 +
+ +
+
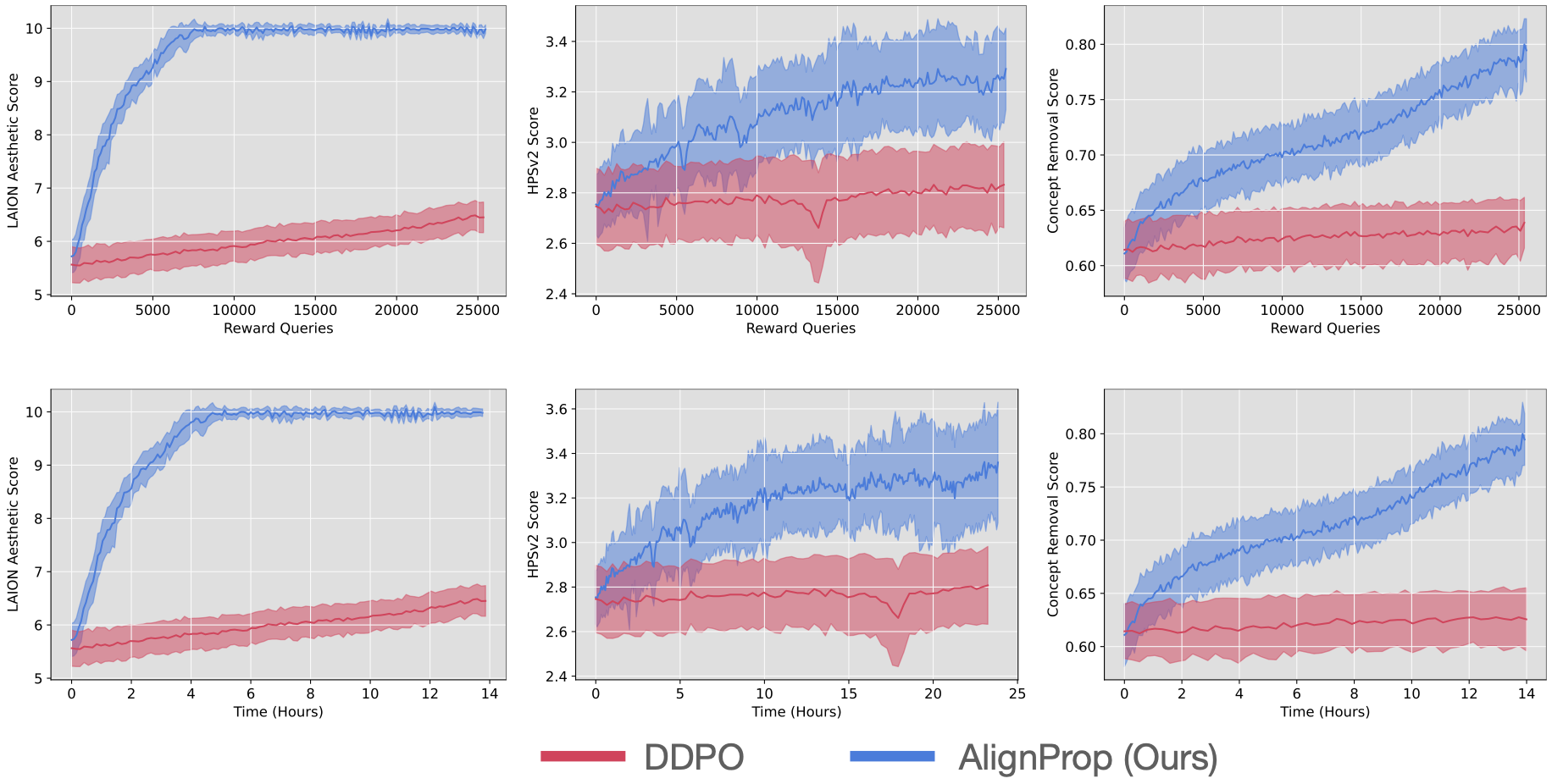













 +
+
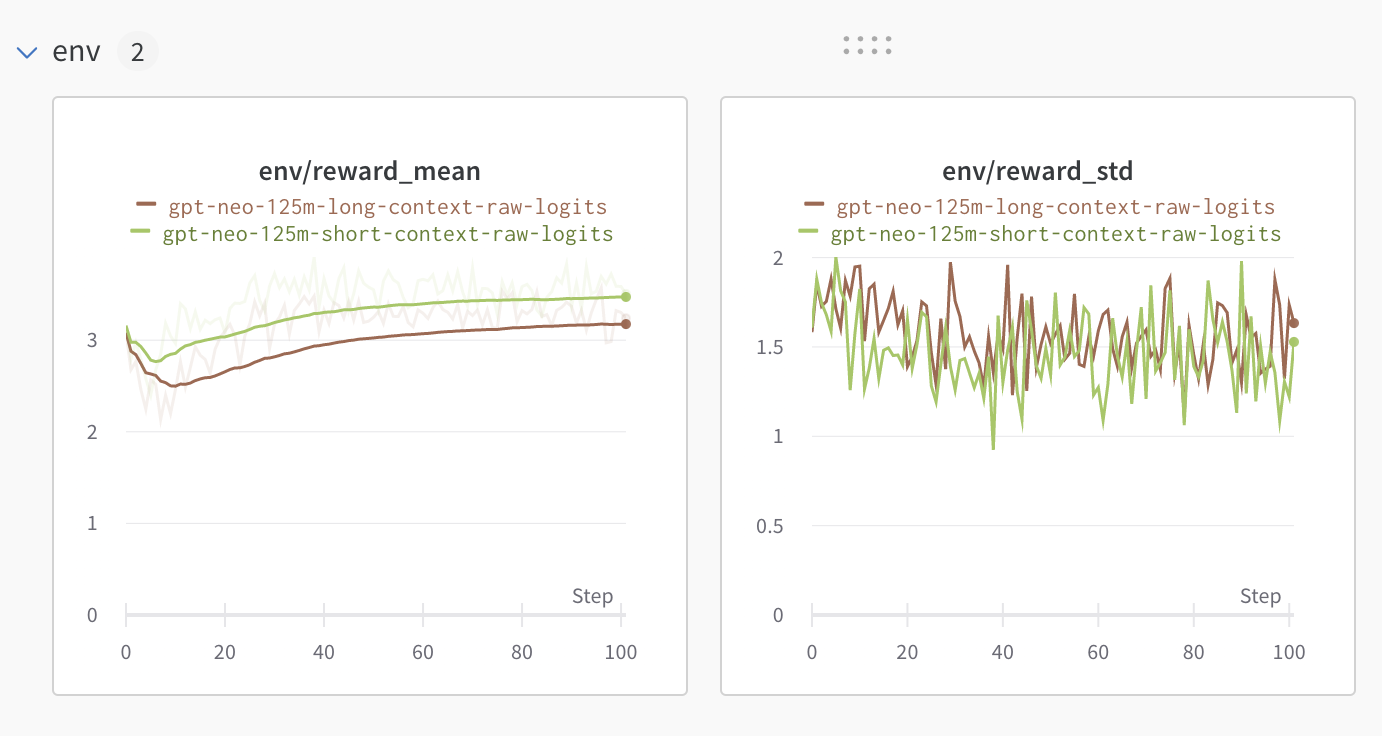
 +
+
 +
+
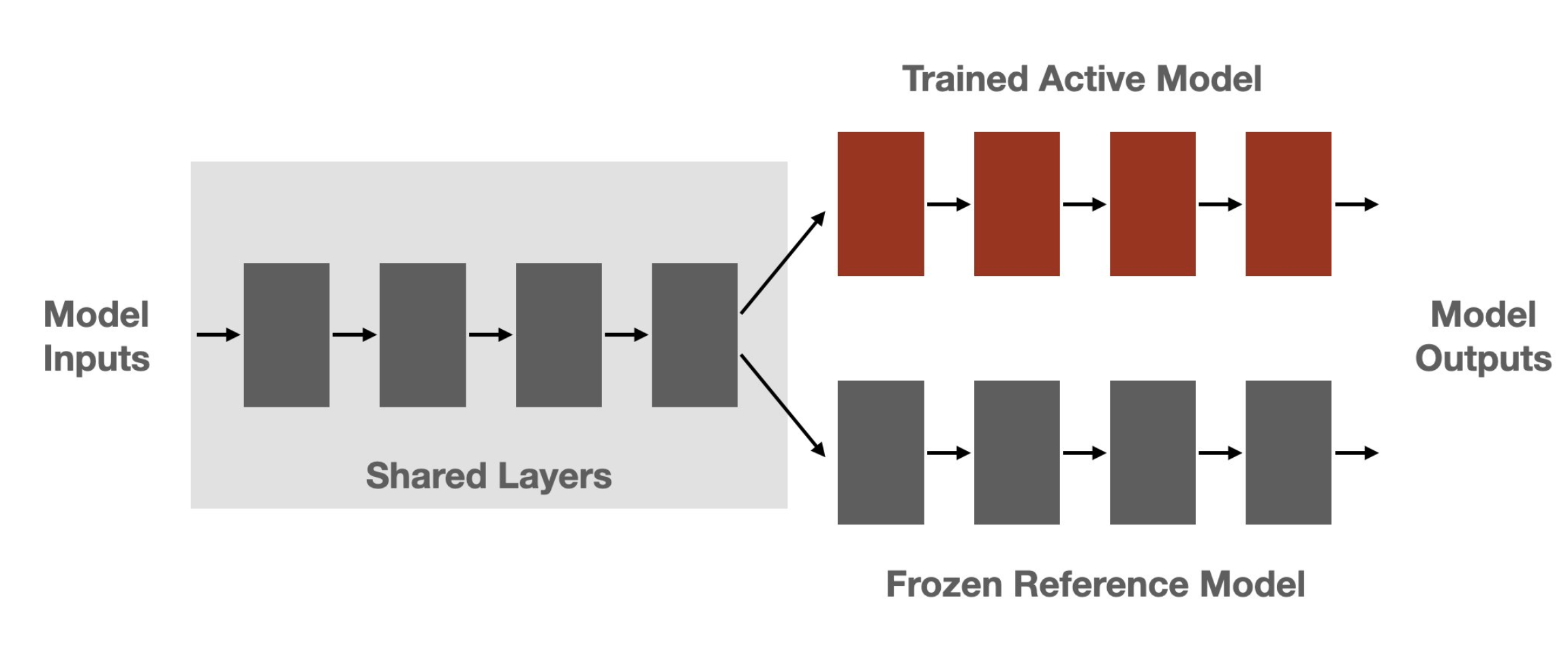
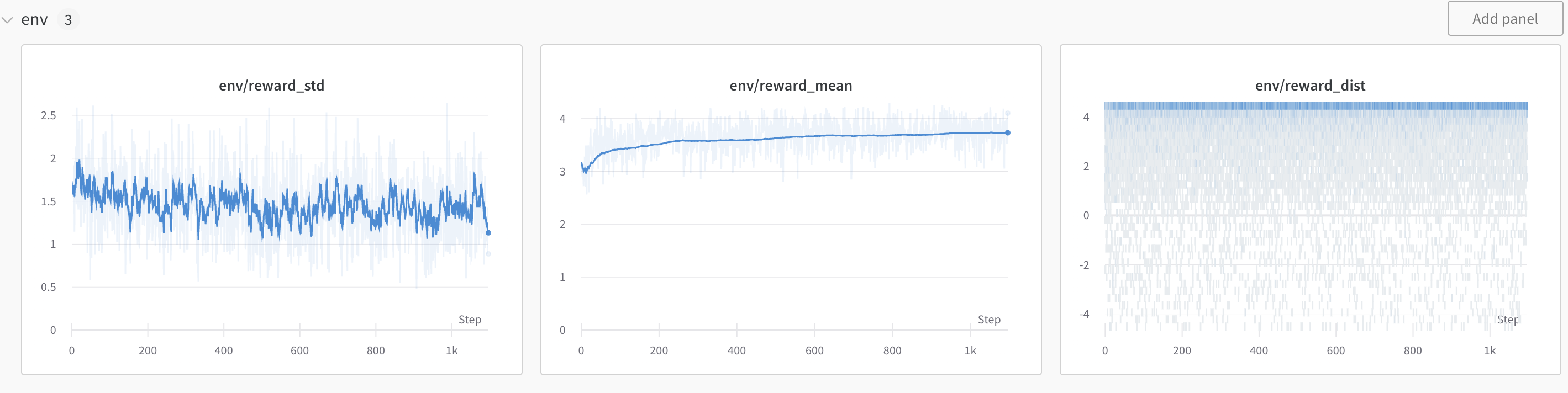 +
+
 +
+
 +
+ 
 +
+ +
+
 +
+
 +
+ ## Minimal example
diff --git a/docs/source/rloo_trainer.md b/docs/source/rloo_trainer.md
index 71d189be7d..127f297321 100644
--- a/docs/source/rloo_trainer.md
+++ b/docs/source/rloo_trainer.md
@@ -68,7 +68,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
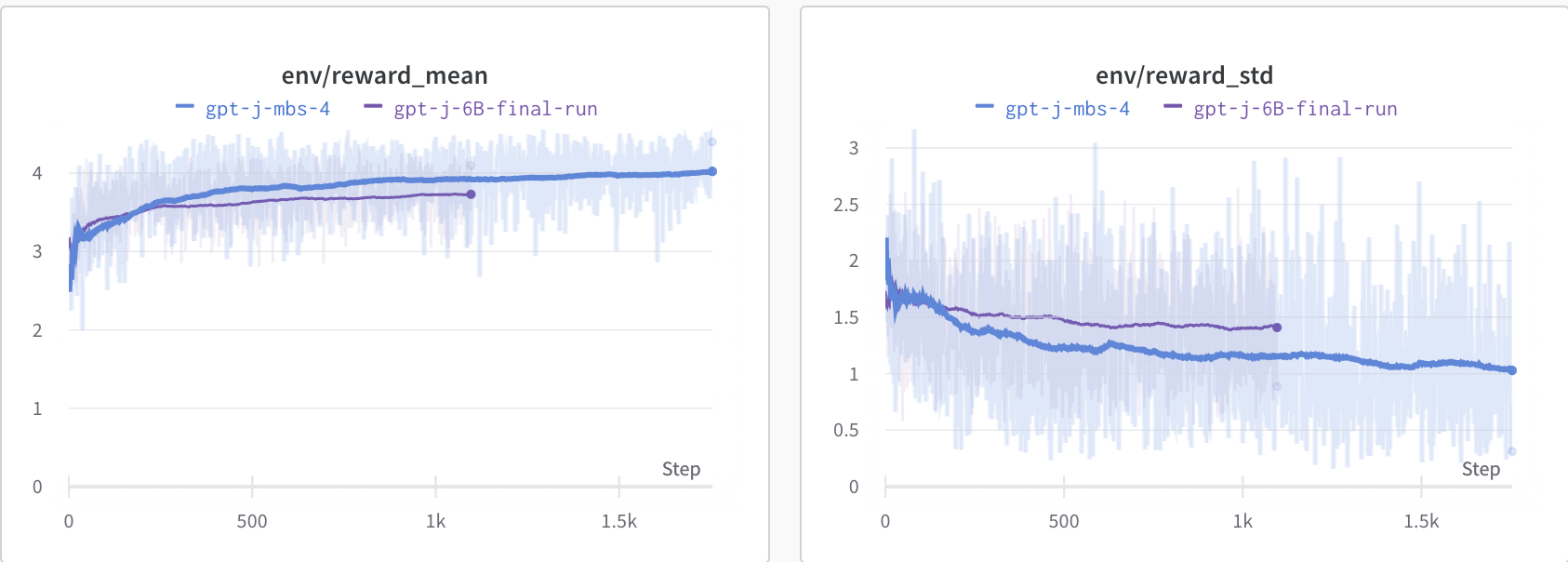
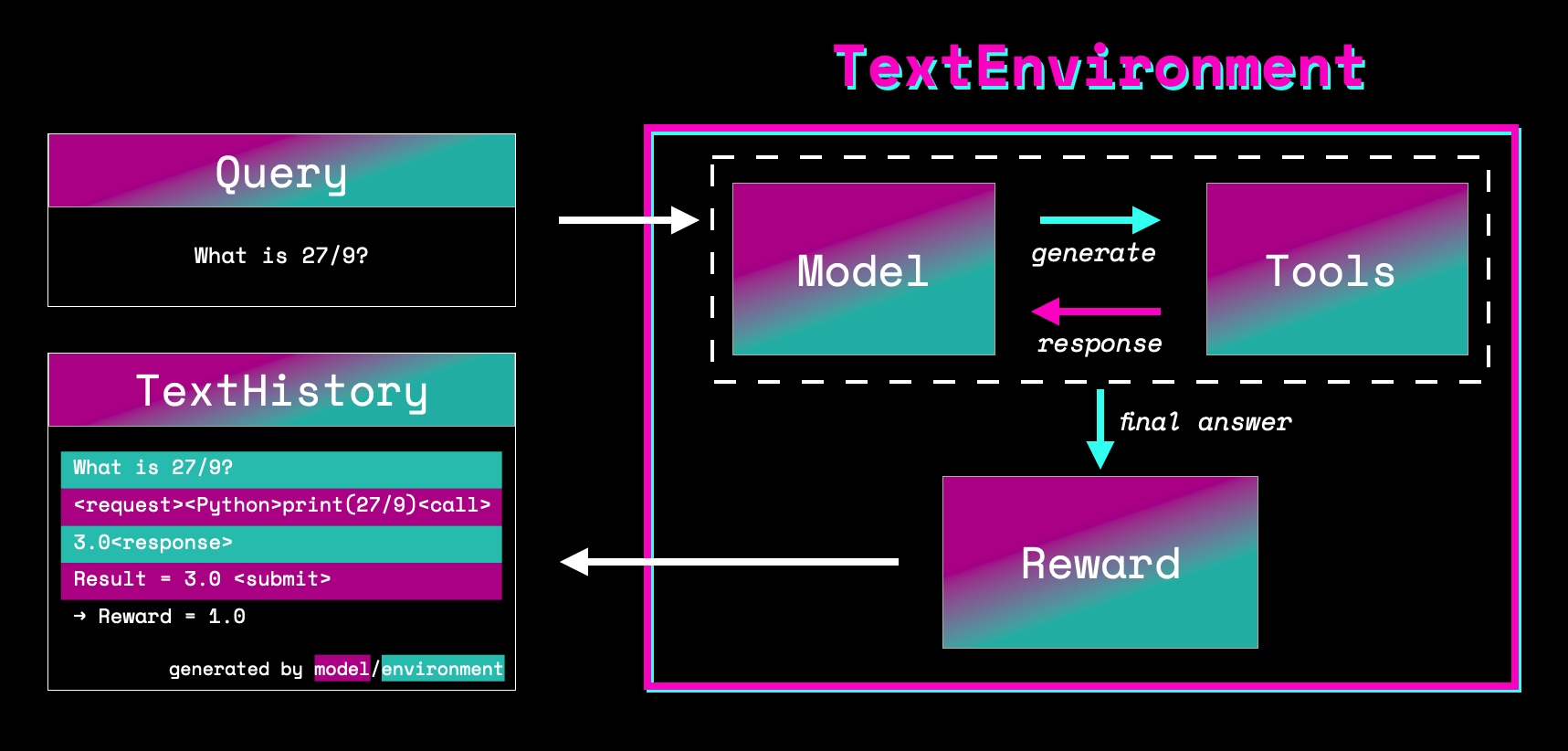
To help you understand what your model is doing, we periodically log some sample completions from the model. Here is an example of a completion. In an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/u2sqci34), it looks like the following, allowing you to see the model's response at different stages of training. By default we generate `--num_sample_generations 10` during training, but you can customize the number of generations.
-
+
In the logs the sampled generations look like
@@ -251,7 +251,7 @@ The RLOO checkpoint gets a 51.2% preferred rate vs the 33.0% preference rate of
Metrics:
-
+
```bash
diff --git a/docs/source/sft_trainer.mdx b/docs/source/sft_trainer.mdx
index e83088ee09..6921946c89 100644
--- a/docs/source/sft_trainer.mdx
+++ b/docs/source/sft_trainer.mdx
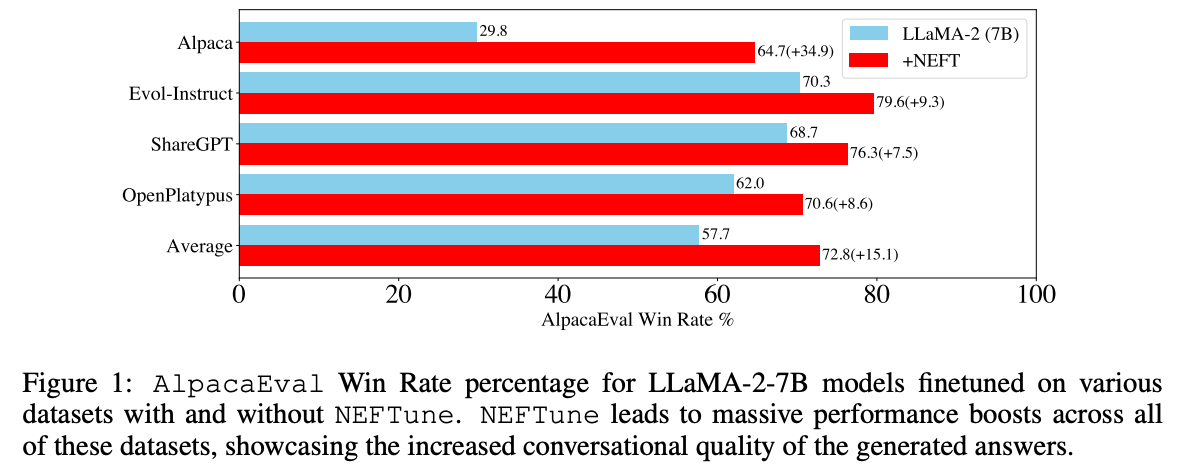
@@ -502,7 +502,7 @@ NEFTune is a technique to boost the performance of chat models and was introduce
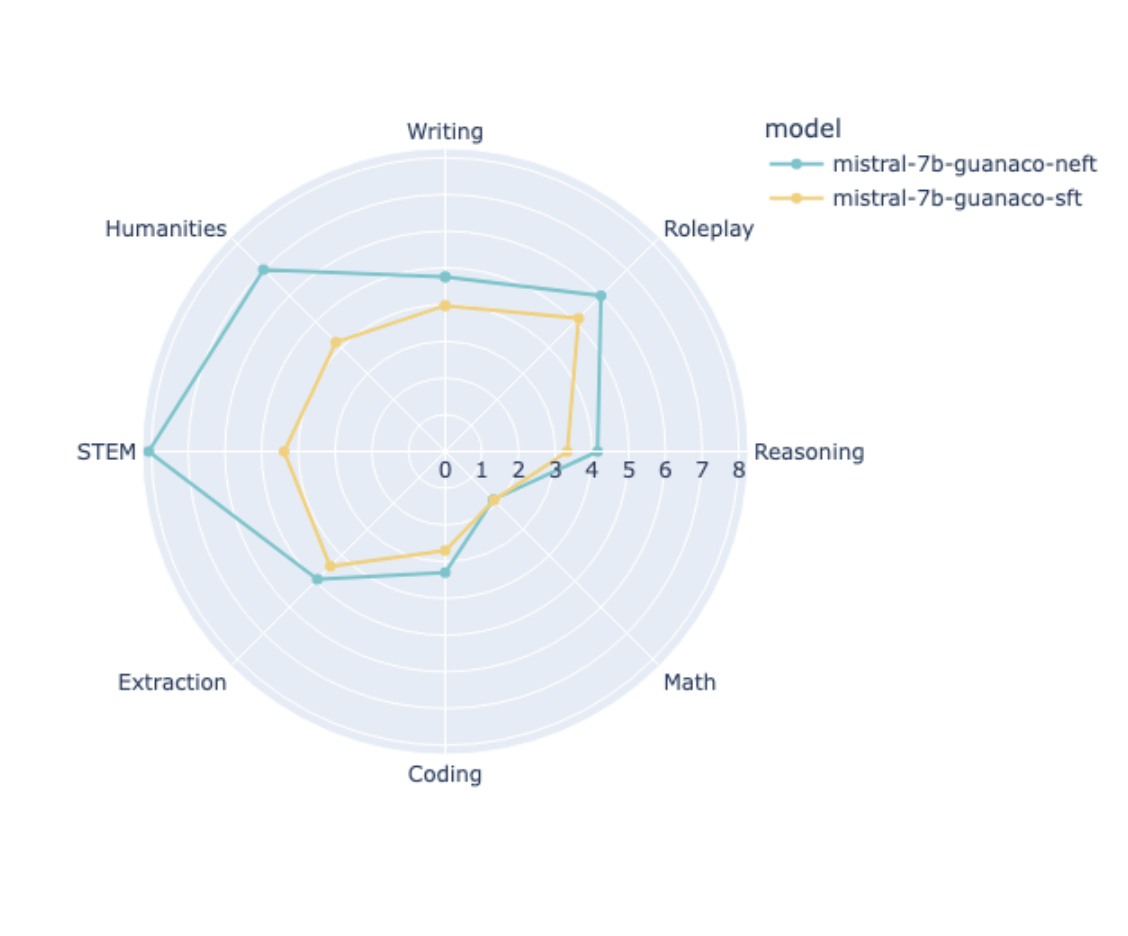
> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
## Minimal example
diff --git a/docs/source/rloo_trainer.md b/docs/source/rloo_trainer.md
index 71d189be7d..127f297321 100644
--- a/docs/source/rloo_trainer.md
+++ b/docs/source/rloo_trainer.md
@@ -68,7 +68,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
To help you understand what your model is doing, we periodically log some sample completions from the model. Here is an example of a completion. In an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/u2sqci34), it looks like the following, allowing you to see the model's response at different stages of training. By default we generate `--num_sample_generations 10` during training, but you can customize the number of generations.
-
+
In the logs the sampled generations look like
@@ -251,7 +251,7 @@ The RLOO checkpoint gets a 51.2% preferred rate vs the 33.0% preference rate of
Metrics:
-
+
```bash
diff --git a/docs/source/sft_trainer.mdx b/docs/source/sft_trainer.mdx
index e83088ee09..6921946c89 100644
--- a/docs/source/sft_trainer.mdx
+++ b/docs/source/sft_trainer.mdx
@@ -502,7 +502,7 @@ NEFTune is a technique to boost the performance of chat models and was introduce
> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
 +
+
 +
+
 +
+
 +
+
 +
+
 \n",
+ "
\n",
+ " \n",
"
\n",
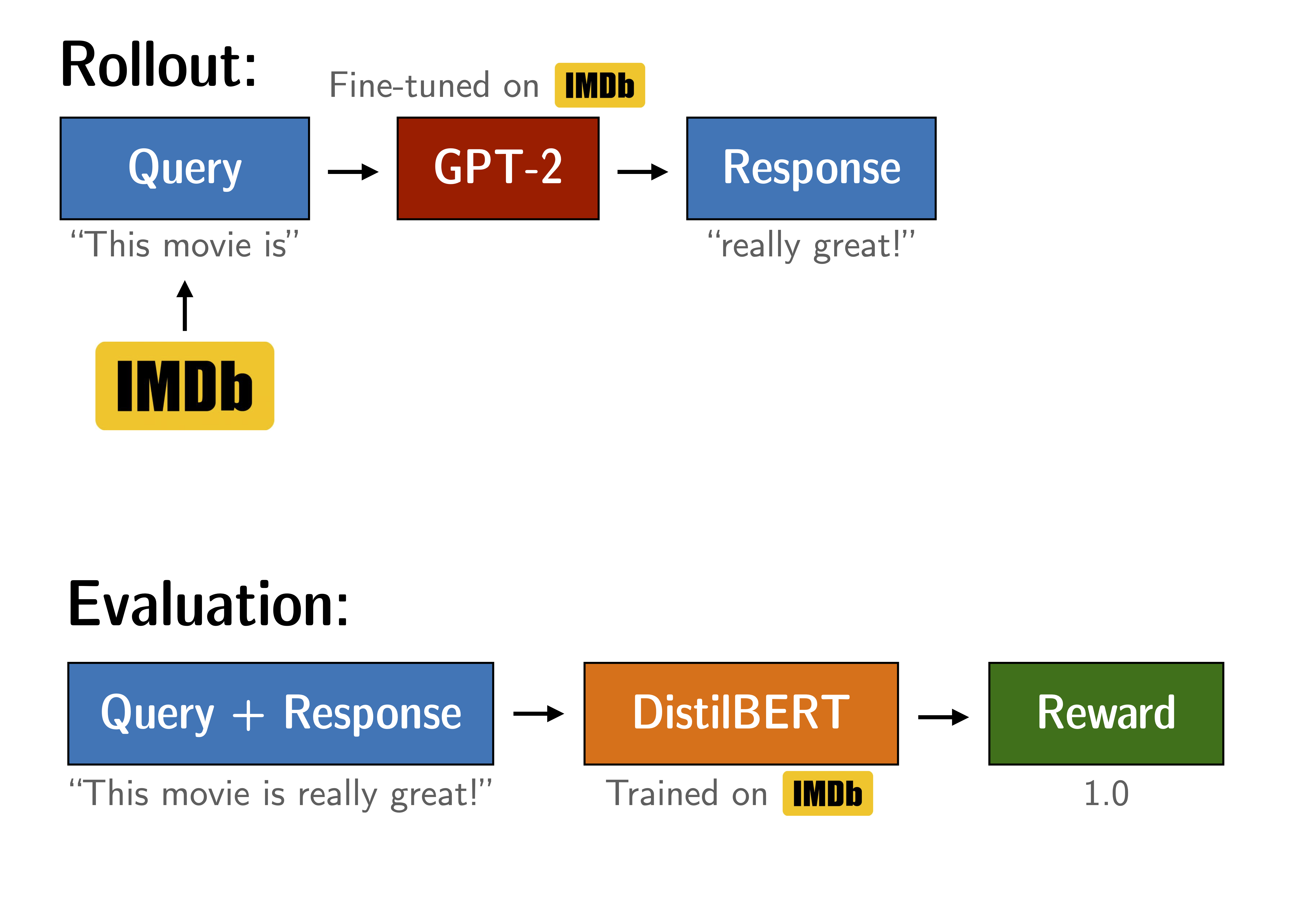
"Figure: Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face.
\n", " +
+