Stabilize, optimize, and increase robustness of QuickSort #45222
Conversation
|
It seems like solving #11429 as a side-effect, but at the cost of losing in-place property. |
Good observation! I've added tests to confirm, and indeed it does. |
115f851 to
cde1695
Compare
cde1695 to
3318c34
Compare
|
This depends on workspaces which depend on OffsetArrays. Hold pending availability of OffsetArrays in Sort.jl. |
ab83655 to
0010aaf
Compare
|
We're proceeding with workspaces/buffers for sorting without OffsetArrays. We will use a similar approach here as in radix_sort. It will work but be a bit ugly and have a bit of runtime overhead for certain inputs with offset indexing. |
| # Randomize quicksort pivot selection. This code is here because of bootstrapping: | ||
| # we need to sort things before we load this standard library. | ||
| # TODO move this into Sort.jl | ||
| Base.Sort.select_pivot(lo::Integer, hi::Integer) = rand(lo:hi) |
There was a problem hiding this comment.
Would it be better to use something other than the global RNG? Perhaps introduce a dedicated stream for sorting operations? I certainly wouldn't anticipate that sort would affect the global RNG and it would take me a while to trace the source of the consumption to here. Technically, a user shouldn't care... but that isn't to say they won't.
There was a problem hiding this comment.
I don't think we should try to make the promise that algorithms in Base/Stdlib won't generate random numbers using the global rng. A ton of stuff needs random numbers (eg median, some matrix factorization algorithms (for pivoting), possibly thread scheduling). I think we shouldn't set the expectation that users should care about the global RNG state.
There was a problem hiding this comment.
While it would be nice to not alter the global RNG seed, to maintain our "everything is task scheduling independent, even random numbers" guarantee, which, I believe, is much more important than "sorting doesn't change global RNG state", I think we would need to have a different dedicated stream for each task, which is far too expensive; or we would need to branch a new stream from the global RNG without altering the global RNG's state, which could introduce very hard to anticipate correlations between the randomness of sorting and of other generations akin to but much subtler (and less likely to come up) than #6573
In general, I think everything should use the global RNG, and if someone wants a stream nothing else touches, then they are responsible for creating their own dedicated stream.
There is a warning at the top of https://docs.julialang.org/en/v1/stdlib/Random/ that is somewhat relevant, though it doesn't directly apply to this.
There was a problem hiding this comment.
Beat me to it :) I totally agree.
There was a problem hiding this comment.
This seems to have caused a bug in Zygote: FluxML/Zygote.jl#1351. Possibly this should just be a pure Zygote fix, but I thought it would be good to be aware that this has the potential to cause some bugs in cases where this function was assumed not to affect the RNG state.
There was a problem hiding this comment.
it's internal usage in various places is incorrect.
Do you have an example?
In 1.8 we also had pathological (and more easily constructed) quadratic cases
For example, the "sawtooth" ordering:
julia> n = 10^6;
julia> x = vcat(3n:4n,2n:3n,n:2n,0:n);
julia> @time sort!(shuffle!(x));
0.477350 seconds
julia> x = vcat(3n:4n,2n:3n,n:2n,0:n);
julia> @time sort!(x);
134.471621 seconds
julia> VERSION
v"1.8.5"There was a problem hiding this comment.
I don't have a clean MWE, but there are two clunkier examples in #48230 (Zygote is one breakage, and then the repl which is a theoretical one since we probably get a dispatch to insertionsort in practice)
(And I haven't traced where the precise internal usage is in the case of the REPL.)
There was a problem hiding this comment.
But you could imagine it could have a lot of consequences in various non-barebones environments where sort! is used incautiously, e.g. maybe in Pluto notebook, for whatever reason a sort! is run when processing a cell output (this is purely hypothetical). Ideally we'd want the same code with the same seed to run the same in a these environments, which would be in danger if rand is introduced to sort! without carefully examining such cases
There was a problem hiding this comment.
The default rng should not be used for reproducible random streams.
There was a problem hiding this comment.
It's very common practice to begin a piece of code with Random.seed!(...) to make it reproducible. Faulty a strategy as it may be, it would be confusing if calls to sort! made by non user -facing code broke this. That's why I think those calls should eventually be changed to something which can be relied not to affect the global RNG.
In any case, I don't want to debate this point too much here since I'm not pushing for this to affect 1.9.
This fixes a hang where string interpolation in "precompile(Tuple{typeof(show), $IO, $T})\n"
uses sorting which uses rand(lo:hi) which uses an itterated approach which runs forever because
every random UInt64 is 0.
TODO find a better place for this initialization to prevent this bug from cropping up again
perhaps initialize the moment rand is defined (that may be hard).
Co-authored-by: Petr Vana <petvana@centrum.cz>
|
Bump <3 |
| @@ -434,4 +434,10 @@ true | |||
| """ | |||
| seed!(rng::AbstractRNG, ::Nothing) = seed!(rng) | |||
|
|
|||
| # Randomize quicksort pivot selection. This code is here because of bootstrapping: | |||
| # we need to sort things before we load this standard library. | |||
| # TODO move this into Sort.jl | |||
There was a problem hiding this comment.
now that the compiler's sort is separated, is this still necessary?
There was a problem hiding this comment.
Yes. If someone filters out the Random stdlib, I'd like to use hash-based pivot selection rather than error trying to use rand.
There was a problem hiding this comment.
If sorting were split into a small portion in base that works alone and a larger stdlib that pirates base's sorting to make it run a bit faster and depends on Random, then this code would be able to move to the sorting stdlib, so the TODO is still appropriate.
There was a problem hiding this comment.
And if you mean can we remove that redefinition entirely, yes we can. But it would come at a performance penalty (likely negligible) and at the cost of allowing pathological inputs to be intentionally created.
The way you explain this suggests to me that a better keyword for that PR would have been something like |
|
c.f. #45222 (comment)
|
"Quicksort is unstable and attempts to stabilize it hurt performance" (citation needed).
I believe I have simultaneously stabilized and sped up quicksort, which should allow us to simplify sorting policy.
Instability comes from the partition algorithm. We currently use something like this
Which is an efficient in place unstable partition algorithm.
If we allow ourselves scratch space to conduct the partition, we can use something like this instead
This new approach is still unstable, but it is predictably unstable. Everything before the pivot is stable, and everything after it is reversed. After several nested partitions, we still only need to reverse half the elements one time to reintroduce stability.
Benchmarks reveal that this approach is typically faster than the original, possibly because the order of comparisons and computations is known at the beginning of the partition rather than depending on the branches during the partition. In effect, the branches in this new algorithm have less impact on future code execution. I have not profiled this implementation at the CPU level and don't know for sure why it is a speedup.
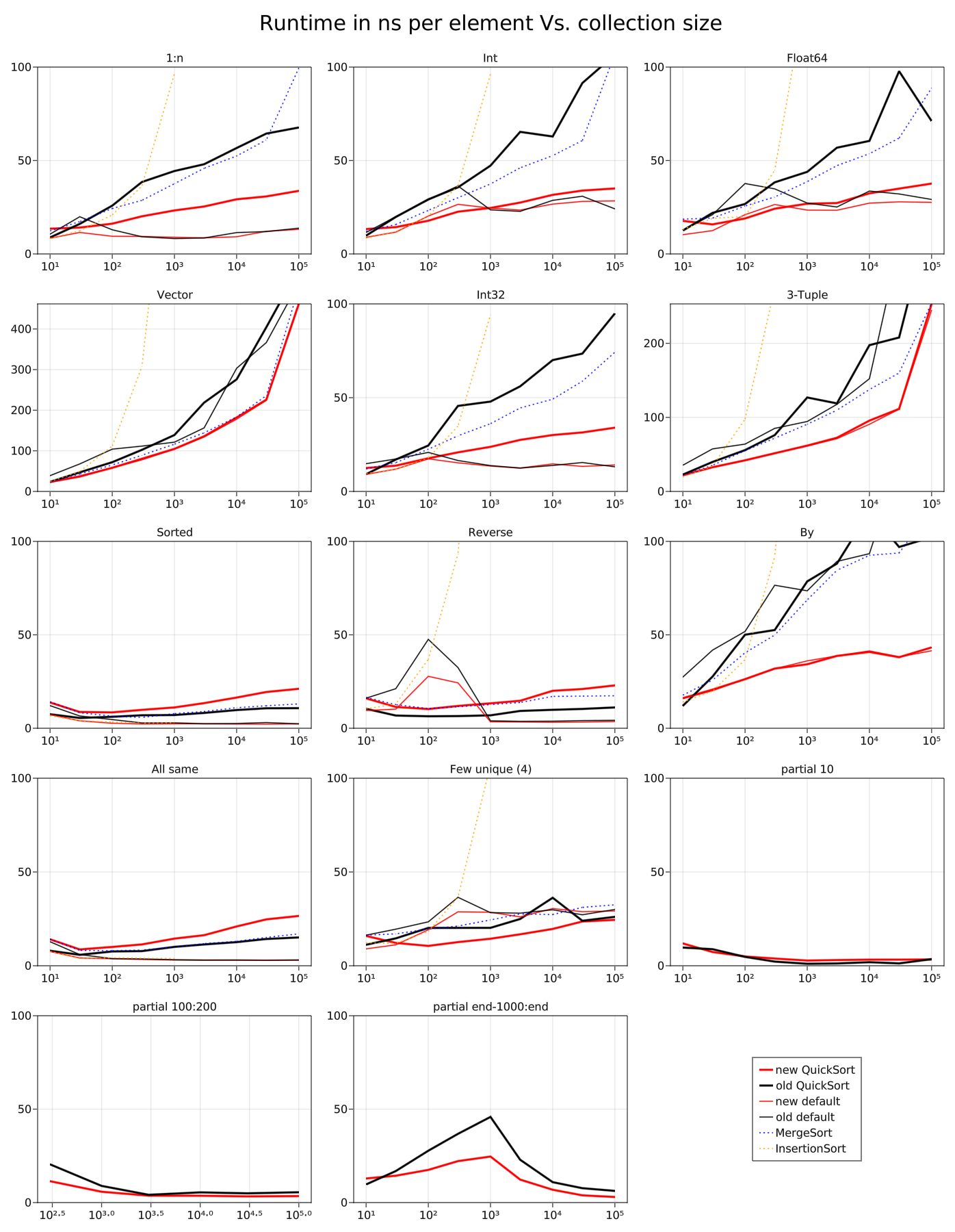
Caveat 1: I benchmarked on a somewhat inconsistently noisy machine.Caveat 2: This is sometimes a slowdown. See graphs.
Future work indicated by this PR includes
partition!.Closes #11429
Closes #42713
Closes #32675