diff --git a/.circleci/config.yml b/.circleci/config.yml
index 626096f..7395140 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -7,7 +7,7 @@ jobs:
steps:
- checkout
- restore_cache:
- key: conda-env-{{ checksum "environment.ci.yml" }}
+ key: conda-env-{{ checksum "environment.circleci.yml" }}
- run:
name: Install GCC
command: |
@@ -16,28 +16,26 @@ jobs:
- run:
name: Create conda environment
command: |
- conda env create -f environment.ci.yml || true
- source activate graphchain-ci-env
+ conda update -n base conda
+ conda env create -f environment.circleci.yml || true
+ source activate graphchain-circleci-env
echo $CONDA_PREFIX
- save_cache:
- key: conda-env-{{ checksum "environment.ci.yml" }}
+ key: conda-env-{{ checksum "environment.circleci.yml" }}
paths:
- - /opt/conda/envs/graphchain-ci-env
+ - /opt/conda/envs/graphchain-circleci-env
- run:
- name: Lint with flake8
+ name: Run linters
command: |
- source activate graphchain-ci-env
- flake8 . --max-complexity=10
- - run:
- name: Lint with mypy
- command: |
- source activate graphchain-ci-env
- mypy . --ignore-missing-imports
+ source activate graphchain-circleci-env
+ flake8 graphchain --max-complexity=10
+ pydocstyle graphchain --convention=numpy
+ mypy graphchain --ignore-missing-imports --strict
- run:
name: Run tests
command: |
- source activate graphchain-ci-env
- pytest -v
+ source activate graphchain-circleci-env
+ pytest -vx --cov=graphchain graphchain
workflows:
version: 2
diff --git a/.gitignore b/.gitignore
index 5ab890b..9955653 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,2 +1,115 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.terraform
+
+# VSCode
+.vscode/
+
+# notebooks
+notebooks/
+*.ipynb
+
.*/
__*/
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..801ca3f
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2018 radix.ai
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
\ No newline at end of file
diff --git a/README.md b/README.md
index c9e1d56..24658e2 100644
--- a/README.md
+++ b/README.md
@@ -1,11 +1,164 @@
-[](https://circleci.com/gh/radix-ai/graphchain/tree/master) [](https://www.gnu.org/licenses/gpl-3.0)
+[](https://circleci.com/gh/radix-ai/graphchain/tree/master) [](https://choosealicense.com/licenses/mit/) [](https://pypi.python.org/pypi/graphchain/) [](http://graphchain.readthedocs.io/)
# Graphchain
## What is graphchain?
-Graphchain is like joblib.Memory for dask graphs.
+Graphchain is like [joblib.Memory](https://joblib.readthedocs.io/en/latest/memory.html#memory) for dask graphs. [Dask graph computations](http://dask.pydata.org/en/latest/spec.html) are cached to a local or remote location of your choice, specified by a [PyFilesystem FS URL](https://docs.pyfilesystem.org/en/latest/openers.html).
-## Example usage
+When you change your dask graph (by changing a computation's implementation or its inputs), graphchain will take care to only recompute the minimum number of computations necessary to fetch the result. This allows you to iterate quickly over your graph without spending time on recomputing previously computed keys.
-Checkout the `examples` folder for API usage examples.
+
+ 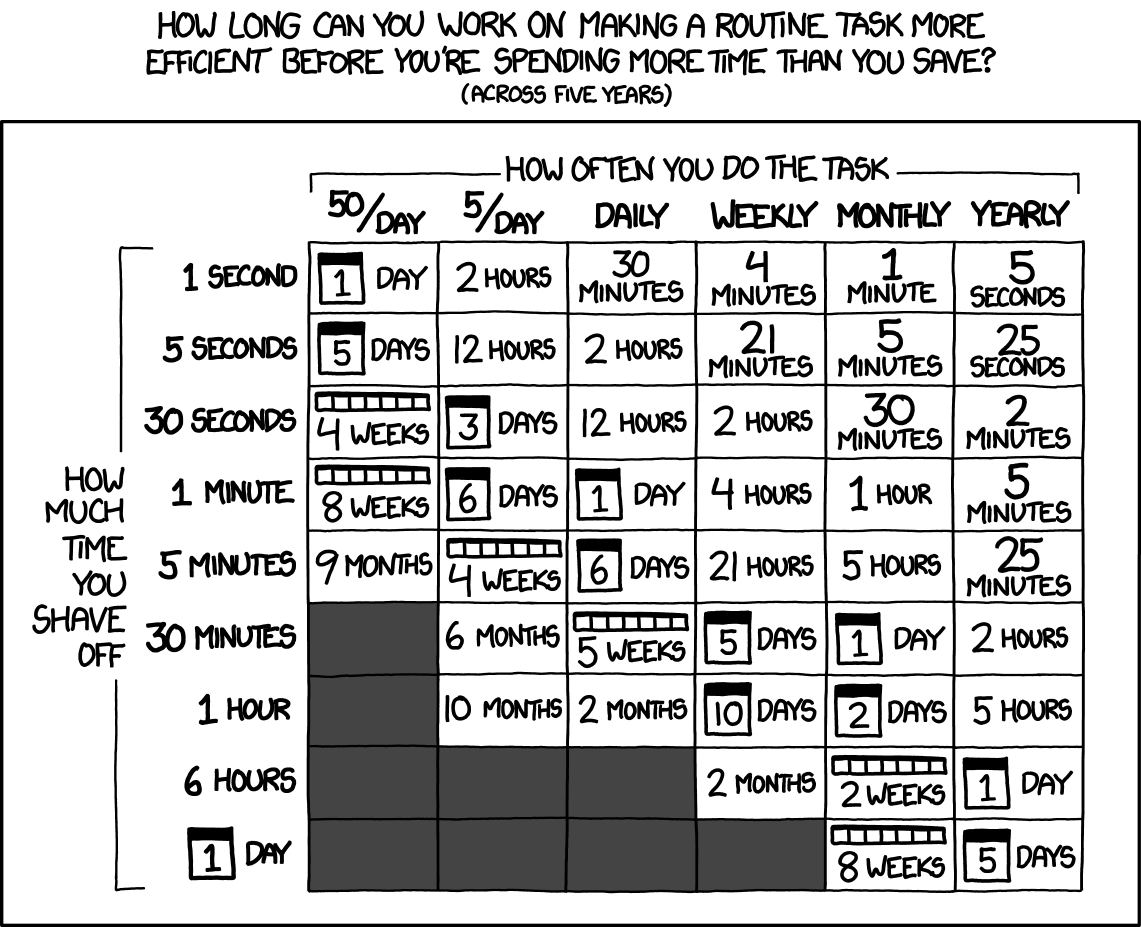
+ Source: xkcd.com/1205/
+
+
+The main difference between graphchain and joblib.Memory is that in graphchain a computation's materialised inputs are _not_ serialised and hashed (which can be very expensive when the inputs are large objects such as pandas DataFrames). Instead, a chain of hashes (hence the name graphchain) of the computation object and its dependencies (which are also computation objects) is used to identify the cache file.
+
+Additionally, the result of a computation is only cached if it is estimated that loading that computation from cache will save time compared to simply computing the computation. The decision on whether to cache depends on the characteristics of the cache location, which are different when caching to the local filesystem compared to caching to S3 for example.
+
+## Usage by example
+
+### Basic usage
+
+Install graphchain with pip to get started:
+
+```bash
+pip install graphchain
+```
+
+To demonstrate how graphchain can save you time, let's first create a simple dask graph that (1) creates a few pandas DataFrames, (2) runs a relatively heavy operation on these DataFrames, and (3) summarises the results.
+
+```python
+import dask
+import graphchain
+import pandas as pd
+
+def create_dataframe(num_rows, num_cols):
+ print('Creating DataFrame...')
+ return pd.DataFrame(data=[range(num_cols)]*num_rows)
+
+def complicated_computation(df, num_quantiles):
+ print('Running complicated computation on DataFrame...')
+ return df.quantile(q=[i / num_quantiles for i in range(num_quantiles)])
+
+def summarise_dataframes(*dfs):
+ print('Summing DataFrames...')
+ return sum(df.sum().sum() for df in dfs)
+
+dsk = {
+ 'df_a': (create_dataframe, 10_000, 1000),
+ 'df_b': (create_dataframe, 10_000, 1000),
+ 'df_c': (complicated_computation, 'df_a', 2048),
+ 'df_d': (complicated_computation, 'df_b', 2048),
+ 'result': (summarise_dataframes, 'df_c', 'df_d')
+}
+```
+
+Using `dask.get` to fetch the `'result'` key takes about 6 seconds:
+
+```python
+>>> %time dask.get(dsk, 'result')
+
+Creating DataFrame...
+Running complicated computation on DataFrame...
+Creating DataFrame...
+Running complicated computation on DataFrame...
+Summing DataFrames...
+
+CPU times: user 7.39 s, sys: 686 ms, total: 8.08 s
+Wall time: 6.19 s
+```
+
+On the other hand, using `graphchain.get` for the first time to fetch `'result'` takes only 4 seconds:
+
+```python
+>>> %time graphchain.get(dsk, 'result')
+
+Creating DataFrame...
+Running complicated computation on DataFrame...
+Summing DataFrames...
+
+CPU times: user 4.7 s, sys: 519 ms, total: 5.22 s
+Wall time: 4.04 s
+```
+
+The reason `graphchain.get` is faster than `dask.get` is because it can load `df_b` and `df_d` from cache after `df_a` and `df_c` have been computed and cached. Note that graphchain will only cache the result of a computation if loading that computation from cache is estimated to be faster than simply running the computation.
+
+Running `graphchain.get` a second time to fetch `'result'` will be almost instant since this time the result itself is also available from cache:
+
+```python
+>>> %time graphchain.get(dsk, 'result')
+
+CPU times: user 4.79 ms, sys: 1.79 ms, total: 6.58 ms
+Wall time: 5.34 ms
+```
+
+Now let's say we want to change how the result is summarised from a sum to an average:
+
+```python
+def summarise_dataframes(*dfs):
+ print('Averaging DataFrames...')
+ return sum(df.mean().mean() for df in dfs) / len(dfs)
+```
+
+If we then ask graphchain to fetch `'result'`, it will detect that only `summarise_dataframes` has changed and therefore only recompute this function with inputs loaded from cache:
+
+```python
+>>> %time graphchain.get(dsk, 'result')
+
+Averaging DataFrames...
+
+CPU times: user 123 ms, sys: 37.2 ms, total: 160 ms
+Wall time: 86.6 ms
+```
+
+### Storing the graphchain cache remotely
+
+Graphchain's cache is by default `./__graphchain_cache__`, but you can ask graphchain to use a cache at any [PyFilesystem FS URL](https://docs.pyfilesystem.org/en/latest/openers.html) such as `s3://mybucket/__graphchain_cache__`:
+
+```python
+graphchain.get(dsk, 'result', location='s3://mybucket/__graphchain_cache__')
+```
+
+### Excluding keys from being cached
+
+In some cases you may not want a key to be cached. To avoid writing certain keys to the graphchain cache, you can use the `skip_keys` argument:
+
+```python
+graphchain.get(dsk, 'result', skip_keys=['result'])
+```
+
+### Using graphchain with dask.delayed
+
+Alternatively, you can use graphchain together with dask.delayed for easier dask graph creation:
+
+```python
+@dask.delayed
+def create_dataframe(num_rows, num_cols):
+ print('Creating DataFrame...')
+ return pd.DataFrame(data=[range(num_cols)]*num_rows)
+
+@dask.delayed
+def complicated_computation(df, num_quantiles):
+ print('Running complicated computation on DataFrame...')
+ return df.quantile(q=[i / num_quantiles for i in range(num_quantiles)])
+
+@dask.delayed
+def summarise_dataframes(*dfs):
+ print('Summing DataFrames...')
+ return sum(df.sum().sum() for df in dfs)
+
+df_a = create_dataframe(num_rows=50_000, num_cols=500, seed=42)
+df_b = create_dataframe(num_rows=50_000, num_cols=500, seed=42)
+df_c = complicated_computation(df_a, window=3)
+df_d = complicated_computation(df_b, window=3)
+result = summarise_dataframes(df_c, df_d)
+```
+
+After which you can compute `result` by setting the `delayed_optimize` method to `graphchain.optimize`:
+
+```python
+with dask.config.set(scheduler='sync', delayed_optimize=graphchain.optimize):
+ result.compute(location='s3://mybucket/__graphchain_cache__')
+```
diff --git a/docs/Makefile b/docs/Makefile
new file mode 100644
index 0000000..298ea9e
--- /dev/null
+++ b/docs/Makefile
@@ -0,0 +1,19 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line.
+SPHINXOPTS =
+SPHINXBUILD = sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
diff --git a/docs/api.rst b/docs/api.rst
new file mode 100644
index 0000000..61729d9
--- /dev/null
+++ b/docs/api.rst
@@ -0,0 +1,5 @@
+API
+===
+
+.. automodule:: graphchain
+ :members:
diff --git a/docs/conf.py b/docs/conf.py
new file mode 100644
index 0000000..ea5e61f
--- /dev/null
+++ b/docs/conf.py
@@ -0,0 +1,195 @@
+# -*- coding: utf-8 -*-
+#
+# Configuration file for the Sphinx documentation builder.
+#
+# This file does only contain a selection of the most common options. For a
+# full list see the documentation:
+# http://www.sphinx-doc.org/en/master/config
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import sys
+
+sys.path.insert(0, os.path.abspath('..'))
+
+
+# -- Project information -----------------------------------------------------
+
+project = 'Graphchain'
+copyright = '2018, radix.ai'
+author = 'radix.ai'
+
+# The short X.Y version
+version = ''
+# The full version, including alpha/beta/rc tags
+release = '1.0.0'
+
+
+# -- General configuration ---------------------------------------------------
+
+# If your documentation needs a minimal Sphinx version, state it here.
+#
+# needs_sphinx = '1.0'
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.coverage',
+ 'sphinx.ext.viewcode',
+ 'sphinx.ext.napoleon',
+ 'm2r'
+]
+
+# Napoleon settings
+napoleon_google_docstring = False
+napoleon_numpy_docstring = True
+napoleon_include_init_with_doc = False
+napoleon_include_private_with_doc = False
+napoleon_include_special_with_doc = True
+napoleon_use_admonition_for_examples = False
+napoleon_use_admonition_for_notes = False
+napoleon_use_admonition_for_references = False
+napoleon_use_ivar = False
+napoleon_use_param = True
+napoleon_use_rtype = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = ['.rst', '.md']
+# source_suffix = '.rst'
+
+# The master toctree document.
+master_doc = 'index'
+
+# The language for content autogenerated by Sphinx. Refer to documentation
+# for a list of supported languages.
+#
+# This is also used if you do content translation via gettext catalogs.
+# Usually you set "language" from the command line for these cases.
+language = None
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# The name of the Pygments (syntax highlighting) style to use.
+pygments_style = None
+
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = 'sphinx_rtd_theme'
+
+# Theme options are theme-specific and customize the look and feel of a theme
+# further. For a list of options available for each theme, see the
+# documentation.
+#
+# html_theme_options = {}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+
+# Custom sidebar templates, must be a dictionary that maps document names
+# to template names.
+#
+# The default sidebars (for documents that don't match any pattern) are
+# defined by theme itself. Builtin themes are using these templates by
+# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
+# 'searchbox.html']``.
+#
+# html_sidebars = {}
+
+
+# -- Options for HTMLHelp output ---------------------------------------------
+
+# Output file base name for HTML help builder.
+htmlhelp_basename = 'graphchaindoc'
+
+
+# -- Options for LaTeX output ------------------------------------------------
+
+latex_elements: dict = {
+ # The paper size ('letterpaper' or 'a4paper').
+ #
+ # 'papersize': 'letterpaper',
+
+ # The font size ('10pt', '11pt' or '12pt').
+ #
+ # 'pointsize': '10pt',
+
+ # Additional stuff for the LaTeX preamble.
+ #
+ # 'preamble': '',
+
+ # Latex figure (float) alignment
+ #
+ # 'figure_align': 'htbp',
+}
+
+# Grouping the document tree into LaTeX files. List of tuples
+# (source start file, target name, title,
+# author, documentclass [howto, manual, or own class]).
+latex_documents = [
+ (master_doc, 'Graphchain.tex', 'Graphchain Documentation',
+ 'radix.ai', 'manual'),
+]
+
+
+# -- Options for manual page output ------------------------------------------
+
+# One entry per manual page. List of tuples
+# (source start file, name, description, authors, manual section).
+man_pages = [
+ (master_doc, 'Graphchain', 'Graphchain Documentation',
+ [author], 1)
+]
+
+
+# -- Options for Texinfo output ----------------------------------------------
+
+# Grouping the document tree into Texinfo files. List of tuples
+# (source start file, target name, title, author,
+# dir menu entry, description, category)
+texinfo_documents = [
+ (master_doc, 'Graphchain', 'Graphchain Documentation',
+ author, 'Graphchain', 'One line description of project.',
+ 'Miscellaneous'),
+]
+
+
+# -- Options for Epub output -------------------------------------------------
+
+# Bibliographic Dublin Core info.
+epub_title = project
+
+# The unique identifier of the text. This can be a ISBN number
+# or the project homepage.
+#
+# epub_identifier = ''
+
+# A unique identification for the text.
+#
+# epub_uid = ''
+
+# A list of files that should not be packed into the epub file.
+epub_exclude_files = ['search.html']
+
+
+# -- Extension configuration -------------------------------------------------
diff --git a/docs/index.rst b/docs/index.rst
new file mode 100644
index 0000000..71fe494
--- /dev/null
+++ b/docs/index.rst
@@ -0,0 +1,8 @@
+Overview
+========
+
+.. toctree::
+ :maxdepth: 3
+
+ introduction.rst
+ api.rst
diff --git a/docs/introduction.rst b/docs/introduction.rst
new file mode 100644
index 0000000..97d4958
--- /dev/null
+++ b/docs/introduction.rst
@@ -0,0 +1 @@
+.. mdinclude:: ../README.md
diff --git a/environment.ci.yml b/environment.ci.yml
deleted file mode 100644
index 1de2f0f..0000000
--- a/environment.ci.yml
+++ /dev/null
@@ -1,13 +0,0 @@
-name: graphchain-ci-env
-channels:
- - defaults
- - conda-forge
-dependencies:
- - dask=0.18
- - flake8=3.5
- - fs-s3fs=0.1
- - joblib=0.12
- - mypy<0.700
- - pytest=3.6
- - pip:
- - lz4~=2.0.2
\ No newline at end of file
diff --git a/environment.circleci.yml b/environment.circleci.yml
new file mode 100644
index 0000000..a3dc8a1
--- /dev/null
+++ b/environment.circleci.yml
@@ -0,0 +1,19 @@
+name: graphchain-circleci-env
+channels:
+ - defaults
+ - conda-forge
+dependencies:
+ - cloudpickle=0.6
+ - dask=0.19
+ - flake8=3.5
+ - flake8-comprehensions=1.4
+ - fs-s3fs=0.1
+ - joblib=0.12
+ - mypy<0.700
+ - pydocstyle=2.1
+ - pytest=3.8
+ - pytest-cov=2.6
+ - pytest-xdist=1.23
+ - pip:
+ - flake8-bugbear~=18.8.0
+ - lz4~=2.1.0
diff --git a/environment.dev.yml b/environment.dev.yml
deleted file mode 100644
index 8f76133..0000000
--- a/environment.dev.yml
+++ /dev/null
@@ -1,16 +0,0 @@
-name: graphchain-env
-channels:
- - defaults
- - conda-forge
-dependencies:
- - dask
- - flake8
- - fs-s3fs
- - isort
- - joblib
- - jupyterlab
- - mypy
- - pytest
- - pip:
- - autopep8
- - lz4
\ No newline at end of file
diff --git a/environment.local.yml b/environment.local.yml
new file mode 100644
index 0000000..3365b86
--- /dev/null
+++ b/environment.local.yml
@@ -0,0 +1,26 @@
+name: graphchain-local-env
+channels:
+ - defaults
+ - conda-forge
+dependencies:
+ - autopep8
+ - cloudpickle
+ - dask
+ - flake8
+ - flake8-comprehensions
+ - fs-s3fs
+ - isort
+ - joblib
+ - jupyterlab
+ - m2r
+ - mypy
+ - pydocstyle
+ - pytest
+ - pytest-cov
+ - pytest-xdist
+ - sphinx
+ - sphinx_rtd_theme
+ - twine
+ - pip:
+ - flake8-bugbear
+ - lz4
diff --git a/examples/__init__.py b/examples/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/examples/example_1.py b/examples/example_1.py
deleted file mode 100644
index 2a26c8d..0000000
--- a/examples/example_1.py
+++ /dev/null
@@ -1,96 +0,0 @@
-import logging
-from time import sleep
-
-import dask
-
-from graphchain import optimize
-
-logging.getLogger("graphchain.graphchain").setLevel(logging.DEBUG)
-logging.getLogger("graphchain.funcutils").setLevel(logging.INFO)
-
-
-def delayed_graph_ex1():
- @dask.delayed
- def foo(x):
- return x + 1
-
- @dask.delayed
- def bar(*args):
- return sum(args) + 1
-
- v1 = foo(1) # return 2
- v2 = foo(1) # returns 2
- v3 = bar(v1, v2, 1) # returns 6
- return (v3, 6) # DAG and expected result
-
-
-def delayed_graph_ex2():
-
- # Functions
- @dask.delayed
- def foo(argument):
- sleep(1)
- return argument
-
- @dask.delayed
- def bar(argument):
- sleep(1)
- return argument + 2
-
- @dask.delayed
- def baz(*args):
- sleep(1)
- return sum(args)
-
- @dask.delayed
- def boo(*args):
- sleep(1)
- return len(args) + sum(args)
-
- @dask.delayed
- def goo(*args):
- sleep(1)
- return sum(args) + 1
-
- @dask.delayed
- def top(argument, argument2):
- sleep(3)
- return argument - argument2
-
- # Constants
- v1 = dask.delayed(1)
- v2 = dask.delayed(2)
- v3 = dask.delayed(3)
- v4 = dask.delayed(0)
- v5 = dask.delayed(-1)
- v6 = dask.delayed(-2)
- d1 = dask.delayed(-3)
-
- boo1 = boo(foo(v1), bar(v2), baz(v3))
- goo1 = goo(foo(v4), v6, bar(v5))
- baz2 = baz(boo1, goo1)
- top1 = top(d1, baz2)
- return (top1, -14) # DAG and expected result
-
-
-def compute_with_graphchain(dsk):
- cachedir = "./__graphchain_cache__"
-
- with dask.set_options(delayed_optimize=optimize):
- result = dsk.compute(cachedir=cachedir, compression=True)
- return result
-
-
-def test_ex1():
- dsk, result = delayed_graph_ex1()
- assert compute_with_graphchain(dsk) == result
-
-
-def test_ex2():
- dsk, result = delayed_graph_ex2()
- assert compute_with_graphchain(dsk) == result
-
-
-if __name__ == "__main__":
- test_ex1()
- test_ex2()
diff --git a/examples/example_2.py b/examples/example_2.py
deleted file mode 100644
index ac1a9de..0000000
--- a/examples/example_2.py
+++ /dev/null
@@ -1,77 +0,0 @@
-import logging
-from time import sleep
-
-import dask
-
-from graphchain import optimize
-
-logging.getLogger("graphchain.graphchain").setLevel(logging.DEBUG)
-logging.getLogger("graphchain.funcutils").setLevel(logging.INFO)
-
-
-def delayed_graph_example():
-
- # Functions
- @dask.delayed
- def foo(argument):
- sleep(1)
- return argument
-
- @dask.delayed
- def bar(argument):
- sleep(1)
- return argument + 2
-
- @dask.delayed
- def baz(*args):
- sleep(1)
- return sum(args)
-
- @dask.delayed
- # hash miss
- def boo(*args):
- sleep(1)
- return len(args) + sum(args)
-
- @dask.delayed
- def goo(*args):
- sleep(1)
- return sum(args) + 1
-
- @dask.delayed
- def top(argument, argument2):
- sleep(3)
- return argument - argument2
-
- # Constants
- v1 = dask.delayed(1)
- v2 = dask.delayed(2)
- v3 = dask.delayed(3)
- v4 = dask.delayed(0)
- v5 = dask.delayed(-1)
- v6 = dask.delayed(-2)
- d1 = dask.delayed(-3)
- boo1 = boo(foo(v1), bar(v2), baz(v3))
- goo1 = goo(foo(v4), v6, bar(v5))
- baz2 = baz(boo1, goo1)
- top1 = top(d1, baz2)
-
- skipkeys = [boo1.key]
- return (top1, -14, skipkeys) # DAG and expected result
-
-
-def compute_with_graphchain(dsk, skipkeys):
- cachedir = "./__graphchain_cache__"
- with dask.set_options(delayed_optimize=optimize):
- result = dsk.compute(
- cachedir=cachedir, compression=True, no_cache_keys=skipkeys)
- return result
-
-
-def test_example():
- dsk, result, skipkeys = delayed_graph_example()
- assert compute_with_graphchain(dsk, skipkeys) == result
-
-
-if __name__ == "__main__":
- test_example()
diff --git a/examples/example_3.py b/examples/example_3.py
deleted file mode 100644
index 35c561c..0000000
--- a/examples/example_3.py
+++ /dev/null
@@ -1,107 +0,0 @@
-import logging
-from time import sleep
-
-import dask
-
-from graphchain import optimize
-from graphchain.errors import GraphchainCompressionMismatch
-
-logging.getLogger("graphchain.graphchain").setLevel(logging.DEBUG)
-logging.getLogger("graphchain.funcutils").setLevel(logging.INFO)
-
-
-def delayed_graph_example():
-
- # Functions
- @dask.delayed
- def foo(argument):
- sleep(1)
- return argument
-
- @dask.delayed
- def bar(argument):
- sleep(1)
- return argument + 2
-
- @dask.delayed
- def baz(*args):
- sleep(1)
- return sum(args)
-
- @dask.delayed
- def boo(*args):
- sleep(1)
- return len(args) + sum(args)
-
- @dask.delayed
- def goo(*args):
- sleep(1)
- return sum(args) + 1
-
- @dask.delayed
- def top(argument, argument2):
- sleep(3)
- return argument - argument2
-
- # Constants
- v1 = dask.delayed(1)
- v2 = dask.delayed(2)
- v3 = dask.delayed(3)
- v4 = dask.delayed(0)
- v5 = dask.delayed(-1)
- v6 = dask.delayed(-2)
- d1 = dask.delayed(-3)
- boo1 = boo(foo(v1), bar(v2), baz(v3))
- goo1 = goo(foo(v4), v6, bar(v5))
- baz2 = baz(boo1, goo1)
- top1 = top(d1, baz2)
- skipkeys = [boo1.key]
- return (top1, -14, skipkeys) # DAG and expected result
-
-
-def compute_with_graphchain(dsk, skipkeys):
- cachedir = "./__hashchain__"
- try:
- with dask.set_options(delayed_optimize=optimize):
- result = dsk.compute(
- compression=True,
- no_cache_keys=skipkeys,
- cachedir=cachedir)
- return result
- except GraphchainCompressionMismatch:
- print("[ERROR] Hashchain compression option mismatch.")
-
-
-def compute_with_graphchain_s3(dsk, skipkeys):
- cachedir = "s3://graphchain-test-bucket/__hashchain__"
- try:
- with dask.set_options(delayed_optimize=optimize):
- result = dsk.compute(
- compression=True,
- no_cache_keys=skipkeys,
- cachedir=cachedir)
- return result
- except GraphchainCompressionMismatch:
- print("[ERROR] Hashchain compression option mismatch.")
- except Exception:
- print("[ERROR] Unknown error somewhere.")
-
-
-def test_example():
- dsk, result, skipkeys = delayed_graph_example()
- try:
- assert compute_with_graphchain(dsk, skipkeys) == result
- except AssertionError:
- print("[ERROR] Results did not match.")
-
-
-def test_example_s3():
- dsk, result, skipkeys = delayed_graph_example()
- try:
- assert compute_with_graphchain_s3(dsk, skipkeys) == result
- except AssertionError:
- print("[ERROR] Results did not match.")
-
-
-if __name__ == "__main__":
- test_example()
diff --git a/examples/example_4.py b/examples/example_4.py
deleted file mode 100644
index 448f6db..0000000
--- a/examples/example_4.py
+++ /dev/null
@@ -1,28 +0,0 @@
-import logging
-
-import dask
-
-import graphchain
-
-
-def foo(x):
- return x + 1
-
-
-def bar(*args):
- return sum(args)
-
-
-dsk = {'foo1': (foo, 1), 'foo2': (foo, 1), 'top': (bar, 'foo1', 'foo2')}
-keys = ['top']
-
-logging.getLogger("graphchain.graphchain").setLevel(logging.INFO)
-logging.getLogger("graphchain.funcutils").setLevel(logging.WARNING)
-# First run example
-result = graphchain.get(dsk, ['top'], get=dask.get)
-assert result == (4, )
-
-# Second run example
-with dask.set_options(get=dask.threaded.get):
- result = graphchain.get(dsk, keys)
-assert result == (4, )
diff --git a/graphchain/__init__.py b/graphchain/__init__.py
index f4ad022..ba11766 100644
--- a/graphchain/__init__.py
+++ b/graphchain/__init__.py
@@ -1,6 +1,4 @@
-from .graphchain import optimize, get
-from .errors import GraphchainCompressionMismatch
+"""Graphchain is a cache for dask graphs."""
+from .core import get, optimize
-__all__ = [
- "optimize", "get", "GraphchainCompressionMismatch"
-]
+__all__ = ['get', 'optimize']
diff --git a/graphchain/core.py b/graphchain/core.py
new file mode 100644
index 0000000..d53cbfe
--- /dev/null
+++ b/graphchain/core.py
@@ -0,0 +1,405 @@
+"""Graphchain core."""
+import datetime as dt
+import functools
+import logging
+import pickle
+import time
+from typing import (Any, Callable, Container, Hashable, Iterable, Optional,
+ Union)
+
+import cloudpickle
+import dask
+import fs
+import fs.base
+import joblib
+
+from .utils import get_size, str_to_posix_fully_portable_filename
+
+logger = logging.getLogger(__name__)
+
+
+class CachedComputation:
+ """A replacement for computations in dask graphs."""
+
+ def __init__(
+ self,
+ dsk: dict,
+ key: Hashable,
+ computation: Any,
+ location: Union[str, fs.base.FS],
+ write_to_cache: Union[bool, str]='auto') -> None:
+ """Cache a dask graph computation.
+
+ Parameters
+ ----------
+ location
+ A PyFilesystem FS URL to store the cached computations in. Can be a
+ local directory such as ``'./__graphchain_cache__'`` or a remote
+ directory such as ``'s3://bucket/__graphchain_cache__'``. You can
+ also pass a PyFilesystem itself instead.
+ dsk
+ The dask graph this computation is a part of.
+ key
+ The key corresponding to this computation in the dask graph.
+ computation
+ The computation to cache.
+ write_to_cache
+ Whether or not to cache this computation. If set to ``'auto'``,
+ will only write to cache if it is expected this will speed up
+ future gets of this computation, taking into account the
+ characteristics of the ``location`` filesystem.
+
+ Returns
+ -------
+ CachedComputation
+ A wrapper for the computation object to replace the original
+ computation with in the dask graph.
+ """
+ self.dsk = dsk
+ self.key = key
+ self.computation = computation
+ self.location = location
+ self.write_to_cache = write_to_cache
+
+ @property # type: ignore
+ @functools.lru_cache() # type: ignore
+ def cache_fs(self) -> fs.base.FS:
+ """Open a PyFilesystem FS to the cache directory."""
+ # create=True does not yet work for S3FS [1]. This should probably be
+ # left to the user as we don't know in which region to create the
+ # bucket, among other configuration options.
+ # [1] https://github.com/PyFilesystem/s3fs/issues/23
+ if isinstance(self.location, fs.base.FS):
+ return self.location
+ return fs.open_fs(self.location, create=True)
+
+ def __repr__(self) -> str:
+ """Represent this ``CachedComputation`` object as a string."""
+ return f''
+
+ def _subs_dependencies_with_hash(self, computation: Any) -> Any:
+ """Replace key references in a computation by their hashes."""
+ dependencies = dask.core.get_dependencies(
+ self.dsk, task=0 if computation is None else computation)
+ for dep in dependencies:
+ computation = dask.core.subs(
+ computation,
+ dep,
+ self.dsk[dep].hash
+ if isinstance(self.dsk[dep], CachedComputation)
+ else self.dsk[dep][0].hash)
+ return computation
+
+ def _subs_tasks_with_src(self, computation: Any) -> Any:
+ """Replace task functions by their source code."""
+ if type(computation) is list:
+ # This computation is a list of computations.
+ computation = [
+ self._subs_tasks_with_src(x) for x in computation]
+ elif dask.core.istask(computation):
+ # This computation is a task.
+ src = joblib.func_inspect.get_func_code(computation[0])[0]
+ computation = (src,) + computation[1:]
+ return computation
+
+ def compute_hash(self) -> str:
+ """Compute a hash of this computation object and its dependencies."""
+ # Replace dependencies with their hashes and functions with source.
+ computation = self._subs_dependencies_with_hash(self.computation)
+ computation = self._subs_tasks_with_src(computation)
+ # Return the hash of the resulting computation.
+ comp_hash = joblib.hash(cloudpickle.dumps(computation)) # type: str
+ return comp_hash
+
+ @property
+ def hash(self) -> str:
+ """Return the hash of this ``CachedComputation``."""
+ if not hasattr(self, '_hash'):
+ self._hash = self.compute_hash()
+ return self._hash
+
+ def estimate_load_time(self, result: Any) -> float:
+ """Estimate the time to load the given result from cache."""
+ compression_ratio = 2
+ size = get_size(result) / compression_ratio
+ # Use typical SSD latency and bandwith if cache_fs is an OSFS, else use
+ # typical S3 latency and bandwidth.
+ read_latency = float(dask.config.get(
+ 'cache_latency',
+ 1e-4 if isinstance(self.cache_fs, fs.osfs.OSFS) else 50e-3))
+ read_throughput = float(dask.config.get(
+ 'cache_throughput',
+ 500e6 if isinstance(self.cache_fs, fs.osfs.OSFS) else 50e6))
+ return read_latency + size / read_throughput
+
+ @functools.lru_cache() # type: ignore
+ def read_time(self, timing_type: str) -> float:
+ """Read the time to load, compute, or store from file."""
+ time_filename = f'{self.hash}.time.{timing_type}'
+ with self.cache_fs.open(time_filename, 'r') as fid: # type: ignore
+ return float(fid.read())
+
+ def write_time(self, timing_type: str, seconds: float) -> None:
+ """Write the time to load, compute, or store from file."""
+ time_filename = f'{self.hash}.time.{timing_type}'
+ with self.cache_fs.open(time_filename, 'w') as fid: # type: ignore
+ fid.write(str(seconds))
+
+ def write_log(self, log_type: str) -> None:
+ """Write the timestamp of a load, compute, or store operation."""
+ key = str_to_posix_fully_portable_filename(str(self.key))
+ now = str_to_posix_fully_portable_filename(str(dt.datetime.now()))
+ log_filename = f'.{now}.{log_type}.{key}.log'
+ with self.cache_fs.open(log_filename, 'w') as fid: # type: ignore
+ fid.write(self.hash)
+
+ def time_to_result(self, memoize: bool=True) -> float:
+ """Estimate the time to load or compute this computation."""
+ if hasattr(self, '_time_to_result'):
+ return self._time_to_result # type: ignore
+ if memoize:
+ try:
+ try:
+ load_time = self.read_time('load')
+ except Exception:
+ load_time = self.read_time('store') / 2
+ self._time_to_result = load_time
+ return load_time
+ except Exception:
+ pass
+ compute_time = self.read_time('compute')
+ dependency_time = 0
+ dependencies = dask.core.get_dependencies(
+ self.dsk, task=0 if self.computation is None else self.computation)
+ for dep in dependencies:
+ dependency_time += self.dsk[dep][0].time_to_result()
+ total_time = compute_time + dependency_time
+ if memoize:
+ self._time_to_result = total_time
+ return total_time
+
+ @property
+ def cache_filename(self) -> str:
+ """Filename of the cache file to load or store."""
+ return f'{self.hash}.joblib.lz4'
+
+ def cache_file_exists(self) -> bool:
+ """Check if this ``CachedComputation``'s cache file exists."""
+ return self.cache_fs.exists(self.cache_filename) # type: ignore
+
+ def load(self) -> Any:
+ """Load this result of this computation from cache."""
+ try:
+ # Load from cache.
+ start_time = time.perf_counter()
+ logger.info(
+ f'LOAD {self} from {self.cache_fs}/{self.cache_filename}')
+ fn = self.cache_filename
+ with self.cache_fs.open(fn, 'rb') as fid: # type: ignore
+ result = joblib.load(fid)
+ load_time = time.perf_counter() - start_time
+ # Write load time and log operation.
+ self.write_time('load', load_time)
+ self.write_log('load')
+ return result
+ except Exception:
+ logger.exception(f'Could not read {self.cache_filename}.')
+ raise
+
+ def compute(self, *args: Any, **kwargs: Any) -> Any:
+ """Compute this computation."""
+ # Compute the computation.
+ logger.info(f'COMPUTE {self}')
+ start_time = time.perf_counter()
+ if dask.core.istask(self.computation):
+ result = self.computation[0](*args, **kwargs)
+ else:
+ result = args[0]
+ compute_time = time.perf_counter() - start_time
+ # Write compute time and log operation
+ self.write_time('compute', compute_time)
+ self.write_log('compute')
+ return result
+
+ def store(self, result: Any) -> None:
+ """Store the result of this computation in the cache."""
+ if not self.cache_file_exists():
+ logger.info(
+ f'STORE {self} to {self.cache_fs}/{self.cache_filename}')
+ try:
+ # Store to cache.
+ start_time = time.perf_counter()
+ with self.cache_fs.open( # type: ignore
+ self.cache_filename, 'wb') as fid:
+ joblib.dump(result, fid, protocol=pickle.HIGHEST_PROTOCOL)
+ store_time = time.perf_counter() - start_time
+ # Write store time and log operation
+ self.write_time('store', store_time)
+ self.write_log('store')
+ except Exception:
+ # Not crucial to stop if caching fails.
+ logger.exception(f'Could not write {self.cache_filename}.')
+ # Try to delete leftovers if they were created by accident.
+ try:
+ self.cache_fs.remove(self.cache_filename) # type: ignore
+ except Exception:
+ pass
+
+ def patch_computation_in_graph(self) -> None:
+ """Patch the graph to use this CachedComputation."""
+ if self.cache_file_exists():
+ # If there are cache candidates to load this computation from,
+ # remove all dependencies for this task from the graph as far as
+ # dask is concerned.
+ self.dsk[self.key] = (self,)
+ else:
+ # If there are no cache candidates, wrap the execution of the
+ # computation with this CachedComputation's __call__ method and
+ # keep references to its dependencies.
+ self.dsk[self.key] = \
+ (self,) + self.computation[1:] \
+ if dask.core.istask(self.computation) else \
+ (self, self.computation)
+
+ def __call__(self, *args: Any, **kwargs: Any) -> Any:
+ """Load this computation from cache, or compute and then store it."""
+ # Load.
+ if self.cache_file_exists():
+ return self.load()
+ # Compute.
+ result = self.compute(*args, **kwargs)
+ # Store.
+ write_to_cache = self.write_to_cache
+ if write_to_cache == 'auto':
+ compute_time = self.time_to_result(memoize=False)
+ estimated_load_time = self.estimate_load_time(result)
+ write_to_cache = estimated_load_time < compute_time
+ logger.debug(
+ f'{"Going" if write_to_cache else "Not going"} to cache {self}'
+ f' because estimated_load_time={estimated_load_time} '
+ f'{"<" if write_to_cache else ">="} '
+ f'compute_time={compute_time}')
+ if write_to_cache:
+ self.store(result)
+ return result
+
+
+def optimize(
+ dsk: dict,
+ keys: Optional[Union[Hashable, Iterable[Hashable]]]=None,
+ skip_keys: Optional[Container[Hashable]]=None,
+ location: Union[str, fs.base.FS]="./__graphchain_cache__") -> dict:
+ """Optimize a dask graph with cached computations.
+
+ According to the dask graph specification [1]_, a dask graph is a
+ dictionary that maps `keys` to `computations`. A computation can be:
+
+ 1. Another key in the graph.
+ 2. A literal.
+ 3. A task, which is of the form ``(callable, *args)``.
+ 4. A list of other computations.
+
+ This optimizer replaces all computations in a graph with
+ ``CachedComputation``'s, so that getting items from the graph will be
+ backed by a cache of your choosing. With this cache, only the very minimum
+ number of computations will actually be computed to return the values
+ corresponding to the given keys.
+
+ ``CachedComputation`` objects *do not* hash task inputs (which is the
+ approach that ``functools.lru_cache`` and ``joblib.Memory`` take) to
+ identify which cache file to load. Instead, a chain of hashes (hence the
+ name ``graphchain``) of the computation object and its dependencies (which
+ are also computation objects) is used to identify the cache file.
+
+ Since it is generally cheap to hash the graph's computation objects,
+ ``graphchain``'s cache is likely to be much faster than hashing task
+ inputs, which can be slow for large objects such as ``pandas.DataFrame``'s.
+
+ Parameters
+ ----------
+ dsk
+ The dask graph to optimize with caching computations.
+ keys
+ Not used. Is present for compatibility with dask optimizers [2]_.
+ skip_keys
+ A container of keys not to cache.
+ location
+ A PyFilesystem FS URL to store the cached computations in. Can be a
+ local directory such as ``'./__graphchain_cache__'`` or a remote
+ directory such as ``'s3://bucket/__graphchain_cache__'``. You can
+ also pass a PyFilesystem itself instead.
+
+ Returns
+ -------
+ dict
+ A copy of the dask graph where the computations have been replaced
+ by ``CachedComputation``'s.
+
+ References
+ ----------
+ .. [1] http://dask.pydata.org/en/latest/spec.html
+ .. [2] http://dask.pydata.org/en/latest/optimize.html
+ """
+ # Verify that the graph is a DAG.
+ dsk = dsk.copy()
+ assert dask.core.isdag(dsk, list(dsk.keys()))
+ # Open or create the cache FS.
+ # TODO(lsorber): lazily evaluate this for compatibility with `distributed`?
+ if isinstance(location, str):
+ location = fs.open_fs(location, create=True)
+ # Replace graph computations by CachedComputations.
+ skip_keys = skip_keys or set()
+ for key, computation in dsk.items():
+ dsk[key] = CachedComputation(
+ dsk, key, computation, location,
+ write_to_cache=False if key in skip_keys else 'auto')
+ # Remove task arguments if we can load from cache.
+ for key in dsk:
+ dsk[key].patch_computation_in_graph()
+ return dsk
+
+
+def get(
+ dsk: dict,
+ keys: Union[Hashable, Iterable[Hashable]],
+ skip_keys: Optional[Container[Hashable]]=None,
+ location: Union[str, fs.base.FS]="./__graphchain_cache__",
+ scheduler: Optional[Callable]=None) -> Any:
+ """Get one or more keys from a dask graph with caching.
+
+ Optimizes a dask graph with ``graphchain.optimize`` and then computes the
+ requested keys with the desired scheduler, which is by default
+ ``dask.get``.
+
+ See ``graphchain.optimize`` for more information on how ``graphchain``'s
+ cache mechanism works.
+
+ Parameters
+ ----------
+ dsk
+ The dask graph to query.
+ keys
+ The keys to compute.
+ skip_keys
+ A container of keys not to cache.
+ location
+ A PyFilesystem FS URL to store the cached computations in. Can be a
+ local directory such as ``'./__graphchain_cache__'`` or a remote
+ directory such as ``'s3://bucket/__graphchain_cache__'``. You can
+ also pass a PyFilesystem itself instead.
+ scheduler
+ The dask scheduler to use to retrieve the keys from the graph.
+
+ Returns
+ -------
+ Any
+ The computed values corresponding to the given keys.
+ """
+ cached_dsk = optimize(dsk, keys, skip_keys=skip_keys, location=location)
+ scheduler = \
+ scheduler or \
+ dask.config.get('get', None) or \
+ dask.config.get('scheduler', None) or \
+ dask.get
+ return scheduler(cached_dsk, keys)
diff --git a/graphchain/errors.py b/graphchain/errors.py
deleted file mode 100644
index d45d91c..0000000
--- a/graphchain/errors.py
+++ /dev/null
@@ -1,13 +0,0 @@
-"""
-Module containing basic exceptions used trhoughout the
-`graphchain.py` and `funcutils.py` modules.
-"""
-
-
-class GraphchainCompressionMismatch(EnvironmentError):
- """
- Simple exception that is raised whenever the compression
- option in the `optimize` function does not match the one
- present in the `graphchain.json` file if such file exists.
- """
- pass
diff --git a/graphchain/funcutils.py b/graphchain/funcutils.py
deleted file mode 100644
index 6059bc7..0000000
--- a/graphchain/funcutils.py
+++ /dev/null
@@ -1,278 +0,0 @@
-"""
-Utility functions employed by the graphchain module.
-"""
-import json
-
-import fs
-import joblib
-import lz4.frame
-from joblib import hash as joblib_hash
-from joblib.func_inspect import get_func_code as joblib_getsource
-
-from .errors import GraphchainCompressionMismatch
-from .logger import add_logger, mute_dependency_loggers
-
-logger = add_logger(name="graphchain", logfile="stdout")
-GRAPHCHAIN_FILENAME = "graphchain.json"
-CACHE_DIRNAME = "cache"
-
-
-def get_storage(cachedir):
- """Open a PyFilesystem filesystem given an FS URL.
-
- Args:
- cachedir (str): The FS URL to open. Can be a local directory such as
- "./__graphchain_cache__" or a remote directory such as
- "s3://mybucket/__graphchain_cache__".
-
- Returns:
- fs.FS: A PyFilesystem filesystem object that has created the directory
- structure.
- """
- mute_dependency_loggers()
- storage = fs.open_fs(cachedir, create=True)
- return storage
-
-
-def load_hashchain(storage, compress=False):
- """
- Loads the `hash-chain` file found in the root directory of
- the `storage` filesystem object.
- """
- if not storage.isdir(CACHE_DIRNAME):
- logger.info(f"Initializing {CACHE_DIRNAME}")
- storage.makedirs(CACHE_DIRNAME, recreate=True)
-
- if not storage.isfile(GRAPHCHAIN_FILENAME):
- logger.info(f"Initializing {GRAPHCHAIN_FILENAME}")
- obj = dict()
- write_hashchain(obj, storage, compress=compress)
- else:
- with storage.open(GRAPHCHAIN_FILENAME, "r") as fid:
- hashchaindata = json.load(fid)
-
- # Check compression option consistency
- compr_option_lz4 = hashchaindata["compress"] == "lz4"
- if compr_option_lz4 ^ compress:
- raise GraphchainCompressionMismatch(
- f"compress option mismatch: "
- f"file={compr_option_lz4}, "
- f"optimizer={compress}.")
-
- # Prune hashchain based on cache
- obj = hashchaindata["hashchain"]
- filelist_cache = storage.listdir(CACHE_DIRNAME)
- hash_list = {_file.split(".")[0] for _file in filelist_cache}
- to_delete = set(obj.keys()) - hash_list
- for _hash in to_delete:
- del obj[_hash]
- write_hashchain(obj, storage, compress=compress)
-
- return obj
-
-
-def write_hashchain(obj, storage, version=1, compress=False):
- """
- Writes a `hash-chain` contained in ``obj`` to a file
- indicated by ``filename``.
- """
- hashchaindata = {
- "version": str(version),
- "compress": "lz4" if compress else "none",
- "hashchain": obj
- }
- with storage.open(GRAPHCHAIN_FILENAME, "w") as fid:
- fid.write(json.dumps(hashchaindata, indent=4))
-
-
-def wrap_to_store(key,
- obj,
- storage,
- objhash,
- compress=False,
- skipcache=False):
- """
- Wraps a callable object in order to execute it and store its result.
- """
- def exec_store_wrapper(*args, **kwargs):
- """
- Simple execute and store wrapper.
- """
- if callable(obj):
- objname = f"key={key} function={obj.__name__} hash={objhash}"
- else:
- objname = f"key={key} literal={type(obj)} hash={objhash}"
- logger.info(f"EXECUTE {objname}")
- ret = obj(*args, **kwargs) if callable(obj) else obj
- if not skipcache:
- fileext = ".pickle.lz4" if compress else ".pickle"
- filepath = fs.path.join(CACHE_DIRNAME, objhash + fileext)
- if not storage.isfile(filepath):
- logger.info(f"STORE {objname}")
- try:
- with storage.open(filepath, "wb") as fid:
- if compress:
- with lz4.frame.open(fid, mode='wb') as _fid:
- joblib.dump(ret, _fid, protocol=4)
- else:
- joblib.dump(ret, fid, protocol=4)
- except Exception:
- logger.exception("Could not dump object.")
- else:
- logger.warning(f"FILE_EXISTS {objname}")
- return ret
-
- return exec_store_wrapper
-
-
-def wrap_to_load(key, obj, storage, objhash, compress=False):
- """
- Wraps a callable object in order not to execute it and rather
- load its result.
- """
- def loading_wrapper():
- """
- Simple load wrapper.
- """
- assert storage.isdir(CACHE_DIRNAME)
- filepath = fs.path.join(
- CACHE_DIRNAME, f"{objhash}.pickle{'.lz4' if compress else ''}")
- if callable(obj):
- objname = f"key={key} function={obj.__name__} hash={objhash}"
- else:
- objname = f"key={key} literal={type(obj)} hash={objhash}"
- logger.info(f"LOAD {objname}")
- with storage.open(filepath, "rb") as fid:
- if compress:
- with lz4.frame.open(fid, mode="r") as _fid:
- ret = joblib.load(_fid)
- else:
- ret = joblib.load(fid)
- return ret
-
- return loading_wrapper
-
-
-def get_hash(task, keyhashmap=None):
- """
- Calculates and returns the hash corresponding to a dask task
- ``task`` using the hashes of its dependencies, input arguments
- and source code of the function associated to the task. Any
- available hashes are passed in ``keyhashmap``.
- """
- # assert task is not None
- fnhash_list = []
- arghash_list = []
- dephash_list = []
-
- if isinstance(task, tuple):
- # A tuple would correspond to a delayed function
- for taskelem in task:
- if callable(taskelem):
- # function
- sourcecode = joblib_getsource(taskelem)[0]
- fnhash_list.append(joblib_hash(sourcecode))
- else:
- try:
- # Assume a dask graph key.
- dephash_list.append(keyhashmap[taskelem])
- except Exception:
- # Else hash the object.
- arghash_list.extend(recursive_hash(taskelem))
- else:
- try:
- # Assume a dask graph key.
- dephash_list.append(keyhashmap[task])
- except Exception:
- # Else hash the object.
- arghash_list.extend(recursive_hash(task))
-
- # Calculate subhashes
- src_hash = joblib_hash("".join(fnhash_list))
- arg_hash = joblib_hash("".join(arghash_list))
- dep_hash = joblib_hash("".join(dephash_list))
-
- subhashes = {"src": src_hash, "arg": arg_hash, "dep": dep_hash}
- objhash = joblib_hash(src_hash + arg_hash + dep_hash)
- return objhash, subhashes
-
-
-def analyze_hash_miss(hashchain, htask, hcomp, taskname, skipcache):
- """
- Function that analyzes and gives out a printout of
- possible hass miss reasons. The importance of a
- candidate is calculated as Ic = Nm/Nc where:
- - Ic is an imporance coefficient;
- - Nm is the number of subhashes matched;
- - Nc is the number that candidate code
- appears.
- For example, if there are 1 candidates with
- a code 2 (i.e. arguments hash match) and
- 10 candidates with code 6 (i.e. code and
- arguments match), the more important candidate
- is the one with a sing
- """
- if not skipcache:
- from collections import defaultdict
- codecm = defaultdict(int) # codes count map
- for key in hashchain.keys():
- hashmatches = (hashchain[key]["src"] == hcomp["src"],
- hashchain[key]["arg"] == hcomp["arg"],
- hashchain[key]["dep"] == hcomp["dep"])
- codecm[hashmatches] += 1
-
- dists = {k: sum(k) / codecm[k] for k in codecm.keys()}
- sdists = sorted(list(dists.items()), key=lambda x: x[1], reverse=True)
-
- def ok_or_missing(arg):
- """
- Function that returns 'OK' if the input
- argument is True and 'MISSING' otherwise.
- """
- if arg is True:
- out = "HIT"
- elif arg is False:
- out = "MISS"
- else:
- out = "ERROR"
- return out
-
- msgstr = f"CACHE MISS for key={taskname} with " + \
- "src={:>4} arg={:>4} dep={:>4} ({} candidates)"
- if sdists:
- for value in sdists:
- code, _ = value
- logger.debug(
- msgstr.format(
- ok_or_missing(code[0]), ok_or_missing(code[1]),
- ok_or_missing(code[2]), codecm[code]))
- else:
- logger.debug(msgstr.format("NONE", "NONE", "NONE", 0))
- else:
- # The key is never cached hence removed from 'graphchain.json'
- logger.debug(f"CACHE SKIPPED for key={taskname}")
-
-
-def recursive_hash(coll, prev_hash=None):
- """
- Function that recursively hashes collections of objects.
- """
- if prev_hash is None:
- prev_hash = []
-
- if (not isinstance(coll, list) and not isinstance(coll, dict)
- and not isinstance(coll, tuple) and not isinstance(coll, set)):
- if callable(coll):
- prev_hash.append(joblib_hash(joblib_getsource(coll)[0]))
- else:
- prev_hash.append(joblib_hash(coll))
- elif isinstance(coll, dict):
- # Special case for dicts: inspect both keys and values
- for (key, val) in coll.items():
- recursive_hash(key, prev_hash)
- recursive_hash(val, prev_hash)
- else:
- for val in coll:
- recursive_hash(val, prev_hash)
-
- return prev_hash
diff --git a/graphchain/graphchain.py b/graphchain/graphchain.py
deleted file mode 100644
index e48337c..0000000
--- a/graphchain/graphchain.py
+++ /dev/null
@@ -1,158 +0,0 @@
-"""
-Graphchain is a `hash-chain` optimizer for dask delayed execution graphs.
-It employes a hashing mechanism to check wether the state associated to
-a task that is to be run (i.e. its function source code, input arguments
-and other input dask-related dependencies) has already been `hashed`
-(and hence, an output is available) or, it is new/changed. Depending
-on the current state, the current task becomes a load-from-disk operation
-or an execute-and-store-to-disk one. This is done is such a manner that
-the minimimum number of load/execute operations are performed, minimizing
-both persistency and computational demands.
-
-Examples:
- Applying the hash-chain based optimizer on `dask.delayed` generated
- execution graphs is straightforward, by using the
- >>> from graphchain import optimize
- >>> with dask.set_options(delayed_optimize = optimize):
- result = dsk.compute(...) # <-- arguments go there
-
- A full example can be found in `examples/example_1.py`. For more
- documentation on customizing the optimization of dask graphs,
- check the `Customizing Optimization` section from the dask
- documentation at https://dask.pydata.org/en/latest/optimize.html.
-"""
-import warnings
-from collections import deque
-
-import dask
-from dask.core import get_dependencies, toposort
-
-from .funcutils import (analyze_hash_miss, get_hash, get_storage,
- load_hashchain, wrap_to_load, wrap_to_store,
- write_hashchain)
-
-
-def optimize(dsk,
- keys=None,
- no_cache_keys=None,
- compress=False,
- cachedir="./__graphchain_cache__"):
- """
- Optimizes a dask delayed execution graph by caching individual
- task outputs and by loading the outputs of or executing the minimum
- number of tasks necessary to obtain the requested output.
-
- Args:
- dsk (dict): Input dask graph.
- keys (list, optional): The dask graph output keys. Defaults to None.
- no_cache_keys (list, optional): Keys for which no caching will occur;
- the keys still still contribute to the hashchain.
- Defaults to None.
- compress (bool, optional): Enables LZ4 compression of the task outputs.
- Defaults to False.
- cachedir (str, optional): The graphchain cache directory.
- Defaults to "./__graphchain_cache__". You can also specify a
- PyFilesystem FS URL such as "s3://mybucket/__graphchain_cache__" to
- store the cache on another filesystem such as S3.
-
- Returns:
- dict: An optimized dask graph.
- """
- if keys is None:
- warnings.warn("Nothing to optimize because `keys` argument is `None`.")
- return dsk
-
- if no_cache_keys is None:
- no_cache_keys = []
-
- storage = get_storage(cachedir)
- hashchain = load_hashchain(storage, compress=compress)
-
- allkeys = toposort(dsk) # All keys in the graph, topologically sorted.
- work = deque(dsk.keys()) # keys to be traversed
- solved = set() # keys of computable tasks
- dependencies = {k: get_dependencies(dsk, k) for k in allkeys}
- keyhashmaps = {} # key:hash mapping
- newdsk = dsk.copy() # output task graph
- hashes_to_store = set() # list of hashes that correspond # noqa
- # to keys whose output will be stored # noqa
- while work:
- key = work.popleft()
- deps = dependencies[key]
-
- if not deps or set(deps).issubset(solved):
- # Leaf or solvable node
- solved.add(key)
- task = dsk.get(key)
- htask, hcomp = get_hash(task, keyhashmaps)
- keyhashmaps[key] = htask
- skipcache = key in no_cache_keys
-
- # Account for different task types: i.e. functions/constants
- if isinstance(task, tuple):
- fno = task[0]
- fnargs = task[1:]
- else:
- fno = task
- fnargs = []
-
- # Check if the hash matches anything available
- if (htask in hashchain.keys() and not skipcache
- and htask not in hashes_to_store):
- # Hash match and output cacheable
- fnw = wrap_to_load(key, fno, storage, htask, compress=compress)
- newdsk[key] = (fnw, )
- elif htask in hashchain.keys() and skipcache:
- # Hash match and output *non-cachable*
- fnw = wrap_to_store(
- key,
- fno,
- storage,
- htask,
- compress=compress,
- skipcache=skipcache)
- newdsk[key] = (fnw, *fnargs)
- else:
- # Hash miss
- analyze_hash_miss(hashchain, htask, hcomp, key, skipcache)
- hashchain[htask] = hcomp
- hashes_to_store.add(htask)
- fnw = wrap_to_store(
- key,
- fno,
- storage,
- htask,
- compress=compress,
- skipcache=skipcache)
- newdsk[key] = (fnw, *fnargs)
- else:
- # Non-solvable node
- work.append(key)
-
- # Write the hashchain
- write_hashchain(hashchain, storage, compress=compress)
- return newdsk
-
-
-def get(dsk, keys=None, scheduler=None, **kwargs):
- """A cache-optimized equivalent to dask.get.
-
- Optimizes an input graph using a hash-chain based approach. I.e., apply
- `graphchain.optimize` to the graph and get the requested keys.
-
- Args:
- dsk (dict): Input dask graph.
- keys (list, optional): The dask graph output keys. Defaults to None.
- scheduler (optional): dask get method to be used.
- **kwargs (optional) Keyword arguments for the 'optimize' function;
- can be any of the following: 'no_cache_keys', 'compress',
- 'cachedir'.
-
- Returns:
- The computed values corresponding to the desired keys, specified
- in the 'keys' argument.
- """
- newdsk = optimize(dsk, keys, **kwargs)
- scheduler = scheduler or dask.context._globals.get("get") or dask.get
- ret = scheduler(newdsk, keys)
- return ret
diff --git a/graphchain/logger.py b/graphchain/logger.py
deleted file mode 100644
index dec876c..0000000
--- a/graphchain/logger.py
+++ /dev/null
@@ -1,47 +0,0 @@
-"""
-Utilities related to logging.
-"""
-import logging
-
-
-def add_logger(name=__name__,
- logfile=None,
- fmt="%(asctime)s %(name)s %(levelname)s %(message)s",
- level=logging.INFO):
- """Adds a logger.
-
- Args:
- name (str): Name of the logger.
- logfile (str, optional): A file to be used for logging.
- Possible values are None (do not log anything),
- "stdout" (print to STDOUT) or "" which will
- create a log file with the argument's name.
- Defaults to None.
- fmt (str, optional): Format string for the 'logging.Formatter'.
- Defaults to '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
- level (int, optional): Minimum logging level to be logged.
- Defaults to 'logging.INFO' or 10.
-
- Returns:
- logging.Logger: A logging object.
- """
- formatter = logging.Formatter(fmt=fmt)
- logger = logging.getLogger(name)
- logger.setLevel(level)
- if logfile is None:
- handler = logging.NullHandler()
- elif logfile == "stdout":
- handler = logging.StreamHandler()
- else:
- handler = logging.FileHandler(logfile, mode="w")
- handler.setFormatter(formatter)
- logger.addHandler(handler)
- return logger
-
-
-def mute_dependency_loggers():
- """Mutes various dependency loggers."""
- logging.getLogger('s3transfer').setLevel(logging.CRITICAL)
- logging.getLogger('boto3').setLevel(logging.CRITICAL)
- logging.getLogger('botocore').setLevel(logging.CRITICAL)
- return None
diff --git a/graphchain/tests/__init__.py b/graphchain/tests/__init__.py
index e69de29..a023c07 100644
--- a/graphchain/tests/__init__.py
+++ b/graphchain/tests/__init__.py
@@ -0,0 +1 @@
+"""Graphchain module tests."""
diff --git a/graphchain/tests/test_graphchain.py b/graphchain/tests/test_graphchain.py
index 83f8118..e0ff84f 100644
--- a/graphchain/tests/test_graphchain.py
+++ b/graphchain/tests/test_graphchain.py
@@ -1,26 +1,23 @@
-"""
-Test module for the graphchain and funcutils modules.
-Based on the 'pytest' test framework.
-"""
+"""Test module for the graphchain core."""
+import functools
import os
import shutil
-from collections import Iterable
+import tempfile
+from typing import Callable, Tuple
import dask
import fs
import pytest
-from dask.core import get_dependencies
-from ..funcutils import load_hashchain
-from ..graphchain import optimize
+from ..core import CachedComputation, optimize
-@pytest.fixture(scope="function")
-def dask_dag_generation():
- """
- Generates a dask compatible graph of the form,
- which will be used as a basis for the functional
- testing of the graphchain module:
+@pytest.fixture(scope="function") # type: ignore
+def dask_graph() -> dict:
+ r"""Generate an example dask graph.
+
+ Will be used as a basis for the functional testing of the graphchain
+ module:
O top(..)
____|____
@@ -37,28 +34,28 @@ def dask_dag_generation():
| | | | |
v1 v2 v3 v4 v5
"""
-
# Functions
- def foo(argument):
+ def foo(argument: int) -> int:
return argument
- def bar(argument):
+ def bar(argument: int) -> int:
return argument + 2
- def baz(*args):
+ def baz(*args: int) -> int:
return sum(args)
- def boo(*args):
+ def boo(*args: int) -> int:
return len(args) + sum(args)
- def goo(*args):
+ def goo(*args: int) -> int:
return sum(args) + 1
- def top(argument, argument2):
+ def top(argument: int, argument2: int) -> int:
return argument - argument2
# Graph (for the function definitions above)
dsk = {
+ "v0": None,
"v1": 1,
"v2": 2,
"v3": 3,
@@ -79,239 +76,140 @@ def top(argument, argument2):
return dsk
-def test_dag(dask_dag_generation):
- """
- Tests that the dask DAG can be traversed correctly
- and that the actual result for the 'top1' key is correct.
- """
- dsk = dask_dag_generation
- result = dask.get(dsk, ["top1"])
- assert result == (-14, )
-
+@pytest.fixture(scope="module") # type: ignore
+def temp_dir() -> str:
+ """Create a temporary directory to store the cache in."""
+ with tempfile.TemporaryDirectory(prefix='__graphchain_cache__') as tmpdir:
+ yield tmpdir
-@pytest.fixture(scope="module")
-def temporary_directory():
- """
- Creates the directory used for the graphchain tests.
- After the tests finish, it will be removed.
- """
- directory = os.path.abspath("__pytest_graphchain_cache__")
- if os.path.isdir(directory):
- shutil.rmtree(directory, ignore_errors=True)
- os.mkdir(directory, mode=0o777)
- yield directory
- shutil.rmtree(directory, ignore_errors=True)
- print(f"Cleanup of {directory} complete.")
+@pytest.fixture(scope="module") # type: ignore
+def temp_dir_s3() -> str:
+ """Create the directory used for the graphchain tests on S3."""
+ location = "s3://graphchain-test-bucket/__pytest_graphchain_cache__"
+ yield location
-@pytest.fixture(scope="function", params=[False, True])
-def optimizer(temporary_directory, request):
- """
- Returns a parametrized version of the ``optimize``
- function necessary to test caching and with and
- without LZ4 compression.
- """
- tmpdir = temporary_directory
- if request.param:
- filesdir = os.path.join(tmpdir, "compressed")
- else:
- filesdir = os.path.join(tmpdir, "uncompressed")
- def graphchain_opt_func(dsk, keys=["top1"]):
- return optimize(
- dsk, keys=keys, cachedir=filesdir, compress=request.param)
-
- return graphchain_opt_func, request.param, filesdir
-
-
-@pytest.fixture(scope="function")
-def optimizer_exec_only_nodes(temporary_directory):
- """
- Returns a parametrized version of the ``optimize``
- function necessary to test execution-only nodes
- within graphchain-optimized dask graphs.
- """
- tmpdir = temporary_directory
- filesdir = os.path.join(tmpdir, "compressed")
+def test_dag(dask_graph: dict) -> None:
+ """Test that the graph can be traversed and its result is correct."""
+ dsk = dask_graph
+ result = dask.get(dsk, ["top1"])
+ assert result == (-14, )
- def graphchain_opt_func(dsk, keys=["top1"]):
- return optimize(
- dsk,
- keys=keys,
- cachedir=filesdir,
- compress=False,
- no_cache_keys=["boo1"]) # "boo1" is hardcoded
- return graphchain_opt_func, filesdir
+@pytest.fixture(scope="function") # type: ignore
+def optimizer(temp_dir: str) -> Tuple[str, Callable]:
+ """Prefill the graphchain optimizer's parameters."""
+ return temp_dir, functools.partial(
+ optimize,
+ keys=('top1',),
+ location=temp_dir)
-@pytest.fixture(scope="module")
-def temporary_s3_storage():
- """
- Creates the directory used for the graphchain tests
- using Amazon S3 storage. After the tests finish, the
- directory will be removed.
- """
- cachedir = "s3://graphchain-test-bucket/__pytest_graphchain_cache__"
- yield cachedir
- storage = fs.open_fs("s3://graphchain-test-bucket", create=True)
- storage.removetree('')
- storage.close()
- print(f"Cleanup of {cachedir} (on Amazon S3) complete.")
+@pytest.fixture(scope="function") # type: ignore
+def optimizer_exec_only_nodes(temp_dir: str) -> Tuple[str, Callable]:
+ """Prefill the graphchain optimizer's parameters."""
+ return temp_dir, functools.partial(
+ optimize,
+ keys=('top1',),
+ location=temp_dir,
+ skip_keys=['boo1'])
-@pytest.fixture(scope="function", params=[False, True])
-def optimizer_s3(temporary_s3_storage, request):
- """
- Returns a parametrized version of the ``optimize``
- function necessary to test the support for Amazon S3
- storage.
- """
- def graphchain_opt_func(dsk, keys=["top1"]):
- return optimize(
- dsk,
- keys=keys,
- compress=request.param,
- cachedir=temporary_s3_storage)
+@pytest.fixture(scope="function") # type: ignore
+def optimizer_s3(temp_dir_s3: str) -> Tuple[str, Callable]:
+ """Prefill the graphchain optimizer's parameters."""
+ return temp_dir_s3, functools.partial(
+ optimize,
+ keys=('top1',),
+ location=temp_dir_s3)
- return graphchain_opt_func, temporary_s3_storage, request.param
+def test_first_run(dask_graph: dict, optimizer: Tuple[str, Callable]) -> None:
+ """First run.
-def test_first_run(dask_dag_generation, optimizer):
- """
- Tests a first run of the graphchain optimization
- function ``optimize``. It checks the final result,
- that that all function calls are wrapped - for
- execution and output storing, that the hashchain is
- created, that hashed outputs (the .pickle[.lz4] files)
- are generated and that the name of each file is a key
- in the hashchain.
+ Tests a first run of the graphchain optimization function ``optimize``. It
+ checks the final result, that that all function calls are wrapped - for
+ execution and output storing, that the hashchain is created, that hashed
+ outputs (the .pickle[.lz4] files) are generated and that the name of
+ each file is a key in the hashchain.
"""
- dsk = dask_dag_generation
- fopt, compress, filesdir = optimizer
-
- if compress:
- data_ext = ".pickle.lz4"
- else:
- data_ext = ".pickle"
- hashchainfile = "graphchain.json"
+ dsk = dask_graph
+ cache_dir, graphchain_optimize = optimizer
# Run optimizer
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
# Check the final result
result = dask.get(newdsk, ["top1"])
assert result == (-14, )
# Check that all functions have been wrapped
- for key, task in dsk.items():
+ for key, _task in dsk.items():
newtask = newdsk[key]
- assert newtask[0].__name__ == "exec_store_wrapper"
- if isinstance(task, Iterable):
- assert newtask[1:] == task[1:]
- else:
- assert not newtask[1:]
+ assert isinstance(newtask[0], CachedComputation)
# Check that the hash files are written and that each
# filename can be found as a key in the hashchain
# (the association of hash <-> DAG tasks is not tested)
- storage = fs.osfs.OSFS(filesdir)
+ storage = fs.osfs.OSFS(cache_dir)
filelist = storage.listdir("/")
- filelist_cache = storage.listdir("cache")
- nfiles = sum(map(lambda x: x.endswith(data_ext), filelist_cache))
-
- assert hashchainfile in filelist
- assert nfiles == len(dsk)
-
- hashchain = load_hashchain(storage, compress=compress)
+ nfiles = len(filelist)
+ assert nfiles >= len(dsk)
storage.close()
- for filename in filelist_cache:
- if len(filename) == 43:
- assert filename[-11:] == ".pickle.lz4"
- elif len(filename) == 39:
- assert filename[-7:] == ".pickle"
- else: # there should be no other files in the directory
- assert False
- assert str.split(filename, ".")[0] in hashchain.keys()
+def NO_test_single_run_s3(
+ dask_graph: dict,
+ optimizer_s3: Tuple[str, Callable]) -> None:
+ """Run on S3.
-def DISABLED_test_single_run_s3(dask_dag_generation, optimizer_s3):
- """
- Tests a single run of the graphchain optimization
- function ``optimize`` using Amazon S3 as a
- persistency layer. It checks the final result,
- that that all function calls are wrapped - for
- execution and output storing, that the hashchain is
- created, that hashed outputs (the .pickle[.lz4] files)
- are generated and that the name of each file is a key
- in the hashchain.
+ Tests a single run of the graphchain optimization function ``optimize``
+ using Amazon S3 as a persistency layer. It checks the final result, that
+ all function calls are wrapped - for execution and output storing, that the
+ hashchain is created, that hashed outputs (the .pickle[.lz4] files)
+ are generated and that the name of each file is a key in the hashchain.
"""
- dsk = dask_dag_generation
- fopt, filesdir, compress = optimizer_s3
+ dsk = dask_graph
+ cache_dir, graphchain_optimize = optimizer_s3
# Run optimizer
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
# Check the final result
result = dask.get(newdsk, ["top1"])
assert result == (-14, )
- if compress:
- data_ext = ".pickle.lz4"
- else:
- data_ext = ".pickle"
- hashchainfile = "graphchain.json"
+ data_ext = ".pickle.lz4"
# Check that all functions have been wrapped
- for key, task in dsk.items():
+ for key, _task in dsk.items():
newtask = newdsk[key]
- assert newtask[0].__name__ == "exec_store_wrapper"
- if isinstance(task, Iterable):
- assert newtask[1:] == task[1:]
- else:
- assert not newtask[1:]
+ isinstance(newtask, CachedComputation)
# Check that the hash files are written and that each
# filename can be found as a key in the hashchain
# (the association of hash <-> DAG tasks is not tested)
- storage = fs.open_fs(filesdir)
+ storage = fs.open_fs(cache_dir)
filelist = storage.listdir("/")
- filelist_cache = storage.listdir("/cache")
- nfiles = sum(map(lambda x: x.endswith(data_ext), filelist_cache))
-
- assert hashchainfile in filelist
+ nfiles = sum(map(lambda x: x.endswith(data_ext), filelist))
assert nfiles == len(dsk)
- hashchain = load_hashchain(storage, compress=compress)
-
- for filename in filelist_cache:
- if len(filename) == 43:
- assert filename[-11:] == ".pickle.lz4"
- elif len(filename) == 39:
- assert filename[-7:] == ".pickle"
- else: # there should be no other files in the directory
- assert False
- assert str.split(filename, ".")[0] in hashchain.keys()
-
- # Cleanup (the main directory will be removed by the
- # temporary directory fixture)
- storage.removetree('cache')
- storage.remove('graphchain.json')
- assert not storage.listdir('/')
+def test_second_run(
+ dask_graph: dict,
+ optimizer: Tuple[str, Callable]) -> None:
+ """Second run.
-def test_second_run(dask_dag_generation, optimizer):
+ Tests a second run of the graphchain optimization function `optimize`. It
+ checks the final result, that that all function calls are wrapped - for
+ loading and the the result key has no dependencies.
"""
- Tests a second run of the graphchain optimization function `optimize`.
- It checks the final result, that that all function calls are
- wrapped - for loading and the the result key has no dependencies.
- """
- dsk = dask_dag_generation
- fopt, _, _ = optimizer
+ dsk = dask_graph
+ _, graphchain_optimize = optimizer
# Run optimizer
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
# Check the final result
result = dask.get(newdsk, ["top1"])
@@ -321,28 +219,30 @@ def test_second_run(dask_dag_generation, optimizer):
for key in dsk.keys():
newtask = newdsk[key]
assert isinstance(newtask, tuple)
- assert newtask[0].__name__ == "loading_wrapper"
- assert len(newtask) == 1 # only the loading wrapper
+ assert isinstance(newtask[0], CachedComputation)
-def test_node_changes(dask_dag_generation, optimizer):
- """
- Tests the functionality of the graphchain in the event of changes
- in the structure of the graph, namely by altering the functions/constants
- associated to the tasks. After optimization, the afected nodes should
- be wrapped in a storeand execution wrapper and their dependency lists
- should not be empty.
+def test_node_changes(
+ dask_graph: dict,
+ optimizer: Tuple[str, Callable]) -> None:
+ """Test node changes.
+
+ Tests the functionality of the graphchain in the event of changes in the
+ structure of the graph, namely by altering the functions/constants
+ associated to the tasks. After optimization, the afected nodes should be
+ wrapped in a storeand execution wrapper and their dependency lists should
+ not be empty.
"""
- dsk = dask_dag_generation
- fopt, _, _ = optimizer
+ dsk = dask_graph
+ _, graphchain_optimize = optimizer
# Replacement function 'goo'
- def goo(*args):
+ def goo(*args: int) -> int:
# hash miss!
return sum(args) + 1
# Replacement function 'top'
- def top(argument, argument2):
+ def top(argument: int, argument2: int) -> int:
# hash miss!
return argument - argument2
@@ -353,70 +253,53 @@ def top(argument, argument2):
"v2": (1000, {"v2", "bar1", "boo1", "baz2", "top1"}, (-1012, ))
}
- for (modkey, (taskobj, affected_nodes, result)) in moddata.items():
+ for (modkey, (taskobj, _affected_nodes, result)) in moddata.items():
workdsk = dsk.copy()
if callable(taskobj):
workdsk[modkey] = (taskobj, *dsk[modkey][1:])
else:
workdsk[modkey] = taskobj
- newdsk = fopt(workdsk, keys=["top1"])
+ newdsk = graphchain_optimize(workdsk, keys=["top1"])
assert result == dask.get(newdsk, ["top1"])
- for key, newtask in newdsk.items():
- if callable(taskobj):
- if key in affected_nodes:
- assert newtask[0].__name__ == "exec_store_wrapper"
- assert get_dependencies(newdsk, key)
- else:
- assert newtask[0].__name__ == "loading_wrapper"
- assert not get_dependencies(newdsk, key)
- else:
- if key in affected_nodes and key == modkey:
- assert newtask[0].__name__ == "exec_store_wrapper"
- assert not get_dependencies(newdsk, key)
- elif key in affected_nodes:
- assert newtask[0].__name__ == "exec_store_wrapper"
- assert get_dependencies(newdsk, key)
- else:
- assert newtask[0].__name__ == "loading_wrapper"
- assert not get_dependencies(newdsk, key)
-
-
-def test_exec_only_nodes(dask_dag_generation, optimizer_exec_only_nodes):
- """
- Tests that execution-only nodes execute in the event
- that dependencies of their parent nodes (i.e. in the
- dask graph) get modified.
+
+def test_exec_only_nodes(
+ dask_graph: dict,
+ optimizer_exec_only_nodes: Tuple[str, Callable]) -> None:
+ """Test skipping some tasks.
+
+ Tests that execution-only nodes execute in the event that dependencies of
+ their parent nodes (i.e. in the dask graph) get modified.
"""
- dsk = dask_dag_generation
- fopt, filesdir = optimizer_exec_only_nodes
+ dsk = dask_graph
+ cache_dir, graphchain_optimize = optimizer_exec_only_nodes
# Cleanup temporary directory
- filelist = os.listdir(filesdir)
+ filelist = os.listdir(cache_dir)
for entry in filelist:
- entrypath = os.path.join(filesdir, entry)
+ entrypath = os.path.join(cache_dir, entry)
if os.path.isdir(entrypath):
shutil.rmtree(entrypath, ignore_errors=True)
else:
os.remove(entrypath)
- filelist = os.listdir(filesdir)
+ filelist = os.listdir(cache_dir)
assert not filelist
# Run optimizer first time
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
result = dask.get(newdsk, ["top1"])
assert result == (-14, )
# Modify function
- def goo(*args):
+ def goo(*args: int) -> int:
# hash miss this!
return sum(args) + 1
dsk["goo1"] = (goo, *dsk["goo1"][1:])
# Run optimizer a second time
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
# Check the final result:
# The output of node 'boo1' is needed at node 'baz2'
@@ -427,56 +310,51 @@ def goo(*args):
assert result == (-14, )
-def test_cache_deletion(dask_dag_generation, optimizer):
- """
- Tests the ability to obtain results in the event that
- cache files are deleted (in the even of a cache-miss,
- the exec-store wrapper should be re-run by the
- load-wrapper).
+def test_cache_deletion(
+ dask_graph: dict,
+ optimizer: Tuple[str, Callable]) -> None:
+ """Test cache deletion.
+
+ Tests the ability to obtain results in the event that cache files are
+ deleted (in the even of a cache-miss, the exec-store wrapper should be
+ re-run by the load-wrapper).
"""
- dsk = dask_dag_generation
- fopt, compress, filesdir = optimizer
- storage = fs.osfs.OSFS(filesdir)
+ dsk = dask_graph
+ cache_dir, graphchain_optimize = optimizer
+ storage = fs.osfs.OSFS(cache_dir)
# Cleanup first
storage.removetree("/")
# Run optimizer (first time)
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
result = dask.get(newdsk, ["top1"])
- # Remove all of the cache
- filelist_cache = storage.listdir("cache")
- for _file in filelist_cache:
- storage.remove(fs.path.join("cache", _file))
-
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
result = dask.get(newdsk, ["top1"])
# Check the final result
assert result == (-14, )
-def test_identical_nodes(optimizer):
- """
- Small test for the presence of identical nodes.
- """
- fopt, compress, filesdir = optimizer
+def test_identical_nodes(optimizer: Tuple[str, Callable]) -> None:
+ """Small test for the presence of identical nodes."""
+ cache_dir, graphchain_optimize = optimizer
- def foo(x):
+ def foo(x: int) -> int:
return x + 1
- def bar(*args):
+ def bar(*args: int) -> int:
return sum(args)
dsk = {"foo1": (foo, 1), "foo2": (foo, 1), "top1": (bar, "foo1", "foo2")}
# First run
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
result = dask.get(newdsk, ["top1"])
assert result == (4, )
# Second run
- newdsk = fopt(dsk, keys=["top1"])
+ newdsk = graphchain_optimize(dsk, keys=["top1"])
result = dask.get(newdsk, ["top1"])
assert result == (4, )
diff --git a/graphchain/utils.py b/graphchain/utils.py
new file mode 100644
index 0000000..b51e638
--- /dev/null
+++ b/graphchain/utils.py
@@ -0,0 +1,84 @@
+"""Utility functions used by graphchain."""
+import string
+import sys
+from typing import Any, Optional
+
+
+def _fast_get_size(obj: Any) -> int:
+ if hasattr(obj, '__len__') and len(obj) <= 0:
+ return 0
+ if hasattr(obj, 'sample') and hasattr(obj, 'memory_usage'): # DF, Series.
+ n = min(len(obj), 1000)
+ s = obj.sample(n=n).memory_usage(index=True, deep=True)
+ if hasattr(s, 'sum'):
+ s = s.sum()
+ if hasattr(s, 'compute'):
+ s = s.compute()
+ s = s / n * len(obj)
+ return int(s)
+ elif hasattr(obj, 'nbytes'): # Numpy.
+ return int(obj.nbytes)
+ elif hasattr(obj, 'data') and hasattr(obj.data, 'nbytes'): # Sparse.
+ return int(3 * obj.data.nbytes)
+ raise TypeError('Could not determine size of the given object.')
+
+
+def _slow_get_size(obj: Any, seen: Optional[set]=None) -> int:
+ size = sys.getsizeof(obj)
+ seen = seen or set()
+ obj_id = id(obj)
+ if obj_id in seen:
+ return 0
+ seen.add(obj_id)
+ if isinstance(obj, dict):
+ size += sum(get_size(v, seen) for v in obj.values())
+ size += sum(get_size(k, seen) for k in obj.keys())
+ elif hasattr(obj, '__dict__'):
+ size += get_size(obj.__dict__, seen)
+ elif hasattr(obj, '__iter__') and \
+ not isinstance(obj, (str, bytes, bytearray)):
+ size += sum(get_size(i, seen) for i in obj)
+ return size
+
+
+def get_size(obj: Any, seen: Optional[set]=None) -> int:
+ """Recursively compute the size of an object.
+
+ Parameters
+ ----------
+ obj
+ The object to get the size of.
+
+ Returns
+ -------
+ int
+ The (approximate) size in bytes of the given object.
+ """
+ # Short-circuit some types.
+ try:
+ return _fast_get_size(obj)
+ except TypeError:
+ pass
+ # General-purpose size computation.
+ return _slow_get_size(obj, seen)
+
+
+def str_to_posix_fully_portable_filename(s: str) -> str:
+ """Convert key to POSIX fully portable filename [1].
+
+ Parameters
+ ----------
+ s
+ The string to convert to a POSIX fully portable filename.
+
+ Returns
+ -------
+ str
+ A POSIX fully portable filename.
+
+ References
+ ----------
+ .. [1] https://en.wikipedia.org/wiki/Filename
+ """
+ safechars = string.ascii_letters + string.digits + '._-'
+ return ''.join(c if c in safechars else '-' for c in s)
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000..caa7fd2
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,36 @@
+"""Setup module for graphchain."""
+
+from os import path
+
+from setuptools import find_packages, setup
+
+here = path.abspath(path.dirname(__file__))
+with open(path.join(here, 'README.md'), encoding='utf-8') as f:
+ long_description = f.read()
+
+setup(
+ name='graphchain',
+ version='1.0.0',
+ description='An efficient cache for the execution of dask graphs',
+ long_description=long_description,
+ long_description_content_type='text/markdown',
+ url='https://github.com/radix-ai/graphchain',
+ author='radix.ai',
+ author_email='developers@radix.ai',
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'Intended Audience :: Developers',
+ 'Topic :: Software Development :: Libraries :: Python Modules',
+ 'License :: OSI Approved :: MIT License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 3.6',
+ ],
+ keywords='dask graph cache distributed',
+ packages=find_packages(exclude=['contrib', 'docs', 'tests']),
+ install_requires=['cloudpickle', 'dask', 'fs-s3fs', 'joblib', 'lz4'],
+ project_urls={
+ 'Bug Reports': 'https://github.com/radix-ai/graphchain/issues',
+ 'Source': 'https://github.com/radix-ai/graphchain',
+ },
+)