diff --git a/README.md b/README.md
index 39688919559..0ce31cf8820 100644
--- a/README.md
+++ b/README.md
@@ -68,6 +68,7 @@ The master branch works with **PyTorch 1.6+**.
- **State of the art**
The toolbox stems from the codebase developed by the *MMDet* team, who won [COCO Detection Challenge](http://cocodataset.org/#detection-leaderboard) in 2018, and we keep pushing it forward.
+ The newly released [RTMDet](configs/rtmdet) also obtains new state-of-the-art results on real-time instance segmentation and rotated object detection tasks and the best parameter-accuracy trade-off on object detection.
@@ -75,6 +76,24 @@ Apart from MMDetection, we also released [MMEngine](https://github.com/open-mmla
## What's New
+### Highlight
+
+We are excited to announce our latest work on real-time object recognition tasks, **RTMDet**, a family of fully convolutional single-stage detectors. RTMDet not only achieves the best parameter-accuracy trade-off on object detection from tiny to extra-large model sizes but also obtains new state-of-the-art performance on instance segmentation and rotated object detection tasks. Details can be found in the [technical report](https://arxiv.org/abs/2212.07784). Pre-trained models are [here](configs/rtmdet).
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
+
+| Task | Dataset | AP | FPS(TRT FP16 BS1 3090) |
+| ------------------------ | ------- | ------------------------------------ | ---------------------- |
+| Object Detection | COCO | 52.8 | 322 |
+| Instance Segmentation | COCO | 44.6 | 188 |
+| Rotated Object Detection | DOTA | 78.9(single-scale)/81.3(multi-scale) | 121 |
+
+
+

+
@@ -206,6 +226,7 @@ Results and models are available in the [model zoo](docs/en/model_zoo.md).
Mask2Former (ArXiv'2021)
CondInst (ECCV 2020)
SparseInst (CVPR 2022)
+ RTMDet (ArXiv'2022)
|
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 4255bfae257..a8359cfcefc 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -67,6 +67,7 @@ MMDetection 是一个基于 PyTorch 的目标检测开源工具箱。它是 [Ope
- **性能高**
MMDetection 这个算法库源自于 COCO 2018 目标检测竞赛的冠军团队 *MMDet* 团队开发的代码,我们在之后持续进行了改进和提升。
+ 新发布的 [RTMDet](configs/rtmdet) 还在实时实例分割和旋转目标检测任务中取得了最先进的成果,同时也在目标检测模型中取得了最佳的的参数量和精度平衡。
@@ -74,6 +75,24 @@ MMDetection 是一个基于 PyTorch 的目标检测开源工具箱。它是 [Ope
## 最新进展
+### 亮点
+
+我们很高兴向大家介绍我们在实时目标识别任务方面的最新成果 RTMDet,包含了一系列的全卷积单阶段检测模型。 RTMDet 不仅在从 tiny 到 extra-large 尺寸的目标检测模型上上实现了最佳的参数量和精度的平衡,而且在实时实例分割和旋转目标检测任务上取得了最先进的成果。 更多细节请参阅[技术报告](https://arxiv.org/abs/2212.07784)。 预训练模型可以在[这里](configs/rtmdet)找到。
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
+
+| Task | Dataset | AP | FPS(TRT FP16 BS1 3090) |
+| ------------------------ | ------- | ------------------------------------ | ---------------------- |
+| Object Detection | COCO | 52.8 | 322 |
+| Instance Segmentation | COCO | 44.6 | 188 |
+| Rotated Object Detection | DOTA | 78.9(single-scale)/81.3(multi-scale) | 121 |
+
+
+
+ |
@@ -207,6 +227,7 @@ MMDetection 是一个基于 PyTorch 的目标检测开源工具箱。它是 [Ope
Mask2Former (ArXiv'2021)
CondInst (ECCV 2020)
SparseInst (CVPR 2022)
+ RTMDet (ArXiv'2022)
|
diff --git a/configs/rtmdet/README.md b/configs/rtmdet/README.md
index f677baa5b0a..1c06812a748 100644
--- a/configs/rtmdet/README.md
+++ b/configs/rtmdet/README.md
@@ -1,25 +1,83 @@
-# RTMDet
+# RTMDet: An Empirical Study of Designing Real-Time Object Detectors
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
## Abstract
-Our tech-report will be released soon.
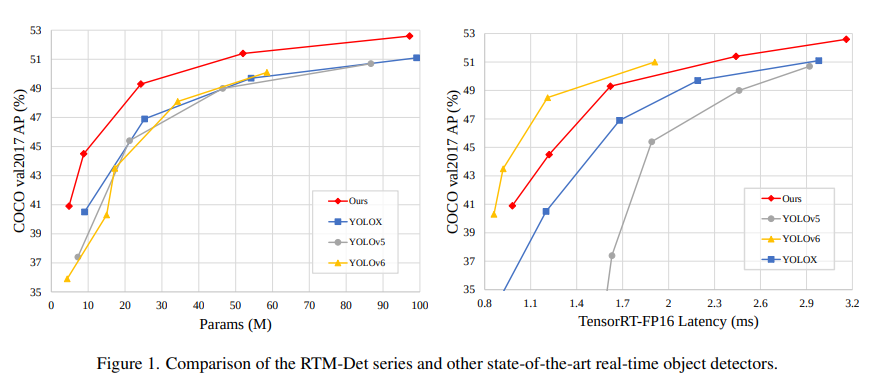
+In this paper, we aim to design an efficient real-time object detector that exceeds the YOLO series and is easily extensible for many object recognition tasks such as instance segmentation and rotated object detection. To obtain a more efficient model architecture, we explore an architecture that has compatible capacities in the backbone and neck, constructed by a basic building block that consists of large-kernel depth-wise convolutions. We further introduce soft labels when calculating matching costs in the dynamic label assignment to improve accuracy. Together with better training techniques, the resulting object detector, named RTMDet, achieves 52.8% AP on COCO with 300+ FPS on an NVIDIA 3090 GPU, outperforming the current mainstream industrial detectors. RTMDet achieves the best parameter-accuracy trade-off with tiny/small/medium/large/extra-large model sizes for various application scenarios, and obtains new state-of-the-art performance on real-time instance segmentation and rotated object detection. We hope the experimental results can provide new insights into designing versatile real-time object detectors for many object recognition tasks.
- 
+ 
+
+ |