本笔记为阿里云天池龙珠计划Python训练营的学习内容,链接为:https://tianchi.aliyun.com/specials/promotion/aicamppython

- 2022 年 02 月 14 日版本
- 本文档是以 CC 开源的模式的发布,你能且将获得本文档的 PDF 版本已经 Jupyter Notebook 版本
- 本文档并不申明自己的版权信息,为了更好的知识传播,我们授权你使用本文档,你可以使用它,进行二次创作,进行分发,进行修改,并可以以此为蓝本进行授课。
- 请保留本文档的原始来源。
- 本文档首先在国际人学校组织的“阿里云天池 Python 训练营课程”中使用。
- 本文档由林肯老师首次组织和编辑。你可以通过网址 数据大咖 找到他。

函数是Python编程中的核心内容之一。函数的最大优点是可以增强代码的重用性和可读性。Python 中有很多内置函数,但内置函数并不能满足用户的需求,这时用户可以创建自定义函数。本章将介绍如何自定义函数。
Python中的自定义函数需要遵循一定的规范,比如定义时的关键字是什么、返回值关键字是什么、参数的写法,以及如何调用自定义函数等。下面来介绍一下相关的知识点。
在自定义函数时,有固定的语法格式。语法格式如下:
def 函数名(参数):
函数体
return 返回值-
def:函数的关键字,不能没有,也不能改,有此关键字就表示是自定义函数。函数名:函数的名称,根据函数名调用函数。函数名是包含字母、数字、下画线的任意组合,不能以数字开头。函数名可以任意命名,建议尽量定义成可以表示函数功能的名称。
-
参数:为函数体提供数据。参数是被放在小括号中的,可以设置多个参数,参数之间用逗号分隔。在小括号的后面加冒号。
-
return 返回值:整体作为自定义函数的可选参数,用于设置自定义函数的返回值。也就是说,自定义函数可能有返回值,也可能没有返回值,视情况而定。
注意,函数体和返回值语句要做缩进处理,也就是从冒号开始换行的语句都要做缩进处理。
了解了自定义函数的语法格式后,下面学习自定义函数的创建与调用,比如创建一个单价与数量相乘的函数并调用。因为代码是自上而下运行的,所以一定要先定义函数,再调用函数。自定义函数案例的代码如下所示。
# 有返回值的自定义函数
def total_sum1(price,amount):
money=price*amount
return money
# 无返回值的自定义函数
def total_sum2(price,amount):
str='单价:{} 数量:{} 金额:{}'.format(price,amount,price*amount)
print(str)
# 调用自定义函数
print(total_sum1(10,20))
total_sum2(10,20)本案例将每个人1~12月的工资进行平均,然后写入N列对应的单元格,如图所示。
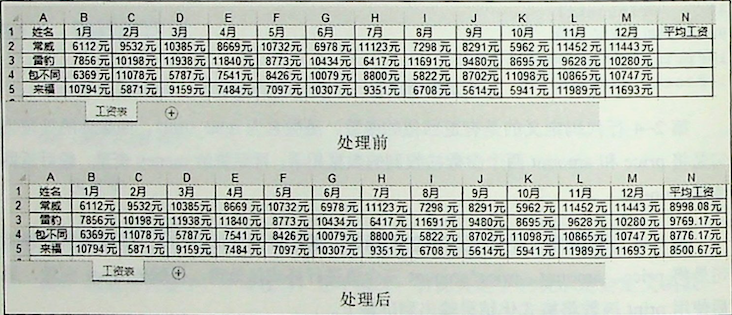
本案例的编程思路是将每个人所有的工资求和,再除以月份数,按此思路自定义一个平均函数即可。
# 自定义平均函数
def average(lst):
num=sum(lst)/len(lst) #平均处理。
avg=float('{:.2f}'.format(num)) #格式化平均值。
return avg #返回平均值。
# 数据平均处理
import xlrd #导入xls文件读取库。
from xlutils.copy import copy #导计工作簿复制函数。
wb=xlrd.open_workbook('./28-functions-1.xls');ws=wb.sheet_by_name('工资表') #读取工作簿和工作表。
nwb=copy(wb);nws=nwb.get_sheet('工资表') #复制工作簿,以及读取副本工作簿下的工作表。
for row_num in range(1,ws.nrows): #循环行号。
salary_list=ws.row_values(row_num)[1:-1] #获取1到12月份的工资列表。
nws.write(row_num,13,average(salary_list)) #调用平均函数average对salary_list列表求平均。
nwb.save('/28-functions-2.xls') #保存副本工作簿。-
第2~5行代码自定义平均函数average(lst)。其中,lst为必选参数,指定要进行平均计算的列表或元组。
-
第13行代码 nws.write(row_num,13,average(salary_list)),其中 average(salary_list)表示使用average函数对每行的工资数据进行平均,然后将结果写入N列对应的单元格。
必选参数就是函数调用时必须要传入值的参数,既不能多,也不能少。必选参数也可以叫作位置参数。
下面是一个小案例,根据固定的分数确定等级,代码如下所示。
# 自定义函数。
def level(number,lv1,lv2,lv3):
if number>=90:
return lv1
elif number>=60:
return lv2
elif number>=0:
return lv3
# 自定义函数的调用。
for score in [95,63,58,69,41,88,96]:
print(score,level(score,'优','中','差'))-
第2~8行代码自定义等级函数level(number,lv1,lv2,lv3),该函数的参数说明如下。number:必选参数,输入用于判断的数字。
- lvl:必选参数,当大于或等于90分时对应的等级。
- lv2:必选参数,当大于或等于60分且小于90分时对应的等级。
- lv3:必选参数,当大于或等于0分且小于60分时对应的等级。
-
第10行和第11行代码将[95,63,58,69,41,88,96]列表中的元素循环赋值给 score变量,score变量作为level函数的第1个参数,将第2、3、4个参数分别写入“优”“中”“差”3个等级。最后运行 print(score,level(score,'优,'中',差'))后,返回的结果如图所示。

本案例给“卡号表”工作表B列的卡号做分段处理,每4位分一段,如果不够4位,也要分成一段,如图所示。
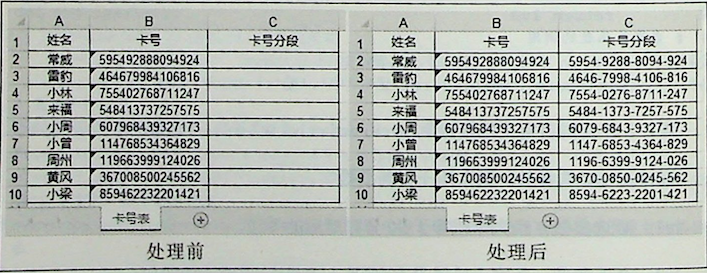
本案例的编程思路是定义一个分段截取函数,可以让用户指定每段长度,也可以指定分段之间的分隔符,然后将B列中的卡号放到自定义函数中运行,最后将处理好的结果写入C列单元格。
# 自定义函数
def intercept(s,num,delimiter):
s1 = str(s) #将要分段的对象转换为字符串类型。
lst = [s1[n:n+num] for n in range(0,len(s1),num)] #对数据进行分段处理。
s2 = delimiter.join(lst) #合并分段的列表。
return s2 #将合并结果返回函数。
# 自定义函数应用
import xlrd #导入xls文件读取库。
from xlutils.copy import copy #导计工作簿复制函数。
wb = xlrd.open_workbook(./29-functions-1.xls');ws=wb.sheet_by_name('卡号表') #读取工作簿和工作表。
nwb = copy(wb);nws=nwb.get_sheet('卡号表') #复制工作簿,以及读取副本工作簿下的工作表。
for row_num in range(1,ws.nrows): #循环行号。
val = ws.cell_value(row_num,1)#读取B列单元格值。
nws.write(row_num,2,intercept(val,4,'-'))#截取指定长度的字符进行分段,再写入单元格。
nwb.save('./29-functions-2.xls') #保存副本工作簿。-
第2~6行代码自定义切片函数 intercept(s,num,delimiter),该函数的参数说明如下。
- s:必选参数,指定要分的段数。
- num:必选参数,表示每段的长度。
- delimiter:必选参数,表示每段之间的分隔符。
-
第13行代码 nws.write(row_num,2,intercept(val,4,'-')),其中 intercept(val,4,'-')部分使用自定义的intercept函数,看一下此函数的实参,val表示B列的每个卡号,每 4 个字符为一段,将"-"作为分隔符进行分段,最后将处理好的结果写入C列对应的单元格。
可选参数表示在调用函数时可传可不传该参数的值。在定义可选参数时,要设置一个值,这个值叫作默认值,所以可选参数也叫作默认参数。在调用函数时,如果可选参数没有传入值,则使用可选参数的默认值。
在自定义函数时,既有必选参数,又有可选参数,要先定义必选参数,再定义可选参数。在调用函数时也一样,要先传必选参数,再传可选参数。
比如,现在要自定义一个类似于Excel中的MID函数的函数,在对序列对象做切片时,可以指定位置和截取长度。案例代码如下所示。
# 自定义函数。
def mid(iterable,start = 0,length = 1):
return iterable[start:start+length]
# 自定义函数调用。
print(mid('abcdefgh'))
print(mid('abcdefgh',2))
print(mid('abcdefgh',2,4))-
第2~3行代码自定义函数 mid(iterable,start=0,length=1),该函数的参数说明如下。iterable:必选参数,提供可以被切片的对象,比如字符串、列表、元组。
-
start:可选参数,切片的起始位置,默认值是0,也就是从开始的位置切片。
-
length:可选参数,切片的长度,默认值是1。
-
-
第5~7行代码调用mid函数做测试。
-
第5行代码 print(mid('abcdefgh')),mid函数只提供了第1个参数,第2个参数和第3个参数都使用默认值,等价于print(mid('abcdefgh',0,1)),返回结果为'a'。
-
第6行代码 print(mid('abcdefgh',2)),mid函数提供了第1个参数和第2个参数,第3个参数使用默认值,等价于print(mid('abcdefgh',2,1)),返回结果为'c'。
-
第7行代码 print(mid('abcdefgh',2,4)),mid函数提供了全部参数,返回结果为'cdef。
-
本案例根据“销售表”工作表中A列的产品名称,到“单价表”工作表中查询对应的产品价格,再用查询到的产品价格乘以产品数量得到产品金额,将产品金额写入“销售表”工作表的C列单元格,如图所示。
本案例的编程思路是自定义一个类似于Excel工作表函数 vlookup的函数。
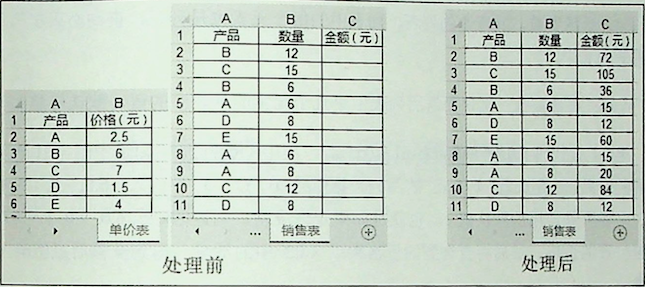
# 自定义vlookup函数
def vlookup(val,lst,num=1):
r = lst[0].index(val) #对lst列表第1个元素使用index函数进行查找。得到返回值赋值给r变量。
v = lst[num][r] #再使用num和r变量确定截取位置。
return v #将截取的值返回给函数
# 自定义函数应用
import xlrd #导入读取xls文件的库。
from xlutils.copy import copy#导入复制工作簿函数。
wb = xlrd.open_workbook('./30-functions-1.xls')#读取工作簿。
ws_price = wb.sheet_by_name('单价表') #读取工作簿下的工作表。
ws_Sale = wb.sheet_by_name('销售表') #读取工作簿下的工作表。
nwb = copy(wb);nws=nwb.get_sheet('销售表') #复制工作簿,以及读取副本工作簿下的工作表。
lst = [ws_price.col_values(0)[1:],ws_price.col_values(1)[1:]] #读取'单价表'下的产品列和单价列。
for row_num in range(1,ws_Sale.nrows): #循环'销售表'中的行号。
val1 = ws_Sale.cell_value(row_num,0) #读取'销售表'A列的品名。
val2 = ws_Sale.cell_value(row_num,1) #读取'销售表'B列的数量。
val3 = vlookup(val1,lst)*val2 #将val1中的品名去lst列表查找,返回对应的单价,再乘以val2的数量,得到金额。
nws.write(row_num,2,val3) #将计算出来的金额写入'销售表'的C列单元格。
nwb.save('./30-functions-2.xls') #保存副本工作簿。-
第 2~5 行代码自定义查询函数 vlookup(val,lst,num=1),该函数的参数说明如下。
- val:必选参数,要查询的值。
- lst:必选参数,要查询的列表,列表中的每个元素也是列表,查询必须在第0个元素的列表中。
- num:可选参数,确认要返回列表中第几个元素的列表中的值,默认值是1。
-
第 17 行代码 val3=vlookup(val1,lst)*val2,其中 vlookup(vall,lst)中的 val1 表示要查询的产品,lst是放置“单价表”的两列数据[['A','B','C','D','E'],[2.5,6.0,7.0,1.5,4.0]],第3个参数是使用的默认值1,也就是如果查询成功,则返回[2.5,6.0,7.0,1.5,4.0]中对应位置的价格。最后将查询到的价格乘以 val2 中的数量,得到金额后赋值给 val3 变量。
在函数调用时,通过“参数=值”的形式传入实参的方式叫作关键字参数,可以让函数更加清晰、易于使用,同时参数的书写可以不按顺序。
关键字参数分为普通关键字参数和命名关键字参数。普通关键字参数可以用“参数=值”的方式传入实参,也可以按参数位置的先后顺序直接传入实参。命名关键字参数必须用“参数=值”的方式传入实参。
下面看看普通关键字参数与命名关键字参数的不同写法与传参方式,代码如下所 示。
# 自定义函数
def counter1(iterable,min,max):#普通关键字参数。
lst=[v for v in iterable if v>=min and v<=max]
return len(lst)
def counter2(iterable,*,min,max):#命名关键字参数。
lst=[v for v in iterable if v>=min and v<=max]
return len(lst)
# 调用自定义函数
print(counter1([2,3,8,3,4,5,9],3,8)) #按位置传递实参。
print(counter1(max = 8,min = 3,iterable = [2,3,8,3,4,5,9])) #按关键字参数传递实参。
print(counter1([2,3,8,3,4,5,9],3,max = 8)) ##部分按位置传递实参,部分按关键字参数传递实参。
print(counter2([2,3,8,3,4,5,9],3,8)) #按位置传递实参会出错。
print(counter2(max = 8,min = 3,iterable = [2,3,8,3,4,5,9])) #按关键字参数传递实参。
print(counter2([2,3,8,3,4,5,9],max = 8,min = 3))#部分按位置传递实参,部分按关键字参数传递实参。-
第 2~7 行代码自定义条件计数函数counterl(iterable,min,max)和counter2(iterable,*,min,max),它们的参数都相同,参数说明如下。
- iterable:必选参数,提供要判断的序列数字。
- min:必选参数,定义范围最小值。
- max:必选参数,定义范围最大值。
通过观察发现,counterl 函数和counter2函数基本一样,唯一不同点就是counter2函数的参数中有一个*(星号),它起什么作用呢?星号前面的是普通的关键字参数,星号后面的是命名关键字参数。也就是说,星号起到分隔的作用,便于用户区分。接下来调用一下这两个函数,看它们的使用方法有何区别。
-
第 9 行代码 print(counter1([2,3,8,3,4,5,9],3,8)),普通关键字参数可以按位置传参数,只要顺序不乱,返回的结果就不会错。
-
第 10 行代码 print(counterl(max=8,min=3,iterable=[2,3,8,3,4,5,9]),这是标准的关键参数传递方式,传递参数的顺序可以打乱,只要把形参和实参一一对应上就可以了。
-
第 11 行代码 print(counter1([2,3,8,3,4,5,9],3,max=8)),这是位置参数与关键字参数混合传递方式,同时包含这两种形式,一定是先位置参数,后关键字参数。前两个参数是按照位置传递参数的,第3个参数是使用关键字参数传递参数的。
-
第 12 行代码 print(counter2([2,3,8,3,4,5,9],3,8)),因为counter2函数中有命名关键字参数,所以这种位置传参方式会出错。min和max两个参数必须按“参数=值”的方式来书写,前面的iterable参数可以不按“参数=值”的方式来书写。
-
第 13 行代码 print(counter2(max=8,min=3,iterable=2,3,8,3,4,5,9])),counter2函数的所有参数都按“参数=值”的方式来书写,这种方式也能正常运行。
-
第14行代码 print(counter2([2,3,8,3,4,5,9],max=8,min=3)),counter2 函数按混合传参方式来书写也是可以的,注意位置传参方式要写在最前面。
本案例以“工资表”工作表的“部门”列为基准,合并“姓名”列,如图所示。本案例的编程思路是创建一个字典,将指定列的数据作为键,将指定的另一列的数据作为值,循环装入字典中,再对字典中每个键对应的值去重,然后根据指定的分隔符合并,最后将结果返回给自定义的函数即可,也就是把整个数据处理放在自定义函数中。
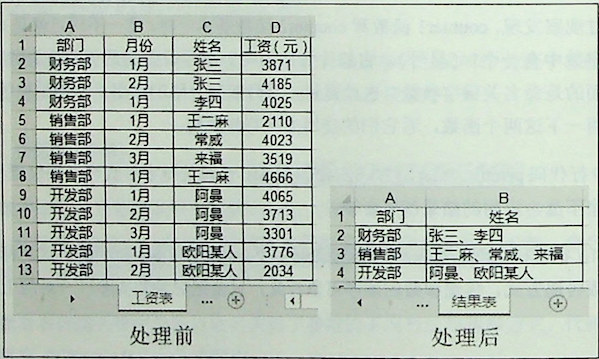
# 自定义combine函数。
def combine(range,join_range,delimiter=' '):
dic={}#初始化dic变量为空字典。
for x,y in zip(range,join_range):#将range和join_range接收的值使用zip函数做组合转换,并赋值给x,y变量。
if not x in dic:#如果x在dic字典中不存在。
dic[x]=[y]#则以x为键,y为值,创建键值,注意y是写在列表中的。
else:#否则。
dic[x].append(y)#如果x键存在,则将y添加到对应的值列表中。
l=[(k,delimiter.join([str(i) for i in dict.fromkeys(i)])) for k,i in dic.items()]#将键对应值列表去重合并。
return l#l变量是列表,列表中的元素是元组类型,元组中分别存储是dic字典的键,及dic字典对应值合并后的字符串。
# 自定义函数应用
import xlrd #导入xls文件读取库。
from xlutils.copy import copy #导计工作簿复制函数。
wb=xlrd.open_workbook('./31-functions-1.xls');ws=wb.sheet_by_name('工资表') #读取工作簿和工作表。
nwb=copy(wb);nws=nwb.get_sheet('结果表') #复制工作簿,以及读取副本工作簿下的工作表。
row_num=0#初始化row_num变量为。
for x,y in combine(delimiter='、',range=ws.col_values(0),join_range=ws.col_values(2)):#调用combine函数。
nws.write(row_num,0,x)#将range参数中的值去重后写入'结果表'工作表A列。
nws.write(row_num,1,y)#将join_range参数中的值去重合并再写入'结果表'工作表B列。
row_num +=1#累加row_num变量。
nwb.save('./31-functions-2.xls')#保存副本工作簿。-
第2~10行代码,自定义合并函数 combine(range,join_range,delimiter=''),该函数的参数说明如下。
- range:必选参数,指定基准列。
- join_range:必选参数,指定合并列。
- delimiter:可选参数,对列进行合并时指定的分隔符,默认值是空格。
-
第17行代码 for x,y in combine(delimiter='、',range=ws.col_values(0)join_range=ws.col_values(2)):,调用了combine函数。delimiter参数指定的分隔符是“、”;range参数指定的基准列是ws.col_values(0),也就是“工资表”的A列;join_range 参数指定的合并列是ws.col_values(2),也就是“工资表”的B列。combine函数的3个参数 顺序因为使用的是关键字参数方式,所以顺序可以打乱。combine 函数的返回值是列表,列表中的元素是元组,元组中包含了部门和对应 的姓名,结果为[(部门','姓名'),(财务部,张三、李四),('销售部,'王二麻、常威、来福),('开发部,阿曼、欧阳某人)]。最后将列表中的值循环写入“结果表”工作表即可。
不定长参数是指定义的函数参数个数不确定,可以将不定长参数收纳在指定的容 器中。不定长参数分为以下两种。
*args:以一个星号开头,然后接arg变量,这种参数接收的值存储在元组中,即 args是一个元组类型。
**kwargs:以两个星号开头,然后接kwargs变量,这种参数接收的值存储在字 典中,即kwargs是一个字典类型。
args与kwargs变量名称不是固定的,只是约定俗成的一种命名方式,用户可以修改成其他名称。不定长参数必须放在必选参数之后。
*args和**kwargs 接收的数据类型不限,完全根据需求而定。
下面是一个小案例,代码如下所示。
# 自定义函数
def subtotal(iterable,*args):
print(args)#在屏幕打印args中的内容。
return [fun(iterable) for fun in args]#根据args接收的函数返回处理结果。
# 调用自定义函数
print(subtotal([7,8,9,10],max,min,sum))-
第2~4行代码自定义汇总函数 subtotal(iterable,*args),该函数的参数说明如下。iterable:必选参数,提供要判断的序列数字。*args:可选参数,指定汇总函数。
-
第6行代码 print(subtotal([7,8,9,10],max,min,sum)),iterable变量的值是[7,8,9,10]列表,汇总函数是max、min、sum,这3个函数都将存储在args变量中。运行第3行代码 print(args),屏幕上的输出结果为(<built-in function max>,<built-infunction min>,<built-in function sum>),可以看到元组的每个元素是函数对象。用每个函数去处理[7,8,9,10]即可,此行代码只是为了便于理解而写的,可以省略不写。最后调用subtotal函数,返回的结果为[10,7,34]。
下面是一个小案例,代码如下所示。
# 自定义函数
def subtotals(iterable,**kwargs):
print(kwargs)#在屏幕打印args中的内容。
return [(key,item(iterable)) for key,item in kwargs.items()]#根据args接收的函数返回处理结果。
# 调用自定义函数
print(subtotals([7,8,9,10],求和=sum,最大=max,计数=len))-
第2~4行代码自定义汇总函数 subtotals(iterable,**kwargs),该函数的参数说明如 下。iterable:必选参数,提供要判断的序列数字。**kwargs:可选参数,按字典的键值方式指定汇总函数。
-
第6行代码 print(subtotals([7,8,9,10],求和=sum,最大=max,计数=len)),iterable变量的值是[7,8,9,10]列表,汇总函数的指定方式是求和=sum,最大=max,计数=len,这3对键值都将存储在kwargs变量中。
运行第3行代码print(kwargs),屏幕上的输出结果为{'求和':<built-in function sum>, '最大':<built-in function max>,'计数:<built-in function len>},可以看到字典中的键是汇总名称,值是对应的函数名称,用值的每个函数去处理[7,8,9,10]即可。此行代码是为了便于理解而写的,可以省略不写。
-
最后调用subtotals函数,返回的结果为[(求和',34),(最大',10),(计数',4)]。
在本案例中,“书单表”工作表的B列是书名,书名之间使用空格('')和竖线('|')进行分隔,现在要用规范的书名号来分隔,修改前后的效果如图所示。

本案例的编程思路是定义一个可以替换指定多个旧字符串为统一新字符串的函 数,然后调用该函数处理B列的书名即可。
# 自定义replaces函数。
def replaces(string,new,*old):
for o in old: #循环old参数中的元素赋值给o变量。
string = string.replace(o,new) #将o变量中的值,替换为new变量中的值,最后再赋值给string参数。
return string #循环替换完成后,将string中的值返回给replaces函数。
# 自定义函数应用
import xlrd #导入xls文件读取库。
from xlutils.copy import copy #导计工作簿复制函数。
wb=xlrd.open_workbook('./32-books-1.xls');ws=wb.sheet_by_name('书单表') #读取工作簿和工作表。
nwb=copy(wb);nws=nwb.get_sheet('书单表') #复制工作簿,以及读取副本工作簿下的工作表。
for row_num in range(1,ws.nrows): #循环'书单表'的行号,赋值给row_num。
val1=ws.cell_value(row_num,1) #获取B列单元格的书名,并赋值给val变量。
val2='《'+replaces(val1,'》《',' ','|')+'》' #将' '和'|'替换为'》、《',再补齐两端书名号,赋值给val2变量。
nws.write(row_num,2,val2) #将处理好后的val2变量写入C列单元格。
nwb.save(./32-books-2.xls') #保存副本工作簿。-
第2~5行代码,自定义替换函数 replaces(string,new,*old),参数说明如下。
- string:必选参数,原字符串。
- new:必选参数,指定要替换的新字符串。
- *old:可选参数,指定替换的旧字符串,可以指定多个。
-
第13行代码 val2='《'+replaces(vall,'》《',' ',")+'》',调用replaces函数,string 参数是vall变量,也就是B列单元格的书名。new参数是“》《”,表示将要替换的新字符串,old参数获取的是(,T),表示将空格('')和竖线(")都替换为“》《”。最后将替换结果赋值给val2变量。
匿名函数指无须定义标识符的函数或子程序。Python 中用 lambda 关键字定义匿名函数,只用表达式而无须声明。使用匿名函数有一个好处,就是匿名函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,可以把匿名函数赋值给一个变量,这样变量名就相当于函数名,可以利用变量来调用该函数。
在Python中,lambda是一个关键字,用来引入表达式的语法。相比def函数,lambda是单一的表达式,而不是语句块。在lambda中只能封装有限的业务逻辑,lambda定义的匿名函数纯粹是为了编写简单函数而设计的,def函数则专注于处理更大的业务。
匿名函数的语法结构如图所示。

下面看看匿名函数的定义和调用,代码如下所示。
print(lambda x:x*10) #定义匿名函数。
print((lambda x:x*10)(20)) #定义及调用匿名函数。
fun=lambda x:x*10 #匿名函数赋值给变量。
print(fun(20)) #将变量名当做函数名调。匿名函数与def定义的普通函数一样,可以有不同类型的参数,案例代码如下所 示。
fun1=lambda x,y:x+y #必选参数的匿名函数。
print(fun1(10,20)) #调用fun1函数。
fun2=lambda x,y=20:x+y #可选参数的匿名函数。
print(fun2(10)) #调用fun2函数。
fun3=lambda l,*fun:[f(l) for f in fun] #不定长参数的匿名函数1。
print(fun3([3,4,5],sum,max,min)) #调用fun3函数。
fun4=lambda l,**fun:[k+':'+str(i(l)) for k,i in fun.items()] #不定长参数的匿名函数2。
print(fun4([3,4,5],求和=sum,最大=max,最小=min)) #调用fun4函数。-
第 1 行代码 fun1 = lambda x,y:x+y,必选参数是x和y,处理表达式是将两个参数相加,再将匿名函数赋值给fun1变量。
-
第 2 行代码 print(funl(10,20)),给fun1变量传入参数并输出,结果为30。
-
第 3 行代码 fun2=lambdax,y=20:x+y,x是必选参数,y是可选参数,默认值是20,处理表达式是将两个参数相加,再将匿名函数赋值给fun2变量。
-
第 4 行代码 print(fun2(10)),x 参数接收的是10,而y参数使用默认值20,最后fun2 的输出结果为 20.
-
第 5 行代码 fun3=lambda l,*fun:[f(l) for f in fun],l 是必选参数,*fun是不定长参数,用元组存储数据,处理表达式是用fun元组接收到的函数去处理1参数中的值,再将匿名函数赋值给fun3变量。
-
第 6 行代码 print(fun3([3,4,5],sum,max,min)),l 参数接收的是[3,4,5],而fun参数 接收的是(<built-in function sum>,<built-in function max>,<built-in function min>),最后fun3的输出结果为[12,5,3]。
-
第 7 行代码 fun4=lambda l,**fun:[k+':'+str(i(l))for k,i in fun.items()],l 是必选参数,**fun是不定长参数,用字典存储数据。处理表达式是用fun字典接收到的函数去处理1参数中的值,再将匿名函数赋值给fun4变量。
-
第8行代码 print(fun4([3,4,5],求和=sum,最大=max,最小=min)),l 参数接收的是 [3,4,5],而fun参数接收的是{'求和:<built-in function sum>,'最大:<built-in function max>,'最小':<built-in function min>},最后fun4的输出结果为['求和:12,'最大:5','最 小:3']。
本案例根据“身份证表”工作表A列单元格的身份证号第17位数字判断性别,奇数为男,偶数为女,然后将结果写入B列单元格,如图所示。

本案例的编程思路是使用匿名函数定义一个判断性别的函数,然后调用即可。
import xlrd #导入读取xls文件的库。
from xlutils.copy import copy #导入工作簿复制函数。
wb=xlrd.open_workbook('./33-ids-1.xls');ws=wb.sheet_by_name('身份证表') #读取工作簿和工作表。
nwb=copy(wb);nws=nwb.get_sheet('身份证表') #复制工作簿,并且读取副本工作簿中的工作表。
for row_num in range(1,ws.nrows):#循环'身份证表'工作表的行号。
card=lambda id:'男' if int(id[-2])%2==1 else '女'#自定义根据身份证号判断性别的匿名函数。
val=ws.cell_value(row_num, 0)#获取A列的身份证号,并赋值给val变量。
nws.write(row_num,1,card(val))#将val做为匿名函数card的参数,将判断出的性别写入B列单元格。
nwb.save('./33-ids-2.xls')#保存副本工作簿。自定义函数可以被单独存放在一个 .py 文件中,这样其他 .py 文件也可以调用,实现自定义函数的复用。下面介绍如何调用指定 .py 文件中的自定义函数。我们将之前学习的一部分自定义函数放在 fun.py 文件中,然后在另外的 .py 文件中调用,代码如下所示。
def average(lst):#平均函数
num=sum(lst)/len(lst) #平均处理。
avg=float('{:.2f}'.format(num)) #格式化平均值。
return avg #返回平均值。
def intercept(s,num,delimiter):#分段函数
s1=str(s) #将要分段的对象转换为字符串类型。
lst=[s1[n:n+num] for n in range(0,len(s1),num)] #对数据进行分段处理。
s2=delimiter.join(lst) #合并分段的列表。
return s2 #将合并结果返回函数。
def vlookup(val,lst,num=1):#模仿vlookup
r=lst[0].index(val) #对lst列表第1个元素使用index函数进行查找。得到返回值赋值给r变量。
v=lst[num][r] #再使用num和r变量确定截取位置。
return v #将截取的值返回给函数
def combine(range,join_range,delimiter=' '):#分类合并字符串
dic={} #初始化dic变量为空字典。
for x,y in zip(range,join_range): #将range和join_range接收的值使用zip函数做组合转换,并赋值给x,y变量。
if not x in dic: #如果x在dic字典中不存在。
dic[x]=[y] #则以x为键,y为值,创建键值,注意y是写在列表中的。
else:#否则。
dic[x].append(y) #如果x键存在,则将y添加到对应的值列表中。
l=[(k,delimiter.join([str(i) for i in dict.fromkeys(i)])) for k,i in dic.items()] #将键对应值列表去重合并。
return l #l变量是列表,列表中的元素是元组类型,元组中分别存储是dic字典的键,及dic字典对应值合并后的字符串。18-7-1.py 文件与 fun.py 文件存放在同一个文件夹中,如图所示。

fun.py 文件中存放的是自定义函数,要求在 18-7-1.py 文件中调用 fun.py 文件中的函数。顺便说一句,在图中还有一个“pycache”文件夹,是在导入 fun.py 文件时产生的文件夹,目的是让程序启动更快一点,当用户的脚本更改时,它将被重新编译,如果删除文件或删除整个文件夹并再次运行程序,它将重新出现,一般忽略即可。
import fun #导入函数文件名。
print(fun.average([1,2,3,4,5,6])) #调用fun文件下的average函数。
print(fun.intercept('5120124575',4,'-')) #调用fun文件下的intercept函数。
from fun import * #导入函数文件名下的所有函数。
print(intercept('4523465745',4,'、')) #直接调用函数
from fun import average #导入函数文件名下指定的函数。
print(average([4,2,7])) #直接调用函数- 第1行代码 import fun,直接导入函数文件名,注意不要写扩展名.py。
- 第2行代码和第3行代码调用函数,fun.average 表示调用 fun 文件中的 average函数。同理,fun.Intercept表示调用fun文件中的intercept函数。
- 第5行代码 from fun import * ,表示导入 fun 件中的所有函数。
- 第6行代码直接调用 intercept函数。
- 第8行代码 from fun import average,表示只导入fun文件中的average函数。
- 第9行代码就可以调用average函数了,但也只能调用average函数,因为只导入了average函数。

调用不同文件夹中的函数的案例代码如下。
from demo.fun import * #导入文件夹下指定的fun.py文件下的所有函数。
print(average([1,2,3,4,5,6])) #直接调用函数
print(intercept('5120124575',4,'-')) #直接调用函数
from demo.fun import average #导入文件夹下指定的fun.py文件下的所有函数。
print(average([43,52,12])) #直接调用函数-
第 1 行代码 from demo.fun import *,其中 demo.fun 表示 demo 文件夹中的fun.py 文件,导入该文件中的所有函数。
-
第 2 行代码和第3行代码直接调用 fun.py 文件中的 average 函数和 intercept 函数。
-
第 5 行代码 from demo.fun import average,表示导入demo 文件夹中 fun.py 文件的 average 函数。
-
第 6 行代码直接调用average函数,但也只能调用average函数,因为只导入了该 函数。