По сути, первая сверточная нейронная сеть. В ней было всего 3 слоя: convolution, pooling, non-lenearity.
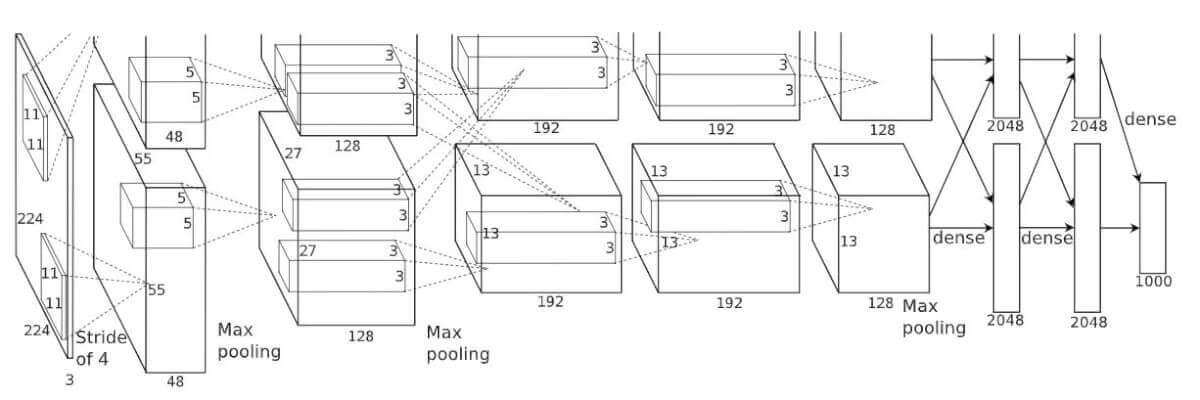
- был использован Relu вместо нелинейной функции активации - это сильно ускорило обучение
- была использована методика dropout - позволяет уменьшить переобучение, но увеличивает время обучения
- перекрытие maxPooling, что позволяет избежать эффектов усреднения (average pooling)
- имеет большее количество фильтров на слое
- используется SGD
Размеры фильтров - 9x9, 11x11
Таким образом, AlexNet содержит 5 сверточных слоев и 3 полносвязных слоя. Relu применяется после каждого сверточного и полносвязного слоя. Дропаут применяется перед первым и вторым полносвязными слоями.
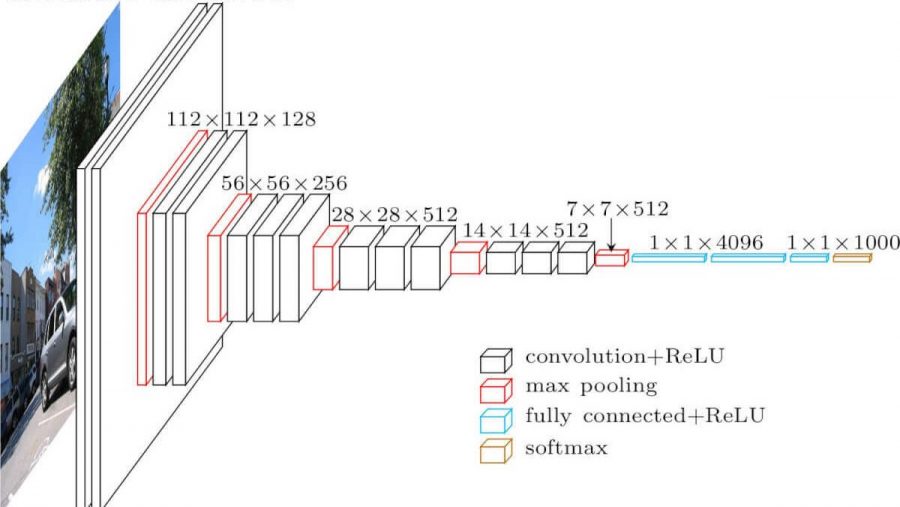
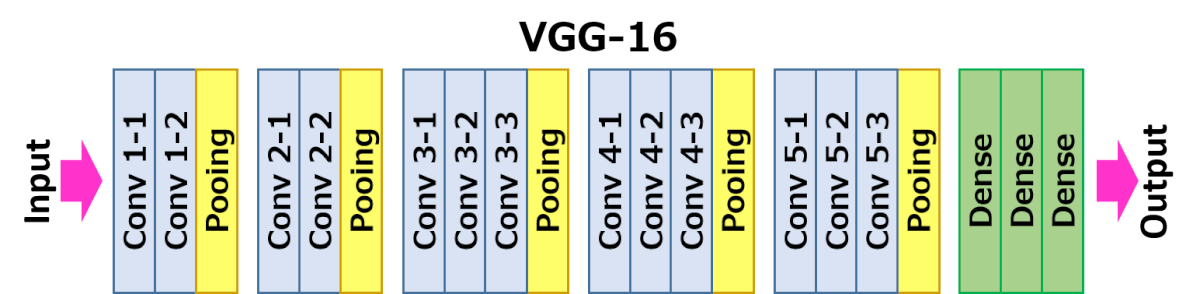
- вместо фильтров 11x11, 9x9, 5x5 используются более мелкие фильтры (3x3) идущие друг за другом.
Объединение таких фильтров в последовательность дало отличный результат
позволило эмулировать более крупные рецептивные поля - во многих слоях используется большое количество свойств, поэтому обучение требовало больших вычислительных затрат
Недостатки: - очень медленная скорость обучения
- очень много весит сама архитектура сети
Модель показывает лучшие результаты по сравнению с предшественниками. Было показано, что глубина представления положительно влияет на точность классификации.
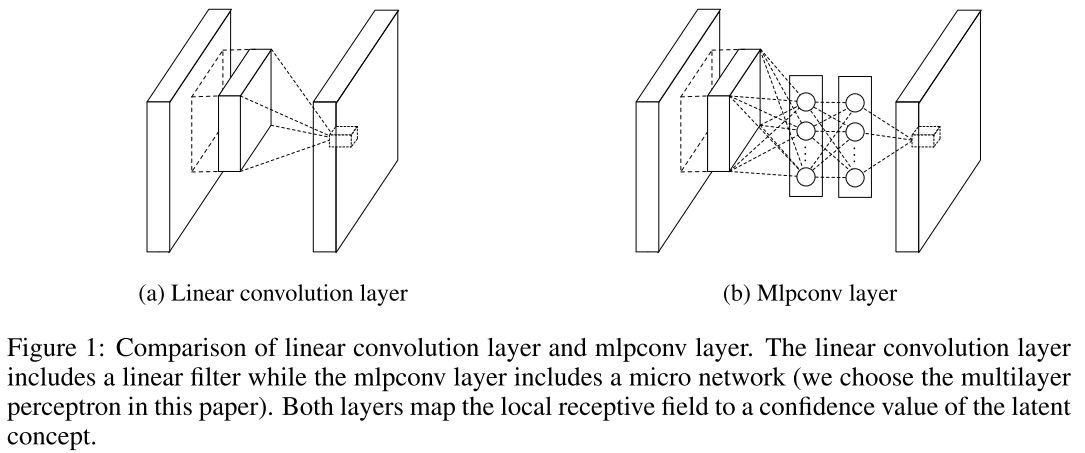
- использование сверток 1x1 (mlconv) - применяются для пространственного комбинирования свойств после свертки в рамках карт свойств
- использовали NiN-блоки для уменьшения количества свойств
- представлена архитектура batch-normalization-inception
- По мере возможности используются только свёртки 3x3
- простая, но революционная идея - подаём выходные данные двух успешных свёрточных слоёв и обходим входные данные для следующего слоя
- был продемонстрирован пример обучения сети из нескольких сотен и даже тысячи слоев
Очень мощная комбинация большинства недавно созданных архитектур. Использует довольно мало параметров и дает очень высокие результаты.
Это сеть на основе кодировщика и декодера. Кодировщик построен по обычной схеме CNN для категоризации, а декодер представляет собой сеть с повышением дискретизации (upsampling netowrk), предназначенную для сегментирования посредством распространения категорий обратно в изображение исходного размера. Для сегментации изображений использовались только нейросети, никаких других алгоритмов.

Также существует довольно большое количество не столь известных моделей:
- Inception v4
- FractalNet
- Xception
- SqueezeNet
- использовать нелинейность ELU без пакетной нормализации (batchnorm) или ReLU с нормализацией
- применять выученную трансформацию цветового пространства RGB
- использовать политику линейного ухудшения скорости обучения (linear learning rate decay policy)
- использовать сумму среднего и максимального pooling-слоя
- использовать мини-пакет размером 128 или 256. Если для вашей видеокарты этого слишком много, уменьшайте скорость обучения пропорционально размеру пакета
- использовать полносвязные слои в качестве свёрточных и усреднять прогнозы для выдачи финального решения.
- если увеличиваете размера обучающего датасета, удостоверьтесь, что не достигли плато в обучении. Чистота данных важнее размера
- если не можете увеличить размер входного изображения, уменьшайте страйд в последующих слоях, эффект будет примерно таким же
- если ваша сеть обладает сложной и высокооптимизированной архитектурой, как в GoogLeNet, то модифицируйте её с осторожностью
Довольно простая, но оттого и красивая идея: нейросеть, которая умеет восстанавливать на выходе исходный сигнал, который был подан на вход.
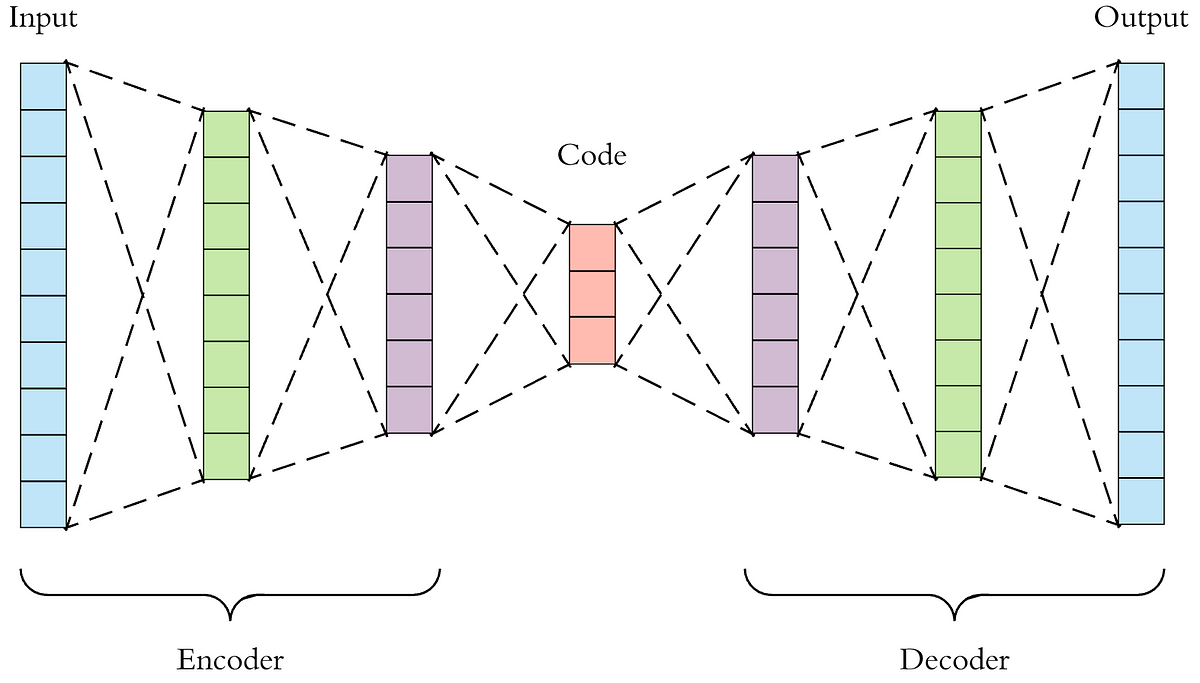
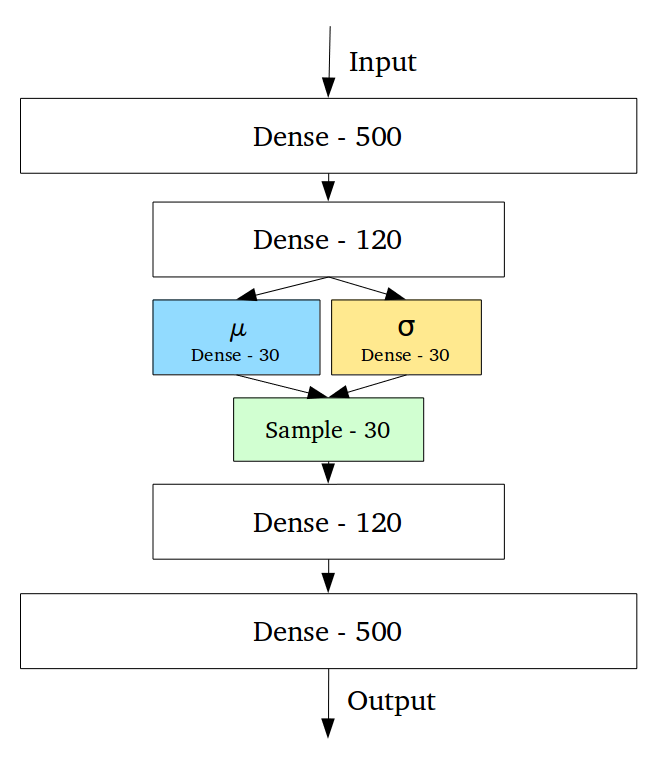
- вариационный автоэнкодер. У простого AE есть недостаток - его эмбеддинги не являются непрерывными. Таким образом, нельзя подавать произвольные сигналы и перемещаться межде различными эмбеддингами, поскольку есть вероятность попасть в область пространства, которая ничему не соответствует из обучаемого множества. VAE решает этому проблему. Он интерполирует пространство эмбеддингов, делая его непрерывным и позволяет перемещаться между различными классами.
Непрерывность скрытого пространства достигается неожиданным способом: энкодер выдаёт не один вектор размера n, а два вектора размера n – вектор средних значений µ и вектор стандартных отклонений σ.
Ссылка с хорошим описанием