Процесс — экземпляр программы во время выполнения, независимый объект, которому выделены системные ресурсы (например,
процессорное время и память). Каждый процесс выполняется в отдельном адресном пространстве: один процесс не может
получить доступ к переменным и структурам данных другого. Если процесс хочет получить доступ к чужим ресурсам,
необходимо использовать межпроцессное взаимодействие. Это могут быть конвейеры, файлы, каналы связи между компьютерами и
многое другое.
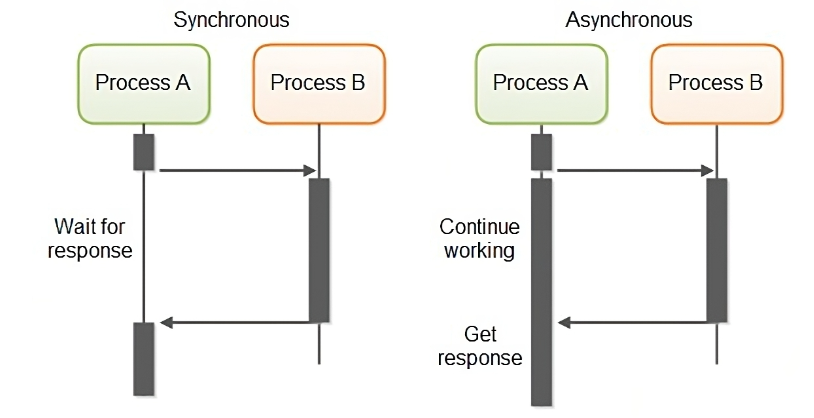
Синхронным (synchronous) называется такое взаимодействие между компонентами, при котором клиент, отослав запрос,
блокируется и может продолжать работу только после получения ответа от сервера. По этой причине такой вид взаимодействия
называют иногда блокирующим (blocking).
В рамках асинхронного (asynchronous) или неблокирующего (non blocking) взаимодействия клиент после отправки запроса
серверу может продолжать работу, даже если ответ на запрос еще не пришел. Асинхронное взаимодействие позволяет получить
более высокую производительность системы за счет использования времени между отправкой запроса и получением ответа на
него для выполнения других задач. Другое важное преимущество асинхронного взаимодействия — меньшая зависимость клиента
от сервера, возможность продолжать работу, даже если машина, на которой находится сервер, стала недоступной. Это
свойство используется для организации надежной связи между компонентами, даже если и клиент, и сервер не все время
находятся в рабочем состоянии.
Celery – это система для управления очередями задач. Принципиально умеет 2 вещи: брать задачи из очереди и выполнять задачи по расписанию.
Celery - это распределённая очередь задач, реализованная на языке Python.
Celery - это простая, гибкая и надежная распределенная система для обработки огромного количества сообщений, включая в себя инструменты, необходимые для поддержки такой системы.
Это очередь задач с упором на обработку в реальном времени, а также с поддержкой планирования задач.
Celery имеет открытый исходный код и находится под лицензией BSD.
Итак, что же умеет Celery:
- Выполнять асинхронно задания
- Выполнять периодические задания (умная замена cron)
- Выполнять отложенные задания
- Распределенное выполнение (может быть запущен на N серверах)
- В пределах одного worker’а возможно конкурентное выполнение нескольких задач (одновременно)
- Выполнять задание повторно, если вылез exception
- Ограничивать количество заданий в единицу времени (rate limit для задания или глобально)
- Несложно мониторить выполнение заданий
- Выполнять подзадания
- Присылать отчеты об exception’ах
- Проверять выполнилось ли задание
Задачей является предварительно написанный код (чаще всего функция), предназначенный для выполнения определённой цели (отправка имейла, обработка файла, и т. д.)
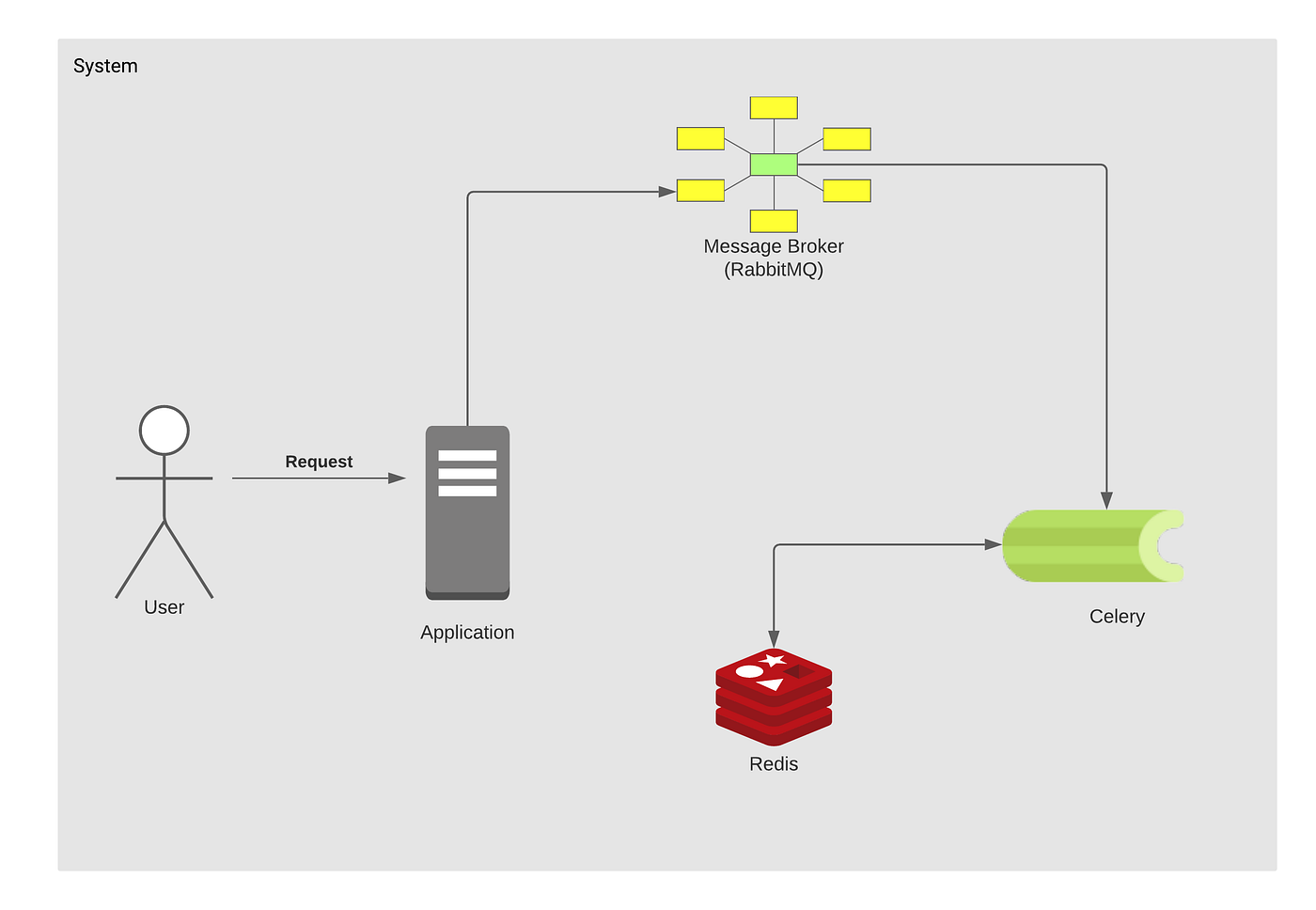
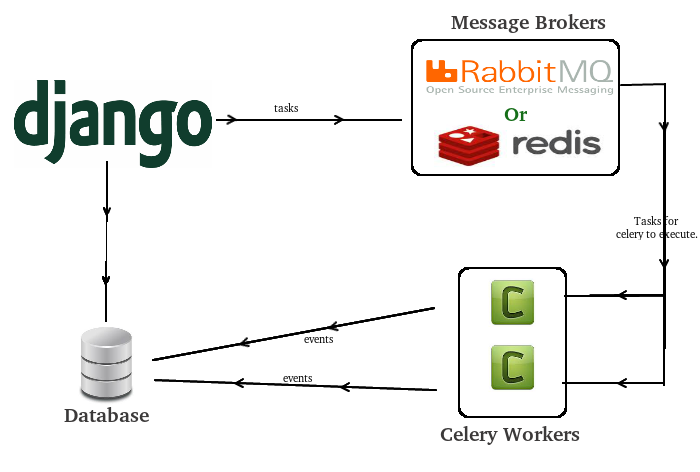
Брокер сообщений (он же диспетчер очереди) — это посредник(транспорт), который принимает и отдает сообщения (задачи) между отдельными модулями/приложениями внутри некоторой сложной системы, где модули/приложения должны общаться между собой — то есть пересылать данные друг другу.
Брокером может выступать как специальное ПО, например, RabbitMQ, так и некоторые NoSQL, например Redis. О них подробнее ниже.
Воркер - это отдельно запущенный процесс для выполнения определённых задач, Celery запускается на одном или нескольких воркерах, чтобы выполнять задачи параллельно на каждом воркере.
В рамках Celery бэкэнд выступает в качестве хранилища результатов выполнения задач. Это может быть как SQL, так и NoSQL база данных. Хотя, по сути что угодно может быть хранилищем, хоть обычный файл (я таких реализаций не встречал, но технически возможно).
-
Producer (поставщик) ‒ программа, отправляющая сообщения. В нашем случае, это чаще всего будет Django.
-
Queue (очередь) ‒ очередь сообщений (задач). Она существует внутри брокера. Любое количество поставщиков может отправлять сообщения в одну очередь, также любое количество подписчиков может получать сообщения из одной очереди. В схемах очередь будет обозначена стеком и подписана именем. Чаще всего за очередь будет отвечать Redis.
-
Consumer (подписчик) ‒ программа, принимающая сообщения. Обычно подписчик находится в состоянии ожидания сообщений. Это будет процесс Celery, который запустили специально для этой цели. Обрабатывает задачи, и складывает результат в backend.
Поставщик, подписчик и брокер не обязаны находиться на одной физической машине.
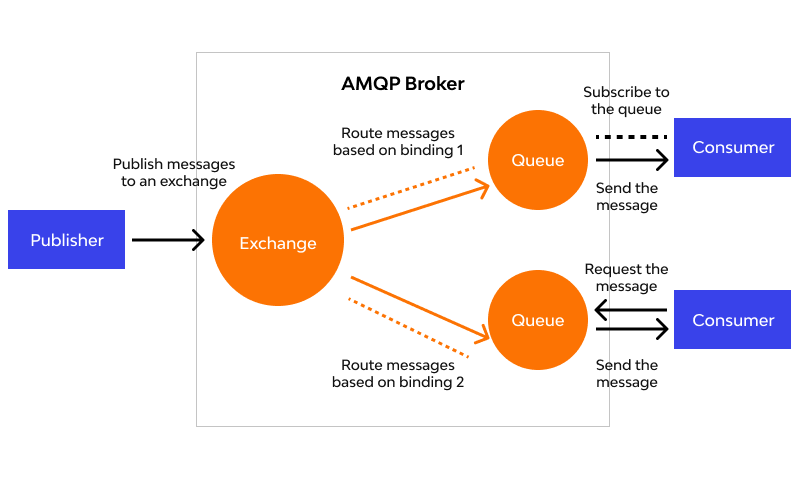
AMQP (Advanced Message Queuing Protocol) — открытый протокол для передачи сообщений между компонентами системы. Основная идея состоит в том, что отдельные подсистемы (или независимые приложения) могут обмениваться произвольным образом сообщениями через AMQP-брокер, который осуществляет маршрутизацию, возможно гарантирует доставку, распределение потоков данных, подписку на нужные типы сообщений.
RabbitMQ – это брокер сообщений с открытым исходным кодом. Он маршрутизирует сообщения по всем базовым принципам
протокола AMQP, описанным в спецификации. Отправитель передает сообщение брокеру, а тот доставляет его получателю.
RabbitMQ реализует и дополняет протокол AMPQ.
Redis (Remote Dictionary Server) – это быстрое хранилище данных типа «ключ‑значение» в памяти с
открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди.
Для Celery крайне рекомендую использовать именно Redis, годами проверенное решение.

Для установки celery мы можем использовать pip:
pip install celery
Celery 4.0+ официально уже не поддерживается для Windows
Варианты запуска
-
Использовать Linux
-
WSL 2 (для Windows 10)
Установка самого сервиса
sudo apt install redis-server
Для линукса, или Windows
Для работы также необходима и библиотека
pip install redis
Все три процесса должны быть запущены одновременно! И Python, который будет отправлять сообщения, и Redis, который будет очередью, и Celery worker, который будет выполнять задачи
Если вы используете
Windowsто для того, чтобы все следующие примеры работали, необходимо использовать только конкретные версии пакетов и версию Python 3.6!
А вообще не надо этим заниматься на винде :)
python == 3.6
celery == 3.1.25
redis == 2.10.6
Создадим файл tasks.py
Для использования необходимо создать "приложение", в котором необходимо указать название и брокера.
from celery import Celery
broker_url = 'redis://localhost'
app = Celery('tasks', broker=broker_url)
@app.task # декорирование функции для использования её через Celery
def add(x, y):
return x + yМы не вызывали задачу!!
Для того чтобы мы могли вызвать задачу, необходимо, чтобы у вас были запущены два отдельных приложения, первое Redis Server:
Запускаем и оставляем работать!
Celery запускать нужно при запущенном виртуальном окружении!
celery -A tasks worker --loglevel=INFO
Также запускаем и не закрываем!
-A app_name - имя приложения, worker - запустить воркер, loglevel - уровень деталей отображаемой информации.
Для запуска задач есть много разных способов, тут рассмотрим базовый.
Открываем консоль:
from tasks import add
add.delay(4, 4)Для запуска задачи немедленно используется метод delay.
Запуск задач возвращает не результат, а AsyncResult, для того чтобы получать значения, необходимо при создании
приложения указать параметр backend, который отвечает за то, где будут храниться результаты, таким параметром может
быть Redis:
broker_url = 'redis://localhost'
app = Celery('tasks', broker=broker_url, backend=broker_url)Обратите внимание, мы используем Redis и в качестве брокера, и в качестве бэкэнда сразу.
Результат будет иметь достаточно большое кол-во методов и атрибутов.
Основные два метода это ready() и get():
ready() - булево поле, которое отвечает за то, завершилась задача или еще в процессе.
get() - ждет выполнения задачи и возвращает результат. Рекомендуется использовать после ready(), чтобы не ждать
выполнения впустую.
result = add.delay(4, 4)
result.ready()
True
result.get()
8Иногда описание параметров задачи и ее вызов могут быть в совершенно разных местах, для этого существует механизм подписи:
s1 = add.s(2, 2)
res = s1.delay()
res.get()В этом примере s1 - это подпись задачи, то есть задача, заготовленная для выполнения, её можно сериализовать и
отправить по сети, например, а выполнить в уже совершенно других местах.
Или если вы не знаете параметры целиком:
# incomplete partial: add(?, 2)
s2 = add.s(2)
# resolves the partial: add(8, 2)
res = s2.delay(8)
res.get()Задачи можно группировать:
from celery import group
from proj.tasks import add
group(add.s(i, i) for i in range(10))().get()Есть три варианта запуска задач:
apply_async(args[, kwargs[, …]])
Отправка сообщения с указанием дополнительных параметров:
delay(*args, **kwargs)
Отправка сообщения без каких-либо параметров самого сообщения:
calling (__call__)
Просто вызов, декоратор не мешает нам просто вызвать функцию без Celery. :)
сountdown- выполнить через определённый промежуток времени
add.apply_async((2, 2), countdown=10)
# выполнить через 10 секундeta- выполнить в конкретное время
add.apply_async((2, 2), eta=now() + timedelta(seconds=10))
# выполнить через 10 секундexpires- время, после которого перестать выполнять задачу, можно указать как цифру, так и время
add.apply_async((4, 5), countdown=60, expires=120)
add.apply_async((4, 5), expires=now() + timedelta(days=2))link- выполнить другую задачу по завершению текущей, основываясь на результатах текущей
add.apply_async((2, 2), link=add.s(16))
# ( 2 + 2 ) + 16Celery может выполнять какие-либо задачи просто по графику.
Для этого нужно настроить приложение:
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': 30.0,
'args': (16, 16)
},
}
app.conf.timezone = 'UTC'Ключ словаря - это только название, можно указать что угодно.
Таск - это выполняемый таск. :)
args - его аргументы.
schedule - частота выполнения в секундах.
from celery.schedules import crontab
app.conf.beat_schedule = {
# Executes every Monday morning at 7:30 a.m.
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}Cron - система задания расписания, можно сделать практически какое угодно.
from celery.schedules import solar
app.conf.beat_schedule = {
# Executes at sunset in Melbourne
'add-at-melbourne-sunset': {
'task': 'tasks.add',
'schedule': solar('sunset', -37.81753, 144.96715),
'args': (16, 16),
},
}В данном случае выполнять во время заката по указанным координатам, параметров много, например, закат с учётом зданий ;)
Для запуска по расписанию нужно запускать отдельный воркер для расписания (смотреть в доке)
Для использования Celery в Django рекомендуется создать еще один файл celery.py на одном уровне с settings.py
from __future__ import absolute_import
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'djangoProject1.settings')
from django.conf import settings # noqa
app = Celery('djangoProject1')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)app.autodiscover_tasks(lambda: settings.INSTALLED_APPS) - эта строчка будет отвечать за автоматический поиск таков во
всех приложениях.
На том же уровне, где и settings.py создать\использовать файл __init__.py в зависимости от версии Python.
# __init__.py
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)Все задачи необходимо покрывать не стандартным декоратором task, а декоратором shared_task, тогда Django сможет
автоматически найти все таски в приложении.
# tasks.py
from celery import shared_task
from demoapp.models import Widget
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
@shared_task
def xsum(numbers):
return sum(numbers)
@shared_task
def count_widgets():
return Widget.objects.count()
@shared_task
def rename_widget(widget_id, name):
w = Widget.objects.get(id=widget_id)
w.name = name
w.save()Также для Django существует много различных расширений, например:
django-celery-results - чтобы хранить результаты в БД или кеше Django, за подробностями в доку.
django-celery-beat - настройка для периодических задач, сразу вшитая в админку Django, за подробностями опять же в
доку.
Чтобы понять многопоточность, сначала вникнем, что такое процесс. Процесс – это часть виртуальной памяти и ресурсов, которую ОС выделяет для выполнения программы. Если открыть несколько экземпляров одного приложения, под каждый система выделит по процессу. В современных браузерах за каждую вкладку может отвечать отдельный процесс.
Вы наверняка сталкивались с «Диспетчером задач» в Windows (в Linux — «Системный монитор») и знаете, что лишние запущенные процессы грузят систему, а самые «тяжёлые» из них часто зависают, так что их приходится завершать принудительно.
Но пользователи любят многозадачность: хлебом не корми — дай открыть с десяток окон и попрыгать туда-сюда. Налицо дилемма: нужно обеспечить одновременную работу приложений и при этом снизить нагрузку на систему, чтобы она не тормозила. Допустим, «железу» не угнаться за потребностями владельцев — нужно решать вопрос на программном уровне.
Мы хотим, чтобы в единицу времени процессор успевал выполнить больше команд и обработать больше данных. То есть нам надо уместить в каждом кванте времени больше выполненного кода. Представьте единицу выполнения кода в виде объекта — это и есть поток.
К сложному делу легче подступиться, если разбить его на несколько простых. Так и при работе с памятью: «тяжёлый» процесс делят на потоки, которые занимают меньше ресурсов и скорее доносят код до вычислителя (как именно — см. ниже).
У каждого приложения есть как минимум один процесс, а у каждого процесса — минимум один поток, который называют главным, и из которого при необходимости запускают новые.
-
Потоки используют память, выделенную под процесс, а процессы требуют себе отдельное место в памяти. Поэтому потоки создаются и завершаются быстрее: системе не нужно каждый раз выделять им новое адресное пространство, а потом высвобождать его.
-
Процессы работают каждый со своими данными — обмениваться чем-то они могут только через механизм межпроцессного взаимодействия. Потоки обращаются к данным и ресурсам друг друга напрямую: что изменил один — сразу доступно всем. Поток может контролировать «собратьев» по процессу, в то время как процесс контролирует исключительно своих «дочек». Поэтому переключаться между потоками быстрее и коммуникация между ними организована проще.
Какой отсюда вывод? Если вам нужно как можно быстрее обработать большой объём данных, разбейте его на куски, которые можно обрабатывать отдельными потоками, а затем соберите результат воедино. Это лучше, чем плодить жадные до ресурсов процессы.
Но почему такое популярное приложение как Firefox идёт по пути создания нескольких процессов? Потому что именно для браузера изолированная работа вкладок — это надёжно и гибко. Если с одним процессом что-то не так, необязательно завершать программу целиком — есть возможность сохранить хотя бы часть данных.
Что такое многопоточность? Вот мы и подошли к главному. Многопоточность — это когда процесс приложения разбит на потоки, которые параллельно — в одну единицу времени — обрабатываются процессором.
Вычислительная нагрузка распределяется между двумя или более ядрами, так что интерфейс и другие компоненты программы не замедляют работу друг друга.
Многопоточные приложения можно запускать и на одноядерных процессорах, но тогда потоки выполняются по очереди: первый поработал, его состояние сохранили — дали поработать второму, сохранили — вернулись к первому или запустили третий, и т. д.

В информатике поток — это минимальная единица работы, запланированная для выполнения операционной системой.
О потоках нужно знать следующее:
- Они существуют внутри процесса;
- В одном процессе может быть несколько потоков;
- Потоки в одном процессе разделяют состояние и память родительского процесса.
- Потоки работают параллельно.
В Python существует встроенный модуль threading, самым простым примером использования будет следующий код:
import time
from threading import Thread
def sleep_me(i):
print("Поток %i засыпает на 5 секунд.\n" % i)
time.sleep(5)
print("Поток %i сейчас проснулся.\n" % i)
for i in range(10):
th = Thread(target=sleep_me, args=(i,))
th.start()Вывод будет примерно следующим:
Поток 0 засыпает на 5 секунд.
Поток 3 засыпает на 5 секунд.
Поток 1 засыпает на 5 секунд.
Поток 4 засыпает на 5 секунд.
Поток 2 засыпает на 5 секунд.
Поток 5 засыпает на 5 секунд.
Поток 6 засыпает на 5 секунд.
Поток 7 засыпает на 5 секунд.
Поток 8 засыпает на 5 секунд.
Поток 9 засыпает на 5 секунд.
Поток 0 сейчас проснулся.
Поток 3 сейчас проснулся.
Поток 1 сейчас проснулся.
Поток 4 сейчас проснулся.
Поток 2 сейчас проснулся.
Поток 5 сейчас проснулся.
Поток 6 сейчас проснулся.
Поток 7 сейчас проснулся.
Поток 8 сейчас проснулся.
Поток 9 сейчас проснулся.
Порядок может быть вообще любым, и мы этот порядок не контролируем!
Эта функция возвращает количество исполняемых на текущий момент потоков. Изменим последнюю программу, чтобы она выглядела вот так:
import time
import threading
from threading import Thread
def sleep_me(i):
print("Поток %i засыпает на 5 секунд." % i)
time.sleep(5)
print("Поток %i сейчас проснулся." % i)
for i in range(10):
th = Thread(target=sleep_me, args=(i,))
th.start()
print("Запущено потоков: %i." % threading.active_count())Результат будет примерно такой:
Поток 0 засыпает на 5 секунд.
Запущено потоков: 2.
Поток 1 засыпает на 5 секунд.
Запущено потоков: 3.
Поток 2 засыпает на 5 секунд.
Запущено потоков: 4.
Поток 3 засыпает на 5 секунд.
Запущено потоков: 5.
Поток 4 засыпает на 5 секунд.
Запущено потоков: 6.
Поток 5 засыпает на 5 секунд.
Запущено потоков: 7.
Поток 6 засыпает на 5 секунд.
Запущено потоков: 8.
Поток 7 засыпает на 5 секунд.
Запущено потоков: 9.
Поток 8 засыпает на 5 секунд.
Запущено потоков: 10.
Поток 9 засыпает на 5 секунд.
Запущено потоков: 11.
Поток 0 сейчас проснулся.
Поток 5 сейчас проснулся.
Поток 2 сейчас проснулся.
Поток 9 сейчас проснулся.
Поток 3 сейчас проснулся.
Поток 7 сейчас проснулся.
Поток 1 сейчас проснулся.
Поток 8 сейчас проснулся.
Поток 6 сейчас проснулся.
Поток 4 сейчас проснулся.
Также обратите внимание, что после запуска всех потоков счетчик показывает число 11, а не 10. Причина в том, что основной поток также учитывается наравне с 10 остальными.
Имеется ряд проблем, возникающих при использовании многопоточности – попытка множества потоков получить доступ к одному
и тому же фрагменту данных может привести к проблемам несовместимости или получению искаженной информации (например,
фраза HWeol,rldo вместо Hello, World на консоли). Подобные проблемы возникают, когда компьютеру не указан способ
организации потоков.
Как правильно приказать компьютеру синхронизировать потоки? Для этого используются примитивы синхронизации — простые программные механизмы, обеспечивающие гармоничное взаимодействие потоков друг с другом.
В этом посте представлены некоторые популярные примитивы синхронизации в Python, определенные в стандартном модуле
threading.py.
Изучим Locks, RLocks, Semaphores, Events, Conditions и Barriers. Разумеется, можно создавать собственные
примитивы пользовательской синхронизации. Начнем с Locks как с простейшего из примитивов и постепенно перейдем к более
сложным.
Примитив Lock, простейший примитив в Python. Для Lock возможны только два состояния ‑ заблокирован и разблокирован.
Примитив создается в разблокированном состоянии и содержит два метода – acquire() и release(). Метод acquire()
блокирует Lock и выполнение блока до тех пор, пока метод release() из другой сопрограммы не разблокирует его. Затем
он снова блокирует Lock и возвращает значение True. Метод release() вызывается только в заблокированном состоянии
– устанавливает состояние разблокировки и немедленно возвращает управление. Вызов release() в разблокированном
состоянии приводит к RunTimeError.
from threading import Lock, Thread
lock = Lock()
def add_one(li):
lock.acquire()
try:
li.append(1)
finally:
lock.release()
def add_two(li):
lock.acquire()
try:
li.append(2)
finally:
lock.release()
# то же самое, что и конструкция:
# with lock:
# li.append(2)
threads = []
list_to_append = []
for func in [add_one, add_two]:
threads.append(Thread(target=func, args=(list_to_append,)))
threads[-1].start()
for thread in threads:
"""
Waits for threads to complete before moving on with the main script.
"""
thread.join()
print(list_to_append)Если не использовать Lock, то мы не можем быть уверены, что в конце получится [1, 2], могло бы получится и [2, 1]
Стандартный Lock не знает, какой поток блокируется в данный момент. Если блокировка сохраняется, блокируется любой из
потоков, пытающихся получить доступ, даже если этот тот же самый поток, который уже удерживает блокировку. Именно для
таких случаев и используется RLock — блокировка повторного входа. Вы можете расширить код в следующем фрагменте,
добавив выходные инструкции для демонстрации возможностей RLock предотвращать нежелательную блокировку.
import threading
num = 0
lock = threading.Lock()
lock.acquire()
num += 1
lock.acquire() # This will block.
num += 2
lock.release()
# With RLock, that problem doesn't happen.
lock = threading.RLock()
lock.acquire()
num += 3
lock.acquire() # This won’t block.
num += 4
lock.release()
lock.release() # You need to call release once for each call to acquire.Возможно рекурсивное использование RLock — когда родительский вызов функции блокирует вложенный вызов. Таким образом,
RLock используются для вложенного доступа к общим ресурсам.
Семафоры – это просто дополнительные счетчики. Вызов acquire() будет блокироваться семафором только после превышения
определенного количества запущенных потоков acquire(). Значение соответствующего счетчика уменьшается на каждый вызов
acquire() и увеличивается на каждый вызов release(). Значение ValueError будет возникать, если вызовы release()
будут пытаться увеличивать значение счетчика после достижения заданного максимального значения (количества потоков,
которые допустимы семафором acquire() до применения блокировки). Следующий код демонстрирует использование семафоров
для простой задачи производитель-потребитель.
from threading import Thread, BoundedSemaphore
from time import sleep, time
ticket_office = BoundedSemaphore(value=3)
def ticket_buyer(number):
start_service = time()
with ticket_office:
sleep(1)
print(f"client {number}, service time: {time() - start_service}")
buyer = [Thread(target=ticket_buyer, args=(i,)) for i in range(5)]
for b in buyer:
b.start()Примерный вывод:
client 0, service time: 1.0011110305786133
client 2, service time: 1.0013604164123535
client 1, service time: 1.001556158065796
client 3, service time: 2.002437114715576
client 4, service time: 2.0027763843536377
Как только первые потоки освободились, работу начали следующие.
События по своему назначению и алгоритму работы похожи на рассмотренные ранее условные переменные. Основная задача,
которую они решают – это взаимодействие между потоками через механизм оповещения. Объект класса Event управляет
внутренним флагом, который сбрасывается с помощью метода clear() и устанавливается методом set(). Потоки, которые
используют объект Event для синхронизации блокируются при вызове метода wait(), если флаг сброшен.
Методы класса Event:
-
is_set()возвращает True, если флаг находится во взведенном состоянии. -
set()переводит флаг во взведенное состояние. -
clear()переводит флаг в сброшенное состояние. -
wait(timeout=None)блокирует вызвавший данный метод поток, если флаг соответствующего Event-объекта находится в сброшенном состоянии. Время нахождения в состоянии блокировки можно задать через параметрtimeout.
from threading import Thread, Event
event = Event()
def worker(name: str):
event.wait() # ждём, пока флаг не изменится
print(f"Worker: {name}")
# Clear event
event.clear()
# Create and start workers
workers = [Thread(target=worker, args=(f"wrk {i}",)) for i in range(5)]
for w in workers:
w.start()
print("Main thread")
event.set() # Взводим флаг, чем и запускам функции сверхуMain thread
Worker: wrk 1
Worker: wrk 2
Worker: wrk 3
Worker: wrk 4
Worker: wrk 0
Их порядок мы не контролируем, только событие, по которому они срабатывают.
События на стероидах.
При создании объекта Condition вы можете передать в конструктор объект Lock или RLock, с которым хотите работать.
Перечислим методы объекта Condition с кратким описанием:
-acquire(*args) - захват объекта-блокировки.
-release() - освобождение объекта-блокировки.
-wait(timeout=None) - блокировка выполнения потока до оповещения о снятии блокировки. Через параметр timeout можно
задать время ожидания оповещения о снятии блокировки. Если вызвать wait() на условной переменной, у которой
предварительно не был вызван acquire(), то будет выброшено исключение RuntimeError.
-notify(n=1) снимает блокировку с остановленного методом wait() потока. Если необходимо разблокировать несколько
потоков, то для этого следует передать их количество через аргумент n.
-notify_all() снимает блокировку со всех остановленных методом wait() потоков.
from threading import Thread, Condition
condition = Condition()
def worker_wait(name: str):
condition.acquire()
print(f"Worker: {name} after ac")
condition.wait()
print(f"Worker: {name} after w")
condition.release()
def worker_notify(name: str):
condition.acquire()
print(f"Worker: {name} after ac")
condition.notify()
print(f"Worker: {name} after n")
condition.release()
# Create and start workers
workers_wait = [Thread(target=worker_wait, args=(f"wrk {i}",)) for i in range(5)]
workers_notify = [Thread(target=worker_notify, args=(f"wrk {i + 5}",)) for i in range(5)]
for w in workers_wait:
w.start()
for w in workers_notify:
w.start()Результат:
Worker: wrk 0 after ac
Worker: wrk 1 after ac
Worker: wrk 2 after ac
Worker: wrk 3 after ac
Worker: wrk 4 after ac
Worker: wrk 5 after ac
Worker: wrk 5 after n
Worker: wrk 0 after w
Worker: wrk 6 after ac
Worker: wrk 6 after n
Worker: wrk 1 after w
Worker: wrk 7 after ac
Worker: wrk 7 after n
Worker: wrk 8 after ac
Worker: wrk 8 after n
Worker: wrk 2 after w
Worker: wrk 9 after ac
Worker: wrk 9 after n
Worker: wrk 3 after w
Worker: wrk 4 after w
Process finished with exit code 0
Первые 5 запускаются и останавливаются на команде wait().
6-ой (с номером 5) тоже блокируется и вызывает notify(), чем и "отпускает" поток с номером 0.
Модуль threading предоставляет удобный инструмент для запуска задач по таймеру – класс Timer. При создании таймера
указывается функция, которая будет выполнена, когда он сработает. Timer реализован как поток, является наследником от
Thread, поэтому для его запуска необходимо вызвать start(), если необходимо остановить работу таймера, то вызовите
cancel().
Конструктор класса Timer:
Timer(interval, function, args=None, kwargs=None)Параметры:
-
interval- количество секунд, по истечении которых будет вызвана функцияfunction. -
function- функция, вызов которой нужно осуществить по таймеру. -
args,kwargs- аргументы функцииfunction.
Методы класса Timer:
cancel()останавливает выполнение таймера.
from threading import Timer
timer = Timer(interval=3, function=lambda: print("Message from Timer!"))
timer.start()Программа пойдёт дальше, а функция будет выполнена через 3 секунды.
Еще бывает барьер, но его мы рассматривать не будем. Он позволяет реализовать алгоритм, когда необходимо дождаться завершения работы группы потоков, прежде чем продолжить выполнение задачи.

Шикарная статья на тему
Python Global Interpreter Lock (GIL) — это своеобразная блокировка, позволяющая только одному потоку управлять интерпретатором Python. Это означает, что в любой момент времени будет выполняться только один конкретный поток.
Работа GIL может казаться несущественной для разработчиков, создающих однопоточные программы. Но во многопоточных программах отсутствие GIL может негативно сказываться на производительности процессоро-зависимых программ.
Поскольку GIL позволяет работать только одному потоку даже в многопоточном приложении, он заработал репутацию «печально известной» функции.
Фактически Python не вызывает много потоков одновременно, а только очень быстро их переключает, что делает все многопоточные вычисления по факту однопоточными.
Python подсчитывает количество ссылок для корректного управления памятью. Это означает, что созданные в Python объекты имеют переменную подсчёта ссылок, в которой хранится количество всех ссылок на этот объект. Как только эта переменная становится равной нулю, память, выделенная под этот объект, освобождается.
Вот небольшой пример кода, демонстрирующий работу переменных подсчёта ссылок:
import sys
a = []
b = a
sys.getrefcount(a)
3В этом примере количество ссылок на пустой массив равно 3. На этот массив ссылаются: переменная a, переменная b и
аргумент, переданный функции sys.getrefcount().
Проблема, которую решает GIL, связана с тем, что в многопоточном приложении сразу несколько потоков могут увеличивать или уменьшать значения этого счётчика ссылок. Это может привести к тому, что память очистится неправильно и удалится тот объект, на который ещё существует ссылка.
Счётчик ссылок можно защитить, добавив блокираторы на все структуры данных, которые распространяются по нескольким потокам. В таком случае счётчик будет изменяться исключительно последовательно.
Но добавление блокировки к нескольким объектам может привести к появлению другой проблемы — взаимоблокировки (англ. deadlocks), которая получается только если блокировка есть более чем на одном объекте. К тому же эта проблема тоже снижала бы производительность из-за многократной установки блокираторов.
GIL — это одиночный блокиратор самого интерпретатора Python. Он добавляет правило: любое выполнение байт-кода в Python
требует блокировки интерпретатора. В таком случае можно исключить взаимоблокировку, т. к. GIL будет единственной
блокировкой в приложении. К тому же его влияние на производительность процессора совсем не критично. Однако стоит
помнить, что GIL уверенно делает любую программу однопоточной.
Несмотря на то, что GIL используется и в других интерпретаторах, например в Ruby, он не является единственным решением
этой проблемы. Некоторые языки решают проблему потокобезопасного освобождения памяти с помощью сборки мусора.
Если GIL у вас вызывает проблемы, вот несколько решений, которые вы можете попробовать:
Многопроцессорность против многопоточности. Довольно популярное решение, поскольку у каждого Python-процесса есть собственный интерпретатор с выделенной под него памятью, поэтому с GIL проблем не будет.
Корутины. О них на следующем занятии.
В версии Python 3.13 планируются значительные изменения в работе GIL. Основные цели этих изменений:
-
Улучшение поддержки параллельного выполнения: Новые изменения направлены на снижение ограничений, накладываемых GIL на многопоточные программы. В Python 3.13 будет внедрен новый механизм управления GIL, который позволит потокам более эффективно работать с разделяемыми данными и снизить время ожидания.
-
Улучшение работы с многопроцессорными системами: Важное направление — это оптимизация работы на многоядерных процессорах. Внесенные изменения позволят более эффективно использовать ресурсы современных процессоров, уменьшая влияние GIL на производительность.
-
Обратная совместимость и стабильность: Важным аспектом является то, что изменения будут внедряться так, чтобы минимизировать их влияние на существующий код и экосистему Python. Разработчики активно работают над тем, чтобы сохранить обратную совместимость и обеспечить плавный переход на новую версию.
Изменения в GIL могут существенно повлиять на разработку многопоточных приложений на Python. Для разработчиков это означает:
- Повышение производительности: Программы, использующие многопоточность, могут работать быстрее и эффективнее, особенно на многоядерных системах.
- Упрощение параллелизма: Снижение ограничений GIL позволит разработчикам легче реализовывать параллельные алгоритмы без необходимости переключаться на другие языки или библиотеки для достижения высокой производительности.
- Потенциальные обновления и оптимизации кода: Хотя изменения будут стремиться сохранить обратную совместимость, возможно, что некоторым разработчикам потребуется адаптировать код для полного использования новых возможностей.

Сначала поговорим о параллельной обработке. Это способ одновременно разбивать и запускать программные задачи на нескольких микропроцессорах. По сути, это попытка сократить время обработки и это то, чего мы можем достичь с помощью компьютера с двумя или более процессорами, или с использованием компьютерной сети. Мы также называем это параллельными вычислениями.
Итак, теперь перейдем к Python Multiprocessing, это способ повысить производительность путем создания параллельного кода. Производители процессоров делают это возможным, добавляя больше ядер к своим процессорам. В многопроцессорной системе приложения разбиваются на более мелкие подпрограммы для самостоятельной работы. Взгляните на однопроцессорную систему. Учитывая несколько процессов одновременно, он пытается прерывать и переключаться между задачами. Как бы вы себя чувствовали, будучи единственным шеф-поваром на кухне с сотнями клиентов? Вы должны были бы выполнять все обычные задачи от выпечки до замеса теста.
-
Мультипроцессор – компьютер с несколькими центральными процессорами.
-
Многоядерный процессор – один вычислительный компонент с более чем одной независимой фактической единицей обработки/ядрами.
В любом случае процессор может выполнять несколько задач одновременно, назначая процессор для каждой задачи.
Пример:
from multiprocessing import Process
def square(n):
print("Число в квадрате ", n ** 2)
def cube(n):
print("Число в кубе", n ** 3)
if __name__ == "__main__":
p1 = Process(target=square, args=(7,))
p2 = Process(target=cube, args=(7,))
p1.start()
p2.start()
p1.join()
p2.join()
print("Мы закончили")Отличие от многопоточности в том, что в этом случае каждый отдельный процесс будет выполняться отдельным ядром или процессором, и никак не блокируется GIL.
Но процедура создания нового процесса достаточно дорогостоящая, и нет никакого смысла создавать новый процесс для простых действий.
У каждого процесса есть id, название и т. д. эти данные всегда можно извлечь.
Так же как и с потоками у нас может быть ситуация, когда разные процессы обрабатывают одни и те же данные, и чтобы быть уверенным, что действия не происходят одновременно, мы можем заблокировать процесс, синтаксис идентичен.
from multiprocessing import Process, Lock
lock = Lock()
def printer(item):
lock.acquire()
try:
print(item)
finally:
lock.release()
if __name__ == "__main__":
items = ['nacho', 'salsa', 7]
for item in items:
p = Process(target=printer, args=(item,))
p.start()Для многопроцессорности работают ровно те же самые блокировки, как и для многопоточности.
Пул - это возможность создать сразу необходимое количество процессов, а не делать это по одному. В данном примере мы сразу создаём 3 процесса для трех параллельных вычислений.
from multiprocessing import Pool
def double(n):
return n * 2
if __name__ == '__main__':
nums = [2, 3, 6]
pool = Pool(processes=3)
print(pool.map(double, nums))Если нам необходимо вычислять одно действие на трёх процессорах, нам поможет функция apply_async():
from multiprocessing import Pool
def double(n):
return n * 2
if __name__ == '__main__':
pool = Pool(processes=3)
result = pool.apply_async(double, (7,))
print(result.get())