46、Webpack、Vite #47
Comments
使用webpack4提升180%编译速度
实际上,搭载 webpack-parallel-uglify-plugin 插件,这个过程可以倍速提升。我们都知道 node 是单线程的,但node能够fork子进程,基于此,webpack-parallel-uglify-plugin 能够把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程,从而实现并发编译,进而大幅提升js压缩速度
Webpack优化——将你的构建效率提速翻倍
可以断言的是,大部分的执行时长应该都是消耗在编译 JS、CSS 的 Loader 以及对这两类代码执行压缩操作的 Plugin 上 为什么会这样呢?因为在对我们的代码进行编译或者压缩的过程中,都需要执行这样的一个流程:编译器(这里可以指 webpack)需要将我们写下的字符串代码转化成 AST(语法分析树),就是如下图所示的一个树形对象: 显而易见,编译器肯定不能用正则去显式替换字符串来实现这样一个复杂的编译流程,而编译器需要做的就是遍历这棵树,找到正确的节点并替换成编译后的值,过程就像下图这样: 之所以构建时长会集中消耗在代码的编译或压缩过程中,正是因为它们需要去遍历树以替换字符或者说转换语法,因此都需要经历"转化 AST -> 遍历树 -> 转化回代码"这样一个过程
module.exports = {
module: {
rules: [
{
test: /\.ext$/,
use: ['cache-loader', ...loaders],
include: path.resolve('src'),
},
],
},
};
这里的优化手段大家肯定已经想到了,自然是我们的 happypack。这似乎已经是一个老生常谈的话题了,从3时代开始,happypack 就已经成为了众多 webpack 工程项目接入多核编译的不二选择,几乎所有的人,在提到 webpack 效率优化时,怎么样也会说出 happypack 这个词语。所以,在前端社区繁荣的今天,从 happypack 出现的那时候起,就有许多优秀的质量文如雨后春笋般层出不穷。所以今天在这里,对于 happypack 我就不做过多细节上的介绍了,想必大家对它也再熟悉不过了,我就带着大家简单回顾一下它的使用方法吧 const HappyPack = require('happypack')
const os = require('os')
// 开辟一个线程池
// 拿到系统CPU的最大核数,happypack 将编译工作灌满所有线程
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length })
module.exports = {
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: 'happypack/loader?id=js',
},
],
},
plugins: [
new HappyPack({
id: 'js',
threadPool: happyThreadPool,
loaders: [
{
loader: 'babel-loader',
},
],
}),
],
}所以配置起来逻辑其实很简单,就是用 happypack 提供的 Plugin 为你的 Loaders 做一层包装就好了,向外暴露一个id ,而在你的 module.rules 里,就不需要写loader了,直接引用这个 id 即可,所以赶紧用 happypack 对那些你测出来的代价比较昂贵的 loaders 们做一层多核编译的包装吧。 而对于一些编译代价昂贵的 webpack 插件,一般都会提供 parallel 这样的配置项供你开启多核编译,因此,只要你善于去它的官网发现,一定会有意想不到的收获噢~
对于一些不常变更的静态依赖,比如我们项目中常见的 React 全家桶,亦或是用到的一些工具库,比如 lodash 等等,我们不希望这些依赖被集成进每一次构建逻辑中,因为它们真的太少时候会被变更了,所以每次的构建的输入输出都应该是相同的。因此,我们会设法将这些静态依赖从每一次的构建逻辑中抽离出去,以提升我们每次构建的构建效率。 常见的方案有两种,一种是使用 webpack-dll-plugin 的方式,在首次构建时候就将这些静态依赖单独打包,后续只需要引用这个早就被打好的静态依赖包即可,有点类似“预编译”的概念;另一种,也是业内常见的 Externals的方式,我们将这些不需要打包的静态资源从构建逻辑中剔除出去,而使用 CDN 的方式,去引用它们。 webpack-dll-plugin 与 Externals 的抉择 webpack-dll-plugin 的三宗原罪: 需要配置在每次构建时都不参与编译的静态依赖,并在首次构建时为它们预编译出一份 JS 文件(后文将称其为 lib 文件),每次更新依赖需要手动进行维护,一旦增删依赖或者变更资源版本忘记更新,就会出现 Error 或者版本错误。 无法接入浏览器的新特性 script type="module",对于某些依赖库提供的原生 ES Modules 的引入方式(比如 vue 的新版引入方式)无法得到支持,没法更好地适配高版本浏览器提供的优良特性以实现更好地性能优化。 将所有资源预编译成一份文件,并将这份文件显式注入项目构建的 HTML 模板中,这样的做法,在 HTTP1 时代是被推崇的,因为那样能减少资源的请求数量,但在 HTTP2 时代如果拆成多个 CDN Link,就能够更充分地利用 HTTP2 的多路复用特性。口说无凭,直接上图验证结论:使用 webpack-dll-plugin 生成的 lib 文件,整体资源作为一个文件加载,需要 400 多毫秒 如果你的公司没有成熟的 CDN 服务,但又想对项目中的静态依赖进行抽离该怎么办呢?那笔者的建议还是选择 webpack-dll-plugin 来优化你的构建效率。如果你还是觉得每次更新依赖都需要去维护一个 lib 文件特别麻烦,那我还是特别提醒你,在使用 Externals 时选择一个靠谱的 CDN 是一件特别重要的事,毕竟这些依赖比如 React 都是你网站的骨架,少了他们可是连站点都运行不起来了噢。 这个理解起来不费劲,操作起来很费劲。所幸,在Webpack5中已经不用它了,而是用HardSourceWebpackPlugin,一样的优化效果,但是使用却及其简单
|
webpack (HMR hot-reload Hot Module Replacement)https://mp.weixin.qq.com/s/2L9Y0pdwTTmd8U2kXHFlPA 1.当修改了一个或多个文件; |
|
code split chunk 分包 splitchunks w4版本 |
webpack tree shakingTree-Shaking这个名词,很多前端coder已经耳熟能详了,它代表的大意就是删除没用到的代码。这样的功能对于构建大型应用时是非常好的,因为日常开发经常需要引用各种库。但大多时候仅仅使用了这些库的某些部分,并非需要全部,此时Tree-Shaking如果能帮助我们删除掉没有使用的代码,将会大大缩减打包后的代码量。 Tree-Shaking在前端界由rollup首先提出并实现,后续webpack在2.x版本也借助于UglifyJS实现了。自那以后,在各类讨论优化打包的文章中,都能看到Tree-Shaking的身影。
先说原因:都是副作用的锅, 也是由于babel编译 + webpack打包的编译,一些我们原本看似没有副作用的代码,便转化为了(可能)有副作用的。 总结上面讲了这么多,我最后再总结下,在当下阶段,在tree-shaking上能够尽力的事。
故而,在当下阶段,依旧没有比较简单好用的方法,便于我们完整的进行tree-shaking。所以说,想做好一件事真难啊。不仅需要靠个人的努力,还需要考虑到历史的进程。 https://juejin.im/post/5a4dc842518825698e7279a9 |
Vite 原理
|
Vite 和 webpack 区别
Webpack 的方式是将你的所有的代码统一进行编译,包括所有的 router 以及下面的模块,模块下还有各个组件。打包成浏览器可以识别的代码,都打包完成之后,启动服务器,统一给浏览器使用。
Vite 的方式是直接先启动服务器,其实图上少了一个步骤,在启动服务器之前会先读取你的 package.json 文件,识别出需要进行预编译的包,先进行预编译之后,再去启动服务器。 |
什么是Webpack
可以看做一个模块化打包机,分析项目结构,处理模块化依赖,转换成为浏览器可运行的代码。
构建把一系列前端代码自动化去处理复杂的流程,解放生产力。
Webpack事件流机制
Webpack是基于事件流的插件集合,它的工作流程就是将各个插件串联起来,而实现这一切的核心就是Tapable,Tapable是一个类似Node.js的EventEmitter的库,主要是控制钩子函数的发布与订阅,控制着webpack的插件系统。Webpack中最核心的负责编译的Compiler和负责创建的捆绑包的Compilation都是Tapable实例。
Tapable库暴露很多Hook类,为插件提供挂载的钩子
Tapable使用实际例子:
Webpack中Tapable的应用
Webpack流程概览
Webpack首先会把配置参数和命令行的参数及默认参数合并,并初始化需要使用的插件和配置插件等执行环境所需要的参数;初始化完成后会调用Compiler的run来真正启动webpack编译构建过程,webpack的构建流程包括compile、make、build、seal、emit阶段,执行完这些阶段就完成了构建过程。
WEBPACK打包示意图
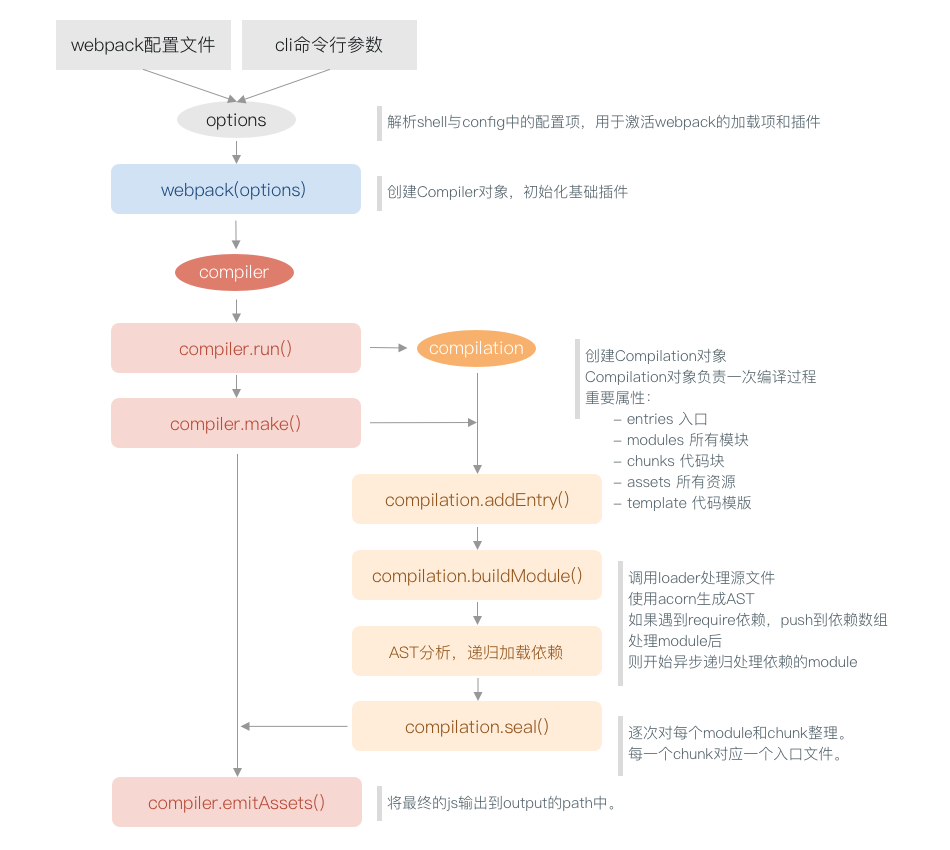
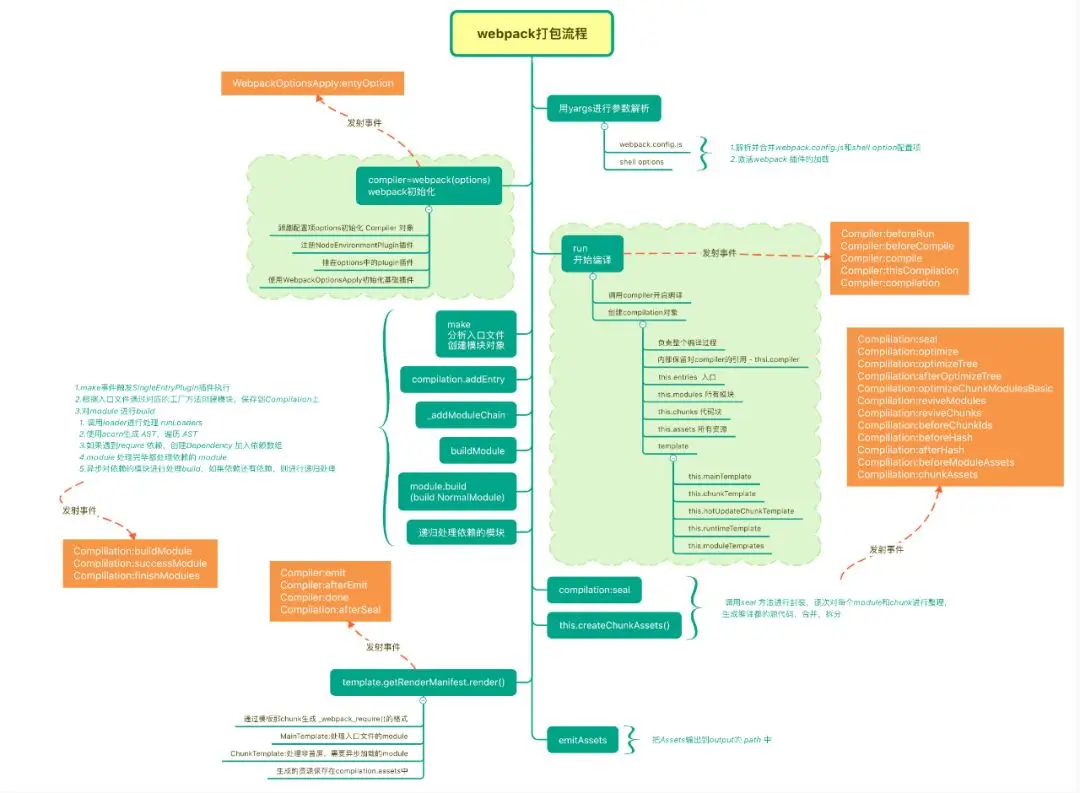
Webpack流程详解及源码解析
分为三个阶段: 初始化阶段,编译阶段,输出文件(chunk)
初始化阶段
编译阶段
输出阶段
The text was updated successfully, but these errors were encountered: