diff --git a/README.md b/README.md
index 69f751b9e5..a17557cb81 100644
--- a/README.md
+++ b/README.md
@@ -117,6 +117,7 @@ Results and models are available in the [model zoo](docs/en/model_zoo.md).
- [x] [ConvNeXt (CVPR'2022)](configs/convnext)
- [x] [MAE (CVPR'2022)](configs/mae)
- [x] [PoolFormer (CVPR'2022)](configs/poolformer)
+- [x] [SegNeXt (NeurIPS'2022)](configs/segnext)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 709e6ef195..e09b515ab5 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -98,6 +98,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [ConvNeXt (CVPR'2022)](configs/convnext)
- [x] [MAE (CVPR'2022)](configs/mae)
- [x] [PoolFormer (CVPR'2022)](configs/poolformer)
+- [x] [SegNeXt (NeurIPS'2022)](configs/segnext)
diff --git a/configs/segnext/README.md b/configs/segnext/README.md
new file mode 100644
index 0000000000..315f4e23e8
--- /dev/null
+++ b/configs/segnext/README.md
@@ -0,0 +1,63 @@
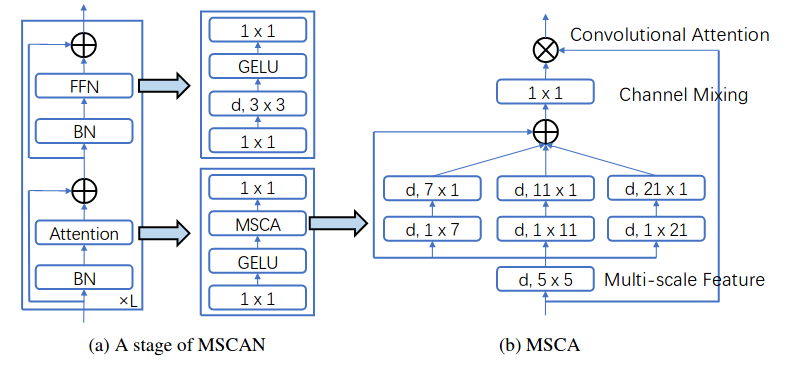
+# SegNeXt
+
+> [SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation](https://arxiv.org/abs/2209.08575)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available at [this https URL](https://github.com/uyzhang/JSeg) (Jittor) and [this https URL](https://github.com/Visual-Attention-Network/SegNeXt) (Pytorch).
+
+
+
+
+
+