target_sizes.unbind(1)
- scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
- boxes = boxes * scale_fct[:, None, :]
+ if target_sizes is not None:
+ if isinstance(target_sizes, List):
+ img_h = torch.Tensor([i[0] for i in target_sizes])
+ img_w = torch.Tensor([i[1] for i in target_sizes])
+ else:
+ img_h, img_w = target_sizes.unbind(1)
+ scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1).to(boxes.device)
+ boxes = boxes * scale_fct[:, None, :]
results = []
for s, l, b in zip(scores, labels, boxes):
diff --git a/src/transformers/models/dinov2/modeling_dinov2.py b/src/transformers/models/dinov2/modeling_dinov2.py
index 66bac639f6731b..ddf70f08b750fb 100644
--- a/src/transformers/models/dinov2/modeling_dinov2.py
+++ b/src/transformers/models/dinov2/modeling_dinov2.py
@@ -103,12 +103,13 @@ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width:
height, width = height + 0.1, width + 0.1
patch_pos_embed = patch_pos_embed.reshape(1, int(math.sqrt(num_positions)), int(math.sqrt(num_positions)), dim)
patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+ target_dtype = patch_pos_embed.dtype
patch_pos_embed = nn.functional.interpolate(
- patch_pos_embed,
+ patch_pos_embed.to(dtype=torch.float32),
scale_factor=(float(height / math.sqrt(num_positions)), float(width / math.sqrt(num_positions))),
mode="bicubic",
align_corners=False,
- )
+ ).to(dtype=target_dtype)
if int(height) != patch_pos_embed.shape[-2] or int(width) != patch_pos_embed.shape[-1]:
raise ValueError("Width or height does not match with the interpolated position embeddings")
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
@@ -116,7 +117,8 @@ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width:
def forward(self, pixel_values: torch.Tensor, bool_masked_pos: Optional[torch.Tensor] = None) -> torch.Tensor:
batch_size, _, height, width = pixel_values.shape
- embeddings = self.patch_embeddings(pixel_values)
+ target_dtype = self.patch_embeddings.projection.weight.dtype
+ embeddings = self.patch_embeddings(pixel_values.to(dtype=target_dtype))
if bool_masked_pos is not None:
embeddings = torch.where(
diff --git a/src/transformers/models/esm/tokenization_esm.py b/src/transformers/models/esm/tokenization_esm.py
index 065eaae1d50520..478527c0ecd17f 100644
--- a/src/transformers/models/esm/tokenization_esm.py
+++ b/src/transformers/models/esm/tokenization_esm.py
@@ -14,10 +14,9 @@
# limitations under the License.
"""Tokenization classes for ESM."""
import os
-from typing import List, Optional, Union
+from typing import List, Optional
from ...tokenization_utils import PreTrainedTokenizer
-from ...tokenization_utils_base import AddedToken
from ...utils import logging
@@ -91,11 +90,10 @@ def _convert_token_to_id(self, token: str) -> int:
def _tokenize(self, text, **kwargs):
return text.split()
- def get_vocab_size(self, with_added_tokens=False):
- return len(self._id_to_token)
-
def get_vocab(self):
- return {token: i for i, token in enumerate(self.all_tokens)}
+ base_vocab = self._token_to_id.copy()
+ base_vocab.update(self.added_tokens_encoder)
+ return base_vocab
def token_to_id(self, token: str) -> int:
return self._token_to_id.get(token, self._token_to_id.get(self.unk_token))
@@ -156,7 +154,4 @@ def save_vocabulary(self, save_directory, filename_prefix):
@property
def vocab_size(self) -> int:
- return self.get_vocab_size(with_added_tokens=False)
-
- def _add_tokens(self, new_tokens: Union[List[str], List[AddedToken]], special_tokens: bool = False) -> int:
- return super()._add_tokens(new_tokens, special_tokens=True)
+ return len(self.all_tokens)
diff --git a/src/transformers/models/gpt_neox/modeling_gpt_neox.py b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
index dc255b34851b23..0d4a8ae8ad9dc4 100755
--- a/src/transformers/models/gpt_neox/modeling_gpt_neox.py
+++ b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
@@ -390,7 +390,7 @@ def forward(
elif hasattr(self.config, "_pre_quantization_dtype"):
target_dtype = self.config._pre_quantization_dtype
else:
- target_dtype = self.q_proj.weight.dtype
+ target_dtype = self.query_key_value.weight.dtype
logger.warning_once(
f"The input hidden states seems to be silently casted in float32, this might be related to"
@@ -526,8 +526,8 @@ def attention_mask_func(attention_scores, ltor_mask):
return attention_scores
-# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with LlamaRotary->GPTNeoXRotary
class GPTNeoXRotaryEmbedding(nn.Module):
+ # Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
@@ -549,8 +549,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
@@ -558,15 +558,15 @@ def forward(self, x, seq_len=None):
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
- self.cos_cached[:seq_len].to(dtype=x.dtype),
- self.sin_cached[:seq_len].to(dtype=x.dtype),
+ self.cos_cached[:seq_len],
+ self.sin_cached[:seq_len],
)
-# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->GPTNeoX
class GPTNeoXLinearScalingRotaryEmbedding(GPTNeoXRotaryEmbedding):
"""GPTNeoXRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+ # Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
@@ -579,14 +579,14 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
-# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->GPTNeoX
class GPTNeoXDynamicNTKScalingRotaryEmbedding(GPTNeoXRotaryEmbedding):
"""GPTNeoXRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
+ # Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
@@ -606,8 +606,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def rotate_half(x):
diff --git a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
index d92787677161e0..dbef70021d5c40 100755
--- a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
+++ b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
@@ -235,6 +235,7 @@ def _attn(self, query, key, value, attention_mask=None, head_mask=None):
# Copied from transformers.models.gpt_neox.modeling_gpt_neox.GPTNeoXRotaryEmbedding with GPTNeoXRotaryEmbedding->RotaryEmbedding
class RotaryEmbedding(nn.Module):
+ # Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
@@ -256,8 +257,8 @@ def _set_cos_sin_cache(self, seq_len, device, dtype):
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
- self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
- self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+ self.register_buffer("cos_cached", emb.cos(), persistent=False)
+ self.register_buffer("sin_cached", emb.sin(), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
@@ -265,8 +266,8 @@ def forward(self, x, seq_len=None):
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
- self.cos_cached[:seq_len].to(dtype=x.dtype),
- self.sin_cached[:seq_len].to(dtype=x.dtype),
+ self.cos_cached[:seq_len],
+ self.sin_cached[:seq_len],
)
diff --git a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
index b6c765851213bd..f5edb52520045b 100644
--- a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
@@ -944,6 +944,12 @@ class TFLayoutLMPreTrainedModel(TFPreTrainedModel):
config_class = LayoutLMConfig
base_model_prefix = "layoutlm"
+ @property
+ def input_signature(self):
+ signature = super().input_signature
+ signature["bbox"] = tf.TensorSpec(shape=(None, None, 4), dtype=tf.int32, name="bbox")
+ return signature
+
LAYOUTLM_START_DOCSTRING = r"""
diff --git a/src/transformers/models/llava/convert_llava_weights_to_hf.py b/src/transformers/models/llava/convert_llava_weights_to_hf.py
index 65b58236db1053..bb40668f32c7d0 100644
--- a/src/transformers/models/llava/convert_llava_weights_to_hf.py
+++ b/src/transformers/models/llava/convert_llava_weights_to_hf.py
@@ -27,6 +27,25 @@
)
+EPILOG_TXT = """Example:
+ python transformers/src/transformers/models/llava/convert_llava_weights_to_hf.py --text_model_id lmsys/vicuna-7b-v1.5 --vision_model_id openai/clip-vit-large-patch14-336 --output_hub_path org/llava-v1.5-7b-conv --old_state_dict_id liuhaotian/llava-v1.5-7b
+
+Example for creating the old state dict file with Python:
+
+ import torch
+ from llava.model.language_model.llava_llama import LlavaLlamaForCausalLM
+
+ # load model
+ kwargs = {"device_map": "auto", "torch_dtype": torch.float16}
+ model = LlavaLlamaForCausalLM.from_pretrained("liuhaotian/llava-v1.5-7b", low_cpu_mem_usage=True, **kwargs)
+
+ # load vision tower
+ model.get_vision_tower().load_model()
+
+ # Save state dict
+ torch.save(model.state_dict(), "tmp/hf_models/llava-v1.5-7b/model_state_dict.bin")
+"""
+
KEYS_TO_MODIFY_MAPPING = {
"model.vision_tower.": "",
"model.mm_projector": "multi_modal_projector",
@@ -42,6 +61,8 @@
def convert_state_dict_to_hf(state_dict):
new_state_dict = {}
for key, value in state_dict.items():
+ if key.endswith(".inv_freq"):
+ continue
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
if key_to_modify in key:
key = key.replace(key_to_modify, new_key)
@@ -55,7 +76,7 @@ def convert_llava_llama_to_hf(text_model_id, vision_model_id, output_hub_path, o
text_config = AutoConfig.from_pretrained(text_model_id)
tokenizer = AutoTokenizer.from_pretrained(text_model_id)
- tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special=True)
+ tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special_tokens=True)
tokenizer.add_special_tokens({"pad_token": ""})
image_processor = CLIPImageProcessor.from_pretrained(vision_model_id)
@@ -93,15 +114,16 @@ def convert_llava_llama_to_hf(text_model_id, vision_model_id, output_hub_path, o
tuple((dist.sample() for _ in range(model.language_model.lm_head.weight.data[32000:].shape[0]))),
dim=0,
)
- model.config.vocab_size = model.config.vocab_size + pad_shape
- model.config.text_config.vocab_size = model.config.text_config.vocab_size + pad_shape
model.push_to_hub(output_hub_path)
processor.push_to_hub(output_hub_path)
def main():
- parser = argparse.ArgumentParser()
+ parser = argparse.ArgumentParser(
+ epilog=EPILOG_TXT,
+ formatter_class=argparse.RawDescriptionHelpFormatter,
+ )
parser.add_argument(
"--text_model_id",
help="Hub location of the text model",
diff --git a/src/transformers/models/phi/modeling_phi.py b/src/transformers/models/phi/modeling_phi.py
index d6ad4e46608eb9..823807a475db4f 100644
--- a/src/transformers/models/phi/modeling_phi.py
+++ b/src/transformers/models/phi/modeling_phi.py
@@ -506,7 +506,7 @@ def forward(
value_states = value_states.to(target_dtype)
attn_output = self._flash_attention_forward(
- query_states, key_states, value_states, attention_mask, q_len, dropout=attn_dropout, softmax_scale=1.0
+ query_states, key_states, value_states, attention_mask, q_len, dropout=attn_dropout, softmax_scale=None
)
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
diff --git a/src/transformers/models/qwen2/__init__.py b/src/transformers/models/qwen2/__init__.py
new file mode 100644
index 00000000000000..9fd51aaffee86c
--- /dev/null
+++ b/src/transformers/models/qwen2/__init__.py
@@ -0,0 +1,80 @@
+# Copyright 2024 The Qwen Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_tokenizers_available,
+ is_torch_available,
+)
+
+
+_import_structure = {
+ "configuration_qwen2": ["QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP", "Qwen2Config"],
+ "tokenization_qwen2": ["Qwen2Tokenizer"],
+}
+
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["tokenization_qwen2_fast"] = ["Qwen2TokenizerFast"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_qwen2"] = [
+ "Qwen2ForCausalLM",
+ "Qwen2Model",
+ "Qwen2PreTrainedModel",
+ "Qwen2ForSequenceClassification",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_qwen2 import QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP, Qwen2Config
+ from .tokenization_qwen2 import Qwen2Tokenizer
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .tokenization_qwen2_fast import Qwen2TokenizerFast
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_qwen2 import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ Qwen2PreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/qwen2/configuration_qwen2.py b/src/transformers/models/qwen2/configuration_qwen2.py
new file mode 100644
index 00000000000000..0bbfd1cf1601ed
--- /dev/null
+++ b/src/transformers/models/qwen2/configuration_qwen2.py
@@ -0,0 +1,144 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Qwen2 model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "Qwen/Qwen2-7B-beta": "https://huggingface.co/Qwen/Qwen2-7B-beta/resolve/main/config.json",
+}
+
+
+class Qwen2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen2Model`]. It is used to instantiate a
+ Qwen2 model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of
+ Qwen2-7B-beta [Qwen/Qwen2-7B-beta](https://huggingface.co/Qwen/Qwen2-7B-beta).
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 151936):
+ Vocabulary size of the Qwen2 model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`Qwen2Model`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 22016):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 32):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 32768):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ use_sliding_window (`bool`, *optional*, defaults to `False`):
+ Whether to use sliding window attention.
+ sliding_window (`int`, *optional*, defaults to 4096):
+ Sliding window attention (SWA) window size. If not specified, will default to `4096`.
+ max_window_layers (`int`, *optional*, defaults to 28):
+ The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+
+ ```python
+ >>> from transformers import Qwen2Model, Qwen2Config
+
+ >>> # Initializing a Qwen2 style configuration
+ >>> configuration = Qwen2Config()
+
+ >>> # Initializing a model from the Qwen2-7B style configuration
+ >>> model = Qwen2Model(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "qwen2"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ def __init__(
+ self,
+ vocab_size=151936,
+ hidden_size=4096,
+ intermediate_size=22016,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=32,
+ hidden_act="silu",
+ max_position_embeddings=32768,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ use_sliding_window=False,
+ sliding_window=4096,
+ max_window_layers=28,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.max_window_layers = max_window_layers
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_dropout = attention_dropout
+
+ super().__init__(
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/src/transformers/models/qwen2/modeling_qwen2.py b/src/transformers/models/qwen2/modeling_qwen2.py
new file mode 100644
index 00000000000000..f8290928a5ca9e
--- /dev/null
+++ b/src/transformers/models/qwen2/modeling_qwen2.py
@@ -0,0 +1,1401 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Qwen2 model."""
+import inspect
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache
+from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
+from ...modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_qwen2 import Qwen2Config
+
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
+
+
+logger = logging.get_logger(__name__)
+
+
+_CHECKPOINT_FOR_DOC = "Qwen/Qwen2-7B-beta"
+_CONFIG_FOR_DOC = "Qwen2Config"
+
+QWEN2_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "Qwen/Qwen2-7B-beta",
+ # See all Qwen2 models at https://huggingface.co/models?filter=qwen2
+]
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Qwen2
+class Qwen2RMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Qwen2RMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Qwen2
+class Qwen2RotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
+ )
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralMLP with Mistral->Qwen2
+class Qwen2MLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+class Qwen2Attention(nn.Module):
+ """
+ Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
+ and "Generating Long Sequences with Sparse Transformers".
+ """
+
+ def __init__(self, config: Qwen2Config, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
+ "to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
+ "when creating this class."
+ )
+
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+ self.attention_dropout = config.attention_dropout
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+ self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
+ self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
+
+ self.rotary_emb = Qwen2RotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class Qwen2FlashAttention2(Qwen2Attention):
+ """
+ Qwen2 flash attention module, following Qwen2 attention module. This module inherits from `Qwen2Attention`
+ as the weights of the module stays untouched. The only required change would be on the forward pass
+ where it needs to correctly call the public API of flash attention and deal with padding tokens
+ in case the input contains any of them. Additionally, for sliding window attention, we apply SWA only to the bottom
+ config.max_window_layers layers.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ):
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window
+ )
+
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ "The current flash attention version does not support sliding window attention, for a more memory efficient implementation"
+ " make sure to upgrade flash-attn library."
+ )
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (
+ getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents
+ ):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
+ f" {past_key.shape}"
+ )
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
+
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ use_sliding_windows=False,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`int`, *optional*):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_sliding_windows (`bool`, *optional*):
+ Whether to activate sliding window attention.
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Decide whether to use SWA or not by layer index.
+ if use_sliding_windows and self.layer_idx >= self.config.max_window_layers:
+ use_sliding_windows = False
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ if not use_sliding_windows:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ if not use_sliding_windows:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.mistral.modeling_mistral.MistralFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ batch_size, kv_seq_len, num_heads, head_dim = key_layer.shape
+
+ # On the first iteration we need to properly re-create the padding mask
+ # by slicing it on the proper place
+ if kv_seq_len != attention_mask.shape[-1]:
+ attention_mask_num_tokens = attention_mask.shape[-1]
+ attention_mask = attention_mask[:, attention_mask_num_tokens - kv_seq_len :]
+
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+
+ key_layer = index_first_axis(key_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+ value_layer = index_first_axis(value_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaSdpaAttention with Llama->Qwen2
+class Qwen2SdpaAttention(Qwen2Attention):
+ """
+ Qwen2 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
+ `Qwen2Attention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
+ SDPA API.
+ """
+
+ # Adapted from Qwen2Attention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "Qwen2Model is using Qwen2SdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if query_states.device.type == "cuda" and attention_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.attention_dropout if self.training else 0.0,
+ # The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
+ is_causal=self.is_causal and attention_mask is None and q_len > 1,
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+QWEN2_ATTENTION_CLASSES = {
+ "eager": Qwen2Attention,
+ "flash_attention_2": Qwen2FlashAttention2,
+ "sdpa": Qwen2SdpaAttention,
+}
+
+
+class Qwen2DecoderLayer(nn.Module):
+ def __init__(self, config: Qwen2Config, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ if config.use_sliding_window and config._attn_implementation != "flash_attention_2":
+ logger.warning_once(
+ f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; "
+ "unexpected results may be encountered."
+ )
+ self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
+
+ self.mlp = Qwen2MLP(config)
+ self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+QWEN2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`Qwen2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2PreTrainedModel(PreTrainedModel):
+ config_class = Qwen2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["Qwen2DecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+QWEN2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance;
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2Model(Qwen2PreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen2DecoderLayer`]
+
+ Args:
+ config: Qwen2Config
+ """
+
+ def __init__(self, config: Qwen2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self._attn_implementation = config._attn_implementation
+ self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ " this may lead to unexpected behaviour for Flash Attention version of Qwen2. Make sure to "
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+
+ if self._attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class Qwen2ForCausalLM(Qwen2PreTrainedModel):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = Qwen2Model(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, Qwen2ForCausalLM
+
+ >>> model = Qwen2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ # Omit tokens covered by past_key_values
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
+ input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (
+ max_cache_length is not None
+ and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length
+ ):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
+ )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Qwen2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`Qwen2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ QWEN2_START_DOCSTRING,
+)
+class Qwen2ForSequenceClassification(Qwen2PreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = Qwen2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ # if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
+ sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
+ sequence_lengths = sequence_lengths % input_ids.shape[-1]
+ sequence_lengths = sequence_lengths.to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/src/transformers/models/qwen2/tokenization_qwen2.py b/src/transformers/models/qwen2/tokenization_qwen2.py
new file mode 100644
index 00000000000000..fe8e5ded8363cd
--- /dev/null
+++ b/src/transformers/models/qwen2/tokenization_qwen2.py
@@ -0,0 +1,345 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for Qwen2."""
+
+import json
+import os
+import unicodedata
+from functools import lru_cache
+from typing import Optional, Tuple
+
+import regex as re
+
+from ...tokenization_utils import AddedToken, PreTrainedTokenizer
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {
+ "vocab_file": "vocab.json",
+ "merges_file": "merges.txt",
+}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
+ "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
+}
+
+MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
+
+PRETOKENIZE_REGEX = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
+
+
+@lru_cache()
+# Copied from transformers.models.gpt2.tokenization_gpt2.bytes_to_unicode
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
+ characters the bpe code barfs on.
+
+ The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab
+ if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for
+ decent coverage. This is a significant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup
+ tables between utf-8 bytes and unicode strings.
+ """
+ bs = (
+ list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ )
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+# Copied from transformers.models.gpt2.tokenization_gpt2.get_pairs
+def get_pairs(word):
+ """
+ Return set of symbol pairs in a word.
+
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+class Qwen2Tokenizer(PreTrainedTokenizer):
+ """
+ Construct a Qwen2 tokenizer. Based on byte-level Byte-Pair-Encoding.
+
+ Same with GPT2Tokenzier, this tokenizer has been trained to treat spaces like parts of the tokens so a word will
+ be encoded differently whether it is at the beginning of the sentence (without space) or not:
+
+ ```python
+ >>> from transformers import Qwen2Tokenizer
+
+ >>> tokenizer = Qwen2Tokenizer.from_pretrained("Qwen/Qwen-tokenizer")
+ >>> tokenizer("Hello world")["input_ids"]
+ [9707, 1879]
+
+ >>> tokenizer(" Hello world")["input_ids"]
+ [21927, 1879]
+ ```
+ This is expected.
+
+ You should not use GPT2Tokenizer instead, because of the different pretokenization rules.
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ Path to the vocabulary file.
+ merges_file (`str`):
+ Path to the merges file.
+ errors (`str`, *optional*, defaults to `"replace"`):
+ Paradigm to follow when decoding bytes to UTF-8. See
+ [bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
+ unk_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ bos_token (`str`, *optional*):
+ The beginning of sequence token. Not applicable for this tokenizer.
+ eos_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The end of sequence token.
+ pad_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The token used for padding, for example when batching sequences of different lengths.
+ clean_up_tokenization_spaces (`bool`, *optional*, defaults to `False`):
+ Whether or not the model should cleanup the spaces that were added when splitting the input text during the
+ tokenization process. Not applicable to this tokenizer, since tokenization does not add spaces.
+ split_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the special tokens should be split during the tokenization process. The default behavior is
+ to not split special tokens. This means that if `<|endoftext|>` is the `eos_token`, then `tokenizer.tokenize("<|endoftext|>") =
+ ['<|endoftext|>`]. Otherwise, if `split_special_tokens=True`, then `tokenizer.tokenize("<|endoftext|>")` will be give `['<',
+ '|', 'endo', 'ft', 'ext', '|', '>']`. This argument is only supported for `slow` tokenizers for the moment.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = MAX_MODEL_INPUT_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+
+ def __init__(
+ self,
+ vocab_file,
+ merges_file,
+ errors="replace",
+ unk_token="<|endoftext|>",
+ bos_token=None,
+ eos_token="<|endoftext|>",
+ pad_token="<|endoftext|>",
+ clean_up_tokenization_spaces=False,
+ split_special_tokens=False,
+ **kwargs,
+ ):
+ # Qwen vocab does not contain control tokens; added tokens need to be special
+ bos_token = (
+ AddedToken(bos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(bos_token, str)
+ else bos_token
+ )
+ eos_token = (
+ AddedToken(eos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+ unk_token = (
+ AddedToken(unk_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ pad_token = (
+ AddedToken(pad_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+
+ with open(vocab_file, encoding="utf-8") as vocab_handle:
+ self.encoder = json.load(vocab_handle)
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.errors = errors # how to handle errors in decoding
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ bpe_merges = []
+ with open(merges_file, encoding="utf-8") as merges_handle:
+ for line in merges_handle:
+ line = line.strip()
+ if not line or line.startswith("#"):
+ continue
+ bpe_merges.append(tuple(line.split()))
+ self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
+ # NOTE: the cache can grow without bound and will get really large for long running processes
+ # (esp. for texts of language that do not use space between word, e.g. Chinese); technically
+ # not a memory leak but appears as one.
+ # GPT2Tokenizer has the same problem, so let's be consistent.
+ self.cache = {}
+
+ self.pat = re.compile(PRETOKENIZE_REGEX)
+
+ if kwargs.get("add_prefix_space", False):
+ logger.warning_once(
+ f"{self.__class__.__name} does not support `add_prefix_space`, setting it to True has no effect."
+ )
+
+ super().__init__(
+ errors=errors,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ pad_token=pad_token,
+ unk_token=unk_token,
+ clean_up_tokenization_spaces=clean_up_tokenization_spaces,
+ split_special_tokens=split_special_tokens,
+ **kwargs,
+ )
+
+ @property
+ def vocab_size(self) -> int:
+ return len(self.encoder)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.get_vocab
+ def get_vocab(self):
+ return dict(self.encoder, **self.added_tokens_encoder)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.bpe
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token)
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ except ValueError:
+ new_word.extend(word[i:])
+ break
+ else:
+ new_word.extend(word[i:j])
+ i = j
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = " ".join(word)
+ self.cache[token] = word
+ return word
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._tokenize
+ def _tokenize(self, text):
+ """Tokenize a string."""
+ bpe_tokens = []
+ for token in re.findall(self.pat, text):
+ token = "".join(
+ self.byte_encoder[b] for b in token.encode("utf-8")
+ ) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
+ bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
+ return bpe_tokens
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_token_to_id
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.encoder.get(token, self.encoder.get(self.unk_token))
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_id_to_token
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ return self.decoder.get(index)
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.convert_tokens_to_string
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ text = "".join(tokens)
+ text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
+ return text
+
+ def decode(
+ self,
+ token_ids,
+ skip_special_tokens: bool = False,
+ clean_up_tokenization_spaces: Optional[bool] = False,
+ spaces_between_special_tokens: bool = False,
+ **kwargs,
+ ) -> str:
+ # `spaces_between_special_tokens` defaults to True for _decode in slow tokenizers
+ # and cannot be configured elsewhere, but it should default to False for Qwen2Tokenizer
+ return super().decode(
+ token_ids,
+ skip_special_tokens=skip_special_tokens,
+ clean_up_tokenization_spaces=clean_up_tokenization_spaces,
+ spaces_between_special_tokens=spaces_between_special_tokens,
+ **kwargs,
+ )
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+ merge_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
+ )
+
+ with open(vocab_file, "w", encoding="utf-8") as f:
+ f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
+
+ index = 0
+ with open(merge_file, "w", encoding="utf-8") as writer:
+ writer.write("#version: 0.2\n")
+ for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
+ if index != token_index:
+ logger.warning(
+ f"Saving vocabulary to {merge_file}: BPE merge indices are not consecutive."
+ " Please check that the tokenizer is not corrupted!"
+ )
+ index = token_index
+ writer.write(" ".join(bpe_tokens) + "\n")
+ index += 1
+
+ return vocab_file, merge_file
+
+ def prepare_for_tokenization(self, text, **kwargs):
+ text = unicodedata.normalize("NFC", text)
+ return (text, kwargs)
diff --git a/src/transformers/models/qwen2/tokenization_qwen2_fast.py b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
new file mode 100644
index 00000000000000..178af4e62f2bfa
--- /dev/null
+++ b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
@@ -0,0 +1,143 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for Qwen2."""
+
+from typing import Optional, Tuple
+
+from ...tokenization_utils import AddedToken
+from ...tokenization_utils_fast import PreTrainedTokenizerFast
+from ...utils import logging
+from .tokenization_qwen2 import Qwen2Tokenizer
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {
+ "vocab_file": "vocab.json",
+ "merges_file": "merges.txt",
+ "tokenizer_file": "tokenizer.json",
+}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
+ "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
+ "tokenizer_file": {
+ "qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/tokenizer.json"
+ },
+}
+
+MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
+
+
+class Qwen2TokenizerFast(PreTrainedTokenizerFast):
+ """
+ Construct a "fast" Qwen2 tokenizer (backed by HuggingFace's *tokenizers* library). Based on byte-level
+ Byte-Pair-Encoding.
+
+ Same with GPT2Tokenzier, this tokenizer has been trained to treat spaces like parts of the tokens so a word will
+ be encoded differently whether it is at the beginning of the sentence (without space) or not:
+
+ ```python
+ >>> from transformers import Qwen2TokenizerFast
+
+ >>> tokenizer = Qwen2TokenizerFast.from_pretrained("Qwen/Qwen-tokenizer")
+ >>> tokenizer("Hello world")["input_ids"]
+ [9707, 1879]
+
+ >>> tokenizer(" Hello world")["input_ids"]
+ [21927, 1879]
+ ```
+ This is expected.
+
+ This tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should
+ refer to this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`, *optional*):
+ Path to the vocabulary file.
+ merges_file (`str`, *optional*):
+ Path to the merges file.
+ tokenizer_file (`str`, *optional*):
+ Path to [tokenizers](https://github.com/huggingface/tokenizers) file (generally has a .json extension) that
+ contains everything needed to load the tokenizer.
+ unk_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead. Not applicable to this tokenizer.
+ bos_token (`str`, *optional*):
+ The beginning of sequence token. Not applicable for this tokenizer.
+ eos_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The end of sequence token.
+ pad_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
+ The token used for padding, for example when batching sequences of different lengths.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = MAX_MODEL_INPUT_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+ slow_tokenizer_class = Qwen2Tokenizer
+
+ def __init__(
+ self,
+ vocab_file=None,
+ merges_file=None,
+ tokenizer_file=None,
+ unk_token="<|endoftext|>",
+ bos_token=None,
+ eos_token="<|endoftext|>",
+ pad_token="<|endoftext|>",
+ **kwargs,
+ ):
+ # We need to at least pass vocab_file and merges_file to base class
+ # in case a slow tokenizer needs to be initialized; other can be
+ # configured through files.
+ # following GPT2TokenizerFast, also adding unk_token, bos_token, and eos_token
+
+ bos_token = (
+ AddedToken(bos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(bos_token, str)
+ else bos_token
+ )
+ eos_token = (
+ AddedToken(eos_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+ unk_token = (
+ AddedToken(unk_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ pad_token = (
+ AddedToken(pad_token, lstrip=False, rstrip=False, special=True, normalized=False)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+
+ super().__init__(
+ vocab_file,
+ merges_file,
+ tokenizer_file=tokenizer_file,
+ unk_token=unk_token,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ pad_token=pad_token,
+ **kwargs,
+ )
+
+ # Copied from transformers.models.gpt2.tokenization_gpt2_fast.GPT2TokenizerFast.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ files = self._tokenizer.model.save(save_directory, name=filename_prefix)
+ return tuple(files)
diff --git a/src/transformers/models/rwkv/modeling_rwkv.py b/src/transformers/models/rwkv/modeling_rwkv.py
index 35fd7976ccf653..ef3f294c0d5d82 100644
--- a/src/transformers/models/rwkv/modeling_rwkv.py
+++ b/src/transformers/models/rwkv/modeling_rwkv.py
@@ -778,6 +778,24 @@ def get_output_embeddings(self):
def set_output_embeddings(self, new_embeddings):
self.head = new_embeddings
+ def generate(self, *args, **kwargs):
+ # Thin wrapper to raise exceptions when trying to generate with methods that manipulate `past_key_values`.
+ # RWKV is one of the few models that don't have it (it has `state` instead, which has different properties and
+ # usage).
+ try:
+ gen_output = super().generate(*args, **kwargs)
+ except AttributeError as exc:
+ # Expected exception: "AttributeError: '(object name)' object has no attribute 'past_key_values'"
+ if "past_key_values" in str(exc):
+ raise AttributeError(
+ "You tried to call `generate` with a decoding strategy that manipulates `past_key_values`. RWKV "
+ "doesn't have that attribute, try another generation strategy instead. For the available "
+ "generation strategies, check this doc: https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
+ )
+ else:
+ raise exc
+ return gen_output
+
def prepare_inputs_for_generation(self, input_ids, state=None, inputs_embeds=None, **kwargs):
# only last token for inputs_ids if the state is passed along.
if state is not None:
diff --git a/src/transformers/models/siglip/modeling_siglip.py b/src/transformers/models/siglip/modeling_siglip.py
index b497b57fe2157a..1df70200d32bd5 100644
--- a/src/transformers/models/siglip/modeling_siglip.py
+++ b/src/transformers/models/siglip/modeling_siglip.py
@@ -1123,7 +1123,8 @@ def forward(
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
- >>> inputs = processor(text=texts, images=image, return_tensors="pt")
+ >>> # important: we pass `padding=max_length` since the model was trained with this
+ >>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
diff --git a/src/transformers/models/siglip/processing_siglip.py b/src/transformers/models/siglip/processing_siglip.py
index ecb229d28a57c9..f21cf735480212 100644
--- a/src/transformers/models/siglip/processing_siglip.py
+++ b/src/transformers/models/siglip/processing_siglip.py
@@ -50,9 +50,9 @@ def __call__(
self,
text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
images: ImageInput = None,
- padding: Union[bool, str, PaddingStrategy] = "max_length",
+ padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
- max_length=None,
+ max_length: int = None,
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
) -> BatchFeature:
"""
@@ -71,7 +71,7 @@ def __call__(
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
number of channels, H and W are image height and width.
- padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `max_length`):
+ padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `False`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding
index) among:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
diff --git a/src/transformers/models/switch_transformers/modeling_switch_transformers.py b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
index b123a6de2341e1..416549b7b75c72 100644
--- a/src/transformers/models/switch_transformers/modeling_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
@@ -898,7 +898,7 @@ def __init__(self, config, embed_tokens=None):
config.num_layers = config.num_decoder_layers if self.is_decoder else config.num_layers
self.block = nn.ModuleList()
for i in range(config.num_layers):
- is_sparse = (i % sparse_step == 1) if sparse_step > 0 else False
+ is_sparse = (i % sparse_step == 1 or sparse_step == 1) if sparse_step > 0 else False
self.block.append(
SwitchTransformersBlock(config, has_relative_attention_bias=bool(i == 0), is_sparse=is_sparse)
diff --git a/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py b/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
index a96d56084ce008..2914cfdfcd4b42 100644
--- a/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
+++ b/src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
@@ -46,6 +46,8 @@
def convert_state_dict_to_hf(state_dict):
new_state_dict = {}
for key, value in state_dict.items():
+ if key.endswith(".inv_freq"):
+ continue
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
if key_to_modify in key:
key = key.replace(key_to_modify, new_key)
@@ -58,7 +60,7 @@ def convert_vipllava_llama_to_hf(text_model_id, vision_model_id, output_hub_path
text_config = AutoConfig.from_pretrained(text_model_id)
tokenizer = AutoTokenizer.from_pretrained(text_model_id)
- tokenizer.add_tokens(AddedToken("", special=True, normalized=False))
+ tokenizer.add_tokens(AddedToken("", special=True, normalized=False), special_tokens=True)
tokenizer.add_special_tokens({"pad_token": ""})
image_processor = CLIPImageProcessor.from_pretrained(vision_model_id)
@@ -97,8 +99,6 @@ def convert_vipllava_llama_to_hf(text_model_id, vision_model_id, output_hub_path
tuple((dist.sample() for _ in range(model.language_model.lm_head.weight.data[32000:].shape[0]))),
dim=0,
)
- model.config.vocab_size = model.config.vocab_size + pad_shape
- model.config.text_config.vocab_size = model.config.text_config.vocab_size + pad_shape
model.push_to_hub(output_hub_path)
processor.push_to_hub(output_hub_path)
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index ddfa2e21263f0f..6d4501ce97f5d8 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -37,6 +37,7 @@
XVectorOutput,
)
from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import is_torch_greater_or_equal_than_1_13
from ...utils import (
ModelOutput,
add_code_sample_docstrings,
@@ -1333,7 +1334,11 @@ def load_adapter(self, target_lang: str, force_load=True, **kwargs):
cache_dir=cache_dir,
)
- state_dict = torch.load(weight_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weight_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
except EnvironmentError:
# Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
diff --git a/src/transformers/models/wav2vec2_bert/__init__.py b/src/transformers/models/wav2vec2_bert/__init__.py
new file mode 100644
index 00000000000000..594f108bcaad96
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/__init__.py
@@ -0,0 +1,70 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available
+
+
+_import_structure = {
+ "configuration_wav2vec2_bert": [
+ "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "Wav2Vec2BertConfig",
+ ],
+ "processing_wav2vec2_bert": ["Wav2Vec2BertProcessor"],
+}
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_wav2vec2_bert"] = [
+ "WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "Wav2Vec2BertForAudioFrameClassification",
+ "Wav2Vec2BertForCTC",
+ "Wav2Vec2BertForSequenceClassification",
+ "Wav2Vec2BertForXVector",
+ "Wav2Vec2BertModel",
+ "Wav2Vec2BertPreTrainedModel",
+ ]
+
+if TYPE_CHECKING:
+ from .configuration_wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ Wav2Vec2BertConfig,
+ )
+ from .processing_wav2vec2_bert import Wav2Vec2BertProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_wav2vec2_bert import (
+ WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertPreTrainedModel,
+ )
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
new file mode 100644
index 00000000000000..12593107ef939d
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
@@ -0,0 +1,314 @@
+# coding=utf-8
+# Copyright 2024 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Wav2Vec2Bert model configuration"""
+
+import functools
+import operator
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/w2v-bert-2.0": "https://huggingface.co/facebook/w2v-bert-2.0/resolve/main/config.json",
+}
+
+
+class Wav2Vec2BertConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Wav2Vec2BertModel`]. It is used to
+ instantiate an Wav2Vec2Bert model according to the specified arguments, defining the model architecture.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the Wav2Vec2Bert
+ [facebook/wav2vec2-bert-rel-pos-large](https://huggingface.co/facebook/wav2vec2-bert-rel-pos-large)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*):
+ Vocabulary size of the Wav2Vec2Bert model. Defines the number of different tokens that can be
+ represented by the `inputs_ids` passed when calling [`Wav2Vec2BertModel`]. Vocabulary size of the
+ model. Defines the different tokens that can be represented by the *inputs_ids* passed to the forward
+ method of [`Wav2Vec2BertModel`].
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 4096):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ feature_projection_input_dim (`int`, *optional*, defaults to 160):
+ Input dimension of this model, i.e the dimension after processing input audios with [`SeamlessM4TFeatureExtractor`] or [`Wav2Vec2BertProcessor`].
+ hidden_act (`str` or `function`, *optional*, defaults to `"swish"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"`, `"swish"` and `"gelu_new"` are supported.
+ hidden_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ activation_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for activations inside the fully connected layer.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ feat_proj_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for the feature projection.
+ final_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for the final projection layer of [`Wav2Vec2BertForCTC`].
+ layerdrop (`float`, *optional*, defaults to 0.1):
+ The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
+ details.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+ apply_spec_augment (`bool`, *optional*, defaults to `True`):
+ Whether to apply *SpecAugment* data augmentation to the outputs of the feature encoder. For reference see
+ [SpecAugment: A Simple Data Augmentation Method for Automatic Speech
+ Recognition](https://arxiv.org/abs/1904.08779).
+ mask_time_prob (`float`, *optional*, defaults to 0.05):
+ Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking
+ procecure generates `mask_time_prob*len(time_axis)/mask_time_length ``independent masks over the axis. If
+ reasoning from the propability of each feature vector to be chosen as the start of the vector span to be
+ masked, *mask_time_prob* should be `prob_vector_start*mask_time_length`. Note that overlap may decrease the
+ actual percentage of masked vectors. This is only relevant if `apply_spec_augment is True`.
+ mask_time_length (`int`, *optional*, defaults to 10):
+ Length of vector span along the time axis.
+ mask_time_min_masks (`int`, *optional*, defaults to 2):
+ The minimum number of masks of length `mask_feature_length` generated along the time axis, each time step,
+ irrespectively of `mask_feature_prob`. Only relevant if `mask_time_prob*len(time_axis)/mask_time_length <
+ mask_time_min_masks`.
+ mask_feature_prob (`float`, *optional*, defaults to 0.0):
+ Percentage (between 0 and 1) of all feature vectors along the feature axis which will be masked. The
+ masking procecure generates `mask_feature_prob*len(feature_axis)/mask_time_length` independent masks over
+ the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector
+ span to be masked, *mask_feature_prob* should be `prob_vector_start*mask_feature_length`. Note that overlap
+ may decrease the actual percentage of masked vectors. This is only relevant if `apply_spec_augment is
+ True`.
+ mask_feature_length (`int`, *optional*, defaults to 10):
+ Length of vector span along the feature axis.
+ mask_feature_min_masks (`int`, *optional*, defaults to 0):
+ The minimum number of masks of length `mask_feature_length` generated along the feature axis, each time
+ step, irrespectively of `mask_feature_prob`. Only relevant if
+ `mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks`.
+ ctc_loss_reduction (`str`, *optional*, defaults to `"sum"`):
+ Specifies the reduction to apply to the output of `torch.nn.CTCLoss`. Only relevant when training an
+ instance of [`Wav2Vec2BertForCTC`].
+ ctc_zero_infinity (`bool`, *optional*, defaults to `False`):
+ Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`. Infinite losses mainly
+ occur when the inputs are too short to be aligned to the targets. Only relevant when training an instance
+ of [`Wav2Vec2BertForCTC`].
+ use_weighted_layer_sum (`bool`, *optional*, defaults to `False`):
+ Whether to use a weighted average of layer outputs with learned weights. Only relevant when using an
+ instance of [`Wav2Vec2BertForSequenceClassification`].
+ classifier_proj_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the projection before token mean-pooling for classification.
+ tdnn_dim (`Tuple[int]` or `List[int]`, *optional*, defaults to `(512, 512, 512, 512, 1500)`):
+ A tuple of integers defining the number of output channels of each 1D convolutional layer in the *TDNN*
+ module of the *XVector* model. The length of *tdnn_dim* defines the number of *TDNN* layers.
+ tdnn_kernel (`Tuple[int]` or `List[int]`, *optional*, defaults to `(5, 3, 3, 1, 1)`):
+ A tuple of integers defining the kernel size of each 1D convolutional layer in the *TDNN* module of the
+ *XVector* model. The length of *tdnn_kernel* has to match the length of *tdnn_dim*.
+ tdnn_dilation (`Tuple[int]` or `List[int]`, *optional*, defaults to `(1, 2, 3, 1, 1)`):
+ A tuple of integers defining the dilation factor of each 1D convolutional layer in *TDNN* module of the
+ *XVector* model. The length of *tdnn_dilation* has to match the length of *tdnn_dim*.
+ xvector_output_dim (`int`, *optional*, defaults to 512):
+ Dimensionality of the *XVector* embedding vectors.
+ pad_token_id (`int`, *optional*, defaults to 0): The id of the _beginning-of-stream_ token.
+ bos_token_id (`int`, *optional*, defaults to 1): The id of the _padding_ token.
+ eos_token_id (`int`, *optional*, defaults to 2): The id of the _end-of-stream_ token.
+ add_adapter (`bool`, *optional*, defaults to `False`):
+ Whether a convolutional attention network should be stacked on top of the Wav2Vec2Bert Encoder. Can be very
+ useful for warm-starting Wav2Vec2Bert for SpeechEncoderDecoder models.
+ adapter_kernel_size (`int`, *optional*, defaults to 3):
+ Kernel size of the convolutional layers in the adapter network. Only relevant if `add_adapter is True`.
+ adapter_stride (`int`, *optional*, defaults to 2):
+ Stride of the convolutional layers in the adapter network. Only relevant if `add_adapter is True`.
+ num_adapter_layers (`int`, *optional*, defaults to 1):
+ Number of convolutional layers that should be used in the adapter network. Only relevant if `add_adapter is
+ True`.
+ adapter_act (`str` or `function`, *optional*, defaults to `"relu"`):
+ The non-linear activation function (function or string) in the adapter layers. If string, `"gelu"`,
+ `"relu"`, `"selu"`, `"swish"` and `"gelu_new"` are supported.
+ use_intermediate_ffn_before_adapter (`bool`, *optional*, defaults to `False`):
+ Whether an intermediate feed-forward block should be stacked on top of the Wav2Vec2Bert Encoder and before the adapter network.
+ Only relevant if `add_adapter is True`.
+ output_hidden_size (`int`, *optional*):
+ Dimensionality of the encoder output layer. If not defined, this defaults to *hidden-size*. Only relevant
+ if `add_adapter is True`.
+ position_embeddings_type (`str`, *optional*, defaults to `"relative_key"`):
+ Can be specified to :
+ - `rotary`, for rotary position embeddings.
+ - `relative`, for relative position embeddings.
+ - `relative_key`, for relative position embeddings as defined by Shaw in [Self-Attention
+ with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ If left to `None`, no relative position embeddings is applied.
+ rotary_embedding_base (`int`, *optional*, defaults to 10000):
+ If `"rotary"` position embeddings are used, defines the size of the embedding base.
+ max_source_positions (`int`, *optional*, defaults to 5000):
+ if `"relative"` position embeddings are used, defines the maximum source input positions.
+ left_max_position_embeddings (`int`, *optional*, defaults to 64):
+ If `"relative_key"` (aka Shaw) position embeddings are used, defines the left clipping value for relative positions.
+ right_max_position_embeddings (`int`, *optional*, defaults to 8):
+ If `"relative_key"` (aka Shaw) position embeddings are used, defines the right clipping value for relative positions.
+ conv_depthwise_kernel_size (`int`, *optional*, defaults to 31):
+ Kernel size of convolutional depthwise 1D layer in Conformer blocks.
+ conformer_conv_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all convolutional layers in Conformer blocks.
+ Example:
+
+ ```python
+ >>> from transformers import Wav2Vec2BertConfig, Wav2Vec2BertModel
+
+ >>> # Initializing a Wav2Vec2Bert facebook/wav2vec2-bert-rel-pos-large style configuration
+ >>> configuration = Wav2Vec2BertConfig()
+
+ >>> # Initializing a model (with random weights) from the facebook/wav2vec2-bert-rel-pos-large style configuration
+ >>> model = Wav2Vec2BertModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "wav2vec2-bert"
+
+ def __init__(
+ self,
+ vocab_size=None,
+ hidden_size=1024,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ intermediate_size=4096,
+ feature_projection_input_dim=160,
+ hidden_act="swish",
+ hidden_dropout=0.0,
+ activation_dropout=0.0,
+ attention_dropout=0.0,
+ feat_proj_dropout=0.0,
+ final_dropout=0.1,
+ layerdrop=0.1,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ apply_spec_augment=True,
+ mask_time_prob=0.05,
+ mask_time_length=10,
+ mask_time_min_masks=2,
+ mask_feature_prob=0.0,
+ mask_feature_length=10,
+ mask_feature_min_masks=0,
+ ctc_loss_reduction="sum",
+ ctc_zero_infinity=False,
+ use_weighted_layer_sum=False,
+ classifier_proj_size=768,
+ tdnn_dim=(512, 512, 512, 512, 1500),
+ tdnn_kernel=(5, 3, 3, 1, 1),
+ tdnn_dilation=(1, 2, 3, 1, 1),
+ xvector_output_dim=512,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ add_adapter=False,
+ adapter_kernel_size=3,
+ adapter_stride=2,
+ num_adapter_layers=1,
+ adapter_act="relu",
+ use_intermediate_ffn_before_adapter=False,
+ output_hidden_size=None,
+ position_embeddings_type="relative_key",
+ rotary_embedding_base=10000,
+ max_source_positions=5000,
+ left_max_position_embeddings=64,
+ right_max_position_embeddings=8,
+ conv_depthwise_kernel_size=31,
+ conformer_conv_dropout=0.1,
+ **kwargs,
+ ):
+ super().__init__(**kwargs, pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id)
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.num_attention_heads = num_attention_heads
+ self.feature_projection_input_dim = feature_projection_input_dim
+ self.hidden_dropout = hidden_dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.feat_proj_dropout = feat_proj_dropout
+ self.final_dropout = final_dropout
+ self.layerdrop = layerdrop
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.vocab_size = vocab_size
+ self.use_weighted_layer_sum = use_weighted_layer_sum
+ self.max_source_positions = max_source_positions
+
+ if position_embeddings_type is not None and position_embeddings_type not in [
+ "rotary",
+ "relative",
+ "relative_key",
+ ]:
+ raise ValueError(
+ """
+ `position_embeddings_type` is not valid. It must be one of the following values:
+ `["rotary", "relative", "relative_key"]` or left as `None`.
+ """
+ )
+ self.position_embeddings_type = position_embeddings_type
+ self.rotary_embedding_base = rotary_embedding_base
+ self.left_max_position_embeddings = left_max_position_embeddings
+ self.right_max_position_embeddings = right_max_position_embeddings
+
+ # Conformer-block related
+ self.conv_depthwise_kernel_size = conv_depthwise_kernel_size
+ self.conformer_conv_dropout = conformer_conv_dropout
+
+ # fine-tuning config parameters for SpecAugment: https://arxiv.org/abs/1904.08779
+ self.apply_spec_augment = apply_spec_augment
+ self.mask_time_prob = mask_time_prob
+ self.mask_time_length = mask_time_length
+ self.mask_time_min_masks = mask_time_min_masks
+ self.mask_feature_prob = mask_feature_prob
+ self.mask_feature_length = mask_feature_length
+ self.mask_feature_min_masks = mask_feature_min_masks
+
+ # ctc loss
+ self.ctc_loss_reduction = ctc_loss_reduction
+ self.ctc_zero_infinity = ctc_zero_infinity
+
+ # adapter
+ self.add_adapter = add_adapter
+ self.adapter_kernel_size = adapter_kernel_size
+ self.adapter_stride = adapter_stride
+ self.num_adapter_layers = num_adapter_layers
+ self.adapter_act = adapter_act
+ self.output_hidden_size = output_hidden_size if output_hidden_size is not None else hidden_size
+ if use_intermediate_ffn_before_adapter and not add_adapter:
+ raise ValueError("`use_intermediate_ffn_before_adapter` is `True` but `add_adapter` is `False`.")
+ self.use_intermediate_ffn_before_adapter = use_intermediate_ffn_before_adapter
+
+ # SequenceClassification-specific parameter. Feel free to ignore for other classes.
+ self.classifier_proj_size = classifier_proj_size
+
+ # XVector-specific parameters. Feel free to ignore for other classes.
+ self.tdnn_dim = list(tdnn_dim)
+ self.tdnn_kernel = list(tdnn_kernel)
+ self.tdnn_dilation = list(tdnn_dilation)
+ self.xvector_output_dim = xvector_output_dim
+
+ @property
+ def inputs_to_logits_ratio(self):
+ return functools.reduce(operator.mul, self.conv_stride, 1)
diff --git a/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py b/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
new file mode 100644
index 00000000000000..8b77cd71f7f7e0
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
@@ -0,0 +1,218 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Wav2Vec2Bert BERT checkpoint."""
+
+
+import argparse
+
+import torch
+import torchaudio
+from fairseq2.data import Collater
+from fairseq2.data.audio import WaveformToFbankConverter
+from fairseq2.nn.padding import get_seqs_and_padding_mask
+from seamless_communication.models.conformer_shaw import load_conformer_shaw_model
+
+from transformers import (
+ SeamlessM4TFeatureExtractor,
+ Wav2Vec2BertConfig,
+ Wav2Vec2BertModel,
+ logging,
+)
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+wav2vec_convert_list = [
+ ("encoder_frontend.model_dim_proj", "feature_projection.projection"),
+ ("encoder_frontend.post_extract_layer_norm", "feature_projection.layer_norm"),
+ ("encoder_frontend.pos_encoder.conv", "encoder.pos_conv_embed.conv"),
+ ("encoder.inner.layers", "encoder.layers"),
+ ("encoder.inner_layer_norm", "encoder.layer_norm"),
+ ("encoder.adaptor_layers", "adapter.layers"),
+ ("inner_proj", "intermediate_dense"),
+ ("self_attn.output_proj", "self_attn.linear_out"),
+ ("output_proj", "output_dense"),
+ ("self_attn.k_proj", "self_attn.linear_k"),
+ ("self_attn.v_proj", "self_attn.linear_v"),
+ ("self_attn.q_proj", "self_attn.linear_q"),
+ ("self_attn.sdpa.u_bias", "self_attn.pos_bias_u"),
+ ("self_attn.sdpa.v_bias", "self_attn.pos_bias_v"),
+ ("self_attn.sdpa.rel_k_embed", "self_attn.distance_embedding"),
+ ("self_attn.sdpa.r_proj", "self_attn.linear_pos"),
+ ("conv.pointwise_conv1", "conv_module.pointwise_conv1"),
+ ("conv.pointwise_conv2", "conv_module.pointwise_conv2"),
+ ("conv.depthwise_conv", "conv_module.depthwise_conv"),
+ ("conv.layer_norm", "conv_module.depthwise_layer_norm"),
+ ("conv_layer_norm", "conv_module.layer_norm"),
+ ("encoder.proj1", "intermediate_ffn.intermediate_dense"),
+ ("encoder.proj2", "intermediate_ffn.output_dense"),
+ ("encoder.layer_norm", "inner_layer_norm"),
+ ("masker.temporal_mask_embed", "masked_spec_embed"),
+]
+
+keys_to_remove = {
+ "quantizer.entry_proj",
+ "final_proj",
+ "final_target_proj",
+ "quantizer.entries",
+ "quantizer.num_updates",
+}
+
+
+def param_count(model):
+ return sum(p[1].numel() for p in model.named_parameters() if "final_proj" not in p[0])
+
+
+def _convert_model(
+ original_model,
+ hf_model,
+ convert_list,
+):
+ state_dict = original_model.state_dict()
+
+ for k, v in list(state_dict.items()):
+ new_key = k
+ for old_layer_name, new_layer_name in convert_list:
+ if old_layer_name in new_key:
+ new_key = new_key.replace(old_layer_name, new_layer_name)
+
+ # must do it by hand
+ if ".layer_norm" in new_key and new_key.split(".layer_norm")[0][-1].isnumeric():
+ new_key = new_key.replace("layer_norm", "final_layer_norm")
+
+ add_key = True
+ for key in keys_to_remove:
+ if key in new_key:
+ state_dict.pop(k)
+ add_key = False
+ break
+
+ if add_key:
+ state_dict[new_key] = state_dict.pop(k)
+
+ extra_keys = set(state_dict.keys()) - set(hf_model.state_dict().keys())
+ extra_keys = set({k for k in extra_keys if "num_updates" not in k}) # filter unecessary param
+ missing_keys = set(hf_model.state_dict().keys()) - set(state_dict.keys())
+ if len(extra_keys) != 0:
+ raise ValueError(f"extra keys found: {extra_keys}")
+ if len(missing_keys) != 0:
+ raise ValueError(f"missing keys: {missing_keys}")
+ hf_model.load_state_dict(state_dict, strict=True)
+ n_params = param_count(hf_model)
+
+ logger.info(f"model loaded: {round(n_params/1e6,1)}M params")
+
+ hf_model.eval()
+ del state_dict
+
+ return hf_model
+
+
+@torch.no_grad()
+def convert_wav2vec2_bert_checkpoint(
+ checkpoint_path,
+ pytorch_dump_folder_path,
+ config_path=None,
+ repo_id=None,
+):
+ """
+ Copy/paste/tweak model's weights to transformers design.
+ """
+ if config_path is not None:
+ config = Wav2Vec2BertConfig.from_pretrained(config_path, hidden_act="swish")
+ else:
+ config = Wav2Vec2BertConfig(apply_spec_augment=False)
+
+ hf_wav2vec = Wav2Vec2BertModel(config)
+
+ model = load_conformer_shaw_model(checkpoint_path, dtype=torch.float32)
+ model.eval()
+
+ hf_wav2vec = _convert_model(model, hf_wav2vec, wav2vec_convert_list)
+
+ hf_wav2vec.save_pretrained(pytorch_dump_folder_path)
+
+ if repo_id:
+ hf_wav2vec.push_to_hub(repo_id, create_pr=True)
+
+ # save feature extractor
+ fe = SeamlessM4TFeatureExtractor(padding_value=1)
+ fe._set_processor_class("Wav2Vec2BertProcessor")
+ fe.save_pretrained(pytorch_dump_folder_path)
+
+ if repo_id:
+ fe.push_to_hub(repo_id, create_pr=True)
+
+ if args.audio_path:
+ waveform, sample_rate = torchaudio.load(args.audio_path)
+ waveform = torchaudio.functional.resample(waveform, sample_rate, fe.sampling_rate)
+
+ fbank_converter = WaveformToFbankConverter(
+ num_mel_bins=80,
+ waveform_scale=2**15,
+ channel_last=True,
+ standardize=True,
+ dtype=torch.float32,
+ )
+ collater = Collater(pad_value=1)
+
+ decoded_audio = {"waveform": waveform.T, "sample_rate": fe.sampling_rate, "format": -1}
+ src = collater(fbank_converter(decoded_audio))["fbank"]
+ seqs, padding_mask = get_seqs_and_padding_mask(src)
+
+ with torch.inference_mode():
+ seqs, padding_mask = model.encoder_frontend(seqs, padding_mask)
+ original_output, padding_mask = model.encoder(seqs, padding_mask)
+
+ hf_wav2vec.eval()
+
+ inputs = fe(waveform, return_tensors="pt", padding=True)
+ with torch.no_grad():
+ outputs = hf_wav2vec(**inputs)
+
+ torch.testing.assert_close(original_output, outputs.last_hidden_state, atol=5e-3, rtol=5e-3)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ help="Path to the output PyTorch model.",
+ )
+ parser.add_argument(
+ "--checkpoint_path", default="conformer_shaw", type=str, help="Path to seamless communication checkpoint"
+ )
+ parser.add_argument(
+ "--config_path",
+ default=None,
+ type=str,
+ help="Path to hf config.json of model to convert",
+ )
+ parser.add_argument("--repo_id", default=None, type=str, help="Push to this repo id if precised.")
+ parser.add_argument(
+ "--audio_path",
+ default=None,
+ type=str,
+ help="If specified, check that the original model and the converted model produce the same outputs.",
+ )
+
+ args = parser.parse_args()
+ convert_wav2vec2_bert_checkpoint(
+ args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path, args.repo_id
+ )
diff --git a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
new file mode 100644
index 00000000000000..034da900ee8ab3
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
@@ -0,0 +1,1667 @@
+# coding=utf-8
+# Copyright 2024 The Seamless Authors and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Wav2Vec2-BERT model."""
+
+import math
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss
+
+from ...activations import ACT2FN
+from ...integrations.deepspeed import is_deepspeed_zero3_enabled
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_outputs import (
+ BaseModelOutput,
+ CausalLMOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+ Wav2Vec2BaseModelOutput,
+ XVectorOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+)
+from .configuration_wav2vec2_bert import Wav2Vec2BertConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+_HIDDEN_STATES_START_POSITION = 2
+
+# General docstring
+_CONFIG_FOR_DOC = "Wav2Vec2BertConfig"
+
+# Base docstring
+_BASE_CHECKPOINT_FOR_DOC = "facebook/w2v-bert-2.0"
+_PRETRAINED_CHECKPOINT_FOR_DOC = "hf-audio/wav2vec2-bert-CV16-en"
+_EXPECTED_OUTPUT_SHAPE = [1, 146, 1024]
+
+# CTC docstring
+_CTC_EXPECTED_OUTPUT = "'mr quilter is the apostle of the middle classes and we are glad to welcome his gospel'"
+_CTC_EXPECTED_LOSS = 17.04
+
+
+WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/w2v-bert-2.0",
+ # See all Wav2Vec2-BERT models at https://huggingface.co/models?filter=wav2vec2-bert
+]
+
+
+# Copied from transformers.models.seamless_m4t_v2.modeling_seamless_m4t_v2._compute_new_attention_mask
+def _compute_new_attention_mask(hidden_states: torch.Tensor, seq_lens: torch.Tensor):
+ """
+ Computes an attention mask of the form `(batch, seq_len)` with an attention for each element in the batch that
+ stops at the corresponding element in `seq_lens`.
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch, seq_len, *)`):
+ The sequences to mask, where `*` is any number of sequence-specific dimensions including none.
+ seq_lens (`torch.Tensor` of shape `(batch)`:
+ Each element represents the length of the sequence at the same index in `hidden_states`
+ Returns:
+ `torch.FloatTensor`: The float attention mask of shape `(batch, seq_len)`
+ """
+ batch_size, mask_seq_len = hidden_states.shape[:2]
+
+ indices = torch.arange(mask_seq_len, device=seq_lens.device).expand(batch_size, -1)
+
+ bool_mask = indices >= seq_lens.unsqueeze(1).expand(-1, mask_seq_len)
+
+ mask = hidden_states.new_ones((batch_size, mask_seq_len))
+
+ mask = mask.masked_fill(bool_mask, 0)
+
+ return mask
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
+def _compute_mask_indices(
+ shape: Tuple[int, int],
+ mask_prob: float,
+ mask_length: int,
+ attention_mask: Optional[torch.LongTensor] = None,
+ min_masks: int = 0,
+) -> np.ndarray:
+ """
+ Computes random mask spans for a given shape. Used to implement [SpecAugment: A Simple Data Augmentation Method for
+ ASR](https://arxiv.org/abs/1904.08779). Note that this method is not optimized to run on TPU and should be run on
+ CPU as part of the preprocessing during training.
+
+ Args:
+ shape: The shape for which to compute masks. This should be of a tuple of size 2 where
+ the first element is the batch size and the second element is the length of the axis to span.
+ mask_prob: The percentage of the whole axis (between 0 and 1) which will be masked. The number of
+ independently generated mask spans of length `mask_length` is computed by
+ `mask_prob*shape[1]/mask_length`. Note that due to overlaps, `mask_prob` is an upper bound and the
+ actual percentage will be smaller.
+ mask_length: size of the mask
+ min_masks: minimum number of masked spans
+ attention_mask: A (right-padded) attention mask which independently shortens the feature axis of
+ each batch dimension.
+ """
+ batch_size, sequence_length = shape
+
+ if mask_length < 1:
+ raise ValueError("`mask_length` has to be bigger than 0.")
+
+ if mask_length > sequence_length:
+ raise ValueError(
+ f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length}"
+ f" and `sequence_length`: {sequence_length}`"
+ )
+
+ # epsilon is used for probabilistic rounding
+ epsilon = np.random.rand(1).item()
+
+ def compute_num_masked_span(input_length):
+ """Given input length, compute how many spans should be masked"""
+ num_masked_span = int(mask_prob * input_length / mask_length + epsilon)
+ num_masked_span = max(num_masked_span, min_masks)
+
+ # make sure num masked span <= sequence_length
+ if num_masked_span * mask_length > sequence_length:
+ num_masked_span = sequence_length // mask_length
+
+ # make sure num_masked span is also <= input_length - (mask_length - 1)
+ if input_length - (mask_length - 1) < num_masked_span:
+ num_masked_span = max(input_length - (mask_length - 1), 0)
+
+ return num_masked_span
+
+ # compute number of masked spans in batch
+ input_lengths = (
+ attention_mask.sum(-1).detach().tolist()
+ if attention_mask is not None
+ else [sequence_length for _ in range(batch_size)]
+ )
+
+ # SpecAugment mask to fill
+ spec_aug_mask = np.zeros((batch_size, sequence_length), dtype=bool)
+ spec_aug_mask_idxs = []
+
+ max_num_masked_span = compute_num_masked_span(sequence_length)
+
+ if max_num_masked_span == 0:
+ return spec_aug_mask
+
+ for input_length in input_lengths:
+ # compute num of masked spans for this input
+ num_masked_span = compute_num_masked_span(input_length)
+
+ # get random indices to mask
+ spec_aug_mask_idx = np.random.choice(
+ np.arange(input_length - (mask_length - 1)), num_masked_span, replace=False
+ )
+
+ # pick first sampled index that will serve as a dummy index to pad vector
+ # to ensure same dimension for all batches due to probabilistic rounding
+ # Picking first sample just pads those vectors twice.
+ if len(spec_aug_mask_idx) == 0:
+ # this case can only happen if `input_length` is strictly smaller then
+ # `sequence_length` in which case the last token has to be a padding
+ # token which we can use as a dummy mask id
+ dummy_mask_idx = sequence_length - 1
+ else:
+ dummy_mask_idx = spec_aug_mask_idx[0]
+
+ spec_aug_mask_idx = np.concatenate(
+ [spec_aug_mask_idx, np.ones(max_num_masked_span - num_masked_span, dtype=np.int32) * dummy_mask_idx]
+ )
+ spec_aug_mask_idxs.append(spec_aug_mask_idx)
+
+ spec_aug_mask_idxs = np.array(spec_aug_mask_idxs)
+
+ # expand masked indices to masked spans
+ spec_aug_mask_idxs = np.broadcast_to(
+ spec_aug_mask_idxs[:, :, None], (batch_size, max_num_masked_span, mask_length)
+ )
+ spec_aug_mask_idxs = spec_aug_mask_idxs.reshape(batch_size, max_num_masked_span * mask_length)
+
+ # add offset to the starting indexes so that indexes now create a span
+ offsets = np.arange(mask_length)[None, None, :]
+ offsets = np.broadcast_to(offsets, (batch_size, max_num_masked_span, mask_length)).reshape(
+ batch_size, max_num_masked_span * mask_length
+ )
+ spec_aug_mask_idxs = spec_aug_mask_idxs + offsets
+
+ # ensure that we cannot have indices larger than sequence_length
+ if spec_aug_mask_idxs.max() > sequence_length - 1:
+ spec_aug_mask_idxs[spec_aug_mask_idxs > sequence_length - 1] = sequence_length - 1
+
+ # scatter indices to mask
+ np.put_along_axis(spec_aug_mask, spec_aug_mask_idxs, 1, -1)
+
+ return spec_aug_mask
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2._sample_negative_indices
+def _sample_negative_indices(
+ features_shape: Tuple, num_negatives: int, mask_time_indices: Optional[np.ndarray] = None
+):
+ """
+ Sample `num_negatives` vectors from feature vectors.
+ """
+ batch_size, sequence_length = features_shape
+
+ # generate indices of the positive vectors themselves, repeat them `num_negatives` times
+ sequence_length_range = np.arange(sequence_length)
+
+ # get `num_negatives` random vector indices from the same utterance
+ sampled_negative_indices = np.zeros(shape=(batch_size, sequence_length, num_negatives), dtype=np.int32)
+
+ mask_time_indices = (
+ mask_time_indices.astype(bool) if mask_time_indices is not None else np.ones(features_shape, dtype=bool)
+ )
+
+ for batch_idx in range(batch_size):
+ high = mask_time_indices[batch_idx].sum() - 1
+ mapped_masked_indices = sequence_length_range[mask_time_indices[batch_idx]]
+
+ feature_indices = np.broadcast_to(np.arange(high + 1)[:, None], (high + 1, num_negatives))
+ sampled_indices = np.random.randint(0, high, size=(high + 1, num_negatives))
+ # avoid sampling the same positive vector, but keep the distribution uniform
+ sampled_indices[sampled_indices >= feature_indices] += 1
+
+ # remap to actual indices
+ sampled_negative_indices[batch_idx][mask_time_indices[batch_idx]] = mapped_masked_indices[sampled_indices]
+
+ # correct for batch size
+ sampled_negative_indices[batch_idx] += batch_idx * sequence_length
+
+ return sampled_negative_indices
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerRotaryPositionalEmbedding with Wav2Vec2Conformer->Wav2Vec2Bert
+class Wav2Vec2BertRotaryPositionalEmbedding(nn.Module):
+ """Rotary positional embedding
+ Reference : https://blog.eleuther.ai/rotary-embeddings/ Paper: https://arxiv.org/pdf/2104.09864.pdf
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ dim = config.hidden_size // config.num_attention_heads
+ base = config.rotary_embedding_base
+
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
+ # Ignore copy
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.cached_sequence_length = None
+ self.cached_rotary_positional_embedding = None
+
+ def forward(self, hidden_states):
+ sequence_length = hidden_states.shape[1]
+
+ if sequence_length == self.cached_sequence_length and self.cached_rotary_positional_embedding is not None:
+ return self.cached_rotary_positional_embedding
+
+ self.cached_sequence_length = sequence_length
+ # Embeddings are computed in the dtype of the inv_freq constant
+ time_stamps = torch.arange(sequence_length).type_as(self.inv_freq)
+ freqs = torch.einsum("i,j->ij", time_stamps, self.inv_freq)
+ embeddings = torch.cat((freqs, freqs), dim=-1)
+
+ cos_embeddings = embeddings.cos()[:, None, None, :]
+ sin_embeddings = embeddings.sin()[:, None, None, :]
+ # Computed embeddings are cast to the dtype of the hidden state inputs
+ self.cached_rotary_positional_embedding = torch.stack([cos_embeddings, sin_embeddings]).type_as(hidden_states)
+ return self.cached_rotary_positional_embedding
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerRelPositionalEmbedding with Wav2Vec2Conformer->Wav2Vec2Bert
+class Wav2Vec2BertRelPositionalEmbedding(nn.Module):
+ """Relative positional encoding module."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.max_len = config.max_source_positions
+ self.d_model = config.hidden_size
+ self.pe = None
+ self.extend_pe(torch.tensor(0.0).expand(1, self.max_len))
+
+ def extend_pe(self, x):
+ # Reset the positional encodings
+ if self.pe is not None:
+ # self.pe contains both positive and negative parts
+ # the length of self.pe is 2 * input_len - 1
+ if self.pe.size(1) >= x.size(1) * 2 - 1:
+ if self.pe.dtype != x.dtype or self.pe.device != x.device:
+ self.pe = self.pe.to(dtype=x.dtype, device=x.device)
+ return
+ # Suppose `i` is the position of query vector and `j` is the
+ # position of key vector. We use positive relative positions when keys
+ # are to the left (i>j) and negative relative positions otherwise (i (batch, 2*channel, dim)
+ hidden_states = self.pointwise_conv1(hidden_states)
+ # => (batch, channel, dim)
+ hidden_states = self.glu(hidden_states)
+
+ # Pad the sequence entirely on the left because of causal convolution.
+ hidden_states = torch.nn.functional.pad(hidden_states, (self.depthwise_conv.kernel_size[0] - 1, 0))
+
+ # 1D Depthwise Conv
+ hidden_states = self.depthwise_conv(hidden_states)
+
+ hidden_states = self.depthwise_layer_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
+
+ hidden_states = self.activation(hidden_states)
+
+ hidden_states = self.pointwise_conv2(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = hidden_states.transpose(1, 2)
+ return hidden_states
+
+
+class Wav2Vec2BertSelfAttention(nn.Module):
+ """Construct an Wav2Vec2BertSelfAttention object.
+ Can be enhanced with rotary or relative position embeddings.
+ """
+
+ def __init__(self, config, is_adapter_attention=False):
+ super().__init__()
+ hidden_size = config.hidden_size if not is_adapter_attention else config.output_hidden_size
+
+ self.head_size = hidden_size // config.num_attention_heads
+ self.num_heads = config.num_attention_heads
+ self.position_embeddings_type = config.position_embeddings_type if not is_adapter_attention else None
+
+ self.linear_q = nn.Linear(hidden_size, hidden_size)
+ self.linear_k = nn.Linear(hidden_size, hidden_size)
+ self.linear_v = nn.Linear(hidden_size, hidden_size)
+ self.linear_out = nn.Linear(hidden_size, hidden_size)
+
+ self.dropout = nn.Dropout(p=config.attention_dropout)
+
+ if self.position_embeddings_type == "relative":
+ # linear transformation for positional encoding
+ self.linear_pos = nn.Linear(hidden_size, hidden_size, bias=False)
+ # these two learnable bias are used in matrix c and matrix d
+ # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
+ self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
+
+ if self.position_embeddings_type == "relative_key":
+ self.left_max_position_embeddings = config.left_max_position_embeddings
+ self.right_max_position_embeddings = config.right_max_position_embeddings
+ num_positions = self.left_max_position_embeddings + self.right_max_position_embeddings + 1
+ self.distance_embedding = nn.Embedding(num_positions, self.head_size)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ relative_position_embeddings: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # self-attention mechanism
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+
+ # make sure query/key states can be != value states
+ query_key_states = hidden_states
+ value_states = hidden_states
+
+ if self.position_embeddings_type == "rotary":
+ if relative_position_embeddings is None:
+ raise ValueError(
+ "`relative_position_embeddings` has to be defined when `self.position_embeddings_type == 'rotary'"
+ )
+ query_key_states = self._apply_rotary_embedding(query_key_states, relative_position_embeddings)
+
+ # project query_key_states and value_states
+ query = self.linear_q(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
+ key = self.linear_k(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
+ value = self.linear_v(value_states).view(batch_size, -1, self.num_heads, self.head_size)
+
+ # => (batch, head, time1, d_k)
+ query = query.transpose(1, 2)
+ key = key.transpose(1, 2)
+ value = value.transpose(1, 2)
+
+ if self.position_embeddings_type == "relative":
+ if relative_position_embeddings is None:
+ raise ValueError(
+ "`relative_position_embeddings` has to be defined when `self.position_embeddings_type =="
+ " 'relative'"
+ )
+ # apply relative_position_embeddings to qk scores
+ # as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
+ scores = self._apply_relative_embeddings(
+ query=query, key=key, relative_position_embeddings=relative_position_embeddings
+ )
+ else:
+ scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_size)
+
+ if self.position_embeddings_type == "relative_key":
+ query_length, key_length = query.shape[2], key.shape[2]
+
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_r - position_ids_l
+ distance = torch.clamp(distance, -self.left_max_position_embeddings, self.right_max_position_embeddings)
+
+ positional_embedding = self.distance_embedding(distance + self.left_max_position_embeddings)
+ positional_embedding = positional_embedding.to(dtype=query.dtype) # fp16 compatibility
+
+ relative_position_attn_weights = torch.einsum("bhld,lrd->bhlr", query, positional_embedding)
+ scores = scores + (relative_position_attn_weights / math.sqrt(self.head_size))
+
+ # apply attention_mask if necessary
+ if attention_mask is not None:
+ scores = scores + attention_mask
+
+ # => (batch, head, time1, time2)
+ probs = torch.softmax(scores, dim=-1)
+ probs = self.dropout(probs)
+
+ # => (batch, head, time1, d_k)
+ hidden_states = torch.matmul(probs, value)
+
+ # => (batch, time1, hidden_size)
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, self.num_heads * self.head_size)
+ hidden_states = self.linear_out(hidden_states)
+
+ return hidden_states, probs
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerSelfAttention._apply_rotary_embedding
+ def _apply_rotary_embedding(self, hidden_states, relative_position_embeddings):
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+ hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads, self.head_size)
+
+ cos = relative_position_embeddings[0, :sequence_length, ...]
+ sin = relative_position_embeddings[1, :sequence_length, ...]
+
+ # rotate hidden_states with rotary embeddings
+ hidden_states = hidden_states.transpose(0, 1)
+ rotated_states_begin = hidden_states[..., : self.head_size // 2]
+ rotated_states_end = hidden_states[..., self.head_size // 2 :]
+ rotated_states = torch.cat((-rotated_states_end, rotated_states_begin), dim=rotated_states_begin.ndim - 1)
+ hidden_states = (hidden_states * cos) + (rotated_states * sin)
+ hidden_states = hidden_states.transpose(0, 1)
+
+ hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads * self.head_size)
+
+ return hidden_states
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerSelfAttention._apply_relative_embeddings
+ def _apply_relative_embeddings(self, query, key, relative_position_embeddings):
+ # 1. project positional embeddings
+ # => (batch, head, 2*time1-1, d_k)
+ proj_relative_position_embeddings = self.linear_pos(relative_position_embeddings)
+ proj_relative_position_embeddings = proj_relative_position_embeddings.view(
+ relative_position_embeddings.size(0), -1, self.num_heads, self.head_size
+ )
+ proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(1, 2)
+ proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(2, 3)
+
+ # 2. Add bias to query
+ # => (batch, head, time1, d_k)
+ query = query.transpose(1, 2)
+ q_with_bias_u = (query + self.pos_bias_u).transpose(1, 2)
+ q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
+
+ # 3. attention score: first compute matrix a and matrix c
+ # as described in https://arxiv.org/abs/1901.02860 Section 3.3
+ # => (batch, head, time1, time2)
+ scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
+
+ # 4. then compute matrix b and matrix d
+ # => (batch, head, time1, 2*time1-1)
+ scores_bd = torch.matmul(q_with_bias_v, proj_relative_position_embeddings)
+
+ # 5. shift matrix b and matrix d
+ zero_pad = torch.zeros((*scores_bd.size()[:3], 1), device=scores_bd.device, dtype=scores_bd.dtype)
+ scores_bd_padded = torch.cat([zero_pad, scores_bd], dim=-1)
+ scores_bd_padded_shape = scores_bd.size()[:2] + (scores_bd.shape[3] + 1, scores_bd.shape[2])
+ scores_bd_padded = scores_bd_padded.view(*scores_bd_padded_shape)
+ scores_bd = scores_bd_padded[:, :, 1:].view_as(scores_bd)
+ scores_bd = scores_bd[:, :, :, : scores_bd.size(-1) // 2 + 1]
+
+ # 6. sum matrices
+ # => (batch, head, time1, time2)
+ scores = (scores_ac + scores_bd) / math.sqrt(self.head_size)
+
+ return scores
+
+
+class Wav2Vec2BertEncoderLayer(nn.Module):
+ """Conformer block based on https://arxiv.org/abs/2005.08100."""
+
+ def __init__(self, config):
+ super().__init__()
+ embed_dim = config.hidden_size
+ dropout = config.attention_dropout
+
+ # Feed-forward 1
+ self.ffn1_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn1 = Wav2Vec2BertFeedForward(config)
+
+ # Self-Attention
+ self.self_attn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.self_attn_dropout = nn.Dropout(dropout)
+ self.self_attn = Wav2Vec2BertSelfAttention(config)
+
+ # Conformer Convolution
+ self.conv_module = Wav2Vec2BertConvolutionModule(config)
+
+ # Feed-forward 2
+ self.ffn2_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn2 = Wav2Vec2BertFeedForward(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask: Optional[torch.Tensor] = None,
+ relative_position_embeddings: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ conv_attention_mask: Optional[torch.Tensor] = None,
+ ):
+ hidden_states = hidden_states
+
+ # 1. Feed-Forward 1 layer
+ residual = hidden_states
+ hidden_states = self.ffn1_layer_norm(hidden_states)
+ hidden_states = self.ffn1(hidden_states)
+ hidden_states = hidden_states * 0.5 + residual
+ residual = hidden_states
+
+ # 2. Self-Attention layer
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weigts = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ relative_position_embeddings=relative_position_embeddings,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.self_attn_dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ # 3. Convolutional Layer
+ residual = hidden_states
+ hidden_states = self.conv_module(hidden_states, attention_mask=conv_attention_mask)
+ hidden_states = residual + hidden_states
+
+ # 4. Feed-Forward 2 Layer
+ residual = hidden_states
+ hidden_states = self.ffn2_layer_norm(hidden_states)
+ hidden_states = self.ffn2(hidden_states)
+ hidden_states = hidden_states * 0.5 + residual
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ return hidden_states, attn_weigts
+
+
+class Wav2Vec2BertEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ if config.position_embeddings_type == "relative":
+ self.embed_positions = Wav2Vec2BertRelPositionalEmbedding(config)
+ elif config.position_embeddings_type == "rotary":
+ self.embed_positions = Wav2Vec2BertRotaryPositionalEmbedding(config)
+ else:
+ self.embed_positions = None
+
+ self.dropout = nn.Dropout(config.hidden_dropout)
+ self.layers = nn.ModuleList([Wav2Vec2BertEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ conv_attention_mask = attention_mask
+ if attention_mask is not None:
+ # make sure padded tokens output 0
+ hidden_states = hidden_states.masked_fill(~attention_mask.bool().unsqueeze(-1), 0.0)
+
+ # extend attention_mask
+ attention_mask = 1.0 - attention_mask[:, None, None, :].to(dtype=hidden_states.dtype)
+ attention_mask = attention_mask * torch.finfo(hidden_states.dtype).min
+ attention_mask = attention_mask.expand(
+ attention_mask.shape[0], 1, attention_mask.shape[-1], attention_mask.shape[-1]
+ )
+
+ hidden_states = self.dropout(hidden_states)
+
+ if self.embed_positions is not None:
+ relative_position_embeddings = self.embed_positions(hidden_states)
+ else:
+ relative_position_embeddings = None
+
+ deepspeed_zero3_is_enabled = is_deepspeed_zero3_enabled()
+
+ for i, layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ dropout_probability = torch.rand([])
+
+ skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
+ if not skip_the_layer or deepspeed_zero3_is_enabled:
+ # under deepspeed zero3 all gpus must run in sync
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer.__call__,
+ hidden_states,
+ attention_mask,
+ relative_position_embeddings,
+ output_attentions,
+ conv_attention_mask,
+ )
+ else:
+ layer_outputs = layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ relative_position_embeddings=relative_position_embeddings,
+ output_attentions=output_attentions,
+ conv_attention_mask=conv_attention_mask,
+ )
+ hidden_states = layer_outputs[0]
+
+ if skip_the_layer:
+ layer_outputs = (None, None)
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class Wav2Vec2BertAdapter(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ # feature dim might need to be down-projected
+ if config.output_hidden_size != config.hidden_size:
+ self.proj = nn.Linear(config.hidden_size, config.output_hidden_size)
+ self.proj_layer_norm = nn.LayerNorm(config.output_hidden_size, eps=config.layer_norm_eps)
+ else:
+ self.proj = self.proj_layer_norm = None
+ self.layers = nn.ModuleList(Wav2Vec2BertAdapterLayer(config) for _ in range(config.num_adapter_layers))
+ self.layerdrop = config.layerdrop
+
+ self.kernel_size = config.adapter_kernel_size
+ self.stride = config.adapter_stride
+
+ def _compute_sub_sample_lengths_from_attention_mask(self, seq_lens):
+ if seq_lens is None:
+ return seq_lens
+ pad = self.kernel_size // 2
+ seq_lens = ((seq_lens + 2 * pad - self.kernel_size) / self.stride) + 1
+ return seq_lens.floor()
+
+ def forward(self, hidden_states, attention_mask=None):
+ # down project hidden_states if necessary
+ if self.proj is not None and self.proj_layer_norm is not None:
+ hidden_states = self.proj(hidden_states)
+ hidden_states = self.proj_layer_norm(hidden_states)
+
+ sub_sampled_lengths = None
+ if attention_mask is not None:
+ sub_sampled_lengths = (attention_mask.size(1) - (1 - attention_mask.int()).sum(1)).to(hidden_states.device)
+
+ for layer in self.layers:
+ layerdrop_prob = torch.rand([])
+ sub_sampled_lengths = self._compute_sub_sample_lengths_from_attention_mask(sub_sampled_lengths)
+ if not self.training or (layerdrop_prob > self.layerdrop):
+ hidden_states = layer(
+ hidden_states, attention_mask=attention_mask, sub_sampled_lengths=sub_sampled_lengths
+ )
+
+ return hidden_states
+
+
+class Wav2Vec2BertAdapterLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ embed_dim = config.output_hidden_size
+ dropout = config.conformer_conv_dropout
+
+ self.kernel_size = config.adapter_kernel_size
+ self.stride = config.adapter_stride
+
+ # 1. residual convolution
+ self.residual_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.residual_conv = nn.Conv1d(
+ embed_dim,
+ 2 * embed_dim,
+ self.kernel_size,
+ stride=self.stride,
+ padding=self.stride // 2,
+ )
+ self.activation = nn.GLU(dim=1)
+
+ # Self-Attention
+ self.self_attn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.self_attn_conv = nn.Conv1d(
+ embed_dim,
+ 2 * embed_dim,
+ self.kernel_size,
+ stride=self.stride,
+ padding=self.stride // 2,
+ )
+ self.self_attn = Wav2Vec2BertSelfAttention(config, is_adapter_attention=True)
+ self.self_attn_dropout = nn.Dropout(dropout)
+
+ # Feed-forward
+ self.ffn_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.ffn = Wav2Vec2BertFeedForward(config, act_fn=config.adapter_act, hidden_size=embed_dim)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ sub_sampled_lengths: Optional[torch.Tensor] = None,
+ ):
+ residual = self.residual_layer_norm(hidden_states)
+
+ # Apply pooling to the residual to match the sequence length of the
+ # multi-head attention output.
+ # (batch, seq_len, feature_dim) -> (batch, feature_dim, seq_len)
+ residual = residual.transpose(1, 2)
+ residual = self.residual_conv(residual)
+ residual = self.activation(residual)
+ # (batch, feature_dim, seq_len) -> (batch, seq_len, feature_dim)
+ residual = residual.transpose(1, 2)
+
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ # Apply pooling before feeding to the multihead-attention layer.
+ # (batch, seq_len, feature_dim) -> (batch, feature_dim, seq_len)
+ hidden_states = hidden_states.transpose(1, 2)
+ hidden_states = self.self_attn_conv(hidden_states)
+ hidden_states = self.activation(hidden_states)
+ # (batch, feature_dim, seq_len) -> (batch, seq_len, feature_dim)
+ hidden_states = hidden_states.transpose(1, 2)
+
+ if attention_mask is not None:
+ attention_mask = _compute_new_attention_mask(hidden_states=hidden_states, seq_lens=sub_sampled_lengths)
+ attention_mask = _prepare_4d_attention_mask(
+ attention_mask,
+ hidden_states.dtype,
+ )
+
+ # The rest of the computation is identical to a vanilla Transformer
+ # encoder layer.
+ hidden_states, attn_weigths = self.self_attn(
+ hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.self_attn_dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ residual = hidden_states
+
+ hidden_states = self.ffn_layer_norm(hidden_states)
+ hidden_states = self.ffn(hidden_states) + residual
+
+ return hidden_states
+
+
+# Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerPreTrainedModel with Wav2Vec2Conformer->Wav2Vec2Bert,wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+class Wav2Vec2BertPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = Wav2Vec2BertConfig
+ base_model_prefix = "wav2vec2_bert"
+ main_input_name = "input_features"
+ supports_gradient_checkpointing = True
+
+ # Ignore copy
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, Wav2Vec2BertSelfAttention):
+ if hasattr(module, "pos_bias_u"):
+ nn.init.xavier_uniform_(module.pos_bias_u)
+ if hasattr(module, "pos_bias_v"):
+ nn.init.xavier_uniform_(module.pos_bias_v)
+ elif isinstance(module, Wav2Vec2BertFeatureProjection):
+ k = math.sqrt(1 / module.projection.in_features)
+ nn.init.uniform_(module.projection.weight, a=-k, b=k)
+ nn.init.uniform_(module.projection.bias, a=-k, b=k)
+ elif isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (nn.LayerNorm, nn.GroupNorm)):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, nn.Conv1d):
+ nn.init.kaiming_normal_(module.weight)
+
+ if module.bias is not None:
+ k = math.sqrt(module.groups / (module.in_channels * module.kernel_size[0]))
+ nn.init.uniform_(module.bias, a=-k, b=k)
+
+ # Ignore copy
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[torch.LongTensor, int], add_adapter: Optional[bool] = None
+ ):
+ """
+ Computes the output length of the convolutional layers
+ """
+
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
+ def _conv_out_length(input_length, kernel_size, stride, padding):
+ # 1D convolutional layer output length formula taken
+ # from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
+ return torch.div(input_length + 2 * padding - kernel_size, stride, rounding_mode="floor") + 1
+
+ if add_adapter:
+ padding = self.config.adapter_kernel_size // 2
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(
+ input_lengths, self.config.adapter_kernel_size, self.config.adapter_stride, padding
+ )
+
+ return input_lengths
+
+ def _get_feature_vector_attention_mask(
+ self, feature_vector_length: int, attention_mask: torch.LongTensor, add_adapter=None
+ ):
+ # Effectively attention_mask.sum(-1), but not inplace to be able to run
+ # on inference mode.
+ non_padded_lengths = attention_mask.cumsum(dim=-1)[:, -1]
+
+ output_lengths = self._get_feat_extract_output_lengths(non_padded_lengths, add_adapter=add_adapter)
+ output_lengths = output_lengths.to(torch.long)
+
+ batch_size = attention_mask.shape[0]
+
+ attention_mask = torch.zeros(
+ (batch_size, feature_vector_length), dtype=attention_mask.dtype, device=attention_mask.device
+ )
+ # these two operations makes sure that all values before the output lengths idxs are attended to
+ attention_mask[(torch.arange(attention_mask.shape[0], device=attention_mask.device), output_lengths - 1)] = 1
+ attention_mask = attention_mask.flip([-1]).cumsum(-1).flip([-1]).bool()
+ return attention_mask
+
+
+WAV2VEC2_BERT_START_DOCSTRING = r"""
+ Wav2Vec2Bert was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
+ Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael
+ Auli.
+
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving etc.).
+
+ This model is a PyTorch [nn.Module](https://pytorch.org/docs/stable/nn.html#nn.Module) sub-class. Use it as a
+ regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
+
+ Parameters:
+ config ([`Wav2Vec2BertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+WAV2VEC2_BERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_features (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Float values of input raw speech waveform. Values can be obtained by loading a `.flac` or `.wav` audio file
+ into an array of type `List[float]` or a `numpy.ndarray`, *e.g.* via the soundfile library (`pip install
+ soundfile`). To prepare the array into `input_features`, the [`AutoProcessor`] should be used for padding and
+ conversion into a tensor of type `torch.FloatTensor`. See [`Wav2Vec2BertProcessor.__call__`] for details.
+ attention_mask (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing convolution and attention on padding token indices. Mask values selected in `[0,
+ 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Wav2Vec2Bert Model transformer outputting raw hidden-states without any specific head on top.",
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertModel(Wav2Vec2BertPreTrainedModel):
+ def __init__(self, config: Wav2Vec2BertConfig):
+ super().__init__(config)
+ self.config = config
+ self.feature_projection = Wav2Vec2BertFeatureProjection(config)
+
+ # model only needs masking vector if mask prob is > 0.0
+ if config.mask_time_prob > 0.0 or config.mask_feature_prob > 0.0:
+ self.masked_spec_embed = nn.Parameter(torch.FloatTensor(config.hidden_size).uniform_())
+
+ self.encoder = Wav2Vec2BertEncoder(config)
+
+ self.adapter = Wav2Vec2BertAdapter(config) if config.add_adapter else None
+
+ self.intermediate_ffn = None
+ if config.use_intermediate_ffn_before_adapter:
+ self.intermediate_ffn = Wav2Vec2BertFeedForward(config, act_fn="relu")
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2Model._mask_hidden_states
+ def _mask_hidden_states(
+ self,
+ hidden_states: torch.FloatTensor,
+ mask_time_indices: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.LongTensor] = None,
+ ):
+ """
+ Masks extracted features along time axis and/or along feature axis according to
+ [SpecAugment](https://arxiv.org/abs/1904.08779).
+ """
+
+ # `config.apply_spec_augment` can set masking to False
+ if not getattr(self.config, "apply_spec_augment", True):
+ return hidden_states
+
+ # generate indices & apply SpecAugment along time axis
+ batch_size, sequence_length, hidden_size = hidden_states.size()
+
+ if mask_time_indices is not None:
+ # apply SpecAugment along time axis with given mask_time_indices
+ hidden_states[mask_time_indices] = self.masked_spec_embed.to(hidden_states.dtype)
+ elif self.config.mask_time_prob > 0 and self.training:
+ mask_time_indices = _compute_mask_indices(
+ (batch_size, sequence_length),
+ mask_prob=self.config.mask_time_prob,
+ mask_length=self.config.mask_time_length,
+ attention_mask=attention_mask,
+ min_masks=self.config.mask_time_min_masks,
+ )
+ mask_time_indices = torch.tensor(mask_time_indices, device=hidden_states.device, dtype=torch.bool)
+ hidden_states[mask_time_indices] = self.masked_spec_embed.to(hidden_states.dtype)
+
+ if self.config.mask_feature_prob > 0 and self.training:
+ # generate indices & apply SpecAugment along feature axis
+ mask_feature_indices = _compute_mask_indices(
+ (batch_size, hidden_size),
+ mask_prob=self.config.mask_feature_prob,
+ mask_length=self.config.mask_feature_length,
+ min_masks=self.config.mask_feature_min_masks,
+ )
+ mask_feature_indices = torch.tensor(mask_feature_indices, device=hidden_states.device, dtype=torch.bool)
+ mask_feature_indices = mask_feature_indices[:, None].expand(-1, sequence_length, -1)
+ hidden_states[mask_feature_indices] = 0
+
+ return hidden_states
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_PRETRAINED_CHECKPOINT_FOR_DOC,
+ output_type=Wav2Vec2BaseModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ mask_time_indices: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, Wav2Vec2BaseModelOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ hidden_states, extract_features = self.feature_projection(input_features)
+ hidden_states = self._mask_hidden_states(
+ hidden_states, mask_time_indices=mask_time_indices, attention_mask=attention_mask
+ )
+
+ encoder_outputs = self.encoder(
+ hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = encoder_outputs[0]
+
+ if self.intermediate_ffn:
+ expanded_hidden_states = self.intermediate_ffn(hidden_states)
+ hidden_states = hidden_states + 0.5 * expanded_hidden_states
+
+ if self.adapter is not None:
+ hidden_states = self.adapter(hidden_states, attention_mask=attention_mask)
+
+ if not return_dict:
+ return (hidden_states, extract_features) + encoder_outputs[1:]
+
+ return Wav2Vec2BaseModelOutput(
+ last_hidden_state=hidden_states,
+ extract_features=extract_features,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """Wav2Vec2Bert Model with a `language modeling` head on top for Connectionist Temporal Classification (CTC).""",
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForCTC(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForCTC.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config, target_lang: Optional[str] = None):
+ super().__init__(config)
+
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ self.dropout = nn.Dropout(config.final_dropout)
+
+ self.target_lang = target_lang
+
+ if config.vocab_size is None:
+ raise ValueError(
+ f"You are trying to instantiate {self.__class__} with a configuration that "
+ "does not define the vocabulary size of the language model head. Please "
+ "instantiate the model as follows: `Wav2Vec2BertForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
+ "or define `vocab_size` of your model's configuration."
+ )
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_PRETRAINED_CHECKPOINT_FOR_DOC,
+ output_type=CausalLMOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_CTC_EXPECTED_OUTPUT,
+ expected_loss=_CTC_EXPECTED_LOSS,
+ )
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, CausalLMOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, target_length)`, *optional*):
+ Labels for connectionist temporal classification. Note that `target_length` has to be smaller or equal to
+ the sequence length of the output logits. Indices are selected in `[-100, 0, ..., config.vocab_size - 1]`.
+ All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ...,
+ config.vocab_size - 1]`.
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ hidden_states = self.dropout(hidden_states)
+
+ logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ if labels.max() >= self.config.vocab_size:
+ raise ValueError(f"Label values must be <= vocab_size: {self.config.vocab_size}")
+
+ # retrieve loss input_lengths from attention_mask
+ attention_mask = (
+ attention_mask
+ if attention_mask is not None
+ else torch.ones(input_features.shape[:2], device=input_features.device, dtype=torch.long)
+ )
+ input_lengths = self._get_feat_extract_output_lengths(attention_mask.sum([-1])).to(torch.long)
+
+ # assuming that padded tokens are filled with -100
+ # when not being attended to
+ labels_mask = labels >= 0
+ target_lengths = labels_mask.sum(-1)
+ flattened_targets = labels.masked_select(labels_mask)
+
+ # ctc_loss doesn't support fp16
+ log_probs = nn.functional.log_softmax(logits, dim=-1, dtype=torch.float32).transpose(0, 1)
+
+ with torch.backends.cudnn.flags(enabled=False):
+ loss = nn.functional.ctc_loss(
+ log_probs,
+ flattened_targets,
+ input_lengths,
+ target_lengths,
+ blank=self.config.pad_token_id,
+ reduction=self.config.ctc_loss_reduction,
+ zero_infinity=self.config.ctc_zero_infinity,
+ )
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return CausalLMOutput(
+ loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions
+ )
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with a sequence classification head on top (a linear layer over the pooled output) for
+ tasks like SUPERB Keyword Spotting.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForSequenceClassification(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForSequenceClassification.__init__ with Wav2Vec2->Wav2Vec2Bert,wav2vec2->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Wav2Vec2Bert adapters (config.add_adapter=True)"
+ )
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.projector = nn.Linear(config.hidden_size, config.classifier_proj_size)
+ self.classifier = nn.Linear(config.classifier_proj_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForSequenceClassification.forward with Wav2Vec2->Wav2Vec2Bert,wav2vec2->wav2vec2_bert,WAV_2_VEC_2->WAV2VEC2_BERT, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ hidden_states = self.projector(hidden_states)
+ if attention_mask is None:
+ pooled_output = hidden_states.mean(dim=1)
+ else:
+ padding_mask = self._get_feature_vector_attention_mask(hidden_states.shape[1], attention_mask)
+ hidden_states[~padding_mask] = 0.0
+ pooled_output = hidden_states.sum(dim=1) / padding_mask.sum(dim=1).view(-1, 1)
+
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with a frame classification head on top for tasks like Speaker Diarization.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForAudioFrameClassification(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of Wav2Vec2Bert adapters (config.add_adapter=True)"
+ )
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+ self.num_labels = config.num_labels
+
+ self.init_weights()
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.freeze_base_model with wav2vec2_conformer->wav2vec2_bert
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=TokenClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForAudioFrameClassification.forward with wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, TokenClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ logits = self.classifier(hidden_states)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), torch.argmax(labels.view(-1, self.num_labels), axis=1))
+
+ if not return_dict:
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2.AMSoftmaxLoss
+class AMSoftmaxLoss(nn.Module):
+ def __init__(self, input_dim, num_labels, scale=30.0, margin=0.4):
+ super(AMSoftmaxLoss, self).__init__()
+ self.scale = scale
+ self.margin = margin
+ self.num_labels = num_labels
+ self.weight = nn.Parameter(torch.randn(input_dim, num_labels), requires_grad=True)
+ self.loss = nn.CrossEntropyLoss()
+
+ def forward(self, hidden_states, labels):
+ labels = labels.flatten()
+ weight = nn.functional.normalize(self.weight, dim=0)
+ hidden_states = nn.functional.normalize(hidden_states, dim=1)
+ cos_theta = torch.mm(hidden_states, weight)
+ psi = cos_theta - self.margin
+
+ onehot = nn.functional.one_hot(labels, self.num_labels)
+ logits = self.scale * torch.where(onehot.bool(), psi, cos_theta)
+ loss = self.loss(logits, labels)
+
+ return loss
+
+
+# Copied from transformers.models.wav2vec2.modeling_wav2vec2.TDNNLayer
+class TDNNLayer(nn.Module):
+ def __init__(self, config, layer_id=0):
+ super().__init__()
+ self.in_conv_dim = config.tdnn_dim[layer_id - 1] if layer_id > 0 else config.tdnn_dim[layer_id]
+ self.out_conv_dim = config.tdnn_dim[layer_id]
+ self.kernel_size = config.tdnn_kernel[layer_id]
+ self.dilation = config.tdnn_dilation[layer_id]
+
+ self.kernel = nn.Linear(self.in_conv_dim * self.kernel_size, self.out_conv_dim)
+ self.activation = nn.ReLU()
+
+ def forward(self, hidden_states):
+ hidden_states = hidden_states.unsqueeze(1)
+ hidden_states = nn.functional.unfold(
+ hidden_states,
+ (self.kernel_size, self.in_conv_dim),
+ stride=(1, self.in_conv_dim),
+ dilation=(self.dilation, 1),
+ )
+ hidden_states = hidden_states.transpose(1, 2)
+ hidden_states = self.kernel(hidden_states)
+
+ hidden_states = self.activation(hidden_states)
+ return hidden_states
+
+
+@add_start_docstrings(
+ """
+ Wav2Vec2Bert Model with an XVector feature extraction head on top for tasks like Speaker Verification.
+ """,
+ WAV2VEC2_BERT_START_DOCSTRING,
+)
+class Wav2Vec2BertForXVector(Wav2Vec2BertPreTrainedModel):
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.__init__ with Wav2Vec2Conformer->Wav2Vec2Bert,WAV2VEC2_CONFORMER->WAV2VEC2_BERT,wav2vec2_conformer->wav2vec2_bert
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.wav2vec2_bert = Wav2Vec2BertModel(config)
+ num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
+ if config.use_weighted_layer_sum:
+ self.layer_weights = nn.Parameter(torch.ones(num_layers) / num_layers)
+ self.projector = nn.Linear(config.hidden_size, config.tdnn_dim[0])
+
+ tdnn_layers = [TDNNLayer(config, i) for i in range(len(config.tdnn_dim))]
+ self.tdnn = nn.ModuleList(tdnn_layers)
+
+ self.feature_extractor = nn.Linear(config.tdnn_dim[-1] * 2, config.xvector_output_dim)
+ self.classifier = nn.Linear(config.xvector_output_dim, config.xvector_output_dim)
+
+ self.objective = AMSoftmaxLoss(config.xvector_output_dim, config.num_labels)
+
+ self.init_weights()
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.freeze_base_model with wav2vec2_conformer->wav2vec2_bert
+ def freeze_base_model(self):
+ """
+ Calling this function will disable the gradient computation for the base model so that its parameters will not
+ be updated during training. Only the classification head will be updated.
+ """
+ for param in self.wav2vec2_bert.parameters():
+ param.requires_grad = False
+
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector._get_tdnn_output_lengths
+ def _get_tdnn_output_lengths(self, input_lengths: Union[torch.LongTensor, int]):
+ """
+ Computes the output length of the TDNN layers
+ """
+
+ def _conv_out_length(input_length, kernel_size, stride):
+ # 1D convolutional layer output length formula taken
+ # from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
+ return (input_length - kernel_size) // stride + 1
+
+ for kernel_size in self.config.tdnn_kernel:
+ input_lengths = _conv_out_length(input_lengths, kernel_size, 1)
+
+ return input_lengths
+
+ @add_start_docstrings_to_model_forward(WAV2VEC2_BERT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_BASE_CHECKPOINT_FOR_DOC,
+ output_type=XVectorOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ )
+ # Copied from transformers.models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForXVector.forward with wav2vec2_conformer->wav2vec2_bert, input_values->input_features
+ def forward(
+ self,
+ input_features: Optional[torch.Tensor],
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: Optional[torch.Tensor] = None,
+ ) -> Union[Tuple, XVectorOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = True if self.config.use_weighted_layer_sum else output_hidden_states
+
+ outputs = self.wav2vec2_bert(
+ input_features,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.use_weighted_layer_sum:
+ hidden_states = outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
+ norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
+ hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
+ else:
+ hidden_states = outputs[0]
+
+ hidden_states = self.projector(hidden_states)
+
+ for tdnn_layer in self.tdnn:
+ hidden_states = tdnn_layer(hidden_states)
+
+ # Statistic Pooling
+ if attention_mask is None:
+ mean_features = hidden_states.mean(dim=1)
+ std_features = hidden_states.std(dim=1)
+ else:
+ feat_extract_output_lengths = self._get_feat_extract_output_lengths(attention_mask.sum(dim=1))
+ tdnn_output_lengths = self._get_tdnn_output_lengths(feat_extract_output_lengths)
+ mean_features = []
+ std_features = []
+ for i, length in enumerate(tdnn_output_lengths):
+ mean_features.append(hidden_states[i, :length].mean(dim=0))
+ std_features.append(hidden_states[i, :length].std(dim=0))
+ mean_features = torch.stack(mean_features)
+ std_features = torch.stack(std_features)
+ statistic_pooling = torch.cat([mean_features, std_features], dim=-1)
+
+ output_embeddings = self.feature_extractor(statistic_pooling)
+ logits = self.classifier(output_embeddings)
+
+ loss = None
+ if labels is not None:
+ loss = self.objective(logits, labels)
+
+ if not return_dict:
+ output = (logits, output_embeddings) + outputs[_HIDDEN_STATES_START_POSITION:]
+ return ((loss,) + output) if loss is not None else output
+
+ return XVectorOutput(
+ loss=loss,
+ logits=logits,
+ embeddings=output_embeddings,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py
new file mode 100644
index 00000000000000..ec792ce75a0248
--- /dev/null
+++ b/src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py
@@ -0,0 +1,145 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Speech processor class for Wav2Vec2-BERT
+"""
+import warnings
+
+from ...processing_utils import ProcessorMixin
+from ..seamless_m4t.feature_extraction_seamless_m4t import SeamlessM4TFeatureExtractor
+from ..wav2vec2.tokenization_wav2vec2 import Wav2Vec2CTCTokenizer
+
+
+class Wav2Vec2BertProcessor(ProcessorMixin):
+ r"""
+ Constructs a Wav2Vec2-BERT processor which wraps a Wav2Vec2-BERT feature extractor and a Wav2Vec2 CTC tokenizer into a single
+ processor.
+
+ [`Wav2Vec2Processor`] offers all the functionalities of [`SeamlessM4TFeatureExtractor`] and [`PreTrainedTokenizer`].
+ See the docstring of [`~Wav2Vec2Processor.__call__`] and [`~Wav2Vec2Processor.decode`] for more information.
+
+ Args:
+ feature_extractor (`SeamlessM4TFeatureExtractor`):
+ An instance of [`SeamlessM4TFeatureExtractor`]. The feature extractor is a required input.
+ tokenizer ([`PreTrainedTokenizer`]):
+ An instance of [`PreTrainedTokenizer`]. The tokenizer is a required input.
+ """
+
+ feature_extractor_class = "SeamlessM4TFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer):
+ super().__init__(feature_extractor, tokenizer)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ try:
+ return super().from_pretrained(pretrained_model_name_or_path, **kwargs)
+ except OSError:
+ warnings.warn(
+ f"Loading a tokenizer inside {cls.__name__} from a config that does not"
+ " include a `tokenizer_class` attribute is deprecated and will be "
+ "removed in v5. Please add `'tokenizer_class': 'Wav2Vec2CTCTokenizer'`"
+ " attribute to either your `config.json` or `tokenizer_config.json` "
+ "file to suppress this warning: ",
+ FutureWarning,
+ )
+
+ feature_extractor = SeamlessM4TFeatureExtractor.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
+
+ return cls(feature_extractor=feature_extractor, tokenizer=tokenizer)
+
+ def __call__(self, audio=None, text=None, **kwargs):
+ """
+ Main method to prepare for the model one or several sequences(s) and audio(s). This method forwards the `audio`
+ and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.__call__`] if `audio` is not
+ `None` to pre-process the audio. To prepare the target sequences(s), this method forwards the `text` and `kwargs` arguments to
+ PreTrainedTokenizer's [`~PreTrainedTokenizer.__call__`] if `text` is not `None`. Please refer to the doctsring of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ audio (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The audio or batch of audios to be prepared. Each audio can be NumPy array or PyTorch tensor. In case
+ of a NumPy array/PyTorch tensor, each audio should be of shape (C, T), where C is a number of channels,
+ and T the sample length of the audio.
+ kwargs (*optional*):
+ Remaining dictionary of keyword arguments that will be passed to the feature extractor and/or the
+ tokenizer.
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+ - **input_features** -- Audio input features to be fed to a model. Returned when `audio` is not `None`.
+ - **attention_mask** -- List of indices specifying which timestamps should be attended to by the model when `audio` is not `None`.
+ When only `text` is specified, returns the token attention mask.
+ - **labels** -- List of token ids to be fed to a model. Returned when both `text` and `audio` are not `None`.
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None` and `audio` is `None`.
+ """
+
+ sampling_rate = kwargs.pop("sampling_rate", None)
+
+ if audio is None and text is None:
+ raise ValueError("You need to specify either an `audio` or `text` input to process.")
+
+ if audio is not None:
+ inputs = self.feature_extractor(audio, sampling_rate=sampling_rate, **kwargs)
+ if text is not None:
+ encodings = self.tokenizer(text, **kwargs)
+
+ if text is None:
+ return inputs
+ elif audio is None:
+ return encodings
+ else:
+ inputs["labels"] = encodings["input_ids"]
+ return inputs
+
+ def pad(self, input_features=None, labels=None, **kwargs):
+ """
+ If `input_features` is not `None`, this method forwards the `input_features` and `kwargs` arguments to SeamlessM4TFeatureExtractor's [`~SeamlessM4TFeatureExtractor.pad`] to pad the input features.
+ If `labels` is not `None`, this method forwards the `labels` and `kwargs` arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.pad`] to pad the label(s).
+ Please refer to the doctsring of the above two methods for more information.
+ """
+ if input_features is None and labels is None:
+ raise ValueError("You need to specify either an `input_features` or `labels` input to pad.")
+
+ if input_features is not None:
+ input_features = self.feature_extractor.pad(input_features, **kwargs)
+ if labels is not None:
+ labels = self.tokenizer.pad(labels, **kwargs)
+
+ if labels is None:
+ return input_features
+ elif input_features is None:
+ return labels
+ else:
+ input_features["labels"] = labels["input_ids"]
+ return input_features
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer
+ to the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/transformers/models/whisper/generation_whisper.py b/src/transformers/models/whisper/generation_whisper.py
new file mode 100644
index 00000000000000..c45fffb984b113
--- /dev/null
+++ b/src/transformers/models/whisper/generation_whisper.py
@@ -0,0 +1,1493 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import math
+import warnings
+import zlib
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ...generation.configuration_utils import GenerationConfig
+from ...generation.logits_process import (
+ ForceTokensLogitsProcessor,
+ LogitsProcessorList,
+ SuppressTokensAtBeginLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+ WhisperNoSpeechDetection,
+ WhisperTimeStampLogitsProcessor,
+)
+from ...generation.stopping_criteria import StoppingCriteriaList
+from ...modeling_outputs import BaseModelOutput
+from ...utils import logging
+from .tokenization_whisper import TASK_IDS, TO_LANGUAGE_CODE
+
+
+logger = logging.get_logger(__name__)
+
+
+def _median_filter(inputs: torch.Tensor, filter_width: int) -> torch.Tensor:
+ """
+ Applies a median filter of width `filter_width` along the last dimension of the input.
+
+ The `inputs` tensor is assumed to be 3- or 4-dimensional.
+ """
+ if filter_width <= 0 or filter_width % 2 != 1:
+ raise ValueError("`filter_width` should be an odd number")
+
+ pad_width = filter_width // 2
+ if inputs.shape[-1] <= pad_width:
+ return inputs
+
+ # Pad the left and right edges.
+ inputs = nn.functional.pad(inputs, (pad_width, pad_width, 0, 0), mode="reflect")
+
+ # sort() is faster than torch.median (https://github.com/pytorch/pytorch/issues/51450)
+ result = inputs.unfold(-1, filter_width, 1).sort()[0][..., pad_width]
+ return result
+
+
+def _dynamic_time_warping(matrix: np.ndarray):
+ """
+ Measures similarity between two temporal sequences: the input audio and the output tokens. Used to generate
+ token-level timestamps.
+ """
+ output_length, input_length = matrix.shape
+ cost = np.ones((output_length + 1, input_length + 1), dtype=np.float32) * np.inf
+ trace = -np.ones((output_length + 1, input_length + 1), dtype=np.float32)
+
+ cost[0, 0] = 0
+ for j in range(1, input_length + 1):
+ for i in range(1, output_length + 1):
+ c0 = cost[i - 1, j - 1]
+ c1 = cost[i - 1, j]
+ c2 = cost[i, j - 1]
+
+ if c0 < c1 and c0 < c2:
+ c, t = c0, 0
+ elif c1 < c0 and c1 < c2:
+ c, t = c1, 1
+ else:
+ c, t = c2, 2
+
+ cost[i, j] = matrix[i - 1, j - 1] + c
+ trace[i, j] = t
+
+ # backtrace
+ i = trace.shape[0] - 1
+ j = trace.shape[1] - 1
+ trace[0, :] = 2
+ trace[:, 0] = 1
+
+ text_indices = []
+ time_indices = []
+ while i > 0 or j > 0:
+ text_indices.append(i - 1)
+ time_indices.append(j - 1)
+ if trace[i, j] == 0:
+ i -= 1
+ j -= 1
+ elif trace[i, j] == 1:
+ i -= 1
+ elif trace[i, j] == 2:
+ j -= 1
+ else:
+ raise RuntimeError(
+ f"Internal error in dynamic time warping. Unexpected trace[{i}, {j}]. Please file a bug report."
+ )
+
+ text_indices = np.array(text_indices)[::-1]
+ time_indices = np.array(time_indices)[::-1]
+ return text_indices, time_indices
+
+
+def _get_attr_from_logit_processors(logits_processor, logit_processor_class, attribute_name):
+ logit_processor = next((cls for cls in logits_processor if isinstance(cls, logit_processor_class)), None)
+ if logit_processor:
+ return getattr(logit_processor, attribute_name, None)
+ return None
+
+
+def _pad_to_max_length(current_segments, pad_token_id, padding="right", bos_token_tensor=None, cut_off_length=None):
+ max_total_length = 0
+ sequences = []
+ if padding not in ["right", "left"]:
+ raise ValueError(f"`padding` must be either 'right' or 'left', not {padding}")
+
+ for current_segment_list in current_segments:
+ if current_segment_list is not None and len([d["tokens"] for d in current_segment_list]) > 0:
+ sequence = torch.cat([d["tokens"] for d in current_segment_list], dim=-1)
+
+ if cut_off_length is not None:
+ sequence = sequence[-cut_off_length:]
+
+ if bos_token_tensor is not None:
+ sequence = torch.cat([bos_token_tensor, sequence])
+
+ sequences.append(sequence)
+ max_total_length = max(max_total_length, len(sequences[-1]))
+ else:
+ sequences.append(bos_token_tensor)
+
+ for i in range(len(current_segments)):
+ pad_length = max_total_length - len(sequences[i])
+ pad = (0, pad_length) if padding == "right" else (pad_length, 0)
+ sequences[i] = F.pad(sequences[i], pad=pad, value=pad_token_id)
+
+ sequences = torch.stack(sequences, dim=0)
+ return sequences
+
+
+class WhisperGenerationMixin:
+ def _extract_token_timestamps(self, generate_outputs, alignment_heads, time_precision=0.02, num_frames=None):
+ """
+ Calculates token-level timestamps using the encoder-decoder cross-attentions and dynamic time-warping (DTW) to
+ map each output token to a position in the input audio. If `num_frames` is specified, the encoder-decoder
+ cross-attentions will be cropped before applying DTW.
+
+ Returns:
+ tensor containing the timestamps in seconds for each predicted token
+ """
+ # Create a list with `decoder_layers` elements, each a tensor of shape
+ # (batch size, attention_heads, output length, input length).
+ cross_attentions = []
+ for i in range(self.config.decoder_layers):
+ cross_attentions.append(torch.cat([x[i] for x in generate_outputs.cross_attentions], dim=2))
+
+ # Select specific cross-attention layers and heads. This is a tensor
+ # of shape (batch size, num selected, output length, input length).
+ weights = torch.stack([cross_attentions[l][:, h] for l, h in alignment_heads])
+ weights = weights.permute([1, 0, 2, 3])
+
+ if "beam_indices" in generate_outputs:
+ # If beam search has been used, the output sequences may have been generated for more timesteps than their sequence_lengths
+ # since the beam search strategy chooses the most probable sequences at the end of the search.
+ # In that case, the cross_attentions weights are too long and we have to make sure that they have the right output_length
+ weight_length = (generate_outputs.beam_indices != -1).sum(-1).max()
+ weights = weights[:, :, :weight_length]
+
+ # If beam index is still -1, it means that the associated token id is EOS
+ # We need to replace the index with 0 since index_select gives an error if any of the indexes is -1.
+ beam_indices = generate_outputs.beam_indices[:, :weight_length]
+ beam_indices = beam_indices.masked_fill(beam_indices == -1, 0)
+
+ # Select the cross attention from the right beam for each output sequences
+ weights = torch.stack(
+ [
+ torch.index_select(weights[:, :, i, :], dim=0, index=beam_indices[:, i])
+ for i in range(beam_indices.shape[1])
+ ],
+ dim=2,
+ )
+
+ timestamps = torch.zeros_like(generate_outputs.sequences, dtype=torch.float32)
+ batch_size = timestamps.shape[0]
+
+ if num_frames is not None:
+ # two cases:
+ # 1. num_frames is the same for each sample -> compute the DTW matrix for each sample in parallel
+ # 2. num_frames is different, compute the DTW matrix for each sample sequentially
+
+ # we're using np.unique because num_frames can be int/list/tuple
+ if len(np.unique(num_frames)) == 1:
+ # if num_frames is the same, no need to recompute matrix, std and mean for each element of the batch
+ num_frames = num_frames if isinstance(num_frames, int) else num_frames[0]
+
+ weights = weights[..., : num_frames // 2]
+ else:
+ # num_frames is of shape (batch_size,) whereas batch_size is truely batch_size*num_return_sequences
+ repeat_time = batch_size if isinstance(num_frames, int) else batch_size // len(num_frames)
+ num_frames = np.repeat(num_frames, repeat_time)
+
+ if num_frames is None or isinstance(num_frames, int):
+ # Normalize and smoothen the weights.
+ std = torch.std(weights, dim=-2, keepdim=True, unbiased=False)
+ mean = torch.mean(weights, dim=-2, keepdim=True)
+ weights = (weights - mean) / std
+ weights = _median_filter(weights, self.config.median_filter_width)
+
+ # Average the different cross-attention heads.
+ weights = weights.mean(dim=1)
+
+ # Perform dynamic time warping on each element of the batch.
+ for batch_idx in range(batch_size):
+ if num_frames is not None and isinstance(num_frames, (tuple, list, np.ndarray)):
+ matrix = weights[batch_idx, ..., : num_frames[batch_idx] // 2]
+
+ # Normalize and smoothen the weights.
+ std = torch.std(matrix, dim=-2, keepdim=True, unbiased=False)
+ mean = torch.mean(matrix, dim=-2, keepdim=True)
+ matrix = (matrix - mean) / std
+ matrix = _median_filter(matrix, self.config.median_filter_width)
+
+ # Average the different cross-attention heads.
+ matrix = matrix.mean(dim=0)
+ else:
+ matrix = weights[batch_idx]
+
+ text_indices, time_indices = _dynamic_time_warping(-matrix.cpu().double().numpy())
+ jumps = np.pad(np.diff(text_indices), (1, 0), constant_values=1).astype(bool)
+ jump_times = time_indices[jumps] * time_precision
+ timestamps[batch_idx, 1:] = torch.tensor(jump_times)
+
+ return timestamps
+
+ def generate(
+ self,
+ input_features: Optional[torch.Tensor] = None,
+ generation_config: Optional[GenerationConfig] = None,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
+ synced_gpus: bool = False,
+ return_timestamps: Optional[bool] = None,
+ task: Optional[str] = None,
+ language: Optional[str] = None,
+ is_multilingual: Optional[bool] = None,
+ prompt_ids: Optional[torch.Tensor] = None,
+ condition_on_prev_tokens: Optional[bool] = None,
+ temperature: Optional[Union[float, Tuple[float, ...]]] = None,
+ compression_ratio_threshold: Optional[float] = None,
+ logprob_threshold: Optional[float] = None,
+ no_speech_threshold: Optional[float] = None,
+ num_segment_frames: Optional[int] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ time_precision: float = 0.02,
+ return_token_timestamps: Optional[bool] = None,
+ return_segments: bool = False,
+ return_dict_in_generate: Optional[bool] = None,
+ **kwargs,
+ ):
+ """
+ Transcribes or translates log-mel input features to a sequence of auto-regressively generated token ids.
+
+
+
+ Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
+ model's default generation configuration. You can override any `generation_config` by passing the corresponding
+ parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
+
+ For an overview of generation strategies and code examples, check out the [following
+ guide](./generation_strategies).
+
+
+
+ Parameters:
+ input_features (`torch.Tensor` of shape `(batch_size, feature_size, sequence_length)`, *optional*):
+ Float values of log-mel features extracted from the raw speech waveform. The raw speech waveform can be obtained by
+ loading a `.flac` or `.wav` audio file into an array of type `List[float]` or a `numpy.ndarray`, *e.g.* via
+ the soundfile library (`pip install soundfile`). To prepare the array into `input_features`, the
+ [`AutoFeatureExtractor`] should be used for extracting the mel features, padding and conversion into a
+ tensor of type `torch.FloatTensor`. See [`~WhisperFeatureExtractor.__call__`] for details.
+ generation_config (`~generation.GenerationConfig`, *optional*):
+ The generation configuration to be used as base parametrization for the generation call. `**kwargs`
+ passed to generate matching the attributes of `generation_config` will override them. If
+ `generation_config` is not provided, the default will be used, which had the following loading
+ priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
+ configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
+ default values, whose documentation should be checked to parameterize generation.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ Custom logits processors that complement the default logits processors built from arguments and
+ generation config. If a logit processor is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ Custom stopping criteria that complement the default stopping criteria built from arguments and a
+ generation config. If a stopping criteria is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
+ If provided, this function constraints the beam search to allowed tokens only at each step. If not
+ provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
+ `input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
+ on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
+ for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
+ Retrieval](https://arxiv.org/abs/2010.00904).
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ return_timestamps (`bool`, *optional*):
+ Whether to return the timestamps with the text. This enables the `WhisperTimestampsLogitsProcessor`.
+ task (`str`, *optional*):
+ Task to use for generation, either "translate" or "transcribe". The `model.config.forced_decoder_ids`
+ will be updated accordingly.
+ language (`str`, *optional*):
+ Language token to use for generation, can be either in the form of `<|en|>`, `en` or `english`. You can
+ find all the possible language tokens in the `model.generation_config.lang_to_id` dictionary.
+ is_multilingual (`bool`, *optional*):
+ Whether or not the model is multilingual.
+ prompt_ids (`torch.Tensor`, *optional*):
+ Rank-1 tensor of token IDs created by passing text to [`~WhisperProcessor.get_prompt_ids`] that is
+ provided as a prompt to each chunk. This can be used to provide or "prompt-engineer" a context for
+ transcription, e.g. custom vocabularies or proper nouns to make it more likely to predict those words
+ correctly. It cannot be used in conjunction with `decoder_start_token_id` as it overwrites this value.
+ condition_on_prev_tokens (`bool`, *optional*):
+ Only relevant for long-form transcription. Whether to condition each segment on the previous segment.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ temperature (`float` or list of `float`, *optional*):
+ The temperature to be used for generation. Passing a single `float` value and `do_sample=True` activates
+ generation using sampling. For long-form transcription, temperature fallback can be activated by passing
+ a list of float values such as (0.0, 0.2, 0.4, 0.6, 0.8, 1.0). As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ compression_ratio_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the zlib compression rate of each segment will be computed. If the compression rate of
+ a segment is higher than `compression_ratio_threshold`, temperature fallback is activated: the generated segment is discarded and the generation is
+ repeated using a higher temperature. The intuition behind this feature is that segments with very high compression rates
+ suffer from a lot of repetition. The unwanted repetition can be reduced by injecting more randomness by increasing the temperature. If `compression_ratio_threshold` is defined
+ make sure that `temperature` is a list of values. A common value for `compression_ratio_threshold` is 1.35.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ logprob_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the average log-probability of each segment will be computed. If the log-probability of
+ a given segment is lower than `logprob_threshold`, temperature fallback is activated: the generated segment is discarded and the generation is
+ repeated using a higher temperature. The intuition behind this feature is that segments of low log-probability
+ can be improved by injecting more randomness by increasing the temperature. If `logprob_threshold` is defined
+ make sure that `temperature` is a list of values. A common value for `logprob_threshold` is -1.0.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ no_speech_threshold (`float`, *optional*):
+ Only relevant for long-form transcription. If defined, the "no-speech" token combined with the `logprob_threshold`
+ is used to determine whether a segment contains only silence. In this case, the transcription for this segment
+ is skipped.
+ As shown in the [the Whisper paper](https://cdn.openai.com/papers/whisper.pdf), this can help to improve
+ performance.
+ num_segment_frames (`int`, *optional*):
+ The number of frames a single segment is made of. If not defined, `num_segment_frames` defaults to the model's stride
+ times the maximum input length.
+ attention_mask (`torch.Tensor`, *optional*):
+ `attention_mask` needs to be passed when doing long-form transcription using a batch size > 1.
+ time_precision (`int`, *optional*, defaults to 0.02):
+ The duration of output token in seconds. *E.g.* 0.02 means that a generated token on average accounts
+ for 20 ms.
+ return_token_timestamps (`bool`, *optional*):
+ Whether to return token-level timestamps with the text. This can be used with or without the
+ `return_timestamps` option. To get word-level timestamps, use the tokenizer to group the tokens into
+ words.
+ return_segments (`bool`, *optional*, defaults to `False`):
+ Whether to additionally return a list of all segments. Note that this option can only be enabled
+ when doing long-form transcription.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of just returning the generated tokens.
+ Note that when doing long-form transcription, `return_dict_in_generate` can only be enabled when
+ `return_segments` is set True. In this case the generation outputs of each segment is added to each
+ segment.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
+ forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
+ specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
+
+ Return:
+ [`~utils.ModelOutput`] or `torch.LongTensor` or `Dict[str, Any]`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
+ or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor` or a dict of segments when `return_segments=True`.
+
+ If the passed input is > 30 seconds / > 3000 mel input features and `return_segments=True` then a dictionary of generated sequence ids, called `sequences` and a list of each generated segment is returned.
+
+ else if the passed input is <= 30 seconds / >= 3000 mel input features, the possible [`~utils.ModelOutput`] types are:
+
+ - [`~generation.GenerateEncoderDecoderOutput`],
+ - [`~generation.GenerateBeamEncoderDecoderOutput`]
+
+ else only the generated output sequence ids are returned.
+
+ Example:
+
+ - *Longform transcription*: To transcribe or translate audios longer than 30 seconds, process the audio files without truncation and pass all mel features at once to generate.
+
+ ```python
+ >>> import torch
+ >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
+ >>> from datasets import load_dataset, Audio
+
+ >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
+ >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ >>> model.cuda()
+
+ >>> # load audios > 30 seconds
+ >>> ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
+ >>> # resample to 16kHz
+ >>> ds = ds.cast_column("audio", Audio(sampling_rate=16000))
+ >>> # take first 8 audios and retrieve array
+ >>> audio = ds[:8]["audio"]
+ >>> audio = [x["array"] for x in audio]
+
+ >>> # make sure to NOT truncate the input audio, to return the `attention_mask` and to pad to the longest audio
+ >>> inputs = processor(audio, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True, sampling_rate=16_000)
+ >>> inputs = inputs.to("cuda", torch.float32)
+
+ >>> # transcribe audio to ids
+ >>> generated_ids = model.generate(**inputs)
+
+ >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ >>> transcription[0]
+ ' Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!'
+ ```
+
+ - *Shortform transcription*: If passed mel input features are < 30 seconds, the whole audio will be transcribed with a single call to generate.
+
+ ```python
+ >>> import torch
+ >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
+ >>> from datasets import load_dataset
+
+ >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
+ >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+
+ >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+
+ >>> inputs = processor(ds[0]["audio"]["array"], return_tensors="pt")
+ >>> input_features = inputs.input_features
+
+ >>> generated_ids = model.generate(inputs=input_features)
+
+ >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+ >>> transcription
+ ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
+ ```
+
+ """
+ # 0. deprecate old inputs
+ if "inputs" in kwargs:
+ input_features = kwargs.pop("inputs")
+ warnings.warn(
+ "The input name `inputs` is deprecated. Please make sure to use `input_features` instead.",
+ FutureWarning,
+ )
+ # 1. copy generation config
+ if generation_config is None:
+ generation_config = copy.deepcopy(self.generation_config)
+ else:
+ generation_config = copy.deepcopy(generation_config)
+
+ # 2. set global generate variables
+ input_stride = self.model.encoder.conv1.stride[0] * self.model.encoder.conv2.stride[0]
+ num_segment_frames = input_stride * self.config.max_source_positions
+ total_input_frames = self._retrieve_total_input_frames(
+ input_features=input_features, input_stride=input_stride, kwargs=kwargs
+ )
+ is_shortform = total_input_frames <= num_segment_frames
+
+ if is_shortform:
+ # warn user of ignored inputs
+ self._maybe_warn_unused_inputs(
+ condition_on_prev_tokens=condition_on_prev_tokens,
+ temperature=temperature,
+ compression_ratio_threshold=compression_ratio_threshold,
+ logprob_threshold=logprob_threshold,
+ no_speech_threshold=no_speech_threshold,
+ total_input_frames=total_input_frames,
+ )
+
+ # 3. Make sure generation config is correctly set
+ # Make sure the generation config is correctly set depending on whether timestamps are to be returned or not
+ self._set_return_outputs(
+ return_dict_in_generate=return_dict_in_generate,
+ return_token_timestamps=return_token_timestamps,
+ is_shortform=is_shortform,
+ logprob_threshold=logprob_threshold,
+ generation_config=generation_config,
+ )
+ self._set_return_timestamps(
+ return_timestamps=return_timestamps, is_shortform=is_shortform, generation_config=generation_config
+ )
+ self._set_language_and_task(
+ language=language, task=task, is_multilingual=is_multilingual, generation_config=generation_config
+ )
+ # pass self.config for backward compatibility
+ self._set_forced_decoder_ids(
+ task=task,
+ language=language,
+ prompt_ids=prompt_ids,
+ generation_config=generation_config,
+ config=self.config,
+ kwargs=kwargs,
+ )
+ self._set_token_ids(generation_config=generation_config, config=self.config, kwargs=kwargs)
+ self._set_num_frames(
+ return_token_timestamps=return_token_timestamps, generation_config=generation_config, kwargs=kwargs
+ )
+ self._set_thresholds_and_condition(
+ generation_config=generation_config,
+ logprob_threshold=logprob_threshold,
+ compression_ratio_threshold=compression_ratio_threshold,
+ no_speech_threshold=no_speech_threshold,
+ condition_on_prev_tokens=condition_on_prev_tokens,
+ )
+
+ # 4. Retrieve logits processors
+ logits_processor = self._retrieve_logit_processors(
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ no_speech_threshold=no_speech_threshold,
+ is_shortform=is_shortform,
+ num_beams=kwargs.get("num_beams", 1),
+ )
+
+ # 5. If we're in shortform mode, simple generate the whole input at once and return the output
+ if is_shortform:
+ if temperature is not None:
+ kwargs["temperature"] = temperature
+
+ outputs = super().generate(
+ input_features,
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ synced_gpus=synced_gpus,
+ **kwargs,
+ )
+
+ if generation_config.return_token_timestamps and hasattr(generation_config, "alignment_heads"):
+ outputs["token_timestamps"] = self._extract_token_timestamps(
+ outputs, generation_config.alignment_heads, num_frames=generation_config.num_frames
+ )
+
+ return outputs
+
+ # 6. Else we're in longform mode which is more complex.
+ # We need to chunk the audio input depending on when the model generates timestamp tokens
+
+ # 6.1 Set and retrieve global longform generation variables
+ self._set_condition_on_prev_tokens(
+ condition_on_prev_tokens=condition_on_prev_tokens, generation_config=generation_config
+ )
+
+ timestamp_begin = generation_config.no_timestamps_token_id + 1
+ temperatures = [temperature] if not isinstance(temperature, (list, tuple)) else temperature
+ temperature = temperatures[0]
+ batch_size = input_features.shape[0]
+
+ max_frames, seek = self._retrieve_max_frames_and_seek(
+ batch_size=batch_size, attention_mask=attention_mask, total_input_frames=total_input_frames
+ )
+ init_tokens = self._retrieve_init_tokens_from_forced_decoder_ids(generation_config=generation_config)
+
+ # 6.2 Preppare running variables, list for generation
+ cur_bsz = batch_size
+ current_segments = [[] for _ in range(batch_size)]
+ batch_idx_map = list(range(batch_size))
+ do_condition_on_prev_tokens = [condition_on_prev_tokens for _ in range(batch_size)]
+
+ # 6.2 Transcribe audio until we reach the end of all input audios
+ while (seek < max_frames).any():
+ # 6.3 NOTE: When in longform transcription mode and batch size > 1 we need to dynamically reduce the batch size during the loop
+ # in case one audio finished earlier than another one. Thus, we need to keep a table of "previous-index-2-current-index" in order
+ # to know which original audio is being decoded
+ # Set updated index map, duration of previously decoded chunks and number of max frames of current decoding chunk
+ input_features, cur_bsz, batch_idx_map = self._maybe_reduce_batch(
+ input_features=input_features,
+ seek=seek,
+ max_frames=max_frames,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ )
+ time_offset = seek * time_precision / input_stride
+ seek_num_frames = (max_frames - seek).clamp(max=num_segment_frames)
+
+ # 6.4 cut out next 30s segment from input features
+ segment_input = self._get_input_segment(
+ input_features=input_features,
+ seek=seek,
+ seek_num_frames=seek_num_frames,
+ num_segment_frames=num_segment_frames,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ )
+
+ # 6.5 prepare decoder input ids
+ suppress_tokens = _get_attr_from_logit_processors(
+ logits_processor, SuppressTokensLogitsProcessor, "suppress_tokens"
+ )
+ decoder_input_ids, kwargs = self._prepare_decoder_input_ids(
+ cur_bsz=cur_bsz,
+ init_tokens=init_tokens,
+ current_segments=current_segments,
+ batch_idx_map=batch_idx_map,
+ do_condition_on_prev_tokens=do_condition_on_prev_tokens,
+ generation_config=generation_config,
+ config=self.config,
+ device=segment_input.device,
+ suppress_tokens=suppress_tokens,
+ kwargs=kwargs,
+ )
+
+ # 6.6 set max new tokens or max length
+ kwargs = self._set_max_new_tokens_and_length(
+ config=self.config,
+ decoder_input_ids=decoder_input_ids,
+ generation_config=generation_config,
+ kwargs=kwargs,
+ )
+
+ # 6.7 Set current `begin_index` for all logit processors
+ for proc in logits_processor:
+ if hasattr(proc, "set_begin_index"):
+ proc.set_begin_index(decoder_input_ids.shape[-1])
+
+ # 6.8 Run generate with fallback
+ seek_sequences, seek_outputs, should_skip, do_condition_on_prev_tokens = self.generate_with_fallback(
+ segment_input=segment_input,
+ decoder_input_ids=decoder_input_ids,
+ cur_bsz=cur_bsz,
+ batch_idx_map=batch_idx_map,
+ seek=seek,
+ num_segment_frames=num_segment_frames,
+ max_frames=max_frames,
+ temperatures=temperatures,
+ generation_config=generation_config,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ synced_gpus=synced_gpus,
+ return_token_timestamps=return_token_timestamps,
+ do_condition_on_prev_tokens=do_condition_on_prev_tokens,
+ kwargs=kwargs,
+ )
+
+ # 6.9 In every generated sequence, split by timestamp tokens and extract segments
+ for i, seek_sequence in enumerate(seek_sequences):
+ prev_i = batch_idx_map[i]
+
+ if should_skip[i]:
+ seek[prev_i] += seek_num_frames[prev_i]
+ continue
+
+ segments, segment_offset = self._retrieve_segment(
+ seek_sequence=seek_sequence,
+ seek_outputs=seek_outputs,
+ time_offset=time_offset,
+ timestamp_begin=timestamp_begin,
+ seek_num_frames=seek_num_frames,
+ time_precision=time_precision,
+ input_stride=input_stride,
+ prev_idx=prev_i,
+ idx=i,
+ )
+
+ current_segments[prev_i] += segments
+ seek[prev_i] += segment_offset
+
+ # 7. Once all segments are added to the list of all segments, called `current_segments`, we extract the predicted
+ # output tokens from the list of dicts. If we use batch size > 1, we make sure to pad the output
+ sequences = _pad_to_max_length(current_segments, generation_config.pad_token_id, padding="right")
+
+ # 8. If we return all segments, the predicted output sequences are put under `"sequences"`.
+ if return_segments:
+ return {"sequences": sequences, "segments": current_segments}
+
+ return sequences
+
+ def generate_with_fallback(
+ self,
+ segment_input,
+ decoder_input_ids,
+ cur_bsz,
+ batch_idx_map,
+ seek,
+ num_segment_frames,
+ max_frames,
+ temperatures,
+ generation_config,
+ logits_processor,
+ stopping_criteria,
+ prefix_allowed_tokens_fn,
+ synced_gpus,
+ return_token_timestamps,
+ do_condition_on_prev_tokens,
+ kwargs,
+ ):
+ # 6.6 Batch generate current chunk
+ seek_sequence_list = [None for _ in range(cur_bsz)]
+ seek_outputs_list = [None for _ in range(cur_bsz)]
+ needs_fallback = [False for _ in range(cur_bsz)]
+ should_skip = [False for _ in range(cur_bsz)]
+ fallback_index_map = list(range(cur_bsz))
+
+ if generation_config.no_speech_threshold is not None:
+ self._setup_no_speech_detection(logits_processor, segment_input, decoder_input_ids, kwargs)
+
+ for fallback_idx, temperature in enumerate(temperatures):
+ generation_config.do_sample = temperature is not None and temperature > 0.0
+ generation_config.temperature = temperature
+ generation_config.num_beams = kwargs.pop("num_beams", 1) if not generation_config.do_sample else 1
+
+ seek_outputs = super().generate(
+ segment_input,
+ generation_config,
+ logits_processor,
+ stopping_criteria,
+ prefix_allowed_tokens_fn,
+ synced_gpus,
+ decoder_input_ids=decoder_input_ids,
+ **kwargs,
+ )
+
+ # post-process sequence tokens and outputs to be in list form
+ sequence_tokens, seek_outputs = self._postprocess_outputs(
+ seek_outputs, return_token_timestamps, generation_config
+ )
+
+ # remove all previously passed decoder input ids
+ seek_sequences = sequence_tokens[:, decoder_input_ids.shape[-1] :]
+
+ # 6.7 Extract cut sequences from every sequence and check if fallback should be applied
+ # Loop over each decoded audio individually as each decoding can be of a different length
+ new_fallback_index_map = []
+ new_segment_input = []
+ new_decoder_input_ids = []
+ new_decoder_attention_mask = []
+
+ for i, seek_sequence in enumerate(seek_sequences):
+ # make sure we cut a predicted EOS token if we are not finished with the generation yet
+ prev_i = batch_idx_map[fallback_index_map[i]]
+ is_not_final = (seek[prev_i] + num_segment_frames) < max_frames[prev_i]
+
+ # remove eos token id
+ if is_not_final and seek_sequence[-1] == generation_config.eos_token_id:
+ seek_sequence = seek_sequence[:-1]
+
+ # remove all padding tokens
+ if seek_sequence[-1] == generation_config.pad_token_id:
+ num_paddings = (seek_sequence == generation_config.pad_token_id).sum()
+ seek_sequence = seek_sequence[:-num_paddings]
+
+ # check which sequences in batch need fallback & which should be skipped
+ needs_fallback[i], should_skip[i] = self._need_fallback(
+ seek_sequence,
+ seek_outputs,
+ i,
+ logits_processor,
+ generation_config,
+ self.config.vocab_size,
+ temperature,
+ )
+
+ seek_sequence_list[fallback_index_map[i]] = seek_sequence
+ seek_outputs_list[fallback_index_map[i]] = seek_outputs[i]
+ do_condition_on_prev_tokens[fallback_index_map[i]] = (
+ generation_config.condition_on_prev_tokens and temperature is not None and temperature < 0.5
+ )
+
+ if needs_fallback[i]:
+ new_fallback_index_map.append(fallback_index_map[i])
+ new_segment_input.append(segment_input[i])
+ new_decoder_input_ids.append(decoder_input_ids[i])
+ if "decoder_attention_mask" in kwargs:
+ new_decoder_attention_mask.append(kwargs["decoder_attention_mask"][i])
+
+ fallback_index_map = new_fallback_index_map
+
+ # if no sequence needs to be run with temperature fallback, we're finished
+ if len(fallback_index_map) == 0 or fallback_idx == len(temperatures) - 1:
+ seek_sequences = seek_sequence_list
+ seek_outputs = seek_outputs_list
+ break
+
+ # if we're still in the loop, make sure that decoder_input_ids and segment inputs are tensors
+ decoder_input_ids = torch.stack(new_decoder_input_ids)
+ segment_input = torch.stack(new_segment_input)
+ if "decoder_attention_mask" in kwargs:
+ kwargs["decoder_attention_mask"] = torch.stack(new_decoder_attention_mask)
+
+ return seek_sequences, seek_outputs, should_skip, do_condition_on_prev_tokens
+
+ def _postprocess_outputs(self, seek_outputs, return_token_timestamps, generation_config):
+ if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
+ num_frames = getattr(generation_config, "num_frames", None)
+ seek_outputs["token_timestamps"] = self._extract_token_timestamps(
+ seek_outputs, generation_config.alignment_heads, num_frames=num_frames
+ )
+
+ if generation_config.return_dict_in_generate:
+
+ def split_by_batch_index(values, key, batch_idx):
+ if key == "scores":
+ return [v[batch_idx].cpu() for v in values]
+ if key == "past_key_values":
+ # we don't save `past_key_values` as this is too costly
+ return None
+ return values[batch_idx].cpu()
+
+ sequence_tokens = seek_outputs["sequences"]
+ seek_outputs = [
+ {k: split_by_batch_index(v, k, i) for k, v in seek_outputs.items()}
+ for i in range(sequence_tokens.shape[0])
+ ]
+ else:
+ sequence_tokens = seek_outputs
+
+ return sequence_tokens, seek_outputs
+
+ def _need_fallback(
+ self,
+ seek_sequence,
+ seek_outputs,
+ index,
+ logits_processor,
+ generation_config,
+ vocab_size,
+ temperature,
+ ):
+ needs_fallback = False
+ should_skip = False
+ if generation_config.compression_ratio_threshold is not None:
+ compression_ratio = self._retrieve_compression_ratio(seek_sequence, vocab_size)
+
+ if compression_ratio > generation_config.compression_ratio_threshold:
+ needs_fallback = True
+
+ if generation_config.logprob_threshold is not None:
+ if "sequences_scores" in seek_outputs[0]:
+ logprobs = [s["sequences_scores"] for s in seek_outputs][index]
+ else:
+ scores = seek_outputs[index]["scores"]
+ logprobs = self._retrieve_avg_logprobs(
+ scores, seek_sequence, generation_config.eos_token_id, temperature
+ )
+
+ if logprobs < generation_config.logprob_threshold:
+ needs_fallback = True
+
+ if generation_config.no_speech_threshold is not None:
+ no_speech_prob = _get_attr_from_logit_processors(
+ logits_processor, WhisperNoSpeechDetection, "no_speech_prob"
+ )
+
+ if (
+ logprobs < generation_config.logprob_threshold
+ and no_speech_prob[index] > generation_config.no_speech_threshold
+ ):
+ needs_fallback = False
+ should_skip = True
+
+ return needs_fallback, should_skip
+
+ @staticmethod
+ def _setup_no_speech_detection(logits_processor, segment_input, decoder_input_ids, kwargs):
+ set_inputs = _get_attr_from_logit_processors(logits_processor, WhisperNoSpeechDetection, "set_inputs")
+ extra_kwargs = {k: v for k, v in kwargs.items() if torch.is_tensor(v)}
+ set_inputs({"inputs": segment_input, "decoder_input_ids": decoder_input_ids, **extra_kwargs})
+
+ @staticmethod
+ def _retrieve_total_input_frames(input_features, input_stride, kwargs):
+ if input_features is not None:
+ return input_features.shape[-1]
+
+ if "encoder_outputs" in kwargs:
+ encoder_outputs_shape = (
+ kwargs["encoder_outputs"][0].shape
+ if isinstance(kwargs["encoder_outputs"], BaseModelOutput)
+ else kwargs["encoder_outputs"].shape
+ )
+ return encoder_outputs_shape[1] * input_stride
+
+ raise ValueError("Make sure to provide either `input_features` or `encoder_outputs` to `generate`.")
+
+ @staticmethod
+ def _maybe_warn_unused_inputs(
+ condition_on_prev_tokens,
+ temperature,
+ compression_ratio_threshold,
+ logprob_threshold,
+ no_speech_threshold,
+ total_input_frames,
+ ):
+ warning_prefix = (
+ f"Audio input consists of only {total_input_frames}. "
+ "Short-form transcription is activated."
+ "{}, but will be ignored."
+ )
+ if condition_on_prev_tokens is not None:
+ logger.warn(warning_prefix.format(f"condition_on_prev_tokens is set to {condition_on_prev_tokens}"))
+
+ if compression_ratio_threshold is not None:
+ logger.warn(warning_prefix.format(f"compression_ratio_threshold is set to {compression_ratio_threshold}"))
+
+ if logprob_threshold is not None:
+ logger.warn(warning_prefix.format(f"logprob_threshold is set to {logprob_threshold}"))
+
+ if no_speech_threshold is not None:
+ logger.warn(warning_prefix.format(f"no_speech_threshold is set to {no_speech_threshold}"))
+
+ # when passing temperature as a list it cannot just be ignored => throw error in this case
+ if isinstance(temperature, (list, tuple)):
+ raise ValueError(
+ f"Audio input consists of only {total_input_frames}. Short-form transcription is activated."
+ f"temperature cannot be set to {temperature} which can only be used for temperature fallback for long-form generation. Make sure to set `temperature` to a float value or `None` for short-form generation."
+ )
+
+ @staticmethod
+ def _set_return_outputs(
+ return_dict_in_generate, return_token_timestamps, is_shortform, logprob_threshold, generation_config
+ ):
+ if return_dict_in_generate is None:
+ return_dict_in_generate = generation_config.return_dict_in_generate
+
+ generation_config.return_token_timestamps = return_token_timestamps
+ if return_token_timestamps:
+ return_dict_in_generate = True
+ generation_config.output_attentions = True
+ generation_config.output_scores = True
+
+ if not is_shortform and logprob_threshold is not None:
+ return_dict_in_generate = True
+ generation_config.output_scores = True
+
+ generation_config.return_dict_in_generate = return_dict_in_generate
+
+ @staticmethod
+ def _set_return_timestamps(return_timestamps, is_shortform, generation_config):
+ if return_timestamps is True:
+ if not hasattr(generation_config, "no_timestamps_token_id"):
+ raise ValueError(
+ "You are trying to return timestamps, but the generation config is not properly set. "
+ "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
+ "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
+ )
+ generation_config.return_timestamps = True
+ elif not is_shortform:
+ if return_timestamps is False:
+ raise ValueError(
+ "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
+ "requires the model to predict timestamp tokens. Please either pass `return_timestamps=True` or make sure to pass no more than 3000 mel input features."
+ )
+
+ if not hasattr(generation_config, "no_timestamps_token_id"):
+ raise ValueError(
+ "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
+ "requires the generation config to have `no_timestamps_token_id` correctly. "
+ "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
+ "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
+ "or make sure to pass no more than 3000 mel input features."
+ )
+
+ logger.info("Setting `return_timestamps=True` for long-form generation.")
+ generation_config.return_timestamps = True
+ else:
+ generation_config.return_timestamps = False
+
+ @staticmethod
+ def _set_language_and_task(language, task, is_multilingual, generation_config):
+ if is_multilingual is not None:
+ if not hasattr(generation_config, "is_multilingual"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `is_multilingual` argument "
+ "to `generate`. Please update the generation config as per the instructions "
+ "https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ generation_config.is_multilingual = is_multilingual
+
+ if hasattr(generation_config, "is_multilingual") and not generation_config.is_multilingual:
+ if task is not None or language is not None:
+ raise ValueError(
+ "Cannot specify `task` or `language` for an English-only model. If the model is intended to be "
+ "multilingual, pass `is_multilingual=True` to generate, or update the generation config."
+ )
+
+ if language is not None:
+ if not hasattr(generation_config, "lang_to_id"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `language` argument "
+ "to `generate`. Either set the language using the `forced_decoder_ids` in the model config, "
+ "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ language = language.lower()
+ generation_config.language = language
+
+ if task is not None:
+ if not hasattr(generation_config, "task_to_id"):
+ raise ValueError(
+ "The generation config is outdated and is thus not compatible with the `task` argument "
+ "to `generate`. Either set the task using the `forced_decoder_ids` in the model config, "
+ "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
+ )
+ generation_config.task = task
+
+ @staticmethod
+ def _set_forced_decoder_ids(task, language, prompt_ids, generation_config, config, kwargs):
+ forced_decoder_ids = None
+ # Legacy code for backward compatibility
+ if hasattr(config, "forced_decoder_ids") and config.forced_decoder_ids is not None:
+ forced_decoder_ids = config.forced_decoder_ids
+ elif hasattr(generation_config, "forced_decoder_ids") and generation_config.forced_decoder_ids is not None:
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ else:
+ forced_decoder_ids = kwargs.pop("forced_decoder_ids", None)
+
+ if task is not None or language is not None or (forced_decoder_ids is None and prompt_ids is not None):
+ forced_decoder_ids = []
+ if hasattr(generation_config, "language"):
+ if generation_config.language in generation_config.lang_to_id.keys():
+ language_token = generation_config.language
+ elif generation_config.language in TO_LANGUAGE_CODE.keys():
+ language_token = f"<|{TO_LANGUAGE_CODE[generation_config.language]}|>"
+ elif generation_config.language in TO_LANGUAGE_CODE.values():
+ language_token = f"<|{generation_config.language}|>"
+ else:
+ is_language_code = len(generation_config.language) == 2
+ raise ValueError(
+ f"Unsupported language: {generation_config.language}. Language should be one of:"
+ f" {list(TO_LANGUAGE_CODE.values()) if is_language_code else list(TO_LANGUAGE_CODE.keys())}."
+ )
+ if language_token not in generation_config.lang_to_id:
+ raise ValueError(
+ f"{language_token} is not supported by this specific model as it is not in the `generation_config.lang_to_id`."
+ "(You should just add it to the generation config)"
+ )
+ forced_decoder_ids.append((1, generation_config.lang_to_id[language_token]))
+ else:
+ forced_decoder_ids.append((1, None)) # automatically detect the language
+
+ if hasattr(generation_config, "task"):
+ if generation_config.task in TASK_IDS:
+ forced_decoder_ids.append((2, generation_config.task_to_id[generation_config.task]))
+ else:
+ raise ValueError(
+ f"The `{generation_config.task}`task is not supported. The task should be one of `{TASK_IDS}`"
+ )
+ elif hasattr(generation_config, "task_to_id"):
+ forced_decoder_ids.append((2, generation_config.task_to_id["transcribe"])) # defaults to transcribe
+ if hasattr(generation_config, "no_timestamps_token_id") and not generation_config.return_timestamps:
+ idx = forced_decoder_ids[-1][0] + 1 if forced_decoder_ids else 1
+ forced_decoder_ids.append((idx, generation_config.no_timestamps_token_id))
+
+ if forced_decoder_ids is not None:
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ if prompt_ids is not None:
+ if kwargs.get("decoder_start_token_id") is not None:
+ raise ValueError(
+ "When specifying `prompt_ids`, you cannot also specify `decoder_start_token_id` as it gets overwritten."
+ )
+ prompt_ids = prompt_ids.tolist()
+ decoder_start_token_id, *text_prompt_ids = prompt_ids
+ # Slicing the text prompt ids in a manner consistent with the OpenAI implementation
+ # to accomodate context space for the prefix (see https://github.com/openai/whisper/blob/c09a7ae299c4c34c5839a76380ae407e7d785914/whisper/decoding.py#L599)
+ text_prompt_ids = text_prompt_ids[-config.max_target_positions // 2 - 1 :]
+ # Set the decoder_start_token_id to <|startofprev|>
+ kwargs.update({"decoder_start_token_id": decoder_start_token_id})
+
+ # If the user passes `max_new_tokens`, increase its number to account for the prompt
+ if kwargs.get("max_new_tokens", None) is not None:
+ kwargs["max_new_tokens"] += len(text_prompt_ids)
+ if kwargs["max_new_tokens"] >= config.max_target_positions:
+ raise ValueError(
+ f"The length of the sliced `prompt_ids` is {len(text_prompt_ids)}, and the `max_new_tokens` "
+ f"{kwargs['max_new_tokens'] - len(text_prompt_ids)}. Thus, the combined length of the sliced "
+ f"`prompt_ids` and `max_new_tokens` is: {kwargs['max_new_tokens']}. This exceeds the "
+ f"`max_target_positions` of the Whisper model: {config.max_target_positions}. "
+ "You should either reduce the length of your prompt, or reduce the value of `max_new_tokens`, "
+ f"so that their combined length is less that {config.max_target_positions}."
+ )
+
+ # Reformat the forced_decoder_ids to incorporate the prompt
+ non_prompt_forced_decoder_ids = (
+ kwargs.pop("forced_decoder_ids", None) or generation_config.forced_decoder_ids
+ )
+ forced_decoder_ids = [
+ *text_prompt_ids,
+ generation_config.decoder_start_token_id,
+ *[token for _, token in non_prompt_forced_decoder_ids],
+ ]
+ forced_decoder_ids = [(rank + 1, token) for rank, token in enumerate(forced_decoder_ids)]
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ @staticmethod
+ def _set_token_ids(generation_config, config, kwargs):
+ eos_token_id = kwargs.pop("eos_token_id", None)
+ decoder_start_token_id = kwargs.pop("decoder_start_token_id", None)
+
+ eos_token_id = eos_token_id if eos_token_id is not None else generation_config.eos_token_id
+ decoder_start_token_id = (
+ decoder_start_token_id if decoder_start_token_id is not None else generation_config.decoder_start_token_id
+ )
+
+ generation_config.eos_token_id = eos_token_id if eos_token_id is not None else config.eos_token_id
+ generation_config.decoder_start_token_id = (
+ decoder_start_token_id if decoder_start_token_id is not None else config.decoder_start_token_id
+ )
+
+ @staticmethod
+ def _set_num_frames(return_token_timestamps, generation_config, kwargs):
+ if return_token_timestamps:
+ if getattr(generation_config, "task", None) == "translate":
+ logger.warning("Token-level timestamps may not be reliable for task 'translate'.")
+ if not hasattr(generation_config, "alignment_heads"):
+ raise ValueError(
+ "Model generation config has no `alignment_heads`, token-level timestamps not available. "
+ "See https://gist.github.com/hollance/42e32852f24243b748ae6bc1f985b13a on how to add this property to the generation config."
+ )
+
+ generation_config.num_frames = kwargs.pop("num_frames", None)
+
+ @staticmethod
+ def _set_thresholds_and_condition(
+ generation_config,
+ logprob_threshold,
+ compression_ratio_threshold,
+ no_speech_threshold,
+ condition_on_prev_tokens,
+ ):
+ generation_config.logprob_threshold = (
+ logprob_threshold
+ if logprob_threshold is not None
+ else getattr(generation_config, "logprob_threshold", None)
+ )
+ generation_config.compression_ratio_threshold = (
+ compression_ratio_threshold
+ if compression_ratio_threshold is not None
+ else getattr(generation_config, "compression_ratio_threshold", None)
+ )
+ generation_config.no_speech_threshold = (
+ no_speech_threshold
+ if no_speech_threshold is not None
+ else getattr(generation_config, "no_speech_threshold", None)
+ )
+ generation_config.condition_on_prev_tokens = (
+ condition_on_prev_tokens
+ if condition_on_prev_tokens is not None
+ else getattr(generation_config, "condition_on_prev_tokens", None)
+ )
+
+ @staticmethod
+ def _set_condition_on_prev_tokens(condition_on_prev_tokens, generation_config):
+ condition_on_prev_tokens = (
+ condition_on_prev_tokens
+ if condition_on_prev_tokens is not None
+ else getattr(generation_config, "condition_on_prev_tokens", False)
+ )
+ generation_config.condition_on_prev_tokens = condition_on_prev_tokens
+
+ @staticmethod
+ def _retrieve_max_frames_and_seek(batch_size, attention_mask, total_input_frames):
+ if batch_size > 1 and attention_mask is None:
+ raise ValueError(
+ "When doing long-form audio transcription, make sure to pass an `attention_mask`. You can retrieve the `attention_mask` by doing `processor(audio, ..., return_attention_mask=True)` "
+ )
+ elif batch_size > 1:
+ max_frames = attention_mask.sum(-1).cpu().to(torch.long)
+ seek = torch.zeros((batch_size,), dtype=torch.long)
+ else:
+ max_frames = torch.ones((1,), dtype=torch.long) * total_input_frames
+ seek = torch.zeros((1,), dtype=torch.long)
+
+ return max_frames, seek
+
+ @staticmethod
+ def _retrieve_init_tokens_from_forced_decoder_ids(generation_config):
+ init_tokens = [generation_config.decoder_start_token_id]
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ if forced_decoder_ids is not None and forced_decoder_ids[0][0] == 1:
+ i = 1
+ while len(forced_decoder_ids) > 0 and forced_decoder_ids[0][0] == i:
+ init_tokens += [forced_decoder_ids[0][1]]
+ forced_decoder_ids = forced_decoder_ids[1:]
+ i += 1
+
+ forced_decoder_ids = forced_decoder_ids if len(forced_decoder_ids) > 0 else None
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ return init_tokens
+
+ def _retrieve_logit_processors(
+ self, generation_config, logits_processor, no_speech_threshold, is_shortform, num_beams
+ ):
+ forced_decoder_ids = generation_config.forced_decoder_ids
+ if generation_config.return_timestamps is True:
+ last_forced_decoder_ids = forced_decoder_ids[-1][-1] if forced_decoder_ids is not None else None
+ if last_forced_decoder_ids == generation_config.no_timestamps_token_id:
+ # remove no_timestamp to be forcefully generated if we want to return timestamps
+ # this is also important to make sure `WhisperTimeStampLogitsProcessor` functions correctly
+ forced_decoder_ids = forced_decoder_ids[:-1] if len(forced_decoder_ids) > 1 else None
+ # Make sure that if list is empty we set it to None
+ generation_config.forced_decoder_ids = forced_decoder_ids
+
+ begin_index = len(forced_decoder_ids) + 1 if forced_decoder_ids is not None else 1
+
+ if generation_config.return_timestamps is True:
+ timestamp_processor = WhisperTimeStampLogitsProcessor(generation_config, begin_index=begin_index)
+ logits_processor = (
+ [timestamp_processor] if logits_processor is None else [timestamp_processor] + logits_processor
+ )
+
+ if generation_config.suppress_tokens is not None:
+ suppress_tokens_processor = SuppressTokensLogitsProcessor(generation_config.suppress_tokens)
+ logits_processor = (
+ [suppress_tokens_processor]
+ if logits_processor is None
+ else [suppress_tokens_processor] + logits_processor
+ )
+ generation_config.suppress_tokens = None
+
+ if generation_config.begin_suppress_tokens is not None:
+ begin_suppress_processor = SuppressTokensAtBeginLogitsProcessor(
+ generation_config.begin_suppress_tokens, begin_index=begin_index
+ )
+ logits_processor = (
+ [begin_suppress_processor]
+ if logits_processor is None
+ else [begin_suppress_processor] + logits_processor
+ )
+ generation_config.begin_suppress_tokens = None
+
+ if no_speech_threshold is not None and not is_shortform:
+ no_speech_detector = WhisperNoSpeechDetection(
+ no_speech_token=generation_config.no_timestamps_token_id - 1,
+ begin_index=begin_index,
+ scores_is_logprobs=num_beams > 1,
+ )
+ logits_processor = (
+ [no_speech_detector] if logits_processor is None else [no_speech_detector] + logits_processor
+ )
+ no_speech_detector.set_model(self)
+
+ if is_shortform and generation_config.forced_decoder_ids is not None:
+ forced_tokens_proc = ForceTokensLogitsProcessor(generation_config.forced_decoder_ids)
+ # TODO(Patrick): It's important that the `forced_tokens_proc` processor is appended after
+ # the suppress_tokens processor or else it might happen that all token logits are suppressed to -inf
+ # which would lead to unexpected behavior
+ # The better approach here is to NOT make use of the `forced_tokens_proc` for Whisper and instead
+ # initialize all of them as `decoder_input_ids`.
+ logits_processor = (
+ [forced_tokens_proc] if logits_processor is None else logits_processor + [forced_tokens_proc]
+ )
+ generation_config.forced_decoder_ids = None
+
+ return logits_processor
+
+ @staticmethod
+ def _maybe_reduce_batch(input_features, seek, max_frames, cur_bsz, batch_idx_map):
+ prev_bsz = cur_bsz
+ new_batch_idx_map = []
+ for i in range(prev_bsz):
+ prev_i = batch_idx_map[i]
+ if seek[prev_i] >= max_frames[prev_i]:
+ cut_index = i + (cur_bsz - prev_bsz)
+ cur_bsz -= 1
+ input_features = torch.cat([input_features[:cut_index], input_features[cut_index + 1 :]], dim=0)
+ else:
+ # cut out index that goes away
+ new_batch_idx_map.append(prev_i)
+
+ return input_features, cur_bsz, new_batch_idx_map
+
+ @staticmethod
+ def _get_input_segment(input_features, seek, seek_num_frames, num_segment_frames, cur_bsz, batch_idx_map):
+ segment_input = []
+ for i in range(cur_bsz):
+ prev_i = batch_idx_map[i]
+ segment_input_slice = input_features[i : i + 1, :, seek[prev_i] : seek[prev_i] + seek_num_frames[prev_i]]
+
+ if segment_input_slice.shape[-1] < num_segment_frames:
+ # pad to 3000 if necessary
+ segment_input_slice = F.pad(
+ segment_input_slice, pad=(0, num_segment_frames - segment_input_slice.shape[-1])
+ )
+
+ segment_input.append(segment_input_slice)
+
+ segment_input = torch.cat(segment_input, dim=0)
+
+ return segment_input
+
+ @staticmethod
+ def _prepare_decoder_input_ids(
+ cur_bsz,
+ init_tokens,
+ current_segments,
+ batch_idx_map,
+ do_condition_on_prev_tokens,
+ generation_config,
+ config,
+ device,
+ suppress_tokens,
+ kwargs,
+ ):
+ cut_off_length = config.max_target_positions // 2 - 1
+
+ one_tensor = torch.ones((cur_bsz, 1), device=device, dtype=torch.long)
+ decoder_input_ids = torch.cat([t * one_tensor for t in init_tokens], dim=-1)
+
+ prev_start_of_text = getattr(generation_config, "prev_sot_token_id", None)
+ if prev_start_of_text is None:
+ prev_start_of_text = suppress_tokens[-2] if suppress_tokens is not None else None
+
+ if any(do_condition_on_prev_tokens) and len(current_segments[0]) > 0:
+ # according to https://github.com/openai/whisper/blob/e58f28804528831904c3b6f2c0e473f346223433/whisper/decoding.py#L609
+ active_segments = [current_segments[i] if do_condition_on_prev_tokens[i] else None for i in batch_idx_map]
+ prev_start_of_text = getattr(generation_config, "prev_bos_token_id", None) or prev_start_of_text
+
+ bos_token_tensor = prev_start_of_text * one_tensor[0]
+ prev_tokens = _pad_to_max_length(
+ active_segments,
+ generation_config.pad_token_id,
+ padding="left",
+ bos_token_tensor=bos_token_tensor,
+ cut_off_length=cut_off_length,
+ )
+ decoder_input_ids = torch.cat([prev_tokens, decoder_input_ids], dim=-1)
+
+ kwargs["decoder_attention_mask"] = decoder_input_ids != generation_config.pad_token_id
+ else:
+ # make sure `"decoder_attention_mask"` is not passed to forward
+ kwargs.pop("decoder_attention_mask", None)
+
+ return decoder_input_ids, kwargs
+
+ @staticmethod
+ def _set_max_new_tokens_and_length(config, decoder_input_ids, generation_config, kwargs):
+ num_initial_tokens = min(config.max_target_positions // 2 - 1, decoder_input_ids.shape[-1] - 1)
+
+ passed_max_length = kwargs.pop("max_length", None)
+ passed_max_new_tokens = kwargs.pop("max_new_tokens", None)
+ max_length_config = getattr(generation_config, "max_length", None)
+ max_new_tokens_config = getattr(generation_config, "max_new_tokens", None)
+
+ max_new_tokens = None
+ max_length = None
+
+ # Make sure we don't get larger than `max_length`
+ if passed_max_length is not None and passed_max_new_tokens is None:
+ max_length = min(passed_max_length + num_initial_tokens, config.max_target_positions)
+ logger.info(
+ f"Increase max_length from {passed_max_length} to {max_length} since input is conditioned on previous segment."
+ )
+ elif max_length_config is not None and passed_max_new_tokens is None and max_new_tokens_config is None:
+ max_length = min(generation_config.max_length + num_initial_tokens, config.max_target_positions)
+ logger.info(
+ f"Increase max_length from {max_length_config} to {max_length} since input is conditioned on previous segment."
+ )
+ elif (
+ passed_max_new_tokens is not None
+ and passed_max_new_tokens + decoder_input_ids.shape[-1] > config.max_target_positions
+ ):
+ max_new_tokens = config.max_target_positions - decoder_input_ids.shape[-1]
+ elif (
+ passed_max_new_tokens is None
+ and max_new_tokens_config is not None
+ and max_new_tokens_config + decoder_input_ids.shape[-1] > config.max_target_positions
+ ):
+ max_new_tokens = config.max_target_positions - decoder_input_ids.shape[-1]
+
+ if max_new_tokens is not None:
+ kwargs["max_new_tokens"] = max_new_tokens
+
+ if max_length is not None:
+ kwargs["max_length"] = max_length
+
+ return kwargs
+
+ @staticmethod
+ def _retrieve_compression_ratio(tokens, vocab_size):
+ """Compute byte length of zlib compressed token bytes vs. byte length of raw token bytes"""
+ length = int(math.log2(vocab_size) / 8) + 1
+ token_bytes = b"".join([t.to_bytes(length, "little") for t in tokens.tolist()])
+ compression_ratio = len(token_bytes) / len(zlib.compress(token_bytes))
+
+ return compression_ratio
+
+ @staticmethod
+ def _retrieve_avg_logprobs(scores, tokens, eos_token_id, temperature):
+ rescale_temperature = temperature if temperature > 0.0 else 1
+ scores = torch.stack(scores).to(tokens.device)
+
+ if scores.shape[0] > tokens.shape[0]:
+ scores = scores[: tokens.shape[0]]
+ else:
+ tokens = tokens[-scores.shape[0] :]
+
+ logprobs = F.log_softmax((scores * rescale_temperature).float(), dim=-1).to(scores.dtype)
+
+ # retrieve logprob of selected tokens and sum
+ sum_logprobs = sum((logprobs[i][tokens[i]] * (tokens[i] != eos_token_id)) for i in range(logprobs.shape[0]))
+ length = (tokens != eos_token_id).sum(-1) if eos_token_id is not None else tokens.shape[0]
+
+ avg_logprobs = sum_logprobs / (length + 1)
+ return avg_logprobs
+
+ @staticmethod
+ def _retrieve_segment(
+ seek_sequence,
+ seek_outputs,
+ time_offset,
+ timestamp_begin,
+ seek_num_frames,
+ time_precision,
+ input_stride,
+ prev_idx,
+ idx,
+ ):
+ # find the predicted "end of segment" predictions of Whisper
+ # "end of segment" predictions occur whenever Whisper predicts a timestamp token
+ timestamp_tokens: torch.Tensor = seek_sequence.ge(timestamp_begin)
+ single_timestamp_ending = timestamp_tokens[-2:].tolist() == [False, True]
+ timestamp_segment_indices = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0]
+ timestamp_segment_indices.add_(1)
+
+ # If whisper predicted a "end of segment" via a timestep token, let's go ever each
+ # "end of segment" prediction and slice the decoding into segments accordingly
+ if len(timestamp_segment_indices) > 0:
+ # if the output contains two consecutive timestamp tokens
+ slices = timestamp_segment_indices.tolist()
+ segments = []
+ if single_timestamp_ending:
+ slices.append(len(seek_sequence))
+
+ last_slice = 0
+ # Add each segment to list of all segments
+ for current_slice in slices:
+ sliced_tokens = seek_sequence[last_slice:current_slice]
+ start_timestamp_pos = sliced_tokens[0].item() - timestamp_begin
+ end_timestamp_pos = sliced_tokens[-1].item() - timestamp_begin
+ segments.append(
+ {
+ "start": time_offset[prev_idx] + start_timestamp_pos * time_precision,
+ "end": time_offset[prev_idx] + end_timestamp_pos * time_precision,
+ "tokens": sliced_tokens,
+ "result": seek_outputs[idx],
+ }
+ )
+ last_slice = current_slice
+
+ if single_timestamp_ending:
+ # single timestamp at the end means no speech after the last timestamp.
+ segment_offset = seek_num_frames[prev_idx]
+ else:
+ # otherwise, ignore the unfinished segment and seek to the last timestamp
+ # here we throw away all predictions after the last predicted "end of segment"
+ # since we are cutting right in the middle of an audio
+ last_timestamp_pos = seek_sequence[last_slice - 1].item() - timestamp_begin
+ segment_offset = last_timestamp_pos * input_stride
+ else:
+ # If whisper does not predict any "end of segment" token, then
+ # the whole decoding is considered a segment and we add it to the list of segments
+ timestamps = seek_sequence[timestamp_tokens.nonzero().flatten()]
+ last_timestamp_pos = seek_num_frames[prev_idx]
+ if timestamps.numel() > 0 and timestamps[-1].item() != timestamp_begin:
+ # no consecutive timestamps but it has a timestamp; use the last one.
+ last_timestamp_pos = timestamps[-1].item() - timestamp_begin
+
+ segments = [
+ {
+ "start": time_offset[prev_idx],
+ "end": time_offset[prev_idx] + last_timestamp_pos * time_precision,
+ "tokens": seek_sequence,
+ "result": seek_outputs[idx],
+ }
+ ]
+ segment_offset = seek_num_frames[prev_idx]
+
+ return segments, segment_offset
diff --git a/src/transformers/models/whisper/modeling_whisper.py b/src/transformers/models/whisper/modeling_whisper.py
index a3550c791c7318..76ea27a954a84a 100644
--- a/src/transformers/models/whisper/modeling_whisper.py
+++ b/src/transformers/models/whisper/modeling_whisper.py
@@ -13,10 +13,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch Whisper model."""
-
-import copy
import math
-import warnings
from typing import Optional, Tuple, Union
import numpy as np
@@ -27,7 +24,6 @@
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
-from ...generation.logits_process import WhisperTimeStampLogitsProcessor
from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
from ...modeling_outputs import (
BaseModelOutput,
@@ -47,7 +43,7 @@
replace_return_docstrings,
)
from .configuration_whisper import WhisperConfig
-from .tokenization_whisper import TASK_IDS, TO_LANGUAGE_CODE
+from .generation_whisper import WhisperGenerationMixin
if is_flash_attn_2_available():
@@ -57,6 +53,8 @@
logger = logging.get_logger(__name__)
+_HIDDEN_STATES_START_POSITION = 1
+
_CONFIG_FOR_DOC = "WhisperConfig"
_CHECKPOINT_FOR_DOC = "openai/whisper-tiny"
@@ -229,87 +227,15 @@ def compute_num_masked_span(input_length):
return spec_aug_mask
-def _median_filter(inputs: torch.Tensor, filter_width: int) -> torch.Tensor:
- """
- Applies a median filter of width `filter_width` along the last dimension of the input.
-
- The `inputs` tensor is assumed to be 3- or 4-dimensional.
- """
- if filter_width <= 0 or filter_width % 2 != 1:
- raise ValueError("`filter_width` should be an odd number")
-
- pad_width = filter_width // 2
- if inputs.shape[-1] <= pad_width:
- return inputs
-
- # Pad the left and right edges.
- inputs = nn.functional.pad(inputs, (pad_width, pad_width, 0, 0), mode="reflect")
-
- # sort() is faster than torch.median (https://github.com/pytorch/pytorch/issues/51450)
- result = inputs.unfold(-1, filter_width, 1).sort()[0][..., pad_width]
- return result
-
-
-def _dynamic_time_warping(matrix: np.ndarray):
- """
- Measures similarity between two temporal sequences: the input audio and the output tokens. Used to generate
- token-level timestamps.
- """
- output_length, input_length = matrix.shape
- cost = np.ones((output_length + 1, input_length + 1), dtype=np.float32) * np.inf
- trace = -np.ones((output_length + 1, input_length + 1), dtype=np.float32)
-
- cost[0, 0] = 0
- for j in range(1, input_length + 1):
- for i in range(1, output_length + 1):
- c0 = cost[i - 1, j - 1]
- c1 = cost[i - 1, j]
- c2 = cost[i, j - 1]
-
- if c0 < c1 and c0 < c2:
- c, t = c0, 0
- elif c1 < c0 and c1 < c2:
- c, t = c1, 1
- else:
- c, t = c2, 2
-
- cost[i, j] = matrix[i - 1, j - 1] + c
- trace[i, j] = t
-
- # backtrace
- i = trace.shape[0] - 1
- j = trace.shape[1] - 1
- trace[0, :] = 2
- trace[:, 0] = 1
-
- text_indices = []
- time_indices = []
- while i > 0 or j > 0:
- text_indices.append(i - 1)
- time_indices.append(j - 1)
- if trace[i, j] == 0:
- i -= 1
- j -= 1
- elif trace[i, j] == 1:
- i -= 1
- elif trace[i, j] == 2:
- j -= 1
- else:
- raise RuntimeError(
- f"Internal error in dynamic time warping. Unexpected trace[{i}, {j}]. Please file a bug report."
- )
-
- text_indices = np.array(text_indices)[::-1]
- time_indices = np.array(time_indices)[::-1]
- return text_indices, time_indices
-
-
class WhisperPositionalEmbedding(nn.Embedding):
def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):
super().__init__(num_positions, embedding_dim)
- def forward(self, input_ids, past_key_values_length=0):
- return self.weight[past_key_values_length : past_key_values_length + input_ids.shape[1]]
+ def forward(self, input_ids, past_key_values_length=0, position_ids=None):
+ if position_ids is None:
+ return self.weight[past_key_values_length : past_key_values_length + input_ids.shape[1]]
+ else:
+ return self.weight[position_ids]
class WhisperAttention(nn.Module):
@@ -1356,6 +1282,7 @@ def forward(
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
+ position_ids=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
@@ -1459,9 +1386,13 @@ def forward(
# embed positions
if input_ids is not None:
- positions = self.embed_positions(input_ids, past_key_values_length=past_key_values_length)
+ positions = self.embed_positions(
+ input_ids, past_key_values_length=past_key_values_length, position_ids=position_ids
+ )
else:
- positions = self.embed_positions(inputs_embeds, past_key_values_length=past_key_values_length)
+ positions = self.embed_positions(
+ inputs_embeds, past_key_values_length=past_key_values_length, position_ids=position_ids
+ )
hidden_states = inputs_embeds + positions
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
@@ -1643,6 +1574,7 @@ def forward(
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
decoder_inputs_embeds: Optional[Tuple[torch.FloatTensor]] = None,
+ decoder_position_ids: Optional[Tuple[torch.LongTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
@@ -1701,6 +1633,7 @@ def forward(
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
+ position_ids=decoder_position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
@@ -1726,7 +1659,7 @@ def forward(
"The Whisper Model with a language modeling head. Can be used for automatic speech recognition.",
WHISPER_START_DOCSTRING,
)
-class WhisperForConditionalGeneration(WhisperPreTrainedModel):
+class WhisperForConditionalGeneration(WhisperGenerationMixin, WhisperPreTrainedModel):
base_model_prefix = "model"
_tied_weights_keys = ["proj_out.weight"]
@@ -1774,6 +1707,7 @@ def forward(
encoder_outputs: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
decoder_inputs_embeds: Optional[Tuple[torch.FloatTensor]] = None,
+ decoder_position_ids: Optional[Tuple[torch.LongTensor]] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
@@ -1828,6 +1762,7 @@ def forward(
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
decoder_inputs_embeds=decoder_inputs_embeds,
+ decoder_position_ids=decoder_position_ids,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
@@ -1858,647 +1793,6 @@ def forward(
encoder_attentions=outputs.encoder_attentions,
)
- def generate(
- self,
- input_features: Optional[torch.Tensor] = None,
- generation_config=None,
- logits_processor=None,
- stopping_criteria=None,
- prefix_allowed_tokens_fn=None,
- synced_gpus=False,
- return_timestamps=None,
- task=None,
- language=None,
- is_multilingual=None,
- prompt_ids: Optional[torch.Tensor] = None,
- num_segment_frames: Optional[int] = None,
- return_token_timestamps: Optional[bool] = None,
- return_segments: bool = False,
- attention_mask: Optional[torch.Tensor] = None,
- time_precision: int = 0.02,
- return_dict_in_generate: Optional[bool] = None,
- **kwargs,
- ):
- """
- Transcribes or translates passed mel input features to a sequence of token ids.
-
-
-
- Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
- model's default generation configuration. You can override any `generation_config` by passing the corresponding
- parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
-
- For an overview of generation strategies and code examples, check out the [following
- guide](./generation_strategies).
-
-
-
- Parameters:
- inputs (`torch.Tensor` of varying shape depending on the modality, *optional*):
- The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
- method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
- should of in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
- `input_ids`, `input_values`, `input_features`, or `pixel_values`.
- generation_config (`~generation.GenerationConfig`, *optional*):
- The generation configuration to be used as base parametrization for the generation call. `**kwargs`
- passed to generate matching the attributes of `generation_config` will override them. If
- `generation_config` is not provided, the default will be used, which had the following loading
- priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
- configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
- default values, whose documentation should be checked to parameterize generation.
- logits_processor (`LogitsProcessorList`, *optional*):
- Custom logits processors that complement the default logits processors built from arguments and
- generation config. If a logit processor is passed that is already created with the arguments or a
- generation config an error is thrown. This feature is intended for advanced users.
- stopping_criteria (`StoppingCriteriaList`, *optional*):
- Custom stopping criteria that complement the default stopping criteria built from arguments and a
- generation config. If a stopping criteria is passed that is already created with the arguments or a
- generation config an error is thrown. This feature is intended for advanced users.
- prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
- If provided, this function constraints the beam search to allowed tokens only at each step. If not
- provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
- `input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
- on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
- for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
- Retrieval](https://arxiv.org/abs/2010.00904).
- synced_gpus (`bool`, *optional*, defaults to `False`):
- Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
- return_timestamps (`bool`, *optional*):
- Whether to return the timestamps with the text. This enables the `WhisperTimestampsLogitsProcessor`.
- task (`str`, *optional*):
- Task to use for generation, either "translate" or "transcribe". The `model.config.forced_decoder_ids`
- will be updated accordingly.
- language (`str`, *optional*):
- Language token to use for generation, can be either in the form of `<|en|>`, `en` or `english`. You can
- find all the possible language tokens in the `model.generation_config.lang_to_id` dictionary.
- is_multilingual (`bool`, *optional*):
- Whether or not the model is multilingual.
- prompt_ids (`torch.Tensor`, *optional*):
- Rank-1 tensor of token IDs created by passing text to [`~WhisperProcessor.get_prompt_ids`] that is
- provided as a prompt to each chunk. This can be used to provide or "prompt-engineer" a context for
- transcription, e.g. custom vocabularies or proper nouns to make it more likely to predict those words
- correctly. It cannot be used in conjunction with `decoder_start_token_id` as it overwrites this value.
- return_token_timestamps (`bool`, *optional*):
- Whether to return token-level timestamps with the text. This can be used with or without the
- `return_timestamps` option. To get word-level timestamps, use the tokenizer to group the tokens into
- words.
- return_segments (`bool`, *optional*, defaults to `False`):
- Whether to additionally return a list of all segments. Note that this option can only be enabled
- when doing long-form transcription.
- attention_mask (`torch.Tensor`, *optional*):
- `attention_mask` needs to be passed when doing long-form transcription using a batch size > 1.
- time_precision (`int`, *optional*, defaults to 0.02):
- The duration of output token in seconds. *E.g.* 0.02 means that a generated token on average accounts
- for 20 ms.
- return_dict_in_generate (`bool`, *optional*, defaults to `False`):
- Whether or not to return a [`~utils.ModelOutput`] instead of just returning the generated tokens.
- Note that when doing long-form transcription, `return_dict_in_generate` can only be enabled when
- `return_segments` is set True. In this case the generation outputs of each segment is added to each
- segment.
- kwargs (`Dict[str, Any]`, *optional*):
- Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
- forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
- specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
-
- Return:
- [`~utils.ModelOutput`] or `torch.LongTensor` or `Dict[str, Any]`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
- or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor` or a dict of segments when `return_segments=True`.
-
- If the passed input is > 30 seconds / > 3000 mel input features and `return_segments=True` then a dictionary of generated sequence ids, called `sequences` and a list of each generated segment is returned.
-
- else if the passed input is <= 30 seconds / >= 3000 mel input features, the possible [`~utils.ModelOutput`] types are:
-
- - [`~generation.GenerateEncoderDecoderOutput`],
- - [`~generation.GenerateBeamEncoderDecoderOutput`]
-
- else only the generated output sequence ids are returned.
-
- Example:
-
- - *Longform transcription*: To transcribe or translate audios longer than 30 seconds, process the audio files without truncation and pass all mel features at once to generate.
-
- ```python
- >>> import torch
- >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
- >>> from datasets import load_dataset, Audio
-
- >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
- >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
- >>> model.cuda()
-
- >>> # load audios > 30 seconds
- >>> ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
- >>> # resample to 16kHz
- >>> ds = ds.cast_column("audio", Audio(sampling_rate=16000))
- >>> # take first 8 audios and retrieve array
- >>> audio = ds[:8]["audio"]
- >>> audio = [x["array"] for x in audio]
-
- >>> # make sure to NOT truncate the input audio, to return the `attention_mask` and to pad to the longest audio
- >>> inputs = processor(audio, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True, sampling_rate=16_000)
- >>> inputs = inputs.to("cuda", torch.float32)
-
- >>> # transcribe audio to ids
- >>> generated_ids = model.generate(**inputs)
-
- >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
- >>> transcription[0]
- ' Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!'
- ```
-
- - *Shortform transcription*: If passed mel input features are < 30 seconds, the whole audio will be transcribed with a single call to generate.
-
- ```python
- >>> import torch
- >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
- >>> from datasets import load_dataset
-
- >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
- >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
-
- >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
-
- >>> inputs = processor(ds[0]["audio"]["array"], return_tensors="pt")
- >>> input_features = inputs.input_features
-
- >>> generated_ids = model.generate(inputs=input_features)
-
- >>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
- >>> transcription
- ' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'
- ```
-
- """
-
- if "inputs" in kwargs:
- input_features = kwargs.pop("inputs")
- warnings.warn(
- "The input name `inputs` is deprecated. Please make sure to use `input_features` instead.",
- FutureWarning,
- )
-
- if generation_config is None:
- generation_config = copy.deepcopy(self.generation_config)
-
- return_dict_in_generate = (
- return_dict_in_generate
- if return_dict_in_generate is not None
- else generation_config.return_dict_in_generate
- )
-
- input_stride = self.model.encoder.conv1.stride[0] * self.model.encoder.conv2.stride[0]
- if num_segment_frames is None:
- num_segment_frames = input_stride * self.config.max_source_positions
-
- # 1. Check whether we're in shortform or longform mode
- if input_features is not None:
- total_input_frames = input_features.shape[-1]
- elif "encoder_outputs" in kwargs:
- encoder_outputs_shape = (
- kwargs["encoder_outputs"][0].shape
- if isinstance(kwargs["encoder_outputs"], BaseModelOutput)
- else kwargs["encoder_outputs"].shape
- )
- total_input_frames = encoder_outputs_shape[1] * input_stride
- else:
- raise ValueError("Make sure to provide either `input_features` or `encoder_outputs` to `generate`.")
-
- is_shortform = total_input_frames <= num_segment_frames
-
- # 2. Make sure the generation config is correctly set depending on whether timestamps are to be returned or not
- if return_timestamps is True:
- if not hasattr(generation_config, "no_timestamps_token_id"):
- raise ValueError(
- "You are trying to return timestamps, but the generation config is not properly set. "
- "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
- "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
- )
- generation_config.return_timestamps = return_timestamps
- elif not is_shortform:
- if return_timestamps is False:
- raise ValueError(
- "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
- "requires the model to predict timestamp tokens. Please either pass `return_timestamps=True` or make sure to pass no more than 3000 mel input features."
- )
-
- if not hasattr(generation_config, "no_timestamps_token_id"):
- raise ValueError(
- "You have passed more than 3000 mel input features (> 30 seconds) which automatically enables long-form generation which "
- "requires the generation config to have `no_timestamps_token_id` correctly. "
- "Make sure to initialize the generation config with the correct attributes that are needed such as `no_timestamps_token_id`. "
- "For more details on how to generate the approtiate config, refer to https://github.com/huggingface/transformers/issues/21878#issuecomment-1451902363"
- "or make sure to pass no more than 3000 mel input features."
- )
-
- logger.info("Setting `return_timestamps=True` for long-form generation.")
- generation_config.return_timestamps = True
- else:
- generation_config.return_timestamps = False
-
- # 3. Make sure to correctly set language-related parameters
- if is_multilingual is not None:
- if not hasattr(generation_config, "is_multilingual"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `is_multilingual` argument "
- "to `generate`. Please update the generation config as per the instructions "
- "https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- generation_config.is_multilingual = is_multilingual
-
- if hasattr(generation_config, "is_multilingual") and not generation_config.is_multilingual:
- if task is not None or language is not None:
- raise ValueError(
- "Cannot specify `task` or `language` for an English-only model. If the model is intended to be "
- "multilingual, pass `is_multilingual=True` to generate, or update the generation config."
- )
-
- if language is not None:
- if not hasattr(generation_config, "lang_to_id"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `language` argument "
- "to `generate`. Either set the language using the `forced_decoder_ids` in the model config, "
- "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- language = language.lower()
- generation_config.language = language
- if task is not None:
- if not hasattr(generation_config, "task_to_id"):
- raise ValueError(
- "The generation config is outdated and is thus not compatible with the `task` argument "
- "to `generate`. Either set the task using the `forced_decoder_ids` in the model config, "
- "or update the generation config as per the instructions https://github.com/huggingface/transformers/issues/25084#issuecomment-1664398224"
- )
- generation_config.task = task
-
- # 4. Add forced decoder ids depending on passed `language`, `task`,`prompt_ids`, `return_token_timestamps` and `return_timestamps`
- forced_decoder_ids = None
- # Legacy code for backward compatibility
- if hasattr(self.config, "forced_decoder_ids") and self.config.forced_decoder_ids is not None:
- forced_decoder_ids = self.config.forced_decoder_ids
- elif (
- hasattr(self.generation_config, "forced_decoder_ids")
- and self.generation_config.forced_decoder_ids is not None
- ):
- forced_decoder_ids = self.generation_config.forced_decoder_ids
- else:
- forced_decoder_ids = kwargs.get("forced_decoder_ids", None)
-
- if task is not None or language is not None or (forced_decoder_ids is None and prompt_ids is not None):
- forced_decoder_ids = []
- if hasattr(generation_config, "language"):
- if generation_config.language in generation_config.lang_to_id.keys():
- language_token = generation_config.language
- elif generation_config.language in TO_LANGUAGE_CODE.keys():
- language_token = f"<|{TO_LANGUAGE_CODE[generation_config.language]}|>"
- elif generation_config.language in TO_LANGUAGE_CODE.values():
- language_token = f"<|{generation_config.language}|>"
- else:
- is_language_code = len(generation_config.language) == 2
- raise ValueError(
- f"Unsupported language: {generation_config.language}. Language should be one of:"
- f" {list(TO_LANGUAGE_CODE.values()) if is_language_code else list(TO_LANGUAGE_CODE.keys())}."
- )
- if language_token not in generation_config.lang_to_id:
- raise ValueError(
- f"{language_token} is not supported by this specific model as it is not in the `generation_config.lang_to_id`."
- "(You should just add it to the generation config)"
- )
- forced_decoder_ids.append((1, generation_config.lang_to_id[language_token]))
- else:
- forced_decoder_ids.append((1, None)) # automatically detect the language
-
- if hasattr(generation_config, "task"):
- if generation_config.task in TASK_IDS:
- forced_decoder_ids.append((2, generation_config.task_to_id[generation_config.task]))
- else:
- raise ValueError(
- f"The `{generation_config.task}`task is not supported. The task should be one of `{TASK_IDS}`"
- )
- elif hasattr(generation_config, "task_to_id"):
- forced_decoder_ids.append((2, generation_config.task_to_id["transcribe"])) # defaults to transcribe
- if hasattr(generation_config, "no_timestamps_token_id") and not generation_config.return_timestamps:
- idx = forced_decoder_ids[-1][0] + 1 if forced_decoder_ids else 1
- forced_decoder_ids.append((idx, generation_config.no_timestamps_token_id))
-
- if forced_decoder_ids is not None:
- generation_config.forced_decoder_ids = forced_decoder_ids
-
- if prompt_ids is not None:
- if kwargs.get("decoder_start_token_id") is not None:
- raise ValueError(
- "When specifying `prompt_ids`, you cannot also specify `decoder_start_token_id` as it gets overwritten."
- )
- prompt_ids = prompt_ids.tolist()
- decoder_start_token_id, *text_prompt_ids = prompt_ids
- # Slicing the text prompt ids in a manner consistent with the OpenAI implementation
- # to accomodate context space for the prefix (see https://github.com/openai/whisper/blob/c09a7ae299c4c34c5839a76380ae407e7d785914/whisper/decoding.py#L599)
- text_prompt_ids = text_prompt_ids[-self.config.max_target_positions // 2 - 1 :]
- # Set the decoder_start_token_id to <|startofprev|>
- kwargs.update({"decoder_start_token_id": decoder_start_token_id})
-
- # If the user passes `max_new_tokens`, increase its number to account for the prompt
- if kwargs.get("max_new_tokens", None) is not None:
- kwargs["max_new_tokens"] += len(text_prompt_ids)
- if kwargs["max_new_tokens"] >= self.config.max_target_positions:
- raise ValueError(
- f"The length of the sliced `prompt_ids` is {len(text_prompt_ids)}, and the `max_new_tokens` "
- f"{kwargs['max_new_tokens'] - len(text_prompt_ids)}. Thus, the combined length of the sliced "
- f"`prompt_ids` and `max_new_tokens` is: {kwargs['max_new_tokens']}. This exceeds the "
- f"`max_target_positions` of the Whisper model: {self.config.max_target_positions}. "
- "You should either reduce the length of your prompt, or reduce the value of `max_new_tokens`, "
- f"so that their combined length is less that {self.config.max_target_positions}."
- )
-
- # Reformat the forced_decoder_ids to incorporate the prompt
- non_prompt_forced_decoder_ids = (
- kwargs.pop("forced_decoder_ids", None) or generation_config.forced_decoder_ids
- )
- forced_decoder_ids = [
- *text_prompt_ids,
- generation_config.decoder_start_token_id,
- *[token for _rank, token in non_prompt_forced_decoder_ids],
- ]
- forced_decoder_ids = [(rank + 1, token) for rank, token in enumerate(forced_decoder_ids)]
- generation_config.forced_decoder_ids = forced_decoder_ids
-
- if return_token_timestamps:
- kwargs["output_attentions"] = True
- return_dict_in_generate = True
- kwargs["output_scores"] = True
-
- if getattr(generation_config, "task", None) == "translate":
- logger.warning("Token-level timestamps may not be reliable for task 'translate'.")
- if not hasattr(generation_config, "alignment_heads"):
- raise ValueError(
- "Model generation config has no `alignment_heads`, token-level timestamps not available. "
- "See https://gist.github.com/hollance/42e32852f24243b748ae6bc1f985b13a on how to add this property to the generation config."
- )
-
- if kwargs.get("num_frames") is not None:
- generation_config.num_frames = kwargs.pop("num_frames")
-
- if generation_config.return_timestamps is True:
- last_forced_decoder_ids = (
- generation_config.forced_decoder_ids[-1][-1]
- if hasattr(self.config, "forced_decoder_ids") and self.config.forced_decoder_ids
- else None
- )
- if last_forced_decoder_ids == self.generation_config.no_timestamps_token_id:
- # remove no_timestamp to be forcefully generated if we want to return timestamps
- # this is also important to make sure `WhisperTimeStampLogitsProcessor` functions correctly
- forced_decoder_ids = generation_config.forced_decoder_ids[:-1]
- # Make sure that if list is empty we set it to None
- generation_config.forced_decoder_ids = None if len(forced_decoder_ids) == 0 else forced_decoder_ids
-
- timestamp_processor = [WhisperTimeStampLogitsProcessor(generation_config)]
- logits_processor = (
- timestamp_processor if logits_processor is None else timestamp_processor + logits_processor
- )
-
- # 5. If we're in shortform mode, simple generate the whole input at once and return the output
- if is_shortform:
- outputs = super().generate(
- input_features,
- generation_config,
- logits_processor,
- stopping_criteria,
- prefix_allowed_tokens_fn,
- synced_gpus,
- return_dict_in_generate=return_dict_in_generate,
- **kwargs,
- )
-
- if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
- num_frames = getattr(generation_config, "num_frames", None)
- outputs["token_timestamps"] = self._extract_token_timestamps(
- outputs, generation_config.alignment_heads, num_frames=num_frames
- )
-
- return outputs
-
- # 6. Else we're in longform mode which is more complex. We need to chunk the audio input depending on when the model generated
- # timestamp tokens
- # 6.1 Set running parameters for while loop
- if not return_segments and return_dict_in_generate:
- raise ValueError(
- "Make sure to set `return_segments=True` to return generation outputs as part of the `'segments' key.`"
- )
-
- # if input is longer than 30 seconds we default to long-form generation
- timestamp_begin = self.generation_config.no_timestamps_token_id + 1
- # input stride is mel frames per encoder output vector which is the product of all conv strides
- batch_size = input_features.shape[0]
-
- if batch_size > 1 and attention_mask is None:
- raise ValueError(
- "When doing long-form audio transcription, make sure to pass an `attention_mask`. You can retrieve the `attention_mask` by doing `processor(audio, ..., return_attention_mask=True)` "
- )
- elif batch_size > 1:
- max_frames = attention_mask.sum(-1).cpu().to(torch.long)
- seek = torch.zeros((batch_size,), dtype=torch.long)
- else:
- max_frames = torch.ones((1,), dtype=torch.long) * total_input_frames
- seek = torch.zeros((1,), dtype=torch.long)
-
- current_segments = [[] for _ in range(batch_size)]
- cur_to_prev_index_map = list(range(batch_size))
-
- # batch size can decrease during the run
- cur_bsz = prev_bsz = batch_size
-
- # 6.2 Transcribe audio until we reach the end of all input audios
- while (seek < max_frames).any():
- prev_bsz = cur_bsz
-
- # 6.3 NOTE: When in longform transcription mode and batch size > 1 we need to dynamically reduce the batch size during the loop
- # in case one audio finished earlier than another one. Thus, we need to keep a table of "previous-index-2-current-index" in order
- # to know which original audio is being decoded
- new_cur_to_prev_index_map = []
- for i in range(prev_bsz):
- prev_i = cur_to_prev_index_map[i]
- if seek[prev_i] >= max_frames[prev_i]:
- cut_index = i + (cur_bsz - prev_bsz)
- cur_bsz -= 1
- input_features = torch.cat([input_features[:cut_index], input_features[cut_index + 1 :]], dim=0)
- else:
- # cut out index that goes away
- new_cur_to_prev_index_map.append(prev_i)
-
- # 6.4 Set updated index map, duration of previously decoded chunks and number of max frames of current decoding chunk
- cur_to_prev_index_map = new_cur_to_prev_index_map
- time_offset = seek * time_precision / input_stride
- seek_num_frames = (max_frames - seek).clamp(max=num_segment_frames)
-
- # 6.5 Make sure that all inputs are padded to the same input length
- segment_input = []
- for i in range(cur_bsz):
- prev_i = cur_to_prev_index_map[i]
- segment_input_slice = input_features[
- i : i + 1, :, seek[prev_i] : seek[prev_i] + seek_num_frames[prev_i]
- ]
-
- if segment_input_slice.shape[-1] < num_segment_frames:
- # pad to 3000 if necessary
- segment_input_slice = F.pad(
- segment_input_slice, pad=(0, num_segment_frames - segment_input_slice.shape[-1])
- )
-
- segment_input.append(segment_input_slice)
-
- segment_input = torch.cat(segment_input, dim=0)
-
- # 6.6 Batch generate current chunk
- seek_outputs = super().generate(
- segment_input,
- generation_config,
- logits_processor,
- stopping_criteria,
- prefix_allowed_tokens_fn,
- synced_gpus,
- return_dict_in_generate=return_dict_in_generate,
- **kwargs,
- )
-
- if return_token_timestamps and hasattr(generation_config, "alignment_heads"):
- num_frames = getattr(generation_config, "num_frames", None)
- seek_outputs["token_timestamps"] = self._extract_token_timestamps(
- seek_outputs, generation_config.alignment_heads, num_frames=num_frames
- )
-
- if return_dict_in_generate:
- seek_sequences = seek_outputs["sequences"]
- seek_outputs = [
- {k: v[i] for k, v in seek_outputs.items()}
- for i in range(next(iter(seek_outputs.values())).size(0))
- ]
- else:
- seek_sequences = seek_outputs
-
- # 6.7 Loop over each decoded audio individually as each decoding can be of a different length
- for i, seek_sequence in enumerate(seek_sequences):
- prev_i = cur_to_prev_index_map[i]
-
- # make sure we cut a predicted EOS token if we are not finished with the generation yet
- is_not_final = (seek[prev_i] + num_segment_frames) < max_frames[prev_i]
- if is_not_final and seek_sequence[-1] == self.generation_config.eos_token_id:
- seek_sequence = seek_sequence[:-1]
-
- # remove all padding tokens
- if seek_sequence[-1] == self.generation_config.pad_token_id:
- num_paddings = (seek_sequence == self.generation_config.pad_token_id).sum()
- seek_sequence = seek_sequence[:-num_paddings]
-
- segments, segment_offset = self._retrieve_segment(
- seek_sequence=seek_sequence,
- seek_outputs=seek_outputs,
- time_offset=time_offset,
- timestamp_begin=timestamp_begin,
- seek_num_frames=seek_num_frames,
- cur_bsz=cur_bsz,
- time_precision=time_precision,
- input_stride=input_stride,
- prev_idx=prev_i,
- idx=i,
- )
-
- current_segments[prev_i] += segments
- seek[prev_i] += segment_offset
-
- # 7. Once all segments are added to the list of all segments, called `current_segments`, we extract the predicted
- # output tokens from the list of dicts. If we use batch size > 1, we make sure to pad the output
- sequences = []
- max_total_length = 0
- for current_segment_list in current_segments:
- sequences.append(torch.cat([d["tokens"] for d in current_segment_list], dim=-1))
- max_total_length = max(max_total_length, len(sequences[-1]))
-
- for i in range(batch_size):
- sequences[i] = F.pad(
- sequences[i], pad=(0, max_total_length - len(sequences[i])), value=self.generation_config.pad_token_id
- )
-
- sequences = torch.stack(sequences, dim=0)
-
- # 8. If we return all segments, the predicted output sequences are put under `"sequences"`.
- if return_segments:
- return {"sequences": sequences, "segments": current_segments}
-
- return sequences
-
- @staticmethod
- def _retrieve_segment(
- seek_sequence,
- seek_outputs,
- time_offset,
- timestamp_begin,
- seek_num_frames,
- cur_bsz,
- time_precision,
- input_stride,
- prev_idx,
- idx,
- ):
- # find the predicted "end of segment" predictions of Whisper
- # "end of segment" predictions occur whenever Whisper predicts a timestamp token
- timestamp_tokens: torch.Tensor = seek_sequence.ge(timestamp_begin)
- single_timestamp_ending = timestamp_tokens[-2:].tolist() == cur_bsz * [[False, True]]
- timestamp_segment_indices = torch.where(timestamp_tokens[:-1] & timestamp_tokens[1:])[0]
-
- # If whisper predicted a "end of segment" via a timestep token, let's go ever each
- # "end of segment" prediction and slice the decoding into segments accordingly
- if len(timestamp_segment_indices) > 0:
- # if the output contains two consecutive timestamp tokens
- slices = timestamp_segment_indices.tolist()
- segments = []
- if single_timestamp_ending:
- slices.append(len(seek_sequence))
-
- last_slice = 0
- # Add each segment to list of all segments
- for current_slice in slices:
- sliced_tokens = seek_sequence[last_slice + 1 : current_slice + 1]
- start_timestamp_pos = sliced_tokens[0].item() - timestamp_begin
- end_timestamp_pos = sliced_tokens[-1].item() - timestamp_begin
- segments.append(
- {
- "start": time_offset[prev_idx] + start_timestamp_pos * time_precision,
- "end": time_offset[prev_idx] + end_timestamp_pos * time_precision,
- "tokens": sliced_tokens,
- "result": seek_outputs[idx],
- }
- )
- last_slice = current_slice
-
- if single_timestamp_ending:
- # single timestamp at the end means no speech after the last timestamp.
- segment_offset = seek_num_frames[prev_idx]
- else:
- # otherwise, ignore the unfinished segment and seek to the last timestamp
- # here we throw away all predictions after the last predicted "end of segment"
- # since we are cutting right in the middle of an audio
- last_timestamp_pos = seek_sequence[last_slice].item() - timestamp_begin
- segment_offset = last_timestamp_pos * input_stride
- else:
- # If whisper does not predict any "end of segment" token, then
- # the whole decoding is considered a segment and we add it to the list of segments
- timestamps = seek_sequence[timestamp_tokens.nonzero().flatten()]
- last_timestamp_pos = seek_num_frames[prev_idx]
- if timestamps.numel() > 0 and timestamps[-1].item() != timestamp_begin:
- # no consecutive timestamps but it has a timestamp; use the last one.
- last_timestamp_pos = timestamps[-1].item() - timestamp_begin
-
- segments = [
- {
- "start": time_offset[prev_idx],
- "end": time_offset[prev_idx] + last_timestamp_pos * time_precision,
- "tokens": seek_sequence,
- "result": seek_outputs[idx],
- }
- ]
- segment_offset = seek_num_frames[prev_idx]
-
- return segments, segment_offset
-
def prepare_inputs_for_generation(
self,
decoder_input_ids,
@@ -2506,8 +1800,13 @@ def prepare_inputs_for_generation(
use_cache=None,
encoder_outputs=None,
attention_mask=None,
+ decoder_attention_mask=None,
**kwargs,
):
+ decoder_position_ids = None
+ if decoder_attention_mask is not None:
+ decoder_position_ids = (decoder_attention_mask.cumsum(-1) - 1).clamp(min=0)
+
if past_key_values is not None:
past_length = past_key_values[0][0].shape[2]
@@ -2520,12 +1819,16 @@ def prepare_inputs_for_generation(
decoder_input_ids = decoder_input_ids[:, remove_prefix_length:]
+ if decoder_position_ids is not None and decoder_position_ids.shape[1] > decoder_input_ids.shape[1]:
+ decoder_position_ids = decoder_position_ids[:, remove_prefix_length:]
+
return {
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"use_cache": use_cache,
- "decoder_attention_mask": None,
+ "decoder_attention_mask": decoder_attention_mask,
+ "decoder_position_ids": decoder_position_ids,
}
@staticmethod
@@ -2537,99 +1840,6 @@ def _reorder_cache(past_key_values, beam_idx):
)
return reordered_past
- def _extract_token_timestamps(self, generate_outputs, alignment_heads, time_precision=0.02, num_frames=None):
- """
- Calculates token-level timestamps using the encoder-decoder cross-attentions and dynamic time-warping (DTW) to
- map each output token to a position in the input audio. If `num_frames` is specified, the encoder-decoder
- cross-attentions will be cropped before applying DTW.
-
- Returns:
- tensor containing the timestamps in seconds for each predicted token
- """
- # Create a list with `decoder_layers` elements, each a tensor of shape
- # (batch size, attention_heads, output length, input length).
- cross_attentions = []
- for i in range(self.config.decoder_layers):
- cross_attentions.append(torch.cat([x[i] for x in generate_outputs.cross_attentions], dim=2))
-
- # Select specific cross-attention layers and heads. This is a tensor
- # of shape (batch size, num selected, output length, input length).
- weights = torch.stack([cross_attentions[l][:, h] for l, h in alignment_heads])
- weights = weights.permute([1, 0, 2, 3])
-
- if "beam_indices" in generate_outputs:
- # If beam search has been used, the output sequences may have been generated for more timesteps than their sequence_lengths
- # since the beam search strategy chooses the most probable sequences at the end of the search.
- # In that case, the cross_attentions weights are too long and we have to make sure that they have the right output_length
- weight_length = (generate_outputs.beam_indices != -1).sum(-1).max()
- weights = weights[:, :, :weight_length]
-
- # If beam index is still -1, it means that the associated token id is EOS
- # We need to replace the index with 0 since index_select gives an error if any of the indexes is -1.
- beam_indices = generate_outputs.beam_indices[:, :weight_length]
- beam_indices = beam_indices.masked_fill(beam_indices == -1, 0)
-
- # Select the cross attention from the right beam for each output sequences
- weights = torch.stack(
- [
- torch.index_select(weights[:, :, i, :], dim=0, index=beam_indices[:, i])
- for i in range(beam_indices.shape[1])
- ],
- dim=2,
- )
-
- timestamps = torch.zeros_like(generate_outputs.sequences, dtype=torch.float32)
- batch_size = timestamps.shape[0]
-
- if num_frames is not None:
- # two cases:
- # 1. num_frames is the same for each sample -> compute the DTW matrix for each sample in parallel
- # 2. num_frames is different, compute the DTW matrix for each sample sequentially
-
- # we're using np.unique because num_frames can be int/list/tuple
- if len(np.unique(num_frames)) == 1:
- # if num_frames is the same, no need to recompute matrix, std and mean for each element of the batch
- num_frames = num_frames if isinstance(num_frames, int) else num_frames[0]
-
- weights = weights[..., : num_frames // 2]
- else:
- # num_frames is of shape (batch_size,) whereas batch_size is truely batch_size*num_return_sequences
- repeat_time = batch_size if isinstance(num_frames, int) else batch_size // len(num_frames)
- num_frames = np.repeat(num_frames, repeat_time)
-
- if num_frames is None or isinstance(num_frames, int):
- # Normalize and smoothen the weights.
- std = torch.std(weights, dim=-2, keepdim=True, unbiased=False)
- mean = torch.mean(weights, dim=-2, keepdim=True)
- weights = (weights - mean) / std
- weights = _median_filter(weights, self.config.median_filter_width)
-
- # Average the different cross-attention heads.
- weights = weights.mean(dim=1)
-
- # Perform dynamic time warping on each element of the batch.
- for batch_idx in range(batch_size):
- if num_frames is not None and isinstance(num_frames, (tuple, list, np.ndarray)):
- matrix = weights[batch_idx, ..., : num_frames[batch_idx] // 2]
-
- # Normalize and smoothen the weights.
- std = torch.std(matrix, dim=-2, keepdim=True, unbiased=False)
- mean = torch.mean(matrix, dim=-2, keepdim=True)
- matrix = (matrix - mean) / std
- matrix = _median_filter(matrix, self.config.median_filter_width)
-
- # Average the different cross-attention heads.
- matrix = matrix.mean(dim=0)
- else:
- matrix = weights[batch_idx]
-
- text_indices, time_indices = _dynamic_time_warping(-matrix.cpu().double().numpy())
- jumps = np.pad(np.diff(text_indices), (1, 0), constant_values=1).astype(bool)
- jump_times = time_indices[jumps] * time_precision
- timestamps[batch_idx, 1:] = torch.tensor(jump_times)
-
- return timestamps
-
class WhisperDecoderWrapper(WhisperPreTrainedModel):
"""
@@ -2957,6 +2167,11 @@ def forward(
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ if self.config.use_weighted_layer_sum:
+ output_hidden_states = True
+ elif output_hidden_states is None:
+ output_hidden_states = self.config.output_hidden_states
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if encoder_outputs is None:
@@ -2969,7 +2184,8 @@ def forward(
)
if self.config.use_weighted_layer_sum:
- hidden_states = torch.stack(encoder_outputs, dim=1)
+ hidden_states = encoder_outputs[_HIDDEN_STATES_START_POSITION]
+ hidden_states = torch.stack(hidden_states, dim=1)
norm_weights = nn.functional.softmax(self.layer_weights, dim=-1)
hidden_states = (hidden_states * norm_weights.view(-1, 1, 1)).sum(dim=1)
else:
diff --git a/src/transformers/models/whisper/tokenization_whisper.py b/src/transformers/models/whisper/tokenization_whisper.py
index a54103ccef8f53..127f5be6193d72 100644
--- a/src/transformers/models/whisper/tokenization_whisper.py
+++ b/src/transformers/models/whisper/tokenization_whisper.py
@@ -530,10 +530,21 @@ def _decode_with_timestamps(self, token_ids, skip_special_tokens=False, time_pre
"""
timestamp_begin = self.all_special_ids[-1] + 1
outputs = [[]]
+
+ cur_max_timestamp = 0.0
+ prev_segments_len = 0.0
+
for token in token_ids:
if token >= timestamp_begin:
- timestamp = f"<|{(token - timestamp_begin) * time_precision:.2f}|>"
- outputs.append(timestamp)
+ timestamp = float((token - timestamp_begin) * time_precision)
+
+ if timestamp < cur_max_timestamp:
+ # next segment has started
+ prev_segments_len += cur_max_timestamp
+
+ cur_max_timestamp = timestamp
+
+ outputs.append(f"<|{(timestamp + prev_segments_len):.2f}|>")
outputs.append([])
else:
outputs[-1].append(token)
@@ -553,6 +564,9 @@ def _compute_offsets(self, token_ids, time_precision=0.02):
The time ratio to convert from token to time.
"""
offsets = []
+ # ensure torch tensor of token ids is placed on cpu
+ if "torch" in str(type(token_ids)) and (hasattr(token_ids, "cpu") and callable(token_ids.cpu)):
+ token_ids = token_ids.cpu()
token_ids = np.array(token_ids)
if token_ids.shape[0] > 1 and len(token_ids.shape) > 1:
raise ValueError("Can only process a single input at a time")
@@ -628,7 +642,7 @@ def decode(
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_offsets: bool = False,
- time_precision=0.02,
+ time_precision: float = 0.02,
decode_with_timestamps: bool = False,
normalize: bool = False,
basic_normalize: bool = False,
diff --git a/src/transformers/models/whisper/tokenization_whisper_fast.py b/src/transformers/models/whisper/tokenization_whisper_fast.py
index ee44bb5918d2b0..509175be994f75 100644
--- a/src/transformers/models/whisper/tokenization_whisper_fast.py
+++ b/src/transformers/models/whisper/tokenization_whisper_fast.py
@@ -224,10 +224,21 @@ def _decode_with_timestamps(self, token_ids, skip_special_tokens=False, time_pre
"""
timestamp_begin = self.all_special_ids[-1] + 1
outputs = [[]]
+
+ cur_max_timestamp = 0.0
+ prev_segments_len = 0.0
+
for token in token_ids:
if token >= timestamp_begin:
- timestamp = f"<|{(token - timestamp_begin) * time_precision:.2f}|>"
- outputs.append(timestamp)
+ timestamp = float((token - timestamp_begin) * time_precision)
+
+ if timestamp < cur_max_timestamp:
+ # next segment has started
+ prev_segments_len += cur_max_timestamp
+
+ cur_max_timestamp = timestamp
+
+ outputs.append(f"<|{(timestamp + prev_segments_len):.2f}|>")
outputs.append([])
else:
outputs[-1].append(token)
@@ -248,6 +259,9 @@ def _compute_offsets(self, token_ids, time_precision=0.02):
The time ratio to convert from token to time.
"""
offsets = []
+ # ensure torch tensor of token ids is placed on cpu
+ if "torch" in str(type(token_ids)) and (hasattr(token_ids, "cpu") and callable(token_ids.cpu)):
+ token_ids = token_ids.cpu()
token_ids = np.array(token_ids)
if token_ids.shape[0] > 1 and len(token_ids.shape) > 1:
raise ValueError("Can only process a single input at a time")
@@ -327,7 +341,7 @@ def decode(
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_offsets: bool = False,
- time_precision=0.02,
+ time_precision: float = 0.02,
decode_with_timestamps: bool = False,
normalize: bool = False,
basic_normalize: bool = False,
diff --git a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
index 582f3733d6e837..48bb28bf4ee2c6 100644
--- a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
@@ -47,7 +47,7 @@
logger = logging.get_logger(__name__)
-_CHECKPOINT_FOR_DOC = "xlm-roberta-xlarge"
+_CHECKPOINT_FOR_DOC = "facebook/xlm-roberta-xl"
_CONFIG_FOR_DOC = "XLMRobertaXLConfig"
XLM_ROBERTA_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
@@ -653,7 +653,7 @@ def _init_weights(self, module):
@add_start_docstrings(
- "The bare XLM-RoBERTa-xlarge Model transformer outputting raw hidden-states without any specific head on top.",
+ "The bare XLM-RoBERTa-XL Model transformer outputting raw hidden-states without any specific head on top.",
XLM_ROBERTA_XL_START_DOCSTRING,
)
class XLMRobertaXLModel(XLMRobertaXLPreTrainedModel):
@@ -833,7 +833,7 @@ def forward(
@add_start_docstrings(
- """XLM-RoBERTa-xlarge Model with a `language modeling` head on top for CLM fine-tuning.""",
+ """XLM-RoBERTa-XL Model with a `language modeling` head on top for CLM fine-tuning.""",
XLM_ROBERTA_XL_START_DOCSTRING,
)
class XLMRobertaXLForCausalLM(XLMRobertaXLPreTrainedModel):
@@ -990,7 +990,7 @@ def _reorder_cache(self, past_key_values, beam_idx):
@add_start_docstrings(
- """XLM-RoBERTa-xlarge Model with a `language modeling` head on top.""", XLM_ROBERTA_XL_START_DOCSTRING
+ """XLM-RoBERTa-XL Model with a `language modeling` head on top.""", XLM_ROBERTA_XL_START_DOCSTRING
)
class XLMRobertaXLForMaskedLM(XLMRobertaXLPreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.weight", "lm_head.decoder.bias"]
@@ -1081,7 +1081,7 @@ def forward(
class XLMRobertaXLLMHead(nn.Module):
- """XLM-Roberta-xlarge Head for masked language modeling."""
+ """XLM-RoBERTa-XL Head for masked language modeling."""
def __init__(self, config):
super().__init__()
@@ -1109,7 +1109,7 @@ def _tie_weights(self):
@add_start_docstrings(
"""
- XLM-RoBERTa-xlarge Model transformer with a sequence classification/regression head on top (a linear layer on top
+ XLM-RoBERTa-XL Model transformer with a sequence classification/regression head on top (a linear layer on top
of the pooled output) e.g. for GLUE tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1203,7 +1203,7 @@ def forward(
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a multiple choice classification head on top (a linear layer on top of the pooled
+ XLM-RoBERTa-XL Model with a multiple choice classification head on top (a linear layer on top of the pooled
output and a softmax) e.g. for RocStories/SWAG tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1294,7 +1294,7 @@ def forward(
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a token classification head on top (a linear layer on top of the hidden-states
+ XLM-RoBERTa-XL Model with a token classification head on top (a linear layer on top of the hidden-states
output) e.g. for Named-Entity-Recognition (NER) tasks.
""",
XLM_ROBERTA_XL_START_DOCSTRING,
@@ -1405,7 +1405,7 @@ def forward(self, features, **kwargs):
@add_start_docstrings(
"""
- XLM-Roberta-xlarge Model with a span classification head on top for extractive question-answering tasks like SQuAD
+ XLM-RoBERTa-XL Model with a span classification head on top for extractive question-answering tasks like SQuAD
(a linear layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
XLM_ROBERTA_XL_START_DOCSTRING,
diff --git a/src/transformers/pipelines/automatic_speech_recognition.py b/src/transformers/pipelines/automatic_speech_recognition.py
index 32e61db42af5ff..2c8bf5e2ad9084 100644
--- a/src/transformers/pipelines/automatic_speech_recognition.py
+++ b/src/transformers/pipelines/automatic_speech_recognition.py
@@ -17,11 +17,10 @@
import numpy as np
import requests
-from ..modelcard import ModelCard
from ..tokenization_utils import PreTrainedTokenizer
from ..utils import is_torch_available, is_torchaudio_available, logging
from .audio_utils import ffmpeg_read
-from .base import ArgumentHandler, ChunkPipeline, infer_framework_load_model
+from .base import ChunkPipeline
if TYPE_CHECKING:
@@ -35,7 +34,7 @@
if is_torch_available():
import torch
- from ..models.auto.modeling_auto import MODEL_FOR_CTC_MAPPING_NAMES, MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
+ from ..models.auto.modeling_auto import MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
def rescale_stride(stride, ratio):
@@ -155,11 +154,15 @@ class AutomaticSpeechRecognitionPipeline(ChunkPipeline):
model ([`PreTrainedModel`] or [`TFPreTrainedModel`]):
The model that will be used by the pipeline to make predictions. This needs to be a model inheriting from
[`PreTrainedModel`] for PyTorch and [`TFPreTrainedModel`] for TensorFlow.
+ feature_extractor ([`SequenceFeatureExtractor`]):
+ The feature extractor that will be used by the pipeline to encode waveform for the model.
tokenizer ([`PreTrainedTokenizer`]):
The tokenizer that will be used by the pipeline to encode data for the model. This object inherits from
[`PreTrainedTokenizer`].
- feature_extractor ([`SequenceFeatureExtractor`]):
- The feature extractor that will be used by the pipeline to encode waveform for the model.
+ decoder (`pyctcdecode.BeamSearchDecoderCTC`, *optional*):
+ [PyCTCDecode's
+ BeamSearchDecoderCTC](https://github.com/kensho-technologies/pyctcdecode/blob/2fd33dc37c4111417e08d89ccd23d28e9b308d19/pyctcdecode/decoder.py#L180)
+ can be passed for language model boosted decoding. See [`Wav2Vec2ProcessorWithLM`] for more information.
chunk_length_s (`float`, *optional*, defaults to 0):
The input length for in each chunk. If `chunk_length_s = 0` then chunking is disabled (default).
@@ -190,10 +193,9 @@ class AutomaticSpeechRecognitionPipeline(ChunkPipeline):
device (Union[`int`, `torch.device`], *optional*):
Device ordinal for CPU/GPU supports. Setting this to `None` will leverage CPU, a positive will run the
model on the associated CUDA device id.
- decoder (`pyctcdecode.BeamSearchDecoderCTC`, *optional*):
- [PyCTCDecode's
- BeamSearchDecoderCTC](https://github.com/kensho-technologies/pyctcdecode/blob/2fd33dc37c4111417e08d89ccd23d28e9b308d19/pyctcdecode/decoder.py#L180)
- can be passed for language model boosted decoding. See [`Wav2Vec2ProcessorWithLM`] for more information.
+ torch_dtype (Union[`int`, `torch.dtype`], *optional*):
+ The data-type (dtype) of the computation. Setting this to `None` will use float32 precision. Set to
+ `torch.float16` or `torch.bfloat16` to use half-precision in the respective dtypes.
"""
@@ -203,77 +205,14 @@ def __init__(
feature_extractor: Union["SequenceFeatureExtractor", str] = None,
tokenizer: Optional[PreTrainedTokenizer] = None,
decoder: Optional[Union["BeamSearchDecoderCTC", str]] = None,
- modelcard: Optional[ModelCard] = None,
- framework: Optional[str] = None,
- task: str = "",
- args_parser: ArgumentHandler = None,
device: Union[int, "torch.device"] = None,
torch_dtype: Optional[Union[str, "torch.dtype"]] = None,
- binary_output: bool = False,
**kwargs,
):
- if framework is None:
- framework, model = infer_framework_load_model(model, config=model.config)
-
- self.task = task
- self.model = model
- self.tokenizer = tokenizer
- self.feature_extractor = feature_extractor
- self.modelcard = modelcard
- self.framework = framework
-
- # `accelerate` device map
- hf_device_map = getattr(self.model, "hf_device_map", None)
-
- if hf_device_map is not None and device is not None:
- raise ValueError(
- "The model has been loaded with `accelerate` and therefore cannot be moved to a specific device. Please "
- "discard the `device` argument when creating your pipeline object."
- )
-
- if self.framework == "tf":
- raise ValueError("The AutomaticSpeechRecognitionPipeline is only available in PyTorch.")
-
- # We shouldn't call `model.to()` for models loaded with accelerate
- if device is not None and not (isinstance(device, int) and device < 0):
- self.model.to(device)
-
- if device is None:
- if hf_device_map is not None:
- # Take the first device used by `accelerate`.
- device = next(iter(hf_device_map.values()))
- else:
- device = -1
-
- if is_torch_available() and self.framework == "pt":
- if isinstance(device, torch.device):
- self.device = device
- elif isinstance(device, str):
- self.device = torch.device(device)
- elif device < 0:
- self.device = torch.device("cpu")
- else:
- self.device = torch.device(f"cuda:{device}")
- else:
- self.device = device if device is not None else -1
- self.torch_dtype = torch_dtype
- self.binary_output = binary_output
-
- # Update config and generation_config with task specific parameters
- task_specific_params = self.model.config.task_specific_params
- if task_specific_params is not None and task in task_specific_params:
- self.model.config.update(task_specific_params.get(task))
- if self.model.can_generate():
- self.model.generation_config.update(**task_specific_params.get(task))
-
- self.call_count = 0
- self._batch_size = kwargs.pop("batch_size", None)
- self._num_workers = kwargs.pop("num_workers", None)
-
# set the model type so we can check we have the right pre- and post-processing parameters
- if self.model.config.model_type == "whisper":
+ if model.config.model_type == "whisper":
self.type = "seq2seq_whisper"
- elif self.model.__class__.__name__ in MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.values():
+ elif model.__class__.__name__ in MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.values():
self.type = "seq2seq"
elif (
feature_extractor._processor_class
@@ -285,11 +224,7 @@ def __init__(
else:
self.type = "ctc"
- self._preprocess_params, self._forward_params, self._postprocess_params = self._sanitize_parameters(**kwargs)
-
- mapping = MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES.copy()
- mapping.update(MODEL_FOR_CTC_MAPPING_NAMES)
- self.check_model_type(mapping)
+ super().__init__(model, tokenizer, feature_extractor, device=device, torch_dtype=torch_dtype, **kwargs)
def __call__(
self,
@@ -582,8 +517,11 @@ def _forward(self, model_inputs, return_timestamps=False, generate_kwargs=None):
out["stride"] = stride
else:
- input_values = model_inputs.pop("input_values")
- outputs = self.model(input_values=input_values, attention_mask=attention_mask)
+ inputs = {
+ self.model.main_input_name: model_inputs.pop(self.model.main_input_name),
+ "attention_mask": attention_mask,
+ }
+ outputs = self.model(**inputs)
logits = outputs.logits
if self.type == "ctc_with_lm":
diff --git a/src/transformers/processing_utils.py b/src/transformers/processing_utils.py
index 41236fe9e1d3c9..f727f308ac3a20 100644
--- a/src/transformers/processing_utils.py
+++ b/src/transformers/processing_utils.py
@@ -16,14 +16,28 @@
Processing saving/loading class for common processors.
"""
+import copy
+import inspect
+import json
import os
import warnings
from pathlib import Path
-from typing import Optional, Union
+from typing import Any, Dict, Optional, Tuple, Union
from .dynamic_module_utils import custom_object_save
from .tokenization_utils_base import PreTrainedTokenizerBase
-from .utils import PushToHubMixin, copy_func, direct_transformers_import, logging
+from .utils import (
+ PROCESSOR_NAME,
+ PushToHubMixin,
+ add_model_info_to_auto_map,
+ cached_file,
+ copy_func,
+ direct_transformers_import,
+ download_url,
+ is_offline_mode,
+ is_remote_url,
+ logging,
+)
logger = logging.get_logger(__name__)
@@ -85,10 +99,70 @@ def __init__(self, *args, **kwargs):
setattr(self, attribute_name, arg)
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this processor instance.
+ """
+ output = copy.deepcopy(self.__dict__)
+
+ # Get the kwargs in `__init__`.
+ sig = inspect.signature(self.__init__)
+ # Only save the attributes that are presented in the kwargs of `__init__`.
+ attrs_to_save = sig.parameters
+ # Don't save attributes like `tokenizer`, `image processor` etc.
+ attrs_to_save = [x for x in attrs_to_save if x not in self.__class__.attributes]
+ # extra attributes to be kept
+ attrs_to_save += ["auto_map"]
+
+ output = {k: v for k, v in output.items() if k in attrs_to_save}
+
+ output["processor_class"] = self.__class__.__name__
+
+ if "tokenizer" in output:
+ del output["tokenizer"]
+ if "image_processor" in output:
+ del output["image_processor"]
+ if "feature_extractor" in output:
+ del output["feature_extractor"]
+
+ # Some attributes have different names but containing objects that are not simple strings
+ output = {
+ k: v
+ for k, v in output.items()
+ if not (isinstance(v, PushToHubMixin) or v.__class__.__name__ == "BeamSearchDecoderCTC")
+ }
+
+ return output
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this feature_extractor instance in JSON format.
+ """
+ dictionary = self.to_dict()
+
+ return json.dumps(dictionary, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this processor instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
def __repr__(self):
attributes_repr = [f"- {name}: {repr(getattr(self, name))}" for name in self.attributes]
attributes_repr = "\n".join(attributes_repr)
- return f"{self.__class__.__name__}:\n{attributes_repr}"
+ return f"{self.__class__.__name__}:\n{attributes_repr}\n\n{self.to_json_string()}"
def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
"""
@@ -139,6 +213,7 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
if self._auto_class is not None:
attrs = [getattr(self, attribute_name) for attribute_name in self.attributes]
configs = [(a.init_kwargs if isinstance(a, PreTrainedTokenizerBase) else a) for a in attrs]
+ configs.append(self)
custom_object_save(self, save_directory, config=configs)
for attribute_name in self.attributes:
@@ -156,6 +231,15 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
if isinstance(attribute, PreTrainedTokenizerBase):
del attribute.init_kwargs["auto_map"]
+ # If we save using the predefined names, we can load using `from_pretrained`
+ output_processor_file = os.path.join(save_directory, PROCESSOR_NAME)
+
+ # For now, let's not save to `processor_config.json` if the processor doesn't have extra attributes and
+ # `auto_map` is not specified.
+ if set(self.to_dict().keys()) != {"processor_class"}:
+ self.to_json_file(output_processor_file)
+ logger.info(f"processor saved in {output_processor_file}")
+
if push_to_hub:
self._upload_modified_files(
save_directory,
@@ -165,6 +249,152 @@ def save_pretrained(self, save_directory, push_to_hub: bool = False, **kwargs):
token=kwargs.get("token"),
)
+ if set(self.to_dict().keys()) == {"processor_class"}:
+ return []
+ return [output_processor_file]
+
+ @classmethod
+ def get_processor_dict(
+ cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
+ ) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ """
+ From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
+ processor of type [`~processing_utils.ProcessingMixin`] using `from_args_and_dict`.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+
+ Returns:
+ `Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the processor object.
+ """
+ cache_dir = kwargs.pop("cache_dir", None)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ token = kwargs.pop("token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", "")
+
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+
+ user_agent = {"file_type": "processor", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if os.path.isdir(pretrained_model_name_or_path):
+ processor_file = os.path.join(pretrained_model_name_or_path, PROCESSOR_NAME)
+ if os.path.isfile(pretrained_model_name_or_path):
+ resolved_processor_file = pretrained_model_name_or_path
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ processor_file = pretrained_model_name_or_path
+ resolved_processor_file = download_url(pretrained_model_name_or_path)
+ else:
+ processor_file = PROCESSOR_NAME
+ try:
+ # Load from local folder or from cache or download from model Hub and cache
+ resolved_processor_file = cached_file(
+ pretrained_model_name_or_path,
+ processor_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ subfolder=subfolder,
+ )
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
+ # the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load processor for '{pretrained_model_name_or_path}'. If you were trying to load"
+ " it from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a {PROCESSOR_NAME} file"
+ )
+
+ try:
+ # Load processor dict
+ with open(resolved_processor_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ processor_dict = json.loads(text)
+
+ except json.JSONDecodeError:
+ raise EnvironmentError(
+ f"It looks like the config file at '{resolved_processor_file}' is not a valid JSON file."
+ )
+
+ if is_local:
+ logger.info(f"loading configuration file {resolved_processor_file}")
+ else:
+ logger.info(f"loading configuration file {processor_file} from cache at {resolved_processor_file}")
+
+ if "auto_map" in processor_dict and not is_local:
+ processor_dict["auto_map"] = add_model_info_to_auto_map(
+ processor_dict["auto_map"], pretrained_model_name_or_path
+ )
+
+ return processor_dict, kwargs
+
+ @classmethod
+ def from_args_and_dict(cls, args, processor_dict: Dict[str, Any], **kwargs):
+ """
+ Instantiates a type of [`~processing_utils.ProcessingMixin`] from a Python dictionary of parameters.
+
+ Args:
+ processor_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the processor object. Such a dictionary can be
+ retrieved from a pretrained checkpoint by leveraging the
+ [`~processing_utils.ProcessingMixin.to_dict`] method.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the processor object.
+
+ Returns:
+ [`~processing_utils.ProcessingMixin`]: The processor object instantiated from those
+ parameters.
+ """
+ processor_dict = processor_dict.copy()
+ return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
+
+ # Unlike image processors or feature extractors whose `__init__` accept `kwargs`, processor don't have `kwargs`.
+ # We have to pop up some unused (but specific) arguments to make it work.
+ if "processor_class" in processor_dict:
+ del processor_dict["processor_class"]
+
+ if "auto_map" in processor_dict:
+ del processor_dict["auto_map"]
+
+ processor = cls(*args, **processor_dict)
+
+ # Update processor with kwargs if needed
+ for key in set(kwargs.keys()):
+ if hasattr(processor, key):
+ setattr(processor, key, kwargs.pop(key))
+
+ logger.info(f"Processor {processor}")
+ if return_unused_kwargs:
+ return processor, kwargs
+ else:
+ return processor
+
@classmethod
def from_pretrained(
cls,
@@ -226,7 +456,19 @@ def from_pretrained(
kwargs["token"] = token
args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
- return cls(*args)
+
+ # Existing processors on the Hub created before #27761 being merged don't have `processor_config.json` (if not
+ # updated afterward), and we need to keep `from_pretrained` work. So here it fallbacks to the empty dict.
+ # However, for models added in the future, we won't get the expected error if this file is missing.
+ try:
+ processor_dict, kwargs = cls.get_processor_dict(pretrained_model_name_or_path, **kwargs)
+ except EnvironmentError as e:
+ if "does not appear to have a file named processor_config.json." in str(e):
+ processor_dict, kwargs = {}, kwargs
+ else:
+ raise
+
+ return cls.from_args_and_dict(args, processor_dict, **kwargs)
@classmethod
def register_for_auto_class(cls, auto_class="AutoProcessor"):
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 6850f4dca067ea..f7a15a7fbff1fa 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -64,7 +64,7 @@
from .modeling_utils import PreTrainedModel, load_sharded_checkpoint, unwrap_model
from .models.auto.modeling_auto import MODEL_FOR_CAUSAL_LM_MAPPING_NAMES, MODEL_MAPPING_NAMES
from .optimization import Adafactor, get_scheduler
-from .pytorch_utils import ALL_LAYERNORM_LAYERS
+from .pytorch_utils import ALL_LAYERNORM_LAYERS, is_torch_greater_or_equal_than_1_13
from .tokenization_utils_base import PreTrainedTokenizerBase
from .trainer_callback import (
CallbackHandler,
@@ -2103,7 +2103,11 @@ def _load_from_checkpoint(self, resume_from_checkpoint, model=None):
logger.warning(
"Enabling FP16 and loading from smp < 1.10 checkpoint together is not suppported."
)
- state_dict = torch.load(weights_file, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weights_file,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# Required for smp to not auto-translate state_dict from hf to smp (is already smp).
state_dict["_smp_is_partial"] = False
load_result = model.load_state_dict(state_dict, strict=True)
@@ -2116,7 +2120,11 @@ def _load_from_checkpoint(self, resume_from_checkpoint, model=None):
if self.args.save_safetensors and os.path.isfile(safe_weights_file):
state_dict = safetensors.torch.load_file(safe_weights_file, device="cpu")
else:
- state_dict = torch.load(weights_file, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ weights_file,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# workaround for FSDP bug https://github.com/pytorch/pytorch/issues/82963
# which takes *args instead of **kwargs
@@ -2184,7 +2192,11 @@ def _load_best_model(self):
if self.args.save_safetensors and os.path.isfile(best_safe_model_path):
state_dict = safetensors.torch.load_file(best_safe_model_path, device="cpu")
else:
- state_dict = torch.load(best_model_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ best_model_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
state_dict["_smp_is_partial"] = False
load_result = model.load_state_dict(state_dict, strict=True)
@@ -2213,7 +2225,11 @@ def _load_best_model(self):
if self.args.save_safetensors and os.path.isfile(best_safe_model_path):
state_dict = safetensors.torch.load_file(best_safe_model_path, device="cpu")
else:
- state_dict = torch.load(best_model_path, map_location="cpu", weights_only=True)
+ state_dict = torch.load(
+ best_model_path,
+ map_location="cpu",
+ weights_only=is_torch_greater_or_equal_than_1_13,
+ )
# If the model is on the GPU, it still works!
# workaround for FSDP bug https://github.com/pytorch/pytorch/issues/82963
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index 0c1da8334ea706..463f134217582c 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -1844,11 +1844,6 @@ def _setup_devices(self) -> "torch.device":
device = torch.device("cuda", local_rank)
self._n_gpu = 1
torch.cuda.set_device(device)
- elif is_torch_xpu_available() and "ACCELERATE_USE_XPU" not in os.environ:
- os.environ["ACCELERATE_USE_XPU"] = "true"
- self.distributed_state = PartialState(timeout=timedelta(seconds=self.ddp_timeout))
- device = torch.device("xpu:0")
- self._n_gpu = 1
elif is_sagemaker_dp_enabled():
self.distributed_state = PartialState(_use_sagemaker_dp=True)
self._n_gpu = 1
@@ -1877,12 +1872,6 @@ def _setup_devices(self) -> "torch.device":
elif is_sagemaker_dp_enabled() or is_sagemaker_mp_enabled():
# Already set _n_gpu
pass
- elif self.distributed_state.distributed_type == DistributedType.MULTI_XPU:
- if "ACCELERATE_USE_XPU" not in os.environ:
- os.environ["ACCELERATE_USE_XPU"] = "true"
- self._n_gpu = 1
- device = torch.device("xpu:0")
- torch.xpu.set_device(device)
elif self.distributed_state.distributed_type == DistributedType.NO:
if self.use_mps_device:
warnings.warn(
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index 780090aec5e934..bb05dd28ef318c 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -217,6 +217,7 @@
CONFIG_NAME = "config.json"
FEATURE_EXTRACTOR_NAME = "preprocessor_config.json"
IMAGE_PROCESSOR_NAME = FEATURE_EXTRACTOR_NAME
+PROCESSOR_NAME = "processor_config.json"
GENERATION_CONFIG_NAME = "generation_config.json"
MODEL_CARD_NAME = "modelcard.json"
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 4d89b2942f7997..a897403d959655 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -6715,6 +6715,34 @@ def load_tf_weights_in_qdqbert(*args, **kwargs):
requires_backends(load_tf_weights_in_qdqbert, ["torch"])
+class Qwen2ForCausalLM(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2ForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2Model(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2PreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class RagModel(metaclass=DummyObject):
_backends = ["torch"]
@@ -8730,6 +8758,51 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class Wav2Vec2BertForAudioFrameClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForCTC(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertForXVector(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Wav2Vec2BertPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_tokenizers_objects.py b/src/transformers/utils/dummy_tokenizers_objects.py
index b8cc21303a815a..863cb3ad03ad55 100644
--- a/src/transformers/utils/dummy_tokenizers_objects.py
+++ b/src/transformers/utils/dummy_tokenizers_objects.py
@@ -331,6 +331,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["tokenizers"])
+class Qwen2TokenizerFast(metaclass=DummyObject):
+ _backends = ["tokenizers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["tokenizers"])
+
+
class RealmTokenizerFast(metaclass=DummyObject):
_backends = ["tokenizers"]
diff --git a/tests/generation/test_utils.py b/tests/generation/test_utils.py
index c41bc3b21a4ee3..2c16f41ae171dc 100644
--- a/tests/generation/test_utils.py
+++ b/tests/generation/test_utils.py
@@ -88,6 +88,7 @@
TopKLogitsWarper,
TopPLogitsWarper,
)
+ from transformers.generation.utils import _speculative_sampling
class GenerationTesterMixin:
@@ -1539,6 +1540,39 @@ def test_contrastive_generate_low_memory(self):
)
self.assertListEqual(low_output.tolist(), high_output.tolist())
+ def test_beam_search_low_memory(self):
+ # Check that choosing 'low_memory' does not change the model output
+ for model_class in self.all_generative_model_classes:
+ if any(model_name in model_class.__name__.lower() for model_name in ["fsmt", "reformer"]):
+ self.skipTest("Won't fix: old model with different cache format")
+ if any(
+ model_name in model_class.__name__.lower()
+ for model_name in [
+ "bloom",
+ "ctrl",
+ "gptbigcode",
+ "transo_xl",
+ "xlnet",
+ "cpm",
+ ]
+ ):
+ self.skipTest("May fix in the future: need model-specific fixes")
+ config, input_ids, attention_mask, max_length = self._get_input_ids_and_config(batch_size=2)
+ # batch_size=1 is ok, but batch_size>1 will cause non-identical output
+
+ config.use_cache = True
+ config.is_decoder = True
+
+ # test output equality of low versus high memory
+ model = model_class(config).to(torch_device).eval()
+
+ low_output = model.generate(input_ids, max_new_tokens=8, num_beams=5, early_stopping=True, low_memory=True)
+
+ high_output = model.generate(
+ input_ids, max_new_tokens=8, num_beams=5, early_stopping=True, low_memory=False
+ )
+ self.assertListEqual(low_output.tolist(), high_output.tolist())
+
@is_flaky() # Read NOTE (1) below. If there are API issues, all attempts will fail.
def test_assisted_decoding_matches_greedy_search(self):
# This test ensures that the assisted generation does not introduce output changes over greedy search.
@@ -2391,6 +2425,43 @@ def test_top_k_top_p_filtering_with_filter_value(self):
self.assertTrue(torch.allclose(expected_output, output, atol=1e-12))
+ def test_speculative_sampling(self):
+ # assume vocab size 10, input length 5 + 3 generated candidates
+ candidate_input_ids = torch.tensor([[8, 0, 3, 9, 8, 1, 4, 5]]) # input tokens
+ candidate_logits = torch.tensor(
+ [
+ [
+ [-10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # generated 1
+ [-10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # generated 4
+ [-10.0, -10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0], # generated 5
+ ]
+ ]
+ )
+ candidate_length = 3
+ inf = float("inf")
+ new_logits = torch.tensor(
+ [
+ [
+ [-10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # accepts 1
+ [-10.0, -10.0, -10.0, -10.0, 10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # accepts 4
+ [-inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, 10.0, -inf], # rejects 5, accepts 8
+ [-10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0, -10.0], # N/A
+ ]
+ ]
+ )
+ last_assistant_token_is_eos = False
+ max_matches = 5
+ validated_tokens, n_matches = _speculative_sampling(
+ candidate_input_ids,
+ candidate_logits,
+ candidate_length,
+ new_logits,
+ last_assistant_token_is_eos,
+ max_matches,
+ )
+ self.assertTrue(n_matches.item() == 2)
+ self.assertTrue(validated_tokens.tolist()[0] == [1, 4, 8])
+
@require_torch
class GenerationIntegrationTests(unittest.TestCase, GenerationIntegrationTestsMixin):
@@ -2766,6 +2837,19 @@ def test_transition_scores_group_beam_search_encoder_decoder(self):
self.assertTrue(torch.allclose(transition_scores_sum, outputs.sequences_scores, atol=1e-3))
+ def test_beam_search_low_memory(self):
+ tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ tokenizer.pad_token_id = tokenizer.eos_token_id
+ model_inputs = tokenizer("I", return_tensors="pt")["input_ids"]
+
+ low_output = model.generate(model_inputs, max_new_tokens=40, num_beams=5, early_stopping=True, low_memory=True)
+
+ high_output = model.generate(
+ model_inputs, max_new_tokens=40, num_beams=5, early_stopping=True, low_memory=False
+ )
+ self.assertListEqual(low_output.tolist(), high_output.tolist())
+
@slow
def test_beam_search_example_integration(self):
# PT-only test: TF doesn't have a BeamSearchScorer
diff --git a/tests/models/auto/test_processor_auto.py b/tests/models/auto/test_processor_auto.py
index bf4a92475deec9..6cab1cbe817607 100644
--- a/tests/models/auto/test_processor_auto.py
+++ b/tests/models/auto/test_processor_auto.py
@@ -42,7 +42,7 @@
)
from transformers.testing_utils import TOKEN, USER, get_tests_dir, is_staging_test
from transformers.tokenization_utils import TOKENIZER_CONFIG_FILE
-from transformers.utils import FEATURE_EXTRACTOR_NAME, is_tokenizers_available
+from transformers.utils import FEATURE_EXTRACTOR_NAME, PROCESSOR_NAME, is_tokenizers_available
sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
@@ -91,6 +91,34 @@ def test_processor_from_local_directory_from_extractor_config(self):
self.assertIsInstance(processor, Wav2Vec2Processor)
+ def test_processor_from_processor_class(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ feature_extractor = Wav2Vec2FeatureExtractor()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
+
+ processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+
+ # save in new folder
+ processor.save_pretrained(tmpdirname)
+
+ if not os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # create one manually in order to perform this test's objective
+ config_dict = {"processor_class": "Wav2Vec2Processor"}
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as fp:
+ json.dump(config_dict, fp)
+
+ # drop `processor_class` in tokenizer config
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
def test_processor_from_feat_extr_processor_class(self):
with tempfile.TemporaryDirectory() as tmpdirname:
feature_extractor = Wav2Vec2FeatureExtractor()
@@ -101,6 +129,15 @@ def test_processor_from_feat_extr_processor_class(self):
# save in new folder
processor.save_pretrained(tmpdirname)
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
# drop `processor_class` in tokenizer
with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "r") as f:
config_dict = json.load(f)
@@ -123,6 +160,15 @@ def test_processor_from_tokenizer_processor_class(self):
# save in new folder
processor.save_pretrained(tmpdirname)
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "r") as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
# drop `processor_class` in feature extractor
with open(os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME), "r") as f:
config_dict = json.load(f)
@@ -270,6 +316,45 @@ class NewProcessor(ProcessorMixin):
if CustomConfig in PROCESSOR_MAPPING._extra_content:
del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ def test_from_pretrained_dynamic_processor_with_extra_attributes(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ pass
+
+ class NewTokenizer(BertTokenizer):
+ pass
+
+ class NewProcessor(ProcessorMixin):
+ feature_extractor_class = "AutoFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer, processor_attr_1=1, processor_attr_2=True):
+ super().__init__(feature_extractor, tokenizer)
+
+ self.processor_attr_1 = processor_attr_1
+ self.processor_attr_2 = processor_attr_2
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoProcessor.register(CustomConfig, NewProcessor)
+ # If remote code is not set, the default is to use local classes.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", processor_attr_2=False
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertEqual(processor.processor_attr_1, 1)
+ self.assertEqual(processor.processor_attr_2, False)
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+
def test_auto_processor_creates_tokenizer(self):
processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-bert")
self.assertEqual(processor.__class__.__name__, "BertTokenizerFast")
diff --git a/tests/models/clip/test_processor_clip.py b/tests/models/clip/test_processor_clip.py
index fb88ef27053206..a76d3b33b829f4 100644
--- a/tests/models/clip/test_processor_clip.py
+++ b/tests/models/clip/test_processor_clip.py
@@ -26,6 +26,8 @@
from transformers.testing_utils import require_vision
from transformers.utils import IMAGE_PROCESSOR_NAME, is_vision_available
+from ...test_processing_common import ProcessorTesterMixin
+
if is_vision_available():
from PIL import Image
@@ -34,7 +36,9 @@
@require_vision
-class CLIPProcessorTest(unittest.TestCase):
+class CLIPProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = CLIPProcessor
+
def setUp(self):
self.tmpdirname = tempfile.mkdtemp()
diff --git a/tests/models/conditional_detr/test_modeling_conditional_detr.py b/tests/models/conditional_detr/test_modeling_conditional_detr.py
index 10d788bd692f0d..657b202fbfe626 100644
--- a/tests/models/conditional_detr/test_modeling_conditional_detr.py
+++ b/tests/models/conditional_detr/test_modeling_conditional_detr.py
@@ -399,6 +399,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/deformable_detr/test_modeling_deformable_detr.py b/tests/models/deformable_detr/test_modeling_deformable_detr.py
index 8cfe6ca451d91e..ffb1fc175c4063 100644
--- a/tests/models/deformable_detr/test_modeling_deformable_detr.py
+++ b/tests/models/deformable_detr/test_modeling_deformable_detr.py
@@ -476,6 +476,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/deta/test_modeling_deta.py b/tests/models/deta/test_modeling_deta.py
index 8db3485703d1fc..8025e65bd02d1c 100644
--- a/tests/models/deta/test_modeling_deta.py
+++ b/tests/models/deta/test_modeling_deta.py
@@ -449,6 +449,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/esm/test_tokenization_esm.py b/tests/models/esm/test_tokenization_esm.py
index 539baaf34150d9..aac03b535edce3 100644
--- a/tests/models/esm/test_tokenization_esm.py
+++ b/tests/models/esm/test_tokenization_esm.py
@@ -87,3 +87,25 @@ def test_tokenize_special_tokens(self):
self.assertEqual(len(token_2), 1)
self.assertEqual(token_1[0], SPECIAL_TOKEN_1)
self.assertEqual(token_2[0], SPECIAL_TOKEN_2)
+
+ def test_add_tokens(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ vocab_size = len(tokenizer)
+ self.assertEqual(tokenizer.add_tokens(""), 0)
+ self.assertEqual(tokenizer.add_tokens("testoken"), 1)
+ self.assertEqual(tokenizer.add_tokens(["testoken1", "testtoken2"]), 2)
+ self.assertEqual(len(tokenizer), vocab_size + 3)
+
+ self.assertEqual(tokenizer.add_special_tokens({}), 0)
+ self.assertEqual(tokenizer.add_special_tokens({"bos_token": "[BOS]", "eos_token": "[EOS]"}), 2)
+ self.assertRaises(AssertionError, tokenizer.add_special_tokens, {"additional_special_tokens": ""})
+ self.assertEqual(tokenizer.add_special_tokens({"additional_special_tokens": [""]}), 1)
+ self.assertEqual(
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", ""]}), 2
+ )
+ self.assertIn("", tokenizer.special_tokens_map["additional_special_tokens"])
+ self.assertIsInstance(tokenizer.special_tokens_map["additional_special_tokens"], list)
+ self.assertGreaterEqual(len(tokenizer.special_tokens_map["additional_special_tokens"]), 2)
+
+ self.assertEqual(len(tokenizer), vocab_size + 8)
diff --git a/tests/models/gpt_neox/test_modeling_gpt_neox.py b/tests/models/gpt_neox/test_modeling_gpt_neox.py
index 8777bd3abd629b..19e3db2a61fb91 100644
--- a/tests/models/gpt_neox/test_modeling_gpt_neox.py
+++ b/tests/models/gpt_neox/test_modeling_gpt_neox.py
@@ -355,3 +355,13 @@ def test_lm_generate_gptneox(self):
output_str = tokenizer.batch_decode(output_ids)[0]
self.assertEqual(output_str, expected_output)
+
+ def pythia_integration_test(self):
+ model_name_or_path = "EleutherAI/pythia-70m"
+ model = GPTNeoXForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16).to(torch_device)
+ EXPECTED_LOGITS = torch.tensor([1069.0000, 228.7500, 1072.0000, 1072.0000, 1069.0000, 1068.0000, 1068.0000, 1071.0000, 1071.0000, 1071.0000, 1073.0000, 1070.0000, 1071.0000, 1075.0000, 1073.0000, 1075.0000, 1074.0000, 1069.0000, 1072.0000, 1071.0000, 1071.0000, 1071.0000, 1070.0000, 1069.0000, 1069.0000, 1069.0000, 1070.0000, 1075.0000, 1073.0000, 1074.0000]) # fmt: skip
+ input_ids = [29, 93, 303, 64, 5478, 49651, 10394, 187, 34, 12939, 875]
+ # alternative: tokenizer('<|im_start|>system\nA chat between')
+ input_ids = torch.as_tensor(input_ids)[None].to(torch_device)
+ outputs = model(input_ids)["logits"][:, -1][0, :30]
+ self.assertTrue(torch.allclose(EXPECTED_LOGITS, outputs, atol=1e-5))
diff --git a/tests/models/llama/test_modeling_llama.py b/tests/models/llama/test_modeling_llama.py
index 2a52590369176a..c1cc479123f0a0 100644
--- a/tests/models/llama/test_modeling_llama.py
+++ b/tests/models/llama/test_modeling_llama.py
@@ -457,10 +457,10 @@ def test_eager_matches_sdpa_generate(self):
"""
max_new_tokens = 30
- tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
+ tokenizer = LlamaTokenizer.from_pretrained("saibo/llama-1B")
model_sdpa = LlamaForCausalLM.from_pretrained(
- "meta-llama/Llama-2-7b-hf",
+ "saibo/llama-1B",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(torch_device)
@@ -468,7 +468,7 @@ def test_eager_matches_sdpa_generate(self):
self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
model_eager = LlamaForCausalLM.from_pretrained(
- "meta-llama/Llama-2-7b-hf",
+ "saibo/llama-1B",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
attn_implementation="eager",
@@ -488,7 +488,11 @@ def test_eager_matches_sdpa_generate(self):
if not has_sdpa:
raise ValueError("The SDPA model should have SDPA attention layers")
- texts = ["hi", "Hello this is a very long sentence my friend", "Today I am in Paris and"]
+ texts = [
+ "hi here's a longer context, getting longer and",
+ "Hello this is a very long sentence my friend, very long for real",
+ "Today I am in Paris and",
+ ]
for padding_side in ["left", "right"]:
tokenizer.padding_side = padding_side
diff --git a/tests/models/maskformer/test_modeling_maskformer.py b/tests/models/maskformer/test_modeling_maskformer.py
index c4f014c5bbb5bb..7e48d761423830 100644
--- a/tests/models/maskformer/test_modeling_maskformer.py
+++ b/tests/models/maskformer/test_modeling_maskformer.py
@@ -362,6 +362,24 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(transformer_decoder_hidden_states.grad)
self.assertIsNotNone(attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_auxiliary_loss = True
+ config.output_auxiliary_logits = True
+ config.output_hidden_states = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_logits)
+ self.assertEqual(len(outputs.auxiliary_logits), self.model_tester.num_channels - 1)
+
TOLERANCE = 1e-4
diff --git a/tests/models/qwen2/__init__.py b/tests/models/qwen2/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/qwen2/test_modeling_qwen2.py b/tests/models/qwen2/test_modeling_qwen2.py
new file mode 100644
index 00000000000000..587312bfa21d73
--- /dev/null
+++ b/tests/models/qwen2/test_modeling_qwen2.py
@@ -0,0 +1,604 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Qwen2 model. """
+
+
+import gc
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, Qwen2Config, is_torch_available, set_seed
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_bitsandbytes,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Qwen2ForCausalLM,
+ Qwen2ForSequenceClassification,
+ Qwen2Model,
+ )
+
+
+class Qwen2ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ max_window_layers=3,
+ use_sliding_window=True,
+ sliding_window=2,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ bos_token_id=1,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.max_window_layers = max_window_layers
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.scope = scope
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return Qwen2Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ max_window_layers=self.max_window_layers,
+ use_sliding_window=self.use_sliding_window,
+ sliding_window=self.sliding_window,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ )
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Qwen2
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = Qwen2Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Qwen2
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = Qwen2Model(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Qwen2
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = Qwen2ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Qwen2
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = Qwen2ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTest with Mistral->Qwen2
+class Qwen2ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (Qwen2Model, Qwen2ForCausalLM, Qwen2ForSequenceClassification) if is_torch_available() else ()
+ all_generative_model_classes = (Qwen2ForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Qwen2Model,
+ "text-classification": Qwen2ForSequenceClassification,
+ "text-generation": Qwen2ForCausalLM,
+ "zero-shot": Qwen2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
+ def setUp(self):
+ self.model_tester = Qwen2ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Qwen2Config, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_Qwen2_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ print(config)
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = Qwen2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ @unittest.skip("Qwen2 buffers include complex numbers, which breaks this test")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip("Qwen2 uses GQA on all models so the KV cache is a non standard format")
+ def test_past_key_values_format(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_padding_right(self):
+ import torch
+
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
+ dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device)
+
+ model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False)
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ with self.assertRaises(ValueError):
+ _ = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_use_cache(self):
+ import torch
+
+ max_new_tokens = 30
+
+ for model_class in self.all_generative_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # NOTE: Qwen2 apparently does not support right padding + use_cache with FA2.
+ dummy_attention_mask[:, -1] = 1
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_padding_right(self):
+ self.skipTest("Qwen2 flash attention does not support right padding")
+
+
+@require_torch
+class Qwen2IntegrationTest(unittest.TestCase):
+ @slow
+ def test_model_450m_logits(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto")
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ with torch.no_grad():
+ out = model(input_ids).logits.cpu()
+ # Expected mean on dim = -1
+ EXPECTED_MEAN = torch.tensor([[-2.5548, -2.5737, -3.0600, -2.5906, -2.8478, -2.8118, -2.9325, -2.7694]])
+ torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, atol=1e-2, rtol=1e-2)
+ # slicing logits[0, 0, 0:30]
+ EXPECTED_SLICE = torch.tensor([-5.8781, -5.8616, -0.1052, -4.7200, -5.8781, -5.8774, -5.8773, -5.8777, -5.8781, -5.8780, -5.8781, -5.8779, -1.0787, 1.7583, -5.8779, -5.8780, -5.8783, -5.8778, -5.8776, -5.8781, -5.8784, -5.8778, -5.8778, -5.8777, -5.8779, -5.8778, -5.8776, -5.8780, -5.8779, -5.8781]) # fmt: skip
+ print(out[0, 0, :30])
+ torch.testing.assert_close(out[0, 0, :30], EXPECTED_SLICE, atol=1e-4, rtol=1e-4)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_450m_generation(self):
+ EXPECTED_TEXT_COMPLETION = """My favourite condiment is 100% ketchup. I love it on everything. I’m not a big"""
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-450m-beta", use_fast=False)
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @require_bitsandbytes
+ @slow
+ @require_flash_attn
+ def test_model_450m_long_prompt(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta",
+ device_map="auto",
+ load_in_4bit=True,
+ attn_implementation="flash_attention_2",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ @require_torch_sdpa
+ def test_model_450m_long_prompt_sdpa(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta",
+ device_map="auto",
+ attn_implementation="sdpa",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = assistant_model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ EXPECTED_TEXT_COMPLETION = """My favourite condiment is 100% ketchup. I love it on everything. I’m not a big"""
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-450m-beta", use_fast=False)
+
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ def test_speculative_generation(self):
+ EXPECTED_TEXT_COMPLETION = (
+ "My favourite condiment is 100% Sriracha. I love the heat, the tang and the fact costs"
+ )
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-beta", use_fast=False)
+ model = Qwen2ForCausalLM.from_pretrained("Qwen/Qwen2-450m-beta", device_map="auto", torch_dtype=torch.float16)
+ assistant_model = Qwen2ForCausalLM.from_pretrained(
+ "Qwen/Qwen2-450m-beta", device_map="auto", torch_dtype=torch.float16
+ )
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ set_seed(0)
+ generated_ids = model.generate(
+ input_ids, max_new_tokens=20, do_sample=True, temperature=0.3, assistant_model=assistant_model
+ )
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/tests/models/qwen2/test_tokenization_qwen2.py b/tests/models/qwen2/test_tokenization_qwen2.py
new file mode 100644
index 00000000000000..565520367f57f4
--- /dev/null
+++ b/tests/models/qwen2/test_tokenization_qwen2.py
@@ -0,0 +1,204 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+
+from transformers import AddedToken, Qwen2Tokenizer, Qwen2TokenizerFast
+from transformers.models.qwen2.tokenization_qwen2 import VOCAB_FILES_NAMES, bytes_to_unicode
+from transformers.testing_utils import require_tokenizers, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_tokenizers
+class Qwen2TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = Qwen2Tokenizer
+ rust_tokenizer_class = Qwen2TokenizerFast
+ test_slow_tokenizer = True
+ test_rust_tokenizer = True
+ space_between_special_tokens = False
+ from_pretrained_kwargs = None
+ test_seq2seq = False
+
+ def setUp(self):
+ super().setUp()
+
+ # this make sure the vocabuary is complete at the byte level.
+ vocab = list(bytes_to_unicode().values())
+ # the vocabulary, note:
+ # - `"\u0120n"`, `"\u0120lowest"`, `"\u0120newer"`, and `"\u0120wider"` are ineffective, because there are
+ # not in the merges.
+ # - `"01"` is ineffective, because the merge is ineffective due to pretokenization.
+ vocab.extend(
+ [
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "01",
+ ";}",
+ ";}\u010a",
+ "\u00cf\u0135",
+ ]
+ )
+
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+
+ # note: `"0 1"` is in the merges, but the pretokenization rules render it ineffective
+ merges = [
+ "#version: 0.2",
+ "\u0120 l",
+ "\u0120l o",
+ "\u0120lo w",
+ "e r",
+ "0 1",
+ "; }",
+ ";} \u010a",
+ "\u00cf \u0135",
+ ]
+
+ self.special_tokens_map = {"eos_token": "<|endoftext|>"}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ def get_tokenizer(self, **kwargs):
+ kwargs.update(self.special_tokens_map)
+ return Qwen2Tokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs):
+ kwargs.update(self.special_tokens_map)
+ return Qwen2TokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ # this case should cover
+ # - NFC normalization (code point U+03D3 has different normalization forms under NFC, NFD, NFKC, and NFKD)
+ # - the pretokenization rules (spliting digits and merging symbols with \n\r)
+ input_text = "lower lower newer 010;}\n<|endoftext|>\u03d2\u0301"
+ output_text = "lower lower newer 010;}\n<|endoftext|>\u03d3"
+ return input_text, output_text
+
+ def test_python_full_tokenizer(self):
+ tokenizer = self.get_tokenizer()
+ sequence, _ = self.get_input_output_texts(tokenizer)
+ bpe_tokens = [
+ "l",
+ "o",
+ "w",
+ "er",
+ "\u0120low",
+ "er",
+ "\u0120",
+ "n",
+ "e",
+ "w",
+ "er",
+ "\u0120",
+ "0",
+ "1",
+ "0",
+ ";}\u010a",
+ "<|endoftext|>",
+ "\u00cf\u0135",
+ ]
+ tokens = tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens
+ input_bpe_tokens = [75, 78, 86, 260, 259, 260, 220, 77, 68, 86, 260, 220, 15, 16, 15, 266, 268, 267]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @unittest.skip("We disable the test of pretokenization as it is not reversible.")
+ def test_pretokenized_inputs(self):
+ # the test case in parent class uses str.split to "pretokenize",
+ # which eats the whitespaces, which, in turn, is not reversible.
+ # the results, by nature, should be different.
+ pass
+
+ def test_nfc_normalization(self):
+ # per https://unicode.org/faq/normalization.html, there are three characters whose normalization forms
+ # under NFC, NFD, NFKC, and NFKD are all different
+ # using these, we can make sure only NFC is applied
+ input_string = "\u03d2\u0301\u03d2\u0308\u017f\u0307" # the NFD form
+ output_string = "\u03d3\u03d4\u1e9b" # the NFC form
+
+ if self.test_slow_tokenizer:
+ tokenizer = self.get_tokenizer()
+ tokenizer_output_string, _ = tokenizer.prepare_for_tokenization(input_string)
+ self.assertEqual(tokenizer_output_string, output_string)
+
+ if self.test_rust_tokenizer:
+ tokenizer = self.get_rust_tokenizer()
+ # we can check the class of the normalizer, but it would be okay if Sequence([NFD, NFC]) is used
+ # let's check the output instead
+ tokenizer_output_string = tokenizer.backend_tokenizer.normalizer.normalize_str(input_string)
+ self.assertEqual(tokenizer_output_string, output_string)
+
+ def test_slow_tokenizer_decode_spaces_between_special_tokens_default(self):
+ # Qwen2Tokenzier changes the default `spaces_between_special_tokens` in `decode` to False
+ if not self.test_slow_tokenizer:
+ return
+
+ # tokenizer has a special token: `"<|endfotext|>"` as eos, but it is not `legacy_added_tokens`
+ # special tokens in `spaces_between_special_tokens` means spaces between `legacy_added_tokens`
+ # that would be `"<|im_start|>"` and `"<|im_end|>"` in Qwen/Qwen2 Models
+ token_ids = [259, 260, 268, 269, 26]
+ sequence = " lower<|endoftext|><|im_start|>;"
+ sequence_with_space = " lower<|endoftext|> <|im_start|> ;"
+
+ tokenizer = self.get_tokenizer()
+ # let's add a legacy_added_tokens
+ im_start = AddedToken(
+ "<|im_start|>", single_word=False, lstrip=False, rstrip=False, special=True, normalized=False
+ )
+ tokenizer.add_tokens([im_start])
+
+ # `spaces_between_special_tokens` defaults to False
+ self.assertEqual(tokenizer.decode(token_ids), sequence)
+
+ # but it can be set to True
+ self.assertEqual(tokenizer.decode(token_ids, spaces_between_special_tokens=True), sequence_with_space)
+
+ @slow
+ def test_tokenizer_integration(self):
+ sequences = [
+ "Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides "
+ "general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet...) for Natural "
+ "Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained "
+ "models in 100+ languages and deep interoperability between Jax, PyTorch and TensorFlow.",
+ "🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。",
+ """```python\ntokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-tokenizer")\n"""
+ """tokenizer("世界,你好!")```""",
+ ]
+
+ expected_encoding = {'input_ids': [[8963, 388, 320, 69514, 3881, 438, 4510, 27414, 32852, 388, 323, 4510, 27414, 21334, 35722, 1455, 529, 8, 5707, 4586, 58238, 77235, 320, 61437, 11, 479, 2828, 12, 17, 11, 11830, 61437, 64, 11, 1599, 10994, 11, 27604, 321, 33, 529, 11, 29881, 6954, 32574, 369, 18448, 11434, 45451, 320, 45, 23236, 8, 323, 18448, 11434, 23470, 320, 30042, 38, 8, 448, 916, 220, 18, 17, 10, 80669, 4119, 304, 220, 16, 15, 15, 10, 15459, 323, 5538, 94130, 2897, 1948, 619, 706, 11, 5355, 51, 21584, 323, 94986, 13], [144834, 80532, 93685, 83744, 34187, 73670, 104261, 29490, 62189, 103937, 104034, 102830, 98841, 104034, 104949, 9370, 5333, 58143, 102011, 1773, 37029, 98841, 104034, 104949, 73670, 101940, 100768, 104997, 33108, 100912, 105054, 90395, 100136, 106831, 45181, 64355, 104034, 113521, 101975, 33108, 85329, 1773, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643], [73594, 12669, 198, 85593, 284, 8979, 37434, 6387, 10442, 35722, 445, 48, 16948, 45274, 16948, 34841, 3135, 1138, 85593, 445, 99489, 3837, 108386, 6313, 899, 73594, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643, 151643]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: off
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="Qwen/Qwen-tokenizer",
+ revision="5909c8222473b2c73b0b73fb054552cd4ef6a8eb",
+ sequences=sequences,
+ )
diff --git a/tests/models/t5/test_tokenization_t5.py b/tests/models/t5/test_tokenization_t5.py
index a141dea86b71a5..5fa0e19c792b29 100644
--- a/tests/models/t5/test_tokenization_t5.py
+++ b/tests/models/t5/test_tokenization_t5.py
@@ -424,6 +424,41 @@ def test_some_edge_cases(self):
self.assertEqual(tokens, [])
self.assertEqual(tokens, tokenizer.sp_model.encode("▁", out_type=str))
+ def test_fast_slow_edge_cases(self):
+ # We are testing spaces before and spaces after special tokens + space transformations
+ slow_tokenizer = T5Tokenizer.from_pretrained("t5-base", legacy=False)
+ fast_tokenizer = T5TokenizerFast.from_pretrained("t5-base", legacy=False, from_slow=True)
+ slow_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=False))
+ fast_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=False))
+
+ edge_case = "Hey!. HowHey !"
+ EXPECTED_SLOW = ["▁Hey", "!", "", ".", "▁How", "", "He", "y", "", "!"] # fmt: skip
+ with self.subTest(f"slow {edge_case} normalized = False"):
+ self.assertEqual(slow_tokenizer.tokenize(edge_case), EXPECTED_SLOW)
+ with self.subTest(f"Fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(edge_case), EXPECTED_SLOW)
+
+ hard_case = "Hey! . How Hey ! . "
+ EXPECTED_SLOW = ["▁Hey", "!", "", ".", "▁How", "", "▁Hey", "", "▁", "!", "▁", "."] # fmt: skip
+ with self.subTest(f"slow {edge_case} normalized = False"):
+ self.assertEqual(slow_tokenizer.tokenize(hard_case), EXPECTED_SLOW)
+ with self.subTest(f"fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(hard_case), EXPECTED_SLOW)
+
+ fast_tokenizer = T5TokenizerFast.from_pretrained("t5-base", legacy=False, from_slow=True)
+ fast_tokenizer.add_tokens(AddedToken("", rstrip=False, lstrip=False, normalized=True))
+
+ # `normalized=True` is the default normalization scheme when adding a token. Normalize -> don't strip the space.
+ # the issue now is that our slow tokenizer should NOT strip the space if we want to simulate sentencepiece token addition.
+
+ EXPECTED_FAST = ["▁Hey", "!", "", ".", "▁How", "", "He", "y", "▁", "", "!"] # fmt: skip
+ with self.subTest(f"fast {edge_case} normalized = True"):
+ self.assertEqual(fast_tokenizer.tokenize(edge_case), EXPECTED_FAST)
+
+ EXPECTED_FAST = ['▁Hey', '!', '▁', '', '.', '▁How', '', '▁Hey','▁', '', '▁', '!', '▁', '.'] # fmt: skip
+ with self.subTest(f"fast {edge_case} normalized = False"):
+ self.assertEqual(fast_tokenizer.tokenize(hard_case), EXPECTED_FAST)
+
@require_sentencepiece
@require_tokenizers
diff --git a/tests/models/table_transformer/test_modeling_table_transformer.py b/tests/models/table_transformer/test_modeling_table_transformer.py
index d81c52ff1307c9..851ef36a1a12d3 100644
--- a/tests/models/table_transformer/test_modeling_table_transformer.py
+++ b/tests/models/table_transformer/test_modeling_table_transformer.py
@@ -411,6 +411,22 @@ def test_retain_grad_hidden_states_attentions(self):
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/wav2vec2_bert/__init__.py b/tests/models/wav2vec2_bert/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py b/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py
new file mode 100644
index 00000000000000..a4a0a95972c9f7
--- /dev/null
+++ b/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py
@@ -0,0 +1,913 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Wav2Vec2-BERT model. """
+import tempfile
+import unittest
+
+from datasets import load_dataset
+
+from transformers import Wav2Vec2BertConfig, is_torch_available
+from transformers.testing_utils import (
+ is_pt_flax_cross_test,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AutoFeatureExtractor,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForXVector,
+ Wav2Vec2BertModel,
+ )
+ from transformers.models.wav2vec2_bert.modeling_wav2vec2_bert import (
+ _compute_mask_indices,
+ _sample_negative_indices,
+ )
+
+
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTester with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertModelTester:
+ # Ignore copy
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=200, # speech is longer
+ is_training=False,
+ hidden_size=16,
+ feature_projection_input_dim=16,
+ num_conv_pos_embeddings=16,
+ num_conv_pos_embedding_groups=2,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ hidden_dropout_prob=0.1,
+ intermediate_size=20,
+ layer_norm_eps=1e-5,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ mask_time_prob=0.5,
+ mask_time_length=2,
+ vocab_size=32,
+ do_stable_layer_norm=False,
+ num_adapter_layers=2,
+ adapter_stride=2,
+ tdnn_dim=(32, 32),
+ tdnn_kernel=(5, 3),
+ tdnn_dilation=(1, 2),
+ xvector_output_dim=32,
+ position_embeddings_type="relative",
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.feature_projection_input_dim = feature_projection_input_dim
+ self.num_conv_pos_embeddings = num_conv_pos_embeddings
+ self.num_conv_pos_embedding_groups = num_conv_pos_embedding_groups
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.intermediate_size = intermediate_size
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.vocab_size = vocab_size
+ self.do_stable_layer_norm = do_stable_layer_norm
+ self.num_adapter_layers = num_adapter_layers
+ self.adapter_stride = adapter_stride
+ self.mask_time_prob = mask_time_prob
+ self.mask_time_length = mask_time_length
+ self.scope = scope
+ self.tdnn_dim = tdnn_dim
+ self.tdnn_kernel = tdnn_kernel
+ self.tdnn_dilation = tdnn_dilation
+ self.xvector_output_dim = xvector_output_dim
+ self.position_embeddings_type = position_embeddings_type
+
+ self.output_seq_length = self.seq_length
+ self.encoder_seq_length = self.output_seq_length
+
+ self.adapter_output_seq_length = self.output_seq_length
+
+ for _ in range(num_adapter_layers):
+ self.adapter_output_seq_length = (self.adapter_output_seq_length - 1) // adapter_stride + 1
+
+ # Ignore copy
+ def prepare_config_and_inputs(self, position_embeddings_type="relative"):
+ input_shape = [self.batch_size, self.seq_length, self.feature_projection_input_dim]
+
+ input_features = floats_tensor(input_shape, self.vocab_size)
+ attention_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config(position_embeddings_type=position_embeddings_type)
+
+ return config, input_features, attention_mask
+
+ # Ignore copy
+ def get_config(self, position_embeddings_type="relative"):
+ return Wav2Vec2BertConfig(
+ hidden_size=self.hidden_size,
+ feature_projection_input_dim=self.feature_projection_input_dim,
+ mask_time_prob=self.mask_time_prob,
+ mask_time_length=self.mask_time_length,
+ num_conv_pos_embeddings=self.num_conv_pos_embeddings,
+ num_conv_pos_embedding_groups=self.num_conv_pos_embedding_groups,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ intermediate_size=self.intermediate_size,
+ layer_norm_eps=self.layer_norm_eps,
+ do_stable_layer_norm=self.do_stable_layer_norm,
+ hidden_act=self.hidden_act,
+ initializer_range=self.initializer_range,
+ vocab_size=self.vocab_size,
+ num_adapter_layers=self.num_adapter_layers,
+ adapter_stride=self.adapter_stride,
+ tdnn_dim=self.tdnn_dim,
+ tdnn_kernel=self.tdnn_kernel,
+ tdnn_dilation=self.tdnn_dilation,
+ xvector_output_dim=self.xvector_output_dim,
+ position_embeddings_type=position_embeddings_type,
+ )
+
+ def create_and_check_model(self, config, input_features, attention_mask):
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_model_with_adapter(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_model_with_adapter_for_ctc(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 2 * config.hidden_size
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size)
+ )
+
+ # Ignore copy
+ def create_and_check_model_with_intermediate_ffn_before_adapter(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.use_intermediate_ffn_before_adapter = True
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ # also try with different adapter proj dim
+ config.output_hidden_size = 8
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ def create_and_check_model_with_adapter_proj_dim(self, config, input_features, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 8
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_features, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
+ )
+
+ def create_and_check_model_float16(self, config, input_features, attention_mask):
+ model = Wav2Vec2BertModel(config=config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = Wav2Vec2BertModel.from_pretrained(tmpdirname, torch_dtype=torch.float16)
+
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ result = model(input_features.type(dtype=torch.float16), attention_mask=attention_mask)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_batch_inference(self, config, input_features, *args):
+ # test does not pass for models making use of `group_norm`
+ # check: https://github.com/pytorch/fairseq/issues/3227
+ model = Wav2Vec2BertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ input_features = input_features[:3]
+ attention_mask = torch.ones(input_features.shape, device=torch_device, dtype=torch.bool)
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0.0
+
+ batch_outputs = model(input_features, attention_mask=attention_mask).last_hidden_state
+
+ for i in range(input_features.shape[0]):
+ input_slice = input_features[i : i + 1, : input_lengths[i]]
+ output = model(input_slice).last_hidden_state
+
+ batch_output = batch_outputs[i : i + 1, : output.shape[1]]
+ self.parent.assertTrue(torch.allclose(output, batch_output, atol=1e-3))
+
+ def check_ctc_loss(self, config, input_features, *args):
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_features = input_features[:3]
+ # Ignore copy
+ attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], min(max_length_labels) - 1), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ model.config.ctc_loss_reduction = "sum"
+ sum_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+
+ model.config.ctc_loss_reduction = "mean"
+ mean_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(sum_loss, float))
+ self.parent.assertTrue(isinstance(mean_loss, float))
+
+ def check_seq_classifier_loss(self, config, input_features, *args):
+ model = Wav2Vec2BertForSequenceClassification(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_features = input_features[:3]
+ # Ignore copy
+ attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ masked_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
+ unmasked_loss = model(input_features, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(masked_loss, float))
+ self.parent.assertTrue(isinstance(unmasked_loss, float))
+ self.parent.assertTrue(masked_loss != unmasked_loss)
+
+ def check_ctc_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForCTC(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # Ignore copy
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ if max_length_labels[i] < labels.shape[-1]:
+ # it's important that we make sure that target lengths are at least
+ # one shorter than logit lengths to prevent -inf
+ labels[i, max_length_labels[i] - 1 :] = -100
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_seq_classifier_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForSequenceClassification(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze everything but the classification head
+ model.freeze_base_model()
+
+ input_features = input_features[:3]
+
+ # Ignore copy
+ input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_xvector_training(self, config, input_features, *args):
+ config.ctc_zero_infinity = True
+ model = Wav2Vec2BertForXVector(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze everything but the classification head
+ model.freeze_base_model()
+
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_features[i, input_lengths[i] :] = 0.0
+
+ loss = model(input_features, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_labels_out_of_vocab(self, config, input_features, *args):
+ model = Wav2Vec2BertForCTC(config)
+ model.to(torch_device)
+ model.train()
+
+ input_features = input_features[:3]
+
+ input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size + 100)
+
+ with self.parent.assertRaises(ValueError):
+ model(input_features, labels=labels)
+
+ def prepare_config_and_inputs_for_common(self):
+ config, input_features, attention_mask = self.prepare_config_and_inputs()
+ inputs_dict = {"input_features": input_features, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTest with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ # Ignore copy
+ all_model_classes = (
+ (
+ Wav2Vec2BertForCTC,
+ Wav2Vec2BertModel,
+ Wav2Vec2BertForSequenceClassification,
+ Wav2Vec2BertForAudioFrameClassification,
+ Wav2Vec2BertForXVector,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ pipeline_model_mapping = (
+ {
+ "audio-classification": Wav2Vec2BertForSequenceClassification,
+ "automatic-speech-recognition": Wav2Vec2BertForCTC,
+ "feature-extraction": Wav2Vec2BertModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_headmasking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Wav2Vec2BertModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Wav2Vec2BertConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_relative(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ # Ignore copy
+ def test_model_with_relative_key(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_rotary(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_no_rel_pos(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type=None)
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_adapter(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter(*config_and_inputs)
+
+ def test_model_with_adapter_for_ctc(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs)
+
+ # Ignore copy
+ def test_model_with_intermediate_ffn_before_adapter(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_intermediate_ffn_before_adapter(*config_and_inputs)
+
+ def test_model_with_adapter_proj_dim(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_relative(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ # Ignore copy
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_relative_key(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_model_float16_with_rotary(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
+ self.model_tester.create_and_check_model_float16(*config_and_inputs)
+
+ def test_ctc_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_loss(*config_and_inputs)
+
+ def test_seq_classifier_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_loss(*config_and_inputs)
+
+ def test_ctc_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_training(*config_and_inputs)
+
+ def test_seq_classifier_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_training(*config_and_inputs)
+
+ def test_xvector_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_xvector_training(*config_and_inputs)
+
+ def test_labels_out_of_vocab(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_labels_out_of_vocab(*config_and_inputs)
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="`input_ids` is renamed to `input_features`")
+ def test_forward_signature(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
+ def test_model_common_attributes(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="non-robust architecture does not exist in Flax")
+ @is_pt_flax_cross_test
+ def test_equivalence_flax_to_pt(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="non-robust architecture does not exist in Flax")
+ @is_pt_flax_cross_test
+ def test_equivalence_pt_to_flax(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ # set layer drop to 0
+ model.config.layerdrop = 0.0
+
+ input_features = inputs_dict["input_features"]
+
+ input_lengths = torch.tensor(
+ [input_features.shape[1] for _ in range(input_features.shape[0])], dtype=torch.long, device=torch_device
+ )
+ output_lengths = model._get_feat_extract_output_lengths(input_lengths)
+
+ labels = ids_tensor((input_features.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size)
+ inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"])
+ inputs_dict["labels"] = labels
+
+ outputs = model(**inputs_dict)
+
+ output = outputs[0]
+
+ # Encoder-/Decoder-only models
+ hidden_states = outputs.hidden_states[0]
+ attentions = outputs.attentions[0]
+
+ hidden_states.retain_grad()
+ attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+ self.assertIsNotNone(attentions.grad)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv.weight",
+ "conv.parametrizations.weight",
+ "masked_spec_embed",
+ "codevectors",
+ "quantizer.weight_proj.weight",
+ "project_hid.weight",
+ "project_hid.bias",
+ "project_q.weight",
+ "project_q.bias",
+ "pos_bias_v",
+ "pos_bias_u",
+ "pointwise_conv1",
+ "pointwise_conv2",
+ "feature_projection.projection.weight",
+ "feature_projection.projection.bias",
+ "objective.weight",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "weight_g") and module.weight_g is not None:
+ module.weight_g.data.fill_(3)
+ if hasattr(module, "weight_v") and module.weight_v is not None:
+ module.weight_v.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+ if hasattr(module, "pos_bias_u") and module.pos_bias_u is not None:
+ module.pos_bias_u.data.fill_(3)
+ if hasattr(module, "pos_bias_v") and module.pos_bias_v is not None:
+ module.pos_bias_v.data.fill_(3)
+ if hasattr(module, "codevectors") and module.codevectors is not None:
+ module.codevectors.data.fill_(3)
+ if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None:
+ module.masked_spec_embed.data.fill_(3)
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working")
+ def test_mask_feature_prob_ctc(self):
+ pass
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working")
+ def test_mask_time_prob_ctc(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ # Ignore copy
+ model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
+ self.assertIsNotNone(model)
+
+
+@require_torch
+# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerUtilsTest with Conformer->Bert, input_values->input_features
+class Wav2Vec2BertUtilsTest(unittest.TestCase):
+ def test_compute_mask_indices(self):
+ batch_size = 4
+ sequence_length = 60
+ mask_prob = 0.5
+ mask_length = 1
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ self.assertListEqual(mask.sum(axis=-1).tolist(), [mask_prob * sequence_length for _ in range(batch_size)])
+
+ def test_compute_mask_indices_low_prob(self):
+ # with these settings num_masked_spans=0.5, which means probabilistic rounding
+ # ensures that in 5 out of 10 method calls, num_masked_spans=0, and in
+ # the other 5 out of 10, cases num_masked_spans=1
+ n_trials = 100
+ batch_size = 4
+ sequence_length = 100
+ mask_prob = 0.05
+ mask_length = 10
+
+ count_dimensions_masked = 0
+ count_dimensions_not_masked = 0
+
+ for _ in range(n_trials):
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ num_masks = torch.sum(mask).item()
+
+ if num_masks > 0:
+ count_dimensions_masked += 1
+ else:
+ count_dimensions_not_masked += 1
+
+ # as we test for at least 10 masked dimension and at least
+ # 10 non-masked dimension, this test could fail with probability:
+ # P(100 coin flips, at most 9 heads) = 1.66e-18
+ self.assertGreater(count_dimensions_masked, int(n_trials * 0.1))
+ self.assertGreater(count_dimensions_not_masked, int(n_trials * 0.1))
+
+ def test_compute_mask_indices_overlap(self):
+ batch_size = 4
+ sequence_length = 80
+ mask_prob = 0.5
+ mask_length = 4
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ # because of overlap mask don't have to add up exactly to `mask_prob * sequence_length`, but have to be smaller or equal
+ for batch_sum in mask.sum(axis=-1):
+ self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
+
+ def test_compute_mask_indices_attn_mask_overlap(self):
+ batch_size = 4
+ sequence_length = 80
+ mask_prob = 0.5
+ mask_length = 4
+
+ attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ attention_mask[:2, sequence_length // 2 :] = 0
+
+ mask = _compute_mask_indices(
+ (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask
+ )
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ for batch_sum in mask.sum(axis=-1):
+ self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
+
+ self.assertTrue(mask[:2, sequence_length // 2 :].sum() == 0)
+
+ def test_compute_mask_indices_short_audio(self):
+ batch_size = 4
+ sequence_length = 100
+ mask_prob = 0.05
+ mask_length = 10
+
+ attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ # force one example to be heavily padded
+ attention_mask[0, 5:] = 0
+
+ mask = _compute_mask_indices(
+ (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask, min_masks=2
+ )
+
+ # make sure that non-padded examples cannot be padded
+ self.assertFalse(mask[0][attention_mask[0].to(torch.bool).cpu()].any())
+
+ # Ignore copy
+ @unittest.skip(reason="Kept to make #Copied from working. Test a class used for pretraining, not yet supported.")
+ def test_compute_perplexity(self):
+ pass
+
+ def test_sample_negatives(self):
+ batch_size = 2
+ sequence_length = 10
+ hidden_size = 4
+ num_negatives = 3
+
+ features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
+ sequence_length, hidden_size
+ ) # each value in vector consits of same value
+ features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
+
+ # sample negative indices
+ sampled_negative_indices = _sample_negative_indices((batch_size, sequence_length), num_negatives, None)
+ sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
+ negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
+ negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
+ self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
+
+ # make sure no negatively sampled vector is actually a positive one
+ for negative in negatives:
+ self.assertTrue(((negative - features) == 0).sum() == 0.0)
+
+ # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
+ self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
+
+ def test_sample_negatives_with_mask(self):
+ batch_size = 2
+ sequence_length = 10
+ hidden_size = 4
+ num_negatives = 3
+
+ # second half of last input tensor is padded
+ mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
+ mask[-1, sequence_length // 2 :] = 0
+
+ features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
+ sequence_length, hidden_size
+ ) # each value in vector consits of same value
+ features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
+
+ # replace masked feature vectors with -100 to test that those are not sampled
+ features = torch.where(mask[:, :, None].expand(features.shape).bool(), features, -100)
+
+ # sample negative indices
+ sampled_negative_indices = _sample_negative_indices(
+ (batch_size, sequence_length), num_negatives, mask.cpu().numpy()
+ )
+ sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
+ negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
+ negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
+
+ self.assertTrue((negatives >= 0).all().item())
+
+ self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
+
+ # make sure no negatively sampled vector is actually a positive one
+ for negative in negatives:
+ self.assertTrue(((negative - features) == 0).sum() == 0.0)
+
+ # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
+ self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
+
+
+@require_torch
+@slow
+class Wav2Vec2BertModelIntegrationTest(unittest.TestCase):
+ def _load_datasamples(self, num_samples):
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").filter(lambda x: x["id"] in [f"1272-141231-000{i}" for i in range(num_samples)])
+ speech_samples = speech_samples[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ def test_inference_w2v2_bert(self):
+ model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
+ model.to(torch_device)
+ feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/w2v-bert-2.0")
+
+ input_speech = self._load_datasamples(2)
+
+ inputs = feature_extractor(input_speech, return_tensors="pt", padding=True).to(torch_device)
+
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**inputs, output_attentions=True)
+
+ # fmt: off
+ expected_slice_0 = torch.tensor(
+ [[-0.0098, -0.0570, -0.1286, 0.0439, -0.1037, -0.0235],
+ [-0.0767, 0.0574, -0.3224, 0.0482, 0.0440, -0.0193],
+ [ 0.0220, -0.0878, -0.2027, -0.0028, -0.0666, 0.0721],
+ [ 0.0307, -0.1099, 0.0273, -0.0416, -0.0715, 0.0094],
+ [ 0.0758, -0.0291, 0.1084, 0.0004, -0.0751, -0.0116],
+ [ 0.0349, -0.0343, -0.0098, 0.0415, -0.0617, 0.0241],
+ [-0.0193, -0.0171, 0.1965, 0.0797, -0.0308, 0.2033],
+ [-0.0323, -0.0315, 0.0948, 0.0944, -0.0254, 0.1241],
+ [-0.0493, 0.0010, -0.1762, 0.0034, -0.0787, 0.0832],
+ [ 0.0043, -0.1228, -0.0739, 0.0266, -0.0337, -0.0068]]
+ ).to(torch_device)
+ # fmt: on
+
+ # fmt: off
+ expected_slice_1 = torch.tensor(
+ [[-0.0348, -0.0521, -0.3036, 0.0285, -0.0715, -0.0453],
+ [-0.0102, 0.0114, -0.3266, 0.0027, -0.0558, 0.0038],
+ [ 0.0454, 0.0148, -0.2418, -0.0392, -0.0455, 0.0478],
+ [-0.0013, 0.0825, -0.1730, -0.0091, -0.0426, 0.0360],
+ [-0.0227, 0.0687, -0.1168, 0.0569, -0.0160, 0.0759],
+ [-0.0318, 0.0562, -0.0508, 0.0605, 0.0150, 0.0953],
+ [-0.0415, 0.0438, 0.0233, 0.0336, 0.0262, 0.0860],
+ [-0.0163, 0.0048, 0.0807, 0.0119, 0.0712, 0.0158],
+ [ 0.0244, -0.0145, 0.0262, -0.0237, 0.0283, -0.0125],
+ [-0.0587, -0.0516, -0.0368, -0.0196, 0.0307, -0.1434]]
+ ).to(torch_device)
+ # fmt: on
+
+ self.assertTrue((outputs.last_hidden_state[0, 25:35, 4:10] - expected_slice_0).abs().max() <= 1e-4)
+ self.assertTrue((outputs.last_hidden_state[1, 25:35, 4:10] - expected_slice_1).abs().max() <= 1e-4)
+
+ self.assertAlmostEqual(outputs.last_hidden_state[1].mean().item(), 3.3123e-05)
+ self.assertAlmostEqual(outputs.last_hidden_state[1].std().item(), 0.1545, delta=2e-5)
+
+ self.assertListEqual(list(outputs.last_hidden_state.shape), [2, 326, 1024])
diff --git a/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py b/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py
new file mode 100644
index 00000000000000..b6b1506f5e4d68
--- /dev/null
+++ b/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py
@@ -0,0 +1,156 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+from transformers.models.seamless_m4t import SeamlessM4TFeatureExtractor
+from transformers.models.wav2vec2 import Wav2Vec2CTCTokenizer
+from transformers.models.wav2vec2.tokenization_wav2vec2 import VOCAB_FILES_NAMES
+from transformers.models.wav2vec2_bert import Wav2Vec2BertProcessor
+from transformers.utils import FEATURE_EXTRACTOR_NAME
+
+from ..wav2vec2.test_feature_extraction_wav2vec2 import floats_list
+
+
+# Copied from tests.models.wav2vec2.test_processor_wav2vec2.Wav2Vec2ProcessorTest with Wav2Vec2FeatureExtractor->SeamlessM4TFeatureExtractor, Wav2Vec2Processor->Wav2Vec2BertProcessor
+class Wav2Vec2BertProcessorTest(unittest.TestCase):
+ def setUp(self):
+ vocab = " | E T A O N I H S R D L U M W C F G Y P B V K ' X J Q Z".split(" ")
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+
+ self.add_kwargs_tokens_map = {
+ "pad_token": "",
+ "unk_token": "",
+ "bos_token": "",
+ "eos_token": "",
+ }
+ feature_extractor_map = {
+ "feature_size": 1,
+ "padding_value": 0.0,
+ "sampling_rate": 16000,
+ "return_attention_mask": False,
+ "do_normalize": True,
+ }
+
+ self.tmpdirname = tempfile.mkdtemp()
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.feature_extraction_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+
+ with open(self.feature_extraction_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(feature_extractor_map) + "\n")
+
+ def get_tokenizer(self, **kwargs_init):
+ kwargs = self.add_kwargs_tokens_map.copy()
+ kwargs.update(kwargs_init)
+ return Wav2Vec2CTCTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return SeamlessM4TFeatureExtractor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ tokenizer = self.get_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+
+ processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = Wav2Vec2BertProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+ self.assertIsInstance(processor.tokenizer, Wav2Vec2CTCTokenizer)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, SeamlessM4TFeatureExtractor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = Wav2Vec2BertProcessor(
+ tokenizer=self.get_tokenizer(), feature_extractor=self.get_feature_extractor()
+ )
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_normalize=False, padding_value=1.0)
+
+ processor = Wav2Vec2BertProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, Wav2Vec2CTCTokenizer)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, SeamlessM4TFeatureExtractor)
+
+ def test_feature_extractor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ raw_speech = floats_list((3, 1000))
+
+ input_feat_extract = feature_extractor(raw_speech, return_tensors="np")
+ input_processor = processor(raw_speech, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "This is a test string"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_tokenizer_decode(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ self.assertListEqual(
+ processor.model_input_names,
+ feature_extractor.model_input_names,
+ msg="`processor` and `feature_extractor` model input names do not match",
+ )
diff --git a/tests/models/whisper/test_modeling_whisper.py b/tests/models/whisper/test_modeling_whisper.py
index 0192b83f929afc..505d2e991033d8 100644
--- a/tests/models/whisper/test_modeling_whisper.py
+++ b/tests/models/whisper/test_modeling_whisper.py
@@ -18,6 +18,7 @@
import inspect
import os
import random
+import re
import tempfile
import time
import unittest
@@ -84,6 +85,7 @@ def __init__(
self.batch_size = batch_size
self.max_length = max_length
self.count = 0
+ self.begin_index = 0
self.let_pass = [[] for _ in range(batch_size)]
for k in range(batch_size):
@@ -91,9 +93,12 @@ def __init__(
for _ in range(10000):
self.let_pass[k].append(random.randint(1, 10) <= 3)
+ def set_begin_index(self, begin_index: int):
+ self.begin_index = begin_index
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
# we don't want to randomely sample timestamp tokens
- if input_ids.shape[-1] > 1:
+ if input_ids.shape[-1] != self.begin_index:
scores[:, self.timestamp_begin :] = -float("inf")
self.no_time_stamp_counter = [x + 1 for x in self.no_time_stamp_counter]
@@ -1314,7 +1319,7 @@ def test_generate_with_prompt_ids_max_length(self):
model.generate(input_features, max_new_tokens=1, prompt_ids=prompt_ids)
- def test_longform_generate_single_batch(self):
+ def _check_longform_generate_single_batch(self, condition_on_prev_tokens):
config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = WhisperForConditionalGeneration(config).eval().to(torch_device)
@@ -1354,20 +1359,30 @@ def test_longform_generate_single_batch(self):
timestamp_begin = vocab_size - num_timestamp_tokens
model.generation_config.no_timestamps_token_id = timestamp_begin - 1
model.generation_config.eos_token_id = None
+ model.config.eos_token_id = None
model.generation_config._detect_timestamp_from_logprob = False
# make sure that we only have the same begin token
model.generation_config.max_initial_timestamp_index = 0
+ model.generation_config.prev_bos_token_id = timestamp_begin - 3
+
+ gen_kwargs = {
+ "logits_processor": logits_processor,
+ "return_segments": True,
+ "condition_on_prev_tokens": condition_on_prev_tokens,
+ }
- outputs = model.generate(long_input_features, logits_processor=logits_processor, return_segments=True)
+ if condition_on_prev_tokens:
+ gen_kwargs["no_speech_threshold"] = 0.6
+ gen_kwargs["temperature"] = (0.0, 0.2, 0.4, 0.6, 0.8, 1.0)
+ gen_kwargs["compression_ratio_threshold"] = 2.4
+ gen_kwargs["logprob_threshold"] = -1.0
+
+ outputs = model.generate(long_input_features, **gen_kwargs)
segments = outputs["segments"][0]
- for i, segment in enumerate(segments):
+ for _, segment in enumerate(segments):
assert segment["start"] <= segment["end"], "start has to be smaller equal end"
- assert (
- segment["tokens"][0] == model.generation_config.decoder_start_token_id
- or segment["tokens"][0] >= timestamp_begin
- ), "First segment token should be a timestamp token"
assert any(
s > timestamp_begin for s in segment["tokens"][1:]
), f"At least one segment token should be a timestamp token, but not first., {segment['tokens']}"
@@ -1375,7 +1390,13 @@ def test_longform_generate_single_batch(self):
segment["tokens"].shape[-1] <= max_length
), "make sure that no segment is larger than max generation length"
- def test_longform_generate_multi_batch(self):
+ def test_longform_generate_single_batch(self):
+ self._check_longform_generate_single_batch(condition_on_prev_tokens=False)
+
+ def test_longform_generate_single_batch_cond_prev(self):
+ self._check_longform_generate_single_batch(condition_on_prev_tokens=True)
+
+ def _check_longform_generate_multi_batch(self, condition_on_prev_tokens):
config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
model = WhisperForConditionalGeneration(config).eval().to(torch_device)
@@ -1383,7 +1404,6 @@ def test_longform_generate_multi_batch(self):
# len = 250 with num_input_frames = 60
long_input_features = torch.cat([input_features.repeat(1, 1, 4), input_features[:, :, :10]], dim=-1)
- long_input_features[:1, :, :200]
input_features_2 = long_input_features[1:]
attention_mask = torch.ones(
(2, long_input_features.shape[-1]), dtype=input_features.dtype, device=input_features.device
@@ -1395,25 +1415,34 @@ def test_longform_generate_multi_batch(self):
batch_size = 1
num_timestamp_tokens = 20
- max_length = 16
+ max_new_tokens = 16
timestamp_begin = vocab_size - num_timestamp_tokens
model.generation_config.no_timestamps_token_id = timestamp_begin - 1
model.generation_config.eos_token_id = None
+ model.config.eos_token_id = None
model.generation_config._detect_timestamp_from_logprob = False
# make sure that we only have the same begin token
model.generation_config.max_initial_timestamp_index = 0
+ model.generation_config.max_new_tokens = max_new_tokens
+ model.generation_config.prev_bos_token_id = timestamp_begin - 3
logits_processor = [
DummyTimestampLogitProcessor(
vocab_size - num_timestamp_tokens,
vocab_size,
batch_size=batch_size,
- max_length=max_length,
+ max_length=max_new_tokens,
min_space=4,
seed=1,
)
]
- outputs_2 = model.generate(input_features_2, logits_processor=logits_processor, return_segments=True)
+ outputs_2 = model.generate(
+ input_features_2,
+ max_new_tokens=max_new_tokens,
+ logits_processor=logits_processor,
+ condition_on_prev_tokens=condition_on_prev_tokens,
+ return_segments=True,
+ )
tokens_2 = outputs_2["sequences"][0]
segments_2 = outputs_2["segments"][0]
@@ -1423,24 +1452,37 @@ def test_longform_generate_multi_batch(self):
vocab_size - num_timestamp_tokens,
vocab_size,
batch_size=batch_size,
- max_length=max_length,
+ max_length=max_new_tokens,
min_space=4,
seed=0,
)
]
- outputs = model.generate(
- long_input_features, attention_mask=attention_mask, logits_processor=logits_processor, return_segments=True
- )
+ gen_kwargs = {
+ "logits_processor": logits_processor,
+ "return_segments": True,
+ "condition_on_prev_tokens": condition_on_prev_tokens,
+ "attention_mask": attention_mask,
+ "max_new_tokens": max_new_tokens,
+ }
+
+ outputs = model.generate(long_input_features, **gen_kwargs)
tokens = outputs["sequences"][1]
segments = outputs["segments"][1]
- assert tokens_2.tolist() == tokens.tolist()
+ # make sure batched and non-batched is the same
+ assert tokens_2.tolist() == tokens[: tokens_2.shape[-1]].tolist()
for seg1, seg2 in zip(segments_2, segments):
assert seg1["start"] == seg2["start"]
assert seg1["end"] == seg2["end"]
assert seg1["tokens"].tolist() == seg2["tokens"].tolist()
+ def test_longform_generate_multi_batch(self):
+ self._check_longform_generate_multi_batch(condition_on_prev_tokens=False)
+
+ def test_longform_generate_multi_batch_cond_prev(self):
+ self._check_longform_generate_multi_batch(condition_on_prev_tokens=True)
+
@require_torch
@require_torchaudio
@@ -2089,12 +2131,59 @@ def test_whisper_longform_single_batch(self):
assert decoded == EXPECTED_TEXT
+ decoded_with_timestamps = processor.batch_decode(result, skip_special_tokens=True, decode_with_timestamps=True)
+
+ no_timestamp_matches = re.split(r"<\|[\d\.]+\|>", decoded_with_timestamps[0])
+
+ assert ["".join(no_timestamp_matches)] == EXPECTED_TEXT
+
+ timestamp_matches = re.findall(r"<\|[\d\.]+\|>", decoded_with_timestamps[0])
+
+ timestamp_floats = [float(t[2:-2]) for t in timestamp_matches]
+
+ is_increasing = all(timestamp_floats[i] <= timestamp_floats[i + 1] for i in range(len(timestamp_floats) - 1))
+
+ assert is_increasing
+
+ @slow
+ def test_whisper_longform_single_batch_prev_cond(self):
+ # fmt: off
+ EXPECTED_TEXT = [""" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grieved doubts whether Sir Frederick Layton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-gards and atom paintings, and Mason's exquisite itals are as national as a jingo poem. Mr. Birk at Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. When Mr. John Collier gives his sitter a cheerful slap in the back, before he says like a shampooer and a Turkish bath, next man it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. He tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Makes a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire, any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man, and remarks was pleasing courtesy in felicitous grace that many faces are feeling. Unfortunately his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tupper of painting. By Harry Quilter M. A. A man said to the universe, Sir, I exist. Sweat covered Breon's body trickling into the tight-lowing cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retroveilities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered as muscles into complete relaxation. Only his heart and lungs worked on at a strong measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the twenties needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenties, he must have drawn his gun because the intruder said quickly, but that away you're being a fool. But there was silence then, and still wondering, Breon was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. A red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing. Just thrust and parry and victory to the stronger. Your man who entered the twenties had his own training tricks. They were appeared to be an immediate association with the death trauma, as if the two were inextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Breon's death was in some ways easier than defeat. Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue. Breon sensed it and knew the fifth point was his. Then the powerful twist that's rested aside, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, accooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggido long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions, as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Where is my brother now, inquired Shaggy. In the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. That's funny, remarked Betsy thoughtfully. I don't believe Anne knew any magic, or she'd have worked it before. I do not know, confessed Shaggy. True, agreed Calico. Calico went to the big gong, and pounded on it, just as we're good to be used to do. But no one answered the summons. Having returned to the royal cavern, Calico first pounded the gong, and then sat in the throne, wearing Regidos discarded Ruby Crown, and holding in his hand to scepter, which Regidos had so often thrown at his head."""]
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny.en")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
+ model = model.to("cuda")
+
+ ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean")
+ one_audio = np.concatenate([x["array"] for x in ds["validation"]["audio"]], dtype=np.float32)
+
+ input_features = processor(one_audio, return_tensors="pt", truncation=False, padding="longest")[
+ "input_features"
+ ]
+ input_features = input_features.to(device="cuda")
+
+ gen_kwargs = {
+ "return_timestamps": True,
+ "no_speech_threshold": 0.6,
+ "temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
+ "compression_ratio_threshold": 1.35,
+ "condition_on_prev_tokens": True,
+ "logprob_threshold": -1.0,
+ }
+
+ torch.manual_seed(0)
+ result = model.generate(input_features, **gen_kwargs)
+ decoded = processor.batch_decode(result, skip_special_tokens=True)
+
+ assert decoded == EXPECTED_TEXT
+
@slow
def test_whisper_longform_multi_batch(self):
# fmt: off
EXPECTED_TEXT_1 = [" Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-gards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Birkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampooer and a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. Painting he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Mix a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing a poster or near the fire, and the ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man. And remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only unfortunately his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the Tupper of painting. a Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the tight-wing cloth that was the only germany war. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were, triggered his muscles into complete relaxation. Oily his heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, knights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenty's he must have drawn his gun, because the intruder said quickly, but that away you're being a fool. Out there was silence then, and still wondering, Breon was once more asleep. Ten seconds he asked the handler who was needing his aching muscles. a red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the twenties had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were andextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the twenties and death during the last round was, in some ways, easier than defeat. Breeding deeply, Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. I rolled the mazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue, pre-inscented and new to fifth point was his. Then the powerful twist that's rest of the side, in and under the guard, because you were sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, a cooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions, as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, return Calico. Where is my brother now? choir-dshaggy, in the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh, no, I'm quite sure he didn't. That's funny, remarked Betsy thoughtfully. I don't believe and knew any magic, or she'd have worked it before. I do not know, confess shaggy. True, a great calico. Calico went to the big gong and pounded on it, just as Virgado used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the throne, wearing Virgados discarded Ruby Crown, and holding in his hand to scepter, which Virgado had so often thrown at his head. head."]
EXPECTED_TEXT_2 = [" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-gards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Burkett Foster's landscapes smile at one much in the same way that Mr. Carker."]
- EXPECTED_TEXT_3 = [" possible. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grieved doubts whether Sir Frederick Layton's work is really greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-guards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Birk at Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampooer and a Turkish bath, next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. Under general principles of art, Mr. Quilter writes with equal lucidity. Painting, he tells us, is of a different quality to mathematics and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Mix a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire. any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man, and remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the titling cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes. Even to soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered as muscles into complete relaxation. Oily his heart and lungs worked on at a strong measured rate. He was in In reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenty's he must have drawn his gun, because the intruder said quickly, but that away you're being a fool. Out there was silence then, and still wondering, Breon was once more asleep. Ten seconds he asked the handler who was needing his aching muscles. a red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the twenties had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were andextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the twenties and death during the last round was, in some ways, easier than defeat. Breeding deeply, Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue, re-insunced it and knew the fifth point was his. Then the powerful twist that's rest of the side, in and under the guard, because you were sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, a cooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled and disgraced, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Where is my brother now? quared shaggy. In the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. And that's funny, remarked Betsy thoughtfully. I don't believe Anne knew any magic, or she'd have worked it before. I do not know, confess Shaggy. True, a great calico. Calico went to the big gong and pounded on it, just as we're good to have used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the thrown wearing ruggedos discarded ruby crown and holding in his hand to septor which Ruggato had so often thrown at his head."]
+ EXPECTED_TEXT_3 = [" possible. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grieved doubts whether Sir Frederick Layton's work is really greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of up-guards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Birk at Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampooer and a Turkish bath, next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. Under general principles of art, Mr. Quilter writes with equal lucidity. Painting, he tells us, is of a different quality to mathematics and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Mix a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire. any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man, and remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the titling cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes. Even to soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered as muscles into complete relaxation. Oily his heart and lungs worked on at a strong measured rate. He was in In reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenty's he must have drawn his gun, because the intruder said quickly, but that away you're being a fool. Out there was silence then, and still wondering, Breon was once more asleep. Ten seconds he asked the handler who was needing his aching muscles. a red-haired mountain of a man with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the twenties had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were andextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the twenties and death during the last round was, in some ways, easier than defeat. Breeding deeply, Breon's softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our rogue, re-insunced it and knew the fifth point was his. Then the powerful twist that's rest of the side, in and under the guard, because you were sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, a cooing dove. He has gone and gone for good, answered Polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled and disgraced, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard, since Shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Where is my brother now? quared shaggy. In the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. And that's funny, remarked Betsy thoughtfully. I don't believe Anne knew any magic, or she'd have worked it before. I do not know, confess Shaggy. True, a great calico. Calico went to the big gong and pounded on it, just as we're good to have used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the thrown wearing ruggedos discarded ruby crown and holding in his hand to septor which ruggedo had so often thrown at his head."]
EXPECTED_TEXT_4 = [' Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter\'s manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton\'s work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell\'s pictures are a sort of up-gards and atom paintings, and Mason\'s exquisite idles are as national as a jingo poem. Mr. Birk at Foster\'s landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. Mr. John Collier gives his sitter a cheerful slap in the back, before he says, like a shampoo or a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate an expression. On the general principles of art, Mr. Quilter writes with equal lucidity. he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, there are two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures. Makes the customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing upholsterer. Near the fire, any ornaments Fred brought home from India on the mantelboard. In fact, he is quite severe on Mr. Ruskin for not recognizing that a picture should denote the frailty of man. And remarks was pleasing courtesy in Felicitis Grace that many faces are feeling. Only, unfortunately, his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the Tupper of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon\'s body trickling into the tight-lowing cloth that was the only german he wore. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators, retrovealities not worth thinking about. His instant panic was followed by a small sharp blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzers were triggered his muscles into complete relaxation. Oli\'s heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the twenties needed undisturbed rest. Therefore, nights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, The thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I\'m here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The twenties, he must have drawn his gun because the intruder said quickly, but that away you\'re being a fool. out, through his silence then, and still wondering, Breon was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. A red-haired mountain of a man, with an apparently inexhaustible store of energy. There could be little art in this last and final round of fencing. Just thrust and parry, and victory to the stronger. man who entered the twenties had his own training tricks. They were appeared to be an immediate association with the death trauma, as if the two were inextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported except at two points, the head and heels. This is physically impossible when conscious. had died before during the 20s and death during the last round was in some ways easier than defeat. Breathing deeply, Breon\'s softly spoke the auto-hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. Our role looked amazed at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Breon saw something close to panic on his opponent\'s face when the man finally recognized his error. A wave of despair rolled out from our rogue. Breon sensed it and knew the fifth point was his. Then the powerful twist that\'s rested aside, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle without a bow, while poor Shaggy sits there, accooing dove. He has gone, and gone for good," answered Polychrom, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with says he stepped forward and burst the stout chains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has flooded disgrace, and your friends are asking for you. I begged Ruggadot long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn\'t work too hard, said Shaggy. He doesn\'t work at all. In fact, there\'s nothing he can do in these dominions as well as our gnomes, whose numbers are so great that it worries us to keep them all busy. Not exactly, we\'ve turned Calico. Where is my brother now, inquired Shaggy. In the metal forest. Where is that? The middle forest is in the great domed cavern, the largest and all-ard dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I\'m quite sure he didn\'t. That\'s funny, remarked Betsy thoughtfully. I don\'t believe Anne knew any magic, or she\'d have worked it before. I do not know, confess Shaggy. True, agreed Calico. Calico went to the big gong and pounded on it just as Virgato used to do, but no one answered the summons. Having returned to the Royal Cavern, Calico first pounded the gong and then sat in the throne, wearing Virgato\'s discarded ruby crown and holding in his hand to scepter which reggative head so often thrown at his head.']
# fmt: on
@@ -2138,18 +2227,62 @@ def test_whisper_longform_multi_batch(self):
assert decoded_all[2:3] == EXPECTED_TEXT_3
assert decoded_all[3:4] == EXPECTED_TEXT_4
+ @slow
+ def test_whisper_longform_multi_batch_prev_cond(self):
+ # fmt: off
+ EXPECTED_TEXT_1 = [" Mr. Quilters manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca. The Nils, pictures are sort of upguards and atom paintings and Mason's exquisite itals are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says like a shampooer and a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate and expression. On the general principles of art, Mr. Quilters writes with equal lucidity. Painting he tells us is of a different quality to mathematics and finish in art is adding more effect. As for etchings, there are of two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures makes a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing apostorer. Near the fire, any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin, for not recognizing that a picture should denote the frailty of man. And remarks with pleasing courtesy and solicitous grace that many phases of feeling only, unfortunately, his own work never does get good. Mr. Quilters has missed his chance, for he has failed even to make himself the tougher of painting. My hair equal to M.A. A man said to the universe, Sir, I exist. Sweat covered Breon's body, trickling into the tight-wing cloth that was the only garment he wore. The cut on his chest still dripping blood. The ache of his overstrain dyes. Even the soaring arena around him with thousands of spectators, retrievalidies not worth thinking about. His instant panic was followed by a small sharp blow, high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzer's were triggered as muscles into complete relaxation. Only his heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, knights and the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. To 20s, he must have drawn his gun because the intruder said quickly, but that away, you're being a fool. Out, the resoundance then, and still wondering, Brienne was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. Our red-haired mountain of a man, with an apparently inexhaustible story of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the 20s had his own training tricks. There appeared to be an immediate association with the death trauma as if the two were inexplicably linked into one. This strengthened enables someone in a trance to hold his body stiff and unsupported, except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the 20s, and death during the last round was, in some ways, easier than defeat. Breathing deeply, Brienne softly spoke the other hypnotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. I rolled the maze at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Brienne saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our role. Brienne sensed it and knew the fifth point was his. Then the powerful twist that's right to the side, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle with a bow, while poor shaggy sits there, a cooling dove. He has gone and gone for good, answered polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stoutchanges as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled in disgrace in your friends, they're asking for you. I begged Ruggano a long ago to send him away, but he would not do so. I also offered to help you run into escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard since shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions, as well as our nooms, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico, whereas my brother now inquired shaggy in the metal forest. Where is that? The metal forest is in the great domed cavern, the largest and all our dominions replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. That's funny, remarked to Bedsey thoughtfully. I don't believe Anne knew any magic or she'd have worked before. I do not know, confessed shaggy. True, agreed Calico. Calico went to the big gong and pounded on it just as Ruggano used to do, but no one answered the summons. Having returned to the royal cavern, Calico first pounded the gong and then sat in the throne, wearing Ruggano's discarded ruby crown. And holding in his hand the scepter which Ruggano had so often thrown at his head."]
+ EXPECTED_TEXT_2 = [" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Latins' work is really Greek after all, and can discover in it but little of rocky Ithaca. Lennials, pictures are a sort of upguards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker"]
+ EXPECTED_TEXT_3 = [" gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly drawn from eating in its results occur most readily to the mind. He has grave doubts whether Sir Frederick Latins work is really Greek after all and can discover in it but little of rocky ithaka. Lennils, pictures, are a sort of upguards and atom paintings and Mason's exquisite itals are as national as a jingo poem. Mr. Birkut Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says like a shampooer and a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate and expression. Under general principles of art, Mr. Quilter writes with equal lucidity. Painting he tells us is of a different quality to mathematics and finish in art is adding more effect. As for etchings, thereof two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures makes a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing apostoror. Near the fire, any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin, for not recognizing that a picture should denote the frailty of man. And remarks with pleasing courtesy and falseness graced that many phases of feeling, only unfortunately his own work never does get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tougher of painting. By Harry Quilter M.A. A man said to the universe, Sir, I exist. Sweat-covered Breon's body trickling into the tight-wing cloth that was the only garment you wore. The cut on his chest still dripping blood. The ache of his overstrained eyes. Even the soaring arena around him with thousands of spectators were trivealed, not worth thinking about. His instant panic was followed by a small sharp, blow high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzer's were triggered as muscles into complete relaxation. Only his heart and lungs worked on at a strong, measured rate. He was in reverie sliding out on the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, knights in the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. The 20s, he must have drawn his gun because the intruder said quickly, but that away, he'll be in the fool. Out, there is silence then, and still wondering, Brienne was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. A red-haired mountain of a man, with an apparently inexhaustible story of energy. There could be little art in this last and final round of fencing, just thrust and parry and victory to the stronger. Every man who entered the 20s had his own training tricks. There appeared to be an immediate association with the death trauma, as if the two were inextricably linked into one. The strength that enables someone in a trance to hold his body stiff and unsupported, except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the 20s, and death during the last round was, in some ways, easier than defeat. Breathing deeply, Brienne softly spoke the autohydrotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. I rolled up the maze at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Brienne saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our ol' Brienne sensed it and knew the fifth point was his. Then the powerful twist that's right to decide, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle with a bow, while poor shaggy sits there, a cooling dove. He has gone and gone for good, answered polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stoutchains as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled in disgrace in your friends, they're asking for you. I begged Ruggano a long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard since shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions as well as our nooms, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Whereas my brother now, in Quaragejjegi, in the metal forest. Where is that? The metal forest is in the great Dome to Cavern, the largest and all our dominions, replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. That's funny remarked by the bad sea thoughtfully. I don't believe Anne knew any magic or she'd have worked it before. I do not know, confessed shaggy. True, a great Calico. Calico went to the big gong and pounded on it, just as we're good or used to do, but no one answered the summons. Having returned to the royal cavern, Calico first pounded the gong and then sat in the throne, wearing reggos, discarded ruby crown, and holding in his hand to scepter which reggos had so often thrown at his head."]
+ EXPECTED_TEXT_4 = [" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Latins' work is really Greek after all, and can discover in it but little of rocky Ithaca. Lennils, pictures, are a sort of upguards and atom paintings, and Mason's exquisite idles are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says, like a shampooer in a Turkish bath. Next man, it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate and expression. On the general principles of art, Mr. Quilter writes with equal lucidity. Painting he tells us is of a different quality to mathematics, and finish in art is adding more effect. As for etchings, thereof two kinds, British and foreign. He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures makes a customary appeal to the last judgment and reminds us that in the great days of art Michelangelo was the furnishing apostorer. Near the fire, any ornaments Fred brought home from India on the mental board. In fact, he is quite severe on Mr. Ruskin, for not recognizing that a picture should denote the frailty of man. And remarks with pleasing courtesy and solicitous grace that many phases of feeling only, unfortunately, his own work never does, get good. Mr. Quilter has missed his chance, for he has failed even to make himself the tougher of painting. By Harry Quilter, M.A. A man said to the universe, Sir, I exist. Sweat covered Breon's body, trickling into the tight-wing cloth that was the only garment you wore. The cut on his chest still dripping blood. The ache of his overstrained eyes, even the soaring arena around him with thousands of spectators were trivialities not worth thinking about. His instant panic was followed by a small sharp blow, high on his chest. One minute, a voice said, and a time buzzer sounded. A minute is not a very large measure of time, and his body needed every fraction of it. The buzzer's were triggered as muscles into complete relaxation. Only his heart and lungs worked on at a strong, measured rate. He was in reverie, sliding along the borders of consciousness. The contestants in the 20s needed undisturbed rest. Therefore, knights and the dormitories were as quiet as death. Particularly so, on this last night, when only two of the little cubicles were occupied, the thousands of others standing with dark empty doors. The other voice snapped with a harsh urgency, clearly used to command. I'm here because the matter is of utmost importance, and brand is the one I must see. Now stand aside. To 20s, he must have drawn his gun because the intruder said quickly, but that away, you're being a fool. Out, there is silence then, and still wondering, Brienne was once more asleep. Ten seconds, he asked the handler who was needing his aching muscles. I've read here at Mountain of a Man, with an apparently inexhaustible story of energy. There could be little art in this last and final round of fencing. Just thrust and parry and victory to the stronger. Every man who entered the 20s had his own training tricks. There appeared to be an immediate association with the death trauma, as if the two were inexplicably linked into one. Just strengthed and enabled someone in a trance to hold his body stiff and unsupported, except at two points, the head and heels. This is physically impossible when conscious. Others had died before during the 20s, and death during the last round was, in some ways, easier than defeat. Breathing deeply, Brienne softly spoke the autohydrotic phrases that triggered the process. When the buzzer sounded, he pulled his foil from his second startled grasp and ran forward. I rolled up the maze at the sudden fury of the attack, then smiled. He thought it was the last burst of energy. He knew how close they both were to exhaustion. Brienne saw something close to panic on his opponent's face when the man finally recognized his error. A wave of despair rolled out from our ol' Brienne sensed it and knew the fifth point was his. Then the powerful twist that's right to the side, in and under the guard, because he was sleeping instead of conquering, the lovely rose princess has become a fiddle with a bow, while poor shaggy sits there, a cooling dove. She has gone and gone for good, answered polychrome, who had managed to squeeze into the room beside the dragon, and had witnessed the occurrences with much interest. I have remained a prisoner only because I wished to be one. And with this, he stepped forward and burst the stoutchanges as easily as if they had been threads. The little girl had been asleep, but she heard the wraps and opened the door. The king has fled in disgrace and your friends are asking for you. I begged Ruggano a long ago to send him away, but he would not do so. I also offered to help your brother to escape, but he would not go. He eats and sleeps very steadily, replied the new king. I hope he doesn't work too hard since shaggy. He doesn't work at all. In fact, there's nothing he can do in these dominions as well as our nooms, whose numbers are so great that it worries us to keep them all busy. Not exactly, we've turned Calico. Where is my brother now, in Quaragejji, in the metal forest? Where is that? The metal forest is in the great Dome to Cavern, the largest and all our dominions replied Calico. Calico hesitated. However, if we look sharp, we may be able to discover one of these secret ways. Oh no, I'm quite sure he didn't. That's funny, remarked a bit, see you thoughtfully. I don't believe Anne knew any magic or she'd have worked it before. I do not know, confessed shaggy. True, agreed Calico. Calico went to the big gong and pounded on it just as we're good we used to do, but no one answered the summons. Having returned to the royal cavern, Calico first pounded the gong and then sat in the throne, wearing reggos, discarded ruby crown and holding it his hand to scepter which reggo had so often thrown at his head."]
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny")
+ model = model.to("cuda")
+
+ ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean")
+ one_audio = np.concatenate([x["array"] for x in ds["validation"]["audio"]], dtype=np.float32)
+ audios = []
+ audios.append(one_audio[110000:])
+ audios.append(one_audio[:800000])
+ audios.append(one_audio[80000:])
+ audios.append(one_audio[:])
+
+ gen_kwargs = {
+ "return_timestamps": True,
+ "no_speech_threshold": 0.6,
+ "temperature": 0.0,
+ "compression_ratio_threshold": 1.35,
+ "condition_on_prev_tokens": True,
+ "logprob_threshold": -1.0,
+ }
+
+ decoded_single = []
+ for audio in audios:
+ inputs = processor(audio, return_tensors="pt", truncation=False)
+ inputs = inputs.to(device="cuda")
+
+ result = model.generate(**inputs, **gen_kwargs)
+ decoded_single.append(processor.batch_decode(result, skip_special_tokens=True))
+
+ # exact match
+ assert decoded_single[0] == EXPECTED_TEXT_1
+ assert decoded_single[1] == EXPECTED_TEXT_2
+ assert decoded_single[2] == EXPECTED_TEXT_3
+ assert decoded_single[3] == EXPECTED_TEXT_4
+
@slow
def test_whisper_longform_multi_batch_hard(self):
# fmt: off
EXPECTED_TEXT = [
- " Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!",
+ " Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile.",
" Folks, I spend a lot of time right over there, night after night after night, actually. Carefully selecting for you the day's noosiest, most aerodynamic headlines, stress testing, and those topical anti-lock breaks and power steering, painstakingly stitching, leather seating so soft, it would make JD power and her associates blush to create the luxury sedan that is my nightly monologue. But sometimes, you sometimes, folks. I lurched a consciousness in the back of an abandoned school and slap myself awake with a crusty floor mat. Before using a mouse-bitten timing belt to strap some old plywood to a couple of discarded oil drums, then by the light of a heathen moon, render a gas tank out of an empty big gulp, fill with white claw and denatured alcohol, then light a match and let her rip and the demented one man soapbox derby of news that is my segment. Me, Guadalupe! No!",
" Ladies and gentlemen, you know, I spent a lot of time right over there Raising the finest Holstein news cattle firmly yet tenderly milking the latest headlines from their jokes swollen teats Churning the daily stories into the decadent proven-style style triple cream breed that is my nightly monologue But sometimes sometimes folks I stagger home hungry after being released by the police and Root around in the neighbor's trash can for an old milk carton scrape out the blooming dairy residue into the remains of a wet cheese rod I won from a rat in a pre-donned street fight. Put it in a discarded paint can to leave it to ferment next to a trash fire then hunker down and hallucinate while eating the listeria laden demon custard of news that is my segment. You mean one of them.",
" Folks, if you watch this show, you know I spend most of my time right over there carefully sorting through the day's biggest stories and selecting only the most subtle and unblemished ostrich and crocodile news leather, which I then entrust to artisan graduates of the Ichol Gregoire Ferrandi, who carefully dye them in a palette of bright zesty shades and adorn them in the finest and most topical inlay work using hand tools and double magnifying glasses, then assemble them according to now classic and elegant geometry using our signature saddles stitching. In line it with bees, wax, coated linen, finely attached a mallet, hammered strap, pearled hardware, and close-shit to create for you the one-of-a-kind hoke couture, Erme's Birkin bag that is my monologue. But sometimes, sometimes folks, sometimes. Sometimes I wake up in the last car of an abandoned roller coaster at Coney Island where I'm I'm hiding from the triads. I have some engine lubricants out of a safe way bag and stagger down the shore to tear the sail off a beach schooner. Then I rip the coaxial cable out of an RV and elderly couple from Utah, Hank, and Mabel lovely folks. And use it to stitch the sail into a loose pouch like a rock sack. And I stow away in the back of a garbage truck to the junkyard where I pick through to the debris for only the broken toys that make me the saddest until I have loaded for you. The Hobo Fugitives bug out, bindle of news that is my segment. Me one!",
" You know, folks, I spent a lot of time crafting for you a bespoke playlist of the day's biggest stories right over there. Meticulously selecting the most topical chakra affirming scented candles, and using Feng Shui to perfectly align the joke energy in the exclusive boutique yoga retreat that is my monologue. But sometimes just sometimes I go to the dumpster behind the waffle house at three in the morning, take off my shirt, cover myself, and used fry oil, wrap my hands with some double-duct tape by stole from the broken car window. Pound a six-pack of blueberry hard-seltzer and a sack of pills I stole from a parked ambulance. Then arm wrestle a raccoon in the back alley vision quest of news that is my segment. Meanwhile!",
" You know, folks, I spend most of my time right over there. Mining the day's biggest, most important stories, collecting the finest, most topical iron or hand hammering it into joke panels. Then I craft sheets of bronze and blazing with patterns that tell an epic tale of conquest and glory. Then, using the Germanic tradition press-black process, I place thin sheets of foil against the scenes and by hammering or otherwise applying pressure from the back, I project these scenes into a pair of cheat cards in a faceplate and, finally, using fluted strips of white alloyed molding, I divide the designs into framed panels and hold it all together using bronze rivets to create the beautiful and intimidating, Anglo-Saxon battle helm that is my nightly monologue. Sometimes, sometimes folks. Sometimes, just sometimes, I come into my sense as fully naked on the deck of a pirate besieged melee container ship that picked me up floating on the detached door of a portapotty in the Indian Ocean. Then after a sunstroke-induced realization of the crew of this ship plans to sell me an exchange for a bag of oranges to fight off scurvy, I lead a mutiny using only a PVC pipe at a pool chain that accepting my new role as Captain and declaring myself king of the windarc seas. I grab a dirty mop bucket covered in barnacles and adorn it with the teeth of the vanquished to create the sopping wet pirate crown of news that is my segment. Meanwhile!",
" Folks, if you watch this show, you know I spend most of my time right over there carefully blending for you the day's Newsiest most topical flower eggs milk and butter and Stranding into a fine batter to make delicate and informative comedy pancakes Then I glaze them in the juice and zest of the most relevant midnight Valencia oranges and douse it all and a fine Dela main de voyage cognac Before prom baying and basting them tables. I deserve for you the James Beard award worthy crepe suzzette That is my nightly monologue, but sometimes just sometimes folks. I wake up in the baggage hold of Greyhound bus. It's being hoisted by the scrap yard claw toward the burn pit. Escape to a nearby abandoned price chopper where I scrounge for old bread scraps and busted open bags of starfruit candies and expired eggs. Chuck it all on a dirty hubcap and slap it over a tire fire before using the legs of a strain, pair of sweatpants and as oven mitts to extract and serve the demented transience poundcake of news that is my segment. Me, Guadalupe!",
- " Folks, if you watched the show and I hope you do, I spent a lot of time right over there. Tiredlessly studying the lineage of the days most important thoroughbred stories and whole-stiner headlines, working with the best trainers, money can buy to rear their comedy offspring with a hand that is stern yet gentle into the triple crown winning equine specimen. That is my nightly monologue, but sometimes, sometimes, folks, I break into an unincorporated veterinary genetics lab and grab whatever test tubes I can find and then under a grow light I got from a discarded chia pet. I mixed the pilfered DNA of a horse and whatever was in a tube labeled Keith Colan extra. Slurrying the concoction with caffeine pills and a microwave red bull, I screamed, sang a prayer to Janice, initiator of human life and God of transformation as a half horse, half man, freak. Seizes to life before me and the hideous collection of loose animal parts and corrupted man tissue that is my segment. Meanwhile!",
+ " Folks, if you watched the show and I hope you do, I spent a lot of time right over there. Tiredlessly studying the lineage of the days most important thoroughbred stories and whole-stiner headlines, working with the best trainers, money can buy to rear their comedy offspring with a hand that is stern yet gentle into the triple crown winning equine specimen. That is my nightly monologue, but sometimes, sometimes, folks, I break into an unincorporated veterinary genetics lab and grab whatever test tubes I can find and then under a grow light I got from a discarded chia pet. I mixed the pilfered DNA of a horse and whatever was in a tube labeled Keith Colan extra. Slurrying the concoction with caffeine pills and a microwave red bull, I screamed, sang a prayer to Janice, initiator of human life and God of transformation as a half horse, half man, freak. Seizes to life before me and the hideous collection of loose animal parts and corrupted man tissue that is my segment. Meanwhile!"
]
# fmt: on
@@ -2185,6 +2318,55 @@ def test_whisper_longform_multi_batch_hard(self):
assert decoded_all[i] == decoded_single[i]
assert decoded_all[i] == EXPECTED_TEXT[i]
+ @slow
+ def test_whisper_longform_multi_batch_hard_prev_cond(self):
+ # fmt: off
+ EXPECTED_TEXT = [
+ " Folks, if you watch the show, you know I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories, developing the central headline pawns, definitely maneuvering an oh-so-topical night to F6, faming of classic Sicilian, named or variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a Fisher show's in lip-nitsky attack that culminates in the elegant lethal slow played all pass on checkmate that is my nightly monologue, but sometimes sometimes folks I sometimes I start a little wake-up side down in the monkey bars of a condemned playground on a super fun site, get all hepped up on goofballs, rummage that would discard a tag bag of defective toys, yank out a fistball of disembodied doll limbs, toss them on a stain kid's place mad from a defunked denies, set up a table inside a rusty cargo container down by the warf and challenge toothless drifters to the godless bughouse blitz of tournament that is my segment.",
+ " Folks, I spent a lot of time right over there night after night, actually. Carefully selecting for you the day's newsiest, most aerodynamic headlines, stress testing on those topical anti-lock breaks and power steering, painstakingly stitching, leather seating, so soft, it would make JD power and her associates blush. To create the luxury sedan that is my nightly monologue, but sometimes I just sometimes focus. I lurched to consciousness in the back of an abandoned school bus and slapped myself awake with a crusty floor mat. Before using a mouse-bitten timing belt to strap some old plywood to a couple of discarded oil drums, then by the light of a heathen-moon render a gas tank out of an empty big gulp, filled with white claw and de-natured alcohol, then light a match, letter-ripping the dis-mented one-man soapbox derby of news that is my segment.",
+ " Ladies and gentlemen, you know, I spent a lot of time right over there, raising the finest hosting news cattle firmly, yet tenderly milking the latest headlines from their jokes, swollen teats, churning the daily stories into the decadent Provincil style triple cream-breed. It is my nightly monologue, but sometimes sometimes I stagger home hungry after being released by the police and root around in the neighbors trash can for an old milk carton scrape out the blooming dairy residue into the remains of a wet cheese rind I won from a rat and a pre-drawn street fight. Put it into discarded paint can to leave it to ferment next to a trash fire than a hunker down in hallucinate while eating the lusteria latent demon custard of news that is my segment.",
+ " Folks, you watched this show, you know I spend most of my time right over there, carefully sorting through the days, big stories, and selecting only the most subtle, and unblemished ostrich and crocodile news leather, which I then entrust to artisan graduates of the Ickel Greg Waferandi, who carefully died them in a pallet of bright, zesty shades, and adorn them in the finest most topical inlay work, using hand tools and double magnifying glasses, then assemble them according to now classic and elegant geometry using our signature saddle stitching, and line it with bees, wax, coated linen, and finally attach a mallet hammered strap, perled hardware, and close-shet to create for you the one of a kind hope, kutur, earn-may is burkin bag that is my monologue, but sometimes, sometimes, sometimes. Sometimes, sometimes I wake up in the last car of an abandoned roller coaster at Kony Island, where I'm hiding from the triads, I have some engine lubricants out of a safe way bag and staggered down the shore to tear the sail off a beach sooner than I ripped the coaxial cable out of an RV and elderly couple from Utah, Hank, and Mabel Lovelyfokes, and use it to stitch the sail into a loose pouch like rock sack, and I stole a bag of a garbage truck to the junkyard, where I picked through to the debris for only the broken toys that make me the saddest, until I have loaded for you. The hobo fugitives bug out Bindle of news that is my segment.",
+ " You know, folks, I spent a lot of time crafting for you a bespoke playlist of the day's big stories right over there. meticulously selecting the most topical chakra affirming scented candles, using Feng Shui, to perfectly align the joke energy in the exclusive boutique yoga retreat that is my monologue, but sometimes just sometimes, I go to the dumpster behind the waffle house at three in the morning, take off my shirt, cover myself and use fry oil, wrap my hands and some old duct tape I stole from a broken car window, pound a six pack of blueberry hard-seller and a second pill, as I stole from a park damsel, and it's then arm wrestle a raccoon in the back alley vision quest of news that is my segment.",
+ " You know, folks, I spend most of my time right over there. Mining the days, biggest, most important stories, collecting the finest, most topical iron or hand hammering it into joke panels, then I craft sheets of bronze and blazing with patterns that tell an epic tale of conquest and glory. Then, using the Germanic tradition press, black process, I place thin sheets of foil against the scenes and by hammering or otherwise applying pressure from the back, I project these scenes into a pair of cheat cards and a face plate, and finally using fluted strips of white alloyed molding I divide the designs into framed panels and hold it all together using bronze rivets to create the beautiful and intimidating Anglo-Saxon battle helm that is my nightly monologue. Sometimes, sometimes, folks. Sometimes, just sometimes, I come to my senses fully naked on the deck of a pirate, beceived, melee, container ship that picked me up floating on the detainees. Then after I sunstroke in juice, realization of the crew of this ship plans to sell me and exchange for a bag of oranges to fight off scurvy, I lead a mutiny using only a PVC pipe in a pool chain that accepting my new role as captain and declaring myself king of the wind arc seas. I grab a dirty muck bucket covered in barnacles and a dornet with the teeth of the vanquished to create the softening wet pirate crown of news that is my segment. I'm going to use the white paper to create the softened white paper to create the softened white paper to create the softened white pirate crown of news that is my segment. Meanwhile.",
+ " Folks, if you watch this show, you know I spend most of my time right over there carefully blending for you the day's newsiest, most topical flower eggs, milk and butter. And straining into a fine batter to make delicate and informative comedy pancakes, then I glaze them in the juice and zest of the most relevant midnight valencio oranges. And doubts at all, and I find delimane de voyage cognac, before from bang and basting them tables, I deserve you the James Beard Award worthy creeps to ZET. That is my nightly monologue, but sometimes sometimes folks I wake up in the baggage hole of Greyhound bus, it's being hoisted by the scrapyard claw toward the burn pit. Escape to a nearby abandoned price chopper where I scrounge for old bread scraps, busted open bags of starfruit candies and expired eggs. Chuck it all on a dirty hubcap and slap it over a tire fire before using the legs of a strained pair of sweatpants and as ovenmets to extract and serve the demented transients pound cake of news that is my segment. Me wild!",
+ " Folks, if you watch the show and I hope you do, I spend a lot of time right over there. Tirelessly studying the lineage of the day's most important thoroughbred stories and whole-stiner headlines, working with the best trainers money can buy to rear their comedy offspring with a hand that is stern yet gentle into the triple crown winning equine specimen that is my nightly monologue. But sometimes sometimes folks I break into an unincorporated veterinary genetics lab. And grab whatever test tubes I can find and then under a grow light I got from it a discarded chia pet. I mixed the pill for DNA of a horse and whatever was in a tube labeled Keith Cole and extra. Sloering the concoction with caffeine pills and a microwave bread bowl, I screamed sing a prayer to Janice initiator of human life and God of transformation as a half horse, half man freak, seasons to life before me. And the hideous collection of loose animal parts and corrupted men tissue that is my segment. Meanwhile.",
+ ]
+ # fmt: on
+
+ processor = WhisperProcessor.from_pretrained("openai/whisper-tiny")
+ model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny")
+ model = model.to("cuda")
+
+ ds = load_dataset("distil-whisper/meanwhile", "default")["test"]
+ ds = ds.cast_column("audio", Audio(sampling_rate=16000))
+
+ num_samples = 8
+
+ audio = ds[:num_samples]["audio"]
+ audios = [x["array"] for x in audio]
+
+ inputs = processor(
+ audios, return_tensors="pt", truncation=False, padding="longest", return_attention_mask=True
+ )
+ inputs = inputs.to(device="cuda")
+
+ gen_kwargs = {
+ "return_timestamps": True,
+ "no_speech_threshold": 0.6,
+ "temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
+ "compression_ratio_threshold": 1.35,
+ "condition_on_prev_tokens": True,
+ "logprob_threshold": -1.0,
+ "num_beams": 5,
+ }
+
+ torch.manual_seed(0)
+ result = model.generate(**inputs, **gen_kwargs)
+ decoded_all = processor.batch_decode(result, skip_special_tokens=True)
+
+ for i in range(num_samples):
+ assert decoded_all[i] == EXPECTED_TEXT[i]
+
def prepare_whisper_encoder_inputs_dict(config, input_features, head_mask=None):
if head_mask is None:
@@ -2292,16 +2474,15 @@ def get_subsampled_output_lengths(self, input_lengths):
def encoder_seq_length(self):
return self.get_subsampled_output_lengths(self.seq_length)
- def create_and_check_model_forward(self, config, inputs_dict, freeze_encoder=False):
- model = WhisperForAudioClassification(config=config).to(torch_device).eval()
-
- if freeze_encoder:
- model.freeze_encoder()
+ def create_and_check_model_forward(self, config, inputs_dict, use_weighted_layer_sum=False):
+ config.use_weighted_layer_sum = use_weighted_layer_sum
+ model = WhisperForAudioClassification(config=config)
+ model.to(torch_device).eval()
input_features = inputs_dict["input_features"]
- # first forward pass
- last_hidden_state = model(input_features).logits
+ with torch.no_grad():
+ last_hidden_state = model(input_features).logits
self.parent.assertTrue(last_hidden_state.shape, (13, 2))
@@ -2336,6 +2517,14 @@ def test_forward_signature(self):
expected_arg_names = ["input_features", "head_mask", "encoder_outputs"]
self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ def test_forward_pass(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_forward(*config_and_inputs)
+
+ def test_forward_pass_weighted_layer_sum(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_forward(*config_and_inputs, use_weighted_layer_sum=True)
+
@unittest.skip(reason="Some undefined behavior encountered with tiny versions of this model. Skip for now.")
def test_cpu_offload(self):
pass
diff --git a/tests/pipelines/test_pipelines_automatic_speech_recognition.py b/tests/pipelines/test_pipelines_automatic_speech_recognition.py
index 3da55ab9da107f..7b6a9f30c55ac9 100644
--- a/tests/pipelines/test_pipelines_automatic_speech_recognition.py
+++ b/tests/pipelines/test_pipelines_automatic_speech_recognition.py
@@ -298,6 +298,23 @@ def test_torch_large(self):
output = speech_recognizer(filename)
self.assertEqual(output, {"text": "A MAN SAID TO THE UNIVERSE SIR I EXIST"})
+ @require_torch
+ @slow
+ def test_torch_large_with_input_features(self):
+ speech_recognizer = pipeline(
+ task="automatic-speech-recognition",
+ model="hf-audio/wav2vec2-bert-CV16-en",
+ framework="pt",
+ )
+ waveform = np.tile(np.arange(1000, dtype=np.float32), 34)
+ output = speech_recognizer(waveform)
+ self.assertEqual(output, {"text": ""})
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation").sort("id")
+ filename = ds[40]["file"]
+ output = speech_recognizer(filename)
+ self.assertEqual(output, {"text": "a man said to the universe sir i exist"})
+
@slow
@require_torch
@slow
@@ -1135,7 +1152,7 @@ def test_with_local_lm_fast(self):
@slow
def test_whisper_longform(self):
# fmt: off
- EXPECTED_RESULT = """ Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out of fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct denny's, set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile!"""
+ EXPECTED_RESULT = """ Folks, if you watch the show, you know, I spent a lot of time right over there. Patiently and astutely scrutinizing the boxwood and mahogany chest set of the day's biggest stories developing the central headline pawns, definitely maneuvering an oso topical night to F6, fainting a classic Sicilian, nade door variation on the news, all the while seeing eight moves deep and patiently marshalling the latest press releases into a fisher's shows in Lip Nitsky attack that culminates in the elegant lethal slow-played, all-passant checkmate that is my nightly monologue. But sometimes, sometimes, folks, I. CHEERING AND APPLAUSE Sometimes I startle away, cubside down in the monkey bars of a condemned playground on a super fun site. Get all hept up on goofballs. Rummage that were discarded tag bag of defective toys. Yank out a fist bowl of disembodied doll limbs, toss them on a stained kid's place mat from a defunct dennies. set up a table inside a rusty cargo container down by the Wharf and challenged toothless drifters to the godless bughouse blitz of tournament that is my segment. Meanwhile."""
# fmt: on
processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index 69cf04d37a6bab..b5189124a78b15 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -84,6 +84,8 @@
is_accelerate_available,
is_flax_available,
is_tf_available,
+ is_torch_bf16_available_on_device,
+ is_torch_fp16_available_on_device,
is_torch_fx_available,
is_torch_sdpa_available,
)
@@ -3382,8 +3384,13 @@ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
if not self.all_model_classes[0]._supports_sdpa:
self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
- if torch_device == "cpu" and torch_dtype == "float16":
- self.skipTest("float16 not supported on cpu")
+ if torch_dtype == "float16" and not is_torch_fp16_available_on_device(torch_device):
+ self.skipTest(f"float16 not supported on {torch_device} (on the specific device currently used)")
+
+ if torch_dtype == "bfloat16" and not is_torch_bf16_available_on_device(torch_device):
+ self.skipTest(
+ f"bfloat16 not supported on {torch_device} (on the specific device currently used, e.g. Nvidia T4 GPU)"
+ )
# Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
if torch_dtype == "float16":
@@ -3400,7 +3407,7 @@ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
("cpu", True, torch.bfloat16): 1e-2,
("cuda", False, torch.float32): 1e-6,
("cuda", False, torch.bfloat16): 1e-2,
- ("cuda", False, torch.float16): 1e-3,
+ ("cuda", False, torch.float16): 5e-3,
("cuda", True, torch.float32): 1e-6,
("cuda", True, torch.bfloat16): 1e-2,
("cuda", True, torch.float16): 5e-3,
@@ -3412,7 +3419,7 @@ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
("cpu", True, torch.bfloat16): 1e-2,
("cuda", False, torch.float32): 1e-4,
("cuda", False, torch.bfloat16): 1e-2,
- ("cuda", False, torch.float16): 1e-3,
+ ("cuda", False, torch.float16): 5e-3,
("cuda", True, torch.float32): 1e-4,
("cuda", True, torch.bfloat16): 3e-2,
("cuda", True, torch.float16): 5e-3,
diff --git a/tests/test_modeling_utils.py b/tests/test_modeling_utils.py
index a5eb0d1c561ca4..aac78e955c3ed6 100755
--- a/tests/test_modeling_utils.py
+++ b/tests/test_modeling_utils.py
@@ -43,8 +43,8 @@
TOKEN,
USER,
CaptureLogger,
+ LoggingLevel,
TestCasePlus,
- is_flaky,
is_staging_test,
require_accelerate,
require_flax,
@@ -290,16 +290,14 @@ def test_model_from_pretrained_hub_subfolder_sharded(self):
self.assertIsNotNone(model)
- @is_flaky(
- description="Capturing logs is flaky: https://app.circleci.com/pipelines/github/huggingface/transformers/81004/workflows/4919e5c9-0ea2-457b-ad4f-65371f79e277/jobs/1038999"
- )
def test_model_from_pretrained_with_different_pretrained_model_name(self):
model = T5ForConditionalGeneration.from_pretrained(TINY_T5)
self.assertIsNotNone(model)
logger = logging.get_logger("transformers.configuration_utils")
- with CaptureLogger(logger) as cl:
- BertModel.from_pretrained(TINY_T5)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ BertModel.from_pretrained(TINY_T5)
self.assertTrue("You are using a model of type t5 to instantiate a model of type bert" in cl.out)
def test_model_from_config_torch_dtype(self):
@@ -1024,9 +1022,6 @@ def test_tied_weights_reload(self):
# Should only complain about the missing bias
self.assertListEqual(load_info["missing_keys"], ["decoder.bias"])
- @is_flaky(
- description="Capturing logs is flaky: https://app.circleci.com/pipelines/github/huggingface/transformers/81004/workflows/4919e5c9-0ea2-457b-ad4f-65371f79e277/jobs/1038999"
- )
def test_unexpected_keys_warnings(self):
model = ModelWithHead(PretrainedConfig())
logger = logging.get_logger("transformers.modeling_utils")
@@ -1034,8 +1029,9 @@ def test_unexpected_keys_warnings(self):
model.save_pretrained(tmp_dir)
# Loading the model with a new class, we don't get a warning for unexpected weights, just an info
- with CaptureLogger(logger) as cl:
- _, loading_info = BaseModel.from_pretrained(tmp_dir, output_loading_info=True)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ _, loading_info = BaseModel.from_pretrained(tmp_dir, output_loading_info=True)
self.assertNotIn("were not used when initializing ModelWithHead", cl.out)
self.assertEqual(
set(loading_info["unexpected_keys"]),
@@ -1046,8 +1042,9 @@ def test_unexpected_keys_warnings(self):
state_dict = model.state_dict()
state_dict["added_key"] = copy.deepcopy(state_dict["linear.weight"])
safe_save_file(state_dict, os.path.join(tmp_dir, SAFE_WEIGHTS_NAME), metadata={"format": "pt"})
- with CaptureLogger(logger) as cl:
- _, loading_info = ModelWithHead.from_pretrained(tmp_dir, output_loading_info=True)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ _, loading_info = ModelWithHead.from_pretrained(tmp_dir, output_loading_info=True)
self.assertIn("were not used when initializing ModelWithHead: ['added_key']", cl.out)
self.assertEqual(loading_info["unexpected_keys"], ["added_key"])
@@ -1056,75 +1053,82 @@ def test_warn_if_padding_and_no_attention_mask(self):
with self.subTest("Ensure no warnings when pad_token_id is None."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config_no_pad_token = PretrainedConfig()
- config_no_pad_token.pad_token_id = None
- model = ModelWithHead(config_no_pad_token)
- input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config_no_pad_token = PretrainedConfig()
+ config_no_pad_token.pad_token_id = None
+ model = ModelWithHead(config_no_pad_token)
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertNotIn("We strongly recommend passing in an `attention_mask`", cl.out)
with self.subTest("Ensure no warnings when there is an attention_mask."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- model = ModelWithHead(config)
- input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
self.assertNotIn("We strongly recommend passing in an `attention_mask`", cl.out)
with self.subTest("Ensure no warnings when there are no pad_token_ids in the input_ids."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- model = ModelWithHead(config)
- input_ids = torch.tensor([[1, 345, 232, 328, 740, 140, 1695, 69, 6078, 2341, 25]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[1, 345, 232, 328, 740, 140, 1695, 69, 6078, 2341, 25]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertNotIn("We strongly recommend passing in an `attention_mask`", cl.out)
with self.subTest("Ensure a warning is shown when the input_ids start with a pad_token_id."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- model = ModelWithHead(config)
- input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 432, 5232]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 432, 5232]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertIn("We strongly recommend passing in an `attention_mask`", cl.out)
with self.subTest("Ensure a warning is shown when the input_ids end with a pad_token_id."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- model = ModelWithHead(config)
- input_ids = torch.tensor([[432, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[432, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertIn("We strongly recommend passing in an `attention_mask`", cl.out)
with self.subTest("Ensure that the warning is shown at most once."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- model = ModelWithHead(config)
- input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertEqual(cl.out.count("We strongly recommend passing in an `attention_mask`"), 1)
with self.subTest("Ensure a different warning is shown when the pad_token_id is equal to the bos_token_id."):
logger.warning_once.cache_clear()
- with CaptureLogger(logger) as cl:
- config = PretrainedConfig()
- config.pad_token_id = 0
- config.bos_token_id = config.pad_token_id
- model = ModelWithHead(config)
- input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
- model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
+ with LoggingLevel(logging.WARNING):
+ with CaptureLogger(logger) as cl:
+ config = PretrainedConfig()
+ config.pad_token_id = 0
+ config.bos_token_id = config.pad_token_id
+ model = ModelWithHead(config)
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 0, 0]])
+ model.warn_if_padding_and_no_attention_mask(input_ids, attention_mask=None)
self.assertIn("You may ignore this warning if your `pad_token_id`", cl.out)
if not is_torchdynamo_available():
diff --git a/tests/test_processing_common.py b/tests/test_processing_common.py
new file mode 100644
index 00000000000000..402e6a73515122
--- /dev/null
+++ b/tests/test_processing_common.py
@@ -0,0 +1,128 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import tempfile
+import unittest
+
+from transformers import CLIPTokenizerFast, ProcessorMixin
+from transformers.models.auto.processing_auto import processor_class_from_name
+from transformers.testing_utils import (
+ check_json_file_has_correct_format,
+ require_tokenizers,
+ require_torch,
+ require_vision,
+)
+from transformers.utils import is_vision_available
+
+
+if is_vision_available():
+ from transformers import CLIPImageProcessor
+
+
+@require_torch
+class ProcessorTesterMixin:
+ processor_class = None
+
+ def prepare_processor_dict(self):
+ return {}
+
+ def get_component(self, attribute, **kwargs):
+ assert attribute in self.processor_class.attributes
+ component_class_name = getattr(self.processor_class, f"{attribute}_class")
+ if isinstance(component_class_name, tuple):
+ component_class_name = component_class_name[0]
+
+ component_class = processor_class_from_name(component_class_name)
+ component = component_class.from_pretrained(self.tmpdirname, **kwargs) # noqa
+
+ return component
+
+ def prepare_components(self):
+ components = {}
+ for attribute in self.processor_class.attributes:
+ component = self.get_component(attribute)
+ components[attribute] = component
+
+ return components
+
+ def get_processor(self):
+ components = self.prepare_components()
+ processor = self.processor_class(**components, **self.prepare_processor_dict())
+ return processor
+
+ def test_processor_to_json_string(self):
+ processor = self.get_processor()
+ obj = json.loads(processor.to_json_string())
+ for key, value in self.prepare_processor_dict().items():
+ self.assertEqual(obj[key], value)
+ self.assertEqual(getattr(processor, key, None), value)
+
+ def test_processor_from_and_save_pretrained(self):
+ processor_first = self.get_processor()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_files = processor_first.save_pretrained(tmpdirname)
+ if len(saved_files) > 0:
+ check_json_file_has_correct_format(saved_files[0])
+ processor_second = self.processor_class.from_pretrained(tmpdirname)
+
+ self.assertEqual(processor_second.to_dict(), processor_first.to_dict())
+
+
+class MyProcessor(ProcessorMixin):
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "CLIPImageProcessor"
+ tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
+
+ def __init__(self, image_processor=None, tokenizer=None, processor_attr_1=1, processor_attr_2=True):
+ super().__init__(image_processor, tokenizer)
+
+ self.processor_attr_1 = processor_attr_1
+ self.processor_attr_2 = processor_attr_2
+
+
+@require_tokenizers
+@require_vision
+class ProcessorTest(unittest.TestCase):
+ processor_class = MyProcessor
+
+ def prepare_processor_dict(self):
+ return {"processor_attr_1": 1, "processor_attr_2": False}
+
+ def get_processor(self):
+ image_processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
+ tokenizer = CLIPTokenizerFast.from_pretrained("openai/clip-vit-large-patch14")
+ processor = MyProcessor(image_processor, tokenizer, **self.prepare_processor_dict())
+
+ return processor
+
+ def test_processor_to_json_string(self):
+ processor = self.get_processor()
+ obj = json.loads(processor.to_json_string())
+ for key, value in self.prepare_processor_dict().items():
+ self.assertEqual(obj[key], value)
+ self.assertEqual(getattr(processor, key, None), value)
+
+ def test_processor_from_and_save_pretrained(self):
+ processor_first = self.get_processor()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_file = processor_first.save_pretrained(tmpdirname)[0]
+ check_json_file_has_correct_format(saved_file)
+ processor_second = self.processor_class.from_pretrained(tmpdirname)
+
+ self.assertEqual(processor_second.to_dict(), processor_first.to_dict())
diff --git a/tests/trainer/test_trainer.py b/tests/trainer/test_trainer.py
index d34a72b2ca5140..55cc35cf6aa3eb 100644
--- a/tests/trainer/test_trainer.py
+++ b/tests/trainer/test_trainer.py
@@ -50,6 +50,7 @@
TOKEN,
USER,
CaptureLogger,
+ LoggingLevel,
TestCasePlus,
backend_device_count,
execute_subprocess_async,
@@ -1290,17 +1291,19 @@ def test_log_level(self):
else:
self.assertNotIn(log_info_string, cl.out)
- # test with low log_level - lower than info
- with CaptureLogger(logger) as cl:
- trainer = get_regression_trainer(log_level="debug")
- trainer.train()
- self.assertIn(log_info_string, cl.out)
+ with LoggingLevel(logging.INFO):
+ # test with low log_level - lower than info
+ with CaptureLogger(logger) as cl:
+ trainer = get_regression_trainer(log_level="debug")
+ trainer.train()
+ self.assertIn(log_info_string, cl.out)
- # test with high log_level - should be quiet
- with CaptureLogger(logger) as cl:
- trainer = get_regression_trainer(log_level="error")
- trainer.train()
- self.assertNotIn(log_info_string, cl.out)
+ with LoggingLevel(logging.INFO):
+ # test with high log_level - should be quiet
+ with CaptureLogger(logger) as cl:
+ trainer = get_regression_trainer(log_level="error")
+ trainer.train()
+ self.assertNotIn(log_info_string, cl.out)
def test_save_checkpoints(self):
with tempfile.TemporaryDirectory() as tmpdir:
diff --git a/utils/check_docstrings.py b/utils/check_docstrings.py
index 3c466310397946..f63ca3aba92c6e 100644
--- a/utils/check_docstrings.py
+++ b/utils/check_docstrings.py
@@ -762,6 +762,7 @@
"VitMatteForImageMatting",
"VitsTokenizer",
"VivitModel",
+ "Wav2Vec2BertForCTC",
"Wav2Vec2CTCTokenizer",
"Wav2Vec2Config",
"Wav2Vec2ConformerConfig",
diff --git a/utils/not_doctested.txt b/utils/not_doctested.txt
index 611c515b82ca62..6087758f5ac6ff 100644
--- a/utils/not_doctested.txt
+++ b/utils/not_doctested.txt
@@ -198,6 +198,7 @@ docs/source/en/model_doc/pop2piano.md
docs/source/en/model_doc/prophetnet.md
docs/source/en/model_doc/pvt.md
docs/source/en/model_doc/qdqbert.md
+docs/source/en/model_doc/qwen2.md
docs/source/en/model_doc/rag.md
docs/source/en/model_doc/realm.md
docs/source/en/model_doc/reformer.md
@@ -745,6 +746,10 @@ src/transformers/models/pvt/image_processing_pvt.py
src/transformers/models/pvt/modeling_pvt.py
src/transformers/models/qdqbert/configuration_qdqbert.py
src/transformers/models/qdqbert/modeling_qdqbert.py
+src/transformers/models/qwen2/configuration_qwen2.py
+src/transformers/models/qwen2/modeling_qwen2.py
+src/transformers/models/qwen2/tokenization_qwen2.py
+src/transformers/models/qwen2/tokenization_qwen2_fast.py
src/transformers/models/rag/configuration_rag.py
src/transformers/models/rag/modeling_rag.py
src/transformers/models/rag/modeling_tf_rag.py
@@ -873,6 +878,7 @@ src/transformers/models/wav2vec2/convert_wav2vec2_original_pytorch_checkpoint_to
src/transformers/models/wav2vec2/convert_wav2vec2_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
src/transformers/models/wav2vec2_conformer/convert_wav2vec2_conformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/wavlm/convert_wavlm_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/wavlm/convert_wavlm_original_s3prl_checkpoint_to_pytorch.py