diff --git a/README.md b/README.md
index 73f5f8fe26..00620bcb3e 100644
--- a/README.md
+++ b/README.md
@@ -121,6 +121,7 @@ Supported methods:
- [x] [DPT (ArXiv'2021)](configs/dpt)
- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
+- [x] [K-Net (NeurIPS'2021)](configs/knet)
Supported datasets:
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 657f50c814..afaaa8a3e6 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -120,6 +120,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [DPT (ArXiv'2021)](configs/dpt)
- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
+- [x] [K-Net (NeurIPS'2021)](configs/knet)
已支持的数据集:
diff --git a/configs/knet/README.md b/configs/knet/README.md
new file mode 100644
index 0000000000..ef223360bd
--- /dev/null
+++ b/configs/knet/README.md
@@ -0,0 +1,49 @@
+# K-Net
+
+[K-Net: Towards Unified Image Segmentation](https://arxiv.org/abs/2106.14855)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
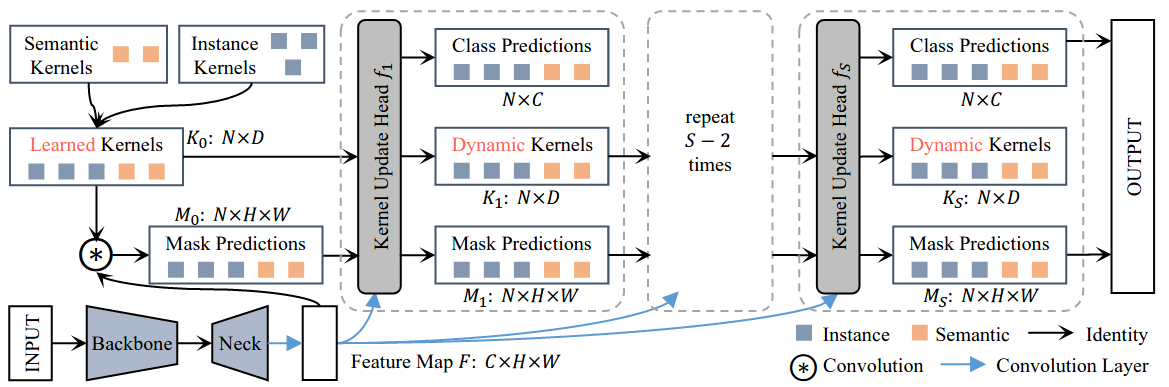
+Semantic, instance, and panoptic segmentations have been addressed using different and specialized frameworks despite their underlying connections. This paper presents a unified, simple, and effective framework for these essentially similar tasks. The framework, named K-Net, segments both instances and semantic categories consistently by a group of learnable kernels, where each kernel is responsible for generating a mask for either a potential instance or a stuff class. To remedy the difficulties of distinguishing various instances, we propose a kernel update strategy that enables each kernel dynamic and conditional on its meaningful group in the input image. K-Net can be trained in an end-to-end manner with bipartite matching, and its training and inference are naturally NMS-free and box-free. Without bells and whistles, K-Net surpasses all previous published state-of-the-art single-model results of panoptic segmentation on MS COCO test-dev split and semantic segmentation on ADE20K val split with 55.2% PQ and 54.3% mIoU, respectively. Its instance segmentation performance is also on par with Cascade Mask R-CNN on MS COCO with 60%-90% faster inference speeds. Code and models will be released at [this https URL](https://github.com/ZwwWayne/K-Net/).
+
+
+
+
+