2、HTTPS/HTTP/HTTP2 工作原理及通信、网络协议 #3
Comments
|
HTTPS协议和HTTP协议的区别:
|
|
TCP 3次握手 (1)客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的报文1。 为什么需要“三次握手” 在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。在另一部经典的《计算机网络》一书中讲“三次握手”的目的是为了解决“网络中存在延迟的重复分组”的问题。这两种不用的表述其实阐明的是同一个问题。 谢希仁版《计算机网络》中的例子是这样的,“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”。 主要目的防止server端一直等待,浪费资源。 |
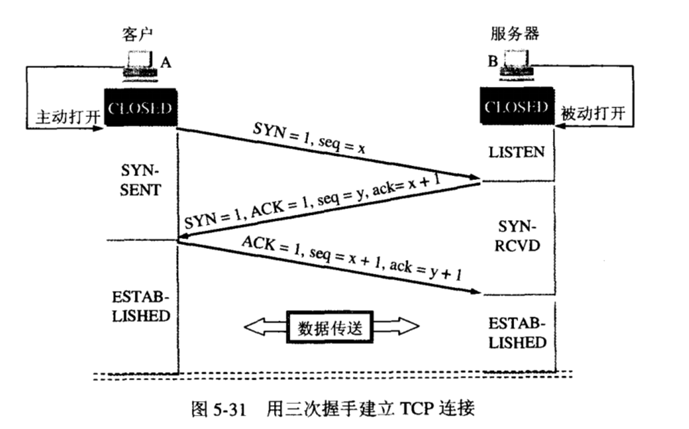
|
连接终止协议(四次挥手) (1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
那可能有人会有疑问,在tcp连接握手时为何ACK是和SYN一起发送,这里ACK却没有和FIN一起发送呢。原因是因为tcp是全双工模式,接收到FIN时意味将没有数据再发来,但是还是可以继续发送数据。 总结TCP三次握手:1、客户端发送syn包到服务器,等待服务器确认接收。2、服务器确认接收syn包并确认客户的syn,并发送回来一个syn+ack的包给客户端。3、客户端确认接收服务器的syn+ack包,并向服务器发送确认包ack,二者相互建立联系后,完成tcp三次握手。四次握手就是中间多了一层 等待服务器再一次响应回复相关数据的过程 三次是最少的安全次数,两次不安全,四次浪费资源 |

当我们在浏览器中输入 www.baidu.com/** 访问 百度的时候浏览器做了哪些事情
|
HTTPHTTP地位Web使用一种名为HTTP(HyperText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器等一系列运作流程。而协议是指规则的约定。可以说,Web是建立在HTTP协议上通信的。 HTTP最初的目的是为了让研究者共享知识信息,所以它的主要作用就是文档传输,它是一种用于传输文档的协议。 TCP/IP 协议族TCP/IP 协议族是Internet最基本的协议,HTTP协议是它的一个子集。TCP/IP协议族按层次分为以下四层:
应用层规定了向用户提供应用服务时通信的协议,如: TCP/IP 协议族内预存了各类通用的应用服务协议。比如,FTP(File Transfer Protocol,文件传输协议)和DNS(Domain Name System,域名系统)服务就是其中的两类以及HTTP协议。 DNS域名系统提供域名(如:www.baidu.com)到IP地址(如:119.75.217.109)之间的解析服务
传输层对接上层应用层,提供处于网络连接中两台计算机之间的数据传输所使用的协议。 在传输层有两个性质不同的协议:
TCP协议是全双工的,即发送数据和接收数据是同步进行的,就好像我们打电话一样,说话的同时也能听见。TCP协议在建立和断开连接时有三次握手和四次挥手,因此在传输的过程中更稳定可靠但同时就没UDP那么高效了。 UDP协议是面向无连接的,也就是说在正式传递数据之前不需要先建立连接。UDP 协议不保证有序且不丢失的传递到对端,也就是说不够稳定,但也正因如此,UDP协议比TCP更加高效和轻便。
网络层规定了数据通过怎样的传输路线到达对方计算机传送给对方(IP协议等)。 与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的所用就是在众多的选项内选择一条传输路线。就跟携程提供的回家路线图作用一样。
用来处理连接网络的硬件部分,包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡,以太网),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。 发送端在层与层之间传输数据时,每经过一层时会被打上一个该层所属的首部信息。反之,接收端在层与层之间传输数据时,每经过一层时会把对应的首部信息去除。 几种链接的区别
看图区分三种链接: HTTP/2.0在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream),理解这两个概念是理解下面多路复用的前提。
HTTP/3.0HTTP/2.0 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。反而对于 HTTP/1.0 来说,可以开启多个 TCP 连接,出现丢包反倒只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。 QUIC 基于 UDP,但是UDP本身存在不稳定性等诸多问题,所以QUIC在UDP的基础上新增了很多功能,比如多路复用、0-RTT、使用 TLS1.3 加密、流量控制、有序交付、重传等等功能。优点诸多,参考这里:
|
|
其他部分 报文, 代理服务器等 https://juejin.im/post/5cd0438c6fb9a031ec6d3ab2 |
|
keep - alive https://lotabout.me/2019/Things-about-keepalive/ |
HTTPS:
1、HTTPS的工作原理
HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的具体描述如下:
这里浏览器与网站互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。另外,HTTPS一般使用的加密与HASH算法如下:
The text was updated successfully, but these errors were encountered: