(1)无主动变道能力
- 问题描述:变道需要存在多条参考线,且主车的前方和后方一定距离内不能有障碍物,旁边车道在一定距离内也不能有障碍物。借道条件苛刻:仅单条参考线、规划起始速度小于借道速度、阻挡障碍物离地图中overlap足够远、为长时间阻挡障碍物、障碍物在规划终点范围内和非可侧面通过障碍物这6个条件才能借道,难以触发,过于保守。
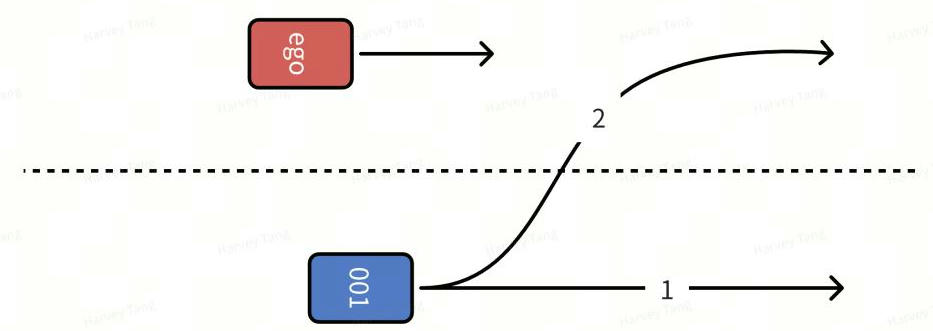
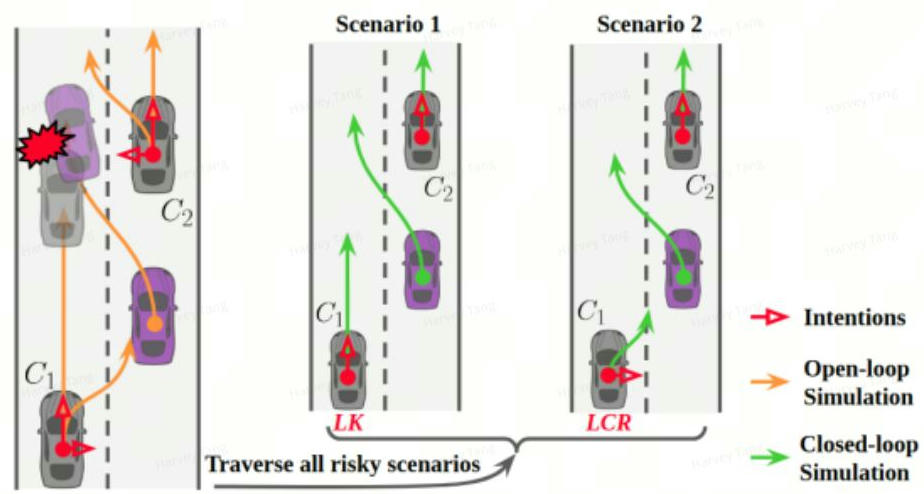
- 解决方案:如图所示,考虑交互目标的多个潜在意图,生成自车轨迹。
(2)横向边界生成与优化筛选仅考虑静态障碍物
-
问题描述:最终输出的path在ST图中障碍物可能过于密集,速度规划无解空间或者为局部最优解,横向动作非最优解,致后续速度决策规划负担过大。
-
解决方案:打开横向空间,多策略找到更优的策略减少障碍物数量。
(3)纵向决策基于自车path和障碍物预测线构建ST图
-
问题描述:ST图过于依赖预测的精度,预测稳定性差很可能导致前后帧自车出现决策不连贯(他车cutin轨迹但实际未cutin),前后帧Yield不一致。他车cutin概率不定时,会出现预测线在两车道间摇摆或者按Apollo的预测逻辑可能产生两条预测线,导致自车planning规划不连贯导致突然的大减速或者过于保守,预测线把解空间大部分堵住只能减速。
-
解决方案:contingency planning。
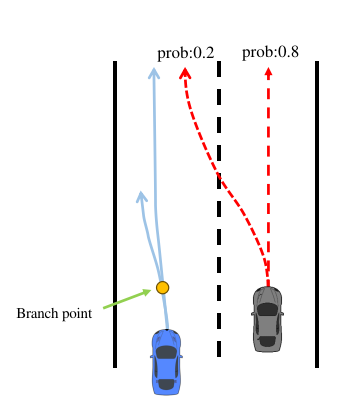
(4)纵向决策DP失败
-
问题描述:障碍物进入speed_fallback,横向解空间太小,纵向DP难以处理多障碍物场景,无可行解进入speed_fallback过于危险。
-
解决方案:横向空间打开,纵向加一些安全措施。
(5)Apollo无法考虑自车与障碍物的交互博弈
-
问题描述:对于cutin、merge和路口场景过于保守,没考虑交互,对于cutin、路口这种解空间本来就小的场景难以找到合适解,过于保守。
-
解决方案:场景树+多决策。
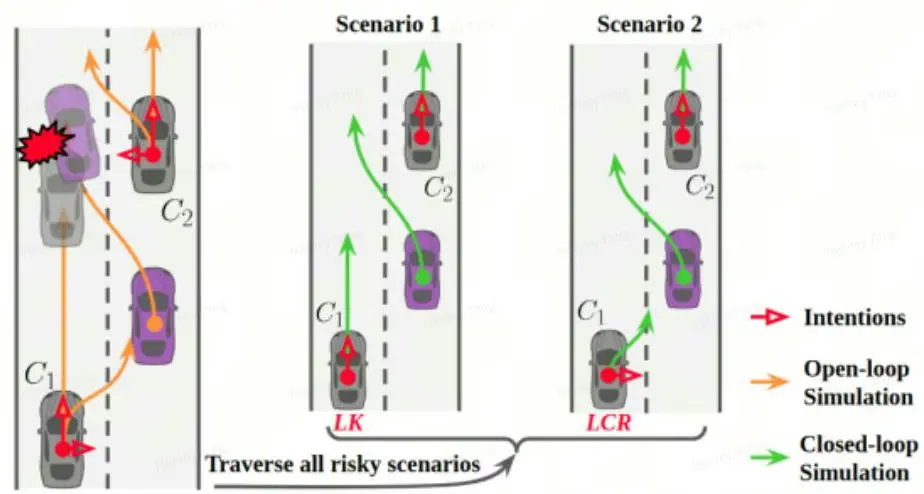
(6)Apollo将障碍物的预测轨迹全考虑进去
-
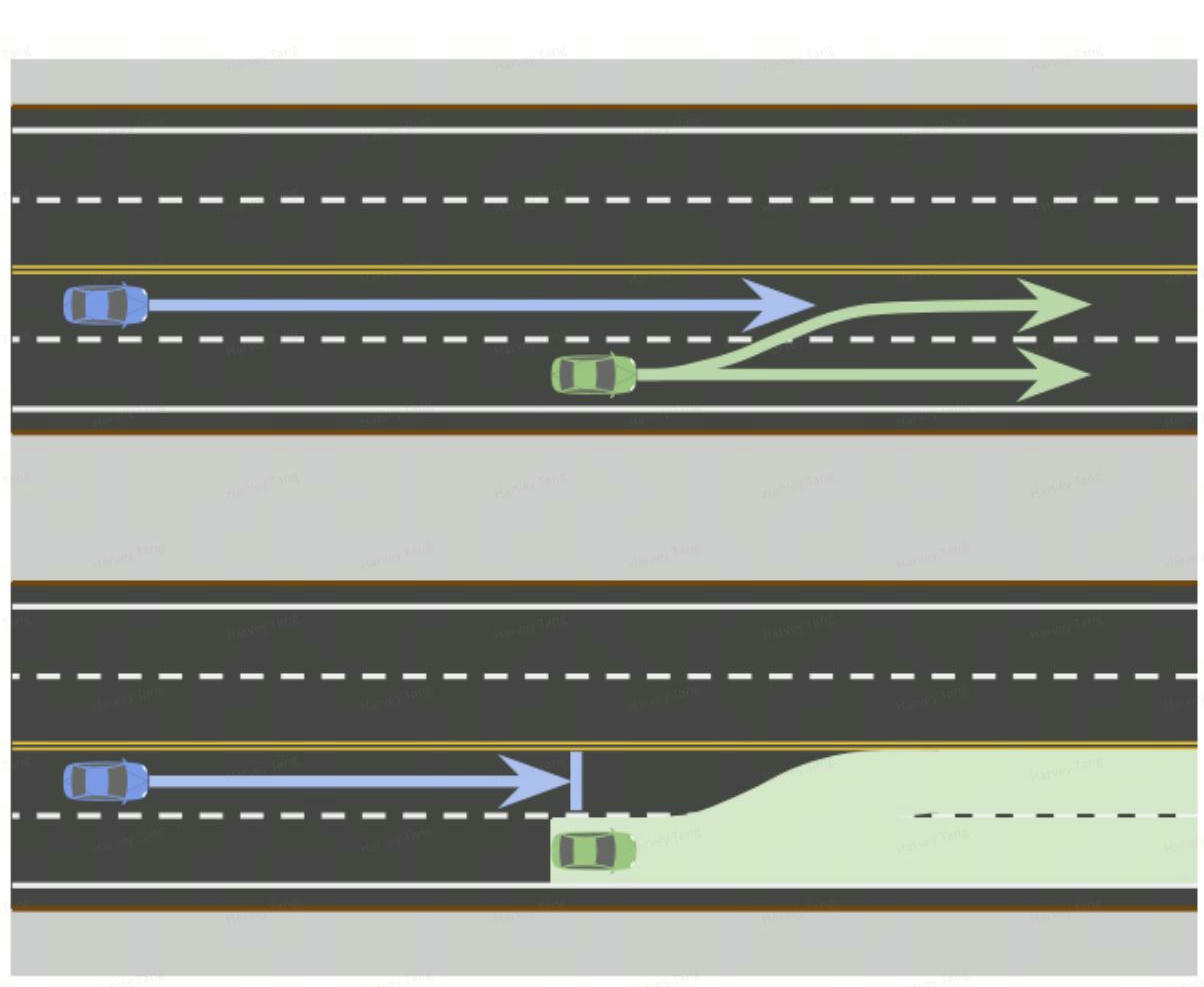
问题描述:将障碍物的预测轨迹全考虑进去,当做两个不同障碍物,最终会造成自车如下图第二个图所示,带来行为过于保守,即全信预测前且将预测线先验概率均当做1处理,封死部分可行解空间,过于保守。
-
解决方案:构建多场景(multi-scenario)来处理各种不同情况。
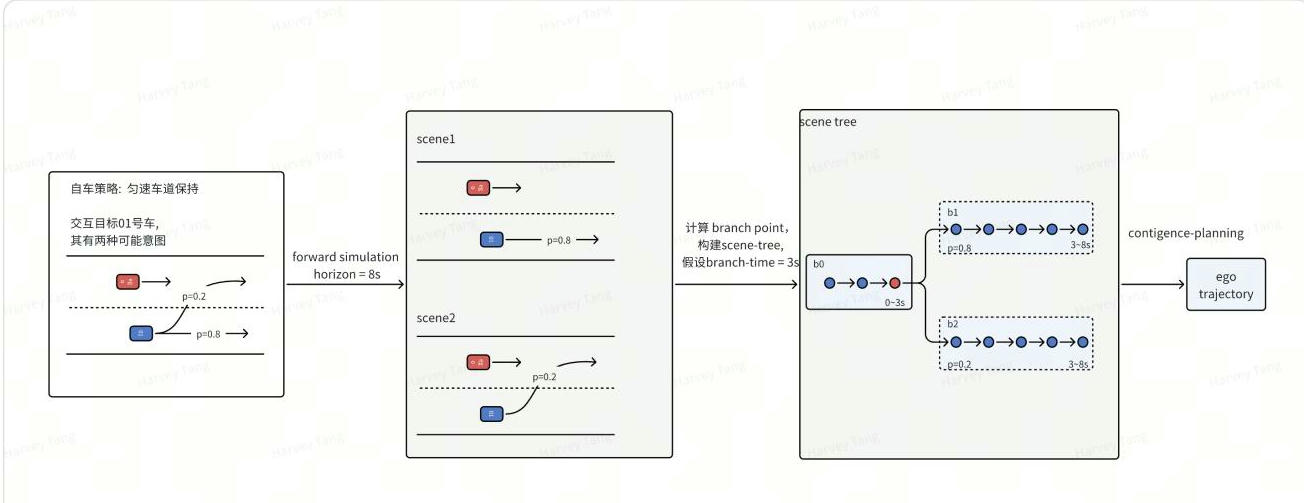
为解决 1)Apollo解空间过小行为过于保守; 2)对多模态的信息使用不充分;使用多决策交互博弈来构建场景树,结合contingency planning,构建出更优的路径。
定义特定的自车策略,在每种自车策略下模拟自车和他车的交互博弈过程,通过闭环前推轨迹(forward_simulation )计算联合状态,得到一个个场景,通过比较ego状态,把这些场景组合成场景树(ego-policy-conditioned scene-tree)。然后通过防御性规划(contingency-planning)基于场景树构建优化自车轨迹。
// 参数初始化
[horizon, max_branch_time, divergence_threshold] = Init()
// 语义级别的自车策略
ego_policy_set = GetEgoPolicySet()
for ego_policy_set do
/* ego-policy-conditioned scenes */
[prob, intention] = PredictIntentionTrajectories() // 预测模块
key_agents = GetKeyAgents()
intention_combinations = GetIntentionCombination()
for intention_combinations do
scene = ForwardSimulation()
scenes <-- scene
end
scene_tree = SceneTreeConstruction()
traj = ContingencyPlanning()
trajs <-- traj
R = PolicyEvaluation()
end
[policy, traj] = PolicySelection();- 构建场景树
为每一种ego-policy构建一个场景树,计算branch-point,合并ego的轨迹差异不大的部分。
- contigency planning
基于场景树,通过contigency planning生成自车轨迹树。
任务实现在变道决策(LaneChangeDecider)之前,参考线生成之后,输出一条最优的先验轨迹给到下游横纵向规划作为参考。
输入:
- ReferenceLineInfo,参考线信息
- Obstacle, 障碍物预测的轨迹、感知的boundingbox、速度和id等
- VehicleState,自车的状态,包括x,y,速度和加速度
输出:
- Optimal trajectory,Optimal policy
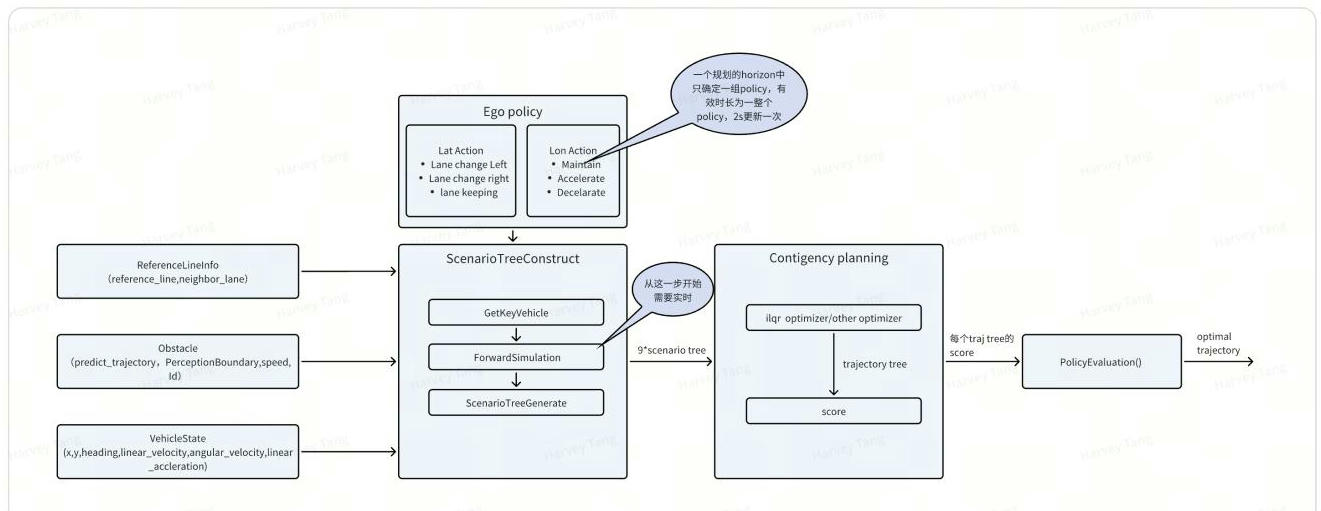
场景树的构建包括以下三个步骤:
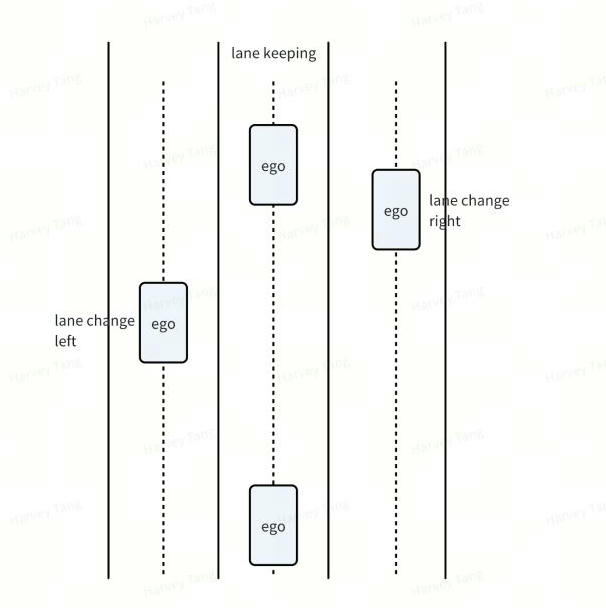
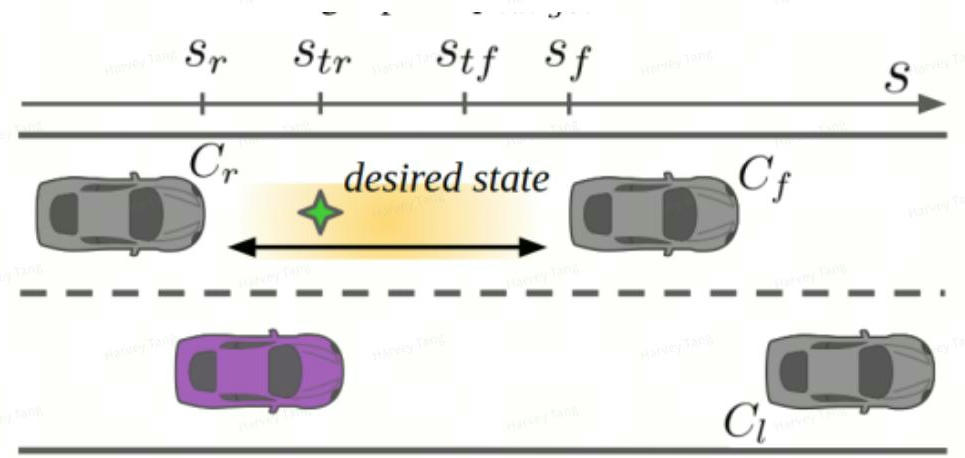
a. 自车策略的构建, 定义横向动作与纵向动作, 并对动作空间进行组合得到多种自车策略。整个 Planning Horizon采用一个策略,类似于MPDM,通过planning cycle进行自车策略的更新。横向动作空间包括了{Lane change left、Lane change right、lane keeping}纵向动作空间包括了{Accelerate、Maintain、Decelerate}
b. 筛选关键交互车辆, 对自车轨迹按照语义动作采样得到一条粗略轨迹作为开环仿真的, 将他车OpenloopSimForward的预测轨迹作为开环仿真的结果,找出可能存在危险的车辆作为关键车辆。对于路口场景,仅考虑对向方向第一辆车。
c. 基于关键车辆的不同预测轨迹,分别进行前向模拟,得到不同的自车轨迹,对于每1s的不同场景自车轨迹进行评估,并根据自车的位置、速度和朝向来构建场景树,对一定阈值范围内的场景视为相似场景, 共享节点, 否则分支并最终构成场景树
作用: 获取自车Planning Horizon的可行策略, 打开横纵向解空间
输入:Ego的横向动作集合和纵向动作集合
输出:Ego的候选动作(组合横纵向动作)的集合
伪代码: 自车的横向动作集合:{Lane change left、Lane change right、lane keeping}
自车的纵向动作集合:{Accelerate、Maintain、Decelerate}
动作组合出自车的横纵向行为共有9种
lat_behavior = ["LCL", "LCR", "LK"]
lon_behavior = ["Accelerate", "Maintain", "Decelerate"]
candidate_policy = []
def GetEgoPolicySet(lat_behavior: List[str], lon_behavior: List[str]) -> List[List[str]]:
for lat_action in lat_behavior:
for lon_action in lon_behavior:
candidate_policy.append([lat_action, lon_action])
return candidate_policy作用:根据自车当前的状态,获取与自车交互的候选车辆
输入:自车的初始状态
输出:候选的交互车辆
伪代码:建立一个基于自车位置的动态筛选框,考虑横向距离为15m内,纵向前瞻距离为巡航速度与交互时间乘积与planning horizon的最小值,后方考虑距离为30m的空间对该框架内的障碍物加入候选交互车辆,同时对于该范围内预测轨迹大于1条的车辆,加入候选关键车辆。
candidate_interaction_agent = dict()
candidate_key_agent = dict()
def GetIntentionAgents(obstacles):
interaction_lat_horizon = config.lat_interaction_distance
interaction_lon_forward_horizon = min(planning_horizon, curise_speed * interaction_time)
interaction_lon_backward_horizon = config.lon_interaction_backward_distance
for agent in obstacles:
if (agent.end_s < interaction_lon_forward_horizon and
agent.start_s > interaction_lat_backward_horizon and
agent.start_l > -interaction_lat_horizon and
agent.end_l < interaction_lat_horizon):
candidate_interaction_agent[agent.id()] = agent
if (candidate_interaction_agent[agent.id()].trajectory_size > 1):
candidate_key_agent[agent.id()] = agent作用:基于开环仿真筛选与自车交互的关键车辆
输入:candidate_key_agent
输出:final_key_agent
伪代码:
筛选关键车辆的思路参考以下论文中的开环仿真方式:
EPSILON: An Efficient Planning System for Automated Vehicles in Highly Interactive Environments
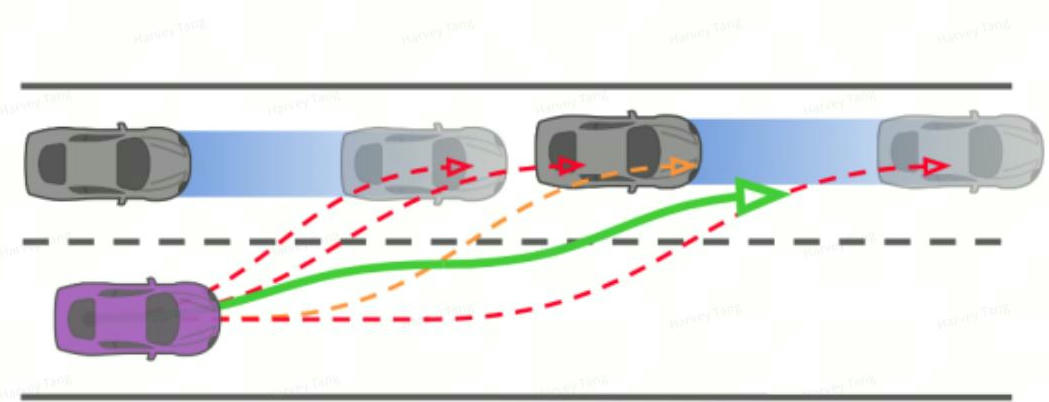
在不考虑交互的前提下开环仿真来找到可能会与自车发生碰撞的车辆,将这些车辆作为关键车辆,如下图所示:
横向推演:基于自车的横向语义动作和目标参考路径的横向位置,不考虑周围agent下推演自车 planning Horizon下的转角变化
纵向推演:基于自车的纵向语义动作和自车当前的速度,改变自车的desired velocity,不考虑 leading agent和rear agent下推演自车在planning Horizon下的纵向速度
综合自车的横向推演和纵向推演可以得到自车开环planning Horizon下的轨迹
他车的推演方式: 直接采用预测轨迹作为开环前推轨迹
final_key_agent = dict()
lat_model = pure_pursuit
lon_model = intelligent_driving_model
def GetKeyAgents(candidate_key_agent, ego_policy):
steer_state = lat_model(ego_policy)
speed_state = lon_model(ego_policy)
ego_trajectory = CombineLatAndLon(steer_state, speed_state)
for key_agent in candidate_key_agent:
for trajectory in key_agent.trajectory:
if (HasOverlap(ego_trajectory, trajectory)):
final_key_agent[key_agent.id()] = key_agent
break
作用:基于预测轨迹获取他车的初始意图
输入:障碍物的预测轨迹、自车位置和自车策略
输出:其他智能体的意图(非关键车辆最大概率意图,关键车辆多意图)
伪代码:获取他车的意图为了后续根据不同的意图组成不同的关键场景, 根据前面筛选的交互车辆和关键车辆,关键车辆考虑多个意图对自车带来的影响。基于预测给出的障碍物轨迹,基于规则判断障碍物的初始意图,并基于MOBIL模型实时更新障碍物的意图
key_agent_intention = dict()
no_key_agent_intention = dict()
def GetOtherAgentIntention(candidate_interact_agent):
for agent in candidate_interact_agent:
trajectory, prob = GetTrajectoryFromPrediction(agent, ego_state)
for i in range(trajectory.size()):
if (i == 0):
intention, prob = GetHiddenIntention(agent, ego_state)
else:
intention, prob = MobilModel(agent)
if (agent.id()) not in final_key_agent:
no_key_agent_intention[agent.id()] = [(intention[prob.index(max(prob))], 1)]
else:
key_agent_prob_intention = []
for i in range(len(intention)):
key_agent_prob_intention.append((intention[i], prob[i]))
key_agent_intention[agent.id()] = key_agent_prob_intention
作用:基于自车策略和不同关键智能体的意图组合成不同意图组合的场景
输入:交互车辆和关键车辆的意图,自车的策略
输出:关键场景意图组合
伪代码:
forward_sim_agent = []
forward_sim_all_scene = []
max_intention_num = 0
def GetIntentionCombination(candidate_interact_agent, key_final_agent):
for agent in candidate_interact_agent:
if (agent not in key_final_agent):
forward_sim_agent.append(agent)
else:
all_combination = combine_intention(key_final_agent, [])
for i in range(len(all_combination)):
forward_sim_single_scene = []
forward_sim_single_scene = forward_sim_agent + all_combination[i]
forward_sim_all_scene.append(forward_sim_single_scene)
def combine_intentions(obstacles, combination=[]):
if not obstacles:
all_combination.append(combination)
else:
obstacle = obstacles[0]
for intention in obstacle.intentions:
new_combination = combination + [intention]
new_obstacles = obstacles[1:]
combine_intentions(new_obstacles, new_combination)
return all_combination
作用:对每个场景(意图组合)进行闭环外推,不需要太精细的轨迹(epsilon中是0.2s的步长),主要是确认大致的交互关系。参考epsilon选择context-aware的纯跟踪+IDM进行。
输入:自车车辆信息(包含车辆物理信息, 位姿状态信息, 自车意图, 车道信息以及一些标签),交互车辆信息(包含车辆物理信息,位姿状态信息,横向意图or车辆预测轨迹,车道信息以及一些标签)
输出:未来一段时间的联合状态
数据类型定义:
class ForwardSimEgoState {
// * constant
double lat_range;
OnLaneForwardSimulation::Param sim_param;
// * update on layer-level
// 横向策略以及纵向策略
common::LongitudinalBehavior lon_behavior{LongitudinalBehavior::kMaintain};
common::LateralBehavior lat_behavior{LateralBehavior::kUndefined};
common::Lane current_lane;
common::Lane target_lane;
// * update on step-level
common::Vehicle vehicle;
};
class ForwardSimAgentState {
int id = kInvalidAgentId;
common::Vehicle vehicle;
OnLaneForwardSimulation::Param sim_param;
// * lat
common::ProbDistOfLatBehaviors lat_probs;
common::LateralBehavior lat_behavior{LateralBehavior::kUndefined};
std::vector<PredictionTrajectory> prediction_trajectories;
common::Lane lane;
// * other
double lat_range;
};
流程:使用自车和他车当前时刻的状态以及意图进行考虑交互的闭环前推
闭环外推横向外推方式:context-aware pure-pursuit (参考epsilon)
- 变道情况下没车时的跟踪路径为相邻车道的中心线,有车时的跟踪路径为考虑安全情况下的偏移路径, 类似于Apollo当前变道不clear时的观察区域。
- 后续优化:当前横向偏移为固定值,后续可考虑用社会力模型建模自车周围的情况求解动态横向偏移。
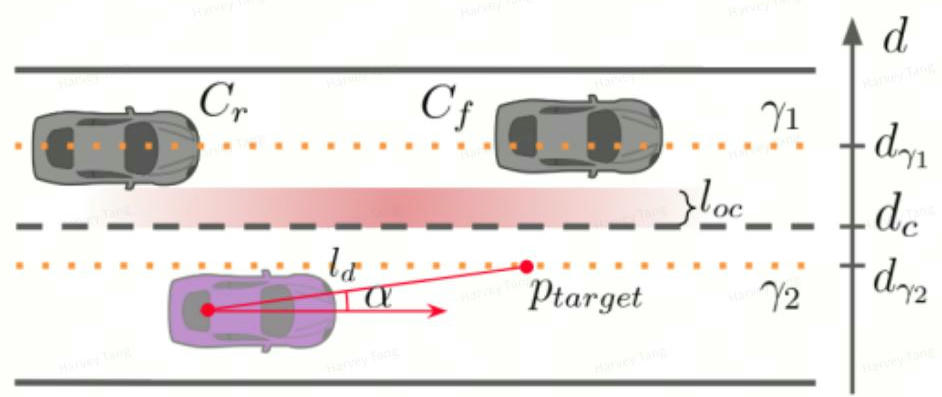
- 对变道前后状态设置clear条件, 保证变道时纵向的安全性
ForwardSimulation(std::vector<double> dt_steps, ForwardSimEgoState forward_sim_ego_state,
std::vector<ForwardSimAgentState> forward_sim_agent_states,
Trajectory* ego_traj, std::unordered_map<int, Trajectory*> surround_trajs)
{
for (ego_policy_set) do:
// 初始化自车状态,对相关的参数继续进行赋值,具体数据结构定义需进一步设计
fs_ego_state = InitVehicleState();
for (dt_steps) do
{
all_sim_vehicles <-- ego_vehicle;
all_sim_vehicles <-- all_agent_vehicle;
// ego forward simulation
all_sim_vehicles.SetEgoVehicleInvalid();
EgoForwardSimulation(forward_sim_ego_state, all_sim_vehicles,
dt_step, &state_output);
ego_traj.push_back(state_output);
all_sim_vehicles.SetEgoVehicleValid();
// agent vehicle forward simulation
for (forward_sim_agent_states) do
{
all_sim_vehicles.SetThisAgentVehicleInvalid();
AgentForwardSimulation(forward_sim_agent_state.second,
dt_step, &state_output);
surround_traj.push_back(state_output);
all_sim_vehicles.SetThisAgentVehicleValid();
}
// update ego and agent state
all_sim_vehicles.UpdateEgoVehicleState();
all_sim_vehicles.UpdateAllAgentVehicleState();
}
}
}
// EgoForwardSimulation和AgentForwardSimulation的具体实现参考Epsilon针对每一个ego-policy构建一个场景树,这一步主要是计算场景的分歧点。
计算Branch point: 如果使用固定的时间点进行分叉,分支数量会随着场景组合的数量指数增长
这里计算参考MARC: Multipolicy and Risk-aware Contingency Planning for Autonomous Driving
由于自车轨迹是与场景上下文交互的累积结果,因此它们的差异可以用来揭示场景的分歧。 ego轨迹差异大于一定阈值的时间点作为分叉点。

(a) scene divergence (b) trajectory tree (c) risk-neutral vs risk-averse
场景树分叉的判断标准: 由于场景外推以0.2s外推一个状态,可以选择每5个节点,即1s进行一次场景树的合并判断, 找到分叉点,最晚分叉点设置为4s。
伪代码:
planning_horizon = 8
max_branch_time = 4
dt_step = 0.2
def SceneTreeConstruction(all_ego_trajectories):
for t in np.splice(0, planning_horizon, dt_step * merge_step):
if (t < max_branch_time and CalDis(all_ego_trajectories[0:t]) < param.max_dis):
continue
else:
merge_states = Merge(all_ego_trajectories[0:t])
root_branch = BuildBranch(merge_states)
for ego_traj in all_ego_trajectories:
states = GetAllStates(ego_traj[t:])
cur_branch = BuildBranch(states)
root_branch.child_branch.append(cur_branch)
cur_branch.pre_branch = root_branch
def Merge(all_ego_state):
for pos, vel, acc, jerk in all_ego_state:
new_pos = w1 * pos_1 + w2 * pos_2 + ...
new_vel = w1 * vel_1 + w2 * vel_2 + ...
new_acc = w1 * acc_1 + w2 * acc_2 + ...
new_jerk = w1 * jerk_1 + w2 * jerk_2 + ...
SetNewState(new_pos, new_vel, new_acc, new_jerk)
merge_states = State(new_pos, new_vel, new_acc, new_jerk)
return merge_states
def SetNewState(pos, vel, acc, jerk):
ego_state.pos = pos
ego_state.vel = vel
ego_state.acc = acc
ego_state.jerk = jerk
输入:
- VehicleState: 自车的状态
- Obstacle: 障碍物预测的轨迹、感知的boundingbox、速度和id等
- scene_tree_set: 包含自车轨迹的粗解
输出:
- Optimal trajectory
- Optimal policy
伪代码:针对输入的带有轨迹粗解的场景树进行优化。优化方式为针对每一条枝干即 EgoPolicySet示意图中的每一个branch中的轨迹进行优化,生成一条条可供行驶的轨迹,再进行拼接并保证分支点的连续性约束, 形成轨迹树。最终将经过评分筛选后的最优策略下的轨迹树的共享段作为最优轨迹输出
// 场景树集合 (包含自车意图,agent意图及对应的agent的预测轨迹,以及自车轨迹的粗解)
scene_tree_set = SceneTreeSet()
// 获取轨迹树集合
for scene_tree_set do
// ilqr的优化需要的输入有:自车状态、自车轨迹粗解、障碍物预测轨迹、目标速度
traj_tree = GetTrajectoryTreeByOptimizer(scene_tree)
traj_tree_set <-- traj_tree
F_traj = GetCostEvaluation(traj_tree)
F_traj_set <-- F_traj
end
// 计算自车每个policy的打分
for ego_policy_set do
R = GetReward(F_trajectory, F_efficiency, F_navigation, F_uncertainty)
R_set <-- R
end
// 根据打分获取最优policy对应的最优轨迹树作为输出
optimal_traj_tree = PolicySelection(traj_tree_set, scene_tree_set, R_set)
optimal_trajectory = GetOptimalTrajectory(optimal_traj_tree)
output: optimal_trajectory
作用:获取自车各个不同policy下的轨迹树
输入:各个不同policy下的场景树(包含自车意图、agent意图及对应的agent的预测轨迹, 自车轨迹的粗解)
输出:自车不同policy下的轨迹树集合
伪代码:针对集合中的每一段场景树中的轨迹初解调用ilqr求解器生成轨迹树集合
bool GetTrajectoryTreeSet(std::vector<SceneTree>& scene_tree_set);
for scene_tree_set do
traj_tree = GetTrajectoryTree(scene_tree, VehicleState)
traj_tree_set <-- traj_tree
F_traj = GetCostEvaluation(traj_tree) // 供后续计算policy的R使用
F_traj_set <-- F_traj
end作用:根据单棵场景树、障碍物预测轨迹、初始状态生成该意图下的轨迹树
输入:某policy下的场景树、障碍物预测轨迹、初始状态
输出:某policy下的轨迹树
伪代码:根据场景树每一段branch中的粗解进行优化,保证分叉点的状态连续,最终生成轨迹树
void GetTrajectoryTree(scene_tree, obstacle, vehicle_state)
{
std::queue<Branch> branch_pool;
branch_pool.add(scene_tree.root_branch);
// 遍历树,根据每个branch的粗解计算轨迹
init_state = vehicle_state;
while (!branch_pool.empty())
{
auto cur_branch = branch_pool.front();
branch_pool.pop();
// 初始化ilqr需要的参数,自车状态、自车轨迹粗解、障碍物预测轨迹、目标速度
ilqr_init_state = init_state;
ilqr_reference_line = cur_branch.branch_coarse_traj;
[start_time, end_time] = GetTrajTime(cur_branch.branch_coarse_traj);
ilqr_obstacle_traj = GetObstacleTrajectory(obstacle, start_time, end_time);
ilqr_target_speed = GetTargetSpeed(cur_branch.branch_coarse_traj);
// ilqr求解
cost, branch_accurate_traj = IlqrOptimizer(ilqr_init_state,
ilqr_reference_line, ilqr_obstacle_traj, ilqr_target_speed);
cur_branch.SetBranchAccurateTraj(branch_accurate_traj);
// 该段轨迹代价记录
cur_branch.SetAccurateTrajCost(CalCostInBranch(cost));
// 遍历后续叶节点
for (cur_branch.child_branch do)
{
branch_pool.add(child_branch);
}
Update(init_state);
}
}
作用:根据优化后的结果对自车意图下对应的轨迹树进行打分,得到最优策略对应的输出轨迹 输入:scene_tree_set、traj_tree_set 输出:optimal traj
伪代码:
GetOptimalTrajectory(scene_tree_set)
{
min_cost_sum = kinf;
min_policy_id = 0;
for (scene_tree_set) do
{
// 对每个Policy下的表现进行打分
PolicySetScore(scene_tree);
if (min_cost_sum > scene_tree.cost_sum)
{
min_cost_sum = scene_tree.cost_sum;
min_policy_id = id;
}
}
// 根据最优轨迹树生成最优轨迹
optimal_traj = ChooseOptimalTrajectory(min_policy_id);
}作用: 根据每个策略下轨迹树的情况, 进行综合打分
输入:scene_tree
输出:scene_tree的得分
伪代码:
1. 目前考虑
2. 安全成本Fs:通过自动驾驶车辆和其他车辆轨迹之间的距离来衡量的,以及ilqr的成本相关的代价
3. 效率成本Fe:根据计划的平均速度与期望速度之间的差距计算
4. 导航成本Fn:通过线路和目标车辆之间的差异来获得
5. 不确定性成本Fu:则通过分支时间和不同分支之间的差异来衡量
cost_fs = CalSaftyCost(traj_tree, obstacle);
cost_fe = CalEfficiencyCost(traj_tree, desired_speed);
cost_fn = CalNavigationCost(traj_tree, reference_line);
cost_fu = CalUncertaintyCost(traj_tree);
cost_sum = w_1 * cost_fs + w_2 * cost_fe + w_3 * cost_fn + w_4 * cost_fu;
作用:根据输入的policyset中的打分情况选择最优的轨迹树,再根据最优的轨迹树输出最优轨迹
输入:scene_tree_set、 traj_tree_set(scene_tree和traj_tree在同一个数据类型中实现)
输出:optimal traj
伪代码:
Trajectory ChooseOptimalTrajectory(std::vector<SceneTree>& scene_tree_set, int min_policy_id)
optimal_id = min_policy_id
optimal_traj_tree = traj_tree_set.at(traj_tree)
optimal_traj = GetTraj(optimal_traj_tree) {
// 共享段长度足够,直接输出共享段
if (optimal_traj_tree.root_Branch.nodes.size() > Flag_min_traj_length) {
return GenerateTrajectory(optimal_traj_tree.root_Branch.nodes);
} else {
// 共享段长度不足,输出概率最大的分支
return GenerateMostLikelyTrajectory(optimal_traj_tree);
}
}
| 小gap变道 | 1.mp4 (15.02MB) 2.mp4 (12.81MB) 3.mp4 (15.4MB) |
|---|---|
| 旁边快速车辆,灵活切换gap | 4.mp4 (20.56MB) |
| cut-in车辆,更新变道点 | 5.mp4 (16.97MB) |
| 前方死车,旁边密集车流 | 6.mp4 (29.05MB) |
| 绕行后变道,成功避开死车 | 7.mp4 (23.03MB) |
| 低速行驶多次变道,和前方车辆行为保持一致 | 8.mp4 (84.47MB) 9.mp4 (67.89MB) |
| 路口前效率变道 | 10.mp4 (15.39MB) |