ဒီအပိုင်းကနေစပြီးတော့ကျနော်ထပ်ဖြည့်ချင်တဲ့ content လေးတွေထပ်ဖြည့်သွားပါမယ်။ ပြီးခဲ့တဲ့ relationship, join တွေအပိုင်းပြီးရင်အခြေခံအတွက်လုံလောက်ပြီလို့ပြောလို့ရပါတယ်။ နောက်အပိုင်းတွေကတော့ advance ဖြစ်လာတဲ့အတွက် အခေါ်အဝေါ်လေးတွေကအစဖတ်ရတာနည်းနည်းခက်နိုင်ပါတယ်။ ကျနော်တတ်နိုင်သလောက်တော့နားလည်ရလွယ်အောင်စဉ်းစားပြီးရှင်းပြပေးထားပါတယ်။ ဒီအပိုင်းတွေကိုဖတ်ရင်းနဲ့တစ်ခြားသော online က resources တွေနဲ့လည်းတွဲဖက်ပြီးပိုစဉ်းစားနိုင်ဖို့အကြံပြုပါတယ်ခင်ဗျာ။
Database ထဲမှာ data တွေများလာတဲ့အခါမှာပြန်ထုတ်ယူရတဲ့နေရာမှာကိုယ်လိုချင်တဲ့ data တွေအတိုင်းထပ်အပ်ကျဖို့ဆိုတာခက်ခဲလာနိုင်ပါတယ်။ Normalization ရဲ့အကူအညီနဲ့ဒီလိုအခက်အခဲတွေကိုကျော်လွှားနိုင်ပါတယ်။ Normalization ဟာ data redundancy (data ဆုံးရှုံးမှု) ဖြစ်နိုင်မှုကိုလျော့ချနိုင်ပြီးတော့ data integrity (data စစ်မှန်မှု) ကိုပိုမိုကောင်းမွန်လာနိုင်စေပါတယ်။
ဥပမာအားဖြင့် Normalize မလုပ်ထားတဲ့ data တွေဆို data ဆွဲထုတ်တဲ့အချိန်မှာထပ်နေတဲ့အချိန်မှာထပ်နေတဲ့ data တွေပါလာနိုင်တာမျိုး၊ data ထည့်တဲ့အချိန်မှာ attribute တွေမကိုက်လို့ထည့်မရတာမျိုး၊ ကိုယ်ဖျက်ချင်တာကတစ်မျိုး၊ attributes တွေရောယှက်ပြီးတော့ပျက်သွားတာကတစ်မျိုးတွေဖြစ်တတ်ပါတယ်။
Normalization ဆိုတာတစ်နည်းအားဖြင့် data တွေကို organize ဖြစ်အောင်လုပ်ထားတာပါပဲ။ Database ထဲမှာရှိတဲ့ tables နဲ့ columns တွေကိုသတ်မှတ်ထားတဲ့ constraints (စည်းမျဉ်း) တွေနဲ့ organize လုပ်ထားခြင်းပဲဖြစ်ပါတယ်။
ဒီဆောင်းပါးမှာ Normalization form ၆ ခုကိုရေးပေးသွားမှာဖြစ်ပါတယ်။
1NF မှာတော့ atomicity ဖြစ်ရမယ်။ တစ်နည်းအားဖြင့် Table တစ်လုံးထဲမှာ multi value attribute တွေမရှိရဘူး၊ column တစ်ခုက multiple value မရှိနေရဘူး။
အောက်က table ကိုနမူနာကြည့်မယ်ဆို authors column က value တွေကိုတစ်ခုထက်ပိုပြီးကိုင်ထားပါတယ်။ ဒါဆိုရင် atomicity မဖြစ်တော့ဘူး 1NF ပြောင်းပေးရပါမယ်။
| book_id | title | authors | genre |
|---|---|---|---|
| 1 | The Art of SQL | Jane Doe, John Smith | Database |
| 2 | SQL Mastery | Jane Doe, Alice Johnson | Programming |
| 3 | Query Tactics | John Smith, Alice Johnson | Database |
Table ကို books နဲ့ authorsနှစ်ခုအဖြစ်ခွဲပေးလိုက်ပါမယ်။
Books Table:
| book_id | title | genre |
|---|---|---|
| 1 | The Art of SQL | Database |
| 2 | SQL Mastery | Programming |
| 3 | Query Tactics | Database |
Authors Table:
| book_id | author_name |
|---|---|
| 1 | Jane Doe |
| 1 | John Smith |
| 2 | Jane Doe |
| 2 | Alice Johnson |
| 3 | John Smith |
| 3 | Alice Johnson |
1NF ပြောင်းအပြီးမှာ table တိုင်းရဲ့ column တိုင်းမှာ atomic value တွေပဲရှိနေတော့ပါမယ်။ authors table မှာတော့ books table ကို reference လုပ်နိုင်အောင် book_idထည့်ပေးထားလိုက်ပါတယ်။ table ကနှစ်လုံးမခွဲလည်းရပါတယ်၊ တစ်လုံးထဲမှာပဲ row တွေပြောင်းထည့်ပြီးသိမ်းခြင်းအားဖြင့်လည်း 1NF ကိုပြေလည်စေပါတယ်။
Candidate Key & Non-prime attribute
2NF ကိုဆက်မသွားခင် candidate key ဆိုတဲ့အရာတစ်ခုကိုမိတ်ဆက်ပေးချင်ပါတယ်။ Candidate key ဆိုတာကတော့ table တစ်လုံးထဲမှာ record တစ်ကြောင်းကို unique ဖြစ်တယ်လို့သတ်မှတ်နိုင်တဲ့ တစ်ခု သို့ တစ်ခုထက်ပိုတဲ့ columns တွေကိုဆိုလိုခြင်းဖြစ်ပါတယ်။
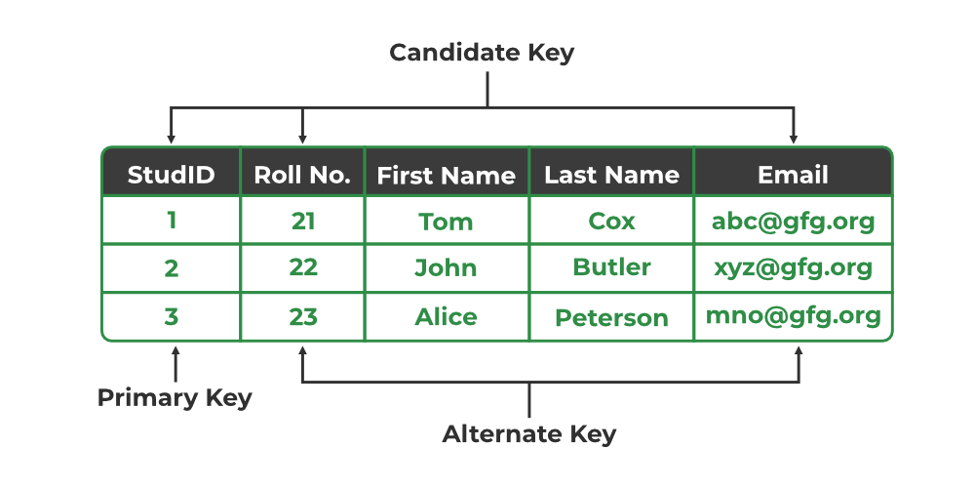 Credit geekforgeek
Credit geekforgeek
Non-prime attribute ဆိုတာကတော့ candidate keys မဟုတ်တဲ့ attribute တစ်ခုကိုဆိုလိုခြင်းဖြစ်ပါတယ်။
2NF ဖြစ်ဖို့အတွက် table က 1NF ဖြစ်ပြီးသားဖြစ်ရပါတယ်။ နောက်တစ်ခုကတော့ partial dependency မဖြစ်ရပါဘူး။ Partial dependency ဆိုတာကိုနားလည်နိုင်ဖို့အောက်ကဥပမာကိုကြည့်နိုင်ပါတယ်။
| student_id | course_id | course_name |
|---|---|---|
| 1 | 101 | Database Fundamentals |
| 2 | 102 | Advanced SQL Queries |
| 3 | 103 | Data Modeling and Design |
ဒီ table မှာ student_id course_id က candidate keys တွေဖြစ်နေပါတယ်။ course_name ကတော့ non-prime attribute ဖြစ်ပါတယ်။ course_name က course_idကိုသွားချိတ် (depend) ဖြစ်နေပါတယ်။ course_id ကလည်း candidate key ထဲက proper subset တစ်ခုဖြစ်ပါတယ်။ ဒီလိုမျိုး non-prime attribute က proper subset of candidate key ကိုသွားပြီးမှီခိုနေတယ် (depend) ဖြစ်နေတယ်ဆို partial dependency ဖြစ်နေတယ်လို့ဆိုနိုင်ပါတယ်။
ဒါကို 2NF ပြောင်းဖို့အတွက်အောက်ကလို table တွေခွဲထားနိုင်ပါတယ်။
course table
| course_id | course_name |
|---|---|
| 101 | Database Fundamentals |
| 102 | Advanced SQL Queries |
| 103 | Data Modeling and Design |
student_course table
| student_id | course_id |
|---|---|
| 1 | 101 |
| 2 | 102 |
| 3 | 103 |
ဒီလိုခွဲထုတ်လိုက်ခြင်းဖြင့် non-prime attribute ဟာသူနဲ့သက်ဆိုင်တဲ့ primary key ပေါ်မှာပဲ depend လုပ်သွားမှာဖြစ်ပါတယ်။
Stuents column attribute တွေရှိနေသေးရင်students table သက်သက်ထပ်ထုတ်ထားနိုင်ပါတယ်။
3NF ပြောင်းဖို့အတွက်ဆို table က 2NF ဖြစ်ထားရမယ်။ Transitive dependencies တွေမရှိရဘူး။
- Non-prime attribute တစ်ခုကနောက် non-prime attribute တစ်ခုကိုမှီခိုနေမယ်။
- တစ်နည်းအားဖြင့် A က B ကို depend ဖြစ်မယ်၊ B က primary key ကို depend ဖြစ်မယ်ဆိုရင် A က primary key အပေါ် transitively depend ဖြစ်သွားတယ်လို့ဆိုနိုင်ပါတယ်။
နားလည်လွယ်ဖို့အောက်ကဥပမာကိုကြည့်ရအောင်။
| employee_id | department_id | department_name | manager_name |
|---|---|---|---|
| 1 | 101 | IT | Alice Johnson |
| 2 | 102 | HR | Bob Smith |
| 3 | 101 | IT | Alice Johnson |
manager_name ဆိုတဲ့ column က department_id ကို depend ဖြစ်နေတယ်၊ department_id က primary key ဖြစ်တဲ့ employee_id ကို depend ဖြစ်နေတဲ့အတွက် transitive dependency ဖြစ်နေတယ်လို့သတ်မှတ်နိုင်ပါတယ်။
3NF ပြောင်းဖို့အတွက် managers နဲ့ departments table တွေကိုသက်သက်စီခွဲချနိုင်ပါတယ်။
departments Table
| department_id | department_name |
|---|---|
| 101 | IT |
| 102 | HR |
managers Table
| department_id | manager_name |
|---|---|
| 101 | Alice Johnson |
| 102 | Bob Smith |
employees Table ကတော့ joint table ဖြစ်သွားပါမယ်။
| employee_id | department_id |
|---|---|
| 1 | 101 |
| 2 | 102 |
| 3 | 101 |
ဒါဆိုရင် manager_name သည် primary key အပေါ်မှာ transitively မဟုတ်ဘဲ directly depend ဖြစ်သွားပါပြီ။
BCNF ကိုမဆက်ခင် superkey အကြောင်းအရင်ရှင်းပေးချင်ပါသေးတယ်။
Superkey
Superkey ဆိုတာကတော့ table ထဲမှာ row တိုင်းကို unique ဖြစ်နေနိုင်တဲ့ attribute တစ်ခုသို့ တစ်ခုထက်ပိုတဲ့ attribute set လိုက်လည်းဖြစ်နိုင်ပါတယ်။ တစ်နည်းအားဖြင့် superkey ဟာ candidate key တစ်ခု သို့ set of candidate keys လည်းဖြစ်နိုင်သလို တစ်ခြားသော attribute တွေလည်းဖြစ်နိုင်ပါတယ်။
ဥပမာ attribute A, B, C ရှိမယ်၊ {A, B} ဟာuniqueness ကိုထိန်းထားနိုင်မယ်ဆို superkey ဖြစ်နိုင်မယ်။ သို့ပေမယ့် unique ဖြစ်နိုင်တယ်ဆို superkey အဖြစ် C ကိုလည်းထည့်နိုင်သလို {B, C} ပဲလည်းဖြစ်နိုင်တယ်။ Table ရဲ့ primary key ကို {A, B} လို့သတ်မှတ်ထားတယ်ဆို {A, B} က candidate key အဖြစ်ရှိမယ်၊ superkey လည်းဖြစ်မယ်။ candidate key ကိုယ်တိုင်ကိုက minimal super key အဖြစ်နဲ့တည်ရှိနေတာဖြစ်ပါတယ်။ ဆိုတော့ recap ပြန်လုပ်ရမယ်ဆို
- primary key တိုင်းက candidate key
- candidate key တိုင်းက superkey
- သို့ပေမယ့် superkey တိုင်းကတော့ candidate, primary key မဖြစ်နိုင်ပါဘူး။
Image credit: geekforgeek
BCNF form ရောက်ဖို့အတွက်ဆို
- 3rd normal form ကိုရောက်ပြီးသားဖြစ်ရမယ်။
- Dependency တိုင်းမှာ determinant က super key ဖြစ်ရမယ်။
- E.g. A->B dependency မှာ left side က determinant သည် super key ဖြစ်ရမယ်။ အောက်က table တွေနဲ့ဥပမာထပ်ကြည့်ရအောင်။
| Employee_ID | project_name | Skill |
|---|---|---|
| 101 | projectA | Java |
| 101 | projectB | SQL |
| 102 | projectC | Python |
| 103 | projectA | Go |
employee တစ်ယောက်ဟာ project တစ်ခုထက်ပိုပြီးရှိနိုင်တယ်။ အပေါ်က table မှာ employee_id နဲ့ project_id ကိုပေါင်းလိုက်ရင် unique ဖြစ်ပြီးတော့ primary key ဖြစ်သွားပါတယ်၊ skill ကိုလည်းလှမ်းပြီးတော့ဆွဲထုတ်နိုင်ပါတယ်။ dependency ကနှစ်ခုထွက်သွားပါမယ်။
- Employee_id + project_id -> skill က dependency တစ်ခုရှိလာမယ်။ Skill တစ်ခုကို project တစ်ခုစီမှာပဲသုံးနေတယ်၊ Project တစ်ခုမှာတော့ skill တစ်ခုထပ်ပိုပြီးရှိနိုင်တဲ့အတွက်
- Skill -> project_id dependency တစ်ခုရှိပါမယ်။ Skill သည် non-prime attribute ဖြစ်ပါတယ်၊ superkey ဖြစ်မနေပါဘူး။ ဒီအတွက်ကြောင့်အပေါ်က table သည် BCNF form ဖြစ်တယ်လို့ဆိုလို့မရပါဘူး။
အောက်ကအတိုင်းခွဲချလိုက်မယ်ဆိုရင်တော့ BCNF ကိုပြေလည်သွားစေမှာဖြစ်ပါတယ်။
employee table
| Employee_ID | skill_id |
|---|---|
| 101 | 1 |
| 101 | 2 |
| 102 | 3 |
| 103 | 4 |
skills table
| skill_id | skill_name | project_name |
|---|---|---|
| 1 | Java | ProjectA |
| 2 | SQL | ProjectB |
| 3 | Python | ProjectC |
| 4 | Go | ProjectA |
4NF ကိုပြေလည်စေဖို့အတွက်ဆို table က
- BCNF ဖြစ်ထားရမယ်။
- multi-value dependencies တွေရှိနေလို့မဖြစ်ပါဘူး။ Multi-value dependencies ဖြစ်နိုင်တဲ့အချက်တွေက
- A->B dependency မှာ single A အတွက် B values တွေတစ်ခုထက်မကရှိနေမယ်
- Table ကအနည်းဆုံး column 3 ခုရှိရမယ်
- နှစ်ခုထဲဆို multi-row ခွဲချလိုက်ရုံနဲ့ multi-values မဖြစ်နိုင်တော့ပါဘူး။
- A->B က multi-values dependency ဖြစ်နေတယ်ဆို B->C ကတစ်ခုနဲ့တစ်ခု depend ဖြစ်နေလို့မရပါဘူး။
အောက်က table ကိုနမူနာကြည့်ရအောင်
| customer_id | product | interest |
|---|---|---|
| 1 | Laptop | Gaming |
| 1 | Smartphone | Programming |
| 2 | laptop | Photography |
| 2 | Smartphone | Gaming |
customer_id 1 က product နှစ်ခု၊ interest နှစ်ခုမှာ record တွေရှိနိုင်ပါတယ်။ သေချာစဉ်းစားကြည့်လိုက်မယ်ဆို table structure ကမသေသပ်တာကိုတွေ့ရမယ်၊ product နဲ့ interest က independent ဖြစ်နေတဲ့အတွက် row နှစ်ကြောင်းထပ်ထွက်လာစေနိုင်ပါတယ်။ ဒီလိုမျိုးပေါ့
| customer_id | product | interest |
|---|---|---|
| 1 | Laptop | Gaming |
| 1 | Smartphone | Programming |
| 1 | Laptop | Programming |
| 1 | Smartphone | Gaming |
Multi-value dependency ကြောင့်မလိုအပ်ဘဲ row တွေကို repeat ဖြစ်စေပါတယ်။
အောက်ကလိုမျိုးခွဲချပြီးတော့ပြေလည်အောင်လုပ်ပေးနိုင်ပါတယ်။
orders table
| order_id | customer_id | product |
|---|---|---|
| 1 | 1 | Laptop |
| 2 | 2 | Smartphone |
interest table
| interest_id | customer_id | interest |
|---|---|---|
| 1 | 1 | Gaming |
| 2 | 1 | Programming |
| 3 | 2 | Photography |
| 4 | 2 | Gaming |
customers table ကသက်သက်နောက် table တစ်လုံးအနေနဲ့ရှိနေပါမယ်။
5NF ပြေလည်ဖို့အတွက်ဆို table တွေဟာ
- 4th normal form ပြေလည်ပြီးသားဖြစ်ရမယ်။
- Join dependency မရှိရဘူး။
- Joining ကြောင့် data ဆုံးရှုံးမှုမရှိစေရဘူး။
- DB ထဲမှာရှိတဲ့ tables တွေဟာတတ်နိုင်သလောက်မတူညီတဲ့ keys တွေနဲ့ tables အသေးတွေပြန်ခွဲထားနိုင်ရမယ်
- တူညီတဲ့ key နဲ့ခွဲမယ်ဆိုဆုံးတော့မှာမဟုတ်ပါ။
- Table ပြန်ခွဲတဲ့နေရာမှာလည်း business logic ပေါ်မူတည်ပါသေးတယ်။
5th normal form ကို Project join normal form လို့လည်းခေါ်ပါတယ်။
ပိုနားလည်လွယ်အောင်အောက်ကဥပမာတွေကိုဆက်ကြည့်ရအောင်။
| ProjectID | EmployeeID | ProjectName | EmployeeName | HoursWorked |
|---|---|---|---|---|
| 101 | 1 | Project A | John Doe | 20 |
| 101 | 2 | Project A | Jane Smith | 15 |
| 102 | 1 | Project B | John Doe | 25 |
| 102 | 3 | Project B | Bob Johnson | 30 |
ဒီ table မှာ project_id + employee_id က primary key ဖြစ်မယ်။ သို့ပေမယ့်ဒီ primary key မှာ project_name data တွေထပ်နေတဲ့အတွက် data redundancy(data ဆုံးရှုံးမှု) ရှိနေပါတယ်။
Table ကို 5th normal form ပြောင်းမယ်ဆိုဒီလိုဖြစ်သွားပါမယ်။
project table
| ProjectID | ProjectName |
|---|---|
| 101 | Project A |
| 102 | Project B |
employee table
| EmployeeID | EmployeeName |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
| 3 | Bob Johnson |
work_hour table
| ID | ProjectID | EmployeeID | HoursWorked |
|---|---|---|---|
| 1 | 101 | 1 | 20 |
| 2 | 101 | 2 | 15 |
| 3 | 102 | 1 | 25 |
| 4 | 102 | 3 | 30 |
မတူညီတဲ့ keys တွေနဲ့ table အသေးလေးတွေပြန်ခွဲချလိုက်မယ်။ Join လုပ်ကြည့်မယ်ဆိုလည်း data ဆုံးရှုံးမှုမရှိနိုင်တော့တာကိုတွေ့ရပါမယ်။
Normalization ကိုနားလည်သွားမယ်ဆို database တွေကို optimize လုပ်နိုင်လာမယ့်အပြင် data redundancy ဖြစ်နိုင်မှုကိုကျော်ဖြတ်နိုင်မယ်၊ data integrity ပိုကောင်းလာပါလိမ့်မယ်။ ဒါ့အပြင် data dependencies အကြောင်းတွေ ၊ multi-values အကြောင်းတွေကိုပါနားလည်သွားမယ့်အတွက် structure ကျတဲ့ databases တွေကိုတည်ဆောက်နိုင်သွားမှာဖြစ်ပါတယ်။
နိဂုံးချုပ်ရမယ်ဆိုတစ်ကယ်လက်တွေ့ project တွေမလုပ်သေးဘူးတဲ့သူတွေအတွက် normalization ကိုကွက်ကွက်ကွင်းကွင်းနားလည်ဖို့ဆိုတာခက်ပါတယ်။ ဒီ article series လေးကနေအတိုင်းအတာတစ်ခုအ ထိသဘောတရားကိုနားလည်သွားပြီး လက်တွေ့လုပ်တဲ့အခါမှာ memory တစ်ခုအနေနဲ့ပြန်ပြီးအသုံးချနိုင်သွားတယ်၊ ဆက်စပ်နိုင်သွားဖို့မျှော်လင့်ပါတယ်။