An implementation of the REINFORCE algorithm.
REINFORCE is form of policy gradient that uses a Monte Carlo rollout
to compute rewards. It accumulates the rewards for the entire episode and then discounts them weighting earier rewards heavier using
the equation:
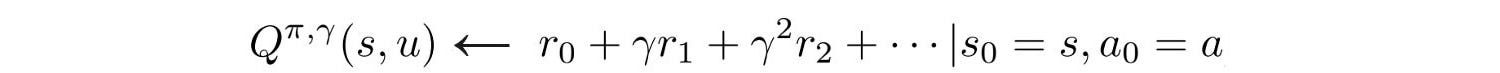
The gradient is computed by the softmax loss of the discounted rewards with respect to the episode states. Actions are then sampled from the softmax distribution.

See the experiments folder for example implementations.
- more environments
- Paper: http://www-anw.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf
- Tutorial: https://www.freecodecamp.org/news/an-introduction-to-policy-gradients-with-cartpole-and-doom-495b5ef2207f
- Tutorial: https://medium.com/@jonathan_hui/rl-policy-gradients-explained-9b13b688b146
- Sample python code: https://github.com/rlcode/reinforcement-learning/blob/master/2-cartpole/3-reinforce/cartpole_reinforce.py