
Get hands-on experience of implementation of RNN (LSTM) in Pytorch;
Get familiar with Finacial data with Deep Learning;
Pytorch --1.2.0
Numpy --1.17.2
Pandas -- 0.23.0
usage: main.py [-h] [--dataroot DATAROOT] [--batchsize BATCHSIZE]
[--nhidden_encoder NHIDDEN_ENCODER]
[--nhidden_decoder NHIDDEN_DECODER] [--ntimestep NTIMESTEP]
[--epochs EPOCHS] [--lr LR]
PyTorch implementation of paper 'A Dual-Stage Attention-Based Recurrent Neural
Network for Time Series Prediction'
optional arguments:
-h, --help show this help message and exit
--dataroot DATAROOT path to dataset
--batchsize BATCHSIZE
input batch size [128]
--nhidden_encoder NHIDDEN_ENCODER
size of hidden states for the encoder m [64, 128]
--nhidden_decoder NHIDDEN_DECODER
size of hidden states for the decoder p [64, 128]
--ntimestep NTIMESTEP
the number of time steps in the window T [10]
--epochs EPOCHS number of epochs to train [10, 200, 500]
--lr LR learning rate [0.001] reduced by 0.1 after each 10000
iterations
An example of training process is as follows:
python3 main --lr 0.0001 --epochs 50
 |
 |
|---|



In the paper "A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction".

Figure 1: Graphical illustration of the dual-stage attention-based recurrent neural network.
The Dual-Stage Attention-Based RNN (a.k.a. DA-RNN) model belongs to the general class of Nonlinear Autoregressive Exogenous (NARX) models, which predict the current value of a time series based on historical values of this series plus the historical values of multiple exogenous time series.
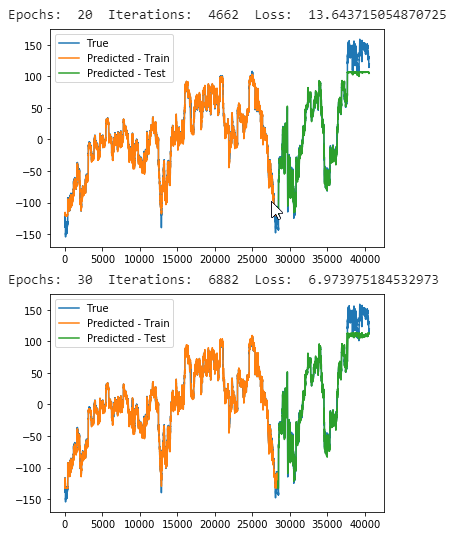
In the NASDAQ 100 Stock dataset, we collected the stock prices of 81 major corporations under NASDAQ 100, which are used as the driving time series. The index value of the NASDAQ 100 is used as the target series. The frequency of the data collection is minute-by-minute. This data covers the period from July 26, 2016 to December 22, 2016, 105 days in total. Each day contains 390 data points from the opening to closing of the market except that there are 210 data points on November 25 and 180 data points on December 22. In our experiments, we use the first 35,100 data points as the training set and the following 2,730 data points as the validation set. The last 2,730 data points are used as the test set. This dataset is publicly available and will be continuously enlarged to aid the research in this direction.
| Category | Description |
|---|---|
| Optimization method | minibatch stochastic gradient descent (SGD) together with the Adam optimizer |
| number of time steps in the window T | T = 10 |
| size of hidden states for the encoder m | m = p = 64, 128 |
| size of hidden states for the decoder p | m = p = 64, 128 |
| Evaluation Metrics |