面试题整理 #22
Comments
数据转换1、 实现一个函数筛选出客户1290所有的消费数据:即将下面的数据data转换成push输出 原数据 转换后 |
|
答案: |
CSS盒模型
BFChttps://blog.csdn.net/sinat_36422236/article/details/88763187 BFC是什么BFC(Block formatting context)直译为"块级格式化上下文"。它是一个独立的渲染区域,只有Block-level box参与, 它规定了内部的Block-level Box如何布局,并且与这个区域外部毫不相干。 利用BFC避免margin重叠。<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>防止margin重叠</title>
</head>
<style>
*{
margin: 0;
padding: 0;
}
p {
color: #f55;
background: yellow;
width: 200px;
line-height: 100px;
text-align:center;
margin: 30px;
}
div{
overflow: hidden; /* 为了构造成两个BFC,这样margin就不会重叠了*/
}
</style>
<body>
<p>�看看我的 margin是多少</p>
<div>
<p>�看看我的 margin是多少</p>
</div>
</body>
</html>解决float重叠为了解决float浮动重叠,BFC的区域不会与float box重叠。 .right {
overflow: hidden;
height: 300px;
background: rgb(170, 54, 236);
text-align: center;
line-height: 300px;
font-size: 40px;
}清除浮动计算BFC的高度时,浮动元素也参与计算。 .par {
border: 5px solid rgb(91, 243, 30);
width: 300px;
overflow: hidden;
}
.child {
border: 5px solid rgb(233, 250, 84);
width:100px;
height: 100px;
float: left;
}水平垂直居中行内元素CSS设置行内元素的垂直居中
div{height:30px; line-height:30px} /*DIV内的行内元素均会垂直居中*/
PS:当然,如果既要水平居中又要垂直居中,那么综合一下
div{text-align:center; height:30px; line-height:30px}
垂直居中:vertical-align: middle;
水平居中:text-align:center;块级元素两列、三列布局两列: <!--左右侧栏的位置可以更更改-->
<div id="left"></div>
<div id="right"></div>
<!--中间栏放最后-->
<div id="main"></div>
*{
margin:0;
padding:0;
height:100%;
}
#left{
width:300px;
background-color:yellow;
float:left;
}
#right{
width:200px;
background-color:orange;
float:right;
}
#main{
background-color:aqua;
margin-left:300px;
margin-right:200px;
}4 flexbox #box{
height: 500px;
padding: 0;
margin: 0;
display: flex;
}
#left{
background: yellow;
order: 1;
flex: 20%;
} #content{
flex:3 1 60%;
background: blue;
order: 2;
} #right{
flex: 20%;
background: red;
order: 3;
}两栏等高 移动端适配(css函数)查看桌面文件 1px问题从第一部分的讨论可知 viewport 的 initial-scale 具有缩放页面的效果。对于 dpr=2 的屏幕,1px压缩一半便可与1px的设备像素比匹配,这就可以通过将缩放比 initial-scale 设置为 0.5=1/2 而实现。以此类推 dpr=3的屏幕可以将 initial-scale设置为 0.33=1/3 来实现。 动画@Keyframe:https://www.runoob.com/cssref/css3-pr-animation-keyframes.html css3特性@function () {@return .... 继承样式 @@mixin textrow($row : 1) {
overflow: hidden;
text-overflow: ellipsis;
display: -webkit-box;
-webkit-line-clamp: $row;
-webkit-box-orient: vertical;
}flex: 0 1 auto是什么意思首先明确一点是, flex 是 flex-grow、flex-shrink、flex-basis的缩写。 flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。 flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。 flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。 回流重绘 |
webpackwebpack dev实时预览Webpack 在启动时可以开启监听模式,开启监听模式后 Webpack 会监听本地文件系统的变化,发生变化时重新构建出新的结果。Webpack 默认是关闭监听模式的,你可以在启动 Webpack 时通过 webpack --watch 来开启监听模式。通过 DevServer 启动的 Webpack 会开启监听模式,当发生变化时重新执行完构建后通知 DevServer。 DevServer 会让 Webpack 在构建出的 JavaScript 代码里注入一个代理客户端用于控制网页,网页和 DevServer 之间通过 WebSocket 协议通信, 以方便 DevServer 主动向客户端发送命令。 DevServer 在收到来自 Webpack 的文件变化通知时通过注入的客户端控制网页刷新。 模块热替换除了通过重新刷新整个网页来实现实时预览,DevServer 还有一种被称作模块热替换的刷新技术。 模块热替换能做到在不重新加载整个网页的情况下,通过将被更新过的模块替换老的模块,再重新执行一次来实现实时预览。 模块热替换相对于默认的刷新机制能提供更快的响应和更好的开发体验。 模块热替换默认是关闭的,要开启模块热替换,你只需在启动 DevServer 时带上 --hot 参数,重启 DevServer 后再去更新文件就能体验到模块热替换的神奇了。 支持 Source Maphttps://webpack.wuhaolin.cn/1%E5%85%A5%E9%97%A8/1-6%E4%BD%BF%E7%94%A8DevServer.html webpack 优化webpack tree-shakingES6 module 特点:
我们已经知道,想要使用 tree shaking 必须注意以下…… 使用 ES2015 模块语法(即 import 和 export)。 在项目 package.json 文件中,添加一个 "sideEffects" 属性。 通过将 mode 选项设置为 production,启用 minification(代码压缩) 和 tree shaking。
CDN 加速https://webpack.wuhaolin.cn/4%E4%BC%98%E5%8C%96/4-9CDN%E5%8A%A0%E9%80%9F.html 按需加载查看webpack4优化配置
const HotList = React.lazy(() => import(/* webpackChunkName: "index-page" */ '../../components/hotList'));
压缩代码查看webpack4优化配置 webpack异步加载(动态导入)https://juejin.im/post/5d26e7d1518825290726f67a 多页面打包autoWebPlugin source-map6.cheap-module-eval-source-map: 常用于开发环境,使用 cheap 模式可以大幅提高 souremap 生成的效率,加上 module 同时会对引入的库做映射,eval 提高打包构建速度,并且不会产生 .map 文件减少网络请求。 凡是带 eval 的模式都不能用于生产环境,因为其不会产生 .map 文件,会导致打包后的文件变得非常大。通常我们并不关心列信息,所以都会使用 cheap 模式,但是我们也还是需要对第三方库做映射,以便精准找到错误的位置。 抽取公共代码splitChunks 多线程thread-loader 在 worker 池(worker pool)中运行的 loader 是受到限制的。例如: 这些 loader 不能产生新的文件。 // threadLoader文件
const threadLoader = workerParallelJobs => {
const options = { workerParallelJobs }
if (constants.APP_ENV === 'dev') {
Object.assign(options, { poolTimeout: Infinity })
}
return { loader: 'thread-loader', options }
}
// 配置文件
module.exports = [
{
test: /\.svg$/,
loader: [cacheLoader, threadLoader(), '@svgr/webpack'],
include: [resolve('src')]
}
]缓存loadercache-loader HappyPackHappyPack 允许 Webpack 使用 Node 多线程进行构建来提升构建的速度。 new HappyPack({
id: 'jsx',
threads: 4,
loaders: ['babel-loader?presets[]=react,presets[]=latest&compact=false'],
})其中,threads 指明 HappyPack 使用多少子进程来进行编译,一般设置为 4 为最佳。 完整版配置const path = require("path");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");//css分离打包
const UglifyJsPlugin = require("uglifyjs-webpack-plugin");//js压缩
const OptimizeCSSAssetsPlugin = require("optimize-css-assets-webpack-plugin"); //css压缩
const createHtml =require("./config/create-html");// html配置
const getEntry = require("./config/get-entry");
const entry = getEntry("./src/pages");
const htmlArr = createHtml("./src/pages");
//主配置
module.exports = (env, argv) => ({
entry: entry,
output: {
path: path.join(__dirname, "build"),
filename: "[name].js"
},
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: {
loader:"babel-loader",
options:{
presets: [ //presets 属性告诉 Babel 要转换的源码使用了哪些新的语法特性,一个 Presets 对一组新语法特性提供支持,多个 Presets 可以叠加。 Presets 其实是一组 Plugins 的集合,每一个 Plugin 完成一个新语法的转换工作。
"@babel/preset-env",
"@babel/preset-react",
{"plugins": ["@babel/plugin-proposal-class-properties"]} //这句很重要 不然箭头函数出错
],
}
},
},
{
test: /\.css$/,
use: ["style-loader", "css-loader"],
exclude: /node_modules/,
},
{
test: /\.(scss|css)$/, //css打包 路径在plugins里
use: [
argv.mode == "development" ? { loader: "style-loader"} :MiniCssExtractPlugin.loader,
{ loader: "css-loader", options: { url: false, sourceMap: true } },
{ loader: "sass-loader", options: { sourceMap: true } }
],
exclude: /node_modules/,
},
{
test: /\.(png|jpg)$/,
loader: 'url-loader?limit=8192&name=images/[hash:8].[name].[ext]',
options:{
publicPath:'/'
}
},
],
},
devServer: {
port: 3100,
open: true,
},
resolve:{
alias:{optimization
src:path.resolve(__dirname,"src/"),
component:path.resolve(__dirname,"src/component/"),
store:path.resolve(__dirname,"src/store/"),
}
},
plugins: [
...htmlArr, // html插件数组
new MiniCssExtractPlugin({ //分离css插件
filename: "[name].css",
chunkFilename: "[id].css"
})
],
optimization: {
minimizer: [//压缩js
new UglifyJsPlugin({
cache: true,
parallel: true,
sourceMap: false
}),
new OptimizeCSSAssetsPlugin({})
],
splitChunks: { //压缩css
cacheGroups: {
styles: {
name: "styles",
test: /\.css$/,
chunks: "all",
enforce: true
}
}
}
}
});webpack工作原理https://juejin.im/post/5ec169786fb9a043721b46ad#heading-3 webpack plugin编写:https://webpack.wuhaolin.cn/5%E5%8E%9F%E7%90%86/5-4%E7%BC%96%E5%86%99Plugin.html 流程概括Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。 bundle.js 能直接运行在浏览器中的原因在于输出的文件中通过 webpack_require 函数定义了一个可以在浏览器中执行的加载函数来模拟 Node.js 中的 require 语句。 模块化历程https://www.processon.com/view/link/5c8409bbe4b02b2ce492286a#map webpack打包原理 |
算法深度优先遍历// 递归
function deepTraversal(node,nodeList) {
if (node) {
nodeList.push(node);
var children = node.children;
for (var i = 0; i < children.length; i++) {
deepTraversal(children[i],nodeList);
}
return nodeList;
}
}
// 非递归
function deepTraversal(node) {
var nodeList = [];
if (node) {
var stack = [];
stack.push(node);
while (stack.length != 0) {
var childrenItem = stack.pop();
nodeList.push(childrenItem);
var childrenList = childrenItem.children;
for (var i = childrenList.length - 1; i >= 0; i--)
stack.push(childrenList[i]);
}
}
return nodeList;
}
var root = document.getElementById('root')
console.log(deepTraversal(root))广度优先遍历//
function wideTraversal(node) {
var nodes = [];
if (node != null) {
var queue = [];
queue.unshift(node);
while (queue.length != 0) {
var item = queue.shift();
nodes.push(item);
var children = item.children;
for (var i = 0; i < children.length; i++)
queue.push(children[i]);
}
}
return nodes;
}
var root = document.getElementById('root');
console.log(wideTraversal(root)); var nodes = {
node: 6,
left: {
node: 5,
left: {
node: 4
},
right: {
node: 3
}
},
right: {
node: 2,
right: {
node: 1
}
}
}
function BFS(node, nodeList, stack) {
if(node) {
if (nodeList.length === 0) {
nodeList.push(node.node);
}
if(node.left) {
stack.unshift(node.left)
nodeList.push(node.left.node);
}
if(node.right) {
stack.unshift(node.right)
nodeList.push(node.right.node);
}
node = stack.pop()
BFS(node, nodeList, stack)
}
return nodeList;
}
let res = BFS(nodes, [], [])setlet a = new Set([1, 2, 3]);
let b = new Set([4, 3, 2]);
// 并集
let union = new Set([...a, ...b]);
// Set {1, 2, 3, 4}
// 交集
let intersect = new Set([...a].filter(x => b.has(x)));
// set {2, 3}
// 差集
let difference = new Set([...a].filter(x => !b.has(x)));
// Set {1}二叉树路径总和https://leetcode-cn.com/problems/path-sum/solution/javascript-di-gui-die-dai-by-guyuejiajie/ /**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {number} sum
* @return {boolean}
*/
var hasPathSum = function(root, sum) {
if (root === null) return false;
if (root.left === null && root.right === null && root.val === sum)
return true;
let left = hasPathSum(root.left, sum - root.val);
let right = hasPathSum(root.right, sum - root.val);
return left || right;
};/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {number} sum
* @return {boolean}
*/
var hasPathSum = function(root, sum) {
if (root === null) return false;
let stack = [root];
let sumStack = [sum - root.val];
while (stack.length > 0) {
let node = stack.pop();
let curSum = sumStack.pop();
if (node.left === null && node.right === null && curSum === 0) {
return true;
}
if (node.right !== null) {
stack.push(node.right);
sumStack.push(curSum - node.right.val);
}
if (node.left !== null) {
stack.push(node.left);
sumStack.push(curSum - node.left.val);
}
}
return false;
}反转链表/*function ListNode(x){
this.val = x;
this.next = null;
}*/
function ReverseList(pHead) {
var node=pHead, arr=[];
while(node!=null){
arr.push(node.val);
node=node.next;
}
node = pHead;
while(node!=null){
node.val = arr.pop();
node = node.next;
}
return pHead;
}数组里的两数的和var twoSum = function(nums, target) {
let map = {};//key数字 value下标
let loop = 0;//循环次数
let dis;//目标与当前值的差
while(loop < nums.length){
dis = target - nums[loop];
if(map[dis] != undefined){
return [map[dis], loop];
}
map[nums[loop]] = loop;
loop++;
}
return;
};将数组扁平化并去除其中重复数据,最终得到一个升序且不重复的数组已知如下数组: Array.from(new Set(arr.flat(Infinity))).sort((a,b)=>{ return a-b})Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)。
Set本身是一个构造函数,用来生成 Set 数据结构。 Set.prototype.constructor:构造函数,默认就是Set函数。 Set.prototype.add(value):添加某个值,返回 Set 结构本身。
const map = new Map([
['name', '张三'],
['title', 'Author']
]);
map.size // 2
map.has('name') // true
map.get('name') // "张三"
map.has('title') // true
map.get('title') // "Author"链表环结点 ???二分查找https://segmentfault.com/a/1190000008584438 function bsearch(array, low, high, target) {
if(low > high ) return -1;
var mid = Math.floor((low + hight)/2)
if (array[mid]> target){
return bsearch(array, low, mid -1, target);
} else if (array[mid]< target){
return bsearch(array, mid+1, high, target);
} else {return mid;}
}// 用二分查找法找寻下界
function BSearchUpperBound(array, low, high, target) {
if(low > high || target < array[low]) return -1;
var mid = Math.floor((low + high) / 2);
while (high > low) {
if(array[mid] > target) {
high = mid;
} else {
low = mid + 1;
}
mid = Math.floor((low+high)/2);
}
return mid-1
}合并两个有序链表/*function ListNode(x){
this.val = x;
this.next = null;
}*/
function Merge(pHead1, pHead2) {
// write code here
if (pHead1 == null) {
return pHead2;
} else if (pHead2 == null) {
return pHead1;
}
var result = {};
if (pHead1.val < pHead2.val) {
result = pHead1;
result.next = Merge(pHead1.next, pHead2);
} else {
result = pHead2;
result.next = Merge(pHead1, pHead2.next);
}
return result;
}二叉树镜像/* function TreeNode(x) {
this.val = x;
this.left = null;
this.right = null;
} */
function Mirror(root)
{
// write code here
if(root === null) {
return;
}
var temp = root.left;
root.left = root.right;
root.right = temp;
Mirror(root.left);
Mirror(root.right);
}二叉树前中后遍历https://juejin.im/entry/5847c17a128fe10058bcf2c5
// 前序遍历
var preListRec = []; //定义保存先序遍历结果的数组
var preOrderRec = function(node) {
if (node) { //判断二叉树是否为空
preListRec.push(node.value); //将结点的值存入数组中
preOrderRec(node.left); //递归遍历左子树
preOrderRec(node.right); //递归遍历右子树
}
}
preOrderRec(tree);
console.log(preListRec);// 前序遍历 非递归
var preListUnRec = []; //定义保存先序遍历结果的数组
var preOrderUnRecursion = function(node) {
if (node) { //判断二叉树是否为空
var stack = [node]; //将二叉树压入栈
while (stack.length !== 0) { //如果栈不为空,则循环遍历
node = stack.pop(); //从栈中取出一个结点
preListUnRec.push(node.value); //将取出结点的值存入数组中
if (node.right) stack.push(node.right); //如果存在右子树,将右子树压入栈
if (node.left) stack.push(node.left); //如果存在左子树,将左子树压入栈
}
}
}
preOrderUnRecursion(tree);
console.log(preListUnRec);// 中序遍历
var inListRec = []; //定义保存中序遍历结果的数组
var inOrderRec = function(node) {
if (node) { //判断二叉树是否为空
inOrderRec(node.left); //递归遍历左子树
inListRec.push(node.value); //将结点的值存入数组中
inOrderRec(node.right); //递归遍历右子树
}
}
inOrderRec(tree);
console.log(inListRec);
//[ 'a', '+', 'b', '*', 'c', '-', 'd', '/', 'e' ]// 后序遍历
var postListRec = []; //定义保存后序遍历结果的数组
var postOrderRec = function(node) {
if (node) { //判断二叉树是否为空
postOrderRec(node.left); //递归遍历左子树
postOrderRec(node.right); //递归遍历右子树
postListRec.push(node.value); //将结点的值存入数组中
}
}
postOrderRec(tree);
console.log(postListRec);
//[ 'a', 'b', 'c', '*', '+', 'd', 'e', '/', '-' ]二叉树深度 2var maxDepth = function(root) {
if (!root) return 0;
else {
let leftDepth = maxDepth(root.left),
rightDepth = maxDepth(root.right);
let childDepth = leftDepth > rightDepth ? leftDepth : rightDepth;
return childDepth + 1;
}
};最长公共子序列 2 ???删除链表中重复结点 2 ???链表表示大数求和 2 ???function addTwoNumbers(l1, l2) {
let res;
let temp; // 当前的节点
let isMoreThan10 = false;
while (l1 && l2) { // 两个链表公共部分
const sum = l1.val + l2.val;
const r = sum % 10;
if (temp) {
// 一边创建一边取下一个
temp.next = new ListNode();
temp = temp.next;
}
if (!res) {
// 第一次进来
res = new ListNode(r);
temp = res;
}
// 所有的加法操作都要这样
temp.val = (r + isMoreThan10) % 10;
isMoreThan10 = sum + isMoreThan10 > 9;
l1 = l1.next;
l2 = l2.next;
}
// 剩下那段
let rest = l1 || l2;
while (rest) {
temp.next = rest;
temp = temp.next;
if (isMoreThan10) {
isMoreThan10 = temp.val + 1 > 9;
temp.val = (temp.val + 1) % 10;
}
rest = rest.next;
}
// 如果还有进位,追加一个1
if (isMoreThan10) {
temp.next = new ListNode(1);
}
return res;
}二叉树的最近公共祖先https://leetcode-cn.com/problems/er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof/ var lowestCommonAncestor = function(root, p, q) {
if (!root || root === p || root === q) return root;
const left = lowestCommonAncestor(root.left, p, q);
const right = lowestCommonAncestor(root.right, p, q);
if (!left) return right; // 左子树找不到,返回右子树
if (!right) return left; // 右子树找不到,返回左子树
return root;
};复杂度分析 二叉树同行输出/* function TreeNode(x) {
this.val = x;
this.left = null;
this.right = null;
} */
function Print(pRoot)
{
if(!pRoot){
return [];
}
var queue = [],
result = [];
queue.push(pRoot);
while(queue.length){
var len = queue.length;
var tempArr = [];
for(var i = 0;i<len;i++){
var temp = queue.shift();
tempArr.push(temp.val);
if(temp.left){
queue.push(temp.left);
}
if(temp.right){
queue.push(temp.right);
}
}
result.push(tempArr);
}
return result;
}function Print(pRoot)
{
// write code here
if(!pRoot) return [];
let list = [];
function depthP(root, depth, list){
if(!root) return;
if(!list[depth]) list[depth] = [];
list[depth].push(root.val);
depthP(root.left, depth+1, list);
depthP(root.right, depth+1, list);
}
depthP(pRoot, 0, list);
return list
}LRU ???跳台阶和变态跳台阶https://www.nowcoder.com/profile/2902658/codeBookDetail?submissionId=32971873 function jumpFloor(number)
{
if (number < 2) {
return 1
}
let arr = [1, 1]
for (let i = 2; i <= number; i ++) {
arr[i] = arr[i - 1] + arr[i - 2]
}
return arr[number]
}https://www.nowcoder.com/profile/291358634/codeBookDetail?submissionId=77010415 function jumpFloorII(number)
{
// write code here
if(number===0){
return 0;
}
if(number===1){
return 1
}
if(number>=2){
return 2*jumpFloorII(number-1);
}
}之字形打印二叉树与同行类似,加个flag就行 数组扁平化function flatten(arr) {
return arr.reduce((result, item)=> {
return result.concat(Array.isArray(item) ? flatten(item) : item);
}, []);
}快速排序var quickSort = function(arr) {
if (arr.length <= 1) { return arr; }
var pivotIndex = Math.floor(arr.length / 2);
var pivot = arr.splice(pivotIndex, 1)[0];
var left = [];
var right = [];
for (var i = 0; i < arr.length; i++){
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot], quickSort(right));
}; |
js基础一 继承1 原型链继承
Cat.prototype = new Animal();
Cat.prototype.constructor = Cat;
var cat1 = new Cat('大毛', '黄色');
alert(cat1.species);2 类式继承class P {
constructor (height) {
this.height = height;
}
fn() {
}
}
class Sun extends P {
constructor(length) {
super(length);
// 如果子类中存在构造函数,则需要在使用“this”之前首先调用 super()。
this.name = 'Square';
}
}extends核心代码 function _inherits(subType, superType) {
// 创建对象,创建父类原型的一个副本
// 增强对象,弥补因重写原型而失去的默认的constructor属性
// 指定对象,将新创建的对象赋值给子类的原型
subType.prototype = Object.create(superType && superType.prototype, {
constructor: {
value: subType,
enumerable: false,
writable: true,
configurable: true
}
})
if (superType) {
Object.setPrototypeOf
? Object.setPrototypeOf(subType, superType)
: subType.__proto__ = superType;
}
}Object.create(proto[, propertiesObject])
3 借用构造继承,几种组合继承方式使用父类的构造函数来增强子类实例,等同于复制父类的实例给子类(不使用原型) function SuperType(){
this.color=["red","green","blue"];
}
function SubType(){
//继承自SuperType
SuperType.call(this);
}
var instance1 = new SubType();
instance1.color.push("black");
alert(instance1.color);//"red,green,blue,black"
var instance2 = new SubType();
alert(instance2.color);//"red,green,blue"核心代码是SuperType.call(this),创建子类实例时调用SuperType构造函数,于是SubType的每个实例都会将SuperType中的属性复制一份。
4 组合继承组合上述两种方法就是组合继承。用原型链实现对原型属性和方法的继承,用借用构造函数技术来实现实例属性的继承。 function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
// 继承属性
// 第二次调用SuperType()
SuperType.call(this, name);
this.age = age;
}
// 继承方法
// 构建原型链
// 第一次调用SuperType()
SubType.prototype = new SuperType();
// 重写SubType.prototype的constructor属性,指向自己的构造函数SubType
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //275 三个继承方式的优缺点,优化列出代码基于构造函数的继承,可以执行父类构造函数,不能继承方法 二 fetch取消https://juejin.im/entry/5af85b6f518825426a1fc8c8 var controller = new AbortController();
var signal = controller.signal;
// AbortController兼容性问题
abortBtn.addEventListener('click', function() {
controller.abort();
console.log('Download aborted');
});
function fetchVideo() {
...
fetch(url, {signal}).then(function(response) {
...
}).catch(function(e) {
reports.textContent = 'Download error: ' + e.message;
})
}function wrap (func, ...args) {
const cancel = {};
return () => {
const promiseHandle = new Promise((resolve, reject) => {
Object.defineProperty(cancel, 'signal', {
set () {
reject('Abort');
}
})
func(...args).then(v => resolve(v)).catch(err => reject(err))
});
return Object.assign(promiseHandle, {
cancel () {
cancel.signal = true;
}
});
}
}三 instanceof语法: // a instanceof b
function _instanceof (a, b) {
while (a) {
if (a.__proto__ === b.prototype) return true;
a = a.__proto__;
}
return false;
}typeof和instanceof的区别 四 .promise封装setstate手写promise then方法里,判断this.state的状态,并return的promise,如果是FulFiled和Rejected执行then方法里的参数,如果是值直接返回,function则执行后判断是否是promise再继续返回。如果状态是pending,则把执行then方法里参数的内容push到一个队列中等待resolve后执行。 catch方法里,就是then传入参数(null, OnReject); const PENDING = 1;
const FULFILLED = 2;
const REJECTED = 3;
function MyPromise(executor) {
let self = this;
this.resolveQueue = [];
this.rejectQueue = [];
this.state = PENDING;
this.val = undefined;
function resolve(val) {
if (self.state === PENDING) {
setTimeout(() => {
self.state = FULFILLED;
self.val = val;
self.resolveQueue.forEach(cb => cb(val));
});
}
}
function reject(err) {
if (self.state === PENDING) {
setTimeout(() => {
self.state = REJECTED;
self.val = err;
self.rejectQueue.forEach(cb => cb(err));
});
}
}
try {
// 回调是异步执行 函数是同步执行
executor(resolve, reject);
} catch(err) {
reject(err);
}
}
MyPromise.prototype.then = function(onResolve, onReject) {
let self = this;
// 不传值的话默认是一个返回原值的函数
onResolve = typeof onResolve === 'function' ? onResolve : (v => v);
onReject = typeof onReject === 'function' ? onReject : (e => { throw e });
if (self.state === FULFILLED) {
return new MyPromise(function(resolve, reject) {
setTimeout(() => {
try {
let x = onResolve(self.val);
if (x instanceof MyPromise) {
x.then(resolve);
} else {
resolve(x);
}
} catch(e) {
reject(e);
}
});
});
}
if (self.state === REJECTED) {
return new MyPromise(function(resolve, reject) {
setTimeout(() => {
try {
let x = onReject(self.val);
if (x instanceof MyPromise) {
x.then(resolve);
} else {
resolve(x);
}
} catch(e) {
reject(e);
}
});
});
}
if (self.state === PENDING) {
return new MyPromise(function(resolve, reject) {
self.resolveQueue.push((val) => {
try {
let x = onResolve(val);
if (x instanceof MyPromise) {
x.then(resolve);
} else {
resolve(x);
}
} catch(e) {
reject(e);
}
});
self.rejectQueue.push((val) => {
try {
let x = onReject(val);
if (x instanceof MyPromise) {
x.then(resolve);
} else {
resolve(x);
}
} catch(e) {
reject(e);
}
});
});
}
}
MyPromise.prototype.catch = function(onReject) {
return this.then(null, onReject);
}all方法, 有一个计数变量用于记录已经执行完的promise,还有一个存储执行的promise结果的数组,当变量达到promise.length,则执行resolve返回结果数组;如果出现err,则直接reject; MyPromise.prototype.all = function (promises) {
return new MyPromise(function(resolve, reject) => {
let cnt = 0;
let res = [];
for(let i = 0; i< promises.length; i++) {
promises[i].then(res => {
result[i] = res;
if (++cnt === promises.length) resolve(result);
}, err => reject(err))
}
})
}
MyPromise.prototype.race = function(promises) {
return new MyPromise(function(resolve, reject) {
for (let i = 0; i < promises.length; i++) {
promises[i].then(resolve, reject);
}
});
}
MyPromise.prototype.resolve = function(val) {
return new MyPromise(function(resolve, reject) {
resolve(val);
});
}
MyPromise.reject = function(err) {
return new MyPromise(function(resolve, reject) {
reject(err);
})
}promise化setState function promiseSetState(state, callback) {
var _this = this;
return new Promise((resolve, reject) => {
_this.setState(state, () => {
callback();
resolve();
})
})
}promise.prototype.retry(函数名,次数,delay时长(ms)) retry = function(fn, times,delay) {
var err = null;
retrun new Promise((resolve, reject) => {
var attempt = function() {
fn().then(resolve).catch((err) => {
console.log(`Attempt #${times} failed`);
if (0 == times) {
reject(err);
} else {
times--;
setTimeout(function(){
attempt()
}, delay);
}
})
}
attempt();
})
}五 实现一个newfunction _new(func, ...args) {
if(typeof func !== 'function') {
return new Error('参数必须是一个函数');
}
let obj = Object.create(func.prototype); // 返回值:一个新对象,带着指定的原型对象和属性(也就是func.ptototype)。
let res = func.call(obj, ...args);
if (res !== null && (typeof res === 'object' || typeof res === 'function')) {
return res;
}
return obj;
}为什么执行func.call(obj, ...args)?是因为func.call(obj, ...args)在obj这个对象作用域下执行func的构造函数,也就是下面的函数: function func() {
// some code
this.a = 'a';
// some code
}这样obj作用域下就有了func的属性值。 function fn(){
this.a = 'a'
return 'hello'
}
let f1 = new fn()
f1() // VM1074:1 Uncaught TypeError: f1 is not a function
f1 // fn {a: "a"} !!!!注意不是return的‘hello’而是fn {a: "a"}对象。function fn(){
this.a = 'a'
return {b : 'b'}
}
let f1 = new fn()
f1() // VM1074:1 Uncaught TypeError: f1 is not a function
f1 // {b: "b"}实例没有constructor,实例的constructor都是指向new的构造函数的。 六 手写 bind、call 和 applycall: Function.prototype.call = function(context, ...bindArgs) {
context = (typeof context === 'object' ? context : window)
let key = new Symbol();
context[key] = this;
let result = context[key](...bindArgs);
delete context[key]
return result
}bind: Function.prototype.bind = function(context, ...bindArgs) {
// func为调用bind原函数
const func = this;
context = context || window;
if (typeof func !== 'function') {
throw new TypeError('Bind must be called on a function');
}
// bind 返回一个绑定 this 的函数
return function(...callArgs) {
let args = bindArgs.concat(callArgs);
return func.call(context, ...args);
}
}apply第二个参数为一个数组,call是多个参数: Function.prototype.apply = function(context, args) {
context = context || window;
context.func = this;
if (typeof context.func !== 'function') {
throw new TypeError('apply must be called on a function');
}
let res = context.func(...args);
delete context.func;
return res;
}七 async await、Promise、setTimeout执行顺序队列任务优先级:promise.Trick()>promise的回调>setTimeout>setImmediate 写一个eventEmitter类,包括on()、off()、once()、emit()方法class EventEmitter() {
constructor() {
this._events = {};
}
on(event, callback) {
let callbacks = this._events[event] || [];
this._events[event] = callbacks.push(callback);
return this;
}
off(event, callback) {
let callbacks = this._events[event];
this._events[event] = callbacks && callbacks.filter(fn => {
return fn !== callback;
})
return this;
}
once(event, callback) {
let wrap = (...args) => {
callback.apply(this, arguments);
this.off(event, wrap);
}
this.on(event, wrap);
return this;
}
emit(event, ...args) {
const callbacks = this._events[eventName]
callbacks.map(cb => {
cb(...args)
})
return this;
}
}八、==的隐式转化比较运算 x==y, 其中 x 和 y 是值,返回 true 或者 false。这样的比较按如下方式进行:
1、若 Type(x) 与 Type(y) 相同, 则
1* 若 Type(x) 为 Undefined, 返回 true。
2* 若 Type(x) 为 Null, 返回 true。
3* 若 Type(x) 为 Number, 则
(1)、若 x 为 NaN, 返回 false。
(2)、若 y 为 NaN, 返回 false。
(3)、若 x 与 y 为相等数值, 返回 true。
(4)、若 x 为 +0 且 y 为 −0, 返回 true。
(5)、若 x 为 −0 且 y 为 +0, 返回 true。
(6)、返回 false。
4* 若 Type(x) 为 String, 则当 x 和 y 为完全相同的字符序列(长度相等且相同字符在相同位置)时返回 true。 否则, 返回 false。
5* 若 Type(x) 为 Boolean, 当 x 和 y 为同为 true 或者同为 false 时返回 true。 否则, 返回 false。
6* 当 x 和 y 为引用同一对象时返回 true。否则,返回 false。
2、若 x 为 null 且 y 为 undefined, 返回 true。
3、若 x 为 undefined 且 y 为 null, 返回 true。
4、若 Type(x) 为 Number 且 Type(y) 为 String,返回比较 x == ToNumber(y) 的结果。
5、若 Type(x) 为 String 且 Type(y) 为 Number,返回比较 ToNumber(x) == y 的结果。
6、若 Type(x) 为 Boolean, 返回比较 ToNumber(x) == y 的结果。
7、若 Type(y) 为 Boolean, 返回比较 x == ToNumber(y) 的结果。
8、若 Type(x) 为 String 或 Number,且 Type(y) 为 Object,返回比较 x == ToPrimitive(y) 的结果。
9、若 Type(x) 为 Object 且 Type(y) 为 String 或 Number, 返回比较 ToPrimitive(x) == y 的结果。
10、返回 false。上面主要分为两类,x、y类型相同时,和类型不相同时。 类型相同时,没有类型转换,主要注意NaN不与任何值相等,包括它自己,即NaN !== NaN。 1、x,y 为null、undefined两者中一个 // 返回true 2、x、y为Number和String类型时,则转换为Number类型比较。 3、有Boolean类型时,Boolean转化为Number类型比较。 4、一个Object类型,一个String或Number类型,将Object类型进行原始转换后,按上面流程进行原始值比较。 Obj=》string=》number Bool=》number Undefined=》 九 闭包一个可以操作外部其他函数定义的局部变量的函数 使用闭包的注意点1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。 2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。 var name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
return this.name;
}
};
alert(object.getNameFunc());// My Objectvar name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
return function(){
return this.name;
};
}
};
alert(object.getNameFunc()());
// The Windowvar name = "The Window";
var object = {
name : "My Object",
getNameFunc : function(){
var that = this;
return function(){
return that.name;
};
}
};
alert(object.getNameFunc()());
// My Object十、slice和spliceslice:返回一个新的对象;这一对象是一个由 begin 和 end 决定的原数组的浅拷贝(包括 begin,不包括end)。原始数组不会被改变。如果该参数为负数, 则它表示在原数组中的倒数第几个元素结束抽取。 splice:splice() 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。 const months = ['Jan', 'March', 'April', 'June'];
months.splice(1, 0, 'Feb');
// inserts at index 1
console.log(months);
// expected output: Array ["Jan", "Feb", "March", "April", "June"]
months.splice(4, 1, 'May');
// replaces 1 element at index 4
console.log(months);
// expected output: Array ["Jan", "Feb", "March", "April", "May"]十一、跨域https://juejin.im/post/5c23993de51d457b8c1f4ee1 1 JSONP// index.html
function jsonp({url, params, callback}) {
return new Promise((resolve, reject) => {
let script = document.createElement('script');
window[callback] = function(data) {
resolve(data);
document.body.removeChild(script)
}
let params = {...params, callback};
let arrs = [];
for(let key in params) {
arrs.push(`${key}=${params[key]}`)
}
script.src = `${url}?${arrs.join('&')}`;
document.body.appendChild(script);
})
}
jsonp({
url: 'http://localhost:3000/say',
params: { wd: 'Iloveyou' },
callback: 'show'
}).then(data => {
console.log(data)
})// server.js
let express = require('express');
let app = express();
app.get('/say', function(req, res) {
let { wd, callback} = req.query;
res.end( `${callback}('我不爱你')`);
})jQuery的jsonp形式 $.ajax({
url:"http://crossdomain.com/jsonServerResponse",
dataType:"jsonp",
type:"get",//可以省略
jsonpCallback:"show",//->自定义传递给服务器的函数名,而不是使用jQuery自动生成的,可省略
jsonp:"callback",//->把传递函数名的那个形参callback,可省略
success:function(data) {
console.log(data);
}
});2 CORS浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。 只要同时满足以下两大条件,就属于简单请求。 不符合以上条件的请求就肯定是复杂请求了。 复杂请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求,该请求是 option 方法的,通过该请求来知道服务端是否允许跨域请求。 // index.html
let xhr = new XHLHttpRequest();
document.cookie = 'name=xiamen';
xhr.withCredentials = true;
xhr.open('PUT', 'http://localhost:4000/getData', true);
xhr.setRequestHeader('name', 'xiamen')
xhr.onreadystatechange = function() {
if ((xhr.status >= 200 && xhr.status < 300) || xhr.status === 304) {
console.log(xhr.response)
//得到响应头,后台需设置Access-Control-Expose-Headers
console.log(xhr.getResponseHeader('name'))
}
}
xhr.send();app.use(function(req, res, next) {
let origin = req.headers.origin;
if (whitList.includes(origin)) {
// 设置哪个源可以访问我
res.setHeader('Access-Control-Allow-Origin', origin)
// 允许携带哪个头访问我
res.setHeader('Access-Control-Allow-Headers', 'name')
// 允许哪个方法访问我
res.setHeader('Access-Control-Allow-Methods', 'PUT')
// 允许携带cookie
res.setHeader('Access-Control-Allow-Credentials', true)
// 预检的存活时间
res.setHeader('Access-Control-Max-Age', 6)
// 允许返回的头
res.setHeader('Access-Control-Expose-Headers', 'name')
if (req.method === 'OPTIONS') {
res.end() // OPTIONS请求不做任何处理
}
}
next();
})
app.put('/getData', function(req, res) {
console.log(req.headers)
res.setHeader('name', 'jw') //返回一个响应头,后台需设置
res.end('我不爱你')
})
app.get('/getData', function(req, res) {
console.log(req.headers)
res.end('我不爱你')
})
app.use(express.static(__dirname))
app.listen(4000)上述代码由http://localhost:3000/index.html向http://localhost:4000/跨域请求,正如我们上面所说的,后端是实现 CORS 通信的关键。 3 postMessagepostMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一,它可用于解决以下方面的问题: 页面和其打开的新窗口的数据传递 postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
message: 将要发送到其他 window的数据。 targetOrigin:通过窗口的origin属性来指定哪些窗口能接收到消息事件,其值可以是字符串"*"(表示无限制)或者一个URI。在发送消息的时候,如果目标窗口的协议、主机地址或端口这三者的任意一项不匹配targetOrigin提供的值,那么消息就不会被发送;只有三者完全匹配,消息才会被发送。 transfer(可选):是一串和message 同时传递的 Transferable 对象. 这些对象的所有权将被转移给消息的接收方,而发送一方将不再保有所有权。 //a.html
<iframe src="http://localhost:4000/b.html" frameborder="0" id="frame" onload="load()"></iframe> //等它加载完触发一个事件
//内嵌在http://localhost:3000/a.html
<script>
function load() {
let frame = document.getElementById('frame');
frame.contentWindow.postMessage('woaini', 'http://localhost:4000')// 发送数据
window.onmessage = function(e) {
console.log(e.data)
}
}
</script>// b.html
window.onmessage = function(e) {
console.log(e.data)
e.source.postMessage('我不爱你', e.origin)
}websocket本地文件socket.html向localhost:3000发生数据和接受数据 // socket.html
<script>
let socket = new WebSocket('ws://localhost:3000');
socket.onopen = function() {
socket.send('iu')
}
socket.onmessage = function(e) {
console.log(e.data)
}
</script>// server.js
let express = require('express');
let app = express();
let WebSocket = require('ws');//记得安装ws
let wss = new WebSocket.Server({port: 3000});
wss.on('connection', function(ws) {
wx.on('message', function(data) {
console.log(data);
ws.send('i love iu')
})
})node中间件代理Nginx反向代理Nginx正向代理:正向代理指的是,一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。即,目标服务器在前端设置 十二、事件委托function eventDelegate (parentSelector, targetSelector, events, foo) {
// 触发执行的函数
function triFunction (e) {
// 兼容性处理
var event = e || window.event;
// 获取到目标阶段指向的元素
var target = event.target || event.srcElement;
// 获取到代理事件的函数
var currentTarget = event.currentTarget;
// 处理 matches 的兼容性
if (!Element.prototype.matches) {
Element.prototype.matches =
Element.prototype.matchesSelector ||
Element.prototype.mozMatchesSelector ||
Element.prototype.msMatchesSelector ||
Element.prototype.oMatchesSelector ||
Element.prototype.webkitMatchesSelector ||
function(s) {
var matches = (this.document || this.ownerDocument).querySelectorAll(s),
i = matches.length;
while (--i >= 0 && matches.item(i) !== this) {}
return i > -1;
};
}
// 遍历外层并且匹配
while (target !== currentTarget) {
// 判断是否匹配到我们所需要的元素上
if (target.matches(targetSelector)) {
var sTarget = target;
// 执行绑定的函数,注意 this
foo.call(sTarget, Array.prototype.slice.call(arguments))
}
target = target.parentNode;
}
}
// 如果有多个事件的话需要全部一一绑定事件
events.split('.').forEach(function (evt) {
// 多个父层元素的话也需要一一绑定
Array.prototype.slice.call(document.querySelectorAll(parentSelector)).forEach(function ($p) {
$p.addEventListener(evt, triFunction);
});
});
}十三、tab 页面间通信ZSI2017/blog#10 // one.html
<script>
window.addEventListener("storage",function(ev){
if(ev.key === "message") {
// removeItem 同样触发storage 事件,此时ev.newValue 为空
if(!ev.newValue)
return;
var message = JSON.parse(ev.newValue);
console.log(message);
}
});
function sendMessage(message) {
console.log("exacted sendMessage");
localStorage.setItem('message',message);
localStorage.removeItem("message");
};
document.querySelector('button').onclick = function(){
sendMessage('this is message from A');
}
// 发送消息给B 页面。// second.html
<script>
window.addEventListener("storage",function(ev){
if(ev.key === "message") {
if(!ev.newValue)
return;
var message = ev.newValue;
console.log(message)
// 发送消息给A 页面
sendMessage("message echo from B");
}
});
function sendMessage(message) {
localStorage.setItem('message',JSON.stringify(message));
localStorage.removeItem("message");
}
</script>十四、前端做并发请求控制请实现如下的函数,可以批量请求数据,所有的 URL 地址在 urls 参数中,同时可以通过 max 参数控制请求的并发度,当所有请求结束之后,需要执行 callback 回调函数。发请求的函数可以直接 使用 fetch 即可 function handleFetchQueue(urls, max, callback) {
const urlCount = urls.length;
const requestsQueue = [];
const results = [];
let i = 0;
const handleRequest = (url) => {
const req = fetch(url).then(res => {
const len = results.push(res);
if (len < urlCount && i + 1 < urlCount) {
requestsQueue.shift();
handleRequest(urls[++i])
} else if (len === urlCount) {
'function' === typeof callback && callback(results)
}
}).catch(e => {
results.push(e)
});
if (requestsQueue.push(req) < max) {
handleRequest(urls[++i])
}
};
handleRequest(urls[i])
}十五、节流防抖函数节流: 指定时间间隔内只会执行一次任务; 上文函数节流和函数防抖的实现中,调用fn的时候都是用的fn.apply(this, arguments)调用,而不是fn()直接调用。主要原因是为了fn函数内的this与原本的事件回调函数绑定的this保持一致。 function throttle(fn, interval = 300) {
let canRun = true;
return function () {
if (!canRun) return;
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, interval);
};
}function debounce(fn, interval = 300) {
let timeout = null;
return function () {
clearTimeout(timeout);
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, interval);
};
}十七、实现cohttps://juejin.im/post/5e9e6005e51d4546f70d2777#heading-9 十八、arguments变数组arguments对象不是一个 Array 。它类似于Array,但除了length属性和索引元素之外没有任何Array属性。例如,它没有 pop 方法。但是它可以被转换为一个真正的Array var args = Array.prototype.slice.call(arguments);
var args = [].slice.call(arguments);
// es2015
const args = Array.from(arguments);
const args = [...arguments];十九、获取页面所有img并且下载//一个对象,存储页面图片数量和下载的数量
var monitorObj = {
imgTotal: 0,
imgLoaded: 0
}
//创建a标签,赋予图片对象相关属性,并插入body
var createA = function (obj) {
var a = document.createElement("a");
a.id = obj.id;
a.target = "_blank";//注意:要在新页面打开
a.href = obj.url;
a.download = obj.url;
document.body.appendChild(a);
}
//获取页面的图片
var imgs = document.images;
//创建每个图片对象的对应a标签
for (var i = 0; i < imgs.length;i++){
var obj = {
id: "img_" + i,
url: imgs[i].src
}
//过滤掉不属于这几种类型的图片
if (["JPG", "JPEG", "PNG","GIF"].indexOf(obj.url.substr(obj.url.lastIndexOf(".")+1).toUpperCase()) < 0) {
continue;
}
//这里是为了去掉知乎用户头像的图片,头像大小是50*50
if (imgs[i].width <= 50 || imgs[i].height <= 50) {
continue;
}
//统计图片数量
monitorObj.imgTotal++;
createA(obj);
}
//开始下载图片
for (var i = 0; i < imgs.length; i++) {
if (document.getElementById("img_" + i)) {
//重点:触发a标签的click事件
document.getElementById("img_" + i).click();
monitorObj.imgLoaded++; //统计已下载的图片数量
}
}
console.log("已下载:"+monitorObj.imgLoaded + "/" + monitorObj.imgTotal);二十、 [1,2,3].map(parseInt) 执行结果[1,NaN,NaN] 二十一、如何实现for循环内定时器依次输出123二十二、mixin原理Object.assign 二十三、curry函数实现https://segmentfault.com/a/1190000017064541 function curry(fn) {
var length = fn.length; //获取原函数的参数个数
var args = []; // args存储传入参数
return function curryFn() {
// 将arguments转换成数组
var curryArgs = Array.prototype.slice.call(arguments);
args = args.concat(curryArgs);
if (args.length > length) {
throw new Error('arguments length error')
}
// 存储的参数个数等于原函数参数个数时执行原函数
if (args.length === length) {
return fn.apply(null, args);
}
// 否则继续返回函数
return curryFn;
};
}二十四、js实现依赖注入装饰器 + reflect-metadata 二十五、react setState promise化https://juejin.im/post/59a699fd6fb9a0247d4f5970 this问题https://zhuanlan.zhihu.com/p/37911534 ES6classFoo类的Symbol.iterator方法前有一个星号,表示该方法是一个 Generator 函数。Symbol.iterator方法返回一个Foo类的默认遍历器,for...of循环会自动调用这个遍历器 super 注意,super虽然代表了父类A的构造函数,但是返回的是子类B的实例,即super内部的this指的是B的实例,因此super()在这里相当于A.prototype.constructor.call(this)。 super作为函数时,super()只能用在子类的构造函数之中,用在其他地方就会报错。 class A {
p() {
return 2;
}
}
class B extends A {
constructor() {
super();
console.log(super.p()); // 2
}
}
let b = new B();子类B当中的super.p(),就是将super当作一个对象使用。这时,super在普通方法之中,指向A.prototype,所以super.p()就相当于A.prototype.p()。 副作用 纯函数https://www.jianshu.com/p/5d88a569f6c1 | 和 ||https://www.jianshu.com/p/86b994348a16 懒加载https://juejin.im/post/5b0c3b53f265da09253cbed0 async/await实现深拷贝https://juejin.im/post/5b235b726fb9a00e8a3e4e88
// 只解决date,reg类型,其他的可以自己添加
function deepCopy(obj, hash = new WeakMap()) {
let cloneObj
let Constructor = obj.constructor
switch(Constructor){
case RegExp:
cloneObj = new Constructor(obj)
break
case Date:
cloneObj = new Constructor(obj.getTime())
break
default:
if(hash.has(obj)) return hash.get(obj)
cloneObj = new Constructor()
hash.set(obj, cloneObj)
}
for (let key in obj) {
cloneObj[key] = isObj(obj[key]) ? deepCopy(obj[key], hash) : obj[key];
}
return cloneObj
}
async和deferhttps://juejin.im/entry/5a7ad55ef265da4e81238da9 将连字符串转为驼峰var camelCase = (function () {
var DEFAULT_REGEX = /[-_]+(.)?/g;
function toUpper(match, group1) {
return group1 ? group1.toUpperCase() : '';
}
return function (str, delimiters) {
return str.replace(delimiters ? new RegExp('[' + delimiters + ']+(.)?', 'g') : DEFAULT_REGEX, toUpper);
};
})(); |
nodenode的module和Es6的module
canary中: node eventloopProcess.nextTick,setImmediate 和promise.then 的优先级 在node.js中process.nextTick > Promise.then > setTimeout > setImmediate 从上图中,大致看出node中的事件循环的顺序:
在浏览器中Promise.then > setImmediate > setTimeout > requestAnimationFrame 浏览器和node 事件循环setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})浏览器端运行结果:promise3=>timer1=>promise1=>timer2=>promise2 Node端运行结果分两种情况: 如果是node11版本一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这就跟浏览器端运行一致,最后的结果为timer1=>promise1=>timer2=>promise2 如果是第二个定时器还未在完成队列中,最后的结果为timer1=>promise1=>timer2=>promise2 node事件循环:宏任务=>微任务 koa的原理https://wiki.maoyan.com/display/~ousiwei/Koa function compose (middleware) {
return function (context, next) {
// 记录上一次执行中间件的位置 #
let index = -1
return dispatch(0)
function dispatch (i) {
// 理论上 i 会大于 index,因为每次执行一次都会把 i递增,
// 如果相等或者小于,则说明next()执行了多次
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
// 取到当前的中间件
let fn = middleware[i]
if (i === middleware.length) fn = next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, function next () {
return dispatch(i + 1)
}))
} catch (err) {
return Promise.reject(err)
}
}
}
}koa-body原理koa-body自己的代码其实没几行,先处理一堆参数(大多是传给co-body和formidable用的),然后用type-is这个包(ctx.is函数)判断出请求的数据类型,然后根据不同类型用co-body和formidable来解析,拿到解析结果以后放到body或者files里面,齐活。 使用过的koa2中间件https://chenshenhai.github.io/koa2-note/note/route/koa-router.html const Koa = require('koa');
const fs = require('fs');
const app = new Koa()
const Router = require('koa-router')
let home = new Router()
// 子路由
home.get('/', async (ctx) => {
let html = `
<ul>
<li><a href="/page/helloworld">/page/helloworld</a></li>
<li><a href="/page/404">/page/404</a></li>
</ul>
`
ctx.body = html;
})
// 子路由2
let page = new Router();
page.get('/404', async ( ctx )=>{
ctx.body = '404 page!'
}).get('/helloworld', async ( ctx )=>{
ctx.body = 'helloworld page!'
});
let router = new Router()
router.use('/', home.routes(), home.allowedMethods())
router.use('/page', page.routes(), page.allowedMethods())
// 加载路由中间件
app.use(router.routes()).use(router.allowedMethods())
app.listen(3000, () => {
console.log('[demo] route-use-middleware is starting at port 3000')
})介绍自己写过的中间件进程和线程ruanyifeng.com/blog/2013/04/processes_and_threads.html |
ReactsetState异步同步https://zhuanlan.zhihu.com/p/39512941
react中this.state.count和 {count} = this.state的区别http://www.ptbird.cn/react-hook-usestate-setState.html#menu_index_5 react里的this绑定https://juejin.im/post/5cc7ea71f265da03867e5dda class Logger {
printName(name = 'there') {
this.print(`Hello ${name}`);
}
print(text) {
console.log(text);
}
}
const logger = new Logger();
const { printName } = logger;
printName(); // TypeError: Cannot read property 'print' of undefined上面代码中,printName方法中的this,默认指向Logger类的实例。但是,如果将这个方法提取出来单独使用,this会指向该方法运行时所在的环境(由于 class 内部是严格模式,所以 this 实际指向的是undefined),从而导致找不到print方法而报错。 react生命周期https://www.jianshu.com/p/514fe21b9914 shouldComponentUpdate(nextProps,nextState){
if(nextState.Number == this.state.Number){
return false
}
}
class Child extends Component {
constructor(props) {
super(props);
this.state = {
someThings: props.someThings
};
}
componentWillReceiveProps(nextProps) { // 父组件重传props时就会调用这个方法 在componentWillReceiveProps方法中,将props转换成自己的state 在该函数(componentWillReceiveProps)中调用 this.setState() 将不会引起第二次渲染。
//是因为componentWillReceiveProps中判断props是否变化了,若变化了,this.setState将引起state变化,从而引起render,此时就没必要再做第二次因重传props引起的render了,不然重复做一样的渲染了。
this.setState({someThings: nextProps.someThings});
}
render() {
return <div>{this.state.someThings}</div>
}
}
key diff操作react和vue的区别react和vue的区别 hook用法和原理思想https://zh-hans.reactjs.org/docs/hooks-reference.html#usememo 只在最顶层使用 Hook不要在循环,条件或嵌套函数中调用 Hook, 确保总是在你的 React 函数的最顶层调用他们。遵守这条规则,你就能确保 Hook 在每一次渲染中都按照同样的顺序被调用。这让 React 能够在多次的 useState 和 useEffect 调用之间保持 hook 状态的正确。(如果你对此感到好奇,我们在下面会有更深入的解释。) 只在 React 函数中调用 Hook不要在普通的 JavaScript 函数中调用 Hook。你可以: ✅ 在 React 的函数组件中调用 Hook fiber新旧生命周期(放弃)从Mixin到HOC再到Hookhttps://juejin.im/post/5cad39b3f265da03502b1c0a mixin缺点: function setMixin(target, mixin) {
if (arguments[2]) {
for (var i = 2, len = arguments.length; i < len; i++) {
target.prototype[arguments[i]] = mixin.prototype[arguments[i]];
}
}
else {
for (var methodName in mixin.prototype) {
if (!Object.hasOwnProperty(target.prototype, methodName)) {
target.prototype[methodName] = mixin.prototype[methodName];
}
}
}
}
setMixin(User,LogMixin,'actionLog');
setMixin(Goods,LogMixin,'requestLog');HOC
function stylHOC(wrappedComponent) {
return class extends Component {
render() {
return (
<div>
<div className="title">{this.props.title}</div>
<WrappedComponent {...this.props} />
</div>
)
}
}
}
Mixin 可能会相互依赖,相互耦合,不利于代码维护
高阶组件就是一个没有副作用的纯函数,各个高阶组件不会互相依赖耦合
Hooks// 模拟componentDidUpdate
// componentDidUpdate就相当于除去第一次调用的useEffect,我们可以借助useRef生成一个标识,来记录是否为第一次执行:
function useDidUpdate(callback, prop) {
const init = useRef(true);
useEffect(() => {
if (init.current) {
init.current = false;
} else {
return callback();
}
}, prop);
}
实现tree组件https://exp-team.github.io/blog/2017/04/05/js/react-tree-data/ Redux基本组成和设计单向数据流redux异步 |
浏览器和网络1 浏览器与Node的事件循环(Event Loop)有何区别https://juejin.im/post/5c337ae06fb9a049bc4cd218 进程与线程进程是 CPU资源分配的最小单位;线程是 CPU调度的最小单位 进程好比图中的工厂,有单独的专属自己的工厂资源。 线程好比图中的工人,多个工人在一个工厂中协作工作,工厂与工人是 1:n的关系。也就是说一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线; 工厂的空间是工人们共享的,这象征一个进程的内存空间是共享的,每个线程都可用这些共享内存。 微任务API:queueMicrotask() 方法 。react setstate异步效果实现就是通过queueMicrotask(); 补充Javascript单线程任务被分为同步任务和异步任务,同步任务会在调用栈中按照顺序等待主线程依次执行,异步任务会在异步任务有了结果后,将注册的回调函数放入任务队列中等待主线程空闲的时候(调用栈被清空),被读取到栈内等待主线程的执行。 2 webSocket和Sockethttps://blog.csdn.net/wwd0501/article/details/54582912 网络https://mp.weixin.qq.com/s/baMDhvKQXs7OAQUosfefgg header定长包体:(res/req) 不定长包体:(res/req) Accept-Ranges: none 而对于客户端而言,它需要指定请求哪一部分,通过Range这个请求头字段确定,格式为bytes=x-y。接下来就来讨论一下这个 Range 的书写格式: 0-499表示从开始到第 499 个字节。 // 单段数据 XSS和CSRF[浅说 XSS 和 CSRF · Issue #68 · dwqs/blog · GitHub|https://github.com/dwqs/blog/issues/68] HTTP 中如何处理表单数据的提交?在 http 中,有两种主要的表单提交的方式,体现在两种不同的Content-Type取值: application/x-www-form-urlencoded multipart/form-data 由于表单提交一般是POST请求,很少考虑GET,因此这里我们将默认提交的数据放在请求体中。 HTTP1.1 如何解决 HTTP 的队头阻塞问题HTTP 传输是基于请求-应答的模式进行的,报文必须是一发一收,但值得注意的是,里面的任务被放在一个任务队列中串行执行,一旦队首的请求处理太慢,就会阻塞后面请求的处理。这就是著名的HTTP队头阻塞问题。 Cookie和Sessioncookie生命周期
安全相关如果带上Secure,说明只能通过 HTTPS 传输 cookie。 如果 cookie 字段带上HttpOnly,那么说明只能通过 HTTP 协议传输,不能通过 JS 访问,这也是预防 XSS 攻击的重要手段。
从攻击者角度,根据产生XSS攻击的数据是否是持久存储的,可以分成存储型和反射型 cookie缺点容量缺陷。Cookie 的体积上限只有4KB,只能用来存储少量的信息。 性能缺陷。Cookie 紧跟域名,不管域名下面的某一个地址需不需要这个 Cookie ,请求都会携带上完整的 Cookie,这样随着请求数的增多,其实会造成巨大的性能浪费的,因为请求携带了很多不必要的内容。但可以通过Domain和Path指定作用域来解决。 安全缺陷。由于 Cookie 以纯文本的形式在浏览器和服务器中传递,很容易被非法用户截获,然后进行一系列的篡改,在 Cookie 的有效期内重新发送给服务器,这是相当危险的。另外,在HttpOnly为 false 的情况下,Cookie 信息能直接通过 JS 脚本来读取。 浏览器缓存https://segmentfault.com/a/1190000006741200 1.web缓存原因: 2.缓存器分类:
流程描述: 1)首先浏览器请求的时候会判断浏览器是否有缓存,如果有缓存会判断是否过期(expries和 catch-control的max-age)
跨域浏览器遵循同源政策(scheme(协议)、host(主机)和port(端口)都相同则为同源)。非同源站点有这样一些限制:
WebKit 渲染引擎和V8 引擎都在渲染进程当中。 现在数据传递给了浏览器主进程,主进程接收到后,才真正地发出相应的网络请求。 在服务端处理完数据后,将响应返回,主进程检查到跨域,且没有cors(后面会详细说)响应头,将响应体全部丢掉,并不会发送给渲染进程。这就达到了拦截数据的目的。 HTTP三次握手
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。 完成三次握手,客户端与服务器开始传送数据。这样就保证了,每次传送数据都会准确到达目标设备了。 TCP四次挥手 1.客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。 2.服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。 3.服务器B关闭与客户端A的连接,发送一个FIN给客户端A。 4.客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。 七层协议https://blog.csdn.net/qq_18425655/article/details/52314970 HTTPS加密图解http HTTP2有哪些改进头部压缩 多路复用 当然还有一些颠覆性的功能实现: 设置请求优先级 服务器推送 这些重大的提升本质上也是为了解决 HTTP 本身的问题而产生的。接下来我们来看看 HTTP/2 解决了哪些问题,以及解决方式具体是如何的。 头部压缩:HPACK 算法是专门为 HTTP/2 服务的,它主要的亮点有两个:
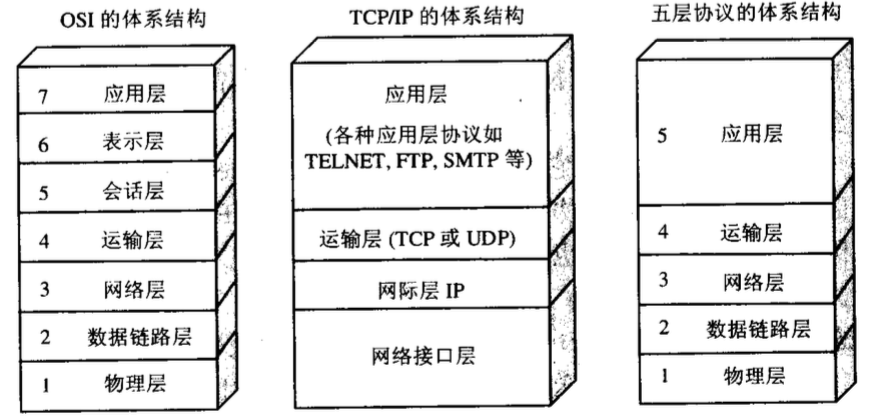
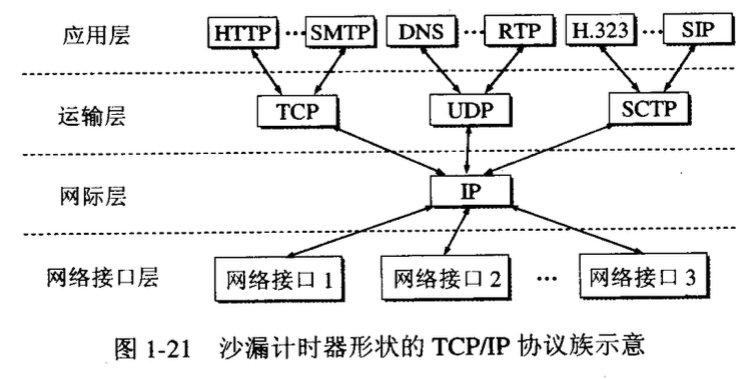
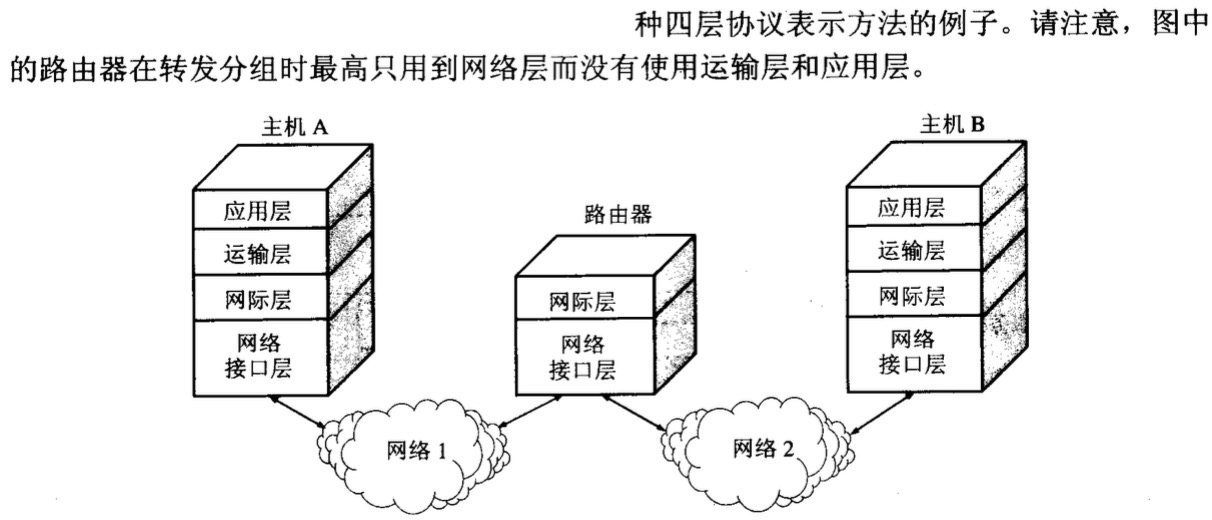
多路复用首先,HTTP/2 认为明文传输对机器而言太麻烦了,不方便计算机的解析,因为对于文本而言会有多义性的字符,比如回车换行到底是内容还是分隔符,在内部需要用到状态机去识别,效率比较低。于是 HTTP/2 干脆把报文全部换成二进制格式,全部传输01串,方便了机器的解析。 原来Headers + Body的报文格式如今被拆分成了一个个二进制的帧,用Headers帧存放头部字段,Data帧存放请求体数据。分帧之后,服务器看到的不再是一个个完整的 HTTP 请求报文,而是一堆乱序的二进制帧。这些二进制帧不存在先后关系,因此也就不会排队等待,也就没有了 HTTP 的队头阻塞问题。 通信双方都可以给对方发送二进制帧,这种二进制帧的双向传输的序列,也叫做流(Stream)。HTTP/2 用流来在一个 TCP 连接上来进行多个数据帧的通信,这就是多路复用的概念。 可能你会有一个疑问,既然是乱序首发,那最后如何来处理这些乱序的数据帧呢? 首先要声明的是,所谓的乱序,指的是不同 ID 的 Stream 是乱序的,但同一个 Stream ID 的帧一定是按顺序传输的。二进制帧到达后对方会将 Stream ID 相同的二进制帧组装成完整的请求报文和响应报文。当然,在二进制帧当中还有其他的一些字段,实现了优先级和流量控制等功能。 输入地址到页面展示经过的步骤(DNS, TCP握手, HTTP服务器) 2.浏览器查找域名的IP地址 3.浏览器发送一个http请求到web服务器(这里还有三次握手) 请求报文:(get和post区别) 4.Facebook服务器回复永久重定向 我们在网站建设中,时常会遇到需要网页重定向的情况: 5.浏览器重定向 6.服务器的处理请求 7.服务器发回一个HTML响应 8.浏览器开始解析HTML文件。 9.浏览器在解析HTML文件的过程中又会碰到一些要求获得的其他URL,如获得HTML的过程一样,将发送get请求获得每一个文件。 10.浏览器发送异步请求(AJAX) |

小程序 + 拓展gpu加速当发生座位图动画时,需要在动画结束时开启gpu加速,启用gpu加速,解决座位图放大后,ios设备锁屏开屏选座,选座图片不展示问题; <view bindtransitionend="setOrigin"></view>
setOrigin() {
this.setData({ allowScroll: true });
// 必须要分两步,因为要先设置可滑动,之后才能够scroll,如果写在一起会导致滑动不生效;
setTimeout(() => {
this.setState({
gpuSpeed: true, // 启用gpu加速,解决座位图放大后,ios设备锁屏开屏选座,选座图片不展示问题
})
}, 50)
}
... ...
function hanleScale() {
... ...
// gpu加速先关掉再运行动画,不然会闪烁
context.setData({ gpuSpeed: false }, () => {
context.setData({
scaleFrom: scaleInfo.scaleTo,
scaleInfo,
allowScroll,
originX,
originY,
});
});
} |
Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件。 Java被设计成允许应用程序可以运行在任意的语言,而不需要程序员为每一个平台单独重写或者是重新编译。Java虚拟机让这个变为可能,因为它知道底层硬件平台的指令长度和其他特性。各个平台只要安装了Java虚拟机,即可运行Java程序。 Java运行时环境(JRE)是将要执行Java程序的Java虚拟机。它同时也包含了执行applet需要的浏览器插件。 “static”关键字表明一个变量或者方法,属于类而不是实例,可以在没有所属的类的实例的情况下被访问。 Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。 static变量在Java中是属于类的,它在所有的实例中的值是一样的。当类被Java虚拟机载入的时候,会对static变量进行初始化。如果你的代码尝试不用实例来访问非static的变量,编译器会报错,因为这些变量还没有被创建出来,还没有跟任何实例关联上。 Java语言支持的8中基本数据类型是:
一个字节等于8个bit。 自动装箱是Java编译器在基本数据类型和对应的对象包装类型之间做的一个转化。比如:把int转化成Integer,double转化成double,等等。反之就是自动拆箱。
扩展:请列举Java集合类!
扩展:HashMap原理(面试重点):https://blog.csdn.net/zyjtoto/article/details/94174588
|
pythonhttps://zhuanlan.zhihu.com/p/41199930 深拷贝和浅拷贝之间的区别是什么?答:深拷贝就是将一个对象拷贝到另一个对象中,这意味着如果你对一个对象的拷贝做出改变时,不会影响原对象。在Python中,我们使用函数deepcopy()执行深拷贝,导入模块copy,如下所示: >>> import copy
>>> b=copy.deepcopy(a)
而浅拷贝则是将一个对象的引用拷贝到另一个对象上,所以如果我们在拷贝中改动,会影响到原对象。我们使用函数function()执行浅拷贝,使用如下所示: >>> b=copy.copy(a)
列表和元组之间的区别是?答:二者的主要区别是列表是可变的,而元组是不可变的。举个例子,如下所示: >>> mylist=[1,3,3]
>>> mylist[1]=2
>>> mytuple=(1,3,3)
>>> mytuple[1]=2
Traceback (most recent call last):
File "<pyshell#97>", line 1, in <module>
mytuple[1]=2会出现以下报错: TypeError: ‘tuple’ object does not support item assignment关于列表和元组的更多内容,可以查看这里: https://data-flair.training/blogs/python-tuples-vs-lists/ 解释一下Python中的三元运算子不像C++,我们在Python中没有?:,但我们有这个: [on true] if [expression] else [on false]
如果表达式为True,就执行[on true]中的语句。否则,就执行[on false]中的语句。 下面是使用它的方法: >>> a,b=2,3
>>> min=a if a<b else b
>>> min运行结果: 2
>>> print("Hi") if a<b else print("Bye")运行结果: Hi在Python中如何实现多线程?一个线程就是一个轻量级进程,多线程能让我们一次执行多个线程。我们都知道,Python是多线程语言,其内置有多线程工具包。 Python中的GIL(全局解释器锁)确保一次执行单个线程。一个线程保存GIL并在将其传递给下个线程之前执行一些操作,这会让我们产生并行运行的错觉。但实际上,只是线程在CPU上轮流运行。当然,所有的传递会增加程序执行的内存压力。 解释一下Python中的继承当一个类继承自另一个类,它就被称为一个子类/派生类,继承自父类/基类/超类。它会继承/获取所有类成员(属性和方法)。 继承能让我们重新使用代码,也能更容易的创建和维护应用。Python支持如下种类的继承: 单继承:一个类继承自单个基类 https://data-flair.training/blogs/python-inheritance/ Python中的字典是什么?字典是C++和Java等编程语言中所没有的东西,它具有键值对。 >>> roots={25:5,16:4,9:3,4:2,1:1}
>>> type(roots)
<class 'dict'>
>>> roots[9]运行结果为: 3字典是不可变的,我们也能用一个推导式来创建它。 >>> roots={x**2:x for x in range(5,0,-1)}
>>> roots运行结果: {25: 5, 16: 4, 9: 3, 4: 2, 1: 1}请解释使用*args和**kwargs的含义当我们不知道向函数传递多少参数时,比如我们向传递一个列表或元组,我们就使用*args。 >>> def func(*args):
for i in args:
print(i)
>>> func(3,2,1,4,7)运行结果为: 3
2
1
4
7在我们不知道该传递多少关键字参数时,使用**kwargs来收集关键字参数。 >>> def func(**kwargs):
for i in kwargs:
print(i,kwargs[i])
>>> func(a=1,b=2,c=7)运行结果为: a.1
b.2
c.7请写一个Python逻辑,计算一个文件中的大写字母数量>>> import os
>>> os.chdir('C:\\Users\\lifei\\Desktop')
>>> with open('Today.txt') as today:
count=0
for i in today.read():
if i.isupper():
count+=1
print(count)运行结果: 26 |


5种方式实现值交换
var temp = a; a = b; b = temp; (传统,但需要借助临时变量)
a ^= b; b ^= a; a ^= b; (需要两个整数)
b = [a, a = b][0] (借助数组)
[a, b] = [b, a]; (ES6,解构赋值)
a = a + b; b = a - b; a = a - b; (小学奥赛题)
5种方式去掉小数部分
2,3,4种方法是对位进行操作,故数字大小范围限制更大,在 正负2的31次方(2,147,483,648) 之间
parseInt(num)
~~num
num >> 0
num | 0
Math.floor(num) //或ceil等
判断 x 是否是整数
function isInt(x) {
return (x ^ 0) === x
}
// return Math.round(x) === x
// return (typeof x === 'number') && (x % 1 === 0)
// ES6 -> Number.isInteger()
递归求阶乘
function factorial(n) {
return (n > 1) ? n * f(n - 1) : n
}
判断符号是否相同
function sameSign(a, b) {
return (a ^ b) >= 0
}
克隆数组
arr.slice(0)
数组去重
// ES6
Array.from(new Set(arr))
// ES5
arr.filter(function(ele, index, array){
return index===array.indexOf(ele)
})
数组最大值
function maxArr(arr) {
return Math.max.apply(null, arr)
}
数组最小值
function minArr(arr) {
return Math.min.apply(null, arr)
}
随机获取数组的一个成员
function randomOne(arr) {
return arr[Math.floor(Math.random() * arr.length)]
}
产生随机颜色
function getRandomColor() {
return
#${Math.random().toString(16).substr(2, 6)}}
随机生成指定长度的字符串
function randomStr(n) {
let standard = 'abcdefghijklmnopqrstuvwxyz9876543210'
let len = standard.length
let result = ''
for (let i = 0; i < n; i++) {
result += standard.charAt(Math.floor(Math.random() * len))
}
return result
}
简易对象的深拷贝
JSON.parse(JSON.stringify(obj))
美化console
console.info("%c哈哈", "color: #3190e8; font-size: 30px; font-family: sans-serif");
The text was updated successfully, but these errors were encountered: