diff --git a/.circleci/config.yml b/.circleci/config.yml
index 44d50547804f04..d5e9ac799fe728 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -157,6 +157,7 @@ jobs:
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
+ - run: python -c "from transformers import *" || (echo '🚨 import failed, this means you introduced unprotected imports! 🚨'; exit 1)
- run: ruff check examples tests src utils
- run: ruff format tests src utils --check
- run: python utils/custom_init_isort.py --check_only
diff --git a/.github/workflows/build-docker-images.yml b/.github/workflows/build-docker-images.yml
index 3c7df0f2da4bb6..23424ffb83ac63 100644
--- a/.github/workflows/build-docker-images.yml
+++ b/.github/workflows/build-docker-images.yml
@@ -198,41 +198,44 @@ jobs:
push: true
tags: huggingface/transformers-pytorch-gpu
-# Need to be fixed with the help from Guillaume.
-# latest-pytorch-amd:
-# name: "Latest PyTorch (AMD) [dev]"
-# runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
-# steps:
-# - name: Set up Docker Buildx
-# uses: docker/setup-buildx-action@v3
-# - name: Check out code
-# uses: actions/checkout@v3
-# - name: Login to DockerHub
-# uses: docker/login-action@v3
-# with:
-# username: ${{ secrets.DOCKERHUB_USERNAME }}
-# password: ${{ secrets.DOCKERHUB_PASSWORD }}
-# - name: Build and push
-# uses: docker/build-push-action@v5
-# with:
-# context: ./docker/transformers-pytorch-amd-gpu
-# build-args: |
-# REF=main
-# push: true
-# tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
-# # Push CI images still need to be re-built daily
-# -
-# name: Build and push (for Push CI) in a daily basis
-# # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
-# # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
-# if: inputs.image_postfix != '-push-ci'
-# uses: docker/build-push-action@v5
-# with:
-# context: ./docker/transformers-pytorch-amd-gpu
-# build-args: |
-# REF=main
-# push: true
-# tags: huggingface/transformers-pytorch-amd-gpu-push-ci
+ latest-pytorch-amd:
+ name: "Latest PyTorch (AMD) [dev]"
+ runs-on: [intel-cpu, 8-cpu, ci]
+ steps:
+ -
+ name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+ -
+ name: Check out code
+ uses: actions/checkout@v3
+ -
+ name: Login to DockerHub
+ uses: docker/login-action@v3
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_PASSWORD }}
+ -
+ name: Build and push
+ uses: docker/build-push-action@v5
+ with:
+ context: ./docker/transformers-pytorch-amd-gpu
+ build-args: |
+ REF=main
+ push: true
+ tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
+ # Push CI images still need to be re-built daily
+ -
+ name: Build and push (for Push CI) in a daily basis
+ # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
+ # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
+ if: inputs.image_postfix != '-push-ci'
+ uses: docker/build-push-action@v5
+ with:
+ context: ./docker/transformers-pytorch-amd-gpu
+ build-args: |
+ REF=main
+ push: true
+ tags: huggingface/transformers-pytorch-amd-gpu-push-ci
latest-tensorflow:
name: "Latest TensorFlow [dev]"
@@ -262,41 +265,44 @@ jobs:
push: true
tags: huggingface/transformers-tensorflow-gpu
- # latest-pytorch-deepspeed-amd:
- # name: "PyTorch + DeepSpeed (AMD) [dev]"
-
- # runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
- # steps:
- # - name: Set up Docker Buildx
- # uses: docker/setup-buildx-action@v3
- # - name: Check out code
- # uses: actions/checkout@v3
- # - name: Login to DockerHub
- # uses: docker/login-action@v3
- # with:
- # username: ${{ secrets.DOCKERHUB_USERNAME }}
- # password: ${{ secrets.DOCKERHUB_PASSWORD }}
- # - name: Build and push
- # uses: docker/build-push-action@v5
- # with:
- # context: ./docker/transformers-pytorch-deepspeed-amd-gpu
- # build-args: |
- # REF=main
- # push: true
- # tags: huggingface/transformers-pytorch-deepspeed-amd-gpu${{ inputs.image_postfix }}
- # # Push CI images still need to be re-built daily
- # -
- # name: Build and push (for Push CI) in a daily basis
- # # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
- # # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
- # if: inputs.image_postfix != '-push-ci'
- # uses: docker/build-push-action@v5
- # with:
- # context: ./docker/transformers-pytorch-deepspeed-amd-gpu
- # build-args: |
- # REF=main
- # push: true
- # tags: huggingface/transformers-pytorch-deepspeed-amd-gpu-push-ci
+ latest-pytorch-deepspeed-amd:
+ name: "PyTorch + DeepSpeed (AMD) [dev]"
+ runs-on: [intel-cpu, 8-cpu, ci]
+ steps:
+ -
+ name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+ -
+ name: Check out code
+ uses: actions/checkout@v3
+ -
+ name: Login to DockerHub
+ uses: docker/login-action@v3
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_PASSWORD }}
+ -
+ name: Build and push
+ uses: docker/build-push-action@v5
+ with:
+ context: ./docker/transformers-pytorch-deepspeed-amd-gpu
+ build-args: |
+ REF=main
+ push: true
+ tags: huggingface/transformers-pytorch-deepspeed-amd-gpu${{ inputs.image_postfix }}
+ # Push CI images still need to be re-built daily
+ -
+ name: Build and push (for Push CI) in a daily basis
+ # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
+ # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
+ if: inputs.image_postfix != '-push-ci'
+ uses: docker/build-push-action@v5
+ with:
+ context: ./docker/transformers-pytorch-deepspeed-amd-gpu
+ build-args: |
+ REF=main
+ push: true
+ tags: huggingface/transformers-pytorch-deepspeed-amd-gpu-push-ci
latest-quantization-torch-docker:
name: "Latest Pytorch + Quantization [dev]"
diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index 99f0f15230a017..e3e3b5f2df37f1 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -16,6 +16,7 @@ jobs:
package: transformers
notebook_folder: transformers_doc
languages: de en es fr hi it ko pt tr zh ja te
+ custom_container: huggingface/transformers-doc-builder
secrets:
token: ${{ secrets.HUGGINGFACE_PUSH }}
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/.github/workflows/build_pr_documentation.yml b/.github/workflows/build_pr_documentation.yml
index f6fa4c8d537cc6..c8d073ea34688f 100644
--- a/.github/workflows/build_pr_documentation.yml
+++ b/.github/workflows/build_pr_documentation.yml
@@ -15,3 +15,4 @@ jobs:
pr_number: ${{ github.event.number }}
package: transformers
languages: de en es fr hi it ko pt tr zh ja te
+ custom_container: huggingface/transformers-doc-builder
diff --git a/Makefile b/Makefile
index 424880ce150a6e..49535b5694d6fd 100644
--- a/Makefile
+++ b/Makefile
@@ -51,12 +51,14 @@ repo-consistency:
# this target runs checks on all files
quality:
+ @python -c "from transformers import *" || (echo '🚨 import failed, this means you introduced unprotected imports! 🚨'; exit 1)
ruff check $(check_dirs) setup.py conftest.py
ruff format --check $(check_dirs) setup.py conftest.py
python utils/custom_init_isort.py --check_only
python utils/sort_auto_mappings.py --check_only
python utils/check_doc_toc.py
+
# Format source code automatically and check is there are any problems left that need manual fixing
extra_style_checks:
diff --git a/README.md b/README.md
index 245fcdb4212717..8518fc09dce800 100644
--- a/README.md
+++ b/README.md
@@ -473,6 +473,7 @@ Current number of checkpoints: ** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_de.md b/README_de.md
index 2fdd6412741574..66fae9870653df 100644
--- a/README_de.md
+++ b/README_de.md
@@ -469,6 +469,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_es.md b/README_es.md
index 01a42817383f9d..e4f4dedc3ea0cf 100644
--- a/README_es.md
+++ b/README_es.md
@@ -446,6 +446,7 @@ Número actual de puntos de control: ** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_fr.md b/README_fr.md
index 68993116bd997d..c2da27829ecbb5 100644
--- a/README_fr.md
+++ b/README_fr.md
@@ -467,6 +467,7 @@ Nombre actuel de points de contrôle : ** (de Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) publié dans l'article [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) parWenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (de NVIDIA) a été publié dans l'article [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) par Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev et Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (de l'équipe Qwen, Alibaba Group) a été publié avec le rapport technique [Qwen Technical Report](https://arxiv.org/abs/2309.16609) par Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou et Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (de l'équipe Qwen, Alibaba Group) a été publié avec le rapport technique [blog post](https://qwenlm.github.io/blog/qwen-moe/) par Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (de Facebook) a été publié dans l'article [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) par Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (de Google Research) a été publié dans l'article [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) par Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat et Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (de Google Research) a été publié dans l'article [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) par Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_hd.md b/README_hd.md
index 6746e674d09d7b..a5bd56ee1c1dce 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -420,6 +420,7 @@ conda install conda-forge::transformers
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. से) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. द्वाराअनुसंधान पत्र [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) के साथ जारी किया गया
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA से) साथ वाला पेपर [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) हाओ वू, पैट्रिक जुड, जिआओजी झांग, मिखाइल इसेव और पॉलियस माइकेविसियस द्वारा।
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group से) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. द्वाराअनुसंधान पत्र [Qwen Technical Report](https://arxiv.org/abs/2309.16609) के साथ जारी किया गया
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group से) Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou. द्वाराअनुसंधान पत्र [blog post](https://qwenlm.github.io/blog/qwen-moe/) के साथ जारी किया गया
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (फेसबुक से) साथ में कागज [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) पैट्रिक लुईस, एथन पेरेज़, अलेक्जेंड्रा पिक्टस, फैबियो पेट्रोनी, व्लादिमीर कारपुखिन, नमन गोयल, हेनरिक कुटलर, माइक लुईस, वेन-ताउ यिह, टिम रॉकटाशेल, सेबस्टियन रिडेल, डौवे कीला द्वारा।
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google अनुसंधान से) केल्विन गु, केंटन ली, ज़ोरा तुंग, पानुपोंग पसुपत और मिंग-वेई चांग द्वारा साथ में दिया गया पेपर [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)।
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_ja.md b/README_ja.md
index ac922c3609dc7a..e42a5680a79d7f 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -480,6 +480,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797)
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group から) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. から公開された研究論文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group から) Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou. から公開された研究論文 [blog post](https://qwenlm.github.io/blog/qwen-moe/)
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
diff --git a/README_ko.md b/README_ko.md
index 6cf517a05d37d1..95cb1b0b79d5b0 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -395,6 +395,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. 에서 제공)은 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.의 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797)논문과 함께 발표했습니다.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA 에서) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 의 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 논문과 함께 발표했습니다.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group 에서 제공)은 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.의 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)논문과 함께 발표했습니다.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group 에서 제공)은 Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.의 [blog post](https://qwenlm.github.io/blog/qwen-moe/)논문과 함께 발표했습니다.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook 에서) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 의 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 논문과 함께 발표했습니다.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research 에서) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 의 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 논문과 함께 발표했습니다.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research 에서) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 의 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 논문과 함께 발표했습니다.
diff --git a/README_pt-br.md b/README_pt-br.md
index 9c36ea5744e2b2..7d10ce5e8c986c 100644
--- a/README_pt-br.md
+++ b/README_pt-br.md
@@ -478,6 +478,7 @@ Número atual de pontos de verificação: ** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_ru.md b/README_ru.md
index 646c46fc752bc1..03cc1b919e889f 100644
--- a/README_ru.md
+++ b/README_ru.md
@@ -468,6 +468,7 @@ conda install conda-forge::transformers
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_te.md b/README_te.md
index 0c8dd51f2b48d4..fa762d5659b5da 100644
--- a/README_te.md
+++ b/README_te.md
@@ -470,6 +470,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_vi.md b/README_vi.md
index face3bf7d1fae8..e7cad3b3649cc4 100644
--- a/README_vi.md
+++ b/README_vi.md
@@ -469,6 +469,7 @@ Số lượng điểm kiểm tra hiện tại: ** (từ Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) được phát hành với bài báo [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (từ NVIDIA) được phát hành với bài báo [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (từ the Qwen team, Alibaba Group) được phát hành với bài báo [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (từ the Qwen team, Alibaba Group) được phát hành với bài báo [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (từ Facebook) được phát hành với bài báo [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (từ Google Research) được phát hành với bài báo [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (từ Google Research) được phát hành với bài báo [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index e59fc7be3e0829..8ac4d5c388ee15 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -419,6 +419,7 @@ conda install conda-forge::transformers
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (来自 Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) 伴随论文 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) 由 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao 发布。
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (来自 the Qwen team, Alibaba Group) 伴随论文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609) 由 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu 发布。
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (来自 the Qwen team, Alibaba Group) 伴随论文 [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou 发布.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (来自 Facebook) 伴随论文 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 由 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 发布。
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (来自 Google Research) 伴随论文 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 由 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 825833e0633c32..0e31d8e6b52f4a 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -431,6 +431,7 @@ conda install conda-forge::transformers
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
+1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
diff --git a/SECURITY.md b/SECURITY.md
index a16cfe099f8f78..f5a3acc5a91b93 100644
--- a/SECURITY.md
+++ b/SECURITY.md
@@ -1,6 +1,40 @@
# Security Policy
+## Hugging Face Hub, remote artefacts, and remote code
+
+Transformers is open-source software that is tightly coupled to the Hugging Face Hub. While you have the ability to use it
+offline with pre-downloaded model weights, it provides a very simple way to download, use, and manage models locally.
+
+When downloading artefacts that have been uploaded by others on any platform, you expose yourself to risks. Please
+read below for the security recommendations in order to keep your runtime and local environment safe.
+
+### Remote artefacts
+
+Models uploaded on the Hugging Face Hub come in different formats. We heavily recommend uploading and downloading
+models in the [`safetensors`](https://github.com/huggingface/safetensors) format (which is the default prioritized
+by the transformers library), as developed specifically to prevent arbitrary code execution on your system.
+
+To avoid loading models from unsafe formats(e.g. [pickle](https://docs.python.org/3/library/pickle.html), you should use the `use_safetenstors` parameter. If doing so, in the event that no .safetensors file is present, transformers will error when loading the model.
+
+### Remote code
+
+#### Modeling
+
+Transformers supports many model architectures, but is also the bridge between your Python runtime and models that
+are stored in model repositories on the Hugging Face Hub.
+
+These models require the `trust_remote_code=True` parameter to be set when using them; please **always** verify
+the content of the modeling files when using this argument. We recommend setting a revision in order to ensure you
+protect yourself from updates on the repository.
+
+#### Tools
+
+Through the `Agent` framework, remote tools can be downloaded to be used by the Agent. You're to specify these tools
+yourself, but please keep in mind that their code will be run on your machine if the Agent chooses to run them.
+
+Please inspect the code of the tools before passing them to the Agent to protect your runtime and local setup.
+
## Reporting a Vulnerability
-🤗 We have our bug bounty program set up with HackerOne. Please feel free to submit vulnerability reports to our private program at https://hackerone.com/hugging_face.
+🤗 Please feel free to submit vulnerability reports to our private bug bounty program at https://hackerone.com/hugging_face. You'll need to request access to the program by emailing security@huggingface.co.
Note that you'll need to be invited to our program, so send us a quick email at security@huggingface.co if you've found a vulnerability.
diff --git a/docker/transformers-pytorch-amd-gpu/Dockerfile b/docker/transformers-pytorch-amd-gpu/Dockerfile
index 46ca1a531b4ab4..0b070c93a64f3d 100644
--- a/docker/transformers-pytorch-amd-gpu/Dockerfile
+++ b/docker/transformers-pytorch-amd-gpu/Dockerfile
@@ -34,3 +34,6 @@ RUN python3 -m pip uninstall -y tensorflow flax
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
+
+# Remove nvml as it is not compatible with ROCm
+RUN python3 -m pip uninstall py3nvml pynvml -y
diff --git a/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile b/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
index 1fa384dfa2bc03..fc6f912235be10 100644
--- a/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
+++ b/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
@@ -42,4 +42,7 @@ RUN python3 -m pip install --no-cache-dir ./transformers[accelerate,testing,sent
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
-RUN python3 -c "from deepspeed.launcher.runner import main"
\ No newline at end of file
+RUN python3 -c "from deepspeed.launcher.runner import main"
+
+# Remove nvml as it is not compatible with ROCm
+RUN python3 -m pip uninstall py3nvml pynvml -y
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 0fc3d82f53612c..af44de4d1067b1 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -172,7 +172,7 @@
title: GPU inference
title: Optimizing inference
- local: big_models
- title: Instantiating a big model
+ title: Instantiate a big model
- local: debugging
title: Debugging
- local: tf_xla
@@ -462,6 +462,8 @@
title: QDQBert
- local: model_doc/qwen2
title: Qwen2
+ - local: model_doc/qwen2_moe
+ title: Qwen2MoE
- local: model_doc/rag
title: RAG
- local: model_doc/realm
diff --git a/docs/source/en/add_new_model.md b/docs/source/en/add_new_model.md
index 56436be97fa052..efbe4a82759a06 100644
--- a/docs/source/en/add_new_model.md
+++ b/docs/source/en/add_new_model.md
@@ -192,46 +192,46 @@ its attention layer, etc. We will be more than happy to help you.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
-```bash
-git clone https://github.com/[your Github handle]/transformers.git
-cd transformers
-git remote add upstream https://github.com/huggingface/transformers.git
-```
+ ```bash
+ git clone https://github.com/[your Github handle]/transformers.git
+ cd transformers
+ git remote add upstream https://github.com/huggingface/transformers.git
+ ```
3. Set up a development environment, for instance by running the following command:
-```bash
-python -m venv .env
-source .env/bin/activate
-pip install -e ".[dev]"
-```
+ ```bash
+ python -m venv .env
+ source .env/bin/activate
+ pip install -e ".[dev]"
+ ```
-Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
-failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
-(PyTorch, TensorFlow and/or Flax) then do:
+ Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
+ failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
+ (PyTorch, TensorFlow and/or Flax) then do:
-```bash
-pip install -e ".[quality]"
-```
+ ```bash
+ pip install -e ".[quality]"
+ ```
-which should be enough for most use cases. You can then return to the parent directory
+ which should be enough for most use cases. You can then return to the parent directory
-```bash
-cd ..
-```
+ ```bash
+ cd ..
+ ```
4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
instructions on https://pytorch.org/get-started/locally/.
-**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
+ **Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
5. To port *brand_new_bert*, you will also need access to its original repository:
-```bash
-git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
-cd brand_new_bert
-pip install -e .
-```
+ ```bash
+ git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
+ cd brand_new_bert
+ pip install -e .
+ ```
Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
@@ -421,29 +421,29 @@ You should do the following:
1. Create a branch with a descriptive name from your main branch
-```bash
-git checkout -b add_brand_new_bert
-```
+ ```bash
+ git checkout -b add_brand_new_bert
+ ```
2. Commit the automatically generated code:
-```bash
-git add .
-git commit
-```
+ ```bash
+ git add .
+ git commit
+ ```
3. Fetch and rebase to current main
-```bash
-git fetch upstream
-git rebase upstream/main
-```
+ ```bash
+ git fetch upstream
+ git rebase upstream/main
+ ```
4. Push the changes to your account using:
-```bash
-git push -u origin a-descriptive-name-for-my-changes
-```
+ ```bash
+ git push -u origin a-descriptive-name-for-my-changes
+ ```
5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
@@ -759,7 +759,7 @@ In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLO
Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
-`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
+`BrandNewBertModelTester`/`BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
ways:
- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
@@ -776,7 +776,7 @@ It is very important to find/extract the original tokenizer file and to manage t
Transformers' implementation of the tokenizer.
To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
-that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
+that inputs a string and returns the `input_ids`. It could look similar to this (in pseudo-code):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
@@ -827,7 +827,7 @@ the community to add some *Tips* to show how the model should be used. Don't hes
regarding the docstrings.
Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
-correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
+correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always good to remind oneself that documentation should
be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
point of the community with the model.
diff --git a/docs/source/en/add_tensorflow_model.md b/docs/source/en/add_tensorflow_model.md
index 52c7e3b1ada118..23a1e2d17082bb 100644
--- a/docs/source/en/add_tensorflow_model.md
+++ b/docs/source/en/add_tensorflow_model.md
@@ -109,52 +109,52 @@ instructions below to set up your environment and open a draft PR.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
-```bash
-git clone https://github.com/[your Github handle]/transformers.git
-cd transformers
-git remote add upstream https://github.com/huggingface/transformers.git
-```
+ ```bash
+ git clone https://github.com/[your Github handle]/transformers.git
+ cd transformers
+ git remote add upstream https://github.com/huggingface/transformers.git
+ ```
-3. Set up a development environment, for instance by running the following command:
+3. Set up a development environment, for instance by running the following commands:
-```bash
-python -m venv .env
-source .env/bin/activate
-pip install -e ".[dev]"
-```
+ ```bash
+ python -m venv .env
+ source .env/bin/activate
+ pip install -e ".[dev]"
+ ```
-Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
-failure with this command. If that's the case make sure to install TensorFlow then do:
+ Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
+ failure with this command. If that's the case make sure to install TensorFlow then do:
-```bash
-pip install -e ".[quality]"
-```
+ ```bash
+ pip install -e ".[quality]"
+ ```
-**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
+ **Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
-4. Create a branch with a descriptive name from your main branch
+4. Create a branch with a descriptive name from your main branch:
-```bash
-git checkout -b add_tf_brand_new_bert
-```
+ ```bash
+ git checkout -b add_tf_brand_new_bert
+ ```
-5. Fetch and rebase to current main
+5. Fetch and rebase to current main:
-```bash
-git fetch upstream
-git rebase upstream/main
-```
+ ```bash
+ git fetch upstream
+ git rebase upstream/main
+ ```
6. Add an empty `.py` file in `transformers/src/models/brandnewbert/` named `modeling_tf_brandnewbert.py`. This will
be your TensorFlow model file.
7. Push the changes to your account using:
-```bash
-git add .
-git commit -m "initial commit"
-git push -u origin add_tf_brand_new_bert
-```
+ ```bash
+ git add .
+ git commit -m "initial commit"
+ git push -u origin add_tf_brand_new_bert
+ ```
8. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
diff --git a/docs/source/en/big_models.md b/docs/source/en/big_models.md
index 729d32ca202951..0c1737af1abd7e 100644
--- a/docs/source/en/big_models.md
+++ b/docs/source/en/big_models.md
@@ -14,110 +14,202 @@ rendered properly in your Markdown viewer.
-->
-# Instantiating a big model
+# Instantiate a big model
-When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
-from PyTorch is:
+A barrier to accessing very large pretrained models is the amount of memory required. When loading a pretrained PyTorch model, you usually:
-1. Create your model with random weights.
+1. Create a model with random weights.
2. Load your pretrained weights.
-3. Put those pretrained weights in your random model.
+3. Put those pretrained weights in the model.
-Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you get out of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
+The first two steps both require a full version of the model in memory and if the model weighs several GBs, you may not have enough memory for two copies of it. This problem is amplified in distributed training environments because each process loads a pretrained model and stores two copies in memory.
-
+> [!TIP]
+> The randomly created model is initialized with "empty" tensors, which take space in memory without filling it. The random values are whatever was in this chunk of memory at the time. To improve loading speed, the [`_fast_init`](https://github.com/huggingface/transformers/blob/c9f6e5e35156e068b227dd9b15521767f6afd4d2/src/transformers/modeling_utils.py#L2710) parameter is set to `True` by default to skip the random initialization for all weights that are correctly loaded.
-Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instantiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
-
-
-
-In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
+This guide will show you how Transformers can help you load large pretrained models despite their memory requirements.
## Sharded checkpoints
-Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
+From Transformers v4.18.0, a checkpoint larger than 10GB is automatically sharded by the [`~PreTrainedModel.save_pretrained`] method. It is split into several smaller partial checkpoints and creates an index file that maps parameter names to the files they're stored in.
-You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
+The maximum shard size is controlled with the `max_shard_size` parameter, but by default it is 5GB, because it is easier to run on free-tier GPU instances without running out of memory.
-```py
-from transformers import AutoModel
-
-model = AutoModel.from_pretrained("google-bert/bert-base-cased")
-```
-
-If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
+For example, let's shard [BioMistral/BioMistral-7B](https://hf.co/BioMistral/BioMistral-7B).
```py
->>> import os
->>> import tempfile
-
>>> with tempfile.TemporaryDirectory() as tmp_dir:
-... model.save_pretrained(tmp_dir)
+... model.save_pretrained(tmp_dir, max_shard_size="5GB")
... print(sorted(os.listdir(tmp_dir)))
-['config.json', 'pytorch_model.bin']
+['config.json', 'generation_config.json', 'model-00001-of-00006.safetensors', 'model-00002-of-00006.safetensors', 'model-00003-of-00006.safetensors', 'model-00004-of-00006.safetensors', 'model-00005-of-00006.safetensors', 'model-00006-of-00006.safetensors', 'model.safetensors.index.json']
```
-Now let's use a maximum shard size of 200MB:
+The sharded checkpoint is reloaded with the [`~PreTrainedModel.from_pretrained`] method.
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
-... model.save_pretrained(tmp_dir, max_shard_size="200MB")
-... print(sorted(os.listdir(tmp_dir)))
-['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
+... model.save_pretrained(tmp_dir, max_shard_size="5GB")
+... new_model = AutoModel.from_pretrained(tmp_dir)
```
-On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
+The main advantage of sharded checkpoints for big models is that each shard is loaded after the previous one, which caps the memory usage to only the model size and the largest shard size.
+
+You could also directly load a sharded checkpoint inside a model without the [`~PreTrainedModel.from_pretrained`] method (similar to PyTorch's `load_state_dict()` method for a full checkpoint). In this case, use the [`~modeling_utils.load_sharded_checkpoint`] method.
```py
+>>> from transformers.modeling_utils import load_sharded_checkpoint
+
>>> with tempfile.TemporaryDirectory() as tmp_dir:
-... model.save_pretrained(tmp_dir, max_shard_size="200MB")
-... new_model = AutoModel.from_pretrained(tmp_dir)
+... model.save_pretrained(tmp_dir, max_shard_size="5GB")
+... load_sharded_checkpoint(model, tmp_dir)
```
-The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
+### Shard metadata
-Behind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
+The index file determines which keys are in the checkpoint and where the corresponding weights are stored. This file is loaded like any other JSON file and you can get a dictionary from it.
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
-... model.save_pretrained(tmp_dir, max_shard_size="200MB")
-... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
+... model.save_pretrained(tmp_dir, max_shard_size="5GB")
+... with open(os.path.join(tmp_dir, "model.safetensors.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
-The metadata just consists of the total size of the model for now. We plan to add other information in the future:
+The `metadata` key provides the total model size.
```py
>>> index["metadata"]
-{'total_size': 433245184}
+{'total_size': 28966928384}
```
-The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
+The `weight_map` key maps each parameter name (typically `state_dict` in a PyTorch model) to the shard it's stored in.
```py
>>> index["weight_map"]
-{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
- 'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
+{'lm_head.weight': 'model-00006-of-00006.safetensors',
+ 'model.embed_tokens.weight': 'model-00001-of-00006.safetensors',
+ 'model.layers.0.input_layernorm.weight': 'model-00001-of-00006.safetensors',
+ 'model.layers.0.mlp.down_proj.weight': 'model-00001-of-00006.safetensors',
...
+}
```
-If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
+## Accelerate's Big Model Inference
+
+> [!TIP]
+> Make sure you have Accelerate v0.9.0 or later and PyTorch v1.9.0 or later installed.
+
+From Transformers v4.20.0, the [`~PreTrainedModel.from_pretrained`] method is supercharged with Accelerate's [Big Model Inference](https://hf.co/docs/accelerate/usage_guides/big_modeling) feature to efficiently handle really big models! Big Model Inference creates a *model skeleton* on PyTorch's [**meta**](https://pytorch.org/docs/main/meta.html) device. The randomly initialized parameters are only created when the pretrained weights are loaded. This way, you aren't keeping two copies of the model in memory at the same time (one for the randomly initialized model and one for the pretrained weights), and the maximum memory consumed is only the full model size.
+
+To enable Big Model Inference in Transformers, set `low_cpu_mem_usage=True` in the [`~PreTrainedModel.from_pretrained`] method.
```py
->>> from transformers.modeling_utils import load_sharded_checkpoint
+from transformers import AutoModelForCausalLM
->>> with tempfile.TemporaryDirectory() as tmp_dir:
-... model.save_pretrained(tmp_dir, max_shard_size="200MB")
-... load_sharded_checkpoint(model, tmp_dir)
+gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", low_cpu_mem_usage=True)
+```
+
+Accelerate automatically dispatches the model weights across all available devices, starting with the fastest device (GPU) first and then offloading to the slower devices (CPU and even hard drive). This is enabled by setting `device_map="auto"` in the [`~PreTrainedModel.from_pretrained`] method. When you pass the `device_map` parameter, `low_cpu_mem_usage` is automatically set to `True` so you don't need to specify it.
+
+```py
+from transformers import AutoModelForCausalLM
+
+# these loading methods are equivalent
+gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto")
+gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", low_cpu_mem_usage=True)
```
-## Low memory loading
+You can also write your own `device_map` by mapping each layer to a device. It should map all model parameters to a device, but you don't have to detail where all the submodules of a layer go if the entire layer is on the same device.
-Sharded checkpoints reduce the memory usage during step 2 of the workflow mentioned above, but in order to use that model in a low memory setting, we recommend leveraging our tools based on the Accelerate library.
+```python
+device_map = {"model.layers.1": 0, "model.layers.14": 1, "model.layers.31": "cpu", "lm_head": "disk"}
+```
+
+Access `hf_device_map` attribute to see how Accelerate split the model across devices.
+
+```py
+gemma.hf_device_map
+```
+
+```python out
+{'model.embed_tokens': 0,
+ 'model.layers.0': 0,
+ 'model.layers.1': 0,
+ 'model.layers.2': 0,
+ 'model.layers.3': 0,
+ 'model.layers.4': 0,
+ 'model.layers.5': 0,
+ 'model.layers.6': 0,
+ 'model.layers.7': 0,
+ 'model.layers.8': 0,
+ 'model.layers.9': 0,
+ 'model.layers.10': 0,
+ 'model.layers.11': 0,
+ 'model.layers.12': 0,
+ 'model.layers.13': 0,
+ 'model.layers.14': 'cpu',
+ 'model.layers.15': 'cpu',
+ 'model.layers.16': 'cpu',
+ 'model.layers.17': 'cpu',
+ 'model.layers.18': 'cpu',
+ 'model.layers.19': 'cpu',
+ 'model.layers.20': 'cpu',
+ 'model.layers.21': 'cpu',
+ 'model.layers.22': 'cpu',
+ 'model.layers.23': 'cpu',
+ 'model.layers.24': 'cpu',
+ 'model.layers.25': 'cpu',
+ 'model.layers.26': 'cpu',
+ 'model.layers.27': 'cpu',
+ 'model.layers.28': 'cpu',
+ 'model.layers.29': 'cpu',
+ 'model.layers.30': 'cpu',
+ 'model.layers.31': 'cpu',
+ 'model.norm': 'cpu',
+ 'lm_head': 'cpu'}
+```
-Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
+## Model data type
+
+PyTorch model weights are normally instantiated as torch.float32 and it can be an issue if you try to load a model as a different data type. For example, you'd need twice as much memory to load the weights in torch.float32 and then again to load them in your desired data type, like torch.float16.
+
+> [!WARNING]
+> Due to how PyTorch is designed, the `torch_dtype` parameter only supports floating data types.
+
+To avoid wasting memory like this, explicitly set the `torch_dtype` parameter to the desired data type or set `torch_dtype="auto"` to load the weights with the most optimal memory pattern (the data type is automatically derived from the model weights).
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM
+
+gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", torch_dtype=torch.float16)
+```
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM
+
+gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", torch_dtype="auto")
+```
+
+
+
+
+You can also set the data type to use for models instantiated from scratch.
+
+```python
+import torch
+from transformers import AutoConfig, AutoModel
+
+my_config = AutoConfig.from_pretrained("google/gemma-2b", torch_dtype=torch.float16)
+model = AutoModel.from_config(my_config)
+```
diff --git a/docs/source/en/generation_strategies.md b/docs/source/en/generation_strategies.md
index 2e26f4b679e2cc..b70b17116fcd88 100644
--- a/docs/source/en/generation_strategies.md
+++ b/docs/source/en/generation_strategies.md
@@ -87,7 +87,7 @@ to stop generation whenever the full generation exceeds some amount of time. To
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
-sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
+sequences that start with a lower probability initial tokens and would've been ignored by the greedy search. Visualize how it works [here](https://huggingface.co/spaces/m-ric/beam_search_visualizer).
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
@@ -254,6 +254,12 @@ Unlike greedy search, beam-search decoding keeps several hypotheses at each time
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
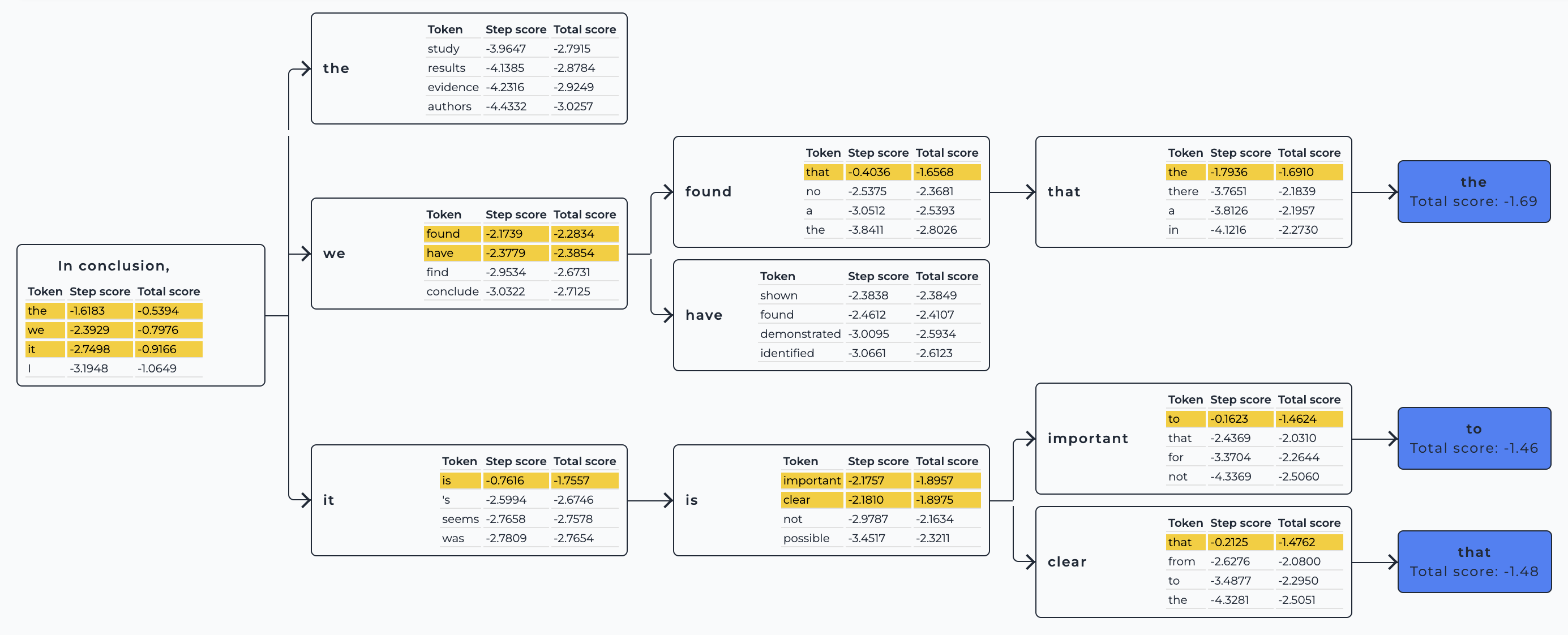
+
+  +
+
+You can visualize how beam-search decoding works in [this interactive demo](https://huggingface.co/spaces/m-ric/beam_search_visualizer): type your input sentence, and play with the parameters to see how the decoding beams change.
+
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
```python
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index dfa2b0a1d05791..ffa9ae3f4b0b41 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -240,6 +240,7 @@ Flax), PyTorch, and/or TensorFlow.
| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/main_classes/model.md b/docs/source/en/main_classes/model.md
index da907f80ee486a..a8ae2ad08bf8be 100644
--- a/docs/source/en/main_classes/model.md
+++ b/docs/source/en/main_classes/model.md
@@ -40,104 +40,6 @@ for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
- push_to_hub
- all
-
-
-### Large model loading
-
-In Transformers 4.20.0, the [`~PreTrainedModel.from_pretrained`] method has been reworked to accommodate large models using [Accelerate](https://huggingface.co/docs/accelerate/big_modeling). This requires Accelerate >= 0.9.0 and PyTorch >= 1.9.0. Instead of creating the full model, then loading the pretrained weights inside it (which takes twice the size of the model in RAM, one for the randomly initialized model, one for the weights), there is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded.
-
-This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint). This way the maximum RAM used is the full size of the model only.
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
-```
-
-Moreover, you can directly place the model on different devices if it doesn't fully fit in RAM (only works for inference for now). With `device_map="auto"`, Accelerate will determine where to put each layer to maximize the use of your fastest devices (GPUs) and offload the rest on the CPU, or even the hard drive if you don't have enough GPU RAM (or CPU RAM). Even if the model is split across several devices, it will run as you would normally expect.
-
-When passing a `device_map`, `low_cpu_mem_usage` is automatically set to `True`, so you don't need to specify it:
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
-```
-
-You can inspect how the model was split across devices by looking at its `hf_device_map` attribute:
-
-```py
-t0pp.hf_device_map
-```
-
-```python out
-{'shared': 0,
- 'decoder.embed_tokens': 0,
- 'encoder': 0,
- 'decoder.block.0': 0,
- 'decoder.block.1': 1,
- 'decoder.block.2': 1,
- 'decoder.block.3': 1,
- 'decoder.block.4': 1,
- 'decoder.block.5': 1,
- 'decoder.block.6': 1,
- 'decoder.block.7': 1,
- 'decoder.block.8': 1,
- 'decoder.block.9': 1,
- 'decoder.block.10': 1,
- 'decoder.block.11': 1,
- 'decoder.block.12': 1,
- 'decoder.block.13': 1,
- 'decoder.block.14': 1,
- 'decoder.block.15': 1,
- 'decoder.block.16': 1,
- 'decoder.block.17': 1,
- 'decoder.block.18': 1,
- 'decoder.block.19': 1,
- 'decoder.block.20': 1,
- 'decoder.block.21': 1,
- 'decoder.block.22': 'cpu',
- 'decoder.block.23': 'cpu',
- 'decoder.final_layer_norm': 'cpu',
- 'decoder.dropout': 'cpu',
- 'lm_head': 'cpu'}
-```
-
-You can also write your own device map following the same format (a dictionary layer name to device). It should map all parameters of the model to a given device, but you don't have to detail where all the submodules of one layer go if that layer is entirely on the same device. For instance, the following device map would work properly for T0pp (as long as you have the GPU memory):
-
-```python
-device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
-```
-
-Another way to minimize the memory impact of your model is to instantiate it at a lower precision dtype (like `torch.float16`) or use direct quantization techniques as described below.
-
-### Model Instantiation dtype
-
-Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
-load a model whose weights are in fp16, since it'd require twice as much memory. To overcome this limitation, you can
-either explicitly pass the desired `dtype` using `torch_dtype` argument:
-
-```python
-model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
-```
-
-or, if you want the model to always load in the most optimal memory pattern, you can use the special value `"auto"`,
-and then `dtype` will be automatically derived from the model's weights:
-
-```python
-model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
-```
-
-Models instantiated from scratch can also be told which `dtype` to use with:
-
-```python
-config = T5Config.from_pretrained("t5")
-model = AutoModel.from_config(config)
-```
-
-Due to Pytorch design, this functionality is only available for floating dtypes.
-
-
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index dbb87b5a4148c7..7d925027333119 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -24,7 +24,7 @@ This model was contributed by [Connor Henderson](https://huggingface.co/connor-h
## 🤗 Model Architecture
-FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with with conformer blocks as done in the ESPnet library.
+FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
#### FastSpeech2 Model Architecture

diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index 4708edde0b65d4..b2afbbd3b2ec40 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -60,6 +60,73 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
+## Usage example
+
+The `generate()` method can be used to generate text using GPT2 model.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+
+>>> prompt = "GPT2 is a model developed by OpenAI."
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## Using Flash Attention 2
+
+Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+```
+
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `gpt2` checkpoint and the Flash Attention 2 version of the model using a sequence length of 512.
+
+
+
+
+You can visualize how beam-search decoding works in [this interactive demo](https://huggingface.co/spaces/m-ric/beam_search_visualizer): type your input sentence, and play with the parameters to see how the decoding beams change.
+
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
```python
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index dfa2b0a1d05791..ffa9ae3f4b0b41 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -240,6 +240,7 @@ Flax), PyTorch, and/or TensorFlow.
| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/main_classes/model.md b/docs/source/en/main_classes/model.md
index da907f80ee486a..a8ae2ad08bf8be 100644
--- a/docs/source/en/main_classes/model.md
+++ b/docs/source/en/main_classes/model.md
@@ -40,104 +40,6 @@ for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
- push_to_hub
- all
-
-
-### Large model loading
-
-In Transformers 4.20.0, the [`~PreTrainedModel.from_pretrained`] method has been reworked to accommodate large models using [Accelerate](https://huggingface.co/docs/accelerate/big_modeling). This requires Accelerate >= 0.9.0 and PyTorch >= 1.9.0. Instead of creating the full model, then loading the pretrained weights inside it (which takes twice the size of the model in RAM, one for the randomly initialized model, one for the weights), there is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded.
-
-This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint). This way the maximum RAM used is the full size of the model only.
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
-```
-
-Moreover, you can directly place the model on different devices if it doesn't fully fit in RAM (only works for inference for now). With `device_map="auto"`, Accelerate will determine where to put each layer to maximize the use of your fastest devices (GPUs) and offload the rest on the CPU, or even the hard drive if you don't have enough GPU RAM (or CPU RAM). Even if the model is split across several devices, it will run as you would normally expect.
-
-When passing a `device_map`, `low_cpu_mem_usage` is automatically set to `True`, so you don't need to specify it:
-
-```py
-from transformers import AutoModelForSeq2SeqLM
-
-t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
-```
-
-You can inspect how the model was split across devices by looking at its `hf_device_map` attribute:
-
-```py
-t0pp.hf_device_map
-```
-
-```python out
-{'shared': 0,
- 'decoder.embed_tokens': 0,
- 'encoder': 0,
- 'decoder.block.0': 0,
- 'decoder.block.1': 1,
- 'decoder.block.2': 1,
- 'decoder.block.3': 1,
- 'decoder.block.4': 1,
- 'decoder.block.5': 1,
- 'decoder.block.6': 1,
- 'decoder.block.7': 1,
- 'decoder.block.8': 1,
- 'decoder.block.9': 1,
- 'decoder.block.10': 1,
- 'decoder.block.11': 1,
- 'decoder.block.12': 1,
- 'decoder.block.13': 1,
- 'decoder.block.14': 1,
- 'decoder.block.15': 1,
- 'decoder.block.16': 1,
- 'decoder.block.17': 1,
- 'decoder.block.18': 1,
- 'decoder.block.19': 1,
- 'decoder.block.20': 1,
- 'decoder.block.21': 1,
- 'decoder.block.22': 'cpu',
- 'decoder.block.23': 'cpu',
- 'decoder.final_layer_norm': 'cpu',
- 'decoder.dropout': 'cpu',
- 'lm_head': 'cpu'}
-```
-
-You can also write your own device map following the same format (a dictionary layer name to device). It should map all parameters of the model to a given device, but you don't have to detail where all the submodules of one layer go if that layer is entirely on the same device. For instance, the following device map would work properly for T0pp (as long as you have the GPU memory):
-
-```python
-device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
-```
-
-Another way to minimize the memory impact of your model is to instantiate it at a lower precision dtype (like `torch.float16`) or use direct quantization techniques as described below.
-
-### Model Instantiation dtype
-
-Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
-load a model whose weights are in fp16, since it'd require twice as much memory. To overcome this limitation, you can
-either explicitly pass the desired `dtype` using `torch_dtype` argument:
-
-```python
-model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
-```
-
-or, if you want the model to always load in the most optimal memory pattern, you can use the special value `"auto"`,
-and then `dtype` will be automatically derived from the model's weights:
-
-```python
-model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
-```
-
-Models instantiated from scratch can also be told which `dtype` to use with:
-
-```python
-config = T5Config.from_pretrained("t5")
-model = AutoModel.from_config(config)
-```
-
-Due to Pytorch design, this functionality is only available for floating dtypes.
-
-
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
diff --git a/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/source/en/model_doc/fastspeech2_conformer.md
index dbb87b5a4148c7..7d925027333119 100644
--- a/docs/source/en/model_doc/fastspeech2_conformer.md
+++ b/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -24,7 +24,7 @@ This model was contributed by [Connor Henderson](https://huggingface.co/connor-h
## 🤗 Model Architecture
-FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with with conformer blocks as done in the ESPnet library.
+FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
#### FastSpeech2 Model Architecture

diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index 4708edde0b65d4..b2afbbd3b2ec40 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -60,6 +60,73 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
+## Usage example
+
+The `generate()` method can be used to generate text using GPT2 model.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+
+>>> prompt = "GPT2 is a model developed by OpenAI."
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## Using Flash Attention 2
+
+Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+```
+
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `gpt2` checkpoint and the Flash Attention 2 version of the model using a sequence length of 512.
+
+
+
+
", 0.0),
- ("", 0.0),
+ (self.original_tokenizer.convert_ids_to_tokens(0), 0.0),
+ (self.original_tokenizer.convert_ids_to_tokens(1), 0.0),
+ (self.original_tokenizer.convert_ids_to_tokens(2), 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
return vocab
@@ -1371,9 +1371,9 @@ def tokenizer(self, proto):
)
tokenizer.add_special_tokens(
[
- AddedToken("", normalized=False, special=True),
- AddedToken("", normalized=False, special=True),
- AddedToken("", normalized=False, special=True),
+ AddedToken(self.original_tokenizer.convert_ids_to_tokens(0), normalized=False, special=True),
+ AddedToken(self.original_tokenizer.convert_ids_to_tokens(1), normalized=False, special=True),
+ AddedToken(self.original_tokenizer.convert_ids_to_tokens(2), normalized=False, special=True),
]
)
else:
diff --git a/src/transformers/dynamic_module_utils.py b/src/transformers/dynamic_module_utils.py
index 72fd0367a0f401..a89105029868a1 100644
--- a/src/transformers/dynamic_module_utils.py
+++ b/src/transformers/dynamic_module_utils.py
@@ -592,8 +592,9 @@ def resolve_trust_remote_code(trust_remote_code, model_name, has_local_code, has
if has_local_code:
trust_remote_code = False
elif has_remote_code and TIME_OUT_REMOTE_CODE > 0:
+ prev_sig_handler = None
try:
- signal.signal(signal.SIGALRM, _raise_timeout_error)
+ prev_sig_handler = signal.signal(signal.SIGALRM, _raise_timeout_error)
signal.alarm(TIME_OUT_REMOTE_CODE)
while trust_remote_code is None:
answer = input(
@@ -614,6 +615,10 @@ def resolve_trust_remote_code(trust_remote_code, model_name, has_local_code, has
f"load the model. You can inspect the repository content at https://hf.co/{model_name}.\n"
f"Please pass the argument `trust_remote_code=True` to allow custom code to be run."
)
+ finally:
+ if prev_sig_handler is not None:
+ signal.signal(signal.SIGALRM, prev_sig_handler)
+ signal.alarm(0)
elif has_remote_code:
# For the CI which puts the timeout at 0
_raise_timeout_error(None, None)
diff --git a/src/transformers/generation/__init__.py b/src/transformers/generation/__init__.py
index 8f2a6ad9600d97..6653f3c8d123e9 100644
--- a/src/transformers/generation/__init__.py
+++ b/src/transformers/generation/__init__.py
@@ -82,6 +82,7 @@
"MaxNewTokensCriteria",
"MaxLengthCriteria",
"MaxTimeCriteria",
+ "EosTokenCriteria",
"StoppingCriteria",
"StoppingCriteriaList",
"validate_stopping_criteria",
@@ -161,6 +162,7 @@
"FlaxTopKLogitsWarper",
"FlaxTopPLogitsWarper",
"FlaxWhisperTimeStampLogitsProcessor",
+ "FlaxNoRepeatNGramLogitsProcessor",
]
_import_structure["flax_utils"] = [
"FlaxGenerationMixin",
@@ -216,6 +218,7 @@
WhisperTimeStampLogitsProcessor,
)
from .stopping_criteria import (
+ EosTokenCriteria,
MaxLengthCriteria,
MaxNewTokensCriteria,
MaxTimeCriteria,
@@ -292,6 +295,7 @@
FlaxLogitsProcessorList,
FlaxLogitsWarper,
FlaxMinLengthLogitsProcessor,
+ FlaxNoRepeatNGramLogitsProcessor,
FlaxSuppressTokensAtBeginLogitsProcessor,
FlaxSuppressTokensLogitsProcessor,
FlaxTemperatureLogitsWarper,
diff --git a/src/transformers/generation/candidate_generator.py b/src/transformers/generation/candidate_generator.py
index ff4eea9765f093..08590219561531 100644
--- a/src/transformers/generation/candidate_generator.py
+++ b/src/transformers/generation/candidate_generator.py
@@ -131,11 +131,9 @@ def __init__(
if assistant_model.config.is_encoder_decoder:
# both are encoder-decoder
self.input_ids_key = "decoder_input_ids"
- self.attention_key = "decoder_attention_mask"
elif "encoder_outputs" in assistant_kwargs:
# special case for encoder-decoder with decoder-only assistant (like DistilWhisper)
self.input_ids_key = "input_ids"
- self.attention_key = "attention_mask"
self.assistant_kwargs["attention_mask"] = self.assistant_kwargs.get(
"decoder_attention_mask",
torch.ones((input_ids.shape[0], 1), device=input_ids.device, dtype=torch.long),
@@ -143,15 +141,8 @@ def __init__(
else:
# both are decoder-only
self.input_ids_key = "input_ids"
- self.attention_key = "attention_mask"
# Prepare generation-related options.
- eos_token_id = generation_config.eos_token_id
- if isinstance(eos_token_id, int):
- eos_token_id = [eos_token_id]
- self.eos_token_id_tensor = (
- torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
- )
self.logits_processor = logits_processor
self.generation_config = copy.deepcopy(generation_config)
self.generation_config.return_dict_in_generate = True
@@ -247,15 +238,20 @@ class PromptLookupCandidateGenerator(CandidateGenerator):
The maximum ngram size to be considered for matching in the prompt
num_output_tokens (`int`):
The number of tokens to be output as candidate tokens.
+ max_length (`int`):
+ The number of total maximum tokens that can be generated. For decoder-only models that includes the prompt length.
+ Defaults to 20, which is the max length used as default in generation config.
"""
def __init__(
self,
num_output_tokens: int = 10,
max_matching_ngram_size: int = None,
+ max_length: int = 20,
):
self.num_output_tokens = num_output_tokens
self.max_matching_ngram_size = max_matching_ngram_size if max_matching_ngram_size else 2
+ self.max_length = max_length
if self.max_matching_ngram_size <= 0 or self.num_output_tokens <= 0:
raise ValueError("Invalid max_matching_ngram_size or num_output_tokens")
@@ -273,6 +269,10 @@ def get_candidates(self, input_ids: torch.LongTensor) -> Tuple[torch.LongTensor,
"""
input_length = input_ids.size(1)
+ # Don't generate more than `max_length - 1` candidates since the target model generates one extra token.
+ if self.max_length == input_length + 1:
+ return input_ids, None
+
chosen_ids = None
match_found = False
for ngram_size in range(min(self.max_matching_ngram_size, input_length - 1), 0, -1):
@@ -292,7 +292,7 @@ def get_candidates(self, input_ids: torch.LongTensor) -> Tuple[torch.LongTensor,
for idx in match_indices:
start_idx = idx + ngram_size
end_idx = start_idx + self.num_output_tokens
- end_idx = min(end_idx, input_length)
+ end_idx = min(end_idx, input_length, self.max_length)
if start_idx < end_idx:
chosen_ids = input_ids[0, start_idx:end_idx]
diff --git a/src/transformers/generation/flax_logits_process.py b/src/transformers/generation/flax_logits_process.py
index 5c30b92755a426..84b5a38d5de4da 100644
--- a/src/transformers/generation/flax_logits_process.py
+++ b/src/transformers/generation/flax_logits_process.py
@@ -18,6 +18,7 @@
import jax
import jax.lax as lax
import jax.numpy as jnp
+from jax.experimental import sparse
from ..utils import add_start_docstrings
from ..utils.logging import get_logger
@@ -455,3 +456,89 @@ def handle_cumulative_probs(logprobs_k, scores_k):
scores = jax.vmap(handle_cumulative_probs)(logprobs, scores)
return scores
+
+
+class FlaxNoRepeatNGramLogitsProcessor(FlaxLogitsProcessor):
+ r"""
+ [`FlaxLogitsProcessor`] that enforces no repetition of n-grams. See
+ [Fairseq](https://github.com/pytorch/fairseq/blob/a07cb6f40480928c9e0548b737aadd36ee66ac76/fairseq/sequence_generator.py#L345).
+
+ Args:
+ ngram_size (`int`):
+ All ngrams of size `ngram_size` can only occur once.
+ """
+
+ def __init__(self, ngram_size: int):
+ if not isinstance(ngram_size, int) or ngram_size <= 0:
+ raise ValueError(f"`ngram_size` has to be a strictly positive integer, but is {ngram_size}")
+ self.ngram_size = ngram_size
+
+ def get_previous_ngrams(self, input_ids: jnp.ndarray, vocab_size: int, cur_len: int):
+ """
+ get a matrix of size (batch_size,) + (vocab_size,)*n (for n-grams) that
+ represent the n-grams that occured previously.
+ The BCOO representation allow to store only the few non-zero entries, instead of the full (huge) matrix
+ """
+ batch_size, seq_len = input_ids.shape
+ # number of n-grams in the whole sequence
+ seq_ngrams = seq_len - (self.ngram_size - 1)
+ # number of n-grams in the currently generated sequence
+ cur_ngrams = cur_len - (self.ngram_size - 1)
+
+ def body_fun(i, val):
+ b = i % batch_size
+ pos = i // batch_size
+ return val.at[i].set(
+ jnp.array(
+ [
+ b,
+ ]
+ + [jnp.array(input_ids)[b, pos + j] for j in range(self.ngram_size)]
+ )
+ )
+
+ shape = (batch_size * seq_ngrams, self.ngram_size + 1)
+ all_update_indices = jax.lax.fori_loop(
+ 0, batch_size * cur_ngrams, body_fun, jnp.zeros(shape, dtype=input_ids.dtype)
+ )
+
+ # ignore the n-grams not yet generated
+ data = (jnp.arange(batch_size * seq_ngrams) < batch_size * cur_ngrams).astype("float32")
+
+ return sparse.BCOO((data, all_update_indices), shape=(batch_size,) + (vocab_size,) * self.ngram_size)
+
+ def get_banned_tokens_mask(self, latest_tokens: jnp.ndarray, previous_ngrams) -> jnp.ndarray:
+ """
+ Determines which tokens must be banned given latest tokens and the previously seen
+ ngrams.
+ """
+
+ @sparse.sparsify
+ @jax.vmap
+ def inner_fn(latest_tokens, previous_ngrams):
+ return previous_ngrams[tuple(latest_tokens)]
+
+ return sparse.bcoo_todense(inner_fn(latest_tokens, previous_ngrams))
+
+ def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
+ def true_fn():
+ _, vocab_size = scores.shape
+ # store the previously seen n-grams
+ previous_ngrams = self.get_previous_ngrams(input_ids, vocab_size, cur_len)
+
+ # get the n-1 last tokens that prefix the n-gram being generated
+ latest_tokens = jnp.zeros((input_ids.shape[0], self.ngram_size - 1), dtype=input_ids.dtype)
+ latest_tokens = jax.lax.dynamic_update_slice(
+ latest_tokens,
+ jax.lax.dynamic_slice(
+ input_ids, (0, cur_len - (self.ngram_size - 1)), (input_ids.shape[0], (self.ngram_size - 1))
+ ),
+ (0, 0),
+ )
+
+ # compute the banned tokens, ie all the tokens that when added to the latest tokens lead to a n-gram that was previously generated
+ banned_tokens_indices_mask = self.get_banned_tokens_mask(latest_tokens, previous_ngrams).astype("bool")
+ return jnp.where(banned_tokens_indices_mask, -float("inf"), scores)
+
+ output = jax.lax.cond((cur_len >= self.ngram_size - 1), true_fn, lambda: scores)
+ return output
diff --git a/src/transformers/generation/flax_utils.py b/src/transformers/generation/flax_utils.py
index 3a89c1ed41d2d5..08480ac983e805 100644
--- a/src/transformers/generation/flax_utils.py
+++ b/src/transformers/generation/flax_utils.py
@@ -40,6 +40,7 @@
FlaxForceTokensLogitsProcessor,
FlaxLogitsProcessorList,
FlaxMinLengthLogitsProcessor,
+ FlaxNoRepeatNGramLogitsProcessor,
FlaxSuppressTokensAtBeginLogitsProcessor,
FlaxSuppressTokensLogitsProcessor,
FlaxTemperatureLogitsWarper,
@@ -534,6 +535,8 @@ def _get_logits_processor(
[input_ids_seq_length + i[0] - 1, i[1]] for i in generation_config.forced_decoder_ids
]
processors.append(FlaxForceTokensLogitsProcessor(forced_decoder_ids))
+ if generation_config.no_repeat_ngram_size is not None and generation_config.no_repeat_ngram_size > 0:
+ processors.append(FlaxNoRepeatNGramLogitsProcessor(generation_config.no_repeat_ngram_size))
processors = self._merge_criteria_processor_list(processors, logits_processor)
return processors
diff --git a/src/transformers/generation/logits_process.py b/src/transformers/generation/logits_process.py
index 5181b59ab565f3..527bb9bc1ee349 100644
--- a/src/transformers/generation/logits_process.py
+++ b/src/transformers/generation/logits_process.py
@@ -261,8 +261,8 @@ class TemperatureLogitsWarper(LogitsWarper):
>>> generate_kwargs = {"max_new_tokens": 10, "do_sample": True, "temperature": 1.0, "num_return_sequences": 2}
>>> outputs = model.generate(**inputs, **generate_kwargs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
- ['Hugging Face Company is a joint venture between GEO Group, one of',
- 'Hugging Face Company is not an exact science – but what we believe does']
+ ['Hugging Face Company is one of these companies that is going to take a',
+ "Hugging Face Company is a brand created by Brian A. O'Neil"]
>>> # However, with temperature close to 0, it approximates greedy decoding strategies (invariant)
>>> generate_kwargs["temperature"] = 0.0001
@@ -419,7 +419,7 @@ class TopPLogitsWarper(LogitsWarper):
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
- >>> set_seed(0)
+ >>> set_seed(1)
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
@@ -428,7 +428,9 @@ class TopPLogitsWarper(LogitsWarper):
>>> # With sampling, the output is unexpected -- sometimes too unexpected.
>>> outputs = model.generate(**inputs, do_sample=True)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
- A sequence: 1, 2, 0, 2, 2. 2, 2, 2, 2
+ A sequence: 1, 2, 3 | < 4 (left-hand pointer) ;
+
+
>>> # With `top_p` sampling, the output gets restricted to high-probability tokens.
>>> # Pro tip: In practice, LLMs use `top_p` in the 0.9-0.95 range.
@@ -483,7 +485,7 @@ class TopKLogitsWarper(LogitsWarper):
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
- >>> set_seed(0)
+ >>> set_seed(1)
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
@@ -492,7 +494,7 @@ class TopKLogitsWarper(LogitsWarper):
>>> # With sampling, the output is unexpected -- sometimes too unexpected.
>>> outputs = model.generate(**inputs, do_sample=True)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
- A sequence: A, B, C, D, G, H, I. A, M
+ A sequence: A, B, C, D, E — S — O, P — R
>>> # With `top_k` sampling, the output gets restricted the k most likely tokens.
>>> # Pro tip: In practice, LLMs use `top_k` in the 5-50 range.
@@ -624,7 +626,7 @@ class EpsilonLogitsWarper(LogitsWarper):
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
- >>> set_seed(0)
+ >>> set_seed(1)
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
@@ -633,7 +635,9 @@ class EpsilonLogitsWarper(LogitsWarper):
>>> # With sampling, the output is unexpected -- sometimes too unexpected.
>>> outputs = model.generate(**inputs, do_sample=True)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
- A sequence: 1, 2, 0, 2, 2. 2, 2, 2, 2
+ A sequence: 1, 2, 3 | < 4 (left-hand pointer) ;
+
+
>>> # With epsilon sampling, the output gets restricted to high-probability tokens. Note that this is similar to
>>> # Top P sampling, which restricts tokens based on their cumulative probability.
@@ -701,7 +705,7 @@ class EtaLogitsWarper(LogitsWarper):
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
- >>> set_seed(0)
+ >>> set_seed(1)
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
@@ -710,7 +714,9 @@ class EtaLogitsWarper(LogitsWarper):
>>> # With sampling, the output is unexpected -- sometimes too unexpected.
>>> outputs = model.generate(**inputs, do_sample=True)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
- A sequence: 1, 2, 0, 2, 2. 2, 2, 2, 2
+ A sequence: 1, 2, 3 | < 4 (left-hand pointer) ;
+
+
>>> # With eta sampling, the output gets restricted to high-probability tokens. You can see it as a dynamic form of
>>> # epsilon sampling that adapts its cutoff probability based on the entropy (high entropy = lower cutoff).
@@ -1211,16 +1217,16 @@ class PrefixConstrainedLogitsProcessor(LogitsProcessor):
>>> # We can contrain it with `prefix_allowed_tokens_fn` to force a certain behavior based on a prefix.
>>> # For instance, we can force an entire entity to be generated when its beginning is detected.
- >>> entity = tokenizer(" Bob Marley", return_tensors="pt").input_ids[0] # 3 tokens
+ >>> entity = tokenizer(" Bob Marley", return_tensors="pt").input_ids[0] # 3 tokens
>>> def prefix_allowed_tokens_fn(batch_id, input_ids):
... '''
... Attempts to generate 'Bob Marley' when 'Bob' is detected.
... In this case, `batch_id` is not used, but you can set rules for each batch member.
... '''
... if input_ids[-1] == entity[0]:
- ... return entity[1]
+ ... return [entity[1].item()]
... elif input_ids[-2] == entity[0] and input_ids[-1] == entity[1]:
- ... return entity[2]
+ ... return [entity[2].item()]
... return list(range(tokenizer.vocab_size)) # If no match, allow all tokens
>>> outputs = model.generate(**inputs, max_new_tokens=5, prefix_allowed_tokens_fn=prefix_allowed_tokens_fn)
@@ -1618,13 +1624,13 @@ class LogitNormalization(LogitsProcessor, LogitsWarper):
>>> # By default, the scores are not normalized -- the sum of their exponentials is NOT a normalized probability
>>> # distribution, summing to 1
>>> outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
- >>> print(torch.sum(torch.exp(outputs.scores[-1])))
- tensor(816.3250)
+ >>> print(torch.allclose(torch.sum(torch.exp(outputs.scores[-1])), torch.Tensor((1.000,)), rtol=1e-4))
+ False
>>> # Normalizing them may have a positive impact on beam methods, or when using the scores on your application
>>> outputs = model.generate(**inputs, renormalize_logits=True, return_dict_in_generate=True, output_scores=True)
- >>> print(torch.sum(torch.exp(outputs.scores[-1])))
- tensor(1.0000)
+ >>> print(torch.allclose(torch.sum(torch.exp(outputs.scores[-1])), torch.Tensor((1.000,)), rtol=1e-4))
+ True
```
"""
@@ -1655,7 +1661,7 @@ class SuppressTokensAtBeginLogitsProcessor(LogitsProcessor):
>>> # Whisper has `begin_suppress_tokens` set by default (= `[220, 50256]`). 50256 is the EOS token, so this means
>>> # it can't generate and EOS token in the first iteration, but it can in the others.
>>> outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
- >>> print(outputs.scores[1][0, 50256]) # 1 (and not 0) is the first freely generated token
+ >>> print(outputs.scores[0][0, 50256])
tensor(-inf)
>>> print(outputs.scores[-1][0, 50256]) # in other places we can see some probability mass for EOS
tensor(29.9010)
@@ -1664,7 +1670,7 @@ class SuppressTokensAtBeginLogitsProcessor(LogitsProcessor):
>>> outputs = model.generate(
... **inputs, return_dict_in_generate=True, output_scores=True, begin_suppress_tokens=None
... )
- >>> print(outputs.scores[1][0, 50256])
+ >>> print(outputs.scores[0][0, 50256])
tensor(11.2027)
```
"""
@@ -1713,7 +1719,7 @@ class SuppressTokensLogitsProcessor(LogitsProcessor):
>>> # If we disable `suppress_tokens`, we can generate it.
>>> outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True, suppress_tokens=None)
>>> print(outputs.scores[1][0, 1])
- tensor(5.7738)
+ tensor(6.0678)
```
"""
@@ -1735,36 +1741,6 @@ class ForceTokensLogitsProcessor(LogitsProcessor):
indices that will be forced before generation. The processor will set their log probs to `inf` so that they are
sampled at their corresponding index. Originally created for
[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper).
-
- Examples:
- ```python
- >>> from transformers import AutoProcessor, WhisperForConditionalGeneration
- >>> from datasets import load_dataset
-
- >>> processor = AutoProcessor.from_pretrained("openai/whisper-tiny.en")
- >>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny.en")
- >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
- >>> inputs = processor(ds[0]["audio"]["array"], return_tensors="pt")
-
- >>> # This Whisper model forces the generation to start with `50362` at the first position by default, i.e.
- >>> # `"forced_decoder_ids": [[1, 50362]]`. This means all other tokens are masked out.
- >>> outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
- >>> print(
- ... all(outputs.scores[0][0, i] == float("-inf") for i in range(processor.tokenizer.vocab_size) if i != 50362)
- ... )
- True
- >>> print(outputs.scores[0][0, 50362])
- tensor(0.)
-
- >>> # If we disable `forced_decoder_ids`, we stop seeing that effect
- >>> outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True, forced_decoder_ids=None)
- >>> print(
- ... all(outputs.scores[0][0, i] == float("-inf") for i in range(processor.tokenizer.vocab_size) if i != 50362)
- ... )
- False
- >>> print(outputs.scores[0][0, 50362])
- tensor(19.3140)
- ```
"""
def __init__(self, force_token_map: List[List[int]], _has_warned: Optional[bool] = False):
diff --git a/src/transformers/generation/stopping_criteria.py b/src/transformers/generation/stopping_criteria.py
index f4624296d237f7..bac537b71b96ec 100644
--- a/src/transformers/generation/stopping_criteria.py
+++ b/src/transformers/generation/stopping_criteria.py
@@ -2,7 +2,7 @@
import warnings
from abc import ABC
from copy import deepcopy
-from typing import Optional
+from typing import List, Optional, Union
import torch
@@ -129,6 +129,27 @@ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwa
return torch.full((input_ids.shape[0],), is_done, device=input_ids.device, dtype=torch.bool)
+class EosTokenCriteria(StoppingCriteria):
+ """
+ This class can be used to stop generation whenever the "end-of-sequence" token is generated.
+ By default, it uses the `model.generation_config.eos_token_id`.
+
+ Args:
+ eos_token_id (`Union[int, List[int]]`):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ """
+
+ def __init__(self, eos_token_id: Union[int, List[int]]):
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ self.eos_token_id = torch.tensor(eos_token_id)
+
+ @add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
+ is_done = torch.isin(input_ids[:, -1], self.eos_token_id.to(input_ids.device))
+ return is_done
+
+
class StoppingCriteriaList(list):
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
diff --git a/src/transformers/generation/utils.py b/src/transformers/generation/utils.py
index b2f330548f56b5..cb3ac0ff1d121c 100644
--- a/src/transformers/generation/utils.py
+++ b/src/transformers/generation/utils.py
@@ -75,6 +75,7 @@
UnbatchedClassifierFreeGuidanceLogitsProcessor,
)
from .stopping_criteria import (
+ EosTokenCriteria,
MaxLengthCriteria,
MaxTimeCriteria,
StoppingCriteria,
@@ -436,9 +437,6 @@ def _maybe_initialize_input_ids_for_generation(
shape = encoder_outputs.last_hidden_state.size()[:-1]
return torch.ones(shape, dtype=torch.long, device=self.device) * -100
- if bos_token_id is None:
- raise ValueError("`bos_token_id` has to be defined when no `input_ids` are provided.")
-
# If there is some tensor in `model_kwargs`, we can infer the batch size from it. This is helpful with
# soft-prompting or in multimodal implementations built on top of decoder-only language models.
batch_size = 1
@@ -449,6 +447,10 @@ def _maybe_initialize_input_ids_for_generation(
if "inputs_embeds" in model_kwargs:
return torch.ones((batch_size, 0), dtype=torch.long, device=self.device)
+
+ if bos_token_id is None:
+ raise ValueError("`bos_token_id` has to be defined when no `input_ids` are provided.")
+
return torch.ones((batch_size, 1), dtype=torch.long, device=self.device) * bos_token_id
def _prepare_attention_mask_for_generation(
@@ -689,6 +691,7 @@ def _get_candidate_generator(
candidate_generator = PromptLookupCandidateGenerator(
num_output_tokens=generation_config.prompt_lookup_num_tokens,
max_matching_ngram_size=generation_config.max_matching_ngram_size,
+ max_length=generation_config.max_length,
)
else:
candidate_generator = AssistedCandidateGenerator(
@@ -891,6 +894,8 @@ def _get_stopping_criteria(
)
if generation_config.max_time is not None:
criteria.append(MaxTimeCriteria(max_time=generation_config.max_time))
+ if generation_config.eos_token_id is not None:
+ criteria.append(EosTokenCriteria(eos_token_id=generation_config.eos_token_id))
criteria = self._merge_criteria_processor_list(criteria, stopping_criteria)
return criteria
@@ -1305,7 +1310,7 @@ def generate(
Return:
[`~utils.ModelOutput`] or `torch.LongTensor`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
- or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor`.
+ or when `config.return_dict_in_generate=True`) or a `torch.LongTensor`.
If the model is *not* an encoder-decoder model (`model.config.is_encoder_decoder=False`), the possible
[`~utils.ModelOutput`] types are:
@@ -1514,7 +1519,6 @@ def generate(
logits_warper=self._get_logits_warper(generation_config) if generation_config.do_sample else None,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1529,7 +1533,6 @@ def generate(
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1549,7 +1552,6 @@ def generate(
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1578,7 +1580,6 @@ def generate(
logits_warper=logits_warper,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1612,7 +1613,6 @@ def generate(
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1652,7 +1652,6 @@ def generate(
logits_warper=logits_warper,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1686,7 +1685,6 @@ def generate(
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1760,7 +1758,6 @@ def typeerror():
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
pad_token_id=generation_config.pad_token_id,
- eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
output_logits=generation_config.output_logits,
return_dict_in_generate=generation_config.return_dict_in_generate,
@@ -1915,11 +1912,28 @@ def _contrastive_search(
logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
- sequential = sequential if sequential is not None else self.generation_config.low_memory
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
- eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
+ sequential = sequential if sequential is not None else self.generation_config.low_memory
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_logits = output_logits if output_logits is not None else self.generation_config.output_logits
output_attentions = (
@@ -2185,12 +2199,6 @@ def _contrastive_search(
is_encoder_decoder=self.config.is_encoder_decoder,
)
- # if eos_token was found in one sentence, set sentence to finished
- if eos_token_id_tensor is not None:
- unfinished_sequences = unfinished_sequences.mul(
- next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
- )
-
# stop when each sentence is finished
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
@@ -2364,10 +2372,27 @@ def _greedy_search(
)
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
- eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
@@ -2462,12 +2487,6 @@ def _greedy_search(
is_encoder_decoder=self.config.is_encoder_decoder,
)
- # if eos_token was found in one sentence, set sentence to finished
- if eos_token_id_tensor is not None:
- unfinished_sequences = unfinished_sequences.mul(
- next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
- )
-
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
@@ -2649,10 +2668,27 @@ def _sample(
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
- eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_logits = output_logits if output_logits is not None else self.generation_config.output_logits
output_attentions = (
@@ -2750,12 +2786,6 @@ def _sample(
is_encoder_decoder=self.config.is_encoder_decoder,
)
- # if eos_token was found in one sentence, set sentence to finished
- if eos_token_id_tensor is not None:
- unfinished_sequences = unfinished_sequences.mul(
- next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
- )
-
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
@@ -2965,7 +2995,25 @@ def _beam_search(
if len(stopping_criteria) == 0:
warnings.warn("You don't have defined any stopping_criteria, this will likely loop forever", UserWarning)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private and beam scorer refactored
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
@@ -2986,6 +3034,8 @@ def _beam_search(
num_beams = beam_scorer.num_beams
batch_beam_size, cur_len = input_ids.shape
+ if "inputs_embeds" in model_kwargs:
+ cur_len = model_kwargs["inputs_embeds"].shape[1]
model_kwargs["cache_position"] = torch.arange(cur_len, device=input_ids.device)
if num_beams * batch_size != batch_beam_size:
@@ -3350,7 +3400,25 @@ def _beam_sample(
)
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private and beam scorer refactored
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
@@ -3371,6 +3439,8 @@ def _beam_sample(
num_beams = beam_scorer.num_beams
batch_beam_size, cur_len = input_ids.shape
+ if "inputs_embeds" in model_kwargs:
+ cur_len = model_kwargs["inputs_embeds"].shape[1]
model_kwargs["cache_position"] = torch.arange(cur_len, device=input_ids.device)
# init attention / hidden states / scores tuples
@@ -3687,7 +3757,25 @@ def _group_beam_search(
)
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private and beam scorer refactored
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
@@ -3711,6 +3799,8 @@ def _group_beam_search(
device = input_ids.device
batch_beam_size, cur_len = input_ids.shape
+ if "inputs_embeds" in model_kwargs:
+ cur_len = model_kwargs["inputs_embeds"].shape[1]
model_kwargs["cache_position"] = torch.arange(cur_len, device=input_ids.device)
if return_dict_in_generate and output_scores:
@@ -4088,7 +4178,25 @@ def _constrained_beam_search(
if len(stopping_criteria) == 0:
warnings.warn("You don't have defined any stopping_criteria, this will likely loop forever", UserWarning)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private and beam scorer refactored
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
@@ -4109,6 +4217,8 @@ def _constrained_beam_search(
num_beams = constrained_beam_scorer.num_beams
batch_beam_size, cur_len = input_ids.shape
+ if "inputs_embeds" in model_kwargs:
+ cur_len = model_kwargs["inputs_embeds"].shape[1]
model_kwargs["cache_position"] = torch.arange(cur_len, device=input_ids.device)
if num_beams * batch_size != batch_beam_size:
@@ -4420,12 +4530,27 @@ def _assisted_decoding(
logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
- eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
- if eos_token_id is not None and pad_token_id is None:
- raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ if eos_token_id is not None:
+ logger.warning_once(
+ "`eos_token_id` is deprecated in this function and will be removed in v4.41, use"
+ " `stopping_criteria=StoppingCriteriaList([EosTokenCriteria(eos_token_id=eos_token_id)])` instead."
+ " Otherwise make sure to set `model.generation_config.eos_token_id`",
+ FutureWarning,
+ )
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+ else:
+ # TODO remove when the method is totally private and beam scorer refactored
+ # need to get `eos_token_id` and add stopping criteria, so that generation does not go forever
+ eos_token_id = [
+ criteria.eos_token_id.tolist() for criteria in stopping_criteria if hasattr(criteria, "eos_token_id")
+ ]
+ eos_token_id = eos_token_id[0] if eos_token_id else None
+ if eos_token_id is None and self.generation_config.eos_token_id is not None:
+ eos_token_id = self.generation_config.eos_token_id
+ stopping_criteria.append(EosTokenCriteria(eos_token_id=eos_token_id))
+
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
- eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_logits = output_logits if output_logits is not None else self.generation_config.output_logits
output_attentions = (
@@ -4461,9 +4586,6 @@ def _assisted_decoding(
unfinished_sequences = torch.ones(batch_size, dtype=torch.long, device=input_ids.device)
model_kwargs["cache_position"] = torch.arange(cur_len, device=input_ids.device)
- # other auxiliary variables
- max_len = stopping_criteria[0].max_length
-
this_peer_finished = False
while self._has_unfinished_sequences(this_peer_finished, synced_gpus, device=input_ids.device):
cur_len = input_ids.shape[-1]
@@ -4475,13 +4597,7 @@ def _assisted_decoding(
candidate_logits = candidate_logits.to(self.device)
candidate_length = candidate_input_ids.shape[1] - input_ids.shape[1]
- last_assistant_token_is_eos = (
- ~candidate_input_ids[:, -1]
- .tile(eos_token_id_tensor.shape[0], 1)
- .ne(eos_token_id_tensor.unsqueeze(1))
- .prod(dim=0)
- .bool()
- )
+ is_done_candidate = stopping_criteria(candidate_input_ids, None)
# 2. Use the original model to obtain the next token logits given the candidate sequence. We obtain
# `candidate_length + 1` relevant logits from this process: in the event that all candidates are correct,
@@ -4524,15 +4640,13 @@ def _assisted_decoding(
# 3. Select the accepted tokens. There are two possible cases:
# Case 1: `do_sample=True` and we have logits for the candidates (originally from speculative decoding)
# 👉 Apply algorithm 1 from the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf).
- max_matches = max_len - cur_len - 1
if do_sample and candidate_logits is not None:
valid_tokens, n_matches = _speculative_sampling(
candidate_input_ids,
candidate_logits,
candidate_length,
new_logits,
- last_assistant_token_is_eos,
- max_matches,
+ is_done_candidate,
)
# Case 2: all other cases (originally from assisted generation) 👉 Compare the tokens selected from the
@@ -4549,9 +4663,8 @@ def _assisted_decoding(
n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
# Ensure we don't generate beyond max_len or an EOS token
- if last_assistant_token_is_eos and n_matches == candidate_length:
+ if is_done_candidate and n_matches == candidate_length:
n_matches -= 1
- n_matches = min(n_matches, max_matches)
valid_tokens = selected_tokens[:, : n_matches + 1]
# 4. Update variables according to the number of matching assistant tokens. Remember: the token generated
@@ -4624,15 +4737,6 @@ def _assisted_decoding(
is_encoder_decoder=self.config.is_encoder_decoder,
)
- # if eos_token was found in one sentence, set sentence to finished
- if eos_token_id_tensor is not None:
- unfinished_sequences = unfinished_sequences.mul(
- input_ids[:, -1]
- .tile(eos_token_id_tensor.shape[0], 1)
- .ne(eos_token_id_tensor.unsqueeze(1))
- .prod(dim=0)
- )
-
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
@@ -4677,8 +4781,7 @@ def _speculative_sampling(
candidate_logits,
candidate_length,
new_logits,
- last_assistant_token_is_eos,
- max_matches,
+ is_done_candidate,
):
"""
Applies sampling as in the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf, algorithm 1). Returns
@@ -4703,16 +4806,14 @@ def _speculative_sampling(
n_matches = ((~is_accepted).cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
# Ensure we don't generate beyond max_len or an EOS token (not in algorithm 1, but needed for correct behavior)
- if last_assistant_token_is_eos and n_matches == candidate_length:
+ if is_done_candidate and n_matches == candidate_length:
# Output length is assumed to be `n_matches + 1`. Since we won't generate another token with the target model
# due to acceptance on EOS we fix `n_matches`
n_matches -= 1
valid_tokens = new_candidate_input_ids[:, : n_matches + 1]
else:
- n_matches = min(n_matches, max_matches)
-
# Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
- gamma = min(candidate_logits.shape[1], max_matches)
+ gamma = candidate_logits.shape[1]
p_n_plus_1 = p[:, n_matches, :]
if n_matches < gamma:
q_n_plus_1 = q[:, n_matches, :]
diff --git a/src/transformers/integrations/bitsandbytes.py b/src/transformers/integrations/bitsandbytes.py
index e038768b97f6b6..f340c1db823731 100644
--- a/src/transformers/integrations/bitsandbytes.py
+++ b/src/transformers/integrations/bitsandbytes.py
@@ -156,7 +156,10 @@ def _replace_with_bnb_linear(
if (isinstance(module, nn.Linear) or isinstance(module, Conv1D)) and name not in modules_to_not_convert:
# Check if the current key is not in the `modules_to_not_convert`
- if not any(key in ".".join(current_key_name) for key in modules_to_not_convert):
+ current_key_name_str = ".".join(current_key_name)
+ if not any(
+ (key + "." in current_key_name_str) or (key == current_key_name_str) for key in modules_to_not_convert
+ ):
with init_empty_weights():
if isinstance(module, Conv1D):
in_features, out_features = module.weight.shape
diff --git a/src/transformers/integrations/deepspeed.py b/src/transformers/integrations/deepspeed.py
index b0db718dba016b..4754c37a1eb38c 100644
--- a/src/transformers/integrations/deepspeed.py
+++ b/src/transformers/integrations/deepspeed.py
@@ -21,7 +21,7 @@
from functools import partialmethod
from ..dependency_versions_check import dep_version_check
-from ..utils import is_accelerate_available, is_torch_available, logging
+from ..utils import is_accelerate_available, is_torch_available, is_torch_mlu_available, logging
if is_torch_available():
@@ -38,6 +38,9 @@ def is_deepspeed_available():
# AND checking it has an author field in the metadata that is HuggingFace.
if package_exists:
try:
+ if is_torch_mlu_available():
+ _ = importlib_metadata.metadata("deepspeed-mlu")
+ return True
_ = importlib_metadata.metadata("deepspeed")
return True
except importlib_metadata.PackageNotFoundError:
diff --git a/src/transformers/integrations/integration_utils.py b/src/transformers/integrations/integration_utils.py
index 147cac5fc10b24..45ef3c3c840b8e 100644
--- a/src/transformers/integrations/integration_utils.py
+++ b/src/transformers/integrations/integration_utils.py
@@ -131,6 +131,13 @@ def is_mlflow_available():
return importlib.util.find_spec("mlflow") is not None
+def get_mlflow_version():
+ try:
+ return importlib.metadata.version("mlflow")
+ except importlib.metadata.PackageNotFoundError:
+ return importlib.metadata.version("mlflow-skinny")
+
+
def is_dagshub_available():
return None not in [importlib.util.find_spec("dagshub"), importlib.util.find_spec("mlflow")]
@@ -1002,7 +1009,7 @@ def setup(self, args, state, model):
# "synchronous" flag is only available with mlflow version >= 2.8.0
# https://github.com/mlflow/mlflow/pull/9705
# https://github.com/mlflow/mlflow/releases/tag/v2.8.0
- if packaging.version.parse(importlib.metadata.version("mlflow")) >= packaging.version.parse("2.8.0"):
+ if packaging.version.parse(get_mlflow_version()) >= packaging.version.parse("2.8.0"):
self._async_log = True
logger.debug(
f"MLflow experiment_name={self._experiment_name}, run_name={args.run_name}, nested={self._nested_run},"
diff --git a/src/transformers/modeling_utils.py b/src/transformers/modeling_utils.py
index 263ae5d2f988cf..fd0afa521a1453 100644
--- a/src/transformers/modeling_utils.py
+++ b/src/transformers/modeling_utils.py
@@ -29,7 +29,8 @@
from contextlib import contextmanager
from dataclasses import dataclass
from functools import partial, wraps
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+from threading import Thread
+from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
from zipfile import is_zipfile
import torch
@@ -572,6 +573,79 @@ def set_initialized_submodules(model, state_dict_keys):
return not_initialized_submodules
+def _end_ptr(tensor: torch.Tensor) -> int:
+ # extract the end of the pointer if the tensor is a slice of a bigger tensor
+ if tensor.nelement():
+ stop = tensor.view(-1)[-1].data_ptr() + tensor.element_size()
+ else:
+ stop = tensor.data_ptr()
+ return stop
+
+
+def _get_tied_weight_keys(module: nn.Module, prefix=""):
+ tied_weight_keys = []
+ if getattr(module, "_tied_weights_keys", None) is not None:
+ names = [f"{prefix}.{k}" if prefix else k for k in module._tied_weights_keys]
+ tied_weight_keys.extend(names)
+ if getattr(module, "_dynamic_tied_weights_keys", None) is not None:
+ names = [f"{prefix}.{k}" if prefix else k for k in module._dynamic_tied_weights_keys]
+ tied_weight_keys.extend(names)
+ for name, submodule in module.named_children():
+ local_prefix = f"{prefix}.{name}" if prefix else name
+ tied_weight_keys.extend(_get_tied_weight_keys(submodule, prefix=local_prefix))
+ return tied_weight_keys
+
+
+def _find_disjoint(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], List[str]]:
+ filtered_tensors = []
+ for shared in tensors:
+ if len(shared) < 2:
+ filtered_tensors.append(shared)
+ continue
+
+ areas = []
+ for name in shared:
+ tensor = state_dict[name]
+ areas.append((tensor.data_ptr(), _end_ptr(tensor), name))
+ areas.sort()
+
+ _, last_stop, last_name = areas[0]
+ filtered_tensors.append({last_name})
+ for start, stop, name in areas[1:]:
+ if start >= last_stop:
+ filtered_tensors.append({name})
+ else:
+ filtered_tensors[-1].add(name)
+ last_stop = stop
+ disjoint_tensors = []
+ shared_tensors = []
+ for tensors in filtered_tensors:
+ if len(tensors) == 1:
+ disjoint_tensors.append(tensors.pop())
+ else:
+ shared_tensors.append(tensors)
+ return shared_tensors, disjoint_tensors
+
+
+def _find_identical(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], Set[str]]:
+ shared_tensors = []
+ identical = []
+ for shared in tensors:
+ if len(shared) < 2:
+ continue
+
+ areas = collections.defaultdict(set)
+ for name in shared:
+ tensor = state_dict[name]
+ area = (tensor.device, tensor.data_ptr(), _end_ptr(tensor))
+ areas[area].add(name)
+ if len(areas) == 1:
+ identical.append(shared)
+ else:
+ shared_tensors.append(shared)
+ return shared_tensors, identical
+
+
def _load_state_dict_into_model(model_to_load, state_dict, start_prefix):
# Convert old format to new format if needed from a PyTorch state_dict
old_keys = []
@@ -1645,15 +1719,24 @@ def tie_weights(self):
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
- self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.encoder, self.decoder, self.base_model_prefix, "encoder"
+ )
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()
@staticmethod
- def _tie_encoder_decoder_weights(encoder: nn.Module, decoder: nn.Module, base_model_prefix: str):
+ def _tie_encoder_decoder_weights(
+ encoder: nn.Module, decoder: nn.Module, base_model_prefix: str, base_encoder_name: str
+ ):
uninitialized_encoder_weights: List[str] = []
+ tied_weights: List[str] = []
if decoder.__class__ != encoder.__class__:
logger.info(
f"{decoder.__class__} and {encoder.__class__} are not equal. In this case make sure that all encoder"
@@ -1664,8 +1747,11 @@ def tie_encoder_to_decoder_recursively(
decoder_pointer: nn.Module,
encoder_pointer: nn.Module,
module_name: str,
+ base_encoder_name: str,
uninitialized_encoder_weights: List[str],
depth=0,
+ total_decoder_name="",
+ total_encoder_name="",
):
assert isinstance(decoder_pointer, nn.Module) and isinstance(
encoder_pointer, nn.Module
@@ -1673,8 +1759,10 @@ def tie_encoder_to_decoder_recursively(
if hasattr(decoder_pointer, "weight"):
assert hasattr(encoder_pointer, "weight")
encoder_pointer.weight = decoder_pointer.weight
+ tied_weights.append(f"{base_encoder_name}{total_encoder_name}.weight")
if hasattr(decoder_pointer, "bias"):
assert hasattr(encoder_pointer, "bias")
+ tied_weights.append(f"{base_encoder_name}{total_encoder_name}.bias")
encoder_pointer.bias = decoder_pointer.bias
return
@@ -1712,19 +1800,26 @@ def tie_encoder_to_decoder_recursively(
decoder_modules[decoder_name],
encoder_modules[encoder_name],
module_name + "/" + name,
+ base_encoder_name,
uninitialized_encoder_weights,
depth=depth + 1,
+ total_encoder_name=f"{total_encoder_name}.{encoder_name}",
+ total_decoder_name=f"{total_decoder_name}.{decoder_name}",
)
all_encoder_weights.remove(module_name + "/" + encoder_name)
uninitialized_encoder_weights += list(all_encoder_weights)
# tie weights recursively
- tie_encoder_to_decoder_recursively(decoder, encoder, base_model_prefix, uninitialized_encoder_weights)
+ tie_encoder_to_decoder_recursively(
+ decoder, encoder, base_model_prefix, base_encoder_name, uninitialized_encoder_weights
+ )
+
if len(uninitialized_encoder_weights) > 0:
logger.warning(
f"The following encoder weights were not tied to the decoder {uninitialized_encoder_weights}"
)
+ return tied_weights
def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
"""Tie or clone module weights depending of whether we are using TorchScript or not"""
@@ -2401,34 +2496,49 @@ def save_pretrained(
# These are all the pointers of shared tensors.
shared_ptrs = {ptr: names for ptr, names in ptrs.items() if len(names) > 1}
- warn_names = set()
+ error_names = []
+ to_delete_names = set()
+ # Recursively descend to find tied weight keys
+ _tied_weights_keys = _get_tied_weight_keys(self)
for names in shared_ptrs.values():
# Removing the keys which are declared as known duplicates on
# load. This allows to make sure the name which is kept is consistent.
- if self._tied_weights_keys is not None:
+ if _tied_weights_keys is not None:
found = 0
for name in sorted(names):
- matches_pattern = any(re.search(pat, name) for pat in self._tied_weights_keys)
+ matches_pattern = any(re.search(pat, name) for pat in _tied_weights_keys)
if matches_pattern and name in state_dict:
found += 1
if found < len(names):
- del state_dict[name]
-
- # When not all duplicates have been cleaned, still remove those keys, but put a clear warning.
- # If the link between tensors was done at runtime then `from_pretrained` will not get
- # the key back leading to random tensor. A proper warning will be shown
- # during reload (if applicable), but since the file is not necessarily compatible with
- # the config, better show a proper warning.
- found = 0
- for name in names:
- if name in state_dict:
- found += 1
- if found > 1:
- del state_dict[name]
- warn_names.add(name)
- if len(warn_names) > 0:
- logger.warning_once(
- f"Removed shared tensor {warn_names} while saving. This should be OK, but check by verifying that you don't receive any warning while reloading",
+ to_delete_names.add(name)
+ # We are entering a place where the weights and the transformers configuration do NOT match.
+ shared_names, disjoint_names = _find_disjoint(shared_ptrs.values(), state_dict)
+ # Those are actually tensor sharing but disjoint from each other, we can safely clone them
+ # Reloaded won't have the same property, but it shouldn't matter in any meaningful way.
+ for name in disjoint_names:
+ state_dict[name] = state_dict[name].clone()
+
+ # When not all duplicates have been cleaned, still remove those keys, but put a clear warning.
+ # If the link between tensors was done at runtime then `from_pretrained` will not get
+ # the key back leading to random tensor. A proper warning will be shown
+ # during reload (if applicable), but since the file is not necessarily compatible with
+ # the config, better show a proper warning.
+ shared_names, identical_names = _find_identical(shared_names, state_dict)
+ # delete tensors that have identical storage
+ for inames in identical_names:
+ known = inames.intersection(to_delete_names)
+ for name in known:
+ del state_dict[name]
+ unknown = inames.difference(to_delete_names)
+ if len(unknown) > 1:
+ error_names.append(unknown)
+
+ if shared_names:
+ error_names.append(set(shared_names))
+
+ if len(error_names) > 0:
+ raise RuntimeError(
+ f"The weights trying to be saved contained shared tensors {error_names} that are mismatching the transformers base configuration. Try saving using `safe_serialization=False` or remove this tensor sharing.",
)
# Shard the model if it is too big.
@@ -3228,9 +3338,39 @@ def from_pretrained(
)
if resolved_archive_file is not None:
is_sharded = True
- if resolved_archive_file is None:
- # Otherwise, maybe there is a TF or Flax model file. We try those to give a helpful error
- # message.
+
+ if resolved_archive_file is not None:
+ if filename in [WEIGHTS_NAME, WEIGHTS_INDEX_NAME]:
+ # If the PyTorch file was found, check if there is a safetensors file on the repository
+ # If there is no safetensors file on the repositories, start an auto conversion
+ safe_weights_name = SAFE_WEIGHTS_INDEX_NAME if is_sharded else SAFE_WEIGHTS_NAME
+ has_file_kwargs = {
+ "revision": revision,
+ "proxies": proxies,
+ "token": token,
+ }
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "resume_download": resume_download,
+ "local_files_only": local_files_only,
+ "user_agent": user_agent,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ **has_file_kwargs,
+ }
+ if not has_file(pretrained_model_name_or_path, safe_weights_name, **has_file_kwargs):
+ Thread(
+ target=auto_conversion,
+ args=(pretrained_model_name_or_path,),
+ kwargs={"ignore_errors_during_conversion": True, **cached_file_kwargs},
+ name="Thread-autoconversion",
+ ).start()
+ else:
+ # Otherwise, no PyTorch file was found, maybe there is a TF or Flax model file.
+ # We try those to give a helpful error message.
has_file_kwargs = {
"revision": revision,
"proxies": proxies,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 526118ff856ba8..0599d3b876e6af 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -184,6 +184,7 @@
pvt_v2,
qdqbert,
qwen2,
+ qwen2_moe,
rag,
realm,
reformer,
diff --git a/src/transformers/models/albert/configuration_albert.py b/src/transformers/models/albert/configuration_albert.py
index 690be7fbbf2c0c..c5ddded4833481 100644
--- a/src/transformers/models/albert/configuration_albert.py
+++ b/src/transformers/models/albert/configuration_albert.py
@@ -19,18 +19,7 @@
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
-
-
-ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/config.json",
- "albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/config.json",
- "albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/config.json",
- "albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/config.json",
- "albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/config.json",
- "albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/config.json",
- "albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/config.json",
- "albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class AlbertConfig(PretrainedConfig):
diff --git a/src/transformers/models/albert/modeling_albert.py b/src/transformers/models/albert/modeling_albert.py
index 25ae832b03a00a..87f5a9e30c8f54 100755
--- a/src/transformers/models/albert/modeling_albert.py
+++ b/src/transformers/models/albert/modeling_albert.py
@@ -52,17 +52,7 @@
_CONFIG_FOR_DOC = "AlbertConfig"
-ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "albert/albert-base-v1",
- "albert/albert-large-v1",
- "albert/albert-xlarge-v1",
- "albert/albert-xxlarge-v1",
- "albert/albert-base-v2",
- "albert/albert-large-v2",
- "albert/albert-xlarge-v2",
- "albert/albert-xxlarge-v2",
- # See all ALBERT models at https://huggingface.co/models?filter=albert
-]
+from ..deprecated._archive_maps import ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_albert(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/albert/modeling_tf_albert.py b/src/transformers/models/albert/modeling_tf_albert.py
index 1225465c5260a8..5aa521bb73dea7 100644
--- a/src/transformers/models/albert/modeling_tf_albert.py
+++ b/src/transformers/models/albert/modeling_tf_albert.py
@@ -65,17 +65,8 @@
_CHECKPOINT_FOR_DOC = "albert/albert-base-v2"
_CONFIG_FOR_DOC = "AlbertConfig"
-TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "albert/albert-base-v1",
- "albert/albert-large-v1",
- "albert/albert-xlarge-v1",
- "albert/albert-xxlarge-v1",
- "albert/albert-base-v2",
- "albert/albert-large-v2",
- "albert/albert-xlarge-v2",
- "albert/albert-xxlarge-v2",
- # See all ALBERT models at https://huggingface.co/models?filter=albert
-]
+
+from ..deprecated._archive_maps import TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFAlbertPreTrainingLoss:
diff --git a/src/transformers/models/albert/tokenization_albert.py b/src/transformers/models/albert/tokenization_albert.py
index 7baaa0a6000e6f..786f9eeafc513c 100644
--- a/src/transformers/models/albert/tokenization_albert.py
+++ b/src/transformers/models/albert/tokenization_albert.py
@@ -29,29 +29,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/spiece.model",
- "albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/spiece.model",
- "albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/spiece.model",
- "albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/spiece.model",
- "albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/spiece.model",
- "albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/spiece.model",
- "albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/spiece.model",
- "albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/spiece.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "albert/albert-base-v1": 512,
- "albert/albert-large-v1": 512,
- "albert/albert-xlarge-v1": 512,
- "albert/albert-xxlarge-v1": 512,
- "albert/albert-base-v2": 512,
- "albert/albert-large-v2": 512,
- "albert/albert-xlarge-v2": 512,
- "albert/albert-xxlarge-v2": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -130,8 +107,6 @@ class AlbertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/albert/tokenization_albert_fast.py b/src/transformers/models/albert/tokenization_albert_fast.py
index 91cf403d07eefd..e0b09a73560ac1 100644
--- a/src/transformers/models/albert/tokenization_albert_fast.py
+++ b/src/transformers/models/albert/tokenization_albert_fast.py
@@ -32,39 +32,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/spiece.model",
- "albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/spiece.model",
- "albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/spiece.model",
- "albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/spiece.model",
- "albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/spiece.model",
- "albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/spiece.model",
- "albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/spiece.model",
- "albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/spiece.model",
- },
- "tokenizer_file": {
- "albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/tokenizer.json",
- "albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/tokenizer.json",
- "albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/tokenizer.json",
- "albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/tokenizer.json",
- "albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/tokenizer.json",
- "albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/tokenizer.json",
- "albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/tokenizer.json",
- "albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "albert/albert-base-v1": 512,
- "albert/albert-large-v1": 512,
- "albert/albert-xlarge-v1": 512,
- "albert/albert-xxlarge-v1": 512,
- "albert/albert-base-v2": 512,
- "albert/albert-large-v2": 512,
- "albert/albert-xlarge-v2": 512,
- "albert/albert-xxlarge-v2": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -117,8 +84,6 @@ class AlbertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = AlbertTokenizer
def __init__(
diff --git a/src/transformers/models/align/configuration_align.py b/src/transformers/models/align/configuration_align.py
index b7f377d4813679..a4b3149d971a15 100644
--- a/src/transformers/models/align/configuration_align.py
+++ b/src/transformers/models/align/configuration_align.py
@@ -27,9 +27,8 @@
logger = logging.get_logger(__name__)
-ALIGN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "kakaobrain/align-base": "https://huggingface.co/kakaobrain/align-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ALIGN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class AlignTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/align/modeling_align.py b/src/transformers/models/align/modeling_align.py
index f48fcbace12f4f..3dce9d383da151 100644
--- a/src/transformers/models/align/modeling_align.py
+++ b/src/transformers/models/align/modeling_align.py
@@ -47,10 +47,7 @@
_CONFIG_FOR_DOC = "AlignConfig"
-ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "kakaobrain/align-base",
- # See all ALIGN models at https://huggingface.co/models?filter=align
-]
+from ..deprecated._archive_maps import ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
ALIGN_START_DOCSTRING = r"""
@@ -403,7 +400,7 @@ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
return hidden_states
-# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetDepthwiseLayer with with EfficientNet->AlignVision
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetDepthwiseLayer with EfficientNet->AlignVision
class AlignVisionDepthwiseLayer(nn.Module):
r"""
This corresponds to the depthwise convolution phase of each block in the original implementation.
@@ -443,7 +440,7 @@ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
return hidden_states
-# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetSqueezeExciteLayer with with EfficientNet->AlignVision
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetSqueezeExciteLayer with EfficientNet->AlignVision
class AlignVisionSqueezeExciteLayer(nn.Module):
r"""
This corresponds to the Squeeze and Excitement phase of each block in the original implementation.
diff --git a/src/transformers/models/altclip/configuration_altclip.py b/src/transformers/models/altclip/configuration_altclip.py
index b9d451d2c05050..590f2b526e8c4b 100755
--- a/src/transformers/models/altclip/configuration_altclip.py
+++ b/src/transformers/models/altclip/configuration_altclip.py
@@ -22,10 +22,8 @@
logger = logging.get_logger(__name__)
-ALTCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "BAAI/AltCLIP": "https://huggingface.co/BAAI/AltCLIP/resolve/main/config.json",
- # See all AltCLIP models at https://huggingface.co/models?filter=altclip
-}
+
+from ..deprecated._archive_maps import ALTCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class AltCLIPTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/altclip/modeling_altclip.py b/src/transformers/models/altclip/modeling_altclip.py
index 2f511bace5fa25..0d27d87de7f4f1 100755
--- a/src/transformers/models/altclip/modeling_altclip.py
+++ b/src/transformers/models/altclip/modeling_altclip.py
@@ -40,10 +40,8 @@
_CHECKPOINT_FOR_DOC = "BAAI/AltCLIP"
_CONFIG_FOR_DOC = "AltCLIPConfig"
-ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "BAAI/AltCLIP",
- # See all AltCLIP models at https://huggingface.co/models?filter=altclip
-]
+
+from ..deprecated._archive_maps import ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
ALTCLIP_START_DOCSTRING = r"""
diff --git a/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
index 81a087f07f69f1..94a7af6006fd7d 100644
--- a/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
+++ b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
@@ -21,11 +21,8 @@
logger = logging.get_logger(__name__)
-AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "MIT/ast-finetuned-audioset-10-10-0.4593": (
- "https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ASTConfig(PretrainedConfig):
diff --git a/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
index 3fddccdea75273..5ec18e2c7f16b2 100644
--- a/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
+++ b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
@@ -45,10 +45,7 @@
_SEQ_CLASS_EXPECTED_LOSS = 0.17
-AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "MIT/ast-finetuned-audioset-10-10-0.4593",
- # See all Audio Spectrogram Transformer models at https://huggingface.co/models?filter=ast
-]
+from ..deprecated._archive_maps import AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ASTEmbeddings(nn.Module):
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 80551b84522350..bf46066002feb9 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -27,6 +27,10 @@
logger = logging.get_logger(__name__)
+
+from ..deprecated._archive_maps import CONFIG_ARCHIVE_MAP_MAPPING_NAMES # noqa: F401, E402
+
+
CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
@@ -191,6 +195,7 @@
("pvt_v2", "PvtV2Config"),
("qdqbert", "QDQBertConfig"),
("qwen2", "Qwen2Config"),
+ ("qwen2_moe", "Qwen2MoeConfig"),
("rag", "RagConfig"),
("realm", "RealmConfig"),
("reformer", "ReformerConfig"),
@@ -276,230 +281,6 @@
]
)
-CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
- [
- # Add archive maps here)
- ("albert", "ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("align", "ALIGN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("altclip", "ALTCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("audio-spectrogram-transformer", "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("autoformer", "AUTOFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bark", "BARK_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bart", "BART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("beit", "BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bert", "BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("big_bird", "BIG_BIRD_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bigbird_pegasus", "BIGBIRD_PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("biogpt", "BIOGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bit", "BIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("blenderbot", "BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("blenderbot-small", "BLENDERBOT_SMALL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("blip", "BLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("blip-2", "BLIP_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bloom", "BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bridgetower", "BRIDGETOWER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("bros", "BROS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("camembert", "CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("canine", "CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("chinese_clip", "CHINESE_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("clap", "CLAP_PRETRAINED_MODEL_ARCHIVE_LIST"),
- ("clip", "CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("clipseg", "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("clvp", "CLVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("codegen", "CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("cohere", "COHERE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("conditional_detr", "CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("convbert", "CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("convnextv2", "CONVNEXTV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("cpmant", "CPMANT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("ctrl", "CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("cvt", "CVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("data2vec-audio", "DATA2VEC_AUDIO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("data2vec-text", "DATA2VEC_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("data2vec-vision", "DATA2VEC_VISION_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("deberta", "DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("deberta-v2", "DEBERTA_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("deformable_detr", "DEFORMABLE_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("deit", "DEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("depth_anything", "DEPTH_ANYTHING_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("deta", "DETA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("detr", "DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("dinat", "DINAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("dinov2", "DINOV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("distilbert", "DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("donut-swin", "DONUT_SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("dpr", "DPR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("dpt", "DPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("efficientformer", "EFFICIENTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("efficientnet", "EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("electra", "ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("encodec", "ENCODEC_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("ernie", "ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("ernie_m", "ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("esm", "ESM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("falcon", "FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("fastspeech2_conformer", "FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("flaubert", "FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("flava", "FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("fnet", "FNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("focalnet", "FOCALNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("fsmt", "FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("funnel", "FUNNEL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("fuyu", "FUYU_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gemma", "GEMMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("git", "GIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("glpn", "GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gpt2", "GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gpt_bigcode", "GPT_BIGCODE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gpt_neo", "GPT_NEO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gpt_neox", "GPT_NEOX_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gpt_neox_japanese", "GPT_NEOX_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gptj", "GPTJ_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("gptsan-japanese", "GPTSAN_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("graphormer", "GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("groupvit", "GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("hubert", "HUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("ibert", "IBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("idefics", "IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("imagegpt", "IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("informer", "INFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("instructblip", "INSTRUCTBLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("jukebox", "JUKEBOX_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("kosmos-2", "KOSMOS2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("layoutlm", "LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("layoutlmv2", "LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("lilt", "LILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("llama", "LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("llava", "LLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("llava_next", "LLAVA_NEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("longt5", "LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("lxmert", "LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("m2m_100", "M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mamba", "MAMBA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("markuplm", "MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mask2former", "MASK2FORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("maskformer", "MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mbart", "MBART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mctct", "MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mega", "MEGA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("megatron-bert", "MEGATRON_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mgp-str", "MGP_STR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mistral", "MISTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mixtral", "MIXTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mobilenet_v1", "MOBILENET_V1_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mobilenet_v2", "MOBILENET_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mobilevit", "MOBILEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mobilevitv2", "MOBILEVITV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mpnet", "MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mpt", "MPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mra", "MRA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("musicgen", "MUSICGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("musicgen_melody", "MUSICGEN_MELODY_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("mvp", "MVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("nat", "NAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("nezha", "NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("nllb-moe", "NLLB_MOE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("nystromformer", "NYSTROMFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("oneformer", "ONEFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("open-llama", "OPEN_LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("openai-gpt", "OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("opt", "OPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("owlv2", "OWLV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("owlvit", "OWLVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("patchtsmixer", "PATCHTSMIXER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("patchtst", "PATCHTST_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pegasus", "PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pegasus_x", "PEGASUS_X_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("perceiver", "PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("persimmon", "PERSIMMON_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("phi", "PHI_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pix2struct", "PIX2STRUCT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("plbart", "PLBART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("poolformer", "POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pop2piano", "POP2PIANO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("prophetnet", "PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pvt", "PVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("pvt_v2", "PVT_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("qdqbert", "QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("qwen2", "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("realm", "REALM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("regnet", "REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("rembert", "REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("resnet", "RESNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("retribert", "RETRIBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("roberta", "ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("roberta-prelayernorm", "ROBERTA_PRELAYERNORM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("roc_bert", "ROC_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("roformer", "ROFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("rwkv", "RWKV_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("sam", "SAM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("seamless_m4t", "SEAMLESS_M4T_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("seamless_m4t_v2", "SEAMLESS_M4T_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("segformer", "SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("seggpt", "SEGGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("sew", "SEW_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("sew-d", "SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("siglip", "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("speech_to_text", "SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("speech_to_text_2", "SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("speecht5", "SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("splinter", "SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("squeezebert", "SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("stablelm", "STABLELM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("starcoder2", "STARCODER2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("superpoint", "SUPERPOINT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("swiftformer", "SWIFTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("swin2sr", "SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("swinv2", "SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("switch_transformers", "SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("t5", "T5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("table-transformer", "TABLE_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("tapas", "TAPAS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("time_series_transformer", "TIME_SERIES_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("timesformer", "TIMESFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("transfo-xl", "TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("tvlt", "TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("tvp", "TVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("udop", "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("univnet", "UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("van", "VAN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("videomae", "VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vipllava", "VIPLLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("visual_bert", "VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vit", "VIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vit_hybrid", "VIT_HYBRID_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vit_mae", "VIT_MAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vit_msn", "VIT_MSN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vitdet", "VITDET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vitmatte", "VITMATTE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vits", "VITS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("vivit", "VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("wav2vec2", "WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("wav2vec2-bert", "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("wav2vec2-conformer", "WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("whisper", "WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xclip", "XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xglm", "XGLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xlm", "XLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xlm-prophetnet", "XLM_PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xlm-roberta", "XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xlnet", "XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("xmod", "XMOD_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("yolos", "YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
- ]
-)
-
MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
@@ -687,6 +468,7 @@
("pvt_v2", "PVTv2"),
("qdqbert", "QDQBert"),
("qwen2", "Qwen2"),
+ ("qwen2_moe", "Qwen2MoE"),
("rag", "RAG"),
("realm", "REALM"),
("reformer", "Reformer"),
@@ -906,11 +688,6 @@ def __init__(self, mapping):
def _initialize(self):
if self._initialized:
return
- warnings.warn(
- "ALL_PRETRAINED_CONFIG_ARCHIVE_MAP is deprecated and will be removed in v5 of Transformers. "
- "It does not contain all available model checkpoints, far from it. Checkout hf.co/models for that.",
- FutureWarning,
- )
for model_type, map_name in self._mapping.items():
module_name = model_type_to_module_name(model_type)
@@ -945,9 +722,6 @@ def __contains__(self, item):
return item in self._data
-ALL_PRETRAINED_CONFIG_ARCHIVE_MAP = _LazyLoadAllMappings(CONFIG_ARCHIVE_MAP_MAPPING_NAMES)
-
-
def _get_class_name(model_class: Union[str, List[str]]):
if isinstance(model_class, (list, tuple)):
return " or ".join([f"[`{c}`]" for c in model_class if c is not None])
@@ -1192,3 +966,6 @@ def register(model_type, config, exist_ok=False):
"match!"
)
CONFIG_MAPPING.register(model_type, config, exist_ok=exist_ok)
+
+
+ALL_PRETRAINED_CONFIG_ARCHIVE_MAP = _LazyLoadAllMappings(CONFIG_ARCHIVE_MAP_MAPPING_NAMES)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index dcdf54b7d90183..150dea04f3745a 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -182,6 +182,7 @@
("pvt_v2", "PvtV2Model"),
("qdqbert", "QDQBertModel"),
("qwen2", "Qwen2Model"),
+ ("qwen2_moe", "Qwen2MoeModel"),
("reformer", "ReformerModel"),
("regnet", "RegNetModel"),
("rembert", "RemBertModel"),
@@ -467,6 +468,7 @@
("prophetnet", "ProphetNetForCausalLM"),
("qdqbert", "QDQBertLMHeadModel"),
("qwen2", "Qwen2ForCausalLM"),
+ ("qwen2_moe", "Qwen2MoeForCausalLM"),
("reformer", "ReformerModelWithLMHead"),
("rembert", "RemBertForCausalLM"),
("roberta", "RobertaForCausalLM"),
@@ -871,6 +873,7 @@
("plbart", "PLBartForSequenceClassification"),
("qdqbert", "QDQBertForSequenceClassification"),
("qwen2", "Qwen2ForSequenceClassification"),
+ ("qwen2_moe", "Qwen2MoeForSequenceClassification"),
("reformer", "ReformerForSequenceClassification"),
("rembert", "RemBertForSequenceClassification"),
("roberta", "RobertaForSequenceClassification"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 37e58d88170e03..4bc5d8105316bf 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -354,6 +354,13 @@
"Qwen2TokenizerFast" if is_tokenizers_available() else None,
),
),
+ (
+ "qwen2_moe",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
("rag", ("RagTokenizer", None)),
("realm", ("RealmTokenizer", "RealmTokenizerFast" if is_tokenizers_available() else None)),
(
diff --git a/src/transformers/models/autoformer/configuration_autoformer.py b/src/transformers/models/autoformer/configuration_autoformer.py
index 7604233e327369..11909ac5c38c4c 100644
--- a/src/transformers/models/autoformer/configuration_autoformer.py
+++ b/src/transformers/models/autoformer/configuration_autoformer.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-AUTOFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "huggingface/autoformer-tourism-monthly": "https://huggingface.co/huggingface/autoformer-tourism-monthly/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import AUTOFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class AutoformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/autoformer/modeling_autoformer.py b/src/transformers/models/autoformer/modeling_autoformer.py
index 78dbb8a5de5f41..8a993fad32785f 100644
--- a/src/transformers/models/autoformer/modeling_autoformer.py
+++ b/src/transformers/models/autoformer/modeling_autoformer.py
@@ -167,10 +167,7 @@ class AutoformerModelOutput(ModelOutput):
static_features: Optional[torch.FloatTensor] = None
-AUTOFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "huggingface/autoformer-tourism-monthly",
- # See all Autoformer models at https://huggingface.co/models?filter=autoformer
-]
+from ..deprecated._archive_maps import AUTOFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesFeatureEmbedder with TimeSeries->Autoformer
diff --git a/src/transformers/models/bark/configuration_bark.py b/src/transformers/models/bark/configuration_bark.py
index 15efb11dc7d4a5..a6bf2b546af1fd 100644
--- a/src/transformers/models/bark/configuration_bark.py
+++ b/src/transformers/models/bark/configuration_bark.py
@@ -25,11 +25,6 @@
logger = logging.get_logger(__name__)
-BARK_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "suno/bark-small": "https://huggingface.co/suno/bark-small/resolve/main/config.json",
- "suno/bark": "https://huggingface.co/suno/bark/resolve/main/config.json",
-}
-
BARK_SUBMODELCONFIG_START_DOCSTRING = """
This is the configuration class to store the configuration of a [`{model}`]. It is used to instantiate the model
according to the specified arguments, defining the model architecture. Instantiating a configuration with the
diff --git a/src/transformers/models/bark/modeling_bark.py b/src/transformers/models/bark/modeling_bark.py
index f26b723a49d237..de04614075cf80 100644
--- a/src/transformers/models/bark/modeling_bark.py
+++ b/src/transformers/models/bark/modeling_bark.py
@@ -63,11 +63,8 @@
_CHECKPOINT_FOR_DOC = "suno/bark-small"
_CONFIG_FOR_DOC = "BarkConfig"
-BARK_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "suno/bark-small",
- "suno/bark",
- # See all Bark models at https://huggingface.co/models?filter=bark
-]
+
+from ..deprecated._archive_maps import BARK_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
diff --git a/src/transformers/models/bart/configuration_bart.py b/src/transformers/models/bart/configuration_bart.py
index 8c03be9a6202a8..1a6214c2eecfc5 100644
--- a/src/transformers/models/bart/configuration_bart.py
+++ b/src/transformers/models/bart/configuration_bart.py
@@ -26,11 +26,6 @@
logger = logging.get_logger(__name__)
-BART_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/config.json",
- # See all BART models at https://huggingface.co/models?filter=bart
-}
-
class BartConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/bart/modeling_bart.py b/src/transformers/models/bart/modeling_bart.py
index 1f90b82a104d42..630688d1fd41a4 100755
--- a/src/transformers/models/bart/modeling_bart.py
+++ b/src/transformers/models/bart/modeling_bart.py
@@ -78,10 +78,7 @@
_QA_EXPECTED_OUTPUT = "' nice puppet'"
-BART_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/bart-large",
- # see all BART models at https://huggingface.co/models?filter=bart
-]
+from ..deprecated._archive_maps import BART_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
@@ -2096,7 +2093,7 @@ def forward(self, *args, **kwargs):
@add_start_docstrings(
"""
- BART decoder with with a language modeling head on top (linear layer with weights tied to the input embeddings).
+ BART decoder with a language modeling head on top (linear layer with weights tied to the input embeddings).
""",
BART_START_DOCSTRING,
)
diff --git a/src/transformers/models/bart/tokenization_bart.py b/src/transformers/models/bart/tokenization_bart.py
index b21e81000f2daf..5207b9c92b07ff 100644
--- a/src/transformers/models/bart/tokenization_bart.py
+++ b/src/transformers/models/bart/tokenization_bart.py
@@ -30,33 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
# See all BART models at https://huggingface.co/models?filter=bart
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/bart-base": "https://huggingface.co/facebook/bart-base/resolve/main/vocab.json",
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/vocab.json",
- "facebook/bart-large-mnli": "https://huggingface.co/facebook/bart-large-mnli/resolve/main/vocab.json",
- "facebook/bart-large-cnn": "https://huggingface.co/facebook/bart-large-cnn/resolve/main/vocab.json",
- "facebook/bart-large-xsum": "https://huggingface.co/facebook/bart-large-xsum/resolve/main/vocab.json",
- "yjernite/bart_eli5": "https://huggingface.co/yjernite/bart_eli5/resolve/main/vocab.json",
- },
- "merges_file": {
- "facebook/bart-base": "https://huggingface.co/facebook/bart-base/resolve/main/merges.txt",
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/merges.txt",
- "facebook/bart-large-mnli": "https://huggingface.co/facebook/bart-large-mnli/resolve/main/merges.txt",
- "facebook/bart-large-cnn": "https://huggingface.co/facebook/bart-large-cnn/resolve/main/merges.txt",
- "facebook/bart-large-xsum": "https://huggingface.co/facebook/bart-large-xsum/resolve/main/merges.txt",
- "yjernite/bart_eli5": "https://huggingface.co/yjernite/bart_eli5/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/bart-base": 1024,
- "facebook/bart-large": 1024,
- "facebook/bart-large-mnli": 1024,
- "facebook/bart-large-cnn": 1024,
- "facebook/bart-large-xsum": 1024,
- "yjernite/bart_eli5": 1024,
-}
@lru_cache()
@@ -177,8 +150,6 @@ class BartTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/bart/tokenization_bart_fast.py b/src/transformers/models/bart/tokenization_bart_fast.py
index 850c9636833aa2..e9fb8497c907b9 100644
--- a/src/transformers/models/bart/tokenization_bart_fast.py
+++ b/src/transformers/models/bart/tokenization_bart_fast.py
@@ -30,41 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
# See all BART models at https://huggingface.co/models?filter=bart
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/bart-base": "https://huggingface.co/facebook/bart-base/resolve/main/vocab.json",
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/vocab.json",
- "facebook/bart-large-mnli": "https://huggingface.co/facebook/bart-large-mnli/resolve/main/vocab.json",
- "facebook/bart-large-cnn": "https://huggingface.co/facebook/bart-large-cnn/resolve/main/vocab.json",
- "facebook/bart-large-xsum": "https://huggingface.co/facebook/bart-large-xsum/resolve/main/vocab.json",
- "yjernite/bart_eli5": "https://huggingface.co/yjernite/bart_eli5/resolve/main/vocab.json",
- },
- "merges_file": {
- "facebook/bart-base": "https://huggingface.co/facebook/bart-base/resolve/main/merges.txt",
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/merges.txt",
- "facebook/bart-large-mnli": "https://huggingface.co/facebook/bart-large-mnli/resolve/main/merges.txt",
- "facebook/bart-large-cnn": "https://huggingface.co/facebook/bart-large-cnn/resolve/main/merges.txt",
- "facebook/bart-large-xsum": "https://huggingface.co/facebook/bart-large-xsum/resolve/main/merges.txt",
- "yjernite/bart_eli5": "https://huggingface.co/yjernite/bart_eli5/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "facebook/bart-base": "https://huggingface.co/facebook/bart-base/resolve/main/tokenizer.json",
- "facebook/bart-large": "https://huggingface.co/facebook/bart-large/resolve/main/tokenizer.json",
- "facebook/bart-large-mnli": "https://huggingface.co/facebook/bart-large-mnli/resolve/main/tokenizer.json",
- "facebook/bart-large-cnn": "https://huggingface.co/facebook/bart-large-cnn/resolve/main/tokenizer.json",
- "facebook/bart-large-xsum": "https://huggingface.co/facebook/bart-large-xsum/resolve/main/tokenizer.json",
- "yjernite/bart_eli5": "https://huggingface.co/yjernite/bart_eli5/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/bart-base": 1024,
- "facebook/bart-large": 1024,
- "facebook/bart-large-mnli": 1024,
- "facebook/bart-large-cnn": 1024,
- "facebook/bart-large-xsum": 1024,
- "yjernite/bart_eli5": 1024,
-}
class BartTokenizerFast(PreTrainedTokenizerFast):
@@ -149,8 +114,6 @@ class BartTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = BartTokenizer
diff --git a/src/transformers/models/barthez/tokenization_barthez.py b/src/transformers/models/barthez/tokenization_barthez.py
index f6ea253402f69a..d9bd67cf51b773 100644
--- a/src/transformers/models/barthez/tokenization_barthez.py
+++ b/src/transformers/models/barthez/tokenization_barthez.py
@@ -29,21 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "moussaKam/mbarthez": "https://huggingface.co/moussaKam/mbarthez/resolve/main/sentencepiece.bpe.model",
- "moussaKam/barthez": "https://huggingface.co/moussaKam/barthez/resolve/main/sentencepiece.bpe.model",
- "moussaKam/barthez-orangesum-title": (
- "https://huggingface.co/moussaKam/barthez-orangesum-title/resolve/main/sentencepiece.bpe.model"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "moussaKam/mbarthez": 1024,
- "moussaKam/barthez": 1024,
- "moussaKam/barthez-orangesum-title": 1024,
-}
SPIECE_UNDERLINE = "▁"
@@ -119,8 +104,6 @@ class BarthezTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/barthez/tokenization_barthez_fast.py b/src/transformers/models/barthez/tokenization_barthez_fast.py
index fb4a114b43bf62..e988b0d518a3f3 100644
--- a/src/transformers/models/barthez/tokenization_barthez_fast.py
+++ b/src/transformers/models/barthez/tokenization_barthez_fast.py
@@ -33,28 +33,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "moussaKam/mbarthez": "https://huggingface.co/moussaKam/mbarthez/resolve/main/sentencepiece.bpe.model",
- "moussaKam/barthez": "https://huggingface.co/moussaKam/barthez/resolve/main/sentencepiece.bpe.model",
- "moussaKam/barthez-orangesum-title": (
- "https://huggingface.co/moussaKam/barthez-orangesum-title/resolve/main/sentencepiece.bpe.model"
- ),
- },
- "tokenizer_file": {
- "moussaKam/mbarthez": "https://huggingface.co/moussaKam/mbarthez/resolve/main/tokenizer.json",
- "moussaKam/barthez": "https://huggingface.co/moussaKam/barthez/resolve/main/tokenizer.json",
- "moussaKam/barthez-orangesum-title": (
- "https://huggingface.co/moussaKam/barthez-orangesum-title/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "moussaKam/mbarthez": 1024,
- "moussaKam/barthez": 1024,
- "moussaKam/barthez-orangesum-title": 1024,
-}
SPIECE_UNDERLINE = "▁"
@@ -111,8 +89,6 @@ class BarthezTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = BarthezTokenizer
diff --git a/src/transformers/models/bartpho/tokenization_bartpho.py b/src/transformers/models/bartpho/tokenization_bartpho.py
index 6b9dc266b29ff4..d936be41c2c786 100644
--- a/src/transformers/models/bartpho/tokenization_bartpho.py
+++ b/src/transformers/models/bartpho/tokenization_bartpho.py
@@ -31,17 +31,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "monolingual_vocab_file": "dict.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "vinai/bartpho-syllable": "https://huggingface.co/vinai/bartpho-syllable/resolve/main/sentencepiece.bpe.model",
- },
- "monolingual_vocab_file": {
- "vinai/bartpho-syllable": "https://huggingface.co/vinai/bartpho-syllable/resolve/main/dict.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"vinai/bartpho-syllable": 1024}
-
class BartphoTokenizer(PreTrainedTokenizer):
"""
@@ -114,8 +103,6 @@ class BartphoTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/beit/configuration_beit.py b/src/transformers/models/beit/configuration_beit.py
index b579eeea37c480..dbb1e755e94b36 100644
--- a/src/transformers/models/beit/configuration_beit.py
+++ b/src/transformers/models/beit/configuration_beit.py
@@ -26,12 +26,8 @@
logger = logging.get_logger(__name__)
-BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/beit-base-patch16-224-pt22k": (
- "https://huggingface.co/microsoft/beit-base-patch16-224-pt22k/resolve/main/config.json"
- ),
- # See all BEiT models at https://huggingface.co/models?filter=beit
-}
+
+from ..deprecated._archive_maps import BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BeitConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index da4721656c0285..d04717039ec909 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -60,10 +60,8 @@
_IMAGE_CLASS_CHECKPOINT = "microsoft/beit-base-patch16-224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-BEIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/beit-base-patch16-224",
- # See all BEiT models at https://huggingface.co/models?filter=beit
-]
+
+from ..deprecated._archive_maps import BEIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/bert/configuration_bert.py b/src/transformers/models/bert/configuration_bert.py
index 1f79260f510ff2..e692f8284c2bac 100644
--- a/src/transformers/models/bert/configuration_bert.py
+++ b/src/transformers/models/bert/configuration_bert.py
@@ -24,49 +24,8 @@
logger = logging.get_logger(__name__)
-BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/config.json",
- "google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/config.json",
- "google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/config.json",
- "google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/config.json",
- "google-bert/bert-base-multilingual-uncased": "https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/config.json",
- "google-bert/bert-base-multilingual-cased": "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/config.json",
- "google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/config.json",
- "google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/config.json",
- "google-bert/bert-large-uncased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/config.json"
- ),
- "google-bert/bert-large-cased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/config.json"
- ),
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/config.json"
- ),
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/config.json"
- ),
- "google-bert/bert-base-cased-finetuned-mrpc": "https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/config.json",
- "google-bert/bert-base-german-dbmdz-cased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/config.json",
- "google-bert/bert-base-german-dbmdz-uncased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/config.json",
- "cl-tohoku/bert-base-japanese": "https://huggingface.co/cl-tohoku/bert-base-japanese/resolve/main/config.json",
- "cl-tohoku/bert-base-japanese-whole-word-masking": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json"
- ),
- "cl-tohoku/bert-base-japanese-char": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-char/resolve/main/config.json"
- ),
- "cl-tohoku/bert-base-japanese-char-whole-word-masking": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-char-whole-word-masking/resolve/main/config.json"
- ),
- "TurkuNLP/bert-base-finnish-cased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/config.json"
- ),
- "TurkuNLP/bert-base-finnish-uncased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/config.json"
- ),
- "wietsedv/bert-base-dutch-cased": "https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/config.json",
- # See all BERT models at https://huggingface.co/models?filter=bert
-}
+
+from ..deprecated._archive_maps import BERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BertConfig(PretrainedConfig):
diff --git a/src/transformers/models/bert/modeling_bert.py b/src/transformers/models/bert/modeling_bert.py
index 4c068c4d4f1d76..262fc79f0d4039 100755
--- a/src/transformers/models/bert/modeling_bert.py
+++ b/src/transformers/models/bert/modeling_bert.py
@@ -15,7 +15,6 @@
# limitations under the License.
"""PyTorch BERT model."""
-
import math
import os
import warnings
@@ -77,31 +76,7 @@
_SEQ_CLASS_EXPECTED_LOSS = 0.01
-BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google-bert/bert-base-uncased",
- "google-bert/bert-large-uncased",
- "google-bert/bert-base-cased",
- "google-bert/bert-large-cased",
- "google-bert/bert-base-multilingual-uncased",
- "google-bert/bert-base-multilingual-cased",
- "google-bert/bert-base-chinese",
- "google-bert/bert-base-german-cased",
- "google-bert/bert-large-uncased-whole-word-masking",
- "google-bert/bert-large-cased-whole-word-masking",
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad",
- "google-bert/bert-base-cased-finetuned-mrpc",
- "google-bert/bert-base-german-dbmdz-cased",
- "google-bert/bert-base-german-dbmdz-uncased",
- "cl-tohoku/bert-base-japanese",
- "cl-tohoku/bert-base-japanese-whole-word-masking",
- "cl-tohoku/bert-base-japanese-char",
- "cl-tohoku/bert-base-japanese-char-whole-word-masking",
- "TurkuNLP/bert-base-finnish-cased-v1",
- "TurkuNLP/bert-base-finnish-uncased-v1",
- "wietsedv/bert-base-dutch-cased",
- # See all BERT models at https://huggingface.co/models?filter=bert
-]
+from ..deprecated._archive_maps import BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_bert(model, config, tf_checkpoint_path):
@@ -1152,7 +1127,7 @@ def forward(
"""Bert Model with a `language modeling` head on top for CLM fine-tuning.""", BERT_START_DOCSTRING
)
class BertLMHeadModel(BertPreTrainedModel):
- _tied_weights_keys = ["predictions.decoder.bias", "cls.predictions.decoder.weight"]
+ _tied_weights_keys = ["cls.predictions.decoder.bias", "cls.predictions.decoder.weight"]
def __init__(self, config):
super().__init__(config)
diff --git a/src/transformers/models/bert/modeling_tf_bert.py b/src/transformers/models/bert/modeling_tf_bert.py
index cc1218bbea2e42..9d027d84316582 100644
--- a/src/transformers/models/bert/modeling_tf_bert.py
+++ b/src/transformers/models/bert/modeling_tf_bert.py
@@ -89,29 +89,8 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'LABEL_1'"
_SEQ_CLASS_EXPECTED_LOSS = 0.01
-TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google-bert/bert-base-uncased",
- "google-bert/bert-large-uncased",
- "google-bert/bert-base-cased",
- "google-bert/bert-large-cased",
- "google-bert/bert-base-multilingual-uncased",
- "google-bert/bert-base-multilingual-cased",
- "google-bert/bert-base-chinese",
- "google-bert/bert-base-german-cased",
- "google-bert/bert-large-uncased-whole-word-masking",
- "google-bert/bert-large-cased-whole-word-masking",
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad",
- "google-bert/bert-base-cased-finetuned-mrpc",
- "cl-tohoku/bert-base-japanese",
- "cl-tohoku/bert-base-japanese-whole-word-masking",
- "cl-tohoku/bert-base-japanese-char",
- "cl-tohoku/bert-base-japanese-char-whole-word-masking",
- "TurkuNLP/bert-base-finnish-cased-v1",
- "TurkuNLP/bert-base-finnish-uncased-v1",
- "wietsedv/bert-base-dutch-cased",
- # See all BERT models at https://huggingface.co/models?filter=bert
-]
+
+from ..deprecated._archive_maps import TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFBertPreTrainingLoss:
diff --git a/src/transformers/models/bert/tokenization_bert.py b/src/transformers/models/bert/tokenization_bert.py
index c95e9ff0f8b43c..f645d7c08a327b 100644
--- a/src/transformers/models/bert/tokenization_bert.py
+++ b/src/transformers/models/bert/tokenization_bert.py
@@ -28,91 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/vocab.txt",
- "google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/vocab.txt",
- "google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/vocab.txt",
- "google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-multilingual-uncased": (
- "https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-multilingual-cased": "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/vocab.txt",
- "google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/vocab.txt",
- "google-bert/bert-large-uncased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-cased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-cased-finetuned-mrpc": (
- "https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-german-dbmdz-cased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-german-dbmdz-uncased": (
- "https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/vocab.txt"
- ),
- "TurkuNLP/bert-base-finnish-cased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/vocab.txt"
- ),
- "TurkuNLP/bert-base-finnish-uncased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/vocab.txt"
- ),
- "wietsedv/bert-base-dutch-cased": (
- "https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google-bert/bert-base-uncased": 512,
- "google-bert/bert-large-uncased": 512,
- "google-bert/bert-base-cased": 512,
- "google-bert/bert-large-cased": 512,
- "google-bert/bert-base-multilingual-uncased": 512,
- "google-bert/bert-base-multilingual-cased": 512,
- "google-bert/bert-base-chinese": 512,
- "google-bert/bert-base-german-cased": 512,
- "google-bert/bert-large-uncased-whole-word-masking": 512,
- "google-bert/bert-large-cased-whole-word-masking": 512,
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": 512,
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": 512,
- "google-bert/bert-base-cased-finetuned-mrpc": 512,
- "google-bert/bert-base-german-dbmdz-cased": 512,
- "google-bert/bert-base-german-dbmdz-uncased": 512,
- "TurkuNLP/bert-base-finnish-cased-v1": 512,
- "TurkuNLP/bert-base-finnish-uncased-v1": 512,
- "wietsedv/bert-base-dutch-cased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google-bert/bert-base-uncased": {"do_lower_case": True},
- "google-bert/bert-large-uncased": {"do_lower_case": True},
- "google-bert/bert-base-cased": {"do_lower_case": False},
- "google-bert/bert-large-cased": {"do_lower_case": False},
- "google-bert/bert-base-multilingual-uncased": {"do_lower_case": True},
- "google-bert/bert-base-multilingual-cased": {"do_lower_case": False},
- "google-bert/bert-base-chinese": {"do_lower_case": False},
- "google-bert/bert-base-german-cased": {"do_lower_case": False},
- "google-bert/bert-large-uncased-whole-word-masking": {"do_lower_case": True},
- "google-bert/bert-large-cased-whole-word-masking": {"do_lower_case": False},
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": {"do_lower_case": True},
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": {"do_lower_case": False},
- "google-bert/bert-base-cased-finetuned-mrpc": {"do_lower_case": False},
- "google-bert/bert-base-german-dbmdz-cased": {"do_lower_case": False},
- "google-bert/bert-base-german-dbmdz-uncased": {"do_lower_case": True},
- "TurkuNLP/bert-base-finnish-cased-v1": {"do_lower_case": False},
- "TurkuNLP/bert-base-finnish-uncased-v1": {"do_lower_case": True},
- "wietsedv/bert-base-dutch-cased": {"do_lower_case": False},
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -177,9 +92,6 @@ class BertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/bert/tokenization_bert_fast.py b/src/transformers/models/bert/tokenization_bert_fast.py
index e7754b2fb5a128..f4897772847029 100644
--- a/src/transformers/models/bert/tokenization_bert_fast.py
+++ b/src/transformers/models/bert/tokenization_bert_fast.py
@@ -28,135 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/vocab.txt",
- "google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/vocab.txt",
- "google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/vocab.txt",
- "google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-multilingual-uncased": (
- "https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-multilingual-cased": "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/vocab.txt",
- "google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/vocab.txt",
- "google-bert/bert-large-uncased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-cased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
- ),
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-cased-finetuned-mrpc": (
- "https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/vocab.txt"
- ),
- "google-bert/bert-base-german-dbmdz-cased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/vocab.txt",
- "google-bert/bert-base-german-dbmdz-uncased": (
- "https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/vocab.txt"
- ),
- "TurkuNLP/bert-base-finnish-cased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/vocab.txt"
- ),
- "TurkuNLP/bert-base-finnish-uncased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/vocab.txt"
- ),
- "wietsedv/bert-base-dutch-cased": (
- "https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/tokenizer.json",
- "google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/tokenizer.json",
- "google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/tokenizer.json",
- "google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/tokenizer.json",
- "google-bert/bert-base-multilingual-uncased": (
- "https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-base-multilingual-cased": (
- "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/tokenizer.json",
- "google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/tokenizer.json",
- "google-bert/bert-large-uncased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-large-cased-whole-word-masking": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
- "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-base-cased-finetuned-mrpc": (
- "https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-base-german-dbmdz-cased": (
- "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/tokenizer.json"
- ),
- "google-bert/bert-base-german-dbmdz-uncased": (
- "https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/tokenizer.json"
- ),
- "TurkuNLP/bert-base-finnish-cased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/tokenizer.json"
- ),
- "TurkuNLP/bert-base-finnish-uncased-v1": (
- "https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/tokenizer.json"
- ),
- "wietsedv/bert-base-dutch-cased": (
- "https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google-bert/bert-base-uncased": 512,
- "google-bert/bert-large-uncased": 512,
- "google-bert/bert-base-cased": 512,
- "google-bert/bert-large-cased": 512,
- "google-bert/bert-base-multilingual-uncased": 512,
- "google-bert/bert-base-multilingual-cased": 512,
- "google-bert/bert-base-chinese": 512,
- "google-bert/bert-base-german-cased": 512,
- "google-bert/bert-large-uncased-whole-word-masking": 512,
- "google-bert/bert-large-cased-whole-word-masking": 512,
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": 512,
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": 512,
- "google-bert/bert-base-cased-finetuned-mrpc": 512,
- "google-bert/bert-base-german-dbmdz-cased": 512,
- "google-bert/bert-base-german-dbmdz-uncased": 512,
- "TurkuNLP/bert-base-finnish-cased-v1": 512,
- "TurkuNLP/bert-base-finnish-uncased-v1": 512,
- "wietsedv/bert-base-dutch-cased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google-bert/bert-base-uncased": {"do_lower_case": True},
- "google-bert/bert-large-uncased": {"do_lower_case": True},
- "google-bert/bert-base-cased": {"do_lower_case": False},
- "google-bert/bert-large-cased": {"do_lower_case": False},
- "google-bert/bert-base-multilingual-uncased": {"do_lower_case": True},
- "google-bert/bert-base-multilingual-cased": {"do_lower_case": False},
- "google-bert/bert-base-chinese": {"do_lower_case": False},
- "google-bert/bert-base-german-cased": {"do_lower_case": False},
- "google-bert/bert-large-uncased-whole-word-masking": {"do_lower_case": True},
- "google-bert/bert-large-cased-whole-word-masking": {"do_lower_case": False},
- "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": {"do_lower_case": True},
- "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": {"do_lower_case": False},
- "google-bert/bert-base-cased-finetuned-mrpc": {"do_lower_case": False},
- "google-bert/bert-base-german-dbmdz-cased": {"do_lower_case": False},
- "google-bert/bert-base-german-dbmdz-uncased": {"do_lower_case": True},
- "TurkuNLP/bert-base-finnish-cased-v1": {"do_lower_case": False},
- "TurkuNLP/bert-base-finnish-uncased-v1": {"do_lower_case": True},
- "wietsedv/bert-base-dutch-cased": {"do_lower_case": False},
-}
-
class BertTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -199,9 +70,6 @@ class BertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = BertTokenizer
def __init__(
diff --git a/src/transformers/models/bert_generation/tokenization_bert_generation.py b/src/transformers/models/bert_generation/tokenization_bert_generation.py
index 3b6298fcbd8f6e..772eb123c39888 100644
--- a/src/transformers/models/bert_generation/tokenization_bert_generation.py
+++ b/src/transformers/models/bert_generation/tokenization_bert_generation.py
@@ -29,16 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "bert_for_seq_generation": (
- "https://huggingface.co/google/bert_for_seq_generation_L-24_bbc_encoder/resolve/main/spiece.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"bert_for_seq_generation": 512}
-
class BertGenerationTokenizer(PreTrainedTokenizer):
"""
@@ -82,8 +72,6 @@ class BertGenerationTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
prefix_tokens: List[int] = []
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/bert_japanese/tokenization_bert_japanese.py b/src/transformers/models/bert_japanese/tokenization_bert_japanese.py
index b2d1ac19580191..fe5cd06f7f5854 100644
--- a/src/transformers/models/bert_japanese/tokenization_bert_japanese.py
+++ b/src/transformers/models/bert_japanese/tokenization_bert_japanese.py
@@ -36,51 +36,6 @@
SPIECE_UNDERLINE = "▁"
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "cl-tohoku/bert-base-japanese": "https://huggingface.co/cl-tohoku/bert-base-japanese/resolve/main/vocab.txt",
- "cl-tohoku/bert-base-japanese-whole-word-masking": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/vocab.txt"
- ),
- "cl-tohoku/bert-base-japanese-char": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-char/resolve/main/vocab.txt"
- ),
- "cl-tohoku/bert-base-japanese-char-whole-word-masking": (
- "https://huggingface.co/cl-tohoku/bert-base-japanese-char-whole-word-masking/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "cl-tohoku/bert-base-japanese": 512,
- "cl-tohoku/bert-base-japanese-whole-word-masking": 512,
- "cl-tohoku/bert-base-japanese-char": 512,
- "cl-tohoku/bert-base-japanese-char-whole-word-masking": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "cl-tohoku/bert-base-japanese": {
- "do_lower_case": False,
- "word_tokenizer_type": "mecab",
- "subword_tokenizer_type": "wordpiece",
- },
- "cl-tohoku/bert-base-japanese-whole-word-masking": {
- "do_lower_case": False,
- "word_tokenizer_type": "mecab",
- "subword_tokenizer_type": "wordpiece",
- },
- "cl-tohoku/bert-base-japanese-char": {
- "do_lower_case": False,
- "word_tokenizer_type": "mecab",
- "subword_tokenizer_type": "character",
- },
- "cl-tohoku/bert-base-japanese-char-whole-word-masking": {
- "do_lower_case": False,
- "word_tokenizer_type": "mecab",
- "subword_tokenizer_type": "character",
- },
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -136,9 +91,6 @@ class BertJapaneseTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/bertweet/tokenization_bertweet.py b/src/transformers/models/bertweet/tokenization_bertweet.py
index 74bc040c25b13d..7f14ed61dac0f2 100644
--- a/src/transformers/models/bertweet/tokenization_bertweet.py
+++ b/src/transformers/models/bertweet/tokenization_bertweet.py
@@ -35,19 +35,6 @@
"merges_file": "bpe.codes",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "vinai/bertweet-base": "https://huggingface.co/vinai/bertweet-base/resolve/main/vocab.txt",
- },
- "merges_file": {
- "vinai/bertweet-base": "https://huggingface.co/vinai/bertweet-base/resolve/main/bpe.codes",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "vinai/bertweet-base": 128,
-}
-
def get_pairs(word):
"""
@@ -117,8 +104,6 @@ class BertweetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/big_bird/configuration_big_bird.py b/src/transformers/models/big_bird/configuration_big_bird.py
index 9802e758539858..f803d56839d744 100644
--- a/src/transformers/models/big_bird/configuration_big_bird.py
+++ b/src/transformers/models/big_bird/configuration_big_bird.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-BIG_BIRD_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/bigbird-roberta-base": "https://huggingface.co/google/bigbird-roberta-base/resolve/main/config.json",
- "google/bigbird-roberta-large": "https://huggingface.co/google/bigbird-roberta-large/resolve/main/config.json",
- "google/bigbird-base-trivia-itc": "https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/config.json",
- # See all BigBird models at https://huggingface.co/models?filter=big_bird
-}
+
+from ..deprecated._archive_maps import BIG_BIRD_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BigBirdConfig(PretrainedConfig):
diff --git a/src/transformers/models/big_bird/modeling_big_bird.py b/src/transformers/models/big_bird/modeling_big_bird.py
index 008985f760e867..510c98079501ef 100755
--- a/src/transformers/models/big_bird/modeling_big_bird.py
+++ b/src/transformers/models/big_bird/modeling_big_bird.py
@@ -54,12 +54,9 @@
_CHECKPOINT_FOR_DOC = "google/bigbird-roberta-base"
_CONFIG_FOR_DOC = "BigBirdConfig"
-BIG_BIRD_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/bigbird-roberta-base",
- "google/bigbird-roberta-large",
- "google/bigbird-base-trivia-itc",
- # See all BigBird models at https://huggingface.co/models?filter=big_bird
-]
+
+from ..deprecated._archive_maps import BIG_BIRD_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
_TRIVIA_QA_MAPPING = {
"big_bird_attention": "attention/self",
diff --git a/src/transformers/models/big_bird/tokenization_big_bird.py b/src/transformers/models/big_bird/tokenization_big_bird.py
index e7c43a86a6cab4..58dc57ef6d2e04 100644
--- a/src/transformers/models/big_bird/tokenization_big_bird.py
+++ b/src/transformers/models/big_bird/tokenization_big_bird.py
@@ -30,24 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/bigbird-roberta-base": "https://huggingface.co/google/bigbird-roberta-base/resolve/main/spiece.model",
- "google/bigbird-roberta-large": (
- "https://huggingface.co/google/bigbird-roberta-large/resolve/main/spiece.model"
- ),
- "google/bigbird-base-trivia-itc": (
- "https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/spiece.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/bigbird-roberta-base": 4096,
- "google/bigbird-roberta-large": 4096,
- "google/bigbird-base-trivia-itc": 4096,
-}
-
class BigBirdTokenizer(PreTrainedTokenizer):
"""
@@ -97,8 +79,6 @@ class BigBirdTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/big_bird/tokenization_big_bird_fast.py b/src/transformers/models/big_bird/tokenization_big_bird_fast.py
index 24fc33d8052962..fa37cd4ac7e7d3 100644
--- a/src/transformers/models/big_bird/tokenization_big_bird_fast.py
+++ b/src/transformers/models/big_bird/tokenization_big_bird_fast.py
@@ -32,35 +32,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/bigbird-roberta-base": "https://huggingface.co/google/bigbird-roberta-base/resolve/main/spiece.model",
- "google/bigbird-roberta-large": (
- "https://huggingface.co/google/bigbird-roberta-large/resolve/main/spiece.model"
- ),
- "google/bigbird-base-trivia-itc": (
- "https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/spiece.model"
- ),
- },
- "tokenizer_file": {
- "google/bigbird-roberta-base": (
- "https://huggingface.co/google/bigbird-roberta-base/resolve/main/tokenizer.json"
- ),
- "google/bigbird-roberta-large": (
- "https://huggingface.co/google/bigbird-roberta-large/resolve/main/tokenizer.json"
- ),
- "google/bigbird-base-trivia-itc": (
- "https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/bigbird-roberta-base": 4096,
- "google/bigbird-roberta-large": 4096,
- "google/bigbird-base-trivia-itc": 4096,
-}
-
SPIECE_UNDERLINE = "▁"
@@ -107,8 +78,6 @@ class BigBirdTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = BigBirdTokenizer
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
index 1c78803c4b1146..5cdcbca775bf4d 100644
--- a/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
@@ -26,18 +26,8 @@
logger = logging.get_logger(__name__)
-BIGBIRD_PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/bigbird-pegasus-large-arxiv": (
- "https://huggingface.co/google/bigbird-pegasus-large-arxiv/resolve/main/config.json"
- ),
- "google/bigbird-pegasus-large-pubmed": (
- "https://huggingface.co/google/bigbird-pegasus-large-pubmed/resolve/main/config.json"
- ),
- "google/bigbird-pegasus-large-bigpatent": (
- "https://huggingface.co/google/bigbird-pegasus-large-bigpatent/resolve/main/config.json"
- ),
- # See all BigBirdPegasus models at https://huggingface.co/models?filter=bigbird_pegasus
-}
+
+from ..deprecated._archive_maps import BIGBIRD_PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BigBirdPegasusConfig(PretrainedConfig):
diff --git a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
index baf08143431693..b863beb75e18c3 100755
--- a/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
+++ b/src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
@@ -54,12 +54,7 @@
_EXPECTED_OUTPUT_SHAPE = [1, 7, 1024]
-BIGBIRD_PEGASUS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/bigbird-pegasus-large-arxiv",
- "google/bigbird-pegasus-large-pubmed",
- "google/bigbird-pegasus-large-bigpatent",
- # See all BigBirdPegasus models at https://huggingface.co/models?filter=bigbird_pegasus
-]
+from ..deprecated._archive_maps import BIGBIRD_PEGASUS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
diff --git a/src/transformers/models/biogpt/configuration_biogpt.py b/src/transformers/models/biogpt/configuration_biogpt.py
index 1fb2933f2843eb..1b4155c0aea3bb 100644
--- a/src/transformers/models/biogpt/configuration_biogpt.py
+++ b/src/transformers/models/biogpt/configuration_biogpt.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-BIOGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/biogpt": "https://huggingface.co/microsoft/biogpt/resolve/main/config.json",
- # See all BioGPT models at https://huggingface.co/models?filter=biogpt
-}
+
+from ..deprecated._archive_maps import BIOGPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BioGptConfig(PretrainedConfig):
diff --git a/src/transformers/models/biogpt/modeling_biogpt.py b/src/transformers/models/biogpt/modeling_biogpt.py
index d98f0886dfa95c..30df3e0847a631 100755
--- a/src/transformers/models/biogpt/modeling_biogpt.py
+++ b/src/transformers/models/biogpt/modeling_biogpt.py
@@ -47,11 +47,7 @@
_CONFIG_FOR_DOC = "BioGptConfig"
-BIOGPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/biogpt",
- "microsoft/BioGPT-Large",
- # See all BioGPT models at https://huggingface.co/models?filter=biogpt
-]
+from ..deprecated._archive_maps import BIOGPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.opt.modeling_opt.OPTLearnedPositionalEmbedding with OPT->BioGpt
diff --git a/src/transformers/models/biogpt/tokenization_biogpt.py b/src/transformers/models/biogpt/tokenization_biogpt.py
index 093991ecb3885d..e16742ec5aa4f0 100644
--- a/src/transformers/models/biogpt/tokenization_biogpt.py
+++ b/src/transformers/models/biogpt/tokenization_biogpt.py
@@ -28,17 +28,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/biogpt": "https://huggingface.co/microsoft/biogpt/resolve/main/vocab.json",
- },
- "merges_file": {"microsoft/biogpt": "https://huggingface.co/microsoft/biogpt/resolve/main/merges.txt"},
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/biogpt": 1024,
-}
-
def get_pairs(word):
"""
@@ -97,8 +86,6 @@ class BioGptTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/bit/configuration_bit.py b/src/transformers/models/bit/configuration_bit.py
index d11a8e38185113..2ec6307421bfaa 100644
--- a/src/transformers/models/bit/configuration_bit.py
+++ b/src/transformers/models/bit/configuration_bit.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-BIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/bit-50": "https://huggingface.co/google/bit-50/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import BIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BitConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/bit/modeling_bit.py b/src/transformers/models/bit/modeling_bit.py
index 49bc75b5f0aa6b..27141a9009e540 100644
--- a/src/transformers/models/bit/modeling_bit.py
+++ b/src/transformers/models/bit/modeling_bit.py
@@ -56,10 +56,8 @@
_IMAGE_CLASS_CHECKPOINT = "google/bit-50"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tiger cat"
-BIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/bit-50",
- # See all BiT models at https://huggingface.co/models?filter=bit
-]
+
+from ..deprecated._archive_maps import BIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def get_padding_value(padding=None, kernel_size=7, stride=1, dilation=1) -> Tuple[Tuple, bool]:
diff --git a/src/transformers/models/blenderbot/configuration_blenderbot.py b/src/transformers/models/blenderbot/configuration_blenderbot.py
index 4f55a96bf62b71..00608710592998 100644
--- a/src/transformers/models/blenderbot/configuration_blenderbot.py
+++ b/src/transformers/models/blenderbot/configuration_blenderbot.py
@@ -27,10 +27,8 @@
logger = logging.get_logger(__name__)
-BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/config.json",
- # See all Blenderbot models at https://huggingface.co/models?filter=blenderbot
-}
+
+from ..deprecated._archive_maps import BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BlenderbotConfig(PretrainedConfig):
diff --git a/src/transformers/models/blenderbot/modeling_blenderbot.py b/src/transformers/models/blenderbot/modeling_blenderbot.py
index 28b81387c13e62..5fa17abcdd294e 100755
--- a/src/transformers/models/blenderbot/modeling_blenderbot.py
+++ b/src/transformers/models/blenderbot/modeling_blenderbot.py
@@ -53,10 +53,7 @@
_CHECKPOINT_FOR_DOC = "facebook/blenderbot-400M-distill"
-BLENDERBOT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/blenderbot-3B",
- # See all Blenderbot models at https://huggingface.co/models?filter=blenderbot
-]
+from ..deprecated._archive_maps import BLENDERBOT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/blenderbot/tokenization_blenderbot.py b/src/transformers/models/blenderbot/tokenization_blenderbot.py
index 29386c1233adf0..b812f84b7d2d45 100644
--- a/src/transformers/models/blenderbot/tokenization_blenderbot.py
+++ b/src/transformers/models/blenderbot/tokenization_blenderbot.py
@@ -34,16 +34,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/vocab.json"},
- "merges_file": {"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/merges.txt"},
- "tokenizer_config_file": {
- "facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/tokenizer_config.json"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/blenderbot-3B": 128}
-
@lru_cache()
# Copied from transformers.models.roberta.tokenization_roberta.bytes_to_unicode
@@ -166,8 +156,6 @@ class BlenderbotTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
# Copied from transformers.models.roberta.tokenization_roberta.RobertaTokenizer.__init__ with Roberta->Blenderbot, RoBERTa->Blenderbot
diff --git a/src/transformers/models/blenderbot/tokenization_blenderbot_fast.py b/src/transformers/models/blenderbot/tokenization_blenderbot_fast.py
index 6245025b503d53..879173282da1e2 100644
--- a/src/transformers/models/blenderbot/tokenization_blenderbot_fast.py
+++ b/src/transformers/models/blenderbot/tokenization_blenderbot_fast.py
@@ -33,16 +33,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/vocab.json"},
- "merges_file": {"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/merges.txt"},
- "tokenizer_config_file": {
- "facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/tokenizer_config.json"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/blenderbot-3B": 128}
-
class BlenderbotTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -126,8 +116,6 @@ class BlenderbotTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = BlenderbotTokenizer
diff --git a/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py b/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
index b41330656d39ab..8b54bd3760feea 100644
--- a/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
@@ -27,10 +27,7 @@
logger = logging.get_logger(__name__)
-BLENDERBOT_SMALL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/config.json",
- # See all BlenderbotSmall models at https://huggingface.co/models?filter=blenderbot_small
-}
+from ..deprecated._archive_maps import BLENDERBOT_SMALL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BlenderbotSmallConfig(PretrainedConfig):
diff --git a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
index f9a9508e590557..da07669a4e777d 100755
--- a/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
@@ -49,10 +49,7 @@
_CONFIG_FOR_DOC = "BlenderbotSmallConfig"
-BLENDERBOT_SMALL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/blenderbot_small-90M",
- # See all BlenderbotSmall models at https://huggingface.co/models?filter=blenderbot_small
-]
+from ..deprecated._archive_maps import BLENDERBOT_SMALL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/blenderbot_small/tokenization_blenderbot_small.py b/src/transformers/models/blenderbot_small/tokenization_blenderbot_small.py
index 240495d73894ef..820868c8cbb769 100644
--- a/src/transformers/models/blenderbot_small/tokenization_blenderbot_small.py
+++ b/src/transformers/models/blenderbot_small/tokenization_blenderbot_small.py
@@ -33,22 +33,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/vocab.json"
- },
- "merges_file": {
- "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/merges.txt"
- },
- "tokenizer_config_file": {
- "facebook/blenderbot_small-90M": (
- "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/tokenizer_config.json"
- )
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/blenderbot_small-90M": 512}
-
def get_pairs(word):
"""
@@ -92,8 +76,6 @@ class BlenderbotSmallTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/blenderbot_small/tokenization_blenderbot_small_fast.py b/src/transformers/models/blenderbot_small/tokenization_blenderbot_small_fast.py
index 4bf0017b5f2a29..a0c61505b14c3d 100644
--- a/src/transformers/models/blenderbot_small/tokenization_blenderbot_small_fast.py
+++ b/src/transformers/models/blenderbot_small/tokenization_blenderbot_small_fast.py
@@ -30,24 +30,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/vocab.json"
- },
- "merges_file": {
- "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/merges.txt"
- },
- "tokenizer_config_file": {
- "facebook/blenderbot_small-90M": (
- "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/tokenizer_config.json"
- )
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/blenderbot_small-90M": 512,
-}
-
class BlenderbotSmallTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -59,8 +41,6 @@ class BlenderbotSmallTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = BlenderbotSmallTokenizer
def __init__(
diff --git a/src/transformers/models/blip/configuration_blip.py b/src/transformers/models/blip/configuration_blip.py
index 42e35958ced3cf..2a76660c0f8ead 100644
--- a/src/transformers/models/blip/configuration_blip.py
+++ b/src/transformers/models/blip/configuration_blip.py
@@ -23,24 +23,8 @@
logger = logging.get_logger(__name__)
-BLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Salesforce/blip-vqa-base": "https://huggingface.co/Salesforce/blip-vqa-base/resolve/main/config.json",
- "Salesforce/blip-vqa-capfit-large": (
- "https://huggingface.co/Salesforce/blip-vqa-base-capfit/resolve/main/config.json"
- ),
- "Salesforce/blip-image-captioning-base": (
- "https://huggingface.co/Salesforce/blip-image-captioning-base/resolve/main/config.json"
- ),
- "Salesforce/blip-image-captioning-large": (
- "https://huggingface.co/Salesforce/blip-image-captioning-large/resolve/main/config.json"
- ),
- "Salesforce/blip-itm-base-coco": "https://huggingface.co/Salesforce/blip-itm-base-coco/resolve/main/config.json",
- "Salesforce/blip-itm-large-coco": "https://huggingface.co/Salesforce/blip-itm-large-coco/resolve/main/config.json",
- "Salesforce/blip-itm-base-flikr": "https://huggingface.co/Salesforce/blip-itm-base-flikr/resolve/main/config.json",
- "Salesforce/blip-itm-large-flikr": (
- "https://huggingface.co/Salesforce/blip-itm-large-flikr/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import BLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BlipTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/blip/modeling_blip.py b/src/transformers/models/blip/modeling_blip.py
index 1dc79efb6546af..39506478f17926 100644
--- a/src/transformers/models/blip/modeling_blip.py
+++ b/src/transformers/models/blip/modeling_blip.py
@@ -41,17 +41,8 @@
_CHECKPOINT_FOR_DOC = "Salesforce/blip-vqa-base"
-BLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/blip-vqa-base",
- "Salesforce/blip-vqa-capfilt-large",
- "Salesforce/blip-image-captioning-base",
- "Salesforce/blip-image-captioning-large",
- "Salesforce/blip-itm-base-coco",
- "Salesforce/blip-itm-large-coco",
- "Salesforce/blip-itm-base-flickr",
- "Salesforce/blip-itm-large-flickr",
- # See all BLIP models at https://huggingface.co/models?filter=blip
-]
+
+from ..deprecated._archive_maps import BLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.clip.modeling_clip.contrastive_loss
diff --git a/src/transformers/models/blip/modeling_tf_blip.py b/src/transformers/models/blip/modeling_tf_blip.py
index 5952aa145c9f78..37098467a7ad6c 100644
--- a/src/transformers/models/blip/modeling_tf_blip.py
+++ b/src/transformers/models/blip/modeling_tf_blip.py
@@ -48,17 +48,8 @@
_CHECKPOINT_FOR_DOC = "Salesforce/blip-vqa-base"
-TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/blip-vqa-base",
- "Salesforce/blip-vqa-capfilt-large",
- "Salesforce/blip-image-captioning-base",
- "Salesforce/blip-image-captioning-large",
- "Salesforce/blip-itm-base-coco",
- "Salesforce/blip-itm-large-coco",
- "Salesforce/blip-itm-base-flickr",
- "Salesforce/blip-itm-large-flickr",
- # See all BLIP models at https://huggingface.co/models?filter=blip
-]
+
+from ..deprecated._archive_maps import TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.clip.modeling_tf_clip.contrastive_loss
diff --git a/src/transformers/models/blip_2/configuration_blip_2.py b/src/transformers/models/blip_2/configuration_blip_2.py
index 85749888a54bba..f5645f5deed57c 100644
--- a/src/transformers/models/blip_2/configuration_blip_2.py
+++ b/src/transformers/models/blip_2/configuration_blip_2.py
@@ -25,9 +25,8 @@
logger = logging.get_logger(__name__)
-BLIP_2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "salesforce/blip2-opt-2.7b": "https://huggingface.co/salesforce/blip2-opt-2.7b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import BLIP_2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Blip2VisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/blip_2/modeling_blip_2.py b/src/transformers/models/blip_2/modeling_blip_2.py
index c776df1bc04b7a..935e041eb8360d 100644
--- a/src/transformers/models/blip_2/modeling_blip_2.py
+++ b/src/transformers/models/blip_2/modeling_blip_2.py
@@ -47,10 +47,8 @@
_CHECKPOINT_FOR_DOC = "Salesforce/blip2-opt-2.7b"
-BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/blip2-opt-2.7b",
- # See all BLIP-2 models at https://huggingface.co/models?filter=blip
-]
+
+from ..deprecated._archive_maps import BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/bloom/configuration_bloom.py b/src/transformers/models/bloom/configuration_bloom.py
index 17395625e0177e..e04877485e3f54 100644
--- a/src/transformers/models/bloom/configuration_bloom.py
+++ b/src/transformers/models/bloom/configuration_bloom.py
@@ -29,14 +29,8 @@
logger = logging.get_logger(__name__)
-BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "bigscience/bloom": "https://huggingface.co/bigscience/bloom/resolve/main/config.json",
- "bigscience/bloom-560m": "https://huggingface.co/bigscience/bloom-560m/blob/main/config.json",
- "bigscience/bloom-1b1": "https://huggingface.co/bigscience/bloom-1b1/blob/main/config.json",
- "bigscience/bloom-1b7": "https://huggingface.co/bigscience/bloom-1b7/blob/main/config.json",
- "bigscience/bloom-3b": "https://huggingface.co/bigscience/bloom-3b/blob/main/config.json",
- "bigscience/bloom-7b1": "https://huggingface.co/bigscience/bloom-7b1/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BloomConfig(PretrainedConfig):
diff --git a/src/transformers/models/bloom/modeling_bloom.py b/src/transformers/models/bloom/modeling_bloom.py
index 14700d6f12d3f7..05b18f5938106e 100644
--- a/src/transformers/models/bloom/modeling_bloom.py
+++ b/src/transformers/models/bloom/modeling_bloom.py
@@ -43,15 +43,8 @@
_CHECKPOINT_FOR_DOC = "bigscience/bloom-560m"
_CONFIG_FOR_DOC = "BloomConfig"
-BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "bigscience/bigscience-small-testing",
- "bigscience/bloom-560m",
- "bigscience/bloom-1b1",
- "bigscience/bloom-1b7",
- "bigscience/bloom-3b",
- "bigscience/bloom-7b1",
- "bigscience/bloom",
-]
+
+from ..deprecated._archive_maps import BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
diff --git a/src/transformers/models/bloom/tokenization_bloom_fast.py b/src/transformers/models/bloom/tokenization_bloom_fast.py
index c0189e08b3d149..3a0972d87ae349 100644
--- a/src/transformers/models/bloom/tokenization_bloom_fast.py
+++ b/src/transformers/models/bloom/tokenization_bloom_fast.py
@@ -27,18 +27,6 @@
VOCAB_FILES_NAMES = {"tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "tokenizer_file": {
- "bigscience/tokenizer": "https://huggingface.co/bigscience/tokenizer/blob/main/tokenizer.json",
- "bigscience/bloom-560m": "https://huggingface.co/bigscience/bloom-560m/blob/main/tokenizer.json",
- "bigscience/bloom-1b1": "https://huggingface.co/bigscience/bloom-1b1/blob/main/tokenizer.json",
- "bigscience/bloom-1b7": "https://huggingface.co/bigscience/bloom-1b7/blob/main/tokenizer.json",
- "bigscience/bloom-3b": "https://huggingface.co/bigscience/bloom-3b/blob/main/tokenizer.json",
- "bigscience/bloom-7b1": "https://huggingface.co/bigscience/bloom-7b1/blob/main/tokenizer.json",
- "bigscience/bloom": "https://huggingface.co/bigscience/bloom/blob/main/tokenizer.json",
- },
-}
-
class BloomTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -94,7 +82,6 @@ class BloomTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = None
# No `max_model_input_sizes` as BLOOM uses ALiBi positional embeddings
diff --git a/src/transformers/models/bridgetower/configuration_bridgetower.py b/src/transformers/models/bridgetower/configuration_bridgetower.py
index c12c1600e9b449..2d3340ad62ab67 100644
--- a/src/transformers/models/bridgetower/configuration_bridgetower.py
+++ b/src/transformers/models/bridgetower/configuration_bridgetower.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-BRIDGETOWER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "BridgeTower/bridgetower-base": "https://huggingface.co/BridgeTower/bridgetower-base/blob/main/config.json",
- "BridgeTower/bridgetower-base-itm-mlm": (
- "https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm/blob/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import BRIDGETOWER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BridgeTowerVisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/bridgetower/modeling_bridgetower.py b/src/transformers/models/bridgetower/modeling_bridgetower.py
index f5822070db6a3d..bcace39b299bcf 100644
--- a/src/transformers/models/bridgetower/modeling_bridgetower.py
+++ b/src/transformers/models/bridgetower/modeling_bridgetower.py
@@ -44,11 +44,8 @@
_CHECKPOINT_FOR_DOC = "BridgeTower/bridgetower-base"
_TOKENIZER_FOR_DOC = "RobertaTokenizer"
-BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "BridgeTower/bridgetower-base",
- "BridgeTower/bridgetower-base-itm-mlm",
- # See all bridgetower models at https://huggingface.co/BridgeTower
-]
+
+from ..deprecated._archive_maps import BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
BRIDGETOWER_START_DOCSTRING = r"""
diff --git a/src/transformers/models/bros/configuration_bros.py b/src/transformers/models/bros/configuration_bros.py
index 4384810a55a013..547bbf39ad2ccd 100644
--- a/src/transformers/models/bros/configuration_bros.py
+++ b/src/transformers/models/bros/configuration_bros.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-BROS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "jinho8345/bros-base-uncased": "https://huggingface.co/jinho8345/bros-base-uncased/blob/main/config.json",
- "jinho8345/bros-large-uncased": "https://huggingface.co/jinho8345/bros-large-uncased/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import BROS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class BrosConfig(PretrainedConfig):
diff --git a/src/transformers/models/bros/modeling_bros.py b/src/transformers/models/bros/modeling_bros.py
index d3a17b23c94d48..32f0338f0ec061 100755
--- a/src/transformers/models/bros/modeling_bros.py
+++ b/src/transformers/models/bros/modeling_bros.py
@@ -47,11 +47,9 @@
_CHECKPOINT_FOR_DOC = "jinho8345/bros-base-uncased"
_CONFIG_FOR_DOC = "BrosConfig"
-BROS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "jinho8345/bros-base-uncased",
- "jinho8345/bros-large-uncased",
- # See all Bros models at https://huggingface.co/models?filter=bros
-]
+
+from ..deprecated._archive_maps import BROS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
BROS_START_DOCSTRING = r"""
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
diff --git a/src/transformers/models/camembert/configuration_camembert.py b/src/transformers/models/camembert/configuration_camembert.py
index d904c35ad7b7a5..d29ca067db2790 100644
--- a/src/transformers/models/camembert/configuration_camembert.py
+++ b/src/transformers/models/camembert/configuration_camembert.py
@@ -25,15 +25,8 @@
logger = logging.get_logger(__name__)
-CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "almanach/camembert-base": "https://huggingface.co/almanach/camembert-base/resolve/main/config.json",
- "umberto-commoncrawl-cased-v1": (
- "https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1/resolve/main/config.json"
- ),
- "umberto-wikipedia-uncased-v1": (
- "https://huggingface.co/Musixmatch/umberto-wikipedia-uncased-v1/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CamembertConfig(PretrainedConfig):
diff --git a/src/transformers/models/camembert/modeling_camembert.py b/src/transformers/models/camembert/modeling_camembert.py
index cd0b329b6ae00d..26250896b23d8a 100644
--- a/src/transformers/models/camembert/modeling_camembert.py
+++ b/src/transformers/models/camembert/modeling_camembert.py
@@ -51,12 +51,9 @@
_CHECKPOINT_FOR_DOC = "almanach/camembert-base"
_CONFIG_FOR_DOC = "CamembertConfig"
-CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "almanach/camembert-base",
- "Musixmatch/umberto-commoncrawl-cased-v1",
- "Musixmatch/umberto-wikipedia-uncased-v1",
- # See all CamemBERT models at https://huggingface.co/models?filter=camembert
-]
+
+from ..deprecated._archive_maps import CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
CAMEMBERT_START_DOCSTRING = r"""
diff --git a/src/transformers/models/camembert/modeling_tf_camembert.py b/src/transformers/models/camembert/modeling_tf_camembert.py
index e3e3fca4cef440..9ec998593d51b9 100644
--- a/src/transformers/models/camembert/modeling_tf_camembert.py
+++ b/src/transformers/models/camembert/modeling_tf_camembert.py
@@ -65,9 +65,8 @@
_CHECKPOINT_FOR_DOC = "almanach/camembert-base"
_CONFIG_FOR_DOC = "CamembertConfig"
-TF_CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- # See all CamemBERT models at https://huggingface.co/models?filter=camembert
-]
+
+from ..deprecated._archive_maps import TF_CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
CAMEMBERT_START_DOCSTRING = r"""
diff --git a/src/transformers/models/camembert/tokenization_camembert.py b/src/transformers/models/camembert/tokenization_camembert.py
index 0949db02fbb850..51d70b198bba4a 100644
--- a/src/transformers/models/camembert/tokenization_camembert.py
+++ b/src/transformers/models/camembert/tokenization_camembert.py
@@ -29,15 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "almanach/camembert-base": "https://huggingface.co/almanach/camembert-base/resolve/main/sentencepiece.bpe.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "almanach/camembert-base": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -113,8 +104,6 @@ class CamembertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/camembert/tokenization_camembert_fast.py b/src/transformers/models/camembert/tokenization_camembert_fast.py
index 627971eb51db3e..d1f0db688a464a 100644
--- a/src/transformers/models/camembert/tokenization_camembert_fast.py
+++ b/src/transformers/models/camembert/tokenization_camembert_fast.py
@@ -34,18 +34,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "almanach/camembert-base": "https://huggingface.co/almanach/camembert-base/resolve/main/sentencepiece.bpe.model",
- },
- "tokenizer_file": {
- "almanach/camembert-base": "https://huggingface.co/almanach/camembert-base/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "almanach/camembert-base": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -103,8 +91,6 @@ class CamembertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = CamembertTokenizer
diff --git a/src/transformers/models/canine/configuration_canine.py b/src/transformers/models/canine/configuration_canine.py
index f1e1bb415892a2..c5a77a5c4b47bc 100644
--- a/src/transformers/models/canine/configuration_canine.py
+++ b/src/transformers/models/canine/configuration_canine.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/canine-s": "https://huggingface.co/google/canine-s/resolve/main/config.json",
- # See all CANINE models at https://huggingface.co/models?filter=canine
-}
+
+from ..deprecated._archive_maps import CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CanineConfig(PretrainedConfig):
diff --git a/src/transformers/models/canine/modeling_canine.py b/src/transformers/models/canine/modeling_canine.py
index 378a5775256f70..023287153afc38 100644
--- a/src/transformers/models/canine/modeling_canine.py
+++ b/src/transformers/models/canine/modeling_canine.py
@@ -52,11 +52,9 @@
_CHECKPOINT_FOR_DOC = "google/canine-s"
_CONFIG_FOR_DOC = "CanineConfig"
-CANINE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/canine-s",
- "google/canine-r",
- # See all CANINE models at https://huggingface.co/models?filter=canine
-]
+
+from ..deprecated._archive_maps import CANINE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# Support up to 16 hash functions.
_PRIMES = [31, 43, 59, 61, 73, 97, 103, 113, 137, 149, 157, 173, 181, 193, 211, 223]
diff --git a/src/transformers/models/canine/tokenization_canine.py b/src/transformers/models/canine/tokenization_canine.py
index 25932ae75d2a87..024507f77877d7 100644
--- a/src/transformers/models/canine/tokenization_canine.py
+++ b/src/transformers/models/canine/tokenization_canine.py
@@ -23,10 +23,6 @@
logger = logging.get_logger(__name__)
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "nielsr/canine-s": 2048,
-}
-
# Unicode defines 1,114,112 total “codepoints”
UNICODE_VOCAB_SIZE = 1114112
@@ -73,8 +69,6 @@ class CanineTokenizer(PreTrainedTokenizer):
The maximum sentence length the model accepts.
"""
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
-
def __init__(
self,
bos_token=chr(CLS),
diff --git a/src/transformers/models/chinese_clip/configuration_chinese_clip.py b/src/transformers/models/chinese_clip/configuration_chinese_clip.py
index 53b6d49b3f6698..349833d1f2c335 100644
--- a/src/transformers/models/chinese_clip/configuration_chinese_clip.py
+++ b/src/transformers/models/chinese_clip/configuration_chinese_clip.py
@@ -30,11 +30,8 @@
logger = logging.get_logger(__name__)
-CHINESE_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "OFA-Sys/chinese-clip-vit-base-patch16": (
- "https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import CHINESE_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ChineseCLIPTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/chinese_clip/modeling_chinese_clip.py b/src/transformers/models/chinese_clip/modeling_chinese_clip.py
index a16fb081b19357..d8e97c20b24cd0 100644
--- a/src/transformers/models/chinese_clip/modeling_chinese_clip.py
+++ b/src/transformers/models/chinese_clip/modeling_chinese_clip.py
@@ -48,10 +48,8 @@
_CHECKPOINT_FOR_DOC = "OFA-Sys/chinese-clip-vit-base-patch16"
_CONFIG_FOR_DOC = "ChineseCLIPConfig"
-CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "OFA-Sys/chinese-clip-vit-base-patch16",
- # See all Chinese-CLIP models at https://huggingface.co/models?filter=chinese_clip
-]
+
+from ..deprecated._archive_maps import CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
diff --git a/src/transformers/models/clap/configuration_clap.py b/src/transformers/models/clap/configuration_clap.py
index 1a02d8460937d0..0a36402249e210 100644
--- a/src/transformers/models/clap/configuration_clap.py
+++ b/src/transformers/models/clap/configuration_clap.py
@@ -23,11 +23,6 @@
logger = logging.get_logger(__name__)
-CLAP_PRETRAINED_MODEL_ARCHIVE_LIST = {
- "laion/clap-htsat-fused": "https://huggingface.co/laion/clap-htsat-fused/resolve/main/config.json",
- "laion/clap-htsat-unfused": "https://huggingface.co/laion/clap-htsat-unfused/resolve/main/config.json",
-}
-
class ClapTextConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/clap/modeling_clap.py b/src/transformers/models/clap/modeling_clap.py
index 6310b9675fb654..b2c0df4866b15f 100644
--- a/src/transformers/models/clap/modeling_clap.py
+++ b/src/transformers/models/clap/modeling_clap.py
@@ -44,11 +44,8 @@
_CHECKPOINT_FOR_DOC = "laion/clap-htsat-fused"
-CLAP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "laion/clap-htsat-fused",
- "laion/clap-htsat-unfused",
- # See all clap models at https://huggingface.co/models?filter=clap
-]
+
+from ..deprecated._archive_maps import CLAP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Adapted from: https://github.com/LAION-AI/CLAP/blob/6ad05a971ba0622f6acee8c41993e0d02bbed639/src/open_clip/utils.py#L191
diff --git a/src/transformers/models/clip/configuration_clip.py b/src/transformers/models/clip/configuration_clip.py
index 8c3e30ee0517af..a48cb73a9715ba 100644
--- a/src/transformers/models/clip/configuration_clip.py
+++ b/src/transformers/models/clip/configuration_clip.py
@@ -30,10 +30,8 @@
logger = logging.get_logger(__name__)
-CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/config.json",
- # See all CLIP models at https://huggingface.co/models?filter=clip
-}
+
+from ..deprecated._archive_maps import CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CLIPTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/clip/modeling_clip.py b/src/transformers/models/clip/modeling_clip.py
index 06ee5f6e325db4..a4ce51625ebf76 100644
--- a/src/transformers/models/clip/modeling_clip.py
+++ b/src/transformers/models/clip/modeling_clip.py
@@ -48,10 +48,8 @@
_IMAGE_CLASS_CHECKPOINT = "openai/clip-vit-base-patch32"
_IMAGE_CLASS_EXPECTED_OUTPUT = "LABEL_0"
-CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/clip-vit-base-patch32",
- # See all CLIP models at https://huggingface.co/models?filter=clip
-]
+
+from ..deprecated._archive_maps import CLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# contrastive loss function, adapted from
diff --git a/src/transformers/models/clip/modeling_tf_clip.py b/src/transformers/models/clip/modeling_tf_clip.py
index d8dd7f0bd83c40..c7e8ba7f5c954e 100644
--- a/src/transformers/models/clip/modeling_tf_clip.py
+++ b/src/transformers/models/clip/modeling_tf_clip.py
@@ -51,10 +51,8 @@
_CHECKPOINT_FOR_DOC = "openai/clip-vit-base-patch32"
-TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/clip-vit-base-patch32",
- # See all CLIP models at https://huggingface.co/models?filter=clip
-]
+
+from ..deprecated._archive_maps import TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/clip/tokenization_clip.py b/src/transformers/models/clip/tokenization_clip.py
index f62ef65c5ede02..7b4ad88b80a9e0 100644
--- a/src/transformers/models/clip/tokenization_clip.py
+++ b/src/transformers/models/clip/tokenization_clip.py
@@ -33,24 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/vocab.json",
- },
- "merges_file": {
- "openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai/clip-vit-base-patch32": 77,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "openai/clip-vit-base-patch32": {},
-}
-
@lru_cache()
def bytes_to_unicode():
@@ -296,8 +278,6 @@ class CLIPTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/clip/tokenization_clip_fast.py b/src/transformers/models/clip/tokenization_clip_fast.py
index 3b092b0f8d50fc..6198958a034f43 100644
--- a/src/transformers/models/clip/tokenization_clip_fast.py
+++ b/src/transformers/models/clip/tokenization_clip_fast.py
@@ -28,24 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/vocab.json",
- },
- "merges_file": {
- "openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "openai/clip-vit-base-patch32": (
- "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai/clip-vit-base-patch32": 77,
-}
-
class CLIPTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -74,8 +56,6 @@ class CLIPTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = CLIPTokenizer
diff --git a/src/transformers/models/clipseg/configuration_clipseg.py b/src/transformers/models/clipseg/configuration_clipseg.py
index 555d226e10d507..07ba08f4759c93 100644
--- a/src/transformers/models/clipseg/configuration_clipseg.py
+++ b/src/transformers/models/clipseg/configuration_clipseg.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "CIDAS/clipseg-rd64": "https://huggingface.co/CIDAS/clipseg-rd64/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CLIPSegTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/clipseg/modeling_clipseg.py b/src/transformers/models/clipseg/modeling_clipseg.py
index b250e09ad26dc9..06e4c83e7e532b 100644
--- a/src/transformers/models/clipseg/modeling_clipseg.py
+++ b/src/transformers/models/clipseg/modeling_clipseg.py
@@ -42,10 +42,8 @@
_CHECKPOINT_FOR_DOC = "CIDAS/clipseg-rd64-refined"
-CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "CIDAS/clipseg-rd64-refined",
- # See all CLIPSeg models at https://huggingface.co/models?filter=clipseg
-]
+
+from ..deprecated._archive_maps import CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# contrastive loss function, adapted from
diff --git a/src/transformers/models/clvp/configuration_clvp.py b/src/transformers/models/clvp/configuration_clvp.py
index 3d20b5c16d5d10..00906e7d7f86b6 100644
--- a/src/transformers/models/clvp/configuration_clvp.py
+++ b/src/transformers/models/clvp/configuration_clvp.py
@@ -28,9 +28,8 @@
logger = logging.get_logger(__name__)
-CLVP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "susnato/clvp_dev": "https://huggingface.co/susnato/clvp_dev/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import CLVP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ClvpEncoderConfig(PretrainedConfig):
diff --git a/src/transformers/models/clvp/modeling_clvp.py b/src/transformers/models/clvp/modeling_clvp.py
index b660f54e5d820f..654989dcbd6039 100644
--- a/src/transformers/models/clvp/modeling_clvp.py
+++ b/src/transformers/models/clvp/modeling_clvp.py
@@ -55,10 +55,8 @@
_CHECKPOINT_FOR_DOC = "susnato/clvp_dev"
-CLVP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "susnato/clvp_dev",
- # See all Clvp models at https://huggingface.co/models?filter=clvp
-]
+
+from ..deprecated._archive_maps import CLVP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.clip.modeling_clip.contrastive_loss
diff --git a/src/transformers/models/clvp/tokenization_clvp.py b/src/transformers/models/clvp/tokenization_clvp.py
index f09245f94be8c5..d77564f718a53b 100644
--- a/src/transformers/models/clvp/tokenization_clvp.py
+++ b/src/transformers/models/clvp/tokenization_clvp.py
@@ -33,19 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "clvp_dev": "https://huggingface.co/susnato/clvp_dev/blob/main/vocab.json",
- },
- "merges_file": {
- "clvp_dev": "https://huggingface.co/susnato/clvp_dev/blob/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "clvp_dev": 1024,
-}
-
@lru_cache()
# Copied from transformers.models.gpt2.tokenization_gpt2.bytes_to_unicode
@@ -145,8 +132,6 @@ class ClvpTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = [
"input_ids",
"attention_mask",
diff --git a/src/transformers/models/code_llama/tokenization_code_llama.py b/src/transformers/models/code_llama/tokenization_code_llama.py
index db280bbc156150..fa1433e107b925 100644
--- a/src/transformers/models/code_llama/tokenization_code_llama.py
+++ b/src/transformers/models/code_llama/tokenization_code_llama.py
@@ -30,17 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "hf-internal-testing/llama-code-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer.model",
- },
- "tokenizer_file": {
- "hf-internal-testing/llama-code-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer_config.json",
- },
-}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "hf-internal-testing/llama-code-tokenizer": 2048,
-}
SPIECE_UNDERLINE = "▁"
B_INST, E_INST = "[INST]", "[/INST]"
@@ -123,8 +112,6 @@ class CodeLlamaTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/codegen/configuration_codegen.py b/src/transformers/models/codegen/configuration_codegen.py
index 73c019870f1f6a..e16dd1fadcf74a 100644
--- a/src/transformers/models/codegen/configuration_codegen.py
+++ b/src/transformers/models/codegen/configuration_codegen.py
@@ -25,20 +25,7 @@
logger = logging.get_logger(__name__)
-CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Salesforce/codegen-350M-nl": "https://huggingface.co/Salesforce/codegen-350M-nl/resolve/main/config.json",
- "Salesforce/codegen-350M-multi": "https://huggingface.co/Salesforce/codegen-350M-multi/resolve/main/config.json",
- "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/config.json",
- "Salesforce/codegen-2B-nl": "https://huggingface.co/Salesforce/codegen-2B-nl/resolve/main/config.json",
- "Salesforce/codegen-2B-multi": "https://huggingface.co/Salesforce/codegen-2B-multi/resolve/main/config.json",
- "Salesforce/codegen-2B-mono": "https://huggingface.co/Salesforce/codegen-2B-mono/resolve/main/config.json",
- "Salesforce/codegen-6B-nl": "https://huggingface.co/Salesforce/codegen-6B-nl/resolve/main/config.json",
- "Salesforce/codegen-6B-multi": "https://huggingface.co/Salesforce/codegen-6B-multi/resolve/main/config.json",
- "Salesforce/codegen-6B-mono": "https://huggingface.co/Salesforce/codegen-6B-mono/resolve/main/config.json",
- "Salesforce/codegen-16B-nl": "https://huggingface.co/Salesforce/codegen-16B-nl/resolve/main/config.json",
- "Salesforce/codegen-16B-multi": "https://huggingface.co/Salesforce/codegen-16B-multi/resolve/main/config.json",
- "Salesforce/codegen-16B-mono": "https://huggingface.co/Salesforce/codegen-16B-mono/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CodeGenConfig(PretrainedConfig):
diff --git a/src/transformers/models/codegen/modeling_codegen.py b/src/transformers/models/codegen/modeling_codegen.py
index f37ceccaace988..41f23900c29a2c 100644
--- a/src/transformers/models/codegen/modeling_codegen.py
+++ b/src/transformers/models/codegen/modeling_codegen.py
@@ -34,21 +34,7 @@
_CONFIG_FOR_DOC = "CodeGenConfig"
-CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/codegen-350M-nl",
- "Salesforce/codegen-350M-multi",
- "Salesforce/codegen-350M-mono",
- "Salesforce/codegen-2B-nl",
- "Salesforce/codegen-2B-multi",
- "Salesforce/codegen-2B-mono",
- "Salesforce/codegen-6B-nl",
- "Salesforce/codegen-6B-multi",
- "Salesforce/codegen-6B-mono",
- "Salesforce/codegen-16B-nl",
- "Salesforce/codegen-16B-multi",
- "Salesforce/codegen-16B-mono",
- # See all CodeGen models at https://huggingface.co/models?filter=codegen
-]
+from ..deprecated._archive_maps import CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
diff --git a/src/transformers/models/codegen/tokenization_codegen.py b/src/transformers/models/codegen/tokenization_codegen.py
index c79a6d46e4ad34..abf64e1892250e 100644
--- a/src/transformers/models/codegen/tokenization_codegen.py
+++ b/src/transformers/models/codegen/tokenization_codegen.py
@@ -42,19 +42,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/vocab.json",
- },
- "merges_file": {
- "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "Salesforce/codegen-350M-mono": 2048,
-}
-
@lru_cache()
def bytes_to_unicode():
@@ -150,8 +137,6 @@ class CodeGenTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/codegen/tokenization_codegen_fast.py b/src/transformers/models/codegen/tokenization_codegen_fast.py
index 3c2661db396162..fb9f0442e03001 100644
--- a/src/transformers/models/codegen/tokenization_codegen_fast.py
+++ b/src/transformers/models/codegen/tokenization_codegen_fast.py
@@ -41,24 +41,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/vocab.json",
- },
- "merges_file": {
- "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "Salesforce/codegen-350M-mono": (
- "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "Salesforce/codegen-350M-mono": 2048,
-}
-
class CodeGenTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -112,8 +94,6 @@ class CodeGenTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = CodeGenTokenizer
diff --git a/src/transformers/models/cohere/modeling_cohere.py b/src/transformers/models/cohere/modeling_cohere.py
index db748013ff35e1..e949bc14482e74 100644
--- a/src/transformers/models/cohere/modeling_cohere.py
+++ b/src/transformers/models/cohere/modeling_cohere.py
@@ -825,12 +825,6 @@ def __init__(self, config: CohereConfig):
self.norm = CohereLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.gradient_checkpointing = False
- # Register a causal mask to separate causal and padding mask creation. Merging happens in the attention class.
- # NOTE: This is not friendly with TorchScript, ONNX, ExportedProgram serialization for very large `max_position_embeddings`.
- causal_mask = torch.full(
- (config.max_position_embeddings, config.max_position_embeddings), fill_value=True, dtype=torch.bool
- )
- self.register_buffer("causal_mask", torch.triu(causal_mask, diagonal=1), persistent=False)
# Initialize weights and apply final processing
self.post_init()
@@ -969,7 +963,7 @@ def _update_causal_mask(self, attention_mask, input_tensor, cache_position):
dtype, device = input_tensor.dtype, input_tensor.device
min_dtype = torch.finfo(dtype).min
sequence_length = input_tensor.shape[1]
- if hasattr(self.layers[0].self_attn, "past_key_value"): # static cache
+ if hasattr(getattr(self.layers[0], "self_attn", {}), "past_key_value"): # static cache
target_length = self.config.max_position_embeddings
else: # dynamic cache
target_length = (
@@ -1145,7 +1139,7 @@ def prepare_inputs_for_generation(
# TODO joao: standardize interface for the different Cache classes and remove of this if
has_static_cache = False
if past_key_values is None:
- past_key_values = getattr(self.model.layers[0].self_attn, "past_key_value", None)
+ past_key_values = getattr(getattr(self.model.layers[0], "self_attn", {}), "past_key_value", None)
has_static_cache = past_key_values is not None
past_length = 0
diff --git a/src/transformers/models/conditional_detr/configuration_conditional_detr.py b/src/transformers/models/conditional_detr/configuration_conditional_detr.py
index 7a6cd436385852..945e5edb32ad30 100644
--- a/src/transformers/models/conditional_detr/configuration_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/configuration_conditional_detr.py
@@ -26,11 +26,8 @@
logger = logging.get_logger(__name__)
-CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/conditional-detr-resnet-50": (
- "https://huggingface.co/microsoft/conditional-detr-resnet-50/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ConditionalDetrConfig(PretrainedConfig):
diff --git a/src/transformers/models/conditional_detr/modeling_conditional_detr.py b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
index b6ea7cdf4cc3af..d8ff371fad77d1 100644
--- a/src/transformers/models/conditional_detr/modeling_conditional_detr.py
+++ b/src/transformers/models/conditional_detr/modeling_conditional_detr.py
@@ -60,10 +60,8 @@
_CONFIG_FOR_DOC = "ConditionalDetrConfig"
_CHECKPOINT_FOR_DOC = "microsoft/conditional-detr-resnet-50"
-CONDITIONAL_DETR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/conditional-detr-resnet-50",
- # See all Conditional DETR models at https://huggingface.co/models?filter=conditional_detr
-]
+
+from ..deprecated._archive_maps import CONDITIONAL_DETR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/convbert/configuration_convbert.py b/src/transformers/models/convbert/configuration_convbert.py
index 62019796664660..d309ca396baffc 100644
--- a/src/transformers/models/convbert/configuration_convbert.py
+++ b/src/transformers/models/convbert/configuration_convbert.py
@@ -24,14 +24,8 @@
logger = logging.get_logger(__name__)
-CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "YituTech/conv-bert-base": "https://huggingface.co/YituTech/conv-bert-base/resolve/main/config.json",
- "YituTech/conv-bert-medium-small": (
- "https://huggingface.co/YituTech/conv-bert-medium-small/resolve/main/config.json"
- ),
- "YituTech/conv-bert-small": "https://huggingface.co/YituTech/conv-bert-small/resolve/main/config.json",
- # See all ConvBERT models at https://huggingface.co/models?filter=convbert
-}
+
+from ..deprecated._archive_maps import CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ConvBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/convbert/modeling_convbert.py b/src/transformers/models/convbert/modeling_convbert.py
index 032b9d0ce18ba3..d88add4e1390ef 100755
--- a/src/transformers/models/convbert/modeling_convbert.py
+++ b/src/transformers/models/convbert/modeling_convbert.py
@@ -45,12 +45,8 @@
_CHECKPOINT_FOR_DOC = "YituTech/conv-bert-base"
_CONFIG_FOR_DOC = "ConvBertConfig"
-CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "YituTech/conv-bert-base",
- "YituTech/conv-bert-medium-small",
- "YituTech/conv-bert-small",
- # See all ConvBERT models at https://huggingface.co/models?filter=convbert
-]
+
+from ..deprecated._archive_maps import CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_convbert(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/convbert/modeling_tf_convbert.py b/src/transformers/models/convbert/modeling_tf_convbert.py
index e6855c68e2f8a9..7206b3558ace8a 100644
--- a/src/transformers/models/convbert/modeling_tf_convbert.py
+++ b/src/transformers/models/convbert/modeling_tf_convbert.py
@@ -60,12 +60,8 @@
_CHECKPOINT_FOR_DOC = "YituTech/conv-bert-base"
_CONFIG_FOR_DOC = "ConvBertConfig"
-TF_CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "YituTech/conv-bert-base",
- "YituTech/conv-bert-medium-small",
- "YituTech/conv-bert-small",
- # See all ConvBERT models at https://huggingface.co/models?filter=convbert
-]
+
+from ..deprecated._archive_maps import TF_CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.albert.modeling_tf_albert.TFAlbertEmbeddings with Albert->ConvBert
diff --git a/src/transformers/models/convbert/tokenization_convbert.py b/src/transformers/models/convbert/tokenization_convbert.py
index 8c359886cf7435..c0fe2c018341c5 100644
--- a/src/transformers/models/convbert/tokenization_convbert.py
+++ b/src/transformers/models/convbert/tokenization_convbert.py
@@ -26,29 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "YituTech/conv-bert-base": "https://huggingface.co/YituTech/conv-bert-base/resolve/main/vocab.txt",
- "YituTech/conv-bert-medium-small": (
- "https://huggingface.co/YituTech/conv-bert-medium-small/resolve/main/vocab.txt"
- ),
- "YituTech/conv-bert-small": "https://huggingface.co/YituTech/conv-bert-small/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "YituTech/conv-bert-base": 512,
- "YituTech/conv-bert-medium-small": 512,
- "YituTech/conv-bert-small": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "YituTech/conv-bert-base": {"do_lower_case": True},
- "YituTech/conv-bert-medium-small": {"do_lower_case": True},
- "YituTech/conv-bert-small": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -116,9 +93,6 @@ class ConvBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/convbert/tokenization_convbert_fast.py b/src/transformers/models/convbert/tokenization_convbert_fast.py
index 14909876ded885..65bedb73fe9171 100644
--- a/src/transformers/models/convbert/tokenization_convbert_fast.py
+++ b/src/transformers/models/convbert/tokenization_convbert_fast.py
@@ -27,29 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "YituTech/conv-bert-base": "https://huggingface.co/YituTech/conv-bert-base/resolve/main/vocab.txt",
- "YituTech/conv-bert-medium-small": (
- "https://huggingface.co/YituTech/conv-bert-medium-small/resolve/main/vocab.txt"
- ),
- "YituTech/conv-bert-small": "https://huggingface.co/YituTech/conv-bert-small/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "YituTech/conv-bert-base": 512,
- "YituTech/conv-bert-medium-small": 512,
- "YituTech/conv-bert-small": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "YituTech/conv-bert-base": {"do_lower_case": True},
- "YituTech/conv-bert-medium-small": {"do_lower_case": True},
- "YituTech/conv-bert-small": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with bert-base-cased->YituTech/conv-bert-base, Bert->ConvBert, BERT->ConvBERT
class ConvBertTokenizerFast(PreTrainedTokenizerFast):
@@ -93,9 +70,6 @@ class ConvBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = ConvBertTokenizer
def __init__(
diff --git a/src/transformers/models/convnext/configuration_convnext.py b/src/transformers/models/convnext/configuration_convnext.py
index 48647bd1224ecd..f84c31079ea34e 100644
--- a/src/transformers/models/convnext/configuration_convnext.py
+++ b/src/transformers/models/convnext/configuration_convnext.py
@@ -27,10 +27,8 @@
logger = logging.get_logger(__name__)
-CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/convnext-tiny-224": "https://huggingface.co/facebook/convnext-tiny-224/resolve/main/config.json",
- # See all ConvNeXT models at https://huggingface.co/models?filter=convnext
-}
+
+from ..deprecated._archive_maps import CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ConvNextConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/convnext/modeling_convnext.py b/src/transformers/models/convnext/modeling_convnext.py
index a952e5d8165e15..147d2ac22dac45 100755
--- a/src/transformers/models/convnext/modeling_convnext.py
+++ b/src/transformers/models/convnext/modeling_convnext.py
@@ -54,10 +54,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/convnext-tiny-224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/convnext-tiny-224",
- # See all ConvNext models at https://huggingface.co/models?filter=convnext
-]
+
+from ..deprecated._archive_maps import CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/convnextv2/configuration_convnextv2.py b/src/transformers/models/convnextv2/configuration_convnextv2.py
index 3d7d1fa7397714..ccee03eef6a492 100644
--- a/src/transformers/models/convnextv2/configuration_convnextv2.py
+++ b/src/transformers/models/convnextv2/configuration_convnextv2.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-CONVNEXTV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/convnextv2-tiny-1k-224": "https://huggingface.co/facebook/convnextv2-tiny-1k-224/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import CONVNEXTV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ConvNextV2Config(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/convnextv2/modeling_convnextv2.py b/src/transformers/models/convnextv2/modeling_convnextv2.py
index 8d166200d12253..7439f212971ec1 100644
--- a/src/transformers/models/convnextv2/modeling_convnextv2.py
+++ b/src/transformers/models/convnextv2/modeling_convnextv2.py
@@ -54,10 +54,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/convnextv2-tiny-1k-224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/convnextv2-tiny-1k-224",
- # See all ConvNextV2 models at https://huggingface.co/models?filter=convnextv2
-]
+
+from ..deprecated._archive_maps import CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/convnextv2/modeling_tf_convnextv2.py b/src/transformers/models/convnextv2/modeling_tf_convnextv2.py
index d4bef6f161d2bf..0debe6fd0c54d6 100644
--- a/src/transformers/models/convnextv2/modeling_tf_convnextv2.py
+++ b/src/transformers/models/convnextv2/modeling_tf_convnextv2.py
@@ -61,11 +61,6 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/convnextv2-tiny-1k-224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/convnextv2-tiny-1k-224",
- # See all ConvNextV2 models at https://huggingface.co/models?filter=convnextv2
-]
-
# Copied from transformers.models.convnext.modeling_tf_convnext.TFConvNextDropPath with ConvNext->ConvNextV2
class TFConvNextV2DropPath(keras.layers.Layer):
diff --git a/src/transformers/models/cpm/tokenization_cpm.py b/src/transformers/models/cpm/tokenization_cpm.py
index 67281b3cf185f8..ac454898b5572a 100644
--- a/src/transformers/models/cpm/tokenization_cpm.py
+++ b/src/transformers/models/cpm/tokenization_cpm.py
@@ -28,18 +28,11 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "TsinghuaAI/CPM-Generate": "https://huggingface.co/TsinghuaAI/CPM-Generate/resolve/main/spiece.model",
- }
-}
-
class CpmTokenizer(PreTrainedTokenizer):
"""Runs pre-tokenization with Jieba segmentation tool. It is used in CPM models."""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
def __init__(
self,
diff --git a/src/transformers/models/cpm/tokenization_cpm_fast.py b/src/transformers/models/cpm/tokenization_cpm_fast.py
index 8e8f927e813b64..9b7b6da118ab4b 100644
--- a/src/transformers/models/cpm/tokenization_cpm_fast.py
+++ b/src/transformers/models/cpm/tokenization_cpm_fast.py
@@ -25,15 +25,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "TsinghuaAI/CPM-Generate": "https://huggingface.co/TsinghuaAI/CPM-Generate/resolve/main/spiece.model",
- },
- "tokenizer_file": {
- "TsinghuaAI/CPM-Generate": "https://huggingface.co/TsinghuaAI/CPM-Generate/resolve/main/tokenizer.json",
- },
-}
-
class CpmTokenizerFast(PreTrainedTokenizerFast):
"""Runs pre-tokenization with Jieba segmentation tool. It is used in CPM models."""
diff --git a/src/transformers/models/cpmant/configuration_cpmant.py b/src/transformers/models/cpmant/configuration_cpmant.py
index 0ad5208566b337..62bbce8ada50e1 100644
--- a/src/transformers/models/cpmant/configuration_cpmant.py
+++ b/src/transformers/models/cpmant/configuration_cpmant.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-CPMANT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openbmb/cpm-ant-10b": "https://huggingface.co/openbmb/cpm-ant-10b/blob/main/config.json"
- # See all CPMAnt models at https://huggingface.co/models?filter=cpmant
-}
+
+from ..deprecated._archive_maps import CPMANT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CpmAntConfig(PretrainedConfig):
diff --git a/src/transformers/models/cpmant/modeling_cpmant.py b/src/transformers/models/cpmant/modeling_cpmant.py
index 405d892c70ed70..63bb467e64e354 100755
--- a/src/transformers/models/cpmant/modeling_cpmant.py
+++ b/src/transformers/models/cpmant/modeling_cpmant.py
@@ -36,10 +36,8 @@
_CHECKPOINT_FOR_DOC = "openbmb/cpm-ant-10b"
_CONFIG_FOR_DOC = "CpmAntConfig"
-CPMANT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openbmb/cpm-ant-10b",
- # See all CPMAnt models at https://huggingface.co/models?filter=cpmant
-]
+
+from ..deprecated._archive_maps import CPMANT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class CpmAntLayerNorm(nn.Module):
diff --git a/src/transformers/models/cpmant/tokenization_cpmant.py b/src/transformers/models/cpmant/tokenization_cpmant.py
index c10f48e2de282e..a5e66c7679c728 100644
--- a/src/transformers/models/cpmant/tokenization_cpmant.py
+++ b/src/transformers/models/cpmant/tokenization_cpmant.py
@@ -31,16 +31,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openbmb/cpm-ant-10b": "https://huggingface.co/openbmb/cpm-ant-10b/blob/main/vocab.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openbmb/cpm-ant-10b": 1024,
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -111,8 +101,6 @@ class CpmAntTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
add_prefix_space = False
diff --git a/src/transformers/models/ctrl/configuration_ctrl.py b/src/transformers/models/ctrl/configuration_ctrl.py
index 553e919b4a77d8..0c5a68bf6fcbdc 100644
--- a/src/transformers/models/ctrl/configuration_ctrl.py
+++ b/src/transformers/models/ctrl/configuration_ctrl.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Salesforce/ctrl": "https://huggingface.co/Salesforce/ctrl/resolve/main/config.json"
-}
+
+from ..deprecated._archive_maps import CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CTRLConfig(PretrainedConfig):
diff --git a/src/transformers/models/ctrl/modeling_ctrl.py b/src/transformers/models/ctrl/modeling_ctrl.py
index 3814f897d545fa..250ec8fc92dffe 100644
--- a/src/transformers/models/ctrl/modeling_ctrl.py
+++ b/src/transformers/models/ctrl/modeling_ctrl.py
@@ -33,10 +33,8 @@
_CONFIG_FOR_DOC = "CTRLConfig"
-CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/ctrl"
- # See all CTRL models at https://huggingface.co/models?filter=ctrl
-]
+
+from ..deprecated._archive_maps import CTRL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def angle_defn(pos, i, d_model_size):
diff --git a/src/transformers/models/ctrl/modeling_tf_ctrl.py b/src/transformers/models/ctrl/modeling_tf_ctrl.py
index 19a6a84fc75f16..6569b9e7d7b788 100644
--- a/src/transformers/models/ctrl/modeling_tf_ctrl.py
+++ b/src/transformers/models/ctrl/modeling_tf_ctrl.py
@@ -43,10 +43,8 @@
_CHECKPOINT_FOR_DOC = "Salesforce/ctrl"
_CONFIG_FOR_DOC = "CTRLConfig"
-TF_CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/ctrl"
- # See all CTRL models at https://huggingface.co/models?filter=Salesforce/ctrl
-]
+
+from ..deprecated._archive_maps import TF_CTRL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def angle_defn(pos, i, d_model_size):
diff --git a/src/transformers/models/ctrl/tokenization_ctrl.py b/src/transformers/models/ctrl/tokenization_ctrl.py
index 3aac022897d4c0..fdae22d2c30019 100644
--- a/src/transformers/models/ctrl/tokenization_ctrl.py
+++ b/src/transformers/models/ctrl/tokenization_ctrl.py
@@ -32,14 +32,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"Salesforce/ctrl": "https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-vocab.json"},
- "merges_file": {"Salesforce/ctrl": "https://raw.githubusercontent.com/salesforce/ctrl/master/ctrl-merges.txt"},
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "Salesforce/ctrl": 256,
-}
CONTROL_CODES = {
"Pregnancy": 168629,
@@ -134,8 +126,6 @@ class CTRLTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
control_codes = CONTROL_CODES
def __init__(self, vocab_file, merges_file, unk_token="", **kwargs):
diff --git a/src/transformers/models/cvt/configuration_cvt.py b/src/transformers/models/cvt/configuration_cvt.py
index f1d96fc17ea59d..412387af5e8a7b 100644
--- a/src/transformers/models/cvt/configuration_cvt.py
+++ b/src/transformers/models/cvt/configuration_cvt.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-CVT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/cvt-13": "https://huggingface.co/microsoft/cvt-13/resolve/main/config.json",
- # See all Cvt models at https://huggingface.co/models?filter=cvt
-}
+
+from ..deprecated._archive_maps import CVT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class CvtConfig(PretrainedConfig):
diff --git a/src/transformers/models/cvt/modeling_cvt.py b/src/transformers/models/cvt/modeling_cvt.py
index ef7e3671e69d35..25cf3963cbe10c 100644
--- a/src/transformers/models/cvt/modeling_cvt.py
+++ b/src/transformers/models/cvt/modeling_cvt.py
@@ -45,15 +45,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-CVT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/cvt-13",
- "microsoft/cvt-13-384",
- "microsoft/cvt-13-384-22k",
- "microsoft/cvt-21",
- "microsoft/cvt-21-384",
- "microsoft/cvt-21-384-22k",
- # See all Cvt models at https://huggingface.co/models?filter=cvt
-]
+from ..deprecated._archive_maps import CVT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/cvt/modeling_tf_cvt.py b/src/transformers/models/cvt/modeling_tf_cvt.py
index c69973bdc828af..5664412effb594 100644
--- a/src/transformers/models/cvt/modeling_tf_cvt.py
+++ b/src/transformers/models/cvt/modeling_tf_cvt.py
@@ -49,15 +49,8 @@
# General docstring
_CONFIG_FOR_DOC = "CvtConfig"
-TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/cvt-13",
- "microsoft/cvt-13-384",
- "microsoft/cvt-13-384-22k",
- "microsoft/cvt-21",
- "microsoft/cvt-21-384",
- "microsoft/cvt-21-384-22k",
- # See all Cvt models at https://huggingface.co/models?filter=cvt
-]
+
+from ..deprecated._archive_maps import TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/data2vec/configuration_data2vec_audio.py b/src/transformers/models/data2vec/configuration_data2vec_audio.py
index e37def379fbb15..32d505f157d63f 100644
--- a/src/transformers/models/data2vec/configuration_data2vec_audio.py
+++ b/src/transformers/models/data2vec/configuration_data2vec_audio.py
@@ -22,11 +22,6 @@
logger = logging.get_logger(__name__)
-DATA2VEC_AUDIO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/data2vec-base-960h": "https://huggingface.co/facebook/data2vec-audio-base-960h/resolve/main/config.json",
- # See all Data2VecAudio models at https://huggingface.co/models?filter=data2vec-audio
-}
-
class Data2VecAudioConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/data2vec/configuration_data2vec_text.py b/src/transformers/models/data2vec/configuration_data2vec_text.py
index 01a81e95b412b7..cd52db2d326e9f 100644
--- a/src/transformers/models/data2vec/configuration_data2vec_text.py
+++ b/src/transformers/models/data2vec/configuration_data2vec_text.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-DATA2VEC_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/data2vec-text-base": "https://huggingface.co/data2vec/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import DATA2VEC_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Data2VecTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/data2vec/configuration_data2vec_vision.py b/src/transformers/models/data2vec/configuration_data2vec_vision.py
index 5d8e4a252a7c29..9a9de9c4be5a0d 100644
--- a/src/transformers/models/data2vec/configuration_data2vec_vision.py
+++ b/src/transformers/models/data2vec/configuration_data2vec_vision.py
@@ -25,11 +25,8 @@
logger = logging.get_logger(__name__)
-DATA2VEC_VISION_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/data2vec-vision-base-ft": (
- "https://huggingface.co/facebook/data2vec-vision-base-ft/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import DATA2VEC_VISION_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Data2VecVisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/data2vec/modeling_data2vec_audio.py b/src/transformers/models/data2vec/modeling_data2vec_audio.py
index b3dde2438ab98f..b5300cca084fa6 100755
--- a/src/transformers/models/data2vec/modeling_data2vec_audio.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_audio.py
@@ -62,13 +62,7 @@
_CTC_EXPECTED_LOSS = 66.95
-DATA2VEC_AUDIO_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/data2vec-audio-base",
- "facebook/data2vec-audio-base-10m",
- "facebook/data2vec-audio-base-100h",
- "facebook/data2vec-audio-base-960h",
- # See all Data2VecAudio models at https://huggingface.co/models?filter=data2vec-audio
-]
+from ..deprecated._archive_maps import DATA2VEC_AUDIO_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
diff --git a/src/transformers/models/data2vec/modeling_data2vec_text.py b/src/transformers/models/data2vec/modeling_data2vec_text.py
index 567cc7b5c34f5e..7dcc53e2cc15c8 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_text.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_text.py
@@ -55,10 +55,7 @@
_CONFIG_FOR_DOC = "Data2VecTextConfig"
-DATA2VEC_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/data2vec-text-base",
- # See all data2vec models at https://huggingface.co/models?filter=data2vec-text
-]
+from ..deprecated._archive_maps import DATA2VEC_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->Data2VecText
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index 77c9363fa217c4..44088d498f6035 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -57,10 +57,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/data2vec-vision-base-ft1k"
_IMAGE_CLASS_EXPECTED_OUTPUT = "remote control, remote"
-DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/data2vec-vision-base-ft1k",
- # See all Data2VecVision models at https://huggingface.co/models?filter=data2vec-vision
-]
+
+from ..deprecated._archive_maps import DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
index bc8ff9cfc9e619..e65a61fae5f881 100644
--- a/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
@@ -65,11 +65,6 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/data2vec-vision-base-ft1k"
_IMAGE_CLASS_EXPECTED_OUTPUT = "remote control, remote"
-TF_DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/data2vec-vision-base-ft1k",
- # See all Data2VecVision models at https://huggingface.co/models?filter=data2vec-vision
-]
-
@dataclass
class TFData2VecVisionModelOutputWithPooling(TFBaseModelOutputWithPooling):
diff --git a/src/transformers/models/deberta/configuration_deberta.py b/src/transformers/models/deberta/configuration_deberta.py
index f6db66f0d8d99c..5907f0869d6821 100644
--- a/src/transformers/models/deberta/configuration_deberta.py
+++ b/src/transformers/models/deberta/configuration_deberta.py
@@ -27,14 +27,8 @@
logger = logging.get_logger(__name__)
-DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/config.json",
- "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/config.json",
- "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/config.json",
- "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/config.json",
- "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/config.json",
- "microsoft/deberta-xlarge-mnli": "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DebertaConfig(PretrainedConfig):
diff --git a/src/transformers/models/deberta/modeling_deberta.py b/src/transformers/models/deberta/modeling_deberta.py
index b5136bcb88cd67..42dae5c80894a8 100644
--- a/src/transformers/models/deberta/modeling_deberta.py
+++ b/src/transformers/models/deberta/modeling_deberta.py
@@ -53,14 +53,7 @@
_QA_TARGET_END_INDEX = 14
-DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/deberta-base",
- "microsoft/deberta-large",
- "microsoft/deberta-xlarge",
- "microsoft/deberta-base-mnli",
- "microsoft/deberta-large-mnli",
- "microsoft/deberta-xlarge-mnli",
-]
+from ..deprecated._archive_maps import DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ContextPooler(nn.Module):
diff --git a/src/transformers/models/deberta/modeling_tf_deberta.py b/src/transformers/models/deberta/modeling_tf_deberta.py
index 2a2a586c3592ef..3cef6a50c873f4 100644
--- a/src/transformers/models/deberta/modeling_tf_deberta.py
+++ b/src/transformers/models/deberta/modeling_tf_deberta.py
@@ -53,10 +53,8 @@
_CONFIG_FOR_DOC = "DebertaConfig"
_CHECKPOINT_FOR_DOC = "kamalkraj/deberta-base"
-TF_DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "kamalkraj/deberta-base",
- # See all DeBERTa models at https://huggingface.co/models?filter=DeBERTa
-]
+
+from ..deprecated._archive_maps import TF_DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFDebertaContextPooler(keras.layers.Layer):
diff --git a/src/transformers/models/deberta/tokenization_deberta.py b/src/transformers/models/deberta/tokenization_deberta.py
index 6a48b188d61897..b846a7891562d6 100644
--- a/src/transformers/models/deberta/tokenization_deberta.py
+++ b/src/transformers/models/deberta/tokenization_deberta.py
@@ -28,43 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/vocab.json",
- "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/vocab.json",
- "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/vocab.json",
- "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/vocab.json",
- "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/vocab.json",
- "microsoft/deberta-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/merges.txt",
- "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/merges.txt",
- "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/merges.txt",
- "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/merges.txt",
- "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/merges.txt",
- "microsoft/deberta-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/merges.txt"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/deberta-base": 512,
- "microsoft/deberta-large": 512,
- "microsoft/deberta-xlarge": 512,
- "microsoft/deberta-base-mnli": 512,
- "microsoft/deberta-large-mnli": 512,
- "microsoft/deberta-xlarge-mnli": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/deberta-base": {"do_lower_case": False},
- "microsoft/deberta-large": {"do_lower_case": False},
-}
-
# Copied from transformers.models.gpt2.tokenization_gpt2.bytes_to_unicode
def bytes_to_unicode():
@@ -172,8 +135,6 @@ class DebertaTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "token_type_ids"]
def __init__(
diff --git a/src/transformers/models/deberta/tokenization_deberta_fast.py b/src/transformers/models/deberta/tokenization_deberta_fast.py
index 6d157fdf3c7066..07226443d30a9c 100644
--- a/src/transformers/models/deberta/tokenization_deberta_fast.py
+++ b/src/transformers/models/deberta/tokenization_deberta_fast.py
@@ -29,43 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/vocab.json",
- "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/vocab.json",
- "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/vocab.json",
- "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/vocab.json",
- "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/vocab.json",
- "microsoft/deberta-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/merges.txt",
- "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/merges.txt",
- "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/merges.txt",
- "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/merges.txt",
- "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/merges.txt",
- "microsoft/deberta-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/merges.txt"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/deberta-base": 512,
- "microsoft/deberta-large": 512,
- "microsoft/deberta-xlarge": 512,
- "microsoft/deberta-base-mnli": 512,
- "microsoft/deberta-large-mnli": 512,
- "microsoft/deberta-xlarge-mnli": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/deberta-base": {"do_lower_case": False},
- "microsoft/deberta-large": {"do_lower_case": False},
-}
-
class DebertaTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -133,8 +96,6 @@ class DebertaTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "token_type_ids"]
slow_tokenizer_class = DebertaTokenizer
diff --git a/src/transformers/models/deberta_v2/configuration_deberta_v2.py b/src/transformers/models/deberta_v2/configuration_deberta_v2.py
index 68f2112754a4c1..25348849e2f240 100644
--- a/src/transformers/models/deberta_v2/configuration_deberta_v2.py
+++ b/src/transformers/models/deberta_v2/configuration_deberta_v2.py
@@ -27,16 +27,8 @@
logger = logging.get_logger(__name__)
-DEBERTA_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/deberta-v2-xlarge": "https://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/config.json",
- "microsoft/deberta-v2-xxlarge": "https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/config.json",
- "microsoft/deberta-v2-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xlarge-mnli/resolve/main/config.json"
- ),
- "microsoft/deberta-v2-xxlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import DEBERTA_V2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DebertaV2Config(PretrainedConfig):
@@ -85,7 +77,7 @@ class DebertaV2Config(PretrainedConfig):
as `max_position_embeddings`.
pad_token_id (`int`, *optional*, defaults to 0):
The value used to pad input_ids.
- position_biased_input (`bool`, *optional*, defaults to `False`):
+ position_biased_input (`bool`, *optional*, defaults to `True`):
Whether add absolute position embedding to content embedding.
pos_att_type (`List[str]`, *optional*):
The type of relative position attention, it can be a combination of `["p2c", "c2p"]`, e.g. `["p2c"]`,
diff --git a/src/transformers/models/deberta_v2/modeling_deberta_v2.py b/src/transformers/models/deberta_v2/modeling_deberta_v2.py
index a8f064369268b0..dfe18b0d4964af 100644
--- a/src/transformers/models/deberta_v2/modeling_deberta_v2.py
+++ b/src/transformers/models/deberta_v2/modeling_deberta_v2.py
@@ -44,12 +44,8 @@
_QA_TARGET_START_INDEX = 2
_QA_TARGET_END_INDEX = 9
-DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/deberta-v2-xlarge",
- "microsoft/deberta-v2-xxlarge",
- "microsoft/deberta-v2-xlarge-mnli",
- "microsoft/deberta-v2-xxlarge-mnli",
-]
+
+from ..deprecated._archive_maps import DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.deberta.modeling_deberta.ContextPooler
diff --git a/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py b/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
index 05b222ec8a595f..546e7f1a8d0038 100644
--- a/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
+++ b/src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
@@ -52,10 +52,8 @@
_CONFIG_FOR_DOC = "DebertaV2Config"
_CHECKPOINT_FOR_DOC = "kamalkraj/deberta-v2-xlarge"
-TF_DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "kamalkraj/deberta-v2-xlarge",
- # See all DeBERTa models at https://huggingface.co/models?filter=deberta-v2
-]
+
+from ..deprecated._archive_maps import TF_DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.deberta.modeling_tf_deberta.TFDebertaContextPooler with Deberta->DebertaV2
diff --git a/src/transformers/models/deberta_v2/tokenization_deberta_v2.py b/src/transformers/models/deberta_v2/tokenization_deberta_v2.py
index 0cf8807ca61f2c..a92103945416d7 100644
--- a/src/transformers/models/deberta_v2/tokenization_deberta_v2.py
+++ b/src/transformers/models/deberta_v2/tokenization_deberta_v2.py
@@ -26,32 +26,6 @@
logger = logging.get_logger(__name__)
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/deberta-v2-xlarge": "https://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/spm.model",
- "microsoft/deberta-v2-xxlarge": "https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/spm.model",
- "microsoft/deberta-v2-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xlarge-mnli/resolve/main/spm.model"
- ),
- "microsoft/deberta-v2-xxlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli/resolve/main/spm.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/deberta-v2-xlarge": 512,
- "microsoft/deberta-v2-xxlarge": 512,
- "microsoft/deberta-v2-xlarge-mnli": 512,
- "microsoft/deberta-v2-xxlarge-mnli": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/deberta-v2-xlarge": {"do_lower_case": False},
- "microsoft/deberta-v2-xxlarge": {"do_lower_case": False},
- "microsoft/deberta-v2-xlarge-mnli": {"do_lower_case": False},
- "microsoft/deberta-v2-xxlarge-mnli": {"do_lower_case": False},
-}
VOCAB_FILES_NAMES = {"vocab_file": "spm.model"}
@@ -106,9 +80,6 @@ class DebertaV2Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py b/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py
index dab376ce95be8a..cb92a61edf1afb 100644
--- a/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py
+++ b/src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py
@@ -32,33 +32,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spm.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/deberta-v2-xlarge": "https://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/spm.model",
- "microsoft/deberta-v2-xxlarge": "https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/spm.model",
- "microsoft/deberta-v2-xlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xlarge-mnli/resolve/main/spm.model"
- ),
- "microsoft/deberta-v2-xxlarge-mnli": (
- "https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli/resolve/main/spm.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/deberta-v2-xlarge": 512,
- "microsoft/deberta-v2-xxlarge": 512,
- "microsoft/deberta-v2-xlarge-mnli": 512,
- "microsoft/deberta-v2-xxlarge-mnli": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/deberta-v2-xlarge": {"do_lower_case": False},
- "microsoft/deberta-v2-xxlarge": {"do_lower_case": False},
- "microsoft/deberta-v2-xlarge-mnli": {"do_lower_case": False},
- "microsoft/deberta-v2-xxlarge-mnli": {"do_lower_case": False},
-}
-
class DebertaV2TokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -110,9 +83,6 @@ class DebertaV2TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = DebertaV2Tokenizer
def __init__(
diff --git a/src/transformers/models/decision_transformer/configuration_decision_transformer.py b/src/transformers/models/decision_transformer/configuration_decision_transformer.py
index 88ff005469cd6d..d2c1914bee06ee 100644
--- a/src/transformers/models/decision_transformer/configuration_decision_transformer.py
+++ b/src/transformers/models/decision_transformer/configuration_decision_transformer.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-DECISION_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "edbeeching/decision-transformer-gym-hopper-medium": (
- "https://huggingface.co/edbeeching/decision-transformer-gym-hopper-medium/resolve/main/config.json"
- ),
- # See all DecisionTransformer models at https://huggingface.co/models?filter=decision_transformer
-}
+
+from ..deprecated._archive_maps import DECISION_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DecisionTransformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/decision_transformer/modeling_decision_transformer.py b/src/transformers/models/decision_transformer/modeling_decision_transformer.py
index fdfb5b37d22e62..6f939460aab86f 100755
--- a/src/transformers/models/decision_transformer/modeling_decision_transformer.py
+++ b/src/transformers/models/decision_transformer/modeling_decision_transformer.py
@@ -43,10 +43,8 @@
_CHECKPOINT_FOR_DOC = "edbeeching/decision-transformer-gym-hopper-medium"
_CONFIG_FOR_DOC = "DecisionTransformerConfig"
-DECISION_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "edbeeching/decision-transformer-gym-hopper-medium",
- # See all DecisionTransformer models at https://huggingface.co/models?filter=decision_transformer
-]
+
+from ..deprecated._archive_maps import DECISION_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.gpt2.modeling_gpt2.load_tf_weights_in_gpt2
@@ -110,7 +108,7 @@ def load_tf_weights_in_gpt2(model, config, gpt2_checkpoint_path):
class DecisionTransformerGPT2Attention(nn.Module):
def __init__(self, config, is_cross_attention=False, layer_idx=None):
super().__init__()
-
+ self.config = config
max_positions = config.max_position_embeddings
self.register_buffer(
"bias",
@@ -148,6 +146,7 @@ def __init__(self, config, is_cross_attention=False, layer_idx=None):
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
+ self.is_causal = True
self.pruned_heads = set()
@@ -348,6 +347,7 @@ def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.Fl
# Copied from transformers.models.gpt2.modeling_gpt2.GPT2Block with GPT2->DecisionTransformerGPT2
class DecisionTransformerGPT2Block(nn.Module):
+ # Ignore copy
def __init__(self, config, layer_idx=None):
super().__init__()
hidden_size = config.hidden_size
@@ -499,7 +499,6 @@ def get_input_embeddings(self):
def set_input_embeddings(self, new_embeddings):
self.wte = new_embeddings
- # Copied from transformers.models.gpt2.modeling_gpt2.GPT2Model.forward
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
@@ -550,7 +549,7 @@ def forward(
position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0)
- # GPT2Attention mask.
+ # Attention mask.
if attention_mask is not None:
if batch_size <= 0:
raise ValueError("batch_size has to be defined and > 0")
diff --git a/src/transformers/models/deformable_detr/configuration_deformable_detr.py b/src/transformers/models/deformable_detr/configuration_deformable_detr.py
index eb3b3807ab624b..6d32f6220df586 100644
--- a/src/transformers/models/deformable_detr/configuration_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/configuration_deformable_detr.py
@@ -21,10 +21,8 @@
logger = logging.get_logger(__name__)
-DEFORMABLE_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "SenseTime/deformable-detr": "https://huggingface.co/sensetime/deformable-detr/resolve/main/config.json",
- # See all Deformable DETR models at https://huggingface.co/models?filter=deformable-detr
-}
+
+from ..deprecated._archive_maps import DEFORMABLE_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DeformableDetrConfig(PretrainedConfig):
diff --git a/src/transformers/models/deformable_detr/modeling_deformable_detr.py b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
index 4c122832ff2027..1e2296d177c4de 100755
--- a/src/transformers/models/deformable_detr/modeling_deformable_detr.py
+++ b/src/transformers/models/deformable_detr/modeling_deformable_detr.py
@@ -152,10 +152,8 @@ def backward(context, grad_output):
_CONFIG_FOR_DOC = "DeformableDetrConfig"
_CHECKPOINT_FOR_DOC = "sensetime/deformable-detr"
-DEFORMABLE_DETR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "sensetime/deformable-detr",
- # See all Deformable DETR models at https://huggingface.co/models?filter=deformable-detr
-]
+
+from ..deprecated._archive_maps import DEFORMABLE_DETR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/deit/configuration_deit.py b/src/transformers/models/deit/configuration_deit.py
index 20b874ff54a0dd..394c6ff93704cc 100644
--- a/src/transformers/models/deit/configuration_deit.py
+++ b/src/transformers/models/deit/configuration_deit.py
@@ -26,12 +26,8 @@
logger = logging.get_logger(__name__)
-DEIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/deit-base-distilled-patch16-224": (
- "https://huggingface.co/facebook/deit-base-patch16-224/resolve/main/config.json"
- ),
- # See all DeiT models at https://huggingface.co/models?filter=deit
-}
+
+from ..deprecated._archive_maps import DEIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DeiTConfig(PretrainedConfig):
diff --git a/src/transformers/models/deit/modeling_deit.py b/src/transformers/models/deit/modeling_deit.py
index b8bd9d6ce629db..d8f904b9388d52 100644
--- a/src/transformers/models/deit/modeling_deit.py
+++ b/src/transformers/models/deit/modeling_deit.py
@@ -59,10 +59,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-DEIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/deit-base-distilled-patch16-224",
- # See all DeiT models at https://huggingface.co/models?filter=deit
-]
+from ..deprecated._archive_maps import DEIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class DeiTEmbeddings(nn.Module):
diff --git a/src/transformers/models/deit/modeling_tf_deit.py b/src/transformers/models/deit/modeling_tf_deit.py
index c6215c63b8ae8c..aec5f6df95922a 100644
--- a/src/transformers/models/deit/modeling_tf_deit.py
+++ b/src/transformers/models/deit/modeling_tf_deit.py
@@ -65,10 +65,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-TF_DEIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/deit-base-distilled-patch16-224",
- # See all DeiT models at https://huggingface.co/models?filter=deit
-]
+from ..deprecated._archive_maps import TF_DEIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/deprecated/_archive_maps.py b/src/transformers/models/deprecated/_archive_maps.py
new file mode 100644
index 00000000000000..f195ac0706e054
--- /dev/null
+++ b/src/transformers/models/deprecated/_archive_maps.py
@@ -0,0 +1,2765 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from collections import OrderedDict
+
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class DeprecatedDict(dict):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def __getitem__(self, item):
+ logger.warning(
+ "Archive maps are deprecated and will be removed in version v4.40.0 as they are no longer relevant. "
+ "If looking to get all checkpoints for a given architecture, we recommend using `huggingface_hub` "
+ "with the list_models method."
+ )
+ return self[item]
+
+
+class DeprecatedList(list):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def __getitem__(self, item):
+ logger.warning_once(
+ "Archive maps are deprecated and will be removed in version v4.40.0 as they are no longer relevant. "
+ "If looking to get all checkpoints for a given architecture, we recommend using `huggingface_hub` "
+ "with the `list_models` method."
+ )
+ return super().__getitem__(item)
+
+
+ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/config.json",
+ "albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/config.json",
+ "albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/config.json",
+ "albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/config.json",
+ "albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/config.json",
+ "albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/config.json",
+ "albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/config.json",
+ "albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/config.json",
+ }
+)
+
+ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "albert/albert-base-v1",
+ "albert/albert-large-v1",
+ "albert/albert-xlarge-v1",
+ "albert/albert-xxlarge-v1",
+ "albert/albert-base-v2",
+ "albert/albert-large-v2",
+ "albert/albert-xlarge-v2",
+ "albert/albert-xxlarge-v2",
+ ]
+)
+
+TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "albert/albert-base-v1",
+ "albert/albert-large-v1",
+ "albert/albert-xlarge-v1",
+ "albert/albert-xxlarge-v1",
+ "albert/albert-base-v2",
+ "albert/albert-large-v2",
+ "albert/albert-xlarge-v2",
+ "albert/albert-xxlarge-v2",
+ ]
+)
+
+ALIGN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"kakaobrain/align-base": "https://huggingface.co/kakaobrain/align-base/resolve/main/config.json"}
+)
+
+ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["kakaobrain/align-base"])
+
+ALTCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"BAAI/AltCLIP": "https://huggingface.co/BAAI/AltCLIP/resolve/main/config.json"}
+)
+
+ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["BAAI/AltCLIP"])
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "MIT/ast-finetuned-audioset-10-10-0.4593": "https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593/resolve/main/config.json"
+ }
+)
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["MIT/ast-finetuned-audioset-10-10-0.4593"]
+)
+
+AUTOFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "huggingface/autoformer-tourism-monthly": "https://huggingface.co/huggingface/autoformer-tourism-monthly/resolve/main/config.json"
+ }
+)
+
+AUTOFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["huggingface/autoformer-tourism-monthly"])
+
+BARK_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["suno/bark-small", "suno/bark"])
+
+BART_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/bart-large"])
+
+BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/beit-base-patch16-224-pt22k": "https://huggingface.co/microsoft/beit-base-patch16-224-pt22k/resolve/main/config.json"
+ }
+)
+
+BEIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/beit-base-patch16-224"])
+
+BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/config.json",
+ "google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/config.json",
+ "google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/config.json",
+ "google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/config.json",
+ "google-bert/bert-base-multilingual-uncased": "https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/config.json",
+ "google-bert/bert-base-multilingual-cased": "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/config.json",
+ "google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/config.json",
+ "google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/config.json",
+ "google-bert/bert-large-uncased-whole-word-masking": "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/config.json",
+ "google-bert/bert-large-cased-whole-word-masking": "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/config.json",
+ "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": "https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/config.json",
+ "google-bert/bert-large-cased-whole-word-masking-finetuned-squad": "https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/config.json",
+ "google-bert/bert-base-cased-finetuned-mrpc": "https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/config.json",
+ "google-bert/bert-base-german-dbmdz-cased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/config.json",
+ "google-bert/bert-base-german-dbmdz-uncased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/config.json",
+ "cl-tohoku/bert-base-japanese": "https://huggingface.co/cl-tohoku/bert-base-japanese/resolve/main/config.json",
+ "cl-tohoku/bert-base-japanese-whole-word-masking": "https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json",
+ "cl-tohoku/bert-base-japanese-char": "https://huggingface.co/cl-tohoku/bert-base-japanese-char/resolve/main/config.json",
+ "cl-tohoku/bert-base-japanese-char-whole-word-masking": "https://huggingface.co/cl-tohoku/bert-base-japanese-char-whole-word-masking/resolve/main/config.json",
+ "TurkuNLP/bert-base-finnish-cased-v1": "https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/config.json",
+ "TurkuNLP/bert-base-finnish-uncased-v1": "https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/config.json",
+ "wietsedv/bert-base-dutch-cased": "https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/config.json",
+ }
+)
+
+BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google-bert/bert-base-uncased",
+ "google-bert/bert-large-uncased",
+ "google-bert/bert-base-cased",
+ "google-bert/bert-large-cased",
+ "google-bert/bert-base-multilingual-uncased",
+ "google-bert/bert-base-multilingual-cased",
+ "google-bert/bert-base-chinese",
+ "google-bert/bert-base-german-cased",
+ "google-bert/bert-large-uncased-whole-word-masking",
+ "google-bert/bert-large-cased-whole-word-masking",
+ "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
+ "google-bert/bert-large-cased-whole-word-masking-finetuned-squad",
+ "google-bert/bert-base-cased-finetuned-mrpc",
+ "google-bert/bert-base-german-dbmdz-cased",
+ "google-bert/bert-base-german-dbmdz-uncased",
+ "cl-tohoku/bert-base-japanese",
+ "cl-tohoku/bert-base-japanese-whole-word-masking",
+ "cl-tohoku/bert-base-japanese-char",
+ "cl-tohoku/bert-base-japanese-char-whole-word-masking",
+ "TurkuNLP/bert-base-finnish-cased-v1",
+ "TurkuNLP/bert-base-finnish-uncased-v1",
+ "wietsedv/bert-base-dutch-cased",
+ ]
+)
+
+TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google-bert/bert-base-uncased",
+ "google-bert/bert-large-uncased",
+ "google-bert/bert-base-cased",
+ "google-bert/bert-large-cased",
+ "google-bert/bert-base-multilingual-uncased",
+ "google-bert/bert-base-multilingual-cased",
+ "google-bert/bert-base-chinese",
+ "google-bert/bert-base-german-cased",
+ "google-bert/bert-large-uncased-whole-word-masking",
+ "google-bert/bert-large-cased-whole-word-masking",
+ "google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
+ "google-bert/bert-large-cased-whole-word-masking-finetuned-squad",
+ "google-bert/bert-base-cased-finetuned-mrpc",
+ "cl-tohoku/bert-base-japanese",
+ "cl-tohoku/bert-base-japanese-whole-word-masking",
+ "cl-tohoku/bert-base-japanese-char",
+ "cl-tohoku/bert-base-japanese-char-whole-word-masking",
+ "TurkuNLP/bert-base-finnish-cased-v1",
+ "TurkuNLP/bert-base-finnish-uncased-v1",
+ "wietsedv/bert-base-dutch-cased",
+ ]
+)
+
+BIG_BIRD_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/bigbird-roberta-base": "https://huggingface.co/google/bigbird-roberta-base/resolve/main/config.json",
+ "google/bigbird-roberta-large": "https://huggingface.co/google/bigbird-roberta-large/resolve/main/config.json",
+ "google/bigbird-base-trivia-itc": "https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/config.json",
+ }
+)
+
+BIG_BIRD_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google/bigbird-roberta-base", "google/bigbird-roberta-large", "google/bigbird-base-trivia-itc"]
+)
+
+BIGBIRD_PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/bigbird-pegasus-large-arxiv": "https://huggingface.co/google/bigbird-pegasus-large-arxiv/resolve/main/config.json",
+ "google/bigbird-pegasus-large-pubmed": "https://huggingface.co/google/bigbird-pegasus-large-pubmed/resolve/main/config.json",
+ "google/bigbird-pegasus-large-bigpatent": "https://huggingface.co/google/bigbird-pegasus-large-bigpatent/resolve/main/config.json",
+ }
+)
+
+BIGBIRD_PEGASUS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/bigbird-pegasus-large-arxiv",
+ "google/bigbird-pegasus-large-pubmed",
+ "google/bigbird-pegasus-large-bigpatent",
+ ]
+)
+
+BIOGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/biogpt": "https://huggingface.co/microsoft/biogpt/resolve/main/config.json"}
+)
+
+BIOGPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/biogpt", "microsoft/BioGPT-Large"])
+
+BIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/bit-50": "https://huggingface.co/google/bit-50/resolve/main/config.json"}
+)
+
+BIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/bit-50"])
+
+BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/config.json"}
+)
+
+BLENDERBOT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/blenderbot-3B"])
+
+BLENDERBOT_SMALL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "facebook/blenderbot_small-90M": "https://huggingface.co/facebook/blenderbot_small-90M/resolve/main/config.json",
+ # See all BlenderbotSmall models at https://huggingface.co/models?filter=blenderbot_small
+}
+
+BLENDERBOT_SMALL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/blenderbot_small-90M"])
+
+BLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "Salesforce/blip-vqa-base": "https://huggingface.co/Salesforce/blip-vqa-base/resolve/main/config.json",
+ "Salesforce/blip-vqa-capfit-large": "https://huggingface.co/Salesforce/blip-vqa-base-capfit/resolve/main/config.json",
+ "Salesforce/blip-image-captioning-base": "https://huggingface.co/Salesforce/blip-image-captioning-base/resolve/main/config.json",
+ "Salesforce/blip-image-captioning-large": "https://huggingface.co/Salesforce/blip-image-captioning-large/resolve/main/config.json",
+ "Salesforce/blip-itm-base-coco": "https://huggingface.co/Salesforce/blip-itm-base-coco/resolve/main/config.json",
+ "Salesforce/blip-itm-large-coco": "https://huggingface.co/Salesforce/blip-itm-large-coco/resolve/main/config.json",
+ "Salesforce/blip-itm-base-flikr": "https://huggingface.co/Salesforce/blip-itm-base-flikr/resolve/main/config.json",
+ "Salesforce/blip-itm-large-flikr": "https://huggingface.co/Salesforce/blip-itm-large-flikr/resolve/main/config.json",
+ }
+)
+
+BLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "Salesforce/blip-vqa-base",
+ "Salesforce/blip-vqa-capfilt-large",
+ "Salesforce/blip-image-captioning-base",
+ "Salesforce/blip-image-captioning-large",
+ "Salesforce/blip-itm-base-coco",
+ "Salesforce/blip-itm-large-coco",
+ "Salesforce/blip-itm-base-flickr",
+ "Salesforce/blip-itm-large-flickr",
+ ]
+)
+
+TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "Salesforce/blip-vqa-base",
+ "Salesforce/blip-vqa-capfilt-large",
+ "Salesforce/blip-image-captioning-base",
+ "Salesforce/blip-image-captioning-large",
+ "Salesforce/blip-itm-base-coco",
+ "Salesforce/blip-itm-large-coco",
+ "Salesforce/blip-itm-base-flickr",
+ "Salesforce/blip-itm-large-flickr",
+ ]
+)
+
+BLIP_2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"salesforce/blip2-opt-2.7b": "https://huggingface.co/salesforce/blip2-opt-2.7b/resolve/main/config.json"}
+)
+
+BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Salesforce/blip2-opt-2.7b"])
+
+BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "bigscience/bloom": "https://huggingface.co/bigscience/bloom/resolve/main/config.json",
+ "bigscience/bloom-560m": "https://huggingface.co/bigscience/bloom-560m/blob/main/config.json",
+ "bigscience/bloom-1b1": "https://huggingface.co/bigscience/bloom-1b1/blob/main/config.json",
+ "bigscience/bloom-1b7": "https://huggingface.co/bigscience/bloom-1b7/blob/main/config.json",
+ "bigscience/bloom-3b": "https://huggingface.co/bigscience/bloom-3b/blob/main/config.json",
+ "bigscience/bloom-7b1": "https://huggingface.co/bigscience/bloom-7b1/blob/main/config.json",
+ }
+)
+
+BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "bigscience/bigscience-small-testing",
+ "bigscience/bloom-560m",
+ "bigscience/bloom-1b1",
+ "bigscience/bloom-1b7",
+ "bigscience/bloom-3b",
+ "bigscience/bloom-7b1",
+ "bigscience/bloom",
+ ]
+)
+
+BRIDGETOWER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "BridgeTower/bridgetower-base": "https://huggingface.co/BridgeTower/bridgetower-base/blob/main/config.json",
+ "BridgeTower/bridgetower-base-itm-mlm": "https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm/blob/main/config.json",
+ }
+)
+
+BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["BridgeTower/bridgetower-base", "BridgeTower/bridgetower-base-itm-mlm"]
+)
+
+BROS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "jinho8345/bros-base-uncased": "https://huggingface.co/jinho8345/bros-base-uncased/blob/main/config.json",
+ "jinho8345/bros-large-uncased": "https://huggingface.co/jinho8345/bros-large-uncased/blob/main/config.json",
+ }
+)
+
+BROS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["jinho8345/bros-base-uncased", "jinho8345/bros-large-uncased"])
+
+CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "almanach/camembert-base": "https://huggingface.co/almanach/camembert-base/resolve/main/config.json",
+ "umberto-commoncrawl-cased-v1": "https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1/resolve/main/config.json",
+ "umberto-wikipedia-uncased-v1": "https://huggingface.co/Musixmatch/umberto-wikipedia-uncased-v1/resolve/main/config.json",
+ }
+)
+
+CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["almanach/camembert-base", "Musixmatch/umberto-commoncrawl-cased-v1", "Musixmatch/umberto-wikipedia-uncased-v1"]
+)
+
+TF_CAMEMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList([])
+
+CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/canine-s": "https://huggingface.co/google/canine-s/resolve/main/config.json"}
+)
+
+CANINE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/canine-s", "google/canine-r"])
+
+CHINESE_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "OFA-Sys/chinese-clip-vit-base-patch16": "https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/resolve/main/config.json"
+ }
+)
+
+CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["OFA-Sys/chinese-clip-vit-base-patch16"])
+
+CLAP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["laion/clap-htsat-fused", "laion/clap-htsat-unfused"])
+
+CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/config.json"}
+)
+
+CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai/clip-vit-base-patch32"])
+
+TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai/clip-vit-base-patch32"])
+
+CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"CIDAS/clipseg-rd64": "https://huggingface.co/CIDAS/clipseg-rd64/resolve/main/config.json"}
+)
+
+CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["CIDAS/clipseg-rd64-refined"])
+
+CLVP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"susnato/clvp_dev": "https://huggingface.co/susnato/clvp_dev/resolve/main/config.json"}
+)
+
+CLVP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["susnato/clvp_dev"])
+
+CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "Salesforce/codegen-350M-nl": "https://huggingface.co/Salesforce/codegen-350M-nl/resolve/main/config.json",
+ "Salesforce/codegen-350M-multi": "https://huggingface.co/Salesforce/codegen-350M-multi/resolve/main/config.json",
+ "Salesforce/codegen-350M-mono": "https://huggingface.co/Salesforce/codegen-350M-mono/resolve/main/config.json",
+ "Salesforce/codegen-2B-nl": "https://huggingface.co/Salesforce/codegen-2B-nl/resolve/main/config.json",
+ "Salesforce/codegen-2B-multi": "https://huggingface.co/Salesforce/codegen-2B-multi/resolve/main/config.json",
+ "Salesforce/codegen-2B-mono": "https://huggingface.co/Salesforce/codegen-2B-mono/resolve/main/config.json",
+ "Salesforce/codegen-6B-nl": "https://huggingface.co/Salesforce/codegen-6B-nl/resolve/main/config.json",
+ "Salesforce/codegen-6B-multi": "https://huggingface.co/Salesforce/codegen-6B-multi/resolve/main/config.json",
+ "Salesforce/codegen-6B-mono": "https://huggingface.co/Salesforce/codegen-6B-mono/resolve/main/config.json",
+ "Salesforce/codegen-16B-nl": "https://huggingface.co/Salesforce/codegen-16B-nl/resolve/main/config.json",
+ "Salesforce/codegen-16B-multi": "https://huggingface.co/Salesforce/codegen-16B-multi/resolve/main/config.json",
+ "Salesforce/codegen-16B-mono": "https://huggingface.co/Salesforce/codegen-16B-mono/resolve/main/config.json",
+ }
+)
+
+CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "Salesforce/codegen-350M-nl",
+ "Salesforce/codegen-350M-multi",
+ "Salesforce/codegen-350M-mono",
+ "Salesforce/codegen-2B-nl",
+ "Salesforce/codegen-2B-multi",
+ "Salesforce/codegen-2B-mono",
+ "Salesforce/codegen-6B-nl",
+ "Salesforce/codegen-6B-multi",
+ "Salesforce/codegen-6B-mono",
+ "Salesforce/codegen-16B-nl",
+ "Salesforce/codegen-16B-multi",
+ "Salesforce/codegen-16B-mono",
+ ]
+)
+
+CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/conditional-detr-resnet-50": "https://huggingface.co/microsoft/conditional-detr-resnet-50/resolve/main/config.json"
+ }
+)
+
+CONDITIONAL_DETR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/conditional-detr-resnet-50"])
+
+CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "YituTech/conv-bert-base": "https://huggingface.co/YituTech/conv-bert-base/resolve/main/config.json",
+ "YituTech/conv-bert-medium-small": "https://huggingface.co/YituTech/conv-bert-medium-small/resolve/main/config.json",
+ "YituTech/conv-bert-small": "https://huggingface.co/YituTech/conv-bert-small/resolve/main/config.json",
+ }
+)
+
+CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["YituTech/conv-bert-base", "YituTech/conv-bert-medium-small", "YituTech/conv-bert-small"]
+)
+
+TF_CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["YituTech/conv-bert-base", "YituTech/conv-bert-medium-small", "YituTech/conv-bert-small"]
+)
+
+CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/convnext-tiny-224": "https://huggingface.co/facebook/convnext-tiny-224/resolve/main/config.json"}
+)
+
+CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/convnext-tiny-224"])
+
+CONVNEXTV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/convnextv2-tiny-1k-224": "https://huggingface.co/facebook/convnextv2-tiny-1k-224/resolve/main/config.json"
+ }
+)
+
+CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/convnextv2-tiny-1k-224"])
+
+CPMANT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"openbmb/cpm-ant-10b": "https://huggingface.co/openbmb/cpm-ant-10b/blob/main/config.json"}
+)
+
+CPMANT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openbmb/cpm-ant-10b"])
+
+CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"Salesforce/ctrl": "https://huggingface.co/Salesforce/ctrl/resolve/main/config.json"}
+)
+
+CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Salesforce/ctrl"])
+
+TF_CTRL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Salesforce/ctrl"])
+
+CVT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/cvt-13": "https://huggingface.co/microsoft/cvt-13/resolve/main/config.json"}
+)
+
+CVT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "microsoft/cvt-13",
+ "microsoft/cvt-13-384",
+ "microsoft/cvt-13-384-22k",
+ "microsoft/cvt-21",
+ "microsoft/cvt-21-384",
+ "microsoft/cvt-21-384-22k",
+ ]
+)
+
+TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "microsoft/cvt-13",
+ "microsoft/cvt-13-384",
+ "microsoft/cvt-13-384-22k",
+ "microsoft/cvt-21",
+ "microsoft/cvt-21-384",
+ "microsoft/cvt-21-384-22k",
+ ]
+)
+
+DATA2VEC_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/data2vec-text-base": "https://huggingface.co/data2vec/resolve/main/config.json"}
+)
+
+DATA2VEC_VISION_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/data2vec-vision-base-ft": "https://huggingface.co/facebook/data2vec-vision-base-ft/resolve/main/config.json"
+ }
+)
+
+DATA2VEC_AUDIO_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "facebook/data2vec-audio-base",
+ "facebook/data2vec-audio-base-10m",
+ "facebook/data2vec-audio-base-100h",
+ "facebook/data2vec-audio-base-960h",
+ ]
+)
+
+DATA2VEC_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/data2vec-text-base"])
+
+DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/data2vec-vision-base-ft1k"])
+
+DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/config.json",
+ "microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/config.json",
+ "microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/config.json",
+ "microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/config.json",
+ "microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/config.json",
+ "microsoft/deberta-xlarge-mnli": "https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/config.json",
+ }
+)
+
+DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "microsoft/deberta-base",
+ "microsoft/deberta-large",
+ "microsoft/deberta-xlarge",
+ "microsoft/deberta-base-mnli",
+ "microsoft/deberta-large-mnli",
+ "microsoft/deberta-xlarge-mnli",
+ ]
+)
+
+TF_DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["kamalkraj/deberta-base"])
+
+DEBERTA_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/deberta-v2-xlarge": "https://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/config.json",
+ "microsoft/deberta-v2-xxlarge": "https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/config.json",
+ "microsoft/deberta-v2-xlarge-mnli": "https://huggingface.co/microsoft/deberta-v2-xlarge-mnli/resolve/main/config.json",
+ "microsoft/deberta-v2-xxlarge-mnli": "https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli/resolve/main/config.json",
+ }
+)
+
+DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "microsoft/deberta-v2-xlarge",
+ "microsoft/deberta-v2-xxlarge",
+ "microsoft/deberta-v2-xlarge-mnli",
+ "microsoft/deberta-v2-xxlarge-mnli",
+ ]
+)
+
+TF_DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["kamalkraj/deberta-v2-xlarge"])
+
+DECISION_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "edbeeching/decision-transformer-gym-hopper-medium": "https://huggingface.co/edbeeching/decision-transformer-gym-hopper-medium/resolve/main/config.json"
+ }
+)
+
+DECISION_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["edbeeching/decision-transformer-gym-hopper-medium"]
+)
+
+DEFORMABLE_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"SenseTime/deformable-detr": "https://huggingface.co/sensetime/deformable-detr/resolve/main/config.json"}
+)
+
+DEFORMABLE_DETR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["sensetime/deformable-detr"])
+
+DEIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/deit-base-distilled-patch16-224": "https://huggingface.co/facebook/deit-base-patch16-224/resolve/main/config.json"
+ }
+)
+
+DEIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/deit-base-distilled-patch16-224"])
+
+TF_DEIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/deit-base-distilled-patch16-224"])
+
+MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"speechbrain/m-ctc-t-large": "https://huggingface.co/speechbrain/m-ctc-t-large/resolve/main/config.json"}
+)
+
+MCTCT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["speechbrain/m-ctc-t-large"])
+
+OPEN_LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"s-JoL/Open-Llama-V1": "https://huggingface.co/s-JoL/Open-Llama-V1/blob/main/config.json"}
+)
+
+RETRIBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "yjernite/retribert-base-uncased": "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/config.json"
+ }
+)
+
+RETRIBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["yjernite/retribert-base-uncased"])
+
+TRAJECTORY_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "CarlCochet/trajectory-transformer-halfcheetah-medium-v2": "https://huggingface.co/CarlCochet/trajectory-transformer-halfcheetah-medium-v2/resolve/main/config.json"
+ }
+)
+
+TRAJECTORY_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["CarlCochet/trajectory-transformer-halfcheetah-medium-v2"]
+)
+
+TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"transfo-xl/transfo-xl-wt103": "https://huggingface.co/transfo-xl/transfo-xl-wt103/resolve/main/config.json"}
+)
+
+TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["transfo-xl/transfo-xl-wt103"])
+
+TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["transfo-xl/transfo-xl-wt103"])
+
+VAN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "Visual-Attention-Network/van-base": "https://huggingface.co/Visual-Attention-Network/van-base/blob/main/config.json"
+ }
+)
+
+VAN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Visual-Attention-Network/van-base"])
+
+DEPTH_ANYTHING_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "LiheYoung/depth-anything-small-hf": "https://huggingface.co/LiheYoung/depth-anything-small-hf/resolve/main/config.json"
+ }
+)
+
+DEPTH_ANYTHING_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["LiheYoung/depth-anything-small-hf"])
+
+DETA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"ut/deta": "https://huggingface.co/ut/deta/resolve/main/config.json"}
+)
+
+DETA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["jozhang97/deta-swin-large-o365"])
+
+DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/detr-resnet-50": "https://huggingface.co/facebook/detr-resnet-50/resolve/main/config.json"}
+)
+
+DETR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/detr-resnet-50"])
+
+DINAT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"shi-labs/dinat-mini-in1k-224": "https://huggingface.co/shi-labs/dinat-mini-in1k-224/resolve/main/config.json"}
+)
+
+DINAT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["shi-labs/dinat-mini-in1k-224"])
+
+DINOV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/dinov2-base": "https://huggingface.co/facebook/dinov2-base/resolve/main/config.json"}
+)
+
+DINOV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/dinov2-base"])
+
+DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/config.json",
+ "distilbert-base-uncased-distilled-squad": "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/config.json",
+ "distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/config.json",
+ "distilbert-base-cased-distilled-squad": "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/config.json",
+ "distilbert-base-german-cased": "https://huggingface.co/distilbert-base-german-cased/resolve/main/config.json",
+ "distilbert-base-multilingual-cased": "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/config.json",
+ "distilbert-base-uncased-finetuned-sst-2-english": "https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/resolve/main/config.json",
+ }
+)
+
+DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "distilbert-base-uncased",
+ "distilbert-base-uncased-distilled-squad",
+ "distilbert-base-cased",
+ "distilbert-base-cased-distilled-squad",
+ "distilbert-base-german-cased",
+ "distilbert-base-multilingual-cased",
+ "distilbert-base-uncased-finetuned-sst-2-english",
+ ]
+)
+
+TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "distilbert-base-uncased",
+ "distilbert-base-uncased-distilled-squad",
+ "distilbert-base-cased",
+ "distilbert-base-cased-distilled-squad",
+ "distilbert-base-multilingual-cased",
+ "distilbert-base-uncased-finetuned-sst-2-english",
+ ]
+)
+
+DONUT_SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"naver-clova-ix/donut-base": "https://huggingface.co/naver-clova-ix/donut-base/resolve/main/config.json"}
+)
+
+DONUT_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["naver-clova-ix/donut-base"])
+
+DPR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/dpr-ctx_encoder-single-nq-base": "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/config.json",
+ "facebook/dpr-question_encoder-single-nq-base": "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/config.json",
+ "facebook/dpr-reader-single-nq-base": "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/config.json",
+ "facebook/dpr-ctx_encoder-multiset-base": "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/config.json",
+ "facebook/dpr-question_encoder-multiset-base": "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/config.json",
+ "facebook/dpr-reader-multiset-base": "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/config.json",
+ }
+)
+
+DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-ctx_encoder-single-nq-base", "facebook/dpr-ctx_encoder-multiset-base"]
+)
+
+DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-question_encoder-single-nq-base", "facebook/dpr-question_encoder-multiset-base"]
+)
+
+DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-reader-single-nq-base", "facebook/dpr-reader-multiset-base"]
+)
+
+TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-ctx_encoder-single-nq-base", "facebook/dpr-ctx_encoder-multiset-base"]
+)
+
+TF_DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-question_encoder-single-nq-base", "facebook/dpr-question_encoder-multiset-base"]
+)
+
+TF_DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/dpr-reader-single-nq-base", "facebook/dpr-reader-multiset-base"]
+)
+
+DPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"Intel/dpt-large": "https://huggingface.co/Intel/dpt-large/resolve/main/config.json"}
+)
+
+DPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Intel/dpt-large", "Intel/dpt-hybrid-midas"])
+
+EFFICIENTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "snap-research/efficientformer-l1-300": "https://huggingface.co/snap-research/efficientformer-l1-300/resolve/main/config.json"
+ }
+)
+
+EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["snap-research/efficientformer-l1-300"])
+
+TF_EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["snap-research/efficientformer-l1-300"])
+
+EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/efficientnet-b7": "https://huggingface.co/google/efficientnet-b7/resolve/main/config.json"}
+)
+
+EFFICIENTNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/efficientnet-b7"])
+
+ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/electra-small-generator": "https://huggingface.co/google/electra-small-generator/resolve/main/config.json",
+ "google/electra-base-generator": "https://huggingface.co/google/electra-base-generator/resolve/main/config.json",
+ "google/electra-large-generator": "https://huggingface.co/google/electra-large-generator/resolve/main/config.json",
+ "google/electra-small-discriminator": "https://huggingface.co/google/electra-small-discriminator/resolve/main/config.json",
+ "google/electra-base-discriminator": "https://huggingface.co/google/electra-base-discriminator/resolve/main/config.json",
+ "google/electra-large-discriminator": "https://huggingface.co/google/electra-large-discriminator/resolve/main/config.json",
+ }
+)
+
+ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/electra-small-generator",
+ "google/electra-base-generator",
+ "google/electra-large-generator",
+ "google/electra-small-discriminator",
+ "google/electra-base-discriminator",
+ "google/electra-large-discriminator",
+ ]
+)
+
+TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/electra-small-generator",
+ "google/electra-base-generator",
+ "google/electra-large-generator",
+ "google/electra-small-discriminator",
+ "google/electra-base-discriminator",
+ "google/electra-large-discriminator",
+ ]
+)
+
+ENCODEC_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/encodec_24khz": "https://huggingface.co/facebook/encodec_24khz/resolve/main/config.json",
+ "facebook/encodec_48khz": "https://huggingface.co/facebook/encodec_48khz/resolve/main/config.json",
+ }
+)
+
+ENCODEC_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/encodec_24khz", "facebook/encodec_48khz"])
+
+ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "nghuyong/ernie-1.0-base-zh": "https://huggingface.co/nghuyong/ernie-1.0-base-zh/resolve/main/config.json",
+ "nghuyong/ernie-2.0-base-en": "https://huggingface.co/nghuyong/ernie-2.0-base-en/resolve/main/config.json",
+ "nghuyong/ernie-2.0-large-en": "https://huggingface.co/nghuyong/ernie-2.0-large-en/resolve/main/config.json",
+ "nghuyong/ernie-3.0-base-zh": "https://huggingface.co/nghuyong/ernie-3.0-base-zh/resolve/main/config.json",
+ "nghuyong/ernie-3.0-medium-zh": "https://huggingface.co/nghuyong/ernie-3.0-medium-zh/resolve/main/config.json",
+ "nghuyong/ernie-3.0-mini-zh": "https://huggingface.co/nghuyong/ernie-3.0-mini-zh/resolve/main/config.json",
+ "nghuyong/ernie-3.0-micro-zh": "https://huggingface.co/nghuyong/ernie-3.0-micro-zh/resolve/main/config.json",
+ "nghuyong/ernie-3.0-nano-zh": "https://huggingface.co/nghuyong/ernie-3.0-nano-zh/resolve/main/config.json",
+ "nghuyong/ernie-gram-zh": "https://huggingface.co/nghuyong/ernie-gram-zh/resolve/main/config.json",
+ "nghuyong/ernie-health-zh": "https://huggingface.co/nghuyong/ernie-health-zh/resolve/main/config.json",
+ }
+)
+
+ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "nghuyong/ernie-1.0-base-zh",
+ "nghuyong/ernie-2.0-base-en",
+ "nghuyong/ernie-2.0-large-en",
+ "nghuyong/ernie-3.0-base-zh",
+ "nghuyong/ernie-3.0-medium-zh",
+ "nghuyong/ernie-3.0-mini-zh",
+ "nghuyong/ernie-3.0-micro-zh",
+ "nghuyong/ernie-3.0-nano-zh",
+ "nghuyong/ernie-gram-zh",
+ "nghuyong/ernie-health-zh",
+ ]
+)
+
+ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "susnato/ernie-m-base_pytorch": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/config.json",
+ "susnato/ernie-m-large_pytorch": "https://huggingface.co/susnato/ernie-m-large_pytorch/blob/main/config.json",
+ }
+)
+
+ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["susnato/ernie-m-base_pytorch", "susnato/ernie-m-large_pytorch"]
+)
+
+ESM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/esm-1b": "https://huggingface.co/facebook/esm-1b/resolve/main/config.json"}
+)
+
+ESM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/esm2_t6_8M_UR50D", "facebook/esm2_t12_35M_UR50D"])
+
+FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "tiiuae/falcon-40b": "https://huggingface.co/tiiuae/falcon-40b/resolve/main/config.json",
+ "tiiuae/falcon-7b": "https://huggingface.co/tiiuae/falcon-7b/resolve/main/config.json",
+ }
+)
+
+FALCON_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "tiiuae/falcon-40b",
+ "tiiuae/falcon-40b-instruct",
+ "tiiuae/falcon-7b",
+ "tiiuae/falcon-7b-instruct",
+ "tiiuae/falcon-rw-7b",
+ "tiiuae/falcon-rw-1b",
+ ]
+)
+
+FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "espnet/fastspeech2_conformer_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_hifigan/raw/main/config.json"
+ }
+)
+
+FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"espnet/fastspeech2_conformer": "https://huggingface.co/espnet/fastspeech2_conformer/raw/main/config.json"}
+)
+
+FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "espnet/fastspeech2_conformer_with_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_with_hifigan/raw/main/config.json"
+ }
+)
+
+FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["espnet/fastspeech2_conformer"])
+
+FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "flaubert/flaubert_small_cased": "https://huggingface.co/flaubert/flaubert_small_cased/resolve/main/config.json",
+ "flaubert/flaubert_base_uncased": "https://huggingface.co/flaubert/flaubert_base_uncased/resolve/main/config.json",
+ "flaubert/flaubert_base_cased": "https://huggingface.co/flaubert/flaubert_base_cased/resolve/main/config.json",
+ "flaubert/flaubert_large_cased": "https://huggingface.co/flaubert/flaubert_large_cased/resolve/main/config.json",
+ }
+)
+
+FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "flaubert/flaubert_small_cased",
+ "flaubert/flaubert_base_uncased",
+ "flaubert/flaubert_base_cased",
+ "flaubert/flaubert_large_cased",
+ ]
+)
+
+TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList([])
+
+FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/flava-full": "https://huggingface.co/facebook/flava-full/resolve/main/config.json"}
+)
+
+FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/flava-full"])
+
+FNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/fnet-base": "https://huggingface.co/google/fnet-base/resolve/main/config.json",
+ "google/fnet-large": "https://huggingface.co/google/fnet-large/resolve/main/config.json",
+ }
+)
+
+FNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/fnet-base", "google/fnet-large"])
+
+FOCALNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/focalnet-tiny": "https://huggingface.co/microsoft/focalnet-tiny/resolve/main/config.json"}
+)
+
+FOCALNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/focalnet-tiny"])
+
+FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({})
+
+FUNNEL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "funnel-transformer/small": "https://huggingface.co/funnel-transformer/small/resolve/main/config.json",
+ "funnel-transformer/small-base": "https://huggingface.co/funnel-transformer/small-base/resolve/main/config.json",
+ "funnel-transformer/medium": "https://huggingface.co/funnel-transformer/medium/resolve/main/config.json",
+ "funnel-transformer/medium-base": "https://huggingface.co/funnel-transformer/medium-base/resolve/main/config.json",
+ "funnel-transformer/intermediate": "https://huggingface.co/funnel-transformer/intermediate/resolve/main/config.json",
+ "funnel-transformer/intermediate-base": "https://huggingface.co/funnel-transformer/intermediate-base/resolve/main/config.json",
+ "funnel-transformer/large": "https://huggingface.co/funnel-transformer/large/resolve/main/config.json",
+ "funnel-transformer/large-base": "https://huggingface.co/funnel-transformer/large-base/resolve/main/config.json",
+ "funnel-transformer/xlarge": "https://huggingface.co/funnel-transformer/xlarge/resolve/main/config.json",
+ "funnel-transformer/xlarge-base": "https://huggingface.co/funnel-transformer/xlarge-base/resolve/main/config.json",
+ }
+)
+
+FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "funnel-transformer/small",
+ "funnel-transformer/small-base",
+ "funnel-transformer/medium",
+ "funnel-transformer/medium-base",
+ "funnel-transformer/intermediate",
+ "funnel-transformer/intermediate-base",
+ "funnel-transformer/large",
+ "funnel-transformer/large-base",
+ "funnel-transformer/xlarge-base",
+ "funnel-transformer/xlarge",
+ ]
+)
+
+TF_FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "funnel-transformer/small",
+ "funnel-transformer/small-base",
+ "funnel-transformer/medium",
+ "funnel-transformer/medium-base",
+ "funnel-transformer/intermediate",
+ "funnel-transformer/intermediate-base",
+ "funnel-transformer/large",
+ "funnel-transformer/large-base",
+ "funnel-transformer/xlarge-base",
+ "funnel-transformer/xlarge",
+ ]
+)
+
+FUYU_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"adept/fuyu-8b": "https://huggingface.co/adept/fuyu-8b/resolve/main/config.json"}
+)
+
+GEMMA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({})
+
+GIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/git-base": "https://huggingface.co/microsoft/git-base/resolve/main/config.json"}
+)
+
+GIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/git-base"])
+
+GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"vinvino02/glpn-kitti": "https://huggingface.co/vinvino02/glpn-kitti/resolve/main/config.json"}
+)
+
+GLPN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["vinvino02/glpn-kitti"])
+
+GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/config.json",
+ "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/config.json",
+ "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/config.json",
+ "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/config.json",
+ "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/config.json",
+ }
+)
+
+GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "openai-community/gpt2",
+ "openai-community/gpt2-medium",
+ "openai-community/gpt2-large",
+ "openai-community/gpt2-xl",
+ "distilbert/distilgpt2",
+ ]
+)
+
+TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "openai-community/gpt2",
+ "openai-community/gpt2-medium",
+ "openai-community/gpt2-large",
+ "openai-community/gpt2-xl",
+ "distilbert/distilgpt2",
+ ]
+)
+
+GPT_BIGCODE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "bigcode/gpt_bigcode-santacoder": "https://huggingface.co/bigcode/gpt_bigcode-santacoder/resolve/main/config.json"
+ }
+)
+
+GPT_BIGCODE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["bigcode/gpt_bigcode-santacoder"])
+
+GPT_NEO_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"EleutherAI/gpt-neo-1.3B": "https://huggingface.co/EleutherAI/gpt-neo-1.3B/resolve/main/config.json"}
+)
+
+GPT_NEO_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["EleutherAI/gpt-neo-1.3B"])
+
+GPT_NEOX_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"EleutherAI/gpt-neox-20b": "https://huggingface.co/EleutherAI/gpt-neox-20b/resolve/main/config.json"}
+)
+
+GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["EleutherAI/gpt-neox-20b"])
+
+GPT_NEOX_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"abeja/gpt-neox-japanese-2.7b": "https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/config.json"}
+)
+
+GPT_NEOX_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/config.json"]
+)
+
+GPTJ_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"EleutherAI/gpt-j-6B": "https://huggingface.co/EleutherAI/gpt-j-6B/resolve/main/config.json"}
+)
+
+GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["EleutherAI/gpt-j-6B"])
+
+GPTSAN_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "tanreinama/GPTSAN-2.8B-spout_is_uniform": "https://huggingface.co/tanreinama/GPTSAN-2.8B-spout_is_uniform/resolve/main/config.json"
+ }
+)
+
+GPTSAN_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Tanrei/GPTSAN-japanese"])
+
+GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"graphormer-base": "https://huggingface.co/clefourrier/graphormer-base-pcqm4mv2/resolve/main/config.json"}
+)
+
+GRAPHORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["clefourrier/graphormer-base-pcqm4mv1", "clefourrier/graphormer-base-pcqm4mv2"]
+)
+
+GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"nvidia/groupvit-gcc-yfcc": "https://huggingface.co/nvidia/groupvit-gcc-yfcc/resolve/main/config.json"}
+)
+
+GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["nvidia/groupvit-gcc-yfcc"])
+
+TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["nvidia/groupvit-gcc-yfcc"])
+
+HUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/hubert-base-ls960": "https://huggingface.co/facebook/hubert-base-ls960/resolve/main/config.json"}
+)
+
+HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/hubert-base-ls960"])
+
+TF_HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/hubert-base-ls960"])
+
+IBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "kssteven/ibert-roberta-base": "https://huggingface.co/kssteven/ibert-roberta-base/resolve/main/config.json",
+ "kssteven/ibert-roberta-large": "https://huggingface.co/kssteven/ibert-roberta-large/resolve/main/config.json",
+ "kssteven/ibert-roberta-large-mnli": "https://huggingface.co/kssteven/ibert-roberta-large-mnli/resolve/main/config.json",
+ }
+)
+
+IBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["kssteven/ibert-roberta-base", "kssteven/ibert-roberta-large", "kssteven/ibert-roberta-large-mnli"]
+)
+
+IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "HuggingFaceM4/idefics-9b": "https://huggingface.co/HuggingFaceM4/idefics-9b/blob/main/config.json",
+ "HuggingFaceM4/idefics-80b": "https://huggingface.co/HuggingFaceM4/idefics-80b/blob/main/config.json",
+ }
+)
+
+IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["HuggingFaceM4/idefics-9b", "HuggingFaceM4/idefics-80b"])
+
+IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"openai/imagegpt-small": "", "openai/imagegpt-medium": "", "openai/imagegpt-large": ""}
+)
+
+IMAGEGPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["openai/imagegpt-small", "openai/imagegpt-medium", "openai/imagegpt-large"]
+)
+
+INFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "huggingface/informer-tourism-monthly": "https://huggingface.co/huggingface/informer-tourism-monthly/resolve/main/config.json"
+ }
+)
+
+INFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["huggingface/informer-tourism-monthly"])
+
+INSTRUCTBLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "Salesforce/instruct-blip-flan-t5": "https://huggingface.co/Salesforce/instruct-blip-flan-t5/resolve/main/config.json"
+ }
+)
+
+INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Salesforce/instructblip-flan-t5-xl"])
+
+JUKEBOX_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "openai/jukebox-5b-lyrics": "https://huggingface.co/openai/jukebox-5b-lyrics/blob/main/config.json",
+ "openai/jukebox-1b-lyrics": "https://huggingface.co/openai/jukebox-1b-lyrics/blob/main/config.json",
+ }
+)
+
+JUKEBOX_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai/jukebox-1b-lyrics", "openai/jukebox-5b-lyrics"])
+
+KOSMOS2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/kosmos-2-patch14-224": "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/config.json"
+ }
+)
+
+KOSMOS2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/kosmos-2-patch14-224"])
+
+LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/layoutlm-base-uncased": "https://huggingface.co/microsoft/layoutlm-base-uncased/resolve/main/config.json",
+ "microsoft/layoutlm-large-uncased": "https://huggingface.co/microsoft/layoutlm-large-uncased/resolve/main/config.json",
+ }
+)
+
+LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["layoutlm-base-uncased", "layoutlm-large-uncased"])
+
+TF_LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/layoutlm-base-uncased", "microsoft/layoutlm-large-uncased"]
+)
+
+LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "layoutlmv2-base-uncased": "https://huggingface.co/microsoft/layoutlmv2-base-uncased/resolve/main/config.json",
+ "layoutlmv2-large-uncased": "https://huggingface.co/microsoft/layoutlmv2-large-uncased/resolve/main/config.json",
+ }
+)
+
+LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/layoutlmv2-base-uncased", "microsoft/layoutlmv2-large-uncased"]
+)
+
+LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/resolve/main/config.json"}
+)
+
+LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/layoutlmv3-base", "microsoft/layoutlmv3-large"])
+
+TF_LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/layoutlmv3-base", "microsoft/layoutlmv3-large"]
+)
+
+LED_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/config.json"}
+)
+
+LED_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["allenai/led-base-16384"])
+
+LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/levit-128S": "https://huggingface.co/facebook/levit-128S/resolve/main/config.json"}
+)
+
+LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/levit-128S"])
+
+LILT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "SCUT-DLVCLab/lilt-roberta-en-base": "https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base/resolve/main/config.json"
+ }
+)
+
+LILT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["SCUT-DLVCLab/lilt-roberta-en-base"])
+
+LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({})
+
+LLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"llava-hf/llava-v1.5-7b": "https://huggingface.co/llava-hf/llava-v1.5-7b/resolve/main/config.json"}
+)
+
+LLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["llava-hf/llava-1.5-7b-hf", "llava-hf/llava-1.5-13b-hf", "llava-hf/bakLlava-v1-hf"]
+)
+
+LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/config.json",
+ "allenai/longformer-large-4096": "https://huggingface.co/allenai/longformer-large-4096/resolve/main/config.json",
+ "allenai/longformer-large-4096-finetuned-triviaqa": "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/config.json",
+ "allenai/longformer-base-4096-extra.pos.embd.only": "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/config.json",
+ "allenai/longformer-large-4096-extra.pos.embd.only": "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/config.json",
+ }
+)
+
+LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "allenai/longformer-base-4096",
+ "allenai/longformer-large-4096",
+ "allenai/longformer-large-4096-finetuned-triviaqa",
+ "allenai/longformer-base-4096-extra.pos.embd.only",
+ "allenai/longformer-large-4096-extra.pos.embd.only",
+ ]
+)
+
+TF_LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "allenai/longformer-base-4096",
+ "allenai/longformer-large-4096",
+ "allenai/longformer-large-4096-finetuned-triviaqa",
+ "allenai/longformer-base-4096-extra.pos.embd.only",
+ "allenai/longformer-large-4096-extra.pos.embd.only",
+ ]
+)
+
+LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/long-t5-local-base": "https://huggingface.co/google/long-t5-local-base/blob/main/config.json",
+ "google/long-t5-local-large": "https://huggingface.co/google/long-t5-local-large/blob/main/config.json",
+ "google/long-t5-tglobal-base": "https://huggingface.co/google/long-t5-tglobal-base/blob/main/config.json",
+ "google/long-t5-tglobal-large": "https://huggingface.co/google/long-t5-tglobal-large/blob/main/config.json",
+ }
+)
+
+LONGT5_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/long-t5-local-base",
+ "google/long-t5-local-large",
+ "google/long-t5-tglobal-base",
+ "google/long-t5-tglobal-large",
+ ]
+)
+
+LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "studio-ousia/luke-base": "https://huggingface.co/studio-ousia/luke-base/resolve/main/config.json",
+ "studio-ousia/luke-large": "https://huggingface.co/studio-ousia/luke-large/resolve/main/config.json",
+ }
+)
+
+LUKE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["studio-ousia/luke-base", "studio-ousia/luke-large"])
+
+LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"unc-nlp/lxmert-base-uncased": "https://huggingface.co/unc-nlp/lxmert-base-uncased/resolve/main/config.json"}
+)
+
+TF_LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["unc-nlp/lxmert-base-uncased"])
+
+M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/m2m100_418M": "https://huggingface.co/facebook/m2m100_418M/resolve/main/config.json"}
+)
+
+M2M_100_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/m2m100_418M"])
+
+MAMBA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"state-spaces/mamba-2.8b": "https://huggingface.co/state-spaces/mamba-2.8b/resolve/main/config.json"}
+)
+
+MAMBA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList([])
+
+MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/config.json",
+ "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/config.json",
+ }
+)
+
+MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/markuplm-base", "microsoft/markuplm-large"])
+
+MASK2FORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/mask2former-swin-small-coco-instance": "https://huggingface.co/facebook/mask2former-swin-small-coco-instance/blob/main/config.json"
+ }
+)
+
+MASK2FORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/mask2former-swin-small-coco-instance"])
+
+MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/maskformer-swin-base-ade": "https://huggingface.co/facebook/maskformer-swin-base-ade/blob/main/config.json"
+ }
+)
+
+MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/maskformer-swin-base-ade"])
+
+MEGA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"mnaylor/mega-base-wikitext": "https://huggingface.co/mnaylor/mega-base-wikitext/resolve/main/config.json"}
+)
+
+MEGA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["mnaylor/mega-base-wikitext"])
+
+MEGATRON_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({})
+
+MEGATRON_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["nvidia/megatron-bert-cased-345m"])
+
+MGP_STR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"alibaba-damo/mgp-str-base": "https://huggingface.co/alibaba-damo/mgp-str-base/resolve/main/config.json"}
+)
+
+MGP_STR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["alibaba-damo/mgp-str-base"])
+
+MISTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "mistralai/Mistral-7B-v0.1": "https://huggingface.co/mistralai/Mistral-7B-v0.1/resolve/main/config.json",
+ "mistralai/Mistral-7B-Instruct-v0.1": "https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1/resolve/main/config.json",
+ }
+)
+
+MIXTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"mistral-ai/Mixtral-8x7B": "https://huggingface.co/mistral-ai/Mixtral-8x7B/resolve/main/config.json"}
+)
+
+MOBILEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/mobilebert-uncased": "https://huggingface.co/google/mobilebert-uncased/resolve/main/config.json"}
+)
+
+MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/mobilebert-uncased"])
+
+TF_MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/mobilebert-uncased"])
+
+MOBILENET_V1_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/mobilenet_v1_1.0_224": "https://huggingface.co/google/mobilenet_v1_1.0_224/resolve/main/config.json",
+ "google/mobilenet_v1_0.75_192": "https://huggingface.co/google/mobilenet_v1_0.75_192/resolve/main/config.json",
+ }
+)
+
+MOBILENET_V1_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google/mobilenet_v1_1.0_224", "google/mobilenet_v1_0.75_192"]
+)
+
+MOBILENET_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/mobilenet_v2_1.4_224": "https://huggingface.co/google/mobilenet_v2_1.4_224/resolve/main/config.json",
+ "google/mobilenet_v2_1.0_224": "https://huggingface.co/google/mobilenet_v2_1.0_224/resolve/main/config.json",
+ "google/mobilenet_v2_0.75_160": "https://huggingface.co/google/mobilenet_v2_0.75_160/resolve/main/config.json",
+ "google/mobilenet_v2_0.35_96": "https://huggingface.co/google/mobilenet_v2_0.35_96/resolve/main/config.json",
+ }
+)
+
+MOBILENET_V2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/mobilenet_v2_1.4_224",
+ "google/mobilenet_v2_1.0_224",
+ "google/mobilenet_v2_0.37_160",
+ "google/mobilenet_v2_0.35_96",
+ ]
+)
+
+MOBILEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "apple/mobilevit-small": "https://huggingface.co/apple/mobilevit-small/resolve/main/config.json",
+ "apple/mobilevit-x-small": "https://huggingface.co/apple/mobilevit-x-small/resolve/main/config.json",
+ "apple/mobilevit-xx-small": "https://huggingface.co/apple/mobilevit-xx-small/resolve/main/config.json",
+ "apple/deeplabv3-mobilevit-small": "https://huggingface.co/apple/deeplabv3-mobilevit-small/resolve/main/config.json",
+ "apple/deeplabv3-mobilevit-x-small": "https://huggingface.co/apple/deeplabv3-mobilevit-x-small/resolve/main/config.json",
+ "apple/deeplabv3-mobilevit-xx-small": "https://huggingface.co/apple/deeplabv3-mobilevit-xx-small/resolve/main/config.json",
+ }
+)
+
+MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "apple/mobilevit-small",
+ "apple/mobilevit-x-small",
+ "apple/mobilevit-xx-small",
+ "apple/deeplabv3-mobilevit-small",
+ "apple/deeplabv3-mobilevit-x-small",
+ "apple/deeplabv3-mobilevit-xx-small",
+ ]
+)
+
+TF_MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "apple/mobilevit-small",
+ "apple/mobilevit-x-small",
+ "apple/mobilevit-xx-small",
+ "apple/deeplabv3-mobilevit-small",
+ "apple/deeplabv3-mobilevit-x-small",
+ "apple/deeplabv3-mobilevit-xx-small",
+ ]
+)
+
+MOBILEVITV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"apple/mobilevitv2-1.0": "https://huggingface.co/apple/mobilevitv2-1.0/resolve/main/config.json"}
+)
+
+MOBILEVITV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["apple/mobilevitv2-1.0-imagenet1k-256"])
+
+MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/config.json"}
+)
+
+MPNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/mpnet-base"])
+
+TF_MPNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/mpnet-base"])
+
+MPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"mosaicml/mpt-7b": "https://huggingface.co/mosaicml/mpt-7b/resolve/main/config.json"}
+)
+
+MPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "mosaicml/mpt-7b",
+ "mosaicml/mpt-7b-storywriter",
+ "mosaicml/mpt-7b-instruct",
+ "mosaicml/mpt-7b-8k",
+ "mosaicml/mpt-7b-8k-instruct",
+ "mosaicml/mpt-7b-8k-chat",
+ "mosaicml/mpt-30b",
+ "mosaicml/mpt-30b-instruct",
+ "mosaicml/mpt-30b-chat",
+ ]
+)
+
+MRA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"uw-madison/mra-base-512-4": "https://huggingface.co/uw-madison/mra-base-512-4/resolve/main/config.json"}
+)
+
+MRA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["uw-madison/mra-base-512-4"])
+
+MUSICGEN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/musicgen-small": "https://huggingface.co/facebook/musicgen-small/resolve/main/config.json"}
+)
+
+MUSICGEN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/musicgen-small"])
+
+MUSICGEN_MELODY_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/musicgen-melody": "https://huggingface.co/facebook/musicgen-melody/resolve/main/config.json"}
+)
+
+MUSICGEN_MELODY_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/musicgen-melody"])
+
+MVP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "RUCAIBox/mvp",
+ "RUCAIBox/mvp-data-to-text",
+ "RUCAIBox/mvp-open-dialog",
+ "RUCAIBox/mvp-question-answering",
+ "RUCAIBox/mvp-question-generation",
+ "RUCAIBox/mvp-story",
+ "RUCAIBox/mvp-summarization",
+ "RUCAIBox/mvp-task-dialog",
+ "RUCAIBox/mtl-data-to-text",
+ "RUCAIBox/mtl-multi-task",
+ "RUCAIBox/mtl-open-dialog",
+ "RUCAIBox/mtl-question-answering",
+ "RUCAIBox/mtl-question-generation",
+ "RUCAIBox/mtl-story",
+ "RUCAIBox/mtl-summarization",
+ ]
+)
+
+NAT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"shi-labs/nat-mini-in1k-224": "https://huggingface.co/shi-labs/nat-mini-in1k-224/resolve/main/config.json"}
+)
+
+NAT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["shi-labs/nat-mini-in1k-224"])
+
+NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"sijunhe/nezha-cn-base": "https://huggingface.co/sijunhe/nezha-cn-base/resolve/main/config.json"}
+)
+
+NEZHA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["sijunhe/nezha-cn-base", "sijunhe/nezha-cn-large", "sijunhe/nezha-base-wwm", "sijunhe/nezha-large-wwm"]
+)
+
+NLLB_MOE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/nllb-moe-54B": "https://huggingface.co/facebook/nllb-moe-54b/resolve/main/config.json"}
+)
+
+NLLB_MOE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/nllb-moe-54b"])
+
+NYSTROMFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"uw-madison/nystromformer-512": "https://huggingface.co/uw-madison/nystromformer-512/resolve/main/config.json"}
+)
+
+NYSTROMFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["uw-madison/nystromformer-512"])
+
+ONEFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "shi-labs/oneformer_ade20k_swin_tiny": "https://huggingface.co/shi-labs/oneformer_ade20k_swin_tiny/blob/main/config.json"
+ }
+)
+
+ONEFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["shi-labs/oneformer_ade20k_swin_tiny"])
+
+OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/config.json"}
+)
+
+OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai-community/openai-gpt"])
+
+TF_OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai-community/openai-gpt"])
+
+OPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "facebook/opt-125m",
+ "facebook/opt-350m",
+ "facebook/opt-1.3b",
+ "facebook/opt-2.7b",
+ "facebook/opt-6.7b",
+ "facebook/opt-13b",
+ "facebook/opt-30b",
+ ]
+)
+
+OWLV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/owlv2-base-patch16": "https://huggingface.co/google/owlv2-base-patch16/resolve/main/config.json"}
+)
+
+OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/owlv2-base-patch16-ensemble"])
+
+OWLVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/owlvit-base-patch32": "https://huggingface.co/google/owlvit-base-patch32/resolve/main/config.json",
+ "google/owlvit-base-patch16": "https://huggingface.co/google/owlvit-base-patch16/resolve/main/config.json",
+ "google/owlvit-large-patch14": "https://huggingface.co/google/owlvit-large-patch14/resolve/main/config.json",
+ }
+)
+
+OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google/owlvit-base-patch32", "google/owlvit-base-patch16", "google/owlvit-large-patch14"]
+)
+
+PATCHTSMIXER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "ibm/patchtsmixer-etth1-pretrain": "https://huggingface.co/ibm/patchtsmixer-etth1-pretrain/resolve/main/config.json"
+ }
+)
+
+PATCHTSMIXER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["ibm/patchtsmixer-etth1-pretrain"])
+
+PATCHTST_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"ibm/patchtst-base": "https://huggingface.co/ibm/patchtst-base/resolve/main/config.json"}
+)
+
+PATCHTST_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["ibm/patchtst-etth1-pretrain"])
+
+PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/pegasus-large": "https://huggingface.co/google/pegasus-large/resolve/main/config.json"}
+)
+
+PEGASUS_X_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/pegasus-x-base": "https://huggingface.co/google/pegasus-x-base/resolve/main/config.json",
+ "google/pegasus-x-large": "https://huggingface.co/google/pegasus-x-large/resolve/main/config.json",
+ }
+)
+
+PEGASUS_X_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/pegasus-x-base", "google/pegasus-x-large"])
+
+PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"deepmind/language-perceiver": "https://huggingface.co/deepmind/language-perceiver/resolve/main/config.json"}
+)
+
+PERCEIVER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["deepmind/language-perceiver"])
+
+PERSIMMON_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"adept/persimmon-8b-base": "https://huggingface.co/adept/persimmon-8b-base/resolve/main/config.json"}
+)
+
+PHI_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/phi-1": "https://huggingface.co/microsoft/phi-1/resolve/main/config.json",
+ "microsoft/phi-1_5": "https://huggingface.co/microsoft/phi-1_5/resolve/main/config.json",
+ "microsoft/phi-2": "https://huggingface.co/microsoft/phi-2/resolve/main/config.json",
+ }
+)
+
+PHI_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/phi-1", "microsoft/phi-1_5", "microsoft/phi-2"])
+
+PIX2STRUCT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/pix2struct-textcaps-base": "https://huggingface.co/google/pix2struct-textcaps-base/resolve/main/config.json"
+ }
+)
+
+PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/pix2struct-textcaps-base",
+ "google/pix2struct-textcaps-large",
+ "google/pix2struct-base",
+ "google/pix2struct-large",
+ "google/pix2struct-ai2d-base",
+ "google/pix2struct-ai2d-large",
+ "google/pix2struct-widget-captioning-base",
+ "google/pix2struct-widget-captioning-large",
+ "google/pix2struct-screen2words-base",
+ "google/pix2struct-screen2words-large",
+ "google/pix2struct-docvqa-base",
+ "google/pix2struct-docvqa-large",
+ "google/pix2struct-ocrvqa-base",
+ "google/pix2struct-ocrvqa-large",
+ "google/pix2struct-chartqa-base",
+ "google/pix2struct-inforgraphics-vqa-base",
+ "google/pix2struct-inforgraphics-vqa-large",
+ ]
+)
+
+PLBART_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"uclanlp/plbart-base": "https://huggingface.co/uclanlp/plbart-base/resolve/main/config.json"}
+)
+
+PLBART_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["uclanlp/plbart-base", "uclanlp/plbart-cs-java", "uclanlp/plbart-multi_task-all"]
+)
+
+POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"sail/poolformer_s12": "https://huggingface.co/sail/poolformer_s12/resolve/main/config.json"}
+)
+
+POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["sail/poolformer_s12"])
+
+POP2PIANO_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"sweetcocoa/pop2piano": "https://huggingface.co/sweetcocoa/pop2piano/blob/main/config.json"}
+)
+
+POP2PIANO_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["sweetcocoa/pop2piano"])
+
+PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/prophetnet-large-uncased": "https://huggingface.co/microsoft/prophetnet-large-uncased/resolve/main/config.json"
+ }
+)
+
+PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/prophetnet-large-uncased"])
+
+PVT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({"pvt-tiny-224": "https://huggingface.co/Zetatech/pvt-tiny-224"})
+
+PVT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Zetatech/pvt-tiny-224"])
+
+QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/config.json"}
+)
+
+QDQBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google-bert/bert-base-uncased"])
+
+QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"Qwen/Qwen2-7B-beta": "https://huggingface.co/Qwen/Qwen2-7B-beta/resolve/main/config.json"}
+)
+
+REALM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/realm-cc-news-pretrained-embedder": "https://huggingface.co/google/realm-cc-news-pretrained-embedder/resolve/main/config.json",
+ "google/realm-cc-news-pretrained-encoder": "https://huggingface.co/google/realm-cc-news-pretrained-encoder/resolve/main/config.json",
+ "google/realm-cc-news-pretrained-scorer": "https://huggingface.co/google/realm-cc-news-pretrained-scorer/resolve/main/config.json",
+ "google/realm-cc-news-pretrained-openqa": "https://huggingface.co/google/realm-cc-news-pretrained-openqa/aresolve/main/config.json",
+ "google/realm-orqa-nq-openqa": "https://huggingface.co/google/realm-orqa-nq-openqa/resolve/main/config.json",
+ "google/realm-orqa-nq-reader": "https://huggingface.co/google/realm-orqa-nq-reader/resolve/main/config.json",
+ "google/realm-orqa-wq-openqa": "https://huggingface.co/google/realm-orqa-wq-openqa/resolve/main/config.json",
+ "google/realm-orqa-wq-reader": "https://huggingface.co/google/realm-orqa-wq-reader/resolve/main/config.json",
+ }
+)
+
+REALM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/realm-cc-news-pretrained-embedder",
+ "google/realm-cc-news-pretrained-encoder",
+ "google/realm-cc-news-pretrained-scorer",
+ "google/realm-cc-news-pretrained-openqa",
+ "google/realm-orqa-nq-openqa",
+ "google/realm-orqa-nq-reader",
+ "google/realm-orqa-wq-openqa",
+ "google/realm-orqa-wq-reader",
+ ]
+)
+
+REFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/reformer-crime-and-punishment": "https://huggingface.co/google/reformer-crime-and-punishment/resolve/main/config.json",
+ "google/reformer-enwik8": "https://huggingface.co/google/reformer-enwik8/resolve/main/config.json",
+ }
+)
+
+REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google/reformer-crime-and-punishment", "google/reformer-enwik8"]
+)
+
+REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/regnet-y-040": "https://huggingface.co/facebook/regnet-y-040/blob/main/config.json"}
+)
+
+REGNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/regnet-y-040"])
+
+TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/regnet-y-040"])
+
+REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/rembert": "https://huggingface.co/google/rembert/resolve/main/config.json"}
+)
+
+REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/rembert"])
+
+TF_REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/rembert"])
+
+RESNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/resnet-50": "https://huggingface.co/microsoft/resnet-50/blob/main/config.json"}
+)
+
+RESNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/resnet-50"])
+
+TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/resnet-50"])
+
+ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/config.json",
+ "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/config.json",
+ "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/config.json",
+ "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/config.json",
+ "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/config.json",
+ "openai-community/roberta-large-openai-detector": "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/config.json",
+ }
+)
+
+ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/roberta-base",
+ "FacebookAI/roberta-large",
+ "FacebookAI/roberta-large-mnli",
+ "distilbert/distilroberta-base",
+ "openai-community/roberta-base-openai-detector",
+ "openai-community/roberta-large-openai-detector",
+ ]
+)
+
+TF_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/roberta-base",
+ "FacebookAI/roberta-large",
+ "FacebookAI/roberta-large-mnli",
+ "distilbert/distilroberta-base",
+ ]
+)
+
+ROBERTA_PRELAYERNORM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "andreasmadsen/efficient_mlm_m0.40": "https://huggingface.co/andreasmadsen/efficient_mlm_m0.40/resolve/main/config.json"
+ }
+)
+
+ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "andreasmadsen/efficient_mlm_m0.15",
+ "andreasmadsen/efficient_mlm_m0.20",
+ "andreasmadsen/efficient_mlm_m0.30",
+ "andreasmadsen/efficient_mlm_m0.40",
+ "andreasmadsen/efficient_mlm_m0.50",
+ "andreasmadsen/efficient_mlm_m0.60",
+ "andreasmadsen/efficient_mlm_m0.70",
+ "andreasmadsen/efficient_mlm_m0.80",
+ ]
+)
+
+TF_ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "andreasmadsen/efficient_mlm_m0.15",
+ "andreasmadsen/efficient_mlm_m0.20",
+ "andreasmadsen/efficient_mlm_m0.30",
+ "andreasmadsen/efficient_mlm_m0.40",
+ "andreasmadsen/efficient_mlm_m0.50",
+ "andreasmadsen/efficient_mlm_m0.60",
+ "andreasmadsen/efficient_mlm_m0.70",
+ "andreasmadsen/efficient_mlm_m0.80",
+ ]
+)
+
+ROC_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"weiweishi/roc-bert-base-zh": "https://huggingface.co/weiweishi/roc-bert-base-zh/resolve/main/config.json"}
+)
+
+ROC_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["weiweishi/roc-bert-base-zh"])
+
+ROFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "junnyu/roformer_chinese_small": "https://huggingface.co/junnyu/roformer_chinese_small/resolve/main/config.json",
+ "junnyu/roformer_chinese_base": "https://huggingface.co/junnyu/roformer_chinese_base/resolve/main/config.json",
+ "junnyu/roformer_chinese_char_small": "https://huggingface.co/junnyu/roformer_chinese_char_small/resolve/main/config.json",
+ "junnyu/roformer_chinese_char_base": "https://huggingface.co/junnyu/roformer_chinese_char_base/resolve/main/config.json",
+ "junnyu/roformer_small_discriminator": "https://huggingface.co/junnyu/roformer_small_discriminator/resolve/main/config.json",
+ "junnyu/roformer_small_generator": "https://huggingface.co/junnyu/roformer_small_generator/resolve/main/config.json",
+ }
+)
+
+ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "junnyu/roformer_chinese_small",
+ "junnyu/roformer_chinese_base",
+ "junnyu/roformer_chinese_char_small",
+ "junnyu/roformer_chinese_char_base",
+ "junnyu/roformer_small_discriminator",
+ "junnyu/roformer_small_generator",
+ ]
+)
+
+TF_ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "junnyu/roformer_chinese_small",
+ "junnyu/roformer_chinese_base",
+ "junnyu/roformer_chinese_char_small",
+ "junnyu/roformer_chinese_char_base",
+ "junnyu/roformer_small_discriminator",
+ "junnyu/roformer_small_generator",
+ ]
+)
+
+RWKV_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "RWKV/rwkv-4-169m-pile": "https://huggingface.co/RWKV/rwkv-4-169m-pile/resolve/main/config.json",
+ "RWKV/rwkv-4-430m-pile": "https://huggingface.co/RWKV/rwkv-4-430m-pile/resolve/main/config.json",
+ "RWKV/rwkv-4-1b5-pile": "https://huggingface.co/RWKV/rwkv-4-1b5-pile/resolve/main/config.json",
+ "RWKV/rwkv-4-3b-pile": "https://huggingface.co/RWKV/rwkv-4-3b-pile/resolve/main/config.json",
+ "RWKV/rwkv-4-7b-pile": "https://huggingface.co/RWKV/rwkv-4-7b-pile/resolve/main/config.json",
+ "RWKV/rwkv-4-14b-pile": "https://huggingface.co/RWKV/rwkv-4-14b-pile/resolve/main/config.json",
+ "RWKV/rwkv-raven-1b5": "https://huggingface.co/RWKV/rwkv-raven-1b5/resolve/main/config.json",
+ "RWKV/rwkv-raven-3b": "https://huggingface.co/RWKV/rwkv-raven-3b/resolve/main/config.json",
+ "RWKV/rwkv-raven-7b": "https://huggingface.co/RWKV/rwkv-raven-7b/resolve/main/config.json",
+ "RWKV/rwkv-raven-14b": "https://huggingface.co/RWKV/rwkv-raven-14b/resolve/main/config.json",
+ }
+)
+
+RWKV_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "RWKV/rwkv-4-169m-pile",
+ "RWKV/rwkv-4-430m-pile",
+ "RWKV/rwkv-4-1b5-pile",
+ "RWKV/rwkv-4-3b-pile",
+ "RWKV/rwkv-4-7b-pile",
+ "RWKV/rwkv-4-14b-pile",
+ "RWKV/rwkv-raven-1b5",
+ "RWKV/rwkv-raven-3b",
+ "RWKV/rwkv-raven-7b",
+ "RWKV/rwkv-raven-14b",
+ ]
+)
+
+SAM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/sam-vit-huge": "https://huggingface.co/facebook/sam-vit-huge/resolve/main/config.json",
+ "facebook/sam-vit-large": "https://huggingface.co/facebook/sam-vit-large/resolve/main/config.json",
+ "facebook/sam-vit-base": "https://huggingface.co/facebook/sam-vit-base/resolve/main/config.json",
+ }
+)
+
+SAM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/sam-vit-huge", "facebook/sam-vit-large", "facebook/sam-vit-base"]
+)
+
+TF_SAM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["facebook/sam-vit-huge", "facebook/sam-vit-large", "facebook/sam-vit-base"]
+)
+
+SEAMLESS_M4T_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/hf-seamless-m4t-medium": "https://huggingface.co/facebook/hf-seamless-m4t-medium/resolve/main/config.json"
+ }
+)
+
+SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/hf-seamless-m4t-medium"])
+
+SEAMLESS_M4T_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"": "https://huggingface.co//resolve/main/config.json"}
+)
+
+SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/seamless-m4t-v2-large"])
+
+SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "nvidia/segformer-b0-finetuned-ade-512-512": "https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512/resolve/main/config.json"
+ }
+)
+
+SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["nvidia/segformer-b0-finetuned-ade-512-512"])
+
+TF_SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["nvidia/segformer-b0-finetuned-ade-512-512"])
+
+SEGGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"BAAI/seggpt-vit-large": "https://huggingface.co/BAAI/seggpt-vit-large/resolve/main/config.json"}
+)
+
+SEGGPT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["BAAI/seggpt-vit-large"])
+
+SEW_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"asapp/sew-tiny-100k": "https://huggingface.co/asapp/sew-tiny-100k/resolve/main/config.json"}
+)
+
+SEW_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["asapp/sew-tiny-100k", "asapp/sew-small-100k", "asapp/sew-mid-100k"]
+)
+
+SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"asapp/sew-d-tiny-100k": "https://huggingface.co/asapp/sew-d-tiny-100k/resolve/main/config.json"}
+)
+
+SEW_D_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "asapp/sew-d-tiny-100k",
+ "asapp/sew-d-small-100k",
+ "asapp/sew-d-mid-100k",
+ "asapp/sew-d-mid-k127-100k",
+ "asapp/sew-d-base-100k",
+ "asapp/sew-d-base-plus-100k",
+ "asapp/sew-d-mid-400k",
+ "asapp/sew-d-mid-k127-400k",
+ "asapp/sew-d-base-plus-400k",
+ ]
+)
+
+SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/config.json"
+ }
+)
+
+SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/siglip-base-patch16-224"])
+
+SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/s2t-small-librispeech-asr": "https://huggingface.co/facebook/s2t-small-librispeech-asr/resolve/main/config.json"
+ }
+)
+
+SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/s2t-small-librispeech-asr"])
+
+TF_SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/s2t-small-librispeech-asr"])
+
+SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/s2t-wav2vec2-large-en-de": "https://huggingface.co/facebook/s2t-wav2vec2-large-en-de/resolve/main/config.json"
+ }
+)
+
+SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/speecht5_asr": "https://huggingface.co/microsoft/speecht5_asr/resolve/main/config.json",
+ "microsoft/speecht5_tts": "https://huggingface.co/microsoft/speecht5_tts/resolve/main/config.json",
+ "microsoft/speecht5_vc": "https://huggingface.co/microsoft/speecht5_vc/resolve/main/config.json",
+ }
+)
+
+SPEECHT5_PRETRAINED_HIFIGAN_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/speecht5_hifigan": "https://huggingface.co/microsoft/speecht5_hifigan/resolve/main/config.json"}
+)
+
+SPEECHT5_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/speecht5_asr", "microsoft/speecht5_tts", "microsoft/speecht5_vc"]
+)
+
+SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "tau/splinter-base": "https://huggingface.co/tau/splinter-base/resolve/main/config.json",
+ "tau/splinter-base-qass": "https://huggingface.co/tau/splinter-base-qass/resolve/main/config.json",
+ "tau/splinter-large": "https://huggingface.co/tau/splinter-large/resolve/main/config.json",
+ "tau/splinter-large-qass": "https://huggingface.co/tau/splinter-large-qass/resolve/main/config.json",
+ }
+)
+
+SPLINTER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["tau/splinter-base", "tau/splinter-base-qass", "tau/splinter-large", "tau/splinter-large-qass"]
+)
+
+SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "squeezebert/squeezebert-uncased": "https://huggingface.co/squeezebert/squeezebert-uncased/resolve/main/config.json",
+ "squeezebert/squeezebert-mnli": "https://huggingface.co/squeezebert/squeezebert-mnli/resolve/main/config.json",
+ "squeezebert/squeezebert-mnli-headless": "https://huggingface.co/squeezebert/squeezebert-mnli-headless/resolve/main/config.json",
+ }
+)
+
+SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["squeezebert/squeezebert-uncased", "squeezebert/squeezebert-mnli", "squeezebert/squeezebert-mnli-headless"]
+)
+
+STABLELM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"stabilityai/stablelm-3b-4e1t": "https://huggingface.co/stabilityai/stablelm-3b-4e1t/resolve/main/config.json"}
+)
+
+STARCODER2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict({})
+
+SWIFTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"MBZUAI/swiftformer-xs": "https://huggingface.co/MBZUAI/swiftformer-xs/resolve/main/config.json"}
+)
+
+SWIFTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["MBZUAI/swiftformer-xs"])
+
+SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/swin-tiny-patch4-window7-224": "https://huggingface.co/microsoft/swin-tiny-patch4-window7-224/resolve/main/config.json"
+ }
+)
+
+SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/swin-tiny-patch4-window7-224"])
+
+TF_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/swin-tiny-patch4-window7-224"])
+
+SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "caidas/swin2sr-classicalsr-x2-64": "https://huggingface.co/caidas/swin2sr-classicalsr-x2-64/resolve/main/config.json"
+ }
+)
+
+SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["caidas/swin2SR-classical-sr-x2-64"])
+
+SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/swinv2-tiny-patch4-window8-256": "https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256/resolve/main/config.json"
+ }
+)
+
+SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/swinv2-tiny-patch4-window8-256"])
+
+SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/switch-base-8": "https://huggingface.co/google/switch-base-8/blob/main/config.json"}
+)
+
+SWITCH_TRANSFORMERS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/switch-base-8",
+ "google/switch-base-16",
+ "google/switch-base-32",
+ "google/switch-base-64",
+ "google/switch-base-128",
+ "google/switch-base-256",
+ "google/switch-large-128",
+ "google/switch-xxl-128",
+ "google/switch-c-2048",
+ ]
+)
+
+T5_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google-t5/t5-small": "https://huggingface.co/google-t5/t5-small/resolve/main/config.json",
+ "google-t5/t5-base": "https://huggingface.co/google-t5/t5-base/resolve/main/config.json",
+ "google-t5/t5-large": "https://huggingface.co/google-t5/t5-large/resolve/main/config.json",
+ "google-t5/t5-3b": "https://huggingface.co/google-t5/t5-3b/resolve/main/config.json",
+ "google-t5/t5-11b": "https://huggingface.co/google-t5/t5-11b/resolve/main/config.json",
+ }
+)
+
+T5_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google-t5/t5-small", "google-t5/t5-base", "google-t5/t5-large", "google-t5/t5-3b", "google-t5/t5-11b"]
+)
+
+TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["google-t5/t5-small", "google-t5/t5-base", "google-t5/t5-large", "google-t5/t5-3b", "google-t5/t5-11b"]
+)
+
+TABLE_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/table-transformer-detection": "https://huggingface.co/microsoft/table-transformer-detection/resolve/main/config.json"
+ }
+)
+
+TABLE_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/table-transformer-detection"])
+
+TAPAS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/tapas-base-finetuned-sqa": "https://huggingface.co/google/tapas-base-finetuned-sqa/resolve/main/config.json",
+ "google/tapas-base-finetuned-wtq": "https://huggingface.co/google/tapas-base-finetuned-wtq/resolve/main/config.json",
+ "google/tapas-base-finetuned-wikisql-supervised": "https://huggingface.co/google/tapas-base-finetuned-wikisql-supervised/resolve/main/config.json",
+ "google/tapas-base-finetuned-tabfact": "https://huggingface.co/google/tapas-base-finetuned-tabfact/resolve/main/config.json",
+ }
+)
+
+TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/tapas-large",
+ "google/tapas-large-finetuned-sqa",
+ "google/tapas-large-finetuned-wtq",
+ "google/tapas-large-finetuned-wikisql-supervised",
+ "google/tapas-large-finetuned-tabfact",
+ "google/tapas-base",
+ "google/tapas-base-finetuned-sqa",
+ "google/tapas-base-finetuned-wtq",
+ "google/tapas-base-finetuned-wikisql-supervised",
+ "google/tapas-base-finetuned-tabfact",
+ "google/tapas-small",
+ "google/tapas-small-finetuned-sqa",
+ "google/tapas-small-finetuned-wtq",
+ "google/tapas-small-finetuned-wikisql-supervised",
+ "google/tapas-small-finetuned-tabfact",
+ "google/tapas-mini",
+ "google/tapas-mini-finetuned-sqa",
+ "google/tapas-mini-finetuned-wtq",
+ "google/tapas-mini-finetuned-wikisql-supervised",
+ "google/tapas-mini-finetuned-tabfact",
+ "google/tapas-tiny",
+ "google/tapas-tiny-finetuned-sqa",
+ "google/tapas-tiny-finetuned-wtq",
+ "google/tapas-tiny-finetuned-wikisql-supervised",
+ "google/tapas-tiny-finetuned-tabfact",
+ ]
+)
+
+TF_TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "google/tapas-large",
+ "google/tapas-large-finetuned-sqa",
+ "google/tapas-large-finetuned-wtq",
+ "google/tapas-large-finetuned-wikisql-supervised",
+ "google/tapas-large-finetuned-tabfact",
+ "google/tapas-base",
+ "google/tapas-base-finetuned-sqa",
+ "google/tapas-base-finetuned-wtq",
+ "google/tapas-base-finetuned-wikisql-supervised",
+ "google/tapas-base-finetuned-tabfact",
+ "google/tapas-small",
+ "google/tapas-small-finetuned-sqa",
+ "google/tapas-small-finetuned-wtq",
+ "google/tapas-small-finetuned-wikisql-supervised",
+ "google/tapas-small-finetuned-tabfact",
+ "google/tapas-mini",
+ "google/tapas-mini-finetuned-sqa",
+ "google/tapas-mini-finetuned-wtq",
+ "google/tapas-mini-finetuned-wikisql-supervised",
+ "google/tapas-mini-finetuned-tabfact",
+ "google/tapas-tiny",
+ "google/tapas-tiny-finetuned-sqa",
+ "google/tapas-tiny-finetuned-wtq",
+ "google/tapas-tiny-finetuned-wikisql-supervised",
+ "google/tapas-tiny-finetuned-tabfact",
+ ]
+)
+
+TIME_SERIES_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "huggingface/time-series-transformer-tourism-monthly": "https://huggingface.co/huggingface/time-series-transformer-tourism-monthly/resolve/main/config.json"
+ }
+)
+
+TIME_SERIES_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["huggingface/time-series-transformer-tourism-monthly"]
+)
+
+TIMESFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/timesformer": "https://huggingface.co/facebook/timesformer/resolve/main/config.json"}
+)
+
+TIMESFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/timesformer-base-finetuned-k400"])
+
+TROCR_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/trocr-base-handwritten": "https://huggingface.co/microsoft/trocr-base-handwritten/resolve/main/config.json"
+ }
+)
+
+TROCR_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/trocr-base-handwritten"])
+
+TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"ZinengTang/tvlt-base": "https://huggingface.co/ZinengTang/tvlt-base/blob/main/config.json"}
+)
+
+TVLT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["ZinengTang/tvlt-base"])
+
+TVP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"Intel/tvp-base": "https://huggingface.co/Intel/tvp-base/resolve/main/config.json"}
+)
+
+TVP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["Intel/tvp-base", "Intel/tvp-base-ANet"])
+
+UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/config.json"}
+)
+
+UDOP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/udop-large"])
+
+UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/unispeech-large-1500h-cv": "https://huggingface.co/microsoft/unispeech-large-1500h-cv/resolve/main/config.json"
+ }
+)
+
+UNISPEECH_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/unispeech-large-1500h-cv", "microsoft/unispeech-large-multi-lingual-1500h-cv"]
+)
+
+UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/unispeech-sat-base-100h-libri-ft": "https://huggingface.co/microsoft/unispeech-sat-base-100h-libri-ft/resolve/main/config.json"
+ }
+)
+
+UNISPEECH_SAT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList([])
+
+UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"dg845/univnet-dev": "https://huggingface.co/dg845/univnet-dev/resolve/main/config.json"}
+)
+
+UNIVNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["dg845/univnet-dev"])
+
+VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"MCG-NJU/videomae-base": "https://huggingface.co/MCG-NJU/videomae-base/resolve/main/config.json"}
+)
+
+VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["MCG-NJU/videomae-base"])
+
+VILT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"dandelin/vilt-b32-mlm": "https://huggingface.co/dandelin/vilt-b32-mlm/blob/main/config.json"}
+)
+
+VILT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["dandelin/vilt-b32-mlm"])
+
+VIPLLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"ybelkada/vip-llava-7b-hf": "https://huggingface.co/llava-hf/vip-llava-7b-hf/resolve/main/config.json"}
+)
+
+VIPLLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["llava-hf/vip-llava-7b-hf"])
+
+VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "uclanlp/visualbert-vqa": "https://huggingface.co/uclanlp/visualbert-vqa/resolve/main/config.json",
+ "uclanlp/visualbert-vqa-pre": "https://huggingface.co/uclanlp/visualbert-vqa-pre/resolve/main/config.json",
+ "uclanlp/visualbert-vqa-coco-pre": "https://huggingface.co/uclanlp/visualbert-vqa-coco-pre/resolve/main/config.json",
+ "uclanlp/visualbert-vcr": "https://huggingface.co/uclanlp/visualbert-vcr/resolve/main/config.json",
+ "uclanlp/visualbert-vcr-pre": "https://huggingface.co/uclanlp/visualbert-vcr-pre/resolve/main/config.json",
+ "uclanlp/visualbert-vcr-coco-pre": "https://huggingface.co/uclanlp/visualbert-vcr-coco-pre/resolve/main/config.json",
+ "uclanlp/visualbert-nlvr2": "https://huggingface.co/uclanlp/visualbert-nlvr2/resolve/main/config.json",
+ "uclanlp/visualbert-nlvr2-pre": "https://huggingface.co/uclanlp/visualbert-nlvr2-pre/resolve/main/config.json",
+ "uclanlp/visualbert-nlvr2-coco-pre": "https://huggingface.co/uclanlp/visualbert-nlvr2-coco-pre/resolve/main/config.json",
+ }
+)
+
+VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "uclanlp/visualbert-vqa",
+ "uclanlp/visualbert-vqa-pre",
+ "uclanlp/visualbert-vqa-coco-pre",
+ "uclanlp/visualbert-vcr",
+ "uclanlp/visualbert-vcr-pre",
+ "uclanlp/visualbert-vcr-coco-pre",
+ "uclanlp/visualbert-nlvr2",
+ "uclanlp/visualbert-nlvr2-pre",
+ "uclanlp/visualbert-nlvr2-coco-pre",
+ ]
+)
+
+VIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/vit-base-patch16-224": "https://huggingface.co/vit-base-patch16-224/resolve/main/config.json"}
+)
+
+VIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/vit-base-patch16-224"])
+
+VIT_HYBRID_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"google/vit-hybrid-base-bit-384": "https://huggingface.co/vit-hybrid-base-bit-384/resolve/main/config.json"}
+)
+
+VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/vit-hybrid-base-bit-384"])
+
+VIT_MAE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/vit-mae-base": "https://huggingface.co/facebook/vit-mae-base/resolve/main/config.json"}
+)
+
+VIT_MAE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/vit-mae-base"])
+
+VIT_MSN_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"sayakpaul/vit-msn-base": "https://huggingface.co/sayakpaul/vit-msn-base/resolve/main/config.json"}
+)
+
+VIT_MSN_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/vit-msn-small"])
+
+VITDET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/vit-det-base": "https://huggingface.co/facebook/vit-det-base/resolve/main/config.json"}
+)
+
+VITDET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/vit-det-base"])
+
+VITMATTE_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "hustvl/vitmatte-small-composition-1k": "https://huggingface.co/hustvl/vitmatte-small-composition-1k/resolve/main/config.json"
+ }
+)
+
+VITMATTE_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["hustvl/vitmatte-small-composition-1k"])
+
+VITS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/mms-tts-eng": "https://huggingface.co/facebook/mms-tts-eng/resolve/main/config.json"}
+)
+
+VITS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/mms-tts-eng"])
+
+VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "google/vivit-b-16x2-kinetics400": "https://huggingface.co/google/vivit-b-16x2-kinetics400/resolve/main/config.json"
+ }
+)
+
+VIVIT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["google/vivit-b-16x2-kinetics400"])
+
+WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/wav2vec2-base-960h": "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/config.json"}
+)
+
+WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "facebook/wav2vec2-base-960h",
+ "facebook/wav2vec2-large-960h",
+ "facebook/wav2vec2-large-960h-lv60",
+ "facebook/wav2vec2-large-960h-lv60-self",
+ ]
+)
+
+TF_WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "facebook/wav2vec2-base-960h",
+ "facebook/wav2vec2-large-960h",
+ "facebook/wav2vec2-large-960h-lv60",
+ "facebook/wav2vec2-large-960h-lv60-self",
+ ]
+)
+
+WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/w2v-bert-2.0": "https://huggingface.co/facebook/w2v-bert-2.0/resolve/main/config.json"}
+)
+
+WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/w2v-bert-2.0"])
+
+WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/wav2vec2-conformer-rel-pos-large": "https://huggingface.co/facebook/wav2vec2-conformer-rel-pos-large/resolve/main/config.json"
+ }
+)
+
+WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/wav2vec2-conformer-rel-pos-large"])
+
+WAVLM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/wavlm-base": "https://huggingface.co/microsoft/wavlm-base/resolve/main/config.json"}
+)
+
+WAVLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["microsoft/wavlm-base", "microsoft/wavlm-base-plus", "microsoft/wavlm-large"]
+)
+
+WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/config.json"}
+)
+
+WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai/whisper-base"])
+
+TF_WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["openai/whisper-base"])
+
+XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"microsoft/xclip-base-patch32": "https://huggingface.co/microsoft/xclip-base-patch32/resolve/main/config.json"}
+)
+
+XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/xclip-base-patch32"])
+
+XGLM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"facebook/xglm-564M": "https://huggingface.co/facebook/xglm-564M/resolve/main/config.json"}
+)
+
+XGLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/xglm-564M"])
+
+TF_XGLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/xglm-564M"])
+
+XLM_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "FacebookAI/xlm-mlm-en-2048": "https://huggingface.co/FacebookAI/xlm-mlm-en-2048/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-ende-1024": "https://huggingface.co/FacebookAI/xlm-mlm-ende-1024/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enfr-1024/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-enro-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enro-1024/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-tlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-tlm-xnli15-1024/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-xnli15-1024/resolve/main/config.json",
+ "FacebookAI/xlm-clm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-clm-enfr-1024/resolve/main/config.json",
+ "FacebookAI/xlm-clm-ende-1024": "https://huggingface.co/FacebookAI/xlm-clm-ende-1024/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-17-1280": "https://huggingface.co/FacebookAI/xlm-mlm-17-1280/resolve/main/config.json",
+ "FacebookAI/xlm-mlm-100-1280": "https://huggingface.co/FacebookAI/xlm-mlm-100-1280/resolve/main/config.json",
+ }
+)
+
+XLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/xlm-mlm-en-2048",
+ "FacebookAI/xlm-mlm-ende-1024",
+ "FacebookAI/xlm-mlm-enfr-1024",
+ "FacebookAI/xlm-mlm-enro-1024",
+ "FacebookAI/xlm-mlm-tlm-xnli15-1024",
+ "FacebookAI/xlm-mlm-xnli15-1024",
+ "FacebookAI/xlm-clm-enfr-1024",
+ "FacebookAI/xlm-clm-ende-1024",
+ "FacebookAI/xlm-mlm-17-1280",
+ "FacebookAI/xlm-mlm-100-1280",
+ ]
+)
+
+TF_XLM_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/xlm-mlm-en-2048",
+ "FacebookAI/xlm-mlm-ende-1024",
+ "FacebookAI/xlm-mlm-enfr-1024",
+ "FacebookAI/xlm-mlm-enro-1024",
+ "FacebookAI/xlm-mlm-tlm-xnli15-1024",
+ "FacebookAI/xlm-mlm-xnli15-1024",
+ "FacebookAI/xlm-clm-enfr-1024",
+ "FacebookAI/xlm-clm-ende-1024",
+ "FacebookAI/xlm-mlm-17-1280",
+ "FacebookAI/xlm-mlm-100-1280",
+ ]
+)
+
+XLM_PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "microsoft/xprophetnet-large-wiki100-cased": "https://huggingface.co/microsoft/xprophetnet-large-wiki100-cased/resolve/main/config.json"
+ }
+)
+
+XLM_PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["microsoft/xprophetnet-large-wiki100-cased"])
+
+XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "FacebookAI/xlm-roberta-base": "https://huggingface.co/FacebookAI/xlm-roberta-base/resolve/main/config.json",
+ "FacebookAI/xlm-roberta-large": "https://huggingface.co/FacebookAI/xlm-roberta-large/resolve/main/config.json",
+ "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-dutch/resolve/main/config.json",
+ "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-spanish/resolve/main/config.json",
+ "FacebookAI/xlm-roberta-large-finetuned-conll03-english": "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-english/resolve/main/config.json",
+ "FacebookAI/xlm-roberta-large-finetuned-conll03-german": "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-german/resolve/main/config.json",
+ }
+)
+
+XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/xlm-roberta-base",
+ "FacebookAI/xlm-roberta-large",
+ "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch",
+ "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish",
+ "FacebookAI/xlm-roberta-large-finetuned-conll03-english",
+ "FacebookAI/xlm-roberta-large-finetuned-conll03-german",
+ ]
+)
+
+TF_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "FacebookAI/xlm-roberta-base",
+ "FacebookAI/xlm-roberta-large",
+ "joeddav/xlm-roberta-large-xnli",
+ "cardiffnlp/twitter-xlm-roberta-base-sentiment",
+ ]
+)
+
+FLAX_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ ["FacebookAI/xlm-roberta-base", "FacebookAI/xlm-roberta-large"]
+)
+
+XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/xlm-roberta-xl": "https://huggingface.co/facebook/xlm-roberta-xl/resolve/main/config.json",
+ "facebook/xlm-roberta-xxl": "https://huggingface.co/facebook/xlm-roberta-xxl/resolve/main/config.json",
+ }
+)
+
+XLM_ROBERTA_XL_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["facebook/xlm-roberta-xl", "facebook/xlm-roberta-xxl"])
+
+XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "xlnet/xlnet-base-cased": "https://huggingface.co/xlnet/xlnet-base-cased/resolve/main/config.json",
+ "xlnet/xlnet-large-cased": "https://huggingface.co/xlnet/xlnet-large-cased/resolve/main/config.json",
+ }
+)
+
+XLNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["xlnet/xlnet-base-cased", "xlnet/xlnet-large-cased"])
+
+TF_XLNET_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["xlnet/xlnet-base-cased", "xlnet/xlnet-large-cased"])
+
+XMOD_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {
+ "facebook/xmod-base": "https://huggingface.co/facebook/xmod-base/resolve/main/config.json",
+ "facebook/xmod-large-prenorm": "https://huggingface.co/facebook/xmod-large-prenorm/resolve/main/config.json",
+ "facebook/xmod-base-13-125k": "https://huggingface.co/facebook/xmod-base-13-125k/resolve/main/config.json",
+ "facebook/xmod-base-30-125k": "https://huggingface.co/facebook/xmod-base-30-125k/resolve/main/config.json",
+ "facebook/xmod-base-30-195k": "https://huggingface.co/facebook/xmod-base-30-195k/resolve/main/config.json",
+ "facebook/xmod-base-60-125k": "https://huggingface.co/facebook/xmod-base-60-125k/resolve/main/config.json",
+ "facebook/xmod-base-60-265k": "https://huggingface.co/facebook/xmod-base-60-265k/resolve/main/config.json",
+ "facebook/xmod-base-75-125k": "https://huggingface.co/facebook/xmod-base-75-125k/resolve/main/config.json",
+ "facebook/xmod-base-75-269k": "https://huggingface.co/facebook/xmod-base-75-269k/resolve/main/config.json",
+ }
+)
+
+XMOD_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(
+ [
+ "facebook/xmod-base",
+ "facebook/xmod-large-prenorm",
+ "facebook/xmod-base-13-125k",
+ "facebook/xmod-base-30-125k",
+ "facebook/xmod-base-30-195k",
+ "facebook/xmod-base-60-125k",
+ "facebook/xmod-base-60-265k",
+ "facebook/xmod-base-75-125k",
+ "facebook/xmod-base-75-269k",
+ ]
+)
+
+YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"hustvl/yolos-small": "https://huggingface.co/hustvl/yolos-small/resolve/main/config.json"}
+)
+
+YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["hustvl/yolos-small"])
+
+YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP = DeprecatedDict(
+ {"uw-madison/yoso-4096": "https://huggingface.co/uw-madison/yoso-4096/resolve/main/config.json"}
+)
+
+YOSO_PRETRAINED_MODEL_ARCHIVE_LIST = DeprecatedList(["uw-madison/yoso-4096"])
+
+
+CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
+ [
+ # Add archive maps here)
+ ("albert", "ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("align", "ALIGN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("altclip", "ALTCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("audio-spectrogram-transformer", "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("autoformer", "AUTOFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bark", "BARK_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bart", "BART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("beit", "BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bert", "BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("big_bird", "BIG_BIRD_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bigbird_pegasus", "BIGBIRD_PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("biogpt", "BIOGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bit", "BIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("blenderbot", "BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("blenderbot-small", "BLENDERBOT_SMALL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("blip", "BLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("blip-2", "BLIP_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bloom", "BLOOM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bridgetower", "BRIDGETOWER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("bros", "BROS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("camembert", "CAMEMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("canine", "CANINE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("chinese_clip", "CHINESE_CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("clap", "CLAP_PRETRAINED_MODEL_ARCHIVE_LIST"),
+ ("clip", "CLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("clipseg", "CLIPSEG_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("clvp", "CLVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("codegen", "CODEGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("conditional_detr", "CONDITIONAL_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("convbert", "CONVBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("convnext", "CONVNEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("convnextv2", "CONVNEXTV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("cpmant", "CPMANT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("ctrl", "CTRL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("cvt", "CVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("data2vec-audio", "DATA2VEC_AUDIO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("data2vec-text", "DATA2VEC_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("data2vec-vision", "DATA2VEC_VISION_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("deberta", "DEBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("deberta-v2", "DEBERTA_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("deformable_detr", "DEFORMABLE_DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("deit", "DEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("depth_anything", "DEPTH_ANYTHING_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("deta", "DETA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("detr", "DETR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("dinat", "DINAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("dinov2", "DINOV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("distilbert", "DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("donut-swin", "DONUT_SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("dpr", "DPR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("dpt", "DPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("efficientformer", "EFFICIENTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("efficientnet", "EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("electra", "ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("encodec", "ENCODEC_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("ernie", "ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("ernie_m", "ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("esm", "ESM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("falcon", "FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("fastspeech2_conformer", "FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("flaubert", "FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("flava", "FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("fnet", "FNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("focalnet", "FOCALNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("fsmt", "FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("funnel", "FUNNEL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("fuyu", "FUYU_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gemma", "GEMMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("git", "GIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("glpn", "GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gpt2", "GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gpt_bigcode", "GPT_BIGCODE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gpt_neo", "GPT_NEO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gpt_neox", "GPT_NEOX_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gpt_neox_japanese", "GPT_NEOX_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gptj", "GPTJ_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("gptsan-japanese", "GPTSAN_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("graphormer", "GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("groupvit", "GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("hubert", "HUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("ibert", "IBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("idefics", "IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("imagegpt", "IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("informer", "INFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("instructblip", "INSTRUCTBLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("jukebox", "JUKEBOX_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("kosmos-2", "KOSMOS2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("layoutlm", "LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("layoutlmv2", "LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("layoutlmv3", "LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("led", "LED_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("levit", "LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("lilt", "LILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("llama", "LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("llava", "LLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("longformer", "LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("longt5", "LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("luke", "LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("lxmert", "LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("m2m_100", "M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mamba", "MAMBA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("markuplm", "MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mask2former", "MASK2FORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("maskformer", "MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mbart", "MBART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mctct", "MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mega", "MEGA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("megatron-bert", "MEGATRON_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mgp-str", "MGP_STR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mistral", "MISTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mixtral", "MIXTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mobilenet_v1", "MOBILENET_V1_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mobilenet_v2", "MOBILENET_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mobilevit", "MOBILEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mobilevitv2", "MOBILEVITV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mpnet", "MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mpt", "MPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mra", "MRA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("musicgen", "MUSICGEN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("mvp", "MVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("nat", "NAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("nezha", "NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("nllb-moe", "NLLB_MOE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("nystromformer", "NYSTROMFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("oneformer", "ONEFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("open-llama", "OPEN_LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("openai-gpt", "OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("opt", "OPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("owlv2", "OWLV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("owlvit", "OWLVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("patchtsmixer", "PATCHTSMIXER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("patchtst", "PATCHTST_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("pegasus", "PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("pegasus_x", "PEGASUS_X_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("perceiver", "PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("persimmon", "PERSIMMON_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("phi", "PHI_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("pix2struct", "PIX2STRUCT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("plbart", "PLBART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("poolformer", "POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("pop2piano", "POP2PIANO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("prophetnet", "PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("pvt", "PVT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("qdqbert", "QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("qwen2", "QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("realm", "REALM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("regnet", "REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("rembert", "REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("resnet", "RESNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("retribert", "RETRIBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("roberta", "ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("roberta-prelayernorm", "ROBERTA_PRELAYERNORM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("roc_bert", "ROC_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("roformer", "ROFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("rwkv", "RWKV_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("sam", "SAM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("seamless_m4t", "SEAMLESS_M4T_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("seamless_m4t_v2", "SEAMLESS_M4T_V2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("segformer", "SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("seggpt", "SEGGPT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("sew", "SEW_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("sew-d", "SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("siglip", "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("speech_to_text", "SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("speech_to_text_2", "SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("speecht5", "SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("splinter", "SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("squeezebert", "SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("stablelm", "STABLELM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("starcoder2", "STARCODER2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swiftformer", "SWIFTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swin", "SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swin2sr", "SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("swinv2", "SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("switch_transformers", "SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("t5", "T5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("table-transformer", "TABLE_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("tapas", "TAPAS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("time_series_transformer", "TIME_SERIES_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("timesformer", "TIMESFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("transfo-xl", "TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("tvlt", "TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("tvp", "TVP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("udop", "UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("univnet", "UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("van", "VAN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("videomae", "VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vipllava", "VIPLLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("visual_bert", "VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vit", "VIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vit_hybrid", "VIT_HYBRID_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vit_mae", "VIT_MAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vit_msn", "VIT_MSN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vitdet", "VITDET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vitmatte", "VITMATTE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vits", "VITS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("vivit", "VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("wav2vec2", "WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("wav2vec2-bert", "WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("wav2vec2-conformer", "WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("whisper", "WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xclip", "XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xglm", "XGLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xlm", "XLM_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xlm-prophetnet", "XLM_PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xlm-roberta", "XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xlnet", "XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("xmod", "XMOD_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("yolos", "YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("yoso", "YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ]
+)
diff --git a/src/transformers/models/deprecated/mctct/configuration_mctct.py b/src/transformers/models/deprecated/mctct/configuration_mctct.py
index 9d4eab0d3f3d4a..6546b18eab0522 100644
--- a/src/transformers/models/deprecated/mctct/configuration_mctct.py
+++ b/src/transformers/models/deprecated/mctct/configuration_mctct.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "speechbrain/m-ctc-t-large": "https://huggingface.co/speechbrain/m-ctc-t-large/resolve/main/config.json",
- # See all M-CTC-T models at https://huggingface.co/models?filter=mctct
-}
+
+from .._archive_maps import MCTCT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MCTCTConfig(PretrainedConfig):
diff --git a/src/transformers/models/deprecated/mctct/modeling_mctct.py b/src/transformers/models/deprecated/mctct/modeling_mctct.py
index cb3186c9dd37b8..2d9ef6cf724c28 100755
--- a/src/transformers/models/deprecated/mctct/modeling_mctct.py
+++ b/src/transformers/models/deprecated/mctct/modeling_mctct.py
@@ -52,10 +52,7 @@
_CTC_EXPECTED_LOSS = 1885.65
-MCTCT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "speechbrain/m-ctc-t-large",
- # See all M-CTC-T models at https://huggingface.co/models?filter=mctct
-]
+from .._archive_maps import MCTCT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class MCTCTConv1dSubsampler(nn.Module):
diff --git a/src/transformers/models/deprecated/open_llama/configuration_open_llama.py b/src/transformers/models/deprecated/open_llama/configuration_open_llama.py
index 5786abac850dd3..0111e031251a2c 100644
--- a/src/transformers/models/deprecated/open_llama/configuration_open_llama.py
+++ b/src/transformers/models/deprecated/open_llama/configuration_open_llama.py
@@ -25,9 +25,8 @@
logger = logging.get_logger(__name__)
-OPEN_LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "s-JoL/Open-Llama-V1": "https://huggingface.co/s-JoL/Open-Llama-V1/blob/main/config.json",
-}
+
+from .._archive_maps import OPEN_LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class OpenLlamaConfig(PretrainedConfig):
@@ -67,6 +66,8 @@ class OpenLlamaConfig(PretrainedConfig):
relevant if `config.is_decoder=True`.
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
rope_scaling (`Dict`, *optional*):
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
@@ -114,6 +115,7 @@ def __init__(
attention_dropout_prob=0.1,
use_stable_embedding=True,
shared_input_output_embedding=True,
+ rope_theta=10000.0,
rope_scaling=None,
**kwargs,
):
@@ -134,6 +136,7 @@ def __init__(
self.attention_dropout_prob = attention_dropout_prob
self.use_stable_embedding = use_stable_embedding
self.shared_input_output_embedding = shared_input_output_embedding
+ self.rope_theta = rope_theta
self.rope_scaling = rope_scaling
self._rope_scaling_validation()
@@ -155,8 +158,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/deprecated/open_llama/modeling_open_llama.py b/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
index 71c42447cd2bbe..098f8c7da50d5e 100644
--- a/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
+++ b/src/transformers/models/deprecated/open_llama/modeling_open_llama.py
@@ -214,6 +214,7 @@ def __init__(self, config: OpenLlamaConfig):
self.head_dim = self.hidden_size // self.num_heads
self.max_position_embeddings = config.max_position_embeddings
self.dropout_prob = config.attention_dropout_prob
+ self.rope_theta = config.rope_theta
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
diff --git a/src/transformers/models/deprecated/retribert/configuration_retribert.py b/src/transformers/models/deprecated/retribert/configuration_retribert.py
index 3861b9c90f33ef..c188c7347a8fb8 100644
--- a/src/transformers/models/deprecated/retribert/configuration_retribert.py
+++ b/src/transformers/models/deprecated/retribert/configuration_retribert.py
@@ -20,12 +20,7 @@
logger = logging.get_logger(__name__)
-# TODO: upload to AWS
-RETRIBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "yjernite/retribert-base-uncased": (
- "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/config.json"
- ),
-}
+from .._archive_maps import RETRIBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RetriBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/deprecated/retribert/modeling_retribert.py b/src/transformers/models/deprecated/retribert/modeling_retribert.py
index 00d47bce5121d4..7dba8a276eeb56 100644
--- a/src/transformers/models/deprecated/retribert/modeling_retribert.py
+++ b/src/transformers/models/deprecated/retribert/modeling_retribert.py
@@ -32,10 +32,8 @@
logger = logging.get_logger(__name__)
-RETRIBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "yjernite/retribert-base-uncased",
- # See all RetriBert models at https://huggingface.co/models?filter=retribert
-]
+
+from .._archive_maps import RETRIBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# INTERFACE FOR ENCODER AND TASK SPECIFIC MODEL #
diff --git a/src/transformers/models/deprecated/retribert/tokenization_retribert.py b/src/transformers/models/deprecated/retribert/tokenization_retribert.py
index d0904e3c931e40..c991f3972230bd 100644
--- a/src/transformers/models/deprecated/retribert/tokenization_retribert.py
+++ b/src/transformers/models/deprecated/retribert/tokenization_retribert.py
@@ -27,23 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "yjernite/retribert-base-uncased": (
- "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "yjernite/retribert-base-uncased": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "yjernite/retribert-base-uncased": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -111,9 +94,6 @@ class RetriBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
# Copied from transformers.models.bert.tokenization_bert.BertTokenizer.__init__
diff --git a/src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py b/src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py
index 07f7964b9f3f8e..97fbfc07d30ca6 100644
--- a/src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py
+++ b/src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py
@@ -28,28 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "yjernite/retribert-base-uncased": (
- "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "yjernite/retribert-base-uncased": (
- "https://huggingface.co/yjernite/retribert-base-uncased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "yjernite/retribert-base-uncased": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "yjernite/retribert-base-uncased": {"do_lower_case": True},
-}
-
class RetriBertTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -95,9 +73,6 @@ class RetriBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = RetriBertTokenizer
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/deprecated/tapex/tokenization_tapex.py b/src/transformers/models/deprecated/tapex/tokenization_tapex.py
index a5ee093c56bd26..cd3d353b526c4a 100644
--- a/src/transformers/models/deprecated/tapex/tokenization_tapex.py
+++ b/src/transformers/models/deprecated/tapex/tokenization_tapex.py
@@ -36,23 +36,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/tapex-base": "https://huggingface.co/microsoft/tapex-base/resolve/main/vocab.json",
- },
- "merges_file": {
- "microsoft/tapex-base": "https://huggingface.co/microsoft/tapex-base/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/tapex-base": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/tapex-base": {"do_lower_case": True},
-}
-
class TapexTruncationStrategy(ExplicitEnum):
"""
@@ -264,9 +247,6 @@ class TapexTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py b/src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
index cfad075c6ae848..eccb71fcc429e7 100644
--- a/src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
+++ b/src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-TRAJECTORY_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "CarlCochet/trajectory-transformer-halfcheetah-medium-v2": (
- "https://huggingface.co/CarlCochet/trajectory-transformer-halfcheetah-medium-v2/resolve/main/config.json"
- ),
- # See all TrajectoryTransformer models at https://huggingface.co/models?filter=trajectory_transformer
-}
+
+from .._archive_maps import TRAJECTORY_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TrajectoryTransformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py b/src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
index 40c08e4d1d441a..5c98aa45dc2739 100644
--- a/src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
+++ b/src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
@@ -41,10 +41,8 @@
_CHECKPOINT_FOR_DOC = "CarlCochet/trajectory-transformer-halfcheetah-medium-v2"
_CONFIG_FOR_DOC = "TrajectoryTransformerConfig"
-TRAJECTORY_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "CarlCochet/trajectory-transformer-halfcheetah-medium-v2",
- # See all TrajectoryTransformer models at https://huggingface.co/models?filter=trajectory_transformer
-]
+
+from .._archive_maps import TRAJECTORY_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_trajectory_transformer(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/deprecated/transfo_xl/configuration_transfo_xl.py b/src/transformers/models/deprecated/transfo_xl/configuration_transfo_xl.py
index f7d5f2f87fb1ad..50bf94ae7ea398 100644
--- a/src/transformers/models/deprecated/transfo_xl/configuration_transfo_xl.py
+++ b/src/transformers/models/deprecated/transfo_xl/configuration_transfo_xl.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "transfo-xl/transfo-xl-wt103": "https://huggingface.co/transfo-xl/transfo-xl-wt103/resolve/main/config.json",
-}
+
+from .._archive_maps import TRANSFO_XL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TransfoXLConfig(PretrainedConfig):
diff --git a/src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py b/src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
index ab2725df0c4dcf..27200a5d63f18b 100644
--- a/src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
+++ b/src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
@@ -51,10 +51,8 @@
_CHECKPOINT_FOR_DOC = "transfo-xl/transfo-xl-wt103"
_CONFIG_FOR_DOC = "TransfoXLConfig"
-TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "transfo-xl/transfo-xl-wt103",
- # See all Transformer XL models at https://huggingface.co/models?filter=transfo-xl
-]
+
+from .._archive_maps import TF_TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFPositionalEmbedding(keras.layers.Layer):
diff --git a/src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py b/src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
index 1b8f222f508a35..897a3899c74cbd 100644
--- a/src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
+++ b/src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
@@ -42,10 +42,8 @@
_CHECKPOINT_FOR_DOC = "transfo-xl/transfo-xl-wt103"
_CONFIG_FOR_DOC = "TransfoXLConfig"
-TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "transfo-xl/transfo-xl-wt103",
- # See all Transformer XL models at https://huggingface.co/models?filter=transfo-xl
-]
+
+from .._archive_maps import TRANSFO_XL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def build_tf_to_pytorch_map(model, config):
diff --git a/src/transformers/models/deprecated/transfo_xl/tokenization_transfo_xl.py b/src/transformers/models/deprecated/transfo_xl/tokenization_transfo_xl.py
index 12d360076fba4f..7290a7a83b8566 100644
--- a/src/transformers/models/deprecated/transfo_xl/tokenization_transfo_xl.py
+++ b/src/transformers/models/deprecated/transfo_xl/tokenization_transfo_xl.py
@@ -55,15 +55,6 @@
"vocab_file": "vocab.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "pretrained_vocab_file": {
- "transfo-xl/transfo-xl-wt103": "https://huggingface.co/transfo-xl/transfo-xl-wt103/resolve/main/vocab.pkl",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "transfo-xl/transfo-xl-wt103": None,
-}
PRETRAINED_CORPUS_ARCHIVE_MAP = {
"transfo-xl/transfo-xl-wt103": "https://huggingface.co/transfo-xl/transfo-xl-wt103/resolve/main/corpus.bin",
@@ -162,8 +153,6 @@ class TransfoXLTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids"]
def __init__(
diff --git a/src/transformers/models/deprecated/van/configuration_van.py b/src/transformers/models/deprecated/van/configuration_van.py
index 85f228193c450e..f58d0215694a93 100644
--- a/src/transformers/models/deprecated/van/configuration_van.py
+++ b/src/transformers/models/deprecated/van/configuration_van.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-VAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Visual-Attention-Network/van-base": (
- "https://huggingface.co/Visual-Attention-Network/van-base/blob/main/config.json"
- ),
-}
+
+from .._archive_maps import VAN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VanConfig(PretrainedConfig):
diff --git a/src/transformers/models/deprecated/van/modeling_van.py b/src/transformers/models/deprecated/van/modeling_van.py
index e0f88467e1e75b..6fa2b73482e358 100644
--- a/src/transformers/models/deprecated/van/modeling_van.py
+++ b/src/transformers/models/deprecated/van/modeling_van.py
@@ -47,10 +47,8 @@
_IMAGE_CLASS_CHECKPOINT = "Visual-Attention-Network/van-base"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-VAN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Visual-Attention-Network/van-base",
- # See all VAN models at https://huggingface.co/models?filter=van
-]
+
+from .._archive_maps import VAN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.convnext.modeling_convnext.drop_path
diff --git a/src/transformers/models/depth_anything/configuration_depth_anything.py b/src/transformers/models/depth_anything/configuration_depth_anything.py
index 7fa7745c32d3fd..3d58a3874eedf3 100644
--- a/src/transformers/models/depth_anything/configuration_depth_anything.py
+++ b/src/transformers/models/depth_anything/configuration_depth_anything.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-DEPTH_ANYTHING_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "LiheYoung/depth-anything-small-hf": "https://huggingface.co/LiheYoung/depth-anything-small-hf/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import DEPTH_ANYTHING_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DepthAnythingConfig(PretrainedConfig):
diff --git a/src/transformers/models/depth_anything/modeling_depth_anything.py b/src/transformers/models/depth_anything/modeling_depth_anything.py
index 6497759f17825e..788b0d911396f1 100644
--- a/src/transformers/models/depth_anything/modeling_depth_anything.py
+++ b/src/transformers/models/depth_anything/modeling_depth_anything.py
@@ -38,10 +38,8 @@
# General docstring
_CONFIG_FOR_DOC = "DepthAnythingConfig"
-DEPTH_ANYTHING_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "LiheYoung/depth-anything-small-hf",
- # See all Depth Anything models at https://huggingface.co/models?filter=depth_anything
-]
+
+from ..deprecated._archive_maps import DEPTH_ANYTHING_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
DEPTH_ANYTHING_START_DOCSTRING = r"""
diff --git a/src/transformers/models/deta/configuration_deta.py b/src/transformers/models/deta/configuration_deta.py
index d5a3709b91e372..1604bc56e6396d 100644
--- a/src/transformers/models/deta/configuration_deta.py
+++ b/src/transformers/models/deta/configuration_deta.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-DETA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "ut/deta": "https://huggingface.co/ut/deta/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import DETA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DetaConfig(PretrainedConfig):
diff --git a/src/transformers/models/deta/modeling_deta.py b/src/transformers/models/deta/modeling_deta.py
index 0c2dfdf3b0a24c..35d9b67d2f9923 100644
--- a/src/transformers/models/deta/modeling_deta.py
+++ b/src/transformers/models/deta/modeling_deta.py
@@ -151,10 +151,8 @@ def backward(context, grad_output):
_CONFIG_FOR_DOC = "DetaConfig"
_CHECKPOINT_FOR_DOC = "jozhang97/deta-swin-large-o365"
-DETA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "jozhang97/deta-swin-large-o365",
- # See all DETA models at https://huggingface.co/models?filter=deta
-]
+
+from ..deprecated._archive_maps import DETA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/detr/configuration_detr.py b/src/transformers/models/detr/configuration_detr.py
index f13c1ef09a0c5c..9b9b5afacd0b7f 100644
--- a/src/transformers/models/detr/configuration_detr.py
+++ b/src/transformers/models/detr/configuration_detr.py
@@ -27,10 +27,8 @@
logger = logging.get_logger(__name__)
-DETR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/detr-resnet-50": "https://huggingface.co/facebook/detr-resnet-50/resolve/main/config.json",
- # See all DETR models at https://huggingface.co/models?filter=detr
-}
+
+from ..deprecated._archive_maps import DETR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DetrConfig(PretrainedConfig):
diff --git a/src/transformers/models/detr/modeling_detr.py b/src/transformers/models/detr/modeling_detr.py
index 1e548b61d3a7d2..d7fcdfc5bc7e83 100644
--- a/src/transformers/models/detr/modeling_detr.py
+++ b/src/transformers/models/detr/modeling_detr.py
@@ -60,10 +60,8 @@
_CONFIG_FOR_DOC = "DetrConfig"
_CHECKPOINT_FOR_DOC = "facebook/detr-resnet-50"
-DETR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/detr-resnet-50",
- # See all DETR models at https://huggingface.co/models?filter=detr
-]
+
+from ..deprecated._archive_maps import DETR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/dinat/configuration_dinat.py b/src/transformers/models/dinat/configuration_dinat.py
index 83c3227f66b247..4bd38c73857a97 100644
--- a/src/transformers/models/dinat/configuration_dinat.py
+++ b/src/transformers/models/dinat/configuration_dinat.py
@@ -21,10 +21,8 @@
logger = logging.get_logger(__name__)
-DINAT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "shi-labs/dinat-mini-in1k-224": "https://huggingface.co/shi-labs/dinat-mini-in1k-224/resolve/main/config.json",
- # See all Dinat models at https://huggingface.co/models?filter=dinat
-}
+
+from ..deprecated._archive_maps import DINAT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DinatConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/dinat/modeling_dinat.py b/src/transformers/models/dinat/modeling_dinat.py
index 71470efece28c1..72bf6d1170094c 100644
--- a/src/transformers/models/dinat/modeling_dinat.py
+++ b/src/transformers/models/dinat/modeling_dinat.py
@@ -68,10 +68,8 @@ def natten2dav(*args, **kwargs):
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-DINAT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "shi-labs/dinat-mini-in1k-224",
- # See all Dinat models at https://huggingface.co/models?filter=dinat
-]
+from ..deprecated._archive_maps import DINAT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# drop_path and DinatDropPath are from the timm library.
diff --git a/src/transformers/models/dinov2/configuration_dinov2.py b/src/transformers/models/dinov2/configuration_dinov2.py
index 037f889ebf2a8c..b5fe872a706fc7 100644
--- a/src/transformers/models/dinov2/configuration_dinov2.py
+++ b/src/transformers/models/dinov2/configuration_dinov2.py
@@ -27,9 +27,8 @@
logger = logging.get_logger(__name__)
-DINOV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/dinov2-base": "https://huggingface.co/facebook/dinov2-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import DINOV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Dinov2Config(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/dinov2/modeling_dinov2.py b/src/transformers/models/dinov2/modeling_dinov2.py
index accdf0a9b23bee..c25022f6ec22d8 100644
--- a/src/transformers/models/dinov2/modeling_dinov2.py
+++ b/src/transformers/models/dinov2/modeling_dinov2.py
@@ -58,10 +58,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-DINOV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dinov2-base",
- # See all DINOv2 models at https://huggingface.co/models?filter=dinov2
-]
+from ..deprecated._archive_maps import DINOV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class Dinov2Embeddings(nn.Module):
diff --git a/src/transformers/models/distilbert/configuration_distilbert.py b/src/transformers/models/distilbert/configuration_distilbert.py
index 97b5b7c869064b..5f6b004dc0bbb9 100644
--- a/src/transformers/models/distilbert/configuration_distilbert.py
+++ b/src/transformers/models/distilbert/configuration_distilbert.py
@@ -23,23 +23,8 @@
logger = logging.get_logger(__name__)
-DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/config.json",
- "distilbert-base-uncased-distilled-squad": (
- "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/config.json"
- ),
- "distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/config.json",
- "distilbert-base-cased-distilled-squad": (
- "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/config.json"
- ),
- "distilbert-base-german-cased": "https://huggingface.co/distilbert-base-german-cased/resolve/main/config.json",
- "distilbert-base-multilingual-cased": (
- "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/config.json"
- ),
- "distilbert-base-uncased-finetuned-sst-2-english": (
- "https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import DISTILBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DistilBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/distilbert/modeling_distilbert.py b/src/transformers/models/distilbert/modeling_distilbert.py
index 023b4dc13ade1c..3a65e0296116dc 100755
--- a/src/transformers/models/distilbert/modeling_distilbert.py
+++ b/src/transformers/models/distilbert/modeling_distilbert.py
@@ -62,16 +62,8 @@
_CHECKPOINT_FOR_DOC = "distilbert-base-uncased"
_CONFIG_FOR_DOC = "DistilBertConfig"
-DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "distilbert-base-uncased",
- "distilbert-base-uncased-distilled-squad",
- "distilbert-base-cased",
- "distilbert-base-cased-distilled-squad",
- "distilbert-base-german-cased",
- "distilbert-base-multilingual-cased",
- "distilbert-base-uncased-finetuned-sst-2-english",
- # See all DistilBERT models at https://huggingface.co/models?filter=distilbert
-]
+
+from ..deprecated._archive_maps import DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# UTILS AND BUILDING BLOCKS OF THE ARCHITECTURE #
@@ -114,10 +106,6 @@ def __init__(self, config: PretrainedConfig):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.dim, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.dim)
- if config.sinusoidal_pos_embds:
- create_sinusoidal_embeddings(
- n_pos=config.max_position_embeddings, dim=config.dim, out=self.position_embeddings.weight
- )
self.LayerNorm = nn.LayerNorm(config.dim, eps=1e-12)
self.dropout = nn.Dropout(config.dropout)
@@ -642,6 +630,10 @@ def _init_weights(self, module: nn.Module):
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
+ elif isinstance(module, Embeddings) and self.config.sinusoidal_pos_embds:
+ create_sinusoidal_embeddings(
+ self.config.max_position_embeddings, self.config.dim, module.position_embeddings.weight
+ )
DISTILBERT_START_DOCSTRING = r"""
diff --git a/src/transformers/models/distilbert/modeling_tf_distilbert.py b/src/transformers/models/distilbert/modeling_tf_distilbert.py
index 39fd470597fa87..c41deac3f2e57e 100644
--- a/src/transformers/models/distilbert/modeling_tf_distilbert.py
+++ b/src/transformers/models/distilbert/modeling_tf_distilbert.py
@@ -62,15 +62,8 @@
_CHECKPOINT_FOR_DOC = "distilbert-base-uncased"
_CONFIG_FOR_DOC = "DistilBertConfig"
-TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "distilbert-base-uncased",
- "distilbert-base-uncased-distilled-squad",
- "distilbert-base-cased",
- "distilbert-base-cased-distilled-squad",
- "distilbert-base-multilingual-cased",
- "distilbert-base-uncased-finetuned-sst-2-english",
- # See all DistilBERT models at https://huggingface.co/models?filter=distilbert
-]
+
+from ..deprecated._archive_maps import TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFEmbeddings(keras.layers.Layer):
diff --git a/src/transformers/models/distilbert/tokenization_distilbert.py b/src/transformers/models/distilbert/tokenization_distilbert.py
index 014c41d1243b6f..ff8854ba3dcf89 100644
--- a/src/transformers/models/distilbert/tokenization_distilbert.py
+++ b/src/transformers/models/distilbert/tokenization_distilbert.py
@@ -27,42 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/vocab.txt",
- "distilbert-base-uncased-distilled-squad": (
- "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/vocab.txt"
- ),
- "distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/vocab.txt",
- "distilbert-base-cased-distilled-squad": (
- "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/vocab.txt"
- ),
- "distilbert-base-german-cased": "https://huggingface.co/distilbert-base-german-cased/resolve/main/vocab.txt",
- "distilbert-base-multilingual-cased": (
- "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "distilbert-base-uncased": 512,
- "distilbert-base-uncased-distilled-squad": 512,
- "distilbert-base-cased": 512,
- "distilbert-base-cased-distilled-squad": 512,
- "distilbert-base-german-cased": 512,
- "distilbert-base-multilingual-cased": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "distilbert-base-uncased": {"do_lower_case": True},
- "distilbert-base-uncased-distilled-squad": {"do_lower_case": True},
- "distilbert-base-cased": {"do_lower_case": False},
- "distilbert-base-cased-distilled-squad": {"do_lower_case": False},
- "distilbert-base-german-cased": {"do_lower_case": False},
- "distilbert-base-multilingual-cased": {"do_lower_case": False},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -129,9 +93,6 @@ class DistilBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/distilbert/tokenization_distilbert_fast.py b/src/transformers/models/distilbert/tokenization_distilbert_fast.py
index adb90f857d75fe..f1d69a27d67c08 100644
--- a/src/transformers/models/distilbert/tokenization_distilbert_fast.py
+++ b/src/transformers/models/distilbert/tokenization_distilbert_fast.py
@@ -28,58 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/vocab.txt",
- "distilbert-base-uncased-distilled-squad": (
- "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/vocab.txt"
- ),
- "distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/vocab.txt",
- "distilbert-base-cased-distilled-squad": (
- "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/vocab.txt"
- ),
- "distilbert-base-german-cased": "https://huggingface.co/distilbert-base-german-cased/resolve/main/vocab.txt",
- "distilbert-base-multilingual-cased": (
- "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "distilbert-base-uncased": "https://huggingface.co/distilbert-base-uncased/resolve/main/tokenizer.json",
- "distilbert-base-uncased-distilled-squad": (
- "https://huggingface.co/distilbert-base-uncased-distilled-squad/resolve/main/tokenizer.json"
- ),
- "distilbert-base-cased": "https://huggingface.co/distilbert-base-cased/resolve/main/tokenizer.json",
- "distilbert-base-cased-distilled-squad": (
- "https://huggingface.co/distilbert-base-cased-distilled-squad/resolve/main/tokenizer.json"
- ),
- "distilbert-base-german-cased": (
- "https://huggingface.co/distilbert-base-german-cased/resolve/main/tokenizer.json"
- ),
- "distilbert-base-multilingual-cased": (
- "https://huggingface.co/distilbert-base-multilingual-cased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "distilbert-base-uncased": 512,
- "distilbert-base-uncased-distilled-squad": 512,
- "distilbert-base-cased": 512,
- "distilbert-base-cased-distilled-squad": 512,
- "distilbert-base-german-cased": 512,
- "distilbert-base-multilingual-cased": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "distilbert-base-uncased": {"do_lower_case": True},
- "distilbert-base-uncased-distilled-squad": {"do_lower_case": True},
- "distilbert-base-cased": {"do_lower_case": False},
- "distilbert-base-cased-distilled-squad": {"do_lower_case": False},
- "distilbert-base-german-cased": {"do_lower_case": False},
- "distilbert-base-multilingual-cased": {"do_lower_case": False},
-}
-
class DistilBertTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -122,9 +70,6 @@ class DistilBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = DistilBertTokenizer
diff --git a/src/transformers/models/donut/configuration_donut_swin.py b/src/transformers/models/donut/configuration_donut_swin.py
index 9de3181b55bc3a..e57ddb255a7118 100644
--- a/src/transformers/models/donut/configuration_donut_swin.py
+++ b/src/transformers/models/donut/configuration_donut_swin.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-DONUT_SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "naver-clova-ix/donut-base": "https://huggingface.co/naver-clova-ix/donut-base/resolve/main/config.json",
- # See all Donut models at https://huggingface.co/models?filter=donut-swin
-}
+
+from ..deprecated._archive_maps import DONUT_SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DonutSwinConfig(PretrainedConfig):
diff --git a/src/transformers/models/donut/modeling_donut_swin.py b/src/transformers/models/donut/modeling_donut_swin.py
index ed79b8ef8ec85a..b2aa8d61b1d8d1 100644
--- a/src/transformers/models/donut/modeling_donut_swin.py
+++ b/src/transformers/models/donut/modeling_donut_swin.py
@@ -48,10 +48,8 @@
_CHECKPOINT_FOR_DOC = "https://huggingface.co/naver-clova-ix/donut-base"
_EXPECTED_OUTPUT_SHAPE = [1, 49, 768]
-DONUT_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "naver-clova-ix/donut-base",
- # See all Donut Swin models at https://huggingface.co/models?filter=donut
-]
+
+from ..deprecated._archive_maps import DONUT_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/dpr/configuration_dpr.py b/src/transformers/models/dpr/configuration_dpr.py
index 3b6785c6b540f5..74ac90a4beb508 100644
--- a/src/transformers/models/dpr/configuration_dpr.py
+++ b/src/transformers/models/dpr/configuration_dpr.py
@@ -20,26 +20,8 @@
logger = logging.get_logger(__name__)
-DPR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/dpr-ctx_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/config.json"
- ),
- "facebook/dpr-question_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/config.json"
- ),
- "facebook/dpr-reader-single-nq-base": (
- "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/config.json"
- ),
- "facebook/dpr-ctx_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/config.json"
- ),
- "facebook/dpr-question_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/config.json"
- ),
- "facebook/dpr-reader-multiset-base": (
- "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import DPR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DPRConfig(PretrainedConfig):
diff --git a/src/transformers/models/dpr/modeling_dpr.py b/src/transformers/models/dpr/modeling_dpr.py
index 1071a42d810076..0a45ec75207c29 100644
--- a/src/transformers/models/dpr/modeling_dpr.py
+++ b/src/transformers/models/dpr/modeling_dpr.py
@@ -39,18 +39,12 @@
_CONFIG_FOR_DOC = "DPRConfig"
_CHECKPOINT_FOR_DOC = "facebook/dpr-ctx_encoder-single-nq-base"
-DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-ctx_encoder-single-nq-base",
- "facebook/dpr-ctx_encoder-multiset-base",
-]
-DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-question_encoder-single-nq-base",
- "facebook/dpr-question_encoder-multiset-base",
-]
-DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-reader-single-nq-base",
- "facebook/dpr-reader-multiset-base",
-]
+
+from ..deprecated._archive_maps import ( # noqa: F401, E402
+ DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+ DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+ DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+)
##########
diff --git a/src/transformers/models/dpr/modeling_tf_dpr.py b/src/transformers/models/dpr/modeling_tf_dpr.py
index 0a6aa47640d03c..e8cb1464f70da8 100644
--- a/src/transformers/models/dpr/modeling_tf_dpr.py
+++ b/src/transformers/models/dpr/modeling_tf_dpr.py
@@ -39,18 +39,12 @@
_CONFIG_FOR_DOC = "DPRConfig"
-TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-ctx_encoder-single-nq-base",
- "facebook/dpr-ctx_encoder-multiset-base",
-]
-TF_DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-question_encoder-single-nq-base",
- "facebook/dpr-question_encoder-multiset-base",
-]
-TF_DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/dpr-reader-single-nq-base",
- "facebook/dpr-reader-multiset-base",
-]
+
+from ..deprecated._archive_maps import ( # noqa: F401, E402
+ TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+ TF_DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+ TF_DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+)
##########
diff --git a/src/transformers/models/dpr/tokenization_dpr.py b/src/transformers/models/dpr/tokenization_dpr.py
index b2ae84addc75ef..1362047ce283e2 100644
--- a/src/transformers/models/dpr/tokenization_dpr.py
+++ b/src/transformers/models/dpr/tokenization_dpr.py
@@ -27,88 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-CONTEXT_ENCODER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-ctx_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-ctx_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-ctx_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-ctx_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-QUESTION_ENCODER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-question_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-question_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-question_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-question_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-READER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-reader-single-nq-base": (
- "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-reader-multiset-base": (
- "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-reader-single-nq-base": (
- "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-reader-multiset-base": (
- "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-
-CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-ctx_encoder-single-nq-base": 512,
- "facebook/dpr-ctx_encoder-multiset-base": 512,
-}
-QUESTION_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-question_encoder-single-nq-base": 512,
- "facebook/dpr-question_encoder-multiset-base": 512,
-}
-READER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-reader-single-nq-base": 512,
- "facebook/dpr-reader-multiset-base": 512,
-}
-
-
-CONTEXT_ENCODER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-ctx_encoder-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-ctx_encoder-multiset-base": {"do_lower_case": True},
-}
-QUESTION_ENCODER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-question_encoder-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-question_encoder-multiset-base": {"do_lower_case": True},
-}
-READER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-reader-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-reader-multiset-base": {"do_lower_case": True},
-}
-
class DPRContextEncoderTokenizer(BertTokenizer):
r"""
@@ -121,9 +39,6 @@ class DPRContextEncoderTokenizer(BertTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = CONTEXT_ENCODER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = CONTEXT_ENCODER_PRETRAINED_INIT_CONFIGURATION
class DPRQuestionEncoderTokenizer(BertTokenizer):
@@ -137,9 +52,6 @@ class DPRQuestionEncoderTokenizer(BertTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = QUESTION_ENCODER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = QUESTION_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = QUESTION_ENCODER_PRETRAINED_INIT_CONFIGURATION
DPRSpanPrediction = collections.namedtuple(
@@ -404,7 +316,4 @@ class DPRReaderTokenizer(CustomDPRReaderTokenizerMixin, BertTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = READER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = READER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = READER_PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/dpr/tokenization_dpr_fast.py b/src/transformers/models/dpr/tokenization_dpr_fast.py
index 784ed1344cf6f4..730f200a6876f1 100644
--- a/src/transformers/models/dpr/tokenization_dpr_fast.py
+++ b/src/transformers/models/dpr/tokenization_dpr_fast.py
@@ -28,88 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-CONTEXT_ENCODER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-ctx_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-ctx_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-ctx_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-ctx_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-QUESTION_ENCODER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-question_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-question_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-question_encoder-single-nq-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-question_encoder-multiset-base": (
- "https://huggingface.co/facebook/dpr-question_encoder-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-READER_PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/dpr-reader-single-nq-base": (
- "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/vocab.txt"
- ),
- "facebook/dpr-reader-multiset-base": (
- "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "facebook/dpr-reader-single-nq-base": (
- "https://huggingface.co/facebook/dpr-reader-single-nq-base/resolve/main/tokenizer.json"
- ),
- "facebook/dpr-reader-multiset-base": (
- "https://huggingface.co/facebook/dpr-reader-multiset-base/resolve/main/tokenizer.json"
- ),
- },
-}
-
-CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-ctx_encoder-single-nq-base": 512,
- "facebook/dpr-ctx_encoder-multiset-base": 512,
-}
-QUESTION_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-question_encoder-single-nq-base": 512,
- "facebook/dpr-question_encoder-multiset-base": 512,
-}
-READER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/dpr-reader-single-nq-base": 512,
- "facebook/dpr-reader-multiset-base": 512,
-}
-
-
-CONTEXT_ENCODER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-ctx_encoder-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-ctx_encoder-multiset-base": {"do_lower_case": True},
-}
-QUESTION_ENCODER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-question_encoder-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-question_encoder-multiset-base": {"do_lower_case": True},
-}
-READER_PRETRAINED_INIT_CONFIGURATION = {
- "facebook/dpr-reader-single-nq-base": {"do_lower_case": True},
- "facebook/dpr-reader-multiset-base": {"do_lower_case": True},
-}
-
class DPRContextEncoderTokenizerFast(BertTokenizerFast):
r"""
@@ -122,9 +40,6 @@ class DPRContextEncoderTokenizerFast(BertTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = CONTEXT_ENCODER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = CONTEXT_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = CONTEXT_ENCODER_PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = DPRContextEncoderTokenizer
@@ -139,9 +54,6 @@ class DPRQuestionEncoderTokenizerFast(BertTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = QUESTION_ENCODER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = QUESTION_ENCODER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = QUESTION_ENCODER_PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = DPRQuestionEncoderTokenizer
@@ -403,8 +315,5 @@ class DPRReaderTokenizerFast(CustomDPRReaderTokenizerMixin, BertTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = READER_PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = READER_PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = READER_PRETRAINED_INIT_CONFIGURATION
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = DPRReaderTokenizer
diff --git a/src/transformers/models/dpt/configuration_dpt.py b/src/transformers/models/dpt/configuration_dpt.py
index 97b9e2e9a834e0..9bdc8d1ef0affb 100644
--- a/src/transformers/models/dpt/configuration_dpt.py
+++ b/src/transformers/models/dpt/configuration_dpt.py
@@ -24,10 +24,8 @@
logger = logging.get_logger(__name__)
-DPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Intel/dpt-large": "https://huggingface.co/Intel/dpt-large/resolve/main/config.json",
- # See all DPT models at https://huggingface.co/models?filter=dpt
-}
+
+from ..deprecated._archive_maps import DPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DPTConfig(PretrainedConfig):
diff --git a/src/transformers/models/dpt/modeling_dpt.py b/src/transformers/models/dpt/modeling_dpt.py
index e986e71d4851da..aad3330279f051 100755
--- a/src/transformers/models/dpt/modeling_dpt.py
+++ b/src/transformers/models/dpt/modeling_dpt.py
@@ -55,11 +55,7 @@
_EXPECTED_OUTPUT_SHAPE = [1, 577, 1024]
-DPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Intel/dpt-large",
- "Intel/dpt-hybrid-midas",
- # See all DPT models at https://huggingface.co/models?filter=dpt
-]
+from ..deprecated._archive_maps import DPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/efficientformer/configuration_efficientformer.py b/src/transformers/models/efficientformer/configuration_efficientformer.py
index fecb90a886e8eb..1641c90711f5d4 100644
--- a/src/transformers/models/efficientformer/configuration_efficientformer.py
+++ b/src/transformers/models/efficientformer/configuration_efficientformer.py
@@ -22,11 +22,8 @@
logger = logging.get_logger(__name__)
-EFFICIENTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "snap-research/efficientformer-l1-300": (
- "https://huggingface.co/snap-research/efficientformer-l1-300/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import EFFICIENTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class EfficientFormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/efficientformer/modeling_efficientformer.py b/src/transformers/models/efficientformer/modeling_efficientformer.py
index 5f03a5ab747235..70075cff55d7d9 100644
--- a/src/transformers/models/efficientformer/modeling_efficientformer.py
+++ b/src/transformers/models/efficientformer/modeling_efficientformer.py
@@ -50,10 +50,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "Egyptian cat"
-EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "snap-research/efficientformer-l1-300",
- # See all EfficientFormer models at https://huggingface.co/models?filter=efficientformer
-]
+from ..deprecated._archive_maps import EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class EfficientFormerPatchEmbeddings(nn.Module):
diff --git a/src/transformers/models/efficientformer/modeling_tf_efficientformer.py b/src/transformers/models/efficientformer/modeling_tf_efficientformer.py
index 113eafb88d8493..77b62999e772ec 100644
--- a/src/transformers/models/efficientformer/modeling_tf_efficientformer.py
+++ b/src/transformers/models/efficientformer/modeling_tf_efficientformer.py
@@ -59,10 +59,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "LABEL_281"
-TF_EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "snap-research/efficientformer-l1-300",
- # See all EfficientFormer models at https://huggingface.co/models?filter=efficientformer
-]
+from ..deprecated._archive_maps import TF_EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFEfficientFormerPatchEmbeddings(keras.layers.Layer):
diff --git a/src/transformers/models/efficientnet/configuration_efficientnet.py b/src/transformers/models/efficientnet/configuration_efficientnet.py
index 49e50a45e11537..77106c70d7d553 100644
--- a/src/transformers/models/efficientnet/configuration_efficientnet.py
+++ b/src/transformers/models/efficientnet/configuration_efficientnet.py
@@ -26,9 +26,8 @@
logger = logging.get_logger(__name__)
-EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/efficientnet-b7": "https://huggingface.co/google/efficientnet-b7/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class EfficientNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/efficientnet/modeling_efficientnet.py b/src/transformers/models/efficientnet/modeling_efficientnet.py
index 2513f9b2fde142..5b7ff534eedfe4 100644
--- a/src/transformers/models/efficientnet/modeling_efficientnet.py
+++ b/src/transformers/models/efficientnet/modeling_efficientnet.py
@@ -52,10 +52,8 @@
_IMAGE_CLASS_CHECKPOINT = "google/efficientnet-b7"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-EFFICIENTNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/efficientnet-b7",
- # See all EfficientNet models at https://huggingface.co/models?filter=efficientnet
-]
+
+from ..deprecated._archive_maps import EFFICIENTNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
EFFICIENTNET_START_DOCSTRING = r"""
diff --git a/src/transformers/models/electra/configuration_electra.py b/src/transformers/models/electra/configuration_electra.py
index d45f62930212ec..b6d1368a9d22d2 100644
--- a/src/transformers/models/electra/configuration_electra.py
+++ b/src/transformers/models/electra/configuration_electra.py
@@ -25,20 +25,8 @@
logger = logging.get_logger(__name__)
-ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/electra-small-generator": "https://huggingface.co/google/electra-small-generator/resolve/main/config.json",
- "google/electra-base-generator": "https://huggingface.co/google/electra-base-generator/resolve/main/config.json",
- "google/electra-large-generator": "https://huggingface.co/google/electra-large-generator/resolve/main/config.json",
- "google/electra-small-discriminator": (
- "https://huggingface.co/google/electra-small-discriminator/resolve/main/config.json"
- ),
- "google/electra-base-discriminator": (
- "https://huggingface.co/google/electra-base-discriminator/resolve/main/config.json"
- ),
- "google/electra-large-discriminator": (
- "https://huggingface.co/google/electra-large-discriminator/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import ELECTRA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ElectraConfig(PretrainedConfig):
diff --git a/src/transformers/models/electra/modeling_electra.py b/src/transformers/models/electra/modeling_electra.py
index 3aaa6141004fb3..2138aa97c6dca9 100644
--- a/src/transformers/models/electra/modeling_electra.py
+++ b/src/transformers/models/electra/modeling_electra.py
@@ -53,15 +53,8 @@
_CHECKPOINT_FOR_DOC = "google/electra-small-discriminator"
_CONFIG_FOR_DOC = "ElectraConfig"
-ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/electra-small-generator",
- "google/electra-base-generator",
- "google/electra-large-generator",
- "google/electra-small-discriminator",
- "google/electra-base-discriminator",
- "google/electra-large-discriminator",
- # See all ELECTRA models at https://huggingface.co/models?filter=electra
-]
+
+from ..deprecated._archive_maps import ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_electra(model, config, tf_checkpoint_path, discriminator_or_generator="discriminator"):
diff --git a/src/transformers/models/electra/modeling_tf_electra.py b/src/transformers/models/electra/modeling_tf_electra.py
index b0c8b4fa285d54..ba60cd8f5d5754 100644
--- a/src/transformers/models/electra/modeling_tf_electra.py
+++ b/src/transformers/models/electra/modeling_tf_electra.py
@@ -65,15 +65,8 @@
_CHECKPOINT_FOR_DOC = "google/electra-small-discriminator"
_CONFIG_FOR_DOC = "ElectraConfig"
-TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/electra-small-generator",
- "google/electra-base-generator",
- "google/electra-large-generator",
- "google/electra-small-discriminator",
- "google/electra-base-discriminator",
- "google/electra-large-discriminator",
- # See all ELECTRA models at https://huggingface.co/models?filter=electra
-]
+
+from ..deprecated._archive_maps import TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfAttention with Bert->Electra
diff --git a/src/transformers/models/electra/tokenization_electra.py b/src/transformers/models/electra/tokenization_electra.py
index 6ea9a600a6e957..ceb3e7560215c2 100644
--- a/src/transformers/models/electra/tokenization_electra.py
+++ b/src/transformers/models/electra/tokenization_electra.py
@@ -26,46 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/electra-small-generator": (
- "https://huggingface.co/google/electra-small-generator/resolve/main/vocab.txt"
- ),
- "google/electra-base-generator": "https://huggingface.co/google/electra-base-generator/resolve/main/vocab.txt",
- "google/electra-large-generator": (
- "https://huggingface.co/google/electra-large-generator/resolve/main/vocab.txt"
- ),
- "google/electra-small-discriminator": (
- "https://huggingface.co/google/electra-small-discriminator/resolve/main/vocab.txt"
- ),
- "google/electra-base-discriminator": (
- "https://huggingface.co/google/electra-base-discriminator/resolve/main/vocab.txt"
- ),
- "google/electra-large-discriminator": (
- "https://huggingface.co/google/electra-large-discriminator/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/electra-small-generator": 512,
- "google/electra-base-generator": 512,
- "google/electra-large-generator": 512,
- "google/electra-small-discriminator": 512,
- "google/electra-base-discriminator": 512,
- "google/electra-large-discriminator": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google/electra-small-generator": {"do_lower_case": True},
- "google/electra-base-generator": {"do_lower_case": True},
- "google/electra-large-generator": {"do_lower_case": True},
- "google/electra-small-discriminator": {"do_lower_case": True},
- "google/electra-base-discriminator": {"do_lower_case": True},
- "google/electra-large-discriminator": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -133,9 +93,6 @@ class ElectraTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/electra/tokenization_electra_fast.py b/src/transformers/models/electra/tokenization_electra_fast.py
index e76082de174dee..7b9d6a36cb9210 100644
--- a/src/transformers/models/electra/tokenization_electra_fast.py
+++ b/src/transformers/models/electra/tokenization_electra_fast.py
@@ -24,65 +24,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/electra-small-generator": (
- "https://huggingface.co/google/electra-small-generator/resolve/main/vocab.txt"
- ),
- "google/electra-base-generator": "https://huggingface.co/google/electra-base-generator/resolve/main/vocab.txt",
- "google/electra-large-generator": (
- "https://huggingface.co/google/electra-large-generator/resolve/main/vocab.txt"
- ),
- "google/electra-small-discriminator": (
- "https://huggingface.co/google/electra-small-discriminator/resolve/main/vocab.txt"
- ),
- "google/electra-base-discriminator": (
- "https://huggingface.co/google/electra-base-discriminator/resolve/main/vocab.txt"
- ),
- "google/electra-large-discriminator": (
- "https://huggingface.co/google/electra-large-discriminator/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "google/electra-small-generator": (
- "https://huggingface.co/google/electra-small-generator/resolve/main/tokenizer.json"
- ),
- "google/electra-base-generator": (
- "https://huggingface.co/google/electra-base-generator/resolve/main/tokenizer.json"
- ),
- "google/electra-large-generator": (
- "https://huggingface.co/google/electra-large-generator/resolve/main/tokenizer.json"
- ),
- "google/electra-small-discriminator": (
- "https://huggingface.co/google/electra-small-discriminator/resolve/main/tokenizer.json"
- ),
- "google/electra-base-discriminator": (
- "https://huggingface.co/google/electra-base-discriminator/resolve/main/tokenizer.json"
- ),
- "google/electra-large-discriminator": (
- "https://huggingface.co/google/electra-large-discriminator/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/electra-small-generator": 512,
- "google/electra-base-generator": 512,
- "google/electra-large-generator": 512,
- "google/electra-small-discriminator": 512,
- "google/electra-base-discriminator": 512,
- "google/electra-large-discriminator": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google/electra-small-generator": {"do_lower_case": True},
- "google/electra-base-generator": {"do_lower_case": True},
- "google/electra-large-generator": {"do_lower_case": True},
- "google/electra-small-discriminator": {"do_lower_case": True},
- "google/electra-base-discriminator": {"do_lower_case": True},
- "google/electra-large-discriminator": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with Bert->Electra , BERT->ELECTRA
class ElectraTokenizerFast(PreTrainedTokenizerFast):
@@ -126,9 +67,6 @@ class ElectraTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = ElectraTokenizer
def __init__(
diff --git a/src/transformers/models/encodec/configuration_encodec.py b/src/transformers/models/encodec/configuration_encodec.py
index af493c325bece5..4e18bb178adf23 100644
--- a/src/transformers/models/encodec/configuration_encodec.py
+++ b/src/transformers/models/encodec/configuration_encodec.py
@@ -26,10 +26,8 @@
logger = logging.get_logger(__name__)
-ENCODEC_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/encodec_24khz": "https://huggingface.co/facebook/encodec_24khz/resolve/main/config.json",
- "facebook/encodec_48khz": "https://huggingface.co/facebook/encodec_48khz/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ENCODEC_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class EncodecConfig(PretrainedConfig):
diff --git a/src/transformers/models/encodec/modeling_encodec.py b/src/transformers/models/encodec/modeling_encodec.py
index bf7503efb459c1..bd56661b198009 100644
--- a/src/transformers/models/encodec/modeling_encodec.py
+++ b/src/transformers/models/encodec/modeling_encodec.py
@@ -40,11 +40,7 @@
_CONFIG_FOR_DOC = "EncodecConfig"
-ENCODEC_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/encodec_24khz",
- "facebook/encodec_48khz",
- # See all EnCodec models at https://huggingface.co/models?filter=encodec
-]
+from ..deprecated._archive_maps import ENCODEC_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py b/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
index 1a6adcee1f8386..16248fee64ce59 100644
--- a/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
+++ b/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
@@ -262,9 +262,16 @@ def tie_weights(self):
if self.config.tie_encoder_decoder:
# tie encoder and decoder base model
decoder_base_model_prefix = self.decoder.base_model_prefix
- self._tie_encoder_decoder_weights(
- self.encoder, self.decoder._modules[decoder_base_model_prefix], self.decoder.base_model_prefix
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.encoder,
+ self.decoder._modules[decoder_base_model_prefix],
+ self.decoder.base_model_prefix,
+ "encoder",
)
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
def get_encoder(self):
return self.encoder
diff --git a/src/transformers/models/ernie/configuration_ernie.py b/src/transformers/models/ernie/configuration_ernie.py
index 7278a74eced517..81ed03596303ee 100644
--- a/src/transformers/models/ernie/configuration_ernie.py
+++ b/src/transformers/models/ernie/configuration_ernie.py
@@ -24,18 +24,8 @@
logger = logging.get_logger(__name__)
-ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "nghuyong/ernie-1.0-base-zh": "https://huggingface.co/nghuyong/ernie-1.0-base-zh/resolve/main/config.json",
- "nghuyong/ernie-2.0-base-en": "https://huggingface.co/nghuyong/ernie-2.0-base-en/resolve/main/config.json",
- "nghuyong/ernie-2.0-large-en": "https://huggingface.co/nghuyong/ernie-2.0-large-en/resolve/main/config.json",
- "nghuyong/ernie-3.0-base-zh": "https://huggingface.co/nghuyong/ernie-3.0-base-zh/resolve/main/config.json",
- "nghuyong/ernie-3.0-medium-zh": "https://huggingface.co/nghuyong/ernie-3.0-medium-zh/resolve/main/config.json",
- "nghuyong/ernie-3.0-mini-zh": "https://huggingface.co/nghuyong/ernie-3.0-mini-zh/resolve/main/config.json",
- "nghuyong/ernie-3.0-micro-zh": "https://huggingface.co/nghuyong/ernie-3.0-micro-zh/resolve/main/config.json",
- "nghuyong/ernie-3.0-nano-zh": "https://huggingface.co/nghuyong/ernie-3.0-nano-zh/resolve/main/config.json",
- "nghuyong/ernie-gram-zh": "https://huggingface.co/nghuyong/ernie-gram-zh/resolve/main/config.json",
- "nghuyong/ernie-health-zh": "https://huggingface.co/nghuyong/ernie-health-zh/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ErnieConfig(PretrainedConfig):
diff --git a/src/transformers/models/ernie/modeling_ernie.py b/src/transformers/models/ernie/modeling_ernie.py
index 291ab6c54d1e50..a65f453205d5c5 100644
--- a/src/transformers/models/ernie/modeling_ernie.py
+++ b/src/transformers/models/ernie/modeling_ernie.py
@@ -56,19 +56,7 @@
_CONFIG_FOR_DOC = "ErnieConfig"
-ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nghuyong/ernie-1.0-base-zh",
- "nghuyong/ernie-2.0-base-en",
- "nghuyong/ernie-2.0-large-en",
- "nghuyong/ernie-3.0-base-zh",
- "nghuyong/ernie-3.0-medium-zh",
- "nghuyong/ernie-3.0-mini-zh",
- "nghuyong/ernie-3.0-micro-zh",
- "nghuyong/ernie-3.0-nano-zh",
- "nghuyong/ernie-gram-zh",
- "nghuyong/ernie-health-zh",
- # See all ERNIE models at https://huggingface.co/models?filter=ernie
-]
+from ..deprecated._archive_maps import ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ErnieEmbeddings(nn.Module):
diff --git a/src/transformers/models/ernie_m/configuration_ernie_m.py b/src/transformers/models/ernie_m/configuration_ernie_m.py
index 85917dc8288deb..96451c9d9c999c 100644
--- a/src/transformers/models/ernie_m/configuration_ernie_m.py
+++ b/src/transformers/models/ernie_m/configuration_ernie_m.py
@@ -20,12 +20,7 @@
from typing import Dict
from ...configuration_utils import PretrainedConfig
-
-
-ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "susnato/ernie-m-base_pytorch": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/config.json",
- "susnato/ernie-m-large_pytorch": "https://huggingface.co/susnato/ernie-m-large_pytorch/blob/main/config.json",
-}
+from ..deprecated._archive_maps import ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ErnieMConfig(PretrainedConfig):
diff --git a/src/transformers/models/ernie_m/modeling_ernie_m.py b/src/transformers/models/ernie_m/modeling_ernie_m.py
index c1be3cfba142a1..ac56e120a0c3d4 100755
--- a/src/transformers/models/ernie_m/modeling_ernie_m.py
+++ b/src/transformers/models/ernie_m/modeling_ernie_m.py
@@ -44,11 +44,8 @@
_CONFIG_FOR_DOC = "ErnieMConfig"
_TOKENIZER_FOR_DOC = "ErnieMTokenizer"
-ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "susnato/ernie-m-base_pytorch",
- "susnato/ernie-m-large_pytorch",
- # See all ErnieM models at https://huggingface.co/models?filter=ernie_m
-]
+
+from ..deprecated._archive_maps import ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Adapted from paddlenlp.transformers.ernie_m.modeling.ErnieEmbeddings
diff --git a/src/transformers/models/ernie_m/tokenization_ernie_m.py b/src/transformers/models/ernie_m/tokenization_ernie_m.py
index b1b8cc845024c8..0bd7edea1cab3a 100644
--- a/src/transformers/models/ernie_m/tokenization_ernie_m.py
+++ b/src/transformers/models/ernie_m/tokenization_ernie_m.py
@@ -36,27 +36,6 @@
"vocab_file": "vocab.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "ernie-m-base": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/vocab.txt",
- "ernie-m-large": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/vocab.txt",
- },
- "sentencepiece_model_file": {
- "ernie-m-base": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/sentencepiece.bpe.model",
- "ernie-m-large": "https://huggingface.co/susnato/ernie-m-base_pytorch/blob/main/sentencepiece.bpe.model",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "ernie-m-base": 514,
- "ernie-m-large": 514,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "ernie-m-base": {"do_lower_case": False},
- "ernie-m-large": {"do_lower_case": False},
-}
-
# Adapted from paddlenlp.transformers.ernie_m.tokenizer.ErnieMTokenizer
class ErnieMTokenizer(PreTrainedTokenizer):
@@ -89,9 +68,6 @@ class ErnieMTokenizer(PreTrainedTokenizer):
model_input_names: List[str] = ["input_ids"]
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
resource_files_names = RESOURCE_FILES_NAMES
def __init__(
diff --git a/src/transformers/models/esm/configuration_esm.py b/src/transformers/models/esm/configuration_esm.py
index 75f8609ab0ffbd..31d309cb04a017 100644
--- a/src/transformers/models/esm/configuration_esm.py
+++ b/src/transformers/models/esm/configuration_esm.py
@@ -24,10 +24,8 @@
logger = logging.get_logger(__name__)
# TODO Update this
-ESM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/esm-1b": "https://huggingface.co/facebook/esm-1b/resolve/main/config.json",
- # See all ESM models at https://huggingface.co/models?filter=esm
-}
+
+from ..deprecated._archive_maps import ESM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class EsmConfig(PretrainedConfig):
diff --git a/src/transformers/models/esm/modeling_esm.py b/src/transformers/models/esm/modeling_esm.py
index 2349ce580023d4..a97ea58d7b81d9 100755
--- a/src/transformers/models/esm/modeling_esm.py
+++ b/src/transformers/models/esm/modeling_esm.py
@@ -40,12 +40,8 @@
_CHECKPOINT_FOR_DOC = "facebook/esm2_t6_8M_UR50D"
_CONFIG_FOR_DOC = "EsmConfig"
-ESM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/esm2_t6_8M_UR50D",
- "facebook/esm2_t12_35M_UR50D",
- # This is not a complete list of all ESM models!
- # See all ESM models at https://huggingface.co/models?filter=esm
-]
+
+from ..deprecated._archive_maps import ESM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def rotate_half(x):
diff --git a/src/transformers/models/esm/modeling_tf_esm.py b/src/transformers/models/esm/modeling_tf_esm.py
index 2c780b4bdd60c3..2688c207b0adac 100644
--- a/src/transformers/models/esm/modeling_tf_esm.py
+++ b/src/transformers/models/esm/modeling_tf_esm.py
@@ -52,13 +52,6 @@
_CHECKPOINT_FOR_DOC = "facebook/esm2_t6_8M_UR50D"
_CONFIG_FOR_DOC = "EsmConfig"
-TF_ESM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/esm2_t6_8M_UR50D",
- "facebook/esm2_t12_35M_UR50D",
- # This is not a complete list of all ESM models!
- # See all ESM models at https://huggingface.co/models?filter=esm
-]
-
def rotate_half(x):
x1, x2 = tf.split(x, 2, axis=-1)
diff --git a/src/transformers/models/esm/tokenization_esm.py b/src/transformers/models/esm/tokenization_esm.py
index 478527c0ecd17f..27a889c87ea0b4 100644
--- a/src/transformers/models/esm/tokenization_esm.py
+++ b/src/transformers/models/esm/tokenization_esm.py
@@ -24,18 +24,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/esm2_t6_8M_UR50D": "https://huggingface.co/facebook/esm2_t6_8M_UR50D/resolve/main/vocab.txt",
- "facebook/esm2_t12_35M_UR50D": "https://huggingface.co/facebook/esm2_t12_35M_UR50D/resolve/main/vocab.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/esm2_t6_8M_UR50D": 1024,
- "facebook/esm2_t12_35M_UR50D": 1024,
-}
-
def load_vocab_file(vocab_file):
with open(vocab_file, "r") as f:
@@ -49,8 +37,6 @@ class EsmTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/falcon/configuration_falcon.py b/src/transformers/models/falcon/configuration_falcon.py
index fe0a450a24eb0c..23ed4acb5e3608 100644
--- a/src/transformers/models/falcon/configuration_falcon.py
+++ b/src/transformers/models/falcon/configuration_falcon.py
@@ -19,10 +19,8 @@
logger = logging.get_logger(__name__)
-FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "tiiuae/falcon-40b": "https://huggingface.co/tiiuae/falcon-40b/resolve/main/config.json",
- "tiiuae/falcon-7b": "https://huggingface.co/tiiuae/falcon-7b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FALCON_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FalconConfig(PretrainedConfig):
@@ -179,8 +177,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/falcon/modeling_falcon.py b/src/transformers/models/falcon/modeling_falcon.py
index d2c9125ddcffde..f1cff3f181ac56 100644
--- a/src/transformers/models/falcon/modeling_falcon.py
+++ b/src/transformers/models/falcon/modeling_falcon.py
@@ -58,14 +58,9 @@
logger = logging.get_logger(__name__)
-FALCON_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "tiiuae/falcon-40b",
- "tiiuae/falcon-40b-instruct",
- "tiiuae/falcon-7b",
- "tiiuae/falcon-7b-instruct",
- "tiiuae/falcon-rw-7b",
- "tiiuae/falcon-rw-1b",
-]
+from ..deprecated._archive_maps import FALCON_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
+
_CHECKPOINT_FOR_DOC = "Rocketknight1/falcon-rw-1b"
_CONFIG_FOR_DOC = "FalconConfig"
diff --git a/src/transformers/models/fastspeech2_conformer/configuration_fastspeech2_conformer.py b/src/transformers/models/fastspeech2_conformer/configuration_fastspeech2_conformer.py
index 46dc10adb2900e..adb038ad1b2a0b 100644
--- a/src/transformers/models/fastspeech2_conformer/configuration_fastspeech2_conformer.py
+++ b/src/transformers/models/fastspeech2_conformer/configuration_fastspeech2_conformer.py
@@ -23,17 +23,11 @@
logger = logging.get_logger(__name__)
-FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "espnet/fastspeech2_conformer": "https://huggingface.co/espnet/fastspeech2_conformer/raw/main/config.json",
-}
-
-FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "espnet/fastspeech2_conformer_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_hifigan/raw/main/config.json",
-}
-
-FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "espnet/fastspeech2_conformer_with_hifigan": "https://huggingface.co/espnet/fastspeech2_conformer_with_hifigan/raw/main/config.json",
-}
+from ..deprecated._archive_maps import ( # noqa: F401, E402
+ FASTSPEECH2_CONFORMER_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP, # noqa: F401, E402
+ FASTSPEECH2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP, # noqa: F401, E402
+ FASTSPEECH2_CONFORMER_WITH_HIFIGAN_PRETRAINED_CONFIG_ARCHIVE_MAP, # noqa: F401, E402
+)
class FastSpeech2ConformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py b/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
index cc57747c59a4be..c46ef2a8365f0c 100644
--- a/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
+++ b/src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
@@ -33,10 +33,8 @@
logger = logging.get_logger(__name__)
-FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "espnet/fastspeech2_conformer",
- # See all FastSpeech2Conformer models at https://huggingface.co/models?filter=fastspeech2_conformer
-]
+
+from ..deprecated._archive_maps import FASTSPEECH2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/fastspeech2_conformer/tokenization_fastspeech2_conformer.py b/src/transformers/models/fastspeech2_conformer/tokenization_fastspeech2_conformer.py
index c4fd208cef3b40..bc52006ad66579 100644
--- a/src/transformers/models/fastspeech2_conformer/tokenization_fastspeech2_conformer.py
+++ b/src/transformers/models/fastspeech2_conformer/tokenization_fastspeech2_conformer.py
@@ -27,18 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "espnet/fastspeech2_conformer": "https://huggingface.co/espnet/fastspeech2_conformer/raw/main/vocab.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- # Set to somewhat arbitrary large number as the model input
- # isn't constrained by the relative positional encoding
- "espnet/fastspeech2_conformer": 4096,
-}
-
class FastSpeech2ConformerTokenizer(PreTrainedTokenizer):
"""
@@ -61,9 +49,7 @@ class FastSpeech2ConformerTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/flaubert/configuration_flaubert.py b/src/transformers/models/flaubert/configuration_flaubert.py
index ba6d79891fa90d..fb4ef2992cbb88 100644
--- a/src/transformers/models/flaubert/configuration_flaubert.py
+++ b/src/transformers/models/flaubert/configuration_flaubert.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "flaubert/flaubert_small_cased": "https://huggingface.co/flaubert/flaubert_small_cased/resolve/main/config.json",
- "flaubert/flaubert_base_uncased": "https://huggingface.co/flaubert/flaubert_base_uncased/resolve/main/config.json",
- "flaubert/flaubert_base_cased": "https://huggingface.co/flaubert/flaubert_base_cased/resolve/main/config.json",
- "flaubert/flaubert_large_cased": "https://huggingface.co/flaubert/flaubert_large_cased/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FLAUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FlaubertConfig(PretrainedConfig):
diff --git a/src/transformers/models/flaubert/modeling_flaubert.py b/src/transformers/models/flaubert/modeling_flaubert.py
index 4786fc6d5781a7..49c2008cd10ac6 100644
--- a/src/transformers/models/flaubert/modeling_flaubert.py
+++ b/src/transformers/models/flaubert/modeling_flaubert.py
@@ -51,22 +51,17 @@
_CHECKPOINT_FOR_DOC = "flaubert/flaubert_base_cased"
_CONFIG_FOR_DOC = "FlaubertConfig"
-FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "flaubert/flaubert_small_cased",
- "flaubert/flaubert_base_uncased",
- "flaubert/flaubert_base_cased",
- "flaubert/flaubert_large_cased",
- # See all Flaubert models at https://huggingface.co/models?filter=flaubert
-]
+
+from ..deprecated._archive_maps import FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.xlm.modeling_xlm.create_sinusoidal_embeddings
def create_sinusoidal_embeddings(n_pos, dim, out):
position_enc = np.array([[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)] for pos in range(n_pos)])
+ out.requires_grad = False
out[:, 0::2] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
out[:, 1::2] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))
out.detach_()
- out.requires_grad = False
# Copied from transformers.models.xlm.modeling_xlm.get_masks
@@ -375,6 +370,10 @@ def _init_weights(self, module):
if isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
+ if isinstance(module, FlaubertModel) and self.config.sinusoidal_embeddings:
+ create_sinusoidal_embeddings(
+ self.config.max_position_embeddings, self.config.emb_dim, out=module.position_embeddings.weight
+ )
class FlaubertModel(FlaubertPreTrainedModel):
@@ -412,8 +411,6 @@ def __init__(self, config): # , dico, is_encoder, with_output):
# embeddings
self.position_embeddings = nn.Embedding(config.max_position_embeddings, self.dim)
- if config.sinusoidal_embeddings:
- create_sinusoidal_embeddings(config.max_position_embeddings, self.dim, out=self.position_embeddings.weight)
if config.n_langs > 1 and config.use_lang_emb:
self.lang_embeddings = nn.Embedding(self.n_langs, self.dim)
self.embeddings = nn.Embedding(self.n_words, self.dim, padding_idx=self.pad_index)
diff --git a/src/transformers/models/flaubert/modeling_tf_flaubert.py b/src/transformers/models/flaubert/modeling_tf_flaubert.py
index 23f66e56a98a99..08e573daa99458 100644
--- a/src/transformers/models/flaubert/modeling_tf_flaubert.py
+++ b/src/transformers/models/flaubert/modeling_tf_flaubert.py
@@ -67,9 +67,9 @@
_CHECKPOINT_FOR_DOC = "flaubert/flaubert_base_cased"
_CONFIG_FOR_DOC = "FlaubertConfig"
-TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- # See all Flaubert models at https://huggingface.co/models?filter=flaubert
-]
+
+from ..deprecated._archive_maps import TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
FLAUBERT_START_DOCSTRING = r"""
diff --git a/src/transformers/models/flaubert/tokenization_flaubert.py b/src/transformers/models/flaubert/tokenization_flaubert.py
index b1b34cc0f78da7..20f9926422064d 100644
--- a/src/transformers/models/flaubert/tokenization_flaubert.py
+++ b/src/transformers/models/flaubert/tokenization_flaubert.py
@@ -32,47 +32,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "flaubert/flaubert_small_cased": (
- "https://huggingface.co/flaubert/flaubert_small_cased/resolve/main/vocab.json"
- ),
- "flaubert/flaubert_base_uncased": (
- "https://huggingface.co/flaubert/flaubert_base_uncased/resolve/main/vocab.json"
- ),
- "flaubert/flaubert_base_cased": "https://huggingface.co/flaubert/flaubert_base_cased/resolve/main/vocab.json",
- "flaubert/flaubert_large_cased": (
- "https://huggingface.co/flaubert/flaubert_large_cased/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "flaubert/flaubert_small_cased": (
- "https://huggingface.co/flaubert/flaubert_small_cased/resolve/main/merges.txt"
- ),
- "flaubert/flaubert_base_uncased": (
- "https://huggingface.co/flaubert/flaubert_base_uncased/resolve/main/merges.txt"
- ),
- "flaubert/flaubert_base_cased": "https://huggingface.co/flaubert/flaubert_base_cased/resolve/main/merges.txt",
- "flaubert/flaubert_large_cased": (
- "https://huggingface.co/flaubert/flaubert_large_cased/resolve/main/merges.txt"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "flaubert/flaubert_small_cased": 512,
- "flaubert/flaubert_base_uncased": 512,
- "flaubert/flaubert_base_cased": 512,
- "flaubert/flaubert_large_cased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "flaubert/flaubert_small_cased": {"do_lowercase": False},
- "flaubert/flaubert_base_uncased": {"do_lowercase": True},
- "flaubert/flaubert_base_cased": {"do_lowercase": False},
- "flaubert/flaubert_large_cased": {"do_lowercase": False},
-}
-
def convert_to_unicode(text):
"""
@@ -216,9 +175,6 @@ class FlaubertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/flava/configuration_flava.py b/src/transformers/models/flava/configuration_flava.py
index 6ea4403e0fb555..2c8642bfd2759f 100644
--- a/src/transformers/models/flava/configuration_flava.py
+++ b/src/transformers/models/flava/configuration_flava.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/flava-full": "https://huggingface.co/facebook/flava-full/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FlavaImageConfig(PretrainedConfig):
diff --git a/src/transformers/models/flava/modeling_flava.py b/src/transformers/models/flava/modeling_flava.py
index 0e5cfe1b68c441..19f19d4c9d5666 100644
--- a/src/transformers/models/flava/modeling_flava.py
+++ b/src/transformers/models/flava/modeling_flava.py
@@ -55,10 +55,9 @@
_CONFIG_CLASS_FOR_MULTIMODAL_MODEL_DOC = "FlavaMultimodalConfig"
_EXPECTED_IMAGE_OUTPUT_SHAPE = [1, 197, 768]
-FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/flava-full",
- # See all flava models at https://huggingface.co/models?filter=flava
-]
+from ..deprecated._archive_maps import FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
+
FLAVA_CODEBOOK_PRETRAINED_MODEL_ARCHIVE_LIST = ["facebook/flava-image-codebook"]
LOGIT_SCALE_CLAMP_MIN = 0
LOGIT_SCALE_CLAMP_MAX = 4.6052
diff --git a/src/transformers/models/fnet/configuration_fnet.py b/src/transformers/models/fnet/configuration_fnet.py
index 993feb676dac80..4678cae92e2a29 100644
--- a/src/transformers/models/fnet/configuration_fnet.py
+++ b/src/transformers/models/fnet/configuration_fnet.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-FNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/fnet-base": "https://huggingface.co/google/fnet-base/resolve/main/config.json",
- "google/fnet-large": "https://huggingface.co/google/fnet-large/resolve/main/config.json",
- # See all FNet models at https://huggingface.co/models?filter=fnet
-}
+
+from ..deprecated._archive_maps import FNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/fnet/modeling_fnet.py b/src/transformers/models/fnet/modeling_fnet.py
index dac75178d5f4e6..5724faee56cf85 100755
--- a/src/transformers/models/fnet/modeling_fnet.py
+++ b/src/transformers/models/fnet/modeling_fnet.py
@@ -59,11 +59,8 @@
_CHECKPOINT_FOR_DOC = "google/fnet-base"
_CONFIG_FOR_DOC = "FNetConfig"
-FNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/fnet-base",
- "google/fnet-large",
- # See all FNet models at https://huggingface.co/models?filter=fnet
-]
+
+from ..deprecated._archive_maps import FNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Adapted from https://github.com/google-research/google-research/blob/master/f_net/fourier.py
diff --git a/src/transformers/models/fnet/tokenization_fnet.py b/src/transformers/models/fnet/tokenization_fnet.py
index 919d60531a3536..a38114eb6d01ae 100644
--- a/src/transformers/models/fnet/tokenization_fnet.py
+++ b/src/transformers/models/fnet/tokenization_fnet.py
@@ -28,17 +28,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/fnet-base": "https://huggingface.co/google/fnet-base/resolve/main/spiece.model",
- "google/fnet-large": "https://huggingface.co/google/fnet-large/resolve/main/spiece.model",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/fnet-base": 512,
- "google/fnet-large": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -96,8 +85,6 @@ class FNetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "token_type_ids"]
def __init__(
diff --git a/src/transformers/models/fnet/tokenization_fnet_fast.py b/src/transformers/models/fnet/tokenization_fnet_fast.py
index 2179751e558e60..f279ad9ca7d0e2 100644
--- a/src/transformers/models/fnet/tokenization_fnet_fast.py
+++ b/src/transformers/models/fnet/tokenization_fnet_fast.py
@@ -32,21 +32,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/fnet-base": "https://huggingface.co/google/fnet-base/resolve/main/spiece.model",
- "google/fnet-large": "https://huggingface.co/google/fnet-large/resolve/main/spiece.model",
- },
- "tokenizer_file": {
- "google/fnet-base": "https://huggingface.co/google/fnet-base/resolve/main/tokenizer.json",
- "google/fnet-large": "https://huggingface.co/google/fnet-large/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/fnet-base": 512,
- "google/fnet-large": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -87,8 +72,6 @@ class FNetTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "token_type_ids"]
slow_tokenizer_class = FNetTokenizer
diff --git a/src/transformers/models/focalnet/configuration_focalnet.py b/src/transformers/models/focalnet/configuration_focalnet.py
index c1d4e2e86cb1f2..7f590b9c2c00a4 100644
--- a/src/transformers/models/focalnet/configuration_focalnet.py
+++ b/src/transformers/models/focalnet/configuration_focalnet.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-FOCALNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/focalnet-tiny": "https://huggingface.co/microsoft/focalnet-tiny/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FOCALNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FocalNetConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/focalnet/modeling_focalnet.py b/src/transformers/models/focalnet/modeling_focalnet.py
index b0033c855985e7..a452f4171d1b6a 100644
--- a/src/transformers/models/focalnet/modeling_focalnet.py
+++ b/src/transformers/models/focalnet/modeling_focalnet.py
@@ -54,10 +54,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-FOCALNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/focalnet-tiny",
- # See all FocalNet models at https://huggingface.co/models?filter=focalnet
-]
+from ..deprecated._archive_maps import FOCALNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/fsmt/configuration_fsmt.py b/src/transformers/models/fsmt/configuration_fsmt.py
index 493e6b6bf5d67d..68abe47c019aba 100644
--- a/src/transformers/models/fsmt/configuration_fsmt.py
+++ b/src/transformers/models/fsmt/configuration_fsmt.py
@@ -21,7 +21,8 @@
logger = logging.get_logger(__name__)
-FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+from ..deprecated._archive_maps import FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class DecoderConfig(PretrainedConfig):
diff --git a/src/transformers/models/fsmt/tokenization_fsmt.py b/src/transformers/models/fsmt/tokenization_fsmt.py
index a631f0747648cb..8b0be1f8be2498 100644
--- a/src/transformers/models/fsmt/tokenization_fsmt.py
+++ b/src/transformers/models/fsmt/tokenization_fsmt.py
@@ -33,26 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "src_vocab_file": {
- "stas/tiny-wmt19-en-de": "https://huggingface.co/stas/tiny-wmt19-en-de/resolve/main/vocab-src.json"
- },
- "tgt_vocab_file": {
- "stas/tiny-wmt19-en-de": "https://huggingface.co/stas/tiny-wmt19-en-de/resolve/main/vocab-tgt.json"
- },
- "merges_file": {"stas/tiny-wmt19-en-de": "https://huggingface.co/stas/tiny-wmt19-en-de/resolve/main/merges.txt"},
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"stas/tiny-wmt19-en-de": 1024}
-PRETRAINED_INIT_CONFIGURATION = {
- "stas/tiny-wmt19-en-de": {
- "langs": ["en", "de"],
- "model_max_length": 1024,
- "special_tokens_map_file": None,
- "full_tokenizer_file": None,
- }
-}
-
def get_pairs(word):
"""
@@ -179,9 +159,6 @@ class FSMTTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/funnel/configuration_funnel.py b/src/transformers/models/funnel/configuration_funnel.py
index 228216163b246c..0b49c22fb4c345 100644
--- a/src/transformers/models/funnel/configuration_funnel.py
+++ b/src/transformers/models/funnel/configuration_funnel.py
@@ -20,22 +20,8 @@
logger = logging.get_logger(__name__)
-FUNNEL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "funnel-transformer/small": "https://huggingface.co/funnel-transformer/small/resolve/main/config.json",
- "funnel-transformer/small-base": "https://huggingface.co/funnel-transformer/small-base/resolve/main/config.json",
- "funnel-transformer/medium": "https://huggingface.co/funnel-transformer/medium/resolve/main/config.json",
- "funnel-transformer/medium-base": "https://huggingface.co/funnel-transformer/medium-base/resolve/main/config.json",
- "funnel-transformer/intermediate": (
- "https://huggingface.co/funnel-transformer/intermediate/resolve/main/config.json"
- ),
- "funnel-transformer/intermediate-base": (
- "https://huggingface.co/funnel-transformer/intermediate-base/resolve/main/config.json"
- ),
- "funnel-transformer/large": "https://huggingface.co/funnel-transformer/large/resolve/main/config.json",
- "funnel-transformer/large-base": "https://huggingface.co/funnel-transformer/large-base/resolve/main/config.json",
- "funnel-transformer/xlarge": "https://huggingface.co/funnel-transformer/xlarge/resolve/main/config.json",
- "funnel-transformer/xlarge-base": "https://huggingface.co/funnel-transformer/xlarge-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FUNNEL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FunnelConfig(PretrainedConfig):
diff --git a/src/transformers/models/funnel/modeling_funnel.py b/src/transformers/models/funnel/modeling_funnel.py
index 50f8df3743a82b..ce0c7789487d8f 100644
--- a/src/transformers/models/funnel/modeling_funnel.py
+++ b/src/transformers/models/funnel/modeling_funnel.py
@@ -49,18 +49,9 @@
_CONFIG_FOR_DOC = "FunnelConfig"
_CHECKPOINT_FOR_DOC = "funnel-transformer/small"
-FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "funnel-transformer/small", # B4-4-4H768
- "funnel-transformer/small-base", # B4-4-4H768, no decoder
- "funnel-transformer/medium", # B6-3x2-3x2H768
- "funnel-transformer/medium-base", # B6-3x2-3x2H768, no decoder
- "funnel-transformer/intermediate", # B6-6-6H768
- "funnel-transformer/intermediate-base", # B6-6-6H768, no decoder
- "funnel-transformer/large", # B8-8-8H1024
- "funnel-transformer/large-base", # B8-8-8H1024, no decoder
- "funnel-transformer/xlarge-base", # B10-10-10H1024
- "funnel-transformer/xlarge", # B10-10-10H1024, no decoder
-]
+
+from ..deprecated._archive_maps import FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
INF = 1e6
diff --git a/src/transformers/models/funnel/modeling_tf_funnel.py b/src/transformers/models/funnel/modeling_tf_funnel.py
index 4e4a544523f6e8..b50b96df1c5408 100644
--- a/src/transformers/models/funnel/modeling_tf_funnel.py
+++ b/src/transformers/models/funnel/modeling_tf_funnel.py
@@ -62,18 +62,9 @@
_CONFIG_FOR_DOC = "FunnelConfig"
-TF_FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "funnel-transformer/small", # B4-4-4H768
- "funnel-transformer/small-base", # B4-4-4H768, no decoder
- "funnel-transformer/medium", # B6-3x2-3x2H768
- "funnel-transformer/medium-base", # B6-3x2-3x2H768, no decoder
- "funnel-transformer/intermediate", # B6-6-6H768
- "funnel-transformer/intermediate-base", # B6-6-6H768, no decoder
- "funnel-transformer/large", # B8-8-8H1024
- "funnel-transformer/large-base", # B8-8-8H1024, no decoder
- "funnel-transformer/xlarge-base", # B10-10-10H1024
- "funnel-transformer/xlarge", # B10-10-10H1024, no decoder
-]
+
+from ..deprecated._archive_maps import TF_FUNNEL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
INF = 1e6
diff --git a/src/transformers/models/funnel/tokenization_funnel.py b/src/transformers/models/funnel/tokenization_funnel.py
index 9b0d3c1b6c5221..a1580deccfb3f7 100644
--- a/src/transformers/models/funnel/tokenization_funnel.py
+++ b/src/transformers/models/funnel/tokenization_funnel.py
@@ -40,31 +40,6 @@
"xlarge-base",
]
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "funnel-transformer/small": "https://huggingface.co/funnel-transformer/small/resolve/main/vocab.txt",
- "funnel-transformer/small-base": "https://huggingface.co/funnel-transformer/small-base/resolve/main/vocab.txt",
- "funnel-transformer/medium": "https://huggingface.co/funnel-transformer/medium/resolve/main/vocab.txt",
- "funnel-transformer/medium-base": (
- "https://huggingface.co/funnel-transformer/medium-base/resolve/main/vocab.txt"
- ),
- "funnel-transformer/intermediate": (
- "https://huggingface.co/funnel-transformer/intermediate/resolve/main/vocab.txt"
- ),
- "funnel-transformer/intermediate-base": (
- "https://huggingface.co/funnel-transformer/intermediate-base/resolve/main/vocab.txt"
- ),
- "funnel-transformer/large": "https://huggingface.co/funnel-transformer/large/resolve/main/vocab.txt",
- "funnel-transformer/large-base": "https://huggingface.co/funnel-transformer/large-base/resolve/main/vocab.txt",
- "funnel-transformer/xlarge": "https://huggingface.co/funnel-transformer/xlarge/resolve/main/vocab.txt",
- "funnel-transformer/xlarge-base": (
- "https://huggingface.co/funnel-transformer/xlarge-base/resolve/main/vocab.txt"
- ),
- }
-}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {f"funnel-transformer/{name}": 512 for name in _model_names}
-PRETRAINED_INIT_CONFIGURATION = {f"funnel-transformer/{name}": {"do_lower_case": True} for name in _model_names}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -135,9 +110,6 @@ class FunnelTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
cls_token_type_id: int = 2
def __init__(
diff --git a/src/transformers/models/funnel/tokenization_funnel_fast.py b/src/transformers/models/funnel/tokenization_funnel_fast.py
index 17946eb74b5839..9ff2a3bfefc57e 100644
--- a/src/transformers/models/funnel/tokenization_funnel_fast.py
+++ b/src/transformers/models/funnel/tokenization_funnel_fast.py
@@ -41,55 +41,6 @@
"xlarge-base",
]
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "funnel-transformer/small": "https://huggingface.co/funnel-transformer/small/resolve/main/vocab.txt",
- "funnel-transformer/small-base": "https://huggingface.co/funnel-transformer/small-base/resolve/main/vocab.txt",
- "funnel-transformer/medium": "https://huggingface.co/funnel-transformer/medium/resolve/main/vocab.txt",
- "funnel-transformer/medium-base": (
- "https://huggingface.co/funnel-transformer/medium-base/resolve/main/vocab.txt"
- ),
- "funnel-transformer/intermediate": (
- "https://huggingface.co/funnel-transformer/intermediate/resolve/main/vocab.txt"
- ),
- "funnel-transformer/intermediate-base": (
- "https://huggingface.co/funnel-transformer/intermediate-base/resolve/main/vocab.txt"
- ),
- "funnel-transformer/large": "https://huggingface.co/funnel-transformer/large/resolve/main/vocab.txt",
- "funnel-transformer/large-base": "https://huggingface.co/funnel-transformer/large-base/resolve/main/vocab.txt",
- "funnel-transformer/xlarge": "https://huggingface.co/funnel-transformer/xlarge/resolve/main/vocab.txt",
- "funnel-transformer/xlarge-base": (
- "https://huggingface.co/funnel-transformer/xlarge-base/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "funnel-transformer/small": "https://huggingface.co/funnel-transformer/small/resolve/main/tokenizer.json",
- "funnel-transformer/small-base": (
- "https://huggingface.co/funnel-transformer/small-base/resolve/main/tokenizer.json"
- ),
- "funnel-transformer/medium": "https://huggingface.co/funnel-transformer/medium/resolve/main/tokenizer.json",
- "funnel-transformer/medium-base": (
- "https://huggingface.co/funnel-transformer/medium-base/resolve/main/tokenizer.json"
- ),
- "funnel-transformer/intermediate": (
- "https://huggingface.co/funnel-transformer/intermediate/resolve/main/tokenizer.json"
- ),
- "funnel-transformer/intermediate-base": (
- "https://huggingface.co/funnel-transformer/intermediate-base/resolve/main/tokenizer.json"
- ),
- "funnel-transformer/large": "https://huggingface.co/funnel-transformer/large/resolve/main/tokenizer.json",
- "funnel-transformer/large-base": (
- "https://huggingface.co/funnel-transformer/large-base/resolve/main/tokenizer.json"
- ),
- "funnel-transformer/xlarge": "https://huggingface.co/funnel-transformer/xlarge/resolve/main/tokenizer.json",
- "funnel-transformer/xlarge-base": (
- "https://huggingface.co/funnel-transformer/xlarge-base/resolve/main/tokenizer.json"
- ),
- },
-}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {f"funnel-transformer/{name}": 512 for name in _model_names}
-PRETRAINED_INIT_CONFIGURATION = {f"funnel-transformer/{name}": {"do_lower_case": True} for name in _model_names}
-
class FunnelTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -136,10 +87,7 @@ class FunnelTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = FunnelTokenizer
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
cls_token_type_id: int = 2
def __init__(
diff --git a/src/transformers/models/fuyu/configuration_fuyu.py b/src/transformers/models/fuyu/configuration_fuyu.py
index 9376ccb5ef4ee4..40b09492d8f161 100644
--- a/src/transformers/models/fuyu/configuration_fuyu.py
+++ b/src/transformers/models/fuyu/configuration_fuyu.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-FUYU_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "adept/fuyu-8b": "https://huggingface.co/adept/fuyu-8b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import FUYU_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class FuyuConfig(PretrainedConfig):
@@ -200,8 +199,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/fuyu/modeling_fuyu.py b/src/transformers/models/fuyu/modeling_fuyu.py
index 94d9704631fbac..f94bac569fc9bb 100644
--- a/src/transformers/models/fuyu/modeling_fuyu.py
+++ b/src/transformers/models/fuyu/modeling_fuyu.py
@@ -290,7 +290,9 @@ def forward(
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
if image_patches is not None and past_key_values is None:
patch_embeddings = [
- self.vision_embed_tokens(patch.to(self.vision_embed_tokens.weight.dtype)).squeeze(0)
+ self.vision_embed_tokens(patch.to(self.vision_embed_tokens.weight.dtype))
+ .squeeze(0)
+ .to(inputs_embeds.device)
for patch in image_patches
]
inputs_embeds = self.gather_continuous_embeddings(
diff --git a/src/transformers/models/gemma/configuration_gemma.py b/src/transformers/models/gemma/configuration_gemma.py
index cf7be344e82bc1..87e5a2c6693f0d 100644
--- a/src/transformers/models/gemma/configuration_gemma.py
+++ b/src/transformers/models/gemma/configuration_gemma.py
@@ -20,7 +20,8 @@
logger = logging.get_logger(__name__)
-GEMMA_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+from ..deprecated._archive_maps import GEMMA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GemmaConfig(PretrainedConfig):
diff --git a/src/transformers/models/gemma/modeling_gemma.py b/src/transformers/models/gemma/modeling_gemma.py
index 8360b4080781ff..2d93c43425f99a 100644
--- a/src/transformers/models/gemma/modeling_gemma.py
+++ b/src/transformers/models/gemma/modeling_gemma.py
@@ -719,10 +719,6 @@ def _setup_cache(self, cache_cls, max_batch_size, max_cache_len: Optional[int] =
"make sure to use `sdpa` in the mean time, and open an issue at https://github.com/huggingface/transformers"
)
- if max_cache_len > self.model.causal_mask.shape[-1] or self.device != self.model.causal_mask.device:
- causal_mask = torch.full((max_cache_len, max_cache_len), fill_value=1, device=self.device)
- self.register_buffer("causal_mask", torch.triu(causal_mask, diagonal=1), persistent=False)
-
for layer in self.model.layers:
weights = layer.self_attn.o_proj.weight
layer.self_attn.past_key_value = cache_cls(
@@ -975,7 +971,7 @@ def _update_causal_mask(self, attention_mask, input_tensor, cache_position):
dtype, device = input_tensor.dtype, input_tensor.device
min_dtype = torch.finfo(dtype).min
sequence_length = input_tensor.shape[1]
- if hasattr(self.layers[0].self_attn, "past_key_value"): # static cache
+ if hasattr(getattr(self.layers[0], "self_attn", {}), "past_key_value"): # static cache
target_length = self.config.max_position_embeddings
else: # dynamic cache
target_length = (
@@ -1147,7 +1143,7 @@ def prepare_inputs_for_generation(
# TODO joao: standardize interface for the different Cache classes and remove of this if
has_static_cache = False
if past_key_values is None:
- past_key_values = getattr(self.model.layers[0].self_attn, "past_key_value", None)
+ past_key_values = getattr(getattr(self.model.layers[0], "self_attn", {}), "past_key_value", None)
has_static_cache = past_key_values is not None
past_length = 0
diff --git a/src/transformers/models/git/configuration_git.py b/src/transformers/models/git/configuration_git.py
index bfc2b4bf745bc7..0c28bbabff6b0b 100644
--- a/src/transformers/models/git/configuration_git.py
+++ b/src/transformers/models/git/configuration_git.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-GIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/git-base": "https://huggingface.co/microsoft/git-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import GIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GitVisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/git/modeling_git.py b/src/transformers/models/git/modeling_git.py
index c4baed9e0bc98c..c8953d498428ea 100644
--- a/src/transformers/models/git/modeling_git.py
+++ b/src/transformers/models/git/modeling_git.py
@@ -45,10 +45,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/git-base"
_CONFIG_FOR_DOC = "GitConfig"
-GIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/git-base",
- # See all GIT models at https://huggingface.co/models?filter=git
-]
+
+from ..deprecated._archive_maps import GIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/glpn/configuration_glpn.py b/src/transformers/models/glpn/configuration_glpn.py
index 5408ee94a8ade4..c3341192169aa0 100644
--- a/src/transformers/models/glpn/configuration_glpn.py
+++ b/src/transformers/models/glpn/configuration_glpn.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "vinvino02/glpn-kitti": "https://huggingface.co/vinvino02/glpn-kitti/resolve/main/config.json",
- # See all GLPN models at https://huggingface.co/models?filter=glpn
-}
+
+from ..deprecated._archive_maps import GLPN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GLPNConfig(PretrainedConfig):
diff --git a/src/transformers/models/glpn/modeling_glpn.py b/src/transformers/models/glpn/modeling_glpn.py
index d2ddef5c41e1e5..e5d30b62720c9d 100755
--- a/src/transformers/models/glpn/modeling_glpn.py
+++ b/src/transformers/models/glpn/modeling_glpn.py
@@ -46,10 +46,8 @@
_CHECKPOINT_FOR_DOC = "vinvino02/glpn-kitti"
_EXPECTED_OUTPUT_SHAPE = [1, 512, 15, 20]
-GLPN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "vinvino02/glpn-kitti",
- # See all GLPN models at https://huggingface.co/models?filter=glpn
-]
+
+from ..deprecated._archive_maps import GLPN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/gpt2/configuration_gpt2.py b/src/transformers/models/gpt2/configuration_gpt2.py
index 395e2b4873fec8..45495c0012fdd8 100644
--- a/src/transformers/models/gpt2/configuration_gpt2.py
+++ b/src/transformers/models/gpt2/configuration_gpt2.py
@@ -25,13 +25,8 @@
logger = logging.get_logger(__name__)
-GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/config.json",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/config.json",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/config.json",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/config.json",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPT2Config(PretrainedConfig):
diff --git a/src/transformers/models/gpt2/modeling_gpt2.py b/src/transformers/models/gpt2/modeling_gpt2.py
index e1b357cefb649c..1409a3fc3f0fcb 100644
--- a/src/transformers/models/gpt2/modeling_gpt2.py
+++ b/src/transformers/models/gpt2/modeling_gpt2.py
@@ -22,6 +22,7 @@
from typing import Optional, Tuple, Union
import torch
+import torch.nn.functional as F
import torch.utils.checkpoint
from torch import nn
from torch.cuda.amp import autocast
@@ -42,6 +43,8 @@
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
logging,
replace_return_docstrings,
)
@@ -49,19 +52,31 @@
from .configuration_gpt2 import GPT2Config
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input
+
+
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "openai-community/gpt2"
_CONFIG_FOR_DOC = "GPT2Config"
-GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai-community/gpt2",
- "openai-community/gpt2-medium",
- "openai-community/gpt2-large",
- "openai-community/gpt2-xl",
- "distilbert/distilgpt2",
- # See all GPT-2 models at https://huggingface.co/models?filter=gpt2
-]
+
+from ..deprecated._archive_maps import GPT2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
def load_tf_weights_in_gpt2(model, config, gpt2_checkpoint_path):
@@ -123,7 +138,7 @@ def load_tf_weights_in_gpt2(model, config, gpt2_checkpoint_path):
class GPT2Attention(nn.Module):
def __init__(self, config, is_cross_attention=False, layer_idx=None):
super().__init__()
-
+ self.config = config
max_positions = config.max_position_embeddings
self.register_buffer(
"bias",
@@ -161,6 +176,7 @@ def __init__(self, config, is_cross_attention=False, layer_idx=None):
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
+ self.is_causal = True
self.pruned_heads = set()
@@ -341,6 +357,210 @@ def forward(
return outputs # a, present, (attentions)
+class GPT2FlashAttention2(GPT2Attention):
+ """
+ GPT2 flash attention module. This module inherits from `GPT2Attention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def forward(
+ self,
+ hidden_states: Optional[Tuple[torch.FloatTensor]],
+ layer_past: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
+ bsz, _, _ = hidden_states.size()
+ if encoder_hidden_states is not None:
+ if not hasattr(self, "q_attn"):
+ raise ValueError(
+ "If class is used as cross attention, the weights `q_attn` have to be defined. "
+ "Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
+ )
+
+ query = self.q_attn(hidden_states)
+ key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
+ attention_mask = encoder_attention_mask
+ else:
+ query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
+
+ query = self._split_heads(query, self.num_heads, self.head_dim)
+ key = self._split_heads(key, self.num_heads, self.head_dim)
+ value = self._split_heads(value, self.num_heads, self.head_dim)
+
+ if layer_past is not None:
+ past_key = layer_past[0]
+ past_value = layer_past[1]
+ key = torch.cat((past_key, key), dim=-2)
+ value = torch.cat((past_value, value), dim=-2)
+
+ present = None
+ if use_cache is True:
+ present = (key, value)
+
+ query_length = query.shape[2]
+ tgt_len = key.shape[2]
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ query = query.transpose(1, 2).view(bsz, query_length, self.num_heads, self.head_dim)
+ key = key.transpose(1, 2).view(bsz, tgt_len, self.num_heads, self.head_dim)
+ value = value.transpose(1, 2).view(bsz, tgt_len, self.num_heads, self.head_dim)
+
+ attn_dropout = self.attn_dropout.p if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (LlamaRMSNorm handles it correctly)
+
+ if query.dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.c_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query = query.to(target_dtype)
+ key = key.to(target_dtype)
+ value = value.to(target_dtype)
+
+ attn_output = self._flash_attention_forward(
+ query, key, value, attention_mask, query_length, dropout=attn_dropout
+ )
+
+ attn_weights_reshaped = attn_output.reshape(bsz, query_length, self.num_heads * self.head_dim)
+ attn_output = self.c_proj(attn_weights_reshaped)
+ attn_output = self.resid_dropout(attn_output)
+
+ outputs = (attn_output, present)
+ if output_attentions:
+ outputs += (attn_weights_reshaped,)
+
+ return outputs
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
+ def _flash_attention_forward(
+ self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
class GPT2MLP(nn.Module):
def __init__(self, intermediate_size, config):
super().__init__()
@@ -358,18 +578,25 @@ def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.Fl
return hidden_states
+GPT2_ATTENTION_CLASSES = {
+ "eager": GPT2Attention,
+ "flash_attention_2": GPT2FlashAttention2,
+}
+
+
class GPT2Block(nn.Module):
def __init__(self, config, layer_idx=None):
super().__init__()
hidden_size = config.hidden_size
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
+ attention_class = GPT2_ATTENTION_CLASSES[config._attn_implementation]
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
- self.attn = GPT2Attention(config, layer_idx=layer_idx)
+ self.attn = attention_class(config=config, layer_idx=layer_idx)
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
if config.add_cross_attention:
- self.crossattention = GPT2Attention(config, is_cross_attention=True, layer_idx=layer_idx)
+ self.crossattention = attention_class(config=config, is_cross_attention=True, layer_idx=layer_idx)
self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.mlp = GPT2MLP(inner_dim, config)
@@ -449,6 +676,7 @@ class GPT2PreTrainedModel(PreTrainedModel):
supports_gradient_checkpointing = True
_no_split_modules = ["GPT2Block"]
_skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
def __init__(self, *inputs, **kwargs):
super().__init__(*inputs, **kwargs)
@@ -679,6 +907,7 @@ def __init__(self, config):
self.model_parallel = False
self.device_map = None
self.gradient_checkpointing = False
+ self._attn_implementation = config._attn_implementation
# Initialize weights and apply final processing
self.post_init()
@@ -796,25 +1025,26 @@ def forward(
position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0)
- # GPT2Attention mask.
+ # Attention mask.
if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
+ if self._attn_implementation == "flash_attention_2":
+ attention_mask = attention_mask if 0 in attention_mask else None
+ else:
+ # We create a 3D attention mask from a 2D tensor mask.
+ # Sizes are [batch_size, 1, 1, to_seq_length]
+ # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
+ # this attention mask is more simple than the triangular masking of causal attention
+ # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
+ attention_mask = attention_mask[:, None, None, :]
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and the dtype's smallest value for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
+ attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
@@ -823,7 +1053,8 @@ def forward(
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
- encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ if self._attn_implementation != "flash_attention_2":
+ encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_attention_mask = None
diff --git a/src/transformers/models/gpt2/modeling_tf_gpt2.py b/src/transformers/models/gpt2/modeling_tf_gpt2.py
index 2c17593e26808c..26a4e7a398ae8d 100644
--- a/src/transformers/models/gpt2/modeling_tf_gpt2.py
+++ b/src/transformers/models/gpt2/modeling_tf_gpt2.py
@@ -58,14 +58,8 @@
_CHECKPOINT_FOR_DOC = "openai-community/gpt2"
_CONFIG_FOR_DOC = "GPT2Config"
-TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai-community/gpt2",
- "openai-community/gpt2-medium",
- "openai-community/gpt2-large",
- "openai-community/gpt2-xl",
- "distilbert/distilgpt2",
- # See all GPT-2 models at https://huggingface.co/models?filter=openai-community/gpt2
-]
+
+from ..deprecated._archive_maps import TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFAttention(keras.layers.Layer):
diff --git a/src/transformers/models/gpt2/tokenization_gpt2.py b/src/transformers/models/gpt2/tokenization_gpt2.py
index 801e997344a194..36f3ca8fadb527 100644
--- a/src/transformers/models/gpt2/tokenization_gpt2.py
+++ b/src/transformers/models/gpt2/tokenization_gpt2.py
@@ -33,31 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/vocab.json",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/vocab.json",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/vocab.json",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/vocab.json",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/vocab.json",
- },
- "merges_file": {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/merges.txt",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/merges.txt",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/merges.txt",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/merges.txt",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai-community/gpt2": 1024,
- "openai-community/gpt2-medium": 1024,
- "openai-community/gpt2-large": 1024,
- "openai-community/gpt2-xl": 1024,
- "distilbert/distilgpt2": 1024,
-}
-
@lru_cache()
def bytes_to_unicode():
@@ -154,8 +129,6 @@ class GPT2Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/gpt2/tokenization_gpt2_fast.py b/src/transformers/models/gpt2/tokenization_gpt2_fast.py
index c4e49d23d146e4..fb3a5d4a0ce3f2 100644
--- a/src/transformers/models/gpt2/tokenization_gpt2_fast.py
+++ b/src/transformers/models/gpt2/tokenization_gpt2_fast.py
@@ -30,38 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/vocab.json",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/vocab.json",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/vocab.json",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/vocab.json",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/vocab.json",
- },
- "merges_file": {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/merges.txt",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/merges.txt",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/merges.txt",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/merges.txt",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "openai-community/gpt2": "https://huggingface.co/openai-community/gpt2/resolve/main/tokenizer.json",
- "openai-community/gpt2-medium": "https://huggingface.co/openai-community/gpt2-medium/resolve/main/tokenizer.json",
- "openai-community/gpt2-large": "https://huggingface.co/openai-community/gpt2-large/resolve/main/tokenizer.json",
- "openai-community/gpt2-xl": "https://huggingface.co/openai-community/gpt2-xl/resolve/main/tokenizer.json",
- "distilbert/distilgpt2": "https://huggingface.co/distilbert/distilgpt2/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai-community/gpt2": 1024,
- "openai-community/gpt2-medium": 1024,
- "openai-community/gpt2-large": 1024,
- "openai-community/gpt2-xl": 1024,
- "distilbert/distilgpt2": 1024,
-}
-
class GPT2TokenizerFast(PreTrainedTokenizerFast):
"""
@@ -115,8 +83,6 @@ class GPT2TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = GPT2Tokenizer
diff --git a/src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py b/src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py
index 9cbaf3e18485f5..ef5e02ffdc43af 100644
--- a/src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py
+++ b/src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-GPT_BIGCODE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "bigcode/gpt_bigcode-santacoder": "https://huggingface.co/bigcode/gpt_bigcode-santacoder/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import GPT_BIGCODE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTBigCodeConfig(PretrainedConfig):
diff --git a/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py b/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py
index 25938342c2efb2..4e3b8498480c9e 100644
--- a/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py
+++ b/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py
@@ -52,10 +52,8 @@
_CHECKPOINT_FOR_DOC = "bigcode/gpt_bigcode-santacoder"
_CONFIG_FOR_DOC = "GPTBigCodeConfig"
-GPT_BIGCODE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "bigcode/gpt_bigcode-santacoder",
- # See all GPTBigCode models at https://huggingface.co/models?filter=gpt_bigcode
-]
+
+from ..deprecated._archive_maps import GPT_BIGCODE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Fused kernels
diff --git a/src/transformers/models/gpt_neo/configuration_gpt_neo.py b/src/transformers/models/gpt_neo/configuration_gpt_neo.py
index 842614b280c574..411b392180b018 100644
--- a/src/transformers/models/gpt_neo/configuration_gpt_neo.py
+++ b/src/transformers/models/gpt_neo/configuration_gpt_neo.py
@@ -25,10 +25,8 @@
logger = logging.get_logger(__name__)
-GPT_NEO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "EleutherAI/gpt-neo-1.3B": "https://huggingface.co/EleutherAI/gpt-neo-1.3B/resolve/main/config.json",
- # See all GPTNeo models at https://huggingface.co/models?filter=gpt_neo
-}
+
+from ..deprecated._archive_maps import GPT_NEO_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTNeoConfig(PretrainedConfig):
diff --git a/src/transformers/models/gpt_neo/modeling_gpt_neo.py b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
index 5e1ca2f1915fd9..2fbf4677ca6f44 100755
--- a/src/transformers/models/gpt_neo/modeling_gpt_neo.py
+++ b/src/transformers/models/gpt_neo/modeling_gpt_neo.py
@@ -67,10 +67,9 @@
_CONFIG_FOR_DOC = "GPTNeoConfig"
-GPT_NEO_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "EleutherAI/gpt-neo-1.3B",
- # See all GPTNeo models at https://huggingface.co/models?filter=gpt_neo
-]
+
+from ..deprecated._archive_maps import GPT_NEO_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
_CHECKPOINT_FOR_DOC = "EleutherAI/gpt-neo-1.3B"
diff --git a/src/transformers/models/gpt_neox/configuration_gpt_neox.py b/src/transformers/models/gpt_neox/configuration_gpt_neox.py
index 99fbb2f7be7998..7f583f139448f9 100644
--- a/src/transformers/models/gpt_neox/configuration_gpt_neox.py
+++ b/src/transformers/models/gpt_neox/configuration_gpt_neox.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-GPT_NEOX_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "EleutherAI/gpt-neox-20b": "https://huggingface.co/EleutherAI/gpt-neox-20b/resolve/main/config.json",
- # See all GPTNeoX models at https://huggingface.co/models?filter=gpt_neox
-}
+
+from ..deprecated._archive_maps import GPT_NEOX_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTNeoXConfig(PretrainedConfig):
@@ -105,6 +103,7 @@ class GPTNeoXConfig(PretrainedConfig):
```"""
model_type = "gpt_neox"
+ keys_to_ignore_at_inference = ["past_key_values"]
def __init__(
self,
@@ -168,8 +167,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/gpt_neox/modeling_gpt_neox.py b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
index 2ab552f118c120..83c99202ac9379 100755
--- a/src/transformers/models/gpt_neox/modeling_gpt_neox.py
+++ b/src/transformers/models/gpt_neox/modeling_gpt_neox.py
@@ -52,10 +52,8 @@
_REAL_CHECKPOINT_FOR_DOC = "EleutherAI/gpt-neox-20b"
_CONFIG_FOR_DOC = "GPTNeoXConfig"
-GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "EleutherAI/gpt-neox-20b",
- # See all GPTNeoX models at https://huggingface.co/models?filter=gpt_neox
-]
+
+from ..deprecated._archive_maps import GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
diff --git a/src/transformers/models/gpt_neox/tokenization_gpt_neox_fast.py b/src/transformers/models/gpt_neox/tokenization_gpt_neox_fast.py
index 16ed6b1e753e54..dceb512e8fc106 100644
--- a/src/transformers/models/gpt_neox/tokenization_gpt_neox_fast.py
+++ b/src/transformers/models/gpt_neox/tokenization_gpt_neox_fast.py
@@ -26,16 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "tokenizer_file": {
- "EleutherAI/gpt-neox-20b": "https://huggingface.co/EleutherAI/gpt-neox-20b/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "gpt-neox-20b": 2048,
-}
-
class GPTNeoXTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -91,8 +81,6 @@ class GPTNeoXTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/gpt_neox_japanese/configuration_gpt_neox_japanese.py b/src/transformers/models/gpt_neox_japanese/configuration_gpt_neox_japanese.py
index ddf3d4dec8b9d0..8ee73257b64c7c 100644
--- a/src/transformers/models/gpt_neox_japanese/configuration_gpt_neox_japanese.py
+++ b/src/transformers/models/gpt_neox_japanese/configuration_gpt_neox_japanese.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-GPT_NEOX_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "abeja/gpt-neox-japanese-2.7b": "https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import GPT_NEOX_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTNeoXJapaneseConfig(PretrainedConfig):
diff --git a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
index 4ac7c4d4e0025f..9fdff2c8387006 100755
--- a/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
+++ b/src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
@@ -34,10 +34,8 @@
_CHECKPOINT_FOR_DOC = "abeja/gpt-neox-japanese-2.7b"
_CONFIG_FOR_DOC = "GPTNeoXJapaneseConfig"
-GPT_NEOX_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST = {
- "https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/config.json",
- # See all GPTNeoXJapanese models at https://huggingface.co/models?filter=gpt_neox_japanese
-}
+
+from ..deprecated._archive_maps import GPT_NEOX_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class GPTNeoXJapanesePreTrainedModel(PreTrainedModel):
diff --git a/src/transformers/models/gpt_neox_japanese/tokenization_gpt_neox_japanese.py b/src/transformers/models/gpt_neox_japanese/tokenization_gpt_neox_japanese.py
index fae50aa8ffdbb0..fd0fe796dcab02 100644
--- a/src/transformers/models/gpt_neox_japanese/tokenization_gpt_neox_japanese.py
+++ b/src/transformers/models/gpt_neox_japanese/tokenization_gpt_neox_japanese.py
@@ -29,19 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "emoji_file": "emoji.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "abeja/gpt-neox-japanese-2.7b": "https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/vocab.txt",
- },
- "emoji_file": {
- "abeja/gpt-neox-japanese-2.7b": "https://huggingface.co/abeja/gpt-neox-japanese-2.7b/resolve/main/emoji.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "abeja/gpt-neox-japanese-2.7b": 2048,
-}
-
def load_vocab_and_emoji(vocab_file, emoji_file):
"""Loads a vocabulary file and emoji file into a dictionary."""
@@ -112,8 +99,6 @@ class GPTNeoXJapaneseTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/gpt_sw3/tokenization_gpt_sw3.py b/src/transformers/models/gpt_sw3/tokenization_gpt_sw3.py
index d740c13d3594a2..7bb2e51f04a078 100644
--- a/src/transformers/models/gpt_sw3/tokenization_gpt_sw3.py
+++ b/src/transformers/models/gpt_sw3/tokenization_gpt_sw3.py
@@ -19,28 +19,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "AI-Sweden-Models/gpt-sw3-126m": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-126m/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-356m": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-356m/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-1.3b": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-1.3b/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-6.7b": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-6.7b/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-6.7b-v2": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-6.7b-v2/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-20b": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-20b/resolve/main/spiece.model",
- "AI-Sweden-Models/gpt-sw3-40b": "https://huggingface.co/AI-Sweden-Models/gpt-sw3-20b/resolve/main/spiece.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "AI-Sweden-Models/gpt-sw3-126m": 2048,
- "AI-Sweden-Models/gpt-sw3-356m": 2048,
- "AI-Sweden-Models/gpt-sw3-1.3b": 2048,
- "AI-Sweden-Models/gpt-sw3-6.7b": 2048,
- "AI-Sweden-Models/gpt-sw3-6.7b-v2": 2048,
- "AI-Sweden-Models/gpt-sw3-20b": 2048,
- "AI-Sweden-Models/gpt-sw3-40b": 2048,
-}
-
class GPTSw3Tokenizer(PreTrainedTokenizer):
"""
@@ -105,8 +83,6 @@ class GPTSw3Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/gptj/configuration_gptj.py b/src/transformers/models/gptj/configuration_gptj.py
index 47b12242793213..56d6042764a19a 100644
--- a/src/transformers/models/gptj/configuration_gptj.py
+++ b/src/transformers/models/gptj/configuration_gptj.py
@@ -24,10 +24,8 @@
logger = logging.get_logger(__name__)
-GPTJ_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "EleutherAI/gpt-j-6B": "https://huggingface.co/EleutherAI/gpt-j-6B/resolve/main/config.json",
- # See all GPT-J models at https://huggingface.co/models?filter=gpt_j
-}
+
+from ..deprecated._archive_maps import GPTJ_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTJConfig(PretrainedConfig):
diff --git a/src/transformers/models/gptj/modeling_gptj.py b/src/transformers/models/gptj/modeling_gptj.py
index 144dbba0552745..3c6ddac4ecf4ca 100644
--- a/src/transformers/models/gptj/modeling_gptj.py
+++ b/src/transformers/models/gptj/modeling_gptj.py
@@ -57,10 +57,7 @@
_CONFIG_FOR_DOC = "GPTJConfig"
-GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "EleutherAI/gpt-j-6B",
- # See all GPT-J models at https://huggingface.co/models?filter=gptj
-]
+from ..deprecated._archive_maps import GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
diff --git a/src/transformers/models/gptj/modeling_tf_gptj.py b/src/transformers/models/gptj/modeling_tf_gptj.py
index d948fc63c09ad4..5c315b5b66f049 100644
--- a/src/transformers/models/gptj/modeling_tf_gptj.py
+++ b/src/transformers/models/gptj/modeling_tf_gptj.py
@@ -55,11 +55,6 @@
_CHECKPOINT_FOR_DOC = "EleutherAI/gpt-j-6B"
_CONFIG_FOR_DOC = "GPTJConfig"
-GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "EleutherAI/gpt-j-6B",
- # See all GPT-J models at https://huggingface.co/models?filter=gptj
-]
-
def create_sinusoidal_positions(num_pos: int, dim: int) -> tf.Tensor:
inv_freq = tf.cast(1.0 / (10000 ** (tf.range(0, dim, 2) / dim)), tf.float32)
diff --git a/src/transformers/models/gptsan_japanese/configuration_gptsan_japanese.py b/src/transformers/models/gptsan_japanese/configuration_gptsan_japanese.py
index c25e4b0e1ea2a9..e0a17d1c114aef 100644
--- a/src/transformers/models/gptsan_japanese/configuration_gptsan_japanese.py
+++ b/src/transformers/models/gptsan_japanese/configuration_gptsan_japanese.py
@@ -19,11 +19,8 @@
logger = logging.get_logger(__name__)
-GPTSAN_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "tanreinama/GPTSAN-2.8B-spout_is_uniform": (
- "https://huggingface.co/tanreinama/GPTSAN-2.8B-spout_is_uniform/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import GPTSAN_JAPANESE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GPTSanJapaneseConfig(PretrainedConfig):
diff --git a/src/transformers/models/gptsan_japanese/modeling_gptsan_japanese.py b/src/transformers/models/gptsan_japanese/modeling_gptsan_japanese.py
index d9b7003050b11a..59252bc567a462 100644
--- a/src/transformers/models/gptsan_japanese/modeling_gptsan_japanese.py
+++ b/src/transformers/models/gptsan_japanese/modeling_gptsan_japanese.py
@@ -44,10 +44,8 @@
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
-GPTSAN_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Tanrei/GPTSAN-japanese",
- # See all GPTSAN-japanese models at https://huggingface.co/models?filter=gptsan-japanese
-]
+
+from ..deprecated._archive_maps import GPTSAN_JAPANESE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.switch_transformers.modeling_switch_transformers.router_z_loss_func
diff --git a/src/transformers/models/gptsan_japanese/tokenization_gptsan_japanese.py b/src/transformers/models/gptsan_japanese/tokenization_gptsan_japanese.py
index df3f94dc1e8965..2a2b465d8c4909 100644
--- a/src/transformers/models/gptsan_japanese/tokenization_gptsan_japanese.py
+++ b/src/transformers/models/gptsan_japanese/tokenization_gptsan_japanese.py
@@ -37,19 +37,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "emoji_file": "emoji.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "Tanrei/GPTSAN-japanese": "https://huggingface.co/Tanrei/GPTSAN-japanese/blob/main/vocab.txt",
- },
- "emoji_file": {
- "Tanrei/GPTSAN-japanese": "https://huggingface.co/Tanrei/GPTSAN-japanese/blob/main/emoji.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "Tanrei/GPTSAN-japanese": 1280,
-}
-
def load_vocab_and_emoji(vocab_file, emoji_file):
"""Loads a vocabulary file and emoji file into a dictionary."""
@@ -150,8 +137,6 @@ class GPTSanJapaneseTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "token_type_ids"]
def __init__(
diff --git a/src/transformers/models/graphormer/configuration_graphormer.py b/src/transformers/models/graphormer/configuration_graphormer.py
index 9d49fbea29448d..8d1f1359843174 100644
--- a/src/transformers/models/graphormer/configuration_graphormer.py
+++ b/src/transformers/models/graphormer/configuration_graphormer.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- # pcqm4mv1 now deprecated
- "graphormer-base": "https://huggingface.co/clefourrier/graphormer-base-pcqm4mv2/resolve/main/config.json",
- # See all Graphormer models at https://huggingface.co/models?filter=graphormer
-}
+
+from ..deprecated._archive_maps import GRAPHORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GraphormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/graphormer/modeling_graphormer.py b/src/transformers/models/graphormer/modeling_graphormer.py
index ec56d8eda0d877..8b484fe1e433e5 100755
--- a/src/transformers/models/graphormer/modeling_graphormer.py
+++ b/src/transformers/models/graphormer/modeling_graphormer.py
@@ -37,11 +37,7 @@
_CONFIG_FOR_DOC = "GraphormerConfig"
-GRAPHORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "clefourrier/graphormer-base-pcqm4mv1",
- "clefourrier/graphormer-base-pcqm4mv2",
- # See all Graphormer models at https://huggingface.co/models?filter=graphormer
-]
+from ..deprecated._archive_maps import GRAPHORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def quant_noise(module: nn.Module, p: float, block_size: int):
diff --git a/src/transformers/models/groupvit/configuration_groupvit.py b/src/transformers/models/groupvit/configuration_groupvit.py
index bfec885244948c..3c46c277f3519e 100644
--- a/src/transformers/models/groupvit/configuration_groupvit.py
+++ b/src/transformers/models/groupvit/configuration_groupvit.py
@@ -30,9 +30,8 @@
logger = logging.get_logger(__name__)
-GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "nvidia/groupvit-gcc-yfcc": "https://huggingface.co/nvidia/groupvit-gcc-yfcc/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class GroupViTTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/groupvit/modeling_groupvit.py b/src/transformers/models/groupvit/modeling_groupvit.py
index c99c96ec87f89d..ec383b0fcfa6cb 100644
--- a/src/transformers/models/groupvit/modeling_groupvit.py
+++ b/src/transformers/models/groupvit/modeling_groupvit.py
@@ -43,10 +43,8 @@
_CHECKPOINT_FOR_DOC = "nvidia/groupvit-gcc-yfcc"
-GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nvidia/groupvit-gcc-yfcc",
- # See all GroupViT models at https://huggingface.co/models?filter=groupvit
-]
+
+from ..deprecated._archive_maps import GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# contrastive loss function, adapted from
diff --git a/src/transformers/models/groupvit/modeling_tf_groupvit.py b/src/transformers/models/groupvit/modeling_tf_groupvit.py
index d04f9afb7d3599..31c76083e02287 100644
--- a/src/transformers/models/groupvit/modeling_tf_groupvit.py
+++ b/src/transformers/models/groupvit/modeling_tf_groupvit.py
@@ -66,10 +66,8 @@
_CHECKPOINT_FOR_DOC = "nvidia/groupvit-gcc-yfcc"
-TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nvidia/groupvit-gcc-yfcc",
- # See all GroupViT models at https://huggingface.co/models?filter=groupvit
-]
+
+from ..deprecated._archive_maps import TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/herbert/tokenization_herbert.py b/src/transformers/models/herbert/tokenization_herbert.py
index 1747a59c6fc2fa..6e37922028e7be 100644
--- a/src/transformers/models/herbert/tokenization_herbert.py
+++ b/src/transformers/models/herbert/tokenization_herbert.py
@@ -29,18 +29,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/vocab.json"
- },
- "merges_file": {
- "allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/merges.txt"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"allegro/herbert-base-cased": 514}
-PRETRAINED_INIT_CONFIGURATION = {}
-
# Copied from transformers.models.xlm.tokenization_xlm.get_pairs
def get_pairs(word):
@@ -302,9 +290,6 @@ class HerbertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/herbert/tokenization_herbert_fast.py b/src/transformers/models/herbert/tokenization_herbert_fast.py
index 67e38c1c5ee7bd..4cd5db58f1b93a 100644
--- a/src/transformers/models/herbert/tokenization_herbert_fast.py
+++ b/src/transformers/models/herbert/tokenization_herbert_fast.py
@@ -24,18 +24,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/vocab.json"
- },
- "merges_file": {
- "allegro/herbert-base-cased": "https://huggingface.co/allegro/herbert-base-cased/resolve/main/merges.txt"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"allegro/herbert-base-cased": 514}
-PRETRAINED_INIT_CONFIGURATION = {}
-
class HerbertTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -57,9 +45,6 @@ class HerbertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = HerbertTokenizer
def __init__(
diff --git a/src/transformers/models/hubert/configuration_hubert.py b/src/transformers/models/hubert/configuration_hubert.py
index 3067c6efb185fb..00a3244a31074d 100644
--- a/src/transformers/models/hubert/configuration_hubert.py
+++ b/src/transformers/models/hubert/configuration_hubert.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-HUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/hubert-base-ls960": "https://huggingface.co/facebook/hubert-base-ls960/resolve/main/config.json",
- # See all Hubert models at https://huggingface.co/models?filter=hubert
-}
+
+from ..deprecated._archive_maps import HUBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class HubertConfig(PretrainedConfig):
diff --git a/src/transformers/models/hubert/modeling_hubert.py b/src/transformers/models/hubert/modeling_hubert.py
index a45dcb2d11fe1f..f9e223f9a384d0 100755
--- a/src/transformers/models/hubert/modeling_hubert.py
+++ b/src/transformers/models/hubert/modeling_hubert.py
@@ -58,10 +58,7 @@
_SEQ_CLASS_EXPECTED_LOSS = 8.53
-HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/hubert-base-ls960",
- # See all Hubert models at https://huggingface.co/models?filter=hubert
-]
+from ..deprecated._archive_maps import HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
diff --git a/src/transformers/models/hubert/modeling_tf_hubert.py b/src/transformers/models/hubert/modeling_tf_hubert.py
index 258763beb13208..0dc696f8a78917 100644
--- a/src/transformers/models/hubert/modeling_tf_hubert.py
+++ b/src/transformers/models/hubert/modeling_tf_hubert.py
@@ -45,10 +45,9 @@
_CONFIG_FOR_DOC = "HubertConfig"
-TF_HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/hubert-base-ls960",
- # See all Hubert models at https://huggingface.co/models?filter=hubert
-]
+
+from ..deprecated._archive_maps import TF_HUBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/ibert/configuration_ibert.py b/src/transformers/models/ibert/configuration_ibert.py
index 249061ceae3273..94e040d417ef8d 100644
--- a/src/transformers/models/ibert/configuration_ibert.py
+++ b/src/transformers/models/ibert/configuration_ibert.py
@@ -25,13 +25,8 @@
logger = logging.get_logger(__name__)
-IBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "kssteven/ibert-roberta-base": "https://huggingface.co/kssteven/ibert-roberta-base/resolve/main/config.json",
- "kssteven/ibert-roberta-large": "https://huggingface.co/kssteven/ibert-roberta-large/resolve/main/config.json",
- "kssteven/ibert-roberta-large-mnli": (
- "https://huggingface.co/kssteven/ibert-roberta-large-mnli/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import IBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class IBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/ibert/modeling_ibert.py b/src/transformers/models/ibert/modeling_ibert.py
index 0dcdaaf6998fd2..54c37f507e3a63 100644
--- a/src/transformers/models/ibert/modeling_ibert.py
+++ b/src/transformers/models/ibert/modeling_ibert.py
@@ -47,11 +47,8 @@
_CHECKPOINT_FOR_DOC = "kssteven/ibert-roberta-base"
_CONFIG_FOR_DOC = "IBertConfig"
-IBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "kssteven/ibert-roberta-base",
- "kssteven/ibert-roberta-large",
- "kssteven/ibert-roberta-large-mnli",
-]
+
+from ..deprecated._archive_maps import IBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class IBertEmbeddings(nn.Module):
diff --git a/src/transformers/models/idefics/configuration_idefics.py b/src/transformers/models/idefics/configuration_idefics.py
index a61c96e0a418c0..07a92432aee3af 100644
--- a/src/transformers/models/idefics/configuration_idefics.py
+++ b/src/transformers/models/idefics/configuration_idefics.py
@@ -25,10 +25,8 @@
logger = logging.get_logger(__name__)
-IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "HuggingFaceM4/idefics-9b": "https://huggingface.co/HuggingFaceM4/idefics-9b/blob/main/config.json",
- "HuggingFaceM4/idefics-80b": "https://huggingface.co/HuggingFaceM4/idefics-80b/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class IdeficsVisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/idefics/modeling_idefics.py b/src/transformers/models/idefics/modeling_idefics.py
index 0023fd2014940d..47024d24e60623 100644
--- a/src/transformers/models/idefics/modeling_idefics.py
+++ b/src/transformers/models/idefics/modeling_idefics.py
@@ -48,11 +48,8 @@
_CONFIG_FOR_DOC = "IdeficsConfig"
-IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "HuggingFaceM4/idefics-9b",
- "HuggingFaceM4/idefics-80b",
- # See all Idefics models at https://huggingface.co/models?filter=idefics
-]
+
+from ..deprecated._archive_maps import IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/imagegpt/configuration_imagegpt.py b/src/transformers/models/imagegpt/configuration_imagegpt.py
index 85f44a4e344d2a..2a8d62f9b5e629 100644
--- a/src/transformers/models/imagegpt/configuration_imagegpt.py
+++ b/src/transformers/models/imagegpt/configuration_imagegpt.py
@@ -27,11 +27,8 @@
logger = logging.get_logger(__name__)
-IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai/imagegpt-small": "",
- "openai/imagegpt-medium": "",
- "openai/imagegpt-large": "",
-}
+
+from ..deprecated._archive_maps import IMAGEGPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ImageGPTConfig(PretrainedConfig):
diff --git a/src/transformers/models/imagegpt/modeling_imagegpt.py b/src/transformers/models/imagegpt/modeling_imagegpt.py
index 33f7ee99c4f692..3b9be17246e81e 100755
--- a/src/transformers/models/imagegpt/modeling_imagegpt.py
+++ b/src/transformers/models/imagegpt/modeling_imagegpt.py
@@ -42,12 +42,8 @@
_CHECKPOINT_FOR_DOC = "openai/imagegpt-small"
_CONFIG_FOR_DOC = "ImageGPTConfig"
-IMAGEGPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/imagegpt-small",
- "openai/imagegpt-medium",
- "openai/imagegpt-large",
- # See all Image GPT models at https://huggingface.co/models?filter=imagegpt
-]
+
+from ..deprecated._archive_maps import IMAGEGPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_imagegpt(model, config, imagegpt_checkpoint_path):
diff --git a/src/transformers/models/informer/configuration_informer.py b/src/transformers/models/informer/configuration_informer.py
index dedf09bb2bbbb9..93b3f3556c97fe 100644
--- a/src/transformers/models/informer/configuration_informer.py
+++ b/src/transformers/models/informer/configuration_informer.py
@@ -22,12 +22,8 @@
logger = logging.get_logger(__name__)
-INFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "huggingface/informer-tourism-monthly": (
- "https://huggingface.co/huggingface/informer-tourism-monthly/resolve/main/config.json"
- ),
- # See all Informer models at https://huggingface.co/models?filter=informer
-}
+
+from ..deprecated._archive_maps import INFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class InformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/informer/modeling_informer.py b/src/transformers/models/informer/modeling_informer.py
index 0fe108a6402425..cf20477f375dd9 100644
--- a/src/transformers/models/informer/modeling_informer.py
+++ b/src/transformers/models/informer/modeling_informer.py
@@ -40,10 +40,7 @@
_CONFIG_FOR_DOC = "InformerConfig"
-INFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "huggingface/informer-tourism-monthly",
- # See all Informer models at https://huggingface.co/models?filter=informer
-]
+from ..deprecated._archive_maps import INFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesFeatureEmbedder with TimeSeries->Informer
@@ -893,7 +890,7 @@ def _init_weights(self, module):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
+ elif isinstance(module, nn.Embedding) and not isinstance(module, InformerSinusoidalPositionalEmbedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
diff --git a/src/transformers/models/instructblip/configuration_instructblip.py b/src/transformers/models/instructblip/configuration_instructblip.py
index 98c06d2fe899c4..152389d337f19b 100644
--- a/src/transformers/models/instructblip/configuration_instructblip.py
+++ b/src/transformers/models/instructblip/configuration_instructblip.py
@@ -25,9 +25,8 @@
logger = logging.get_logger(__name__)
-INSTRUCTBLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Salesforce/instruct-blip-flan-t5": "https://huggingface.co/Salesforce/instruct-blip-flan-t5/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import INSTRUCTBLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class InstructBlipVisionConfig(PretrainedConfig):
diff --git a/src/transformers/models/instructblip/modeling_instructblip.py b/src/transformers/models/instructblip/modeling_instructblip.py
index ba78b9143d343f..b18d46723179e2 100644
--- a/src/transformers/models/instructblip/modeling_instructblip.py
+++ b/src/transformers/models/instructblip/modeling_instructblip.py
@@ -47,10 +47,8 @@
_CHECKPOINT_FOR_DOC = "Salesforce/instructblip-flan-t5-xl"
-INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Salesforce/instructblip-flan-t5-xl",
- # See all InstructBLIP models at https://huggingface.co/models?filter=instructblip
-]
+
+from ..deprecated._archive_maps import INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/jukebox/configuration_jukebox.py b/src/transformers/models/jukebox/configuration_jukebox.py
index d4a8f0a0072cfc..4c680513102488 100644
--- a/src/transformers/models/jukebox/configuration_jukebox.py
+++ b/src/transformers/models/jukebox/configuration_jukebox.py
@@ -23,10 +23,9 @@
logger = logging.get_logger(__name__)
-JUKEBOX_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai/jukebox-5b-lyrics": "https://huggingface.co/openai/jukebox-5b-lyrics/blob/main/config.json",
- "openai/jukebox-1b-lyrics": "https://huggingface.co/openai/jukebox-1b-lyrics/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import JUKEBOX_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
+
_LARGE_ATTENTION = [
"block_attn",
diff --git a/src/transformers/models/jukebox/modeling_jukebox.py b/src/transformers/models/jukebox/modeling_jukebox.py
index 236d1f4ff37bca..282cfdc5b4439b 100755
--- a/src/transformers/models/jukebox/modeling_jukebox.py
+++ b/src/transformers/models/jukebox/modeling_jukebox.py
@@ -33,11 +33,8 @@
logger = logging.get_logger(__name__)
-JUKEBOX_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/jukebox-1b-lyrics",
- "openai/jukebox-5b-lyrics",
- # See all Jukebox models at https://huggingface.co/models?filter=jukebox
-]
+
+from ..deprecated._archive_maps import JUKEBOX_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def filter_logits(logits, top_k=0, top_p=0.0, filter_value=-float("Inf")):
diff --git a/src/transformers/models/jukebox/tokenization_jukebox.py b/src/transformers/models/jukebox/tokenization_jukebox.py
index 0eb4b0961f9daa..cd478d6f6bb140 100644
--- a/src/transformers/models/jukebox/tokenization_jukebox.py
+++ b/src/transformers/models/jukebox/tokenization_jukebox.py
@@ -39,22 +39,6 @@
"genres_file": "genres.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "artists_file": {
- "jukebox": "https://huggingface.co/ArthurZ/jukebox/blob/main/artists.json",
- },
- "genres_file": {
- "jukebox": "https://huggingface.co/ArthurZ/jukebox/blob/main/genres.json",
- },
- "lyrics_file": {
- "jukebox": "https://huggingface.co/ArthurZ/jukebox/blob/main/lyrics.json",
- },
-}
-
-PRETRAINED_LYRIC_TOKENS_SIZES = {
- "jukebox": 512,
-}
-
class JukeboxTokenizer(PreTrainedTokenizer):
"""
@@ -112,8 +96,6 @@ class JukeboxTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_lyric_input_size = PRETRAINED_LYRIC_TOKENS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/kosmos2/configuration_kosmos2.py b/src/transformers/models/kosmos2/configuration_kosmos2.py
index 198016a92871cc..ae5afd637b28be 100644
--- a/src/transformers/models/kosmos2/configuration_kosmos2.py
+++ b/src/transformers/models/kosmos2/configuration_kosmos2.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-KOSMOS2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/kosmos-2-patch14-224": (
- "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/config.json"
- ),
- # See all KOSMOS-2 models at https://huggingface.co/models?filter=kosmos-2
-}
+
+from ..deprecated._archive_maps import KOSMOS2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Kosmos2TextConfig(PretrainedConfig):
diff --git a/src/transformers/models/kosmos2/modeling_kosmos2.py b/src/transformers/models/kosmos2/modeling_kosmos2.py
index 7bbbbe8d765c23..2e3a945c331592 100644
--- a/src/transformers/models/kosmos2/modeling_kosmos2.py
+++ b/src/transformers/models/kosmos2/modeling_kosmos2.py
@@ -46,10 +46,8 @@
_CONFIG_FOR_DOC = Kosmos2Config
-KOSMOS2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/kosmos-2-patch14-224",
- # See all KOSMOS-2 models at https://huggingface.co/models?filter=kosmos-2
-]
+
+from ..deprecated._archive_maps import KOSMOS2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
diff --git a/src/transformers/models/layoutlm/configuration_layoutlm.py b/src/transformers/models/layoutlm/configuration_layoutlm.py
index 77d62ded403b92..c7c6886fedbec5 100644
--- a/src/transformers/models/layoutlm/configuration_layoutlm.py
+++ b/src/transformers/models/layoutlm/configuration_layoutlm.py
@@ -23,14 +23,8 @@
logger = logging.get_logger(__name__)
-LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/layoutlm-base-uncased": (
- "https://huggingface.co/microsoft/layoutlm-base-uncased/resolve/main/config.json"
- ),
- "microsoft/layoutlm-large-uncased": (
- "https://huggingface.co/microsoft/layoutlm-large-uncased/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LayoutLMConfig(PretrainedConfig):
diff --git a/src/transformers/models/layoutlm/modeling_layoutlm.py b/src/transformers/models/layoutlm/modeling_layoutlm.py
index c2ecede73d3955..c570fdb124adc1 100644
--- a/src/transformers/models/layoutlm/modeling_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_layoutlm.py
@@ -43,10 +43,8 @@
_CONFIG_FOR_DOC = "LayoutLMConfig"
_CHECKPOINT_FOR_DOC = "microsoft/layoutlm-base-uncased"
-LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "layoutlm-base-uncased",
- "layoutlm-large-uncased",
-]
+
+from ..deprecated._archive_maps import LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
LayoutLMLayerNorm = nn.LayerNorm
@@ -613,7 +611,6 @@ class LayoutLMPreTrainedModel(PreTrainedModel):
"""
config_class = LayoutLMConfig
- pretrained_model_archive_map = LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST
base_model_prefix = "layoutlm"
supports_gradient_checkpointing = True
diff --git a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
index 21e7c64069d9a0..0125fc3ed60232 100644
--- a/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
+++ b/src/transformers/models/layoutlm/modeling_tf_layoutlm.py
@@ -54,10 +54,8 @@
_CONFIG_FOR_DOC = "LayoutLMConfig"
-TF_LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/layoutlm-base-uncased",
- "microsoft/layoutlm-large-uncased",
-]
+
+from ..deprecated._archive_maps import TF_LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFLayoutLMEmbeddings(keras.layers.Layer):
diff --git a/src/transformers/models/layoutlm/tokenization_layoutlm.py b/src/transformers/models/layoutlm/tokenization_layoutlm.py
index 6105d5d77c15dd..836b1aab8800a9 100644
--- a/src/transformers/models/layoutlm/tokenization_layoutlm.py
+++ b/src/transformers/models/layoutlm/tokenization_layoutlm.py
@@ -27,27 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlm-base-uncased": (
- "https://huggingface.co/microsoft/layoutlm-base-uncased/resolve/main/vocab.txt"
- ),
- "microsoft/layoutlm-large-uncased": (
- "https://huggingface.co/microsoft/layoutlm-large-uncased/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlm-base-uncased": 512,
- "microsoft/layoutlm-large-uncased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/layoutlm-base-uncased": {"do_lower_case": True},
- "microsoft/layoutlm-large-uncased": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -115,9 +94,6 @@ class LayoutLMTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/layoutlm/tokenization_layoutlm_fast.py b/src/transformers/models/layoutlm/tokenization_layoutlm_fast.py
index c0bc1072f7f5f1..fa3d95132b0eff 100644
--- a/src/transformers/models/layoutlm/tokenization_layoutlm_fast.py
+++ b/src/transformers/models/layoutlm/tokenization_layoutlm_fast.py
@@ -28,35 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlm-base-uncased": (
- "https://huggingface.co/microsoft/layoutlm-base-uncased/resolve/main/vocab.txt"
- ),
- "microsoft/layoutlm-large-uncased": (
- "https://huggingface.co/microsoft/layoutlm-large-uncased/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "microsoft/layoutlm-base-uncased": (
- "https://huggingface.co/microsoft/layoutlm-base-uncased/resolve/main/tokenizer.json"
- ),
- "microsoft/layoutlm-large-uncased": (
- "https://huggingface.co/microsoft/layoutlm-large-uncased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlm-base-uncased": 512,
- "microsoft/layoutlm-large-uncased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/layoutlm-base-uncased": {"do_lower_case": True},
- "microsoft/layoutlm-large-uncased": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with Bert->LayoutLM,BERT->LayoutLM
class LayoutLMTokenizerFast(PreTrainedTokenizerFast):
@@ -100,9 +71,6 @@ class LayoutLMTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = LayoutLMTokenizer
def __init__(
diff --git a/src/transformers/models/layoutlmv2/configuration_layoutlmv2.py b/src/transformers/models/layoutlmv2/configuration_layoutlmv2.py
index 839cfd18ed8d75..4528923a5d7598 100644
--- a/src/transformers/models/layoutlmv2/configuration_layoutlmv2.py
+++ b/src/transformers/models/layoutlmv2/configuration_layoutlmv2.py
@@ -20,11 +20,9 @@
logger = logging.get_logger(__name__)
-LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "layoutlmv2-base-uncased": "https://huggingface.co/microsoft/layoutlmv2-base-uncased/resolve/main/config.json",
- "layoutlmv2-large-uncased": "https://huggingface.co/microsoft/layoutlmv2-large-uncased/resolve/main/config.json",
- # See all LayoutLMv2 models at https://huggingface.co/models?filter=layoutlmv2
-}
+
+from ..deprecated._archive_maps import LAYOUTLMV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
+
# soft dependency
if is_detectron2_available():
diff --git a/src/transformers/models/layoutlmv2/modeling_layoutlmv2.py b/src/transformers/models/layoutlmv2/modeling_layoutlmv2.py
index 4a85923cb9b811..41939b044a8438 100755
--- a/src/transformers/models/layoutlmv2/modeling_layoutlmv2.py
+++ b/src/transformers/models/layoutlmv2/modeling_layoutlmv2.py
@@ -53,11 +53,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/layoutlmv2-base-uncased"
_CONFIG_FOR_DOC = "LayoutLMv2Config"
-LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/layoutlmv2-base-uncased",
- "microsoft/layoutlmv2-large-uncased",
- # See all LayoutLMv2 models at https://huggingface.co/models?filter=layoutlmv2
-]
+
+from ..deprecated._archive_maps import LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class LayoutLMv2Embeddings(nn.Module):
@@ -489,7 +486,6 @@ class LayoutLMv2PreTrainedModel(PreTrainedModel):
"""
config_class = LayoutLMv2Config
- pretrained_model_archive_map = LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST
base_model_prefix = "layoutlmv2"
def _init_weights(self, module):
diff --git a/src/transformers/models/layoutlmv2/tokenization_layoutlmv2.py b/src/transformers/models/layoutlmv2/tokenization_layoutlmv2.py
index b09bd08715ff5c..c9a138391e0f25 100644
--- a/src/transformers/models/layoutlmv2/tokenization_layoutlmv2.py
+++ b/src/transformers/models/layoutlmv2/tokenization_layoutlmv2.py
@@ -36,29 +36,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlmv2-base-uncased": (
- "https://huggingface.co/microsoft/layoutlmv2-base-uncased/resolve/main/vocab.txt"
- ),
- "microsoft/layoutlmv2-large-uncased": (
- "https://huggingface.co/microsoft/layoutlmv2-large-uncased/resolve/main/vocab.txt"
- ),
- }
-}
-
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlmv2-base-uncased": 512,
- "microsoft/layoutlmv2-large-uncased": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/layoutlmv2-base-uncased": {"do_lower_case": True},
- "microsoft/layoutlmv2-large-uncased": {"do_lower_case": True},
-}
-
LAYOUTLMV2_ENCODE_KWARGS_DOCSTRING = r"""
add_special_tokens (`bool`, *optional*, defaults to `True`):
@@ -218,9 +195,6 @@ class LayoutLMv2Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
def __init__(
self,
diff --git a/src/transformers/models/layoutlmv2/tokenization_layoutlmv2_fast.py b/src/transformers/models/layoutlmv2/tokenization_layoutlmv2_fast.py
index bed4e133aa3c5c..aa2bf6b3226b18 100644
--- a/src/transformers/models/layoutlmv2/tokenization_layoutlmv2_fast.py
+++ b/src/transformers/models/layoutlmv2/tokenization_layoutlmv2_fast.py
@@ -45,27 +45,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlmv2-base-uncased": (
- "https://huggingface.co/microsoft/layoutlmv2-base-uncased/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "microsoft/layoutlmv2-base-uncased": (
- "https://huggingface.co/microsoft/layoutlmv2-base-uncased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlmv2-base-uncased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/layoutlmv2-base-uncased": {"do_lower_case": True},
-}
-
class LayoutLMv2TokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -114,9 +93,6 @@ class LayoutLMv2TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = LayoutLMv2Tokenizer
def __init__(
diff --git a/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py b/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py
index d7cddb6002f3e8..d6f9b6c9f10f9a 100644
--- a/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py
@@ -32,9 +32,8 @@
logger = logging.get_logger(__name__)
-LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LayoutLMv3Config(PretrainedConfig):
diff --git a/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py b/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
index 3148155a435047..0db2bd775fe439 100644
--- a/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
@@ -41,11 +41,9 @@
_CONFIG_FOR_DOC = "LayoutLMv3Config"
-LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/layoutlmv3-base",
- "microsoft/layoutlmv3-large",
- # See all LayoutLMv3 models at https://huggingface.co/models?filter=layoutlmv3
-]
+
+from ..deprecated._archive_maps import LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
LAYOUTLMV3_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
diff --git a/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py b/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
index b52cfba54c0a7a..531eb59d876359 100644
--- a/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
@@ -57,11 +57,9 @@
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]],
]
-TF_LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/layoutlmv3-base",
- "microsoft/layoutlmv3-large",
- # See all LayoutLMv3 models at https://huggingface.co/models?filter=layoutlmv3
-]
+
+from ..deprecated._archive_maps import TF_LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py b/src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py
index 351e811b814f6d..89f899f22f4ecc 100644
--- a/src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py
+++ b/src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py
@@ -40,22 +40,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/raw/main/vocab.json",
- "microsoft/layoutlmv3-large": "https://huggingface.co/microsoft/layoutlmv3-large/raw/main/vocab.json",
- },
- "merges_file": {
- "microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/raw/main/merges.txt",
- "microsoft/layoutlmv3-large": "https://huggingface.co/microsoft/layoutlmv3-large/raw/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlmv3-base": 512,
- "microsoft/layoutlmv3-large": 512,
-}
-
LAYOUTLMV3_ENCODE_KWARGS_DOCSTRING = r"""
add_special_tokens (`bool`, *optional*, defaults to `True`):
@@ -270,8 +254,6 @@ class LayoutLMv3Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "bbox"]
def __init__(
diff --git a/src/transformers/models/layoutlmv3/tokenization_layoutlmv3_fast.py b/src/transformers/models/layoutlmv3/tokenization_layoutlmv3_fast.py
index 3d7445e4493117..07bedf36133ad8 100644
--- a/src/transformers/models/layoutlmv3/tokenization_layoutlmv3_fast.py
+++ b/src/transformers/models/layoutlmv3/tokenization_layoutlmv3_fast.py
@@ -45,22 +45,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/raw/main/vocab.json",
- "microsoft/layoutlmv3-large": "https://huggingface.co/microsoft/layoutlmv3-large/raw/main/vocab.json",
- },
- "merges_file": {
- "microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/raw/main/merges.txt",
- "microsoft/layoutlmv3-large": "https://huggingface.co/microsoft/layoutlmv3-large/raw/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/layoutlmv3-base": 512,
- "microsoft/layoutlmv3-large": 512,
-}
-
class LayoutLMv3TokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -131,8 +115,6 @@ class LayoutLMv3TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = LayoutLMv3Tokenizer
diff --git a/src/transformers/models/layoutxlm/tokenization_layoutxlm.py b/src/transformers/models/layoutxlm/tokenization_layoutxlm.py
index 44a31f8580b226..bbfdf44a1e6020 100644
--- a/src/transformers/models/layoutxlm/tokenization_layoutxlm.py
+++ b/src/transformers/models/layoutxlm/tokenization_layoutxlm.py
@@ -32,8 +32,6 @@
)
from ...utils import PaddingStrategy, TensorType, add_end_docstrings, logging
from ..xlm_roberta.tokenization_xlm_roberta import (
- PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES,
- PRETRAINED_VOCAB_FILES_MAP,
SPIECE_UNDERLINE,
VOCAB_FILES_NAMES,
)
@@ -225,8 +223,6 @@ class LayoutXLMTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/layoutxlm/tokenization_layoutxlm_fast.py b/src/transformers/models/layoutxlm/tokenization_layoutxlm_fast.py
index 31c4579d4766c0..e899d8b22e4df6 100644
--- a/src/transformers/models/layoutxlm/tokenization_layoutxlm_fast.py
+++ b/src/transformers/models/layoutxlm/tokenization_layoutxlm_fast.py
@@ -31,8 +31,6 @@
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import PaddingStrategy, TensorType, add_end_docstrings, is_sentencepiece_available, logging
from ..xlm_roberta.tokenization_xlm_roberta_fast import (
- PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES,
- PRETRAINED_VOCAB_FILES_MAP,
VOCAB_FILES_NAMES,
)
@@ -212,8 +210,6 @@ class LayoutXLMTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = LayoutXLMTokenizer
diff --git a/src/transformers/models/led/configuration_led.py b/src/transformers/models/led/configuration_led.py
index d9efc308fec319..59a2793cc89e08 100644
--- a/src/transformers/models/led/configuration_led.py
+++ b/src/transformers/models/led/configuration_led.py
@@ -22,10 +22,8 @@
logger = logging.get_logger(__name__)
-LED_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/config.json",
- # See all LED models at https://huggingface.co/models?filter=led
-}
+
+from ..deprecated._archive_maps import LED_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LEDConfig(PretrainedConfig):
diff --git a/src/transformers/models/led/modeling_led.py b/src/transformers/models/led/modeling_led.py
index c10a8de11584d2..b2a5f440e0f25d 100755
--- a/src/transformers/models/led/modeling_led.py
+++ b/src/transformers/models/led/modeling_led.py
@@ -53,10 +53,7 @@
_CONFIG_FOR_DOC = "LEDConfig"
-LED_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "allenai/led-base-16384",
- # See all LED models at https://huggingface.co/models?filter=led
-]
+from ..deprecated._archive_maps import LED_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
diff --git a/src/transformers/models/led/tokenization_led.py b/src/transformers/models/led/tokenization_led.py
index e82739b4964ef5..aaf09e6d149eb1 100644
--- a/src/transformers/models/led/tokenization_led.py
+++ b/src/transformers/models/led/tokenization_led.py
@@ -32,21 +32,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
# See all LED models at https://huggingface.co/models?filter=LED
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/vocab.json",
- },
- "merges_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "allenai/led-base-16384": 16384,
-}
@lru_cache()
@@ -169,8 +154,6 @@ class LEDTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
# Copied from transformers.models.bart.tokenization_bart.BartTokenizer.__init__
diff --git a/src/transformers/models/led/tokenization_led_fast.py b/src/transformers/models/led/tokenization_led_fast.py
index 5c80491a84bf5b..ca15eb997bed5b 100644
--- a/src/transformers/models/led/tokenization_led_fast.py
+++ b/src/transformers/models/led/tokenization_led_fast.py
@@ -30,22 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/vocab.json",
- },
- "merges_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "allenai/led-base-16384": "https://huggingface.co/allenai/led-base-16384/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "allenai/led-base-16384": 16384,
-}
-
class LEDTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -129,8 +113,6 @@ class LEDTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = LEDTokenizer
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/levit/configuration_levit.py b/src/transformers/models/levit/configuration_levit.py
index 3a9546a652e692..fd840f519f26f9 100644
--- a/src/transformers/models/levit/configuration_levit.py
+++ b/src/transformers/models/levit/configuration_levit.py
@@ -26,10 +26,8 @@
logger = logging.get_logger(__name__)
-LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/levit-128S": "https://huggingface.co/facebook/levit-128S/resolve/main/config.json",
- # See all LeViT models at https://huggingface.co/models?filter=levit
-}
+
+from ..deprecated._archive_maps import LEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LevitConfig(PretrainedConfig):
diff --git a/src/transformers/models/levit/modeling_levit.py b/src/transformers/models/levit/modeling_levit.py
index 38a9ee1abc5c06..11eda7bcc57938 100644
--- a/src/transformers/models/levit/modeling_levit.py
+++ b/src/transformers/models/levit/modeling_levit.py
@@ -47,10 +47,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/levit-128S"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/levit-128S",
- # See all LeViT models at https://huggingface.co/models?filter=levit
-]
+
+from ..deprecated._archive_maps import LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/lilt/configuration_lilt.py b/src/transformers/models/lilt/configuration_lilt.py
index 3db595e86e1795..f1cfa98c6c3c13 100644
--- a/src/transformers/models/lilt/configuration_lilt.py
+++ b/src/transformers/models/lilt/configuration_lilt.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-LILT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "SCUT-DLVCLab/lilt-roberta-en-base": (
- "https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import LILT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LiltConfig(PretrainedConfig):
diff --git a/src/transformers/models/lilt/modeling_lilt.py b/src/transformers/models/lilt/modeling_lilt.py
index e21f8ab2ce6044..adf8edcdc2ab71 100644
--- a/src/transformers/models/lilt/modeling_lilt.py
+++ b/src/transformers/models/lilt/modeling_lilt.py
@@ -40,10 +40,8 @@
_CONFIG_FOR_DOC = "LiltConfig"
-LILT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "SCUT-DLVCLab/lilt-roberta-en-base",
- # See all LiLT models at https://huggingface.co/models?filter=lilt
-]
+
+from ..deprecated._archive_maps import LILT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class LiltTextEmbeddings(nn.Module):
diff --git a/src/transformers/models/llama/configuration_llama.py b/src/transformers/models/llama/configuration_llama.py
index b62a1053094b91..6d0f68162cce43 100644
--- a/src/transformers/models/llama/configuration_llama.py
+++ b/src/transformers/models/llama/configuration_llama.py
@@ -25,7 +25,8 @@
logger = logging.get_logger(__name__)
-LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+from ..deprecated._archive_maps import LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LlamaConfig(PretrainedConfig):
@@ -178,8 +179,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/llama/modeling_flax_llama.py b/src/transformers/models/llama/modeling_flax_llama.py
index 73fb1cbb955044..1e7fb5d1a1cd94 100644
--- a/src/transformers/models/llama/modeling_flax_llama.py
+++ b/src/transformers/models/llama/modeling_flax_llama.py
@@ -198,24 +198,32 @@ def setup(self):
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.attention_softmax_in_fp32 = self.dtype is not jnp.float32
dense = partial(
nn.Dense,
- self.embed_dim,
use_bias=config.attention_bias,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
- self.q_proj, self.k_proj, self.v_proj = dense(), dense(), dense()
- self.o_proj = dense()
+ self.q_proj = dense(self.num_heads * self.head_dim)
+ self.k_proj = dense(self.num_key_value_heads * self.head_dim)
+ self.v_proj = dense(self.num_key_value_heads * self.head_dim)
+ self.o_proj = dense(self.embed_dim)
+ if (self.head_dim * self.num_heads) != self.embed_dim:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.embed_dim}"
+ f" and `num_heads`: {self.num_heads})."
+ )
self.causal_mask = make_causal_mask(jnp.ones((1, config.max_position_embeddings), dtype="bool"), dtype="bool")
self.rotary_emb = FlaxLlamaRotaryEmbedding(config, dtype=self.dtype)
- def _split_heads(self, hidden_states):
- return hidden_states.reshape(hidden_states.shape[:2] + (self.num_heads, self.head_dim))
+ def _split_heads(self, hidden_states, num_heads):
+ return hidden_states.reshape(hidden_states.shape[:2] + (num_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.embed_dim,))
@@ -266,9 +274,9 @@ def __call__(
key = self.k_proj(hidden_states)
value = self.v_proj(hidden_states)
- query = self._split_heads(query)
- key = self._split_heads(key)
- value = self._split_heads(value)
+ query = self._split_heads(query, self.num_heads)
+ key = self._split_heads(key, self.num_key_value_heads)
+ value = self._split_heads(value, self.num_key_value_heads)
key, query = self.rotary_emb(key, query, position_ids)
@@ -298,6 +306,9 @@ def __call__(
if self.has_variable("cache", "cached_key") or init_cache:
key, value, attention_mask = self._concatenate_to_cache(key, value, query, attention_mask)
+ key = jnp.repeat(key, self.num_key_value_groups, axis=2)
+ value = jnp.repeat(value, self.num_key_value_groups, axis=2)
+
# transform boolean mask into float mask
attention_bias = lax.select(
attention_mask > 0,
diff --git a/src/transformers/models/llama/modeling_llama.py b/src/transformers/models/llama/modeling_llama.py
index f5f3dc02ee9dce..8d0baf63c7b3fe 100644
--- a/src/transformers/models/llama/modeling_llama.py
+++ b/src/transformers/models/llama/modeling_llama.py
@@ -1064,7 +1064,7 @@ def _update_causal_mask(self, attention_mask, input_tensor, cache_position):
dtype, device = input_tensor.dtype, input_tensor.device
min_dtype = torch.finfo(dtype).min
sequence_length = input_tensor.shape[1]
- if hasattr(self.layers[0].self_attn, "past_key_value"): # static cache
+ if hasattr(getattr(self.layers[0], "self_attn", {}), "past_key_value"): # static cache
target_length = self.config.max_position_embeddings
else: # dynamic cache
target_length = (
@@ -1240,7 +1240,7 @@ def prepare_inputs_for_generation(
# TODO joao: standardize interface for the different Cache classes and remove of this if
has_static_cache = False
if past_key_values is None:
- past_key_values = getattr(self.model.layers[0].self_attn, "past_key_value", None)
+ past_key_values = getattr(getattr(self.model.layers[0], "self_attn", {}), "past_key_value", None)
has_static_cache = past_key_values is not None
past_length = 0
diff --git a/src/transformers/models/llama/tokenization_llama.py b/src/transformers/models/llama/tokenization_llama.py
index 2f8997274ce758..744e2e3fe2c280 100644
--- a/src/transformers/models/llama/tokenization_llama.py
+++ b/src/transformers/models/llama/tokenization_llama.py
@@ -37,17 +37,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer.model",
- },
- "tokenizer_file": {
- "hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer_config.json",
- },
-}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "hf-internal-testing/llama-tokenizer": 2048,
-}
SPIECE_UNDERLINE = "▁"
B_INST, E_INST = "[INST]", "[/INST]"
@@ -137,8 +126,6 @@ class LlamaTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
@@ -308,6 +295,8 @@ def convert_tokens_to_string(self, tokens):
prev_is_special = True
current_sub_tokens = []
else:
+ if prev_is_special and i == 1 and self.add_prefix_space and not token.startswith(SPIECE_UNDERLINE):
+ out_string += " "
current_sub_tokens.append(token)
prev_is_special = False
out_string += self.sp_model.decode(current_sub_tokens)
diff --git a/src/transformers/models/llama/tokenization_llama_fast.py b/src/transformers/models/llama/tokenization_llama_fast.py
index fee77119870585..07c01be893cf17 100644
--- a/src/transformers/models/llama/tokenization_llama_fast.py
+++ b/src/transformers/models/llama/tokenization_llama_fast.py
@@ -33,14 +33,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer.model",
- },
- "tokenizer_file": {
- "hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer_config.json",
- },
-}
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<>\n", "\n<>\n\n"
@@ -105,7 +97,6 @@ class LlamaTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
slow_tokenizer_class = LlamaTokenizer
padding_side = "left"
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/llava/configuration_llava.py b/src/transformers/models/llava/configuration_llava.py
index d70175c4738a93..8c322f41de7de2 100644
--- a/src/transformers/models/llava/configuration_llava.py
+++ b/src/transformers/models/llava/configuration_llava.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-LLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "llava-hf/llava-v1.5-7b": "https://huggingface.co/llava-hf/llava-v1.5-7b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import LLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LlavaConfig(PretrainedConfig):
@@ -147,6 +146,10 @@ def vocab_size(self):
)
return self._vocab_size
+ @vocab_size.setter
+ def vocab_size(self, value):
+ self._vocab_size = value
+
def to_dict(self):
output = super().to_dict()
output.pop("_vocab_size", None)
diff --git a/src/transformers/models/llava/modeling_llava.py b/src/transformers/models/llava/modeling_llava.py
index 13b8375647e23e..f195c1140be86b 100644
--- a/src/transformers/models/llava/modeling_llava.py
+++ b/src/transformers/models/llava/modeling_llava.py
@@ -38,12 +38,8 @@
_CONFIG_FOR_DOC = "LlavaConfig"
-LLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "llava-hf/llava-1.5-7b-hf",
- "llava-hf/llava-1.5-13b-hf",
- "llava-hf/bakLlava-v1-hf",
- # See all Llava models at https://huggingface.co/models?filter=llava
-]
+
+from ..deprecated._archive_maps import LLAVA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
@@ -344,6 +340,12 @@ def _merge_input_ids_with_image_features(self, image_features, inputs_embeds, in
final_attention_mask |= image_to_overwrite
position_ids = (final_attention_mask.cumsum(-1) - 1).masked_fill_((final_attention_mask == 0), 1)
+ # 6. Mask out the embedding at padding positions, as we later use the past_key_value value to determine the non-attended tokens.
+ batch_indices, pad_indices = torch.where(input_ids == self.pad_token_id)
+ indices_to_mask = new_token_positions[batch_indices, pad_indices]
+
+ final_embedding[batch_indices, indices_to_mask] = 0
+
if labels is None:
final_labels = None
@@ -449,10 +451,11 @@ def forward(
batch_index, non_attended_tokens = torch.where(first_layer_past_key_value.float().sum(-2) == 0)
# Get the target length
- target_seqlen = first_layer_past_key_value.shape[-1] + 1
+ target_length = input_ids.shape[1]
+ past_length = first_layer_past_key_value.shape[-1]
extended_attention_mask = torch.ones(
- (attention_mask.shape[0], target_seqlen - attention_mask.shape[1]),
+ (attention_mask.shape[0], past_length),
dtype=attention_mask.dtype,
device=attention_mask.device,
)
@@ -467,7 +470,7 @@ def forward(
# Zero-out the places where we don't need to attend
extended_attention_mask[new_batch_index, new_non_attended_tokens] = 0
- attention_mask = torch.cat((attention_mask, extended_attention_mask), dim=1)
+ attention_mask = torch.cat((extended_attention_mask, attention_mask[:, -target_length:]), dim=1)
position_ids = torch.sum(attention_mask, dim=1).unsqueeze(-1) - 1
outputs = self.language_model(
diff --git a/src/transformers/models/llava_next/modeling_llava_next.py b/src/transformers/models/llava_next/modeling_llava_next.py
index 845269830c533c..54ad4d5a504007 100644
--- a/src/transformers/models/llava_next/modeling_llava_next.py
+++ b/src/transformers/models/llava_next/modeling_llava_next.py
@@ -356,7 +356,6 @@ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None, pad_to_m
def _merge_input_ids_with_image_features(self, image_features, inputs_embeds, input_ids, attention_mask, labels):
num_images, num_image_patches, embed_dim = image_features.shape
batch_size, sequence_length = input_ids.shape
-
left_padding = not torch.sum(input_ids[:, -1] == torch.tensor(self.pad_token_id))
# 1. Create a mask to know where special image tokens are
special_image_token_mask = input_ids == self.config.image_token_index
@@ -418,6 +417,12 @@ def _merge_input_ids_with_image_features(self, image_features, inputs_embeds, in
final_attention_mask |= image_to_overwrite
position_ids = (final_attention_mask.cumsum(-1) - 1).masked_fill_((final_attention_mask == 0), 1)
+ # 6. Mask out the embedding at padding positions, as we later use the past_key_value value to determine the non-attended tokens.
+ batch_indices, pad_indices = torch.where(input_ids == self.pad_token_id)
+ indices_to_mask = new_token_positions[batch_indices, pad_indices]
+
+ final_embedding[batch_indices, indices_to_mask] = 0
+
if labels is None:
final_labels = None
diff --git a/src/transformers/models/longformer/configuration_longformer.py b/src/transformers/models/longformer/configuration_longformer.py
index 2935dd4aaaae25..7dce8a74a631c7 100644
--- a/src/transformers/models/longformer/configuration_longformer.py
+++ b/src/transformers/models/longformer/configuration_longformer.py
@@ -28,19 +28,8 @@
logger = logging.get_logger(__name__)
-LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/config.json",
- "allenai/longformer-large-4096": "https://huggingface.co/allenai/longformer-large-4096/resolve/main/config.json",
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/config.json"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/config.json"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import LONGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LongformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/longformer/modeling_longformer.py b/src/transformers/models/longformer/modeling_longformer.py
index aefd225869ca8e..f8c7c44ef9918c 100755
--- a/src/transformers/models/longformer/modeling_longformer.py
+++ b/src/transformers/models/longformer/modeling_longformer.py
@@ -42,14 +42,8 @@
_CHECKPOINT_FOR_DOC = "allenai/longformer-base-4096"
_CONFIG_FOR_DOC = "LongformerConfig"
-LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "allenai/longformer-base-4096",
- "allenai/longformer-large-4096",
- "allenai/longformer-large-4096-finetuned-triviaqa",
- "allenai/longformer-base-4096-extra.pos.embd.only",
- "allenai/longformer-large-4096-extra.pos.embd.only",
- # See all Longformer models at https://huggingface.co/models?filter=longformer
-]
+
+from ..deprecated._archive_maps import LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/longformer/modeling_tf_longformer.py b/src/transformers/models/longformer/modeling_tf_longformer.py
index 1cbfb286955585..907fbbddf1e68f 100644
--- a/src/transformers/models/longformer/modeling_tf_longformer.py
+++ b/src/transformers/models/longformer/modeling_tf_longformer.py
@@ -56,14 +56,8 @@
LARGE_NEGATIVE = -1e8
-TF_LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "allenai/longformer-base-4096",
- "allenai/longformer-large-4096",
- "allenai/longformer-large-4096-finetuned-triviaqa",
- "allenai/longformer-base-4096-extra.pos.embd.only",
- "allenai/longformer-large-4096-extra.pos.embd.only",
- # See all Longformer models at https://huggingface.co/models?filter=longformer
-]
+
+from ..deprecated._archive_maps import TF_LONGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/longformer/tokenization_longformer.py b/src/transformers/models/longformer/tokenization_longformer.py
index cf0477bac1056f..51728d77808158 100644
--- a/src/transformers/models/longformer/tokenization_longformer.py
+++ b/src/transformers/models/longformer/tokenization_longformer.py
@@ -29,47 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/vocab.json",
- "allenai/longformer-large-4096": (
- "https://huggingface.co/allenai/longformer-large-4096/resolve/main/vocab.json"
- ),
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/vocab.json"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/vocab.json"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/merges.txt",
- "allenai/longformer-large-4096": (
- "https://huggingface.co/allenai/longformer-large-4096/resolve/main/merges.txt"
- ),
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/merges.txt"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/merges.txt"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/merges.txt"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "allenai/longformer-base-4096": 4096,
- "allenai/longformer-large-4096": 4096,
- "allenai/longformer-large-4096-finetuned-triviaqa": 4096,
- "allenai/longformer-base-4096-extra.pos.embd.only": 4096,
- "allenai/longformer-large-4096-extra.pos.embd.only": 4096,
-}
-
@lru_cache()
# Copied from transformers.models.roberta.tokenization_roberta.bytes_to_unicode
@@ -192,8 +151,6 @@ class LongformerTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/longformer/tokenization_longformer_fast.py b/src/transformers/models/longformer/tokenization_longformer_fast.py
index e40ebff3b65c13..02b74818a23ef8 100644
--- a/src/transformers/models/longformer/tokenization_longformer_fast.py
+++ b/src/transformers/models/longformer/tokenization_longformer_fast.py
@@ -28,64 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/vocab.json",
- "allenai/longformer-large-4096": (
- "https://huggingface.co/allenai/longformer-large-4096/resolve/main/vocab.json"
- ),
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/vocab.json"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/vocab.json"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "allenai/longformer-base-4096": "https://huggingface.co/allenai/longformer-base-4096/resolve/main/merges.txt",
- "allenai/longformer-large-4096": (
- "https://huggingface.co/allenai/longformer-large-4096/resolve/main/merges.txt"
- ),
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/merges.txt"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/merges.txt"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/merges.txt"
- ),
- },
- "tokenizer_file": {
- "allenai/longformer-base-4096": (
- "https://huggingface.co/allenai/longformer-base-4096/resolve/main/tokenizer.json"
- ),
- "allenai/longformer-large-4096": (
- "https://huggingface.co/allenai/longformer-large-4096/resolve/main/tokenizer.json"
- ),
- "allenai/longformer-large-4096-finetuned-triviaqa": (
- "https://huggingface.co/allenai/longformer-large-4096-finetuned-triviaqa/resolve/main/tokenizer.json"
- ),
- "allenai/longformer-base-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-base-4096-extra.pos.embd.only/resolve/main/tokenizer.json"
- ),
- "allenai/longformer-large-4096-extra.pos.embd.only": (
- "https://huggingface.co/allenai/longformer-large-4096-extra.pos.embd.only/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "allenai/longformer-base-4096": 4096,
- "allenai/longformer-large-4096": 4096,
- "allenai/longformer-large-4096-finetuned-triviaqa": 4096,
- "allenai/longformer-base-4096-extra.pos.embd.only": 4096,
- "allenai/longformer-large-4096-extra.pos.embd.only": 4096,
-}
-
# Copied from transformers.models.roberta.tokenization_roberta_fast.RobertaTokenizerFast with FacebookAI/roberta-base->allenai/longformer-base-4096, RoBERTa->Longformer all-casing, Roberta->Longformer
class LongformerTokenizerFast(PreTrainedTokenizerFast):
@@ -170,8 +112,6 @@ class LongformerTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = LongformerTokenizer
diff --git a/src/transformers/models/longt5/configuration_longt5.py b/src/transformers/models/longt5/configuration_longt5.py
index 0095af0e246cce..f6e8284ed0af84 100644
--- a/src/transformers/models/longt5/configuration_longt5.py
+++ b/src/transformers/models/longt5/configuration_longt5.py
@@ -22,12 +22,8 @@
logger = logging.get_logger(__name__)
-LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/long-t5-local-base": "https://huggingface.co/google/long-t5-local-base/blob/main/config.json",
- "google/long-t5-local-large": "https://huggingface.co/google/long-t5-local-large/blob/main/config.json",
- "google/long-t5-tglobal-base": "https://huggingface.co/google/long-t5-tglobal-base/blob/main/config.json",
- "google/long-t5-tglobal-large": "https://huggingface.co/google/long-t5-tglobal-large/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import LONGT5_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LongT5Config(PretrainedConfig):
diff --git a/src/transformers/models/longt5/modeling_longt5.py b/src/transformers/models/longt5/modeling_longt5.py
index 5189db98a158cb..e16e0951208f77 100644
--- a/src/transformers/models/longt5/modeling_longt5.py
+++ b/src/transformers/models/longt5/modeling_longt5.py
@@ -51,12 +51,8 @@
_CHECKPOINT_FOR_DOC = "google/long-t5-local-base"
# TODO: Update before the merge
-LONGT5_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/long-t5-local-base",
- "google/long-t5-local-large",
- "google/long-t5-tglobal-base",
- "google/long-t5-tglobal-large",
-]
+
+from ..deprecated._archive_maps import LONGT5_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def _pad_to_multiple(x: torch.Tensor, block_len: int, dim: int, pad_value: int = 0) -> torch.Tensor:
diff --git a/src/transformers/models/luke/configuration_luke.py b/src/transformers/models/luke/configuration_luke.py
index 53ab1a352803bc..257c9a25535f33 100644
--- a/src/transformers/models/luke/configuration_luke.py
+++ b/src/transformers/models/luke/configuration_luke.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "studio-ousia/luke-base": "https://huggingface.co/studio-ousia/luke-base/resolve/main/config.json",
- "studio-ousia/luke-large": "https://huggingface.co/studio-ousia/luke-large/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import LUKE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LukeConfig(PretrainedConfig):
diff --git a/src/transformers/models/luke/modeling_luke.py b/src/transformers/models/luke/modeling_luke.py
index 1742283ef685d4..3523e739f5b69f 100644
--- a/src/transformers/models/luke/modeling_luke.py
+++ b/src/transformers/models/luke/modeling_luke.py
@@ -43,11 +43,8 @@
_CONFIG_FOR_DOC = "LukeConfig"
_CHECKPOINT_FOR_DOC = "studio-ousia/luke-base"
-LUKE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "studio-ousia/luke-base",
- "studio-ousia/luke-large",
- # See all LUKE models at https://huggingface.co/models?filter=luke
-]
+
+from ..deprecated._archive_maps import LUKE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/luke/tokenization_luke.py b/src/transformers/models/luke/tokenization_luke.py
index e8ad725d050b1c..d37258f2a40012 100644
--- a/src/transformers/models/luke/tokenization_luke.py
+++ b/src/transformers/models/luke/tokenization_luke.py
@@ -53,25 +53,6 @@
"entity_vocab_file": "entity_vocab.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "studio-ousia/luke-base": "https://huggingface.co/studio-ousia/luke-base/resolve/main/vocab.json",
- "studio-ousia/luke-large": "https://huggingface.co/studio-ousia/luke-large/resolve/main/vocab.json",
- },
- "merges_file": {
- "studio-ousia/luke-base": "https://huggingface.co/studio-ousia/luke-base/resolve/main/merges.txt",
- "studio-ousia/luke-large": "https://huggingface.co/studio-ousia/luke-large/resolve/main/merges.txt",
- },
- "entity_vocab_file": {
- "studio-ousia/luke-base": "https://huggingface.co/studio-ousia/luke-base/resolve/main/entity_vocab.json",
- "studio-ousia/luke-large": "https://huggingface.co/studio-ousia/luke-large/resolve/main/entity_vocab.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "studio-ousia/luke-base": 512,
- "studio-ousia/luke-large": 512,
-}
ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING = r"""
return_token_type_ids (`bool`, *optional*):
@@ -287,8 +268,6 @@ class LukeTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/lxmert/configuration_lxmert.py b/src/transformers/models/lxmert/configuration_lxmert.py
index 6ced7d2acadf4e..b79fb67908d27e 100644
--- a/src/transformers/models/lxmert/configuration_lxmert.py
+++ b/src/transformers/models/lxmert/configuration_lxmert.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "unc-nlp/lxmert-base-uncased": "https://huggingface.co/unc-nlp/lxmert-base-uncased/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import LXMERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class LxmertConfig(PretrainedConfig):
diff --git a/src/transformers/models/lxmert/modeling_lxmert.py b/src/transformers/models/lxmert/modeling_lxmert.py
index 226e2e7197a7ee..6e2ae7d22e7cac 100644
--- a/src/transformers/models/lxmert/modeling_lxmert.py
+++ b/src/transformers/models/lxmert/modeling_lxmert.py
@@ -43,10 +43,6 @@
_CHECKPOINT_FOR_DOC = "unc-nlp/lxmert-base-uncased"
_CONFIG_FOR_DOC = "LxmertConfig"
-LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "unc-nlp/lxmert-base-uncased",
-]
-
class GeLU(nn.Module):
def __init__(self):
diff --git a/src/transformers/models/lxmert/modeling_tf_lxmert.py b/src/transformers/models/lxmert/modeling_tf_lxmert.py
index 22ce04a0011bf2..c4741196031a79 100644
--- a/src/transformers/models/lxmert/modeling_tf_lxmert.py
+++ b/src/transformers/models/lxmert/modeling_tf_lxmert.py
@@ -53,9 +53,8 @@
_CHECKPOINT_FOR_DOC = "unc-nlp/lxmert-base-uncased"
_CONFIG_FOR_DOC = "LxmertConfig"
-TF_LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "unc-nlp/lxmert-base-uncased",
-]
+
+from ..deprecated._archive_maps import TF_LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/lxmert/tokenization_lxmert.py b/src/transformers/models/lxmert/tokenization_lxmert.py
index 1557be1add6864..8d2fca9328ddc4 100644
--- a/src/transformers/models/lxmert/tokenization_lxmert.py
+++ b/src/transformers/models/lxmert/tokenization_lxmert.py
@@ -26,20 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "unc-nlp/lxmert-base-uncased": "https://huggingface.co/unc-nlp/lxmert-base-uncased/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "unc-nlp/lxmert-base-uncased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "unc-nlp/lxmert-base-uncased": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -107,9 +93,6 @@ class LxmertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/lxmert/tokenization_lxmert_fast.py b/src/transformers/models/lxmert/tokenization_lxmert_fast.py
index 7d9758a601b49c..e31fdbcf761d50 100644
--- a/src/transformers/models/lxmert/tokenization_lxmert_fast.py
+++ b/src/transformers/models/lxmert/tokenization_lxmert_fast.py
@@ -24,25 +24,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "unc-nlp/lxmert-base-uncased": "https://huggingface.co/unc-nlp/lxmert-base-uncased/resolve/main/vocab.txt",
- },
- "tokenizer_file": {
- "unc-nlp/lxmert-base-uncased": (
- "https://huggingface.co/unc-nlp/lxmert-base-uncased/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "unc-nlp/lxmert-base-uncased": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "unc-nlp/lxmert-base-uncased": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with bert-base-cased->unc-nlp/lxmert-base-uncased, BERT->Lxmert, Bert->Lxmert
class LxmertTokenizerFast(PreTrainedTokenizerFast):
@@ -86,9 +67,6 @@ class LxmertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = LxmertTokenizer
def __init__(
diff --git a/src/transformers/models/m2m_100/configuration_m2m_100.py b/src/transformers/models/m2m_100/configuration_m2m_100.py
index 1b15658c03d714..b211527e8088b4 100644
--- a/src/transformers/models/m2m_100/configuration_m2m_100.py
+++ b/src/transformers/models/m2m_100/configuration_m2m_100.py
@@ -25,10 +25,8 @@
logger = logging.get_logger(__name__)
-M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/m2m100_418M": "https://huggingface.co/facebook/m2m100_418M/resolve/main/config.json",
- # See all M2M100 models at https://huggingface.co/models?filter=m2m_100
-}
+
+from ..deprecated._archive_maps import M2M_100_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class M2M100Config(PretrainedConfig):
diff --git a/src/transformers/models/m2m_100/modeling_m2m_100.py b/src/transformers/models/m2m_100/modeling_m2m_100.py
index 1aad2bde81c8c7..9e2ff11ad88184 100755
--- a/src/transformers/models/m2m_100/modeling_m2m_100.py
+++ b/src/transformers/models/m2m_100/modeling_m2m_100.py
@@ -49,10 +49,7 @@
_CHECKPOINT_FOR_DOC = "facebook/m2m100_418M"
-M2M_100_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/m2m100_418M",
- # See all M2M100 models at https://huggingface.co/models?filter=m2m_100
-]
+from ..deprecated._archive_maps import M2M_100_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/m2m_100/tokenization_m2m_100.py b/src/transformers/models/m2m_100/tokenization_m2m_100.py
index 1346af81412add..96f79ee4e725ef 100644
--- a/src/transformers/models/m2m_100/tokenization_m2m_100.py
+++ b/src/transformers/models/m2m_100/tokenization_m2m_100.py
@@ -34,24 +34,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/m2m100_418M": "https://huggingface.co/facebook/m2m100_418M/resolve/main/vocab.json",
- "facebook/m2m100_1.2B": "https://huggingface.co/facebook/m2m100_1.2B/resolve/main/vocab.json",
- },
- "spm_file": {
- "facebook/m2m100_418M": "https://huggingface.co/facebook/m2m100_418M/resolve/main/sentencepiece.bpe.model",
- "facebook/m2m100_1.2B": "https://huggingface.co/facebook/m2m100_1.2B/resolve/main/sentencepiece.bpe.model",
- },
- "tokenizer_config_file": {
- "facebook/m2m100_418M": "https://huggingface.co/facebook/m2m100_418M/resolve/main/tokenizer_config.json",
- "facebook/m2m100_1.2B": "https://huggingface.co/facebook/m2m100_1.2B/resolve/main/tokenizer_config.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/m2m100_418M": 1024,
-}
# fmt: off
FAIRSEQ_LANGUAGE_CODES = {
@@ -121,8 +103,6 @@ class M2M100Tokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/mamba/configuration_mamba.py b/src/transformers/models/mamba/configuration_mamba.py
index ec5e615c0bfa70..695d9a62737dca 100644
--- a/src/transformers/models/mamba/configuration_mamba.py
+++ b/src/transformers/models/mamba/configuration_mamba.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-MAMBA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "state-spaces/mamba-2.8b": "https://huggingface.co/state-spaces/mamba-2.8b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MAMBA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MambaConfig(PretrainedConfig):
diff --git a/src/transformers/models/mamba/modeling_mamba.py b/src/transformers/models/mamba/modeling_mamba.py
index a3325b3af87c95..4c3cfaa48d5175 100644
--- a/src/transformers/models/mamba/modeling_mamba.py
+++ b/src/transformers/models/mamba/modeling_mamba.py
@@ -56,7 +56,8 @@
_CHECKPOINT_FOR_DOC = "state-spaces/mamba-130m-hf"
_CONFIG_FOR_DOC = "MambaConfig"
-MAMBA_PRETRAINED_MODEL_ARCHIVE_LIST = [] # See all Mamba models at https://huggingface.co/models?filter=mamba
+
+from ..deprecated._archive_maps import MAMBA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class MambaCache:
@@ -229,7 +230,7 @@ def slow_forward(self, input_states, cache_params: Optional[MambaCache]=None):
# 2. Convolution sequence transformation
if cache_params is not None:
- ssm_state = cache_params.ssm_states[self.layer_idx]
+ ssm_state = cache_params.ssm_states[self.layer_idx].clone()
if cache_params.seqlen_offset > 0:
conv_state = cache_params.conv_states[self.layer_idx] # [batch, intermediate_size, conv_kernel_size]
conv_state = torch.roll(conv_state, shifts=-1, dims=-1)
@@ -500,8 +501,15 @@ def __init__(self, config):
self.gradient_checkpointing = False
self.norm_f = MambaRMSNorm(config.hidden_size, eps=config.layer_norm_epsilon)
# Initialize weights and apply final processing
+ self._register_load_state_dict_pre_hook(self.load_hook)
self.post_init()
+ def load_hook(self, state_dict, prefix, *args):
+ for k in state_dict:
+ if "embedding." in k:
+ state_dict[k.replace("embedding.", "embeddings.")] = state_dict.pop(k)
+ break
+
def get_input_embeddings(self):
return self.embeddings
diff --git a/src/transformers/models/marian/configuration_marian.py b/src/transformers/models/marian/configuration_marian.py
index 201788673e6c21..5921fde981be26 100644
--- a/src/transformers/models/marian/configuration_marian.py
+++ b/src/transformers/models/marian/configuration_marian.py
@@ -25,11 +25,6 @@
logger = logging.get_logger(__name__)
-MARIAN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Helsinki-NLP/opus-mt-en-de": "https://huggingface.co/Helsinki-NLP/opus-mt-en-de/resolve/main/config.json",
- # See all Marian models at https://huggingface.co/models?filter=marian
-}
-
class MarianConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/marian/modeling_marian.py b/src/transformers/models/marian/modeling_marian.py
index d52a060d4723c8..10d7f1b6b2d16d 100755
--- a/src/transformers/models/marian/modeling_marian.py
+++ b/src/transformers/models/marian/modeling_marian.py
@@ -51,12 +51,6 @@
_CHECKPOINT_FOR_DOC = "Helsinki-NLP/opus-mt-en-de"
-MARIAN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Helsinki-NLP/opus-mt-en-de",
- # See all Marian models at https://huggingface.co/models?filter=marian
-]
-
-
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
@@ -1349,7 +1343,13 @@ def tie_weights(self):
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
- self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.encoder, self.decoder, self.base_model_prefix, "encoder"
+ )
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
for module in self.modules():
if hasattr(module, "_tie_weights"):
diff --git a/src/transformers/models/marian/tokenization_marian.py b/src/transformers/models/marian/tokenization_marian.py
index ead3ddd70e30fe..4f0d90b6f0dffe 100644
--- a/src/transformers/models/marian/tokenization_marian.py
+++ b/src/transformers/models/marian/tokenization_marian.py
@@ -35,25 +35,6 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "source_spm": {
- "Helsinki-NLP/opus-mt-en-de": "https://huggingface.co/Helsinki-NLP/opus-mt-en-de/resolve/main/source.spm"
- },
- "target_spm": {
- "Helsinki-NLP/opus-mt-en-de": "https://huggingface.co/Helsinki-NLP/opus-mt-en-de/resolve/main/target.spm"
- },
- "vocab": {
- "Helsinki-NLP/opus-mt-en-de": "https://huggingface.co/Helsinki-NLP/opus-mt-en-de/resolve/main/vocab.json"
- },
- "tokenizer_config_file": {
- "Helsinki-NLP/opus-mt-en-de": (
- "https://huggingface.co/Helsinki-NLP/opus-mt-en-de/resolve/main/tokenizer_config.json"
- )
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"Helsinki-NLP/opus-mt-en-de": 512}
-PRETRAINED_INIT_CONFIGURATION = {}
SPIECE_UNDERLINE = "▁"
@@ -120,9 +101,6 @@ class MarianTokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
language_code_re = re.compile(">>.+<<") # type: re.Pattern
diff --git a/src/transformers/models/markuplm/configuration_markuplm.py b/src/transformers/models/markuplm/configuration_markuplm.py
index ff0ab96919834e..aeb80ae51f96ba 100644
--- a/src/transformers/models/markuplm/configuration_markuplm.py
+++ b/src/transformers/models/markuplm/configuration_markuplm.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/config.json",
- "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MARKUPLM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MarkupLMConfig(PretrainedConfig):
diff --git a/src/transformers/models/markuplm/modeling_markuplm.py b/src/transformers/models/markuplm/modeling_markuplm.py
index 24ca0c4972aaa0..2058ce27951676 100755
--- a/src/transformers/models/markuplm/modeling_markuplm.py
+++ b/src/transformers/models/markuplm/modeling_markuplm.py
@@ -52,10 +52,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/markuplm-base"
_CONFIG_FOR_DOC = "MarkupLMConfig"
-MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/markuplm-base",
- "microsoft/markuplm-large",
-]
+
+from ..deprecated._archive_maps import MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class XPathEmbeddings(nn.Module):
@@ -708,7 +706,6 @@ class MarkupLMPreTrainedModel(PreTrainedModel):
"""
config_class = MarkupLMConfig
- pretrained_model_archive_map = MARKUPLM_PRETRAINED_MODEL_ARCHIVE_LIST
base_model_prefix = "markuplm"
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights with Bert->MarkupLM
diff --git a/src/transformers/models/markuplm/tokenization_markuplm.py b/src/transformers/models/markuplm/tokenization_markuplm.py
index 24fa4b7763a9e1..c77865abc934c9 100644
--- a/src/transformers/models/markuplm/tokenization_markuplm.py
+++ b/src/transformers/models/markuplm/tokenization_markuplm.py
@@ -39,23 +39,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/vocab.json",
- "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/vocab.json",
- },
- "merges_file": {
- "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/merges.txt",
- "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/merges.txt",
- },
-}
-
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/markuplm-base": 512,
- "microsoft/markuplm-large": 512,
-}
-
MARKUPLM_ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING = r"""
add_special_tokens (`bool`, *optional*, defaults to `True`):
@@ -198,8 +181,6 @@ class MarkupLMTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/markuplm/tokenization_markuplm_fast.py b/src/transformers/models/markuplm/tokenization_markuplm_fast.py
index a0933631b65b7a..ff0e4ffeb56e9f 100644
--- a/src/transformers/models/markuplm/tokenization_markuplm_fast.py
+++ b/src/transformers/models/markuplm/tokenization_markuplm_fast.py
@@ -43,23 +43,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/vocab.json",
- "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/vocab.json",
- },
- "merges_file": {
- "microsoft/markuplm-base": "https://huggingface.co/microsoft/markuplm-base/resolve/main/merges.txt",
- "microsoft/markuplm-large": "https://huggingface.co/microsoft/markuplm-large/resolve/main/merges.txt",
- },
-}
-
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/markuplm-base": 512,
- "microsoft/markuplm-large": 512,
-}
-
@lru_cache()
def bytes_to_unicode():
@@ -156,8 +139,6 @@ class MarkupLMTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = MarkupLMTokenizer
def __init__(
diff --git a/src/transformers/models/mask2former/configuration_mask2former.py b/src/transformers/models/mask2former/configuration_mask2former.py
index 0b5aa9aa0c71f6..f0d13b8e030ed1 100644
--- a/src/transformers/models/mask2former/configuration_mask2former.py
+++ b/src/transformers/models/mask2former/configuration_mask2former.py
@@ -18,15 +18,9 @@
from ...configuration_utils import PretrainedConfig
from ...utils import logging
from ..auto import CONFIG_MAPPING
+from ..deprecated._archive_maps import MASK2FORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
-MASK2FORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/mask2former-swin-small-coco-instance": (
- "https://huggingface.co/facebook/mask2former-swin-small-coco-instance/blob/main/config.json"
- )
- # See all Mask2Former models at https://huggingface.co/models?filter=mask2former
-}
-
logger = logging.get_logger(__name__)
diff --git a/src/transformers/models/mask2former/modeling_mask2former.py b/src/transformers/models/mask2former/modeling_mask2former.py
index 628b50e448ee71..3a9a74345363a6 100644
--- a/src/transformers/models/mask2former/modeling_mask2former.py
+++ b/src/transformers/models/mask2former/modeling_mask2former.py
@@ -54,10 +54,8 @@
_CHECKPOINT_FOR_DOC = "facebook/mask2former-swin-small-coco-instance"
_IMAGE_PROCESSOR_FOR_DOC = "Mask2FormerImageProcessor"
-MASK2FORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/mask2former-swin-small-coco-instance",
- # See all mask2former models at https://huggingface.co/models?filter=mask2former
-]
+
+from ..deprecated._archive_maps import MASK2FORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/maskformer/configuration_maskformer.py b/src/transformers/models/maskformer/configuration_maskformer.py
index 758ac4eb20bfc5..653350ca056dda 100644
--- a/src/transformers/models/maskformer/configuration_maskformer.py
+++ b/src/transformers/models/maskformer/configuration_maskformer.py
@@ -18,17 +18,11 @@
from ...configuration_utils import PretrainedConfig
from ...utils import logging
from ..auto import CONFIG_MAPPING
+from ..deprecated._archive_maps import MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
from ..detr import DetrConfig
from ..swin import SwinConfig
-MASKFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/maskformer-swin-base-ade": (
- "https://huggingface.co/facebook/maskformer-swin-base-ade/blob/main/config.json"
- )
- # See all MaskFormer models at https://huggingface.co/models?filter=maskformer
-}
-
logger = logging.get_logger(__name__)
diff --git a/src/transformers/models/maskformer/modeling_maskformer.py b/src/transformers/models/maskformer/modeling_maskformer.py
index e61146e9c4326a..4419a36e9f840a 100644
--- a/src/transformers/models/maskformer/modeling_maskformer.py
+++ b/src/transformers/models/maskformer/modeling_maskformer.py
@@ -57,10 +57,8 @@
_CONFIG_FOR_DOC = "MaskFormerConfig"
_CHECKPOINT_FOR_DOC = "facebook/maskformer-swin-base-ade"
-MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/maskformer-swin-base-ade",
- # See all MaskFormer models at https://huggingface.co/models?filter=maskformer
-]
+
+from ..deprecated._archive_maps import MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/mbart/configuration_mbart.py b/src/transformers/models/mbart/configuration_mbart.py
index 176ce52dbfab97..4823047dcf3151 100644
--- a/src/transformers/models/mbart/configuration_mbart.py
+++ b/src/transformers/models/mbart/configuration_mbart.py
@@ -25,11 +25,6 @@
logger = logging.get_logger(__name__)
-MBART_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/mbart-large-cc25": "https://huggingface.co/facebook/mbart-large-cc25/resolve/main/config.json",
- # See all MBART models at https://huggingface.co/models?filter=mbart
-}
-
class MBartConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/mbart/modeling_mbart.py b/src/transformers/models/mbart/modeling_mbart.py
index 2f1d031d1a6d9c..fc23e2c675dbf2 100755
--- a/src/transformers/models/mbart/modeling_mbart.py
+++ b/src/transformers/models/mbart/modeling_mbart.py
@@ -61,11 +61,6 @@
# Base model docstring
_EXPECTED_OUTPUT_SHAPE = [1, 8, 1024]
-MBART_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/mbart-large-cc25",
- # See all MBART models at https://huggingface.co/models?filter=mbart
-]
-
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
def _get_unpad_data(attention_mask):
diff --git a/src/transformers/models/mbart/tokenization_mbart.py b/src/transformers/models/mbart/tokenization_mbart.py
index 37f4c849ab9ddd..d9da6cb45cb388 100644
--- a/src/transformers/models/mbart/tokenization_mbart.py
+++ b/src/transformers/models/mbart/tokenization_mbart.py
@@ -29,21 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/mbart-large-en-ro": (
- "https://huggingface.co/facebook/mbart-large-en-ro/resolve/main/sentencepiece.bpe.model"
- ),
- "facebook/mbart-large-cc25": (
- "https://huggingface.co/facebook/mbart-large-cc25/resolve/main/sentencepiece.bpe.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/mbart-large-en-ro": 1024,
- "facebook/mbart-large-cc25": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ["ar_AR", "cs_CZ", "de_DE", "en_XX", "es_XX", "et_EE", "fi_FI", "fr_XX", "gu_IN", "hi_IN", "it_IT", "ja_XX", "kk_KZ", "ko_KR", "lt_LT", "lv_LV", "my_MM", "ne_NP", "nl_XX", "ro_RO", "ru_RU", "si_LK", "tr_TR", "vi_VN", "zh_CN"] # fmt: skip
@@ -70,8 +55,6 @@ class MBartTokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/mbart/tokenization_mbart_fast.py b/src/transformers/models/mbart/tokenization_mbart_fast.py
index 8638ab974e2ac7..71107bf0cdaf47 100644
--- a/src/transformers/models/mbart/tokenization_mbart_fast.py
+++ b/src/transformers/models/mbart/tokenization_mbart_fast.py
@@ -35,25 +35,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/mbart-large-en-ro": (
- "https://huggingface.co/facebook/mbart-large-en-ro/resolve/main/sentencepiece.bpe.model"
- ),
- "facebook/mbart-large-cc25": (
- "https://huggingface.co/facebook/mbart-large-cc25/resolve/main/sentencepiece.bpe.model"
- ),
- },
- "tokenizer_file": {
- "facebook/mbart-large-en-ro": "https://huggingface.co/facebook/mbart-large-en-ro/resolve/main/tokenizer.json",
- "facebook/mbart-large-cc25": "https://huggingface.co/facebook/mbart-large-cc25/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/mbart-large-en-ro": 1024,
- "facebook/mbart-large-cc25": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ["ar_AR", "cs_CZ", "de_DE", "en_XX", "es_XX", "et_EE", "fi_FI", "fr_XX", "gu_IN", "hi_IN", "it_IT", "ja_XX", "kk_KZ", "ko_KR", "lt_LT", "lv_LV", "my_MM", "ne_NP", "nl_XX", "ro_RO", "ru_RU", "si_LK", "tr_TR", "vi_VN", "zh_CN"] # fmt: skip
@@ -83,8 +64,6 @@ class MBartTokenizerFast(PreTrainedTokenizerFast):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = MBartTokenizer
diff --git a/src/transformers/models/mbart50/tokenization_mbart50.py b/src/transformers/models/mbart50/tokenization_mbart50.py
index cd4e52f42efabc..7acc6ecbf36bbd 100644
--- a/src/transformers/models/mbart50/tokenization_mbart50.py
+++ b/src/transformers/models/mbart50/tokenization_mbart50.py
@@ -29,17 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/mbart-large-50-one-to-many-mmt": (
- "https://huggingface.co/facebook/mbart-large-50-one-to-many-mmt/resolve/main/sentencepiece.bpe.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/mbart-large-50-one-to-many-mmt": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ["ar_AR", "cs_CZ", "de_DE", "en_XX", "es_XX", "et_EE", "fi_FI", "fr_XX", "gu_IN", "hi_IN", "it_IT", "ja_XX", "kk_KZ", "ko_KR", "lt_LT", "lv_LV", "my_MM", "ne_NP", "nl_XX", "ro_RO", "ru_RU", "si_LK", "tr_TR", "vi_VN", "zh_CN", "af_ZA", "az_AZ", "bn_IN", "fa_IR", "he_IL", "hr_HR", "id_ID", "ka_GE", "km_KH", "mk_MK", "ml_IN", "mn_MN", "mr_IN", "pl_PL", "ps_AF", "pt_XX", "sv_SE", "sw_KE", "ta_IN", "te_IN", "th_TH", "tl_XX", "uk_UA", "ur_PK", "xh_ZA", "gl_ES", "sl_SI"] # fmt: skip
@@ -104,8 +93,6 @@ class MBart50Tokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/mbart50/tokenization_mbart50_fast.py b/src/transformers/models/mbart50/tokenization_mbart50_fast.py
index 701e30d916d955..cc4678f5f53cce 100644
--- a/src/transformers/models/mbart50/tokenization_mbart50_fast.py
+++ b/src/transformers/models/mbart50/tokenization_mbart50_fast.py
@@ -34,22 +34,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/mbart-large-50-one-to-many-mmt": (
- "https://huggingface.co/facebook/mbart-large-50-one-to-many-mmt/resolve/main/sentencepiece.bpe.model"
- ),
- },
- "tokenizer_file": {
- "facebook/mbart-large-50-one-to-many-mmt": (
- "https://huggingface.co/facebook/mbart-large-50-one-to-many-mmt/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/mbart-large-50-one-to-many-mmt": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ["ar_AR", "cs_CZ", "de_DE", "en_XX", "es_XX", "et_EE", "fi_FI", "fr_XX", "gu_IN", "hi_IN", "it_IT", "ja_XX", "kk_KZ", "ko_KR", "lt_LT", "lv_LV", "my_MM", "ne_NP", "nl_XX", "ro_RO", "ru_RU", "si_LK", "tr_TR", "vi_VN", "zh_CN", "af_ZA", "az_AZ", "bn_IN", "fa_IR", "he_IL", "hr_HR", "id_ID", "ka_GE", "km_KH", "mk_MK", "ml_IN", "mn_MN", "mr_IN", "pl_PL", "ps_AF", "pt_XX", "sv_SE", "sw_KE", "ta_IN", "te_IN", "th_TH", "tl_XX", "uk_UA", "ur_PK", "xh_ZA", "gl_ES", "sl_SI"] # fmt: skip
@@ -100,8 +84,6 @@ class MBart50TokenizerFast(PreTrainedTokenizerFast):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = MBart50Tokenizer
diff --git a/src/transformers/models/mega/configuration_mega.py b/src/transformers/models/mega/configuration_mega.py
index 34f858569cd558..993a21cf7035d6 100644
--- a/src/transformers/models/mega/configuration_mega.py
+++ b/src/transformers/models/mega/configuration_mega.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-MEGA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "mnaylor/mega-base-wikitext": "https://huggingface.co/mnaylor/mega-base-wikitext/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MEGA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MegaConfig(PretrainedConfig):
diff --git a/src/transformers/models/mega/modeling_mega.py b/src/transformers/models/mega/modeling_mega.py
index dda31f5d949ea4..069c717a737572 100644
--- a/src/transformers/models/mega/modeling_mega.py
+++ b/src/transformers/models/mega/modeling_mega.py
@@ -50,10 +50,8 @@
_CHECKPOINT_FOR_DOC = "mnaylor/mega-base-wikitext"
_CONFIG_FOR_DOC = "MegaConfig"
-MEGA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "mnaylor/mega-base-wikitext",
- # See all Mega models at https://huggingface.co/models?filter=mega
-]
+
+from ..deprecated._archive_maps import MEGA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class MegaEmbeddings(nn.Module):
diff --git a/src/transformers/models/megatron_bert/configuration_megatron_bert.py b/src/transformers/models/megatron_bert/configuration_megatron_bert.py
index 02cdf289432b38..177bc146a22261 100644
--- a/src/transformers/models/megatron_bert/configuration_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/configuration_megatron_bert.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-MEGATRON_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- # See all MEGATRON_BERT models at https://huggingface.co/models?filter=bert
-}
+
+from ..deprecated._archive_maps import MEGATRON_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MegatronBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/megatron_bert/modeling_megatron_bert.py b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
index 9111f937bc2a06..528bcca3d9bc00 100755
--- a/src/transformers/models/megatron_bert/modeling_megatron_bert.py
+++ b/src/transformers/models/megatron_bert/modeling_megatron_bert.py
@@ -57,10 +57,8 @@
_CONFIG_FOR_DOC = "MegatronBertConfig"
_CHECKPOINT_FOR_DOC = "nvidia/megatron-bert-cased-345m"
-MEGATRON_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nvidia/megatron-bert-cased-345m",
- # See all MegatronBERT models at https://huggingface.co/models?filter=megatron_bert
-]
+
+from ..deprecated._archive_maps import MEGATRON_BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_megatron_bert(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/mgp_str/configuration_mgp_str.py b/src/transformers/models/mgp_str/configuration_mgp_str.py
index 4644b4f0cc1769..2d341309a8a41c 100644
--- a/src/transformers/models/mgp_str/configuration_mgp_str.py
+++ b/src/transformers/models/mgp_str/configuration_mgp_str.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-MGP_STR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "alibaba-damo/mgp-str-base": "https://huggingface.co/alibaba-damo/mgp-str-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MGP_STR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MgpstrConfig(PretrainedConfig):
diff --git a/src/transformers/models/mgp_str/modeling_mgp_str.py b/src/transformers/models/mgp_str/modeling_mgp_str.py
index 8914e59a207001..e35c414d735fc4 100644
--- a/src/transformers/models/mgp_str/modeling_mgp_str.py
+++ b/src/transformers/models/mgp_str/modeling_mgp_str.py
@@ -44,10 +44,8 @@
# Base docstring
_CHECKPOINT_FOR_DOC = "alibaba-damo/mgp-str-base"
-MGP_STR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "alibaba-damo/mgp-str-base",
- # See all MGP-STR models at https://huggingface.co/models?filter=mgp-str
-]
+
+from ..deprecated._archive_maps import MGP_STR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/mgp_str/tokenization_mgp_str.py b/src/transformers/models/mgp_str/tokenization_mgp_str.py
index 7fe11061154093..a34ba744c1960c 100644
--- a/src/transformers/models/mgp_str/tokenization_mgp_str.py
+++ b/src/transformers/models/mgp_str/tokenization_mgp_str.py
@@ -26,14 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "mgp-str": "https://huggingface.co/alibaba-damo/mgp-str-base/blob/main/vocab.json",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"mgp-str": 27}
-
class MgpstrTokenizer(PreTrainedTokenizer):
"""
@@ -58,8 +50,6 @@ class MgpstrTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(self, vocab_file, unk_token="[GO]", bos_token="[GO]", eos_token="[s]", pad_token="[GO]", **kwargs):
with open(vocab_file, encoding="utf-8") as vocab_handle:
diff --git a/src/transformers/models/mistral/configuration_mistral.py b/src/transformers/models/mistral/configuration_mistral.py
index a6c4634f611d1b..83dd0e7a621cff 100644
--- a/src/transformers/models/mistral/configuration_mistral.py
+++ b/src/transformers/models/mistral/configuration_mistral.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-MISTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "mistralai/Mistral-7B-v0.1": "https://huggingface.co/mistralai/Mistral-7B-v0.1/resolve/main/config.json",
- "mistralai/Mistral-7B-Instruct-v0.1": "https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MISTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MistralConfig(PretrainedConfig):
diff --git a/src/transformers/models/mixtral/configuration_mixtral.py b/src/transformers/models/mixtral/configuration_mixtral.py
index ac2dbed16e10cb..a452260fb8ac6f 100644
--- a/src/transformers/models/mixtral/configuration_mixtral.py
+++ b/src/transformers/models/mixtral/configuration_mixtral.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-MIXTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "mistral-ai/Mixtral-8x7B": "https://huggingface.co/mistral-ai/Mixtral-8x7B/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MIXTRAL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MixtralConfig(PretrainedConfig):
@@ -93,6 +92,8 @@ class MixtralConfig(PretrainedConfig):
allow the model to output the auxiliary loss. See [here]() for more details
router_aux_loss_coef (`float`, *optional*, defaults to 0.001):
The aux loss factor for the total loss.
+ router_jitter_noise (`float`, *optional*, defaults to 0.0):
+ Amount of noise to add to the router.
```python
>>> from transformers import MixtralModel, MixtralConfig
@@ -134,6 +135,7 @@ def __init__(
num_local_experts=8,
output_router_logits=False,
router_aux_loss_coef=0.001,
+ router_jitter_noise=0.0,
**kwargs,
):
self.vocab_size = vocab_size
@@ -160,6 +162,7 @@ def __init__(
self.num_local_experts = num_local_experts
self.output_router_logits = output_router_logits
self.router_aux_loss_coef = router_aux_loss_coef
+ self.router_jitter_noise = router_jitter_noise
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
diff --git a/src/transformers/models/mixtral/modeling_mixtral.py b/src/transformers/models/mixtral/modeling_mixtral.py
index 4c4c44bd2297d8..e9e801bb71670b 100644
--- a/src/transformers/models/mixtral/modeling_mixtral.py
+++ b/src/transformers/models/mixtral/modeling_mixtral.py
@@ -837,9 +837,14 @@ def __init__(self, config):
self.experts = nn.ModuleList([MixtralBlockSparseTop2MLP(config) for _ in range(self.num_experts)])
+ # Jitter parameters
+ self.jitter_noise = config.router_jitter_noise
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape
+ if self.training and self.jitter_noise > 0:
+ hidden_states *= torch.empty_like(hidden_states).uniform_(1.0 - self.jitter_noise, 1.0 + self.jitter_noise)
hidden_states = hidden_states.view(-1, hidden_dim)
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
diff --git a/src/transformers/models/mluke/tokenization_mluke.py b/src/transformers/models/mluke/tokenization_mluke.py
index 028de5d4f79c8c..3ef5e64ed2f6a7 100644
--- a/src/transformers/models/mluke/tokenization_mluke.py
+++ b/src/transformers/models/mluke/tokenization_mluke.py
@@ -52,21 +52,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "entity_vocab_file": "entity_vocab.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "studio-ousia/mluke-base": "https://huggingface.co/studio-ousia/mluke-base/resolve/main/vocab.json",
- },
- "merges_file": {
- "studio-ousia/mluke-base": "https://huggingface.co/studio-ousia/mluke-base/resolve/main/merges.txt",
- },
- "entity_vocab_file": {
- "studio-ousia/mluke-base": "https://huggingface.co/studio-ousia/mluke-base/resolve/main/entity_vocab.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "studio-ousia/mluke-base": 512,
-}
ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING = r"""
return_token_type_ids (`bool`, *optional*):
@@ -230,8 +215,6 @@ class MLukeTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/mobilebert/configuration_mobilebert.py b/src/transformers/models/mobilebert/configuration_mobilebert.py
index b14d25ea9ed507..d66dba8c02bde9 100644
--- a/src/transformers/models/mobilebert/configuration_mobilebert.py
+++ b/src/transformers/models/mobilebert/configuration_mobilebert.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-MOBILEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/mobilebert-uncased": "https://huggingface.co/google/mobilebert-uncased/resolve/main/config.json"
-}
+
+from ..deprecated._archive_maps import MOBILEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MobileBertConfig(PretrainedConfig):
@@ -104,12 +103,8 @@ class MobileBertConfig(PretrainedConfig):
>>> # Accessing the model configuration
>>> configuration = model.config
```
-
- Attributes: pretrained_config_archive_map (Dict[str, str]): A dictionary containing all the available pre-trained
- checkpoints.
"""
- pretrained_config_archive_map = MOBILEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP
model_type = "mobilebert"
def __init__(
diff --git a/src/transformers/models/mobilebert/modeling_mobilebert.py b/src/transformers/models/mobilebert/modeling_mobilebert.py
index 70f2ebc7bfd8f7..8dc0aafa70fc25 100644
--- a/src/transformers/models/mobilebert/modeling_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_mobilebert.py
@@ -76,7 +76,8 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'others'"
_SEQ_CLASS_EXPECTED_LOSS = "4.72"
-MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = ["google/mobilebert-uncased"]
+
+from ..deprecated._archive_maps import MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_mobilebert(model, config, tf_checkpoint_path):
@@ -685,7 +686,6 @@ class MobileBertPreTrainedModel(PreTrainedModel):
"""
config_class = MobileBertConfig
- pretrained_model_archive_map = MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST
load_tf_weights = load_tf_weights_in_mobilebert
base_model_prefix = "mobilebert"
diff --git a/src/transformers/models/mobilebert/modeling_tf_mobilebert.py b/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
index 6ccc996557532b..8526e636a2ac48 100644
--- a/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
+++ b/src/transformers/models/mobilebert/modeling_tf_mobilebert.py
@@ -84,10 +84,8 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'others'"
_SEQ_CLASS_EXPECTED_LOSS = "4.72"
-TF_MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/mobilebert-uncased",
- # See all MobileBERT models at https://huggingface.co/models?filter=mobilebert
-]
+
+from ..deprecated._archive_maps import TF_MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPreTrainingLoss
diff --git a/src/transformers/models/mobilebert/tokenization_mobilebert.py b/src/transformers/models/mobilebert/tokenization_mobilebert.py
index f27873e92fcfa9..ccfdcc31ff9be9 100644
--- a/src/transformers/models/mobilebert/tokenization_mobilebert.py
+++ b/src/transformers/models/mobilebert/tokenization_mobilebert.py
@@ -29,15 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"mobilebert-uncased": "https://huggingface.co/google/mobilebert-uncased/resolve/main/vocab.txt"}
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"mobilebert-uncased": 512}
-
-
-PRETRAINED_INIT_CONFIGURATION = {}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -105,9 +96,6 @@ class MobileBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/mobilebert/tokenization_mobilebert_fast.py b/src/transformers/models/mobilebert/tokenization_mobilebert_fast.py
index 2b137d2ed60a35..21057924092e9c 100644
--- a/src/transformers/models/mobilebert/tokenization_mobilebert_fast.py
+++ b/src/transformers/models/mobilebert/tokenization_mobilebert_fast.py
@@ -29,18 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"mobilebert-uncased": "https://huggingface.co/google/mobilebert-uncased/resolve/main/vocab.txt"},
- "tokenizer_file": {
- "mobilebert-uncased": "https://huggingface.co/google/mobilebert-uncased/resolve/main/tokenizer.json"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"mobilebert-uncased": 512}
-
-
-PRETRAINED_INIT_CONFIGURATION = {}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with BERT->MobileBERT,Bert->MobileBert
class MobileBertTokenizerFast(PreTrainedTokenizerFast):
@@ -84,9 +72,6 @@ class MobileBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = MobileBertTokenizer
def __init__(
diff --git a/src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py b/src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
index 59f025c621d25d..2b575cb6a1dc48 100644
--- a/src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
+++ b/src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
@@ -26,11 +26,8 @@
logger = logging.get_logger(__name__)
-MOBILENET_V1_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/mobilenet_v1_1.0_224": "https://huggingface.co/google/mobilenet_v1_1.0_224/resolve/main/config.json",
- "google/mobilenet_v1_0.75_192": "https://huggingface.co/google/mobilenet_v1_0.75_192/resolve/main/config.json",
- # See all MobileNetV1 models at https://huggingface.co/models?filter=mobilenet_v1
-}
+
+from ..deprecated._archive_maps import MOBILENET_V1_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MobileNetV1Config(PretrainedConfig):
diff --git a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
index 3963e60f3562bd..adfb5c5670d81b 100755
--- a/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
+++ b/src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
@@ -43,11 +43,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-MOBILENET_V1_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/mobilenet_v1_1.0_224",
- "google/mobilenet_v1_0.75_192",
- # See all MobileNetV1 models at https://huggingface.co/models?filter=mobilenet_v1
-]
+from ..deprecated._archive_maps import MOBILENET_V1_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def _build_tf_to_pytorch_map(model, config, tf_weights=None):
diff --git a/src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py b/src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py
index 161f0e6d8fff42..dd9f6d17cd340a 100644
--- a/src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py
+++ b/src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py
@@ -26,13 +26,8 @@
logger = logging.get_logger(__name__)
-MOBILENET_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/mobilenet_v2_1.4_224": "https://huggingface.co/google/mobilenet_v2_1.4_224/resolve/main/config.json",
- "google/mobilenet_v2_1.0_224": "https://huggingface.co/google/mobilenet_v2_1.0_224/resolve/main/config.json",
- "google/mobilenet_v2_0.75_160": "https://huggingface.co/google/mobilenet_v2_0.75_160/resolve/main/config.json",
- "google/mobilenet_v2_0.35_96": "https://huggingface.co/google/mobilenet_v2_0.35_96/resolve/main/config.json",
- # See all MobileNetV2 models at https://huggingface.co/models?filter=mobilenet_v2
-}
+
+from ..deprecated._archive_maps import MOBILENET_V2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MobileNetV2Config(PretrainedConfig):
diff --git a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
index b76e68f9067ec7..789da484010fb8 100755
--- a/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
+++ b/src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
@@ -53,13 +53,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-MOBILENET_V2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/mobilenet_v2_1.4_224",
- "google/mobilenet_v2_1.0_224",
- "google/mobilenet_v2_0.37_160",
- "google/mobilenet_v2_0.35_96",
- # See all MobileNetV2 models at https://huggingface.co/models?filter=mobilenet_v2
-]
+from ..deprecated._archive_maps import MOBILENET_V2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def _build_tf_to_pytorch_map(model, config, tf_weights=None):
diff --git a/src/transformers/models/mobilevit/configuration_mobilevit.py b/src/transformers/models/mobilevit/configuration_mobilevit.py
index 24429bbbcc58c7..8f13112447f113 100644
--- a/src/transformers/models/mobilevit/configuration_mobilevit.py
+++ b/src/transformers/models/mobilevit/configuration_mobilevit.py
@@ -26,21 +26,8 @@
logger = logging.get_logger(__name__)
-MOBILEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "apple/mobilevit-small": "https://huggingface.co/apple/mobilevit-small/resolve/main/config.json",
- "apple/mobilevit-x-small": "https://huggingface.co/apple/mobilevit-x-small/resolve/main/config.json",
- "apple/mobilevit-xx-small": "https://huggingface.co/apple/mobilevit-xx-small/resolve/main/config.json",
- "apple/deeplabv3-mobilevit-small": (
- "https://huggingface.co/apple/deeplabv3-mobilevit-small/resolve/main/config.json"
- ),
- "apple/deeplabv3-mobilevit-x-small": (
- "https://huggingface.co/apple/deeplabv3-mobilevit-x-small/resolve/main/config.json"
- ),
- "apple/deeplabv3-mobilevit-xx-small": (
- "https://huggingface.co/apple/deeplabv3-mobilevit-xx-small/resolve/main/config.json"
- ),
- # See all MobileViT models at https://huggingface.co/models?filter=mobilevit
-}
+
+from ..deprecated._archive_maps import MOBILEVIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MobileViTConfig(PretrainedConfig):
diff --git a/src/transformers/models/mobilevit/modeling_mobilevit.py b/src/transformers/models/mobilevit/modeling_mobilevit.py
index 1de0f6adbf0e54..939982148cc606 100755
--- a/src/transformers/models/mobilevit/modeling_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_mobilevit.py
@@ -59,15 +59,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "apple/mobilevit-small",
- "apple/mobilevit-x-small",
- "apple/mobilevit-xx-small",
- "apple/deeplabv3-mobilevit-small",
- "apple/deeplabv3-mobilevit-x-small",
- "apple/deeplabv3-mobilevit-xx-small",
- # See all MobileViT models at https://huggingface.co/models?filter=mobilevit
-]
+from ..deprecated._archive_maps import MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def make_divisible(value: int, divisor: int = 8, min_value: Optional[int] = None) -> int:
diff --git a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
index 20249799363347..8434c9685e570f 100644
--- a/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
+++ b/src/transformers/models/mobilevit/modeling_tf_mobilevit.py
@@ -61,15 +61,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-TF_MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "apple/mobilevit-small",
- "apple/mobilevit-x-small",
- "apple/mobilevit-xx-small",
- "apple/deeplabv3-mobilevit-small",
- "apple/deeplabv3-mobilevit-x-small",
- "apple/deeplabv3-mobilevit-xx-small",
- # See all MobileViT models at https://huggingface.co/models?filter=mobilevit
-]
+from ..deprecated._archive_maps import TF_MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def make_divisible(value: int, divisor: int = 8, min_value: Optional[int] = None) -> int:
diff --git a/src/transformers/models/mobilevitv2/configuration_mobilevitv2.py b/src/transformers/models/mobilevitv2/configuration_mobilevitv2.py
index c3bc44f38e0420..f8f1be141b52bd 100644
--- a/src/transformers/models/mobilevitv2/configuration_mobilevitv2.py
+++ b/src/transformers/models/mobilevitv2/configuration_mobilevitv2.py
@@ -26,9 +26,8 @@
logger = logging.get_logger(__name__)
-MOBILEVITV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "apple/mobilevitv2-1.0": "https://huggingface.co/apple/mobilevitv2-1.0/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MOBILEVITV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MobileViTV2Config(PretrainedConfig):
diff --git a/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py b/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
index 842e78946e9df7..c6c446b1862adc 100644
--- a/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
+++ b/src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
@@ -57,10 +57,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-MOBILEVITV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "apple/mobilevitv2-1.0-imagenet1k-256"
- # See all MobileViTV2 models at https://huggingface.co/models?filter=mobilevitv2
-]
+from ..deprecated._archive_maps import MOBILEVITV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.mobilevit.modeling_mobilevit.make_divisible
diff --git a/src/transformers/models/mpnet/configuration_mpnet.py b/src/transformers/models/mpnet/configuration_mpnet.py
index fe492a963e5af2..a8cb07894bde1c 100644
--- a/src/transformers/models/mpnet/configuration_mpnet.py
+++ b/src/transformers/models/mpnet/configuration_mpnet.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MPNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MPNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/mpnet/modeling_mpnet.py b/src/transformers/models/mpnet/modeling_mpnet.py
index 86194607e21750..d9b9f90d398d90 100644
--- a/src/transformers/models/mpnet/modeling_mpnet.py
+++ b/src/transformers/models/mpnet/modeling_mpnet.py
@@ -45,14 +45,11 @@
_CONFIG_FOR_DOC = "MPNetConfig"
-MPNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/mpnet-base",
-]
+from ..deprecated._archive_maps import MPNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class MPNetPreTrainedModel(PreTrainedModel):
config_class = MPNetConfig
- pretrained_model_archive_map = MPNET_PRETRAINED_MODEL_ARCHIVE_LIST
base_model_prefix = "mpnet"
def _init_weights(self, module):
diff --git a/src/transformers/models/mpnet/modeling_tf_mpnet.py b/src/transformers/models/mpnet/modeling_tf_mpnet.py
index fe2825c76cee29..b57132d81398d0 100644
--- a/src/transformers/models/mpnet/modeling_tf_mpnet.py
+++ b/src/transformers/models/mpnet/modeling_tf_mpnet.py
@@ -63,9 +63,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/mpnet-base"
_CONFIG_FOR_DOC = "MPNetConfig"
-TF_MPNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/mpnet-base",
-]
+
+from ..deprecated._archive_maps import TF_MPNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFMPNetPreTrainedModel(TFPreTrainedModel):
diff --git a/src/transformers/models/mpnet/tokenization_mpnet.py b/src/transformers/models/mpnet/tokenization_mpnet.py
index 51b8d0ff15fd5a..003575300e8572 100644
--- a/src/transformers/models/mpnet/tokenization_mpnet.py
+++ b/src/transformers/models/mpnet/tokenization_mpnet.py
@@ -28,20 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/mpnet-base": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/mpnet-base": {"do_lower_case": True},
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -125,9 +111,6 @@ class MPNetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/mpnet/tokenization_mpnet_fast.py b/src/transformers/models/mpnet/tokenization_mpnet_fast.py
index 1c9b1d5922278b..433c3028fc2093 100644
--- a/src/transformers/models/mpnet/tokenization_mpnet_fast.py
+++ b/src/transformers/models/mpnet/tokenization_mpnet_fast.py
@@ -30,23 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/vocab.txt",
- },
- "tokenizer_file": {
- "microsoft/mpnet-base": "https://huggingface.co/microsoft/mpnet-base/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/mpnet-base": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/mpnet-base": {"do_lower_case": True},
-}
-
class MPNetTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -104,9 +87,6 @@ class MPNetTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = MPNetTokenizer
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/mpt/configuration_mpt.py b/src/transformers/models/mpt/configuration_mpt.py
index cc91966b6b0d01..5c1cb4d783b307 100644
--- a/src/transformers/models/mpt/configuration_mpt.py
+++ b/src/transformers/models/mpt/configuration_mpt.py
@@ -25,9 +25,8 @@
logger = logging.get_logger(__name__)
-MPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "mosaicml/mpt-7b": "https://huggingface.co/mosaicml/mpt-7b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MptAttentionConfig(PretrainedConfig):
diff --git a/src/transformers/models/mpt/modeling_mpt.py b/src/transformers/models/mpt/modeling_mpt.py
index fc4af29d8c696d..864e9c09ca3cb7 100644
--- a/src/transformers/models/mpt/modeling_mpt.py
+++ b/src/transformers/models/mpt/modeling_mpt.py
@@ -42,18 +42,8 @@
_CHECKPOINT_FOR_DOC = "mosaicml/mpt-7b"
_CONFIG_FOR_DOC = "MptConfig"
-MPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "mosaicml/mpt-7b",
- "mosaicml/mpt-7b-storywriter",
- "mosaicml/mpt-7b-instruct",
- "mosaicml/mpt-7b-8k",
- "mosaicml/mpt-7b-8k-instruct",
- "mosaicml/mpt-7b-8k-chat",
- "mosaicml/mpt-30b",
- "mosaicml/mpt-30b-instruct",
- "mosaicml/mpt-30b-chat",
- # See all MPT models at https://huggingface.co/models?filter=mpt
-]
+
+from ..deprecated._archive_maps import MPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def build_mpt_alibi_tensor(num_heads, sequence_length, alibi_bias_max=8, device=None):
diff --git a/src/transformers/models/mra/configuration_mra.py b/src/transformers/models/mra/configuration_mra.py
index 5ae2f5b13bc2e3..2b3bec041633ea 100644
--- a/src/transformers/models/mra/configuration_mra.py
+++ b/src/transformers/models/mra/configuration_mra.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-MRA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "uw-madison/mra-base-512-4": "https://huggingface.co/uw-madison/mra-base-512-4/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import MRA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MraConfig(PretrainedConfig):
diff --git a/src/transformers/models/mra/modeling_mra.py b/src/transformers/models/mra/modeling_mra.py
index 6e33753817027c..846578997c4a84 100644
--- a/src/transformers/models/mra/modeling_mra.py
+++ b/src/transformers/models/mra/modeling_mra.py
@@ -53,10 +53,9 @@
_CONFIG_FOR_DOC = "MraConfig"
_TOKENIZER_FOR_DOC = "AutoTokenizer"
-MRA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "uw-madison/mra-base-512-4",
- # See all Mra models at https://huggingface.co/models?filter=mra
-]
+
+from ..deprecated._archive_maps import MRA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
mra_cuda_kernel = None
diff --git a/src/transformers/models/mt5/modeling_mt5.py b/src/transformers/models/mt5/modeling_mt5.py
index 100273a5ac5628..84a9f78ca91ec5 100644
--- a/src/transformers/models/mt5/modeling_mt5.py
+++ b/src/transformers/models/mt5/modeling_mt5.py
@@ -59,14 +59,6 @@
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
-MT5_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/mt5-small",
- "google/mt5-base",
- "google/mt5-large",
- "google/mt5-xl",
- "google/mt5-xxl",
- # See all mT5 models at https://huggingface.co/models?filter=mt5
-]
PARALLELIZE_DOCSTRING = r"""
This is an experimental feature and is a subject to change at a moment's notice.
@@ -560,7 +552,7 @@ def forward(
if len(past_key_value) != expected_num_past_key_values:
raise ValueError(
f"There should be {expected_num_past_key_values} past states. "
- f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"{'2 (key / value) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
f"Got {len(past_key_value)} past key / value states"
)
diff --git a/src/transformers/models/musicgen/configuration_musicgen.py b/src/transformers/models/musicgen/configuration_musicgen.py
index c0f56626409ba9..b102d67630254b 100644
--- a/src/transformers/models/musicgen/configuration_musicgen.py
+++ b/src/transformers/models/musicgen/configuration_musicgen.py
@@ -21,10 +21,8 @@
logger = logging.get_logger(__name__)
-MUSICGEN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/musicgen-small": "https://huggingface.co/facebook/musicgen-small/resolve/main/config.json",
- # See all Musicgen models at https://huggingface.co/models?filter=musicgen
-}
+
+from ..deprecated._archive_maps import MUSICGEN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MusicgenDecoderConfig(PretrainedConfig):
@@ -241,3 +239,20 @@ def from_sub_models_config(
# This is a property because you might want to change the codec model on the fly
def sampling_rate(self):
return self.audio_encoder.sampling_rate
+
+ @property
+ def _attn_implementation(self):
+ # This property is made private for now (as it cannot be changed and a PreTrainedModel.use_attn_implementation method needs to be implemented.)
+ if hasattr(self, "_attn_implementation_internal"):
+ if self._attn_implementation_internal is None:
+ # `config.attn_implementation` should never be None, for backward compatibility.
+ return "eager"
+ else:
+ return self._attn_implementation_internal
+ else:
+ return "eager"
+
+ @_attn_implementation.setter
+ def _attn_implementation(self, value):
+ self._attn_implementation_internal = value
+ self.decoder._attn_implementation = value
diff --git a/src/transformers/models/musicgen/modeling_musicgen.py b/src/transformers/models/musicgen/modeling_musicgen.py
index bb5a5277f362b1..7e7c7cb7232c5c 100644
--- a/src/transformers/models/musicgen/modeling_musicgen.py
+++ b/src/transformers/models/musicgen/modeling_musicgen.py
@@ -22,13 +22,19 @@
import torch
import torch.nn as nn
+import torch.nn.functional as F
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...generation.configuration_utils import GenerationConfig
from ...generation.logits_process import ClassifierFreeGuidanceLogitsProcessor, LogitsProcessorList
from ...generation.stopping_criteria import StoppingCriteriaList
-from ...modeling_attn_mask_utils import _prepare_4d_attention_mask, _prepare_4d_causal_attention_mask
+from ...modeling_attn_mask_utils import (
+ _prepare_4d_attention_mask,
+ _prepare_4d_attention_mask_for_sdpa,
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPastAndCrossAttentions,
@@ -40,6 +46,8 @@
from ...utils import (
add_start_docstrings,
add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
logging,
replace_return_docstrings,
)
@@ -48,6 +56,10 @@
from .configuration_musicgen import MusicgenConfig, MusicgenDecoderConfig
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
if TYPE_CHECKING:
from ...generation.streamers import BaseStreamer
@@ -56,10 +68,21 @@
_CONFIG_FOR_DOC = "MusicgenConfig"
_CHECKPOINT_FOR_DOC = "facebook/musicgen-small"
-MUSICGEN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/musicgen-small",
- # See all Musicgen models at https://huggingface.co/models?filter=musicgen
-]
+
+from ..deprecated._archive_maps import MUSICGEN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
@dataclass
@@ -304,29 +327,361 @@ def forward(
return attn_output, attn_weights_reshaped, past_key_value
+# Copied from transformers.models.bart.modeling_bart.BartFlashAttention2 with Bart->Musicgen
+class MusicgenFlashAttention2(MusicgenAttention):
+ """
+ Musicgen flash attention module. This module inherits from `MusicgenAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def _reshape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # MusicgenFlashAttention2 attention does not support output_attentions
+ if output_attentions:
+ raise ValueError("MusicgenFlashAttention2 attention does not support output_attentions")
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self._reshape(self.q_proj(hidden_states), -1, bsz)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2)
+ value_states = past_key_value[1].transpose(1, 2)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._reshape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0].transpose(1, 2), key_states], dim=1)
+ value_states = torch.cat([past_key_value[1].transpose(1, 2), value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states.transpose(1, 2), value_states.transpose(1, 2))
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len, dropout=self.dropout
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, -1)
+ attn_output = self.out_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
+ def _flash_attention_forward(
+ self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.bart.modeling_bart.BartSdpaAttention with Bart->Musicgen
+class MusicgenSdpaAttention(MusicgenAttention):
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+ if output_attentions or layer_head_mask is not None:
+ # TODO: Improve this warning with e.g. `model.config._attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "MusicgenModel is using MusicgenSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True` or `layer_head_mask` not None. Falling back to the manual attention"
+ ' implementation, but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states,
+ key_value_states=key_value_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ query_states = self._shape(query_states, tgt_len, bsz)
+
+ # NOTE: SDPA with memory-efficient backend is currently (torch==2.1.2) bugged when using non-contiguous inputs and a custom attn_mask,
+ # but we are fine here as `_shape` do call `.contiguous()`. Reference: https://github.com/pytorch/pytorch/issues/112577
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout if self.training else 0.0,
+ # The tgt_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case tgt_len == 1.
+ is_causal=self.is_causal and attention_mask is None and tgt_len > 1,
+ )
+
+ if attn_output.size() != (bsz, self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+MUSICGEN_ATTENTION_CLASSES = {
+ "eager": MusicgenAttention,
+ "sdpa": MusicgenSdpaAttention,
+ "flash_attention_2": MusicgenFlashAttention2,
+}
+
+
class MusicgenDecoderLayer(nn.Module):
def __init__(self, config: MusicgenDecoderConfig):
super().__init__()
self.embed_dim = config.hidden_size
- self.self_attn = MusicgenAttention(
+ self.self_attn = MUSICGEN_ATTENTION_CLASSES[config._attn_implementation](
embed_dim=self.embed_dim,
num_heads=config.num_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
bias=False,
+ is_causal=True,
+ config=config,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
- self.encoder_attn = MusicgenAttention(
+ self.encoder_attn = MUSICGEN_ATTENTION_CLASSES[config._attn_implementation](
self.embed_dim,
config.num_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
bias=False,
+ config=config,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.ffn_dim, bias=False)
@@ -434,6 +789,8 @@ class MusicgenPreTrainedModel(PreTrainedModel):
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = ["MusicgenDecoderLayer", "MusicgenAttention"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
def _init_weights(self, module):
std = self.config.initializer_factor
@@ -669,6 +1026,7 @@ def __init__(self, config: MusicgenDecoderConfig):
self.layers = nn.ModuleList([MusicgenDecoderLayer(config) for _ in range(config.num_hidden_layers)])
self.layer_norm = nn.LayerNorm(config.hidden_size)
+ self.attn_implementation = config._attn_implementation
self.gradient_checkpointing = False
# Initialize weights and apply final processing
@@ -723,16 +1081,40 @@ def forward(
if inputs_embeds is None:
inputs_embeds = sum([self.embed_tokens[codebook](input[:, codebook]) for codebook in range(num_codebooks)])
- attention_mask = _prepare_4d_causal_attention_mask(
- attention_mask, input_shape, inputs_embeds, past_key_values_length
- )
+ if self.attn_implementation == "flash_attention_2":
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self.attn_implementation == "sdpa" and head_mask is None and not output_attentions:
+ # output_attentions=True & cross_attn_head_mask can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ input_shape,
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask, input_shape, inputs_embeds, past_key_values_length
+ )
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
- # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
- encoder_attention_mask = _prepare_4d_attention_mask(
- encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
- )
+ if self.attn_implementation == "flash_attention_2":
+ encoder_attention_mask = encoder_attention_mask if 0 in encoder_attention_mask else None
+ elif self.attn_implementation == "sdpa" and cross_attn_head_mask is None and not output_attentions:
+ # output_attentions=True & cross_attn_head_mask can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ encoder_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ encoder_attention_mask,
+ inputs_embeds.dtype,
+ tgt_len=input_shape[-1],
+ )
+ else:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ encoder_attention_mask = _prepare_4d_attention_mask(
+ encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
+ )
# embed positions
positions = self.embed_positions(input, past_key_values_length)
@@ -1411,6 +1793,8 @@ class MusicgenForConditionalGeneration(PreTrainedModel):
base_model_prefix = "encoder_decoder"
main_input_name = "input_ids"
supports_gradient_checkpointing = True
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
def __init__(
self,
@@ -1507,9 +1891,16 @@ def tie_weights(self):
if self.config.tie_encoder_decoder:
# tie text encoder and decoder base model
decoder_base_model_prefix = self.decoder.base_model_prefix
- self._tie_encoder_decoder_weights(
- self.text_encoder, self.decoder._modules[decoder_base_model_prefix], self.decoder.base_model_prefix
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.text_encoder,
+ self.decoder._modules[decoder_base_model_prefix],
+ self.decoder.base_model_prefix,
+ "text_encoder",
)
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
def get_audio_encoder(self):
return self.audio_encoder
diff --git a/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py b/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
index 89459371299ff7..335c0514163f1f 100644
--- a/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
+++ b/src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
@@ -21,9 +21,7 @@
logger = logging.get_logger(__name__)
-MUSICGEN_MELODY_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/musicgen-melody": "https://huggingface.co/facebook/musicgen-melody/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import MUSICGEN_MELODY_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class MusicgenMelodyDecoderConfig(PretrainedConfig):
@@ -254,3 +252,20 @@ def from_sub_models_config(
# This is a property because you might want to change the codec model on the fly
def sampling_rate(self):
return self.audio_encoder.sampling_rate
+
+ @property
+ def _attn_implementation(self):
+ # This property is made private for now (as it cannot be changed and a PreTrainedModel.use_attn_implementation method needs to be implemented.)
+ if hasattr(self, "_attn_implementation_internal"):
+ if self._attn_implementation_internal is None:
+ # `config.attn_implementation` should never be None, for backward compatibility.
+ return "eager"
+ else:
+ return self._attn_implementation_internal
+ else:
+ return "eager"
+
+ @_attn_implementation.setter
+ def _attn_implementation(self, value):
+ self._attn_implementation_internal = value
+ self.decoder._attn_implementation = value
diff --git a/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py b/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
index 8b5c5c2f571767..0840635f6535b2 100644
--- a/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
+++ b/src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
@@ -22,13 +22,14 @@
import torch
import torch.nn as nn
+import torch.nn.functional as F
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN
from ...generation.configuration_utils import GenerationConfig
from ...generation.logits_process import ClassifierFreeGuidanceLogitsProcessor, LogitsProcessorList
from ...generation.stopping_criteria import StoppingCriteriaList
-from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
+from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
from ...modeling_outputs import (
BaseModelOutputWithPast,
ModelOutput,
@@ -37,6 +38,8 @@
from ...utils import (
add_start_docstrings,
add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
logging,
replace_return_docstrings,
)
@@ -45,6 +48,10 @@
from .configuration_musicgen_melody import MusicgenMelodyConfig, MusicgenMelodyDecoderConfig
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
if TYPE_CHECKING:
from ...generation.streamers import BaseStreamer
@@ -53,10 +60,20 @@
_CONFIG_FOR_DOC = "MusicgenMelodyConfig"
_CHECKPOINT_FOR_DOC = "facebook/musicgen-melody"
-MUSICGEN_MELODY_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/musicgen-melody",
- # See all Musicgen Melody models at https://huggingface.co/models?filter=musicgen_melody
-]
+from ..deprecated._archive_maps import MUSICGEN_MELODY_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
@dataclass
@@ -324,17 +341,348 @@ def forward(
return attn_output, attn_weights_reshaped, past_key_value
+# Copied from transformers.models.bart.modeling_bart.BartFlashAttention2 with Bart->MusicgenMelody
+class MusicgenMelodyFlashAttention2(MusicgenMelodyAttention):
+ """
+ MusicgenMelody flash attention module. This module inherits from `MusicgenMelodyAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def _reshape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # MusicgenMelodyFlashAttention2 attention does not support output_attentions
+ if output_attentions:
+ raise ValueError("MusicgenMelodyFlashAttention2 attention does not support output_attentions")
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self._reshape(self.q_proj(hidden_states), -1, bsz)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2)
+ value_states = past_key_value[1].transpose(1, 2)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._reshape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0].transpose(1, 2), key_states], dim=1)
+ value_states = torch.cat([past_key_value[1].transpose(1, 2), value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states.transpose(1, 2), value_states.transpose(1, 2))
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = self._flash_attention_forward(
+ query_states, key_states, value_states, attention_mask, q_len, dropout=self.dropout
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, -1)
+ attn_output = self.out_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
+ def _flash_attention_forward(
+ self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(
+ key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.bart.modeling_bart.BartSdpaAttention with Bart->MusicgenMelody
+class MusicgenMelodySdpaAttention(MusicgenMelodyAttention):
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+ if output_attentions or layer_head_mask is not None:
+ # TODO: Improve this warning with e.g. `model.config._attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "MusicgenMelodyModel is using MusicgenMelodySdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True` or `layer_head_mask` not None. Falling back to the manual attention"
+ ' implementation, but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states,
+ key_value_states=key_value_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ query_states = self._shape(query_states, tgt_len, bsz)
+
+ # NOTE: SDPA with memory-efficient backend is currently (torch==2.1.2) bugged when using non-contiguous inputs and a custom attn_mask,
+ # but we are fine here as `_shape` do call `.contiguous()`. Reference: https://github.com/pytorch/pytorch/issues/112577
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout if self.training else 0.0,
+ # The tgt_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case tgt_len == 1.
+ is_causal=self.is_causal and attention_mask is None and tgt_len > 1,
+ )
+
+ if attn_output.size() != (bsz, self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+MUSICGEN_MELODY_ATTENTION_CLASSES = {
+ "eager": MusicgenMelodyAttention,
+ "sdpa": MusicgenMelodySdpaAttention,
+ "flash_attention_2": MusicgenMelodyFlashAttention2,
+}
+
+
class MusicgenMelodyDecoderLayer(nn.Module):
def __init__(self, config: MusicgenMelodyDecoderConfig):
super().__init__()
self.embed_dim = config.hidden_size
- self.self_attn = MusicgenMelodyAttention(
+ self.self_attn = MUSICGEN_MELODY_ATTENTION_CLASSES[config._attn_implementation](
embed_dim=self.embed_dim,
num_heads=config.num_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
bias=False,
+ is_causal=True,
+ config=config,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
@@ -414,6 +762,8 @@ class MusicgenMelodyPreTrainedModel(PreTrainedModel):
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = ["MusicgenMelodyDecoderLayer", "MusicgenMelodyAttention"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
def _init_weights(self, module):
std = self.config.initializer_factor
@@ -626,6 +976,7 @@ def __init__(self, config: MusicgenMelodyDecoderConfig):
self.layers = nn.ModuleList([MusicgenMelodyDecoderLayer(config) for _ in range(config.num_hidden_layers)])
self.layer_norm = nn.LayerNorm(config.hidden_size)
+ self.attn_implementation = config._attn_implementation
self.gradient_checkpointing = False
# Initialize weights and apply final processing
@@ -695,9 +1046,21 @@ def forward(
input_shape = inputs_embeds.size()[:-1]
- attention_mask = _prepare_4d_causal_attention_mask(
- attention_mask, input_shape, inputs_embeds, past_key_values_length
- )
+ if self.attn_implementation == "flash_attention_2":
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self.attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ input_shape,
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask, input_shape, inputs_embeds, past_key_values_length
+ )
# embed positions
positions = self.embed_positions(inputs_embeds, past_key_values_length)
@@ -1373,6 +1736,8 @@ class MusicgenMelodyForConditionalGeneration(PreTrainedModel):
config_class = MusicgenMelodyConfig
main_input_name = "input_ids"
supports_gradient_checkpointing = True
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
def __init__(
self,
@@ -1445,9 +1810,16 @@ def tie_weights(self):
if self.config.tie_encoder_decoder:
# tie text encoder and decoder base model
decoder_base_model_prefix = self.decoder.base_model_prefix
- self._tie_encoder_decoder_weights(
- self.text_encoder, self.decoder._modules[decoder_base_model_prefix], self.decoder.base_model_prefix
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.text_encoder,
+ self.decoder._modules[decoder_base_model_prefix],
+ self.decoder.base_model_prefix,
+ "text_encoder",
)
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
def get_text_encoder(self):
return self.text_encoder
diff --git a/src/transformers/models/mvp/configuration_mvp.py b/src/transformers/models/mvp/configuration_mvp.py
index 9f60c79efa6d1f..00f6b142496921 100644
--- a/src/transformers/models/mvp/configuration_mvp.py
+++ b/src/transformers/models/mvp/configuration_mvp.py
@@ -21,10 +21,6 @@
logger = logging.get_logger(__name__)
-MVP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/config.json",
-}
-
class MvpConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/mvp/modeling_mvp.py b/src/transformers/models/mvp/modeling_mvp.py
index 88106a07878c4c..fe289dc81e6a43 100644
--- a/src/transformers/models/mvp/modeling_mvp.py
+++ b/src/transformers/models/mvp/modeling_mvp.py
@@ -53,24 +53,8 @@
# Base model docstring
_EXPECTED_OUTPUT_SHAPE = [1, 8, 1024]
-MVP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "RUCAIBox/mvp",
- "RUCAIBox/mvp-data-to-text",
- "RUCAIBox/mvp-open-dialog",
- "RUCAIBox/mvp-question-answering",
- "RUCAIBox/mvp-question-generation",
- "RUCAIBox/mvp-story",
- "RUCAIBox/mvp-summarization",
- "RUCAIBox/mvp-task-dialog",
- "RUCAIBox/mtl-data-to-text",
- "RUCAIBox/mtl-multi-task",
- "RUCAIBox/mtl-open-dialog",
- "RUCAIBox/mtl-question-answering",
- "RUCAIBox/mtl-question-generation",
- "RUCAIBox/mtl-story",
- "RUCAIBox/mtl-summarization",
- # See all MVP models at https://huggingface.co/models?filter=mvp
-]
+
+from ..deprecated._archive_maps import MVP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/mvp/tokenization_mvp.py b/src/transformers/models/mvp/tokenization_mvp.py
index d6f5e980bbaeb6..5a159320b7a3e0 100644
--- a/src/transformers/models/mvp/tokenization_mvp.py
+++ b/src/transformers/models/mvp/tokenization_mvp.py
@@ -30,21 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
# See all MVP models at https://huggingface.co/models?filter=mvp
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/vocab.json",
- },
- "added_tokens.json": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/added_tokens.json",
- },
- "merges_file": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "RUCAIBox/mvp": 1024,
-}
@lru_cache()
@@ -165,8 +150,6 @@ class MvpTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/mvp/tokenization_mvp_fast.py b/src/transformers/models/mvp/tokenization_mvp_fast.py
index a6ff13c0898936..5901c2bece4097 100644
--- a/src/transformers/models/mvp/tokenization_mvp_fast.py
+++ b/src/transformers/models/mvp/tokenization_mvp_fast.py
@@ -30,24 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
# See all MVP models at https://huggingface.co/models?filter=mvp
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/vocab.json",
- },
- "added_tokens.json": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/added_tokens.json",
- },
- "merges_file": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "RUCAIBox/mvp": "https://huggingface.co/RUCAIBox/mvp/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "RUCAIBox/mvp": 1024,
-}
class MvpTokenizerFast(PreTrainedTokenizerFast):
@@ -132,8 +114,6 @@ class MvpTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = MvpTokenizer
diff --git a/src/transformers/models/nat/configuration_nat.py b/src/transformers/models/nat/configuration_nat.py
index 4dff9c84dad209..bb3b85a80c263b 100644
--- a/src/transformers/models/nat/configuration_nat.py
+++ b/src/transformers/models/nat/configuration_nat.py
@@ -21,10 +21,8 @@
logger = logging.get_logger(__name__)
-NAT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "shi-labs/nat-mini-in1k-224": "https://huggingface.co/shi-labs/nat-mini-in1k-224/resolve/main/config.json",
- # See all Nat models at https://huggingface.co/models?filter=nat
-}
+
+from ..deprecated._archive_maps import NAT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class NatConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/nat/modeling_nat.py b/src/transformers/models/nat/modeling_nat.py
index 7384e2ac4c1257..2434b65161a47c 100644
--- a/src/transformers/models/nat/modeling_nat.py
+++ b/src/transformers/models/nat/modeling_nat.py
@@ -68,10 +68,8 @@ def natten2dav(*args, **kwargs):
_IMAGE_CLASS_EXPECTED_OUTPUT = "tiger cat"
-NAT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "shi-labs/nat-mini-in1k-224",
- # See all Nat models at https://huggingface.co/models?filter=nat
-]
+from ..deprecated._archive_maps import NAT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# drop_path and NatDropPath are from the timm library.
diff --git a/src/transformers/models/nezha/configuration_nezha.py b/src/transformers/models/nezha/configuration_nezha.py
index e47f6e721f615e..a19c27d62a4a92 100644
--- a/src/transformers/models/nezha/configuration_nezha.py
+++ b/src/transformers/models/nezha/configuration_nezha.py
@@ -1,9 +1,5 @@
from ... import PretrainedConfig
-
-
-NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "sijunhe/nezha-cn-base": "https://huggingface.co/sijunhe/nezha-cn-base/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class NezhaConfig(PretrainedConfig):
@@ -64,7 +60,6 @@ class NezhaConfig(PretrainedConfig):
>>> configuration = model.config
```"""
- pretrained_config_archive_map = NEZHA_PRETRAINED_CONFIG_ARCHIVE_MAP
model_type = "nezha"
def __init__(
diff --git a/src/transformers/models/nezha/modeling_nezha.py b/src/transformers/models/nezha/modeling_nezha.py
index 918a10b2759a2d..6d983bd2378903 100644
--- a/src/transformers/models/nezha/modeling_nezha.py
+++ b/src/transformers/models/nezha/modeling_nezha.py
@@ -55,13 +55,8 @@
_CHECKPOINT_FOR_DOC = "sijunhe/nezha-cn-base"
_CONFIG_FOR_DOC = "NezhaConfig"
-NEZHA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "sijunhe/nezha-cn-base",
- "sijunhe/nezha-cn-large",
- "sijunhe/nezha-base-wwm",
- "sijunhe/nezha-large-wwm",
- # See all Nezha models at https://huggingface.co/models?filter=nezha
-]
+
+from ..deprecated._archive_maps import NEZHA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_nezha(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/nllb/tokenization_nllb.py b/src/transformers/models/nllb/tokenization_nllb.py
index ee2285e8263acb..f517121157f5d3 100644
--- a/src/transformers/models/nllb/tokenization_nllb.py
+++ b/src/transformers/models/nllb/tokenization_nllb.py
@@ -29,17 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/nllb-200-distilled-600M": (
- "https://huggingface.co/facebook/nllb-200-distilled-600M/blob/main/sentencepiece.bpe.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/nllb-200-distilled-600M": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ['ace_Arab', 'ace_Latn', 'acm_Arab', 'acq_Arab', 'aeb_Arab', 'afr_Latn', 'ajp_Arab', 'aka_Latn', 'amh_Ethi', 'apc_Arab', 'arb_Arab', 'ars_Arab', 'ary_Arab', 'arz_Arab', 'asm_Beng', 'ast_Latn', 'awa_Deva', 'ayr_Latn', 'azb_Arab', 'azj_Latn', 'bak_Cyrl', 'bam_Latn', 'ban_Latn', 'bel_Cyrl', 'bem_Latn', 'ben_Beng', 'bho_Deva', 'bjn_Arab', 'bjn_Latn', 'bod_Tibt', 'bos_Latn', 'bug_Latn', 'bul_Cyrl', 'cat_Latn', 'ceb_Latn', 'ces_Latn', 'cjk_Latn', 'ckb_Arab', 'crh_Latn', 'cym_Latn', 'dan_Latn', 'deu_Latn', 'dik_Latn', 'dyu_Latn', 'dzo_Tibt', 'ell_Grek', 'eng_Latn', 'epo_Latn', 'est_Latn', 'eus_Latn', 'ewe_Latn', 'fao_Latn', 'pes_Arab', 'fij_Latn', 'fin_Latn', 'fon_Latn', 'fra_Latn', 'fur_Latn', 'fuv_Latn', 'gla_Latn', 'gle_Latn', 'glg_Latn', 'grn_Latn', 'guj_Gujr', 'hat_Latn', 'hau_Latn', 'heb_Hebr', 'hin_Deva', 'hne_Deva', 'hrv_Latn', 'hun_Latn', 'hye_Armn', 'ibo_Latn', 'ilo_Latn', 'ind_Latn', 'isl_Latn', 'ita_Latn', 'jav_Latn', 'jpn_Jpan', 'kab_Latn', 'kac_Latn', 'kam_Latn', 'kan_Knda', 'kas_Arab', 'kas_Deva', 'kat_Geor', 'knc_Arab', 'knc_Latn', 'kaz_Cyrl', 'kbp_Latn', 'kea_Latn', 'khm_Khmr', 'kik_Latn', 'kin_Latn', 'kir_Cyrl', 'kmb_Latn', 'kon_Latn', 'kor_Hang', 'kmr_Latn', 'lao_Laoo', 'lvs_Latn', 'lij_Latn', 'lim_Latn', 'lin_Latn', 'lit_Latn', 'lmo_Latn', 'ltg_Latn', 'ltz_Latn', 'lua_Latn', 'lug_Latn', 'luo_Latn', 'lus_Latn', 'mag_Deva', 'mai_Deva', 'mal_Mlym', 'mar_Deva', 'min_Latn', 'mkd_Cyrl', 'plt_Latn', 'mlt_Latn', 'mni_Beng', 'khk_Cyrl', 'mos_Latn', 'mri_Latn', 'zsm_Latn', 'mya_Mymr', 'nld_Latn', 'nno_Latn', 'nob_Latn', 'npi_Deva', 'nso_Latn', 'nus_Latn', 'nya_Latn', 'oci_Latn', 'gaz_Latn', 'ory_Orya', 'pag_Latn', 'pan_Guru', 'pap_Latn', 'pol_Latn', 'por_Latn', 'prs_Arab', 'pbt_Arab', 'quy_Latn', 'ron_Latn', 'run_Latn', 'rus_Cyrl', 'sag_Latn', 'san_Deva', 'sat_Beng', 'scn_Latn', 'shn_Mymr', 'sin_Sinh', 'slk_Latn', 'slv_Latn', 'smo_Latn', 'sna_Latn', 'snd_Arab', 'som_Latn', 'sot_Latn', 'spa_Latn', 'als_Latn', 'srd_Latn', 'srp_Cyrl', 'ssw_Latn', 'sun_Latn', 'swe_Latn', 'swh_Latn', 'szl_Latn', 'tam_Taml', 'tat_Cyrl', 'tel_Telu', 'tgk_Cyrl', 'tgl_Latn', 'tha_Thai', 'tir_Ethi', 'taq_Latn', 'taq_Tfng', 'tpi_Latn', 'tsn_Latn', 'tso_Latn', 'tuk_Latn', 'tum_Latn', 'tur_Latn', 'twi_Latn', 'tzm_Tfng', 'uig_Arab', 'ukr_Cyrl', 'umb_Latn', 'urd_Arab', 'uzn_Latn', 'vec_Latn', 'vie_Latn', 'war_Latn', 'wol_Latn', 'xho_Latn', 'ydd_Hebr', 'yor_Latn', 'yue_Hant', 'zho_Hans', 'zho_Hant', 'zul_Latn'] # fmt: skip
@@ -116,8 +105,6 @@ class NllbTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/nllb/tokenization_nllb_fast.py b/src/transformers/models/nllb/tokenization_nllb_fast.py
index d71de82d414202..2004580bf65c7f 100644
--- a/src/transformers/models/nllb/tokenization_nllb_fast.py
+++ b/src/transformers/models/nllb/tokenization_nllb_fast.py
@@ -35,23 +35,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/nllb-200-distilled-600M": (
- "https://huggingface.co/facebook/nllb-200-distilled-600M/resolve/main/sentencepiece.bpe.model"
- ),
- },
- "tokenizer_file": {
- "facebook/nllb-200-distilled-600M": (
- "https://huggingface.co/facebook/nllb-200-distilled-600M/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/nllb-large-en-ro": 1024,
- "facebook/nllb-200-distilled-600M": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = ['ace_Arab', 'ace_Latn', 'acm_Arab', 'acq_Arab', 'aeb_Arab', 'afr_Latn', 'ajp_Arab', 'aka_Latn', 'amh_Ethi', 'apc_Arab', 'arb_Arab', 'ars_Arab', 'ary_Arab', 'arz_Arab', 'asm_Beng', 'ast_Latn', 'awa_Deva', 'ayr_Latn', 'azb_Arab', 'azj_Latn', 'bak_Cyrl', 'bam_Latn', 'ban_Latn', 'bel_Cyrl', 'bem_Latn', 'ben_Beng', 'bho_Deva', 'bjn_Arab', 'bjn_Latn', 'bod_Tibt', 'bos_Latn', 'bug_Latn', 'bul_Cyrl', 'cat_Latn', 'ceb_Latn', 'ces_Latn', 'cjk_Latn', 'ckb_Arab', 'crh_Latn', 'cym_Latn', 'dan_Latn', 'deu_Latn', 'dik_Latn', 'dyu_Latn', 'dzo_Tibt', 'ell_Grek', 'eng_Latn', 'epo_Latn', 'est_Latn', 'eus_Latn', 'ewe_Latn', 'fao_Latn', 'pes_Arab', 'fij_Latn', 'fin_Latn', 'fon_Latn', 'fra_Latn', 'fur_Latn', 'fuv_Latn', 'gla_Latn', 'gle_Latn', 'glg_Latn', 'grn_Latn', 'guj_Gujr', 'hat_Latn', 'hau_Latn', 'heb_Hebr', 'hin_Deva', 'hne_Deva', 'hrv_Latn', 'hun_Latn', 'hye_Armn', 'ibo_Latn', 'ilo_Latn', 'ind_Latn', 'isl_Latn', 'ita_Latn', 'jav_Latn', 'jpn_Jpan', 'kab_Latn', 'kac_Latn', 'kam_Latn', 'kan_Knda', 'kas_Arab', 'kas_Deva', 'kat_Geor', 'knc_Arab', 'knc_Latn', 'kaz_Cyrl', 'kbp_Latn', 'kea_Latn', 'khm_Khmr', 'kik_Latn', 'kin_Latn', 'kir_Cyrl', 'kmb_Latn', 'kon_Latn', 'kor_Hang', 'kmr_Latn', 'lao_Laoo', 'lvs_Latn', 'lij_Latn', 'lim_Latn', 'lin_Latn', 'lit_Latn', 'lmo_Latn', 'ltg_Latn', 'ltz_Latn', 'lua_Latn', 'lug_Latn', 'luo_Latn', 'lus_Latn', 'mag_Deva', 'mai_Deva', 'mal_Mlym', 'mar_Deva', 'min_Latn', 'mkd_Cyrl', 'plt_Latn', 'mlt_Latn', 'mni_Beng', 'khk_Cyrl', 'mos_Latn', 'mri_Latn', 'zsm_Latn', 'mya_Mymr', 'nld_Latn', 'nno_Latn', 'nob_Latn', 'npi_Deva', 'nso_Latn', 'nus_Latn', 'nya_Latn', 'oci_Latn', 'gaz_Latn', 'ory_Orya', 'pag_Latn', 'pan_Guru', 'pap_Latn', 'pol_Latn', 'por_Latn', 'prs_Arab', 'pbt_Arab', 'quy_Latn', 'ron_Latn', 'run_Latn', 'rus_Cyrl', 'sag_Latn', 'san_Deva', 'sat_Beng', 'scn_Latn', 'shn_Mymr', 'sin_Sinh', 'slk_Latn', 'slv_Latn', 'smo_Latn', 'sna_Latn', 'snd_Arab', 'som_Latn', 'sot_Latn', 'spa_Latn', 'als_Latn', 'srd_Latn', 'srp_Cyrl', 'ssw_Latn', 'sun_Latn', 'swe_Latn', 'swh_Latn', 'szl_Latn', 'tam_Taml', 'tat_Cyrl', 'tel_Telu', 'tgk_Cyrl', 'tgl_Latn', 'tha_Thai', 'tir_Ethi', 'taq_Latn', 'taq_Tfng', 'tpi_Latn', 'tsn_Latn', 'tso_Latn', 'tuk_Latn', 'tum_Latn', 'tur_Latn', 'twi_Latn', 'tzm_Tfng', 'uig_Arab', 'ukr_Cyrl', 'umb_Latn', 'urd_Arab', 'uzn_Latn', 'vec_Latn', 'vie_Latn', 'war_Latn', 'wol_Latn', 'xho_Latn', 'ydd_Hebr', 'yor_Latn', 'yue_Hant', 'zho_Hans', 'zho_Hant', 'zul_Latn'] # fmt: skip
@@ -127,8 +110,6 @@ class NllbTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = NllbTokenizer
diff --git a/src/transformers/models/nllb_moe/configuration_nllb_moe.py b/src/transformers/models/nllb_moe/configuration_nllb_moe.py
index 435d7caa17c63e..48172824ff2425 100644
--- a/src/transformers/models/nllb_moe/configuration_nllb_moe.py
+++ b/src/transformers/models/nllb_moe/configuration_nllb_moe.py
@@ -19,9 +19,8 @@
logger = logging.get_logger(__name__)
-NLLB_MOE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/nllb-moe-54B": "https://huggingface.co/facebook/nllb-moe-54b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import NLLB_MOE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class NllbMoeConfig(PretrainedConfig):
diff --git a/src/transformers/models/nllb_moe/modeling_nllb_moe.py b/src/transformers/models/nllb_moe/modeling_nllb_moe.py
index e02c0b0fd77506..4ef66b7bd5740c 100644
--- a/src/transformers/models/nllb_moe/modeling_nllb_moe.py
+++ b/src/transformers/models/nllb_moe/modeling_nllb_moe.py
@@ -53,10 +53,8 @@
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
-NLLB_MOE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/nllb-moe-54b",
- # See all NLLB-MOE models at https://huggingface.co/models?filter=nllb-moe
-]
+
+from ..deprecated._archive_maps import NLLB_MOE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/nougat/tokenization_nougat_fast.py b/src/transformers/models/nougat/tokenization_nougat_fast.py
index d02aec75752123..ef6b613bba3888 100644
--- a/src/transformers/models/nougat/tokenization_nougat_fast.py
+++ b/src/transformers/models/nougat/tokenization_nougat_fast.py
@@ -49,14 +49,7 @@
"""
-PRETRAINED_VOCAB_FILES_MAP = {
- "tokenizer_file": {
- "facebook/nougat-base": "https://huggingface.co/facebook/nougat-base/tokenizer/blob/main/tokenizer.json",
- },
-}
-
VOCAB_FILES_NAMES = {"tokenizer_file": "tokenizer.json"}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/nougat-base": 3584}
def markdown_compatible(text: str) -> str:
@@ -409,8 +402,6 @@ class NougatTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = None
diff --git a/src/transformers/models/nystromformer/configuration_nystromformer.py b/src/transformers/models/nystromformer/configuration_nystromformer.py
index e59b1ce8108b1a..af6e8d2c21b099 100644
--- a/src/transformers/models/nystromformer/configuration_nystromformer.py
+++ b/src/transformers/models/nystromformer/configuration_nystromformer.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-NYSTROMFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "uw-madison/nystromformer-512": "https://huggingface.co/uw-madison/nystromformer-512/resolve/main/config.json",
- # See all Nystromformer models at https://huggingface.co/models?filter=nystromformer
-}
+
+from ..deprecated._archive_maps import NYSTROMFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class NystromformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/nystromformer/modeling_nystromformer.py b/src/transformers/models/nystromformer/modeling_nystromformer.py
index 950f8d27fa8e5a..1da61bc59e6a7a 100755
--- a/src/transformers/models/nystromformer/modeling_nystromformer.py
+++ b/src/transformers/models/nystromformer/modeling_nystromformer.py
@@ -43,10 +43,8 @@
_CHECKPOINT_FOR_DOC = "uw-madison/nystromformer-512"
_CONFIG_FOR_DOC = "NystromformerConfig"
-NYSTROMFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "uw-madison/nystromformer-512",
- # See all Nyströmformer models at https://huggingface.co/models?filter=nystromformer
-]
+
+from ..deprecated._archive_maps import NYSTROMFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class NystromformerEmbeddings(nn.Module):
diff --git a/src/transformers/models/oneformer/configuration_oneformer.py b/src/transformers/models/oneformer/configuration_oneformer.py
index c4c28519479054..1cbd2ab7dbc18f 100644
--- a/src/transformers/models/oneformer/configuration_oneformer.py
+++ b/src/transformers/models/oneformer/configuration_oneformer.py
@@ -22,12 +22,8 @@
logger = logging.get_logger(__name__)
-ONEFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "shi-labs/oneformer_ade20k_swin_tiny": (
- "https://huggingface.co/shi-labs/oneformer_ade20k_swin_tiny/blob/main/config.json"
- ),
- # See all OneFormer models at https://huggingface.co/models?filter=oneformer
-}
+
+from ..deprecated._archive_maps import ONEFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class OneFormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/oneformer/modeling_oneformer.py b/src/transformers/models/oneformer/modeling_oneformer.py
index 79ad21c39f88de..6af4226995bfa1 100644
--- a/src/transformers/models/oneformer/modeling_oneformer.py
+++ b/src/transformers/models/oneformer/modeling_oneformer.py
@@ -51,10 +51,8 @@
_CONFIG_FOR_DOC = "OneFormerConfig"
_CHECKPOINT_FOR_DOC = "shi-labs/oneformer_ade20k_swin_tiny"
-ONEFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "shi-labs/oneformer_ade20k_swin_tiny",
- # See all OneFormer models at https://huggingface.co/models?filter=oneformer
-]
+
+from ..deprecated._archive_maps import ONEFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
if is_scipy_available():
diff --git a/src/transformers/models/openai/configuration_openai.py b/src/transformers/models/openai/configuration_openai.py
index 38e646b39342df..422922c7912dec 100644
--- a/src/transformers/models/openai/configuration_openai.py
+++ b/src/transformers/models/openai/configuration_openai.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/config.json"
-}
+
+from ..deprecated._archive_maps import OPENAI_GPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class OpenAIGPTConfig(PretrainedConfig):
diff --git a/src/transformers/models/openai/modeling_openai.py b/src/transformers/models/openai/modeling_openai.py
index 747118bd27f228..637aa90cff9f1d 100644
--- a/src/transformers/models/openai/modeling_openai.py
+++ b/src/transformers/models/openai/modeling_openai.py
@@ -46,10 +46,8 @@
_CHECKPOINT_FOR_DOC = "openai-community/openai-gpt"
_CONFIG_FOR_DOC = "OpenAIGPTConfig"
-OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai-community/openai-gpt",
- # See all OpenAI GPT models at https://huggingface.co/models?filter=openai-community/openai-gpt
-]
+
+from ..deprecated._archive_maps import OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_openai_gpt(model, config, openai_checkpoint_folder_path):
diff --git a/src/transformers/models/openai/modeling_tf_openai.py b/src/transformers/models/openai/modeling_tf_openai.py
index 34bc5aa522d20a..b826936c51fbd6 100644
--- a/src/transformers/models/openai/modeling_tf_openai.py
+++ b/src/transformers/models/openai/modeling_tf_openai.py
@@ -55,10 +55,8 @@
_CHECKPOINT_FOR_DOC = "openai-community/openai-gpt"
_CONFIG_FOR_DOC = "OpenAIGPTConfig"
-TF_OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai-community/openai-gpt",
- # See all OpenAI GPT models at https://huggingface.co/models?filter=openai-community/openai-gpt
-]
+
+from ..deprecated._archive_maps import TF_OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFAttention(keras.layers.Layer):
diff --git a/src/transformers/models/openai/tokenization_openai.py b/src/transformers/models/openai/tokenization_openai.py
index e189b15035b8c0..4f2b27916092b2 100644
--- a/src/transformers/models/openai/tokenization_openai.py
+++ b/src/transformers/models/openai/tokenization_openai.py
@@ -32,19 +32,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/vocab.json"
- },
- "merges_file": {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/merges.txt"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai-community/openai-gpt": 512,
-}
-
# Copied from transformers.models.bert.tokenization_bert.whitespace_tokenize
def whitespace_tokenize(text):
@@ -268,8 +255,6 @@ class OpenAIGPTTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(self, vocab_file, merges_file, unk_token="", **kwargs):
diff --git a/src/transformers/models/openai/tokenization_openai_fast.py b/src/transformers/models/openai/tokenization_openai_fast.py
index e1f04722ee27e1..214db5385044eb 100644
--- a/src/transformers/models/openai/tokenization_openai_fast.py
+++ b/src/transformers/models/openai/tokenization_openai_fast.py
@@ -26,22 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/vocab.json"
- },
- "merges_file": {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/merges.txt"
- },
- "tokenizer_file": {
- "openai-community/openai-gpt": "https://huggingface.co/openai-community/openai-gpt/resolve/main/tokenizer.json"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai-community/openai-gpt": 512,
-}
-
class OpenAIGPTTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -65,8 +49,6 @@ class OpenAIGPTTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = OpenAIGPTTokenizer
diff --git a/src/transformers/models/opt/configuration_opt.py b/src/transformers/models/opt/configuration_opt.py
index 2918ee269aebe4..a9802d2ef337c8 100644
--- a/src/transformers/models/opt/configuration_opt.py
+++ b/src/transformers/models/opt/configuration_opt.py
@@ -19,15 +19,6 @@
logger = logging.get_logger(__name__)
-OPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/opt-125m": "https://huggingface.co/facebook/opt-125m/blob/main/config.json",
- "facebook/opt-350m": "https://huggingface.co/facebook/opt-350m/blob/main/config.json",
- "facebook/opt-1.3b": "https://huggingface.co/facebook/opt-1.3b/blob/main/config.json",
- "facebook/opt-2.7b": "https://huggingface.co/facebook/opt-2.7b/blob/main/config.json",
- "facebook/opt-6.7b": "https://huggingface.co/facebook/opt-6.7b/blob/main/config.json",
- "facebook/opt-13b": "https://huggingface.co/facebook/opt-13b/blob/main/config.json",
-}
-
class OPTConfig(PretrainedConfig):
r"""
diff --git a/src/transformers/models/opt/modeling_opt.py b/src/transformers/models/opt/modeling_opt.py
index a350c9019d7af0..5e9e53a2ac3251 100644
--- a/src/transformers/models/opt/modeling_opt.py
+++ b/src/transformers/models/opt/modeling_opt.py
@@ -60,16 +60,8 @@
_SEQ_CLASS_EXPECTED_LOSS = 1.71
_SEQ_CLASS_EXPECTED_OUTPUT = "'LABEL_0'"
-OPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/opt-125m",
- "facebook/opt-350m",
- "facebook/opt-1.3b",
- "facebook/opt-2.7b",
- "facebook/opt-6.7b",
- "facebook/opt-13b",
- "facebook/opt-30b",
- # See all OPT models at https://huggingface.co/models?filter=opt
-]
+
+from ..deprecated._archive_maps import OPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
diff --git a/src/transformers/models/owlv2/configuration_owlv2.py b/src/transformers/models/owlv2/configuration_owlv2.py
index fd15c0e7972fc5..fe96ff8fa4c5f1 100644
--- a/src/transformers/models/owlv2/configuration_owlv2.py
+++ b/src/transformers/models/owlv2/configuration_owlv2.py
@@ -27,9 +27,8 @@
logger = logging.get_logger(__name__)
-OWLV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/owlv2-base-patch16": "https://huggingface.co/google/owlv2-base-patch16/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import OWLV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
# Copied from transformers.models.owlvit.configuration_owlvit.OwlViTTextConfig with OwlViT->Owlv2, owlvit-base-patch32->owlv2-base-patch16, owlvit->owlv2, OWL-ViT->OWLv2
diff --git a/src/transformers/models/owlv2/modeling_owlv2.py b/src/transformers/models/owlv2/modeling_owlv2.py
index 3506ce0fec4e3a..d99b269012d183 100644
--- a/src/transformers/models/owlv2/modeling_owlv2.py
+++ b/src/transformers/models/owlv2/modeling_owlv2.py
@@ -47,10 +47,8 @@
_CHECKPOINT_FOR_DOC = "google/owlv2-base-patch16-ensemble"
# See all Owlv2 models at https://huggingface.co/models?filter=owlv2
-OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/owlv2-base-patch16-ensemble",
- # See all OWLv2 models at https://huggingface.co/models?filter=owlv2
-]
+
+from ..deprecated._archive_maps import OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.clip.modeling_clip.contrastive_loss with clip->owlv2
diff --git a/src/transformers/models/owlvit/configuration_owlvit.py b/src/transformers/models/owlvit/configuration_owlvit.py
index 254619cccd153e..d223cdf81270d7 100644
--- a/src/transformers/models/owlvit/configuration_owlvit.py
+++ b/src/transformers/models/owlvit/configuration_owlvit.py
@@ -30,11 +30,8 @@
logger = logging.get_logger(__name__)
-OWLVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/owlvit-base-patch32": "https://huggingface.co/google/owlvit-base-patch32/resolve/main/config.json",
- "google/owlvit-base-patch16": "https://huggingface.co/google/owlvit-base-patch16/resolve/main/config.json",
- "google/owlvit-large-patch14": "https://huggingface.co/google/owlvit-large-patch14/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import OWLVIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class OwlViTTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/owlvit/modeling_owlvit.py b/src/transformers/models/owlvit/modeling_owlvit.py
index 64e99564308792..751f9c9a52ee9f 100644
--- a/src/transformers/models/owlvit/modeling_owlvit.py
+++ b/src/transformers/models/owlvit/modeling_owlvit.py
@@ -47,11 +47,8 @@
_CHECKPOINT_FOR_DOC = "google/owlvit-base-patch32"
# See all OwlViT models at https://huggingface.co/models?filter=owlvit
-OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/owlvit-base-patch32",
- "google/owlvit-base-patch16",
- "google/owlvit-large-patch14",
-]
+
+from ..deprecated._archive_maps import OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.clip.modeling_clip.contrastive_loss with clip->owlvit
diff --git a/src/transformers/models/patchtsmixer/configuration_patchtsmixer.py b/src/transformers/models/patchtsmixer/configuration_patchtsmixer.py
index 527b5a8327dcc4..2f4f1dc7619215 100644
--- a/src/transformers/models/patchtsmixer/configuration_patchtsmixer.py
+++ b/src/transformers/models/patchtsmixer/configuration_patchtsmixer.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-PATCHTSMIXER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "ibm/patchtsmixer-etth1-pretrain": "https://huggingface.co/ibm/patchtsmixer-etth1-pretrain/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import PATCHTSMIXER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PatchTSMixerConfig(PretrainedConfig):
diff --git a/src/transformers/models/patchtsmixer/modeling_patchtsmixer.py b/src/transformers/models/patchtsmixer/modeling_patchtsmixer.py
index 5bccccb8132b27..dade06dfde053a 100644
--- a/src/transformers/models/patchtsmixer/modeling_patchtsmixer.py
+++ b/src/transformers/models/patchtsmixer/modeling_patchtsmixer.py
@@ -39,10 +39,7 @@
_CONFIG_FOR_DOC = "PatchTSMixerConfig"
-PATCHTSMIXER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "ibm/patchtsmixer-etth1-pretrain",
- # See all PatchTSMixer models at https://huggingface.co/models?filter=patchtsmixer
-]
+from ..deprecated._archive_maps import PATCHTSMIXER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
PATCHTSMIXER_START_DOCSTRING = r"""
diff --git a/src/transformers/models/patchtst/configuration_patchtst.py b/src/transformers/models/patchtst/configuration_patchtst.py
index 5cf949304e91fe..dc95429d90995a 100644
--- a/src/transformers/models/patchtst/configuration_patchtst.py
+++ b/src/transformers/models/patchtst/configuration_patchtst.py
@@ -22,10 +22,8 @@
logger = logging.get_logger(__name__)
-PATCHTST_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "ibm/patchtst-base": "https://huggingface.co/ibm/patchtst-base/resolve/main/config.json",
- # See all PatchTST models at https://huggingface.co/ibm/models?filter=patchtst
-}
+
+from ..deprecated._archive_maps import PATCHTST_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PatchTSTConfig(PretrainedConfig):
diff --git a/src/transformers/models/patchtst/modeling_patchtst.py b/src/transformers/models/patchtst/modeling_patchtst.py
index 08ce54712612d6..22b206726e16d3 100755
--- a/src/transformers/models/patchtst/modeling_patchtst.py
+++ b/src/transformers/models/patchtst/modeling_patchtst.py
@@ -33,10 +33,8 @@
_CONFIG_FOR_DOC = "PatchTSTConfig"
-PATCHTST_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "ibm/patchtst-etth1-pretrain",
- # See all PatchTST models at https://huggingface.co/models?filter=patchtst
-]
+
+from ..deprecated._archive_maps import PATCHTST_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.BartAttention with Bart->PatchTST
diff --git a/src/transformers/models/pegasus/configuration_pegasus.py b/src/transformers/models/pegasus/configuration_pegasus.py
index 51b506c4e03938..39d3865fd57b4e 100644
--- a/src/transformers/models/pegasus/configuration_pegasus.py
+++ b/src/transformers/models/pegasus/configuration_pegasus.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/pegasus-large": "https://huggingface.co/google/pegasus-large/resolve/main/config.json",
- # See all PEGASUS models at https://huggingface.co/models?filter=pegasus
-}
+
+from ..deprecated._archive_maps import PEGASUS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PegasusConfig(PretrainedConfig):
diff --git a/src/transformers/models/pegasus/modeling_pegasus.py b/src/transformers/models/pegasus/modeling_pegasus.py
index 91fdb9c1db5931..069c6aa6fe6316 100755
--- a/src/transformers/models/pegasus/modeling_pegasus.py
+++ b/src/transformers/models/pegasus/modeling_pegasus.py
@@ -50,12 +50,6 @@
_CONFIG_FOR_DOC = "PegasusConfig"
-PEGASUS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/pegasus-large",
- # See all PEGASUS models at https://huggingface.co/models?filter=pegasus
-]
-
-
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
diff --git a/src/transformers/models/pegasus/tokenization_pegasus.py b/src/transformers/models/pegasus/tokenization_pegasus.py
index e1c8f6933ffc87..2763b739a9644a 100644
--- a/src/transformers/models/pegasus/tokenization_pegasus.py
+++ b/src/transformers/models/pegasus/tokenization_pegasus.py
@@ -26,14 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"google/pegasus-xsum": "https://huggingface.co/google/pegasus-xsum/resolve/main/spiece.model"}
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/pegasus-xsum": 512,
-}
-
logger = logging.get_logger(__name__)
@@ -98,8 +90,6 @@ class PegasusTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/pegasus/tokenization_pegasus_fast.py b/src/transformers/models/pegasus/tokenization_pegasus_fast.py
index 3bc1726876e819..f1252e959ebc24 100644
--- a/src/transformers/models/pegasus/tokenization_pegasus_fast.py
+++ b/src/transformers/models/pegasus/tokenization_pegasus_fast.py
@@ -36,17 +36,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"google/pegasus-xsum": "https://huggingface.co/google/pegasus-xsum/resolve/main/spiece.model"},
- "tokenizer_file": {
- "google/pegasus-xsum": "https://huggingface.co/google/pegasus-xsum/resolve/main/tokenizer.json"
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/pegasus-xsum": 512,
-}
-
class PegasusTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -93,8 +82,6 @@ class PegasusTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = PegasusTokenizer
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/pegasus_x/configuration_pegasus_x.py b/src/transformers/models/pegasus_x/configuration_pegasus_x.py
index be092c018a427a..fa1f3da6d364a3 100644
--- a/src/transformers/models/pegasus_x/configuration_pegasus_x.py
+++ b/src/transformers/models/pegasus_x/configuration_pegasus_x.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-PEGASUS_X_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/pegasus-x-base": "https://huggingface.co/google/pegasus-x-base/resolve/main/config.json",
- "google/pegasus-x-large": "https://huggingface.co/google/pegasus-x-large/resolve/main/config.json",
- # See all PEGASUS-X models at https://huggingface.co/models?filter=pegasus-x
-}
+
+from ..deprecated._archive_maps import PEGASUS_X_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PegasusXConfig(PretrainedConfig):
diff --git a/src/transformers/models/pegasus_x/modeling_pegasus_x.py b/src/transformers/models/pegasus_x/modeling_pegasus_x.py
index 49539514378a08..f31ccccbb16348 100755
--- a/src/transformers/models/pegasus_x/modeling_pegasus_x.py
+++ b/src/transformers/models/pegasus_x/modeling_pegasus_x.py
@@ -49,11 +49,7 @@
_CONFIG_FOR_DOC = "PegasusXConfig"
-PEGASUS_X_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/pegasus-x-base",
- "google/pegasus-x-large",
- # See all PEGASUS models at https://huggingface.co/models?filter=pegasus-x
-]
+from ..deprecated._archive_maps import PEGASUS_X_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclasses.dataclass
diff --git a/src/transformers/models/perceiver/configuration_perceiver.py b/src/transformers/models/perceiver/configuration_perceiver.py
index d741b287e5db7c..eb9458989cad01 100644
--- a/src/transformers/models/perceiver/configuration_perceiver.py
+++ b/src/transformers/models/perceiver/configuration_perceiver.py
@@ -27,10 +27,8 @@
logger = logging.get_logger(__name__)
-PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "deepmind/language-perceiver": "https://huggingface.co/deepmind/language-perceiver/resolve/main/config.json",
- # See all Perceiver models at https://huggingface.co/models?filter=perceiver
-}
+
+from ..deprecated._archive_maps import PERCEIVER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PerceiverConfig(PretrainedConfig):
diff --git a/src/transformers/models/perceiver/modeling_perceiver.py b/src/transformers/models/perceiver/modeling_perceiver.py
index bb7ac2bc3139e1..5de7635355ddb3 100755
--- a/src/transformers/models/perceiver/modeling_perceiver.py
+++ b/src/transformers/models/perceiver/modeling_perceiver.py
@@ -51,10 +51,8 @@
_CHECKPOINT_FOR_DOC = "deepmind/language-perceiver"
_CONFIG_FOR_DOC = "PerceiverConfig"
-PERCEIVER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "deepmind/language-perceiver",
- # See all Perceiver models at https://huggingface.co/models?filter=perceiver
-]
+
+from ..deprecated._archive_maps import PERCEIVER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/persimmon/configuration_persimmon.py b/src/transformers/models/persimmon/configuration_persimmon.py
index 6997e159d522a3..8408ef8dea20bb 100644
--- a/src/transformers/models/persimmon/configuration_persimmon.py
+++ b/src/transformers/models/persimmon/configuration_persimmon.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-PERSIMMON_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "adept/persimmon-8b-base": "https://huggingface.co/adept/persimmon-8b-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import PERSIMMON_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PersimmonConfig(PretrainedConfig):
@@ -152,8 +151,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/phi/configuration_phi.py b/src/transformers/models/phi/configuration_phi.py
index 1b495cc8e22063..59d63ae65da062 100644
--- a/src/transformers/models/phi/configuration_phi.py
+++ b/src/transformers/models/phi/configuration_phi.py
@@ -22,11 +22,8 @@
logger = logging.get_logger(__name__)
-PHI_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/phi-1": "https://huggingface.co/microsoft/phi-1/resolve/main/config.json",
- "microsoft/phi-1_5": "https://huggingface.co/microsoft/phi-1_5/resolve/main/config.json",
- "microsoft/phi-2": "https://huggingface.co/microsoft/phi-2/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import PHI_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PhiConfig(PretrainedConfig):
@@ -182,8 +179,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/phi/modeling_phi.py b/src/transformers/models/phi/modeling_phi.py
index c3cb119f0aa043..13719166edf9d9 100644
--- a/src/transformers/models/phi/modeling_phi.py
+++ b/src/transformers/models/phi/modeling_phi.py
@@ -62,12 +62,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/phi-1"
_CONFIG_FOR_DOC = "PhiConfig"
-PHI_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/phi-1",
- "microsoft/phi-1_5",
- "microsoft/phi-2",
- # See all Phi models at https://huggingface.co/models?filter=phi
-]
+
+from ..deprecated._archive_maps import PHI_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
diff --git a/src/transformers/models/phobert/tokenization_phobert.py b/src/transformers/models/phobert/tokenization_phobert.py
index 1275947776d463..f312f495015012 100644
--- a/src/transformers/models/phobert/tokenization_phobert.py
+++ b/src/transformers/models/phobert/tokenization_phobert.py
@@ -32,22 +32,6 @@
"merges_file": "bpe.codes",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "vinai/phobert-base": "https://huggingface.co/vinai/phobert-base/resolve/main/vocab.txt",
- "vinai/phobert-large": "https://huggingface.co/vinai/phobert-large/resolve/main/vocab.txt",
- },
- "merges_file": {
- "vinai/phobert-base": "https://huggingface.co/vinai/phobert-base/resolve/main/bpe.codes",
- "vinai/phobert-large": "https://huggingface.co/vinai/phobert-large/resolve/main/bpe.codes",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "vinai/phobert-base": 256,
- "vinai/phobert-large": 256,
-}
-
def get_pairs(word):
"""
@@ -115,8 +99,6 @@ class PhobertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/pix2struct/configuration_pix2struct.py b/src/transformers/models/pix2struct/configuration_pix2struct.py
index 2449d496f286f2..12bf998d58c00a 100644
--- a/src/transformers/models/pix2struct/configuration_pix2struct.py
+++ b/src/transformers/models/pix2struct/configuration_pix2struct.py
@@ -23,11 +23,8 @@
logger = logging.get_logger(__name__)
-PIX2STRUCT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/pix2struct-textcaps-base": (
- "https://huggingface.co/google/pix2struct-textcaps-base/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import PIX2STRUCT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Pix2StructTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/pix2struct/modeling_pix2struct.py b/src/transformers/models/pix2struct/modeling_pix2struct.py
index 42f3002ac632cf..e8032fcef6690b 100644
--- a/src/transformers/models/pix2struct/modeling_pix2struct.py
+++ b/src/transformers/models/pix2struct/modeling_pix2struct.py
@@ -49,26 +49,7 @@
_CONFIG_FOR_DOC = "Pix2StructConfig"
-PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/pix2struct-textcaps-base",
- "google/pix2struct-textcaps-large",
- "google/pix2struct-base",
- "google/pix2struct-large",
- "google/pix2struct-ai2d-base",
- "google/pix2struct-ai2d-large",
- "google/pix2struct-widget-captioning-base",
- "google/pix2struct-widget-captioning-large",
- "google/pix2struct-screen2words-base",
- "google/pix2struct-screen2words-large",
- "google/pix2struct-docvqa-base",
- "google/pix2struct-docvqa-large",
- "google/pix2struct-ocrvqa-base",
- "google/pix2struct-ocrvqa-large",
- "google/pix2struct-chartqa-base",
- "google/pix2struct-inforgraphics-vqa-base",
- "google/pix2struct-inforgraphics-vqa-large",
- # See all Pix2StructVision models at https://huggingface.co/models?filter=pix2struct
-]
+from ..deprecated._archive_maps import PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Adapted from transformers.models.t5.modeling_t5.T5LayerNorm with T5->Pix2Struct
diff --git a/src/transformers/models/plbart/configuration_plbart.py b/src/transformers/models/plbart/configuration_plbart.py
index 836cf5900c8e09..555a2fcc7572ff 100644
--- a/src/transformers/models/plbart/configuration_plbart.py
+++ b/src/transformers/models/plbart/configuration_plbart.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-PLBART_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "uclanlp/plbart-base": "https://huggingface.co/uclanlp/plbart-base/resolve/main/config.json",
- # See all PLBART models at https://huggingface.co/models?filter=plbart
-}
+
+from ..deprecated._archive_maps import PLBART_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PLBartConfig(PretrainedConfig):
diff --git a/src/transformers/models/plbart/modeling_plbart.py b/src/transformers/models/plbart/modeling_plbart.py
index 3c17eceabbb223..d60b7ee4b046ee 100644
--- a/src/transformers/models/plbart/modeling_plbart.py
+++ b/src/transformers/models/plbart/modeling_plbart.py
@@ -54,12 +54,8 @@
_CHECKPOINT_FOR_DOC = "uclanlp/plbart-base"
_CONFIG_FOR_DOC = "PLBartConfig"
-PLBART_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "uclanlp/plbart-base",
- "uclanlp/plbart-cs-java",
- "uclanlp/plbart-multi_task-all",
- # See all PLBART models at https://huggingface.co/models?filter=plbart
-]
+
+from ..deprecated._archive_maps import PLBART_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.mbart.modeling_mbart.shift_tokens_right
diff --git a/src/transformers/models/plbart/tokenization_plbart.py b/src/transformers/models/plbart/tokenization_plbart.py
index e50849b51d2d59..9ab2e33f7f0dba 100644
--- a/src/transformers/models/plbart/tokenization_plbart.py
+++ b/src/transformers/models/plbart/tokenization_plbart.py
@@ -29,63 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "uclanlp/plbart-base": "https://huggingface.co/uclanlp/plbart-base/resolve/main/sentencepiece.bpe.model",
- "uclanlp/plbart-c-cpp-defect-detection": (
- "https://huggingface.co/uclanlp/plbart-c-cpp-defect-detection/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-cs-java": "https://huggingface.co/uclanlp/plbart-cs-java/resolve/main/sentencepiece.bpe.model",
- "uclanlp/plbart-en_XX-java": (
- "https://huggingface.co/uclanlp/plbart-en_XX-java/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-go-en_XX": (
- "https://huggingface.co/uclanlp/plbart-go-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-java-clone-detection": (
- "https://huggingface.co/uclanlp/plbart-java-clone-detection/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-java-cs": "https://huggingface.co/uclanlp/plbart-java-cs/resolve/main/sentencepiece.bpe.model",
- "uclanlp/plbart-java-en_XX": (
- "https://huggingface.co/uclanlp/plbart-java-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-javascript-en_XX": (
- "https://huggingface.co/uclanlp/plbart-javascript-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-php-en_XX": (
- "https://huggingface.co/uclanlp/plbart-php-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-python-en_XX": (
- "https://huggingface.co/uclanlp/plbart-python-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-refine-java-medium": (
- "https://huggingface.co/uclanlp/plbart-refine-java-medium/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-refine-java-small": (
- "https://huggingface.co/uclanlp/plbart-refine-java-small/resolve/main/sentencepiece.bpe.model"
- ),
- "uclanlp/plbart-ruby-en_XX": (
- "https://huggingface.co/uclanlp/plbart-ruby-en_XX/resolve/main/sentencepiece.bpe.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "uclanlp/plbart-base": 1024,
- "uclanlp/plbart-c-cpp-defect-detection": 1024,
- "uclanlp/plbart-cs-java": 1024,
- "uclanlp/plbart-en_XX-java": 1024,
- "uclanlp/plbart-go-en_XX": 1024,
- "uclanlp/plbart-java-clone-detection": 1024,
- "uclanlp/plbart-java-cs": 1024,
- "uclanlp/plbart-java-en_XX": 1024,
- "uclanlp/plbart-javascript-en_XX": 1024,
- "uclanlp/plbart-php-en_XX": 1024,
- "uclanlp/plbart-python-en_XX": 1024,
- "uclanlp/plbart-refine-java-medium": 1024,
- "uclanlp/plbart-refine-java-small": 1024,
- "uclanlp/plbart-ruby-en_XX": 1024,
-}
FAIRSEQ_LANGUAGE_CODES = {
"base": ["__java__", "__python__", "__en_XX__"],
@@ -166,8 +109,6 @@ class PLBartTokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/poolformer/configuration_poolformer.py b/src/transformers/models/poolformer/configuration_poolformer.py
index d859cefc90efd7..be0f18c0a31035 100644
--- a/src/transformers/models/poolformer/configuration_poolformer.py
+++ b/src/transformers/models/poolformer/configuration_poolformer.py
@@ -25,10 +25,8 @@
logger = logging.get_logger(__name__)
-POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "sail/poolformer_s12": "https://huggingface.co/sail/poolformer_s12/resolve/main/config.json",
- # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
-}
+
+from ..deprecated._archive_maps import POOLFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PoolFormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/poolformer/modeling_poolformer.py b/src/transformers/models/poolformer/modeling_poolformer.py
index c5a8c7a0d27a85..80208bd1fc33e0 100755
--- a/src/transformers/models/poolformer/modeling_poolformer.py
+++ b/src/transformers/models/poolformer/modeling_poolformer.py
@@ -43,10 +43,8 @@
_IMAGE_CLASS_CHECKPOINT = "sail/poolformer_s12"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "sail/poolformer_s12",
- # See all PoolFormer models at https://huggingface.co/models?filter=poolformer
-]
+
+from ..deprecated._archive_maps import POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/pop2piano/configuration_pop2piano.py b/src/transformers/models/pop2piano/configuration_pop2piano.py
index 15bf1ac438dd43..ff0d4f37b23e0b 100644
--- a/src/transformers/models/pop2piano/configuration_pop2piano.py
+++ b/src/transformers/models/pop2piano/configuration_pop2piano.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-POP2PIANO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "sweetcocoa/pop2piano": "https://huggingface.co/sweetcocoa/pop2piano/blob/main/config.json"
-}
+
+from ..deprecated._archive_maps import POP2PIANO_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Pop2PianoConfig(PretrainedConfig):
diff --git a/src/transformers/models/pop2piano/modeling_pop2piano.py b/src/transformers/models/pop2piano/modeling_pop2piano.py
index d3638d25b97a0d..c85135ccfea2d9 100644
--- a/src/transformers/models/pop2piano/modeling_pop2piano.py
+++ b/src/transformers/models/pop2piano/modeling_pop2piano.py
@@ -64,10 +64,8 @@
_CONFIG_FOR_DOC = "Pop2PianoConfig"
_CHECKPOINT_FOR_DOC = "sweetcocoa/pop2piano"
-POP2PIANO_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "sweetcocoa/pop2piano",
- # See all Pop2Piano models at https://huggingface.co/models?filter=pop2piano
-]
+
+from ..deprecated._archive_maps import POP2PIANO_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
POP2PIANO_INPUTS_DOCSTRING = r"""
@@ -589,7 +587,7 @@ def forward(
if len(past_key_value) != expected_num_past_key_values:
raise ValueError(
f"There should be {expected_num_past_key_values} past states. "
- f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"{'2 (key / value) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
f"Got {len(past_key_value)} past key / value states"
)
diff --git a/src/transformers/models/pop2piano/tokenization_pop2piano.py b/src/transformers/models/pop2piano/tokenization_pop2piano.py
index 0d25dcdfc7d57b..3c5844ae7c4115 100644
--- a/src/transformers/models/pop2piano/tokenization_pop2piano.py
+++ b/src/transformers/models/pop2piano/tokenization_pop2piano.py
@@ -35,12 +35,6 @@
"vocab": "vocab.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab": {
- "sweetcocoa/pop2piano": "https://huggingface.co/sweetcocoa/pop2piano/blob/main/vocab.json",
- },
-}
-
def token_time_to_note(number, cutoff_time_idx, current_idx):
current_idx += number
@@ -83,7 +77,6 @@ class Pop2PianoTokenizer(PreTrainedTokenizer):
model_input_names = ["token_ids", "attention_mask"]
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
def __init__(
self,
diff --git a/src/transformers/models/prophetnet/configuration_prophetnet.py b/src/transformers/models/prophetnet/configuration_prophetnet.py
index 4072709af9615b..e07936a14cd302 100644
--- a/src/transformers/models/prophetnet/configuration_prophetnet.py
+++ b/src/transformers/models/prophetnet/configuration_prophetnet.py
@@ -22,11 +22,8 @@
logger = logging.get_logger(__name__)
-PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/prophetnet-large-uncased": (
- "https://huggingface.co/microsoft/prophetnet-large-uncased/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ProphetNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/prophetnet/modeling_prophetnet.py b/src/transformers/models/prophetnet/modeling_prophetnet.py
index 81eb503ddbe944..c7d9028cdaf709 100644
--- a/src/transformers/models/prophetnet/modeling_prophetnet.py
+++ b/src/transformers/models/prophetnet/modeling_prophetnet.py
@@ -43,10 +43,8 @@
_CONFIG_FOR_DOC = "ProphenetConfig"
_CHECKPOINT_FOR_DOC = "microsoft/prophetnet-large-uncased"
-PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/prophetnet-large-uncased",
- # See all ProphetNet models at https://huggingface.co/models?filter=prophetnet
-]
+
+from ..deprecated._archive_maps import PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
PROPHETNET_START_DOCSTRING = r"""
diff --git a/src/transformers/models/prophetnet/tokenization_prophetnet.py b/src/transformers/models/prophetnet/tokenization_prophetnet.py
index 483188ca55d0c3..cd387520af18ef 100644
--- a/src/transformers/models/prophetnet/tokenization_prophetnet.py
+++ b/src/transformers/models/prophetnet/tokenization_prophetnet.py
@@ -26,22 +26,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "prophetnet.tokenizer"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/prophetnet-large-uncased": (
- "https://huggingface.co/microsoft/prophetnet-large-uncased/resolve/main/prophetnet.tokenizer"
- ),
- }
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/prophetnet-large-uncased": {"do_lower_case": True},
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/prophetnet-large-uncased": 512,
-}
-
# Copied from transformers.models.bert.tokenization_bert.whitespace_tokenize
def whitespace_tokenize(text):
@@ -327,9 +311,6 @@ class ProphetNetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
# first name has to correspond to main model input name
# to make sure `tokenizer.pad(...)` works correctly
diff --git a/src/transformers/models/pvt/configuration_pvt.py b/src/transformers/models/pvt/configuration_pvt.py
index ac7d5add7f5971..7fc99b49cf0d78 100644
--- a/src/transformers/models/pvt/configuration_pvt.py
+++ b/src/transformers/models/pvt/configuration_pvt.py
@@ -28,10 +28,8 @@
logger = logging.get_logger(__name__)
-PVT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "pvt-tiny-224": "https://huggingface.co/Zetatech/pvt-tiny-224",
- # See all PVT models at https://huggingface.co/models?filter=pvt
-}
+
+from ..deprecated._archive_maps import PVT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class PvtConfig(PretrainedConfig):
diff --git a/src/transformers/models/pvt/modeling_pvt.py b/src/transformers/models/pvt/modeling_pvt.py
index 58ed0ae68fedd6..b169af0cbd5668 100755
--- a/src/transformers/models/pvt/modeling_pvt.py
+++ b/src/transformers/models/pvt/modeling_pvt.py
@@ -49,10 +49,8 @@
_IMAGE_CLASS_CHECKPOINT = "Zetatech/pvt-tiny-224"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-PVT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Zetatech/pvt-tiny-224"
- # See all PVT models at https://huggingface.co/models?filter=pvt
-]
+
+from ..deprecated._archive_maps import PVT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.beit.modeling_beit.drop_path
diff --git a/src/transformers/models/pvt_v2/__init__.py b/src/transformers/models/pvt_v2/__init__.py
index e9297e7908d3f7..4825eda165050a 100644
--- a/src/transformers/models/pvt_v2/__init__.py
+++ b/src/transformers/models/pvt_v2/__init__.py
@@ -25,7 +25,7 @@
_import_structure = {
- "configuration_pvt_v2": ["PVT_V2_PRETRAINED_CONFIG_ARCHIVE_MAP", "PvtV2Config"],
+ "configuration_pvt_v2": ["PvtV2Config"],
}
try:
@@ -35,7 +35,6 @@
pass
else:
_import_structure["modeling_pvt_v2"] = [
- "PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST",
"PvtV2ForImageClassification",
"PvtV2Model",
"PvtV2PreTrainedModel",
@@ -44,7 +43,7 @@
if TYPE_CHECKING:
- from .configuration_pvt_v2 import PVT_V2_PRETRAINED_CONFIG_ARCHIVE_MAP, PvtV2Config
+ from .configuration_pvt_v2 import PvtV2Config
try:
if not is_torch_available():
@@ -53,7 +52,6 @@
pass
else:
from .modeling_pvt_v2 import (
- PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST,
PvtV2Backbone,
PvtV2ForImageClassification,
PvtV2Model,
diff --git a/src/transformers/models/pvt_v2/configuration_pvt_v2.py b/src/transformers/models/pvt_v2/configuration_pvt_v2.py
index 1ff3a50232518b..f6d7de299ba37d 100644
--- a/src/transformers/models/pvt_v2/configuration_pvt_v2.py
+++ b/src/transformers/models/pvt_v2/configuration_pvt_v2.py
@@ -25,16 +25,6 @@
logger = logging.get_logger(__name__)
-PVT_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "pvt_v2_b0": "https://huggingface.co/OpenGVLab/pvt_v2_b0",
- "pvt_v2_b1": "https://huggingface.co/OpenGVLab/pvt_v2_b1",
- "pvt_v2_b2": "https://huggingface.co/OpenGVLab/pvt_v2_b2",
- "pvt_v2_b2_linear": "https://huggingface.co/OpenGVLab/pvt_v2_b2_linear",
- "pvt_v2_b3": "https://huggingface.co/OpenGVLab/pvt_v2_b3",
- "pvt_v2_b4": "https://huggingface.co/OpenGVLab/pvt_v2_b4",
- "pvt_v2_b5": "https://huggingface.co/OpenGVLab/pvt_v2_b5",
-}
-
class PvtV2Config(BackboneConfigMixin, PretrainedConfig):
r"""
diff --git a/src/transformers/models/pvt_v2/modeling_pvt_v2.py b/src/transformers/models/pvt_v2/modeling_pvt_v2.py
index 7df2015c1ccb22..a2e1e7a674524f 100644
--- a/src/transformers/models/pvt_v2/modeling_pvt_v2.py
+++ b/src/transformers/models/pvt_v2/modeling_pvt_v2.py
@@ -49,17 +49,6 @@
_IMAGE_CLASS_CHECKPOINT = "OpenGVLab/pvt_v2_b0"
_IMAGE_CLASS_EXPECTED_OUTPUT = "LABEL_281" # ImageNet ID for "tabby, tabby cat"
-PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "OpenGVLab/pvt_v2_b0",
- "OpenGVLab/pvt_v2_b1",
- "OpenGVLab/pvt_v2_b2",
- "OpenGVLab/pvt_v2_b2_linear",
- "OpenGVLab/pvt_v2_b3",
- "OpenGVLab/pvt_v2_b4",
- "OpenGVLab/pvt_v2_b5",
- # See all PVT models at https://huggingface.co/models?filter=pvt_v2
-]
-
# Copied from transformers.models.beit.modeling_beit.drop_path
def drop_path(input: torch.Tensor, drop_prob: float = 0.0, training: bool = False) -> torch.Tensor:
diff --git a/src/transformers/models/qdqbert/configuration_qdqbert.py b/src/transformers/models/qdqbert/configuration_qdqbert.py
index 1efa2ef811ecbe..9a48424cc063c1 100644
--- a/src/transformers/models/qdqbert/configuration_qdqbert.py
+++ b/src/transformers/models/qdqbert/configuration_qdqbert.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/config.json",
- # QDQBERT models can be loaded from any BERT checkpoint, available at https://huggingface.co/models?filter=bert
-}
+
+from ..deprecated._archive_maps import QDQBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class QDQBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/qdqbert/modeling_qdqbert.py b/src/transformers/models/qdqbert/modeling_qdqbert.py
index 8c610ecaedbfc4..c5e9af7025842b 100755
--- a/src/transformers/models/qdqbert/modeling_qdqbert.py
+++ b/src/transformers/models/qdqbert/modeling_qdqbert.py
@@ -69,10 +69,8 @@
_CHECKPOINT_FOR_DOC = "google-bert/bert-base-uncased"
_CONFIG_FOR_DOC = "QDQBertConfig"
-QDQBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google-bert/bert-base-uncased",
- # See all BERT models at https://huggingface.co/models?filter=bert
-]
+
+from ..deprecated._archive_maps import QDQBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_qdqbert(model, tf_checkpoint_path):
diff --git a/src/transformers/models/qwen2/configuration_qwen2.py b/src/transformers/models/qwen2/configuration_qwen2.py
index 0bbfd1cf1601ed..2513866d3e62d8 100644
--- a/src/transformers/models/qwen2/configuration_qwen2.py
+++ b/src/transformers/models/qwen2/configuration_qwen2.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Qwen/Qwen2-7B-beta": "https://huggingface.co/Qwen/Qwen2-7B-beta/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import QWEN2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Qwen2Config(PretrainedConfig):
diff --git a/src/transformers/models/qwen2/modeling_qwen2.py b/src/transformers/models/qwen2/modeling_qwen2.py
index bfba4a45324818..7ca32c37685c3c 100644
--- a/src/transformers/models/qwen2/modeling_qwen2.py
+++ b/src/transformers/models/qwen2/modeling_qwen2.py
@@ -58,11 +58,6 @@
_CHECKPOINT_FOR_DOC = "Qwen/Qwen2-7B-beta"
_CONFIG_FOR_DOC = "Qwen2Config"
-QWEN2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Qwen/Qwen2-7B-beta",
- # See all Qwen2 models at https://huggingface.co/models?filter=qwen2
-]
-
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
def _get_unpad_data(attention_mask):
diff --git a/src/transformers/models/qwen2/tokenization_qwen2.py b/src/transformers/models/qwen2/tokenization_qwen2.py
index 9f8607c9ef6ca4..22cffcb608152f 100644
--- a/src/transformers/models/qwen2/tokenization_qwen2.py
+++ b/src/transformers/models/qwen2/tokenization_qwen2.py
@@ -33,10 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
- "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
-}
MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
@@ -136,8 +132,6 @@ class Qwen2Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = MAX_MODEL_INPUT_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/qwen2/tokenization_qwen2_fast.py b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
index 467aa6d947e1f3..82e3073788679c 100644
--- a/src/transformers/models/qwen2/tokenization_qwen2_fast.py
+++ b/src/transformers/models/qwen2/tokenization_qwen2_fast.py
@@ -30,13 +30,6 @@
"tokenizer_file": "tokenizer.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/vocab.json"},
- "merges_file": {"qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/merges.txt"},
- "tokenizer_file": {
- "qwen/qwen-tokenizer": "https://huggingface.co/qwen/qwen-tokenizer/resolve/main/tokenizer.json"
- },
-}
MAX_MODEL_INPUT_SIZES = {"qwen/qwen-tokenizer": 32768}
@@ -84,8 +77,6 @@ class Qwen2TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = MAX_MODEL_INPUT_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = Qwen2Tokenizer
diff --git a/src/transformers/models/qwen2_moe/__init__.py b/src/transformers/models/qwen2_moe/__init__.py
new file mode 100644
index 00000000000000..f083b454d554a0
--- /dev/null
+++ b/src/transformers/models/qwen2_moe/__init__.py
@@ -0,0 +1,62 @@
+# Copyright 2024 The Qwen Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_torch_available,
+)
+
+
+_import_structure = {
+ "configuration_qwen2_moe": ["QWEN2MOE_PRETRAINED_CONFIG_ARCHIVE_MAP", "Qwen2MoeConfig"],
+}
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_qwen2_moe"] = [
+ "Qwen2MoeForCausalLM",
+ "Qwen2MoeModel",
+ "Qwen2MoePreTrainedModel",
+ "Qwen2MoeForSequenceClassification",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_qwen2_moe import QWEN2MOE_PRETRAINED_CONFIG_ARCHIVE_MAP, Qwen2MoeConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_qwen2_moe import (
+ Qwen2MoeForCausalLM,
+ Qwen2MoeForSequenceClassification,
+ Qwen2MoeModel,
+ Qwen2MoePreTrainedModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py b/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
new file mode 100644
index 00000000000000..e3f516ed9c2de4
--- /dev/null
+++ b/src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
@@ -0,0 +1,175 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Qwen2MoE model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+QWEN2MOE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "Qwen/Qwen1.5-MoE-A2.7B": "https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B/resolve/main/config.json",
+}
+
+
+class Qwen2MoeConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`Qwen2MoeModel`]. It is used to instantiate a
+ Qwen2MoE model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of
+ Qwen1.5-MoE-A2.7B" [Qwen/Qwen1.5-MoE-A2.7B"](https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B").
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 151936):
+ Vocabulary size of the Qwen2MoE model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`Qwen2MoeModel`]
+ hidden_size (`int`, *optional*, defaults to 2048):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 5632):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 16):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 32768):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied.
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ use_sliding_window (`bool`, *optional*, defaults to `False`):
+ Whether to use sliding window attention.
+ sliding_window (`int`, *optional*, defaults to 4096):
+ Sliding window attention (SWA) window size. If not specified, will default to `4096`.
+ max_window_layers (`int`, *optional*, defaults to 28):
+ The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ decoder_sparse_step (`int`, *optional*, defaults to 1):
+ The frequency of the MoE layer.
+ moe_intermediate_size (`int`, *optional*, defaults to 1408):
+ Intermediate size of the routed expert.
+ shared_expert_intermediate_size (`int`, *optional*, defaults to 5632):
+ Intermediate size of the shared expert.
+ num_experts_per_tok (`int`, *optional*, defaults to 4):
+ Number of selected experts.
+ num_experts (`int`, *optional*, defaults to 60):
+ Number of routed experts.
+ norm_topk_prob (`bool`, *optional*, defaults to `False`):
+ Whether to normalize the topk probabilities.
+ output_router_logits (`bool`, *optional*, defaults to `False`):
+ Whether or not the router logits should be returned by the model. Enabeling this will also
+ allow the model to output the auxiliary loss, including load balancing loss and router z-loss.
+ router_aux_loss_coef (`float`, *optional*, defaults to 0.001):
+ The aux loss factor for the total loss.
+
+ ```python
+ >>> from transformers import Qwen2MoeModel, Qwen2MoeConfig
+
+ >>> # Initializing a Qwen2MoE style configuration
+ >>> configuration = Qwen2MoeConfig()
+
+ >>> # Initializing a model from the Qwen1.5-MoE-A2.7B" style configuration
+ >>> model = Qwen2MoeModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "qwen2_moe"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ def __init__(
+ self,
+ vocab_size=151936,
+ hidden_size=2048,
+ intermediate_size=5632,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ num_key_value_heads=16,
+ hidden_act="silu",
+ max_position_embeddings=32768,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ use_sliding_window=False,
+ sliding_window=4096,
+ max_window_layers=28,
+ attention_dropout=0.0,
+ decoder_sparse_step=1,
+ moe_intermediate_size=1408,
+ shared_expert_intermediate_size=5632,
+ num_experts_per_tok=4,
+ num_experts=60,
+ norm_topk_prob=False,
+ output_router_logits=False,
+ router_aux_loss_coef=0.001,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.max_window_layers = max_window_layers
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_dropout = attention_dropout
+
+ # MoE arguments
+ self.decoder_sparse_step = decoder_sparse_step
+ self.moe_intermediate_size = moe_intermediate_size
+ self.shared_expert_intermediate_size = shared_expert_intermediate_size
+ self.num_experts_per_tok = num_experts_per_tok
+ self.num_experts = num_experts
+ self.norm_topk_prob = norm_topk_prob
+ self.output_router_logits = output_router_logits
+ self.router_aux_loss_coef = router_aux_loss_coef
+
+ super().__init__(
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py b/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
new file mode 100644
index 00000000000000..e921af9232dd25
--- /dev/null
+++ b/src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
@@ -0,0 +1,1601 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Qwen2MoE model."""
+import inspect
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache
+from ...modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_causal_attention_mask_for_sdpa
+from ...modeling_outputs import MoeCausalLMOutputWithPast, MoeModelOutputWithPast, SequenceClassifierOutputWithPast
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_qwen2_moe import Qwen2MoeConfig
+
+
+if is_flash_attn_2_available():
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "Qwen/Qwen1.5-MoE-A2.7B"
+_CONFIG_FOR_DOC = "Qwen2MoeConfig"
+
+QWEN2MOE_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "Qwen/Qwen1.5-MoE-A2.7B",
+ # See all Qwen2 models at https://huggingface.co/models?filter=qwen2
+]
+
+
+# Copied from transformers.models.mixtral.modeling_mixtral.load_balancing_loss_func
+def load_balancing_loss_func(
+ gate_logits: torch.Tensor, num_experts: torch.Tensor = None, top_k=2, attention_mask: Optional[torch.Tensor] = None
+) -> float:
+ r"""
+ Computes auxiliary load balancing loss as in Switch Transformer - implemented in Pytorch.
+
+ See Switch Transformer (https://arxiv.org/abs/2101.03961) for more details. This function implements the loss
+ function presented in equations (4) - (6) of the paper. It aims at penalizing cases where the routing between
+ experts is too unbalanced.
+
+ Args:
+ gate_logits (Union[`torch.Tensor`, Tuple[torch.Tensor]):
+ Logits from the `gate`, should be a tuple of model.config.num_hidden_layers tensors of
+ shape [batch_size X sequence_length, num_experts].
+ attention_mask (`torch.Tensor`, None):
+ The attention_mask used in forward function
+ shape [batch_size X sequence_length] if not None.
+ num_experts (`int`, *optional*):
+ Number of experts
+
+ Returns:
+ The auxiliary loss.
+ """
+ if gate_logits is None or not isinstance(gate_logits, tuple):
+ return 0
+
+ if isinstance(gate_logits, tuple):
+ compute_device = gate_logits[0].device
+ concatenated_gate_logits = torch.cat([layer_gate.to(compute_device) for layer_gate in gate_logits], dim=0)
+
+ routing_weights = torch.nn.functional.softmax(concatenated_gate_logits, dim=-1)
+
+ _, selected_experts = torch.topk(routing_weights, top_k, dim=-1)
+
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_experts)
+
+ if attention_mask is None:
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.mean(expert_mask.float(), dim=0)
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.mean(routing_weights, dim=0)
+ else:
+ batch_size, sequence_length = attention_mask.shape
+ num_hidden_layers = concatenated_gate_logits.shape[0] // (batch_size * sequence_length)
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of expert_mask
+ expert_attention_mask = (
+ attention_mask[None, :, :, None, None]
+ .expand((num_hidden_layers, batch_size, sequence_length, top_k, num_experts))
+ .reshape(-1, top_k, num_experts)
+ .to(compute_device)
+ )
+
+ # Compute the percentage of tokens routed to each experts
+ tokens_per_expert = torch.sum(expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(
+ expert_attention_mask, dim=0
+ )
+
+ # Compute the mask that masks all padding tokens as 0 with the same shape of tokens_per_expert
+ router_per_expert_attention_mask = (
+ attention_mask[None, :, :, None]
+ .expand((num_hidden_layers, batch_size, sequence_length, num_experts))
+ .reshape(-1, num_experts)
+ .to(compute_device)
+ )
+
+ # Compute the average probability of routing to these experts
+ router_prob_per_expert = torch.sum(routing_weights * router_per_expert_attention_mask, dim=0) / torch.sum(
+ router_per_expert_attention_mask, dim=0
+ )
+
+ overall_loss = torch.sum(tokens_per_expert * router_prob_per_expert.unsqueeze(0))
+ return overall_loss * num_experts
+
+
+# Copied from transformers.models.llama.modeling_llama._get_unpad_data
+def _get_unpad_data(attention_mask):
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Qwen2Moe
+class Qwen2MoeRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Qwen2MoeRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralRotaryEmbedding with Mistral->Qwen2Moe
+class Qwen2MoeRotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(
+ seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
+ )
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
+
+ freqs = torch.outer(t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.mistral.modeling_mistral.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`):
+ The position indices of the tokens corresponding to the query and key tensors. For example, this can be
+ used to pass offsetted position ids when working with a KV-cache.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos[position_ids].unsqueeze(unsqueeze_dim)
+ sin = sin[position_ids].unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Modified from transformers.models.mistral.modeling_mistral.MistralMLP with Mistral->Qwen2Moe
+class Qwen2MoeMLP(nn.Module):
+ def __init__(self, config, intermediate_size=None):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+
+
+# Copied from transformers.models.llama.modeling_llama.repeat_kv
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+# Copied from transformers.models.qwen2.modeling_qwen2.Qwen2Attention with Qwen2->Qwen2Moe
+class Qwen2MoeAttention(nn.Module):
+ """
+ Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
+ and "Generating Long Sequences with Sparse Transformers".
+ """
+
+ def __init__(self, config: Qwen2MoeConfig, layer_idx: Optional[int] = None):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ if layer_idx is None:
+ logger.warning_once(
+ f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
+ "to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
+ "when creating this class."
+ )
+
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.num_key_value_heads = config.num_key_value_heads
+ self.num_key_value_groups = self.num_heads // self.num_key_value_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.is_causal = True
+ self.attention_dropout = config.attention_dropout
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+ self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
+ self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
+ self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
+
+ self.rotary_emb = Qwen2MoeRotaryEmbedding(
+ self.head_dim,
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+# Copied from transformers.models.qwen2.modeling_qwen2.Qwen2FlashAttention2 with Qwen2->Qwen2Moe
+class Qwen2MoeFlashAttention2(Qwen2MoeAttention):
+ """
+ Qwen2Moe flash attention module, following Qwen2Moe attention module. This module inherits from `Qwen2MoeAttention`
+ as the weights of the module stays untouched. The only required change would be on the forward pass
+ where it needs to correctly call the public API of flash attention and deal with padding tokens
+ in case the input contains any of them. Additionally, for sliding window attention, we apply SWA only to the bottom
+ config.max_window_layers layers.
+ """
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ **kwargs,
+ ):
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
+ )
+
+ # overwrite attention_mask with padding_mask
+ attention_mask = kwargs.pop("padding_mask")
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ raise ValueError(
+ f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
+ "with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+
+ # Because the input can be padded, the absolute sequence length depends on the max position id.
+ rotary_seq_len = max(kv_seq_len, position_ids[:, -1].max().item()) + 1
+ cos, sin = self.rotary_emb(value_states, seq_len=rotary_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ use_sliding_windows = (
+ _flash_supports_window_size
+ and getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and self.config.use_sliding_window
+ )
+
+ if not _flash_supports_window_size:
+ logger.warning_once(
+ "The current flash attention version does not support sliding window attention, for a more memory efficient implementation"
+ " make sure to upgrade flash-attn library."
+ )
+
+ if past_key_value is not None:
+ # Activate slicing cache only if the config has a value `sliding_windows` attribute
+ cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
+ if (
+ getattr(self.config, "sliding_window", None) is not None
+ and kv_seq_len > self.config.sliding_window
+ and cache_has_contents
+ ):
+ slicing_tokens = 1 - self.config.sliding_window
+
+ past_key = past_key_value[self.layer_idx][0]
+ past_value = past_key_value[self.layer_idx][1]
+
+ past_key = past_key[:, :, slicing_tokens:, :].contiguous()
+ past_value = past_value[:, :, slicing_tokens:, :].contiguous()
+
+ if past_key.shape[-2] != self.config.sliding_window - 1:
+ raise ValueError(
+ f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
+ f" {past_key.shape}"
+ )
+
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, slicing_tokens:]
+ attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
+
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+ dropout_rate = 0.0 if not self.training else self.attention_dropout
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in float16 just to be sure everything works as expected.
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ # Reashape to the expected shape for Flash Attention
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+
+ attn_output = self._flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ use_sliding_windows=use_sliding_windows,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+ def _flash_attention_forward(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ query_length,
+ dropout=0.0,
+ softmax_scale=None,
+ use_sliding_windows=False,
+ ):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_sliding_windows (`bool`, *optional*):
+ Whether to activate sliding window attention.
+ """
+ if not self._flash_attn_uses_top_left_mask:
+ causal = self.is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
+ causal = self.is_causal and query_length != 1
+
+ # Decide whether to use SWA or not by layer index.
+ if use_sliding_windows and self.layer_idx >= self.config.max_window_layers:
+ use_sliding_windows = False
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ if not use_sliding_windows:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+ else:
+ if not use_sliding_windows:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ )
+ else:
+ attn_output = flash_attn_func(
+ query_states,
+ key_states,
+ value_states,
+ dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ window_size=(self.config.sliding_window, self.config.sliding_window),
+ )
+
+ return attn_output
+
+ # Copied from transformers.models.mistral.modeling_mistral.MistralFlashAttention2._upad_input
+ def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
+ batch_size, kv_seq_len, num_heads, head_dim = key_layer.shape
+
+ # On the first iteration we need to properly re-create the padding mask
+ # by slicing it on the proper place
+ if kv_seq_len != attention_mask.shape[-1]:
+ attention_mask_num_tokens = attention_mask.shape[-1]
+ attention_mask = attention_mask[:, attention_mask_num_tokens - kv_seq_len :]
+
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+
+ key_layer = index_first_axis(key_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+ value_layer = index_first_axis(value_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k)
+
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(
+ query_layer.reshape(batch_size * kv_seq_len, num_heads, head_dim), indices_k
+ )
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+# Copied from transformers.models.mistral.modeling_mistral.MistralSdpaAttention with Mistral->Qwen2Moe
+class Qwen2MoeSdpaAttention(Qwen2MoeAttention):
+ """
+ Qwen2Moe attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
+ `Qwen2MoeAttention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
+ SDPA API.
+ """
+
+ # Adapted from Qwen2MoeAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "Qwen2MoeModel is using Qwen2MoeSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
+ 'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if query_states.device.type == "cuda" and attention_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.attention_dropout if self.training else 0.0,
+ # The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
+ is_causal=self.is_causal and attention_mask is None and q_len > 1,
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.view(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+QWEN2MOE_ATTENTION_CLASSES = {
+ "eager": Qwen2MoeAttention,
+ "flash_attention_2": Qwen2MoeFlashAttention2,
+ "sdpa": Qwen2MoeSdpaAttention,
+}
+
+
+class Qwen2MoeSparseMoeBlock(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.num_experts = config.num_experts
+ self.top_k = config.num_experts_per_tok
+ self.norm_topk_prob = config.norm_topk_prob
+
+ # gating
+ self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)
+ self.experts = nn.ModuleList(
+ [Qwen2MoeMLP(config, intermediate_size=config.moe_intermediate_size) for _ in range(self.num_experts)]
+ )
+
+ self.shared_expert = Qwen2MoeMLP(config, intermediate_size=config.shared_expert_intermediate_size)
+ self.shared_expert_gate = torch.nn.Linear(config.hidden_size, 1, bias=False)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """ """
+ batch_size, sequence_length, hidden_dim = hidden_states.shape
+ hidden_states = hidden_states.view(-1, hidden_dim)
+ # router_logits: (batch * sequence_length, n_experts)
+ router_logits = self.gate(hidden_states)
+
+ routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
+ routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
+ if self.norm_topk_prob:
+ routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
+ # we cast back to the input dtype
+ routing_weights = routing_weights.to(hidden_states.dtype)
+
+ final_hidden_states = torch.zeros(
+ (batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
+ )
+
+ # One hot encode the selected experts to create an expert mask
+ # this will be used to easily index which expert is going to be sollicitated
+ expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
+
+ # Loop over all available experts in the model and perform the computation on each expert
+ for expert_idx in range(self.num_experts):
+ expert_layer = self.experts[expert_idx]
+ idx, top_x = torch.where(expert_mask[expert_idx])
+
+ if top_x.shape[0] == 0:
+ continue
+
+ # in torch it is faster to index using lists than torch tensors
+ top_x_list = top_x.tolist()
+ idx_list = idx.tolist()
+
+ # Index the correct hidden states and compute the expert hidden state for
+ # the current expert. We need to make sure to multiply the output hidden
+ # states by `routing_weights` on the corresponding tokens (top-1 and top-2)
+ current_state = hidden_states[None, top_x_list].reshape(-1, hidden_dim)
+ current_hidden_states = expert_layer(current_state) * routing_weights[top_x_list, idx_list, None]
+
+ # However `index_add_` only support torch tensors for indexing so we'll use
+ # the `top_x` tensor here.
+ final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
+
+ shared_expert_output = self.shared_expert(hidden_states)
+ shared_expert_output = F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output
+
+ final_hidden_states = final_hidden_states + shared_expert_output
+
+ final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
+ return final_hidden_states, router_logits
+
+
+class Qwen2MoeDecoderLayer(nn.Module):
+ def __init__(self, config: Qwen2MoeConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = QWEN2MOE_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
+
+ if config.num_experts > 0 and (layer_idx + 1) % config.decoder_sparse_step == 0:
+ self.mlp = Qwen2MoeSparseMoeBlock(config)
+ else:
+ self.mlp = Qwen2MoeMLP(config, intermediate_size=config.intermediate_size)
+
+ self.input_layernorm = Qwen2MoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Qwen2MoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ output_router_logits: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ if "padding_mask" in kwargs:
+ warnings.warn(
+ "Passing `padding_mask` is deprecated and will be removed in v4.37. "
+ "Please make sure use `attention_mask` instead.`"
+ )
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss,
+ and should not be returned during inference.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+
+ hidden_states = self.mlp(hidden_states)
+ if isinstance(hidden_states, tuple):
+ hidden_states, router_logits = hidden_states
+ else:
+ router_logits = None
+
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ if output_router_logits:
+ outputs += (router_logits,)
+
+ return outputs
+
+
+QWEN2MOE_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`Qwen2MoeConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2MoE Model outputting raw hidden-states without any specific head on top.",
+ QWEN2MOE_START_DOCSTRING,
+)
+class Qwen2MoePreTrainedModel(PreTrainedModel):
+ config_class = Qwen2MoeConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["Qwen2MoeDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+QWEN2MOE_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance;
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Qwen2MoE Model outputting raw hidden-states without any specific head on top.",
+ QWEN2MOE_START_DOCSTRING,
+)
+class Qwen2MoeModel(Qwen2MoePreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen2MoeDecoderLayer`]
+
+ Args:
+ config: Qwen2MoeConfig
+ """
+
+ def __init__(self, config: Qwen2MoeConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [Qwen2MoeDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self._attn_implementation = config._attn_implementation
+ self.norm = Qwen2MoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2MOE_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else self.config.output_router_logits
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ past_key_values_length = 0
+
+ if use_cache:
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_key_values_length = past_key_values.get_usable_length(seq_length)
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
+ is_padding_right = attention_mask[:, -1].sum().item() != batch_size
+ if is_padding_right:
+ raise ValueError(
+ "You are attempting to perform batched generation with padding_side='right'"
+ " this may lead to unexpected behaviour for Flash Attention version of Qwen2MoE. Make sure to "
+ " call `tokenizer.padding_side = 'left'` before tokenizing the input. "
+ )
+
+ if self._attn_implementation == "flash_attention_2":
+ # 2d mask is passed through the layers
+ attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
+ elif self._attn_implementation == "sdpa" and not output_attentions:
+ # output_attentions=True can not be supported when using SDPA, and we fall back on
+ # the manual implementation that requires a 4D causal mask in all cases.
+ attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ )
+ else:
+ # 4d mask is passed through the layers
+ attention_mask = _prepare_4d_causal_attention_mask(
+ attention_mask,
+ (batch_size, seq_length),
+ inputs_embeds,
+ past_key_values_length,
+ sliding_window=self.config.sliding_window,
+ )
+
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_router_logits = () if output_router_logits else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ output_router_logits,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ output_router_logits=output_router_logits,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if output_router_logits and layer_outputs[-1] is not None:
+ all_router_logits += (layer_outputs[-1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = None
+ if use_cache:
+ next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_router_logits]
+ if v is not None
+ )
+ return MoeModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ router_logits=all_router_logits,
+ )
+
+
+class Qwen2MoeForCausalLM(Qwen2MoePreTrainedModel):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = Qwen2MoeModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ self.router_aux_loss_coef = config.router_aux_loss_coef
+ self.num_experts = config.num_experts
+ self.num_experts_per_tok = config.num_experts_per_tok
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(QWEN2MOE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=MoeCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_router_logits: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, MoeCausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, Qwen2MoeForCausalLM
+
+ >>> model = Qwen2MoeForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_router_logits = (
+ output_router_logits if output_router_logits is not None else self.config.output_router_logits
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ output_router_logits=output_router_logits,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+ logits = logits.float()
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ aux_loss = None
+ if output_router_logits:
+ aux_loss = load_balancing_loss_func(
+ outputs.router_logits if return_dict else outputs[-1],
+ self.num_experts,
+ self.num_experts_per_tok,
+ attention_mask,
+ )
+ if labels is not None:
+ loss += self.router_aux_loss_coef * aux_loss.to(loss.device) # make sure to reside in the same device
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ if output_router_logits:
+ output = (aux_loss,) + output
+ return (loss,) + output if loss is not None else output
+
+ return MoeCausalLMOutputWithPast(
+ loss=loss,
+ aux_loss=aux_loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ router_logits=outputs.router_logits,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ # Omit tokens covered by past_key_values
+ if past_key_values is not None:
+ if isinstance(past_key_values, Cache):
+ cache_length = past_key_values.get_seq_length()
+ past_length = past_key_values.seen_tokens
+ max_cache_length = past_key_values.get_max_length()
+ else:
+ cache_length = past_length = past_key_values[0][0].shape[2]
+ max_cache_length = None
+
+ # Keep only the unprocessed tokens:
+ # 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
+ # some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
+ # input)
+ if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
+ input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
+ # 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
+ # input_ids based on the past_length.
+ elif past_length < input_ids.shape[1]:
+ input_ids = input_ids[:, past_length:]
+ # 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
+
+ # If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
+ if (
+ max_cache_length is not None
+ and attention_mask is not None
+ and cache_length + input_ids.shape[1] > max_cache_length
+ ):
+ attention_mask = attention_mask[:, -max_cache_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
+ )
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Qwen2MoE Model transformer with a sequence classification head on top (linear layer).
+
+ [`Qwen2MoeForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ QWEN2MOE_START_DOCSTRING,
+)
+# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with Llama->Qwen2Moe, LLAMA->QWEN2MOE
+class Qwen2MoeForSequenceClassification(Qwen2MoePreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = Qwen2MoeModel(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(QWEN2MOE_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ # if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
+ sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
+ sequence_lengths = sequence_lengths % input_ids.shape[-1]
+ sequence_lengths = sequence_lengths.to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/src/transformers/models/realm/configuration_realm.py b/src/transformers/models/realm/configuration_realm.py
index b7e25c8d15de72..3725c37922a6ad 100644
--- a/src/transformers/models/realm/configuration_realm.py
+++ b/src/transformers/models/realm/configuration_realm.py
@@ -20,25 +20,8 @@
logger = logging.get_logger(__name__)
-REALM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/realm-cc-news-pretrained-embedder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-embedder/resolve/main/config.json"
- ),
- "google/realm-cc-news-pretrained-encoder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-encoder/resolve/main/config.json"
- ),
- "google/realm-cc-news-pretrained-scorer": (
- "https://huggingface.co/google/realm-cc-news-pretrained-scorer/resolve/main/config.json"
- ),
- "google/realm-cc-news-pretrained-openqa": (
- "https://huggingface.co/google/realm-cc-news-pretrained-openqa/aresolve/main/config.json"
- ),
- "google/realm-orqa-nq-openqa": "https://huggingface.co/google/realm-orqa-nq-openqa/resolve/main/config.json",
- "google/realm-orqa-nq-reader": "https://huggingface.co/google/realm-orqa-nq-reader/resolve/main/config.json",
- "google/realm-orqa-wq-openqa": "https://huggingface.co/google/realm-orqa-wq-openqa/resolve/main/config.json",
- "google/realm-orqa-wq-reader": "https://huggingface.co/google/realm-orqa-wq-reader/resolve/main/config.json",
- # See all REALM models at https://huggingface.co/models?filter=realm
-}
+
+from ..deprecated._archive_maps import REALM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RealmConfig(PretrainedConfig):
diff --git a/src/transformers/models/realm/modeling_realm.py b/src/transformers/models/realm/modeling_realm.py
index 1b202ffd09b1c9..86f28942893399 100644
--- a/src/transformers/models/realm/modeling_realm.py
+++ b/src/transformers/models/realm/modeling_realm.py
@@ -42,17 +42,8 @@
_SCORER_CHECKPOINT_FOR_DOC = "google/realm-cc-news-pretrained-scorer"
_CONFIG_FOR_DOC = "RealmConfig"
-REALM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/realm-cc-news-pretrained-embedder",
- "google/realm-cc-news-pretrained-encoder",
- "google/realm-cc-news-pretrained-scorer",
- "google/realm-cc-news-pretrained-openqa",
- "google/realm-orqa-nq-openqa",
- "google/realm-orqa-nq-reader",
- "google/realm-orqa-wq-openqa",
- "google/realm-orqa-wq-reader",
- # See all REALM models at https://huggingface.co/models?filter=realm
-]
+
+from ..deprecated._archive_maps import REALM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_realm(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/realm/tokenization_realm.py b/src/transformers/models/realm/tokenization_realm.py
index bf6b63277488b9..c4ff7e38a3e552 100644
--- a/src/transformers/models/realm/tokenization_realm.py
+++ b/src/transformers/models/realm/tokenization_realm.py
@@ -28,49 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/realm-cc-news-pretrained-embedder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-embedder/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-encoder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-encoder/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-scorer": (
- "https://huggingface.co/google/realm-cc-news-pretrained-scorer/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-openqa": (
- "https://huggingface.co/google/realm-cc-news-pretrained-openqa/aresolve/main/vocab.txt"
- ),
- "google/realm-orqa-nq-openqa": "https://huggingface.co/google/realm-orqa-nq-openqa/resolve/main/vocab.txt",
- "google/realm-orqa-nq-reader": "https://huggingface.co/google/realm-orqa-nq-reader/resolve/main/vocab.txt",
- "google/realm-orqa-wq-openqa": "https://huggingface.co/google/realm-orqa-wq-openqa/resolve/main/vocab.txt",
- "google/realm-orqa-wq-reader": "https://huggingface.co/google/realm-orqa-wq-reader/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/realm-cc-news-pretrained-embedder": 512,
- "google/realm-cc-news-pretrained-encoder": 512,
- "google/realm-cc-news-pretrained-scorer": 512,
- "google/realm-cc-news-pretrained-openqa": 512,
- "google/realm-orqa-nq-openqa": 512,
- "google/realm-orqa-nq-reader": 512,
- "google/realm-orqa-wq-openqa": 512,
- "google/realm-orqa-wq-reader": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google/realm-cc-news-pretrained-embedder": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-encoder": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-scorer": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-openqa": {"do_lower_case": True},
- "google/realm-orqa-nq-openqa": {"do_lower_case": True},
- "google/realm-orqa-nq-reader": {"do_lower_case": True},
- "google/realm-orqa-wq-openqa": {"do_lower_case": True},
- "google/realm-orqa-wq-reader": {"do_lower_case": True},
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -138,9 +95,6 @@ class RealmTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/realm/tokenization_realm_fast.py b/src/transformers/models/realm/tokenization_realm_fast.py
index 59b23f45ee0b30..7315bf1c250182 100644
--- a/src/transformers/models/realm/tokenization_realm_fast.py
+++ b/src/transformers/models/realm/tokenization_realm_fast.py
@@ -29,75 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/realm-cc-news-pretrained-embedder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-embedder/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-encoder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-encoder/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-scorer": (
- "https://huggingface.co/google/realm-cc-news-pretrained-scorer/resolve/main/vocab.txt"
- ),
- "google/realm-cc-news-pretrained-openqa": (
- "https://huggingface.co/google/realm-cc-news-pretrained-openqa/aresolve/main/vocab.txt"
- ),
- "google/realm-orqa-nq-openqa": "https://huggingface.co/google/realm-orqa-nq-openqa/resolve/main/vocab.txt",
- "google/realm-orqa-nq-reader": "https://huggingface.co/google/realm-orqa-nq-reader/resolve/main/vocab.txt",
- "google/realm-orqa-wq-openqa": "https://huggingface.co/google/realm-orqa-wq-openqa/resolve/main/vocab.txt",
- "google/realm-orqa-wq-reader": "https://huggingface.co/google/realm-orqa-wq-reader/resolve/main/vocab.txt",
- },
- "tokenizer_file": {
- "google/realm-cc-news-pretrained-embedder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-embedder/resolve/main/tokenizer.jsont"
- ),
- "google/realm-cc-news-pretrained-encoder": (
- "https://huggingface.co/google/realm-cc-news-pretrained-encoder/resolve/main/tokenizer.json"
- ),
- "google/realm-cc-news-pretrained-scorer": (
- "https://huggingface.co/google/realm-cc-news-pretrained-scorer/resolve/main/tokenizer.json"
- ),
- "google/realm-cc-news-pretrained-openqa": (
- "https://huggingface.co/google/realm-cc-news-pretrained-openqa/aresolve/main/tokenizer.json"
- ),
- "google/realm-orqa-nq-openqa": (
- "https://huggingface.co/google/realm-orqa-nq-openqa/resolve/main/tokenizer.json"
- ),
- "google/realm-orqa-nq-reader": (
- "https://huggingface.co/google/realm-orqa-nq-reader/resolve/main/tokenizer.json"
- ),
- "google/realm-orqa-wq-openqa": (
- "https://huggingface.co/google/realm-orqa-wq-openqa/resolve/main/tokenizer.json"
- ),
- "google/realm-orqa-wq-reader": (
- "https://huggingface.co/google/realm-orqa-wq-reader/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/realm-cc-news-pretrained-embedder": 512,
- "google/realm-cc-news-pretrained-encoder": 512,
- "google/realm-cc-news-pretrained-scorer": 512,
- "google/realm-cc-news-pretrained-openqa": 512,
- "google/realm-orqa-nq-openqa": 512,
- "google/realm-orqa-nq-reader": 512,
- "google/realm-orqa-wq-openqa": 512,
- "google/realm-orqa-wq-reader": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "google/realm-cc-news-pretrained-embedder": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-encoder": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-scorer": {"do_lower_case": True},
- "google/realm-cc-news-pretrained-openqa": {"do_lower_case": True},
- "google/realm-orqa-nq-openqa": {"do_lower_case": True},
- "google/realm-orqa-nq-reader": {"do_lower_case": True},
- "google/realm-orqa-wq-openqa": {"do_lower_case": True},
- "google/realm-orqa-wq-reader": {"do_lower_case": True},
-}
-
class RealmTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -143,9 +74,6 @@ class RealmTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = RealmTokenizer
def __init__(
diff --git a/src/transformers/models/reformer/configuration_reformer.py b/src/transformers/models/reformer/configuration_reformer.py
index e01f25a5fbfe8f..35e8628ce0fa45 100755
--- a/src/transformers/models/reformer/configuration_reformer.py
+++ b/src/transformers/models/reformer/configuration_reformer.py
@@ -21,12 +21,8 @@
logger = logging.get_logger(__name__)
-REFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/reformer-crime-and-punishment": (
- "https://huggingface.co/google/reformer-crime-and-punishment/resolve/main/config.json"
- ),
- "google/reformer-enwik8": "https://huggingface.co/google/reformer-enwik8/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import REFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ReformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/reformer/modeling_reformer.py b/src/transformers/models/reformer/modeling_reformer.py
index 7096a57d0fa4ee..e6768e897eca0c 100755
--- a/src/transformers/models/reformer/modeling_reformer.py
+++ b/src/transformers/models/reformer/modeling_reformer.py
@@ -50,11 +50,8 @@
_CHECKPOINT_FOR_DOC = "google/reformer-crime-and-punishment"
_CONFIG_FOR_DOC = "ReformerConfig"
-REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/reformer-crime-and-punishment",
- "google/reformer-enwik8",
- # See all Reformer models at https://huggingface.co/models?filter=reformer
-]
+
+from ..deprecated._archive_maps import REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Define named tuples for nn.Modules here
diff --git a/src/transformers/models/reformer/tokenization_reformer.py b/src/transformers/models/reformer/tokenization_reformer.py
index 364a2d42edfff0..efc692185b71f3 100644
--- a/src/transformers/models/reformer/tokenization_reformer.py
+++ b/src/transformers/models/reformer/tokenization_reformer.py
@@ -32,18 +32,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/reformer-crime-and-punishment": (
- "https://huggingface.co/google/reformer-crime-and-punishment/resolve/main/spiece.model"
- )
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/reformer-crime-and-punishment": 524288,
-}
-
class ReformerTokenizer(PreTrainedTokenizer):
"""
@@ -89,8 +77,6 @@ class ReformerTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/reformer/tokenization_reformer_fast.py b/src/transformers/models/reformer/tokenization_reformer_fast.py
index eb8c86b3cd1221..fb0f2c8b8e94c0 100644
--- a/src/transformers/models/reformer/tokenization_reformer_fast.py
+++ b/src/transformers/models/reformer/tokenization_reformer_fast.py
@@ -36,23 +36,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/reformer-crime-and-punishment": (
- "https://huggingface.co/google/reformer-crime-and-punishment/resolve/main/spiece.model"
- )
- },
- "tokenizer_file": {
- "google/reformer-crime-and-punishment": (
- "https://huggingface.co/google/reformer-crime-and-punishment/resolve/main/tokenizer.json"
- )
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/reformer-crime-and-punishment": 524288,
-}
-
class ReformerTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -86,8 +69,6 @@ class ReformerTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = ReformerTokenizer
diff --git a/src/transformers/models/regnet/configuration_regnet.py b/src/transformers/models/regnet/configuration_regnet.py
index 4969e426bcb3dd..629ac733917e3a 100644
--- a/src/transformers/models/regnet/configuration_regnet.py
+++ b/src/transformers/models/regnet/configuration_regnet.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/regnet-y-040": "https://huggingface.co/facebook/regnet-y-040/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import REGNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RegNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/regnet/modeling_regnet.py b/src/transformers/models/regnet/modeling_regnet.py
index 2295fbeeabfdfd..915e4cbae46bee 100644
--- a/src/transformers/models/regnet/modeling_regnet.py
+++ b/src/transformers/models/regnet/modeling_regnet.py
@@ -46,10 +46,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/regnet-y-040"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-REGNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/regnet-y-040",
- # See all regnet models at https://huggingface.co/models?filter=regnet
-]
+
+from ..deprecated._archive_maps import REGNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class RegNetConvLayer(nn.Module):
diff --git a/src/transformers/models/regnet/modeling_tf_regnet.py b/src/transformers/models/regnet/modeling_tf_regnet.py
index bca515fbf3355b..a8c296027fc6c3 100644
--- a/src/transformers/models/regnet/modeling_tf_regnet.py
+++ b/src/transformers/models/regnet/modeling_tf_regnet.py
@@ -50,10 +50,8 @@
_IMAGE_CLASS_CHECKPOINT = "facebook/regnet-y-040"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/regnet-y-040",
- # See all regnet models at https://huggingface.co/models?filter=regnet
-]
+
+from ..deprecated._archive_maps import TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFRegNetConvLayer(keras.layers.Layer):
diff --git a/src/transformers/models/rembert/configuration_rembert.py b/src/transformers/models/rembert/configuration_rembert.py
index 0b5833c1c771de..fa51a79f6012b6 100644
--- a/src/transformers/models/rembert/configuration_rembert.py
+++ b/src/transformers/models/rembert/configuration_rembert.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/rembert": "https://huggingface.co/google/rembert/resolve/main/config.json",
- # See all RemBERT models at https://huggingface.co/models?filter=rembert
-}
+
+from ..deprecated._archive_maps import REMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RemBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/rembert/modeling_rembert.py b/src/transformers/models/rembert/modeling_rembert.py
index b53464cdeca262..9c04ed10b8e9d8 100755
--- a/src/transformers/models/rembert/modeling_rembert.py
+++ b/src/transformers/models/rembert/modeling_rembert.py
@@ -52,10 +52,8 @@
_CONFIG_FOR_DOC = "RemBertConfig"
_CHECKPOINT_FOR_DOC = "google/rembert"
-REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/rembert",
- # See all RemBERT models at https://huggingface.co/models?filter=rembert
-]
+
+from ..deprecated._archive_maps import REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def load_tf_weights_in_rembert(model, config, tf_checkpoint_path):
diff --git a/src/transformers/models/rembert/modeling_tf_rembert.py b/src/transformers/models/rembert/modeling_tf_rembert.py
index 58b13bc35be382..94667c25379b02 100644
--- a/src/transformers/models/rembert/modeling_tf_rembert.py
+++ b/src/transformers/models/rembert/modeling_tf_rembert.py
@@ -62,10 +62,8 @@
_CONFIG_FOR_DOC = "RemBertConfig"
-TF_REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/rembert",
- # See all RemBERT models at https://huggingface.co/models?filter=rembert
-]
+
+from ..deprecated._archive_maps import TF_REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFRemBertEmbeddings(keras.layers.Layer):
diff --git a/src/transformers/models/rembert/tokenization_rembert.py b/src/transformers/models/rembert/tokenization_rembert.py
index 9403e911769184..a2b1f9abc2c989 100644
--- a/src/transformers/models/rembert/tokenization_rembert.py
+++ b/src/transformers/models/rembert/tokenization_rembert.py
@@ -29,16 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/rembert": "https://huggingface.co/google/rembert/resolve/main/sentencepiece.model",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/rembert": 256,
-}
-
class RemBertTokenizer(PreTrainedTokenizer):
"""
@@ -93,8 +83,6 @@ class RemBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/rembert/tokenization_rembert_fast.py b/src/transformers/models/rembert/tokenization_rembert_fast.py
index 947cc4bc9601c4..b7165e362a4f7a 100644
--- a/src/transformers/models/rembert/tokenization_rembert_fast.py
+++ b/src/transformers/models/rembert/tokenization_rembert_fast.py
@@ -32,18 +32,6 @@
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/rembert": "https://huggingface.co/google/rembert/resolve/main/sentencepiece.model",
- },
- "tokenizer_file": {
- "google/rembert": "https://huggingface.co/google/rembert/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/rembert": 256,
-}
SPIECE_UNDERLINE = "▁"
@@ -96,8 +84,6 @@ class RemBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = RemBertTokenizer
def __init__(
diff --git a/src/transformers/models/resnet/configuration_resnet.py b/src/transformers/models/resnet/configuration_resnet.py
index 250589c1de2cce..8e1938cb9ce986 100644
--- a/src/transformers/models/resnet/configuration_resnet.py
+++ b/src/transformers/models/resnet/configuration_resnet.py
@@ -27,9 +27,8 @@
logger = logging.get_logger(__name__)
-RESNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/resnet-50": "https://huggingface.co/microsoft/resnet-50/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import RESNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ResNetConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/resnet/modeling_resnet.py b/src/transformers/models/resnet/modeling_resnet.py
index df460d58f042b5..ab2ff4814e8722 100644
--- a/src/transformers/models/resnet/modeling_resnet.py
+++ b/src/transformers/models/resnet/modeling_resnet.py
@@ -53,10 +53,8 @@
_IMAGE_CLASS_CHECKPOINT = "microsoft/resnet-50"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tiger cat"
-RESNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/resnet-50",
- # See all resnet models at https://huggingface.co/models?filter=resnet
-]
+
+from ..deprecated._archive_maps import RESNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ResNetConvLayer(nn.Module):
diff --git a/src/transformers/models/resnet/modeling_tf_resnet.py b/src/transformers/models/resnet/modeling_tf_resnet.py
index faf5c635ba8d9c..98e9a32d293fe4 100644
--- a/src/transformers/models/resnet/modeling_tf_resnet.py
+++ b/src/transformers/models/resnet/modeling_tf_resnet.py
@@ -49,10 +49,8 @@
_IMAGE_CLASS_CHECKPOINT = "microsoft/resnet-50"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tiger cat"
-TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/resnet-50",
- # See all resnet models at https://huggingface.co/models?filter=resnet
-]
+
+from ..deprecated._archive_maps import TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFResNetConvLayer(keras.layers.Layer):
diff --git a/src/transformers/models/roberta/configuration_roberta.py b/src/transformers/models/roberta/configuration_roberta.py
index 8cc35d6090ceeb..aa549556d949fd 100644
--- a/src/transformers/models/roberta/configuration_roberta.py
+++ b/src/transformers/models/roberta/configuration_roberta.py
@@ -24,14 +24,8 @@
logger = logging.get_logger(__name__)
-ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/config.json",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/config.json",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/config.json",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/config.json",
- "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/config.json",
- "openai-community/roberta-large-openai-detector": "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RobertaConfig(PretrainedConfig):
diff --git a/src/transformers/models/roberta/modeling_roberta.py b/src/transformers/models/roberta/modeling_roberta.py
index f755bd9d566a92..e1f15722e43bdf 100644
--- a/src/transformers/models/roberta/modeling_roberta.py
+++ b/src/transformers/models/roberta/modeling_roberta.py
@@ -51,15 +51,8 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/roberta-base"
_CONFIG_FOR_DOC = "RobertaConfig"
-ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/roberta-base",
- "FacebookAI/roberta-large",
- "FacebookAI/roberta-large-mnli",
- "distilbert/distilroberta-base",
- "openai-community/roberta-base-openai-detector",
- "openai-community/roberta-large-openai-detector",
- # See all RoBERTa models at https://huggingface.co/models?filter=roberta
-]
+
+from ..deprecated._archive_maps import ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class RobertaEmbeddings(nn.Module):
diff --git a/src/transformers/models/roberta/modeling_tf_roberta.py b/src/transformers/models/roberta/modeling_tf_roberta.py
index 0bc5e85e808a56..f48bb796c17b4c 100644
--- a/src/transformers/models/roberta/modeling_tf_roberta.py
+++ b/src/transformers/models/roberta/modeling_tf_roberta.py
@@ -65,13 +65,8 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/roberta-base"
_CONFIG_FOR_DOC = "RobertaConfig"
-TF_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/roberta-base",
- "FacebookAI/roberta-large",
- "FacebookAI/roberta-large-mnli",
- "distilbert/distilroberta-base",
- # See all RoBERTa models at https://huggingface.co/models?filter=roberta
-]
+
+from ..deprecated._archive_maps import TF_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFRobertaEmbeddings(keras.layers.Layer):
diff --git a/src/transformers/models/roberta/tokenization_roberta.py b/src/transformers/models/roberta/tokenization_roberta.py
index c7dc51b972944c..072c44ac4dd359 100644
--- a/src/transformers/models/roberta/tokenization_roberta.py
+++ b/src/transformers/models/roberta/tokenization_roberta.py
@@ -32,38 +32,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/vocab.json",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/vocab.json",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/vocab.json",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/vocab.json",
- "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/vocab.json",
- "openai-community/roberta-large-openai-detector": (
- "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/merges.txt",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/merges.txt",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/merges.txt",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/merges.txt",
- "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/merges.txt",
- "openai-community/roberta-large-openai-detector": (
- "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/merges.txt"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "FacebookAI/roberta-base": 512,
- "FacebookAI/roberta-large": 512,
- "FacebookAI/roberta-large-mnli": 512,
- "distilbert/distilroberta-base": 512,
- "openai-community/roberta-base-openai-detector": 512,
- "openai-community/roberta-large-openai-detector": 512,
-}
-
@lru_cache()
def bytes_to_unicode():
@@ -183,8 +151,6 @@ class RobertaTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/roberta/tokenization_roberta_fast.py b/src/transformers/models/roberta/tokenization_roberta_fast.py
index 00341e870f8bc8..702af8a33e1b94 100644
--- a/src/transformers/models/roberta/tokenization_roberta_fast.py
+++ b/src/transformers/models/roberta/tokenization_roberta_fast.py
@@ -28,50 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/vocab.json",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/vocab.json",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/vocab.json",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/vocab.json",
- "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/vocab.json",
- "openai-community/roberta-large-openai-detector": (
- "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/vocab.json"
- ),
- },
- "merges_file": {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/merges.txt",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/merges.txt",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/merges.txt",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/merges.txt",
- "openai-community/roberta-base-openai-detector": "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/merges.txt",
- "openai-community/roberta-large-openai-detector": (
- "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/merges.txt"
- ),
- },
- "tokenizer_file": {
- "FacebookAI/roberta-base": "https://huggingface.co/FacebookAI/roberta-base/resolve/main/tokenizer.json",
- "FacebookAI/roberta-large": "https://huggingface.co/FacebookAI/roberta-large/resolve/main/tokenizer.json",
- "FacebookAI/roberta-large-mnli": "https://huggingface.co/FacebookAI/roberta-large-mnli/resolve/main/tokenizer.json",
- "distilbert/distilroberta-base": "https://huggingface.co/distilbert/distilroberta-base/resolve/main/tokenizer.json",
- "openai-community/roberta-base-openai-detector": (
- "https://huggingface.co/openai-community/roberta-base-openai-detector/resolve/main/tokenizer.json"
- ),
- "openai-community/roberta-large-openai-detector": (
- "https://huggingface.co/openai-community/roberta-large-openai-detector/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "FacebookAI/roberta-base": 512,
- "FacebookAI/roberta-large": 512,
- "FacebookAI/roberta-large-mnli": 512,
- "distilbert/distilroberta-base": 512,
- "openai-community/roberta-base-openai-detector": 512,
- "openai-community/roberta-large-openai-detector": 512,
-}
-
class RobertaTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -155,8 +111,6 @@ class RobertaTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = RobertaTokenizer
diff --git a/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py b/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
index f9325138165a7c..379a71abf1fbb1 100644
--- a/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
+++ b/src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
@@ -24,11 +24,8 @@
logger = logging.get_logger(__name__)
-ROBERTA_PRELAYERNORM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "andreasmadsen/efficient_mlm_m0.40": (
- "https://huggingface.co/andreasmadsen/efficient_mlm_m0.40/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import ROBERTA_PRELAYERNORM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
# Copied from transformers.models.roberta.configuration_roberta.RobertaConfig with FacebookAI/roberta-base->andreasmadsen/efficient_mlm_m0.40,RoBERTa->RoBERTa-PreLayerNorm,Roberta->RobertaPreLayerNorm,roberta->roberta-prelayernorm
diff --git a/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py b/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
index 7c37950e478b6f..468cb1a243ca89 100644
--- a/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
+++ b/src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
@@ -51,17 +51,8 @@
_CHECKPOINT_FOR_DOC = "andreasmadsen/efficient_mlm_m0.40"
_CONFIG_FOR_DOC = "RobertaPreLayerNormConfig"
-ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "andreasmadsen/efficient_mlm_m0.15",
- "andreasmadsen/efficient_mlm_m0.20",
- "andreasmadsen/efficient_mlm_m0.30",
- "andreasmadsen/efficient_mlm_m0.40",
- "andreasmadsen/efficient_mlm_m0.50",
- "andreasmadsen/efficient_mlm_m0.60",
- "andreasmadsen/efficient_mlm_m0.70",
- "andreasmadsen/efficient_mlm_m0.80",
- # See all RoBERTaWithPreLayerNorm models at https://huggingface.co/models?filter=roberta_with_prelayernorm
-]
+
+from ..deprecated._archive_maps import ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->RobertaPreLayerNorm
diff --git a/src/transformers/models/roberta_prelayernorm/modeling_tf_roberta_prelayernorm.py b/src/transformers/models/roberta_prelayernorm/modeling_tf_roberta_prelayernorm.py
index 6d111deaaba5cd..b3a0070788eaf7 100644
--- a/src/transformers/models/roberta_prelayernorm/modeling_tf_roberta_prelayernorm.py
+++ b/src/transformers/models/roberta_prelayernorm/modeling_tf_roberta_prelayernorm.py
@@ -65,17 +65,8 @@
_CHECKPOINT_FOR_DOC = "andreasmadsen/efficient_mlm_m0.40"
_CONFIG_FOR_DOC = "RobertaPreLayerNormConfig"
-TF_ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "andreasmadsen/efficient_mlm_m0.15",
- "andreasmadsen/efficient_mlm_m0.20",
- "andreasmadsen/efficient_mlm_m0.30",
- "andreasmadsen/efficient_mlm_m0.40",
- "andreasmadsen/efficient_mlm_m0.50",
- "andreasmadsen/efficient_mlm_m0.60",
- "andreasmadsen/efficient_mlm_m0.70",
- "andreasmadsen/efficient_mlm_m0.80",
- # See all RoBERTaWithPreLayerNorm models at https://huggingface.co/models?filter=roberta_with_prelayernorm
-]
+
+from ..deprecated._archive_maps import TF_ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_tf_roberta.TFRobertaEmbeddings with Roberta->RobertaPreLayerNorm
diff --git a/src/transformers/models/roc_bert/configuration_roc_bert.py b/src/transformers/models/roc_bert/configuration_roc_bert.py
index 6a8dfd9e835b98..26f74ee4c462d0 100644
--- a/src/transformers/models/roc_bert/configuration_roc_bert.py
+++ b/src/transformers/models/roc_bert/configuration_roc_bert.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-ROC_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "weiweishi/roc-bert-base-zh": "https://huggingface.co/weiweishi/roc-bert-base-zh/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ROC_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RoCBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/roc_bert/modeling_roc_bert.py b/src/transformers/models/roc_bert/modeling_roc_bert.py
index f3de92fed38941..51850c9af1d5c0 100644
--- a/src/transformers/models/roc_bert/modeling_roc_bert.py
+++ b/src/transformers/models/roc_bert/modeling_roc_bert.py
@@ -72,10 +72,8 @@
_QA_TARGET_END_INDEX = 15
# Maske language modeling
-ROC_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "weiweishi/roc-bert-base-zh",
- # See all RoCBert models at https://huggingface.co/models?filter=roc_bert
-]
+
+from ..deprecated._archive_maps import ROC_BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bert.modeling_bert.load_tf_weights_in_bert with bert->roc_bert
diff --git a/src/transformers/models/roc_bert/tokenization_roc_bert.py b/src/transformers/models/roc_bert/tokenization_roc_bert.py
index 0bbdc04e536ec4..85e1cd1d3228af 100644
--- a/src/transformers/models/roc_bert/tokenization_roc_bert.py
+++ b/src/transformers/models/roc_bert/tokenization_roc_bert.py
@@ -47,28 +47,6 @@
"word_pronunciation_file": "word_pronunciation.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "weiweishi/roc-bert-base-zh": "https://huggingface.co/weiweishi/roc-bert-base-zh/resolve/main/vocab.txt"
- },
- "word_shape_file": {
- "weiweishi/roc-bert-base-zh": "https://huggingface.co/weiweishi/roc-bert-base-zh/resolve/main/word_shape.json"
- },
- "word_pronunciation_file": {
- "weiweishi/roc-bert-base-zh": (
- "https://huggingface.co/weiweishi/roc-bert-base-zh/resolve/main/word_pronunciation.json"
- )
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "weiweishi/roc-bert-base-zh": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "weiweishi/roc-bert-base-zh": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -135,9 +113,6 @@ class RoCBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/roformer/configuration_roformer.py b/src/transformers/models/roformer/configuration_roformer.py
index 89875db7702e47..adde64345d9ee4 100644
--- a/src/transformers/models/roformer/configuration_roformer.py
+++ b/src/transformers/models/roformer/configuration_roformer.py
@@ -24,23 +24,8 @@
logger = logging.get_logger(__name__)
-ROFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "junnyu/roformer_chinese_small": "https://huggingface.co/junnyu/roformer_chinese_small/resolve/main/config.json",
- "junnyu/roformer_chinese_base": "https://huggingface.co/junnyu/roformer_chinese_base/resolve/main/config.json",
- "junnyu/roformer_chinese_char_small": (
- "https://huggingface.co/junnyu/roformer_chinese_char_small/resolve/main/config.json"
- ),
- "junnyu/roformer_chinese_char_base": (
- "https://huggingface.co/junnyu/roformer_chinese_char_base/resolve/main/config.json"
- ),
- "junnyu/roformer_small_discriminator": (
- "https://huggingface.co/junnyu/roformer_small_discriminator/resolve/main/config.json"
- ),
- "junnyu/roformer_small_generator": (
- "https://huggingface.co/junnyu/roformer_small_generator/resolve/main/config.json"
- ),
- # See all RoFormer models at https://huggingface.co/models?filter=roformer
-}
+
+from ..deprecated._archive_maps import ROFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RoFormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/roformer/modeling_flax_roformer.py b/src/transformers/models/roformer/modeling_flax_roformer.py
index 10a9bdece68cdb..6e154b311d4d46 100644
--- a/src/transformers/models/roformer/modeling_flax_roformer.py
+++ b/src/transformers/models/roformer/modeling_flax_roformer.py
@@ -43,16 +43,6 @@
_CHECKPOINT_FOR_DOC = "junnyu/roformer_chinese_base"
_CONFIG_FOR_DOC = "RoFormerConfig"
-FLAX_ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "junnyu/roformer_chinese_small",
- "junnyu/roformer_chinese_base",
- "junnyu/roformer_chinese_char_small",
- "junnyu/roformer_chinese_char_base",
- "junnyu/roformer_small_discriminator",
- "junnyu/roformer_small_generator",
- # See all RoFormer models at https://huggingface.co/models?filter=roformer
-]
-
ROFORMER_START_DOCSTRING = r"""
diff --git a/src/transformers/models/roformer/modeling_roformer.py b/src/transformers/models/roformer/modeling_roformer.py
index 7aa9a0b12d7d30..b2a63221a8dc90 100644
--- a/src/transformers/models/roformer/modeling_roformer.py
+++ b/src/transformers/models/roformer/modeling_roformer.py
@@ -52,15 +52,8 @@
_CHECKPOINT_FOR_DOC = "junnyu/roformer_chinese_base"
_CONFIG_FOR_DOC = "RoFormerConfig"
-ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "junnyu/roformer_chinese_small",
- "junnyu/roformer_chinese_base",
- "junnyu/roformer_chinese_char_small",
- "junnyu/roformer_chinese_char_base",
- "junnyu/roformer_small_discriminator",
- "junnyu/roformer_small_generator",
- # See all RoFormer models at https://huggingface.co/models?filter=roformer
-]
+
+from ..deprecated._archive_maps import ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->RoFormer
diff --git a/src/transformers/models/roformer/modeling_tf_roformer.py b/src/transformers/models/roformer/modeling_tf_roformer.py
index eb52a0993444e6..3c1ba63ce1863c 100644
--- a/src/transformers/models/roformer/modeling_tf_roformer.py
+++ b/src/transformers/models/roformer/modeling_tf_roformer.py
@@ -64,15 +64,8 @@
_CHECKPOINT_FOR_DOC = "junnyu/roformer_chinese_base"
_CONFIG_FOR_DOC = "RoFormerConfig"
-TF_ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "junnyu/roformer_chinese_small",
- "junnyu/roformer_chinese_base",
- "junnyu/roformer_chinese_char_small",
- "junnyu/roformer_chinese_char_base",
- "junnyu/roformer_small_discriminator",
- "junnyu/roformer_small_generator",
- # See all RoFormer models at https://huggingface.co/models?filter=roformer
-]
+
+from ..deprecated._archive_maps import TF_ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFRoFormerSinusoidalPositionalEmbedding(keras.layers.Layer):
diff --git a/src/transformers/models/roformer/tokenization_roformer.py b/src/transformers/models/roformer/tokenization_roformer.py
index 27a7281600a328..ebaf8e56b1f519 100644
--- a/src/transformers/models/roformer/tokenization_roformer.py
+++ b/src/transformers/models/roformer/tokenization_roformer.py
@@ -27,44 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "junnyu/roformer_chinese_small": "https://huggingface.co/junnyu/roformer_chinese_small/resolve/main/vocab.txt",
- "junnyu/roformer_chinese_base": "https://huggingface.co/junnyu/roformer_chinese_base/resolve/main/vocab.txt",
- "junnyu/roformer_chinese_char_small": (
- "https://huggingface.co/junnyu/roformer_chinese_char_small/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_chinese_char_base": (
- "https://huggingface.co/junnyu/roformer_chinese_char_base/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_small_discriminator": (
- "https://huggingface.co/junnyu/roformer_small_discriminator/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_small_generator": (
- "https://huggingface.co/junnyu/roformer_small_generator/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "junnyu/roformer_chinese_small": 1536,
- "junnyu/roformer_chinese_base": 1536,
- "junnyu/roformer_chinese_char_small": 512,
- "junnyu/roformer_chinese_char_base": 512,
- "junnyu/roformer_small_discriminator": 128,
- "junnyu/roformer_small_generator": 128,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "junnyu/roformer_chinese_small": {"do_lower_case": True},
- "junnyu/roformer_chinese_base": {"do_lower_case": True},
- "junnyu/roformer_chinese_char_small": {"do_lower_case": True},
- "junnyu/roformer_chinese_char_base": {"do_lower_case": True},
- "junnyu/roformer_small_discriminator": {"do_lower_case": True},
- "junnyu/roformer_small_generator": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -360,9 +322,6 @@ class RoFormerTokenizer(PreTrainedTokenizer):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
def __init__(
self,
diff --git a/src/transformers/models/roformer/tokenization_roformer_fast.py b/src/transformers/models/roformer/tokenization_roformer_fast.py
index bed5935e90f308..1f073c03a545a8 100644
--- a/src/transformers/models/roformer/tokenization_roformer_fast.py
+++ b/src/transformers/models/roformer/tokenization_roformer_fast.py
@@ -29,44 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "junnyu/roformer_chinese_small": "https://huggingface.co/junnyu/roformer_chinese_small/resolve/main/vocab.txt",
- "junnyu/roformer_chinese_base": "https://huggingface.co/junnyu/roformer_chinese_base/resolve/main/vocab.txt",
- "junnyu/roformer_chinese_char_small": (
- "https://huggingface.co/junnyu/roformer_chinese_char_small/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_chinese_char_base": (
- "https://huggingface.co/junnyu/roformer_chinese_char_base/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_small_discriminator": (
- "https://huggingface.co/junnyu/roformer_small_discriminator/resolve/main/vocab.txt"
- ),
- "junnyu/roformer_small_generator": (
- "https://huggingface.co/junnyu/roformer_small_generator/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "junnyu/roformer_chinese_small": 1536,
- "junnyu/roformer_chinese_base": 1536,
- "junnyu/roformer_chinese_char_small": 512,
- "junnyu/roformer_chinese_char_base": 512,
- "junnyu/roformer_small_discriminator": 128,
- "junnyu/roformer_small_generator": 128,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "junnyu/roformer_chinese_small": {"do_lower_case": True},
- "junnyu/roformer_chinese_base": {"do_lower_case": True},
- "junnyu/roformer_chinese_char_small": {"do_lower_case": True},
- "junnyu/roformer_chinese_char_base": {"do_lower_case": True},
- "junnyu/roformer_small_discriminator": {"do_lower_case": True},
- "junnyu/roformer_small_generator": {"do_lower_case": True},
-}
-
class RoFormerTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -89,9 +51,6 @@ class RoFormerTokenizerFast(PreTrainedTokenizerFast):
```"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = RoFormerTokenizer
def __init__(
diff --git a/src/transformers/models/rwkv/configuration_rwkv.py b/src/transformers/models/rwkv/configuration_rwkv.py
index 6e82a59935dcef..a6abfc549e6670 100644
--- a/src/transformers/models/rwkv/configuration_rwkv.py
+++ b/src/transformers/models/rwkv/configuration_rwkv.py
@@ -21,18 +21,8 @@
logger = logging.get_logger(__name__)
-RWKV_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "RWKV/rwkv-4-169m-pile": "https://huggingface.co/RWKV/rwkv-4-169m-pile/resolve/main/config.json",
- "RWKV/rwkv-4-430m-pile": "https://huggingface.co/RWKV/rwkv-4-430m-pile/resolve/main/config.json",
- "RWKV/rwkv-4-1b5-pile": "https://huggingface.co/RWKV/rwkv-4-1b5-pile/resolve/main/config.json",
- "RWKV/rwkv-4-3b-pile": "https://huggingface.co/RWKV/rwkv-4-3b-pile/resolve/main/config.json",
- "RWKV/rwkv-4-7b-pile": "https://huggingface.co/RWKV/rwkv-4-7b-pile/resolve/main/config.json",
- "RWKV/rwkv-4-14b-pile": "https://huggingface.co/RWKV/rwkv-4-14b-pile/resolve/main/config.json",
- "RWKV/rwkv-raven-1b5": "https://huggingface.co/RWKV/rwkv-raven-1b5/resolve/main/config.json",
- "RWKV/rwkv-raven-3b": "https://huggingface.co/RWKV/rwkv-raven-3b/resolve/main/config.json",
- "RWKV/rwkv-raven-7b": "https://huggingface.co/RWKV/rwkv-raven-7b/resolve/main/config.json",
- "RWKV/rwkv-raven-14b": "https://huggingface.co/RWKV/rwkv-raven-14b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import RWKV_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class RwkvConfig(PretrainedConfig):
diff --git a/src/transformers/models/rwkv/modeling_rwkv.py b/src/transformers/models/rwkv/modeling_rwkv.py
index e6dfa46f2a0539..79e06d141bb846 100644
--- a/src/transformers/models/rwkv/modeling_rwkv.py
+++ b/src/transformers/models/rwkv/modeling_rwkv.py
@@ -44,19 +44,8 @@
_CHECKPOINT_FOR_DOC = "RWKV/rwkv-4-169m-pile"
_CONFIG_FOR_DOC = "RwkvConfig"
-RWKV_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "RWKV/rwkv-4-169m-pile",
- "RWKV/rwkv-4-430m-pile",
- "RWKV/rwkv-4-1b5-pile",
- "RWKV/rwkv-4-3b-pile",
- "RWKV/rwkv-4-7b-pile",
- "RWKV/rwkv-4-14b-pile",
- "RWKV/rwkv-raven-1b5",
- "RWKV/rwkv-raven-3b",
- "RWKV/rwkv-raven-7b",
- "RWKV/rwkv-raven-14b",
- # See all RWKV models at https://huggingface.co/models?filter=rwkv
-]
+
+from ..deprecated._archive_maps import RWKV_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
rwkv_cuda_kernel = None
diff --git a/src/transformers/models/sam/configuration_sam.py b/src/transformers/models/sam/configuration_sam.py
index 2eb75e122e64e9..5afe75eb8eae43 100644
--- a/src/transformers/models/sam/configuration_sam.py
+++ b/src/transformers/models/sam/configuration_sam.py
@@ -21,11 +21,8 @@
logger = logging.get_logger(__name__)
-SAM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/sam-vit-huge": "https://huggingface.co/facebook/sam-vit-huge/resolve/main/config.json",
- "facebook/sam-vit-large": "https://huggingface.co/facebook/sam-vit-large/resolve/main/config.json",
- "facebook/sam-vit-base": "https://huggingface.co/facebook/sam-vit-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SAM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SamPromptEncoderConfig(PretrainedConfig):
diff --git a/src/transformers/models/sam/modeling_sam.py b/src/transformers/models/sam/modeling_sam.py
index 7fc9e670ce9b29..385fb9c00aea4f 100644
--- a/src/transformers/models/sam/modeling_sam.py
+++ b/src/transformers/models/sam/modeling_sam.py
@@ -37,12 +37,8 @@
_CONFIG_FOR_DOC = "SamConfig"
_CHECKPOINT_FOR_DOC = "facebook/sam-vit-huge"
-SAM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/sam-vit-huge",
- "facebook/sam-vit-large",
- "facebook/sam-vit-base",
- # See all SAM models at https://huggingface.co/models?filter=sam
-]
+
+from ..deprecated._archive_maps import SAM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/sam/modeling_tf_sam.py b/src/transformers/models/sam/modeling_tf_sam.py
index db7b9d32cdfdbc..f527337cd6cdaa 100644
--- a/src/transformers/models/sam/modeling_tf_sam.py
+++ b/src/transformers/models/sam/modeling_tf_sam.py
@@ -40,12 +40,8 @@
_CONFIG_FOR_DOC = "SamConfig"
_CHECKPOINT_FOR_DOC = "facebook/sam-vit-huge"
-TF_SAM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/sam-vit-huge",
- "facebook/sam-vit-large",
- "facebook/sam-vit-base",
- # See all SAM models at https://huggingface.co/models?filter=sam
-]
+
+from ..deprecated._archive_maps import TF_SAM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py b/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
index b4407ed74112f1..8ae61f1defece6 100644
--- a/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
+++ b/src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-SEAMLESS_M4T_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/hf-seamless-m4t-medium": "https://huggingface.co/facebook/hf-seamless-m4t-medium/resolve/main/config.json",
- # See all SeamlessM4T models at https://huggingface.co/models?filter=seamless_m4t
-}
+
+from ..deprecated._archive_maps import SEAMLESS_M4T_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SeamlessM4TConfig(PretrainedConfig):
diff --git a/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py b/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
index 6b00754930b333..f619dd9e799919 100755
--- a/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
+++ b/src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
@@ -50,14 +50,11 @@
_CHECKPOINT_FOR_DOC = "facebook/hf-seamless-m4t-medium"
_CONFIG_FOR_DOC = "SeamlessM4TConfig"
-SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/hf-seamless-m4t-medium",
- # See all SeamlessM4T models at https://huggingface.co/models?filter=seamless_m4t
-]
-
-SPEECHT5_PRETRAINED_HIFIGAN_CONFIG_ARCHIVE_MAP = {
- "microsoft/speecht5_hifigan": "https://huggingface.co/microsoft/speecht5_hifigan/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import ( # noqa: F401, E402
+ SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST, # noqa: F401, E402
+ SPEECHT5_PRETRAINED_HIFIGAN_CONFIG_ARCHIVE_MAP, # noqa: F401, E402
+)
@dataclass
diff --git a/src/transformers/models/seamless_m4t/tokenization_seamless_m4t.py b/src/transformers/models/seamless_m4t/tokenization_seamless_m4t.py
index 99dd1f0955063c..bb6beb760a0e14 100644
--- a/src/transformers/models/seamless_m4t/tokenization_seamless_m4t.py
+++ b/src/transformers/models/seamless_m4t/tokenization_seamless_m4t.py
@@ -32,13 +32,6 @@
logger = logging.get_logger(__name__)
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/hf-seamless-m4t-medium": (
- "https://huggingface.co/facebook/hf-seamless-m4t-medium/blob/main/sentencepiece.bpe.model"
- ),
- }
-}
SPIECE_UNDERLINE = "▁"
@@ -46,11 +39,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/hf-seamless-m4t-medium": 2048,
-}
-
-
class SeamlessM4TTokenizer(PreTrainedTokenizer):
"""
Construct a SeamlessM4T tokenizer.
@@ -126,8 +114,6 @@ class SeamlessM4TTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/seamless_m4t/tokenization_seamless_m4t_fast.py b/src/transformers/models/seamless_m4t/tokenization_seamless_m4t_fast.py
index b7bedfb38a6295..a236db3cb57cf3 100644
--- a/src/transformers/models/seamless_m4t/tokenization_seamless_m4t_fast.py
+++ b/src/transformers/models/seamless_m4t/tokenization_seamless_m4t_fast.py
@@ -37,19 +37,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/hf-seamless-m4t-medium": "https://huggingface.co/facebook/hf-seamless-m4t-medium/resolve/main/vocab.txt",
- },
- "tokenizer_file": {
- "facebook/hf-seamless-m4t-medium": "https://huggingface.co/facebook/hf-seamless-m4t-medium/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/hf-seamless-m4t-medium": 2048,
-}
-
class SeamlessM4TTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -121,8 +108,6 @@ class SeamlessM4TTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = SeamlessM4TTokenizer
model_input_names = ["input_ids", "attention_mask"]
diff --git a/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py b/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
index 28c521f6a589b8..e03523d3e0d8b4 100644
--- a/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
+++ b/src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-SEAMLESS_M4T_V2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "": "https://huggingface.co//resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SEAMLESS_M4T_V2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SeamlessM4Tv2Config(PretrainedConfig):
diff --git a/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py b/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
index fd64051f6c57b7..c7f90f6c0a23f2 100644
--- a/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
+++ b/src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
@@ -50,10 +50,8 @@
_CHECKPOINT_FOR_DOC = ""
_CONFIG_FOR_DOC = "SeamlessM4Tv2Config"
-SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/seamless-m4t-v2-large",
- # See all SeamlessM4T-v2 models at https://huggingface.co/models?filter=seamless_m4t_v2
-]
+
+from ..deprecated._archive_maps import SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
SPEECHT5_PRETRAINED_HIFIGAN_CONFIG_ARCHIVE_MAP = {
diff --git a/src/transformers/models/segformer/configuration_segformer.py b/src/transformers/models/segformer/configuration_segformer.py
index ad1c2053295b1f..aba2693ba33bbf 100644
--- a/src/transformers/models/segformer/configuration_segformer.py
+++ b/src/transformers/models/segformer/configuration_segformer.py
@@ -27,12 +27,8 @@
logger = logging.get_logger(__name__)
-SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "nvidia/segformer-b0-finetuned-ade-512-512": (
- "https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512/resolve/main/config.json"
- ),
- # See all SegFormer models at https://huggingface.co/models?filter=segformer
-}
+
+from ..deprecated._archive_maps import SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SegformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/segformer/modeling_segformer.py b/src/transformers/models/segformer/modeling_segformer.py
index 47f42b5e0ed5de..d1205630dd1042 100755
--- a/src/transformers/models/segformer/modeling_segformer.py
+++ b/src/transformers/models/segformer/modeling_segformer.py
@@ -51,10 +51,8 @@
_IMAGE_CLASS_CHECKPOINT = "nvidia/mit-b0"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nvidia/segformer-b0-finetuned-ade-512-512",
- # See all SegFormer models at https://huggingface.co/models?filter=segformer
-]
+
+from ..deprecated._archive_maps import SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class SegFormerImageClassifierOutput(ImageClassifierOutput):
diff --git a/src/transformers/models/segformer/modeling_tf_segformer.py b/src/transformers/models/segformer/modeling_tf_segformer.py
index 75c8ee2b398b8b..d215059ff611ab 100644
--- a/src/transformers/models/segformer/modeling_tf_segformer.py
+++ b/src/transformers/models/segformer/modeling_tf_segformer.py
@@ -55,10 +55,8 @@
_IMAGE_CLASS_CHECKPOINT = "nvidia/mit-b0"
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-TF_SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "nvidia/segformer-b0-finetuned-ade-512-512",
- # See all SegFormer models at https://huggingface.co/models?filter=segformer
-]
+
+from ..deprecated._archive_maps import TF_SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.convnext.modeling_tf_convnext.TFConvNextDropPath with ConvNext->Segformer
diff --git a/src/transformers/models/seggpt/configuration_seggpt.py b/src/transformers/models/seggpt/configuration_seggpt.py
index 37c81f10323a2f..38607d775a6582 100644
--- a/src/transformers/models/seggpt/configuration_seggpt.py
+++ b/src/transformers/models/seggpt/configuration_seggpt.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-SEGGPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "BAAI/seggpt-vit-large": "https://huggingface.co/BAAI/seggpt-vit-large/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SEGGPT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SegGptConfig(PretrainedConfig):
diff --git a/src/transformers/models/seggpt/modeling_seggpt.py b/src/transformers/models/seggpt/modeling_seggpt.py
index 87175fdf38ce6e..79fd309eaf808f 100644
--- a/src/transformers/models/seggpt/modeling_seggpt.py
+++ b/src/transformers/models/seggpt/modeling_seggpt.py
@@ -47,10 +47,7 @@
_EXPECTED_OUTPUT_SHAPE = [3, 896, 448]
-SEGGPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "BAAI/seggpt-vit-large",
- # See all SegGpt models at https://huggingface.co/models?filter=seggpt
-]
+from ..deprecated._archive_maps import SEGGPT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/sew/configuration_sew.py b/src/transformers/models/sew/configuration_sew.py
index f5db6fd2c1044a..b14ce441d000cb 100644
--- a/src/transformers/models/sew/configuration_sew.py
+++ b/src/transformers/models/sew/configuration_sew.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-SEW_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "asapp/sew-tiny-100k": "https://huggingface.co/asapp/sew-tiny-100k/resolve/main/config.json",
- # See all SEW models at https://huggingface.co/models?filter=sew
-}
+
+from ..deprecated._archive_maps import SEW_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SEWConfig(PretrainedConfig):
diff --git a/src/transformers/models/sew/modeling_sew.py b/src/transformers/models/sew/modeling_sew.py
index a5ebb9b2bb4245..950a91fb6a54b1 100644
--- a/src/transformers/models/sew/modeling_sew.py
+++ b/src/transformers/models/sew/modeling_sew.py
@@ -55,12 +55,8 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'_unknown_'"
_SEQ_CLASS_EXPECTED_LOSS = 9.52
-SEW_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "asapp/sew-tiny-100k",
- "asapp/sew-small-100k",
- "asapp/sew-mid-100k",
- # See all SEW models at https://huggingface.co/models?filter=sew
-]
+
+from ..deprecated._archive_maps import SEW_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
diff --git a/src/transformers/models/sew_d/configuration_sew_d.py b/src/transformers/models/sew_d/configuration_sew_d.py
index 2f08ff81f50e46..9e96a1f22b30bf 100644
--- a/src/transformers/models/sew_d/configuration_sew_d.py
+++ b/src/transformers/models/sew_d/configuration_sew_d.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "asapp/sew-d-tiny-100k": "https://huggingface.co/asapp/sew-d-tiny-100k/resolve/main/config.json",
- # See all SEW-D models at https://huggingface.co/models?filter=sew-d
-}
+
+from ..deprecated._archive_maps import SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SEWDConfig(PretrainedConfig):
diff --git a/src/transformers/models/sew_d/modeling_sew_d.py b/src/transformers/models/sew_d/modeling_sew_d.py
index 8e890f207d410a..aadcf6f6693c5b 100644
--- a/src/transformers/models/sew_d/modeling_sew_d.py
+++ b/src/transformers/models/sew_d/modeling_sew_d.py
@@ -55,18 +55,8 @@
_SEQ_CLASS_EXPECTED_OUTPUT = "'_unknown_'"
_SEQ_CLASS_EXPECTED_LOSS = 3.16
-SEW_D_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "asapp/sew-d-tiny-100k",
- "asapp/sew-d-small-100k",
- "asapp/sew-d-mid-100k",
- "asapp/sew-d-mid-k127-100k",
- "asapp/sew-d-base-100k",
- "asapp/sew-d-base-plus-100k",
- "asapp/sew-d-mid-400k",
- "asapp/sew-d-mid-k127-400k",
- "asapp/sew-d-base-plus-400k",
- # See all SEW models at https://huggingface.co/models?filter=sew-d
-]
+
+from ..deprecated._archive_maps import SEW_D_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
diff --git a/src/transformers/models/siglip/configuration_siglip.py b/src/transformers/models/siglip/configuration_siglip.py
index 990bad7ace3808..872e5c3b965ba9 100644
--- a/src/transformers/models/siglip/configuration_siglip.py
+++ b/src/transformers/models/siglip/configuration_siglip.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SiglipTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/siglip/modeling_siglip.py b/src/transformers/models/siglip/modeling_siglip.py
index 07f6dd67210aed..6e225803b4a00c 100644
--- a/src/transformers/models/siglip/modeling_siglip.py
+++ b/src/transformers/models/siglip/modeling_siglip.py
@@ -53,10 +53,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "LABEL_1"
-SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/siglip-base-patch16-224",
- # See all SigLIP models at https://huggingface.co/models?filter=siglip
-]
+from ..deprecated._archive_maps import SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def _trunc_normal_(tensor, mean, std, a, b):
diff --git a/src/transformers/models/siglip/tokenization_siglip.py b/src/transformers/models/siglip/tokenization_siglip.py
index 043d1d27b8f629..41277320a37ab2 100644
--- a/src/transformers/models/siglip/tokenization_siglip.py
+++ b/src/transformers/models/siglip/tokenization_siglip.py
@@ -37,15 +37,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/spiece.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google/siglip-base-patch16-224": 256,
-}
SPIECE_UNDERLINE = "▁"
@@ -92,8 +83,6 @@ class SiglipTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/speech_to_text/configuration_speech_to_text.py b/src/transformers/models/speech_to_text/configuration_speech_to_text.py
index fb1a8e1b5ac2ed..67dee8dc0bc361 100644
--- a/src/transformers/models/speech_to_text/configuration_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/configuration_speech_to_text.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/s2t-small-librispeech-asr": (
- "https://huggingface.co/facebook/s2t-small-librispeech-asr/resolve/main/config.json"
- ),
- # See all Speech2Text models at https://huggingface.co/models?filter=speech_to_text
-}
+
+from ..deprecated._archive_maps import SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Speech2TextConfig(PretrainedConfig):
diff --git a/src/transformers/models/speech_to_text/modeling_speech_to_text.py b/src/transformers/models/speech_to_text/modeling_speech_to_text.py
index a5ec9e9fd3b737..6898cc081fe91f 100755
--- a/src/transformers/models/speech_to_text/modeling_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/modeling_speech_to_text.py
@@ -44,10 +44,7 @@
_CONFIG_FOR_DOC = "Speech2TextConfig"
-SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/s2t-small-librispeech-asr",
- # See all Speech2Text models at https://huggingface.co/models?filter=speech_to_text
-]
+from ..deprecated._archive_maps import SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py b/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
index 927d8e09ba2fdc..8fd6bd21a593c9 100755
--- a/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
@@ -56,10 +56,7 @@
_CHECKPOINT_FOR_DOC = "facebook/s2t-small-librispeech-asr"
-TF_SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/s2t-small-librispeech-asr",
- # See all Speech2Text models at https://huggingface.co/models?filter=speech_to_text
-]
+from ..deprecated._archive_maps import TF_SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/speech_to_text/tokenization_speech_to_text.py b/src/transformers/models/speech_to_text/tokenization_speech_to_text.py
index b7104da7f1a873..27db0a671ebc7d 100644
--- a/src/transformers/models/speech_to_text/tokenization_speech_to_text.py
+++ b/src/transformers/models/speech_to_text/tokenization_speech_to_text.py
@@ -34,18 +34,6 @@
"spm_file": "sentencepiece.bpe.model",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/s2t-small-librispeech-asr": (
- "https://huggingface.co/facebook/s2t-small-librispeech-asr/resolve/main/vocab.json"
- ),
- },
- "spm_file": {
- "facebook/s2t-small-librispeech-asr": (
- "https://huggingface.co/facebook/s2t-small-librispeech-asr/resolve/main/sentencepiece.bpe.model"
- )
- },
-}
MAX_MODEL_INPUT_SIZES = {
"facebook/s2t-small-librispeech-asr": 1024,
@@ -104,8 +92,6 @@ class Speech2TextTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = MAX_MODEL_INPUT_SIZES
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
diff --git a/src/transformers/models/speech_to_text_2/configuration_speech_to_text_2.py b/src/transformers/models/speech_to_text_2/configuration_speech_to_text_2.py
index 5dd34cb86baae4..cbb3be82552266 100644
--- a/src/transformers/models/speech_to_text_2/configuration_speech_to_text_2.py
+++ b/src/transformers/models/speech_to_text_2/configuration_speech_to_text_2.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/s2t-wav2vec2-large-en-de": (
- "https://huggingface.co/facebook/s2t-wav2vec2-large-en-de/resolve/main/config.json"
- ),
- # See all Speech2Text models at https://huggingface.co/models?filter=speech2text2
-}
+
+from ..deprecated._archive_maps import SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Speech2Text2Config(PretrainedConfig):
diff --git a/src/transformers/models/speech_to_text_2/modeling_speech_to_text_2.py b/src/transformers/models/speech_to_text_2/modeling_speech_to_text_2.py
index 4f5885f8c81ef4..20f8555bd9ecb2 100755
--- a/src/transformers/models/speech_to_text_2/modeling_speech_to_text_2.py
+++ b/src/transformers/models/speech_to_text_2/modeling_speech_to_text_2.py
@@ -37,12 +37,6 @@
_CHECKPOINT_FOR_DOC = "facebook/s2t-wav2vec2-large-en-de"
-SPEECH_TO_TEXT_2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/s2t-wav2vec2-large-en-de",
- # See all Speech2Text2 models at https://huggingface.co/models?filter=speech2text2
-]
-
-
# Copied from transformers.models.speech_to_text.modeling_speech_to_text.Speech2TextSinusoidalPositionalEmbedding with Speech2Text->Speech2Text2
class Speech2Text2SinusoidalPositionalEmbedding(nn.Module):
"""This module produces sinusoidal positional embeddings of any length."""
diff --git a/src/transformers/models/speech_to_text_2/tokenization_speech_to_text_2.py b/src/transformers/models/speech_to_text_2/tokenization_speech_to_text_2.py
index 074576a6c0e0b0..8d6818356f3f2a 100644
--- a/src/transformers/models/speech_to_text_2/tokenization_speech_to_text_2.py
+++ b/src/transformers/models/speech_to_text_2/tokenization_speech_to_text_2.py
@@ -31,23 +31,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/s2t-wav2vec2-large-en-de": (
- "https://huggingface.co/facebook/s2t-wav2vec2-large-en-de/resolve/main/vocab.json"
- ),
- },
- "tokenizer_config_file": {
- "facebook/s2t-wav2vec2-large-en-de": (
- "https://huggingface.co/facebook/s2t-wav2vec2-large-en-de/resolve/main/tokenizer_config.json"
- ),
- },
- "merges_file": {
- "facebook/s2t-wav2vec2-large-en-de": (
- "https://huggingface.co/facebook/s2t-wav2vec2-large-en-de/resolve/main/merges.txt"
- ),
- },
-}
BPE_TOKEN_MERGES = ""
BPE_TOKEN_VOCAB = "@@ "
@@ -67,7 +50,6 @@ def get_pairs(word):
# Speech2Text2 has no max input length
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/s2t-wav2vec2-large-en-de": 1024}
class Speech2Text2Tokenizer(PreTrainedTokenizer):
@@ -95,8 +77,6 @@ class Speech2Text2Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/speecht5/configuration_speecht5.py b/src/transformers/models/speecht5/configuration_speecht5.py
index c7cd7d2f62ffcc..36cb4995a83f05 100644
--- a/src/transformers/models/speecht5/configuration_speecht5.py
+++ b/src/transformers/models/speecht5/configuration_speecht5.py
@@ -23,11 +23,9 @@
logger = logging.get_logger(__name__)
-SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/speecht5_asr": "https://huggingface.co/microsoft/speecht5_asr/resolve/main/config.json",
- "microsoft/speecht5_tts": "https://huggingface.co/microsoft/speecht5_tts/resolve/main/config.json",
- "microsoft/speecht5_vc": "https://huggingface.co/microsoft/speecht5_vc/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
+
SPEECHT5_PRETRAINED_HIFIGAN_CONFIG_ARCHIVE_MAP = {
"microsoft/speecht5_hifigan": "https://huggingface.co/microsoft/speecht5_hifigan/resolve/main/config.json",
diff --git a/src/transformers/models/speecht5/modeling_speecht5.py b/src/transformers/models/speecht5/modeling_speecht5.py
index e9f9f1e1711e98..c4b9aca6f08d31 100644
--- a/src/transformers/models/speecht5/modeling_speecht5.py
+++ b/src/transformers/models/speecht5/modeling_speecht5.py
@@ -47,12 +47,7 @@
_CONFIG_FOR_DOC = "SpeechT5Config"
-SPEECHT5_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/speecht5_asr",
- "microsoft/speecht5_tts",
- "microsoft/speecht5_vc",
- # See all SpeechT5 models at https://huggingface.co/models?filter=speecht5
-]
+from ..deprecated._archive_maps import SPEECHT5_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.shift_tokens_right
diff --git a/src/transformers/models/speecht5/tokenization_speecht5.py b/src/transformers/models/speecht5/tokenization_speecht5.py
index 9f5ed8a5e00ff1..41cb296f8f0d08 100644
--- a/src/transformers/models/speecht5/tokenization_speecht5.py
+++ b/src/transformers/models/speecht5/tokenization_speecht5.py
@@ -30,20 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spm_char.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/speecht5_asr": "https://huggingface.co/microsoft/speecht5_asr/resolve/main/spm_char.model",
- "microsoft/speecht5_tts": "https://huggingface.co/microsoft/speecht5_tts/resolve/main/spm_char.model",
- "microsoft/speecht5_vc": "https://huggingface.co/microsoft/speecht5_vc/resolve/main/spm_char.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/speecht5_asr": 1024,
- "microsoft/speecht5_tts": 1024,
- "microsoft/speecht5_vc": 1024,
-}
-
class SpeechT5Tokenizer(PreTrainedTokenizer):
"""
@@ -89,8 +75,6 @@ class SpeechT5Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/splinter/configuration_splinter.py b/src/transformers/models/splinter/configuration_splinter.py
index e7325f01656f12..5248c74c1a3efc 100644
--- a/src/transformers/models/splinter/configuration_splinter.py
+++ b/src/transformers/models/splinter/configuration_splinter.py
@@ -20,13 +20,8 @@
logger = logging.get_logger(__name__)
-SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "tau/splinter-base": "https://huggingface.co/tau/splinter-base/resolve/main/config.json",
- "tau/splinter-base-qass": "https://huggingface.co/tau/splinter-base-qass/resolve/main/config.json",
- "tau/splinter-large": "https://huggingface.co/tau/splinter-large/resolve/main/config.json",
- "tau/splinter-large-qass": "https://huggingface.co/tau/splinter-large-qass/resolve/main/config.json",
- # See all Splinter models at https://huggingface.co/models?filter=splinter
-}
+
+from ..deprecated._archive_maps import SPLINTER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SplinterConfig(PretrainedConfig):
diff --git a/src/transformers/models/splinter/modeling_splinter.py b/src/transformers/models/splinter/modeling_splinter.py
index 75187c36b930a4..b643601d0ebd49 100755
--- a/src/transformers/models/splinter/modeling_splinter.py
+++ b/src/transformers/models/splinter/modeling_splinter.py
@@ -37,13 +37,8 @@
_CHECKPOINT_FOR_DOC = "tau/splinter-base"
_CONFIG_FOR_DOC = "SplinterConfig"
-SPLINTER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "tau/splinter-base",
- "tau/splinter-base-qass",
- "tau/splinter-large",
- "tau/splinter-large-qass",
- # See all Splinter models at https://huggingface.co/models?filter=splinter
-]
+
+from ..deprecated._archive_maps import SPLINTER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class SplinterEmbeddings(nn.Module):
diff --git a/src/transformers/models/splinter/tokenization_splinter.py b/src/transformers/models/splinter/tokenization_splinter.py
index 909905979be38c..ee82e19c6cb9b3 100644
--- a/src/transformers/models/splinter/tokenization_splinter.py
+++ b/src/transformers/models/splinter/tokenization_splinter.py
@@ -28,29 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "tau/splinter-base": "https://huggingface.co/tau/splinter-base/resolve/main/vocab.txt",
- "tau/splinter-base-qass": "https://huggingface.co/tau/splinter-base-qass/resolve/main/vocab.txt",
- "tau/splinter-large": "https://huggingface.co/tau/splinter-large/resolve/main/vocab.txt",
- "tau/splinter-large-qass": "https://huggingface.co/tau/splinter-large-qass/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "tau/splinter-base": 512,
- "tau/splinter-base-qass": 512,
- "tau/splinter-large": 512,
- "tau/splinter-large-qass": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "tau/splinter-base": {"do_lower_case": False},
- "tau/splinter-base-qass": {"do_lower_case": False},
- "tau/splinter-large": {"do_lower_case": False},
- "tau/splinter-large-qass": {"do_lower_case": False},
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -117,9 +94,6 @@ class SplinterTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/splinter/tokenization_splinter_fast.py b/src/transformers/models/splinter/tokenization_splinter_fast.py
index 97db72caadc05c..0371fdf2828eb2 100644
--- a/src/transformers/models/splinter/tokenization_splinter_fast.py
+++ b/src/transformers/models/splinter/tokenization_splinter_fast.py
@@ -28,29 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "tau/splinter-base": "https://huggingface.co/tau/splinter-base/resolve/main/vocab.txt",
- "tau/splinter-base-qass": "https://huggingface.co/tau/splinter-base-qass/resolve/main/vocab.txt",
- "tau/splinter-large": "https://huggingface.co/tau/splinter-large/resolve/main/vocab.txt",
- "tau/splinter-large-qass": "https://huggingface.co/tau/splinter-large-qass/resolve/main/vocab.txt",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "tau/splinter-base": 512,
- "tau/splinter-base-qass": 512,
- "tau/splinter-large": 512,
- "tau/splinter-large-qass": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "tau/splinter-base": {"do_lower_case": False},
- "tau/splinter-base-qass": {"do_lower_case": False},
- "tau/splinter-large": {"do_lower_case": False},
- "tau/splinter-large-qass": {"do_lower_case": False},
-}
-
class SplinterTokenizerFast(PreTrainedTokenizerFast):
r"""
@@ -95,9 +72,6 @@ class SplinterTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = SplinterTokenizer
def __init__(
diff --git a/src/transformers/models/squeezebert/configuration_squeezebert.py b/src/transformers/models/squeezebert/configuration_squeezebert.py
index 4926a73177670d..2e8710bb5c5859 100644
--- a/src/transformers/models/squeezebert/configuration_squeezebert.py
+++ b/src/transformers/models/squeezebert/configuration_squeezebert.py
@@ -23,15 +23,8 @@
logger = logging.get_logger(__name__)
-SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "squeezebert/squeezebert-uncased": (
- "https://huggingface.co/squeezebert/squeezebert-uncased/resolve/main/config.json"
- ),
- "squeezebert/squeezebert-mnli": "https://huggingface.co/squeezebert/squeezebert-mnli/resolve/main/config.json",
- "squeezebert/squeezebert-mnli-headless": (
- "https://huggingface.co/squeezebert/squeezebert-mnli-headless/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SqueezeBertConfig(PretrainedConfig):
@@ -105,12 +98,8 @@ class SqueezeBertConfig(PretrainedConfig):
>>> # Accessing the model configuration
>>> configuration = model.config
```
-
- Attributes: pretrained_config_archive_map (Dict[str, str]): A dictionary containing all the available pre-trained
- checkpoints.
"""
- pretrained_config_archive_map = SQUEEZEBERT_PRETRAINED_CONFIG_ARCHIVE_MAP
model_type = "squeezebert"
def __init__(
diff --git a/src/transformers/models/squeezebert/modeling_squeezebert.py b/src/transformers/models/squeezebert/modeling_squeezebert.py
index 0ac1260c82b007..b5657f6e6f5003 100644
--- a/src/transformers/models/squeezebert/modeling_squeezebert.py
+++ b/src/transformers/models/squeezebert/modeling_squeezebert.py
@@ -42,11 +42,8 @@
_CHECKPOINT_FOR_DOC = "squeezebert/squeezebert-uncased"
_CONFIG_FOR_DOC = "SqueezeBertConfig"
-SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "squeezebert/squeezebert-uncased",
- "squeezebert/squeezebert-mnli",
- "squeezebert/squeezebert-mnli-headless",
-]
+
+from ..deprecated._archive_maps import SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class SqueezeBertEmbeddings(nn.Module):
diff --git a/src/transformers/models/squeezebert/tokenization_squeezebert.py b/src/transformers/models/squeezebert/tokenization_squeezebert.py
index c655ba8ddaa2bb..30f866770d2465 100644
--- a/src/transformers/models/squeezebert/tokenization_squeezebert.py
+++ b/src/transformers/models/squeezebert/tokenization_squeezebert.py
@@ -27,31 +27,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "squeezebert/squeezebert-uncased": (
- "https://huggingface.co/squeezebert/squeezebert-uncased/resolve/main/vocab.txt"
- ),
- "squeezebert/squeezebert-mnli": "https://huggingface.co/squeezebert/squeezebert-mnli/resolve/main/vocab.txt",
- "squeezebert/squeezebert-mnli-headless": (
- "https://huggingface.co/squeezebert/squeezebert-mnli-headless/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "squeezebert/squeezebert-uncased": 512,
- "squeezebert/squeezebert-mnli": 512,
- "squeezebert/squeezebert-mnli-headless": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "squeezebert/squeezebert-uncased": {"do_lower_case": True},
- "squeezebert/squeezebert-mnli": {"do_lower_case": True},
- "squeezebert/squeezebert-mnli-headless": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert.load_vocab
def load_vocab(vocab_file):
@@ -119,9 +94,6 @@ class SqueezeBertTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/squeezebert/tokenization_squeezebert_fast.py b/src/transformers/models/squeezebert/tokenization_squeezebert_fast.py
index a06aaf615e10a6..985fe657f0c3b6 100644
--- a/src/transformers/models/squeezebert/tokenization_squeezebert_fast.py
+++ b/src/transformers/models/squeezebert/tokenization_squeezebert_fast.py
@@ -28,42 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "squeezebert/squeezebert-uncased": (
- "https://huggingface.co/squeezebert/squeezebert-uncased/resolve/main/vocab.txt"
- ),
- "squeezebert/squeezebert-mnli": "https://huggingface.co/squeezebert/squeezebert-mnli/resolve/main/vocab.txt",
- "squeezebert/squeezebert-mnli-headless": (
- "https://huggingface.co/squeezebert/squeezebert-mnli-headless/resolve/main/vocab.txt"
- ),
- },
- "tokenizer_file": {
- "squeezebert/squeezebert-uncased": (
- "https://huggingface.co/squeezebert/squeezebert-uncased/resolve/main/tokenizer.json"
- ),
- "squeezebert/squeezebert-mnli": (
- "https://huggingface.co/squeezebert/squeezebert-mnli/resolve/main/tokenizer.json"
- ),
- "squeezebert/squeezebert-mnli-headless": (
- "https://huggingface.co/squeezebert/squeezebert-mnli-headless/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "squeezebert/squeezebert-uncased": 512,
- "squeezebert/squeezebert-mnli": 512,
- "squeezebert/squeezebert-mnli-headless": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "squeezebert/squeezebert-uncased": {"do_lower_case": True},
- "squeezebert/squeezebert-mnli": {"do_lower_case": True},
- "squeezebert/squeezebert-mnli-headless": {"do_lower_case": True},
-}
-
# Copied from transformers.models.bert.tokenization_bert_fast.BertTokenizerFast with Bert->SqueezeBert,BERT->SqueezeBERT
class SqueezeBertTokenizerFast(PreTrainedTokenizerFast):
@@ -107,9 +71,6 @@ class SqueezeBertTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = SqueezeBertTokenizer
def __init__(
diff --git a/src/transformers/models/stablelm/configuration_stablelm.py b/src/transformers/models/stablelm/configuration_stablelm.py
index b3e7f3216c86c3..f1e3ab45170edb 100644
--- a/src/transformers/models/stablelm/configuration_stablelm.py
+++ b/src/transformers/models/stablelm/configuration_stablelm.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-STABLELM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "stabilityai/stablelm-3b-4e1t": "https://huggingface.co/stabilityai/stablelm-3b-4e1t/resolve/main/config.json",
- # See all StableLM models at https://huggingface.co/models?filter=stablelm
-}
+
+from ..deprecated._archive_maps import STABLELM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class StableLmConfig(PretrainedConfig):
@@ -170,8 +168,7 @@ def _rope_scaling_validation(self):
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
raise ValueError(
- "`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
- f"got {self.rope_scaling}"
+ "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}"
)
rope_scaling_type = self.rope_scaling.get("type", None)
rope_scaling_factor = self.rope_scaling.get("factor", None)
diff --git a/src/transformers/models/starcoder2/configuration_starcoder2.py b/src/transformers/models/starcoder2/configuration_starcoder2.py
index d569ebb4f7ce26..8337135442c86f 100644
--- a/src/transformers/models/starcoder2/configuration_starcoder2.py
+++ b/src/transformers/models/starcoder2/configuration_starcoder2.py
@@ -20,7 +20,8 @@
logger = logging.get_logger(__name__)
-STARCODER2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
+
+from ..deprecated._archive_maps import STARCODER2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Starcoder2Config(PretrainedConfig):
diff --git a/src/transformers/models/superpoint/modeling_superpoint.py b/src/transformers/models/superpoint/modeling_superpoint.py
index d3fc9bfd5a98d5..a4350e6d79af6e 100644
--- a/src/transformers/models/superpoint/modeling_superpoint.py
+++ b/src/transformers/models/superpoint/modeling_superpoint.py
@@ -423,7 +423,7 @@ def forward(
Examples:
```python
- >>> from transformers import AutoImageProcessor, AutoModel
+ >>> from transformers import AutoImageProcessor, SuperPointForKeypointDetection
>>> import torch
>>> from PIL import Image
>>> import requests
@@ -432,7 +432,7 @@ def forward(
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
- >>> model = AutoModel.from_pretrained("magic-leap-community/superpoint")
+ >>> model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
diff --git a/src/transformers/models/swiftformer/configuration_swiftformer.py b/src/transformers/models/swiftformer/configuration_swiftformer.py
index 3e06b2feab24e9..3c7a9eebbd9101 100644
--- a/src/transformers/models/swiftformer/configuration_swiftformer.py
+++ b/src/transformers/models/swiftformer/configuration_swiftformer.py
@@ -26,9 +26,8 @@
logger = logging.get_logger(__name__)
-SWIFTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "MBZUAI/swiftformer-xs": "https://huggingface.co/MBZUAI/swiftformer-xs/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import SWIFTFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SwiftFormerConfig(PretrainedConfig):
diff --git a/src/transformers/models/swiftformer/modeling_swiftformer.py b/src/transformers/models/swiftformer/modeling_swiftformer.py
index 0c59c6b5b2de62..c447c0ce1204e4 100644
--- a/src/transformers/models/swiftformer/modeling_swiftformer.py
+++ b/src/transformers/models/swiftformer/modeling_swiftformer.py
@@ -52,10 +52,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-SWIFTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "MBZUAI/swiftformer-xs",
- # See all SwiftFormer models at https://huggingface.co/models?filter=swiftformer
-]
+from ..deprecated._archive_maps import SWIFTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class SwiftFormerPatchEmbedding(nn.Module):
diff --git a/src/transformers/models/swin/configuration_swin.py b/src/transformers/models/swin/configuration_swin.py
index 20da7ac113148f..9bf460870f9ee0 100644
--- a/src/transformers/models/swin/configuration_swin.py
+++ b/src/transformers/models/swin/configuration_swin.py
@@ -27,12 +27,8 @@
logger = logging.get_logger(__name__)
-SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/swin-tiny-patch4-window7-224": (
- "https://huggingface.co/microsoft/swin-tiny-patch4-window7-224/resolve/main/config.json"
- ),
- # See all Swin models at https://huggingface.co/models?filter=swin
-}
+
+from ..deprecated._archive_maps import SWIN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SwinConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/swin/modeling_swin.py b/src/transformers/models/swin/modeling_swin.py
index a3f0643512a34f..c841faddf0df91 100644
--- a/src/transformers/models/swin/modeling_swin.py
+++ b/src/transformers/models/swin/modeling_swin.py
@@ -56,10 +56,8 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/swin-tiny-patch4-window7-224",
- # See all Swin models at https://huggingface.co/models?filter=swin
-]
+from ..deprecated._archive_maps import SWIN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# drop_path, SwinPatchEmbeddings, SwinPatchMerging and SwinDropPath are from the timm library.
diff --git a/src/transformers/models/swin/modeling_tf_swin.py b/src/transformers/models/swin/modeling_tf_swin.py
index 6632759f68bb22..b9a10793406916 100644
--- a/src/transformers/models/swin/modeling_tf_swin.py
+++ b/src/transformers/models/swin/modeling_tf_swin.py
@@ -61,10 +61,8 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-TF_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/swin-tiny-patch4-window7-224",
- # See all Swin models at https://huggingface.co/models?filter=swin
-]
+from ..deprecated._archive_maps import TF_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# drop_path, TFSwinPatchEmbeddings, TFSwinPatchMerging and TFSwinDropPath are tensorflow
# implementations of PyTorch functionalities in the timm library.
diff --git a/src/transformers/models/swin2sr/configuration_swin2sr.py b/src/transformers/models/swin2sr/configuration_swin2sr.py
index 81c6af31e27f23..1858be52a5ab45 100644
--- a/src/transformers/models/swin2sr/configuration_swin2sr.py
+++ b/src/transformers/models/swin2sr/configuration_swin2sr.py
@@ -20,11 +20,8 @@
logger = logging.get_logger(__name__)
-SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "caidas/swin2sr-classicalsr-x2-64": (
- "https://huggingface.co/caidas/swin2sr-classicalsr-x2-64/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import SWIN2SR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Swin2SRConfig(PretrainedConfig):
diff --git a/src/transformers/models/swin2sr/modeling_swin2sr.py b/src/transformers/models/swin2sr/modeling_swin2sr.py
index 86dbcbaa65f9e4..1ef628a1443d66 100644
--- a/src/transformers/models/swin2sr/modeling_swin2sr.py
+++ b/src/transformers/models/swin2sr/modeling_swin2sr.py
@@ -49,10 +49,7 @@
_EXPECTED_OUTPUT_SHAPE = [1, 180, 488, 648]
-SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "caidas/swin2SR-classical-sr-x2-64",
- # See all Swin2SR models at https://huggingface.co/models?filter=swin2sr
-]
+from ..deprecated._archive_maps import SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/swinv2/configuration_swinv2.py b/src/transformers/models/swinv2/configuration_swinv2.py
index 3c839e3f94bad6..41acd48f53259c 100644
--- a/src/transformers/models/swinv2/configuration_swinv2.py
+++ b/src/transformers/models/swinv2/configuration_swinv2.py
@@ -21,11 +21,8 @@
logger = logging.get_logger(__name__)
-SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/swinv2-tiny-patch4-window8-256": (
- "https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import SWINV2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Swinv2Config(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/swinv2/modeling_swinv2.py b/src/transformers/models/swinv2/modeling_swinv2.py
index 5dc3dd0de8d636..16c68ee63f695d 100644
--- a/src/transformers/models/swinv2/modeling_swinv2.py
+++ b/src/transformers/models/swinv2/modeling_swinv2.py
@@ -56,10 +56,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "Egyptian cat"
-SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/swinv2-tiny-patch4-window8-256",
- # See all Swinv2 models at https://huggingface.co/models?filter=swinv2
-]
+from ..deprecated._archive_maps import SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# drop_path, Swinv2PatchEmbeddings, Swinv2PatchMerging and Swinv2DropPath are from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/swin_transformer_v2.py.
diff --git a/src/transformers/models/switch_transformers/configuration_switch_transformers.py b/src/transformers/models/switch_transformers/configuration_switch_transformers.py
index f90874af4da67a..fb531003178af0 100644
--- a/src/transformers/models/switch_transformers/configuration_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/configuration_switch_transformers.py
@@ -19,9 +19,8 @@
logger = logging.get_logger(__name__)
-SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/switch-base-8": "https://huggingface.co/google/switch-base-8/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import SWITCH_TRANSFORMERS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class SwitchTransformersConfig(PretrainedConfig):
diff --git a/src/transformers/models/switch_transformers/modeling_switch_transformers.py b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
index 416549b7b75c72..375d94043e6c13 100644
--- a/src/transformers/models/switch_transformers/modeling_switch_transformers.py
+++ b/src/transformers/models/switch_transformers/modeling_switch_transformers.py
@@ -54,18 +54,8 @@
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
-SWITCH_TRANSFORMERS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/switch-base-8",
- "google/switch-base-16",
- "google/switch-base-32",
- "google/switch-base-64",
- "google/switch-base-128",
- "google/switch-base-256",
- "google/switch-large-128",
- "google/switch-xxl-128",
- "google/switch-c-2048",
- # See all SwitchTransformers models at https://huggingface.co/models?filter=switch_transformers
-]
+
+from ..deprecated._archive_maps import SWITCH_TRANSFORMERS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def router_z_loss_func(router_logits: torch.Tensor) -> float:
diff --git a/src/transformers/models/t5/configuration_t5.py b/src/transformers/models/t5/configuration_t5.py
index 6a1d3c529e0ac5..2633ee630dff90 100644
--- a/src/transformers/models/t5/configuration_t5.py
+++ b/src/transformers/models/t5/configuration_t5.py
@@ -22,13 +22,8 @@
logger = logging.get_logger(__name__)
-T5_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google-t5/t5-small": "https://huggingface.co/google-t5/t5-small/resolve/main/config.json",
- "google-t5/t5-base": "https://huggingface.co/google-t5/t5-base/resolve/main/config.json",
- "google-t5/t5-large": "https://huggingface.co/google-t5/t5-large/resolve/main/config.json",
- "google-t5/t5-3b": "https://huggingface.co/google-t5/t5-3b/resolve/main/config.json",
- "google-t5/t5-11b": "https://huggingface.co/google-t5/t5-11b/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import T5_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class T5Config(PretrainedConfig):
diff --git a/src/transformers/models/t5/modeling_t5.py b/src/transformers/models/t5/modeling_t5.py
index a3febdd1aa7bb6..930d098186a5a3 100644
--- a/src/transformers/models/t5/modeling_t5.py
+++ b/src/transformers/models/t5/modeling_t5.py
@@ -59,14 +59,8 @@
# This dict contains ids and associated url
# for the pretrained weights provided with the models
####################################################
-T5_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google-t5/t5-small",
- "google-t5/t5-base",
- "google-t5/t5-large",
- "google-t5/t5-3b",
- "google-t5/t5-11b",
- # See all T5 models at https://huggingface.co/models?filter=t5
-]
+
+from ..deprecated._archive_maps import T5_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
####################################################
@@ -683,7 +677,7 @@ def forward(
if len(past_key_value) != expected_num_past_key_values:
raise ValueError(
f"There should be {expected_num_past_key_values} past states. "
- f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"{'2 (key / value) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
f"Got {len(past_key_value)} past key / value states"
)
diff --git a/src/transformers/models/t5/modeling_tf_t5.py b/src/transformers/models/t5/modeling_tf_t5.py
index c809659477bcc6..834abbad8a2885 100644
--- a/src/transformers/models/t5/modeling_tf_t5.py
+++ b/src/transformers/models/t5/modeling_tf_t5.py
@@ -58,14 +58,9 @@
_CONFIG_FOR_DOC = "T5Config"
-TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google-t5/t5-small",
- "google-t5/t5-base",
- "google-t5/t5-large",
- "google-t5/t5-3b",
- "google-t5/t5-11b",
- # See all T5 models at https://huggingface.co/models?filter=t5
-]
+
+from ..deprecated._archive_maps import TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
####################################################
# TF 2.0 Models are constructed using Keras imperative API by sub-classing
@@ -629,7 +624,7 @@ def call(
if len(past_key_value) != expected_num_past_key_values:
raise ValueError(
f"There should be {expected_num_past_key_values} past states. "
- f"{'2 (past / key) for cross attention' if expected_num_past_key_values == 4 else ''}. "
+ f"{'2 (key / value) for cross attention' if expected_num_past_key_values == 4 else ''}. "
f"Got {len(past_key_value)} past key / value states"
)
diff --git a/src/transformers/models/t5/tokenization_t5.py b/src/transformers/models/t5/tokenization_t5.py
index fba83ae9203eeb..7292808adc6b56 100644
--- a/src/transformers/models/t5/tokenization_t5.py
+++ b/src/transformers/models/t5/tokenization_t5.py
@@ -37,25 +37,8 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google-t5/t5-small": "https://huggingface.co/google-t5/t5-small/resolve/main/spiece.model",
- "google-t5/t5-base": "https://huggingface.co/google-t5/t5-base/resolve/main/spiece.model",
- "google-t5/t5-large": "https://huggingface.co/google-t5/t5-large/resolve/main/spiece.model",
- "google-t5/t5-3b": "https://huggingface.co/google-t5/t5-3b/resolve/main/spiece.model",
- "google-t5/t5-11b": "https://huggingface.co/google-t5/t5-11b/resolve/main/spiece.model",
- }
-}
-
# TODO(PVP) - this should be removed in Transformers v5
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google-t5/t5-small": 512,
- "google-t5/t5-base": 512,
- "google-t5/t5-large": 512,
- "google-t5/t5-3b": 512,
- "google-t5/t5-11b": 512,
-}
SPIECE_UNDERLINE = "▁"
@@ -140,8 +123,6 @@ class T5Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/t5/tokenization_t5_fast.py b/src/transformers/models/t5/tokenization_t5_fast.py
index bf1ef13cb519a7..e9f2033812e698 100644
--- a/src/transformers/models/t5/tokenization_t5_fast.py
+++ b/src/transformers/models/t5/tokenization_t5_fast.py
@@ -35,32 +35,8 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "google-t5/t5-small": "https://huggingface.co/google-t5/t5-small/resolve/main/spiece.model",
- "google-t5/t5-base": "https://huggingface.co/google-t5/t5-base/resolve/main/spiece.model",
- "google-t5/t5-large": "https://huggingface.co/google-t5/t5-large/resolve/main/spiece.model",
- "google-t5/t5-3b": "https://huggingface.co/google-t5/t5-3b/resolve/main/spiece.model",
- "google-t5/t5-11b": "https://huggingface.co/google-t5/t5-11b/resolve/main/spiece.model",
- },
- "tokenizer_file": {
- "google-t5/t5-small": "https://huggingface.co/google-t5/t5-small/resolve/main/tokenizer.json",
- "google-t5/t5-base": "https://huggingface.co/google-t5/t5-base/resolve/main/tokenizer.json",
- "google-t5/t5-large": "https://huggingface.co/google-t5/t5-large/resolve/main/tokenizer.json",
- "google-t5/t5-3b": "https://huggingface.co/google-t5/t5-3b/resolve/main/tokenizer.json",
- "google-t5/t5-11b": "https://huggingface.co/google-t5/t5-11b/resolve/main/tokenizer.json",
- },
-}
-
# TODO(PVP) - this should be removed in Transformers v5
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "google-t5/t5-small": 512,
- "google-t5/t5-base": 512,
- "google-t5/t5-large": 512,
- "google-t5/t5-3b": 512,
- "google-t5/t5-11b": 512,
-}
class T5TokenizerFast(PreTrainedTokenizerFast):
@@ -103,8 +79,6 @@ class T5TokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = T5Tokenizer
diff --git a/src/transformers/models/table_transformer/configuration_table_transformer.py b/src/transformers/models/table_transformer/configuration_table_transformer.py
index 12b62ee9736c7f..9a2ff6bbab3b24 100644
--- a/src/transformers/models/table_transformer/configuration_table_transformer.py
+++ b/src/transformers/models/table_transformer/configuration_table_transformer.py
@@ -26,11 +26,8 @@
logger = logging.get_logger(__name__)
-TABLE_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/table-transformer-detection": (
- "https://huggingface.co/microsoft/table-transformer-detection/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import TABLE_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TableTransformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/table_transformer/modeling_table_transformer.py b/src/transformers/models/table_transformer/modeling_table_transformer.py
index 7f86b0ab53320b..8e577a65a5fe00 100644
--- a/src/transformers/models/table_transformer/modeling_table_transformer.py
+++ b/src/transformers/models/table_transformer/modeling_table_transformer.py
@@ -60,10 +60,8 @@
_CONFIG_FOR_DOC = "TableTransformerConfig"
_CHECKPOINT_FOR_DOC = "microsoft/table-transformer-detection"
-TABLE_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/table-transformer-detection",
- # See all Table Transformer models at https://huggingface.co/models?filter=table-transformer
-]
+
+from ..deprecated._archive_maps import TABLE_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/tapas/configuration_tapas.py b/src/transformers/models/tapas/configuration_tapas.py
index f466ab42545f04..b448afd0022062 100644
--- a/src/transformers/models/tapas/configuration_tapas.py
+++ b/src/transformers/models/tapas/configuration_tapas.py
@@ -24,22 +24,7 @@
from ...configuration_utils import PretrainedConfig
-
-
-TAPAS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/tapas-base-finetuned-sqa": (
- "https://huggingface.co/google/tapas-base-finetuned-sqa/resolve/main/config.json"
- ),
- "google/tapas-base-finetuned-wtq": (
- "https://huggingface.co/google/tapas-base-finetuned-wtq/resolve/main/config.json"
- ),
- "google/tapas-base-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-base-finetuned-wikisql-supervised/resolve/main/config.json"
- ),
- "google/tapas-base-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-base-finetuned-tabfact/resolve/main/config.json"
- ),
-}
+from ..deprecated._archive_maps import TAPAS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TapasConfig(PretrainedConfig):
diff --git a/src/transformers/models/tapas/modeling_tapas.py b/src/transformers/models/tapas/modeling_tapas.py
index 1e7a4372bb015e..e2ce847926b38f 100644
--- a/src/transformers/models/tapas/modeling_tapas.py
+++ b/src/transformers/models/tapas/modeling_tapas.py
@@ -56,39 +56,9 @@
_CONFIG_FOR_DOC = "TapasConfig"
_CHECKPOINT_FOR_DOC = "google/tapas-base"
-TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- # large models
- "google/tapas-large",
- "google/tapas-large-finetuned-sqa",
- "google/tapas-large-finetuned-wtq",
- "google/tapas-large-finetuned-wikisql-supervised",
- "google/tapas-large-finetuned-tabfact",
- # base models
- "google/tapas-base",
- "google/tapas-base-finetuned-sqa",
- "google/tapas-base-finetuned-wtq",
- "google/tapas-base-finetuned-wikisql-supervised",
- "google/tapas-base-finetuned-tabfact",
- # small models
- "google/tapas-small",
- "google/tapas-small-finetuned-sqa",
- "google/tapas-small-finetuned-wtq",
- "google/tapas-small-finetuned-wikisql-supervised",
- "google/tapas-small-finetuned-tabfact",
- # mini models
- "google/tapas-mini",
- "google/tapas-mini-finetuned-sqa",
- "google/tapas-mini-finetuned-wtq",
- "google/tapas-mini-finetuned-wikisql-supervised",
- "google/tapas-mini-finetuned-tabfact",
- # tiny models
- "google/tapas-tiny",
- "google/tapas-tiny-finetuned-sqa",
- "google/tapas-tiny-finetuned-wtq",
- "google/tapas-tiny-finetuned-wikisql-supervised",
- "google/tapas-tiny-finetuned-tabfact",
- # See all TAPAS models at https://huggingface.co/models?filter=tapas
-]
+
+from ..deprecated._archive_maps import TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
EPSILON_ZERO_DIVISION = 1e-10
CLOSE_ENOUGH_TO_LOG_ZERO = -10000.0
diff --git a/src/transformers/models/tapas/modeling_tf_tapas.py b/src/transformers/models/tapas/modeling_tf_tapas.py
index 79b1a9ebfc7b6c..6b2ed5fab455a8 100644
--- a/src/transformers/models/tapas/modeling_tf_tapas.py
+++ b/src/transformers/models/tapas/modeling_tf_tapas.py
@@ -75,39 +75,9 @@
_CONFIG_FOR_DOC = "TapasConfig"
_CHECKPOINT_FOR_DOC = "google/tapas-base"
-TF_TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- # large models
- "google/tapas-large",
- "google/tapas-large-finetuned-sqa",
- "google/tapas-large-finetuned-wtq",
- "google/tapas-large-finetuned-wikisql-supervised",
- "google/tapas-large-finetuned-tabfact",
- # base models
- "google/tapas-base",
- "google/tapas-base-finetuned-sqa",
- "google/tapas-base-finetuned-wtq",
- "google/tapas-base-finetuned-wikisql-supervised",
- "google/tapas-base-finetuned-tabfact",
- # small models
- "google/tapas-small",
- "google/tapas-small-finetuned-sqa",
- "google/tapas-small-finetuned-wtq",
- "google/tapas-small-finetuned-wikisql-supervised",
- "google/tapas-small-finetuned-tabfact",
- # mini models
- "google/tapas-mini",
- "google/tapas-mini-finetuned-sqa",
- "google/tapas-mini-finetuned-wtq",
- "google/tapas-mini-finetuned-wikisql-supervised",
- "google/tapas-mini-finetuned-tabfact",
- # tiny models
- "google/tapas-tiny",
- "google/tapas-tiny-finetuned-sqa",
- "google/tapas-tiny-finetuned-wtq",
- "google/tapas-tiny-finetuned-wikisql-supervised",
- "google/tapas-tiny-finetuned-tabfact",
- # See all TAPAS models at https://huggingface.co/models?filter=tapas
-]
+
+from ..deprecated._archive_maps import TF_TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
EPSILON_ZERO_DIVISION = 1e-10
CLOSE_ENOUGH_TO_LOG_ZERO = -10000.0
diff --git a/src/transformers/models/tapas/tokenization_tapas.py b/src/transformers/models/tapas/tokenization_tapas.py
index 7ec1e68f21d75c..124d48df24ca20 100644
--- a/src/transformers/models/tapas/tokenization_tapas.py
+++ b/src/transformers/models/tapas/tokenization_tapas.py
@@ -48,92 +48,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- # large models
- "google/tapas-large-finetuned-sqa": (
- "https://huggingface.co/google/tapas-large-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-large-finetuned-wtq": (
- "https://huggingface.co/google/tapas-large-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-large-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-large-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-large-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-large-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- # base models
- "google/tapas-base-finetuned-sqa": (
- "https://huggingface.co/google/tapas-base-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-base-finetuned-wtq": (
- "https://huggingface.co/google/tapas-base-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-base-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-base-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-base-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-base-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- # medium models
- "google/tapas-medium-finetuned-sqa": (
- "https://huggingface.co/google/tapas-medium-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-medium-finetuned-wtq": (
- "https://huggingface.co/google/tapas-medium-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-medium-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-medium-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-medium-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-medium-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- # small models
- "google/tapas-small-finetuned-sqa": (
- "https://huggingface.co/google/tapas-small-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-small-finetuned-wtq": (
- "https://huggingface.co/google/tapas-small-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-small-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-small-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-small-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-small-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- # tiny models
- "google/tapas-tiny-finetuned-sqa": (
- "https://huggingface.co/google/tapas-tiny-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-tiny-finetuned-wtq": (
- "https://huggingface.co/google/tapas-tiny-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-tiny-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-tiny-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-tiny-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-tiny-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- # mini models
- "google/tapas-mini-finetuned-sqa": (
- "https://huggingface.co/google/tapas-mini-finetuned-sqa/resolve/main/vocab.txt"
- ),
- "google/tapas-mini-finetuned-wtq": (
- "https://huggingface.co/google/tapas-mini-finetuned-wtq/resolve/main/vocab.txt"
- ),
- "google/tapas-mini-finetuned-wikisql-supervised": (
- "https://huggingface.co/google/tapas-mini-finetuned-wikisql-supervised/resolve/main/vocab.txt"
- ),
- "google/tapas-mini-finetuned-tabfact": (
- "https://huggingface.co/google/tapas-mini-finetuned-tabfact/resolve/main/vocab.txt"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {name: 512 for name in PRETRAINED_VOCAB_FILES_MAP.keys()}
-PRETRAINED_INIT_CONFIGURATION = {name: {"do_lower_case": True} for name in PRETRAINED_VOCAB_FILES_MAP.keys()}
-
class TapasTruncationStrategy(ExplicitEnum):
"""
@@ -315,8 +229,6 @@ class TapasTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/time_series_transformer/configuration_time_series_transformer.py b/src/transformers/models/time_series_transformer/configuration_time_series_transformer.py
index a2e31ba48d3bc8..f53f3aad1ec947 100644
--- a/src/transformers/models/time_series_transformer/configuration_time_series_transformer.py
+++ b/src/transformers/models/time_series_transformer/configuration_time_series_transformer.py
@@ -22,12 +22,8 @@
logger = logging.get_logger(__name__)
-TIME_SERIES_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "huggingface/time-series-transformer-tourism-monthly": (
- "https://huggingface.co/huggingface/time-series-transformer-tourism-monthly/resolve/main/config.json"
- ),
- # See all TimeSeriesTransformer models at https://huggingface.co/models?filter=time_series_transformer
-}
+
+from ..deprecated._archive_maps import TIME_SERIES_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TimeSeriesTransformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py b/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
index b6e86735c6a3d0..ab46d3a92a1853 100644
--- a/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
+++ b/src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
@@ -46,10 +46,7 @@
_CONFIG_FOR_DOC = "TimeSeriesTransformerConfig"
-TIME_SERIES_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "huggingface/time-series-transformer-tourism-monthly",
- # See all TimeSeriesTransformer models at https://huggingface.co/models?filter=time_series_transformer
-]
+from ..deprecated._archive_maps import TIME_SERIES_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TimeSeriesFeatureEmbedder(nn.Module):
diff --git a/src/transformers/models/timesformer/configuration_timesformer.py b/src/transformers/models/timesformer/configuration_timesformer.py
index e910564fb1bbf5..79a86b7b5b370d 100644
--- a/src/transformers/models/timesformer/configuration_timesformer.py
+++ b/src/transformers/models/timesformer/configuration_timesformer.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-TIMESFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/timesformer": "https://huggingface.co/facebook/timesformer/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import TIMESFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TimesformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/timesformer/modeling_timesformer.py b/src/transformers/models/timesformer/modeling_timesformer.py
index 73ce6bf7737f62..337447250842ee 100644
--- a/src/transformers/models/timesformer/modeling_timesformer.py
+++ b/src/transformers/models/timesformer/modeling_timesformer.py
@@ -36,10 +36,8 @@
_CONFIG_FOR_DOC = "TimesformerConfig"
_CHECKPOINT_FOR_DOC = "facebook/timesformer"
-TIMESFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/timesformer-base-finetuned-k400",
- # See all TimeSformer models at https://huggingface.co/models?filter=timesformer
-]
+
+from ..deprecated._archive_maps import TIMESFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Adapted from https://github.com/facebookresearch/TimeSformer/blob/a5ef29a7b7264baff199a30b3306ac27de901133/timesformer/models/vit.py#L155
diff --git a/src/transformers/models/trocr/configuration_trocr.py b/src/transformers/models/trocr/configuration_trocr.py
index 4964ab27acb818..ab282db97bfc55 100644
--- a/src/transformers/models/trocr/configuration_trocr.py
+++ b/src/transformers/models/trocr/configuration_trocr.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-TROCR_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/trocr-base-handwritten": (
- "https://huggingface.co/microsoft/trocr-base-handwritten/resolve/main/config.json"
- ),
- # See all TrOCR models at https://huggingface.co/models?filter=trocr
-}
+
+from ..deprecated._archive_maps import TROCR_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TrOCRConfig(PretrainedConfig):
diff --git a/src/transformers/models/trocr/modeling_trocr.py b/src/transformers/models/trocr/modeling_trocr.py
index a21f6338ba2e6e..72ead7143ad492 100644
--- a/src/transformers/models/trocr/modeling_trocr.py
+++ b/src/transformers/models/trocr/modeling_trocr.py
@@ -37,10 +37,7 @@
_CHECKPOINT_FOR_DOC = "microsoft/trocr-base-handwritten"
-TROCR_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/trocr-base-handwritten",
- # See all TrOCR models at https://huggingface.co/models?filter=trocr
-]
+from ..deprecated._archive_maps import TROCR_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.bart.modeling_bart.BartLearnedPositionalEmbedding with Bart->TrOCR
diff --git a/src/transformers/models/tvlt/configuration_tvlt.py b/src/transformers/models/tvlt/configuration_tvlt.py
index 1200eb470b75bd..063befc9d77f92 100644
--- a/src/transformers/models/tvlt/configuration_tvlt.py
+++ b/src/transformers/models/tvlt/configuration_tvlt.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "ZinengTang/tvlt-base": "https://huggingface.co/ZinengTang/tvlt-base/blob/main/config.json",
-}
+
+from ..deprecated._archive_maps import TVLT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TvltConfig(PretrainedConfig):
diff --git a/src/transformers/models/tvlt/modeling_tvlt.py b/src/transformers/models/tvlt/modeling_tvlt.py
index d2fe1040a3ed71..f841c47ea4bc56 100644
--- a/src/transformers/models/tvlt/modeling_tvlt.py
+++ b/src/transformers/models/tvlt/modeling_tvlt.py
@@ -45,10 +45,8 @@
_CONFIG_FOR_DOC = "TvltConfig"
_CHECKPOINT_FOR_DOC = "ZinengTang/tvlt-base"
-TVLT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "ZinengTang/tvlt-base",
- # See all TVLT models at https://huggingface.co/ZinengTang/tvlt-base
-]
+
+from ..deprecated._archive_maps import TVLT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/tvp/configuration_tvp.py b/src/transformers/models/tvp/configuration_tvp.py
index f39a0ab5dfcdbf..85b7ac6a41cbcc 100644
--- a/src/transformers/models/tvp/configuration_tvp.py
+++ b/src/transformers/models/tvp/configuration_tvp.py
@@ -24,9 +24,7 @@
logger = logging.get_logger(__name__)
-TVP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "Intel/tvp-base": "https://huggingface.co/Intel/tvp-base/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import TVP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class TvpConfig(PretrainedConfig):
diff --git a/src/transformers/models/tvp/modeling_tvp.py b/src/transformers/models/tvp/modeling_tvp.py
index 159b4926af7e8f..da8e85da74cfbd 100644
--- a/src/transformers/models/tvp/modeling_tvp.py
+++ b/src/transformers/models/tvp/modeling_tvp.py
@@ -34,11 +34,8 @@
logger = logging.get_logger(__name__)
-TVP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "Intel/tvp-base",
- "Intel/tvp-base-ANet",
- # See all Tvp models at https://huggingface.co/models?filter=tvp
-]
+
+from ..deprecated._archive_maps import TVP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/udop/configuration_udop.py b/src/transformers/models/udop/configuration_udop.py
index 8647a7bae29acf..ba124d0aa15e6d 100644
--- a/src/transformers/models/udop/configuration_udop.py
+++ b/src/transformers/models/udop/configuration_udop.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/udop-large": "https://huggingface.co/microsoft/udop-large/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import UDOP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class UdopConfig(PretrainedConfig):
diff --git a/src/transformers/models/udop/modeling_udop.py b/src/transformers/models/udop/modeling_udop.py
index 62192eea7f5a5e..7e242c8b52e913 100644
--- a/src/transformers/models/udop/modeling_udop.py
+++ b/src/transformers/models/udop/modeling_udop.py
@@ -46,10 +46,8 @@
logger = logging.getLogger(__name__)
-UDOP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/udop-large",
- # See all UDOP models at https://huggingface.co/models?filter=udop
-]
+
+from ..deprecated._archive_maps import UDOP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
_CONFIG_FOR_DOC = "UdopConfig"
@@ -942,7 +940,7 @@ def forward(
if len(past_key_value) != expected_num_past_key_values:
raise ValueError(
f"There should be {expected_num_past_key_values} past states. "
- f"{'2 (past / key) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
+ f"{'2 (key / value) for cross attention. ' if expected_num_past_key_values == 4 else ''}"
f"Got {len(past_key_value)} past key / value states"
)
diff --git a/src/transformers/models/umt5/configuration_umt5.py b/src/transformers/models/umt5/configuration_umt5.py
index ccd2392d720a24..9365717c282ae6 100644
--- a/src/transformers/models/umt5/configuration_umt5.py
+++ b/src/transformers/models/umt5/configuration_umt5.py
@@ -22,11 +22,6 @@
logger = logging.get_logger(__name__)
-UMT5_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/umt5-small": "https://huggingface.co/google/umt5-small/resolve/main/config.json",
- # See all umt5 models at https://huggingface.co/models?filter=umt5
-}
-
class UMT5Config(PretrainedConfig):
r"""
diff --git a/src/transformers/models/unispeech/configuration_unispeech.py b/src/transformers/models/unispeech/configuration_unispeech.py
index d7234339031eaa..25a003ae9f5f9a 100644
--- a/src/transformers/models/unispeech/configuration_unispeech.py
+++ b/src/transformers/models/unispeech/configuration_unispeech.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/unispeech-large-1500h-cv": (
- "https://huggingface.co/microsoft/unispeech-large-1500h-cv/resolve/main/config.json"
- ),
- # See all UniSpeech models at https://huggingface.co/models?filter=unispeech
-}
+
+from ..deprecated._archive_maps import UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class UniSpeechConfig(PretrainedConfig):
diff --git a/src/transformers/models/unispeech/modeling_unispeech.py b/src/transformers/models/unispeech/modeling_unispeech.py
index 11965bdb50e978..473bc7d4ff12e4 100755
--- a/src/transformers/models/unispeech/modeling_unispeech.py
+++ b/src/transformers/models/unispeech/modeling_unispeech.py
@@ -56,11 +56,8 @@
_CTC_EXPECTED_OUTPUT = "'mister quilter is the apposl of the midle classes and weare glad to welcom his gosepl'"
_CTC_EXPECTED_LOSS = 17.17
-UNISPEECH_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/unispeech-large-1500h-cv",
- "microsoft/unispeech-large-multi-lingual-1500h-cv",
- # See all UniSpeech models at https://huggingface.co/models?filter=unispeech
-]
+
+from ..deprecated._archive_maps import UNISPEECH_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py b/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
index fea89da119acbd..1e6e40ad48515e 100644
--- a/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
@@ -23,12 +23,8 @@
logger = logging.get_logger(__name__)
-UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/unispeech-sat-base-100h-libri-ft": (
- "https://huggingface.co/microsoft/unispeech-sat-base-100h-libri-ft/resolve/main/config.json"
- ),
- # See all UniSpeechSat models at https://huggingface.co/models?filter=unispeech_sat
-}
+
+from ..deprecated._archive_maps import UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class UniSpeechSatConfig(PretrainedConfig):
diff --git a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
index aec02db00fef24..f38da0d47f5c3d 100755
--- a/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
+++ b/src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
@@ -72,9 +72,8 @@
_XVECTOR_CHECKPOINT = "microsoft/unispeech-sat-base-plus-sv"
_XVECTOR_EXPECTED_OUTPUT = 0.97
-UNISPEECH_SAT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- # See all UniSpeechSat models at https://huggingface.co/models?filter=unispeech_sat
-]
+
+from ..deprecated._archive_maps import UNISPEECH_SAT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/univnet/configuration_univnet.py b/src/transformers/models/univnet/configuration_univnet.py
index c9dbbb5328210e..933db21d5ae381 100644
--- a/src/transformers/models/univnet/configuration_univnet.py
+++ b/src/transformers/models/univnet/configuration_univnet.py
@@ -20,9 +20,7 @@
logger = logging.get_logger(__name__)
-UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "dg845/univnet-dev": "https://huggingface.co/dg845/univnet-dev/resolve/main/config.json",
-}
+from ..deprecated._archive_maps import UNIVNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class UnivNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/univnet/modeling_univnet.py b/src/transformers/models/univnet/modeling_univnet.py
index dc9beddec525b8..c2551d72653196 100644
--- a/src/transformers/models/univnet/modeling_univnet.py
+++ b/src/transformers/models/univnet/modeling_univnet.py
@@ -32,10 +32,8 @@
_CHECKPOINT_FOR_DOC = "dg845/univnet-dev"
-UNIVNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "dg845/univnet-dev",
- # See all UnivNet models at https://huggingface.co/models?filter=univnet
-]
+
+from ..deprecated._archive_maps import UNIVNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/upernet/modeling_upernet.py b/src/transformers/models/upernet/modeling_upernet.py
index b889ae4eb4ce82..2d5b4443e35df3 100644
--- a/src/transformers/models/upernet/modeling_upernet.py
+++ b/src/transformers/models/upernet/modeling_upernet.py
@@ -27,11 +27,6 @@
from .configuration_upernet import UperNetConfig
-UPERNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openmmlab/upernet-convnext-tiny",
- # See all UperNet models at https://huggingface.co/models?filter=upernet
-]
-
# General docstring
_CONFIG_FOR_DOC = "UperNetConfig"
diff --git a/src/transformers/models/videomae/configuration_videomae.py b/src/transformers/models/videomae/configuration_videomae.py
index 1645b4985dac79..ba3d1d82736bc2 100644
--- a/src/transformers/models/videomae/configuration_videomae.py
+++ b/src/transformers/models/videomae/configuration_videomae.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "MCG-NJU/videomae-base": "https://huggingface.co/MCG-NJU/videomae-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VideoMAEConfig(PretrainedConfig):
diff --git a/src/transformers/models/videomae/modeling_videomae.py b/src/transformers/models/videomae/modeling_videomae.py
index aac69b6c536be4..6beb18bb77ce0a 100644
--- a/src/transformers/models/videomae/modeling_videomae.py
+++ b/src/transformers/models/videomae/modeling_videomae.py
@@ -47,10 +47,8 @@
_CONFIG_FOR_DOC = "VideoMAEConfig"
_CHECKPOINT_FOR_DOC = "MCG-NJU/videomae-base"
-VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "MCG-NJU/videomae-base",
- # See all VideoMAE models at https://huggingface.co/models?filter=videomae
-]
+
+from ..deprecated._archive_maps import VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/vilt/configuration_vilt.py b/src/transformers/models/vilt/configuration_vilt.py
index bd419285e98ca0..0ad4bde69494d7 100644
--- a/src/transformers/models/vilt/configuration_vilt.py
+++ b/src/transformers/models/vilt/configuration_vilt.py
@@ -20,9 +20,8 @@
logger = logging.get_logger(__name__)
-VILT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "dandelin/vilt-b32-mlm": "https://huggingface.co/dandelin/vilt-b32-mlm/blob/main/config.json"
-}
+
+from ..deprecated._archive_maps import VILT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ViltConfig(PretrainedConfig):
diff --git a/src/transformers/models/vilt/modeling_vilt.py b/src/transformers/models/vilt/modeling_vilt.py
index 9ffa9fff013c88..5545b881bd670a 100755
--- a/src/transformers/models/vilt/modeling_vilt.py
+++ b/src/transformers/models/vilt/modeling_vilt.py
@@ -48,10 +48,8 @@
_CONFIG_FOR_DOC = "ViltConfig"
_CHECKPOINT_FOR_DOC = "dandelin/vilt-b32-mlm"
-VILT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "dandelin/vilt-b32-mlm",
- # See all ViLT models at https://huggingface.co/models?filter=vilt
-]
+
+from ..deprecated._archive_maps import VILT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/vipllava/configuration_vipllava.py b/src/transformers/models/vipllava/configuration_vipllava.py
index bba02bea789a6b..d57f4179492ea2 100644
--- a/src/transformers/models/vipllava/configuration_vipllava.py
+++ b/src/transformers/models/vipllava/configuration_vipllava.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-VIPLLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "ybelkada/vip-llava-7b-hf": "https://huggingface.co/llava-hf/vip-llava-7b-hf/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import VIPLLAVA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VipLlavaConfig(PretrainedConfig):
diff --git a/src/transformers/models/vipllava/modeling_vipllava.py b/src/transformers/models/vipllava/modeling_vipllava.py
index 48e29179388c32..dda9549a4f2e8e 100644
--- a/src/transformers/models/vipllava/modeling_vipllava.py
+++ b/src/transformers/models/vipllava/modeling_vipllava.py
@@ -38,10 +38,8 @@
_CONFIG_FOR_DOC = "VipLlavaConfig"
-VIPLLAVA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "llava-hf/vip-llava-7b-hf",
- # See all VipLlava models at https://huggingface.co/models?filter=vipllava
-]
+
+from ..deprecated._archive_maps import VIPLLAVA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
@@ -347,6 +345,12 @@ def _merge_input_ids_with_image_features(self, image_features, inputs_embeds, in
final_attention_mask |= image_to_overwrite
position_ids = (final_attention_mask.cumsum(-1) - 1).masked_fill_((final_attention_mask == 0), 1)
+ # 6. Mask out the embedding at padding positions, as we later use the past_key_value value to determine the non-attended tokens.
+ batch_indices, pad_indices = torch.where(input_ids == self.pad_token_id)
+ indices_to_mask = new_token_positions[batch_indices, pad_indices]
+
+ final_embedding[batch_indices, indices_to_mask] = 0
+
if labels is None:
final_labels = None
@@ -442,11 +446,11 @@ def forward(
# Sum all dimensions of head_dim (-1) to avoid random errors such as: https://github.com/huggingface/transformers/pull/28032#issuecomment-1863691941
batch_index, non_attended_tokens = torch.where(first_layer_past_key_value.float().sum(-1) == 0)
- # Get the target length
- target_seqlen = first_layer_past_key_value.shape[-2] + 1
+ target_length = input_ids.shape[1]
+ past_length = first_layer_past_key_value.shape[-1]
extended_attention_mask = torch.ones(
- (attention_mask.shape[0], target_seqlen - attention_mask.shape[1]),
+ (attention_mask.shape[0], past_length),
dtype=attention_mask.dtype,
device=attention_mask.device,
)
@@ -461,7 +465,7 @@ def forward(
# Zero-out the places where we don't need to attend
extended_attention_mask[new_batch_index, new_non_attended_tokens] = 0
- attention_mask = torch.cat((attention_mask, extended_attention_mask), dim=1)
+ attention_mask = torch.cat((extended_attention_mask, attention_mask[:, -target_length:]), dim=1)
position_ids = torch.sum(attention_mask, dim=1).unsqueeze(-1) - 1
outputs = self.language_model(
diff --git a/src/transformers/models/visual_bert/configuration_visual_bert.py b/src/transformers/models/visual_bert/configuration_visual_bert.py
index 9b675ff602bc77..2edf5466e347b8 100644
--- a/src/transformers/models/visual_bert/configuration_visual_bert.py
+++ b/src/transformers/models/visual_bert/configuration_visual_bert.py
@@ -20,24 +20,8 @@
logger = logging.get_logger(__name__)
-VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "uclanlp/visualbert-vqa": "https://huggingface.co/uclanlp/visualbert-vqa/resolve/main/config.json",
- "uclanlp/visualbert-vqa-pre": "https://huggingface.co/uclanlp/visualbert-vqa-pre/resolve/main/config.json",
- "uclanlp/visualbert-vqa-coco-pre": (
- "https://huggingface.co/uclanlp/visualbert-vqa-coco-pre/resolve/main/config.json"
- ),
- "uclanlp/visualbert-vcr": "https://huggingface.co/uclanlp/visualbert-vcr/resolve/main/config.json",
- "uclanlp/visualbert-vcr-pre": "https://huggingface.co/uclanlp/visualbert-vcr-pre/resolve/main/config.json",
- "uclanlp/visualbert-vcr-coco-pre": (
- "https://huggingface.co/uclanlp/visualbert-vcr-coco-pre/resolve/main/config.json"
- ),
- "uclanlp/visualbert-nlvr2": "https://huggingface.co/uclanlp/visualbert-nlvr2/resolve/main/config.json",
- "uclanlp/visualbert-nlvr2-pre": "https://huggingface.co/uclanlp/visualbert-nlvr2-pre/resolve/main/config.json",
- "uclanlp/visualbert-nlvr2-coco-pre": (
- "https://huggingface.co/uclanlp/visualbert-nlvr2-coco-pre/resolve/main/config.json"
- ),
- # See all VisualBERT models at https://huggingface.co/models?filter=visual_bert
-}
+
+from ..deprecated._archive_maps import VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VisualBertConfig(PretrainedConfig):
diff --git a/src/transformers/models/visual_bert/modeling_visual_bert.py b/src/transformers/models/visual_bert/modeling_visual_bert.py
index 4af7696fc39634..07c8b7a4b5173c 100755
--- a/src/transformers/models/visual_bert/modeling_visual_bert.py
+++ b/src/transformers/models/visual_bert/modeling_visual_bert.py
@@ -48,18 +48,8 @@
_CONFIG_FOR_DOC = "VisualBertConfig"
_CHECKPOINT_FOR_DOC = "uclanlp/visualbert-vqa-coco-pre"
-VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "uclanlp/visualbert-vqa",
- "uclanlp/visualbert-vqa-pre",
- "uclanlp/visualbert-vqa-coco-pre",
- "uclanlp/visualbert-vcr",
- "uclanlp/visualbert-vcr-pre",
- "uclanlp/visualbert-vcr-coco-pre",
- "uclanlp/visualbert-nlvr2",
- "uclanlp/visualbert-nlvr2-pre",
- "uclanlp/visualbert-nlvr2-coco-pre",
- # See all VisualBERT models at https://huggingface.co/models?filter=visual_bert
-]
+
+from ..deprecated._archive_maps import VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class VisualBertEmbeddings(nn.Module):
diff --git a/src/transformers/models/vit/configuration_vit.py b/src/transformers/models/vit/configuration_vit.py
index 5eda0385c30c1d..4b505b5d9cbb6d 100644
--- a/src/transformers/models/vit/configuration_vit.py
+++ b/src/transformers/models/vit/configuration_vit.py
@@ -26,10 +26,8 @@
logger = logging.get_logger(__name__)
-VIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/vit-base-patch16-224": "https://huggingface.co/vit-base-patch16-224/resolve/main/config.json",
- # See all ViT models at https://huggingface.co/models?filter=vit
-}
+
+from ..deprecated._archive_maps import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ViTConfig(PretrainedConfig):
diff --git a/src/transformers/models/vit/modeling_vit.py b/src/transformers/models/vit/modeling_vit.py
index 734ccf6a9e80f4..4ccdd1deaf4ca1 100644
--- a/src/transformers/models/vit/modeling_vit.py
+++ b/src/transformers/models/vit/modeling_vit.py
@@ -57,10 +57,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "Egyptian cat"
-VIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/vit-base-patch16-224",
- # See all ViT models at https://huggingface.co/models?filter=vit
-]
+from ..deprecated._archive_maps import VIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ViTEmbeddings(nn.Module):
diff --git a/src/transformers/models/vit_hybrid/configuration_vit_hybrid.py b/src/transformers/models/vit_hybrid/configuration_vit_hybrid.py
index 2875e62dd47200..8a8a808ec60d05 100644
--- a/src/transformers/models/vit_hybrid/configuration_vit_hybrid.py
+++ b/src/transformers/models/vit_hybrid/configuration_vit_hybrid.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-VIT_HYBRID_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/vit-hybrid-base-bit-384": "https://huggingface.co/vit-hybrid-base-bit-384/resolve/main/config.json",
- # See all ViT hybrid models at https://huggingface.co/models?filter=vit
-}
+
+from ..deprecated._archive_maps import VIT_HYBRID_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ViTHybridConfig(PretrainedConfig):
diff --git a/src/transformers/models/vit_hybrid/modeling_vit_hybrid.py b/src/transformers/models/vit_hybrid/modeling_vit_hybrid.py
index 3dc715af511ca8..6fe9f8d2b6c9bd 100644
--- a/src/transformers/models/vit_hybrid/modeling_vit_hybrid.py
+++ b/src/transformers/models/vit_hybrid/modeling_vit_hybrid.py
@@ -47,10 +47,7 @@
_IMAGE_CLASS_EXPECTED_OUTPUT = "tabby, tabby cat"
-VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/vit-hybrid-base-bit-384",
- # See all ViT hybrid models at https://huggingface.co/models?filter=vit-hybrid
-]
+from ..deprecated._archive_maps import VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ViTHybridEmbeddings(nn.Module):
diff --git a/src/transformers/models/vit_mae/configuration_vit_mae.py b/src/transformers/models/vit_mae/configuration_vit_mae.py
index 42697f382c3959..c5866ef40b497c 100644
--- a/src/transformers/models/vit_mae/configuration_vit_mae.py
+++ b/src/transformers/models/vit_mae/configuration_vit_mae.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-VIT_MAE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/vit-mae-base": "https://huggingface.co/facebook/vit-mae-base/resolve/main/config.json",
- # See all ViT MAE models at https://huggingface.co/models?filter=vit-mae
-}
+
+from ..deprecated._archive_maps import VIT_MAE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ViTMAEConfig(PretrainedConfig):
diff --git a/src/transformers/models/vit_mae/modeling_vit_mae.py b/src/transformers/models/vit_mae/modeling_vit_mae.py
index 910353217fa9fc..bfbe59ea903a1a 100755
--- a/src/transformers/models/vit_mae/modeling_vit_mae.py
+++ b/src/transformers/models/vit_mae/modeling_vit_mae.py
@@ -45,10 +45,8 @@
_CONFIG_FOR_DOC = "ViTMAEConfig"
_CHECKPOINT_FOR_DOC = "facebook/vit-mae-base"
-VIT_MAE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/vit-mae-base",
- # See all ViTMAE models at https://huggingface.co/models?filter=vit_mae
-]
+
+from ..deprecated._archive_maps import VIT_MAE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/vit_msn/configuration_vit_msn.py b/src/transformers/models/vit_msn/configuration_vit_msn.py
index 4ee05e3c393be0..296434346625f5 100644
--- a/src/transformers/models/vit_msn/configuration_vit_msn.py
+++ b/src/transformers/models/vit_msn/configuration_vit_msn.py
@@ -21,10 +21,8 @@
logger = logging.get_logger(__name__)
-VIT_MSN_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "sayakpaul/vit-msn-base": "https://huggingface.co/sayakpaul/vit-msn-base/resolve/main/config.json",
- # See all ViT MSN models at https://huggingface.co/models?filter=vit_msn
-}
+
+from ..deprecated._archive_maps import VIT_MSN_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class ViTMSNConfig(PretrainedConfig):
diff --git a/src/transformers/models/vit_msn/modeling_vit_msn.py b/src/transformers/models/vit_msn/modeling_vit_msn.py
index 6b10eb9f245059..45d1779b5f8c80 100644
--- a/src/transformers/models/vit_msn/modeling_vit_msn.py
+++ b/src/transformers/models/vit_msn/modeling_vit_msn.py
@@ -37,10 +37,8 @@
_CONFIG_FOR_DOC = "ViTMSNConfig"
_CHECKPOINT_FOR_DOC = "facebook/vit-msn-small"
-VIT_MSN_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/vit-msn-small",
- # See all ViTMSN models at https://huggingface.co/models?filter=vit_msn
-]
+
+from ..deprecated._archive_maps import VIT_MSN_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class ViTMSNEmbeddings(nn.Module):
diff --git a/src/transformers/models/vitdet/configuration_vitdet.py b/src/transformers/models/vitdet/configuration_vitdet.py
index 2b1f37e311434c..2a7973dde87979 100644
--- a/src/transformers/models/vitdet/configuration_vitdet.py
+++ b/src/transformers/models/vitdet/configuration_vitdet.py
@@ -22,9 +22,8 @@
logger = logging.get_logger(__name__)
-VITDET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/vit-det-base": "https://huggingface.co/facebook/vit-det-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import VITDET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VitDetConfig(BackboneConfigMixin, PretrainedConfig):
diff --git a/src/transformers/models/vitdet/modeling_vitdet.py b/src/transformers/models/vitdet/modeling_vitdet.py
index 7af69d28697cd8..5d12b0b58593bb 100644
--- a/src/transformers/models/vitdet/modeling_vitdet.py
+++ b/src/transformers/models/vitdet/modeling_vitdet.py
@@ -42,10 +42,7 @@
_CONFIG_FOR_DOC = "VitDetConfig"
-VITDET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/vit-det-base",
- # See all ViTDet models at https://huggingface.co/models?filter=vitdet
-]
+from ..deprecated._archive_maps import VITDET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class VitDetEmbeddings(nn.Module):
diff --git a/src/transformers/models/vitmatte/configuration_vitmatte.py b/src/transformers/models/vitmatte/configuration_vitmatte.py
index 13f9942c9e0013..275640d1d079a1 100644
--- a/src/transformers/models/vitmatte/configuration_vitmatte.py
+++ b/src/transformers/models/vitmatte/configuration_vitmatte.py
@@ -24,9 +24,8 @@
logger = logging.get_logger(__name__)
-VITMATTE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "hustvl/vitmatte-small-composition-1k": "https://huggingface.co/hustvl/vitmatte-small-composition-1k/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import VITMATTE_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VitMatteConfig(PretrainedConfig):
diff --git a/src/transformers/models/vitmatte/modeling_vitmatte.py b/src/transformers/models/vitmatte/modeling_vitmatte.py
index 465f5da6adf5ab..f371c608607a5f 100644
--- a/src/transformers/models/vitmatte/modeling_vitmatte.py
+++ b/src/transformers/models/vitmatte/modeling_vitmatte.py
@@ -28,15 +28,10 @@
replace_return_docstrings,
)
from ...utils.backbone_utils import load_backbone
+from ..deprecated._archive_maps import VITMATTE_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
from .configuration_vitmatte import VitMatteConfig
-VITMATTE_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "hustvl/vitmatte-small-composition-1k",
- # See all VitMatte models at https://huggingface.co/models?filter=vitmatte
-]
-
-
# General docstring
_CONFIG_FOR_DOC = "VitMatteConfig"
diff --git a/src/transformers/models/vits/configuration_vits.py b/src/transformers/models/vits/configuration_vits.py
index 72f69e75a51b16..5538e53d4be1b8 100644
--- a/src/transformers/models/vits/configuration_vits.py
+++ b/src/transformers/models/vits/configuration_vits.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-VITS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/mms-tts-eng": "https://huggingface.co/facebook/mms-tts-eng/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import VITS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VitsConfig(PretrainedConfig):
diff --git a/src/transformers/models/vits/modeling_vits.py b/src/transformers/models/vits/modeling_vits.py
index 18309f3a107d6c..df8cf9350b3128 100644
--- a/src/transformers/models/vits/modeling_vits.py
+++ b/src/transformers/models/vits/modeling_vits.py
@@ -42,11 +42,7 @@
_CONFIG_FOR_DOC = "VitsConfig"
-VITS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/mms-tts-eng",
- # See all VITS models at https://huggingface.co/models?filter=vits
- # and all MMS models at https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts
-]
+from ..deprecated._archive_maps import VITS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/vits/tokenization_vits.py b/src/transformers/models/vits/tokenization_vits.py
index 0563be326cdb51..c8b115c176bcef 100644
--- a/src/transformers/models/vits/tokenization_vits.py
+++ b/src/transformers/models/vits/tokenization_vits.py
@@ -32,17 +32,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/mms-tts-eng": "https://huggingface.co/facebook/mms-tts-eng/resolve/main/vocab.json",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- # This model does not have a maximum input length.
- "facebook/mms-tts-eng": 4096,
-}
-
def has_non_roman_characters(input_string):
# Find any character outside the ASCII range
@@ -77,8 +66,6 @@ class VitsTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/vivit/configuration_vivit.py b/src/transformers/models/vivit/configuration_vivit.py
index 0e367fcb9b79b1..28ac13496f82f8 100644
--- a/src/transformers/models/vivit/configuration_vivit.py
+++ b/src/transformers/models/vivit/configuration_vivit.py
@@ -20,12 +20,8 @@
logger = logging.get_logger(__name__)
-VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "google/vivit-b-16x2-kinetics400": (
- "https://huggingface.co/google/vivit-b-16x2-kinetics400/resolve/main/config.json"
- ),
- # See all Vivit models at https://huggingface.co/models?filter=vivit
-}
+
+from ..deprecated._archive_maps import VIVIT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class VivitConfig(PretrainedConfig):
diff --git a/src/transformers/models/vivit/modeling_vivit.py b/src/transformers/models/vivit/modeling_vivit.py
index a9c3f5fd651543..08efb85e1f0254 100755
--- a/src/transformers/models/vivit/modeling_vivit.py
+++ b/src/transformers/models/vivit/modeling_vivit.py
@@ -36,10 +36,8 @@
_CHECKPOINT_FOR_DOC = "google/vivit-b-16x2-kinetics400"
_CONFIG_FOR_DOC = "VivitConfig"
-VIVIT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "google/vivit-b-16x2-kinetics400",
- # See all Vivit models at https://huggingface.co/models?filter=vivit
-]
+
+from ..deprecated._archive_maps import VIVIT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class VivitTubeletEmbeddings(nn.Module):
diff --git a/src/transformers/models/wav2vec2/configuration_wav2vec2.py b/src/transformers/models/wav2vec2/configuration_wav2vec2.py
index fadf1b6b6a5262..252674bb3da3fd 100644
--- a/src/transformers/models/wav2vec2/configuration_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/configuration_wav2vec2.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/wav2vec2-base-960h": "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/config.json",
- # See all Wav2Vec2 models at https://huggingface.co/models?filter=wav2vec2
-}
+
+from ..deprecated._archive_maps import WAV_2_VEC_2_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Wav2Vec2Config(PretrainedConfig):
diff --git a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
index e6a6cb4a756bb0..a8e39b0754af75 100644
--- a/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
@@ -52,13 +52,9 @@
_CHECKPOINT_FOR_DOC = "facebook/wav2vec2-base-960h"
_CONFIG_FOR_DOC = "Wav2Vec2Config"
-TF_WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/wav2vec2-base-960h",
- "facebook/wav2vec2-large-960h",
- "facebook/wav2vec2-large-960h-lv60",
- "facebook/wav2vec2-large-960h-lv60-self",
- # See all Wav2Vec2 models at https://huggingface.co/models?filter=wav2vec2
-]
+
+from ..deprecated._archive_maps import TF_WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/wav2vec2/modeling_wav2vec2.py b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
index 082dd18dce844e..d40af1739c25db 100755
--- a/src/transformers/models/wav2vec2/modeling_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/modeling_wav2vec2.py
@@ -89,13 +89,7 @@
_XVECTOR_EXPECTED_OUTPUT = 0.98
-WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/wav2vec2-base-960h",
- "facebook/wav2vec2-large-960h",
- "facebook/wav2vec2-large-960h-lv60",
- "facebook/wav2vec2-large-960h-lv60-self",
- # See all Wav2Vec2 models at https://huggingface.co/models?filter=wav2vec2
-]
+from ..deprecated._archive_maps import WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/wav2vec2/tokenization_wav2vec2.py b/src/transformers/models/wav2vec2/tokenization_wav2vec2.py
index 00bb00fba375e7..34848a841e9f71 100644
--- a/src/transformers/models/wav2vec2/tokenization_wav2vec2.py
+++ b/src/transformers/models/wav2vec2/tokenization_wav2vec2.py
@@ -16,7 +16,6 @@
import json
import os
-import sys
import warnings
from dataclasses import dataclass
from itertools import groupby
@@ -56,19 +55,8 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/wav2vec2-base-960h": "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/vocab.json",
- },
- "tokenizer_config_file": {
- "facebook/wav2vec2-base-960h": (
- "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/tokenizer_config.json"
- ),
- },
-}
# Wav2Vec2 has no max input length
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/wav2vec2-base-960h": sys.maxsize}
WAV2VEC2_KWARGS_DOCSTRING = r"""
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `False`):
@@ -125,7 +113,6 @@ class Wav2Vec2CTCTokenizerOutput(ModelOutput):
class Wav2Vec2CTCTokenizer(PreTrainedTokenizer):
-
"""
Constructs a Wav2Vec2CTC tokenizer.
@@ -157,8 +144,6 @@ class Wav2Vec2CTCTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
@@ -434,7 +419,9 @@ def _decode(
result = []
for token in filtered_tokens:
- if skip_special_tokens and token in self.all_special_ids:
+ if skip_special_tokens and (
+ token in self.all_special_ids or (token != self.pad_token and token in self.all_special_tokens)
+ ):
continue
result.append(token)
@@ -895,7 +882,9 @@ def _decode(
result = []
for token in filtered_tokens:
- if skip_special_tokens and token in self.all_special_ids:
+ if skip_special_tokens and (
+ token in self.all_special_ids or (token != self.pad_token and token in self.all_special_tokens)
+ ):
continue
result.append(token)
diff --git a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
index 621aede3e3f1c3..4183c1e4c06e7b 100644
--- a/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
+++ b/src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
@@ -21,9 +21,8 @@
logger = logging.get_logger(__name__)
-WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/w2v-bert-2.0": "https://huggingface.co/facebook/w2v-bert-2.0/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import WAV2VEC2_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Wav2Vec2BertConfig(PretrainedConfig):
diff --git a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
index 858f270a87f138..6519faa931d688 100644
--- a/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
+++ b/src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
@@ -64,10 +64,7 @@
_CTC_EXPECTED_LOSS = 17.04
-WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/w2v-bert-2.0",
- # See all Wav2Vec2-BERT models at https://huggingface.co/models?filter=wav2vec2-bert
-]
+from ..deprecated._archive_maps import WAV2VEC2_BERT_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.seamless_m4t_v2.modeling_seamless_m4t_v2._compute_new_attention_mask
diff --git a/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py b/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
index 9983f01bbf13eb..1b99edcece527b 100644
--- a/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
+++ b/src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
@@ -23,11 +23,8 @@
logger = logging.get_logger(__name__)
-WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/wav2vec2-conformer-rel-pos-large": (
- "https://huggingface.co/facebook/wav2vec2-conformer-rel-pos-large/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import WAV2VEC2_CONFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class Wav2Vec2ConformerConfig(PretrainedConfig):
diff --git a/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py b/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
index 3ba2ff7bb3ae70..8354a88a517fa9 100644
--- a/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
+++ b/src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
@@ -65,10 +65,7 @@
_CTC_EXPECTED_LOSS = 64.21
-WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/wav2vec2-conformer-rel-pos-large",
- # See all Wav2Vec2Conformer models at https://huggingface.co/models?filter=wav2vec2-conformer
-]
+from ..deprecated._archive_maps import WAV2VEC2_CONFORMER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py b/src/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py
index c10b679409de12..8809e2c2e87c89 100644
--- a/src/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py
+++ b/src/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py
@@ -16,7 +16,6 @@
import json
import os
-import sys
from dataclasses import dataclass
from itertools import groupby
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
@@ -53,21 +52,8 @@
"tokenizer_config_file": "tokenizer_config.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/wav2vec2-lv-60-espeak-cv-ft": (
- "https://huggingface.co/facebook/wav2vec2-lv-60-espeak-cv-ft/resolve/main/vocab.json"
- ),
- },
- "tokenizer_config_file": {
- "facebook/wav2vec2-lv-60-espeak-cv-ft": (
- "https://huggingface.co/facebook/wav2vec2-lv-60-espeak-cv-ft/resolve/main/tokenizer_config.json"
- ),
- },
-}
# Wav2Vec2Phoneme has no max input length
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/wav2vec2-lv-60-espeak-cv-ft": sys.maxsize}
ListOfDict = List[Dict[str, Union[int, str]]]
@@ -125,8 +111,6 @@ class Wav2Vec2PhonemeCTCTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/wavlm/configuration_wavlm.py b/src/transformers/models/wavlm/configuration_wavlm.py
index 589741c520fad0..c0f5f90fe321af 100644
--- a/src/transformers/models/wavlm/configuration_wavlm.py
+++ b/src/transformers/models/wavlm/configuration_wavlm.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-WAVLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/wavlm-base": "https://huggingface.co/microsoft/wavlm-base/resolve/main/config.json",
- # See all WavLM models at https://huggingface.co/models?filter=wavlm
-}
+
+from ..deprecated._archive_maps import WAVLM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class WavLMConfig(PretrainedConfig):
diff --git a/src/transformers/models/wavlm/modeling_wavlm.py b/src/transformers/models/wavlm/modeling_wavlm.py
index bfe0ced2b5a69d..f46fc1ef4f01da 100755
--- a/src/transformers/models/wavlm/modeling_wavlm.py
+++ b/src/transformers/models/wavlm/modeling_wavlm.py
@@ -70,12 +70,8 @@
_XVECTOR_CHECKPOINT = "microsoft/wavlm-base-plus-sv"
_XVECTOR_EXPECTED_OUTPUT = 0.97
-WAVLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/wavlm-base",
- "microsoft/wavlm-base-plus",
- "microsoft/wavlm-large",
- # See all WavLM models at https://huggingface.co/models?filter=wavlm
-]
+
+from ..deprecated._archive_maps import WAVLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.wav2vec2.modeling_wav2vec2._compute_mask_indices
diff --git a/src/transformers/models/whisper/configuration_whisper.py b/src/transformers/models/whisper/configuration_whisper.py
index 5af3242141804e..ec9c64df1bdb81 100644
--- a/src/transformers/models/whisper/configuration_whisper.py
+++ b/src/transformers/models/whisper/configuration_whisper.py
@@ -29,9 +29,9 @@
logger = logging.get_logger(__name__)
-WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import WHISPER_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
+
# fmt: off
NON_SPEECH_TOKENS = [
diff --git a/src/transformers/models/whisper/generation_whisper.py b/src/transformers/models/whisper/generation_whisper.py
index 0810707bd05108..8eca0c48b5dd6a 100644
--- a/src/transformers/models/whisper/generation_whisper.py
+++ b/src/transformers/models/whisper/generation_whisper.py
@@ -12,7 +12,6 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-import copy
import math
import warnings
import zlib
@@ -474,11 +473,8 @@ def generate(
"The input name `inputs` is deprecated. Please make sure to use `input_features` instead.",
FutureWarning,
)
- # 1. copy generation config
- if generation_config is None:
- generation_config = copy.deepcopy(self.generation_config)
- else:
- generation_config = copy.deepcopy(generation_config)
+ # 1. prepare generation config
+ generation_config, kwargs = self._prepare_generation_config(generation_config, **kwargs)
# 2. set global generate variables
input_stride = self.model.encoder.conv1.stride[0] * self.model.encoder.conv2.stride[0]
diff --git a/src/transformers/models/whisper/modeling_tf_whisper.py b/src/transformers/models/whisper/modeling_tf_whisper.py
index e5d59c00d3ed08..4d5dda71e8aaf3 100644
--- a/src/transformers/models/whisper/modeling_tf_whisper.py
+++ b/src/transformers/models/whisper/modeling_tf_whisper.py
@@ -52,10 +52,8 @@
_CONFIG_FOR_DOC = "WhisperConfig"
-TF_WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/whisper-base",
- # See all Whisper models at https://huggingface.co/models?filter=whisper
-]
+from ..deprecated._archive_maps import TF_WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/whisper/modeling_whisper.py b/src/transformers/models/whisper/modeling_whisper.py
index 45f2d9fc5ccca6..b85375a4098d76 100644
--- a/src/transformers/models/whisper/modeling_whisper.py
+++ b/src/transformers/models/whisper/modeling_whisper.py
@@ -59,10 +59,7 @@
_CHECKPOINT_FOR_DOC = "openai/whisper-tiny"
-WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "openai/whisper-base",
- # See all Whisper models at https://huggingface.co/models?filter=whisper
-]
+from ..deprecated._archive_maps import WHISPER_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
@@ -1864,7 +1861,7 @@ def forward(self, *args, **kwargs):
@add_start_docstrings(
"""
- Whisper decoder with with a language modeling head on top (linear layer with weights tied to the input embeddings).
+ Whisper decoder with a language modeling head on top (linear layer with weights tied to the input embeddings).
""",
WHISPER_START_DOCSTRING,
)
diff --git a/src/transformers/models/whisper/tokenization_whisper.py b/src/transformers/models/whisper/tokenization_whisper.py
index f853c60e260f50..25e80d477fda3b 100644
--- a/src/transformers/models/whisper/tokenization_whisper.py
+++ b/src/transformers/models/whisper/tokenization_whisper.py
@@ -34,15 +34,6 @@
"normalizer_file": "normalizer.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/vocab.json",
- },
- "merges_file": {"openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/merges_file.txt"},
- "normalizer_file": {
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/normalizer.json"
- },
-}
MAX_MODEL_INPUT_SIZES = {
"openai/whisper-base": 448,
@@ -257,8 +248,6 @@ class WhisperTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = MAX_MODEL_INPUT_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/whisper/tokenization_whisper_fast.py b/src/transformers/models/whisper/tokenization_whisper_fast.py
index dc5a3e0dc1f784..0463d521d5839c 100644
--- a/src/transformers/models/whisper/tokenization_whisper_fast.py
+++ b/src/transformers/models/whisper/tokenization_whisper_fast.py
@@ -39,54 +39,6 @@
"normalizer_file": "normalizer.json",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "openai/whisper-tiny": "https://huggingface.co/openai/whisper-tiny/resolve/main/vocab.json",
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/vocab.json",
- "openai/whisper-small": "https://huggingface.co/openai/whisper-small/resolve/main/vocab.json",
- "openai/whisper-medium": "https://huggingface.co/openai/whisper-medium/resolve/main/vocab.json",
- "openai/whisper-large": "https://huggingface.co/openai/whisper-large/resolve/main/vocab.json",
- "openai/whisper-tiny.en": "https://huggingface.co/openai/whisper-tiny.en/resolve/main/vocab.json",
- "openai/whisper-base.en": "https://huggingface.co/openai/whisper-base.en/resolve/main/vocab.json",
- "openai/whisper-small.en": "https://huggingface.co/openai/whisper-small.en/resolve/main/vocab.json",
- "openai/whisper-medium.en": "https://huggingface.co/openai/whisper-medium.en/resolve/main/vocab.json",
- },
- "merges_file": {
- "openai/whisper-tiny": "https://huggingface.co/openai/whisper-tiny/resolve/main/merges.txt",
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/merges.txt",
- "openai/whisper-small": "https://huggingface.co/openai/whisper-small/resolve/main/merges.txt",
- "openai/whisper-medium": "https://huggingface.co/openai/whisper-medium/resolve/main/merges.txt",
- "openai/whisper-large": "https://huggingface.co/openai/whisper-large/resolve/main/merges.txt",
- "openai/whisper-tiny.en": "https://huggingface.co/openai/whisper-tiny.en/resolve/main/merges.txt",
- "openai/whisper-base.en": "https://huggingface.co/openai/whisper-base.en/resolve/main/merges.txt",
- "openai/whisper-small.en": "https://huggingface.co/openai/whisper-small.en/resolve/main/merges.txt",
- "openai/whisper-medium.en": "https://huggingface.co/openai/whisper-medium.en/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "openai/whisper-tiny": "https://huggingface.co/openai/whisper-tiny/resolve/main/tokenizer.json",
- "openai/whisper-base": "https://huggingface.co/openai/whisper-base/resolve/main/tokenizer.json",
- "openai/whisper-small": "https://huggingface.co/openai/whisper-small/resolve/main/tokenizer.json",
- "openai/whisper-medium": "https://huggingface.co/openai/whisper-medium/resolve/main/tokenizer.json",
- "openai/whisper-large": "https://huggingface.co/openai/whisper-large/resolve/main/tokenizer.json",
- "openai/whisper-tiny.en": "https://huggingface.co/openai/whisper-tiny.en/resolve/main/tokenizer.json",
- "openai/whisper-base.en": "https://huggingface.co/openai/whisper-base.en/resolve/main/tokenizer.json",
- "openai/whisper-small.en": "https://huggingface.co/openai/whisper-small.en/resolve/main/tokenizer.json",
- "openai/whisper-medium.en": "https://huggingface.co/openai/whisper-medium.en/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "openai/whisper-tiny": 1500,
- "openai/whisper-base": 1500,
- "openai/whisper-small": 1500,
- "openai/whisper-medium": 1500,
- "openai/whisper-large": 1500,
- "openai/whisper-tiny.en": 1500,
- "openai/whisper-base.en": 1500,
- "openai/whisper-small.en": 1500,
- "openai/whisper-medium.en": 1500,
-}
-
class WhisperTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -128,8 +80,6 @@ class WhisperTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = WhisperTokenizer
diff --git a/src/transformers/models/x_clip/configuration_x_clip.py b/src/transformers/models/x_clip/configuration_x_clip.py
index c7e23ae3ba80cf..7795269b7e517a 100644
--- a/src/transformers/models/x_clip/configuration_x_clip.py
+++ b/src/transformers/models/x_clip/configuration_x_clip.py
@@ -23,9 +23,8 @@
logger = logging.get_logger(__name__)
-XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/xclip-base-patch32": "https://huggingface.co/microsoft/xclip-base-patch32/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XCLIPTextConfig(PretrainedConfig):
diff --git a/src/transformers/models/x_clip/modeling_x_clip.py b/src/transformers/models/x_clip/modeling_x_clip.py
index e341b9639d87f0..c9791fdfcc00df 100644
--- a/src/transformers/models/x_clip/modeling_x_clip.py
+++ b/src/transformers/models/x_clip/modeling_x_clip.py
@@ -41,10 +41,8 @@
_CHECKPOINT_FOR_DOC = "microsoft/xclip-base-patch32"
-XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/xclip-base-patch32",
- # See all X-CLIP models at https://huggingface.co/models?filter=x-clip
-]
+
+from ..deprecated._archive_maps import XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# contrastive loss function, adapted from
diff --git a/src/transformers/models/xglm/configuration_xglm.py b/src/transformers/models/xglm/configuration_xglm.py
index 9377bbce6f01ec..c67c67a4b29073 100644
--- a/src/transformers/models/xglm/configuration_xglm.py
+++ b/src/transformers/models/xglm/configuration_xglm.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-XGLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/xglm-564M": "https://huggingface.co/facebook/xglm-564M/resolve/main/config.json",
- # See all XGLM models at https://huggingface.co/models?filter=xglm
-}
+
+from ..deprecated._archive_maps import XGLM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XGLMConfig(PretrainedConfig):
diff --git a/src/transformers/models/xglm/modeling_tf_xglm.py b/src/transformers/models/xglm/modeling_tf_xglm.py
index 4157cc061695e9..e3003fdbc53ab6 100644
--- a/src/transformers/models/xglm/modeling_tf_xglm.py
+++ b/src/transformers/models/xglm/modeling_tf_xglm.py
@@ -55,10 +55,7 @@
_CONFIG_FOR_DOC = "XGLMConfig"
-TF_XGLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/xglm-564M",
- # See all XGLM models at https://huggingface.co/models?filter=xglm
-]
+from ..deprecated._archive_maps import TF_XGLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
LARGE_NEGATIVE = -1e8
diff --git a/src/transformers/models/xglm/modeling_xglm.py b/src/transformers/models/xglm/modeling_xglm.py
index ee98f2090c2c19..7ec48b6f9d2461 100755
--- a/src/transformers/models/xglm/modeling_xglm.py
+++ b/src/transformers/models/xglm/modeling_xglm.py
@@ -37,10 +37,8 @@
_CONFIG_FOR_DOC = "XGLMConfig"
-XGLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/xglm-564M",
- # See all XGLM models at https://huggingface.co/models?filter=xglm
-]
+from ..deprecated._archive_maps import XGLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
XGLM_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
diff --git a/src/transformers/models/xglm/tokenization_xglm.py b/src/transformers/models/xglm/tokenization_xglm.py
index a8c93dc3bc4a6b..818ca163da02af 100644
--- a/src/transformers/models/xglm/tokenization_xglm.py
+++ b/src/transformers/models/xglm/tokenization_xglm.py
@@ -29,16 +29,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/xglm-564M": "https://huggingface.co/facebook/xglm-564M/resolve/main/sentencepiece.bpe.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/xglm-564M": 2048,
-}
-
class XGLMTokenizer(PreTrainedTokenizer):
"""
@@ -105,8 +95,6 @@ class XGLMTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/xglm/tokenization_xglm_fast.py b/src/transformers/models/xglm/tokenization_xglm_fast.py
index 62db9dd694abd3..2f8b0480c82dff 100644
--- a/src/transformers/models/xglm/tokenization_xglm_fast.py
+++ b/src/transformers/models/xglm/tokenization_xglm_fast.py
@@ -32,19 +32,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "facebook/xglm-564M": "https://huggingface.co/facebook/xglm-564M/resolve/main/sentencepiece.bpe.model",
- },
- "tokenizer_file": {
- "facebook/xglm-564M": "https://huggingface.co/facebook/xglm-564M/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "facebook/xglm-564M": 2048,
-}
-
class XGLMTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -95,8 +82,6 @@ class XGLMTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = XGLMTokenizer
diff --git a/src/transformers/models/xlm/configuration_xlm.py b/src/transformers/models/xlm/configuration_xlm.py
index 2992a3ab322d63..3b1dadd5657e20 100644
--- a/src/transformers/models/xlm/configuration_xlm.py
+++ b/src/transformers/models/xlm/configuration_xlm.py
@@ -23,18 +23,8 @@
logger = logging.get_logger(__name__)
-XLM_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "FacebookAI/xlm-mlm-en-2048": "https://huggingface.co/FacebookAI/xlm-mlm-en-2048/resolve/main/config.json",
- "FacebookAI/xlm-mlm-ende-1024": "https://huggingface.co/FacebookAI/xlm-mlm-ende-1024/resolve/main/config.json",
- "FacebookAI/xlm-mlm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enfr-1024/resolve/main/config.json",
- "FacebookAI/xlm-mlm-enro-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enro-1024/resolve/main/config.json",
- "FacebookAI/xlm-mlm-tlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-tlm-xnli15-1024/resolve/main/config.json",
- "FacebookAI/xlm-mlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-xnli15-1024/resolve/main/config.json",
- "FacebookAI/xlm-clm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-clm-enfr-1024/resolve/main/config.json",
- "FacebookAI/xlm-clm-ende-1024": "https://huggingface.co/FacebookAI/xlm-clm-ende-1024/resolve/main/config.json",
- "FacebookAI/xlm-mlm-17-1280": "https://huggingface.co/FacebookAI/xlm-mlm-17-1280/resolve/main/config.json",
- "FacebookAI/xlm-mlm-100-1280": "https://huggingface.co/FacebookAI/xlm-mlm-100-1280/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import XLM_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XLMConfig(PretrainedConfig):
diff --git a/src/transformers/models/xlm/modeling_tf_xlm.py b/src/transformers/models/xlm/modeling_tf_xlm.py
index 173f1d0acdb03d..45447a4236e118 100644
--- a/src/transformers/models/xlm/modeling_tf_xlm.py
+++ b/src/transformers/models/xlm/modeling_tf_xlm.py
@@ -66,19 +66,8 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/xlm-mlm-en-2048"
_CONFIG_FOR_DOC = "XLMConfig"
-TF_XLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/xlm-mlm-en-2048",
- "FacebookAI/xlm-mlm-ende-1024",
- "FacebookAI/xlm-mlm-enfr-1024",
- "FacebookAI/xlm-mlm-enro-1024",
- "FacebookAI/xlm-mlm-tlm-xnli15-1024",
- "FacebookAI/xlm-mlm-xnli15-1024",
- "FacebookAI/xlm-clm-enfr-1024",
- "FacebookAI/xlm-clm-ende-1024",
- "FacebookAI/xlm-mlm-17-1280",
- "FacebookAI/xlm-mlm-100-1280",
- # See all XLM models at https://huggingface.co/models?filter=xlm
-]
+
+from ..deprecated._archive_maps import TF_XLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def create_sinusoidal_embeddings(n_pos, dim, out):
diff --git a/src/transformers/models/xlm/modeling_xlm.py b/src/transformers/models/xlm/modeling_xlm.py
index de07829974d747..aca93ffb6a30b2 100755
--- a/src/transformers/models/xlm/modeling_xlm.py
+++ b/src/transformers/models/xlm/modeling_xlm.py
@@ -53,27 +53,16 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/xlm-mlm-en-2048"
_CONFIG_FOR_DOC = "XLMConfig"
-XLM_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/xlm-mlm-en-2048",
- "FacebookAI/xlm-mlm-ende-1024",
- "FacebookAI/xlm-mlm-enfr-1024",
- "FacebookAI/xlm-mlm-enro-1024",
- "FacebookAI/xlm-mlm-tlm-xnli15-1024",
- "FacebookAI/xlm-mlm-xnli15-1024",
- "FacebookAI/xlm-clm-enfr-1024",
- "FacebookAI/xlm-clm-ende-1024",
- "FacebookAI/xlm-mlm-17-1280",
- "FacebookAI/xlm-mlm-100-1280",
- # See all XLM models at https://huggingface.co/models?filter=xlm
-]
+
+from ..deprecated._archive_maps import XLM_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def create_sinusoidal_embeddings(n_pos, dim, out):
position_enc = np.array([[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)] for pos in range(n_pos)])
+ out.requires_grad = False
out[:, 0::2] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
out[:, 1::2] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))
out.detach_()
- out.requires_grad = False
def get_masks(slen, lengths, causal, padding_mask=None):
@@ -256,6 +245,10 @@ def _init_weights(self, module):
if isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
+ if isinstance(module, XLMModel) and self.config.sinusoidal_embeddings:
+ create_sinusoidal_embeddings(
+ self.config.max_position_embeddings, self.config.emb_dim, out=module.position_embeddings.weight
+ )
@dataclass
@@ -425,8 +418,6 @@ def __init__(self, config):
# embeddings
self.position_embeddings = nn.Embedding(config.max_position_embeddings, self.dim)
- if config.sinusoidal_embeddings:
- create_sinusoidal_embeddings(config.max_position_embeddings, self.dim, out=self.position_embeddings.weight)
if config.n_langs > 1 and config.use_lang_emb:
self.lang_embeddings = nn.Embedding(self.n_langs, self.dim)
self.embeddings = nn.Embedding(self.n_words, self.dim, padding_idx=self.pad_index)
diff --git a/src/transformers/models/xlm/tokenization_xlm.py b/src/transformers/models/xlm/tokenization_xlm.py
index a99b5cb73c9e71..b39e4c2708c791 100644
--- a/src/transformers/models/xlm/tokenization_xlm.py
+++ b/src/transformers/models/xlm/tokenization_xlm.py
@@ -33,397 +33,6 @@
"merges_file": "merges.txt",
}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "FacebookAI/xlm-mlm-en-2048": "https://huggingface.co/FacebookAI/xlm-mlm-en-2048/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-ende-1024": "https://huggingface.co/FacebookAI/xlm-mlm-ende-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enfr-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-enro-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enro-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-tlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-tlm-xnli15-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-xnli15-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-clm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-clm-enfr-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-clm-ende-1024": "https://huggingface.co/FacebookAI/xlm-clm-ende-1024/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-17-1280": "https://huggingface.co/FacebookAI/xlm-mlm-17-1280/resolve/main/vocab.json",
- "FacebookAI/xlm-mlm-100-1280": "https://huggingface.co/FacebookAI/xlm-mlm-100-1280/resolve/main/vocab.json",
- },
- "merges_file": {
- "FacebookAI/xlm-mlm-en-2048": "https://huggingface.co/FacebookAI/xlm-mlm-en-2048/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-ende-1024": "https://huggingface.co/FacebookAI/xlm-mlm-ende-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enfr-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-enro-1024": "https://huggingface.co/FacebookAI/xlm-mlm-enro-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-tlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-tlm-xnli15-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-xnli15-1024": "https://huggingface.co/FacebookAI/xlm-mlm-xnli15-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-clm-enfr-1024": "https://huggingface.co/FacebookAI/xlm-clm-enfr-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-clm-ende-1024": "https://huggingface.co/FacebookAI/xlm-clm-ende-1024/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-17-1280": "https://huggingface.co/FacebookAI/xlm-mlm-17-1280/resolve/main/merges.txt",
- "FacebookAI/xlm-mlm-100-1280": "https://huggingface.co/FacebookAI/xlm-mlm-100-1280/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "FacebookAI/xlm-mlm-en-2048": 512,
- "FacebookAI/xlm-mlm-ende-1024": 512,
- "FacebookAI/xlm-mlm-enfr-1024": 512,
- "FacebookAI/xlm-mlm-enro-1024": 512,
- "FacebookAI/xlm-mlm-tlm-xnli15-1024": 512,
- "FacebookAI/xlm-mlm-xnli15-1024": 512,
- "FacebookAI/xlm-clm-enfr-1024": 512,
- "FacebookAI/xlm-clm-ende-1024": 512,
- "FacebookAI/xlm-mlm-17-1280": 512,
- "FacebookAI/xlm-mlm-100-1280": 512,
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "FacebookAI/xlm-mlm-en-2048": {"do_lowercase_and_remove_accent": True},
- "FacebookAI/xlm-mlm-ende-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {0: "de", 1: "en"},
- "lang2id": {"de": 0, "en": 1},
- },
- "FacebookAI/xlm-mlm-enfr-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {0: "en", 1: "fr"},
- "lang2id": {"en": 0, "fr": 1},
- },
- "FacebookAI/xlm-mlm-enro-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {0: "en", 1: "ro"},
- "lang2id": {"en": 0, "ro": 1},
- },
- "FacebookAI/xlm-mlm-tlm-xnli15-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {
- 0: "ar",
- 1: "bg",
- 2: "de",
- 3: "el",
- 4: "en",
- 5: "es",
- 6: "fr",
- 7: "hi",
- 8: "ru",
- 9: "sw",
- 10: "th",
- 11: "tr",
- 12: "ur",
- 13: "vi",
- 14: "zh",
- },
- "lang2id": {
- "ar": 0,
- "bg": 1,
- "de": 2,
- "el": 3,
- "en": 4,
- "es": 5,
- "fr": 6,
- "hi": 7,
- "ru": 8,
- "sw": 9,
- "th": 10,
- "tr": 11,
- "ur": 12,
- "vi": 13,
- "zh": 14,
- },
- },
- "FacebookAI/xlm-mlm-xnli15-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {
- 0: "ar",
- 1: "bg",
- 2: "de",
- 3: "el",
- 4: "en",
- 5: "es",
- 6: "fr",
- 7: "hi",
- 8: "ru",
- 9: "sw",
- 10: "th",
- 11: "tr",
- 12: "ur",
- 13: "vi",
- 14: "zh",
- },
- "lang2id": {
- "ar": 0,
- "bg": 1,
- "de": 2,
- "el": 3,
- "en": 4,
- "es": 5,
- "fr": 6,
- "hi": 7,
- "ru": 8,
- "sw": 9,
- "th": 10,
- "tr": 11,
- "ur": 12,
- "vi": 13,
- "zh": 14,
- },
- },
- "FacebookAI/xlm-clm-enfr-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {0: "en", 1: "fr"},
- "lang2id": {"en": 0, "fr": 1},
- },
- "FacebookAI/xlm-clm-ende-1024": {
- "do_lowercase_and_remove_accent": True,
- "id2lang": {0: "de", 1: "en"},
- "lang2id": {"de": 0, "en": 1},
- },
- "FacebookAI/xlm-mlm-17-1280": {
- "do_lowercase_and_remove_accent": False,
- "id2lang": {
- 0: "ar",
- 1: "de",
- 2: "en",
- 3: "es",
- 4: "fr",
- 5: "hi",
- 6: "it",
- 7: "ja",
- 8: "ko",
- 9: "nl",
- 10: "pl",
- 11: "pt",
- 12: "ru",
- 13: "sv",
- 14: "tr",
- 15: "vi",
- 16: "zh",
- },
- "lang2id": {
- "ar": 0,
- "de": 1,
- "en": 2,
- "es": 3,
- "fr": 4,
- "hi": 5,
- "it": 6,
- "ja": 7,
- "ko": 8,
- "nl": 9,
- "pl": 10,
- "pt": 11,
- "ru": 12,
- "sv": 13,
- "tr": 14,
- "vi": 15,
- "zh": 16,
- },
- },
- "FacebookAI/xlm-mlm-100-1280": {
- "do_lowercase_and_remove_accent": False,
- "id2lang": {
- 0: "af",
- 1: "als",
- 2: "am",
- 3: "an",
- 4: "ang",
- 5: "ar",
- 6: "arz",
- 7: "ast",
- 8: "az",
- 9: "bar",
- 10: "be",
- 11: "bg",
- 12: "bn",
- 13: "br",
- 14: "bs",
- 15: "ca",
- 16: "ceb",
- 17: "ckb",
- 18: "cs",
- 19: "cy",
- 20: "da",
- 21: "de",
- 22: "el",
- 23: "en",
- 24: "eo",
- 25: "es",
- 26: "et",
- 27: "eu",
- 28: "fa",
- 29: "fi",
- 30: "fr",
- 31: "fy",
- 32: "ga",
- 33: "gan",
- 34: "gl",
- 35: "gu",
- 36: "he",
- 37: "hi",
- 38: "hr",
- 39: "hu",
- 40: "hy",
- 41: "ia",
- 42: "id",
- 43: "is",
- 44: "it",
- 45: "ja",
- 46: "jv",
- 47: "ka",
- 48: "kk",
- 49: "kn",
- 50: "ko",
- 51: "ku",
- 52: "la",
- 53: "lb",
- 54: "lt",
- 55: "lv",
- 56: "mk",
- 57: "ml",
- 58: "mn",
- 59: "mr",
- 60: "ms",
- 61: "my",
- 62: "nds",
- 63: "ne",
- 64: "nl",
- 65: "nn",
- 66: "no",
- 67: "oc",
- 68: "pl",
- 69: "pt",
- 70: "ro",
- 71: "ru",
- 72: "scn",
- 73: "sco",
- 74: "sh",
- 75: "si",
- 76: "simple",
- 77: "sk",
- 78: "sl",
- 79: "sq",
- 80: "sr",
- 81: "sv",
- 82: "sw",
- 83: "ta",
- 84: "te",
- 85: "th",
- 86: "tl",
- 87: "tr",
- 88: "tt",
- 89: "uk",
- 90: "ur",
- 91: "uz",
- 92: "vi",
- 93: "war",
- 94: "wuu",
- 95: "yi",
- 96: "zh",
- 97: "zh_classical",
- 98: "zh_min_nan",
- 99: "zh_yue",
- },
- "lang2id": {
- "af": 0,
- "als": 1,
- "am": 2,
- "an": 3,
- "ang": 4,
- "ar": 5,
- "arz": 6,
- "ast": 7,
- "az": 8,
- "bar": 9,
- "be": 10,
- "bg": 11,
- "bn": 12,
- "br": 13,
- "bs": 14,
- "ca": 15,
- "ceb": 16,
- "ckb": 17,
- "cs": 18,
- "cy": 19,
- "da": 20,
- "de": 21,
- "el": 22,
- "en": 23,
- "eo": 24,
- "es": 25,
- "et": 26,
- "eu": 27,
- "fa": 28,
- "fi": 29,
- "fr": 30,
- "fy": 31,
- "ga": 32,
- "gan": 33,
- "gl": 34,
- "gu": 35,
- "he": 36,
- "hi": 37,
- "hr": 38,
- "hu": 39,
- "hy": 40,
- "ia": 41,
- "id": 42,
- "is": 43,
- "it": 44,
- "ja": 45,
- "jv": 46,
- "ka": 47,
- "kk": 48,
- "kn": 49,
- "ko": 50,
- "ku": 51,
- "la": 52,
- "lb": 53,
- "lt": 54,
- "lv": 55,
- "mk": 56,
- "ml": 57,
- "mn": 58,
- "mr": 59,
- "ms": 60,
- "my": 61,
- "nds": 62,
- "ne": 63,
- "nl": 64,
- "nn": 65,
- "no": 66,
- "oc": 67,
- "pl": 68,
- "pt": 69,
- "ro": 70,
- "ru": 71,
- "scn": 72,
- "sco": 73,
- "sh": 74,
- "si": 75,
- "simple": 76,
- "sk": 77,
- "sl": 78,
- "sq": 79,
- "sr": 80,
- "sv": 81,
- "sw": 82,
- "ta": 83,
- "te": 84,
- "th": 85,
- "tl": 86,
- "tr": 87,
- "tt": 88,
- "uk": 89,
- "ur": 90,
- "uz": 91,
- "vi": 92,
- "war": 93,
- "wuu": 94,
- "yi": 95,
- "zh": 96,
- "zh_classical": 97,
- "zh_min_nan": 98,
- "zh_yue": 99,
- },
- },
-}
-
def get_pairs(word):
"""
@@ -582,9 +191,6 @@ class XLMTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
diff --git a/src/transformers/models/xlm_prophetnet/configuration_xlm_prophetnet.py b/src/transformers/models/xlm_prophetnet/configuration_xlm_prophetnet.py
index 88ca83a73226ce..f1a903c227bf59 100644
--- a/src/transformers/models/xlm_prophetnet/configuration_xlm_prophetnet.py
+++ b/src/transformers/models/xlm_prophetnet/configuration_xlm_prophetnet.py
@@ -23,11 +23,8 @@
logger = logging.get_logger(__name__)
-XLM_PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "microsoft/xprophetnet-large-wiki100-cased": (
- "https://huggingface.co/microsoft/xprophetnet-large-wiki100-cased/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import XLM_PROPHETNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XLMProphetNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py b/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py
index e705b95b177877..53b8a1fc20cbb5 100644
--- a/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py
+++ b/src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py
@@ -44,10 +44,9 @@
_CONFIG_FOR_DOC = "XLMProphetNetConfig"
-XLM_PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "microsoft/xprophetnet-large-wiki100-cased",
- # See all XLMProphetNet models at https://huggingface.co/models?filter=xprophetnet
-]
+
+from ..deprecated._archive_maps import XLM_PROPHETNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
# Copied from src.transformers.models.prophetnet.modeling_prophetnet.PROPHETNET_START_DOCSTRING with ProphetNetConfig->XLMProphetNetConfig
XLM_PROPHETNET_START_DOCSTRING = r"""
diff --git a/src/transformers/models/xlm_prophetnet/tokenization_xlm_prophetnet.py b/src/transformers/models/xlm_prophetnet/tokenization_xlm_prophetnet.py
index c024d5d16dc04a..fa65fa5cbfbaf2 100644
--- a/src/transformers/models/xlm_prophetnet/tokenization_xlm_prophetnet.py
+++ b/src/transformers/models/xlm_prophetnet/tokenization_xlm_prophetnet.py
@@ -28,22 +28,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "prophetnet.tokenizer"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "microsoft/xprophetnet-large-wiki100-cased": (
- "https://huggingface.co/microsoft/xprophetnet-large-wiki100-cased/resolve/main/prophetnet.tokenizer"
- ),
- }
-}
-
-PRETRAINED_INIT_CONFIGURATION = {
- "microsoft/xprophetnet-large-wiki100-cased": {"do_lower_case": False},
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "microsoft/xprophetnet-large-wiki100-cased": 512,
-}
-
def load_vocab(vocab_file):
"""Loads a vocabulary file into a dictionary."""
@@ -124,8 +108,6 @@ class XLMProphetNetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py b/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
index 65c536ba437346..3da0fbecd609fa 100644
--- a/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
@@ -24,22 +24,8 @@
logger = logging.get_logger(__name__)
-XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "FacebookAI/xlm-roberta-base": "https://huggingface.co/FacebookAI/xlm-roberta-base/resolve/main/config.json",
- "FacebookAI/xlm-roberta-large": "https://huggingface.co/FacebookAI/xlm-roberta-large/resolve/main/config.json",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-dutch/resolve/main/config.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-spanish/resolve/main/config.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-english/resolve/main/config.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-german/resolve/main/config.json"
- ),
-}
+
+from ..deprecated._archive_maps import XLM_ROBERTA_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XLMRobertaConfig(PretrainedConfig):
diff --git a/src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py b/src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py
index 0017be6bd8c145..2caffc0b905f7f 100644
--- a/src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py
@@ -51,11 +51,8 @@
remat = nn_partitioning.remat
-FLAX_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/xlm-roberta-base",
- "FacebookAI/xlm-roberta-large",
- # See all XLM-RoBERTa models at https://huggingface.co/models?filter=xlm-roberta
-]
+
+from ..deprecated._archive_maps import FLAX_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_flax_roberta.create_position_ids_from_input_ids
diff --git a/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py b/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
index dcf1b018b2af66..3b0efe6bd700b7 100644
--- a/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
@@ -67,13 +67,9 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/xlm-roberta-base"
_CONFIG_FOR_DOC = "XLMRobertaConfig"
-TF_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/xlm-roberta-base",
- "FacebookAI/xlm-roberta-large",
- "joeddav/xlm-roberta-large-xnli",
- "cardiffnlp/twitter-xlm-roberta-base-sentiment",
- # See all XLM-RoBERTa models at https://huggingface.co/models?filter=xlm-roberta
-]
+
+from ..deprecated._archive_maps import TF_XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
XLM_ROBERTA_START_DOCSTRING = r"""
diff --git a/src/transformers/models/xlm_roberta/modeling_xlm_roberta.py b/src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
index 8abd77b8c30215..0d829aaee63582 100644
--- a/src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
@@ -51,15 +51,8 @@
_CHECKPOINT_FOR_DOC = "FacebookAI/xlm-roberta-base"
_CONFIG_FOR_DOC = "XLMRobertaConfig"
-XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "FacebookAI/xlm-roberta-base",
- "FacebookAI/xlm-roberta-large",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish",
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english",
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german",
- # See all XLM-RoBERTa models at https://huggingface.co/models?filter=xlm-roberta
-]
+
+from ..deprecated._archive_maps import XLM_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->XLMRoberta
diff --git a/src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py b/src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
index 3f87bd9b0dd9fa..20300a19ceeb7d 100644
--- a/src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
+++ b/src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
@@ -31,34 +31,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "FacebookAI/xlm-roberta-base": "https://huggingface.co/FacebookAI/xlm-roberta-base/resolve/main/sentencepiece.bpe.model",
- "FacebookAI/xlm-roberta-large": "https://huggingface.co/FacebookAI/xlm-roberta-large/resolve/main/sentencepiece.bpe.model",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-dutch/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-spanish/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-english/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-german/resolve/main/sentencepiece.bpe.model"
- ),
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "FacebookAI/xlm-roberta-base": 512,
- "FacebookAI/xlm-roberta-large": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": 512,
-}
-
class XLMRobertaTokenizer(PreTrainedTokenizer):
"""
@@ -128,8 +100,6 @@ class XLMRobertaTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/src/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py b/src/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py
index 8f2c1e02a0a37e..f32e71515498f7 100644
--- a/src/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py
+++ b/src/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py
@@ -34,50 +34,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "sentencepiece.bpe.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "FacebookAI/xlm-roberta-base": "https://huggingface.co/FacebookAI/xlm-roberta-base/resolve/main/sentencepiece.bpe.model",
- "FacebookAI/xlm-roberta-large": "https://huggingface.co/FacebookAI/xlm-roberta-large/resolve/main/sentencepiece.bpe.model",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-dutch/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-spanish/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-english/resolve/main/sentencepiece.bpe.model"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-german/resolve/main/sentencepiece.bpe.model"
- ),
- },
- "tokenizer_file": {
- "FacebookAI/xlm-roberta-base": "https://huggingface.co/FacebookAI/xlm-roberta-base/resolve/main/tokenizer.json",
- "FacebookAI/xlm-roberta-large": "https://huggingface.co/FacebookAI/xlm-roberta-large/resolve/main/tokenizer.json",
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-dutch/resolve/main/tokenizer.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll02-spanish/resolve/main/tokenizer.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-english/resolve/main/tokenizer.json"
- ),
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": (
- "https://huggingface.co/FacebookAI/xlm-roberta-large-finetuned-conll03-german/resolve/main/tokenizer.json"
- ),
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "FacebookAI/xlm-roberta-base": 512,
- "FacebookAI/xlm-roberta-large": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll02-dutch": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll02-spanish": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll03-english": 512,
- "FacebookAI/xlm-roberta-large-finetuned-conll03-german": 512,
-}
-
class XLMRobertaTokenizerFast(PreTrainedTokenizerFast):
"""
@@ -131,8 +87,6 @@ class XLMRobertaTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
slow_tokenizer_class = XLMRobertaTokenizer
diff --git a/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
index acb9c630970975..23deeea7435e7f 100644
--- a/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
@@ -24,11 +24,8 @@
logger = logging.get_logger(__name__)
-XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/xlm-roberta-xl": "https://huggingface.co/facebook/xlm-roberta-xl/resolve/main/config.json",
- "facebook/xlm-roberta-xxl": "https://huggingface.co/facebook/xlm-roberta-xxl/resolve/main/config.json",
- # See all XLM-RoBERTa-XL models at https://huggingface.co/models?filter=xlm-roberta-xl
-}
+
+from ..deprecated._archive_maps import XLM_ROBERTA_XL_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XLMRobertaXLConfig(PretrainedConfig):
diff --git a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
index 2799752ca4bdd9..1c17652dfa0cb4 100644
--- a/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+++ b/src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
@@ -50,11 +50,8 @@
_CHECKPOINT_FOR_DOC = "facebook/xlm-roberta-xl"
_CONFIG_FOR_DOC = "XLMRobertaXLConfig"
-XLM_ROBERTA_XL_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/xlm-roberta-xl",
- "facebook/xlm-roberta-xxl",
- # See all RoBERTa models at https://huggingface.co/models?filter=xlm-roberta-xl
-]
+
+from ..deprecated._archive_maps import XLM_ROBERTA_XL_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class XLMRobertaXLEmbeddings(nn.Module):
diff --git a/src/transformers/models/xlnet/configuration_xlnet.py b/src/transformers/models/xlnet/configuration_xlnet.py
index 8528bb06394d25..f81c456b61df69 100644
--- a/src/transformers/models/xlnet/configuration_xlnet.py
+++ b/src/transformers/models/xlnet/configuration_xlnet.py
@@ -23,10 +23,8 @@
logger = logging.get_logger(__name__)
-XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "xlnet/xlnet-base-cased": "https://huggingface.co/xlnet/xlnet-base-cased/resolve/main/config.json",
- "xlnet/xlnet-large-cased": "https://huggingface.co/xlnet/xlnet-large-cased/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import XLNET_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XLNetConfig(PretrainedConfig):
diff --git a/src/transformers/models/xlnet/modeling_tf_xlnet.py b/src/transformers/models/xlnet/modeling_tf_xlnet.py
index 598af1b707a5e9..188f5e39a2fba1 100644
--- a/src/transformers/models/xlnet/modeling_tf_xlnet.py
+++ b/src/transformers/models/xlnet/modeling_tf_xlnet.py
@@ -60,11 +60,8 @@
_CHECKPOINT_FOR_DOC = "xlnet/xlnet-base-cased"
_CONFIG_FOR_DOC = "XLNetConfig"
-TF_XLNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "xlnet/xlnet-base-cased",
- "xlnet/xlnet-large-cased",
- # See all XLNet models at https://huggingface.co/models?filter=xlnet
-]
+
+from ..deprecated._archive_maps import TF_XLNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
class TFXLNetRelativeAttention(keras.layers.Layer):
diff --git a/src/transformers/models/xlnet/modeling_xlnet.py b/src/transformers/models/xlnet/modeling_xlnet.py
index 6def87ef07b4e3..78ca545751a4af 100755
--- a/src/transformers/models/xlnet/modeling_xlnet.py
+++ b/src/transformers/models/xlnet/modeling_xlnet.py
@@ -43,11 +43,8 @@
_CHECKPOINT_FOR_DOC = "xlnet/xlnet-base-cased"
_CONFIG_FOR_DOC = "XLNetConfig"
-XLNET_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "xlnet/xlnet-base-cased",
- "xlnet/xlnet-large-cased",
- # See all XLNet models at https://huggingface.co/models?filter=xlnet
-]
+
+from ..deprecated._archive_maps import XLNET_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
def build_tf_xlnet_to_pytorch_map(model, config, tf_weights=None):
diff --git a/src/transformers/models/xlnet/tokenization_xlnet.py b/src/transformers/models/xlnet/tokenization_xlnet.py
index 808a7ff5bfc07f..8d87f34ba2462e 100644
--- a/src/transformers/models/xlnet/tokenization_xlnet.py
+++ b/src/transformers/models/xlnet/tokenization_xlnet.py
@@ -30,17 +30,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "xlnet/xlnet-base-cased": "https://huggingface.co/xlnet/xlnet-base-cased/resolve/main/spiece.model",
- "xlnet/xlnet-large-cased": "https://huggingface.co/xlnet/xlnet-large-cased/resolve/main/spiece.model",
- }
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "xlnet/xlnet-base-cased": None,
- "xlnet/xlnet-large-cased": None,
-}
# Segments (not really needed)
SEG_ID_A = 0
@@ -126,8 +115,6 @@ class XLNetTokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
padding_side = "left"
def __init__(
diff --git a/src/transformers/models/xlnet/tokenization_xlnet_fast.py b/src/transformers/models/xlnet/tokenization_xlnet_fast.py
index c43016a1a77799..d77307e7a3dfba 100644
--- a/src/transformers/models/xlnet/tokenization_xlnet_fast.py
+++ b/src/transformers/models/xlnet/tokenization_xlnet_fast.py
@@ -34,21 +34,6 @@
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "xlnet/xlnet-base-cased": "https://huggingface.co/xlnet/xlnet-base-cased/resolve/main/spiece.model",
- "xlnet/xlnet-large-cased": "https://huggingface.co/xlnet/xlnet-large-cased/resolve/main/spiece.model",
- },
- "tokenizer_file": {
- "xlnet/xlnet-base-cased": "https://huggingface.co/xlnet/xlnet-base-cased/resolve/main/tokenizer.json",
- "xlnet/xlnet-large-cased": "https://huggingface.co/xlnet/xlnet-large-cased/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "xlnet/xlnet-base-cased": None,
- "xlnet/xlnet-large-cased": None,
-}
SPIECE_UNDERLINE = "▁"
@@ -122,8 +107,6 @@ class XLNetTokenizerFast(PreTrainedTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
padding_side = "left"
slow_tokenizer_class = XLNetTokenizer
diff --git a/src/transformers/models/xmod/configuration_xmod.py b/src/transformers/models/xmod/configuration_xmod.py
index abf7a3275c5415..21eb9ba2ea2f7d 100644
--- a/src/transformers/models/xmod/configuration_xmod.py
+++ b/src/transformers/models/xmod/configuration_xmod.py
@@ -24,17 +24,8 @@
logger = logging.get_logger(__name__)
-XMOD_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "facebook/xmod-base": "https://huggingface.co/facebook/xmod-base/resolve/main/config.json",
- "facebook/xmod-large-prenorm": "https://huggingface.co/facebook/xmod-large-prenorm/resolve/main/config.json",
- "facebook/xmod-base-13-125k": "https://huggingface.co/facebook/xmod-base-13-125k/resolve/main/config.json",
- "facebook/xmod-base-30-125k": "https://huggingface.co/facebook/xmod-base-30-125k/resolve/main/config.json",
- "facebook/xmod-base-30-195k": "https://huggingface.co/facebook/xmod-base-30-195k/resolve/main/config.json",
- "facebook/xmod-base-60-125k": "https://huggingface.co/facebook/xmod-base-60-125k/resolve/main/config.json",
- "facebook/xmod-base-60-265k": "https://huggingface.co/facebook/xmod-base-60-265k/resolve/main/config.json",
- "facebook/xmod-base-75-125k": "https://huggingface.co/facebook/xmod-base-75-125k/resolve/main/config.json",
- "facebook/xmod-base-75-269k": "https://huggingface.co/facebook/xmod-base-75-269k/resolve/main/config.json",
-}
+
+from ..deprecated._archive_maps import XMOD_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class XmodConfig(PretrainedConfig):
diff --git a/src/transformers/models/xmod/modeling_xmod.py b/src/transformers/models/xmod/modeling_xmod.py
index ba5ba6b7271b23..2bf76a40d46974 100644
--- a/src/transformers/models/xmod/modeling_xmod.py
+++ b/src/transformers/models/xmod/modeling_xmod.py
@@ -41,18 +41,8 @@
logger = logging.get_logger(__name__)
-XMOD_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "facebook/xmod-base",
- "facebook/xmod-large-prenorm",
- "facebook/xmod-base-13-125k",
- "facebook/xmod-base-30-125k",
- "facebook/xmod-base-30-195k",
- "facebook/xmod-base-60-125k",
- "facebook/xmod-base-60-265k",
- "facebook/xmod-base-75-125k",
- "facebook/xmod-base-75-269k",
- # See all X-MOD models at https://huggingface.co/models?filter=xmod
-]
+
+from ..deprecated._archive_maps import XMOD_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->Xmod
diff --git a/src/transformers/models/yolos/configuration_yolos.py b/src/transformers/models/yolos/configuration_yolos.py
index 9398d29e0417f7..098210f1a732e2 100644
--- a/src/transformers/models/yolos/configuration_yolos.py
+++ b/src/transformers/models/yolos/configuration_yolos.py
@@ -26,10 +26,8 @@
logger = logging.get_logger(__name__)
-YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "hustvl/yolos-small": "https://huggingface.co/hustvl/yolos-small/resolve/main/config.json",
- # See all YOLOS models at https://huggingface.co/models?filter=yolos
-}
+
+from ..deprecated._archive_maps import YOLOS_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class YolosConfig(PretrainedConfig):
diff --git a/src/transformers/models/yolos/modeling_yolos.py b/src/transformers/models/yolos/modeling_yolos.py
index 86ab375cdf8346..864be38a7d786b 100755
--- a/src/transformers/models/yolos/modeling_yolos.py
+++ b/src/transformers/models/yolos/modeling_yolos.py
@@ -63,10 +63,7 @@
_EXPECTED_OUTPUT_SHAPE = [1, 3401, 384]
-YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "hustvl/yolos-small",
- # See all YOLOS models at https://huggingface.co/models?filter=yolos
-]
+from ..deprecated._archive_maps import YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
@dataclass
diff --git a/src/transformers/models/yoso/configuration_yoso.py b/src/transformers/models/yoso/configuration_yoso.py
index 02d7f44d3cf2a0..fe2d4d4403780a 100644
--- a/src/transformers/models/yoso/configuration_yoso.py
+++ b/src/transformers/models/yoso/configuration_yoso.py
@@ -20,10 +20,8 @@
logger = logging.get_logger(__name__)
-YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "uw-madison/yoso-4096": "https://huggingface.co/uw-madison/yoso-4096/resolve/main/config.json",
- # See all YOSO models at https://huggingface.co/models?filter=yoso
-}
+
+from ..deprecated._archive_maps import YOSO_PRETRAINED_CONFIG_ARCHIVE_MAP # noqa: F401, E402
class YosoConfig(PretrainedConfig):
diff --git a/src/transformers/models/yoso/modeling_yoso.py b/src/transformers/models/yoso/modeling_yoso.py
index 41e34a6c66c42b..b1fed0acc468df 100644
--- a/src/transformers/models/yoso/modeling_yoso.py
+++ b/src/transformers/models/yoso/modeling_yoso.py
@@ -51,10 +51,9 @@
_CHECKPOINT_FOR_DOC = "uw-madison/yoso-4096"
_CONFIG_FOR_DOC = "YosoConfig"
-YOSO_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "uw-madison/yoso-4096",
- # See all YOSO models at https://huggingface.co/models?filter=yoso
-]
+
+from ..deprecated._archive_maps import YOSO_PRETRAINED_MODEL_ARCHIVE_LIST # noqa: F401, E402
+
lsh_cumulation = None
diff --git a/src/transformers/optimization.py b/src/transformers/optimization.py
index d0cadbf69f2717..ce9f9b78dcebe4 100644
--- a/src/transformers/optimization.py
+++ b/src/transformers/optimization.py
@@ -324,6 +324,69 @@ def get_inverse_sqrt_schedule(
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
+def _get_cosine_schedule_with_warmup_lr_lambda(
+ current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_cycles: float, min_lr_rate: float = 0.0
+):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1, num_warmup_steps))
+ progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
+ factor = 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
+ factor = factor * (1 - min_lr_rate) + min_lr_rate
+ return max(0, factor)
+
+
+def get_cosine_with_min_lr_schedule_with_warmup(
+ optimizer: Optimizer,
+ num_warmup_steps: int,
+ num_training_steps: int,
+ num_cycles: float = 0.5,
+ last_epoch: int = -1,
+ min_lr: float = None,
+ min_lr_rate: float = None,
+):
+ """
+ Create a schedule with a learning rate that decreases following the values of the cosine function between the
+ initial lr set in the optimizer to min_lr, after a warmup period during which it increases linearly between 0 and the
+ initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ num_training_steps (`int`):
+ The total number of training steps.
+ num_cycles (`float`, *optional*, defaults to 0.5):
+ The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0
+ following a half-cosine).
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+ min_lr (`float`, *optional*):
+ The minimum learning rate to reach after the cosine schedule.
+ min_lr_rate (`float`, *optional*):
+ The minimum learning rate as a ratio of the initial learning rate. If set, `min_lr` should not be set.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+
+ if min_lr is not None and min_lr_rate is not None:
+ raise ValueError("Only one of min_lr or min_lr_rate should be set")
+ elif min_lr is not None:
+ min_lr_rate = min_lr / optimizer.defaults["lr"]
+ elif min_lr_rate is None:
+ raise ValueError("One of min_lr or min_lr_rate should be set through the `lr_scheduler_kwargs`")
+
+ lr_lambda = partial(
+ _get_cosine_schedule_with_warmup_lr_lambda,
+ num_warmup_steps=num_warmup_steps,
+ num_training_steps=num_training_steps,
+ num_cycles=num_cycles,
+ min_lr_rate=min_lr_rate,
+ )
+ return LambdaLR(optimizer, lr_lambda, last_epoch)
+
+
TYPE_TO_SCHEDULER_FUNCTION = {
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
@@ -333,6 +396,7 @@ def get_inverse_sqrt_schedule(
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
SchedulerType.INVERSE_SQRT: get_inverse_sqrt_schedule,
SchedulerType.REDUCE_ON_PLATEAU: get_reduce_on_plateau_schedule,
+ SchedulerType.COSINE_WITH_MIN_LR: get_cosine_with_min_lr_schedule_with_warmup,
}
diff --git a/src/transformers/pipelines/base.py b/src/transformers/pipelines/base.py
index 023b168b831ddd..fa1f2fcf5dfa06 100644
--- a/src/transformers/pipelines/base.py
+++ b/src/transformers/pipelines/base.py
@@ -41,6 +41,7 @@
is_tf_available,
is_torch_available,
is_torch_cuda_available,
+ is_torch_mlu_available,
is_torch_npu_available,
is_torch_xpu_available,
logging,
@@ -851,6 +852,8 @@ def __init__(
self.device = torch.device(device)
elif device < 0:
self.device = torch.device("cpu")
+ elif is_torch_mlu_available():
+ self.device = torch.device(f"mlu:{device}")
elif is_torch_cuda_available():
self.device = torch.device(f"cuda:{device}")
elif is_torch_npu_available():
@@ -861,7 +864,7 @@ def __init__(
raise ValueError(f"{device} unrecognized or not available.")
else:
self.device = device if device is not None else -1
- self.torch_dtype = torch_dtype
+
self.binary_output = binary_output
# We shouldn't call `model.to()` for models loaded with accelerate
@@ -964,6 +967,13 @@ def predict(self, X):
"""
return self(X)
+ @property
+ def torch_dtype(self) -> Optional["torch.dtype"]:
+ """
+ Torch dtype of the model (if it's Pytorch model), `None` otherwise.
+ """
+ return getattr(self.model, "dtype", None)
+
@contextmanager
def device_placement(self):
"""
@@ -988,6 +998,9 @@ def device_placement(self):
if self.device.type == "cuda":
with torch.cuda.device(self.device):
yield
+ elif self.device.type == "mlu":
+ with torch.mlu.device(self.device):
+ yield
else:
yield
@@ -1019,8 +1032,6 @@ def _ensure_tensor_on_device(self, inputs, device):
elif isinstance(inputs, tuple):
return tuple([self._ensure_tensor_on_device(item, device) for item in inputs])
elif isinstance(inputs, torch.Tensor):
- if device == torch.device("cpu") and inputs.dtype in {torch.float16, torch.bfloat16}:
- inputs = inputs.float()
return inputs.to(device)
else:
return inputs
diff --git a/src/transformers/pipelines/video_classification.py b/src/transformers/pipelines/video_classification.py
index f8596ce14c714a..5702f23c5f6090 100644
--- a/src/transformers/pipelines/video_classification.py
+++ b/src/transformers/pipelines/video_classification.py
@@ -3,13 +3,19 @@
import requests
-from ..utils import add_end_docstrings, is_decord_available, is_torch_available, logging, requires_backends
+from ..utils import (
+ add_end_docstrings,
+ is_av_available,
+ is_torch_available,
+ logging,
+ requires_backends,
+)
from .base import Pipeline, build_pipeline_init_args
-if is_decord_available():
+if is_av_available():
+ import av
import numpy as np
- from decord import VideoReader
if is_torch_available():
@@ -33,7 +39,7 @@ class VideoClassificationPipeline(Pipeline):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
- requires_backends(self, "decord")
+ requires_backends(self, "av")
self.check_model_type(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES)
def _sanitize_parameters(self, top_k=None, num_frames=None, frame_sampling_rate=None):
@@ -90,14 +96,13 @@ def preprocess(self, video, num_frames=None, frame_sampling_rate=1):
if video.startswith("http://") or video.startswith("https://"):
video = BytesIO(requests.get(video).content)
- videoreader = VideoReader(video)
- videoreader.seek(0)
+ container = av.open(video)
start_idx = 0
end_idx = num_frames * frame_sampling_rate - 1
indices = np.linspace(start_idx, end_idx, num=num_frames, dtype=np.int64)
- video = videoreader.get_batch(indices).asnumpy()
+ video = read_video_pyav(container, indices)
video = list(video)
model_inputs = self.image_processor(video, return_tensors=self.framework)
@@ -120,3 +125,16 @@ def postprocess(self, model_outputs, top_k=5):
scores = scores.tolist()
ids = ids.tolist()
return [{"score": score, "label": self.model.config.id2label[_id]} for score, _id in zip(scores, ids)]
+
+
+def read_video_pyav(container, indices):
+ frames = []
+ container.seek(0)
+ start_index = indices[0]
+ end_index = indices[-1]
+ for i, frame in enumerate(container.decode(video=0)):
+ if i > end_index:
+ break
+ if i >= start_index and i in indices:
+ frames.append(frame)
+ return np.stack([x.to_ndarray(format="rgb24") for x in frames])
diff --git a/src/transformers/pipelines/zero_shot_audio_classification.py b/src/transformers/pipelines/zero_shot_audio_classification.py
index ca9f5e4fcfd495..c3606e3c2b83df 100644
--- a/src/transformers/pipelines/zero_shot_audio_classification.py
+++ b/src/transformers/pipelines/zero_shot_audio_classification.py
@@ -35,6 +35,12 @@ class ZeroShotAudioClassificationPipeline(Pipeline):
Zero shot audio classification pipeline using `ClapModel`. This pipeline predicts the class of an audio when you
provide an audio and a set of `candidate_labels`.
+
+
+ The default `hypothesis_template` is : `"This is a sound of {}."`. Make sure you update it for your usage.
+
+
+
Example:
```python
>>> from transformers import pipeline
diff --git a/src/transformers/safetensors_conversion.py b/src/transformers/safetensors_conversion.py
index 46de0e5755fdf0..5d3af9e8aad13a 100644
--- a/src/transformers/safetensors_conversion.py
+++ b/src/transformers/safetensors_conversion.py
@@ -84,24 +84,28 @@ def get_conversion_pr_reference(api: HfApi, model_id: str, **kwargs):
return sha
-def auto_conversion(pretrained_model_name_or_path: str, **cached_file_kwargs):
- api = HfApi(token=cached_file_kwargs.get("token"))
- sha = get_conversion_pr_reference(api, pretrained_model_name_or_path, **cached_file_kwargs)
-
- if sha is None:
- return None, None
- cached_file_kwargs["revision"] = sha
- del cached_file_kwargs["_commit_hash"]
-
- # This is an additional HEAD call that could be removed if we could infer sharded/non-sharded from the PR
- # description.
- sharded = api.file_exists(
- pretrained_model_name_or_path,
- "model.safetensors.index.json",
- revision=sha,
- token=cached_file_kwargs.get("token"),
- )
- filename = "model.safetensors.index.json" if sharded else "model.safetensors"
-
- resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
- return resolved_archive_file, sha, sharded
+def auto_conversion(pretrained_model_name_or_path: str, ignore_errors_during_conversion=False, **cached_file_kwargs):
+ try:
+ api = HfApi(token=cached_file_kwargs.get("token"))
+ sha = get_conversion_pr_reference(api, pretrained_model_name_or_path, **cached_file_kwargs)
+
+ if sha is None:
+ return None, None
+ cached_file_kwargs["revision"] = sha
+ del cached_file_kwargs["_commit_hash"]
+
+ # This is an additional HEAD call that could be removed if we could infer sharded/non-sharded from the PR
+ # description.
+ sharded = api.file_exists(
+ pretrained_model_name_or_path,
+ "model.safetensors.index.json",
+ revision=sha,
+ token=cached_file_kwargs.get("token"),
+ )
+ filename = "model.safetensors.index.json" if sharded else "model.safetensors"
+
+ resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
+ return resolved_archive_file, sha, sharded
+ except Exception as e:
+ if not ignore_errors_during_conversion:
+ raise e
diff --git a/src/transformers/testing_utils.py b/src/transformers/testing_utils.py
index 8b7814163739ce..8297cb981ef1fb 100644
--- a/src/transformers/testing_utils.py
+++ b/src/transformers/testing_utils.py
@@ -52,11 +52,13 @@
)
from .integrations.deepspeed import is_deepspeed_available
from .utils import (
+ ACCELERATE_MIN_VERSION,
is_accelerate_available,
is_apex_available,
is_aqlm_available,
is_auto_awq_available,
is_auto_gptq_available,
+ is_av_available,
is_bitsandbytes_available,
is_bs4_available,
is_cv2_available,
@@ -364,11 +366,13 @@ def require_nltk(test_case):
return unittest.skipUnless(is_nltk_available(), "test requires NLTK")(test_case)
-def require_accelerate(test_case):
+def require_accelerate(test_case, min_version: str = ACCELERATE_MIN_VERSION):
"""
Decorator marking a test that requires accelerate. These tests are skipped when accelerate isn't installed.
"""
- return unittest.skipUnless(is_accelerate_available(), "test requires accelerate")(test_case)
+ return unittest.skipUnless(
+ is_accelerate_available(min_version), f"test requires accelerate version >= {min_version}"
+ )(test_case)
def require_fsdp(test_case, min_version: str = "1.12.0"):
@@ -791,13 +795,13 @@ def require_torch_xpu(test_case):
def require_torch_multi_xpu(test_case):
"""
- Decorator marking a test that requires a multi-XPU setup with IPEX and atleast one XPU device. These tests are
+ Decorator marking a test that requires a multi-XPU setup with IPEX and at least one XPU device. These tests are
skipped on a machine without IPEX or multiple XPUs.
To run *only* the multi_xpu tests, assuming all test names contain multi_xpu: $ pytest -sv ./tests -k "multi_xpu"
"""
if not is_torch_xpu_available():
- return unittest.skip("test requires IPEX and atleast one XPU device")(test_case)
+ return unittest.skip("test requires IPEX and at least one XPU device")(test_case)
return unittest.skipUnless(torch.xpu.device_count() > 1, "test requires multiple XPUs")(test_case)
@@ -1010,6 +1014,13 @@ def require_aqlm(test_case):
return unittest.skipUnless(is_aqlm_available(), "test requires aqlm")(test_case)
+def require_av(test_case):
+ """
+ Decorator marking a test that requires av
+ """
+ return unittest.skipUnless(is_av_available(), "test requires av")(test_case)
+
+
def require_bitsandbytes(test_case):
"""
Decorator marking a test that requires the bitsandbytes library. Will be skipped when the library or its hard dependency torch is not installed.
diff --git a/src/transformers/tokenization_utils_base.py b/src/transformers/tokenization_utils_base.py
index e5cd6dce0646a1..7d56ed204423c0 100644
--- a/src/transformers/tokenization_utils_base.py
+++ b/src/transformers/tokenization_utils_base.py
@@ -1484,13 +1484,6 @@ def all_special_ids(self) -> List[int]:
high-level keys being the `__init__` keyword name of each vocabulary file required by the model, the
low-level being the `short-cut-names` of the pretrained models with, as associated values, the `url` to the
associated pretrained vocabulary file.
- - **max_model_input_sizes** (`Dict[str, Optional[int]]`) -- A dictionary with, as keys, the `short-cut-names`
- of the pretrained models, and as associated values, the maximum length of the sequence inputs of this model,
- or `None` if the model has no maximum input size.
- - **pretrained_init_configuration** (`Dict[str, Dict[str, Any]]`) -- A dictionary with, as keys, the
- `short-cut-names` of the pretrained models, and as associated values, a dictionary of specific arguments to
- pass to the `__init__` method of the tokenizer class for this pretrained model when loading the tokenizer
- with the [`~tokenization_utils_base.PreTrainedTokenizerBase.from_pretrained`] method.
- **model_input_names** (`List[str]`) -- A list of inputs expected in the forward pass of the model.
- **padding_side** (`str`) -- The default value for the side on which the model should have padding applied.
Should be `'right'` or `'left'`.
@@ -1561,8 +1554,6 @@ class PreTrainedTokenizerBase(SpecialTokensMixin, PushToHubMixin):
vocab_files_names: Dict[str, str] = {}
pretrained_vocab_files_map: Dict[str, Dict[str, str]] = {}
- pretrained_init_configuration: Dict[str, Dict[str, Any]] = {}
- max_model_input_sizes: Dict[str, Optional[int]] = {}
_auto_class: Optional[str] = None
# first name has to correspond to main model input name
@@ -2224,23 +2215,6 @@ def _from_pretrained(
# Update with newly provided kwargs
init_kwargs.update(kwargs)
- # Set max length if needed
- if pretrained_model_name_or_path in cls.max_model_input_sizes:
- # if we're using a pretrained model, ensure the tokenizer
- # wont index sequences longer than the number of positional embeddings
-
- model_max_length = cls.max_model_input_sizes[pretrained_model_name_or_path]
- if model_max_length is not None and isinstance(model_max_length, (int, float)):
- model_max_length = min(init_kwargs.get("model_max_length", int(1e30)), model_max_length)
- # TODO(PVP) - uncomment following line in Transformers v5
- # init_kwargs["model_max_length"] = model_max_length
- # TODO(PVP) - remove in Transformers v5
- # ---
- init_kwargs["model_max_length"] = cls._eventually_correct_t5_max_length(
- pretrained_model_name_or_path, model_max_length, init_kwargs.get("model_max_length")
- )
- # ---
-
# Merge resolved_vocab_files arguments in init_kwargs.
added_tokens_file = resolved_vocab_files.pop("added_tokens_file", None)
special_tokens_map_file = resolved_vocab_files.pop("special_tokens_map_file", None)
@@ -3657,7 +3631,7 @@ def truncate_sequences(
ids = ids[ids_to_move:]
pair_ids = pair_ids[pair_ids_to_move:] if pair_ids is not None else None
else:
- raise ValueError("invalid truncation strategy:" + str(self.truncation_side))
+ raise ValueError(f"invalid truncation strategy:{self.truncation_side}")
elif truncation_strategy == TruncationStrategy.ONLY_SECOND and pair_ids is not None:
if len(pair_ids) > num_tokens_to_remove:
@@ -3669,7 +3643,7 @@ def truncate_sequences(
overflowing_tokens = pair_ids[:window_len]
pair_ids = pair_ids[num_tokens_to_remove:]
else:
- raise ValueError("invalid truncation strategy:" + str(self.truncation_side))
+ raise ValueError(f"invalid truncation strategy:{self.truncation_side}")
else:
logger.error(
f"We need to remove {num_tokens_to_remove} to truncate the input "
@@ -3753,7 +3727,7 @@ def _pad(
encoded_inputs["special_tokens_mask"] = [1] * difference + encoded_inputs["special_tokens_mask"]
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
else:
- raise ValueError("Invalid padding strategy:" + str(self.padding_side))
+ raise ValueError(f"Invalid padding strategy:{self.padding_side}")
return encoded_inputs
diff --git a/src/transformers/trainer.py b/src/transformers/trainer.py
index 2cb426ac2ce88b..6bcf4796f8d565 100755
--- a/src/transformers/trainer.py
+++ b/src/transformers/trainer.py
@@ -52,7 +52,7 @@
from huggingface_hub import ModelCard, create_repo, upload_folder
from packaging import version
from torch import nn
-from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler
+from torch.utils.data import DataLoader, Dataset, IterableDataset, RandomSampler, SequentialSampler
from . import __version__
from .configuration_utils import PretrainedConfig
@@ -151,6 +151,7 @@
is_sagemaker_dp_enabled,
is_sagemaker_mp_enabled,
is_torch_compile_available,
+ is_torch_mlu_available,
is_torch_neuroncore_available,
is_torch_npu_available,
is_torch_xla_available,
@@ -353,7 +354,7 @@ def __init__(
model: Union[PreTrainedModel, nn.Module] = None,
args: TrainingArguments = None,
data_collator: Optional[DataCollator] = None,
- train_dataset: Optional[Dataset] = None,
+ train_dataset: Optional[Union[Dataset, IterableDataset]] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
model_init: Optional[Callable[[], PreTrainedModel]] = None,
@@ -1048,6 +1049,36 @@ def create_optimizer(self):
return self.optimizer
+ def get_num_trainable_parameters(self):
+ """
+ Get the number of trainable parameters.
+ """
+ return sum(p.numel() for p in self.model.parameters() if p.requires_grad)
+
+ def get_learning_rates(self):
+ """
+ Returns the learning rate of each parameter from self.optimizer.
+ """
+ if self.optimizer is None:
+ raise ValueError("Trainer optimizer is None, please make sure you have setup the optimizer before.")
+ return [group["lr"] for group in self.optimizer.param_groups]
+
+ def get_optimizer_group(self, param: Optional[Union[str, torch.nn.parameter.Parameter]] = None):
+ """
+ Returns optimizer group for a parameter if given, else returns all optimizer groups for params.
+
+ Args:
+ param (`str` or `torch.nn.parameter.Parameter`, *optional*):
+ The parameter for which optimizer group needs to be returned.
+ """
+ if self.optimizer is None:
+ raise ValueError("Trainer optimizer is None, please make sure you have setup the optimizer before.")
+ if param is not None:
+ for group in self.optimizer.param_groups:
+ if param in group["params"]:
+ return group
+ return [group["params"] for group in self.optimizer.param_groups]
+
@staticmethod
def get_optimizer_cls_and_kwargs(
args: TrainingArguments, model: Optional[PreTrainedModel] = None
@@ -1529,6 +1560,34 @@ def ipex_optimize_model(self, model, training=False, dtype=torch.float32):
return model
+ def compare_trainer_and_checkpoint_args(self, training_args, trainer_state):
+ attributes_map = {
+ "logging_steps": "logging_steps",
+ "eval_steps": "eval_steps",
+ "save_steps": "save_steps",
+ }
+
+ has_warning = False
+ warning_str = "Warning: The following arguments do not match the ones in the `trainer_state.json` within the checkpoint directory: "
+ for arg_attr, state_attr in attributes_map.items():
+ arg_value = getattr(training_args, arg_attr, None)
+ state_value = getattr(trainer_state, state_attr, None)
+
+ if arg_value is not None and state_value is not None and arg_value != state_value:
+ warning_str += f"\n\t{arg_attr}: {arg_value} (from args) != {state_value} (from trainer_state.json)"
+ has_warning = True
+
+ # train bs is special as we need to account for multi-GPU
+ train_bs_args = training_args.per_device_train_batch_size
+ train_bs_state = trainer_state.train_batch_size // max(1, training_args.n_gpu)
+
+ if train_bs_args != train_bs_state:
+ warning_str += f"\n\tper_device_train_batch_size: {train_bs_args} (from args) != {train_bs_state} (from trainer_state.json)"
+ has_warning = True
+
+ if has_warning:
+ logger.warning_once(warning_str)
+
def _wrap_model(self, model, training=True, dataloader=None):
if self.args.use_ipex:
dtype = torch.bfloat16 if self.use_cpu_amp else torch.float32
@@ -1991,6 +2050,7 @@ def _inner_training_loop(
os.path.join(resume_from_checkpoint, TRAINER_STATE_NAME)
):
self.state = TrainerState.load_from_json(os.path.join(resume_from_checkpoint, TRAINER_STATE_NAME))
+ self.compare_trainer_and_checkpoint_args(self.args, self.state)
epochs_trained = self.state.global_step // num_update_steps_per_epoch
if not args.ignore_data_skip:
steps_trained_in_current_epoch = self.state.global_step % (num_update_steps_per_epoch)
@@ -2097,7 +2157,12 @@ def _inner_training_loop(
"a `main_input_name` attribute to the model class you are using."
)
else:
- self.state.num_input_tokens_seen += self.accelerator.gather(inputs[main_input_name]).numel()
+ input_device = inputs[main_input_name].device
+ self.state.num_input_tokens_seen += torch.sum(
+ self.accelerator.gather(
+ torch.tensor(inputs[main_input_name].numel(), device=input_device, dtype=torch.int64)
+ )
+ ).item()
if rng_to_sync:
self._load_rng_state(resume_from_checkpoint)
rng_to_sync = False
@@ -2642,6 +2707,17 @@ def _load_rng_state(self, checkpoint):
f"Didn't manage to set back the RNG states of the NPU because of the following error:\n {e}"
"\nThis won't yield the same results as if the training had not been interrupted."
)
+ if is_torch_mlu_available():
+ if self.args.parallel_mode == ParallelMode.DISTRIBUTED:
+ torch.mlu.random.set_rng_state_all(checkpoint_rng_state["mlu"])
+ else:
+ try:
+ torch.mlu.random.set_rng_state(checkpoint_rng_state["mlu"])
+ except Exception as e:
+ logger.info(
+ f"Didn't manage to set back the RNG states of the MLU because of the following error:\n {e}"
+ "\nThis won't yield the same results as if the training had not been interrupted."
+ )
def _save_checkpoint(self, model, trial, metrics=None):
# In all cases, including ddp/dp/deepspeed, self.model is always a reference to the model we
@@ -2716,6 +2792,12 @@ def _save_rng_state(self, output_dir):
else:
rng_states["npu"] = torch.npu.random.get_rng_state()
+ if is_torch_mlu_available():
+ if self.args.parallel_mode == ParallelMode.DISTRIBUTED:
+ rng_states["mlu"] = torch.mlu.random.get_rng_state_all()
+ else:
+ rng_states["mlu"] = torch.mlu.random.get_rng_state()
+
# A process can arrive here before the process 0 has a chance to save the model, in which case output_dir may
# not yet exist.
os.makedirs(output_dir, exist_ok=True)
@@ -4247,8 +4329,23 @@ def _add_sm_patterns_to_gitignore(self) -> None:
self.repo.git_push()
def create_accelerator_and_postprocess(self):
- grad_acc_kwargs = {"num_steps": self.args.gradient_accumulation_steps}
+ grad_acc_kwargs = {}
+ if is_accelerate_available("0.28.0") and self.args.accelerator_config.gradient_accumulation_kwargs is not None:
+ grad_acc_kwargs = self.args.accelerator_config.gradient_accumulation_kwargs
+
+ # check if num_steps is attempted to be passed in gradient_accumulation_kwargs
+ if "num_steps" in grad_acc_kwargs and self.args.gradient_accumulation_steps > 1:
+ # raise because we do not know which setting is intended.
+ raise ValueError(
+ "The `AcceleratorConfig`'s `num_steps` is set but `gradient_accumulation_steps` is greater than 1 in the passed `TrainingArguments`"
+ "If using the passed `AcceleratorConfig` is desired, do not set the `TrainingArguments` `gradient_accumulation_steps`."
+ )
+ elif "num_steps" not in grad_acc_kwargs:
+ # take the gradient_accumulation_steps setting from TrainingArguments.
+ grad_acc_kwargs["num_steps"] = self.args.gradient_accumulation_steps
+
grad_acc_kwargs["sync_with_dataloader"] = False
+
gradient_accumulation_plugin = GradientAccumulationPlugin(**grad_acc_kwargs)
accelerator_config = self.args.accelerator_config.to_dict()
@@ -4260,6 +4357,8 @@ def create_accelerator_and_postprocess(self):
even_batches=accelerator_config.pop("even_batches"),
use_seedable_sampler=accelerator_config.pop("use_seedable_sampler"),
)
+ # this would have been updated above, no need for it anymore
+ accelerator_config.pop("gradient_accumulation_kwargs")
args = {
"deepspeed_plugin": self.args.deepspeed_plugin,
"gradient_accumulation_plugin": gradient_accumulation_plugin,
diff --git a/src/transformers/trainer_pt_utils.py b/src/transformers/trainer_pt_utils.py
index 394d29411d4da5..47ed90bed4a2e3 100644
--- a/src/transformers/trainer_pt_utils.py
+++ b/src/transformers/trainer_pt_utils.py
@@ -34,13 +34,18 @@
import torch
import torch.distributed as dist
from torch import nn
-from torch.optim.lr_scheduler import LRScheduler
from torch.utils.data import Dataset, IterableDataset, RandomSampler, Sampler
from torch.utils.data.distributed import DistributedSampler
from .integrations.deepspeed import is_deepspeed_zero3_enabled
from .tokenization_utils_base import BatchEncoding
-from .utils import is_sagemaker_mp_enabled, is_torch_xla_available, is_training_run_on_sagemaker, logging
+from .utils import (
+ is_sagemaker_mp_enabled,
+ is_torch_available,
+ is_torch_xla_available,
+ is_training_run_on_sagemaker,
+ logging,
+)
if is_training_run_on_sagemaker():
@@ -49,6 +54,15 @@
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
+if is_torch_available():
+ from .pytorch_utils import is_torch_greater_or_equal_than_2_0
+
+ if is_torch_greater_or_equal_than_2_0:
+ from torch.optim.lr_scheduler import LRScheduler
+ else:
+ from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+
+
# this is used to suppress an undesired warning emitted by pytorch versions 1.4.2-1.7.0
try:
from torch.optim.lr_scheduler import SAVE_STATE_WARNING
@@ -1171,6 +1185,15 @@ class AcceleratorConfig:
training results are fully reproducable using a different sampling technique. While seed-to-seed results
may differ, on average the differences are neglible when using multiple different seeds to compare. Should
also be ran with [`~utils.set_seed`] for the best results.
+ gradient_accumulation_kwargs (`dict`, *optional*):
+ Additional kwargs to configure gradient accumulation, see [`accelerate.utils.GradientAccumulationPlugin`].
+ Any of the following (optional) keys are acceptable:
+ num_steps (`int`): Will take precedence over [`~.TrainingArguments.gradient_accumulation_steps`] if
+ the latter is set to 1, otherwise an exception will be raised.
+ adjust_scheduler (`bool`): Whether to adjust the scheduler steps to account for [`~.TrainingArguments.gradient_accumulation_steps`].
+ The [`accelerate.utils.GradientAccumulationPlugin`] default is `True`.
+ sync_each_batch (`bool`): Whether to synchronize the gradients at each data batch.
+ The [`accelerate.utils.GradientAccumulationPlugin`] default is `False`.
"""
@@ -1209,6 +1232,19 @@ class AcceleratorConfig:
"multiple different seeds to compare. Should also be ran with [`~utils.set_seed`] for the best results."
},
)
+ gradient_accumulation_kwargs: Optional[Dict] = field(
+ default=None,
+ metadata={
+ "help": "Additional kwargs to configure gradient accumulation, see [`accelerate.utils.GradientAccumulationPlugin`]. "
+ "Any of the following (optional) keys are acceptable: "
+ " num_steps (`int`): Will take precedence over [`~.TrainingArguments.gradient_accumulation_steps`] if "
+ " the latter is set to 1, otherwise an exception will be raised. "
+ " adjust_scheduler (`bool`): Whether to adjust the scheduler steps to account for [`~.TrainingArguments.gradient_accumulation_steps`]. "
+ " The [`accelerate.utils.GradientAccumulationPlugin`] default is `True`. "
+ " sync_each_batch (`bool`): Whether to synchronize the gradients at each data batch. "
+ " The [`accelerate.utils.GradientAccumulationPlugin`] default is `False`."
+ },
+ )
@classmethod
def from_json_file(cls, json_file):
diff --git a/src/transformers/trainer_utils.py b/src/transformers/trainer_utils.py
index cd8bd79278e328..5c57ce0696f634 100644
--- a/src/transformers/trainer_utils.py
+++ b/src/transformers/trainer_utils.py
@@ -35,6 +35,7 @@
is_tf_available,
is_torch_available,
is_torch_cuda_available,
+ is_torch_mlu_available,
is_torch_mps_available,
is_torch_npu_available,
is_torch_xla_available,
@@ -100,6 +101,8 @@ def set_seed(seed: int, deterministic: bool = False):
# ^^ safe to call this function even if cuda is not available
if deterministic:
torch.use_deterministic_algorithms(True)
+ if is_torch_mlu_available():
+ torch.mlu.manual_seed_all(seed)
if is_torch_npu_available():
torch.npu.manual_seed_all(seed)
if is_torch_xpu_available():
@@ -408,6 +411,7 @@ class SchedulerType(ExplicitEnum):
CONSTANT_WITH_WARMUP = "constant_with_warmup"
INVERSE_SQRT = "inverse_sqrt"
REDUCE_ON_PLATEAU = "reduce_lr_on_plateau"
+ COSINE_WITH_MIN_LR = "cosine_with_min_lr"
class TrainerMemoryTracker:
@@ -454,7 +458,7 @@ def __init__(self, skip_memory_metrics=False):
import psutil # noqa
- if is_torch_cuda_available():
+ if is_torch_cuda_available() or is_torch_mlu_available():
import torch
self.torch = torch
@@ -527,6 +531,9 @@ def start(self):
if torch.cuda.is_available():
self.torch.cuda.reset_peak_memory_stats()
self.torch.cuda.empty_cache()
+ elif is_torch_mlu_available():
+ self.torch.mlu.reset_peak_memory_stats()
+ self.torch.mlu.empty_cache()
elif is_torch_xpu_available():
self.torch.xpu.reset_peak_memory_stats()
self.torch.xpu.empty_cache()
@@ -540,6 +547,8 @@ def start(self):
if self.torch is not None:
if torch.cuda.is_available():
self.gpu_mem_used_at_start = self.torch.cuda.memory_allocated()
+ elif is_torch_mlu_available():
+ self.gpu_mem_used_at_start = self.torch.mlu.memory_allocated()
elif is_torch_xpu_available():
self.gpu_mem_used_at_start = self.torch.xpu.memory_allocated()
elif is_torch_npu_available():
@@ -571,6 +580,8 @@ def stop(self, stage):
if self.torch is not None:
if torch.cuda.is_available():
self.torch.cuda.empty_cache()
+ elif is_torch_mlu_available():
+ self.torch.mlu.empty_cache()
elif is_torch_xpu_available():
self.torch.xpu.empty_cache()
elif is_torch_npu_available():
@@ -588,6 +599,9 @@ def stop(self, stage):
if torch.cuda.is_available():
self.gpu_mem_used_now = self.torch.cuda.memory_allocated()
self.gpu_mem_used_peak = self.torch.cuda.max_memory_allocated()
+ elif is_torch_mlu_available():
+ self.gpu_mem_used_now = self.torch.mlu.memory_allocated()
+ self.gpu_mem_used_peak = self.torch.mlu.max_memory_allocated()
elif is_torch_xpu_available():
self.gpu_mem_used_now = self.torch.xpu.memory_allocated()
self.gpu_mem_used_peak = self.torch.xpu.max_memory_allocated()
diff --git a/src/transformers/training_args.py b/src/transformers/training_args.py
index a52a77e9a766d6..e7dcc54deb4cc7 100644
--- a/src/transformers/training_args.py
+++ b/src/transformers/training_args.py
@@ -46,6 +46,7 @@
is_torch_available,
is_torch_bf16_cpu_available,
is_torch_bf16_gpu_available,
+ is_torch_mlu_available,
is_torch_neuroncore_available,
is_torch_npu_available,
is_torch_tf32_available,
@@ -993,7 +994,7 @@ class TrainingArguments:
default=None,
metadata={
"help": "The backend to be used for distributed training",
- "choices": ["nccl", "gloo", "mpi", "ccl", "hccl"],
+ "choices": ["nccl", "gloo", "mpi", "ccl", "hccl", "cncl"],
},
)
tpu_num_cores: Optional[int] = field(
@@ -1549,6 +1550,7 @@ def __post_init__(self):
self.framework == "pt"
and is_torch_available()
and (self.device.type != "cuda")
+ and (self.device.type != "mlu")
and (self.device.type != "npu")
and (self.device.type != "xpu")
and (get_xla_device_type(self.device) not in ["GPU", "CUDA"])
@@ -1556,13 +1558,14 @@ def __post_init__(self):
):
raise ValueError(
"FP16 Mixed precision training with AMP or APEX (`--fp16`) and FP16 half precision evaluation"
- " (`--fp16_full_eval`) can only be used on CUDA or NPU devices or certain XPU devices (with IPEX)."
+ " (`--fp16_full_eval`) can only be used on CUDA or MLU devices or NPU devices or certain XPU devices (with IPEX)."
)
if (
self.framework == "pt"
and is_torch_available()
and (self.device.type != "cuda")
+ and (self.device.type != "mlu")
and (self.device.type != "npu")
and (self.device.type != "xpu")
and (get_xla_device_type(self.device) not in ["GPU", "CUDA"])
@@ -1572,7 +1575,7 @@ def __post_init__(self):
):
raise ValueError(
"BF16 Mixed precision training with AMP (`--bf16`) and BF16 half precision evaluation"
- " (`--bf16_full_eval`) can only be used on CUDA, XPU (with IPEX), NPU or CPU/TPU/NeuronCore devices."
+ " (`--bf16_full_eval`) can only be used on CUDA, XPU (with IPEX), NPU, MLU or CPU/TPU/NeuronCore devices."
)
if self.torchdynamo is not None:
@@ -1999,6 +2002,10 @@ def _setup_devices(self) -> "torch.device":
device = torch.device("xpu:0")
torch.xpu.set_device(device)
self._n_gpu = 1
+ elif is_torch_mlu_available():
+ device = torch.device("mlu:0")
+ torch.mlu.set_device(device)
+ self._n_gpu = 1
elif is_torch_npu_available():
device = torch.device("npu:0")
torch.npu.set_device(device)
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index b8da221a8c914c..d33a6732458f71 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -109,6 +109,7 @@
is_aqlm_available,
is_auto_awq_available,
is_auto_gptq_available,
+ is_av_available,
is_bitsandbytes_available,
is_bs4_available,
is_coloredlogs_available,
@@ -184,6 +185,7 @@
is_torch_fp16_available_on_device,
is_torch_fx_available,
is_torch_fx_proxy,
+ is_torch_mlu_available,
is_torch_mps_available,
is_torch_neuroncore_available,
is_torch_npu_available,
diff --git a/src/transformers/utils/dummy_detectron2_objects.py b/src/transformers/utils/dummy_detectron2_objects.py
index 41dfb6f81d34ef..22ec32fe30a1b9 100644
--- a/src/transformers/utils/dummy_detectron2_objects.py
+++ b/src/transformers/utils/dummy_detectron2_objects.py
@@ -2,9 +2,6 @@
from ..utils import requires_backends
-LAYOUTLM_V2_PRETRAINED_MODEL_ARCHIVE_LIST = None
-
-
class LayoutLMv2Model:
def __init__(self, *args, **kwargs):
requires_backends(self, ["detectron2"])
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 5b698e0afe50dd..1bdab80a13f667 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -6806,9 +6806,6 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
-PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST = None
-
-
class PvtV2Backbone(metaclass=DummyObject):
_backends = ["torch"]
@@ -6942,6 +6939,34 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class Qwen2MoeForCausalLM(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2MoeForSequenceClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2MoeModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class Qwen2MoePreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class RagModel(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/import_utils.py b/src/transformers/utils/import_utils.py
index 3835831e88a44e..486df111856ae9 100644
--- a/src/transformers/utils/import_utils.py
+++ b/src/transformers/utils/import_utils.py
@@ -94,6 +94,7 @@ def _is_package_available(pkg_name: str, return_version: bool = False) -> Union[
_accelerate_available, _accelerate_version = _is_package_available("accelerate", return_version=True)
_apex_available = _is_package_available("apex")
_aqlm_available = _is_package_available("aqlm")
+_av_available = importlib.util.find_spec("av") is not None
_bitsandbytes_available = _is_package_available("bitsandbytes")
_galore_torch_available = _is_package_available("galore_torch")
# `importlib.metadata.version` doesn't work with `bs4` but `beautifulsoup4`. For `importlib.util.find_spec`, reversed.
@@ -585,6 +586,29 @@ def is_torch_npu_available(check_device=False):
return hasattr(torch, "npu") and torch.npu.is_available()
+@lru_cache()
+def is_torch_mlu_available(check_device=False):
+ "Checks if `torch_mlu` is installed and potentially if a MLU is in the environment"
+ if not _torch_available or importlib.util.find_spec("torch_mlu") is None:
+ return False
+
+ import torch
+ import torch_mlu # noqa: F401
+
+ from ..dependency_versions_table import deps
+
+ deps["deepspeed"] = "deepspeed-mlu>=0.10.1"
+
+ if check_device:
+ try:
+ # Will raise a RuntimeError if no MLU is found
+ _ = torch.mlu.device_count()
+ return torch.mlu.is_available()
+ except RuntimeError:
+ return False
+ return hasattr(torch, "mlu") and torch.mlu.is_available()
+
+
def is_torchdynamo_available():
if not is_torch_available():
return False
@@ -656,6 +680,10 @@ def is_aqlm_available():
return _aqlm_available
+def is_av_available():
+ return _av_available
+
+
def is_ninja_available():
r"""
Code comes from *torch.utils.cpp_extension.is_ninja_available()*. Returns `True` if the
@@ -777,9 +805,7 @@ def is_protobuf_available():
def is_accelerate_available(min_version: str = ACCELERATE_MIN_VERSION):
- if min_version is not None:
- return _accelerate_available and version.parse(_accelerate_version) >= version.parse(min_version)
- return _accelerate_available
+ return _accelerate_available and version.parse(_accelerate_version) >= version.parse(min_version)
def is_fsdp_available(min_version: str = FSDP_MIN_VERSION):
@@ -1012,6 +1038,16 @@ def is_mlx_available():
return _mlx_available
+# docstyle-ignore
+AV_IMPORT_ERROR = """
+{0} requires the PyAv library but it was not found in your environment. You can install it with:
+```
+pip install av
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+
# docstyle-ignore
CV2_IMPORT_ERROR = """
{0} requires the OpenCV library but it was not found in your environment. You can install it with:
@@ -1336,6 +1372,7 @@ def is_mlx_available():
BACKENDS_MAPPING = OrderedDict(
[
+ ("av", (is_av_available, AV_IMPORT_ERROR)),
("bs4", (is_bs4_available, BS4_IMPORT_ERROR)),
("cv2", (is_cv2_available, CV2_IMPORT_ERROR)),
("datasets", (is_datasets_available, DATASETS_IMPORT_ERROR)),
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py
index 15dc223595cb2f..61f4e81d744193 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py
@@ -20,11 +20,6 @@
logger = logging.get_logger(__name__)
-{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/config.json",
- # See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
-}
-
class {{cookiecutter.camelcase_modelname}}Config(PretrainedConfig):
r"""
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py
index fdfa32726c34e3..d903c18b2f06f3 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py
@@ -64,11 +64,6 @@
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
-TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "{{cookiecutter.checkpoint_identifier}}",
- # See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
-]
-
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Embeddings(keras.layers.Layer):
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
index 3c4295f71501f7..db109b27fc8aae 100755
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
@@ -57,11 +57,6 @@
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
-{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "{{cookiecutter.checkpoint_identifier}}",
- # See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
-]
-
def load_tf_weights_in_{{cookiecutter.lowercase_modelname}}(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
@@ -1588,11 +1583,6 @@ def forward(
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
-{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "{{cookiecutter.checkpoint_identifier}}",
- # See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
-]
-
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py
index 6d5b3fe79682ef..cdb5070e3d9955 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py
@@ -40,8 +40,7 @@
{{cookiecutter.camelcase_modelname}}Model,
)
from transformers.models.{{cookiecutter.lowercase_modelname}}.modeling_{{cookiecutter.lowercase_modelname}} import (
- {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
+ {{cookiecutter.uppercase_modelname}} )
class {{cookiecutter.camelcase_modelname}}ModelTester:
@@ -453,9 +452,9 @@ def test_model_as_decoder_with_default_input_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "{{coockiecutter.checkpoint_identifier}}"
+ model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py
index 257dda17b4dc3b..f5ed661ade3625 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py
@@ -30,7 +30,6 @@
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
- "{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
@@ -46,7 +45,6 @@
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
- "{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
@@ -63,7 +61,6 @@
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
- "TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
@@ -122,7 +119,7 @@
# Below: " # Models"
# Replace with:
- "models.{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config", "{{cookiecutter.camelcase_modelname}}Tokenizer"],
+ "models.{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.camelcase_modelname}}Config", "{{cookiecutter.camelcase_modelname}}Tokenizer"],
# End.
# To replace in: "src/transformers/__init__.py"
@@ -130,7 +127,6 @@
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
- {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
@@ -144,7 +140,6 @@
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
- {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
@@ -159,8 +154,7 @@
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
- TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
- TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
+ TF_{{cookiecutter.uppercase_modelname}} TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
@@ -209,9 +203,9 @@
from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}TokenizerFast
# End.
-# Below: " from .models.albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig"
+# Below: " from .models.albert import AlbertConfig"
# Replace with:
- from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config, {{cookiecutter.camelcase_modelname}}Tokenizer
+ from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}{{cookiecutter.camelcase_modelname}}Config, {{cookiecutter.camelcase_modelname}}Tokenizer
# End.
@@ -229,11 +223,6 @@
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}Config"),
# End.
-# Below: "# Add archive maps here"
-# Replace with:
- ("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP"),
-# End.
-
# Below: "# Add full (and cased) model names here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}"),
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py
index 6e6c93698367fe..3712c970296ea1 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py
@@ -30,15 +30,6 @@
}
}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
-}
-
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BertTokenizerFast):
r"""
@@ -53,8 +44,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(BertTokenizerFast):
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
@@ -67,22 +56,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(BertTokenizerFast):
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
- },
- "merges_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
- },
- "tokenizer_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 1024,
-}
-
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BartTokenizerFast):
r"""
@@ -96,8 +69,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(BartTokenizerFast):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
@@ -114,19 +85,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(BartTokenizerFast):
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
- },
- "tokenizer_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 1024,
-}
-
class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
@@ -137,8 +95,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast)
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
def __init__(
diff --git a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py
index a9c072f977d25f..2f627adeb7df20 100644
--- a/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py
+++ b/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py
@@ -29,15 +29,6 @@
}
}
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 512,
-}
-
-
-PRETRAINED_INIT_CONFIGURATION = {
- "{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
-}
-
class {{cookiecutter.camelcase_modelname}}Tokenizer(BertTokenizer):
r"""
@@ -52,8 +43,6 @@ class {{cookiecutter.camelcase_modelname}}Tokenizer(BertTokenizer):
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
from ...utils import logging
@@ -64,19 +53,6 @@ class {{cookiecutter.camelcase_modelname}}Tokenizer(BertTokenizer):
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
- },
- "merges_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 1024,
-}
-
class {{cookiecutter.camelcase_modelname}}Tokenizer(BartTokenizer):
"""
@@ -90,8 +66,6 @@ class {{cookiecutter.camelcase_modelname}}Tokenizer(BartTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
from typing import List, Optional
@@ -107,15 +81,6 @@ class {{cookiecutter.camelcase_modelname}}Tokenizer(BartTokenizer):
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
-PRETRAINED_VOCAB_FILES_MAP = {
- "vocab_file": {
- "{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
- },
-}
-
-PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
- "{{cookiecutter.checkpoint_identifier}}": 1024,
-}
class {{cookiecutter.camelcase_modelname}}Tokenizer(PreTrainedTokenizer):
"""
@@ -127,8 +92,6 @@ class {{cookiecutter.camelcase_modelname}}Tokenizer(PreTrainedTokenizer):
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
@@ -269,8 +232,6 @@ class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast)
"""
vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
diff --git a/tests/generation/test_flax_logits_process.py b/tests/generation/test_flax_logits_process.py
index a45d75ae244bb6..bd5f8f648cbb5b 100644
--- a/tests/generation/test_flax_logits_process.py
+++ b/tests/generation/test_flax_logits_process.py
@@ -33,6 +33,7 @@
FlaxForcedEOSTokenLogitsProcessor,
FlaxLogitsProcessorList,
FlaxMinLengthLogitsProcessor,
+ FlaxNoRepeatNGramLogitsProcessor,
FlaxTemperatureLogitsWarper,
FlaxTopKLogitsWarper,
FlaxTopPLogitsWarper,
@@ -197,6 +198,26 @@ def test_forced_eos_token_logits_processor(self):
scores = logits_processor(input_ids, scores, cur_len=cur_len)
self.assertFalse(jnp.isinf(scores).any())
+ def test_no_repeat_ngram_dist_processor(self):
+ vocab_size = 3
+ batch_size = 2
+
+ cur_len = 4
+ input_ids = np.array([[1, 1, 2, 1], [0, 1, 0, 1]], dtype="i4")
+ scores = self._get_uniform_logits(batch_size, vocab_size)
+
+ no_repeat_proc_2_gram = FlaxNoRepeatNGramLogitsProcessor(2)
+ no_repeat_proc_3_gram = FlaxNoRepeatNGramLogitsProcessor(3)
+
+ filtered_scores_2_gram = no_repeat_proc_2_gram(input_ids, scores, cur_len=cur_len)
+ filtered_scores_3_gram = no_repeat_proc_3_gram(input_ids, scores, cur_len=cur_len)
+
+ # 2-gram would forbid 2nd and 3rd token (1,2) at 1st batch and 1st token (0) at 2nd batch
+ self.assertListEqual(jnp.isinf(filtered_scores_2_gram).tolist(), [[False, True, True], [True, False, False]])
+
+ # 3-gram would forbid no token at 1st batch and 1st token (0) at 2nd batch
+ self.assertListEqual(jnp.isinf(filtered_scores_3_gram).tolist(), [[False, False, False], [True, False, False]])
+
def test_processor_list(self):
batch_size = 4
sequence_length = 10
@@ -216,6 +237,7 @@ def test_processor_list(self):
temp_dist_warp = FlaxTemperatureLogitsWarper(temperature=0.5)
top_k_warp = FlaxTopKLogitsWarper(3)
top_p_warp = FlaxTopPLogitsWarper(0.8)
+ no_repeat_proc = FlaxNoRepeatNGramLogitsProcessor(2)
# instantiate all logits processors
min_dist_proc = FlaxMinLengthLogitsProcessor(min_length=10, eos_token_id=eos_token_id)
@@ -231,10 +253,19 @@ def test_processor_list(self):
scores = min_dist_proc(input_ids, scores, cur_len=cur_len)
scores = bos_dist_proc(input_ids, scores, cur_len=cur_len)
scores = eos_dist_proc(input_ids, scores, cur_len=cur_len)
+ scores = no_repeat_proc(input_ids, scores, cur_len=cur_len)
# with processor list
processor = FlaxLogitsProcessorList(
- [temp_dist_warp, top_k_warp, top_p_warp, min_dist_proc, bos_dist_proc, eos_dist_proc]
+ [
+ temp_dist_warp,
+ top_k_warp,
+ top_p_warp,
+ min_dist_proc,
+ bos_dist_proc,
+ eos_dist_proc,
+ no_repeat_proc,
+ ]
)
scores_comp = processor(input_ids, scores_comp, cur_len=cur_len)
@@ -263,6 +294,7 @@ def test_processor_list_jitted(self):
temp_dist_warp = FlaxTemperatureLogitsWarper(temperature=0.5)
top_k_warp = FlaxTopKLogitsWarper(3)
top_p_warp = FlaxTopPLogitsWarper(0.8)
+ no_repeat_proc = FlaxNoRepeatNGramLogitsProcessor(2)
# instantiate all logits processors
min_dist_proc = FlaxMinLengthLogitsProcessor(min_length=10, eos_token_id=eos_token_id)
@@ -279,12 +311,21 @@ def run_no_processor_list(input_ids, scores, cur_len):
scores = min_dist_proc(input_ids, scores, cur_len=cur_len)
scores = bos_dist_proc(input_ids, scores, cur_len=cur_len)
scores = eos_dist_proc(input_ids, scores, cur_len=cur_len)
+ scores = no_repeat_proc(input_ids, scores, cur_len=cur_len)
return scores
# with processor list
def run_processor_list(input_ids, scores, cur_len):
processor = FlaxLogitsProcessorList(
- [temp_dist_warp, top_k_warp, top_p_warp, min_dist_proc, bos_dist_proc, eos_dist_proc]
+ [
+ temp_dist_warp,
+ top_k_warp,
+ top_p_warp,
+ min_dist_proc,
+ bos_dist_proc,
+ eos_dist_proc,
+ no_repeat_proc,
+ ]
)
scores = processor(input_ids, scores, cur_len=cur_len)
return scores
diff --git a/tests/generation/test_stopping_criteria.py b/tests/generation/test_stopping_criteria.py
index 7fa118c9e3550d..0c770972a7fdff 100644
--- a/tests/generation/test_stopping_criteria.py
+++ b/tests/generation/test_stopping_criteria.py
@@ -26,6 +26,7 @@
import torch
from transformers.generation import (
+ EosTokenCriteria,
MaxLengthCriteria,
MaxNewTokensCriteria,
MaxTimeCriteria,
@@ -98,6 +99,22 @@ def test_max_time_criteria(self):
criteria = MaxTimeCriteria(max_time=0.1, initial_timestamp=time.time() - 0.2)
self.assertTrue(all(criteria(input_ids, scores)))
+ def test_eos_token_criteria(self):
+ criteria = EosTokenCriteria(eos_token_id=0)
+
+ input_ids, scores = self._get_tensors(5)
+ input_ids[:, -1] = 0
+ self.assertTrue(all(criteria(input_ids, scores)))
+
+ input_ids, scores = self._get_tensors(5)
+ input_ids[:2, -1] = 0
+ input_ids[2, -1] = 1
+ self.assertListEqual(criteria(input_ids, scores).tolist(), [True, True, False])
+
+ input_ids, scores = self._get_tensors(5)
+ input_ids[:, -1] = 1
+ self.assertListEqual(criteria(input_ids, scores).tolist(), [False, False, False])
+
def test_validate_stopping_criteria(self):
validate_stopping_criteria(StoppingCriteriaList([MaxLengthCriteria(10)]), 10)
diff --git a/tests/generation/test_utils.py b/tests/generation/test_utils.py
index 91e9c3876a56a3..b346b745d8bcbe 100644
--- a/tests/generation/test_utils.py
+++ b/tests/generation/test_utils.py
@@ -717,6 +717,19 @@ def test_beam_sample_generate(self):
)
self.assertTrue(output_generate.shape[-1] == max_length)
+ if "inputs_embeds" in set(inspect.signature(model.prepare_inputs_for_generation).parameters):
+ input_embeds = model.get_input_embeddings()(input_ids)
+ beam_kwargs.update({"inputs_embeds": input_embeds})
+ output_generate2 = self._beam_sample_generate(
+ model=model,
+ input_ids=None,
+ attention_mask=attention_mask,
+ max_length=max_length,
+ beam_kwargs=beam_kwargs,
+ logits_warper_kwargs=logits_warper_kwargs,
+ )
+
+ torch.testing.assert_close(output_generate[:, input_embeds.shape[1] :], output_generate2)
def test_beam_sample_generate_dict_output(self):
for model_class in self.all_generative_model_classes:
@@ -1888,14 +1901,12 @@ def test_speculative_sampling(self):
]
)
last_assistant_token_is_eos = False
- max_matches = 5
validated_tokens, n_matches = _speculative_sampling(
candidate_input_ids,
candidate_logits,
candidate_length,
new_logits,
last_assistant_token_is_eos,
- max_matches,
)
self.assertTrue(n_matches.item() == 2)
self.assertTrue(validated_tokens.tolist()[0] == [1, 4, 8])
@@ -2808,3 +2819,16 @@ def test_return_unprocessed_logit_scores(self):
self.assertTrue(y_prob > 0.001 and n_prob > 0.001)
self.assertTrue(y_prob <= 1.0 and n_prob <= 1.0)
+
+ def test_generate_from_inputs_embeds_with_bos_token_id_is_none(self):
+ article = "Today a dragon flew over Paris."
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-gpt2").to(torch_device)
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-gpt2")
+ input_ids = tokenizer(article, return_tensors="pt").input_ids.to(torch_device)
+ inputs_embeds = model.get_input_embeddings()(input_ids)
+
+ model.generate(inputs_embeds=inputs_embeds, max_length=20, bos_token_id=None)
+
+ # bos_token_id is required when no input ids nor inputs_embeds is passed
+ with self.assertRaises(ValueError):
+ model.generate(max_length=20, bos_token_id=None)
diff --git a/tests/models/albert/test_modeling_albert.py b/tests/models/albert/test_modeling_albert.py
index 823315bc6785bb..d1e5631b342d33 100644
--- a/tests/models/albert/test_modeling_albert.py
+++ b/tests/models/albert/test_modeling_albert.py
@@ -38,7 +38,6 @@
AlbertForTokenClassification,
AlbertModel,
)
- from transformers.models.albert.modeling_albert import ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST
class AlbertModelTester:
@@ -322,9 +321,9 @@ def test_model_various_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AlbertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "albert/albert-base-v1"
+ model = AlbertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/albert/test_modeling_tf_albert.py b/tests/models/albert/test_modeling_tf_albert.py
index 7bea29fa9cb1d5..a3dab618eecb4a 100644
--- a/tests/models/albert/test_modeling_tf_albert.py
+++ b/tests/models/albert/test_modeling_tf_albert.py
@@ -32,7 +32,6 @@
from transformers import TF_MODEL_FOR_PRETRAINING_MAPPING
from transformers.models.albert.modeling_tf_albert import (
- TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
TFAlbertForMaskedLM,
TFAlbertForMultipleChoice,
TFAlbertForPreTraining,
@@ -302,9 +301,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_ALBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFAlbertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "albert/albert-base-v1"
+ model = TFAlbertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/align/test_modeling_align.py b/tests/models/align/test_modeling_align.py
index 2f3297899474c3..ee50a1a74bd2da 100644
--- a/tests/models/align/test_modeling_align.py
+++ b/tests/models/align/test_modeling_align.py
@@ -51,7 +51,6 @@
AlignTextModel,
AlignVisionModel,
)
- from transformers.models.align.modeling_align import ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -238,9 +237,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AlignVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "kakaobrain/align-base"
+ model = AlignVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class AlignTextModelTester:
@@ -390,9 +389,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AlignTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "kakaobrain/align-base"
+ model = AlignTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class AlignModelTester:
@@ -599,9 +598,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ALIGN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AlignModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "kakaobrain/align-base"
+ model = AlignModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/altclip/test_modeling_altclip.py b/tests/models/altclip/test_modeling_altclip.py
index 10b0e167d727b6..8c5be789c02b81 100755
--- a/tests/models/altclip/test_modeling_altclip.py
+++ b/tests/models/altclip/test_modeling_altclip.py
@@ -43,7 +43,6 @@
import torch.nn as nn
from transformers import AltCLIPModel, AltCLIPTextModel, AltCLIPVisionModel
- from transformers.models.altclip.modeling_altclip import ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -365,9 +364,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AltCLIPTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "BAAI/AltCLIP"
+ model = AltCLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class AltCLIPModelTester:
@@ -560,9 +559,9 @@ def _create_and_check_torchscript(self, config, inputs_dict):
@slow
def test_model_from_pretrained(self):
- for model_name in ALTCLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = AltCLIPModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "BAAI/AltCLIP"
+ model = AltCLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_vision
diff --git a/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
index ce596d84e37282..564ca4d48c6a7f 100644
--- a/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
+++ b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
@@ -33,9 +33,6 @@
from torch import nn
from transformers import ASTForAudioClassification, ASTModel
- from transformers.models.audio_spectrogram_transformer.modeling_audio_spectrogram_transformer import (
- AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_torchaudio_available():
@@ -212,9 +209,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ASTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "MIT/ast-finetuned-audioset-10-10-0.4593"
+ model = ASTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on some audio from AudioSet
diff --git a/tests/models/auto/test_modeling_auto.py b/tests/models/auto/test_modeling_auto.py
index ab5fa95796eac5..a8e42d77f90e36 100644
--- a/tests/models/auto/test_modeling_auto.py
+++ b/tests/models/auto/test_modeling_auto.py
@@ -85,10 +85,6 @@
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
MODEL_MAPPING,
)
- from transformers.models.bert.modeling_bert import BERT_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.gpt2.modeling_gpt2 import GPT2_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.t5.modeling_t5 import T5_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.tapas.modeling_tapas import TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST
@require_torch
@@ -98,138 +94,134 @@ def setUp(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
-
- model = AutoModel.from_pretrained(model_name)
- model, loading_info = AutoModel.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertModel)
-
- self.assertEqual(len(loading_info["missing_keys"]), 0)
- # When using PyTorch checkpoint, the expected value is `8`. With `safetensors` checkpoint (if it is
- # installed), the expected value becomes `7`.
- EXPECTED_NUM_OF_UNEXPECTED_KEYS = 7 if is_safetensors_available() else 8
- self.assertEqual(len(loading_info["unexpected_keys"]), EXPECTED_NUM_OF_UNEXPECTED_KEYS)
- self.assertEqual(len(loading_info["mismatched_keys"]), 0)
- self.assertEqual(len(loading_info["error_msgs"]), 0)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModel.from_pretrained(model_name)
+ model, loading_info = AutoModel.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertModel)
+
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+ # When using PyTorch checkpoint, the expected value is `8`. With `safetensors` checkpoint (if it is
+ # installed), the expected value becomes `7`.
+ EXPECTED_NUM_OF_UNEXPECTED_KEYS = 7 if is_safetensors_available() else 8
+ self.assertEqual(len(loading_info["unexpected_keys"]), EXPECTED_NUM_OF_UNEXPECTED_KEYS)
+ self.assertEqual(len(loading_info["mismatched_keys"]), 0)
+ self.assertEqual(len(loading_info["error_msgs"]), 0)
@slow
def test_model_for_pretraining_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
-
- model = AutoModelForPreTraining.from_pretrained(model_name)
- model, loading_info = AutoModelForPreTraining.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForPreTraining)
- # Only one value should not be initialized and in the missing keys.
- for key, value in loading_info.items():
- self.assertEqual(len(value), 0)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForPreTraining.from_pretrained(model_name)
+ model, loading_info = AutoModelForPreTraining.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForPreTraining)
+ # Only one value should not be initialized and in the missing keys.
+ for key, value in loading_info.items():
+ self.assertEqual(len(value), 0)
@slow
def test_lmhead_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = AutoModelWithLMHead.from_pretrained(model_name)
- model, loading_info = AutoModelWithLMHead.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForMaskedLM)
+ model = AutoModelWithLMHead.from_pretrained(model_name)
+ model, loading_info = AutoModelWithLMHead.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
@slow
def test_model_for_causal_lm(self):
- for model_name in GPT2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, GPT2Config)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, GPT2Config)
- model = AutoModelForCausalLM.from_pretrained(model_name)
- model, loading_info = AutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, GPT2LMHeadModel)
+ model = AutoModelForCausalLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, GPT2LMHeadModel)
@slow
def test_model_for_masked_lm(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = AutoModelForMaskedLM.from_pretrained(model_name)
- model, loading_info = AutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForMaskedLM)
+ model = AutoModelForMaskedLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
@slow
def test_model_for_encoder_decoder_lm(self):
- for model_name in T5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, T5Config)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, T5Config)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
- model, loading_info = AutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, T5ForConditionalGeneration)
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, T5ForConditionalGeneration)
@slow
def test_sequence_classification_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
-
- model = AutoModelForSequenceClassification.from_pretrained(model_name)
- model, loading_info = AutoModelForSequenceClassification.from_pretrained(
- model_name, output_loading_info=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForSequenceClassification)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForSequenceClassification.from_pretrained(model_name)
+ model, loading_info = AutoModelForSequenceClassification.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForSequenceClassification)
@slow
def test_question_answering_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = AutoModelForQuestionAnswering.from_pretrained(model_name)
- model, loading_info = AutoModelForQuestionAnswering.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForQuestionAnswering)
+ model = AutoModelForQuestionAnswering.from_pretrained(model_name)
+ model, loading_info = AutoModelForQuestionAnswering.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForQuestionAnswering)
@slow
def test_table_question_answering_model_from_pretrained(self):
- for model_name in TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST[5:6]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, TapasConfig)
-
- model = AutoModelForTableQuestionAnswering.from_pretrained(model_name)
- model, loading_info = AutoModelForTableQuestionAnswering.from_pretrained(
- model_name, output_loading_info=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TapasForQuestionAnswering)
+ model_name = "google/tapas-base"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, TapasConfig)
+
+ model = AutoModelForTableQuestionAnswering.from_pretrained(model_name)
+ model, loading_info = AutoModelForTableQuestionAnswering.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TapasForQuestionAnswering)
@slow
def test_token_classification_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
-
- model = AutoModelForTokenClassification.from_pretrained(model_name)
- model, loading_info = AutoModelForTokenClassification.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForTokenClassification)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForTokenClassification.from_pretrained(model_name)
+ model, loading_info = AutoModelForTokenClassification.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForTokenClassification)
@slow
def test_auto_backbone_timm_model_from_pretrained(self):
diff --git a/tests/models/auto/test_modeling_tf_auto.py b/tests/models/auto/test_modeling_tf_auto.py
index e0758610871a86..53a07b197057e7 100644
--- a/tests/models/auto/test_modeling_tf_auto.py
+++ b/tests/models/auto/test_modeling_tf_auto.py
@@ -65,10 +65,6 @@
TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
TF_MODEL_MAPPING,
)
- from transformers.models.bert.modeling_tf_bert import TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.gpt2.modeling_tf_gpt2 import TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.t5.modeling_tf_t5 import TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.tapas.modeling_tf_tapas import TF_TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST
class NewModelConfig(BertConfig):
@@ -107,54 +103,54 @@ def test_model_for_pretraining_from_pretrained(self):
@slow
def test_model_for_causal_lm(self):
- for model_name in TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, GPT2Config)
+ model_name = "openai-community/gpt2"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, GPT2Config)
- model = TFAutoModelForCausalLM.from_pretrained(model_name)
- model, loading_info = TFAutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFGPT2LMHeadModel)
+ model = TFAutoModelForCausalLM.from_pretrained(model_name)
+ model, loading_info = TFAutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFGPT2LMHeadModel)
@slow
def test_lmhead_model_from_pretrained(self):
- for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "openai-community/gpt2"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = TFAutoModelWithLMHead.from_pretrained(model_name)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFBertForMaskedLM)
+ model = TFAutoModelWithLMHead.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFBertForMaskedLM)
@slow
def test_model_for_masked_lm(self):
- for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "openai-community/gpt2"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = TFAutoModelForMaskedLM.from_pretrained(model_name)
- model, loading_info = TFAutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFBertForMaskedLM)
+ model = TFAutoModelForMaskedLM.from_pretrained(model_name)
+ model, loading_info = TFAutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFBertForMaskedLM)
@slow
def test_model_for_encoder_decoder_lm(self):
- for model_name in TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, T5Config)
+ model_name = "openai-community/gpt2"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, T5Config)
- model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name)
- model, loading_info = TFAutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFT5ForConditionalGeneration)
+ model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name)
+ model, loading_info = TFAutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFT5ForConditionalGeneration)
@slow
def test_sequence_classification_model_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'openai-community/gpt2'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
@@ -166,7 +162,7 @@ def test_sequence_classification_model_from_pretrained(self):
@slow
def test_question_answering_model_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'openai-community/gpt2'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
@@ -179,17 +175,17 @@ def test_question_answering_model_from_pretrained(self):
@slow
@require_tensorflow_probability
def test_table_question_answering_model_from_pretrained(self):
- for model_name in TF_TAPAS_PRETRAINED_MODEL_ARCHIVE_LIST[5:6]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, TapasConfig)
+ model_name = "google/tapas-base"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, TapasConfig)
- model = TFAutoModelForTableQuestionAnswering.from_pretrained(model_name)
- model, loading_info = TFAutoModelForTableQuestionAnswering.from_pretrained(
- model_name, output_loading_info=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFTapasForQuestionAnswering)
+ model = TFAutoModelForTableQuestionAnswering.from_pretrained(model_name)
+ model, loading_info = TFAutoModelForTableQuestionAnswering.from_pretrained(
+ model_name, output_loading_info=True
+ )
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFTapasForQuestionAnswering)
def test_from_pretrained_identifier(self):
model = TFAutoModelWithLMHead.from_pretrained(SMALL_MODEL_IDENTIFIER)
diff --git a/tests/models/auto/test_modeling_tf_pytorch.py b/tests/models/auto/test_modeling_tf_pytorch.py
index 77b19a8e3a7976..5b9036cbf1cf18 100644
--- a/tests/models/auto/test_modeling_tf_pytorch.py
+++ b/tests/models/auto/test_modeling_tf_pytorch.py
@@ -45,9 +45,6 @@
TFRobertaForMaskedLM,
TFT5ForConditionalGeneration,
)
- from transformers.models.bert.modeling_tf_bert import TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.gpt2.modeling_tf_gpt2 import TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST
- from transformers.models.t5.modeling_tf_t5 import TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST
if is_torch_available():
from transformers import (
@@ -74,7 +71,7 @@
class TFPTAutoModelTest(unittest.TestCase):
@slow
def test_model_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google-bert/bert-base-uncased'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
@@ -90,7 +87,7 @@ def test_model_from_pretrained(self):
@slow
def test_model_for_pretraining_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google-bert/bert-base-uncased'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
@@ -106,85 +103,79 @@ def test_model_for_pretraining_from_pretrained(self):
@slow
def test_model_for_causal_lm(self):
- for model_name in TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, GPT2Config)
-
- model = TFAutoModelForCausalLM.from_pretrained(model_name, from_pt=True)
- model, loading_info = TFAutoModelForCausalLM.from_pretrained(
- model_name, output_loading_info=True, from_pt=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFGPT2LMHeadModel)
-
- model = AutoModelForCausalLM.from_pretrained(model_name, from_tf=True)
- model, loading_info = AutoModelForCausalLM.from_pretrained(
- model_name, output_loading_info=True, from_tf=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, GPT2LMHeadModel)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, GPT2Config)
+
+ model = TFAutoModelForCausalLM.from_pretrained(model_name, from_pt=True)
+ model, loading_info = TFAutoModelForCausalLM.from_pretrained(
+ model_name, output_loading_info=True, from_pt=True
+ )
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFGPT2LMHeadModel)
+
+ model = AutoModelForCausalLM.from_pretrained(model_name, from_tf=True)
+ model, loading_info = AutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True, from_tf=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, GPT2LMHeadModel)
@slow
def test_lmhead_model_from_pretrained(self):
- for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
- model = TFAutoModelWithLMHead.from_pretrained(model_name, from_pt=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFBertForMaskedLM)
+ model = TFAutoModelWithLMHead.from_pretrained(model_name, from_pt=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFBertForMaskedLM)
- model = AutoModelWithLMHead.from_pretrained(model_name, from_tf=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForMaskedLM)
+ model = AutoModelWithLMHead.from_pretrained(model_name, from_tf=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
@slow
def test_model_for_masked_lm(self):
- for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, BertConfig)
-
- model = TFAutoModelForMaskedLM.from_pretrained(model_name, from_pt=True)
- model, loading_info = TFAutoModelForMaskedLM.from_pretrained(
- model_name, output_loading_info=True, from_pt=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFBertForMaskedLM)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = TFAutoModelForMaskedLM.from_pretrained(model_name, from_pt=True)
+ model, loading_info = TFAutoModelForMaskedLM.from_pretrained(
+ model_name, output_loading_info=True, from_pt=True
+ )
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFBertForMaskedLM)
- model = AutoModelForMaskedLM.from_pretrained(model_name, from_tf=True)
- model, loading_info = AutoModelForMaskedLM.from_pretrained(
- model_name, output_loading_info=True, from_tf=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, BertForMaskedLM)
+ model = AutoModelForMaskedLM.from_pretrained(model_name, from_tf=True)
+ model, loading_info = AutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True, from_tf=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
@slow
def test_model_for_encoder_decoder_lm(self):
- for model_name in TF_T5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = AutoConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, T5Config)
-
- model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name, from_pt=True)
- model, loading_info = TFAutoModelForSeq2SeqLM.from_pretrained(
- model_name, output_loading_info=True, from_pt=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, TFT5ForConditionalGeneration)
-
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name, from_tf=True)
- model, loading_info = AutoModelForSeq2SeqLM.from_pretrained(
- model_name, output_loading_info=True, from_tf=True
- )
- self.assertIsNotNone(model)
- self.assertIsInstance(model, T5ForConditionalGeneration)
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, T5Config)
+
+ model = TFAutoModelForSeq2SeqLM.from_pretrained(model_name, from_pt=True)
+ model, loading_info = TFAutoModelForSeq2SeqLM.from_pretrained(
+ model_name, output_loading_info=True, from_pt=True
+ )
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TFT5ForConditionalGeneration)
+
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_name, from_tf=True)
+ model, loading_info = AutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True, from_tf=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, T5ForConditionalGeneration)
@slow
def test_sequence_classification_model_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google-bert/bert-base-uncased'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
@@ -200,7 +191,7 @@ def test_sequence_classification_model_from_pretrained(self):
@slow
def test_question_answering_model_from_pretrained(self):
- # for model_name in TF_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google-bert/bert-base-uncased'
for model_name in ["google-bert/bert-base-uncased"]:
config = AutoConfig.from_pretrained(model_name)
self.assertIsNotNone(config)
diff --git a/tests/models/auto/test_tokenization_auto.py b/tests/models/auto/test_tokenization_auto.py
index 7d4a302e4f02a2..ad96064308ab5c 100644
--- a/tests/models/auto/test_tokenization_auto.py
+++ b/tests/models/auto/test_tokenization_auto.py
@@ -25,8 +25,6 @@
import transformers
from transformers import (
- BERT_PRETRAINED_CONFIG_ARCHIVE_MAP,
- GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP,
AutoTokenizer,
BertConfig,
BertTokenizer,
@@ -72,13 +70,13 @@ def setUp(self):
@slow
def test_tokenizer_from_pretrained(self):
- for model_name in (x for x in BERT_PRETRAINED_CONFIG_ARCHIVE_MAP.keys() if "japanese" not in x):
+ for model_name in {"google-bert/bert-base-uncased", "google-bert/bert-base-cased"}:
tokenizer = AutoTokenizer.from_pretrained(model_name)
self.assertIsNotNone(tokenizer)
self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
self.assertGreater(len(tokenizer), 0)
- for model_name in GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP.keys():
+ for model_name in ["openai-community/gpt2", "openai-community/gpt2-medium"]:
tokenizer = AutoTokenizer.from_pretrained(model_name)
self.assertIsNotNone(tokenizer)
self.assertIsInstance(tokenizer, (GPT2Tokenizer, GPT2TokenizerFast))
diff --git a/tests/models/bark/test_modeling_bark.py b/tests/models/bark/test_modeling_bark.py
index 8744cb168ff691..04a6ad99b8d27c 100644
--- a/tests/models/bark/test_modeling_bark.py
+++ b/tests/models/bark/test_modeling_bark.py
@@ -879,7 +879,7 @@ def test_resize_embeddings_untied(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference(self):
+ def test_flash_attn_2_inference_equivalence(self):
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
return
@@ -936,7 +936,7 @@ def test_flash_attn_2_inference(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
return
diff --git a/tests/models/beit/test_modeling_beit.py b/tests/models/beit/test_modeling_beit.py
index f82cf40cdadcb4..50287cb7bc948d 100644
--- a/tests/models/beit/test_modeling_beit.py
+++ b/tests/models/beit/test_modeling_beit.py
@@ -42,7 +42,6 @@
BeitModel,
)
from transformers.models.auto.modeling_auto import MODEL_FOR_BACKBONE_MAPPING_NAMES, MODEL_MAPPING_NAMES
- from transformers.models.beit.modeling_beit import BEIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -385,9 +384,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BEIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BeitModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/beit-base-patch16-224"
+ model = BeitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/bert/test_modeling_bert.py b/tests/models/bert/test_modeling_bert.py
index bc38356852935b..bdc812ff27657b 100644
--- a/tests/models/bert/test_modeling_bert.py
+++ b/tests/models/bert/test_modeling_bert.py
@@ -42,7 +42,6 @@
BertModel,
logging,
)
- from transformers.models.bert.modeling_bert import BERT_PRETRAINED_MODEL_ARCHIVE_LIST
class BertModelTester:
@@ -596,9 +595,9 @@ def test_for_warning_if_padding_and_no_attention_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google-bert/bert-base-uncased"
+ model = BertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_accelerator
diff --git a/tests/models/big_bird/test_modeling_big_bird.py b/tests/models/big_bird/test_modeling_big_bird.py
index e3ae650c563402..02af95879a532c 100644
--- a/tests/models/big_bird/test_modeling_big_bird.py
+++ b/tests/models/big_bird/test_modeling_big_bird.py
@@ -41,7 +41,6 @@
BigBirdForTokenClassification,
BigBirdModel,
)
- from transformers.models.big_bird.modeling_big_bird import BIG_BIRD_PRETRAINED_MODEL_ARCHIVE_LIST
class BigBirdModelTester:
@@ -561,9 +560,9 @@ def test_retain_grad_hidden_states_attentions(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BIG_BIRD_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BigBirdForPreTraining.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/bigbird-roberta-base"
+ model = BigBirdForPreTraining.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_model_various_attn_type(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
diff --git a/tests/models/biogpt/test_modeling_biogpt.py b/tests/models/biogpt/test_modeling_biogpt.py
index b74cbdcb0f5652..58dd39e86a5867 100644
--- a/tests/models/biogpt/test_modeling_biogpt.py
+++ b/tests/models/biogpt/test_modeling_biogpt.py
@@ -36,7 +36,6 @@
BioGptModel,
BioGptTokenizer,
)
- from transformers.models.biogpt.modeling_biogpt import BIOGPT_PRETRAINED_MODEL_ARCHIVE_LIST
class BioGptModelTester:
@@ -382,9 +381,9 @@ def test_batch_generation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BIOGPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BioGptModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/biogpt"
+ model = BioGptModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Copied from tests.models.opt.test_modeling_opt.OPTModelTest.test_opt_sequence_classification_model with OPT->BioGpt,opt->biogpt,prepare_config_and_inputs->prepare_config_and_inputs_for_common
def test_biogpt_sequence_classification_model(self):
@@ -415,6 +414,10 @@ def test_biogpt_sequence_classification_model_for_multi_label(self):
result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+ @unittest.skip("The `input_embeds` when fed don't produce the same results.")
+ def test_beam_sample_generate(self):
+ pass
+
@require_torch
class BioGptModelIntegrationTest(unittest.TestCase):
diff --git a/tests/models/bit/test_modeling_bit.py b/tests/models/bit/test_modeling_bit.py
index 1705aad976c091..dbc4cacdeb970d 100644
--- a/tests/models/bit/test_modeling_bit.py
+++ b/tests/models/bit/test_modeling_bit.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import BitBackbone, BitForImageClassification, BitImageProcessor, BitModel
- from transformers.models.bit.modeling_bit import BIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -269,9 +268,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BitModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/bit-50"
+ model = BitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -285,13 +284,11 @@ def prepare_img():
class BitModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return (
- BitImageProcessor.from_pretrained(BIT_PRETRAINED_MODEL_ARCHIVE_LIST[0]) if is_vision_available() else None
- )
+ return BitImageProcessor.from_pretrained("google/bit-50") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
- model = BitForImageClassification.from_pretrained(BIT_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(torch_device)
+ model = BitForImageClassification.from_pretrained("google/bit-50").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/blip/test_modeling_blip.py b/tests/models/blip/test_modeling_blip.py
index 51f1690ff1f5cc..9529abc2726df5 100644
--- a/tests/models/blip/test_modeling_blip.py
+++ b/tests/models/blip/test_modeling_blip.py
@@ -57,7 +57,6 @@
BlipTextModel,
BlipVisionModel,
)
- from transformers.models.blip.modeling_blip import BLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -223,9 +222,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class BlipTextModelTester:
@@ -369,9 +368,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self):
super().test_pt_tf_model_equivalence(allow_missing_keys=True)
@@ -579,9 +578,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self):
super().test_pt_tf_model_equivalence(allow_missing_keys=True)
@@ -1038,9 +1037,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
@@ -1254,9 +1253,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/blip/test_modeling_blip_text.py b/tests/models/blip/test_modeling_blip_text.py
index c004a8934ef0a2..3c12a7e9ea428a 100644
--- a/tests/models/blip/test_modeling_blip_text.py
+++ b/tests/models/blip/test_modeling_blip_text.py
@@ -29,7 +29,6 @@
import torch
from transformers import BlipTextModel
- from transformers.models.blip.modeling_blip import BLIP_PRETRAINED_MODEL_ARCHIVE_LIST
class BlipTextModelTester:
@@ -173,9 +172,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BlipTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = BlipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self):
super().test_pt_tf_model_equivalence(allow_missing_keys=True)
diff --git a/tests/models/blip/test_modeling_tf_blip.py b/tests/models/blip/test_modeling_tf_blip.py
index 11e18403dcfa48..a35eb7a1bdee79 100644
--- a/tests/models/blip/test_modeling_tf_blip.py
+++ b/tests/models/blip/test_modeling_tf_blip.py
@@ -45,7 +45,6 @@
TFBlipVisionModel,
)
from transformers.modeling_tf_utils import keras
- from transformers.models.blip.modeling_tf_blip import TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -191,9 +190,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class TFBlipTextModelTester:
@@ -319,9 +318,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
@@ -428,9 +427,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
@@ -716,9 +715,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Tested in individual model tests")
def test_compile_tf_model(self):
@@ -831,9 +830,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/blip/test_modeling_tf_blip_text.py b/tests/models/blip/test_modeling_tf_blip_text.py
index a21bdd109f89a1..7583b61b5802a3 100644
--- a/tests/models/blip/test_modeling_tf_blip_text.py
+++ b/tests/models/blip/test_modeling_tf_blip_text.py
@@ -31,7 +31,6 @@
import tensorflow as tf
from transformers import TFBlipTextModel
- from transformers.models.blip.modeling_tf_blip import TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST
class BlipTextModelTester:
@@ -173,9 +172,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFBlipTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip-vqa-base"
+ model = TFBlipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
diff --git a/tests/models/blip_2/test_modeling_blip_2.py b/tests/models/blip_2/test_modeling_blip_2.py
index 4abbba22f50f52..ccf3051a170fca 100644
--- a/tests/models/blip_2/test_modeling_blip_2.py
+++ b/tests/models/blip_2/test_modeling_blip_2.py
@@ -49,7 +49,6 @@
from torch import nn
from transformers import Blip2ForConditionalGeneration, Blip2Model, Blip2VisionModel
- from transformers.models.blip_2.modeling_blip_2 import BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -217,9 +216,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Blip2VisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2VisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class Blip2QFormerModelTester:
@@ -504,9 +503,9 @@ def test_load_vision_qformer_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = Blip2ForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2ForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# this class is based on `T5ModelTester` found in tests/models/t5/test_modeling_t5.py
@@ -766,9 +765,9 @@ def test_load_vision_qformer_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLIP_2_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = Blip2ForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2ForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_get_text_features(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/bloom/test_modeling_bloom.py b/tests/models/bloom/test_modeling_bloom.py
index 95160179c204a5..d0ee36dc3ca1d9 100644
--- a/tests/models/bloom/test_modeling_bloom.py
+++ b/tests/models/bloom/test_modeling_bloom.py
@@ -30,7 +30,6 @@
import torch
from transformers import (
- BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST,
BloomForCausalLM,
BloomForQuestionAnswering,
BloomForSequenceClassification,
@@ -396,9 +395,9 @@ def test_past_key_values_format(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BloomModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "bigscience/bigscience-small-testing"
+ model = BloomModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_accelerator
diff --git a/tests/models/bloom/test_tokenization_bloom.py b/tests/models/bloom/test_tokenization_bloom.py
index 4fbfcb8923ee0b..fec0f83af90bdb 100644
--- a/tests/models/bloom/test_tokenization_bloom.py
+++ b/tests/models/bloom/test_tokenization_bloom.py
@@ -132,13 +132,6 @@ def test_encodings_from_xnli_dataset(self):
predicted_text = [tokenizer.decode(x, clean_up_tokenization_spaces=False) for x in output_tokens]
self.assertListEqual(predicted_text, input_text)
- def test_pretrained_model_lists(self):
- # The test has to be overriden because BLOOM uses ALiBi positional embeddings that does not have
- # any sequence length constraints. This test of the parent class will fail since it relies on the
- # maximum sequence length of the positoonal embeddings.
- self.assertGreaterEqual(len(self.tokenizer_class.pretrained_vocab_files_map), 1)
- self.assertGreaterEqual(len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]), 1)
-
@require_jinja
def test_tokenization_for_chat(self):
tokenizer = self.get_rust_tokenizer()
diff --git a/tests/models/bridgetower/test_modeling_bridgetower.py b/tests/models/bridgetower/test_modeling_bridgetower.py
index 8c7bd00ee6683a..971ea4f08a815a 100644
--- a/tests/models/bridgetower/test_modeling_bridgetower.py
+++ b/tests/models/bridgetower/test_modeling_bridgetower.py
@@ -49,7 +49,6 @@
BridgeTowerForMaskedLM,
BridgeTowerModel,
)
- from transformers.models.bridgetower.modeling_bridgetower import BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -356,9 +355,9 @@ def test_for_masked_language_modeling(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BridgeTowerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "BridgeTower/bridgetower-base"
+ model = BridgeTowerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_save_load_fast_init_from_base(self):
diff --git a/tests/models/bros/test_modeling_bros.py b/tests/models/bros/test_modeling_bros.py
index c4fbaa2f98d3df..755deefcb48383 100644
--- a/tests/models/bros/test_modeling_bros.py
+++ b/tests/models/bros/test_modeling_bros.py
@@ -35,9 +35,6 @@
BrosSpadeEEForTokenClassification,
BrosSpadeELForTokenClassification,
)
- from transformers.models.bros.modeling_bros import (
- BROS_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
class BrosModelTester:
@@ -370,9 +367,9 @@ def test_for_spade_el_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in BROS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = BrosModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "jinho8345/bros-base-uncased"
+ model = BrosModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def prepare_bros_batch_inputs():
diff --git a/tests/models/byt5/test_tokenization_byt5.py b/tests/models/byt5/test_tokenization_byt5.py
index bfc36070b2ada3..3793241d7e1a7d 100644
--- a/tests/models/byt5/test_tokenization_byt5.py
+++ b/tests/models/byt5/test_tokenization_byt5.py
@@ -300,10 +300,6 @@ def test_decode_single_bytes(self):
self.assertTrue(tokenizer.decode([255]) == "")
- # tokenizer can be instantiated without any pretrained files, so no need for pretrained tokenizer list
- def test_pretrained_model_lists(self):
- pass
-
# tokenizer does not have vocabulary
def test_get_vocab(self):
pass
diff --git a/tests/models/canine/test_modeling_canine.py b/tests/models/canine/test_modeling_canine.py
index f10823fc566499..eeb5aa40dda7df 100644
--- a/tests/models/canine/test_modeling_canine.py
+++ b/tests/models/canine/test_modeling_canine.py
@@ -36,7 +36,6 @@
CanineForTokenClassification,
CanineModel,
)
- from transformers.models.canine.modeling_canine import CANINE_PRETRAINED_MODEL_ARCHIVE_LIST
class CanineModelTester:
@@ -527,9 +526,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CANINE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CanineModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/canine-s"
+ model = CanineModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/canine/test_tokenization_canine.py b/tests/models/canine/test_tokenization_canine.py
index eb3e6d9b4af4c9..ec987f6dd64afb 100644
--- a/tests/models/canine/test_tokenization_canine.py
+++ b/tests/models/canine/test_tokenization_canine.py
@@ -320,10 +320,6 @@ def test_np_encode_plus_sent_to_model(self):
def test_torch_encode_plus_sent_to_model(self):
pass
- # tokenizer can be instantiated without any pretrained files, so no need for pretrained tokenizer list
- def test_pretrained_model_lists(self):
- pass
-
# tokenizer does not have vocabulary
def test_get_vocab(self):
pass
diff --git a/tests/models/chinese_clip/test_modeling_chinese_clip.py b/tests/models/chinese_clip/test_modeling_chinese_clip.py
index 06c946bf107d03..8ee9028eca26d5 100644
--- a/tests/models/chinese_clip/test_modeling_chinese_clip.py
+++ b/tests/models/chinese_clip/test_modeling_chinese_clip.py
@@ -48,7 +48,6 @@
ChineseCLIPTextModel,
ChineseCLIPVisionModel,
)
- from transformers.models.chinese_clip.modeling_chinese_clip import CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -385,9 +384,9 @@ def test_model_as_decoder_with_default_input_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ChineseCLIPTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_training(self):
pass
@@ -495,9 +494,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ChineseCLIPVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class ChineseCLIPModelTester:
@@ -693,9 +692,9 @@ def _create_and_check_torchscript(self, config, inputs_dict):
@slow
def test_model_from_pretrained(self):
- for model_name in CHINESE_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ChineseCLIPModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of Pikachu
diff --git a/tests/models/clap/test_modeling_clap.py b/tests/models/clap/test_modeling_clap.py
index fe3e8b0e547e1e..f06fabf0a23732 100644
--- a/tests/models/clap/test_modeling_clap.py
+++ b/tests/models/clap/test_modeling_clap.py
@@ -49,7 +49,6 @@
ClapTextModel,
ClapTextModelWithProjection,
)
- from transformers.models.clap.modeling_clap import CLAP_PRETRAINED_MODEL_ARCHIVE_LIST
class ClapAudioModelTester:
@@ -275,16 +274,16 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLAP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClapAudioModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "laion/clap-htsat-fused"
+ model = ClapAudioModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_model_with_projection_from_pretrained(self):
- for model_name in CLAP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClapAudioModelWithProjection.from_pretrained(model_name)
- self.assertIsNotNone(model)
- self.assertTrue(hasattr(model, "audio_projection"))
+ model_name = "laion/clap-htsat-fused"
+ model = ClapAudioModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "audio_projection"))
class ClapTextModelTester:
@@ -444,16 +443,16 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLAP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClapTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "laion/clap-htsat-fused"
+ model = ClapTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_model_with_projection_from_pretrained(self):
- for model_name in CLAP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClapTextModelWithProjection.from_pretrained(model_name)
- self.assertIsNotNone(model)
- self.assertTrue(hasattr(model, "text_projection"))
+ model_name = "laion/clap-htsat-fused"
+ model = ClapTextModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "text_projection"))
class ClapModelTester:
@@ -650,9 +649,9 @@ def test_load_audio_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLAP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClapModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "laion/clap-htsat-fused"
+ model = ClapModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
diff --git a/tests/models/clip/test_modeling_clip.py b/tests/models/clip/test_modeling_clip.py
index fbcb22575af992..16c8f47b782fad 100644
--- a/tests/models/clip/test_modeling_clip.py
+++ b/tests/models/clip/test_modeling_clip.py
@@ -58,7 +58,6 @@
CLIPVisionModel,
CLIPVisionModelWithProjection,
)
- from transformers.models.clip.modeling_clip import CLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -250,16 +249,16 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = CLIPVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_model_with_projection_from_pretrained(self):
- for model_name in CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPVisionModelWithProjection.from_pretrained(model_name)
- self.assertIsNotNone(model)
- self.assertTrue(hasattr(model, "visual_projection"))
+ model_name = "openai/clip-vit-base-patch32"
+ model = CLIPVisionModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "visual_projection"))
class CLIPTextModelTester:
@@ -415,16 +414,16 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = CLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_model_with_projection_from_pretrained(self):
- for model_name in CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPTextModelWithProjection.from_pretrained(model_name)
- self.assertIsNotNone(model)
- self.assertTrue(hasattr(model, "text_projection"))
+ model_name = "openai/clip-vit-base-patch32"
+ model = CLIPTextModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "text_projection"))
class CLIPModelTester:
@@ -741,9 +740,9 @@ def test_equivalence_flax_to_pt(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = CLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class CLIPForImageClassificationModelTester(CLIPModelTester):
diff --git a/tests/models/clip/test_modeling_tf_clip.py b/tests/models/clip/test_modeling_tf_clip.py
index 8feeeebd0d80cb..4e1ec7f88eb706 100644
--- a/tests/models/clip/test_modeling_tf_clip.py
+++ b/tests/models/clip/test_modeling_tf_clip.py
@@ -39,7 +39,6 @@
from transformers import TFCLIPModel, TFCLIPTextModel, TFCLIPVisionModel, TFSharedEmbeddings
from transformers.modeling_tf_utils import keras
- from transformers.models.clip.modeling_tf_clip import TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -257,9 +256,9 @@ def check_hidden_states_output(inputs_dict, config, model_class):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFCLIPVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = TFCLIPVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_saved_model_creation_extended(self):
@@ -423,9 +422,9 @@ def test_inputs_embeds(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFCLIPTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = TFCLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_saved_model_creation_extended(self):
@@ -607,9 +606,9 @@ def test_keras_save_load(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFCLIPModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/clip-vit-base-patch32"
+ model = TFCLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Currently `saved_model` doesn't work with nested outputs.")
@slow
diff --git a/tests/models/clipseg/test_modeling_clipseg.py b/tests/models/clipseg/test_modeling_clipseg.py
index 8f3ab2b04fa2e3..6b82a9af41c3d8 100644
--- a/tests/models/clipseg/test_modeling_clipseg.py
+++ b/tests/models/clipseg/test_modeling_clipseg.py
@@ -52,7 +52,6 @@
from transformers import CLIPSegForImageSegmentation, CLIPSegModel, CLIPSegTextModel, CLIPSegVisionModel
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.clipseg.modeling_clipseg import CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -224,9 +223,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPSegVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "CIDAS/clipseg-rd64-refined"
+ model = CLIPSegVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class CLIPSegTextModelTester:
@@ -365,9 +364,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPSegTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "CIDAS/clipseg-rd64-refined"
+ model = CLIPSegTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class CLIPSegModelTester:
@@ -768,9 +767,9 @@ def test_training(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CLIPSegModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "CIDAS/clipseg-rd64-refined"
+ model = CLIPSegModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/clvp/test_modeling_clvp.py b/tests/models/clvp/test_modeling_clvp.py
index 59e6c1be402cdc..7d5064377f7f76 100644
--- a/tests/models/clvp/test_modeling_clvp.py
+++ b/tests/models/clvp/test_modeling_clvp.py
@@ -45,7 +45,6 @@
import torch
from transformers import ClvpEncoder, ClvpForCausalLM, ClvpModel, ClvpModelForConditionalGeneration
- from transformers.models.clvp.modeling_clvp import CLVP_PRETRAINED_MODEL_ARCHIVE_LIST
from transformers import ClvpFeatureExtractor, ClvpTokenizer
@@ -541,9 +540,9 @@ def test_load_speech_text_decoder_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CLVP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ClvpModelForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "susnato/clvp_dev"
+ model = ClvpModelForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Since Clvp has a lot of different models connected with each other it's better to test each of them individually along
diff --git a/tests/models/codegen/test_modeling_codegen.py b/tests/models/codegen/test_modeling_codegen.py
index e042ccac71dab0..9dce2713f53f88 100644
--- a/tests/models/codegen/test_modeling_codegen.py
+++ b/tests/models/codegen/test_modeling_codegen.py
@@ -30,7 +30,7 @@
if is_torch_available():
import torch
- from transformers import CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST, AutoTokenizer, CodeGenForCausalLM, CodeGenModel
+ from transformers import AutoTokenizer, CodeGenForCausalLM, CodeGenModel
class CodeGenModelTester:
@@ -456,9 +456,9 @@ def test_batch_generation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CODEGEN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CodeGenModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/codegen-350M-nl"
+ model = CodeGenModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/convbert/test_modeling_convbert.py b/tests/models/convbert/test_modeling_convbert.py
index 281a8e477b0b9b..80a31c9bc24a98 100644
--- a/tests/models/convbert/test_modeling_convbert.py
+++ b/tests/models/convbert/test_modeling_convbert.py
@@ -38,7 +38,6 @@
ConvBertForTokenClassification,
ConvBertModel,
)
- from transformers.models.convbert.modeling_convbert import CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST
class ConvBertModelTester:
@@ -307,9 +306,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ConvBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "YituTech/conv-bert-base"
+ model = ConvBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/convnext/test_modeling_convnext.py b/tests/models/convnext/test_modeling_convnext.py
index a56c38e3876b50..9f0789dffcb8aa 100644
--- a/tests/models/convnext/test_modeling_convnext.py
+++ b/tests/models/convnext/test_modeling_convnext.py
@@ -31,7 +31,6 @@
import torch
from transformers import ConvNextBackbone, ConvNextForImageClassification, ConvNextModel
- from transformers.models.convnext.modeling_convnext import CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -257,9 +256,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CONVNEXT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ConvNextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/convnext-tiny-224"
+ model = ConvNextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/convnextv2/test_modeling_convnextv2.py b/tests/models/convnextv2/test_modeling_convnextv2.py
index b13028dba8045d..5d78d31c3e63dc 100644
--- a/tests/models/convnextv2/test_modeling_convnextv2.py
+++ b/tests/models/convnextv2/test_modeling_convnextv2.py
@@ -32,7 +32,6 @@
import torch
from transformers import ConvNextV2Backbone, ConvNextV2ForImageClassification, ConvNextV2Model
- from transformers.models.convnextv2.modeling_convnextv2 import CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -306,9 +305,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CONVNEXTV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ConvNextV2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/convnextv2-tiny-1k-224"
+ model = ConvNextV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/ctrl/test_modeling_ctrl.py b/tests/models/ctrl/test_modeling_ctrl.py
index 71dcd02ed59f7e..6d44bdfb4ae672 100644
--- a/tests/models/ctrl/test_modeling_ctrl.py
+++ b/tests/models/ctrl/test_modeling_ctrl.py
@@ -29,7 +29,6 @@
import torch
from transformers import (
- CTRL_PRETRAINED_MODEL_ARCHIVE_LIST,
CTRLForSequenceClassification,
CTRLLMHeadModel,
CTRLModel,
@@ -245,9 +244,9 @@ def test_ctrl_lm_head_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CTRL_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CTRLModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/ctrl"
+ model = CTRLModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/ctrl/test_modeling_tf_ctrl.py b/tests/models/ctrl/test_modeling_tf_ctrl.py
index 29a8b6fb6a36f6..d8317c919d480c 100644
--- a/tests/models/ctrl/test_modeling_tf_ctrl.py
+++ b/tests/models/ctrl/test_modeling_tf_ctrl.py
@@ -31,7 +31,6 @@
from transformers.modeling_tf_utils import keras
from transformers.models.ctrl.modeling_tf_ctrl import (
- TF_CTRL_PRETRAINED_MODEL_ARCHIVE_LIST,
TFCTRLForSequenceClassification,
TFCTRLLMHeadModel,
TFCTRLModel,
@@ -249,9 +248,9 @@ def test_model_common_attributes(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_CTRL_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFCTRLModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/ctrl"
+ model = TFCTRLModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/cvt/test_modeling_cvt.py b/tests/models/cvt/test_modeling_cvt.py
index aef8108e1766c4..8e9376de274ddf 100644
--- a/tests/models/cvt/test_modeling_cvt.py
+++ b/tests/models/cvt/test_modeling_cvt.py
@@ -31,7 +31,6 @@
import torch
from transformers import CvtForImageClassification, CvtModel
- from transformers.models.cvt.modeling_cvt import CVT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -236,9 +235,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in CVT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = CvtModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/cvt-13"
+ model = CvtModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -252,11 +251,11 @@ def prepare_img():
class CvtModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return AutoImageProcessor.from_pretrained(CVT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ return AutoImageProcessor.from_pretrained("microsoft/cvt-13")
@slow
def test_inference_image_classification_head(self):
- model = CvtForImageClassification.from_pretrained(CVT_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(torch_device)
+ model = CvtForImageClassification.from_pretrained("microsoft/cvt-13").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/cvt/test_modeling_tf_cvt.py b/tests/models/cvt/test_modeling_tf_cvt.py
index 4ec245ad49c3ed..0cae0bbcf23828 100644
--- a/tests/models/cvt/test_modeling_tf_cvt.py
+++ b/tests/models/cvt/test_modeling_tf_cvt.py
@@ -23,7 +23,6 @@
from transformers import TFCvtForImageClassification, TFCvtModel
from transformers.modeling_tf_utils import keras
- from transformers.models.cvt.modeling_tf_cvt import TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -251,9 +250,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFCvtModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/cvt-13"
+ model = TFCvtModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -267,11 +266,11 @@ def prepare_img():
class TFCvtModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return AutoImageProcessor.from_pretrained(TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ return AutoImageProcessor.from_pretrained("microsoft/cvt-13")
@slow
def test_inference_image_classification_head(self):
- model = TFCvtForImageClassification.from_pretrained(TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ model = TFCvtForImageClassification.from_pretrained("microsoft/cvt-13")
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/data2vec/test_modeling_data2vec_text.py b/tests/models/data2vec/test_modeling_data2vec_text.py
index afaa8a76addb7b..5a3edaa7ad2d5e 100644
--- a/tests/models/data2vec/test_modeling_data2vec_text.py
+++ b/tests/models/data2vec/test_modeling_data2vec_text.py
@@ -39,7 +39,6 @@
Data2VecTextModel,
)
from transformers.models.data2vec.modeling_data2vec_text import (
- DATA2VEC_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
Data2VecTextForTextEmbeddings,
create_position_ids_from_input_ids,
)
@@ -470,9 +469,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DATA2VEC_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Data2VecTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/data2vec-text-base"
+ model = Data2VecTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_create_position_ids_respects_padding_index(self):
"""Ensure that the default position ids only assign a sequential . This is a regression
diff --git a/tests/models/data2vec/test_modeling_data2vec_vision.py b/tests/models/data2vec/test_modeling_data2vec_vision.py
index 3e00dd0bf314d4..c426a6ca7e98ce 100644
--- a/tests/models/data2vec/test_modeling_data2vec_vision.py
+++ b/tests/models/data2vec/test_modeling_data2vec_vision.py
@@ -36,7 +36,6 @@
Data2VecVisionModel,
)
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.data2vec.modeling_data2vec_vision import DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -298,9 +297,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Data2VecVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/data2vec-vision-base-ft1k"
+ model = Data2VecVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/data2vec/test_modeling_tf_data2vec_vision.py b/tests/models/data2vec/test_modeling_tf_data2vec_vision.py
index 685a9e46808a2d..bb6e0d5476d576 100644
--- a/tests/models/data2vec/test_modeling_tf_data2vec_vision.py
+++ b/tests/models/data2vec/test_modeling_tf_data2vec_vision.py
@@ -40,9 +40,6 @@
TFData2VecVisionModel,
)
from transformers.modeling_tf_utils import keras
- from transformers.models.data2vec.modeling_tf_data2vec_vision import (
- TF_DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_vision_available():
from PIL import Image
@@ -455,9 +452,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_DATA2VEC_VISION_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFData2VecVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/data2vec-vision-base-ft1k"
+ model = TFData2VecVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/deberta/test_modeling_deberta.py b/tests/models/deberta/test_modeling_deberta.py
index 52758e2222aeaf..d511279c785ba2 100644
--- a/tests/models/deberta/test_modeling_deberta.py
+++ b/tests/models/deberta/test_modeling_deberta.py
@@ -32,7 +32,6 @@
DebertaForTokenClassification,
DebertaModel,
)
- from transformers.models.deberta.modeling_deberta import DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST
class DebertaModelTester(object):
@@ -274,9 +273,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DebertaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/deberta-base"
+ model = DebertaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/deberta_v2/test_modeling_deberta_v2.py b/tests/models/deberta_v2/test_modeling_deberta_v2.py
index abfbe7402c93a0..80df003b1efe28 100644
--- a/tests/models/deberta_v2/test_modeling_deberta_v2.py
+++ b/tests/models/deberta_v2/test_modeling_deberta_v2.py
@@ -33,7 +33,6 @@
DebertaV2ForTokenClassification,
DebertaV2Model,
)
- from transformers.models.deberta_v2.modeling_deberta_v2 import DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST
class DebertaV2ModelTester(object):
@@ -292,9 +291,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DebertaV2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/deberta-v2-xlarge"
+ model = DebertaV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/decision_transformer/test_modeling_decision_transformer.py b/tests/models/decision_transformer/test_modeling_decision_transformer.py
index d99521b2f19eb1..f7f362dce8359a 100644
--- a/tests/models/decision_transformer/test_modeling_decision_transformer.py
+++ b/tests/models/decision_transformer/test_modeling_decision_transformer.py
@@ -31,9 +31,6 @@
import torch
from transformers import DecisionTransformerModel
- from transformers.models.decision_transformer.modeling_decision_transformer import (
- DECISION_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
class DecisionTransformerModelTester:
@@ -164,9 +161,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DECISION_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DecisionTransformerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "edbeeching/decision-transformer-gym-hopper-medium"
+ model = DecisionTransformerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/deit/test_modeling_deit.py b/tests/models/deit/test_modeling_deit.py
index 07f581bfeb2b9b..9a54f16dab689f 100644
--- a/tests/models/deit/test_modeling_deit.py
+++ b/tests/models/deit/test_modeling_deit.py
@@ -50,7 +50,6 @@
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES,
MODEL_MAPPING_NAMES,
)
- from transformers.models.deit.modeling_deit import DEIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -367,9 +366,9 @@ def test_problem_types(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DEIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DeiTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/deit-base-distilled-patch16-224"
+ model = DeiTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/deit/test_modeling_tf_deit.py b/tests/models/deit/test_modeling_tf_deit.py
index 848370a113297c..26980e84207d50 100644
--- a/tests/models/deit/test_modeling_tf_deit.py
+++ b/tests/models/deit/test_modeling_tf_deit.py
@@ -41,7 +41,6 @@
TFDeiTModel,
)
from transformers.modeling_tf_utils import keras
- from transformers.models.deit.modeling_tf_deit import TF_DEIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -252,9 +251,9 @@ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_DEIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFDeiTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/deit-base-distilled-patch16-224"
+ model = TFDeiTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/depth_anything/test_modeling_depth_anything.py b/tests/models/depth_anything/test_modeling_depth_anything.py
index 9657fb604453e2..3b807abf714ec7 100644
--- a/tests/models/depth_anything/test_modeling_depth_anything.py
+++ b/tests/models/depth_anything/test_modeling_depth_anything.py
@@ -30,7 +30,6 @@
import torch
from transformers import DepthAnythingForDepthEstimation
- from transformers.models.depth_anything.modeling_depth_anything import DEPTH_ANYTHING_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -205,9 +204,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DEPTH_ANYTHING_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DepthAnythingForDepthEstimation.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "LiheYoung/depth-anything-small-hf"
+ model = DepthAnythingForDepthEstimation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/dinat/test_modeling_dinat.py b/tests/models/dinat/test_modeling_dinat.py
index c29339881eb495..158ce7739534ac 100644
--- a/tests/models/dinat/test_modeling_dinat.py
+++ b/tests/models/dinat/test_modeling_dinat.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import DinatBackbone, DinatForImageClassification, DinatModel
- from transformers.models.dinat.modeling_dinat import DINAT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -330,9 +329,9 @@ def test_hidden_states_output(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DINAT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DinatModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "shi-labs/dinat-mini-in1k-224"
+ model = DinatModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/dinov2/test_modeling_dinov2.py b/tests/models/dinov2/test_modeling_dinov2.py
index f0365cac2a59ee..9896f2c2bb5a93 100644
--- a/tests/models/dinov2/test_modeling_dinov2.py
+++ b/tests/models/dinov2/test_modeling_dinov2.py
@@ -38,7 +38,6 @@
from torch import nn
from transformers import Dinov2Backbone, Dinov2ForImageClassification, Dinov2Model
- from transformers.models.dinov2.modeling_dinov2 import DINOV2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -287,9 +286,9 @@ def test_feed_forward_chunking(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DINOV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Dinov2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dinov2-base"
+ model = Dinov2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/distilbert/test_modeling_distilbert.py b/tests/models/distilbert/test_modeling_distilbert.py
index 9ab9d01577a974..6bd821859ea2d0 100644
--- a/tests/models/distilbert/test_modeling_distilbert.py
+++ b/tests/models/distilbert/test_modeling_distilbert.py
@@ -30,7 +30,6 @@
import torch
from transformers import (
- DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
DistilBertForMaskedLM,
DistilBertForMultipleChoice,
DistilBertForQuestionAnswering,
@@ -38,6 +37,7 @@
DistilBertForTokenClassification,
DistilBertModel,
)
+ from transformers.models.distilbert.modeling_distilbert import _create_sinusoidal_embeddings
class DistilBertModelTester(object):
@@ -239,6 +239,15 @@ def test_distilbert_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_distilbert_model(*config_and_inputs)
+ def test_distilbert_model_with_sinusoidal_encodings(self):
+ config = DistilBertConfig(sinusoidal_pos_embds=True)
+ model = DistilBertModel(config=config)
+ sinusoidal_pos_embds = torch.empty((config.max_position_embeddings, config.dim), dtype=torch.float32)
+ _create_sinusoidal_embeddings(config.max_position_embeddings, config.dim, sinusoidal_pos_embds)
+ self.model_tester.parent.assertTrue(
+ torch.equal(model.embeddings.position_embeddings.weight, sinusoidal_pos_embds)
+ )
+
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_distilbert_for_masked_lm(*config_and_inputs)
@@ -261,9 +270,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DistilBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "distilbert-base-uncased"
+ model = DistilBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_accelerator
@@ -292,7 +301,7 @@ def test_torchscript_device_change(self):
@require_torch_accelerator
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference(self):
+ def test_flash_attn_2_inference_equivalence(self):
import torch
for model_class in self.all_model_classes:
@@ -344,7 +353,7 @@ def test_flash_attn_2_inference(self):
@require_torch_accelerator
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
import torch
for model_class in self.all_model_classes:
diff --git a/tests/models/distilbert/test_modeling_tf_distilbert.py b/tests/models/distilbert/test_modeling_tf_distilbert.py
index 937dd24d6d77b4..270cea00de6e69 100644
--- a/tests/models/distilbert/test_modeling_tf_distilbert.py
+++ b/tests/models/distilbert/test_modeling_tf_distilbert.py
@@ -30,7 +30,6 @@
import tensorflow as tf
from transformers.models.distilbert.modeling_tf_distilbert import (
- TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
TFDistilBertForMaskedLM,
TFDistilBertForMultipleChoice,
TFDistilBertForQuestionAnswering,
@@ -233,9 +232,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in list(TF_DISTILBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]):
- model = TFDistilBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "distilbert/distilbert-base-cased"
+ model = TFDistilBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/donut/test_modeling_donut_swin.py b/tests/models/donut/test_modeling_donut_swin.py
index 23b7094d9b743f..4d9be165bb9148 100644
--- a/tests/models/donut/test_modeling_donut_swin.py
+++ b/tests/models/donut/test_modeling_donut_swin.py
@@ -31,7 +31,6 @@
from torch import nn
from transformers import DonutSwinModel
- from transformers.models.donut.modeling_donut_swin import DONUT_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST
class DonutSwinModelTester:
@@ -334,9 +333,9 @@ def test_hidden_states_output_with_padding(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DONUT_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DonutSwinModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "naver-clova-ix/donut-base"
+ model = DonutSwinModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/dpr/test_modeling_dpr.py b/tests/models/dpr/test_modeling_dpr.py
index b6a687a351b0be..7a41820f2d8ea7 100644
--- a/tests/models/dpr/test_modeling_dpr.py
+++ b/tests/models/dpr/test_modeling_dpr.py
@@ -29,11 +29,6 @@
import torch
from transformers import DPRContextEncoder, DPRQuestionEncoder, DPRReader, DPRReaderTokenizer
- from transformers.models.dpr.modeling_dpr import (
- DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST,
- DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST,
- DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
class DPRModelTester:
@@ -230,21 +225,21 @@ def test_init_changed_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPRContextEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = DPRContextEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPRContextEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = DPRContextEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPRQuestionEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = DPRQuestionEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPRReader.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = DPRReader.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/dpr/test_modeling_tf_dpr.py b/tests/models/dpr/test_modeling_tf_dpr.py
index 11351408623343..92d74e72e33bd4 100644
--- a/tests/models/dpr/test_modeling_tf_dpr.py
+++ b/tests/models/dpr/test_modeling_tf_dpr.py
@@ -30,9 +30,6 @@
import tensorflow as tf
from transformers import (
- TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST,
- TF_DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST,
- TF_DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST,
BertConfig,
DPRConfig,
TFDPRContextEncoder,
@@ -213,21 +210,21 @@ def test_dpr_reader_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFDPRContextEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = TFDPRContextEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in TF_DPR_CONTEXT_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFDPRContextEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = TFDPRContextEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in TF_DPR_QUESTION_ENCODER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFDPRQuestionEncoder.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = TFDPRQuestionEncoder.from_pretrained(model_name)
+ self.assertIsNotNone(model)
- for model_name in TF_DPR_READER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFDPRReader.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/dpr-ctx_encoder-single-nq-base"
+ model = TFDPRReader.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/dpt/test_modeling_dpt.py b/tests/models/dpt/test_modeling_dpt.py
index ffd6edbad4bff1..a49f8d5d9465bb 100644
--- a/tests/models/dpt/test_modeling_dpt.py
+++ b/tests/models/dpt/test_modeling_dpt.py
@@ -32,7 +32,6 @@
from transformers import DPTForDepthEstimation, DPTForSemanticSegmentation, DPTModel
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.dpt.modeling_dpt import DPT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -280,9 +279,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Intel/dpt-large"
+ model = DPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/dpt/test_modeling_dpt_auto_backbone.py b/tests/models/dpt/test_modeling_dpt_auto_backbone.py
index ea500b47a3c88a..01d5398edd60f1 100644
--- a/tests/models/dpt/test_modeling_dpt_auto_backbone.py
+++ b/tests/models/dpt/test_modeling_dpt_auto_backbone.py
@@ -31,7 +31,6 @@
from transformers import DPTForDepthEstimation
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.dpt.modeling_dpt import DPT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -244,9 +243,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = DPTForDepthEstimation.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Intel/dpt-large"
+ model = DPTForDepthEstimation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/dpt/test_modeling_dpt_hybrid.py b/tests/models/dpt/test_modeling_dpt_hybrid.py
index 2a6e8429ab5575..a63e736e41dbec 100644
--- a/tests/models/dpt/test_modeling_dpt_hybrid.py
+++ b/tests/models/dpt/test_modeling_dpt_hybrid.py
@@ -32,7 +32,6 @@
from transformers import DPTForDepthEstimation, DPTForSemanticSegmentation, DPTModel
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.dpt.modeling_dpt import DPT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -295,9 +294,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in DPT_PRETRAINED_MODEL_ARCHIVE_LIST[1:]:
- model = DPTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Intel/dpt-hybrid-midas"
+ model = DPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_raise_readout_type(self):
# We do this test only for DPTForDepthEstimation since it is the only model that uses readout_type
diff --git a/tests/models/efficientformer/test_modeling_efficientformer.py b/tests/models/efficientformer/test_modeling_efficientformer.py
index 070c7fccae6053..15a4cb0be38d91 100644
--- a/tests/models/efficientformer/test_modeling_efficientformer.py
+++ b/tests/models/efficientformer/test_modeling_efficientformer.py
@@ -40,9 +40,6 @@
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES,
MODEL_MAPPING_NAMES,
)
- from transformers.models.efficientformer.modeling_efficientformer import (
- EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_vision_available():
@@ -371,9 +368,9 @@ def test_problem_types(self):
@slow
def test_model_from_pretrained(self):
- for model_name in EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = EfficientFormerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "snap-research/efficientformer-l1-300"
+ model = EfficientFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/efficientformer/test_modeling_tf_efficientformer.py b/tests/models/efficientformer/test_modeling_tf_efficientformer.py
index 35cbeb75ae0ae5..fcd6958ed3dc70 100644
--- a/tests/models/efficientformer/test_modeling_tf_efficientformer.py
+++ b/tests/models/efficientformer/test_modeling_tf_efficientformer.py
@@ -38,9 +38,6 @@
TFEfficientFormerModel,
)
from transformers.modeling_tf_utils import keras
- from transformers.models.efficientformer.modeling_tf_efficientformer import (
- TF_EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_vision_available():
@@ -299,9 +296,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_EFFICIENTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFEfficientFormerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "snap-research/efficientformer-l1-300"
+ model = TFEfficientFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/efficientnet/test_modeling_efficientnet.py b/tests/models/efficientnet/test_modeling_efficientnet.py
index 19d66aca95ae2b..dbca9b31a2f859 100644
--- a/tests/models/efficientnet/test_modeling_efficientnet.py
+++ b/tests/models/efficientnet/test_modeling_efficientnet.py
@@ -30,7 +30,6 @@
import torch
from transformers import EfficientNetForImageClassification, EfficientNetModel
- from transformers.models.efficientnet.modeling_efficientnet import EFFICIENTNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -212,9 +211,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in EFFICIENTNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = EfficientNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/efficientnet-b7"
+ model = EfficientNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@is_pipeline_test
@require_vision
diff --git a/tests/models/electra/test_modeling_electra.py b/tests/models/electra/test_modeling_electra.py
index a5d3fa585e1f6e..f6cab710779079 100644
--- a/tests/models/electra/test_modeling_electra.py
+++ b/tests/models/electra/test_modeling_electra.py
@@ -39,7 +39,6 @@
ElectraForTokenClassification,
ElectraModel,
)
- from transformers.models.electra.modeling_electra import ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST
class ElectraModelTester:
@@ -463,9 +462,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ElectraModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/electra-small-generator"
+ model = ElectraModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_for_causal_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
diff --git a/tests/models/electra/test_modeling_tf_electra.py b/tests/models/electra/test_modeling_tf_electra.py
index 537cb1df2f9c51..aba6db1efa1501 100644
--- a/tests/models/electra/test_modeling_tf_electra.py
+++ b/tests/models/electra/test_modeling_tf_electra.py
@@ -593,7 +593,7 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- # for model_name in TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google/electra-small-generator'
for model_name in ["google/electra-small-discriminator"]:
model = TFElectraModel.from_pretrained(model_name)
self.assertIsNotNone(model)
diff --git a/tests/models/ernie/test_modeling_ernie.py b/tests/models/ernie/test_modeling_ernie.py
index 6fc557219c8545..da19d08e466154 100644
--- a/tests/models/ernie/test_modeling_ernie.py
+++ b/tests/models/ernie/test_modeling_ernie.py
@@ -41,7 +41,6 @@
ErnieForTokenClassification,
ErnieModel,
)
- from transformers.models.ernie.modeling_ernie import ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST
class ErnieModelTester:
@@ -569,9 +568,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ErnieModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nghuyong/ernie-1.0-base-zh"
+ model = ErnieModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_accelerator
diff --git a/tests/models/ernie_m/test_modeling_ernie_m.py b/tests/models/ernie_m/test_modeling_ernie_m.py
index 1fafcd34bafcf8..e429a12e6e0f64 100644
--- a/tests/models/ernie_m/test_modeling_ernie_m.py
+++ b/tests/models/ernie_m/test_modeling_ernie_m.py
@@ -36,7 +36,6 @@
ErnieMForTokenClassification,
ErnieMModel,
)
- from transformers.models.ernie_m.modeling_ernie_m import ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST
class ErnieMModelTester:
@@ -298,9 +297,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ErnieMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "susnato/ernie-m-base_pytorch"
+ model = ErnieMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/esm/test_modeling_esm.py b/tests/models/esm/test_modeling_esm.py
index 7e99f86bbf626b..db3ccd6fd2387e 100644
--- a/tests/models/esm/test_modeling_esm.py
+++ b/tests/models/esm/test_modeling_esm.py
@@ -30,7 +30,6 @@
from transformers import EsmForMaskedLM, EsmForSequenceClassification, EsmForTokenClassification, EsmModel
from transformers.models.esm.modeling_esm import (
- ESM_PRETRAINED_MODEL_ARCHIVE_LIST,
EsmEmbeddings,
create_position_ids_from_input_ids,
)
@@ -243,9 +242,9 @@ def test_esm_gradient_checkpointing(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ESM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = EsmModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/esm2_t6_8M_UR50D"
+ model = EsmModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_create_position_ids_respects_padding_index(self):
"""Ensure that the default position ids only assign a sequential . This is a regression
diff --git a/tests/models/esm/test_modeling_tf_esm.py b/tests/models/esm/test_modeling_tf_esm.py
index 0e92e352fea589..4accc16256dcc6 100644
--- a/tests/models/esm/test_modeling_tf_esm.py
+++ b/tests/models/esm/test_modeling_tf_esm.py
@@ -32,7 +32,6 @@
from transformers.modeling_tf_utils import keras
from transformers.models.esm.modeling_tf_esm import (
- TF_ESM_PRETRAINED_MODEL_ARCHIVE_LIST,
TFEsmForMaskedLM,
TFEsmForSequenceClassification,
TFEsmForTokenClassification,
@@ -253,9 +252,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_ESM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFEsmModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/esm2_t6_8M_UR50D"
+ model = TFEsmModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Protein models do not support embedding resizing.")
def test_resize_token_embeddings(self):
diff --git a/tests/models/falcon/test_modeling_falcon.py b/tests/models/falcon/test_modeling_falcon.py
index fa7ea2af816cb0..35708d868d0384 100644
--- a/tests/models/falcon/test_modeling_falcon.py
+++ b/tests/models/falcon/test_modeling_falcon.py
@@ -27,7 +27,14 @@
is_torch_available,
set_seed,
)
-from transformers.testing_utils import require_bitsandbytes, require_torch, require_torch_sdpa, slow, torch_device
+from transformers.testing_utils import (
+ is_flaky,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
@@ -45,6 +52,11 @@
FalconForTokenClassification,
FalconModel,
)
+ from transformers.models.falcon.modeling_falcon import (
+ FalconDynamicNTKScalingRotaryEmbedding,
+ FalconLinearScalingRotaryEmbedding,
+ FalconRotaryEmbedding,
+ )
class FalconModelTester:
@@ -408,7 +420,8 @@ def test_past_key_values_format(self):
)
@parameterized.expand([("linear",), ("dynamic",)])
- def test_model_rope_scaling(self, scaling_type):
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling_from_config with Llama->Falcon
+ def test_model_rope_scaling_from_config(self, scaling_type):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
short_input = ids_tensor([1, 10], config.vocab_size)
long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
@@ -438,6 +451,67 @@ def test_model_rope_scaling(self, scaling_type):
# The output should be different for long inputs
self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+
+ # Sanity check original RoPE
+ original_rope = FalconRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, short_input_length)
+ original_cos_long, original_sin_long = original_rope(x, long_input_length)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = FalconLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, short_input_length)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[new_position, :], original_cos_long[original_position, :])
+ torch.testing.assert_close(linear_sin_long[new_position, :], original_sin_long[original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = FalconDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, short_input_length)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+ # TODO: @Fxmarty
+ @is_flaky(max_attempts=3, description="flaky on some models.")
@require_torch_sdpa
@slow
def test_eager_matches_sdpa_generate(self):
diff --git a/tests/models/flaubert/test_modeling_flaubert.py b/tests/models/flaubert/test_modeling_flaubert.py
index fc275bdd8a02ad..de0fd88db466ff 100644
--- a/tests/models/flaubert/test_modeling_flaubert.py
+++ b/tests/models/flaubert/test_modeling_flaubert.py
@@ -36,7 +36,7 @@
FlaubertModel,
FlaubertWithLMHeadModel,
)
- from transformers.models.flaubert.modeling_flaubert import FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST
+ from transformers.models.flaubert.modeling_flaubert import create_sinusoidal_embeddings
class FlaubertModelTester(object):
@@ -432,6 +432,14 @@ def test_flaubert_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_model(*config_and_inputs)
+ # Copied from tests/models/distilbert/test_modeling_distilbert.py with Distilbert->Flaubert
+ def test_flaubert_model_with_sinusoidal_encodings(self):
+ config = FlaubertConfig(sinusoidal_embeddings=True)
+ model = FlaubertModel(config=config)
+ sinusoidal_pos_embds = torch.empty((config.max_position_embeddings, config.emb_dim), dtype=torch.float32)
+ create_sinusoidal_embeddings(config.max_position_embeddings, config.emb_dim, sinusoidal_pos_embds)
+ self.model_tester.parent.assertTrue(torch.equal(model.position_embeddings.weight, sinusoidal_pos_embds))
+
def test_flaubert_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_flaubert_lm_head(*config_and_inputs)
@@ -458,9 +466,9 @@ def test_flaubert_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlaubertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "flaubert/flaubert_small_cased"
+ model = FlaubertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_accelerator
diff --git a/tests/models/flaubert/test_modeling_tf_flaubert.py b/tests/models/flaubert/test_modeling_tf_flaubert.py
index 6d74b55ce3448e..534b529935a6b8 100644
--- a/tests/models/flaubert/test_modeling_tf_flaubert.py
+++ b/tests/models/flaubert/test_modeling_tf_flaubert.py
@@ -30,7 +30,6 @@
import tensorflow as tf
from transformers import (
- TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
FlaubertConfig,
TFFlaubertForMultipleChoice,
TFFlaubertForQuestionAnsweringSimple,
@@ -357,9 +356,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_FLAUBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFFlaubertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "hf-internal-testing/tiny-random-flaubert"
+ model = TFFlaubertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/flava/test_modeling_flava.py b/tests/models/flava/test_modeling_flava.py
index 48200dd30c9d88..2b628e14134443 100644
--- a/tests/models/flava/test_modeling_flava.py
+++ b/tests/models/flava/test_modeling_flava.py
@@ -57,10 +57,6 @@
FlavaMultimodalModel,
FlavaTextModel,
)
- from transformers.models.flava.modeling_flava import (
- FLAVA_CODEBOOK_PRETRAINED_MODEL_ARCHIVE_LIST,
- FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
else:
FlavaModel = None
FlavaForPreTraining = None
@@ -335,9 +331,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlavaImageModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/flava-full"
+ model = FlavaImageModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class FlavaTextModelTester:
@@ -498,9 +494,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlavaTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/flava-full"
+ model = FlavaTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class FlavaMultimodalModelTester:
@@ -662,9 +658,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlavaMultimodalModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/flava-full"
+ model = FlavaMultimodalModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class FlavaImageCodebookTester:
@@ -795,9 +791,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FLAVA_CODEBOOK_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlavaImageCodebook.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/flava-full"
+ model = FlavaImageCodebook.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class FlavaModelTester:
@@ -1081,9 +1077,9 @@ def test_load_image_text_config(self):
# overwrite from common since FlavaModel/TFFlavaModel return FLAVAOutput/TFFLAVAOutput
@slow
def test_model_from_pretrained(self):
- for model_name in FLAVA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FlavaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/flava-full"
+ model = FlavaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class FlavaForPreTrainingTester(FlavaModelTester):
diff --git a/tests/models/fnet/test_modeling_fnet.py b/tests/models/fnet/test_modeling_fnet.py
index 83b84edddccd50..5941e2006c50cd 100644
--- a/tests/models/fnet/test_modeling_fnet.py
+++ b/tests/models/fnet/test_modeling_fnet.py
@@ -43,7 +43,6 @@
FNetTokenizerFast,
)
from transformers.models.fnet.modeling_fnet import (
- FNET_PRETRAINED_MODEL_ARCHIVE_LIST,
FNetBasicFourierTransform,
is_scipy_available,
)
@@ -464,9 +463,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/fnet-base"
+ model = FNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
@@ -560,7 +559,7 @@ def test_inference_long_sentence(self):
max_length=512,
)
- torch.testing.assert_allclose(inputs["input_ids"], torch.tensor([[4, 13, 283, 2479, 106, 8, 6, 845, 5, 168, 65, 367, 6, 845, 5, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3]])) # fmt: skip
+ torch.testing.assert_close(inputs["input_ids"], torch.tensor([[4, 13, 283, 2479, 106, 8, 6, 845, 5, 168, 65, 367, 6, 845, 5, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3]])) # fmt: skip
inputs = {k: v.to(torch_device) for k, v in inputs.items()}
diff --git a/tests/models/focalnet/test_modeling_focalnet.py b/tests/models/focalnet/test_modeling_focalnet.py
index 2b6f8cf9ab1522..fb2bb1c2c152fa 100644
--- a/tests/models/focalnet/test_modeling_focalnet.py
+++ b/tests/models/focalnet/test_modeling_focalnet.py
@@ -37,7 +37,6 @@
FocalNetForMaskedImageModeling,
FocalNetModel,
)
- from transformers.models.focalnet.modeling_focalnet import FOCALNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -387,9 +386,9 @@ def test_hidden_states_output_with_padding(self):
@slow
def test_model_from_pretrained(self):
- for model_name in FOCALNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = FocalNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/focalnet-tiny"
+ model = FocalNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/gemma/test_modeling_gemma.py b/tests/models/gemma/test_modeling_gemma.py
index 1b32f1b16ee486..8c3aa392ba9f62 100644
--- a/tests/models/gemma/test_modeling_gemma.py
+++ b/tests/models/gemma/test_modeling_gemma.py
@@ -462,7 +462,7 @@ def test_flash_attn_2_generate_use_cache(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
self.skipTest("Gemma flash attention does not support right padding")
@require_torch_sdpa
diff --git a/tests/models/gemma/test_tokenization_gemma.py b/tests/models/gemma/test_tokenization_gemma.py
index 5e485da491f8fd..0e1fe54e355583 100644
--- a/tests/models/gemma/test_tokenization_gemma.py
+++ b/tests/models/gemma/test_tokenization_gemma.py
@@ -153,10 +153,6 @@ def test_pickle_subword_regularization_tokenizer(self):
def test_subword_regularization_tokenizer(self):
pass
- @unittest.skip("This test will be removed from main @LysandreJik")
- def test_pretrained_model_lists(self):
- pass
-
@unittest.skip("Skipping")
def test_torch_encode_plus_sent_to_model(self):
pass
diff --git a/tests/models/git/test_modeling_git.py b/tests/models/git/test_modeling_git.py
index c503abfb89db1a..6a891f17b06ad3 100644
--- a/tests/models/git/test_modeling_git.py
+++ b/tests/models/git/test_modeling_git.py
@@ -33,7 +33,6 @@
from torch import nn
from transformers import MODEL_FOR_CAUSAL_LM_MAPPING, GitForCausalLM, GitModel, GitVisionModel
- from transformers.models.git.modeling_git import GIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -196,9 +195,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GitVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/git-base"
+ model = GitVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class GitModelTester:
@@ -450,9 +449,9 @@ def test_model_various_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GitModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/git-base"
+ model = GitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="GIT has pixel values as additional input")
def test_beam_search_generate_dict_outputs_use_cache(self):
diff --git a/tests/models/glpn/test_modeling_glpn.py b/tests/models/glpn/test_modeling_glpn.py
index aab49c849101cd..b733164ec1d43f 100644
--- a/tests/models/glpn/test_modeling_glpn.py
+++ b/tests/models/glpn/test_modeling_glpn.py
@@ -30,7 +30,6 @@
from transformers import GLPNConfig, GLPNForDepthEstimation, GLPNModel
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.glpn.modeling_glpn import GLPN_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -309,9 +308,9 @@ def test_training(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GLPN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GLPNModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "vinvino02/glpn-kitti"
+ model = GLPNModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -326,8 +325,8 @@ def prepare_img():
class GLPNModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_depth_estimation(self):
- image_processor = GLPNImageProcessor.from_pretrained(GLPN_PRETRAINED_MODEL_ARCHIVE_LIST[0])
- model = GLPNForDepthEstimation.from_pretrained(GLPN_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(torch_device)
+ image_processor = GLPNImageProcessor.from_pretrained("vinvino02/glpn-kitti")
+ model = GLPNForDepthEstimation.from_pretrained("vinvino02/glpn-kitti").to(torch_device)
image = prepare_img()
inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
diff --git a/tests/models/gpt2/test_modeling_gpt2.py b/tests/models/gpt2/test_modeling_gpt2.py
index c9ecbdde6673a1..cde28cbc58617e 100644
--- a/tests/models/gpt2/test_modeling_gpt2.py
+++ b/tests/models/gpt2/test_modeling_gpt2.py
@@ -19,8 +19,17 @@
import math
import unittest
+import pytest
+
from transformers import GPT2Config, is_torch_available
-from transformers.testing_utils import backend_empty_cache, require_torch, slow, torch_device
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
@@ -32,7 +41,6 @@
import torch
from transformers import (
- GPT2_PRETRAINED_MODEL_ARCHIVE_LIST,
GPT2DoubleHeadsModel,
GPT2ForQuestionAnswering,
GPT2ForSequenceClassification,
@@ -701,9 +709,9 @@ def test_batch_generation_2heads(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GPT2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GPT2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai-community/gpt2"
+ model = GPT2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
@@ -859,3 +867,40 @@ def test_contrastive_search_gpt2(self):
"but said in a statement to The Associated Press that"
],
)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_padding_left(self):
+ """
+ Overwritting the common test as the test is flaky on tiny models
+ """
+ model = GPT2LMHeadModel.from_pretrained("gpt2", torch_dtype=torch.float16).to(0)
+
+ tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
+
+ texts = ["hi", "Hello this is a very long sentence"]
+
+ tokenizer.padding_side = "left"
+ tokenizer.pad_token = tokenizer.eos_token
+
+ inputs = tokenizer(texts, return_tensors="pt", padding=True).to(0)
+
+ output_native = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_native = tokenizer.batch_decode(output_native)
+
+ model = GPT2LMHeadModel.from_pretrained(
+ "gpt2", device_map={"": 0}, attn_implementation="flash_attention_2", torch_dtype=torch.float16
+ )
+
+ output_fa_2 = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_fa_2 = tokenizer.batch_decode(output_fa_2)
+
+ expected_output = [
+ "<|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>hi, who was born in the city of Kolkata, was a member of the Kolkata",
+ "Hello this is a very long sentence. I'm sorry. I'm sorry. I'm sorry. I'm sorry. I'm sorry",
+ ]
+
+ self.assertListEqual(output_native, output_fa_2)
+ self.assertListEqual(output_native, expected_output)
diff --git a/tests/models/gpt2/test_modeling_tf_gpt2.py b/tests/models/gpt2/test_modeling_tf_gpt2.py
index 060d4b71985bc8..c56d837939c598 100644
--- a/tests/models/gpt2/test_modeling_tf_gpt2.py
+++ b/tests/models/gpt2/test_modeling_tf_gpt2.py
@@ -31,7 +31,6 @@
from transformers import GPT2Tokenizer
from transformers.models.gpt2.modeling_tf_gpt2 import (
- TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST,
TFGPT2DoubleHeadsModel,
TFGPT2ForSequenceClassification,
TFGPT2LMHeadModel,
@@ -422,9 +421,9 @@ def test_gpt2_sequence_classification_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_GPT2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFGPT2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai-community/gpt2"
+ model = TFGPT2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# overwrite from common since ONNX runtime optimization doesn't work with tf.gather() when the argument
# `batch_dims` > 0"
diff --git a/tests/models/gpt_neo/test_modeling_gpt_neo.py b/tests/models/gpt_neo/test_modeling_gpt_neo.py
index d4a9dd90eb8022..ce0aeadf16baf7 100644
--- a/tests/models/gpt_neo/test_modeling_gpt_neo.py
+++ b/tests/models/gpt_neo/test_modeling_gpt_neo.py
@@ -31,7 +31,6 @@
import torch
from transformers import (
- GPT_NEO_PRETRAINED_MODEL_ARCHIVE_LIST,
GPT2Tokenizer,
GPTNeoForCausalLM,
GPTNeoForQuestionAnswering,
@@ -601,6 +600,6 @@ def test_batch_generation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GPT_NEO_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GPTNeoModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "EleutherAI/gpt-neo-1.3B"
+ model = GPTNeoModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
diff --git a/tests/models/gpt_neox/test_modeling_gpt_neox.py b/tests/models/gpt_neox/test_modeling_gpt_neox.py
index 19e3db2a61fb91..92d130b35101bb 100644
--- a/tests/models/gpt_neox/test_modeling_gpt_neox.py
+++ b/tests/models/gpt_neox/test_modeling_gpt_neox.py
@@ -38,6 +38,11 @@
GPTNeoXForTokenClassification,
GPTNeoXModel,
)
+ from transformers.models.gpt_neox.modeling_gpt_neox import (
+ GPTNeoXDynamicNTKScalingRotaryEmbedding,
+ GPTNeoXLinearScalingRotaryEmbedding,
+ GPTNeoXRotaryEmbedding,
+ )
class GPTNeoXModelTester:
@@ -301,7 +306,8 @@ def test_feed_forward_chunking(self):
pass
@parameterized.expand([("linear",), ("dynamic",)])
- def test_model_rope_scaling(self, scaling_type):
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling_from_config with Llama->GPTNeoX
+ def test_model_rope_scaling_from_config(self, scaling_type):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
short_input = ids_tensor([1, 10], config.vocab_size)
long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
@@ -331,6 +337,66 @@ def test_model_rope_scaling(self, scaling_type):
# The output should be different for long inputs
self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+ # Copied from tests.models.falcon.test_modeling_falcon.FalconModelTest.test_model_rope_scaling with Falcon->GPTNeoX, rope_theta->rotary_emb_base
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+
+ # Sanity check original RoPE
+ original_rope = GPTNeoXRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rotary_emb_base,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, short_input_length)
+ original_cos_long, original_sin_long = original_rope(x, long_input_length)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = GPTNeoXLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rotary_emb_base,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, short_input_length)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[new_position, :], original_cos_long[original_position, :])
+ torch.testing.assert_close(linear_sin_long[new_position, :], original_sin_long[original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = GPTNeoXDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rotary_emb_base,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, short_input_length)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
@require_torch
class GPTNeoXLanguageGenerationTest(unittest.TestCase):
diff --git a/tests/models/gptj/test_modeling_gptj.py b/tests/models/gptj/test_modeling_gptj.py
index fd88b85a13e435..2ef2e391215e7b 100644
--- a/tests/models/gptj/test_modeling_gptj.py
+++ b/tests/models/gptj/test_modeling_gptj.py
@@ -40,7 +40,6 @@
import torch
from transformers import (
- GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST,
AutoTokenizer,
GPTJForCausalLM,
GPTJForQuestionAnswering,
@@ -524,9 +523,9 @@ def test_batch_generation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GPTJ_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GPTJModel.from_pretrained(model_name, revision="float16", torch_dtype=torch.float16)
- self.assertIsNotNone(model)
+ model_name = "EleutherAI/gpt-j-6B"
+ model = GPTJModel.from_pretrained(model_name, revision="float16", torch_dtype=torch.float16)
+ self.assertIsNotNone(model)
@require_flash_attn
@require_torch_gpu
diff --git a/tests/models/graphormer/test_modeling_graphormer.py b/tests/models/graphormer/test_modeling_graphormer.py
index b6a994f4597f5c..ddb72543f51a59 100644
--- a/tests/models/graphormer/test_modeling_graphormer.py
+++ b/tests/models/graphormer/test_modeling_graphormer.py
@@ -34,7 +34,6 @@
from torch import tensor
from transformers import GraphormerForGraphClassification, GraphormerModel
- from transformers.models.graphormer.modeling_graphormer import GRAPHORMER_PRETRAINED_MODEL_ARCHIVE_LIST
class GraphormerModelTester:
@@ -472,9 +471,9 @@ def test_for_graph_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GRAPHORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GraphormerForGraphClassification.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "clefourrier/graphormer-base-pcqm4mv1"
+ model = GraphormerForGraphClassification.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/groupvit/test_modeling_groupvit.py b/tests/models/groupvit/test_modeling_groupvit.py
index 9f44c3d9ee6a21..5ec9bbbf1a8a65 100644
--- a/tests/models/groupvit/test_modeling_groupvit.py
+++ b/tests/models/groupvit/test_modeling_groupvit.py
@@ -44,7 +44,6 @@
from torch import nn
from transformers import GroupViTModel, GroupViTTextModel, GroupViTVisionModel
- from transformers.models.groupvit.modeling_groupvit import GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -352,9 +351,9 @@ def test_retain_grad_hidden_states_attentions(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GroupViTVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class GroupViTTextModelTester:
@@ -492,9 +491,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GroupViTTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class GroupViTModelTester:
@@ -706,9 +705,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = GroupViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/groupvit/test_modeling_tf_groupvit.py b/tests/models/groupvit/test_modeling_tf_groupvit.py
index 968d955846d8a8..be5ff803d94034 100644
--- a/tests/models/groupvit/test_modeling_tf_groupvit.py
+++ b/tests/models/groupvit/test_modeling_tf_groupvit.py
@@ -47,7 +47,6 @@
from transformers import TFGroupViTModel, TFGroupViTTextModel, TFGroupViTVisionModel, TFSharedEmbeddings
from transformers.modeling_tf_utils import keras
- from transformers.models.groupvit.modeling_tf_groupvit import TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -314,9 +313,9 @@ def test_pt_tf_model_equivalence(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFGroupViTVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = TFGroupViTVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(
"TFGroupViTVisionModel does not convert `hidden_states` and `attentions` to tensors as they are all of"
@@ -485,9 +484,9 @@ def test_inputs_embeds(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFGroupViTTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = TFGroupViTTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_saved_model_creation_extended(self):
@@ -697,9 +696,9 @@ def test_keras_save_load(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_GROUPVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFGroupViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = TFGroupViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Currently `saved_model` doesn't work with nested outputs.")
@slow
diff --git a/tests/models/ibert/test_modeling_ibert.py b/tests/models/ibert/test_modeling_ibert.py
index b552cb75a5a69f..fd3809acff3e73 100644
--- a/tests/models/ibert/test_modeling_ibert.py
+++ b/tests/models/ibert/test_modeling_ibert.py
@@ -30,7 +30,6 @@
from torch import nn
from transformers import (
- IBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
IBertForMaskedLM,
IBertForMultipleChoice,
IBertForQuestionAnswering,
@@ -292,9 +291,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in IBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = IBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "kssteven/ibert-roberta-base"
+ model = IBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_create_position_ids_respects_padding_index(self):
"""Ensure that the default position ids only assign a sequential . This is a regression
diff --git a/tests/models/idefics/test_modeling_idefics.py b/tests/models/idefics/test_modeling_idefics.py
index 28530c72194585..3059b5a2f542f2 100644
--- a/tests/models/idefics/test_modeling_idefics.py
+++ b/tests/models/idefics/test_modeling_idefics.py
@@ -40,7 +40,6 @@
from transformers import IdeficsForVisionText2Text, IdeficsModel, IdeficsProcessor
from transformers.models.idefics.configuration_idefics import IdeficsPerceiverConfig, IdeficsVisionConfig
- from transformers.models.idefics.modeling_idefics import IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST
from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_0
else:
is_torch_greater_or_equal_than_2_0 = False
@@ -562,9 +561,9 @@ def check_hidden_states_output(inputs_dict, config, model_class):
@slow
def test_model_from_pretrained(self):
- for model_name in IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = IdeficsModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "HuggingFaceM4/idefics-9b"
+ model = IdeficsModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch_sdpa
@slow
diff --git a/tests/models/imagegpt/test_modeling_imagegpt.py b/tests/models/imagegpt/test_modeling_imagegpt.py
index 40ea7ce0f4f559..e18f74533520d6 100644
--- a/tests/models/imagegpt/test_modeling_imagegpt.py
+++ b/tests/models/imagegpt/test_modeling_imagegpt.py
@@ -40,7 +40,6 @@
import torch
from transformers import (
- IMAGEGPT_PRETRAINED_MODEL_ARCHIVE_LIST,
ImageGPTForCausalImageModeling,
ImageGPTForImageClassification,
ImageGPTModel,
@@ -336,9 +335,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in IMAGEGPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ImageGPTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai/imagegpt-small"
+ model = ImageGPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/informer/test_modeling_informer.py b/tests/models/informer/test_modeling_informer.py
index f3ebe91ac52dba..d932e68b3c4f1b 100644
--- a/tests/models/informer/test_modeling_informer.py
+++ b/tests/models/informer/test_modeling_informer.py
@@ -35,7 +35,11 @@
import torch
from transformers import InformerConfig, InformerForPrediction, InformerModel
- from transformers.models.informer.modeling_informer import InformerDecoder, InformerEncoder
+ from transformers.models.informer.modeling_informer import (
+ InformerDecoder,
+ InformerEncoder,
+ InformerSinusoidalPositionalEmbedding,
+ )
@require_torch
@@ -164,6 +168,12 @@ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+ embed_positions = InformerSinusoidalPositionalEmbedding(
+ config.context_length + config.prediction_length, config.d_model
+ )
+ self.parent.assertTrue(torch.equal(model.encoder.embed_positions.weight, embed_positions.weight))
+ self.parent.assertTrue(torch.equal(model.decoder.embed_positions.weight, embed_positions.weight))
+
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
diff --git a/tests/models/instructblip/test_modeling_instructblip.py b/tests/models/instructblip/test_modeling_instructblip.py
index 9ed95b56b65a93..8cbbde9868b2b2 100644
--- a/tests/models/instructblip/test_modeling_instructblip.py
+++ b/tests/models/instructblip/test_modeling_instructblip.py
@@ -54,7 +54,6 @@
from torch import nn
from transformers import InstructBlipForConditionalGeneration, InstructBlipVisionModel
- from transformers.models.instructblip.modeling_instructblip import INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -222,9 +221,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = InstructBlipVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/instructblip-flan-t5-xl"
+ model = InstructBlipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class InstructBlipQFormerModelTester:
@@ -526,9 +525,9 @@ def test_load_vision_qformer_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in INSTRUCTBLIP_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = InstructBlipForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Salesforce/instructblip-flan-t5-xl"
+ model = InstructBlipForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/jukebox/test_modeling_jukebox.py b/tests/models/jukebox/test_modeling_jukebox.py
index ea0ee1397773f7..f064f442fcdc4d 100644
--- a/tests/models/jukebox/test_modeling_jukebox.py
+++ b/tests/models/jukebox/test_modeling_jukebox.py
@@ -189,13 +189,13 @@ def test_conditioning(self):
self.assertListEqual(metadata.numpy()[0][:10].tolist(), self.EXPECTED_Y_COND)
audio_conditioning, metadata_conditioning, lyric_tokens = top_prior.get_cond(music_token_conds, metadata)
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
audio_conditioning[0][0][:30].detach(), torch.tensor(self.EXPECTED_AUDIO_COND), atol=1e-4, rtol=1e-4
)
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
metadata_conditioning[0][0][:30].detach(), torch.tensor(self.EXPECTED_META_COND), atol=1e-4, rtol=1e-4
)
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
lyric_tokens[0, :30].detach(), torch.tensor(self.EXPECTED_LYRIC_COND), atol=1e-4, rtol=1e-4
)
@@ -213,21 +213,21 @@ def test_primed_sampling(self):
zs = model._sample(
zs, tokens, sample_levels=[0], save_results=False, sample_length=40 * model.priors[0].raw_to_tokens
)
- torch.testing.assert_allclose(zs[0][0][:40], torch.tensor(self.EXPECTED_PRIMED_0))
+ torch.testing.assert_close(zs[0][0][:40], torch.tensor(self.EXPECTED_PRIMED_0))
upper_2 = torch.cat((zs[0], torch.zeros(1, 2048 - zs[0].shape[-1])), dim=-1).long()
zs = [upper_2, model.vqvae.encode(waveform, start_level=1, bs_chunks=waveform.shape[0])[0], None]
zs = model._sample(
zs, tokens, sample_levels=[1], save_results=False, sample_length=40 * model.priors[1].raw_to_tokens
)
- torch.testing.assert_allclose(zs[1][0][:40], torch.tensor(self.EXPECTED_PRIMED_1))
+ torch.testing.assert_close(zs[1][0][:40], torch.tensor(self.EXPECTED_PRIMED_1))
upper_1 = torch.cat((zs[1], torch.zeros(1, 2048 - zs[1].shape[-1])), dim=-1).long()
zs = [upper_2, upper_1, model.vqvae.encode(waveform, start_level=0, bs_chunks=waveform.shape[0])[0]]
zs = model._sample(
zs, tokens, sample_levels=[2], save_results=False, sample_length=40 * model.priors[2].raw_to_tokens
)
- torch.testing.assert_allclose(zs[2][0][:40].cpu(), torch.tensor(self.EXPECTED_PRIMED_2))
+ torch.testing.assert_close(zs[2][0][:40].cpu(), torch.tensor(self.EXPECTED_PRIMED_2))
@slow
def test_vqvae(self):
@@ -236,11 +236,11 @@ def test_vqvae(self):
x = torch.rand((1, 5120, 1))
with torch.no_grad():
zs = model.vqvae.encode(x, start_level=2, bs_chunks=x.shape[0])
- torch.testing.assert_allclose(zs[0][0], torch.tensor(self.EXPECTED_VQVAE_ENCODE))
+ torch.testing.assert_close(zs[0][0], torch.tensor(self.EXPECTED_VQVAE_ENCODE))
with torch.no_grad():
x = model.vqvae.decode(zs, start_level=2, bs_chunks=x.shape[0])
- torch.testing.assert_allclose(x[0, :40, 0], torch.tensor(self.EXPECTED_VQVAE_DECODE), atol=1e-4, rtol=1e-4)
+ torch.testing.assert_close(x[0, :40, 0], torch.tensor(self.EXPECTED_VQVAE_DECODE), atol=1e-4, rtol=1e-4)
@require_torch
@@ -379,19 +379,19 @@ def test_slow_sampling(self):
model.priors[0].to(torch_device)
zs = [torch.zeros(1, 0, dtype=torch.long).to(torch_device) for _ in range(3)]
zs = model._sample(zs, labels, [0], sample_length=60 * model.priors[0].raw_to_tokens, save_results=False)
- torch.testing.assert_allclose(zs[0][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_2))
+ torch.testing.assert_close(zs[0][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_2))
model.priors[0].cpu()
set_seed(0)
model.priors[1].to(torch_device)
zs = model._sample(zs, labels, [1], sample_length=60 * model.priors[1].raw_to_tokens, save_results=False)
- torch.testing.assert_allclose(zs[1][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_1))
+ torch.testing.assert_close(zs[1][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_1))
model.priors[1].cpu()
set_seed(0)
model.priors[2].to(torch_device)
zs = model._sample(zs, labels, [2], sample_length=60 * model.priors[2].raw_to_tokens, save_results=False)
- torch.testing.assert_allclose(zs[2][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_0))
+ torch.testing.assert_close(zs[2][0].cpu(), torch.tensor(self.EXPECTED_GPU_OUTPUTS_0))
@slow
@require_torch_accelerator
diff --git a/tests/models/kosmos2/test_modeling_kosmos2.py b/tests/models/kosmos2/test_modeling_kosmos2.py
index 7fbb40e8289976..9bc95b8bd44cb4 100644
--- a/tests/models/kosmos2/test_modeling_kosmos2.py
+++ b/tests/models/kosmos2/test_modeling_kosmos2.py
@@ -44,7 +44,6 @@
import torch
from transformers import Kosmos2ForConditionalGeneration, Kosmos2Model
- from transformers.models.kosmos2.modeling_kosmos2 import KOSMOS2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -425,9 +424,9 @@ def check_same_values(layer_1, layer_2):
@slow
def test_model_from_pretrained(self):
- for model_name in KOSMOS2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Kosmos2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/kosmos-2-patch14-224"
+ model = Kosmos2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def _create_and_check_torchscript(self, config, inputs_dict):
if not self.test_torchscript:
diff --git a/tests/models/layoutlm/test_modeling_tf_layoutlm.py b/tests/models/layoutlm/test_modeling_tf_layoutlm.py
index 96ce692a668241..14fc59ff713ff7 100644
--- a/tests/models/layoutlm/test_modeling_tf_layoutlm.py
+++ b/tests/models/layoutlm/test_modeling_tf_layoutlm.py
@@ -31,7 +31,6 @@
import tensorflow as tf
from transformers.models.layoutlm.modeling_tf_layoutlm import (
- TF_LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST,
TFLayoutLMForMaskedLM,
TFLayoutLMForQuestionAnswering,
TFLayoutLMForSequenceClassification,
@@ -265,9 +264,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_LAYOUTLM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFLayoutLMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/layoutlm-base-uncased"
+ model = TFLayoutLMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# TODO (Joao): fix me
@unittest.skip("Onnx compliancy broke with TF 2.10")
diff --git a/tests/models/layoutlmv2/test_modeling_layoutlmv2.py b/tests/models/layoutlmv2/test_modeling_layoutlmv2.py
index f1a0cc6c43fe96..d70721e04c9108 100644
--- a/tests/models/layoutlmv2/test_modeling_layoutlmv2.py
+++ b/tests/models/layoutlmv2/test_modeling_layoutlmv2.py
@@ -36,7 +36,6 @@
LayoutLMv2ForTokenClassification,
LayoutLMv2Model,
)
- from transformers.models.layoutlmv2.modeling_layoutlmv2 import LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_detectron2_available():
from detectron2.structures.image_list import ImageList
@@ -422,9 +421,9 @@ def test_model_is_small(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LAYOUTLMV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LayoutLMv2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/layoutlmv2-base-uncased"
+ model = LayoutLMv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/layoutlmv3/test_modeling_layoutlmv3.py b/tests/models/layoutlmv3/test_modeling_layoutlmv3.py
index bf9a0b83144a52..f280633c6ab732 100644
--- a/tests/models/layoutlmv3/test_modeling_layoutlmv3.py
+++ b/tests/models/layoutlmv3/test_modeling_layoutlmv3.py
@@ -40,7 +40,6 @@
LayoutLMv3ForTokenClassification,
LayoutLMv3Model,
)
- from transformers.models.layoutlmv3.modeling_layoutlmv3 import LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -368,9 +367,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LayoutLMv3Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/layoutlmv3-base"
+ model = LayoutLMv3Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/layoutlmv3/test_modeling_tf_layoutlmv3.py b/tests/models/layoutlmv3/test_modeling_tf_layoutlmv3.py
index 5ea4cb625c46d9..6ae2e5090ea109 100644
--- a/tests/models/layoutlmv3/test_modeling_tf_layoutlmv3.py
+++ b/tests/models/layoutlmv3/test_modeling_tf_layoutlmv3.py
@@ -36,7 +36,6 @@
import tensorflow as tf
from transformers import (
- TF_LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST,
TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING,
TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
@@ -468,9 +467,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_LAYOUTLMV3_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFLayoutLMv3Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/layoutlmv3-base"
+ model = TFLayoutLMv3Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/levit/test_modeling_levit.py b/tests/models/levit/test_modeling_levit.py
index fee3eaa086bd73..38c9c885944b4e 100644
--- a/tests/models/levit/test_modeling_levit.py
+++ b/tests/models/levit/test_modeling_levit.py
@@ -40,7 +40,6 @@
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES,
MODEL_MAPPING_NAMES,
)
- from transformers.models.levit.modeling_levit import LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -382,9 +381,9 @@ def test_problem_types(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LevitModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/levit-128S"
+ model = LevitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -398,13 +397,11 @@ def prepare_img():
class LevitModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return LevitImageProcessor.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ return LevitImageProcessor.from_pretrained("facebook/levit-128S")
@slow
def test_inference_image_classification_head(self):
- model = LevitForImageClassificationWithTeacher.from_pretrained(LEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(
- torch_device
- )
+ model = LevitForImageClassificationWithTeacher.from_pretrained("facebook/levit-128S").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/lilt/test_modeling_lilt.py b/tests/models/lilt/test_modeling_lilt.py
index 653178e2ad66db..0d0ed720c53a2f 100644
--- a/tests/models/lilt/test_modeling_lilt.py
+++ b/tests/models/lilt/test_modeling_lilt.py
@@ -34,7 +34,6 @@
LiltForTokenClassification,
LiltModel,
)
- from transformers.models.lilt.modeling_lilt import LILT_PRETRAINED_MODEL_ARCHIVE_LIST
class LiltModelTester:
@@ -295,9 +294,9 @@ def test_training_gradient_checkpointing_use_reentrant_false(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LILT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LiltModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "SCUT-DLVCLab/lilt-roberta-en-base"
+ model = LiltModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/llama/test_modeling_llama.py b/tests/models/llama/test_modeling_llama.py
index 36dc8d6bcdf4e8..e0a3990bd8de30 100644
--- a/tests/models/llama/test_modeling_llama.py
+++ b/tests/models/llama/test_modeling_llama.py
@@ -51,6 +51,11 @@
LlamaModel,
LlamaTokenizer,
)
+ from transformers.models.llama.modeling_llama import (
+ LlamaDynamicNTKScalingRotaryEmbedding,
+ LlamaLinearScalingRotaryEmbedding,
+ LlamaRotaryEmbedding,
+ )
class LlamaModelTester:
@@ -370,7 +375,7 @@ def test_save_load_fast_init_from_base(self):
pass
@parameterized.expand([("linear",), ("dynamic",)])
- def test_model_rope_scaling(self, scaling_type):
+ def test_model_rope_scaling_from_config(self, scaling_type):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
short_input = ids_tensor([1, 10], config.vocab_size)
long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
@@ -400,6 +405,69 @@ def test_model_rope_scaling(self, scaling_type):
# The output should be different for long inputs
self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = LlamaRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, position_ids_short)
+ original_cos_long, original_sin_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = LlamaLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, position_ids_short)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:, :short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[:, new_position, :], original_cos_long[:, original_position, :])
+ torch.testing.assert_close(linear_sin_long[:, new_position, :], original_sin_long[:, original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = LlamaDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
@require_flash_attn
@require_torch_gpu
@require_bitsandbytes
diff --git a/tests/models/llama/test_tokenization_llama.py b/tests/models/llama/test_tokenization_llama.py
index 0cee3347c40815..5a0bcea48af17a 100644
--- a/tests/models/llama/test_tokenization_llama.py
+++ b/tests/models/llama/test_tokenization_llama.py
@@ -581,6 +581,19 @@ def test_special_token_special_word(self):
decoded_tokens = tokenizer.decode(input_ids)
self.assertEqual(decoded_tokens, " Hello how")
+ # Let's make sure the space is preserved
+ input_ids = tokenizer.encode("hello", add_special_tokens=True)
+ self.assertEqual(input_ids, [1, 22172])
+ tokens = tokenizer.tokenize("hello")
+ self.assertEqual(tokens, ["▁hello"])
+ decoded_tokens = tokenizer.decode(input_ids)
+ self.assertEqual(decoded_tokens, " hello")
+
+ input_ids = tokenizer.encode("hello", add_special_tokens=False)
+ self.assertEqual(input_ids, [22172])
+ decoded_tokens = tokenizer.decode(input_ids)
+ self.assertEqual(decoded_tokens, "hello")
+
def test_some_edge_cases(self):
tokenizer = LlamaTokenizer.from_pretrained("huggyllama/llama-7b", legacy=False)
diff --git a/tests/models/llava/test_modeling_llava.py b/tests/models/llava/test_modeling_llava.py
index 27c99dda16923e..d6bb2b56ac43cc 100644
--- a/tests/models/llava/test_modeling_llava.py
+++ b/tests/models/llava/test_modeling_llava.py
@@ -22,12 +22,20 @@
from transformers import (
AutoProcessor,
+ AutoTokenizer,
LlavaConfig,
LlavaForConditionalGeneration,
is_torch_available,
is_vision_available,
)
-from transformers.testing_utils import require_bitsandbytes, require_torch, require_torch_gpu, slow, torch_device
+from transformers.testing_utils import (
+ require_bitsandbytes,
+ require_torch,
+ require_torch_gpu,
+ require_vision,
+ slow,
+ torch_device,
+)
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
@@ -470,10 +478,45 @@ def test_small_model_integration_test_llama_batched_regression(self):
output = model.generate(**inputs, max_new_tokens=20)
- EXPECTED_DECODED_TEXT = ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this serene location, one should be cautious about the weather conditions and potential', 'USER: \nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: \nAnd this?\nASSISTANT: A cat sleeping on a bed.'] # fmt: skip
+ EXPECTED_DECODED_TEXT = ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this place, which appears to be a dock or pier extending over a body of water', 'USER: \nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: \nAnd this?\nASSISTANT: A cat sleeping on a bed.'] # fmt: skip
self.assertEqual(processor.batch_decode(output, skip_special_tokens=True), EXPECTED_DECODED_TEXT)
+ @slow
+ @require_torch
+ @require_vision
+ def test_batched_generation(self):
+ model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf").to(torch_device)
+
+ processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
+
+ prompt1 = "\n\nUSER: What's the the difference of two images?\nASSISTANT:"
+ prompt2 = "\nUSER: Describe the image.\nASSISTANT:"
+ prompt3 = "\nUSER: Describe the image.\nASSISTANT:"
+ url1 = "https://images.unsplash.com/photo-1552053831-71594a27632d?q=80&w=3062&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
+ url2 = "https://images.unsplash.com/photo-1617258683320-61900b281ced?q=80&w=3087&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
+ image1 = Image.open(requests.get(url1, stream=True).raw)
+ image2 = Image.open(requests.get(url2, stream=True).raw)
+
+ inputs = processor(
+ text=[prompt1, prompt2, prompt3],
+ images=[image1, image2, image1, image2],
+ return_tensors="pt",
+ padding=True,
+ ).to(torch_device)
+
+ model = model.eval()
+
+ EXPECTED_OUTPUT = [
+ "\n \nUSER: What's the the difference of two images?\nASSISTANT: In the two images, the primary difference is the presence of a small dog holding a flower in one",
+ "\nUSER: Describe the image.\nASSISTANT: The image features a small, fluffy dog sitting on a sidewalk. The dog is holding",
+ "\nUSER: Describe the image.\nASSISTANT: The image features a lone, adult llama standing on a grassy hill. The llama",
+ ]
+
+ generate_ids = model.generate(**inputs, max_new_tokens=20)
+ outputs = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+ self.assertEqual(outputs, EXPECTED_OUTPUT)
+
@slow
@require_bitsandbytes
def test_llava_index_error_bug(self):
@@ -533,3 +576,29 @@ def test_llava_merge_inputs_error_bug(self):
labels=input_ids,
).loss
loss.backward()
+
+ def test_tokenizer_integration(self):
+ slow_tokenizer = AutoTokenizer.from_pretrained("liuhaotian/llava-v1.6-34b", use_fast=False)
+ slow_tokenizer.add_tokens("", True)
+
+ fast_tokenizer = AutoTokenizer.from_pretrained(
+ "liuhaotian/llava-v1.6-34b",
+ bos_token="<|startoftext|>",
+ eos_token="<|endoftext|>",
+ from_slow=True,
+ legacy=False,
+ )
+ fast_tokenizer.add_tokens("", True)
+
+ prompt = "<|im_start|>system\nAnswer the questions.<|im_end|><|im_start|>user\n\nWhat is shown in this image?<|im_end|><|im_start|>assistant\n"
+ # If the token is added as special, it's not normalized, and the only diff is the extra space after special tokens.
+ # https://github.com/huggingface/transformers/pull/28881 is the fix for this.
+ self.assertEqual(
+ slow_tokenizer.tokenize(prompt),
+ ['<|im_start|>', 'system', '\n', 'Answer', '▁the', '▁questions', '.', '<|im_end|>', '<|im_start|>', 'user', '\n', '', '\n', 'What', '▁is', '▁shown', '▁in', '▁this', '▁image', '?', '<|im_end|>', '<|im_start|>', 'ass', 'istant', '\n']
+ ) # fmt: skip
+
+ self.assertEqual(
+ fast_tokenizer.tokenize(prompt),
+ ['<|im_start|>', '▁system', '\n', 'Answer', '▁the', '▁questions', '.', '<|im_end|>', '<|im_start|>', '▁user', '\n', '', '▁', '\n', 'What', '▁is', '▁shown', '▁in', '▁this', '▁image', '?', '<|im_end|>', '<|im_start|>', '▁assistant', '\n']
+ ) # fmt: skip
diff --git a/tests/models/longt5/test_modeling_longt5.py b/tests/models/longt5/test_modeling_longt5.py
index 5a8075c2dbe7ea..c65af001e103f1 100644
--- a/tests/models/longt5/test_modeling_longt5.py
+++ b/tests/models/longt5/test_modeling_longt5.py
@@ -39,7 +39,6 @@
LongT5ForConditionalGeneration,
LongT5Model,
)
- from transformers.models.longt5.modeling_longt5 import LONGT5_PRETRAINED_MODEL_ARCHIVE_LIST
class LongT5ModelTester:
@@ -590,9 +589,9 @@ def test_encoder_decoder_shared_weights(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LONGT5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LongT5Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/long-t5-local-base"
+ model = LongT5Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
def test_export_to_onnx(self):
diff --git a/tests/models/luke/test_modeling_luke.py b/tests/models/luke/test_modeling_luke.py
index 4f1ed2e2e3d38b..a35d5ec3dc9daa 100644
--- a/tests/models/luke/test_modeling_luke.py
+++ b/tests/models/luke/test_modeling_luke.py
@@ -38,7 +38,6 @@
LukeModel,
LukeTokenizer,
)
- from transformers.models.luke.modeling_luke import LUKE_PRETRAINED_MODEL_ARCHIVE_LIST
class LukeModelTester:
@@ -699,9 +698,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LUKE_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = LukeModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "studio-ousia/luke-base"
+ model = LukeModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
diff --git a/tests/models/lxmert/test_modeling_lxmert.py b/tests/models/lxmert/test_modeling_lxmert.py
index 63d83de36b7546..723fef6061b3e4 100644
--- a/tests/models/lxmert/test_modeling_lxmert.py
+++ b/tests/models/lxmert/test_modeling_lxmert.py
@@ -38,7 +38,6 @@
LxmertForQuestionAnswering,
LxmertModel,
)
- from transformers.models.lxmert.modeling_lxmert import LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_tf_available():
@@ -584,10 +583,10 @@ def test_lxmert_question_answering_labels_resize(self):
@slow
def test_model_from_pretrained(self):
- for model_name in LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = LxmertModel.from_pretrained(model_name)
- model.to(torch_device)
- self.assertIsNotNone(model)
+ model_name = "unc-nlp/lxmert-base-uncased"
+ model = LxmertModel.from_pretrained(model_name)
+ model.to(torch_device)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -772,7 +771,7 @@ def prepare_tf_inputs_from_pt_inputs(self, pt_inputs_dict):
class LxmertModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_no_head_absolute_embedding(self):
- model = LxmertModel.from_pretrained(LXMERT_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ model = LxmertModel.from_pretrained("unc-nlp/lxmert-base-uncased")
input_ids = torch.tensor([[101, 345, 232, 328, 740, 140, 1695, 69, 6078, 1588, 102]])
num_visual_features = 10
_, visual_feats = np.random.seed(0), np.random.rand(1, num_visual_features, model.config.visual_feat_dim)
diff --git a/tests/models/m2m_100/test_tokenization_m2m_100.py b/tests/models/m2m_100/test_tokenization_m2m_100.py
index ced6cf13dea375..76cadf2f3bc3e0 100644
--- a/tests/models/m2m_100/test_tokenization_m2m_100.py
+++ b/tests/models/m2m_100/test_tokenization_m2m_100.py
@@ -94,10 +94,6 @@ def test_get_vocab(self):
# The length of the vocab keys can be different
# self.assertEqual(len(vocab_keys), tokenizer.vocab_size)
- @unittest.skip("Skip this test while all models are still to be uploaded.")
- def test_pretrained_model_lists(self):
- pass
-
def test_full_tokenizer(self):
tokenizer = self.get_tokenizer()
diff --git a/tests/models/mamba/test_modeling_mamba.py b/tests/models/mamba/test_modeling_mamba.py
index 8bd121933b8052..3b77e26dcce298 100644
--- a/tests/models/mamba/test_modeling_mamba.py
+++ b/tests/models/mamba/test_modeling_mamba.py
@@ -170,7 +170,7 @@ def create_and_check_mamba_model(self, config, input_ids, *args):
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(len(result.hidden_states), config.num_hidden_layers + 1)
- def create_and_check_causl_lm(self, config, input_ids, *args):
+ def create_and_check_causal_lm(self, config, input_ids, *args):
model = MambaForCausalLM(config)
model.to(torch_device)
model.eval()
@@ -197,7 +197,30 @@ def create_and_check_state_equivalency(self, config, input_ids, *args):
self.parent.assertTrue(torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5))
# TODO the orignal mamba does not support decoding more than 1 token neither do we
- def create_and_check_forward_and_backwards(self, config, input_ids, *args, gradient_checkpointing=False):
+ def create_and_check_mamba_cached_slow_forward_and_backwards(
+ self, config, input_ids, *args, gradient_checkpointing=False
+ ):
+ model = MambaModel(config)
+ model.to(torch_device)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ # create cache
+ cache = model(input_ids, use_cache=True).cache_params
+ cache.seqlen_offset = 0
+
+ # use cache
+ token_emb = model.embeddings(input_ids)
+ outputs = model.layers[0].mixer.slow_forward(token_emb, cache)
+
+ loss = torch.log(1 + torch.abs(outputs.sum()))
+ self.parent.assertEqual(loss.shape, ())
+ self.parent.assertEqual(outputs.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ loss.backward()
+
+ def create_and_check_mamba_lm_head_forward_and_backwards(
+ self, config, input_ids, *args, gradient_checkpointing=False
+ ):
model = MambaForCausalLM(config)
model.to(torch_device)
if gradient_checkpointing:
@@ -304,12 +327,20 @@ def test_mamba_model(self):
def test_mamba_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
- self.model_tester.create_and_check_causl_lm(*config_and_inputs)
+ self.model_tester.create_and_check_causal_lm(*config_and_inputs)
def test_state_equivalency(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_state_equivalency(*config_and_inputs)
+ def test_mamba_cached_slow_forward_and_backwards(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_mamba_cached_slow_forward_and_backwards(*config_and_inputs)
+
+ def test_mamba_lm_head_forward_and_backwards(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_mamba_lm_head_forward_and_backwards(*config_and_inputs)
+
def test_initialization(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/mega/test_modeling_mega.py b/tests/models/mega/test_modeling_mega.py
index e07f4efedd7b48..872f0a38af8e8f 100644
--- a/tests/models/mega/test_modeling_mega.py
+++ b/tests/models/mega/test_modeling_mega.py
@@ -44,7 +44,6 @@
MegaForTokenClassification,
MegaModel,
)
- from transformers.models.mega.modeling_mega import MEGA_PRETRAINED_MODEL_ARCHIVE_LIST
class MegaModelTester:
@@ -672,9 +671,9 @@ def test_sequence_classification_model_for_multi_label(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MEGA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MegaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "mnaylor/mega-base-wikitext"
+ model = MegaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Does not work on the tiny model as we keep hitting edge cases.")
def test_cpu_offload(self):
diff --git a/tests/models/mistral/test_modeling_mistral.py b/tests/models/mistral/test_modeling_mistral.py
index 5e91e70ecd5b62..432097e9d1302d 100644
--- a/tests/models/mistral/test_modeling_mistral.py
+++ b/tests/models/mistral/test_modeling_mistral.py
@@ -24,6 +24,7 @@
from transformers import AutoTokenizer, MistralConfig, is_torch_available, set_seed
from transformers.testing_utils import (
backend_empty_cache,
+ is_flaky,
require_bitsandbytes,
require_flash_attn,
require_torch,
@@ -309,6 +310,13 @@ def is_pipeline_test_to_skip(
):
return True
+ # TODO: @Fxmarty
+ @is_flaky(max_attempts=3, description="flaky on some models.")
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ super().test_eager_matches_sdpa_generate()
+
def setUp(self):
self.model_tester = MistralModelTester(self)
self.config_tester = ConfigTester(self, config_class=MistralConfig, hidden_size=37)
@@ -458,7 +466,7 @@ def test_flash_attn_2_generate_use_cache(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
self.skipTest("Mistral flash attention does not support right padding")
diff --git a/tests/models/mixtral/test_modeling_mixtral.py b/tests/models/mixtral/test_modeling_mixtral.py
index df31ec0050d08b..98654c51335594 100644
--- a/tests/models/mixtral/test_modeling_mixtral.py
+++ b/tests/models/mixtral/test_modeling_mixtral.py
@@ -22,9 +22,11 @@
from transformers import MixtralConfig, is_torch_available
from transformers.testing_utils import (
+ is_flaky,
require_flash_attn,
require_torch,
require_torch_gpu,
+ require_torch_sdpa,
slow,
torch_device,
)
@@ -42,7 +44,6 @@
class MixtralModelTester:
- # Copied from tests.models.mistral.test_modeling_mistral.MistralModelTester.__init__
def __init__(
self,
parent,
@@ -69,6 +70,7 @@ def __init__(
num_choices=4,
pad_token_id=0,
scope=None,
+ router_jitter_noise=0.1,
):
self.parent = parent
self.batch_size = batch_size
@@ -94,6 +96,7 @@ def __init__(
self.num_choices = num_choices
self.pad_token_id = pad_token_id
self.scope = scope
+ self.router_jitter_noise = router_jitter_noise
# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTester.prepare_config_and_inputs
def prepare_config_and_inputs(self):
@@ -137,6 +140,7 @@ def get_config(self):
pad_token_id=self.pad_token_id,
num_experts_per_tok=2,
num_local_experts=2,
+ router_jitter_noise=self.router_jitter_noise,
)
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Mixtral
@@ -305,6 +309,13 @@ def is_pipeline_test_to_skip(
):
return True
+ # TODO: @Fxmarty
+ @is_flaky(max_attempts=3, description="flaky on some models.")
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ super().test_eager_matches_sdpa_generate()
+
def setUp(self):
self.model_tester = MixtralModelTester(self)
self.config_tester = ConfigTester(self, config_class=MixtralConfig, hidden_size=37)
@@ -454,7 +465,7 @@ def test_flash_attn_2_generate_use_cache(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
self.skipTest("Mixtral flash attention does not support right padding")
# Ignore copy
diff --git a/tests/models/mobilebert/test_modeling_tf_mobilebert.py b/tests/models/mobilebert/test_modeling_tf_mobilebert.py
index b2b1e58ec0b3b5..c6c7d00da0fb29 100644
--- a/tests/models/mobilebert/test_modeling_tf_mobilebert.py
+++ b/tests/models/mobilebert/test_modeling_tf_mobilebert.py
@@ -313,7 +313,7 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- # for model_name in TF_MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ # model_name = 'google/mobilebert-uncased'
for model_name in ["google/mobilebert-uncased"]:
model = TFMobileBertModel.from_pretrained(model_name)
self.assertIsNotNone(model)
diff --git a/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py b/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
index 6262475b8d0c71..3be955a729b0b7 100644
--- a/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
+++ b/tests/models/mobilenet_v1/test_modeling_mobilenet_v1.py
@@ -30,7 +30,6 @@
import torch
from transformers import MobileNetV1ForImageClassification, MobileNetV1Model
- from transformers.models.mobilenet_v1.modeling_mobilenet_v1 import MOBILENET_V1_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -212,9 +211,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MOBILENET_V1_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MobileNetV1Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/mobilenet_v1_1.0_224"
+ model = MobileNetV1Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py b/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
index 17dfe452c2672d..f8a1ce8d26c820 100644
--- a/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
+++ b/tests/models/mobilenet_v2/test_modeling_mobilenet_v2.py
@@ -30,7 +30,6 @@
import torch
from transformers import MobileNetV2ForImageClassification, MobileNetV2ForSemanticSegmentation, MobileNetV2Model
- from transformers.models.mobilenet_v2.modeling_mobilenet_v2 import MOBILENET_V2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -267,9 +266,9 @@ def test_for_semantic_segmentation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MOBILENET_V2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MobileNetV2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/mobilenet_v2_1.4_224"
+ model = MobileNetV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@is_flaky(description="is_flaky https://github.com/huggingface/transformers/issues/29516")
def test_batching_equivalence(self):
diff --git a/tests/models/mobilevit/test_modeling_mobilevit.py b/tests/models/mobilevit/test_modeling_mobilevit.py
index fc2ea5eba38321..0fb94f38d6e3db 100644
--- a/tests/models/mobilevit/test_modeling_mobilevit.py
+++ b/tests/models/mobilevit/test_modeling_mobilevit.py
@@ -30,7 +30,6 @@
import torch
from transformers import MobileViTForImageClassification, MobileViTForSemanticSegmentation, MobileViTModel
- from transformers.models.mobilevit.modeling_mobilevit import MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -272,9 +271,9 @@ def test_for_semantic_segmentation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MobileViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "apple/mobilevit-small"
+ model = MobileViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/mobilevit/test_modeling_tf_mobilevit.py b/tests/models/mobilevit/test_modeling_tf_mobilevit.py
index 289d739774abd8..3132b93649ddff 100644
--- a/tests/models/mobilevit/test_modeling_tf_mobilevit.py
+++ b/tests/models/mobilevit/test_modeling_tf_mobilevit.py
@@ -34,7 +34,6 @@
import tensorflow as tf
from transformers import TFMobileViTForImageClassification, TFMobileViTForSemanticSegmentation, TFMobileViTModel
- from transformers.models.mobilevit.modeling_tf_mobilevit import TF_MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -366,9 +365,9 @@ def test_loss_computation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_MOBILEVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFMobileViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "apple/mobilevit-small"
+ model = TFMobileViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/mobilevitv2/test_modeling_mobilevitv2.py b/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
index 1fb6be94a2400c..ff45a8c0b69f6e 100644
--- a/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
+++ b/tests/models/mobilevitv2/test_modeling_mobilevitv2.py
@@ -31,7 +31,6 @@
from transformers import MobileViTV2ForImageClassification, MobileViTV2ForSemanticSegmentation, MobileViTV2Model
from transformers.models.mobilevitv2.modeling_mobilevitv2 import (
- MOBILEVITV2_PRETRAINED_MODEL_ARCHIVE_LIST,
make_divisible,
)
@@ -279,9 +278,9 @@ def test_for_semantic_segmentation(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MOBILEVITV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MobileViTV2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "apple/mobilevitv2-1.0-imagenet1k-256"
+ model = MobileViTV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/mpt/test_modeling_mpt.py b/tests/models/mpt/test_modeling_mpt.py
index e70b344d8c95a7..40385fc3fd8e71 100644
--- a/tests/models/mpt/test_modeling_mpt.py
+++ b/tests/models/mpt/test_modeling_mpt.py
@@ -30,7 +30,6 @@
import torch
from transformers import (
- MPT_PRETRAINED_MODEL_ARCHIVE_LIST,
AutoTokenizer,
MptForCausalLM,
MptForQuestionAnswering,
@@ -429,9 +428,9 @@ def test_model_weights_reload_no_missing_tied_weights(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MptModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "mosaicml/mpt-7b"
+ model = MptModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
diff --git a/tests/models/mra/test_modeling_mra.py b/tests/models/mra/test_modeling_mra.py
index a1b4b4464ce63f..a0bf0ec65e2d7a 100644
--- a/tests/models/mra/test_modeling_mra.py
+++ b/tests/models/mra/test_modeling_mra.py
@@ -36,7 +36,6 @@
MraForTokenClassification,
MraModel,
)
- from transformers.models.mra.modeling_mra import MRA_PRETRAINED_MODEL_ARCHIVE_LIST
class MraModelTester:
@@ -352,9 +351,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MRA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MraModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "uw-madison/mra-base-512-4"
+ model = MraModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="MRA does not output attentions")
def test_attention_outputs(self):
diff --git a/tests/models/mt5/test_modeling_mt5.py b/tests/models/mt5/test_modeling_mt5.py
index 9e7dd443e2b8c2..f6f138cb331032 100644
--- a/tests/models/mt5/test_modeling_mt5.py
+++ b/tests/models/mt5/test_modeling_mt5.py
@@ -51,7 +51,6 @@
MT5ForTokenClassification,
MT5Model,
)
- from transformers.models.mt5.modeling_mt5 import MT5_PRETRAINED_MODEL_ARCHIVE_LIST
# Copied from tests.models.t5.test_modeling_t5.T5ModelTester with T5->MT5
@@ -546,7 +545,7 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
-# Copied from tests.models.t5.test_modeling_t5.T5ModelTest with T5->MT5
+# Copied from tests.models.t5.test_modeling_t5.T5ModelTest with T5->MT5, google-t5/t5-small->google/mt5-small
class MT5ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(MT5Model, MT5ForConditionalGeneration, MT5ForSequenceClassification, MT5ForQuestionAnswering)
@@ -835,9 +834,9 @@ def test_v1_1_resize_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in MT5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = MT5Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/mt5-small"
+ model = MT5Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Test has a segmentation fault on torch 1.8.0")
def test_export_to_onnx(self):
diff --git a/tests/models/musicgen/test_modeling_musicgen.py b/tests/models/musicgen/test_modeling_musicgen.py
index adc3bf234ef82a..df1df64c9cf3b1 100644
--- a/tests/models/musicgen/test_modeling_musicgen.py
+++ b/tests/models/musicgen/test_modeling_musicgen.py
@@ -16,9 +16,12 @@
import copy
import inspect
import math
+import tempfile
import unittest
import numpy as np
+from parameterized import parameterized
+from pytest import mark
from transformers import (
EncodecConfig,
@@ -30,12 +33,15 @@
)
from transformers.testing_utils import (
is_torch_available,
+ require_flash_attn,
require_torch,
require_torch_fp16,
+ require_torch_gpu,
+ require_torch_sdpa,
slow,
torch_device,
)
-from transformers.utils import cached_property
+from transformers.utils import cached_property, is_torch_bf16_available_on_device, is_torch_fp16_available_on_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
@@ -277,6 +283,615 @@ def test_greedy_generate_stereo_outputs(self):
self.assertNotIn(config.pad_token_id, output_generate)
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, 1:] = 1
+ dummy_attention_mask[:, :1] = 0
+
+ # Ignore copy
+ outputs = model(dummy_input, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ # Ignore copy
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(dummy_input, **other_inputs)
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[1:], logits[1:], atol=4e-2, rtol=4e-2)
+
+ # check with inference + dropout
+ model.train()
+ _ = model_fa(dummy_input, **other_inputs)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence_right_padding
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ if model.config.is_encoder_decoder:
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ else:
+ outputs = model(dummy_input, output_hidden_states=True)
+ outputs_fa = model_fa(dummy_input, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+ # Ignore copy
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(dummy_input, **other_inputs)
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[:-1], logits[:-1], atol=4e-2, rtol=4e-2)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_left_padding
+ def test_flash_attn_2_generate_left_padding(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # make sure we do left padding
+ dummy_attention_mask[:, :-1] = 0
+ dummy_attention_mask[:, -1:] = 1
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_padding_right
+ def test_flash_attn_2_generate_padding_right(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # make sure we do right padding
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_use_cache
+ def test_flash_attn_2_generate_use_cache(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_inference
+ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
+ if not self.all_model_classes[0]._supports_sdpa:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ if torch_dtype == "float16" and not is_torch_fp16_available_on_device(torch_device):
+ self.skipTest(f"float16 not supported on {torch_device} (on the specific device currently used)")
+
+ if torch_dtype == "bfloat16" and not is_torch_bf16_available_on_device(torch_device):
+ self.skipTest(
+ f"bfloat16 not supported on {torch_device} (on the specific device currently used, e.g. Nvidia T4 GPU)"
+ )
+
+ # Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
+ if torch_dtype == "float16":
+ torch_dtype = torch.float16
+ elif torch_dtype == "bfloat16":
+ torch_dtype = torch.bfloat16
+ elif torch_dtype == "float32":
+ torch_dtype = torch.float32
+
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ rtols = {
+ ("cpu", False, torch.float32): 1e-4,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-4,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-4,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-4,
+ ("cuda", True, torch.bfloat16): 3e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+
+ def get_mean_reldiff(failcase, x, ref, atol, rtol):
+ return f"{failcase}: mean relative difference: {((x - ref).abs() / (ref.abs() + 1e-12)).mean():.3e}, torch atol = {atol}, torch rtol = {rtol}"
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ is_encoder_decoder = model.config.is_encoder_decoder
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname, torch_dtype=torch_dtype)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch_dtype,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa and model_sdpa.config.model_type != "falcon":
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # We use these for loops instead of parameterized.expand just for the interest of avoiding loading/saving 8 times the model,
+ # but it would be nicer to have an efficient way to use parameterized.expand
+ fail_cases = []
+ for padding_side in ["left", "right"]:
+ for use_mask in [False, True]:
+ for batch_size in [1, 5]:
+ # Ignore copy
+ batch_size_input_ids = self.model_tester.num_codebooks * batch_size
+ dummy_input = inputs_dict[model.main_input_name]
+
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ dummy_input = dummy_input.to(torch_dtype)
+
+ # Ignore copy
+ dummy_input = dummy_input[:batch_size_input_ids]
+ # Ignore copy
+ if dummy_input.shape[0] != batch_size_input_ids:
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ # Ignore copy
+ extension = torch.rand(
+ batch_size_input_ids - dummy_input.shape[0],
+ *dummy_input.shape[1:],
+ dtype=torch_dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+ else:
+ # Ignore copy
+ extension = torch.randint(
+ high=5,
+ size=(batch_size_input_ids - dummy_input.shape[0], *dummy_input.shape[1:]),
+ dtype=dummy_input.dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+
+ if not use_mask:
+ dummy_attention_mask = None
+ else:
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+ if dummy_attention_mask is None:
+ if is_encoder_decoder:
+ seqlen = inputs_dict.get("decoder_input_ids", dummy_input).shape[-1]
+ else:
+ seqlen = dummy_input.shape[-1]
+ dummy_attention_mask = (
+ torch.ones(batch_size, seqlen).to(torch.int64).to(torch_device)
+ )
+
+ dummy_attention_mask = dummy_attention_mask[:batch_size]
+ if dummy_attention_mask.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - dummy_attention_mask.shape[0],
+ *dummy_attention_mask.shape[1:],
+ dtype=dummy_attention_mask.dtype,
+ device=torch_device,
+ )
+ dummy_attention_mask = torch.cat((dummy_attention_mask, extension), dim=0)
+ dummy_attention_mask = dummy_attention_mask.to(torch_device)
+
+ dummy_attention_mask[:] = 1
+ if padding_side == "left":
+ dummy_attention_mask[-1, :-1] = 1
+ dummy_attention_mask[-1, -4:] = 0
+ elif padding_side == "right":
+ dummy_attention_mask[-1, 1:] = 1
+ dummy_attention_mask[-1, :3] = 0
+
+ for enable_kernels in [False, True]:
+ failcase = f"padding_side={padding_side}, use_mask={use_mask}, batch_size={batch_size}, enable_kernels={enable_kernels}"
+
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+
+ # Otherwise fails for e.g. WhisperEncoderModel
+ if "attention_mask" in inspect.signature(model_eager.forward).parameters:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ # TODO: test gradients as well (& for FA2 as well!)
+ with torch.no_grad():
+ with torch.backends.cuda.sdp_kernel(
+ enable_flash=enable_kernels,
+ enable_math=True,
+ enable_mem_efficient=enable_kernels,
+ ):
+ outputs_eager = model_eager(dummy_input, **other_inputs)
+ outputs_sdpa = model_sdpa(dummy_input, **other_inputs)
+
+ logits_eager = (
+ outputs_eager.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_eager.decoder_hidden_states[-1]
+ )
+ logits_sdpa = (
+ outputs_sdpa.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_sdpa.decoder_hidden_states[-1]
+ )
+
+ if torch_device in ["cpu", "cuda"]:
+ atol = atols[torch_device, enable_kernels, torch_dtype]
+ rtol = rtols[torch_device, enable_kernels, torch_dtype]
+ else:
+ atol = 1e-7
+ rtol = 1e-4
+
+ # Masked tokens output slightly deviates - we don't mind that.
+ if use_mask:
+ if padding_side == "left":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, :-4]
+ sub_eager = logits_eager[-1, :-4]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, -4:]
+ # sub_eager = logits_eager[-1, -4:]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+ elif padding_side == "right":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, 3:]
+ sub_eager = logits_eager[-1, 3:]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, :3]
+ # sub_eager = logits_eager[-1, :3]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+
+ else:
+ if not torch.allclose(logits_sdpa, logits_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, logits_sdpa, logits_eager, atol, rtol)
+ )
+
+ self.assertTrue(len(fail_cases) == 0, "\n".join(fail_cases))
+
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_generate
+ def test_eager_matches_sdpa_generate(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_sdpa:
+ self.skipTest(f"{model_class.__name__} does not support SDPA")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model_sdpa = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # Just test that a large cache works as expected
+ res_eager = model_eager.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ res_sdpa = model_sdpa.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(res_eager, res_sdpa))
+
def prepare_musicgen_inputs_dict(
config,
@@ -941,6 +1556,639 @@ def test_greedy_generate_stereo_outputs(self):
self.assertNotIn(config.pad_token_id, output_generate)
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, 1:] = 1
+ dummy_attention_mask[:, :1] = 0
+
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+ # Ignore copy
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+ # Ignore copy
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+ # Ignore copy
+ outputs = model(dummy_input, **other_inputs)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[1:], logits[1:], atol=4e-2, rtol=4e-2)
+
+ # check with inference + dropout
+ model.train()
+ _ = model_fa(dummy_input, **other_inputs)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence_right_padding
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+ # Ignore copy
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+ # Ignore copy
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+ # Ignore copy
+ outputs = model(dummy_input, **other_inputs)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[:-1], logits[:-1], atol=4e-2, rtol=4e-2)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_left_padding
+ def test_flash_attn_2_generate_left_padding(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask")
+ if dummy_attention_mask is None:
+ dummy_attention_mask = torch.ones_like(dummy_input)
+
+ # make sure we do left padding
+ dummy_attention_mask[:, :-1] = 0
+ dummy_attention_mask[:, -1:] = 1
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_padding_right
+ def test_flash_attn_2_generate_padding_right(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask")
+ if dummy_attention_mask is None:
+ dummy_attention_mask = torch.ones_like(dummy_input)
+ # make sure we do right padding
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_use_cache
+ def test_flash_attn_2_generate_use_cache(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_inference
+ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
+ if not self.all_model_classes[0]._supports_sdpa:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ if torch_dtype == "float16" and not is_torch_fp16_available_on_device(torch_device):
+ self.skipTest(f"float16 not supported on {torch_device} (on the specific device currently used)")
+
+ if torch_dtype == "bfloat16" and not is_torch_bf16_available_on_device(torch_device):
+ self.skipTest(
+ f"bfloat16 not supported on {torch_device} (on the specific device currently used, e.g. Nvidia T4 GPU)"
+ )
+
+ # Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
+ if torch_dtype == "float16":
+ torch_dtype = torch.float16
+ elif torch_dtype == "bfloat16":
+ torch_dtype = torch.bfloat16
+ elif torch_dtype == "float32":
+ torch_dtype = torch.float32
+
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ rtols = {
+ ("cpu", False, torch.float32): 1e-4,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-4,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-4,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-4,
+ ("cuda", True, torch.bfloat16): 3e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+
+ def get_mean_reldiff(failcase, x, ref, atol, rtol):
+ return f"{failcase}: mean relative difference: {((x - ref).abs() / (ref.abs() + 1e-12)).mean():.3e}, torch atol = {atol}, torch rtol = {rtol}"
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ is_encoder_decoder = model.config.is_encoder_decoder
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname, torch_dtype=torch_dtype)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch_dtype,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa and model_sdpa.config.model_type != "falcon":
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # We use these for loops instead of parameterized.expand just for the interest of avoiding loading/saving 8 times the model,
+ # but it would be nicer to have an efficient way to use parameterized.expand
+ fail_cases = []
+ for padding_side in ["left", "right"]:
+ for use_mask in [False, True]:
+ for batch_size in [1, 5]:
+ dummy_input = inputs_dict[model.main_input_name]
+
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ dummy_input = dummy_input.to(torch_dtype)
+
+ dummy_input = dummy_input[:batch_size]
+ if dummy_input.shape[0] != batch_size:
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ extension = torch.rand(
+ batch_size - dummy_input.shape[0],
+ *dummy_input.shape[1:],
+ dtype=torch_dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+ else:
+ extension = torch.randint(
+ high=5,
+ size=(batch_size - dummy_input.shape[0], *dummy_input.shape[1:]),
+ dtype=dummy_input.dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+
+ if not use_mask:
+ dummy_attention_mask = None
+ else:
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+ if dummy_attention_mask is None:
+ # Ignore copy
+ seqlen = inputs_dict.get("decoder_input_ids", dummy_input).shape[-1]
+ # Ignore copy
+ dummy_attention_mask = (
+ torch.ones(batch_size, seqlen).to(torch.int64).to(torch_device)
+ )
+
+ dummy_attention_mask = dummy_attention_mask[:batch_size]
+ if dummy_attention_mask.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - dummy_attention_mask.shape[0],
+ *dummy_attention_mask.shape[1:],
+ dtype=dummy_attention_mask.dtype,
+ device=torch_device,
+ )
+ dummy_attention_mask = torch.cat((dummy_attention_mask, extension), dim=0)
+ dummy_attention_mask = dummy_attention_mask.to(torch_device)
+
+ dummy_attention_mask[:] = 1
+ if padding_side == "left":
+ dummy_attention_mask[-1, :-1] = 1
+ dummy_attention_mask[-1, -4:] = 0
+ elif padding_side == "right":
+ dummy_attention_mask[-1, 1:] = 1
+ dummy_attention_mask[-1, :3] = 0
+
+ for enable_kernels in [False, True]:
+ failcase = f"padding_side={padding_side}, use_mask={use_mask}, batch_size={batch_size}, enable_kernels={enable_kernels}"
+ # Ignore copy
+ batch_size_input_ids = self.model_tester.num_codebooks * batch_size
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)[
+ :batch_size_input_ids
+ ]
+ # Ignore copy
+ if decoder_input_ids.shape[0] != batch_size_input_ids:
+ # Ignore copy
+ extension = torch.ones(
+ batch_size_input_ids - decoder_input_ids.shape[0],
+ *decoder_input_ids.shape[1:],
+ dtype=decoder_input_ids.dtype,
+ device=torch_device,
+ )
+ decoder_input_ids = torch.cat((decoder_input_ids, extension), dim=0)
+ decoder_input_ids = decoder_input_ids.to(torch_device)
+
+ # TODO: never an `attention_mask` arg here?
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+
+ # TODO: test gradients as well (& for FA2 as well!)
+ # Ignore copy
+ with torch.no_grad():
+ with torch.backends.cuda.sdp_kernel(
+ enable_flash=enable_kernels,
+ enable_math=True,
+ enable_mem_efficient=enable_kernels,
+ ):
+ outputs_eager = model_eager(dummy_input, **other_inputs)
+ outputs_sdpa = model_sdpa(dummy_input, **other_inputs)
+
+ logits_eager = (
+ outputs_eager.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_eager.decoder_hidden_states[-1]
+ )
+ logits_sdpa = (
+ outputs_sdpa.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_sdpa.decoder_hidden_states[-1]
+ )
+
+ if torch_device in ["cpu", "cuda"]:
+ atol = atols[torch_device, enable_kernels, torch_dtype]
+ rtol = rtols[torch_device, enable_kernels, torch_dtype]
+ else:
+ atol = 1e-7
+ rtol = 1e-4
+
+ # Masked tokens output slightly deviates - we don't mind that.
+ if use_mask:
+ if padding_side == "left":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, :-4]
+ sub_eager = logits_eager[-1, :-4]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, -4:]
+ # sub_eager = logits_eager[-1, -4:]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+ elif padding_side == "right":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, 3:]
+ sub_eager = logits_eager[-1, 3:]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, :3]
+ # sub_eager = logits_eager[-1, :3]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+
+ else:
+ if not torch.allclose(logits_sdpa, logits_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, logits_sdpa, logits_eager, atol, rtol)
+ )
+
+ self.assertTrue(len(fail_cases) == 0, "\n".join(fail_cases))
+
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_generate
+ def test_eager_matches_sdpa_generate(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_sdpa:
+ self.skipTest(f"{model_class.__name__} does not support SDPA")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model_sdpa = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # Just test that a large cache works as expected
+ res_eager = model_eager.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ res_sdpa = model_sdpa.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(res_eager, res_sdpa))
+
def get_bip_bip(bip_duration=0.125, duration=0.5, sample_rate=32000):
"""Produces a series of 'bip bip' sounds at a given frequency."""
diff --git a/tests/models/musicgen_melody/test_modeling_musicgen_melody.py b/tests/models/musicgen_melody/test_modeling_musicgen_melody.py
index 7bb346d8abdac2..667958a2513bdb 100644
--- a/tests/models/musicgen_melody/test_modeling_musicgen_melody.py
+++ b/tests/models/musicgen_melody/test_modeling_musicgen_melody.py
@@ -16,9 +16,12 @@
import copy
import inspect
import math
+import tempfile
import unittest
import numpy as np
+from parameterized import parameterized
+from pytest import mark
from transformers import (
EncodecConfig,
@@ -30,13 +33,16 @@
from transformers.testing_utils import (
is_torch_available,
is_torchaudio_available,
+ require_flash_attn,
require_torch,
require_torch_fp16,
+ require_torch_gpu,
+ require_torch_sdpa,
require_torchaudio,
slow,
torch_device,
)
-from transformers.utils import cached_property
+from transformers.utils import cached_property, is_torch_bf16_available_on_device, is_torch_fp16_available_on_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
@@ -277,6 +283,615 @@ def test_greedy_generate_stereo_outputs(self):
self.assertIsInstance(output_generate, GenerateDecoderOnlyOutput)
self.assertNotIn(config.pad_token_id, output_generate)
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.models.musicgen.test_modeling_musicgen.MusicgenDecoderTest.test_flash_attn_2_inference_equivalence
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, 1:] = 1
+ dummy_attention_mask[:, :1] = 0
+
+ # Ignore copy
+ outputs = model(dummy_input, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ # Ignore copy
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(dummy_input, **other_inputs)
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[1:], logits[1:], atol=4e-2, rtol=4e-2)
+
+ # check with inference + dropout
+ model.train()
+ _ = model_fa(dummy_input, **other_inputs)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.models.musicgen.test_modeling_musicgen.MusicgenDecoderTest.test_flash_attn_2_inference_equivalence_right_padding
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ if model.config.is_encoder_decoder:
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ else:
+ outputs = model(dummy_input, output_hidden_states=True)
+ outputs_fa = model_fa(dummy_input, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+ # Ignore copy
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(dummy_input, **other_inputs)
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[:-1], logits[:-1], atol=4e-2, rtol=4e-2)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_left_padding
+ def test_flash_attn_2_generate_left_padding(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # make sure we do left padding
+ dummy_attention_mask[:, :-1] = 0
+ dummy_attention_mask[:, -1:] = 1
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_padding_right
+ def test_flash_attn_2_generate_padding_right(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # make sure we do right padding
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.models.musicgen.test_modeling_musicgen.MusicgenDecoderTest.test_flash_attn_2_generate_use_cache
+ def test_flash_attn_2_generate_use_cache(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.models.musicgen.test_modeling_musicgen.MusicgenDecoderTest.test_eager_matches_sdpa_inference
+ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
+ if not self.all_model_classes[0]._supports_sdpa:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ if torch_dtype == "float16" and not is_torch_fp16_available_on_device(torch_device):
+ self.skipTest(f"float16 not supported on {torch_device} (on the specific device currently used)")
+
+ if torch_dtype == "bfloat16" and not is_torch_bf16_available_on_device(torch_device):
+ self.skipTest(
+ f"bfloat16 not supported on {torch_device} (on the specific device currently used, e.g. Nvidia T4 GPU)"
+ )
+
+ # Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
+ if torch_dtype == "float16":
+ torch_dtype = torch.float16
+ elif torch_dtype == "bfloat16":
+ torch_dtype = torch.bfloat16
+ elif torch_dtype == "float32":
+ torch_dtype = torch.float32
+
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ rtols = {
+ ("cpu", False, torch.float32): 1e-4,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-4,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-4,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-4,
+ ("cuda", True, torch.bfloat16): 3e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+
+ def get_mean_reldiff(failcase, x, ref, atol, rtol):
+ return f"{failcase}: mean relative difference: {((x - ref).abs() / (ref.abs() + 1e-12)).mean():.3e}, torch atol = {atol}, torch rtol = {rtol}"
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ is_encoder_decoder = model.config.is_encoder_decoder
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname, torch_dtype=torch_dtype)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch_dtype,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa and model_sdpa.config.model_type != "falcon":
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # We use these for loops instead of parameterized.expand just for the interest of avoiding loading/saving 8 times the model,
+ # but it would be nicer to have an efficient way to use parameterized.expand
+ fail_cases = []
+ for padding_side in ["left", "right"]:
+ for use_mask in [False, True]:
+ for batch_size in [1, 5]:
+ # Ignore copy
+ batch_size_input_ids = self.model_tester.num_codebooks * batch_size
+ dummy_input = inputs_dict[model.main_input_name]
+
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ dummy_input = dummy_input.to(torch_dtype)
+
+ # Ignore copy
+ dummy_input = dummy_input[:batch_size_input_ids]
+ # Ignore copy
+ if dummy_input.shape[0] != batch_size_input_ids:
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ # Ignore copy
+ extension = torch.rand(
+ batch_size_input_ids - dummy_input.shape[0],
+ *dummy_input.shape[1:],
+ dtype=torch_dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+ else:
+ # Ignore copy
+ extension = torch.randint(
+ high=5,
+ size=(batch_size_input_ids - dummy_input.shape[0], *dummy_input.shape[1:]),
+ dtype=dummy_input.dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+
+ if not use_mask:
+ dummy_attention_mask = None
+ else:
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+ if dummy_attention_mask is None:
+ if is_encoder_decoder:
+ seqlen = inputs_dict.get("decoder_input_ids", dummy_input).shape[-1]
+ else:
+ seqlen = dummy_input.shape[-1]
+ dummy_attention_mask = (
+ torch.ones(batch_size, seqlen).to(torch.int64).to(torch_device)
+ )
+
+ dummy_attention_mask = dummy_attention_mask[:batch_size]
+ if dummy_attention_mask.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - dummy_attention_mask.shape[0],
+ *dummy_attention_mask.shape[1:],
+ dtype=dummy_attention_mask.dtype,
+ device=torch_device,
+ )
+ dummy_attention_mask = torch.cat((dummy_attention_mask, extension), dim=0)
+ dummy_attention_mask = dummy_attention_mask.to(torch_device)
+
+ dummy_attention_mask[:] = 1
+ if padding_side == "left":
+ dummy_attention_mask[-1, :-1] = 1
+ dummy_attention_mask[-1, -4:] = 0
+ elif padding_side == "right":
+ dummy_attention_mask[-1, 1:] = 1
+ dummy_attention_mask[-1, :3] = 0
+
+ for enable_kernels in [False, True]:
+ failcase = f"padding_side={padding_side}, use_mask={use_mask}, batch_size={batch_size}, enable_kernels={enable_kernels}"
+
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+
+ # Otherwise fails for e.g. WhisperEncoderModel
+ if "attention_mask" in inspect.signature(model_eager.forward).parameters:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ # TODO: test gradients as well (& for FA2 as well!)
+ with torch.no_grad():
+ with torch.backends.cuda.sdp_kernel(
+ enable_flash=enable_kernels,
+ enable_math=True,
+ enable_mem_efficient=enable_kernels,
+ ):
+ outputs_eager = model_eager(dummy_input, **other_inputs)
+ outputs_sdpa = model_sdpa(dummy_input, **other_inputs)
+
+ logits_eager = (
+ outputs_eager.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_eager.decoder_hidden_states[-1]
+ )
+ logits_sdpa = (
+ outputs_sdpa.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_sdpa.decoder_hidden_states[-1]
+ )
+
+ if torch_device in ["cpu", "cuda"]:
+ atol = atols[torch_device, enable_kernels, torch_dtype]
+ rtol = rtols[torch_device, enable_kernels, torch_dtype]
+ else:
+ atol = 1e-7
+ rtol = 1e-4
+
+ # Masked tokens output slightly deviates - we don't mind that.
+ if use_mask:
+ if padding_side == "left":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, :-4]
+ sub_eager = logits_eager[-1, :-4]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, -4:]
+ # sub_eager = logits_eager[-1, -4:]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+ elif padding_side == "right":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, 3:]
+ sub_eager = logits_eager[-1, 3:]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, :3]
+ # sub_eager = logits_eager[-1, :3]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+
+ else:
+ if not torch.allclose(logits_sdpa, logits_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, logits_sdpa, logits_eager, atol, rtol)
+ )
+
+ self.assertTrue(len(fail_cases) == 0, "\n".join(fail_cases))
+
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.models.musicgen.test_modeling_musicgen.MusicgenDecoderTest.test_eager_matches_sdpa_generate
+ def test_eager_matches_sdpa_generate(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_sdpa:
+ self.skipTest(f"{model_class.__name__} does not support SDPA")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model_sdpa = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # Just test that a large cache works as expected
+ res_eager = model_eager.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ res_sdpa = model_sdpa.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(res_eager, res_sdpa))
+
def prepare_musicgen_melody_inputs_dict(
config,
@@ -923,6 +1538,639 @@ def test_greedy_generate_stereo_outputs(self):
self.assertNotIn(config.pad_token_id, output_generate)
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, 1:] = 1
+ dummy_attention_mask[:, :1] = 0
+
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+ # Ignore copy
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+ # Ignore copy
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+ # Ignore copy
+ outputs = model(dummy_input, **other_inputs)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[1:], logits[1:], atol=4e-2, rtol=4e-2)
+
+ # check with inference + dropout
+ model.train()
+ _ = model_fa(dummy_input, **other_inputs)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_inference_equivalence_right_padding
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ # Ignore copy
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ # Ignore copy
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)
+ # Ignore copy
+ outputs = model(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, decoder_input_ids=decoder_input_ids, output_hidden_states=True)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+ # Ignore copy
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+ # Ignore copy
+ outputs = model(dummy_input, **other_inputs)
+ # Ignore copy
+ outputs_fa = model_fa(dummy_input, **other_inputs)
+
+ logits = (
+ outputs.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs.decoder_hidden_states[-1]
+ )
+ logits_fa = (
+ outputs_fa.hidden_states[-1]
+ if not model.config.is_encoder_decoder
+ else outputs_fa.decoder_hidden_states[-1]
+ )
+
+ assert torch.allclose(logits_fa[:-1], logits[:-1], atol=4e-2, rtol=4e-2)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_left_padding
+ def test_flash_attn_2_generate_left_padding(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask")
+ if dummy_attention_mask is None:
+ dummy_attention_mask = torch.ones_like(dummy_input)
+
+ # make sure we do left padding
+ dummy_attention_mask[:, :-1] = 0
+ dummy_attention_mask[:, -1:] = 1
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_padding_right
+ def test_flash_attn_2_generate_padding_right(self):
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = inputs_dict[model.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask")
+ if dummy_attention_mask is None:
+ dummy_attention_mask = torch.ones_like(dummy_input)
+ # make sure we do right padding
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ out = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ out_fa = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=8, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(out, out_fa))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_flash_attn_2_generate_use_cache
+ def test_flash_attn_2_generate_use_cache(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_inference
+ def test_eager_matches_sdpa_inference(self, torch_dtype: str):
+ if not self.all_model_classes[0]._supports_sdpa:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ if torch_dtype == "float16" and not is_torch_fp16_available_on_device(torch_device):
+ self.skipTest(f"float16 not supported on {torch_device} (on the specific device currently used)")
+
+ if torch_dtype == "bfloat16" and not is_torch_bf16_available_on_device(torch_device):
+ self.skipTest(
+ f"bfloat16 not supported on {torch_device} (on the specific device currently used, e.g. Nvidia T4 GPU)"
+ )
+
+ # Not sure whether it's fine to put torch.XXX in a decorator if torch is not available so hacking it here instead.
+ if torch_dtype == "float16":
+ torch_dtype = torch.float16
+ elif torch_dtype == "bfloat16":
+ torch_dtype = torch.bfloat16
+ elif torch_dtype == "float32":
+ torch_dtype = torch.float32
+
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ rtols = {
+ ("cpu", False, torch.float32): 1e-4,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-4,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-4,
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-4,
+ ("cuda", True, torch.bfloat16): 3e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+
+ def get_mean_reldiff(failcase, x, ref, atol, rtol):
+ return f"{failcase}: mean relative difference: {((x - ref).abs() / (ref.abs() + 1e-12)).mean():.3e}, torch atol = {atol}, torch rtol = {rtol}"
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ is_encoder_decoder = model.config.is_encoder_decoder
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname, torch_dtype=torch_dtype)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch_dtype,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa and model_sdpa.config.model_type != "falcon":
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # We use these for loops instead of parameterized.expand just for the interest of avoiding loading/saving 8 times the model,
+ # but it would be nicer to have an efficient way to use parameterized.expand
+ fail_cases = []
+ for padding_side in ["left", "right"]:
+ for use_mask in [False, True]:
+ for batch_size in [1, 5]:
+ dummy_input = inputs_dict[model.main_input_name]
+
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ dummy_input = dummy_input.to(torch_dtype)
+
+ dummy_input = dummy_input[:batch_size]
+ if dummy_input.shape[0] != batch_size:
+ if dummy_input.dtype in [torch.float32, torch.bfloat16, torch.float16]:
+ extension = torch.rand(
+ batch_size - dummy_input.shape[0],
+ *dummy_input.shape[1:],
+ dtype=torch_dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+ else:
+ extension = torch.randint(
+ high=5,
+ size=(batch_size - dummy_input.shape[0], *dummy_input.shape[1:]),
+ dtype=dummy_input.dtype,
+ device=torch_device,
+ )
+ dummy_input = torch.cat((dummy_input, extension), dim=0).to(torch_device)
+
+ if not use_mask:
+ dummy_attention_mask = None
+ else:
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+ if dummy_attention_mask is None:
+ # Ignore copy
+ seqlen = inputs_dict.get("decoder_input_ids", dummy_input).shape[-1]
+ # Ignore copy
+ dummy_attention_mask = (
+ torch.ones(batch_size, seqlen).to(torch.int64).to(torch_device)
+ )
+
+ dummy_attention_mask = dummy_attention_mask[:batch_size]
+ if dummy_attention_mask.shape[0] != batch_size:
+ extension = torch.ones(
+ batch_size - dummy_attention_mask.shape[0],
+ *dummy_attention_mask.shape[1:],
+ dtype=dummy_attention_mask.dtype,
+ device=torch_device,
+ )
+ dummy_attention_mask = torch.cat((dummy_attention_mask, extension), dim=0)
+ dummy_attention_mask = dummy_attention_mask.to(torch_device)
+
+ dummy_attention_mask[:] = 1
+ if padding_side == "left":
+ dummy_attention_mask[-1, :-1] = 1
+ dummy_attention_mask[-1, -4:] = 0
+ elif padding_side == "right":
+ dummy_attention_mask[-1, 1:] = 1
+ dummy_attention_mask[-1, :3] = 0
+
+ for enable_kernels in [False, True]:
+ failcase = f"padding_side={padding_side}, use_mask={use_mask}, batch_size={batch_size}, enable_kernels={enable_kernels}"
+ # Ignore copy
+ batch_size_input_ids = self.model_tester.num_codebooks * batch_size
+ # Ignore copy
+ decoder_input_ids = inputs_dict.get("decoder_input_ids", dummy_input)[
+ :batch_size_input_ids
+ ]
+ # Ignore copy
+ if decoder_input_ids.shape[0] != batch_size_input_ids:
+ # Ignore copy
+ extension = torch.ones(
+ batch_size_input_ids - decoder_input_ids.shape[0],
+ *decoder_input_ids.shape[1:],
+ dtype=decoder_input_ids.dtype,
+ device=torch_device,
+ )
+ decoder_input_ids = torch.cat((decoder_input_ids, extension), dim=0)
+ decoder_input_ids = decoder_input_ids.to(torch_device)
+
+ # TODO: never an `attention_mask` arg here?
+ # Ignore copy
+ other_inputs = {
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": dummy_attention_mask,
+ "output_hidden_states": True,
+ }
+
+ # TODO: test gradients as well (& for FA2 as well!)
+ # Ignore copy
+ with torch.no_grad():
+ with torch.backends.cuda.sdp_kernel(
+ enable_flash=enable_kernels,
+ enable_math=True,
+ enable_mem_efficient=enable_kernels,
+ ):
+ outputs_eager = model_eager(dummy_input, **other_inputs)
+ outputs_sdpa = model_sdpa(dummy_input, **other_inputs)
+
+ logits_eager = (
+ outputs_eager.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_eager.decoder_hidden_states[-1]
+ )
+ logits_sdpa = (
+ outputs_sdpa.hidden_states[-1]
+ if not is_encoder_decoder
+ else outputs_sdpa.decoder_hidden_states[-1]
+ )
+
+ if torch_device in ["cpu", "cuda"]:
+ atol = atols[torch_device, enable_kernels, torch_dtype]
+ rtol = rtols[torch_device, enable_kernels, torch_dtype]
+ else:
+ atol = 1e-7
+ rtol = 1e-4
+
+ # Masked tokens output slightly deviates - we don't mind that.
+ if use_mask:
+ if padding_side == "left":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, :-4]
+ sub_eager = logits_eager[-1, :-4]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, -4:]
+ # sub_eager = logits_eager[-1, -4:]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+ elif padding_side == "right":
+ sub_sdpa = logits_sdpa[:-1]
+ sub_eager = logits_eager[:-1]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ sub_sdpa = logits_sdpa[-1, 3:]
+ sub_eager = logits_eager[-1, 3:]
+ if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, sub_sdpa, sub_eager, atol, rtol)
+ )
+
+ # Testing the padding tokens is not really meaningful but anyway
+ # sub_sdpa = logits_sdpa[-1, :3]
+ # sub_eager = logits_eager[-1, :3]
+ # if not torch.allclose(sub_sdpa, sub_eager, atol=atol, rtol=rtol):
+ # fail_cases.append(get_mean_reldiff(failcase, sub_sdpa, sub_eager, 4e-2, 4e-2))
+
+ else:
+ if not torch.allclose(logits_sdpa, logits_eager, atol=atol, rtol=rtol):
+ fail_cases.append(
+ get_mean_reldiff(failcase, logits_sdpa, logits_eager, atol, rtol)
+ )
+
+ self.assertTrue(len(fail_cases) == 0, "\n".join(fail_cases))
+
+ @require_torch_sdpa
+ @slow
+ # Copied from tests.test_modeling_common.ModelTesterMixin.test_eager_matches_sdpa_generate
+ def test_eager_matches_sdpa_generate(self):
+ max_new_tokens = 30
+
+ # Ignore copy
+ for model_class in self.greedy_sample_model_classes:
+ if not model_class._supports_sdpa:
+ self.skipTest(f"{model_class.__name__} does not support SDPA")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+
+ model_sdpa = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ # Just test that a large cache works as expected
+ res_eager = model_eager.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ res_sdpa = model_sdpa.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=max_new_tokens, do_sample=False
+ )
+
+ self.assertTrue(torch.allclose(res_eager, res_sdpa))
+
# Copied from tests.models.musicgen.test_modeling_musicgen.get_bip_bip
def get_bip_bip(bip_duration=0.125, duration=0.5, sample_rate=32000):
diff --git a/tests/models/nat/test_modeling_nat.py b/tests/models/nat/test_modeling_nat.py
index cbdbfc83c5e0ad..6a68311cc6b9e9 100644
--- a/tests/models/nat/test_modeling_nat.py
+++ b/tests/models/nat/test_modeling_nat.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import NatBackbone, NatForImageClassification, NatModel
- from transformers.models.nat.modeling_nat import NAT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -327,9 +326,9 @@ def test_hidden_states_output(self):
@slow
def test_model_from_pretrained(self):
- for model_name in NAT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = NatModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "shi-labs/nat-mini-in1k-224"
+ model = NatModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/nezha/test_modeling_nezha.py b/tests/models/nezha/test_modeling_nezha.py
index a71823d8a5f62a..311866758be65e 100644
--- a/tests/models/nezha/test_modeling_nezha.py
+++ b/tests/models/nezha/test_modeling_nezha.py
@@ -40,7 +40,6 @@
NezhaForTokenClassification,
NezhaModel,
)
- from transformers.models.nezha.modeling_nezha import NEZHA_PRETRAINED_MODEL_ARCHIVE_LIST
class NezhaModelTester:
@@ -432,9 +431,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in NEZHA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = NezhaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "sijunhe/nezha-cn-base"
+ model = NezhaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@slow
@require_torch_gpu
diff --git a/tests/models/nllb_moe/test_modeling_nllb_moe.py b/tests/models/nllb_moe/test_modeling_nllb_moe.py
index 2e8ba30ce675a6..6997b896a5c890 100644
--- a/tests/models/nllb_moe/test_modeling_nllb_moe.py
+++ b/tests/models/nllb_moe/test_modeling_nllb_moe.py
@@ -387,12 +387,10 @@ def inference_no_head(self):
EXPECTED_DECODER_STATE = torch.Tensor([-6.0425e-02, -2.0015e-01, 6.0575e-02, -8.6366e-01, -1.1310e+00, 6.8369e-01, 7.5615e-01, 7.3555e-01, 2.3071e-01, 1.5954e+00, -7.0728e-01, -2.2647e-01, -1.3292e+00, 4.8246e-01, -6.9153e-01, -1.8199e-02, -7.3664e-01, 1.5902e-03, 1.0760e-01, 1.0298e-01, -9.3933e-01, -4.6567e-01, 8.0417e-01, 1.5243e+00, 5.5844e-01, -9.9239e-02, 1.4885e+00, 7.1527e-02, -5.2612e-01, 9.4435e-02])
# fmt: on
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
output.encoder_last_hidden_state[1, 0, :30], EXPECTED_ENCODER_STATE, rtol=6e-3, atol=9e-3
)
- torch.testing.assert_allclose(
- output.last_hidden_state[1, 0, :30], EXPECTED_DECODER_STATE, rtol=6e-3, atol=9e-3
- )
+ torch.testing.assert_close(output.last_hidden_state[1, 0, :30], EXPECTED_DECODER_STATE, rtol=6e-3, atol=9e-3)
def test_inference_logits(self):
r"""
@@ -405,7 +403,7 @@ def test_inference_logits(self):
output = model(**self.model_inputs)
EXPECTED_LOGTIS = torch.Tensor([-0.3059, 0.0000, 9.3029, 0.6456, -0.9148, 1.7836, 0.6478, 0.9438, -0.5272, -0.6617, -1.2717, 0.4564, 0.1345, -0.2301, -1.0140, 1.1427, -1.5535, 0.1337, 0.2082, -0.8112, -0.3842, -0.3377, 0.1256, 0.6450, -0.0452, 0.0219, 1.4274, -0.4991, -0.2063, -0.4409,]) # fmt: skip
- torch.testing.assert_allclose(output.logits[1, 0, :30], EXPECTED_LOGTIS, rtol=6e-3, atol=9e-3)
+ torch.testing.assert_close(output.logits[1, 0, :30], EXPECTED_LOGTIS, rtol=6e-3, atol=9e-3)
@unittest.skip("This requires 300GB of RAM")
def test_large_logits(self):
@@ -419,13 +417,11 @@ def test_large_logits(self):
EXPECTED_LOGTIS = torch.Tensor([ 0.3834, 0.2057, 4.5399, 0.8301, 0.4810, 0.9325, 0.9928, 0.9574, 0.5517, 0.9156, 0.2698, 0.6728, 0.7121, 0.3080, 0.4693, 0.5756, 1.0407, 0.2219, 0.3714, 0.5699, 0.5547, 0.8472, 0.3178, 0.1286, 0.1791, 0.9391, 0.5153, -0.2146, 0.1689, 0.6816])
# fmt: on
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
output.encoder_last_hidden_state[1, 0, :30], EXPECTED_ENCODER_STATE, rtol=6e-3, atol=9e-3
)
- torch.testing.assert_allclose(
- output.last_hidden_state[1, 0, :30], EXPECTED_DECODER_STATE, rtol=6e-3, atol=9e-3
- )
- torch.testing.assert_allclose(output.logits[1, 0, :30], EXPECTED_LOGTIS, rtol=6e-3, atol=9e-3)
+ torch.testing.assert_close(output.last_hidden_state[1, 0, :30], EXPECTED_DECODER_STATE, rtol=6e-3, atol=9e-3)
+ torch.testing.assert_close(output.logits[1, 0, :30], EXPECTED_LOGTIS, rtol=6e-3, atol=9e-3)
@unittest.skip("This requires 300GB of RAM")
def test_seq_to_seq_generation(self):
@@ -564,10 +560,10 @@ def test_second_expert_policy(self):
# `sampling` and `random` do not affect the mask of the top_1 router
# fmt: on
- torch.testing.assert_allclose(router_probs_all, EXPECTED_ROUTER_ALL, 1e-4, 1e-4)
- torch.testing.assert_allclose(router_probs_sp, EXPECTED_ROUTER_SP, 1e-4, 1e-4)
- torch.testing.assert_allclose(router_probs, EXPECTED_ROUTER, 1e-4, 1e-4)
+ torch.testing.assert_close(router_probs_all, EXPECTED_ROUTER_ALL, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(router_probs_sp, EXPECTED_ROUTER_SP, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(router_probs, EXPECTED_ROUTER, rtol=1e-4, atol=1e-4)
- torch.testing.assert_allclose(top_1_mask_all, EXPECTED_TOP_1_ALL, 1e-4, 1e-4)
- torch.testing.assert_allclose(top_1_mask_sp, EXPECTED_TOP_1_SP, 1e-4, 1e-4)
- torch.testing.assert_allclose(top_1_mask, EXPECTED_TOP_1_SP, 1e-4, 1e-4)
+ torch.testing.assert_close(top_1_mask_all, EXPECTED_TOP_1_ALL, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(top_1_mask_sp, EXPECTED_TOP_1_SP, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(top_1_mask, EXPECTED_TOP_1_SP, rtol=1e-4, atol=1e-4)
diff --git a/tests/models/nystromformer/test_modeling_nystromformer.py b/tests/models/nystromformer/test_modeling_nystromformer.py
index ae06670103c88f..f5bcb0ba5fe600 100644
--- a/tests/models/nystromformer/test_modeling_nystromformer.py
+++ b/tests/models/nystromformer/test_modeling_nystromformer.py
@@ -36,7 +36,6 @@
NystromformerForTokenClassification,
NystromformerModel,
)
- from transformers.models.nystromformer.modeling_nystromformer import NYSTROMFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
class NystromformerModelTester:
@@ -284,9 +283,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in NYSTROMFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = NystromformerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "uw-madison/nystromformer-512"
+ model = NystromformerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/openai/test_modeling_openai.py b/tests/models/openai/test_modeling_openai.py
index 718c224bf04895..49e6d50bc4287a 100644
--- a/tests/models/openai/test_modeling_openai.py
+++ b/tests/models/openai/test_modeling_openai.py
@@ -29,7 +29,6 @@
import torch
from transformers import (
- OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST,
OpenAIGPTConfig,
OpenAIGPTDoubleHeadsModel,
OpenAIGPTForSequenceClassification,
@@ -270,9 +269,9 @@ def test_openai_gpt_classification_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = OpenAIGPTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai-community/openai-gpt"
+ model = OpenAIGPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/openai/test_modeling_tf_openai.py b/tests/models/openai/test_modeling_tf_openai.py
index 6704ec97532b33..f6bf7c521765a3 100644
--- a/tests/models/openai/test_modeling_tf_openai.py
+++ b/tests/models/openai/test_modeling_tf_openai.py
@@ -30,7 +30,6 @@
import tensorflow as tf
from transformers.models.openai.modeling_tf_openai import (
- TF_OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST,
TFOpenAIGPTDoubleHeadsModel,
TFOpenAIGPTForSequenceClassification,
TFOpenAIGPTLMHeadModel,
@@ -253,9 +252,9 @@ def test_openai_gpt_sequence_classification_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_OPENAI_GPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFOpenAIGPTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openai-community/openai-gpt"
+ model = TFOpenAIGPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/owlv2/test_modeling_owlv2.py b/tests/models/owlv2/test_modeling_owlv2.py
index 74fbaa58d0e40b..d29f8c08c0a091 100644
--- a/tests/models/owlv2/test_modeling_owlv2.py
+++ b/tests/models/owlv2/test_modeling_owlv2.py
@@ -50,7 +50,6 @@
from torch import nn
from transformers import Owlv2ForObjectDetection, Owlv2Model, Owlv2TextModel, Owlv2VisionModel
- from transformers.models.owlv2.modeling_owlv2 import OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -138,7 +137,7 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
-# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTVisionModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2
+# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTVisionModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2, owlvit-base-patch32->owlv2-base-patch16-ensemble
class Owlv2VisionModelTest(ModelTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_common.py, as OWLV2 does not use input_ids, inputs_embeds,
@@ -219,9 +218,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Owlv2VisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlv2-base-patch16-ensemble"
+ model = Owlv2VisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTTextModelTester with OwlViT->Owlv2
@@ -315,7 +314,7 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
-# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTTextModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2
+# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTTextModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2, owlvit-base-patch32->owlv2-base-patch16-ensemble
class Owlv2TextModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (Owlv2TextModel,) if is_torch_available() else ()
fx_compatible = False
@@ -367,9 +366,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Owlv2TextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlv2-base-patch16-ensemble"
+ model = Owlv2TextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class Owlv2ModelTester:
@@ -430,7 +429,7 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
-# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2
+# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTModelTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2, owlvit-base-patch32->owlv2-base-patch16-ensemble
class Owlv2ModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (Owlv2Model,) if is_torch_available() else ()
pipeline_model_mapping = (
@@ -578,9 +577,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Owlv2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlv2-base-patch16-ensemble"
+ model = Owlv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTForObjectDetectionTester with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2
@@ -644,7 +643,7 @@ def prepare_config_and_inputs_for_common(self):
@require_torch
-# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTForObjectDetectionTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2
+# Copied from tests.models.owlvit.test_modeling_owlvit.OwlViTForObjectDetectionTest with OwlViT->Owlv2, OWL-ViT->OwlV2, OWLVIT->OWLV2, owlvit-base-patch32->owlv2-base-patch16-ensemble
class Owlv2ForObjectDetectionTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (Owlv2ForObjectDetection,) if is_torch_available() else ()
fx_compatible = False
@@ -777,9 +776,9 @@ def _create_and_check_torchscript(self, config, inputs_dict):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Owlv2ForObjectDetection.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlv2-base-patch16-ensemble"
+ model = Owlv2ForObjectDetection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/owlvit/test_modeling_owlvit.py b/tests/models/owlvit/test_modeling_owlvit.py
index 1966aaeda2501c..370de654471179 100644
--- a/tests/models/owlvit/test_modeling_owlvit.py
+++ b/tests/models/owlvit/test_modeling_owlvit.py
@@ -50,7 +50,6 @@
from torch import nn
from transformers import OwlViTForObjectDetection, OwlViTModel, OwlViTTextModel, OwlViTVisionModel
- from transformers.models.owlvit.modeling_owlvit import OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -217,9 +216,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = OwlViTVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlvit-base-patch32"
+ model = OwlViTVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class OwlViTTextModelTester:
@@ -363,9 +362,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = OwlViTTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlvit-base-patch32"
+ model = OwlViTTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class OwlViTModelTester:
@@ -573,9 +572,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = OwlViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlvit-base-patch32"
+ model = OwlViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class OwlViTForObjectDetectionTester:
@@ -770,9 +769,9 @@ def _create_and_check_torchscript(self, config, inputs_dict):
@slow
def test_model_from_pretrained(self):
- for model_name in OWLVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = OwlViTForObjectDetection.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/owlvit-base-patch32"
+ model = OwlViTForObjectDetection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/perceiver/test_modeling_perceiver.py b/tests/models/perceiver/test_modeling_perceiver.py
index a529c4430ff312..fbd237bc105874 100644
--- a/tests/models/perceiver/test_modeling_perceiver.py
+++ b/tests/models/perceiver/test_modeling_perceiver.py
@@ -56,7 +56,6 @@
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES,
MODEL_MAPPING_NAMES,
)
- from transformers.models.perceiver.modeling_perceiver import PERCEIVER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -832,9 +831,9 @@ def test_load_with_mismatched_shapes(self):
@slow
def test_model_from_pretrained(self):
- for model_name in PERCEIVER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = PerceiverModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "deepmind/language-perceiver"
+ model = PerceiverModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/perceiver/test_tokenization_perceiver.py b/tests/models/perceiver/test_tokenization_perceiver.py
index b5d149e5f29fb8..ff2b6e68dcc0c5 100644
--- a/tests/models/perceiver/test_tokenization_perceiver.py
+++ b/tests/models/perceiver/test_tokenization_perceiver.py
@@ -270,10 +270,6 @@ def test_decode_invalid_byte_id(self):
tokenizer = self.perceiver_tokenizer
self.assertEqual(tokenizer.decode([178]), "�")
- # tokenizer can be instantiated without any pretrained files, so no need for pretrained tokenizer list
- def test_pretrained_model_lists(self):
- pass
-
# tokenizer does not have vocabulary
def test_get_vocab(self):
pass
diff --git a/tests/models/persimmon/test_modeling_persimmon.py b/tests/models/persimmon/test_modeling_persimmon.py
index 864db992772772..79cee8a64863cb 100644
--- a/tests/models/persimmon/test_modeling_persimmon.py
+++ b/tests/models/persimmon/test_modeling_persimmon.py
@@ -45,6 +45,11 @@
PersimmonForSequenceClassification,
PersimmonModel,
)
+ from transformers.models.persimmon.modeling_persimmon import (
+ PersimmonDynamicNTKScalingRotaryEmbedding,
+ PersimmonLinearScalingRotaryEmbedding,
+ PersimmonRotaryEmbedding,
+ )
# Copied from tests.models.llama.test_modeling_llama.LlamaModelTester with Llama->Persimmon
@@ -365,8 +370,8 @@ def test_save_load_fast_init_from_base(self):
pass
@parameterized.expand([("linear",), ("dynamic",)])
- # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling with Llama->Persimmon
- def test_model_rope_scaling(self, scaling_type):
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling_from_config with Llama->Persimmon
+ def test_model_rope_scaling_from_config(self, scaling_type):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
short_input = ids_tensor([1, 10], config.vocab_size)
long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
@@ -396,6 +401,66 @@ def test_model_rope_scaling(self, scaling_type):
# The output should be different for long inputs
self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+ # Copied from tests.models.falcon.test_modeling_falcon.FalconModelTest.test_model_rope_scaling with Falcon->Persimmon
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+
+ # Sanity check original RoPE
+ original_rope = PersimmonRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, short_input_length)
+ original_cos_long, original_sin_long = original_rope(x, long_input_length)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = PersimmonLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, short_input_length)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[new_position, :], original_cos_long[original_position, :])
+ torch.testing.assert_close(linear_sin_long[new_position, :], original_sin_long[original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = PersimmonDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, short_input_length)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
@require_torch
class PersimmonIntegrationTest(unittest.TestCase):
diff --git a/tests/models/phi/test_modeling_phi.py b/tests/models/phi/test_modeling_phi.py
index d69bbb32c1a682..e3c145bfa268ca 100644
--- a/tests/models/phi/test_modeling_phi.py
+++ b/tests/models/phi/test_modeling_phi.py
@@ -19,8 +19,9 @@
import unittest
import pytest
+from parameterized import parameterized
-from transformers import PhiConfig, is_torch_available
+from transformers import PhiConfig, is_torch_available, set_seed
from transformers.testing_utils import (
require_bitsandbytes,
require_flash_attn,
@@ -46,6 +47,11 @@
PhiForTokenClassification,
PhiModel,
)
+ from transformers.models.phi.modeling_phi import (
+ PhiDynamicNTKScalingRotaryEmbedding,
+ PhiLinearScalingRotaryEmbedding,
+ PhiRotaryEmbedding,
+ )
class PhiModelTester:
@@ -360,6 +366,98 @@ def test_phi_sequence_classification_model_for_multi_label(self):
result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+ @parameterized.expand([("linear",), ("dynamic",)])
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling_from_config with Llama->Phi
+ def test_model_rope_scaling_from_config(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = PhiModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = PhiModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ self.assertTrue(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ # Copied from tests.models.falcon.test_modeling_falcon.FalconModelTest.test_model_rope_scaling with Falcon->Phi
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+
+ # Sanity check original RoPE
+ original_rope = PhiRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, short_input_length)
+ original_cos_long, original_sin_long = original_rope(x, long_input_length)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = PhiLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, short_input_length)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[new_position, :], original_cos_long[original_position, :])
+ torch.testing.assert_close(linear_sin_long[new_position, :], original_sin_long[original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = PhiDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, short_input_length)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
@require_flash_attn
@require_torch_gpu
@require_bitsandbytes
diff --git a/tests/models/pix2struct/test_modeling_pix2struct.py b/tests/models/pix2struct/test_modeling_pix2struct.py
index 0745362272966c..abc29bfbb71929 100644
--- a/tests/models/pix2struct/test_modeling_pix2struct.py
+++ b/tests/models/pix2struct/test_modeling_pix2struct.py
@@ -48,7 +48,6 @@
Pix2StructTextModel,
Pix2StructVisionModel,
)
- from transformers.models.pix2struct.modeling_pix2struct import PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -222,9 +221,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Pix2StructVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/pix2struct-textcaps-base"
+ model = Pix2StructVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class Pix2StructTextModelTester:
@@ -371,9 +370,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in PIX2STRUCT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Pix2StructTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/pix2struct-textcaps-base"
+ model = Pix2StructTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class Pix2StructModelTester:
diff --git a/tests/models/poolformer/test_modeling_poolformer.py b/tests/models/poolformer/test_modeling_poolformer.py
index e387053f110ada..ca5c3015a7dff5 100644
--- a/tests/models/poolformer/test_modeling_poolformer.py
+++ b/tests/models/poolformer/test_modeling_poolformer.py
@@ -30,7 +30,6 @@
import torch
from transformers import MODEL_MAPPING, PoolFormerConfig, PoolFormerForImageClassification, PoolFormerModel
- from transformers.models.poolformer.modeling_poolformer import POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -209,9 +208,9 @@ def test_training(self):
@slow
def test_model_from_pretrained(self):
- for model_name in POOLFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = PoolFormerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "sail/poolformer_s12"
+ model = PoolFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/pop2piano/test_modeling_pop2piano.py b/tests/models/pop2piano/test_modeling_pop2piano.py
index a99f713a7bd098..594f79b08378e9 100644
--- a/tests/models/pop2piano/test_modeling_pop2piano.py
+++ b/tests/models/pop2piano/test_modeling_pop2piano.py
@@ -44,7 +44,6 @@
import torch
from transformers import Pop2PianoForConditionalGeneration
- from transformers.models.pop2piano.modeling_pop2piano import POP2PIANO_PRETRAINED_MODEL_ARCHIVE_LIST
@require_torch
@@ -607,9 +606,9 @@ def test_v1_1_resize_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in POP2PIANO_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Pop2PianoForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "sweetcocoa/pop2piano"
+ model = Pop2PianoForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_onnx
def test_export_to_onnx(self):
diff --git a/tests/models/pvt/test_modeling_pvt.py b/tests/models/pvt/test_modeling_pvt.py
index 3b8c917f1d7592..d18a336a4a950f 100644
--- a/tests/models/pvt/test_modeling_pvt.py
+++ b/tests/models/pvt/test_modeling_pvt.py
@@ -37,7 +37,6 @@
from transformers import PvtConfig, PvtForImageClassification, PvtImageProcessor, PvtModel
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.pvt.modeling_pvt import PVT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -254,9 +253,9 @@ def test_training(self):
@slow
def test_model_from_pretrained(self):
- for model_name in PVT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = PvtModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "Zetatech/pvt-tiny-224"
+ model = PvtModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/pvt_v2/test_modeling_pvt_v2.py b/tests/models/pvt_v2/test_modeling_pvt_v2.py
index b8c53ac3e79921..9d8dfafa7cffc0 100644
--- a/tests/models/pvt_v2/test_modeling_pvt_v2.py
+++ b/tests/models/pvt_v2/test_modeling_pvt_v2.py
@@ -19,6 +19,7 @@
import unittest
from transformers import PvtV2Backbone, PvtV2Config, is_torch_available, is_vision_available
+from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
from transformers.testing_utils import (
require_accelerate,
require_torch,
@@ -38,8 +39,6 @@
import torch
from transformers import AutoImageProcessor, PvtV2ForImageClassification, PvtV2Model
- from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.pvt_v2.modeling_pvt_v2 import PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -312,9 +311,9 @@ def test_forward_signature(self):
@slow
def test_model_from_pretrained(self):
- for model_name in PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = PvtV2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "OpenGVLab/pvt_v2_b0"
+ model = PvtV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/qdqbert/test_modeling_qdqbert.py b/tests/models/qdqbert/test_modeling_qdqbert.py
index e8c6d17986d2d5..ed7f5a32391420 100644
--- a/tests/models/qdqbert/test_modeling_qdqbert.py
+++ b/tests/models/qdqbert/test_modeling_qdqbert.py
@@ -39,7 +39,6 @@
QDQBertLMHeadModel,
QDQBertModel,
)
- from transformers.models.qdqbert.modeling_qdqbert import QDQBERT_PRETRAINED_MODEL_ARCHIVE_LIST
class QDQBertModelTester:
@@ -537,9 +536,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in QDQBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = QDQBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google-bert/bert-base-uncased"
+ model = QDQBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Override
def test_feed_forward_chunking(self):
diff --git a/tests/models/qwen2/test_modeling_qwen2.py b/tests/models/qwen2/test_modeling_qwen2.py
index 587312bfa21d73..21ee694bdca4f7 100644
--- a/tests/models/qwen2/test_modeling_qwen2.py
+++ b/tests/models/qwen2/test_modeling_qwen2.py
@@ -320,6 +320,14 @@ def is_pipeline_test_to_skip(
):
return True
+ # Ignore copy
+ # TODO: @Fxmarty
+ @require_torch_sdpa
+ @slow
+ @unittest.skip(reason="Currently failing.")
+ def test_eager_matches_sdpa_generate(self):
+ super().test_eager_matches_sdpa_generate()
+
def setUp(self):
self.model_tester = Qwen2ModelTester(self)
self.config_tester = ConfigTester(self, config_class=Qwen2Config, hidden_size=37)
@@ -469,7 +477,7 @@ def test_flash_attn_2_generate_use_cache(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
self.skipTest("Qwen2 flash attention does not support right padding")
diff --git a/tests/models/qwen2_moe/__init__.py b/tests/models/qwen2_moe/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/qwen2_moe/test_modeling_qwen2_moe.py b/tests/models/qwen2_moe/test_modeling_qwen2_moe.py
new file mode 100644
index 00000000000000..e322e5f8490092
--- /dev/null
+++ b/tests/models/qwen2_moe/test_modeling_qwen2_moe.py
@@ -0,0 +1,678 @@
+# coding=utf-8
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Qwen2MoE model. """
+
+
+import gc
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, Qwen2MoeConfig, is_torch_available, set_seed
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_bitsandbytes,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Qwen2MoeForCausalLM,
+ Qwen2MoeForSequenceClassification,
+ Qwen2MoeModel,
+ )
+
+
+class Qwen2MoeModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=5,
+ max_window_layers=3,
+ use_sliding_window=True,
+ sliding_window=2,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ expert_interval=1,
+ moe_intermediate_size=12,
+ shared_expert_intermediate_size=36,
+ shared_expert_gate=True,
+ num_experts_per_tok=2,
+ num_experts=8,
+ norm_topk_prob=False,
+ output_router_logits=False,
+ router_aux_loss_coef=0.001,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ bos_token_id=1,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.max_window_layers = max_window_layers
+ self.use_sliding_window = use_sliding_window
+ self.sliding_window = sliding_window
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.scope = scope
+ self.expert_interval = expert_interval
+ self.moe_intermediate_size = moe_intermediate_size
+ self.shared_expert_intermediate_size = shared_expert_intermediate_size
+ self.shared_expert_gate = shared_expert_gate
+ self.num_experts_per_tok = num_experts_per_tok
+ self.num_experts = num_experts
+ self.norm_topk_prob = norm_topk_prob
+ self.output_router_logits = output_router_logits
+ self.router_aux_loss_coef = router_aux_loss_coef
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return Qwen2MoeConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ max_window_layers=self.max_window_layers,
+ use_sliding_window=self.use_sliding_window,
+ sliding_window=self.sliding_window,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ expert_interval=self.expert_interval,
+ moe_intermediate_size=self.moe_intermediate_size,
+ shared_expert_intermediate_size=self.shared_expert_intermediate_size,
+ shared_expert_gate=self.shared_expert_gate,
+ num_experts_per_tok=self.num_experts_per_tok,
+ num_experts=self.num_experts,
+ norm_topk_prob=self.norm_topk_prob,
+ output_router_logits=self.output_router_logits,
+ router_aux_loss_coef=self.router_aux_loss_coef,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ )
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Qwen2Moe
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = Qwen2MoeModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Qwen2Moe
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = Qwen2MoeModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Qwen2Moe
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = Qwen2MoeForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Qwen2Moe
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = Qwen2MoeForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTest with Mistral->Qwen2Moe
+class Qwen2MoeModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (Qwen2MoeModel, Qwen2MoeForCausalLM, Qwen2MoeForSequenceClassification) if is_torch_available() else ()
+ )
+ all_generative_model_classes = (Qwen2MoeForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Qwen2MoeModel,
+ "text-classification": Qwen2MoeForSequenceClassification,
+ "text-generation": Qwen2MoeForCausalLM,
+ "zero-shot": Qwen2MoeForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
+ ):
+ return True
+
+ # Ignore copy
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ super().test_eager_matches_sdpa_generate()
+
+ def setUp(self):
+ self.model_tester = Qwen2MoeModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Qwen2MoeConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_Qwen2Moe_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ print(config)
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2MoeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2Moe_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = Qwen2MoeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_Qwen2Moe_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = Qwen2MoeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ @unittest.skip("Qwen2Moe buffers include complex numbers, which breaks this test")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip("Qwen2Moe uses GQA on all models so the KV cache is a non standard format")
+ def test_past_key_values_format(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_padding_right(self):
+ import torch
+
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to(
+ torch_device
+ )
+
+ dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device)
+ dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device)
+
+ model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False)
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ with self.assertRaises(ValueError):
+ _ = model.generate(
+ dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_generate_use_cache(self):
+ import torch
+
+ max_new_tokens = 30
+
+ for model_class in self.all_generative_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ if dummy_input.dtype in [torch.float32, torch.bfloat16]:
+ dummy_input = dummy_input.to(torch.float16)
+
+ # make sure that all models have enough positions for generation
+ if hasattr(config, "max_position_embeddings"):
+ config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1
+
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input))
+ # NOTE: Qwen2Moe apparently does not support right padding + use_cache with FA2.
+ dummy_attention_mask[:, -1] = 1
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+ low_cpu_mem_usage=True,
+ ).to(torch_device)
+
+ # Just test that a large cache works as expected
+ _ = model.generate(
+ dummy_input,
+ attention_mask=dummy_attention_mask,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ use_cache=True,
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ self.skipTest("Qwen2Moe flash attention does not support right padding")
+
+ # Ignore copy
+ def test_load_balancing_loss(self):
+ r"""
+ Let's make sure we can actually compute the loss and do a backward on it.
+ """
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.num_experts = 8
+ config.expert_interval = 2
+ config.output_router_logits = True
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = Qwen2MoeForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask)
+ self.assertEqual(result.router_logits[0].shape, (91, config.num_experts))
+ torch.testing.assert_close(result.aux_loss.cpu(), torch.tensor(2, dtype=torch.float32), rtol=1e-2, atol=1e-2)
+
+ # First, we make sure that adding padding tokens doesn't change the loss
+ # loss(input_ids, attention_mask=None) == loss(input_ids + padding, attention_mask=attention_mask_with_padding)
+ pad_length = 1000
+ # Add padding tokens (assume that pad_token_id=1) to input_ids
+ padding_block = torch.ones(input_ids.shape[0], pad_length, dtype=torch.int32).to(torch_device)
+ padded_input_ids = torch.cat((padding_block, input_ids), dim=1) # this is to simulate padding to the left
+ padded_attention_mask = padded_input_ids.ne(1).to(torch_device)
+
+ padded_result = model(padded_input_ids, attention_mask=padded_attention_mask)
+ torch.testing.assert_close(result.aux_loss.cpu(), padded_result.aux_loss.cpu(), rtol=1e-4, atol=1e-4)
+
+ # We make sure that the loss of includding padding tokens != the loss without padding tokens
+ # if attention_mask=None --> we don't exclude padding tokens
+ include_padding_result = model(padded_input_ids, attention_mask=None)
+
+ # This is to mimic torch.testing.assert_not_close
+ self.assertNotAlmostEqual(include_padding_result.aux_loss.item(), result.aux_loss.item())
+
+
+@require_torch
+class Qwen2MoeIntegrationTest(unittest.TestCase):
+ @slow
+ def test_model_a2_7b_logits(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+ model = Qwen2MoeForCausalLM.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B", device_map="auto")
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ with torch.no_grad():
+ out = model(input_ids).logits.cpu()
+ # Expected mean on dim = -1
+ EXPECTED_MEAN = torch.tensor([[-4.2125, -3.6416, -4.9136, -4.3005, -4.9938, -3.4393, -3.5195, -4.1621]])
+ torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, atol=1e-2, rtol=1e-2)
+ # slicing logits[0, 0, 0:30]
+ EXPECTED_SLICE = torch.tensor([2.3013, -0.6595, -0.1389, -1.4095, -1.7381, -1.7609, -2.0449, -2.4289, -3.0271, -2.1351, -0.6568, -4.6012, -1.9102, -0.7475, -3.1377, 4.6904, 7.1936, 7.0991, 6.4414, 6.1720, 6.2617, 5.8751, 5.6997, 5.6011, 5.5828, -3.9505, -0.5384, -0.3392, 1.2445, 2.0714]) # fmt: skip
+ print(out[0, 0, :30])
+ torch.testing.assert_close(out[0, 0, :30], EXPECTED_SLICE, atol=1e-4, rtol=1e-4)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_a2_7b_generation(self):
+ EXPECTED_TEXT_COMPLETION = """To be or not to be, that is the question. This is the question that has been asked by many people over the"""
+ prompt = "To be or not to"
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B", use_fast=False)
+ model = Qwen2MoeForCausalLM.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B", device_map="auto")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @require_bitsandbytes
+ @slow
+ @require_flash_attn
+ def test_model_a2_7b_long_prompt(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2MoeForCausalLM.from_pretrained(
+ "Qwen/Qwen1.5-MoE-A2.7B",
+ device_map="auto",
+ load_in_4bit=True,
+ attn_implementation="flash_attention_2",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ @require_torch_sdpa
+ def test_model_a2_7b_long_prompt_sdpa(self):
+ EXPECTED_OUTPUT_TOKEN_IDS = [306, 338]
+ # An input with 4097 tokens that is above the size of the sliding window
+ input_ids = [1] + [306, 338] * 2048
+ model = Qwen2MoeForCausalLM.from_pretrained(
+ "Qwen/Qwen1.5-MoE-A2.7B",
+ device_map="auto",
+ attn_implementation="sdpa",
+ )
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ # Assisted generation
+ assistant_model = model
+ assistant_model.generation_config.num_assistant_tokens = 2
+ assistant_model.generation_config.num_assistant_tokens_schedule = "constant"
+ generated_ids = assistant_model.generate(input_ids, max_new_tokens=4, temperature=0)
+ self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist())
+
+ del assistant_model
+
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ EXPECTED_TEXT_COMPLETION = """To be or not to be, that is the question. This is the question that has been asked by many people over the"""
+ prompt = "To be or not to"
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B", use_fast=False)
+
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ def test_speculative_generation(self):
+ EXPECTED_TEXT_COMPLETION = (
+ "To be or not to be, that is the question.\nThe answer is to be, of course. But what does it"
+ )
+ prompt = "To be or not to"
+ tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B", use_fast=False)
+ model = Qwen2MoeForCausalLM.from_pretrained(
+ "Qwen/Qwen1.5-MoE-A2.7B", device_map="auto", torch_dtype=torch.float16
+ )
+ assistant_model = Qwen2MoeForCausalLM.from_pretrained(
+ "Qwen/Qwen1.5-MoE-A2.7B", device_map="auto", torch_dtype=torch.float16
+ )
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ set_seed(0)
+ generated_ids = model.generate(
+ input_ids, max_new_tokens=20, do_sample=True, temperature=0.3, assistant_model=assistant_model
+ )
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/tests/models/reformer/test_modeling_reformer.py b/tests/models/reformer/test_modeling_reformer.py
index 11cd7e1a33b45a..d3996a31c6a9eb 100644
--- a/tests/models/reformer/test_modeling_reformer.py
+++ b/tests/models/reformer/test_modeling_reformer.py
@@ -37,7 +37,6 @@
from torch import nn
from transformers import (
- REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
ReformerForMaskedLM,
ReformerForQuestionAnswering,
ReformerForSequenceClassification,
@@ -616,9 +615,9 @@ def setUp(self):
@slow
def test_model_from_pretrained(self):
- for model_name in REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ReformerModelWithLMHead.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/reformer-crime-and-punishment"
+ model = ReformerModelWithLMHead.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def _check_attentions_for_generate(
self, batch_size, attentions, min_length, max_length, config, use_cache=False, num_beam_groups=1
diff --git a/tests/models/regnet/test_modeling_regnet.py b/tests/models/regnet/test_modeling_regnet.py
index 420609bf0300f0..8840a141fa40e8 100644
--- a/tests/models/regnet/test_modeling_regnet.py
+++ b/tests/models/regnet/test_modeling_regnet.py
@@ -31,7 +31,6 @@
from torch import nn
from transformers import RegNetForImageClassification, RegNetModel
- from transformers.models.regnet.modeling_regnet import REGNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -220,9 +219,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RegNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/regnet-y-040"
+ model = RegNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -236,15 +235,11 @@ def prepare_img():
class RegNetModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return (
- AutoImageProcessor.from_pretrained(REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
- if is_vision_available()
- else None
- )
+ return AutoImageProcessor.from_pretrained("facebook/regnet-y-040") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
- model = RegNetForImageClassification.from_pretrained(REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(torch_device)
+ model = RegNetForImageClassification.from_pretrained("facebook/regnet-y-040").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/regnet/test_modeling_tf_regnet.py b/tests/models/regnet/test_modeling_tf_regnet.py
index a2f2bf92ef46c4..70adc9c8756170 100644
--- a/tests/models/regnet/test_modeling_tf_regnet.py
+++ b/tests/models/regnet/test_modeling_tf_regnet.py
@@ -32,7 +32,7 @@
if is_tf_available():
import tensorflow as tf
- from transformers import TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST, TFRegNetForImageClassification, TFRegNetModel
+ from transformers import TFRegNetForImageClassification, TFRegNetModel
if is_vision_available():
@@ -252,9 +252,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFRegNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/regnet-y-040"
+ model = TFRegNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -268,15 +268,11 @@ def prepare_img():
class RegNetModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return (
- AutoImageProcessor.from_pretrained(TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
- if is_vision_available()
- else None
- )
+ return AutoImageProcessor.from_pretrained("facebook/regnet-y-040") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
- model = TFRegNetForImageClassification.from_pretrained(TF_REGNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ model = TFRegNetForImageClassification.from_pretrained("facebook/regnet-y-040")
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/rembert/test_modeling_rembert.py b/tests/models/rembert/test_modeling_rembert.py
index 557a42243df861..fe21ae2ecf4907 100644
--- a/tests/models/rembert/test_modeling_rembert.py
+++ b/tests/models/rembert/test_modeling_rembert.py
@@ -38,7 +38,6 @@
RemBertForTokenClassification,
RemBertModel,
)
- from transformers.models.rembert.modeling_rembert import REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST
class RemBertModelTester:
@@ -465,9 +464,9 @@ def test_model_as_decoder_with_default_input_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in REMBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RemBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/rembert"
+ model = RemBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/resnet/test_modeling_resnet.py b/tests/models/resnet/test_modeling_resnet.py
index 543013bc41b063..0fd32bc72f018f 100644
--- a/tests/models/resnet/test_modeling_resnet.py
+++ b/tests/models/resnet/test_modeling_resnet.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import ResNetBackbone, ResNetForImageClassification, ResNetModel
- from transformers.models.resnet.modeling_resnet import RESNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -273,9 +272,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ResNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/resnet-50"
+ model = ResNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -289,15 +288,11 @@ def prepare_img():
class ResNetModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return (
- AutoImageProcessor.from_pretrained(RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
- if is_vision_available()
- else None
- )
+ return AutoImageProcessor.from_pretrained("microsoft/resnet-50") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
- model = ResNetForImageClassification.from_pretrained(RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(torch_device)
+ model = ResNetForImageClassification.from_pretrained("microsoft/resnet-50").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/resnet/test_modeling_tf_resnet.py b/tests/models/resnet/test_modeling_tf_resnet.py
index 827fc807dfe5ab..a8e2ce93ee3bb9 100644
--- a/tests/models/resnet/test_modeling_tf_resnet.py
+++ b/tests/models/resnet/test_modeling_tf_resnet.py
@@ -35,7 +35,6 @@
import tensorflow as tf
from transformers import TFResNetForImageClassification, TFResNetModel
- from transformers.models.resnet.modeling_tf_resnet import TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -214,9 +213,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFResNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/resnet-50"
+ model = TFResNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
@@ -230,15 +229,11 @@ def prepare_img():
class TFResNetModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
- return (
- AutoImageProcessor.from_pretrained(TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
- if is_vision_available()
- else None
- )
+ return AutoImageProcessor.from_pretrained("microsoft/resnet-50") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
- model = TFResNetForImageClassification.from_pretrained(TF_RESNET_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ model = TFResNetForImageClassification.from_pretrained("microsoft/resnet-50")
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/roberta/test_modeling_roberta.py b/tests/models/roberta/test_modeling_roberta.py
index 402d60d37a42a4..700f0d1cf71bcf 100644
--- a/tests/models/roberta/test_modeling_roberta.py
+++ b/tests/models/roberta/test_modeling_roberta.py
@@ -38,7 +38,6 @@
RobertaModel,
)
from transformers.models.roberta.modeling_roberta import (
- ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST,
RobertaEmbeddings,
create_position_ids_from_input_ids,
)
@@ -477,9 +476,9 @@ def test_for_question_answering(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RobertaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "FacebookAI/roberta-base"
+ model = RobertaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_create_position_ids_respects_padding_index(self):
"""Ensure that the default position ids only assign a sequential . This is a regression
diff --git a/tests/models/roberta/test_modeling_tf_roberta.py b/tests/models/roberta/test_modeling_tf_roberta.py
index 37377ab5ba52e6..8125a7f0a07a98 100644
--- a/tests/models/roberta/test_modeling_tf_roberta.py
+++ b/tests/models/roberta/test_modeling_tf_roberta.py
@@ -31,7 +31,6 @@
import tensorflow as tf
from transformers.models.roberta.modeling_tf_roberta import (
- TF_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST,
TFRobertaForCausalLM,
TFRobertaForMaskedLM,
TFRobertaForMultipleChoice,
@@ -655,9 +654,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFRobertaModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "FacebookAI/roberta-base"
+ model = TFRobertaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/roberta_prelayernorm/test_modeling_roberta_prelayernorm.py b/tests/models/roberta_prelayernorm/test_modeling_roberta_prelayernorm.py
index c975718778daf4..3536ccc87106b6 100644
--- a/tests/models/roberta_prelayernorm/test_modeling_roberta_prelayernorm.py
+++ b/tests/models/roberta_prelayernorm/test_modeling_roberta_prelayernorm.py
@@ -38,7 +38,6 @@
RobertaPreLayerNormModel,
)
from transformers.models.roberta_prelayernorm.modeling_roberta_prelayernorm import (
- ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST,
RobertaPreLayerNormEmbeddings,
create_position_ids_from_input_ids,
)
@@ -482,11 +481,10 @@ def test_for_question_answering(self):
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
@slow
- # Copied from tests.models.roberta.test_modeling_roberta.RobertaModelTest.test_model_from_pretrained with ROBERTA->ROBERTA_PRELAYERNORM,Roberta->RobertaPreLayerNorm
def test_model_from_pretrained(self):
- for model_name in ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RobertaPreLayerNormModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "andreasmadsen/efficient_mlm_m0.15"
+ model = RobertaPreLayerNormModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# Copied from tests.models.roberta.test_modeling_roberta.RobertaModelTest.test_create_position_ids_respects_padding_index with Roberta->RobertaPreLayerNorm
def test_create_position_ids_respects_padding_index(self):
diff --git a/tests/models/roberta_prelayernorm/test_modeling_tf_roberta_prelayernorm.py b/tests/models/roberta_prelayernorm/test_modeling_tf_roberta_prelayernorm.py
index 384fa2e9e40013..2138541603dd5a 100644
--- a/tests/models/roberta_prelayernorm/test_modeling_tf_roberta_prelayernorm.py
+++ b/tests/models/roberta_prelayernorm/test_modeling_tf_roberta_prelayernorm.py
@@ -31,7 +31,6 @@
import tensorflow as tf
from transformers.models.roberta_prelayernorm.modeling_tf_roberta_prelayernorm import (
- TF_ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST,
TFRobertaPreLayerNormForCausalLM,
TFRobertaPreLayerNormForMaskedLM,
TFRobertaPreLayerNormForMultipleChoice,
@@ -551,7 +550,7 @@ def prepare_config_and_inputs_for_common(self):
@require_tf
-# Copied from tests.models.roberta.test_modeling_tf_roberta.TFRobertaModelTest with ROBERTA->ROBERTA_PRELAYERNORM,Roberta->RobertaPreLayerNorm
+# Copied from tests.models.roberta.test_modeling_tf_roberta.TFRobertaModelTest with ROBERTA->ROBERTA_PRELAYERNORM,Roberta->RobertaPreLayerNorm,FacebookAI/roberta-base->andreasmadsen/efficient_mlm_m0.15
class TFRobertaPreLayerNormModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
@@ -657,9 +656,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_ROBERTA_PRELAYERNORM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFRobertaPreLayerNormModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "andreasmadsen/efficient_mlm_m0.15"
+ model = TFRobertaPreLayerNormModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/roc_bert/test_modeling_roc_bert.py b/tests/models/roc_bert/test_modeling_roc_bert.py
index d1caca6b6f9417..d52304ade90a79 100644
--- a/tests/models/roc_bert/test_modeling_roc_bert.py
+++ b/tests/models/roc_bert/test_modeling_roc_bert.py
@@ -39,7 +39,6 @@
RoCBertForTokenClassification,
RoCBertModel,
)
- from transformers.models.roc_bert.modeling_roc_bert import ROC_BERT_PRETRAINED_MODEL_ARCHIVE_LIST
class RoCBertModelTester:
@@ -718,9 +717,9 @@ def test_model_as_decoder_with_default_input_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ROC_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RoCBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "weiweishi/roc-bert-base-zh"
+ model = RoCBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/roformer/test_modeling_roformer.py b/tests/models/roformer/test_modeling_roformer.py
index 6c130ae1746c03..64ce38c5152541 100644
--- a/tests/models/roformer/test_modeling_roformer.py
+++ b/tests/models/roformer/test_modeling_roformer.py
@@ -38,7 +38,6 @@
RoFormerModel,
)
from transformers.models.roformer.modeling_roformer import (
- ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
RoFormerSelfAttention,
RoFormerSinusoidalPositionalEmbedding,
)
@@ -482,9 +481,9 @@ def test_model_as_decoder_with_default_input_mask(self):
@slow
def test_model_from_pretrained(self):
- for model_name in ROFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RoFormerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "junnyu/roformer_chinese_small"
+ model = RoFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
diff --git a/tests/models/rwkv/test_modeling_rwkv.py b/tests/models/rwkv/test_modeling_rwkv.py
index 4ca5cfdf9e130b..d2a41a863d22d1 100644
--- a/tests/models/rwkv/test_modeling_rwkv.py
+++ b/tests/models/rwkv/test_modeling_rwkv.py
@@ -30,7 +30,6 @@
import torch
from transformers import (
- RWKV_PRETRAINED_MODEL_ARCHIVE_LIST,
RwkvForCausalLM,
RwkvModel,
)
@@ -419,9 +418,9 @@ def test_attention_outputs(self):
@slow
def test_model_from_pretrained(self):
- for model_name in RWKV_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = RwkvModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "RWKV/rwkv-4-169m-pile"
+ model = RwkvModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skipIf(
diff --git a/tests/models/sam/test_modeling_sam.py b/tests/models/sam/test_modeling_sam.py
index 3e63edb23a0c6d..ee9eeefd33cb84 100644
--- a/tests/models/sam/test_modeling_sam.py
+++ b/tests/models/sam/test_modeling_sam.py
@@ -34,7 +34,6 @@
from torch import nn
from transformers import SamModel, SamProcessor
- from transformers.models.sam.modeling_sam import SAM_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -442,9 +441,9 @@ def check_pt_tf_outputs(self, tf_outputs, pt_outputs, model_class, tol=5e-5, nam
@slow
def test_model_from_pretrained(self):
- for model_name in SAM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SamModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/sam-vit-huge"
+ model = SamModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def prepare_image():
@@ -726,7 +725,7 @@ def test_inference_mask_generation_two_points_point_batch(self):
iou_scores = outputs.iou_scores.cpu()
self.assertTrue(iou_scores.shape == (1, 2, 3))
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
iou_scores, torch.tensor([[[0.9105, 0.9825, 0.9675], [0.7646, 0.7943, 0.7774]]]), atol=1e-4, rtol=1e-4
)
@@ -754,7 +753,7 @@ def test_inference_mask_generation_three_boxes_point_batch(self):
iou_scores = outputs.iou_scores.cpu()
self.assertTrue(iou_scores.shape == (1, 3, 3))
- torch.testing.assert_allclose(iou_scores, EXPECTED_IOU, atol=1e-4, rtol=1e-4)
+ torch.testing.assert_close(iou_scores, EXPECTED_IOU, atol=1e-4, rtol=1e-4)
def test_dummy_pipeline_generation(self):
generator = pipeline("mask-generation", model="facebook/sam-vit-base", device=torch_device)
diff --git a/tests/models/seamless_m4t/test_modeling_seamless_m4t.py b/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
index 365775171e8c52..c08e559057021e 100644
--- a/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
+++ b/tests/models/seamless_m4t/test_modeling_seamless_m4t.py
@@ -46,9 +46,6 @@
SeamlessM4TForTextToText,
SeamlessM4TModel,
)
- from transformers.models.seamless_m4t.modeling_seamless_m4t import (
- SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_speech_available():
from transformers import SeamlessM4TProcessor
@@ -379,9 +376,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SeamlessM4TModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/hf-seamless-m4t-medium"
+ model = SeamlessM4TModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def _get_input_ids_and_config(self, batch_size=2):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -667,9 +664,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SEAMLESS_M4T_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SeamlessM4TModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/hf-seamless-m4t-medium"
+ model = SeamlessM4TModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py b/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py
index 795f3d80422b2e..699641fcfd7526 100644
--- a/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py
+++ b/tests/models/seamless_m4t_v2/test_modeling_seamless_m4t_v2.py
@@ -45,9 +45,6 @@
SeamlessM4Tv2ForTextToText,
SeamlessM4Tv2Model,
)
- from transformers.models.seamless_m4t_v2.modeling_seamless_m4t_v2 import (
- SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST,
- )
if is_speech_available():
from transformers import SeamlessM4TProcessor
@@ -395,9 +392,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = SeamlessM4Tv2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/seamless-m4t-v2-large"
+ model = SeamlessM4Tv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def _get_input_ids_and_config(self, batch_size=2):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -662,9 +659,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SEAMLESS_M4T_V2_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = SeamlessM4Tv2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/seamless-m4t-v2-large"
+ model = SeamlessM4Tv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/segformer/test_modeling_segformer.py b/tests/models/segformer/test_modeling_segformer.py
index de64de5ad1b976..fb383385131415 100644
--- a/tests/models/segformer/test_modeling_segformer.py
+++ b/tests/models/segformer/test_modeling_segformer.py
@@ -34,7 +34,6 @@
SegformerModel,
)
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.segformer.modeling_segformer import SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -335,9 +334,9 @@ def test_training(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SegformerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/segformer-b0-finetuned-ade-512-512"
+ model = SegformerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/segformer/test_modeling_tf_segformer.py b/tests/models/segformer/test_modeling_tf_segformer.py
index aca621f5097dd0..16b5740a081807 100644
--- a/tests/models/segformer/test_modeling_tf_segformer.py
+++ b/tests/models/segformer/test_modeling_tf_segformer.py
@@ -34,7 +34,6 @@
import tensorflow as tf
from transformers import TFSegformerForImageClassification, TFSegformerForSemanticSegmentation, TFSegformerModel
- from transformers.models.segformer.modeling_tf_segformer import TF_SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -438,9 +437,9 @@ def check_pt_tf_outputs(self, tf_outputs, pt_outputs, model_class, tol=2e-4, nam
@slow
def test_model_from_pretrained(self):
- for model_name in TF_SEGFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFSegformerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "nvidia/segformer-b0-finetuned-ade-512-512"
+ model = TFSegformerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/seggpt/test_modeling_seggpt.py b/tests/models/seggpt/test_modeling_seggpt.py
index 5f7920f9a3a5fd..d4a8a46f037851 100644
--- a/tests/models/seggpt/test_modeling_seggpt.py
+++ b/tests/models/seggpt/test_modeling_seggpt.py
@@ -39,7 +39,6 @@
from torch import nn
from transformers import SegGptForImageSegmentation, SegGptModel
- from transformers.models.seggpt.modeling_seggpt import SEGGPT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -301,9 +300,9 @@ def recursive_check(batched_object, single_row_object, model_name, key):
@slow
def test_model_from_pretrained(self):
- for model_name in SEGGPT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SegGptModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "BAAI/seggpt-vit-large"
+ model = SegGptModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def prepare_img():
diff --git a/tests/models/siglip/test_modeling_siglip.py b/tests/models/siglip/test_modeling_siglip.py
index 45212751a85d65..8880168484eced 100644
--- a/tests/models/siglip/test_modeling_siglip.py
+++ b/tests/models/siglip/test_modeling_siglip.py
@@ -48,7 +48,6 @@
from torch import nn
from transformers import SiglipForImageClassification, SiglipModel, SiglipTextModel, SiglipVisionModel
- from transformers.models.siglip.modeling_siglip import SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -217,9 +216,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SiglipVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/siglip-base-patch16-224"
+ model = SiglipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class SiglipTextModelTester:
@@ -374,9 +373,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SiglipTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/siglip-base-patch16-224"
+ model = SiglipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class SiglipModelTester:
@@ -578,11 +577,10 @@ def test_load_vision_text_config(self):
self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
@slow
- # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model_from_pretrained with CLIPModel->SiglipModel, CLIP->SIGLIP
def test_model_from_pretrained(self):
- for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SiglipModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/siglip-base-patch16-224"
+ model = SiglipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class SiglipForImageClassificationModelTester(SiglipModelTester):
diff --git a/tests/models/siglip/test_tokenization_siglip.py b/tests/models/siglip/test_tokenization_siglip.py
index fb3cb5b3f10400..839c0c32002ddc 100644
--- a/tests/models/siglip/test_tokenization_siglip.py
+++ b/tests/models/siglip/test_tokenization_siglip.py
@@ -348,14 +348,6 @@ def test_sentencepiece_tokenize_and_convert_tokens_to_string(self):
special_tokens_string_rust = rust_tokenizer.convert_tokens_to_string(special_tokens)
self.assertEqual(special_tokens_string, special_tokens_string_rust)
- # overwritten from `test_tokenization_common` since Siglip has no max length
- # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_pretrained_model_lists with T5->Siglip
- def test_pretrained_model_lists(self):
- # We should have at least one default checkpoint for each tokenizer
- # We should specify the max input length as well (used in some part to list the pretrained checkpoints)
- self.assertGreaterEqual(len(self.tokenizer_class.pretrained_vocab_files_map), 1)
- self.assertGreaterEqual(len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]), 1)
-
@slow
def test_tokenizer_integration(self):
tokenizer = SiglipTokenizer.from_pretrained("google/siglip-base-patch16-224")
diff --git a/tests/models/splinter/test_modeling_splinter.py b/tests/models/splinter/test_modeling_splinter.py
index 90ee07c354588b..b6a2588c87052a 100644
--- a/tests/models/splinter/test_modeling_splinter.py
+++ b/tests/models/splinter/test_modeling_splinter.py
@@ -29,7 +29,6 @@
import torch
from transformers import SplinterConfig, SplinterForPreTraining, SplinterForQuestionAnswering, SplinterModel
- from transformers.models.splinter.modeling_splinter import SPLINTER_PRETRAINED_MODEL_ARCHIVE_LIST
class SplinterModelTester:
@@ -328,9 +327,9 @@ def test_inputs_embeds(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SPLINTER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SplinterModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "tau/splinter-base"
+ model = SplinterModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# overwrite from common since `SplinterForPreTraining` could contain different number of question tokens in inputs.
# When the batch is distributed to multiple devices, each replica could get different values for the maximal number
diff --git a/tests/models/squeezebert/test_modeling_squeezebert.py b/tests/models/squeezebert/test_modeling_squeezebert.py
index bf86792f57f1ef..1682146e1ad884 100644
--- a/tests/models/squeezebert/test_modeling_squeezebert.py
+++ b/tests/models/squeezebert/test_modeling_squeezebert.py
@@ -28,7 +28,6 @@
import torch
from transformers import (
- SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST,
SqueezeBertForMaskedLM,
SqueezeBertForMultipleChoice,
SqueezeBertForQuestionAnswering,
@@ -277,9 +276,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SQUEEZEBERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SqueezeBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "squeezebert/squeezebert-uncased"
+ model = SqueezeBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_sentencepiece
diff --git a/tests/models/stablelm/test_modeling_stablelm.py b/tests/models/stablelm/test_modeling_stablelm.py
index 2497dfc3eee6c4..0f01fa8fca64fa 100644
--- a/tests/models/stablelm/test_modeling_stablelm.py
+++ b/tests/models/stablelm/test_modeling_stablelm.py
@@ -21,6 +21,7 @@
from transformers import StableLmConfig, is_torch_available, set_seed
from transformers.testing_utils import (
+ is_flaky,
require_bitsandbytes,
require_flash_attn,
require_torch,
@@ -44,6 +45,11 @@
StableLmForSequenceClassification,
StableLmModel,
)
+ from transformers.models.stablelm.modeling_stablelm import (
+ StableLmDynamicNTKScalingRotaryEmbedding,
+ StableLmLinearScalingRotaryEmbedding,
+ StableLmRotaryEmbedding,
+ )
# Copied from transformers.tests.models.persimmon.test_modeling_persimmon.PersimmonModelTester with Persimmon -> StableLm
@@ -351,7 +357,8 @@ def test_stablelm_sequence_classification_model_for_multi_label(self):
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
@parameterized.expand([("linear",), ("dynamic",)])
- def test_model_rope_scaling(self, scaling_type):
+ # Copied from tests.models.llama.test_modeling_llama.LlamaModelTest.test_model_rope_scaling_from_config with Llama->StableLm
+ def test_model_rope_scaling_from_config(self, scaling_type):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
short_input = ids_tensor([1, 10], config.vocab_size)
long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
@@ -381,6 +388,66 @@ def test_model_rope_scaling(self, scaling_type):
# The output should be different for long inputs
self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+ # Copied from tests.models.falcon.test_modeling_falcon.FalconModelTest.test_model_rope_scaling with Falcon->StableLm
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ hidden_size = config.hidden_size
+ num_heads = config.num_attention_heads
+ head_dim = hidden_size // num_heads
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+
+ # Sanity check original RoPE
+ original_rope = StableLmRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ ).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, short_input_length)
+ original_cos_long, original_sin_long = original_rope(x, long_input_length)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ linear_scaling_rope = StableLmLinearScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, short_input_length)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[new_position, :], original_cos_long[original_position, :])
+ torch.testing.assert_close(linear_sin_long[new_position, :], original_sin_long[original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ ntk_scaling_rope = StableLmDynamicNTKScalingRotaryEmbedding(
+ head_dim,
+ max_position_embeddings=config.max_position_embeddings,
+ base=config.rope_theta,
+ scaling_factor=scaling_factor,
+ ).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, short_input_length)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, long_input_length)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
@require_torch
class StableLmModelIntegrationTest(unittest.TestCase):
@@ -434,6 +501,8 @@ def test_model_3b_long_prompt(self):
self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-3:].tolist())
# Copied from transformers.tests.models.llama.test_modeling_llama.LlamaModelTest.test_eager_matches_sdpa_generate with Llama->StableLm,saibo/llama-1B->stabilityai/stablelm-3b-4e1t
+ # TODO: @Fxmarty
+ @is_flaky(max_attempts=3, description="flaky on some models.")
@require_torch_sdpa
@slow
def test_eager_matches_sdpa_generate(self):
diff --git a/tests/models/starcoder2/test_modeling_starcoder2.py b/tests/models/starcoder2/test_modeling_starcoder2.py
index f0794c46dcee63..95f604d06b3713 100644
--- a/tests/models/starcoder2/test_modeling_starcoder2.py
+++ b/tests/models/starcoder2/test_modeling_starcoder2.py
@@ -461,7 +461,7 @@ def test_flash_attn_2_generate_use_cache(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
self.skipTest("Starcoder2 flash attention does not support right padding")
diff --git a/tests/models/swiftformer/test_modeling_swiftformer.py b/tests/models/swiftformer/test_modeling_swiftformer.py
index a1e6229d5a6e81..c54e092809a009 100644
--- a/tests/models/swiftformer/test_modeling_swiftformer.py
+++ b/tests/models/swiftformer/test_modeling_swiftformer.py
@@ -37,7 +37,6 @@
from torch import nn
from transformers import SwiftFormerForImageClassification, SwiftFormerModel
- from transformers.models.swiftformer.modeling_swiftformer import SWIFTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -186,9 +185,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SWIFTFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SwiftFormerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "MBZUAI/swiftformer-xs"
+ model = SwiftFormerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="SwiftFormer does not output attentions")
def test_attention_outputs(self):
diff --git a/tests/models/swin/test_modeling_swin.py b/tests/models/swin/test_modeling_swin.py
index cd0b99fdc986a2..9220784e23029a 100644
--- a/tests/models/swin/test_modeling_swin.py
+++ b/tests/models/swin/test_modeling_swin.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import SwinBackbone, SwinForImageClassification, SwinForMaskedImageModeling, SwinModel
- from transformers.models.swin.modeling_swin import SWIN_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -446,9 +445,9 @@ def test_hidden_states_output_with_padding(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SWIN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SwinModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/swin-tiny-patch4-window7-224"
+ model = SwinModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/swin/test_modeling_tf_swin.py b/tests/models/swin/test_modeling_tf_swin.py
index e15ecbc41dbec0..f05ef7a434316b 100644
--- a/tests/models/swin/test_modeling_tf_swin.py
+++ b/tests/models/swin/test_modeling_tf_swin.py
@@ -36,7 +36,6 @@
from transformers.modeling_tf_utils import keras
from transformers.models.swin.modeling_tf_swin import (
- TF_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST,
TFSwinForImageClassification,
TFSwinForMaskedImageModeling,
TFSwinModel,
@@ -374,9 +373,9 @@ def test_inputs_requiring_padding(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_SWIN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFSwinModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/swin-tiny-patch4-window7-224"
+ model = TFSwinModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_vision
diff --git a/tests/models/swin2sr/test_modeling_swin2sr.py b/tests/models/swin2sr/test_modeling_swin2sr.py
index 556b65a249a22f..44ca7b92492be2 100644
--- a/tests/models/swin2sr/test_modeling_swin2sr.py
+++ b/tests/models/swin2sr/test_modeling_swin2sr.py
@@ -29,7 +29,6 @@
from torch import nn
from transformers import Swin2SRForImageSuperResolution, Swin2SRModel
- from transformers.models.swin2sr.modeling_swin2sr import SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -233,9 +232,9 @@ def test_model_common_attributes(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SWIN2SR_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Swin2SRModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "caidas/swin2SR-classical-sr-x2-64"
+ model = Swin2SRModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# overwriting because of `logit_scale` parameter
def test_initialization(self):
diff --git a/tests/models/swinv2/test_modeling_swinv2.py b/tests/models/swinv2/test_modeling_swinv2.py
index 73f731cd60abbb..b8f97ee7c23bc6 100644
--- a/tests/models/swinv2/test_modeling_swinv2.py
+++ b/tests/models/swinv2/test_modeling_swinv2.py
@@ -32,7 +32,6 @@
from torch import nn
from transformers import Swinv2Backbone, Swinv2ForImageClassification, Swinv2ForMaskedImageModeling, Swinv2Model
- from transformers.models.swinv2.modeling_swinv2 import SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
@@ -432,9 +431,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SWINV2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = Swinv2Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/swinv2-tiny-patch4-window8-256"
+ model = Swinv2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Swinv2 does not support feedforward chunking yet")
def test_feed_forward_chunking(self):
diff --git a/tests/models/switch_transformers/test_modeling_switch_transformers.py b/tests/models/switch_transformers/test_modeling_switch_transformers.py
index b21fa405c39f9c..6eb4ab4cb3fd4d 100644
--- a/tests/models/switch_transformers/test_modeling_switch_transformers.py
+++ b/tests/models/switch_transformers/test_modeling_switch_transformers.py
@@ -45,7 +45,6 @@
SwitchTransformersTop1Router,
)
from transformers.models.switch_transformers.modeling_switch_transformers import (
- SWITCH_TRANSFORMERS_PRETRAINED_MODEL_ARCHIVE_LIST,
load_balancing_loss_func,
router_z_loss_func,
)
@@ -670,9 +669,9 @@ def test_v1_1_resize_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in SWITCH_TRANSFORMERS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = SwitchTransformersModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/switch-base-8"
+ model = SwitchTransformersModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Test has a segmentation fault on torch 1.8.0")
def test_export_to_onnx(self):
@@ -1054,7 +1053,7 @@ def test_small_logits(self):
hf_logits = model(input_ids, decoder_input_ids=decoder_input_ids).last_hidden_state.cpu()
hf_logits = hf_logits[0, 0, :30]
- torch.testing.assert_allclose(hf_logits, EXPECTED_MEAN_LOGITS, rtol=6e-3, atol=9e-3)
+ torch.testing.assert_close(hf_logits, EXPECTED_MEAN_LOGITS, rtol=6e-3, atol=9e-3)
@unittest.skip(
"Unless we stop stripping left and right by default for all special tokens, the expected ids obtained here will not match the original ones. Wait for https://github.com/huggingface/transformers/pull/23909 to be merged"
diff --git a/tests/models/t5/test_modeling_t5.py b/tests/models/t5/test_modeling_t5.py
index c0a43dfeab69cc..c215bda5e1de7d 100644
--- a/tests/models/t5/test_modeling_t5.py
+++ b/tests/models/t5/test_modeling_t5.py
@@ -56,7 +56,6 @@
T5Model,
T5Tokenizer,
)
- from transformers.models.t5.modeling_t5 import T5_PRETRAINED_MODEL_ARCHIVE_LIST
class T5ModelTester:
@@ -838,9 +837,9 @@ def test_v1_1_resize_embeddings(self):
@slow
def test_model_from_pretrained(self):
- for model_name in T5_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = T5Model.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google-t5/t5-small"
+ model = T5Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Test has a segmentation fault on torch 1.8.0")
def test_export_to_onnx(self):
diff --git a/tests/models/t5/test_tokenization_t5.py b/tests/models/t5/test_tokenization_t5.py
index 388388ff238861..ed753612fc30f7 100644
--- a/tests/models/t5/test_tokenization_t5.py
+++ b/tests/models/t5/test_tokenization_t5.py
@@ -227,7 +227,7 @@ def test_outputs_not_longer_than_maxlen(self):
# Since T5 does NOT have a max input length,
# this test should be changed to the following in Transformers v5:
# self.assertEqual(batch.input_ids.shape, (2, 8001))
- self.assertEqual(batch.input_ids.shape, (2, 512))
+ self.assertEqual(batch.input_ids.shape, (2, 8001))
def test_eos_in_input(self):
tokenizer = self.t5_base_tokenizer
@@ -362,12 +362,6 @@ def test_special_tokens_initialization_with_non_empty_additional_special_tokens(
)
# overwritten from `test_tokenization_common` since T5 has no max length
- def test_pretrained_model_lists(self):
- # We should have at least one default checkpoint for each tokenizer
- # We should specify the max input length as well (used in some part to list the pretrained checkpoints)
- self.assertGreaterEqual(len(self.tokenizer_class.pretrained_vocab_files_map), 1)
- self.assertGreaterEqual(len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]), 1)
-
@slow
def test_tokenizer_integration(self):
expected_encoding = {'input_ids': [[31220, 7, 41, 14034, 801, 38, 3, 102, 63, 17, 127, 524, 18, 7031, 2032, 277, 11, 3, 102, 63, 17, 127, 524, 18, 2026, 17, 10761, 18, 7041, 61, 795, 879, 18, 19681, 4648, 7, 41, 12920, 382, 6, 350, 6383, 4949, 6, 2158, 12920, 382, 9, 6, 3, 4, 11160, 6, 2043, 17153, 279, 49, 17, 6, 3, 4, 434, 9688, 11439, 21, 6869, 10509, 17725, 41, 567, 9138, 61, 11, 6869, 10509, 11946, 41, 18207, 517, 61, 28, 147, 3538, 1220, 7140, 10761, 2250, 16, 910, 1220, 8024, 11, 1659, 1413, 32, 883, 2020, 344, 2215, 226, 6, 12901, 382, 127, 524, 11, 4738, 7, 127, 15390, 5, 1], [272, 24203, 19, 876, 12, 554, 18, 9719, 1659, 2647, 26352, 6497, 7, 45, 73, 9339, 400, 26, 1499, 57, 22801, 10760, 30, 321, 646, 11, 269, 2625, 16, 66, 7500, 5, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [37, 1704, 4216, 3, 20400, 4418, 7, 147, 8, 19743, 1782, 5, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: skip
diff --git a/tests/models/tapas/test_tokenization_tapas.py b/tests/models/tapas/test_tokenization_tapas.py
index 4100e02b136c97..8f2bf9bb69d333 100644
--- a/tests/models/tapas/test_tokenization_tapas.py
+++ b/tests/models/tapas/test_tokenization_tapas.py
@@ -1268,10 +1268,6 @@ def test_full_tokenizer(self):
self.assertListEqual(column_ids.tolist(), expected_results["column_ids"])
self.assertListEqual(row_ids.tolist(), expected_results["row_ids"])
- @unittest.skip("Skip this test while all models are still to be uploaded.")
- def test_pretrained_model_lists(self):
- pass
-
@unittest.skip("Doesn't support another framework than PyTorch")
def test_np_encode_plus_sent_to_model(self):
pass
diff --git a/tests/models/timesformer/test_modeling_timesformer.py b/tests/models/timesformer/test_modeling_timesformer.py
index d4e71c8c599967..3d97d2c0f67099 100644
--- a/tests/models/timesformer/test_modeling_timesformer.py
+++ b/tests/models/timesformer/test_modeling_timesformer.py
@@ -40,7 +40,6 @@
TimesformerForVideoClassification,
TimesformerModel,
)
- from transformers.models.timesformer.modeling_timesformer import TIMESFORMER_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -213,9 +212,9 @@ def test_for_video_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TIMESFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TimesformerModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/timesformer-base-finetuned-k400"
+ model = TimesformerModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
if not self.has_attentions:
diff --git a/tests/models/tvlt/test_modeling_tvlt.py b/tests/models/tvlt/test_modeling_tvlt.py
index 3ee7f7adc7ffd5..ce27946ee72173 100644
--- a/tests/models/tvlt/test_modeling_tvlt.py
+++ b/tests/models/tvlt/test_modeling_tvlt.py
@@ -41,7 +41,6 @@
import torch.nn as nn
from transformers import TvltForAudioVisualClassification, TvltForPreTraining, TvltModel
- from transformers.models.tvlt.modeling_tvlt import TVLT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_datasets_available():
@@ -414,9 +413,9 @@ def test_for_pretraining(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TVLT_PRETRAINED_MODEL_ARCHIVE_LIST:
- model = TvltModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "ZinengTang/tvlt-base"
+ model = TvltModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_training(self):
if not self.model_tester.is_training:
diff --git a/tests/models/udop/test_modeling_udop.py b/tests/models/udop/test_modeling_udop.py
index 3947da62cc6fe6..7041f25f4e73b9 100644
--- a/tests/models/udop/test_modeling_udop.py
+++ b/tests/models/udop/test_modeling_udop.py
@@ -39,7 +39,6 @@
import torch
from transformers import UdopEncoderModel, UdopForConditionalGeneration, UdopModel, UdopProcessor
- from transformers.models.udop.modeling_udop import UDOP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -359,9 +358,9 @@ def test_save_load_low_cpu_mem_usage(self):
@slow
def test_model_from_pretrained(self):
- for model_name in UDOP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = UdopForConditionalGeneration.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/udop-large"
+ model = UdopForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class UdopEncoderOnlyModelTester:
diff --git a/tests/models/udop/test_tokenization_udop.py b/tests/models/udop/test_tokenization_udop.py
index 0519ee062237f7..720eb09952140d 100644
--- a/tests/models/udop/test_tokenization_udop.py
+++ b/tests/models/udop/test_tokenization_udop.py
@@ -1726,10 +1726,6 @@ def test_batch_encode_dynamic_overflowing(self):
def test_alignement_methods(self):
pass
- @unittest.skip("#TODO will be removed in main")
- def test_pretrained_model_lists(self):
- pass
-
@unittest.skip("UDOP tokenizer requires boxes besides sequences.")
def test_maximum_encoding_length_pair_input(self):
pass
diff --git a/tests/models/umt5/test_modeling_umt5.py b/tests/models/umt5/test_modeling_umt5.py
index 5bd961dbb3d1e3..16c93908cddb46 100644
--- a/tests/models/umt5/test_modeling_umt5.py
+++ b/tests/models/umt5/test_modeling_umt5.py
@@ -763,7 +763,7 @@ def test_small_integration_test(self):
]
)
# fmt: on
- torch.testing.assert_allclose(input_ids, EXPECTED_IDS)
+ torch.testing.assert_close(input_ids, EXPECTED_IDS)
generated_ids = model.generate(input_ids.to(torch_device))
EXPECTED_FILLING = [
diff --git a/tests/models/upernet/test_modeling_upernet.py b/tests/models/upernet/test_modeling_upernet.py
index c51b254ed52a04..234cd8af09b8c5 100644
--- a/tests/models/upernet/test_modeling_upernet.py
+++ b/tests/models/upernet/test_modeling_upernet.py
@@ -32,7 +32,6 @@
import torch
from transformers import UperNetForSemanticSegmentation
- from transformers.models.upernet.modeling_upernet import UPERNET_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -248,9 +247,9 @@ def test_tied_model_weights_key_ignore(self):
@slow
def test_model_from_pretrained(self):
- for model_name in UPERNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = UperNetForSemanticSegmentation.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "openmmlab/upernet-convnext-tiny"
+ model = UperNetForSemanticSegmentation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of ADE20k
diff --git a/tests/models/videomae/test_modeling_videomae.py b/tests/models/videomae/test_modeling_videomae.py
index 2fd9f90c308558..e5b1c6b78e40dd 100644
--- a/tests/models/videomae/test_modeling_videomae.py
+++ b/tests/models/videomae/test_modeling_videomae.py
@@ -41,7 +41,6 @@
VideoMAEForVideoClassification,
VideoMAEModel,
)
- from transformers.models.videomae.modeling_videomae import VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -237,9 +236,9 @@ def test_for_pretraining(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = VideoMAEModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "MCG-NJU/videomae-base"
+ model = VideoMAEModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
if not self.has_attentions:
diff --git a/tests/models/vilt/test_modeling_vilt.py b/tests/models/vilt/test_modeling_vilt.py
index afc883ef8f3e79..4c877c2e185215 100644
--- a/tests/models/vilt/test_modeling_vilt.py
+++ b/tests/models/vilt/test_modeling_vilt.py
@@ -40,7 +40,6 @@
ViltModel,
)
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
- from transformers.models.vilt.modeling_vilt import VILT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
import PIL
@@ -528,9 +527,9 @@ def test_retain_grad_hidden_states_attentions(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VILT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ViltModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "dandelin/vilt-b32-mlm"
+ model = ViltModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/visual_bert/test_modeling_visual_bert.py b/tests/models/visual_bert/test_modeling_visual_bert.py
index c366e9145ea7c1..249ccdd84b01d4 100644
--- a/tests/models/visual_bert/test_modeling_visual_bert.py
+++ b/tests/models/visual_bert/test_modeling_visual_bert.py
@@ -36,7 +36,6 @@
VisualBertForVisualReasoning,
VisualBertModel,
)
- from transformers.models.visual_bert.modeling_visual_bert import VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST
class VisualBertModelTester:
@@ -551,9 +550,9 @@ def test_model_for_flickr(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = VisualBertModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "uclanlp/visualbert-vqa"
+ model = VisualBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
diff --git a/tests/models/vit/test_modeling_vit.py b/tests/models/vit/test_modeling_vit.py
index c8181d2c2b5a2e..7298543a563438 100644
--- a/tests/models/vit/test_modeling_vit.py
+++ b/tests/models/vit/test_modeling_vit.py
@@ -39,7 +39,6 @@
from torch import nn
from transformers import ViTForImageClassification, ViTForMaskedImageModeling, ViTModel
- from transformers.models.vit.modeling_vit import VIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -237,9 +236,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ViTModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/vit-base-patch16-224"
+ model = ViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/vit_hybrid/test_modeling_vit_hybrid.py b/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
index e9fc3de258689b..d48a8853921649 100644
--- a/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
+++ b/tests/models/vit_hybrid/test_modeling_vit_hybrid.py
@@ -31,7 +31,6 @@
from torch import nn
from transformers import ViTHybridForImageClassification, ViTHybridImageProcessor, ViTHybridModel
- from transformers.models.vit_hybrid.modeling_vit_hybrid import VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -217,9 +216,9 @@ def test_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ViTHybridModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/vit-hybrid-base-bit-384"
+ model = ViTHybridModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@is_flaky(description="is_flaky https://github.com/huggingface/transformers/issues/29516")
def test_batching_equivalence(self):
@@ -238,16 +237,14 @@ class ViTModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
return (
- ViTHybridImageProcessor.from_pretrained(VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST[0])
+ ViTHybridImageProcessor.from_pretrained("google/vit-hybrid-base-bit-384")
if is_vision_available()
else None
)
@slow
def test_inference_image_classification_head(self):
- model = ViTHybridForImageClassification.from_pretrained(VIT_HYBRID_PRETRAINED_MODEL_ARCHIVE_LIST[0]).to(
- torch_device
- )
+ model = ViTHybridForImageClassification.from_pretrained("google/vit-hybrid-base-bit-384").to(torch_device)
image_processor = self.default_image_processor
image = prepare_img()
diff --git a/tests/models/vit_mae/test_modeling_vit_mae.py b/tests/models/vit_mae/test_modeling_vit_mae.py
index b5196f12bb4ecc..ffb679d646ffda 100644
--- a/tests/models/vit_mae/test_modeling_vit_mae.py
+++ b/tests/models/vit_mae/test_modeling_vit_mae.py
@@ -35,7 +35,6 @@
from torch import nn
from transformers import ViTMAEForPreTraining, ViTMAEModel
- from transformers.models.vit.modeling_vit import VIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -276,9 +275,9 @@ def test_batching_equivalence(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ViTMAEModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/vit-base-patch16-224"
+ model = ViTMAEModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/vit_msn/test_modeling_vit_msn.py b/tests/models/vit_msn/test_modeling_vit_msn.py
index a4cc370ec21c7a..5fe494c105cb62 100644
--- a/tests/models/vit_msn/test_modeling_vit_msn.py
+++ b/tests/models/vit_msn/test_modeling_vit_msn.py
@@ -31,7 +31,6 @@
from torch import nn
from transformers import ViTMSNForImageClassification, ViTMSNModel
- from transformers.models.vit_msn.modeling_vit_msn import VIT_MSN_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -192,9 +191,9 @@ def test_for_image_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIT_MSN_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = ViTMSNModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/vit-msn-small"
+ model = ViTMSNModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/vitmatte/test_modeling_vitmatte.py b/tests/models/vitmatte/test_modeling_vitmatte.py
index c93e82bafbc65b..4a8e85160bcb51 100644
--- a/tests/models/vitmatte/test_modeling_vitmatte.py
+++ b/tests/models/vitmatte/test_modeling_vitmatte.py
@@ -36,7 +36,6 @@
import torch
from transformers import VitDetConfig, VitMatteForImageMatting
- from transformers.models.vitmatte.modeling_vitmatte import VITMATTE_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -195,9 +194,9 @@ def test_model(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VITMATTE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = VitMatteForImageMatting.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "hustvl/vitmatte-small-composition-1k"
+ model = VitMatteForImageMatting.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="ViTMatte does not support retaining gradient on attention logits")
def test_retain_grad_hidden_states_attentions(self):
diff --git a/tests/models/vivit/test_modeling_vivit.py b/tests/models/vivit/test_modeling_vivit.py
index 152cfac155b8a1..9b299c9afa40ce 100644
--- a/tests/models/vivit/test_modeling_vivit.py
+++ b/tests/models/vivit/test_modeling_vivit.py
@@ -37,7 +37,6 @@
from torch import nn
from transformers import MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING, VivitForVideoClassification, VivitModel
- from transformers.models.vivit.modeling_vivit import VIVIT_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -225,9 +224,9 @@ def test_for_video_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in VIVIT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = VivitModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "google/vivit-b-16x2-kinetics400"
+ model = VivitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
diff --git a/tests/models/wav2vec2/test_feature_extraction_wav2vec2.py b/tests/models/wav2vec2/test_feature_extraction_wav2vec2.py
index c4ab09b6069a2b..29e4bf3e28701a 100644
--- a/tests/models/wav2vec2/test_feature_extraction_wav2vec2.py
+++ b/tests/models/wav2vec2/test_feature_extraction_wav2vec2.py
@@ -20,7 +20,7 @@
import numpy as np
-from transformers import WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST, Wav2Vec2Config, Wav2Vec2FeatureExtractor
+from transformers import Wav2Vec2Config, Wav2Vec2FeatureExtractor
from transformers.testing_utils import require_torch, slow
from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
@@ -224,10 +224,10 @@ def test_pretrained_checkpoints_are_set_correctly(self):
# this test makes sure that models that are using
# group norm don't have their feature extractor return the
# attention_mask
- for model_id in WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST:
- config = Wav2Vec2Config.from_pretrained(model_id)
- feat_extract = Wav2Vec2FeatureExtractor.from_pretrained(model_id)
+ model_id = "facebook/wav2vec2-base-960h"
+ config = Wav2Vec2Config.from_pretrained(model_id)
+ feat_extract = Wav2Vec2FeatureExtractor.from_pretrained(model_id)
- # only "layer" feature extraction norm should make use of
- # attention_mask
- self.assertEqual(feat_extract.return_attention_mask, config.feat_extract_norm == "layer")
+ # only "layer" feature extraction norm should make use of
+ # attention_mask
+ self.assertEqual(feat_extract.return_attention_mask, config.feat_extract_norm == "layer")
diff --git a/tests/models/wav2vec2/test_tokenization_wav2vec2.py b/tests/models/wav2vec2/test_tokenization_wav2vec2.py
index 7310b1484841d9..6c98e0e0c8a702 100644
--- a/tests/models/wav2vec2/test_tokenization_wav2vec2.py
+++ b/tests/models/wav2vec2/test_tokenization_wav2vec2.py
@@ -13,6 +13,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tests for the Wav2Vec2 tokenizer."""
+
import inspect
import json
import os
@@ -24,7 +25,6 @@
import numpy as np
from transformers import (
- WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST,
AddedToken,
Wav2Vec2Config,
Wav2Vec2CTCTokenizer,
@@ -145,8 +145,10 @@ def test_tokenizer_decode_added_tokens(self):
[24, 22, 5, tokenizer.word_delimiter_token_id, 24, 22, 5, 77, tokenizer.pad_token_id, 34, 34],
]
batch_tokens = tokenizer.batch_decode(sample_ids)
+ batch_tokens_2 = tokenizer.batch_decode(sample_ids, skip_special_tokens=True)
self.assertEqual(batch_tokens, ["HELLO!?!?$$$", "BYE BYE$$$"])
+ self.assertEqual(batch_tokens_2, ["HELO!?!?", "BYE BYE"])
def test_call(self):
# Tests that all call wrap to encode_plus and batch_encode_plus
@@ -357,13 +359,13 @@ def test_pretrained_checkpoints_are_set_correctly(self):
# this test makes sure that models that are using
# group norm don't have their tokenizer return the
# attention_mask
- for model_id in WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST:
- config = Wav2Vec2Config.from_pretrained(model_id)
- tokenizer = Wav2Vec2Tokenizer.from_pretrained(model_id)
+ model_id = "facebook/wav2vec2-base-960h"
+ config = Wav2Vec2Config.from_pretrained(model_id)
+ tokenizer = Wav2Vec2Tokenizer.from_pretrained(model_id)
- # only "layer" feature extraction norm should make use of
- # attention_mask
- self.assertEqual(tokenizer.return_attention_mask, config.feat_extract_norm == "layer")
+ # only "layer" feature extraction norm should make use of
+ # attention_mask
+ self.assertEqual(tokenizer.return_attention_mask, config.feat_extract_norm == "layer")
class Wav2Vec2CTCTokenizerTest(TokenizerTesterMixin, unittest.TestCase):
@@ -453,18 +455,20 @@ def test_tokenizer_decode_special(self):
def test_tokenizer_decode_added_tokens(self):
tokenizer = self.tokenizer_class.from_pretrained("facebook/wav2vec2-base-960h")
- tokenizer.add_tokens(["!", "?"])
+ tokenizer.add_tokens(["!", "?", ""])
tokenizer.add_special_tokens({"cls_token": "$$$"})
# fmt: off
sample_ids = [
- [11, 5, 15, tokenizer.pad_token_id, 15, 8, 98, 32, 32, 33, tokenizer.word_delimiter_token_id, 32, 32, 33, 34, 34],
- [24, 22, 5, tokenizer.word_delimiter_token_id, 24, 22, 5, 77, tokenizer.pad_token_id, 34, 34],
+ [11, 5, 15, tokenizer.pad_token_id, 15, 8, 98, 32, 32, 33, tokenizer.word_delimiter_token_id, 32, 32, 33, 34, 34, 35, 35],
+ [24, 22, 5, tokenizer.word_delimiter_token_id, 24, 22, 5, 77, tokenizer.pad_token_id, 34, 34, 35, 35],
]
# fmt: on
batch_tokens = tokenizer.batch_decode(sample_ids)
+ batch_tokens_2 = tokenizer.batch_decode(sample_ids, skip_special_tokens=True)
- self.assertEqual(batch_tokens, ["HELLO!?!?$$$", "BYE BYE$$$"])
+ self.assertEqual(batch_tokens, ["HELLO!?!?$$$", "BYE BYE$$$"])
+ self.assertEqual(batch_tokens_2, ["HELO!?!?", "BYE BYE"])
def test_special_characters_in_vocab(self):
sent = "ʈʰ æ æ̃ ˧ kʰ"
@@ -703,10 +707,6 @@ def test_offsets_integration(self):
self.assertListEqual(expected_word_time_stamps_start, word_time_stamps_start)
self.assertListEqual(expected_word_time_stamps_end, word_time_stamps_end)
- def test_pretrained_model_lists(self):
- # Wav2Vec2Model has no max model length => no testing
- pass
-
# overwrite from test_tokenization_common
def test_add_tokens_tokenizer(self):
tokenizers = self.get_tokenizers(do_lower_case=False)
diff --git a/tests/models/wav2vec2_phoneme/test_tokenization_wav2vec2_phoneme.py b/tests/models/wav2vec2_phoneme/test_tokenization_wav2vec2_phoneme.py
index 56e38f2cf5d738..ea81c88ede2ee0 100644
--- a/tests/models/wav2vec2_phoneme/test_tokenization_wav2vec2_phoneme.py
+++ b/tests/models/wav2vec2_phoneme/test_tokenization_wav2vec2_phoneme.py
@@ -337,10 +337,6 @@ def test_internal_consistency(self):
pass
@unittest.skip("Wav2Vec2PhonemeModel has no max model length => no testing")
- def test_pretrained_model_lists(self):
- pass
-
- # overwrite common
def test_add_tokens_tokenizer(self):
tokenizers = self.get_tokenizers(do_lower_case=False)
for tokenizer in tokenizers:
diff --git a/tests/models/whisper/test_modeling_whisper.py b/tests/models/whisper/test_modeling_whisper.py
index b79f3a2c0da406..7ff6387ff212a4 100644
--- a/tests/models/whisper/test_modeling_whisper.py
+++ b/tests/models/whisper/test_modeling_whisper.py
@@ -888,7 +888,7 @@ def _check_outputs(self, output, input_ids, config, use_cache=False, num_return_
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference(self):
+ def test_flash_attn_2_inference_equivalence(self):
import torch
for model_class in self.all_model_classes:
@@ -934,7 +934,7 @@ def test_flash_attn_2_inference(self):
@require_torch_gpu
@pytest.mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
import torch
for model_class in self.all_model_classes:
diff --git a/tests/models/x_clip/test_modeling_x_clip.py b/tests/models/x_clip/test_modeling_x_clip.py
index bf8339c93e45c0..fc5c1679a65976 100644
--- a/tests/models/x_clip/test_modeling_x_clip.py
+++ b/tests/models/x_clip/test_modeling_x_clip.py
@@ -43,7 +43,6 @@
from torch import nn
from transformers import XCLIPModel, XCLIPTextModel, XCLIPVisionModel
- from transformers.models.x_clip.modeling_x_clip import XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -216,9 +215,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XCLIPVisionModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/xclip-base-patch32"
+ model = XCLIPVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_gradient_checkpointing_backward_compatibility(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
@@ -454,9 +453,9 @@ def test_save_load_fast_init_to_base(self):
@slow
def test_model_from_pretrained(self):
- for model_name in XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XCLIPTextModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/xclip-base-patch32"
+ model = XCLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
class XCLIPModelTester:
@@ -684,9 +683,9 @@ def test_load_vision_text_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in XCLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XCLIPModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "microsoft/xclip-base-patch32"
+ model = XCLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on a spaghetti video
diff --git a/tests/models/xglm/test_modeling_tf_xglm.py b/tests/models/xglm/test_modeling_tf_xglm.py
index 3950ccf6524f1f..e651d274232725 100644
--- a/tests/models/xglm/test_modeling_tf_xglm.py
+++ b/tests/models/xglm/test_modeling_tf_xglm.py
@@ -29,7 +29,6 @@
import tensorflow as tf
from transformers.models.xglm.modeling_tf_xglm import (
- TF_XGLM_PRETRAINED_MODEL_ARCHIVE_LIST,
TFXGLMForCausalLM,
TFXGLMModel,
)
@@ -161,9 +160,9 @@ def test_config(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_XGLM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFXGLMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/xglm-564M"
+ model = TFXGLMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip(reason="Currently, model embeddings are going to undergo a major refactor.")
def test_resize_token_embeddings(self):
diff --git a/tests/models/xglm/test_modeling_xglm.py b/tests/models/xglm/test_modeling_xglm.py
index e482b1b384f3ee..5669da7e2638da 100644
--- a/tests/models/xglm/test_modeling_xglm.py
+++ b/tests/models/xglm/test_modeling_xglm.py
@@ -36,7 +36,7 @@
if is_torch_available():
import torch
- from transformers import XGLM_PRETRAINED_MODEL_ARCHIVE_LIST, XGLMForCausalLM, XGLMModel, XGLMTokenizer
+ from transformers import XGLMForCausalLM, XGLMModel, XGLMTokenizer
class XGLMModelTester:
@@ -349,9 +349,9 @@ def test_xglm_weight_initialization(self):
@slow
def test_model_from_pretrained(self):
- for model_name in XGLM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XGLMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "facebook/xglm-564M"
+ model = XGLMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Does not work on the tiny model as we keep hitting edge cases.")
def test_model_parallelism(self):
diff --git a/tests/models/xlm/test_modeling_tf_xlm.py b/tests/models/xlm/test_modeling_tf_xlm.py
index 51ba6c2476b180..139f29db007b4a 100644
--- a/tests/models/xlm/test_modeling_tf_xlm.py
+++ b/tests/models/xlm/test_modeling_tf_xlm.py
@@ -30,7 +30,6 @@
import tensorflow as tf
from transformers import (
- TF_XLM_PRETRAINED_MODEL_ARCHIVE_LIST,
TFXLMForMultipleChoice,
TFXLMForQuestionAnsweringSimple,
TFXLMForSequenceClassification,
@@ -360,9 +359,9 @@ def test_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_XLM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFXLMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "FacebookAI/xlm-mlm-en-2048"
+ model = TFXLMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_tf
diff --git a/tests/models/xlm/test_modeling_xlm.py b/tests/models/xlm/test_modeling_xlm.py
index 09ad95e81ac822..268ba79d5931ff 100644
--- a/tests/models/xlm/test_modeling_xlm.py
+++ b/tests/models/xlm/test_modeling_xlm.py
@@ -36,7 +36,7 @@
XLMModel,
XLMWithLMHeadModel,
)
- from transformers.models.xlm.modeling_xlm import XLM_PRETRAINED_MODEL_ARCHIVE_LIST
+ from transformers.models.xlm.modeling_xlm import create_sinusoidal_embeddings
class XLMModelTester:
@@ -433,6 +433,14 @@ def test_xlm_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_xlm_model(*config_and_inputs)
+ # Copied from tests/models/distilbert/test_modeling_distilbert.py with Distilbert->XLM
+ def test_xlm_model_with_sinusoidal_encodings(self):
+ config = XLMConfig(sinusoidal_embeddings=True)
+ model = XLMModel(config=config)
+ sinusoidal_pos_embds = torch.empty((config.max_position_embeddings, config.emb_dim), dtype=torch.float32)
+ create_sinusoidal_embeddings(config.max_position_embeddings, config.emb_dim, sinusoidal_pos_embds)
+ self.model_tester.parent.assertTrue(torch.equal(model.position_embeddings.weight, sinusoidal_pos_embds))
+
def test_xlm_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_xlm_lm_head(*config_and_inputs)
@@ -505,9 +513,9 @@ def _check_hidden_states_for_generate(
@slow
def test_model_from_pretrained(self):
- for model_name in XLM_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XLMModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "FacebookAI/xlm-mlm-en-2048"
+ model = XLMModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/xlnet/test_modeling_tf_xlnet.py b/tests/models/xlnet/test_modeling_tf_xlnet.py
index 5d17299f9b3926..ea223914a35976 100644
--- a/tests/models/xlnet/test_modeling_tf_xlnet.py
+++ b/tests/models/xlnet/test_modeling_tf_xlnet.py
@@ -32,7 +32,6 @@
import tensorflow as tf
from transformers.models.xlnet.modeling_tf_xlnet import (
- TF_XLNET_PRETRAINED_MODEL_ARCHIVE_LIST,
TFXLNetForMultipleChoice,
TFXLNetForQuestionAnsweringSimple,
TFXLNetForSequenceClassification,
@@ -415,9 +414,9 @@ def test_xlnet_for_multiple_choice(self):
@slow
def test_model_from_pretrained(self):
- for model_name in TF_XLNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = TFXLNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "xlnet/xlnet-base-cased"
+ model = TFXLNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@unittest.skip("Some of the XLNet models misbehave with flexible input shapes.")
def test_compile_tf_model(self):
diff --git a/tests/models/xlnet/test_modeling_xlnet.py b/tests/models/xlnet/test_modeling_xlnet.py
index cd5a3d52b34801..ff89a9aca3eca2 100644
--- a/tests/models/xlnet/test_modeling_xlnet.py
+++ b/tests/models/xlnet/test_modeling_xlnet.py
@@ -37,7 +37,6 @@
XLNetLMHeadModel,
XLNetModel,
)
- from transformers.models.xlnet.modeling_xlnet import XLNET_PRETRAINED_MODEL_ARCHIVE_LIST
class XLNetModelTester:
@@ -685,9 +684,9 @@ def _check_attentions_for_generate(
@slow
def test_model_from_pretrained(self):
- for model_name in XLNET_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = XLNetModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "xlnet/xlnet-base-cased"
+ model = XLNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
@require_torch
diff --git a/tests/models/yolos/test_modeling_yolos.py b/tests/models/yolos/test_modeling_yolos.py
index 4b2aff30948767..64a439f27a4e45 100644
--- a/tests/models/yolos/test_modeling_yolos.py
+++ b/tests/models/yolos/test_modeling_yolos.py
@@ -31,7 +31,6 @@
from torch import nn
from transformers import YolosForObjectDetection, YolosModel
- from transformers.models.yolos.modeling_yolos import YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
@@ -319,9 +318,9 @@ def test_for_object_detection(self):
@slow
def test_model_from_pretrained(self):
- for model_name in YOLOS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = YolosModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "hustvl/yolos-small"
+ model = YolosModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
diff --git a/tests/models/yoso/test_modeling_yoso.py b/tests/models/yoso/test_modeling_yoso.py
index 67d7b9edc4e4c3..ca41b074bc3dd9 100644
--- a/tests/models/yoso/test_modeling_yoso.py
+++ b/tests/models/yoso/test_modeling_yoso.py
@@ -36,7 +36,6 @@
YosoForTokenClassification,
YosoModel,
)
- from transformers.models.yoso.modeling_yoso import YOSO_PRETRAINED_MODEL_ARCHIVE_LIST
class YosoModelTester:
@@ -351,9 +350,9 @@ def test_for_token_classification(self):
@slow
def test_model_from_pretrained(self):
- for model_name in YOSO_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- model = YosoModel.from_pretrained(model_name)
- self.assertIsNotNone(model)
+ model_name = "uw-madison/yoso-4096"
+ model = YosoModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
def test_attention_outputs(self):
return
diff --git a/tests/pipelines/test_pipelines_common.py b/tests/pipelines/test_pipelines_common.py
index 5e3e15f39c10ea..13b97aff3216b5 100644
--- a/tests/pipelines/test_pipelines_common.py
+++ b/tests/pipelines/test_pipelines_common.py
@@ -199,6 +199,29 @@ def test_unbatch_attentions_hidden_states(self):
outputs = text_classifier(["This is great !"] * 20, batch_size=32)
self.assertEqual(len(outputs), 20)
+ @require_torch
+ def test_torch_dtype_property(self):
+ import torch
+
+ model_id = "hf-internal-testing/tiny-random-distilbert"
+
+ # If dtype is specified in the pipeline constructor, the property should return that type
+ pipe = pipeline(model=model_id, torch_dtype=torch.float16)
+ self.assertEqual(pipe.torch_dtype, torch.float16)
+
+ # If the underlying model changes dtype, the property should return the new type
+ pipe.model.to(torch.bfloat16)
+ self.assertEqual(pipe.torch_dtype, torch.bfloat16)
+
+ # If dtype is NOT specified in the pipeline constructor, the property should just return
+ # the dtype of the underlying model (default)
+ pipe = pipeline(model=model_id)
+ self.assertEqual(pipe.torch_dtype, torch.float32)
+
+ # If underlying model doesn't have dtype property, simply return None
+ pipe.model = None
+ self.assertIsNone(pipe.torch_dtype)
+
@is_pipeline_test
class PipelineScikitCompatTest(unittest.TestCase):
diff --git a/tests/pipelines/test_pipelines_image_to_text.py b/tests/pipelines/test_pipelines_image_to_text.py
index e2d59968ebf4a6..c77353a261f91d 100644
--- a/tests/pipelines/test_pipelines_image_to_text.py
+++ b/tests/pipelines/test_pipelines_image_to_text.py
@@ -290,7 +290,7 @@ def test_conditional_generation_llava(self):
outputs,
[
{
- "generated_text": " \nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud?\nASSISTANT: Lava"
+ "generated_text": "\nUSER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud?\nASSISTANT: Lava"
}
],
)
diff --git a/tests/pipelines/test_pipelines_video_classification.py b/tests/pipelines/test_pipelines_video_classification.py
index 33e06e30f5ae0b..d23916bad84fae 100644
--- a/tests/pipelines/test_pipelines_video_classification.py
+++ b/tests/pipelines/test_pipelines_video_classification.py
@@ -21,7 +21,7 @@
from transformers.testing_utils import (
is_pipeline_test,
nested_simplify,
- require_decord,
+ require_av,
require_tf,
require_torch,
require_torch_or_tf,
@@ -34,7 +34,7 @@
@is_pipeline_test
@require_torch_or_tf
@require_vision
-@require_decord
+@require_av
class VideoClassificationPipelineTests(unittest.TestCase):
model_mapping = MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index ca9ac62bf28bc2..7241993b6d1bd3 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -462,10 +462,10 @@ def _init_weights(self, module):
([0.2975, 0.2131, -0.1379, -0.0796, -0.3012, -0.0057, -0.2381, -0.2439, -0.0174, 0.0475])
)
init_instance = MyClass()
- torch.testing.assert_allclose(init_instance.linear.bias, expected_bias, rtol=1e-3, atol=1e-4)
+ torch.testing.assert_close(init_instance.linear.bias, expected_bias, rtol=1e-3, atol=1e-4)
set_seed(0)
- torch.testing.assert_allclose(
+ torch.testing.assert_close(
init_instance.linear.weight, nn.init.kaiming_uniform_(no_init_instance.linear.weight, np.sqrt(5))
)
@@ -3245,7 +3245,7 @@ def test_flash_attn_2_conversion(self):
@require_torch_gpu
@mark.flash_attn_test
@slow
- def test_flash_attn_2_inference(self):
+ def test_flash_attn_2_inference_equivalence(self):
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
@@ -3260,9 +3260,7 @@ def test_flash_attn_2_inference(self):
)
model_fa.to(torch_device)
- model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
- )
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
model.to(torch_device)
dummy_input = inputs_dict[model.main_input_name][:1]
@@ -3340,7 +3338,7 @@ def test_flash_attn_2_inference(self):
@require_torch_gpu
@mark.flash_attn_test
@slow
- def test_flash_attn_2_inference_padding_right(self):
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
for model_class in self.all_model_classes:
if not model_class._supports_flash_attn_2:
self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
@@ -3355,9 +3353,7 @@ def test_flash_attn_2_inference_padding_right(self):
)
model_fa.to(torch_device)
- model = model_class.from_pretrained(
- tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
- )
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
model.to(torch_device)
dummy_input = inputs_dict[model.main_input_name][:1]
diff --git a/tests/test_modeling_utils.py b/tests/test_modeling_utils.py
index 46df1feae92785..e6f57d68cc6a37 100755
--- a/tests/test_modeling_utils.py
+++ b/tests/test_modeling_utils.py
@@ -20,6 +20,7 @@
import os.path
import sys
import tempfile
+import threading
import unittest
import unittest.mock as mock
import uuid
@@ -85,7 +86,6 @@
from torch import nn
from transformers import (
- BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
AutoModelForCausalLM,
AutoTokenizer,
BertConfig,
@@ -101,7 +101,7 @@
_prepare_4d_attention_mask,
_prepare_4d_causal_attention_mask,
)
- from transformers.modeling_utils import shard_checkpoint
+ from transformers.modeling_utils import _find_disjoint, _find_identical, shard_checkpoint
# Fake pretrained models for tests
class BaseModel(PreTrainedModel):
@@ -217,29 +217,29 @@ def check_models_equal(model1, model2):
class ModelUtilsTest(TestCasePlus):
@slow
def test_model_from_pretrained(self):
- for model_name in BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
- config = BertConfig.from_pretrained(model_name)
- self.assertIsNotNone(config)
- self.assertIsInstance(config, PretrainedConfig)
+ model_name = "google-bert/bert-base-uncased"
+ config = BertConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, PretrainedConfig)
- model = BertModel.from_pretrained(model_name)
- model, loading_info = BertModel.from_pretrained(model_name, output_loading_info=True)
- self.assertIsNotNone(model)
- self.assertIsInstance(model, PreTrainedModel)
+ model = BertModel.from_pretrained(model_name)
+ model, loading_info = BertModel.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, PreTrainedModel)
- self.assertEqual(len(loading_info["missing_keys"]), 0)
- self.assertEqual(len(loading_info["unexpected_keys"]), 8)
- self.assertEqual(len(loading_info["mismatched_keys"]), 0)
- self.assertEqual(len(loading_info["error_msgs"]), 0)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+ self.assertEqual(len(loading_info["unexpected_keys"]), 8)
+ self.assertEqual(len(loading_info["mismatched_keys"]), 0)
+ self.assertEqual(len(loading_info["error_msgs"]), 0)
- config = BertConfig.from_pretrained(model_name, output_attentions=True, output_hidden_states=True)
+ config = BertConfig.from_pretrained(model_name, output_attentions=True, output_hidden_states=True)
- # Not sure this is the intended behavior. TODO fix Lysandre & Thom
- config.name_or_path = model_name
+ # Not sure this is the intended behavior. TODO fix Lysandre & Thom
+ config.name_or_path = model_name
- model = BertModel.from_pretrained(model_name, output_attentions=True, output_hidden_states=True)
- self.assertEqual(model.config.output_hidden_states, True)
- self.assertEqual(model.config, config)
+ model = BertModel.from_pretrained(model_name, output_attentions=True, output_hidden_states=True)
+ self.assertEqual(model.config.output_hidden_states, True)
+ self.assertEqual(model.config, config)
def test_model_from_pretrained_subfolder(self):
config = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert")
@@ -256,6 +256,26 @@ def test_model_from_pretrained_subfolder(self):
self.assertTrue(check_models_equal(model, model_loaded))
+ def test_model_manually_shared_disjointed_tensors_optimum(self):
+ config = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert")
+ model = BertModel(config)
+
+ # Let's fuse qkv
+ attn = model.encoder.layer[0].attention.self
+ q = attn.query.weight
+ k = attn.key.weight
+ v = attn.value.weight
+ # Force some shared storage
+ qkv = torch.stack([q, k, v], dim=0)
+ attn.query.weight = torch.nn.Parameter(qkv[0])
+ attn.key.weight = torch.nn.Parameter(qkv[1])
+ attn.value.weight = torch.nn.Parameter(qkv[2])
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model_loaded = BertModel.from_pretrained(tmp_dir)
+
+ self.assertTrue(check_models_equal(model, model_loaded))
+
def test_model_from_pretrained_subfolder_sharded(self):
config = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert")
model = BertModel(config)
@@ -1429,7 +1449,7 @@ def test_safetensors_on_the_fly_wrong_user_opened_pr(self):
bot_opened_pr_title = None
for discussion in discussions:
- if discussion.author == "SFconvertBot":
+ if discussion.author == "SFconvertbot":
bot_opened_pr = True
bot_opened_pr_title = discussion.title
@@ -1452,6 +1472,51 @@ def test_safetensors_on_the_fly_specific_revision(self):
with self.assertRaises(EnvironmentError):
BertModel.from_pretrained(self.repo_name, use_safetensors=True, token=self.token, revision="new-branch")
+ def test_absence_of_safetensors_triggers_conversion(self):
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ # Push a model on `main`
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False)
+
+ # Download the model that doesn't have safetensors
+ BertModel.from_pretrained(self.repo_name, token=self.token)
+
+ for thread in threading.enumerate():
+ if thread.name == "Thread-autoconversion":
+ thread.join(timeout=10)
+
+ with self.subTest("PR was open with the safetensors account"):
+ discussions = self.api.get_repo_discussions(self.repo_name)
+
+ bot_opened_pr = None
+ bot_opened_pr_title = None
+
+ for discussion in discussions:
+ if discussion.author == "SFconvertbot":
+ bot_opened_pr = True
+ bot_opened_pr_title = discussion.title
+
+ self.assertTrue(bot_opened_pr)
+ self.assertEqual(bot_opened_pr_title, "Adding `safetensors` variant of this model")
+
+ @mock.patch("transformers.safetensors_conversion.spawn_conversion")
+ def test_absence_of_safetensors_triggers_conversion_failed(self, spawn_conversion_mock):
+ spawn_conversion_mock.side_effect = HTTPError()
+
+ config = BertConfig(
+ vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37
+ )
+ initial_model = BertModel(config)
+
+ # Push a model on `main`
+ initial_model.push_to_hub(self.repo_name, token=self.token, safe_serialization=False)
+
+ # The auto conversion is mocked to always raise; ensure that it doesn't raise in the main thread
+ BertModel.from_pretrained(self.repo_name, token=self.token)
+
@require_torch
@is_staging_test
@@ -2177,3 +2242,40 @@ def test_partial_stacked_causal_mask(self):
]
self.assertEqual(decoded_0, decoded_1b)
+
+
+@require_torch
+class TestTensorSharing(TestCasePlus):
+ def test_disjoint(self):
+ main = torch.zeros(10)
+ a = main[:5]
+ b = main[5:]
+ state_dict = {"a": a, "b": b}
+
+ shared_names, disjoint_names = _find_disjoint([{"a", "b"}], state_dict)
+ self.assertEqual(shared_names, [])
+ self.assertEqual(disjoint_names, ["a", "b"])
+
+ a = main[::2]
+ b = main[1::2]
+ state_dict = {"a": a, "b": b}
+
+ shared_names, disjoint_names = _find_disjoint([{"a", "b"}], state_dict)
+ self.assertEqual(shared_names, [{"a", "b"}])
+ self.assertEqual(disjoint_names, [])
+
+ def test_identical(self):
+ a = torch.zeros(10)
+ b = a
+ state_dict = {"a": a, "b": b}
+
+ shared_names, identical_names = _find_identical([{"a", "b"}], state_dict)
+ self.assertEqual(shared_names, [])
+ self.assertEqual(identical_names, [{"a", "b"}])
+
+ b = a[:5]
+ state_dict = {"a": a, "b": b}
+
+ shared_names, identical_names = _find_identical([{"a", "b"}], state_dict)
+ self.assertEqual(shared_names, [{"a", "b"}])
+ self.assertEqual(identical_names, [])
diff --git a/tests/test_tokenization_common.py b/tests/test_tokenization_common.py
index 8216db084cb5f7..4ff17ab5573a9c 100644
--- a/tests/test_tokenization_common.py
+++ b/tests/test_tokenization_common.py
@@ -1023,24 +1023,6 @@ def test_encode_decode_with_spaces(self):
decoded = tokenizer.decode(encoded, spaces_between_special_tokens=False)
self.assertIn(decoded, ["[ABC][SAMPLE][DEF]", "[ABC][SAMPLE][DEF]".lower()])
- def test_pretrained_model_lists(self):
- # We should have at least one default checkpoint for each tokenizer
- # We should specify the max input length as well (used in some part to list the pretrained checkpoints)
- self.assertGreaterEqual(len(self.tokenizer_class.pretrained_vocab_files_map), 1)
- self.assertGreaterEqual(len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]), 1)
- self.assertEqual(
- len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]),
- len(self.tokenizer_class.max_model_input_sizes),
- )
-
- weights_list = list(self.tokenizer_class.max_model_input_sizes.keys())
- weights_lists_2 = []
- for file_id, map_list in self.tokenizer_class.pretrained_vocab_files_map.items():
- weights_lists_2.append(list(map_list.keys()))
-
- for weights_list_2 in weights_lists_2:
- self.assertListEqual(weights_list, weights_list_2)
-
def test_mask_output(self):
tokenizers = self.get_tokenizers(do_lower_case=False)
for tokenizer in tokenizers:
diff --git a/tests/tokenization/test_tokenization_fast.py b/tests/tokenization/test_tokenization_fast.py
index 6e24009ecd0830..ac073529e251ea 100644
--- a/tests/tokenization/test_tokenization_fast.py
+++ b/tests/tokenization/test_tokenization_fast.py
@@ -70,11 +70,6 @@ def test_added_tokens_serialization(self):
def test_additional_special_tokens_serialization(self):
pass
- def test_pretrained_model_lists(self):
- # We disable this test for PreTrainedTokenizerFast because it is the only tokenizer that is not linked to any
- # model
- pass
-
def test_prepare_for_model(self):
# We disable this test for PreTrainedTokenizerFast because it is the only tokenizer that is not linked to any
# model
diff --git a/tests/trainer/test_trainer.py b/tests/trainer/test_trainer.py
index ebc628146b96b8..483022a09e6fab 100644
--- a/tests/trainer/test_trainer.py
+++ b/tests/trainer/test_trainer.py
@@ -24,6 +24,7 @@
import sys
import tempfile
import unittest
+from functools import partial
from itertools import product
from pathlib import Path
from typing import Dict, List
@@ -92,6 +93,7 @@
SAFE_WEIGHTS_NAME,
WEIGHTS_INDEX_NAME,
WEIGHTS_NAME,
+ is_accelerate_available,
is_apex_available,
is_bitsandbytes_available,
is_safetensors_available,
@@ -127,6 +129,9 @@
if is_safetensors_available():
import safetensors.torch
+# for version specific tests in TrainerIntegrationTest
+require_accelerate_version_min_0_28 = partial(require_accelerate, min_version="0.28")
+GRAD_ACCUM_KWARGS_VERSION_AVAILABLE = is_accelerate_available("0.28")
PATH_SAMPLE_TEXT = f"{get_tests_dir()}/fixtures/sample_text.txt"
@@ -706,6 +711,29 @@ def test_lr_scheduler_kwargs(self):
self.assertEqual(sched1.lr_lambdas[0].args, sched2.lr_lambdas[0].args)
self.assertEqual(sched1.lr_lambdas[0].keywords, sched2.lr_lambdas[0].keywords)
+ def test_cosine_with_min_lr_scheduler(self):
+ train_dataset = RegressionDataset()
+ model = RegressionModel()
+ num_steps, num_warmup_steps = 10, 2
+ extra_kwargs = {"min_lr": 1e-5} # Non-default arguments
+ args = TrainingArguments(
+ "./regression",
+ lr_scheduler_type="cosine_with_min_lr",
+ lr_scheduler_kwargs=extra_kwargs,
+ learning_rate=0.2,
+ warmup_steps=num_warmup_steps,
+ )
+ trainer = Trainer(model, args, train_dataset=train_dataset)
+ trainer.create_optimizer_and_scheduler(num_training_steps=num_steps)
+
+ # Checking that the scheduler was created
+ self.assertIsNotNone(trainer.lr_scheduler)
+
+ # Check the last learning rate
+ for _ in range(num_steps):
+ trainer.lr_scheduler.step()
+ self.assertEqual(trainer.lr_scheduler.get_last_lr()[0], 1e-5)
+
def test_reduce_lr_on_plateau_args(self):
# test passed arguments for a custom ReduceLROnPlateau scheduler
train_dataset = RegressionDataset(length=64)
@@ -2485,6 +2513,44 @@ def test_checkpoint_rotation(self):
trainer.state.best_model_checkpoint = os.path.join(tmp_dir, "checkpoint-5")
self.check_checkpoint_deletion(trainer, tmp_dir, [5, 25])
+ def test_compare_trainer_and_checkpoint_args_logging(self):
+ logger = logging.get_logger()
+
+ with tempfile.TemporaryDirectory() as tmpdir, CaptureLogger(logger) as cl:
+ trainer = get_regression_trainer(
+ output_dir=tmpdir,
+ train_len=128,
+ eval_steps=5,
+ gradient_accumulation_steps=2,
+ per_device_train_batch_size=4,
+ save_steps=5,
+ learning_rate=0.1,
+ )
+ trainer.train()
+
+ checkpoint = os.path.join(tmpdir, "checkpoint-5")
+ checkpoint_trainer = get_regression_trainer(
+ output_dir=tmpdir,
+ train_len=256,
+ eval_steps=10,
+ gradient_accumulation_steps=4,
+ per_device_train_batch_size=8,
+ save_steps=10,
+ learning_rate=0.1,
+ )
+ checkpoint_trainer.train(resume_from_checkpoint=checkpoint)
+
+ self.assertIn("save_steps: 10 (from args) != 5 (from trainer_state.json)", cl.out)
+
+ self.assertIn(
+ "per_device_train_batch_size: 8 (from args) != 4 (from trainer_state.json)",
+ cl.out,
+ )
+ self.assertIn(
+ "eval_steps: 10 (from args) != 5 (from trainer_state.json)",
+ cl.out,
+ )
+
def check_mem_metrics(self, trainer, check_func):
metrics = trainer.train().metrics
check_func("init_mem_cpu_alloc_delta", metrics)
@@ -2814,6 +2880,10 @@ def test_accelerator_config_empty(self):
self.assertEqual(trainer.accelerator.even_batches, True)
self.assertEqual(trainer.accelerator.use_seedable_sampler, True)
+ if GRAD_ACCUM_KWARGS_VERSION_AVAILABLE:
+ # gradient accumulation kwargs configures gradient_state
+ self.assertNotIn("sync_each_batch", trainer.accelerator.gradient_state.plugin_kwargs)
+
def test_accelerator_config_from_dict(self):
# Checks that accelerator kwargs can be passed through
# and the accelerator is initialized respectively
@@ -2822,15 +2892,19 @@ def test_accelerator_config_from_dict(self):
model = RegressionPreTrainedModel(config)
eval_dataset = SampleIterableDataset()
+ accelerator_config = {
+ "split_batches": True,
+ "dispatch_batches": True,
+ "even_batches": False,
+ "use_seedable_sampler": True,
+ }
+ if GRAD_ACCUM_KWARGS_VERSION_AVAILABLE:
+ accelerator_config["gradient_accumulation_kwargs"] = {"sync_each_batch": True}
+
# Leaves all options as something *not* basic
args = RegressionTrainingArguments(
output_dir=tmp_dir,
- accelerator_config={
- "split_batches": True,
- "dispatch_batches": True,
- "even_batches": False,
- "use_seedable_sampler": True,
- },
+ accelerator_config=accelerator_config,
)
trainer = Trainer(model=model, args=args, eval_dataset=eval_dataset)
self.assertEqual(trainer.accelerator.split_batches, True)
@@ -2838,6 +2912,9 @@ def test_accelerator_config_from_dict(self):
self.assertEqual(trainer.accelerator.even_batches, False)
self.assertEqual(trainer.accelerator.use_seedable_sampler, True)
+ if GRAD_ACCUM_KWARGS_VERSION_AVAILABLE:
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["sync_each_batch"], True)
+
def test_accelerator_config_from_yaml(self):
# Checks that accelerator kwargs can be passed through
# and the accelerator is initialized respectively
@@ -2850,6 +2927,8 @@ def test_accelerator_config_from_yaml(self):
"even_batches": False,
"use_seedable_sampler": False,
}
+ if GRAD_ACCUM_KWARGS_VERSION_AVAILABLE:
+ accelerator_config["gradient_accumulation_kwargs"] = {"sync_each_batch": True}
json.dump(accelerator_config, f)
config = RegressionModelConfig(a=1.5, b=2.5)
model = RegressionPreTrainedModel(config)
@@ -2863,11 +2942,18 @@ def test_accelerator_config_from_yaml(self):
self.assertEqual(trainer.accelerator.even_batches, False)
self.assertEqual(trainer.accelerator.use_seedable_sampler, False)
+ if GRAD_ACCUM_KWARGS_VERSION_AVAILABLE:
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["sync_each_batch"], True)
+
def test_accelerator_config_from_dataclass(self):
# Checks that accelerator kwargs can be passed through
# and the accelerator is initialized respectively
+
accelerator_config = AcceleratorConfig(
- split_batches=True, dispatch_batches=True, even_batches=False, use_seedable_sampler=False
+ split_batches=True,
+ dispatch_batches=True,
+ even_batches=False,
+ use_seedable_sampler=False,
)
config = RegressionModelConfig(a=1.5, b=2.5)
model = RegressionPreTrainedModel(config)
@@ -2880,6 +2966,35 @@ def test_accelerator_config_from_dataclass(self):
self.assertEqual(trainer.accelerator.even_batches, False)
self.assertEqual(trainer.accelerator.use_seedable_sampler, False)
+ @require_accelerate_version_min_0_28
+ def test_accelerate_config_from_dataclass_grad_accum(self):
+ # Checks that accelerator kwargs can be passed through
+ # and the accelerator is initialized respectively
+
+ grad_acc_kwargs = {
+ "num_steps": 10,
+ "adjust_scheduler": False,
+ "sync_with_dataloader": False,
+ "sync_each_batch": True,
+ }
+ accelerator_config = AcceleratorConfig(
+ split_batches=True,
+ dispatch_batches=True,
+ even_batches=False,
+ use_seedable_sampler=False,
+ gradient_accumulation_kwargs=grad_acc_kwargs,
+ )
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ model = RegressionPreTrainedModel(config)
+ eval_dataset = SampleIterableDataset()
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ args = RegressionTrainingArguments(output_dir=tmp_dir, accelerator_config=accelerator_config)
+ trainer = Trainer(model=model, args=args, eval_dataset=eval_dataset)
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["num_steps"], 10)
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["adjust_scheduler"], False)
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["sync_with_dataloader"], False)
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["sync_each_batch"], True)
+
def test_accelerator_config_from_partial(self):
# Checks that accelerator kwargs can be passed through
# and the accelerator is initialized respectively
@@ -2951,6 +3066,44 @@ def test_accelerator_config_only_deprecated_args(self):
trainer = Trainer(model=model, args=args, eval_dataset=eval_dataset)
self.assertEqual(trainer.accelerator.split_batches, True)
+ @require_accelerate_version_min_0_28
+ def test_accelerator_config_from_dict_grad_accum_num_steps(self):
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config = RegressionModelConfig(a=1.5, b=2.5)
+ model = RegressionPreTrainedModel(config)
+ eval_dataset = SampleIterableDataset()
+
+ # case - TrainingArguments.gradient_accumulation_steps == 1
+ # - gradient_accumulation_kwargs['num_steps] == 1
+ # results in grad accum set to 1
+ args = RegressionTrainingArguments(
+ output_dir=tmp_dir,
+ gradient_accumulation_steps=1,
+ accelerator_config={
+ "gradient_accumulation_kwargs": {
+ "num_steps": 1,
+ }
+ },
+ )
+ trainer = Trainer(model=model, args=args, eval_dataset=eval_dataset)
+ self.assertEqual(trainer.accelerator.gradient_state.plugin_kwargs["num_steps"], 1)
+
+ # case - TrainingArguments.gradient_accumulation_steps > 1
+ # - gradient_accumulation_kwargs['num_steps] specified
+ # results in exception raised
+ args = RegressionTrainingArguments(
+ output_dir=tmp_dir,
+ gradient_accumulation_steps=2,
+ accelerator_config={
+ "gradient_accumulation_kwargs": {
+ "num_steps": 10,
+ }
+ },
+ )
+ with self.assertRaises(Exception) as context:
+ trainer = Trainer(model=model, args=args, eval_dataset=eval_dataset)
+ self.assertTrue("The `AcceleratorConfig`'s `num_steps` is set but" in str(context.exception))
+
@require_torch
@is_staging_test
@@ -3769,3 +3922,41 @@ def test_hyperparameter_search_backends(self):
list(ALL_HYPERPARAMETER_SEARCH_BACKENDS.keys()),
list(HPSearchBackend),
)
+
+
+@require_torch
+class OptimizerAndModelInspectionTest(unittest.TestCase):
+ def test_get_num_trainable_parameters(self):
+ model = nn.Sequential(nn.Linear(128, 64), nn.Linear(64, 32))
+ # in_features * out_features + bias
+ layer_1 = 128 * 64 + 64
+ layer_2 = 64 * 32 + 32
+ trainer = Trainer(model=model)
+ self.assertEqual(trainer.get_num_trainable_parameters(), layer_1 + layer_2)
+ # Freeze the last layer
+ for param in model[-1].parameters():
+ param.requires_grad = False
+ self.assertEqual(trainer.get_num_trainable_parameters(), layer_1)
+
+ def test_get_learning_rates(self):
+ model = nn.Sequential(nn.Linear(128, 64))
+ trainer = Trainer(model=model)
+ with self.assertRaises(ValueError):
+ trainer.get_learning_rates()
+ trainer.create_optimizer()
+ self.assertEqual(trainer.get_learning_rates(), [5e-05, 5e-05])
+
+ def test_get_optimizer_group(self):
+ model = nn.Sequential(nn.Linear(128, 64))
+ trainer = Trainer(model=model)
+ # ValueError is raised if optimizer is None
+ with self.assertRaises(ValueError):
+ trainer.get_optimizer_group()
+ trainer.create_optimizer()
+ # Get groups
+ num_groups = len(trainer.get_optimizer_group())
+ self.assertEqual(num_groups, 2)
+ # Get group of parameter
+ param = next(model.parameters())
+ group = trainer.get_optimizer_group(param)
+ self.assertIn(param, group["params"])
diff --git a/tests/utils/test_add_new_model_like.py b/tests/utils/test_add_new_model_like.py
index b7eceb6e76c34c..9c150b32bd70d9 100644
--- a/tests/utils/test_add_new_model_like.py
+++ b/tests/utils/test_add_new_model_like.py
@@ -883,7 +883,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
from ...utils import _LazyModule, is_flax_available, is_tf_available, is_tokenizers_available, is_torch_available
_import_structure = {
- "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"],
+ "configuration_gpt2": ["GPT2Config", "GPT2OnnxConfig"],
"tokenization_gpt2": ["GPT2Tokenizer"],
}
@@ -920,7 +920,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
_import_structure["modeling_flax_gpt2"] = ["FlaxGPT2Model"]
if TYPE_CHECKING:
- from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig
+ from .configuration_gpt2 import GPT2Config, GPT2OnnxConfig
from .tokenization_gpt2 import GPT2Tokenizer
try:
@@ -967,7 +967,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available
_import_structure = {
- "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"],
+ "configuration_gpt2": ["GPT2Config", "GPT2OnnxConfig"],
}
try:
@@ -995,7 +995,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
_import_structure["modeling_flax_gpt2"] = ["FlaxGPT2Model"]
if TYPE_CHECKING:
- from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig
+ from .configuration_gpt2 import GPT2Config, GPT2OnnxConfig
try:
if not is_torch_available():
@@ -1033,7 +1033,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
from ...utils import _LazyModule, is_tokenizers_available, is_torch_available
_import_structure = {
- "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"],
+ "configuration_gpt2": ["GPT2Config", "GPT2OnnxConfig"],
"tokenization_gpt2": ["GPT2Tokenizer"],
}
@@ -1054,7 +1054,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
_import_structure["modeling_gpt2"] = ["GPT2Model"]
if TYPE_CHECKING:
- from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig
+ from .configuration_gpt2 import GPT2Config, GPT2OnnxConfig
from .tokenization_gpt2 import GPT2Tokenizer
try:
@@ -1085,7 +1085,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
from ...utils import _LazyModule, is_torch_available
_import_structure = {
- "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"],
+ "configuration_gpt2": ["GPT2Config", "GPT2OnnxConfig"],
}
try:
@@ -1097,7 +1097,7 @@ def test_clean_frameworks_in_init_with_gpt(self):
_import_structure["modeling_gpt2"] = ["GPT2Model"]
if TYPE_CHECKING:
- from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig
+ from .configuration_gpt2 import GPT2Config, GPT2OnnxConfig
try:
if not is_torch_available():
@@ -1135,7 +1135,7 @@ def test_clean_frameworks_in_init_with_vit(self):
from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available, is_vision_available
_import_structure = {
- "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"],
+ "configuration_vit": ["ViTConfig"],
}
try:
@@ -1171,7 +1171,7 @@ def test_clean_frameworks_in_init_with_vit(self):
_import_structure["modeling_flax_vit"] = ["FlaxViTModel"]
if TYPE_CHECKING:
- from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig
+ from .configuration_vit import ViTConfig
try:
if not is_vision_available():
@@ -1217,7 +1217,7 @@ def test_clean_frameworks_in_init_with_vit(self):
from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available
_import_structure = {
- "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"],
+ "configuration_vit": ["ViTConfig"],
}
try:
@@ -1245,7 +1245,7 @@ def test_clean_frameworks_in_init_with_vit(self):
_import_structure["modeling_flax_vit"] = ["FlaxViTModel"]
if TYPE_CHECKING:
- from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig
+ from .configuration_vit import ViTConfig
try:
if not is_torch_available():
@@ -1283,7 +1283,7 @@ def test_clean_frameworks_in_init_with_vit(self):
from ...utils import _LazyModule, is_torch_available, is_vision_available
_import_structure = {
- "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"],
+ "configuration_vit": ["ViTConfig"],
}
try:
@@ -1303,7 +1303,7 @@ def test_clean_frameworks_in_init_with_vit(self):
_import_structure["modeling_vit"] = ["ViTModel"]
if TYPE_CHECKING:
- from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig
+ from .configuration_vit import ViTConfig
try:
if not is_vision_available():
@@ -1333,7 +1333,7 @@ def test_clean_frameworks_in_init_with_vit(self):
from ...utils import _LazyModule, is_torch_available
_import_structure = {
- "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"],
+ "configuration_vit": ["ViTConfig"],
}
try:
@@ -1345,7 +1345,7 @@ def test_clean_frameworks_in_init_with_vit(self):
_import_structure["modeling_vit"] = ["ViTModel"]
if TYPE_CHECKING:
- from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig
+ from .configuration_vit import ViTConfig
try:
if not is_torch_available():
diff --git a/utils/check_copies.py b/utils/check_copies.py
index 435f0bd89eed36..60a2fac4c8f57d 100644
--- a/utils/check_copies.py
+++ b/utils/check_copies.py
@@ -309,7 +309,18 @@ def split_code_into_blocks(
"""
splits = []
# `indent - 4` is the indent level of the target class/func header
- target_block_name = re.search(rf"^{' ' * (indent - 4)}((class|def)\s+\S+)(\(|\:)", lines[start_index]).groups()[0]
+ try:
+ target_block_name = re.search(
+ rf"^{' ' * (indent - 4)}((class|def)\s+\S+)(\(|\:)", lines[start_index]
+ ).groups()[0]
+ except Exception:
+ start_context = min(start_index - 10, 0)
+ end_context = min(end_index + 10, len(lines))
+ raise ValueError(
+ f"Tried to split a class or function. It did not work. Error comes from line {start_index}: \n```\n"
+ + "".join(lines[start_context:end_context])
+ + "```\n"
+ )
# from now on, the `block` means inner blocks unless explicitly specified
indent_str = " " * indent
@@ -593,8 +604,23 @@ def check_codes_match(observed_code: str, theoretical_code: str) -> Optional[int
_re_func_match = re.compile(r"def\s+([^\(]+)\(")
for re_pattern in [_re_class_match, _re_func_match]:
if re_pattern.match(observed_code_header) is not None:
- observed_obj_name = re_pattern.search(observed_code_header).groups()[0]
- theoretical_name = re_pattern.search(theoretical_code_header).groups()[0]
+ try:
+ observed_obj_name = re_pattern.search(observed_code_header).groups()[0]
+ except Exception:
+ raise ValueError(
+ "Tried to split a class or function. It did not work. Error comes from: \n```\n"
+ + observed_code_header
+ + "\n```\n"
+ )
+
+ try:
+ theoretical_name = re_pattern.search(theoretical_code_header).groups()[0]
+ except Exception:
+ raise ValueError(
+ "Tried to split a class or function. It did not work. Error comes from: \n```\n"
+ + theoretical_code_header
+ + "\n```\n"
+ )
theoretical_code_header = theoretical_code_header.replace(theoretical_name, observed_obj_name)
# Find the first diff. Line 0 is special since we need to compare with the function/class names ignored.
diff --git a/utils/not_doctested.txt b/utils/not_doctested.txt
index e5b4cadbd0b416..b57ed3b791b608 100644
--- a/utils/not_doctested.txt
+++ b/utils/not_doctested.txt
@@ -201,6 +201,7 @@ docs/source/en/model_doc/prophetnet.md
docs/source/en/model_doc/pvt.md
docs/source/en/model_doc/qdqbert.md
docs/source/en/model_doc/qwen2.md
+docs/source/en/model_doc/qwen2_moe.md
docs/source/en/model_doc/rag.md
docs/source/en/model_doc/realm.md
docs/source/en/model_doc/reformer.md
@@ -759,6 +760,8 @@ src/transformers/models/qwen2/configuration_qwen2.py
src/transformers/models/qwen2/modeling_qwen2.py
src/transformers/models/qwen2/tokenization_qwen2.py
src/transformers/models/qwen2/tokenization_qwen2_fast.py
+src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
+src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
src/transformers/models/rag/configuration_rag.py
src/transformers/models/rag/modeling_rag.py
src/transformers/models/rag/modeling_tf_rag.py