-
Notifications
You must be signed in to change notification settings - Fork 0
/
misc.ts
546 lines (513 loc) · 18.6 KB
/
misc.ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
/**
* Cast an object to a type.
* Check the type at runtime.
* @param item Check the type of this item.
* @param ty The expected type. This should be a class.
* @param notes This will be included in the error message.
* @returns item
* @throws If the item is not of the correct type, throw an `Error` with a detailed message.
*/
export function assertClass<T extends object>(
item: unknown,
ty: { new (): T },
notes = "Assertion Failed."
): T {
const failed = (typeFound: string) => {
throw new Error(
`${notes} Expected type: ${ty.name}. Found type: ${typeFound}.`
);
};
if (item === null) {
failed("null");
} else if (typeof item != "object") {
failed(typeof item);
} else if (!(item instanceof ty)) {
failed(item.constructor.name);
} else {
return item;
}
throw new Error("wtf");
}
/**
* This is a wrapper around setTimeout() that works with await.
*
* `await sleep(100)`;
* @param ms How long in milliseconds to sleep.
* @returns A promise that you can wait on.
*/
export function sleep(ms: number) {
// https://stackoverflow.com/a/39914235/971955
return new Promise((resolve) => setTimeout(resolve, ms));
}
/**
* On success `parsed` points to the XML Document.
* On success `error` points to an HTMLElement explaining the problem.
* Exactly one of those two fields will be undefined.
*/
export type XmlStatus =
| { parsed: Document; error?: undefined }
| { parsed?: undefined; error: HTMLElement };
/**
* Check if the input is a valid XML file.
* @param xmlStr The input to be parsed.
* @returns If the input valid, return the XML document. If the input is invalid, this returns an HTMLElement explaining the problem.
*/
export function testXml(xmlStr: string): XmlStatus {
const parser = new DOMParser();
const dom = parser.parseFromString(xmlStr, "application/xml");
// https://developer.mozilla.org/en-US/docs/Web/API/DOMParser/parseFromString
// says that parseFromString() will throw an error if the input is invalid.
//
// https://developer.mozilla.org/en-US/docs/Web/Guide/Parsing_and_serializing_XML
// says dom.documentElement.nodeName == "parsererror" will be true if the input
// is invalid.
//
// Neither of those is true when I tested it in Chrome. Nothing is thrown.
// If the input is "" I get:
// dom.documentElement.nodeName returns "html",
// doc.documentElement.firstElementChild.nodeName returns "body" and
// doc.documentElement.firstElementChild.firstElementChild.nodeName = "parsererror".
// It seems that the <parsererror> can move around. It looks like it's trying to
// create as much of the XML tree as it can, then it inserts <parsererror> whenever
// and wherever it gets stuck. It sometimes generates additional XML after the
// parsererror, so .lastElementChild might not find the problem.
//
// In case of an error the <parsererror> element will be an instance of
// HTMLElement. A valid XML document can include an element with name name
// "parsererror", however it will NOT be an instance of HTMLElement.
//
// getElementsByTagName('parsererror') might be faster than querySelectorAll().
for (const element of Array.from(dom.querySelectorAll("parsererror"))) {
if (element instanceof HTMLElement) {
// Found the error.
return { error: element };
}
}
// No errors found.
return { parsed: dom };
}
/**
* This is my preferred way to parse an XML document. Any and all errors result in
* `undefined`. `See testXml()` if you need better error messages.
* @param bytes The input as a string.
*
* If the input is undefined, immediately return undefined. This makes it easy to
* propagate errors and only check for undefined once, at the end.
* @returns The root element of the resulting XML Document, or undefined in case of any errors.
*/
export function parseXml(bytes : string | undefined) : Element | undefined {
if (bytes === undefined) {
return undefined;
} else {
const parsed = testXml(bytes);
return parsed?.parsed?.documentElement;
}
}
/**
* Walk through a path into an XML (or similar) document.
*
* Note that tag names must be unique. If you have an element like
* ```
* <parent>
* <twin />
* <twin />
* <unique />
* </parent>
* ```
* and you say `followPath(parent, "twin")` the result will be `undefined` because we don't know which twin to return.
* `followPath(parent, "unique")` will return the last child element.
* @param from Start from this element.
* @param path A list of instructions, like `0` to take the first child element or a string to look for an element with that tag name.
* @returns The requested `Element`, or `undefined` if there were any problems.
*/
export function followPath(from : Element | undefined, ...path : readonly (number | string)[]) : Element | undefined {
for (const transition of path) {
if (from === undefined) {
return undefined;
} else if (typeof transition === "number") {
// Element.children includes only element nodes.
from = from.children[transition];
} else {
const hasCorrectName = from.getElementsByTagName(transition);
if (hasCorrectName.length != 1) {
// Not found or ambiguous.
return undefined;
} else {
from = hasCorrectName[0];
}
}
}
return from;
}
/**
*
* @param attributeName The name of the attribute we want to read.
* @param from Start the search from this `Element`.
* @param path We use `followPath()` to find an `Element` then we look for the attribute there.
* Leave this empty to look for the attribute directly in `from`.
* @returns The value of the attribute. Or `undefined` if there are any problems.
*/
export function getAttribute(attributeName : string, from : Element | undefined, ...path : readonly (number |string)[]) : string | undefined {
from = followPath(from, ...path);
if (from === undefined) {
return undefined;
}
if (!from.hasAttribute(attributeName)) {
// MDN recommends explicitly checking for this.
// https://developer.mozilla.org/en-US/docs/Web/API/Element/getAttribute#non-existing_attributes
return undefined;
}
return from.getAttribute(attributeName)??undefined;
}
/**
* There are a lot of ways to convert a string to a number in JavaScript.
* And they are all slightly different!
*
* This is my preferred way to parse a number. The base comes from the
* standard parseFloat command(). Any errors are reported as undefined,
* so you can choose to get rid of them with ??.
*
* I get rid of NaNs and infinities. I don't think I every really send
* an infinity over the network or save it in a file. These become
* undefined, just like errors.
* @param source The input to parse.
* @returns A finite number or undefined if the parse failed.
*/
export function parseFloatX(
source: string | undefined | null
): number | undefined {
if (source === undefined || source === null) {
return undefined;
}
// TODO parseFloat is generally my favorite of the build it methods to
// convert to a number. But "9x" and "9" both return 9. In my C++
// version (and others) "9x" would fail.
const result = parseFloat(source);
if (isFinite(result)) {
return result;
} else {
return undefined;
}
}
/**
* There are a lot of ways to convert a string to a number in JavaScript.
* And they are all slightly different!
*
* I get rid of NaNs, infinities, numbers with a fraction, or integers
* that are too big to fit into JavaScript numbers. These are all
* converted into undefined.
* @param source The input to parse
* @returns A finite integer or undefined if the parse failed.
*/
export function parseIntX(
source: string | undefined | null
): number | undefined {
const result = parseFloatX(source);
if (result === undefined) {
return undefined;
} else if (
result > Number.MAX_SAFE_INTEGER ||
result < Number.MIN_SAFE_INTEGER ||
result != Math.floor(result)
) {
return undefined;
} else {
return result;
}
}
/**
* Convert a number in time_t format into a JavaScript Date object.
* @param source The time in time_t format. In Unix & C it's common to count the number of seconds past
* the Unix epoch as an integer. As opposed to Java which counts the number of milliseconds past the
* Unix epoch as an integer, or JavaScript which counts the number of milliseconds past the epoch as
* a floating point number. We interpret 0 was a way to say no value.
* @returns A `Date` if possible, or undefined on any error.
*/
export function parseTimeT(
source: string | number | undefined | null
): Date | undefined {
if (typeof source === "string") {
source = parseIntX(source);
}
if (source === undefined || source === null) {
return undefined;
}
if (source <= 0) {
// 0 can be a valid date, but it is also often used to say no value.
// I'm choosing no value because it matches most of the data I read.
// I'm converting negative numbers into undefined just to be consistent;
// It would be weird if the 1 and -1 converted into times that were
// 2 seconds apart, but 0 converted into an error.
return undefined;
}
return new Date(source * 1000);
}
/**
* Parse the entire body of a CSV file at once.
* @param data An entire CSV file.
* @returns An array, one element per line. Each element is a sub array, one element per column.
*/
export const csvStringToArray = (data : string) => {
// Source:
// https://gist.github.com/Jezternz/c8e9fafc2c114e079829974e3764db75?permalink_comment_id=3457862#gistcomment-3457862
const re = /(,|\r?\n|\r|^)(?:"([^"]*(?:""[^"]*)*)"|([^,\r\n]*))/gi
const result : string[][] = [[]]
let matches
while ((matches = re.exec(data))) {
if (matches[1].length && matches[1] !== ',') result.push([])
result[result.length - 1].push(
matches[2] !== undefined ? matches[2].replace(/""/g, '"') : matches[3]
)
}
return result
}
/**
* Pick any arbitrary element from the set.
* @param set
* @returns An item in the set. Unless the set is empty, then it returns undefined.
*/
export function pickAny<T>(set: ReadonlySet<T>): T | undefined {
const first = set.values().next();
if (first.done) {
return undefined;
} else {
return first.value;
}
}
/**
*
* @param array Pick from here.
* @returns A randomly selected element of the array.
* @throws An error if the array is empty.
*/
export function pick<T>(array: ArrayLike<T>): T {
return array[(Math.random() * array.length) | 0];
}
/**
* This is like calling `input.map(transform).filter(item => item !=== undefined)`.
* But if I used that line typescript would get the output type wrong.
* `Array.prototype.flatMap()` is a standard and traditional alternative.
* @param input The values to be handed to `transform()` one at a time.
* @param transform The function to be called on each input.
* `index` is the index of the current input, just like in Array.prototype.forEach().
* @returns The items returned by `transform()`, with any undefined items removed.
*/
export function filterMap<Input, Output>(
input: Input[],
transform: (input: Input, index: number) => Output | undefined
) {
const result: Output[] = [];
input.forEach((input, index) => {
const possibleElement = transform(input, index);
if (undefined !== possibleElement) {
result.push(possibleElement);
}
});
return result;
}
/**
* Easier than `new Promise()`.
* @returns An object including a promise and the methods to resolve or reject that promise.
*/
export function makePromise<T = void>() {
let resolve!: (value: T | PromiseLike<T>) => void;
let reject!: (reason?: any) => void;
const promise = new Promise<T>((resolve1, reject1) => {
resolve = resolve1;
reject = reject1;
});
return { promise, resolve, reject };
}
/**
* Fri Sep 12 275760 17:00:00 GMT-0700 (Pacific Daylight Time)
* This is a value commonly used as the largest date.
*
* Strictly speaking this could get a little higher, but this is what is always used on the internet.
*
* Warning: If you pass this value to MySQL it will overflow and fail poorly.
*/
export const MAX_DATE = new Date(8640000000000000);
/**
* Mon Apr 19 -271821 16:07:02 GMT-0752 (Pacific Daylight Time)
* This is a value commonly used as the smallest date.
*
* Strictly speaking this could get a little lower, but this is what is always used on the internet.
*
* Warning: If you pass this value to MySQL it will overflow and fail poorly.
*/
export const MIN_DATE = new Date(-8640000000000000);
export function dateIsValid(date: Date): boolean {
return isFinite(date.getTime());
}
/**
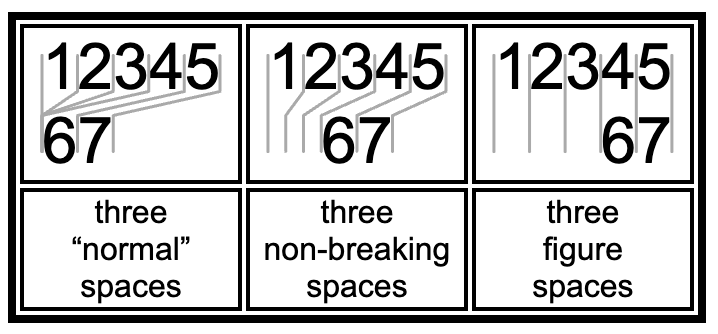
* Looks like a space. But otherwise treated like a normal character.
* In particular, HTML will __not__ combine multiple `NON_BREAKING_SPACE` characters like it does for normal spaces.
*
* If you are writing to element.innerHTML you could use "&nbsp;" to get the same result. If you are writing to
* element.innerText or anything that is not HTML, you need to use this constant.
*
* Google slides still treats this like a normal space. 🙁
*
* 
*/
export const NON_BREAKING_SPACE = "\xa0";
/**
* Looks like a space. Is the width of a digit.
*
* HTML completely ignores some “normal” spaces.
* HTML always draws a figure space.
*
* 
*/
export const FIGURE_SPACE = "\u2007";
// https://dev.to/chrismilson/zip-iterator-in-typescript-ldm
export type Iterableify<T> = { [K in keyof T]: Iterable<T[K]> };
/**
* Given a list of iterables, make a single iterable.
* The resulting iterable will contain arrays.
* The first entry in the output will contain the first entry in each of the inputs.
* The nth entry in the output will contain the nth entry in each of the inputs.
* This will stop iterating when the first of the inputs runs out of data.
* ```
* for (const [rowHeader, rowBody] of zip(sharedStuff.rowHeaders, thisTable.rowBodies)) {
* ...
* }
* ```
* @param toZip Any number of iterables.
*/
export function* zip<T extends Array<any>>(
...toZip: Iterableify<T>
): Generator<T> {
// Get iterators for all of the iterables.
const iterators = toZip.map((i) => i[Symbol.iterator]());
while (true) {
// Advance all of the iterators.
const results = iterators.map((i) => i.next());
// If any of the iterators are done, we should stop.
if (results.some(({ done }) => done)) {
break;
}
// We can assert the yield type, since we know none
// of the iterators are done.
yield results.map(({ value }) => value) as T;
}
}
export function* count(start = 0, end = Infinity, step = 1) {
for (let i = start; i < end; i += step) {
yield i;
}
}
/**
* Create and initialize an array.
* @param count The number of items in the array.
* @param callback A function which will take the (zero based) array index as an input and will return the value to put into the array at that index.
* @returns An array containing all of the results.
*/
export function initializedArray<T>(
count: number,
callback: (index: number) => T
): T[] {
const result: T[] = [];
for (let i = 0; i < count; i++) {
result.push(callback(i));
}
return result;
}
/**
* @deprecated Use `initializedArray()`. `countMap` was my first attempt at a name and I don't like it!
*/
export const countMap = initializedArray;
export function sum(items: number[]): number {
return items.reduce((accumulator, current) => accumulator + current, 0);
}
/**
* For use with `makeLinear()` and `makeBoundedLinear()`.
*/
export type LinearFunction = (x: number) => number;
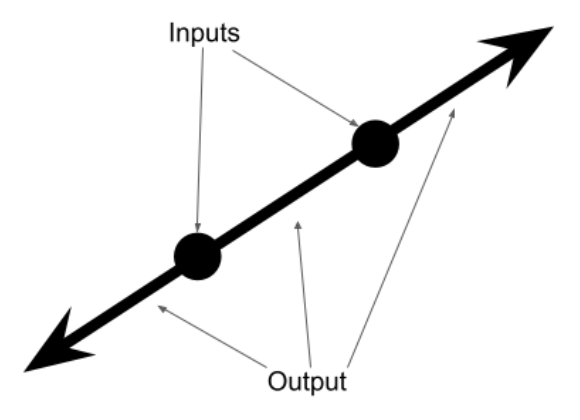
/**
* Linear interpolation and extrapolation.
*
* Given two points, this function will find the line that lines on those two points.
* And it will return a function that will find all points on that line.
* @param x1 One valid input.
* @param y1 The expected output at x1.
* @param x2 Another valid input. Must differ from x2.
* @param y2 The expected output at x2.
* @returns A function of a line. Give an x as input and it will return the expected y.
* 
*/
export function makeLinear(
x1: number,
y1: number,
x2: number,
y2: number
): LinearFunction {
const slope = (y2 - y1) / (x2 - x1);
return function (x: number) {
return (x - x1) * slope + y1;
};
}
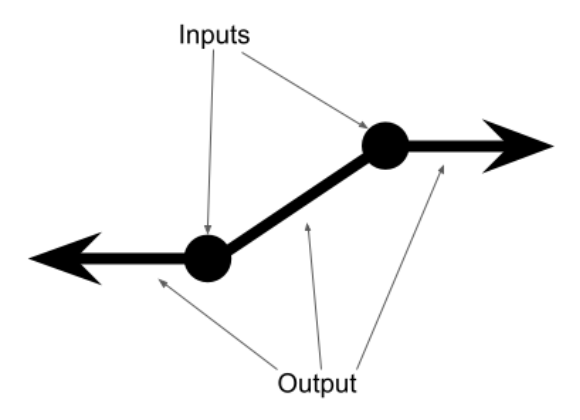
/**
* Linear interpolation.
*
* Given two points, this function will find the line segment that connects the two points.
* @param x1 One valid input.
* @param y1 The expected output at x1.
* @param x2 Another valid input.
* @param y2 The expected output at x2.
* @returns A function that takes x as an input.
* If x is between x1 and x2, return the corresponding y from the line segment.
* Outside of the line segment, the function is flat.
* I.e. f(-Infinity) == f(min(x1,x2) - 100) == f(min(x1,x2)).
* And f(Infinity) == f(max(x1,x2) + 100) == f(max(x1,x2)).
* 
*/
export function makeBoundedLinear(
x1: number,
y1: number,
x2: number,
y2: number
): LinearFunction {
if (x2 < x1) {
[x1, y1, x2, y2] = [x2, y2, x1, y1];
}
// Now x1 <= x2;
const slope = (y2 - y1) / (x2 - x1);
return function (x: number) {
if (x <= x1) {
return y1;
} else if (x >= x2) {
return y2;
} else {
return (x - x1) * slope + y1;
}
};
}
export function polarToRectangular(r: number, θ: number) {
return { x: Math.sin(θ) * r, y: Math.cos(θ) * r };
}
/**
* Create all permutations of an array.
* @param toPermute The items that need to find a location. Initially all items are here.
* @param prefix The items that are already in the correct place. Initially this is empty. New items will be added to the end of this list.
* @returns Something you can iterate over to get all permutations of the original array.
*/
export function* permutations<T>(
toPermute: readonly T[],
prefix: readonly T[] = []
): Generator<readonly T[], void, undefined> {
if (toPermute.length == 0) {
yield prefix;
} else {
for (let index = 0; index < toPermute.length; index++) {
const nextItem = toPermute[index];
const newPrefix = [...prefix, nextItem];
const stillNeedToPermute = [
...toPermute.slice(0, index),
...toPermute.slice(index + 1),
];
yield* permutations(stillNeedToPermute, newPrefix);
}
}
}
//console.log(Array.from(permutations(["A", "B", "C"])), Array.from(permutations([1 , 2, 3, 4])), Array.from(permutations([])));