We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
玩转nodeJs文件模块
50+行代码搞定一行命令更新Npm包
上列两篇文章介绍了作者在开发一个工具库中,拥抱NodeJs简化一些重复性工作的实践。
但还不够!!!还可以再简化。 上图,从isNaN.ts 转成isNaN.md,在/*...*/写好注释直接生成该方法的文档介绍,这是我想要的。
isNaN.ts
isNaN.md
/*...*/
类似jsDoc工具提供的功能。
其实,学习编程的过程就是学习造轮子的过程,咱也不重新造轮子,仿写一个最简单的功能即可。
JavaScript注释一般有两种方式:单行注释、多行注释
单行注释
//单行注释
多行注释
/** *多行注释 * */
使用的是TypeScript语言,它是JavaScript的超集,注释方式与JavaScript完全是一样的。
我们只考虑多行注释,忽略掉单行注释。
多行注释应该包含以下部分:
方法的描述,具体做什么的
使用者需要知晓该方法是哪个版本新增的
调用方法需要传入的参数详情
调用方法后,它返回的值
使用该方法的具体示例代码
多行注释时,需要规定关键字段用于表示上述部分的内容。
规定:@desc、@version、@param、@return、@example 分别表示方法描述、该方法新增的版本、方法传入的参数详情、方法调用返回的值、示例代码。
@desc、@version、@param、@return、@example
提取代码文件中的多行注释
代码文件不止一个,这边需要遍历获取/src/xx/ 路径下所有的.ts 文件:
/src/xx/
.ts
import { srcPath } from "../build/const" import getSrcLists from "../build/getSrcLists" (async () => { const lists = await getSrcLists(srcPath) })()
srcPath 即为目录src 路径, const srcPath = path.join(__dirname, '../src'); 一行代码得到src绝对路径。
srcPath
src
const srcPath = path.join(__dirname, '../src');
getSrcLists 方法用于获取src目录下所有的文件或文件夹:
getSrcLists
import fsPromises from "fs/promises"; export default async (examplePath: string) => { const dirs = await fsPromises.readdir(examplePath) const isIncludes = (dir: any[] | string) => dir.includes('.DS_Store') if (isIncludes(dirs)) { const index = dirs.findIndex((dir) => isIncludes(dir)) dirs.splice(index, 1) } return dirs }
调用NodeJS原生文件模块fs/promises下的fsPromises.readdir(examplePath)方法,即可获取到examplePath路径下所有的文件或文件夹。
fs/promises
fsPromises.readdir(examplePath)
examplePath
有坑小心,MacBook系统有文件夹下会自动生成.DS_Store 文件的问题,至于什么是.DS_Store 各位读者自己去寻找答案了。.DS_Store我们不需要,而且会导致拼接路径读取文件时报错,这里需要将其移除掉。
.DS_Store
src目录结构如下:
/src /Array /customKey.ts /getMax.ts /... /Date /isDate.ts /... /...
想获取.ts文件,即路径上还需要再拼接一个文件夹名,再次调用getSrcLists方法:
import { srcPath } from "../build/const" import getSrcLists from "../build/getSrcLists" import path from "path" (async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) }) })()
接下来,重复调用path.resolve(filePath, file)路径再拼接上xxx.ts文件名,即为完整的xxx.ts 路径:
path.resolve(filePath, file)
xxx.ts
import { srcPath } from "../build/const" import getSrcLists from "../build/getSrcLists" import path from "path" (async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) files.forEach(async file => { const srcFilePath = path.resolve(filePath, file) const content = await fsPromises.readFile(srcFilePath, 'utf-8') }) }) })()
最后终于可以fsPromises.readFile(srcFilePath, 'utf-8') 把拼接完整路径的xxx.ts文件内容读取出来。
fsPromises.readFile(srcFilePath, 'utf-8')
每一个xxx.ts 文件可能导出不止一个方法,例如:
对于这种情况,我们依然往对应的.md文件内叠加内容。
.md
针对上述问题,需要把每一个xxx.ts文件中的每一个多行注释块提取单独处理。
TypeScript使用的是ES6模块化,import ... from "..." 导入,export 关键字导出。每一个导出的方法必须使用export,这个是不变的。如此针对读取xxx.ts内容后,以export分割内容,即可把每个xxx.ts文件内的每一个多行注释块分离出来:
import ... from "..."
export
import { srcPath } from "../build/const" import getSrcLists from "../build/getSrcLists" import path from "path" (async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) files.forEach(async file => { const srcFilePath = path.resolve(filePath, file) const content = await fsPromises.readFile(srcFilePath, 'utf-8') //新增 const exportsArray = content.split('export') }) }) })()
为方便下一步提取多行注释中的关键字段,要做的是把多行注释干净的提取出来,不需要有任何其他代码片段,正则exec这个时候就能派上用场:
exec
import { srcPath } from "../build/const" import getSrcLists from "../build/getSrcLists" import path from "path" import { ANNOTATION } from "./const" //新增 function getAnnotation(content: string) { const execContent = ANNOTATION.exec(content) if (isEmpty(execContent)) return const comment = (execContent as any[])[0] return comment } (async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) files.forEach(async file => { const srcFilePath = path.resolve(filePath, file) const content = await fsPromises.readFile(srcFilePath, 'utf-8') const exportsArray = content.split('export') //新增 const promises: any[] = [] exportsArray.forEach(exportsContent => { if (isEmpty(exportsContent)) return promises.push(Promise.resolve().then(() => getAnnotation(exportsContent))) }) }) }) })()
其中ANNOTATION 值即为正则/\/\*(\s|.)*?\*\//
ANNOTATION
/\/\*(\s|.)*?\*\//
提取多行注释中的关键字段
通过上面步骤,我们就可以完整的获取到干净的多行注释,现在要获取多行注释中的关键字段,如@desc 。
@desc
多行注释是以/**开头,*/结束,它们对于我们来说是多余字符,所以在获取关键字段前,我们先将其处理掉。
/**
*/
//省略 import { ANNOTATION, CHAR } from "./const" //新增 function getQuery(comment: string) { comment = comment.replace(/\*\/$/, '')// */替换成"" let splitComment = comment.split(CHAR) splitComment = splitComment.slice(1, splitComment.length).map(val => (CHAR + val.replace(/((\* $)|(\* ))/gm, '')).trim()) return splitComment } function getAnnotation(content: string) { const execContent = ANNOTATION.exec(content) if (isEmpty(execContent)) return const comment = (execContent as any[])[0] return getQuery(comment) } //省略
CHAR 常量值为@,关键字段均是以@ 开头定义,所以用@再次分割内容,将内容分割多个部分,分割后数据清理/**。这是多行注释的开头,分割后索引为0,将其剔除splitComment.slice(1, splitComment.length),保留的数据由于只对@、/**、*/做了处理,所以现有数据头部存在* 特殊字符。
CHAR
@
0
splitComment.slice(1, splitComment.length)
@、/**、*/
*
(CHAR + val.replace(/((\* $)|(\* ))/gm, '')).trim() 这行它做了三件事:替换*为""、去除字符串两端空字符、重新将@拼接。
(CHAR + val.replace(/((\* $)|(\* ))/gm, '')).trim()
整理关键字段内容,以合适的数据结构存储
这个时候,splitComment 变量值即存储了所以的关键字段内容,数据结构为:
splitComment
["@desc 判断参数是否为`NaN`","@version v3.3.5",...]
这样的数据结构并不方便取值,所以要把现在的数据结构转变下。
//省略 //新增 function cacheMap(comments: string[]) { const map = new Map<string, Set<string>>() const reg = /^@([a-z]*) / comments.forEach((comment) => { const regComment = reg.exec(comment) if (isEmpty(regComment)) return const readyComment = comment.replace(reg, '') const key = (((regComment as any[])[0]) as string).trim().replace(CHAR, '') const mapValue = map.get(key) if (mapValue) { mapValue.add(readyComment) return } const set = new Set<string>() set.add(readyComment) map.set(key, set) }) return map } function getQuery(comment: string) { comment = comment.replace(/\*\/$/, '') let splitComment = comment.split(CHAR) splitComment = splitComment.slice(1, splitComment.length).map(val => (CHAR + val.replace(/((\* $)|(\* ))/gm, '')).trim()) return cacheMap(splitComment) } //省略
依然是使用正则const reg = /^@([a-z]*) /,在遍历comments数组时,将@desc 等关键字段捕获。如"@desc 判断参数是否为`NaN`" 捕获出"@desc ",并在原字符串上将其替换成"",原字符串变成"判断参数是否为`NaN`"。
const reg = /^@([a-z]*) /
comments
"@desc 判断参数是否为`NaN`"
"@desc "
""
"判断参数是否为`NaN`"
捕获出的"@desc "再去除掉@、去除掉两端空字符,把desc 作为Map对象的Key值;原字符串"判断参数是否为`NaN`"作为Set对象的Value值;将该Set对象作为Map对象中Key值为desc的Value。
desc
使用Set对象的原因:支持多个相同关键字段
/** * ... * @param value(any):参数1 * @param value(any):参数2 * ... */
如上注释,多个@param 描述参数,实际中多个参数是正常的,因此我们要做的是获取多个相同关键字段内容时去重,使用Set对象是最方便的。
@param
经过cacheMap 方法处理后,最终的数据结构为:
cacheMap
Map:{ desc:Set["判断参数是否为`NaN`"], version: Set["v3.3.5"], ... }
提前定好文档模板,对应位置填写入关键字段内容
template.ts:
//省略 export const generateDocs = async (doc: docs, callBack: () => string) => { const filePath = callBack() const splitFilePath = filePath.split(path.sep) const file = splitFilePath[splitFilePath.length - 1] if (or(isEmptyObj(doc), isEmpty(doc.version))) { err(`请完善${file}文档`) process.exit(1); } return `${doc.desc ? getSetValue(doc.desc) : ''} **添加版本** ${getSetValue(doc.version)} **参数** ${doc.param ? getSetValue(doc.param) : ''} **返回** ${doc.return ? getSetValue(doc.return) : ''} **例子** ${doc.example ? getExample(getSetValue(doc.example)) : await generateExample(filePath)}` }
仅粘贴核心部分,其中该部分很容易理解。doc 为对象,由Map对象转化成Object对象,然后判断param、return 等字段是否存在,存在则将字段值传递给getSetValue 方法。
doc
param、return
getSetValue
function getSetValue(set: Set<string>) { let setValue = '' set.forEach((s) => { setValue += `${s} \n` }) return setValue }
其他逻辑是处理一些边界。
完整代码:medash/template.ts at dev · CatsAndMice/medash (github.com)
最后创建.md文件,写入内容
(async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) files.forEach(async file => { //省略 const promises: any[] = [] exportsArray.forEach(exportsContent => { if (isEmpty(exportsContent)) return promises.push(Promise.resolve().then(() => getAnnotation(exportsContent))) }) let docsContent = '' Promise.all(promises).then(async (result) => { const docsPromises: any[] = [] result.forEach((res) => { //拼接字符串 const promiseFn = async () => { const isMapNoSize = isMap(res) && isEmpty(res.size) if (or(isEmpty(res), isMapNoSize)) return const docs = await generateDocs((mapToObj(res as Map<string, Set<string>>)) as docs, () => getLastPath(srcFilePath)) if (isEmpty(docs)) return docsContent += `${docs} \n` return docsContent } //Promise类型统一添加至数组中 docsPromises.push(promiseFn()) }) }) }) }) })()
Promise.all(promises) 等待所有的Promise结束后,我们再遍历所有Promise返回的结果,将生成的内容逻辑代码,使用async函数promiseFn包裹,执行promiseFn()并push至docsPromises数组。
Promise.all(promises)
Promise
async
promiseFn
promiseFn()
push
docsPromises
同样的逻辑,还是使用 Promise.all,等待docsPromises数组中所有的Promise对象出结果后,说明所有生成的内容已拼接赋值于docsContent 变量:
Promise.all
docsContent
(async () => { const lists = await getSrcLists(srcPath) lists.forEach(async list => { const filePath = path.resolve(srcPath, list) const files = await getSrcLists(filePath) files.forEach(async file => { //省略 let docsContent = '' Promise.all(promises).then(async (result) => { const docsPromises: any[] = [] result.forEach((res) => { //拼接字符串 const promiseFn = async () => { const isMapNoSize = isMap(res) && isEmpty(res.size) if (or(isEmpty(res), isMapNoSize)) return const docs = await generateDocs((mapToObj(res as Map<string, Set<string>>)) as docs, () => getLastPath(srcFilePath)) if (isEmpty(docs)) return docsContent += `${docs} \n` return docsContent } //Promise类型统一添加至数组中 docsPromises.push(promiseFn()) }) //新增 //所有的Promise完成后,docsContent已拼接完成 Promise.all(docsPromises).then(() => { const splitFilePath = filePath.split(path.sep) const mdPath = path.join(docsPath, splitFilePath[splitFilePath.length - 1]) isEmpty(docsContent) ? null : createDocs(mdPath, file.replace(/\.[a-z]*$/, ''), docsContent) }) }) }) }) })()
createDocs 就是一个创建、写入内容的方法逻辑,相对容易不进行粘贴了。
createDocs
至此,一个最简单的文档生成功能就完成了。
完整代码:medash/index.ts at dev · CatsAndMice/medash (github.com)
原创不易!如果我的文章对你有帮助,你的👍就是对我的最大支持^ _^。
点赞+评论+收藏 = 学会。
我正在参与掘金技术社区创作者签约计划招募活动,点击链接报名投稿。
The text was updated successfully, but these errors were encountered:
No branches or pull requests
玩转nodeJs文件模块
50+行代码搞定一行命令更新Npm包
上列两篇文章介绍了作者在开发一个工具库中,拥抱NodeJs简化一些重复性工作的实践。
但还不够!!!还可以再简化。
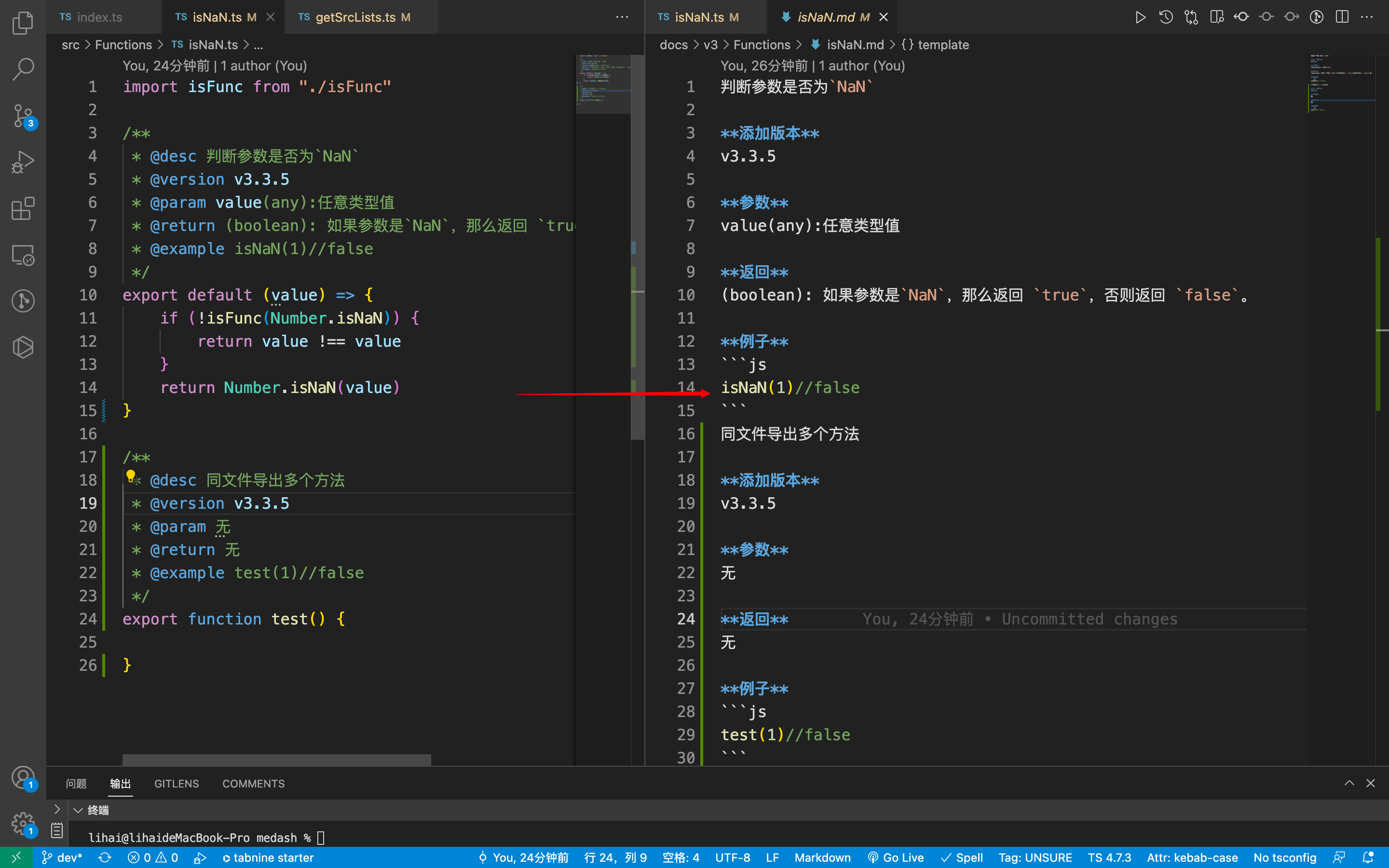
上图,从
isNaN.ts转成isNaN.md,在/*...*/写好注释直接生成该方法的文档介绍,这是我想要的。类似jsDoc工具提供的功能。
其实,学习编程的过程就是学习造轮子的过程,咱也不重新造轮子,仿写一个最简单的功能即可。
step1:前置构思
JavaScript注释一般有两种方式:单行注释、多行注释
单行注释
//单行注释多行注释
使用的是TypeScript语言,它是JavaScript的超集,注释方式与JavaScript完全是一样的。
我们只考虑多行注释,忽略掉单行注释。
多行注释应该包含以下部分:
方法的描述,具体做什么的
使用者需要知晓该方法是哪个版本新增的
调用方法需要传入的参数详情
调用方法后,它返回的值
使用该方法的具体示例代码
多行注释时,需要规定关键字段用于表示上述部分的内容。
规定:
@desc、@version、@param、@return、@example分别表示方法描述、该方法新增的版本、方法传入的参数详情、方法调用返回的值、示例代码。step2: 实现思路
提取代码文件中的多行注释
代码文件不止一个,这边需要遍历获取
/src/xx/路径下所有的.ts文件:srcPath即为目录src路径,const srcPath = path.join(__dirname, '../src');一行代码得到src绝对路径。getSrcLists方法用于获取src目录下所有的文件或文件夹:调用NodeJS原生文件模块
fs/promises下的fsPromises.readdir(examplePath)方法,即可获取到examplePath路径下所有的文件或文件夹。有坑小心,MacBook系统有文件夹下会自动生成
.DS_Store文件的问题,至于什么是.DS_Store各位读者自己去寻找答案了。.DS_Store我们不需要,而且会导致拼接路径读取文件时报错,这里需要将其移除掉。src目录结构如下:/src /Array /customKey.ts /getMax.ts /... /Date /isDate.ts /... /...想获取
.ts文件,即路径上还需要再拼接一个文件夹名,再次调用getSrcLists方法:接下来,重复调用
path.resolve(filePath, file)路径再拼接上xxx.ts文件名,即为完整的xxx.ts路径:最后终于可以
fsPromises.readFile(srcFilePath, 'utf-8')把拼接完整路径的xxx.ts文件内容读取出来。每一个
xxx.ts文件可能导出不止一个方法,例如:对于这种情况,我们依然往对应的
.md文件内叠加内容。针对上述问题,需要把每一个
xxx.ts文件中的每一个多行注释块提取单独处理。TypeScript使用的是ES6模块化,
import ... from "..."导入,export关键字导出。每一个导出的方法必须使用export,这个是不变的。如此针对读取xxx.ts内容后,以export分割内容,即可把每个xxx.ts文件内的每一个多行注释块分离出来:为方便下一步提取多行注释中的关键字段,要做的是把多行注释干净的提取出来,不需要有任何其他代码片段,正则
exec这个时候就能派上用场:其中
ANNOTATION值即为正则/\/\*(\s|.)*?\*\//提取多行注释中的关键字段
通过上面步骤,我们就可以完整的获取到干净的多行注释,现在要获取多行注释中的关键字段,如
@desc。多行注释是以
/**开头,*/结束,它们对于我们来说是多余字符,所以在获取关键字段前,我们先将其处理掉。CHAR常量值为@,关键字段均是以@开头定义,所以用@再次分割内容,将内容分割多个部分,分割后数据清理/**。这是多行注释的开头,分割后索引为0,将其剔除splitComment.slice(1, splitComment.length),保留的数据由于只对@、/**、*/做了处理,所以现有数据头部存在*特殊字符。(CHAR + val.replace(/((\* $)|(\* ))/gm, '')).trim()这行它做了三件事:替换*为""、去除字符串两端空字符、重新将@拼接。整理关键字段内容,以合适的数据结构存储
这个时候,
splitComment变量值即存储了所以的关键字段内容,数据结构为:这样的数据结构并不方便取值,所以要把现在的数据结构转变下。
依然是使用正则
const reg = /^@([a-z]*) /,在遍历comments数组时,将@desc等关键字段捕获。如"@desc 判断参数是否为`NaN`"捕获出"@desc ",并在原字符串上将其替换成"",原字符串变成"判断参数是否为`NaN`"。捕获出的
"@desc "再去除掉@、去除掉两端空字符,把desc作为Map对象的Key值;原字符串"判断参数是否为`NaN`"作为Set对象的Value值;将该Set对象作为Map对象中Key值为desc的Value。使用Set对象的原因:支持多个相同关键字段
如上注释,多个
@param描述参数,实际中多个参数是正常的,因此我们要做的是获取多个相同关键字段内容时去重,使用Set对象是最方便的。经过
cacheMap方法处理后,最终的数据结构为:Map:{ desc:Set["判断参数是否为`NaN`"], version: Set["v3.3.5"], ... }提前定好文档模板,对应位置填写入关键字段内容
template.ts:
仅粘贴核心部分,其中该部分很容易理解。
doc为对象,由Map对象转化成Object对象,然后判断param、return等字段是否存在,存在则将字段值传递给getSetValue方法。其他逻辑是处理一些边界。
完整代码:medash/template.ts at dev · CatsAndMice/medash (github.com)
最后创建
.md文件,写入内容Promise.all(promises)等待所有的Promise结束后,我们再遍历所有Promise返回的结果,将生成的内容逻辑代码,使用async函数promiseFn包裹,执行promiseFn()并push至docsPromises数组。同样的逻辑,还是使用
Promise.all,等待docsPromises数组中所有的Promise对象出结果后,说明所有生成的内容已拼接赋值于docsContent变量:createDocs就是一个创建、写入内容的方法逻辑,相对容易不进行粘贴了。至此,一个最简单的文档生成功能就完成了。
完整代码:medash/index.ts at dev · CatsAndMice/medash (github.com)
最后
原创不易!如果我的文章对你有帮助,你的👍就是对我的最大支持^ _^。
点赞+评论+收藏 = 学会。
我正在参与掘金技术社区创作者签约计划招募活动,点击链接报名投稿。
The text was updated successfully, but these errors were encountered: