FRM: Federated Reputation Models for "Securing Federated Sensitive Topic Classification against Poisoning Attacks"
This repository is based on a fork of the repository of Attack-Resistant Federated Learning with Residual-based Reweighting at a workshop of AAAI 21, a benchmark for residual based Federated Learning. Our NDSS'23 paper Securing Federated Sensitive Topic Classification against Poisoning Attacks extends upon this residual-based method as it is more robust and applicable to large text datasets as our SURL dataset, contrary to previous state-of-the-art as FLTrust that focused only on several datasets containing images and one containing short activity descriptors of the HAR dataset.
Our NDSS'23 framework uses reputation scores over time (historical) and freshness in order to consider a time decay (algorithmic) function that penalises updates more when the occur in the beginning of a window of time --s as specified in our parameters options.py. These can be tuned as a know and are new enhancements we provide on top of the existing core framework of the AAAI paper providing us the most common SOTA algorithms.
In our paper we present a novel aggregation algorithm based and extended upon residual-based reweighting to defend against poisoning attacks in federated learning for text as well as image datastes. Our aggregation algorithm combines repeated median regression with a reweighting scheme in iteratively reweighted least squares fashion as precedessor work but we also add robust reputation estimators to produce better defenses againts label flipping and backdoor attacks. Our secure aggregation algorithm outperforms other alternative algorithms in the presence of label-flipping and backdoor attacks. We also provide theoretical guarantees for the estimator of the aggregation algorithm.
- This repository also uses code from federated learning.
- Previous Results: some algorithms can successfully defend Gaussian Noise Attacks, Label-Flipping Attacks and Backdoor Attacks.
| # of attackers | 0 | 1 | 2 | 3 | 4 | Average |
|---|---|---|---|---|---|---|
| FedAvg | 88.96% | 85.74% | 82.49% | 82.35% | 82.11% | 84.33% |
| Median | 88.11% | 87.69% | 87.15% | 85.85% | 82.01% | 86.16% |
| Trimmed Mean | 88.70% | 88.52% | 87.44% | 85.36% | 82.35% | 86.47% |
| Repeated Median | 88.60% | 87.76% | 86.97% | 85.77% | 81.82% | 86.19% |
| FoolsGold | 9.70% | 9.57% | 10.72% | 11.42% | 9.98% | 10.28% |
| Residual-Based | 89.17% | 88.60% | 86.66% | 86.09% | 85.81% | 87.27% |
Results of label-flipping attacks on CIFAR-10 dataset with different numbers of attackers.
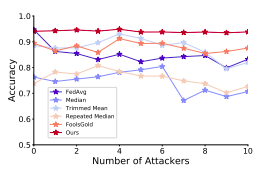
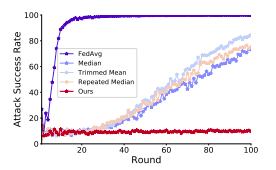
Results of label-flipping attacks on the MNIST dataset (left). Result of backdoor attack success rate on CIFAR-10 (right).
Authors and License: Tianyue Chu and Alvaro Garcia-Recuero. Licensed under Creative Commons NC-ND 4.0
Our framework provides secure Federated Learning because we make sure our model bounds updates into a linear regression boundary defined by the repeated median as in a previous AAAI work, but with additional features, namely a robust, parametrizable reputation model including freshness or sliding window, historical behaviour of client. etc.
If you find [Securing Federated Sensitive Topic Classification against Poisoning Attacks] useful in your research, please consider citing:
@article{NDSS23FLsecure,
title={Securing Federated Sensitive Topic Classification against
Poisoning Attacks},
author={Chu, T., Garcia-Recuero, A., Iordanu, C., Smaragdakis, G., Laoutaris, N.},
journal={NDSS 2023},
year={2023}
}
- Colab Pro.
- Pytorch from the offical repository.
- Install packages: tensorboardX, etc.
pip install tensorboardX
-
The full code will automatically download CIFAR dataset. This reposiroty is using the SURL dataset only.
-
Colab setup
- Mount drive first.
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
import sys
sys.path.insert(0, '/content/drive/My Drive/ColabNotebooks/')
- Test data paths.
!ls '/content/drive/MyDrive/Colab Notebooks/data/sensitive_websites_dataset_clean.csv'
- Update system packages
!sudo apt-get update
!sudo apt install python3.8
!sudo apt install python3-pip
- Install Pipenv to manage libraries
!python3.8 -m pip install pipenv
- Install libraries and pytorch compatible version with Colab.
!pipenv install tqdm torch tensorboardX requests numpy torchvision sklearn scipy pandas ipykernel matplotlib
- Install torch with cuda version for Colab
!pipenv shell
Then enter pip install -q torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html subcommand inside pipenv shell and type exit when done.
- Test GPU is available.
import torch
torch.cuda.is_available()
- IF you want to check in which device address is the GPU available.
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
- And finally print it all
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Select the Runtime > "Change runtime type" menu to enable a GPU accelerator, ')
print('and then re-execute this cell.')
else:
print(gpu_info)
Wed Jan 12 20:47:47 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.46 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 34C P0 25W / 250W | 2MiB / 16280MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Label Flipping attack on SURL
!pipenv run python main_nn.py --model URLNet --dataset URL --epochs 100 --gpu 0 --iid 0 --num_users 7 --num_attackers 3 --attack_label 0 --agg irls --reputation_active 1 --kappa 0.3 --a 0.5
Change --agg tag to select aggregation algorithm and change --num_attackers to specify the number of attackers. Note that in our experiments the --num_users + --num_attackers comprises the 100% of users. Also, we add a new set of parameters, a boolean --reputation_active, --a, --eta, --W , --a, --z, --s as specified in options.py.
!pipenv run python main_nn.py --model URLNet --dataset URL --epochs 100 --gpu 0 --iid 0 --num_users 7 --num_attackers 3 --agg irls --reputation_active 1 --is_backdoor 1 --backdoor_label 0 --kappa 0.3 --a 0.5
Our plots with results are shown in our online camera ready paper for NDSS 23