diff --git a/README.md b/README.md
index c461d786fd2e..908d2e690faa 100644
--- a/README.md
+++ b/README.md
@@ -244,6 +244,7 @@ Current number of checkpoints: ** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/master/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
diff --git a/README_ko.md b/README_ko.md
index 1bf1270c03b1..d6bc4ae44a4a 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -227,6 +227,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/master/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index fe69542ddd8f..c5878ca2004f 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -251,6 +251,7 @@ conda install -c huggingface transformers
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (来自 Google Research) 伴随论文 [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) 由 Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting 发布。
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (来自 OpenAI) 伴随论文 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 由 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 发布。
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (来自 YituTech) 伴随论文 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 由 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 发布。
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/master/model_doc/convnext)** (来自 Facebook AI) 伴随论文 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 由 Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 发布。
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (来自 Tsinghua University) 伴随论文 [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) 由 Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun 发布。
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (来自 Salesforce) 伴随论文 [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) 由 Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher 发布。
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (来自 Microsoft) 伴随论文 [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) 由 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index f65b9a82a997..bd9cb706aa05 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -263,6 +263,7 @@ conda install -c huggingface transformers
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/master/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index f1cb9a80f31a..70d2455d0aea 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -22,7 +22,7 @@
- local: model_summary
title: Summary of the models
- local: training
- title: Fine-tuning a pretrained model
+ title: Fine-tune a pretrained model
- local: accelerate
title: Distributed training with 🤗 Accelerate
- local: model_sharing
@@ -33,6 +33,8 @@
title: Multi-lingual models
title: Tutorials
- sections:
+ - local: create_a_model
+ title: Create a custom model
- local: examples
title: Examples
- local: troubleshooting
@@ -150,6 +152,8 @@
title: CamemBERT
- local: model_doc/canine
title: CANINE
+ - local: model_doc/convnext
+ title: ConvNeXT
- local: model_doc/clip
title: CLIP
- local: model_doc/convbert
diff --git a/docs/source/create_a_model.mdx b/docs/source/create_a_model.mdx
new file mode 100644
index 000000000000..8a1b80b09303
--- /dev/null
+++ b/docs/source/create_a_model.mdx
@@ -0,0 +1,323 @@
+
+
+# Create a custom model
+
+An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
+
+- Load and customize a model configuration.
+- Create a model architecture.
+- Create a slow and fast tokenizer for text.
+- Create a feature extractor for audio or image tasks.
+- Create a processor for multimodal tasks.
+
+## Configuration
+
+A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
+
+Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
+
+```py
+>>> from transformers import DistilBertConfig
+
+>>> config = DistilBertConfig()
+>>> print(config)
+DistilBertConfig {
+ "activation": "gelu",
+ "attention_dropout": 0.1,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
+
+- Try a different activation function with the `activation` parameter.
+- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
+
+```py
+>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
+>>> print(my_config)
+DistilBertConfig {
+ "activation": "relu",
+ "attention_dropout": 0.4,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
+```
+
+Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
+
+```py
+>>> my_config.save_pretrained(save_directory="./your_model_save_path")
+```
+
+To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+```
+
+
+
+You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
+
+
+
+## Model
+
+The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module) subclass. This means models are compatible with each of their respective framework's usage.
+
+Load your custom configuration attributes into the model:
+
+```py
+>>> from transformers import DistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> model = DistilBertModel(my_config)
+===PT-TF-SPLIT===
+>>> from transformers import TFDistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> tf_model = TFDistilBertModel(my_config)
+```
+
+This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
+
+Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
+===PT-TF-SPLIT===
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
+```
+
+When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+===PT-TF-SPLIT===
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+```
+
+### Model heads
+
+At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
+
+For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
+
+```py
+>>> from transformers import DistilBertForSequenceClassification
+
+>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+===PT-TF-SPLIT===
+>>> from transformers import TFDistilBertForSequenceClassification
+
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
+
+```py
+>>> from transformers import DistilBertForQuestionAnswering
+
+>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+===PT-TF-SPLIT===
+>>> from transformers import TFDistilBertForQuestionAnswering
+
+>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+## Tokenizer
+
+The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
+
+- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
+- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to it's Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
+
+Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
+
+
+
+Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
+
+
+
+If you trained your own tokenizer, you can create one from your *vocabulary* file:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
+```
+
+It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
+
+```py
+>>> from transformers import DistilBertTokenizerFast
+
+>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
+
+
+
+## Feature Extractor
+
+A feature extractor processes audio or image inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`ImageFeatureExtractionMixin`] class for processing image features or the [`SequenceFeatureExtractor`] class for processing audio inputs.
+
+Depending on whether you are working on an audio or vision task, create a feature extractor associated with the model you're using. For example, create a default [`ViTFeatureExtractor`] if you are using [ViT](model_doc/vit) for image classification:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> vit_extractor = ViTFeatureExtractor()
+>>> print(vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": true,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": 2,
+ "size": 224
+}
+```
+
+
+
+If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
+
+
+
+Modify any of the [`ViTFeatureExtractor`] parameters to create your custom feature extractor:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> print(my_vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": false,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.3,
+ 0.3,
+ 0.3
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": "PIL.Image.BOX",
+ "size": 224
+}
+```
+
+For audio inputs, you can create a [`Wav2Vec2FeatureExtractor`] and customize the parameters in a similar way:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": true,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 16000
+}
+```
+
+## Processor
+
+For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps a feature extractor and tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
+
+Create a feature extractor to handle the audio inputs:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
+```
+
+Create a tokenizer to handle the text inputs:
+
+```py
+>>> from transformers import Wav2Vec2CTCTokenizer
+
+>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
+```
+
+Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
+
+```py
+>>> from transformers import Wav2Vec2Processor
+
+>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
\ No newline at end of file
diff --git a/docs/source/index.mdx b/docs/source/index.mdx
index 6f97693065c8..f6fc659ed47a 100644
--- a/docs/source/index.mdx
+++ b/docs/source/index.mdx
@@ -70,6 +70,7 @@ conversion utilities for the following models.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
@@ -176,6 +177,7 @@ Flax), PyTorch, and/or TensorFlow.
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNext | ❌ | ❌ | ✅ | ❌ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ❌ | ✅ | ✅ | ❌ |
diff --git a/docs/source/main_classes/deepspeed.mdx b/docs/source/main_classes/deepspeed.mdx
index 3fdf694629ac..a558cf5390e8 100644
--- a/docs/source/main_classes/deepspeed.mdx
+++ b/docs/source/main_classes/deepspeed.mdx
@@ -1805,6 +1805,170 @@ Please note that if you're not using the [`Trainer`] integration, you're complet
[[autodoc]] deepspeed.HfDeepSpeedConfig
- all
+### DeepSpeed ZeRO Inference
+
+Here is an example of how one could do DeepSpeed ZeRO Inference without using [`Trainer`] when one can't fit a model onto a single GPU. The solution includes using additional GPUs or/and offloading GPU memory to CPU memory.
+
+The important nuance to understand here is that the way ZeRO is designed you can process different inputs on different GPUs in parallel.
+
+The example has copious notes and is self-documenting.
+
+Make sure to:
+
+1. disable CPU offload if you have enough GPU memory (since it slows things down)
+2. enable bf16 if you own an Ampere or a newer GPU to make things faster. If you don't have that hardware you may enable fp16 as long as you don't use any model that was pre-trained in bf16 mixed precision (such as most t5 models). These usually overflow in fp16 and you will see garbage as output.
+
+```python
+#!/usr/bin/env python
+
+# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
+# into a single GPU
+#
+# 1. Use 1 GPU with CPU offload
+# 2. Or use multiple GPUs instead
+#
+# First you need to install deepspeed: pip install deepspeed
+#
+# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
+# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
+#
+# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
+# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
+# process multiple inputs at once.
+#
+# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
+# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
+# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
+# run faster if you don't want offload to CPU - so disable that section then.
+#
+# To deploy on 1 gpu:
+#
+# deepspeed --num_gpus 1 t0.py
+# or:
+# python -m torch.distributed.run --nproc_per_node=1 t0.py
+#
+# To deploy on 2 gpus:
+#
+# deepspeed --num_gpus 2 t0.py
+# or:
+# python -m torch.distributed.run --nproc_per_node=2 t0.py
+
+
+from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
+from transformers.deepspeed import HfDeepSpeedConfig
+import deepspeed
+import os
+import torch
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
+
+# distributed setup
+local_rank = int(os.getenv("LOCAL_RANK", "0"))
+world_size = int(os.getenv("WORLD_SIZE", "1"))
+torch.cuda.set_device(local_rank)
+deepspeed.init_distributed()
+
+model_name = "bigscience/T0_3B"
+
+config = AutoConfig.from_pretrained(model_name)
+model_hidden_size = config.d_model
+
+# batch size has to be divisible by world_size, but can be bigger than world_size
+train_batch_size = 1 * world_size
+
+# ds_config notes
+#
+# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
+# faster.
+#
+# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
+# all official t5 models are bf16-pretrained
+#
+# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
+# - want CPU offload
+#
+# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
+# - which params should remain on gpus - the larger the value the smaller the offload size
+#
+# For indepth info on Deepspeed config see
+# https://huggingface.co/docs/transformers/master/main_classes/deepspeed
+
+# keeping the same format as json for consistency, except it uses lower case for true/false
+# fmt: off
+ds_config = {
+ "fp16": {
+ "enabled": False
+ },
+ "bf16": {
+ "enabled": False
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": True
+ },
+ "overlap_comm": True,
+ "contiguous_gradients": True,
+ "reduce_bucket_size": model_hidden_size * model_hidden_size,
+ "stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
+ "stage3_param_persistence_threshold": 10 * model_hidden_size
+ },
+ "steps_per_print": 2000,
+ "train_batch_size": train_batch_size,
+ "train_micro_batch_size_per_gpu": 1,
+ "wall_clock_breakdown": False
+}
+# fmt: on
+
+# next line instructs transformers to partition the model directly over multiple gpus using
+# deepspeed.zero.Init when model's `from_pretrained` method is called.
+#
+# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
+#
+# otherwise the model will first be loaded normally and only partitioned at forward time which is
+# less efficient and when there is little CPU RAM may fail
+dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
+
+# now a model can be loaded.
+model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
+
+# initialise Deepspeed ZeRO and store only the engine object
+ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
+ds_engine.module.eval() # inference
+
+# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
+# If you use more GPUs adjust for more.
+# And of course if you have just one input to process you then need to pass the same string to both gpus
+# If you use only one GPU, then you will have only rank 0.
+rank = torch.distributed.get_rank()
+if rank == 0:
+ text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
+elif rank == 1:
+ text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
+
+tokenizer = AutoTokenizer.from_pretrained(model_name)
+inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
+with torch.no_grad():
+ outputs = ds_engine.module.generate(inputs, synced_gpus=True)
+text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
+print(f"rank{rank}:\n in={text_in}\n out={text_out}")
+```
+
+Let's save it as `t0.py` and run it:
+```
+$ deepspeed --num_gpus 2 t0.py
+rank0:
+ in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
+ out=Positive
+rank1:
+ in=Is this review positive or negative? Review: this is the worst restaurant ever
+ out=negative
+```
+
+This was a very basic example and you will want to adapt it to your needs.
+
+
## Main DeepSpeed Resources
- [Project's github](https://github.com/microsoft/deepspeed)
diff --git a/docs/source/model_doc/auto.mdx b/docs/source/model_doc/auto.mdx
index ab7d02d5498e..3588445b09ec 100644
--- a/docs/source/model_doc/auto.mdx
+++ b/docs/source/model_doc/auto.mdx
@@ -150,6 +150,10 @@ Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
[[autodoc]] AutoModelForImageSegmentation
+## AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
## TFAutoModel
[[autodoc]] TFAutoModel
diff --git a/docs/source/model_doc/convnext.mdx b/docs/source/model_doc/convnext.mdx
new file mode 100644
index 000000000000..e3a04d371e64
--- /dev/null
+++ b/docs/source/model_doc/convnext.mdx
@@ -0,0 +1,66 @@
+
+
+# ConvNeXT
+
+## Overview
+
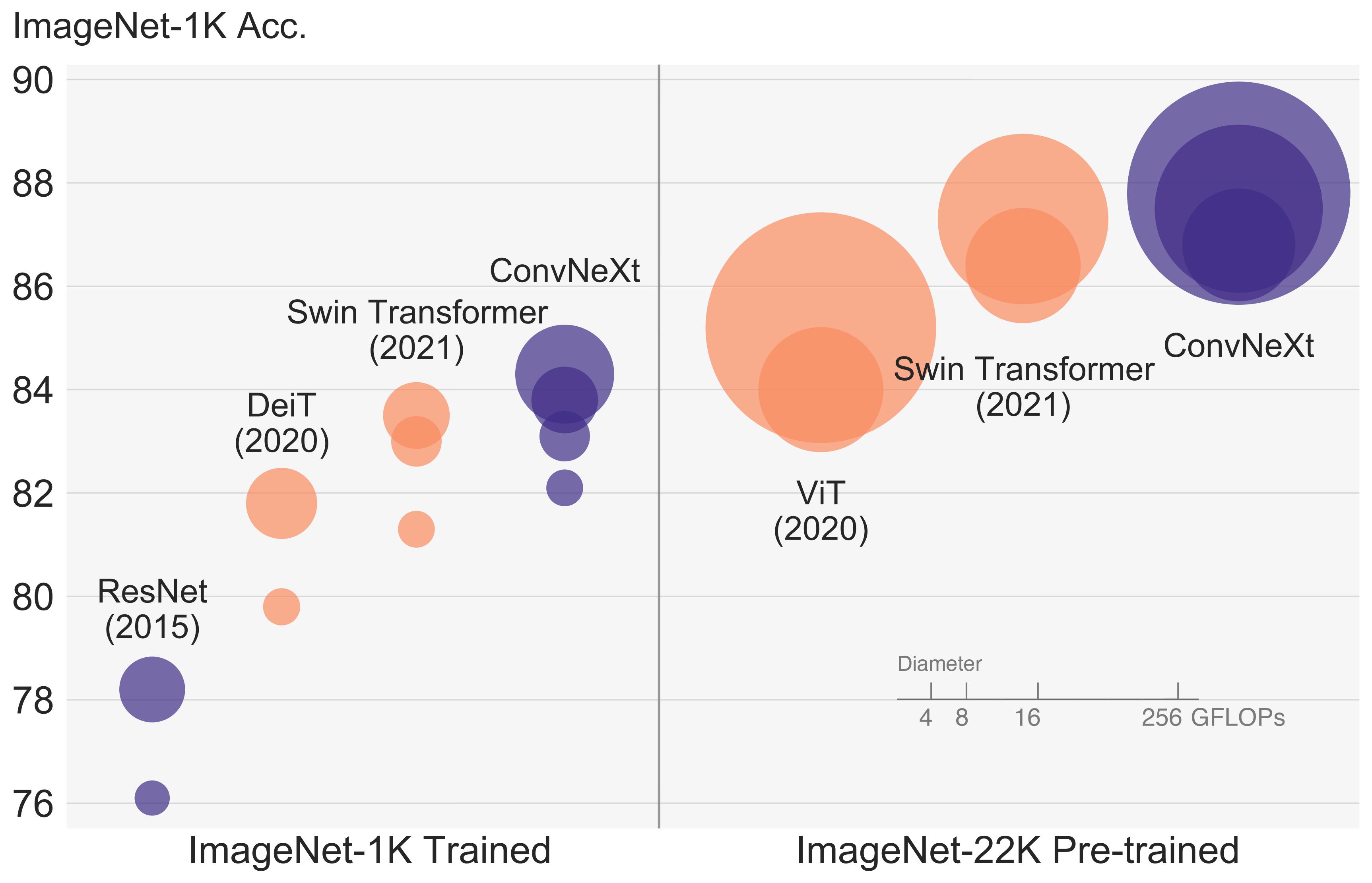
+The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
+
+The abstract from the paper is the following:
+
+*The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model.
+A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers
+(e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide
+variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive
+biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design
+of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models
+dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
+and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
+
+Tips:
+
+- See the code examples below each model regarding usage.
+
+ +
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## ConvNeXT specific outputs
+
+[[autodoc]] models.convnext.modeling_convnext.ConvNextModelOutput
+
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/parallelism.mdx b/docs/source/parallelism.mdx
index 61af187136b6..c832c740ffdf 100644
--- a/docs/source/parallelism.mdx
+++ b/docs/source/parallelism.mdx
@@ -308,9 +308,14 @@ ZeRO stage 3 is not a good choice either for the same reason - more inter-node c
And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
Implementations:
-- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed)
+- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
- [OSLO](https://github.com/tunib-ai/oslo)
+Important papers:
+
+- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
+https://arxiv.org/abs/2201.11990)
+
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## FlexFlow
diff --git a/docs/source/serialization.mdx b/docs/source/serialization.mdx
index 83d291f7672e..2be3fc3735ad 100644
--- a/docs/source/serialization.mdx
+++ b/docs/source/serialization.mdx
@@ -43,17 +43,17 @@ and are designed to be easily extendable to other architectures.
Ready-made configurations include the following architectures:
-
+
- ALBERT
- BART
- BERT
- CamemBERT
- DistilBERT
+- ELECTRA
- GPT Neo
- I-BERT
- LayoutLM
-- Longformer
- Marian
- mBART
- OpenAI GPT-2
diff --git a/examples/pytorch/speech-recognition/README.md b/examples/pytorch/speech-recognition/README.md
index 7db7811ba2c5..a462cf338576 100644
--- a/examples/pytorch/speech-recognition/README.md
+++ b/examples/pytorch/speech-recognition/README.md
@@ -127,6 +127,62 @@ python -m torch.distributed.launch \
On 8 V100 GPUs, this script should run in *ca.* 18 minutes and yield a CTC loss of **0.39** and word error rate
of **0.36**.
+
+### Multi GPU CTC with Dataset Streaming
+
+The following command shows how to use [Dataset Streaming mode](https://huggingface.co/docs/datasets/dataset_streaming.html)
+to fine-tune [XLS-R](https://huggingface.co/transformers/master/model_doc/xls_r.html)
+on [Common Voice](https://huggingface.co/datasets/common_voice) using 4 GPUs in half-precision.
+
+Streaming mode imposes several constraints on training:
+1. We need to construct a tokenizer beforehand and define it via `--tokenizer_name_or_path`.
+2. `--num_train_epochs` has to be replaced by `--max_steps`. Similarly, all other epoch-based arguments have to be
+replaced by step-based ones.
+3. Full dataset shuffling on each epoch is not possible, since we don't have the whole dataset available at once.
+However, the `--shuffle_buffer_size` argument controls how many examples we can pre-download before shuffling them.
+
+
+```bash
+**python -m torch.distributed.launch \
+ --nproc_per_node 4 run_speech_recognition_ctc_streaming.py \
+ --dataset_name="common_voice" \
+ --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
+ --tokenizer_name_or_path="anton-l/wav2vec2-tokenizer-turkish" \
+ --dataset_config_name="tr" \
+ --train_split_name="train+validation" \
+ --eval_split_name="test" \
+ --output_dir="wav2vec2-xls-r-common_voice-tr-ft" \
+ --overwrite_output_dir \
+ --max_steps="5000" \
+ --per_device_train_batch_size="8" \
+ --gradient_accumulation_steps="2" \
+ --learning_rate="5e-4" \
+ --warmup_steps="500" \
+ --evaluation_strategy="steps" \
+ --text_column_name="sentence" \
+ --save_steps="500" \
+ --eval_steps="500" \
+ --logging_steps="1" \
+ --layerdrop="0.0" \
+ --eval_metrics wer cer \
+ --save_total_limit="1" \
+ --mask_time_prob="0.3" \
+ --mask_time_length="10" \
+ --mask_feature_prob="0.1" \
+ --mask_feature_length="64" \
+ --freeze_feature_encoder \
+ --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
+ --max_duration_in_seconds="20" \
+ --shuffle_buffer_size="500" \
+ --fp16 \
+ --push_to_hub \
+ --do_train --do_eval \
+ --gradient_checkpointing**
+```
+
+On 4 V100 GPUs, this script should run in *ca.* 3h 31min and yield a CTC loss of **0.35** and word error rate
+of **0.29**.
+
### Examples CTC
The following tables present a couple of example runs on the most popular speech-recognition datasets.
@@ -175,6 +231,7 @@ they can serve as a baseline to improve upon.
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.35 | - | 1 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo/blob/main/run.sh) |
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft/blob/main/run.sh) |
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) | 0.21 | - | 2 GPU Titan 24 GB RAM | 15h10 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-1b-common_voice-tr-ft/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` in streaming mode | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.29 | - | 4 GPU V100 | 3h31 | [here](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream) | [run.sh](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream/blob/main/run.sh) |
#### Multilingual Librispeech CTC
diff --git a/examples/pytorch/speech-recognition/requirements.txt b/examples/pytorch/speech-recognition/requirements.txt
index b8c475e40a1e..219959a4b267 100644
--- a/examples/pytorch/speech-recognition/requirements.txt
+++ b/examples/pytorch/speech-recognition/requirements.txt
@@ -1,4 +1,4 @@
-datasets >= 1.13.3
+datasets >= 1.18.0
torch >= 1.5
torchaudio
librosa
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index eea78f58ae7c..b09b0b33f270 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
-require_version("datasets>=1.13.3", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
@@ -146,7 +146,8 @@ class DataTrainingArguments:
train_split_name: str = field(
default="train+validation",
metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train+validation'"
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
},
)
eval_split_name: str = field(
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index 40bc9aeb9a56..ee5530caebd1 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
new file mode 100644
index 000000000000..9e69178088f6
--- /dev/null
+++ b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
@@ -0,0 +1,659 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+""" Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition in streaming mode"""
+
+import logging
+import os
+import re
+import sys
+import warnings
+from dataclasses import dataclass, field
+from typing import Dict, List, Optional, Union
+
+import datasets
+import numpy as np
+import torch
+from datasets import IterableDatasetDict, interleave_datasets, load_dataset, load_metric
+from torch.utils.data import IterableDataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForCTC,
+ AutoProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainerCallback,
+ TrainingArguments,
+ Wav2Vec2Processor,
+ set_seed,
+)
+from transformers.trainer_pt_utils import IterableDatasetShard
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
+check_min_version("4.17.0.dev0")
+
+require_version("datasets>=1.18.2", "To fix: pip install 'datasets>=1.18.2'")
+
+
+logger = logging.getLogger(__name__)
+
+
+def list_field(default=None, metadata=None):
+ return field(default_factory=lambda: default, metadata=metadata)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ tokenizer_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ freeze_feature_encoder: bool = field(
+ default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
+ )
+ attention_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
+ )
+ activation_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
+ )
+ feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
+ hidden_dropout: float = field(
+ default=0.0,
+ metadata={
+ "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
+ },
+ )
+ final_dropout: float = field(
+ default=0.0,
+ metadata={"help": "The dropout probability for the final projection layer."},
+ )
+ mask_time_prob: float = field(
+ default=0.05,
+ metadata={
+ "help": "Probability of each feature vector along the time axis to be chosen as the start of the vector"
+ "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature"
+ "vectors will be masked along the time axis."
+ },
+ )
+ mask_time_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the time axis."},
+ )
+ mask_feature_prob: float = field(
+ default=0.0,
+ metadata={
+ "help": "Probability of each feature vector along the feature axis to be chosen as the start of the vector"
+ "span to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature bins will be masked along the time axis."
+ },
+ )
+ mask_feature_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the feature axis."},
+ )
+ layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
+ ctc_loss_reduction: Optional[str] = field(
+ default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: str = field(
+ metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: str = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_split_name: str = field(
+ default="train+validation",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
+ },
+ )
+ eval_split_name: str = field(
+ default="test",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'test'"
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of validation examples to this "
+ "value if set."
+ },
+ )
+ shuffle_buffer_size: Optional[int] = field(
+ default=500,
+ metadata={
+ "help": "The number of streamed examples to download before shuffling them. The large the buffer, "
+ "the closer it is to real offline shuffling."
+ },
+ )
+ chars_to_ignore: Optional[List[str]] = list_field(
+ default=None,
+ metadata={"help": "A list of characters to remove from the transcripts."},
+ )
+ eval_metrics: List[str] = list_field(
+ default=["wer"],
+ metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds."},
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether to only do data preprocessing and skip training. "
+ "This is especially useful when data preprocessing errors out in distributed training due to timeout. "
+ "In this case, one should run the preprocessing in a non-distributed setup with `preprocessing_only=True` "
+ "so that the cached datasets can consequently be loaded in distributed training"
+ },
+ )
+ use_auth_token: bool = field(
+ default=False,
+ metadata={
+ "help": "If :obj:`True`, will use the token generated when running"
+ ":obj:`transformers-cli login` as HTTP bearer authorization for remote files."
+ },
+ )
+ phoneme_language: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "The target language that should be used be"
+ " passed to the tokenizer for tokenization. Note that"
+ " this is only relevant if the model classifies the"
+ " input audio to a sequence of phoneme sequences."
+ },
+ )
+
+
+@dataclass
+class DataCollatorCTCWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor (:class:`~transformers.AutoProcessor`)
+ The processor used for proccessing the data.
+ padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ max_length (:obj:`int`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ max_length_labels (:obj:`int`, `optional`):
+ Maximum length of the ``labels`` returned list and optionally padding length (see above).
+ pad_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ """
+
+ processor: AutoProcessor
+ padding: Union[bool, str] = "longest"
+ max_length: Optional[int] = None
+ pad_to_multiple_of: Optional[int] = None
+ pad_to_multiple_of_labels: Optional[int] = None
+
+ def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lenghts and need
+ # different padding methods
+ input_features = []
+ label_features = []
+ for feature in features:
+ if self.max_length and feature["input_values"].shape[-1] > self.max_length:
+ continue
+ input_features.append({"input_values": feature["input_values"]})
+ label_features.append({"input_ids": feature["labels"]})
+
+ batch = self.processor.pad(
+ input_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ return_tensors="pt",
+ )
+
+ with self.processor.as_target_processor():
+ labels_batch = self.processor.pad(
+ label_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of_labels,
+ return_tensors="pt",
+ )
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ batch["labels"] = labels
+
+ return batch
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # 1. First, let's load the dataset
+ raw_datasets = IterableDatasetDict()
+ raw_column_names = {}
+
+ def load_streaming_dataset(split, sampling_rate, **kwargs):
+ if "+" in split:
+ dataset_splits = [load_dataset(split=split_name, **kwargs) for split_name in split.split("+")]
+ # `features` and `cast_column` won't be available after interleaving, so we'll use them here
+ features = dataset_splits[0].features
+ # make sure that the dataset decodes audio with a correct sampling rate
+ dataset_splits = [
+ dataset.cast_column(data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate))
+ for dataset in dataset_splits
+ ]
+
+ interleaved_dataset = interleave_datasets(dataset_splits)
+ return interleaved_dataset, features
+ else:
+ dataset = load_dataset(split=split, **kwargs)
+ features = dataset.features
+ # make sure that the dataset decodes audio with a correct sampling rate
+ dataset = dataset.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate)
+ )
+ return dataset, features
+
+ # `datasets` takes care of automatically loading and resampling the audio,
+ # so we just need to set the correct target sampling rate and normalize the input
+ # via the `feature_extractor`
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
+ )
+
+ if training_args.do_train:
+ raw_datasets["train"], train_features = load_streaming_dataset(
+ path=data_args.dataset_name,
+ name=data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ use_auth_token=data_args.use_auth_token,
+ streaming=True,
+ sampling_rate=feature_extractor.sampling_rate,
+ )
+ raw_column_names["train"] = list(train_features.keys())
+
+ if data_args.audio_column_name not in raw_column_names["train"]:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--audio_column_name` to the correct audio column - one of "
+ f"{', '.join(raw_column_names['train'])}."
+ )
+
+ if data_args.text_column_name not in raw_column_names["train"]:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(raw_column_names['train'])}."
+ )
+
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].take(range(data_args.max_train_samples))
+
+ if training_args.do_eval:
+ raw_datasets["eval"], eval_features = load_streaming_dataset(
+ path=data_args.dataset_name,
+ name=data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ use_auth_token=data_args.use_auth_token,
+ streaming=True,
+ sampling_rate=feature_extractor.sampling_rate,
+ )
+ raw_column_names["eval"] = list(eval_features.keys())
+
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].take(range(data_args.max_eval_samples))
+
+ # 2. We remove some special characters from the datasets
+ # that make training complicated and do not help in transcribing the speech
+ # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
+ # that could be easily picked up by the model
+ chars_to_ignore_regex = (
+ f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
+ )
+ text_column_name = data_args.text_column_name
+
+ def remove_special_characters(batch):
+ if chars_to_ignore_regex is not None:
+ batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
+ else:
+ batch["target_text"] = batch[text_column_name].lower() + " "
+ return batch
+
+ with training_args.main_process_first(desc="dataset map special characters removal"):
+ for split, dataset in raw_datasets.items():
+ raw_datasets[split] = dataset.map(
+ remove_special_characters,
+ ).remove_columns([text_column_name])
+
+ # 3. Next, let's load the config as we might need it to create
+ # the tokenizer
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
+ )
+
+ # 4. Now we can instantiate the tokenizer and model
+ # Note for distributed training, the .from_pretrained methods guarantee that only
+ # one local process can concurrently download model & vocab.
+
+ tokenizer_name_or_path = model_args.tokenizer_name_or_path
+ if tokenizer_name_or_path is None:
+ raise ValueError(
+ "Tokenizer has to be created before training in streaming mode. Please specify --tokenizer_name_or_path"
+ )
+ # load feature_extractor and tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ config=config,
+ use_auth_token=data_args.use_auth_token,
+ )
+
+ # adapt config
+ config.update(
+ {
+ "feat_proj_dropout": model_args.feat_proj_dropout,
+ "attention_dropout": model_args.attention_dropout,
+ "hidden_dropout": model_args.hidden_dropout,
+ "final_dropout": model_args.final_dropout,
+ "mask_time_prob": model_args.mask_time_prob,
+ "mask_time_length": model_args.mask_time_length,
+ "mask_feature_prob": model_args.mask_feature_prob,
+ "mask_feature_length": model_args.mask_feature_length,
+ "gradient_checkpointing": training_args.gradient_checkpointing,
+ "layerdrop": model_args.layerdrop,
+ "ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "pad_token_id": tokenizer.pad_token_id,
+ "vocab_size": len(tokenizer),
+ "activation_dropout": model_args.activation_dropout,
+ }
+ )
+
+ # create model
+ model = AutoModelForCTC.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ config=config,
+ use_auth_token=data_args.use_auth_token,
+ )
+
+ # freeze encoder
+ if model_args.freeze_feature_encoder:
+ model.freeze_feature_encoder()
+
+ # 5. Now we preprocess the datasets including loading the audio, resampling and normalization
+ audio_column_name = data_args.audio_column_name
+
+ # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
+ phoneme_language = data_args.phoneme_language
+
+ # Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ def prepare_dataset(batch):
+ # load audio
+ sample = batch[audio_column_name]
+
+ inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
+ batch["input_values"] = inputs.input_values[0]
+ batch["input_length"] = len(batch["input_values"])
+
+ # encode targets
+ additional_kwargs = {}
+ if phoneme_language is not None:
+ additional_kwargs["phonemizer_lang"] = phoneme_language
+
+ batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
+ return batch
+
+ vectorized_datasets = IterableDatasetDict()
+ with training_args.main_process_first(desc="dataset map preprocessing"):
+ for split, dataset in raw_datasets.items():
+ vectorized_datasets[split] = (
+ dataset.map(prepare_dataset)
+ .remove_columns(raw_column_names[split] + ["target_text"])
+ .with_format("torch")
+ )
+ if split == "train":
+ vectorized_datasets[split] = vectorized_datasets[split].shuffle(
+ buffer_size=data_args.shuffle_buffer_size,
+ seed=training_args.seed,
+ )
+
+ # 6. Next, we can prepare the training.
+ # Let's use word error rate (WER) as our evaluation metric,
+ # instantiate a data collator and the trainer
+
+ # Define evaluation metrics during training, *i.e.* word error rate, character error rate
+ eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
+
+ def compute_metrics(pred):
+ pred_logits = pred.predictions
+ pred_ids = np.argmax(pred_logits, axis=-1)
+
+ pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(pred_ids)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
+
+ metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
+
+ return metrics
+
+ # Now save everything to be able to create a single processor later
+ if is_main_process(training_args.local_rank):
+ # save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ try:
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+ except (OSError, KeyError):
+ warnings.warn(
+ "Loading a processor from a feature extractor config that does not"
+ " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
+ " attribute to your `preprocessor_config.json` file to suppress this warning: "
+ " `'processor_class': 'Wav2Vec2Processor'`",
+ FutureWarning,
+ )
+ processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
+
+ # Instantiate custom data collator
+ max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
+ data_collator = DataCollatorCTCWithPadding(processor=processor, max_length=max_input_length)
+
+ # trainer callback to reinitialize and reshuffle the streamable datasets at the beginning of each epoch
+ class ShuffleCallback(TrainerCallback):
+ def on_epoch_begin(self, args, state, control, train_dataloader, **kwargs):
+ if isinstance(train_dataloader.dataset, IterableDatasetShard):
+ pass # set_epoch() is handled by the Trainer
+ elif isinstance(train_dataloader.dataset, IterableDataset):
+ train_dataloader.dataset.set_epoch(train_dataloader.dataset._epoch + 1)
+
+ # Initialize Trainer
+ trainer = Trainer(
+ model=model,
+ data_collator=data_collator,
+ args=training_args,
+ compute_metrics=compute_metrics,
+ train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
+ eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
+ tokenizer=processor,
+ callbacks=[ShuffleCallback()],
+ )
+
+ # 7. Finally, we can start training
+
+ # Training
+ if training_args.do_train:
+
+ # use last checkpoint if exist
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+
+ metrics = train_result.metrics
+ if data_args.max_train_samples:
+ metrics["train_samples"] = data_args.max_train_samples
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+ if data_args.max_eval_samples:
+ metrics["eval_samples"] = data_args.max_eval_samples
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "speech-recognition",
+ "tags": ["automatic-speech-recognition", data_args.dataset_name],
+ "dataset_args": f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split: {data_args.eval_split_name}",
+ "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
+ }
+ if "common_voice" in data_args.dataset_name:
+ kwargs["language"] = config_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 0a133f71ebd0..bb022ba3682d 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -201,6 +201,7 @@
"CLIPVisionConfig",
],
"models.convbert": ["CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvBertConfig", "ConvBertTokenizer"],
+ "models.convnext": ["CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvNextConfig"],
"models.cpm": ["CpmTokenizer"],
"models.ctrl": ["CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP", "CTRLConfig", "CTRLTokenizer"],
"models.deberta": ["DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP", "DebertaConfig", "DebertaTokenizer"],
@@ -513,6 +514,7 @@
_import_structure["models.beit"].append("BeitFeatureExtractor")
_import_structure["models.clip"].append("CLIPFeatureExtractor")
_import_structure["models.clip"].append("CLIPProcessor")
+ _import_structure["models.convnext"].append("ConvNextFeatureExtractor")
_import_structure["models.deit"].append("DeiTFeatureExtractor")
_import_structure["models.detr"].append("DetrFeatureExtractor")
_import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
@@ -688,6 +690,7 @@
"AutoModelForObjectDetection",
"AutoModelForPreTraining",
"AutoModelForQuestionAnswering",
+ "AutoModelForSemanticSegmentation",
"AutoModelForSeq2SeqLM",
"AutoModelForSequenceClassification",
"AutoModelForSpeechSeq2Seq",
@@ -837,6 +840,14 @@
"load_tf_weights_in_convbert",
]
)
+ _import_structure["models.convnext"].extend(
+ [
+ "CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ConvNextForImageClassification",
+ "ConvNextModel",
+ "ConvNextPreTrainedModel",
+ ]
+ )
_import_structure["models.ctrl"].extend(
[
"CTRL_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -1560,6 +1571,7 @@
"get_polynomial_decay_schedule_with_warmup",
"get_scheduler",
]
+ _import_structure["pytorch_utils"] = []
_import_structure["sagemaker"] = []
_import_structure["trainer"] = ["Trainer"]
_import_structure["trainer_pt_utils"] = ["torch_distributed_zero_first"]
@@ -2391,6 +2403,7 @@
CLIPVisionConfig,
)
from .models.convbert import CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvBertConfig, ConvBertTokenizer
+ from .models.convnext import CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvNextConfig
from .models.cpm import CpmTokenizer
from .models.ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig, CTRLTokenizer
from .models.deberta import DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP, DebertaConfig, DebertaTokenizer
@@ -2654,6 +2667,7 @@
from .image_utils import ImageFeatureExtractionMixin
from .models.beit import BeitFeatureExtractor
from .models.clip import CLIPFeatureExtractor, CLIPProcessor
+ from .models.convnext import ConvNextFeatureExtractor
from .models.deit import DeiTFeatureExtractor
from .models.detr import DetrFeatureExtractor
from .models.imagegpt import ImageGPTFeatureExtractor
@@ -2797,6 +2811,7 @@
AutoModelForObjectDetection,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
+ AutoModelForSemanticSegmentation,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForSpeechSeq2Seq,
@@ -2921,6 +2936,12 @@
ConvBertPreTrainedModel,
load_tf_weights_in_convbert,
)
+ from .models.convnext import (
+ CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ConvNextForImageClassification,
+ ConvNextModel,
+ ConvNextPreTrainedModel,
+ )
from .models.ctrl import (
CTRL_PRETRAINED_MODEL_ARCHIVE_LIST,
CTRLForSequenceClassification,
diff --git a/src/transformers/commands/add_new_model_like.py b/src/transformers/commands/add_new_model_like.py
index e443a235c42e..3ba5d71099de 100644
--- a/src/transformers/commands/add_new_model_like.py
+++ b/src/transformers/commands/add_new_model_like.py
@@ -1189,6 +1189,16 @@ def create_new_model_like(
if "tokenization" not in str(f) and "processor" not in str(f) and "feature_extraction" not in str(f)
]
+ def disable_fx_test(filename: Path) -> bool:
+ with open(filename) as fp:
+ content = fp.read()
+ new_content = re.sub(r"fx_compatible\s*=\s*True", "fx_compatible = False", content)
+ with open(filename, "w") as fp:
+ fp.write(new_content)
+ return content != new_content
+
+ disabled_fx_test = False
+
for test_file in files_to_adapt:
new_test_file_name = test_file.name.replace(
old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
@@ -1201,6 +1211,13 @@ def create_new_model_like(
dest_file=dest_file,
add_copied_from=False,
)
+ disabled_fx_test = disabled_fx_test | disable_fx_test(dest_file)
+
+ if disabled_fx_test:
+ print(
+ "The tests for symbolic tracing with torch.fx were disabled, you can add those once symbolic tracing works "
+ "for your new model."
+ )
# 4. Add model to auto classes
add_model_to_auto_classes(old_model_patterns, new_model_patterns, model_classes)
diff --git a/src/transformers/file_utils.py b/src/transformers/file_utils.py
index 1a4387d848f2..abc26cada9bd 100644
--- a/src/transformers/file_utils.py
+++ b/src/transformers/file_utils.py
@@ -322,7 +322,7 @@
HUGGINGFACE_CO_PREFIX = HUGGINGFACE_CO_RESOLVE_ENDPOINT + "/{model_id}/resolve/{revision}/{filename}"
# This is the version of torch required to run torch.fx features and torch.onnx with dictionary inputs.
-TORCH_FX_REQUIRED_VERSION = version.parse("1.9")
+TORCH_FX_REQUIRED_VERSION = version.parse("1.10")
TORCH_ONNX_DICT_INPUTS_MINIMUM_VERSION = version.parse("1.8")
_is_offline_mode = True if os.environ.get("TRANSFORMERS_OFFLINE", "0").upper() in ENV_VARS_TRUE_VALUES else False
diff --git a/src/transformers/generation_utils.py b/src/transformers/generation_utils.py
index 90bc5e19b76f..537c7cdecc3d 100644
--- a/src/transformers/generation_utils.py
+++ b/src/transformers/generation_utils.py
@@ -48,6 +48,7 @@
StoppingCriteriaList,
validate_stopping_criteria,
)
+from .pytorch_utils import torch_int_div
from .utils import logging
@@ -2024,7 +2025,7 @@ def beam_search(
next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
)
- next_indices = (next_tokens / vocab_size).long()
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2345,7 +2346,7 @@ def beam_sample(
next_token_scores, _indices = torch.sort(next_token_scores, descending=True, dim=1)
next_tokens = torch.gather(next_tokens, -1, _indices)
- next_indices = next_tokens // vocab_size
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2678,7 +2679,7 @@ def group_beam_search(
next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True
)
- next_indices = next_tokens // vocab_size
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2706,7 +2707,7 @@ def group_beam_search(
# (beam_idx // group_size) -> batch_idx
# (beam_idx % group_size) -> offset of idx inside the group
reordering_indices[batch_group_indices] = (
- num_beams * (beam_idx // group_size) + group_start_idx + (beam_idx % group_size)
+ num_beams * torch_int_div(beam_idx, group_size) + group_start_idx + (beam_idx % group_size)
)
# Store scores, attentions and hidden_states when required
diff --git a/src/transformers/modeling_flax_pytorch_utils.py b/src/transformers/modeling_flax_pytorch_utils.py
index 2cc9575b5580..03e85875d0bc 100644
--- a/src/transformers/modeling_flax_pytorch_utils.py
+++ b/src/transformers/modeling_flax_pytorch_utils.py
@@ -82,19 +82,13 @@ def is_key_or_prefix_key_in_dict(key: Tuple[str]) -> bool:
if pt_tuple_key[-1] == "weight" and is_key_or_prefix_key_in_dict(renamed_pt_tuple_key):
return renamed_pt_tuple_key, pt_tensor
- # conv layer
+ # 2D conv layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 4 and not is_key_or_prefix_key_in_dict(pt_tuple_key):
pt_tensor = pt_tensor.transpose(2, 3, 1, 0)
return renamed_pt_tuple_key, pt_tensor
- # conv1d layer
- renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
- if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 3 and not is_key_or_prefix_key_in_dict(pt_tuple_key):
- pt_tensor = pt_tensor.transpose(2, 1, 0)
- return renamed_pt_tuple_key, pt_tensor
-
- # linear layer
+ # linear and 1D conv layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight" and not is_key_or_prefix_key_in_dict(pt_tuple_key):
pt_tensor = pt_tensor.T
diff --git a/src/transformers/modeling_outputs.py b/src/transformers/modeling_outputs.py
index c7f4a27fb38c..b0f3e01861ff 100644
--- a/src/transformers/modeling_outputs.py
+++ b/src/transformers/modeling_outputs.py
@@ -812,3 +812,32 @@ class Seq2SeqQuestionAnsweringModelOutput(ModelOutput):
encoder_last_hidden_state: Optional[torch.FloatTensor] = None
encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class SemanticSegmentationModelOutput(ModelOutput):
+ """
+ Base class for outputs of semantic segmentation models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels, height, width)`):
+ Classification scores for each pixel.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, patch_size, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 60477b18b54a..4845ff074306 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -23,7 +23,6 @@
from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
import torch
-from packaging import version
from torch import Tensor, device, nn
from torch.nn import CrossEntropyLoss
@@ -248,6 +247,27 @@ def invert_attention_mask(self, encoder_attention_mask: Tensor) -> Tensor:
return encoder_extended_attention_mask
+ def create_extended_attention_mask_for_decoder(self, input_shape, attention_mask, device):
+ batch_size, seq_length = input_shape
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones((batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ return extended_attention_mask
+
def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
@@ -272,26 +292,9 @@ def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
- batch_size, seq_length = input_shape
- seq_ids = torch.arange(seq_length, device=device)
- causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
- # in case past_key_values are used we need to add a prefix ones mask to the causal mask
- # causal and attention masks must have same type with pytorch version < 1.3
- causal_mask = causal_mask.to(attention_mask.dtype)
-
- if causal_mask.shape[1] < attention_mask.shape[1]:
- prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
- causal_mask = torch.cat(
- [
- torch.ones(
- (batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype
- ),
- causal_mask,
- ],
- axis=-1,
- )
-
- extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ extended_attention_mask = self.create_extended_attention_mask_for_decoder(
+ input_shape, attention_mask, device
+ )
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
@@ -1862,7 +1865,7 @@ def __init__(self, nf, nx):
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
- x = x.view(*size_out)
+ x = x.view(size_out)
return x
@@ -2463,13 +2466,3 @@ def forward(self, hidden_states):
return torch.cat(output_chunks, dim=chunk_dim)
return forward_fn(*input_tensors)
-
-
-def torch_int_div(tensor1, tensor2):
- """
- A function that performs integer division across different versions of PyTorch.
- """
- if version.parse(torch.__version__) < version.parse("1.8.0"):
- return tensor1 // tensor2
- else:
- return torch.div(tensor1, tensor2, rounding_mode="floor")
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index baf2b11ab714..d6cf69197ea9 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -37,6 +37,7 @@
canine,
clip,
convbert,
+ convnext,
cpm,
ctrl,
deberta,
diff --git a/src/transformers/models/albert/modeling_albert.py b/src/transformers/models/albert/modeling_albert.py
index 6f443fb4f8bc..a54a3874adf2 100755
--- a/src/transformers/models/albert/modeling_albert.py
+++ b/src/transformers/models/albert/modeling_albert.py
@@ -293,7 +293,7 @@ def __init__(self, config):
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention.transpose_for_scores
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def prune_heads(self, heads):
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 89d1c73b77d2..7798a51a8d1a 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -43,6 +43,7 @@
"MODEL_FOR_OBJECT_DETECTION_MAPPING",
"MODEL_FOR_PRETRAINING_MAPPING",
"MODEL_FOR_QUESTION_ANSWERING_MAPPING",
+ "MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
"MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
"MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
@@ -65,6 +66,7 @@
"AutoModelForObjectDetection",
"AutoModelForPreTraining",
"AutoModelForQuestionAnswering",
+ "AutoModelForSemanticSegmentation",
"AutoModelForSeq2SeqLM",
"AutoModelForSequenceClassification",
"AutoModelForSpeechSeq2Seq",
@@ -155,6 +157,7 @@
MODEL_FOR_OBJECT_DETECTION_MAPPING,
MODEL_FOR_PRETRAINING_MAPPING,
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING,
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
@@ -177,6 +180,7 @@
AutoModelForObjectDetection,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
+ AutoModelForSemanticSegmentation,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForSpeechSeq2Seq,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index ebd83c1be11c..1d94e90de058 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("convnext", "ConvNextConfig"),
("yoso", "YosoConfig"),
("swin", "SwinConfig"),
("vilt", "ViltConfig"),
@@ -124,6 +125,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here
+ ("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -205,6 +207,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("convnext", "ConvNext"),
("yoso", "YOSO"),
("swin", "Swin"),
("vilt", "ViLT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 4667178c787b..a146c611fb96 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -47,6 +47,7 @@
("swin", "ViTFeatureExtractor"),
("vit_mae", "ViTFeatureExtractor"),
("segformer", "SegformerFeatureExtractor"),
+ ("convnext", "ConvNextFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 94909cfde50b..80190a9d2f96 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("convnext", "ConvNextModel"),
("yoso", "YosoModel"),
("swin", "SwinModel"),
("vilt", "ViltModel"),
@@ -273,16 +274,26 @@
),
),
("swin", "SwinForImageClassification"),
+ ("convnext", "ConvNextForImageClassification"),
]
)
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES = OrderedDict(
[
+ # Do not add new models here, this class will be deprecated in the future.
# Model for Image Segmentation mapping
("detr", "DetrForSegmentation"),
]
)
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Semantic Segmentation mapping
+ ("beit", "BeitForSemanticSegmentation"),
+ ("segformer", "SegformerForSemanticSegmentation"),
+ ]
+)
+
MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("vision-encoder-decoder", "VisionEncoderDecoderModel"),
@@ -603,6 +614,9 @@
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES
)
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES
+)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_LM_MAPPING_NAMES)
MODEL_FOR_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES)
@@ -745,6 +759,15 @@ class AutoModelForImageSegmentation(_BaseAutoModelClass):
AutoModelForImageSegmentation = auto_class_update(AutoModelForImageSegmentation, head_doc="image segmentation")
+class AutoModelForSemanticSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING
+
+
+AutoModelForSemanticSegmentation = auto_class_update(
+ AutoModelForSemanticSegmentation, head_doc="semantic segmentation"
+)
+
+
class AutoModelForObjectDetection(_BaseAutoModelClass):
_model_mapping = MODEL_FOR_OBJECT_DETECTION_MAPPING
diff --git a/src/transformers/models/bart/modeling_bart.py b/src/transformers/models/bart/modeling_bart.py
index 381204cf2d30..70edf96cd2e3 100755
--- a/src/transformers/models/bart/modeling_bart.py
+++ b/src/transformers/models/bart/modeling_bart.py
@@ -1318,6 +1318,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/beit/configuration_beit.py b/src/transformers/models/beit/configuration_beit.py
index b668a2ed8c34..ebc46ee313ad 100644
--- a/src/transformers/models/beit/configuration_beit.py
+++ b/src/transformers/models/beit/configuration_beit.py
@@ -93,6 +93,10 @@ class BeitConfig(PretrainedConfig):
Whether to concatenate the output of the auxiliary head with the input before the classification layer.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
+ legacy_output (`bool`, *optional*, defaults to `False`):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`)
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Example:
@@ -141,6 +145,7 @@ def __init__(
auxiliary_num_convs=1,
auxiliary_concat_input=False,
semantic_loss_ignore_index=255,
+ legacy_output=False,
**kwargs
):
super().__init__(**kwargs)
@@ -176,3 +181,4 @@ def __init__(
self.auxiliary_num_convs = auxiliary_num_convs
self.auxiliary_concat_input = auxiliary_concat_input
self.semantic_loss_ignore_index = semantic_loss_ignore_index
+ self.legacy_output = legacy_output
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index 295d91f7e2ae..d42e4abc8edf 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -17,6 +17,7 @@
import collections.abc
import math
+import warnings
from dataclasses import dataclass
import torch
@@ -31,7 +32,13 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPooling,
+ MaskedLMOutput,
+ SemanticSegmentationModelOutput,
+ SequenceClassifierOutput,
+)
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_beit import BeitConfig
@@ -1114,11 +1121,8 @@ def __init__(self, config):
# Initialize weights and apply final processing
self.post_init()
- def compute_loss(self, logits, auxiliary_logits, labels):
+ def compute_loss(self, upsampled_logits, auxiliary_logits, labels):
# upsample logits to the images' original size
- upsampled_logits = nn.functional.interpolate(
- logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
- )
if auxiliary_logits is not None:
upsampled_auxiliary_logits = nn.functional.interpolate(
auxiliary_logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
@@ -1132,7 +1136,7 @@ def compute_loss(self, logits, auxiliary_logits, labels):
return loss
@add_start_docstrings_to_model_forward(BEIT_INPUTS_DOCSTRING)
- @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ @replace_return_docstrings(output_type=SemanticSegmentationModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values=None,
@@ -1141,11 +1145,17 @@ def forward(
output_attentions=None,
output_hidden_states=None,
return_dict=None,
+ legacy_output=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Ground truth semantic segmentation maps for computing the loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels > 1`, a classification loss is computed (Cross-Entropy).
+ legacy_output (`bool`, *optional*):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`). Will default
+ to `self.config.legacy_output`.
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Returns:
@@ -1164,13 +1174,21 @@ def forward(
>>> inputs = feature_extractor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
- >>> # logits are of shape (batch_size, num_labels, height/4, width/4)
+ >>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ legacy_output = legacy_output if legacy_output is not None else self.config.legacy_output
+ if not legacy_output:
+ warnings.warn(
+ "The output of this model has changed in v4.17.0 and the logits now have the same size as the inputs. "
+ "You can activate the previous behavior by passing `legacy_output=True` to this call or the "
+ "configuration of this model (only until v5, then that argument will be removed).",
+ FutureWarning,
+ )
outputs = self.beit(
pixel_values,
@@ -1197,6 +1215,11 @@ def forward(
features[i] = ops[i](features[i])
logits = self.decode_head(features)
+
+ upsampled_logits = nn.functional.interpolate(
+ logits, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False
+ )
+
auxiliary_logits = None
if self.auxiliary_head is not None:
auxiliary_logits = self.auxiliary_head(features)
@@ -1206,18 +1229,26 @@ def forward(
if self.config.num_labels == 1:
raise ValueError("The number of labels should be greater than one")
else:
- loss = self.compute_loss(logits, auxiliary_logits, labels)
+ loss = self.compute_loss(upsampled_logits, auxiliary_logits, labels)
if not return_dict:
if output_hidden_states:
- output = (logits,) + outputs[2:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[2:]
else:
- output = (logits,) + outputs[3:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[3:]
return ((loss,) + output) if loss is not None else output
- return SequenceClassifierOutput(
- loss=loss,
- logits=logits,
- hidden_states=outputs.hidden_states if output_hidden_states else None,
- attentions=outputs.attentions,
- )
+ if legacy_output:
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
+ else:
+ return SemanticSegmentationModelOutput(
+ loss=loss,
+ logits=upsampled_logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/bert/modeling_bert.py b/src/transformers/models/bert/modeling_bert.py
index 23dfbcee63a9..26c629f78f16 100755
--- a/src/transformers/models/bert/modeling_bert.py
+++ b/src/transformers/models/bert/modeling_bert.py
@@ -252,7 +252,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -341,7 +341,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
index c4db1b8bec5a..aa961e0f599b 100755
--- a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
@@ -2513,6 +2513,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/blenderbot/modeling_blenderbot.py b/src/transformers/models/blenderbot/modeling_blenderbot.py
index df098dd6e195..7751a74f9658 100755
--- a/src/transformers/models/blenderbot/modeling_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_blenderbot.py
@@ -1287,6 +1287,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
index 5875a827fab9..a22c4d0ce6cc 100755
--- a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
@@ -1258,6 +1258,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/convnext/__init__.py b/src/transformers/models/convnext/__init__.py
new file mode 100644
index 000000000000..cdc064d3c994
--- /dev/null
+++ b/src/transformers/models/convnext/__init__.py
@@ -0,0 +1,58 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_convnext": ["CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvNextConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_convnext"] = ["ConvNextFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_convnext"] = [
+ "CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ConvNextForImageClassification",
+ "ConvNextModel",
+ "ConvNextPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_convnext import CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvNextConfig
+
+ if is_vision_available():
+ from .feature_extraction_convnext import ConvNextFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_convnext import (
+ CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ConvNextForImageClassification,
+ ConvNextModel,
+ ConvNextPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure)
diff --git a/src/transformers/models/convnext/configuration_convnext.py b/src/transformers/models/convnext/configuration_convnext.py
new file mode 100644
index 000000000000..8d99c657cc63
--- /dev/null
+++ b/src/transformers/models/convnext/configuration_convnext.py
@@ -0,0 +1,101 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConvNeXT model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/convnext-tiny-224": "https://huggingface.co/facebook/convnext-tiny-224/resolve/main/config.json",
+ # See all ConvNeXT models at https://huggingface.co/models?filter=convnext
+}
+
+
+class ConvNextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ConvNextModel`]. It is used to instantiate an
+ ConvNeXT model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the ConvNeXT
+ [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ patch_size (`int`, optional, defaults to 4):
+ Patch size to use in the patch embedding layer.
+ num_stages (`int`, optional, defaults to 4):
+ The number of stages in the model.
+ hidden_sizes (`List[int]`, *optional*, defaults to [96, 192, 384, 768]):
+ Dimensionality (hidden size) at each stage.
+ depths (`List[int]`, *optional*, defaults to [3, 3, 9, 3]):
+ Depth (number of blocks) for each stage.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in each block. If string, `"gelu"`, `"relu"`,
+ `"selu"` and `"gelu_new"` are supported.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ layer_scale_init_value (`float`, *optional*, defaults to 1e-6):
+ The initial value for the layer scale.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ The drop rate for stochastic depth.
+
+ Example:
+ ```python
+ >>> from transformers import ConvNextModel, ConvNextConfig
+
+ >>> # Initializing a ConvNext convnext-tiny-224 style configuration
+ >>> configuration = ConvNextConfig()
+ >>> # Initializing a model from the convnext-tiny-224 style configuration
+ >>> model = ConvNextModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "convnext"
+
+ def __init__(
+ self,
+ num_channels=3,
+ patch_size=4,
+ num_stages=4,
+ hidden_sizes=None,
+ depths=None,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ is_encoder_decoder=False,
+ layer_scale_init_value=1e-6,
+ drop_path_rate=0.0,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.num_stages = num_stages
+ self.hidden_sizes = [96, 192, 384, 768] if hidden_sizes is None else hidden_sizes
+ self.depths = [3, 3, 9, 3] if depths is None else depths
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.layer_scale_init_value = layer_scale_init_value
+ self.drop_path_rate = drop_path_rate
diff --git a/src/transformers/models/convnext/convert_convnext_to_pytorch.py b/src/transformers/models/convnext/convert_convnext_to_pytorch.py
new file mode 100644
index 000000000000..b58f5b81fd09
--- /dev/null
+++ b/src/transformers/models/convnext/convert_convnext_to_pytorch.py
@@ -0,0 +1,243 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ConvNext checkpoints from the original repository.
+
+URL: https://github.com/facebookresearch/ConvNeXt"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import cached_download, hf_hub_url
+from transformers import ConvNextConfig, ConvNextFeatureExtractor, ConvNextForImageClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_convnext_config(checkpoint_url):
+ config = ConvNextConfig()
+
+ if "tiny" in checkpoint_url:
+ depths = [3, 3, 9, 3]
+ hidden_sizes = [96, 192, 384, 768]
+ if "small" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [96, 192, 384, 768]
+ if "base" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [128, 256, 512, 1024]
+ if "large" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [192, 384, 768, 1536]
+ if "xlarge" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [256, 512, 1024, 2048]
+
+ if "1k" in checkpoint_url:
+ num_labels = 1000
+ filename = "imagenet-1k-id2label.json"
+ expected_shape = (1, 1000)
+ else:
+ num_labels = 21841
+ filename = "imagenet-22k-id2label.json"
+ expected_shape = (1, 21841)
+
+ repo_id = "datasets/huggingface/label-files"
+ config.num_labels = num_labels
+ id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename)), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ if "1k" not in checkpoint_url:
+ # this dataset contains 21843 labels but the model only has 21841
+ # we delete the classes as mentioned in https://github.com/google-research/big_transfer/issues/18
+ del id2label[9205]
+ del id2label[15027]
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+ config.hidden_sizes = hidden_sizes
+ config.depths = depths
+
+ return config, expected_shape
+
+
+def rename_key(name):
+ if "downsample_layers.0.0" in name:
+ name = name.replace("downsample_layers.0.0", "embeddings.patch_embeddings")
+ if "downsample_layers.0.1" in name:
+ name = name.replace("downsample_layers.0.1", "embeddings.norm") # we rename to layernorm later on
+ if "downsample_layers.1.0" in name:
+ name = name.replace("downsample_layers.1.0", "stages.1.downsampling_layer.0")
+ if "downsample_layers.1.1" in name:
+ name = name.replace("downsample_layers.1.1", "stages.1.downsampling_layer.1")
+ if "downsample_layers.2.0" in name:
+ name = name.replace("downsample_layers.2.0", "stages.2.downsampling_layer.0")
+ if "downsample_layers.2.1" in name:
+ name = name.replace("downsample_layers.2.1", "stages.2.downsampling_layer.1")
+ if "downsample_layers.3.0" in name:
+ name = name.replace("downsample_layers.3.0", "stages.3.downsampling_layer.0")
+ if "downsample_layers.3.1" in name:
+ name = name.replace("downsample_layers.3.1", "stages.3.downsampling_layer.1")
+ if "stages" in name and "downsampling_layer" not in name:
+ # stages.0.0. for instance should be renamed to stages.0.layers.0.
+ name = name[: len("stages.0")] + ".layers" + name[len("stages.0") :]
+ if "stages" in name:
+ name = name.replace("stages", "encoder.stages")
+ if "norm" in name:
+ name = name.replace("norm", "layernorm")
+ if "gamma" in name:
+ name = name.replace("gamma", "layer_scale_parameter")
+ if "head" in name:
+ name = name.replace("head", "classifier")
+
+ return name
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@torch.no_grad()
+def convert_convnext_checkpoint(checkpoint_url, pytorch_dump_folder_path):
+ """
+ Copy/paste/tweak model's weights to our ConvNext structure.
+ """
+
+ # define ConvNext configuration based on URL
+ config, expected_shape = get_convnext_config(checkpoint_url)
+ # load original state_dict from URL
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url)["model"]
+ # rename keys
+ for key in state_dict.copy().keys():
+ val = state_dict.pop(key)
+ state_dict[rename_key(key)] = val
+ # add prefix to all keys expect classifier head
+ for key in state_dict.copy().keys():
+ val = state_dict.pop(key)
+ if not key.startswith("classifier"):
+ key = "convnext." + key
+ state_dict[key] = val
+
+ # load HuggingFace model
+ model = ConvNextForImageClassification(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # Check outputs on an image, prepared by ConvNextFeatureExtractor
+ size = 224 if "224" in checkpoint_url else 384
+ feature_extractor = ConvNextFeatureExtractor(size=size)
+ pixel_values = feature_extractor(images=prepare_img(), return_tensors="pt").pixel_values
+
+ logits = model(pixel_values).logits
+
+ # note: the logits below were obtained without center cropping
+ if checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.1210, -0.6605, 0.1918])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.4473, -0.1847, -0.6365])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth":
+ expected_logits = torch.tensor([0.4525, 0.7539, 0.0308])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_384.pth":
+ expected_logits = torch.tensor([0.3561, 0.6350, -0.0384])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth":
+ expected_logits = torch.tensor([0.4174, -0.0989, 0.1489])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_384.pth":
+ expected_logits = torch.tensor([0.2513, -0.1349, -0.1613])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth":
+ expected_logits = torch.tensor([1.2980, 0.3631, -0.1198])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth":
+ expected_logits = torch.tensor([1.2963, 0.1227, 0.1723])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth":
+ expected_logits = torch.tensor([1.7956, 0.8390, 0.2820])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth":
+ expected_logits = torch.tensor([-0.2822, -0.0502, -0.0878])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_384.pth":
+ expected_logits = torch.tensor([-0.5672, -0.0730, -0.4348])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_224.pth":
+ expected_logits = torch.tensor([0.2681, 0.2365, 0.6246])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_384.pth":
+ expected_logits = torch.tensor([-0.2642, 0.3931, 0.5116])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.6677, -0.1873, -0.8379])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_384_ema.pth":
+ expected_logits = torch.tensor([-0.7749, -0.2967, -0.6444])
+ else:
+ raise ValueError(f"Unknown URL: {checkpoint_url}")
+
+ assert torch.allclose(logits[0, :3], expected_logits, atol=1e-3)
+ assert logits.shape == expected_shape
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ print("Pushing model to the hub...")
+ model_name = "convnext"
+ if "tiny" in checkpoint_url:
+ model_name += "-tiny"
+ elif "small" in checkpoint_url:
+ model_name += "-small"
+ elif "base" in checkpoint_url:
+ model_name += "-base"
+ elif "xlarge" in checkpoint_url:
+ model_name += "-xlarge"
+ elif "large" in checkpoint_url:
+ model_name += "-large"
+ if "224" in checkpoint_url:
+ model_name += "-224"
+ elif "384" in checkpoint_url:
+ model_name += "-384"
+ if "22k" in checkpoint_url and "1k" not in checkpoint_url:
+ model_name += "-22k"
+ if "22k" in checkpoint_url and "1k" in checkpoint_url:
+ model_name += "-22k-1k"
+
+ model.push_to_hub(
+ repo_path_or_name=Path(pytorch_dump_folder_path, model_name),
+ organization="nielsr",
+ commit_message="Add model",
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth",
+ type=str,
+ help="URL of the original ConvNeXT checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the output PyTorch model directory.",
+ )
+
+ args = parser.parse_args()
+ convert_convnext_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path)
diff --git a/src/transformers/models/convnext/feature_extraction_convnext.py b/src/transformers/models/convnext/feature_extraction_convnext.py
new file mode 100644
index 000000000000..860bda96b6d2
--- /dev/null
+++ b/src/transformers/models/convnext/feature_extraction_convnext.py
@@ -0,0 +1,168 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for ConvNeXT."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...file_utils import TensorType
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class ConvNextFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a ConvNeXT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize (and optionally center crop) the input to a certain `size`.
+ size (`int`, *optional*, defaults to 224):
+ Resize the input to the given size. If 384 or larger, the image is resized to (`size`, `size`). Else, the
+ smaller edge of the image will be matched to int(`size`/ `crop_pct`), after which the image is cropped to
+ `size`. Only has an effect if `do_resize` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ crop_pct (`float`, *optional*):
+ The percentage of the image to crop. If `None`, then a cropping percentage of 224 / 256 is used. Only has
+ an effect if `do_resize` is set to `True` and `size` < 384.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BICUBIC,
+ crop_pct=None,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing and optional center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ if self.size >= 384:
+ # warping (no cropping) when evaluated at 384 or larger
+ images = [self.resize(image=image, size=self.size, resample=self.resample) for image in images]
+ else:
+ if self.crop_pct is None:
+ self.crop_pct = 224 / 256
+ size = int(self.size / self.crop_pct)
+ # to maintain same ratio w.r.t. 224 images
+ images = [
+ self.resize(image=image, size=size, default_to_square=False, resample=self.resample)
+ for image in images
+ ]
+ images = [self.center_crop(image=image, size=self.size) for image in images]
+
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/convnext/modeling_convnext.py b/src/transformers/models/convnext/modeling_convnext.py
new file mode 100755
index 000000000000..f66c320255bc
--- /dev/null
+++ b/src/transformers/models/convnext/modeling_convnext.py
@@ -0,0 +1,498 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch ConvNext model."""
+
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import logging
+from .configuration_convnext import ConvNextConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ConvNextConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "ConvNextFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "facebook/convnext-tiny-224"
+_EXPECTED_OUTPUT_SHAPE = [1, 768, 7, 7]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "facebook/convnext-tiny-224"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "'tabby, tabby cat'"
+
+CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/convnext-tiny-224",
+ # See all ConvNext models at https://huggingface.co/models?filter=convnext
+]
+
+
+@dataclass
+class ConvNextEncoderOutput(ModelOutput):
+ """
+ Class for [`ConvNextEncoder`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Last hidden states (final feature map) of the last stage of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class ConvNextModelOutput(ModelOutput):
+ """
+ Class for [`ConvNextModel`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Last hidden states (final feature map) of the last stage of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, config.dim[-1])`):
+ Global average pooling of the last feature map followed by a layernorm.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class ConvNextClassifierOutput(ModelOutput):
+ """
+ Class for [`ConvNextForImageClassification`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Stochastic depth implementation
+# Taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+def drop_path(x, drop_prob: float = 0.0, training: bool = False):
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the
+ DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop
+ Connect' is a different form of dropout in a separate paper... See discussion:
+ https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and
+ argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class ConvNextDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob=None):
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class ConvNextLayerNorm(nn.Module):
+ r"""LayerNorm that supports two data formats: channels_last (default) or channels_first.
+ The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch_size, height,
+ width, channels) while channels_first corresponds to inputs with shape (batch_size, channels, height, width).
+ """
+
+ def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(normalized_shape))
+ self.bias = nn.Parameter(torch.zeros(normalized_shape))
+ self.eps = eps
+ self.data_format = data_format
+ if self.data_format not in ["channels_last", "channels_first"]:
+ raise NotImplementedError(f"Unsupported data format: {self.data_format}")
+ self.normalized_shape = (normalized_shape,)
+
+ def forward(self, x):
+ if self.data_format == "channels_last":
+ x = torch.nn.functional.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
+ elif self.data_format == "channels_first":
+ u = x.mean(1, keepdim=True)
+ s = (x - u).pow(2).mean(1, keepdim=True)
+ x = (x - u) / torch.sqrt(s + self.eps)
+ x = self.weight[:, None, None] * x + self.bias[:, None, None]
+ return x
+
+
+class ConvNextEmbeddings(nn.Module):
+ """This class is comparable to (and inspired by) the SwinEmbeddings class
+ found in src/transformers/models/swin/modeling_swin.py.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.patch_embeddings = nn.Conv2d(
+ config.num_channels, config.hidden_sizes[0], kernel_size=config.patch_size, stride=config.patch_size
+ )
+ self.layernorm = ConvNextLayerNorm(config.hidden_sizes[0], eps=1e-6, data_format="channels_first")
+
+ def forward(self, pixel_values):
+ embeddings = self.patch_embeddings(pixel_values)
+ embeddings = self.layernorm(embeddings)
+ return embeddings
+
+
+class ConvNextLayer(nn.Module):
+ """This corresponds to the `Block` class in the original implementation.
+
+ There are two equivalent implementations: [DwConv, LayerNorm (channels_first), Conv, GELU,1x1 Conv]; all in (N, C,
+ H, W) (2) [DwConv, Permute to (N, H, W, C), LayerNorm (channels_last), Linear, GELU, Linear]; Permute back
+
+ The authors used (2) as they find it slightly faster in PyTorch.
+
+ Args:
+ config ([`ConvNextConfig`]): Model configuration class.
+ dim (`int`): Number of input channels.
+ drop_path (`float`): Stochastic depth rate. Default: 0.0.
+ """
+
+ def __init__(self, config, dim, drop_path=0):
+ super().__init__()
+ self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
+ self.layernorm = ConvNextLayerNorm(dim, eps=1e-6)
+ self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
+ self.act = ACT2FN[config.hidden_act]
+ self.pwconv2 = nn.Linear(4 * dim, dim)
+ self.layer_scale_parameter = (
+ nn.Parameter(config.layer_scale_init_value * torch.ones((dim)), requires_grad=True)
+ if config.layer_scale_init_value > 0
+ else None
+ )
+ self.drop_path = ConvNextDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+
+ def forward(self, hidden_states):
+ input = hidden_states
+ x = self.dwconv(hidden_states)
+ x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
+ x = self.layernorm(x)
+ x = self.pwconv1(x)
+ x = self.act(x)
+ x = self.pwconv2(x)
+ if self.layer_scale_parameter is not None:
+ x = self.layer_scale_parameter * x
+ x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
+
+ x = input + self.drop_path(x)
+ return x
+
+
+class ConvNextStage(nn.Module):
+ """ConvNeXT stage, consisting of an optional downsampling layer + multiple residual blocks.
+
+ Args:
+ config ([`ConvNextConfig`]): Model configuration class.
+ in_channels (`int`): Number of input channels.
+ out_channels (`int`): Number of output channels.
+ depth (`int`): Number of residual blocks.
+ drop_path_rates(`List[float]`): Stochastic depth rates for each layer.
+ """
+
+ def __init__(self, config, in_channels, out_channels, kernel_size=2, stride=2, depth=2, drop_path_rates=None):
+ super().__init__()
+
+ if in_channels != out_channels or stride > 1:
+ self.downsampling_layer = nn.Sequential(
+ ConvNextLayerNorm(in_channels, eps=1e-6, data_format="channels_first"),
+ nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride),
+ )
+ else:
+ self.downsampling_layer = nn.Identity()
+ drop_path_rates = drop_path_rates or [0.0] * depth
+ self.layers = nn.Sequential(
+ *[ConvNextLayer(config, dim=out_channels, drop_path=drop_path_rates[j]) for j in range(depth)]
+ )
+
+ def forward(self, hidden_states):
+ hidden_states = self.downsampling_layer(hidden_states)
+ hidden_states = self.layers(hidden_states)
+ return hidden_states
+
+
+class ConvNextEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.stages = nn.ModuleList()
+ drop_path_rates = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+ cur = 0
+ prev_chs = config.hidden_sizes[0]
+ for i in range(config.num_stages):
+ out_chs = config.hidden_sizes[i]
+ stage = ConvNextStage(
+ config,
+ in_channels=prev_chs,
+ out_channels=out_chs,
+ stride=2 if i > 0 else 1,
+ depth=config.depths[i],
+ drop_path_rates=drop_path_rates[cur],
+ )
+ self.stages.append(stage)
+ cur += config.depths[i]
+ prev_chs = out_chs
+
+ def forward(self, hidden_states, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ for i, layer_module in enumerate(self.stages):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ hidden_states = layer_module(hidden_states)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states] if v is not None)
+
+ return ConvNextEncoderOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ )
+
+
+class ConvNextPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ConvNextConfig
+ base_model_prefix = "convnext"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, ConvNextModel):
+ module.gradient_checkpointing = value
+
+
+CONVNEXT_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ConvNextConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+CONVNEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare ConvNext model outputting raw features without any specific head on top.",
+ CONVNEXT_START_DOCSTRING,
+)
+class ConvNextModel(ConvNextPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = ConvNextEmbeddings(config)
+ self.encoder = ConvNextEncoder(config)
+
+ # final layernorm layer
+ self.layernorm = nn.LayerNorm(config.hidden_sizes[-1], eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CONVNEXT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=ConvNextModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(self, pixel_values=None, output_hidden_states=None, return_dict=None):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embedding_output = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+
+ # global average pooling, (N, C, H, W) -> (N, C)
+ pooled_output = self.layernorm(last_hidden_state.mean([-2, -1]))
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return ConvNextModelOutput(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ ConvNext Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for
+ ImageNet.
+ """,
+ CONVNEXT_START_DOCSTRING,
+)
+class ConvNextForImageClassification(ConvNextPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.convnext = ConvNextModel(config)
+
+ # Classifier head
+ self.classifier = (
+ nn.Linear(config.hidden_sizes[-1], config.num_labels) if config.num_labels > 0 else nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CONVNEXT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=ConvNextClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(self, pixel_values=None, labels=None, output_hidden_states=None, return_dict=None):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.convnext(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ pooled_output = outputs.pooler_output if return_dict else outputs[1]
+
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ConvNextClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ )
diff --git a/src/transformers/models/electra/__init__.py b/src/transformers/models/electra/__init__.py
index 1aad02a41277..a8f1ec5db72b 100644
--- a/src/transformers/models/electra/__init__.py
+++ b/src/transformers/models/electra/__init__.py
@@ -22,7 +22,7 @@
_import_structure = {
- "configuration_electra": ["ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP", "ElectraConfig"],
+ "configuration_electra": ["ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP", "ElectraConfig", "ElectraOnnxConfig"],
"tokenization_electra": ["ElectraTokenizer"],
}
@@ -71,7 +71,7 @@
if TYPE_CHECKING:
- from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
+ from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig, ElectraOnnxConfig
from .tokenization_electra import ElectraTokenizer
if is_tokenizers_available():
diff --git a/src/transformers/models/electra/configuration_electra.py b/src/transformers/models/electra/configuration_electra.py
index 43b3b3255dad..9b4525d3dce7 100644
--- a/src/transformers/models/electra/configuration_electra.py
+++ b/src/transformers/models/electra/configuration_electra.py
@@ -15,7 +15,11 @@
# limitations under the License.
""" ELECTRA model configuration"""
+from collections import OrderedDict
+from typing import Mapping
+
from ...configuration_utils import PretrainedConfig
+from ...onnx import OnnxConfig
from ...utils import logging
@@ -170,3 +174,15 @@ def __init__(
self.position_embedding_type = position_embedding_type
self.use_cache = use_cache
self.classifier_dropout = classifier_dropout
+
+
+class ElectraOnnxConfig(OnnxConfig):
+ @property
+ def inputs(self) -> Mapping[str, Mapping[int, str]]:
+ return OrderedDict(
+ [
+ ("input_ids", {0: "batch", 1: "sequence"}),
+ ("attention_mask", {0: "batch", 1: "sequence"}),
+ ("token_type_ids", {0: "batch", 1: "sequence"}),
+ ]
+ )
diff --git a/src/transformers/models/electra/modeling_electra.py b/src/transformers/models/electra/modeling_electra.py
index 054eff4be016..a61045f9c0aa 100644
--- a/src/transformers/models/electra/modeling_electra.py
+++ b/src/transformers/models/electra/modeling_electra.py
@@ -245,7 +245,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -334,7 +334,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/gpt2/modeling_gpt2.py b/src/transformers/models/gpt2/modeling_gpt2.py
index b1988d7edf8e..59df99e8ab91 100644
--- a/src/transformers/models/gpt2/modeling_gpt2.py
+++ b/src/transformers/models/gpt2/modeling_gpt2.py
@@ -193,7 +193,7 @@ def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
- attn_weights = attn_weights / (float(value.size(-1)) ** 0.5)
+ attn_weights = attn_weights / (value.size(-1) ** 0.5)
# Layer-wise attention scaling
if self.scale_attn_by_inverse_layer_idx:
@@ -281,7 +281,7 @@ def _split_heads(self, tensor, num_heads, attn_head_size):
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
@@ -915,7 +915,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -1410,7 +1410,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[range(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/gpt_neo/modeling_gpt_neo.py b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
index 7176cfa790b2..c516ca57a1e5 100755
--- a/src/transformers/models/gpt_neo/modeling_gpt_neo.py
+++ b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
@@ -173,7 +173,7 @@ def _split_heads(self, tensor, num_heads, attn_head_size):
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
@@ -637,7 +637,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -891,7 +891,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[torch.arange(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/gptj/modeling_flax_gptj.py b/src/transformers/models/gptj/modeling_flax_gptj.py
index 90672a132215..780dec88161b 100644
--- a/src/transformers/models/gptj/modeling_flax_gptj.py
+++ b/src/transformers/models/gptj/modeling_flax_gptj.py
@@ -668,8 +668,7 @@ def __call__(
@add_start_docstrings(
"""
- The GPTJ Model transformer with a language modeling head on top (linear layer with weights tied to the input
- embeddings).
+ The GPTJ Model transformer with a language modeling head on top.
""",
GPTJ_START_DOCSTRING,
)
diff --git a/src/transformers/models/gptj/modeling_gptj.py b/src/transformers/models/gptj/modeling_gptj.py
index 869014bee626..a74c74b8fc02 100755
--- a/src/transformers/models/gptj/modeling_gptj.py
+++ b/src/transformers/models/gptj/modeling_gptj.py
@@ -107,7 +107,7 @@ def _split_heads(self, tensor, num_attention_heads, attn_head_size, rotary):
Splits hidden dim into attn_head_size and num_attention_heads
"""
new_shape = tensor.size()[:-1] + (num_attention_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
if rotary:
return tensor
if len(tensor.shape) == 5:
@@ -665,7 +665,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -683,8 +683,7 @@ def custom_forward(*inputs):
@add_start_docstrings(
"""
- The GPT-J Model transformer with a language modeling head on top (linear layer with weights tied to the input
- embeddings).
+ The GPT-J Model transformer with a language modeling head on top.
""",
GPTJ_START_DOCSTRING,
)
@@ -945,7 +944,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[range(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/hubert/modeling_hubert.py b/src/transformers/models/hubert/modeling_hubert.py
index 76cd97ffed6d..928a742deedd 100755
--- a/src/transformers/models/hubert/modeling_hubert.py
+++ b/src/transformers/models/hubert/modeling_hubert.py
@@ -33,7 +33,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_hubert import HubertConfig
@@ -1096,7 +1097,10 @@ def __init__(self, config):
"instantiate the model as follows: `HubertForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1214,6 +1218,10 @@ class HubertForSequenceClassification(HubertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Hubert adapters (config.add_adapter=True)"
+ )
self.hubert = HubertModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/layoutlm/modeling_layoutlm.py b/src/transformers/models/layoutlm/modeling_layoutlm.py
index d595fc8b517a..bbdfeaac83fc 100644
--- a/src/transformers/models/layoutlm/modeling_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_layoutlm.py
@@ -160,7 +160,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -249,7 +249,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/led/modeling_led.py b/src/transformers/models/led/modeling_led.py
index 8054b9ee6d33..e775fd35c933 100755
--- a/src/transformers/models/led/modeling_led.py
+++ b/src/transformers/models/led/modeling_led.py
@@ -2366,6 +2366,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/led/modeling_tf_led.py b/src/transformers/models/led/modeling_tf_led.py
index 38a31e0ca8bd..f273148ac914 100644
--- a/src/transformers/models/led/modeling_tf_led.py
+++ b/src/transformers/models/led/modeling_tf_led.py
@@ -29,7 +29,7 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_tf_outputs import TFBaseModelOutputWithPast
+from ...modeling_tf_outputs import TFBaseModelOutputWithPastAndCrossAttentions
# Public API
from ...modeling_tf_utils import (
@@ -1220,7 +1220,7 @@ def call(
encoder_layer_head_mask: Optional[tf.Tensor] = None,
past_key_value: Optional[Tuple[tf.Tensor]] = None,
training=False,
- ) -> Tuple[tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
+ ) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(seq_len, batch, embed_dim)*
@@ -1254,12 +1254,13 @@ def call(
# Cross-Attention Block
cross_attn_present_key_value = None
+ cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
- hidden_states, _, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
@@ -1285,6 +1286,7 @@ def call(
return (
hidden_states,
self_attn_weights,
+ cross_attn_weights,
present_key_value,
)
@@ -1808,6 +1810,14 @@ def call(
# unpad `hidden_states` because the calling function is expecting a length == input_ids.size(1)
hidden_states = self.compute_hidden_states(hidden_states, padding_len)
+ # undo padding
+ if inputs["output_attentions"]:
+ all_attentions = (
+ tuple([state[:, :, :-padding_len, :] for state in all_attentions])
+ if padding_len > 0
+ else all_attentions
+ )
+
if inputs["output_hidden_states"]:
encoder_states = encoder_states + (hidden_states,)
@@ -2038,6 +2048,7 @@ def call(
# decoder layers
all_hidden_states = ()
all_self_attns = ()
+ all_cross_attentions = ()
present_key_values = ()
# check if head_mask has a correct number of layers specified if desired
@@ -2059,7 +2070,7 @@ def call(
past_key_value = inputs["past_key_values"][idx] if inputs["past_key_values"] is not None else None
- hidden_states, layer_self_attn, present_key_value = decoder_layer(
+ hidden_states, layer_self_attn, layer_cross_attn, present_key_value = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=inputs["encoder_hidden_states"],
@@ -2076,24 +2087,31 @@ def call(
if inputs["output_attentions"]:
all_self_attns += (layer_self_attn,)
+ all_cross_attentions += (layer_cross_attn,)
if inputs["output_hidden_states"]:
all_hidden_states += (hidden_states,)
else:
all_hidden_states = None
- all_self_attns = list(all_self_attns) if inputs["output_attentions"] else None
+ all_self_attns = all_self_attns if inputs["output_attentions"] else None
+ all_cross_attentions = all_cross_attentions if inputs["output_attentions"] else None
present_key_values = (encoder_hidden_states, present_key_values) if inputs["use_cache"] else None
if not inputs["return_dict"]:
- return hidden_states, present_key_values, all_hidden_states, all_self_attns
+ return tuple(
+ v
+ for v in [hidden_states, present_key_values, all_hidden_states, all_self_attns, all_cross_attentions]
+ if v is not None
+ )
else:
- return TFBaseModelOutputWithPast(
+ return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
+ cross_attentions=all_cross_attentions,
)
@@ -2223,6 +2241,7 @@ def call(
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
@@ -2475,6 +2494,7 @@ def call(
past_key_values=outputs.past_key_values, # index 1 of d outputs
decoder_hidden_states=outputs.decoder_hidden_states, # index 2 of d outputs
decoder_attentions=outputs.decoder_attentions, # index 3 of d outputs
+ cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state, # index 0 of encoder outputs
encoder_hidden_states=outputs.encoder_hidden_states, # 1 of e out
encoder_attentions=outputs.encoder_attentions, # 2 of e out
diff --git a/src/transformers/models/longformer/configuration_longformer.py b/src/transformers/models/longformer/configuration_longformer.py
index 59f6fc90bbdb..e3f5ba1a24f0 100644
--- a/src/transformers/models/longformer/configuration_longformer.py
+++ b/src/transformers/models/longformer/configuration_longformer.py
@@ -13,10 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" Longformer configuration"""
-from collections import OrderedDict
-from typing import List, Mapping, Union
+from typing import List, Union
-from ...onnx import OnnxConfig
from ...utils import logging
from ..roberta.configuration_roberta import RobertaConfig
@@ -69,18 +67,3 @@ class LongformerConfig(RobertaConfig):
def __init__(self, attention_window: Union[List[int], int] = 512, sep_token_id: int = 2, **kwargs):
super().__init__(sep_token_id=sep_token_id, **kwargs)
self.attention_window = attention_window
-
-
-class LongformerOnnxConfig(OnnxConfig):
- @property
- def inputs(self) -> Mapping[str, Mapping[int, str]]:
- return OrderedDict(
- [
- ("input_ids", {0: "batch", 1: "sequence"}),
- ("attention_mask", {0: "batch", 1: "sequence"}),
- ]
- )
-
- @property
- def outputs(self) -> Mapping[str, Mapping[int, str]]:
- return OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"}), ("pooler_output", {0: "batch"})])
diff --git a/src/transformers/models/marian/modeling_marian.py b/src/transformers/models/marian/modeling_marian.py
index f3bd96eeb94f..20cbd21f76e8 100755
--- a/src/transformers/models/marian/modeling_marian.py
+++ b/src/transformers/models/marian/modeling_marian.py
@@ -1291,6 +1291,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/mbart/modeling_mbart.py b/src/transformers/models/mbart/modeling_mbart.py
index fc09f0a7e62f..3e747b4b1ebc 100755
--- a/src/transformers/models/mbart/modeling_mbart.py
+++ b/src/transformers/models/mbart/modeling_mbart.py
@@ -1314,6 +1314,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id)
diff --git a/src/transformers/models/megatron_bert/modeling_megatron_bert.py b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
index dbfb76cb5d52..292b920bf5d5 100755
--- a/src/transformers/models/megatron_bert/modeling_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
@@ -223,7 +223,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -312,7 +312,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/mobilebert/modeling_mobilebert.py b/src/transformers/models/mobilebert/modeling_mobilebert.py
index 2a90f1d92aff..acf9607a7367 100644
--- a/src/transformers/models/mobilebert/modeling_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_mobilebert.py
@@ -237,7 +237,7 @@ def __init__(self, config):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -274,7 +274,7 @@ def forward(
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
diff --git a/src/transformers/models/pegasus/modeling_pegasus.py b/src/transformers/models/pegasus/modeling_pegasus.py
index 32923ce44d38..5eed41254e80 100755
--- a/src/transformers/models/pegasus/modeling_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_pegasus.py
@@ -1381,6 +1381,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/realm/modeling_realm.py b/src/transformers/models/realm/modeling_realm.py
index 165e62c0ef6c..118916413863 100644
--- a/src/transformers/models/realm/modeling_realm.py
+++ b/src/transformers/models/realm/modeling_realm.py
@@ -260,7 +260,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -349,7 +349,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/roberta/modeling_roberta.py b/src/transformers/models/roberta/modeling_roberta.py
index 426095e03ed6..88f0aa8d29ec 100644
--- a/src/transformers/models/roberta/modeling_roberta.py
+++ b/src/transformers/models/roberta/modeling_roberta.py
@@ -187,7 +187,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -276,7 +276,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/segformer/configuration_segformer.py b/src/transformers/models/segformer/configuration_segformer.py
index d1790634e6e6..0e0b3a9914eb 100644
--- a/src/transformers/models/segformer/configuration_segformer.py
+++ b/src/transformers/models/segformer/configuration_segformer.py
@@ -83,6 +83,10 @@ class SegformerConfig(PretrainedConfig):
required for the semantic segmentation model.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
+ legacy_output (`bool`, *optional*, defaults to `False`):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`)
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Example:
@@ -124,6 +128,7 @@ def __init__(
is_encoder_decoder=False,
reshape_last_stage=True,
semantic_loss_ignore_index=255,
+ legacy_output=False,
**kwargs
):
super().__init__(**kwargs)
@@ -149,3 +154,4 @@ def __init__(
self.decoder_hidden_size = decoder_hidden_size
self.reshape_last_stage = reshape_last_stage
self.semantic_loss_ignore_index = semantic_loss_ignore_index
+ self.legacy_output = legacy_output
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 6f0a4a1d7894..196d741ce705 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -17,6 +17,7 @@
import collections
import math
+import warnings
import torch
import torch.utils.checkpoint
@@ -30,7 +31,7 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, SequenceClassifierOutput
+from ...modeling_outputs import BaseModelOutput, SemanticSegmentationModelOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_segformer import SegformerConfig
@@ -688,7 +689,7 @@ def __init__(self, config):
self.post_init()
@add_start_docstrings_to_model_forward(SEGFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ @replace_return_docstrings(output_type=SemanticSegmentationModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values,
@@ -696,11 +697,17 @@ def forward(
output_attentions=None,
output_hidden_states=None,
return_dict=None,
+ legacy_output=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Ground truth semantic segmentation maps for computing the loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels > 1`, a classification loss is computed (Cross-Entropy).
+ legacy_output (`bool`, *optional*):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`). Will default
+ to `self.config.legacy_output`.
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Returns:
@@ -719,12 +726,20 @@ def forward(
>>> inputs = feature_extractor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
- >>> logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
+ >>> logits = outputs.logits # shape (batch_size, num_labels, height, width)
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ legacy_output = legacy_output if legacy_output is not None else self.config.legacy_output
+ if not legacy_output:
+ warnings.warn(
+ "The output of this model has changed in v4.17.0 and the logits now have the same size as the inputs. "
+ "You can activate the previous behavior by passing `legacy_output=True` to this call or the "
+ "configuration of this model (only until v5, then that argument will be removed).",
+ FutureWarning,
+ )
outputs = self.segformer(
pixel_values,
@@ -737,28 +752,37 @@ def forward(
logits = self.decode_head(encoder_hidden_states)
+ upsampled_logits = nn.functional.interpolate(
+ logits, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False
+ )
+
loss = None
if labels is not None:
if self.config.num_labels == 1:
raise ValueError("The number of labels should be greater than one")
else:
# upsample logits to the images' original size
- upsampled_logits = nn.functional.interpolate(
- logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
- )
loss_fct = CrossEntropyLoss(ignore_index=self.config.semantic_loss_ignore_index)
loss = loss_fct(upsampled_logits, labels)
if not return_dict:
if output_hidden_states:
- output = (logits,) + outputs[1:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[1:]
else:
- output = (logits,) + outputs[2:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
- return SequenceClassifierOutput(
- loss=loss,
- logits=logits,
- hidden_states=outputs.hidden_states if output_hidden_states else None,
- attentions=outputs.attentions,
- )
+ if legacy_output:
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
+ else:
+ return SemanticSegmentationModelOutput(
+ loss=loss,
+ logits=upsampled_logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/sew/modeling_sew.py b/src/transformers/models/sew/modeling_sew.py
index ecc30478b088..6fd0a1861f4e 100644
--- a/src/transformers/models/sew/modeling_sew.py
+++ b/src/transformers/models/sew/modeling_sew.py
@@ -29,7 +29,8 @@
from ...activations import ACT2FN
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_sew import SEWConfig
@@ -980,7 +981,10 @@ def __init__(self, config):
"instantiate the model as follows: `SEWForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1098,6 +1102,10 @@ class SEWForSequenceClassification(SEWPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of SEW adapters (config.add_adapter=True)"
+ )
self.sew = SEWModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/sew_d/modeling_sew_d.py b/src/transformers/models/sew_d/modeling_sew_d.py
index 33ca04337f82..af7dcba4b9a5 100644
--- a/src/transformers/models/sew_d/modeling_sew_d.py
+++ b/src/transformers/models/sew_d/modeling_sew_d.py
@@ -30,7 +30,8 @@
from ...activations import ACT2FN
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_sew_d import SEWDConfig
@@ -1512,7 +1513,10 @@ def __init__(self, config):
"instantiate the model as follows: `SEWDForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1630,6 +1634,10 @@ class SEWDForSequenceClassification(SEWDPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of SEWD adapters (config.add_adapter=True)"
+ )
self.sew_d = SEWDModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/splinter/modeling_splinter.py b/src/transformers/models/splinter/modeling_splinter.py
index b982a38b62f4..3d15cc682556 100755
--- a/src/transformers/models/splinter/modeling_splinter.py
+++ b/src/transformers/models/splinter/modeling_splinter.py
@@ -127,7 +127,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -216,7 +216,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/t5/modeling_tf_t5.py b/src/transformers/models/t5/modeling_tf_t5.py
index c626662fc155..372f6cf132d7 100644
--- a/src/transformers/models/t5/modeling_tf_t5.py
+++ b/src/transformers/models/t5/modeling_tf_t5.py
@@ -33,7 +33,7 @@
)
from ...modeling_tf_outputs import (
TFBaseModelOutput,
- TFBaseModelOutputWithPast,
+ TFBaseModelOutputWithPastAndCrossAttentions,
TFSeq2SeqLMOutput,
TFSeq2SeqModelOutput,
)
@@ -771,6 +771,7 @@ def call(
present_key_value_states = () if inputs["use_cache"] and self.is_decoder else None
all_hidden_states = () if inputs["output_hidden_states"] else None
all_attentions = () if inputs["output_attentions"] else None
+ all_cross_attentions = () if (inputs["output_attentions"] and self.is_decoder) else None
position_bias = None
encoder_decoder_position_bias = None
@@ -814,6 +815,8 @@ def call(
if inputs["output_attentions"]:
all_attentions = all_attentions + (layer_outputs[3],)
+ if self.is_decoder:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.dropout(hidden_states, training=inputs["training"])
@@ -831,14 +834,17 @@ def call(
outputs = outputs + (all_hidden_states,)
if inputs["output_attentions"]:
outputs = outputs + (all_attentions,)
- return outputs # last-layer hidden state, (all hidden states), (all attentions)
+ if self.is_decoder:
+ outputs + (all_cross_attentions,)
+ return outputs # last-layer hidden state, (past_key_values), (all hidden states), (all attentions), (all_cross_attentions)
if self.is_decoder:
- return TFBaseModelOutputWithPast(
+ return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_value_states,
hidden_states=all_hidden_states,
attentions=all_attentions,
+ cross_attentions=all_cross_attentions,
)
else:
return TFBaseModelOutput(
@@ -1264,6 +1270,7 @@ def call(
past_key_values=past,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
@@ -1508,6 +1515,7 @@ def call(
past_key_values=past,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
diff --git a/src/transformers/models/unispeech/modeling_unispeech.py b/src/transformers/models/unispeech/modeling_unispeech.py
index 3969fa6ab454..768fbfc60932 100755
--- a/src/transformers/models/unispeech/modeling_unispeech.py
+++ b/src/transformers/models/unispeech/modeling_unispeech.py
@@ -35,7 +35,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_unispeech import UniSpeechConfig
@@ -1373,7 +1374,10 @@ def __init__(self, config):
"instantiate the model as follows: `UniSpeechForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1491,6 +1495,10 @@ class UniSpeechForSequenceClassification(UniSpeechPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of UniSpeech adapters (config.add_adapter=True)"
+ )
self.unispeech = UniSpeechModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
index 4a42f9e60f10..ddc98c80019f 100755
--- a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
@@ -35,7 +35,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput, TokenClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_unispeech_sat import UniSpeechSatConfig
@@ -1401,7 +1402,10 @@ def __init__(self, config):
"instantiate the model as follows: `UniSpeechSatForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1519,6 +1523,10 @@ class UniSpeechSatForSequenceClassification(UniSpeechSatPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of UniSpeechSat adapters (config.add_adapter=True)"
+ )
self.unispeech_sat = UniSpeechSatModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1639,6 +1647,10 @@ class UniSpeechSatForAudioFrameClassification(UniSpeechSatPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of UniSpeechSat adapters (config.add_adapter=True)"
+ )
self.unispeech_sat = UniSpeechSatModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
index a8ea74dd5cdb..a32c7084a898 100644
--- a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
@@ -766,6 +766,73 @@ def __call__(self, hidden_states, mask_time_indices=None, deterministic=True, te
return codevectors, perplexity
+class FlaxWav2Vec2Adapter(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ # hidden_states require down-projection if feature dims don't match
+ if self.config.output_hidden_size != self.config.hidden_size:
+ self.proj = nn.Dense(
+ self.config.output_hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.proj_layer_norm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ else:
+ self.proj = self.proj_layer_norm = None
+
+ self.layers = FlaxWav2Vec2AdapterLayersCollection(self.config, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ # down-project hidden_states if required
+ if self.proj is not None and self.proj_layer_norm is not None:
+ hidden_states = self.proj(hidden_states)
+ hidden_states = self.proj_layer_norm(hidden_states)
+
+ hidden_states = self.layers(hidden_states)
+
+ return hidden_states
+
+
+class FlaxWav2Vec2AdapterLayer(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ features=2 * self.config.output_hidden_size,
+ kernel_size=(self.config.adapter_kernel_size,),
+ strides=(self.config.adapter_stride,),
+ padding=((1, 1),),
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ hidden_states = self.conv(hidden_states)
+ hidden_states = nn.glu(hidden_states, axis=2)
+
+ return hidden_states
+
+
+class FlaxWav2Vec2AdapterLayersCollection(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.layers = [
+ FlaxWav2Vec2AdapterLayer(self.config, name=str(i), dtype=self.dtype)
+ for i in range(self.config.num_adapter_layers)
+ ]
+
+ def __call__(self, hidden_states, deterministic=True):
+ for conv_layer in self.layers:
+ hidden_states = conv_layer(hidden_states)
+
+ return hidden_states
+
+
class FlaxWav2Vec2PreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
@@ -840,7 +907,9 @@ def __call__(
rngs=rngs,
)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[jnp.ndarray, int], add_adapter: Optional[bool] = None
+ ):
return self.module._get_feat_extract_output_lengths(input_lengths)
@@ -860,6 +929,8 @@ def setup(self):
else:
raise NotImplementedError("``config.do_stable_layer_norm is False`` is currently not supported.")
+ self.adapter = FlaxWav2Vec2Adapter(self.config) if self.config.add_adapter else None
+
def __call__(
self,
input_values,
@@ -905,6 +976,9 @@ def __call__(
hidden_states = encoder_outputs[0]
+ if self.adapter is not None:
+ hidden_states = self.adapter(hidden_states)
+
if not return_dict:
return (hidden_states, extract_features) + encoder_outputs[1:]
@@ -915,11 +989,15 @@ def __call__(
attentions=encoder_outputs.attentions,
)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[jnp.ndarray, int], add_adapter: Optional[bool] = None
+ ):
"""
Computes the output length of the convolutional layers
"""
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
def _conv_out_length(input_length, kernel_size, stride):
# 1D convolutional layer output length formula taken
# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
@@ -928,6 +1006,10 @@ def _conv_out_length(input_length, kernel_size, stride):
for kernel_size, stride in zip(self.config.conv_kernel, self.config.conv_stride):
input_lengths = _conv_out_length(input_lengths, kernel_size, stride)
+ if add_adapter:
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(input_lengths, 1, self.config.adapter_stride)
+
return input_lengths
@@ -1021,11 +1103,17 @@ def __call__(
return FlaxCausalLMOutput(logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self,
+ input_lengths: Union[jnp.ndarray, int],
+ add_adapter: Optional[bool] = None,
+ ):
"""
Computes the output length of the convolutional layers
"""
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
def _conv_out_length(input_length, kernel_size, stride):
# 1D convolutional layer output length formula taken
# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
@@ -1034,6 +1122,10 @@ def _conv_out_length(input_length, kernel_size, stride):
for kernel_size, stride in zip(self.config.conv_kernel, self.config.conv_stride):
input_lengths = _conv_out_length(input_lengths, kernel_size, stride)
+ if add_adapter:
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(input_lengths, 1, self.config.adapter_stride)
+
return input_lengths
diff --git a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
index d7e15fb4f41e..fb44424a1c74 100644
--- a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
@@ -16,6 +16,7 @@
import inspect
import warnings
+from dataclasses import dataclass
from typing import Any, Dict, Optional, Tuple, Union
import numpy as np
@@ -43,6 +44,9 @@
logger = logging.get_logger(__name__)
+
+_HIDDEN_STATES_START_POSITION = 2
+
_CHECKPOINT_FOR_DOC = "facebook/wav2vec2-base-960h"
_CONFIG_FOR_DOC = "Wav2Vec2Config"
_TOKENIZER_FOR_DOC = "Wav2Vec2Tokenizer"
@@ -58,6 +62,35 @@
LARGE_NEGATIVE = -1e8
+@dataclass
+class TFWav2Vec2BaseModelOutput(ModelOutput):
+ """
+ Output type of [`TFWav2Vec2BaseModelOutput`], with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ extract_features (`tf.Tensor` of shape `(batch_size, sequence_length, conv_dim[-1])`):
+ Sequence of extracted feature vectors of the last convolutional layer of the model.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: tf.Tensor = None
+ extract_features: tf.Tensor = None
+ hidden_states: Optional[Tuple[tf.Tensor]] = None
+ attentions: Optional[Tuple[tf.Tensor]] = None
+
+
def input_values_processing(func, config, input_values, **kwargs):
"""
Process the input of each TensorFlow model including the booleans. In case of a list of symbolic inputs, each input
@@ -707,10 +740,10 @@ def __init__(self, config: Wav2Vec2Config, **kwargs):
self.dropout = tf.keras.layers.Dropout(rate=config.feat_proj_dropout)
def call(self, hidden_states: tf.Tensor, training: bool = False) -> tf.Tensor:
- hidden_states = self.layer_norm(hidden_states)
- hidden_states = self.projection(hidden_states)
+ norm_hidden_states = self.layer_norm(hidden_states)
+ hidden_states = self.projection(norm_hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
- return hidden_states
+ return hidden_states, norm_hidden_states
# Copied from transformers.models.bart.modeling_tf_bart.TFBartAttention with TFBart->TFWav2Vec2
@@ -1222,19 +1255,20 @@ def call(
kwargs_call=kwargs,
)
- hidden_states = self.feature_extractor(
+ extract_features = self.feature_extractor(
tf.cast(inputs["input_values"], tf.float32), training=inputs["training"]
)
+ # extract_features = tf.transpose(extract_features, perm=(0, 2, 1))
if inputs["attention_mask"] is not None:
# compute real output lengths according to convolution formula
output_lengths = self._get_feat_extract_output_lengths(tf.reduce_sum(inputs["attention_mask"], -1))
attention_mask = tf.sequence_mask(
- output_lengths, maxlen=shape_list(hidden_states)[1], dtype=hidden_states.dtype
+ output_lengths, maxlen=shape_list(extract_features)[1], dtype=extract_features.dtype
)
- hidden_states = self.feature_projection(hidden_states, training=inputs["training"])
+ hidden_states, extract_features = self.feature_projection(extract_features, training=inputs["training"])
mask_time_indices = kwargs.get("mask_time_indices", None)
if inputs["training"]:
@@ -1251,10 +1285,11 @@ def call(
hidden_states = encoder_outputs[0]
if not inputs["return_dict"]:
- return (hidden_states,) + encoder_outputs[1:]
+ return (hidden_states, extract_features) + encoder_outputs[1:]
- return TFBaseModelOutput(
+ return TFWav2Vec2BaseModelOutput(
last_hidden_state=hidden_states,
+ extract_features=extract_features,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
@@ -1635,7 +1670,7 @@ def call(
loss = None
if not inputs["return_dict"]:
- output = (logits,) + outputs[1:]
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
return ((loss,) + output) if loss is not None else output
return TFCausalLMOutput(
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index f80a8bd18cc5..f45c0a8e689e 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -41,7 +41,8 @@
SequenceClassifierOutput,
TokenClassifierOutput,
)
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_wav2vec2 import Wav2Vec2Config
@@ -1701,7 +1702,10 @@ def __init__(self, config):
"instantiate the model as follows: `Wav2Vec2ForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1818,6 +1822,10 @@ class Wav2Vec2ForSequenceClassification(Wav2Vec2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Wav2Vec2 adapters (config.add_adapter=True)"
+ )
self.wav2vec2 = Wav2Vec2Model(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1937,6 +1945,10 @@ class Wav2Vec2ForAudioFrameClassification(Wav2Vec2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of Wav2Vec2 adapters (config.add_adapter=True)"
+ )
self.wav2vec2 = Wav2Vec2Model(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/wavlm/modeling_wavlm.py b/src/transformers/models/wavlm/modeling_wavlm.py
index 9f67e6135009..2618ec9bbca2 100755
--- a/src/transformers/models/wavlm/modeling_wavlm.py
+++ b/src/transformers/models/wavlm/modeling_wavlm.py
@@ -35,7 +35,8 @@
add_start_docstrings_to_model_forward,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput, TokenClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_wavlm import WavLMConfig
@@ -1351,7 +1352,10 @@ def __init__(self, config):
"instantiate the model as follows: `WavLMForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1469,6 +1473,10 @@ class WavLMForSequenceClassification(WavLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of WavLM adapters (config.add_adapter=True)"
+ )
self.wavlm = WavLMModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1589,6 +1597,10 @@ class WavLMForAudioFrameClassification(WavLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of WavLM adapters (config.add_adapter=True)"
+ )
self.wavlm = WavLMModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
index cdea06ac57b6..cfeb788ec62e 100644
--- a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
@@ -181,7 +181,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -270,7 +270,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/onnx/features.py b/src/transformers/onnx/features.py
index 41f8970d707f..9f3ad05b4f30 100644
--- a/src/transformers/onnx/features.py
+++ b/src/transformers/onnx/features.py
@@ -7,11 +7,11 @@
from ..models.bert import BertOnnxConfig
from ..models.camembert import CamembertOnnxConfig
from ..models.distilbert import DistilBertOnnxConfig
+from ..models.electra import ElectraOnnxConfig
from ..models.gpt2 import GPT2OnnxConfig
from ..models.gpt_neo import GPTNeoOnnxConfig
from ..models.ibert import IBertOnnxConfig
from ..models.layoutlm import LayoutLMOnnxConfig
-from ..models.longformer import LongformerOnnxConfig
from ..models.marian import MarianOnnxConfig
from ..models.mbart import MBartOnnxConfig
from ..models.roberta import RobertaOnnxConfig
@@ -154,15 +154,6 @@ class FeaturesManager:
"question-answering",
onnx_config_cls=DistilBertOnnxConfig,
),
- "longformer": supported_features_mapping(
- "default",
- "masked-lm",
- "sequence-classification",
- # "multiple-choice",
- "token-classification",
- "question-answering",
- onnx_config_cls=LongformerOnnxConfig,
- ),
"marian": supported_features_mapping(
"default",
"default-with-past",
@@ -219,6 +210,15 @@ class FeaturesManager:
"token-classification",
onnx_config_cls=LayoutLMOnnxConfig,
),
+ "electra": supported_features_mapping(
+ "default",
+ "masked-lm",
+ "causal-lm",
+ "sequence-classification",
+ "token-classification",
+ "question-answering",
+ onnx_config_cls=ElectraOnnxConfig,
+ ),
}
AVAILABLE_FEATURES = sorted(reduce(lambda s1, s2: s1 | s2, (v.keys() for v in _SUPPORTED_MODEL_TYPE.values())))
diff --git a/src/transformers/pipelines/automatic_speech_recognition.py b/src/transformers/pipelines/automatic_speech_recognition.py
index c013a77d860e..e57fb7d5e45c 100644
--- a/src/transformers/pipelines/automatic_speech_recognition.py
+++ b/src/transformers/pipelines/automatic_speech_recognition.py
@@ -265,10 +265,19 @@ def _forward(self, model_inputs):
# it here.
# Consume values so we can let extra information flow freely through
# the pipeline (important for `partial` in microphone)
- input_features = model_inputs.pop("input_features")
- attention_mask = model_inputs.pop("attention_mask")
+ if "input_features" in model_inputs:
+ inputs = model_inputs.pop("input_features")
+ elif "input_values" in model_inputs:
+ inputs = model_inputs.pop("input_values")
+ else:
+ raise ValueError(
+ "Seq2Seq speech recognition model requires either a "
+ f"`input_features` or `input_values` key, but only has {model_inputs.keys()}"
+ )
+
+ attention_mask = model_inputs.pop("attention_mask", None)
tokens = self.model.generate(
- encoder_outputs=encoder(input_features=input_features, attention_mask=attention_mask),
+ encoder_outputs=encoder(inputs, attention_mask=attention_mask),
attention_mask=attention_mask,
)
out = {"tokens": tokens}
diff --git a/src/transformers/pytorch_utils.py b/src/transformers/pytorch_utils.py
new file mode 100644
index 000000000000..b41f438d9c3a
--- /dev/null
+++ b/src/transformers/pytorch_utils.py
@@ -0,0 +1,31 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from packaging import version
+
+from .utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def torch_int_div(tensor1, tensor2):
+ """
+ A function that performs integer division across different versions of PyTorch.
+ """
+ if version.parse(torch.__version__) < version.parse("1.8.0"):
+ return tensor1 // tensor2
+ else:
+ return torch.div(tensor1, tensor2, rounding_mode="floor")
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 5d6f538964c0..0278bf42e558 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -16,7 +16,6 @@
The Trainer class, to easily train a 🤗 Transformers from scratch or finetune it on a new task.
"""
-import collections
import contextlib
import inspect
import math
@@ -54,7 +53,7 @@
import torch
from packaging import version
from torch import nn
-from torch.utils.data import DataLoader, Dataset, IterableDataset, RandomSampler, SequentialSampler
+from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from huggingface_hub import Repository
@@ -126,6 +125,7 @@
default_hp_space,
denumpify_detensorize,
get_last_checkpoint,
+ has_length,
number_of_arguments,
set_seed,
speed_metrics,
@@ -429,7 +429,7 @@ def __init__(
if args.max_steps > 0:
logger.info("max_steps is given, it will override any value given in num_train_epochs")
- if train_dataset is not None and not isinstance(train_dataset, collections.abc.Sized) and args.max_steps <= 0:
+ if train_dataset is not None and not has_length(train_dataset) and args.max_steps <= 0:
raise ValueError("train_dataset does not implement __len__, max_steps has to be specified")
if (
@@ -585,7 +585,7 @@ def _remove_unused_columns(self, dataset: "datasets.Dataset", description: Optio
return dataset.remove_columns(ignored_columns)
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
- if not isinstance(self.train_dataset, collections.abc.Sized):
+ if not has_length(self.train_dataset):
return None
generator = None
@@ -1190,7 +1190,7 @@ def train(
self.model_wrapped = self.model
# Keeping track whether we can can len() on the dataset or not
- train_dataset_is_sized = isinstance(self.train_dataset, collections.abc.Sized)
+ train_dataset_is_sized = has_length(self.train_dataset)
# Data loader and number of training steps
train_dataloader = self.get_train_dataloader()
@@ -2383,7 +2383,7 @@ def evaluation_loop(
batch_size = dataloader.batch_size
logger.info(f"***** Running {description} *****")
- if isinstance(dataloader.dataset, collections.abc.Sized):
+ if has_length(dataloader.dataset):
logger.info(f" Num examples = {self.num_examples(dataloader)}")
else:
logger.info(" Num examples: Unknown")
@@ -2478,7 +2478,7 @@ def evaluation_loop(
all_labels = labels if all_labels is None else nested_concat(all_labels, labels, padding_index=-100)
# Number of samples
- if not isinstance(eval_dataset, IterableDataset):
+ if has_length(eval_dataset):
num_samples = len(eval_dataset)
# The instance check is weird and does not actually check for the type, but whether the dataset has the right
# methods. Therefore we need to make sure it also has the attribute.
@@ -2872,7 +2872,7 @@ def prediction_loop(
"""
args = self.args
- if not isinstance(dataloader.dataset, collections.abc.Sized):
+ if not has_length(dataloader.dataset):
raise ValueError("dataset must implement __len__")
prediction_loss_only = prediction_loss_only if prediction_loss_only is not None else args.prediction_loss_only
diff --git a/src/transformers/trainer_callback.py b/src/transformers/trainer_callback.py
index e81d0a27f297..51f9f4f2240d 100644
--- a/src/transformers/trainer_callback.py
+++ b/src/transformers/trainer_callback.py
@@ -15,7 +15,6 @@
"""
Callbacks to use with the Trainer class and customize the training loop.
"""
-import collections
import dataclasses
import json
from dataclasses import dataclass
@@ -24,7 +23,7 @@
import numpy as np
from tqdm.auto import tqdm
-from .trainer_utils import IntervalStrategy
+from .trainer_utils import IntervalStrategy, has_length
from .training_args import TrainingArguments
from .utils import logging
@@ -470,7 +469,7 @@ def on_step_end(self, args, state, control, **kwargs):
self.current_step = state.global_step
def on_prediction_step(self, args, state, control, eval_dataloader=None, **kwargs):
- if state.is_local_process_zero and isinstance(eval_dataloader.dataset, collections.abc.Sized):
+ if state.is_local_process_zero and has_length(eval_dataloader.dataset):
if self.prediction_bar is None:
self.prediction_bar = tqdm(total=len(eval_dataloader), leave=self.training_bar is None)
self.prediction_bar.update(1)
diff --git a/src/transformers/trainer_utils.py b/src/transformers/trainer_utils.py
index 2f96ff61525d..e4b896edbd60 100644
--- a/src/transformers/trainer_utils.py
+++ b/src/transformers/trainer_utils.py
@@ -519,6 +519,17 @@ def stop_and_update_metrics(self, metrics=None):
self.update_metrics(stage, metrics)
+def has_length(dataset):
+ """
+ Checks if the dataset implements __len__() and it doesn't raise an error
+ """
+ try:
+ return len(dataset) is not None
+ except TypeError:
+ # TypeError: len() of unsized object
+ return False
+
+
def denumpify_detensorize(metrics):
"""
Recursively calls `.item()` on the element of the dictionary passed
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 21e94075a8da..567883c7a618 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -474,6 +474,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class AutoModelForSemanticSegmentation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForSeq2SeqLM(metaclass=DummyObject):
_backends = ["torch"]
@@ -1108,6 +1115,30 @@ def load_tf_weights_in_convbert(*args, **kwargs):
requires_backends(load_tf_weights_in_convbert, ["torch"])
+CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class ConvNextForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ConvNextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ConvNextPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 9e5efabc062c..1084d2fc4d0c 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -31,6 +31,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class ConvNextFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeiTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/src/transformers/utils/fx.py b/src/transformers/utils/fx.py
index 23a2eb4c1fab..f9cdc407aeb6 100644
--- a/src/transformers/utils/fx.py
+++ b/src/transformers/utils/fx.py
@@ -1,8 +1,24 @@
-import copy
+# coding=utf-8
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
import functools
import inspect
+import math
import random
-from typing import Any, Callable, Dict, List, Optional, Tuple, Type, Union
+from types import ModuleType
+from typing import Any, Callable, Dict, Iterable, List, Optional, Type, Union
import torch
from packaging import version
@@ -26,17 +42,11 @@
GPT2DoubleHeadsModel,
PretrainedConfig,
PreTrainedModel,
+ XLNetForQuestionAnswering,
logging,
)
from ..file_utils import TORCH_FX_REQUIRED_VERSION, importlib_metadata, is_torch_fx_available
from ..models.auto import get_values
-from .fx_transformations import (
- _cache_attributes,
- _patch_arguments_,
- _restore_attributes_,
- transform_to_dynamic_input_,
- transformation,
-)
logger = logging.get_logger(__name__)
@@ -46,6 +56,7 @@ def _generate_supported_model_classes(
model_name: Type[PretrainedConfig],
supported_tasks: Optional[Union[str, List[str]]] = None,
) -> List[Type[PreTrainedModel]]:
+
model_config_class = CONFIG_MAPPING[model_name]
task_mapping = {
"default": MODEL_MAPPING,
@@ -86,15 +97,10 @@ def _generate_supported_model_classes(
"gptj",
"gpt_neo",
"t5",
-]
-
-_REGULAR_SUPPORTED_MODEL_NAMES_AND_TASKS_FOR_DYNAMIC_AXES = [
- "albert",
- "bert",
- "distilbert",
- "mobilebert",
- "electra",
- "megatron-bert",
+ "roberta",
+ # TODO: add support for them as it should be quite easy to do so (small blocking issues).
+ # "layoutlm",
+ # "xlnet",
]
_REGULAR_SUPPORTED_MODELS = []
@@ -106,21 +112,11 @@ def _generate_supported_model_classes(
_SPECIAL_SUPPORTED_MODELS = [
GPT2DoubleHeadsModel,
+ # TODO: add support for them as it should be quite easy to do so (small blocking issues).
+ # XLNetForQuestionAnswering,
]
_SUPPORTED_MODELS = tuple(_REGULAR_SUPPORTED_MODELS + _SPECIAL_SUPPORTED_MODELS)
-_REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = []
-for item in _REGULAR_SUPPORTED_MODEL_NAMES_AND_TASKS_FOR_DYNAMIC_AXES:
- if isinstance(item, dict):
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES.extend(_generate_supported_model_classes(**item))
- else:
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES.extend(_generate_supported_model_classes(item))
-
-_SPECIAL_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = []
-_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = tuple(
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES + _SPECIAL_SUPPORTED_MODELS_FOR_DYNAMIC_AXES
-)
-
class HFProxy(Proxy):
"""
@@ -134,6 +130,7 @@ def __init__(self, node: Node, tracer: Optional[Tracer] = None):
if hasattr(self, "tracer") and self.tracer is not None:
self.device = self.tracer.root.device
self.dtype = next(self.tracer.root.parameters()).dtype
+ self.cache = None
@property
def shape(self):
@@ -145,42 +142,54 @@ def __setitem__(self, key, value):
def __contains__(self, key):
return False
+ def __eq__(self, other):
+ if self.cache is not None:
+ return self.cache == other
+ elif isinstance(other, HFProxy):
+ return True
+ else:
+ return super().__eq__(other)
-def _wrap_method_for_model_recording(model, method_name, cache_name):
- """Helper function that wraps a torch.Tensor method to record its outputs during forward pass."""
- method = getattr(torch.Tensor, method_name)
+ def __ne__(self, other):
+ return not self == other
- @functools.wraps(method)
- def wrapped(*args, **kwargs):
- if not hasattr(model, cache_name):
- setattr(model, cache_name, [])
- cache = getattr(model, cache_name)
- res = method(*args, **kwargs)
- cache.append(res)
- return res
+ def __len__(self):
+ if self.cache is not None:
+ if isinstance(self.cache, int):
+ return self.cache
+ elif isinstance(self.cache, (torch.Size, list, tuple)):
+ return len(self.cache)
+ else:
+ return super().__len__(self)
+ return super().__len__(self)
- return wrapped
+ def __torch_function__(self, orig_method, types, args=None, kwargs=None):
+ proxy = super().__torch_function__(orig_method, types, args=args, kwargs=kwargs)
+ proxy.cache = self.cache
+ return proxy
-def _create_recorded_proxy_method(proxy, method_name, cache_name):
- """
- Helper function that sets a recorded torch.Tensor method as a HFProxy method that will use the recorded values
- during symbolic tracing.
- """
+def _function_to_leaf(func: Callable[..., Any]) -> Callable[..., Any]:
+ """Wrapper that marks func as a leaf function, meaning that it will not be traced through by HFTracer."""
- def method(self, *args, **kwargs):
- cache = getattr(self.tracer.root, cache_name)
- res = cache.pop(0)
- return res
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ return wrapper
- method.__name__ = method_name
- bound_method = method.__get__(proxy, proxy.__class__)
- setattr(proxy, method_name, bound_method)
+def _function_leaf_getter(func_name: str, mapping: Dict[str, Callable[..., Any]]) -> Callable[..., Any]:
+ @functools.wraps(mapping[func_name])
+ def wrapper(*args, **kwargs):
+ return mapping[func_name](*args, **kwargs)
-def _wrap_method_for_model_tracing(model, method_name, cache_name):
+ return wrapper
+
+
+def _create_recorded_proxy_method(proxy: HFProxy, method_name: str, cache_name: str, return_proxy: bool):
"""
- Helper function that sets a recorded torch.Tensor method as a torch.Tensor method that will use the recorded values
+ Helper function that sets a recorded torch.Tensor method as a HFProxy method that will use the recorded values
during symbolic tracing.
"""
@@ -188,55 +197,69 @@ def _wrap_method_for_model_tracing(model, method_name, cache_name):
@functools.wraps(original_method)
def method(*args, **kwargs):
- cache = getattr(model, cache_name)
+ cache = getattr(args[0].tracer.root, cache_name)
res = cache.pop(0)
+ if return_proxy:
+ proxy = args[0].__torch_function__(
+ original_method,
+ None,
+ args=args,
+ kwargs=kwargs,
+ )
+ proxy.cache = res
+ return proxy
return res
- setattr(torch.Tensor, method_name, method)
-
- if method_name == "size":
- setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
-
-
-def _monkey_patch_tensor_methods_for_model_recording(model, method_names):
- """
- Helper function that patches torch.Tensor methods (specified by the method_names list) to record model inference
- before symbolic tracing.
- """
- cache_names = dict()
- original_methods = dict()
- for method_name in method_names:
- cache_name = f"cache_{method_name}"
- cache_names[method_name] = cache_name
- if not hasattr(torch.Tensor, method_name):
- logger.info(f"torch.Tensor has no method called {method_name}, skipping patching.")
- continue
- original_methods[method_name] = getattr(torch.Tensor, method_name)
- setattr(torch.Tensor, method_name, _wrap_method_for_model_recording(model, method_name, cache_name))
-
- if method_name == "size":
- original_methods["shape"] = torch.Tensor.shape
- setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
-
- return cache_names, original_methods
+ method.__name__ = method_name
+ bound_method = method.__get__(proxy, proxy.__class__)
+ setattr(proxy, method_name, bound_method)
-def _reset_tensor_methods(original_methods):
+def _reset_tensor_methods(original_methods: Dict[str, Callable[..., Any]]):
"""Helper function that resets the monkey patched torch.Tensor methods to their original values."""
for name, method in original_methods.items():
setattr(torch.Tensor, name, method)
+def _generate_random_int(low: int = 10, high: int = 20, forbidden_values: Optional[List[int]] = None):
+ if forbidden_values is None:
+ forbidden_values = []
+ value = random.randint(low, high)
+ while value in forbidden_values:
+ value = random.randint(low, high)
+ return value
+
+
class HFTracer(Tracer):
"""
Tracer that is able to symbolically trace models from the library. To do that, it uses the HFProxy instead of the
regular PyTorch torch.fx.Proxy.
"""
- default_methods_to_record = {"__bool__", "size", "dim"}
+ _DEFAULT_METHODS_TO_RECORD = {"__bool__": False, "size": True, "dim": False}
+ from transformers import modeling_utils
+
+ _FUNCTIONS_TO_AUTOWRAP = {
+ torch: {"arange", "zeros", "ones", "full_like", "eye"},
+ modeling_utils.ModuleUtilsMixin: {"create_extended_attention_mask_for_decoder"},
+ }
+
+ def __init__(self, autowrap_modules=(math,), autowrap_functions=(), enable_cpatching=False):
+
+ # Loading the leaf functions register
+ self._leaf_functions_register = {}
+ for module, names in self._FUNCTIONS_TO_AUTOWRAP.items():
+ for name in names:
+ self._register_leaf_function(module, name)
+
+ # TODO: adapt the way leaf function are wrapped with the "autowrap function" feature from Tracer.
+ # autowrap_functions = autowrap_functions + tuple(
+ # patched for (_, _, patched) in self._leaf_functions_register.values()
+ # )
- def __init__(self, batch_size=1, sequence_length=[128, 128], num_choices=-1):
- super().__init__()
+ super().__init__(
+ autowrap_modules=autowrap_modules, autowrap_functions=autowrap_functions, enable_cpatching=enable_cpatching
+ )
if not is_torch_fx_available():
torch_version = version.parse(importlib_metadata.version("torch"))
@@ -245,40 +268,107 @@ def __init__(self, batch_size=1, sequence_length=[128, 128], num_choices=-1):
f"{TORCH_FX_REQUIRED_VERSION} is supported."
)
- encoder_sequence_length = sequence_length[0] if isinstance(sequence_length, (list, tuple)) else sequence_length
- decoder_sequence_length = (
- sequence_length[1] if isinstance(sequence_length, (list, tuple)) else encoder_sequence_length
- )
- self.encoder_shape = [batch_size, encoder_sequence_length]
- self.decoder_shape = (
- [batch_size, decoder_sequence_length] if decoder_sequence_length > 0 else list(self.encoder_shape)
- )
- self.num_choices = num_choices
- if self.num_choices > 0:
- self.encoder_shape = [batch_size, self.num_choices, encoder_sequence_length]
- self.decoder_shape = [batch_size, self.num_choices, decoder_sequence_length]
-
self.prev_module = None
self.recorded_methods = None
- def proxy(self, node: Node):
- p = HFProxy(node, self)
- if self.recorded_methods:
- for method_name, cache_name in self.recorded_methods.items():
- _create_recorded_proxy_method(p, method_name, cache_name)
- return p
+ def _register_leaf_function(self, module: ModuleType, name: str):
+ """Registers the function called name in module as a leaf function."""
+ orig_func = getattr(module, name)
+ patched_func = _function_to_leaf(orig_func)
+ patched_func.__module__ = __name__
+ self._leaf_functions_register[name] = (module, orig_func, patched_func)
+
+ def _patch_leaf_functions_for_root(self, root: PreTrainedModel, restore: bool = False):
+ """Patches leaf functions specifically for root."""
+ for name in self._leaf_functions_register:
+ module, orig_func, patched_func = self._leaf_functions_register[name]
+ if restore:
+ root.__class__.forward.__globals__.pop(name)
+ setattr(module, name, orig_func)
+ else:
+ root.__class__.forward.__globals__[name] = patched_func
+ leaf_getter = _function_leaf_getter(name, root.__class__.forward.__globals__)
+ leaf_getter.__module__ = __name__
+ setattr(module, name, leaf_getter)
+
+ def _method_is_called_in_leaf_module(self, module_ids: List[int]) -> bool:
+ """
+ Finds out if the method (that is being recorded) is called inside a leaf module, this allows to not record
+ outputs that will not be encountered by the tracer.
+ """
+
+ currentframe = inspect.currentframe()
+ while currentframe:
+ if currentframe is None:
+ return False
+ module = currentframe.f_locals.get("self", None)
+ if id(module) in module_ids and self.is_leaf_module(module, "Not used anyway"):
+ return True
+ currentframe = currentframe.f_back
+ return False
+
+ def _wrap_method_for_model_recording(
+ self, model: PreTrainedModel, method_name: str, cache_name: str, module_ids: List[int]
+ ):
+ """Helper function that wraps a torch.Tensor method to record its outputs during forward pass."""
+ method = getattr(torch.Tensor, method_name)
+
+ @functools.wraps(method)
+ def wrapped(*args, **kwargs):
+ if self._method_is_called_in_leaf_module(module_ids):
+ return method(*args, **kwargs)
+ if not hasattr(model, cache_name):
+ setattr(model, cache_name, [])
+ cache = getattr(model, cache_name)
+ res = method(*args, **kwargs)
+ cache.append(res)
+ return res
+
+ return wrapped
+
+ def _monkey_patch_tensor_methods_for_model_recording(self, model: PreTrainedModel, method_names: Iterable[str]):
+ """
+ Helper function that patches torch.Tensor methods (specified by the method_names list) to record model
+ inference before symbolic tracing.
+ """
+ cache_names = {}
+ original_methods = {}
+ module_ids = set(id(mod) for mod in model.modules())
+ for method_name in method_names:
+ cache_name = f"cache_{method_name}"
+ cache_names[method_name] = cache_name
+ if not hasattr(torch.Tensor, method_name):
+ logger.info(f"torch.Tensor has no method called {method_name}, skipping patching.")
+ continue
+ original_methods[method_name] = getattr(torch.Tensor, method_name)
+ setattr(
+ torch.Tensor,
+ method_name,
+ self._wrap_method_for_model_recording(model, method_name, cache_name, module_ids),
+ )
- def _generate_dummy_input(self, model, input_name):
+ if method_name == "size":
+ original_methods["shape"] = torch.Tensor.shape
+ setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
+
+ return cache_names, original_methods
+
+ def _generate_dummy_input(
+ self, model: PreTrainedModel, input_name: str, shape: List[int]
+ ) -> Dict[str, torch.Tensor]:
"""Generates dummy input for model inference recording."""
model_class = model.__class__
device = model.device
- inputs_dict = dict()
+ inputs_dict = {}
if input_name in ["labels", "start_positions", "end_positions"]:
- batch_size = self.encoder_shape[0]
+ batch_size = shape[0]
if model_class in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
- inputs_dict["labels"] = torch.ones(batch_size, dtype=torch.long, device=device)
- elif model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(batch_size, dtype=torch.long, device=device)
+ elif model_class in [
+ *get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING),
+ XLNetForQuestionAnswering,
+ ]:
inputs_dict["start_positions"] = torch.zeros(batch_size, dtype=torch.long, device=device)
inputs_dict["end_positions"] = torch.zeros(batch_size, dtype=torch.long, device=device)
elif model_class in [
@@ -288,59 +378,56 @@ def _generate_dummy_input(self, model, input_name):
]:
inputs_dict["labels"] = torch.zeros(batch_size, dtype=torch.long, device=device)
elif model_class in [
+ *get_values(MODEL_FOR_PRETRAINING_MAPPING),
*get_values(MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_CAUSAL_LM_MAPPING),
*get_values(MODEL_FOR_MASKED_LM_MAPPING),
*get_values(MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING),
GPT2DoubleHeadsModel,
]:
- inputs_dict["labels"] = torch.zeros(self.decoder_shape, dtype=torch.long, device=device)
- elif model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
- inputs_dict["labels"] = torch.zeros(self.encoder_shape, dtype=torch.long, device=device)
+ inputs_dict["labels"] = torch.zeros(shape, dtype=torch.long, device=device)
else:
raise NotImplementedError(f"{model_class} not supported yet.")
elif "mask" in input_name or "ids" in input_name:
- shape = self.encoder_shape if "decoder" not in input_name else self.decoder_shape
- inputs_dict[input_name] = torch.ones(shape, dtype=torch.long, device=device)
+ inputs_dict[input_name] = torch.zeros(shape, dtype=torch.long, device=device)
else:
- shape = self.encoder_shape if "decoder" not in input_name else self.decoder_shape
- shape += [model.config.hidden_size]
- inputs_dict[input_name] = torch.ones(shape, dtype=torch.float, device=device)
+ shape_with_hidden_size = shape + [model.config.hidden_size]
+ inputs_dict[input_name] = torch.zeros(shape_with_hidden_size, dtype=torch.float, device=device)
return inputs_dict
- def record(self, model, input_names, method_names=None):
+ def record(self, model: PreTrainedModel, input_names: List[str], method_names: Optional[Iterable[str]] = None):
"""
- Records torch.Tensor method outputs (specified by the method_names list) that will then be used during symbolic
- tracing.
+ Records torch.Tensor method outputs (specified by method_names) that will then be used during symbolic tracing.
"""
if method_names is None:
- method_names = self.default_methods_to_record
+ method_names = self._DEFAULT_METHODS_TO_RECORD
+
+ # Creating a random input shape to generate dummy inputs.
+ batch_size = _generate_random_int()
+ sequence_length = _generate_random_int()
+ shape = [batch_size, sequence_length]
+
+ if model.__class__ in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
+ num_choices = _generate_random_int(low=2, high=5)
+ shape.insert(1, num_choices)
inputs = {}
for input_name in input_names:
- inputs.update(self._generate_dummy_input(model, input_name))
+ inputs.update(self._generate_dummy_input(model, input_name, shape))
- clone = copy.deepcopy(model)
- cache_names, original_methods = _monkey_patch_tensor_methods_for_model_recording(clone, method_names)
+ cache_names, original_methods = self._monkey_patch_tensor_methods_for_model_recording(model, method_names)
self.original_methods = original_methods
- clone(**inputs)
-
- # Useful because sometime the config is changed at inference time, for instance for
- # classification tasks where config.problem_type can be set.
- model.config = clone.config
+ model(**inputs)
_reset_tensor_methods(original_methods)
self.recorded_methods = {
- method_name: cache_name for method_name, cache_name in cache_names.items() if hasattr(clone, cache_name)
+ method_name: cache_name for method_name, cache_name in cache_names.items() if hasattr(model, cache_name)
}
- for cache_name in self.recorded_methods.values():
- setattr(model, cache_name, getattr(clone, cache_name))
-
def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
if isinstance(attr_val, torch.nn.Parameter):
for n, p in self.root.named_parameters():
@@ -357,7 +444,20 @@ def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
return parameter_proxy_cache[n]
return attr_val
- def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] = None, method_names=None) -> Graph:
+ def proxy(self, node: Node):
+ p = HFProxy(node, self)
+ if self.recorded_methods:
+ for method_name, cache_name in self.recorded_methods.items():
+ return_proxy = self._DEFAULT_METHODS_TO_RECORD[method_name]
+ _create_recorded_proxy_method(p, method_name, cache_name, return_proxy)
+ return p
+
+ def trace(
+ self,
+ root: PreTrainedModel,
+ concrete_args: Optional[Dict[str, Any]] = None,
+ method_names: Optional[Iterable[str]] = None,
+ ) -> Graph:
if concrete_args is None:
concrete_args = {}
@@ -366,11 +466,16 @@ def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] =
self.record(root, input_names, method_names=method_names)
- for method_name, cache_name in self.recorded_methods.items():
- _wrap_method_for_model_tracing(root, method_name, cache_name)
+ # TODO: adapt the way leaf function are wrapped with the "autowrap function" feature from Tracer.
+ autowrap_functions = [patched for (_, _, patched) in self._leaf_functions_register.values()]
+ self._autowrap_function_ids.update(set([id(f) for f in autowrap_functions]))
+
+ self._patch_leaf_functions_for_root(root)
graph = super().trace(root, concrete_args=concrete_args)
+ self._patch_leaf_functions_for_root(root, restore=True)
+
_reset_tensor_methods(self.original_methods)
# TODO: keep this until necessary.
@@ -388,7 +493,7 @@ def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] =
return graph
- def _insert_module_as_submodule(self, mod):
+ def _insert_module_as_submodule(self, mod: nn.Module) -> str:
"""
Helper method which tries to insert a module that was not declared as submodule.
"""
@@ -434,72 +539,19 @@ def path_of_module(self, mod: nn.Module) -> str:
self.prev_module = path
return path
+ def is_leaf_module(self, m: nn.Module, module_qualified_name: str) -> bool:
+ is_loss_module = m.__module__.startswith("torch.nn.modules.loss")
+ return (not is_loss_module) and super().is_leaf_module(m, module_qualified_name)
+
def create_arg(self, a: Any) -> Argument:
if isinstance(a, range):
return super().create_arg(list(a))
return super().create_arg(a)
-@transformation
-def prepare_for_retracing(gm: GraphModule) -> Tuple[GraphModule, Dict[str, Any]]:
- """
- Prepares a GraphModule produced by symbolic_trace for retracing by:
-
- - Caching all the attributes specific to the way the model was initially traced
- - Patching back the model to a "static input shapes" version if it was traced to accept dynamic input shapes
- For instance, the need to retrace a GraphModule can happen when applying quantization.
- """
- attributes = _cache_attributes(gm)
- _patch_arguments_(gm, gm.dynamic2static)
-
- return gm, attributes
-
-
-def restore_after_retracing_(gm: GraphModule, attributes: Dict[str, Any]):
- """Restores a GraphModule that was retraced to its initial state in terms of static / dynamic input shapes."""
- _restore_attributes_(gm, attributes)
- # transform_to_dynamic_input_ will override the static2dynamic and dynamic2static dictionaries which is the desired
- # behaviour as the previously restored dictionaries contain nodes from the original GraphModule as values.
- transform_to_dynamic_input_(gm, is_retracing=True)
- _patch_arguments_(gm, gm.static2dynamic)
- return gm
-
-
-def retrace_graph_with(
- gm: GraphModule, tracer: Tracer = None, func: Callable[[GraphModule], GraphModule] = None
-) -> GraphModule:
- """
- Retraces a GraphModule by either using a tracer or a function using a tracer (for instance
- torch.quantization.quantize_fx.prepare_fx). It takes care of preparing the model for retracing, retracing it and
- restoring anything necessary after the retrace.
- """
- if tracer is None and func is None:
- raise ValueError("Either a tracer or a function using a tracer must be provided.")
- elif tracer is not None and func is not None:
- raise ValueError("Either provide a tracer or a function using a tracer, but not both.")
- else:
- gm, attributes = prepare_for_retracing(gm)
- tracing_func = tracer.trace if tracer else func
- traced = tracing_func(gm)
- restore_after_retracing_(traced, attributes)
- return traced
-
-
-def _generate_random_int(low: int = 10, high: int = 20, forbidden_values: Optional[List[int]] = None):
- if forbidden_values is None:
- forbidden_values = []
- value = random.randint(low, high)
- while value in forbidden_values:
- value = random.randint(low, high)
- return value
-
-
def symbolic_trace(
model: PreTrainedModel,
input_names: Optional[List[str]] = None,
- batch_size: int = 1,
- sequence_length: Union[int, List[int], Tuple[int]] = (128, 128),
- num_choices: int = -1,
) -> GraphModule:
"""
@@ -510,89 +562,33 @@ def symbolic_trace(
The model to trace.
input_names (`List[str]`, *optional*):
The names of the inputs of the traced model. If unset, model.dummy_inputs().keys() are used instead.
- batch_size (`int`, *optional*, defaults to 1):
- The batch size of the traced model inputs.
- sequence_length (`int` or `List[int]]`):
- The sequence length of the traced model inputs. For sequence-to-sequence models with different sequence
- lengths between the encoder and the decoder inputs, this must be `[encoder_sequence_length,
- decoder_sequence_length]`.
- num_choices (`int`, *optional*, defaults to -1):
- The number of possible choices for a multiple choice task.
Returns:
`torch.fx.GraphModule`: A GraphModule constructed by recording operations seen while tracing the model.
Example:
- ```python
- from transformers.utils.fx import symbolic_trace
+ ```python
+ from transformers.utils.fx import symbolic_trace
- traced_model = symbolic_trace(
- model,
- input_names=["input_ids", "attention_mask", "token_type_ids"],
- batch_size=1,
- sequence_length=128,
- )
- ```"""
+ traced_model = symbolic_trace(model, input_names=["input_ids", "attention_mask", "token_type_ids"])
+ ```
+ """
if input_names is None:
input_names = model.dummy_inputs.keys()
sig = inspect.signature(model.forward)
concrete_args = {p.name: p.default for p in sig.parameters.values() if p.name not in input_names}
- # Preparing HFTracer batch_size and sequence_lenght values for potential dynamic axes.
- use_dynamic_batch_size = batch_size <= 0
- if isinstance(sequence_length, (list, tuple)):
- use_dynamic_sequence_length = sequence_length[0] <= 0 or sequence_length[1] <= 0
- else:
- use_dynamic_sequence_length = sequence_length <= 0
-
- if use_dynamic_batch_size or use_dynamic_sequence_length:
- forbidden_values = [
- model.config.num_attention_heads,
- model.config.hidden_size,
- model.config.hidden_size // model.config.num_attention_heads,
- ]
- if use_dynamic_batch_size:
- batch_size = _generate_random_int(forbidden_values=forbidden_values)
- forbidden_values.append(batch_size)
- if use_dynamic_sequence_length:
- encoder_sequence_length = _generate_random_int(forbidden_values=forbidden_values)
- forbidden_values.append(encoder_sequence_length)
- decoder_sequence_length = _generate_random_int(forbidden_values=forbidden_values)
- sequence_length = [encoder_sequence_length, decoder_sequence_length]
-
if not isinstance(model, _SUPPORTED_MODELS):
supported_model_names = ", ".join((cls.__name__ for cls in _SUPPORTED_MODELS))
raise NotImplementedError(
f"Model {model.__class__.__name__} is not supported yet, supported models: {supported_model_names}"
)
- if (use_dynamic_batch_size or use_dynamic_sequence_length) and not isinstance(
- model, _SUPPORTED_MODELS_FOR_DYNAMIC_AXES
- ):
- supported_model_names = ", ".join((cls.__name__ for cls in _SUPPORTED_MODELS_FOR_DYNAMIC_AXES))
- raise NotImplementedError(
- f"Dynamic axes are not supported for {model.__class__.__name__} yet, supported models: {supported_model_names}"
- )
# Tracing.
- tracer = HFTracer(batch_size=batch_size, sequence_length=sequence_length, num_choices=num_choices)
-
+ tracer = HFTracer()
traced_graph = tracer.trace(model, concrete_args=concrete_args)
traced = torch.fx.GraphModule(model, traced_graph)
- traced.config = copy.deepcopy(model.config)
- traced.num_choices = num_choices
- traced.dummy_inputs = {}
-
- for name in input_names:
- traced.dummy_inputs.update(tracer._generate_dummy_input(model, name))
-
- traced.use_dynamic_batch_size = use_dynamic_batch_size
- traced.use_dynamic_sequence_length = use_dynamic_sequence_length
- traced.static_batch_size = batch_size
- traced.static_sequence_length = sequence_length
-
- transform_to_dynamic_input_(traced)
-
return traced
diff --git a/src/transformers/utils/fx_transformations.py b/src/transformers/utils/fx_transformations.py
deleted file mode 100644
index 3e181617af10..000000000000
--- a/src/transformers/utils/fx_transformations.py
+++ /dev/null
@@ -1,321 +0,0 @@
-import copy
-import functools
-import operator
-from inspect import signature
-from typing import Any, Callable, Dict, Optional, Union
-
-import torch
-from torch.fx import Graph, GraphModule, Node
-
-
-# Torch FX transformation convention:
-# - transformations that are supposed to act on a copy of the original GraphModule are decorated with @transformation
-# - transformations that are inplace have a name ending with "_"
-
-
-def _cache_attributes(gm: GraphModule) -> Dict[str, Any]:
- attributes_to_keep = [
- "config",
- "num_choices",
- "dummy_inputs",
- "use_dynamic_batch_size",
- "use_dynamic_sequence_length",
- "static_batch_size",
- "static_sequence_length",
- "static2dynamic",
- "dynamic2static",
- ]
- attributes = {k: getattr(gm, k, None) for k in attributes_to_keep}
- return attributes
-
-
-def _restore_attributes_(gm: GraphModule, attributes: Dict[str, Any]):
- for name, attr in attributes.items():
- setattr(gm, name, attr)
-
-
-def deepcopy_graph(gm: GraphModule) -> GraphModule:
- """
- Performs a deepcopy of the GraphModule while also copying the relevant attributes to know whether the model was
- traced with dynamic axes, and what were the values if that is the case.
- """
-
- # First, create a copy of the module without the graph.
- graph = gm.__dict__.pop("_graph")
- fake_mod = torch.nn.Module()
- fake_mod.__dict__ = copy.deepcopy(gm.__dict__)
- gm.__dict__["_graph"] = graph
-
- # Then, copy the graph.
- val_map = {}
- graph_clone = Graph()
- output_val = graph_clone.graph_copy(graph, val_map=val_map)
- graph_clone.output(output_val)
-
- # Finally create a new GraphModule (or a subclass of GraphModule) from the module and the graph copies.
- # gm.__class__ is used to take into account that gm can be an instance of a subclass of GraphModule.
- clone = gm.__class__(fake_mod, graph_clone)
-
- # Restore the dynamic axes related attributes to the clone.
- attributes = _cache_attributes(gm)
- attributes["dynamic2static"] = {val_map.get(k, k): v for k, v in attributes["dynamic2static"].items()}
- attributes["static2dynamic"] = {v: k for k, v in attributes["dynamic2static"].items()}
- _restore_attributes_(clone, attributes)
-
- return clone
-
-
-def transformation(func):
- """
- Decorator that wraps a torch.fx transformation by feeding it a copy of the GraphModule to transform instead of the
- original.
- """
-
- def map_fn(arg):
- if isinstance(arg, GraphModule):
- return deepcopy_graph(arg)
- return arg
-
- @functools.wraps(func)
- def wrapper(*args, **kwargs):
- new_args = tuple(map_fn(arg) for arg in args)
- new_kwargs = {k: map_fn(v) for k, v in kwargs.items()}
- return func(*new_args, **new_kwargs)
-
- wrapper._is_transformation = True
-
- return wrapper
-
-
-def compose_transformations(
- *args: Callable[[GraphModule], Optional[GraphModule]], inplace: bool = False
-) -> GraphModule:
- """
- Allows to compose transformations together and takes of:
-
- 1. Performing the transformations on a copy of the GraphModule if inplace is set to False, transformations that
- are decorated with @transformation (which means that they are not modifying the original GraphModule) are
- unwrapped to make them inplace.
- 2. Linting and recompiling only at the end of the composition for performance purposes.
- """
- args = list(args)
- if not inplace:
- args.insert(0, deepcopy_graph)
-
- for i, transformation in enumerate(args[:-1]):
- sig = signature(transformation)
-
- # Unwrapping @transformation decorated transformations as performing the transformations inplace or on a copy is
- # already handled by this function.
- if getattr(transformation, "_is_transformation", False):
- transformation = transformation.__wrapped__
-
- # Linting and recompiling only after the last transformation applied to make composition efficient.
- if "lint_and_recompile" in sig.parameters:
- args[i] = functools.partial(transformation, lint_and_recompile=False)
-
- def reduce_func(f, g):
- def compose_f_and_g(gm):
- output_g = g(gm)
- if output_g is None:
- output_g = gm
- output_f = f(output_g)
- if output_f is None:
- output_f = gm
- return output_f
-
- return compose_f_and_g
-
- return functools.reduce(reduce_func, reversed(args), lambda x: x)
-
-
-def remove_unused_nodes_(gm: GraphModule, lint_and_recompile: bool = True):
- """Removes all the unused nodes in a GraphModule."""
- graph = gm.graph
- for node in graph.nodes:
- if not node.users and node.op not in ["placeholder", "output"]:
- graph.erase_node(node)
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _insert_batch_size_node_(gm: GraphModule, lint_and_recompile: bool = True) -> Node:
- """Inserts a node that retrieves the batch size dynamically from the input of the model."""
- graph = gm.graph
- input_names = set(gm.dummy_inputs.keys())
- batch_size_node = None
- for node in graph.nodes:
- if node.op == "placeholder" and node.name in input_names:
- with graph.inserting_after(node):
- batch_size_node = graph.call_method("size", args=(node, 0))
-
- if batch_size_node is None:
- raise ValueError("Could not insert the node that computes the batch size")
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[batch_size_node.name] = None
-
- return batch_size_node
-
-
-def _insert_encoder_sequence_length_node_(gm: GraphModule, lint_and_recompile: bool = True) -> Node:
- """Inserts a node that retrieves the encoder sequence length dynamically from the input of the model."""
- graph = gm.graph
- input_names = set(gm.dummy_inputs.keys())
- encoder_sequence_length_node = None
- for node in graph.nodes:
- if node.op == "placeholder" and node.name in input_names and "decoder" not in node.name:
- with graph.inserting_after(node):
- # There are two cases to handle:
- # 1. num_choices < 0, meaning that the model is not performing a "multiple choice" task, in this case the
- # input shapes is [batch_size, sequence_length] => index 1
- # 2. num_choices > 0, meaning the model is performing a "multiple choice" task, in this case the input
- # shape is [batch_size, num_choices, sequence_length] => index 2
- encoder_sequence_length_node = graph.call_method("size", args=(node, 1 if gm.num_choices < 0 else 2))
-
- if encoder_sequence_length_node is None:
- raise ValueError("Could not insert the node that computes the encoder sequence length")
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[encoder_sequence_length_node.name] = None
-
- return encoder_sequence_length_node
-
-
-def _change_view_methods_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """
- Changes arguments of view ops that refer to static batch size / sequence lengths to make them refer to the
- batch_size / sequence_length nodes.
- """
- graph = gm.graph
- for node in graph.nodes:
- if node.op == "call_method" and node.target == "view":
- if isinstance(node.args[1], tuple):
- node.args = (node.args[0], *node.args[1])
- node.args = tuple((mapping.get(arg, arg) for arg in node.args))
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _patch_getitem_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """Patches getitem nodes by replacing current arguments to their corresponding values in mapping."""
- # TODO: combine this with the patch_argument function which seems to do almost the same thing.
- graph = gm.graph
- for node in graph.nodes:
- if node.op == "call_function" and node.target == operator.getitem:
- indices = node.args[1]
- if isinstance(indices, tuple):
- new_indices = []
- for idx in indices:
- if isinstance(idx, slice):
- new_indices.append(
- slice(
- mapping.get(idx.start, idx.start),
- mapping.get(idx.stop, idx.stop),
- mapping.get(idx.step, idx.step),
- )
- )
- elif isinstance(idx, int):
- new_indices.append(mapping.get(idx, idx))
- else:
- new_indices.append(idx)
-
- node.args = (node.args[0], tuple(new_indices))
- else:
- node.args = (node.args[0], mapping.get(node.args[1], node.args[1]))
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _patch_arguments_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """
- Patches node by replacing their argument to their corresponding values in mapping (supports regular types, tuples
- and slices).
- """
-
- def _patch_slice(s, mapping):
- return slice(mapping.get(s.start, s.start), mapping.get(s.stop, s.stop), mapping.get(s.step, s.step))
-
- graph = gm.graph
- supported_types = (Node, str, int, float)
- for node in graph.nodes:
- new_args = []
- for arg in node.args:
- if isinstance(arg, tuple):
- new_arg = []
- for a in arg:
- if isinstance(a, slice):
- new_arg.append(_patch_slice(a, mapping))
- else:
- new_arg.append(mapping.get(a, a))
- new_args.append(tuple(new_arg))
- elif isinstance(arg, slice):
- new_args.append(_patch_slice(arg, mapping))
- elif isinstance(arg, supported_types):
- new_args.append(mapping.get(arg, arg))
- else:
- new_args.append(arg)
- node.args = tuple(new_args)
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def transform_to_dynamic_input_(gm: GraphModule, is_retracing: bool = False):
- """Transformation that enables traced models to perform inference on dynamic input shapes."""
- graph = gm.graph
- static2dynamic = {}
-
- # Inserting the nodes that will fetch the batch size and sequence lengths dynamically.
- if gm.use_dynamic_batch_size:
- batch_size_node = _insert_batch_size_node_(gm, lint_and_recompile=False)
- static2dynamic[gm.static_batch_size] = batch_size_node
- if gm.num_choices > 0:
- with graph.inserting_after(batch_size_node):
- static2dynamic[gm.static_batch_size * gm.num_choices] = graph.call_function(
- operator.mul, args=(batch_size_node, gm.num_choices)
- )
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[static2dynamic[gm.static_batch_size * gm.num_choices]] = None
-
- if gm.use_dynamic_sequence_length:
- encoder_sequence_length_node = _insert_encoder_sequence_length_node_(gm, lint_and_recompile=False)
- static2dynamic[gm.static_sequence_length[0]] = encoder_sequence_length_node
-
- # TODO: do the same for the decoder.
- pass
-
- _change_view_methods_(gm, static2dynamic, lint_and_recompile=False)
- _patch_getitem_(gm, static2dynamic, lint_and_recompile=False)
-
- remove_unused_nodes_(gm, lint_and_recompile=False)
-
- graph.lint()
- gm.recompile()
-
- gm.static2dynamic = static2dynamic
- gm.dynamic2static = {v: k for (k, v) in static2dynamic.items()}
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
index 63233c4bf9ff..69a0d8176683 100755
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
@@ -2832,6 +2832,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
diff --git a/tests/test_feature_extraction_convnext.py b/tests/test_feature_extraction_convnext.py
new file mode 100644
index 000000000000..1439f3a28cac
--- /dev/null
+++ b/tests/test_feature_extraction_convnext.py
@@ -0,0 +1,195 @@
+# coding=utf-8
+# Copyright 2022s HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from .test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ConvNextFeatureExtractor
+
+
+class ConvNextFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=20,
+ crop_pct=0.875,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "crop_pct": self.crop_pct,
+ }
+
+
+@require_torch
+@require_vision
+class ConvNextFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = ConvNextFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = ConvNextFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "crop_pct"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/test_modeling_albert.py b/tests/test_modeling_albert.py
index d16dcadd5e6a..ab5595f4b6f8 100644
--- a/tests/test_modeling_albert.py
+++ b/tests/test_modeling_albert.py
@@ -231,8 +231,7 @@ class AlbertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_beit.py b/tests/test_modeling_beit.py
index 777247161abd..2304678e79c8 100644
--- a/tests/test_modeling_beit.py
+++ b/tests/test_modeling_beit.py
@@ -92,17 +92,20 @@ def __init__(
self.initializer_range = initializer_range
self.scope = scope
self.out_indices = out_indices
+ self.num_labels = num_labels
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
+ pixel_labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ pixel_labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
config = self.get_config()
- return config, pixel_values, labels
+ return config, pixel_values, labels, pixel_labels
def get_config(self):
return BeitConfig(
@@ -122,7 +125,7 @@ def get_config(self):
out_indices=self.out_indices,
)
- def create_and_check_model(self, config, pixel_values, labels):
+ def create_and_check_model(self, config, pixel_values, labels, pixel_labels):
model = BeitModel(config=config)
model.to(torch_device)
model.eval()
@@ -133,7 +136,7 @@ def create_and_check_model(self, config, pixel_values, labels):
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
- def create_and_check_for_masked_lm(self, config, pixel_values, labels):
+ def create_and_check_for_masked_lm(self, config, pixel_values, labels, pixel_labels):
model = BeitForMaskedImageModeling(config=config)
model.to(torch_device)
model.eval()
@@ -144,7 +147,7 @@ def create_and_check_for_masked_lm(self, config, pixel_values, labels):
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.parent.assertEqual(result.logits.shape, (self.batch_size, num_patches, self.vocab_size))
- def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ def create_and_check_for_image_classification(self, config, pixel_values, labels, pixel_labels):
config.num_labels = self.type_sequence_label_size
model = BeitForImageClassification(config)
model.to(torch_device)
@@ -152,13 +155,23 @@ def create_and_check_for_image_classification(self, config, pixel_values, labels
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+ def create_and_check_for_image_segmentation(self, config, pixel_values, labels, pixel_labels):
+ config.num_labels = self.num_labels
+ model = BeitForSemanticSegmentation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+ result = model(pixel_values, labels=pixel_labels)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
- (
- config,
- pixel_values,
- labels,
- ) = config_and_inputs
+ config, pixel_values, labels, pixel_labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@@ -217,6 +230,10 @@ def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
+ def test_for_image_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_segmentation(*config_and_inputs)
+
def test_training(self):
if not self.model_tester.is_training:
return
@@ -516,14 +533,14 @@ def test_inference_semantic_segmentation(self):
logits = outputs.logits
# verify the logits
- expected_shape = torch.Size((1, 150, 160, 160))
+ expected_shape = torch.Size((1, 150, 640, 640))
self.assertEqual(logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-4.9225, -2.3954, -3.0522], [-2.8822, -1.0046, -1.7561], [-2.9549, -1.3228, -2.1347]],
- [[-5.8168, -3.4129, -4.0778], [-3.8651, -2.2214, -3.0277], [-3.8356, -2.4643, -3.3535]],
- [[-0.0078, 3.9952, 4.0754], [2.9856, 4.6944, 5.0035], [3.2413, 4.7813, 4.9969]],
+ [[-4.9225, -4.9225, -4.6066], [-4.9225, -4.9225, -4.6066], [-4.6675, -4.6675, -4.3617]],
+ [[-5.8168, -5.8168, -5.5163], [-5.8168, -5.8168, -5.5163], [-5.5728, -5.5728, -5.2842]],
+ [[-0.0078, -0.0078, 0.4926], [-0.0078, -0.0078, 0.4926], [0.3664, 0.3664, 0.8309]],
]
).to(torch_device)
diff --git a/tests/test_modeling_bert.py b/tests/test_modeling_bert.py
index 7a6628509799..7b8738fd60f3 100755
--- a/tests/test_modeling_bert.py
+++ b/tests/test_modeling_bert.py
@@ -444,8 +444,7 @@ class BertModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
else ()
)
all_generative_model_classes = (BertLMHeadModel,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index 420b77503198..22cbd66b8149 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -116,8 +116,7 @@ class ModelTesterMixin:
model_tester = None
all_model_classes = ()
all_generative_model_classes = ()
- fx_ready_model_classes = ()
- fx_dynamic_ready_model_classes = ()
+ fx_compatible = False
test_torchscript = True
test_pruning = True
test_resize_embeddings = True
@@ -666,19 +665,14 @@ def test_torch_fx_output_loss(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
self._create_and_check_torch_fx_tracing(config, inputs_dict, output_loss=True)
- def test_torch_fx_dynamic_axes(self):
- config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
- self._create_and_check_torch_fx_tracing(config, inputs_dict, dynamic_axes=True)
-
- def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False, dynamic_axes=False):
- if not is_torch_fx_available():
+ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False):
+ if not is_torch_fx_available() or not self.fx_compatible:
return
configs_no_init = _config_zero_init(config) # To be sure we have no Nan
configs_no_init.return_dict = False
- model_classes = self.fx_ready_model_classes if not dynamic_axes else self.fx_dynamic_ready_model_classes
- for model_class in model_classes:
+ for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
model.to(torch_device)
model.eval()
@@ -687,8 +681,6 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
try:
if model.config.is_encoder_decoder:
model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
- input_ids = inputs["input_ids"]
- decoder_attention_mask = inputs["decoder_attention_mask"]
labels = inputs.get("labels", None)
input_names = ["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask"]
if labels is not None:
@@ -697,17 +689,7 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
model_output = model(**filtered_inputs)
- batch_size = input_ids.shape[0]
- encoder_sequence_length = input_ids.shape[1]
- decoder_sequence_length = decoder_attention_mask.shape[1]
-
- traced_model = symbolic_trace(
- model,
- input_names,
- batch_size=batch_size if not dynamic_axes else -1,
- sequence_length=[encoder_sequence_length, decoder_sequence_length] if not dynamic_axes else -1,
- )
-
+ traced_model = symbolic_trace(model, input_names)
traced_output = traced_model(**filtered_inputs)
else:
input_names = ["input_ids", "attention_mask", "token_type_ids"]
@@ -729,23 +711,12 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
model_output = model(**filtered_inputs)
rank = len(input_ids.shape)
- if rank == 2:
- batch_size, sequence_length = input_ids.shape
- num_choices = -1
- elif rank == 3:
- batch_size, num_choices, sequence_length = input_ids.shape
- else:
+ if rank not in [2, 3]:
raise NotImplementedError(
f"symbolic_trace automatic parameters inference not implemented for input of rank {rank}."
)
- traced_model = symbolic_trace(
- model,
- input_names,
- batch_size=batch_size if not dynamic_axes else -1,
- sequence_length=sequence_length if not dynamic_axes else -1,
- num_choices=num_choices,
- )
+ traced_model = symbolic_trace(model, input_names)
traced_output = traced_model(**filtered_inputs)
except RuntimeError:
diff --git a/tests/test_modeling_convnext.py b/tests/test_modeling_convnext.py
new file mode 100644
index 000000000000..c351685a418e
--- /dev/null
+++ b/tests/test_modeling_convnext.py
@@ -0,0 +1,339 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch ConvNext model. """
+
+
+import inspect
+import unittest
+from typing import Dict, List, Tuple
+
+from transformers import ConvNextConfig
+from transformers.file_utils import cached_property, is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from .test_configuration_common import ConfigTester
+from .test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import ConvNextForImageClassification, ConvNextModel
+ from transformers.models.convnext.modeling_convnext import CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoFeatureExtractor
+
+
+class ConvNextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ num_channels=3,
+ num_stages=4,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[2, 2, 3, 2],
+ is_training=True,
+ use_labels=True,
+ intermediate_size=37,
+ hidden_act="gelu",
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_stages = num_stages
+ self.hidden_sizes = hidden_sizes
+ self.depths = depths
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return ConvNextConfig(
+ num_channels=self.num_channels,
+ hidden_sizes=self.hidden_sizes,
+ depths=self.depths,
+ num_stages=self.num_stages,
+ hidden_act=self.hidden_act,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = ConvNextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ # expected last hidden states: B, C, H // 32, W // 32
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.hidden_sizes[-1], self.image_size // 32, self.image_size // 32),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.type_sequence_label_size
+ model = ConvNextForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ConvNextModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ConvNext does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ConvNextModel,
+ ConvNextForImageClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ConvNextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ConvNextConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.create_and_test_config_common_properties()
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def create_and_test_config_common_properties(self):
+ return
+
+ @unittest.skip(reason="ConvNext does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ConvNext does not support input and output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Model doesn't have attention layers")
+ def test_attention_outputs(self):
+ pass
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_stages = self.model_tester.num_stages
+ self.assertEqual(len(hidden_states), expected_num_stages + 1)
+
+ # ConvNext's feature maps are of shape (batch_size, num_channels, height, width)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 4, self.model_tester.image_size // 4],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+ outputs = model(**inputs)
+ output = outputs[0]
+
+ hidden_states = outputs.hidden_states[0]
+ hidden_states.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=f"Tuple and dict output are not equal. Difference: {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`: {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}.",
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = ConvNextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class ConvNextModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return AutoFeatureExtractor.from_pretrained("facebook/convnext-tiny-224") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.0260, -0.4739, 0.1911]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
diff --git a/tests/test_modeling_distilbert.py b/tests/test_modeling_distilbert.py
index ee8a8cbd3dd9..b81e42bcf175 100644
--- a/tests/test_modeling_distilbert.py
+++ b/tests/test_modeling_distilbert.py
@@ -209,8 +209,7 @@ class DistilBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else None
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
test_pruning = True
test_torchscript = True
test_resize_embeddings = True
diff --git a/tests/test_modeling_electra.py b/tests/test_modeling_electra.py
index be19f8d610db..065d59682693 100644
--- a/tests/test_modeling_electra.py
+++ b/tests/test_modeling_electra.py
@@ -369,10 +369,7 @@ class ElectraModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- all_generative_model_classes = (ElectraForCausalLM,) if is_torch_available() else ()
-
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_gpt2.py b/tests/test_modeling_gpt2.py
index ef51c815e455..cd13be27bbc3 100644
--- a/tests/test_modeling_gpt2.py
+++ b/tests/test_modeling_gpt2.py
@@ -433,7 +433,7 @@ class GPT2ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
)
all_generative_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
all_parallelizable_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_missing_keys = False
test_model_parallel = True
diff --git a/tests/test_modeling_gpt_neo.py b/tests/test_modeling_gpt_neo.py
index a8e5b4babc57..b8f942ef1786 100644
--- a/tests/test_modeling_gpt_neo.py
+++ b/tests/test_modeling_gpt_neo.py
@@ -372,7 +372,7 @@ class GPTNeoModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase
(GPTNeoModel, GPTNeoForCausalLM, GPTNeoForSequenceClassification) if is_torch_available() else ()
)
all_generative_model_classes = (GPTNeoForCausalLM,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_missing_keys = False
test_pruning = False
test_model_parallel = False
diff --git a/tests/test_modeling_gptj.py b/tests/test_modeling_gptj.py
index dd743b80d76a..d6b9f9292621 100644
--- a/tests/test_modeling_gptj.py
+++ b/tests/test_modeling_gptj.py
@@ -363,7 +363,7 @@ class GPTJModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
else ()
)
all_generative_model_classes = (GPTJForCausalLM,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_pruning = False
test_missing_keys = False
test_model_parallel = False
diff --git a/tests/test_modeling_megatron_bert.py b/tests/test_modeling_megatron_bert.py
index a7f47ddea322..7ac507988fe0 100644
--- a/tests/test_modeling_megatron_bert.py
+++ b/tests/test_modeling_megatron_bert.py
@@ -283,9 +283,7 @@ class MegatronBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
-
+ fx_compatible = True
# test_resize_embeddings = False
test_head_masking = False
diff --git a/tests/test_modeling_mobilebert.py b/tests/test_modeling_mobilebert.py
index 716714157a76..6ca14526a6dc 100644
--- a/tests/test_modeling_mobilebert.py
+++ b/tests/test_modeling_mobilebert.py
@@ -269,8 +269,7 @@ class MobileBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_roberta.py b/tests/test_modeling_roberta.py
index d0a8aab6b78e..1a55fda15292 100644
--- a/tests/test_modeling_roberta.py
+++ b/tests/test_modeling_roberta.py
@@ -356,6 +356,7 @@ class RobertaModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCas
else ()
)
all_generative_model_classes = (RobertaForCausalLM,) if is_torch_available() else ()
+ fx_compatible = True
def setUp(self):
self.model_tester = RobertaModelTester(self)
diff --git a/tests/test_modeling_segformer.py b/tests/test_modeling_segformer.py
index 2e84b1f41d17..3bb293065590 100644
--- a/tests/test_modeling_segformer.py
+++ b/tests/test_modeling_segformer.py
@@ -133,11 +133,11 @@ def create_and_check_for_image_segmentation(self, config, pixel_values, labels):
model.eval()
result = model(pixel_values)
self.parent.assertEqual(
- result.logits.shape, (self.batch_size, self.num_labels, self.image_size // 4, self.image_size // 4)
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
)
result = model(pixel_values, labels=labels)
self.parent.assertEqual(
- result.logits.shape, (self.batch_size, self.num_labels, self.image_size // 4, self.image_size // 4)
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
)
def prepare_config_and_inputs_for_common(self):
@@ -245,6 +245,7 @@ def test_attention_outputs(self):
list(attentions[-1].shape[-3:]),
[self.model_tester.num_attention_heads[-1], expected_seq_len, expected_reduced_seq_len],
)
+ out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
@@ -255,7 +256,7 @@ def test_attention_outputs(self):
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
- self.assertEqual(3, len(outputs))
+ self.assertEqual(out_len + 1, len(outputs))
self_attentions = outputs.attentions
@@ -357,16 +358,17 @@ def test_inference_image_segmentation_ade(self):
encoded_inputs = feature_extractor(images=image, return_tensors="pt")
pixel_values = encoded_inputs.pixel_values.to(torch_device)
- outputs = model(pixel_values)
+ with torch.no_grad():
+ outputs = model(pixel_values)
- expected_shape = torch.Size((1, model.config.num_labels, 128, 128))
+ expected_shape = torch.Size((1, model.config.num_labels, 512, 512))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-4.6310, -5.5232, -6.2356], [-5.1921, -6.1444, -6.5996], [-5.4424, -6.2790, -6.7574]],
- [[-12.1391, -13.3122, -13.9554], [-12.8732, -13.9352, -14.3563], [-12.9438, -13.8226, -14.2513]],
- [[-12.5134, -13.4686, -14.4915], [-12.8669, -14.4343, -14.7758], [-13.2523, -14.5819, -15.0694]],
+ [[-4.6309, -4.6309, -4.7425], [-4.6309, -4.6309, -4.7425], [-4.7011, -4.7011, -4.8136]],
+ [[-12.1391, -12.1391, -12.2858], [-12.1391, -12.1391, -12.2858], [-12.2309, -12.2309, -12.3758]],
+ [[-12.5134, -12.5134, -12.6328], [-12.5134, -12.5134, -12.6328], [-12.5576, -12.5576, -12.6865]],
]
).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3, :3], expected_slice, atol=1e-4))
@@ -385,16 +387,17 @@ def test_inference_image_segmentation_city(self):
encoded_inputs = feature_extractor(images=image, return_tensors="pt")
pixel_values = encoded_inputs.pixel_values.to(torch_device)
- outputs = model(pixel_values)
+ with torch.no_grad():
+ outputs = model(pixel_values)
- expected_shape = torch.Size((1, model.config.num_labels, 128, 128))
+ expected_shape = torch.Size((1, model.config.num_labels, 512, 512))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-13.5748, -13.9111, -12.6500], [-14.3500, -15.3683, -14.2328], [-14.7532, -16.0424, -15.6087]],
- [[-17.1651, -15.8725, -12.9653], [-17.2580, -17.3718, -14.8223], [-16.6058, -16.8783, -16.7452]],
- [[-3.6456, -3.0209, -1.4203], [-3.0797, -3.1959, -2.0000], [-1.8757, -1.9217, -1.6997]],
+ [[-13.5729, -13.5729, -13.6149], [-13.5729, -13.5729, -13.6149], [-13.6697, -13.6697, -13.7224]],
+ [[-17.1638, -17.1638, -17.0022], [-17.1638, -17.1638, -17.0022], [-17.1754, -17.1754, -17.0358]],
+ [[-3.6452, -3.6452, -3.5670], [-3.6452, -3.6452, -3.5670], [-3.5744, -3.5744, -3.5079]],
]
).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3, :3], expected_slice, atol=1e-1))
diff --git a/tests/test_modeling_t5.py b/tests/test_modeling_t5.py
index 575850aa9014..c0b5739bca7f 100644
--- a/tests/test_modeling_t5.py
+++ b/tests/test_modeling_t5.py
@@ -509,7 +509,7 @@ class T5ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (T5Model, T5ForConditionalGeneration) if is_torch_available() else ()
all_generative_model_classes = (T5ForConditionalGeneration,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
all_parallelizable_model_classes = (T5Model, T5ForConditionalGeneration) if is_torch_available() else ()
test_pruning = False
test_torchscript = True
diff --git a/tests/test_modeling_tf_led.py b/tests/test_modeling_tf_led.py
index b42e8b538cdc..a77f17f87200 100644
--- a/tests/test_modeling_tf_led.py
+++ b/tests/test_modeling_tf_led.py
@@ -322,7 +322,7 @@ def check_encoder_attentions_output(outputs):
self.assertEqual(len(global_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
- [self.model_tester.num_attention_heads, encoder_seq_length, seq_length],
+ [self.model_tester.num_attention_heads, seq_length, seq_length],
)
self.assertListEqual(
list(global_attentions[0].shape[-3:]),
diff --git a/tests/test_modeling_wav2vec2.py b/tests/test_modeling_wav2vec2.py
index 9c07df5fed9d..b5e1bcd2cde3 100644
--- a/tests/test_modeling_wav2vec2.py
+++ b/tests/test_modeling_wav2vec2.py
@@ -202,6 +202,17 @@ def create_and_check_model_with_adapter(self, config, input_values, attention_ma
result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size)
)
+ def create_and_check_model_with_adapter_for_ctc(self, config, input_values, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 2 * config.hidden_size
+ model = Wav2Vec2ForCTC(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size)
+ )
+
def create_and_check_model_with_adapter_proj_dim(self, config, input_values, attention_mask):
config.add_adapter = True
config.output_hidden_size = 8
@@ -414,6 +425,10 @@ def test_model_with_adapter(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter(*config_and_inputs)
+ def test_model_with_adapter_for_ctc(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs)
+
def test_model_with_adapter_proj_dim(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs)
diff --git a/tests/test_modeling_xlnet.py b/tests/test_modeling_xlnet.py
index 5516b28e17e1..f4e90fbe7749 100644
--- a/tests/test_modeling_xlnet.py
+++ b/tests/test_modeling_xlnet.py
@@ -526,6 +526,7 @@ class XLNetModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase)
all_generative_model_classes = (
(XLNetLMHeadModel,) if is_torch_available() else ()
) # TODO (PVP): Check other models whether language generation is also applicable
+
test_pruning = False
# XLNet has 2 QA models -> need to manually set the correct labels for one of them here
diff --git a/tests/test_onnx_v2.py b/tests/test_onnx_v2.py
index 53b28718a60f..8bd88b74454e 100644
--- a/tests/test_onnx_v2.py
+++ b/tests/test_onnx_v2.py
@@ -174,7 +174,7 @@ def test_values_override(self):
("ibert", "kssteven/ibert-roberta-base"),
("camembert", "camembert-base"),
("distilbert", "distilbert-base-cased"),
- # ("longFormer", "longformer-base-4096"),
+ ("electra", "google/electra-base-generator"),
("roberta", "roberta-base"),
("xlm-roberta", "xlm-roberta-base"),
("layoutlm", "microsoft/layoutlm-base-uncased"),
diff --git a/tests/test_pipelines_automatic_speech_recognition.py b/tests/test_pipelines_automatic_speech_recognition.py
index 6b25fa9d6f8d..15b5f72612cd 100644
--- a/tests/test_pipelines_automatic_speech_recognition.py
+++ b/tests/test_pipelines_automatic_speech_recognition.py
@@ -107,6 +107,24 @@ def test_small_model_pt(self):
output = speech_recognizer(waveform)
self.assertEqual(output, {"text": "(Applaudissements)"})
+ @require_torch
+ def test_small_model_pt_seq2seq(self):
+ model_id = "hf-internal-testing/tiny-random-speech-encoder-decoder"
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_id)
+
+ speech_recognizer = pipeline(
+ task="automatic-speech-recognition",
+ model=model_id,
+ tokenizer=tokenizer,
+ feature_extractor=feature_extractor,
+ framework="pt",
+ )
+
+ waveform = np.tile(np.arange(1000, dtype=np.float32), 34)
+ output = speech_recognizer(waveform)
+ self.assertEqual(output, {"text": "あл ش 湯 清 ه ܬ া लᆨしث ल eか u w 全 u"})
+
@slow
@require_torch
@require_pyctcdecode
diff --git a/utils/check_repo.py b/utils/check_repo.py
index a58319658146..9ee2266ca736 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -118,8 +118,6 @@
"PerceiverForMultimodalAutoencoding",
"PerceiverForOpticalFlow",
"SegformerDecodeHead",
- "SegformerForSemanticSegmentation",
- "BeitForSemanticSegmentation",
"FlaxBeitForMaskedImageModeling",
"BeitForMaskedImageModeling",
"CLIPTextModel",
diff --git a/utils/check_table.py b/utils/check_table.py
index 9c81937f444f..449ad02c3b21 100644
--- a/utils/check_table.py
+++ b/utils/check_table.py
@@ -210,7 +210,7 @@ def check_onnx_model_list(overwrite=False):
"""Check the model list in the serialization.mdx is consistent with the state of the lib and maybe `overwrite`."""
current_list, start_index, end_index, lines = _find_text_in_file(
filename=os.path.join(PATH_TO_DOCS, "serialization.mdx"),
- start_prompt="",
+ start_prompt="",
end_prompt="The ONNX conversion is supported for the PyTorch versions of the models.",
)
new_list = get_onnx_model_list()
+
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## ConvNeXT specific outputs
+
+[[autodoc]] models.convnext.modeling_convnext.ConvNextModelOutput
+
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/parallelism.mdx b/docs/source/parallelism.mdx
index 61af187136b6..c832c740ffdf 100644
--- a/docs/source/parallelism.mdx
+++ b/docs/source/parallelism.mdx
@@ -308,9 +308,14 @@ ZeRO stage 3 is not a good choice either for the same reason - more inter-node c
And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
Implementations:
-- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed)
+- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
- [OSLO](https://github.com/tunib-ai/oslo)
+Important papers:
+
+- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
+https://arxiv.org/abs/2201.11990)
+
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## FlexFlow
diff --git a/docs/source/serialization.mdx b/docs/source/serialization.mdx
index 83d291f7672e..2be3fc3735ad 100644
--- a/docs/source/serialization.mdx
+++ b/docs/source/serialization.mdx
@@ -43,17 +43,17 @@ and are designed to be easily extendable to other architectures.
Ready-made configurations include the following architectures:
-
+
- ALBERT
- BART
- BERT
- CamemBERT
- DistilBERT
+- ELECTRA
- GPT Neo
- I-BERT
- LayoutLM
-- Longformer
- Marian
- mBART
- OpenAI GPT-2
diff --git a/examples/pytorch/speech-recognition/README.md b/examples/pytorch/speech-recognition/README.md
index 7db7811ba2c5..a462cf338576 100644
--- a/examples/pytorch/speech-recognition/README.md
+++ b/examples/pytorch/speech-recognition/README.md
@@ -127,6 +127,62 @@ python -m torch.distributed.launch \
On 8 V100 GPUs, this script should run in *ca.* 18 minutes and yield a CTC loss of **0.39** and word error rate
of **0.36**.
+
+### Multi GPU CTC with Dataset Streaming
+
+The following command shows how to use [Dataset Streaming mode](https://huggingface.co/docs/datasets/dataset_streaming.html)
+to fine-tune [XLS-R](https://huggingface.co/transformers/master/model_doc/xls_r.html)
+on [Common Voice](https://huggingface.co/datasets/common_voice) using 4 GPUs in half-precision.
+
+Streaming mode imposes several constraints on training:
+1. We need to construct a tokenizer beforehand and define it via `--tokenizer_name_or_path`.
+2. `--num_train_epochs` has to be replaced by `--max_steps`. Similarly, all other epoch-based arguments have to be
+replaced by step-based ones.
+3. Full dataset shuffling on each epoch is not possible, since we don't have the whole dataset available at once.
+However, the `--shuffle_buffer_size` argument controls how many examples we can pre-download before shuffling them.
+
+
+```bash
+**python -m torch.distributed.launch \
+ --nproc_per_node 4 run_speech_recognition_ctc_streaming.py \
+ --dataset_name="common_voice" \
+ --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
+ --tokenizer_name_or_path="anton-l/wav2vec2-tokenizer-turkish" \
+ --dataset_config_name="tr" \
+ --train_split_name="train+validation" \
+ --eval_split_name="test" \
+ --output_dir="wav2vec2-xls-r-common_voice-tr-ft" \
+ --overwrite_output_dir \
+ --max_steps="5000" \
+ --per_device_train_batch_size="8" \
+ --gradient_accumulation_steps="2" \
+ --learning_rate="5e-4" \
+ --warmup_steps="500" \
+ --evaluation_strategy="steps" \
+ --text_column_name="sentence" \
+ --save_steps="500" \
+ --eval_steps="500" \
+ --logging_steps="1" \
+ --layerdrop="0.0" \
+ --eval_metrics wer cer \
+ --save_total_limit="1" \
+ --mask_time_prob="0.3" \
+ --mask_time_length="10" \
+ --mask_feature_prob="0.1" \
+ --mask_feature_length="64" \
+ --freeze_feature_encoder \
+ --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
+ --max_duration_in_seconds="20" \
+ --shuffle_buffer_size="500" \
+ --fp16 \
+ --push_to_hub \
+ --do_train --do_eval \
+ --gradient_checkpointing**
+```
+
+On 4 V100 GPUs, this script should run in *ca.* 3h 31min and yield a CTC loss of **0.35** and word error rate
+of **0.29**.
+
### Examples CTC
The following tables present a couple of example runs on the most popular speech-recognition datasets.
@@ -175,6 +231,7 @@ they can serve as a baseline to improve upon.
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.35 | - | 1 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo/blob/main/run.sh) |
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft/blob/main/run.sh) |
| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) | 0.21 | - | 2 GPU Titan 24 GB RAM | 15h10 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-1b-common_voice-tr-ft/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` in streaming mode | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.29 | - | 4 GPU V100 | 3h31 | [here](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream) | [run.sh](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream/blob/main/run.sh) |
#### Multilingual Librispeech CTC
diff --git a/examples/pytorch/speech-recognition/requirements.txt b/examples/pytorch/speech-recognition/requirements.txt
index b8c475e40a1e..219959a4b267 100644
--- a/examples/pytorch/speech-recognition/requirements.txt
+++ b/examples/pytorch/speech-recognition/requirements.txt
@@ -1,4 +1,4 @@
-datasets >= 1.13.3
+datasets >= 1.18.0
torch >= 1.5
torchaudio
librosa
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
index eea78f58ae7c..b09b0b33f270 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -51,7 +51,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
-require_version("datasets>=1.13.3", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
@@ -146,7 +146,8 @@ class DataTrainingArguments:
train_split_name: str = field(
default="train+validation",
metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train+validation'"
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
},
)
eval_split_name: str = field(
diff --git a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
index 40bc9aeb9a56..ee5530caebd1 100755
--- a/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
+++ b/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -49,7 +49,7 @@
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
new file mode 100644
index 000000000000..9e69178088f6
--- /dev/null
+++ b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
@@ -0,0 +1,659 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+""" Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition in streaming mode"""
+
+import logging
+import os
+import re
+import sys
+import warnings
+from dataclasses import dataclass, field
+from typing import Dict, List, Optional, Union
+
+import datasets
+import numpy as np
+import torch
+from datasets import IterableDatasetDict, interleave_datasets, load_dataset, load_metric
+from torch.utils.data import IterableDataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForCTC,
+ AutoProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainerCallback,
+ TrainingArguments,
+ Wav2Vec2Processor,
+ set_seed,
+)
+from transformers.trainer_pt_utils import IterableDatasetShard
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
+check_min_version("4.17.0.dev0")
+
+require_version("datasets>=1.18.2", "To fix: pip install 'datasets>=1.18.2'")
+
+
+logger = logging.getLogger(__name__)
+
+
+def list_field(default=None, metadata=None):
+ return field(default_factory=lambda: default, metadata=metadata)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ tokenizer_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ freeze_feature_encoder: bool = field(
+ default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
+ )
+ attention_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
+ )
+ activation_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
+ )
+ feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
+ hidden_dropout: float = field(
+ default=0.0,
+ metadata={
+ "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
+ },
+ )
+ final_dropout: float = field(
+ default=0.0,
+ metadata={"help": "The dropout probability for the final projection layer."},
+ )
+ mask_time_prob: float = field(
+ default=0.05,
+ metadata={
+ "help": "Probability of each feature vector along the time axis to be chosen as the start of the vector"
+ "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature"
+ "vectors will be masked along the time axis."
+ },
+ )
+ mask_time_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the time axis."},
+ )
+ mask_feature_prob: float = field(
+ default=0.0,
+ metadata={
+ "help": "Probability of each feature vector along the feature axis to be chosen as the start of the vector"
+ "span to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature bins will be masked along the time axis."
+ },
+ )
+ mask_feature_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the feature axis."},
+ )
+ layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
+ ctc_loss_reduction: Optional[str] = field(
+ default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: str = field(
+ metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: str = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_split_name: str = field(
+ default="train+validation",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
+ },
+ )
+ eval_split_name: str = field(
+ default="test",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'test'"
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of validation examples to this "
+ "value if set."
+ },
+ )
+ shuffle_buffer_size: Optional[int] = field(
+ default=500,
+ metadata={
+ "help": "The number of streamed examples to download before shuffling them. The large the buffer, "
+ "the closer it is to real offline shuffling."
+ },
+ )
+ chars_to_ignore: Optional[List[str]] = list_field(
+ default=None,
+ metadata={"help": "A list of characters to remove from the transcripts."},
+ )
+ eval_metrics: List[str] = list_field(
+ default=["wer"],
+ metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds."},
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether to only do data preprocessing and skip training. "
+ "This is especially useful when data preprocessing errors out in distributed training due to timeout. "
+ "In this case, one should run the preprocessing in a non-distributed setup with `preprocessing_only=True` "
+ "so that the cached datasets can consequently be loaded in distributed training"
+ },
+ )
+ use_auth_token: bool = field(
+ default=False,
+ metadata={
+ "help": "If :obj:`True`, will use the token generated when running"
+ ":obj:`transformers-cli login` as HTTP bearer authorization for remote files."
+ },
+ )
+ phoneme_language: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "The target language that should be used be"
+ " passed to the tokenizer for tokenization. Note that"
+ " this is only relevant if the model classifies the"
+ " input audio to a sequence of phoneme sequences."
+ },
+ )
+
+
+@dataclass
+class DataCollatorCTCWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor (:class:`~transformers.AutoProcessor`)
+ The processor used for proccessing the data.
+ padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ max_length (:obj:`int`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ max_length_labels (:obj:`int`, `optional`):
+ Maximum length of the ``labels`` returned list and optionally padding length (see above).
+ pad_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ """
+
+ processor: AutoProcessor
+ padding: Union[bool, str] = "longest"
+ max_length: Optional[int] = None
+ pad_to_multiple_of: Optional[int] = None
+ pad_to_multiple_of_labels: Optional[int] = None
+
+ def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lenghts and need
+ # different padding methods
+ input_features = []
+ label_features = []
+ for feature in features:
+ if self.max_length and feature["input_values"].shape[-1] > self.max_length:
+ continue
+ input_features.append({"input_values": feature["input_values"]})
+ label_features.append({"input_ids": feature["labels"]})
+
+ batch = self.processor.pad(
+ input_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ return_tensors="pt",
+ )
+
+ with self.processor.as_target_processor():
+ labels_batch = self.processor.pad(
+ label_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of_labels,
+ return_tensors="pt",
+ )
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ batch["labels"] = labels
+
+ return batch
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # 1. First, let's load the dataset
+ raw_datasets = IterableDatasetDict()
+ raw_column_names = {}
+
+ def load_streaming_dataset(split, sampling_rate, **kwargs):
+ if "+" in split:
+ dataset_splits = [load_dataset(split=split_name, **kwargs) for split_name in split.split("+")]
+ # `features` and `cast_column` won't be available after interleaving, so we'll use them here
+ features = dataset_splits[0].features
+ # make sure that the dataset decodes audio with a correct sampling rate
+ dataset_splits = [
+ dataset.cast_column(data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate))
+ for dataset in dataset_splits
+ ]
+
+ interleaved_dataset = interleave_datasets(dataset_splits)
+ return interleaved_dataset, features
+ else:
+ dataset = load_dataset(split=split, **kwargs)
+ features = dataset.features
+ # make sure that the dataset decodes audio with a correct sampling rate
+ dataset = dataset.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate)
+ )
+ return dataset, features
+
+ # `datasets` takes care of automatically loading and resampling the audio,
+ # so we just need to set the correct target sampling rate and normalize the input
+ # via the `feature_extractor`
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
+ )
+
+ if training_args.do_train:
+ raw_datasets["train"], train_features = load_streaming_dataset(
+ path=data_args.dataset_name,
+ name=data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ use_auth_token=data_args.use_auth_token,
+ streaming=True,
+ sampling_rate=feature_extractor.sampling_rate,
+ )
+ raw_column_names["train"] = list(train_features.keys())
+
+ if data_args.audio_column_name not in raw_column_names["train"]:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--audio_column_name` to the correct audio column - one of "
+ f"{', '.join(raw_column_names['train'])}."
+ )
+
+ if data_args.text_column_name not in raw_column_names["train"]:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(raw_column_names['train'])}."
+ )
+
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].take(range(data_args.max_train_samples))
+
+ if training_args.do_eval:
+ raw_datasets["eval"], eval_features = load_streaming_dataset(
+ path=data_args.dataset_name,
+ name=data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ use_auth_token=data_args.use_auth_token,
+ streaming=True,
+ sampling_rate=feature_extractor.sampling_rate,
+ )
+ raw_column_names["eval"] = list(eval_features.keys())
+
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].take(range(data_args.max_eval_samples))
+
+ # 2. We remove some special characters from the datasets
+ # that make training complicated and do not help in transcribing the speech
+ # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
+ # that could be easily picked up by the model
+ chars_to_ignore_regex = (
+ f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
+ )
+ text_column_name = data_args.text_column_name
+
+ def remove_special_characters(batch):
+ if chars_to_ignore_regex is not None:
+ batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
+ else:
+ batch["target_text"] = batch[text_column_name].lower() + " "
+ return batch
+
+ with training_args.main_process_first(desc="dataset map special characters removal"):
+ for split, dataset in raw_datasets.items():
+ raw_datasets[split] = dataset.map(
+ remove_special_characters,
+ ).remove_columns([text_column_name])
+
+ # 3. Next, let's load the config as we might need it to create
+ # the tokenizer
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_auth_token=data_args.use_auth_token
+ )
+
+ # 4. Now we can instantiate the tokenizer and model
+ # Note for distributed training, the .from_pretrained methods guarantee that only
+ # one local process can concurrently download model & vocab.
+
+ tokenizer_name_or_path = model_args.tokenizer_name_or_path
+ if tokenizer_name_or_path is None:
+ raise ValueError(
+ "Tokenizer has to be created before training in streaming mode. Please specify --tokenizer_name_or_path"
+ )
+ # load feature_extractor and tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ config=config,
+ use_auth_token=data_args.use_auth_token,
+ )
+
+ # adapt config
+ config.update(
+ {
+ "feat_proj_dropout": model_args.feat_proj_dropout,
+ "attention_dropout": model_args.attention_dropout,
+ "hidden_dropout": model_args.hidden_dropout,
+ "final_dropout": model_args.final_dropout,
+ "mask_time_prob": model_args.mask_time_prob,
+ "mask_time_length": model_args.mask_time_length,
+ "mask_feature_prob": model_args.mask_feature_prob,
+ "mask_feature_length": model_args.mask_feature_length,
+ "gradient_checkpointing": training_args.gradient_checkpointing,
+ "layerdrop": model_args.layerdrop,
+ "ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "pad_token_id": tokenizer.pad_token_id,
+ "vocab_size": len(tokenizer),
+ "activation_dropout": model_args.activation_dropout,
+ }
+ )
+
+ # create model
+ model = AutoModelForCTC.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ config=config,
+ use_auth_token=data_args.use_auth_token,
+ )
+
+ # freeze encoder
+ if model_args.freeze_feature_encoder:
+ model.freeze_feature_encoder()
+
+ # 5. Now we preprocess the datasets including loading the audio, resampling and normalization
+ audio_column_name = data_args.audio_column_name
+
+ # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
+ phoneme_language = data_args.phoneme_language
+
+ # Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ def prepare_dataset(batch):
+ # load audio
+ sample = batch[audio_column_name]
+
+ inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
+ batch["input_values"] = inputs.input_values[0]
+ batch["input_length"] = len(batch["input_values"])
+
+ # encode targets
+ additional_kwargs = {}
+ if phoneme_language is not None:
+ additional_kwargs["phonemizer_lang"] = phoneme_language
+
+ batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
+ return batch
+
+ vectorized_datasets = IterableDatasetDict()
+ with training_args.main_process_first(desc="dataset map preprocessing"):
+ for split, dataset in raw_datasets.items():
+ vectorized_datasets[split] = (
+ dataset.map(prepare_dataset)
+ .remove_columns(raw_column_names[split] + ["target_text"])
+ .with_format("torch")
+ )
+ if split == "train":
+ vectorized_datasets[split] = vectorized_datasets[split].shuffle(
+ buffer_size=data_args.shuffle_buffer_size,
+ seed=training_args.seed,
+ )
+
+ # 6. Next, we can prepare the training.
+ # Let's use word error rate (WER) as our evaluation metric,
+ # instantiate a data collator and the trainer
+
+ # Define evaluation metrics during training, *i.e.* word error rate, character error rate
+ eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
+
+ def compute_metrics(pred):
+ pred_logits = pred.predictions
+ pred_ids = np.argmax(pred_logits, axis=-1)
+
+ pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(pred_ids)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
+
+ metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
+
+ return metrics
+
+ # Now save everything to be able to create a single processor later
+ if is_main_process(training_args.local_rank):
+ # save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ try:
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+ except (OSError, KeyError):
+ warnings.warn(
+ "Loading a processor from a feature extractor config that does not"
+ " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
+ " attribute to your `preprocessor_config.json` file to suppress this warning: "
+ " `'processor_class': 'Wav2Vec2Processor'`",
+ FutureWarning,
+ )
+ processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
+
+ # Instantiate custom data collator
+ max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
+ data_collator = DataCollatorCTCWithPadding(processor=processor, max_length=max_input_length)
+
+ # trainer callback to reinitialize and reshuffle the streamable datasets at the beginning of each epoch
+ class ShuffleCallback(TrainerCallback):
+ def on_epoch_begin(self, args, state, control, train_dataloader, **kwargs):
+ if isinstance(train_dataloader.dataset, IterableDatasetShard):
+ pass # set_epoch() is handled by the Trainer
+ elif isinstance(train_dataloader.dataset, IterableDataset):
+ train_dataloader.dataset.set_epoch(train_dataloader.dataset._epoch + 1)
+
+ # Initialize Trainer
+ trainer = Trainer(
+ model=model,
+ data_collator=data_collator,
+ args=training_args,
+ compute_metrics=compute_metrics,
+ train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
+ eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
+ tokenizer=processor,
+ callbacks=[ShuffleCallback()],
+ )
+
+ # 7. Finally, we can start training
+
+ # Training
+ if training_args.do_train:
+
+ # use last checkpoint if exist
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+
+ metrics = train_result.metrics
+ if data_args.max_train_samples:
+ metrics["train_samples"] = data_args.max_train_samples
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+ if data_args.max_eval_samples:
+ metrics["eval_samples"] = data_args.max_eval_samples
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "speech-recognition",
+ "tags": ["automatic-speech-recognition", data_args.dataset_name],
+ "dataset_args": f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split: {data_args.eval_split_name}",
+ "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
+ }
+ if "common_voice" in data_args.dataset_name:
+ kwargs["language"] = config_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 0a133f71ebd0..bb022ba3682d 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -201,6 +201,7 @@
"CLIPVisionConfig",
],
"models.convbert": ["CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvBertConfig", "ConvBertTokenizer"],
+ "models.convnext": ["CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvNextConfig"],
"models.cpm": ["CpmTokenizer"],
"models.ctrl": ["CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP", "CTRLConfig", "CTRLTokenizer"],
"models.deberta": ["DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP", "DebertaConfig", "DebertaTokenizer"],
@@ -513,6 +514,7 @@
_import_structure["models.beit"].append("BeitFeatureExtractor")
_import_structure["models.clip"].append("CLIPFeatureExtractor")
_import_structure["models.clip"].append("CLIPProcessor")
+ _import_structure["models.convnext"].append("ConvNextFeatureExtractor")
_import_structure["models.deit"].append("DeiTFeatureExtractor")
_import_structure["models.detr"].append("DetrFeatureExtractor")
_import_structure["models.imagegpt"].append("ImageGPTFeatureExtractor")
@@ -688,6 +690,7 @@
"AutoModelForObjectDetection",
"AutoModelForPreTraining",
"AutoModelForQuestionAnswering",
+ "AutoModelForSemanticSegmentation",
"AutoModelForSeq2SeqLM",
"AutoModelForSequenceClassification",
"AutoModelForSpeechSeq2Seq",
@@ -837,6 +840,14 @@
"load_tf_weights_in_convbert",
]
)
+ _import_structure["models.convnext"].extend(
+ [
+ "CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ConvNextForImageClassification",
+ "ConvNextModel",
+ "ConvNextPreTrainedModel",
+ ]
+ )
_import_structure["models.ctrl"].extend(
[
"CTRL_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -1560,6 +1571,7 @@
"get_polynomial_decay_schedule_with_warmup",
"get_scheduler",
]
+ _import_structure["pytorch_utils"] = []
_import_structure["sagemaker"] = []
_import_structure["trainer"] = ["Trainer"]
_import_structure["trainer_pt_utils"] = ["torch_distributed_zero_first"]
@@ -2391,6 +2403,7 @@
CLIPVisionConfig,
)
from .models.convbert import CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvBertConfig, ConvBertTokenizer
+ from .models.convnext import CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvNextConfig
from .models.cpm import CpmTokenizer
from .models.ctrl import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP, CTRLConfig, CTRLTokenizer
from .models.deberta import DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP, DebertaConfig, DebertaTokenizer
@@ -2654,6 +2667,7 @@
from .image_utils import ImageFeatureExtractionMixin
from .models.beit import BeitFeatureExtractor
from .models.clip import CLIPFeatureExtractor, CLIPProcessor
+ from .models.convnext import ConvNextFeatureExtractor
from .models.deit import DeiTFeatureExtractor
from .models.detr import DetrFeatureExtractor
from .models.imagegpt import ImageGPTFeatureExtractor
@@ -2797,6 +2811,7 @@
AutoModelForObjectDetection,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
+ AutoModelForSemanticSegmentation,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForSpeechSeq2Seq,
@@ -2921,6 +2936,12 @@
ConvBertPreTrainedModel,
load_tf_weights_in_convbert,
)
+ from .models.convnext import (
+ CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ConvNextForImageClassification,
+ ConvNextModel,
+ ConvNextPreTrainedModel,
+ )
from .models.ctrl import (
CTRL_PRETRAINED_MODEL_ARCHIVE_LIST,
CTRLForSequenceClassification,
diff --git a/src/transformers/commands/add_new_model_like.py b/src/transformers/commands/add_new_model_like.py
index e443a235c42e..3ba5d71099de 100644
--- a/src/transformers/commands/add_new_model_like.py
+++ b/src/transformers/commands/add_new_model_like.py
@@ -1189,6 +1189,16 @@ def create_new_model_like(
if "tokenization" not in str(f) and "processor" not in str(f) and "feature_extraction" not in str(f)
]
+ def disable_fx_test(filename: Path) -> bool:
+ with open(filename) as fp:
+ content = fp.read()
+ new_content = re.sub(r"fx_compatible\s*=\s*True", "fx_compatible = False", content)
+ with open(filename, "w") as fp:
+ fp.write(new_content)
+ return content != new_content
+
+ disabled_fx_test = False
+
for test_file in files_to_adapt:
new_test_file_name = test_file.name.replace(
old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
@@ -1201,6 +1211,13 @@ def create_new_model_like(
dest_file=dest_file,
add_copied_from=False,
)
+ disabled_fx_test = disabled_fx_test | disable_fx_test(dest_file)
+
+ if disabled_fx_test:
+ print(
+ "The tests for symbolic tracing with torch.fx were disabled, you can add those once symbolic tracing works "
+ "for your new model."
+ )
# 4. Add model to auto classes
add_model_to_auto_classes(old_model_patterns, new_model_patterns, model_classes)
diff --git a/src/transformers/file_utils.py b/src/transformers/file_utils.py
index 1a4387d848f2..abc26cada9bd 100644
--- a/src/transformers/file_utils.py
+++ b/src/transformers/file_utils.py
@@ -322,7 +322,7 @@
HUGGINGFACE_CO_PREFIX = HUGGINGFACE_CO_RESOLVE_ENDPOINT + "/{model_id}/resolve/{revision}/{filename}"
# This is the version of torch required to run torch.fx features and torch.onnx with dictionary inputs.
-TORCH_FX_REQUIRED_VERSION = version.parse("1.9")
+TORCH_FX_REQUIRED_VERSION = version.parse("1.10")
TORCH_ONNX_DICT_INPUTS_MINIMUM_VERSION = version.parse("1.8")
_is_offline_mode = True if os.environ.get("TRANSFORMERS_OFFLINE", "0").upper() in ENV_VARS_TRUE_VALUES else False
diff --git a/src/transformers/generation_utils.py b/src/transformers/generation_utils.py
index 90bc5e19b76f..537c7cdecc3d 100644
--- a/src/transformers/generation_utils.py
+++ b/src/transformers/generation_utils.py
@@ -48,6 +48,7 @@
StoppingCriteriaList,
validate_stopping_criteria,
)
+from .pytorch_utils import torch_int_div
from .utils import logging
@@ -2024,7 +2025,7 @@ def beam_search(
next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
)
- next_indices = (next_tokens / vocab_size).long()
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2345,7 +2346,7 @@ def beam_sample(
next_token_scores, _indices = torch.sort(next_token_scores, descending=True, dim=1)
next_tokens = torch.gather(next_tokens, -1, _indices)
- next_indices = next_tokens // vocab_size
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2678,7 +2679,7 @@ def group_beam_search(
next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True
)
- next_indices = next_tokens // vocab_size
+ next_indices = torch_int_div(next_tokens, vocab_size)
next_tokens = next_tokens % vocab_size
# stateless
@@ -2706,7 +2707,7 @@ def group_beam_search(
# (beam_idx // group_size) -> batch_idx
# (beam_idx % group_size) -> offset of idx inside the group
reordering_indices[batch_group_indices] = (
- num_beams * (beam_idx // group_size) + group_start_idx + (beam_idx % group_size)
+ num_beams * torch_int_div(beam_idx, group_size) + group_start_idx + (beam_idx % group_size)
)
# Store scores, attentions and hidden_states when required
diff --git a/src/transformers/modeling_flax_pytorch_utils.py b/src/transformers/modeling_flax_pytorch_utils.py
index 2cc9575b5580..03e85875d0bc 100644
--- a/src/transformers/modeling_flax_pytorch_utils.py
+++ b/src/transformers/modeling_flax_pytorch_utils.py
@@ -82,19 +82,13 @@ def is_key_or_prefix_key_in_dict(key: Tuple[str]) -> bool:
if pt_tuple_key[-1] == "weight" and is_key_or_prefix_key_in_dict(renamed_pt_tuple_key):
return renamed_pt_tuple_key, pt_tensor
- # conv layer
+ # 2D conv layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 4 and not is_key_or_prefix_key_in_dict(pt_tuple_key):
pt_tensor = pt_tensor.transpose(2, 3, 1, 0)
return renamed_pt_tuple_key, pt_tensor
- # conv1d layer
- renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
- if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 3 and not is_key_or_prefix_key_in_dict(pt_tuple_key):
- pt_tensor = pt_tensor.transpose(2, 1, 0)
- return renamed_pt_tuple_key, pt_tensor
-
- # linear layer
+ # linear and 1D conv layer
renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
if pt_tuple_key[-1] == "weight" and not is_key_or_prefix_key_in_dict(pt_tuple_key):
pt_tensor = pt_tensor.T
diff --git a/src/transformers/modeling_outputs.py b/src/transformers/modeling_outputs.py
index c7f4a27fb38c..b0f3e01861ff 100644
--- a/src/transformers/modeling_outputs.py
+++ b/src/transformers/modeling_outputs.py
@@ -812,3 +812,32 @@ class Seq2SeqQuestionAnsweringModelOutput(ModelOutput):
encoder_last_hidden_state: Optional[torch.FloatTensor] = None
encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class SemanticSegmentationModelOutput(ModelOutput):
+ """
+ Base class for outputs of semantic segmentation models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels, height, width)`):
+ Classification scores for each pixel.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, patch_size, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 60477b18b54a..4845ff074306 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -23,7 +23,6 @@
from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
import torch
-from packaging import version
from torch import Tensor, device, nn
from torch.nn import CrossEntropyLoss
@@ -248,6 +247,27 @@ def invert_attention_mask(self, encoder_attention_mask: Tensor) -> Tensor:
return encoder_extended_attention_mask
+ def create_extended_attention_mask_for_decoder(self, input_shape, attention_mask, device):
+ batch_size, seq_length = input_shape
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones((batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ return extended_attention_mask
+
def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
@@ -272,26 +292,9 @@ def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
- batch_size, seq_length = input_shape
- seq_ids = torch.arange(seq_length, device=device)
- causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
- # in case past_key_values are used we need to add a prefix ones mask to the causal mask
- # causal and attention masks must have same type with pytorch version < 1.3
- causal_mask = causal_mask.to(attention_mask.dtype)
-
- if causal_mask.shape[1] < attention_mask.shape[1]:
- prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
- causal_mask = torch.cat(
- [
- torch.ones(
- (batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype
- ),
- causal_mask,
- ],
- axis=-1,
- )
-
- extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ extended_attention_mask = self.create_extended_attention_mask_for_decoder(
+ input_shape, attention_mask, device
+ )
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
@@ -1862,7 +1865,7 @@ def __init__(self, nf, nx):
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
- x = x.view(*size_out)
+ x = x.view(size_out)
return x
@@ -2463,13 +2466,3 @@ def forward(self, hidden_states):
return torch.cat(output_chunks, dim=chunk_dim)
return forward_fn(*input_tensors)
-
-
-def torch_int_div(tensor1, tensor2):
- """
- A function that performs integer division across different versions of PyTorch.
- """
- if version.parse(torch.__version__) < version.parse("1.8.0"):
- return tensor1 // tensor2
- else:
- return torch.div(tensor1, tensor2, rounding_mode="floor")
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index baf2b11ab714..d6cf69197ea9 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -37,6 +37,7 @@
canine,
clip,
convbert,
+ convnext,
cpm,
ctrl,
deberta,
diff --git a/src/transformers/models/albert/modeling_albert.py b/src/transformers/models/albert/modeling_albert.py
index 6f443fb4f8bc..a54a3874adf2 100755
--- a/src/transformers/models/albert/modeling_albert.py
+++ b/src/transformers/models/albert/modeling_albert.py
@@ -293,7 +293,7 @@ def __init__(self, config):
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention.transpose_for_scores
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def prune_heads(self, heads):
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 89d1c73b77d2..7798a51a8d1a 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -43,6 +43,7 @@
"MODEL_FOR_OBJECT_DETECTION_MAPPING",
"MODEL_FOR_PRETRAINING_MAPPING",
"MODEL_FOR_QUESTION_ANSWERING_MAPPING",
+ "MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
"MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
"MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
@@ -65,6 +66,7 @@
"AutoModelForObjectDetection",
"AutoModelForPreTraining",
"AutoModelForQuestionAnswering",
+ "AutoModelForSemanticSegmentation",
"AutoModelForSeq2SeqLM",
"AutoModelForSequenceClassification",
"AutoModelForSpeechSeq2Seq",
@@ -155,6 +157,7 @@
MODEL_FOR_OBJECT_DETECTION_MAPPING,
MODEL_FOR_PRETRAINING_MAPPING,
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING,
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
@@ -177,6 +180,7 @@
AutoModelForObjectDetection,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
+ AutoModelForSemanticSegmentation,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForSpeechSeq2Seq,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index ebd83c1be11c..1d94e90de058 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
+ ("convnext", "ConvNextConfig"),
("yoso", "YosoConfig"),
("swin", "SwinConfig"),
("vilt", "ViltConfig"),
@@ -124,6 +125,7 @@
CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here
+ ("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -205,6 +207,7 @@
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
+ ("convnext", "ConvNext"),
("yoso", "YOSO"),
("swin", "Swin"),
("vilt", "ViLT"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 4667178c787b..a146c611fb96 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -47,6 +47,7 @@
("swin", "ViTFeatureExtractor"),
("vit_mae", "ViTFeatureExtractor"),
("segformer", "SegformerFeatureExtractor"),
+ ("convnext", "ConvNextFeatureExtractor"),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 94909cfde50b..80190a9d2f96 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -28,6 +28,7 @@
MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
+ ("convnext", "ConvNextModel"),
("yoso", "YosoModel"),
("swin", "SwinModel"),
("vilt", "ViltModel"),
@@ -273,16 +274,26 @@
),
),
("swin", "SwinForImageClassification"),
+ ("convnext", "ConvNextForImageClassification"),
]
)
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES = OrderedDict(
[
+ # Do not add new models here, this class will be deprecated in the future.
# Model for Image Segmentation mapping
("detr", "DetrForSegmentation"),
]
)
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Semantic Segmentation mapping
+ ("beit", "BeitForSemanticSegmentation"),
+ ("segformer", "SegformerForSemanticSegmentation"),
+ ]
+)
+
MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("vision-encoder-decoder", "VisionEncoderDecoderModel"),
@@ -603,6 +614,9 @@
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES
)
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES
+)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_LM_MAPPING_NAMES)
MODEL_FOR_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES)
@@ -745,6 +759,15 @@ class AutoModelForImageSegmentation(_BaseAutoModelClass):
AutoModelForImageSegmentation = auto_class_update(AutoModelForImageSegmentation, head_doc="image segmentation")
+class AutoModelForSemanticSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING
+
+
+AutoModelForSemanticSegmentation = auto_class_update(
+ AutoModelForSemanticSegmentation, head_doc="semantic segmentation"
+)
+
+
class AutoModelForObjectDetection(_BaseAutoModelClass):
_model_mapping = MODEL_FOR_OBJECT_DETECTION_MAPPING
diff --git a/src/transformers/models/bart/modeling_bart.py b/src/transformers/models/bart/modeling_bart.py
index 381204cf2d30..70edf96cd2e3 100755
--- a/src/transformers/models/bart/modeling_bart.py
+++ b/src/transformers/models/bart/modeling_bart.py
@@ -1318,6 +1318,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/beit/configuration_beit.py b/src/transformers/models/beit/configuration_beit.py
index b668a2ed8c34..ebc46ee313ad 100644
--- a/src/transformers/models/beit/configuration_beit.py
+++ b/src/transformers/models/beit/configuration_beit.py
@@ -93,6 +93,10 @@ class BeitConfig(PretrainedConfig):
Whether to concatenate the output of the auxiliary head with the input before the classification layer.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
+ legacy_output (`bool`, *optional*, defaults to `False`):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`)
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Example:
@@ -141,6 +145,7 @@ def __init__(
auxiliary_num_convs=1,
auxiliary_concat_input=False,
semantic_loss_ignore_index=255,
+ legacy_output=False,
**kwargs
):
super().__init__(**kwargs)
@@ -176,3 +181,4 @@ def __init__(
self.auxiliary_num_convs = auxiliary_num_convs
self.auxiliary_concat_input = auxiliary_concat_input
self.semantic_loss_ignore_index = semantic_loss_ignore_index
+ self.legacy_output = legacy_output
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index 295d91f7e2ae..d42e4abc8edf 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -17,6 +17,7 @@
import collections.abc
import math
+import warnings
from dataclasses import dataclass
import torch
@@ -31,7 +32,13 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, MaskedLMOutput, SequenceClassifierOutput
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPooling,
+ MaskedLMOutput,
+ SemanticSegmentationModelOutput,
+ SequenceClassifierOutput,
+)
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_beit import BeitConfig
@@ -1114,11 +1121,8 @@ def __init__(self, config):
# Initialize weights and apply final processing
self.post_init()
- def compute_loss(self, logits, auxiliary_logits, labels):
+ def compute_loss(self, upsampled_logits, auxiliary_logits, labels):
# upsample logits to the images' original size
- upsampled_logits = nn.functional.interpolate(
- logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
- )
if auxiliary_logits is not None:
upsampled_auxiliary_logits = nn.functional.interpolate(
auxiliary_logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
@@ -1132,7 +1136,7 @@ def compute_loss(self, logits, auxiliary_logits, labels):
return loss
@add_start_docstrings_to_model_forward(BEIT_INPUTS_DOCSTRING)
- @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ @replace_return_docstrings(output_type=SemanticSegmentationModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values=None,
@@ -1141,11 +1145,17 @@ def forward(
output_attentions=None,
output_hidden_states=None,
return_dict=None,
+ legacy_output=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Ground truth semantic segmentation maps for computing the loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels > 1`, a classification loss is computed (Cross-Entropy).
+ legacy_output (`bool`, *optional*):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`). Will default
+ to `self.config.legacy_output`.
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Returns:
@@ -1164,13 +1174,21 @@ def forward(
>>> inputs = feature_extractor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
- >>> # logits are of shape (batch_size, num_labels, height/4, width/4)
+ >>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logits
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ legacy_output = legacy_output if legacy_output is not None else self.config.legacy_output
+ if not legacy_output:
+ warnings.warn(
+ "The output of this model has changed in v4.17.0 and the logits now have the same size as the inputs. "
+ "You can activate the previous behavior by passing `legacy_output=True` to this call or the "
+ "configuration of this model (only until v5, then that argument will be removed).",
+ FutureWarning,
+ )
outputs = self.beit(
pixel_values,
@@ -1197,6 +1215,11 @@ def forward(
features[i] = ops[i](features[i])
logits = self.decode_head(features)
+
+ upsampled_logits = nn.functional.interpolate(
+ logits, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False
+ )
+
auxiliary_logits = None
if self.auxiliary_head is not None:
auxiliary_logits = self.auxiliary_head(features)
@@ -1206,18 +1229,26 @@ def forward(
if self.config.num_labels == 1:
raise ValueError("The number of labels should be greater than one")
else:
- loss = self.compute_loss(logits, auxiliary_logits, labels)
+ loss = self.compute_loss(upsampled_logits, auxiliary_logits, labels)
if not return_dict:
if output_hidden_states:
- output = (logits,) + outputs[2:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[2:]
else:
- output = (logits,) + outputs[3:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[3:]
return ((loss,) + output) if loss is not None else output
- return SequenceClassifierOutput(
- loss=loss,
- logits=logits,
- hidden_states=outputs.hidden_states if output_hidden_states else None,
- attentions=outputs.attentions,
- )
+ if legacy_output:
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
+ else:
+ return SemanticSegmentationModelOutput(
+ loss=loss,
+ logits=upsampled_logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/bert/modeling_bert.py b/src/transformers/models/bert/modeling_bert.py
index 23dfbcee63a9..26c629f78f16 100755
--- a/src/transformers/models/bert/modeling_bert.py
+++ b/src/transformers/models/bert/modeling_bert.py
@@ -252,7 +252,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -341,7 +341,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
index c4db1b8bec5a..aa961e0f599b 100755
--- a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
@@ -2513,6 +2513,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/blenderbot/modeling_blenderbot.py b/src/transformers/models/blenderbot/modeling_blenderbot.py
index df098dd6e195..7751a74f9658 100755
--- a/src/transformers/models/blenderbot/modeling_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_blenderbot.py
@@ -1287,6 +1287,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
index 5875a827fab9..a22c4d0ce6cc 100755
--- a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
@@ -1258,6 +1258,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/convnext/__init__.py b/src/transformers/models/convnext/__init__.py
new file mode 100644
index 000000000000..cdc064d3c994
--- /dev/null
+++ b/src/transformers/models/convnext/__init__.py
@@ -0,0 +1,58 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+# rely on isort to merge the imports
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_convnext": ["CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ConvNextConfig"],
+}
+
+if is_vision_available():
+ _import_structure["feature_extraction_convnext"] = ["ConvNextFeatureExtractor"]
+
+if is_torch_available():
+ _import_structure["modeling_convnext"] = [
+ "CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ConvNextForImageClassification",
+ "ConvNextModel",
+ "ConvNextPreTrainedModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_convnext import CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP, ConvNextConfig
+
+ if is_vision_available():
+ from .feature_extraction_convnext import ConvNextFeatureExtractor
+
+ if is_torch_available():
+ from .modeling_convnext import (
+ CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ConvNextForImageClassification,
+ ConvNextModel,
+ ConvNextPreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure)
diff --git a/src/transformers/models/convnext/configuration_convnext.py b/src/transformers/models/convnext/configuration_convnext.py
new file mode 100644
index 000000000000..8d99c657cc63
--- /dev/null
+++ b/src/transformers/models/convnext/configuration_convnext.py
@@ -0,0 +1,101 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConvNeXT model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/convnext-tiny-224": "https://huggingface.co/facebook/convnext-tiny-224/resolve/main/config.json",
+ # See all ConvNeXT models at https://huggingface.co/models?filter=convnext
+}
+
+
+class ConvNextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ConvNextModel`]. It is used to instantiate an
+ ConvNeXT model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the ConvNeXT
+ [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ patch_size (`int`, optional, defaults to 4):
+ Patch size to use in the patch embedding layer.
+ num_stages (`int`, optional, defaults to 4):
+ The number of stages in the model.
+ hidden_sizes (`List[int]`, *optional*, defaults to [96, 192, 384, 768]):
+ Dimensionality (hidden size) at each stage.
+ depths (`List[int]`, *optional*, defaults to [3, 3, 9, 3]):
+ Depth (number of blocks) for each stage.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in each block. If string, `"gelu"`, `"relu"`,
+ `"selu"` and `"gelu_new"` are supported.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ layer_scale_init_value (`float`, *optional*, defaults to 1e-6):
+ The initial value for the layer scale.
+ drop_path_rate (`float`, *optional*, defaults to 0.0):
+ The drop rate for stochastic depth.
+
+ Example:
+ ```python
+ >>> from transformers import ConvNextModel, ConvNextConfig
+
+ >>> # Initializing a ConvNext convnext-tiny-224 style configuration
+ >>> configuration = ConvNextConfig()
+ >>> # Initializing a model from the convnext-tiny-224 style configuration
+ >>> model = ConvNextModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "convnext"
+
+ def __init__(
+ self,
+ num_channels=3,
+ patch_size=4,
+ num_stages=4,
+ hidden_sizes=None,
+ depths=None,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ is_encoder_decoder=False,
+ layer_scale_init_value=1e-6,
+ drop_path_rate=0.0,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.num_stages = num_stages
+ self.hidden_sizes = [96, 192, 384, 768] if hidden_sizes is None else hidden_sizes
+ self.depths = [3, 3, 9, 3] if depths is None else depths
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.layer_scale_init_value = layer_scale_init_value
+ self.drop_path_rate = drop_path_rate
diff --git a/src/transformers/models/convnext/convert_convnext_to_pytorch.py b/src/transformers/models/convnext/convert_convnext_to_pytorch.py
new file mode 100644
index 000000000000..b58f5b81fd09
--- /dev/null
+++ b/src/transformers/models/convnext/convert_convnext_to_pytorch.py
@@ -0,0 +1,243 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ConvNext checkpoints from the original repository.
+
+URL: https://github.com/facebookresearch/ConvNeXt"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+from PIL import Image
+
+import requests
+from huggingface_hub import cached_download, hf_hub_url
+from transformers import ConvNextConfig, ConvNextFeatureExtractor, ConvNextForImageClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_convnext_config(checkpoint_url):
+ config = ConvNextConfig()
+
+ if "tiny" in checkpoint_url:
+ depths = [3, 3, 9, 3]
+ hidden_sizes = [96, 192, 384, 768]
+ if "small" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [96, 192, 384, 768]
+ if "base" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [128, 256, 512, 1024]
+ if "large" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [192, 384, 768, 1536]
+ if "xlarge" in checkpoint_url:
+ depths = [3, 3, 27, 3]
+ hidden_sizes = [256, 512, 1024, 2048]
+
+ if "1k" in checkpoint_url:
+ num_labels = 1000
+ filename = "imagenet-1k-id2label.json"
+ expected_shape = (1, 1000)
+ else:
+ num_labels = 21841
+ filename = "imagenet-22k-id2label.json"
+ expected_shape = (1, 21841)
+
+ repo_id = "datasets/huggingface/label-files"
+ config.num_labels = num_labels
+ id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename)), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ if "1k" not in checkpoint_url:
+ # this dataset contains 21843 labels but the model only has 21841
+ # we delete the classes as mentioned in https://github.com/google-research/big_transfer/issues/18
+ del id2label[9205]
+ del id2label[15027]
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+ config.hidden_sizes = hidden_sizes
+ config.depths = depths
+
+ return config, expected_shape
+
+
+def rename_key(name):
+ if "downsample_layers.0.0" in name:
+ name = name.replace("downsample_layers.0.0", "embeddings.patch_embeddings")
+ if "downsample_layers.0.1" in name:
+ name = name.replace("downsample_layers.0.1", "embeddings.norm") # we rename to layernorm later on
+ if "downsample_layers.1.0" in name:
+ name = name.replace("downsample_layers.1.0", "stages.1.downsampling_layer.0")
+ if "downsample_layers.1.1" in name:
+ name = name.replace("downsample_layers.1.1", "stages.1.downsampling_layer.1")
+ if "downsample_layers.2.0" in name:
+ name = name.replace("downsample_layers.2.0", "stages.2.downsampling_layer.0")
+ if "downsample_layers.2.1" in name:
+ name = name.replace("downsample_layers.2.1", "stages.2.downsampling_layer.1")
+ if "downsample_layers.3.0" in name:
+ name = name.replace("downsample_layers.3.0", "stages.3.downsampling_layer.0")
+ if "downsample_layers.3.1" in name:
+ name = name.replace("downsample_layers.3.1", "stages.3.downsampling_layer.1")
+ if "stages" in name and "downsampling_layer" not in name:
+ # stages.0.0. for instance should be renamed to stages.0.layers.0.
+ name = name[: len("stages.0")] + ".layers" + name[len("stages.0") :]
+ if "stages" in name:
+ name = name.replace("stages", "encoder.stages")
+ if "norm" in name:
+ name = name.replace("norm", "layernorm")
+ if "gamma" in name:
+ name = name.replace("gamma", "layer_scale_parameter")
+ if "head" in name:
+ name = name.replace("head", "classifier")
+
+ return name
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@torch.no_grad()
+def convert_convnext_checkpoint(checkpoint_url, pytorch_dump_folder_path):
+ """
+ Copy/paste/tweak model's weights to our ConvNext structure.
+ """
+
+ # define ConvNext configuration based on URL
+ config, expected_shape = get_convnext_config(checkpoint_url)
+ # load original state_dict from URL
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url)["model"]
+ # rename keys
+ for key in state_dict.copy().keys():
+ val = state_dict.pop(key)
+ state_dict[rename_key(key)] = val
+ # add prefix to all keys expect classifier head
+ for key in state_dict.copy().keys():
+ val = state_dict.pop(key)
+ if not key.startswith("classifier"):
+ key = "convnext." + key
+ state_dict[key] = val
+
+ # load HuggingFace model
+ model = ConvNextForImageClassification(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # Check outputs on an image, prepared by ConvNextFeatureExtractor
+ size = 224 if "224" in checkpoint_url else 384
+ feature_extractor = ConvNextFeatureExtractor(size=size)
+ pixel_values = feature_extractor(images=prepare_img(), return_tensors="pt").pixel_values
+
+ logits = model(pixel_values).logits
+
+ # note: the logits below were obtained without center cropping
+ if checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.1210, -0.6605, 0.1918])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.4473, -0.1847, -0.6365])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth":
+ expected_logits = torch.tensor([0.4525, 0.7539, 0.0308])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_384.pth":
+ expected_logits = torch.tensor([0.3561, 0.6350, -0.0384])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth":
+ expected_logits = torch.tensor([0.4174, -0.0989, 0.1489])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_384.pth":
+ expected_logits = torch.tensor([0.2513, -0.1349, -0.1613])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth":
+ expected_logits = torch.tensor([1.2980, 0.3631, -0.1198])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth":
+ expected_logits = torch.tensor([1.2963, 0.1227, 0.1723])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth":
+ expected_logits = torch.tensor([1.7956, 0.8390, 0.2820])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth":
+ expected_logits = torch.tensor([-0.2822, -0.0502, -0.0878])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_384.pth":
+ expected_logits = torch.tensor([-0.5672, -0.0730, -0.4348])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_224.pth":
+ expected_logits = torch.tensor([0.2681, 0.2365, 0.6246])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_384.pth":
+ expected_logits = torch.tensor([-0.2642, 0.3931, 0.5116])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_224_ema.pth":
+ expected_logits = torch.tensor([-0.6677, -0.1873, -0.8379])
+ elif checkpoint_url == "https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_384_ema.pth":
+ expected_logits = torch.tensor([-0.7749, -0.2967, -0.6444])
+ else:
+ raise ValueError(f"Unknown URL: {checkpoint_url}")
+
+ assert torch.allclose(logits[0, :3], expected_logits, atol=1e-3)
+ assert logits.shape == expected_shape
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ print("Pushing model to the hub...")
+ model_name = "convnext"
+ if "tiny" in checkpoint_url:
+ model_name += "-tiny"
+ elif "small" in checkpoint_url:
+ model_name += "-small"
+ elif "base" in checkpoint_url:
+ model_name += "-base"
+ elif "xlarge" in checkpoint_url:
+ model_name += "-xlarge"
+ elif "large" in checkpoint_url:
+ model_name += "-large"
+ if "224" in checkpoint_url:
+ model_name += "-224"
+ elif "384" in checkpoint_url:
+ model_name += "-384"
+ if "22k" in checkpoint_url and "1k" not in checkpoint_url:
+ model_name += "-22k"
+ if "22k" in checkpoint_url and "1k" in checkpoint_url:
+ model_name += "-22k-1k"
+
+ model.push_to_hub(
+ repo_path_or_name=Path(pytorch_dump_folder_path, model_name),
+ organization="nielsr",
+ commit_message="Add model",
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth",
+ type=str,
+ help="URL of the original ConvNeXT checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the output PyTorch model directory.",
+ )
+
+ args = parser.parse_args()
+ convert_convnext_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path)
diff --git a/src/transformers/models/convnext/feature_extraction_convnext.py b/src/transformers/models/convnext/feature_extraction_convnext.py
new file mode 100644
index 000000000000..860bda96b6d2
--- /dev/null
+++ b/src/transformers/models/convnext/feature_extraction_convnext.py
@@ -0,0 +1,168 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for ConvNeXT."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...file_utils import TensorType
+from ...image_utils import (
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ ImageFeatureExtractionMixin,
+ ImageInput,
+ is_torch_tensor,
+)
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class ConvNextFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a ConvNeXT feature extractor.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize (and optionally center crop) the input to a certain `size`.
+ size (`int`, *optional*, defaults to 224):
+ Resize the input to the given size. If 384 or larger, the image is resized to (`size`, `size`). Else, the
+ smaller edge of the image will be matched to int(`size`/ `crop_pct`), after which the image is cropped to
+ `size`. Only has an effect if `do_resize` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BICUBIC`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ crop_pct (`float`, *optional*):
+ The percentage of the image to crop. If `None`, then a cropping percentage of 224 / 256 is used. Only has
+ an effect if `do_resize` is set to `True` and `size` < 384.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BICUBIC,
+ crop_pct=None,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def __call__(
+ self, images: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several image(s).
+
+
+
+ NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so the most efficient is to pass
+ PIL images.
+
+
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ return_tensors (`str` or [`~file_utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, height,
+ width).
+ """
+ # Input type checking for clearer error
+ valid_images = False
+
+ # Check that images has a valid type
+ if isinstance(images, (Image.Image, np.ndarray)) or is_torch_tensor(images):
+ valid_images = True
+ elif isinstance(images, (list, tuple)):
+ if len(images) == 0 or isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]):
+ valid_images = True
+
+ if not valid_images:
+ raise ValueError(
+ "Images must of type `PIL.Image.Image`, `np.ndarray` or `torch.Tensor` (single example), "
+ "`List[PIL.Image.Image]`, `List[np.ndarray]` or `List[torch.Tensor]` (batch of examples)."
+ )
+
+ is_batched = bool(
+ isinstance(images, (list, tuple))
+ and (isinstance(images[0], (Image.Image, np.ndarray)) or is_torch_tensor(images[0]))
+ )
+
+ if not is_batched:
+ images = [images]
+
+ # transformations (resizing and optional center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ if self.size >= 384:
+ # warping (no cropping) when evaluated at 384 or larger
+ images = [self.resize(image=image, size=self.size, resample=self.resample) for image in images]
+ else:
+ if self.crop_pct is None:
+ self.crop_pct = 224 / 256
+ size = int(self.size / self.crop_pct)
+ # to maintain same ratio w.r.t. 224 images
+ images = [
+ self.resize(image=image, size=size, default_to_square=False, resample=self.resample)
+ for image in images
+ ]
+ images = [self.center_crop(image=image, size=self.size) for image in images]
+
+ if self.do_normalize:
+ images = [self.normalize(image=image, mean=self.image_mean, std=self.image_std) for image in images]
+
+ # return as BatchFeature
+ data = {"pixel_values": images}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/convnext/modeling_convnext.py b/src/transformers/models/convnext/modeling_convnext.py
new file mode 100755
index 000000000000..f66c320255bc
--- /dev/null
+++ b/src/transformers/models/convnext/modeling_convnext.py
@@ -0,0 +1,498 @@
+# coding=utf-8
+# Copyright 2022 Meta Platforms, Inc. and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch ConvNext model."""
+
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import logging
+from .configuration_convnext import ConvNextConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ConvNextConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "ConvNextFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "facebook/convnext-tiny-224"
+_EXPECTED_OUTPUT_SHAPE = [1, 768, 7, 7]
+
+# Image classification docstring
+_IMAGE_CLASS_CHECKPOINT = "facebook/convnext-tiny-224"
+_IMAGE_CLASS_EXPECTED_OUTPUT = "'tabby, tabby cat'"
+
+CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "facebook/convnext-tiny-224",
+ # See all ConvNext models at https://huggingface.co/models?filter=convnext
+]
+
+
+@dataclass
+class ConvNextEncoderOutput(ModelOutput):
+ """
+ Class for [`ConvNextEncoder`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Last hidden states (final feature map) of the last stage of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class ConvNextModelOutput(ModelOutput):
+ """
+ Class for [`ConvNextModel`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Last hidden states (final feature map) of the last stage of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, config.dim[-1])`):
+ Global average pooling of the last feature map followed by a layernorm.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class ConvNextClassifierOutput(ModelOutput):
+ """
+ Class for [`ConvNextForImageClassification`]'s outputs, with potential hidden states (feature maps).
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
+ shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
+ the output of each stage.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# Stochastic depth implementation
+# Taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+def drop_path(x, drop_prob: float = 0.0, training: bool = False):
+ """
+ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the
+ DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop
+ Connect' is a different form of dropout in a separate paper... See discussion:
+ https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and
+ argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument.
+ """
+ if drop_prob == 0.0 or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class ConvNextDropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
+
+ def __init__(self, drop_prob=None):
+ super().__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class ConvNextLayerNorm(nn.Module):
+ r"""LayerNorm that supports two data formats: channels_last (default) or channels_first.
+ The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch_size, height,
+ width, channels) while channels_first corresponds to inputs with shape (batch_size, channels, height, width).
+ """
+
+ def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(normalized_shape))
+ self.bias = nn.Parameter(torch.zeros(normalized_shape))
+ self.eps = eps
+ self.data_format = data_format
+ if self.data_format not in ["channels_last", "channels_first"]:
+ raise NotImplementedError(f"Unsupported data format: {self.data_format}")
+ self.normalized_shape = (normalized_shape,)
+
+ def forward(self, x):
+ if self.data_format == "channels_last":
+ x = torch.nn.functional.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
+ elif self.data_format == "channels_first":
+ u = x.mean(1, keepdim=True)
+ s = (x - u).pow(2).mean(1, keepdim=True)
+ x = (x - u) / torch.sqrt(s + self.eps)
+ x = self.weight[:, None, None] * x + self.bias[:, None, None]
+ return x
+
+
+class ConvNextEmbeddings(nn.Module):
+ """This class is comparable to (and inspired by) the SwinEmbeddings class
+ found in src/transformers/models/swin/modeling_swin.py.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.patch_embeddings = nn.Conv2d(
+ config.num_channels, config.hidden_sizes[0], kernel_size=config.patch_size, stride=config.patch_size
+ )
+ self.layernorm = ConvNextLayerNorm(config.hidden_sizes[0], eps=1e-6, data_format="channels_first")
+
+ def forward(self, pixel_values):
+ embeddings = self.patch_embeddings(pixel_values)
+ embeddings = self.layernorm(embeddings)
+ return embeddings
+
+
+class ConvNextLayer(nn.Module):
+ """This corresponds to the `Block` class in the original implementation.
+
+ There are two equivalent implementations: [DwConv, LayerNorm (channels_first), Conv, GELU,1x1 Conv]; all in (N, C,
+ H, W) (2) [DwConv, Permute to (N, H, W, C), LayerNorm (channels_last), Linear, GELU, Linear]; Permute back
+
+ The authors used (2) as they find it slightly faster in PyTorch.
+
+ Args:
+ config ([`ConvNextConfig`]): Model configuration class.
+ dim (`int`): Number of input channels.
+ drop_path (`float`): Stochastic depth rate. Default: 0.0.
+ """
+
+ def __init__(self, config, dim, drop_path=0):
+ super().__init__()
+ self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
+ self.layernorm = ConvNextLayerNorm(dim, eps=1e-6)
+ self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
+ self.act = ACT2FN[config.hidden_act]
+ self.pwconv2 = nn.Linear(4 * dim, dim)
+ self.layer_scale_parameter = (
+ nn.Parameter(config.layer_scale_init_value * torch.ones((dim)), requires_grad=True)
+ if config.layer_scale_init_value > 0
+ else None
+ )
+ self.drop_path = ConvNextDropPath(drop_path) if drop_path > 0.0 else nn.Identity()
+
+ def forward(self, hidden_states):
+ input = hidden_states
+ x = self.dwconv(hidden_states)
+ x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
+ x = self.layernorm(x)
+ x = self.pwconv1(x)
+ x = self.act(x)
+ x = self.pwconv2(x)
+ if self.layer_scale_parameter is not None:
+ x = self.layer_scale_parameter * x
+ x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
+
+ x = input + self.drop_path(x)
+ return x
+
+
+class ConvNextStage(nn.Module):
+ """ConvNeXT stage, consisting of an optional downsampling layer + multiple residual blocks.
+
+ Args:
+ config ([`ConvNextConfig`]): Model configuration class.
+ in_channels (`int`): Number of input channels.
+ out_channels (`int`): Number of output channels.
+ depth (`int`): Number of residual blocks.
+ drop_path_rates(`List[float]`): Stochastic depth rates for each layer.
+ """
+
+ def __init__(self, config, in_channels, out_channels, kernel_size=2, stride=2, depth=2, drop_path_rates=None):
+ super().__init__()
+
+ if in_channels != out_channels or stride > 1:
+ self.downsampling_layer = nn.Sequential(
+ ConvNextLayerNorm(in_channels, eps=1e-6, data_format="channels_first"),
+ nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride),
+ )
+ else:
+ self.downsampling_layer = nn.Identity()
+ drop_path_rates = drop_path_rates or [0.0] * depth
+ self.layers = nn.Sequential(
+ *[ConvNextLayer(config, dim=out_channels, drop_path=drop_path_rates[j]) for j in range(depth)]
+ )
+
+ def forward(self, hidden_states):
+ hidden_states = self.downsampling_layer(hidden_states)
+ hidden_states = self.layers(hidden_states)
+ return hidden_states
+
+
+class ConvNextEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.stages = nn.ModuleList()
+ drop_path_rates = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
+ cur = 0
+ prev_chs = config.hidden_sizes[0]
+ for i in range(config.num_stages):
+ out_chs = config.hidden_sizes[i]
+ stage = ConvNextStage(
+ config,
+ in_channels=prev_chs,
+ out_channels=out_chs,
+ stride=2 if i > 0 else 1,
+ depth=config.depths[i],
+ drop_path_rates=drop_path_rates[cur],
+ )
+ self.stages.append(stage)
+ cur += config.depths[i]
+ prev_chs = out_chs
+
+ def forward(self, hidden_states, output_hidden_states=False, return_dict=True):
+ all_hidden_states = () if output_hidden_states else None
+
+ for i, layer_module in enumerate(self.stages):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ hidden_states = layer_module(hidden_states)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states] if v is not None)
+
+ return ConvNextEncoderOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ )
+
+
+class ConvNextPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ConvNextConfig
+ base_model_prefix = "convnext"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, ConvNextModel):
+ module.gradient_checkpointing = value
+
+
+CONVNEXT_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ConvNextConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+CONVNEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoFeatureExtractor`]. See
+ [`AutoFeatureExtractor.__call__`] for details.
+
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare ConvNext model outputting raw features without any specific head on top.",
+ CONVNEXT_START_DOCSTRING,
+)
+class ConvNextModel(ConvNextPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = ConvNextEmbeddings(config)
+ self.encoder = ConvNextEncoder(config)
+
+ # final layernorm layer
+ self.layernorm = nn.LayerNorm(config.hidden_sizes[-1], eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CONVNEXT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=ConvNextModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="vision",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(self, pixel_values=None, output_hidden_states=None, return_dict=None):
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embedding_output = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+
+ # global average pooling, (N, C, H, W) -> (N, C)
+ pooled_output = self.layernorm(last_hidden_state.mean([-2, -1]))
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return ConvNextModelOutput(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(
+ """
+ ConvNext Model with an image classification head on top (a linear layer on top of the pooled features), e.g. for
+ ImageNet.
+ """,
+ CONVNEXT_START_DOCSTRING,
+)
+class ConvNextForImageClassification(ConvNextPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.convnext = ConvNextModel(config)
+
+ # Classifier head
+ self.classifier = (
+ nn.Linear(config.hidden_sizes[-1], config.num_labels) if config.num_labels > 0 else nn.Identity()
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(CONVNEXT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_IMAGE_CLASS_CHECKPOINT,
+ output_type=ConvNextClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_IMAGE_CLASS_EXPECTED_OUTPUT,
+ )
+ def forward(self, pixel_values=None, labels=None, output_hidden_states=None, return_dict=None):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.convnext(pixel_values, output_hidden_states=output_hidden_states, return_dict=return_dict)
+
+ pooled_output = outputs.pooler_output if return_dict else outputs[1]
+
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ConvNextClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ )
diff --git a/src/transformers/models/electra/__init__.py b/src/transformers/models/electra/__init__.py
index 1aad02a41277..a8f1ec5db72b 100644
--- a/src/transformers/models/electra/__init__.py
+++ b/src/transformers/models/electra/__init__.py
@@ -22,7 +22,7 @@
_import_structure = {
- "configuration_electra": ["ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP", "ElectraConfig"],
+ "configuration_electra": ["ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP", "ElectraConfig", "ElectraOnnxConfig"],
"tokenization_electra": ["ElectraTokenizer"],
}
@@ -71,7 +71,7 @@
if TYPE_CHECKING:
- from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig
+ from .configuration_electra import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP, ElectraConfig, ElectraOnnxConfig
from .tokenization_electra import ElectraTokenizer
if is_tokenizers_available():
diff --git a/src/transformers/models/electra/configuration_electra.py b/src/transformers/models/electra/configuration_electra.py
index 43b3b3255dad..9b4525d3dce7 100644
--- a/src/transformers/models/electra/configuration_electra.py
+++ b/src/transformers/models/electra/configuration_electra.py
@@ -15,7 +15,11 @@
# limitations under the License.
""" ELECTRA model configuration"""
+from collections import OrderedDict
+from typing import Mapping
+
from ...configuration_utils import PretrainedConfig
+from ...onnx import OnnxConfig
from ...utils import logging
@@ -170,3 +174,15 @@ def __init__(
self.position_embedding_type = position_embedding_type
self.use_cache = use_cache
self.classifier_dropout = classifier_dropout
+
+
+class ElectraOnnxConfig(OnnxConfig):
+ @property
+ def inputs(self) -> Mapping[str, Mapping[int, str]]:
+ return OrderedDict(
+ [
+ ("input_ids", {0: "batch", 1: "sequence"}),
+ ("attention_mask", {0: "batch", 1: "sequence"}),
+ ("token_type_ids", {0: "batch", 1: "sequence"}),
+ ]
+ )
diff --git a/src/transformers/models/electra/modeling_electra.py b/src/transformers/models/electra/modeling_electra.py
index 054eff4be016..a61045f9c0aa 100644
--- a/src/transformers/models/electra/modeling_electra.py
+++ b/src/transformers/models/electra/modeling_electra.py
@@ -245,7 +245,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -334,7 +334,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/gpt2/modeling_gpt2.py b/src/transformers/models/gpt2/modeling_gpt2.py
index b1988d7edf8e..59df99e8ab91 100644
--- a/src/transformers/models/gpt2/modeling_gpt2.py
+++ b/src/transformers/models/gpt2/modeling_gpt2.py
@@ -193,7 +193,7 @@ def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
- attn_weights = attn_weights / (float(value.size(-1)) ** 0.5)
+ attn_weights = attn_weights / (value.size(-1) ** 0.5)
# Layer-wise attention scaling
if self.scale_attn_by_inverse_layer_idx:
@@ -281,7 +281,7 @@ def _split_heads(self, tensor, num_heads, attn_head_size):
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
@@ -915,7 +915,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -1410,7 +1410,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[range(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/gpt_neo/modeling_gpt_neo.py b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
index 7176cfa790b2..c516ca57a1e5 100755
--- a/src/transformers/models/gpt_neo/modeling_gpt_neo.py
+++ b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
@@ -173,7 +173,7 @@ def _split_heads(self, tensor, num_heads, attn_head_size):
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
@@ -637,7 +637,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -891,7 +891,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[torch.arange(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/gptj/modeling_flax_gptj.py b/src/transformers/models/gptj/modeling_flax_gptj.py
index 90672a132215..780dec88161b 100644
--- a/src/transformers/models/gptj/modeling_flax_gptj.py
+++ b/src/transformers/models/gptj/modeling_flax_gptj.py
@@ -668,8 +668,7 @@ def __call__(
@add_start_docstrings(
"""
- The GPTJ Model transformer with a language modeling head on top (linear layer with weights tied to the input
- embeddings).
+ The GPTJ Model transformer with a language modeling head on top.
""",
GPTJ_START_DOCSTRING,
)
diff --git a/src/transformers/models/gptj/modeling_gptj.py b/src/transformers/models/gptj/modeling_gptj.py
index 869014bee626..a74c74b8fc02 100755
--- a/src/transformers/models/gptj/modeling_gptj.py
+++ b/src/transformers/models/gptj/modeling_gptj.py
@@ -107,7 +107,7 @@ def _split_heads(self, tensor, num_attention_heads, attn_head_size, rotary):
Splits hidden dim into attn_head_size and num_attention_heads
"""
new_shape = tensor.size()[:-1] + (num_attention_heads, attn_head_size)
- tensor = tensor.view(*new_shape)
+ tensor = tensor.view(new_shape)
if rotary:
return tensor
if len(tensor.shape) == 5:
@@ -665,7 +665,7 @@ def custom_forward(*inputs):
hidden_states = self.ln_f(hidden_states)
- hidden_states = hidden_states.view(*output_shape)
+ hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
@@ -683,8 +683,7 @@ def custom_forward(*inputs):
@add_start_docstrings(
"""
- The GPT-J Model transformer with a language modeling head on top (linear layer with weights tied to the input
- embeddings).
+ The GPT-J Model transformer with a language modeling head on top.
""",
GPTJ_START_DOCSTRING,
)
@@ -945,7 +944,7 @@ def forward(
f"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
- pooled_logits = logits[range(batch_size), sequence_lengths]
+ pooled_logits = logits[torch.arange(batch_size, device=self.device), sequence_lengths]
loss = None
if labels is not None:
diff --git a/src/transformers/models/hubert/modeling_hubert.py b/src/transformers/models/hubert/modeling_hubert.py
index 76cd97ffed6d..928a742deedd 100755
--- a/src/transformers/models/hubert/modeling_hubert.py
+++ b/src/transformers/models/hubert/modeling_hubert.py
@@ -33,7 +33,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_hubert import HubertConfig
@@ -1096,7 +1097,10 @@ def __init__(self, config):
"instantiate the model as follows: `HubertForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1214,6 +1218,10 @@ class HubertForSequenceClassification(HubertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Hubert adapters (config.add_adapter=True)"
+ )
self.hubert = HubertModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/layoutlm/modeling_layoutlm.py b/src/transformers/models/layoutlm/modeling_layoutlm.py
index d595fc8b517a..bbdfeaac83fc 100644
--- a/src/transformers/models/layoutlm/modeling_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_layoutlm.py
@@ -160,7 +160,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -249,7 +249,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/led/modeling_led.py b/src/transformers/models/led/modeling_led.py
index 8054b9ee6d33..e775fd35c933 100755
--- a/src/transformers/models/led/modeling_led.py
+++ b/src/transformers/models/led/modeling_led.py
@@ -2366,6 +2366,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/led/modeling_tf_led.py b/src/transformers/models/led/modeling_tf_led.py
index 38a31e0ca8bd..f273148ac914 100644
--- a/src/transformers/models/led/modeling_tf_led.py
+++ b/src/transformers/models/led/modeling_tf_led.py
@@ -29,7 +29,7 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_tf_outputs import TFBaseModelOutputWithPast
+from ...modeling_tf_outputs import TFBaseModelOutputWithPastAndCrossAttentions
# Public API
from ...modeling_tf_utils import (
@@ -1220,7 +1220,7 @@ def call(
encoder_layer_head_mask: Optional[tf.Tensor] = None,
past_key_value: Optional[Tuple[tf.Tensor]] = None,
training=False,
- ) -> Tuple[tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
+ ) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(seq_len, batch, embed_dim)*
@@ -1254,12 +1254,13 @@ def call(
# Cross-Attention Block
cross_attn_present_key_value = None
+ cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
- hidden_states, _, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
@@ -1285,6 +1286,7 @@ def call(
return (
hidden_states,
self_attn_weights,
+ cross_attn_weights,
present_key_value,
)
@@ -1808,6 +1810,14 @@ def call(
# unpad `hidden_states` because the calling function is expecting a length == input_ids.size(1)
hidden_states = self.compute_hidden_states(hidden_states, padding_len)
+ # undo padding
+ if inputs["output_attentions"]:
+ all_attentions = (
+ tuple([state[:, :, :-padding_len, :] for state in all_attentions])
+ if padding_len > 0
+ else all_attentions
+ )
+
if inputs["output_hidden_states"]:
encoder_states = encoder_states + (hidden_states,)
@@ -2038,6 +2048,7 @@ def call(
# decoder layers
all_hidden_states = ()
all_self_attns = ()
+ all_cross_attentions = ()
present_key_values = ()
# check if head_mask has a correct number of layers specified if desired
@@ -2059,7 +2070,7 @@ def call(
past_key_value = inputs["past_key_values"][idx] if inputs["past_key_values"] is not None else None
- hidden_states, layer_self_attn, present_key_value = decoder_layer(
+ hidden_states, layer_self_attn, layer_cross_attn, present_key_value = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=inputs["encoder_hidden_states"],
@@ -2076,24 +2087,31 @@ def call(
if inputs["output_attentions"]:
all_self_attns += (layer_self_attn,)
+ all_cross_attentions += (layer_cross_attn,)
if inputs["output_hidden_states"]:
all_hidden_states += (hidden_states,)
else:
all_hidden_states = None
- all_self_attns = list(all_self_attns) if inputs["output_attentions"] else None
+ all_self_attns = all_self_attns if inputs["output_attentions"] else None
+ all_cross_attentions = all_cross_attentions if inputs["output_attentions"] else None
present_key_values = (encoder_hidden_states, present_key_values) if inputs["use_cache"] else None
if not inputs["return_dict"]:
- return hidden_states, present_key_values, all_hidden_states, all_self_attns
+ return tuple(
+ v
+ for v in [hidden_states, present_key_values, all_hidden_states, all_self_attns, all_cross_attentions]
+ if v is not None
+ )
else:
- return TFBaseModelOutputWithPast(
+ return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
+ cross_attentions=all_cross_attentions,
)
@@ -2223,6 +2241,7 @@ def call(
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
@@ -2475,6 +2494,7 @@ def call(
past_key_values=outputs.past_key_values, # index 1 of d outputs
decoder_hidden_states=outputs.decoder_hidden_states, # index 2 of d outputs
decoder_attentions=outputs.decoder_attentions, # index 3 of d outputs
+ cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state, # index 0 of encoder outputs
encoder_hidden_states=outputs.encoder_hidden_states, # 1 of e out
encoder_attentions=outputs.encoder_attentions, # 2 of e out
diff --git a/src/transformers/models/longformer/configuration_longformer.py b/src/transformers/models/longformer/configuration_longformer.py
index 59f6fc90bbdb..e3f5ba1a24f0 100644
--- a/src/transformers/models/longformer/configuration_longformer.py
+++ b/src/transformers/models/longformer/configuration_longformer.py
@@ -13,10 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" Longformer configuration"""
-from collections import OrderedDict
-from typing import List, Mapping, Union
+from typing import List, Union
-from ...onnx import OnnxConfig
from ...utils import logging
from ..roberta.configuration_roberta import RobertaConfig
@@ -69,18 +67,3 @@ class LongformerConfig(RobertaConfig):
def __init__(self, attention_window: Union[List[int], int] = 512, sep_token_id: int = 2, **kwargs):
super().__init__(sep_token_id=sep_token_id, **kwargs)
self.attention_window = attention_window
-
-
-class LongformerOnnxConfig(OnnxConfig):
- @property
- def inputs(self) -> Mapping[str, Mapping[int, str]]:
- return OrderedDict(
- [
- ("input_ids", {0: "batch", 1: "sequence"}),
- ("attention_mask", {0: "batch", 1: "sequence"}),
- ]
- )
-
- @property
- def outputs(self) -> Mapping[str, Mapping[int, str]]:
- return OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"}), ("pooler_output", {0: "batch"})])
diff --git a/src/transformers/models/marian/modeling_marian.py b/src/transformers/models/marian/modeling_marian.py
index f3bd96eeb94f..20cbd21f76e8 100755
--- a/src/transformers/models/marian/modeling_marian.py
+++ b/src/transformers/models/marian/modeling_marian.py
@@ -1291,6 +1291,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/mbart/modeling_mbart.py b/src/transformers/models/mbart/modeling_mbart.py
index fc09f0a7e62f..3e747b4b1ebc 100755
--- a/src/transformers/models/mbart/modeling_mbart.py
+++ b/src/transformers/models/mbart/modeling_mbart.py
@@ -1314,6 +1314,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id)
diff --git a/src/transformers/models/megatron_bert/modeling_megatron_bert.py b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
index dbfb76cb5d52..292b920bf5d5 100755
--- a/src/transformers/models/megatron_bert/modeling_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
@@ -223,7 +223,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -312,7 +312,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/mobilebert/modeling_mobilebert.py b/src/transformers/models/mobilebert/modeling_mobilebert.py
index 2a90f1d92aff..acf9607a7367 100644
--- a/src/transformers/models/mobilebert/modeling_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_mobilebert.py
@@ -237,7 +237,7 @@ def __init__(self, config):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -274,7 +274,7 @@ def forward(
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
diff --git a/src/transformers/models/pegasus/modeling_pegasus.py b/src/transformers/models/pegasus/modeling_pegasus.py
index 32923ce44d38..5eed41254e80 100755
--- a/src/transformers/models/pegasus/modeling_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_pegasus.py
@@ -1381,6 +1381,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
diff --git a/src/transformers/models/realm/modeling_realm.py b/src/transformers/models/realm/modeling_realm.py
index 165e62c0ef6c..118916413863 100644
--- a/src/transformers/models/realm/modeling_realm.py
+++ b/src/transformers/models/realm/modeling_realm.py
@@ -260,7 +260,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -349,7 +349,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/roberta/modeling_roberta.py b/src/transformers/models/roberta/modeling_roberta.py
index 426095e03ed6..88f0aa8d29ec 100644
--- a/src/transformers/models/roberta/modeling_roberta.py
+++ b/src/transformers/models/roberta/modeling_roberta.py
@@ -187,7 +187,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -276,7 +276,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/segformer/configuration_segformer.py b/src/transformers/models/segformer/configuration_segformer.py
index d1790634e6e6..0e0b3a9914eb 100644
--- a/src/transformers/models/segformer/configuration_segformer.py
+++ b/src/transformers/models/segformer/configuration_segformer.py
@@ -83,6 +83,10 @@ class SegformerConfig(PretrainedConfig):
required for the semantic segmentation model.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
+ legacy_output (`bool`, *optional*, defaults to `False`):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`)
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Example:
@@ -124,6 +128,7 @@ def __init__(
is_encoder_decoder=False,
reshape_last_stage=True,
semantic_loss_ignore_index=255,
+ legacy_output=False,
**kwargs
):
super().__init__(**kwargs)
@@ -149,3 +154,4 @@ def __init__(
self.decoder_hidden_size = decoder_hidden_size
self.reshape_last_stage = reshape_last_stage
self.semantic_loss_ignore_index = semantic_loss_ignore_index
+ self.legacy_output = legacy_output
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 6f0a4a1d7894..196d741ce705 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -17,6 +17,7 @@
import collections
import math
+import warnings
import torch
import torch.utils.checkpoint
@@ -30,7 +31,7 @@
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
-from ...modeling_outputs import BaseModelOutput, SequenceClassifierOutput
+from ...modeling_outputs import BaseModelOutput, SemanticSegmentationModelOutput, SequenceClassifierOutput
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_segformer import SegformerConfig
@@ -688,7 +689,7 @@ def __init__(self, config):
self.post_init()
@add_start_docstrings_to_model_forward(SEGFORMER_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ @replace_return_docstrings(output_type=SemanticSegmentationModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values,
@@ -696,11 +697,17 @@ def forward(
output_attentions=None,
output_hidden_states=None,
return_dict=None,
+ legacy_output=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Ground truth semantic segmentation maps for computing the loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels > 1`, a classification loss is computed (Cross-Entropy).
+ legacy_output (`bool`, *optional*):
+ Whether to return the legacy outputs or not (with logits of shape `height / 4 , width / 4`). Will default
+ to `self.config.legacy_output`.
+
+ This argument is only present for backward compatibility reasons and will be removed in v5 of Transformers.
Returns:
@@ -719,12 +726,20 @@ def forward(
>>> inputs = feature_extractor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
- >>> logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
+ >>> logits = outputs.logits # shape (batch_size, num_labels, height, width)
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
+ legacy_output = legacy_output if legacy_output is not None else self.config.legacy_output
+ if not legacy_output:
+ warnings.warn(
+ "The output of this model has changed in v4.17.0 and the logits now have the same size as the inputs. "
+ "You can activate the previous behavior by passing `legacy_output=True` to this call or the "
+ "configuration of this model (only until v5, then that argument will be removed).",
+ FutureWarning,
+ )
outputs = self.segformer(
pixel_values,
@@ -737,28 +752,37 @@ def forward(
logits = self.decode_head(encoder_hidden_states)
+ upsampled_logits = nn.functional.interpolate(
+ logits, size=pixel_values.shape[-2:], mode="bilinear", align_corners=False
+ )
+
loss = None
if labels is not None:
if self.config.num_labels == 1:
raise ValueError("The number of labels should be greater than one")
else:
# upsample logits to the images' original size
- upsampled_logits = nn.functional.interpolate(
- logits, size=labels.shape[-2:], mode="bilinear", align_corners=False
- )
loss_fct = CrossEntropyLoss(ignore_index=self.config.semantic_loss_ignore_index)
loss = loss_fct(upsampled_logits, labels)
if not return_dict:
if output_hidden_states:
- output = (logits,) + outputs[1:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[1:]
else:
- output = (logits,) + outputs[2:]
+ output = (logits if legacy_output else upsampled_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
- return SequenceClassifierOutput(
- loss=loss,
- logits=logits,
- hidden_states=outputs.hidden_states if output_hidden_states else None,
- attentions=outputs.attentions,
- )
+ if legacy_output:
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
+ else:
+ return SemanticSegmentationModelOutput(
+ loss=loss,
+ logits=upsampled_logits,
+ hidden_states=outputs.hidden_states if output_hidden_states else None,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/sew/modeling_sew.py b/src/transformers/models/sew/modeling_sew.py
index ecc30478b088..6fd0a1861f4e 100644
--- a/src/transformers/models/sew/modeling_sew.py
+++ b/src/transformers/models/sew/modeling_sew.py
@@ -29,7 +29,8 @@
from ...activations import ACT2FN
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_sew import SEWConfig
@@ -980,7 +981,10 @@ def __init__(self, config):
"instantiate the model as follows: `SEWForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1098,6 +1102,10 @@ class SEWForSequenceClassification(SEWPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of SEW adapters (config.add_adapter=True)"
+ )
self.sew = SEWModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/sew_d/modeling_sew_d.py b/src/transformers/models/sew_d/modeling_sew_d.py
index 33ca04337f82..af7dcba4b9a5 100644
--- a/src/transformers/models/sew_d/modeling_sew_d.py
+++ b/src/transformers/models/sew_d/modeling_sew_d.py
@@ -30,7 +30,8 @@
from ...activations import ACT2FN
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_sew_d import SEWDConfig
@@ -1512,7 +1513,10 @@ def __init__(self, config):
"instantiate the model as follows: `SEWDForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1630,6 +1634,10 @@ class SEWDForSequenceClassification(SEWDPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of SEWD adapters (config.add_adapter=True)"
+ )
self.sew_d = SEWDModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/splinter/modeling_splinter.py b/src/transformers/models/splinter/modeling_splinter.py
index b982a38b62f4..3d15cc682556 100755
--- a/src/transformers/models/splinter/modeling_splinter.py
+++ b/src/transformers/models/splinter/modeling_splinter.py
@@ -127,7 +127,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -216,7 +216,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/models/t5/modeling_tf_t5.py b/src/transformers/models/t5/modeling_tf_t5.py
index c626662fc155..372f6cf132d7 100644
--- a/src/transformers/models/t5/modeling_tf_t5.py
+++ b/src/transformers/models/t5/modeling_tf_t5.py
@@ -33,7 +33,7 @@
)
from ...modeling_tf_outputs import (
TFBaseModelOutput,
- TFBaseModelOutputWithPast,
+ TFBaseModelOutputWithPastAndCrossAttentions,
TFSeq2SeqLMOutput,
TFSeq2SeqModelOutput,
)
@@ -771,6 +771,7 @@ def call(
present_key_value_states = () if inputs["use_cache"] and self.is_decoder else None
all_hidden_states = () if inputs["output_hidden_states"] else None
all_attentions = () if inputs["output_attentions"] else None
+ all_cross_attentions = () if (inputs["output_attentions"] and self.is_decoder) else None
position_bias = None
encoder_decoder_position_bias = None
@@ -814,6 +815,8 @@ def call(
if inputs["output_attentions"]:
all_attentions = all_attentions + (layer_outputs[3],)
+ if self.is_decoder:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.dropout(hidden_states, training=inputs["training"])
@@ -831,14 +834,17 @@ def call(
outputs = outputs + (all_hidden_states,)
if inputs["output_attentions"]:
outputs = outputs + (all_attentions,)
- return outputs # last-layer hidden state, (all hidden states), (all attentions)
+ if self.is_decoder:
+ outputs + (all_cross_attentions,)
+ return outputs # last-layer hidden state, (past_key_values), (all hidden states), (all attentions), (all_cross_attentions)
if self.is_decoder:
- return TFBaseModelOutputWithPast(
+ return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_value_states,
hidden_states=all_hidden_states,
attentions=all_attentions,
+ cross_attentions=all_cross_attentions,
)
else:
return TFBaseModelOutput(
@@ -1264,6 +1270,7 @@ def call(
past_key_values=past,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
@@ -1508,6 +1515,7 @@ def call(
past_key_values=past,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=inputs["encoder_outputs"].last_hidden_state,
encoder_hidden_states=inputs["encoder_outputs"].hidden_states,
encoder_attentions=inputs["encoder_outputs"].attentions,
diff --git a/src/transformers/models/unispeech/modeling_unispeech.py b/src/transformers/models/unispeech/modeling_unispeech.py
index 3969fa6ab454..768fbfc60932 100755
--- a/src/transformers/models/unispeech/modeling_unispeech.py
+++ b/src/transformers/models/unispeech/modeling_unispeech.py
@@ -35,7 +35,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_unispeech import UniSpeechConfig
@@ -1373,7 +1374,10 @@ def __init__(self, config):
"instantiate the model as follows: `UniSpeechForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1491,6 +1495,10 @@ class UniSpeechForSequenceClassification(UniSpeechPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of UniSpeech adapters (config.add_adapter=True)"
+ )
self.unispeech = UniSpeechModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
index 4a42f9e60f10..ddc98c80019f 100755
--- a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
@@ -35,7 +35,8 @@
replace_return_docstrings,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput, TokenClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_unispeech_sat import UniSpeechSatConfig
@@ -1401,7 +1402,10 @@ def __init__(self, config):
"instantiate the model as follows: `UniSpeechSatForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1519,6 +1523,10 @@ class UniSpeechSatForSequenceClassification(UniSpeechSatPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of UniSpeechSat adapters (config.add_adapter=True)"
+ )
self.unispeech_sat = UniSpeechSatModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1639,6 +1647,10 @@ class UniSpeechSatForAudioFrameClassification(UniSpeechSatPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of UniSpeechSat adapters (config.add_adapter=True)"
+ )
self.unispeech_sat = UniSpeechSatModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
index a8ea74dd5cdb..a32c7084a898 100644
--- a/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
@@ -766,6 +766,73 @@ def __call__(self, hidden_states, mask_time_indices=None, deterministic=True, te
return codevectors, perplexity
+class FlaxWav2Vec2Adapter(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ # hidden_states require down-projection if feature dims don't match
+ if self.config.output_hidden_size != self.config.hidden_size:
+ self.proj = nn.Dense(
+ self.config.output_hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.proj_layer_norm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ else:
+ self.proj = self.proj_layer_norm = None
+
+ self.layers = FlaxWav2Vec2AdapterLayersCollection(self.config, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ # down-project hidden_states if required
+ if self.proj is not None and self.proj_layer_norm is not None:
+ hidden_states = self.proj(hidden_states)
+ hidden_states = self.proj_layer_norm(hidden_states)
+
+ hidden_states = self.layers(hidden_states)
+
+ return hidden_states
+
+
+class FlaxWav2Vec2AdapterLayer(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ features=2 * self.config.output_hidden_size,
+ kernel_size=(self.config.adapter_kernel_size,),
+ strides=(self.config.adapter_stride,),
+ padding=((1, 1),),
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ hidden_states = self.conv(hidden_states)
+ hidden_states = nn.glu(hidden_states, axis=2)
+
+ return hidden_states
+
+
+class FlaxWav2Vec2AdapterLayersCollection(nn.Module):
+ config: Wav2Vec2Config
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.layers = [
+ FlaxWav2Vec2AdapterLayer(self.config, name=str(i), dtype=self.dtype)
+ for i in range(self.config.num_adapter_layers)
+ ]
+
+ def __call__(self, hidden_states, deterministic=True):
+ for conv_layer in self.layers:
+ hidden_states = conv_layer(hidden_states)
+
+ return hidden_states
+
+
class FlaxWav2Vec2PreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
@@ -840,7 +907,9 @@ def __call__(
rngs=rngs,
)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[jnp.ndarray, int], add_adapter: Optional[bool] = None
+ ):
return self.module._get_feat_extract_output_lengths(input_lengths)
@@ -860,6 +929,8 @@ def setup(self):
else:
raise NotImplementedError("``config.do_stable_layer_norm is False`` is currently not supported.")
+ self.adapter = FlaxWav2Vec2Adapter(self.config) if self.config.add_adapter else None
+
def __call__(
self,
input_values,
@@ -905,6 +976,9 @@ def __call__(
hidden_states = encoder_outputs[0]
+ if self.adapter is not None:
+ hidden_states = self.adapter(hidden_states)
+
if not return_dict:
return (hidden_states, extract_features) + encoder_outputs[1:]
@@ -915,11 +989,15 @@ def __call__(
attentions=encoder_outputs.attentions,
)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self, input_lengths: Union[jnp.ndarray, int], add_adapter: Optional[bool] = None
+ ):
"""
Computes the output length of the convolutional layers
"""
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
def _conv_out_length(input_length, kernel_size, stride):
# 1D convolutional layer output length formula taken
# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
@@ -928,6 +1006,10 @@ def _conv_out_length(input_length, kernel_size, stride):
for kernel_size, stride in zip(self.config.conv_kernel, self.config.conv_stride):
input_lengths = _conv_out_length(input_lengths, kernel_size, stride)
+ if add_adapter:
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(input_lengths, 1, self.config.adapter_stride)
+
return input_lengths
@@ -1021,11 +1103,17 @@ def __call__(
return FlaxCausalLMOutput(logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
- def _get_feat_extract_output_lengths(self, input_lengths: Union[jnp.ndarray, int]):
+ def _get_feat_extract_output_lengths(
+ self,
+ input_lengths: Union[jnp.ndarray, int],
+ add_adapter: Optional[bool] = None,
+ ):
"""
Computes the output length of the convolutional layers
"""
+ add_adapter = self.config.add_adapter if add_adapter is None else add_adapter
+
def _conv_out_length(input_length, kernel_size, stride):
# 1D convolutional layer output length formula taken
# from https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
@@ -1034,6 +1122,10 @@ def _conv_out_length(input_length, kernel_size, stride):
for kernel_size, stride in zip(self.config.conv_kernel, self.config.conv_stride):
input_lengths = _conv_out_length(input_lengths, kernel_size, stride)
+ if add_adapter:
+ for _ in range(self.config.num_adapter_layers):
+ input_lengths = _conv_out_length(input_lengths, 1, self.config.adapter_stride)
+
return input_lengths
diff --git a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
index d7e15fb4f41e..fb44424a1c74 100644
--- a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
@@ -16,6 +16,7 @@
import inspect
import warnings
+from dataclasses import dataclass
from typing import Any, Dict, Optional, Tuple, Union
import numpy as np
@@ -43,6 +44,9 @@
logger = logging.get_logger(__name__)
+
+_HIDDEN_STATES_START_POSITION = 2
+
_CHECKPOINT_FOR_DOC = "facebook/wav2vec2-base-960h"
_CONFIG_FOR_DOC = "Wav2Vec2Config"
_TOKENIZER_FOR_DOC = "Wav2Vec2Tokenizer"
@@ -58,6 +62,35 @@
LARGE_NEGATIVE = -1e8
+@dataclass
+class TFWav2Vec2BaseModelOutput(ModelOutput):
+ """
+ Output type of [`TFWav2Vec2BaseModelOutput`], with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ extract_features (`tf.Tensor` of shape `(batch_size, sequence_length, conv_dim[-1])`):
+ Sequence of extracted feature vectors of the last convolutional layer of the model.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: tf.Tensor = None
+ extract_features: tf.Tensor = None
+ hidden_states: Optional[Tuple[tf.Tensor]] = None
+ attentions: Optional[Tuple[tf.Tensor]] = None
+
+
def input_values_processing(func, config, input_values, **kwargs):
"""
Process the input of each TensorFlow model including the booleans. In case of a list of symbolic inputs, each input
@@ -707,10 +740,10 @@ def __init__(self, config: Wav2Vec2Config, **kwargs):
self.dropout = tf.keras.layers.Dropout(rate=config.feat_proj_dropout)
def call(self, hidden_states: tf.Tensor, training: bool = False) -> tf.Tensor:
- hidden_states = self.layer_norm(hidden_states)
- hidden_states = self.projection(hidden_states)
+ norm_hidden_states = self.layer_norm(hidden_states)
+ hidden_states = self.projection(norm_hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
- return hidden_states
+ return hidden_states, norm_hidden_states
# Copied from transformers.models.bart.modeling_tf_bart.TFBartAttention with TFBart->TFWav2Vec2
@@ -1222,19 +1255,20 @@ def call(
kwargs_call=kwargs,
)
- hidden_states = self.feature_extractor(
+ extract_features = self.feature_extractor(
tf.cast(inputs["input_values"], tf.float32), training=inputs["training"]
)
+ # extract_features = tf.transpose(extract_features, perm=(0, 2, 1))
if inputs["attention_mask"] is not None:
# compute real output lengths according to convolution formula
output_lengths = self._get_feat_extract_output_lengths(tf.reduce_sum(inputs["attention_mask"], -1))
attention_mask = tf.sequence_mask(
- output_lengths, maxlen=shape_list(hidden_states)[1], dtype=hidden_states.dtype
+ output_lengths, maxlen=shape_list(extract_features)[1], dtype=extract_features.dtype
)
- hidden_states = self.feature_projection(hidden_states, training=inputs["training"])
+ hidden_states, extract_features = self.feature_projection(extract_features, training=inputs["training"])
mask_time_indices = kwargs.get("mask_time_indices", None)
if inputs["training"]:
@@ -1251,10 +1285,11 @@ def call(
hidden_states = encoder_outputs[0]
if not inputs["return_dict"]:
- return (hidden_states,) + encoder_outputs[1:]
+ return (hidden_states, extract_features) + encoder_outputs[1:]
- return TFBaseModelOutput(
+ return TFWav2Vec2BaseModelOutput(
last_hidden_state=hidden_states,
+ extract_features=extract_features,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
@@ -1635,7 +1670,7 @@ def call(
loss = None
if not inputs["return_dict"]:
- output = (logits,) + outputs[1:]
+ output = (logits,) + outputs[_HIDDEN_STATES_START_POSITION:]
return ((loss,) + output) if loss is not None else output
return TFCausalLMOutput(
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index f80a8bd18cc5..f45c0a8e689e 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -41,7 +41,8 @@
SequenceClassifierOutput,
TokenClassifierOutput,
)
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_wav2vec2 import Wav2Vec2Config
@@ -1701,7 +1702,10 @@ def __init__(self, config):
"instantiate the model as follows: `Wav2Vec2ForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1818,6 +1822,10 @@ class Wav2Vec2ForSequenceClassification(Wav2Vec2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of Wav2Vec2 adapters (config.add_adapter=True)"
+ )
self.wav2vec2 = Wav2Vec2Model(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1937,6 +1945,10 @@ class Wav2Vec2ForAudioFrameClassification(Wav2Vec2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of Wav2Vec2 adapters (config.add_adapter=True)"
+ )
self.wav2vec2 = Wav2Vec2Model(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/wavlm/modeling_wavlm.py b/src/transformers/models/wavlm/modeling_wavlm.py
index 9f67e6135009..2618ec9bbca2 100755
--- a/src/transformers/models/wavlm/modeling_wavlm.py
+++ b/src/transformers/models/wavlm/modeling_wavlm.py
@@ -35,7 +35,8 @@
add_start_docstrings_to_model_forward,
)
from ...modeling_outputs import BaseModelOutput, CausalLMOutput, SequenceClassifierOutput, TokenClassifierOutput
-from ...modeling_utils import PreTrainedModel, torch_int_div
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import torch_int_div
from ...utils import logging
from .configuration_wavlm import WavLMConfig
@@ -1351,7 +1352,10 @@ def __init__(self, config):
"instantiate the model as follows: `WavLMForCTC.from_pretrained(..., vocab_size=vocab_size)`. "
"or define `vocab_size` of your model's configuration."
)
- self.lm_head = nn.Linear(config.hidden_size, config.vocab_size)
+ output_hidden_size = (
+ config.output_hidden_size if hasattr(config, "add_adapter") and config.add_adapter else config.hidden_size
+ )
+ self.lm_head = nn.Linear(output_hidden_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
@@ -1469,6 +1473,10 @@ class WavLMForSequenceClassification(WavLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Sequence classification does not support the use of WavLM adapters (config.add_adapter=True)"
+ )
self.wavlm = WavLMModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
@@ -1589,6 +1597,10 @@ class WavLMForAudioFrameClassification(WavLMPreTrainedModel):
def __init__(self, config):
super().__init__(config)
+ if hasattr(config, "add_adapter") and config.add_adapter:
+ raise ValueError(
+ "Audio frame classification does not support the use of WavLM adapters (config.add_adapter=True)"
+ )
self.wavlm = WavLMModel(config)
num_layers = config.num_hidden_layers + 1 # transformer layers + input embeddings
if config.use_weighted_layer_sum:
diff --git a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
index cdea06ac57b6..cfeb788ec62e 100644
--- a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
@@ -181,7 +181,7 @@ def __init__(self, config, position_embedding_type=None):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
+ x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
@@ -270,7 +270,7 @@ def forward(
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
+ context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
diff --git a/src/transformers/onnx/features.py b/src/transformers/onnx/features.py
index 41f8970d707f..9f3ad05b4f30 100644
--- a/src/transformers/onnx/features.py
+++ b/src/transformers/onnx/features.py
@@ -7,11 +7,11 @@
from ..models.bert import BertOnnxConfig
from ..models.camembert import CamembertOnnxConfig
from ..models.distilbert import DistilBertOnnxConfig
+from ..models.electra import ElectraOnnxConfig
from ..models.gpt2 import GPT2OnnxConfig
from ..models.gpt_neo import GPTNeoOnnxConfig
from ..models.ibert import IBertOnnxConfig
from ..models.layoutlm import LayoutLMOnnxConfig
-from ..models.longformer import LongformerOnnxConfig
from ..models.marian import MarianOnnxConfig
from ..models.mbart import MBartOnnxConfig
from ..models.roberta import RobertaOnnxConfig
@@ -154,15 +154,6 @@ class FeaturesManager:
"question-answering",
onnx_config_cls=DistilBertOnnxConfig,
),
- "longformer": supported_features_mapping(
- "default",
- "masked-lm",
- "sequence-classification",
- # "multiple-choice",
- "token-classification",
- "question-answering",
- onnx_config_cls=LongformerOnnxConfig,
- ),
"marian": supported_features_mapping(
"default",
"default-with-past",
@@ -219,6 +210,15 @@ class FeaturesManager:
"token-classification",
onnx_config_cls=LayoutLMOnnxConfig,
),
+ "electra": supported_features_mapping(
+ "default",
+ "masked-lm",
+ "causal-lm",
+ "sequence-classification",
+ "token-classification",
+ "question-answering",
+ onnx_config_cls=ElectraOnnxConfig,
+ ),
}
AVAILABLE_FEATURES = sorted(reduce(lambda s1, s2: s1 | s2, (v.keys() for v in _SUPPORTED_MODEL_TYPE.values())))
diff --git a/src/transformers/pipelines/automatic_speech_recognition.py b/src/transformers/pipelines/automatic_speech_recognition.py
index c013a77d860e..e57fb7d5e45c 100644
--- a/src/transformers/pipelines/automatic_speech_recognition.py
+++ b/src/transformers/pipelines/automatic_speech_recognition.py
@@ -265,10 +265,19 @@ def _forward(self, model_inputs):
# it here.
# Consume values so we can let extra information flow freely through
# the pipeline (important for `partial` in microphone)
- input_features = model_inputs.pop("input_features")
- attention_mask = model_inputs.pop("attention_mask")
+ if "input_features" in model_inputs:
+ inputs = model_inputs.pop("input_features")
+ elif "input_values" in model_inputs:
+ inputs = model_inputs.pop("input_values")
+ else:
+ raise ValueError(
+ "Seq2Seq speech recognition model requires either a "
+ f"`input_features` or `input_values` key, but only has {model_inputs.keys()}"
+ )
+
+ attention_mask = model_inputs.pop("attention_mask", None)
tokens = self.model.generate(
- encoder_outputs=encoder(input_features=input_features, attention_mask=attention_mask),
+ encoder_outputs=encoder(inputs, attention_mask=attention_mask),
attention_mask=attention_mask,
)
out = {"tokens": tokens}
diff --git a/src/transformers/pytorch_utils.py b/src/transformers/pytorch_utils.py
new file mode 100644
index 000000000000..b41f438d9c3a
--- /dev/null
+++ b/src/transformers/pytorch_utils.py
@@ -0,0 +1,31 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from packaging import version
+
+from .utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def torch_int_div(tensor1, tensor2):
+ """
+ A function that performs integer division across different versions of PyTorch.
+ """
+ if version.parse(torch.__version__) < version.parse("1.8.0"):
+ return tensor1 // tensor2
+ else:
+ return torch.div(tensor1, tensor2, rounding_mode="floor")
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 5d6f538964c0..0278bf42e558 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -16,7 +16,6 @@
The Trainer class, to easily train a 🤗 Transformers from scratch or finetune it on a new task.
"""
-import collections
import contextlib
import inspect
import math
@@ -54,7 +53,7 @@
import torch
from packaging import version
from torch import nn
-from torch.utils.data import DataLoader, Dataset, IterableDataset, RandomSampler, SequentialSampler
+from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from huggingface_hub import Repository
@@ -126,6 +125,7 @@
default_hp_space,
denumpify_detensorize,
get_last_checkpoint,
+ has_length,
number_of_arguments,
set_seed,
speed_metrics,
@@ -429,7 +429,7 @@ def __init__(
if args.max_steps > 0:
logger.info("max_steps is given, it will override any value given in num_train_epochs")
- if train_dataset is not None and not isinstance(train_dataset, collections.abc.Sized) and args.max_steps <= 0:
+ if train_dataset is not None and not has_length(train_dataset) and args.max_steps <= 0:
raise ValueError("train_dataset does not implement __len__, max_steps has to be specified")
if (
@@ -585,7 +585,7 @@ def _remove_unused_columns(self, dataset: "datasets.Dataset", description: Optio
return dataset.remove_columns(ignored_columns)
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
- if not isinstance(self.train_dataset, collections.abc.Sized):
+ if not has_length(self.train_dataset):
return None
generator = None
@@ -1190,7 +1190,7 @@ def train(
self.model_wrapped = self.model
# Keeping track whether we can can len() on the dataset or not
- train_dataset_is_sized = isinstance(self.train_dataset, collections.abc.Sized)
+ train_dataset_is_sized = has_length(self.train_dataset)
# Data loader and number of training steps
train_dataloader = self.get_train_dataloader()
@@ -2383,7 +2383,7 @@ def evaluation_loop(
batch_size = dataloader.batch_size
logger.info(f"***** Running {description} *****")
- if isinstance(dataloader.dataset, collections.abc.Sized):
+ if has_length(dataloader.dataset):
logger.info(f" Num examples = {self.num_examples(dataloader)}")
else:
logger.info(" Num examples: Unknown")
@@ -2478,7 +2478,7 @@ def evaluation_loop(
all_labels = labels if all_labels is None else nested_concat(all_labels, labels, padding_index=-100)
# Number of samples
- if not isinstance(eval_dataset, IterableDataset):
+ if has_length(eval_dataset):
num_samples = len(eval_dataset)
# The instance check is weird and does not actually check for the type, but whether the dataset has the right
# methods. Therefore we need to make sure it also has the attribute.
@@ -2872,7 +2872,7 @@ def prediction_loop(
"""
args = self.args
- if not isinstance(dataloader.dataset, collections.abc.Sized):
+ if not has_length(dataloader.dataset):
raise ValueError("dataset must implement __len__")
prediction_loss_only = prediction_loss_only if prediction_loss_only is not None else args.prediction_loss_only
diff --git a/src/transformers/trainer_callback.py b/src/transformers/trainer_callback.py
index e81d0a27f297..51f9f4f2240d 100644
--- a/src/transformers/trainer_callback.py
+++ b/src/transformers/trainer_callback.py
@@ -15,7 +15,6 @@
"""
Callbacks to use with the Trainer class and customize the training loop.
"""
-import collections
import dataclasses
import json
from dataclasses import dataclass
@@ -24,7 +23,7 @@
import numpy as np
from tqdm.auto import tqdm
-from .trainer_utils import IntervalStrategy
+from .trainer_utils import IntervalStrategy, has_length
from .training_args import TrainingArguments
from .utils import logging
@@ -470,7 +469,7 @@ def on_step_end(self, args, state, control, **kwargs):
self.current_step = state.global_step
def on_prediction_step(self, args, state, control, eval_dataloader=None, **kwargs):
- if state.is_local_process_zero and isinstance(eval_dataloader.dataset, collections.abc.Sized):
+ if state.is_local_process_zero and has_length(eval_dataloader.dataset):
if self.prediction_bar is None:
self.prediction_bar = tqdm(total=len(eval_dataloader), leave=self.training_bar is None)
self.prediction_bar.update(1)
diff --git a/src/transformers/trainer_utils.py b/src/transformers/trainer_utils.py
index 2f96ff61525d..e4b896edbd60 100644
--- a/src/transformers/trainer_utils.py
+++ b/src/transformers/trainer_utils.py
@@ -519,6 +519,17 @@ def stop_and_update_metrics(self, metrics=None):
self.update_metrics(stage, metrics)
+def has_length(dataset):
+ """
+ Checks if the dataset implements __len__() and it doesn't raise an error
+ """
+ try:
+ return len(dataset) is not None
+ except TypeError:
+ # TypeError: len() of unsized object
+ return False
+
+
def denumpify_detensorize(metrics):
"""
Recursively calls `.item()` on the element of the dictionary passed
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 21e94075a8da..567883c7a618 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -474,6 +474,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class AutoModelForSemanticSegmentation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForSeq2SeqLM(metaclass=DummyObject):
_backends = ["torch"]
@@ -1108,6 +1115,30 @@ def load_tf_weights_in_convbert(*args, **kwargs):
requires_backends(load_tf_weights_in_convbert, ["torch"])
+CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class ConvNextForImageClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ConvNextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ConvNextPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 9e5efabc062c..1084d2fc4d0c 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -31,6 +31,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class ConvNextFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class DeiTFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/src/transformers/utils/fx.py b/src/transformers/utils/fx.py
index 23a2eb4c1fab..f9cdc407aeb6 100644
--- a/src/transformers/utils/fx.py
+++ b/src/transformers/utils/fx.py
@@ -1,8 +1,24 @@
-import copy
+# coding=utf-8
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
import functools
import inspect
+import math
import random
-from typing import Any, Callable, Dict, List, Optional, Tuple, Type, Union
+from types import ModuleType
+from typing import Any, Callable, Dict, Iterable, List, Optional, Type, Union
import torch
from packaging import version
@@ -26,17 +42,11 @@
GPT2DoubleHeadsModel,
PretrainedConfig,
PreTrainedModel,
+ XLNetForQuestionAnswering,
logging,
)
from ..file_utils import TORCH_FX_REQUIRED_VERSION, importlib_metadata, is_torch_fx_available
from ..models.auto import get_values
-from .fx_transformations import (
- _cache_attributes,
- _patch_arguments_,
- _restore_attributes_,
- transform_to_dynamic_input_,
- transformation,
-)
logger = logging.get_logger(__name__)
@@ -46,6 +56,7 @@ def _generate_supported_model_classes(
model_name: Type[PretrainedConfig],
supported_tasks: Optional[Union[str, List[str]]] = None,
) -> List[Type[PreTrainedModel]]:
+
model_config_class = CONFIG_MAPPING[model_name]
task_mapping = {
"default": MODEL_MAPPING,
@@ -86,15 +97,10 @@ def _generate_supported_model_classes(
"gptj",
"gpt_neo",
"t5",
-]
-
-_REGULAR_SUPPORTED_MODEL_NAMES_AND_TASKS_FOR_DYNAMIC_AXES = [
- "albert",
- "bert",
- "distilbert",
- "mobilebert",
- "electra",
- "megatron-bert",
+ "roberta",
+ # TODO: add support for them as it should be quite easy to do so (small blocking issues).
+ # "layoutlm",
+ # "xlnet",
]
_REGULAR_SUPPORTED_MODELS = []
@@ -106,21 +112,11 @@ def _generate_supported_model_classes(
_SPECIAL_SUPPORTED_MODELS = [
GPT2DoubleHeadsModel,
+ # TODO: add support for them as it should be quite easy to do so (small blocking issues).
+ # XLNetForQuestionAnswering,
]
_SUPPORTED_MODELS = tuple(_REGULAR_SUPPORTED_MODELS + _SPECIAL_SUPPORTED_MODELS)
-_REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = []
-for item in _REGULAR_SUPPORTED_MODEL_NAMES_AND_TASKS_FOR_DYNAMIC_AXES:
- if isinstance(item, dict):
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES.extend(_generate_supported_model_classes(**item))
- else:
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES.extend(_generate_supported_model_classes(item))
-
-_SPECIAL_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = []
-_SUPPORTED_MODELS_FOR_DYNAMIC_AXES = tuple(
- _REGULAR_SUPPORTED_MODELS_FOR_DYNAMIC_AXES + _SPECIAL_SUPPORTED_MODELS_FOR_DYNAMIC_AXES
-)
-
class HFProxy(Proxy):
"""
@@ -134,6 +130,7 @@ def __init__(self, node: Node, tracer: Optional[Tracer] = None):
if hasattr(self, "tracer") and self.tracer is not None:
self.device = self.tracer.root.device
self.dtype = next(self.tracer.root.parameters()).dtype
+ self.cache = None
@property
def shape(self):
@@ -145,42 +142,54 @@ def __setitem__(self, key, value):
def __contains__(self, key):
return False
+ def __eq__(self, other):
+ if self.cache is not None:
+ return self.cache == other
+ elif isinstance(other, HFProxy):
+ return True
+ else:
+ return super().__eq__(other)
-def _wrap_method_for_model_recording(model, method_name, cache_name):
- """Helper function that wraps a torch.Tensor method to record its outputs during forward pass."""
- method = getattr(torch.Tensor, method_name)
+ def __ne__(self, other):
+ return not self == other
- @functools.wraps(method)
- def wrapped(*args, **kwargs):
- if not hasattr(model, cache_name):
- setattr(model, cache_name, [])
- cache = getattr(model, cache_name)
- res = method(*args, **kwargs)
- cache.append(res)
- return res
+ def __len__(self):
+ if self.cache is not None:
+ if isinstance(self.cache, int):
+ return self.cache
+ elif isinstance(self.cache, (torch.Size, list, tuple)):
+ return len(self.cache)
+ else:
+ return super().__len__(self)
+ return super().__len__(self)
- return wrapped
+ def __torch_function__(self, orig_method, types, args=None, kwargs=None):
+ proxy = super().__torch_function__(orig_method, types, args=args, kwargs=kwargs)
+ proxy.cache = self.cache
+ return proxy
-def _create_recorded_proxy_method(proxy, method_name, cache_name):
- """
- Helper function that sets a recorded torch.Tensor method as a HFProxy method that will use the recorded values
- during symbolic tracing.
- """
+def _function_to_leaf(func: Callable[..., Any]) -> Callable[..., Any]:
+ """Wrapper that marks func as a leaf function, meaning that it will not be traced through by HFTracer."""
- def method(self, *args, **kwargs):
- cache = getattr(self.tracer.root, cache_name)
- res = cache.pop(0)
- return res
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ return wrapper
- method.__name__ = method_name
- bound_method = method.__get__(proxy, proxy.__class__)
- setattr(proxy, method_name, bound_method)
+def _function_leaf_getter(func_name: str, mapping: Dict[str, Callable[..., Any]]) -> Callable[..., Any]:
+ @functools.wraps(mapping[func_name])
+ def wrapper(*args, **kwargs):
+ return mapping[func_name](*args, **kwargs)
-def _wrap_method_for_model_tracing(model, method_name, cache_name):
+ return wrapper
+
+
+def _create_recorded_proxy_method(proxy: HFProxy, method_name: str, cache_name: str, return_proxy: bool):
"""
- Helper function that sets a recorded torch.Tensor method as a torch.Tensor method that will use the recorded values
+ Helper function that sets a recorded torch.Tensor method as a HFProxy method that will use the recorded values
during symbolic tracing.
"""
@@ -188,55 +197,69 @@ def _wrap_method_for_model_tracing(model, method_name, cache_name):
@functools.wraps(original_method)
def method(*args, **kwargs):
- cache = getattr(model, cache_name)
+ cache = getattr(args[0].tracer.root, cache_name)
res = cache.pop(0)
+ if return_proxy:
+ proxy = args[0].__torch_function__(
+ original_method,
+ None,
+ args=args,
+ kwargs=kwargs,
+ )
+ proxy.cache = res
+ return proxy
return res
- setattr(torch.Tensor, method_name, method)
-
- if method_name == "size":
- setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
-
-
-def _monkey_patch_tensor_methods_for_model_recording(model, method_names):
- """
- Helper function that patches torch.Tensor methods (specified by the method_names list) to record model inference
- before symbolic tracing.
- """
- cache_names = dict()
- original_methods = dict()
- for method_name in method_names:
- cache_name = f"cache_{method_name}"
- cache_names[method_name] = cache_name
- if not hasattr(torch.Tensor, method_name):
- logger.info(f"torch.Tensor has no method called {method_name}, skipping patching.")
- continue
- original_methods[method_name] = getattr(torch.Tensor, method_name)
- setattr(torch.Tensor, method_name, _wrap_method_for_model_recording(model, method_name, cache_name))
-
- if method_name == "size":
- original_methods["shape"] = torch.Tensor.shape
- setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
-
- return cache_names, original_methods
+ method.__name__ = method_name
+ bound_method = method.__get__(proxy, proxy.__class__)
+ setattr(proxy, method_name, bound_method)
-def _reset_tensor_methods(original_methods):
+def _reset_tensor_methods(original_methods: Dict[str, Callable[..., Any]]):
"""Helper function that resets the monkey patched torch.Tensor methods to their original values."""
for name, method in original_methods.items():
setattr(torch.Tensor, name, method)
+def _generate_random_int(low: int = 10, high: int = 20, forbidden_values: Optional[List[int]] = None):
+ if forbidden_values is None:
+ forbidden_values = []
+ value = random.randint(low, high)
+ while value in forbidden_values:
+ value = random.randint(low, high)
+ return value
+
+
class HFTracer(Tracer):
"""
Tracer that is able to symbolically trace models from the library. To do that, it uses the HFProxy instead of the
regular PyTorch torch.fx.Proxy.
"""
- default_methods_to_record = {"__bool__", "size", "dim"}
+ _DEFAULT_METHODS_TO_RECORD = {"__bool__": False, "size": True, "dim": False}
+ from transformers import modeling_utils
+
+ _FUNCTIONS_TO_AUTOWRAP = {
+ torch: {"arange", "zeros", "ones", "full_like", "eye"},
+ modeling_utils.ModuleUtilsMixin: {"create_extended_attention_mask_for_decoder"},
+ }
+
+ def __init__(self, autowrap_modules=(math,), autowrap_functions=(), enable_cpatching=False):
+
+ # Loading the leaf functions register
+ self._leaf_functions_register = {}
+ for module, names in self._FUNCTIONS_TO_AUTOWRAP.items():
+ for name in names:
+ self._register_leaf_function(module, name)
+
+ # TODO: adapt the way leaf function are wrapped with the "autowrap function" feature from Tracer.
+ # autowrap_functions = autowrap_functions + tuple(
+ # patched for (_, _, patched) in self._leaf_functions_register.values()
+ # )
- def __init__(self, batch_size=1, sequence_length=[128, 128], num_choices=-1):
- super().__init__()
+ super().__init__(
+ autowrap_modules=autowrap_modules, autowrap_functions=autowrap_functions, enable_cpatching=enable_cpatching
+ )
if not is_torch_fx_available():
torch_version = version.parse(importlib_metadata.version("torch"))
@@ -245,40 +268,107 @@ def __init__(self, batch_size=1, sequence_length=[128, 128], num_choices=-1):
f"{TORCH_FX_REQUIRED_VERSION} is supported."
)
- encoder_sequence_length = sequence_length[0] if isinstance(sequence_length, (list, tuple)) else sequence_length
- decoder_sequence_length = (
- sequence_length[1] if isinstance(sequence_length, (list, tuple)) else encoder_sequence_length
- )
- self.encoder_shape = [batch_size, encoder_sequence_length]
- self.decoder_shape = (
- [batch_size, decoder_sequence_length] if decoder_sequence_length > 0 else list(self.encoder_shape)
- )
- self.num_choices = num_choices
- if self.num_choices > 0:
- self.encoder_shape = [batch_size, self.num_choices, encoder_sequence_length]
- self.decoder_shape = [batch_size, self.num_choices, decoder_sequence_length]
-
self.prev_module = None
self.recorded_methods = None
- def proxy(self, node: Node):
- p = HFProxy(node, self)
- if self.recorded_methods:
- for method_name, cache_name in self.recorded_methods.items():
- _create_recorded_proxy_method(p, method_name, cache_name)
- return p
+ def _register_leaf_function(self, module: ModuleType, name: str):
+ """Registers the function called name in module as a leaf function."""
+ orig_func = getattr(module, name)
+ patched_func = _function_to_leaf(orig_func)
+ patched_func.__module__ = __name__
+ self._leaf_functions_register[name] = (module, orig_func, patched_func)
+
+ def _patch_leaf_functions_for_root(self, root: PreTrainedModel, restore: bool = False):
+ """Patches leaf functions specifically for root."""
+ for name in self._leaf_functions_register:
+ module, orig_func, patched_func = self._leaf_functions_register[name]
+ if restore:
+ root.__class__.forward.__globals__.pop(name)
+ setattr(module, name, orig_func)
+ else:
+ root.__class__.forward.__globals__[name] = patched_func
+ leaf_getter = _function_leaf_getter(name, root.__class__.forward.__globals__)
+ leaf_getter.__module__ = __name__
+ setattr(module, name, leaf_getter)
+
+ def _method_is_called_in_leaf_module(self, module_ids: List[int]) -> bool:
+ """
+ Finds out if the method (that is being recorded) is called inside a leaf module, this allows to not record
+ outputs that will not be encountered by the tracer.
+ """
+
+ currentframe = inspect.currentframe()
+ while currentframe:
+ if currentframe is None:
+ return False
+ module = currentframe.f_locals.get("self", None)
+ if id(module) in module_ids and self.is_leaf_module(module, "Not used anyway"):
+ return True
+ currentframe = currentframe.f_back
+ return False
+
+ def _wrap_method_for_model_recording(
+ self, model: PreTrainedModel, method_name: str, cache_name: str, module_ids: List[int]
+ ):
+ """Helper function that wraps a torch.Tensor method to record its outputs during forward pass."""
+ method = getattr(torch.Tensor, method_name)
+
+ @functools.wraps(method)
+ def wrapped(*args, **kwargs):
+ if self._method_is_called_in_leaf_module(module_ids):
+ return method(*args, **kwargs)
+ if not hasattr(model, cache_name):
+ setattr(model, cache_name, [])
+ cache = getattr(model, cache_name)
+ res = method(*args, **kwargs)
+ cache.append(res)
+ return res
+
+ return wrapped
+
+ def _monkey_patch_tensor_methods_for_model_recording(self, model: PreTrainedModel, method_names: Iterable[str]):
+ """
+ Helper function that patches torch.Tensor methods (specified by the method_names list) to record model
+ inference before symbolic tracing.
+ """
+ cache_names = {}
+ original_methods = {}
+ module_ids = set(id(mod) for mod in model.modules())
+ for method_name in method_names:
+ cache_name = f"cache_{method_name}"
+ cache_names[method_name] = cache_name
+ if not hasattr(torch.Tensor, method_name):
+ logger.info(f"torch.Tensor has no method called {method_name}, skipping patching.")
+ continue
+ original_methods[method_name] = getattr(torch.Tensor, method_name)
+ setattr(
+ torch.Tensor,
+ method_name,
+ self._wrap_method_for_model_recording(model, method_name, cache_name, module_ids),
+ )
- def _generate_dummy_input(self, model, input_name):
+ if method_name == "size":
+ original_methods["shape"] = torch.Tensor.shape
+ setattr(torch.Tensor, "shape", property(getattr(torch.Tensor, method_name)))
+
+ return cache_names, original_methods
+
+ def _generate_dummy_input(
+ self, model: PreTrainedModel, input_name: str, shape: List[int]
+ ) -> Dict[str, torch.Tensor]:
"""Generates dummy input for model inference recording."""
model_class = model.__class__
device = model.device
- inputs_dict = dict()
+ inputs_dict = {}
if input_name in ["labels", "start_positions", "end_positions"]:
- batch_size = self.encoder_shape[0]
+ batch_size = shape[0]
if model_class in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
- inputs_dict["labels"] = torch.ones(batch_size, dtype=torch.long, device=device)
- elif model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(batch_size, dtype=torch.long, device=device)
+ elif model_class in [
+ *get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING),
+ XLNetForQuestionAnswering,
+ ]:
inputs_dict["start_positions"] = torch.zeros(batch_size, dtype=torch.long, device=device)
inputs_dict["end_positions"] = torch.zeros(batch_size, dtype=torch.long, device=device)
elif model_class in [
@@ -288,59 +378,56 @@ def _generate_dummy_input(self, model, input_name):
]:
inputs_dict["labels"] = torch.zeros(batch_size, dtype=torch.long, device=device)
elif model_class in [
+ *get_values(MODEL_FOR_PRETRAINING_MAPPING),
*get_values(MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_CAUSAL_LM_MAPPING),
*get_values(MODEL_FOR_MASKED_LM_MAPPING),
*get_values(MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING),
GPT2DoubleHeadsModel,
]:
- inputs_dict["labels"] = torch.zeros(self.decoder_shape, dtype=torch.long, device=device)
- elif model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
- inputs_dict["labels"] = torch.zeros(self.encoder_shape, dtype=torch.long, device=device)
+ inputs_dict["labels"] = torch.zeros(shape, dtype=torch.long, device=device)
else:
raise NotImplementedError(f"{model_class} not supported yet.")
elif "mask" in input_name or "ids" in input_name:
- shape = self.encoder_shape if "decoder" not in input_name else self.decoder_shape
- inputs_dict[input_name] = torch.ones(shape, dtype=torch.long, device=device)
+ inputs_dict[input_name] = torch.zeros(shape, dtype=torch.long, device=device)
else:
- shape = self.encoder_shape if "decoder" not in input_name else self.decoder_shape
- shape += [model.config.hidden_size]
- inputs_dict[input_name] = torch.ones(shape, dtype=torch.float, device=device)
+ shape_with_hidden_size = shape + [model.config.hidden_size]
+ inputs_dict[input_name] = torch.zeros(shape_with_hidden_size, dtype=torch.float, device=device)
return inputs_dict
- def record(self, model, input_names, method_names=None):
+ def record(self, model: PreTrainedModel, input_names: List[str], method_names: Optional[Iterable[str]] = None):
"""
- Records torch.Tensor method outputs (specified by the method_names list) that will then be used during symbolic
- tracing.
+ Records torch.Tensor method outputs (specified by method_names) that will then be used during symbolic tracing.
"""
if method_names is None:
- method_names = self.default_methods_to_record
+ method_names = self._DEFAULT_METHODS_TO_RECORD
+
+ # Creating a random input shape to generate dummy inputs.
+ batch_size = _generate_random_int()
+ sequence_length = _generate_random_int()
+ shape = [batch_size, sequence_length]
+
+ if model.__class__ in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
+ num_choices = _generate_random_int(low=2, high=5)
+ shape.insert(1, num_choices)
inputs = {}
for input_name in input_names:
- inputs.update(self._generate_dummy_input(model, input_name))
+ inputs.update(self._generate_dummy_input(model, input_name, shape))
- clone = copy.deepcopy(model)
- cache_names, original_methods = _monkey_patch_tensor_methods_for_model_recording(clone, method_names)
+ cache_names, original_methods = self._monkey_patch_tensor_methods_for_model_recording(model, method_names)
self.original_methods = original_methods
- clone(**inputs)
-
- # Useful because sometime the config is changed at inference time, for instance for
- # classification tasks where config.problem_type can be set.
- model.config = clone.config
+ model(**inputs)
_reset_tensor_methods(original_methods)
self.recorded_methods = {
- method_name: cache_name for method_name, cache_name in cache_names.items() if hasattr(clone, cache_name)
+ method_name: cache_name for method_name, cache_name in cache_names.items() if hasattr(model, cache_name)
}
- for cache_name in self.recorded_methods.values():
- setattr(model, cache_name, getattr(clone, cache_name))
-
def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
if isinstance(attr_val, torch.nn.Parameter):
for n, p in self.root.named_parameters():
@@ -357,7 +444,20 @@ def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
return parameter_proxy_cache[n]
return attr_val
- def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] = None, method_names=None) -> Graph:
+ def proxy(self, node: Node):
+ p = HFProxy(node, self)
+ if self.recorded_methods:
+ for method_name, cache_name in self.recorded_methods.items():
+ return_proxy = self._DEFAULT_METHODS_TO_RECORD[method_name]
+ _create_recorded_proxy_method(p, method_name, cache_name, return_proxy)
+ return p
+
+ def trace(
+ self,
+ root: PreTrainedModel,
+ concrete_args: Optional[Dict[str, Any]] = None,
+ method_names: Optional[Iterable[str]] = None,
+ ) -> Graph:
if concrete_args is None:
concrete_args = {}
@@ -366,11 +466,16 @@ def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] =
self.record(root, input_names, method_names=method_names)
- for method_name, cache_name in self.recorded_methods.items():
- _wrap_method_for_model_tracing(root, method_name, cache_name)
+ # TODO: adapt the way leaf function are wrapped with the "autowrap function" feature from Tracer.
+ autowrap_functions = [patched for (_, _, patched) in self._leaf_functions_register.values()]
+ self._autowrap_function_ids.update(set([id(f) for f in autowrap_functions]))
+
+ self._patch_leaf_functions_for_root(root)
graph = super().trace(root, concrete_args=concrete_args)
+ self._patch_leaf_functions_for_root(root, restore=True)
+
_reset_tensor_methods(self.original_methods)
# TODO: keep this until necessary.
@@ -388,7 +493,7 @@ def trace(self, root: PreTrainedModel, concrete_args: Optional[Dict[str, Any]] =
return graph
- def _insert_module_as_submodule(self, mod):
+ def _insert_module_as_submodule(self, mod: nn.Module) -> str:
"""
Helper method which tries to insert a module that was not declared as submodule.
"""
@@ -434,72 +539,19 @@ def path_of_module(self, mod: nn.Module) -> str:
self.prev_module = path
return path
+ def is_leaf_module(self, m: nn.Module, module_qualified_name: str) -> bool:
+ is_loss_module = m.__module__.startswith("torch.nn.modules.loss")
+ return (not is_loss_module) and super().is_leaf_module(m, module_qualified_name)
+
def create_arg(self, a: Any) -> Argument:
if isinstance(a, range):
return super().create_arg(list(a))
return super().create_arg(a)
-@transformation
-def prepare_for_retracing(gm: GraphModule) -> Tuple[GraphModule, Dict[str, Any]]:
- """
- Prepares a GraphModule produced by symbolic_trace for retracing by:
-
- - Caching all the attributes specific to the way the model was initially traced
- - Patching back the model to a "static input shapes" version if it was traced to accept dynamic input shapes
- For instance, the need to retrace a GraphModule can happen when applying quantization.
- """
- attributes = _cache_attributes(gm)
- _patch_arguments_(gm, gm.dynamic2static)
-
- return gm, attributes
-
-
-def restore_after_retracing_(gm: GraphModule, attributes: Dict[str, Any]):
- """Restores a GraphModule that was retraced to its initial state in terms of static / dynamic input shapes."""
- _restore_attributes_(gm, attributes)
- # transform_to_dynamic_input_ will override the static2dynamic and dynamic2static dictionaries which is the desired
- # behaviour as the previously restored dictionaries contain nodes from the original GraphModule as values.
- transform_to_dynamic_input_(gm, is_retracing=True)
- _patch_arguments_(gm, gm.static2dynamic)
- return gm
-
-
-def retrace_graph_with(
- gm: GraphModule, tracer: Tracer = None, func: Callable[[GraphModule], GraphModule] = None
-) -> GraphModule:
- """
- Retraces a GraphModule by either using a tracer or a function using a tracer (for instance
- torch.quantization.quantize_fx.prepare_fx). It takes care of preparing the model for retracing, retracing it and
- restoring anything necessary after the retrace.
- """
- if tracer is None and func is None:
- raise ValueError("Either a tracer or a function using a tracer must be provided.")
- elif tracer is not None and func is not None:
- raise ValueError("Either provide a tracer or a function using a tracer, but not both.")
- else:
- gm, attributes = prepare_for_retracing(gm)
- tracing_func = tracer.trace if tracer else func
- traced = tracing_func(gm)
- restore_after_retracing_(traced, attributes)
- return traced
-
-
-def _generate_random_int(low: int = 10, high: int = 20, forbidden_values: Optional[List[int]] = None):
- if forbidden_values is None:
- forbidden_values = []
- value = random.randint(low, high)
- while value in forbidden_values:
- value = random.randint(low, high)
- return value
-
-
def symbolic_trace(
model: PreTrainedModel,
input_names: Optional[List[str]] = None,
- batch_size: int = 1,
- sequence_length: Union[int, List[int], Tuple[int]] = (128, 128),
- num_choices: int = -1,
) -> GraphModule:
"""
@@ -510,89 +562,33 @@ def symbolic_trace(
The model to trace.
input_names (`List[str]`, *optional*):
The names of the inputs of the traced model. If unset, model.dummy_inputs().keys() are used instead.
- batch_size (`int`, *optional*, defaults to 1):
- The batch size of the traced model inputs.
- sequence_length (`int` or `List[int]]`):
- The sequence length of the traced model inputs. For sequence-to-sequence models with different sequence
- lengths between the encoder and the decoder inputs, this must be `[encoder_sequence_length,
- decoder_sequence_length]`.
- num_choices (`int`, *optional*, defaults to -1):
- The number of possible choices for a multiple choice task.
Returns:
`torch.fx.GraphModule`: A GraphModule constructed by recording operations seen while tracing the model.
Example:
- ```python
- from transformers.utils.fx import symbolic_trace
+ ```python
+ from transformers.utils.fx import symbolic_trace
- traced_model = symbolic_trace(
- model,
- input_names=["input_ids", "attention_mask", "token_type_ids"],
- batch_size=1,
- sequence_length=128,
- )
- ```"""
+ traced_model = symbolic_trace(model, input_names=["input_ids", "attention_mask", "token_type_ids"])
+ ```
+ """
if input_names is None:
input_names = model.dummy_inputs.keys()
sig = inspect.signature(model.forward)
concrete_args = {p.name: p.default for p in sig.parameters.values() if p.name not in input_names}
- # Preparing HFTracer batch_size and sequence_lenght values for potential dynamic axes.
- use_dynamic_batch_size = batch_size <= 0
- if isinstance(sequence_length, (list, tuple)):
- use_dynamic_sequence_length = sequence_length[0] <= 0 or sequence_length[1] <= 0
- else:
- use_dynamic_sequence_length = sequence_length <= 0
-
- if use_dynamic_batch_size or use_dynamic_sequence_length:
- forbidden_values = [
- model.config.num_attention_heads,
- model.config.hidden_size,
- model.config.hidden_size // model.config.num_attention_heads,
- ]
- if use_dynamic_batch_size:
- batch_size = _generate_random_int(forbidden_values=forbidden_values)
- forbidden_values.append(batch_size)
- if use_dynamic_sequence_length:
- encoder_sequence_length = _generate_random_int(forbidden_values=forbidden_values)
- forbidden_values.append(encoder_sequence_length)
- decoder_sequence_length = _generate_random_int(forbidden_values=forbidden_values)
- sequence_length = [encoder_sequence_length, decoder_sequence_length]
-
if not isinstance(model, _SUPPORTED_MODELS):
supported_model_names = ", ".join((cls.__name__ for cls in _SUPPORTED_MODELS))
raise NotImplementedError(
f"Model {model.__class__.__name__} is not supported yet, supported models: {supported_model_names}"
)
- if (use_dynamic_batch_size or use_dynamic_sequence_length) and not isinstance(
- model, _SUPPORTED_MODELS_FOR_DYNAMIC_AXES
- ):
- supported_model_names = ", ".join((cls.__name__ for cls in _SUPPORTED_MODELS_FOR_DYNAMIC_AXES))
- raise NotImplementedError(
- f"Dynamic axes are not supported for {model.__class__.__name__} yet, supported models: {supported_model_names}"
- )
# Tracing.
- tracer = HFTracer(batch_size=batch_size, sequence_length=sequence_length, num_choices=num_choices)
-
+ tracer = HFTracer()
traced_graph = tracer.trace(model, concrete_args=concrete_args)
traced = torch.fx.GraphModule(model, traced_graph)
- traced.config = copy.deepcopy(model.config)
- traced.num_choices = num_choices
- traced.dummy_inputs = {}
-
- for name in input_names:
- traced.dummy_inputs.update(tracer._generate_dummy_input(model, name))
-
- traced.use_dynamic_batch_size = use_dynamic_batch_size
- traced.use_dynamic_sequence_length = use_dynamic_sequence_length
- traced.static_batch_size = batch_size
- traced.static_sequence_length = sequence_length
-
- transform_to_dynamic_input_(traced)
-
return traced
diff --git a/src/transformers/utils/fx_transformations.py b/src/transformers/utils/fx_transformations.py
deleted file mode 100644
index 3e181617af10..000000000000
--- a/src/transformers/utils/fx_transformations.py
+++ /dev/null
@@ -1,321 +0,0 @@
-import copy
-import functools
-import operator
-from inspect import signature
-from typing import Any, Callable, Dict, Optional, Union
-
-import torch
-from torch.fx import Graph, GraphModule, Node
-
-
-# Torch FX transformation convention:
-# - transformations that are supposed to act on a copy of the original GraphModule are decorated with @transformation
-# - transformations that are inplace have a name ending with "_"
-
-
-def _cache_attributes(gm: GraphModule) -> Dict[str, Any]:
- attributes_to_keep = [
- "config",
- "num_choices",
- "dummy_inputs",
- "use_dynamic_batch_size",
- "use_dynamic_sequence_length",
- "static_batch_size",
- "static_sequence_length",
- "static2dynamic",
- "dynamic2static",
- ]
- attributes = {k: getattr(gm, k, None) for k in attributes_to_keep}
- return attributes
-
-
-def _restore_attributes_(gm: GraphModule, attributes: Dict[str, Any]):
- for name, attr in attributes.items():
- setattr(gm, name, attr)
-
-
-def deepcopy_graph(gm: GraphModule) -> GraphModule:
- """
- Performs a deepcopy of the GraphModule while also copying the relevant attributes to know whether the model was
- traced with dynamic axes, and what were the values if that is the case.
- """
-
- # First, create a copy of the module without the graph.
- graph = gm.__dict__.pop("_graph")
- fake_mod = torch.nn.Module()
- fake_mod.__dict__ = copy.deepcopy(gm.__dict__)
- gm.__dict__["_graph"] = graph
-
- # Then, copy the graph.
- val_map = {}
- graph_clone = Graph()
- output_val = graph_clone.graph_copy(graph, val_map=val_map)
- graph_clone.output(output_val)
-
- # Finally create a new GraphModule (or a subclass of GraphModule) from the module and the graph copies.
- # gm.__class__ is used to take into account that gm can be an instance of a subclass of GraphModule.
- clone = gm.__class__(fake_mod, graph_clone)
-
- # Restore the dynamic axes related attributes to the clone.
- attributes = _cache_attributes(gm)
- attributes["dynamic2static"] = {val_map.get(k, k): v for k, v in attributes["dynamic2static"].items()}
- attributes["static2dynamic"] = {v: k for k, v in attributes["dynamic2static"].items()}
- _restore_attributes_(clone, attributes)
-
- return clone
-
-
-def transformation(func):
- """
- Decorator that wraps a torch.fx transformation by feeding it a copy of the GraphModule to transform instead of the
- original.
- """
-
- def map_fn(arg):
- if isinstance(arg, GraphModule):
- return deepcopy_graph(arg)
- return arg
-
- @functools.wraps(func)
- def wrapper(*args, **kwargs):
- new_args = tuple(map_fn(arg) for arg in args)
- new_kwargs = {k: map_fn(v) for k, v in kwargs.items()}
- return func(*new_args, **new_kwargs)
-
- wrapper._is_transformation = True
-
- return wrapper
-
-
-def compose_transformations(
- *args: Callable[[GraphModule], Optional[GraphModule]], inplace: bool = False
-) -> GraphModule:
- """
- Allows to compose transformations together and takes of:
-
- 1. Performing the transformations on a copy of the GraphModule if inplace is set to False, transformations that
- are decorated with @transformation (which means that they are not modifying the original GraphModule) are
- unwrapped to make them inplace.
- 2. Linting and recompiling only at the end of the composition for performance purposes.
- """
- args = list(args)
- if not inplace:
- args.insert(0, deepcopy_graph)
-
- for i, transformation in enumerate(args[:-1]):
- sig = signature(transformation)
-
- # Unwrapping @transformation decorated transformations as performing the transformations inplace or on a copy is
- # already handled by this function.
- if getattr(transformation, "_is_transformation", False):
- transformation = transformation.__wrapped__
-
- # Linting and recompiling only after the last transformation applied to make composition efficient.
- if "lint_and_recompile" in sig.parameters:
- args[i] = functools.partial(transformation, lint_and_recompile=False)
-
- def reduce_func(f, g):
- def compose_f_and_g(gm):
- output_g = g(gm)
- if output_g is None:
- output_g = gm
- output_f = f(output_g)
- if output_f is None:
- output_f = gm
- return output_f
-
- return compose_f_and_g
-
- return functools.reduce(reduce_func, reversed(args), lambda x: x)
-
-
-def remove_unused_nodes_(gm: GraphModule, lint_and_recompile: bool = True):
- """Removes all the unused nodes in a GraphModule."""
- graph = gm.graph
- for node in graph.nodes:
- if not node.users and node.op not in ["placeholder", "output"]:
- graph.erase_node(node)
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _insert_batch_size_node_(gm: GraphModule, lint_and_recompile: bool = True) -> Node:
- """Inserts a node that retrieves the batch size dynamically from the input of the model."""
- graph = gm.graph
- input_names = set(gm.dummy_inputs.keys())
- batch_size_node = None
- for node in graph.nodes:
- if node.op == "placeholder" and node.name in input_names:
- with graph.inserting_after(node):
- batch_size_node = graph.call_method("size", args=(node, 0))
-
- if batch_size_node is None:
- raise ValueError("Could not insert the node that computes the batch size")
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[batch_size_node.name] = None
-
- return batch_size_node
-
-
-def _insert_encoder_sequence_length_node_(gm: GraphModule, lint_and_recompile: bool = True) -> Node:
- """Inserts a node that retrieves the encoder sequence length dynamically from the input of the model."""
- graph = gm.graph
- input_names = set(gm.dummy_inputs.keys())
- encoder_sequence_length_node = None
- for node in graph.nodes:
- if node.op == "placeholder" and node.name in input_names and "decoder" not in node.name:
- with graph.inserting_after(node):
- # There are two cases to handle:
- # 1. num_choices < 0, meaning that the model is not performing a "multiple choice" task, in this case the
- # input shapes is [batch_size, sequence_length] => index 1
- # 2. num_choices > 0, meaning the model is performing a "multiple choice" task, in this case the input
- # shape is [batch_size, num_choices, sequence_length] => index 2
- encoder_sequence_length_node = graph.call_method("size", args=(node, 1 if gm.num_choices < 0 else 2))
-
- if encoder_sequence_length_node is None:
- raise ValueError("Could not insert the node that computes the encoder sequence length")
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[encoder_sequence_length_node.name] = None
-
- return encoder_sequence_length_node
-
-
-def _change_view_methods_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """
- Changes arguments of view ops that refer to static batch size / sequence lengths to make them refer to the
- batch_size / sequence_length nodes.
- """
- graph = gm.graph
- for node in graph.nodes:
- if node.op == "call_method" and node.target == "view":
- if isinstance(node.args[1], tuple):
- node.args = (node.args[0], *node.args[1])
- node.args = tuple((mapping.get(arg, arg) for arg in node.args))
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _patch_getitem_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """Patches getitem nodes by replacing current arguments to their corresponding values in mapping."""
- # TODO: combine this with the patch_argument function which seems to do almost the same thing.
- graph = gm.graph
- for node in graph.nodes:
- if node.op == "call_function" and node.target == operator.getitem:
- indices = node.args[1]
- if isinstance(indices, tuple):
- new_indices = []
- for idx in indices:
- if isinstance(idx, slice):
- new_indices.append(
- slice(
- mapping.get(idx.start, idx.start),
- mapping.get(idx.stop, idx.stop),
- mapping.get(idx.step, idx.step),
- )
- )
- elif isinstance(idx, int):
- new_indices.append(mapping.get(idx, idx))
- else:
- new_indices.append(idx)
-
- node.args = (node.args[0], tuple(new_indices))
- else:
- node.args = (node.args[0], mapping.get(node.args[1], node.args[1]))
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def _patch_arguments_(
- gm: GraphModule, mapping: Union[Dict[Node, int], Dict[int, Node]], lint_and_recompile: bool = True
-):
- """
- Patches node by replacing their argument to their corresponding values in mapping (supports regular types, tuples
- and slices).
- """
-
- def _patch_slice(s, mapping):
- return slice(mapping.get(s.start, s.start), mapping.get(s.stop, s.stop), mapping.get(s.step, s.step))
-
- graph = gm.graph
- supported_types = (Node, str, int, float)
- for node in graph.nodes:
- new_args = []
- for arg in node.args:
- if isinstance(arg, tuple):
- new_arg = []
- for a in arg:
- if isinstance(a, slice):
- new_arg.append(_patch_slice(a, mapping))
- else:
- new_arg.append(mapping.get(a, a))
- new_args.append(tuple(new_arg))
- elif isinstance(arg, slice):
- new_args.append(_patch_slice(arg, mapping))
- elif isinstance(arg, supported_types):
- new_args.append(mapping.get(arg, arg))
- else:
- new_args.append(arg)
- node.args = tuple(new_args)
-
- if lint_and_recompile:
- graph.lint()
- gm.recompile()
-
-
-def transform_to_dynamic_input_(gm: GraphModule, is_retracing: bool = False):
- """Transformation that enables traced models to perform inference on dynamic input shapes."""
- graph = gm.graph
- static2dynamic = {}
-
- # Inserting the nodes that will fetch the batch size and sequence lengths dynamically.
- if gm.use_dynamic_batch_size:
- batch_size_node = _insert_batch_size_node_(gm, lint_and_recompile=False)
- static2dynamic[gm.static_batch_size] = batch_size_node
- if gm.num_choices > 0:
- with graph.inserting_after(batch_size_node):
- static2dynamic[gm.static_batch_size * gm.num_choices] = graph.call_function(
- operator.mul, args=(batch_size_node, gm.num_choices)
- )
- # Useful when retracing for quantization.
- if hasattr(gm, "_qconfig_map"):
- gm._qconfig_map[static2dynamic[gm.static_batch_size * gm.num_choices]] = None
-
- if gm.use_dynamic_sequence_length:
- encoder_sequence_length_node = _insert_encoder_sequence_length_node_(gm, lint_and_recompile=False)
- static2dynamic[gm.static_sequence_length[0]] = encoder_sequence_length_node
-
- # TODO: do the same for the decoder.
- pass
-
- _change_view_methods_(gm, static2dynamic, lint_and_recompile=False)
- _patch_getitem_(gm, static2dynamic, lint_and_recompile=False)
-
- remove_unused_nodes_(gm, lint_and_recompile=False)
-
- graph.lint()
- gm.recompile()
-
- gm.static2dynamic = static2dynamic
- gm.dynamic2static = {v: k for (k, v) in static2dynamic.items()}
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
index 63233c4bf9ff..69a0d8176683 100755
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
@@ -2832,6 +2832,9 @@ def forward(
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
+ if use_cache:
+ logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
+ use_cache = False
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
diff --git a/tests/test_feature_extraction_convnext.py b/tests/test_feature_extraction_convnext.py
new file mode 100644
index 000000000000..1439f3a28cac
--- /dev/null
+++ b/tests/test_feature_extraction_convnext.py
@@ -0,0 +1,195 @@
+# coding=utf-8
+# Copyright 2022s HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from .test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ConvNextFeatureExtractor
+
+
+class ConvNextFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=20,
+ crop_pct=0.875,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "crop_pct": self.crop_pct,
+ }
+
+
+@require_torch
+@require_vision
+class ConvNextFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = ConvNextFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = ConvNextFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+ self.assertTrue(hasattr(feature_extractor, "crop_pct"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL images
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ image_inputs = prepare_image_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = feature_extractor(image_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_images = feature_extractor(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_images.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/test_modeling_albert.py b/tests/test_modeling_albert.py
index d16dcadd5e6a..ab5595f4b6f8 100644
--- a/tests/test_modeling_albert.py
+++ b/tests/test_modeling_albert.py
@@ -231,8 +231,7 @@ class AlbertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_beit.py b/tests/test_modeling_beit.py
index 777247161abd..2304678e79c8 100644
--- a/tests/test_modeling_beit.py
+++ b/tests/test_modeling_beit.py
@@ -92,17 +92,20 @@ def __init__(
self.initializer_range = initializer_range
self.scope = scope
self.out_indices = out_indices
+ self.num_labels = num_labels
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
+ pixel_labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ pixel_labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
config = self.get_config()
- return config, pixel_values, labels
+ return config, pixel_values, labels, pixel_labels
def get_config(self):
return BeitConfig(
@@ -122,7 +125,7 @@ def get_config(self):
out_indices=self.out_indices,
)
- def create_and_check_model(self, config, pixel_values, labels):
+ def create_and_check_model(self, config, pixel_values, labels, pixel_labels):
model = BeitModel(config=config)
model.to(torch_device)
model.eval()
@@ -133,7 +136,7 @@ def create_and_check_model(self, config, pixel_values, labels):
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
- def create_and_check_for_masked_lm(self, config, pixel_values, labels):
+ def create_and_check_for_masked_lm(self, config, pixel_values, labels, pixel_labels):
model = BeitForMaskedImageModeling(config=config)
model.to(torch_device)
model.eval()
@@ -144,7 +147,7 @@ def create_and_check_for_masked_lm(self, config, pixel_values, labels):
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.parent.assertEqual(result.logits.shape, (self.batch_size, num_patches, self.vocab_size))
- def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ def create_and_check_for_image_classification(self, config, pixel_values, labels, pixel_labels):
config.num_labels = self.type_sequence_label_size
model = BeitForImageClassification(config)
model.to(torch_device)
@@ -152,13 +155,23 @@ def create_and_check_for_image_classification(self, config, pixel_values, labels
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+ def create_and_check_for_image_segmentation(self, config, pixel_values, labels, pixel_labels):
+ config.num_labels = self.num_labels
+ model = BeitForSemanticSegmentation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+ result = model(pixel_values, labels=pixel_labels)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
- (
- config,
- pixel_values,
- labels,
- ) = config_and_inputs
+ config, pixel_values, labels, pixel_labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@@ -217,6 +230,10 @@ def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
+ def test_for_image_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_segmentation(*config_and_inputs)
+
def test_training(self):
if not self.model_tester.is_training:
return
@@ -516,14 +533,14 @@ def test_inference_semantic_segmentation(self):
logits = outputs.logits
# verify the logits
- expected_shape = torch.Size((1, 150, 160, 160))
+ expected_shape = torch.Size((1, 150, 640, 640))
self.assertEqual(logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-4.9225, -2.3954, -3.0522], [-2.8822, -1.0046, -1.7561], [-2.9549, -1.3228, -2.1347]],
- [[-5.8168, -3.4129, -4.0778], [-3.8651, -2.2214, -3.0277], [-3.8356, -2.4643, -3.3535]],
- [[-0.0078, 3.9952, 4.0754], [2.9856, 4.6944, 5.0035], [3.2413, 4.7813, 4.9969]],
+ [[-4.9225, -4.9225, -4.6066], [-4.9225, -4.9225, -4.6066], [-4.6675, -4.6675, -4.3617]],
+ [[-5.8168, -5.8168, -5.5163], [-5.8168, -5.8168, -5.5163], [-5.5728, -5.5728, -5.2842]],
+ [[-0.0078, -0.0078, 0.4926], [-0.0078, -0.0078, 0.4926], [0.3664, 0.3664, 0.8309]],
]
).to(torch_device)
diff --git a/tests/test_modeling_bert.py b/tests/test_modeling_bert.py
index 7a6628509799..7b8738fd60f3 100755
--- a/tests/test_modeling_bert.py
+++ b/tests/test_modeling_bert.py
@@ -444,8 +444,7 @@ class BertModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
else ()
)
all_generative_model_classes = (BertLMHeadModel,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index 420b77503198..22cbd66b8149 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -116,8 +116,7 @@ class ModelTesterMixin:
model_tester = None
all_model_classes = ()
all_generative_model_classes = ()
- fx_ready_model_classes = ()
- fx_dynamic_ready_model_classes = ()
+ fx_compatible = False
test_torchscript = True
test_pruning = True
test_resize_embeddings = True
@@ -666,19 +665,14 @@ def test_torch_fx_output_loss(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
self._create_and_check_torch_fx_tracing(config, inputs_dict, output_loss=True)
- def test_torch_fx_dynamic_axes(self):
- config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
- self._create_and_check_torch_fx_tracing(config, inputs_dict, dynamic_axes=True)
-
- def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False, dynamic_axes=False):
- if not is_torch_fx_available():
+ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False):
+ if not is_torch_fx_available() or not self.fx_compatible:
return
configs_no_init = _config_zero_init(config) # To be sure we have no Nan
configs_no_init.return_dict = False
- model_classes = self.fx_ready_model_classes if not dynamic_axes else self.fx_dynamic_ready_model_classes
- for model_class in model_classes:
+ for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
model.to(torch_device)
model.eval()
@@ -687,8 +681,6 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
try:
if model.config.is_encoder_decoder:
model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
- input_ids = inputs["input_ids"]
- decoder_attention_mask = inputs["decoder_attention_mask"]
labels = inputs.get("labels", None)
input_names = ["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask"]
if labels is not None:
@@ -697,17 +689,7 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
model_output = model(**filtered_inputs)
- batch_size = input_ids.shape[0]
- encoder_sequence_length = input_ids.shape[1]
- decoder_sequence_length = decoder_attention_mask.shape[1]
-
- traced_model = symbolic_trace(
- model,
- input_names,
- batch_size=batch_size if not dynamic_axes else -1,
- sequence_length=[encoder_sequence_length, decoder_sequence_length] if not dynamic_axes else -1,
- )
-
+ traced_model = symbolic_trace(model, input_names)
traced_output = traced_model(**filtered_inputs)
else:
input_names = ["input_ids", "attention_mask", "token_type_ids"]
@@ -729,23 +711,12 @@ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=Fa
model_output = model(**filtered_inputs)
rank = len(input_ids.shape)
- if rank == 2:
- batch_size, sequence_length = input_ids.shape
- num_choices = -1
- elif rank == 3:
- batch_size, num_choices, sequence_length = input_ids.shape
- else:
+ if rank not in [2, 3]:
raise NotImplementedError(
f"symbolic_trace automatic parameters inference not implemented for input of rank {rank}."
)
- traced_model = symbolic_trace(
- model,
- input_names,
- batch_size=batch_size if not dynamic_axes else -1,
- sequence_length=sequence_length if not dynamic_axes else -1,
- num_choices=num_choices,
- )
+ traced_model = symbolic_trace(model, input_names)
traced_output = traced_model(**filtered_inputs)
except RuntimeError:
diff --git a/tests/test_modeling_convnext.py b/tests/test_modeling_convnext.py
new file mode 100644
index 000000000000..c351685a418e
--- /dev/null
+++ b/tests/test_modeling_convnext.py
@@ -0,0 +1,339 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch ConvNext model. """
+
+
+import inspect
+import unittest
+from typing import Dict, List, Tuple
+
+from transformers import ConvNextConfig
+from transformers.file_utils import cached_property, is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from .test_configuration_common import ConfigTester
+from .test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import ConvNextForImageClassification, ConvNextModel
+ from transformers.models.convnext.modeling_convnext import CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoFeatureExtractor
+
+
+class ConvNextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ num_channels=3,
+ num_stages=4,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[2, 2, 3, 2],
+ is_training=True,
+ use_labels=True,
+ intermediate_size=37,
+ hidden_act="gelu",
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_stages = num_stages
+ self.hidden_sizes = hidden_sizes
+ self.depths = depths
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return ConvNextConfig(
+ num_channels=self.num_channels,
+ hidden_sizes=self.hidden_sizes,
+ depths=self.depths,
+ num_stages=self.num_stages,
+ hidden_act=self.hidden_act,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = ConvNextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ # expected last hidden states: B, C, H // 32, W // 32
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.hidden_sizes[-1], self.image_size // 32, self.image_size // 32),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.type_sequence_label_size
+ model = ConvNextForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ConvNextModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ConvNext does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ConvNextModel,
+ ConvNextForImageClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ConvNextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ConvNextConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.create_and_test_config_common_properties()
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def create_and_test_config_common_properties(self):
+ return
+
+ @unittest.skip(reason="ConvNext does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ConvNext does not support input and output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Model doesn't have attention layers")
+ def test_attention_outputs(self):
+ pass
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_stages = self.model_tester.num_stages
+ self.assertEqual(len(hidden_states), expected_num_stages + 1)
+
+ # ConvNext's feature maps are of shape (batch_size, num_channels, height, width)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 4, self.model_tester.image_size // 4],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+ outputs = model(**inputs)
+ output = outputs[0]
+
+ hidden_states = outputs.hidden_states[0]
+ hidden_states.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=f"Tuple and dict output are not equal. Difference: {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`: {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}.",
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = ConvNextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class ConvNextModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return AutoFeatureExtractor.from_pretrained("facebook/convnext-tiny-224") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ image = prepare_img()
+ inputs = feature_extractor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.0260, -0.4739, 0.1911]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
diff --git a/tests/test_modeling_distilbert.py b/tests/test_modeling_distilbert.py
index ee8a8cbd3dd9..b81e42bcf175 100644
--- a/tests/test_modeling_distilbert.py
+++ b/tests/test_modeling_distilbert.py
@@ -209,8 +209,7 @@ class DistilBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else None
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
test_pruning = True
test_torchscript = True
test_resize_embeddings = True
diff --git a/tests/test_modeling_electra.py b/tests/test_modeling_electra.py
index be19f8d610db..065d59682693 100644
--- a/tests/test_modeling_electra.py
+++ b/tests/test_modeling_electra.py
@@ -369,10 +369,7 @@ class ElectraModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- all_generative_model_classes = (ElectraForCausalLM,) if is_torch_available() else ()
-
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_gpt2.py b/tests/test_modeling_gpt2.py
index ef51c815e455..cd13be27bbc3 100644
--- a/tests/test_modeling_gpt2.py
+++ b/tests/test_modeling_gpt2.py
@@ -433,7 +433,7 @@ class GPT2ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
)
all_generative_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
all_parallelizable_model_classes = (GPT2LMHeadModel, GPT2DoubleHeadsModel) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_missing_keys = False
test_model_parallel = True
diff --git a/tests/test_modeling_gpt_neo.py b/tests/test_modeling_gpt_neo.py
index a8e5b4babc57..b8f942ef1786 100644
--- a/tests/test_modeling_gpt_neo.py
+++ b/tests/test_modeling_gpt_neo.py
@@ -372,7 +372,7 @@ class GPTNeoModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase
(GPTNeoModel, GPTNeoForCausalLM, GPTNeoForSequenceClassification) if is_torch_available() else ()
)
all_generative_model_classes = (GPTNeoForCausalLM,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_missing_keys = False
test_pruning = False
test_model_parallel = False
diff --git a/tests/test_modeling_gptj.py b/tests/test_modeling_gptj.py
index dd743b80d76a..d6b9f9292621 100644
--- a/tests/test_modeling_gptj.py
+++ b/tests/test_modeling_gptj.py
@@ -363,7 +363,7 @@ class GPTJModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
else ()
)
all_generative_model_classes = (GPTJForCausalLM,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
test_pruning = False
test_missing_keys = False
test_model_parallel = False
diff --git a/tests/test_modeling_megatron_bert.py b/tests/test_modeling_megatron_bert.py
index a7f47ddea322..7ac507988fe0 100644
--- a/tests/test_modeling_megatron_bert.py
+++ b/tests/test_modeling_megatron_bert.py
@@ -283,9 +283,7 @@ class MegatronBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
-
+ fx_compatible = True
# test_resize_embeddings = False
test_head_masking = False
diff --git a/tests/test_modeling_mobilebert.py b/tests/test_modeling_mobilebert.py
index 716714157a76..6ca14526a6dc 100644
--- a/tests/test_modeling_mobilebert.py
+++ b/tests/test_modeling_mobilebert.py
@@ -269,8 +269,7 @@ class MobileBertModelTest(ModelTesterMixin, unittest.TestCase):
if is_torch_available()
else ()
)
- fx_ready_model_classes = all_model_classes
- fx_dynamic_ready_model_classes = all_model_classes
+ fx_compatible = True
# special case for ForPreTraining model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
diff --git a/tests/test_modeling_roberta.py b/tests/test_modeling_roberta.py
index d0a8aab6b78e..1a55fda15292 100644
--- a/tests/test_modeling_roberta.py
+++ b/tests/test_modeling_roberta.py
@@ -356,6 +356,7 @@ class RobertaModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCas
else ()
)
all_generative_model_classes = (RobertaForCausalLM,) if is_torch_available() else ()
+ fx_compatible = True
def setUp(self):
self.model_tester = RobertaModelTester(self)
diff --git a/tests/test_modeling_segformer.py b/tests/test_modeling_segformer.py
index 2e84b1f41d17..3bb293065590 100644
--- a/tests/test_modeling_segformer.py
+++ b/tests/test_modeling_segformer.py
@@ -133,11 +133,11 @@ def create_and_check_for_image_segmentation(self, config, pixel_values, labels):
model.eval()
result = model(pixel_values)
self.parent.assertEqual(
- result.logits.shape, (self.batch_size, self.num_labels, self.image_size // 4, self.image_size // 4)
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
)
result = model(pixel_values, labels=labels)
self.parent.assertEqual(
- result.logits.shape, (self.batch_size, self.num_labels, self.image_size // 4, self.image_size // 4)
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
)
def prepare_config_and_inputs_for_common(self):
@@ -245,6 +245,7 @@ def test_attention_outputs(self):
list(attentions[-1].shape[-3:]),
[self.model_tester.num_attention_heads[-1], expected_seq_len, expected_reduced_seq_len],
)
+ out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
@@ -255,7 +256,7 @@ def test_attention_outputs(self):
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
- self.assertEqual(3, len(outputs))
+ self.assertEqual(out_len + 1, len(outputs))
self_attentions = outputs.attentions
@@ -357,16 +358,17 @@ def test_inference_image_segmentation_ade(self):
encoded_inputs = feature_extractor(images=image, return_tensors="pt")
pixel_values = encoded_inputs.pixel_values.to(torch_device)
- outputs = model(pixel_values)
+ with torch.no_grad():
+ outputs = model(pixel_values)
- expected_shape = torch.Size((1, model.config.num_labels, 128, 128))
+ expected_shape = torch.Size((1, model.config.num_labels, 512, 512))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-4.6310, -5.5232, -6.2356], [-5.1921, -6.1444, -6.5996], [-5.4424, -6.2790, -6.7574]],
- [[-12.1391, -13.3122, -13.9554], [-12.8732, -13.9352, -14.3563], [-12.9438, -13.8226, -14.2513]],
- [[-12.5134, -13.4686, -14.4915], [-12.8669, -14.4343, -14.7758], [-13.2523, -14.5819, -15.0694]],
+ [[-4.6309, -4.6309, -4.7425], [-4.6309, -4.6309, -4.7425], [-4.7011, -4.7011, -4.8136]],
+ [[-12.1391, -12.1391, -12.2858], [-12.1391, -12.1391, -12.2858], [-12.2309, -12.2309, -12.3758]],
+ [[-12.5134, -12.5134, -12.6328], [-12.5134, -12.5134, -12.6328], [-12.5576, -12.5576, -12.6865]],
]
).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3, :3], expected_slice, atol=1e-4))
@@ -385,16 +387,17 @@ def test_inference_image_segmentation_city(self):
encoded_inputs = feature_extractor(images=image, return_tensors="pt")
pixel_values = encoded_inputs.pixel_values.to(torch_device)
- outputs = model(pixel_values)
+ with torch.no_grad():
+ outputs = model(pixel_values)
- expected_shape = torch.Size((1, model.config.num_labels, 128, 128))
+ expected_shape = torch.Size((1, model.config.num_labels, 512, 512))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor(
[
- [[-13.5748, -13.9111, -12.6500], [-14.3500, -15.3683, -14.2328], [-14.7532, -16.0424, -15.6087]],
- [[-17.1651, -15.8725, -12.9653], [-17.2580, -17.3718, -14.8223], [-16.6058, -16.8783, -16.7452]],
- [[-3.6456, -3.0209, -1.4203], [-3.0797, -3.1959, -2.0000], [-1.8757, -1.9217, -1.6997]],
+ [[-13.5729, -13.5729, -13.6149], [-13.5729, -13.5729, -13.6149], [-13.6697, -13.6697, -13.7224]],
+ [[-17.1638, -17.1638, -17.0022], [-17.1638, -17.1638, -17.0022], [-17.1754, -17.1754, -17.0358]],
+ [[-3.6452, -3.6452, -3.5670], [-3.6452, -3.6452, -3.5670], [-3.5744, -3.5744, -3.5079]],
]
).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3, :3], expected_slice, atol=1e-1))
diff --git a/tests/test_modeling_t5.py b/tests/test_modeling_t5.py
index 575850aa9014..c0b5739bca7f 100644
--- a/tests/test_modeling_t5.py
+++ b/tests/test_modeling_t5.py
@@ -509,7 +509,7 @@ class T5ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (T5Model, T5ForConditionalGeneration) if is_torch_available() else ()
all_generative_model_classes = (T5ForConditionalGeneration,) if is_torch_available() else ()
- fx_ready_model_classes = all_model_classes
+ fx_compatible = True
all_parallelizable_model_classes = (T5Model, T5ForConditionalGeneration) if is_torch_available() else ()
test_pruning = False
test_torchscript = True
diff --git a/tests/test_modeling_tf_led.py b/tests/test_modeling_tf_led.py
index b42e8b538cdc..a77f17f87200 100644
--- a/tests/test_modeling_tf_led.py
+++ b/tests/test_modeling_tf_led.py
@@ -322,7 +322,7 @@ def check_encoder_attentions_output(outputs):
self.assertEqual(len(global_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
- [self.model_tester.num_attention_heads, encoder_seq_length, seq_length],
+ [self.model_tester.num_attention_heads, seq_length, seq_length],
)
self.assertListEqual(
list(global_attentions[0].shape[-3:]),
diff --git a/tests/test_modeling_wav2vec2.py b/tests/test_modeling_wav2vec2.py
index 9c07df5fed9d..b5e1bcd2cde3 100644
--- a/tests/test_modeling_wav2vec2.py
+++ b/tests/test_modeling_wav2vec2.py
@@ -202,6 +202,17 @@ def create_and_check_model_with_adapter(self, config, input_values, attention_ma
result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size)
)
+ def create_and_check_model_with_adapter_for_ctc(self, config, input_values, attention_mask):
+ config.add_adapter = True
+ config.output_hidden_size = 2 * config.hidden_size
+ model = Wav2Vec2ForCTC(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size)
+ )
+
def create_and_check_model_with_adapter_proj_dim(self, config, input_values, attention_mask):
config.add_adapter = True
config.output_hidden_size = 8
@@ -414,6 +425,10 @@ def test_model_with_adapter(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter(*config_and_inputs)
+ def test_model_with_adapter_for_ctc(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs)
+
def test_model_with_adapter_proj_dim(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs)
diff --git a/tests/test_modeling_xlnet.py b/tests/test_modeling_xlnet.py
index 5516b28e17e1..f4e90fbe7749 100644
--- a/tests/test_modeling_xlnet.py
+++ b/tests/test_modeling_xlnet.py
@@ -526,6 +526,7 @@ class XLNetModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase)
all_generative_model_classes = (
(XLNetLMHeadModel,) if is_torch_available() else ()
) # TODO (PVP): Check other models whether language generation is also applicable
+
test_pruning = False
# XLNet has 2 QA models -> need to manually set the correct labels for one of them here
diff --git a/tests/test_onnx_v2.py b/tests/test_onnx_v2.py
index 53b28718a60f..8bd88b74454e 100644
--- a/tests/test_onnx_v2.py
+++ b/tests/test_onnx_v2.py
@@ -174,7 +174,7 @@ def test_values_override(self):
("ibert", "kssteven/ibert-roberta-base"),
("camembert", "camembert-base"),
("distilbert", "distilbert-base-cased"),
- # ("longFormer", "longformer-base-4096"),
+ ("electra", "google/electra-base-generator"),
("roberta", "roberta-base"),
("xlm-roberta", "xlm-roberta-base"),
("layoutlm", "microsoft/layoutlm-base-uncased"),
diff --git a/tests/test_pipelines_automatic_speech_recognition.py b/tests/test_pipelines_automatic_speech_recognition.py
index 6b25fa9d6f8d..15b5f72612cd 100644
--- a/tests/test_pipelines_automatic_speech_recognition.py
+++ b/tests/test_pipelines_automatic_speech_recognition.py
@@ -107,6 +107,24 @@ def test_small_model_pt(self):
output = speech_recognizer(waveform)
self.assertEqual(output, {"text": "(Applaudissements)"})
+ @require_torch
+ def test_small_model_pt_seq2seq(self):
+ model_id = "hf-internal-testing/tiny-random-speech-encoder-decoder"
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ feature_extractor = AutoFeatureExtractor.from_pretrained(model_id)
+
+ speech_recognizer = pipeline(
+ task="automatic-speech-recognition",
+ model=model_id,
+ tokenizer=tokenizer,
+ feature_extractor=feature_extractor,
+ framework="pt",
+ )
+
+ waveform = np.tile(np.arange(1000, dtype=np.float32), 34)
+ output = speech_recognizer(waveform)
+ self.assertEqual(output, {"text": "あл ش 湯 清 ه ܬ া लᆨしث ल eか u w 全 u"})
+
@slow
@require_torch
@require_pyctcdecode
diff --git a/utils/check_repo.py b/utils/check_repo.py
index a58319658146..9ee2266ca736 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -118,8 +118,6 @@
"PerceiverForMultimodalAutoencoding",
"PerceiverForOpticalFlow",
"SegformerDecodeHead",
- "SegformerForSemanticSegmentation",
- "BeitForSemanticSegmentation",
"FlaxBeitForMaskedImageModeling",
"BeitForMaskedImageModeling",
"CLIPTextModel",
diff --git a/utils/check_table.py b/utils/check_table.py
index 9c81937f444f..449ad02c3b21 100644
--- a/utils/check_table.py
+++ b/utils/check_table.py
@@ -210,7 +210,7 @@ def check_onnx_model_list(overwrite=False):
"""Check the model list in the serialization.mdx is consistent with the state of the lib and maybe `overwrite`."""
current_list, start_index, end_index, lines = _find_text_in_file(
filename=os.path.join(PATH_TO_DOCS, "serialization.mdx"),
- start_prompt="",
+ start_prompt="",
end_prompt="The ONNX conversion is supported for the PyTorch versions of the models.",
)
new_list = get_onnx_model_list()