- Code for the paper: Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding
- Authors: Sahar Abdelnabi, Mario Fritz
- Videos: Short video, Full video
Recent advances in natural language generation have introduced powerful language models with high-quality output text. However, this raises concerns about the potential misuse of such models for malicious purposes. In this paper, we study natural language watermarking as a defense to help better mark and trace the provenance of text. We introduce the Adversarial Watermarking Transformer (AWT) with a jointly trained encoder-decoder and adversarial training that, given an input text and a binary message, generates an output text that is unobtrusively encoded with the given message. We further study different training and inference strategies to achieve minimal changes to the semantics and correctness of the input text. AWT is the first end-to-end model to hide data in text by automatically learning -without ground truth- word substitutions along with their locations in order to encode the message. We empirically show that our model is effective in largely preserving text utility and decoding the watermark while hiding its presence against adversaries. Additionally, we demonstrate that our method is robust against a range of attacks.

- Main requirements:
- Python 3.7.6
- PyTorch 1.2.0
- To set it up:
conda env create --name awt --file=environment.yml-
Model checkpt of InferSent:
-
get the model infersent2.pkl from: InferSent, place it in 'sent_encoder' directory, or change the argument 'infersent_path' in 'main_train.py' accordingly
-
Download GloVe following the instructions in: inferSent, place it in 'sent_encoder/GloVe' directory, or change the argument 'glove_path' in 'main_train.py' accordingly
-
-
Model checkpt of AWD LSTM LM:
- Download our trained checkpt (trained from the code in: AWD-LSTM)
-
Model checkpt of SBERT:
- Follow instructions from: sentence-transformer
-
- Trained with the fine-tuning step and reaches a comparable perplexity to what was reproted in the AWD-LSTM paper
-
- DAE trained to denoise non-watermarked text (the noise applied is word replacement and word removing)
-
,
- Another trained model (used for attacks)
-
- DAE trained to denoise the watermarked text of
- DAE trained to denoise the watermarked text of
-
- A transformer-based classifier trained on the full AWT output (20 samples), tasked to classify between watermarked and non-watermarked text
-
Download and place in the current directory.
- You will need the WikiText-2 (WT2) dataset. Follow the instructions in: AWD-LSTM to download it
- Phase 1 of training AWT
python main_train.py --msg_len 4 --data data/wikitext-2 --batch_size 80 --epochs 200 --save WT2_mt_noft --optimizer adam --fixed_length 1 --bptt 80 --use_lm_loss 0 --use_semantic_loss 0 --discr_interval 1 --msg_weight 5 --gen_weight 1.5 --reconst_weight 1.5 --scheduler 1- Phase 2 of training AWT
python main_train.py --msg_len 4 --data data/wikitext-2 --batch_size 80 --epochs 200 --save WT2_mt_full --optimizer adam --fixed_length 0 --bptt 80 --discr_interval 3 --msg_weight 6 --gen_weight 1 --reconst_weight 2 --scheduler 1 --shared_encoder 1 --use_semantic_loss 1 --sem_weight 6 --resume WT2_mt_noft --use_lm_loss 1 --lm_weight 1.3- Needs the checkpoints in the current directory
- selecting best sample based on SBERT:
python evaluate_sampling_bert.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [model_gen] --disc_path [model_disc] --use_lm_loss 1 --seed 200 --samples_num [num_samples]- selecting the best sample based on LM loss:
python evaluate_sampling_lm.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [model_gen] --disc_path [model_disc] --use_lm_loss 1 --seed 200 --samples_num [num_samples]- sentences_agg_number is the number of segments to accumulate to calculate the p-value
- threshold on the increase of the LM loss
- thresholds used in the paper: 0.45, 0.5, 0.53, 0.59, 0.7 (encodes from 75% to 95% of the sentences)
- with selective encoding, we use 1-sample
python evaluate_selective_lm_threshold.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences agg. number] --gen_path [model_gen] --disc_path [model_disc] --use_lm_loss 1 --seed 200 --lm_threshold [threshold] --samples_num 1- For selective encoding using SBERT as a metric (sentences with higher SBERT than the threshold will not be used), use:
python evaluate_sampling_bert.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [model_gen] --disc_path [model_disc] --use_lm_loss 1 --seed 200 --samples_num 1 --bert_threshold [dist_threshold]- Encode multiple sentences with the same message, decode the msg from each one, average the posterior probabilities
python evaluate_avg.py --msg_len 4 --data data/wikitext-2 --bptt 80 --gen_path [model_gen] --disc_path [model_disc] --use_lm_loss 1 --seed 200 --samples_num [num_samples] --avg_cycle [number_of_sentences_to_avg]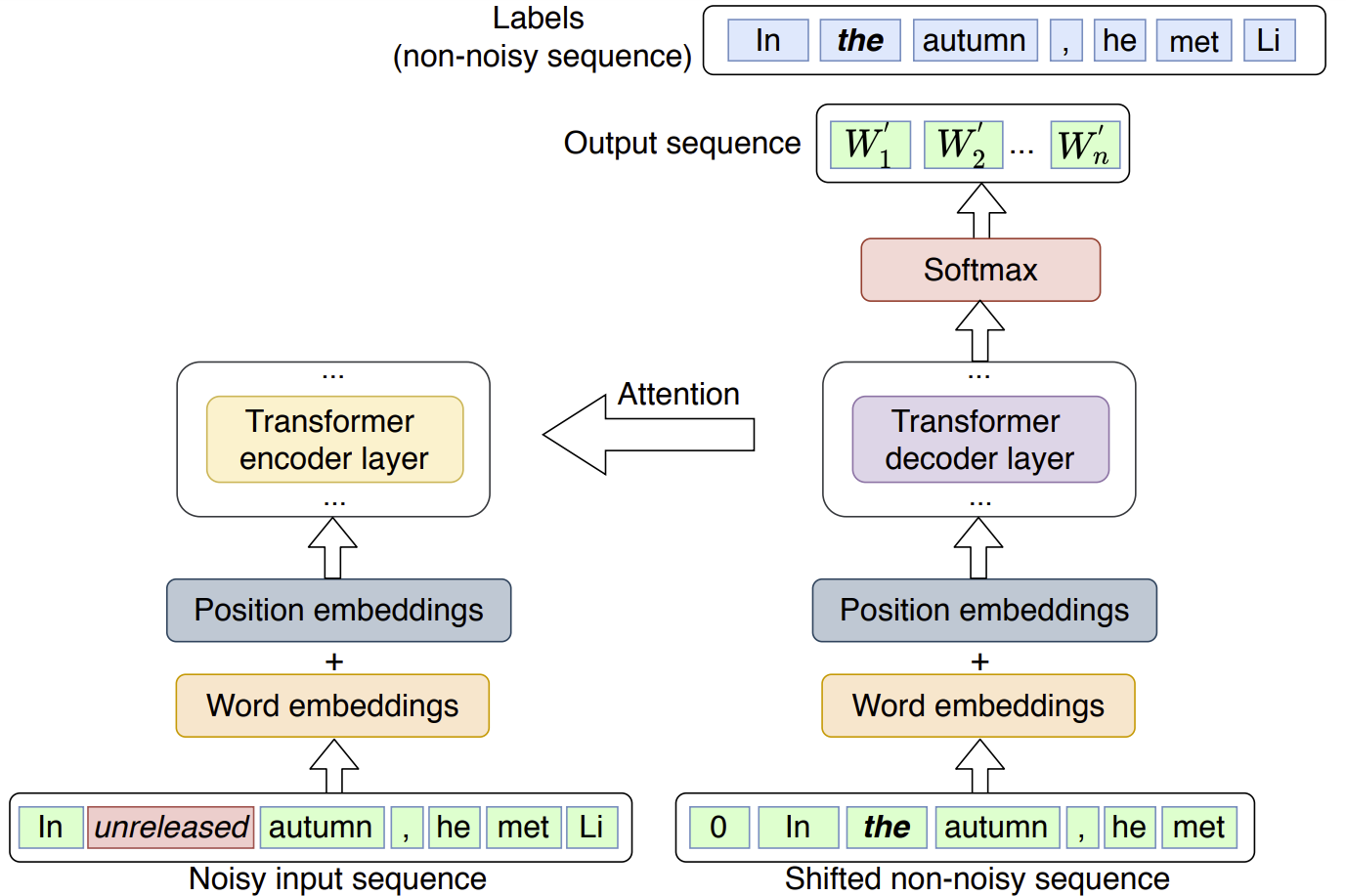
- To train the denosining-autoencoder as in the paper:
python main_train_dae.py --data data/wikitext-2 --bptt 80 --pos_drop 0.1 --optimizer adam --save model1 --batch_size 64 --epochs 2000 --dropoute 0.05 --sub_prob 0.1- sub_prob: prob. of substituting words during training
- dropoute: embedding dropout prob
- Evaluate the DAE on its own on clean data
- apply noise, denoise, then compare to the original text
python evaluate_denoise_autoenc.py --data data/wikitext-2 --bptt 80 --autoenc_attack_path [dae_model_name] --use_lm_loss 1 --seed 200 --sub_prob [sub_noise_prob.]- Run the attack:
- First sample from AWT, then input to the DAE, then decode the msg
python evaluate_denoise_autoenc_attack_greedy.py --data data/wikitext-2 --bptt 80 --msg_len 4 --msgs_segment [sentences_agg_number] --gen_path [awt_model_gen] --disc_path [awt_model_disc] --samples_num [num_samples] --autoenc_attack_path [dae_model_name] --use_lm_loss 1 --seed 200python evaluate_remove_attacks.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [awt_model_gen] --disc_path [awt_model_disc] --use_lm_loss 1 --seed 200 --samples_num [num_samples] --remove_prob [prob_of_removing_words]python evaluate_syn_attack.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [awt_model_gen] --disc_path [awt_model_disc] --use_lm_loss 1 --use_elmo 0 --seed 200 --samples_num [num_samples] --modify_prob [prob_of_replacing_words]- To implement this attack you need to train a second AWT model with different seed (see our checkpoints)
python rewatermarking_attack.py --msg_len 4 --data data/wikitext-2 --bptt 80 --msgs_segment [sentences_agg_number] --gen_path [awt_model_gen_1] --gen_path2 [awt_model_gen_2] --use_lm_loss 1 --seed 200 --samples_num [num_samples] --samples_num_adv [num_samples]- This generates using awt_model_gen_1, re-watermarks with awt_model_gen_2, decode with awt_model_gen_1 again
- samples_num_adv is the number of samples sampled by awt_model_gen_2, we use 1 sample in the paper
- To implement this attack you need to train a second AWT model with a different seed (see our checkpoints)
- You then need to train a denoisining autoencoder on input and output pairs of the second de-watermarking model (the data is in under: 'data_dae_pairs')
python main_train_dae_wm_pairs.py --data data/wikitext-2 --bptt 80 --pos_drop 0.1 --optimizer adam --save model2 --batch_size 64 --epochs 500 --dropoute 0.05where '--data' takes the directory containing the training data (found in 'data_classifier')
- Then you need to apply the denoising autoencoder to the first model (or the second model:
, in case of the white-box setting).
python evaluate_dewatermarking_attack.py --data data/wikitext-2 --bptt 80 --msg_len 4 --msgs_segment [sentences_agg_number] --gen_path [awt_model_gen_1] --disc_path [awt_model_disc_1] --samples_num 1 --autoenc_attack_path [dae_paired_model_path] --use_lm_loss 1 --seed 200 To run the classification on the full AWT output.
-
First, you need to generate watermarked training, test, and validation data. The data we used to run the experiment on the full AWT model can be found already under 'data_classifier' (20 samples with LM metric). For other sampling conditions, you need to generate new data using the previous scripts.
-
To train the classifier in the paper use:
python main_disc.py --data data/wikitext-2 --batch_size 64 --epochs 300 --save WT2_classifier --optimizer adam --fixed_length 0 --bptt 80 --dropout_transformer 0.3 --encoding_layers 3 --classifier transformer --ratio 1where '--data' takes the directory containing the training data (found in 'data_classifier')
- To evaluate the classifier (on the generated data used before), use:
python evaluate_disc.py --data data/wikitext-2 --bptt 80 --disc_path [classifier_name] --seed 200 - The code to reproduce the visualization experiments (histogram counts, words change map count, top changed words)
- You will need to install wordcloud for the words maps
- Follow the notebook files, the needed files of AWT output and the no discriminator output can be found under 'visualization/'
- If you find this code helpful, please cite our paper:
@inproceedings{abdelnabi21oakland,
title = {Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding},
author = {Sahar Abdelnabi and Mario Fritz},
booktitle = {42nd IEEE Symposium on Security and Privacy},
year = {2021}
}- We thank the authors of InferSent, sentence-transformer, and AWD-LSTM for their repositories and pre-trained models which we use in our training and experiments. We acknowledge AWD-LSTM as we use their dataset and parts of our code were modified from theirs.