English Blog | 中文博客
在快速发展的实时目标检测领域,D-FINE 作为一项革命性的方法,显著超越了现有模型(如 YOLOv10、YOLO11 及 RT-DETR v1/v2/v3),提升了实时目标检测的性能上限。经过大规模数据集 Objects365 的预训练,D-FINE 远超其竞争对手 LW-DETR,在 COCO 数据集上实现了高达 59.3% 的 AP,同时保持了卓越的帧率、参数量和计算复杂度。这使得 D-FINE 成为实时目标检测领域的佼佼者,为未来的研究奠定了基础。
目前,D-FINE 的所有代码、权重、日志、编译工具,以及 FiftyOne 可视化工具已经全部开源,感谢 RT-DETR 提供的 codebase。其中还包括了预训练教程、自定义数据集教程等。之后还会陆续更新一些改进心得和调参攻略,欢迎大家多提 issue,共同将 D-FINE 系列发扬光大。同时希望您能随手留下一颗 ⭐,这是对我们最好的鼓励。
Github Repo: https://github.com/Peterande/D-FINE
Arxiv Paper: https://arxiv.org/abs/2410.13842
D-FINE 将基于 DETR 的目标检测器中的回归任务重新定义为 FDR,并在此基础上开发出了无感提升性能的自蒸馏机制 GO-LSD。下面对 FDR 和 GO-LSD 进行简要介绍:
- 初始框预测:与传统 DETR 方法类似,D-FINE 的解码器 (decoder) 会在第一层将 object queries 转变为若干个初始的边界框,这些框不需要特别精准,仅作为一种初始化。
- 细粒度的分布优化:D-FINE 解码层不会像传统方法那样直接解码出新的边界框,而是基于这些初始化的边界框,生成四组概率分布;并迭代地对这四组概率分布进行逐层优化。这些分布本质上是作为检测框的一种“细粒度中间表征”;配合精心设计的加权函数 W(n),D-FINE 能够通过微调这些表征来实现对初始边界框的调整,包含对其上下左右边缘进行细微的小幅度修正亦或是大幅度的搬移,具体的流程如图:
为了方便阅读,我们不在此赘述数学公式及帮助优化的损失函数 Fine-Grained Localization (FGL) Loss,有兴趣的可以根据原文推导。
将边界框回归任务重新定义为 FDR 的主要优势在于:
-
简化的监督:在使用传统的 L1 损失、IoU 损失优化检测框的同时,可以额外用标签和预测结果之间的“残差”来约束这些中间态的概率分布。这使每个解码层 (decoder layer) 能够更有效地关注并解决其当前面临的定位误差,随着层数加深,其优化目标变得越来越简单,从而简化了整体优化过程。
-
复杂场景下的鲁棒性:这些概率分布的值本质上代表了对每个边界“微调”的自信程度。这使 D-FINE 能够在不同网络深度独立建模每个边界的不确定性,从而在遮挡、运动模糊和低光照等复杂的实际场景下表现出更强的鲁棒性,相比直接回归四个固定值要更为稳健。
-
灵活的优化机制:概率分布通过加权求和转化为最终的边界框偏移值。精心设计的加权函数确保在初始框准确时进行细微调整,而在必要时则提供较大的修正。
-
研究潜力与可扩展性:FDR 通过将回归任务转变为同分类任务一致的概率分布预测问题,不仅提高了与其他任务的兼容性,还使得目标检测模型可以受益于知识蒸馏、多任务学习和分布优化等更多领域的创新,为未来的研究打开了新的大门。
根据上文,搭载 FDR 框架的目标检测器满足了以下两点:
-
能够实现知识传递:Hinton 早在 "Distilling the Knowledge in a Neural Network" 一文中就说过:概率即“知识”;网络输出变成了概率分布,而概率分布携带定位知识 (Localization Knowledge),而通过计算 KLD 损失,可以将这些“知识”从深层传递到浅层。这是传统固定框表示(狄拉克 δ 函数)无法实现的。
-
一致的优化目标:由于 FDR 架构中每一个解码层都共享一个共同目标:减少初始边界框与真实边界框之间的残差;因此最后一层生成的精确概率分布可以作为前面每一层的最终目标,并通过蒸馏引导前几层。
于是,基于 FDR,我们提出了 GO-LSD(全局最优定位自蒸馏)。通过在网络层间实现定位知识蒸馏,进一步扩展了 D-FINE 的能力,具体流程如图:
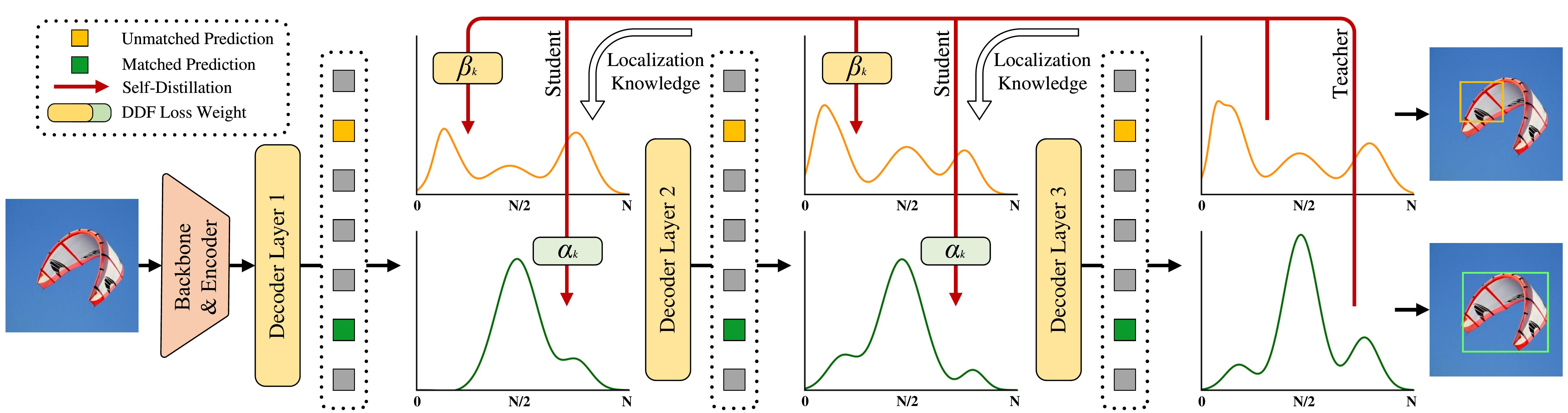
同样的,为了方便阅读,我们不在此赘述数学公式及帮助优化的损失函数 Decoupled Distillation Focal (DDF) Loss,有兴趣的可以根据原文推导。
这产生了一种双赢的协同效应:随着训练的进行,最后一层的预测变得越来越准确,其生成的软标签能够更好地帮助前几层提高预测准确性。反过来,前几层学会更快地定位到准确位置,简化了深层的优化任务,进一步提高了整体准确性。
以下可视化展示了 D-FINE 在各种复杂检测场景中的预测结果。这些场景包括遮挡、低光照、运动模糊、景深效果和密集场景。尽管面对这些挑战,D-FINE 依然能够产生准确的定位结果。

同时下面给出的可视化结果展示了第一层和最后一层的预测结果、对应四条边的分布、以及加权后的分布。可以看到,预测框的定位会随着分布的优化而变得更加精准。

回答:并不会,FDR 和原始的预测几乎没有在速度、参数量和计算复杂度上的任何区别,完全是无感替换。
回答:训练成本的增加主要来源于如何生成分布的标签。我们已经对该过程进行了优化,将额外训练时长和显存占用控制在了 6% 和 2%,几乎无感。
回答:直接应用 FDR 和 GO-LSD 只会显著提高性能,并不会让网络更快、更轻。所以我们对 RT-DETR 进行了一系列的轻量化处理,这些处理带来了性能的下降,但我们的方法弥补了这些损失,实现了速度-参数-计算量-性能的完美平衡。