diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
index c695e8297f..4b4efe4730 100644
--- "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -206,11 +206,11 @@ Eval.dataset.transforms.DetResizeForTest: 尺寸
limit_type: 'min'
```
-如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
-
-

-
-
-
-
-
-
-
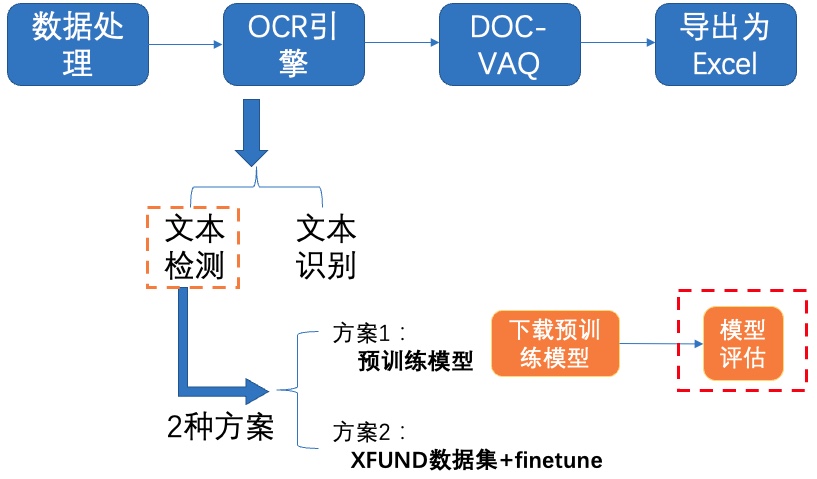 图6 文本检测方案1-模型评估
@@ -311,16 +311,16 @@ CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
-**2)模型评估**
+**2)模型评估**
图6 文本检测方案1-模型评估
@@ -311,16 +311,16 @@ CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
-**2)模型评估**
+**2)模型评估**
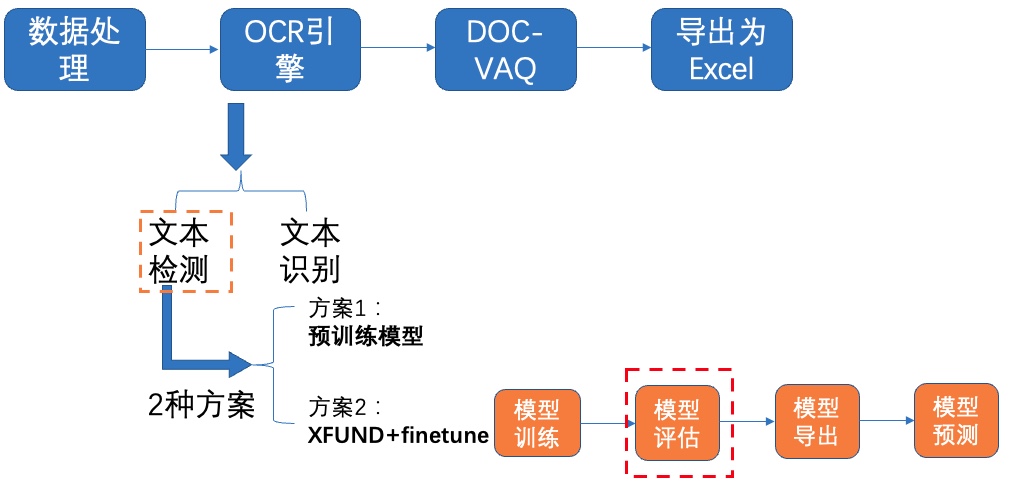 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+
+如需获取已训练模型,请加入PaddleX官方交流频道,获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
-
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+
+如需获取已训练模型,请加入PaddleX官方交流频道,获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
-
-
-
 图19 SER测试效果图
@@ -871,7 +871,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
img_path, result = line.strip().split('\t')
result_key = json.loads(result)
# 写入Excel
- row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
result_key['联系电话'], result_key['通讯地址']]
row = 'A' + str(i)
worksheet1.write_row(row, row_data, format1)
@@ -896,4 +896,3 @@ workbook.close()
- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
- XFUND dataset, https://github.com/doc-analysis/XFUND
-
diff --git "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
index 09d1bbab06..b2bfdb3aae 100644
--- "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
+++ "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -189,11 +189,11 @@ python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o
[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
```
-如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
-
图19 SER测试效果图
@@ -871,7 +871,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
img_path, result = line.strip().split('\t')
result_key = json.loads(result)
# 写入Excel
- row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
result_key['联系电话'], result_key['通讯地址']]
row = 'A' + str(i)
worksheet1.write_row(row, row_data, format1)
@@ -896,4 +896,3 @@ workbook.close()
- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
- XFUND dataset, https://github.com/doc-analysis/XFUND
-
diff --git "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
index 09d1bbab06..b2bfdb3aae 100644
--- "a/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
+++ "b/applications/\346\211\213\345\206\231\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -189,11 +189,11 @@ python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o
[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
```
-如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
-
-
-
-
-
-
-
-
-