简体中文 | English
Serving deployment is a common form of deployment in real-world production environments. By encapsulating inference capabilities as services, clients can access these services through network requests to obtain inference results. PaddleX enables users to achieve low-cost serving deployment for production lines. This document will first introduce the basic process of serving deployment using PaddleX, followed by considerations and potential operations when using the service in a production environment.
Note
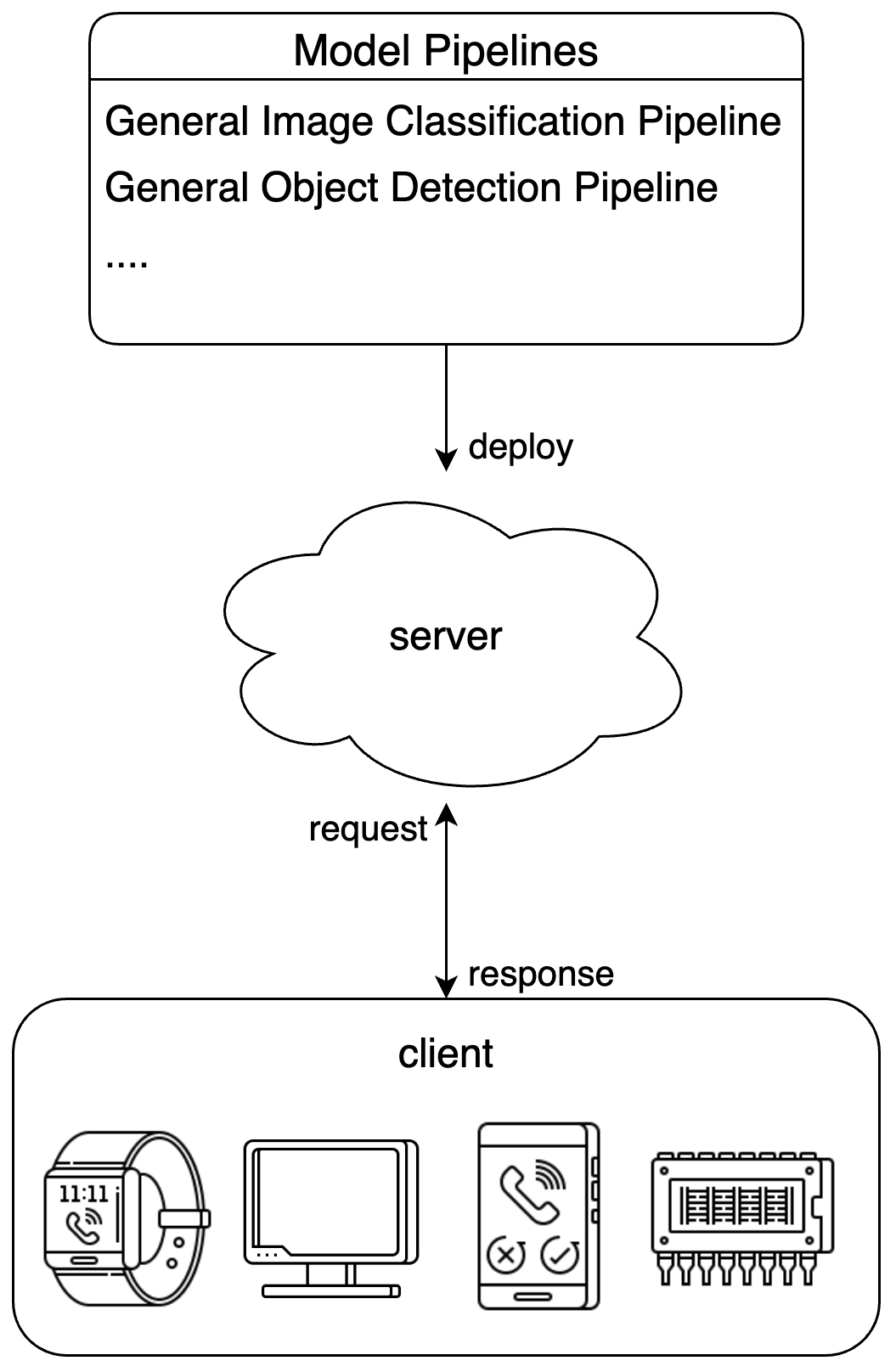
- Serving deployment provides services for model pipelines, not specific to individual pipeline modules.
Serving Deployment Example Diagram:
Execute the following command to install the serving deployment plugin:
paddlex --install servingStart the service through the PaddleX CLI with the following command format:
paddlex --serve --pipeline {pipeline_name_or_path} [{other_command_line_options}]Taking the General Image Classification Pipeline as an example:
paddlex --serve --pipeline image_classificationAfter the service starts successfully, you will see information similar to the following:
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
--pipeline can be specified as an official pipeline name or the path to a local pipeline configuration file. PaddleX uses this to build the pipeline and deploy it as a service. To adjust configurations (such as model path, batch_size, deployment device), please refer to the "Model Application" section in the General Image Classification Pipeline Tutorial (for other pipelines, refer to the corresponding tutorials in the "1.3 Calling the Service" table).
Command-line options related to serving deployment are as follows:
| Name | Description |
|---|---|
--pipeline |
Pipeline name or pipeline configuration file path. |
--device |
Deployment device for the pipeline. Defaults to cpu (If GPU is unavailable) or gpu (If GPU is available). |
--host |
Hostname or IP address bound to the server. Defaults to 0.0.0.0. |
--port |
Port number listened to by the server. Defaults to 8080. |
--use_hpip |
Enables the high-performance inference plugin if specified. |
--serial_number |
Serial number used by the high-performance inference plugin. Only valid when the high-performance inference plugin is enabled. Note that not all pipelines and models support the use of the high-performance inference plugin. For detailed support, please refer to the PaddleX High-Performance Inference Guide. |
--update_license |
Activates the license online if specified. Only valid when the high-performance inference plugin is enabled. |
Please refer to the "Development Integration/Deployment" section in the usage tutorials for each pipeline.
When deploying services into production environments, the stability, efficiency, and security of the services are of paramount importance. Below are some recommendations for deploying services into production.
In scenarios where strict response time requirements are imposed on applications, the PaddleX high-performance inference Plugin can be used to accelerate model inference and pre/post-processing, thereby reducing response time and increasing throughput.
To use the PaddleX high-performance inference Plugin, please refer to the PaddleX High-Performance Inference Guide for installing the high-performance inference plugin, obtaining serial numbers, and activating the plugin. Additionally, not all pipelines, models, and environments support the use of the high-performance inference plugin. For detailed support information, please refer to the section on pipelines and models that support the high-performance inference plugin.
When starting the PaddleX pipeline service, you can specify --use_hpip along with the serial number to use the high-performance inference plugin. If you wish to perform online activation, you should also specify --update_license. Example usage:
paddlex --serve --pipeline image_classification --use_hpip --serial_number {serial_number}
# If you wish to perform online activation
paddlex --serve --pipeline image_classification --use_hpip --serial_number {serial_number} --update_licenseA typical scenario involves an application accepting inputs from the network, with the PaddleX pipeline service acting as a module within the application, interacting with other modules through APIs. In this case, the position of the PaddleX pipeline service within the application is crucial. The service-oriented deployment solution provided by PaddleX focuses on efficiency and ease of use but does not perform sufficient security checks on request bodies. Malicious requests from the network, such as excessively large images or carefully crafted data, can lead to severe consequences like service crashes. Therefore, it is recommended to place the PaddleX pipeline service within the application's internal network, avoiding direct processing of external inputs, and ensuring it only processes trustworthy requests. Appropriate protective measures, such as input validation and authentication, should be added at the application's outer layer.