- 🌳 MIMIC-IT Overview
- Using MIMIC-IT Dataset
- Syphus: the hero behind MIMIC-IT
- Multilingual Instruction-Response Pairs
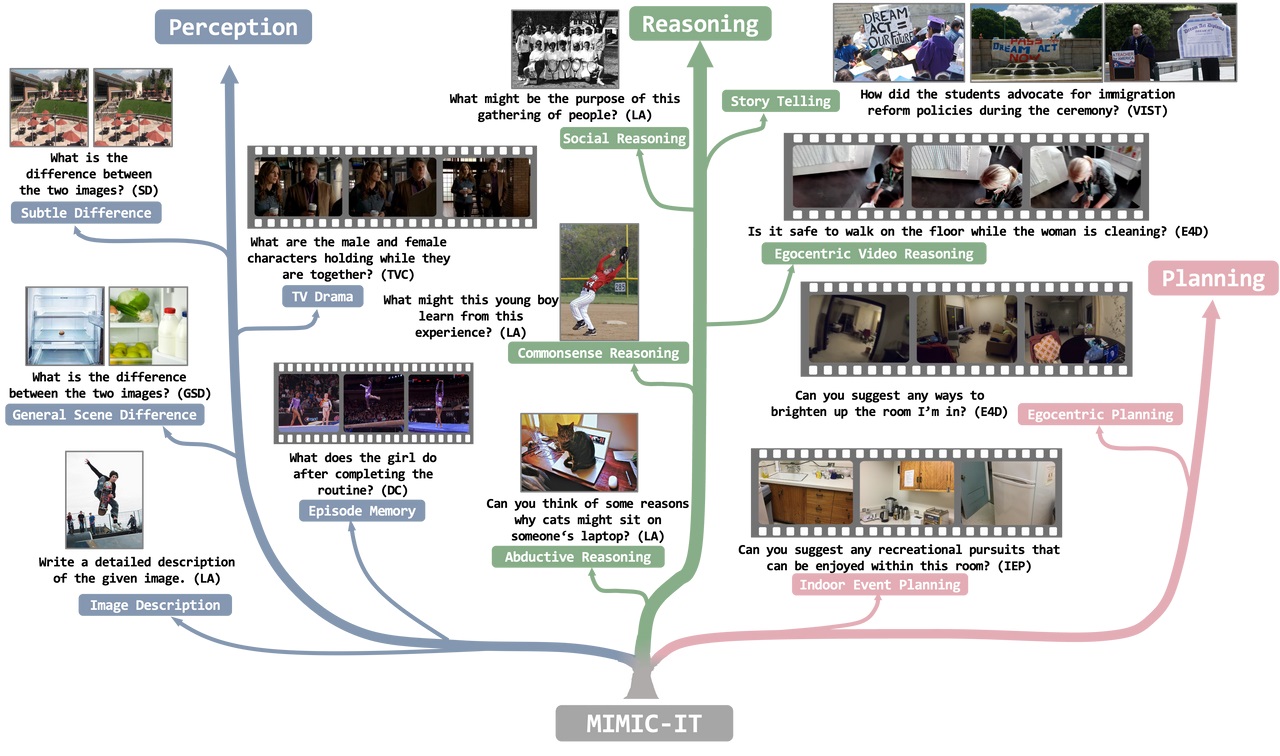
MIMIC-IT offers a diverse and extensive dataset of 2.8M multimodal instruction-response pairs, designed to enhance the performance of Vision-Language Models (VLMs) in real-life scenarios, enabling VLMs to excel in perception, reasoning, and planning while also catering to a multilingual audience.
MIMIC-IT enables the application of egocentric visual assistant model that can serve that can answer your questions like Hey, Do you think I left my keys on the table?. Harness the power of MIMIC-IT to unlock the full potential of your AI-driven visual assistant and elevate your interactive vision-language tasks to new heights.
MIMIC-IT provides multilingual instructions, supporting English, Chinese, Korean, Japanese, German, French, Spanish, and Arabic, thereby allowing a larger global audience to altogether enjoy from the convenience brought about by advancements in artificial intelligence.
We have integrated the MIMIC-IT dataset into the Hugging Face dataset. You can download and utilize the MIMIC-IT dataset from here.
You can following the steps to obtain the MIMIC-IT dataset. Each task (e.g. DC, LA) in MIMIC-IT is composed of three parts, including:
xx.jsonfile: the images in base64 format.xx_instructions.jsonfile: the instruction-response pairs (also includes image ids and related instructions ids for each instruction-response pair) for each task.xx_train.jsonfile: the customized related instruction-response pairs for each instruction.
The following steps will introduce you how to gather them together.
You may need to refer to the Convert-It to convert the image sources from public dataset to the format of xx.json. If you find it is hard to download from the original image sources, you can refer to the Eggs section to seek help there.
You can download the instructions.json and train.json files, from our provided OneDrive folder.
| Tasks/Scenes | Zip File MD5 Checksum | Unzipped File Size |
|---|---|---|
| LA-In-Context | fdc2427451bcfd8a04bab7a1c2305259 | 338 MB |
| DC | 0d373a5f511fd1d9f03ac81bb12e04fe | 171 MB |
| TVC | ea16ec0ef7f35e810e0920e85ed467af | 166 MB |
| VST | 988569e39aaa24da0df547644514b0d4 | 32 MB |
| SN | 1c4751c5b2c0bcaaeb94dbc5fb39e7a6 | 8 MB |
| SD (General Diff) | 7fd998c10baaba9c6e39b66761a456a0 | 8.1 MB |
| SD (Subtle Diff) | 5175198daebb997672a21307e8b18a96 | 5 MB |
| E4D (1st Part) | 504b779dbc852c943adbe7862d6924d7 | 710 MB/3.2 GB |
After downloading, unzip the files and place them in the mimicit_data folder. The folder structure should be as follows:
mimicit_data/DC/DC_instructions.json
mimicit_data/DC/DC_train.jsonThe DC_instructions.json includes a meta object with version, time, and author information. The data object contains instruction-response pairs, each with a unique identifier (e.g., "DC_INS_00001"). Each pair consists of an instruction, an answer, an array of associated image IDs, and an array of related instruction IDs (which can be arranged as in-context examples).
{
"meta":{"version":"0.0.1","time":"2023-06","author":"ntu"},
"data": {
"DC_INS_00001": {
"instruction":"Who is the main focus of the video?",
"answer":"The main focus of the video is a police officer riding a horse down the street.",
"image_ids":["DC_IMG_v_N1c3C_Npr-E_0000","DC_IMG_v_N1c3C_Npr-E_0001","DC_IMG_v_N1c3C_Npr-E_0002",..."],
"rel_ins_ids":["DC_INS_00002","DC_INS_00003","DC_INS_00004","DC_INS_00005","DC_INS_00006","DC_INS_00007","DC_INS_00008"]
},
}
...
} The DC_train.json contains instructions IDs and their associated related instruction IDs. Each instruction is associated with its related instructions. We provide it for more flexibly define each instruction's related instructions. It serves for different in-context learning objectives. In default, the related instructions ids are from rel_ins_ids at DC_instructions.json. But you can define your own related instructions ids for each instruction by just creating your own DC_train.json file.
{
"DC_INS_00001": ["DC_INS_00002", "DC_INS_00003", "DC_INS_00004", "DC_INS_00005", "DC_INS_00006", "DC_INS_00007", "DC_INS_00008"],
...
}Things could be tricky since some image/video sources are not easy to get the access to download them. We also provide the converted xx.json files for you to download directly. You need to agree the same terms and conditions as the original dataset, as well as recognize and appreciate the contributions made by these data sources. Please refer to Google form to apply for the access to download the converted xx.json files.
Access to the images provided is exclusively for contributing positively to the academic research community. Usage of these images is required to align with all pertinent licenses governing their distribution. By engaging with this content, you are making a commitment to utilize the images solely for the stated non-commercial purposes and to comply with the stipulations of the original licenses.
Moreover, filling in and submitting the form with your verifiable name, institutional affiliation, and signature serves as your binding acknowledgment and affirmation to uphold these terms and conditions with integrity.

Embracing Syphus, an automated pipeline that generates top-tier instruction-response pairs in various languages.
Syphus builds on the LLaVA framework and uses ChatGPT to produce pairs based on visual content. It ensures quality by incorporating system messages for tone and style, visual annotations for essential image information, and in-context examples to assist ChatGPT in contextual learning. During the cold-start stage, in-context examples are collected using a heuristic approach with system messages and visual annotations. This stage concludes only when a satisfactory in-context examples are identified.
Finally, the pipeline expands the instruction-response pairs into languages like Chinese, Japanese, Spanish, German, French, Korean, and Arabic.
We provide source code of the framework in syphus folder. You can use it to generate instruction-response pairs on your own dataset following the steps below.
- Configure openai key. Create the following environment variables in your system.
export OPENAI_API_TYPE="xxx"
export OPENAI_API_KEY="xxxxxxxxxxxxxxxxxxx"
export OPENAI_API_BASE="https://xxxx"
export OPENAI_API_VERSION="2023-03-15-xx"
export OPENAI_API_ENGINE="chatgpt0301"- Create a new file in
datasetsfolder and name it asyour_dataset.py. - Create a class named
YourDatasetinyour_dataset.pyand inherit fromabstract_dataset.AbstractDatasetclass. - Implement
_load_query_inputsmethods inYourDatasetclass. This method should return a list of dict, each dict containsidandsentenceskeys.idis the unique id of each querysentencesis a string for each query input.
- Define
system_message,in-context exampleinpromptsfolder. - Define
_load_prefixmethods inYourDatasetclass.- This method should return a dictionary. The keys of the dictionary are
system_message,in_context. - The value of
system_messageis a string. - The value of
in_contextis a list of{"role": role, "content": content_string}.
- This method should return a dictionary. The keys of the dictionary are
- You are done! Run the following command to generate instruction-response pairs on your own dataset.
python main.py --name YourDataset.your_dataset --num_threads 64We will release multilingual instruction-response pairs in the following languages:
