diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 2859dd75bb3359..354e22344a904a 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -300,6 +300,8 @@
title: DeBERTa
- local: model_doc/deberta-v2
title: DeBERTa-v2
+ - local: model_doc/dialogpt
+ title: DialoGPT
title: 文章モデル
- isExpanded: false
sections:
@@ -317,6 +319,14 @@
title: CvT
- local: model_doc/deformable_detr
title: Deformable DETR
+ - local: model_doc/deit
+ title: DeiT
+ - local: model_doc/deta
+ title: DETA
+ - local: model_doc/detr
+ title: DETR
+ - local: model_doc/dinat
+ title: DiNAT
title: ビジョンモデル
- isExpanded: false
sections:
@@ -351,6 +361,8 @@
title: CLVP
- local: model_doc/data2vec
title: Data2Vec
+ - local: model_doc/deplot
+ title: DePlot
title: マルチモーダルモデル
- isExpanded: false
sections:
diff --git a/docs/source/ja/model_doc/deit.md b/docs/source/ja/model_doc/deit.md
new file mode 100644
index 00000000000000..aa8c66c90be0b8
--- /dev/null
+++ b/docs/source/ja/model_doc/deit.md
@@ -0,0 +1,148 @@
+
+
+# DeiT
+
+## Overview
+
+DeiT モデルは、Hugo Touvron、Matthieu Cord、Matthijs Douze、Francisco Massa、Alexandre
+Sablayrolles, Hervé Jégou.によって [Training data-efficient image Transformers & distillation through attention](https://arxiv.org/abs/2012.12877) で提案されました。
+サブレイロール、エルヴェ・ジェグー。 [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) で紹介された [Vision Transformer (ViT)](vit) は、既存の畳み込みニューラルと同等、またはそれを上回るパフォーマンスを発揮できることを示しました。
+Transformer エンコーダ (BERT のような) を使用したネットワーク。ただし、その論文で紹介された ViT モデルには、次のトレーニングが必要でした。
+外部データを使用して、数週間にわたる高価なインフラストラクチャ。 DeiT (データ効率の高い画像変換器) はさらに優れています
+画像分類用に効率的にトレーニングされたトランスフォーマーにより、必要なデータとコンピューティング リソースがはるかに少なくなります。
+オリジナルの ViT モデルとの比較。
+
+論文の要約は次のとおりです。
+
+*最近、純粋に注意に基づくニューラル ネットワークが、画像などの画像理解タスクに対処できることが示されました。
+分類。ただし、これらのビジュアル トランスフォーマーは、
+インフラストラクチャが高価であるため、その採用が制限されています。この作業では、コンボリューションフリーの競争力のあるゲームを作成します。
+Imagenet のみでトレーニングしてトランスフォーマーを作成します。 1 台のコンピューターで 3 日以内にトレーニングを行います。私たちの基準となるビジョン
+トランス (86M パラメータ) は、外部なしで ImageNet 上で 83.1% (単一クロップ評価) のトップ 1 の精度を達成します。
+データ。さらに重要なのは、トランスフォーマーに特有の教師と生徒の戦略を導入することです。蒸留に依存している
+学生が注意を払って教師から学ぶことを保証するトークン。私たちはこのトークンベースに興味を示します
+特に convnet を教師として使用する場合。これにより、convnet と競合する結果を報告できるようになります。
+Imagenet (最大 85.2% の精度が得られます) と他のタスクに転送するときの両方で。私たちはコードを共有し、
+モデル。*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの TensorFlow バージョンは、[amyeroberts](https://huggingface.co/amyeroberts) によって追加されました。
+
+## Usage tips
+
+- ViT と比較して、DeiT モデルはいわゆる蒸留トークンを使用して教師から効果的に学習します (これは、
+ DeiT 論文は、ResNet のようなモデルです)。蒸留トークンは、バックプロパゲーションを通じて、と対話することによって学習されます。
+ セルフアテンション層を介したクラス ([CLS]) とパッチ トークン。
+- 抽出されたモデルを微調整するには 2 つの方法があります。(1) 上部に予測ヘッドを配置するだけの古典的な方法。
+ クラス トークンの最終的な非表示状態を抽出し、蒸留シグナルを使用しない、または (2) 両方の
+ 予測ヘッドはクラス トークンの上と蒸留トークンの上にあります。その場合、[CLS] 予測は
+ head は、head の予測とグラウンド トゥルース ラベル間の通常のクロスエントロピーを使用してトレーニングされます。
+ 蒸留予測ヘッドは、硬蒸留 (予測と予測の間のクロスエントロピー) を使用してトレーニングされます。
+ 蒸留ヘッドと教師が予測したラベル)。推論時に、平均予測を取得します。
+ 最終的な予測として両頭の間で。 (2) は「蒸留による微調整」とも呼ばれます。
+ 下流のデータセットですでに微調整されている教師。モデル的には (1) に相当します。
+ [`DeiTForImageClassification`] と (2) に対応します。
+ [`DeiTForImageClassificationWithTeacher`]。
+- 著者らは (2) についてもソフト蒸留を試みたことに注意してください (この場合、蒸留予測ヘッドは
+ 教師のソフトマックス出力に一致するように KL ダイバージェンスを使用してトレーニングしました)が、ハード蒸留が最良の結果をもたらしました。
+- リリースされたすべてのチェックポイントは、ImageNet-1k のみで事前トレーニングおよび微調整されました。外部データは使用されませんでした。これは
+ JFT-300M データセット/Imagenet-21k などの外部データを使用した元の ViT モデルとは対照的です。
+ 事前トレーニング。
+- DeiT の作者は、より効率的にトレーニングされた ViT モデルもリリースしました。これは、直接プラグインできます。
+ [`ViTModel`] または [`ViTForImageClassification`]。データなどのテクニック
+ はるかに大規模なデータセットでのトレーニングをシミュレートするために、拡張、最適化、正則化が使用されました。
+ (ただし、事前トレーニングには ImageNet-1k のみを使用します)。 4 つのバリエーション (3 つの異なるサイズ) が利用可能です。
+ *facebook/deit-tiny-patch16-224*、*facebook/deit-small-patch16-224*、*facebook/deit-base-patch16-224* および
+ *facebook/deit-base-patch16-384*。以下を行うには [`DeiTImageProcessor`] を使用する必要があることに注意してください。
+ モデル用の画像を準備します。
+
+## Resources
+
+DeiT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- [`DeiTForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+それに加えて:
+
+- [`DeiTForMaskedImageModeling`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) でサポートされています。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DeiTConfig
+
+[[autodoc]] DeiTConfig
+
+## DeiTFeatureExtractor
+
+[[autodoc]] DeiTFeatureExtractor
+ - __call__
+
+## DeiTImageProcessor
+
+[[autodoc]] DeiTImageProcessor
+ - preprocess
+
+
+
+
+## DeiTModel
+
+[[autodoc]] DeiTModel
+ - forward
+
+## DeiTForMaskedImageModeling
+
+[[autodoc]] DeiTForMaskedImageModeling
+ - forward
+
+## DeiTForImageClassification
+
+[[autodoc]] DeiTForImageClassification
+ - forward
+
+## DeiTForImageClassificationWithTeacher
+
+[[autodoc]] DeiTForImageClassificationWithTeacher
+ - forward
+
+
+
+
+## TFDeiTModel
+
+[[autodoc]] TFDeiTModel
+ - call
+
+## TFDeiTForMaskedImageModeling
+
+[[autodoc]] TFDeiTForMaskedImageModeling
+ - call
+
+## TFDeiTForImageClassification
+
+[[autodoc]] TFDeiTForImageClassification
+ - call
+
+## TFDeiTForImageClassificationWithTeacher
+
+[[autodoc]] TFDeiTForImageClassificationWithTeacher
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/deplot.md b/docs/source/ja/model_doc/deplot.md
new file mode 100644
index 00000000000000..26871d1e7dde66
--- /dev/null
+++ b/docs/source/ja/model_doc/deplot.md
@@ -0,0 +1,65 @@
+
+
+# DePlot
+
+## Overview
+
+DePlot は、Fangyu Liu、Julian Martin Aisenschlos、Francesco Piccinno、Syrine Krichene、Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. の論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) で提案されました。パン・
+
+論文の要約には次のように記載されています。
+
+*チャートやプロットなどの視覚言語は人間の世界に遍在しています。プロットやチャートを理解するには、強力な推論スキルが必要です。従来の最先端 (SOTA) モデルには少なくとも数万のトレーニング サンプルが必要であり、その推論能力は、特に人間が作成した複雑なクエリでは依然として大幅に制限されています。この論文では、視覚言語推論に対する最初のワンショット ソリューションを紹介します。私たちは、視覚言語推論の課題を 2 つのステップに分解します。(1) プロットからテキストへの翻訳と、(2) 翻訳されたテキストに対する推論です。この方法の鍵となるのは、プロットまたはチャートの画像を線形化されたテーブルに変換する、DePlot という名前のモダリティ変換モジュールです。その後、DePlot の出力を直接使用して、事前トレーニング済みの大規模言語モデル (LLM) をプロンプトし、LLM の少数ショット推論機能を利用できます。 DePlot を取得するには、統一されたタスク形式とメトリクスを確立することでプロットからテーブルへのタスクを標準化し、このタスクで DePlot をエンドツーエンドでトレーニングします。 DePlot は、プラグアンドプレイ方式で LLM とともに既製で使用できます。 28,000 を超えるデータ ポイントで微調整された SOTA モデルと比較して、ワンショット プロンプトのみを使用する DePlot+LLM は、チャート QA タスクからの人が作成したクエリに関して、微調整された SOTA より 24.0% の改善を達成しました。*
+
+DePlot は、`Pix2Struct` アーキテクチャを使用してトレーニングされたモデルです。 `Pix2Struct` の詳細については、[Pix2Struct ドキュメント](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct) を参照してください。
+DePlot は、`Pix2Struct` アーキテクチャの Visual Question Answering サブセットです。入力された質問を画像上にレンダリングし、答えを予測します。
+
+## Usage example
+
+現在、DePlot で使用できるチェックポイントは 1 つです。
+
+- `google/deplot`: ChartQA データセットで微調整された DePlot
+
+```python
+from transformers import AutoProcessor, Pix2StructForConditionalGeneration
+import requests
+from PIL import Image
+
+model = Pix2StructForConditionalGeneration.from_pretrained("google/deplot")
+processor = AutoProcessor.from_pretrained("google/deplot")
+url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=image, text="Generate underlying data table of the figure below:", return_tensors="pt")
+predictions = model.generate(**inputs, max_new_tokens=512)
+print(processor.decode(predictions[0], skip_special_tokens=True))
+```
+
+## Fine-tuning
+
+DePlot を微調整するには、pix2struct [微調整ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb) を参照してください。 `Pix2Struct` モデルの場合、Adafactor とコサイン学習率スケジューラを使用してモデルを微調整すると、収束が高速化されることがわかりました。
+```python
+from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
+
+optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
+scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
+```
+
+
+
+DePlot は、`Pix2Struct`アーキテクチャを使用してトレーニングされたモデルです。 API リファレンスについては、[`Pix2Struct` ドキュメント](pix2struct) を参照してください。
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/deta.md b/docs/source/ja/model_doc/deta.md
new file mode 100644
index 00000000000000..615f8396577fdb
--- /dev/null
+++ b/docs/source/ja/model_doc/deta.md
@@ -0,0 +1,64 @@
+
+
+# DETA
+
+## Overview
+
+DETA モデルは、[NMS Strikes Back](https://arxiv.org/abs/2212.06137) で Jeffrey Ouyang-Zhang、Jang Hyun Cho、Xingyi Zhou、Philipp Krähenbühl によって提案されました。
+DETA (Detection Transformers with Assignment の略) は、1 対 1 の 2 部ハンガリアン マッチング損失を置き換えることにより、[Deformable DETR](deformable_detr) を改善します。
+非最大抑制 (NMS) を備えた従来の検出器で使用される 1 対多のラベル割り当てを使用します。これにより、最大 2.5 mAP の大幅な増加が得られます。
+
+論文の要約は次のとおりです。
+
+*Detection Transformer (DETR) は、トレーニング中に 1 対 1 の 2 部マッチングを使用してクエリを一意のオブジェクトに直接変換し、エンドツーエンドのオブジェクト検出を可能にします。最近、これらのモデルは、紛れもない優雅さで COCO の従来の検出器を上回りました。ただし、モデル アーキテクチャやトレーニング スケジュールなど、さまざまな設計において従来の検出器とは異なるため、1 対 1 マッチングの有効性は完全には理解されていません。この研究では、DETR での 1 対 1 のハンガリー語マッチングと、非最大監視 (NMS) を備えた従来の検出器での 1 対多のラベル割り当てとの間の厳密な比較を行います。驚くべきことに、NMS を使用した 1 対多の割り当ては、同じ設定の下で標準的な 1 対 1 のマッチングよりも一貫して優れており、最大 2.5 mAP という大幅な向上が見られます。従来の IoU ベースのラベル割り当てを使用して Deformable-DETR をトレーニングする当社の検出器は、ResNet50 バックボーンを使用して 12 エポック (1x スケジュール) 以内に 50.2 COCO mAP を達成し、この設定で既存のすべての従来の検出器またはトランスベースの検出器を上回りました。複数のデータセット、スケジュール、アーキテクチャに関して、私たちは一貫して、パフォーマンスの高い検出トランスフォーマーには二部マッチングが不要であることを示しています。さらに、検出トランスの成功は、表現力豊かなトランス アーキテクチャによるものであると考えています。*
+
+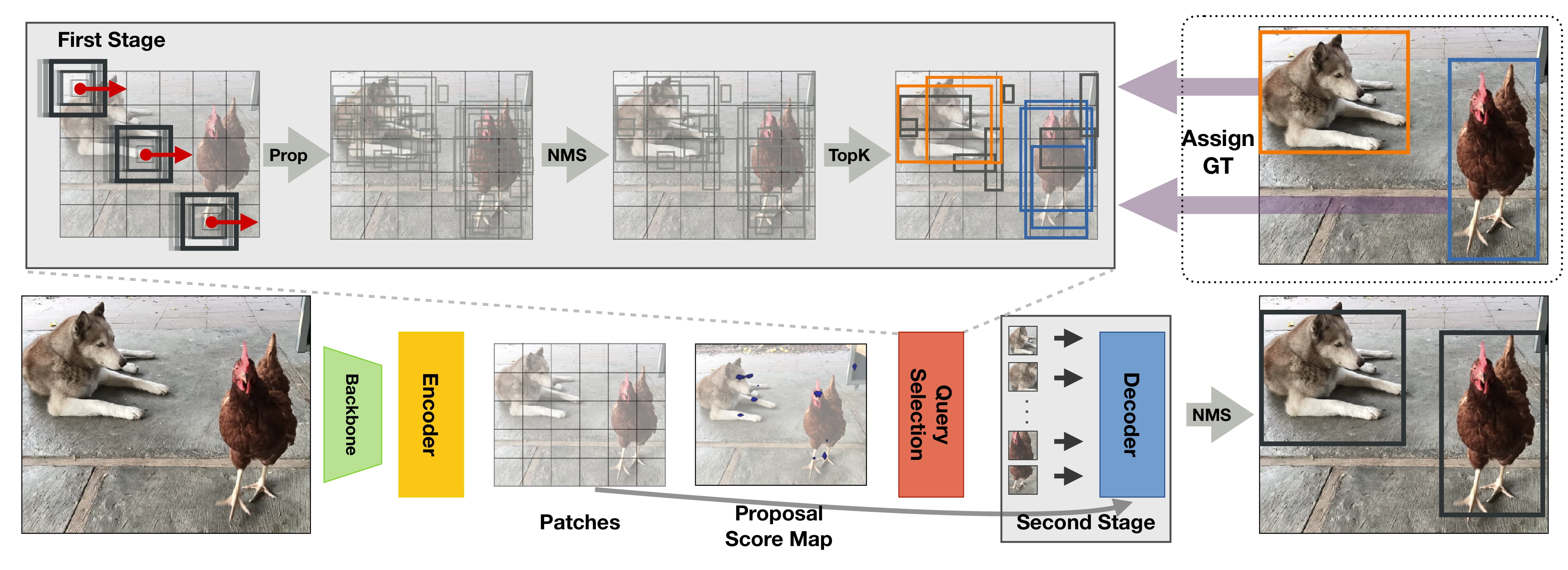 +
+ DETA の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
+
+## Resources
+
+DETA の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- DETA のデモ ノートブックは [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA) にあります。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/source/ja/model_doc/detr.md b/docs/source/ja/model_doc/detr.md
new file mode 100644
index 00000000000000..1b9e64eb5486ee
--- /dev/null
+++ b/docs/source/ja/model_doc/detr.md
@@ -0,0 +1,217 @@
+
+
+# DETR
+
+## Overview
+
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
+畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
+物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
+領域提案、非最大抑制手順、アンカー生成などです。さらに、DETR は次のようにすることもできます。
+デコーダ出力の上にマスク ヘッドを追加するだけで、パノプティック セグメンテーションを実行できるように自然に拡張されています。
+
+論文の要約は次のとおりです。
+
+*物体検出を直接集合予測問題として見る新しい方法を紹介します。私たちのアプローチは、
+検出パイプラインにより、非最大抑制などの多くの手作業で設計されたコンポーネントの必要性が効果的に排除されます。
+タスクに関する事前の知識を明示的にエンコードするプロシージャまたはアンカーの生成。の主な成分は、
+DEtection TRansformer または DETR と呼ばれる新しいフレームワークは、セットベースのグローバル損失であり、
+二部マッチング、およびトランスフォーマー エンコーダー/デコーダー アーキテクチャ。学習されたオブジェクト クエリの固定された小さなセットが与えられると、
+DETR は、オブジェクトとグローバル イメージ コンテキストの関係について推論し、最終セットを直接出力します。
+並行して予想も。新しいモデルは概念的にシンプルであり、多くのモデルとは異なり、特殊なライブラリを必要としません。
+他の最新の検出器。 DETR は、確立された、および同等の精度と実行時のパフォーマンスを実証します。
+困難な COCO 物体検出データセットに基づく、高度に最適化された Faster RCNN ベースライン。さらに、DETR は簡単に実行できます。
+統一された方法でパノプティック セグメンテーションを生成するために一般化されました。競合他社を大幅に上回るパフォーマンスを示しています
+ベースライン*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/detr) にあります。
+
+## How DETR works
+
+[`~transformers.DetrForObjectDetection`] がどのように機能するかを説明する TLDR は次のとおりです。
+
+まず、事前にトレーニングされた畳み込みバックボーンを通じて画像が送信されます (論文では、著者らは次のように使用しています)。
+ResNet-50/ResNet-101)。バッチ ディメンションも追加すると仮定します。これは、バックボーンへの入力が
+画像に 3 つのカラー チャネル (RGB) があると仮定した場合の、形状 `(batch_size, 3, height, width)` のテンソル。 CNNのバックボーン
+通常は `(batch_size, 2048, height/32, width/32)` の形状の、新しい低解像度の特徴マップを出力します。これは
+次に、DETR の Transformer の隠れ次元 (デフォルトでは `256`) に一致するように投影されます。
+`nn.Conv2D` レイヤー。これで、形状 `(batch_size, 256, height/32, width/32)` のテンソルが完成しました。
+特徴マップは平坦化および転置され、形状 `(batch_size, seq_len, d_model)` のテンソルを取得します =
+`(batch_size, width/32*height/32, 256)`。したがって、NLP モデルとの違いは、シーケンスの長さが実際には
+通常よりも長くなりますが、「d_model」は小さくなります (NLP では通常 768 以上です)。
+
+次に、これがエンコーダを介して送信され、同じ形状の `encoder_hidden_states` が出力されます (次のように考えることができます)。
+これらは画像の特徴として)。次に、いわゆる **オブジェクト クエリ**がデコーダを通じて送信されます。これは形状のテンソルです
+`(batch_size, num_queries, d_model)`。通常、`num_queries` は 100 に設定され、ゼロで初期化されます。
+これらの入力埋め込みは学習された位置エンコーディングであり、作成者はこれをオブジェクト クエリと呼び、同様に
+エンコーダでは、それらは各アテンション層の入力に追加されます。各オブジェクト クエリは特定のオブジェクトを検索します。
+画像では。デコーダは、複数のセルフ アテンション レイヤとエンコーダ デコーダ アテンション レイヤを通じてこれらの埋め込みを更新します。
+同じ形状の `decoder_hidden_states` を出力します: `(batch_size, num_queries, d_model)`。次に頭が2つ
+オブジェクト検出のために上部に追加されます。各オブジェクト クエリをオブジェクトの 1 つに分類するための線形レイヤー、または「いいえ」
+オブジェクト」、および各クエリの境界ボックスを予測する MLP。
+
+モデルは **2 部マッチング損失**を使用してトレーニングされます。つまり、実際に行うことは、予測されたクラスを比較することです +
+グラウンド トゥルース アノテーションに対する N = 100 個の各オブジェクト クエリの境界ボックス (同じ長さ N までパディング)
+(したがって、画像にオブジェクトが 4 つしか含まれていない場合、96 個の注釈にはクラスとして「オブジェクトなし」、およびクラスとして「境界ボックスなし」が含まれるだけになります。
+境界ボックス)。 [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) は、検索に使用されます。
+N 個のクエリのそれぞれから N 個の注釈のそれぞれへの最適な 1 対 1 のマッピング。次に、標準クロスエントロピー (
+クラス)、および L1 と [generalized IoU loss](https://giou.stanford.edu/) の線形結合 (
+境界ボックス) は、モデルのパラメーターを最適化するために使用されます。
+
+DETR は、パノプティック セグメンテーション (セマンティック セグメンテーションとインスタンスを統合する) を実行するように自然に拡張できます。
+セグメンテーション)。 [`~transformers.DetrForSegmentation`] はセグメンテーション マスク ヘッドを上に追加します
+[`~transformers.DetrForObjectDetection`]。マスク ヘッドは、共同でトレーニングすることも、2 段階のプロセスでトレーニングすることもできます。
+ここで、最初に [`~transformers.DetrForObjectDetection`] モデルをトレーニングして、両方の周囲の境界ボックスを検出します。
+「もの」(インスタンス)と「もの」(木、道路、空などの背景のもの)をすべて凍結し、すべての重みをフリーズしてのみトレーニングします。
+25 エポックのマスクヘッド。実験的には、これら 2 つのアプローチは同様の結果をもたらします。ボックスの予測は
+ハンガリー語のマッチングはボックス間の距離を使用して計算されるため、トレーニングを可能にするためにはこれが必要です。
+
+## Usage tips
+
+- DETR は、いわゆる **オブジェクト クエリ** を使用して、画像内のオブジェクトを検出します。クエリの数によって最大値が決まります
+ 単一の画像内で検出できるオブジェクトの数。デフォルトでは 100 に設定されます (パラメーターを参照)
+ [`~transformers.DetrConfig`] の `num_queries`)。ある程度の余裕があるのは良いことです (COCO では、
+ 著者は 100 を使用しましたが、COCO イメージ内のオブジェクトの最大数は約 70 です)。
+- DETR のデコーダーは、クエリの埋め込みを並行して更新します。これは GPT-2 のような言語モデルとは異なります。
+ 並列ではなく自己回帰デコードを使用します。したがって、因果的注意マスクは使用されません。
+- DETR は、投影前に各セルフアテンション層とクロスアテンション層の隠れ状態に位置埋め込みを追加します。
+ クエリとキーに。画像の位置埋め込みについては、固定正弦波または学習済みのどちらかを選択できます。
+ 絶対位置埋め込み。デフォルトでは、パラメータ `position_embedding_type` は
+ [`~transformers.DetrConfig`] は `"sine"` に設定されます。
+- DETR の作成者は、トレーニング中に、特にデコーダで補助損失を使用すると役立つことに気づきました。
+ モデルは各クラスの正しい数のオブジェクトを出力します。パラメータ `auxiliary_loss` を設定すると、
+ [`~transformers.DetrConfig`] を`True`に設定し、フィードフォワード ニューラル ネットワークとハンガリー損失を予測します
+ は各デコーダ層の後に追加されます (FFN がパラメータを共有する)。
+- 複数のノードにわたる分散環境でモデルをトレーニングする場合は、
+ _modeling_detr.py_ の _DetrLoss_ クラスの _num_boxes_ 変数。複数のノードでトレーニングする場合、これは次のようにする必要があります
+ 元の実装で見られるように、すべてのノードにわたるターゲット ボックスの平均数に設定されます [こちら](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232) 。
+- [`~transformers.DetrForObjectDetection`] および [`~transformers.DetrForSegmentation`] は次のように初期化できます。
+ [timm ライブラリ](https://github.com/rwightman/pytorch-image-models) で利用可能な畳み込みバックボーン。
+ たとえば、MobileNet バックボーンを使用した初期化は、次の `backbone` 属性を設定することで実行できます。
+ [`~transformers.DetrConfig`] を `"tf_mobilenetv3_small_075"` に設定し、それを使用してモデルを初期化します。
+ 構成。
+- DETR は、最短辺が一定のピクセル数以上になり、最長辺が一定量以上になるように入力画像のサイズを変更します。
+ 最大 1333 ピクセル。トレーニング時に、最短辺がランダムに に設定されるようにスケール拡張が使用されます。
+ 最小 480、最大 800 ピクセル。推論時には、最短辺が 800 に設定されます。
+
+使用できます
+ [`~transformers.DetrImageProcessor`] 用の画像 (およびオプションの COCO 形式の注釈) を準備します。
+ モデル。このサイズ変更により、バッチ内の画像のサイズが異なる場合があります。 DETR は、画像を最大までパディングすることでこの問題を解決します。
+ どのピクセルが実数でどのピクセルがパディングであるかを示すピクセル マスクを作成することによって、バッチ内の最大サイズを決定します。
+ あるいは、画像をバッチ処理するためにカスタムの `collate_fn` を定義することもできます。
+ [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`]。
+- 画像のサイズによって使用されるメモリの量が決まり、したがって「batch_size」も決まります。
+ GPU あたり 2 のバッチ サイズを使用することをお勧めします。詳細については、[この Github スレッド](https://github.com/facebookresearch/detr/issues/150) を参照してください。
+
+DETR モデルをインスタンス化するには 3 つの方法があります (好みに応じて)。
+
+オプション 1: モデル全体の事前トレーニングされた重みを使用して DETR をインスタンス化する
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+オプション 2: Transformer についてはランダムに初期化された重みを使用して DETR をインスタンス化しますが、バックボーンについては事前にトレーニングされた重みを使用します
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+オプション 3: バックボーン + トランスフォーマーのランダムに初期化された重みを使用して DETR をインスタンス化します。
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** |画像内のオブジェクトの周囲の境界ボックスとクラス ラベルを予測する | 画像内のオブジェクト (つまりインスタンス) の周囲のマスクを予測する | 画像内のオブジェクト (インスタンス) と「もの」 (木や道路などの背景) の両方の周囲のマスクを予測します |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+つまり、COCO 検出または COCO パノプティック形式でデータを準備してから、次を使用する必要があります。
+[`~transformers.DetrImageProcessor`] `pixel_values`、`pixel_mask`、およびオプションを作成します。
+「ラベル」。これを使用してモデルをトレーニング (または微調整) できます。評価するには、まず、
+[`~transformers.DetrImageProcessor`] の後処理メソッドの 1 つを使用したモデルの出力。これらはできます
+`CocoEvaluator` または `PanopticEvaluator` のいずれかに提供され、次のようなメトリクスを計算できます。
+平均平均精度 (mAP) とパノラマ品質 (PQ)。後者のオブジェクトは [元のリポジトリ](https://github.com/facebookresearch/detr) に実装されています。評価の詳細については、[サンプル ノートブック](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) を参照してください。
+
+## Resources
+
+DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- カスタム データセットの [`DetrForObjectDetection`] と [`DetrForSegmentation`] の微調整を説明するすべてのサンプル ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) で見つけることができます。 。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetrConfig
+
+[[autodoc]] DetrConfig
+
+## DetrImageProcessor
+
+[[autodoc]] DetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DetrFeatureExtractor
+
+[[autodoc]] DetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
+## DetrModel
+
+[[autodoc]] DetrModel
+ - forward
+
+## DetrForObjectDetection
+
+[[autodoc]] DetrForObjectDetection
+ - forward
+
+## DetrForSegmentation
+
+[[autodoc]] DetrForSegmentation
+ - forward
diff --git a/docs/source/ja/model_doc/dialogpt.md b/docs/source/ja/model_doc/dialogpt.md
new file mode 100644
index 00000000000000..82d6f8481afb47
--- /dev/null
+++ b/docs/source/ja/model_doc/dialogpt.md
@@ -0,0 +1,57 @@
+
+
+# DialoGPT
+
+## Overview
+
+DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
+レディット。
+
+論文の要約は次のとおりです。
+
+*私たちは、大規模で調整可能なニューラル会話応答生成モデル DialoGPT (対話生成事前トレーニング済み) を紹介します。
+変成器)。 Reddit のコメント チェーンから抽出された 1 億 4,700 万件の会話のようなやり取りを対象にトレーニングされました。
+2005 年から 2017 年にかけて、DialoGPT は人間に近いパフォーマンスを達成するために Hugging Face PyTorch トランスフォーマーを拡張しました。
+シングルターンダイアログ設定における自動評価と人間による評価の両方。会話システムが
+DialoGPT を活用すると、強力なベースラインよりも関連性が高く、内容が充実し、コンテキストに一貫性のある応答が生成されます。
+システム。神経反応の研究を促進するために、事前トレーニングされたモデルとトレーニング パイプラインが公開されています。
+よりインテリジェントなオープンドメイン対話システムの生成と開発。*
+
+元のコードは [ここ](https://github.com/microsoft/DialoGPT) にあります。
+
+## Usage tips
+
+
+- DialoGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左よりも。
+- DialoGPT は、会話データの因果言語モデリング (CLM) 目標に基づいてトレーニングされているため、強力です
+ オープンドメイン対話システムにおける応答生成時。
+- DialoGPT を使用すると、[DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium) に示されているように、ユーザーはわずか 10 行のコードでチャット ボットを作成できます。
+
+トレーニング:
+
+DialoGPT をトレーニングまたは微調整するには、因果言語モデリング トレーニングを使用できます。公式論文を引用すると: *私たちは
+OpenAI GPT-2に従って、マルチターン対話セッションを長いテキストとしてモデル化し、生成タスクを言語としてフレーム化します
+モデリング。まず、ダイアログ セッション内のすべてのダイアログ ターンを長いテキスト x_1,..., x_N に連結します (N は
+* 詳細については、元の論文を参照してください。
+
+
+
+DialoGPT のアーキテクチャは GPT2 モデルに基づいています。API リファレンスと例については、[GPT2 のドキュメント ページ](gpt2) を参照してください。
+
+
diff --git a/docs/source/ja/model_doc/dinat.md b/docs/source/ja/model_doc/dinat.md
new file mode 100644
index 00000000000000..a59b073d4669ef
--- /dev/null
+++ b/docs/source/ja/model_doc/dinat.md
@@ -0,0 +1,93 @@
+
+
+# Dilated Neighborhood Attention Transformer
+
+## Overview
+
+DiNAT は [Dilated Neighborhood Attender Transformer](https://arxiv.org/abs/2209.15001) で提案されました。
+Ali Hassani and Humphrey Shi.
+
+[NAT](nat) を拡張するために、拡張近隣アテンション パターンを追加してグローバル コンテキストをキャプチャします。
+そしてそれと比較して大幅なパフォーマンスの向上が見られます。
+
+論文の要約は次のとおりです。
+
+*トランスフォーマーは急速に、さまざまなモダリティにわたって最も頻繁に適用される深層学習アーキテクチャの 1 つになりつつあります。
+ドメインとタスク。ビジョンでは、単純なトランスフォーマーへの継続的な取り組みに加えて、階層型トランスフォーマーが
+また、そのパフォーマンスと既存のフレームワークへの簡単な統合のおかげで、大きな注目を集めました。
+これらのモデルは通常、スライディング ウィンドウの近隣アテンション (NA) などの局所的な注意メカニズムを採用しています。
+または Swin Transformer のシフト ウィンドウ セルフ アテンション。自己注意の二次複雑さを軽減するのに効果的ですが、
+局所的な注意は、自己注意の最も望ましい 2 つの特性を弱めます。それは、長距離の相互依存性モデリングです。
+そして全体的な受容野。このペーパーでは、自然で柔軟で、
+NA への効率的な拡張により、よりグローバルなコンテキストを捕捉し、受容野をゼロから指数関数的に拡張することができます。
+追加費用。 NA のローカルな注目と DiNA のまばらなグローバルな注目は相互に補完し合うため、私たちは
+両方に基づいて構築された新しい階層型ビジョン トランスフォーマーである Dilated Neighborhood Attendant Transformer (DiNAT) を導入します。
+DiNAT のバリアントは、NAT、Swin、ConvNeXt などの強力なベースラインに比べて大幅に改善されています。
+私たちの大規模モデルは、COCO オブジェクト検出において Swin モデルよりも高速で、ボックス AP が 1.5% 優れています。
+COCO インスタンス セグメンテーションでは 1.3% のマスク AP、ADE20K セマンティック セグメンテーションでは 1.1% の mIoU。
+新しいフレームワークと組み合わせた当社の大規模バリアントは、COCO (58.2 PQ) 上の新しい最先端のパノプティック セグメンテーション モデルです。
+および ADE20K (48.5 PQ)、および Cityscapes (44.5 AP) および ADE20K (35.4 AP) のインスタンス セグメンテーション モデル (追加データなし)。
+また、ADE20K (58.2 mIoU) 上の最先端の特殊なセマンティック セグメンテーション モデルとも一致します。
+都市景観 (84.5 mIoU) では 2 位にランクされています (追加データなし)。 *
+
+
+
+
+ DETA の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
+
+## Resources
+
+DETA の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- DETA のデモ ノートブックは [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA) にあります。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/source/ja/model_doc/detr.md b/docs/source/ja/model_doc/detr.md
new file mode 100644
index 00000000000000..1b9e64eb5486ee
--- /dev/null
+++ b/docs/source/ja/model_doc/detr.md
@@ -0,0 +1,217 @@
+
+
+# DETR
+
+## Overview
+
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
+畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
+物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
+領域提案、非最大抑制手順、アンカー生成などです。さらに、DETR は次のようにすることもできます。
+デコーダ出力の上にマスク ヘッドを追加するだけで、パノプティック セグメンテーションを実行できるように自然に拡張されています。
+
+論文の要約は次のとおりです。
+
+*物体検出を直接集合予測問題として見る新しい方法を紹介します。私たちのアプローチは、
+検出パイプラインにより、非最大抑制などの多くの手作業で設計されたコンポーネントの必要性が効果的に排除されます。
+タスクに関する事前の知識を明示的にエンコードするプロシージャまたはアンカーの生成。の主な成分は、
+DEtection TRansformer または DETR と呼ばれる新しいフレームワークは、セットベースのグローバル損失であり、
+二部マッチング、およびトランスフォーマー エンコーダー/デコーダー アーキテクチャ。学習されたオブジェクト クエリの固定された小さなセットが与えられると、
+DETR は、オブジェクトとグローバル イメージ コンテキストの関係について推論し、最終セットを直接出力します。
+並行して予想も。新しいモデルは概念的にシンプルであり、多くのモデルとは異なり、特殊なライブラリを必要としません。
+他の最新の検出器。 DETR は、確立された、および同等の精度と実行時のパフォーマンスを実証します。
+困難な COCO 物体検出データセットに基づく、高度に最適化された Faster RCNN ベースライン。さらに、DETR は簡単に実行できます。
+統一された方法でパノプティック セグメンテーションを生成するために一般化されました。競合他社を大幅に上回るパフォーマンスを示しています
+ベースライン*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/detr) にあります。
+
+## How DETR works
+
+[`~transformers.DetrForObjectDetection`] がどのように機能するかを説明する TLDR は次のとおりです。
+
+まず、事前にトレーニングされた畳み込みバックボーンを通じて画像が送信されます (論文では、著者らは次のように使用しています)。
+ResNet-50/ResNet-101)。バッチ ディメンションも追加すると仮定します。これは、バックボーンへの入力が
+画像に 3 つのカラー チャネル (RGB) があると仮定した場合の、形状 `(batch_size, 3, height, width)` のテンソル。 CNNのバックボーン
+通常は `(batch_size, 2048, height/32, width/32)` の形状の、新しい低解像度の特徴マップを出力します。これは
+次に、DETR の Transformer の隠れ次元 (デフォルトでは `256`) に一致するように投影されます。
+`nn.Conv2D` レイヤー。これで、形状 `(batch_size, 256, height/32, width/32)` のテンソルが完成しました。
+特徴マップは平坦化および転置され、形状 `(batch_size, seq_len, d_model)` のテンソルを取得します =
+`(batch_size, width/32*height/32, 256)`。したがって、NLP モデルとの違いは、シーケンスの長さが実際には
+通常よりも長くなりますが、「d_model」は小さくなります (NLP では通常 768 以上です)。
+
+次に、これがエンコーダを介して送信され、同じ形状の `encoder_hidden_states` が出力されます (次のように考えることができます)。
+これらは画像の特徴として)。次に、いわゆる **オブジェクト クエリ**がデコーダを通じて送信されます。これは形状のテンソルです
+`(batch_size, num_queries, d_model)`。通常、`num_queries` は 100 に設定され、ゼロで初期化されます。
+これらの入力埋め込みは学習された位置エンコーディングであり、作成者はこれをオブジェクト クエリと呼び、同様に
+エンコーダでは、それらは各アテンション層の入力に追加されます。各オブジェクト クエリは特定のオブジェクトを検索します。
+画像では。デコーダは、複数のセルフ アテンション レイヤとエンコーダ デコーダ アテンション レイヤを通じてこれらの埋め込みを更新します。
+同じ形状の `decoder_hidden_states` を出力します: `(batch_size, num_queries, d_model)`。次に頭が2つ
+オブジェクト検出のために上部に追加されます。各オブジェクト クエリをオブジェクトの 1 つに分類するための線形レイヤー、または「いいえ」
+オブジェクト」、および各クエリの境界ボックスを予測する MLP。
+
+モデルは **2 部マッチング損失**を使用してトレーニングされます。つまり、実際に行うことは、予測されたクラスを比較することです +
+グラウンド トゥルース アノテーションに対する N = 100 個の各オブジェクト クエリの境界ボックス (同じ長さ N までパディング)
+(したがって、画像にオブジェクトが 4 つしか含まれていない場合、96 個の注釈にはクラスとして「オブジェクトなし」、およびクラスとして「境界ボックスなし」が含まれるだけになります。
+境界ボックス)。 [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) は、検索に使用されます。
+N 個のクエリのそれぞれから N 個の注釈のそれぞれへの最適な 1 対 1 のマッピング。次に、標準クロスエントロピー (
+クラス)、および L1 と [generalized IoU loss](https://giou.stanford.edu/) の線形結合 (
+境界ボックス) は、モデルのパラメーターを最適化するために使用されます。
+
+DETR は、パノプティック セグメンテーション (セマンティック セグメンテーションとインスタンスを統合する) を実行するように自然に拡張できます。
+セグメンテーション)。 [`~transformers.DetrForSegmentation`] はセグメンテーション マスク ヘッドを上に追加します
+[`~transformers.DetrForObjectDetection`]。マスク ヘッドは、共同でトレーニングすることも、2 段階のプロセスでトレーニングすることもできます。
+ここで、最初に [`~transformers.DetrForObjectDetection`] モデルをトレーニングして、両方の周囲の境界ボックスを検出します。
+「もの」(インスタンス)と「もの」(木、道路、空などの背景のもの)をすべて凍結し、すべての重みをフリーズしてのみトレーニングします。
+25 エポックのマスクヘッド。実験的には、これら 2 つのアプローチは同様の結果をもたらします。ボックスの予測は
+ハンガリー語のマッチングはボックス間の距離を使用して計算されるため、トレーニングを可能にするためにはこれが必要です。
+
+## Usage tips
+
+- DETR は、いわゆる **オブジェクト クエリ** を使用して、画像内のオブジェクトを検出します。クエリの数によって最大値が決まります
+ 単一の画像内で検出できるオブジェクトの数。デフォルトでは 100 に設定されます (パラメーターを参照)
+ [`~transformers.DetrConfig`] の `num_queries`)。ある程度の余裕があるのは良いことです (COCO では、
+ 著者は 100 を使用しましたが、COCO イメージ内のオブジェクトの最大数は約 70 です)。
+- DETR のデコーダーは、クエリの埋め込みを並行して更新します。これは GPT-2 のような言語モデルとは異なります。
+ 並列ではなく自己回帰デコードを使用します。したがって、因果的注意マスクは使用されません。
+- DETR は、投影前に各セルフアテンション層とクロスアテンション層の隠れ状態に位置埋め込みを追加します。
+ クエリとキーに。画像の位置埋め込みについては、固定正弦波または学習済みのどちらかを選択できます。
+ 絶対位置埋め込み。デフォルトでは、パラメータ `position_embedding_type` は
+ [`~transformers.DetrConfig`] は `"sine"` に設定されます。
+- DETR の作成者は、トレーニング中に、特にデコーダで補助損失を使用すると役立つことに気づきました。
+ モデルは各クラスの正しい数のオブジェクトを出力します。パラメータ `auxiliary_loss` を設定すると、
+ [`~transformers.DetrConfig`] を`True`に設定し、フィードフォワード ニューラル ネットワークとハンガリー損失を予測します
+ は各デコーダ層の後に追加されます (FFN がパラメータを共有する)。
+- 複数のノードにわたる分散環境でモデルをトレーニングする場合は、
+ _modeling_detr.py_ の _DetrLoss_ クラスの _num_boxes_ 変数。複数のノードでトレーニングする場合、これは次のようにする必要があります
+ 元の実装で見られるように、すべてのノードにわたるターゲット ボックスの平均数に設定されます [こちら](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232) 。
+- [`~transformers.DetrForObjectDetection`] および [`~transformers.DetrForSegmentation`] は次のように初期化できます。
+ [timm ライブラリ](https://github.com/rwightman/pytorch-image-models) で利用可能な畳み込みバックボーン。
+ たとえば、MobileNet バックボーンを使用した初期化は、次の `backbone` 属性を設定することで実行できます。
+ [`~transformers.DetrConfig`] を `"tf_mobilenetv3_small_075"` に設定し、それを使用してモデルを初期化します。
+ 構成。
+- DETR は、最短辺が一定のピクセル数以上になり、最長辺が一定量以上になるように入力画像のサイズを変更します。
+ 最大 1333 ピクセル。トレーニング時に、最短辺がランダムに に設定されるようにスケール拡張が使用されます。
+ 最小 480、最大 800 ピクセル。推論時には、最短辺が 800 に設定されます。
+
+使用できます
+ [`~transformers.DetrImageProcessor`] 用の画像 (およびオプションの COCO 形式の注釈) を準備します。
+ モデル。このサイズ変更により、バッチ内の画像のサイズが異なる場合があります。 DETR は、画像を最大までパディングすることでこの問題を解決します。
+ どのピクセルが実数でどのピクセルがパディングであるかを示すピクセル マスクを作成することによって、バッチ内の最大サイズを決定します。
+ あるいは、画像をバッチ処理するためにカスタムの `collate_fn` を定義することもできます。
+ [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`]。
+- 画像のサイズによって使用されるメモリの量が決まり、したがって「batch_size」も決まります。
+ GPU あたり 2 のバッチ サイズを使用することをお勧めします。詳細については、[この Github スレッド](https://github.com/facebookresearch/detr/issues/150) を参照してください。
+
+DETR モデルをインスタンス化するには 3 つの方法があります (好みに応じて)。
+
+オプション 1: モデル全体の事前トレーニングされた重みを使用して DETR をインスタンス化する
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+オプション 2: Transformer についてはランダムに初期化された重みを使用して DETR をインスタンス化しますが、バックボーンについては事前にトレーニングされた重みを使用します
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+オプション 3: バックボーン + トランスフォーマーのランダムに初期化された重みを使用して DETR をインスタンス化します。
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** |画像内のオブジェクトの周囲の境界ボックスとクラス ラベルを予測する | 画像内のオブジェクト (つまりインスタンス) の周囲のマスクを予測する | 画像内のオブジェクト (インスタンス) と「もの」 (木や道路などの背景) の両方の周囲のマスクを予測します |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+つまり、COCO 検出または COCO パノプティック形式でデータを準備してから、次を使用する必要があります。
+[`~transformers.DetrImageProcessor`] `pixel_values`、`pixel_mask`、およびオプションを作成します。
+「ラベル」。これを使用してモデルをトレーニング (または微調整) できます。評価するには、まず、
+[`~transformers.DetrImageProcessor`] の後処理メソッドの 1 つを使用したモデルの出力。これらはできます
+`CocoEvaluator` または `PanopticEvaluator` のいずれかに提供され、次のようなメトリクスを計算できます。
+平均平均精度 (mAP) とパノラマ品質 (PQ)。後者のオブジェクトは [元のリポジトリ](https://github.com/facebookresearch/detr) に実装されています。評価の詳細については、[サンプル ノートブック](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) を参照してください。
+
+## Resources
+
+DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+- カスタム データセットの [`DetrForObjectDetection`] と [`DetrForSegmentation`] の微調整を説明するすべてのサンプル ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) で見つけることができます。 。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetrConfig
+
+[[autodoc]] DetrConfig
+
+## DetrImageProcessor
+
+[[autodoc]] DetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DetrFeatureExtractor
+
+[[autodoc]] DetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
+## DetrModel
+
+[[autodoc]] DetrModel
+ - forward
+
+## DetrForObjectDetection
+
+[[autodoc]] DetrForObjectDetection
+ - forward
+
+## DetrForSegmentation
+
+[[autodoc]] DetrForSegmentation
+ - forward
diff --git a/docs/source/ja/model_doc/dialogpt.md b/docs/source/ja/model_doc/dialogpt.md
new file mode 100644
index 00000000000000..82d6f8481afb47
--- /dev/null
+++ b/docs/source/ja/model_doc/dialogpt.md
@@ -0,0 +1,57 @@
+
+
+# DialoGPT
+
+## Overview
+
+DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
+レディット。
+
+論文の要約は次のとおりです。
+
+*私たちは、大規模で調整可能なニューラル会話応答生成モデル DialoGPT (対話生成事前トレーニング済み) を紹介します。
+変成器)。 Reddit のコメント チェーンから抽出された 1 億 4,700 万件の会話のようなやり取りを対象にトレーニングされました。
+2005 年から 2017 年にかけて、DialoGPT は人間に近いパフォーマンスを達成するために Hugging Face PyTorch トランスフォーマーを拡張しました。
+シングルターンダイアログ設定における自動評価と人間による評価の両方。会話システムが
+DialoGPT を活用すると、強力なベースラインよりも関連性が高く、内容が充実し、コンテキストに一貫性のある応答が生成されます。
+システム。神経反応の研究を促進するために、事前トレーニングされたモデルとトレーニング パイプラインが公開されています。
+よりインテリジェントなオープンドメイン対話システムの生成と開発。*
+
+元のコードは [ここ](https://github.com/microsoft/DialoGPT) にあります。
+
+## Usage tips
+
+
+- DialoGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
+ 左よりも。
+- DialoGPT は、会話データの因果言語モデリング (CLM) 目標に基づいてトレーニングされているため、強力です
+ オープンドメイン対話システムにおける応答生成時。
+- DialoGPT を使用すると、[DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium) に示されているように、ユーザーはわずか 10 行のコードでチャット ボットを作成できます。
+
+トレーニング:
+
+DialoGPT をトレーニングまたは微調整するには、因果言語モデリング トレーニングを使用できます。公式論文を引用すると: *私たちは
+OpenAI GPT-2に従って、マルチターン対話セッションを長いテキストとしてモデル化し、生成タスクを言語としてフレーム化します
+モデリング。まず、ダイアログ セッション内のすべてのダイアログ ターンを長いテキスト x_1,..., x_N に連結します (N は
+* 詳細については、元の論文を参照してください。
+
+
+
+DialoGPT のアーキテクチャは GPT2 モデルに基づいています。API リファレンスと例については、[GPT2 のドキュメント ページ](gpt2) を参照してください。
+
+
diff --git a/docs/source/ja/model_doc/dinat.md b/docs/source/ja/model_doc/dinat.md
new file mode 100644
index 00000000000000..a59b073d4669ef
--- /dev/null
+++ b/docs/source/ja/model_doc/dinat.md
@@ -0,0 +1,93 @@
+
+
+# Dilated Neighborhood Attention Transformer
+
+## Overview
+
+DiNAT は [Dilated Neighborhood Attender Transformer](https://arxiv.org/abs/2209.15001) で提案されました。
+Ali Hassani and Humphrey Shi.
+
+[NAT](nat) を拡張するために、拡張近隣アテンション パターンを追加してグローバル コンテキストをキャプチャします。
+そしてそれと比較して大幅なパフォーマンスの向上が見られます。
+
+論文の要約は次のとおりです。
+
+*トランスフォーマーは急速に、さまざまなモダリティにわたって最も頻繁に適用される深層学習アーキテクチャの 1 つになりつつあります。
+ドメインとタスク。ビジョンでは、単純なトランスフォーマーへの継続的な取り組みに加えて、階層型トランスフォーマーが
+また、そのパフォーマンスと既存のフレームワークへの簡単な統合のおかげで、大きな注目を集めました。
+これらのモデルは通常、スライディング ウィンドウの近隣アテンション (NA) などの局所的な注意メカニズムを採用しています。
+または Swin Transformer のシフト ウィンドウ セルフ アテンション。自己注意の二次複雑さを軽減するのに効果的ですが、
+局所的な注意は、自己注意の最も望ましい 2 つの特性を弱めます。それは、長距離の相互依存性モデリングです。
+そして全体的な受容野。このペーパーでは、自然で柔軟で、
+NA への効率的な拡張により、よりグローバルなコンテキストを捕捉し、受容野をゼロから指数関数的に拡張することができます。
+追加費用。 NA のローカルな注目と DiNA のまばらなグローバルな注目は相互に補完し合うため、私たちは
+両方に基づいて構築された新しい階層型ビジョン トランスフォーマーである Dilated Neighborhood Attendant Transformer (DiNAT) を導入します。
+DiNAT のバリアントは、NAT、Swin、ConvNeXt などの強力なベースラインに比べて大幅に改善されています。
+私たちの大規模モデルは、COCO オブジェクト検出において Swin モデルよりも高速で、ボックス AP が 1.5% 優れています。
+COCO インスタンス セグメンテーションでは 1.3% のマスク AP、ADE20K セマンティック セグメンテーションでは 1.1% の mIoU。
+新しいフレームワークと組み合わせた当社の大規模バリアントは、COCO (58.2 PQ) 上の新しい最先端のパノプティック セグメンテーション モデルです。
+および ADE20K (48.5 PQ)、および Cityscapes (44.5 AP) および ADE20K (35.4 AP) のインスタンス セグメンテーション モデル (追加データなし)。
+また、ADE20K (58.2 mIoU) 上の最先端の特殊なセマンティック セグメンテーション モデルとも一致します。
+都市景観 (84.5 mIoU) では 2 位にランクされています (追加データなし)。 *
+
+
+![]() +
+ 異なる拡張値を使用した近隣アテンション。
+元の論文から抜粋。
+
+このモデルは [Ali Hassani](https://huggingface.co/alihassanijr) によって提供されました。
+元のコードは [ここ](https://github.com/SHI-Labs/Neighborhood-Attendance-Transformer) にあります。
+
+## Usage tips
+
+DiNAT は *バックボーン* として使用できます。 「output_hidden_states = True」の場合、
+`hidden_states` と `reshaped_hidden_states` の両方を出力します。 `reshape_hidden_states` は、`(batch_size, height, width, num_channels)` ではなく、`(batch, num_channels, height, width)` の形状を持っています。
+
+ノート:
+- DiNAT は、[NATTEN](https://github.com/SHI-Labs/NATTEN/) による近隣アテンションと拡張近隣アテンションの実装に依存しています。
+[shi-labs.com/natten](https://shi-labs.com/natten) を参照して、Linux 用のビルド済みホイールを使用してインストールするか、`pip install natten` を実行してシステム上に構築できます。
+後者はコンパイルに時間がかかる可能性があることに注意してください。 NATTEN はまだ Windows デバイスをサポートしていません。
+- 現時点ではパッチ サイズ 4 のみがサポートされています。
+
+## Resources
+
+DiNAT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+
+- [`DinatForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DinatConfig
+
+[[autodoc]] DinatConfig
+
+## DinatModel
+
+[[autodoc]] DinatModel
+ - forward
+
+## DinatForImageClassification
+
+[[autodoc]] DinatForImageClassification
+ - forward
+
+ 異なる拡張値を使用した近隣アテンション。
+元の論文から抜粋。
+
+このモデルは [Ali Hassani](https://huggingface.co/alihassanijr) によって提供されました。
+元のコードは [ここ](https://github.com/SHI-Labs/Neighborhood-Attendance-Transformer) にあります。
+
+## Usage tips
+
+DiNAT は *バックボーン* として使用できます。 「output_hidden_states = True」の場合、
+`hidden_states` と `reshaped_hidden_states` の両方を出力します。 `reshape_hidden_states` は、`(batch_size, height, width, num_channels)` ではなく、`(batch, num_channels, height, width)` の形状を持っています。
+
+ノート:
+- DiNAT は、[NATTEN](https://github.com/SHI-Labs/NATTEN/) による近隣アテンションと拡張近隣アテンションの実装に依存しています。
+[shi-labs.com/natten](https://shi-labs.com/natten) を参照して、Linux 用のビルド済みホイールを使用してインストールするか、`pip install natten` を実行してシステム上に構築できます。
+後者はコンパイルに時間がかかる可能性があることに注意してください。 NATTEN はまだ Windows デバイスをサポートしていません。
+- 現時点ではパッチ サイズ 4 のみがサポートされています。
+
+## Resources
+
+DiNAT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+
+- [`DinatForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DinatConfig
+
+[[autodoc]] DinatConfig
+
+## DinatModel
+
+[[autodoc]] DinatModel
+ - forward
+
+## DinatForImageClassification
+
+[[autodoc]] DinatForImageClassification
+ - forward