-
在之前以BERT模型为代表的“预训练语言模型 + 下游任务微调”训练模式成为了自然语言处理研究和应用的标准范式。此处的下游任务微调是基于模型全量参数进行微调。
-
但是,以 GPT3 为代表的预训练语言模型(PLM)参数规模变得越来越大,这使得在消费级硬件上进行全量微调变得不可行。
-
模型全量微调还会损失多样性,存在灾难性遗忘的问题

参数高效微调是指微调少量或额外的模型参数,固定大部分预训练模型(LLM)参数,从而大大降低了计算和存储成本,同时,也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调效果更好,可以更好地泛化到域外场景。
虽然对每个任务进行全量微调非常有效,但它也会为每个预训练任务生成一个独特的大型模型,这使得很难推断微调过程中发生了什么变化,也很难部署, 特别是随着任务数量的增加,很难维护。
理想状况下,我们希望有一种满足以下条件的高效微调方法:
-
到达能够匹配全量微调的效果。
-
仅更改一小部分模型参数。
-
使数据可以通过流的方式到达,而不是同时到达,便于高效的硬件部署。
-
改变的参数在不同下游任务中是一致的。

-
Addition-based(Adapter-like methods 和Soft prompts),
-
Selection-based,
-
Reparametrization-based。
主要思想是通过添加额外的参数或层来扩充现有的预训练模型,并仅训练新添加的参数。到目前为止,这是参数高效微调方法中最大且广泛探索的类别。这种方法又分为:
Adapters:即在Transformer子层后引入小型全连接网络,这种方法被广泛采用。Adapters有多种变体,例如修改适配器的位置、剪枝以及使用重参数化来减少可训练参数的数量。Soft Prompts:GPT-2旨在通过修改输入文本来控制语言模型的行为。然而,这些方法很难进行优化,且存在模型输入长度、训练示例的数量等限制,由此引入了soft 概念。Soft Prompts将模型的一部分输入嵌入通过梯度下降进行微调,将在离散空间中寻找提示的问题转化为连续优化问题。Soft Prompts可以仅对输入层进行训练(《GPT Understands, Too》、Prompt Tuning),也可以对所有层进行训练(Prefix-Tuning)。others:例如LeTS、LST和$(IA)^3$等。
优势:尽管这些方法引入了额外的参数到网络中,但它们通过减少梯度和优化器状态的大小,减少了训练时间,提升了内存效率。此外可以对冻结的模型参数进行量化(参考论文),additive PEFT方法能够微调更大的网络或使用更大的批次大小,这提高了在GPU上的训练吞吐量。此外,在分布式设置中优化较少的参数大大减少了通信量。
Adapters(2019.2.2) 论文《Parameter-Efficient Transfer Learning for NLP》
其核心思想是在神经网络模块基础上添加一些残差模块,并只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。

Feedforward down-project:将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d;Nonlinearity:非线性层;Feedforward up-project:还原输入维度d,作为Adapter模块的输出。通时通过一个skip connection来将Adapter的输入重新加到最终的输出中去(残差连接)
Pfeiffer等人发现,在自注意力层之后(在归一化之后)插入Adapter,可以达到媲美上述在Transformer块中使用两个Adapters的性能。
在 AdaMix 一文中,作者将刚刚提到的 Adapter 定义为:
$$ \mathbb{E}{i}\left(x{s}\right)=w_{i}^{\text {out }} \cdot \operatorname{Ge} L U\left(w_{i}^{\text {in }} \cdot x_{s}\right) $$
out 就是上边图片中的 up 映射,而 in 则是图中的 down 映射,中间非线性层则选用 GeLU 函数。之后本篇文章做的创新呢,就是类似于多专家模型 (MoE: Mixture-of-Experts),提出了 Mixture-of-Adapter,即将每一个 Adpater 视作一个专家。那么已经用 E 来表示单个 Adapter 专家了,加上传统的门控单元 G,模型的输出可以表示为:
$$ h\left(x_{s}\right)=\sum_{i} \mathbb{G}\left(x_{s}\right){i} \mathbb{E}{i}\left(x_{s}\right) $$
这里专家是包含了两个 FFN 层的,那么考虑另一种情况,能不能将这两个 FFN 层分开考虑,例如一共有两个专家,那么在第一个专家第一层输出后,能不能进到第二个专家的第二层,而不是第一层。每个不同的 down 和 up 的组合都可以视作一个专家,整体看上去,就如同下图结构:

本文中,down 和 up 网络的选择在每次训练中就完全随机了,为了保证随机专家情况下不出现预测不匹配的情况,这里也需要监督两个不同专家的输出一致性,整体网络如下图所示:
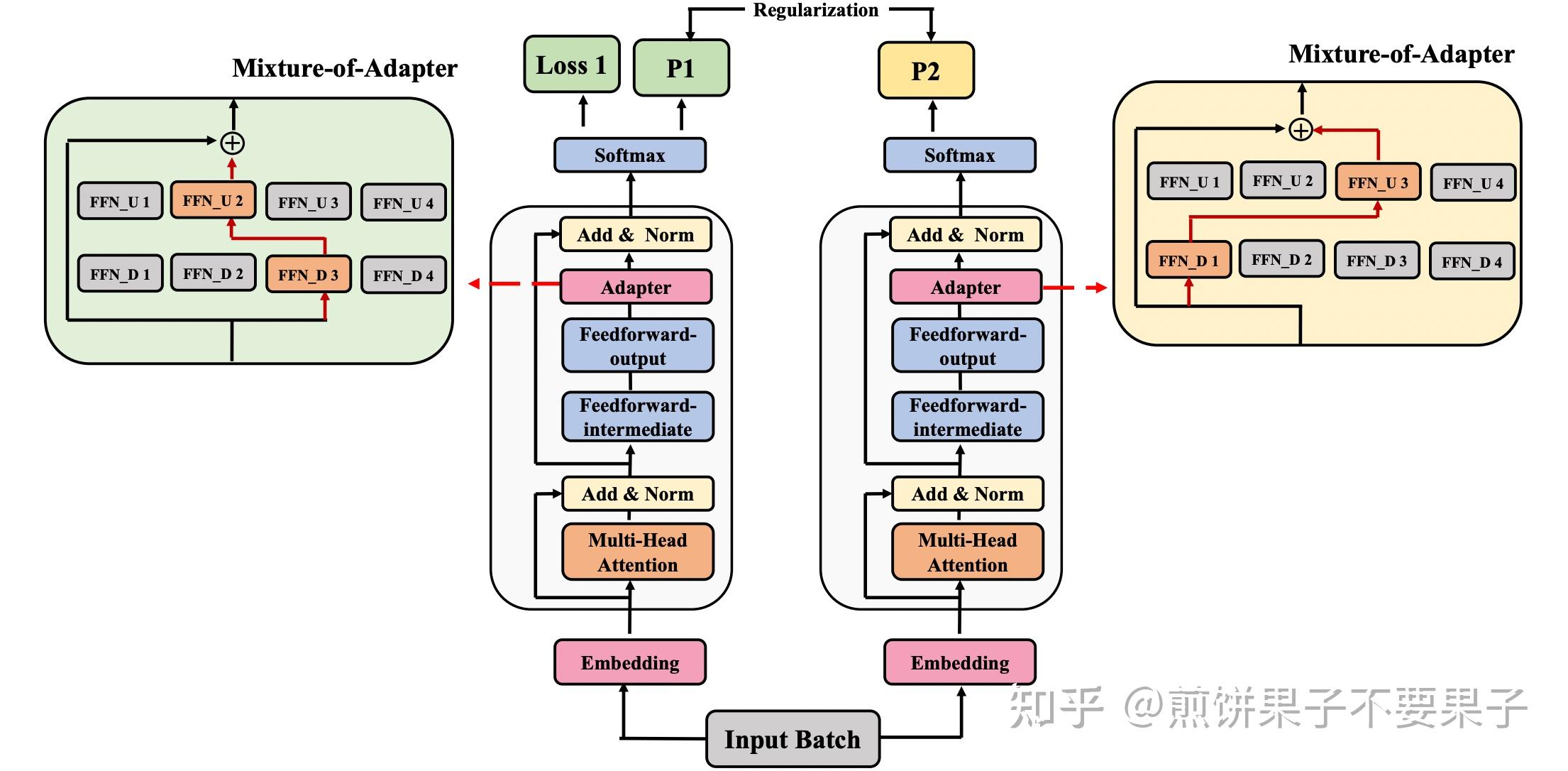
而对于推理阶段,文章提出了另一个创新点,即将所有 Adapter 混合,而不是像传统多专家模型中继续沿用门控单元或是随机分配。
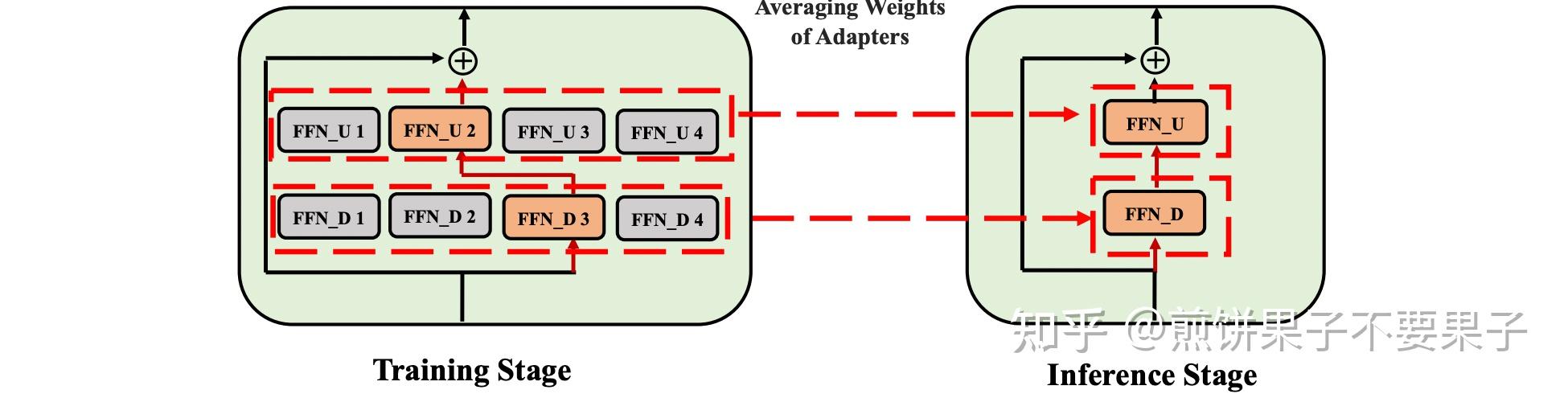
$$ \mathcal{W}{i}^{\prime u p} \leftarrow \frac{1}{M} \sum{j=1}^{M} \mathcal{W}{i j}^{u p} \quad \mathcal{W}{i}^{\prime d o w n} \leftarrow \frac{1}{M} \sum_{j=1}^{M} \mathcal{W}_{i j}^{\text {down }} $$
将所有 Adapter 参数暴力平均,终极目的还是为了让参数和计算量达到最小和最高效
作者还额外议论了一下 Model Ensembling 的关系,感觉其实就是说一下 Ensembling 成本太大
AdapterFusion(EACL 2021 )
Adapter Tuning的优势在于只需添加少量新参数即可有效学习一个任务,这些适配器的参数在一定程度上表示了解决该任务所需的知识。受到启发,作者思考是否可以将来自多个任务的知识结合起来。为此,作者提出了AdapterFusion,这是一种新的两阶段学习算法,可以利用来自多个任务的知识,在大多数情况下性能优于全模型微调和Adapter Tuning
AdapterDrop(EMNLP 2021 )
作者通过对Adapter的计算效率进行分析,发现与全量微调相比,Adapter在训练时快60%,但是在推理时慢4%-6%。基于此,作者提出了AdapterDrop方法缓解该问题,其主要方法有:
- 在不影响任务性能的情况下,对Adapter动态高效的移除,提高模型在反向传播(训练)和正向传播(推理)时的效率。例如,将前五个Transformer层中的Adapter丢弃,推理速度提高了 39%,性能基本保持不变。
- 对 AdapterFusion中的Adapter进行剪枝。实验证明,移除 AdapterFusion 中的大多数Adapter至只保留2个,实现了与具有八个Adapter的完整 AdapterFusion 模型相当的结果,且推理速度提高了 68%。
预训练语言模型(比如BERT),含有很全面的语言知识,并没有针对特定的下游任务,所以直接迁移学习的时候,可能模型不够明白你到底要解决什么问题,要提取哪部分知识,最后效果也就不够好。
标准范式pre-train, fine-tune转变为新范式pre-train, prompt, and predict之后,不再是通过目标工程使语言模型(LMs)适应下游任务,而是在文本提示(prompt)的帮助下,重新制定下游任务,使其看起来更像原始LMs训练期间解决的任务。 所以说,Prompt的核心思想,就是通过人工提示,把预训练模型中特定的知识挖掘出来,从而做到不错的零样本效果,而配合少量标注样本,可以进一步提升效果(提升零样本/小样本学习的效果)。
然而,人工构建模版并不是那么容,而且离散文本输入的鲁棒性是很差的,不同prompt模版效果差很多。最后,这种离散模板表示也无法全局优化;
为了克服这些困难,提出了soft prompts/continuous prompts的概念。简单来说,就是用固定的token代替prompt,拼接上文本输入,当成特殊的embedding输入,来实现自动化构建模板。将寻找最佳提示(hard prompt)的离散优化问题转化为连续优化问题,减小了prompt挖掘、选择的成本。
Prefix-Tuning即基于提示词前缀优化的微调方法,其原理是在输入token之前构造一段任务相关的virtual tokens(虚拟令牌)作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。
Fine-tuning会更新所有Transformer参数,所以对每个任务都要保存一份微调后的模型权重。而Prefix Tuning仅更新前缀部分的参数,这样不同任务只需要保存不同的前缀,微调成本更小。
Prompt Tuning可以看做是Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。
-
model tuning:每个下游任务都要进行一次定制的微调,然后保持不同的预训练模型副本,推理时必须以单独的批次进行
-
Prompt Tuning:只需要为每个任务存储一个小的特定于task prompt,可以使用原始预训练模型进行混合任务推理


直观来看,模版就是由自然语言构成的前缀/后缀,通过这些模版我们使得下游任务跟预训练任务一致,更充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。然而,并不关心模版长什么样,是否由自然语言组成的,只关心模型最终的效果。于是,P-tuning考虑了如下形式的模版:

这里的[u1]~[u6],代表BERT词表里边的[unused1]~[unused6],也就是用未知token来构成模板。然后,我们用标注数据来求出这个模板。(未知token数目是一个超参数,放在前面还是后面也可以调整。)
模板的优化策略。
-
标注数据比较少:此时,我们固定整个模型的权重,只优化
[unused1]~[unused6]这几个token的Embedding。因为要学习的参数很少,因此哪怕标注样本很少,也能把模版学出来,不容易过拟合,而且训练很快。 -
标注数据很充足:此时只优化
[unused1]~[unused6]会导致欠拟合。因此,我们可以放开所有权重微调,原论文在SuperGLUE上的实验就是这样做的。但这样跟直接加个全连接微调有什么区别?作者的话说是这样做效果更好,可能还是因为跟预训练任务更一致了吧。
对比Adapter/Prefix Tuning
-
对比Adapter:P-tuning实际上也是一种类似Adapter的做法,同样是固定原模型的权重,然后插入一些新的可优化参数,只不过这时候新参数是作为模板插入在Embedding层。
-
对比Prefix Tuning:P-Tuning加入的可微virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token插入的位置是可选的,不一定是前缀。
为什么P-tuning优于Fine-tuning
P-tuning和Fine-tuning都是微调所有权重,为什么P-tuning优于Fine-tuning?
这是因为,不管是PET还是P-tuning,它们其实都更接近预训练任务,而加个全连接层的做法,其实还没那么接近预训练任务,所以某种程度上来说,P-tuning有效更加“显然”,反而是加个全连接层微调为什么会有效才是值得疑问的。
在论文《A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks》中,作者的回答是:
- 预训练模型是某种语言模型任务;
- 下游任务可以表示为该种语言模型的某个特殊情形;
- 当输出空间有限的时候,它又近似于加一个全连接层;
- 所以加一个全连接层微调是有效的。
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
-
缺乏通用性。Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
-
缺少深度提示优化。在Prompt Tuning和P-tuning中,prompt只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,prompt的位置的embedding是由之前的transformer层计算出来的,所以:
- 由于序列长度的限制,可调参数的数量是有限的。
- 输入embedding对模型预测只有相对间接的影响。
P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数:从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%,同时也足够参数高效。
- 深层结构中的Prompt能给模型预测带来更直接的影响。

P-tuning v2可以看做是优化后的Prefix Tuning:
移除重参数化的编码器:以前的方法利用重参数化功能来提高训练速度和鲁棒性; 在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型;同时对于某些NLU任务,使用MLP会降低性能
不同任务采用不同的提示长度:提示长度在P-Tuning v2中起着关键作用,不同的NLU任务会在不同的提示长度下达到其最佳性能。通常,简单的分类任务(情感分析等)偏好较短的提示(小于20个令牌);困难的序列标注任务(阅读理解等)则偏好较长的提示(大约100个令牌)
引入多任务学习:先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务可以提供更好的初始化来进一步提升性能
回归传统的分类标签范式:P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
最早的selective PEFT方法是仅微调网络的几个顶层(冻结前层),现代方法通常基于层的类型(Cross-Attention is All You Need)或内部结构,例如仅微调模型的偏置(BitFit)或仅特定的行(Efficient Fine-Tuning of BERT Models on the Edge)。
Adapter Tuning通过在模型的层之间插入针对特定任务的残差模块,并只优化这些残差模块。由于残差模块的参数更少(约3.6%),因此微调成本更低。
本文提出的 Diff pruning 与Adapters类似,但 Diff pruning 不是修改模型的结构,而是通过一个特定任务的 diff 向量扩展基础模型,只需要微调0.5%的预训练参数,即Diff pruning 将特定任务的微调表述为学习一个 diff 向量$ \delta_t$,该向量被添加到预先训练的模型参数 $ \theta_{pretrain}$(固定)中 :

prompt tuning是微调一个soft prompt tokens,而DiffPruning也是冻结大部分语言模型参数只微调一个插入的diff向量,本质上是一样的。
BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models 是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
们希望有一种满足以下条件的高效微调方法:
- 到达能够匹配全量微调的效果。
- 仅更改一小部分模型参数。
- 使数据可以通过流的方式到达,而不是同时到达,便于高效的硬件部署。
- 改变的参数在不同下游任务中是一致的。
Ben-Zaken等人(2021年)提出仅对网络的偏置进行微调。也就是说,在每个线性或卷积层中,权重矩阵W保持不变,只优化偏置向量b
BitFit、Adapter和Diff-Pruning的效果对比,可以发现:
- BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning相当,某些任务上甚至更优。
- BitFit微调结果虽不及fine-tuning,但是远超固定全部模型参数的Frozen方式。
FAR(Vucetic等人,2022年)选择参数矩阵的列进行剪枝,并将线性层重新配置为可训练和冻结的状态。该方法分为两个阶段。
- 阶段一:确定参数矩阵中最重要的行进行更新。这个过程类似于结构化剪枝,并可以使用任何剪枝方法。
- 阶段二:将每个参数W拆分为可训练部分W_t和冻结部分W_f,对偏置也执行类似的操作,然后将结果连接起来,重新配置网络。
Intrinsic SAID(2020.12)《Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning》
在Aghajanyan等人Intrinsic SAID(2020年)的工作中,他们证明了常见的预训练模型具有非常低的内在维度,故存在一种低维度的重新参数化方式,使微调效果媲美fine-tuning。
神经网络包含许多稠密层,这些层执行矩阵乘法。这些层中的权重矩阵通常具有满秩。Intrinsic SAID的研究表明,尽管预训练模型的参数量很大,但每个下游任务对应的Intrinsic Dimension(本征维度)并不大,即使在随机投影到较小子空间时,仍然可以有效学习。换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
受此启发,我们假设权重的更新在适应过程中也具有较低的intrinsic rank(内在秩)。对于一个预训练的权重矩阵$W$,我们不直接微调,而是微调一个增量$\Delta W$来更新模型。

具体来说,在原始的预训练模型PLM旁边增加一个新的通路(相当于一个外挂),通过前后两个矩阵A,B相乘,来模拟本征秩。外挂层和预训练模型层维度都为d,第一层会先将维度d通过全连接层降维至r,第二层再从r通过全连接层映射回d维度,其中,r<<d。
这里的r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多,这一步就叫做低秩分解。
第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可, $ H = W_oX + BA_x$ 所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵$W_o$加到一起作为新权重参数替换原本PLM的即可,对于推理来说,不会增加额外的计算资源。
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间。
AdaLoRA(2023.3)论文《Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning》、QingruZhang/AdaLoRA
之前的Adapter tuning方法和下游任务增量的方法都存在一些问题:
添加小型网络模块:将小型网络模块添加到PLMs中,保持基础模型保持不变的情况下仅针对每个任务微调这些模块,可以用于所有任务。这样,只需引入和更新少量任务特定的参数,就可以适配下游的任务,大大提高了预训练模型的实用性。如:Adapter tuning、Prefix tuning、Prompt Tuning等。这类方法虽然大大减少了内存消耗。但是这些方法存在一些问题,比如:Adapter tuning引入了推理延时;Prefix tuning或Prompt tuning直接优化Prefix和Prompt是非单调的,比较难收敛,并且消耗了输入的token。
下游任务增量更新:对预训练权重的增量更新进行建模,而无需修改模型架构,即W=W0+△W。比如:Diff pruning、LoRA等, 此类方法可以达到与完全微调几乎相当的性能,但是也存在一些问题,比如:Diff pruning需要底层实现来加速非结构化稀疏矩阵的计算,不能直接使用现有的框架,训练过程中需要存储完整的∆W矩阵,相比于全量微调并没有降低计算成本。 LoRA则需要预先指定每个增量矩阵的本征秩 r 相同,忽略了在微调预训练模型时,权重矩阵的重要性在不同模块和层之间存在显著差异,并且只训练了Attention,没有训练FFN,事实上FFN更重要。
基于以上问题进行总结:
- 我们不能预先指定矩阵的秩,需要动态更新增量矩阵的R,因为权重矩阵的重要性在不同模块和层之间存在显著差异。
- 需要找到更加重要的矩阵,分配更多的参数,裁剪不重要的矩阵。找到重要的矩阵,可以提升模型效果;而裁剪不重要的矩阵,可以降低参数计算量,降低模型效果差的风险。
为了弥补这一差距,作者提出了AdaLoRA,它根据权重矩阵的重要性得分,在权重矩阵之间自适应地分配参数预算。
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。具体做法如下:
- 调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
- 以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确SVD分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时,保留未来恢复的可能性并稳定训练。
$$ W = W^{0} + \Delta = W^{0} + P \Lambda Q
$$
在训练损失中添加了额外的惩罚项,以规范奇异矩阵P和Q的正交性,从而避免SVD的大量计算并稳定训练。
虽然最近的量化方法可以减少 LLM 的内存占用,但此类技术仅适用于推理场景。
基于此,作者提出了QLoRA,并首次证明了可以在不降低任何性能的情况下微调量化为 4 bit的模型。
QLoRA(论文: QLORA: Efficient Finetuning of Quantized LLMs),使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
QLORA 有一种低精度存储数据类型(4 bit),还有一种计算数据类型(BFloat16)。实际上,这意味着无论何时使用 QLoRA 权重张量,我们都会将张量反量化为 BFloat16,然后执行 16 位矩阵乘法。QLoRA提出了两种技术实现高保真 4 bit微调——4 bit NormalFloat(NF4) 量化和双量化。此外,还引入了分页优化器,以防止梯度检查点期间的内存峰值,从而导致内存不足的错误,这些错误在过去使得大型模型难以在单台机器上进行微调。具体说明如下:
- 4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的实证结果。
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 分页优化器:使用NVIDIA统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。

MAM Adapters(2021.10)《Towards a Unified View of Parameter-Efficient Transfer Learning》
许多针对语言模型的参数高效微调(PELT)方法,在模型训练参数极大的减少的情况下,模型效果与全量微调相当。但是不同的PELT方法在同一个任务上表现差异可能都非常大,这让针对特定任务选择合适的方法非常繁琐。
基于此,作者提出了UniPELT方法,将不同的PELT方法作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。
UniPELT是 LoRA、Prefix Tuning和Adapter的门控组合,其中:
-
LoRA:通过低秩分解,将优化预训练参数转换为优化外挂层的参数矩阵; -
Prefix Tuning:在每个层的多头注意力中,在key和value的前面添加了l个可调节的前缀向量。具体来说,两组前缀向量$P^k,P^v$与原始键K和值V进行连接。然后在新的前缀键和值上执行多头注意力计算。 -
Adapter:在Transformer块的feed-forward子层之后添加Adapter模块
然后组合这三个模块,每个模块使用门控机制(实现为线性层)来控制,即通过GP参数控制Prefix-tuning方法的开关,GL控制LoRA方法的开关,GA控制Adapter方法的开关。所有可训练参数(图中蓝颜色部分)包括 LoRA 的重参数化矩阵 ,提示调优参数、Adapter参数和门函数权重。整个结构如下图所示:
