-
REST (REpresentational State Transfer) este un stil arhitectural folosit pentru dezvoltarea aplicațiilor web introdus în anul 2000 în teza de doctorat a lui Roy Fielding
-
Această arhitectură are în centrul său conceptul de resursă, reprezentând tipurile de date complexe ce compun aplicația propriu-zisă
-
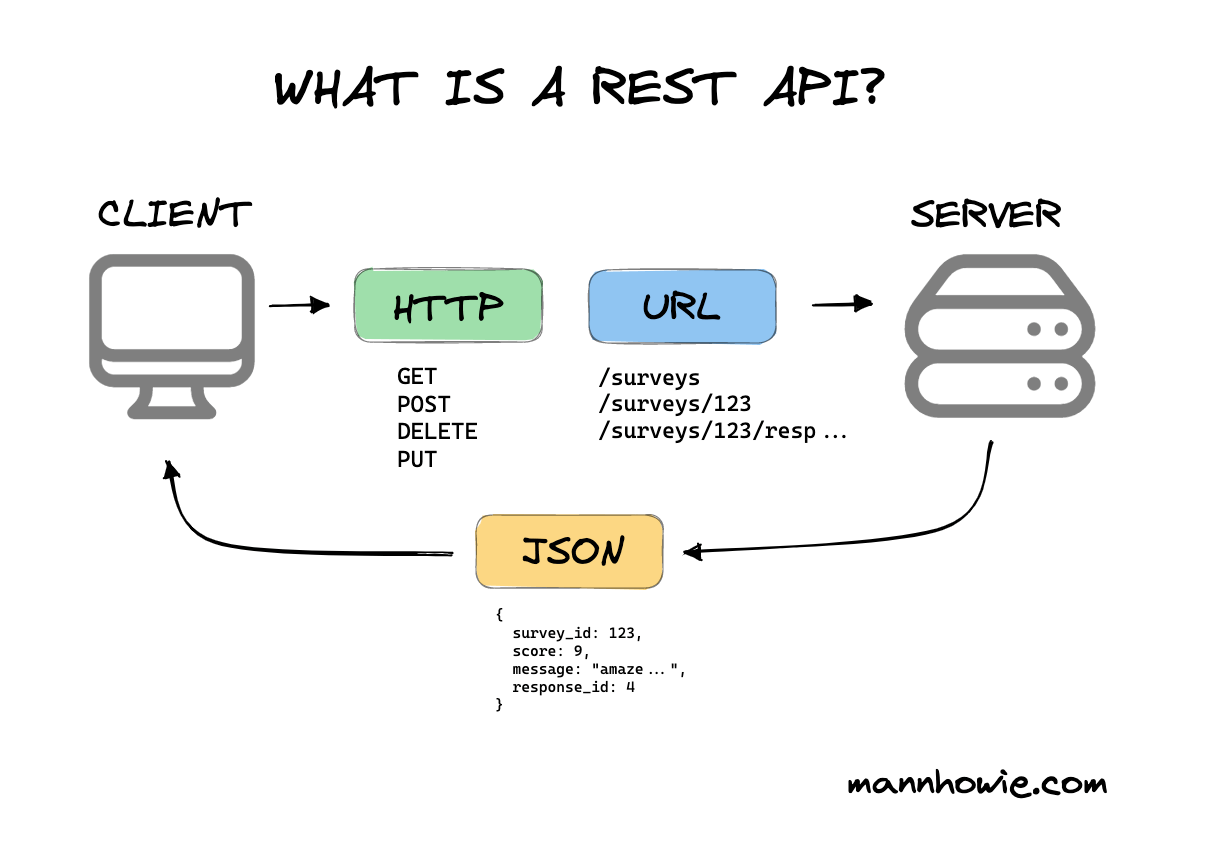
În cadrul unui sistem REST, un client comunică cu un server printr-o interfață uniformă care descrie o colecție de resurse ce pot fi create, listate, interogate, actualizate sau șterse
-
La bază, REST este o serie de bune practici care au ca scop definirea unui sistem scalabil, utilizând instrumente native web-ului
-
Cele mai importante caracteristici REST sunt:
- Arhitectura client-server
- Utilizarea resurselor ca mod de reprezentare a datelor
- Interfața uniformă
- toate resursele descrise în cadrul unui sistem pot fi utilizate printr-o interfață identică din punct de vedere structural
- Lipsa stărilor între request-uri (Stalessness)
- într-un sistem REST, orice request făcut de către un client trebuie să conțină toate informațiile necesare pentru îndeplinirea sa
- Utilizarea verbelor HTTP pentru a descrie o serie de operații standard ce pot fi efectuate asupra resurselor
- Stratificarea sistemului
- pentru a permite scalarea unui sistem, existența unor intermediari, cum ar fi serverele proxy sau mecanismele de cache, nu trebuie să afecteze în vreun fel funcționalitatea sistemului
- Utilizarea cache-ului
- pentru a spori performanța sistemului, părțile componente pot implementa mecanisme de caching care să reutilizeze, pentru o anumită perioadă de timp, răspunsurile deja generate
-
Pe lângă aceste principii necesare, putem defini și o serie de recomandări adiționale care să ofere și mai mult suport pentru implementarea corectă a serviciilor REST:
- Utilizarea JSON ca format de transferare a datelor
- Utilizarea substantivelor la plural în locul verbelor în cadrul URL-urilor
- Utilizarea corectă și uniformă a codurilor de stare (status codes)
- Utilizarea filtrării, a sortării și a paginării pentru a eficientiza accesul la resurse
- Implementarea unui sistem de versionare a URL-urilor
-
Atunci când toate principiile generale ale REST sunt aplicate, discutăm despre un API RESTful, pe când, dacă o parte dintre acestea nu sunt implementate corespunzător, discutăm despre un API REST-like
-
Recomandare: puteți găsi mai multe exemple aici
-
Deși folosite adesea ca echivalente, REST și CRUD sunt două concepte diferite ce sunt utilizate adesea împreună
-
CRUD reprezintă un acronim al cuvintelor CREATE, READ, UPDATE, DELETE și exprimă principalele tipuri de acțiuni care pot fi executate asupra unei resurse
-
Dat fiind faptul ca REST are la bază conceptul de resursă, operațiunile CRUD pot fi utilizate, împreună cu verbele HTTP, pentru a descrie un API REST:
- CREATE - POST - crearea unei resurse
- READ - GET - citirea unei resurse
- UPDATE - PUT/PATCH - actualizarea unei resurse
- DELETE - DELETE - ștergerea unei resurse
-
În general, atunci când vorbim despre REST, o facem în contextul unui REST API, un API, acronim pentru Application Programming Interface, fiind o colecție de metode, exprimate prin URL-uri, ce permit utilizarea resurselor existente la nivelul serverului
-
Fiecare metodă (URL) prezentă în cadrul unui API poartă numele de endpoint, putând spune, deci, că un API este o colecție de endpoint-uri
-
În esență, API-ul definește regulile și interfața generală pentru comunicarea cu un sistem informatic, în timp ce endpoint-urile reprezintă locațiile specifice în cadrul API-ului unde pot fi accesate resurse sau efectuate diferite operații
-
Exercițiu: pornind de la versiunea curentă a aplicației, încearcă să refactorizezi totul astfel încât să respecte principiile REST enumerate anterior
-
nu te teme să ștergi endpoint-uri și funcționalități dacă acestea nu sunt necesare - atunci când folosim un sistem de versionare cum este git codul șters nu este niciodată pierdut, în cazul în care vom avea nevoie de el mai târziu
-
pașii pe care îi poți urma pentru a implementa această cerință sunt:
- modifică valoarea tuturor path-urilor, incluzând forma plurală a substantivului folosit (în cazul de față /movie/ va deveni /movies/)
- redenumește toate fișierele movie.js în movies.js pentru a sincroniza structura proiectului cu interfața
- șterge endpoint-ul random, ce implementează o acțiune și nu respectă principiile REST
- deoarece nu va mai fi folosit, poți dezinstala și pachetul "random" instalat în cadrul seminarului anterior (trebuie să folosești o comandă npm pentru a realiza corect dezinstalarea)
- șterge endpoint-ul search, ce reprezintă la rândul său o acțiune, și mută logica aferentă în endpoint-ul de listare, ce va suporta acum filtrarea rezultatelor pe baza cuvintelor din titlu
- implementează conceptul de versionare a API-ului astfel încât un request gestionat înainte pe ruta /movies/ să fie, acum, gestionat pe ruta /api/v1/movies/
-

-
Un avantaj oferit de implementarea unui API REST este obținerea unui grad ridicat de concordanță între modul în care datele sunt reprezentate în cadrul serverului și a modului în care acestea vor fi expuse clienților, motiv pentru care modelarea resurselor devine și mai importantă
- Recomandare: pentru definirea structurilor ce compun nivelul de persistență poți folosi un tool ca dbdiagram
-
În acest context, persistența datelor se referă la capacitatea de a stoca și menține datele ce compun resursele într-un mod durabil și sigur pentru o perioadă îndelungată
-
Persistența datelor este asigurată de cele mai multe ori prin utilizarea bazelor de date, ce pot fi:
-
relaționale (SQL) - sisteme de gestiune a bazelor de date care utilizează tabele și relații pentru a stoca date în mod structurat
- ex: MySQL, PostgreSQL, Microsoft SQL Server
-
non-relaționale (NoSQL) - soluții de stocare a datelor care nu se bazează pe tabele și relații, ci folosesc alte modele de date, cum ar fi documente, grafuri sau perechi cheie-valoare
- ex: MongoDB, Cassandra, Redis
-
-
În cadrul seminarului vom discuta doar despre utilizarea bazelor de date relaționale, însă, poți citi mai multe despre utilizarea unei baze de date non-relaționale, cum ar fi MongoDB și a ORM-ului mongoose
-
Bazele de date relaționale sunt, în general, aplicații de sine stătătoare ce sunt instanțiate sub forma unui server la care o aplicație back-end, din perspectiva de client, se conectează și execută query-uri SQL
-
Acest server este responsabil pentru gestionarea și administrarea bazei de date, precum și pentru executarea efectivă a tuturor cererilor și calcularea rezultatelor
-
În aplicațiile complexe, utilizarea unei astfel de soluții reprezintă o alegere standard, însă, în cadrul seminarului, pentru a reduce numărul de dependențe externe, vom utiliza o bază de date self-contained: SQLite
-
SQLite este un engine de baze de date SQL încapsulat, nefiind necesar un server pentru utilizarea sa
-
Acesta nu necesită nicio configurare și poate fi folosit imediat pentru stocarea datelor, ce va fi făcută sub forma unui singur fișier
-
Deoarece nu există un server care să execute query-urile asupra bazei de date, aplicația back-end este cea care va face acest lucru, motiv pentru care este nevoie să instalăm o bibliotecă ce implementează engine-ul SQLite
npm install --save sqlite3
-
Pentru testarea conexiunii la o bază de date SQLite și executarea query-urilor de test vom instala extensia SQLite disponibilă pentru Visual Studio Code
-
În general, când discutăm despre interacțiunea dintre o aplicație și o bază de date relațională, sunt două direcții principale ce pot fi urmate:
-
compunerea și executarea directă a query-urilor SQL
- este un procedeu care permite programatorului să aibă control complet asupra query-urilor executate, însă necesită modificarea directă a query-urilor de fiecare dată când un model se schimbă sau o funcționalitate nouă trebuie implementată
-
utilizarea unui ORM (Object-relational mapping)
- un ORM este un instrument ce permite definirea unor obiecte prin intermediul cărora se vor genera, automat, query-uri SQL în funcție de operațiunea dorită
-
-
În industrie, toate aplicațiile complexe folosesc ORM-uri, cele mai importante avantaje fiind:
- interacțiune simplificată, programatică, OOP cu baza de date
- portabilitatea codului ce poate fi utilizat cu mai multe baze de date fără a necesita modificări
- reducerea timpului de dezvoltare
- separarea codului și ascunderea conceptelor strict legate de bazele de date în spatele unor abstractizări generale
- optimizarea query-urilor generate și securizarea implicită a acestora
-
Sequelize este cel mai popular ORM pentru node.js și poate fi utilizat împreună cu o gamă largă de baze de date
-
Înainte de a putea folosi Sequelize, trebuie să instalăm biblioteca aferentă
npm install --save sequelize
-
Pentru a ne conecta la o bază de date, vom adăuga un nou fișier, config.js, în directorul models la nivelul căruia vom defini minimul necesar pentru conectare:
import { Sequelize } from "sequelize"; export const db = new Sequelize({ // specificam tipul bazei de date pe care o vom utiliza dialect: "sqlite", // fisierul in care vor fi stocate datele va fi generat la pornirea aplicatiei storage: "action.db" }); // metoda ce va fi apelata pentru a pregati conexiunea la baza de date // metoda este declarată async deoarece operațiunile authenticate și sync sunt asincrone și folosim keyword-ul await // pentru a aștepta finalizarea execuției export const synchronizeDatabase = async () => { // verifica conexiunea la baza de date await db.authenticate(); // creeaza / actualizeaza tabelele la nivelul bazei de date await db.sync(); };
-
Pe lângă configurarea generală a bazei de date, vom defini o entitate care să descrie resursa Movie pe care am reprezentat-o, anterior, sub forma unui array și care va avea structura:
- id: integer, cheie primară, autoincrementare
- title: string, nenul
- year: integer, nenul, > 1900
- director: string, nenul
- genre: string
- synopsis: text
- duration: integer
- poster: string
-
Pentru a defini entitatea folosind Sequelize vom rescrie conținutul fișierului deja existent movies.js și vom adăuga implementarea:
// importarea bazei de date definite in fisierul config.js import { db } from "./config.js"; // importarea tipurilor de date suportate de sequelize import { DataTypes } from "sequelize"; // vom sterge implementarea anterioara dupa ce vom actualiza codul utilizat in serviciul movies.js export const movies = ["Synechdoche, New York", "i'm thinking of ending things", "mother!", "Aloners", "Blue Valentine"]; // definirea unei tabele noi cu numele Movie export const Movie = db.define("Movie", { id: { // tipul unui camp type: DataTypes.INTEGER, // cheie primara primaryKey: true, // autoincrement autoIncrement: true }, title: { type: DataTypes.STRING, // constrangere de camp nenul allowNull: false }, year: { type: DataTypes.INTEGER, allowNull: false, // validarea ca valoarea minima ce poate fi stocata sa fie mai mare de 1900 validate: { min: 1900 } }, director: { type: DataTypes.STRING, allowNull: false }, genre: { type: DataTypes.STRING }, synopsis: { // utilizarea unui tip de data ce permite inserarea unui text de mari dimensiuni type: DataTypes.TEXT }, duration: { // utilizarea unui tip de data eficient, in concordanta cu plaja de valori ale campului type: DataTypes.TINYINT }, poster: { type: DataTypes.STRING } }, { indexes: [ { // definirea unei constrangeri de unicitate pe baza tripletei titlu, an, regizor unique: true, fields: ['title', 'year', 'director'] } ] });
-
Dacă rulăm aplicația, nu vom observa nicio diferență momentan, deoarece, deși definite, baza de date și modelul Movie nu au fost încă invocate în mod direct, lucru pe care îl vom face apelând metoda synchronizeDatabase în entrypoint-ul aplicației
// start listening for connections import { synchronizeDatabase } from "./models/config.js"; // ..... // vom stoca la nivelul variabilei server configurarea serverului returnata de catre metoda listen // metoda este async deoarece, în interior, vom folosi keyword-ul await pe metoda synchronizeDatbase pentru a aștepta finalizarea // procesului de sincronizare const server = app.listen(PORT, async () => { try { // apelăm metoda ce va sincroniza modelele definite în cadrul aplicației cu baza de date await synchronizeDatabase(); console.log(`Server started on http://localhost:${PORT}`); } catch (err) { console.log("There was an error with the database connection"); // daca apare o eroare in momentul sincronizarii bazei de date, vom opri aplicatia server.close(); } });
-
În momentul repornirii aplicației, vom observa în consolă query-urile executate de către Sequelize pentru a genera tabela Movie la nivelul bazei de date, unde vom regăsi, pe lângă câmpurile configurate explicit, și două câmpuri administrative adăugate automat: createdAt și updatedAt
Executing (default): SELECT 1+1 AS result Executing (default): SELECT name FROM sqlite_master WHERE type='table' AND name='Movies'; Executing (default): CREATE TABLE IF NOT EXISTS `Movies` (`id` INTEGER PRIMARY KEY AUTOINCREMENT, `title` VARCHAR(255) NOT NULL, `year` INTEGER NOT NULL, `director` VARCHAR(255) NOT NULL, `genre` VARCHAR(255), `synopsis` TEXT, `duration` TINYINT, `poster` VARCHAR(255), `createdAt` DATETIME NOT NULL, `updatedAt` DATETIME NOT NULL); Executing (default): PRAGMA INDEX_LIST(`Movies`) Executing (default): CREATE UNIQUE INDEX `movies_title_year_director` ON `Movies` (`title`, `year`, `director`) -
Putem confirma crearea tabelelor utilizând extensia SQLite din Visual Studio Code instalată anterior
-
Ultimul pas pe care trebuie să îl implementăm este actualizarea serviciului pentru gestionarea filmelor pentru a utiliza entitatea Movie în locul array-ului movies (pe care, la finalul refactorizării, îl vom putea șterge)
-
Actualizăm, pe rând, fiecare metodă din serviciu, observând modul în care putem insera, actualiza, extrage și șterge date folosind entitatea Movie
import { Op } from "sequelize"; import { Movie } from "../models/movies.js"; export const getMovies = async (query) => { // extragem toate campurile definite la nivelul entitatii Movie // acestea vor fi folosite pentru validarea filtrelor primite const entityKeys = Object.keys(Movie.getAttributes()); // eliminam din obiectul de query proprietatile pentru care nu dorim sa aplicam filtrarea delete query.id; delete query.poster; // definim o conditie de selectie dinamica pe baza campurilor primite in cadrul apelului // dar inainte vom filtra criteriile primite ce nu reprezinta campuri valide pentru entitatea Movie const whereConditions = Object.keys(query) .filter(key => entityKeys.includes(key)) .map(key => { // in cazul proprietatilor title si director ne dorim o echivalenta partiala // ce poate fi verificata folosind operatorul like if (key === "title" || key === "director") { return { [key]: { [Op.like]: `%${query[key]}%` } } } // pentru toate celelalte campuri dorim sa testam egalitatea return { [key]: query[key] } }); // vom folosi entitatea movie pentru a returna toate filmele return await Movie.findAll({ // proiectie ce va returna doar o parte dintre campurile tabelei attributes: ['id', 'title', 'year', 'director', 'genre', 'poster'], // conditia where construita anterior ce va filtra filmele returnate where: whereConditions }); }; export const getById = async (id) => { // vom folosi entitatea movie pentru a returna un film return await Movie.findOne({ // care sa aiba id-ul primit ca parametru where: { id: id } }); }; export const create = async (movie) => { // înainte de inserare, verificam daca filmul se afla deja in baza de date const existingMovies = await getMovies({ title: movie.title, director: movie.director, year: movie.year }); if (existingMovies.length !== 0) { // daca exista un film publicat in acelasi an, cu acelasi nume si acelasi regizor // aruncam o exceptie throw new Error("Movie already exists"); } // crearea unui nou film // campurile existente in interiorul parametrului primit trebuie sa aiba acelasi nume precum campurile din tabela // altfel, Sequelize le va ignora si va incerca sa introduca doar acele field-uri pentru care poate sa asigure identitatea return await Movie.create(movie); }; export const update = async (movieUpdateData) => { // extragem un film pe baza id-ului const movie = await Movie.findOne({ where: { id: movieUpdateData.id } }); // daca filmul exista, realizam actualizarea lui in baza de date if (!!movie) { // vom sterge din obiectul ce va fi folosit pentru actualizare proprietatea id, pentru a nu permite suprascrierea acesteia delete movieUpdateData.id; // vom actualiza toate celelalte proprietati prezente in parametrul primit // la fel ca in cazul crearii, field-urile din obiectul movieUpdateData trebuie sa aiba acelasi nume ca in tabela movie.set({ ...movieUpdateData }); // salvam schimbarile efectuate pe entitatea identificata await movie.save(); } } export const remove = (id) => { // stergerea unui film pe baza id-ului primit ca parametru Movie.destroy({ where: { id: id } }); }
-
De asemenea, pentru că am introdus o serie de diferențe majore în ceea ce privește structura unui film la nivelul aplicației, este nevoie să actualizăm și controller-ul aferent pentru a implementa funcționalități mai complexe
- analizează codul și încearcă să transpui, în aplicația ta, toate schimbările efectuate
import * as moviesService from "../services/movies.js"; const getMovies = async (req, res) => { res.send({ movies: await moviesService.getMovies(req.query) }); }; const getById = async (req, res) => { const identifiedMovie = await moviesService.getById(req.params.id); if (!!identifiedMovie) { res.send({ movie: identifiedMovie }); } else { res.status(404).send(); } }; const create = async (req, res) => { if (!req.body.title || !req.body.director || !req.body.year) { return res.status(404).send({ message: "Missing title, director or year" }); } try { const movie = await moviesService.create(req.body); res.status(201).send({movie: movie}) } catch (ex) { res.status(500).send({ message: ex.message }); } }; const update = async (req, res) => { if (!req.body.id) { return res.status(400).send({ message: "Movie id is mandatory" }); } await moviesService.update(req.body); res.status(204).send(); } const remove = (req, res) => { moviesService.remove(req.params.id); res.send(); } export { getMovies, getById, create, update, remove }
-
Observăm că structura rutelor nu a fost afectată, motiv pentru care, cu excepția body-ului trimis în metodele de creare și de actualizare, API-ul păstrează aceeași interfață
- Folosește Postman pentru a executa request-uri și extensia SQLite pentru a observa datele la nivelul bazei de date pe măsură ce sunt create și actualizate
-
Recomandare: Sequelize are foarte multe funcționalități ce pot simplifica construirea și executarea query-urilor - citește mai multe în documentația oficială
-
Urmărind exemplul pentru entitatea Movie, încearcă să definești toate structurile necesare pentru implementarea a două entități noi: Person și Collection
-
Structura entității Person
- id: integer, cheie primară, autoincrementare
- firstname: string, nenul
- lastname: string
- email: string, nenul, isEmail
-
Structura entității Collection
- id: integer, cheie primară, autoincrementare
- name: string, nenul
- poster: string
-
-
Pentru fiecare entitate trebuie să implementezi câte un endpoint care să permită:
- listarea (cu suport pentru filtrare)
- extragerea datelor despre o înregistrare individuală
- crearea unei înregistrări
- actualizarea unei înregistrări
- ștergerea unei înregistrări
-
Aplicația funcționează corect doar atunci când toate layerele sunt implementate și testate - ai grijă să nu uiți niciunul :)