Few weeks ago I was privileged to speak as panel member about Chaos Engineering at Contributing Today Meetup. Next to me there where some other great panel members like Jason Yee from Gremlin and maintainers of Chaos Monkey @Netflix. If you are not yet familiar yet, just learn about Principles of Chaos and view the recording on YouTube.
During that session I gave a mini demo how to start experimenting with Chaos Engineering on Kubernetes. For this I chose Litmus Chaos which is one of the promising CNCF sandbox projects for Chaos Engineering mentioned at the CNCF Interactive Landscape.

If you are not aware of the CNCF Cloud Native Interactive Landscape please look here at the Observability and Analysis section.
Some backup slides are available here at SlideShare
Deploying Litmus is easy. For sandbox experiments you just can apply the manifest. Also the documentation is well-updated, so you shouldn't get into problems with any of the cloud provider offerings like AKS, EKS or GKE. For example I have created this demo on GKE without any problems. See below the architecture setup.
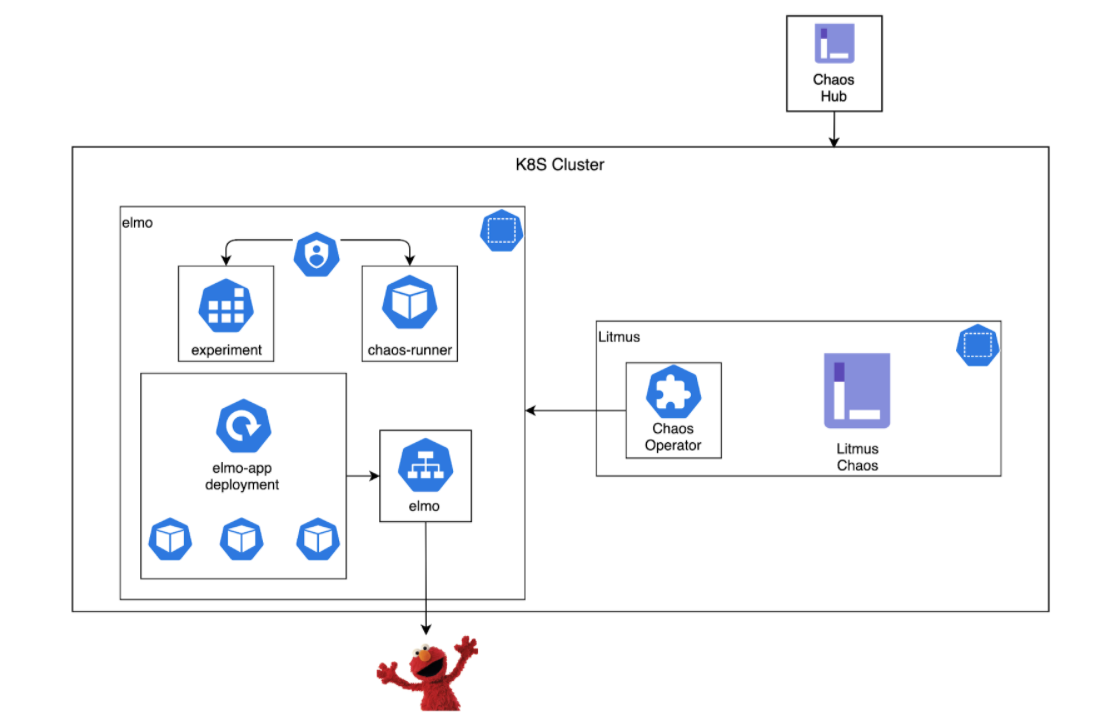
Below the initial steps to take. Please note that these are here to help you getting started. More current information see Getstarted documentation
First apply the manifest to setup the Litmus Operator.
kubectl apply -f https://litmuschaos.github.io/litmus/litmus-operator-v1.13.3.yaml
After some seconds you can check if the Pod is entering a RUNNING state and all CRDs are available.
The following CRDs should be available
- chaosengines (The engine that combines a Chaos experiment with a plan to execute.)
- chaosexperiments (The actual available Chaos experiments to run.)
- chaosresults (The stored results of your Chaos experiment.)
kubectl get pods -n litmus
kubectl get crds | grep chaos
For this exercise I have created a simple Elmo App that is based on nginx and some html content that needs to be loaded. Nothing special here. For convenience I still have the talk-chaos available at Docker hub.

Create the elmo namespace and apply the following manifest to start the Elmo App.
kubectl create ns elmo
kubectl apply -f elmo-app.yaml -n elmo
If everything goes well you wil now have a elmo-app service that is exposed through a LoadBalancer. You can check it with the command below and write down the external ip. For troubleshooting use describe svc or just use a NodePort based service.
kubectl get svc elmo-app -n elmo
Now that we have both Litmus Chaos and our targeted and beloved Elmo App running we can start implementing some prerequisites. Most prerequisites need to be applied on the elmo namespace.
Most important thing here is to think about the hypothesis or scenario to run.
Which experiments do apply here?
What is Elmo App steady-state?
Let's start and select some experiments to help us to reveal system weaknesses.
- First we need make the required chaos experiments available within the
elmo namespace. - Secondly a
service accountto ensure the required and fine grainedrbac permissionsare available for thechaosengineto execute the experiment. - Last thing we must not forget is to
annotateyour target application.
During the demo we will use two generic ways to start with chaos experiments, but I do want to inform you about the great source of experiments that are available for you at Chaos Hub. Like for Kafka, CoreDNS or specific for AWS.
Start with making the generic experiments available for elmo. For simplicity we apply all of them.
kubectl apply -f https://hub.litmuschaos.io/api/chaos/1.13.3?file=charts/generic/experiments.yaml -n elmo
Now we need to setup the rbac permissions, which includes ServiceAccount, Role and Rolebinding objects.
kubectl apply -f elmo-chaos-rbac.yaml -n elmo
Last step is to annotate our deployed Elmo App, so we are sure it's registered as an official target.
kubectl annotate deploy/elmo-app litmuschaos.io/chaos="true" -n elmo --overwrite
Now that we have everything in-place we can start defining our hypothesis.
Let's with our hypothesis that during container, worker node failures our Elmo App is still available for our end users using the browser.
Terminate app pods should not prevent the Elmo App from running and being unavailable for the end user.
Since we are reyling on Kubernetes to provide Pod Replicas, we expect that the Elmo App should run fine without affecting the user experience even when one of the app pods is terminated.
Now let's start defining our Chaos runner. Before actually applying this Chaos Engine, please look at the following values.
- Ensure your
appinfois set correct for both deployment and pods. - Ensure that the
chaosServiceAccountis set as named above. - By default we cleanup the Job when ready, but you can retain it.
- You can customize your
experimentin theexperimentssection.
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: elmo-chaos
namespace: elmo
spec:
appinfo:
appns: 'elmo'
applabel: 'app=elmo-app'
appkind: 'deployment'
# It can be true/false
annotationCheck: 'true'
# It can be active/stop
engineState: 'active'
#ex. values: ns1:name=percona,ns2:run=nginx
auxiliaryAppInfo: ''
chaosServiceAccount: pod-delete-sa
# It can be delete/retain
jobCleanUpPolicy: 'delete'
experiments:
- name: pod-delete
spec:
components:
env:
# set chaos duration (in sec) as desired
- name: TOTAL_CHAOS_DURATION
value: '30'
# set chaos interval (in sec) as desired
- name: CHAOS_INTERVAL
value: '10'
# pod failures without '--force' & default terminationGracePeriodSeconds
- name: FORCE
value: 'false'
Now apply this manifest.
kubectl apply -f chaos-experiment-job.yaml -n elmo
After applying this manifest take a look at the available pods and notice that some new pods are created like the elmo-chaos-runner and the experiment pod called pod-delete itself. Also notice the terminated elmo pods.
kubectl get pods -n elmo -w
Now start monitoring our browser session. You can also use a curl-loop to run a heartbeat.
while true ;do curl http://YourFamousIP; sleep 1 ; done
After the experiment we can conclude that the application became unavailable during the experiment. Of course you already seen that we only have set one replica, which is not providing fault-tolerance.
curl: (7) Failed to connect to 35.23.192.64 port 80: Connection refused
curl: (7) Failed to connect to 35.23.192.64 port 80: Connection refused
curl: (7) Failed to connect to 35.23.192.64 port 80: Connection refused
curl: (7) Failed to connect to 35.23.192.64 port 80: Connection refused
curl: (7) Failed to connect to 35.23.192.64 port 80: Connection refused
To view the actual result from Litmus Chaos experiment we can describe the stored result report, which contains the run history and experiment status either Pass or Fail.
kubectl get chaosresult -n elmo
kubectl describe chaosresult elmo-chaos-pod-delete -n elmo
Let's start with increasing our replica count. Great we have solved our first weakness.
kubectl scale --replicas=3 deploy/elmo-app -n elmo
Poisoning app pods network traffic and introducing latency should not prevent the Elmo App from running and being unavailable for the end user.
Since we are reyling on Kubernetes to provide Pod Replicas and browser cache, we expect that the Elmo App should run fine without affecting the user experience even when one of the app pods is having network latency.
Now let's start defining our Chaos runner. Before actually applying this Chaos Engine, please look at the following values. Take a notice we only have replaced the experiments section.
...
experiments:
- name: pod-network-latency
spec:
components:
env:
#Network interface inside target container
- name: NETWORK_INTERFACE
value: 'eth0'
- name: NETWORK_LATENCY
value: '2000'
- name: TOTAL_CHAOS_DURATION
value: '60' # in seconds
# provide the name of container runtime
# for litmus LIB, it supports docker, containerd, crio
# for pumba LIB, it supports docker only
- name: CONTAINER_RUNTIME
value: 'docker'
# provide the socket file path
- name: SOCKET_PATH
value: '/var/run/docker.sock'
Now apply this manifest.
kubectl apply -f chaos-experiment-bonus.yaml -n elmo
After applying this manifest take a look at the available pods and notice that again some new pods are created like the elmo-bonus-runner and the experiment pod called pod-network-latency itself.
kubectl get pods -n elmo -w
Now start monitoring our browser session.For this you can use Developer tools (part of Chrome or Edge) to measure the actual network load time. You can also use a curl-loop to run a heartbeat.
while true ;do curl http://YourFamousIP; sleep 1 ; done
After this experiment we can conclude that the browser cache is working, but still the first session goes from milliseconds to seconds loading time. To mitigate this is the future we can make use of a Content Delivery Network (CDN) to pre-cache our images like Elmo, even closer to the end user. Implementing an CDN is out of scope for this example.
Again we have found a weakness to solve in our Elmo App Architecture.
To view the actual result from Litmus Chaos experiment we can describe the stored result report, which contains the run history and experiment status either Pass or Fail.
kubectl get chaosresult -n elmo
kubectl describe chaosresult elmo-bonus-pod-network-latency -n elmo
Hopefully running through this gives you some insights why experiments are helpful to spot weaknesses in your system, even it's not Production.
Let's talk 🔥 Chaos 🔥 and get Reliable 👻 !
See litmus-chaos-elmo-demo repository for all mentioned content.