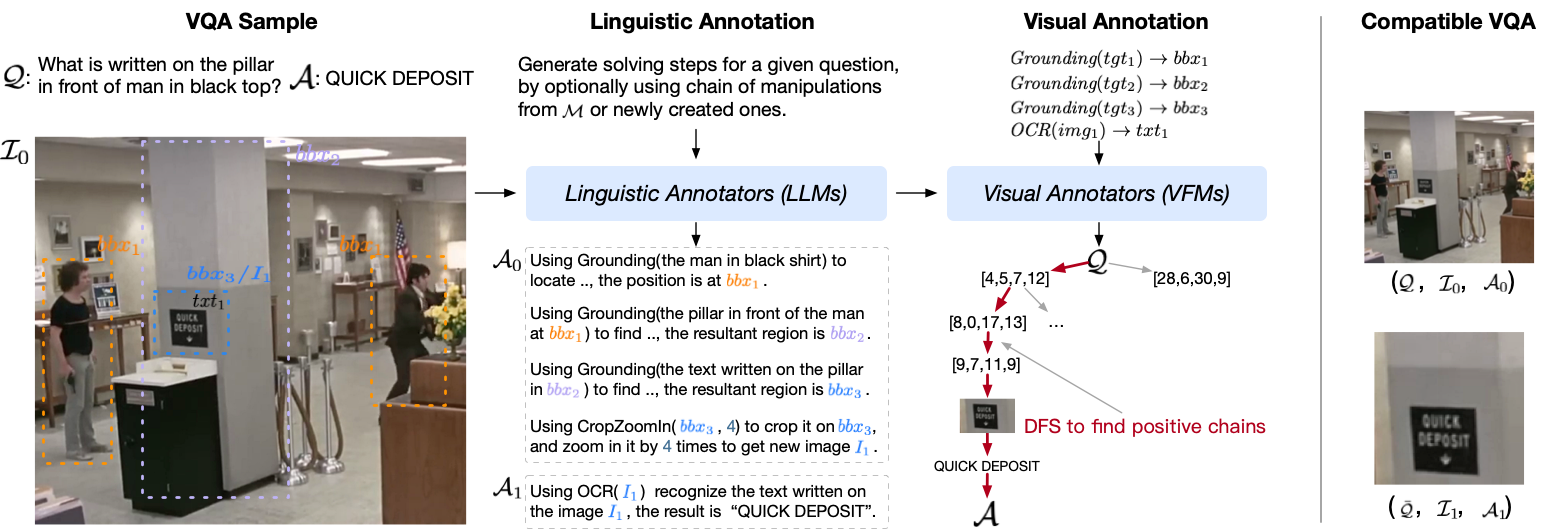
This step prepare the original data source to a unified data format.
- Put (or link) all your data into the
save/rawdirectory according to the scripts inpreparefolder - Just run the following command
`bash run_prepare.shThis command will save the processed results in to save/processed.
This step generate the linguistic solving steps based on GPT4. In addition, we can also generate solving steps for absurd visual question to resist hallucinations based on GPT4-V.
- You need to configure the API tokens for GPT4 and GPT4-V in the scripts that we have written to call these LLMs, at
tools/gpt4.pyandtools/gpt4v.py - Run the following python scripts for generation, this might spend several days accroding to the parallel processes.
python gen_steps_txt.py
python pro_steps_txt.py python gen_absurd.py
python pro_steps_absurd.pyThese command will save the generated results into the directors suffixed with _extract.
This step compensate the visual contents requested by the manipulations in previous generate solving steps.
- Just run the following command
bash run_visual_ann.shThis command will save the compensated results into the directories suffixed with _visual.
As we train CogCoM using the WebDataset data processor, we can easily convert the generated results to this format.
- Just run the following command.
bash run_convert_wds.shThis command will convert all generated results in previous step to the WebDataaset format that we can using it to train CogCoM. The save the directories will be suffixed with _wds.
We have also open-sourced the data we built to train CogCoM to facilitate potential research, which includes:
- Instruction-tuning datasets (MultiInstruct-366K, ShareGPT4V-100K, LLaVAR-34K, ShikraGrounding-14K)
- Automatically synthesized CoM data (84K positive chains)
- Automatically synthesized CoM-test data (8K positive chains)
- Manually annotated CoM-Math data (7K positive chains)
- Download the Instruction-tuning datasets prepared with the
WebDatasetformat (including serialized image bytes) here. - Download all CoM datasets, including both automatically synthesized data and manually annotated math data from here.
Examples of (1) our automatically synthesized data and (2) our manually annotated math data.

Each data sample in the dataset is provided in json format and contains the following attributes:
{
"pid": "[int] Problem ID, e.g., 1",
"image_path": "[string] A file path pointing to the associated image",
"question": "[string] The question text",
"answer": "[string] The correct answer for the problem",
"com_founds": "[list] the tree nodes where the golden answer was found",
"final_com": {
"a,b--c,d": // a: parent's level, b: parent's index, c: current node's level, current node's index,
{
"func": "[string] the current manipulation function",
"param": "[string] the input parameter of current manipulation",
"onbox": "[list] bounding boxes where current manipulation will operate on",
"variables": "[dict] mappings from placeholders to real values in `desc`",
"desc": "[string] the textual description of current reasoning step",
"return": "[list] the return value of current manipulation",
"found": "[bool] whether the golden answer is found at current node",
},
},
"cropped": "[bool] whether the CropZoomIn manipulation is used",
}You can view the CoM samples with reasoning chains using our visualization script /cogcom/data/utils/visualize.ipynb
Click to expand/collapse the visualization page screeshot.

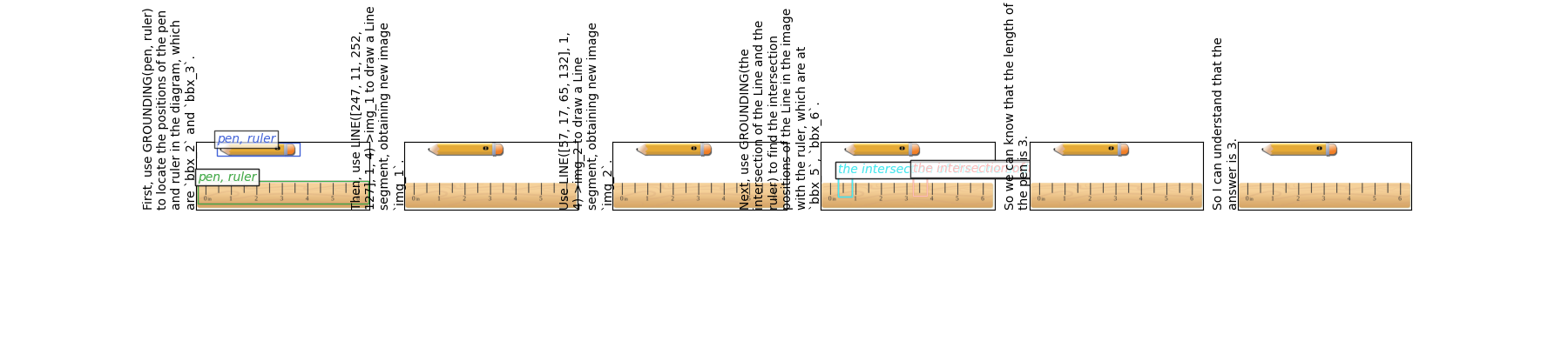
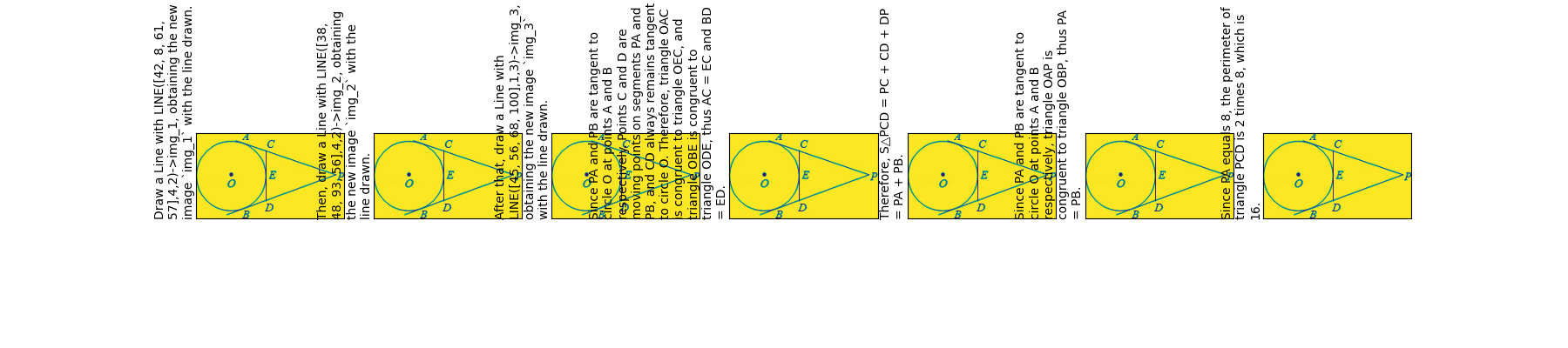
The CoM and CoM-test datasets are derived from existing public datasets: ST-VQA, TextVQA, and TDIUC. The CoM-Math dataset is derived and further manually annotated from the MathVista dataset. Details can be found in the paper. All these source datasets have been preprocessed and labeled for training and evaluation purposes.
The new contributions to our dataset are distributed under the CC BY-SA 4.0 license, including
- The creation of three datasets: CoM, CoM-test, and CoM-Math;
- The filtering and cleaning of source datasets;
- The standard formalization of instances for evaluation purposes;
- The annotations of metadata.
The copyright of the images, questions and the answers belongs to the original authors. Alongside this license, the following conditions apply:
- Purpose: The dataset was primarily designed for use as training sets and test sets.
- Commercial Use: The dataset can be used commercially as training sets and test sets. By accessing or using this dataset, you acknowledge and agree to abide by these terms in conjunction with the CC BY-SA 4.0 license.