给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
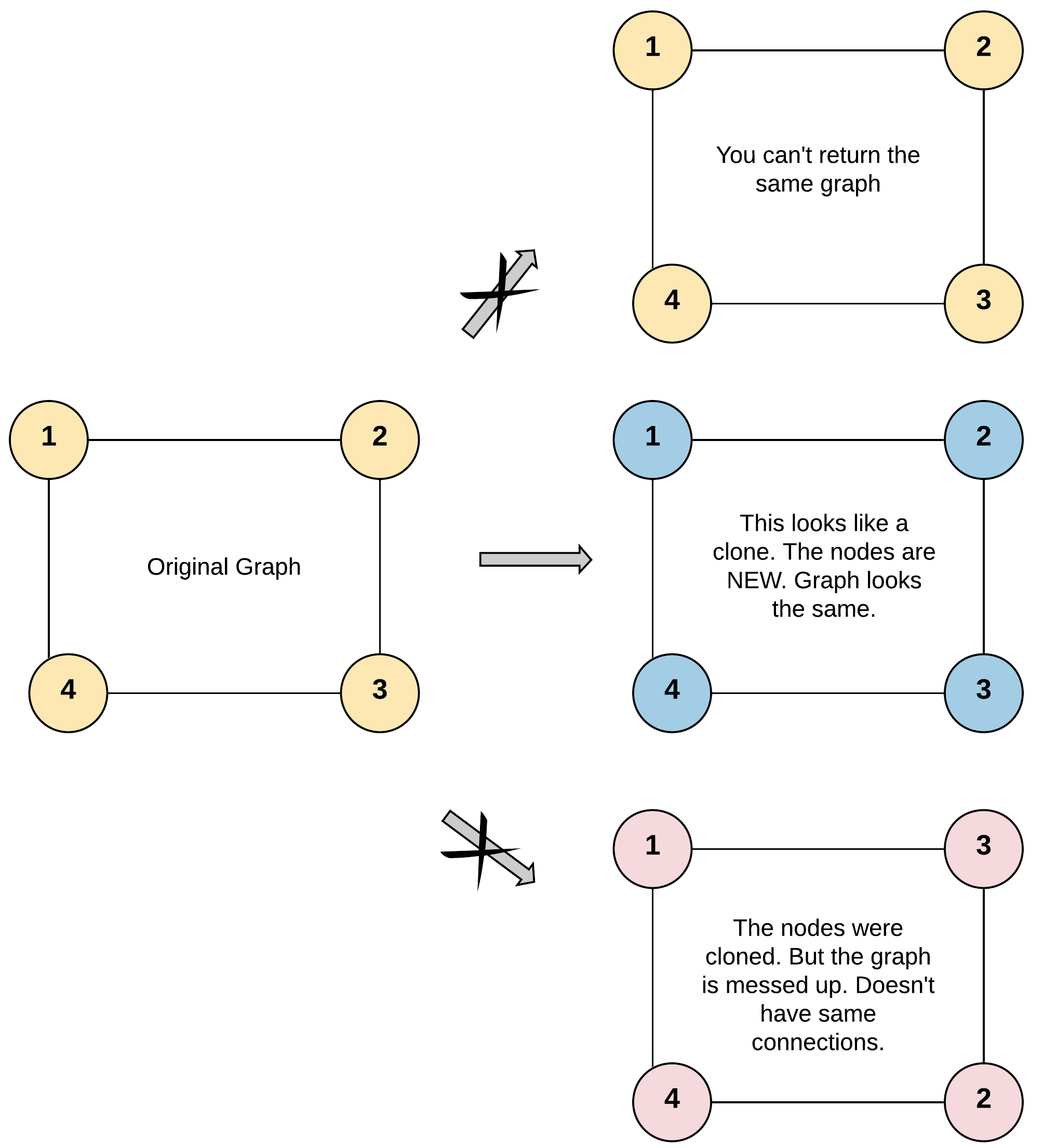
示例 1:
输入:adjList = [[2,4],[1,3],[2,4],[1,3]]
输出:[[2,4],[1,3],[2,4],[1,3]]
解释:
图中有 4 个节点。
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
提示:
- 节点数不超过 100 。
- 每个节点值 Node.val 都是唯一的,1 <= Node.val <= 100。
- 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
- 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
- 图是连通图,你可以从给定节点访问到所有节点。
这道题就是遍历整个图,所以遍历时候要记录已经访问点,我们用一个字典记录。
所以,遍历方法就有两种。
思路一:DFS (深度遍历)
思路二:BFS (广度遍历)
!!! 重点掌握,后面图遍历都和这个有关系!
时间复杂度:O(N),其中 N 表示节点数量。深度优先搜索遍历图的过程中每个节点只会被访问一次。
O(N)。存储克隆节点和原节点的数组需要 O(N)的空间,递归调用栈需要 O(H)的空间,其中 H是图的深度,经过放缩可以得到 O(H)=O(N),因此总体空间复杂度为 O(N)。
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
vector<Node*> visited(101, NULL); //创建一个节点(指针)数组记录每个拷贝过的节点
Node* res = dfs(node, visited);
return res;
}
Node* dfs(Node* node, vector<Node*> &visited) {
if (node==NULL) return node; //如果是空指针,则返回空
if (visited[node->val]) return visited[node->val]; //如果已经被拷贝过,则可以直接返回数组记录的那个指针
Node* cloneNode = new Node(node->val); //创建拷贝节点
visited[node->val] = cloneNode;//更新已拷贝指针记录数组
for (Node* n : node->neighbors) { //对邻接表每一个元素进行拷贝
cloneNode->neighbors.push_back(dfs(n, visited));
}
return cloneNode;
}
};/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
if (node==NULL) return node;
vector<Node*> visited(101, NULL);
Node* cloneNode = new Node(node->val);
// 克隆第一个节点并存储到visited中
visited[node->val] = cloneNode;
queue<Node*> q;
// 将题目给定的节点添加到队列
q.push(node);
while (!q.empty()) {
// 取出队列的头节点
Node* t = q.front();
q.pop();
// 遍历该节点的邻居
for (Node* n : t->neighbors) {
if (!visited[n->val]) {
// 如果没有被访问过,就克隆并存储在哈希表中
visited[n->val] = new Node(n->val);
// 将邻居节点加入队列中
q.push(n);
};
// 更新当前节点的邻居列表
visited[t->val]->neighbors.push_back(visited[n->val]);
}
}
// return cloneNode;
return visited[node->val];
}
};