English | 简体中文




- [2021-12-12] PaddleNLP v2.2 has been officially relealsed! 🎉 For more information please refer to Release Note.
- [2021-12-12] *End-to-end Question Answering Toolkit**🚀RocketQA has been released!:tada:
PaddleNLP is an easy-to-use and high performance NLP library with awesome pre-trained Transformer models, supporting wide-range of NLP tasks from research to industrial applications.
-
Easy-to-Use API
- The API is fully integrated with PaddlePaddle 2.0 high-level API system. It minimizes the number of user actions required for common use cases like data loading, text pre-processing, awesome transfomer models, and fast inference, which enables developer to deal with text problems more productively.
-
Wide-range NLP Task Support
- PaddleNLP support NLP task from research to industrial applications, including Lexical Analysis, Text Classification, Text Matching, Text Generation, Information Extraction, Machine Translation, General Dialogue and Question Answering etc.
-
High Performance Distributed Training
- We provide an industrial level training pipeline for super large-scale Transformer model based on Auto Mixed Precision and Fleet distributed training API by PaddlePaddle, which can support customized model pre-training efficiently.
Welcome to join PaddleNLP SIG for contribution, eg. Dataset, Models and Toolkit.
To connect with other users and contributors, welcome to join our Slack channel.
Scan the QR code below with your Wechat⬇️. You can access to official technical exchange group. Look forward to your participation.

- python >= 3.6
- paddlepaddle >= 2.2
More information about PaddlePaddle installation please refer to PaddlePaddle's Website.
pip install --upgrade paddlenlp
Taskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG scenario, in the meanwhile with extreamly fast infernece satisfying industrial applications.
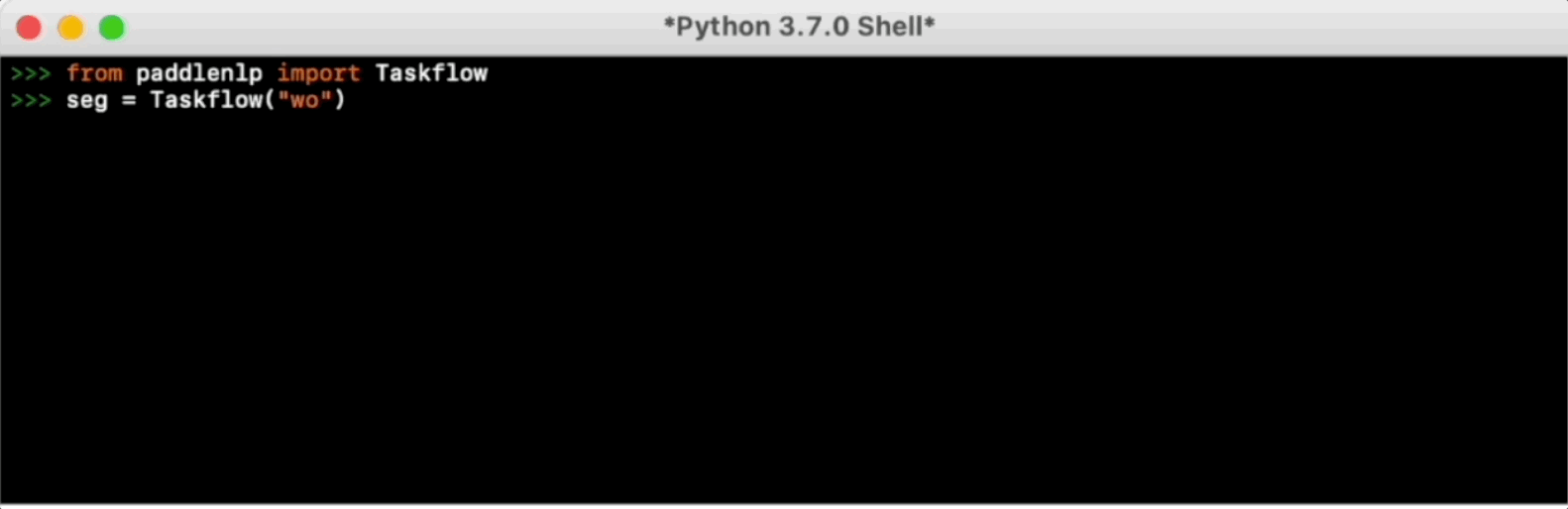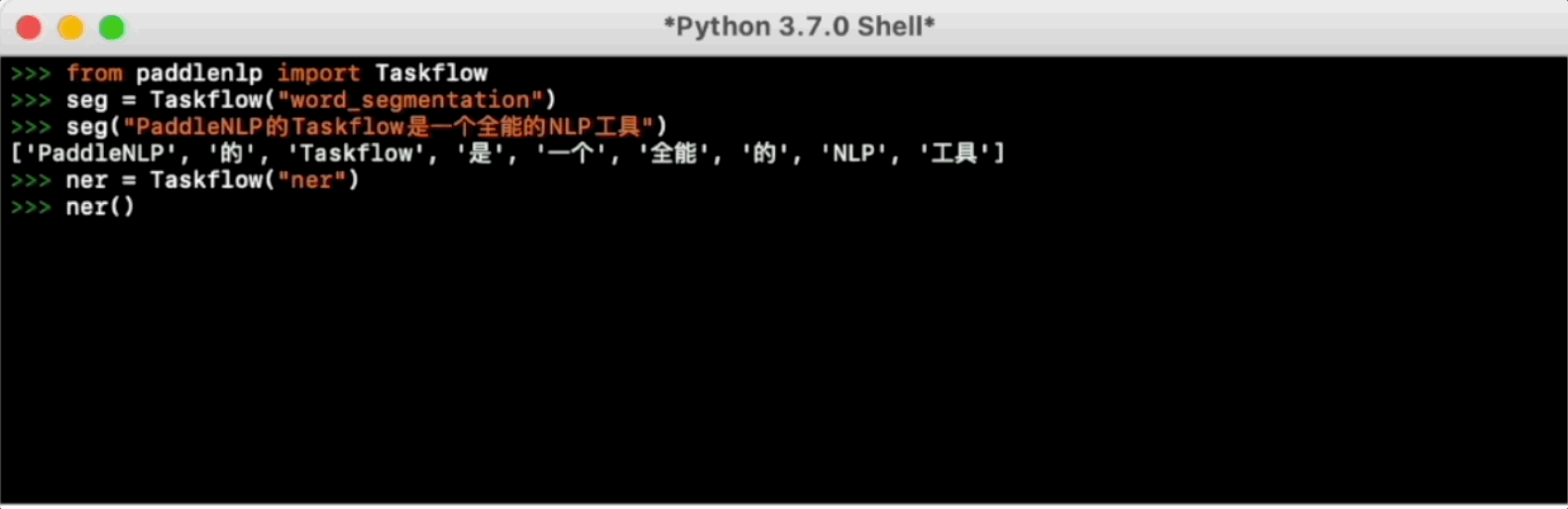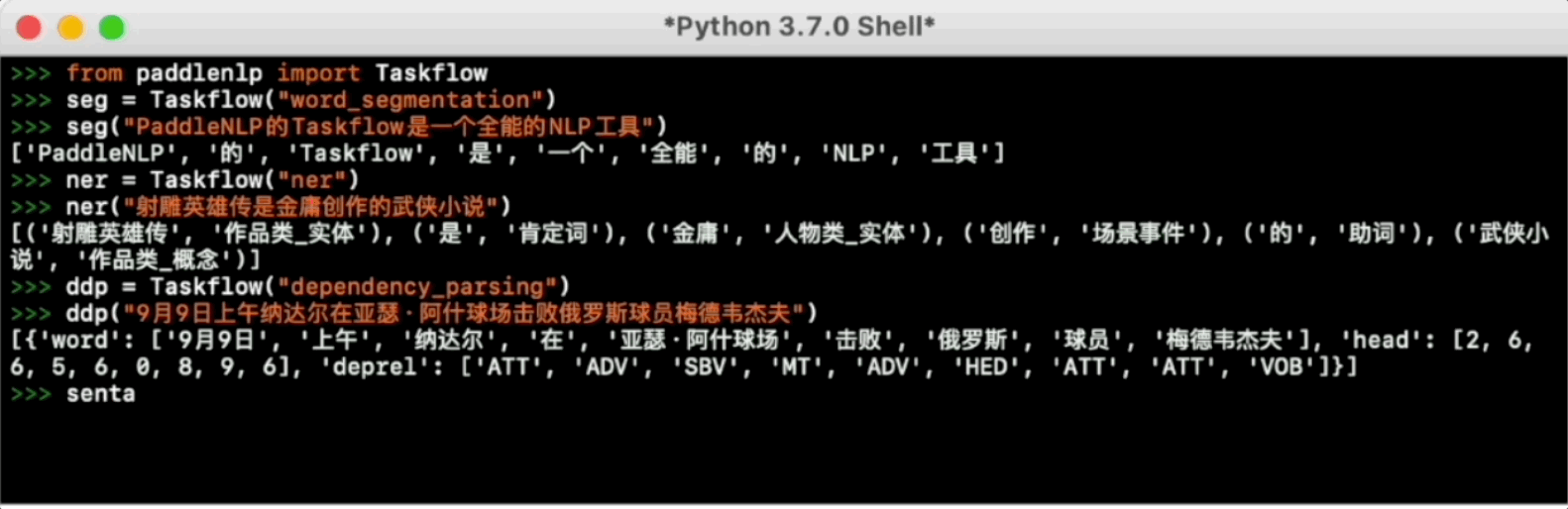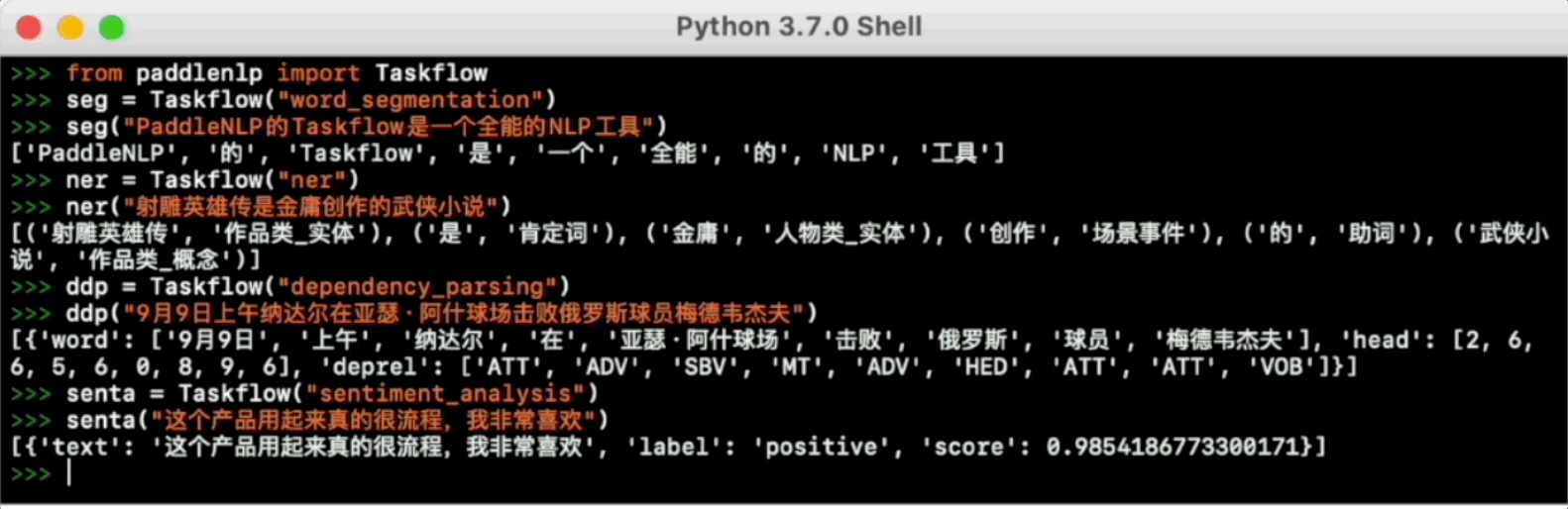
For more usage please refer to Taskflow Docs
We provide 30 network architectures and over 100 pretrained models. Not only includes all the SOTA model like ERNIE, PLATO and SKEP released by Baidu, but also integrates most of the high quality Chinese pretrained model developed by other organizations. Use AutoModel to download pretrained mdoels of different architecture. We welcome all developers to contribute your Transformer models to PaddleNLP! 🤗
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-1.0')
ernie_gram = AutoModel.from_pretrained('ernie-gram-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')PaddleNLP also provides unified API experience for NLP task like semantic representation, text classification, sentence matching, sequence labeling, question answering, etc.
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-1.0')
text = tokenizer('natural language understanding')
# Semantic Representation
model = AutoModel.from_pretrained('ernie-1.0')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# Text Classificaiton and Matching
model = AutoModelForSequenceClassification.from_pretrained('ernie-1.0')
# Sequence Labeling
model = AutoModelForTokenClassification.from_pretrained('ernie-1.0')
# Question Answering
model = AutoModelForQuestionAnswering.from_pretrained('ernie-1.0')For more pretrained model usage, please refer to Transformer API
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])For more dataset API usage please refer to Dataset API.
from paddlenlp.embeddings import TokenEmbedding
wordemb = TokenEmbedding("fasttext.wiki-news.target.word-word.dim300.en")
wordemb.cosine_sim("king", "queen")
>>> 0.77053076
wordemb.cosine_sim("apple", "rail")
>>> 0.29207364For more TokenEmbedding usage, please refer to Embedding API
Please find more API Reference from our readthedocs.
PaddleNLP provides rich application examples covering mainstream NLP task to help developers accelerate problem solving.
- Word Embedding
- Lexical Analysis
- Dependency Parsing
- Language Model
- Semantic Parsing (Text to SQL)⭐
- Text Classification
- Text Matching
- Text Generation
- Text Correction⭐
- Semantic Indexing
- Information Extraction
- Sentiment Analysis🌟
- General Dialogue System
- Machine Translation
- Simultaneous Translation
- Machine Reading Comprehension
- Few-shot Learning🌟
- Text Knowledge Mining🌟
- Model Compression
- Text Graph Learning
- Time Series Prediction
Please refer to our official AI Studio account for more interactive tutorials: PaddleNLP on AI Studio
-
What's Seq2Vec? shows how to use simple API to finish LSTM model and solve sentiment analysis task.
-
Sentiment Analysis with ERNIE shows how to exploit the pretrained ERNIE to solve sentiment analysis problem.
-
Waybill Information Extraction with BiGRU-CRF Model shows how to make use of Bi-GRU plus CRF to finish information extraction task.
-
Waybill Information Extraction with ERNIE shows how to use ERNIE, the Chinese pre-trained model improve information extraction performance.
For more details about our release, please refer to ChangeLog
If you find PaddleNLP useful in your research, please consider cite
@misc{=paddlenlp,
title={PaddleNLP: An Easy-to-use and High Performance NLP Library},
author={PaddleNLP Contributors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleNLP}},
year={2021}
}
We have borrowed from Hugging Face's Transformer🤗 excellent design on pretrained models usage, and we would like to express our gratitude to the authors of Hugging Face and its open source community.
PaddleNLP is provided under the Apache-2.0 License.