diff --git a/README.md b/README.md
index f88d162..705303b 100644
--- a/README.md
+++ b/README.md
@@ -69,17 +69,17 @@ Click-through rate (CTR) prediction is a critical task for various industrial ap
| 33 | DLP-KDD'21 | [MaskNet](./model_zoo/MaskNet) | [MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask](https://arxiv.org/abs/2102.07619) :triangular_flag_on_post:**Sina Weibo** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/MaskNet) | `torch` |
| 34 | SIGIR'21 | [SAM](./model_zoo/SAM) | [Looking at CTR Prediction Again: Is Attention All You Need?](https://arxiv.org/abs/2105.05563) :triangular_flag_on_post:**BOSS Zhipin** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/SAM) | `torch` |
| 35 | KDD'21 | [AOANet](./model_zoo/AOANet) | [Architecture and Operation Adaptive Network for Online Recommendations](https://dl.acm.org/doi/10.1145/3447548.3467133) :triangular_flag_on_post:**Didi Chuxing** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/AOANet) | `torch` |
-| 36 | AAAI'23 | [FinalMLP](./model_zoo/FinalMLP) | [FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction](https://arxiv.org/abs/2304.00902) :triangular_flag_on_post:**Huawei** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FinalMLP) | `torch` |
-| 37 | SIGIR'23 | [FINAL](./model_zoo/FINAL) | FINAL: Factorized Interaction Layer for CTR Prediction :triangular_flag_on_post:**Huawei** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FINAL) | `torch` |
-| 38 | CIKM'23 | [GDCN](./model_zoo/GDCN) | [Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction](https://dl.acm.org/doi/pdf/10.1145/3583780.3615089) :triangular_flag_on_post:**Microsoft** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FinalMLP) | `torch` |
+| 36 | AAAI'23 | [FinalMLP](./model_zoo/FinalMLP) | [FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction](https://arxiv.org/abs/2304.00902) :triangular_flag_on_post:**Huawei** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FinalMLP) | `torch` |
+| 37 | SIGIR'23 | [FINAL](./model_zoo/FINAL) | [FINAL: Factorized Interaction Layer for CTR Prediction](https://dl.acm.org/doi/10.1145/3539618.3591988) :triangular_flag_on_post:**Huawei** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FINAL) | `torch` |
+| 38 | CIKM'23 | [GDCN](./model_zoo/GDCN) | [Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction](https://dl.acm.org/doi/pdf/10.1145/3583780.3615089) :triangular_flag_on_post:**Microsoft** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/FinalMLP) | `torch` |
|| :open_file_folder: **Behavior Sequence Modeling** |
|---|
|
| 39 | KDD'18 | [DIN](./model_zoo/DIN) | [Deep Interest Network for Click-Through Rate Prediction](https://www.kdd.org/kdd2018/accepted-papers/view/deep-interest-network-for-click-through-rate-prediction) :triangular_flag_on_post:**Alibaba** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/DIN) | `torch` |
-| 40 | AAAI'19 | [DIEN](./model_zoo/DIEN) | [Deep Interest Evolution Network for Click-Through Rate Prediction](https://arxiv.org/abs/1809.03672) :triangular_flag_on_post:**Alibaba** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/DIEN) | `torch` |
-| 41 | DLP-KDD'19 | [BST](./model_zoo/BST) | [Behavior Sequence Transformer for E-commerce Recommendation in Alibaba](https://arxiv.org/abs/1905.06874) :triangular_flag_on_post:**Alibaba** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/BST) | `torch` |
-| 42 | CIKM'20 | [DMIN](./model_zoo/DMIN) | [Deep Multi-Interest Network for Click-through Rate Prediction](https://dl.acm.org/doi/10.1145/3340531.3412092) :triangular_flag_on_post:**Alibaba** | | `torch` |
-| 43 | AAAI'20 | [DMR](./model_zoo/DMR) | [Deep Match to Rank Model for Personalized Click-Through Rate Prediction](https://ojs.aaai.org/index.php/AAAI/article/view/5346) :triangular_flag_on_post:**Alibaba** | | `torch` |
-| 44 | Arxiv'21 | [ETA](./model_zoo/ETA) | [End-to-End User Behavior Retrieval in Click-Through RatePrediction Model](https://arxiv.org/abs/2108.04468) :triangular_flag_on_post:**Alibaba** | | `torch` |
-| 45 | CIKM'22 | [SDIM](./model_zoo/SDIM) | [Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction](https://arxiv.org/abs/2205.10249) :triangular_flag_on_post:**Meituan** | | `torch` |
+| 40 | AAAI'19 | [DIEN](./model_zoo/DIEN) | [Deep Interest Evolution Network for Click-Through Rate Prediction](https://arxiv.org/abs/1809.03672) :triangular_flag_on_post:**Alibaba** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/DIEN) | `torch` |
+| 41 | DLP-KDD'19 | [BST](./model_zoo/BST) | [Behavior Sequence Transformer for E-commerce Recommendation in Alibaba](https://arxiv.org/abs/1905.06874) :triangular_flag_on_post:**Alibaba** | [:arrow_upper_right:](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/BST) | `torch` |
+| 42 | CIKM'20 | [DMIN](./model_zoo/DMIN) | [Deep Multi-Interest Network for Click-through Rate Prediction](https://dl.acm.org/doi/10.1145/3340531.3412092) :triangular_flag_on_post:**Alibaba** | | `torch` |
+| 43 | AAAI'20 | [DMR](./model_zoo/DMR) | [Deep Match to Rank Model for Personalized Click-Through Rate Prediction](https://ojs.aaai.org/index.php/AAAI/article/view/5346) :triangular_flag_on_post:**Alibaba** | | `torch` |
+| 44 | Arxiv'21 | [ETA](./model_zoo/ETA) | [End-to-End User Behavior Retrieval in Click-Through RatePrediction Model](https://arxiv.org/abs/2108.04468) :triangular_flag_on_post:**Alibaba** | | `torch` |
+| 45 | CIKM'22 | [SDIM](./model_zoo/SDIM) | [Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction](https://arxiv.org/abs/2205.10249) :triangular_flag_on_post:**Meituan** | | `torch` |
|| :open_file_folder: **Dynamic Weight Network** |
|---|
|
| 46 | NeurIPS'22 | [APG](./model_zoo/APG) | [APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction](https://arxiv.org/abs/2203.16218) :triangular_flag_on_post:**Alibaba** | | `torch` |
| 47 | Arxiv'23 | [PPNet](./model_zoo/PEPNet) | [PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information](https://arxiv.org/abs/2302.01115) :triangular_flag_on_post:**KuaiShou** | | `torch` |
@@ -90,10 +90,13 @@ Click-through rate (CTR) prediction is a critical task for various industrial ap
|| :open_file_folder: **Multi-Domain Modeling** |
|---|
|
| 51 | Arxiv'23 | PEPNet | [PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information](https://arxiv.org/abs/2302.01115) :triangular_flag_on_post:**KuaiShou** | | `torch` |
-+ :point_right: See [reusable dataset splits for CTR prediction](https://openbenchmark.github.io/BARS/datasets/README.html).
-+ :point_right: See [benchmarking configurations and steps](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks).
-+ :point_right: See [the BARS benchmark leaderboard](https://openbenchmark.github.io/BARS/ctr_prediction/leaderboard/README.html#).
+## Benchmarking
+We have evaluated FuxiCTR models on a set of benchmark datasets as follows:
+
++ :star: [Benchmark datasets for CTR prediction](https://github.com/reczoo/Datasets?tab=readme-ov-file#ctr-prediction)
++ :star: [Benchmark configurations and reproducing steps](https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks)
++ :star: [The BARS-CTR benchmark leaderboard](https://openbenchmark.github.io/BARS/ctr_prediction/leaderboard/README.html#)
## Dependencies
@@ -117,7 +120,7 @@ Other packages can be installed via `pip install -r requirements.txt`.
python example2_DeepFM_with_h5_input.py
```
-2. Run an existing model
+2. Run a model on tiny data
Users can easily run each model in the model zoo following the commands below, which is a demo for running DCN. In addition, users can modify the dataset config and model config files to run on their own datasets or with new hyper-parameters. More details can be found in the [readme file](./model_zoo/DCN/DCN_torch/README.md).
@@ -130,20 +133,23 @@ Other packages can be installed via `pip install -r requirements.txt`.
python run_expid.py --expid MODEL_test --gpu 0
```
-3. Implement a new model
+3. Run a model on benchmark data (e.g., Criteo)
+ Users can follow the [benchmark section](#Benchmarking) to get benchmark datasets and running steps. Please see an example here: https://github.com/reczoo/BARS/tree/main/ctr_prediction/benchmarks/DCNv2/DCNv2_criteo_x1
+
+
+4. Implement a new model
- The FuxiCTR code structure is modularized, so that every part can be overwritten by users according to their needs. In many cases, only the model class needs to be implemented for a new customized model. If data preprocessing or data loader is not directly applicable, one can also overwrite a new one through the [core APIs](https://www.processon.com/view/link/63cfcfab4e30670eac4a81c7). We show a concrete example which implements our new model [FinalMLP](https://reczoo.github.io/FinalMLP) that has been recently published in AAAI 2023. More examples can be found in the [model zoo](./model_zoo/).
+ The FuxiCTR library is designed to be modularized, so that every component can be overwritten by users according to their needs. In many cases, only the model class needs to be implemented for a new customized model. If data preprocessing or data loader is not directly applicable, one can also overwrite a new one through the [core APIs](https://www.processon.com/view/link/63cfcfab4e30670eac4a81c7). We show a concrete example which implements our new model [FinalMLP](https://reczoo.github.io/FinalMLP) that has been recently published in AAAI 2023. More examples can be found in the [model zoo](./model_zoo/).
## Citation
-*:bell: If you find our code or benchmarks helpful in your research, please kindly cite the following papers.*
+*:bell: If you find our code or benchmarks helpful in your research, please cite the following papers.*
> Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, Xiuqiang He. [Open Benchmarking for Click-Through Rate Prediction](https://arxiv.org/abs/2009.05794). *The 30th ACM International Conference on Information and Knowledge Management (CIKM)*, 2021. [[Bibtex](https://dblp.org/rec/conf/cikm/ZhuLYZH21.html?view=bibtex)]
> Jieming Zhu, Quanyu Dai, Liangcai Su, Rong Ma, Jinyang Liu, Guohao Cai, Xi Xiao, Rui Zhang. [BARS: Towards Open Benchmarking for Recommender Systems](https://arxiv.org/abs/2205.09626). *The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)*, 2022. [[Bibtex](https://dblp.org/rec/conf/sigir/ZhuDSMLCXZ22.html?view=bibtex)]
-
## Discussion
Welcome to join our WeChat group for any question and discussion. We also have open positions for internships and full-time jobs. If you are interested in research and practice in recommender systems, please reach out via our WeChat group.
diff --git a/fuxictr/version.py b/fuxictr/version.py
index 00f54dd..677777f 100644
--- a/fuxictr/version.py
+++ b/fuxictr/version.py
@@ -1 +1 @@
-__version__="2.1.2"
+__version__="2.1.3"
diff --git a/model_zoo/FINAL/README.md b/model_zoo/FINAL/README.md
index e69de29..6b49fe6 100644
--- a/model_zoo/FINAL/README.md
+++ b/model_zoo/FINAL/README.md
@@ -0,0 +1,93 @@
+# FINAL
+
+Click-through rate (CTR) prediction is one of the fundamental tasks for online advertising and recommendation. Inspired by factorization machines, in this paper, we propose FINAL, a factorized interaction layer that extends the widely-used linear layer and is capable of learning quadratic feature interactions. Similar to MLPs, multiple FINAL layers can be stacked into a FINAL block, yielding feature interactions with an exponential degree growth. We unify feature interactions and MLPs into a single FINAL block and empirically show its effectiveness as a replacement for the MLP block.
+
+> Jieming Zhu, Qinglin Jia, Guohao Cai, Quanyu Dai, Jingjie Li, Zhenhua Dong, Ruiming Tang, Rui Zhang. [FINAL: Factorized Interaction Layer for CTR Prediction](https://dl.acm.org/doi/10.1145/3539618.3591988), in SIGIR 2023.
+
+
+## Requirements
+
+Please install the requirements as follows:
+
+```bash
+pip install -r requirements.txt
+```
+
+## Configuration Guide
+
+
+The `dataset_config.yaml` file contains all the dataset settings as follows.
+
+| Params | Type | Default | Description |
+| ----------------------------- | ---- | ------- | --------------------------------------------------------------------------------------------------------------------------------------- |
+| data_root | str | | the root directory to load and save data data |
+| data_format | str | | input data format, "h5", "csv", or "tfrecord" supported |
+| train_data | str | None | training data path |
+| valid_data | str | None | validation data path |
+| test_data | str | None | test data path |
+| min_categr_count | int | 1 | min count to filter category features, |
+| feature_cols | list | | a list of features with the following dict keys |
+| feature_cols::name | str\|list | | feature column name in csv. A list is allowed in which the features have the same feature type and will be expanded accordingly. |
+| feature_cols::active | bool | | whether to use the feature |
+| feature_cols::dtype | str | | the input data dtype, "int"\|"str" |
+| feature_cols::type | str | | feature type "numeric"\|"categorical"\|"sequence"\|"meta" |
+| label_col | dict | | specify label column |
+| label_col::name | str | | label column name in csv |
+| label_col::dtype | str | | label data dtype |
+
+
+
+The `model_config.yaml` file contains all the model hyper-parameters as follows.
+
+| Params | Type | Default | Description |
+| ----------------------- | --------------- | ----------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| model | str | "FINAL" | model name, which should be same with model class name |
+| dataset_id | str | "TBD" | dataset_id to be determined |
+| loss | str | "binary_crossentropy" | loss function |
+| metrics | list | ['logloss', 'AUC'] | a list of metrics for evaluation |
+| task | str | "binary_classification" | task type supported: ```"regression"```, ```"binary_classification"``` |
+| optimizer | str | "adam" | optimizer used for training |
+| learning_rate | float | 1.0e-3 | learning rate |
+| embedding_regularizer | float\|str | 0 | regularization weight for embedding matrix: L2 regularization is applied by default. Other optional examples: ```"l2(1.e-3)"```, ```"l1(1.e-3)"```, ```"l1_l2(1.e-3, 1.e-3)"```. |
+| net_regularizer | float\|str | 0 | regularization weight for network parameters: L2 regularization is applied by default. Other optional examples: ```"l2(1.e-3)"```, ```"l1(1.e-3)"```, ```"l1_l2(1.e-3, 1.e-3)"```. |
+| batch_size | int | 10000 | batch size, usually a large number for CTR prediction task |
+| embedding_dim | int | 32 | embedding dimension of features. Note that field-wise embedding_dim can be specified in ```feature_specs```. |
+| block1_hidden_units | list | [64, 64, 64] | hidden units of block1 |
+| block1_hidden_activations | str\|list | "relu" | activation function in block1. Particularly, layer-wise activations can be specified as a list, e.g., ["relu", "leakyrelu", "sigmoid"] |
+| block2_hidden_units | list | [64, 64, 64] | hidden units of block2 |
+| block2_hidden_activations | str | "relu" | activation function in block2. Particularly, layer-wise activations can be specified as a list, e.g., ["relu", "leakyrelu", "sigmoid"] |
+| block1_dropout | float | 0 | dropout rate in block1 |
+| block2_dropout | float | 0 | dropout rate in block2 |
+| block_type | str | "2B" | block type: ```"1B"```, ```"2B"``` |
+| batch_norm | bool | True | whether to use BN |
+| use_feature_gating | bool | True | whether to use feature gating |
+| residual_type | str | "concat" | residual type in FactorizedQuadraticInteraction: ```"concat"```, ```"sum"``` |
+| epochs | int | 100 | the max number of epochs for training, which can early stop via monitor metrics. |
+| shuffle | bool | True | whether shuffle the data samples for each epoch of training |
+| seed | int | 2021 | the random seed used for reproducibility |
+| monitor | str\|dict | 'AUC' | the monitor metrics for early stopping. It supports a single metric, e.g., ```"AUC"```. It also supports multiple metrics using a dict, e.g., {"AUC": 2, "logloss": -1} means ```2*AUC - logloss```. |
+| monitor_mode | str | 'max' | ```"max"``` means that the higher the better, while ```"min"``` denotes that the lower the better. |
+| model_root | str | './checkpoints/' | the dir to save model checkpoints and running logs |
+| early_stop_patience | int | 2 | training is stopped when monitor metric fails to become better for ```early_stop_patience=2```consective evaluation intervals. |
+| save_best_only | bool | True | whether to save the best model checkpoint only |
+| eval_steps | int\|None | None | evaluate the model on validation data every ```eval_steps```. By default, ```None``` means evaluation every epoch. |
+
+
+## Results
+
+The evaluation results on AUC:
+
+| Model | Criteo | Avazu | MovieLens | Frappe |
+|:--------:|:---------:|:---------:|:---------:|:---------:|
+| DCN | 81.39 | 76.47 | 96.87 | 98.39 |
+| AutoInt+ | 81.39 | 76.45 | 96.92 | 98.48 |
+| AFN+ | 81.43 | 76.48 | 96.42 | 98.26 |
+| MaskNet | 81.39 | 76.49 | 96.87 | 98.43 |
+| DCNv2 | 81.42 | 76.54 | 96.91 | 98.45 |
+| EDCN | 81.47 | 76.52 | 96.71 | 98.50 |
+| FinalMLP | 81.49 | 76.66 | 97.20 | **98.61** |
+| FINAL_1B | 81.44 | 76.60 | 97.06 | 98.52 |
+| FINAL_2B | **81.54** | **76.71** | **97.25** | 98.57 |
+
+
+For reproducing the results, please refer to https://github.com/reczoo/RecZoo/tree/main/ranking/ctr/FINAL
diff --git a/model_zoo/FINAL/config/model_config.yaml b/model_zoo/FINAL/config/model_config.yaml
index 4b79440..26d4ac7 100644
--- a/model_zoo/FINAL/config/model_config.yaml
+++ b/model_zoo/FINAL/config/model_config.yaml
@@ -25,7 +25,7 @@ FINAL_test:
embedding_dim: 4
block_type: "2B"
batch_norm: True
- use_field_gate: True
+ use_feature_gating: True
block1_hidden_units: [64, 64, 64]
block1_hidden_activations: null
block1_dropout: 0
@@ -53,7 +53,7 @@ FINAL_default: # This is a config template
embedding_dim: 40
block_type: "2B"
batch_norm: True
- use_field_gate: True
+ use_feature_gating: True
block1_hidden_units: [64, 64, 64]
block1_hidden_activations: null
block1_dropout: 0
@@ -66,4 +66,3 @@ FINAL_default: # This is a config template
seed: 20222023
monitor: {'AUC': 1, 'logloss': -1}
monitor_mode: 'max'
-
diff --git a/model_zoo/FINAL/run_expid.py b/model_zoo/FINAL/run_expid.py
index 2e5647b..293525f 100644
--- a/model_zoo/FINAL/run_expid.py
+++ b/model_zoo/FINAL/run_expid.py
@@ -27,7 +27,7 @@
from fuxictr.pytorch.torch_utils import seed_everything
from fuxictr.pytorch.dataloaders import H5DataLoader
from fuxictr.preprocess import FeatureProcessor, build_dataset
-import model
+import src
import gc
import argparse
import os
@@ -61,7 +61,7 @@
feature_map.load(feature_map_json, params)
logging.info("Feature specs: " + print_to_json(feature_map.features))
- model_class = getattr(model, params['model'])
+ model_class = getattr(src, params['model'])
model = model_class(feature_map, **params)
model.count_parameters() # print number of parameters used in model
diff --git a/model_zoo/FINAL/model/FINAL.py b/model_zoo/FINAL/src/FINAL.py
similarity index 75%
rename from model_zoo/FINAL/model/FINAL.py
rename to model_zoo/FINAL/src/FINAL.py
index 4341c4d..e0075f9 100644
--- a/model_zoo/FINAL/model/FINAL.py
+++ b/model_zoo/FINAL/src/FINAL.py
@@ -1,5 +1,5 @@
# =========================================================================
-# Copyright (C) 2022. The FuxiCTR Authors. All rights reserved.
+# Copyright (C) 2023. The FuxiCTR Authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -32,7 +32,7 @@ def __init__(self,
embedding_dim=10,
block_type="2B",
batch_norm=True,
- use_field_gate=False,
+ use_feature_gating=False,
block1_hidden_units=[64, 64, 64],
block1_hidden_activations=None,
block1_dropout=0,
@@ -52,26 +52,26 @@ def __init__(self,
assert block_type in ["1B", "2B"], "block_type={} not supported.".format(block_type)
self.embedding_layer = FeatureEmbedding(feature_map, embedding_dim)
num_fields = feature_map.num_fields
- self.use_field_gate = use_field_gate
- if use_field_gate:
- self.field_gate = FinalGate(num_fields, gate_residual="concat")
+ self.use_feature_gating = use_feature_gating
+ if use_feature_gating:
+ self.feature_gating = FeatureGating(num_fields, gate_residual="concat")
gate_out_dim = embedding_dim * num_fields * 2
self.block_type = block_type
- self.block1 = FinalBlock(input_dim=gate_out_dim if use_field_gate \
- else embedding_dim * num_fields,
- hidden_units=block1_hidden_units,
- hidden_activations=block1_hidden_activations,
- dropout_rates=block1_dropout,
- batch_norm=batch_norm,
- residual_type=residual_type)
+ self.block1 = QuadNet(input_dim=gate_out_dim if use_feature_gating \
+ else embedding_dim * num_fields,
+ hidden_units=block1_hidden_units,
+ hidden_activations=block1_hidden_activations,
+ dropout_rates=block1_dropout,
+ batch_norm=batch_norm,
+ residual_type=residual_type)
self.fc1 = nn.Linear(block1_hidden_units[-1], 1)
if block_type == "2B":
- self.block2 = FinalBlock(input_dim=embedding_dim * num_fields,
- hidden_units=block2_hidden_units,
- hidden_activations=block2_hidden_activations,
- dropout_rates=block2_dropout,
- batch_norm=batch_norm,
- residual_type=residual_type)
+ self.block2 = QuadNet(input_dim=embedding_dim * num_fields,
+ hidden_units=block2_hidden_units,
+ hidden_activations=block2_hidden_activations,
+ dropout_rates=block2_dropout,
+ batch_norm=batch_norm,
+ residual_type=residual_type)
self.fc2 = nn.Linear(block2_hidden_units[-1], 1)
self.compile(kwargs["optimizer"], loss=kwargs["loss"], lr=learning_rate)
self.reset_parameters()
@@ -92,8 +92,8 @@ def forward(self, inputs):
return return_dict
def forward1(self, X):
- if self.use_field_gate:
- X = self.field_gate(X)
+ if self.use_feature_gating:
+ X = self.feature_gating(X)
block1_out = self.block1(X.flatten(start_dim=1))
y_pred = self.fc1(block1_out)
return y_pred
@@ -116,9 +116,9 @@ def add_loss(self, inputs):
return loss
-class FinalGate(nn.Module):
+class FeatureGating(nn.Module):
def __init__(self, num_fields, gate_residual="concat"):
- super(FinalGate, self).__init__()
+ super(FeatureGating, self).__init__()
self.linear = nn.Linear(num_fields, num_fields)
assert gate_residual in ["concat", "sum"]
self.gate_residual = gate_residual
@@ -136,11 +136,11 @@ def forward(self, feature_emb):
return out
-class FinalBlock(nn.Module):
+class QuadNet(nn.Module):
def __init__(self, input_dim, hidden_units=[], hidden_activations=None,
dropout_rates=[], batch_norm=True, residual_type="sum"):
- # Replacement of MLP_Block, identical when order=1
- super(FinalBlock, self).__init__()
+ # Quadratic Interaction Network: Replacement of MLP block
+ super(QuadNet, self).__init__()
if type(dropout_rates) != list:
dropout_rates = [dropout_rates] * len(hidden_units)
if type(hidden_activations) != list:
@@ -151,8 +151,9 @@ def __init__(self, input_dim, hidden_units=[], hidden_activations=None,
self.activation = nn.ModuleList()
hidden_units = [input_dim] + hidden_units
for idx in range(len(hidden_units) - 1):
- self.layer.append(FinalLinear(hidden_units[idx], hidden_units[idx + 1],
- residual_type=residual_type))
+ self.layer.append(FactorizedQuadraticInteraction(hidden_units[idx],
+ hidden_units[idx + 1],
+ residual_type=residual_type))
if batch_norm:
self.norm.append(nn.BatchNorm1d(hidden_units[idx + 1]))
if dropout_rates[idx] > 0:
@@ -172,13 +173,14 @@ def forward(self, X):
return X_i
-class FinalLinear(nn.Module):
+class FactorizedQuadraticInteraction(nn.Module):
def __init__(self, input_dim, output_dim, bias=True, residual_type="sum"):
- """ A replacement of nn.Linear to enhance multiplicative feature interactions.
- `residual_type="concat"` uses the same number of parameters as nn.Linear
- while `residual_type="sum"` doubles the number of parameters.
+ """ FactorizedQuadraticInteraction layer is an improvement of nn.Linear to capture quadratic
+ interactions between features.
+ Setting `residual_type="concat"` keeps the same number of parameters as nn.Linear
+ while `residual_type="sum"` doubles the number of parameters.
"""
- super(FinalLinear, self).__init__()
+ super(FactorizedQuadraticInteraction, self).__init__()
self.residual_type = residual_type
if residual_type == "sum":
output_dim = output_dim * 2
diff --git a/model_zoo/FINAL/model/__init__.py b/model_zoo/FINAL/src/__init__.py
similarity index 100%
rename from model_zoo/FINAL/model/__init__.py
rename to model_zoo/FINAL/src/__init__.py
diff --git a/model_zoo/FinalMLP/README.md b/model_zoo/FinalMLP/README.md
index e69de29..22f4223 100644
--- a/model_zoo/FinalMLP/README.md
+++ b/model_zoo/FinalMLP/README.md
@@ -0,0 +1,120 @@
+# FinalMLP
+
+[](https://paperswithcode.com/sota/click-through-rate-prediction-on-criteo?p=finalmlp-an-enhanced-two-stream-mlp-model-for-1)
+
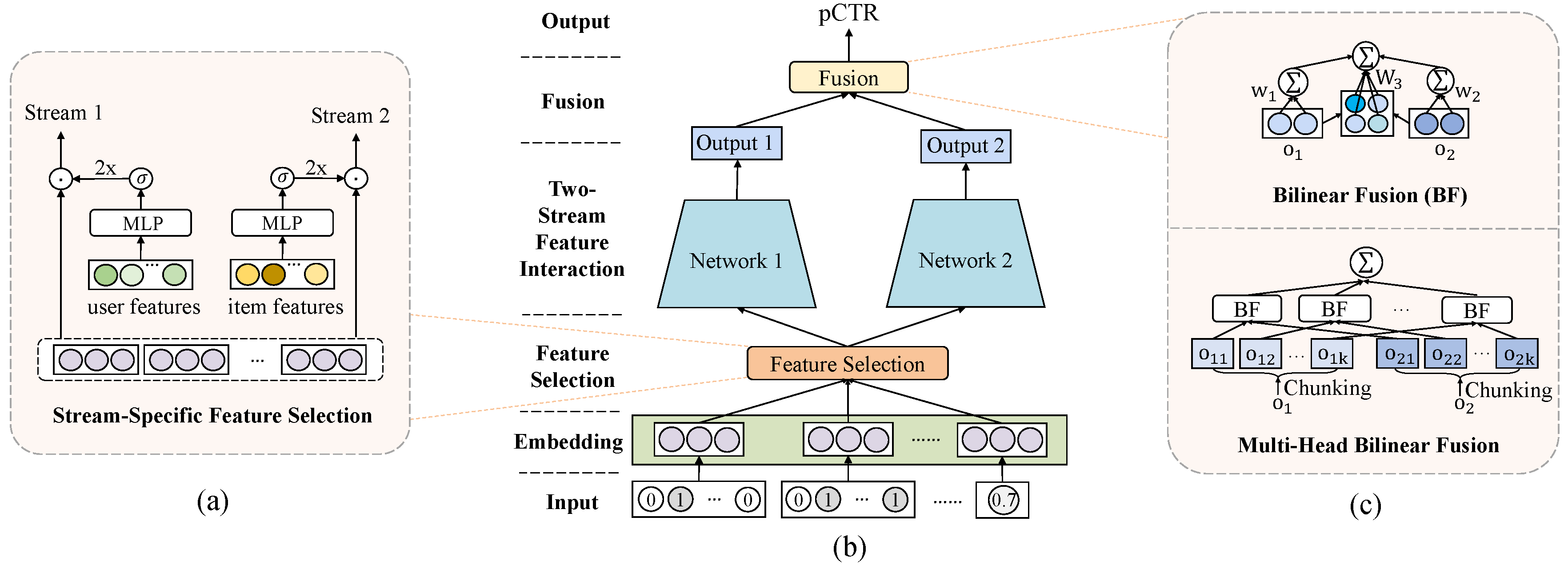
+Click-through rate (CTR) prediction is one of the fundamental tasks for online advertising and recommendation. Although a vanilla MLP is shown inefficient in learning high-order feature interactions, we found that a two-stream MLP model (DualMLP) that simply combines two well-tuned MLP networks can achieve surprisingly good performance. Based on this observation, we further propose feature selection and interaction aggregation layers that can be easily plugged in to build an enhanced two-stream MLP model, namely FinalMLP. We envision that the simple yet effective FinalMLP model could serve as a new strong baseline for future developments of two-stream CTR models.
+
+> Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. [FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction](https://arxiv.org/abs/2304.00902), in AAAI 2023.
+
+## Model Overview
+
+Two-stream models (e.g., DeepFM, DCN) have been widely used for CTR prediction, where two streams are combined to capture complementarty feature interactions. FinalMLP is an enhanced two-stream MLP model that integrates stream-specific feature selection and stream-level interaction aggregation layers.
+
+
+
+